Настоящее изобретение относится к воспроизведению речи и маскировке воспроизводимой речи. Три примера различных ситуаций, в которых предполагается применение маскировки речи, показаны ниже:
1. Совместно используемые пространства офиса, в которых каждый сотрудник может потенциально отвлекаться от порученной задачи при восприятии разговоров других не уважающих правила людей, если они ведутся по телефону или непосредственно. В таких случаях система маскировки речи может повышать рабочий комфорт путем ограничения понятливости речи. Кроме того, может иметься необходимость в поддержании конфиденциальности содержания переговоров (то есть, в повышении конфиденциальности личных переговоров), и система маскировки речи несомненно может помочь выполнить это.
2. Различные ситуации в автомобиле, когда человек ведет потенциально конфиденциальные переговоры при наличии дежурного водителя в кабине автомобиля без физического промежуточного барьера. В этом случае главная задача заключается в сохранении конфиденциальности переговоров, поскольку комфорт для водителя является менее важным при условии, что он не отвлекается.
3. Во врачебном кабинете часто имеются приборы, позволяющие осуществлять связь с регистратором при свободных руках операторов. В неотложных случаях может иметься необходимость упоминания регистратором подробностей о пациенте при использовании этого прибора и то же время при обслуживании другого пациента. В этом случае система маскировки речи может использоваться для гарантии конфиденциальности. Обслуживаемые пациенты должны положительно реагировать на эту маскировку, когда они надеются на абсолютную конфиденциальность со стороны самого доктора.
Системы маскировки речи, которые используются для повышения рабочего комфорта, хорошо известны из предшествующего уровня техники. Однако такие системы в недостаточной степени обеспечивают конфиденциальность переговоров. Большая часть известных систем прежде всего предназначена для повышения рабочего комфорта, а конфиденциальность переговоров считается вторичной.
При рассмотрении единственной акустической сцены, воспроизводимой устройством связи, воспроизведение также может быть ограничено зоной ясной речи путем концентрации излучения или многозонных воспроизведений. Однако помимо затрат на большое количество необходимых громкоговорителей, такая система никогда не будет обеспечивать конфиденциальность переговоров на достаточном уровне, поскольку получаемый уровень абсолютного звукового давления в зоне маскированной речи будет все же в значительной степени выше порога слышимости людей. То же самое справедливо для активных способов подавления/регулирования шума, которыми потенциально можно подавлять не только любой воспроизводимый сигнал, но также и локальные разговоры людей. Кроме того, для этих способов требуется использование по возможности большего количества микрофонов и необходима адаптивная фильтрация, которая, как известно, является задачей, представляющей сложность [4]. В результате активное регулирование шума успешно используется только в случае источников низкочастотного звука или простых сценариев, подобных вентиляционным воздуховодам [4].
Широко используемый способ заключается в генерации маскирующего звука (маскирующего шума), который нельзя отличить (то есть, отделить чувственным восприятием) от речи (маскируемого сигнала), таким образом, чтобы понимание речи исключалось при наличии маскирующего звука. Для таких систем часто используют термин «маскировка звука», поскольку в заданной области обычно воспроизводится звук маскирующего шума некоторого вида. Способ заключается в воспроизведении фонового шума, подобного шуму кондиционера воздуха. Шум накладывается на речь и способствует тому, что она воспроизводится неразборчиво. Хотя такая маскировка может достигаться воспроизведением очень громких маскирующих звуков, в способах маскировки звука предполагается использование нормального маскирующего шума с возможно меньшим уровнем громкости звука.
Часто используют белый шум или розовый шум, который при низких уровнях воспроизведения является не очень эффективным для маскировки речи в такой степени, при которой может достигаться конфиденциальность переговоров. Ранее предложенные способы для усиления эффекта маскировки наведенным шумом кратко излагаются ниже.
В [12] авторы на основании литературных источников показывают, что звуки с ненавязчивыми характеристикой и частотным спектром, такие как звуки ветра или волн, пригодны для достижения конфиденциальности переговоров. Кроме того, в этом документе утверждается, что звук является более навязчивым, если место его происхождения может быть локализовано слушателем. Обнаружено, что при некоторых сценариях равномерное, не локализуемое распределение маскирующего шума является предпочтительным. Поэтому в [12] предложено использовать многочисленные некоррелированные источники шума для образования размытого, однородного, нелокализованного звукового пространства.
Как было обнаружено, предпочтительно, чтобы уровень маскирующего звука изменялся адаптивно в соответствии, например, с характеристиками окружающей обстановки или уровнем речевого сигнала говорящего, который должен маскироваться (см., например, [10], [5]). Кроме того, известно, что автоматическая адаптация спектральных характеристик маскирующего шума в дополнение к адаптации уровня является полезной (см., например, [11], [5]). В этой связи в [6] высказывается предположение о том, что «в адаптивных системе и способе маскировки звука нежелательный звук делится на временные блоки и оцениваются частотный спектр и уровень мощности, а также непрерывно генерируется белый шум с согласованными спектром и уровнем мощности для маскировки нежелательного звука».
В других способах генерируют специфические шумоподобные сигналы, которые способны особенно хорошо маскировать речь [9], или создают маскирующий шум, который «точно согласован с характеристиками источника (речью человека)» [10]. В последнее время для решения определенной задачи превращения речи в неразборчивую речь предложено использовать маскирующий звук, который очень похож на фрагменты речи, путем либо искусственного образования похожих звуков, либо воспроизведения случайных цепочек фрагментов речи из базы данных (см., например, [10], [2]). В [10] используют речевые звуки, чтобы сделать маскируемый звук незаметным. Однако все это может отвлекать, например, водителя, который подвергается воздействию этого звука.
В других способах, которые были предложены для достижения конфиденциальности переговоров, используют, например, генерирование подавляющих сигналов, которыми пытаются исключить намеченную речь на предопределенном месте. В заявке [7] на патент Японии раскрыто такое устройство для защиты конфиденциальности разговоров в салонах транспортных средств. Разговорная речь захватывается, а подавляющий звук подается на место, где разговор не должен быть слышен.
В зависимости от применения маскирующий шум часто воспроизводят либо в большой области вокруг говорящего, либо создают вблизи самого говорящего (см. [10], [3], или же зоны (дополнительно) разделяют физическими средствами [8].
Chatter Blocker [1] предложил способ с маскирующими звуками различных категорий (звуковыми эффектами, музыкальным вибрирующим звуком), которые могут воспроизводиться индивидуально или в сочетании, а уровень их может регулироваться пользователем. В способе используют встроенные громкоговорители воспроизводящего устройства (например, планшетного компьютера) или внешние громкоговорители, соединенные с воспроизводящим устройством.
Задача изобретения заключается в создании улучшенной концепции для воспроизведения речи и для маскировки воспроизводимой речи.
Эта задача решается устройством для воспроизведения речи, предназначенным для воспроизведения речи на основании принимаемого речевого сигнала таким образом, чтобы воспроизводимая речь была разборчивой в зоне ясной речи и неразборчивой в зоне маскированной речи, при этом задача решается устройством для воспроизведения речи, содержащим:
модуль обработки аудио, выполненный с возможностью приема речевого сигнала;
набор речевых громкоговорителей, выполненных с возможностью воспроизведения речи на основании одного или более сигналов речевых громкоговорителей; и
набор громкоговорителей маскирующего звука, выполненных с возможностью создания маскирующего звука на основании одного или более сигналов громкоговорителей маскирующего звука, при этом маскирующим звуком маскируется речь в зоне маскированной речи;
в котором модуль обработки аудио содержит генератор сигналов речевых громкоговорителей, выполненный с возможностью создания одного или более сигналов речевых громкоговорителей на основании речевого сигнала;
в котором модуль обработки аудио содержит модуль анализа речевых сигналов, выполненный с возможностью создания одного или более сигналов анализа на основании спектральных и/или временных характеристик речевого сигнала;
в котором модуль обработки аудио содержит генератор маскирующего звука, выполненный с возможностью создания одного или более сигналов маскирующего звука на основании одного или более сигналов анализа; и
в котором модуль обработки аудио содержит генератор сигналов громкоговорителей маскирующего звука, выполненный с возможностью создания одного или более сигналов громкоговорителей маскирующего звука на основании одного или более сигналов маскирующего звука.
Термин «набор речевых громкоговорителей» относится к одному или более громкоговорителям, способным воспроизводить речь. По аналогии термин «набор громкоговорителей маскирующего звука» относится к одному или более громкоговорителям, способным создавать маскирующие звуки. Однако в общем случае набор речевых громкоговорителей отделен от набора громкоговорителей маскирующего звука, так что конкретный громкоговоритель принадлежит либо к набору речевых громкоговорителей, либо к набору громкоговорителей маскирующего звука, но не к обоим наборам. В результате речевые громкоговорители могут быть расположены так, чтобы речь, воспроизводимая речевыми громкоговорителями, преимущественно направлялась в зону ясной речи, тогда как громкоговорители маскирующего звука могут быть расположены так, чтобы маскирующий звук, создаваемый громкоговорителями маскирующего звука, преимущественно направлялся в зону маскированной речи.
Изобретением предоставляется улучшенная концепция воспроизведения речи, неразборчивой для нежелательного слушателя или нежелательных слушателей (которых можно отнести к любителям подслушивать) и в то же время остающейся понятной для предопределенного слушателя или предопределенных слушателей в другом месте.
В рассматриваемом сценарии воспроизводимая речь предполагается разборчивой в заданной области, которая именуется зоной ясной речи. В то же самое время воспроизводимая речь должна быть неразборчивой в другой заданной области, которая именуется зоной маскированной речи, при этом обе зоны могут быть расположены по соседству. Это желательно, когда неизбежный любитель подслушивать стоит вблизи предопределенного слушателя.
Понимание речи предотвращается посредством маскирующего звука (маскирующего шума), который генерируется адаптивно в зависимости от свойств речи (маскируемого сигнала), воспроизводимой в зоне ясной речи или вблизи нее. Иначе говоря, «маскируемый сигнал» означает речь, которую следует маскировать. Маскирующий звук воспроизводится в зоне маскированной речи или вблизи нее.
Генератор сигналов речевых громкоговорителей может содержать модуль представления сигналов. Аналогичным образом, генератор сигналов громкоговорителей маскирующего звука может содержать модуль представления сигналов.
В противоположность некоторым похожим технологиям задача концепции, описываемой в этой заявке, не заключается в маскировке речи одного или более присутствующих собеседников, а в маскировке воспроизводимой речи, которая, воспроизводится, например, устройством связи при свободных руках оператора, при этом воспроизводимая речь основана на удаленном сигнале, принимаемом устройством связи при свободных руках оператора.
