Настоящее изобретение относится к области аудио обработки, особенно обработки пространственных свойств аудио.
Аудио обработка и/или кодирование усовершенствовались во многих отношениях. Все большим спросом пользуются создаваемые пространственные аудио-приложения. Во многих приложениях обработка аудио сигнала используется для декорелляции или рендеринга сигналов. Такие приложения могут, к примеру, осуществить преобразования моно в стерео, моно/стерео в многоканальный звук, создавать эффекты искусственной реверберации, расширения стерео (Stereo widening) или пользовательские интерактивные эффекты смешивания/рендеринга.
Для некоторых классов сигналов, например шумоподобных сигналов, таких как сигналы похожие на аплодисменты, обычные методы и системы имеют недостатки либо неудовлетворительное качество восприятия, или, если используется объектно-ориентированный подход, высокую вычислительную сложность из-за большого количества акустических событий, которые необходимо моделировать или обработать. Другой пример аудио материала, который является проблематичным, это обычно материал окружения, такой как, шумы, создаваемые стаей птиц, у морского побережья, скачущей лошадью, подразделением солдат на марше и т.д.
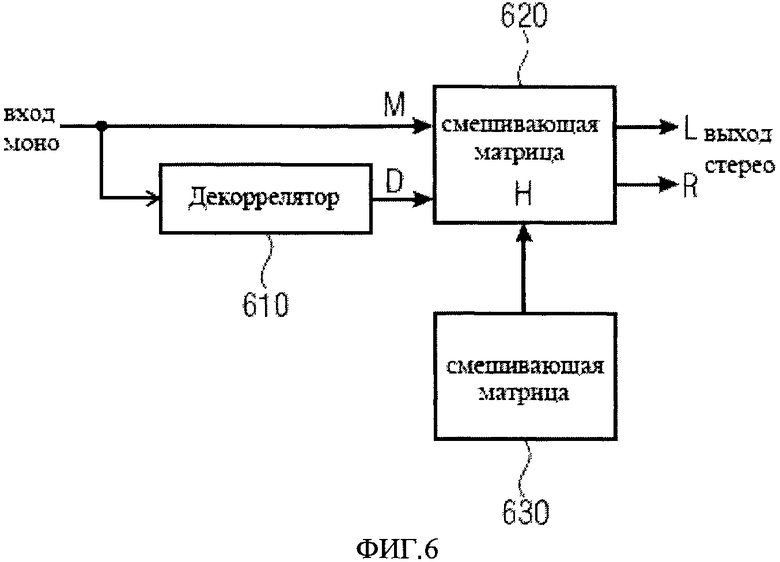
При обычных подходах используют, например, параметрическое стерео или кодирование MPEG-окружения (MPEG = Экспертная группа по вопросам движущегося изображения). На Фиг.6 изображено обычное применение декорреляции для преобразования моно сигнала в стерео. На фиг.6 изображен входной моно сигнал, подаваемый на декоррелятор 610, который обеспечивает декорреляцию входного сигнала на выходе. На смешивающую матрицу 620 подается входной сигнал вместе с сигналом с декоррелятора. В зависимости от параметров управления смешивающей матрицей 630, формируется выходной стерео сигнал. Декореллятор сигнала 610 генерирует декоррелированный сигнал D поступающий на уровень смешивающей матрицы 620 вместе с чистым моно сигналом М. Внутри смешивающей матрицы 620 формируются стерео каналы L (L = левый стереоканал) и R (R = правый стереоканал) в соответствии со смешивающей матрицей Н. Коэффициенты матрицы Н могут быть фиксированы, зависеть от сигнала, или находится под контролем пользователя.
Кроме того матрица может управляться сторонней информацией, передаваемой с сигналом, содержащей параметрическое описание того, как смешать сигналы для создания желаемого многоканального выходного сигнала. Эта информация обычно генерируется кодировщиком сигнала до процесса преобразования.
