ОБЛАСТЬ ТЕХНИКИ, К КОТОРОЙ ОТНОСИТСЯ ИЗОБРЕТЕНИЕ
Изобретение относится к способу кодирования сигнала видеоданных для использования с многовидовым устройством визуализации, способу декодирования сигнала видеоданных, сигналу видеоданных, кодеру сигнала видеоданных для использования с многовидовым устройством визуализации, декодеру сигнала видеоданных, компьютерному программному продукту, содержащему инструкции для кодирования сигнала видеоданных, и компьютерному программному продукту, содержащему инструкции для декодирования сигнала видеоданных.
УРОВЕНЬ ТЕХНИКИ
За последние два десятилетия созрела технология трехмерного дисплея. Трехмерные (3D) дисплейные устройства добавляют третье измерение (глубину) в восприятие просмотра посредством предоставления каждому из глаз зрителя разных видов сцены, которая просматривается.
В результате сейчас мы имеем различные способы просмотра трехмерного изображения/видеосигналов. С одной стороны мы имеем системы трехмерного дисплея основанные на очках, в которых пользователю представляются отличные изображения для его/ее левого глаза и правого глаза. С другой стороны, мы имеем авто-стереоскопические системы трехмерного дисплея, которые предоставляют невооруженному глазу зрителя трехмерный вид сцены.
В системах, основанных на очках, активные/пассивные очки обеспечивают фильтр для разделения отличных изображений как представляемых на экране для соответствующего глаза зрителя. В авто-стереоскопических системах или системах без очков устройства довольно часто являются многовидовыми дисплеями, которые используют средства направления света, например, в форме барьера или двояковыпуклой линзы, для направления левого изображения на левый глаз и правого изображения на правый глаз.
Для того чтобы предоставлять контент для использования со стереоскопическими многовидовыми дисплейными устройствами, со временем были разработаны различные форматы ввода, в частности также для интерфейсов устройства, между устройствами доставки контента, такими как абонентские телевизионные приставки, проигрыватели Blu-ray, с одной стороны, и дисплейными/визуализации устройствами, такими как телевизоры, с другой стороны.
Со временем разнообразные форматы были определены для пересылки видеоданных через интерфейсы устройства, такие как HDMI, DVI или DisplayPort. С введением авто-стереоскопических дисплеев и дисплеев визуализации стереоскопического изображения возникла дополнительная потребность в предоставлении контента для использования при визуализации стереоскопического изображения. Один такой формат раскрывается в PCT заявке WO 2006/137000(A1), которая относится к формату, который описывает то, каким образом информация изображения и глубины, и опционально изображение окклюзии и глубина окклюзии, могут быть перенесены в матричном виде по существующему интерфейсу устройства, такому как HDMI. Общая идея данного подхода состояла в повторном использовании существующего стандартизованного интерфейса устройства для того, чтобы доставлять контент новым авто-стереоскопическим дисплейным устройствам.
Позже формат интерфейса устройства HDMI был адаптирован для того, чтобы также манипулировать видеоданными для использования при генерировании стереоскопического изображения, как раскрывается в документе «High-Definition Multimedia Interface Specification Version 1.4a Extraction of 3D Signaling Portion», который доступен для загрузки с web-сайта HDMI, используя следующую ссылку: http://www.hdmi.org/manufacturer/specification.aspx.
Документ US 2009/0015662 описывает формат стереоскопического изображения. Разностное изображение генерируется между первым и вторым изображением вида. Информация яркости разностного изображения может быть сохранена в первой области цветности, тогда как информация цветности разностного изображения может быть сохранена во второй области цветности.
ЦЕЛЬ ИЗОБРЕТЕНИЯ
Авторы изобретения заметили, что существующие форматы аудио/видео интерфейса, подобные HDMI, обладают лишь ограниченной поддержкой в отношении форматов для изображения, основанного на визуализации, для которой требуется информация изображения и глубины. Например, в HDMI 1.4b присутствует лишь базовая поддержка переноса левого изображения и ассоциированной карты глубины. Соответственно, как представляется, есть возможности для дальнейшего улучшения.
РАСКРЫТИЕ ИЗОБРЕТЕНИЯ
Авторы изобретения поняли, что заодно было бы преимуществом добавить дополнительные форматы, которые, например, также обеспечивают поддержку применительно к передаче стереоизображений и ассоциированной информации глубины. Более того, как будет более подробно рассмотрено позже, дополнительно будет выгодно также обеспечить более законченную поддержку применительно к передаче добавочной информации (подобной SEI) от устройства-источника к устройству-получателю.
В соответствии с первым аспектом изобретения, предоставляется способ кодирования сигнала видеоданных для использования с многовидовым устройством визуализации в соответствии с пунктом 1 формулы изобретения.
Опционально видеосигнал может иметь два (или более) субизображения, основанных на соответствующих изображениях (например именуемых первое изображение и второе изображение) с соответствующих точек наблюдения, например, левой точки наблюдения и правой точки наблюдения. Одно или оба из этих субизображений могут иметь соответствующие субизображения глубины. Метаданные могут быть закодированы в одном или в обоих соответствующих субизображениях глубины. Опционально, там, где формула изобретения определяет, что метаданные кодируются в цветовой составляющей, метаданные могут быть закодированы в двух или более цветовых составляющих.
Предпочтительно информация из карты глубины кодируется в значениях яркости одного или двух дополнительных субизображений, а информация из метаданных кодируется в значениях цветности одного или двух дополнительных субизображений, приводя к обратно совместимому способу транспортировки сигнала видеоданных.
Предпочтительно информация, которая содержится в сигнале видеоданных, содержит, по существу, несжатый двумерный массив данных.
Предпочтительно способ дополнительно содержит этап, на котором передают сигнал видеоданных через интерфейс, используя одну или более поразрядные строки данных к многовидовому устройству визуализации.
Предпочтительно метаданные вставляются в сигнал видеоданных для каждого поля, для каждого кадра, для каждой группы картинок, и/или для каждой сцены.
Предпочтительно метаданные обеспечиваются контрольной суммой, причем метаданные будут использованы либо обработкой карты глубины, либо визуализацией вида, на стороне декодера. Влияние ошибок в метаданных может быть значительным. В интерфейсе данных, который переносит несжатые данные изображения, такие как RGB пиксели, ошибка в значение пикселя не приведет к чрезмерным ошибкам восприятия. Тем не менее ошибка в метаданных может привести к тому, что визуализированные виды для кадра, вычислены на основании неверной информации глубины и/или используя неверные установки визуализации. Влияние этого может быть весьма значительным и как результат, требуется обнаружение такой ошибки и предпочтительным является использование избыточности и/или кода коррекции ошибки.
Предпочтительно метаданные содержат информацию актуализации, указывающую на то, являются ли предоставляемые метаданные новыми, с тем, чтобы содействовать созданию более эффективного процесса управления для манипулирования обработкой метаданных на декодирующей стороне.
Предпочтительно метаданные содержат информацию, указывающую на то, изменились ли метаданные с момента предыдущего кадра. Это кроме того позволяет процессу управления стать более эффективным в том, что не требуется регенерировать/обновлять установки, которые не поменялись (даже несмотря на то, что они были переданы).
