ОБЛАСТЬ ТЕХНИКИ
Техническое решение относится к области компьютерных сетей, а именно к области управления потоками ресурсов в сетях, предназначено для групповой маршрутизации и минимизации группового трафика в программно-конфигурируемых сетях.
УРОВЕНЬ ТЕХНИКИ
Из уровня техники известны следующие решения:
Решения для традиционных сетей.
IP multicast - наиболее распространенная на сегодняшний день реализация multicast для традиционных сетей. Текущим стандартом IP multicast является PIM-SM (Farinacci D. et al. Protocol independent multicast-sparse mode (PIM-SM): Protocol specification. - 1998.), который использует дерево кратчайших путей для соединения граничных узлов в multicast группе, где под граничным узлом понимается некоторый выделенный маршрутизатор, подключенный к сети хотя бы с одним клиентом multicast группы.
Существует множество проблем в практической реализации IP multicast. Одной из важных проблем является то, что протоколы маршрутизации для IP multicast, такие как Protocol Independent Multicast - Sparse Mode (PIM-SM), не предназначены для построения оптимальных деревьев маршрутизации трафика. Деревья кратчайших путей, получаемые в ходе работы данного протокола, могут использовать большое количество физических линий и занимать значительную часть пропускной способности сети в целом, таким образом, не являясь оптимальными с точки зрения загрузки сети.
Построение деревьев маршрутизации, на которых достигается минимум по количеству используемых физических линий, представляет собой задачу построения дерева Штейнера (М. Imase and В.М. Waxman, "Dynamic Steiner tree problem," SIAM lournal on Discrete Mathematics, vol. 4, no. 3, pp. 369-3S4, 1991.). Для произвольных графов, которые соответствуют топологиям традиционных сетей, известно, что задача построения дерева Штейнера является NP-полной (Winter P. Steiner problem in networks: a survey //Networks. - 1987. - T. 17. - №. 2. - C. 129-167), то есть алгоритм нахождения оптимального решения задачи Штейнера скорее всего не является полиномиальным, и таким образом представляет сложность для реализации его в виде распределенного протокола в традиционной сети. Поэтому алгоритмы на основе деревьев Штейнера почти не применяются в существующих multicast протоколах.
Важной проблемой для известных multicast протоколов является потеря пакетов во время процедуры перестроения multicast дерева. Эта процедура запускается при обнаружении отказа сетевых линий или узлов. Потеря пакетов происходит из-за того, что в IP multicast процедура перестроения дерева занимает слишком много времени (Wang X. et al. IP multicast fault recovery in PIM over OSPF //Network Protocols, 2000. Proceedings. 2000 International Conference on. - IEEE, 2000. - C. 116-125.).
Multicast маршрутизация на канальном уровне опирается на протокол STP и IGMP snooping - механизм отслеживания IGMP трафика. Протокол STP представляет собой протокол построения остовного дерева в сети Ethernet, динамически отключающего избыточные (по критериям этого протокола) линии.
IGMP snooping является механизмом, который предотвращает излишнее широковещание multicast трафика на канальном уровне. Коммутатор, поддерживающий IGMP snooping, анализирует проходящие через него IGMP пакеты, выявляя клиентов, подключенных к multicast группам. Это позволяет коммутаторам отправлять multicast трафик только через порты, к которым подключены его потребители, тем самым существенно снижая нагрузку на сеть.
Порты, по которым могут проходить IGMP сообщения, принадлежат STP портам коммутатора, поэтому multicast трафик может проходить только по линиям, принадлежащим остовому дереву Ethernet сети. Таким образом, невозможно производить настройку multicast дерева в зависимости от различных критериев, таких как нагрузка на линии, длина пути от источника до потребителя и т.д. Более того, в случае отключения какой-либо линии, перестроение остовного дерева приведет к тому, что клиенты не будут получать multicast трафик, в течение значительного времени.
Решения для программно-конфигурируемых сетей.
В статье Bondan L.,  L.F., Kist M. Multiflow: Multicast clean-slate with anticipated route calculation on OpenFlow programmable networks //Journal of Applied Computing Research. - 2013. - T. 2. - №. 2. - C. 68-74. предлагается использовать приложение на SDN контроллере NOX, которое производит обработку IGMP запросов от клиентов и установку multicast маршрутов в сети. Для вычисления наилучшего маршрута используется алгоритм Дейкстры для нахождения кратчайшего пути (М.R. Garey, D.S. Johnson, Computers and Intractability: A Guide to the Theory of NP-completeness, W.H. Freeman and Company, 1979.). В качестве весов ребер используется расстояние между узлами в сети (количество hop'ов).
L.F., Kist M. Multiflow: Multicast clean-slate with anticipated route calculation on OpenFlow programmable networks //Journal of Applied Computing Research. - 2013. - T. 2. - №. 2. - C. 68-74. предлагается использовать приложение на SDN контроллере NOX, которое производит обработку IGMP запросов от клиентов и установку multicast маршрутов в сети. Для вычисления наилучшего маршрута используется алгоритм Дейкстры для нахождения кратчайшего пути (М.R. Garey, D.S. Johnson, Computers and Intractability: A Guide to the Theory of NP-completeness, W.H. Freeman and Company, 1979.). В качестве весов ребер используется расстояние между узлами в сети (количество hop'ов).
В статье Iyer A., Kumar P., Mann V. Avalanche: Data center multicast using software defined networking //2014 Sixth International Conference on Communication Systems and Networks (COMSNETS). - IEEE, 2014. - С. 1-8. представлена система для SDN сети, реализующая маршрутизацию multicast трафика в центрах обработки данных (ЦОД). Также был разработан алгоритм маршрутизации multicast трафика, называемый Avalanche Routing Algorithm (AvRA), который минимизирует размер multicast дерева для каждой группы в отдельности.
