Область техники, к которой относится изобретение
Настоящая технология относится к устройству передачи данных, способу передачи данных, приёмному устройству и способу приёма, и, если более точно, относится к устройству передачи данных для передачи множества типов аудиоданных и подобной информации.
Уровень техники
В предшествующем уровне техники, например, таком как трёхмерная (3D) звуковая технология, существует предложенная технология для преобразования закодированных выборочных данных для громкоговорителя, существующих в произвольном местоположении, чтобы воспроизводить их на основе метаданных (например, см патентный документ 1).
Список ссылок
Патентные документы
Патентный документ 1: японский перевод публикации документа № 2014-520491 согласно PCT.
Раскрытие сущности изобретения
Проблемы, которые должны быть решены с помощью изобретения
Существует воспроизведение звука, например, с улучшенным ощущением реалистичности, которое реализуется на приёмной стороне с помощью передаваемых объектных данных, составленных из закодированных выборочных данных и метаданных вместе с канальными данными для канальной системы 5.1 охватывающего объёмного звука, канальной системы 7.1, или подобных систем. В предшествующем уровне техники было предложено передавать поток аудиоданных, включающих в себя закодированные данные, которые получаются с помощью закодированных канальных данных и объектных данных посредством использования способа кодирования MPEG-H 3D Audio (3D audio) на стороне приёма.
Способ кодирования 3D Audio, и такой способ кодирования, как MPEG4 ААС, являются несовместимыми в этих потоковых структурах. Таким образом, когда обеспечивается способ кодирования 3D Audio service, как поддерживающий совместимость с родственным приёмником аудиоданных, может быть обоснована передача, транслируемая одновременно по радио и телевидению. Однако полоса пропускания не может эффективно использоваться, когда одинаковое содержимое передаётся с помощью различных способов кодирования.
Задачей настоящей технологии является обеспечение новой сервисной услуги, которая поддерживает совместимость с родственным приёмником аудиоданных без ухудшения эффективного использования полосы пропускания.
Решения проблем
Концепция настоящей технологии находится в устройстве передачи данных, включающем в себя:
кодирующий модуль, сконфигурированный для генерирования заданного количества потоков аудиоданных, включающих в себя первые закодированные данные и вторые закодированные данные, которые имеют отношение к первым закодированным данным; и
модуль передачи данных, сконфигурированный для передачи контейнера данных в заданном формате, включающий в себя генерированное заданное количество потоков аудиоданных,
при этом кодирующий модуль генерирует заданное количество потоков аудиоданных, в результате чего вторые закодированные данные отвергаются в приёмнике, который не совместим со вторыми закодированными данными.
В соответствии с настоящей технологией, кодирующий модуль генерирует заданное количество потоков аудиоданных, имеющих первые закодированные данные и вторые закодированные данные, которые имеют отношение к первым закодированным данным. В данном случае заданное количество потоков аудиоданных генерируется таким образом, что вторые закодированные данные отвергаются в приёмнике, который не совместим со вторыми закодированными данными.
Например, способ кодирования первых закодированных данных и способ кодирования вторых закодированных данных могут быть различными. В этом случае, например, первые закодированные данные могут быть канальными закодированными данными, а вторые закодированные данные могут быть объектными закодированными данными. Кроме того, в этом случае, например, способ кодирования первых закодированных данных может быть MPEG4 ААС, а способ кодирования вторых закодированных данных может быть MPEG-H 3D Audio.
Модуль передачи данных передаёт контейнер данных в заданном формате, включающим в себя генерированное заданное количество потоков аудиоданных. Например, контейнер данных может быть транспортным потоком данных (MPEG-2 TS), который используется в цифровом широковещательном стандарте. Кроме того, например, контейнер данных может быть контейнером MP4, который используется в распределении через Интернет, или контейнером в других форматах.
Как описывалось выше, в соответствии с настоящей технологией, передаётся заданное количество потоков аудиоданных, имеющих первые закодированные данные и вторые закодированные данные, которые имеют отношение к первым закодированным данным, и заданное количество потоков аудиоданных генерируется таким образом, что вторые закодированные данные отвергаются в приёмнике, который не совместим со вторыми закодированными данными. Таким образом, может обеспечиваться новый сервис, который поддерживает совместимость с родственным приёмником аудиоданных без ухудшения эффективного использования полосы пропускания.
Следует отметить, что в настоящей технологии, например, кодирующий модуль может генерировать потоки аудиоданных, имеющие первые закодированные данные и встраивать вторые закодированные данные в области пользовательских данных потоков аудиоданных. В этом случае в родственном приёмнике аудиоданных, вторые закодированные данные, которые встраиваются в область пользовательских данных, считываются и отвергаются.
В этом случае, например, модуль вставления информации конфигурируется для вставления в слой контейнера данных, при этом может дополнительно включаться информация идентификации, которая идентифицирует, что существуют вторые закодированные данные, которые имеют отношение к первым закодированным данным, встроенным в область пользовательских данных потоков аудиоданных, имеющих первые закодированные данные, включённые в контейнер. С этой конфигурацией на стороне приёма можно легко распознавать, что существуют вторые закодированные данные, встроенные в область пользовательских данных потоков аудиоданных перед выполнением процесса декодирования потоков аудиоданных.
Кроме того, в этом случае, например, первые закодированные данные могут быть канальными закодированными данными, а вторые закодированные данные могут быть объектными закодированными данными, причём объектные закодированные данные заданного количества групп могут быть встроены в область пользовательских данных потока аудиоданных, модуль вставления информации конфигурируется для вставления в слой контейнера данных, может дополнительно включаться информация об определяющим признаке, которая обозначает определяющий признак каждого фрагмента объектных закодированных данных заданного количества групп. С этой конфигурацией на стороне приёма можно легко распознавать определяющий признак каждого фрагмента объектных закодированных данных заданного количества групп перед декодированием объектных закодированных данных, в результате чего объектные закодированные данные необходимой группы могут выборочно декодироваться и использоваться, таким образом можно уменьшать нагрузку при обработке данных.
Кроме того, в настоящей технологии, например, кодирующий модуль может генерировать первый поток аудиоданных, включающий в себя первые закодированные данные, а также может генерировать заданное количество вторых потоков аудиоданных, включающих в себя вторые закодированные данные. В этом случае, в родственном приёмнике аудиоданных заданное количество вторых потоков аудиоданных исключаются из целей для декодирования. Или в этой системе также возможно, что закодированные данные канальной системы 5.1 кодируются с использованием системы ААС, данные канала 2 получаются из данных канальной системы 5.1, а объектные закодированные данные кодируются как вторые закодированные данные с использованием системы MPEG-H. В этом случае приёмник, который не совместим со вторым способом кодирования, кодирует только первые закодированные данные.
В этом случае, например, объектные закодированные данные заданного количества групп могут быть включены в заданное количество вторых потоков аудиоданных, модуль вставления информации конфигурируется для вставления в слой контейнера данных, может дополнительно включаться информация об определяющим признаке, которая обозначает определяющий признак каждого фрагмента объектных закодированных данных заданного количества групп. С этой конфигурацией на стороне приёма можно легко распознавать определяющий признак каждого фрагмента объектных закодированных данных заданного количества групп перед декодированием объектных закодированных данных, в результате чего объектные закодированные данные необходимой группы может выборочно декодироваться и использоваться, таким образом можно уменьшать нагрузку при обработке данных.
Затем, в этом случае, например, модуль вставления информации может быть выполнен для дополнительного вставления в слой контейнера данных информации отношения соответствия потока, которая обозначает к какому второму потоку аудиоданных объектных закодированных данных заданного количества групп соответственно включаются канальные закодированные данные и объектные закодированные данные заданного количества групп. Например, информация отношения соответствия потока может быть выполнена как информация, которая показывает отношение соответствия между групповым идентификатором, идентифицирующим каждый фрагмент закодированных данных множества групп, и идентификатором потока, идентифицирующим каждый поток заданного количества потоков аудиоданных. В этом случае, например, модуль вставления информации может быть выполнен для дополнительного вставления в слой контейнера данных информации с идентификатором потока, которая обозначает каждый идентификатор потока заданного количества потоков аудиоданных. С этой конфигурацией на стороне приёма можно легко распознавать объектные закодированные данные необходимой группы или второй поток аудиоданных, который включает в себя канальные закодированные данные и объектные закодированные данные заданного количества групп, таким образом можно уменьшать нагрузку при обработке данных.
Кроме того, другая концепция настоящей технологии находится в приёмном устройстве, включающем в себя
приёмный модуль, сконфигурированный для приёма контейнера данных в заданном формате, включающем в себя заданное количество потоков аудиоданных, имеющих первые закодированные данные и вторые закодированные данные, которые имеют отношение к первым закодированным данным,
при этом заданное количество потоков аудиоданных генерируется таким образом, что вторые закодированные данные отвергаются в приёмнике, который является несовместимым со вторыми закодированными данными,
приёмное устройство дополнительно включает в себя обрабатывающий модуль, сконфигурированный таким образом, чтобы извлекать первые закодированные данные и вторые закодированные данные из заданного количества потоков аудиоданных, включённых в контейнер, и обрабатывать извлечённые данные.
В соответствии с настоящей технологией, приёмный модуль принимает контейнер в заданном формате, включающем в себя заданное количество потоков аудиоданных, имеющих первые закодированные данные и вторые закодированные данные, которые имеют отношение к первым закодированным данным. Здесь заданное количество потоков аудиоданных генерируется таким образом, что вторые закодированные данные отвергаются в приёмнике, который является несовместимым со вторыми закодированными данными. Затем, с помощью обрабатывающего модуля первые закодированные данные и вторые закодированные данные извлекаются из заданного количества потоков аудиоданных и обрабатываются.
Например, способ кодирования первых закодированных данных и способ кодирования вторых закодированных данных могут быть различными. В этом случае, например, первые закодированные данные могут быть канальными закодированными данными, а вторые закодированные данные могут быть объектными закодированными данными.
Например, контейнер может быть выполнен таким образом, чтобы включать в себя поток аудиоданных, который имеет первые закодированные данные и вторые закодированные данные, встроенные в область пользовательских данных. Кроме того, например, контейнер может включать в себя первый поток аудиоданных, включающий в себя первые закодированные данные и заданное количество вторых потоков аудиоданных, включающих в себя вторые закодированные данные.
Таким образом, в соответствии с настоящей технологией, первые закодированные данные и вторые закодированные данные извлекаются из заданного количества потоков аудиоданных и обрабатываются. Поэтому может быть реализовано высококачественное воспроизведение звука с помощью нового сервиса, использующего вторые закодированные данные в дополнение к первым закодированным данным.
Результаты изобретения
В соответствии с настоящей технологией, может обеспечиваться новый сервис, как поддерживающий совместимость с родственным приёмником аудиоданных без ухудшения эффективного использования полосы пропускания. Следует отметить, что эффект, описанный в этом описании изобретения, является только примером, и не устанавливает какого-либо ограничения, при этом возможно существование дополнительных эффектов.
Краткое описание чертежей
Фиг. 1 является блок-схемой, иллюстрирующей пример конфигурации приёмопередающей системы, в качестве варианта осуществления изобретения.
Фиг. 2(а) и 2(b) являются диаграммами для разъяснения конфигураций при передаче потока аудиоданных (конфигурация (1) потока и конфигурация (2) потока).
Фиг. 3 является блок-схемой, иллюстрирующей пример конфигурации модуля генерирования потока в передатчике для сервисных услуг* в том случае, когда конфигурация при передаче потока аудиоданных является конфигурацией (1) потока.
Фиг. 4 является диаграммой, иллюстрирующей пример конфигурации объектных закодированных данных, которые содержат трёхмерные 3D аудиоданные для передачи.
Фиг. 5 является диаграммой, иллюстрирующей отношение соответствия между группами и определяющими признаками, или подобными параметрами в том случае, когда конфигурация при передаче потока аудиоданных является конфигурацией (1) потока.
Фиг. 6 является диаграммой, иллюстрирующей структуру аудиокадра MPEG4 ААС.
Фиг. 7 является диаграммой, иллюстрирующей конфигурацию элемента потока данных (DSE), в который вставляются метаданные.
Фиг. 8(а) и 8(b) являются диаграммами, иллюстрирующими конфигурацию метаданных “metadata ()” и главную информацию конфигурации.
Фиг. 9 является диаграммой, иллюстрирующей структуру аудиокадра MPEG-H 3D Audio.
Фиг. 10(а) и 10(b) являются диаграммами, иллюстрирующими примеры конфигурации пакета объектных закодированных данных.
Фиг. 11 является диаграммой, иллюстрирующей пример структуры дескриптора служебных данных.
Фиг. 12 является диаграммой, иллюстрирующей отношение соответствия между текущими битами и типами данных 8-битового поля дескриптора служебных данных “ancillary_data_identifier”.
Фиг. 13 является диаграммой, иллюстрирующей пример конфигурации дескриптора структуры потока данных 3D Audio.
Фиг. 14 иллюстрирует содержимое главной информации примера конфигурации дескриптора структуры потока данных 3D Audio.
Фиг. 15 является диаграммой, иллюстрирующей типы содержимого, которое определяется в “contentKind”.
Фиг. 16 является диаграммой, иллюстрирующей пример конфигурации транспортного потока в том случае, когда конфигурация передачи потока аудиоданных является конфигурацией (1) потока.
Фиг. 17 является диаграммой, иллюстрирующей пример конфигурации модуля генерирования потока передатчика для сервисных услуг в том случае, когда конфигурация передачи потока аудиоданных является конфигурацией (2) потока.
Фиг. 18 является диаграммой, иллюстрирующей пример конфигурации (разделённый на два) объектных закодированных данных, составленных из данных передачи 3D Audio.
Фиг. 19 является диаграммой, иллюстрирующей отношение соответствия между группами и определяющими признаками, в том случае, когда конфигурация передачи потока аудиоданных является конфигурацией (2) потока.
Фиг. 20(а) и 20(b) являются диаграммами, иллюстрирующими пример структуры дескриптора идентификатора ID потока аудиоданных 3D Audio.
Фиг. 21 является диаграммой, иллюстрирующей пример конфигурации транспортного потока в том случае, когда конфигурация передачи потока аудиоданных является конфигурацией (2) потока.
Фиг. 22 является блок-схемой, иллюстрирующей пример конфигурации приёмника для сервисных услуг.
Фиг. 23(а) и 23(b) являются диаграммами для объяснения конфигураций принятых потоков аудиоданных (с конфигурацией (1) потока и конфигурацией (2) потока).
Фиг. 24 является диаграммой, схематически иллюстрирующей процесс декодирования в том случае, когда конфигурация передачи потока аудиоданных является конфигурацией (1) потока.
Фиг. 25 является диаграммой, схематически иллюстрирующей процесс декодирования в том случае, когда конфигурация передачи потока аудиоданных является конфигурацией (2) потока.
Фиг. 26 является диаграммой, иллюстрирующей структуру кадра АС3 (АС3 Synchronization frame).
Фиг. 27 является диаграммой, иллюстрирующей пример конфигурации вспомогательных данных АС3 (Auxiliary Data).
Фиг. 28(а) и 28(b) являются диаграммами, иллюстрирующими структуру слоя АС4 простого транспорта (Simple transport).
Фиг. 29(а) и 29(b) являются диаграммами, иллюстрирующими конфигурации схемы таблицы содержания ТОС (ac4_toc()) и вложенного потока данных (ac4_substream_data()).
Фиг. 30 является диаграммой, иллюстрирующей пример конфигурации “umd_info()” в ТОС (ac4_toc()).
Фиг. 31 является диаграммой, иллюстрирующей пример конфигурации “umd_payloads_substream())” во вложенном потоке данных (ac4_substream_data()).
Осуществление изобретения
В последующей части описания будут описываться способы (в дальнейшем определяемые как «варианты осуществления изобретения») для выполнения изобретения. Следует отметить, что описание будет производиться в следующем порядке:
1. Вариант осуществления изобретения
2. Изменённые примеры.
1. Вариант осуществления изобретения
Пример конфигурации приёмопередающей системы
Фиг. 1 иллюстрирует пример конфигурации приёмопередающей системы 10, в качестве варианта осуществления изобретения. Приёмопередающая система 10 включает в себя передатчик 100 для сервисных услуг и приёмник 200 для сервисных услуг. Передатчик 100 для сервисных услуг передаёт транспортный поток TS через радиовещательный диапазон или пакет через компьютерную сеть. Транспортный поток TS включает в себя поток видеоданных и заданное количество, которое является единицей или более, потоков аудиоданных.
Заданное количество потоков аудиоданных включает в себя канальные закодированные данные и заданное количество групп объектных закодированных данных. Заданное количество потоков аудиоданных генерируется таким образом, что объектные закодированные данные отвергаются, когда приёмник является несовместимым с объектными закодированными данными.