Предпочтительно способ дополнительно содержит этап, на котором манипулируют кодированием и переносом стерео видеоданных со стереоинформацией глубины.
В соответствии со вторым аспектом изобретения, предоставляется сигнал видеоданных, причем сигнал (50) видеоданных используется с многовидовым устройством визуализации, как заявлено в пункте 8 формулы изобретения.
В соответствии с третьим аспектом изобретения, предоставляется носитель данных, содержащий сигнал видеоданных по пункту 8 формулы изобретения в постоянном виде. Данный носитель данных может быть в форме запоминающего устройства, такого как накопитель на жестком диске или твердотельный накопитель, или носителя данных в форме оптического диска.
В соответствии с четвертым аспектом изобретения, предоставляется способ декодирования сигнала видеоданных для использования с многовидовым устройством визуализации в соответствии с пунктом 10 формулы изобретения.
В соответствии с пятым аспектом изобретения, предоставляется декодер для декодирования сигнала видеоданных для использования с многовидовым устройством визуализации в соответствии с пунктом 11 формулы изобретения.
В соответствии с шестым аспектом изобретения, предоставляется компьютерный программный продукт, содержащий инструкции для побуждения процессорной системы выполнять способ в соответствии с любым из пунктов 1-7 или 10 формулы изобретения.
В соответствии с седьмым аспектом изобретения, предоставляется кодер сигнала видеоданных для использования с многовидовым устройством визуализации в соответствии с пунктом 15 формулы изобретения.
Эти и прочие аспекты изобретения очевидны из и будут объяснены со ссылкой на описываемые далее варианты осуществления.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
На чертежах:
Фиг.1 показывает схематичное представление переноса 2D+глубина форматов через HDMI,
Фиг.2 показывает схематичное представление переноса стерео+глубина форматов через HDMI,
Фиг.3 показывает структурную схему кодера в соответствии с настоящим изобретением и декодера в соответствии с настоящим изобретением в цепочке 3D визуализации.
Фиг.4 показывает блок-схему способа декодирования в соответствии с настоящим изобретением,
Фиг.5A показывает блок-схему способа кодирования в соответствии с настоящим изобретением,
Фиг.5B показывает блок-схему альтернативного способа кодирования в соответствии с настоящим изобретением, и
Фиг.5C показывает блок-схему еще одного альтернативного способа кодирования в соответствии с настоящим изобретением.
Следует отметить что элементы, которые имеют одни и те же цифровые обозначения на разных фигурах, обладают одними и теми же структурными признаками и одними и теми же функциями, или являются одними и теми же сигналами. Если функция и/или структура такого элемента была объяснена, то нет необходимости в ее повторном объяснении в подробном описании.
ОСУЩЕСТВЛЕНИЕ ИЗОБРЕТЕНИЯ
Авторы изобретения узнали, что видео и ассоциированная информация глубины, предназначенные для многовидового 3D представления, могут быть переданы авто-стереоскопическим дисплеям, используя стандартные форматы межсоединения/интерфейса устройства, подобные HDMI, DVI и/или DisplayPort, посредством разбиения доступных видеокадров на субизображения для видео и глубины.
Поскольку информация изображения, которая, как правило, используется в интерфейсах устройства, разработана с возможностью нести, по меньшей мере, 8-битные элементы дискретизации R, G и B информации, т.е. 24 бита на пиксель, а глубине, ассоциированной с пикселем, как правило, не требуются все 24 бита на пиксель, полоса пропускания передачи в субизображения используется не оптимально.
По этой причине авторы изобретения предпочитают передавать информацию глубины в субизображениях таким образом, что информация глубины кодируется в элементах дискретизации яркости этих субизображений, так что метаданные, которые предназначены улучшить и/или направить процесс генерации вида, могут быть сохранены в элементах дискретизации цветности субизображений глубины. [Т.е. в информации изображения, где хранится субизображение глубины].
Изобретение применяется к авто-стереоскопическому дисплею, который принимает входные сигналы видео и глубины от интерфейса устройства HDMI (или подобного). Изобретение в равной степени применяется к мультимедийным проигрывателям, абонентским телевизионным приставкам, переносным/мобильным устройствам, планшетам, персональным компьютерам, и т.д. с HDMI, DVI, DisplayPort или другим интерфейсом устройства и которые обеспечивают поддержку для основанного на видео и глубине 3D формата.
HDMI является ведущим форматом интерфейса устройства, используемым для передачи видео и аудио от источников контента (мультимедийных проигрывателей, абонентских телевизионных приставок и других источников контента) к устройствам-получателям (дисплеям, TV, AV-приемникам). Стандарт HDMI был исходно определен для поддержки видео разрешений вплоть до разрешения Full HD (1920x1080 и 2048x1080), уже имеет ограниченную поддержку разрешений 2060p (также известного как 4K), таких как 3840x2160 и 4096x2160 и ожидается, что будет иметь более широкую поддержку для форматов 4K в следующих ревизиях стандарта.
Последним доступным Техническим описанием HDMI является Версия 1.4b. В особенности версия 1.4a уже поддерживает передачу стереоскопического видео контента в виде 2-видового стерео; т.е. используя левое и правое изображения стереопары. Более того, существует опция для передачи левого изображения и ассоциированной глубины, также известной как 2D+глубина или изображение+глубина.
В дополнение к видео и аудио, HDMI может передавать ограниченный объем стандартизированных данных управления и конфигурации посредством так называемых InfoFrames (кадров информации). В особенности, существуют альтернативные видео интерфейсы (устройства), такие как DVI и DisplayPort, которые главным образом используются персональными компьютерами.
Применительно к многовидовой трехмерной (3D) визуализации изображения, устройства предпочтительно принимают один или более виды с ассоциированной информацией глубины и метаданными.
В настоящее время разрабатываются различные форматы сжатия для видео и глубины, среди прочих посредством ITU-T (VCEG) и ISO/IEC (MPEG). Эти форматы сжатия также поддерживают включение добавочной информации улучшения (SEI), которая не требуется для процесса декодирования, но может быть полезна для наилучшего возможного представления декодированных изображений.
Тем не менее, в противоположность ситуации с обычным видео, предусматривается, что в частности для авто-стереоскопических дисплейных устройств, часть основанной на изображении визуализации будет проводиться авто-стереоскопическим дисплейным устройством для того, чтобы иметь возможность поддержки различных собственных реализаций дисплейного устройства. В результате, в противоположность ситуации в обычном 2D видео, существует большая потребность в передаче относящихся к визуализации метаданных к авто-стереоскопическим дисплейным устройствам. В частности, предусматривается, что элементы SEI в сжатом потоке могут содержать информацию для улучшения процесса визуализации на авто-стереоскопическом дисплейном устройстве.
Настоящее изобретение решает упомянутые проблемы, используя 2160p элементы дискретизации видео для передачи вплоть до двух видов видео Full HD с соответствующей глубиной и добавочной информацией (метаданными). Для достижения этой цели, видеокадры 2160p подразделяются на 4 квадранта (субизображения), каждый содержащий одну из четырех составляющих: видеокадр Левого вида (L), видеокадр Правого вида (R), глубину для L и глубину для R. В субизображениях глубины применительно к глубине используются только составляющие яркости. Составляющие цветности используются для добавочной информации.
