ПРЕДПОСЫЛКИ СОЗДАНИЯ ИЗОБРЕТЕНИЯ
[0001] Интернет является глобальной системой связи для передачи данных, которая обслуживает миллиарды пользователей по всему миру. Интернет предоставляет пользователям доступ к огромному массиву онлайновых информационных ресурсов и услуг, включая те, что предоставляются посредством Всемирной Паутины (WWW), предприятий, основанных на интрасети, и подобного. Всемирная Паутина организована в качестве совокупности web-сайтов, каждый из которых организован в качестве совокупности web-страниц. Конкретная web-страница может включать в себя широкое разнообразие онлайновой информации разных типов, такую как текст, изображения, графика, аудио и видео. В настоящее время Всемирная Паутина размещает миллиарды web-страниц, которые совокупно в настоящий момент размещают приблизительно один квинтиллион изображений и эти числа продолжают расти в быстром темпе. На сегодняшний день существует много разных поисковых машин, которые предоставляют пользователям возможность поиска требуемой онлайновой информации либо на конкретном вычислительном устройстве, либо в сети, такой как Интернет или частная сеть. Благодаря повсеместному распространению персональных вычислительных устройств разнообразных типов, которые существуют на сегодняшний день (таких как персональные компьютеры, компьютеры класса лэптоп/ноутбук, интеллектуальные телефоны и планшетные компьютеры), и повсеместному распространению Интернет, пользователи повседневно используют одну или более поисковых машин для нахождения конкретных изображений, в которых они заинтересованы.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
[0002] Это краткое изложение сущности изобретения приведено для представления в упрощенной форме подборки концепций, которые дополнительно описываются далее в подробном описании. Данная краткое изложение сущности изобретения не предназначено ни для идентификации ключевых признаков или неотъемлемых признаков заявленного изобретения, ни не для использования в качестве средства при определении объема заявленного изобретения.
[0003] Варианты осуществления инфраструктуры обзора (браузинга) изображений, описываемой в данном документе, главным образом применимы, чтобы позволить пользователю обозревать изображения, которые хранятся в хранилище информации, которое включает в себя множество изображений и текст. В одном примерном варианте осуществления изображения подготавливаются для обзора следующим образом. Применительно к каждому изображению в хранилище, выполняется интеллектуальный анализ (mining) текста в хранилище, чтобы извлечь один или более фрагментов текста об изображении, при этом каждый из этих одного или более фрагментов является семантически релевантным изображению. Затем, применительно к каждому из извлеченных фрагментов текста об изображении, в данном фрагменте обнаруживаются одно или более ключевых понятий, при этом каждое из ключевых понятий представляет собой либо концепт, который относится к изображению, либо объект, который относится к изображению, и данный фрагмент и эти одно или более ключевые понятия ассоциируются с изображением. Каждое из ключевых понятий, которое ассоциировано с каждым из изображений в хранилище, затем связывается гиперссылкой с каждым другим изображением в хранилище, которое имеет данное ключевое понятие, ассоциированное с ним.
[0004] В другом примерном варианте осуществления, где изображения и текст в хранилище информации хранятся в форме web-страниц, каждая из которых структурирована используя код Языка Гипертекстовой Разметки (HTML), хранилище интеллектуально анализируется, чтобы извлечь фрагменты текста касательно конкретного изображения в хранилище. Идентифицируются все web-страницы в хранилище, которые включают в себя это конкретное изображение. Затем генерируется список триад, при этом каждая триада соответствует разной одной из идентифицированных web-страниц и включает в себя Унифицированный Указатель Ресурса (URL) конкретного изображения, URL идентифицированной web-страницы и код HTML для идентифицированной web-страницы. Предписанное количество триад затем случайным образом выбирается из списка триад, при этом данный случайный выбор генерирует случайное подмножество триад. Затем предпринимаются следующие действия в отношении каждой из идентифицированных web-страниц в случайном подмножестве триад. Осуществляется синтаксический разбор кода HTML для идентифицированной web-страницы, дающий результатом древо разбора. Затем находят узлы изображения и узлы текста в древе разбора. Затем определяется линейное упорядочение этих узлов в идентифицированной web-странице. Затем идентифицируется один из узлов изображения, который включает в себя URL конкретного изображения, при этом данная идентификация включает в себя удаление идентифицированной web-страницы из случайного подмножества триад, всякий раз, когда либо ни один из узлов изображения не включает в себя URL конкретного изображения, либо более чем один из узлов изображения включает в себя URL конкретного изображения. Каждый из узлов текста затем разбивается на одно или более предложений, которые затем фильтруются, чтобы изъять любое предложение, которое не начинается с заглавной буквы и не заканчивается должным знаком пунктуации. Затем вычисляется расстояние в символах от каждого из отфильтрованных предложений до идентифицированного узла изображения. Затем генерируется вектор слов предложения для каждого из отфильтрованных предложений. Затем осуществляется агрегация текста, который ассоциирован с идентифицированным узлом изображения в каждой из идентифицированных web-страниц в случайном подмножестве триад, и для данного агрегированного текста генерируется вектор слов изображения. Затем предпринимаются следующие действия для каждого из отфильтрованных предложений в каждой из идентифицированных web-страниц в случайном подмножестве триад. Генерируется балл релевантности для отфильтрованного предложения, представляющий собой оценку того, насколько релевантным конкретному изображению является отфильтрованное предложение, и генерируется балл интересности для отфильтрованного предложения, представляющий собой оценку того, насколько интересным пользователю является отфильтрованное предложение. Затем генерируется общий балл для отфильтрованного изображения из этих баллов релевантности и интересности, при этом данный общий балл указывает на то, насколько релевантным и интересным является отфильтрованное предложение. Выбираются любые из отфильтрованных предложений, у которых объединенный балл релевантности и интересности выше, чем предписанное пороговое значение балла, и эти выбранные отфильтрованные предложения назначаются в качестве фрагментов текста касательно конкретного изображения.
[0005] В еще одном другом примерном варианте осуществления графический интерфейс пользователя (GUI) обзора изображений отображается на устройстве отображения, при этом GUI включает в себя сектор текущего изображения. Затем принимается запрос от пользователя на просмотр требуемого изображения в хранилище информации. Затем требуемое изображение отображается внутри сектора текущего изображения, и один или более активных участков отображаются сверху требуемого изображения, при этом каждый из активных участков связан гиперссылкой с разным фрагментом текста о требуемом изображении, который является семантически релевантным требуемому изображению и включает в себя одно или более ключевых понятий, причем каждое из ключевых понятий представляет собой либо концепт, который относится к требуемому изображению, либо объект, который относится к требуемому изображению, и каждое из ключевых понятий связано гиперссылкой с каждый другим изображением в хранилище, которое имеет данное ключевое понятие, ассоциированное с ним.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[0006] Конкретные признаки, аспекты и преимущества вариантов осуществления инфраструктуры обзора изображений, описываемых в данном документе, станут более понятны с учетом следующего описания, прилагаемой формулы изобретения, и сопроводительных чертежей, где:
[0007] Фиг. 1 является блок-схемой, иллюстрирующей примерный вариант осуществления, в упрощенной форме, процесса для подготовки изображений, которые хранятся в хранилище информации, для обзора.
[0008] Фиг. 2 является блок-схемой, иллюстрирующей примерный вариант осуществления, в упрощенной форме, процесса для интеллектуального анализа текста в хранилище информации, чтобы извлечь один или более фрагменты текста касательно заданного изображения в хранилище.
[0009] Фиг. 3A и 3B являются блок-схемами, иллюстрирующими примерный вариант осуществления, в упрощенной форме, процесса для извлечения законченных предложений из web-страниц в хранилище информации, которые идентифицированы как включающие изображение, и вычисления объединенного бала релевантности и интересности для каждого из извлеченных законченных предложений.
[0010] Фиг. 4 является блок-схемой, иллюстрирующей примерный вариант осуществления, в упрощенной форме, процесса для выбора любого из извлеченных законченных предложений, у которого объединенный балл релевантности и интересности больше чем предписанное пороговое значение балла.
[0011] Фиг. 5 является блок-схемой, иллюстрирующей примерный вариант осуществления, в упрощенной форме, процесса для фильтрации сортированного списка извлеченных законченных предложений с наивысшими баллами.
[0012] Фиг. 6 является блок-схемой, иллюстрирующей примерный вариант осуществления, в упрощенной форме, процесса для обеспечения пользователю возможности обозревать подготовленные изображения.
[0013] Фиг. 7-15 являются схемами, иллюстрирующими примерный вариант осуществления, в упрощенной форме, обобщенной компоновки для графического интерфейса пользователя (GUI), который позволяет пользователю семантически обозревать изображения, которые хранятся в хранилище информации.
[0014] Фиг. 16 является схемой, иллюстрирующей упрощенный пример компьютерной системы общего назначения на которой могут быть реализованы, как описано в данном документе, различные варианты осуществления и элементы инфраструктуры обзора изображений.
[0015] Фиг. 17 является схемой, иллюстрирующей альтернативный вариант осуществления, в упрощенной форме, обобщенной компоновки для GUI, который позволяет пользователю семантически обозревать изображения, которые хранятся в хранилище информации.
ПОДРОБНОЕ ОПИСАНИЕ
[0016] В нижеследующем описании вариантов осуществления инфраструктуры обзора изображений делается отсылка к сопроводительным чертежам, которые формируют его часть и на которых показаны, в качестве иллюстрации, конкретные варианты осуществления, в которых может быть реализована на практике инфраструктура обзора изображений. Следует понимать, что другие варианты осуществления могут быть использованы и структурные изменения могут быть выполнены, не отступая от объема вариантов осуществления инфраструктуры обзора изображений.
[0017] Также следует отметить, что для большей ясности, будет использоваться конкретная терминология при описании вариантов осуществления инфраструктуры обзора изображений, описываемой в данном документе, и применительно к этим вариантам осуществления не предполагается, что они ограничиваются конкретными так выбранными понятиями. Кроме того, следует понимать, что каждое конкретное понятие включает в себя все его технические эквиваленты, которые работают подобным образом в широком смысле, чтобы достигать подобной цели. Ссылка в данном документе на «один вариант осуществления» или «другой вариант осуществления», или «примерный вариант осуществления», или «альтернативный вариант осуществления», или «одну реализацию», или «другую реализацию», или «примерную реализацию», или «альтернативную реализацию» означает, что конкретный признак, конкретная структура, или конкретные характеристики, описанные в связи с вариантом осуществления или реализацией, могут быть включены в, по меньшей мере, один вариант осуществления инфраструктуры обзора изображений. Появления фраз «в одном варианте осуществления», «в другом варианте осуществления», «в примерном варианте осуществления», «в альтернативном варианте осуществления», «в одной реализации», «в другой реализации», «в примерной реализации», и «в альтернативной реализации» в различных местах в техническом описании как не обязательно все относятся к одному и тому же варианту осуществления или реализации, так и не являются отдельными или альтернативными вариантами осуществления/реализациями взаимоисключающими другие варианты осуществления/реализации. Еще кроме того, очередность потока процесса, представляющего собой один или более варианты осуществления или реализации инфраструктуры обзора изображений, как по существу не указывает какой-либо конкретной очередности, так и не предполагает каких-либо ограничений инфраструктуры обзора изображений.
[0018] Понятие «изображение» используется в данном документе для обозначения цифрового изображения, которое может быть просмотрено на компьютерном устройство отображения (таком как компьютерный монитор, среди прочего). Понятие «пользователь» используется в данном документе для обозначения индивидуума, который является использующим компьютер (в данном документе также именуемый вычислительным устройством) для обзора изображений. Понятие «сектор» используется в данном документе для обозначения сегментированной области экрана отображения компьютерного устройства отображения, в которой может быть отображен конкретный тип графического интерфейса пользователя (GUI) и/или информация (такая как одно или более изображения и текст, среди прочего), или конкретный тип действия может выполняться пользователем, при этом GUI/информация/действие в целом ассоциированы с конкретной прикладной программой, которая работает на компьютере. Как понятно в области компьютерных рабочих сред, заданное компьютерное устройство отображения может включать в себя множество разных секторов, которые могут быть расположены по слоям или накладываться один поверх другого.
1.0 Обзор изображений через интеллектуально проанализированные связанные гиперссылкой фрагменты текста
[0019] Вообще говоря, варианты осуществления инфраструктуры обзора изображений, описываемой в данном документе, подготавливают изображения для обзора, при этом изображения хранятся в хранилище информации, которое включает в себя множество изображений и текст. Как только изображения подготовлены для обзора, варианты осуществления инфраструктуры обзора изображений также позволяют пользователю обозревать изображения семантически значимым образом. В примерном варианте осуществления инфраструктуры обзора изображений, описываемой в данном документе, хранилищем информации является Всемирная Паутина (далее просто именуемая Web) и изображения и текст в хранилище хранятся в форме web-страниц, каждая из которых структурирована, используя код Языка Гипертекстовой Разметки (HTML). Тем не менее, следует понимать, что также возможны альтернативные варианты осуществления инфраструктуры обзора изображений, где хранилище информации может быть любым другим типом механизма базы данных, который хранит изображения и текст, а также может хранить другие типы информации, при этом данный механизм базы данных может быть либо распределенным, либо централизованным.
[0020] Варианты осуществления инфраструктуры обзора изображений, описываемой в данном документе, являются преимущественными по различным причинам, включая, но не ограничиваясь, следующие. Как будет понятно из более подробного описания, которое следует ниже, варианты осуществления инфраструктуры обзора изображений предоставляют пользователю, который осуществляет поиск изображений (например, пользователю, который является использующим поисковую машину для осуществления поиска изображения в Web), семантически интересную текстовую информацию касательно изображений, которые просматриваются пользователем. Варианты осуществления инфраструктуры обзора изображений также предлагают другие семантически-связанные изображения пользователю для просмотра. Варианты осуществления инфраструктуры обзора изображений также позволяют пользователю осуществлять семантический обзор изображений в Web (например, пользователь может переходить от одного изображения к следующему семантически значимым образом). Варианты осуществления инфраструктуры обзора изображений также предоставляют пользователю интерфейс пользователя, который является интуитивным и простым в использовании. Таким образом варианты осуществления инфраструктуры обзора изображений оптимизируют результативность и эффективность процесса поиска изображения, и сокращают количество времени, которое требуется пользователю чтобы найти конкретные изображения, которые отвечают их интересам, или удовлетворяют их потребности, или обучают их, или развлекают их, или обеспечивают любое их сочетание.
1.1 ИНФРАСТРУКТУРА ПРОЦЕССА
[0021] Фиг. 1 иллюстрирует примерный вариант осуществления, в упрощенной форме, процесса для подготовки изображений, которые хранятся в хранилище информации, для обзора, при этом хранилище включает в себя множество изображений и текст. Как описано прежде, в примерном варианте осуществления инфраструктуры обзора изображений, описываемой в данном документе, хранилище информации является Web и изображения и текст в хранилище хранятся в форме web-страниц, каждая из которых структурирована используя код HTML. Как приведено в качестве примера на Фиг. 1, процесс начинается в блоке 100 со следующими действиями, предпринимаемыми в отношении каждого из изображений в хранилище. Текст в хранилище интеллектуально анализируется, чтобы извлечь один или более фрагменты текста об изображении, при этом каждый из этих одного или более фрагментов является семантически релевантным изображению и также является семантически интересным пользователю, который читаем фрагмент (блок 102). Это является преимуществом, так как часто полагается, что пользователь либо развлекается, либо обучается, когда они осуществляют обзор изображений, которые хранятся в хранилище. Следующие действия предпринимаются в отношении каждого из извлеченных фрагментов текста об изображении (блок 104). Одно или более ключевые понятия обнаруживаются в извлеченном фрагменте текста об изображении, при этом каждое из извлеченных ключевых понятий представляет собой либо семантически значимый концепт, который относится к изображению, либо семантически значимый объект, который относится к изображению (блок 106). Извлеченный фрагмент текста об изображении и одно или более ключевые понятия, которые обнаружены в данном фрагменте, затем ассоциируются с изображением (блок 108). После того как завершены действия блока 100, каждое из ключевых понятий, которое ассоциировано с каждым из изображений в хранилище, связывается гиперссылкой с каждым другим изображением в хранилище, которое имеет данное ключевое понятие, ассоциированное с ним (блок 110). В примерном варианте осуществления инфраструктуры обзора изображений данное связывание гиперссылкой ключевых понятий с другими изображениями реализуется, используя структуру данных инвертированного индекса.
