Настоящее изобретение относится к компьютерным и мобильным устройствам, и в частности, к выбору содержания на основе неявного взаимодействия пользователя с содержанием, отображаемым на экране.
Пользователи мобильных устройств обычно запускают специальные узкие приложения вместо тяжеловесных обычных браузеров, которые занимают большое количество системных ресурсов. Таким образом, мобильные пользователи не используют обычный поиск почти также часто, как и пользователи персональных компьютеров. Соответственно, наиболее популярными способами монетизации на компьютерных устройствах являются релевантные информационные блоки (такие как реклама, баннеры, рекламные блоки, ссылки на веб страницы, текстовые сообщения, веб-страницы и т.д.) и приложения, встроенные в веб-ресурсы.
Релевантные информационные блоки (релевантные блоки данных) - это небольшая реклама, которая занимает части экранов мобильных устройств, которые обычно совсем малы. Поскольку релевантные информационные блоки также очень малы, они содержат очень простые рекламные данные (то есть короткий текст). Эта простая реклама в основном раздражает пользователей и не привлекает внимания, и не побуждает интерес пользователя.
Традиционный способ рекламирования делает каждую рекламу отличной от другой, даже если две рекламы рекламируют один и тот же тип действия, например, "продажу". Данный рекламный подход может быть эффективен для статичных ситуаций, когда у клиента имеется достаточно времени и находится в соответствующем состоянии сознания для просмотра рекламы. Однако пользователи компьютерных устройств находятся в режиме "на ходу". Эти пользователи не желают тратить много времени и сил, чтобы осознать, что основной смысл двух различных реклам одинаков - "продажа" продуктов различных марок.
Настоящее изобретение предоставляет способ для идентификации искомых кандидатов в отображаемом содержании, включая получение содержания, которое включает необработанное содержание, элементы разметки и стили элементов; идентификацию сырого контента в необработанном содержании; применение части стилей содержания к элементам разметки, чтобы определить, какая последовательность части содержания представляет сплошные логически и визуально связанные части содержания; выполнение синтаксического анализа связанных частей для генерирования множества деревьев разбора; использование словаря, выполнение морфологического анализа для определения частей речи и морфологии слов в связанных частях; выполнение стеммирования над частями речи и построение цепочек, удовлетворяющих правилам грамматики; идентификацию изюма в цепочках и подсчет весов изюма; корректировка весов на основе расстояния соответствующих частей содержания от точки взаимодействия пользователя с содержанием; выбор изюма с наибольшим весом и наивысшей степенью принадлежности области вокруг точки взаимодействия пользователя; корректировка изюма, расположенных около точки взаимодействия и использование точки взаимодействия в качестве входных данных для выбора информации для отображения пользователю и отображение выбранной информации.
Необработанное содержание может быть получено отдельно в качестве элементов разметки и стилей элементов. По крайней мере, некоторые части содержания могут содержать содержание, представленное различными геометрическими частями содержания. Необработанное содержание может представлять собой содержание веб-страницы. Части содержания могут быть связаны логически и геометрически. Части содержания могут включать слова, фразы, предложения, абзацы, все содержание веб-страницы, рекламные материалы, баннеры, трехмерное содержание, видео, части слов, части выражений, части предложений, части изображений, части видео. Логические и геометрические связи могут включать связи между словами, фразами, предложениями, абзацами, всем содержимым веб-страницы, рекламными материалами, баннерами, трехмерным содержанием, видео, частями слов, частями фраз, частями предложений, частями изображений, частями видео. Изюминки могут быть видимы и выбираемы пользователем. Изюминки могут быть использованы в качестве запроса к поисковой системе для генерирования результатов поиска. Запрос модифицируется данными из собранных инфо-данных. Основанные на запросе результаты поиска могут быть представлены пользователю. Перед представлением пользователю результаты поиска модифицируются, как описано далее, и результаты поиска модифицируются для исключения результатов на основании предварительно выбранных параметров поиска: категориях, черном списке сайтов, географического положения, и результаты поиска модифицируются, чтобы включить в себя результаты из других поисковых систем, рекламных сервисов и элементов из других приложений. Изюминки могут быть получены из цепочек с наибольшими весами. Вычисление весов изюма использует собранные инфо-данные. Анализ текста также может включать анализ изображений, анимации, элементов игр, рекламы и трехмерных моделей.
Техническим результатом настоящего решения является автоматическое определение релевантных пунктов, характеризующих возможный интерес пользователя вблизи точки взаимодействия пользователя с контентом для последующего выбора и отображения связанной с ними информации.
На фигурах:
ФИГ. 1 иллюстрирует отображение релевантных информационных блоков на компьютерном устройстве в соответствии с иллюстративным вариантом;
ФИГ. 2 иллюстрирует архитектуру системы в соответствии с иллюстративным вариантом;
ФИГ. 3 иллюстрирует блок-схему способа точного подбора рекламы в соответствии с иллюстративным вариантом;
ФИГ. 4 иллюстрирует блок-схему способа точного подбора рекламных материалов в соответствии с иллюстративным вариантом;
ФИГ. 5 иллюстрирует блок-схему способа точного подбора рекламных материалов, в соответствии с иллюстративным вариантом;
ФИГ. 6 иллюстрирует примерный анализ отображенных элементов содержания;
ФИГ. 7 иллюстрирует блок-схему способа для построения семантического текстового профиля;
ФИГ. 8 иллюстрирует блок-схему основного способа системы для подбора релевантных элементов (в данном примере, элементы являются словами в тексте);
ФИГ. 9 иллюстрирует точный подбор рекламных материалов и графическое представление целевой рекламы пользователю;
ФИГ. 10 демонстрирует пример логической связи между элементами содержания;
ФИГ. 11 иллюстрирует пример релевантных/значимых слов и связанных и ними слов;
ФИГ. 12 показана диаграмма аппроксимации, на которой показана концентрация плотности вероятностей встречающихся особенных элементов для содержания из ФИГ. 11.
ФИГУРЫ 13-15 иллюстрируют анализ вычисления уровня элементов для идентификации изюма;
ФИГ. 16 иллюстрирует еще один иллюстративный вариант изобретения по отображению информации, в зависимости от того, как пользователь взаимодействует на своем компьютерном устройстве.
Согласно иллюстративному варианту система может показывать один или несколько релевантных информационных блоков, связанных с определенным контекстом, и нечетко выбранными элементами показанных данных для любых текстовых или графических данных. Релевантные информационные блоки могут быть показаны на основе "собранных инфо-данных": местоположения пользователя, контекста содержания, контекста веб-страницы, содержания веб-страницы, истории просмотра Интернета пользователем, статистики медиа-сайтов, части содержания веб-сайта, метаданных страницы, открытых данных социального профиля пользователя (т.е. возраста, пола, должности, интересов, дружбы), тегов, связанных с текущим пользователем, предоставленных сторонними сервисами (DMP, DSP) и других, т.е. всех данных из доступных источников посредством компьютерных устройств. Такая информация может быть собрана в фоновом режиме с рекламного сервера, сервера издателя, компьютерного устройства (компьютерных устройств) пользователя, устройств и систем (включая почтовые серверы, социальные сервисы, облачные серверы/сервисы, веб-сервисы), подключенных к компьютерному устройству пользователя.
Стоит отметить, что релевантный информационный блок может быть в форме дополнительной информации в различных форматах, которая может быть актуальна для пользователя. Например, релевантный информационный блок-изображение, может быть текстовыми блоками, (такими как рекламные баннеры, рекламные релевантные информационные блоки, ссылки на веб-страницы, выделенные части текста), медиа-данными, веб-страницами и др. Релевантные информационные блоки называются рекламой. Вместе с тем любая релевантная информация может быть отображена пользователю.
Список релевантных информационных блоков генерируется автоматически на основе содержания веб-страницы или выбранной порции содержания (или части содержания) (текста, изображения, части текста, части изображения, мультимедиа, всего содержания веб-страницы, рекламы, баннеров, трехмерного содержания, видео, частей слов, частей фраз, частей предложений, частей изображений, частей видео, видеопотока, части видеопотока, аудиопотока, части аудиопотока, трехмерных моделей и т.д.) и его контекста. Кроме того, любое сочетание целевых параметров может быть принято во внимание для генерирования релевантных информационных блоков. Контекст веб-страницы сканируется и функция интерфейса программного приложения вычисляет атрибуты контента с предустановленными параметрами, которые добавляются для каждого элемента структуру содержания. Стоит отметить, что атрибуты содержания могут быть предварительно рассчитано. Функция интерфейса программного приложения проводит явные (или неявные) ассоциации элементов с их атрибутами. Интерфейс программного приложения анализирует предоставленную часть текста и активирует элементы управления, которые инициируют переход к релевантному информационному блоку (блокам).
Иллюстративный вариант преимущественно использует узкий контекст содержания, явно выбранного пользователем. Изначально, некоторые существенные части или содержание страницы будут выделены для выбора их пользователем, после того как пользователь укажет точку на экране содержимого страницы (кликнет мышью, коснется экрана). Релевантные информационные блоки показываются на основе интересов пользователя, указанной частью текста или части содержания (или гиперссылки и ее содержания) и целевыми параметрами. В иллюстративном варианте релевантная область, прилегающая к части текста, выбранного пользователем, называется контекстом. Выбранное содержание может быть словом или комбинацией слов (выражением), и контекст может включать предложение, абзац или весь текст (в случае небольшого текста).
Согласно иллюстративному варианту пользователи могут уведомить систему о своей заинтересованности в той или иной части содержания, используя, например, инфракрасную камеру, инфракрасный датчик или видеокамеру, где датчик регистратор (интегрированное или внешнее устройство типа Kinect) заменяет физический "сенсорный экран" и распознает жесты пользователей и ассоциирует их с контекстом на экране. Кроме того, текст может быть выделен с помощью мыши. В случае использования мыши пользователь может выделить часть контекста (то есть часть текста или изображения) и использовать щелчок правой кнопкой мыши на выбранном контексте и выбрать в меню "показать релевантный блок данных". Движения и клики мышью могут быть реализованы с помощью клавиатуры. Кроме того, может быть использована специальная кнопка клавиатуры для отображения релевантных блоков данных. Кроме того, пользователи могут использовать микрофон, например, Siri-подобные модели (то есть датчик с фоновым модулем распознавания голоса, который может быть интегрированным, внешним или серверным).
Пользователь указывает часть контекста и свои пожелания посредством голосового комментария, кинестетического детектора (то есть пользователь использует джойстик), мыши или носимых датчиков (то есть специальных перчаток), детектора движения глаз (пользователь может использовать устройство, например, такое как Google-очки или специальная камера), который может распознать часть контекста, на который смотрит пользователь, по положению глаз пользователя и команды (например, двойное мигание) для "активирования" данного решения. Стоит отметить, что иллюстративный вариант использует только часть текста, который считается в качестве выражения интереса пользователей.
Выражение может содержать термин, именованную сущность или фразу, которые, будучи дополненными заголовком всей страницы/параграфа, могут быть использованы для суженного выбора. Дополнительным преимуществом такой явной "активации" является то, что она определяет пользователя, который находится в состоянии "изыскания", "любопытства" или "спроса". В отличие от гиперссылок любая часть текста - кликабельна (то есть выбираемой). Клик, прикосновение, глазом, кинетическое или другое действие, выполненное на элементе страницы (то есть тексте, изображении, медиа-контенте, части текста, части аудио/видео файла) ведет к списку релевантных информационных блоков (страниц, ссылок на страницы, ссылок на элементы страницы), соответствующих содержанию, контексту, конкретному выбору и профилю пользователя и целевым параметрам. Таким образом, пользователю показывается самый релевантный информационный блок.
Согласно одному иллюстративному варианту некоторые элементы могут быть исключены из предварительного просмотра, или они могут быть заменены общими изображениями (или значками). Использование значков вместо некоторых менее релевантных элементов страниц снижает сетевой трафик и нагрузку на мобильное устройство. Это также повышает скорость отображения веб-страниц. Почти любой активируемый (кликабельный, касабельный и др.) текст принимает в счет близлежащий контекст и ведет не на одну страницу, а на список релевантных информационных блоков/страниц, соответствующий содержанию, контексту, конкретному выбору и профилю пользователя.
Согласно другому иллюстративному варианту реализуется основанная на содержании динамическая реклама по запросу. Любой тип содержания (например, видео, аудио, текст и т.д.) имеет тенденцию вызывать или увеличивать желание людей, просматривающих (или прослушивающих) содержание. Существует прямая связь между содержанием и некоторыми желаниями, вызванными содержанием. Согласно иллюстративному варианту данная связь используется для целевой рекламы.
Любая часть содержания (и соответствующего контекста), которая создает определенные желания и ассоциации, может быть использована для нацеливания рекламы (релевантных информационных блоков) на пользователя. Однако основной проблемой является то, что элементы в цепочке Текст → Желание → Удовлетворение, описанное в терминах слово-векторы, не являются близкими друг к другу геометрически. Это значит, что страница или описания продукта, удовлетворяющие определенному желанию, могут не содержать слов первоначального Текста и не именовать или неявно относиться к самому желанию. Таким образом, необходим некоторый анализ ассоциаций Текст-Желание-Удовлетворение. За исключением очевидных случаев ассоциации между Текстом и Удовлетворением могут быть сделаны статистически на основе пользовательских переходов.
Стоит отметить, что когда реклама актуальна с точки зрения пользовательских желаний и ожиданий, она больше не рассматривается пользователем как реклама. Вместо этого, пользователь воспринимает целевую рекламу как полезную информацию. Согласно иллюстративному варианту, пользователю предоставляется возможность явно указать часть содержания (например, параграф внутри текста или название продукта), которая провоцирует интерес (или желания). Набор пользовательских целей/желаний (элементов содержания, которые обозначают потенциальный пользовательский интерес) реализован как набор атрибутов элемента (атрибутов информационного блока), автоматически сгенерированного для данного содержания. Система определяет наиболее подходящие атрибуты элемента содержания для конкретного пользователя.
Согласно иллюстративному варианту атрибуты элемента содержания описывают возможные намерения пользователя в отношении тем, раскрытых в содержании и/или смежным темам. Атрибуты элемента содержания могут быть реализованы в виде ранжированного списка ключевых слов, биграмм, дескрипторов тем и т.д., извлеченных из контекста и расширенных синонимом и статистически связанными дескрипторами. Дескрипторы представляют собой простые текстовые метки, расширяющие набор известных слов. Например, процесс может быть описан следующим образом:
текст "СВР - Сингулярных величин разложение - линейной алгебры алгоритм", после лексического анализа и стеммирования помечаются следующим начальным списком дескрипторов:
[кс|свр, кс|сингулярных, кс|величин, кс|разложение, кс|лин, кс|алгебры, кс|алгоритм, бг|сингулярных + величин, бг|величин + разложение, бг|лин + алгебре, бг|алгебре + алгоритм].
Далее список отправляется на категоризацию. После детектирования директорий (маркировки) список расширен на основе словарей категорий следующими метками:
[кат|компьютерные + технологии, кат|компьютеры + устройства, кат [образование].
После получения конкретной части предложения, указанной пользователем, например, ‘свр’, алгоритм способен обнаружить (из статистики), что поиск с ключевым словом "свр" на тему компьютерных технологий не является приводящей к операции (т.е. не ведет к покупке или регистрации, или к чему-то коммерчески значимому). Таким образом, возможные требования, ассоциирующиеся с данными категориями (и контекстом) ограничены до "Узнать больше". Поэтому к контекстным дескрипторам добавляется новая метка:
[нам|узнать + больше]. Здесь, приставки кс|, бг|, кат| и нам| обозначают ключевое слово, биграмму, категорию и намерение, соответственно.
Анализируется все содержание. Когда пользователь выбирает небольшую часть содержания, кликнув на ней, атрибуты элемента содержания, отражающие данную часть, генерируются и используются для нацеливания пользователя на соответствующую рекламу. Для этого система распознает части содержания, части речи, значение слов и др. При помощи технологии ОЕЯ (Обработки Естественного Языка) и семантического анализа содержания и контекста.
Учитывая, что ОЕЯ обработка может занять значительное время в зависимости от размера содержания, задержки могут повлиять на удобство использования системы. Атрибуты элемента содержания самого содержания могут быть сгенерированы заранее и закешированы, и захешированы для последующего использования. Таким образом, пользователю показывается высокорелевантная реклама по запросу, где реклама предоставляется в ответ на прямой запрос клиента (в отличие от принудительного режима), и эта реклама представляется как полезные рекомендации, а не как прямая реклама. Эта реклама является более эффективной, чем случайным образом отображаемая статическая реклама или мигающие релевантные информационные блоки. Другими словами, пользователь указывает на определенную часть содержания и явным образом указывает, что он хочет увидеть.
Это имеет преимущества по сравнению с обычной рекламой Google™, которая требует от пользователя переключиться на поиск Google™ и ввести поисковую строку. Это особенно важно на компьютерных устройствах (мобильных телефонах, ноутбуках, настольных компьютерах, игровых консолях, телевизорах, интернет-планшетах, планшетных компьютерах, ультра-мобильных компьютерах, мобильных интернет-устройствах, электронных книгах, смартфонах и др.), поскольку поиск (используя Google™ или другие средства) сильно привязан к способности ввода, который весьма ограничен в отношении компьютерных устройств. На стационарных компьютерах случай "Читать → Выбрать → Поисковый выбор" гораздо проще, чем на компьютерных устройствах. Иллюстративный пример обеспечивает пользователей быстрым вызовом: "Читать → Указать → Искать".
Стоит отметить, что ОЕЯ технология обеспечивает автоматизированный анализ частей текста, выбранных пользователем, и определение содержания текста. ОЕЯ также определяет основные объекты, такие как ассоциации, субъекта, географический объект, количество/объем, деньги/валюту, проценты, данные компании и др. Список объектов может быть расширен с помощью атрибутов элемента и целевыми данными (например, временем, географическим местоположением, личными предпочтениями, ассоциациями пользователя, регистрациями и членством в социальных сетях, полом, языком и др.). Согласно иллюстративному варианту NPL помогает пользователю, когда пользователь испытывает трудности с запоминанием и вводом поискового текста или с выбором, копированием и вставкой нужного текста, или с выделением текста и запуском поиска.
Согласно иллюстративному варианту система использует ОЕЯ и "угадывания" частей текста, которые могут представлять интерес для пользователя, на основе приблизительного местоположения в тексте. Известные способы Извлечения Сущностей (ИС алгоритмы) могут быть использованы наряду со статистическим анализом степени необычности слов в части речи (ЧР) для конкретного параграфа, текста и его категории. Необычные слова (например, слова которые провоцируют интерес пользователя к определенной части содержания) могут быть сгруппированы по пользовательским интересам. Необычные слова используются как "изюминка" - пункты интересов, которые система может предложить пользователю.
Согласно одному иллюстративному варианту вместо поискового запроса могут быть использованы содержание и связанные с ним атрибуты элемента содержания на основе явного выбора пользователя. Атрибуты элемента содержания - это набор формализованных свойств, вытекающих из смысла содержания. Атрибуты элемента содержания (метаданные) представлены в виде машиночитаемого языка, включающего ключевые слова, биграммы, n-граммы, обнаруженные именованные сущности, ожидаемые категории, а также пользовательские категории и теги, основанные на частотных распределениях. Иными словами, используются все возможные данные, которые могут быть использованы для определения релевантности рекламы.