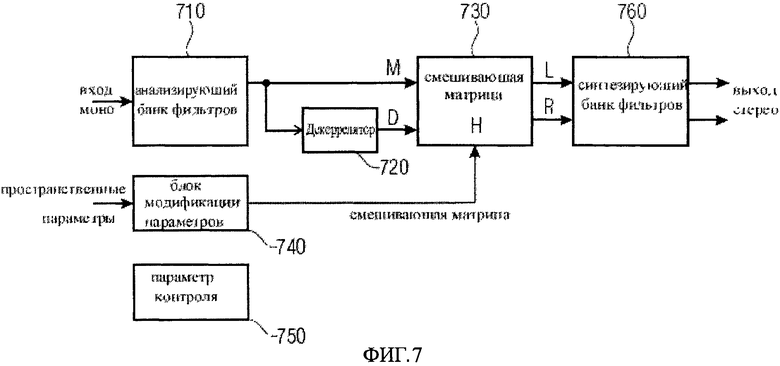
Обычно это делается в пространственном параметрическом аудио кодировании, как, например, в параметрическом стерео, см. J. Breebaart, S. van de Par, A. Kohlrausch, E. Schuijers, "High-Quality Parametric Spatial Audio Coding at Low Bitrates" in AES 116th Convention, Berlin, Preprint 6072, May 2004 и в MPEG Surround, cf. J.Herre, K.Kjörling, J.Breebaart, et. al., "MPEG Surround - the ISO/MPEG Standard for Efficient and Compatible Multi-Channel Audio Coding" in Proceedings of the 122nd AES Convention, Vienna, Austria, May 2007. Типичная структура параметрического стерео декодера показана на рис.7. В этом примере процесс декорреляции выполняется с преобразованным сигналом, сформированным анализирующим банком фильтров 710, который преобразует входной моно сигнал в другое представление, например, представление в виде ряда частотных диапазонов в частотной области.
В частотной области декоррелятор 720 генерирует соответствующий декореллированный сигнал, который преобразуется в смешивающей матрице 730. Смешивающая матрица 730 управляется параметрами, которые обеспечиваются блоком модификации параметров 740, который в свою очередь получает их с пространственными входными параметрами и объединяет с параметрами уровня контроля 750. В примере, показанном на фиг.7 пространственные параметры могут изменяться пользователем или дополнительными средствами, как, например, постобработка для стерео рендеринга/презентации. В этом случае параметры смешивания могут быть объединены с параметрами стерео фильтров, чтобы сформировать входные параметры для смешивающей матрицы 730. Измерение параметров может осуществляться блоком изменения параметров 740. Выход смешивающей матрицы 730 соединен с синтезирующим банком фильтров 760, который формирует выходной стерео сигнал.
Как описано выше, выходной сигнал L/R смешивающей матрицы Н может быть вычислен из входного моно сигнала М и декоррелированного сигнала D, например, в соответствии с выражением
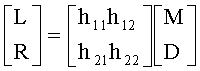
Декоррелированный звук на выходе матрицы смешивания может управляться на основе передаваемых параметров, таких как, ICC (ICC= Межканальная корреляция) и/или смешанных или определяемых пользователем параметров.
Еще один традиционный подход основан на методе временных перестановок. Специальный метод декорреляции таких сигналов как сигналы похожие на аплодисменты можно найти, например, в Gerard Hotho, Steven van de Par, Jeroen Breebaart, "Multichannel Coding of Applause Signals," in EURASIP Journal on Advances in Signal Processing, Vol.1, Art.10, 2008. Здесь, монофонический аудио сигнал сегментируется с использованием перекрывающихся временных сегментов, которые временно перестанавливаются псевдо случайным образом в пределах «супер»-блока, чтобы сформировать некоррелированные выходные каналы. Перестановки являются взаимно независимыми для n выходных каналов.
Другой подход - чередующееся переключение оригинальных и задержанных копий каналов, чтобы получить декоррелированный сигнал, см. Немецкий патент 102007018032.4-55. В некоторых известных объектно-ориентированных системах, например см. Wagner, Andreas; Walther, Andreas; Melchoir, Frank; Strauβ, Michael; "Generation of Highly Immersive Atmospheres for Wave Field Synthesis Reproduction" at 116th International EAS Convention, Berlin, 2004, где описывается как создать эффекты, создающие эффект присутствия, для многих объектов, таких как один хлопок, с применением синтеза поля волн.
Еще одним подходом является так называемое «направленное аудио кодирование» (DirAC), которое является методом рендеринга звука и применимо для различных систем воспроизведения звука, см. Pulkki, Ville, "Spatial Sound Reproduction with Directional Audio Coding" in J. Audio Eng. Soc., Vol.55, No. 6, 2007. В части анализа в одном месте оцениваются диффузия и направление прибытия звука, зависящие от времени и частоты. В части синтеза сигналы от микрофонов делятся сначала на диффузные и не диффузные части и затем воспроизводятся с помощью различных методов.