В первом способе, как иллюстрируется в конфигурации (1) потока на фиг. 2(а), генерируется поток аудиоданных (главный поток), включающий в себя канальные закодированные данные, которые кодируются с помощью MPEG4 AAC, и заданное количество групп объектных закодированных данных, которые кодируются с помощью MPEG-H 3D Audio и встраиваются в область пользовательских данных потока аудиоданных.
Во втором способе, как иллюстрируется в конфигурации (2) потока на фиг. 2(b), генерируется поток аудиоданных (главный поток), включающий в себя канальные закодированные данные, которые кодируются с помощью MPEG4 AAC, и генерируется заданное количество потоков аудиоданных (вложенных потоков данных 1-N), включающих в себя заданное количество групп объектных закодированных данных, которые кодируются с помощью MPEG-H 3D Audio.
Приёмник 200 для сервисных услуг принимает от передатчика 100 для сервисных услуг транспортный поток TS, передаваемый с использованием радиовещательного диапазона или пакета через компьютерную сеть. Как описывалось выше, транспортный поток TS включает в себя заданное количество потоков аудиоданных, включающих в себя канальные закодированные данные и заданное количество групп объектных закодированных данных в добавление к потоку видеоданных. Приёмник 200 для сервисных услуг выполняет процесс декодирования в отношении потока видеоданных и получает выход видеоданных.
Кроме того, когда приёмник 200 для сервисных услуг является совместимым с объектными закодированными данными, этот приёмник 200 для сервисных услуг извлекает канальные закодированные данные и объектные закодированные данные из заданного количества потоков аудиоданных и выполняет процесс декодирования для получения вывода аудиоданных, соответствующего выводу видеоданных. С другой стороны, когда приёмник 200 для сервисных услуг не является совместимым с объектными закодированными данными, приёмник 200 для сервисных услуг извлекает только канальные закодированные данные из заданного количества потоков аудиоданных и выполняет процесс декодирования для получения вывода аудиоданных, соответствующего выводу видеоданных.
Модуль генерирования потока передатчика для сервисных услуг
(вариант, в котором используется конфигурация (1) потока).
В первую очередь будет описываться случай, когда поток аудиоданных имеет конфигурацию (1) потока, показанную на фиг. 2(а). Фиг. 3 иллюстрирует пример конфигурации модуля 110А генерирования потока, включённого в состав передатчика 100 для сервисных услуг в вышеуказанном случае.
Модуль 110 генерирования потока включает в себя кодер 112 сигнала изображения, кодер 113 канала аудиоданных, кодер 114 звукового объекта, и устройство 115 форматирования TS. Кодер 112 сигнала изображения вводит видеоданные SV, кодирует видеоданные SV, и генерирует поток видеоданных.
Кодер 114 звукового объекта вводит объектные данные, которые содержат аудиоданные SA, и генерирует поток аудиоданных (объектные закодированные данные) посредством кодирования объектных данных с помощью MPEG-H 3D Audio. Кодер 113 канала аудиоданных вводит канальные данные, которые содержат аудиоданные SA, генерирует поток аудиоданных посредством кодирования канальных данных с помощью MPEG4 ААС, а также встраивает поток аудиоданных, сгенерированный в кодере 114 звукового объекта, в область пользовательских данных потока аудиоданных.
Фиг. 4 иллюстрирует пример конфигурации объектных закодированных данных. В этот пример конфигурации включаются два фрагмента объектных закодированных данных. Эти два фрагмента объектных закодированных данных являются закодированными данными многонаправленного звукового объекта (IAO) и речевого диалогового объекта (SDO).
Закодированные данные многонаправленного звукового объекта являются объектными закодированными данными для многонаправленного звука и включают в себя закодированные выборочные данные SCE1 и метаданные EXE_E1 (Object metadata) 1 для представления с помощью преобразования закодированных выборочных данных SCE1 с помощью громкоговорителя, существующего в произвольном местоположении.
Закодированные данные речевого диалогового объекта являются объектными закодированными данными для разговорного языка. В этом примере существуют закодированные данные речевого диалогового объекта, которые соответственно, согласуются с первым и вторым языками. Закодированные данные речевого диалогового объекта, соответствующие первому языку, включают в себя закодированные выборочные данные SCE2 и метаданные EXE_E1 (Object metadata) 2 для воспроизведения посредством преобразования закодированных выборочных данных SCE2 с помощью громкоговорителя, существующего в произвольном местоположении. Кроме того, закодированные данные речевого диалогового объекта, соответствующие второму языку, включают в себя закодированные выборочные данные SCE3 и метаданные EXE_E1 (Object metadata) 3 для воспроизведения посредством преобразования закодированных выборочных данных SCE3 с помощью громкоговорителя, существующего в произвольном местоположении.
Объектные закодированные данные различаются с помощью использования концепции групп (Group), в соответствии с типом данных. В соответствии с проиллюстрированным примером, закодированные данные многонаправленного звукового объекта устанавливаются как группа 1, закодированные данные речевого диалогового объекта, соответствующие первому языку, устанавливаются как группа 2, и закодированные данные речевого диалогового объекта, соответствующие второму языку, устанавливаются как группа 3.
Кроме того, данные, которые могут быть выбраны между группами на приёмной стороне, регистрируются в группе переключения (SW Group) и кодируются. Затем эти группы могут группироваться как предварительно установленная группа (preset Group) и воспроизводиться в соответствии с используемым случаем. В проиллюстрированном примере группа 1 и группа 2 группируются как предварительно установленная группа 1 (Рreset Group 1), а группа 1 и группа 3 группируются как предварительно установленная группа 2 (Рreset Group 2).
Фиг. 5 иллюстрирует отношение соответствия или подобную характеристику между группами и определяющими признаками. В данном случае групповой идентификатор ID (Group ID) является идентификатором для идентификации группы. Определяющий признак (attribute) представляет определяющий признак закодированных данных каждой группы. Идентификатор ID группы переключения (switch Group ID) является идентификатором для идентификации группы переключения. Идентификатор группы ID предварительной установки (preset Group ID) является идентификатором для идентификации группы предварительной установки. Идентификатор ID потока (sub Stream ID) является идентификатором для идентификации потока. Тип (Kind) представляет тип содержимого каждой группы.
Проиллюстрированное отношение соответствия показывает, что закодированные данные группы 1 (Group 1) являются объектными закодированными данными для многонаправленного звука (закодированные данные многонаправленного звукового объекта), составляют группу переключения и они встроены в область пользовательских данных потока аудиоданных, включающих в себя канальные закодированные данные.
Кроме того, проиллюстрированное отношение соответствия показывает, что закодированные данные группы 2 (Group 2) являются объектными закодированными данными для разговорного языка (объектными закодированными данными для речевого диалогового объекта) в отношении первого языка, составляют группу Switch Group 1 и встраиваются в область пользовательских данных потока аудиоданных, включающих в себя канальные закодированные данные. Кроме того, проиллюстрированное отношение соответствия показывает, что закодированные данные группы 3 (Group 3) являются объектными закодированными данными для разговорного языка (объектными закодированными данными для речевого диалогового объекта) в отношении второго языка, составляют группу Switch Group 1 и встраиваются в область пользовательских данных потока аудиоданных, включающих в себя канальные закодированные данные.
Кроме того, проиллюстрированное отношение соответствия показывает, что предварительно установленная группа 1 (Рreset Group 1) включает в себя первую и вторую группы Group 1 и Group 2. Кроме того, проиллюстрированное отношение соответствия показывает, что предварительно установленная группа 2 (Рreset Group 2) включает в себя первую и третью группы Group 1 и Group 3.
Фиг. 6 иллюстрирует структуру аудиокадра MPEG4 ААС. Аудиокадр включает в себя множество элементов. В начале каждого элемента (element) располагается трёхбитовый идентификатор (ID) “id_syn_ele”, таким образом может быть идентифицировано содержимое элемента.
Аудиокадр включает в себя такие элементы, как единичный элемент канала (SCE), парный элемент канала (CPE), низкочастотный элемент (LFE), элемент (DSE) потока данных, элемент (PCE) конфигурации программы, и наполняющий элемент (FIL). Элементы SCE, CPE и LFE включают в себя закодированные выборочные данные, которые содержат канальные закодированные данные. Например, в случае использования канальных закодированных данных канальной системы 5.1 охватывающего объёмного звука, аудиокадр включает в себя единичный элемент канала (SCE), два CPE и единичный LFE.
Элемент PCE включает в себя количество элементов канала и коэффициент понижающего микширования (down_mix). Элемент FIL используется для определения информации расширения (extension). В элемент DSE могут помещаться пользовательские данные, а идентификатором “id_syn_ele” этого элемента является “0x4”. В элемент DSE встраиваются объектные закодированные данные.
Фиг. 7 иллюстрирует конфигурацию (Syntax) элемента (DSE) потока данных (Data Stream Element ()). Четырёхбитовое поле “element_instance_tag” представляет тип данных в DSE; однако это значение может быть установлено на «0», когда DSE используется как общие пользовательские данные. Поле “data_byte_align_flag” устанавливается на «1», в результате чего байты всего элемента DSE синхронизируются. Значение “count” или “esc_count”, которое представляет количество добавленных байтов, устанавливается соответствующим образом, согласно размера пользовательских данных. Элементы “count” или “esc_count” могут насчитывать до 510 байтов. Другими словами, размер данных, помещаемых в единичный элемент DSE, максимально составляет 510 байтов. В поле “data_stream_byte” вставляются метаданные “metadata ()”.
Фиг. 8(а) иллюстрирует конфигурацию (Syntax) метаданных “metadata ()”, а фиг. 8(b) иллюстрирует содержимое (semantics) главной информации в конфигурации. Восьмибитовое поле “metadata_type” обозначает тип метаданных. Например, “0x10” представляет объектные закодированные данные системы MPEG-H (MPEG-H 3D audio).
Восьмибитовое поле “count” обозначает номер счётчика метаданных в возрастающем хронологическом порядке. Как описывалось выше, размер данных, помещаемых в единичный элемент DSE, достигает 510 байтов; однако, размер объектных закодированных данных может превышать 510 байтов. В таком случае используется более чем один элемент DSE и номер счётчика, обозначаемый с помощью поля “count”, выполняется таким образом, чтобы представлять соединение этих элементов DSE. В области “data_byte” размещаются объектные закодированные данные.
Фиг. 9 иллюстрирует структуру аудиокадра MPEG-H 3D Audio. Этот аудиокадр составлен из множества пакетов потока аудиоданных MPEG (mpeg Audio Stream Packet). Каждый из пакетов потока аудиоданных MPEG составлен из заголовка (Header) и полезной информации пакета (Payload).
Заголовок включает в себя такую информацию, как тип пакета (Packet Type), метка пакета (Packet Label), длина пакета (Packet Length). В этой полезной информации пакета (Payload) размещается информация, определяемая типом пакета в заголовке. Информация о полезной информации пакета включает в себя элемент “SYNC”, соответствующий синхронизирующему стартовому коду, “Frame”, который является действительными данными, и “Config”, который представляет конфигурацию элемента “Frame”.
В соответствии с настоящим вариантом осуществления изобретения, “Frame” включает в себя объектные закодированные данные, которые составляют данные передачи 3D Audio. Канальные закодированные данные, содержащие данные передачи 3D Audio, включаются в аудиокадр MPEG4 ААС, как описывалось выше. Объектные закодированные данные составлены из закодированных выборочных данных единичного элемента канала (SCE) и метаданных для представления с помощью преобразования закодированных выборочных данных с помощью громкоговорителя, существующего в произвольном местоположении (см. фиг. 4). Метаданные включаются как расширительный элемент (Ext_element).
Фиг. 10(а) иллюстрирует пример конфигурации пакета объектных закодированных данных. В этом примере в пакет включаются объектные закодированные данные единственной группы. Информация “#obj=1”, включённая в “Config”, показывает существование “Frame”, включающего в себя объектные закодированные данные единственной группы.
Информация “GroupID[0]=1”, зарегистрированная в “AudioSceneInfo()” в “Config”, показывает, что размещается элемент “Frame”, включающий в себя закодированные данные группы 1. В данном случае значение метки пакета (PL) назначается таким образом, что оно идентично значению в “Config”, и каждому соответствующему ему элементу “Frame”. В данном случае элемент “Frame”, включающий в себя закодированные данные группы 1 (Group 1), составлен из элемента “Frame”, включающего в себя метаданные, как расширительный элемент (Ext_element), и элемента “Frame”, включающего в себя закодированные выборочные данные единичного элемента канала (SCE).
Фиг. 10(b) иллюстрирует другой пример конфигурации пакета объектных закодированных данных. В этом примере в пакет включаются объектные закодированные данные двух групп. Информация “#obj=2”, включённая в “Config”, показывает существование элемента “Frame”, включающего в себя объектные закодированные данные двух групп.
Информация “GroupID[1]=2, Group ID[2]=3, SW_GRPID[0]=1”, зарегистрированная в “AudioSceneInfo()” в этом порядке в “Config”, показывает, что элемент “Frame”, имеющий закодированные данные группы 2 (Group 2) и элемент “Frame”, имеющий закодированные данные группы 3 (Group 3) размещаются в этом порядке, и эти группы составляют Switch Group 1. В этом случае значение метки пакета (PL) назначается таким образом, что оно идентично значению в “Config”, и каждому соответствующему ему элементу “Frame”.
В данном случае элемент “Frame”, включающий в себя закодированные данные группы 2 (Group 2), составлен из элемента “Frame”, включающего в себя метаданные, как расширительный элемент (Ext_element), и элемента “Frame”, включающего в себя закодированные выборочные данные единичного элемента канала (SCE). Аналогичным образом, элемент “Frame”, имеющий закодированные данные группы 3 (Group 3), составлен из элемента “Frame”, включающего в себя метаданные, как расширительный элемент (Ext_element), и элемента “Frame”, включающего в себя закодированные выборочные данные единичного элемента канала (SCE).
Снова обращаясь к фиг. 3, можно увидеть, что устройство 115 форматирования TS преобразует в пакеты выходной поток видеоданных из кодера 112 сигнала изображения и выходной поток аудиоданных из кодера 113 канала аудиоданных, как пакеты PES (пакеты в составе пакетированного элементарного потока), дополнительно мультиплексирует посредством пакетирования данных как транспортный пакет, и получает транспортный поток TS как мультиплексированный поток.
Кроме того, устройство 115 форматирования TS вставляет информацию идентификации, которая идентифицирует, что объектные закодированные данные, относящиеся к канальным закодированным данным, включённым в состав потока аудиоданных, вставляются в область пользовательских данных потока аудиоданных в слое контейнера, который находится в сфере действия таблицы структуры программ (РМТ), в соответствии с настоящим вариантом осуществления изобретения. Устройство 115 форматирования TS вставляет информацию идентификации в цикл элементарного потока аудиоданных, соответствующего потоку аудиоданных, посредством использования существующего дескриптора служебных данных “ancillary_data_identifier”.
Фиг. 11 иллюстрирует пример структуры (Syntax) дескриптора служебных данных. Восьмибитовое поле “descriptor_tag” показывает тип дескриптора. В этом случае поле показывает дескриптор служебных данных. Восьмибитовое поле “descriptor_length” показывает длину (размер) дескриптора, а также показывает длину последующих байтов как длину дескриптора.
Восьмибитовое поле “ancillary_data_descriptor” показывает какой тип данных встраивается в область пользовательских данных потока аудиоданных. В этом случае, когда каждый бит устанавливается на «1», это показывает, что встраиваются данные такого типа, которые соответствуют биту. Фиг. 12 иллюстрирует отношение соответствия между текущими битами и типами данных в текущем состоянии. В соответствии с настоящим вариантом осуществления изобретения, объектные закодированные данные (Object data) заново определяются в бите 7 как тип данных, и когда в бите 7 устанавливается «1», происходит идентификация того, что объектные закодированные данные встраиваются в область пользовательских данных потока аудиоданных.
Кроме того, устройство 115 форматирования TS вставляет информацию об определяющем признаке, которая показывает соответствующие определяющие признаки объектных закодированных данных заданного количества групп в слое контейнера, который находится в сфере действия таблицы структуры программ (РМТ), в соответствии с настоящим вариантом осуществления изобретения. Устройство 115 форматирования TS вставляет информацию об определяющем признаке, или подобную информацию в цикл элементарного потока аудиоданных, соответствующего потоку аудиоданных, посредством использования дескриптора конфигурации потока аудиоданных 3D Audio (3Daudio_stream_config_descriptor).