Согласно иллюстративному варианту используется двухкомпонентное нацеливание (или двухуровневое представление запроса) рекламы. Реклама нацелена на пользователя на основе комбинации контекстных атрибутов элемента содержания и выбора или явного указания слов. Этот новый подход обеспечивает преимущества над рекламой, основанной на поиске или на релевантных информационных блоках, которые используют либо общую тему страницы, либо явный поисковый запрос.
Специалист примет во внимание, что нацеленная реклама по запросу выигрышна для компьютерных устройств, имеющих небольшой размер экрана. Постоянно висящие релевантные информационные блоки (реклама) занимают место на экране и требуют изменения исходного содержания. Согласно иллюстративному варианту контекст (т.е. объект, такой как предложение или часть предложения, часть изображения, параграф статьи, фрагмент видео, изображение, трехмерная модель и т.д.), указанный пользователем, используется для рекламы вместо одиночного поискового условия, вырванного из контекста.
Таким образом, согласно иллюстративному варианту нерелевантная реклама будет полностью устранена. Реклама показывается по запросу, вместо релевантных информационных блоков, которые занимают пространство экрана. Реклама отображается согласно части содержания, явно выбранного пользователем. Таким образом, реклама показывает только релевантную информацию на основе части содержания, в отличие от некоторой общей рекламы на базе всего содержания.
Зная набор призывов "желаемого содержания" реклама может быть сгенерирована и показана. Например, отель - бронирование, отзывы; ресторан - меню, резервирование столика; продукт - купить, отзывы и т.д. Согласно иллюстративному варианту список ключевых объектов и их категории автоматически генерируются с помощью технологии Обработки Естественного Языка.
Например, если статья посвящена горнолыжному курорту и пользователь щелкнул на части, описывающей один из курортных отелей, то существует высокая вероятность того, что пользователь хочет узнать больше об этом отеле, забронировать там номер или купить билеты на подъемник и др. однако, если пользователь щелкает на новых лыжах, то, скорее всего, он хочет посмотреть некоторые отзывы и выяснить, где он может купить или взять их в прокат. Для реализации данного сценария система используется предварительно определенную ассоциативную модель, которая определяет список возможных действий для каждого типа объектов. Ассоциативная модель формируется на основании обратной связи с пользователем (то есть действиях пользователей). Ассоциативная модель может быть скорректирована на основании собранной статистики и маркетинговых исследований.
В случае, когда выбранная пользователем часть содержания является комплексной и содержит несколько потенциальных целей и пожеланий, процесс отображения рекламы выполняется в два шага. В первом шаге система определяет пожелания пользователя. Во втором шаге реклама генерируется на основании данных из первого шага и отображается пользователю. В первом шаге пользователю предоставляется список (слова и пиктограммы) возможных целей. Пользователя спрашивают, что является самым интересным для него в данный момент. Затем пользователь выбирает одну или несколько целей. Эти данные используются во втором шаге, и пользователю отображается реклама, релевантная выбранным пользовательским целям.
Согласно одному иллюстративному варианту весь экран компьютерного устройства (или его часть) может быть преобразована в одну активную гиперссылку, вместо большого количества гиперссылок (большинство из которых не используется). Это позволяет избежать постоянно отображенной рекламы и релевантных информационных блоков, которые занимают небольшой экран компьютерного устройства. Кроме того, пользователь может видеть неограниченное количество рекламы, поскольку релевантные информационные блоки показываются по запросу и не занимают место на экране в течение длительного времени.
Согласно иллюстративному варианту любое текстовое содержание может быть использовано для целевой рекламы. Система может отображать пользователям несколько релевантных информационных блоков на основе соответствующего контекста. Экранный интерфейс иллюстративного варианта может использовать элементы управления (панели, окна ввода, кнопки, флажки и др.) для дополнительных операций. Пользователь может переопределить запрос с помощью списка опций. Например, система может предоставить кнопку "Я разочарован" или "Не то, что я ищу", что означают, что клиент недоволен предложенной рекламой.
Также система может предоставить способ выбрать рекламу, которая близка (или очень близка) к потребностям клиента, но не вполне отвечает его требованиям. Это обеспечивает пользователю возможность оценить рекламу непосредственно на сайте с помощью кнопок "нравится", "не нравится" и т.д. Далее данная информация может быть использована в качестве обратной связи с рекламодателями для нацеливания рекламы и поощрения пользователей. Оно также обеспечивает клиентам эффект "геймификации" клиентам, например, увеличивает взаимодействие клиентов с рекламой и вовлекает внутренние мотиваторы, такие как чувство независимости и контроля. Активное управление вместе с релевантными информационными блоками изображено на ФИГ. 1.
Согласно иллюстративному варианту нацеленная реклама по запросу видима только временно, в отличие от навязчивых постоянных релевантных информационных блоков. Таким образом, реклама преимущественно не требует "места на полке " и не разрушает оригинальное содержание. Пользователю может быть отображено большое количество рекламы, усиливая эффект рекламы. Реклама не раздражает пользователя (или, по крайней мере, раздражает пользователя меньше, чем обычная реклама), поскольку она генерируется на основе пользовательских предпочтений. Реклама нацелена на конкретного пользователя на основе семантического контекстного анализа, при необходимости без отслеживания действий пользователя. Обеспечивается обратная связь от контентных пользователей.
Пользователи (клиенты) могут щелкнуть на части содержания, которое каким-то образом стимулирует их чувства - это обеспечивает дополнительную обратную связь о качестве содержания. Пользователи могут сообщить медиа-ресурсу напрямую - "это интересно" и "это не интересно". История щелчков и анализ "щелкнутых" частей содержания делает возможным распознавание шаблонов, которые могут помочь сделать содержание более привлекательным для пользователя. Реклама, которая получает больше определенного количества отрицательных пользовательских отзывов в течение периода времени Т, автоматически исключается из процесса представления, а рекламодатель получает уведомление.
Согласно иллюстративному варианту используется несколько порогов уведомлений о качестве с предопределенными действиями для отрицательных и положительных отзывов. Отзывы хранятся на сервере в форме связей: <реклама, временная метка, отзыв>. Только владелец сервера обладает прямым доступом ко всем данным для последующего анализа. Данные отзывов доступны пользователям в агрегированной форме (например, сумма, среднее и т.д.)
Пользователь инициирует процесс обратной связи путем щелканья/касания кнопки обратной связи. Каждая кнопка ассоциируется с идентификатором релевантного информационного блока (идентификатором веб-страницы), который передается на сервер обратной связи. Каждый отзыв регистрируется/сохраняется в базе данных в форме записи, содержащей:
- идентификатор релевантного информационного блока;
- сигнатура пользователя;
- временная метка; и
- тип обратной связи (например, нравится, не нравится, бесполезно, не соответствует теме, дорого, жалоба и др.).
Сигнатура пользователя - это хеш пользовательских данных браузера, которые не содержат никакой личной информации. Идентификатор релевантного информационного блока - это идентификатор рекламного сообщения. Временная метка - это текущее время с точностью до миллисекунд.
Согласно иллюстративному варианту каждый пользователь имеет доступ только к:
- агрегированным записям, отфильтрованным по пользовательской сигнатуре и агрегированным по идентификатору релевантного информационного блока;
- агрегированным записям, не отфильтрованным по идентификатору релевантного информационного блока.
Таким образом, никакие персональные данные, содержащиеся в отзывах других пользователей, не доступны пользователю.
Например, если объект - это новый автомобиль, список ассоциаций может включать поиск дилера, заказ пробной поездки, поиск нового автомобиля в кредит и др. Таким образом, реклама, предлагающая данные услуги, генерируется и отображается пользователю. Архитектура системы показана на ФИГ. 2. Система включает рекламный сервер 240. Рекламный сервер 240 обрабатывает содержание, хранит и выбирает рекламу. Специальные рекламные библиотеки 230 и 250 объединяют рекламный сервер 240 с медиа-ресурсами и приложениями, установленными на компьютерных устройствах.
Рекламные библиотеки 230 и 250 отображают рекламу и обрабатывают пользовательские реакции на рекламу. Например, пользователь может щелкнуть на релевантном информационном блоке, проигнорировать его, запросить перенацеливание или выразить свое разочарование рекламой. Рекламные библиотеки 230 и 250 предназначены для работы с компьютерными устройствами 260 и медиа-сайтами 210 (сайты - набор веб-страниц (со скриптами, файлами, ссылками и т.д.), отображаемыми пользователю посредством веб-браузера).
Согласно иллюстративному варианту содержание хранится на удаленном медиа-сервере (стороннем сервере, на котором размещен меда-ресурс для приложений или сайтов, потребляемых пользователем) 220 и предоставляется медиа-приложениям на компьютерных устройствах 260 или медиа-сайтах 210. Медиа-сервер является сторонним сервером, на котором размещаются медиа-ресурсы для приложений или сайтов, потребляемых пользователем. Издатель - это лицо, который владеет медиа-ресурсом.
Система интеграции с медиа-сервером 220 осуществляется рекламными библиотеками 230 и 250. Анализ содержания проводится на медиа-сервере 220, так что вычислительная нагрузка на клиентов 210 и 260 - минимальна.
Согласно иллюстративному варианту реклама хранится на рекламном сервере 240. Рекламный сервер 240 доступен через универсальные порталы управления 270, доступные компьютерными устройствами 260 и медиа-сайтами 210. После того как пользователь щелкнет на части содержания, модуль ОЕЯ определяет объекты внутри текста, классифицирует объекты и определяет отношения между объектами. Как результат, пользовательские пожелания (желания) ассоциируются с предложениями и параграфами текста. Согласно статистике до 80% слов используются в качестве связующих элементов, которые не отражают пользовательские пожелания. Таким образом, объекты, которые на самом деле вызывают пользовательские пожелания, довольно малочисленны.
Далее создается ассоциативная модель с матрицей. Ассоциативная матрица определяет связи между объектами и пользовательскими пожеланиями, вызванные этими объектами. Ассоциативная матрица также определяет границы этих связей. Иными словами, определяются связи между объектом-желанием и ограничениями приложений для данной пары. Например, пол, время года, общественные события и др. являются важными ограничениями для поведения и желаний людей.
Стоит отметить, что ассоциации базируются на различных факторах и в основном на типе объекта. Например, объект отель имеет один набор ассоциаций, объект ресторан имеет другой набор ассоциаций, и объект автомобиль имеет еще один ассоциативный набор и так далее. Ассоциативная матрица наследует некоторые принципы из концепции "графа интересов" и расширяет их реализацией некоторых новых возможностей.
Например, классификация Эми Джо Кима поведения игроков в игры (соревноваться, исследовать, взаимодействовать, выражать) может быть использована для распознавания слов в содержании, которые ассоциируются с каждым типом поведения (например, слова "проектировать, создавать, строить" связаны с настроением "выражать"), и ассоциируют настроение пользователя с услугами и деятельностью, подходящими для такого настроения. Пирамида Маслова может быть использована для представления приоритезации желаний. Кроме того, могут быть использованы связи между рекламными категориями услуг/продуктов, которые основаны на статистическом распределении (популярности) классификаций в ресурсах (таких как Pinterest). Классификация внешних мотиваторов (статус, доступ, полномочие, материал) и внутренние мотиваторы (компетентность, самостоятельность, родство) может быть также применена к классификации содержания и рекламы.
В качестве результата ассоциации создается список рекламных целей. Ассоциативная модель формируется на основе социологических и статистических данных. Ассоциативная модель постоянно обновляется (обучается) в процессе развертывания системы. Поскольку содержание определяет и стимулирует пожелания (желания) пользователя, содержание может быть проанализировано ОЕЯ только один раз. Затем, может быть создана универсальная модель пользовательских пожеланий путем применения ОЕЯ к ассоциативной матрице. Реклама может быть классифицирована в соответствии с ее отношением к пользовательским желаниям, вместо классификации продуктов/услуг.
В дополнение к ключевым словам (например, марке или названию продукта или услуги), каждый объект в содержании может быть ассоциирован с несколькими возможными деятельностями, которые могут быть выполнены с объектом, например, "купить", "бронирование", "заказ", "послушать", "смотреть" и др. Кроме того, каждый объект может быть ассоциирован с каким-то желанием, например, "безопасность", "голод", "жажда", "любопытство", "любовь" и др. В содержании также могут содержаться ключевые слова взаимодействия, например, "строить", "выиграть", "нравиться", "собирать" и др. Это может помочь в определении текущего состояния клиента для лучшего нацеливания рекламы.
На ФИГ. 3 показана блок-схема способа для точного подбора рекламы, в соответствии с иллюстративным вариантом. В шаге 310 издатель добавляет новое содержание на медиа-ресурс. В шаге 320 метаданные содержания и веб-страницы (т.е. параметры веб-страницы отображенные просматривающему. HTML теги, определяющие метаданные страницы, называются мета-тегами) загружаются с медиа-источника на рекламный сервер. В шаге 330 содержание анализируется, для того чтобы определить цели пользователя (желания) (для генерирования атрибутов элемента содержания, КД). Затем, пользователь выбирает часть содержания в шаге 340, и часть содержания и соответствующие цели (т.е. пользовательские цели, атрибуты элемента содержания) идентифицируются в шаге 350, и процесс переходит к шагу 360.
Если в шаге 360 выявлено более одной потенциальной пользовательской цели, все потенциальные цели показываются в шаге 365, чтобы пользователь мог выбрать одну из них. Далее, процесс переходит к шагу 370, где цель выбирается пользователем, и процесс переходит к шагу 375, где выбирается реклама, соответствующая цели и целевым параметрам. Затем процесс переходит к шагу 380, где выбирается бесплатное (органическое содержание). Далее процесс переходит к шагу 390, где определяется местоположение платного содержания и/или органического содержания на экране компьютерного устройства. Релевантный информационный блок(и) и/или органическое содержание отображается в шаге 395 и процесс завершается в шаге 398.
Стоит отметить, что часть содержания, выбранная пользователем, определяется на начальной стадии процесса. Система обрабатывает пользовательские ошибки, вызванные неверным положением пальца пользователя на экране компьютерного устройства, путем аппроксимации точки касания с несколькими "предугаданными" точками с помощью случайного сдвига [0-Х]. Согласно одному иллюстративному варианту минимальная целевая область - это предложение. Если касание пальцем затрагивает более одного предложения, система автоматически включает весь параграф. Если касание пальцем происходит между параграфами, для ОЕЯ анализа используются оба близлежащих предложения. В случае компьютерных устройств с более крупными экранами, для анализа используется позиция внутри предложения.
Параграфы, например, в HTML формате являются геометрическими объектами с известными границами. Это позволяет определять параграф внутри текста, выбранного пользователем компьютерного устройства. Геометрические границы предложений или других частей текста могут быть рассчитаны также для определения конкретной части текста, выбранного пользователем.
Например, текст:
"UCWeb назвала Индию своей второй штаб-квартирой в апреле. В то время соучредитель и президент Ксяопенг Хе сказал, что компания будет добиваться партнерских отношений в сферах и вертикалях для построения процветающей экосистемы на индийском рынке, где IС Browser был впервые запущен в 2011. Ма на борту будет полезен в качестве работника UCWeb по вводу в различных секторах".
Пользователь, заинтересованный узнать больше о "UC Browser", может коснуться точки рядом с данной фразой, но не точно на ней. Приложение, показывающее эту фразу, трактует событие прикосновения, как связанное со словом "где" (перед "UC Browser"). Иллюстрационный алгоритм помогает найти наиболее вероятные точки интереса. Для иллюстрационного предложения слова "изюминки": "Ксяопенг" (вероятно, именованная сущность), "индийский рынок", "процветающей экосистемы " и "UC Browser". Таким образом, пользователь легко может уточнить свой поиск по "UC Browser" лишь выбрав термин из списка предположений.
Согласно иллюстративному варианту медиа-ресурсы используются для точного нацеливания рекламы. Иллюстративный вариант использует каталог ресурсов, который указывает содержание и пользовательскую историю по ресурсу. Например, некоторые каталоги, использованные для нацеленной рекламы, привлекают конкретную аудиторию -например, у каждой из "финансовых рынков", "банковских новостей", "путешествия", "технических новостей", "бизнес-школ", "малых бизнесов", "разработке", "садоводстве", "недвижимости", "автомобилей" и др. есть своя собственная аудитория. Пользовательская история, собранная на рекламном сервере, может быть использована для расширения/уточнения более подробно пользовательский профиль. Однако пользовательская история служит только в качестве дополнительной (необязательной) информации.
На ФИГ. 4 показана блок-схема способа для точного подбора рекламы согласно иллюстративному варианту. В шаге 410 распознается часть содержания, выбранная пользователем. Метаданные (цели), ассоциирующиеся с выбранной частью содержания, определяются в шаге 420. Далее, метаданные всего содержания применяются в шаге 430. Эти метаданные являются метаданными контекста содержания, иными словами, метаданные - это дополнительные данные, которые описывают содержание (ключевые слова, категории, заглавия и др. ссылки).
В шаге 440 применяются дополнительные ограничения (пол, сайт, тип устройства, расположение, язык, возраст, пол и др.). Если в шаге 450 обнаружено более одной потенциальной пользовательской цели, возможные цели показываются пользователю для выбора одной в шаге 460, и процесс переходит к шагу 470. В противном случае ассоциативная модель (матрица) применяется к цели в шаге 470. Впоследствии ограничения (геолокационные данные, пол, часовой пояс, тип пользовательского устройства, веб-сайт и др.) применяются к пользовательским данным в шаге 480. Затем находится наиболее соответствующая реклама в шаге 490.
Например, когда человек щелкает на предложении с описанием ресторана и музыкальной группы, которая играет в этом ресторане той ночью, в первом шаге алгоритм должен выбрать между "едой" и "музыкой", и затем клиент выбирает категорию "еда", и оказывается, что ресторан имеет другое географическое местоположение чем пользователь (например, пользователь находится в США, а ресторан во Франции), и нет необходимости предлагать этому человеку забронировать столик в этом ресторане, а имело бы больше смысла предложить ему местный ресторан с тем же типом кухни.
Например, содержание может быть связано с автомобилями, а контекст может включать категории "покупка", "ремонт", ‘продажа" и "распродажа". Система принимает во внимание пользовательскую историю посещенных сайтов, тип операционной системы компьютерного устройства, модель компьютерного устройства, финансовый статус пользователя, предпочтения пользователя. Система также принимает во внимание метаданные текущей страницы или метаданные посещенных страниц, пользовательские поисковые запросы, почтовые сообщения и сообщения и комментарии в социальных сетях.
Согласно одному иллюстративному варианту релевантная реклама может быть выбрана на основе ключевых слов и размещения на странице, в настоящее время просматриваемой пользователем. Контекст - это иерархия группы слов или тем, соответствующих содержанию (тексту), расположенному вокруг выбранного слова, предложения, параграфа или части текста. В иллюстративном варианте контекст анализируется, и релевантная реклама показывается в зависимости от веса текста и метаданных, включая дополнительную информацию для нацеливания рекламы. Стоит отметить, что весь текст используется в качестве мета-ссылки. Реклама формируется на рекламном сервере и показывается без изменений в оригинальной структуре страниц. Область, выбранная пользователем, подсвечивается как гиперссылка.