[0022] Следует иметь в виду, что только что описанный интеллектуальный анализ текста в хранилище информации, чтобы извлечь один или более фрагменты текста касательно каждого из изображений в хранилище, может быть выполнен, используя различные способы интеллектуального анализа данных. Примерный вариант осуществления одного такого способа интеллектуального анализа данных более подробно описывается далее. Также следует иметь в виду, что только что описанное обнаружение ключевого понятия может быть выполнено, используя различные традиционные способы. В качестве примера, а не ограничения, в примерном варианте осуществления инфраструктуры обзора изображений, описываемой в данном документе, ключевые понятия являются названиями статей и их вариантами в Wikipedia, и только что описанное обнаружение ключевого понятия выполняется, используя традиционный способ вычисления семантической связанности, который использует основанный на Wikipedia явный семантический анализ. По существу, и как будет понятно из более подробного описания, которое следует, только что описанное связывание гиперссылкой ключевых понятий с изображениями в хранилище основано на измерении связанности ключевых понятий с изображениями.
[0023] Фиг. 2 иллюстрирует примерный вариант осуществления, в упрощенной форме, процесса для интеллектуального анализа текста в хранилище информации, чтобы извлечь один или более фрагменты текста касательно заданного изображения в хранилище. Конкретный вариант осуществления способа интеллектуального анализа данных, приведенный в качестве примера на Фиг. 2, применяется к вышеупомянутому варианту осуществления инфраструктуры обзора изображений, описываемомой в данном документе, при этом хранилище информации является Web, а изображения и текст в хранилище хранятся в форме web-страниц, каждая из которых структурирована, используя код HTML. Как приведено в качестве примера на Фиг. 2, процесс начинается в блоке 200 с идентификации всех web-страниц в хранилище, которые включают изображение. Затем законченные предложения извлекаются из идентифицированных web-страниц и объединенный балл релевантности и интересности вычисляется для каждого из извлеченных законченных предложений (блок 202). Затем выбираются любые из извлеченных законченных предложений (например, любое из отфильтрованных предложений), у которого объединенный балл релевантности и интересности выше, чем предписанное пороговое значение балла (блок 204). Эти выбранные предложения затем назначаются в качестве извлеченных фрагментов текста об изображении (блок 206).
[0024] Фиг. 3A и 3B иллюстрируют примерный вариант осуществления, в упрощенной форме, процесса для извлечения законченных предложений из web-страниц в хранилище информации, которые идентифицированы как включающие заданное изображение, и вычисления объединенного балла релевантности и интересности для каждого из извлеченных законченных предложений. Как приведено в качестве примера на Фиг. 3A, процесс начинается в блоке 300 с генерирования списка триад, при этом каждая триада в списке соответствует разной одной из идентифицированных web-страниц и включает в себя Унифицированный Указатель Ресурса (URL) изображения, URL идентифицированной web-страницы и код HTML для идентифицированной web-страницы. Список триад опционально затем может быть отфильтрован, чтобы изъять любую триаду, у которой идентифицированная web-страница размещается в определенных доменах web-сайта (блок 302). В примерном варианте осуществления инфраструктуры обзора изображений, описываемой в данном документе, данная фильтрация выполняется по URL идентифицированных web-страниц, и домены web-сайта, которые отфильтровываются, включают в себя web-сайты социальных сетей, web-сайты обмена фотографиями, и определенные коммерческие web-сайты. Следует иметь в виду, что домены web-сайта, которые отфильтровываются, могут быть модифицированы на основе заданных требований поисковой машины. Данная фильтрация может опционально также включать в себя один или более другие типы фильтрации web-страниц, включая, но не ограничиваясь, следующие. Список триад может быть отфильтрован, чтобы изъять любую триаду, у которой идентифицированная web-страница составлена не на одном или более предписанных языках (например, список триад может быть отфильтрован, чтобы изъять любые страницы на не английском языке). Список триад также может быть отфильтрован, чтобы изъять любую триаду, у которой идентифицированная web-страница включает в себя определенные типы контента, такой как контент для взрослых (например, непристойный), среди прочих типов контента.
[0025] Вновь обращаясь к Фиг. 3A, после того как список триад отфильтрован (блок 302), затем предписанное количество триад случайным образом выбирается из отфильтрованного списка триад, при этом данный случайный выбор генерирует случайное подмножество триад (блок 304). В примерном варианте осуществления инфраструктуры обзора изображений данное предписанное количество составляет 200. Следует иметь в виду, что данный случайный выбор триад просто задает максимум для количества требуемых для обработки идентифицированных web-страниц применительно к изображению, и, следовательно, служит, чтобы ограничить обработку, которая выполняется для очень распространенных изображений (многие из которых являются неинтересными, такими как пиктограммы компании и подобное). Следует иметь в виду, что в случаях, где количество триад в отфильтрованном списке меньше, чем предписанное количество, выбираются все из триад в отфильтрованном списке.
[0026] Вновь обращаясь к Фиг. 3A, после того, как сгенерировано случайное подмножество триад (блок 304), затем предпринимаются следующие действия применительно к каждой из идентифицированных web-страниц в случайном подмножестве триад (блок 306). Применительно к идентифицированным web-страницам разбирается код HTML, что дает результатом древо разбора, находят узлы изображения и узлы текста в древе разбора, и определяется линейное упорядочение этих узлов в идентифицированных web-страницах (блок 308). В случае, где код HTML для заданной web-страницы не может быть разобран, web-страница может быть просто удалена из случайного подмножества триад. Затем идентифицируется один из узлов изображения, который включает в себя URL изображения (блок 310), при этом данная идентификация включает в себя удаление идентифицированной web-страницы из случайного подмножества триад всякий раз, когда либо ни один из узлов изображения не включает в себя URL изображения (что может произойти, если идентифицированная web-страница изменилась с момента вышеупомянутой агрегации кода HTML), либо более чем один из узлов изображения включает в себя URL изображения (что может произойти, если идентифицированная web-страница ссылается на изображение множество раз). Каждый из узлов текста затем разбивается на одно или более предложения (блок 312), которые затем фильтруются, чтобы изъять любое предложение, которое не начинается с заглавной буквы и не заканчивается должным знаком пунктуации (блок 314). Данная фильтрация, следовательно, гарантирует то, что предложения являются законченными предложениями (например, отбрасываются любые фрагменты предложения). Затем вычисляется расстояние в символах от каждого из отфильтрованных предложений до идентифицированного узла изображения (блок 316), при этом данному расстоянию символов задается один знак (например, он принимается положительным), когда предложение появляется после идентифицированного узла изображения, и данному расстоянию символов задается противоположный знак (например, он принимается отрицательным), когда предложение появляется перед идентифицированным узлом изображения. Затем генерируется вектор слов предложения для каждого из отфильтрованных предложений (блок 318), при этом стоповые слова исключаются из вектора слов предложения и выполняется морфологический поиск.
[0027] Следует иметь в виду, что только что описанный синтаксический разбор кода HTML (блок 308) может быть выполнен различными способами. В качестве примера, а не ограничения, в примерном варианте осуществления инфраструктуры обзора изображений, описываемой в данном документе, данный разбор выполняется, используя традиционный синтаксический анализатор HTML. Следует иметь в виду, что только что описанная идентификация узла изображения (блок 310) может быть выполнена различными способами. В качестве примера, а не ограничения, в примерном варианте осуществления инфраструктуры обзора изображений данная идентификация выполняется, используя разнообразие нормировок для обработки строк. Также следует иметь в виду, что только что описанное разбиение предложения (блок 312) может быть выполнено, используя различные традиционные способы.
[0028] Вновь обращаясь к Фиг. 3A, после того как завершены действия блока 306, осуществляется агрегация текста, который ассоциирован с идентифицированным узлом изображения в каждой из идентифицированных web-страниц в случайном подмножестве триад (блок 320). Затем для данного агрегированного текста генерируется вектор слов изображения (блок 322). Следует иметь в виду, что данный вектор слов изображения служит в качестве общей модели контента изображения. Как приведено в качестве примера на Фиг. 3B, затем предпринимаются следующие действия применительно к каждому из отфильтрованных предложений в каждой из идентифицированных web-страниц в случайном подмножестве триад (блок 324). Генерируется балл релевантности для отфильтрованного предложения (блок 326), при этом данный балл релевантности представляет собой оценку того, насколько семантически релевантным изображению является отфильтрованное предложение. Затем генерируется балл интересности для отфильтрованного предложения (блок 328), при этом данный балл интересности представляет собой оценку того, насколько отфильтрованное предложение является семантически интересным для пользователя. Затем генерируется общий балл для отфильтрованного предложения из этих баллов релевантности и интересности, при этом данный общий балл указывает то, насколько релевантным и интересным является отфильтрованное предложение (блок 330). В примерном варианте осуществления инфраструктуры обзора изображений, описываемой в данном документе, общий балл равен баллу релевантности умноженному на балл интересности. Соответственно и как будет понятно из более подробного описания, которое следует, высокий общий балл указывает на то, что отфильтрованное предложение является как релевантным, так и интересным, а низкий общий балл указывает на то, что отфильтрованное предложение является как не релевантным, так и не интересным.
[0029] В примерном варианте осуществления инфраструктуры обзора изображений, описываемой в данном документе, оба балла релевантности и интересности для каждого из отфильтрованных предложений генерируются, используя обученную функцию регрессии, которая основана на вычислении разных признаков отфильтрованного предложений. В примерном варианте осуществления инфраструктуры обзора изображений, описываемой в данном документе, обученная функция регрессии использует упорядоченную линейную регрессию и данные обучения, которые были получены, используя Amazon Mechanical Turk (MTurk). В частности, пользователей MTurk попросили выставить балл релевантности и интересности большому количеству предложений по шкале от 0,0 до 3,0, при этом 0,0 соответствует тому, что заданное предложение является не релевантным/интересным, а 3,0 соответствует тому, что предложение является весьма релевантным/интересным. Следует иметь в виду, что широкий диапазон разных признаков каждого из отфильтрованных предложений может быть вычислен. В примерном варианте осуществления инфраструктуры обзора изображений эти признаки включали, но не были ограничены, признак терма данных, различные признаки контекста, признак дублирования, признак расстояния, и различные лингвистические признаки. Каждый из этих признаков теперь будет описан более подробно.
[0030] Вычисление признака терма данных заданного отфильтрованного предложения влечет собой вычисление балла совпадения между вектором слов предложения для отфильтрованного предложения и вектором слов изображения. В примерном варианте осуществления инфраструктуры обзора изображений, описываемой в данном документе, данный балл совпадения вычисляется следующим образом. Сначала вектор слов изображения нормируется до единичного вектора. Затем вычисляется скалярное произведение нормированного вектора слов изображения и вектора слов для предложения. Затем опционально предписанное максимальное значение может быть наложено на данное скалярное произведение для того, чтобы избежать чрезмерно доминирующих предложений с большой величиной наложения.
[0031] Признаки контекста являются, по существу, контекстуальными расширениями признака терма данных. В примерном варианте осуществления инфраструктуры обзора изображений, описываемой в данном документе, два разных признака контекста вычисляются для каждого из отфильтрованных предложений, а именно признак локального контекста и признак контекста страницы. Вычисление признака локального контекста влечет собой усреднение признака терма данных через локальное окно вокруг отфильтрованного предложения. Интуитивное представление в основе признака локального контекста состоит в том, что заданное отфильтрованное предложение с большей вероятностью является семантически релевантным изображению и семантически интересным пользователю, если другие отфильтрованные предложения вокруг заданного отфильтрованного предложения также являются семантически релевантными изображению и семантически интересными пользователю. Вычисление признака контекста страницы влечет собой усреднение признака терма данных через расширенное окно, которое больше, чем локальное окно (например, в примерном варианте осуществления инфраструктуры обзора изображений расширенное окно охватывает всю идентифицированную web-страницу из которой было извлечено отфильтрованное предложение). Предписанное максимальное значение может быть опционально наложено на каждый вычисленный признак контекста для того, чтобы избежать чрезмерно доминирующих предложений с большой величиной наложения.
[0032] Вычисление признака дублирования для заданного отфильтрованного предложения влечет собой вычисление наложения между заданным отфильтрованным предложением и другими отфильтрованными предложениями, которые находятся внутри предписанного расстояния от заданного отфильтрованного предложения в идентифицированной web-странице, из которой данное предложение было извлечено. Интуитивное представление в основе признака дублирования состоит в том, что большой объем дублирования часто указывает на спамо-подобный контент. Вычисление признака расстояния для заданного отфильтрованного предложения влечет собой вычисление расстояния, измеренного в символах, между отфильтрованным предложением и изображением в идентифицированной web-странице, из которой данное предложение было извлечено. Верхние и нижние границы могут быть опционально наложены на данное вычисленное расстояние, чтобы избежать крайних случаев. Интуитивное представление в основе признака расстояния состоит в том, что предложения, которые находятся близко к изображению более вероятно являются релевантными изображению. Могут быть вычислены различные лингвистические признаки заданного отфильтрованного предложения, включая, но не ограничиваясь, любой один или более из следующих. Может быть вычислена длина отфильтрованного предложения (например, количество слов в отфильтрованном предложении). Следует иметь в виду, что более длинные предложения, как правило, более интересны пользователю, чем более короткие предложения. Могут быть вычислены различные булевы признаки отфильтрованного предложения, такие как начинается или нет отфильтрованное предложение с указательного местоимения, является или нет отфильтрованное предложение определительным, и начинается или нет отфильтрованное предложение с местоимения первого лица (например, Я или Мы), среди прочих булевых признаков.
[0033] Фиг. 4 иллюстрирует примерный вариант осуществления, в упрощенной форме, процесса для выбора любых из извлеченных законченных предложений, у которых объединенный балл релевантности и интересности больше, чем предписанное пороговое значение балла. Как приведено в качестве примера на Фиг. 4, процесс начинается в блоке 400 со следующих действий, которые предпринимаются применительно к каждой из идентифицированных web-страниц в вышеупомянутом случайном подмножестве триад. Отфильтрованные предложения из идентифицированной web-страницы сортируются по их общим баллам (блок 402). Затем выбирается предписанное количество отфильтрованных предложений с наивысшим баллом (блок 404), при этом данный выбор исключает любые пары из отфильтрованных предложений с наложением слов, которое больше чем предписанный процент. В примерном варианте осуществления инфраструктуры обзора изображений, описываемой в данном документе, данное предписанное количество равно трем и данный предписанный процент равен 85%. Следует иметь в виду, что данное исключение любой пары из отфильтрованных предложений с наложением слов, которое больше чем 85%, служит чтобы исключить любые пары с наивысшим баллом из отфильтрованных предложений, которые являются почти идентичными. После того как завершены действия блока 400, осуществляется слияние всех из выбранных отфильтрованных предложений с наивысшим баллом из всех идентифицированных web-страниц в случайном подмножестве триад в список предложений с наивысшим баллом, и данный список сортируется по общим баллам этих предложений (блок 406). Отсортированный список предложений с наивысшим баллом затем фильтруется для того, чтобы гарантировать высокий уровень качества предложения (блок 408). Примерные операции фильтрации описываются более подробно далее. Отфильтрованный отсортированный список предложений с наивысшим баллом затем выводится наряду с общим баллом для каждого из предложений в данном списке и URL идентифицированной web-страницы, из которой предложение было извлечено (блок 408).
[0034] Фиг. 5 иллюстрирует примерный вариант осуществления, в упрощенной форме, процесса для фильтрации сортированного списка предложений с наивысшим баллом. Как приведено в качестве примера на Фиг. 5, процесс начинается в блоке 500 с фильтрации сортированного списка, чтобы изъять любые предложения в данном списке, у которых общий балл меньше или равен вышеупомянутому предписанному пороговому значению балла. В вышеупомянутом примерном варианте осуществления инфраструктуры обзора изображений, описываемой в данном документе, где баллы релевантности и интересности предложений выставляются по шкале от 0,0 до 3,0., и балл в размере 3,0. соответствует предложению, которое является весьма релевантным/интересным, предписанным пороговым значением балла является 2,75. Затем максимум может быть также опционально задан для количества предложений в сортированном списке (блок 502). В частности, в примерном варианте осуществления инфраструктуры обзора изображений лишь 20 предложений с наивысшим баллом выбираются из сортированного списка. Затем предложения, оставшиеся в сортированном списке, группируются в подмножества из предложений, которые почти дублируют друг друга (например, наложение слов между каждым из предложений в заданном подмножестве находится выше предписанного порогового значения наложения) (блок 504). Всякий раз, когда удовлетворяется набор условий качества (блок 506, Да), предложения, оставшиеся в сортированном списке, назначаются в качестве отфильтрованного сортированного списка предложений с наивысшим баллом (блок 508). Всякий раз, когда не удовлетворяется набор условий качества (блок 506, Нет), все из предложений, оставшиеся в сортированном списке, изымаются из него так, что пустой список назначается в качестве отфильтрованного сортированного списка предложений с наивысшим баллом (блок 510).
