Уровень техники
Настоящее изобретение, в основном, относится к эффективной маршрутизации прерываний для многопоточного процессора, и прежде всего, к измененной приоритетной маршрутизации прерываний ввода/вывода (I/O), что облегчает для хоста или активированного ядра обработку потоков в ожидании.
В целом, по мере повышения в течение последних десятилетий быстродействия процессоров компьютерных систем не наблюдалось пропорционального увеличения скорости получения доступа к памяти. В свою очередь, чем меньше время цикла процессора в вычислительной системе, тем более явной является задержка при ожидании данных из памяти. Эффекты таких задержек могут быть смягчены многопоточностью в пределах процессора вычислительной системы, позволяющей для различных ядер процессора их совместное использование посредством нескольких потоков команд, известных как потоки. Например, во время периода ожидания в первом потоке при производстве обработки посредством ядра, второй поток может использовать ресурсы этого ядра.
Однако для использования в своих интересах периода ожидания ядро должно получать прерывание I/O. Текущая практика управления прерываниями I/O требует от активированного хоста (например, гипервизора) получения прерывания для обработки с более высоким приоритетом, чем любой активированный гость ядра. Таким образом, хост как таковой должен в этом случае выполнять начальную обработку прерывания гостя, а затем диспетчеризировать активированный поток, возможно, тот же самый поток, который воздействовал на ядро, для завершения обработки прерывания I/O. К сожалению, такая действующая практика управления прерываниями I/O посредством хоста, в то время как один из действующих гостевых потоков является активированным для того же прерывания I/O, является причиной возникновения периода ожидания обработки.
Сущность изобретения
Согласно одному варианту осуществления настоящего изобретения способ реализации измененной приоритетной маршрутизации ввода/вывода (I/O) прерывания включает в себя выявление процессором того, является ли прерывание I/O отложенным для ядра, выявление процессором того, активирован ли какой-либо из нескольких гостевых потоков ядра для обработки гостевым потоком прерывания согласно тому выявлению, что прерывание I/O является отложенным, выявление процессором того, находится ли по меньшей мере один из нескольких гостевых потоков, активированных для обработки гостевым потоком, в состоянии ожидания, и согласно тому выявлению, что по меньшей мере один из нескольких гостевых потоков, активированных для обработки гостевым потоком, находится в состоянии ожидания, маршрутизацию посредством процессора прерывания I/O к гостевому потоку, активированному для обработки гостевым потоком и находящемуся в состоянии ожидания.
Технический результат, достигаемый при осуществлении изобретения, заключается в расширении арсенала технических средств для реализации измененной приоритетной маршрутизации прерываний ввода/вывода.
Посредством методов настоящего изобретения осуществляются дополнительные функции и преимущества. Другие варианты осуществления и аспекты изобретения подробно описаны в настоящем документе и считаются частью заявленного изобретения. Для лучшего понимания изобретения в аспекте его преимуществ и признаков следует обратиться к описанию и к чертежам.
Рассматриваемый в качестве изобретения объект обсуждения предпочтительным образом выделен и недвусмысленно заявлен в пунктах формулы изобретения в конце технического описания. Упомянутые ранее и другие признаки, и преимущества изобретения являются очевидными из последующего подробного описания, рассматриваемого совместно с сопровождающими чертежами, на которых:
Фиг. 1 показывает схему вычислительного устройства многопоточной системы, и
Фиг. 2 показывает схему процессора многопоточной системы, и
Фиг. 3-6 показывают последовательности операций многопоточной системы.
Подробное описание
Как указано выше, управление прерываниями I/O посредством хоста многопоточного процессора вызывает возникновение периода ожидания обработки. Таким образом, необходимой является измененная приоритетная маршрутизация ввода/вывода (I/O) прерывания, облегчающая для хоста или активированного ядра оказание предпочтения потокам, находящимся в настоящее время в состоянии ожидания.
В целом, описанные в настоящем документе варианты осуществления настоящего изобретения могут включать в себя многопоточную систему, способ и/или компьютерный программный продукт, использующий по меньшей мере одно ядро из числа нескольких ядер для обработки множественных потоков. Кроме того, в любой момент времени к нескольким ядрам может быть транслирован сигнал прерывания, инициированный за пределами нескольких ядер. После трансляции сигнала прерывания среди активированных ядер из числа нескольких ядер происходит преобразование в последовательную форму, что предоставляет сигнал прерывания только к одному из активированных ядер. Таким образом, прерывания I/O являются незакрепленными прерываниями (например, как только прерывание I/O сделано отложенным в системе, оно сделано отложенным на всех физических ядрах в системе). Каждый поток на таких ядрах может тогда быть активирован или дезактивирован для таких прерываний. Например, активация или дезактивация могут быть основаны на гостевом бите 6 слова состояния программы (PSW.6), гостевом регистре 6 управления (CR6), хостовом PSW.6 и зональной таблице масок (ZMT), как далее описано ниже). Аппаратные средства на каждом ядре, которое активировано в системе независимым образом, вызывают подпрограмму прерывания I/O встроенного программного обеспечения, что указывает встроенному программному обеспечению на то, является ли данное прерывание прерыванием хоста или гостя. После вызова эта подпрограмма встроенного программного обеспечения делает попытку «удаления из очереди» прерывания. В ответ на удаление из очереди, аппаратное оборудование системы дает сигнал одному из ядер (например, первому ядру, которое запрашивает удаление из очереди) о том, что оно успешно удалило прерывание из очереди, и удаляет это прерывание I/O из очереди таким образом, что оно более не является отложенным в системе, если какое-либо другое ядро в системе делает попытку к удалению из очереди того же прерывания I/O, оно уведомляется о том, что удаление из очереди оказалось неудачным. Встроенное программное обеспечение на ядре, которое успешно удалило из очереди прерывание, предоставляет это прерывание I/O либо гипервизору (например, хосту), либо гостевому программному обеспечению, основываясь на приоритете, как он выявляется аппаратными средствами. Если прерывание должно быть предоставлено хосту в то время, когда гость является активным, то требуется произвести обработку посредством встроенного программного обеспечения для сохранения гостевого состояния и для восстановления состояние хоста в аппаратных средствах. После того, как гипервизор получает прерывание, он также тогда должен выполнить дополнительную работу с целью восстановления гостевого состояния и предоставления прерывания I/O соответствующему гостю.
При функционировании, например, когда прерывание I/O предоставляется от канальной подсистемы к системе, соответствующий зоне и подклассу прерывания (ISC) устройства прерывания (например, связанного с прерыванием) бит задается в матрице отложенных прерываний (PIA) каждого ядра. ISM является маской битов, по одному на ISC, например, ISM в CR6 для управления активацией. Запись PIA, индексированная номером зоны, аналогичным образом, может рассматриваться в качестве ISM. В одном варианте осуществления существует 8 ISC, и поэтому PIA содержит 8 битов для каждого поддерживаемого логического раздела (LPAR) или зоны. Единственная запись PIA, имеющая отношение к гостевому потоку, представлена записью, представляющей отложенные прерывания I/O для зоны, в настоящее время работающей на основном оборудовании. Если прерывание I/O является отложенным для действующей зоны и для конкретного ISC, оно активируется в госте, если 1) включена активация I/O в гостевом PSW.6 и 2) бит, соответствующий ISC, включен в бите 8-битовой маски подкласса прерываний (ISM) в гостевом CR6. С точки зрения хоста при выполнении гостя, отложенные прерывания I/O, как обозначено в PIA, могут распространяться на любую зону, включая сюда действующую зону. Если прерывание I/O является отложенным для конкретного ISC в конкретной зоне, оно активируется в хосте, если 1) бит 6 PSW хоста включен, и 2) активация для специфической зоны и ISC включена в соответствующей ZMT. В ZMT имеется по 8 битов активации на поддерживаемую зону, непосредственно соответствующих битам в PIA. Любое прерывание I/O, которое является отложенным для действующей зоны, может быть одновременно активировано как в госте, так и в хосте.
Если прерывание, которое является отложенным в PIA, активируется в одном или нескольких гостевых потоках или в хосте или и там и там, на аппаратном оборудовании ядра вызывается приоритетный процесс прерывания I/O. В предшествующих реализациях, если как гость, так и хост были активированы для конкретного прерывания I/O на любом данном потоке, то данное прерывание I/O предоставляется хосту (например, поскольку хост имеет более высокий приоритет). В описанных в настоящем документе вариантах осуществления в том же случае, прерывание I/O вместо этого может быть предоставлено гостю. Кроме того, были добавлены приоритетные аппаратные средства для предоставления некоторого конкретного прерывания I/O только одному физическому потоку на ядре с приоритетом, распределяемым между активированными гостевыми потоками в зависимости от гостевого состояния ожидания, как обозначено в бите 14 гостевого PSW. Эта система приоритетов предоставляет приоритет потокам в ядре. Кроме того, если прерывание I/O является отложенным и активированным в хосте на этом ядре, и либо никакой гостевой поток на этом ядре не является активированным для этого прерывания, либо это прерывание не распространяется на потоки, работающие на этом ядре, то перед предоставлением данного прерывания хоста (например, путем приема прерывания на этом ядре) добавляется задержка. Это позволяет активированному гостевому потоку на другом ядре, если таковой существует, первым принять прерывание I/O, что непрямым образом предоставляет приоритет ядрам в системе.