Согласно одному иллюстративному варианту реклама, за которую не заплатили, не показывается. Отслеживание платной рекламы выполняется на рекламном сервере, который отправляет уведомляет. Оплаченное содержание хранится как набор записей, которые содержат данные о:
- показах (в течение кампании, месяца, дня);
- пользовательских посещениях после щелканья на релевантном информационном блоке (в течение кампании, месяца, дня);
- операциях (продажах, звонках, CMC и др.);
- рассчитанной стоимости показа рекламы, перехода на сайт, операции (в течение кампании, месяца, дня);
- максимальном и минимальном количестве показов рекламы, перехода на сайт, операции (в течение кампании, месяца, дня);
- максимальных и минимальных ценах за показ рекламы, переход на сайт, операции (в течение кампании, месяца, дня);
- совокупный ценовой лимит;
- совокупный временной лимит.
Согласно одному иллюстративному варианту счета рекламодателя инкрементируются и сравниваются с лимитом, и релевантный информационный блок помечается как неактивный и больше не показывается, если достигнут лимит. Если баланс счета увеличивается, релевантный информационный блок показывается снова. Согласно одному иллюстративному варианту содержание - это мета-ссылка. Пользователь может добраться до связанной страницы при помощи касания, жеста, движения глаз, голоса и др. Щелчок выполняется как специальный жест: движение влево или вправо на параграфе для перехода между параграфами. Ссылка строится динамически на основе результатов семантического анализа.
Контекст данного текстового выражения (который может состоять из слова) в данном текстовом документе является текстовым документом, который включает выражение и окружающий текст. Диапазон окружающего текста определен уровнем контекста, который может принимать значение из части предложения, предложения, параграфа, статьи, набора доменных имен и др. Контекст определенного уровня контекста С считается значимым, если множество его значений А, полученных с помощью функции М : А = М(С), не является пустым, где М - отображение значений. Отображение значений является аппроксимацией функции, определенной на домене структуры содержания, и обладающей своим диапазоном в ограниченном наборе пользовательских реакций или намерений (любопытство, узнать больше, желаю иметь и др.).
Отображение значений показывает потенциальный пользовательский интерес, который может быть переключен при встрече с определенными частями текста. Контекстный уровень определен для конкретного текстового выражения конкретного уровня. Предложение: различать следующие уровни выражений, от небольших элементов до больших: Слово, Группа слов, Составляющая предложения, (последовательность слов между запятыми и др.), Предложение, Группа предложений, Параграф. Следующие контекстные уровни для Слова: Группа слов, Составляющая предложения, Предложение, Группа предложений, параграф, Группа параграфов, Статья, Группа статей, Тема в разделе, Предметная область. Для группы слов: Составляющая предложения, Предложение, Группа предложений, Параграф и др.
Алгоритм извлечения ключевых слов может быть использован в данной реализации изобретения следующим образом:
Вход: текстовый элемент Е, квантиль q
Выход: S - список ключевых слов/биграмм в форме КД (Контекстного Дескриптора)
Для описания ключевых слов в качестве КД используется специальная форма. Простой КД - это пара: (КД_тип, КД_значение), где КД_тип берет значение из {ключевого слова, биграммы, …} и КД_значение - это нормализованное (стеммированный, леммированный, "нижнерегистровый") слово или биграмма.
1. Извлечь все текстовые выражения, которые удовлетворяют следующим шаблонам:
<статья>[прилагательное]{существительное/число}[глагол]
[прилагательное]{существительное/число}[глагол]
Обозначения:
<.> - ровно один элемент
{.} - один или более элементов
[.] - ноль или более элементов
Добавить все эти выражения в мульти-набор R.
2. Удалить стоп-слова (если они являются частью шаблона) из выражений. Стоп-слова - это слова языка, которые считаются низкоинформативными, мусором или шумом, такие как артикли, предложения и др.
3. Подсчитать частоту слов и биграмм, включенных в выражения.
4. Построить распределение. Отсортировать слова и биграммы по этому распределению. Выбрать слова и биграммы с максимальной частотой, используя данный квантиль q.
Добавить эти слова и биграммы в возвращенный набор S. Анализируется только Значимое содержание. Алгоритм полезности может быть использован следующим образом:
Вход: веб-страница Р, квантили q1, q2
Выход: Набор значимых элементов М
1. Рассмотреть данную веб-страницу как набор HTML-заголовков + HTML-элементов, Р = {h1, hN, e1, …, еМ} и мета-информации (мета-описание + мета-содержание) М = {m1, …, mK}.
2. Удалить элементы с низким значением длинны текста и элементы с большим значением относительной концентрации ссылок из Р.
3. Сделать стеммирование слов в Р и М, удалить стоп-слова.
4. Мультинабор значимых элементов S = {}
5. Сделать векторизатор текста на основе мета-информации m1, …, mK', V[m1, …, mК'](х) - вектор-функция. Она показывает, как много слов из {m1, …, mK'} содержится в текстовом элементе х.
6. Добавить в S такие элементы е из Р, которые удовлетворяют условию сум (V[m1, …, mК'](е))/длин(V[m1, mK'])>=q1, где сум (V[m1, …, mК'](е)) - это сумма элементов вектора, длина (V[m1, …, mK']) - длина вектора (что является эквивалентом для "количества аргументов функции ").
7. найти такие заголовки h1, …, hL, что:
h: Сум (V[h](x))-> макс х из Р, где макс - вектор максимальной длины. Назовем их базовыми заголовками. Сделать векторизатор V[h1, …, hL](x)
8. Добавить к S такие элементы е из Р: сум (V[h1, …, hL](e))/len(V[h1, …, hL])>=q2.
9. Добавить к S элементы, которые удовлетворяют некоторым геометрическим условиям. Например, если базовый набор заголовков - {hi}, добавить в S элементов, которые расположены ниже этого заголовка, в заголовок текста на веб-странице.
10. Набор значимых элементов М = Уникальные элементы из S.
Семантический анализ выполняется, когда содержание публикуется в режиме реального времени, или при опросе страниц. Для пользователя не требуется никакого дополнительного программного обеспечения (все работает в браузере, как обычные ссылки). Все вычисления выполняются на серверной стороне. Серверная сторона состоит из следующих сервисов:
СемантическийСерверСодержания - отвечает за предварительную обработку составляющих содержания и за хранение их в машиночитаемом формате;
СереверРекламныхОсобенностей - отвечает за предварительную обработку результирующих текстов и за хранение их в машиночитаемом формате;
ЦелевойСервер - отвечает за анализ читательских запросов по содержанию и выполнение поиска совпадающих результатов, наиболее актуальных сточки зрения намерения пользователя.
Типы результатов могут быть использованы в иллюстративном варианте: продвигаемый результат, взято от рекламодателя, продвинутый, всегда актуальный, органическое содержание показывается, когда не существует релевантного продаваемого содержания.
Примерами органических результатов являются: Обзоры Объектов, Мнения с Форумов (механизмы доверенных советников), Географические Точки, Информация о Ценах и Продажах, Схожие объекты.
В зависимости от выявленных категорий органические результаты могут быть обработаны из GOOGLE, WIKIPEDIA, ETSY и т.д. Органические или продвигаемые результаты могут быть разложены по намерениями пользователей, на которые они нацелены, в зависимости от части содержания: Узнать больше, Интересно, что это, Что в этом нового, Что об этом говорят, Где я могу это найти, Сколько это стоит, Хочу это купить. Стоит отметить, что Органические и Продвигаемые Результаты показываются одновременно.
На ФИГ. 5 показана блок-схема способа для точного подбора рекламы согласно иллюстративному варианту. Рекламодатель может создать новый релевантный информационный блок или целевую группу, или кампанию в шаге 510 (т.е. создать новую рекламу) и вручную определить ключевые слова, а также он может вручную определить целевые параметры. Целевые параметры - это список атрибутов рекламы, который описывает аудиторию, которой должна быть отображена эта реклама, включая возраст пользователя, пол, местоположение, пользовательскую историю просмотров, статистику медиа-сайтов, содержание веб-сайта, метаданные страницы и др. любую социальную информацию о пользователе, доступную глобально, историю просмотров или поисковых запросов. Если ключевые слова определены в шаге 520, то ключевые слова преобразуются в КД в шаге 540, и процесс переходит в шаг 550. Стоит отметить, что шаги 520 и 525 являются независимыми и могут быть выполнены параллельно или последовательно. Если целевые параметры определены в шаге 525, тогда КД создаются на основе целевых параметров в шаге 527, и процесс переходит к шагу 550. Рекламодатель также может указать Единые Указатели Ресурсов своего продукта или услуги. В противном случае ключевые слова создаются автоматически алгоритмом СтраницаВКД в шаге 530. Рекламная категория может быть автоматически определена для каждого релевантного информационного блока в шаге 550, используя следующий алгоритм:
извлекается КД релевантного информационного блока, используя ключевые слова;
определить главную категорию или категории для релевантного информационного блока на основе алгоритма голосования;
категория целевой группы определяется как набор категорий релевантных информационных блоков целевой группы, упорядоченных в порядке убывания частоты встречаемости;
КД и категория извлекаются из контекста. Применяется эвристический алгоритм поиска ключевых слов, специфичных для страницы и для всей категории. Выполняется анализ части речи текста. Наборы КД создаются и голосованием определяются категории.
Релевантная реклама для контекста определяется как реклама, у которой есть категория, соответствующая категории контекста. Сортировка рекламы может быть реализована посредством алгоритма голосования: КД контекста голосует за КД релевантного информационного блока. Количество голосов КД подсчитывается для каждого релевантного информационного блока, и релевантные информационные блоки сортируются в порядке убывания голосов.
КД - это сущность, у которой есть контекстный объект (например, ключевые слова, биграмма) и веса, назначенные объекту. Чем больше вес, тем больше важность объекта. Алгоритм голосования реализуется следующим образом. Объекты кандидаты и объекты участники голосования имеют свои свойства и веса. Изначально, голоса для каждого кандидата равны нулю. Далее для каждого кандидата и для каждого свойства к кандидатам с таким свойством добавляется вес свойства. Победившими кандидатами являются объекты, собравшие наибольшее количество голосов.
Далее процесс переходит к шагу 555. Если рекламодателем добавлены категории исключения, то набор основных рекламных категорий обновляется в шаге 560:
взрослый, автомобили, бизнес, финансы деньги, развлечения новости и сплетни, еда и напитки, игры, здоровье и фитнес, фильмы ТВ, музыка, новости и погода, покупки, социальные сети, общество - латино, общество - мужской образ жизни, общество - женский образ жизни, спорт, стиль и мода, технология, путешествие, утилиты и др.
Затем для каждой категории в шаге 565 создается набор сущностей контекстных дескрипторов (КД), содержащих особенности текста (ключевые слова, биграммы). КД описывает данные страницы следующим образом:
- создается набор поисковых фраз для категории;
- создается набор поисковых фраз для категории;
- Единые Указатели Ресурсов страницы, которые считаются базовыми для данной категории, получаются при помощи Интерфейса Программирования Приложений поисковой системы. Может быть получено произвольное количество Единых Указателей Ресурсов.
- Каждая страница обрабатывается алгоритмом СтраницаВКД, который преобразует содержание страницы в набор КД. КД используются в качестве координат в пространстве контекста для измерения сходства или соответствия между ними. Косинус матрицы используется для подсчета КД.
Набор КД, упорядоченных в порядке убывания частоты встречаемости, определяет категорию. Наиболее частые КД описывают категорию лучше, чем менее частые. Алгоритм для получения КД может быть вручную модифицирован, чтобы отфильтровать результаты алгоритма СтраницаВКД.
Далее процесс переходит в шаг 570. Процесс сохраняет набор КД на сервер. В шаге 575 пользователь выбирает содержание (или часть содержания). Процесс ищет ключевые слова в выбранном содержании в шаге 580. Далее процесс переходит к шагу 582, где определяются категории из ключевых слов, и в шаге 584 система определяет дополнительные объекты на основе целевых параметров. Процесс выбирает рекламу путем сопоставления категорий с сервера в шаге 585. Выбранная реклама отображается пользователю в шаге 590.
Согласно одному иллюстративному варианту используется алгоритм СтраницаВКД. Выбираются метаданные страницы, и удаляются стоп-слова. Выбираются заголовки страниц и из них удаляются стоп-слова. Части, информация, слова, являющиеся метаданными/заголовками и стоп-словами, не учитываются в ходе анализа и могут быть удалены из контента, предназначенного для анализа. Наиболее часто используемые ключевые слова/биграммы выбираются из совокупного текста. Ключевые слова/биграммы преобразуются в КД. Веса назначаются на основе местоположения ключевых слов/биграмм - параграфу назначается больший вес, а заголовку присваивается меньший вес.
ФИГ. 6 иллюстрирует пример анализа отображаемых элементов содержания (см. ФИГ. 3, шаг 340; ФИГ. 4, шаг 410). Видимая область 600 (т.е. внутренняя часть интернет-браузера 650, документа, открытый в текстовом редакторе документ, видеопоток в видеоплеере, изображение в редакторе изображений, некоторый веб-контент, см. Фиг. 1, 6 и т.д.) отображены на компьютерном устройстве, например, сенсорном экране планшета, телевизоре, настольном компьютере или портативном компьютере. Эта область может содержать геометрические объекты, предложения 610, абзацы 620, колонки текста 630 (в данном случае колонки предоставляют дополнительную логическую связь), текстовые заголовки 640 и т.д., которые могут быть идентифицированы пользователем как независимые элементы. Как было сказано выше, такими объектами могут быть: изображение 660, часть изображения (ФИГ. 10, элемент 1040), часть текстового содержания (часть текста, слово, предложение, абзац, схема или их части, график, трехмерная модель или ее части, некое видео и так далее).
Стоит отметить, что логическими и геометрическими связями/отношениями между объектами являются связи между словами, фразами, предложениями, абзацами, всем содержанием веб-страницы, реклама, баннеры, трехмерное содержание, видео, часть слов, часть фраз, части предложений, части изображений, части видео, которые не включают (но не ограничены этим) отношения геометрической смежности, логические зависимости, последовательность и иерархию включений/устройства.
Объекты могут быть разрознены, т.е. находиться на противоположных сторонах экрана. В следствие этого необходимо создать логическую (и/или грамматическую) связь между элементами содержания, а не геометрическую. Объекты 670а and 670б (см. ФИГ. 6) представляют собой предложение, некоторые слова которого были перенесены в другую колонку, тем самым нарушая геометрическую целостность (одна часть предложения является геометрическим элементом 685а, а другая часть - геометрическим элементом 685б, и, поскольку эти элементы расположены в различных областях экрана, они не являются геометрически связанными), однако оставаясь логически связанными (каждое слово принадлежит тому же самому предложению 670а и 670б).
Предложение 620, которое принадлежит геометрическим объектам (здесь - сетке 665, которая разделяет экран на равные области 665), может быть рассмотрено в качестве примера геометрической и логической целостности. Стоит отметить, что условие геометрической целостности также может быть применено к частям изображения, так части изображения, расположенные близко друг к другу, могут считаться связанными, и такая связь может быть уточнена логически: если две или более части изображения имеют схожие цвета по своим краям, то они могут считаться связанными (при необходимости может быть использован дополнительный механизм для определения логической связи в зависимости от весов частей изображения), в противном случае они могут считать несвязанными.
Также может быть использован дополнительный алгоритм и логика, которые могут учитывать различные цвета на границах соседних частей изображения для определения: являются ли данные части связанными или нет. Например, алгоритм может быть запрограммирован для восприятия последовательности цветов (красный-оранжевый-желтый-зеленый-синий-индиго-фиолетовый) связанными, поскольку они принадлежат объекту "радуга". Аналогично, обратная последовательность этих цветов может принадлежать объекту "обратная радуга". Таким образом, геометрическая целостность может сопровождаться логической (грамматической), а также промежуточными алгоритмами, использующими анализ проанализированных компонентов объектов; в то же время логическая (грамматическая) целостность может сопровождаться геометрической, поскольку соседние объекты часто взаимосвязаны.
Если текст разделен на несколько разнесенных частей (например, по различным краям экрана), то слова являются связанными логически, а не геометрически, поскольку они расположены далеко друг от друга. На ФИГ. 10 показывает пример логической связи в выражении 1030, где слова не связаны, поскольку расположены далеко друг от друга. На ФИГ. 10 объект 1010 является логической связью между предложением и заголовком статьи, а объект 1020 является логической связью в пределах предложения. Когда выбрана часть содержания, то могут быть изображены изюминки и интересные слова (и далее могут быть выбраны /указаны пользователем), даже если они расположены в разных частях экрана, поскольку они связаны логически. То есть, анализ и выбор релевантных слов вовлекает части содержания, которые могут быть расположены на любом расстоянии друг от друга, но остаются каким-либо образом связанными друг с другом, либо геометрически, либо лексически, либо грамматически, либо визуально (т.е. похожие изображения или их части).
Стоит отметить, что логическое соединение элементов 630 на ФИГ. 6, также как и объекты 1010, 1020 и 1030 на ФИГ. 10, также являются подразделением на области, описанные ниже. Содержание может быть разделено на области по словам, предложениям, абзацам и т.д., где области отличаются геометрически и размерами.
Также стоит отметить, что объекты могут быть логически связаны друг с другом. Геометрическую целостность целесообразно заменить логической в таких случаях, как: изображение, обтекаемое текстом (см. текст, обтекающий изображение, в частности, элементы 1010 и 1030); текст, разделенный на колонки; текст, формирующий изображение или геометрическую фигуру (в частности части содержания составляют вершины и/или ребра плоскости или многомерных фигур, например, текст, написанный на сторонах куба или в круге).
Пример логической связи можно увидеть при поиске изображений с использованием поисковых систем, поскольку найденные изображения могут располагаться далеко друг от друга геометрически (даже на разных экранах или поисковых вкладках), в то же время оставаясь логически связанными параметрами поиска изображений. Также графический файл с изображением может быть логически связан с изображением, содержащим текст, например, с отсканированным или сфотографированным документом. В этом случае, чтобы установить логическую связь могут быть использованы теги, общие слова, поисковые слова, также как и методы распознавания текста и изображений с привлечением дополнительных алгоритмов для установления связи между объектами. Так, например, объект 1040 связан с текстом на ФИГ. 10 не только геометрически (т.е. будучи расположен рядом с ним и на той же странице), но и посредством содержания изображения 1040, которое может быть проанализировано с целью установления логической связи.
Любое содержание имеет определенное количество выделяющихся точек, т.е. особенностей. Особенности могут относиться к группе логически связанных объектов, видимой области, документам схожей категории, истории пользователя и т.д.
Согласно иллюстративному варианту определяются особенности объекта, которые связаны с видимой областью, документом (например, лентой новостей на странице или любой отдельный новостной объект), документами схожей категории, схожих документов, а также особенностями изображений, которые связаны с другими изображениями или объектами. Изображения отличаются друг от друга, так что существуют некоторые точки внимания, например, различные цвета, различная форма или вид изображенного объекта (если включен анализ изображения). То же самое относится и к частям изображений.
