ОБЛАСТЬ ТЕХНИКИ
[0001] Варианты осуществления настоящего изобретения относятся к области кодеков и, в частности, к способу и устройству согласования скорости полярного кода.
УРОВЕНЬ ТЕХНИКИ
[0002] В системе связи канальное кодирование, как правило, используется для повышения надежности передачи данных, чтобы гарантировать качество связи. Полярный код (polar code) является способом кодирования, который может достигать емкости Шеннона и имеет низкую сложность кодирования-декодирования. Полярный код является линейным блочным кодом. Порождающей матрицей полярного кода является GN., и процесс кодирования полярного кода имеет вид 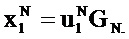
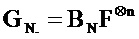
[0003] В настоящем описании 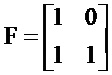
[0004] 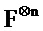
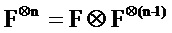
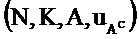
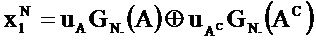
[0005] Для полярного кода может использоваться традиционная технология случайной (псевдослучайной) перфорации гибридного автоматического запроса повторения (HARQ). Так называемая случайная (псевдослучайная) перфорация является случайным (псевдослучайным) выбором места для перфорации. На принимающей стороне LLR в месте перфорации задается равным 0, и все также используются родительский модуль и способ расшифровки кода. В этом случайном (псевдослучайном) способе перфорации частота появления ошибок в кадре является относительно высокой, а эффективность HARQ относительно низкой.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
[0006] Варианты осуществления настоящего изобретения обеспечивают способ и устройство согласования скорости полярного кода, которые могут улучшить эффективность HARQ полярного кода.
[0007] В соответствии с первым аспектом обеспечен способ согласования скорости полярного кода, включающий в себя этапы, на которых: делят систематический полярный код, выводимый полярным кодером, на системные биты и биты проверки на четность; выполняют матричное перемежение BRO над системными битами для получения первой группы перемеженных битов и выполняют матричное перемежение BRO над битами проверки на четность для получения второй группы перемеженных битов; и определяют, на основании первой группы перемеженных битов и второй группы перемеженных битов, выходную последовательность с согласованной скоростью.
[0008] Со ссылкой на первый аспект, в методе реализации первого аспекта этап, на котором выполняют матричное перемежение BRO над системными битами для получения первой группы перемеженных битов включает в себя этапы, на которых: записывают системные биты в строку для формирования первой матрицы M1 строк × M2 столбцов; выполняют первую операцию замены над столбцом первой матрицы для получения второй матрицы, где первая операция замены является операцией BRO с размером M2; выполняют вторую операцию замены над строкой второй матрицы для получения третьей матрицы, где вторая операция замены является операцией BRO с размером M1; и считывают биты в соответствии со столбцом третьей матрицы, и используют эти биты в качестве первой группы перемеженных битов; где M1 и M2 являются положительными целыми числами.
[0009] Со ссылкой на первый аспект и приведенный выше метод реализации первого аспекта, в другом методе реализации первого аспекта этап, на котором выполняют матричное перемежение BRO над системными битами для получения первой группы перемеженных битов, включает в себя этапы, на которых: записывают системные биты в столбец для формирования первой матрицы M1 строк × M2 столбцов; выполняют первую операцию замены над столбцом первой матрицы для получения второй матрицы, где первая операция замены является операцией BRO с размером M2; выполняют вторую операцию замены над строкой второй матрицы для получения третьей матрицы, где вторая операция замены является операцией BRO с размером M1; и считывают биты в соответствии со строкой третьей матрицы, и используют биты в качестве первой группы перемеженных битов; где M1 и M2 являются положительными целыми числами.
[0010] Со ссылкой на первый аспект и приведенные выше методы реализации первого аспекта, в другом методе реализации первого аспекта этап, на котором выполняют матричное перемежение BRO над битами проверки на четность для получения второй группы перемеженных битов, включает в себя этапы, на которых: записывают биты проверки на четность в строку для формирования первой матрицы M1 строк × M2 столбцов; выполняют первую операцию замены над столбцом первой матрицы для получения второй матрицы, где первая операция замены является операцией BRO с размером M2; выполняют вторую операцию замены над строкой второй матрицы для получения третьей матрицы, где вторая операция замены является операцией BRO с размером M1; и считывают биты в соответствии со столбцом третьей матрицы, и используют биты в качестве второй группы перемеженных битов.
[0011] Со ссылкой на первый аспект и приведенные выше методы реализации первого аспекта, в другом методе реализации первого аспекта этап, на котором выполняют матричное перемежение BRO над битами проверки на четность для получения второй группы перемеженных битов, включает в себя этапы, на которых: записывают биты проверки на четность в столбец для формирования первой матрицы M1 строк × M2 столбцов; выполняют первую операцию замены над столбцом первой матрицы для получения второй матрицы, где первая операция замены является операцией BRO с размером M2; выполняют вторую операцию замены над строкой второй матрицы для получения третьей матрицы, где вторая операция замены является операцией BRO с размером M1; и считывают биты в соответствии со строкой третьей матрицы, и используют биты в качестве второй группы перемеженных битов.
[0012] Со ссылкой на первый аспект и приведенные выше методы реализации первого аспекта, в другом методе реализации первого аспекта этап, на котором определяют, на основании первой группы перемеженных битов и второй группы перемеженных битов, выходную последовательность с согласованной скоростью, включает в себя этапы, на которых: последовательно записывают первую группу перемеженных битов и вторую группу перемеженных битов в циклический буфер; определяют местоположение начала выходной последовательности с согласованной скоростью в циклическом буфере в соответствии с версией избыточности; и считывают выходную последовательность с согласованной скоростью из циклического буфера в соответствии с местоположением начала.
[0013] Со ссылкой на первый аспект и приведенные выше методы реализации первого аспекта, в другом методе реализации первого аспекта этап, на котором определяют, на основании первой группы перемеженных битов и второй группы перемеженных битов, выходную последовательность с согласованной скоростью, включает в себя этапы, на которых: последовательно объединяют первую группу перемеженных битов и вторую группу перемеженных битов в третью группу перемеженных битов; и последовательно перехватывают или многократно извлекают биты из третьей группы перемеженных битов для получения выходной последовательности с согласованной скоростью.
[0014] В соответствии со вторым аспектом обеспечен способ согласования скорости полярного кода, включающий в себя этапы, на которых: выполняют матричное перемежение с инвертированием порядка битов BRO над несистематическим полярным кодом, выводимым полярным кодером, для получения перемеженных битов; и определяют, на основании перемеженных битов, выходную последовательность с согласованной скоростью.
[0015] Со ссылкой на второй аспект, в методе реализации второго аспекта этап, на котором выполняют матричное перемежение BRO над полярным кодом, выводимым полярным кодером, для получения перемеженных битов, включает в себя этапы, на которых: записывают биты несистематического полярного кода в строку для формирования первой матрицы M1 строк x M2 столбцов; выполняют первую операцию замены над столбцом первой матрицы для получения второй матрицы, где первая операция замены является операцией BRO с размером M2; выполняют вторую операцию замены над строкой второй матрицы для получения третьей матрицы, где вторая операция замены является операцией BRO с размером M1; и считывают биты в соответствии со столбцом третьей матрицы, и используют биты в качестве перемеженных битов; где M1 и M2 являются положительными целыми числами.
[0016] Со ссылкой на второй аспект и приведенный выше метод реализации второго аспекта, в другом методе реализации второго аспекта этап, на котором выполняют матричное перемежение BRO над полярным кодом, выводимым полярным кодером, для получения перемеженных битов, включает в себя этапы, на которых: записывают биты несистематического полярного кода в столбец для формирования первой матрицы M1 строк x M2 столбцов; выполняют первую операцию замены над столбцом первой матрицы для получения второй матрицы, где первая операция замены является операцией BRO с размером M2; выполняют вторую операцию замены над строкой второй матрицы для получения третьей матрицы, где вторая операция замены является операцией BRO с размером M1; и считывают биты в соответствии со строкой третьей матрицы, и используют биты в качестве перемеженных битов; где M1 и M2 являются положительными целыми числами.
[0017] В соответствии с третьим аспектом обеспечено устройство согласования скорости, включающее в себя: блок группировки, выполненный с возможностью разделения систематического полярного кода, выводимого полярным кодером, на системные биты и биты проверки на четность; блок перемежения, выполненный с возможностью: выполнения матричного перемежения BRO над системными битами для получения первой группы перемеженных битов, и выполнения матричного перемежения BRO над битами проверки на четность для получения второй группы перемеженных битов; и блок определения, выполненный с возможностью определения, на основании первой группы перемеженных битов и второй группы перемеженных битов, выходной последовательности с согласованной скоростью.
[0018] Со ссылкой на третий аспект, в методе реализации третьего аспекта блок перемежения, в частности, выполнен с возможностью: записи битов, которые будут перемежаться, в строку для формирования первой матрицы M1 строк × M2 столбцов; выполнения первой операции замены над столбцом первой матрицы для получения второй матрицы, где первая операция замены является операцией BRO с размером M2; выполнения второй замены над строкой второй матрицы для получения третьей матрицы, где вторая операция замены является операцией BRO с размером M1; и считывания битов в соответствии со столбцом третьей матрицы; где M1 и M2 являются положительными целыми числами.
[0019] Со ссылкой на третий аспект и приведенный выше метод реализации третьего аспекта, в другом методе реализации третьего аспекта блок перемежения, в частности, выполнен с возможностью: записи битов, которые будут перемежаться, в столбец для формирования первой матрицы M1 строк × M2 столбцов; выполнения первой операции замены над столбцом первой матрицы для получения второй матрицы, где первая операция замены является операцией BRO с размером M2; выполнения второй замены над строкой второй матрицы для получения третьей матрицы, где вторая операция замены является операцией BRO с размером M1; и считывания битов в соответствии со строкой третьей матрицы; где M1 и M2 являются положительными целыми числами.
[0020] Со ссылкой на третий аспект и приведенные выше методы реализации третьего аспекта, в другом методе реализации третьего аспекта блок определения, в частности, выполнен с возможностью: последовательной записи первой группы перемеженных битов и второй группы перемеженных битов в циклический буфер; определения местоположения начала выходной последовательности с согласованной скоростью в циклическом буфере в соответствии с версией избыточности; и считывания выходной последовательности с согласованной скоростью из циклического буфера в соответствии с местоположением начала.
[0021] Со ссылкой на третий аспект и приведенные выше методы реализации третьего аспекта, в другом методе реализации третьего аспекта блок определения, в частности, выполнен с возможностью: последовательного объединения первой группы перемеженных битов и второй группы перемеженных битов в третью группу перемеженных битов; и последовательного перехвата или многократного извлечения битов из третьей группы перемеженных битов для получения выходной последовательности с согласованной скоростью.
[0022] В соответствии с четвертым аспектом обеспечено устройство согласования скорости полярного кода, включающее в себя: блок перемежения, выполненный с возможностью выполнения матричного перемежения с инвертированием порядка битов BRO над несистематическим полярным кодом, выводимым полярным кодером, для получения перемеженных битов; и блок определения, выполненный с возможностью определения, на основании перемеженных битов, выходной последовательности с согласованной скоростью.
[0023] Со ссылкой на четвертый аспект, в методе реализации четвертого аспекта блок перемежения, в частности, выполнен с возможностью: записи битов несистематического полярного кода в строку для формирования первой матрицы M1 строк × M2 столбцов; выполнения первой операции замены над столбцом первой матрицы для получения второй матрицы, где первая операция замены является операцией BRO с размером M2; выполнения второй замены над строкой второй матрицы для получения третьей матрицы, где вторая операция замены является операцией BRO с размером M1; и считывания битов в соответствии со столбцом третьей матрицы; где M1 и M2 являются положительными целыми числами.
[0024] Со ссылкой на четвертый аспект и приведенный выше метод реализации четвертого аспекта, в другом методе реализации четвертого аспекта блок перемежения, в частности, выполнен с возможностью: записи битов несистематического полярного кода в столбец для формирования первой матрицы M1 строк × M2 столбцов; выполнения первой операции замены над столбцом первой матрицы для получения второй матрицы, где первая операция замены является операцией BRO с размером M2; выполнения второй замены над строкой второй матрицы для получения третьей матрицы, где вторая операция замены является операцией BRO с размером M1; и считывания битов в соответствии со строкой третьей матрицы; где M1 и M2 являются положительными целыми числами.
[0025] В соответствии с пятым аспектом обеспечено устройство беспроводной связи, включающее в себя полярный кодер, приведенное выше устройство согласования скорости и передатчик.