AvRA это полиномиальный рандомизированный алгоритм, который строит дерево маршрутизации multicast трафика, пытаясь соединить каждого нового члена multicast группы с ближайшей к нему точкой multicast дерева. Алгоритм AvRA не дает оптимального решения для сетей с произвольной топологией. Однако, для часто используемых на практике топологий, таких как Tree и FatTree, алгоритм находит оптимальное решение с вероятностью близкой к единице, алгоритм делает это с высокой вероятностью для большинства реальных сетевых топологий. Например, для Tree и FatTree, вероятность равна 1. В случае если алгоритм AvRA не способен найти оптимальное решение, то находится решение, которое эквивалентно эквивалентное решению, которое нашел бы PIM-SM.
В статье Huang L.Н. et al. Scalable Steiner tree for multicast communications in software-defined networking //arXiv preprint arXiv: 1404.3454. - 2014. предлагается использовать в качестве multicast дерева - дерево под названием Branch-aware Steiner Tree (BST). Отличие BST дерева от дерева Штейнера состоит в том, что при построении минимизируется не только количество используемых линковлиний, но и количество узлов ветвления.
Авторами статьи доказано, что нахождение Branch-aware Steiner Tree это NP-трудная задача. Более того, в то время как для дерева Штейнера существуют аппроксимационные алгоритмы, которые строят решение стоимости не более чем 1.55 * ОРТ (ОРТ - стоимость дерева Штейнера), для Branch-aware Steiner Tree не существует аппроксимационного алгоритма, дающего решение, отличающееся от оптимального на множитель k1-ε, для любого ε>0 (k - число участников multicast группы. Другими словами, решение данной задачи сложно аппроксимировать.
Авторы статьи предлагают k-аппроксимационный алгоритм для решения поставленной задачи. Данный алгоритм называется Branch Aware Edge Reduction Algorithm (BAERA)., Также авторы отмечают, что данный алгоритм который может быть использован для нахождения multicast дерева в SDN сети.
СУЩНОСТЬ ТЕХНИЧЕСКОГО РЕШЕНИЯ
Данное техническое решение направлено на устранение недостатков, присущих существующим аналогам.
Технический результат от использования данного технического решения заключается в минимизации количества multicast трафика по различным критериям и обеспечении устойчивости multicast трафика к отказам линий передач и SDN коммутаторов.
Данный технический результат достигается за счет реализации в L2 среде, при помощи использования технологии SDN, дерева распространения multicast трафика, возможности оптимального перестроения multicast дерева и восстановления передачи multicast трафика после отказов линий передач или SDN коммутаторов, а также возможности выбора различных критериев, по которым строится дерево распространения multicast трафика, а именно критерии Hop, Port speed и Load.
В одном из предпочтительных вариантов реализации предложен способ минимизации многоадресного трафика и обеспечения его отказоустойчивости в ПКС сетях, характеризующийся тем что: определяют multicast группы и активные источники трафика; устанавливают на всех коммутирующих устройствах в сети openflow правила; получают igmp сообщения от клиента на порту коммутирующего устройства; оправляют данное сообщение на контроллер для дальнейшего анализа; на основе полученного на контроллере сообщения, определяют порт, на котором находится клиент, запросивший multicast группу; выбирают источник multicast трафика из списка источников; осуществляют построение пути от источника до multicast клиента по различным критериям; определяют коммутирующие устройства, на которые необходимо установить правила маршрутизации; устанавливают на определенные на предыдущем шаге коммутирующие устройства правила коммутации; определяют контроллером изменения состояния сети; осуществляют перестроение multicast дерева по различным критериям с учетом обновленной на предыдущем шаге топологии сети; определяют наличие клиентов, не получающих multicast трафика; обновляют openflow правила на коммутирующих устройствах таким образом, чтобы все клиенты получали multicast трафик.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
Фиг. 1 - Алгоритм 1: Построение multicast дерева;
Фиг. 2 - Алгоритм 2: Построение дерева кратчайших путей;
Фиг. 3 - Алгоритм 3: Построение maxmin дерева;
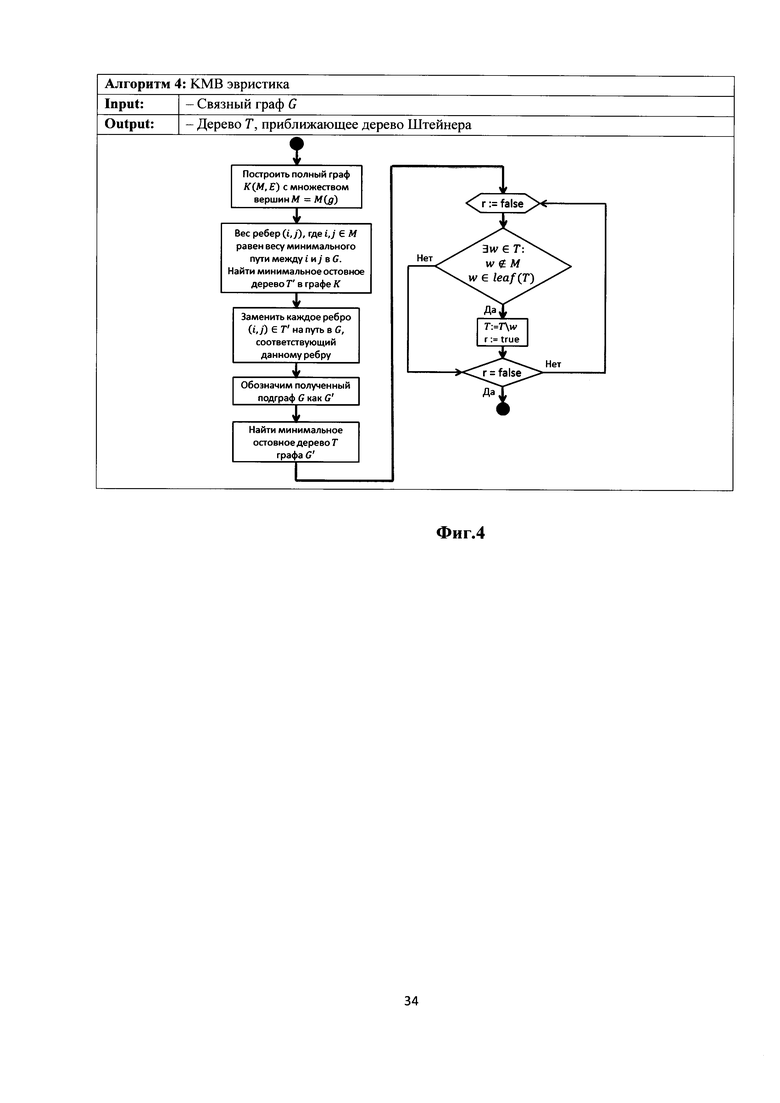
Фиг. 4 - Алгоритм 4: КМВ эвристика.