Особенности могут быть связаны с историей, например, историей просмотров, историей пользователя, историей действий на странице - какие ссылки использовались чаще всего, какая реклама была показана чаще остальных, и каковы были последующие действия по части пользователя и/или системы. Особенности также могут относиться к другим историям пользователей, а именно, какие ссылки были предложены и какие были "прокликаны" чаще всего. Вес определенной ссылки может расти по сравнению с остальными ссылками, поскольку на ней "кликнули" чаще остальных. Еще одним ключевым фактором является анализ связанных со страницей действий: например, покупает ли пользователь чаще, чем на других страницах или просматривает дополнительный рекламный контент.
После того как объекты в видимой области были найдены и были определены геометрически близкие особенные объекты, становится возможным показать их пользователю.
Особенные объекты показываются (например, подсвеченными, подчеркнутыми и т.д.) пользователю. Пользователь может выбрать подсвеченные объекты или, скажем, еще одно слово в тексте, которое интересуется их больше остальных. Вычисление (подсвечивание) выделенных объектов может быть лимитировано определенной частью содержания: обычно, это автономная часть, например, абзац, предложение, слово, изображение - все в связке с заголовком страницы, историей и метаданными. Пользователь может уточнить предложенные ему особенные слова путем расширения выделения объекта(ов), комбинирования выделенных объектов и т.д. После уточнения особенных слов (либо оригинальных, уточненных или выбранных пользователем), пользователю показывается релевантное содержание. Релевантное содержание может содержать рекламные материалы, взятые с рекламного сервера или с сервера рекламодателя, или из другого указанного места, а также может быть общим, взятым из известных источников, таких как YouTube, Wikipedia и т.д. Рекламное и оригинальное содержание могут быть сгенерированы перед их показом пользователю.
Таким образом, на основе истории пользователей, их действий, платежей, активности в социальных сетях, из социального статуса, последних покупок, денежных переводов и т.д. содержание может быть сгенерировано и адаптировано персонально для данного пользователя, и затем показано им: например, специальное предложение по продаже суперкара или не роскошного автомобиля, или нескольких автомобилей в различных ценовых диапазонах. Так, пользователи, возможно, заинтересуются более дешевыми марками, если они просматривали страницы с автомобилями представительского класса и наоборот. Кроме того, пользователю может быть предложен кредит с учетом процентной ставки или суммы кредита, в зависимости размера компании, которой он владеет, ее сферы деятельности и т.д. Система способна определить это на основе посещения других страниц пользователем, используя данные, которые он использовал для того, чтобы попасть на эту страницу (например, социальные сети), данные запросов к поисковым системам, на основании платежей банковской или кредитной картами, к которой имеется доступ, на основании регистрационных данных и любых других данных, которые могут быть собраны (или разрешение на сбор которых будет предоставлен) на компьютере пользователя. Эти данных могут быть сохранены локально или могут быть переданы на сервер.
Вычисление геометрических позиций каждого слова и буквы в тексте является довольно ресурсоемкой операцией. Для вычисления в видимой области площади объектов, представляющих особый интерес, (например, область, в которую указали стилусом или пальцем), могут быть применены следующие способы:
1) Рассмотрим прямоугольник или группу прямоугольников в видимой области. Данная прямоугольная область содержит ряд объектов. Размер площади может варьироваться в зависимости размера объекта, и может быть предопределен на базе эмпирических вычислений, т.е. возможно найти средний размер абзаца, предложения или слова в зависимости от языка, на котором составлен текст. То же самое может быть выполнено для подсчета размера изображения или его части на базе его геометрических размеров, цветовой схемы, размера файла (в мегабайтах) и т.д.
При анализе отображаемых объектов также могут быть применены некоторые элементы, скрытые от пользователя; в HTML и XML это, например, тег описания изображения, т.е. название изображения, которое отображается, только если на изображение навести курсор мыши. Такие элементы могут быть невидимы для пользователя, но они будут учтены при проведении контекстного анализа для того, чтобы найти особенные объекты и определить их связи с другими объектами. Связи могут быть с одним объектом, с несколькими или со всеми доступными объектами. В данном случае объектами является все, что находится на странице, включая те, что обычно скрыты от пользователя, но все еще являются частью содержания. Также связь может существовать с другими объектами, которые связаны с вышеупомянутыми объектами или текущим устройством пользователя, или с объектами на предыдущей странице, объектами, показанными на фоне (открытые приложения, сайты, уровень батареи устройства, время, часовой пояс, карта, геолокация и т.д.), скриптами (например джава-скрипты на странице, даже если они не активны в данный момент, но могут быть активированы при определенных условиях). Результаты выполнения скрипта также могут стать результатом создания ссылки на объект, как и плагины и приложения, которые ожидают результатов выполнения.
2) Алгоритм компоновки (например слева-направо, сверху-вниз) также важен для определения особенных слов и определения выбранной пользователем области в тексте. Данный алгоритм может быть вычислен из атрибутов текста; например, в HTML его можно узнать из разметки страницы, а именно, тэгов: например, тега разрыва строки <br>, тэгов <table> </table>, показывающих, что между ними располагается таблица, или тэгов <strong> </strong>, между которыми располагается текст. Тэги стилей текста, такие как тэг курсива <i> или тег жирного текста <и>, также могут быть проанализированы. Другими словами, для установления алгоритма компоновки объектов в видимой области могут быть использованы все необходимые встроенные особенности элементов, которые отвечают за расположение объектов в видимой или скрытой областях.
Для мобильных приложений (например, приложений для Android или iOS), такое разделение на текстовые и графические области может быть получено из разметки и записано в формате XML. Разметка используется для размещения видимых элементов различными способами.
Разметка представляет собой инструмент описания для вычисления расположения объектов на компоненте (таких как веб-страница, окно приложения, панель с текстом или/и изображениями). Данная функциональность может быть частью приложения или библиотекой приложения. Разметка страницы представляет собой вычисление положения абзацев, табуляций, предложений слов и букв текста, или вычисление расположения изображений, частей изображения, видео, схем, графиков, т.е. относительное расположение объектов компонента (компонент должен уметь отображать визуальную информацию). Все это выполняется посредством настольного издательского программного обеспечения, программ для верстки и сервисов разметки (движков веб-браузеров). Они могут включать шрифтовую разметку и механизмы отрисовки для расчета верного позиционирования символов, которое может конфликтовать со скриптами. В текст также могут быть встроены изображения.
Другой формой разметки является возможность автоматического вычисления положения приложения (или виджета) на базе выравнивания ограничителей без необходимости программисту задавать абсолютные координаты. Программное обеспечения для рисования графов может автоматически распознавать положение вершин и ребер графов для различных целей, таких как минимизация количества пересечения ребер или минимизация общей области или создание эстетически привлекательного результата. Данный тип программного обеспечения используется с разными целями, включая визуализацию и как часть инструментов для автоматизации проектирования в электронике.
Система разметки может быть использована для управления разметкой. Например, система веб-разметки представляет собой программный компонент, который принимает размеченное содержание (такое как HTML, XML, файлы изображения и т.д.) и информацию по форматированию (такую как CSS, XSL и т.д.) и отображает отформатированное содержание на экране. Она отрисовывает окно на области содержания. Система разметки обычно интегрирована в веб-браузеры, системы онлайн помощи или другие приложения, требующие взаимодействия пользователя с веб-содержанием (просмотр страниц, редактирование, копирование и т.д.).
3) Приблизительные размеры объекта (ширина и высота) также могут быть вычислены и использованы для определения особенных областей. Исходя из этого можно предположить, что буквы и цифры в одной части текста имеют те же самые ширину и высоту, которые могут быть подсчитаны на основе атрибутов объектов; например, в HTML размер и стиль шрифта устанавливаются с использованием соответствующих тэгов.
4) С целью вычисления областей и объектов, представляющих особый интерес, в видимой области во внимание принимается точка, которая была указана посредством клика мыши, касания экрана или другим способом с использованием устройств, позволяющих выбрать или указать определенную область или объект (интерактивные очки, различные камеры и сенсоры, например, тепловые, емкостные или резистивные датчики). Эти действия приводят к сосредоточению активности пользователя.
5) Для каждого объекта или группы объектов определяется область, с которой они связаны (так называемый "диапазон объекта "). Это - такие объекты, которые могут попасть в область, вокруг точки касания или клика. Данная область может быть фиксирована или вычислена на базе характеристик устройств (размера экрана, разрешения экрана, видимой области [поскольку некоторые окна, расположенные всегда сверху, могут перекрываться областями экрана], размера окна, например, для веб-браузера или просмотрщика документов [файлов, изображений, смешанного типа и т.д.]). Диапазон объекта используется для включения (или исключения) объекта в (или из) список релевантных объектов, используемых для определения контекстных связей. Другими словами, если область вокруг объекта пересекается с 15-пиксельной областью, вокруг точки касания (или с самой точкой касания, или некоей областью, словом, частью слова или предложения, частью изображения и т.д., выбранными пользователем), то данный объект потенциально релевантен для данной области.
Например, при выборе наиболее релевантных объектов диапазон объекта может быть использован для определения веса объекта. Вес объекта определяет, включен ли объект в список релевантных объектов, поскольку вес объекта может уменьшаться в зависимости от расстояния объекта до других потенциально релевантных объектов или точки касания.
Основы алгоритма: Обычно количество объектов, расположенных в анализируемой части содержания известно, однако это количество также может быть опытным путем аппроксимировано и вычислено. Веб-сайт(ы) состоит из веб-страниц одного типа, или если говорить о научной статье, которая, как правило, имеет определенный стандартизированный дизайн, параметры расположения содержания и разметка не сильно отличаются, и поэтому можно определить среднюю длину слова и предложения (например, средняя длина слова составляет 7 букв, а средняя длина предложения - 12 слов, исключая предлоги и слова-заполнители), а также среднее количество предложений в абзаце, среднее количество абзацев на странице, а также какая часть видимой области занята изображением, так как если эти страницы имеют одинаковую разметку и созданы по одному шаблону, то является возможным сделать вывод, что визуальный элемент определенного типа всегда будет занимать ту же самую часть экранной области. Таким образом, расположение содержания на странице тесно связано с размером окна (отображающим содержание) и его компонентами: например, геометрическое положение элементов содержания может зависеть, кроме их типов, от разрешения экрана устройства, размера окна приложения, отображающего содержание (а именно, от ширины и высоты), размера видимой области окна, отображающего содержание и т.д. Все эти свойства позволяют определить положение элементов внутри отображаемого содержания (окна, виджета и т.д.). При работе с текстом количество символов, слов, предложений, абзацев и изображений может быть вычислено напрямую.
С целью вычисления и анализа релевантных объектов анализируемая область (т.е. видимая часть содержания: текст, изображение, схема, график, видео - либо как целые, либо в виде части), поскольку ее ширина и высота известны, делится на более мелкие области (см. ФИГ. 6) одинакового размера, например, прямоугольной формы. Геометрические размеры (высота, ширина и т.д.) строки, слова, а также отступы по вертикали и горизонтали, также как и другие атрибуты известны или могут быть получены из метаданных объектов. Метаданными объекта являются, например, либо теги (в HTML) либо разметка документа (в MS Word). Стоит отметить, что деление может быть неоднородным, поскольку прямоугольные области для коротких и более длинных строк могут отличаться размерами в два или более раз. В зависимости от своей структуры, в одном и том же содержании могут быть как короткие, так и длинные строки, например, текст может обтекать изображение или он может быть покрыт полупрозрачными элементами содержания (которые отображаются на каком-либо другом слое, расположенном выше).
Вместо прямоугольной области может быть использована любая другая геометрическая фигура: многоугольная, квадратная, круглая. Таким образом, если известен алгоритм разметки содержания, то также может быть установлено, какие объекты попадут в каждую прямоугольную область. Некоторые из этих областей могут быть пустыми (см. ФИГ. 6, элемент 690 и ФИГ. 10), поскольку предложение может закончиться на середине строки или может быть автоматически перемещено на другую страницу (с использованием системы разметки или поисковой системы), если слово - слишком длинное и не умещается на странице.
Стоит отметить, что данный алгоритм для определения нахождения слова (части содержания) внутри области, содержание которой должно быть контекстно проанализировано, и для поиска релевантных слов может быть применен не только к вебстраницам, но и к любому виду документов (включая текстовые документы различных форматов, таких как MS Word, MS Excel и т.д.), изображений (включая векторные), видео, графам, схемам (например, рисункам MS Visio, включая графики), трехмерным моделям (созданным в 3D Studio MAX, Blender, Maya и т.д.) и другим.
Если сам текст неизвестен, но известно его расположение на экране, то на основе его геометрических параметров (приблизительной высоте и ширине объектов) является возможным разделить видимую область на несколько частей, т.е. создать сетку с ячейками одного размера, покрывающую прямоугольную область. Стоит отметить, что таким способом можно создать несколько прямоугольных областей.
Если количество символов в строке известно, то на основе алгоритма разметки (оперируя метаданными страницы, атрибутами текста и изображений, разметкой стронац и документов и т.д.) возможно выяснить, что строка заполнена не полностью, а частично (например, до середины), тогда как пустая область может быть расположена в конце или начале строки, а также в середине страницы (в случае, когда текст обтекает изображение, или страница разделена на колонки и т.д.). Взаиморасположение текста и пустых мест может, соответственно, меняться в зависимости от различных параметров, таких как технические характеристики устройств (различные устройства отображаю одну страницу по-разному), изменения ориентации экрана (с книжной на альбомную и наоборот), изменения масштаба страницы, изменения размера окна веб-браузера, изменения разрешения экрана на устройстве и т.д. Поэтому пустые места будут расположены в разных местах.
Таким образом существует некоторая неопределенность касательно размера пустых мест. Чем больше пустых мест, тем больше неопределенность. Эта неопределенность должна быть добавлена к диапазону.
В этом случае координаты точки касания получается из устройства и преобразуется в сетку, о которой сказано выше, т.е. вычисляется точно тот прямоугольник, которого коснулись. Вычисляются также и примыкающие прямоугольники. При подсчете этих прямоугольников также принимаются во внимание пустые прямоугольники, которые были вычислены ранее (см. выше).
Координаты [х, y] точки касания, т.е. экранные координаты (для того чтобы вычислить эти координаты, например, в Android’e могут быть использованы стандартные способы: например, в языке программирования Java существуют методы getX(int) и getY(int), возвращающие соответственно координаты х и y точки касания экрана), преобразуются в координаты сетки [m, n], где m и n - номера вычисленных прямоугольников сетки, например, начинающиеся с верхнего-левого угла экрана.
Затем согласно алгоритму разбиения видимой области на прямоугольники (например, в направлении сверху-вниз, слева-направо), m и n преобразуются в точное положение (позицию) в тексте (например, если используется упомянутый ранее алгоритм и, скажем, столбец содержит 5 прямоугольников, то 3-ий прямоугольник во втором ряду будет прямоугольником под номером 8). Стоит отметить, что для разбиения видимой области на более мелкие существуют различные алгоритмы, как однородные, так и нет, в зависимости от типа подразделяемого объекта, универсальности его формы, смешан ли он с другими объектами, похож ли на другие, и типов подобластей, на которые разбита видимая область (прямоугольники, многоугольники, треугольники и т.д.). Вычисленная позиция на сетке может быть записана в различных форматах в зависимости от использования конкретного алгоритма: в линейном формате (1, 2, 3…), в плоскостном формате ([х, y]), относительном формате (например, согласно его смещению по отношению к другому объекту: например, если упомянутый объект является центром экрана, то подобласти могут быть пронумерованы по спирали, отсюда могут начинаться линии или расходиться концентрическими кругами, и т.д.).
В алгоритме, работающем в направлении сверху-вниз и слева-направо, сеточные координаты точки касания (Позиции) вычисляются следующим образом: Позиция = n*w+m, где n - длина сроки (в символах).
Далее неопределенности добавляются к упомянутому выше диапазону: +/-R=H*W-L, где L - количество объектов (длина текста), H*W - количество ячеек сетки, W - ширина видимой области (в пикселях).
Таким образом, диапазон, использованный для подсчета изюма, вычисляется как: Позиция +/-R.
Объекты, которые были найдены посредством алгоритма выделения ключевых словосочетаний, помечаются, как объекты, представляющие интерес (интересные слова, интересное подмножество содержания, элементов изюма). Также некоторые объекты, которые связаны с ними логически, уже были определены (они не выделяются в тексте).
На ФИГ. 11, ‘суммарный’ связано с ‘электрический потенциал’ посредством слова. Фотопреобразователи, электрический потенциал, на этой неделе, Управление по Ежемесячник по Электричеству и др. являются изюмом. Комбинация слов "собственникам солнечных систем" и слово "собственникам" являются словами, связанными с изюмом "тех солнечных систем", "тех" лишь показан в качестве части изюма и используется для вычисления изюма, хотя, по сути, не является частью изюма, поскольку не несет полезной информации.
"по Электричеству" и "Ежемесячник" связаны логически, а не геометрически, поскольку они расположены в различных геометрических областях, но логически (грамматически) принадлежат тому же самому изюму.
ФИГ. 12 является диаграммой, на которой показана концентрация плотности вероятности, когда встречается особенное слово. Пики обозначают изюм и/или особенные области (изюм + связанные элементы). Чем выше пик, тем более особенное слово/область.
При поиске релевантных данных, как было сказано выше, изюма. В свою очередь, для его подсчета мы используем семантический профиль текста. Семантический профиль - это код группы или индивидуального объекта, который может быть получен, например, путем использования "Семантических дифференциальных" весов. Семантический профиль позволяет вычислить субъективную близость (схожесть) и удаленность (различие) объектов в семантическом пространстве.
Семантический дифференциал представляет собой метод, используемый для формирования индивидуального или группового семантических пространств. Координатами объекта в семантическом пространстве служат его оценки по ряду биполярных градуированных (3, 5 или 7-мибальных) оценочных шкал. Противоположные концы этих шках заданы вербальными антонимами. Эти шкалы были выбраны из множества тестовых шкал путем факторного анализа.
Термин "семантическое пространство" используется для определения представления значения слова в теориях семантической памяти, которые углубляются в какой-либо вид пространственной модели мнемических форм, например, семантические сети.
Семантическая сеть является информационной моделью предметной области, отображаемая в виде орграфа, вершины которого соответствуют объектам предметной области, и дуги (ребра) определяют их связи. Объектами могут быть идеи, события, особенности, процессы. Таким образом, семантическая сеть представляет собой метод представления знаний. Семантическая сеть представляет семантику предметной области в виде идей и их связей. Таким образом, семантическая сеть является структурой данных, состоящей из узлов, соответствующих идеям и связям, которые указывают на отношения между узлами. Наиболее важными соединениями являются связи "Is-а", которые позволяют создавать иерархию идей в семантической сети, т.е. низкоуровневые узлы наследуют особенности вышестоящих узлов.
Семантический профиль текста строится для получения набора КД, необходимого для определения степени близости между текстовыми документами и их принадлежность к определенным категориям (когда дается список категорий, вручную или в процессе, например, моделирования предметной вероятности простой кластеризации). Для того чтобы определить семантический профиль как можно более правильно, крайне важно структурное подразделение текста, а именно, наличие абзацев и заголовков. Метаданные также могут улучшить алгоритм, а именно, ключевые слова, которые уже были найдены и внесены в список.