[0026] В соответствии с вариантами осуществления настоящего изобретения перемежение системных битов и битов проверки на четность выполняется отдельно для получения выходной последовательности с согласованной скоростью, так что структура последовательности после перемежения является более случайной, что может уменьшить FER (Frame Error Rate, частоту появления ошибок в кадре), тем самым улучшая эффективность HARQ и гарантируя надежность передачи данных.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[0027] Для более подробного описания технических решений в вариантах осуществления настоящего изобретения ниже кратко описываются прилагаемые чертежи, необходимые для описания вариантов осуществления или предшествующего уровня техники. Очевидно, что прилагаемые чертежи в следующем ниже описании показывают просто некоторые варианты осуществления настоящего изобретения, и специалист в области техники может, тем не менее, получить другие чертежи из этих прилагаемых чертежей, не прилагая творческих усилий.
[0028] Фиг. 1 показывает систему беспроводной связи в соответствии с вариантом осуществления настоящего изобретения;
[0029] фиг. 2 показывает систему для исполнения способа обработки полярного кода в среде беспроводной связи;
[0030] фиг. 3 является блок-схемой последовательности операций способа согласования скорости полярного кода в соответствии с одним вариантом осуществления настоящего изобретения;
[0031] фиг. 4 является блок-схемой последовательности операций способа согласования скорости полярного кода в соответствии с другим вариантом осуществления настоящего изобретения;
[0032] фиг. 5 является блок-схемой устройства согласования скорости в соответствии с одним вариантом осуществления настоящего изобретения;
[0033] фиг. 6 является блок-схемой устройства согласования скорости в соответствии с другим вариантом осуществления настоящего изобретения;
[0034] фиг. 7 является схематическим чертежом терминала доступа, который помогает исполнить способ обработки полярного кода в системе беспроводной связи;
[0035] фиг. 8 является схематическим чертежом системы, в которой способ обработки полярного кода исполняется в среде беспроводной связи;
[0036] фиг. 9 показывает систему, в которой способ согласования скорости полярного кода может использоваться в среде беспроводной связи; и
[0037] фиг. 10 показывает систему, в которой способ согласования скорости полярного кода может использоваться в среде беспроводной связи.
ОПИСАНИЕ ВАРИАНТОВ ОСУЩЕСТВЛЕНИЯ
[0038] Приведенное ниже ясно и полностью описывает технические решения в вариантах осуществления настоящего изобретения со ссылкой на прилагаемые чертежи в вариантах осуществления настоящего изобретения. Очевидно, что описанные варианты осуществления являются некоторыми, но не всеми вариантами осуществления настоящего изобретения. Все другие варианты осуществления, полученные специалистом в области техники на основании вариантов осуществления настоящего изобретения, не прилагая творческих усилий, попадают в объем правовой охраны настоящего изобретения.
[0039] Терминология, такая как «компонент», «модуль» и «система», используемая в этом описании, используется для того, чтобы указать относящиеся к компьютеру объекты, аппаратное обеспечение, микропрограммное обеспечение, комбинации аппаратного и программного обеспечения, программное обеспечение или исполняемое программное обеспечение. Например, компонент может быть, но не ограничивается только этим, процессом, который выполняется на процессоре, процессором, объектом, исполняемым файлом, потоком исполнения, программой и/или компьютером. Как показано на фигурах, как вычислительное устройство, так и приложение, которое выполняется на вычислительном устройстве, могут быть компонентами. Один или несколько компонентов могут находиться внутри процесса и/или потока исполнения, и компонент может быть расположен на одном компьютере и/или распределен между двумя или более компьютерами. Кроме того, эти компоненты могут исполняться из различных машиночитаемых носителей, которые хранят различные структуры данных. Например, компоненты могут осуществлять связь путем использования локального и/или удаленного процесса и в соответствии, например, с сигналом, имеющим один или несколько пакетов данных (например, данных от двух компонентов, взаимодействующих с другим компонентом в локальной системе, распределенной системе и/или через сеть, такую как Интернет, взаимодействующих с другими системами путем использования этого сигнала).
[0040] Кроме того, варианты осуществления описаны в отношении терминала доступа. Терминал доступа может также упоминаться как система, абонентская установка, абонентская станция, мобильный узел, мобильная станция, удаленная станция, удаленный терминал, мобильное устройство, пользовательский терминал, терминал, устройство беспроводной связи, пользовательский агент, пользовательское устройство или UE (User Equipment, пользовательское оборудование). Терминал доступа может быть сотовым телефоном, беспроводным телефоном, телефоном SIP (Session Initiation Protocol, протокола инициирования сеансов), станцией WLL (Wireless Local Loop, беспроводной местной линии), PDA (Personal Digital Assistant, персональным цифровым помощником), карманным устройством, имеющим функцию беспроводной связи, вычислительным устройством или другим устройством обработки, соединенным с беспроводным модемом. Кроме того, варианты осуществления описаны в отношении базовой станции. Базовая станция может использоваться для осуществления связи с мобильным устройством; и базовая станция может быть BTS (Base Transceiver Station, базовой приемопередающей станцией) в GSM (Global System of Mobile communication, глобальной системе мобильной связи) или CDMA (Code Division Multiple Access, множественном доступе с кодовым разделением), или может быть NB (NodeB, узлом B) в WCDMA (Wideband Code Division Multiple Access, широкополосном множественном доступе с кодовым разделением), или дополнительно может быть eNB или eNodeB (evolved NodeB, развитым NodeB) в LTE (Long Term Evolution, стандарте «Долгосрочное развитие сетей связи»), ретрансляционной станцией или точкой доступа, устройством базовой станции в будущих сетях 5G и т.п.
[0041] Кроме того, аспекты или признаки настоящего изобретения могут быть реализованы как способ, устройство или продукт, который использует стандартные программирование и/или технологии машиностроения. Термин «продукт», используемый в этой заявке, охватывает компьютерную программу, к которой можно получить доступ с любого машиночитаемого компонента, носителя или среды. Например, машиночитаемый носитель может включать в себя, но не ограничивается только этим: компонент магнитного накопителя (например, жесткий диск, гибкий диск или магнитную ленту), оптический диск (например, CD (Compact Disk, компакт-диск) и DVD (Digital Versatile Disk, цифровой универсальный диск)), компонент смарт-карты и флэш-памяти (например, EPROM (Erasable Programmable Read-Only Memory, стираемая программируемая постоянная память), карта или диск в форме ключа). Кроме того, различные носители данных, описанные в этом описании, могут обозначать одно или несколько устройств и/или других машиночитаемых носителей, которые используются для хранения информации. Термин «машиночитаемый носитель» может включать в себя, но не ограничивается только этим, радиоканал и различные другие носители, которые могут хранить, содержать и/или переносить инструкции и/или данные.
[0042] Обратимся теперь к фиг. 1, фиг. 1 показывает систему 100 беспроводной связи в соответствии с вариантами осуществления, описанными в этом описании. Система 100 включает в себя базовую станцию 102, где базовая станция 102 может включать в себя несколько групп антенн. Например, одна группа антенн может включать в себя антенны 104 и 106, другая группа антенн может включать в себя антенны 108 и 110, и дополнительная группа может включать в себя антенны 112 и 114. Показаны две антенны для каждой группы антенн. Однако может использоваться больше или меньше антенн для каждой группы. Базовая станция 102 может дополнительно включать в себя цепь передатчика и цепь приемника. Специалисту в области техники будет понятно, что как цепь передатчика, так и цепь приемника могут включать в себя несколько компонентов, относящихся к отправке и приему сигналов (например, процессор, модулятор, мультиплексор, демодулятор, демультиплексор или антенну).
[0043] Базовая станция 102 может осуществлять связь с одним или несколькими терминалами доступа (например, терминалом 116 доступа и терминалом 122 доступа). Однако понятно, что базовая станция 102 по существу может осуществлять связь с любым количеством терминалов доступа, аналогичных терминалам 116 и 122 доступа. Терминалы 116 и 122 доступа могут быть, например, сотовым телефоном, смартфоном, портативным компьютером, портативным коммуникационным устройством, портативным вычислительным устройством, устройством спутниковой связи, глобальной системой позиционирования, PDA и/или любым другим соответствующим устройством, выполненным с возможностью осуществления связи в системе 100 беспроводной связи. Как показано на фигуре, терминал 116 доступа осуществляет связь с антеннами 112 и 114, где антенны 112 и 114 отправляют информацию терминалу 116 доступа путем использования прямой линии 118 связи и принимают информацию от терминала 116 доступа путем использования обратной линии 120 связи. Кроме того, терминал 122 доступа осуществляет связь с антеннами 104 и 106, где антенны 104 и 106 отправляют информацию терминалу 122 доступа путем использования прямой линии 124 связи и принимают информацию от терминала 122 доступа путем использования обратной линии 126 связи. В системе FDD (Frequency Division Duplex, дуплексной передачи с частотным разделением), например, прямая линия 118 связи может использовать другую полосу частот, чем обратная линии 120 связи, и прямая линия 124 связи может использовать другую полосу частот, чем обратная линии 126 связи. Кроме того, в системе TDD (Time Division Duplex, дуплексной передачи с временным разделением) прямая линия 118 связи и обратная линия 120 связи могут использовать одну и ту же полосу частот, и прямая линия 124 связи и обратная линия 126 связи могут использовать одну и ту же полосу частот.
[0044] Каждая группа антенн и/или областей, предназначенных для связи, называется сектором базовой станции 102. Например, группа антенн может предназначаться для осуществления связи с терминалом доступа в секторе области, обслуживаемой базовой станцией 102. Во время связи, осуществляемой путем использования прямых линий 118 и 124 связи, передающая антенна базовой станции 102 может улучшить, путем формирования диаграммы направленности, отношения сигнал-шум прямых линий 118 и 124 связи для терминалов 116 и 122 доступа. Кроме того, по сравнению с отправкой базовой станцией путем использования одной антенны информации всем терминалам доступа базовой станции, отправка базовой станцией 102 путем формирования диаграммы направленности информации терминалам 116 и 122 доступа, которые распределены в произвольном порядке в соответствующей зоне покрытия, вызывает меньше помех у мобильного устройства в соседней ячейке.
[0045] В некоторое данное время базовая станция 102, терминал 116 доступа и/или терминал 122 доступа могут быть отправляющим устройством беспроводной связи и/или принимающим устройством беспроводной связи. При отправке данных отправляющее устройство беспроводной связи может закодировать данные для передачи. В частности, отправляющее устройство беспроводной связи может иметь (например, генерировать, получать или хранить в памяти) конкретное количество информационных битов, которые должны быть отправлены принимающему устройству беспроводной связи через канал. Информационные биты могут быть включены в транспортный блок (или несколько транспортных блоков) данных и могут быть сегментированы для генерации нескольких блоков кода. Кроме того, отправляющее устройство беспроводной связи может закодировать каждый блок кода путем использования полярного кодера (который не показан).
[0046] Теперь перейдем к фиг. 2, фиг. 2 показывает систему 200 для исполнения способа обработки полярного кода в среде беспроводной связи. Система 200 включает в себя устройство 202 беспроводной связи, где устройство 202 беспроводной связи, как показано, отправляет данные через канал. Хотя показано, что устройство 202 беспроводной связи отправляет данные, устройство 202 беспроводной связи дополнительно может принимать данные через канал (например, устройство 202 беспроводной связи может одновременно отправлять и принимать данные, устройство 202 беспроводной связи может отправлять и принимать данные в различные моменты времени или может иметь место комбинация этого). Устройство 202 беспроводной связи может быть, например, базовой станцией (например, базовой станцией 102 на фиг. 1) или терминалом доступа (например, терминалом 116 доступа на фиг. 1 или терминалом 122 доступа на фиг. 1).
[0047] Устройство 202 беспроводной связи может включать в себя полярный кодер 204, устройство 205 согласования скорости и передатчик 206.
[0048] Полярный кодер 204 выполнен с возможностью кодирования данных, которые должны быть переданы, для получения соответствующего полярного кода.
[0049] Если полярный код, полученный после кодирования с помощью полярного кодера 204, является систематическим кодом, устройство 205 согласования скорости может быть выполнено с возможностью: разделения систематического полярного кода, выводимого полярным кодером 204, на системные биты и биты проверки на четность, выполнения матричного перемежения BRO над системными битами для получения первой группы перемеженных битов, выполнения матричного перемежения BRO над битами проверки на четность для получения второй группы перемеженных битов, и затем определения, на основании первой группы перемеженных битов и второй группы перемеженных битов, выходной последовательности с согласованной скоростью.