При рассмотрении теперь фиг. 1, показан пример многопоточной системы 100, включающей в себя вычислительное устройство 112. Многопоточная система 100 является только одним примером подходящего вычислительного узла и не предназначается для наложения какого-либо ограничения относительно объема использования или удобства использования вариантов осуществления описанного в настоящем документе изобретения (несомненно, могут быть использованы дополнительные или альтернативные компоненты и/или реализации). Таким образом, многопоточная система 100 и ее элементы могут принимать множество различных форм, и включать в себя множественные и/или альтернативные компоненты и функции. Кроме того, многопоточная система 100 может включать в себя и/или применять в любом числе и комбинации вычислительные устройства и сети, использующие различные коммуникационные технологии, как описано в настоящем документе. В любом случае, многопоточная система 100 является способной к реализации и/или выполнению любого из сформулированных в настоящем документе эксплуатационных качеств.
В многопоточной системе 100 имеется вычислительное устройство 112, которое является пригодным к эксплуатации совместно с многочисленными другими окружениями или конфигурациями общего назначения или особого назначения вычислительной системы. Системы и/или вычислительные устройства, такие как многопоточная система 100 и/или вычислительное устройство 112, могут применять любую из многочисленных операционных компьютерных систем, включая сюда, но ни в коем случае не ограничиваясь, версии и/или варианты операционных систем AIX UNIX и z/OS, поставляемых International Business Machines Corporation, Армонк, Нью-Йорк, операционную систему Microsoft Windows, операционную систему Unix (например, операционную систему Solaris, поставляемую Oracle Corporation, Редвуд-Шорз, Калифорния), операционную систему Linux, операционные системы Mac OS X и iOS, поставляемые Apple Inc., Купертино, Калифорния, BlackBerry OS, поставляемую Research In Motion, Ватерлоо, Канада, и операционную систему Android, разработанную Open Handset Alliance. Примеры вычислительных систем, окружений и/или конфигураций, которые могут быть подходящими для использования с вычислительным устройством 112, включают в себя, но ими не ограничиваются, системы персональных компьютеров, системы серверов, тонкие клиенты, толстые клиенты, карманные компьютеры или устройства ноутбуков, многопроцессорные системы, основанные на микропроцессорах системы, декодеры каналов кабельного телевидения, программируемую бытовую электронику, сетевые ПК, системы миникомпьютеров, компьютерные рабочие станции, серверы, рабочие столы, ноутбуки, сетевые устройства, мэйнфреймовые компьютерные системы и распределенные окружения облачных вычислений, включающие в себя любые из вышеупомянутых систем или устройств и т.п.
Вычислительное устройство 112 может быть описано в общем контексте исполняемых команд компьютерной системы, таких как программные модули, выполняемые компьютерной системой. Обычно программные модули могут включать в себя подпрограммы, программы, объекты, компоненты, логику, структуры данных и так далее, которые выполняют конкретные задачи или реализуют конкретные абстрактные типы данных. Вычислительное устройство 112 может быть осуществлено в распределенных окружениях облачных вычислений, где задачи выполняются отдаленными устройствами обработки, связанными через коммуникационную сеть. В распределенном окружении облачных вычислений программные модули могут быть расположены как в локальных, так и в удаленных носителях информации компьютерной системы, содержащих запоминающие устройства памяти.
Как показано на фиг. 1, вычислительное устройство 112 в многопоточной системе 100 показано в виде вычислительного устройства общего назначения, улучшенного на основании функционирования и функциональности многопоточной системы 100, ее способов и/или элементов. Компоненты вычислительного устройства 112 могут включать в себя, но ими не ограничиваться, один или несколько процессоров или вычислительных устройств (например, процессор 114, включающий в себя по меньшей мере одно ядро 114а, которое поддерживает несколько потоков 115, например, многопоточная система 100 включает в себя ядро 114а процессора 114, содержащее два или более потоков 115), память 116, а также шину 118, которая соединяет различные компоненты системы, включающие в себя процессор 114 и память 116. Вычислительное устройство 112 также обычно включает в себя ряд считываемых компьютерной системой носителей. Такие носители могут быть представлены любыми доступными носителями, которые являются доступными для вычислительного устройства 112, они включают в себя как энергозависимые, так и энергонезависимые носители, съемные и несъемные носители.
Процессор 114 может получать машиночитаемые программные команды из памяти 116, и выполнять эти команды, выполняя таким образом один или несколько процессов, заданных многопоточной системой 100. Процессор 114 может включать в себя любые аппаратные средства обработки, программное обеспечение или комбинацию аппаратного и программного обеспечения, используемого вычислительным устройством 114, которое выполняет машиночитаемые программные команды путем выполнения арифметических, логических операций и/или операций ввода-вывода. Примеры элементов процессора 114 и ядра 114а включают в себя, но ими не ограничиваются, арифметико-логическое устройство, выполняющее арифметические и логические операции, управляющий модуль, который извлекает, декодирует и выполняет команды из памяти, и матричный модуль, который использует множественные элементы параллельных вычислений.
Фиг. 2 показывает вариант осуществления вычислительного окружения, включающего в себя процессор 114, соединенный с контроллером 215. В одном из вариантов вычислительное окружение на основе z/Архитектуры включает в себя сервер System z, предлагаемый International Business Machines Corporation, Армонк, Нью-Йорк. Процессор 114 может включать в себя, например, один или несколько разделов (например, логических разделов LP1-LPn), одно или несколько физических ядер (например, ядро 1 ядро m), и гипервизор 214 уровня 0 (например, администратор логических разделов). Контроллер 215 может включать в себя централизованную логику, ответственную за арбитраж между различными выпускающими запросы процессорами. Например, когда контроллер 215 получает запрос на доступ к памяти, он выявляет, позволен ли доступ к данной ячейке памяти и, если это так, предоставляет содержимое этой ячейки памяти процессору 114 при поддержании непротиворечивости памяти между процессорами в пределах данного комплекса. Другой контроллер 215 может администрировать запросы к адаптерам I/O и от них через интерфейс 130 I/O, а также от сетевого адаптера 132, показанного на фиг. 1.
Физические ядра включают в себя физические процессорные ресурсы, выделенные логическим разделам. Логический раздел может включать в себя один или несколько логических процессоров, каждый из которых представляет собой, полностью или частично, выделенные разделу физические процессорные ресурсы. Физические ядра могут либо быть выделены логическим ядрам конкретного раздела таким образом, что физические процессорные ресурсы базового ядра (ядер) резервируются для данного раздела, либо быть используемыми совместно с логическими ядрами другого раздела таким образом, что физические процессорные ресурсы базовых ресурсов ядра (ядер) являются потенциально доступными для другого раздела. Каждый логический раздел может быть способен к функционированию в качестве отдельной системы. Таким образом, каждый логический раздел может быть независимо сброшен, при желании, первоначально загружен операционной системой (например, операционной системой OS1-OSn), и может работать с различными программами. Операционная система или прикладная программа, работающая в логическом разделе, может представляться как имеющая доступ к полной системе, но в действительности, доступным является только участок всей системы. Комбинация аппаратных средств и лицензированного внутреннего кода (обычно называемого встроенным программным обеспечением, микрокодом или милликодом) предохраняет программу в одном логическом разделе от доступа или вмешательства со стороны программы в другом логическом разделе. Это позволяет нескольким различным логическим разделам действовать на единственном или множественных физических ядрах способом с квантованием времени. В одном варианте осуществления каждое физическое ядро включает в себя один или несколько центральных процессоров (также называемых в настоящем документе «физическими потоками»). В примере, показанном на фиг. 2, каждый логический раздел имеет резидентную операционную систему, которая может отличаться для одного или нескольких логических разделов. Каждый логический раздел является примером виртуальной машины или гостевой конфигурации, в которой операционная система способна к выполнению.