ПОДРОБНОЕ ОПИСАНИЕ ТЕХНИЧЕСКОГО РЕШЕНИЯ
В данном устройстве под системой подразумевается компьютерная система, ЭВМ (электронно-вычислительная машина), ЧПУ (числовое программное управление), ПЛК (программируемый логический контроллер), компьютеризированные системы управления и любые другие устройства, способные выполнять заданную, четко определенную последовательность операций (действий, инструкций).
Под устройством обработки команд подразумевается электронный блок либо интегральная схема (микропроцессор), исполняющая машинные инструкции (программы).
Устройство обработки команд считывает и выполняет машинные инструкции (программы) с одного или более устройства хранения данных. В роли устройства хранения данных могут выступать, но, не ограничиваясь, жесткие диски (HDD), флеш-память, ПЗУ (постоянное запоминающее устройство), твердотельные накопители (SSD), оптические накопители информации (CD, DVD, Blue-Ray диски).
Программа - последовательность инструкций, предназначенных для исполнения устройством управления вычислительной машины или устройством обработки команд.
Для понимания разработанного решения приведем общую постановку задач маршрутизации, оптимизации и отказоустойчивости.
Представим сеть в виде графа G(V;E), где V - множество вершин, соответствующих коммутаторам, а Е - множество ребер, представленных парами (ν, u), если коммутаторы ν и u соединены физической линией. Обозначим через n - количество вершин, а через m - количество ребер графа G.
Для каждой multicast группы g определено множество М=М(g)⊆V, называемое множеством участников группы. Участником группы g называется коммутатор, к которому подключены получатели multicast трафика группы g. Участники могут, как подключаться к некоторой группе, так и отключаться от нее. Среди множества М выделена вершина s - участник группы, называемый сервером группы, сервер является исходной точкой для multicast трафика данной группы.
Для всех ребер (ν, u)∈Е определена функция с(ν,u): Е→Z0 представляющая собой пропускную способность канала между v и u такую, что 0≤с(ν, u). Также определена функция  представляющая собой загрузку канала между v и u в момент времени t.
представляющая собой загрузку канала между v и u в момент времени t.
Задача маршрутизации
В терминах введенных обозначений, задача маршрутизации multicast трафика в сети может быть сформулирована следующим образом: для любой multicast группы g найти подграф Т(g) графа G, такой, что Т является деревом и Т содержит вершины из М. Дерево Т(g) называется multicast деревом для группы g.
Задача оптимизации
Рассматриваются три различных критерия оптимальности multicast дерева Т:
1) Нор
2) Port speed
3) Load
Определение. Длиной пути Р:ν=ρ0,ρ1, …, ρk = u назовем количество дуг в пути Р.
Определение. Кратчайшим путем между вершинами ν и u в графе G(V,E) называется путь P:ν=p0,p1, …, pk = u такой, что  .
.
Определение. Multicast дерево Т назовем оптимальным по критерию Нор, если для любой вершины из ν∈М путь из ν в s в дереве T является кратчайшим путем между ν и s в графе G.
То есть решением задачи будет являться дерево кратчайших путей.
Определение. Maxmin путем по критерию с между вершинами ν и u в графе G, где с:Е→Z0, называется путь P:ν=ρ0,ρl, …, ρk = u такой, что функция 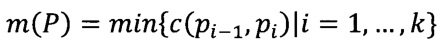 максимальна.
максимальна.
Определение. Multicast дерево Т назовем оптимальным по критерию Port speed, если для любой вершины из ν∈М путь из ν в s в дереве Т является maxmin путем по критерию с между ν и s в графе G где с=с(ν,u) - пропускная способность канала νu.
То есть пути между участниками группы выбираются так, чтобы минимальное значение пропускной способности ребер было максимальным.
Определение. Стоимостью дерева Т называется величина w(T)=Σ(ν,u)∈Tw(ν,u), где w(ν,u) - стоимость ребра между v и u.
Определение. Multicast дерево Т называется является оптимальным по критерию Load, если дерево Т является деревом минимальной стоимости и содержит все вершины ν∈М.
В данной задаче стоимость ребер графа выставляется равной 1, то есть стоимость является индикатором некоторого ребра. Таким образом, построенное дерево является деревом, минимальным по количеству ребер.
Описанная задача является задачей Штейнера на графах. Вершины t∈V\M могут быть использованы, если это необходимо. Вершины t называются точками Штейнера. Доказано, что данная задача является NP-трудной.
Задача обеспечения отказоустойчивости
Решением задачи обеспечения отказоустойчивости является набор операций перестроения multicast дерева Т при изменении состояния сети, такого, что полученное после перестроения дерево Т' является оптимальным с точки зрения критериев, поставленных выше.
Под изменением состояния сети подразумевается:
1) Подключение/отключение клиента от некоторой multicast группы.
2) Отключение/восстановление линии между двумя коммутаторами.
3) Отключение/восстановление некоторого коммутатора.
Данное техническое решение обеспечивает минимизацию количества multicast трафика по различным критериям и устойчивость multicast трафика к отказам линий передач и SDN коммутаторов за счет реализации в L2 среде, при помощи использования технологии SDN, дерева распространения multicast трафика, возможности оптимального перестроения multicast дерева и восстановления передачи multicast трафика после отказов линий передач или SDN коммутаторов, а также возможности выбора различных критериев, по которым строится дерево распространения multicast трафика, а именно критерии Hop, Port speed и Load..