Вкратце, решения известного уровня техники, как правило, предоставляют плохую поддержку основанной на изображении визуализации, т.е. в частности, присутствует недостаточная поддержка применительно к более усовершенствованным/детальным данным карты глубины и присутствует главный недостаток по предоставлению метаданных для усиления/улучшения процесса визуализации вида.
Данное изобретение относится к форматам межсоединения для передачи видео, глубины и метаданных, например между стационарным мультимедийными проигрывателями (включая приемники/декодеры вещания и мобильные устройства) и дисплейными устройствами; т.е., интерфейсам устройства. Одним примером такого формата межсоединения является HDMI. Другими примерами являются DVI и DisplayPort. Изобретение также относится к видео межсоединению внутри устройства, например, между субкомпонентами через витую пару (LVDS).
В зависимости от источника контента, формат межсоединения может содержать либо видео составляющую единственного вида с ассоциированной глубиной или картой несоответствия (2D+глубина), либо два видео вида с одной или двумя дополнительными составляющими глубины (стерео + глубина).
Как будет очевидно специалистам в соответствующей области техники, глубина грубо обратно пропорциональна несоответствию, тем не менее, фактическое отображение глубины в несоответствии в дисплейных устройствах подвержено влиянию различных выборов исполнения таких как, общий объем несоответствия, который может быть сгенерирован дисплеем, выбор распределения конкретного значения глубины нулевому несоответствию, объем разрешенных перекрестных несоответствий, и т.д. Тем не менее, данные глубины, которые предоставляются с данными ввода, используются для деформирования изображений зависимым от глубины образом. Вследствие этого здесь данные несоответствия эквивалентно интерпретируются как данные глубины.
Как указывается выше в отношении 2D + глубина, уже существовал опциональный формат, определенный для прогрессивного видео в HDMI 1.4b (и 1.4a, частично доступный для загрузки с www.hdmi.org). Стерео + глубина не могут быть переданы в HDMI 1.4b из-за ограничений по количеству пикселей, которое может быть передано за секунду. Для этого, требуется более высокая скорость, что как ожидается станет доступно в будущей ревизии HDMI, именуемой в нижеследующем как HDMI 2.0.
Если 2D + глубина передаются через интерфейс, то текстура и глубина принадлежат к одному и тому же (L или R) виду. В стерео случае, два вида текстуры имеют фиксированную ассоциацию с видом левого глаза (L) и видом правого глаза (R). В данном случае, два вида глубины имеют фиксированную зависимость с двумя видами текстуры. Если в стерео случае один из двух видов глубины не присутствует в кодированном битовом потоке, связанная глубина в формате HDMI устанавливается во все нули и соответствующая сигнализация включается в добавочную информацию (метаданные). Как указано выше, эти метаданные включаются в цветовые составляющие пикселей глубины.
Опциональный формат 2D + глубина уже был определен в Приложении H технического описания HDMI 1.4a. Устройства-получатели могут указывать поддержку для этого формата посредством HDMI VSDB в информации EDID. Применительно к 2D + глубина (или «L + глубина»), бит 3D_Structure_ALL_4 должен быть установлен равным 1. Смотри таблицу H-7 документа «High-Definition Multimedia Interface Specification Version 1.4a Extraction of 3D Signaling Portion». Сигнализация от источника к получателю должна быть выполнена посредством Конкретного для Поставщика InfoFrame HDMI путем установки поля 3D_Structure в значение 0100 (L + глубина) в соответствии с таблицей H-2. Данная опция доступна только для прогрессивного видео, предпочтительно с VIC кодами 16 (1080p60) или 31 (1080p50).
Отметим, что несмотря на то, что HDMI обращается к данному формату как L + глубина, составляющая 2D видео может быть ассоциирована либо с левым, либо с правым видом, в зависимости от информации, включенной в метаданные. Кроме того, что было определено в HDMI 1.4b, метаданные должны быть включены в цветовые составляющие пикселей глубины для сигнализации конкретного формата, используемого для передачи видео + глубина и добавочной информации.
HDMI 2.0 поддерживает более высокие тактовые частоты пикселя, чем HDMI 1.4b и включает в себя поддержку для форматов 2160p (разрешения 3840 x 2160 и 4096 x 2160) при частоте кадров вплоть до 60Гц. Форматы 2D + глубина и стерео + глубина могут быть упакованы в 2160p прогрессивные кадры для переноса данных по интерфейсу HDMI 2.0.
Форматы 2160p могут быть объединены с режимами кодирования пикселя RGB или YCBCR, определенными посредством HDMI. Применительно к более высоким частотам кадров единственно доступной опцией является режим кодирования пикселя YCBCR 4:2:0.
Нижеследующие конфигурации (режимы) упаковки кадра являются примерами того, каким образом форматы 2160p HDMI могут быть использованы для передачи видео + глубины:
A. Прогрессивный 2D + глубина
B. Чересстрочный 2D + глубина
C. Прогрессивный стерео + глубина
D. Чересстрочный стерео + глубина
В любом из режимов, каждая активная строка содержит видео (текстуры) пиксели единственной строки, за которой следует эквивалентное количество ассоциированных пикселей глубины, вместе заполняя активную строку. Режим указывается в метаданных, которые кодируются в цветовых составляющих пикселей глубины, начиная с первого пикселя глубины первой активной строки.
Упаковка субизображений текстуры и глубины в активном кадре HDMI для каждого из четырех режимов изображена на Фиг. 1 и Фиг. 2.
Субизображения текстуры имеют горизонтальное разрешение в половину горизонтального разрешения активной строки в одном из двух видео форматах 2160p HDMI, т.е. либо 1920, либо 2048 пикселей.
В прогрессивных режимах, субизображения текстуры имеют вертикальное разрешение в 1080 строк, т.е. половину вертикального разрешения видео форматов 2160p HDMI.
В чересстрочных режимах, субизображения текстуры имеют вертикальное разрешение в 540 строк, т.е. четверть вертикального разрешения видео форматов 2160p HDMI.
Местоположения дискретизации в случае кодирования пикселя YCBCR 4:2:2 и 4:2:0 предпочтительно находятся в соответствии с техническими описания AVC (см. раздел 2.2. документа ISO/IEC 14496-10:2012 - Information technology - Coding of audio-visual objects - Part 10: Advanced Video Coding). Субизображения глубины имеют горизонтальное разрешение либо в 1920, либо в 2048 пикселей, т.е. половину горизонтального разрешения активной строки в одном из двух видео форматах 2160p HDMI.
В прогрессивных режимах, субизображения глубины имеют вертикальное разрешение в 1080 строк, т.е. половину вертикального разрешения видео форматов 2160p HDMI.
В чересстрочных режимах, субизображения глубины имеют вертикальное разрешение в 540 строк, т.е. четверть вертикального разрешения видео форматов 2160p HDMI.
Субизображения глубины содержат значения глубины в диапазоне от 0 до 255, включительно, со смыслом, указываемым посредством метаданных.
В случае кодирования пикселя YCBCR, значения глубины должны быть сохранены в составляющих Y. Составляющие C должны быть установлены равными 0, если они не содержат метаданные. Устройство-получатель должно полагаться только на значения составляющей Y применительно к глубине.