[0035] В примерном варианте осуществления инфраструктуры обзора изображений, описываемой в данном документе, только что описанный набор условий качества включает в себя следующие три условия. Должно быть, по меньшей мере, первое предписанное количество предложений, оставшихся в сортированном списке предложений с наивысшим балом. Предложения, оставшиеся в сортированном списке, должны исходить из, по меньшей мере, второго предписанного количества разных идентифицированных web-страниц. Процент предложений, оставшихся в сортированном списке, которые почти дублируют другое предложение в сортированном списке, должен быть меньше, чем предписанный процент. В примерной реализации данного варианта осуществления первое предписанное количество равно трем, второе предписанное количество равно двум, и предписанный процент равен 40%.
[0036] Как будет понятно из более подробного описания, которое следует, каждое из ключевых понятий, которое обнаруживается в каждом из извлеченных фрагментов текста касательно каждого из изображений в хранилище информации, является либо ключевым словом, либо ключевой фразой (например, последовательностью из двух или более слов, которые формируют составляющую и поэтому функционируют в качестве единого целого). Вновь обращаясь к Фиг. 1, ассоциация между фрагментами текста и изображениями, которая создана в действие блока 108, позволяет поисковой машине осуществлять доступ к каждому из фрагментов текста касательно каждого из изображений в хранилище. Ассоциация между ключевыми понятиями и изображениями, которая также создается в действие блока 108, позволяет поисковой машине также осуществлять доступ к каждому из ключевых понятий, которое обнаружено в каждом из фрагментов текста касательно каждого из изображений в хранилище. Эти ассоциации фрагмент/изображение и ключевое понятие/изображение также позволяют отображать извлеченные фрагменты текста касательно заданного изображения, и ключевые понятия, которые обнаружены в каждом из этих фрагментов текста, пользователю, когда они просматривают изображение. В примерном варианте осуществления инфраструктуры обзора изображений, описываемой в данном документе, где хранилище включает в себя метаданные для каждого из изображений, которое хранится в хранилище, действие блока 108 может быть реализовано следующим образом. Для каждого из изображений в хранилище, каждый из извлеченных фрагментов текста об изображении и одно или более ключевые понятия, которые обнаружены в нем, добавляются в метаданные для изображения.
[0037] Фиг. 6 иллюстрирует примерный вариант осуществления, в упрощенной форме, процесса для обеспечения пользователю возможности обозревать изображения, которые хранятся в хранилище информации. Вариант осуществления процесса, приведенный в качестве примера на Фиг. 6, предполагает, что изображения, которые хранятся в хранилище, уже были подготовлены для обзора, как описано прежде. Как представлено в качестве примера на Фиг. 6, процесс начинается в блоке 600 с отображения GUI обзора изображений на устройстве отображения компьютера, который пользователь использует для обзора изображений. Как будет описано более подробно далее, GUI включает в себя сектор текущего изображения, и опционально также может включать в себя сектор ключевых понятий и сектор истории изображений. Как только пользователь генерирует запрос на просмотр требуемого изображения в хранилище, данный запрос принимается (блок 602), и требуемое изображение отображается внутри сектора текущего изображения (блок 604). Один или более активные участки затем отображаются сверху требуемого изображения, при этом каждый из активных участков связан гиперссылкой с разным фрагментом текста касательно требуемого изображения, который является семантически релевантным требуемому изображению и включает в себя одно или более вышеупомянутые ключевые понятия (блок 606).
[0038] Как понимается в области онлайнового управления информацией, активный участок является выбираемой пользователем, определенной областью заданного элемента информации (такого как изображение или подобное), который отображается в настоящий момент. Следует понимать, что активные участки могут быть отображены различными способами. В примерном варианте осуществления инфраструктуры обзора изображений, описываемой в данном документе, каждый из активных участков отображается в качестве полупрозрачного затененного прямоугольника.
[0039] Вновь обращаясь к Фиг. 6, как только пользователь выбирает один из активных участков, данный выбор пользователя обнаруживается (блок 608) и фрагмент текста, который связан гиперссылкой с выбранным активным участком, отображается в GUI обзора изображений, при этом каждое из ключевых понятий в отображаемом фрагменте текста выделяется таким образом, что пользователь может различать ключевое понятие от оставшейся части текста в отображаемом фрагменте текста (блок 610). Как будет описано более подробно далее, данный фрагмент текста может быть отображен различными способами и в различных местоположения в GUI. Примерные способы выделения ключевого понятия также описываются более подробно далее. Как только пользователь выбирает одно из ключевых понятий в отображаемом фрагменте текста, данный выбор пользователя обнаруживается (блок 612) и выбирается другое изображение из хранилища информации, которое также имеет выбранное ключевое понятие, ассоциированное с ним (блок 614). Данное выбранное другое изображение затем отображается внутри сектора текущего изображения GUI обзора изображений (блок 616). Другими словами, концепт или объект, который представлен посредством выбранного ключевого понятия, также относится к выбранному другому изображению из хранилища информации, которое отображается пользователю. По существу, пользователю предоставляется другое изображение, которое является семантически связанным с требуемым изображением, которые они просматривали прежде. Один или более активные участки затем отображаются сверху выбранного другого изображения, при этом каждый активный участок связан гиперссылкой с разным фрагментом текста касательно выбранного другого изображения, который является семантически релевантным выбранному другому изображению и включает в себя одно или более ключевые понятия (блок 618).
[0040] Следует иметь в виду, что пользователь может выбрать заданный активный участок, или заданное ключевое понятие в отображаемом фрагменте текста, который связан гиперссылкой с активным участком (или заданную миниатюру в секторе истории изображений GUI обзора изображений, которая описывается более подробно позже, или заданное ключевое понятие в секторе ключевых понятий данного GUI), различными способами, включая, но не ограничиваясь, следующие. В случае, когда экран отображения устройства отображения является сенсорным, пользователь может вручную выбирать активный участок/ключевое понятие/миниатюру посредством физического касания его, используя либо один или более пальцы, либо устройство типа пера. В случае, когда компьютер пользователя включает в себя устройство выбора GUI, такое как компьютерная мышь или подобное, пользователь может использовать устройство выбора GUI, чтобы вручную указывать на активный участок/ключевое понятие/миниатюру и затем вручную нажимать кнопку на устройстве выбора GUI (например, пользователь может использовать устройство выбора GUI, чтобы вручную щелкать по активному участку/ключевому понятию/миниатюре); пользователь также может иметь возможность использования устройства выбора GUI, чтобы вручную наводить и удерживать курсор на активном участке/ключевом понятие/миниатюре в течение предписанного периода времени. В случае, когда компьютер пользователя включает в себя подсистему ввода и распознавания голоса, пользователь также может иметь возможность вербально выбирать заданное ключевое понятие в отображаемом фрагменте текста, произнося ключевое понятие.
[0041] Вновь обращаясь к Фиг. 6, также будет понятно, что действие блока 614 может быть реализовано различными способами. В качестве примера, а не ограничения, в примерном варианте осуществления инфраструктуры обзора изображений, описываемой в данном документе, выбор другого изображения из хранилища информации включает в себя выбор другого изображения из хранилища, которое имеет выбранное ключевое понятие, ассоциированное с ним, наибольшее количество раз (например, выбор другого изображения, для которого выбранное ключевое понятие обнаруживается в извлеченных фрагментах текста около наибольшего количества раз). Выбор другого изображения из хранилища может опционально также включать принятие во внимание истории обзора изображений пользователя для того, чтобы избежать отображения одного и того же изображения пользователю вновь.
[0042] В только что описанном процессе для обеспечения пользователю возможности обозревать изображения, которые хранятся в хранилище информации, когда заданное изображение впервые отображается внутри сектора текущего изображения, сверху изображения отображаются только активные участки, которые связаны гиперссылкой с фрагментами текста об изображении. Как описано раньше пользователь затем может выбирать заданный активный участок, чтобы просматривать заданный фрагмент текста об изображении. В альтернативном варианте осуществления инфраструктуры обзора изображений, описываемой в данном документе, когда заданное изображение впервые отображается внутри сектора текущего изображения, один из фрагментов по умолчанию текста об изображении может быть автоматически отображен в GUI обзора изображений в дополнение к активным участкам, отображаемым сверху изображения. В одной реализации данного альтернативного варианта осуществления один из фрагментов по умолчанию текста, который автоматически отображается, является фрагментом текста об изображении, который имеет наибольший объединенный балл релевантности и интересности. В другой реализации данного альтернативного варианта осуществления один из фрагментов по умолчанию текста, который автоматически отображается, является фрагментом текста об изображении, в котором конкретное ключевое понятие, которое пользователь выбирал самым последним (тем самым вызывая изображение, которое будет отображено внутри сектора текущего изображения), или конкретный терм запроса, который пользователь исходно использовал для поиска изображения, встречается наибольшее количество раз. В еще одном другом варианте осуществления данного альтернативного варианта осуществления один из фрагментов по умолчанию текста, который автоматически отображается, выбирается на основании истории ключевых понятий, которые выбирал пользователь. Также может быть использовано любое сочетание этих только что описанных реализаций.
1.2 ИНФРАСТРУКТУРА ИНТЕРФЕЙСА ПОЛЬЗОВАТЕЛЯ
[0043] Фиг. 7-15 иллюстрируют примерный вариант осуществления, в упрощенной форме, обобщенной компоновки для GUI, который обеспечивает пользователю возможность обозревать изображения, которые хранятся в хранилище информации. GUI 700 обзора изображений, приведенный в качестве примера на Фиг. 7-15, предполагает, что изображения, которые хранятся в хранилище, уже были подготовлены для обзора, как описано ранее. Соответственно и как будет понятно из более подробного описания, которое следует, GUI 700, приведенный в качестве примера на Фиг. 7-15, использует вышеупомянутую связанную гиперссылкой структуру, которая создается между ключевыми понятиями и изображениями (например, GUI 700 использует тот факт, что каждое из ключевых понятий, которое ассоциировано с каждым из изображений в хранилище информации, связано гиперссылкой с каждым другим изображением в хранилище, которое имеет данное ключевое понятие, ассоциированное с ним), способом, который позволяет пользователю семантически обозревать изображения, которые хранятся в хранилище. Как приведено в качестве примера на Фиг. 7-15, GUI 700 включает в себя сектор 702 текущего изображения, и может опционально также включать в себя сектор 704 ключевых понятий и сектор 706 истории изображений. Примерные варианты осуществления использования этих разных секторов 702/704/706 описываются более подробно далее.
[0044] Как приведено в качестве примера на Фиг. 7, по приему запроса пользователя на просмотр изображения Эрнеста Резерфорда, которое хранится в хранилище информации, запрошенное изображение 724 Эрнеста Резерфорда отображается внутри сектора 702 текущего изображения. Четыре активных участка 708/710/712/714 также отображаются сверху данного запрошенного изображения 724, при этом каждый из активных участков 708/710/712/714 связан гиперссылкой с разным фрагментом текста (например, фрагментом 716) об изображении 724, который является семантически релевантным изображению 724. По обнаружению выбора пользователем активного участка 708, фрагмент 716 текста, который связан гиперссылкой с выбранным активным участком 708, отображается в GUI 700 обзора изображений. Следует иметь в виду, что данный фрагмент 716 текста (как впрочем и другие фрагменты текста, которые рассматриваются далее) может быть отображен различными способами и в различных местоположения GUI 700, включая, но не ограничиваясь, следующие. В конкретном варианте осуществления GUI приведенном в качестве примера на Фиг. 7-15, каждый фрагмент текста всплывает сверху изображения, которое в настоящий момент отображается внутри сектора текущего изображения и смежно с активным участком, с которым фрагмент связан гиперссылкой. В альтернативном варианте осуществления GUI (не показан) каждый фрагмент текста может всплывать сбоку изображения так, что фрагмент не загораживает изображение. В другом альтернативном варианте осуществления GUI (не показан) GUI может включать в себя сектор фрагмента и каждый фрагмент текста может быть отображен внутри сектора фрагмента. В еще одном другом альтернативном варианте осуществления GUI (не показан) каждый фрагмент текста может всплывать в предписанном фиксированном местоположении сверху изображения (например, внизу изображения, среди прочих фиксированных местоположений). Фрагмент 716 текста включает в себя одно ключевое понятие (Эрнест Резерфорд), которое выделяется таким образом, который позволяет пользователю различать его от оставшейся части текста во фрагменте 716. Данное выделение ключевого понятия может быть выполнено различными способами, включая, но не ограничиваясь, либо выделение жирным шрифтом символов ключевого понятия, либо изменение цвета символов ключевого понятия, либо подчеркивая символы ключевого понятия, либо любым сочетанием этих способов.
[0045] Как приведено в качестве примера на Фиг. 8, по обнаружению выбора пользователем активного участка 710, фрагмент 718 текста, который связан гиперссылкой с выбранным активным участком 710, отображается в GUI 700 обзора изображений. Фрагмент 718 текста включает в себя одно ключевое понятие (Эрнест Резерфорд), которое выделяется. Как приведено в качестве примера на Фиг. 9, по обнаружению выбора пользователем активного участка 712, фрагмент 720 текста, который связан гиперссылкой с выбранным активным участком 712, отображается в GUI 700. Фрагмент 720 текста включает в себя одно ключевое понятие (атом), которое выделяется. Как приведено в качестве примера на Фиг. 10, по обнаружению выбора пользователем активного участка 714, фрагмент 722 текста, который связан гиперссылкой с выбранным активным участком 714, отображается в GUI 700. Фрагмент 722 текста включает в себя четыре ключевых понятия (Англия, Физика, Манчестер и Кембридж), которые выделяются.
[0046] Как приведено в качестве примера на Фиг. 11 и вновь обращаясь к Фиг. 10, по обнаружению выбора пользователем ключевого понятия Кембридж в отображаемом фрагменте 722 текста, другое изображение 728 из хранилища информации, которое также имеет ключевое понятие Кембридж, ассоциированное с ним, отображается внутри сектора 702 текущего изображения, и миниатюра 726 (например, уменьшенное представление) ранее отображаемого изображения 724 отображается внутри сектора 706 истории изображений. Четыре активных участка 730/732/734/736 также отображаются сверху данного другого изображения 728, при этом каждый из активных участков 730/732/734/736 связан гиперссылкой с разным фрагментом текста (например, фрагментом 738) об изображении 728, который является семантически релевантным изображению 728. По обнаружению выбора пользователем активного участка 730, фрагмент 738 текста, который связан гиперссылкой с выбранным активным участком 730, отображается в GUI 700 обзора изображений. Фрагмент 738 текста включает в себя одно ключевое понятие (Кембридж), которое выделяется. Как приведено в качестве примера на Фиг. 12, по обнаружению выбора пользователем активного участка 732, фрагмент 740 текста, который связан гиперссылкой с выбранным активным участком 732, отображается в GUI 700. Фрагмент 740 текста включает в себя два ключевых понятия (Венера и Земля), которые выделяются.
[0047] Как приведено в качестве примера на Фиг. 13 и вновь обращаясь к Фиг. 12, по обнаружению выбора пользователем ключевого понятия Венера в отображаемом фрагменте 740 текста, другое изображение 744 из хранилища информации, которое также имеет ключевое понятие Венера, ассоциированное с ним, отображается внутри сектора 702 текущего изображения, и миниатюра 742 ранее отображаемого изображения 728, отображается внутри сектора 706 истории изображений над миниатюрой 726. Четыре активных участка 746/748/750/752 также отображаются сверху данного другого изображения 744, при этом каждый из активных участков 746/748/750/752 связан гиперссылкой с разным фрагментом текста (например, фрагментом 754) об изображении 744, который является семантически релевантным изображению 744. По обнаружению выбора пользователем активного участка 746, фрагмент 754 текста, который связан гиперссылкой с выбранным активным участком 746, отображается в GUI обзора изображений. Фрагмент 754 текста включает в себя три ключевых понятия (Венера, орбита и планета), которые выделяются. Как приведено в качестве примера на Фиг. 14, по обнаружению выбора пользователем активного участка 750, фрагмент 756 текста, который связан гиперссылкой в выбранным активным участком 750, отображается в GUI 700. Фрагмент 756 текста включает в себя два ключевых понятия (Венера и атмосфера), которые выделяются.