В одном варианте осуществления, показанном на фиг. 2, логические разделы LP1-LPn администрирует гипервизор 214 уровня 0, который реализован посредством встроенного программного обеспечения, работающего на физических ядрах Core 1-Core m. Каждый из числа логических разделов LP1-LPn и гипервизора 214 содержит одну или несколько программ, находящихся в соответствующих участках центрального запоминающего устройства (памяти), связанной с физическими ядрами Core 1-Core m. Один пример гипервизора 214 представлен администратором ресурсов процессора/системы Processor Resource/Systems Manager (PR/SM™), предлагаемым International Business Machines Corporation, Армонк, Нью-Йорк.
При обращении вновь к фиг. 1, память 116 может включать в себя материальное устройство, которое удерживает и сохраняет машиночитаемые программные команды в установленном многопоточной системой 100 порядке для использования процессором 114 вычислительного устройства 112. Память 116 может включать в себя считываемые компьютерной системой носители в виде энергозависимой памяти, такие как оперативная память (RAM) 120, кэш-память (CACHE) 122 и/или система 124 хранения данных. Шина 118 представляет собой один или более из числа любых нескольких типов структур шины, включая сюда шину памяти или контроллер памяти, периферийную шину, ускоренный графический порт, и процессорную или локальную шину, использующую любую из ряда шинных архитектур. В качестве примера, но не ограничения, такая архитектура включает в себя шину Промышленной стандартной архитектуры (ISA), шину Микроканальной архитектуры (МСА), шину Расширенной ISA архитектуры (EISA), локальную шину Ассоциации по стандартам в области видео-электроники (VESA) и шину Взаимодействия периферийных компонентов (PCI).
Исключительно в качестве примера, может быть предоставлена система 124 хранения данных для считывания из несъемных, энергонезависимых магнитных носителей (не показанных и обычно называемых «жестким диском») и для записи в них. Хотя не показаны, могут быть предоставлены магнитный дисковод для считывания из несъемного, энергонезависимого магнитного диска (например, «гибкого диска») и для записи в него, и оптический дисковод для считывания из несъемного, энергонезависимого оптического диска, такого как CD-ROM, DVD-ROM или другие оптические носители, и для записи в них. В таких реализациях каждый дисковод может быть присоединен к шине 118 посредством одного или нескольких интерфейсов носителей данных. Как будет, кроме того, изображено и описано ниже, память 116 может включать в себя по меньшей мере один программный продукт, имеющий набор (например, по меньшей мере один) программных модулей, которые сконфигурированы для выполнения функций предпочтительных вариантов осуществления настоящего изобретения. Система 124 хранения данных (и/или память 116) может включать в себя базу данных, репозиторий данных или другое хранилище данных, и может включать в себя различные виды механизмов для хранения, обращения и осуществления выборки различных видов данных, включая сюда иерархическую базу данных, набор файлов в файловой системе, базу данных приложения в проприетарном формате, систему управления реляционными базами данных (RDBMS) и т.д. Система 124 хранения данных может в большинстве случаев быть включена в состав вычислительного устройства 112, как показано, с помощью операционной системы компьютера, такой как одна из упомянутых выше, к ней получают доступ через сеть посредством любого из числа одного или нескольких способов.
В качестве примера, но не ограничения, программа/сервисная программа 126, имеющая набор (по меньшей мере один) программных модулей 128, может быть сохранена в памяти 116, равно как операционная система, одна или несколько прикладных программ, другие программные модули и данные программы. Каждый элемент из числа операционной системы, одной или нескольких прикладных программ, других программных модулей и данных программы или некоторая комбинация из них может включать в себя реализацию сетевого окружения.
Вычислительное устройство 112 также может сообщаться через интерфейс 130 (I/O) ввода/вывода и/или через сетевой адаптер 132. Интерфейс 130 I/O и/или сетевой адаптер 132 может включать в себя физический и/или виртуальный механизм, используемый вычислительным устройством 112 для сообщения между элементами, являющимися внутренними и/или внешними по отношению к вычислительному устройству 112. Например, интерфейс I/O 130 может сообщаться с одним или несколькими внешними устройствами 140, такими как клавиатура, позиционирующее устройство, дисплей 142, и т.д., с одними или несколькими устройствами, позволяющими пользователю взаимодействовать с вычислительным устройством 112, и/или с любыми устройствами (например, сетевой платой, модемом и т.д.), которые позволяют вычислительному устройству 112 сообщаться с одним или несколькими другими вычислительными устройствами. Кроме того, вычислительное устройство 112 может сообщаться через сетевой адаптер 132 с одной или несколькими сетями, такими как локальная сеть (LAN), общая глобальная сеть (WAN) и/или сеть общего пользования (например, Интернет). Таким образом, интерфейс 130 I/O и/или сетевой адаптер 132 может быть выполнен для получения или отправки сигналов или данных в пределах вычислительного устройства 112 или для него. Как изображено, интерфейс 130 I/O и сетевой адаптер 132 сообщаются с другими компонентами вычислительного устройства 112 через шину 118. Следует понимать, что совместно с вычислительным устройством 112 могут быть использованы, хотя и не показаны, другие аппаратные компоненты и/или компоненты программного обеспечения. Примеры, в том числе, но не ограничиваясь: микрокод, драйверы устройств, резервные вычислительные устройства, массивы внешних дисководов, системы RAID (массивы недорогих дисковых накопителей с избыточностью), устройства записи на ленту, системы архивного хранения данных и т.д.
Хотя на фиг. 1 для многопоточной системы 100 (и других объектов) показаны единичные объекты, эти представления не предназначаются для ограничения и, таким образом, любые объекты могут представлять собой несколько объектов. Например, процессор 114 может включать в себя несколько обрабатывающих ядер, каждое из которых выполняет несколько потоков и является способным к получению прерывания I/O на основе измененной приоритетной маршрутизации, описанной в настоящем документе.
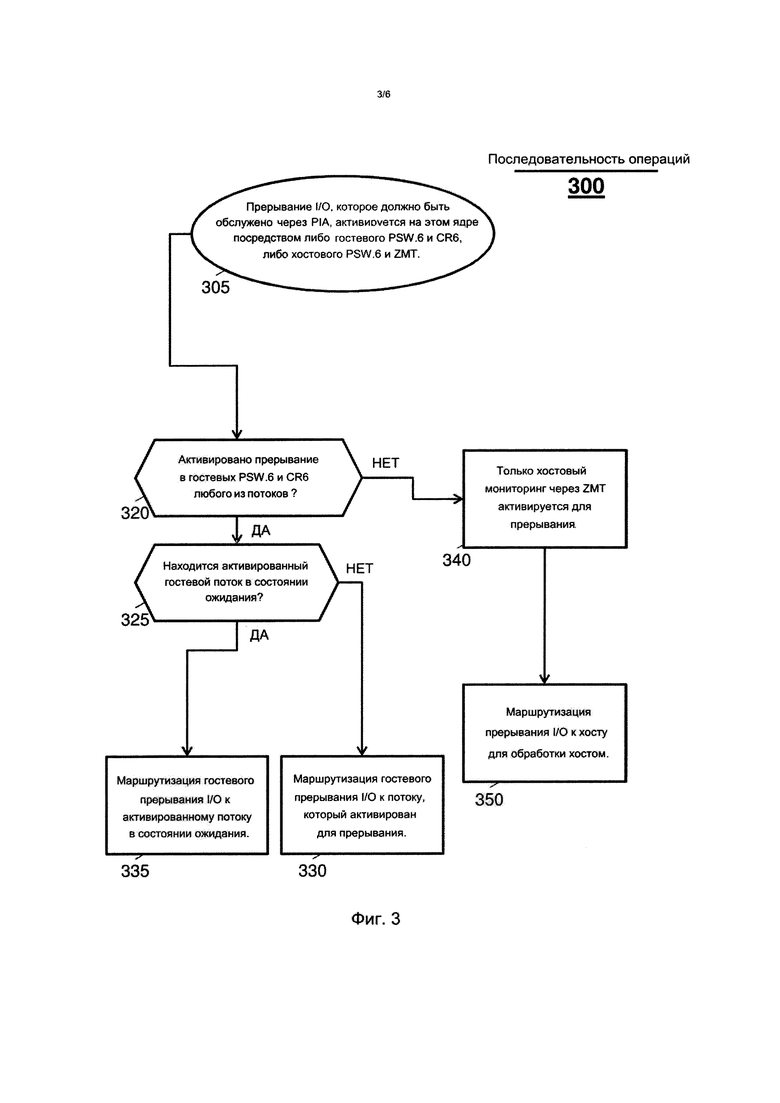
Вариант осуществления измененной приоритетной маршрутизации многопоточной системы 100 описан со ссылками на фиг. 3. Фиг. 3 показывает последовательность 300 операций. Последовательность 300 операций начинается в начальном блоке 305, где прерывание I/O, которое должно быть обслужено и является отложенным в PIA, активируется на одном ядре из числа нескольких ядер. Прерывания I/O активируются для гостевого потока ядра посредством гостевого PSW.6 и ISM в гостевом CR6. Для мониторинга хоста, прерывания I/O всех зон, включая сюда не работающие на ядре в настоящее время зоны, активируются посредством хостового PSW.6 и ZMT. Любое отложенное прерывание I/O для действующей зоны может быть одновременно активировано как в госте, так и в хосте.