Традиционные подходы имеют ряд недостатков. К примеру, управляемое или неуправляемое смешивание аудио сигналов, таких, как аплодисменты может потребовать сильную декорреляцию. Следовательно, с одной стороны, сильная декорреляция необходима для восстановления атмосферы присутствия, к примеру, в концертном зале. С другой стороны, подходящие декоррелирующие фильтры, как, например, фазовые фильтры, снижают качество воспроизведения переходных событий, таких как один хлопок, путем создания эффектов временного смазывания, таких как пре- и пост-эхо, и звон фильтра. Кроме того пространственное расположение событий одиночных хлопков должно быть сделано на временной сетке с хорошим разрешением, в то время как декоррелированное окружение должно быть квазистационарным во времени.
Современные системы согласно J. Breebaart, S. van de Par, A. Kohlrausch, E. Schuijers, "High-Quality Parametric Spatial Audio Coding at Low Bitrates" in AES 116th Convention, Berlin, Preprint 6072, May 2004 and J. Herre, K. Kjörling, J. Breebaart, et. al., "MPEG Surround - the ISO/MPEG Standard for Efficient and Compatible Multi-Channel Audio Coding" in Proceedings of the 122nd AES Convention, Vienna, Austria, May 2007 представляют собой компромисс между временным разрешением и атмосферой устойчивости, между ухудшением качества переходных процессов и атмосферой декорреляции.
Например, если в системе используется метод временных перестановок, будет чувствоваться ухудшение восприятия звука из-за определенных повторяющихся эффектов выходного аудио сигнала. Это объясняется тем фактом, что один и тот же сегмент входного сигнала, появляется не измененным в каждом выходном канале, хотя и в другой момент времени. Более того, чтобы избежать увеличения плотности аплодисментов, некоторые оригинальные каналы не используются при смешивании, и, таким образом, могут быть пропущены некоторые важные события в аудитории.
В известных объектно-ориентированных системах, такие звуковые события создаются большой группой распределенных точечных источников, что приводит к реализации сложных вычислительных алгоритмов.
Объектом настоящего изобретения является улучшение концепции пространственной обработки аудио. Это достигается с использованием устройства по п.1 и метода по п.16 формулы изобретения.
В предлагаемом изобретении показано, что звуковой сигнал может быть разложен на несколько компонент, которые обеспечивают пространственный рендеринг, например, с точки зрения декорреляции или с точки зрения пространственного распределения амплитуд. Другими словами настоящее изобретение основано на обосновании того, что, например, в сценарии с несколькими источниками звука, источники переднего плана и фона можно разделить и представить или декоррелировать по-разному. Как правило, можно выделить различные пространственные глубины и/или протяженности аудио объектов.
Одним из ключевых пунктов настоящего изобретения является разложение сигналов, таких как звук приветствия аудитории, стаи птиц, морского побережья, скачущей лошади, подразделения солдат на марше и т.д., на сигналы переднего плана и заднего плана, где сигналы переднего плана содержат отдельные акустические события, создаваемые, например, близко расположенными источниками и источниками на заднем плане создающими окружающий фон распределенных вдали событий. До окончательного смешивания, эти две части сигнала, обрабатываются отдельно, например, для того, чтобы синтезировать корреляции, сформировать пространственное распределение аудио сигнала и т.д.
Предложенные решения не ограничены различением только частей сигнала переднего плана и заднего плана, они могут отличить нескольких различных аудио частей, которые могут быть представлены или декоррелированы по-разному.
В общем случае аудио сигналы могут быть разбиты на n различных семантических компонентов, которые обрабатываются отдельно. Процесс разложения/разделения различных семантических компонентов может быть реализован во временной и/или в частотной области.
Предложенное решение может обеспечить наилучшее качество восприятия звука при умеренных вычислительных затратах. Предложенное решение обеспечивает новый метод декорреляции/рендеринга, который обеспечивает высокое качество восприятия по умеренным ценам, особенно при обработке сигналов похожих на аплодисменты, как критического аудио материала или других аналогичных, создающих фон, таких как, например, шум, создаваемый стаей птиц, морским побережьем, скачущей лошадью, подразделением солдат на марше и т.д.
