Изобретение относится к способам анализа звуковых сигналов, передаваемых по каналам радиосвязи, телефонии и трактам переговорных устройств для осуществления оценки качества передачи речи.
Оценка качества передачи звуковых сигналов приобретает все большее значение с ростом распространения и использования мобильной связи, систем синтетической телефонии, различных портативных звукозаписывающих и звуковоспроизводящих устройств.
Качество передачи и приема речи - один из основных показателей качества телекоммуникационных систем. При определении качества связи необходимо учитывать не только изменения сигнала, вызванные передачей по сетям связи, но и свойства речи диктора, свойства слуха аудитора и изменение этих свойств со временем.
Количественное измерение качества звука имеет свои специфические особенности, связанные с тем, что, в конечном итоге, приемником звукового сигнала всегда является человек, и он же является источником большинства звуковых сигналов. Соответственно, качество звуковых сигналов определяется не только техническими характеристиками систем обработки и передачи звука, но и свойствами речевого аппарата и слуха людей, изменяющимися со временем и от человека к человеку.
Исторически первым критерием, по которому оценивалось качество передачи речи, была громкость. Именно громкость была положена в основу метода определения эквивалента затухания, рекомендованного Международным консультационным комитетом по телефонии (МККФ) в 1928 году.
Различают субъективные и объективные методы измерения качества речи. Субъективные методы - это методы, в которых слух человека является составной частью измерительного комплекса. Соответственно, объективные методы исключают участие слуха человека из процесса измерений.
Наиболее распространенные методы оценки качества систем передачи речи были разработаны сектором по стандартизации телекоммуникаций Международного союза электросвязи (МСЭ-Т) в середине 90-х годов. Результаты представлены в документе Рекомендация Р.800 (Р.830) "Методы субъективной оценки качества речевой связи". В нем рассмотрены условия проведения тестовых испытаний, содержание тестовых звуковых сигналов, системы оценок и методы анализа полученных результатов. Чаще всего "Методы субъективной оценки качества речевой связи" используют для получения средней субъективной оценки качества речи по пятибалльной шкале (Mean Opinion Score - MOS).
Оценка по шкале MOS определяется путем обработки оценок, даваемых группами аудиторов нескольким звуковым сигналам, воспроизводимым различными аудиосистемами. Каждый аудитор выносит оценку каждого сигнала, после чего результаты усредняются.
К сожалению, тесты рекомендации Р.800 могут приводить к получению неоднозначных результатов. Авторы рекомендации сами предупреждают о некорректности сравнения оценок MOS, полученных в разных условиях. Кроме того, тестирование в соответствии с рекомендацией Р.800 занимает много времени и требует участия в тестировании большого количества тестировщиков.
Для того чтобы перейти от субъективных оценок (MOS) к объективным и автоматизировать измерительный процесс, МСЭ-Т разработал рекомендацию Р.861, основанную на низкоуровневых количественных измерениях. Рекомендация Р.861 представляет собой развитие метода PSQM (Perceptual Speech Quality Measurement), разработанного компанией KPN Research и предназначенного для объективного анализа работы речевых кодеков, характеризуемых малыми искажениями.
Однако использование алгоритма PSQM для оценки работы реальной системы связи невозможно, т.к. в нем не учтены некоторые важные факторы, оказывающие негативное влияние на восприятие речи. К ним относятся: задержки, их флуктуации (джиттер), потеря пакетов, а также клиппирование сигнала по уровню.
В феврале 2001 года вышла новая рекомендация ITU-T Р.862, описывающая более совершенный алгоритм тестирования - PESQ (Perceptual Evaluation of Speech Quality). Алгоритм PESQ включает в себя такие операции, как выравнивание уровней, временное выравнивание, моделирование восприятия человеком и когнитивное моделирование. В результате этих дополнительных операций в алгоритме учитываются: усиление/затухание сигнала в системе связи, временные задержки и джиттер, наиболее значимые для восприятия человеком области спектра. Кроме того, по результатам когнитивного моделирования объективная оценка переводится в субъективное значение MOS.
Недостатком PESQ и других подобных алгоритмов является то, что они основываются на сравнении двух сигналов: исходного и прошедшего через систему связи. Такой подход к тестированию создает целый ряд сложностей, связанных с его организацией и проведением. Требуется организовать запись сигнала на обеих сторонах системы связи и передачу записей на систему тестирования. Кроме того, мониторинг качества связи в режиме реального времени становится весьма затруднительным.
Для решения этой проблемы была разработана новая рекомендация. В мае 2004 года ITU-T утвердил рекомендацию Р.563, определяющую алгоритм мониторинга для оценки качества речевой связи путем прослушивания сеансов связи. Он учитывает односторонние искажения, параметры речевого тракта, естественность и уровень шума в речи. Алгоритм Р.563 применим для предсказания речи без использования отдельного референс-сигнала. По этой причине этот метод рекомендован для неразрушающей оценки качества речи, мониторинга работы сети и оценки с использованием неизвестных источников речи на другой стороне телефонного соединения.
Подход Р.563 может быть представлен как эксперт, прослушивающий реальный телефонный разговор с помощью тестирующего устройства типа обычной телефонной трубки, подключенной в линию параллельно. Это представление объясняет основной способ использования и позволяет пользователю определить характеристики оценок, получаемых по Р.563.
Оценки качества, предсказываемые Р.563, определяются качеством восприятия через обычную телефонную трубку в точке замера. Следовательно, прослушивающее устройство должно быть частью подхода Р.563. Поэтому каждый сигнал должен быть сначала предобработан. Эта предобработка начинается с модели принимающей телефонной трубки. Затем применяется детектор речевой активности (VAD) для определения порций сигнала, содержащих речь, и вычисления уровня речи. И наконец, уровень речи выставляется примерно на - 26 dBov.
Предобработанный сигнал, чтобы быть оцененным, обрабатывается несколькими независимыми анализаторами, которые подобно массиву сенсоров определяют характеристики сигнала. Сначала этот анализ применяется ко всему сигналу. Основываясь на наборе ключевых параметров, определяется класс основных искажений. Основные параметры и определенный класс искажений используются для настройки модели качества речи. Это обеспечивает базовую перцептивную надбавку, когда в одном сигнале происходит одновременно несколько типов искажений, но одни из них проявляются сильнее, чем другие.
Считается, что алгоритм Р.563 обеспечивает высокий уровень корреляции автоматических оценок с экспертными. Однако простейшие тесты на речевой базе данных ITU-T для тестов кодеков заставляют сомневаться в состоятельности распространяемой вместе с описанием реализации алгоритма. Это подтверждает и таблица 1.