В блоке 320 принятия решения последовательность 300 операций производит выявление того, активированы ли гостевые биты управления и биты состояния для отложенного прерывания I/O. Например, последовательность 300 операций выявляет, активировано ли отложенное прерывание I/O в гостевых PSW.6 и CR6 любого из гостевых потоков ядра. Если любой гостевой поток активирован, последовательность 300 операций переходит к блоку 325 принятия решения (например, как обозначено стрелкой «ДА»), где производится выявление того, является ли какой-либо из нескольких гостевых потоков на ядре активированным для прерывания и находящимся в состоянии ожидания. Если никакие гостевые потоки не находятся в состоянии ожидания и не активированы для прерывания I/O, то последовательность 300 операций переходит к блоку 330 (например, как обозначено стрелкой «NO»), где отложенное прерывание I/O маршрутизируется к гостевому потоку, для которого активировано отложенное прерывание I/O. Если по меньшей мере один из нескольких гостевых потоков находится в состоянии ожидания и активирован для отложенного прерывания I/O, то последовательность операций переходит к блоку 335 (например, как обозначено стрелкой «ДА»), где отложенное прерывание I/O маршрутизируется к гостевому потоку в состоянии ожидания, активированному для прерывания. Таким образом, последовательность 300 операций реализует измененную приоритетную маршрутизацию прерываний I/O, облегчающую обработку гостевыми потоками в ожидании. Прежде всего, приоритет маршрутизации прерываний I/O изменяется в следующих случаях: если имеется один или несколько активированных потоков в состоянии ожидания, прерывание передается одному из этих потоков, если какой-либо поток в состоянии ожидания, активированный для отложенного прерывания отсутствует, прерывание I/O передается потоку, активированному для него. Кроме того, при выявлении маршрутизации для множественных потоков в состоянии (335) ожидания или множественных потоков не в состоянии (330) ожидания многопоточная система 100 может использовать на выбор алгоритм маршрутизации, который является случайным или иным.
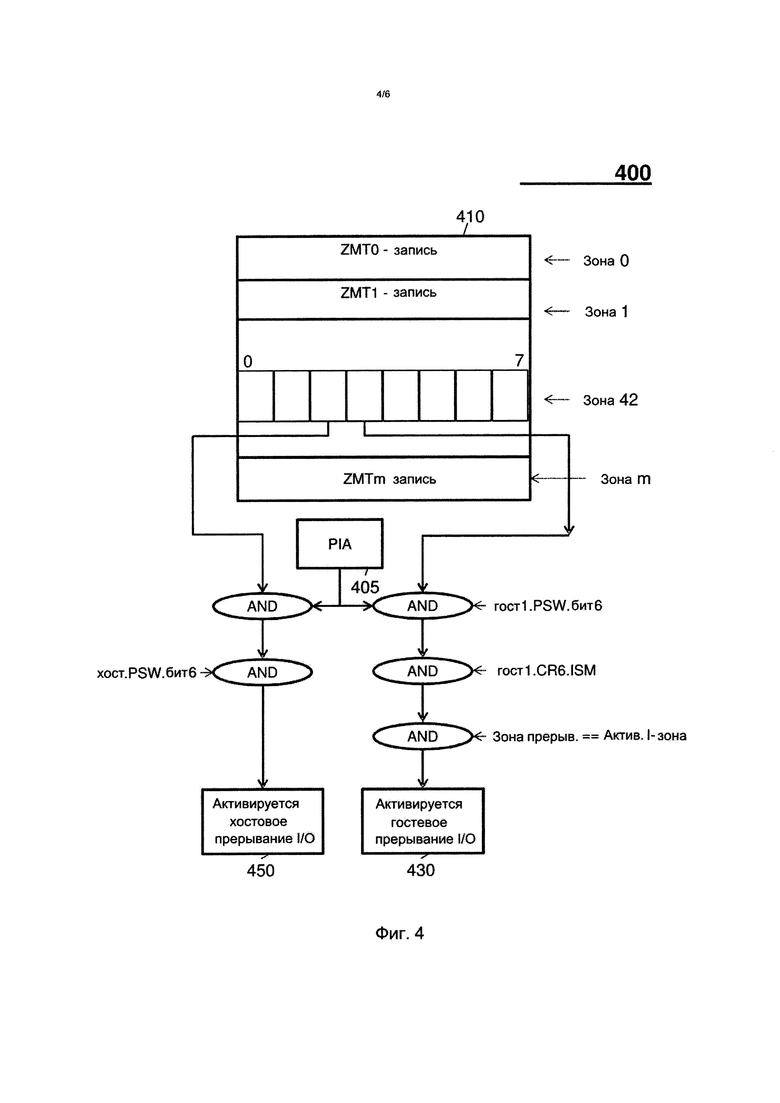
В качестве другого иллюстративного примера фиг. 4 показывает детализированную последовательность 400 операций для маршрутизации прерываний I/O. Таким образом, после того, как аппаратные средства многопоточной системы 100 обнаруживают, что отложенное в PIA 405 прерывание I/O предназначается для активной зоны, а гостевое PSW.6 и гостевой CR6 активированы, то прерывание I/O активируется в госте, как показано в блоке 430. Такая гостевая активация применяется независимо для каждого потока на ядре. Когда PIA 405 имеет прерывание I/O, отложенное для любой зоны, если хостовое PSW.6 и соответствующий бит в ZMT 410 включены (AND), то прерывание активируется посредством мониторинга хоста (за исключением того, что проверка ZMT не применима к зоне 0), как показано в блоке 450. Если конкретное прерывание активируется как в гостевом потоке, так и в хосте на данном ядре, то оно передается гостю.
Вариант осуществления задержки таким образом, что измененная приоритетная маршрутизация может быть использована многопоточной системой 100, описан со ссылками на фиг. 5. Фиг. 5 показывает последовательность 500 операций. Последовательность 500 операций начинается в начальном блоке 505, где прерывание I/O, которое должно быть обслужено и является отложенным в PIA, активируется на одном ядре из числа нескольких ядер. Прерывания I/O активируются для гостевого потока ядра посредством гостевого PSW.6 и ISM в гостевом CR6. Для мониторинга хоста, прерывания I/O всех зон, включая сюда в настоящее время не работающие на ядре зоны, активируются посредством хостового PSW.6 и ZMT (за исключением того, что проверка ZMT не применима к зоне 0). Любое отложенное прерывание I/O для действующей зоны может быть одновременно активировано как в госте, так и в хосте.
В блоке 520 принятия решения последовательность 500 операций производит выявление того, активированы ли гостевые биты управления и биты состояния для отложенного прерывания I/O. Например, последовательность 500 операций выявляет, активировано ли отложенное прерывание I/O в гостевых PSW.6 и CR6 любых из гостевых потоков ядра. Если любой гостевой поток активирован, последовательность 500 операций переходит к блоку 530 (например, как обозначено стрелкой «ДА»), где отложенное прерывание I/O маршрутизируется к гостевому потоку, для которого активировано отложенное прерывание I/O. Если последовательность 500 операций выявляет, что отложенное прерывание I/O не имеет своего соответствующего гостевого PSW.6 и CR6 активированными на каком-либо из нескольких потоков ядра, то последовательность 500 операций переходит к блоку 540 (например, как обозначено стрелкой «НЕТ»). В блоке 540 последовательность 500 операций обнаруживает, что только хостовый мониторинг активируется для отложенного прерывания I/O, и запускает задержку прежде, например, принятия прерывания на этом ядре (если задержка уже не осуществляется). Задержка может быть жестко закодированной или программируемой посредством многопоточной системы, способа и/или компьютерного программного продукта. В блоке 545 последовательность 500 операций проверяет относительно завершения задержки.
Если задержка не завершилась (например, как обозначено стрелкой «НЕТ»), то в блоке 555 принятия решения (при осуществлении задержки прежде принятия прерывания на этом ядре) последовательность 500 операций производит выявление того, имеется ли все еще отложенное прерывание I/O. Если не имеется никакого прерывания I/O (например, если другое ядро приняло прерывание), то последовательность 500 операций переходит к блоку 560 и заканчивает аппаратный приоритетный процесс прерывания I/O (например, как обозначено стрелкой «НЕТ»), Кроме того, в блоке 555 принятия решения, если прерывание I/O все еще является отложенным, последовательность 500 операций переходит назад (например, как обозначено стрелкой «ДА») к блоку 520, где несколько потоков проверяются на активацию гостевого потока для прерывания I/O перед повторной проверкой задержки. В свою очередь, задержка позволяет одному из потоков на ядре или потоку на другом ядре активироваться и принять отложенное прерывание I/O в госте.