В случае кодирования пикселя RGB 4:4:4, значения глубины должны быть сохранены в составляющих R. Составляющие G и B должны быть установлены в то же самое значение, что и составляющая R, если они не содержат метаданные. Устройство-получатель должно полагаться только на значения составляющей R применительно к глубине.
В качестве альтернативы, в случае кодирования пикселя RGB 4:4:4, значения глубины должны быть сохранены в составляющих G. Составляющие R и B должны быть установлены в нулевое значение, если они не содержат метаданные. Устройство-получатель должно полагаться только на значения составляющей G применительно к глубине.
В случае, когда используется больше 8 бит на составляющую (если позволяют частота кадров и тактовый генератор HDMI TMDS), значения глубины сохраняются в самых старших битах составляющей Y.
Канал метаданных содержит указание формата кадра и метаданных. Данный канала содержит последовательность байтов, включенную в пиксели глубины, начиная с первого пикселя глубины в первой строке глубины в каждом кадре, продолжая пикселями глубины со следующей строки в течении такого количества строк, которое необходимо для переноса данных. Байты канала метаданных сохраняются в составляющих C субизображения глубины, при одном из режимов кодирования пикселя YCBCR, и сохраняются в составляющих G и B при режиме кодирования пикселя RGB 4:4:4. В случае, когда доступно более 8 бит на составляющую (если разрешает частота кадров и тактовый генератор HDMI TMDS), байты канала метаданных сохраняются в 8 самых старших битах составляющих.
Отображение байтов метаданных в составляющих при различных режимах кодирования пикселя показано в Таблице 1.
Метаданные включаются в каждый кадр, присутствовало ли или нет изменение в контенте метаданных. Преимущество этого состоит в том, что становится возможным осуществление доступа к метаданным на основе кадра, что разрешает начать визуализацию, когда была передана информация для этого кадра. Так что метаданные могут быть вставлены повторно, присутствовало ли или нет изменение в контенте метаданных, например, для каждого кадра, для каждого поля, для каждой группы картинок, и/или для каждой сцены.
Канал метаданных может быть организован в качестве последовательности пакетов, как показано в Таблице 2.
Синтаксис пакета канала метаданных в свою очередь может быть предложен в таблице 3.
Канал метаданных содержит последовательность из 64-байтных пакетов канала метаданных. Количество пакетов, включенных в последовательность, зависит от объема метаданных, который должен быть передан. Чтобы улучшить ошибкоустойчивость, метаданные передаются три раза. Все байты канала метаданных, следующие за последним пакетом канала метаданных, устанавливаются равными 0. Таким образом здесь метаданные могут быть вставлены повторно, несмотря на то, что отсутствует изменение в метаданных.
Каждый 64-байтный пакет начинается с 4-байтного заголовка, за которым следует 56-байтная полезная нагрузка и 4-байтный код обнаружения ошибок (EDC). Фактические метаданные включаются в поля полезной нагрузки.
packet_id идентифицирует контент пакета в соответствии с таблицей 4.
В особенности, packet_id позволяет устройству, принимающему видео поток, манипулировать метаданными более эффективным образом. Эффективно packet_id 0xF3 в частности указывает что, если эти данные были корректно приняты в предыдущем кадре, тогда текущие метаданные могут быть проигнорированы.
В частности, поскольку метаданные для использования при визуализации могут быть точными по кадру в один момент и могут быть фиксированными для нескольких других кадров, данная информация может быть в частности преимущественной при реализации более эффективного манипулирования управлением метаданными. packet_subcode указывает конфигурацию упаковки кадра текущего кадра в соответствии с нижеследующей таблицей, если самый младший бит packet_id установлен равным 1 (т.е., packet_id установлен в 0xF1 или 0xF3). Во всех других случаях packet_subcode резервируется для будущего использования и устанавливается равным 0.
packet_metadata_type идентифицирует то, какой тип метаданных включается в полезную нагрузку данного пакета. Тип метаданных относится к виду добавочной информации, которая может происходить из добавочной информации улучшения (SEI), которая была включена в кодированный битовый поток, например, битовый поток AVC или HEVC, как стандартизировано ITU-T или ISO/IEC. Тип метаданных также может относиться к типу метаданных, которые были сгенерированы устройством-источником.
packet_count указывает количество пакетов, следующих за данным пакетом, с одним и тем же packet_metadata_type.
ОТМЕТИМ – Последний пакет содержит значение packet_count равное 0.
packet_payload() несет 56 байт общего потока байтов полезной нагрузки пакета, включенные в канал метаданных.
Общий поток байтов полезной нагрузки пакета для одного кадра включается в непрерывный поток пакетов и содержит, например, последовательность данных как представлено в Таблице 5 (в случае двух типов метаданных):

metadata_type>1 */
stuffing_byte устанавливается равным 0x00. Один или более байты набивки включаются в поток байтов вслед за последним байтом метаданных из того же типа для заполнения до конца (при необходимости) полезной нагрузки пакета. Выражение отношения в предшествующем операторе while (пока) является ИСТИНОЙ до тех пор, пока количество байтов в потоке байтов полезной нагрузки пакета не является кратным 56 байтам.
reserved_metadata_bytes() представляет собой дополнительные метаданные, которые могут быть определены в будущем. Такие дополнительные данные должны быть включены в увеличивающиеся значения metadata_type и с возможным включением байтов набивки (если требуется для выравнивания метаданных с пакетами канала метаданных).
packet_edc является 4-байтным полем, содержащим код обнаружения ошибок, вычисленный по первым 60 байтам пакета. Данный EDC использует стандартный CRC-32 многочлен как определено в IEEE 802.3 и ITU-T V.42. Как начальное значение, так и конечное значение XOR равны 0.
Природа метаданных
Метаданные, пересылаемые через сигнал видеоданных, служат для использования при обработке карты глубины или визуализации одного или более видов для дополнительных точек наблюдения многовидовым устройством визуализации. Такие метаданные являются зависимыми от контента. Метаданные предоставляются в соответствии с фактическими видеоданными. Следовательно, они могут меняться в соответствии с фактическими видеоданными, например, из расчета на поле, из расчета на кадр, из расчета на группу картинок, и/или из расчета на сцену. Такие метаданные, по существу, динамичные и не статичные как заголовок, который, например, указывает только то, что данные изображения и глубины присутствуют в разделе двумерной матрицы видеоданных. Опционально метаданные содержат, по меньшей мере, одно из следующего
- метаданные для кодирования предпочтительного направления визуализации для основанной на изображении визуализации;
- метаданные, указывающие отношение между информацией изображения и глубины;
- метаданные для использования при повторном отображении карты глубины или карты несоответствия на целевом дисплее.
Теперь предоставляются различные примеры таких метаданных.