Изобретение прежде всего способствует достижению скрытности речи, а не повышению рабочего комфорта находящихся вблизи сотрудников. Скрытность речи создается, если человек, который находится вблизи говорящего (умышленно или неумышленно), не может постичь смысл речи или понять суть. Это особенно важно в случае телефонного разговора при свободных руках оператора, когда удаленный участник потенциально не осведомлен о любителе подслушивать.
Изобретением охватывается оптимальное встраивание генератора маскирующего шума в устройство для воспроизведения звука, такое как устройство связи. Учитываются следующие аспекты:
-Обеспечение необходимой информацией генератора маскирующего шума.
-Воспроизведение сигнала ясной речи преимущественно в определенной зоне ясной речи.
-Воспроизведение маскирующего шума преимущественно в определенной зоне маскированной речи.
Чтобы обеспечить необходимую информацию для генератора маскирующего шума, принимаемый речевой сигнал до его воспроизведения непосредственно исследуется в устройстве для воспроизведения речи.
Согласно изобретению маскирующий звук адаптируется к поступающему речевому сигналу. Для достижения этого речевой сигнал непосредственно анализируется модулем анализатора речевого сигнала до преобразования речевого сигнала в речь с использованием речевых громкоговорителей. В противоположность этому, в решениях из предшествующего уровня техники речь преобразуется с использованием микрофона в сигнал, который затем анализируется.
Изобретением обеспечивается улучшение адаптации маскирующего звука к воспроизводимой речи. Одна причина этого заключается в том, что является возможной упреждающая адаптация маскирующего звука, поскольку анализ поступающего речевого сигнала в зависимости от времени может быть сделан до получения впоследствии речи. В противоположность этому, в решениях из предшествующего уровня техники с использованием сигнала с микрофона для анализа воспроизводимой речи возможна только последующая адаптация маскирующего звука. В результате маскирующий звук имеет небольшую громкость и может быть получено слабое заглушение, недостаточное для того, чтобы сделать речь неразборчивой в зоне маскированной речи.
Что касается различия терминов «незаметный» и «ненавязчивый», то можно отметить следующее. В системах маскирования речи из предшествующего уровня техники термин «ненавязчивый» может также интерпретироваться как «незаметный». То есть, слушатель будет приноравливаться к равномерному маскирующему шуму и игнорировать его спустя некоторое время. В нашем случае маскирующий шум является столь очевидным, что его невозможно игнорировать, поэтому он не является незаметным, но все же может быть «ненавязчивым» в том смысле, что он является «приятным и не отвлекающим.
Маскировка может осуществляться таким способом, что она будет ненавязчивой и приятной для предопределенного слушателя, и также таким способом, что подслушивающее лицо не будет отвлекаться от любой задачи, относящейся к нему. Следовательно, дальнейшее преимущество настоящего изобретения заключается в том, что возможна генерация такого ненавязчивого, но все же эффективного маскирующего звука.
Создание локализуемого маскирующего звука в случае предложенной концепции не является крайне необходимым, поскольку подслушивающее лицо не отвлекается от своей основной задачи. Маскирующий звук не следует делать незаметным и нет необходимости иметь его постоянно включенным (то есть, если конфиденциальный разговор не поддерживается, маскирующий звук может быть выключен). Подслушивающему лицу хорошо известно, что когда осуществляется телефонный разговор или проводятся переговоры (и только тогда), он будет слышать маскирующий звук, который используется для сокрытия переговоров.
В результате этого, поскольку как предопределенный слушатель, так и подслушивающее лицо допускают существование средства для маскировки переговоров, оба будут допускать наличие такого заметного маскирующего звука.
Маскировке речи согласно изобретению не присущи упомянутые выше ограничения систем подавления шума, поскольку она не основана на точном подавлении звуковых волн, при котором маскировка может достигаться воспроизведением очень громких маскирующих звуков. Вместо этого она направлена на запрещение распознавания речи человека, которое основано на тональной, спектральной и переходной структурах речевого сигнала. Маскирующий звук обычно также имеет тональную, спектральную или переходную структуру (или сочетания из них). Маскирующий шум можно генерировать способом, при котором осуществляется суперпозиция его с маскируемым сигналом на месте нахождения подслушивающего лица, что приводит к выровненному сигналу, из которого удалены различимые признаки речи. С другой стороны, также можно использовать такой маскирующий сигнал, при котором суперпозиция имеет различимые признаки речи с признаками маскирующего звука, в значительной степени делающими неясными признаки речи. Последний способ допускает некоторую степень свободы при выборе маскирующих сигналов и также облегчает достижение маскировки. В обоих случаях возможен достаточный маскирующий звук при низком уровне звука.
В изобретении предлагается концепция представления неразборчивой речи с использованием ненавязчивого маскирующего звука, который не отвлекает подслушивающее лицо от основной выполняемой задачи. (Например, водитель сосредотачивается на вождении. В действительности, прослушивание приятного звука маскирующего шума может даже меньше отвлекать, чем прослушивание разговора. Таким образом, система содействует повышению безопасности движения).
Среда автомобиля является предпочтительным сценарием применения. В этом сценарии имеются достоверные сведения о конкретных условиях в салоне автомобиля (например, о пространственном положении предопределенного слушателя, подслушивающего лица, громкоговорителей, об акустике пространства воспроизведения и т.д.). Таким образом, можно соответственно адаптировать различные этапы обработки. В этом заключается преимущество перед обычными системами маскировки.
В среде автомобиля, взятой в качестве примера, важно, чтобы водитель (приравненный к подслушивающему лицу) не отвлекался от вождения. Таким образом, звуковое пространство, которое локализуется (например, впереди водителя), нисколько не мешает.
Однако изобретение не ограничено средой автомобиля.
Согласно предпочтительному варианту осуществления изобретения генератор сигналов речевых громкоговорителей выполнен с возможностью создания множества сигналов речевых громкоговорителей и независимого регулирования характеристик каждого сигнала речевого громкоговорителя из множества сигналов речевых громкоговорителей, чтобы регулировать пространственные признаки речи. В частности, характеристики регулируемых сигналов речевых громкоговорителей могут содержать уровень и/или временную задержку каждого из сигналов речевых громкоговорителей.
Согласно предпочтительному варианту осуществления изобретения генератор сигналов громкоговорителей маскирующего звука выполнен с возможностью создания множества сигналов громкоговорителей маскирующего звука и независимого регулирования характеристик каждого сигнала громкоговорителя маскирующего звука из множества сигналов громкоговорителей маскирующего звука, чтобы регулировать пространственные признаки маскирующего звука. В частности, характеристики сигналов громкоговорителей маскирующего звука, подлежащие регулированию, могут содержать уровень и/или временную задержку каждого из сигналов громкоговорителей маскирующего звука.
Благодаря этим особенностям способы воспроизведения пространственных звуков можно использовать для повышения действия систем маскировки речи на стороне речевых громкоговорителей, а также на стороне громкоговорителей маскирующего звука.
Средство воспроизведения пространственных звуков можно использовать для повышения уровня речи в зоне ясной речи и в то же время для снижения уровня речи в зоне маскированной речи. И наоборот, то же самое относится к маскирующему звуку. Способами, обладающими таким действием, являются
-концентрация излучения,
-многозонное воспроизведение,
-надлежащее размещение громкоговорителей (предпочтительно вблизи слушателя в каждой зоне).
Из предшествующего уровня техники известно использование речевых громкоговорителей в качестве громкоговорителей маскирующего звука, но это не является хорошим предметом выбора. В этом случае маскирующий звук будет иметь наибольшую интенсивность в зоне ясной речи, что нежелательно. Поэтому не речевые громкоговорители, а другие громкоговорители маскирующего звука могут быть расположены вблизи зоны маскированной речи или в ней, чтобы маскирующий звук воспроизводился преимущественно на этом месте.
Согласно предпочтительному варианту осуществления изобретения генератор маскирующего звука содержит множество источников маскирующего звука, выполненных с возможностью создания исходного сигнала маскирующего звука, и множество модулей адаптации исходных сигналов маскирующего звука, при этом каждый из модулей адаптации исходных сигналов маскирующего звука назначен одному из источников маскирующего звука, при этом назначенный модуль адаптации маскировки выполнен с возможностью адаптации исходного сигнала маскирующего звука соответствующего источника маскирующего звука на основании сигнала анализа, чтобы создавать один сигнал маскирующего звука из одного или более сигналов маскирующего звука.
Этим аспектом изобретения охватывается генератор маскирующего шума. В этом варианте осуществления генератор маскирующего шума отличается от генератора маскирующего шума из предшествующего уровня техники использованием группы многочисленных источников сигнала для генерации маскирующего звука, при этом смешанный маскированный звук может адаптироваться в реальном времени при использовании параметров, получаемых в результате анализа речевого сигнала.
Согласно предпочтительному варианту осуществления изобретения по меньшей мере один источник маскирующего звука представляет собой источник музыки, выполненный с возможностью создания исходного сигнала музыкального маскирующего звука, при этом назначенный модуль адаптации маскировки выполнен с возможностью адаптации исходного сигнала музыкального маскирующего звука на основании сигнала анализа, чтобы создавать один сигнал маскирующего звука из одного или более сигналов маскирующего звука.
Согласно предпочтительному варианту осуществления изобретения по меньшей мере один источник маскирующего звука представляет собой источник непрерывного шума, выполненный с возможностью создания исходного сигнала непрерывного шумового маскирующего звука, при этом назначенный модуль адаптации маскировки выполнен с возможностью адаптации исходного сигнала непрерывного шумового маскирующего звука на основании сигнала анализа, чтобы создавать один сигнал маскирующего звука из одного или более сигналов маскирующего звука.
Согласно предпочтительному варианту осуществления изобретения по меньшей мере один источник маскирующего звука представляет собой источник динамического шума, выполненный с возможностью создания исходного сигнала динамического шумового маскирующего звука, при этом назначенный модуль адаптации маскировки выполнен с возможностью адаптации исходного сигнала динамического шумового маскирующего звука на основании сигнала анализа, чтобы создавать один сигнал маскирующего звука из одного или более сигналов маскирующего звука.