[0048] Как приведено в качестве примера на Фиг. 15 и вновь обращаясь к Фиг. 14, по обнаружению выбора пользователем ключевого понятия атмосфера в отображаемом фрагменте 756 текста, другое изображение 760 из хранилища информации, которое также имеет ключевое понятие атмосфера, ассоциированное с ним, отображается внутри сектора 702 текущего изображения, и миниатюра 758, ранее отображаемого изображения 744, отображается внутри сектора 706 истории изображений над миниатюрой 742 и миниатюрой 726. Три активных участка 762/764/766 также отображаются сверху данного другого изображения 760, при этом каждый из активных участков 762/764/766 связан гиперссылкой с разным фрагментом текста (например, фрагментом 768) об изображении 760, который является семантически релевантным изображению 760. По обнаружению выбора пользователем активного участка 762, фрагмент 768 текста, который связан гиперссылкой с выбранным активным участком 762, отображается GUI 700 обзора изображений. Фрагмент 768 текста включает в себя два ключевых понятия (экзопланета и атмосфера), которые выделяются.
[0049] Вновь обращаясь к Фиг. 11-14, следует иметь в виду, что сектор 706 истории изображений предоставляет пользователю хронологически организованную историю изображений, которые пользователь просмотрел ранее. В случае, когда количество миниатюр (например, 726/742/758), которые должны быть отображены в секторе 706 истории изображений, превышает пространство, которое доступно в нем, полоса прокрутки (не показана) может быть добавлена в сектор истории изображений, тем самым, позволяя пользователю прокручивать миниатюры. По обнаружению выбора пользователем заданной миниатюры в секторе 706 истории изображений, изображение, которое представляется выбранной миниатюрой, повторно отображается внутри сектора 702 текущего изображения, и один или более активные участки (каждый из которых связан гиперссылкой с разным фрагментом текста об изображении) повторно отображаются сверху данного изображения. В качестве примера, а не ограничения, по обнаружению выбора пользователем миниатюры 742 изображение 728 и активные участки 730/732/734/736 повторно отображаются внутри сектора 702 текущего изображения. Также следует иметь в виду, что сектор 706 истории изображений может быть организован различными другими способами. В качестве примера, а не ограничения, и как приведено в качестве примера на Фиг. 13-15, вместо того, что миниатюра самого последнего ранее отображенного изображения помещается над любой миниатюрой(ами), которая может уже существовать внутри сектора 706 истории изображений, миниатюра самого последнего ранее отображаемого изображения может быть помещена ниже любой миниатюр(ы), которая может уже существовать внутри сектора истории изображений.
[0050] Вновь обращаясь к Фиг. 7-15, работа и функциональность сектора 704 ключевых понятий теперь будет описана более подробно. В GUI 700 обзора изображений, приведенном в качестве примера на Фиг. 7-15, список ключевых понятий отображается внутри сектора 704 ключевых понятий, при этом список ключевых понятий включает в себя организованное в алфавитном порядке перечисление всех из ключевых понятий, которые ассоциированы со всеми из изображений, которые хранятся в хранилище информации. В случае, когда количество ключевых понятий в списке ключевых понятий превышает пространство, которое доступно внутри сектора 704 ключевых понятий, полоса прокрутки (не показана) может быть добавлена в сектор ключевых понятий, тем самым позволяя пользователю прокручивать список ключевых понятий. После отображения заданного изображения внутри сектора 702 текущего изображения, список ключевых понятий автоматически прокручивается таким образом, что сегмент списка ключевых понятий, который в настоящий момент отображается внутри сектора 704 ключевых понятий, включает в себя конкретное ключевое понятие в заданном отображаемом фрагменте текста об изображении, которое пользовать только что выбрал (тем самым вызывая отображение изображения внутри сектора текущего изображения), и данное только что выбранное ключевое понятие выделяется в секторе ключевых понятий. В качестве примера, а не ограничения, по обнаружению выбора пользователем ключевого понятия Кембридж в отображаемом фрагменте 722 текста об изображении 724, которое отображается внутри сектора 702 текущего изображения, показанного на Фиг. 10, список ключевых понятий автоматически прокручивается таким образом, что сегмент списка ключевых понятий, который в настоящий момент отображается внутри сектора 704 ключевых понятий, включает в себя только что выбранное ключевое понятие Кембридж и ключевое понятие Кембридж выделяется в секторе ключевых понятий, как показано на Фиг. 11.
[0051] Следует иметь в виду, что различные альтернативные варианты осуществления сектора ключевых понятий также возможно включают, но не ограничивают, следующие. В одном альтернативном варианте осуществления сектора ключевых понятий, когда пользователь начинает новый сеанс обзора изображений, список ключевых понятий в секторе ключевых понятий запускается как пустой, и затем шаг за шагом наполняется разными ключевыми понятиями, которые пользователь выбирает во время сеанса (например, каждое ключевое понятие, которое пользователь выбирает, добавляется в список ключевых понятий). В другом альтернативном варианте осуществления сектора ключевых понятий, когда пользователь начинает новый сеанс обзора изображений, список ключевых понятий в секторе ключевых понятий запускается как пустой, и затем шаг за шагом наполняется всеми из ключевых понятий, которые ассоциированы с разными изображениями, которые отображаются внутри сектора текущего изображения во время сеанса (например, как только новое изображение отображается внутри сектора текущего изображения, все из ключевых понятий, которые ассоциированы с новым изображением, добавляются в список ключевых понятий). В еще одном другом альтернативном варианте осуществления сектора ключевых понятий, когда пользователь начинает новый сеанс обзора изображений, список ключевых понятий в секторе ключевых понятий запускается как пустой, и затем шаг за шагом наполняется ключевым понятием, которое ассоциировано с каждым отличным изображением, которое отображается внутри сектора текущего изображения наибольшее количество раз (например, как только новое изображение отображается внутри сектора текущего изображения, ключевое понятие, которое ассоциировано с новым изображением наибольшее количество раз, добавляется в список ключевых понятий). В еще одном другом альтернативном варианте осуществления сектора ключевых понятий, сектор ключевых понятий включает в себя прямоугольник ввода текста, который позволяет пользователю осуществлять поиск по всем ключевым понятиям, которые ассоциированы со всеми из изображений, которые хранятся в хранилище информации, требуемого ключевого понятия (например, пользователь может осуществлять поиск в хранилище изображений, которые относятся к требуемому мысленному образу или объекту). Данный прямоугольник ввода текста может опционально включать в себя свойство автозаполнения, которое направляет пользователя к ключевым понятиям, которые ассоциированы с изображениями в хранилище. Также может быть использовано любое сочетание этих только что описанных альтернативных вариантов осуществления.
[0052] В примерном варианте осуществления инфраструктуры обзора изображений, описываемой в данном документе, по обнаружению выбора пользователем заданного одного из ключевых понятий в только что описанном списке ключевых понятий, который отображается внутри сектора ключевых понятий, предпринимаются следующие действия. Данный выбор пользователя обнаруживается. Затем выбирается другое изображение из хранилища информации, которое также имеет выбранное ключевое понятие, ассоциированное с ним, при этом данный другой выбор изображения может быть реализован любым из вышеупомянутых способов. Затем данное выбранное другое изображение отображается внутри сектора текущего изображения.
2.0 ДОПОЛНИТЕЛЬНЫЕ ВАРИАНТЫ ОСУЩЕСТВЛЕНИЯ
[0053] Несмотря на то, что инфраструктура обзора изображений была описана посредством конкретного обращения к ее вариантам осуществления, следует понимать что ее вариации и модификации могут быть выполнены, не отступая от истинной сущности и объема инфраструктуры обзора изображений. В качестве примера, а не ограничения, вместо того, чтобы каждое из изображений, которые хранятся в хранилище информации, подготавливалось для обзора заранее до активностей пользователя по обзору изображений, как описано ранее, возможен следующий альтернативный вариант осуществления инфраструктуры обзора изображений, описываемой в данном документе. Текст, который хранится в хранилище, может быть интеллектуально проанализирован, чтобы извлечь вышеупомянутые фрагменты текста касательно заданного изображения, вышеупомянутые ключевые понятия могут быть обнаружены в каждом из этих извлеченных фрагментов, и эти извлеченные фрагменты и обнаруженные ключевые понятия могут быть ассоциированы с изображение на лету по приему запроса пользователя на отображение изображения.
[0054] Дополнительно, по обнаружению выбора пользователем заданного ключевого понятия в заданном отображаемом фрагменте текста касательно заданного изображения, которое в настоящий момент отображается внутри сектора текущего изображения GUI обзора изображений, вместо отображения другого изображения из хранилища информации, которое также имеет выбранное ключевое понятие ассоциированное с ним, внутри сектора текущего изображения, как описано ранее, могут происходить следующие отличные вещи. В одном альтернативном варианте осуществления инфраструктуры обзора изображений, описываемой в данном документе, совокупность миниатюр других изображений, хранящихся в хранилище, которые также имеют выбранное ключевое понятие ассоциированное с ними, может быть отображена внутри сектора текущего изображения, при этом данная совокупность миниатюр может включать в себя либо все из изображений в хранилище, которые также имеют выбранное ключевое понятие ассоциированное с ними, либо предписанное количество других изображений с наивысшим баллом, хранящихся в хранилище, которые также имеют выбранное ключевое понятие ассоциированное с ними. Когда пользователь выбирает конкретную миниатюру в совокупности миниатюр, данный выбор может быть обнаружен и изображение, которое представляется посредством выбранной миниатюры, может быть отображено внутри сектора текущего изображения. В другом альтернативном варианте осуществления инфраструктуры обзора изображений информация касательно выбранного ключевого понятия может быть отображена пользователю.
[0055] Кроме того, по обнаружению выбора пользователем заданного ключевого понятия в заданном отображаемом фрагменте текста касательно заданного изображения, которое в настоящий момент отображается внутри сектора текущего изображения GUI обзора изображений, могут происходить следующие дополнительные отличные вещи. В еще одном другом альтернативном варианте осуществления инфраструктуры обзора изображений, описываемой в данном документе, может быть сгенерирован запрос к поисковой машине, при этом данный запрос может включать в себя либо выбранное ключевое понятие, либо весь отображаемый фрагмент текста, из которого было выбрано ключевое понятие. Затем поисковая машина может осуществлять поиск по хранилищу в отношении информации, которая относится к запросу, и результаты поиска могут быть приняты от поисковой машины и отображены внутри сектора текущего изображения. Следует отметить, что эти результаты поиска могут включать в себя широкое разнообразие информации разных типов, такой как страница из изображений, которые относятся к запросу, среди прочего. По выбору пользователем изображения, которое включено в результаты поиска, выбранное изображение может быть отображено внутри сектора текущего изображения GUI и один или более активные участки могут быть отображены сверху выбранного изображения, при этом каждый из активных участков связан гиперссылкой с разным фрагментом текста касательно выбранного изображения. Следует иметь в виду, что данный конкретный альтернативный вариант осуществления обладает преимуществом, поскольку он учитывает последнюю историю обзора пользователя и также может учитывать последние тенденции того, что смотрели другие пользователи, среди прочего. В еще одном другом варианте осуществления инфраструктуры обзора изображений в настоящий момент имеющие тенденцию к просмотру темы и изображения, которые относятся к выбранному ключевому понятию, могут быть отображены внутри сектора текущего изображения.
[0056] Тем не менее, кроме того, также возможен следующий альтернативный вариант осуществления GUI обзора изображений. Вместо отображения вышеупомянутого требуемого изображения или выбранного другого изображения (далее совокупно просто именуемые заданным изображением) внутри сектора текущего изображения GUI, как описано ранее, граф изображений может быть отображен внутри сектора текущего изображения, при этом данный граф включает в себя миниатюру заданного изображения и миниатюры изображений в хранилище информации, которые связаны гиперссылкой с ключевыми понятиями, которые ассоциированы с заданным изображением (или предписанное подмножество из этих связанных гиперссылкой изображений). Граф изображений также включает в себя графические соединения между разными парами миниатюр в графе, при этом заданное графическое соединение между заданной парой миниатюр указывает на то, что пара изображений в хранилище, которая представлена посредством заданной пары миниатюр, имеют одно или более общие ключевые понятия. Таким образом будет понятно, что граф изображений отображает семантические взаимосвязи между изображениями в хранилище, которые представлены посредством миниатюр на графе.
[0057] Фиг. 17 иллюстрирует примерный вариант осуществления, в упрощенной форме, только что описанного графа изображений. Как приведено в качестве примера на Фиг. 17, граф 1700 изображений включает в себя миниатюры шести разных изображений 1701-1706, при этом миниатюра 1706 представляет собой только что описанное заданное изображение, а миниатюры 1701-1706 представляют собой изображения в хранилище информации, которые связаны гиперссылкой с ключевыми понятиями, которые ассоциированы с заданным изображением. Граф 1700 также включает в себя различные графические соединения (например, соединение 1707 и 1708) между разными парами миниатюр на графе, при этом заданное графическое соединение между заданной парой миниатюр (например, соединение 1707 между миниатюрой 1706 и миниатюрой 1703) указывает на то, что пара изображений в хранилище, которая представлена посредством заданной пары миниатюр, имеет одно или более общие ключевые понятия (например, изображения, представленные посредство миниатюр 1706 и 1703 имеют одно или более общие ключевые понятия). Граф 1700 может интерактивно обозреваться пользователем различными способами, включая, но не ограничиваясь, следующие. По обнаружению выбора пользователем миниатюры 1702, новый граф изображений (не показан) может быть отображен внутри сектора текущего изображения, при этом данный новый граф включает в себя выбранную миниатюру 1702 и миниатюры изображений в хранилище, которые связаны гиперссылкой с ключевыми понятиями, которые ассоциированы с изображением в хранилище, которое представлено посредством выбранной миниатюры 1702. По обнаружению выбора пользователем соединения 1707, различная информация касательно семантической взаимосвязи между изображениями, представленными посредством миниатюр 1706 и 1703 (например, ключевое понятие(я), которое является общим для этих изображений), может быть отображена пользователю.
[0058] Также отмечается, что любое или все из вышеупомянутых вариантов осуществления могут быть использованы в любом сочетании, требуемом, чтобы сформировать дополнительные гибридные варианты осуществления. Несмотря на то, что варианты осуществления инфраструктуры обзора изображений были описаны языком присущим для структурных признаков и/или методологических актов, должно быть понятно, что объем изобретения, определяемый прилагаемой формулой изобретения, не обязательно ограничивается конкретными признаками или актами, описанными ранее. Наоборот, конкретные признаки и акты, описанные ранее, раскрываются в качестве примерных форм реализации формулы изобретения.
3.0 ПРИМЕРНЫЕ РАБОЧИЕ СРЕДЫ
[0059] Варианты осуществления инфраструктуры обзора изображений, описываемой в данном документе, способны работать в рамках многочисленных типов сред или конфигураций вычислительной системы общего назначения или специализированной. Фиг. 16 иллюстрирует упрощенный пример компьютерной системы общего назначения, на которой могут быть реализованы различные варианты осуществления и элементы инфраструктуры обзора изображений, как описывается в данном документе. Отмечается, что любые прямоугольники, которые представлены посредством ломанных или пунктирных линий на Фиг. 16, представляют собой альтернативные варианты осуществления упрощенного вычислительного устройства, и что любой или все из этих альтернативных вариантов осуществления, как описано ниже, могут быть использованы в сочетании с другими альтернативными вариантами осуществления, которые описываются на всем протяжении данного документа.
[0060] Например, Фиг. 16 показывает общую схему системы, показывающую упрощенное вычислительное устройство 1600. Такие вычислительные устройства, как правило, могут быть обнаружены в устройствах с, по меньшей мере, некоторыми минимальными вычислительными возможностями, включая, но не ограничиваясь, персональные компьютеры (PC), серверные компьютеры, переносные вычислительные устройства, компьютеры класса лэптопа или мобильные компьютеры, устройства связи, такие как сотовые телефоны и персональные цифровые помощники (PDA), мультипроцессорные системы, основанные на микропроцессоре системы, телевизионные абонентские приставки, программируемую потребительскую электронику, сетевые ПК, миникомпьютеры, компьютеры класса мэйнфрейм, и аудио или видео мультимедийные проигрыватели.