Поскольку Р.563 предсказывает только оценку качества слушания, все эффекты потери качества, связанные с качеством диалогов, не могут быть учтены. Разработчики Р.563 обращают внимание пользователей на то, что алгоритм Р.563 не обеспечивает всестороннюю оценку качества передачи речи. Искажения, вызванные потерей громкости, задержками, эхом и всем, связанным с двухсторонним взаимодействием, не могу быть учтены алгоритмом. Возможно получение оценок по Р.563, не отражающих реальное качество сигнала.
Проблема с работой распространяемой реализацией алгоритма Р.563 вскрыла необходимость создания альтернативного решения, что и является предметом предлагаемого изобретения.
Наиболее близким техническим решением к заявляемому является способ осуществления машинной оценки качества передачи звуковых сигналов, в котором загружают звуковой сигнал в оперативную память компьютера и осуществляют его обработку, включающую разделение исходного и тестируемого сигналов на фрагменты активной и неактивной фаз, вычисление спектров каждой фазы, разделение полученных спектров активной и неактивной фаз на критические полосы, в том числе логарифмические и резонаторные, расчет значений спектральной энергии, попарное сравнение полученных значений энергий активной и неактивной фаз фрагментов, для определения коэффициентов спектрального подобия, результирующий коэффициент подобия для каждой фазы определяют как среднее значение коэффициентов подобия по всем наборам критических полос, которое и является оценкой качества передачи звукового сигнала каждой фазы (Патент РФ №2312405).
Этот способ обеспечивает универсальность и оптимизацию процесса оценки качества в зависимости от целей получения оценки, но у него есть некоторые недостатки. В частности уже выше отмеченный для алгоритма PESQ, т.к. он основывается на сравнении двух сигналов: исходного и прошедшего через систему связи.
Технической задачей предполагаемого изобретения является разработка объективного способа машинной оценки передачи речевого сигнала без использования тестового сигнала путем сравнения параметров обрабатываемого сигнала с моделями речи, хранящимися в базе ассоциаций.
Технический результат достигается за счет того, что в известный способ машинной оценки качества передачи звуковых сигналов (речи), включающий загрузку звукового сигнала в оперативную память компьютера, выделение в сигнале фрагментов активной и неактивной фаз, вычисление спектров для каждой фазы, разделение полученных спектров каждой фазы на критические полосы и расчет значения спектральных параметров для каждой критической полосы, используемых для определения оценки качества передачи речи, внесены изменения, а именно:
- при загрузке звукового сигнала выполняют нормализацию по уровню амплитуды и из него исключают фрагменты с низким уровнем амплитуды;
- параметры сигнала вычисляют как в спектральной, так и во временной областях;
- исключают из обработки фрагменты активной фазы, соответствующие тональному набору;
до деления на критические полосы осуществляют многоуровневую психоакустическую фильтрацию спектров;
- полученные параметры обрабатываемого сигнала сравнивают с ассоциациями, хранящимися в базе данных;
- выбирают ассоциации, наиболее близкие по всем параметрам к обрабатываемому сигналу;
- оценку качества определяют как сумму взвешенных значений степеней близости;
- базу данных ассоциаций формируют путем сбора статистики по значениям параметров сигналов с известными экспертными оценками качества.
Кроме того, психоакустическую фильтрацию выполняют в два или три уровня, причем:
- на первом уровне осуществляют маскирование сигнала, заключающееся в обнулении компонент спектров, несущественных для восприятия человеком;
- на втором уровне осуществляют нормализацию уровней громкости, заключающуюся в переводе компонент спектра в соответствующие уровни воспринимаемой громкости;
- на третьем уровне фильтрации полученные уровни громкости переводят в количество различимых градаций громкости.
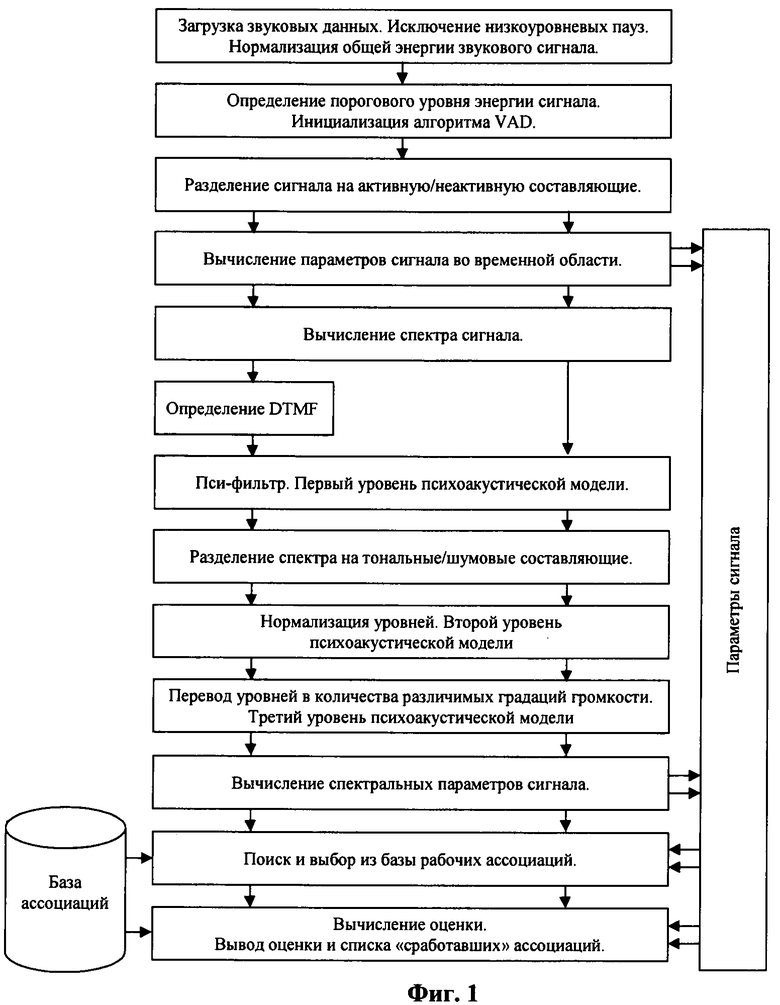
Ниже приводится более подробное описание предлагаемого способа машинной оценки качества передачи речи, получившего название NIQA (Non-Intrustive Quality Analyzer). При описании его используются следующие графические материалы (фиг.1-8).
На фиг.1 приведена общая схема алгоритма NIQA в режиме определения оценки качества. На ней приведены функциональные блоки и приводится название операций алгоритма, осуществляемого в соответствующем блоке.