Таким образом, маскирующий звук может генерироваться так, что он маскирует речь, и в то же время не воспринимается как отвлекающий, фактически может восприниматься как расслабляющий. Преимущество концепции изобретения перед концепцией из предшествующего уровня техники заключается в том, что маскирующий звук можно создавать при использовании множества различных сигналов маскирующего звука с различными характеристиками, которые при существующем положении дел могут автоматически адаптироваться в реальном времени. Вследствие различных характеристик множества сигналов маскирующего звука каждый сигнал может использоваться для решения конкретной задачи (ими могут быть, например, звук морского берега для получения основного эффекта маскировки, фильтрованный шум, быстро адаптирующийся к речевому сигналу, для маскировки важных частей речи и музыка для гарантии, что маскирующий звук не будет беспокоящим). Индивидуальная адаптация сигналов маскирующего звука к ситуации позволяет мгновенно реагировать на изменения речи (например, быстро выбирать сигнал шумового маскирующего звука), хотя при этом маскирующий звук не должен восприниматься как неустановившийся (например, сигнал музыкального маскирующего звука должен выбираться с намного меньшей постоянной времени и в пределах ограниченного диапазона).
Поскольку различные признаки речи наиболее эффективно разрушаются шумом соответствующих различных видов, концепция изобретения является более эффективной, чем концепция из предшествующего уровня техники. При эффективном совместном использовании этих признаков можно создавать менее навязчивый маскирующий звук. В этом изобретении рассматриваются следующие аспекты:
-Определение набора подходящих маскирующих сигналов.
-Получение или генерация таких сигналов.
-Получение информации или использование прогнозирования для определения параметров при смешении.
-Адаптация маскирующих сигналов.
Существует мнение, что более эффективные маскирующие сигналы также являются более навязчивыми. То же самое относится к быстрым изменениям свойств маскирующего сигнала. В изобретении предпочтительно использовать звуки следующих видов:
-Случайный шум, хорошо известный из предшествующего уровня техники и наряду с некоторыми другими представленный в одном источнике сигнала согласно изобретению. Как известно из предшествующего уровня техники, огибающей спектра этого сигнала можно придавать определенную форму для оптимизации маскирующей способности. Известно, что этот сигнал является очень эффективным при маскировке, хотя он также воспринимается как навязчивый.
-Естественные шумы, представляющие собой звуки акустического окружения, которые могут восприниматься в реальном мире. Они включают в себя, но без ограничения ими, звуки морского берега, водопадов, улиц, мест вблизи автомобильных двигателей, скоплений людей и ресторанов. Поскольку людям известны эти шумы, они, возможно, будут восприниматься как менее навязчивые, чем случайный шум. Однако, поскольку свойства этих шумов часто являются нестационарными, их маскирующая способность изменяется во времени.
-Музыкальные сигналы, обычно воспринимаемые как приятные, хотя их маскирующая способность является скорее низкой. Кроме того, для поддержания приятного восприятия они должны изменяться (например, их уровень) медленно. Наконец, музыкальные сигналы также являются нестационарными и для них присущи те же самые проблемы, что и для естественных шумов. Однако в сочетании с некоторым количеством шума (естественного или случайного) они являются эффективными.
Сигналы упомянутых выше видов можно получать с помощью модулей адаптации исходных сигналов маскирующего звука следующими способами:
-Считыванием из записи информации, в которой сигналы сохраняются, при этом их свойства известны заранее. Последнее обстоятельство можно использовать для оптимизации последующей адаптации.
-Искусственным генерированием модулями. В случае сигналов случайного шума, шум обычно должен быть псевдослучайным шумом. В случае естественных шумов свойства шумов можно задавать. Этим преодолеваются ограничения, налагаемые отсутствием регулирования (отсутствием стационарности) записанных сигналов. Для такого генератора «естественного» шума можно использовать внешний источник данных для лучшего соответствия данному сценарию. Например, можно рассматривать частоту вращения двигателя в сценарии в автомобиле для идеальной имитации соответствия шуму двигателя.
-Измерением в реальном времени с помощью микрофона (например, при усилении шума автомобиля).
-Генерированием приятного маскирующего шума (например, подобного шуму волн, подобного шуму ветра), которое может производиться в реальном времени звуковым генератором, который специально рассчитан для маскировки речи. Кроме того, его можно адаптировать к характеристикам различных говорящих субъектов и разговорным стилям (приданием определенной формы спектру путем спектрального сдвига и/или усиления участков спектра).
-Применением того же самого к музыке, сигнал которой также может автоматически формироваться в реальном времени с помощью надлежащих алгоритмов.
-В ином случае использованием предварительно записанных музыки и шума (возможно, будет достаточно коротких петель записи).
В зависимости от маскируемой речи все сигналы, которые смешиваются с образованием маскирующего звука, могут адаптироваться индивидуально. Во время разработки могут иметься определенные параметры, которые отображают эффективность и навязчивость индивидуального маскирующего сигнала, которые в таком случае при оптимизации объединяются в функции стоимости. Важный аспект заключается в том, что предопределенный слушатель не должен заливаться маскирующим шумом. В некоторой степени это уже достигается динамической адаптацией маскирующего звука к речи, поскольку ясная речь будет преобладать на месте нахождения слушателя, при этом активность ясной речи и маскирующего звука будут сильно коррелированными.
Способы адаптации сигнала маскирующего шума для наилучшей возможной маскировки принимаемого речевого сигнала включают в себя:
-Распознавание тональной структуры маскируемого сигнала, который может быть подавлен при следующем свойстве маскирующего шума: тональная структура отличается от тональной структуры маскируемого сигнала. Структура может быть случайной (например, музыкальным шумом) или определенной (например, записью музыки).
-Распознавание спектральной структуры маскируемого сигнала, который может быть подавлен при следующем свойстве маскирующего звука: заполнение спектральных промежутков в суперпозиции маскирующего звука и маскируемого звука должно быть таким, чтобы унимодальный или плоский спектр воспринимался как имеющий такую выраженную пространственную структуру, при которой спектральная структура маскируемого сигнала делается неясной.
-Распознавание переходной структуры маскируемого сигнала, который может быть подавлен при следующем свойстве маскирующего звука: наличие переходной структуры, которая отличается от переходной структуры маскируемого сигнала; присутствующая частота переходных процессов в маскирующем шуме может быть адаптирована к маскируемому сигналу, при этом фактическое инициирование события не зависит от маскируемого сигнала; создание случайной переходной структуры в маскирующем шуме для дальнейшего запутывания подслушивающего лица.
Согласно предпочтительному варианту осуществления модуль обработки аудио содержит модуль адаптивной обработки речи, выполненный с возможностью создания адаптированного речевого сигнала на основании речевого сигнала, при этом генератор сигналов речевых громкоговорителей выполнен с возможностью создания одного или более сигналов речевых громкоговорителей на основании адаптированного речевого сигнала.
При расширенном доступе к устройству для воспроизведения речи маскируемый сигнал (ясный речевой сигнал) может быть модифицирован для облегчения маскирования его. Меры для достижения этого включают в себя:
-Ограничение полосы частотами, которые могут быть в достаточной степени маскированы.
-Задержку, в соответствии с которой генератор маскирующего шума будет иметь больше времени для адаптации маскирующего шума. Кроме того, такая задержка позволит адаптировать маскирующий шум даже до воспроизведения маскируемого сигнала. Таким образом, можно использовать эффекты прямой маскировки, известные из психоакустики. Однако такая задержка должна быть достаточно малой, чтобы она не воспринималась общающимися лицами.
-Обработку/демпфирование/подавление переходных процессов в сигнале ясной речи, которые особенно трудно маскировать. Эту меру следует использовать осторожно, чтобы не ухудшить разборчивость для предопределенного слушателя.
-Снижение изменения уровня, например, с помощью процессора динамики (например, компрессора). Кроме того, при этом будет уменьшаться изменение оптимального маскирующего звука, так что этот звук будет становиться более приятным.
Согласно предпочтительному варианту осуществления изобретения модуль обработки аудио выполнен с возможностью приема сигнала настройки, содержащего информацию относительно настройки набора речевых громкоговорителей и/или настройки набора громкоговорителей маскирующего звука.
Благодаря этим особенностям модуль обработки аудио может быть легко адаптирован к различным конфигурациям громкоговорителей. Сигнал настройки может использоваться в генераторе сигналов речевых громкоговорителей, в генераторе сигналов громкоговорителей маскирующего звука и/или в генераторе маскирующего звука, в частности, в модулях адаптации исходных сигналов маскирующего звука.
Маскирующий звук можно адаптировать в реальном времени не только при использовании параметров, получаемых в результате анализа речевого сигнала. Как отмечается ниже, вместо этого можно использовать дополнительные источники информации.
Основным источником информации для адаптации маскирующего шума является сигнал, подлежащий маскированию (маскируемый сигнал). Он может быть дополнен измеряемыми сигналами. Вследствие причинной зависимости можно непосредственно рассматривать только предшествующие и текущие свойства сигнала. Однако из кодирования речи известно, что огибающую спектра можно в известной мере прогнозировать для отрезка времени в несколько десятков миллисекунд. Такой прогноз можно использовать для адаптации маскирующего звука к предполагаемым свойствам маскируемого звука. Кроме того, это позволяет осуществлять адаптацию маскирующего звука более медленно/гладко, так что он будет восприниматься как более приятный. Следует отметить, что это является альтернативой задержке воспроизводимой ясной речи.
Вторым источником информации могут быть задаваемые пользователем параметры, в соответствии с которыми можно регулировать степень маскировки. Если желательна только небольшая степень конфиденциальности, можно выбирать маскирующий звук таким, чтобы он был очень ненавязчивым. С другой стороны, если содержание речи является конфиденциальным и необходимо, чтобы ни одно слово не было понято подслушивающим лицом, обработку можно адаптировать к этому. В этом случае как предопределенный слушатель, так и подслушивающее лицо будут воспринимать более навязчивый маскирующий шум.
Кроме того, подслушивающее лицо может иметь ограниченный доступ к устройству для обработки звука, так что оно может задавать маскирующий звук исходя из своих предпочтений (например, оно может выбирать между различными маскирующими музыкальными сопровождениями). Важно, чтобы во время применяемых измерений не был период, в течение которого речь является понятной. Поэтому все музыкальное сопровождение должно выбираться заранее, поскольку не каждый фрагмент музыки/музыкального сопровождения пригоден для эффективной маскировки речи.
Согласно предпочтительному варианту осуществления изобретения генератор маскирующего звука выполнен с возможностью приема метеорологического сигнала, содержащего информацию относительно погодных условий, и создания одного или более сигналов маскирующего звука на основании метеорологического сигнала.
Метеорологический датчик может быть датчиком дождя или датчиком скорости ветра, который может использоваться для учета фактической погоды при образовании маскирующего шума (например, при использовании маскирующих звуков дождя или маскирующих звуков ветра).
Согласно предпочтительному варианту осуществления изобретения генератор маскирующего звука выполнен с возможностью приема светового сигнала, содержащего информацию относительно световых условий, и создания одного или более сигналов маскирующего звука на основании светового сигнала.