Фиг. 13 иллюстрирует пример структуры (Syntax) дескриптора конфигурации потока аудиоданных 3D Audio. Кроме того, фиг. 14 иллюстрирует содержимое (Semantics) главной информации в примере структуры. Восьмибитовое поле “descriptor_tag” показывает тип дескриптора. В этом примере показывается дескриптор конфигурации потока аудиоданных 3D Audio. Восьмибитовое поле “descriptor_length” показывает длину (размер) дескриптора, при этом количество последующих байтов показывается как длина дескриптора.
Восьмибитовое поле “NumOfGroups, N” показывает количество групп. Восьмибитовое поле “NumOfPresetGroups, P” показывает количество предварительно установленных групп. Восьмибитовое поле “groupID”, восьмибитовое поле “attribute_of_groupID”, восьмибитовое поле “SwitchGroupID” и восьмибитовое поле “audio_streamID” повторяются много раз, в соответствии с количеством групп.
Поле “groupID” показывает идентификатор группы. Поле “attribute_of_groupID” показывает определяющий признак объектных закодированных данных группы относящихся к этому признаку данных. Поле“SwitchGroupID” является идентификатором, показывающим, к какой группе переключения принадлежит релевантная группа. Значение «0» показывает, что группа не принадлежит к какой-либо группе переключения. Значения, отличающиеся от «0», показывают группу переключения, к которой принадлежит группа. Восьмибитовое поле “contentKind” показывает тип содержимого группы. Поле “audio_streamID” является идентификатором, показывающим поток аудиоданных, в который включается группа. Фиг. 15 показывает тип содержимого, определяемого полем “contentKind”.
Кроме того, восьмибитовое поле “presetGroupID” и восьмибитовое поле “NumOfGroups_in_preset, R” повторяются такое количество раз, которое соответствует количеству предварительно установленных групп. Поле “рresetGroupID” является идентификатором, показывающим сгруппированные группы, как предварительно установленные. Поле “NumOfGroups_in_preset, R” показывает количество групп, которые принадлежат предварительно установленной группе. В этом случае в каждой предварительно установленной группе 8-битовое поле “GroupID” повторяются такое количество раз, которое соответствует количеству групп, принадлежащих настоящей* группе, при этом показываются группы, которые принадлежат предварительно установленной группе.
Фиг. 16 иллюстрирует пример конфигурации транспортного потока TS. В этом примере конфигурации существует элемент “video PES”, который является пакетом PES потока видеоданных, идентифицированного PID1. Кроме того, в этом примере конфигурации существует элемент “audio PES”, который является пакетом PES потока аудиоданных, идентифицированного PID2. Пакет PES составлен из заголовка PES (PES_header) и полезной информации PES (PES_payload).
В данном случае в элемент “audio PES”, который является пакетом PES потока аудиоданных, включаются канальные закодированные данные MPEG4 ААС, а объектные закодированные данные MPEG-H 3D Audio встраиваются в его область пользовательских данных.
Кроме того, в транспортный поток TS включается таблица структуры программ (РМТ), как программно зависимая информация (PSI). Программно зависимая информация (PSI) является информацией, которая описывает, к какой программе принадлежит каждый элементарный поток, включённый в транспортный поток. В РМТ существует программный цикл (Рrogram loop), который описывает информацию, относящуюся ко всей программе.
Кроме того, в таблице структуры программ существует цикл элементарного потока, имеющий информацию, относящуюся к каждому элементарному потоку. В этом примере конфигурации существует цикл элементарного потока видеоданных (video ES loop), соответствующий потоку видеоданных, а также цикл элементарного потока аудиоданных (audio ES loop), соответствующий потоку аудиоданных.
В цикле элементарного потока видеоданных (video ES loop), соответствующем потоку видеоданных, обеспечивается такая информация, как тип потока, идентификатор (PID) пакета, или подобная информация, а также дескриптор, который описывает информацию, относящуюся к потоку видеоданных. Значение “Stream_type” потока видеоданных устанавливается как «0х24», а информация PID (идентификатор пакета) показывает PID1, применяемый к “video PES”, который является пакетом PES потока видеоданных, как описывалось выше. В качестве одного из дескрипторов размещается дескриптор HEVC.
В цикле элементарного потока аудиоданных (audio ES loop), соответствующего потоку аудиоданных, обеспечивается такая информация, как тип потока, идентификатор (PID) пакета, или подобная информация, а также дескриптор, который описывает информацию, относящуюся к потоку аудиоданных. Значение “Stream_type” потока аудиоданных устанавливается как «0х11», а информация PID показывает PID2, применяемый к “ audio PES”, который является пакетом PES потока аудиоданных, как описывалось выше. В цикле элементарного потока аудиоданных обеспечиваются как описанный выше дескриптор служебных данных, так и дескриптор конфигурации потока аудиоданных 3D Audio.
Со ссылкой на фиг. 3 кратко разъясняется функционирование показанного на фиг. 3 модуля 110А генерирования потока. Видеоданные SV подаются к кодеру 112 сигнала изображения. В кодере 112 сигнала изображения видеоданные SV кодируются и включаются в поток видеоданных, включающий в себя закодированные видеоданные. Поток видеоданных обеспечивается для устройства 115 форматирования TS.
Объектные данные, содержащие поток аудиоданных SA, подаются к кодеру 114 звукового объекта. В кодере 114 звукового объекта выполняется кодирование MPEG-H 3D Audio в отношении объектных данных и генерируется поток аудиоданных (объектные закодированные данные). Этот поток аудиоданных поступает к кодеру 113 канала аудиоданных.
Канальные данные, содержащие поток аудиоданных SA, подаются к кодеру 113 канала аудиоданных. В кодере 113 канала аудиоданных выполняется кодирование MPEG4 ААС в отношении канальных данных и генерируется поток аудиоданных (канальные закодированные данные). В этом случае в кодере 113 канала аудиоданных поток аудиоданных (объектные закодированные данные), который генерируется в кодере 114 звукового объекта, встраивается в область пользовательских данных.
Поток видеоданных, генерируемый в кодере 112 сигнала изображения, подаётся к устройству 115 форматирования TS. Кроме того, поток аудиоданных, генерируемый в кодере 113 канала аудиоданных, подаётся к устройству 115 форматирования TS. В устройстве 115 форматирования TS потоки, обеспечиваемые для каждого кодирующего устройства, пакетируются как пакеты PES, затем пакетируются как транспортные пакеты и мультиплексируются, и в результате получается транспортный пакет TS, как мультиплексированный поток.
Кроме того, в устройстве 115 форматирования TS дескриптор служебных данных вставляется в цикл элементарного потока аудиоданных. Этот дескриптор включает в себя информацию идентификации, которая идентифицирует, что объектные закодированные данные вставляются в область пользовательских данных потока аудиоданных.
Кроме того, в устройстве 115 форматирования TS дескриптор конфигурации потока аудиоданных 3D Audio вставляется в цикл элементарного потока аудиоданных. Этот дескриптор включает в себя информацию об определяющем признаке, которая показывает определяющий признак каждого фрагмента объектных закодированных данных заданного количества групп.
Вариант, в котором используется конфигурация (2) потока
Далее будет описываться случай, в котором поток аудиоданных находится в конфигурации (2), показанной на фиг. 2(b). Фиг. 17 иллюстрирует пример конфигурации модуля 110В генерирования потока передатчика, включённого в состав передатчика 100 для сервисных услуг в приведённом выше случае.
Модуль 110В генерирования потока включает в себя кодер 122 сигнала изображения, кодер 123 канала аудиоданных, кодеры со 124-1 по 124-N звукового объекта, и устройство 125 форматирования TS. Кодер 122 сигнала изображения вводит видеоданные SV и кодирует видеоданные SV, чтобы генерировать поток видеоданных.
Кодер 123 канала аудиоданных вводит канальные данные, составленные аудиоданными SA, и кодирует канальные данные с помощью MPEG4 ААС, чтобы генерировать поток аудиоданных (канальные закодированные данные), как главный поток. Кодеры со 124-1 по 124-N звукового объекта, соответственно, вводят объектные данные, которые содержат аудиоданные SA, и кодирует объектные данные с помощью MPEG-H 3D Audio, чтобы генерировать поток аудиоданных (объектные закодированные данные), как вложенные потоки данных.
Например, в случае, когда N=2, кодер 124-1 звукового объекта генерирует вложенный поток 1 данных, а кодер 124-2 звукового объекта генерирует вложенный поток 2 данных. Например, как иллюстрируется на фиг. 18, в примере конфигурации объектные закодированные данные составлены из двух фрагментов объектных закодированных данных, при этом вложенный поток 1 данных включает в себя многонаправленный звуковой объект (IAO), а вложенный поток 2 данных включает в себя речевой диалоговой объект (SDO).
Фиг. 19 иллюстрирует отношение соответствия между группами и определяющими признаками. Здесь групповой идентификатор ID (group ID) является идентификатором для идентификации группы. Определяющий признак (attribute) показывает определяющий признак закодированных данных каждой группы. Идентификатор ID группы переключения (switch Group ID) является идентификатором для идентификации групп, которые могут переключаться между собой. Идентификатор ID группы предварительной установки (preset Group ID) является идентификатором для идентификации группы предварительной установки. Идентификатор ID потока (Stream ID) является идентификатором для идентификации потока. Тип (Kind) представляет тип содержимого каждой группы.
Проиллюстрированное отношение соответствия показывает, что закодированные данные, принадлежащие группе 1 (Group 1) являются объектными закодированными данными (закодированными данными многонаправленного звукового объекта) для многонаправленного звука, не составляют группу переключения, и включаются в состав вложенного потока 1 данных.
Кроме того, проиллюстрированное отношение соответствия показывает, что закодированные данные, принадлежащие группе 2 (Group 2) являются объектными закодированными данными (закодированными данными речевого диалогового объекта) для разговорного первого языка, составляют переключающую группу 1 (switch Group 1), и включаются в состав вложенного потока 2 данных. Кроме того, проиллюстрированное отношение соответствия показывает, что закодированные данные, принадлежащие группе 3 (Group 3) являются объектными закодированными данными (закодированными данными речевого диалогового объекта) для разговорного второго языка, составляют переключающую группу 1 (switch Group 1), и включаются в состав вложенного потока 2 данных.
Кроме того, проиллюстрированное отношение соответствия показывает, что предварительно установленная группа 1 (Рreset Group 1), включает в себя группу 1 (Group 1) и группу 2 (Group 2). Кроме того, проиллюстрированное отношение соответствия показывает, что предварительно установленная группа 2 (Рreset Group 2), включают в себя группу 1 (Group 1) и группу 3 (Group 3).
Снова обращаясь к фиг. 17, можно увидеть, что, устройство 125 форматирования TS пакетирует выходной поток видеоданных из кодера 112 сигнала изображения, выходной поток аудиоданных из кодера 123 канала аудиоданных, и дополнительные выходные потоки аудиоданных из кодеров со 124-1 по 124-N звукового объекта как пакеты PES, мультиплексирует данные как транспортные пакеты, и получает транспортный поток TS, как мультиплексированный поток.
Кроме того, в сфере действия слоя контейнера, который находится в сфере действия таблицы структуры программ (РМТ), в этом варианте осуществления изобретения устройство 125 форматирования TS вставляет информацию об определяющем признаке, показывающую каждый определяющий признак объектных закодированных данных в заданном количестве групп и информацию об отношении соответствия потока, показывающую, к какому вложенному потоку данных принадлежат объектные закодированные данные в заданном количестве групп. Устройство 125 форматирования TS вставляет эти фрагменты информации в цикл элементарного потока аудиоданных, соответствующего одному или более вложенному потоку данных среди заданного количества вложенных потоков данных с помощью использования дескриптора конфигурации потока аудиоданных 3D Audio (3Daudio_stream_config_descriptor) (см. фиг. 13).
Кроме того, в сфере действия слоя контейнера, который находится в сфере действия таблицы структуры программ (РМТ), в этом варианте осуществления изобретения устройство 125 форматирования TS вставляет информацию об идентификаторе потока, показывающую каждый идентификатор потока заданного количества вложенных потоков данных. Устройство 125 форматирования TS вставляет информацию в циклы элементарного потока аудиоданных, которые, соответственно, согласуются с заданным количеством вложенных потоков данных посредством использования дескриптора идентификатора потока аудиоданных 3D Audio (3Daudio_substreamID_descriptor).
Фиг. 20(а) иллюстрирует пример структуры (Syntax) дескриптора ID потока аудиоданных 3D Audio. Кроме того, фиг. 20(b) иллюстрирует содержимое (Semantics) главной информации в примере структуры.
Восьмибитовое поле “descriptor_tag” иллюстрирует тип дескриптора. В этом примере показывается дескриптор ID потока аудиоданных 3D Audio. Восьмибитовое поле “descriptor_length” показывает длину (размер) дескриптора, при этом количество последующих байтов показывается как длина дескриптора. Восьмибитовое поле “audio_streamID” показывается как идентификатор вложенного потока данных.
Фиг. 21 иллюстрирует пример конфигурации транспортного потока TS. В этом примере конфигурации существует пакет PES “video PES” потока видеоданных, идентифицированного с помощью PID1 (идентификатора пакета). Кроме того, в этом примере конфигурации существуют пакеты PES “audio PES” двух потоков аудиоданных, идентифицированных, соответственно, как PID2 и PID3. Пакет PES составлен из заголовка PES (PES_header) и полезной информации PES (PES_payload). В заголовок PES вставляются временные отметки DTS и PTS. Синхронизация между устройствами может поддерживаться во всей системе, например, с помощью применения временных отметок и согласования временных отметок PID2 и PID3 при мультиплексировании.
В пакете PES “audio PES” потока аудиоданных (главный поток), идентифицированного с помощью PID2 (идентификатор пакета), включаются канальные закодированные данные MPEG4 ААС. С другой стороны, в пакете PES “audio PES” потока аудиоданных (вложенный поток), идентифицированного с помощью PID3, включаются объектные закодированные данные MPEG-H 3D Audio.
Кроме того, в транспортный поток TS таблица структуры программ (РМТ) включается как программно зависимая информация (PSI). Эта программно зависимая информация (PSI) является информацией, которая описывает, к какой программе принадлежит каждый элементарный поток, включённый в состав транспортного потока. В таблице структуры программ (РМТ) существует программный цикл (Рrogram loop), который описывает информацию, относящуюся ко всей программе.
Кроме того, в таблице структуры программ (РМТ) существует элементарный потоковый цикл, включающий в себя информацию, относящуюся к каждому элементарному потоку. В этом примере конфигурации существует элементарный потоковый цикл потока видеоданных (video ES loop), соответствующий потоку видеоданных, а также элементарные потоковые циклы потока аудиоданных (audio ES loop), соответствующие двум потокам аудиоданных.
В элементарном потоковом цикле потока видеоданных (video ES loop), соответствующем потоку видеоданных, располагается такая информация, как тип пакета и идентификатор (PID) пакета, а также располагается дескриптор, который описывает информацию, относящуюся к потоку видеоданных. Значение “Stream_type” потока видеоданных устанавливается на «0х24», также предполагается, что информация PID должна показывать PID1, локализованный в пакете PES “video PES” потока видеоданных, как описывалось выше. Дескриптор HEVC (стандарт видеосжатия) также размещается как дескриптор.
В элементарном потоковом цикле потока аудиоданных (audio ES loop), соответствующем потоку аудиоданных (главный поток), располагается такая информация, как тип пакета и идентификатор (PID) пакета, а также располагается дескриптор, который описывает информацию, относящуюся к потоку аудиоданных, соответствующую потоку аудиоданных. Значение “Stream_type” потока аудиоданных устанавливается на «0х11», также предполагается, что информация PID должна показывать PID2, применяемый к пакету PES “ audio PES” потока аудиоданных (главный поток), как описывалось выше.
Кроме того, в элементарном потоковом цикле потока аудиоданных (audio ES loop), соответствующем потоку аудиоданных (вложенный пакет данных), располагается такая информация как тип пакета и идентификатор (PID) пакета, а также располагается дескриптор, который описывает информацию, относящуюся к потоку аудиоданных, соответствующую потоку аудиоданных. Значение “Stream_type” потока аудиоданных устанавливается на «0х2D», также предполагается, что информация PID должна показывать PID3, применяемый к пакету PES “ audio PES” потока аудиоданных (главный поток), как описывалось выше. В качестве дескрипторов размещаются дескриптор конфигурации потока аудиоданных 3D Audio и дескриптор идентификатора ID потока аудиоданных 3D Audio.
Сейчас будет кратко разъясняться функционирование модуля 110В генерирования потока передатчика, проиллюстрированного на фиг. 17. Для кодера 122 сигнала изображения обеспечиваются видео данные SV. Видео данные SV кодируются в кодере 122 сигнала изображения и генерируется поток видеоданных, включающий в себя закодированные видео данные.