Метаданные для использования в основанной на изображении визуализации могут, например, быть метаданными, такими как раскрываемые в документе WO 2011039679, который относится к кодированию предпочтительного направления визуализации в сигнале применительно к основанной на изображении визуализации. Данный документ раскрывает способ кодирования сигнала видеоданных, содержащий этапы, на которых: предоставляют первое изображение сцены, как просматриваемое с первой точки наблюдения; предоставляют информацию визуализации, такую как карту глубины, для того, чтобы обеспечить генерирование, по меньшей мере, одного визуализированного изображения сцены, как просматриваемое с точки наблюдения визуализации; и предоставляют индикатор предпочтительного направления, определяющий предпочтительную ориентацию точки наблюдения визуализации по отношению к первой точке наблюдения; и генерируют сигнал видеоданных, содержащий закодированные данные, представляющие собой первое изображение, информацию визуализации и индикатор предпочтительного направления.
Информация предпочтительного направления визуализации является метаданными, которые являются зависимыми от контента, но, кроме того, являются метаданными, которые требуются для использования устройством, которое проводит визуализацию фактического вида, которое в случае авто-стереоскопического дисплейного устройства, как правило, будет самим дисплейным устройством для того, чтобы позволить изготовителю устройства изготовителю создавать наилучшее возможное дисплейное устройство.
В качестве альтернативы метаданные могут быть указывающими отношение между информацией изображения и глубины, как раскрывается в PCT заявке WO2010070545 (Al). Вновь, информация, кодируемая в потоке, зависит от фактического контента и может быть использована авто-стереоскопическим дисплейным устройством для дальнейшего улучшения визуализации; например, в случае стерео+глубина контента может быть выгодным знать, была или нет информация глубины извлечена из стереоскопического контента и/или происходит ли информация глубины из выполняемого человеком авторинга. В последнем случае, может быть более преимущественным выполнение увеличения разрешения карты глубины низкого разрешения посредством выполняемого с помощью изображения увеличения масштаба, используя, например, кросс-двусторонний фильтр увеличения масштаба, вместо объединения карты глубины низкого разрешения с версией более высокого разрешения на основании оценки несоответствия стереоскопического контента.
В еще одном альтернативном варианте предоставляемые метаданные могут быть метаданными для использования в повторном отображении карты глубины или карты несоответствия на целевом дисплее, как, например, раскрывается в PCT заявке WO2010041176. Данная PCT заявка относится к использованию преобразований параллакса для перенастройки контента для других целевых дисплеев.
Такое повторное отображение глубины/несоответствия является процессом, который является не только зависящим от контента, а обработка этих данных, кроме того, является зависимой от дисплейного устройства. В результате, эти данные преобразования параллакса являются данными, которые предпочтительно предоставляются в сжатом формате совместно с самим контентом. Например, преобразования параллакса могут быть встроены в сжатый контент, который считывается с запоминающего устройства, или носителя данных или принимается от проводной/беспроводной сети. И затем добавляются в качестве метаданных и переносятся к устройству, которое отвечает за визуализацию вида.
Обратимся к Фиг.3. Фиг.3 показывает структурную схему кодера в соответствии с настоящим изобретением и декодера в соответствии с настоящим изобретением в цепочке 3D визуализации.
В верхней левой части фигуры мы можем видеть кодер 310. Кодер 310 является кодером сигнала 50 видеоданных для использования с многовидовым устройством визуализации. Кодер 310 содержит: первый блок 301 получения, выполненный с возможностью получения первого изображения 10 сцены, ассоциированного с первой точкой наблюдения; второй блок 302 получения, выполненный с возможностью получения карты 20 глубины, ассоциированной с первым изображением 10; и третий блок 302 получения, выполненный с возможностью получения метаданных 30 для использования при обработке карты глубины или визуализации одного или более видов применительно к дополнительным точкам наблюдения посредством многовидового устройства визуализации. Кодер 310 дополнительно содержащий: генератор 304, выполненный с возможностью генерирования сигнала 50 видеоданных, причем сигнала 50 видеоданных, содержащего: одно или два субизображения, основанных на первом изображении 10; одно или два дополнительных субизображения, основанных на карте (20) глубины; и метаданные (30), закодированные в одной или двух дополнительных субизображениях.
На всем протяжении данной заявки получение данных кодером рассматривается как включающее в себя либо прием данных от внешнего источника, либо получение данных устройством кодера, либо генерирование данных устройством кодера.
Предпочтительно информация из карты 20 глубины кодируется в значениях яркости одного или двух дополнительных субизображений, а информация из метаданных 30 кодируется в значениях цветности одного или более дополнительных субизображений.
Более предпочтительно информация, содержащаяся в сигнале видеоданных, содержит, по существу, несжатый двумерный массив данных с помещенными в нем соответствующими субизображениями.
Как только сигнал 50 видеоданных кодируется в отношении него может быть выполнены манипуляции посредством обработчика 70, который может в качестве альтернативы сохранять сигнал 50 видеоданных на запоминающем носителе 71 информации, который может быть жестким диском, оптическим диском или энергонезависимым хранилищем памяти, таким как твердотельная память. Тем не менее на практике более вероятно то, что данные передаются обработчиком 70 через проводную 72 или беспроводную сеть 73 или их сочетание (не показано).
Сигнал видеоданных будет впоследствии прибывать на декодер 350 для декодирования сигнала 50 видеоданных, причем декодер, содержащий приемник 351, выполненный с возможностью приема сигнала 50 видеоданных. На данной стадии сигнал видеоданных содержит; первое изображение 10 сцены, ассоциированное с первой точкой наблюдения; карту 20 глубины, ассоциированную с первым изображением 10; и метаданные 30 для использования при обработке карты глубины или визуализации нескольких видов. Сигнал видеоданных впоследствии проходит к де-мультиплексору 352, причем де-мультиплексор выполнен с возможностью де-мультиплексирования сигнала 50 видеоданных с тем, чтобы получить доступ к отдельным составляющим.
Декодер 350 кроме того, по меньшей мере, включает в себя одно из следующего: процессор 353 карты глубины, для обработки карты 20 глубины в зависимости от метаданных 30, или блок 354 визуализации, причем блок визуализации, выполненный с возможностью визуализации одного или более видов или обоих. По меньшей мере, одно из них должно присутствовать для того, чтобы настоящее изобретение имело возможность предоставить преимущество в манипулировании метаданными.
Также опционально декодер 350 также включает в себя многовидовой стереоскопический дисплейный блок 356. Дисплейный блок может быть основанным на барьере или основанным на двояковыпуклой линзе многовидовым дисплейным устройством, или другим видом многовидового дисплейного устройства, для которого требуется визуализация дополнительных видов.
После де-мультиплексирования данных, используя де-мультиплексор 352, метаданные проходят к процессору 355 управления для дальнейшего манипулирования метаданными.