Воплощения настоящего изобретения будут подробно рассмотрены с помощью сопровождающих диаграмм, в которых
Фиг.1а показывает воплощение устройства для определения пространственного многоканального аудио сигнала;
Фиг.1b показывает блок-схему другого решения;
Фиг.2 показывает решение, иллюстрирующие множество сигналов разложения;
Фиг.3 иллюстрирует решение с семантическим разложением сигналов переднего плана и фона;
Фиг.4 иллюстрирует пример метода для получения компонент сигнала фона;
Фиг.5 иллюстрирует синтез источников звука, имеющих большую протяженность;
Фиг.6 иллюстрирует одно применение декоррелятора во временной области в преобразователе моно сигнала в стерео; и
Фиг.7 показывает другое применение декоррелятора в частотной области в преобразователе моно сигнала в стерео.
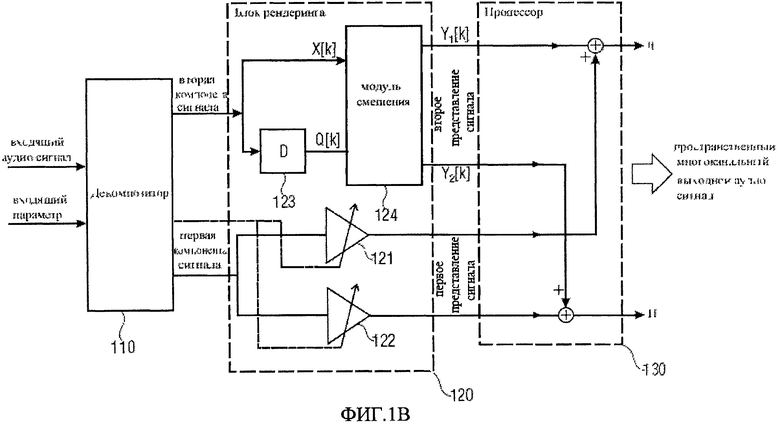
На фиг.1 представлено устройство 100 для определения выходного пространственного многоканального аудио сигнала, основанного на входном звуковом сигнале. В некоторых вариантах устройство может быть выполнено с возможностью формирования выходного пространственного многоканального аудиосигнала на базе входного параметра. Входной параметр может быть создан локально или обеспечиваться вместе с входным аудио сигналом, например, как внешняя информация.
В решении, изображенном на фиг.1 устройство 100 включает в себя декомпозитор 110 для разложения входного аудио и получения первой компоненты сигнала с первым семантическим свойством и второй компоненты сигнала со вторым семантическим свойством, отличающимся от первого семантического свойства.
Устройство 100 далее включает в себя блок рендеринга 120 для рендеринга первой компоненты сигнала, с помощью первой характеристики рендеринга для получения первого отображаемого сигнала, имеющего первое семантическое свойство, и для рендеринга второй компоненты сигнала, с помощью второй характеристики рендеринга для получения второго отображаемого сигнала, имеющего второе семантическое свойство.
Семантическое свойство может соответствовать пространственному свойству, такому как близко или далеко, сосредоточено или распределено, и/или динамическому свойству, как например, является ли сигнал тональным, постоянным или переходным, и/или свойству доминирования, как например, является ли сигнал сигналом переднего плана или фоном, и мера этого соответственно.
Кроме того, в решении, устройство 100 включает процессор 130 для того, чтобы обработать первый предоставленный сигнал и второй предоставленный сигнал, и получить выходной пространственный многоканальный аудио сигнал.
Другими словами декомпозитор 110 выполнен с возможностью разложения аудио сигнала, в некоторых решениях, работа декомпозитора основана на входном параметре. Разложение аудио сигнала основано на семантических, например, пространственных свойствах различных частей аудио сигнала. Кроме того рендеринг, осуществляемый в блоке рендеринга 120, в соответствии с первой и второй характеристиками рендеринга может также быть выполнен с возможностью учета пространственных свойств, которые позволяют, например, в сценарии, где первая компонента сигнала соответствует фону аудио сигнала, и вторая компонента сигнала соответствует основному аудио сигналу, использовать другой рендеринг или декорреляторы. Далее термин «переднего плана» понимается как ссылка на объект аудио, доминирующей в аудио среде так, что потенциальный слушатель может заметить объект аудио переднего плана. Аудио объект переднего плана или источник может быть различен или дифференцирован от фонового звука (звука заднего плана) объекта или источника. Фоновый звук объекта или источника не может быть заметен для потенциального слушателя в аудио среде, как менее доминирующий, чем аудио объект или источник переднего плана. Воплощение изобретения на ограничено аудио объектами или источниками переднего плана, такими как точечный источник звука, где аудио объектам или источникам заднего плана могут соответствовать пространственно более протяженные аудио объекты или источники.