Данные канала, составленные из аудио данных SА, подаются к кодеру 123 канала аудиоданных. В кодере 123 канала аудиоданных данные канала кодируются с помощью MPEG4 ААС, а поток аудиоданных (канальные закодированные данные) генерируется как главный поток.
Кроме того, объектные данные, составленные из аудио данных SА, подаются к кодерам со 124-1 по 124-N звукового объекта. Кодеры со 124-1 по 124-N звукового объекта, соответственно, кодируют объектные данные с помощью MPEG-H 3D Audio и генерируют потоки аудиоданных (объектные закодированные данные) как вложенные потоки данных.
Поток видеоданных, сгенерированный в кодере 122 сигнала изображения, подаётся к устройству 125 форматирования TS. Кроме того, поток аудиоданных (главный поток), сгенерированный в кодере 113 канала аудиоданных, подаётся к устройству 125 форматирования TS. Кроме того, потоки аудиоданных (вложенные пакеты данных), сгенерированные в кодерах со 124-1 по 124-N звукового объекта, обеспечиваются для устройства 125 форматирования TS. В устройстве 125 форматирования TS потоки, обеспечиваемые из каждого кодирующего устройства, пакетируются как пакеты PES и дополнительно мультиплексируются как транспортные пакеты, и получается транспортный поток TS, как мультиплексированный поток.
Кроме того, устройство 115 форматирования TS вставляет дескриптор конфигурации потока аудиоданных 3D Audio в цикл элементарного потока аудиоданных, соответствующий по крайней мере, одному или более вложенных пакетов данных в заданном количестве вложенных пакетов данных. В дескриптор конфигурации потока аудиоданных 3D Audio включается информация об определяющем признаке, показывающая определяющий признак соответствующих фрагментов объектных закодированных данных заданного количества групп, информация отношения соответствия потока, к которой принадлежит вложенный пакет данных каждого фрагмента объектных закодированных данных заданного количества групп, или подобная информация.
Кроме того, в устройство 115 форматирования TS в цикл элементарного потока аудиоданных, соответствующего потоку аудиоданных, т.е. в элементарные потоковые циклы потока аудиоданных, соответственно согласующиеся с заданным количеством вложенных пакетов данных, вставляется дескриптор ID потока аудиоданных 3D Audio. В этот дескриптор включается информация об идентификаторе потока, показывающая каждый идентификатор потока заданного количества потоков аудиоданных.
Пример конфигурации приёмника для сервисных услуг
Фиг. 22 иллюстрирует пример конфигурации приёмника 200 для сервисных услуг. Приёмник 200 для сервисных услуг включает в себя приёмный модуль 201, анализирующий модуль 202 TS, декодер 203 сигнала изображения, обрабатывающая схема 204 сигнала изображения, возбуждающий контур 205 индикаторной панели, индикаторная панель 206. Кроме того, приёмник 200 для сервисных услуг включает в себя мультиплексирующие буферы с 211-1 по 211-М, объединитель 212, декодер 213 звукового канала 3D, обрабатывающая схема 214 звукового выхода, и система 215 громкоговорителей. Кроме того, приёмник 200 для сервисных услуг включает в себя центральный процессор (CPU) 221, постоянное запоминающее устройство 222 типа флэш (flash ROM, флэш-ПЗУ), динамическое запоминающее устройство 223 с произвольной выборкой (DRAM), внутреннюю шину 224, приёмный модуль 225 дистанционного управления, и передатчик 226 дистанционного управления.
Центральный процессор (CPU) 221 управляет работой каждого модуля в приёмнике 200 для сервисных услуг. Постоянное запоминающее устройство 222 типа флэш памяти сохраняет управляющее программное обеспечение и данные. DRAM 223 составляет рабочую область CPU 221. CPU 221 запускает программное обеспечение посредством развёртывания программного обеспечения или данных, считываемых из флэш-ПЗУ 222 в DRAM 223 и управляет каждым модулем в приёмнике 200 для сервисных услуг.
Приёмный модуль 225 дистанционного управления принимает сигнал дистанционного управления (дистанционный код управления), передаваемый из передатчика 226 дистанционного управления и подаёт сигнал к CPU 221. На основе дистанционного кода управления, CPU 221 управляет каждым модулем в приёмнике 200 для сервисных услуг. CPU 221, флэш-ПЗУ 222 и DRAM 223 присоединяются к внутренней шине 224.
Приёмный модуль 201 принимает транспортный поток TS, который передаётся от передатчика 100 для сервисных услуг посредством использования радиовещательного диапазона или пакета через компьютерную сеть. Транспортный поток TS включает в себя заданное количество потоков аудиоданных в добавление к потоку видеоданных.
Фиг. 23(а) и 23(b) иллюстрируют примеры принимаемого потока аудиоданных. Фиг. 23(а) иллюстрирует пример случая с конфигурацией (1) потока. В этом случае существует только главный поток, который включает в себя канальные закодированные данные, кодируемые с помощью MPEG4 ААС, и объектные закодированные данные заданного количества групп, кодируемые с помощью MPEG-H 3D Audio, и встраивается в область пользовательских данных. Главный поток идентифицируется с помощью PID2 (идентификатор пакета).
Фиг. 23(b) иллюстрирует пример случая с конфигурацией (2) потока. В этом случае существует главный поток, который включает в себя канальные закодированные данные, кодируемые с помощью MPEG4 ААС, и заданное количество вложенных потоков данных, при этом один вложенный поток данных в этом примере включает в себя объектные закодированные данные заданного количества групп, кодируемые с помощью MPEG-H 3D Audio. Главный поток идентифицируется с помощью PID2, а вложенный поток данных идентифицируется с помощью PID3. Здесь следует отметить, что в конфигурации потока главный поток может идентифицироваться с помощью PID3, а вложенный поток данных может идентифицироваться с помощью PID2.
Анализирующий модуль 202 TS выделяет пакет потока видеоданных из транспортного потока TS и передаёт пакет потока видеоданных к декодеру 203 сигнала изображения. Декодер 203 сигнала изображения реконфигурирует поток видеоданных из пакета видеоданных, извлекаемых в анализирующем модуле 202 TS, и получает данные несжатого изображения посредством выполнения процесса декодирования.
Обрабатывающая схема 204 сигнала изображения выполняет процесс масштабирования и процесс настройки качества изображения в отношении видеоданных, полученных в декодере 203 сигнала изображения, и получает видеоданные для их отображения. Возбуждающий контур 205 индикаторной панели управляет индикаторной панелью 206 на основе данных изображения для отображения полученных данных в обрабатывающей схеме 204 сигнала изображения. Индикаторная панель 206 состоит, например, из жидкокристаллического дисплея (LCD) или органического электролюминесцентного дисплея (organic EL display).
Кроме того, анализирующий модуль 202 TS выделяет различные виды информации, например, информацию о дескрипторе, из транспортного потока TS и передаёт эту информацию к центральному процессору (CPU) 221. В случае использования конфигурации (1) потока различные виды информации включают в себя информацию дескриптора служебных данных (Аncillary_data_descriptor) и дескриптора конфигурации потока аудиоданных 3D Audio (3Daudio_stream_config_descriptor) (см. фиг. 16). Основываясь на информации дескриптора, CPU 221 может распознавать, что объектные закодированные данные встраиваются в область пользовательских данных главного потока, включённого в состав канальных закодированных данных, а также распознаёт определяющий признак или подобный параметр объектных закодированных данных каждой группы.
Кроме того, в случае использования конфигурации (2) потока различные виды информации включают в себя информацию дескриптора конфигурации потока аудиоданных 3D Audio (3Daudio_stream_config_descriptor) и дескриптора ID потока аудиоданных 3D Audio (3Daudio_substreamID_descriptor) (см. фиг. 21). Основываясь на информации дескриптора, CPU 221 распознаёт определяющий признак объектных закодированных данных каждой группы, а также распознаёт, какой вложенный поток данных включается в объектные закодированные данные, или подобную информацию.
Кроме того, под управлением центрального процессора (CPU) 221 анализирующий модуль 202 TS выборочно выделяет заданное количество потоков аудиоданных, включённых в транспортный поток TS с помощью использования фильтра PID. Другими словами, в случае использования конфигурации (1) потока, выделяется главный поток. С другой стороны, в случае использования конфигурации (2) потока, выделяется главный поток и выделяется заданное количество вложенных потоков данных.
Мультиплексирующие буферы с 211-1 по 211-М, соответственно, импортируют потоки аудиоданных (только главный поток, или главный поток и вложенный поток данных), выделяемые в анализирующем модуле 202 TS. В данном случае предполагается, что номер М мультиплексирующих буферов с 211-1 по 211-М должен быть необходимым и достаточным, и при действительной операции используется количество буферов, соответствующее количеству потоков аудиоданных, выделяемых в анализирующем модуле 202 TS.
Объединитель 212 считывает для каждого аудио кадра поток аудиоданных из мультиплексирующего буфера, в который каждый поток аудиоданных, который должен выделяться с помощью анализирующего модуля 202 TS, импортируется из числа мультиплексирующих буферов с 211-1 по 211-М, и передаёт поток аудиоданных к декодеру 213 звукового канала 3D.
Под управлением центрального процессора (CPU) 221 декодер 213 звукового канала 3D выделяет канальные закодированные данные и объектные закодированные данные, выполняет процесс декодирования и получает аудиоданные, чтобы приводить в действие каждый громкоговоритель системы 215 громкоговорителей. В этом случае, при использовании конфигурации (1) потока, из главного потока выделяются канальные закодированные данные, а объектные закодированные данные выделяются из области пользовательских данных. С другой стороны, в случае использования конфигурации (2) потока, из главного потока выделяются канальные закодированные данные, а объектные закодированные данные выделяются из вложенного потока данных.
Когда декодируются канальные закодированные данные, декодер 213 звукового канала 3D выполняет процесс понижающего микширования и повышающего микширования для конфигурации громкоговорителя системы 215 громкоговорителей, в соответствии с необходимостью, и получает аудиоданные, чтобы приводить в действие каждый громкоговоритель. Кроме того, когда декодируются объектные закодированные данные, декодер 213 звукового канала 3D вычисляет воспроизведение громкоговорителя (соотношение при смешивании для каждого громкоговорителя) на основе объектной информации (метаданные), и смешивает аудиоданные объекта с аудиоданными, чтобы приводить в действие каждый громкоговоритель, в соответствии с результатом вычисления.
Обрабатывающая схема 214 звукового выхода выполняет необходимый процесс, такой как цифроаналоговое преобразование, усиление, или подобные процессы с аудиоданными, которые получаются в декодере 213 звукового канала 3D и используются для приведения в действие каждого громкоговорителя, а также подаёт данные к системе 215 громкоговорителей. Система 215 громкоговорителей включает в себя множество громкоговорителей множества каналов, таких как канал 2, канал 5.1, канал 7.1, канал 22.2 и подобные каналы.
Сейчас будет кратко разъясняться функционирование приёмника 200 для сервисных услуг, проиллюстрированного на фиг. 22. Приёмный модуль 201 принимает транспортный поток TS от передатчика 100 для сервисных услуг, который передаётся с использованием радиовещательного диапазона или пакета через компьютерную сеть. Транспортный поток TS включает в себя заданное количество потоков аудиоданных в добавление к потоку видеоданных.
Например, в случае использования конфигурации (1) потока, такого как поток аудиоданных, существует только главный поток, который включает в себя канальные закодированные данные, закодированные с помощью MPEG4 ААС, и в область пользовательских данных встраивается заданное количество групп объектных закодированных данных, закодированных с помощью MPEG-Н 3D Audio.
Кроме того, например, в случае использования конфигурации (2) потока, такого как поток аудиоданных, существует главный поток, включающий в себя канальные закодированные данные, закодированные с помощью MPEG4 ААС, и существует заданное количество вложенных потоков данных, включающих в себя объектные закодированные данные, закодированных с помощью MPEG-Н 3D Audio, заданного количества групп.
В анализирующем модуле 202 TS пакет потока видеоданных выделяется из транспортного потока TS и подаётся к декодеру 203 сигнала изображения. В декодере 203 сигнала изображения поток видеоданных реконфигурируется из пакета видеоданных, выделяемого в анализирующем модуле 202 TS, и выполняется процесс декодирования, чтобы получать несжатые видеоданные. Видеоданные подаются к обрабатывающей схеме 204 сигнала изображения.
Обрабатывающая схема 204 сигнала изображения выполняет процесс масштабирования и процесс настройки качества изображения, или подобный процесс в отношении видеоданных, полученных в декодере 203 сигнала изображения, и получает видеоданные для их отображения. Видеоданные для отображения подаются к возбуждающему контуру 205 индикаторной панели. На основе видеоданных для отображения возбуждающий контур 205 индикаторной панели управляет индикаторной панелью 206. С помощью этой конфигурации на индикаторной панели 206 отображается изображение, соответствующее видеоданным для отображения.
Кроме того, в анализирующем модуле 202 TS различные типы информации, такие как информация о дескрипторе, выделяются из транспортного потока TS и передаются к центральному процессору (CPU) 221. В случае использования конфигурации (1) потока различные типы информации также включают в себя информацию дескриптора служебных данных и дескриптора конфигурации потока аудиоданных 3D Audio (см. фиг. 16). На основе информации дескриптора CPU 221 распознаёт, что объектные закодированные данные встраиваются в область пользовательских данных главного потока, включая канальные закодированные данные, а также распознаёт определяющий признак объектных закодированных данных каждой группы.
Кроме того, в случае использования конфигурации (2) потока различные типы информации также включают в себя информацию дескриптора конфигурации потока аудиоданных 3D Audio и дескриптора идентификатора ID потока аудиоданных 3D Audio (см. фиг. 21). На основе информации дескриптора CPU 221 распознаёт определяющий признак объектных закодированных данных каждой группы, или распознаёт, в какой вложенный пакет данных включаются объектные закодированные данные каждой группы.
Под управлением центрального процессора (CPU) 221 в анализирующем модуле 202 TS заданное количество потоков аудиоданных, включённых в транспортный поток TS, выборочно выделяются посредством использования PID фильтра. Другими словами, в случае использования конфигурации (1) потока, выделяется главный поток. С другой стороны, в случае использования конфигурации (2) потока, выделяется главный поток, а также выделяется заданное количество вложенных пакетов данных.
В мультиплексирующие буферы с 211-1 по 211-М импортируется поток аудиоданных (только главный поток, или главный поток и вложенный пакет данных), выделенный в анализирующем модуле 202 TS. В объединителе 212 из каждого мультиплексирующего буфера, в который импортируется поток аудиоданных, этот поток аудиоданных считывается из каждого аудиокадра и подаётся к декодеру 213 3D Audio.
Под управлением центрального процессора (CPU) 221 в декодере 213 3D Audio выделяются канальные закодированные данные и объектные закодированные данные, выполняется процесс декодирования и получаются аудиоданные для приведения в действие каждого громкоговорителя системы 215 громкоговорителей. Здесь, в случае использования конфигурации (1) потока, канальные закодированные данные выделяются из главного потока, и объектные закодированные данные также выделяются из его области пользовательских данных. С другой стороны, в случае использования конфигурации (2) потока, из главного потока выделяются канальные закодированные данные, а из вложенного пакета данных выделяются объектные закодированные данные.
В рамках этого описания при декодировании канальных закодированных данных процесс понижающего микширования или повышающего микширования для конфигурации громкоговорителя системы 215 громкоговорителей выполняется в соответствии с необходимостью и получаются аудиоданные для приведения в действие каждого громкоговорителя. Кроме того, когда кодируются объектные закодированные данные, воспроизведение громкоговорителя (соотношение при смешивании для каждого громкоговорителя) вычисляется на основе объектной информации (метаданные), и, в соответствии с результатом вычисления, аудиоданные объекта смешиваются с аудиоданными для приведения в действие каждого громкоговорителя.
Аудиоданные для приведения в действие каждого громкоговорителя, полученные в декодере 213 3D Audio, подаются к обрабатывающей схеме 214 звукового выхода. В обрабатывающей схеме 214 звукового выхода с аудиоданными выполняется необходимый процесс, такой как цифроаналоговое преобразование, усиление, или подобные процессы, для приведения в действие каждого громкоговорителя. Затем обработанные аудиоданные подаются к системе 215 громкоговорителей. С помощью этой конфигурации из системы 215 громкоговорителей получается звуковой выход, соответствующий изображению, отображаемому на индикаторной панели 206.