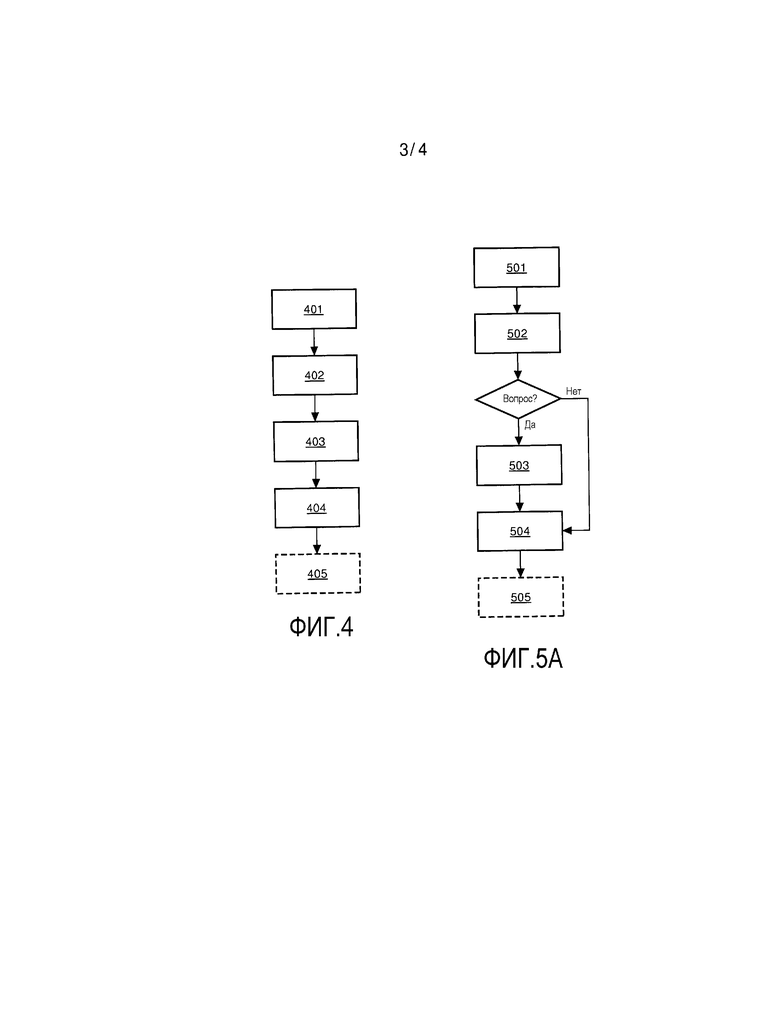
Обращаясь к Фиг.4, Фиг.4 показывает блок-схему способа кодирования в соответствии с настоящим изобретением. Блок-схема изображает процесс кодирования сигнала 50 видеоданных для использования с многовидовым устройством визуализации, причем способ содержит: этап 401 в виде предоставления первого изображения 10 сцены, ассоциированного с первой точкой наблюдения; этап 402 в виде предоставления карты 20 глубины, ассоциированной с первым изображением 10; и этап 403 в виде предоставления 403 метаданных 30 для использования при обработке карты глубины или визуализации одного или более видов для дополнительных точек наблюдения посредством многовидового устройства визуализации. Способ дополнительно содержит этап 404 в виде генерирования 404 сигнала 50 видеоданных, причем сигнал 50 видеоданных содержит одно или два субизображения, основанные на первом изображении 10, одно или два дополнительных субизображения, основанных на карте 20 глубины, и метаданные 30, закодированные в одном или двух дополнительных субизображениях.
Как указывается здесь выше предпочтительно информация из карты 20 глубины кодируется в значениях яркости одного или двух дополнительных субизображений, а информация из метаданных 30 кодируется в значениях цветности одного или двух дополнительных субизображений.
Более предпочтительно информация, содержащаяся в сигнале видеоданных, содержит, по существу, несжатый двумерный массив данных с помещенными в нем соответствующими субизображениями.
Обращаясь к Фиг.5, Фиг.5 показывает блок-схему способа декодирования в соответствии с настоящим изобретением. Блок-схема схематично показывает процесс декодирования сигнала 50 видеоданных, причем способ содержит этап 501 для приема сигнала 50 видеоданных. Сигнал видеоданных содержит: первое изображение 10 сцены, ассоциированное с первой точкой наблюдения; карту 20 глубины, ассоциированную с первым изображением 10; и метаданные 30 для использования при либо обработке карты глубины, либо визуализации нескольких видов, как описывается здесь выше со ссылкой на Фиг.3.
Способ дополнительно содержит этап 502 в виде де-мультиплексирования 502 сигнала 50 видеоданных с тем, чтобы получить доступ к отдельным составляющим. Вслед за де-мультиплексированием, инспектируются метаданные для того, чтобы определить, каким образом должна происходить дальнейшая обработка. В случае когда требуется обработка карты глубины в зависимости от метаданных 30, процесс продолжается с помощью этапа 503; т.е. обработки 503 карты глубины применительно к карте 20 глубины в зависимости от метаданных 30.
В качестве альтернативы, когда не требуется обработка карты глубины; процесс продолжается на этапе 504 с помощью визуализации (504) одного или более видов для дополнительных точек наблюдения в зависимости от метаданных (30). В заключении, опционально, вновь визуализированные виды используются на этапе 505 фактической демонстрации визуализированных видов, используя многовидовое стереоскопическое дисплейное устройство.
В особенности Фиг.5B и 5C предоставляют дополнительные варианты осуществления способа декодирования в соответствии с настоящим изобретением, при этом Фиг.5B показывает вариант осуществления в котором отсутствуют метаданные, предоставляемые для обработки глубины; т.е., сценарий, при котором метаданные используются только для управления процессом визуализации. Поскольку отсутствует обработка глубины на основании метаданных, то данный этап был исключен из блок-схемы.
Аналогичным образом Фиг.5C показывает вариант осуществления при котором отсутствуют метаданные предоставляемые для процесса визуализации, но где всегда присутствуют метаданные, предоставляемые для этапа обработки глубины. В данном сценарии этап 504, который включает в себя визуализацию вида в зависимости от метаданных 30, замещен этапом 504’, который является этапом визуализации вида, который не использует метаданные 30.
Будет понятно, что изобретение также распространяется на компьютерные программы, в частности компьютерные программы на или в носителе, адаптированном для реализации изобретения на практике. Программа может быть в виде исходного кода, объектного кода, промежуточного кода между исходным и объектным кодом, как например, частично компилированном виде, или в любом другом виде, пригодном для использования при реализации способа в соответствии с изобретением. Также будет понятно, что такая программа может иметь много разных архитектурных исполнений. Например, программный код, реализующий функциональные возможности способа или системы в соответствии с изобретением, может быть подразделен на одну или более подпрограммы.
Много разных способов распределения функциональных возможностей между этими подпрограммами будет очевидно специалисту в соответствующей области техники. Подпрограммы могут быть сохранены вместе в одном исполняемом файле для формирования автономной программы. Такой исполняемый файл может содержать исполняемые компьютером инструкции, например, процессорные инструкции и/или инструкции интерпретатора (например, инструкции интерпретатора Java). В качестве альтернативы, одна или более или все подпрограммы могут быть сохранены в, по меньшей мере, одном внешнем файле библиотеки и подключены к основной программе либо статически, либо динамически, например, при исполнении. Основная программа содержит, по меньшей мере, один вызов, по меньшей мере, одной из подпрограмм. Также, подпрограммы могут содержать вызовы функций друг к другу. Вариант осуществления, относящийся к компьютерному программному продукту, содержит исполняемые компьютером инструкции, соответствующие каждому из этапов обработки, по меньшей мере, одного из изложенных способов. Эти инструкции могут быть подразделены на подпрограммы и/или сохранены в одном или более файлах, которые могут быть подключены статически или динамически.