Другими словами в воплощении изобретения первая характеристика рендеринга может быть основана или соответствовать первому семантическому свойству и вторая характеристика рендеринга может быть основана или соответствовать второму семантическому свойству. В одном решении первое семантическое свойство и первая характеристика рендеринга соответствуют аудио источнику или объекту на переднем плане и блок рендеринга 120 может быть выполнен с возможностью использования пространственного распределения амплитуд первой компоненты сигнала. Блок рендеринга 120 может быть далее выполнен с возможностью обеспечения в качестве первого отображаемого сигнала двух амплитудной версии первой компоненты сигнала. В этом решении, второму семантическому свойству и второй характеристике рендеринга соответствуют множество аудио источников или объектов фона, и блок рендеринга 120 может быть выполнен с возможностью применения декорреляции ко второй компоненте сигнала и обеспечения в качестве второго сигнала рендеринга второй компоненты сигнала и его декоррелированной версии.
В решении блок рендеринга 120 можно далее приспособить для рендеринга первой компоненты сигнала, так что первая характеристика рендеринга не имеет особенности введения задержки. Другими словами может не быть декорреляции первой компоненты сигнала. В другом решении первая характеристика рендеринга может иметь задержку, характеризующуюся величиной первой задержки, и вторая характеристика рендеринга может иметь вторую величину задержки, вторая величина задержки, больше, чем первая величина задержки. Другими словами в этом решении как первая компонента сигнала, так и вторая компонента сигнала может быть декоррелирована, однако уровень декорреляции может масштабироваться в соответствии с величинами задержек соответствующих компонент сигналов. Поэтому декорреляция может быть сильнее для второй компоненты сигнала, чем для первой компоненты сигнала.
В решении первая компонента сигнала и вторая компонента сигнала могут перекрываться и/или могут быть синхронны во времени. Другими словами обработка сигналов может осуществляться блочным методом, где один блок образцов входного аудио сигнала может разделяться декомпозитором 110 на ряд блоков компонент сигнала. В решении ряд компонент сигнала может по крайней мере частично перекрываться во временной области, то есть компоненты могут представлять собой перекрытие образцов во временной области. Другими словами компоненты сигнала могут соответствовать частям входного аудио сигнала, которые перекрываются, то есть, которые представляют, по крайней мере, частично одновременные аудиосигналы. В решении первая и вторая компоненты сигнала могут представлять отфильтрованные или преобразованные версии первоначального входного сигнала. Например, они могут представлять части сигнала, извлеченные из составного пространственного сигнала, например, соответствующие близкому источнику звука или более отдаленному источнику звука. В другом решении они могут соответствовать переходному и стационарному компонентам сигнала и т.д.
В решении блок рендеринга 120 может подразделяться на первый блок рендеринга и второй блок рендеринга, где первый блок рендеринга может быть выполнен с возможностью рендеринга первой компоненты сигнала и второй блок рендеринга может быть выполнен с возможностью рендеринга второй компоненты сигнала сигнал. В решении блок рендеринга 120 может осуществляться в виде программного обеспечения, например, как программы, хранящиеся в памяти для выполнения процессором или цифровым сигнальным процессором, который, в свою очередь, выполнен с возможностью для рендеринга компонент сигнала последовательно.
Блок рендеринга 120 может быть выполнен с возможностью декорреляции первой компоненты сигнала для получения первого декоррелированного сигнала и/или декорреляции второй компоненты сигнала для получения второго декоррелированного сигнала. Другими словами блок рендеринга 120 может быть выполнен с возможностью декорреляции обоих компонент сигнала, однако, с использованием различных характеристик декорреляции или рендеринга. В решении блок рендеринга 120 может быть выполнен с возможностью использования распределения амплитуд одной из первой или второй компонент сигнала, вместо, или в дополнение к декорреляции.
Блок рендеринга 120 может быть выполнен с возможностью рендеринга первого и второго сигналов, каждый из которых имеет столько компонентов сколько каналов в пространственном многоканальном аудио сигнале и процессор 130 может быть выполнен с возможностью объединения компонентов из первого и второго представлений сигналов для получения выходного пространственного многоканального звукового сигнала. В других решениях блок рендеринга 120 может быть выполнен с возможностью рендеринга первого и второго сигналов, каждый из которых имеет меньше компонентов, чем выходной пространственный многоканальный звуковой сигнал и где процессор 130 может быть выполнен с возможностью смешивания компонентов первого и второго представлений сигналов для получения выходного пространственного многоканального звукового сигнала.