[0061] Чтобы обеспечить возможность устройству реализовать варианты осуществления инфраструктуры обзора изображений, описываемой в данном документе, устройство должно обладать достаточными вычислительными возможностями и системной памятью, для обеспечения базовых вычислительных операций. В частности, как иллюстрируется на Фиг. 16, вычислительные возможности, главным образом, иллюстрируются посредством одного или более блока(ов) 1610 обработки, и могут также включать в себя один или более блоки 1615 обработки графики (GPU), любой из которых или оба осуществляют связь с системной памятью 1620. Отметим, что блок(и) 1610 обработки упрощенного вычислительного устройства 1600 может быть специализированными микропроцессорами (таким как цифровой сигнальный процессор (DSP), процессор с командными словами очень большой длины (VLIW), программируемая вентильная матрица (FPGA), или другой микроконтроллер) или может быть традиционными центральными блоками обработки (CPU) с одним или более ядрами обработки, включая, но не ограничиваясь, специализированные основанные на GPU ядра в многоядерном CPU.
[0062] В дополнение, упрощенное вычислительное устройство 1600 с Фиг. 16 также может включать в себя другие компоненты, такие как, например, интерфейс 1630 связи. Упрощенное вычислительное устройство 1600 с Фиг. 16 также может включать в себя одно или более традиционные компьютерные устройства 1640 ввода (например, координатно-указательные устройства, клавиатуры, устройства ввода аудио (например, голоса), устройства ввода видео, устройства тактильного ввода, устройства распознавания жеста, устройства для приема проводных или беспроводных передач данных, и подобное). Упрощенное вычислительное устройство 1600 с Фиг. 16 также может включать в себя другие опциональные компоненты, такие как, например, одно или более традиционные компьютерные устройства 1650 вывода (например, устройство(а) 1655 отображения, устройства вывода аудио, устройства вывода видео, устройства для передачи проводных или беспроводных передач данных, и подобное). Отметим, что типичные интерфейсы 1630 связи, устройства 1640 ввода, устройства 1650 вывода, и запоминающие устройства 1660 для компьютера общего назначения хорошо известны специалистам в соответствующей области, и не будут подробно описаны в данном документе.
[0063] Упрощенное вычислительное устройство 1600 с Фиг. 16 также может включать в себя разнообразие машиночитаемых носителей информации. Машиночитаемые носители информации могут быть любыми доступными носителями информации, доступ к которым может быть осуществлен посредством компьютера 1600 через запоминающие устройства 1600, и могут включать в себя как энергозависимые, так и энергонезависимые носители информации, которые либо съемные 1670 и/либо несъемные 1680, для хранения информации, такой как машиночитаемые или исполняемые компьютером инструкции, структуры данных, программные модули, и прочие данные. В качестве примера, а не ограничения, машиночитаемые носители информации могут включать в себя компьютерные запоминающие носители информации и средства связи. Компьютерные запоминающие носители информации относятся к вещественным читаемым компьютером или машиночитаемым носителям информации или запоминающим устройствам, таким как цифровые универсальные диски (DVD), компакт диски (CD), гибкие диски, накопители на ленте, накопители на жестком диске, оптические диски, устройства твердотельной памяти, памяти с произвольным доступом (RAM), постоянной памяти (ROM), электрически стираемой программируемой постоянной памяти (EEPROM), флэш-памяти или другой технологии памяти, магнитным кассетам, магнитным лентам, магнитным дисковым хранилищам, или другим магнитным запоминающим устройствам, или любому другому устройству, которое может быть использовано, чтобы хранить требуемую информацию и доступ к которому может быть осуществлен посредством одного или более вычислительных устройств.
[0064] Удержание информации, такой как машиночитаемые или исполняемые компьютером инструкции, структуры данных, программные модули, и подобное, также может совершаться посредством использования любых из многообразия вышеупомянутых средств связи, чтобы кодировать один или более модулированные сигналы данных или несущие волны, или другие механизмы транспортировки или протоколы связи, и могут включать в себя любой проводной или беспроводной механизм доставки информации. Отметим, что понятие «модулированный сигнал данных» или «несущая волна» главным образом относятся к сигналу, одна или более характеристики которого установлены или изменены таким образом, чтобы кодировать информацию в сигнале. Например, средства связи могут включать в себя проводные средства, такие как проводную сеть или прямое проводное соединение несущее один или более модулированные сигналы данных, и беспроводные средства, такие как акустические, радиочастотные (RF), инфракрасные, лазерные, и прочие беспроводные средства для передачи и/или приема одного или более модулированных сигналов данных или несущих волн. Сочетания любых из вышеприведенных также должны быть включены в объем средств связи.