Стоит отметить, что каждое правило формальной грамматики, использующееся для извлечения изюма, обладает соответствующим весом изюма, который представляет собой значимость цепочки изюма, удовлетворяющей правилу, например:
…
Изюм -> Человек
Человек -> Имя Отчество Фамилия (0.5)
Человек -> Имя Фамилия (0.4)
…
где 0.5 и 0.4 являются весами изюма. Учитывая правила формальной грамматики фрагмента примерного текста, цепочка слов, включающая полное имя (имя, второе имя, фамилия), является изюмом с большим весом, чем цепочка, содержащая только имя и фамилию.
Алгоритм извлечения изюма оперирует с весами изюма, который является набором в правилах формальной грамматики. Таким образом, алгоритм вывода назначает веса цепочке слов. Изюму (или цепочкам) могут быть назначено несколько весов, например, вес длины цепочки и вес "качества" изюма. В совокупности они образуют вектор. В зависимости от изюма и/или весов цепочек можно провести пограничную линию между "сильными" и "слабыми" изюминками для того, чтобы устранить "слабые", если это необходимо.
Модификация алгоритма извлечения изюма, оперирующая с весами, описана ниже. Данная модификация необходима для извлечения одинакового количества изюма из текстов различной длины, количества, достаточного для того, чтобы пользователь не был перегружен им, и достаточного для извлечения, по крайней мере, чего-то из небольших текстов. То есть, чем больше текст, тем строже границы между весами изюмосодержащей цепочки.
Пример (изюм подчеркнут):
Текст1: "… шестеренки первыми до следующей передачи, и затем немедленно переключить сцепление без потери крутящего момента…"
Текст2: "Основной особенностью данной коробки передач (DSG) является то, что в ней существует два независимых вала для четных и нечетных передач, оба из которых работают со своими собственными сцеплениями. Это позволяет переключать шестеренки первыми до следующей передачи, и затем немедленно переключить сцепление без потери крутящего момента."
Текст1 является частью Текста2, но не все изюминки из Текста1 являются подмножествами набора изюминок из текста 2, поскольку чем длиннее текст, тем шире выбор возможных изюминок, и поэтому использующаяся для устранения "слабых" цепочек граница - строже.
Для реализации упомянутых выше идей используется алгоритм извлечения изюма, оперирующий с весами изюма, а именно:
1. Граница весов изюминок задается в виде векторного набора, поскольку существует несколько весовых групп. Данный набор может быть отсортирован в соответствии со снижением "суммарной степени". Минимум изюма текста может быть назначено каждой векторной границе, которая должна удовлетворять требуемому весу. Если получается меньше изюма, чем требуется, то граница понижается. Ради удобства последняя векторная граница состоит из нулевых элементов, а ноль - минимальное количество цепочек, которые должны удовлетворять требуемому весу.
2. Извлекаются цепочки изюма с весами изюма.
3. Затем количество изюма, которое удовлетворяет требуемому весу, проверяется для каждой векторной границе, начиная с первого. Если данное количество - меньше минимального предела, то берется следующая более слабая граница. Когда количество изюма становится равно или больше минимального предела, алгоритм останавливается, и изюм является выходом алгоритма. Эта последовательность повторяется, пока не будет взят последний вектор.
ФИГУРЫ 13-15 иллюстрируют, как вычисляется уровень иерархии с целью вычисления изюма. Уровень анализа элементов контента представляет собой группу элементов контента для анализа, например, изюминки, цепочки т.д. Объект 1510 на ФИГУРАХ 13-15 представляет собой некий контент, отображенный на экране устройства. Это может быть веб-страница, документ (например, текстовый документ с изображениями), видеофайлы и аудиофайлы и т.д. Контент 1510 может содержать изображения, фрагменты видео (на показано на фигуре) или текстовые элементы, такие как абзацы (1540, 1550, 1560, 1570, 1580) или предложения (1541, 1551, 1561, 1562, 1571, 1581). Стоит отметить, что определенный параграф может состоять всего из одного предложения (1541, 1551, 1581, 1571) или нескольких предложений (1561, 1562), в то время, как сами предложения могут состоять из групп слов (не показано на фигуре) и слов (1580, 1590). Объект 1520 является точкой взаимодействия между пользователем и контентом (точка, которая будет кликнута, выбрана касанием, выбрана жестом и т.д.). Объект 1530 является областью, окружающей точку взаимодействия, которая используется для определения потенциальных элементов контента для проведения анализа. Размер области 1530 может быть определен эмпирически или на основе спецификации устройства, типа и размера текста, его разметки, метаданных страницы, различных представленных на странице элементов (например, текста и изображений, изображений и рекламы) и др.
При анализе уровень иерархии используется для извлечения информации для вычисления изюма и выбора отображаемого контента берутся элементы контента, которые расположены внутри или частично внутри области 1530 или близлежащие. Среди таких элементов могут быть слова (см., например, объект 1580), предложения (объекты 1541, 1551, 1561, 1571) и параграфы (объекты 1540, 1550, 1560, 1570). Элементы, которые не находятся внутри области 1530, - такие слова, как 1590, и т.д., предложения 1581 и параграф 1580.
Уровень иерархии, на котором будут проанализированы и извлечены изюминки, определяется согласно распределению на определенном слое, например, слое слова, слое выражения (не показано на фигуре), уровне предложения, уровне параграфа, всего контента и т.д. В данном случае, распределение соответствует особенностям элементов на каждом слое, расположенным внутри области 1530, или на некотором удалении от точки взаимодействия. Фиг. 13 иллюстрирует, как элементы на каждом слое входят в область, окружающую точку касания (объект 1530). Стоит отметить, что уровень иерархии может быть определен словом, выражением, предложением, параграфом, всем контентом, изображением или его компонентом, или частью видеокомпонента, т.е. оптимальный уровень выбирается так, чтобы могли быть видны элементы выделенного контента. Другими словами, если во время анализа выделенных и соседних/прилегающих частей контента оказывается, что наиболее выделяющимися элементами (которые соответствуют пикам на текущем графике) являются слова, то алгоритм работает со словами; если самыми выделяющимися элементами являются параграфы, то алгоритм работает с параграфами. Также следует отметить, что различные уровни иерархии могут быть установлены внутри всего контента или его частей, так что, например, столбец текста может быть обработан, как на уровне слова, так и на уровне предложения.
Такие слова, как "человеческого" или "связь", не полностью расположены внутри области касания 1530, также как и предложение 1541 и абзац 1540, так что эти элементы не очень сильно влияют на выделение ключевых словосочетаний. В основном, следующий анализ похож на распределение весов для каждого элемента на определенном слое. Чем больше элементов находится в области касания, и чем ближе они расположены к точке касания, тем выше вероятность того, что эти элементы станут изюмом во время выделения ключевых словосочетаний (как это происходит со словами и группами слов), поскольку так что изюм будет извлечен из них, как, например, "НЛП" из предложения 1561, или "Модели" из предложения 1562. Такие слова, как "так", "могут", "и", "другими" из предложения 1551 полностью расположены внутри области касания 1530, так что они могли бы стать изюмом, однако они были опущены на более ранней стадии как мусор или "бессмысленные " слова. Такие слова обычно не влияют на извлечение изюма и не могут рассматриваться в качестве изюма. Слово "Поступая" лишь частично расположено в области касания, поэтому не сильно влияет на выделение ключевых словосочетаний, в то время как слово "люди" полностью расположено внутри области и поэтому напрямую влияет на выделение ключевых словосочетаний, в то время как и само может считаться изюмом.
Слова, расположенные за пределами области касания, такие как "общаться" из предложения 1551, не сильно влияют на выделение ключевых словосочетаний, хотя степень их отдаленности может быть учтена при выделении ключевых словосочетаний, например, они могут быть оценены сразу после того, как будет определено, какие слова расположены в области касания, или они могут быть использованы для уточнения выбора. Выбор уточнения (выделения) - также крайне важен, как было сказано ранее. Выделенные слова являются одними из наиболее вероятных элементов, которые станут изюмом. Например, текст на фигуре содержит "Нейро-лингвистическое программирование", "НЛП", которые также могут изюмом, хотя они расположены на краях области прикосновения. Стоит отметить, что синонимы также могут приниматься во внимание при анализе контента: например, "познаний" и "извлечений уроков" могут считаться одним и тем же словом, тем самым увеличивая их встречаемость и понижая их возможность стать изюмом или быть использованными в выделении ключевых словосочетаний.
В то же время еще один вариант слова "общаемся" из предложения 1561 полностью расположено области касания, а это значит, что оно имеет более высокий потенциал, чтобы стать изюмом.
Данное обсуждение демонстрирует примерный анализ на уровне слова. Как и в случае со словами из предложения 1541, слово, потенциал слова для формирования изюминок - крайне низок, поэтому целесообразно рассмотреть анализ на уровне предложения. На данном слое существуют предложения 1562, 1561, 1551, которые имеют больший вес, в то время как предложение 1562 очень сильно отличается от других, так оно может быть немедленно использовано для формирования изюминок. Предложения 1561, 1551 также могут способствовать формированию изюма, однако их вклад имеет меньшую величину, поскольку они содержат гораздо меньше потенциальных изюминок, чем предложение 1562.
На слое абзаца представлены параграфы 1560 и 1550, однако они не слишком сильно отличаются от других параграфов. Вот почему обычно целесообразнее анализировать предложения и слова с потенциальными изюминками, например словами, которые полностью расположены в пределах области, и предложениями 1562.
Поэтому изюминки формируются в основном с помощью пиков слов, которые расположены внутри области касания, в то время как абзац 1580 и его составные части не сильно влияют на изюминки.
Другая реализация изобретения основывается на обработке взаимодействия пользователя и чтении пользовательских намерений. "Намерения" являются действиями с элементами, которые пользователь хочет выделить, или которые (могут быть) интересны ему, а также взаимодействиями типа: выбор, перетаскивание, отправка обратной связи и т.д. Поскольку элементы контента могут быть организованы по-разному в зависимости от стилей контента, конфигурации вычислительного устройства или ориентации и т.д., их логические и геометрические связи могут меняться. Ниже приведен алгоритм выбора гомогенных объектов с определенным (на лету, когда способ может быть изменен во время или после показа объекта) или предопределенным (например, выбранным пользователем, или может быть использован способ по умолчанию) способом планарной компоновки, когда фокусная точка не определена.
Рассмотрим следующую ситуацию: в прямоугольной области экрана, имеющей размер W×H, расположен хорошо упорядоченный набор объектов со схожими размерами (буквы, текст). В то же самое время расположение объекта строго определено или предопределено и описывается функцией: Р = p(n, W, Н, w, h), где Р = <х, y> являются координатами объекта с индексом n; W, Н являются геометрическими размерами области; w, h - средними размерами объекта. Область практически полностью заполнена набором объектов. Здесь "почти" означает, что регион сам по себе является минимальной областью хотя бы одного из заданных размеров, которого достаточно для того, чтобы данный набор объектов и данная функция распределения, например, такая как прямоугольная область абзаца, являлась минимальной для покрытия текста параграфа, однако имела бы пустую область в конце строки или в начале первой строки.
Задачей является найти упорядоченное подмножество объектов [ns, nе], которое с некоторой долей вероятности пересечется с данными координатами, при условии, что координаты области неопределенного клика лежат внутри известной прямоугольной области.
Данная проблема возникает при поиске быстрого решения задачи неопределенного выделения в тексте, которое не требовало бы вычислительно затратных интенсивных расчетов точных координат букв и слов. Представленный ниже алгоритм может быть расширен для анализа не только текстовых объектов с направлением написания слева направо (так называемый европейский стиль письма), но и до объектов с написанием, основанным на символах и до графических объектов.
Иллюстративная функция для текста, размещающегося слева направо и сверху вниз, может выглядеть как:
p(n, W, Н, w, h)=<w*(n mod [W/w]), h*(n div [W/w])>,
где mod и div являются операторами деления с остатком и без остатка соответственно; а [.] является величиной, округленной до ближайшего целого.
Далее данный случай будет считаться наиболее распространенным. Объекты могут быть расположены либо плотно (без пробелов и перекрытий), либо редко (с пробелами или перекрытием). В любом случае, средние геометрические размеры объекта должны быть вычислены, принимая во внимание пробелы или перекрытия.
Решением может являться восстановление параметров текста, когда некоторые из них известны, например L, являющейся длиной текста (количеством объектов), W, Н и β=w/h, которая является средним соотношением между геометрическими размерами объекта и может быть получена статистически для данного шрифта на теле текста.
1. Восстановление h: 
2. Подсчет целых геометрических размеров прямоугольной области, в которых кол - это количество объектов по горизонтали и строки - количество объектов по вертикали:
строки = [H/h]
[кол = [W/h/B]
3. Вычисление <х, y> позиции касания в целочисленных координатах <с, r>:
r=[y/H/h]
c=[x/W/h/β]
4. Вычисление линейной позиции объекта, в зависимости от функции распределения, в упорядоченный список:
n=r*[W/h/β]+c
5. Добавление диапазона
[ns, ne]=r*[W/h/B]+с±([W*H/h2/β]-N).
Другими словами здесь описан способ определения пользовательских интересов, касающихся нескольких объектов, отображенных на веб-странице. После отображения вебстраницы пользователю система определит прямоугольную область (прямоугольные области) на основании области взаимодействия пользователя, содержащей большую ее часть, и которая будет содержать область подсчета элементов, являющейся вычислительно дорогой. Стоит отметить, что веб-страница может содержать несколько элементов. Далее используется алгоритм определения компоновки элементов для размещения элементов контента в прямоугольной области, где элементы контента могут быть плавающими в этой области в зависимости от ее геометрических параметров и размера шрифта. Следующие шаги являются определением средних геометрических пропорций элементов контента; и определением количество плавающих элементов в области.
Выполняется вычисление параметров сетки (строк и столбцов), которые виртуально разбивают область для размещения всех элементов с некоторым приближением. Далее выполняется определение, какая ячейка (ячейки) сетки содержит область пользовательского взаимодействия; и выполняется определение, какая позиция (позиции) в последовательности (иерархии) соответствует ячейкам взаимодействия на основании используемого алгоритма компоновки.
Далее расширяется позиция (позиции) до диапазона (диапазонов) элементов путем добавления и вычитания количества свободных ячеек (которые не были использованы для размещения в сетке), и диапазоны передаются алгоритму извлечению изюма.
ФИГ. 7 иллюстрирует блок-схему способа построения семантического профиля текста. Построение семантического профиля текста начинается, когда пользователь выбирает некоторый контент на странице или касается/щелкает определенного участка, где расположен интересный контент. Далее определяется точка взаимодействия пользователя с контентом страницы/документа (блок 702). Далее в блоке 704 выделяется интересный контент. Затем выделенный/выбранный контент преобразуется с целью достижения основной структурной согласованности, т.е., если пользователь выбирает слово, для анализа будет использовано все предложение; то же самое происходит с выбранной буквой или группой букв; и, если пользователь выберет предложение, то будет использован целый абзац и т.д. (блок 706).
В блоке 708 к алгоритму извлечения изюма добавляются детали, такие как метаданные страницы/документа, контекст, пользовательские метаданные и метаданные устройства и т.д., что приводит к выводу структурированного текста для блока 710. Входом системы является структурированный текст 710, что означает, что система способна различать метаданные, заголовки и основные единицы (блоки) текста (блок 720) на основе их особенностей. Примером структурированного текста является HTML-страница. Далее все различенные части становятся именованными объектами. Все объекты подвергаются процессу стеммирования/нормирования в блоке 730 и очищаются от стоп-слов. Далее все заголовки и элементы метаданных преобразуются в векторную форму (Мешок слов) в блоке 750. (Модель Мешок слов является упрощенным представлением, используемым в обработке естественного языка и получении информации (IR). В данной модели текст (например, предложение или документ) представлен в виде мешка (мультимножества) его слов, игнорируя грамматику и даже порядок слов, однако оставляя множественность.
Недавно модель мешка слов также была использована для компьютерного зрения. Модель сумки слов обычно используется в методах классификации документов, где (частота) встречаемость каждого слова используется как характеристика для обучения классификатора.) Одиночные слова и пары слов (биграммы) используются в качестве особенностей термины. Наиболее часто встречающиеся термины определяются в отдельных текстовых единицах (блок 750). Основные единицы преобразуются в векторную форму в блоке 760. Далее определяются основные единицы с наибольшей близостью к вектору частоты терминов, вычисленному ранее (блок 770). Для того чтобы измерить степень близости, может быть использована, например, дивергенция Кульбака-Лейблера. Наиболее частые термины определяются согласно их долям и затем преобразуются в КД (блок 780). Далее семантический профиль текста в виде КД помещается в базу данных вместе с уникальным идентификатором текста.
ФИГ. 8 иллюстрирует блок-схему основного способа системы выбора релевантных элементов (в данном примере, элементами являются слова в тексте). Стоит отметить, что вид блок-схемы не зависит от языка, на котором написан текст; меняется лишь используемые словари, формальная грамматика и т.д., однако концепция остается той же самой. Входом системы является необработанный текст, содержащий, например, HTML-дескрипторы. Модуль предварительной обработки преобразует данный материал в сырой текст, удаляя все технические конструкции (шаг 810). Далее текст разбивается на части (например, предложения) для облегчения последующей обработки (шаг 820).
Подготовленные данные (например, массив текстовых элементов) подвергается синтаксическому анализу (шаг 830), возвращая множество синтаксических деревьев разбора. Далее используется морфологический анализ (шаг 840) для определения используемых частей речи и формы слов. Для исполнения данного шага применяется специальный набор словарей различных языков (845). Результирующие данные проходят процесс стеммирования/нормирования и создания специальных цепочек (шаг 850). Далее некоторые цепочки, удовлетворяющие правилам формальной грамматики различных языков (865), выбираются (шаг 860), где примененная формальная грамматика имеет правила различных весов, которые используются для определения веса релевантных слов или изюминок. Цепочки выбираются во время установления автоматического контроля над лимитом минимального веса изюма, который, в частности, зависит, от длины текста в окончании предложений и общего количества цепочек, удовлетворяющих правилам. Вес релевантных слов учитывается при выборе контекстных данных, отображаемых пользователю.
В шаге 870 к полученным данным добавляется натуральная форма релевантных слов, которая необходима для корректного представления в необработанном тексте. Таким образом, результатом описанного выше алгоритма, становятся изюминки.
На ФИГ. 9 показан точный выбор рекламы и графическое представление целевой рекламы пользователю. Пользователь может выбрать часть содержания 910. Объект 940 показывается над содержанием или в меню браузера, или в раскладывающемся меню. Пользователь может открыть дополнительное окно 960 (например, новое окно в браузере или окно в текущем браузере). Рекламное или органическое содержание 985 и 990 может быть отображено в окне 960 в предназначенной области 970 вместе с объектами 980 (поиск, текст, YouTube и др.), отражающими намерения пользователя. Показанные рекламное или органическое содержание 985 и 990 выбирается на базе: анализа содержания, категории содержания, языка, выбранной области содержания и пользовательских предпочтений. Стоит отметить, что пользовательские намерения явно отображаются вместе с бесплатным органическим содержанием.