Фиг.1b иллюстрирует еще одно воплощение устройства 100, включающее аналогичные компоненты, которые были введены с помощью фиг.1а. Однако, фиг.1b иллюстрирует решение, имеющее больше деталей. На фиг.1b изображен декомпозитор 110, для получения аудио сигнала и, при необходимости, входного параметра. Как видно из фиг.1b, декомпозитор выполнен с возможностью формирования первой и второй компоненты сигнала для блока рендеринга 120, который обозначен пунктирной линией. В решении, иллюстрированном на фиг.1b предполагается, что первая компонента сигнала соответствует точечному аудио источнику, как первому семантическому свойству и что блок рендеринга 120 выполнен с возможностью выполнения пространственного распределения амплитуды как первой характеристики рендеринга первой компоненты сигнала. В решении первая и вторая компоненты сигнала являются сменными, то есть в других решениях выполнение пространственного распределения амплитуды может применяться ко второй компоненте сигнала.
В решении на фиг.1b блока рендеринга 120 показаны, два масштабируемых усилителя 121 и 122, расположенных на пути проходжения первой компоненты сигнала, усилители выполнен с возможностью усиления двух копий первой компоненты сигнала по-разному. Используемые в решении различные коэффициенты усиления, определяются из входного параметра, в других воплощениях, они могут быть определены из входного аудио сигнала, они могут быть предустановленны, или сформированы локально, возможен, также ввод данных пользователем. Выходные сигналы двух масштабируемых усилителей 121 и 122 подаются на процессор 130, информация относительно которого будет представлена ниже.
Как видно из фиг.1b, декомпозитор 110 формирует вторую компоненту сигнала для блока рендеринга 120, который осуществляет другой рендеринг на пути обработки второй компоненты сигнала. В других решениях первая компонента сигнала может быть обработана в соответствии с приведенным путем обработки второй компоненты сигнала, или вместо второй компоненты сигнала. Первая и вторая компоненты сигнала могут меняться местами.
В решении на фиг.1b, на пути обработки второй компоненты сигнала есть декоррелятор 123, следующий за блоком циклического сдвига или за блоком параметрического стерео или за модулем смешения 124, как второй характеристики рендеринга. Декоррелятор 123 может быть выполнен с возможностью декорреляции второй компоненты сигнала X[k] и для формирования декоррелированной версии Q[k] второй компоненты сигнала для параметрического стерео или модуля смешения 124. На фиг.1b, моно сигнал X[k] поступает на блок декоррелятора "D" 123 и на модуль смешения 124. Блок декоррелятора 123 может формировать декоррелированную версию входного сигнала Q[k}, имеющую аналогичные частотные характеристики и аналогичную среднюю энергию. Модуль смешения 124, может на базе пространственных параметров вычислять коэффициенты смешивающей матрицы и синтезировать выходные каналы Y1[k] и Y2[k]. Модуль смешения описывается выражением
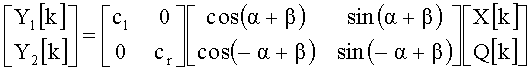
где параметры cl, cr, α и β - константы, или переменные, зависящие от времени или частоты, адаптивно вычисляемые из входного сигнала X[k], или передаваемые как внешняя информация вместе с входным сигналом X[k], например, в формате параметров ILD (ILD = Inter channel Level Difference) и параметов ICC (ICC = Inter Channel Correlation). Сигнал X[k] - принимаемый моно сигнал, Q[k] - декоррелированный сигнал, являющийся декоррелированной версией сигнала X1[k]. Y1[k] и Y2[k] - выходные сигналы.
Декоррелятор 123 может быть реализован как фильтр IIR (IIR = Infinite Impulse Response), произвольный FIR фильтр (FIR = Finite Impulse response) или специальный FIR фильтр, использующий одно подсоединение просто для задержки сигнала.
Параметры cl, cr, α и β могут быть определены различными путями. В некоторых решениях, они просто определяются входными параметрами, которые могут быть обеспечены вместе с входным аудио сигналом, например, с данными нижнего уровня как внешняя информация. В других решениях, они могут формироваться локально или выводиться из свойств входного аудио сигнала.