Согласно предпочтительному варианту осуществления изобретения генератор маскирующего звука выполнен с возможностью приема сигнала времени, содержащего информацию относительно даты и/или времени, и создания одного или более сигналов маскирующего звука на основании сигнала времени.
Световой сигнал, в частности световой сигнал, принимаемый с датчика света, может использоваться для создания маскирующего звука, который естественным образом соответствует световым условиям, которые, в частности, зависят от времени дня, и поэтому звук является менее раздражающим. То же самое может быть достигнуто при использовании сигнала времени, в частности сигнала времени, принимаемого с электронных часов.
Согласно предпочтительному варианту осуществления изобретения генератор маскирующего звука выполнен с возможностью приема сигнала двигателя, содержащего информацию относительно рабочего параметра образующего звук двигателя, и создания одного или более сигналов маскирующего звука на основании сигнала двигателя.
В частности, в сценарии в автомобиле данные, собираемые с двигателя, могут использоваться в качестве параметра при генерации искусственного шума. Кроме того, эта концепция может использоваться в других средствах транспортировки или в случаях, когда стационарные двигатели находятся вблизи устройства.
Согласно предпочтительному варианту осуществления изобретения устройство для воспроизведения речи содержит отслеживающее устройство, выполненное с возможностью отслеживания положения и/или ориентации человека в зоне ясной речи и/или отслеживания положения и/или ориентации человека, при этом отслеживающее устройство выполнено с возможностью создания сигнала отслеживания, содержащего положение и/или ориентацию человека в зоне ясной речи и/или положение и/или ориентацию человека в зоне маскированной речи, при этом модуль обработки аудио выполнен с возможностью приема сигнала отслеживания и создания одного или более сигналов громкоговорителей маскирующего звука на основании сигнала отслеживания.
Система отслеживания может предоставлять в реальном времени информацию о положениях и ориентациях говорящего лица и подслушивающего лица. Эта информация может использоваться, например, для повышения степени маскировки, когда они оба приближаются друг к другу или когда подслушивающее лицо поворачивает голову для лучшей слышимости.
Согласно предпочтительному варианту осуществления изобретения генератор сигналов громкоговорителей маскирующего звука выполнен с возможностью создания сигналов громкоговорителей маскирующего звука таким образом, чтобы маскирующий звук имел такие же пространственные признаки, как речь, в зоне маскированной речи.
Согласно предпочтительному варианту осуществления изобретения устройство для воспроизведения речи содержит один или более микрофонов, назначенных зоне ясной речи и/или зоне маскированной речи, при этом каждый из микрофонов создает сигнал микрофона.
Информация, собираемая модулем анализа речевых сигналов, может поддерживаться сигналами, измеряемыми микрофонами, расположенными в зоне ясной речи или вблизи нее и/или целиком вблизи зоны маскированной речи. В этом сценарии микрофон может добавляться в зону маскированной речи для изменения маскирующего шума на основании маскирующего сигнала, наблюдаемого в зоне маскированной речи.
Согласно предпочтительному варианту осуществления изобретения по меньшей мере два сигнала микрофонов из сигналов микрофонов подаются на генератор сигналов громкоговорителей маскирующего звука и при этом генератор сигналов громкоговорителей маскирующего звука выполнен с возможностью определения пространственных признаков речи в зоне маскированной речи на основании по меньшей мере двух сигналов микрофонов.
По меньшей мере два микрофона можно располагать в зоне маскированной речи или вблизи нее для определения направления прихода маскирующего сигнала и для регулирования генератора сигналов громкоговорителей маскирующего звука на основании этой информации таким образом, чтобы, например, маскируемый сигнал и маскирующий шум имели аналогичные пространственные признаки.
Благодаря этим особенностям в изобретении в качестве опции можно использовать средства пространственного воспроизведения для воспроизведения маскирующего звука в зоне маскированной речи, чтобы обнаруживать аналогичные пространственные свойства (особенно направление источника и направление преобладающих отражений) в качестве нежелательного сигнала ясной речи, который приходит в зону маскированной речи. Этим исключается использование преимущества пространственного слуха подслушивающих лиц в части отделения маскирующего звука от маскируемой речи.
Согласно предпочтительному варианту осуществления изобретения по меньшей мере один сигнал микрофона из сигналов микрофонов подается на генератор маскирующего звука, при этом генератор маскирующего звука выполнен с возможностью создания одного или более сигналов маскирующего звука на основании по меньшей одного сигнала микрофона.
В таких вариантах осуществления микрофон может вводиться в зону маскирующего звука или поблизости от нее для изменения маскирующего шума на основании речи, обнаруживаемой в зоне маскированной речи.
Согласно предпочтительному варианту осуществления изобретения генератор маскирующего звука выполнен с возможностью создания одного или более сигналов маскирующего звука на основании одной или более импульсных характеристик помещения и/или одной или более передаточных функций от набора речевых громкоговорителей до зоны ясной речи, на основании одной или более импульсных характеристик помещения и/или одной или более передаточных функций от набора маскирующих громкоговорителей до зоны ясной речи, на основании одной или более импульсных характеристик помещения и/или одной или более передаточных функций от набора речевых громкоговорителей до зоны маскированной речи и/или на основании одной или более импульсных характеристик помещения и/или одной или более переходных функций от набора громкоговорителей маскирующего звука до зоны маскированной речи.
Дополнительный микрофон может использоваться для измерения импульсных характеристик помещения и/или передаточных функций от системы воспроизведения ясной речи и маскирующего шума до зоны ясной речи и зоны маскированной речи (или по всем четырем путям) для улучшения оценок фактически воспроизводимых акустических сцен в обеих зонах. Эти оценки могут использоваться при адаптивной обработке маскирующего звука.
Согласно дальнейшему аспекту настоящего изобретения предложен способ воспроизведения речи на основании принимаемого речевого сигнала таким образом, чтобы воспроизводимая речь была разборчивой в зоне ясной речи и неразборчивой в зоне маскированной речи, при этом способ содержит этапы, на которых:
принимают речевой сигнал, используя модуль обработки аудио;
воспроизводят речь на основании одного или более сигналов речевых громкоговорителей, используя набор речевых громкоговорителей;
создают маскирующий звук на основании одного или более сигналов громкоговорителей маскирующего звука, используя набор громкоговорителей маскирующего звука, при этом маскирующим звуком маскируют речь в зоне маскированной речи;
создают один или более сигналов речевых громкоговорителей на основании речевого сигнала, используя генератор сигналов речевых громкоговорителей из модуля обработки аудио;
создают один или более сигналов анализа на основании спектральных и/или временных характеристик речевого сигнала, используя модуль анализа речевых сигналов из модуля обработки аудио;
создают один или более сигналов маскирующего звука на основании одного или более сигналов анализа, используя генератор маскирующего звука из модуля обработки аудио; и
создают один или более сигналов громкоговорителей маскирующего звука на основании одного или более сигналов маскирующего звука, используя генератор сигналов громкоговорителей маскирующего звука из модуля обработки аудио.
Кроме того, предложена компьютерная программа для выполнения способа согласно изобретению, когда она выполняется на процессоре.
Далее предпочтительные варианты осуществления изобретения будет рассмотрены со ссылкой на сопроводительные чертежи, на которых:
фиг. 1 - структурная схема устройства для воспроизведения речи согласно первому варианту осуществления изобретения;
фиг. 2 - структурная схема части устройства для воспроизведения речи согласно второму варианту осуществления изобретения;
фиг. 3 - структурная схема части устройства для воспроизведения речи согласно третьему варианту осуществления изобретения; и
фиг. 4 - структурная схема устройства для воспроизведения речи согласно четвертому варианту осуществления изобретения.
Относительно устройств и способов согласно вариантам осуществления, описываемых ниже следует отметить следующее:
Хотя некоторые аспекты описываются применительно к устройству, ясно, что эти аспекты также относятся к соответствующему способу, в котором блок или устройство соответствует этапу способа или особенности этапа способа. По аналогии с этим аспекты, описываемые применительно к этапам способа, также относятся к соответствующему блоку, или детали, или элементу соответствующего устройства.
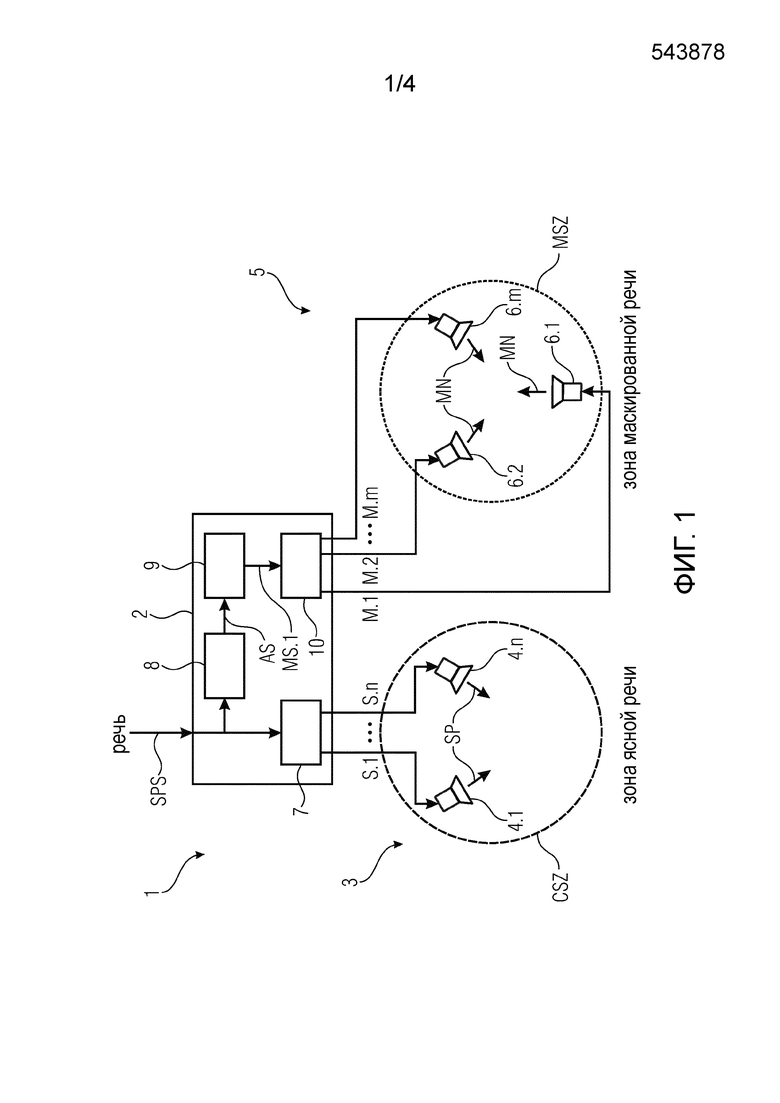
На фиг. 1 показана структурная схема устройства 1 для воспроизведения речи согласно первому варианту осуществления изобретения. Устройство 1 для воспроизведения речи выполнено с возможностью воспроизведения речи SP на основании принимаемого речевого сигнала SPS таким образом, что воспроизводимая речь SP является разборчивой в зоне CSZ ясной речи и неразборчивой в зоне MSZ маскированной речи. Устройство 1 для воспроизведения речи содержит:
модуль 2 обработки аудио, выполненный с возможностью приема речевого сигнала SPS;
набор 3 речевых громкоговорителей 4, выполненных с возможностью воспроизведения речи SP на основании одного или более сигналов S речевых громкоговорителей; и
набор 5 громкоговорителей 6 маскирующего звука, выполненных с возможностью создания маскирующего звука MN на основании одного или более сигналов M.1, M.2, …, M.m громкоговорителей маскирующего звука, при этом маскирующим звуком MN маскируется речь SP в зоне MSZ маскированной речи;
в котором модуль 2 обработки аудио содержит генератор 7 сигналов речевых громкоговорителей, выполненный с возможностью создания одного или более сигналов S.1, …, Sn речевых громкоговорителей на основании речевого сигнала SPS;
в котором модуль 2 обработки аудио содержит модуль 8 анализа речевых сигналов, выполненный с возможностью создания одного или более сигналов AS анализа на основании спектральных и/или временных характеристик речевого сигнала SPS;
в котором модуль 2 обработки аудио содержит генератор 9 маскирующего звука, выполненный с возможностью создания одного или более сигналов MS.1, MS.2, MS.3, MS.4 маскирующего звука на основании одного или более сигналов AS анализа; и
в котором модуль 2 обработки аудио содержит генератор 10 сигналов громкоговорителей маскирующего звука, выполненный с возможностью создания одного или более сигналов M.1, M.2, …, M.m громкоговорителей маскирующего звука на основании одного или более сигналов MS маскирующего звука.