Фиг. 24 схематически иллюстрирует процесс декодирования аудиоданных в том случае, когда конфигурация передачи потока аудиоданных является конфигурацией (1) потока. Транспортный поток TS, как мультиплексированный поток, является входом для анализирующего модуля 202 TS. В анализирующем модуле 202 TS выполняется анализ системного слоя, а информация дескриптора (информация дескриптора служебных данных и дескриптора конфигурации потока аудиоданных 3D Audio) подаётся к центральному процессору (CPU) 221.
На основе информации дескриптора CPU 221 распознаёт, что объектные закодированные данные встраиваются в область пользовательских данных главного потока, включающего в себя канальные закодированные данные, а также распознаёт определяющий признак объектных закодированных данных каждой группы. Под управлением центрального процессора (CPU) 221 в анализирующем модуле 202 TS пакет главного потока выборочно выделяется посредством использования PID фильтра и импортируется в мультиплексирующий буфер 211 (с 211-1 по 211-М).
В декодере звукового канала декодера 213 3D процесс выполняется в отношении главного потока, импортированного в мультиплексирующий буфер 211. Другими словами, в декодере звукового канала элемент (DSE) потока данных, в котором размещаются объектные закодированные данные, выделяется из главного потока и передаётся к CPU 221. В рамках этого описания, в декодере звукового канала соответствующего приёмника поддерживается совместимость, поскольку элемент (DSE) потока данных считывается и выбраковывается.
Кроме того, в декодере звукового канала канальные закодированные данные выделяются из главного потока и выполняется процесс декодирования, для того чтобы получать аудиоданные для приведения в действие каждого громкоговорителя. В этом случае информация о количестве каналов передаётся между декодером звукового канала и центральным процессором (CPU) 221 и в соответствии с необходимостью выполняется процесс понижающего микширования и повышающего микширования для конфигурации громкоговорителя системы 215 громкоговорителей.
В CPU 221 выполняется анализ элемента (DSE) потока данных и объектные закодированные данные, размещаемые в нём, передаются к декодеру звукового объекта декодера 213 звукового канала 3D. В декодере звукового объекта объектные закодированные данные декодируются и получаются метаданные и аудиоданные объекта.
Аудиоданные для приведения в действие каждого громкоговорителя, полученные в кодере звукового канала, подаются к смешивающему/воспроизводящему модулю. Кроме того, метаданные и аудиоданные объекта, полученные в декодере звукового канала также подаются к смешивающему/воспроизводящему модулю.
На основе метаданных объекта в смешивающем/воспроизводящем модуле декодированный выходной сигнал выполняется с помощью вычисления преобразования аудиоданных объекта для речевого пространства* по отношению к заданному выходному параметру громкоговорителя, при этом дополнительно объединяя результат вычисления с канальными данными.
Фиг. 25 схематически иллюстрирует процесс декодирования аудиоданных в том случае, когда конфигурация передачи потока аудиоданных является конфигурацией (2) потока. Транспортный поток TS, как мультиплексированный поток, является входом для анализирующего модуля 202 TS. В анализирующем модуле 202 TS выполняется анализ системного слоя, а информация дескриптора (информация дескриптора конфигурации потока аудиоданных 3D Audio и дескриптора идентификатора ID потока аудиоданных 3D Audio) подаётся к центральному процессору (CPU) 221.
На основе информации дескриптора CPU 221 распознаёт определяющий признак объектных закодированных данных каждой группы, а также с помощью информации дескриптора распознаёт, какой вложенный поток данных каждой группы включается в объектные закодированные данные. Под управлением центрального процессора (CPU) 221 в анализирующем модуле 202 TS пакеты главного потока и заданное количество вложенных потоков данных выборочно выделяются посредством использования PID фильтра и импортируется в мультиплексирующий буфер 211 (с 211-1 по 211-М). Здесь в соответствующем приёмнике пакеты вложенных потоков данных не выделяются посредством использования PID фильтра, и только главный поток выделяется таким образом, чтобы поддерживалась совместимость.
В декодере звукового канала декодера 213 3D audio канальные закодированные данные выделяются из главного потока, который импортируется в мультиплексирующий буфер 211, и выполняется процесс декодирования, для того чтобы можно было получать аудиоданные для приведения в действие каждого громкоговорителя. В этом случае информация количества каналов передаётся между декодером звукового канала и CPU 221, и в соответствии с необходимостью выполняется процесс понижающего микширования и повышающего микширования для конфигурации громкоговорителя системы 215 громкоговорителей.
Кроме того, в декодере звукового объекта декодера 213 3D audio необходимые объектные закодированные данные заданного количества групп выделяются из заданного количества вложенных потоков данных, которые импортируются в мультиплексирующий буфер 211 на основе отбора пользователем, или подобным образом, и выполняется процесс декодирования, в результате чего могут быть получены метаданные и аудиоданные объекта.
Аудиоданные для приведения в действие каждого громкоговорителя, полученные в кодере звукового канала, подаются к смешивающему/воспроизводящему модулю. Кроме того, метаданные и аудиоданные объекта, полученные в декодере звукового объекта, также подаются к смешивающему/воспроизводящему модулю.
На основе метаданных объекта, в смешивающем/воспроизводящем модуле декодирующий выход выполняется с помощью вычисления преобразования аудиоданных объекта для речевого пространства* по отношению к заданному выходному параметру громкоговорителя, и дополнительно объединяя результат вычисления с канальными данными.
Как описывалось выше, в приёмопередающей системе 10, проиллюстрированной на фиг. 1, передатчик 100 для сервисных услуг передаёт заданное количество потоков аудиоданных, включающих в себя канальные закодированные данные и объектные закодированные данные, которые составляют передаваемые данные 3D audio, при этом заданное количество потоков аудиоданных генерируется таким образом, что объектные закодированные данные отвергаются в приёмнике, который является несовместимым с объектными закодированными данными. Таким образом, без ухудшения эффективного использования полосы пропускания может обеспечиваться новая 3D audio сервисная услуга, поскольку поддерживается совместимость с соответствующим приёмником.
2. Примеры модификации
В рамках этого описания, в соответствии с описанным выше вариантом осуществления изобретения, приводится пример в котором способом кодирования канальных закодированных данных является MPEG4 ААС; однако другие способы кодирования, например, такие как АС3 и АС4 также могут рассматриваться подобным образом. Фиг. 26 иллюстрирует структуру кадра АС3 (АС3 Synchronization frame). Канальные данные кодируются таким образом, что общий размер "Audblock 5," "mantissa data," "AUX" и "CRC" не превышает трёх восьмых от полного объёма. В случае использования АС3, метаданные MD вставляются в область "AUX". Фиг. 27 иллюстрирует пример конфигурации (syntax) вспомогательных данных АС3 (Auxiliary Data).
Когда "auxdatae" составляет "1", элемент "aux data" становится таким, чтобы быть разрешённым для использования, и данные в размере, который обозначается с помощью 14 бит (in а bit unit) "auxdatal" определяется в "auxbits". Размер "auxbits" в этом случае записывается в "nauxbits". В случае использования конфигурации (1) потока, "metadata ()", иллюстрируемые в описываемой выше фиг. 8(a), вставляются в "auxbits", а объектные закодированные данные размещаются в поле "data_byte".
Фиг. 28(а) иллюстрирует структуру слоя АС4 простого транспорта (Simple transport). АС4 является одним из кодирующих форматов АС3 audio для следующего поколения. Существует поле кодовой синхрогруппы (syncWord), поле длины кадра (frame Length), поле "RawAc4Frame" в качестве поля для кодирования данных, и поле CRC. Как иллюстрируется на фиг. 28(b), в поле "RawAc4Frame," существует поле таблицы содержания Table Of Content (TOC) в начале и существуют поля заданного количества вложенных потоков данных (Substream) впоследствии.
Как иллюстрируется на 29(b), во вложенном потоке данных (ac4_substream_data()), существует область метаданных (metadata), и в нём также обеспечивается поле "umd_payloads_substream()". В случае использования конфигурации (1) потока, объектные закодированные данные размещаются в поле "umd_payloads_substream()".
В рамках этого описания, как иллюстрируется на 29(а), существует поле "ac4_presentation_info()" в таблице содержания TOC (ac4_toc()), и дополнительно существует поле "umd_info()", которое показывает, что существуют метаданные, вставленные в поле "umd_payloads_substream()).
Фиг. 30 иллюстрирует конфигурацию (syntax) “umd_info()” в ТОС (ac4_toc()). Поле "umd_version" показывает номер версии umd syntax. "K_id" показывает, что произвольно выбранная информация содержится как '0x6.' Комбинация номера версии и значения "k_id" определяется таким образом, чтобы показывать, что существуют метаданные, вставляемые в полезную информацию "umd_payloads_substream()".
Фиг. 31 иллюстрирует конфигурацию (syntax) "umd_payloads_substream()". Пятибитовое поле "umd_payload_id" является значением идентификатора ID, показывающим, что содержится в "object_data_byte", при этом предполагается, что его значение отличается от "0". 16-битовое поле "umd_payload_size" показывает количество битов, последующих за полем. 8-битовое поле "userdata_synccode" является стартовым кодом метаданных и показывает содержимое метаданных. Например, "0x10" показывает, что данные является объектными закодированными данными системы MPEG-H (MPEG-H 3D Audio). В области "object_data_byte" располагаются объектные закодированные данные.
Кроме того, описанный выше вариант осуществления изобретения описывает пример того, что объектные закодированные данные, кодирующиеся с помощью способа MPEG4 ААС, объектные закодированные данные, кодирующиеся с помощью способа MPEG-H 3D Audio, а также способы кодирования канальных закодированных данных и объектных закодированных данных являются различными. Однако, может рассматриваться случай, когда способы кодирования двух типов закодированных данных являются аналогичными способами. Например, может быть случай, что способом кодирования канальных закодированных данных является АС4 и способом кодирования объектных закодированных данных также является АС4.
Кроме того, описанный выше вариант осуществления изобретения описывает пример того, что первыми закодированными данными являются канальные закодированные данные, а вторыми закодированными данными, которые имеют отношение к первым закодированным данным, являются объектные закодированные данные. Однако объединение первых закодированных данных и вторых закодированных данных не ограничивается этим примером. Настоящая технология может аналогичным образом применяться в случае выполнения различных масштабируемых расширений, которыми являются, например, расширение номера канала, расширение частоты дискретизации.
Пример расширения номера канала
Закодированные данные, относящиеся к канальной системе 5.1 охватывающего объёмного звука передаются как первые закодированные данные, а закодированные данные добавленного канала передаются как вторые закодированные данные. Соответствующий декодер декодирует только элемент канальной системы 5.1, а декодер, совместимый с дополнительным каналом, декодирует все элементы.
Расширение частоты дискретизации
Закодированные данные в отношении данных дискретизации аудиоматериала с родственной частотой дискретизации аудиоматериала передаются как первые закодированные данные, а закодированные данные в отношении данных дискретизации аудиоматериала с более высокой частотой дискретизации аудиоматериала передаются как вторые закодированные данные. Соответствующий декодер декодирует только данные с родственной частотой дискретизации аудиоматериала, а декодер, совместимый с более высокой частотой дискретизации аудиоматериала, декодирует все данные.
Кроме того, описанный выше вариант осуществления изобретения описывает пример, в котором контейнер является транспортным потоком (MPEG-2 TS). Однако настоящая технология также может применяться в отношении системы, в которой данные доставляются с помощью контейнера в формате МР4 или в других форматах аналогичным способом. Например, система является системой доставки потока на основе MPEG-DASH или приёмопередающей системой, которая работает с медиа-потоком со структурой MPEG media transport (MMT).
Кроме того, описанный выше вариант осуществления изобретения описывает пример того, что первые закодированные данные являются канальными закодированными данными, а вторые закодированные данные являются объектными закодированными данными. Однако, может рассматриваться случай, когда вторые закодированные данные являются другим типом канальных закодированных данных или включают в себя объектные закодированные данные и канальные закодированные данные.
В рамках этого описания настоящая технология может использовать следующие конфигурации.
(1) Передающее устройство, включающее в себя:
кодирующий модуль, сконфигурированный таким образом, чтобы генерировать заданное количество потоков аудиоданных, включающих в себя первые закодированные данные и вторые закодированные данные, которые имеют отношение к первым закодированным данным; и
передающий модуль, сконфигурированный таким образом, чтобы передавать контейнер данных в заданном формате, включающем в себя сгенерированное заданное количество потоков аудиоданных,
в котором кодирующий модуль генерирует заданное количество потоков аудиоданных таким образом, что вторые закодированные данные отвергаются в приёмнике, который не совместим со вторыми закодированными данными.
(2) Передающее устройство по п. (1), в котором кодирующий способ первых закодированных данных и кодирующий способ вторых закодированных данных являются различными.
(3) Передающее устройство по п. (2), в котором первые закодированные данные являются канальными закодированными данными, а вторые закодированные данные являются объектными закодированными данными.
(4) Передающее устройство по п. (3), в котором способом кодирования первых закодированных данных является MPEG4 ААС, а способом кодирования вторых закодированных данных является MPEG-H 3D Audio.
(5) Передающее устройство по любому из пп. с (1) по (4), в котором кодирующий модуль генерирует потоки аудиоданных, имеющие первые закодированные данные и встраивает вторые закодированные данные в область пользовательских данных потоков аудиоданных.
(6) Передающее устройство по п. (5), дополнительно включающее в себя
модуль вставления информации, сконфигурированный таким образом, чтобы вставлять в слой контейнера данных информацию идентификации, которая идентифицирует, что существуют вторые закодированные данные, которые имеют отношение к первым закодированным данным, встроенные в область пользовательских данных потоков аудиоданных, имеющих первые закодированные данные и включённые в контейнер.
(7) Передающее устройство по пп. (5) или (6), в котором
первые закодированные данные являются канальными закодированными данными, а вторые закодированные данные являются объектными закодированными данными, и
объектные закодированные данные заданного количества групп встраиваются в область пользовательских данных потоков аудиоданных,
передающее устройство дополнительно включает в себя модуль вставления информации, сконфигурированный таким образом, чтобы вставлять в слой контейнера данных информацию определённого признака, которая показывает определяющий признак каждого фрагмента объектных закодированных данных заданного количества групп.
(8) Передающее устройство по любому из пп. с (1) по (4), в котором кодирующий модуль генерирует первый поток аудиоданных, включающий в себя первые закодированные данные, и генерирует заданное количество вторых потоков аудиоданных, включающих в себя вторые закодированные данные.
(9) Передающее устройство по п. (8), в котором объектные закодированные данные заданного количества групп включаются в заданное количество вторых потоков аудиоданных,
передающее устройство дополнительно включает в себя модуль вставления информации, сконфигурированный таким образом, чтобы вставлять в слой контейнера данных информацию определённого признака, которая показывает определяющий признак каждого фрагмента объектных закодированных данных заданного количества групп.
(10) Передающее устройство по п. (9), в котором модуль вставления информации дополнительно вставляет в слой контейнера данных информацию отношения соответствия потока, которая обозначает, в какой из вторых потоков аудиоданных соответственно включается каждый фрагмент объектных закодированных данных заданного количества групп.
(11) Передающее устройство по п. (10), в котором информация отношения соответствия потока является информацией, которая показывает отношение соответствия между групповым идентификатором, идентифицирующим каждый фрагмент объектных закодированных данных заданного количества групп и идентификатором потока, идентифицирующим каждый поток из заданного количества вторых потоков аудиоданных.
(12) Передающее устройство по п. (11), в котором модуль вставления информации дополнительного вставляет в слой контейнера данных информацию с идентификатором потока, которая обозначает каждый идентификатор потока заданного количества вторых потоков аудиоданных.
(13) Способ передачи данных, включающий в себя:
кодирующий этап в генерировании заданного количества потоков аудиоданных, включающих в себя первые закодированные данные и вторые закодированные данные, которые имеют отношение к первым закодированным данным; и
этап передачи, состоящий в передаче с помощью передающего модуля, посредством передачи контейнера данных в заданном формате, включающем в себя сгенерированное заданное количество потоков аудиоданных,
при этом во время кодирующего этапа заданное количество потоков аудиоданных генерируются таким образом, что вторые закодированные данные отвергаются в приёмнике, который не совместим со вторыми закодированными данными.
(14) Приёмное устройство, включающее в себя:
приёмный модуль, сконфигурированный таким образом, чтобы принимать контейнер данных в заданном формате, включающий в себя заданное количество потоков аудиоданных, имеющих первые закодированные данные и вторые закодированные данные, которые имеют отношение к первым закодированным данным,
в котором заданное количество потоков аудиоданных генерируется таким образом, что вторые закодированные данные отвергаются в приёмнике, который не совместим со вторыми закодированными данными,
приёмное устройство дополнительно включает в себя обрабатывающий модуль, сконфигурированный таким образом, чтобы выделять первые закодированные данные и вторые закодированные данные, из заданного количества потоков аудиоданных, включённых в контейнер данных и обрабатывать выделенные данные.