Другой вариант осуществления, относящийся к компьютерному программному продукту, содержит исполняемые компьютером инструкции, соответствующие каждому из средств, по меньшей мере, одной из изложенных систем и/или продуктов. Эти инструкции могут быть подразделены на подпрограммы и/или сохранены в одном или более файлах, которые могут быть подключены статически или динамически.
Носитель компьютерной программы может быть любым объектом или устройством, выполненным с возможностью переноса программы. Например, носитель может включать в себя запоминающий носитель информации, такой как ROM, например, CD ROM или полупроводниковое ROM, или магнитный записывающий носитель информации, например, гибкий диск или жесткий диск. Кроме того носитель может быть передающимся носителем, таким как электрический или оптический сигнал, которые могут переправляться через электрический или оптический кабель или с помощью радио или другого средства. Когда программа воплощается в таком сигнале, носитель может являться таким кабелем или иным устройством или средством. В качестве альтернативы, носитель может быть интегральной микросхемой, в которую встроена программа, причем интегральной микросхемой выполненной с возможностью выполнения, или для использования при выполнении, соответствующего способа.
Следует отметить, что вышеупомянутые варианты осуществления иллюстрируют, нежели ограничивают, изобретение, и что специалисты в соответствующей области техники будут иметь возможность разработки многих альтернативных вариантов осуществления, не отступая от объема прилагаемой формулы изобретения. В формуле изобретения, любые ссылочные знаки, помещенные между круглых скобок, не должны толковаться как ограничивающие формулу изобретения. Использование глагола «содержать» и его спряжений не исключает присутствия элементов или этапов отличных от тех, что сформулированы в пункте формулы изобретения. Артикли единственного числа, предшествующие элементу, не исключают присутствия множества таких элементов. Изобретение может быть реализовано посредством аппаратного обеспечения, содержащего несколько отдельных элементов, и посредством подходящим образом запрограммированного компьютера. В пункте формулы изобретения, который относится к устройству, перечисляющем несколько средств, некоторые из этих средств могут быть воплощены посредством одного и того же элемента аппаратного обеспечения. Тот лишь факт, что некоторые меры изложены во взаимно разных зависимых пунктах формулы изобретения не указывает на то, что сочетание этих мер, не может быть использовано для получения преимущества.
| название | год | авторы | номер документа |
|---|---|---|---|
| ВЫСОКОУРОВНЕВАЯ ПЕРЕДАЧА СЛУЖЕБНЫХ СИГНАЛОВ ДЛЯ ВИДЕОДАННЫХ ТИПА "РЫБИЙ ГЛАЗ" | 2018 |
|
RU2767300C2 |
| КОМБИНИРОВАНИЕ 3D ВИДЕО И ВСПОМОГАТЕЛЬНЫХ ДАННЫХ | 2010 |
|
RU2554465C2 |
| ПЕРЕДАЧА ДАННЫХ 3D ИЗОБРАЖЕНИЯ | 2010 |
|
RU2536388C2 |
| МЕТАДАННЫЕ ДЛЯ ФИЛЬТРАЦИИ ГЛУБИНЫ | 2013 |
|
RU2639686C2 |
| ПЕРЕДАЧА ДАННЫХ 3D ИЗОБРАЖЕНИЯ | 2010 |
|
RU2538333C2 |
| ОБРАБОТКА 3D ОТОБРАЖЕНИЯ СУБТИТРОВ | 2009 |
|
RU2517402C2 |
| УСТРОЙСТВО И СПОСОБ ДЛЯ КОДИРОВАНИЯ И ДЕКОДИРОВАНИЯ ВИДЕО | 2020 |
|
RU2784900C1 |
| ВСПОМОГАТЕЛЬНЫЕ ДАННЫЕ В ТРАНСЛЯЦИИ 3D ИЗОБРАЖЕНИЯ | 2011 |
|
RU2589307C2 |
| РАСШИРЕНИЕ ЗАГОЛОВКА ВЫРЕЗКИ ДЛЯ ТРЕХМЕРНОГО ВИДЕО ДЛЯ ПРОГНОЗИРОВАНИЯ ЗАГОЛОВКОВ ВЫРЕЗОК | 2012 |
|
RU2549168C1 |
| ПЕРЕКЛЮЧЕНИЕ МЕЖДУ ТРЕХМЕРНЫМ И ДВУМЕРНЫМ ВИДЕОИЗОБРАЖЕНИЯМИ | 2010 |
|
RU2547706C2 |



Изобретение относится к способу кодирования сигнала видеоданных. Технический результат заключается в обеспечении возможности добавления дополнительных форматов, обеспечивающих поддержку передачи стереоизображений и ассоциированной информации глубины. Технический результат достигается за счет предоставления первого изображения сцены, ассоциируемого с первой точкой наблюдения, карты глубины, ассоциируемой с первым изображением, метаданных для использования при обработке карты глубины или визуализации одного или более видов для дополнительных точек наблюдения посредством многовидового устройства визуализации, и генерирования сигнала видеоданных. Сигнал видеоданных содержит видеокадры, разбитые на субизображения, содержащие субизображение, основанное на первом изображении, и субизображение глубины, основанное на карте глубины, и метаданные, закодированные в цветовой составляющей субизображения глубины. 5 н. и 8 з.п. ф-лы, 7 ил., 5 табл.
1. Способ кодирования сигнала (50) видеоданных для использования в многовидовом устройстве визуализации, причем способ содержит этапы, на которых:
- предоставляют (401) первое изображение (10) сцены, ассоциированное с первой точкой наблюдения,
- предоставляют (402) карту (20) глубины, ассоциированную с первым изображением (10),
- предоставляют (403) метаданные (30) для использования при
- обработке карты глубины или
- визуализации одного или более видов для дополнительных точек наблюдения
посредством многовидового устройства визуализации,
- генерируют (404) сигнал (50) видеоданных, причем сигнал (50) видеоданных содержит видеокадры, разбитые на субизображения, содержащие:
- первое субизображение, основанное на первом изображении (10),
- первое субизображение глубины, основанное на карте (20) глубины, и
- метаданные (30), закодированные в цветовой составляющей первого субизображения глубины, причем метаданные повторно вставлены в последующие видеокадры, было ли или нет изменение в метаданных, и метаданные, содержащие информацию изменения, указывающую на то, изменились ли метаданные с момента предыдущего кадра с тем, чтобы разрешить упомянутое использование метаданных точно по кадру или фиксировано для нескольких кадров.
2. Способ кодирования по п.1, в котором
- сигнал видеоданных организован в значениях яркости и цветности, карта (20) глубины кодируется в значениях яркости первого субизображения глубины, а метаданные (30) кодируются в значениях цветности первого субизображения глубины; или
- сигнал видеоданных организован в R, G и B составляющих, и карта (20) глубины кодируется в первой составляющей из R, G и B составляющих первого субизображения глубины, а метаданные (30) кодируются в дополнительной составляющей из R, G и B составляющих первого субизображения глубины.
3. Способ кодирования по п.1 или 2, в котором видеокадр, содержащийся в сигнале видеоданных, содержит несжатый двумерный массив данных с помещенными в нем соответствующими субизображениями.