В решении, представленном на фиг.1b, блок рендеринга 120 выполнен с возможностью рендеринга второго сигнала в виде двух выходных сигналов Y1[k] и Y2[k], формируемых модулем смешения 124 и подаваемых на процессор 130.
В соответствии с маршрутом обработки первой компоненты сигнала две версии пространственного распределения амплитуд первой компоненты сигнала, с выходов двух масштабируемых усилителей 121 и 122 также подаются на процессор 130. В других решениях масштабируемые усилители 121 и 122 могут присутствовать в процессоре 130, где только первая компонента сигнала и параметр пространственного распределения амплитуд (панорамирования) могут формироваться блоком рендеринга 120.
Как можно видеть на фиг.1b, процессор 130 может быть выполнен с возможностью обработки или объединения первого отображаемого сигнала и второй отображаемого сигнала, в этом решении просто путем объединения выходов, чтобы обеспечить стерео сигнал, имеющий левый канал L и правый канал R, соответствующие выходному пространственному многоканальному звуковому сигналу фиг.1а.
В решении на фиг.1b, для обоих маршрутов сигналов определены левый и правый каналы стерео сигнала. На маршруте первой компоненты сигнала распределение амплитуд осуществляется двумя масштабируемыми усилителями 121 и 122, таким образом, формируются две компоненты синфазных звуковых сигналов, которые масштабируются по-разному. Это создает впечатление точечного аудио источника как семантического свойства или характеристики рендеринга.
На маршруте обработки второй компоненты сигнала, выходные сигналы Y1[k] и Y2[k], подаются на процессор 130 и обеспечивают сигналы левого и правого каналов, определяемые в модуле смешения 124. Параметры cl, cr, α и β определяют пространственную протяженность соответствующего аудио источника. Другими словами, параметры cl, cr, α и β могут быть выбраны с использованием метода или в диапазоне так, что для R и L каналов любая корреляция между максимальной корреляцией и минимальной корреляцией может быть получена на втором маршруте обработки сигнала как вторая характеристика рендеринга. Более того это можно осуществлять независимо для различных частотных полос. Другими словами, параметры cl, cr, α и β могут быть выбраны с использованием метода или в диапазоне так, что L и R каналы будут синфазные, при моделировании точечного аудио источника как семантического свойства.
Параметры cl, cr, α и β могу также быть выбраны с использованием метода или в диапазоне так, что каналы L и R на втором маршруте обработки сигнала будут декоррелированы, при моделировании пространственно распределенного источника звука как семантического свойства, т.е. моделирование источника звука на заднем плане или пространственно протяженного.
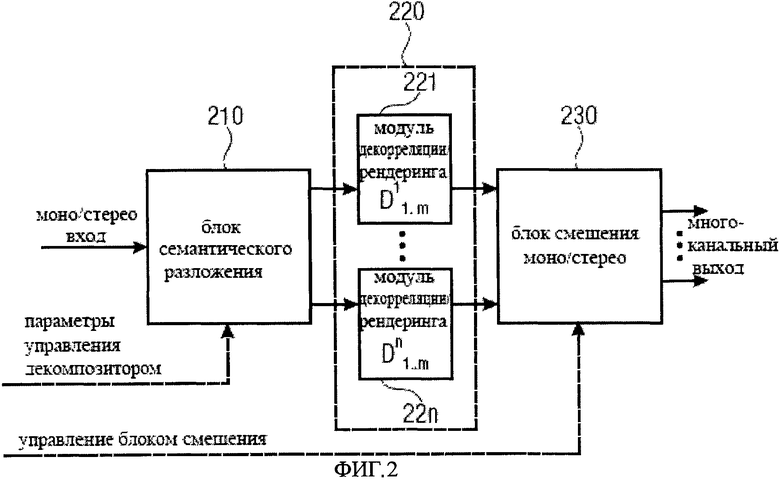
Фиг.2 иллюстрирует другое решение, которое является более общим. На Фиг.2 изображен блок семантического разложения 210, которому соответствует декомпозитор 110. Выход блока семантического разложения 210 является входом стадии рендеринга 220, которому соответствует блок рендеринга 120. На стадия рендеринга 220 состоит из ряда отдельных модулей рендеринга 221-22n, то есть блок семантического разложения 210 выполнен с возможностью разложения моно/стерео входного сигнала на n компонент сигнала, имеющих n семантических свойств. Разложение может осуществляться на основе параметров контроля разложения, которые могут быть предоставлены вместе с моно/стерео входным сигналом, быть предустановленны, создаваться локально или вводиться пользователя, и т.д.