Согласно предпочтительному варианту осуществления изобретения генератор 7 сигналов речевых громкоговорителей выполнен с возможностью создания множества сигналов S.1, …, S.n речевых громкоговорителей и независимого регулирования характеристик каждого сигнала S.1, …, S.n речевых громкоговорителей из множества сигналов S.1, …, S.n речевых громкоговорителей, чтобы регулировать пространственные признаки речи SP. В частности, характеристики сигналов S.1, …, S.n речевых громкоговорителей, подлежащие регулированию, могут содержать уровень и/или временную задержку каждого из сигналов S.1, …, S.n речевых громкоговорителей.
Согласно предпочтительному варианту осуществления изобретения генератор 10 сигналов громкоговорителей маскирующего звука выполнен с возможностью создания множества сигналов M.1, M2, …, M.m громкоговорителей маскирующего звука и независимого регулирования характеристик каждого сигнала M.1, M2, …, M.m громкоговорителей маскирующего звука из множества сигналов M.1, M2, …, M.m громкоговорителей маскирующего звука, чтобы регулировать пространственные признаки маскирующего звука MN. В частности, характеристики сигналов M.1, M.2, …, M.m громкоговорителей маскирующего звука, подлежащие регулированию, содержат уровень и/или временную задержку каждого из сигналов M.1, M.2, …, M.m громкоговорителей маскирующего звука.
Согласно другому аспекту изобретения предложен способ генерации речи SP на основании принимаемого речевого сигнала SPS таким образом, чтобы генерируемая речь SP была разборчивой в зоне CSZ ясной речи и неразборчивой в зоне MSZ маскированной речи, при этом способ содержит этапы, на которых:
принимают речевой сигнал SPS, используя модуль 2 обработки аудио;
генерируют речь SP на основании одного или более сигналов S.1, …, S.n речевых громкоговорителей, используя набор 3 речевых громкоговорителей 4.1, …, 4.n;
генерируют маскирующий звук MN на основании одного или более сигналов громкоговорителей маскирующего звука, используя набор 5 громкоговорителей 6.1, 6.2,…, 6.m маскирующего звука, при этом маскирующим звуком MN маскируют речь SP в зоне MSZ маскированной речи;
создают один или более сигналов S.1, …, S.n речевых громкоговорителей на основании речевого сигнала SPS, используя генератор 7 сигналов речевых громкоговорителей из модуля 2 обработки аудио;
создают один или более сигналов AS анализа на основании спектральных и/или временных характеристик речевого сигнала SPS, используя модуль 8 анализа речевых сигналов из модуля 2 обработки аудио;
создают один или более сигналов MS.1, MS.2, MS.3, MS.4 маскирующего звука на основании одного или более сигналов AS анализа, используя генератор 9 маскирующих звуков из модуля 2 обработки аудио; и
создают один или более сигналов M.1, M.2, …, M.m громкоговорителей маскирующего звука на основании одного или более сигналов MS.1, MS.2, MS.3, MS.4 маскирующего звука, используя генератор 10 сигналов громкоговорителей маскирующего звука из модуля 2 обработки аудио.
Согласно дальнейшему аспекту изобретения предложена компьютерная программа для выполнения способа согласно изобретению при выполнении программы на процессоре.
На фиг. 2 показана структурная схема части устройства для воспроизведения речи согласно второму варианту осуществления изобретения.
Согласно предпочтительному варианту осуществления изобретения генератор 9 маскирующего звука содержит множество источников 11.1, 11.2, 11.3, 11.4 маскирующего звука, выполненных с возможностью образования исходных сигналов RMS.1, RMS.2, RMS.3, RMS.4 маскирующего звука, и множество модулей 12.1, 12.2, 12.3, 12.4 адаптации исходных сигналов маскирующего звука, при этом каждый из модулей 12.1, 12.2, 12.3, 12.4 адаптации исходных сигналов маскирующего звука назначен одному из источников 11.1, 11.2, 11.3, 11.4 маскирующего звука, при этом каждый назначенный модуль 12.1, 12.2, 12.3, 12.4 адаптации маскирования выполнен с возможностью адаптации исходного сигнала RMS.1, RMS.2, RMS.3, RMS.4 маскирующего звука соответствующего источника 11.1, 11.2, 11.3, 11.4 маскирующего звука на основании сигнала AS анализа, чтобы создавать один или более сигналов MS.1, MS.2, MS.3, MS.4 маскирующего звука.
Согласно предпочтительному варианту осуществления изобретения по меньшей мере один источник 11.1, 11.2, 11.3, 11.4 маскирующего звука представляет собой источник 11.1 музыки, выполненный с возможностью образования исходного сигнала RMS.1 музыкального маскирующего звука, при этом назначенный модуль 12.1 адаптации маскировки выполнен с возможностью адаптации исходного сигнала RMS.1 музыкального маскирующего звука на основании сигнала AS анализа, чтобы создавать один сигнал MS.1 маскирующего звука из одного или более сигналов MS.1, MS.2, MS.3, MS.4 маскирующего звука.
Согласно предпочтительному варианту осуществления изобретения по меньшей мере один источник 11.1, 11.2, 11.3, 11.4 маскирующего звука представляет собой источник 11.2 непрерывного шума, выполненный с возможностью создания исходного сигнала RMS.2 непрерывного шумового маскирующего звука, при этом назначенный модуль 12.2 адаптации маскировки выполнен с возможностью адаптации исходного сигнала RMS.2 непрерывного шумового маскирующего звука на основании сигнала AS анализа, чтобы создавать один сигнал MS.2 маскирующего звука из одного или более сигналов MS.1, MS.2, MS.3, MS.4 маскирующего звука.
Согласно предпочтительному варианту осуществления изобретения по меньшей мере один источник 11.1, 11.2, 11.3, 11.4 маскирующего звука представляет собой источник 11.3 динамического шума, выполненный с возможностью создания исходного сигнала RMS.3 динамического шумового маскирующего звука, при этом назначенный модуль 12.3 адаптации маскировки выполнен с возможностью адаптации исходного сигнала RMS.3 динамического шумового маскирующего звука на основании сигнала AS анализа, чтобы создавать один сигнал MS.3 маскирующего звука из одного или более сигналов MS.1, MS.2, MS.3, MS.4 маскирующего звука.
Согласно предпочтительному варианту осуществления изобретения модуль 2 обработки аудио содержит модуль 13 адаптивной обработки речи, выполненный с возможностью образования адаптированного речевого сигнала ASPS на основании речевого сигнала SPS, при этом генератор 7 сигналов речевых громкоговорителей выполнен с возможностью создания одного или более сигналов S.1, …, S.n речевых громкоговорителей на основании адаптированного речевого сигнала ASPS.
Согласно предпочтительному варианту осуществления изобретения модуль 2 обработки аудио выполнен с возможностью приема сигнала SI настройки, содержащего информацию относительно настройки набора 3 речевых громкоговорителей 4.1, …, 4.n и/или настройки набора 5 громкоговорителей 6.1, 6.2, …, 6.m маскирующего звука.
Согласно фиг. 2 речевой сигнал SPS, подлежащий воспроизведению, принимается, например, по линии связи и воспроизводится громкоговорителями 4.1, …, 4.n в зоне CSZ ясной речи или вблизи нее при таком уровне, что речь можно легко понять. В то же самое время маскирующий звук MN создается в зоне MSZ маскированной речи таким образом, что воспроизводимая речь непонятна для людей в зоне MSZ маскированной речи.
Этап 2 обработки включает в себя использование модуля 8 анализа речевых сигналов для анализа поступающего речевого сигнала SPS. Результат AS анализа подается на отдельные блоки 12.1, 12.2, 12.3 адаптивной обработки трех различных маскирующих компонент: музыкальной, непрерывной шумовой и динамической шумовой. Музыкальные и непрерывные шумовые исходные маскирующие звуки (например, запись шума на берегу моря) могут воспроизводиться из устройств 11.1 и 11.2 хранения данных, тогда как динамический шум генерируется в реальном времени синтезатором 11.3. В зависимости от результатов анализа представленного отрезка 8 речи характеристики музыкальных и шумовых сигналов 11.1, 11.2, 11.3 адаптируются для получения хорошего маскирующего шума MN. С отдельных блоков 12.1, 12.2, 12.3 обработки могут выводиться либо монофонические сигналы, либо сигналы многочисленных каналов для создания специфических многоканальных эффектов. Затем обработанные музыкальные и шумовые сигналы MS.1, MS.2, MS.3 смешиваются в генераторе 10 сигналов громкоговорителей маскирующего звука с образованием достаточного количества сигналов M.1, M.2, …, M.n громкоговорителей для подачи на имеющиеся громкоговорители 6.1, 6.2, …, 6.m. Информация по настройке, которая является известной при адаптивной обработке, смешении и представлении сигналов, позволяет наилучшим образом использовать заданные характеристики (например, пространственное положение, частотную характеристику, особенности преобразователя и т.д.) для достижения эффекта маскировки.