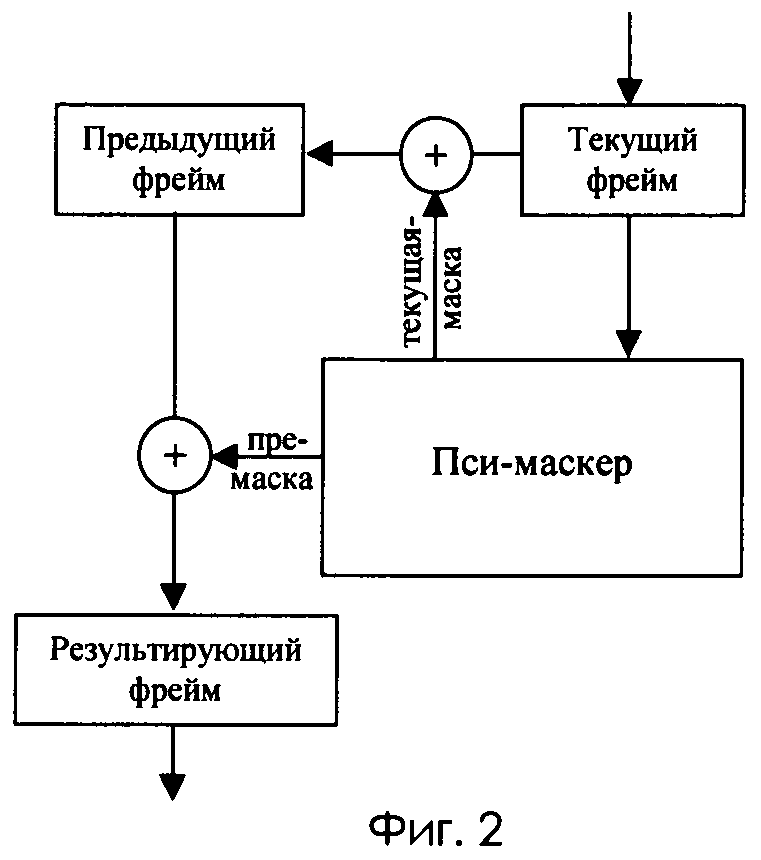
На фиг.2 приведена блок-схема реализации психоакустической фильтрации.
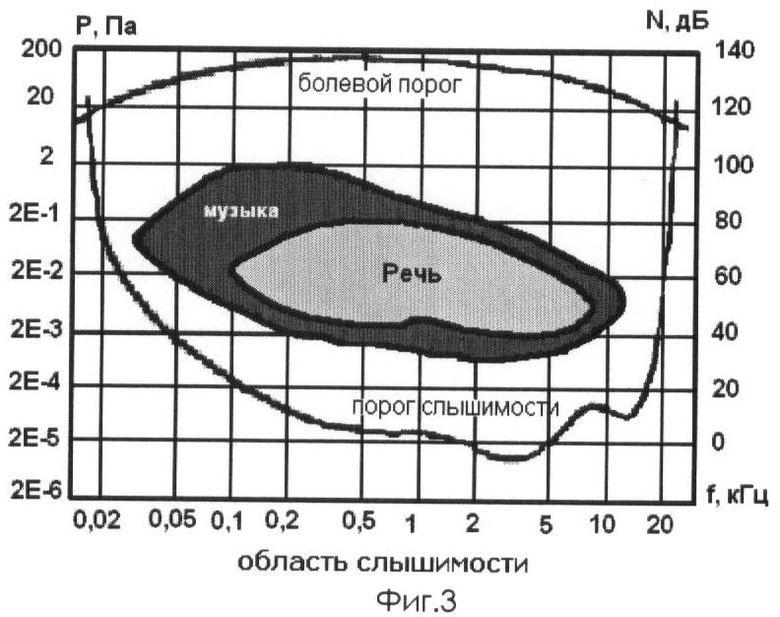
На фиг.3 представлен график зависимости порогов слышимости от частоты.
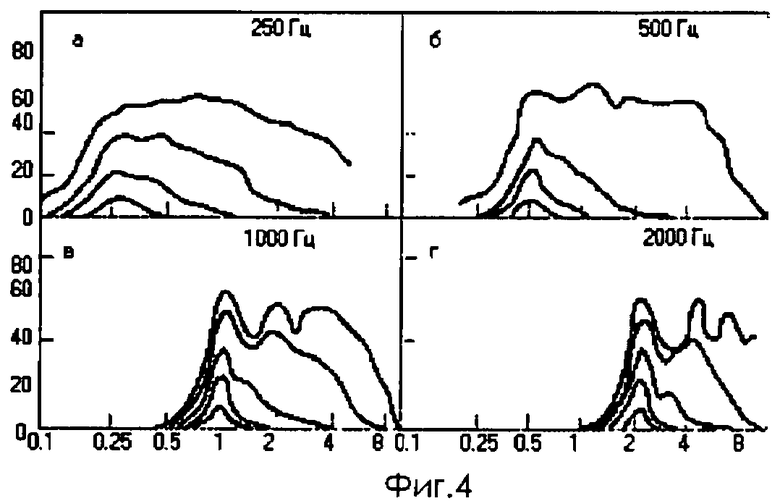
На фиг.4 приведены примеры кривых маскировки для тональных маскеров.
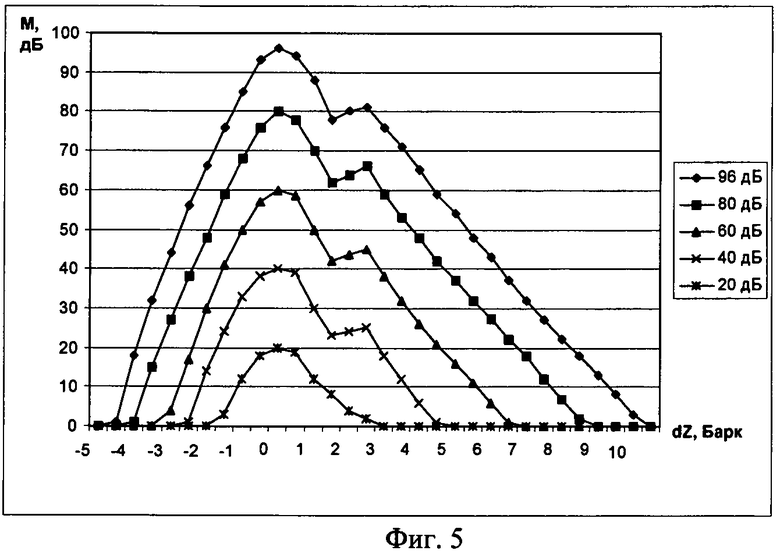
На фиг.5 изображено семейство кривых маскировки для различных уровней маскирующего сигнала.
На фиг.6 представлены кривые маскировки широкополосным белым шумом.
На фиг.7 приведен график кривых равной громкости.
На фиг.8 приведен график кривых амплитудной разрешающей способности слуха.