[0050] Если полярный код, полученный после кодирования с помощью полярного кодера 204, является несистематическим кодом, устройство 205 согласования скорости может быть выполнено с возможностью выполнения матричного перемежения BRO над несистематическим полярным кодом целиком для получения перемеженных битов, а затем определения, на основании перемеженных битов, выходной последовательности с согласованной скоростью.
[0051] Кроме того, передатчик 206 может впоследствии передать по каналу выходную последовательность с согласованной скоростью, которая обработана устройством 205 согласования скорости. Например, передатчик 206 может отправить соответствующие данные другому отличающемуся устройству беспроводной связи (которое не показано).
[0052] В этом варианте осуществления настоящего изобретения, если полярный код, полученный после кодирования с помощью полярного кодера 204, является систематическим кодом, полярный код может называться систематическим полярным кодом. Если полярный код, полученный после кодирования с помощью полярного кодера 204, является несистематическим кодом, полярный код может называться несистематическим полярным кодом.
[0053] Как правило, систематическим кодом называется код, порождающая матрица G которого имеет следующую форму, или эквивалентный код:
G=[Ik, P], где
Ik является единичной матрицей k-го порядка, а P является матрицей проверки на четность.
[0054] Код, за исключением систематического кода, может называться несистематическим кодом.
[0055] Фиг. 3 является блок-схемой последовательности операций способа согласования скорости полярного кода в соответствии с вариантом осуществления настоящего изобретения. Способ на фиг. 3 исполняется кодирующим в полярный код и передающим концом (например, устройством 205 согласования скорости на фиг. 2).
[0056] 301: Разделить систематический полярный код на системные биты и биты проверки на четность.
[0057] Системные биты являются битами, соответствующими части единичной матрицы Ik в приведенной выше порождающей матрице G, а биты проверки на четность являются битами, соответствующими матрице P проверки на четность часть в приведенной выше порождающей матрице G.
[0058] 302: Выполнить матричное перемежение BRO над системными битами для получения первой группы перемеженных битов (Set1), и выполнить матричное перемежение BRO над битами проверки на четность для получения второй группы перемеженных битов (Set2).
[0059] 303: Определить, на основании первой группы перемеженных битов и второй группы перемеженных битов, выходную последовательность с согласованной скоростью.
[0060] В соответствии с этим вариантом осуществления настоящего изобретения системные биты и биты проверки на четность перемежаются по отдельности для получения выходной последовательность с согласованной скоростью, в результате чего структура последовательности после перемежения является более случайной, что может уменьшить FER, тем самым улучшая эффективность HARQ и гарантируя надежность передачи данных.
[0061] Кроме того, поскольку влияние обработки путем перемежения на минимальных расстояниях системных битов и битов проверки на четность отличается, когда системные биты и биты проверки на четность перемежаются отдельно, минимальное расстояние перемеженных битов может быть дополнительно увеличено, тем самым улучшая эффективность согласования скорости полярного кода.
[0062] В этом варианте осуществления настоящего изобретения для матричного перемежения BRO может использоваться перемежитель Matrix_BRO. Перемежитель Matrix_BRO имеет матричное пространство M1 строк x M2 столбцов, где M1 и M2 являются положительными целыми числами. Полагая, что длина битов, которые должны быть перемежены, равна M1×M2, перемежитель Matrix_BRO может сначала записать биты, которые должны быть перемежены, в строку для формирования первой матрицы M1 строк x M2 столбцов. Затем перемежитель Matrix_BRO может выполнить первую операцию замены над столбцом первой матрицы для получения второй матрицы, где первая операция замены является операцией BRO с размером M2, где
πc(i)=BRO(i, M2), и i=1,2,….
[0063] Затем перемежитель Matrix_BRO может выполнять вторую операцию замены над строкой второй матрицы для получения третьей матрицы, где вторая операция замены является операцией BRO с размером M1, где
πr(i)=BRO(i, M1), и i=1,2,….
[0064] Перемежитель Matrix_BRO может считывать биты в соответствии со столбцом второй матрицы и использовать эти биты в качестве результата перемежения.
[0065] В эквивалентном способе обработки перемежитель Matrix_BRO может сначала записать биты, которые будут перемежаться, в столбец для формирования первой матрицы в M1 строк x M2 столбцов. Затем перемежитель Matrix_BRO может выполнить первую операцию замены над столбцом первой матрицы для получения второй матрицы, где первая операция замены является операцией инвертирования порядка битов BRO с размером M2, где
πc(i)=BRO(i, M2), и i=1,2,….
[0066] Затем перемежитель Matrix_BRO может выполнить вторую операцию замены над строкой второй матрицы для получения третьей матрицы, где вторая операция замены является операцией инвертирования порядка битов BRO с размером M1, где
πr(i)= BRO(i, M1), и i=1,2,….
[0067] Перемежитель Matrix_BRO может считывать биты в соответствии со строкой второй матрицы и использовать эти биты в качестве результата перемежения.
[0068] Кроме того, в этом варианте осуществления настоящего изобретения последовательность приведенных выше операций замены не ограничивается. Например, сначала может выполняться замена строки, а затем выполняться замена столбца. Такой эквивалентный способ обработки также попадает в объем вариантов осуществления настоящего изобретения.
[0069] Когда M1 является целочисленной степенью 2, то есть M1=2s, где s является положительным целым числом, BRO(i, M1) может быть получено следующим образом: (1) представить i как двоичное число (b0, b1, …, bs); (2) выполнить инвертирование порядка для двоичного числа для получения (bs, bs-1, …, b1, b0); и (3) преобразовать двоичное число, полученное после инвертирования порядка, в десятичное число, где двоичное число является значением BRO(i, M1).
[0070] Когда M1 не является целочисленной степенью 2, обрезанный BRO получается посредством отображения и обрезания (prune) в случае, когда M1 является целочисленной степенью 2.
[0071] Например, в одном варианте осуществления на этапе 302, когда над системными битами выполняется матричное перемежение BRO для получения первой группы перемеженных битов, системные биты могут быть записаны в строку (или в столбец) для формирования первой матрицы M1 строк × M2 столбцов; первая операция замены выполняется над столбцом первой матрицы для получения второй матрицы, где первая операция замены является операцией BRO с размером M2; затем вторая операция замены выполняется над строкой второй матрицы для получения третьей матрицы, где вторая операция замены является операцией BRO с размером M1; и биты считываются в соответствии со столбцом (или в соответствии со строкой) третьей матрицы и используются в качестве первой группы перемеженных битов; где M1 и M2 являются положительными целыми числами.
[0072] Опционально, в другом варианте осуществления на этапе 302, когда матричное перемежение BRO выполняется над битами проверки на четность для получения второй группы перемеженных битов, биты проверки на четность могут быть записаны в строку (или в столбец) для формирования первой матрицы M1 строк × M2 столбов; первая операция замены выполняется над столбцом первой матрицы для получения второй матрицы, где первая операция замены является операцией BRO с размером M2; затем вторая операция замены выполняется над строкой второй матрицы для получения третьей матрицы, где вторая операция замены является операцией BRO с размером M1; и биты считываются в соответствии со столбцом (или в соответствии со строкой) третьей матрицы и используются в качестве второй группы перемеженных битов; где M1 и M2 являются положительными целыми числами.
[0073] Опционально, в другом варианте осуществления на этапе 303, когда выходная последовательность с согласованной скоростью определяется на основании первой группы перемеженных битов и второй группы перемеженных битов, может использоваться циклический буфер (Circular Buffer). В частности, сначала первая группа перемеженных битов и вторая группа перемеженных битов могут быть последовательно записаны в циклический буфер, то есть сначала первая группа перемеженных битов записывается в циклический буфер, а затем вторая группа перемеженных битов записывается в циклический буфер. Затем может быть определено местоположение начала выходной последовательности с согласованной скоростью в циклическом буфере в соответствии с версией избыточности (RV, Redundancy Version), и могут быть считаны биты из циклического буфера в соответствии с местоположением начала и использованы в качестве выходной последовательности с согласованной скоростью.
[0074] В процессе HARQ полярного кода системные биты и биты проверки на четность имеют различное значение, и, в частности, системные биты являются более важными, чем биты проверки на четность. Предполагается, что первая группа перемеженных битов, полученная путем перемежения системных битов, является группой Set1, а вторая группа перемеженных битов, полученная путем перемежения битов проверки на четность, является группой Set2. Set1 записывается в циклический буфер перед Set2, так что в выходной последовательности с согласованной скоростью может быть зарезервировано больше системных битов, что может улучшить эффективность HARQ полярного кода.
[0075] Опционально, в другом варианте осуществления на этапе 303, когда выходная последовательность с согласованной скоростью определяется на основании первой группы перемеженных битов и второй группы перемеженных битов, первая группа перемеженных битов (Set1) и вторая группа перемеженных битов (Set2) могут быть последовательно объединены в третью группу перемеженных битов (Set3), то есть в Set3 все биты в Set1 расположены перед всеми битами в Set2. Затем биты могут последовательно перехватываться или неоднократно извлекаться из Set3 для получения выходной последовательности с согласованной скоростью, требуемой для каждого раза повторной передачи. Например, когда длина La битов, которые должны быть повторно переданы, короче длины Lb группы Set3, некоторые биты, длина которых равна La, могут быть перехвачены из Set3 в качестве выходной последовательности с согласованной скоростью. В качестве другого примера, когда длина La битов, которые должны быть повторно переданы, больше длины Lb группы Set3, после того, как считаны все биты в Set3, биты в Set3 могут быть считаны опять с начала, и это повторяется до тех пор, пока не будет считана выходная последовательность с согласованной скоростью, длина которой равна La.
[0076] В процессе HARQ полярного кода системные биты и биты проверки на четность имеют различное значение, и, в частности, системные биты являются более важными, чем биты проверки на четность. Поэтому первая группа перемеженных битов Set1, полученная путем перемежения системных битов, помещается перед второй группой перемеженных битов Set2, полученной путем перемежения битов проверки на четность, так что первая группа перемеженных битов Set1 и вторая группа перемеженных битов Set2 объединяются в третью группу перемеженных битов Set3, и, таким образом, больше системных битов может быть зарезервировано в выходной последовательности с согласованной скоростью, которая получается в конце, тем самым улучшая эффективность HARQ полярного кода.
[0077] Фиг. 4 является блок-схемой последовательности операций способа согласования скорости полярного кода в соответствии с другим вариантом осуществления настоящего изобретения. Способ на фиг. 4 исполняется кодирующим в полярный код и передающим концом (например, устройством 205 согласования скорости на фиг. 2).
[0078] 401: Выполнить матричное перемежение BRO над несистематическом полярным кодом, выводимым полярным кодером, для получения перемеженных битов.
[0079] 402: Определить, на основании перемеженных битов, выходную последовательность с согласованной скоростью.
[0080] В соответствии с этим вариантом осуществления настоящего изобретения матричное перемежение BRO выполняется над несистематическим полярным кодом целиком, так что минимальное расстояние перемеженных битов увеличивается, тем самым улучшая эффективность согласования скорости полярного кода.
[0081] Опционально, в одном варианте осуществления на этапе 401, когда матричное перемежение BRO выполняется над несистематическим полярным кодом для получения перемеженных битов, биты несистематического полярного кода могут быть записаны в строку (или в столбец) для формирования первой матрицы M1 строк × M2 столбцов; первая операция замены выполняется над столбцом первой матрицы для получения второй матрицы, где первая операция замены является операцией BRO с размером M2; затем вторая операция замены выполняется над строкой второй матрицы для получения третьей матрицы, где вторая операция замены является операцией BRO с размером M1; и биты считываются в соответствии со столбцом (или в соответствии со строкой) третьей матрицы и используются в качестве перемеженных битов; где M1 и M2 являются положительными целыми числами.
[0082] Опционально, в другом варианте осуществления на этапе 402 перемеженные биты могут быть записаны в циклический буфер, местоположение начала выходной последовательности с согласованной скоростью в циклическом буфере определяется в соответствии с версией избыточности, и выходная последовательность с согласованной скоростью считывается из циклического буфера в соответствии с местоположением начала.
[0083] Опционально, в другом варианте осуществления на этапе 402 биты могут последовательно перехватываться или многократно извлекаться из перемеженных битов для получения выходной последовательности с согласованной скоростью, требуемой для каждого раза повторной передачи.
[0084] В соответствии с этим вариантом осуществления настоящего изобретения перемежение выполняется над несистематическим полярным кодом целиком, так что минимальное расстояние перемеженных битов увеличивается, тем самым улучшая эффективность согласования скорости полярного кода.