В целом, по мере того как последовательность 500 операций проходит циклы итераций во время задержки прежде предоставления хосту прерывания I/O, в конечном счете, желательным результатом является отсутствие каких-либо отложенных прерываний I/O в PIA, поскольку исходное прерывание хоста было принято в качестве гостевого прерывания одним или другим ядром. Если, как выявляется блоком 545, задержка завершилась, последовательность 500 операций переходит к блоку 550, где отложенное прерывание I/O маршрутизируется к хосту для обработки хостом (например, как обозначено стрелкой «ДА»). Таким образом, только если прерывание I/O все еще является отложенным в конце задержки, такое прерывание I/O передается хосту. Кроме того, в одном варианте осуществления все активированные отложенные прерывания I/O принимаются в конце задержки, и задержка не запускается до тех пор, пока все активированные прерывания I/O не окажутся обработанными.
Вариант осуществления измененной приоритетной маршрутизации многопоточной системы 100 описан со ссылками на фиг. 6. Фиг. 6 показывает последовательность 600 операций. Последовательность 600 операций начинается в начальном блоке 605, где прерывание I/O, которое должно быть обслужено и является отложенным в PIA, активируется на одном ядре из числа нескольких ядер. Прерывания I/O активируются для гостевого потока ядра посредством гостевого PSW.6 и ISM в гостевом CR6. Для мониторинга хоста, прерывания I/O всех зон, включая сюда не работающие в настоящее время на ядре зоны, активируются посредством хостового PSW.6 и ZMT. Любое отложенное прерывание I/O для действующей зоны может быть одновременно активировано как в госте, так и в хосте.
В блоке 620 принятия решения последовательность 600 операций производит выявление того, активированы ли гостевые биты управления и биты состояния для отложенного прерывания I/O. Например, последовательность 600 операций выявляет, активировано ли отложенное прерывание I/O в гостевых PSW.6 и CR6 любых из гостевых потоков ядра. Если какой-либо гостевой поток активирован, последовательность 600 операций переходит к блоку 625 принятия решения (например, как обозначено стрелкой «ДА»), где производится выявление того, является ли какой-либо из нескольких гостевых потоков на ядре активированным для прерывания и находящимся в состоянии ожидания. Если никакие гостевые потоки не находятся в состоянии ожидания и не активированы для прерывания I/O, то последовательность 600 операций переходит к блоку 630 (например, как обозначено стрелкой «НЕТ»), где отложенное прерывание I/O маршрутизируется к гостевому потоку, для которого активировано отложенное прерывание I/O. Если по меньшей мере один из нескольких гостевых потоков находится в состоянии ожидания и активирован для отложенного прерывания I/O, то последовательность операций переходит к блоку 635 (например, как обозначено стрелкой «ДА»), где отложенное прерывание I/O маршрутизируется к потоку, активированному для прерывания одного из нескольких гостевых потоков в состоянии ожидания. Многопоточная система 100 может использовать алгоритм маршрутизации, который является случайным или иным для выбора при выявлении маршрутизации множественных активированных потоков в состоянии (635) ожидания, или нескольких активированных потоков не в состоянии (630 ожидания).
Возвращаясь к блоку 620 принятия решения, если последовательность 600 операций выявляет, что отложенное прерывание I/O не имеет своего соответствующего гостевого PSW.6 и CR6 активированными на каком-либо из нескольких потоков ядра, то последовательность 600 операций переходит к блоку 640 (например, как обозначено стрелкой «НЕТ»). В блоке 640 последовательность 600 операций обнаруживает, что только хостовый мониторинг активируется для отложенного прерывания I/O, и запускает задержку прежде принятия представления отложенного прерывания I/O к хосту (если задержка уже не осуществляется). Задержка может быть жестко закодированной или программируемой посредством многопоточной системы, способа и/или компьютерного программного продукта. В блоке 645 последовательность 600 операций проверяет относительно завершения задержки.
Если задержка не завершилась (например, как обозначено стрелкой «НЕТ»), то в блоке 655 принятия решения (при осуществлении задержки прежде принятия прерывания на этом ядре) последовательность 600 операций производит выявление того, имеется ли все еще отложенное прерывание I/O. Если никакого прерывания I/O не имеется, то последовательность 600 операций переходит к блоку 660 и заканчивает аппаратный приоритетный процесс прерывания I/O (например, как обозначено стрелкой «НЕТ»). Кроме того, в блоке 655 принятия решения, если прерывание I/O все еще является отложенным, последовательность 600 операций переходит назад (например, как обозначено стрелкой «ДА») к блоку 620, где несколько потоков проверяются на активацию гостевого потока для прерывания I/O перед повторной проверкой задержки. В свою очередь, задержка позволяет одному из потоков на ядре или потоку на другом ядре активироваться и принять отложенное прерывание I/O в госте.
В целом, по мере того как последовательность 600 операций проходит циклы итераций во время задержки прежде предоставления хосту прерывания I/O, в конечном счете, желательным результатом является отсутствие каких-либо отложенных прерываний I/O в PIA, поскольку исходное прерывание хоста было принято в качестве гостевого прерывания одним или другим ядром. Если, как выявляется блоком 645, задержка завершилась, последовательность 600 операций переходит к блоку 650, где отложенное прерывание I/O маршрутизируется к хосту для обработки хостом (например, как обозначено стрелкой «ДА»). Таким образом, только если прерывание I/O все еще является отложенным в конце задержки, такое прерывание I/O передается хосту. Кроме того, в одном варианте осуществления все активированные отложенные прерывания I/O принимаются в конце задержки, и задержка не запускается до тех пор, пока все активированные прерывания I/O не окажутся обработанными.
Таким образом, ввиду вышеизложенного, многопоточная система 100 предоставляет прерывания I/O гостевому потоку в активированном состоянии ожидания, который находится в наилучшем состоянии для обработки прерывания (например, поскольку не выполняет значимой работы в это время), или за отсутствием такового, активированному гостевому потоку не в состоянии ожидания. Кроме того, путем задержки прерываний I/O, которые на данном ядре активируются только посредством ZMT хоста, многопоточная система 100 предоставляет некоторому гостевому потоку время, необходимое для активации и для принятия прерывания. В свою очередь, от ядра не требуется покидать режим эмуляции (например, прерывать все активные потоки на ядре), и не производится какой-либо ненужной обработки хостом для нахождения активированного для прерываний I/O ядра. Кроме того, поскольку ядро не выводится из режима эмуляции, активированный гостевой поток той же конфигурации может быть повторно диспетчеризирован на ядре для обработки прерывания I/O.
В другом примере многопоточной системы 100, осуществляющей операции и/или методологии измененного приоритета, когда логическое ядро с множественными активными гостевыми потоками диспетчеризируется на физическом ядре, один или несколько из числа потоков могут пребывать в активированном ожидании, в то время как один или несколько других потоков активно воздействуют на ядро. Активные потоки могут быть активированы для прерываний I/O посредством их PSW.6 и CR6, или могут быть отключены для прерываний I/O. Кроме того, хост может производить мониторинг прерываний I/O посредством зональной таблицы масок либо для данной зоны, либо для некоторой другой зоны. Таким образом, если активируется только один поток для прерывания I/O, которое должно быть обслужено, прерывание I/O маршрутизируется к этому потоку. Если имеются множественные потоки, активированные для прерывания I/O, которое должно быть обслужено, и по меньшей мере один из потоков находится в активированном состоянии ожидания, то логика прерываний многопоточной системы 100 направляет прерывание I/O к одному из потоков, который находится в активированном состоянии ожидания. Путем направления предоставления прерывания I/O к потоку, находящемуся в настоящее время в активированном состоянии ожидания, прерывание I/O обрабатывается более быстро на потоке, не выполняющем ничего полезного, и обеспечивается тенденция избегать прерывания выполнения приложения на потоке, который в настоящее время находится в активном состоянии.
В другом примере многопоточной системы 100, осуществляющей операции и/или методологии измененного приоритета, если множественные гостевые потоки активированы для прерывания I/O, которое должно быть обслужено, и ни один из них не находится в активированном состоянии ожидания, логика маршрутизации многопоточной системы 100 может случайным образом или посредством внутреннего алгоритма (например, такого как циклический алгоритм), выбирать поток для получения прерывания I/O на основании активации этого потока. Все другие потоки, которые могут быть активированы для отличного прерывания I/O на основании других битов ISC, удерживаются отключенными до тех пор, пока первый поток не завершит свое принятие прерывания. Как только первый поток завершает принятие, последующие отложенные прерывания I/O подвергаются обработке посредством любых потоков, которые все еще остаются активированными по отношению к любым остающимся подлежащими обслуживанию прерываний I/O. Как указано выше, маршрутизация прерывания I/O может быть направлена к потоку, который находится в настоящее время в состоянии ожидания, если таковой существует.