Согласно предлагаемому техническому решению, предложен способ минимизации многоадресного трафика и обеспечения его отказоустойчивости в ПКС сетях, характеризующийся тем что: определяют multicast группы и активные источники трафика; устанавливают на всех коммутирующих устройствах в сети openflow правила; получают igmp сообщения от клиента на порту коммутирующего устройства; оправляют данное сообщение на контроллер для дальнейшего анализа; на основе полученного на контроллере сообщения, определяют порт, на котором находится клиент, запросивший multicast группу; выбирают источник multicast трафика из списка источников; осуществляют построение пути от источника до multicast клиента по различным критериям; определяют коммутирующие устройства, на которые необходимо установить правила маршрутизации; устанавливают на определенные на предыдущем шаге коммутирующие устройства правила коммутации; определяют контроллером изменения состояния сети; осуществляют перестроение multicast дерева по различным критериям с учетом обновленной на предыдущем шаге топологии сети; определяют наличие клиентов, не получающих multicast трафика; обновляют openflow правила на коммутирующих устройствах таким образом, чтобы все клиенты получали multicast трафик.
1. Алгоритмы решения
1.1 Критерий Нор
Для построения оптимального multicast дерева по критерию Нор необходимо построить дерево кратчайших путей из s в каждую вершину из группы М=М(g). Для построения такого дерева сначала строится остовное дерево кратчайших путей графа G (алг. 2 - Фиг. 2), а затем выбирается минимальное по критерию Нор поддерево, содержащее точки из М (алг. 1 - Фиг. 1).
Алгоритм построения остовного дерева представляет собой обход графа в ширину (Breadth First Search - BFS). На этапе поиска BFS дерево будет сохраняться список висячих вершин, чтобы затем, для получения результирующего multicast дерева, начать удаление поддеревьев, не содержащих вершины из М.
В описании алгоритмов 1, 2 и 3 используются следующие обозначения:
- num - массив номеров вершин
- father - массив родительских вершин в дереве
- list - массив списков смежных вершин
- child - массив счетчиков дочерних вершин
- d - массив значений глубины вершины в дереве
- Q - очередь вершин
- Р - очередь висячих вершин
Построенное по алгоритму 2 multicast дерево оптимально по критерию Нор. Сложность алгоритма 2 составляет O(n+m).
При добавлении multicast клиента v к некоторой группе g, происходит добавление ветви из BFS дерева, содержащей вершину ν, в multicast дерево. При отключении клиента происходит обрезка ветви, содержащей вершину ν, в multicast дереве. Обрезка ветви происходит до некоторой вершины u, имеющей более одного потомка.
1.2 Критерий Port Speed
Для построения Port speed оптимального multicast дерева необходимо построить maxmin дерево Т с корнем в вершине s: 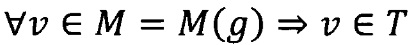 . Также как и в предыдущем пункте, сначала строится остовное дерево, удовлетворяющее требуемому критерию (алг. 3 - Фиг. 3), а затем выбирается минимальное поддерево, содержащее точки из М (алг. 1).
. Также как и в предыдущем пункте, сначала строится остовное дерево, удовлетворяющее требуемому критерию (алг. 3 - Фиг. 3), а затем выбирается минимальное поддерево, содержащее точки из М (алг. 1).
Алгоритм построения maxmin дерева является модифицированным алгоритмом Дейкстры нахождения кратчайших путей от некоторой вершины графа до всех остальных.
Построенное по алгоритму 3 multicast дерево оптимально по критерию Port Speed. Сложность алгоритма 3 составляет O(n2).
1.3 Критерий Load
Для построения Load оптимального multicast дерева необходимо построить дерево Штейнера, соединяющее все вершины из М=М(g). Здесь под весом ребра понимается та пропускной способности линии, которая будет занята, если через эту линию будет проходить multicast трафик группы, для которой строится дерево. Так как для каждой конкретной multicast группы на каждой линии, используемой группой, пропускная способность одинакова, то и веса ребер в графе сети G, используемые в алгоритме построения дерева Штейнера, одинаковы. Также веса ребер обозначают загрузку линии каждой multicast группой в отдельности, поэтому пропускная способность сети, занимаемая другими группами, в алгоритме не учитывается.
В отличие от предыдущих пунктов, где изначально строилось остовное дерево, а потом из него выбирались пути до клиентов, для критерия Load необходимо строить дерево Штейнера для каждого возможного значения множества М в отдельности, то есть при подключении/отключении клиентов, оптимальное дерево в принципе может полностью отличаться от предыдущего. Задача, где клиенты подключаются и отключаются, называется dynamic Steiner tree problem.
Для данной задачи доказано, что не существует аппроксимационного алгоритма с аппроксимационным коэффициентом менее чем 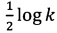 , где
, где 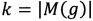 . Поэтому для решения dynamic Steiner tree problem в реальной сети мы предлагаем воспользоваться эвристическими алгоритмами.
. Поэтому для решения dynamic Steiner tree problem в реальной сети мы предлагаем воспользоваться эвристическими алгоритмами.
Рассмотрим использование жадного алгоритма построения дерева Штейнера. Алгоритм работает следующим образом: при подключении очередного клиента, данный клиент соединяется с ближайшей точкой уже построенного дерева Штейнера. Для нахождения кратчайшего пути может быть использован алгоритм Дейкстры, который имеет сложность O(n2). Изначально, когда в multicast группе еще нет клиентов, дерево считается состоящим из одного узла s∈М - являющегося сервером данной группы.