4. Способ кодирования по п.1 или 2, причем способ дополнительно содержит этап, на котором
- передают (405) сигнал видеоданных через интерфейс, используя одну или более поразрядные строки данных, к многовидовому устройству визуализации.
5. Способ кодирования по п.1 или 2, в котором метаданные вставляются в сигнал (50) видеоданных:
- для каждого поля,
- для каждого кадра,
- для каждой группы картинок, и/или
- для каждой сцены.
6. Способ кодирования по п.1 или 2, в котором метаданные обеспечиваются контрольной суммой.
7. Способ кодирования по п.1 или 2, причем способ дополнительно содержит этапы, на которых:
- предоставляют (401) второе изображение (210) сцены, ассоциированное со второй точкой наблюдения,
- предоставляют (402) вторую карту (220) глубины, ассоциированную со вторым изображением (210), и при этом
- этап, на котором генерируют сигнал (50) видеоданных, дополнительно содержит этап, на котором включают
- второе субизображение, основанное на втором изображении (210),
- второе субизображение глубины, основанное на второй карте (20) глубины,
в сигнал (50) видеоданных.
8. Способ декодирования сигнала (50) видеоданных, при этом способ содержит этапы, на которых:
- принимают (501) сигнал (50) видеоданных, причем сигнал видеоданных содержит:
- первое изображение (10) сцены, ассоциированное с первой точкой наблюдения,
- карту (20) глубины, ассоциированную с первым изображением (10),
- метаданные (30) для использования при
- обработке карты глубины или
- визуализации множества видов,
причем сигнал (50) видеоданных содержит видеокадры, разбитые на субизображения, содержащие:
- первое субизображение, основанное на первом изображении (10),
- первое субизображение глубины, основанное на карте (20) глубины, и
- метаданные (30), закодированные в первом субизображении глубины;
- де-мультиплексируют (502) сигнал (50) видеоданных таким образом, чтобы получить доступ к отдельным составляющим и извлечь метаданные (30) из цветовой составляющей первого субизображения глубины, причем метаданные повторно вставлены в последующие видеокадры, было ли или нет изменение в метаданных, и метаданные, содержащие информацию изменения, указывающую на то, изменились ли метаданные с момента предыдущего кадра,
- выполняют по меньшей мере один из следующих этапов, на которых:
- обрабатывают (503) карту глубины применительно к карте (20) глубины в зависимости от метаданных (30) или
- визуализируют (504) один или более видов для дополнительных точек наблюдения в зависимости от метаданных (30),
при этом способ содержит процесс управления для манипулирования обработкой метаданных и для использования информации изменения для того, чтобы определять, обрабатывать ли в дальнейшем метаданные в зависимости от информации изменения либо точно по кадру, либо фиксировано для нескольких кадров.
9. Декодер (350) для декодирования сигнала (50) видеоданных, при этом декодер содержит:
- приемник (351), выполненный с возможностью приема сигнала (50) видеоданных, причем сигнал видеоданных содержит:
- первое изображение (10) сцены, ассоциированное с первой точкой наблюдения,
- карту (20) глубины, ассоциированную с первым изображением (10),
- метаданные (30) для использования при
- обработке карты глубины или
- визуализации множества видов,
причем сигнал (50) видеоданных содержит видеокадры, разбитые на субизображения, содержащие:
- первое субизображение, основанное на первом изображении (10),
- первое субизображение глубины, основанное на карте (20) глубины, и
- метаданные (30), закодированные в первом субизображении глубины;
- де-мультиплексор (352), причем де-мультиплексор выполнен с возможностью де-мультиплексирования сигнала (50) видеоданных таким образом, чтобы получить доступ к отдельным составляющим и извлечь метаданные (30) из цветовой составляющей первого субизображения глубины, причем метаданные повторно вставлены в последующие видеокадры, было ли или нет изменение в метаданных, и метаданные, содержащие информацию, указывающую на то, изменились ли метаданные с момента предыдущего кадра, и по меньшей мере одно из следующего:
- процессор (353) карты глубины, выполненный с возможностью обработки карты (20) глубины в зависимости от метаданных (30); или
- блок (354) визуализации, причем блок визуализации выполнен с возможностью визуализации одного или более видов в зависимости от метаданных (30),
при этом декодер содержит процессор (355) управления для манипулирования обработкой метаданных и для использования информации изменения для того, чтобы определять, обрабатывать ли в дальнейшем метаданные в зависимости от информации изменения либо точно по кадру, либо фиксировано для нескольких кадров.
10. Декодер по п.9, при этом декодер дополнительно содержит многовидовой стереоскопический дисплейный блок (356) для отображения визуализированного одного или более видов.
11. Декодер по любому из пп.9 или 10, дополнительно выполненный с возможностью декодирования любого из сигналов видеоданных, сгенерированных, используя способ по любому из пп.1-7.
12. Считываемый компьютером носитель, содержащий, сохраненные на нем, исполняемые компьютером инструкции, которые при выполнении процессорной системой побуждают процессорную систему выполнять способ по любому из пп.1-7 или 8.
13. Кодер (310) сигнала (50) видеоданных для использования в многовидовом устройстве визуализации, при этом кодер содержит:
- блок (301) получения, выполненный с возможностью получения первого изображения (10) сцены, ассоциированного с первой точкой наблюдения,
- блок (302) получения, выполненный с возможностью получения карты (20) глубины, ассоциированной с первым изображением (10),
- блок (303) получения, выполненный с возможностью получения метаданных (30) для использования при
- обработке карты глубины или
- визуализации одного или более видов для дополнительных точек наблюдения
посредством многовидового устройства визуализации,
- генератор (304), выполненный с возможностью генерирования сигнала (50) видеоданных, причем сигнал (50) видеоданных содержит видеокадры, разбитые на субизображения, содержащие:
- первое субизображение, основанное на первом изображении (10),
- первое субизображение глубины, основанное на карте (20) глубины, и
- метаданные (30), закодированные в цветовой составляющей первого субизображения глубины, причем метаданные повторно вставлены в последующие видеокадры, было ли или нет изменение в метаданных, и метаданные, содержащие информацию, указывающую на то, изменились ли метаданные с момента предыдущего кадра с тем, чтобы разрешить упомянутое использование метаданных точно по кадру или фиксировано для нескольких кадров.
| Изложница с суживающимся книзу сечением и с вертикально перемещающимся днищем | 1924 |
|
SU2012A1 |
| Колосоуборка | 1923 |
|
SU2009A1 |
| Многоступенчатая активно-реактивная турбина | 1924 |
|
SU2013A1 |
| Приспособление для суммирования отрезков прямых линий | 1923 |
|
SU2010A1 |
| Способ приготовления лака | 1924 |
|
SU2011A1 |
| СЕГМЕНТИРОВАННЫЕ МЕТАДАННЫЕ И ИНДЕКСЫ ДЛЯ ПОТОКОВЫХ МУЛЬТИМЕДИЙНЫХ ДАННЫХ | 2008 |
|
RU2477883C2 |
| МЕТОДИКИ МАСШТАБИРУЕМОСТИ НА ОСНОВЕ ИНФОРМАЦИИ СОДЕРЖИМОГО | 2006 |
|
RU2378790C1 |