(15) Приёмное устройство по п. (14), в котором способ кодирования первых закодированных данных и способ кодирования вторых закодированных данных являются различными.
(16) Приёмное устройство по пп. (14) или (15), в котором первые закодированные данные являются канальными закодированными данными, а вторые закодированные данные являются объектными закодированными данными.
(17) Приёмное устройство по любому из пп. с (14) по (16), в котором контейнер данных включает в себя потоки аудиоданных, имеющие первые закодированные данные и вторые закодированные данные, встроенные в область пользовательских данных.
(18) Приёмное устройство по любому из пп. с (14) по (16), в котором контейнер данных включает в себя первый поток аудиоданных, включающий в себя первые закодированные данные и заданное количество вторых потоков аудиоданных, включающих в себя вторые закодированные данные.
(19) Способ приёма данных, включающий в себя:
этап приёма данных, состоящий в приёме с помощью приёмного модуля контейнера данных в заданном формате, включающем в себя заданное количество потоков аудиоданных, имеющих первые закодированные данные и вторые закодированные данные, которые имеют отношение к первым закодированным данным,
при этом заданное количество потоков аудиоданных генерируется таким образом, что вторые закодированные данные отвергаются в приёмнике, который не совместим со вторыми закодированными данными,
способ приёма данных дополнительно включает в себя этап обработки, состоящий в выделении первых закодированных данных и вторых закодированных данных из заданного количества потоков аудиоданных, включённых в состав контейнера данных, и в обработке выделенных данных.
Главной характеристикой настоящей технологии является то, что новый сервис 3D Audio может обеспечиваться как поддерживающий совместимость с родственным приёмником аудиоданных без ухудшения эффективного использования полосы пропускания с помощью передачи потока аудиоданных, который включает в себя канальные закодированные данные и объектные закодированные данные, встроенные в область пользовательских данных потока аудиоданных, или с помощью передачи потока аудиоданных, включающего в себя канальные закодированные данные вместе с потоком аудиоданных, включающим в себя объектные закодированные данные (см. фиг. 2).
Список обозначений ссылочных позиций
10 приёмопередающая система
100 передатчик для сервисных услуг
110А, 110В модуль генерирования потока
112, 122 кодер сигнала изображения
113, 123 кодер канала аудиоданных
114, от 124-1 до 124-N кодер звукового объекта
115, 125 устройство форматирования TS
114 мультиплексор
200 приёмник для сервисных услуг
201 приёмный модуль
202 анализирующий модуль TS
203 декодер сигнала изображения
204 обрабатывающая схема сигнала изображения
205 возбуждающий контур индикаторной панели
206 индикаторная панель
с 211-1 по 211-М мультиплексирующий буфер
212 объединитель
213 декодер звукового канала 3D
214 обрабатывающая схема звукового выхода
215 система громкоговорителей
221 центральный процессор (CPU)
222 постоянное запоминающее устройство типа флэш (flash ROM, флэш-ПЗУ)
223 динамическое запоминающее устройство с произвольной выборкой (DRAM)
224 внутренняя шина
225 приёмный модуль дистанционного управления
226 передатчик дистанционного управления
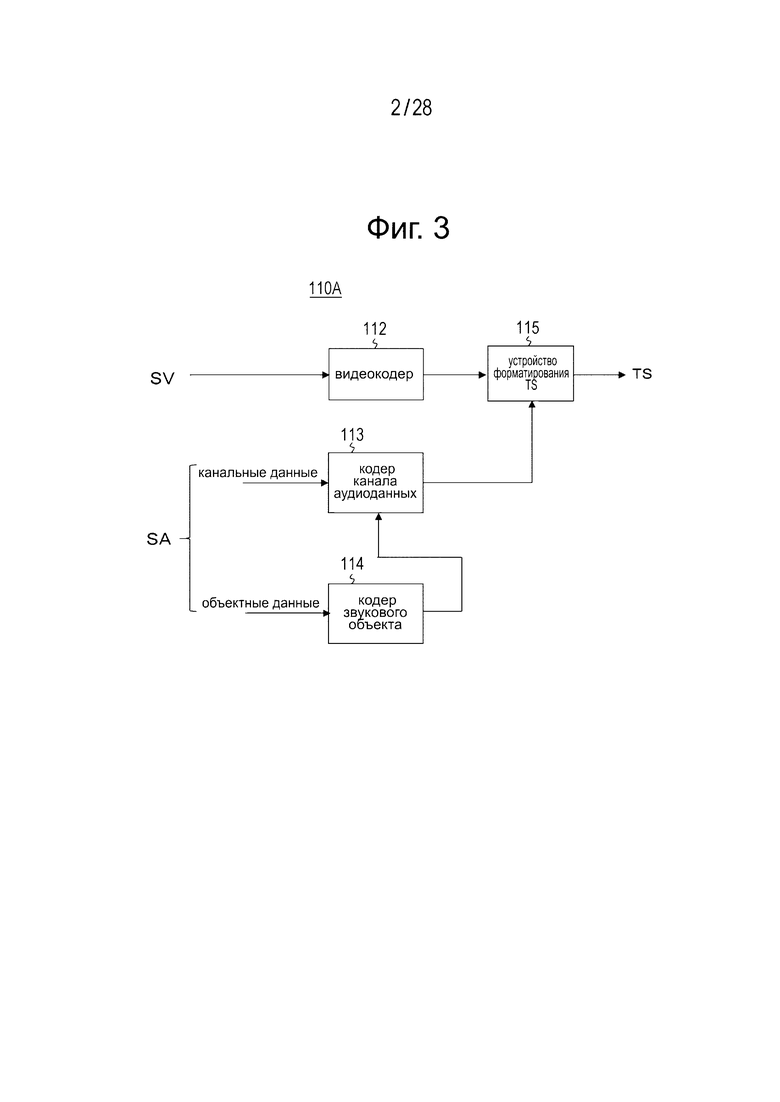
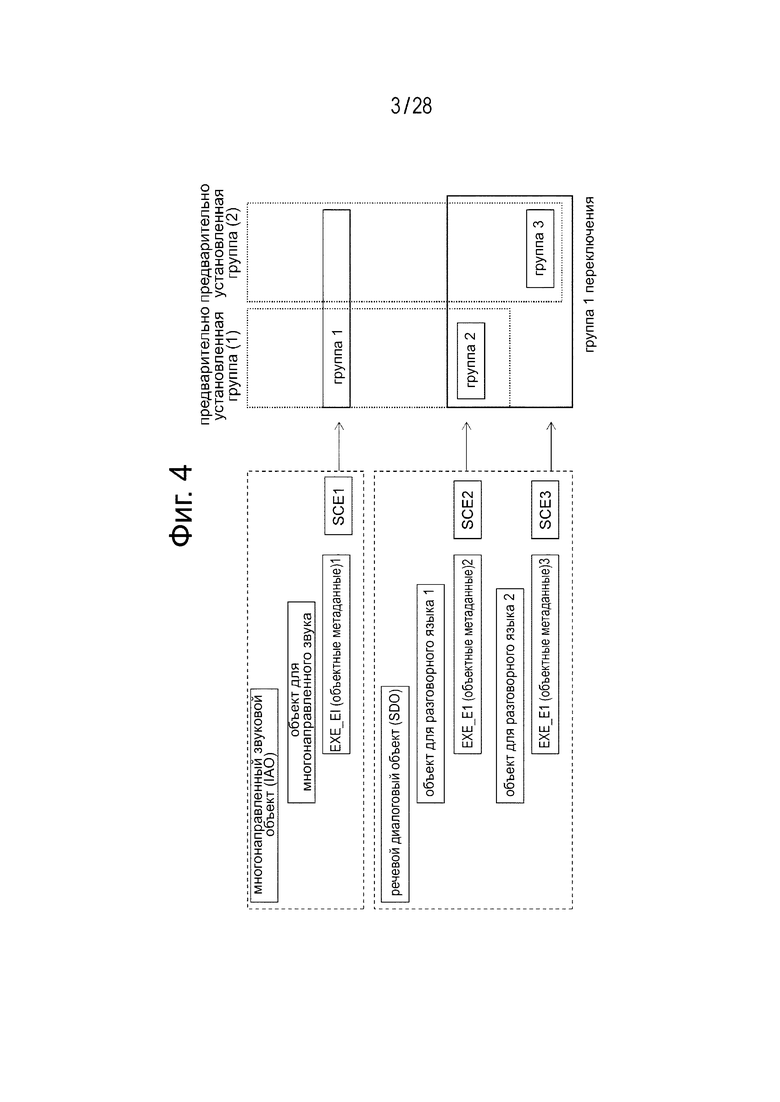


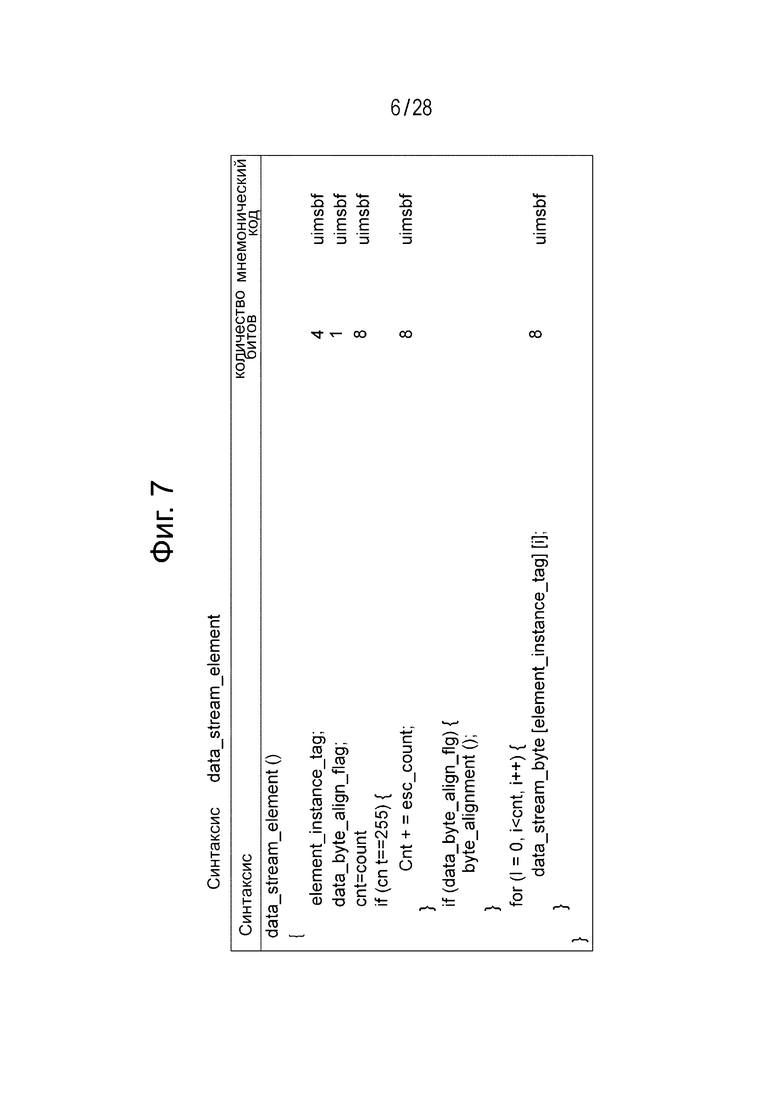

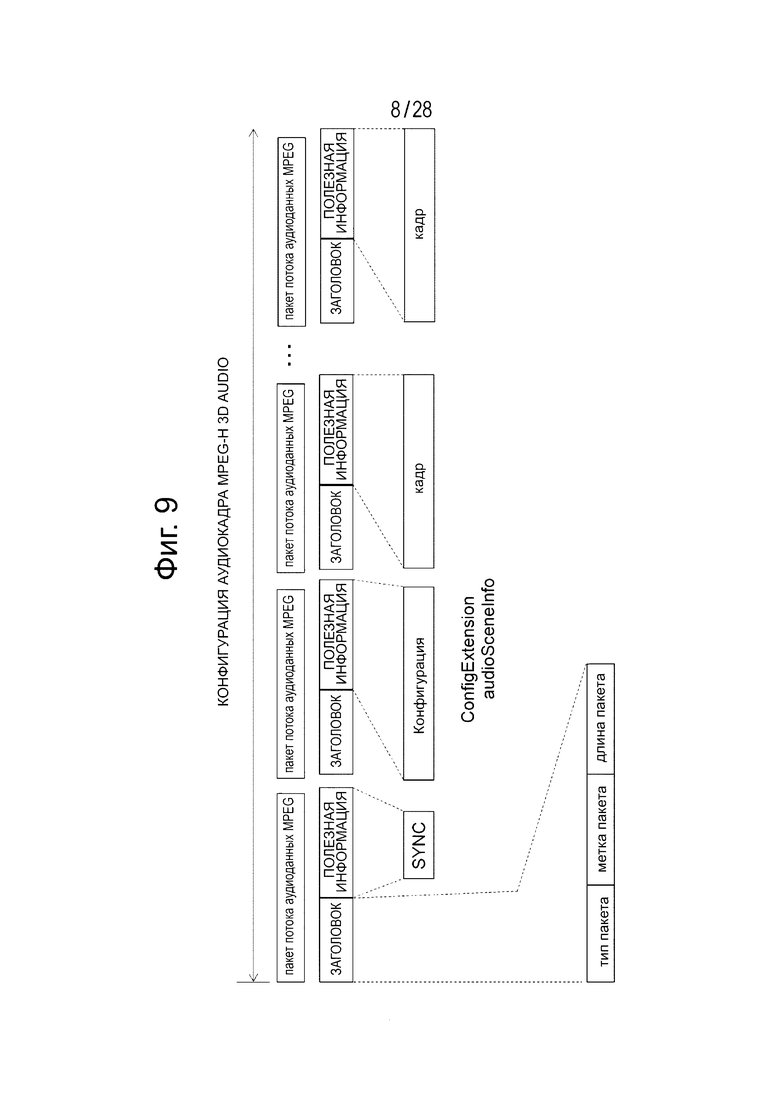

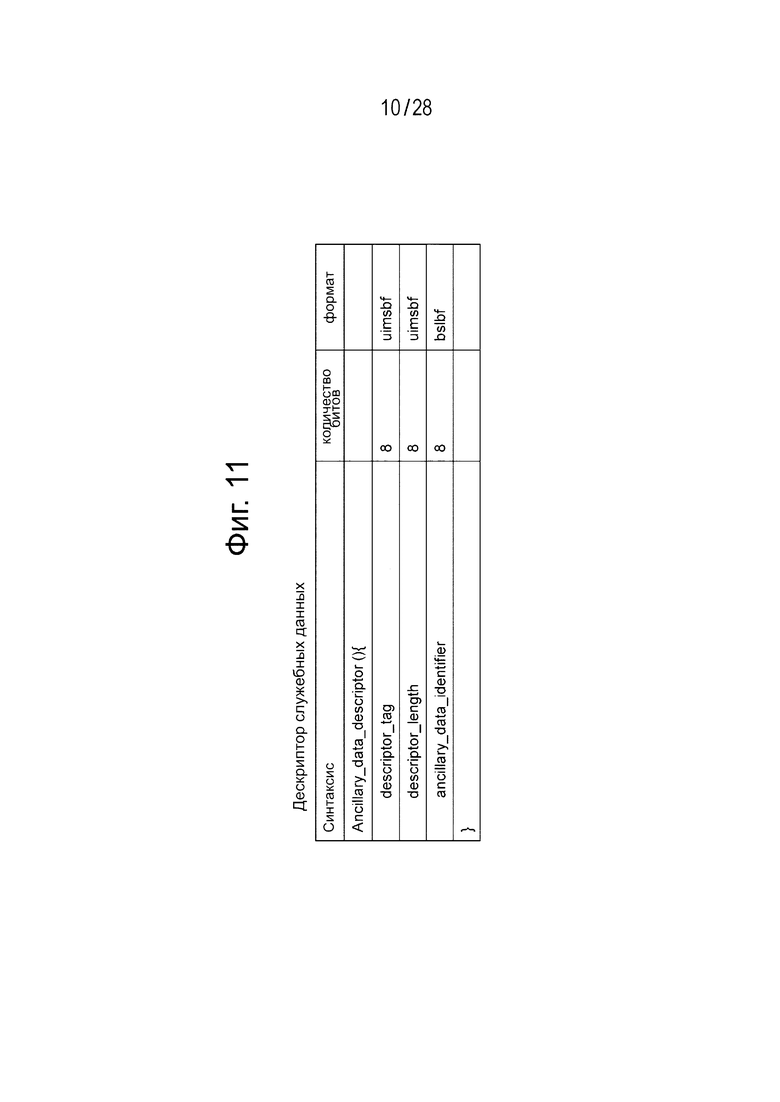
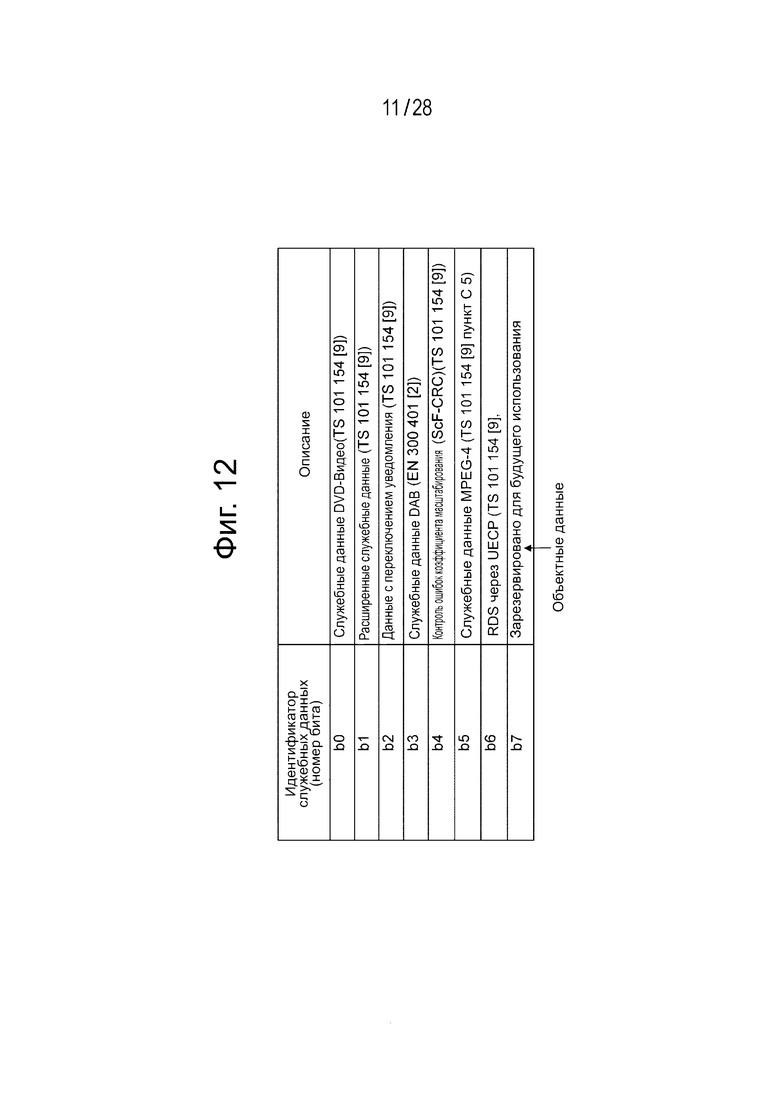
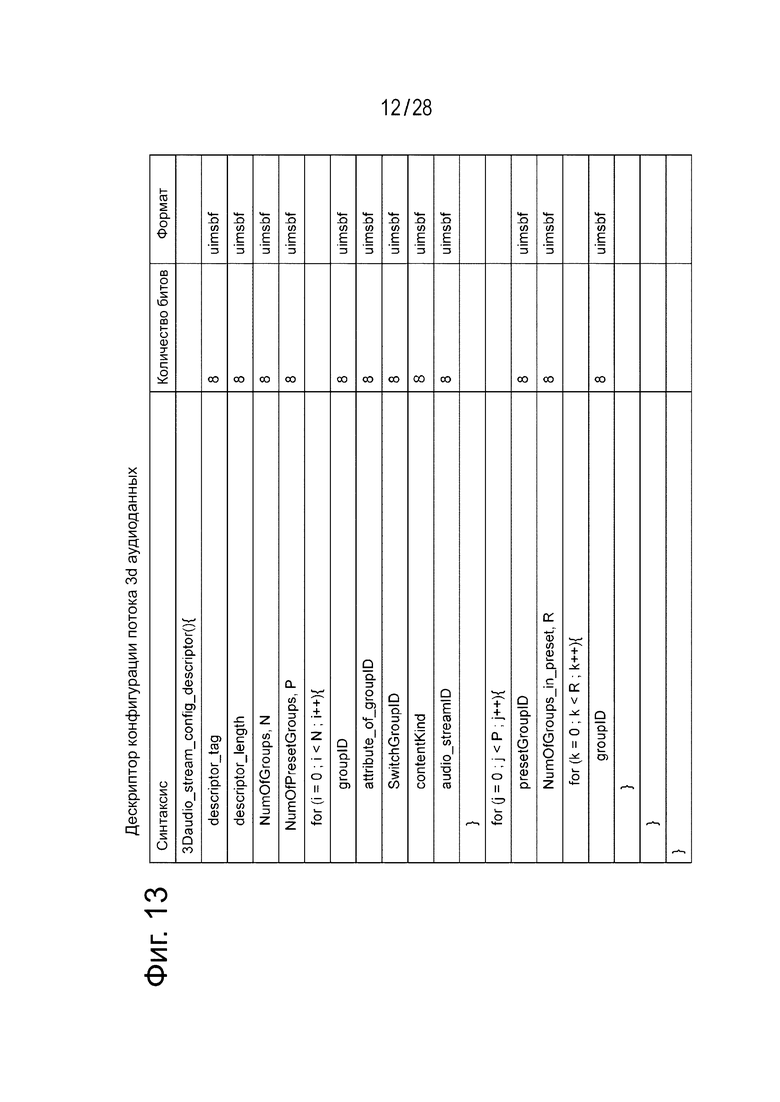


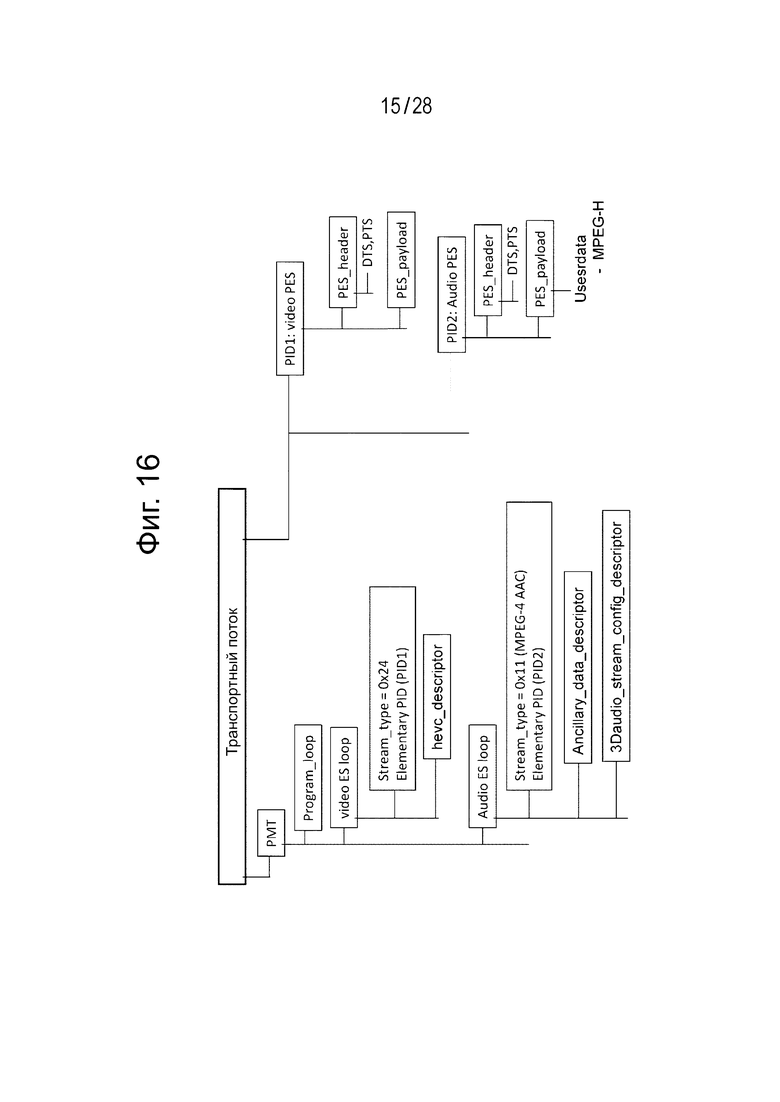


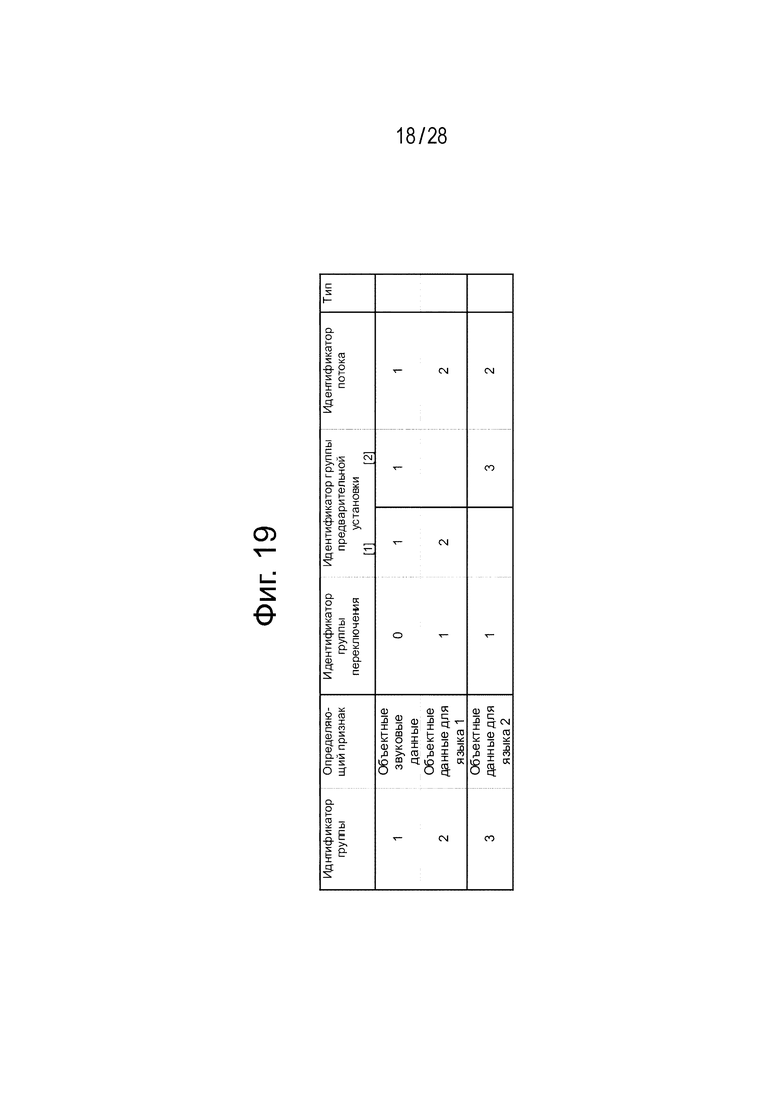
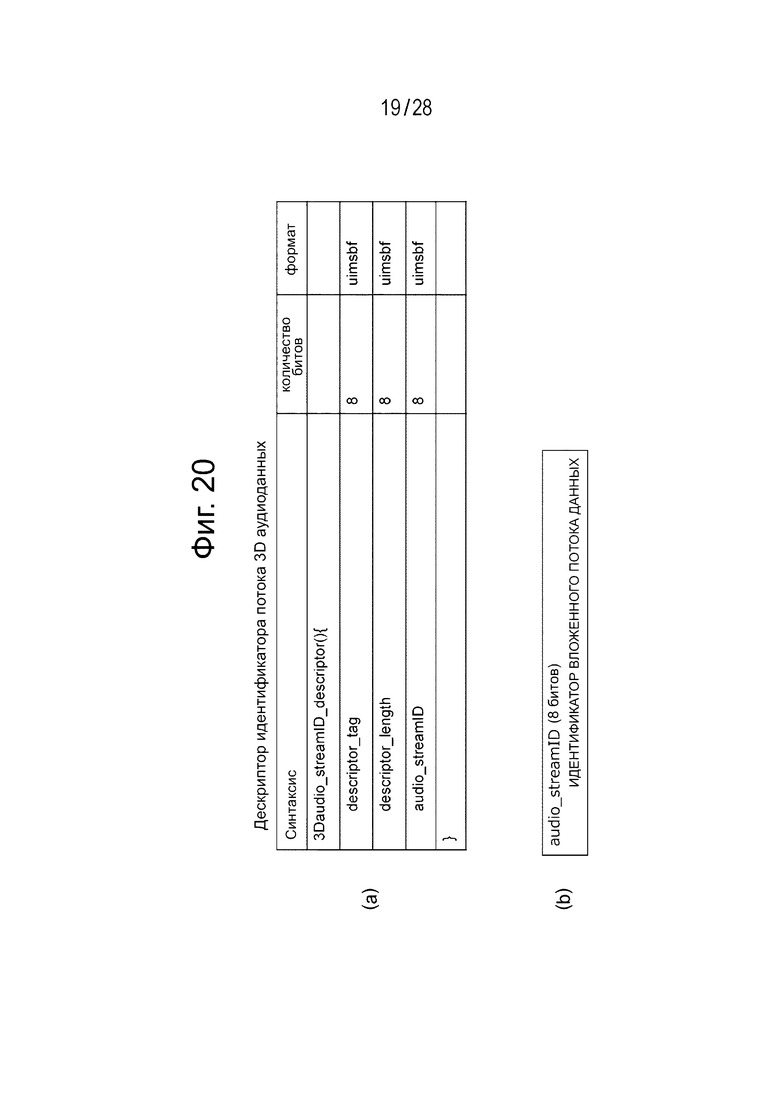


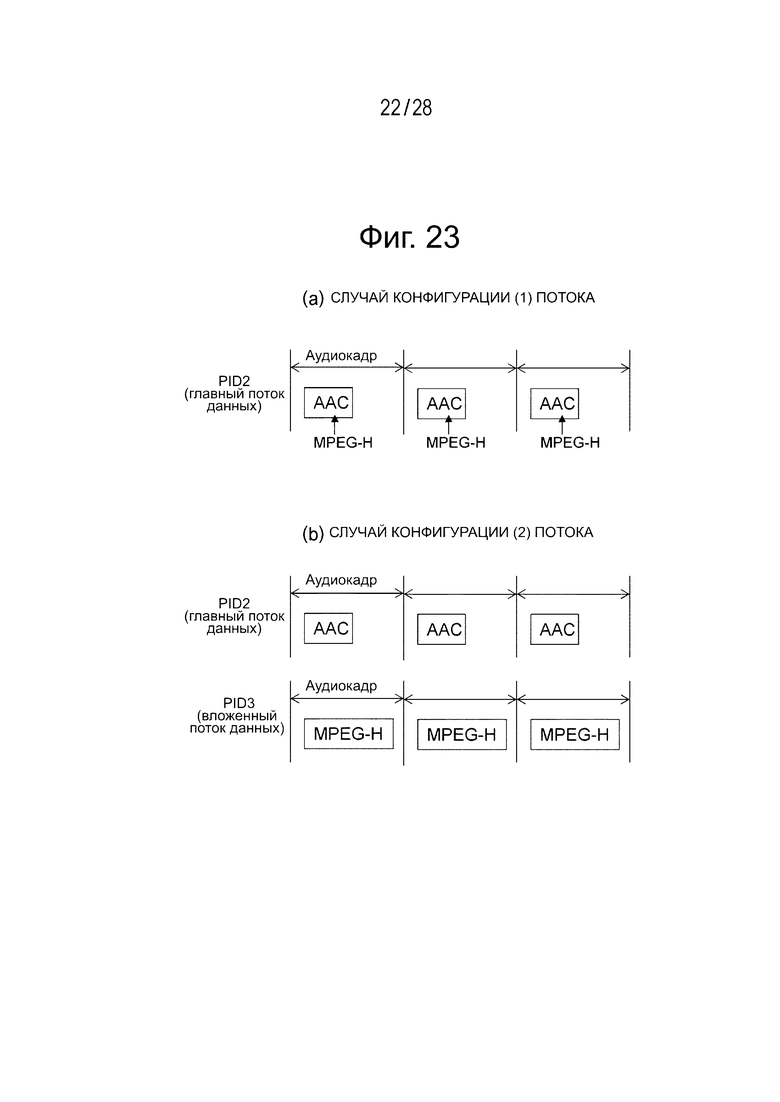


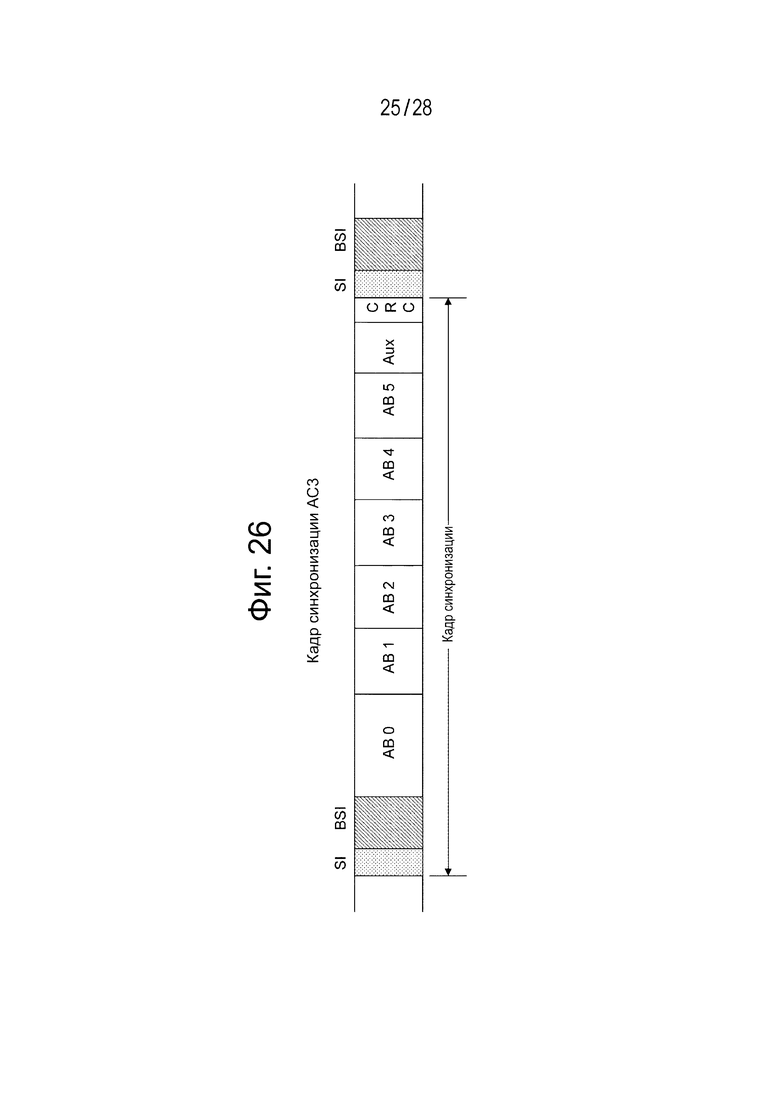

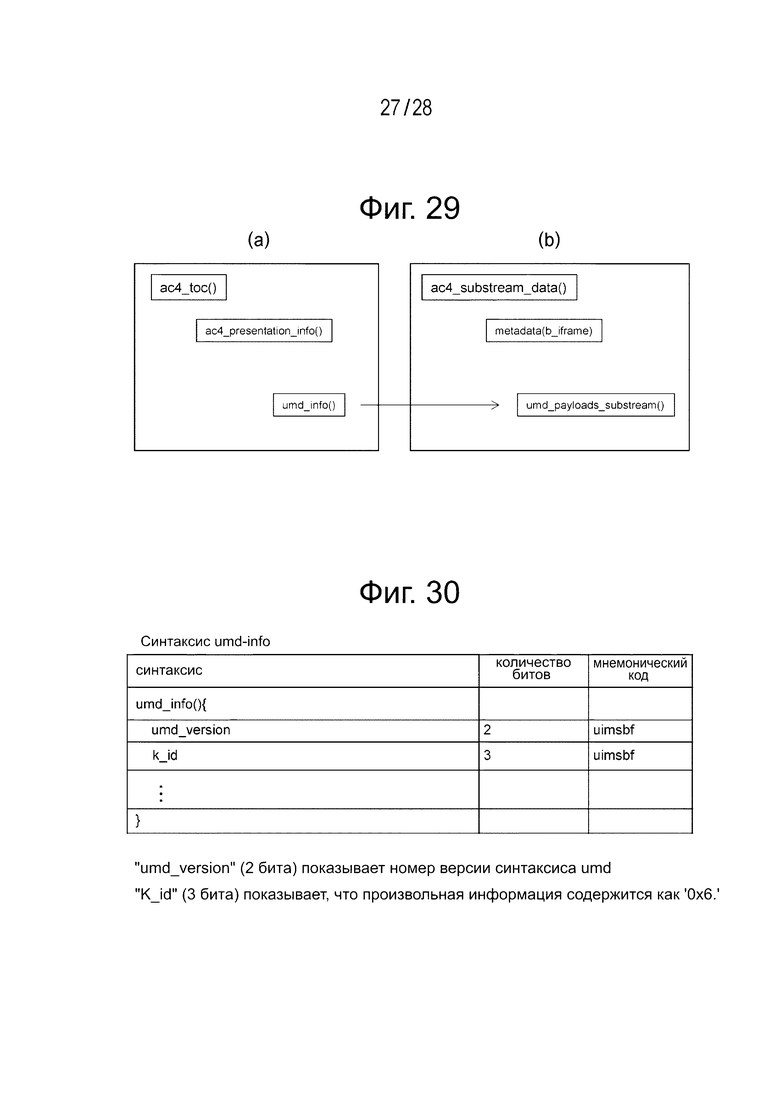

Изобретение относится к средствам для приема и передачи данных. Технический результат заключается в повышении эффективности приемопередачи аудиоданных. Генерируют заданное количество потоков аудиоданных, включающих в себя первые закодированные данные и вторые закодированные данные, которые имеют отношение к первым закодированным данным. Вставляют в уровень контейнера данных информацию идентификации, идентифицирующую наличие вторых закодированных данных, которые имеют отношение к первым закодированным данным, встроены в область пользовательских данных в потоках аудиоданных, имеющих первые закодированные данные, и включены в контейнер, и вставляют в уровень контейнера данных информацию атрибута, которая показывает атрибут каждого фрагмента вторых закодированных данных. Передают с помощью передающего модуля контейнер данных в заданном формате, включающий в себя сгенерированное заданное количество потоков аудиоданных. Первые закодированные данные кодированы с использованием первого способа кодирования, а вторые закодированные данные кодированы с использованием второго способа кодирования. 4 н. и 9 з.п. ф-лы, 31 ил.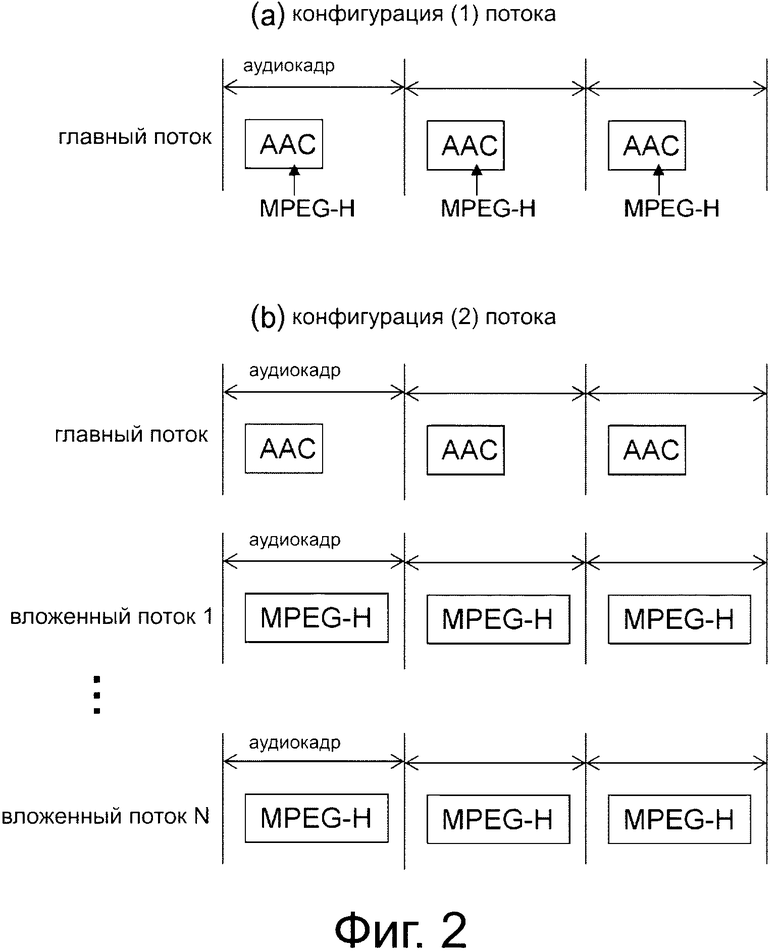