[0065] Кроме того, программное обеспечение, программы, и/или компьютерные программные продукты, воплощающие некоторые или все из разнообразных вариантов осуществления инфраструктуры обзора изображений, описываемой в данном документе, или их сегменты, могут храниться, приниматься, передаваться, или считываться с любого требуемого сочетания читаемых компьютером или машиночитаемых носителей информации или запоминающих устройств и средств связи в форме исполняемых компьютером инструкций или других структур данных.
[0066] В заключение, варианты осуществления инфраструктуры обзора изображений, описываемой в данном документе, могут быть дополнительно описаны в общем контексте исполняемых компьютером инструкций, таких как программные модули, исполняемые посредством вычислительного устройства. В целом, программные модули включают в себя, подпрограммы, программы, объекты, компоненты, структуры данных, и подобное, которые выполняют конкретные задачи или реализуют конкретные абстрактные типы данных. Варианты осуществления инфраструктуры обзора изображений также могут быть воплощены на практике в распределенных вычислительных средах, где задачи выполняются посредством одного или более удаленных устройств обработки, или внутри облака из одного или более устройств, которые связаны посредством одной или более сетей связи. В распределенной вычислительной среде, программные модули могут располагаться как на локальных, так и удаленных компьютерных запоминающих носителях информации, включая устройства хранения носителей информации. Дополнительно, вышеупомянутые инструкции могут быть реализованы, частично или целиком, в качестве аппаратных логических схем, которые могут или могут не включать в себя процессор.
| название | год | авторы | номер документа |
|---|---|---|---|
| ПРЕОБРАЗОВАНИЕ КОНТЕНТА ДЛЯ НЕ ТРЕБУЮЩИХ ВМЕШАТЕЛЬСТВА РАЗВЛЕЧЕНИЙ | 2011 |
|
RU2606585C2 |
| СПОСОБ И УСТРОЙСТВО ДЛЯ ДОБАВЛЕНИЯ АДРЕСА ГИПЕРССЫЛКИ В ЗАКЛАДКУ | 2011 |
|
RU2562397C2 |
| ФИЛЬТРЫ РЕЗУЛЬТАТОВ ПОИСКА ИЗ СОДЕРЖИМОГО РЕСУРСОВ | 2016 |
|
RU2691840C1 |
| ГЕНЕРИРОВАНИЕ ПРЕДЛОЖЕНИЙ БРАУЗЕРА НА ОСНОВЕ ДАННЫХ УСТРОЙСТВА ИНТЕРНЕТА ВЕЩЕЙ | 2015 |
|
RU2711057C2 |
| СЕМАНТИЧЕСКАЯ НАВИГАЦИЯ ПО ВЕБ-КОНТЕНТУ И КОЛЛЕКЦИЯМ ДОКУМЕНТОВ | 2007 |
|
RU2442214C2 |
| ФИЛЬТРЫ РЕЗУЛЬТАТОВ ПОИСКА ИЗ СОДЕРЖИМОГО РЕСУРСОВ | 2016 |
|
RU2719443C2 |
| СИСТЕМА И СПОСОБ ДЛЯ ВЫБОРА ЗНАЧИМЫХ ЭЛЕМЕНТОВ СТРАНИЦЫ С НЕЯВНЫМ УКАЗАНИЕМ КООРДИНАТ ДЛЯ ИДЕНТИФИКАЦИИ И ПРОСМОТРА РЕЛЕВАНТНОЙ ИНФОРМАЦИИ | 2015 |
|
RU2708790C2 |
| МЕТОДИКА ДЛЯ ЭЛЕКТРОННОЙ АГРЕГАЦИИ ИНФОРМАЦИИ | 2011 |
|
RU2625938C2 |
| ХРАНИЛИЩЕ ДАННЫХ ДЛЯ ОСНОВАННОЙ НА ЗНАНИЯХ СИСТЕМЫ ИЗВЛЕЧЕНИЯ ИНФОРМАЦИИ ИЗ ДАННЫХ | 2003 |
|
RU2297665C2 |
| НАСТРОЙКА ВЗАИМОДЕЙСТВИЯ С ПОИСКОМ, ИСПОЛЬЗУЯ ИЗОБРАЖЕНИЯ | 2011 |
|
RU2575808C2 |
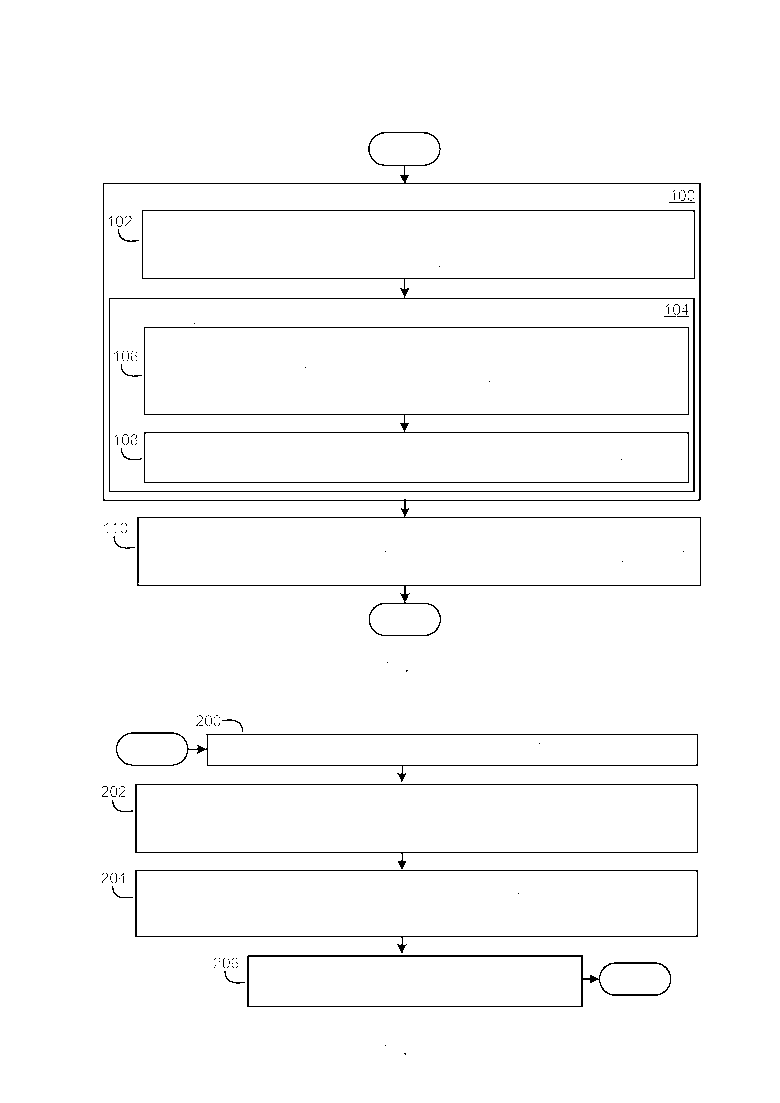
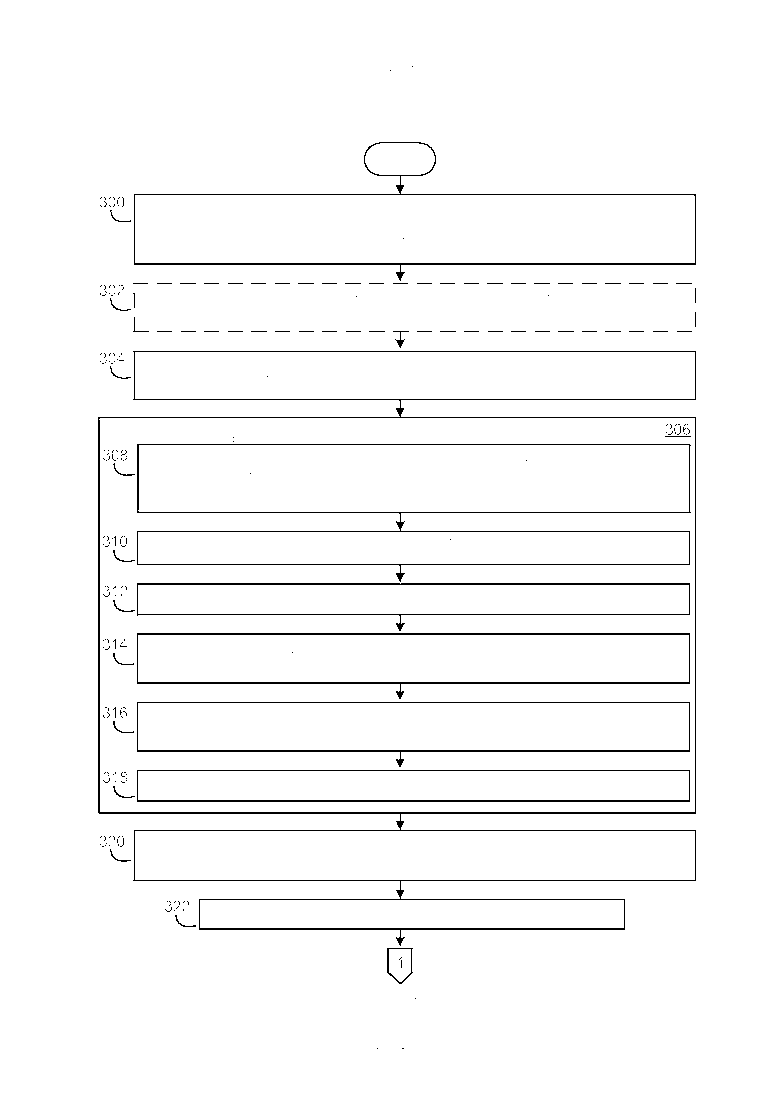
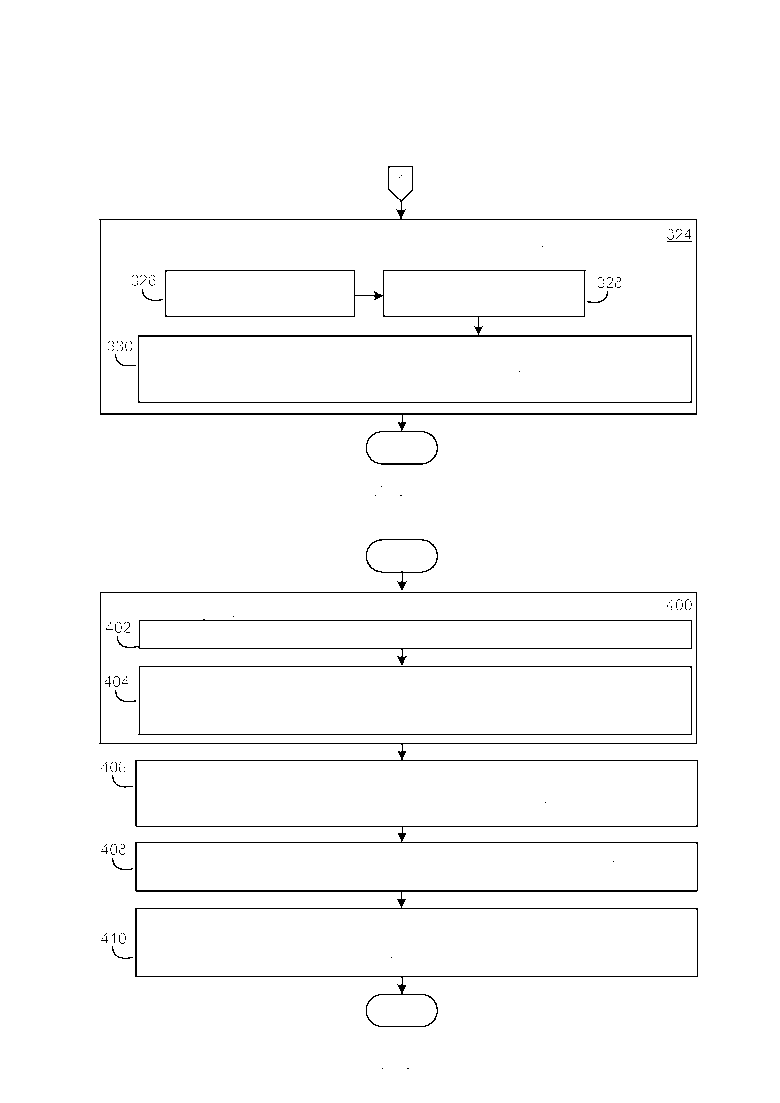
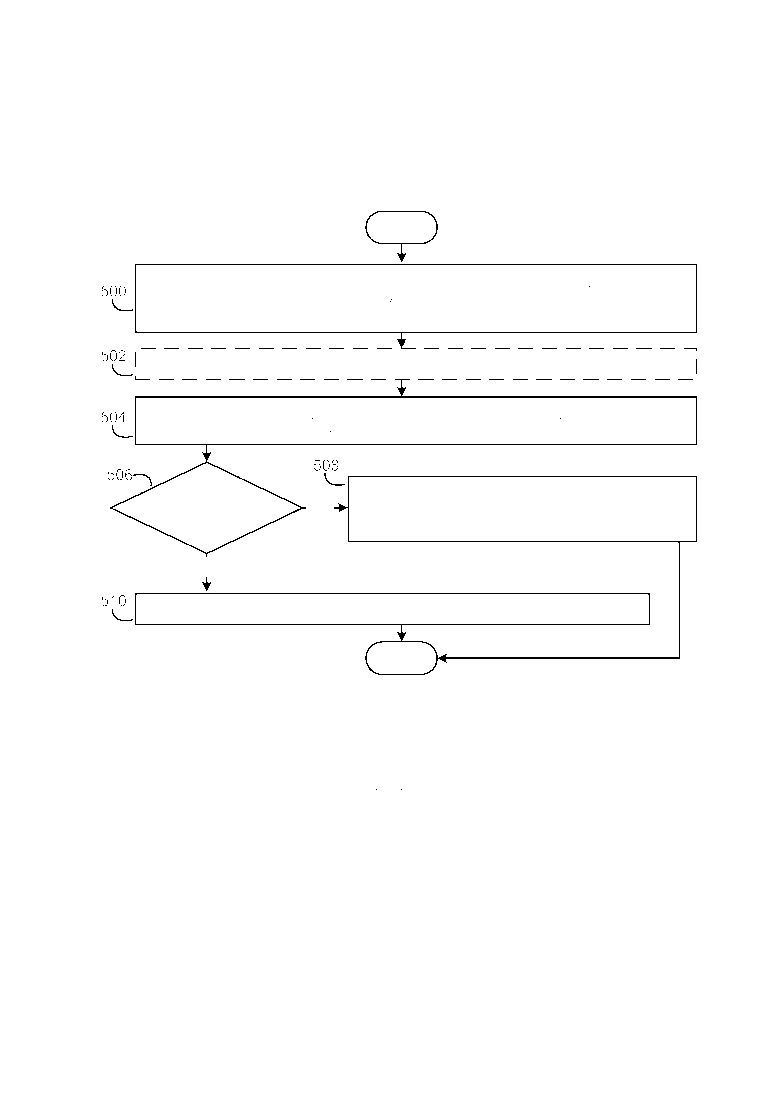
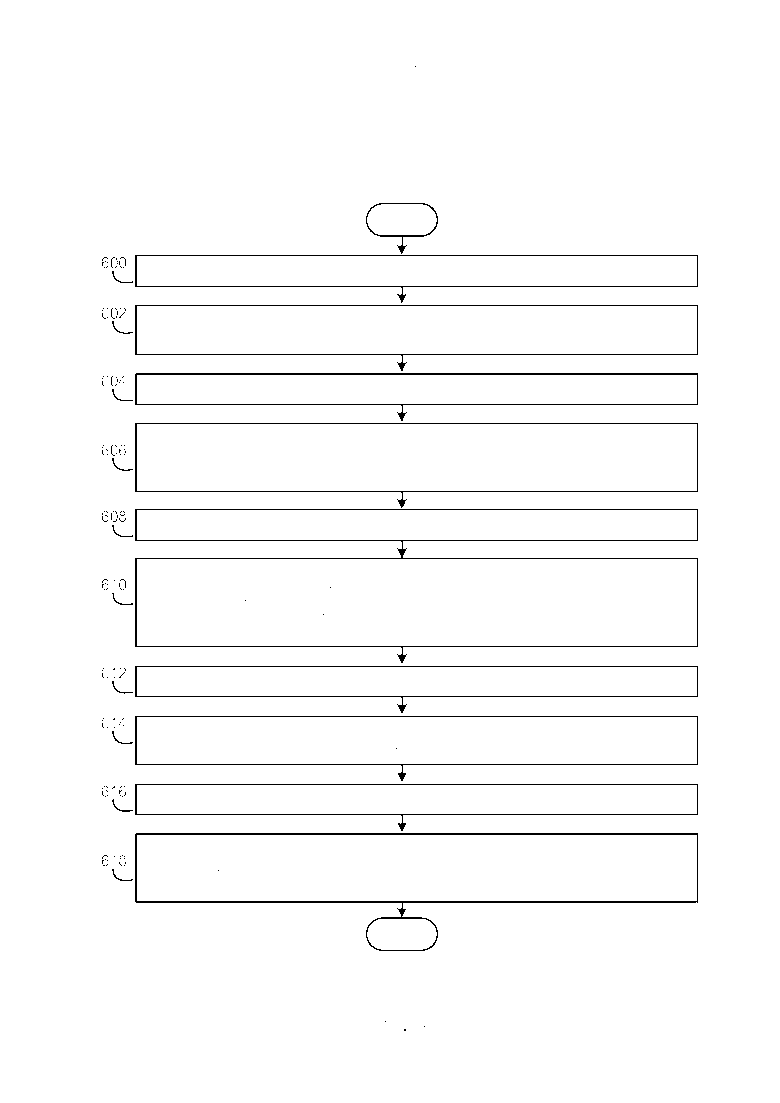
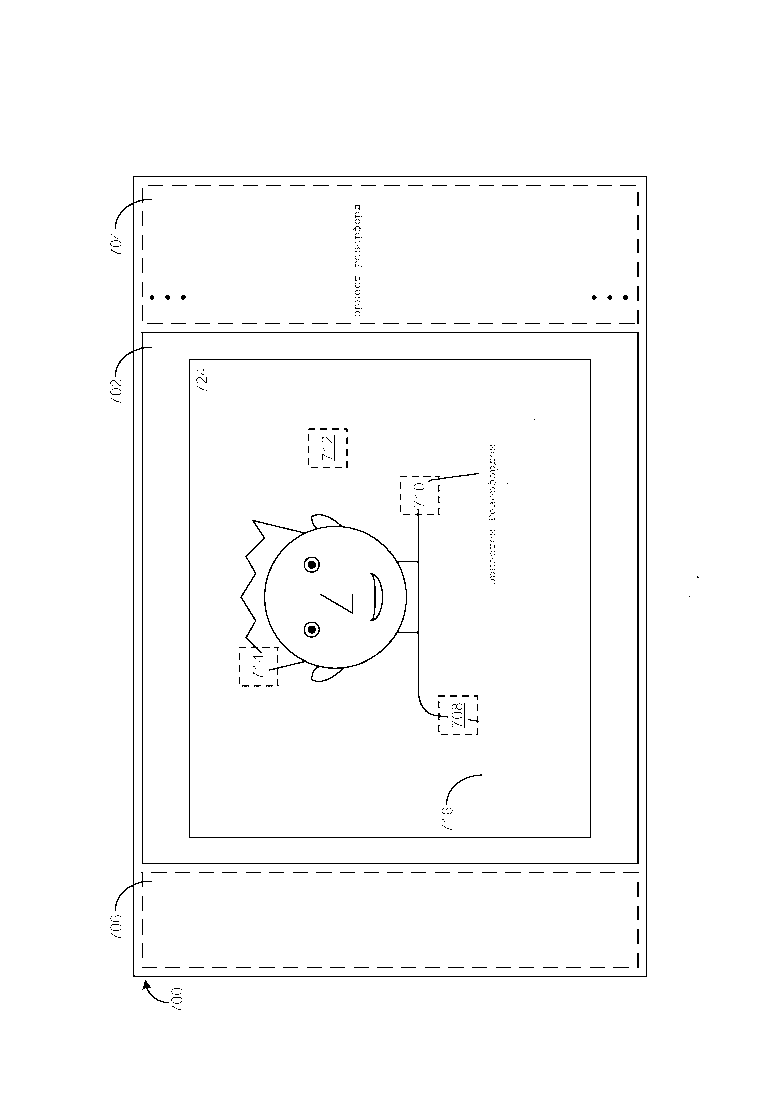
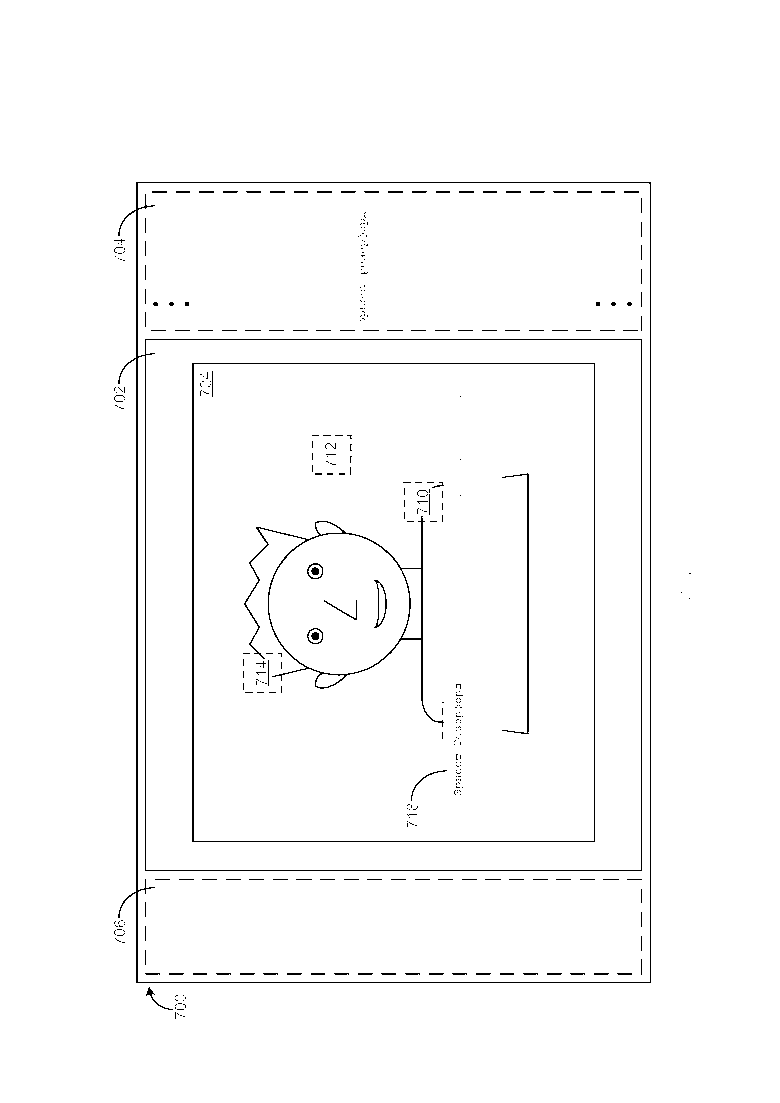
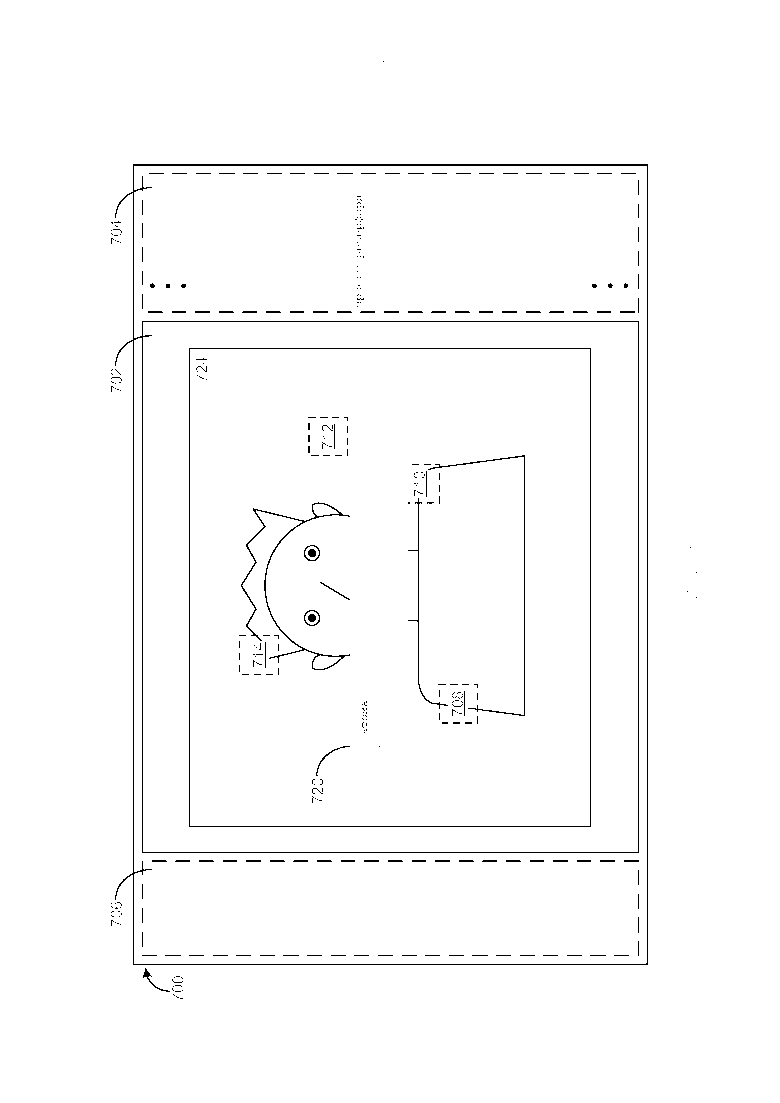
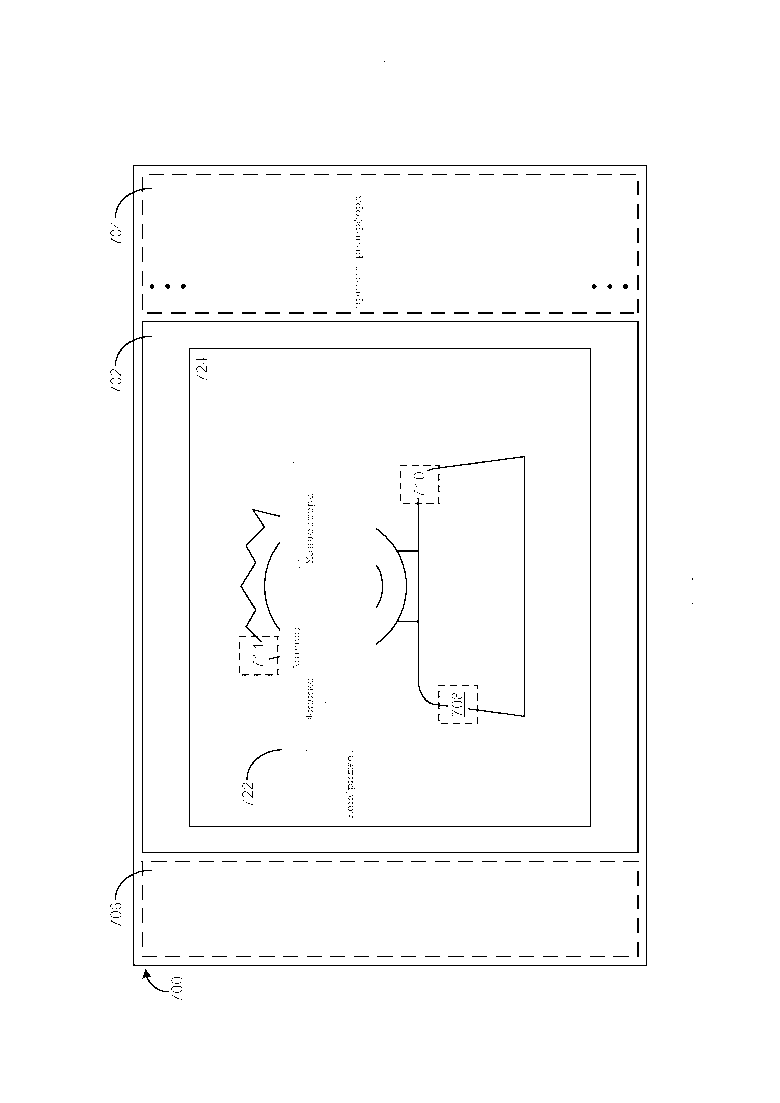
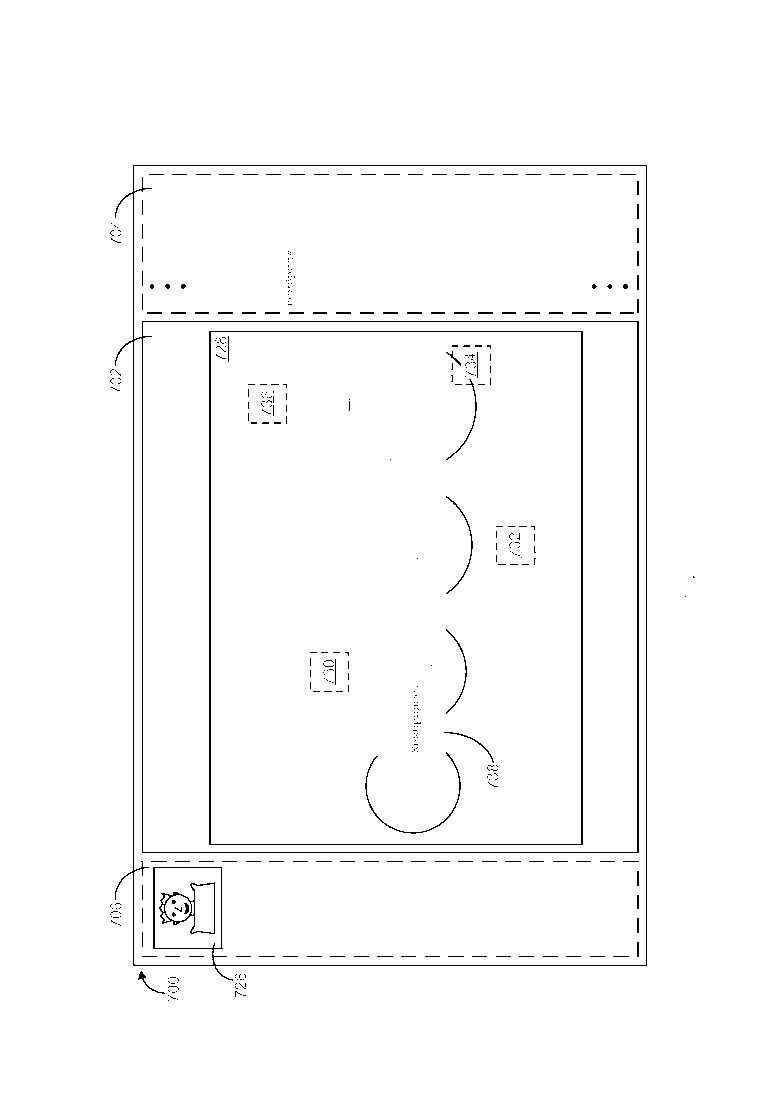
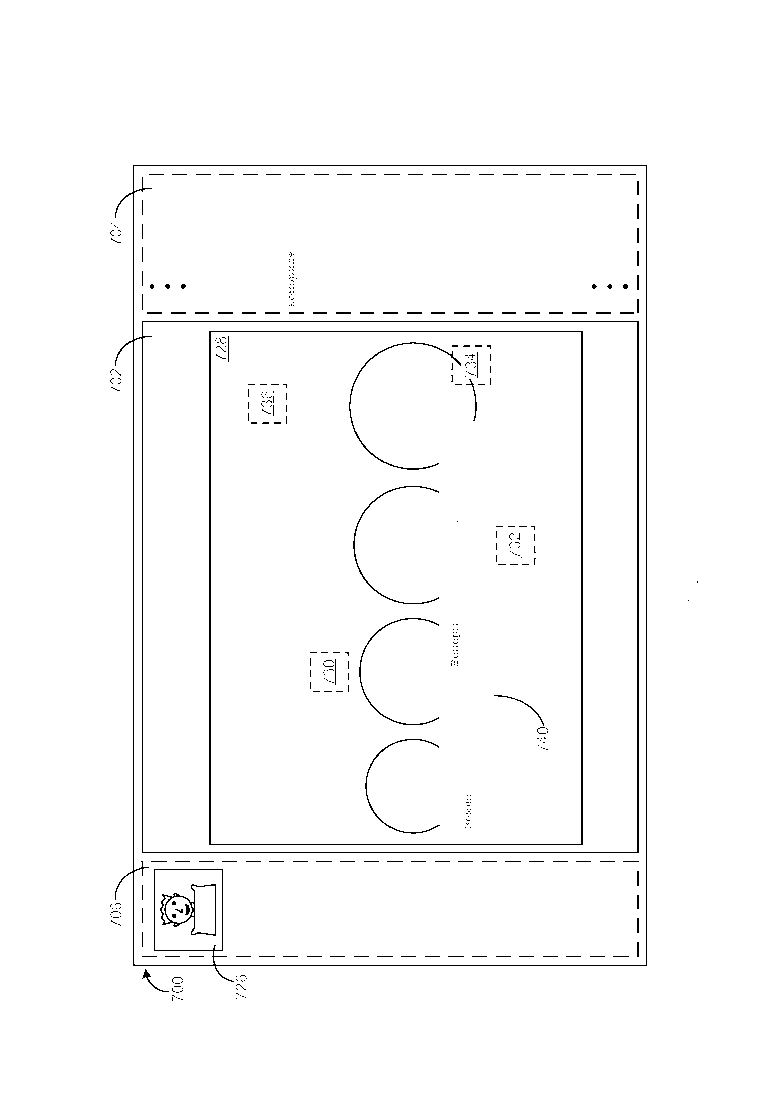
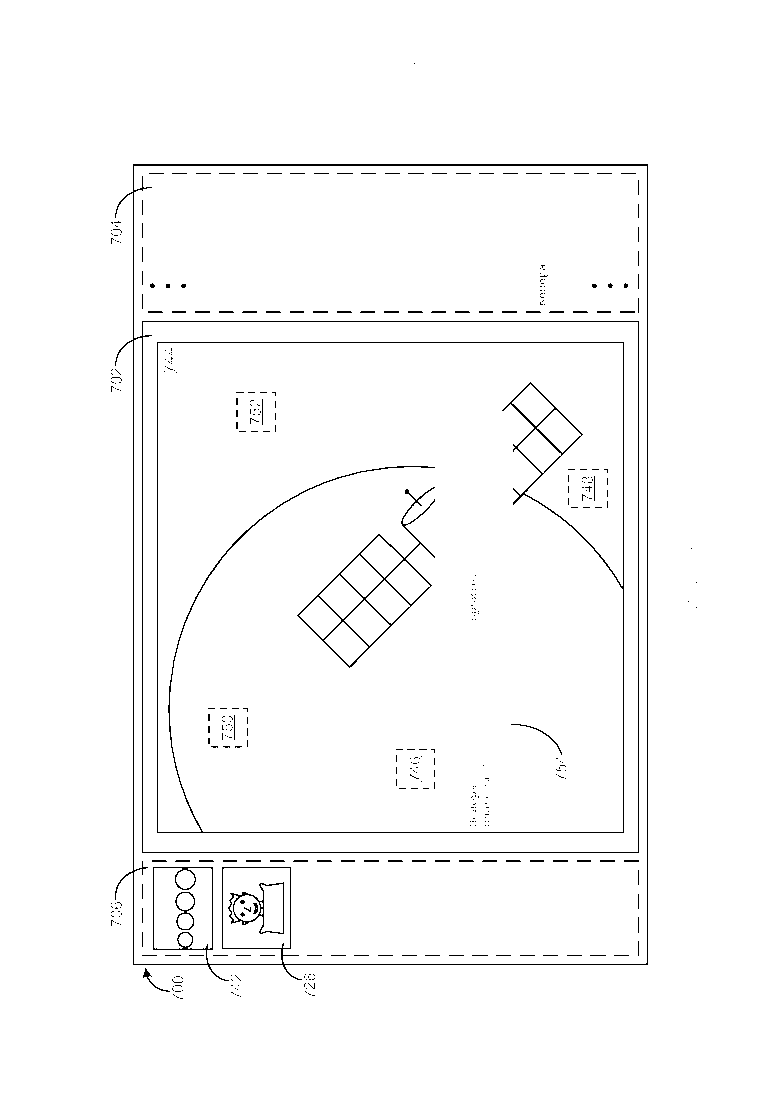
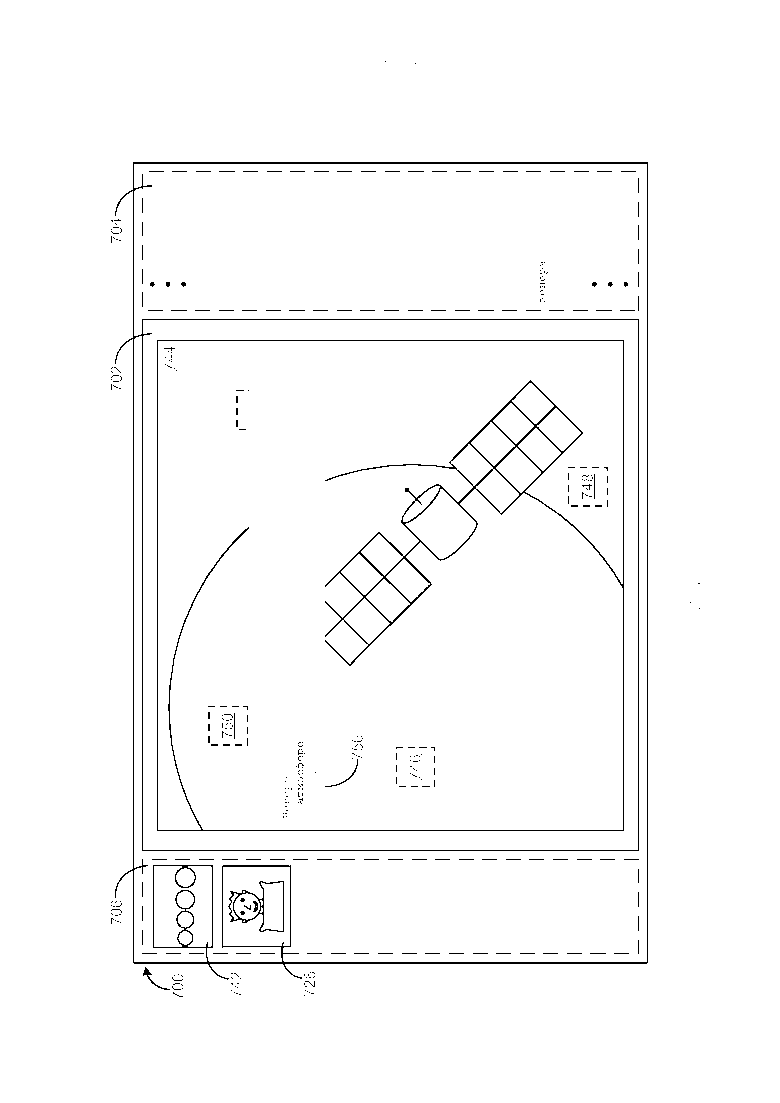
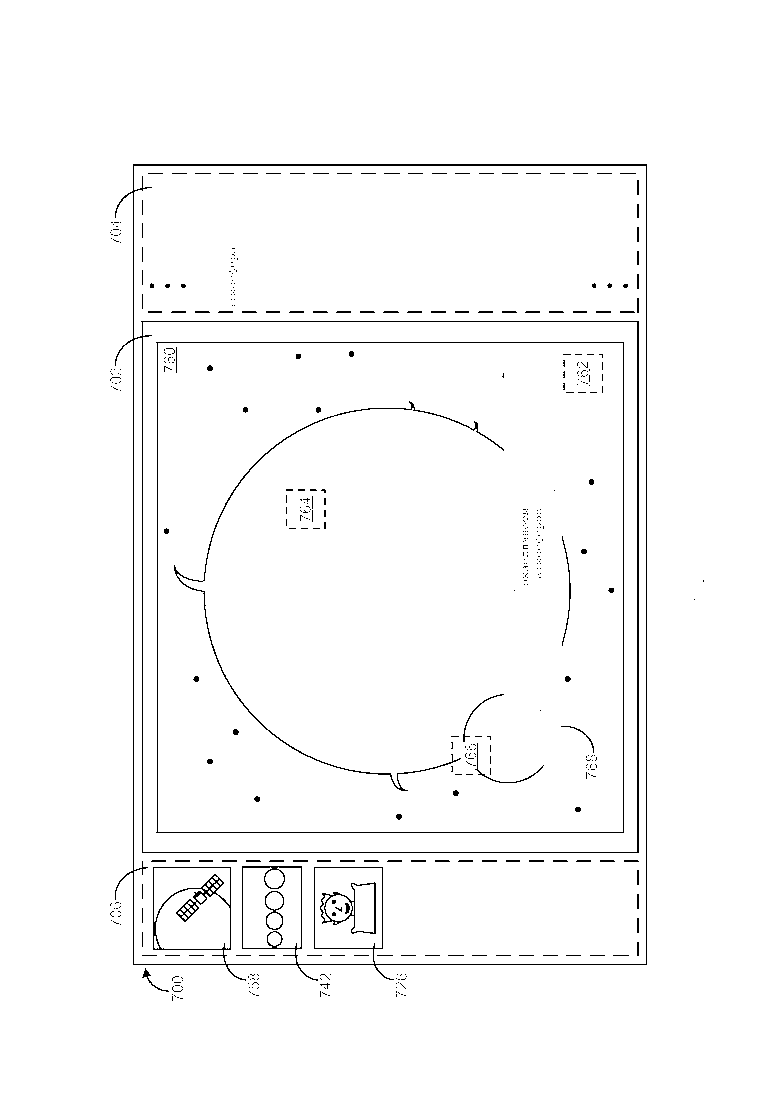
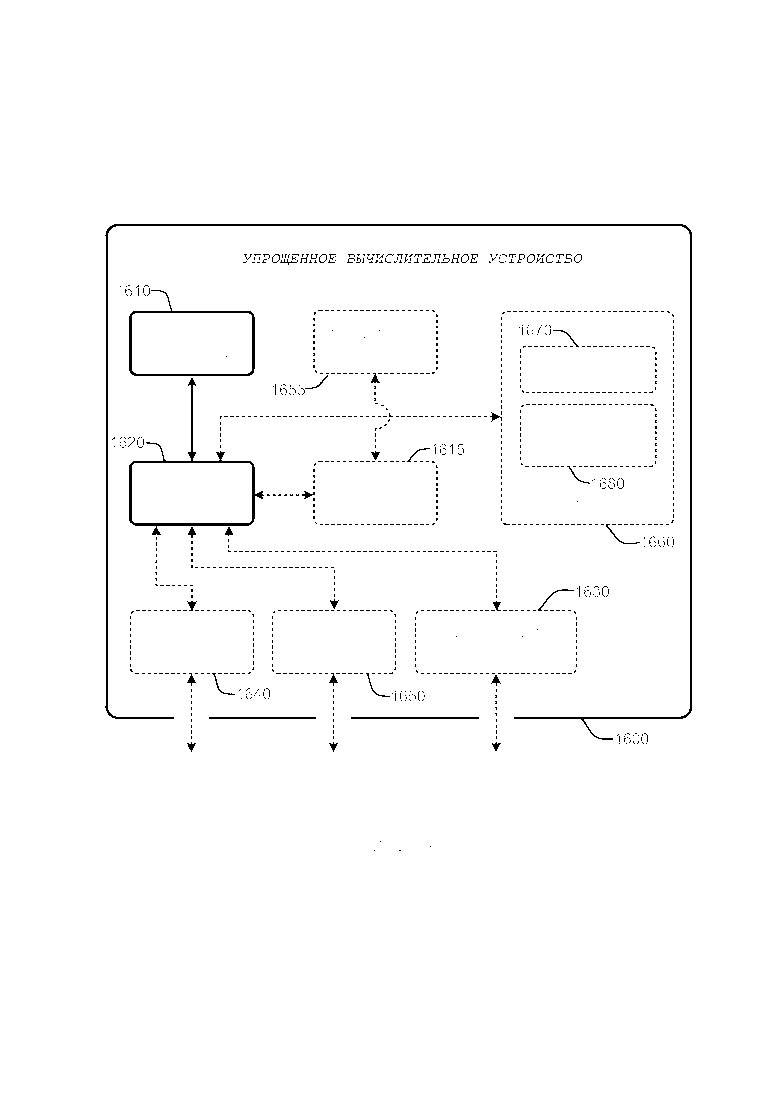
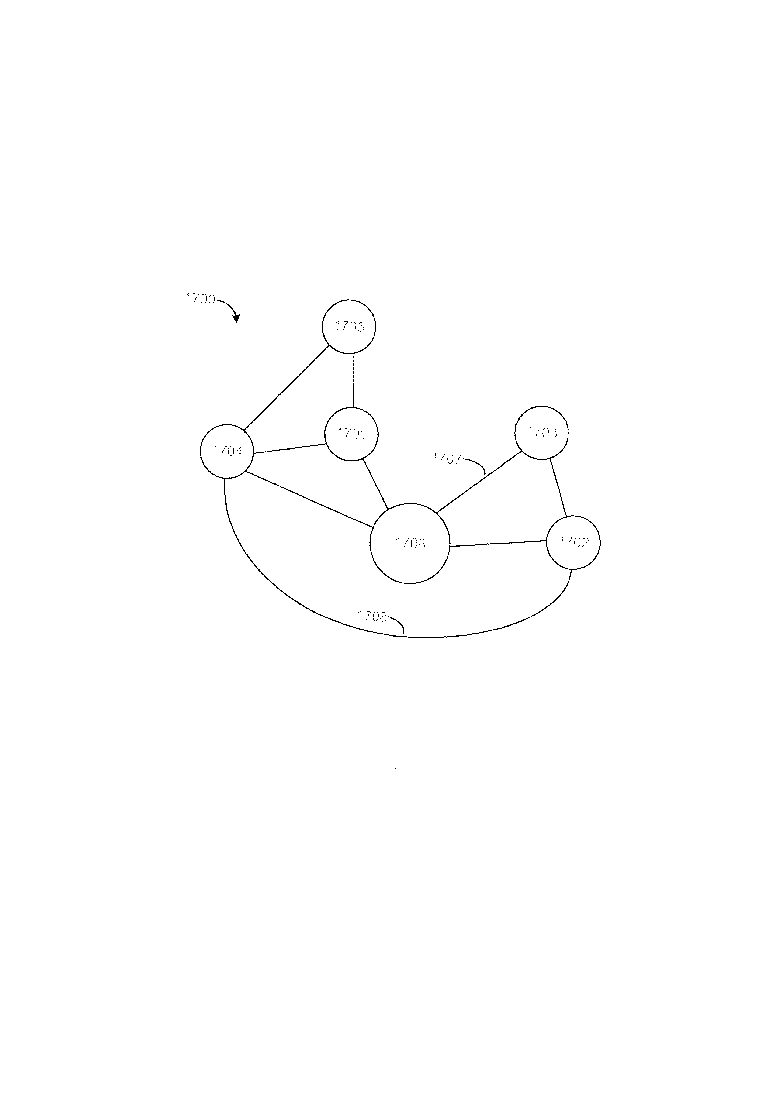
Изобретение относится к вычислительной технике. Технический результат заключается в оптимизации результативности и эффективности процесса поиска изображения и сокращении количества времени, которое требуется пользователю, чтобы найти конкретные изображения. Компьютерно-реализуемый способ подготовки изображений, хранящихся в хранилище информации, для браузинга содержит этапы, на которых для каждого из изображений в хранилище выполняют интеллектуальный анализ текста, чтобы извлечь один или более фрагментов текста об этом изображении, причем каждый из этих фрагментов является семантически релевантным данному изображению, и для каждого из извлеченных фрагментов текста об изображении обнаруживают одно или более ключевых понятий в этом фрагменте, причем ключевое понятие представляет собой семантически значимый концепт, который относится к изображению, и ассоциируют данный фрагмент и ключевое понятие с изображением; и связывают гиперссылкой каждое из ключевых понятий, ассоциированных с изображением, с другими изображениями в хранилище, с которыми ассоциировано данное ключевое понятие, при этом ключевое понятие других изображений представляет собой семантически значимый концепт, относящийся к изображению. 2 н. и 11 з.п. ф-лы, 17 ил.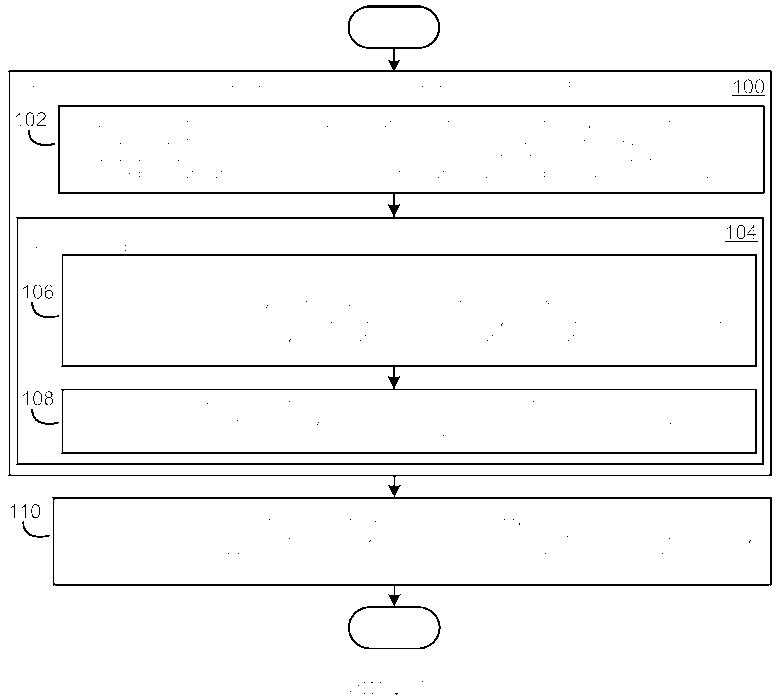
1. Компьютерно-реализуемый способ подготовки изображений, хранящихся в хранилище информации, для браузинга, причем хранилище содержит множество изображений и текст, при этом способ содержит использование компьютера для выполнения следующих этапов способа, на которых:
для каждого из изображений в хранилище,
выполняют интеллектуальный анализ текста в хранилище, чтобы извлечь один или более фрагментов текста об этом изображении, причем каждый из этих одного или более фрагментов является семантически релевантным данному изображению, и
для каждого из извлеченных фрагментов текста об изображении,