[0085] Фиг. 5 является блок-схемой устройства согласования скорости в соответствии с одним вариантом осуществления настоящего изобретения. Устройство 500 согласования скорости на фиг. 5 могут быть расположено в базовой станции или пользовательском оборудовании, и оно включает в себя блок 501 группировки, блок 502 перемежения и блок 503 определения.
[0086] Блок 501 группировки делит систематический полярный код на системные биты и биты проверки на четность. Блок 502 перемежения выполняет матричное перемежение BRO над системными битами для получения первой группы перемеженных битов и выполняет матричное перемежение BRO над битами проверки на четность для получения второй группы перемеженных битов. Блок 503 определения определяет, на основании первой группы перемеженных битов и второй группы перемеженных битов, выходную последовательность с согласованной скоростью.
[0087] В соответствии с этим вариантом осуществления настоящего изобретения системные биты и биты проверки на четность перемежаются по отдельности для получения выходной последовательность с согласованной скоростью, в результате чего структура последовательности после перемежения является более случайной, что может уменьшить FER, тем самым улучшая эффективность HARQ и гарантируя надежность передачи данных.
[0088] Кроме того, поскольку влияние обработки путем перемежения на минимальных расстояниях системных битов и битов проверки на четность отличается, когда системные биты и биты проверки на четность перемежаются отдельно, минимальное расстояние перемеженных битов может быть дополнительно увеличено, тем самым улучшая эффективность согласования скорости полярного кода.
[0089] Опционально, в одном варианте осуществления блок 502 перемежения может использовать перемежитель Matrix_BRO.
[0090] Опционально, в одном варианте осуществления блок 502 перемежения может записать биты (например, системные биты или биты проверки на четность) перемеженных битов в строку (или в столбец) для формирования первой матрицы M1 строк × M2 столбцов; выполнить первую операцию замены над столбцом первой матрицы для получения второй матрицы, где первая операция замены является операцией BRO с размером M2; выполнить вторую операцию замены над строкой второй матрицы для получения третьей матрицы, где вторая операция замены является операцией BRO с размером M1; и считать биты в соответствии со столбцом (или в соответствии со строкой) третьей матрицы; где M1 и M2 являются положительными целыми числами.
[0091] Опционально, в другом варианте осуществления блок 503 определения может последовательно записать первую группу перемеженных битов и вторую группу перемеженных битов в циклический буфер, определить местоположение начала выходной последовательности с согласованной скоростью в циклическом буфере в соответствии с версией избыточности и считать выходную последовательность с согласованной скоростью из циклического буфера в соответствии с местоположением начала.
[0092] В процессе HARQ полярного кода системные биты и биты проверки на четность имеют различное значение, и, в частности, системные биты являются более важными, чем биты проверки на четность. Предполагается, что первая группа перемеженных битов, полученная путем перемежения системных битов, является группой Set1, а вторая группа перемеженных битов, полученная путем перемежения битов проверки на четность, является группой Set2. Set1 записывается в циклический буфер перед Set2, так что в выходной последовательности с согласованной скоростью может быть зарезервировано больше системных битов, что может улучшить эффективность HARQ полярного кода.
[0093] Опционально, в другом варианте осуществления блок 503 определения может последовательно объединить первую группу перемеженных битов и вторую группу перемеженных битов в третью группу перемеженных битов и последовательно перехватывать или многократно извлекать биты из третьей группы перемеженных битов для получения выходной последовательности с согласованной скоростью.
[0094] В процессе HARQ полярного кода системные биты и биты проверки на четность имеют различное значение, и, в частности, системные биты являются более важными, чем биты проверки на четность. Поэтому первая группа перемеженных битов Set1, полученная путем перемежения системных битов, помещается перед второй группой перемеженных битов Set2, полученной путем перемежения битов проверки на четность, так что первая группа перемеженных битов Set1 и вторая группа перемеженных битов Set2 объединяются в третью группу перемеженных битов Set3, и, таким образом, больше системных битов может быть зарезервировано в выходной последовательности с согласованной скоростью, которая получается в конце, тем самым улучшая эффективность HARQ полярного кода.
[0095] Фиг. 6 является блок-схемой устройства согласования скорости в соответствии с другим вариантом осуществления настоящего изобретения. Устройство 600 согласования скорости на фиг. 6 может быть расположено в базовой станции или пользовательском оборудовании, оно включает в себя блок 601 перемежения и блок 602 определения.
[0096] Блок 601 перемежения выполняет матричное перемежение BRO над несистематическим полярным кодом для получения перемеженных битов. Блок 502 определения определяет, на основании перемеженных битов, выходную последовательность с согласованной скоростью.
[0097] В соответствии с этим вариантом осуществления настоящего изобретения матричное перемежение BRO выполняется над несистематическим полярным кодом целиком, так что минимальное расстояние перемеженных битов увеличивается, тем самым улучшая эффективность согласования скорости полярного кода.
[0098] Опционально, в одном варианте осуществления блок 601 перемежения может записать биты, которые будут перемежаться (то есть биты несистематического полярного кода) в строку (или в столбец) для формирования первой матрицы M1 строк × M2 столбцов; выполнить первую операцию замены над столбцом первой матрицы для получения второй матрицы, где первая операция замены является операцией BRO с размером M2; выполнить вторую операцию замены над строкой второй матрицы для получения третьей матрицы, где вторая операция замены является операцией BRO с размером M1; и считать биты в соответствии со столбцом (или в соответствии со строкой) третьей матрицы; где M1 и M2 являются положительными целыми числами.
[0099] Опционально, в другом варианте осуществления блок 602 определения может записать перемеженные биты в циклический буфер, определить местоположение начала выходной последовательности с согласованной скоростью в циклическом буфере в соответствии с версией избыточности и считать выходную последовательность с согласованной скоростью из циклического буфера в соответствии с местоположением начала.
[0100] Опционально, в другом варианте осуществления блок 602 определения может последовательно перехватить или многократно извлечь биты от перемеженных битов для получения выходной последовательности с согласованной скоростью.
[0101] Фиг. 7 является схематическим чертежом терминала 700 доступа, который помогает исполнить приведенный выше способ обработки полярного кода в системе беспроводной связи. Терминал 700 доступа включает в себя приемник 702. Приемник 702 выполнен с возможностью: приема сигнала, например, от приемной антенны (которая не показана), выполнения типичных действий (например, фильтрации, усиления или понижающего преобразования) над принятым сигналом и оцифровки скорректированного сигнала для получения выборки. Приемник 702 может быть, например, приемником MMSE (Minimum Mean-Squared Error, минимальная среднеквадратичная ошибка). Терминал 700 доступа может дополнительно включать в себя демодулятор 704, где демодулятор 704 может быть выполнен с возможностью демодуляции принятых символов и предоставления принятых символов процессору 706 для оценки канала. Процессор 706 может быть процессором, который специально выполнен с возможностью анализа информации, принятой приемником 702, и/или генерации информации, которая должна быть отправлена передатчиком 716, процессором, который выполнен с возможностью управления одним или несколькими компонентами терминала 700 доступа, и/или контроллером, который выполнен с возможностью анализа информации, принятой приемником 702, генерации информации, которая должна быть отправлена передатчиком 716, и управления одним или несколькими компонентами терминала 700 доступа.
[0102] Терминал 700 доступа дополнительно может включать в себя память 708, где память 708 функционально связана с процессором 706 и хранит следующие данные: данные, которые должны быть отправлены, принятые данные и любую другую соответствующую информацию, относящуюся к исполнению различных операций и функций, описанных в этом описании. Память 708 дополнительно может хранить протокол и/или алгоритм, относящийся к обработке полярного кода.
[0103] Понятно, что устройство хранения данных (например, память 708), описанное в этом описании, может быть энергозависимой памятью или энергонезависимой памятью, или может включать в себя как энергозависимую память, так и энергонезависимую память. Иллюстративно, а не в качестве ограничения, энергонезависимая память может включать в себя: ROM (Read-Only Memory, постоянную память), PROM (Programmable ROM, программируемую постоянную память), EPROM (Erasable PROM, стираемую программируемую постоянную память), EEPROМ (Electrically EPROM, электрически стираемую программируемую постоянную память) или флэш-память. Энергозависимая память может включать в себя RAM (Random Access Memory, оперативную память), и она используется в качестве внешнего кэша. Иллюстративно, а не в качестве ограничения, отметим, что может использоваться RAM во множестве форм, например, SRAM (Static RAM, статическая оперативная память), DRAM (Dynamic RAM, динамическая оперативная память), SDRAM (Synchronous DRAM, синхронная динамическая оперативная память), DDR SDRAM (Double Data Rate SDRAM, синхронная динамическая оперативная память с двойной скоростью передачи данных), ESDRAM (Enhanced SDRAM, усовершенствованная синхронная динамическая оперативная память), SLDRAM (Synchlink DRAM, динамическая оперативная память synchlink), и DR RAM (Direct Rambus RAM, оперативная память Direct Rambus). Предполагается, что память 708 в системе и способе, описанных в этом описании, включает в себя, но не ограничивается только этим, эту память и любую другую память соответствующего типа.
[0104] В настоящей заявке приемник 702 может быть дополнительно соединен с устройством 710 согласования скорости. Устройство 710 согласования скорости может быть в основном аналогичным устройству 205 согласования скорости на фиг. 2. Кроме того, терминал 700 доступа может дополнительно включать в себя полярный кодер 712. Полярный кодер 712 в основном аналогичен полярному кодеру 204 на фиг. 2.
[0105] Если полярный кодер 712 получает систематический полярный код посредством кодирования, устройство 710 согласования скорости может быть выполнено с возможностью: разделения систематического полярного кода на системные биты и биты проверки на четность, выполнения матричного перемежения BRO над системными битами для получения первой группы перемеженных битов (Set1), выполнения матричного перемежения BRO над битами проверки на четность для получения второй группы перемеженных битов (Set2) и определения, на основании первой группы перемеженных битов и второй группы перемеженных битов, выходной последовательности с согласованной скоростью.
[0106] В соответствии с этим вариантом осуществления настоящего изобретения системные биты и биты проверки на четность перемежаются по отдельности для получения выходной последовательность с согласованной скоростью, в результате чего структура последовательности после перемежения является более случайной, что может уменьшить FER, тем самым улучшая эффективность HARQ и гарантируя надежность передачи данных.
[0107] Кроме того, поскольку влияние обработки путем перемежения на минимальных расстояниях системных битов и битов проверки на четность отличается, когда системные биты и биты проверки на четность перемежаются отдельно, минимальное расстояние перемеженных битов может быть дополнительно увеличено, тем самым улучшая эффективность согласования скорости полярного кода.
[0108] В другом аспекте, если полярный кодер 712 получает несистематический полярный код посредством кодирования, устройство 710 согласования скорости может быть выполнено с возможностью: выполнения матричного перемежения BRO над несистематическим полярным кодом целиком для получения перемеженных битов и определения, на основании перемеженных битов, выходной последовательности с согласованной скоростью.
[0109] В соответствии с этим вариантом осуществления настоящего изобретения матричное перемежение BRO выполняется над несистематическим полярным кодом целиком, так что минимальное расстояние перемеженных битов увеличивается, тем самым улучшая эффективность согласования скорости полярного кода.
[0110] Обработка путем перемежения, выполняемая устройством 710 согласования скорости, может включать в себя: запись битов, которые будут перемежаться, в строку (или в столбец) для формирования первой матрицы M1 строк × M2 столбцов; выполнение первой операции замены над столбцом первой матрицы для получения второй матрицы, где первая операция замены является операцией BRO с размером M2; выполнение второй операции замены над строкой второй матрицы для получения третьей матрицы, где вторая операция замены является операцией BRO с размером M1; и считывание битов в соответствии со столбцом третьей матрицы; где M1 и M2 являются положительными целыми числами.
[0111] Опционально, в другом варианте осуществления при определении, на основании первой группы перемеженных битов и второй группы перемеженных битов, выходной последовательности с согласованной скоростью устройство 710 согласования скорости может использовать циклический буфер. В частности, сначала устройство 710 согласования скорости может последовательно записать первую группу перемеженных битов и вторую группу перемеженных битов в циклический буфер, то есть сначала записать первую группу перемеженных битов в циклический буфер, а затем записать вторую группу перемеженных битов в циклический буфер. Затем местоположение начала выходной последовательности с согласованной скоростью в циклическом буфере может быть определено в соответствии с версией избыточности, и биты считаны из циклического буфера в соответствии с местоположением начала и использованы в качестве выходной последовательности с согласованной скоростью.