Алгоритм анализа текстовых документов веб-страниц СтраницаВКД является показательной реализацией алгоритма СтраницаВКД:
Параметры преобразования ВКД определяются как ВКД = {ИзображениеВКД, МузыкаВКД, ВидеоВКД, ЧастьИзображенияВКД…} некоторых нетекстовых дескрипторов содержания. В случае музыки речь выбирается и записывается в КД. Для изображений алгоритм распознает изображения, описывает их и сохраняет в КД. Для видео-содержания алгоритм разбивает содержание на аудио-поток и изображения и обрабатывает их раздельно. Алгоритм определяет вытяжку базовых элементов Е - алгоритм может получить метаданные и заголовок. Вытяжка учитывает геометрию страницы и текущий вид и определяет квантиль релевантности q.
Алгоритм исполняет следующие шаги:
1. Определить текстовое содержание Т и нетекстовое содержание Р;
2. Для Р применить преобразование:
Сделать набор преобразованного элемента Р' пустым;
Для каждого р из Р:
Определить тип y=Тип (р)
Применить преобразование ВКД (y, р) для данного типа и получить дескрипторы, и добавить дескрипторы в качестве отдельного набора в Р';
3. Для Т получить набор преобразованных элементов Т' и сохранить t из Т в КД;
4. Получить T' U Р' определить базовые элементы В = Е (T' U Р'). Другие элементы -это А = (T' U Р')\В;
5. Собрать все КД элементы из В в один набор V уникальных элементов. Определить порядок и сгенерировать вектор-функцию векторного аргумента CV, который вычисляет количество пересечений элемента из V с произвольным набором М. Кроме того, вектор веса может быть создан путем применения В к V. Далее CV умножает количество пересечений на вес.
6. набор релевантных R делается пустым;
Для каждого а из А:
Если сумма (СV(а))/длин(СV)>=q, добавить а к R;
Проверить пропущенные элементы, если найдены, уменьшить квантиль наполовину и добавить а к R;
7. Выбрать КД для элементов RUB по квантилю;
8. Отдать результирующий КД.
ФИГ. 16 иллюстрирует еще один иллюстративный вариант изобретения, относящийся к способу отображения информации пользователю в зависимости от того, как пользователь взаимодействует с контентом на своем вычислительном устройстве.
В шаге 2010 пользователь взаимодействует с представленным ему контентом, например, текстом в текстовом документе, изображением в графическом процессоре, видеоклипом в видеофайле и т.д. На основе этого взаимодействия в шаге 2020 высчитываются изюминки. В шаге 2030 на основании выбранных изюминок генерируется запрос на контекст, окружающий точку взаимодействия пользователя, собранную информацию. Данный запрос может быть также использован в качестве входа для поисковой системы (например, поисковой системы стороннего производителя, такого как Google) или запроса базы данных (например, SQL), содержащие информацию, которая может быть найдена с использованием подобного рода запросов (или просто изюминок) и отображена пользователю. Стоит отметить, что информация, которая будет найдена и отображена пользователю, может быть сохранена в любом известном формате, таком как текст, видео, изображение и т.д. Информация может быть рекламой или каким либо источником (например, энциклопедией, популярным вебсайтом и т.д.), или она также может быть скомбинирована, например, реклама, отображаемая пользователю, также может быть объединена с информационным контентом. Часть рекламы такого смешанного контента может иметь несколько добавленной к ней видимых и невидимых (для пользователи и/или системы) тегов, которые, например, позволяют визуально отличить рекламу от информативного (натурального) контента.
Шаг 2040 является опциональным: запрос может быть модифицирован, как было описано выше, например, путем добавления в него частей контекста или собранных инфо-данных. Такая модификация может помочь изменить область поиска, например, путем уточнения запроса или расширения его, или сделать его более релевантным для определенного домена и т.д. Например, если мы добавим "компьютер" к "таблетке", то это сузит поиск только до компьютерных устройств, исключив медицинские товары. В шаге 2050 запрос может быть отправлен в поисковую систему или базу данных, или он может быть обработан с использованием других доступных средств, для поиска релевантной информации, которая является результатами поиска 2060. Далее в шаге 2070 результаты поиска 2060 модифицируются.
Модификация результатов поиска может содержать исключающие и включающие типы модификаций. Исключающие модификации означают удаление элементов из результатов поиска на основании определенных характеристик, например элементов, которые не соответствуют категориям, выбранным пользователем (или системой на основании анализа элементов контента, собранных инфо-данных и т.д.), а также географическому местоположению, языку, возрасту, полу и другим параметрам. Также некоторые найденные элементы могут быть исключены, если они предоставляют ссылки на запрещенные или подозрительные веб-сайты, или признаны небезопасными антивирусным программным обеспечением и так далее. Стоит отметить, что найденные элементы (а также локации, на которые они ссылаются, могут быть обработаны антивирусом, если они являются ссылками на другие веб-сайты) могут быть обработаны антивирусным программным обеспечением и проверены в базах данных, содержащих списки разрешенных/рекомендованных веб-сайтов. В случае если некоторые элементы (ссылки на какой-либо внешний интернет-ресурс и независимые компоненты, такие как реклама, документы и т.д.) признаны не рекомендуемыми, они не будут отображены пользователю. Также они могут быть исключены из списка найденных элементов и запомнены, чтобы не показывать их снова. Например, такие не рекомендуемые элементы, обнаруженные в результате антивирусной проверки, добавляются в бан-лист, поскольку они содержат ссылки на ненадежные источники или вебсайты, которые содержат запрещенную или вредоносную информацию, такую как вредоносный код, скрипты и т.д.
Включающие модификации означают добавление информации из различных источников (таких как локальные хранилища, веб-хранилища, рекламные серверы, онлайн энциклопедии, серверы рекламодателя и т.д. - все упомянутые в объеме настоящего изобретения) к результатам поиска. Таким образом, результаты поиска будут содержать информацию как из поисковых систем, так и предварительно выбранных источников для заданной категории (которая, например, может содержаться в базе данных, сформированной на базе анализа действий пользователя (пользователей)), как было показано выше. Способ, использующийся для смешивания нескольких источников информации для отображения пользователю, описан выше.
| название | год | авторы | номер документа |
|---|---|---|---|
| МЕТОД ОТОБРАЖЕНИЯ РЕЛЕВАНТНОЙ КОНТЕКСТНО-ЗАВИСИМОЙ ИНФОРМАЦИИ | 2014 |
|
RU2683482C2 |
| ИСПОЛЬЗОВАНИЕ СОДЕРЖИМОГО СТРАНИЦЫ ДЛЯ РЕШЕНИЯ ЗАДАЧИ ТОЧНОГО ПОДБОРА РЕКЛАМЫ | 2013 |
|
RU2630382C2 |
| ФРЕЙМВОРК ПРИЕМА ВИДЕО ДЛЯ ПЛАТФОРМЫ ВИЗУАЛЬНОГО ПОИСКА | 2017 |
|
RU2720536C1 |
| ПОДДЕРЖИВАЮЩИЕ ПОДСКАЗКУ РЕКЛАМНЫЕ ОБЪЯВЛЕНИЯ ПОИСКА | 2011 |
|
RU2591185C2 |
| СПОСОБ РАСПРОСТРАНЕНИЯ РЕКЛАМНЫХ И ИНФОРМАЦИОННЫХ СООБЩЕНИЙ В СЕТИ ИНТЕРНЕТ | 2012 |
|
RU2520394C1 |
| ОБНАРУЖЕНИЕ ОБЪЕКТОВ ИЗ ЗАПРОСОВ ВИЗУАЛЬНОГО ПОИСКА | 2017 |
|
RU2729956C2 |
| СИСТЕМА, УСТРОЙСТВО И СПОСОБ УПРАВЛЕНИЯ СООБЩЕНИЯМИ | 2008 |
|
RU2472213C2 |
| СПОСОБ И СИСТЕМА ДЛЯ ОБЕСПЕЧЕНИЯ УРОВНЯ СЕРВИСА ПРИ РЕКЛАМЕ ЭЛЕМЕНТА КОНТЕНТА | 2019 |
|
RU2757406C1 |
| СИСТЕМА И СПОСОБ ИСПОЛЬЗОВАНИЯ КОНТЕНТА ОНЛАЙНОВОГО РАЗГОВОРА ДЛЯ ВЫБОРА РЕКЛАМНОГО КОНТЕНТА И/ИЛИ ДРУГОЙ РЕЛЕВАНТНОЙ ИНФОРМАЦИИ ДЛЯ ОТОБРАЖЕНИЯ | 2006 |