При анализе вычисляют оценку воспринимаемой громкости (она также может быть основана целиком на энергии) речи SP. Музыкальный сигнал MS.1 и шумовые сигналы MS.1 и MS.2 непрерывно адаптируют, чтобы их громкость изменялась относительно громкости речи SP (маскируемого сигнала). При обработке можно использовать различные постоянные адаптации для всех трех компонент. В то время как динамический шум быстро адаптируют к быстрым изменениям маски в речи SP, непрерывный шумовой и музыкальный сигналы MS.1 и MS.2 адаптируют с медленным изменением с течением времени для поддержания общего приятного впечатления от звука. Для музыки и динамического шума минимальные уровни задают такими, чтобы не они не спадали до нуля во время пауз в речи (и чтобы громкость маскирующего звука приближалась к нулевой). Этим дополнительно повышают приятное восприятие.
На фиг. 3 показана структурная схема части устройства для воспроизведения речи согласно третьему варианту осуществления изобретения.
Первая модификация варианта осуществления, описанного ранее, заключается в том, что дополнительная адаптивная обработка речевого сигнала SPS выполняется модулем 13 адаптивной обработки речи, при этом адаптированный речевой сигнал ASPS используется для создания речи SP для зоны CSZ ясной речи. Кроме того, в этом варианте осуществления используются только две отдельные маскирующие компоненты MS.1, MS.4 (то есть, музыкальная и шумовая).
На фиг. 4 показана структурная схема устройства для воспроизведения речи согласно четвертому варианту осуществления изобретения.
Согласно предпочтительному варианту осуществления изобретения генератор 9 маскирующего звука выполнен с возможностью приема метеорологического сигнала WSI, содержащего информацию относительно погодных условий, и создания одного или более сигналов MS.1, MS.2, MS.3, MS.4 маскирующего звука на основании метеорологического сигнала WSI.
Согласно предпочтительному варианту осуществления изобретения генератор 9 маскирующего звука выполнен с возможностью приема светового сигнала LSI, содержащего информацию относительно световых условий, и создания одного или более сигналов MS.1, MS.2, MS.3, MS.4 маскирующего звука на основании светового сигнала LSI.
Согласно предпочтительному варианту осуществления изобретения генератор 9 маскирующего звука выполнен с возможностью приема сигнала TSI времени, содержащего информацию относительно даты и/или времени, и создания одного или более сигналов MS.1, MS.2, MS.3, MS.4 маскирующего звука на основании сигнала TSI времени.
Согласно предпочтительному варианту осуществления изобретения генератор 9 маскирующего звука выполнен с возможностью приема сигнала ESI двигателя, содержащего информацию относительно рабочего параметра образующего звук двигателя EG, и создания одного или более сигналов MS.1, MS.2, MS.3, MS.4 маскирующего звука на основании сигнала ESI двигателя.
Согласно предпочтительному варианту осуществления изобретения устройство 1 для воспроизведения речи содержит отслеживающее устройство 14, выполненное с возможностью отслеживания положения и/или ориентации человека в зоне CSZ ясной речи и/или отслеживания положения и/или ориентации человека в зоне MSZ маскированной речи, при этом отслеживающее устройство 14 выполнено с возможностью создания сигнала TRS отслеживания, содержащего положение и/или ориентацию человека в зоне CSZ ясной речи и/или положение и/или ориентацию человека в зоне MSZ маскированной речи, при этом модуль 2 обработки аудио выполнен с возможностью приема сигнала TRS отслеживания и создания одного или более сигналов M.1, M.2, …, M.m громкоговорителей маскирующего звука на основании сигнала TRS отслеживания.
Согласно предпочтительному варианту осуществления изобретения генератор 10 сигналов громкоговорителей маскирующего звука выполнен с возможностью создания сигналов MSI.1, MSI.2 громкоговорителей маскирующего звука таким образом, чтобы маскирующий звук MN имел такие же пространственные признаки, как речь SP, в зоне MSZ маскированной речи.
Согласно предпочтительному варианту осуществления изобретения устройство 1 для воспроизведения звука содержит один или более микрофонов 15.1, 15.2, назначенных зоне MSZ маскированной речи, при этом каждый из микрофонов 15.1, 15.2 создает сигнал MSI.1, MSI.2 микрофона.
Согласно предпочтительному варианту осуществления изобретения по меньшей мере два сигнала MSI.1, MSI.2 микрофонов из сигналов MSI.1, MSI.2 микрофонов подаются на генератор 10 сигналов громкоговорителей маскирующего звука, и при этом генератор 10 сигналов громкоговорителей маскирующего звука выполнен с возможностью определения пространственных признаков речи SP в зоне MSZ маскированной речи на основании по меньшей мере двух сигналов MSI.1, MSI.2 микрофонов.
Согласно предпочтительному варианту осуществления изобретения по меньшей мере один сигнал MSI.2 микрофона из сигналов MSI.1, MSI.2 микрофонов подается на генератор 9 маскирующего звука, при этом генератор 9 маскирующего звука выполнен с возможностью создания одного или более сигналов MS.1, MS.2, MS.3, MS.4 маскирующего звука на основании по меньшей мере одного сигнала MSI.1, MSI.2 микрофона.
Согласно предпочтительному варианту осуществления изобретения генератор 9 маскирующего звука выполнен с возможностью создания одного или более сигналов MS.1, MS.2, MS.3, MS.4 маскирующего звука на основании одной или более импульсных характеристик помещения и/или одной или более передаточных функций от набора 3 речевых громкоговорителей 4.1, …, 4.n до зоны CSZ ясной речи, на основании одной или более импульсных характеристик помещения и/или одной или более передаточных функций от набора 5 громкоговорителей 6.1, 6.2,…, 6.m маскирующего звука до зоны CSZ ясной речи, на основании одной или более импульсных характеристик помещения и/или одной или более передаточных функции от набора 3 речевых громкоговорителей 4.1, …, 4.n до зоны MSZ маскированной речи и/или на основании одной или более импульсных характеристик помещения и/или передаточных функций от набора 5 громкоговорителей 6.1, 6.2, …, 6.m маскирующего звука до зоны MSZ маскированной речи.
В зависимости от конкретных требований к реализации варианты осуществления изобретения могут выполняться аппаратным обеспечением или программным обеспечением. Выполнение можно осуществлять, используя цифровой носитель данных, например дискету, цифровой универсальный диск, компакт-диск, постоянное запоминающее устройство, программируемое постоянное запоминающее устройство, стираемое программируемое постоянное запоминающее устройство, электронно-перепрограммируемое постоянное запоминающее устройство или флэш-память, при наличии на нем электронно-считываемых управляющих сигналов, который взаимодействует (или способен взаимодействовать) с программируемой компьютерной системой при выполнении соответствующего способа.
В некоторых вариантах осуществления согласно изобретению содержится носитель данных, имеющий электронно-считываемые управляющие сигналы, которые способны взаимодействовать с программируемой компьютерной системой при выполнении одного из способов, описанных в этой заявке.
Обычно варианты осуществления настоящего изобретения могут выполняться как компьютерный программный продукт с программным кодом, при этом программный код используется для выполнения одного из способов, когда компьютерный программный продукт выполняется на компьютере. Программный код может сохраняться, например, на машиночитаемом носителе.
В других вариантах осуществления содержится компьютерная программа для выполнения одного из способов, описанных в этой заявке, которая сохраняется на машиночитаемом носителе или нетранзиторном носителе данных.
Иначе говоря, поэтому вариант осуществления способа изобретения представляет собой компьютерную программу, имеющую программный код для выполнения одного из способов, описанных в этой заявке, когда компьютерная программа выполняется на компьютере.
Поэтому в дальнейшем варианте осуществления способов изобретения используется носитель данных (или цифровой носитель данных или машиночитаемый носитель), содержащий компьютерную программу, записанную на нем, для выполнения одного из способов, описанных в этой заявке.
Поэтому в дальнейшем варианте осуществления способа изобретения используется поток данных или последовательность сигналов, представляющих компьютерную программу для выполнения одного из способов, описанных в этой заявке. Поток данных или последовательность сигналов может быть сконфигурирована, например, для передачи по сети передачи данных, например по Интернету.
В дальнейшем варианте осуществления содержится средство обработки, например компьютер или программируемое логическое устройство, сконфигурированное или адаптированное для выполнения одного из способов, описанных в этой заявке.
В дальнейшем варианте осуществления содержится компьютер, имеющий компьютерную программу, установленную на нем, для выполнения одного из способов, описанных в этой заявке.
В некоторых вариантах осуществления программируемое логическое устройство (например, логическая микросхема, программируемая в условиях эксплуатации) может использоваться для выполнения некоторых или всех функциональных элементов способов, описанных в этой заявке. В некоторых вариантах осуществления логическая микросхема, программируемая в условиях эксплуатации, может взаимодействовать с микропроцессором для выполнения одного из способов, описанных в этой заявке. Обычно предпочтительно выполнять способы с помощью любого аппаратного обеспечения.
Хотя это изобретение было описано применительно к нескольким вариантам осуществления, возможны изменения, перестановки и эквиваленты, которые попадают в объем этого изобретения. Следует отметить, что имеются многочисленные пути реализации способов и составных частей настоящего изобретения. Поэтому предполагается, что нижеследующая прилагаемая формула изобретения будет интерпретироваться как включающая все такие изменения, перестановки или эквиваленты, попадающие в пределы истинной сущности и объем настоящего изобретения.
ССЫЛОЧНЫЕ ПОЗИЦИИ
1 - устройство для воспроизведения речи
2 - модуль обработки аудио
3 - набор речевых громкоговорителей
4 - речевой громкоговоритель
5 - набор громкоговорителей маскирующего звука
6 - громкоговоритель маскирующего звука
7 - генератор сигналов речевых громкоговорителей
8 - модуль анализа речевых сигналов
9 - генератор маскирующего звука
10 - генератор сигналов громкоговорителей маскирующего звука
11 - источник маскирующего звука
12 - модуль адаптации исходных сигналов маскирующего звука
13 - модуль адаптивной обработки речи
14 - отслеживающее устройство
15 - микрофон
SP - речь
SPS - речевой сигнал
CSZ - зона ясной речи
MSZ - зона маскированной речи
S - сигналы речевых громкоговорителей
MN - маскирующий звук
M - сигналы громкоговорителей маскирующего звука
AS - сигнал анализа
MS - сигнал маскирующего звука
RMS - исходный сигнал маскирующего звука
SI - информационный сигнал настройки
ASPS - адаптированный речевой сигнал
WSI - метеорологический сигнал
WS - метеорологический датчик
LSI - световой сигнал
LS - датчик света
TSI - сигнал времени
TS - генератор сигнала времени
TRS - сигнал отслеживания
MSI - сигнал микрофона
ESI - сигнал двигателя
EG - двигатель
СПИСОК ЛИТЕРАТУРЫ
1. Chatterblocker software: www.chatterblocker.com.
2. Babak Arvanaghi and Joel Fechter: Method and apparatus for masking speech in a private environment. United States Patent Application No.: US2013/0185061, 2013.