Проблемой данного подхода состоит в том, что в нем не предусмотрен механизм перестроения дерева в случае отключения клиентов от multicast группы. Можно привести примеры топологий сетей и такие последовательности подключений/отключений клиентов в них, которые могут привести к построению неоптимального дерева. Но, в то же время, перестроение дерева при каждом изменении множества М(g) приведет к тому, что остающиеся в группе клиенты могут испытывать задержки и потери трафика, связанные с перестроением multicast маршрутов. Таким образом, необходим алгоритм перестроения дерева, а также критерий, по которому можно будет определить, что перестроение дерева необходимо.
Для выявления неоптимальности дерева Штейнера необходимо сравнить стоимость дерева с оптимальным решением, и, если разница превышает некоторый порог Δ, то необходимо перестроить дерево. Так как нахождение оптимального дерева NP-полная задача, сравнение дерева будем производить с деревом, построенным по КМВ эвристике, описанная в алгоритме 4 (Фиг. 4).
Важным свойством данной эвристики является то, что для нее доказано, что решение, полученное с помощью данной эвристики, не превышает по стоимости оптимальное решение с множителем  , где
, где  .
.
В алгоритме 4 описана КМВ эвристика.
Стоит отметить, что в строке 4 полученный подграф может не являться деревом, так как пути графа G соответствующие ребрам (i,j)∈Т' могут пересекаться, следовательно, в графе G' могут появиться циклы.
В строке 8 под 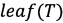 подразумевается множество листовых вершин дерева Т.
подразумевается множество листовых вершин дерева Т.
Таким образом, в строках (6-11) производится удаление таких ветвей дерева Т, на которых нет вершин из М.
Для нахождения путей наименьшей стоимости между всеми вершинами из М, можно воспользоваться алгоритмом Флойда-Уоршелла, который имеет сложность O(n3). Для нахождения минимальных остовных деревьев можно использовать алгоритм Краскала со сложностью O(m log n), таким образом, результирующая сложность построения дерева по КМВ эвристике равна O(n3).
2. Восстановление multicast дерева
Опишем алгоритмы перестроения текущего multicast дерева при следующих событиях:
1) Отключение/восстановление линии между двумя коммутаторами
2) Отключение/восстановление некоторого коммутатора.
Так как отключение/подключение некоторого коммутатора может быть смоделировано последовательным отключением/подключением смежных с данным коммутатором линий, далее будет рассматриваться только первый случай.
При отключении некоторой линии в сети, удаляется ребро е, соответствующее данной линии, и необходимо переподключить клиентов, используя некоторый запасной путь, то есть путь, не содержащий удаленного ребра.
Определение.
Число 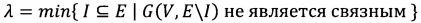 называется числом реберной связности графа.
называется числом реберной связности графа.
То есть реберная связность, это минимальное количество ребер графа, которые нужно удалить, для того, чтобы граф перестал быть связным.
По теореме Менгера между произвольными вершинами графа существует λ непересекающихся по ребрам путей. Таким образом, максимальное количество отказов линий, при которых возможно переподключить клиентов, равняется λ-1.
При отключении некоторой линии, связность multicast дерева может быть нарушена, в результате чего оно распадется на компоненты связности, одна из которых будет содержать вершину s. Таким образом, члены группы, оказавшиеся в компоненте связности, не содержащей вершину s, не будут получать multicast трафик. Следовательно, необходимо производить переподключение членов группы, с которыми была потеряна связь отключенных. Причем переподключение необходимо производить так, чтобы другие члены группы, не затронутые отказом линии, не испытывали задержки или потери трафика, связанные с перестроением multicast дерева.
При удалении некоторого ребра е=νw, при использовании критериев Нор и Port speed будет построено новое дерево Т' в графе G'=G\e, оптимальное для указанных критериев. Дерево  совпадает с
совпадает с 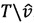 , где
, где  - множество вершин из поддерева с корнем v в дереве Т графа G, так как удаление некоторого ребра
- множество вершин из поддерева с корнем v в дереве Т графа G, так как удаление некоторого ребра  не повлияет на кратчайший или maxmin путь от s до некоторой вершины
не повлияет на кратчайший или maxmin путь от s до некоторой вершины  .
.
Таким образом, изменение multicast дерева необходимо производить только на , следовательно, изменение multicast маршрутов не затронет пользователей из  .
.
При появлении нового ребра е=νw необходимо рассмотреть 2 случая.
Первый - новое ребро есть ребро, которое ранее было удалено из графа G. В этом случае, изменение путей в новом дереве произойдет только для тех клиентов, которых затрагивали некоторые предыдущие удаления ребер. Таким образом, пути до клиентов, которых эти удаления не затрагивали, не будут изменены, и они не испытают задержек/потерь пакетов, связанных с установкой OpenFlow правил в сеть.
Второй - появившееся ребро действительно новое.
В этом случае нет гарантий, что появление ребра не изменит пути до всех клиентов. Данные ребра могут появиться в сети в случае изменения физической конфигурации сети, например с установкой нового оборудования. В этом случае, перестроение multicast дерева является оправданной мерой, потому что оно может привести к оптимальному распределению multicast трафика в сети.
Для критерия Load, клиенты, отключенные от группы, будут поочередно подключаться жадным алгоритмом построения дерева Штейнера к поддереву графа G содержащему вершину s. Поддеревья, которые не содержат вершину s, будут удалены, как и соответствующие им OpenFlow правила в сети.
В случае появления в сети новых линков, дерево Штейнера будет перестроено, только если стоимость multicast дерева превысит стоимость дерева, построенного по КМВ эвристике, на некоторый порог Δ.
3. Реализация
Предлагаемый подход был реализован как сетевое приложение для SDN контроллера RunOS.
Приложение хранит информацию о каждой multicast группе, представленной в сети. Для каждой группы указывается набор пар (коммутатор, порт) определяющий местонахождения серверов, предоставляющих данную multicast группу в сети. В данном случае под сервером может подразумеваться как физический сервер, подключенный к данному порту, так и маршрутизатор, получающий multicast группы по L3 протоколам, таким как PIM, DVMRP и т.д.