|
RU2419863C2 |
| СПОСОБ И УСТРОЙСТВО ДЛЯ ПРЕДОСТАВЛЕНИЯ СЛУЖБЫ, ОСНОВАННОЙ НА МЕСТОПОЛОЖЕНИИ | 2009 |
|
RU2470485C2 |
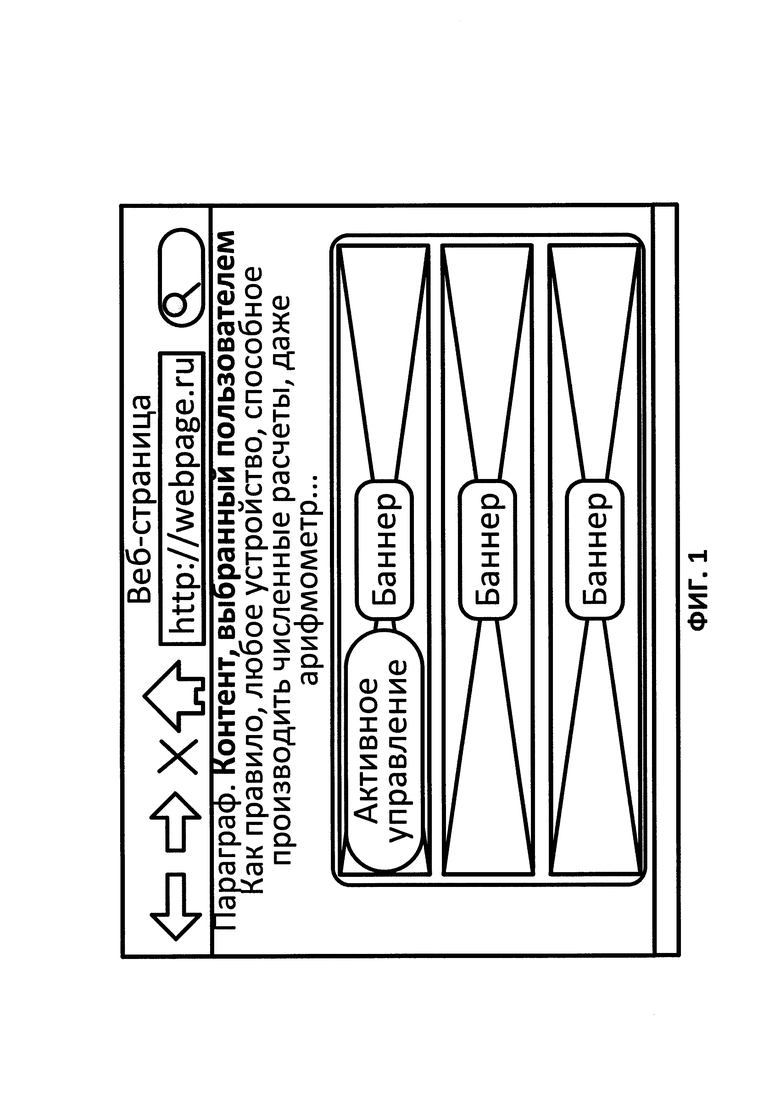
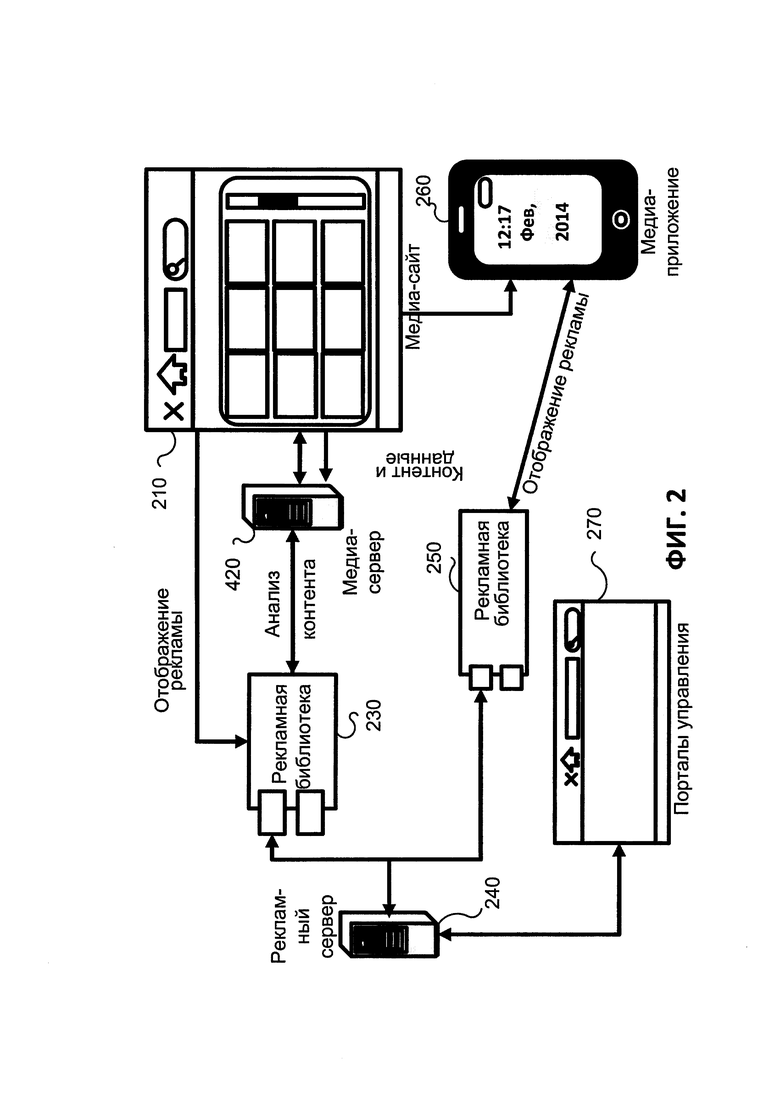
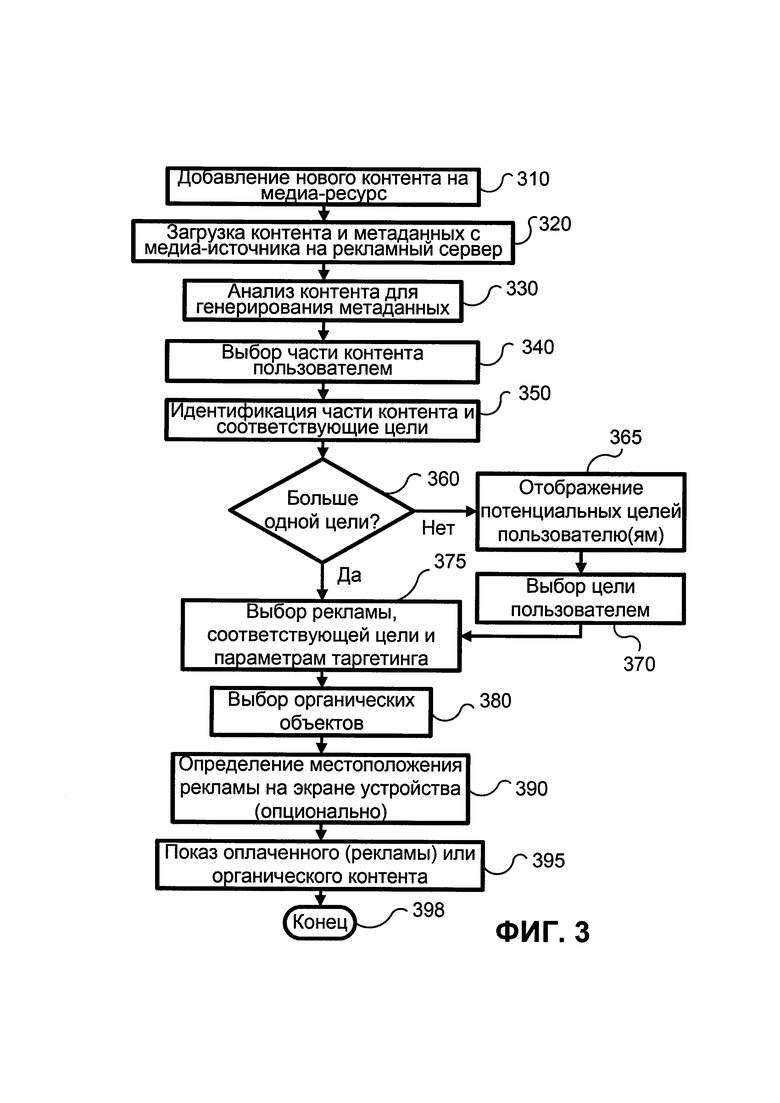
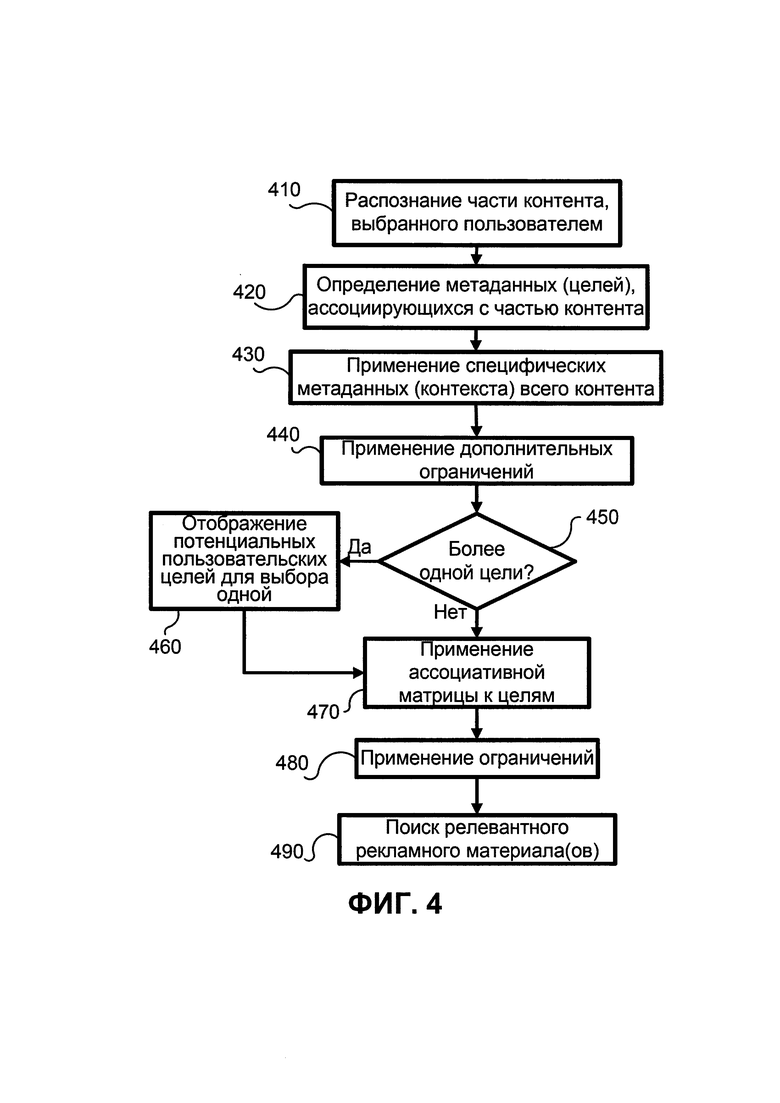
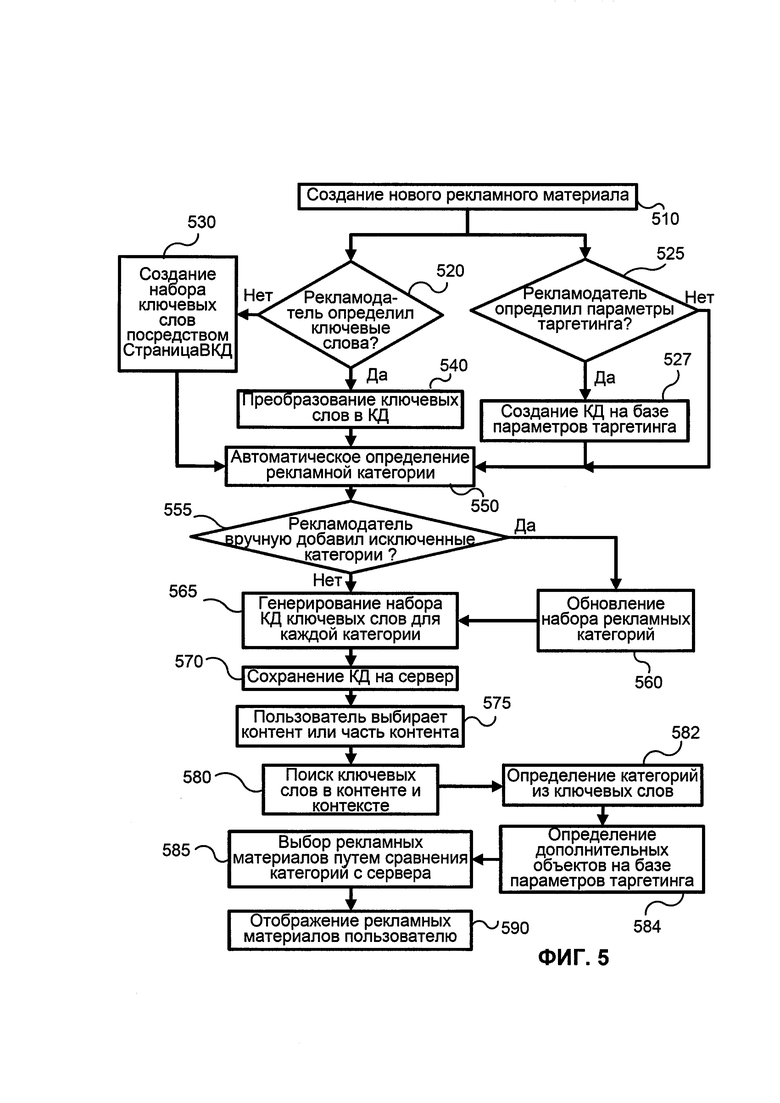
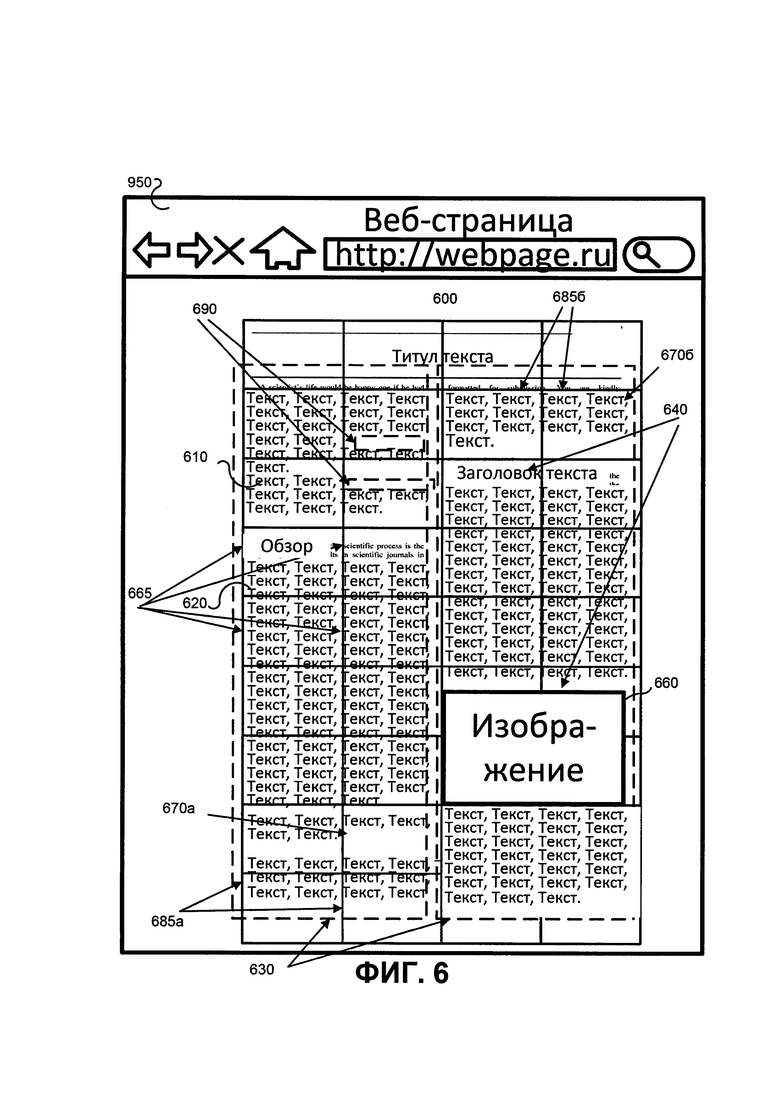
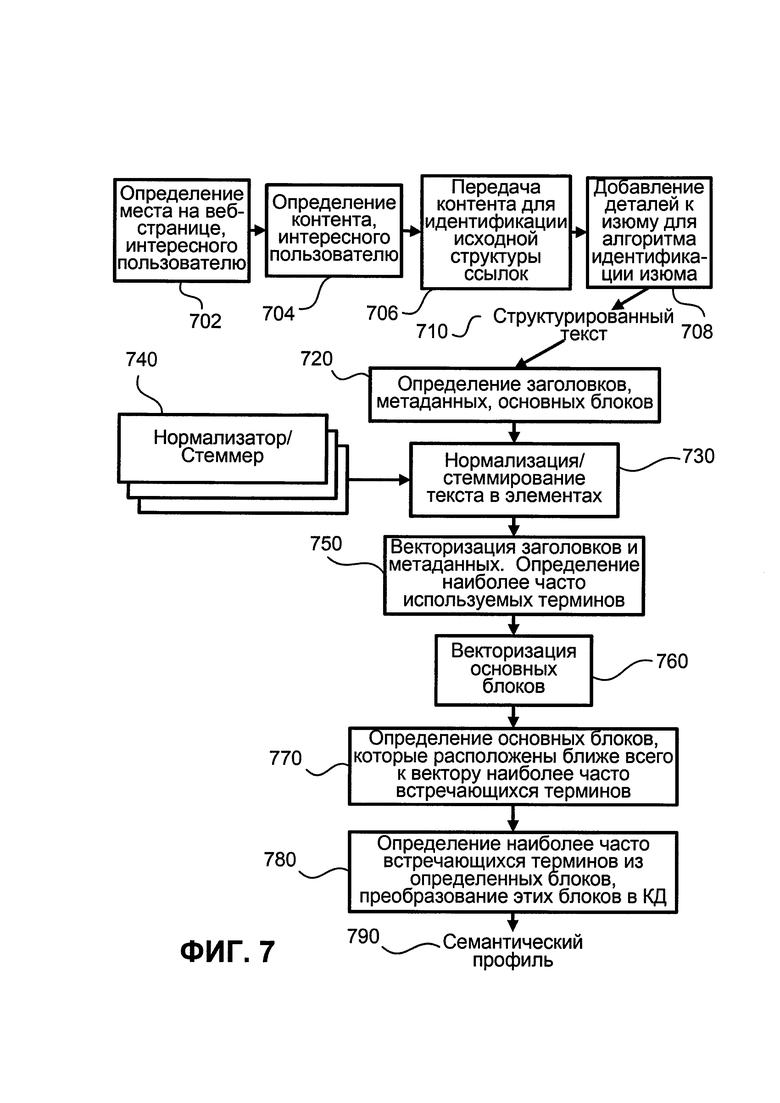
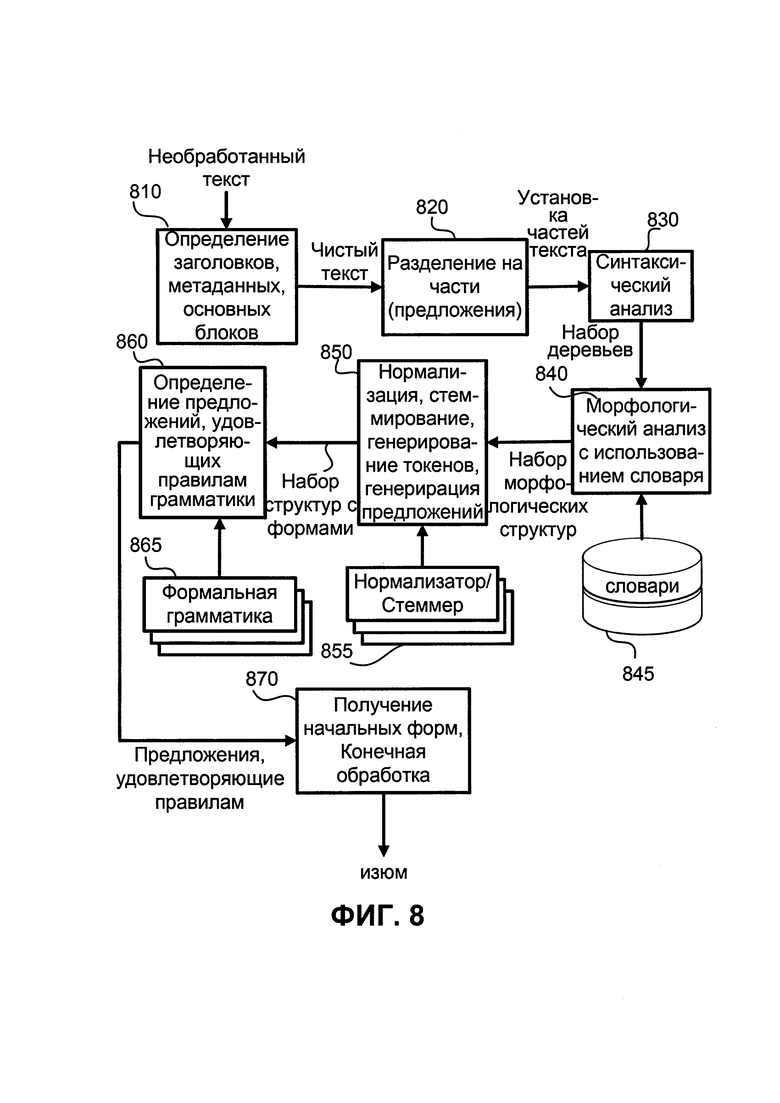
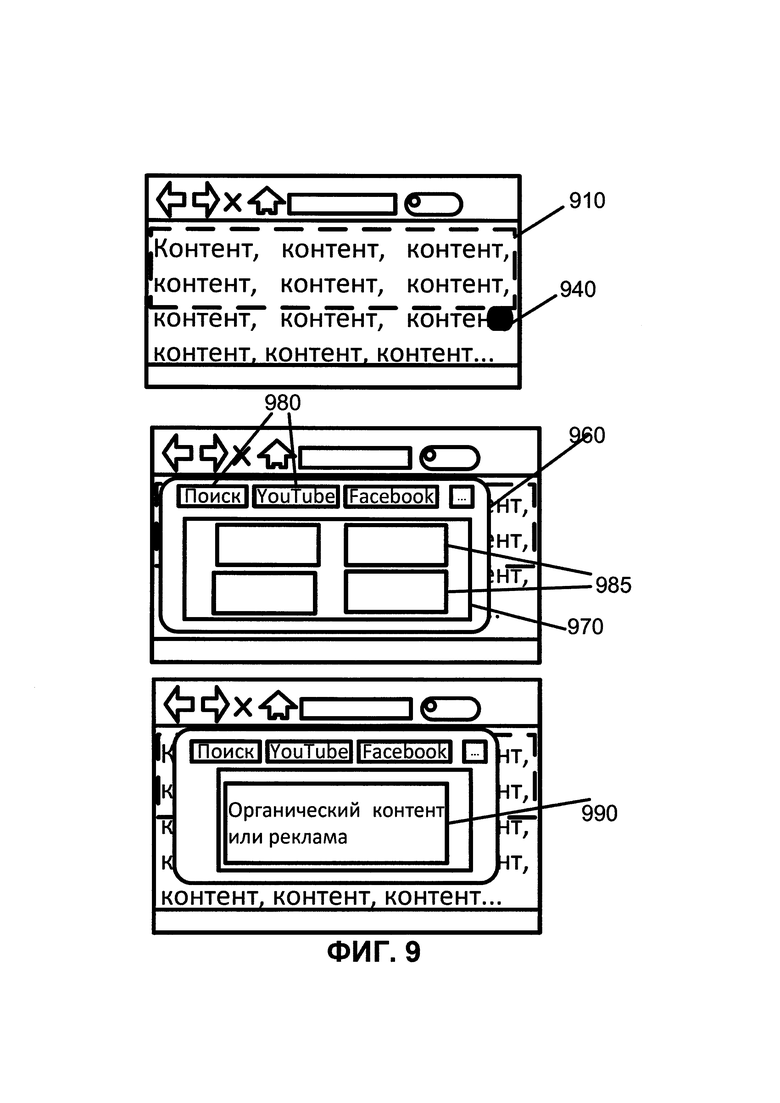


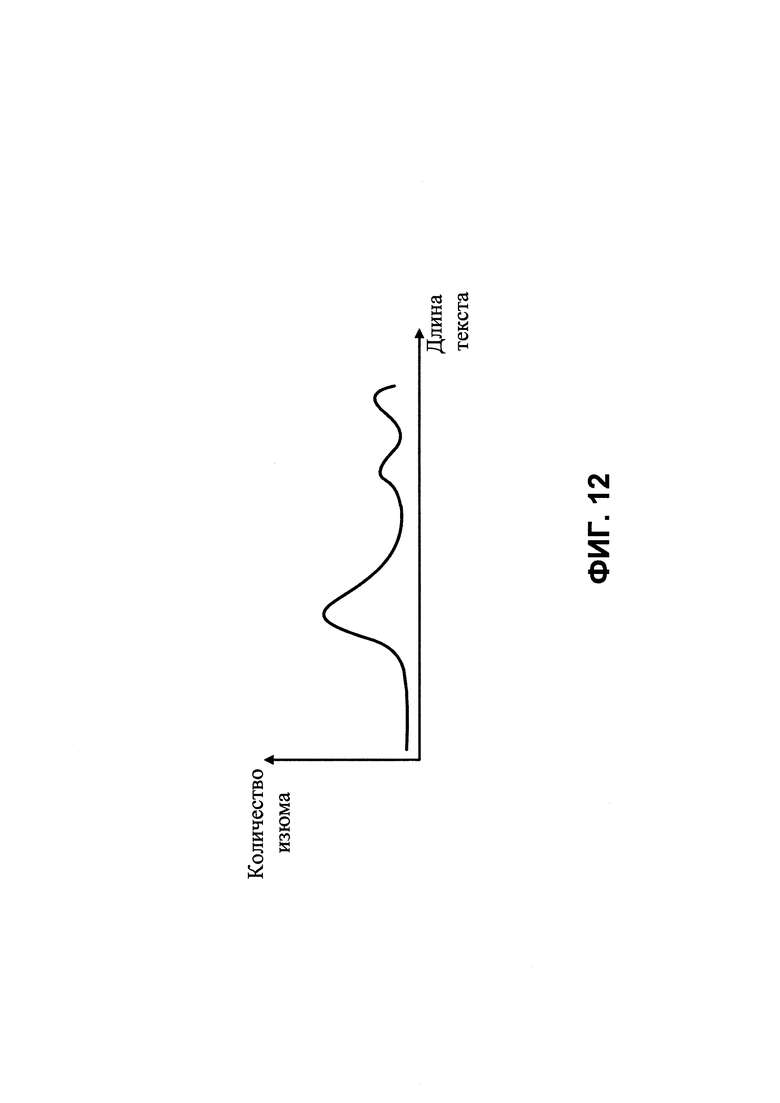
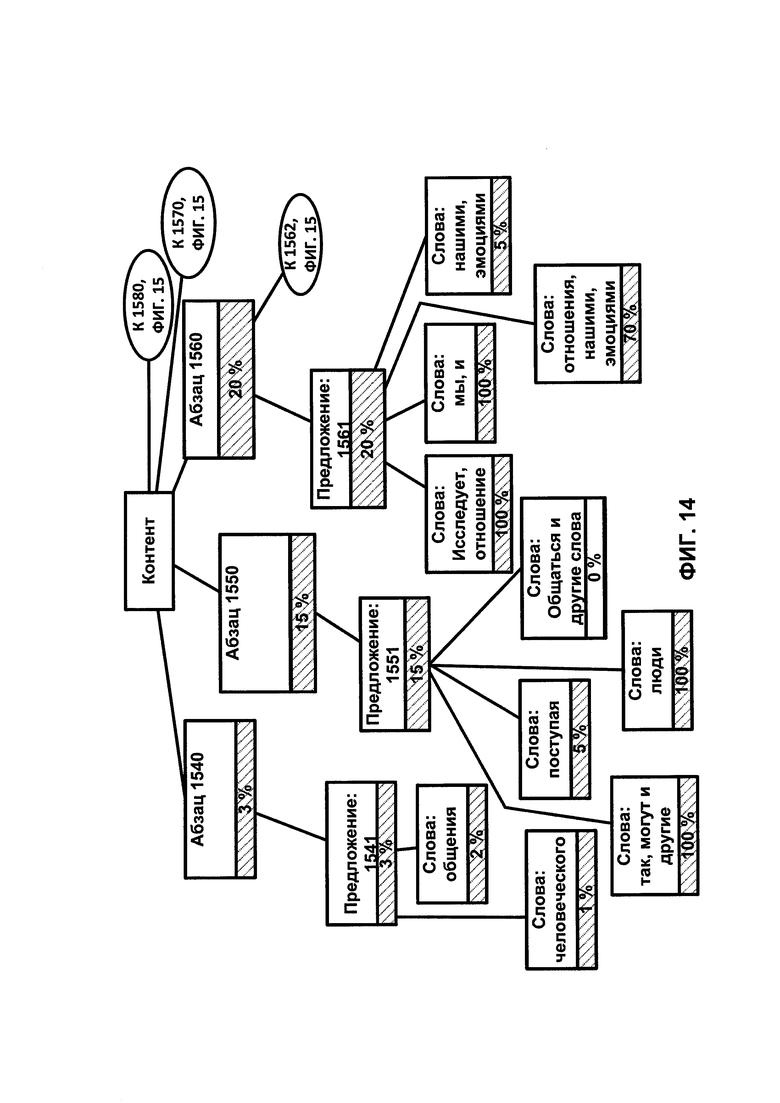
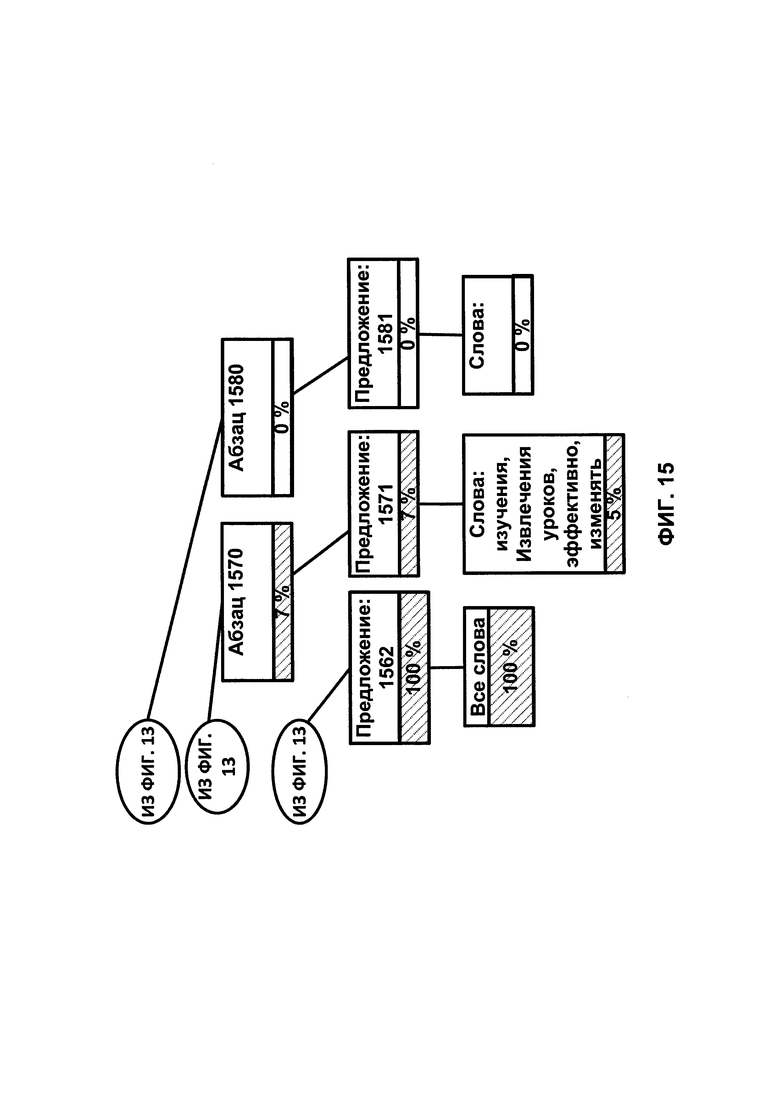
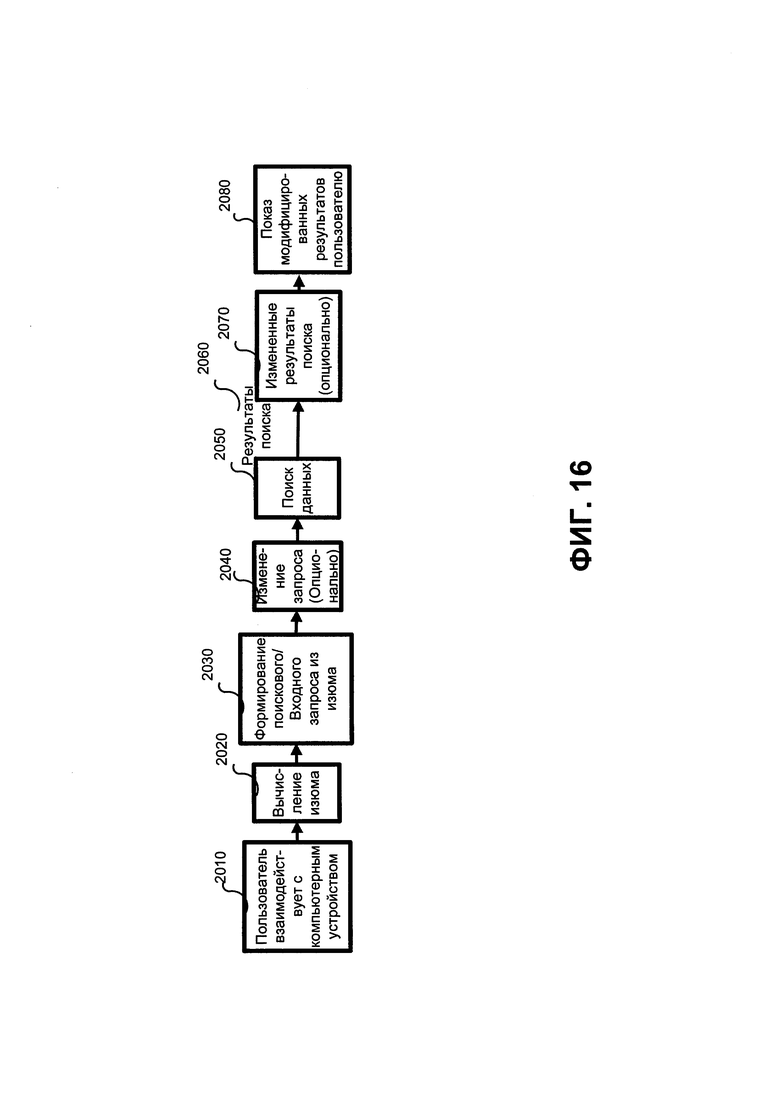
Изобретение относится к способам автоматической идентификации релевантных пунктов. Технический результат заключается в автоматизации определения релевантных пунктов. Способ включает в себя: получение контента, элементы разметки и стили элементов; преобразование контента в сырой контент посредством удаления технических конструкций; применение стилей контента к элементам преобразованного контента; выполнение синтаксического анализа связанных частей контента для генерирования множества деревьев разбора для последующего морфологического анализа; выполнение морфологического анализа связанных частей контента; выполнение стеммирования частей речи и построение цепочек; идентифицирование релевантных пунктов в цепочках и вычисление весов релевантных пунктов; корректирование весов релевантных пунктов на основе расстояния соответствующих частей контента; выбор релевантных пунктов с наибольшим весом и наивысшей степенью принадлежности области вокруг точки взаимодействия пользователя с контентом; корректировка релевантных пунктов; выбор информации для отображения пользователю на основе скорректированных релевантных пунктов и точки взаимодействия пользователя с контентом; отображение выбранной информации. 4 н. и 20 з.п. ф-лы, 16 ил.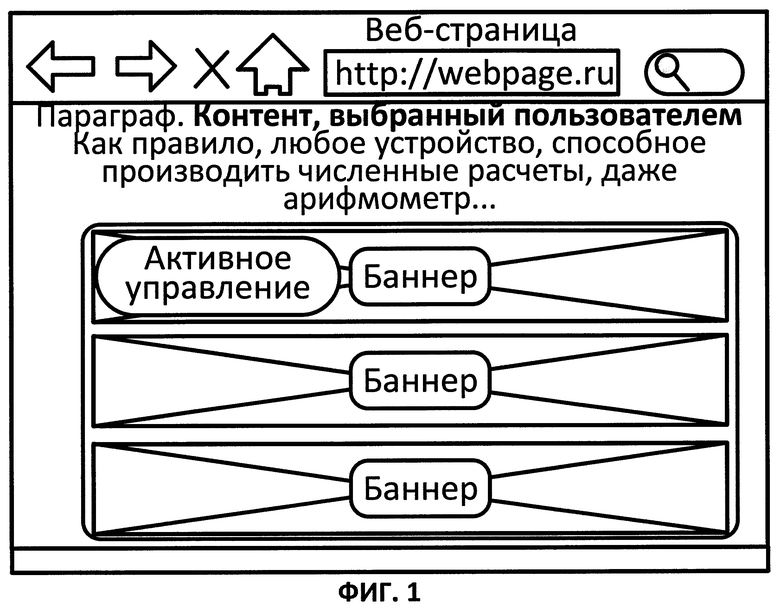
1. Способ автоматической идентификации релевантных пунктов, характеризующих возможный интерес пользователя, в отображаемом контенте, выполняемый компьютерным устройством и включающий:
получение контента, включающего необработанный контент, элементы разметки и стили элементов;
преобразование контента в сырой контент посредством удаления технических конструкций;
применение стилей контента к элементам преобразованного контента для определения, какая последовательность части контента представляет сплошные логически связанные и визуально связанные части контента;
выполнение синтаксического анализа связанных частей контента для генерирования множества деревьев разбора для последующего морфологического анализа;
выполнение морфологического анализа связанных частей контента с использованием словаря для определения частей речи и морфологии слова в связанных частях контента;
выполнение стеммирования частей речи и построение цепочек, удовлетворяющих правилам грамматики;
идентифицирование релевантных пунктов в цепочках и вычисление весов релевантных пунктов;
корректирование весов релевантных пунктов на основе расстояния соответствующих частей контента от точки взаимодействия пользователем с контентом;
выбор релевантных пунктов с наибольшим весом и наивысшей степенью принадлежности области вокруг точки взаимодействия пользователя с контентом;
корректировка релевантных пунктов для необходимого представления в необработанном контенте, находящихся вблизи точки взаимодействия пользователя с контентом;
выбор информации для отображения пользователю на основе скорректированных релевантных пунктов и точки взаимодействия пользователя с контентом, используемой в качестве исходных данных; и
отображение выбранной информации.
2. Способ по п. 1, отличающийся тем, что необработанный контент получается раздельно в виде элементов разметки и стилей элементов.
3. Способ по п. 1, отличающийся тем, что по крайней мере часть необработанного контента содержит контент, представленный различными геометрическими фрагментами контента.
4. Способ по п. 1, отличающийся тем, что необработанный контент представляет собой контент веб-страницы.
5. Способ по п. 1, отличающийся тем, что части контента связаны логически и геометрически.
6. Способ по п. 1, отличающийся тем, что части контента включают слова, выражения, предложения, абзацами, весь контент веб-страницы, рекламные материалы, баннеры, трехмерный контент, видео, части слов, части фраз, части предложения, части изображений, части видео.
7. Способ по п. 1, отличающийся тем, что логические и геометрические связи включают связи между словами, фразами, предложениями, абзацами, всем контентом веб-страницы, рекламными материалами, баннерами, трехмерным контентом, видео, частями слов, частями фраз, частями предложений, частями изображений, частями видео.
8. Способ по п. 1, отличающийся тем, что релевантные пункты видимы пользователю и доступны для выбора пользователем.
9. Способ по п. 1, отличающийся тем, что релевантные пункты используются в качестве поисковых запросов к поисковым системам для генерирования результатов поиска.
10. Способ по п. 9, отличающийся тем, что запрос модифицируется данными из собранных инфо-данных.
11. Способ по п. 10, отличающийся тем, что результаты поиска, основанные на запросе, отображаются пользователю.
12. Способ по п. 11, отличающийся тем, что результаты поиска перед отображением пользователю модифицируются следующим образом:
Результаты поиска модифицируются для исключения результатов на основе предварительно выбранных параметров поиска: категорий, черного списка сайтов, географического местоположения; и
Результаты поиска модифицируются для включения результатов из других поисковых систем, рекламных сервисов и объектов из других приложений.
13. Способ по п. 1, отличающийся тем, что релевантные пункты получаются из цепочек с наибольшими весами.
14. Способ по п. 1, отличающийся тем, что вычисление весов релевантных пунктов использует собранные инфо-данные.
15. Способ по п. 1, отличающийся тем, что анализ текста также включает анализ следующих элементов:
изображения;
анимация;
игровые элементы;
рекламные материалы;
трехмерные модели.
16. Способ автоматического определения областей, представляющих интерес для пользователей, на основе неточного указания пользователем области, содержащей структурированные объекты, и на основе геометрических характеристик элементов, включающий:
получение веб-страницы;
определение элементов контента, представляющих единую логическую концепцию, при этом единая логическая концепция является непрерывными частями контента, части которого отображаются в различных частях веб-страницы согласно HTML-разметке, для идентификации частей текста, размещающихся в нескольких столбцах контента, как единого элемента контента, включая предварительное вычисление атрибутом контента с предустановленными параметрами, которые включают список объектов и их категории для каждого элемента контента;
определение элементов контента, представляющих единую геометрическую концепцию, где единая геометрическая концепция является визуально ограниченной областью, содержащей множество частей контента, для идентификации частей текста, размещающихся в нескольких столбцах контента, как единого элемента контента;
отображение геометрической точки взаимодействия пользователя с ограниченной логической позицией в серии объектов, включающих контент, отображенный в ограниченных частях контента, без точного вычисления положения каждого из объектов;