В другом примере многопоточной системы 100, осуществляющей операции и/или методологии измененного приоритета, при отсутствии потоков на ядре, активированных для прерывания I/O, которое должно быть обслужено, и при хосте, тем не менее, подвергающем ядро мониторингу на предмет прерывания посредством ZMT, которое является в настоящее время отложенным в PIA, хосту немедленно не предоставляется прерывание для обработки. Вместо этого, предоставляется задержка в предоставлении обработки прерывания на ядре, причем прерывание остается отложенным в PIA, а не предоставляется немедленно хосту для обработки. Задержка позволяет либо потоку на данном ядре, либо потоку на некотором другом ядре активироваться для прерывания I/O, а затем произвести его обработку. Таким образом, только после того, как задержка завершилась, а прерывание I/O все еще нуждается в обслуживании, прерывание I/O направляется к хосту для обработки.
В другом примере многопоточной системы 100, осуществляющей операции и/или методологии измененного приоритета, при отсутствии гостевых потоков на ядре, которые как находятся в состоянии ожидания, так и являются активированными для прерывания I/O, которое должно быть обслужено, все же существует по меньшей мере один гостевой поток, который не находится в состоянии ожидания, но является активированным для прерывания, которому активированному и неожидающему потоку не предоставляется незамедлительно прерывание для обработки. Вместо этого, имеется задержка предоставления обработки прерывания на ядре, во время которой прерывание остается отложенным в PIA и не предоставляется незамедлительно гостю для осуществления обработки. Задержка позволяет либо потоку на данном ядре, либо потоку на некотором другом ядре войти в состояние ожидания активированным для прерывания I/O, а затем произвести его обработку. Таким образом, только после того, как задержка завершилась, а прерывание I/O все еще нуждается в обслуживании, прерывание I/O направляется гостю для обработки. В одном варианте осуществления эта задержка является более короткой, чем задержка, описанная выше для направления прерывания хосту. Таким образом, вводится трехуровневое направление, в рамках которого сначала оказывается предпочтение гостевому потоку в состоянии ожидания, затем гостевому потоку не в состоянии ожидания, и наконец, хосту в качестве наименее предпочтительного варианта.
В целом, вычислительные устройства могут включать в себя процессор (например, процессор 114 на фиг. 1) и машиночитаемый информационный носитель (например, память 116 на фиг. 1), где процессор получает машиночитаемые программные команды, например, от машиночитаемого информационного носителя, и выполняет эти команды, выполняя, таким образом, один или несколько процессов, включая сюда один или несколько из числа описанных в настоящем документе процессов.
Машиночитаемые программные команды могут компилироваться или интерпретироваться из компьютерных программ, созданных с помощью команд ассемблера, команд архитектуры системы команд (ISA), машинных команд, машинно-зависимых команд, микрокода, команд встроенного программного обеспечения, присваивающих значение состоянию данных, или иного исходного кода или объектного кода, записанного на любой комбинации из одного или нескольких языков программирования, включая сюда объектно-ориентированные языки программирования, такие как Smalltalk, С++ и т.п., а также обычные языки процедурного программирования, такие как язык программирования «С» или подобные языки программирования. Машиночитаемые программные команды могут выполниться полностью на вычислительном устройстве, частично на вычислительном устройстве, в качестве автономного пакета программного обеспечения, частично на локальном вычислительном устройстве и частично на устройстве удаленного компьютера или полностью на устройстве удаленного компьютера. В последнем сценарии удаленный компьютер может быть присоединен к локальному компьютеру через любой тип сети, включая сюда локальную сеть (LAN) или глобальную сеть (WAN), или присоединение может быть сделано к внешнему компьютеру (например, через Интернет с использованием Интернет-провайдера). В некоторых вариантах осуществления электронные схемы, включающие в себя, например, программируемые логические схемы, программируемые на месте вентильные матрицы (FPGA) или программируемые логические матрицы (PLA) могут выполнять машиночитаемые программные команды посредством использования информации о состоянии машиночитаемых программных команд для настройки электронной схемы с целью выполнения аспектов настоящего изобретения. Машиночитаемые описанные в настоящем документе программные команды могут также быть загружены на соответствующие устройства вычисления/обработки с машиночитаемого информационного носителя или на внешний компьютер или внешнее устройство хранения данных через сеть (например, через произвольную комбинацию вычислительных устройств и присоединений, которая поддерживает коммуникацию). Например, сеть может быть представлена Интернетом, локальной сетью, глобальной сетью и/или беспроводной сетью, может содержать медные кабели передачи, волокна оптической передачи, беспроводную передачу, маршрутизаторы, брандмауэры, переключения, шлюзовые компьютеры и/или граничные серверы, а также использовать различные коммуникационные технологии, такие как радио-технологии, технологии сотовой связи и т.д.
Машиночитаемые информационные носители могут быть представлены материальным устройством, которое удерживает и сохраняет команды для использования устройством выполнения команд (например, вычислительным устройством, как описано выше). Машиночитаемый информационный носитель может быть представлен, например, в том числе, но не ограничиваясь, устройством электронной памяти, магнитным запоминающим устройством, оптическим запоминающим устройством, электромагнитным запоминающим устройством, полупроводниковым запоминающим устройством или любой подходящей комбинацией из вышеупомянутого. Неисчерпывающий список более конкретных примеров машиночитаемых информационных носителей включает в себя следующее: портативная компьютерная дискета, жесткий диск, оперативная память (RAM), постоянная память (ROM), стираемая программируемая постоянная память (EPROM или флэш-память), статическая оперативная память (SRAM), переносной компакт-диск для однократной записи данных (CD-ROM), цифровой универсальный диск (DVD), карта памяти, гибкий диск, механически закодированное устройство, такое как перфокарты или выступающие структуры в канавке с записанными на них командами, а также любая подходящая комбинация из вышеупомянутого. Машиночитаемый информационный носитель, как он рассматривается в настоящем документе, не подлежит истолкованию в качестве представленного преходящими сигналами как таковыми, такими как радиоволны или другие свободно распространяющиеся электромагнитные волны, электромагнитные волны, распространяющиеся через волновод или другие среды передачи (например, проходящие через волоконно-оптический кабель световые импульсы), или передаваемые через провода электрические сигналы.
Таким образом, многопоточная система и способ и/или его элементы могут быть реализованы в виде машиночитаемых программных команд на одном или нескольких вычислительных устройствах, при сохранении их на машиночитаемом информационном носителе, связанном с таковыми. Компьютерный программный продукт может содержать такие машиночитаемые сохраняемые на машиночитаемом информационном носителе программные команды для принуждения и/или побуждения процессора к выполнению операций многопоточной системы и способа. Многопоточная система и способ и/или его элементы, как они реализованы и/или заявлены, улучшают функционирование компьютера и/или процессора как такового, поскольку измененная приоритетная маршрутизация облегчает обработку потоками в ожидании, что повышает эффективность и скорость функционирования ресурса обработки. Таким образом, если прерывание I/O активировано только на уровне хоста на данном ядре, аппаратные средства задерживают вызов встроенного программного обеспечения прерывания I/O в ожидании того, что другой, активированный гостем поток либо на другом процессоре, либо на данном процессоре первым примет прерывание. Этим устраняются издержки удаления из очереди на активированном хостом потоке, но что еще более важно, предоставляется приоритет гостевому потоку, непроизводительные издержки которого в ходе обработки прерывания при обращении с прерыванием являются значительно меньшими. В свою очередь, хост прерывается для обработки любого данного прерывания I/O только в том случае, когда никакой активированный гость не работает. Кроме того, если произвольное данное ядро активируется на уровне как гостя, так и хоста, то аппаратные средства указывают милликоду, что прерывание является гостевым прерыванием. В результате введения многопоточности аппаратные средства также приобретают способность, в случае, когда два потока на любом данном ядре являются активированными для прерывания на гостевом уровне, к предоставлению прерывания тому потоку, который в настоящее время работает в состоянии ожидания, но не тому, который таковым не является.
Аспекты настоящего изобретения описаны в настоящем документе с отсылками на иллюстрации в виде блок-схем и/или блок-диаграмм для способов, устройств (систем) и компьютерных программных продуктов согласно вариантам осуществления изобретения. Подразумевается, что каждый блок иллюстраций в виде блок-схем и/или блок-диаграмм, а также комбинации блоков на иллюстрациях в виде блок-схем и/или блок-диаграмм, могут быть реализованы посредством машиночитаемых программных команд.