1. Передающее устройство, содержащее:
кодирующий модуль, выполненный с возможностью генерировать заданное количество потоков аудиоданных, включающих в себя первые закодированные данные и вторые закодированные данные, которые имеют отношение к первым закодированным данным;
модуль вставки информации, выполненный с возможностью вставлять в уровень контейнера данных информацию идентификации, идентифицирующую наличие вторых закодированных данных, которые имеют отношение к первым закодированным данным, встроены в область пользовательских данных в потоках аудиоданных, имеющих первые закодированные данные, и включены в контейнер, и выполненный с возможностью вставлять в уровень контейнера данных информацию атрибута, которая показывает атрибут каждого фрагмента вторых закодированных данных; и
передающий модуль, выполненный с возможностью передавать контейнер данных в заданном формате, включающий в себя сгенерированное заданное количество потоков аудиоданных,
при этом кодирующий модуль выполнен с возможностью генерировать первые закодированные данные с использованием первого способа кодирования, а вторые закодированные данные с использованием второго способа кодирования, причем первый способ кодирования отличен от второго способа кодирования, так чтобы приемник, не совместимый со вторыми закодированными данными, мог извлечь первые закодированные данные из заданного количества аудиопотоков для выполнения декодирования для получения вывода аудиоданных и отбросить вторые закодированные данные, причем первые закодированные данные являются канальными закодированными данными, а вторые закодированные данные являются объектными закодированными данными.
2. Передающее устройство по п. 1, в котором способом кодирования первых закодированных данных является MPEG4 ААС, а способом кодирования вторых закодированных данных является MPEG-H 3D Audio.
3. Передающее устройство по п. 1, в котором кодирующий модуль выполнен с возможностью генерировать потоки аудиоданных, имеющие первые закодированные данные, и встраивать вторые закодированные данные в область пользовательских данных в потоках аудиоданных.
4. Передающее устройство по п. 3, в котором объектные закодированные данные заданного количества групп встроены в область пользовательских данных в потоках аудиоданных.
5. Передающее устройство по п. 1, в котором кодирующий модуль выполнен с возможностью генерировать первый поток аудиоданных, включающий в себя первые закодированные данные, и генерировать заданное количество вторых потоков аудиоданных, включающих в себя вторые закодированные данные.
6. Передающее устройство по п. 5, в котором модуль вставки информации дополнительно выполнен с возможностью вставлять в уровень контейнера данных информацию отношения соответствия потоков, показывающую, в какой из вторых потоков аудиоданных соответственно включен каждый фрагмент объектных закодированных данных заданного количества групп.
7. Передающее устройство по п. 6, в котором информация отношения соответствия потоков является информацией, показывающее отношение соответствия между групповым идентификатором, идентифицирующим каждый фрагмент объектных закодированных данных заданного количества групп, и идентификатором потока, идентифицирующим каждый поток из заданного количества вторых потоков аудиоданных.
8. Передающее устройство по п. 7, в котором модуль вставки информации дополнительно выполнен с возможностью вставлять в уровень контейнера данных информацию идентификатора потока, показывающую каждый идентификатор потока для заданного количества вторых потоков аудиоданных.
9. Способ передачи данных, содержащий:
этап кодирования, на котором генерируют заданное количество потоков аудиоданных, включающих в себя первые закодированные данные и вторые закодированные данные, которые имеют отношение к первым закодированным данным;
этап вставки, на котором вставляют в уровень контейнера данных информацию идентификации, идентифицирующую наличие вторых закодированных данных, которые имеют отношение к первым закодированным данным, встроены в область пользовательских данных в потоках аудиоданных, имеющих первые закодированные данные, и включены в контейнер, и вставляют в уровень контейнера данных информацию атрибута, которая показывает атрибут каждого фрагмента вторых закодированных данных и