Для лучшего понимания приводим определение терминов, применяемых в тексте описания.
Загрузка - в данном случае имеется в виду считывание отсчетов сигнала из файла, расположенного на жестком диске компьютера или каком-либо ином запоминающем устройстве, в оперативную память компьютера с целью увеличения скорости обработки.
Фрейм или окно (от англ. frame - рамка, остов, скелет) - выборка последовательных отсчетов сигнала заданной длины, обрабатываемых совместно на одном шаге вычислений.
VAD (Voice Activity Detection) - известный алгоритм, позволяющий определять наличие голосовой активности во фреймах звукового сигнала. Используется для разделения сигнала на активную/неактивную фазы.
ДКП (Дискретное Косинусное Преобразование, англ. Discrete Cosine Transform, DCT) - одно из ортогональных преобразований. ДКП является вариантом дискретного преобразования Фурье, в котором используются только действительные числа.
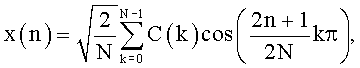
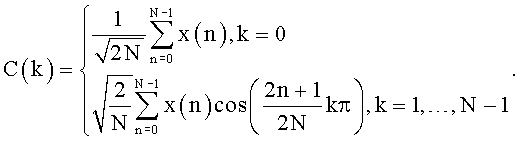
Оконная функция - весовая функция, которая часто используется для управления эффектами, обусловленными наличием боковых лепестков в спектральных оценках (растеканием спектра). Также оконная функция может использоваться для взвешивания отсчетов сигнала при пофрейменной обработке. В качестве примера оконных функций приведем оконную функцию Ханна:
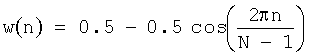
и оконную функцию Хемминга:
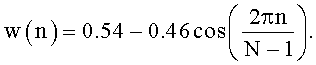
Сигнал DTMF (Dual Tone Multi-Frequency) используют для передачи номерной информации по телефонным линиям. Каждая цифра номера кодируется парой частот (табл.2). Параметры сигналов являются интернациональными и рекомендованы Международным консультационным комитетом по телефонии и телеграфии (CCITT).
Маскирование - обнуление компонент спектра сигнала, являющихся несущественными для восприятия человеком.
Ассоциация - это запись в базе эталонов, соответствующая набору параметров сигналов с некоторыми общими свойствами и общей экспертной оценкой качества. Ассоциации объединены в базу ассоциаций, хранящуюся на материальном носителе.
Сущность алгоритма NIQA на получение оценки качества звучания представлена на следующей схеме (фиг.1).
При загрузке звукового сигнала из него исключаются фрагменты с низким уровнем энергии (по пороговому значению). Исключаемые фрагменты соответствуют "абсолютной" тишине и считаются не влияющими на значение оценки качества звучания.
Далее сигнал разбивается на фреймы, используемые в алгоритме определения речевой активности. Для каждого фрейма вычисляются значения энергий, используемые для увеличения точности настройки параметров VAD. С помощь алгоритма VAD сигнал разделяется на активную/неактивную составляющие, обрабатываемые отдельно. Для активной и пассивной составляющих сигнала строятся гистограммы уровней.
С помощью ДКП формируется спектр сигнала. Для фреймов активной составляющей выполняется проверка на наличие тонального набора. Фреймы, похожие на тональный набор, исключаются из обработки.
К спектру применяется первый уровень психоакустической модели, отвечающей за различные виды маскировки (включая пре- и пост-маскирование), после чего сигнал разделяется на тональную и шумовую составляющие по явным пикам спектральной энергии.
Второй уровень психоакустической модели выполняет нормализацию энергий сигнала - уровни энергий переводятся в значения в фонах. Третий уровень психоакустической модели переводит уровни громкости в количества различимых градаций громкости, что позволяет игнорировать незаметные на слух изменения.
Далее выполняется разбиение спектра сигнала на критические полосы слуха и вычисление значений параметров как на полосах, так и вне полос. По полученным наборам параметров сигнала из базы выбираются ассоциации, наиболее похожие на оцениваемый сигнал - выполняется ассоциирование. Для выбранных ассоциаций определяются степени их влияния на результирующую оценку и сами значения оценок. Результирующая оценка определяется как комбинация оценок для выбранных ассоциаций с соответствующими весами.
Рассмотрим подробнее элементы системы NIQA. Исходный сигнал обрабатывается окном в 240 отсчетов, шаг обработки составляет 80 отсчетов. Для каждого фрейма рассчитывается значение энергии по формуле (1):
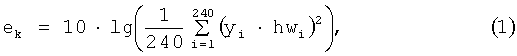
где ek - энергия для фрейма с номером k;
yi - отсчет с номером во фрейме;
hwi - весовой коэффициент оконной функции.
Все вычисленные значения энергий ek сохраняются в массиве, и сортируются. Центральный элемент массива является значением медианы. Теперь пороговое значение энергии E может быть определено по формуле (2):
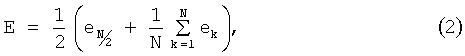
где N - количество фреймов в сигнале;
eN/2 - значение медианы.
Параметры сигнала во временной области определяются в несколько приемов. Так на этапе настройки порогового значения энергии для VAD определяются:
- среднее значение и медиана энергии исходного сигнала;
- средние значения первой и второй производных по энергии.
В процессе обработки сигнала алгоритмом VAD определяются следующие параметры:
- количество смен состояний признака активности VAD;
- количества смен состояний признака активности VAD без учета одинарных и двойных выбросов;
- количества одинарных выбросов VAD в плюс и в минус;
- количества двойных выбросов VAD в плюс и в минус.
Для различных длительностей окон (12 мс, 15 мс, 20 мс и 30 мс) обработки определяются:
- средние значения и дисперсии энергий;
- количества одинарных и двойных переходов через среднее значение в плюс и в минус.
После разделения сигнала на активную/пассивную составляющие для каждой из них и для всего исходного сигнала формируются гистограммы уровней. При построении гистограммы вычисляются три вида признаков:
- обычная гистограмма уровней, считающая частотности попадания отсчетов в диапазоны значений;
- первая и вторая производные по гистограмме уровней.
При обработке тонального набора в спектре сигнала выделяются и маркируются максимумы. Если максимумов менее двух, то фрейм признается не содержащим DTMF-набор. Иначе анализ продолжается. Вычисляется средняя энергия максимумов. Из списка максимумов исключаются максимумы с уровнем ниже среднего. Если после проверки на энергию в списке осталось не два максимума, принимается решение о прекращении проверки.