[0112] В процессе HARQ полярного кода системные биты и биты проверки на четность имеют различное значение, и, в частности, системные биты являются более важными, чем биты проверки на четность. Предполагается, что первая группа перемеженных битов, полученная путем перемежения системных битов, является группой Set1, а вторая группа перемеженных битов, полученная путем перемежения битов проверки на четность, является группой Set2. Set1 записывается в циклический буфер перед Set2, так что в выходной последовательности с согласованной скоростью может быть зарезервировано больше системных битов, что может улучшить эффективность HARQ полярного кода.
[0113] Опционально, в другом варианте осуществления при определении, на основании первой группы перемеженных битов и второй группы перемеженных битов, выходной последовательности с согласованной скоростью устройство 710 согласования скорости может последовательно объединить первую группу перемеженных битов (Set1) и вторую группу перемеженных битов (Set2) в третью группу перемеженных битов (Set3), то есть в Set3 все биты в Set1 расположены перед всеми битами в Set2. Затем биты могут последовательно перехватываться или неоднократно извлекаться из Set3 для получения выходной последовательности с согласованной скоростью, требуемой для каждого раза повторной передачи. Например, когда длина La битов, которые должны быть повторно переданы, короче длины Lb группы Set3, некоторые биты, длина которых равна La, могут быть перехвачены из Set3 в качестве выходной последовательности с согласованной скоростью. В качестве другого примера, когда длина La битов, которые должны быть повторно переданы, больше длины Lb группы Set3, после того, как считаны все биты в Set3, биты в Set3 могут быть считаны опять с начала, и это повторяется до тех пор, пока не будет считана выходная последовательность с согласованной скоростью, длина которой равна La.
[0114] В процессе HARQ полярного кода системные биты и биты проверки на четность имеют различное значение, и, в частности, системные биты являются более важными, чем биты проверки на четность. Поэтому первая группа перемеженных битов Set1, полученная путем перемежения системных битов, помещается перед второй группой перемеженных битов Set2, полученной путем перемежения битов проверки на четность, так что первая группа перемеженных битов Set1 и вторая группа перемеженных битов Set2 объединяются в третью группу перемеженных битов Set3, и, таким образом, больше системных битов может быть зарезервировано в выходной последовательности с согласованной скоростью, которая получается в конце, тем самым улучшая эффективность HARQ полярного кода.
[0115] Опционально, в другом варианте осуществления при определении, на основании перемеженных битов, выходной последовательности с согласованной скоростью, устройство 710 согласования скорости может записать перемеженные биты в циклический буфер, определить местоположение начала выходной последовательности с согласованной скоростью в циклическом буфере в соответствии с версией избыточности и считать выходную последовательность с согласованной скоростью из циклического буфера в соответствии с местоположением начала.
[0116] Опционально, в другом варианте осуществления при определении, на основании перемеженных битов, выходной последовательности с согласованной скоростью, устройство 710 согласования скорости может последовательно перехватить или многократно извлечь биты из перемеженных битов для получения выходной последовательности с согласованной скоростью, требуемой для каждого случая повторной передачи.
[0117] Кроме того, терминал 700 доступа может дополнительно включать в себя модулятор 714 и передатчик 716. Передатчик 716 выполнен с возможностью посылать сигнал, например, базовой станции или другому терминалу доступа. Хотя показано, что полярный кодер 712, устройство 710 согласования скорости и/или модулятор 714 отделены от процессора 706, понятно, что полярный кодер 712, устройство 710 согласования скорости и/или модулятор 714 могут быть частью процессора 706 или нескольких процессоров (которые не показаны).
[0118] Фиг. 8 является схематическим чертежом системы 800, в которой приведенный выше способ обработки полярного кода исполняется в среде беспроводной связи. Система 800 включает в себя базовую станцию 802 (например, точку доступа, NodeB или eNB). У базовой станции 802 есть приемник 810, который принимает сигнал от одного или нескольких терминалов 804 доступа путем использования нескольких приемных антенн 806, и передатчик 824, который передает сигнал одному или нескольким терминалам 804 доступа путем использования передающей антенны 808. Приемник 810 может принимать информацию от приемной антенны 806, и он функционально связан с демодулятором 812, который демодулирует принятую информацию. Символ, полученный после демодуляции, анализируется путем использования процессора 814, аналогичного процессору, описанному на фиг. 7. Процессор 814 соединен с памятью 816. Память 816 выполнена с возможностью хранения данных, которые должны быть отправлены терминалу 804 доступа (или другой базовой станции (которая не показана)), или данных, принятых от терминала 804 доступа (или другой базовой станции (которая не показана)), и/или любой другой соответствующей информации, относящейся к исполнению действий и функций, описанных в этом описании. Процессор 814 дополнительно может быть связан с полярным кодером 818 и устройством 820 согласования скорости.
[0119] В соответствии с одним аспектом этого варианта осуществления настоящего изобретения устройство 820 согласования скорости может быть выполнено с возможностью: разделения систематического полярного кода, выводимого полярным кодером 818, на системные биты и биты проверки на четность, перемежения системных битов для получения первой группы перемеженных битов (Set1), перемежения битов проверки на четность для получения второй группы перемеженных битов (Set2) и определения, на основании первой группы перемеженных битов и второй группы перемеженных битов, выходной последовательности с согласованной скоростью.
[0120] В соответствии с этим вариантом осуществления настоящего изобретения системные биты и биты проверки на четность перемежаются по отдельности для получения выходной последовательность с согласованной скоростью, в результате чего структура последовательности после перемежения является более случайной, что может уменьшить FER, тем самым улучшая эффективность HARQ и гарантируя надежность передачи данных.
[0121] Кроме того, поскольку влияние обработки путем перемежения на минимальных расстояниях системных битов и битов проверки на четность отличается, когда системные биты и биты проверки на четность перемежаются отдельно, минимальное расстояние перемеженных битов может быть дополнительно увеличено, тем самым улучшая эффективность согласования скорости полярного кода.
[0122] В соответствии с другим аспектом этого варианта осуществления настоящего изобретения устройство 820 согласования скорости может быть выполнено с возможностью: выполнения матричного перемежения BRO над несистематическим полярным кодом целиком для получения перемеженных битов, при этом несистематический полярный код выводится полярным кодером 712; и определения, на основании перемеженных битов, выходной последовательности с согласованной скоростью.
[0123] В соответствии с этим вариантом осуществления настоящего изобретения матричное перемежение BRO выполняется над несистематическим полярным кодом целиком, так что минимальное расстояние перемеженных битов увеличивается, тем самым улучшая эффективность согласования скорости полярного кода.
[0124] Опционально, в одном варианте осуществления обработка путем перемежения, выполняемая устройством 820 согласования скорости, может включать в себя: запись битов, которые будут перемежаться, в строку (или в столбец) для формирования первой матрицы M1 строк × M2 столбцов; выполнение первой операции замены над столбцом первой матрицы для получения второй матрицы, где первая операция замены является операцией BRO с размером M2; выполнение второй операции замены над строкой второй матрицы для получения третьей матрицы, при этом вторая операция замены является операцией BRO с размером M1; и считывание битов в соответствии со столбцом (или в соответствии со строкой) третьей матрицы; где M1 и M2 являются положительными целыми числами.
[0125] Опционально, в другом варианте осуществления при определении, на основании первой группы перемеженных битов и второй группы перемеженных битов, выходной последовательности с согласованной скоростью устройство 820 согласования скорости может использовать циклический буфер. В частности, сначала устройство 820 согласования скорости может последовательно записать первую группу перемеженных битов и вторую группу перемеженных битов в циклический буфер, то есть сначала записать первую группу перемеженных битов в циклический буфер, а затем записать вторую группу перемеженных битов в циклический буфер. Затем местоположение начала выходной последовательности с согласованной скоростью в циклическом буфере может быть определено в соответствии с версией избыточности, и биты считываются из циклического буфера в соответствии с местоположением начала и используются в качестве выходной последовательности с согласованной скоростью.
[0126] В процессе HARQ полярного кода системные биты и биты проверки на четность имеют различное значение, и, в частности, системные биты являются более важными, чем биты проверки на четность. Предполагается, что первая группа перемеженных битов, полученная путем перемежения системных битов, является группой Set1, а вторая группа перемеженных битов, полученная путем перемежения битов проверки на четность, является группой Set2. Set1 записывается в циклический буфер перед Set2, так что больше системных битов может быть зарезервировано в выходной последовательности с согласованной скоростью, что может улучшить эффективность HARQ полярного кода.
[0127] Опционально, в другом варианте осуществления при определении, на основании первой группы перемеженных битов и второй группы перемеженных битов, выходной последовательности с согласованной скоростью устройство 820 согласования скорости может последовательно объединить первую группу перемеженных битов (Set1) и вторую группу перемеженных битов (Set2) в третью группу перемеженных битов (Set3), то есть в Set3 все биты в Set1 расположены перед всеми битами в Set2. Затем биты могут быть последовательно перехватываться или неоднократно извлекаться из Set3 для получения выходной последовательности с согласованной скоростью, требуемой для каждого раза повторной передачи. Например, когда длина La битов, которые должны быть повторно переданы, короче длины Lb группы Set3, некоторые биты, длина которых равна La, могут быть перехвачены из Set3 в качестве выходной последовательности с согласованной скоростью. В качестве другого примера, когда длина La битов, которые должны быть повторно переданы, больше длины Lb группы Set3, после того, как считаны все биты в Set3, биты в Set3 могут быть считаны опять с начала, и это повторяется до тех пор, пока не будет считана выходная последовательность с согласованной скоростью, длина которой равна La.
[0128] В процессе HARQ полярного кода системные биты и биты проверки на четность имеют различное значение, и, в частности, системные биты являются более важными, чем биты проверки на четность. Поэтому первая группа перемеженных битов Set1, полученная путем перемежения системных битов, помещается перед второй группой перемеженных битов Set2, полученной путем перемежения битов проверки на четность, так что первая группа перемеженных битов Set1 и вторая группа перемеженных битов Set2 объединяются в третью группу перемеженных битов Set3, и, таким образом, больше системных битов может быть зарезервировано в выходной последовательности с согласованной скоростью, которая получается в конце, тем самым улучшая эффективность HARQ полярного кода.
[0129] Опционально, в другом варианте осуществления при определении, на основании перемеженных битов, выходной последовательности с согласованной скоростью устройство 820 согласования скорости может записать перемеженные биты в циклический буфер, определить местоположение начала выходной последовательности с согласованной скоростью в циклическом буфере в соответствии с версией избыточности и считать выходную последовательность с согласованной скоростью из циклического буфера в соответствии с местоположением начала.
[0130] Опционально, в другом варианте осуществления при определении, на основании перемеженных битов, выходной последовательности с согласованной скоростью устройство 820 согласования скорости может последовательно перехватить или многократно извлечь биты из перемеженных битов для получения выходной последовательности с согласованной скоростью, требуемой для каждого случая повторной передачи.
[0131] Кроме того, в системе 800 модулятор 822 может мультиплексировать кадр, так что передатчик 824 отправляет информацию терминалу 804 доступа путем использования антенны 808. Хотя показано, что полярный кодер 818, устройство 820 согласования скорости и/или модулятор 822 отделены от процессора 814, понятно, что полярный кодер 818, устройство 820 согласования скорости и/или модулятор 822 могут быть частью процессора 814 или нескольких процессоров (которые не показаны).
[0132] Понятно, что варианты осуществления, описанные в этом описании, могут быть реализованы с помощью аппаратного обеспечения, программного обеспечения, микропрограммного обеспечения, промежуточного программного обеспечения, микрокода или их комбинации. Для реализации с помощью аппаратного обеспечения блок обработки может быть реализован в одной или нескольких ASIC (Application Specific Integrated Circuit, специализированных интегральных схемах), DSP (Digital Signal Processing, цифровых сигнальных процессорах), DSPD (DSP Device, устройствах цифровой обработки сигналов), PLD (Programmable Logic Device, программируемых логических устройствах), FPGA (Field-Programmable Gate Array, программируемых пользователем вентильных матрицах), процессорах, контроллерах, микроконтроллерах, микропроцессорах, других электронных блоках, используемых для выполнения функций в этой заявке или их комбинации.
[0133] Когда варианты осуществления реализованы в программном обеспечении, микропрограммном обеспечении, промежуточном программном обеспечении, микрокоде, программном коде или сегменте кода, программное обеспечение, микропрограммное обеспечение, промежуточное программное обеспечение, микрокод, программный код или сегмент кода может храниться, например, в машиночитаемом накопителе компонента хранения. Сегмент кода может указывать процесс, функцию, подпрограмму, программу, процедуру, подпроцедуру, модуль, программную группу, класс или любую комбинацию инструкции, структуры данных или оператора программы. Сегмент кода может быть связан с другим сегментом кода или схемой аппаратного обеспечения путем передачи и/или приема информации, данных, независимой переменной, параметра или содержания памяти. Информация, независимая переменная, параметр, данные и т.п. могут быть переданы, пересланы или отправлены любым соответствующим образом, таким как совместное использование памяти, передача сообщения, передача маркера или сетевая передача.