Такие машиночитаемые программные команды могут быть предоставлены процессору универсального компьютера, специализированного компьютера или другого программируемого устройства обработки данных для образования машины таким образом, что выполняющиеся посредством процессора компьютера или другого программируемого устройства обработки данных команды создают средства для реализации функций/действий, заданных в блоке или блоках блок-схемы и/или блок-диаграммы. Такие машиночитаемые программные команды также могут быть сохранены в машиночитаемом информационном носителе, который может управлять компьютером, программируемым устройством обработки данных и/или другими устройствами для их функционирования особым способом таким образом, что сохраняющий на нем команды машиночитаемый информационный носитель представляет собой изделие, содержащее команды, которые реализуют аспекты функций/действий, заданных в блоке или блоках блок-схемы и/или блок-диаграммы.
Машиночитаемые программные команды могут также быть загружены на компьютер, другое программируемое устройство обработки данных или другое устройство для принуждения серии эксплуатационных этапов к выполнению на компьютере, другом программируемом устройстве или другом устройстве для получения реализуемого компьютером процесса, такого, что команды, выполняющиеся на компьютере, другом программируемом устройстве или другом устройстве, реализуют операции/действия, определенные в блоке или блоках блок-диаграммы и/или блок-схемы.
Блок-схемы и блок-диаграммы на чертежах показывают архитектуру, функциональность и функционирование возможных реализаций систем, способов и компьютерных программных продуктов согласно различным вариантам осуществления настоящего изобретения. В этом отношении каждый блок в блок-схемах или блок-диаграммах может представлять модуль, сегмент или участок команд, который содержит одну или несколько исполнимых команд для реализации указанной логической функции (функций). В некоторых альтернативных реализациях указанные в блоках функции могут осуществляться в порядке, отличном от приведенного на чертежах. Например, два блока, показанные по очереди, могут, фактически, быть выполнены по существу одновременно, или блоки могут иногда выполняться в обратном порядке, в зависимости от предусмотренной к выполнению функциональности. Необходимо также отметить, что каждый блок на иллюстрациях в виде блок-схем и/или блок-диаграмм, а также в комбинациях блоков на иллюстрациях в виде блок-схем и/или блок-диаграмм, может быть реализован посредством основанных на аппаратных средствах систем особого назначения, которые выполняют заданные функции или действия или выполняют комбинации аппаратных и компьютерных команд особого назначения.
Описания различных вариантов осуществления настоящего изобретения были предложены в целях иллюстрации, но не предназначаются для полного охвата или ограничения заявленных вариантов осуществления. Многие модификации и изменения являются очевидными для средних специалистов в области техники без отступления от существа и объема описанных вариантов осуществления. Используемая в настоящем документе терминология выбрана для наилучшего объяснения принципов вариантов осуществления, практического применения или технического улучшения по сравнению с имеющимися в коммерческом доступе технологиями, или для обеспечения другим средним специалистам в области техники возможности понимания описанных в настоящем документе вариантов осуществления.
Используемая в настоящем документе терминология служит исключительно целям описания конкретных вариантов осуществления и не предназначается для ограничения изобретения. При использовании в настоящем документе, формы единственного числа предназначены для включения в себя также и форм множественного числа, если только контекст не указывает на иное недвусмысленным образом. В последующем изложении подразумевается, что термины «содержит» и/или «содержащий» при их использовании в данном техническом описании задают присутствие заявленных признаков, целочисленных переменных, этапов, операций, элементов и/или компонентов, но не исключают присутствия или добавления одного или нескольких других признаков, целочисленных переменных, этапов, операций, элементов, компонентов и/или образованных ими групп.
Изображенные в настоящем документе блок-схемы являются всего лишь примером. Могут быть представлены многочисленные изменения таких диаграмм или описанных в них этапов (или операций) без отклонения от объема изобретения. Например, этапы могут быть выполнены в отличном порядке, или этапы могут быть добавлены, удалены или изменены. Все такие изменения считаются частью заявленного изобретения.
Хотя был описан предпочтительный вариант осуществления изобретения, подразумевается, что специалисты в данной области техники, как сейчас, так и в будущем, могут делать различные улучшения и усовершенствования, находящиеся в пределах объема последующих пунктов формулы изобретения. Эти пункты формулы изобретения подлежат толкованию в плане поддержки надлежащей защиты вышеописанного изобретения.
| название | год | авторы | номер документа |
|---|---|---|---|
| ДИСПЕТЧЕРИЗАЦИЯ МНОЖЕСТВЕННЫХ ПОТОКОВ В КОМПЬЮТЕРЕ | 2015 |
|
RU2666249C2 |
| КОМАНДА ЗАПУСКА ВИРТУАЛЬНОГО ВЫПОЛНЕНИЯ ДЛЯ ДИСПЕТЧЕРИЗАЦИИ МНОЖЕСТВЕННЫХ ПОТОКОВ В КОМПЬЮТЕРЕ | 2015 |
|
RU2667791C2 |
| ДИНАМИЧЕСКОЕ АКТИВИРОВАНИЕ МНОГОПОТОЧНОСТИ | 2015 |
|
RU2662403C2 |
| ВОССТАНОВЛЕНИЕ КОНТЕКСТА ПОТОКА В МНОГОПОТОЧНОЙ КОМПЬЮТЕРНОЙ СИСТЕМЕ | 2015 |
|
RU2670909C9 |
| РАСШИРЕНИЕ И СОКРАЩЕНИЕ АДРЕСА В МНОГОПОТОЧНОЙ КОМПЬЮТЕРНОЙ СИСТЕМЕ | 2015 |
|
RU2661788C2 |
| ОБЛАСТЬ УПРАВЛЕНИЯ ДЛЯ АДМИНИСТРИРОВАНИЯ МНОЖЕСТВЕННЫМИ ПОТОКАМИ В КОМПЬЮТЕРЕ | 2015 |
|
RU2662695C2 |
| КОНФИГУРАЦИЯ АРХИТЕКТУРНОГО РЕЖИМА В ВЫЧИСЛИТЕЛЬНОЙ СИСТЕМЕ | 2015 |
|
RU2664413C2 |
| Связанное с выбранными архитектурными функциями администрирование обработки | 2015 |
|
RU2665243C2 |
| УПРАВЛЕНИЕ СКОРОСТЬЮ, С КОТОРОЙ ОБРАБАТЫВАЮТСЯ ЗАПРОСЫ НА ПРЕРЫВАНИЕ, ФОРМИРУЕМЫЕ АДАПТЕРАМИ | 2010 |
|
RU2526287C2 |
| ПРЕДОСТАВЛЕНИЕ ОДНОЙ ПРОГРАММНОЙ ДОСТУПА ДРУГОЙ ПРОГРАММЕ К СРЕДСТВУ ОТСЛЕЖИВАНИЯ ПРЕДУПРЕЖДЕНИЙ | 2012 |
|
RU2563454C2 |




Изобретение относится к средствам для реализации измененной приоритетной маршрутизации прерываний ввода/вывода (I/O). Технический результат заключается в расширении арсенала технических средств для реализации измененной приоритетной маршрутизации прерываний ввода/вывода. В способе выявляют, является ли прерывание I/O отложенным для ядра и является ли какой-либо из нескольких гостевых потоков ядра активированным для обработки гостевым потоком прерывания в ответ на выявление того, что прерывание I/O является отложенным, находится ли по меньшей мере один из нескольких гостевых потоков, активированных для обработки гостевым потоком, в состоянии ожидания, и на основании выявления того, что по меньшей мере один из нескольких гостевых потоков, активированных для обработки гостевым потоком, определяют находится в состоянии ожидания, осуществляют маршрутизацию прерывания I/O к гостевому потоку, активированному для обработки гостевым потоком и находящемуся в состоянии ожидания. Система реализует заявленный способ. 3 н. и 17 з.п. ф-лы, 6 ил.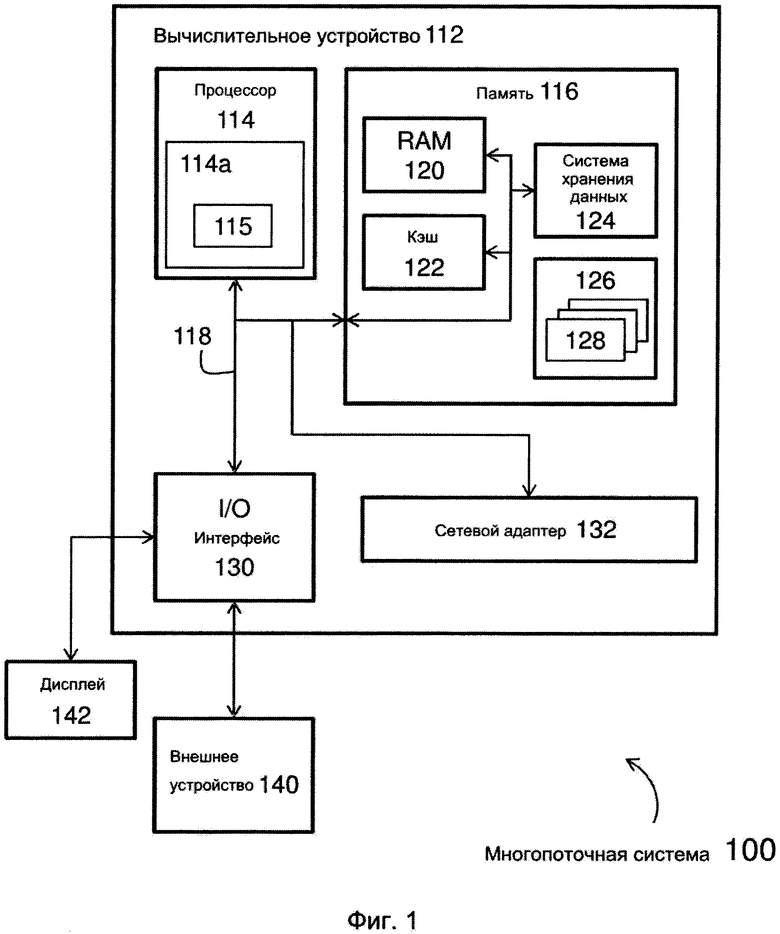
1. Способ реализации измененной приоритетной маршрутизации прерываний ввода/вывода (I/O), содержащий
выявление посредством процессора того, является ли прерывание I/O отложенным для ядра,
выявление посредством процессора того, является ли какой-либо из нескольких гостевых потоков ядра активированным для обработки гостевым потоком прерывания в ответ на выявление того, что прерывание I/O является отложенным,
выявление посредством процессора того, находится ли по меньшей мере один из нескольких гостевых потоков, активированных для обработки гостевым потоком, в состоянии ожидания, и
маршрутизацию посредством процессора прерывания I/O к гостевому потоку, активированному для обработки гостевым потоком и находящемуся в состоянии ожидания, на основании выявления того, что по меньшей мере один из нескольких гостевых потоков, активированных для обработки гостевым потоком, находится в состоянии ожидания.