Индексы максимумов пересчитываются в значения частот и проверяются на принадлежность к частотам, образующим DTMF-набор. Нижняя и верхняя частоты сравниваются с табличными значениями (табл.2). Точность сравнения определяется размерностью спектра. Если оба максимума совпали, проверяется соотношение энергий максимумов. Если оно попадает в допустимый диапазон значений, то фрейм считается относящимся к DTMF-набору. Следующие подряд и отнесенные к DTMF-набору фреймы исключаются из обработки.
Основу психоакустической модели составляют различные полученные экспериментально зависимости. Для наглядности будем пользоваться графическим представлением зависимостей.
Модель включает три уровня: психоакустическую фильтрацию, нормализацию уровней громкости и перевод в различимые градации.
Психоакустическая фильтрация - наиболее сложный уровень обработки. Укрупненная схема психоакустической фильтрации приведена на фиг.2. Поступающий фрейм данных сохраняется в блоке текущего фрейма и передается на вход пси-маскера. На основе поступивших данных формируется пре-маска. Пре-маска накладывается на предыдущий фрейм данных, и результат маскирования принимается за выходное значение фильтра.
Кроме того, маскером формируется текущая маска, являющаяся объединением внутренней и пост-масок. Текущая маска накладывается на текущий фрейм данных, и результат маскирования сохраняется в блоке предыдущего фрейма.
Процесс маскирования описывается формулой (3):
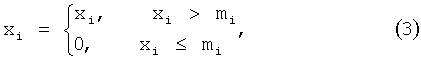
где xi - компонента спектра с номером i;
mi - компонента маски с номером i.
Процедура построения масок включает следующую последовательность действий:
1) загрузка спектра;
2) обработка порога слышимости;
3) маскирование флюидных уровней;
4) разделение спектра на тоны и шумы;
5) построение масок от тональных компонент;
6) построение масок от шумовых компонент;
7) объединение масок от тональных и шумовых компонент;
8) объединение текущей маски с пост-маской;
9) формирование пост-маски для следующего фрейма;
10) формирование маски для предыдущего фрейма;
11) перевод маски в пользовательский диапазон значений.
Загрузка спектра предназначена для перевода спектра из исходного пользовательского формата во внутренний диапазон значений маскера. Процедура загрузки спектра позволяет использовать единый комплект таблиц описания зависимостей для всех способов внешнего представления спектра. Предусмотренные внешние форматы спектров и формулы для их декодирования представлены в таблице 3.
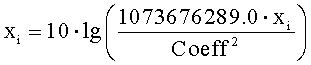
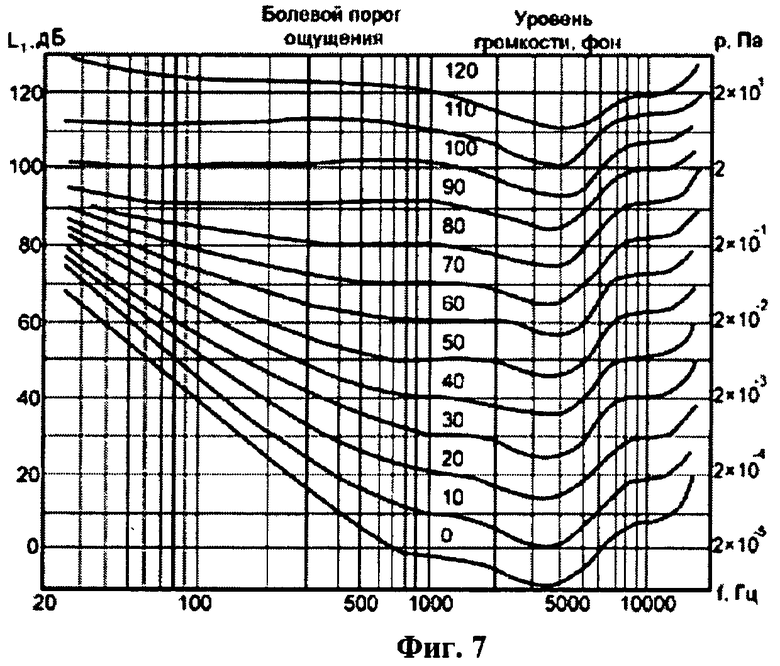
Из графика зависимости порогов от частоты (фиг.3) видно, что порог слышимости в зависимости от частоты меняется в очень широких пределах. Наибольшей чувствительностью ухо обладает в области частот от 2 до 5 кГц, где порог слышимости имеет наименьшую величину.
Со стороны громких звуков также существует ограничение восприятия. Если экстраполировать кривые порога слышимости и болевого порога в области инфразвуковых частот (менее 30 Гц) и ультразвуковых частот (выше 20 кГц), то они пересекутся. Ограненная область - область слухового ощущения или область слышимости. Все воспринимаемые слухом звуки лежат внутри этой области. Кроме болевого порога и порога слышимости на фиг.3 представлены области слышимости музыки и речи. Музыкальные и речевые сигналы занимают только часть слышимой области как по частоте, так и по амплитуде. Так частотный диапазон речи составляет от 100 Гц до 7-8 кГц, а диапазон давлений от 40 до 80 дБ. Музыкальный частотный диапазон: 30 Гц-15 кГц, а диапазон уровней давлений 35-100 дБ. Обработка порога слышимости заключается в построении соответствующей маски. Для всех компонент массива масок mti вызывается функция, интерполирующая значение порога слышимости (4):
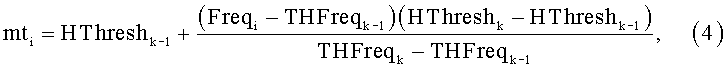
где Freqi - частота, соответствующая компоненте маски с индексом i;
(k-1, k) - индексы ячеек таблицы порога слышимости;
THFreqk-1 и THFreqk - значения частот в ячейках k-1 и k таблицы порога слышимости;
HThreshk-1 и HThreshk - значения интенсивностей в ячейках k-1 и k таблицы порога слышимости.
Частота, соответствующая индексу, определяется как (5):
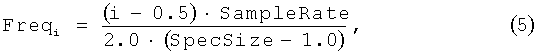
где SampleRate - частота дискретизации сигнала;
SpecSize - размер спектра.
Далее выполняется маскирование флюидных уровней. Цель маскировки флюидных уровней - избежать случайных ошибок вычислений, связанных с эффектом растекания спектра. Значения флюидных уровней рассчитываются относительно максимальной компоненты спектра. Пересчет компонент маски выполняется по формуле (6):
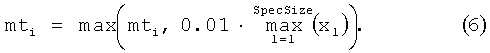
Разделение спектра на тональные и шумовые компоненты связано с различиями в процессе построения масок. Кроме различия в процессе формирования масок требуется учитывать и то, что маски, построенные от тональных компонент спектра, распространяются только на шумовые компоненты и наоборот.