Для подключения к multicast группе или отключения от нее, пользователи сети отправляют IGMP запросы - Join group и Leave group. Поэтому приложение устанавливает на граничные SDN коммутаторы Flow правила, которые перенаправляют любые IGMP пакеты на контроллер.
При подключении к некоторой multicast группе первого клиента, на сервер данной группы отправляется сообщение IGMP Join group для того, чтобы сервер инициировал отправку multicast трафика. При отключении от данной multicast группы последнего клиента, на сервер группы отправляется сообщение IGMP Leave group, для того, чтобы сервер прекратил отправку трафика.
Join и Leave group сообщения отправляются с порта коммутатора, подключенного к данному источнику при помощи отправки на коммутатор OpenFlow сообщения - Packet-Out.
3.1 Multicast маршрутизация
При старте контроллера, приложение получает информацию о сетевой топологии от приложения topology. Далее, для каждой группы, в зависимости от критерия оптимальности для multicast дерева данной группы, строится остовное дерево, в котором впоследствии будет производиться поиск путей, соединяющих multicast сервер с multicast клиентом. Данные остовные деревья строятся на основе алгоритмов, описанных в предыдущей главе.
При старте контроллера, на каждый SDN коммутатор устанавливается правило, которое перенаправляет все IGMP запросы на контроллер. Данные сообщения отправляются на контроллер при помощи OpenFlow сообщений - Packet-In. Приложение на контроллере производит обработку данных запросов. При получении сообщения IGMP join group, контроллер производит поиск пути от multicast сервера до клиента, приславшего запрос на подключение группы. Информацию о том, на какой порт коммутатора поступил запрос, приложение получает из полей сообщения Packet-In.
После нахождения маршрута от сервера до клиента, приложение производит установку соответствующих правил на коммутаторы, входящие в данный путь. Также, если это первый клиент, запросивший данную группу, то отправляется IGMP join group запрос на порт, на котором находится сервер данной multicast группы. Если клиент не является первым подключившимся к данной группе, то путь до клиента начинает устанавливаться не от коммутатора, подключенного к multicast серверу, а от ближайшей точки, находящейся в multicast дереве (ближайшая точка считается в остовном дереве, построенном для данной multicast группы).
На каждый коммутатор устанавливаются правила следующего вида:
Устанавливается Flow правило, в поле match которого установлены in-port и ip-dst. In-port является портом, через который, данный коммутатор соединен с коммутатором, предшествующим в пути от сервера к клиенту. В поле ip-dst установлен ip адрес multicast группы.
Таким образом, данное правило обрабатывает только пакеты, приходящие от multicast сервера и принадлежащие соответствующей группе.
В поле action установлен номер соответствующего данной multicast группе группового OpenFlow правила. Групповые правила выглядят следующим образом:
Группа является All группой, то есть пакеты дублируются на каждый bucket. Набор bucket'oв определяется текущей структурой multicast дерева, то есть, если в остовном дереве данной группы вершина, отождествленная коммутатору, имеет несколько дочерних вершин, то для каждой вершины создается bucket, который отправляет трафик на порт, соединяющий данный коммутатор с коммутатором, соответствующим его дочернему узлу. Таким образом, трафик распространяется по multicast дереву. Далее, данную пару правил (Flow, Group) будем называть multicast правилами.
3.2 Агрегация multicast правил
Так как в сети может быть большое количество multicast групп, большое количество групповых OpenFlow правил может негативно влиять на производительность SDN коммутаторов, поэтому необходим механизм уменьшения количества установленных групповых правил, с сохранением логики маршрутизации multicast трафика для всех текущих групп.
Предлагается метод объединения однотипных групповых правил в одно единственное правило для уменьшения общего количества правил, устанавливаемых на коммутаторы.
Каждое правило, которое устанавливается на коммутаторы приложением multicast, проходит процедуру агрегации. Процедура агрегации правил представляет собой объединение групповых OpenFlow правил с идентичным набором bucket'oв в одно правило, а также изменение поля dst_group на новую группу в соответствующих Flow правилах.
Агрегация multicast правил происходит в два этапа.
Первым этапом является создание объединенных правил, из набора multicast правил, созданных для каждой multicast группы. Для каждого коммутатора приложение хранит список необъединенных multicast правил и список реальных правил, установленных на коммутаторы.
При появлении запроса за создание нового multicast правила на коммутаторе, происходит проверка, установлено ли на коммутаторе данное multicast правило (проверка происходит по идентификаторам группового правила):
- Если правило не установлено, начинается процедура объединения нового правила с существующими, то есть происходит поиск существующего группового правила с идентичным набором bucket'oв.
- Если такое правило найдено, то Flow multicast правило переписывается таким образом, чтобы оно указывало на существующее групповое правило.
- Если такая группа не найдена, то multicast правило будет установлено на коммутатор без изменений.
Также с каждым агрегированным правилом связан счетчик, показывающий количество multicast правил, которые с ним ассоциированы. Правило удаляется с коммутатора только тогда, когда удаляются все такие multicast правила, ассоциированные с ним, то есть счетчик станет равен нулю.
Вторым этапом является обновление состояния коммутаторов.
Обновление состояний происходит после событий, изменяющих конфигурацию multicast правил в сети, таких как, подключение/отключение клиентов, обрывы/восстановления линий, падения/подключения коммутаторов. Данные события влияют на все группы, поэтому состояния коммутаторов изменяются только после процедуры объединения всех правил, связанных со всеми multicast группами.
Во время объединения правил, агрегатор сравнивает списки существующих правил и списки обновленных правил. Если существуют правила, которые участвуют только в одном списке, то они либо удаляются с коммутатора (если их нет в обновленном списке), либо устанавливаются (если их нет на коммутаторе, но они есть в обновленном списке). Также изменяются соответствующие им flow правила.
Для минимизации количества OpenFlow сообщений (если существуют группы, которые нужно удалить, и также существуют группы, которые нужно добавить), вместо пары сообщений - удалить/добавить, отправляется единственное OpenFlow сообщение, которое изменяет набор bucket'oв в удаляемом правиле на набор из нового правила.