определение взаимодействий пользователя с идентифицированными элементами контента;
определение области вокруг точки взаимодействия пользователя с веб-страницей, где любая точка любого текста веб-страницы является гиперссылкой и где, если точка взаимодействия располагается между предложениями, то для синтаксического анализа используется весь параграф, и, если геометрическая точка располагается между двумя параграфами, то для синтаксического анализа используются два прилегающих к ней предложения;
вычисление значимых элементов контента, включающее
вычисление расстояния между элементами контента и точкой взаимодействия;
вычисление степени перекрытия между областью вокруг точки взаимодействия и идентифицированными элементами контента;
вычисление уровня синтаксической и геометрической иерархии на основе уровня пересечения между идентифицированными элементами контента, частью элементов контента и областью взаимодействия пользователя; и
идентификация релевантных пунктов в элементах контента и в области взаимодействия пользователя на основе семантического профиля идентифицированных элементов контента и на основе расстояния, и на основе предварительно вычисленных автоматически сгенерированных атрибутов контента и тегов, ассоциирующихся с пользователем, которые предоставлены третьими сторонами;
выбор информации для отображения пользователю на основе релевантных пунктов и на основе анализа других веб-страниц, связанных с упомянутой вебстраницей; и
отображение выбранной информации, включая замену элементов страницы иконками, отображающими предварительный просмотр выбранной информации.
17. Способ по п. 16, отличающийся тем, что логические и геометрические связи включают отношения смежности и последовательности между словами, выражениями, предложениями, абзацами, всем контентом веб-страницы, рекламными материалами, баннерами, трехмерным контентом, видео, частями слов, частями выражений, частями предложений, частями изображений, частями видео.
18. Способ по п. 16, отличающийся тем, что пользователь взаимодействует с контентом посредством точки касания.
19. Способ по п. 16, отличающийся тем, что пользователь взаимодействует с контентом посредством области, расположенной вокруг точки касания.
20. Способ по п. 16, отличающийся тем, что релевантные пункты, выбранные для шага выбора информации, соответствуют цепочкам элементов, согласованным с грамматикой и имеющим высокие веса.
21. Способ по п. 16, отличающийся тем, что уровень иерархии определяется любым словом, предложением, выражением, абзацем, всем контентом, изображением, видео или частью видео.
22. Способ определения пользовательских интересов, относящихся к нескольким объектам, отображаемым на веб-странице, включающий:
загрузку веб-страницы, содержащей несколько элементов контента;
определение прямоугольной области на основе области взаимодействия пользователя, содержащей значимую часть множества элементов контента, включая предварительное вычисление автоматически сгенерированных атрибутов контента с предустановленными параметрами, которые включают список объектов и их категорий для каждого элемента контента;
определение алгоритма разметки элементов, использующегося для размещения элементов контента в прямоугольной области, в которой элементы контента могут перемещаться в этой области на основе размеров их геометрических параметров и размера шрифта;
определение средних геометрических пропорций элементов контента;
отображение геометрической точки взаимодействия пользователя с ограниченной логической позицией в серии объектов, включающих контент, отображенный в ограниченных частях контента, без точного вычисления положения каждого из объектов, где любая точка любого текста веб-страницы является гиперссылкой и где, если точка взаимодействия располагается между предложениями, то для синтаксического анализа используется весь параграф, и, если геометрическая точка располагается между двумя параграфами, то для синтаксического анализа используются два прилегающих к ней предложения;
определение количества перемещающихся элементов в области;
вычисление параметров сетки, включая строки и столбцы, которые виртуально делят область для размещения всех элементов контента в некотором приближении, для идентификации частей текста, размещающихся в нескольких столбцах контента, как единого элемента контента;
определение, какие ячейки сетки содержат область пользовательского взаимодействия;
определение, какие позиции в последовательности или иерархии соответствуют ячейкам области пользовательского взаимодействия на основе алгоритма разметки перемещающихся элементов;
расширение позиций до диапазонов перемещающихся элементов путем добавления и вычитания количества свободных ячеек, которые не были использованы для размещения в сетке;
передачу диапазонов в алгоритм извлечения релевантных пунктов;
определение релевантных пунктов в элементах контента и в области пользовательского взаимодействия на основе семантического профиля перемещающихся элементов и на основе расстояния, и на основе анализа других веб-страниц, связанных с упомянутой веб-страницей, и на основе предварительно вычисленных автоматически сгенерированных атрибутов контента и тегов, ассоциирующихся с пользователем, предоставляемых третьими сторонами;
и отображение релевантных пунктов.
23. Способ по п. 22, отличающийся тем, что алгоритм определяется на основе разметки и стилей элементов контента.
24. Способ автоматического определения релевантных пунктов, характеризующих возможный интерес пользователя, для поиска на веб-странице, отображенной на устройствах с сенсорным экраном, выполняемый компьютерным устройством и включающий:
получение веб-страницы с необработанным текстом, содержащим элементы HTML;
удаление элементов HTML из необработанного текста для генерирования сырого текста;
разделение сырого текста на несколько частей, представленных массивом, где, по крайней мере, некоторые части текста, содержат текст, представленный в различных частях веб-страницы;
выполнение синтаксического анализа нескольких частей текста для генерирования множества синтаксических деревьев разбора для последующего морфологического анализа;
выполнение морфологического анализа частей текста для определения частей речи и форм слов в нескольких частей текста;
выполнение стеммирования частей речи и построение цепочек, удовлетворяющих правилам формальной грамматики;
применение весов к цепочкам для определения релевантных пунктов; и
использование релевантных пунктов, расположенных около области, выделенной касанием пользователя, в качестве входных данных для поисковой системы для отображения результатов поиска;
выбор информации для отображения пользователю на основе релевантных пунктов и области, выделенной касанием пользователя;
отображение выбранной информации.
| Станок для изготовления деревянных ниточных катушек из цилиндрических, снабженных осевым отверстием, заготовок | 1923 |
|
SU2008A1 |
| Устройство для закрепления лыж на раме мотоциклов и велосипедов взамен переднего колеса | 1924 |
|
SU2015A1 |
| Многоступенчатая активно-реактивная турбина | 1924 |
|
SU2013A1 |
| US 8225196 B2, 17.07.2012 | |||
| Колосоуборка | 1923 |
|
SU2009A1 |
| СИСТЕМА И СПОСОБ ДЛЯ ПРЕДСТАВЛЕНИЯ КОНТЕНТА ПОЛЬЗОВАТЕЛЮ | 2006 |
|
RU2427901C2 |
| Быстродействующий коммутационный аппарат | 1958 |
|
SU119908A1 |
| Изложница с суживающимся книзу сечением и с вертикально перемещающимся днищем | 1924 |
|
SU2012A1 |