При разделении спектра используется следующий алгоритм, выделяющий пики:
- ищутся локальные максимумы, уровень которых превышает некоторое пороговое значение;
- слева и справа от локальных максимумов ищутся локальные минимумы;
- компоненты спектра между найденными парами локальных минимумов считаются тональными;
- оставшиеся компоненты спектра - шумовыми.
Одним из самых важных свойств слуховой системы является эффект слуховой маскировки. Считается, что процессы маскировки происходят в высших отделах головного мозга и связаны со взаимодействием сигналов, приводящим к изменению слуховой чувствительности к маскируемому - в присутствии маскирующего - сигнала.
Степень маскировки определяется как разность в децибелах между уровнем порога слышимости маскируемого тона в присутствии маскирующего тона и уровнем порога слышимости маскируемого тона в тишине. На фиг.4 показаны примеры зависимостей степени маскировки от частоты и уровня маскирующего сигнала для четырех маскируемых сигналов.
Из фиг.4 видно, что уровень маскирования сильно зависит от частоты и уровня маскирующего сигнала. Общее описание всех возможных кривых маскировки представляется весьма затруднительным, поэтому в рамках решаемой задачи было решено использовать упрощенную модель маскировки, близкую к используемой в стандарте MPEG (фиг.5).
При переводе значения частоты из Герц (F) в Барки (z) используется эмпирическая формула (7):
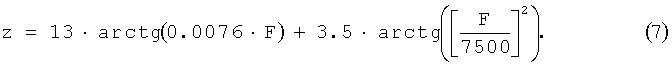
Для каждой выделенной тональной компоненты строятся маски путем интерполяции промежуточных кривых маскировки в зависимости от ее уровня энергии. Результирующая маска (msi) определяется как набор максимумов из значений с совпадающими индексами.
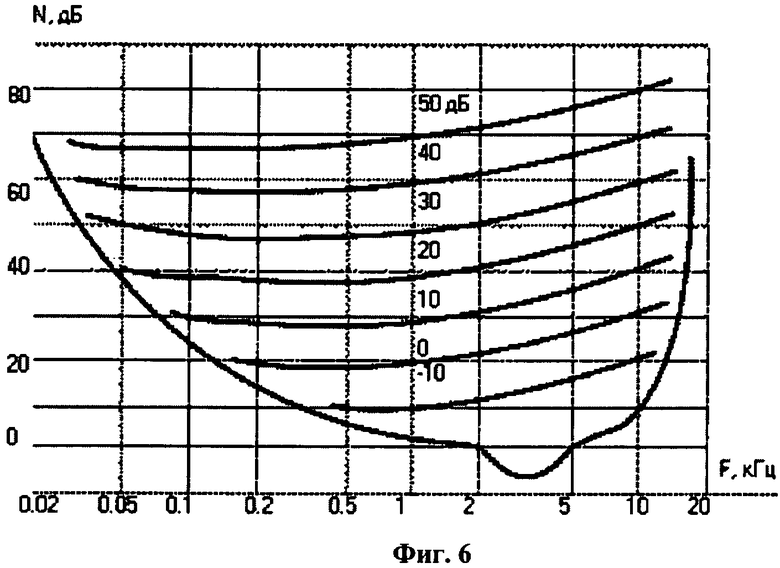
Далее осуществляется построение масок от шумовых компонент. Эффекты маскировки тоном и шумом имеют существенные различия. На фиг.6 представлены результаты исследований маскировки широкополосным белым шумом.
Из графика видно, что уровень маскировки пропорционален уровню шума. Кроме того, эффективность маскирования шумом различных частот различна. На частотах ниже 500 Гц зависимость степени маскирования от частоты низкая, на более высоких частотах - при каждом удвоении частоты степень маскировки повышается примерно на 3 дБ.
Флетчером было показано, что только определенная критическая ширина полосы белого шума участвует в маскировке тона, равного центральной частоте этой полосы. Поэтому при построении маски от шумовых компонент (mni) для каждой тональной компоненты определяется ее собственная критическая полоса, и в пределах этой критической полосы определяется уровень маскирующего шума. Далее степень маскирования определяется согласно кривым маскировки, представленным на фиг.6.
Предусмотрены два варианта определения уровня шума в полосе. В первом случае уровень шума определяется как среднее по всем шумовым компонентам спектра в полосе. Во втором - как среднее между минимальной и максимальной шумовыми компонентами в полосе.
Собственные критические полосы интерполируются исходя из таблиц критических полос, определенных разными авторами (Флетчер, Сапожков, Цвикер, Покровский и др.).
Далее осуществляют объединение масок по следующей процедуре. На вход процедуры объединения поступают пять комплектов масок: маска порога слышимости и флюидных уровней (mti), маски тональных (msi) и шумовых (mni) компонент текущего фрейма, пост-маски тональных (_msi) и шумовых (_mni) компонент от предыдущего фрейма. Первой формируется текущая маска (8):
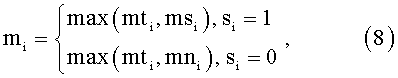
где si - признак, является ли i-тая компонента спектра тональной или шумовой.
Затем выполняется объединение текущей маски с пост-масками (9):
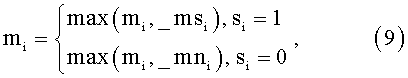
Комплект пост-масок для использования на следующем шаге получается из текущих пороговых, тональных и шумовых масок по формулам (10):
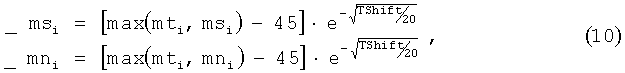
где TSift - шаг окна обработки по сигналу.
Формирование маски для предыдущего фрейма осуществляется следующим образом: пре-маска формируется исходя из текущих пороговых, тональных и шумовых масок, а также величины шага обработки и признаков разделения на тон/шум предыдущего спектра (11):
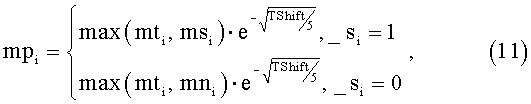
где _si - признак разделения на тон/шум на предыдущем шаге.
Перевод маски в пользовательский диапазон значений - операция, обратная загрузке спектра. Предназначена для перевода спектра обратно в пользовательский формат. Формулы для преобразования в предусмотренные внешние форматы представлены в таблице 4.
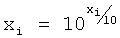
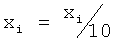
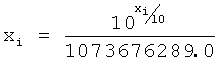
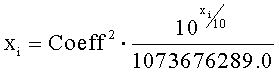
В связи с тем что воспринимаемый уровень громкости звука имеет сложную зависимость от интенсивности и частоты, выполняется нормализация уровней громкости. Для измерения уровня воспринимаемой громкости звука была введена единица измерения фон. Уровень громкости в фонах равен интенсивности звука в децибелах на частоте 1 кГц.