4. Подробное описание алгоритма
4.1 Алгоритм обеспечения multicast маршрутизации
1) Автоматическое определение multicast групп и активных источников трафика, либо задание данных групп администратором сети.
2) Установка на всех коммутаторах в сети OpenFlow правил, которые перехватывают IGMP сообщения с портов, подключенных к хостам в сети, и отправляют на контроллер.
3) Получение IGMP сообщения от клиента на некотором порту коммутатора.
4) Отправка данного сообщения на контроллер для дальнейшего анализа.
5) На основе полученного на контроллере сообщения, определения порта, на котором находится клиент, запросивший multicast группу.
Далее в зависимости от типа полученного на контроллере IGMP сообщения выбирается следующий порядок действий, проводимый контроллером:
Если IGMP сообщение - IGMP join group - выполнение пунктов 6-15:
6) Выбор источника multicast трафика из списка заданных источников.
7) Автоматическое построение пути от источника до multicast клиента по различным критериям (Hop, Port Speed, Load) алгоритмами построения деревьев описанным в п. 1 данного параграфа. Критерий построения деревьев может быть, как заранее задан администратором, так и выбран алгоритмом по умолчанию.
8) Определение коммутаторов, на которые необходимо установить правила маршрутизации.
9) Проведение процедуры агрегации групповых OpenFlow правил (минимизации количества групповых правил), описанной в п. 3.2 данного параграфа.
10) Установка соответствующего набора OpenFlow правил описанного в п. 3.1 данного параграфа.
11) Если подключившийся клиент - первый клиент данной группы, то отправка контроллером IGMP join group источнику multicast трафика при помощи OpenFlow сообщения Packet-Out.
12) Передача multicast трафика от порта, подключенного к источнику до портов, подключенных к клиентам через установленное в сети multicast дерево.
13) Получение multicast трафика на входных портах, соединенных с выбранным источником, либо определение, что данный источник не обладает запрошенной multicast группой. Проверка происходит при помощи считывания счетчиков на правиле обработки multicast трафика на коммутаторе, соединенном с сервером. Если значения счетчиков не изменяются в течение некоторого интервала времени, заданного администратором, то детектируется отсутствие группы на сервере.
Если источник данной группой не обладает, то переход к (6) и выбор другого сервера. Если серверов больше нет, то уведомление администратора сети об отсутствии заданной multicast группы в сети.
14) Периодический опрос multicast клиентов сообщениями IGMP query и периодическая отправка IGMP request источнику multicast трафика.
15) Если какой-либо клиент не отвечает на сообщения IGMP query в течение некоторого заданного администратором промежутка времени - удаление данного клиента из multicast группы и перестроение дерева (переход к (16)).
Если IGMP сообщение - IGMP leave group - выполнение пунктов 16-23:
16) Автоматическое перестроение multicast дерева по различным критериям (Hop, Port Speed, Load) алгоритмами построения деревьев описанным в п. 1 данного параграфа. Критерий построения деревьев может быть, как заранее задан администратором, так и выбран алгоритмом по умолчанию.
17) Определение коммутаторов, на которые необходимо установить правила маршрутизации.
18) Проведение процедуры агрегации групповых OpenFlow правил (минимизации количества групповых правил), описанной в п. 3.2 данного параграфа.
19) Обновление соответствующего набора OpenFlow правил описанного в п. 3.1 данного параграфа, связанного с перестроением multicast дерева.
20) Если отключившийся клиент - последний клиент данной группы, то отправка контроллером IGMP leave group источнику multicast трафика при помощи OpenFlow сообщения Packet-Out.
21) Передача multicast трафика от порта, подключенного к источнику до портов, подключенных к клиентам через перестроенное multicast дерево.
22) Получение multicast трафика на входных портах, соединенных с выбранным источником, либо определение, что данный источник не обладает запрошенной multicast группой. Проверка происходит при помощи считывания счетчиков на правиле обработки multicast трафика на коммутаторе, соединенном с сервером. Если значения счетчиков не изменяются в течение некоторого интервала времени, заданного администратором, то детектируется отсутствие группы на сервере.
Если источник данной группой не обладает, то переход к (6) и выбор другого сервера. Если серверов больше нет, то уведомление администратора сети об отсутствии заданной multicast группы в сети.
23) Периодический опрос оставшихся multicast клиентов сообщениями IGMP query и периодическая отправка IGMP request источнику multicast трафика.
24) Если какой-либо клиент не отвечает на сообщения IGMP query в течении некоторого, заданного администратором, промежутка времени - удаление данного клиента из multicast группы и перестроение дерева (переход к (16)).
Комментарий к пункту (3) описанного алгоритма:
Список источников задается администратором сети в виде пар (коммутатор, порт), к которым подключены источники multicast трафика.
Комментарий к пунктам (5) и (16) описанного алгоритма:
Если в качестве критерия построения multicast выбраны критерии Нор или Port Speed, то способ подключения новых клиентов не зависит от того, сколько клиентов уже подключено к данной группе.
Если в качестве критерия выбран критерий Load, то при подключении первого клиента, данный клиент соединяется с источником multicast трафика кратчайшим путем, построенным по алгоритму Дейкстры. Последующие клиенты подключаются кратчайшим путем с ближайшей к данному клиенту вершиной уже построенного дерева.
Так как данный алгоритм может привести к неоптимальному результату, при каждом подключении/отключении клиента от данной multicast группы, происходит сравнение построенного multicast дерева для данной группы с деревом, построенным по алгоритму 4 параграфа 5. Если разница в количестве используемых сетевых линий между данными деревьями выше некоторого порога А, то multicast дерево заменяется деревом, построенным по алгоритму 4, и происходит изменение соответствующих OpenFlow правил на коммутаторах в сети.
4.1 Алгоритм обеспечения отказоустойчивости multicast трафика
1) Определение контроллером изменения состояния сети: подключение/отключение некоторого коммутатора, подключение/отключение некоторой сетевой линии между коммутаторами.