[0134] Для реализации с помощью программного обеспечения технологии в этом описании могут быть реализованы путем использования модулей (например, процесса и функции) для исполнения функций в этом описании. Программный код может храниться в блоке памяти и исполняться процессором. Блок памяти может быть реализован внутри процессора или вне процессора, и в последнем случае блок памяти может быть связан с процессором с помощью связи путем использования различных средств, известных в области техники.
[0135] Обращаясь к фиг. 9, фиг. 9 показывает систему 900, в которой способ согласования скорости полярного кода может использоваться в среде беспроводной связи. Например, система 900 может по меньшей мере частично располагаться в базовой станции. В соответствии с другим примером система 900 может по меньшей мере частично располагаться в терминале доступа. Следует понимать, что система 900 может быть представлена как включающая в себя функциональный блок, который может быть функциональным блоком, представляющим функцию, реализованную с помощью процессора, программного обеспечения или их комбинации (например, микропрограммного обеспечения). Система 900 включает в себя логику 902, имеющую электронные блоки, которые совместно выполняют операцию.
[0136] Например, логика 902 может включать в себя электронный компонент 904, который выполнен с возможностью разделения систематического полярного кода на системные биты и биты проверки на четность, и электронный компонент 906, который выполнен с возможностью выполнения матричного перемежения BRO над системными битами для получения первой группы перемеженных битов и выполнения матричного перемежения BRO над битами проверки на четность для получения второй группы перемеженных битов. Логика 902 может дополнительно включать в себя электронный компонент 908, который выполнен с возможностью определения, на основании первой группы перемеженных битов и второй группы перемеженных битов, выходной последовательности с согласованной скоростью.
[0137] В соответствии с этим вариантом осуществления настоящего изобретения системные биты и биты проверки на четность перемежаются по отдельности для получения выходной последовательность с согласованной скоростью, в результате чего структура последовательности после перемежения является более случайной, что может уменьшить FER, тем самым улучшая эффективность HARQ и гарантируя надежность передачи данных.
[0138] Кроме того, поскольку влияние обработки путем перемежения на минимальных расстояниях системных битов и битов проверки на четность отличается, когда системные биты и биты проверки на четность перемежаются отдельно, минимальное расстояние перемеженных битов может быть дополнительно увеличено, тем самым улучшая эффективность согласования скорости полярного кода.
[0139] Кроме того, система 900 может включать в себя память 912. Память 912 хранит инструкции, используемые для выполнения функций, относящихся к электронным компонентам 904, 906 и 908. Хотя показано, что электронные компоненты 904, 906 и 908 находятся вне памяти 912, можно понять, что один или несколько электронных компонентов 904, 906 и 908 могут существовать в памяти 912.
[0140] Обращаясь к фиг. 10, фиг. 10 показывает систему 1000, в которой способ согласования скорости полярного кода может использоваться в среде беспроводной связи. Например, система 1000 может по меньшей мере частично располагаться в базовой станции. В соответствии с другим примером система 1000 может по меньшей мере частично располагаться в терминале доступа. Следует понимать, что система 1000 может быть представлена как включающая в себя функциональный блок, который может быть функциональным блоком, представляющим функцию, реализованную с помощью процессора, программного обеспечения или их комбинации (например, микропрограммного обеспечения). Система 1000 включает в себя логику 1002, имеющую электронные блоки, которые совместно выполняют операцию.
[0141] Например, логика 1002 может включать в себя электронный компонент 1004, который выполнен с возможностью выполнения матричного перемежения BRO над несистематическим полярным кодом целиком для получения перемеженных битов, и электронный компонент 1006, который выполнен с возможностью определения, на основании перемеженных битов, выходной последовательности с согласованной скоростью.
[0142] В соответствии с этим вариантом осуществления настоящего изобретения матричное перемежение BRO выполняется над несистематическим полярным кодом целиком, так что минимальное расстояние перемеженных битов увеличивается, тем самым улучшая эффективность согласования скорости полярного кода.
[0143] Кроме того, система 1000 может включать в себя память 1012. Память 1012 хранит инструкции, используемые для выполнения функций, относящихся к электронным компонентам 1004, 1006 и 1008. Хотя показано, что электронные компоненты 1004, 1006 и 1008 находятся вне памяти 1012, можно понять, что один или несколько электронных компонентов 1004, 1006 и 1008 могут существовать в памяти 1012.
[0144] Специалисту в данной области техники может быть известно, что в сочетании с примерами, описанными в вариантах осуществления, раскрытых в этом описании, блоки и этапы алгоритмов могут быть реализованы электронным аппаратным обеспечением или комбинацией программного обеспечения и электронного аппаратного обеспечения. Выполняются ли функции аппаратным обеспечением или программным обеспечением зависит от конкретных приложений и конструктивных ограничений технических решений. Специалист в данной области техники может использовать различные способы для реализации описанных функций для каждого конкретного приложения, но не следует считать, что такая реализация выходит за пределы объема настоящего изобретения.
[0145] Специалисту в данной области техники может быть четко понято, что с целью удобства и краткости описания для подробного рабочего процесса приведенной выше системы, устройства и блока может быть дана ссылка на соответствующий процесс в приведенных выше вариантах осуществления способа, и никакие дополнительные подробности здесь не приводятся.