Второй уровень психоакустической модели осуществляет перевод интенсивностей компонент спектра в соответствующие значения уровня воспринимаемой громкости. Для пересчета используется семейство кривых равной громкости, представленное на фиг.7. По значению частоты и интенсивности компоненты спектра определяется пара кривых равной громкости, между которыми находится нормализуемое значение. Затем с помощью линейной интерполяции определяется соответствующее значение громкости в фонах.
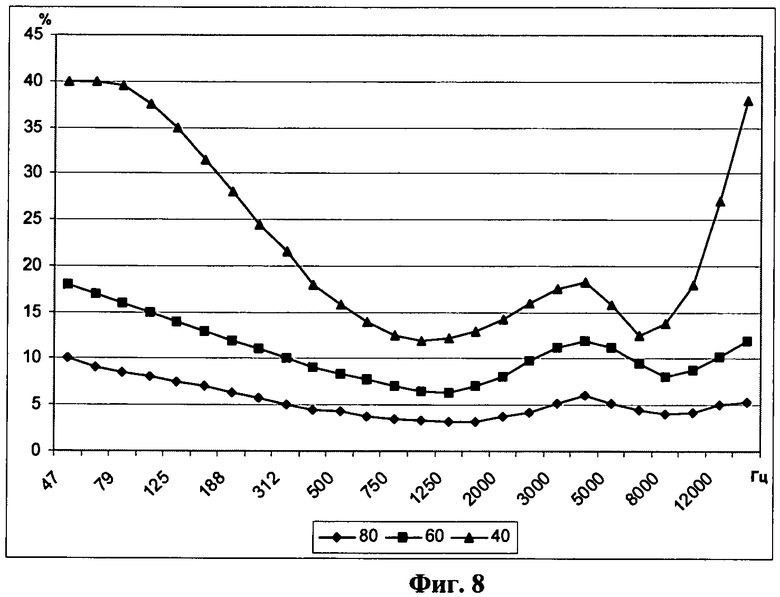
После нормализации уровней громкости возможен перевод в различимые градации громкости. В рамках реализованной психоакустической модели под различимой градацией понимается минимально заметное на слух изменение амплитуды сигнала. Частотная разрешающая способность слуха не учитывается.
Известно, что в зависимости от уровня громкости и частоты сигнала разрешающая способность слуха варьируется от 2 до 40%. Кривые амплитудной разрешающей способности представлены на фиг.8.
Общая громкость сигнала определяется как сумма максимальной громкости по всем компонентам спектра и 0.3 средней громкости по всем остальным компонентам спектра. Т.к. при расчете градаций используются воспринимаемые уровни громкости, вызов третьего уровня психоакустической модели возможен только после применения второго уровня.
Для рассчитанного уровня громкости интерполируется кривая амплитудной разрешающей способности. Для каждой компоненты спектра определяется минимально различимое изменение громкости, и текущий уровень громкости компоненты спектра делится на найденное значение.
Спектральные параметры сигнала рассчитываются внутри критических полос. Формируются две группы параметров: энергетические и соотношения сигнал/шум. К энергетическим параметрам относятся следующие:
- среднее на полосе;
- средняя производная в полосе;
- средняя вторая производная в полосе;
- средний хаос энергии в полосе;
- средний хаос производной в полосе;
- средний хаос второй производной в полосе.
Под "хаосом" понимается дисперсия значений в полосе. Все шесть энергетических параметров рассчитываются по трем массивам спектров: тональных компонент, шумовых компонент и без разделения. Полный комплект энергетических параметров рассчитывается и для активной, и для пассивной составляющих сигнала.
Соотношения сигнал/шум вычисляются на основании средних значений энергий активной и пассивной составляющих сигнала. Всего определяется семь значений - разности между средними уровнями:
- тональных и шумовых компонент в активной части сигнала;
- тональных и шумовых компонент в пассивной части сигнала;
- тональных компонент активной и пассивной частей сигнала;
- тональных компонент активной и шумовых компонент пассивной частей сигнала;
- шумовых компонент активной и тональных компонент пассивной частей сигнала;
- шумовых компонент активной и пассивной частей сигнала;
- активной и пассивной частей сигнала.
Важнейшим элементом предлагаемого способа является база ассоциаций, которые являются моделями речи. Базу ассоциаций формируют путем сбора статистики по значениям параметров сигналов (хранящихся в файлах) с известными экспертными оценками. При формировании базы ассоциаций используются следующие принципы.
1. Каждая группа обучающих файлов дает ассоциацию.
2. Файлы, собираемые в одной группе, должны обладать высокой степенью общности. Полезно разделять группы на несколько подгрупп: по типу голоса (например, мужчины/женщины/дети/старики); по языку, на котором происходит разговор; по темпу и типу речи (например, деловые переговоры/дружеская беседа домохояек) и т.д.
3. При объединении в группу файлов с разными экспертными оценками не следует включать в группу файлы с оценками выше базовой оценки группы. Также не следует включать в круппу файлы, экспертные оценки которых сильно ниже оценок в группе. Так, например, если формируется группа с базовой оценкой 4.0, то в нее не следует включать файлы с оценками 4.2 и выше, или ниже 3.0. Файлы, не входящие в границы диапазона, лучше выделить в отдельные группы.
4. Для "отслеживания" влияния на оцениваемый сигнал различных причин потери качества (например, шум в канале, потеря пакетов, клиппирование сигнала и т.д.) требуется создать свою ассоциацию для каждой причины потери качества с учетом пунктов 2 и 3.
5. Количество файлов в группе не должно быть слишком мало или слишком велико. На данный момент удачным представляется объединение порядка 100 файлов в группе.
Обучающие звуковые сигналы обрабатываются аналогично оцениваемому сигналу и переводятся в пространство признаков. В базе ассоциаций для каждого параметра хранится три значения: среднее значение, дисперсия и количество переобучений. Поскольку количество обучающих данных заранее неизвестно и предусматривается возможность дообучения системы, для вычисления среднего и дисперсии используются следующие рекуррентные формулы (12):
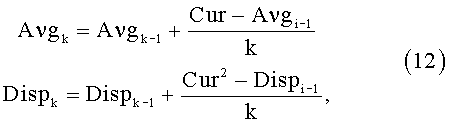
где k - номер шага обучения;
Cur - текущее значение параметра;
Avg - среднее значение параметра;
Disp - дисперсия значений параметра.