2) Автоматическое перестроение multicast дерева по различным критериям (Hop, Port Speed, Load) алгоритмами построения деревьев описанным в п. 1 данного параграфа, с учетом обновленной топологии сети.
3) Определение наличия клиентов, не получающих multicast трафика.
4) Обновление OpenFlow правил на коммутаторах в соответствии с пунктом 2 данного параграфа для того, чтобы все клиенты получали multicast трафик.
5) Переход к (14) предыдущего алгоритма.
Специалисту в данной области, очевидно, что конкретные варианты осуществления способа и системы минимизации многоадресного трафика и обеспечения его отказоустойчивости в ПКС сетях описаны здесь в целях иллюстрации, допустимы различные модификации, не выходящие за рамки и сущности объема изобретения.



Изобретение относится к средствам управления потоками ресурсов в сетях. Технический результат заключается в минимизации количества multicast трафика по различным критериям. Определяют multicast группы и активные источники трафика. Устанавливают на всех коммутирующих устройствах в сети openflow правила. Получают igmp сообщения от клиента на порту коммутирующего устройства. Отправляют данное сообщение на контроллер для дальнейшего анализа. На основе полученного на контроллере сообщения, определяют порт, на котором находится клиент, запросивший multicast группу. Выбирают источник multicast трафика из списка источников. Осуществляют построение пути от источника до multicast клиента по различным критериям. Определяют коммутирующие устройства, на которые необходимо установить правила маршрутизации. Устанавливают на определенные на предыдущем шаге коммутирующие устройства правила коммутации. Определяют контроллером изменения состояния сети. Осуществляют перестроение multicast дерева по различным критериям с учетом обновленной на предыдущем шаге топологии сети. Определяют наличие клиентов, не получающих multicast трафика. Обновляют openflow правила на коммутирующих устройствах таким образом, чтобы все клиенты получали multicast трафик. 2 н.п. ф-лы, 4 ил. 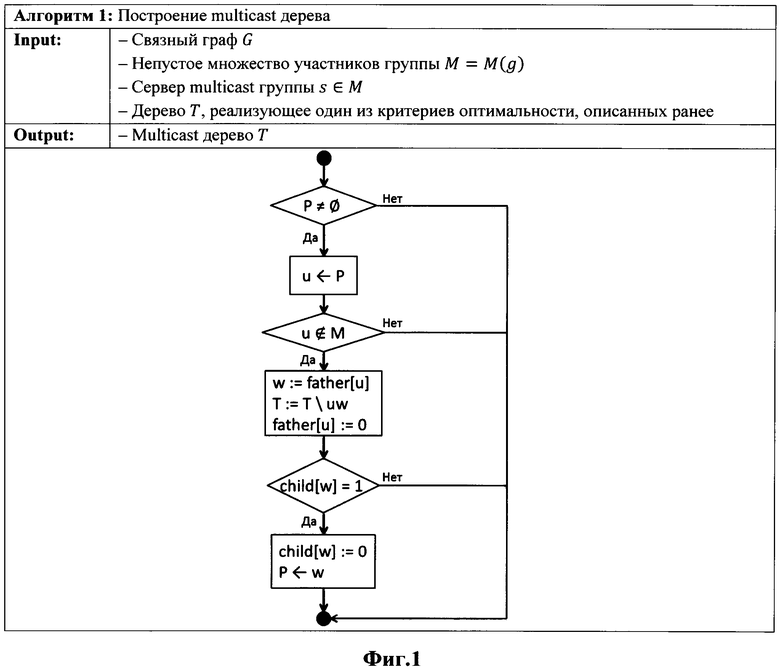
1. Способ минимизации многоадресного трафика и обеспечения его отказоустойчивости в ПКС сетях, характеризующийся тем, что:
- определяют multicast группы и активные источники трафика;
- устанавливают на всех коммутирующих устройствах в сети openflow правила;
- получают igmp сообщения от клиента на порту коммутирующего устройства;
- отправляют данное сообщение на контроллер для дальнейшего анализа;
- на основе полученного на контроллере сообщения, определяют порт, на котором находится клиент, запросивший multicast группу;
- выбирают источник multicast трафика из списка источников;
- осуществляют построение пути от источника до multicast клиента по различным критериям;
- определяют коммутирующие устройства, на которые необходимо установить правила маршрутизации;
- устанавливают на определенные на предыдущем шаге коммутирующие устройства правила коммутации;
- определяют контроллером изменения состояния сети;
- осуществляют перестроение multicast дерева по различным критериям с учетом обновленной на предыдущем шаге топологии сети;
- определяют наличие клиентов, не получающих multicast трафика;
- обновляют openflow правила на коммутирующих устройствах таким образом, чтобы все клиенты получали multicast трафик.
2. Машиночитаемый носитель данных, содержащий исполняемые одним или более процессором машиночитаемые инструкции, которые при их исполнении реализуют выполнение способа минимизации многоадресного трафика и обеспечение его отказоустойчивости в ПКС сетях по п. 1.
| AAKASH IYER et al, Avalanche: Data center multicast using software defined networking, 2014 Sixth International Conference on Communication Systems and Networks (COMSNETS) | |||
| - IEEE, 2014 г | |||
| Топка с несколькими решетками для твердого топлива | 1918 |
|
SU8A1 |
| LIANG-HAO HUANG et al, Scalable Steiner tree for multicast communications in software-defined networking, arXiv preprint arXiv: 1404.3454, 08.05.2014 г., 16 с | |||
| Устройство для закрепления лыж на раме мотоциклов и велосипедов взамен переднего колеса | 1924 |
|
SU2015A1 |
| US 8638789 B1, 28.01.2014 | |||
| СЕТЕВАЯ СИСТЕМА, СПОСОБ ОБРАБОТКИ ПАКЕТОВ И НОСИТЕЛЬ ЗАПИСИ | 2012 |
|
RU2602333C2 |