этап передачи, на котором передают с помощью передающего модуля контейнер данных в заданном формате, включающий в себя сгенерированное заданное количество потоков аудиоданных,
при этом первые закодированные данные кодированы с использованием первого способа кодирования, а вторые закодированные данные кодированы с использованием второго способа кодирования; причем первый способ кодирования отличен от второго способа кодирования, так чтобы приемник, не совместимый со вторыми закодированными данными, мог извлечь первые закодированные данные из заданного количества аудиопотоков для выполнения декодирования для получения вывода аудиоданных и отбросить вторые закодированные данные, причем первые закодированные данные являются канальными закодированными данными, а вторые закодированные данные являются объектными закодированными данными.
10. Приёмное устройство, содержащее:
приёмный модуль, выполненный с возможностью принимать контейнер данных в заданном формате, включающий в себя заданное количество потоков аудиоданных, имеющих первые закодированные данные и вторые закодированные данные, которые имеют отношение к первым закодированным данным, информацию идентификации, идентифицирующую наличие вторых закодированных данных, которые имеют отношение к первым закодированным данным, встроены в область пользовательских данных в потоках аудиоданных, имеющих первые закодированные данные, и включены в контейнер, и информацию атрибута, которая показывает атрибут каждого фрагмента вторых закодированных данных;
при этом первые закодированные данные кодированы с использованием первого способа кодирования, а вторые закодированные данные кодированы с использованием второго способа кодирования; причем первый способ кодирования отличен от второго способа кодирования, так что вторые закодированные данные отбрасываются в приёмнике, который не совместим со вторыми закодированными данными,
при этом приёмное устройство дополнительно включает в себя обрабатывающий модуль, выполненный с возможностью извлекать первые закодированные данные и вторые закодированные данные из заданного количества потоков аудиоданных, включённых в контейнер данных, и обрабатывать извлеченные данные, причем первые закодированные данные являются канальными закодированными данными, а вторые закодированные данные являются объектными закодированными данными.
11. Приёмное устройство по п. 10, в котором контейнер данных включает в себя потоки аудиоданных, имеющие первые закодированные данные и вторые закодированные данные, встроенные в область пользовательских данных.
12. Приёмное устройство по п. 10, в котором контейнер данных включает в себя первый поток аудиоданных, включающий в себя первые закодированные данные, и заданное количество вторых потоков аудиоданных, включающих в себя вторые закодированные данные.
13. Способ приёма данных, содержащий:
этап приёма данных, на котором принимают с помощью приёмного модуля контейнер данных в заданном формате, включающий в себя заданное количество потоков аудиоданных, имеющих первые закодированные данные и вторые закодированные данные, которые имеют отношение к первым закодированным данным, информацию идентификации, идентифицирующую наличие вторых закодированных данных, которые имеют отношение к первым закодированным данным, встроены в область пользовательских данных в потоках аудиоданных, имеющих первые закодированные данные, и включены в контейнер, и информацию атрибута, которая показывает атрибут каждого фрагмента вторых закодированных данных;
при этом первые закодированные данные кодированы с использованием первого способа кодирования, а вторые закодированные данные кодированы с использованием второго способа кодирования; причем первый способ кодирования отличен от второго способа кодирования, так что вторые закодированные данные отбрасываются в приёмнике, который не совместим со вторыми закодированными данными,
при этом способ приёма данных дополнительно включает в себя этап обработки, на котором извлекают первые закодированные данные и вторые закодированные данные из заданного количества потоков аудиоданных, включённых в контейнер данных, и обрабатывают извлеченные данные, причем первые закодированные данные являются канальными закодированными данными, а вторые закодированные данные являются объектными закодированными данными.
| KR 1020130054159 A, 24.05.2013 | |||
| JP 2006139827 A, 01.06.2006 | |||
| Приспособление для суммирования отрезков прямых линий | 1923 |
|
SU2010A1 |
| US 8504591 B2, 06.08.2013 | |||
| Способ защиты переносных электрических установок от опасностей, связанных с заземлением одной из фаз | 1924 |
|
SU2014A1 |
| УСТРОЙСТВО ДЛЯ ФОРМИРОВАНИЯ ВЫХОДНОГО ПРОСТРАНСТВЕННОГО МНОГОКАНАЛЬНОГО АУДИО СИГНАЛА | 2009 |
|
RU2504847C2 |