Для того чтобы значение дисперсии параметра можно было использовать для вычисления подобий и оценок качества, необходимо выполнить "финализацию" вычисления дисперсии (13), чтобы начать дообучение параметра, для этого необходимо соответствующим образом модифицировать значение дисперсии (14):


Для определения степени подобия текущего значения параметра обученному распределению значений (Like) используется выражение (15):
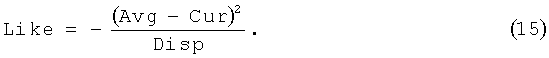
Для определения значения подобия на соотношениях сигнал/шум выражение (15) непригодно, т.к. оно работает только на "убывание" с увеличение отклонения текущего значения параметра от среднего значения распределения. Однако увеличение соотношения сигнал/шум должно увеличивать подобие между двумя сигналами, поэтому вместо выражения (15) используется условное выражение (16):

Значения подобия по всем признакам суммируются с учетом весов. Дополнительно веса навешиваются на группы признаков: параметры во временной области, спектральные энергетические параметры и соотношения сигнал/шум.
Значения подобия рассчитываются для всех ассоциаций базы, после чего по значениям подобия выбираются N лучших ассоциаций. Значения подобия приводятся к одному порядку, и определяют вклад ассоциации в результирующую оценку качества.
Для выбранных N ассоциаций рассчитываются оценки качества. При этом используются полученные значения подобий (15-16), но суммирование по признакам осуществляется с другим набором весов. Значение оценки качества для ассоциации определяется как (17):
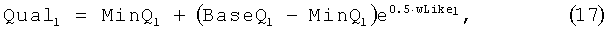
где l - индекс ассоциации, для которой вычисляется оценка;
wLikel - взвешенное среднее подобий по всем признакам для ассоциации l;
MinQl - минимальное значение оценки качества при соотнесении с ассоциацией l;
BaseQl - базовая (максимально возможная) для ассоциации l оценка качества;
Quall - значение оценки качества для ассоциации 1.
Результирующая оценка качества определяется как сумма взвешенных оценок качества по N лучшим ассоциациям.
Предлагаемый способ машинной оценки качества передачи речи обладает рядом преимуществ по сравнению с известными алгоритмами. Он не требует референс сигнала, весь процесс оценки осуществляется компьютером по специальной программе с использованием заранее подготовленных моделей речи (ассоциации, объединенные в базу данных).
Предлагаемый алгоритм машинной оценки качества передачи речи прошел испытания. Для испытания NIQA была использована та же речевая база ITU-T, что использовалась для испытания реализации алгоритма Р.563. Для тестирования были использованы записи фраз на трех языках: английском (376 файлов), французском (576 файлов) и японском (376 файлов). Все записи были разделены на 4 группы (для каждого языка свои) в зависимости от полученных экспертных оценок MOS. По всем группам записей были определены средние экспертные оценки и средние оценки и ошибки NIQA (табл.5). Для сравнения в таблице также приведены средние значения ошибок, полученные при испытании алгоритма Р.563.
Из таблицы видно, что алгоритм NIQA позволяет получить значительно большую точность совпадения вычисляемых оценок с экспертными, чем алгоритм рекомендации Р.563. Точность алгоритма NIQA уступает точности алгоритма Р.563 только на записях японской речи с очень низкими значениями экспертных оценок (в диапазоне от 1 до 2). Во всех остальных случаях точность оценок NIQA оказывается в 2-3 раза выше.
Предполагается с второй половины текущего года внедрить предлагаемый способ для оценки качества передачи речи по различным каналам телефонной и радиосвязи.
Изобретение относится к способам анализа звуковых сигналов, передаваемых по каналам радиосвязи, телефонии и трактам переговорных устройств. Сущность способа машинной оценки качества передачи речи заключается в том, что осуществляют загрузку звукового сигнала в оперативную память компьютера, выделяют в сигнале фрагменты активной и неактивной фаз, вычисляют спектры для каждой фазы, которые разделяют на критические полосы, и рассчитывают значения спектральных параметров для каждой критической полосы, причем параметры сигнала вычисляют как в спектральной, так и во временной областях, исключают из обработки фрагменты активной фазы, соответствующие тональному набору, до деления на критические полосы, осуществляют многоуровневую психоакустическую фильтрацию спектров, полученные параметры обрабатываемого сигнала сравнивают с ассоциациями, хранящимися в базе данных, и выбирают ассоциации, наиболее близкие по всем параметрам к обрабатываемому сигналу, а оценку качества речи определяют как сумму взвешенных значений степеней близости. Технической результат - обеспечение машинной оценки речевого сигнала путем сравнения параметров обрабатываемого сигнала с моделями речи, хранящимися в базе ассоциаций. 3 з.п. ф-лы, 5 табл., 8 ил.
1. Способ машинной оценки качества передачи речи, в котором осуществляют загрузку звукового сигнала в оперативную память компьютера, выделяют в сигнале фрагменты активной и неактивной фаз, вычисляют спектр для каждой фазы, полученные спектры каждой фазы делят на критические полосы и рассчитывают значения спектральных параметров для каждой критической полосы, которые используют для определения оценки качества передачи речи, отличающийся тем, что параметры сигнала вычисляют как в спектральной, так и во временной областях, исключают из обработки фрагменты активной фазы, соответствующие тональному набору, до деления на критические полосы, осуществляют многоуровневую психоакустическую фильтрацию спектров, полученные параметры обрабатываемого сигнала сравнивают с ассоциациями, хранящимися в базе данных, и выбирают ассоциации, наиболее близкие по всем параметрам к обрабатываемому сигналу, а оценку качества определяют как сумму взвешенных значений степеней близости.
2. Способ по п.1, отличающийся тем, что при загрузке звукового сигнала выполняют нормализацию по уровню амплитуды и из него исключают фрагменты с низким уровнем амплитуды.
3. Способ по п.1, отличающийся тем, что выполняют два или три уровня психоакустической фильтрации, причем на первом уровне осуществляют маскирование сигнала, заключающееся в обнулении компонент спектров, несущественных для восприятия человеком, на втором уровне осуществляют нормализацию уровней громкости, заключающуюся в переводе компонент спектра в соответствующие уровни воспринимаемой громкости, а на третьем уровне фильтрации полученные уровни громкости переводят в количество различимых градаций громкости.
4. Способ по п.1, отличающийся тем, что базу данных ассоциаций формируют путем сбора статистики по значениям параметров сигналов с известными экспертными оценками качества.
| СПОСОБ ОСУЩЕСТВЛЕНИЯ МАШИННОЙ ОЦЕНКИ КАЧЕСТВА ЗВУКОВЫХ СИГНАЛОВ | 2005 |
|
RU2312405C2 |
| WO 00/00962 A1, 06.01.2000 | |||
| СПОСОБ АНАЛИЗА И СИНТЕЗА РЕЧИ | 2005 |
|
RU2296377C2 |
| Устройство для образования двойных поперечных швов на рукавном термосклеивающемся материале | 1976 |
|
SU644674A1 |
| US 6427133 B1, 30.07.2002. | |||