3. Robert Bailey, Lawrence Heyl, and Stephan Schell: Systems and methods for altering speech during cellular phone use. United States Patent Application No.: US2009/0171670, 2009.
4. Stephen J. Elliott and Philip A. Nelson: Active noise control. In: Signal Processing Magazine, IEEE, 10(4): 12-35, 1993.
5. Andre L. Esperance and Alex Boudreau: Auto-adjusting sound masking system and method. United States Patent No.: US7460675, 2008.
6. Rafik Goubran and Radamis Botros: Adaptive sound masking system and method. United States Patent Application No.: US2003/0103632, 2003.
7. Nakamura Ikuya and Ogiwara Takashi: Speech privacy protective device. Japanese Patent Applications Nos.: JP3377220 and JP5011780, 1991.
8. Mai Koike, Yasushi Shimizu, Masato Hata and Takashi Yamakawa: Masker sound generation apparatus and program. United States Patent Application No.: US2011/0182438 A1, 2011.
9. Kenneth P. Roy, Thomas J. Johnson, Ronald Fuller and Steve Dove: Architectural sound enhancement with pre-filtered masking sound. United States Patent No.: US7548854, 2009.
10. Jeffrey Specht, Daniel Mapes-Riordan, and William DeKruif: Method and apparatus of overlapping and summing speech for an output that disrupts speech. United States Patent No.: US7376557, 2008.
11. Richard O. Thomalla: Automatic volume and frequency controlled sound masking system. United States Patent No.: US4438526, 1984.
12. Bill G. Watters, Michael Naceyand Thomas R. Horrall: Process and apparatus for speech privacy improvement through incoherent masking noise sound generation in open-plan office spaces and the like. United States Patent No.: US4059726 1977.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ ФОРМИРОВАНИЯ РЕЧЕПОДОБНОГО МАСКИРУЮЩЕГО СИГНАЛА | 2005 |
|
RU2308159C2 |
| СПОСОБ МАШИННОЙ ОЦЕНКИ КАЧЕСТВА ПЕРЕДАЧИ РЕЧИ | 2010 |
|
RU2435232C1 |
| ФОРМИРОВАТЕЛЬ РЕЧЕПОДОБНОГО ШУМОВОГО СИГНАЛА | 2005 |
|
RU2310282C2 |
| СПОСОБ И УСТРОЙСТВО ФОРМИРОВАНИЯ МАСКИРУЮЩЕЙ ПОМЕХИ | 1999 |
|
RU2154893C1 |
| СПОСОБ ЗАЩИТЫ КОНФИДЕНЦИАЛЬНОЙ АКУСТИЧЕСКОЙ ИНФОРМАЦИИ И УСТРОЙСТВО ДЛЯ ЕГО ОСУЩЕСТВЛЕНИЯ | 2007 |
|
RU2348114C2 |
| Способ маскировки электромагнитного канала утечки речевой информации в цифровых радиолиниях связи | 2019 |
|
RU2699826C1 |
| СПОСОБ МАСКИРОВАНИЯ АКУСТИЧЕСКОЙ ЛИНИИ СВЯЗИ | 1998 |
|
RU2167497C2 |
| СПОСОБ ФОРМИРОВАНИЯ МАСКИРУЮЩЕЙ ПОМЕХИ ДЛЯ ЗАЩИТЫ РЕЧЕВОЙ ИНФОРМАЦИИ | 2016 |
|
RU2622631C1 |
| СПОСОБ И УСТРОЙСТВО АКТИВНОЙ ЗАЩИТЫ КОНФИДЕНЦИАЛЬНОЙ РЕЧЕВОЙ ИНФОРМАЦИИ ОТ УТЕЧКИ ПО АКУСТО-ОПТО-ВОЛОКОННОМУ КАНАЛУ НА ОСНОВЕ ВНЕШНЕГО ОПТИЧЕСКОГО ЗАШУМЛЕНИЯ | 2009 |
|
RU2416167C2 |
| УСТРОЙСТВО МАСКИРОВКИ ЭЛЕКТРОМАГНИТНЫХ КАНАЛОВ УТЕЧКИ РЕЧЕВЫХ СИГНАЛОВ ЗВУКОУСИЛИТЕЛЬНОЙ АППАРАТУРЫ | 2005 |
|
RU2282309C1 |



Изобретение относится к устройству для воспроизведения речи, предназначенному для воспроизведения речи на основании принимаемого речевого сигнала таким образом, чтобы воспроизводимая речь была разборчивой в зоне ясной речи и неразборчивой в зоне маскированной речи, при этом устройство для воспроизведения речи содержит: модуль обработки аудио, выполненный с возможностью приема речевого сигнала; набор речевых громкоговорителей, выполненных с возможностью воспроизведения речи на основании одного или более сигналов речевых громкоговорителей; и набор громкоговорителей маскирующего звука, выполненных с возможностью создания маскирующего звука на основании одного или более сигналов громкоговорителей маскирующего звука, при этом маскирующим звуком маскируется речь в зоне маскированной речи; при этом модуль обработки аудио содержит модуль анализа речевых сигналов, выполненный с возможностью создания одного или более сигналов анализа на основании спектральных и/или временных характеристик речевого сигнала, модуль обработки аудио содержит генератор маскирующего звука, выполненный с возможностью создания одного или более сигналов маскирующего звука на основании одного или более сигналов анализа. 3 н. и 18 з.п. ф-лы, 4 ил.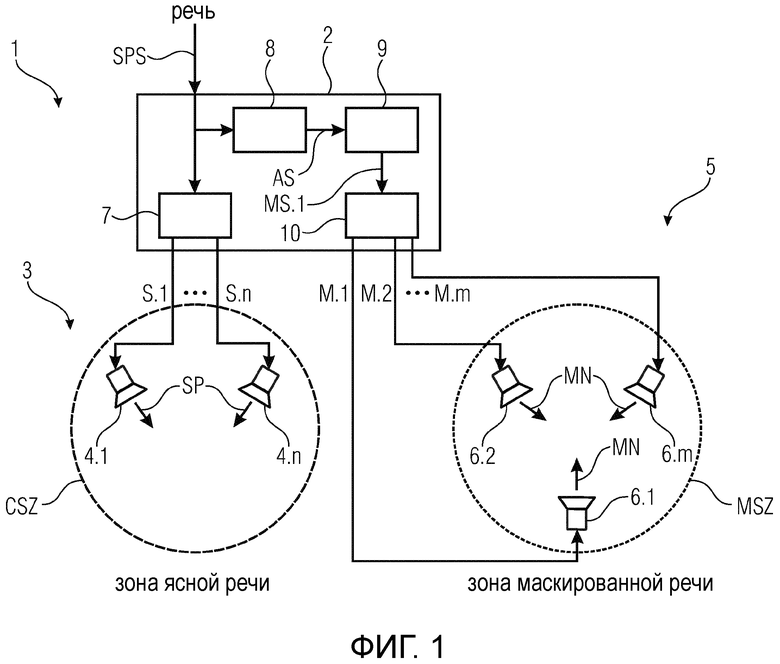
1. Устройство для воспроизведения речи, предназначенное для воспроизведения речи (SP) на основании принимаемого речевого сигнала (SPS) таким образом, чтобы воспроизводимая речь (SP) была разборчивой в зоне (CSZ) ясной речи и неразборчивой в зоне (MSZ) маскированной речи, при этом устройство (1) для воспроизведения речи содержит:
модуль (2) обработки аудио, выполненный с возможностью приема речевого сигнала (SPS);
набор (3) речевых громкоговорителей (4), выполненных с возможностью воспроизведения речи (SP) на основании одного или более сигналов (S) речевых громкоговорителей; и
набор (5) громкоговорителей (6) маскирующего звука, выполненных с возможностью создания маскирующего звука (MN) на основании одного или более сигналов (M.1, M.2, …, M.m) громкоговорителей маскирующего звука, при этом маскирующим звуком (MN) маскируется речь (SP) в зоне (MSZ) маскированной речи;
при этом модуль (2) обработки аудио содержит генератор (7) сигналов речевых громкоговорителей, выполненный с возможностью создания одного или более сигналов (S.1, …, S.n) речевых громкоговорителей на основании речевого сигнала (SPS);
модуль (2) обработки аудио содержит модуль (8) анализа речевых сигналов, выполненный с возможностью создания одного или более сигналов (AS) анализа на основании спектральных и/или временных характеристик речевого сигнала (SPS);
модуль (2) обработки аудио содержит генератор (9) маскирующего звука, выполненный с возможностью создания одного или более сигналов (MS.1, MS.2, MS.3, MS.4) маскирующего звука на основании одного или более сигналов (AS) анализа; и
модуль (2) обработки аудио содержит генератор (10) сигналов громкоговорителей маскирующего звука, выполненный с возможностью создания одного или более сигналов (M.1, M.2, …, M.m) громкоговорителей маскирующего звука на основании одного или более сигналов (MS) маскирующего звука.
2. Устройство для воспроизведения речи по предшествующему пункту, в котором генератор (7) сигналов речевых громкоговорителей выполнен с возможностью создания множества сигналов (S.1, …, S.n) речевых громкоговорителей и независимого регулирования характеристик каждого сигнала (S.1, …, S.n) речевого громкоговорителя из множества сигналов (S.1, …, S.n) речевых громкоговорителей, чтобы регулировать пространственные признаки речи (SP).
3. Устройство для воспроизведения речи по п. 1, в котором генератор (10) сигналов громкоговорителей маскирующего звука выполнен с возможностью создания множества сигналов (M.1, M.2, …, M.m) громкоговорителей маскирующего звука и независимого регулирования характеристик каждого сигнала (M.1, M.2, …, M.m) громкоговорителя маскирующего звука из множества сигналов (M.1, M.2, …, M.m) громкоговорителей маскирующего звука, чтобы регулировать пространственные признаки маскирующего звука (MN).