обнаруживают одно или более ключевых понятий в этом фрагменте, причем каждое из ключевых понятий представляет собой семантически значимый концепт, который относится к упомянутому изображению, и
ассоциируют данный фрагмент и упомянутые одно или более ключевых понятий с упомянутым изображением; и
связывают гиперссылкой каждое из ключевых понятий, ассоциированных с упомянутым изображением, с другими изображениями в хранилище, с которыми ассоциировано данное ключевое понятие, с использованием структуры данных инвертированного индекса, при этом упомянутое ключевое понятие упомянутых других изображений представляет собой семантически значимый концепт, относящийся к упомянутому изображению.
2. Способ по п. 1, в котором изображения и текст в хранилище хранятся в форме web-страниц, и этап способа по выполнению интеллектуального анализа текста в хранилище для извлечения одного или более фрагментов текста об изображении содержит этапы, на которых:
идентифицируют все из web-страниц в хранилище, которые включают в себя упомянутое изображение;
извлекают законченные предложения из идентифицированных web-страниц и вычисляют объединенный балл релевантности и интересности для каждого из извлеченных законченных предложений;
выбирают любые из извлеченных законченных предложений, у которых объединенный балл релевантности и интересности больше, чем предписанное пороговое значение балла; и
назначают эти выбранные предложения в качестве извлеченных фрагментов текста об изображении.
3. Способ по п. 2, дополнительно содержащий этапы, на которых:
генерируют список триад, при этом каждая триада соответствует отличающейся от других одной из идентифицированных web-страниц и включает в себя унифицированный указатель ресурса (URL) конкретного изображения, URL идентифицированной web-страницы и код языка гипертекстовой разметки (HTML-код) для идентифицированной web-страницы;
генерируют случайное подмножество триад путем случайного выбора предписанного количества триад из списка триад;
для каждой из идентифицированных web-страниц в этом случайном подмножестве триад,
генерируют дерево синтаксического разбора посредством синтаксического разбора HTML-кода для идентифицированной web-страницы, при этом дерево разбора содержит узлы изображения и узлы текста, ассоциированные с HTML-кодом;
определяют линейное упорядочение узлов изображения и текста в идентифицированной web-странице;
идентифицируют один из узлов изображения, который включает в себя URL конкретного изображения;
разбивают каждый из узлов текста на одно или более предложений;
выполняют фильтрацию этих одного или более предложений, чтобы изъять любое предложение, которое не начинается с заглавной буквы и не заканчивается должным знаком пунктуации;
вычисляют расстояние в символах от каждого из отфильтрованных предложений до идентифицированного узла изображения;
генерируют вектор слов предложения для каждого из отфильтрованных предложений;
агрегируют текст, который ассоциирован с идентифицированным узлом изображения в каждой из идентифицированных web-страниц в упомянутом случайном подмножестве триад;
генерируют вектор слов изображения для данного агрегированного текста.
4. Способ по п. 3, дополнительно содержащий этапы, на которых:
для каждого из отфильтрованных предложений в каждой из идентифицированных web-страниц в упомянутом случайном подмножестве триад,
генерируют балл релевантности для отфильтрованного предложения, представляющий оценку того, насколько релевантным конкретному изображению является отфильтрованное предложение;
генерируют балл интересности для отфильтрованного предложения, представляющий оценку того, насколько интересным для пользователя является отфильтрованное предложение; и
генерируют общий балл для отфильтрованного изображения из баллов релевантности и интересности, причем данный общий балл показывает, насколько релевантным и интересным является отфильтрованное предложение;
выбирают отфильтрованные предложения, у которых объединенный балл релевантности и интересности выше, чем предписанное пороговое значение балла; и
назначают выбранные отфильтрованные предложения в качестве фрагментов текста о конкретном изображении.
5. Способ по п. 3 или 4, в котором идентификация одного из узлов изображения, который включает в себя URL конкретного изображения, дополнительно содержит этапы, на которых удаляют идентифицированную web-страницу из упомянутого случайного подмножества триад всякий раз, когда либо ни один из узлов изображения не включает в себя URL конкретного изображения, либо более чем один из узлов изображения включает в себя URL конкретного изображения.
6. Компьютерно-реализуемый способ обеспечения пользователю возможности выполнять браузинг изображений, хранящихся в хранилище информации, которые подготовлены способом по любому из пп. 1-5, содержащий использование компьютерной системы, содержащей устройство отображения, для выполнения следующих этапов способа, на которых:
отображают на устройстве отображения графический пользовательский интерфейс (GUI) браузинга изображений, причем GUI содержит сектор текущего изображения;
принимают от пользователя запрос на просмотр требуемого изображения в хранилище;
отображают требуемое изображение внутри сектора текущего изображения; и