[0146] В этих нескольких вариантах осуществления, обеспеченных в этой заявке, следует понимать, что раскрытая система, устройство и способ могут быть реализованы другим образом. Например, описанный вариант осуществления устройства является лишь иллюстративным. Например, деление на блоки является просто делением на логические функции и может быть другим делением в фактической реализации. Например, несколько блоков или компонентов могут быть объединены или интегрированы в другую систему, или некоторые признаки могут игнорироваться или не выполняться. Кроме того, показанные или обсуждавшиеся взаимные связи, или прямые связи, или коммуникационные соединения могут быть реализованы путем использования некоторых интерфейсов. Косвенные связи или коммуникационные соединения между устройствами или блоками могут быть реализованы в электронной, механической или других формах.
[0147] Блоки, описанные как отдельные части, могут быть или не быть физически отдельными, и части, показанные как блоки, могут быть или не быть физическими блоками, могут быть расположены в одном месте или могут быть распределены на нескольких сетевых блоках. Некоторые или все блоки могут быть выбраны в соответствии с фактическими потребностями в достижении целей решений вариантов осуществления.
[0148] Кроме того, функциональные блоки в вариантах осуществления настоящего изобретения могут быть интегрированы в один блок обработки, или каждый из блоков может существовать один физически, или два или более блоков интегрированы в один блок.
[0149] Когда функции реализованы в форме программного функционального блока и продаются или используются в качестве независимого продукта, функции могут храниться на машиночитаемом носителе данных. Основываясь на таком понимании, технические решения настоящего изобретения по существу, или часть, входящая в предшествующий уровень техники, или некоторые из технических решений могут быть реализованы в форме программного продукта. Компьютерный программный продукт храниться на носителе данных и включает в себя несколько инструкций для выдачи команд компьютерному устройству (которое может быть персональным компьютером, сервером, сетевым устройством и т.п.) на выполнение всех или некоторых из этапов способов, описанных в вариантах осуществления настоящего изобретения. Упомянутый выше носитель данных включает в себя: любой носитель, который может хранить программный код, такой как карта флэш-памяти с интерфейсом USB, съемный жесткий диск, постоянную память (ROM, Read-Only Memory), оперативную память (RAM, Random Access Memory), магнитный диск или оптический диск.
[0150] Приведенное выше описание является просто конкретными реализациями настоящего изобретения, оно не предназначено для ограничения объема правовой охраны настоящего изобретения. Любые вариации или замены, очевидные специалисту в области техники, в пределах технического объема, раскрытого в настоящем изобретении, должны попадать в пределы объема правовой охраны настоящего изобретения. Поэтому объем правовой охраны настоящего изобретения должен определяться объемом правовой охраны формулы изобретения.
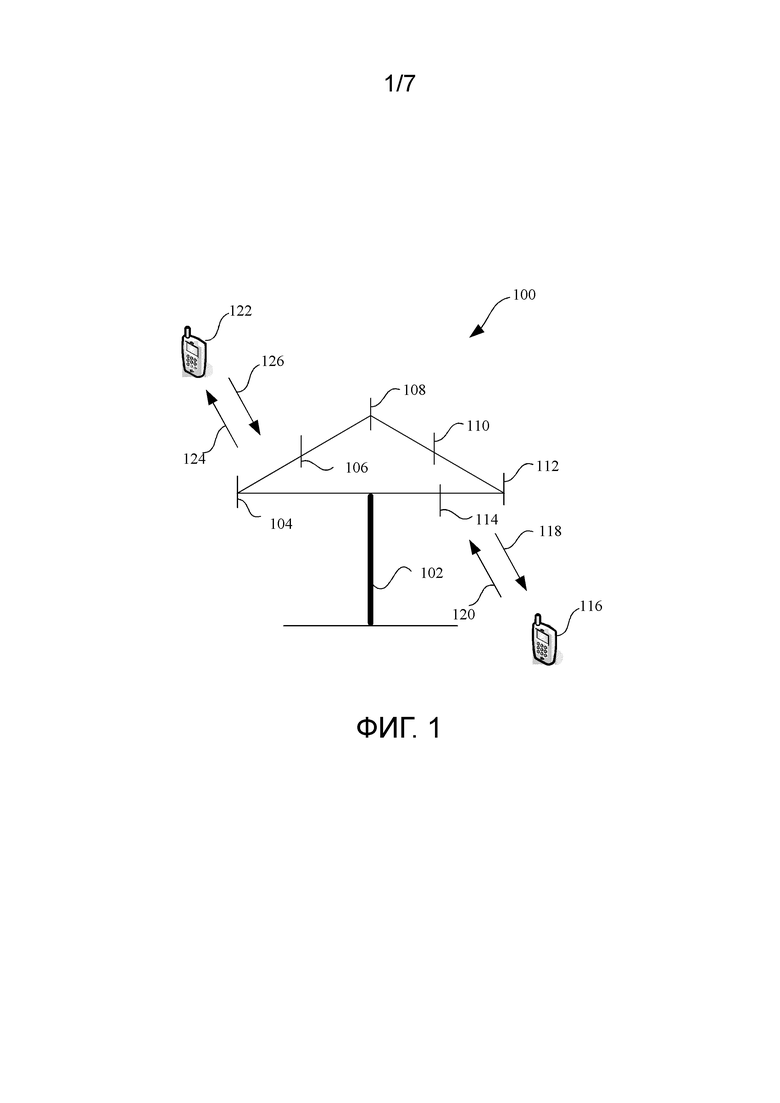
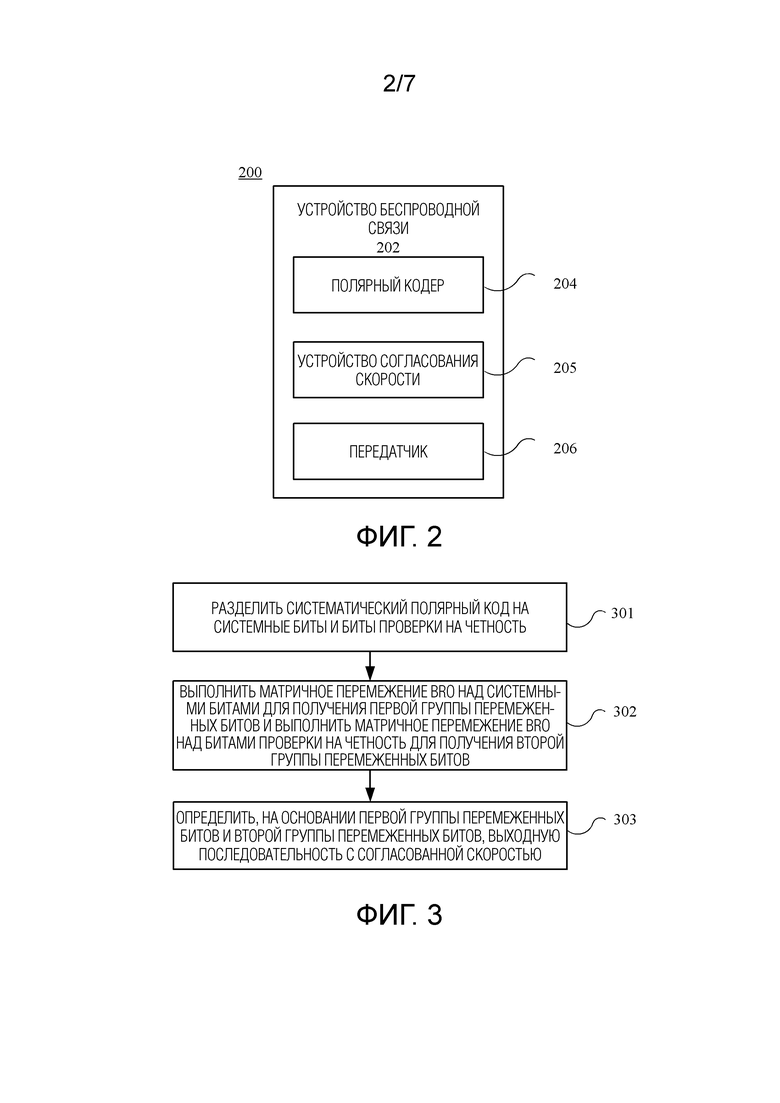
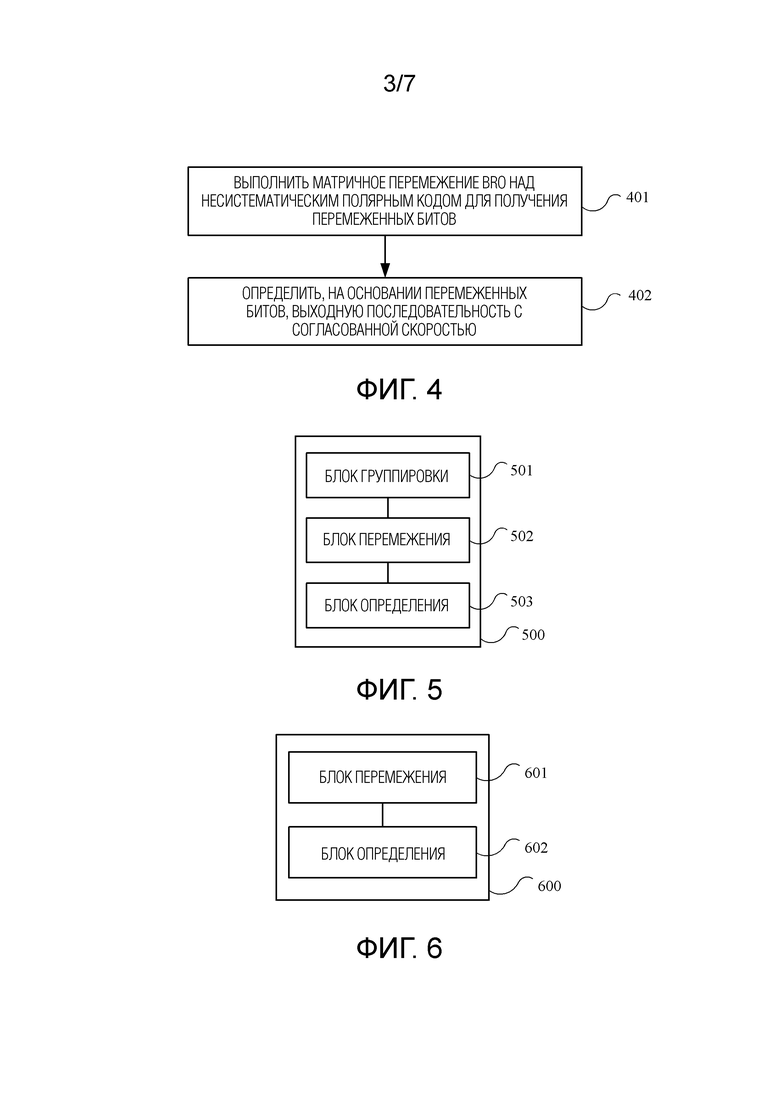
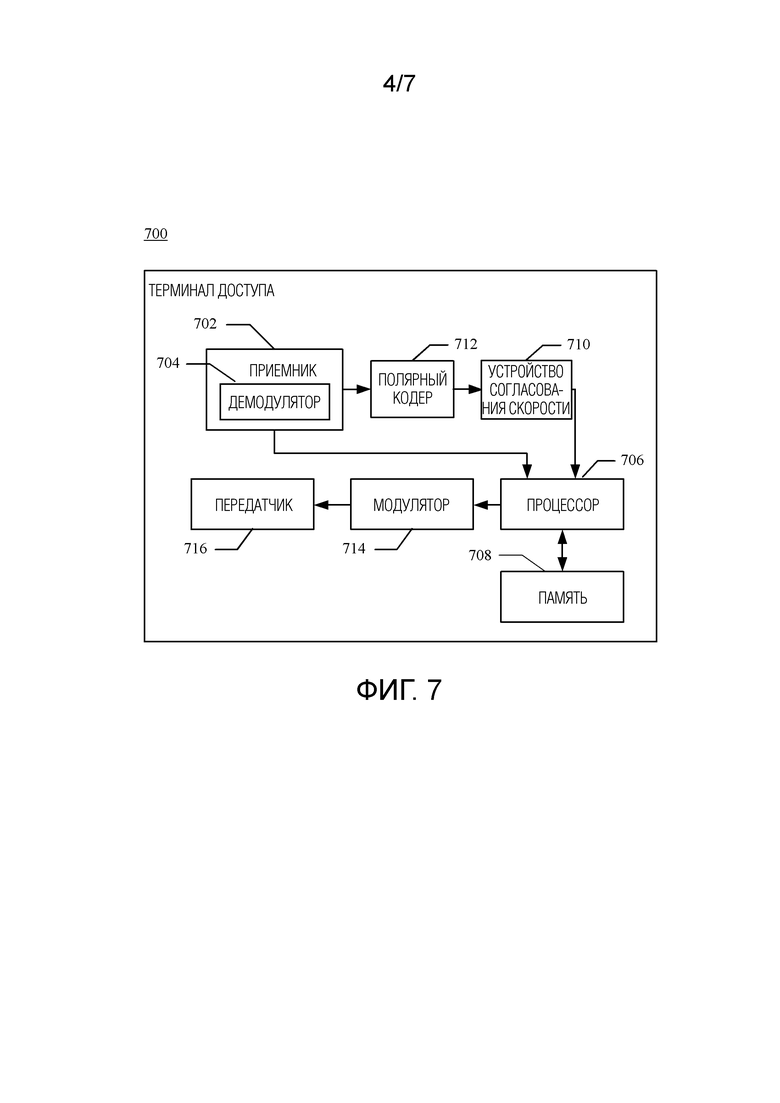
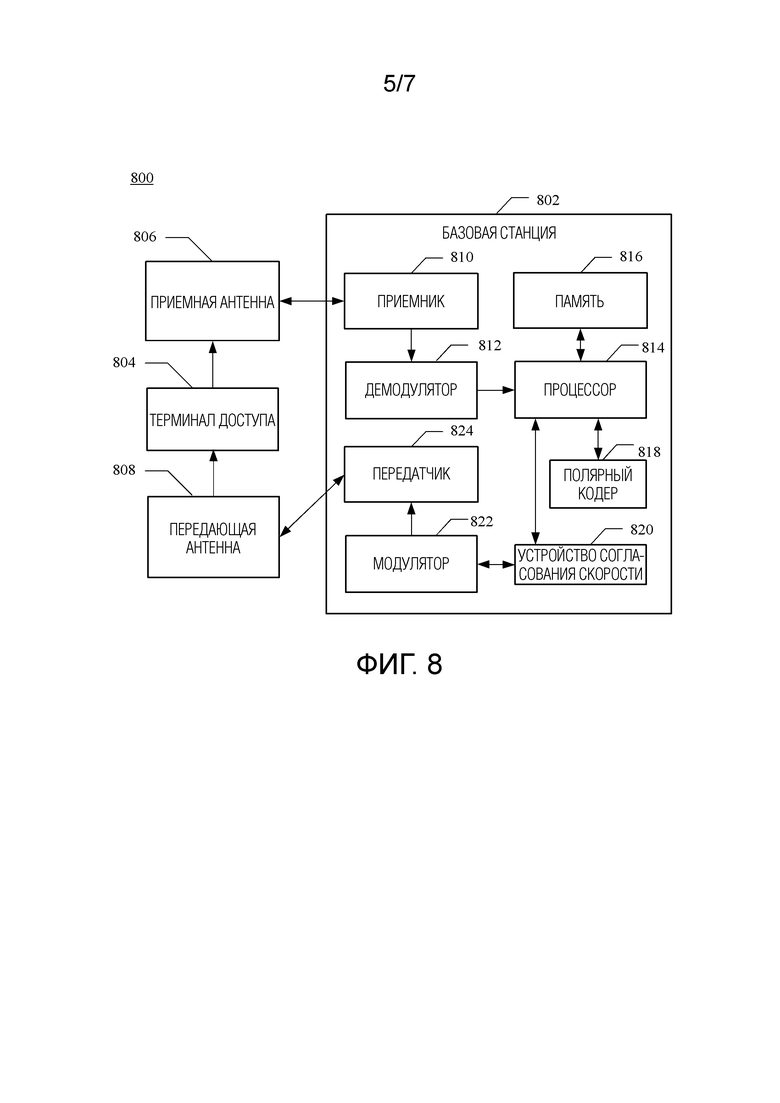
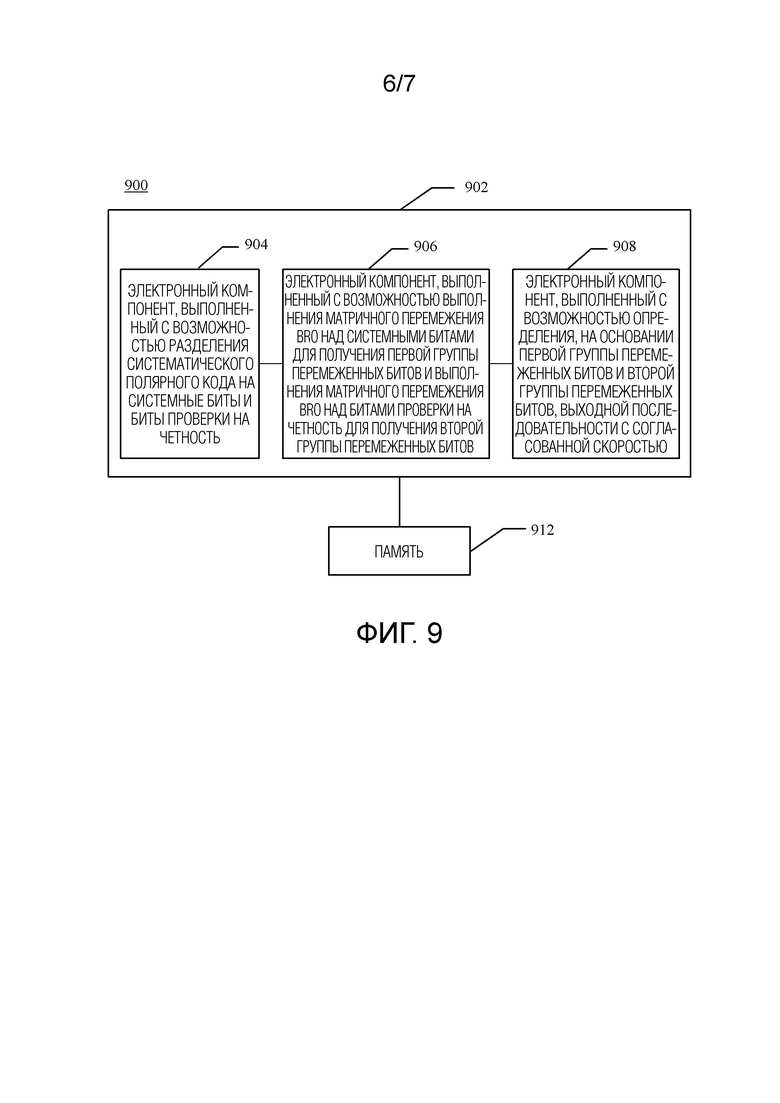
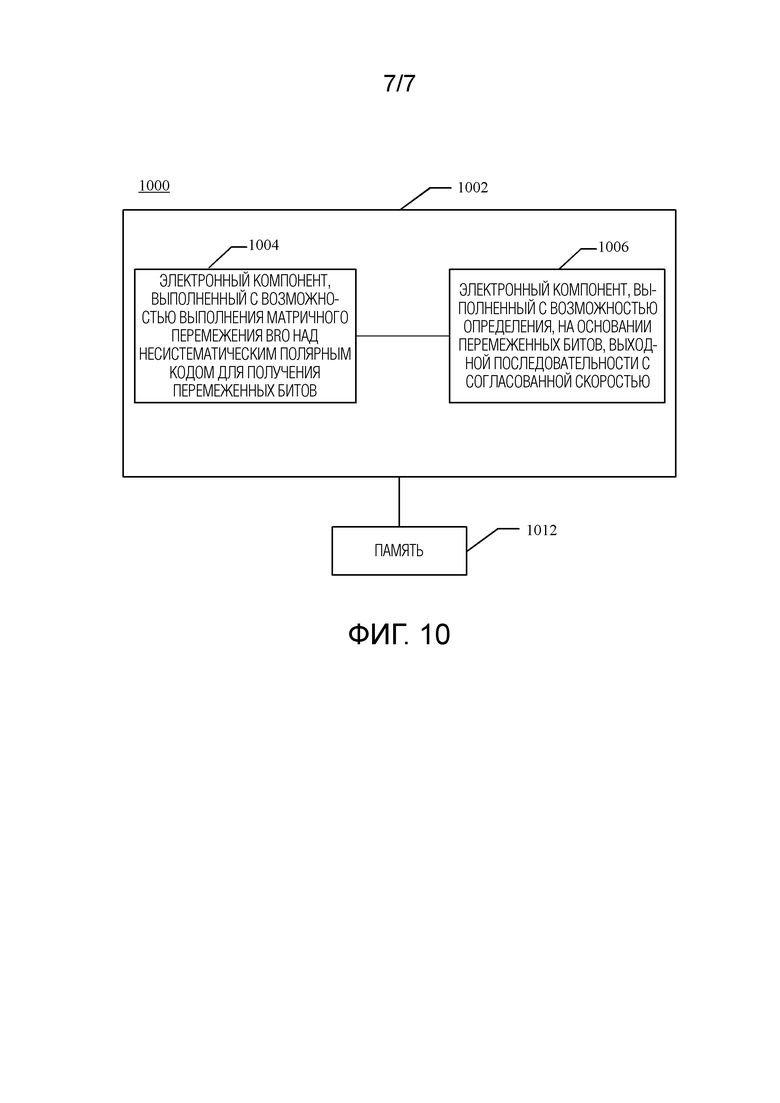
Группа изобретений относится к области кодирования и может быть использована для согласования скорости полярного кода. Техническим результатом является уменьшение частоты появления ошибок в кадре, тем самым улучшая эффективность HARQ и гарантируя надежность передачи данных. Способ включает в себя этапы, на которых: выполняют матричное перемежение с инвертированием порядка битов BRO над несистематическим полярным кодом, выводимым полярным кодером, для получения перемеженных битов и определяют, на основании перемеженных битов, выходную последовательность с согласованной скоростью. 4 н.п. ф-лы, 10 ил.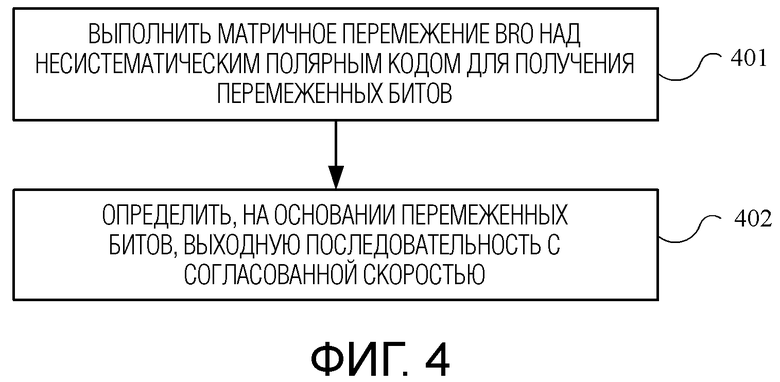
1. Способ согласования скорости полярного кода, содержащий этапы, на которых:
выполняют матричное перемежение с инвертированием порядка битов BRO над несистематическим полярным кодом, выводимым полярным кодером, для получения перемеженных битов и
определяют, на основании перемеженных битов, выходную последовательность с согласованной скоростью;
причем этап, на котором выполняют матричное перемежение BRO над несистематическим полярным кодом, выводимым полярным кодером, для получения перемеженных битов содержит этапы, на которых:
записывают биты несистематического полярного кода в строку для формирования первой матрицы M1 строк × M2 столбцов;
выполняют первую операцию замены над столбцом первой матрицы для получения второй матрицы, при этом первая операция замены является операцией BRO с размером M2;
выполняют вторую операцию замены над строкой второй матрицы для получения третьей матрицы, при этом вторая операция замены является операцией BRO с размером M1; и
считывают биты в соответствии со столбцом третьей матрицы и используют эти биты в качестве перемеженных битов; при этом
M1 и M2 являются положительными целыми числами;
или
этап, на котором выполняют матричное перемежение BRO над полярным кодом, выводимым полярным кодером, для получения перемеженных битов содержит этапы, на которых:
записывают биты несистематического полярного кода в столбец для формирования первой матрицы M1 строк × M2 столбцов;
выполняют первую операцию замены над столбцом первой матрицы для получения второй матрицы, при этом первая операция замены является операцией BRO с размером M2;
выполняют вторую операцию замены над строкой второй матрицы для получения третьей матрицы, при этом вторая операция замены является операцией BRO с размером M1; и
считывают биты в соответствии со строкой третьей матрицы и используют эти биты в качестве перемеженных битов; при этом
M1 и M2 являются положительными целыми числами.
2. Способ согласования скорости полярного кода, содержащий этапы, на которых:
разделяют систематический полярный код, выводимый полярным кодером, на системные биты и биты проверки на четность;
выполняют матричное перемежение с инвертированием порядка битов BRO над системными битами для получения первой группы перемеженных битов и выполняют матричное перемежение BRO над битами проверки на четность для получения второй группы перемеженных битов и
определяют, на основании первой группы перемеженных битов и второй группы перемеженных битов, выходную последовательность с согласованной скоростью;
причем этап, на котором выполняют матричное перемежение BRO над системными битами для получения первой группы перемеженных битов, содержит этапы, на которых:
записывают системные биты в строку для формирования первой матрицы M1 строк × M2 столбцов; выполняют первую операцию замены над столбцом первой матрицы для получения второй матрицы, при этом первая операция замены является операцией BRO с размером M2; выполняют вторую операцию замены над строкой второй матрицы для получения третьей матрицы, при этом вторая операция замены является операцией BRO с размером M1; и считывают биты в соответствии со столбцом третьей матрицы, и используют эти биты в качестве первой группы перемеженных битов или
записывают системные биты в столбец для формирования первой матрицы M1 строк × M2 столбцов; выполняют первую операцию замены над столбцом первой матрицы для получения второй матрицы, при этом первая операция замены является операцией BRO с размером M2; выполняют вторую операцию замены над строкой второй матрицы для получения третьей матрицы, при этом вторая операция замены является операцией BRO с размером M1; и считывают биты в соответствии со строкой третьей матрицы, и используют биты в качестве первой группы перемеженных битов; при этом
M1 и M2 являются положительными целыми числами;
или
этап, на котором выполняют матричное перемежение BRO над битами проверки на четность для получения второй группы перемеженных битов, содержит этапы, на которых:
записывают биты проверки на четность в строку для формирования первой матрицы M1 строк × M2 столбцов; выполняют первую операцию замены над столбцом первой матрицы для получения второй матрицы, при этом первая операция замены является операцией BRO с размером M2; выполняют вторую операцию замены над строкой второй матрицы для получения третьей матрицы, при этом вторая операция замены является операцией BRO с размером M1; и считывают биты в соответствии со столбцом третьей матрицы, и используют биты в качестве второй группы перемеженных битов или
записывают биты проверки на четность в столбец для формирования первой матрицы M1 строк × M2 столбцов; выполняют первую операцию замены над столбцом первой матрицы для получения второй матрицы, при этом первая операция замены является операцией BRO с размером M2; выполняют вторую операцию замены над строкой второй матрицы для получения третьей матрицы, при этом вторая операция замены является операцией BRO с размером M1; и считывают биты в соответствии со строкой третьей матрицы, и используют биты в качестве второй группы перемеженных битов; при этом
M1 и M2 являются положительными целыми числами.
3. Устройство согласования скорости полярного кода, содержащее:
невременную память, выполненную с возможностью хранения инструкций, используемых для выполнения следующих операций:
выполнения матричного перемежения с инвертированием порядка битов BRO над несистематическим полярным кодом, выводимым полярным кодером, для получения перемеженных битов и
определения, на основании перемеженных битов, выходной последовательности с согласованной скоростью,
процессор соединенный с памятью и выполненный с возможностью осуществлять инструкции, хранимые в памяти;
причем этап перемежения включает в себя этапы, на которых: записывают биты несистематического полярного кода в строку для формирования первой матрицы M1 строк × M2 столбцов; выполняют первую операцию замены над столбцом первой матрицы для получения второй матрицы, при этом первая операция замены является операцией BRO в M2 битов; выполняют вторую операцию замены над строкой второй матрицы для получения третьей матрицы, при этом вторая операция замены является операцией BRO в M1 битов; и считывают биты в соответствии со столбцом третьей матрицы; при этом
M1 и M2 являются положительными целыми числами;
или
этап перемежения включает в себя этапы, на которых: записывают биты несистематического полярного кода в столбец для формирования первой матрицы M1 строк × M2 столбцов; выполняют первую операцию замены над столбцом первой матрицы для получения второй матрицы, при этом первая операция замены является операцией BRO в M2 битов; выполняют вторую операцию замены над строкой второй матрицы для получения третьей матрицы, при этом вторая операция замены является операцией BRO в M1 битов; и считывают биты в соответствии со строкой третьей матрицы; при этом
M1 и M2 являются положительными целыми числами.
4. Устройство согласования скорости, содержащее невременную память, выполненную с возможностью хранения инструкций, используемых для выполнения следующих операций:
разделения систематического полярного кода, выводимого полярным кодером, на системные биты и биты проверки на четность;
выполнения матричного перемежения с инвертированием порядка битов BRO над системными битами для получения первой группы перемеженных битов и выполнения матричного перемежения BRO над битами проверки на четность для получения второй группы перемеженных битов; и
определения, на основании первой группы перемеженных битов и второй группы перемеженных битов, выходной последовательности с согласованной скоростью;
причем этап перемежения включает в себя этапы, на которых: записывают биты, которые будут перемежаться, в строку для формирования первой матрицы M1 строк × M2 столбцов; выполняют первую операцию замены над столбцом первой матрицы для получения второй матрицы, при этом первая операция замены является операцией BRO в M2 битов; выполняют вторую операцию замены над строкой второй матрицы для получения третьей матрицы, при этом вторая операция замены является операцией BRO в M1 битов; и считывают биты в соответствии со столбцом третьей матрицы; при этом
M1 и M2 являются положительными целыми числами;
или
этап перемежения включает в себя этапы, на которых:
записывают биты, которые будут перемежаться, в столбец для формирования первой матрицы M1 строк × M2 столбцов; выполняют первую операцию замены над столбцом первой матрицы для получения второй матрицы, при этом первая операция замены является операцией BRO в M2 битов; выполняют вторую замену над строкой второй матрицы для получения третьей матрицы, при этом вторая операция замены является операцией BRO в M1 битов; и считывают биты в соответствии со строкой третьей матрицы; при этом
M1 и M2 являются положительными целыми числами.
| Способ приготовления лака | 1924 |
|
SU2011A1 |
| Станок для изготовления деревянных ниточных катушек из цилиндрических, снабженных осевым отверстием, заготовок | 1923 |
|
SU2008A1 |
| Многоступенчатая активно-реактивная турбина | 1924 |
|
SU2013A1 |
| Колосоуборка | 1923 |
|
SU2009A1 |
| СПОСОБ И УСТРОЙСТВО ДЛЯ ВЫПОЛНЕНИЯ ПЕРЕДАЧИ ВОСХОДЯЩЕЙ ЛИНИИ СВЯЗИ В СИСТЕМЕ МНОЖЕСТВЕННОГО ДОСТУПА С ЧАСТОТНЫМ РАЗДЕЛЕНИЕМ С ОДНОЙ НЕСУЩЕЙ С МНОЖЕСТВОМ ВХОДОВ И МНОЖЕСТВОМ ВЫХОДОВ | 2007 |
|
RU2407177C2 |