2. Способ по п. 1, причем прерывание I/O обозначают в матрице отложенных прерываний как отложенное.
3. Способ по п. 1, причем бит состояния и бит управления для каждого гостевого потока конфигурируют для активирования этого потока для обработки гостевым потоком прерывания.
4. Способ по п. 1, кроме того, включающий в себя маршрутизацию прерывания I/O к одному из нескольких гостевых потоков, активированных для обработки гостевым потоком, на основании выявления того, что ни один из нескольких гостевых потоков, активированных для обработки гостевым потоком, не находится в состоянии ожидания.
5. Способ по п. 1, причем в ответ на выявление того, что более чем один из нескольких гостевых потоков, активированных для обработки гостевым потоком, находятся в состоянии ожидания, для выбора гостевого потока используют алгоритм маршрутизации.
6. Способ по п. 1, кроме того, включающий в себя инициирование задержки маршрутизации прерывания I/O к хосту, на основании выявления того, что ни один из нескольких гостевых потоков не является активированным для обработки гостевым потоком.
7. Способ по п. 6, кроме того, включающий в себя выявление после инициирования задержки того, является ли какой-либо из нескольких гостевых потоков ядра активированным для обработки гостевым потоком.
8. Система для реализации измененной приоритетной маршрутизации прерываний ввода/вывода (I/O), содержащая процессор и память,
причем процессор сконфигурирован для:
выявления того, является ли прерывание I/O отложенным для ядра,
выявления того, является ли какой-либо из нескольких гостевых потоков ядра активированным для обработки гостевым потоком прерывания на основании выявления того, что прерывание I/O является отложенным,
выявления того, находится ли по меньшей мере один из нескольких гостевых потоков, активированных для обработки гостевым потоком, в состоянии ожидания, и
маршрутизации прерывания I/O к гостевому потоку, активированному для обработки гостевым потоком и находящемуся в состоянии ожидания, на основании выявления того, что по меньшей мере один из нескольких гостевых потоков, активированных для обработки гостевым потоком, находится в состоянии ожидания.
9. Система по п. 8, причем прерывание I/O обозначено в матрице отложенных прерываний как отложенное.
10. Система по п. 8, причем бит состояния и бит управления для каждого гостевого потока является сконфигурированными для активирования этого потока для обработки гостевым потоком прерывания.
11. Система по п. 8, причем процессор, кроме того, сконфигурирован для маршрутизации прерывания I/O к одному из нескольких гостевых потоков, активированных для обработки гостевым потоком, на основании выявления того, что ни один из нескольких гостевых потоков, активированных для обработки гостевым потоком, не находится в состоянии ожидания.
12. Система по п. 8, причем в ответ на выявление того, что более чем один из нескольких гостевых потоков, активированных для обработки гостевым потоком, находятся в состоянии ожидания, для выбора гостевого потока используется алгоритм маршрутизации.
13. Система по п. 8, причем процессор, кроме того, сконфигурирован для инициирования задержки маршрутизации прерывания I/O к хосту на основании выявления того, что ни один из нескольких гостевых потоков не является активированным для обработки гостевым потоком.
14. Система по п. 13, причем процессор, кроме того, сконфигурирован для выявления после инициирования задержки того, является ли какой-либо из нескольких гостевых потоков ядра активированным для обработки гостевым потоком.
15. Машиночитаемый информационный носитель, имеющий сохраненные на нем программные команды, реализующие измененную приоритетную маршрутизацию прерываний ввода/вывода (I/O), причем программные команды являются исполняемыми посредством процессора для принуждения процессора к:
выявлению того, является ли прерывание I/O отложенным для ядра,
выявлению того, является ли какой-либо из нескольких гостевых потоков ядра активированным для обработки гостевым потоком прерывания на основании выявления того, что прерывание I/O является отложенным,
выявлению того, находится ли по меньшей мере один из нескольких гостевых потоков, активированных для обработки гостевым потоком, в состоянии ожидания, и
маршрутизации прерывания I/O к гостевому потоку, активированному для обработки гостевым потоком и находящемуся в состоянии ожидания, на основании выявления того, что по меньшей мере один из нескольких гостевых потоков, активированных для обработки гостевым потоком, находится в состоянии ожидания.
16. Машиночитаемый информационный носитель по п. 15, причем прерывание I/O обозначено в матрице отложенных прерываний как отложенное.
17. Машиночитаемый информационный носитель по п. 15, причем бит состояния и бит управления для каждого гостевого потока является сконфигурированными для обработки гостевым потоком прерывания.
18. Машиночитаемый информационный носитель по п. 15, причем программные команды являются также исполняемыми посредством процессора для принуждения процессора к маршрутизации прерывания I/O к одному из нескольких гостевых потоков, активированных для обработки гостевым потоком, на основании выявления того, что ни один из нескольких гостевых потоков, активированных для обработки гостевым потоком, не находится в состоянии ожидания.
19. Машиночитаемый информационный носитель по п. 15, причем в ответ на выявление того, что более чем один из нескольких гостевых потоков, активированных для обработки гостевым потоком, находятся в состоянии ожидания, для выбора гостевого потока используется алгоритм маршрутизации.
20. Машиночитаемый информационный носитель по п. 15, причем программные команды являются также исполняемыми посредством процессора для принуждения процессора к инициированию задержки маршрутизации прерывания I/O к хосту на основании выявления того, что ни один из нескольких гостевых потоков не является активированным для обработки гостевым потоком.
| Приспособление для суммирования отрезков прямых линий | 1923 |
|
SU2010A1 |
| Станок для изготовления деревянных ниточных катушек из цилиндрических, снабженных осевым отверстием, заготовок | 1923 |
|
SU2008A1 |
| ОПТИМИЗИРОВАННАЯ ДЛЯ ПОТОКОВ МНОГОПРОЦЕССОРНАЯ АРХИТЕКТУРА | 2007 |
|
RU2427895C2 |
| УСОВЕРШЕНСТВОВАННЫЙ СПОСОБ И УСТРОЙСТВО ДЛЯ ДИНАМИЧЕСКОГО СМЕЩЕНИЯ МЕЖДУ ПАКЕТАМИ МАРШРУТИЗАЦИИ И КОММУТАЦИИ В СЕТИ ПЕРЕДАЧИ ДАННЫХ | 1997 |
|
RU2189072C2 |