отображают один или более активных участков сверху требуемого изображения, причем каждый из активных участков связан гиперссылкой с отличающимся от других фрагментом текста о требуемом изображении, который является семантически релевантным требуемому изображению и содержит одно или более ключевых понятий, причем каждое из ключевых понятий представляет семантически значимый концепт, который относится к требуемому изображению, причем каждое из ключевых понятий связано гиперссылкой с каждым другим изображением в хранилище, с которым ассоциировано упомянутое ключевое понятие, с использованием структуры данных инвертированного индекса, при этом упомянутое ключевое понятие упомянутых других изображений представляет собой семантически значимый концепт, относящийся к требуемому изображению.
7. Способ по п. 6, дополнительно содержащий этапы, на которых:
обнаруживают выбор пользователем одного из активных участков;
отображают фрагмент текста, который связан гиперссылкой с выбранным активным участком в GUI; и
выделяют каждое из ключевых понятий в отображаемом фрагменте текста таким образом, который позволяет пользователю различать ключевое понятие от остальной части текста в отображаемом фрагменте текста.
8. Способ по п. 7, дополнительно содержащий этапы, на которых:
обнаруживают выбор пользователем одного из ключевых понятий в отображаемом фрагменте текста;
выбирают другое изображение из хранилища информации, с которым также ассоциировано выбранное ключевое понятие;
отображают выбранное другое изображение внутри сектора текущего изображения; и
отображают один или более активных участков сверху выбранного другого изображения, при этом каждый из активных участков связан гиперссылкой с отличающимся от других фрагментом текста о выбранном другом изображении, который является семантически релевантным выбранному другому изображению и содержит одно или более ключевых понятий, причем каждое из ключевых понятий представляет собой концепт, который относится к выбранному другому изображению, или объект, который относится к выбранному другому изображению, причем каждое из ключевых понятий связано гиперссылкой с каждым другим изображением в хранилище, с которым ассоциировано упомянутое ключевое понятие.
9. Способ по п. 8, в котором при упомянутом выборе другого изображения из хранилища информации, с которым также ассоциировано выбранное ключевое понятие, выбирают из хранилища другое изображение, с которым выбранное ключевое понятие ассоциировано наибольшее количество раз.
10. Способ по п. 8, в котором GUI дополнительно содержит сектор истории изображений, который предоставляет пользователю хронологически организованную историю изображений, которые пользователь просматривал ранее, при этом способ дополнительно содержит этапы, на которых:
отображают миниатюру требуемого изображения внутри сектора истории изображений;
обнаруживают выбор пользователем упомянутой миниатюры;
повторно отображают требуемое изображение внутри сектора текущего изображения; и
повторно отображают один или более активных участков сверху требуемого изображения.
11. Способ по п. 7, дополнительно содержащий этапы, на которых:
обнаруживают выбор пользователем одного из ключевых понятий в отображаемом фрагменте текста;
генерируют запрос к поисковой машине, причем данный запрос содержит либо выбранное ключевое понятие, либо весь отображаемый фрагмент текста;
принимают результаты поиска от поисковой машины; и
отображают результаты поиска внутри сектора текущего изображения.
12. Способ по п. 7, дополнительно содержащий этапы, на которых:
обнаруживают выбор пользователем одного из ключевых понятий в отображаемом фрагменте текста; и
отображают миниатюры других изображений в хранилище информации, с которыми также ассоциировано выбранное ключевое понятие, внутри сектора текущего изображения.
13. Способ по п. 6, в котором каждый отличающийся от других фрагмент текста о требуемом изображении содержит объединенный балл релевантности и интересности, при этом способ дополнительно содержит этап, на котором отображают используемый по умолчанию фрагмент текста о требуемом изображении в GUI, причем этот используемый по умолчанию фрагмент текста содержит либо:
фрагмент текста о требуемом изображении, содержащий наивысший объединенный балл релевантности и интересности; либо
фрагмент текста о требуемом изображении, в котором конкретное ключевое понятие, которое пользователь выбирал самым последним, встречается наибольшее количество раз; либо
фрагмент текста о требуемом изображении, в котором конкретный терм запроса, который пользователь изначально использовал для поиска требуемого изображения, встречается наибольшее количество раз.
| Станок для изготовления деревянных ниточных катушек из цилиндрических, снабженных осевым отверстием, заготовок | 1923 |
|
SU2008A1 |
| Станок для изготовления деревянных ниточных катушек из цилиндрических, снабженных осевым отверстием, заготовок | 1923 |
|
SU2008A1 |
| Колосоуборка | 1923 |
|
SU2009A1 |
| Приспособление для суммирования отрезков прямых линий | 1923 |
|
SU2010A1 |
| Изложница с суживающимся книзу сечением и с вертикально перемещающимся днищем | 1924 |
|
SU2012A1 |
| Способ приготовления лака | 1924 |
|
SU2011A1 |
| Способ приготовления лака | 1924 |
|
SU2011A1 |
| ПРИОРИТЕТНОЕ СВЯЗЫВАНИЕ | 2005 |
|
RU2405190C2 |