4. Устройство для воспроизведения речи по п. 1, в котором генератор (9) маскирующего звука содержит множество источников (11.1, 11.2, 11.3, 11.4) маскирующего звука, выполненных с возможностью создания исходного сигнала (RMS.1, RMS.2, RMS.3, RMS.4) маскирующего звука, и множество модулей (12.1, 12.2, 12.3, 12.4) адаптации исходных сигналов маскирующего звука, при этом каждый из модулей (12.1, 12.2, 12.3, 12.4) адаптации исходных сигналов маскирующего звука назначен одному из источников (11.1, 11.2, 11.3, 11.4) маскирующего звука, причем назначенный модуль (12.1, 12.2, 12.3, 12.4) адаптации маскировки выполнен с возможностью адаптации исходного сигнала (RMS.1, RMS.2, RMS.3, RMS.4) маскирующего звука соответствующих источников (11.1, 11.2, 11.3, 11.4) маскирующего звука на основании сигнала (AS) анализа, чтобы создавать один сигнал маскирующего звука из одного или более сигналов (MS.1, MS.2, MS.3, MS.4) маскирующего звука.
5. Устройство для воспроизведения речи по предшествующему пункту, в котором по меньшей мере один источник (11.1, 11.2, 11.3, 11.4) маскирующего звука содержит источник (11.1) музыки, выполненный с возможностью создания исходного сигнала (RMS.1) музыкального маскирующего звука, при этом назначенный модуль (12.1) адаптации маскировки выполнен с возможностью адаптации исходного сигнала (RMS.1) музыкального маскирующего звука на основании сигнала (AS) анализа, чтобы создавать один сигнал (MS.1) маскирующего звука из одного или более сигналов (MS.1, MS.2, MS.3, MS.4) маскирующего звука.
6. Устройство для воспроизведения речи по п. 4, в котором по меньшей мере один источник (11.1, 11.2, 11.3, 11.4) маскирующего звука содержит источник (11.2) непрерывного шума, выполненный с возможностью создания исходного сигнала (RMS.2) непрерывного шумового маскирующего звука, при этом назначенный модуль (12.2) адаптации маскировки выполнен с возможностью адаптации исходного сигнала (RMS.2) непрерывного шумового маскирующего звука на основании сигнала (AS) анализа, чтобы создавать один сигнал (MS.2) маскирующего звука из одного или более сигналов (MS.1, MS.2, MS.3, MS.4) маскирующего звука.
7. Устройство для воспроизведения речи по п. 4, в котором по меньшей мере один источник (11.1, 11.2, 11.3, 11.4) маскирующего звука содержит источник (11.3) динамического шума, выполненный с возможностью создания исходного сигнала (RMS.3) динамического шумового маскирующего звука, при этом назначенный модуль (12.3) адаптации маскировки выполнен с возможностью адаптации исходного сигнала (RMS.3) динамического шумового маскирующего звука на основании сигнала (AS) анализа, чтобы создавать один сигнал (MS.3) маскирующего звука из одного или более сигналов (MS.1, MS.2, MS.3, MS.4) маскирующего звука.
8. Устройство для воспроизведения речи по п. 1, в котором модуль (2) обработки аудио содержит модуль (13) адаптивной обработки речи, выполненный с возможностью создания адаптированного речевого сигнала (ASPS) на основании речевого сигнала (SPS), при этом генератор (7) сигналов речевых громкоговорителей выполнен с возможностью создания одного или более сигналов (S.1, …, S.n) речевых громкоговорителей на основании адаптированного речевого сигнала (ASPS).
9. Устройство для воспроизведения речи по п. 1, в котором модуль (2) обработки аудио выполнен с возможностью приема сигнала (SI) настройки, содержащего информацию относительно настройки набора (3) речевых громкоговорителей (4.1, …, 4.n) и/или настройки набора (5) громкоговорителей (6.1, 6.2, …, 6.m) маскирующего звука.
10. Устройство для воспроизведения речи по п. 1, в котором генератор (9) маскирующего звука выполнен с возможностью приема метеорологического сигнала (WSI), содержащего информацию относительно погодных условий, и создания одного или более сигналов (MS.1, MS.2, MS.3, MS.4) маскирующего звука на основании метеорологического сигнала (WSI).
11. Устройство для воспроизведения речи по п. 1, в котором генератор (9) маскирующего звука выполнен с возможностью приема светового сигнала (LSI), содержащего информацию относительно световых условий, и создания одного или более сигналов (MS.1, MS.2, MS.3, MS.4) маскирующего звука на основании светового сигнала (LSI).
12. Устройство для воспроизведения речи по п. 1, в котором генератор (9) маскирующего звука выполнен с возможностью приема сигнала (TSI) времени, содержащего информацию относительно даты и/или времени, и создания одного или более сигналов (MS.1, MS.2, MS.3, MS.4) маскирующего звука на основании сигнала (TSI) времени.
13. Устройство для воспроизведения речи по п. 1, в котором генератор (9) маскирующего звука выполнен с возможностью приема сигнала (ESI) двигателя, содержащего информацию относительно рабочего параметра образующего звук двигателя (EG), и создания одного или более сигналов (MS.1, MS.2, MS.3, MS.4) маскирующего звука на основании сигнала (ESI) двигателя.
14. Устройство для воспроизведения речи по п. 1, при этом устройство (1) для воспроизведения речи содержит отслеживающее устройство (14), выполненное с возможностью отслеживания положения и/или ориентации человека в зоне (CSZ) ясной речи и/или отслеживания положения и/или ориентации человека в зоне (MSZ) маскированной речи, при этом отслеживающее устройство (14) выполнено с возможностью создания сигнала (TRS) отслеживания, содержащего положение и/или ориентацию человека в зоне (CSZ) ясной речи и/или положение и/или ориентацию человека в зоне (MSZ) маскированной речи, при этом модуль (2) обработки аудио выполнен с возможностью приема сигнала (TRS) отслеживания и создания одного или более сигналов (M.1, M.2, …, M.m) громкоговорителей маскирующего звука на основании сигнала (TRS) отслеживания.
15. Устройство для воспроизведения речи по п. 1, в котором генератор (10) сигналов громкоговорителей маскирующего звука выполнен с возможностью создания сигналов (MSI.1, MSI.2) громкоговорителей маскирующего звука таким образом, чтобы маскирующий звук (MN) имел такие же пространственные признаки, как речь (SP), в зоне (MSZ) маскированной речи.
16. Устройство для воспроизведения речи по п. 1, при этом устройство (1) для воспроизведения речи содержит один или более микрофонов (15.1, 15.2), назначенных зоне (MSZ) маскированной речи, при этом каждый из микрофонов (15.1, 15.2) создает сигнал (MSI.1, MSI.2) микрофона.
17. Устройство для воспроизведения речи по п. 15, в котором по меньшей мере два сигнала (MSI.1, MSI.2) микрофонов из сигналов (MSI.1, MSI.2) микрофонов подаются на генератор (10) сигналов громкоговорителей маскирующего звука, при этом генератор (10) сигналов громкоговорителей маскирующего звука выполнен с возможностью определения пространственных признаков речи (SP) в зоне (MSZ) маскированной речи на основании по меньшей мере двух сигналов (MSI.1, MSI.2) микрофонов.
18. Устройство для воспроизведения речи по п. 16, в котором по меньшей мере один сигнал (MSI.2) микрофона из сигналов (MSI.1, MSI.2) микрофонов подается на генератор (9) маскирующего звука, при этом генератор (9) маскирующего звука выполнен с возможностью создания одного или более сигналов (MS.1, MS.2, MS.3, MS.4) маскирующего звука на основании по меньшей мере одного сигнала (MSI.1, MSI.2) микрофона.
19. Устройство для воспроизведения речи по п. 1, в котором генератор (9) маскирующего звука выполнен с возможностью создания одного или более сигналов (MS.1, MS.2, MS.3, MS.4) маскирующего звука на основании одной или более импульсных характеристик помещения и/или одной или более передаточных функций от набора (3) речевых громкоговорителей (4.1, …, 4.n) до зоны (CSZ) ясной речи, на основании одной или более импульсных характеристик помещения и/или одной или более передаточных функций от набора (5) громкоговорителей (6.1, 6.2, …, 6.m) маскирующего звука до зоны (CSZ) ясной речи, на основании одной или более импульсных характеристик помещения и/или одной или более передаточных функций от набора (3) речевых громкоговорителей (4.1, …, 4.n) до зоны (MSZ) маскированной речи и/или на основании одной или более импульсных характеристик помещения и/или одной или более передаточных функций от набора (5) громкоговорителей (6.1, 6.2, …, 6.m) маскирующего звука до зоны (MSZ) маскированной речи.
20 Способ воспроизведения речи (SP) на основании принимаемого речевого сигнала (SPS) таким образом, чтобы воспроизводимая речь (SP) была разборчивой в зоне (CSZ) ясной речи и неразборчивой в зоне (MSZ) маскированной речи, при этом способ содержит этапы, на которых:
принимают речевой сигнал (SPS), используя модуль (2) обработки аудио;
воспроизводят речь (SP) на основании одного или более сигналов (S.1, …, S.n) речевых громкоговорителей, используя набор (3) речевых громкоговорителей (4.1, …, 4.n);
создают маскирующий звук (MN) на основании одного или более сигналов громкоговорителей маскирующего звука, используя набор (5) громкоговорителей (6.1, 6.2, …, 6.m) маскирующего звука, при этом маскирующим звуком (MN) маскируют речь (SP) в зоне (MSZ) маскированной речи;
создают один или более сигналов (S.1, …, S.n) речевых громкоговорителей на основании речевого сигнала (SPS), используя генератор (7) сигналов речевых громкоговорителей из модуля (2) обработки аудио;
создают один или более сигналов (AS) анализа на основании спектральных и/или временных характеристик речевого сигнала (SPS), используя модуль (8) анализа речевых сигналов из модуля (2) обработки аудио;
создают один или более сигналов (MS.1, MS.2, MS.3, MS.4) маскирующего звука на основании одного или более сигналов (AS) анализа, используя генератор (9) маскирующего звука из модуля (2) обработки аудио; и
создают один или более сигналов (M.1, M.2,…, M.m) громкоговорителей маскирующего звука на основании одного или более сигналов (MS.1, MS.2, MS.3, MS.4) маскирующего звука, используя генератор (10) сигналов громкоговорителей маскирующего звука из модуля (2) обработки аудио.
21. Компьютерная программа для выполнения способа согласно предшествующему пункту, когда она выполняется на процессоре.
| US 2013259254 A1, 03.10.2013 | |||
| US 4052720 A, 04.10.1977 | |||
| WO 2009156928 A1, 30.12.2009 | |||
| RU 2011106029 A, 27.08.2012. |