Другими словами декомпозитор 110 может быть выполнен с возможностью семантического разложения аудио сигнала основанного на дополнительном входном параметре и/или для определения входного параметра из аудио сигнала. Выходные данные декорреляции или стадии рендеринга 220 подаются затем на блок смешения 230, который формирует многоканальный выходной сигнал на основе декорреляции или рендеринга сигналов и при необходимости на основе параметров управления смешением.
Как правило, устройство может разделить звуковой материал на n различных семантических компонент и декоррелировать каждый компонент отдельно с использованием декорреляторов, D1-Dn, изображенных на фиг.2. Другими словами в решении характеристики рендеринга соответствуют семантическим свойствам компонент сигналов. Каждый из декорреляторов или блоков рендеринга может быть выполнен с возможностью учета семантически свойств соответствующего компонента сигнала. Впоследствии обработанные компоненты могут смешаны для получения выходного многоканального сигнала. Различные компоненты могут, например, соответствовать моделируемым объектам переднего плана и фона.
Другими словами блок рендеринга 110 может быть выполнен с возможностью объединения первой компоненты сигнала и первого декоррелированного сигнала для получения стерео или многоканального смешанного сигнала, как рендеринга первого сигнала и/или для объединения второй компоненты сигнала и второго декоррелированного сигнала для получения стерео смешанного сигнала как рендеринга второго сигнала.
Кроме того блок рендеринга 120 может быть выполнен с возможностью рендеринга первой компоненты сигнала в соответствии с аудио характеристикой фона и/или для рендеринга второй компоненты сигнала в соответствии с основной характеристикой аудио или наоборот.
Поскольку, например, сигналы похожие на аплодисменты можно рассматривать как сигналы, состоящие из отдельных хлопков и шума как атмосферы, с очень плотными далекими хлопками, подходящее разложение такого сигнала может быть получено путем разделения изолированных хлопков переднего плана, как одного из компонентов, и фонового шума, как другого компонента. Другими словами, в одном решении, n=2. В таком решении, например, блок рендеринга 120 может быть выполнен с возможностью рендеринга первой компоненты сигнала, путем обеспечения пространственного распределения амплитуд (амплитудного панорамирования) первой компоненты сигнала. Другими словами, корреляция или рендеринг хлопков переднего плана может, в решении, достигаться в ячейке D1, амплитудного панорамирования на рассчитанное место каждого отдельного события.
В решении блок рендеринга 120 может быть выполнен с возможностью рендеринга первой и/или второй компоненты сигнала, например, с использованием фазовой фильтрации первой или второй компонент сигнала для получения первого или второго декоррелированного сигнала.
Другими словами в решении, фон может быть декоррелирован или подвергнут рендерингу с использованием m независимых друг от друга фазовых фильтров D2 1…m. В решении фазовыми фильтрами может быть обработан только квазистационарный фон, эффектов временного запаздывания, возникающих при использовании традиционных методов можно таким образом избежать. При применении амплитудного панорамирования к событиям, создаваемым объектом переднего плана, исходная плотность аплодисментов переднего плана может быть примерно восстановлена в отличие от существующих систем, представленных, например, в работах J.Breebaart, S.van de Par, A.Kohlrausch, E.Schuijers, "High-Quality Parametric Spatial Audio Coding at Low Bitrates" in AES 116th Convention, Berlin, Preprint 6072, May 2004 and J.Herre, K.Kjörling, J.Breebaart, et. al., "MPEG Surround - the ISO/MPEG Standard for Efficient and Compatible Multi-Channel Audio Coding" in Proceedings of the 122nd AES Convention, Vienna, Austria, May 2007.
Другими словами в решении, декомпозитор 110 может быть выполнен с возможностью разложения входного аудио сигнала семантически на базе входного параметра, где входной параметр может передаваться вместе с аудио сигналом, как, например, внешняя информация. В таком решении декомпозитор 110 может быть выполнен с возможностью определения входного параметра из аудио сигнала. В других решениях декомпозитор 110 может быть выполнен с возможностью определения входного параметра как параметра управления, независящего от входного аудио сигнала, который может быть создан локально, предустановлен, или также может быть введен пользователем.
Конструкция блока рендеринга 120 может быть выполнена с возможностью получения пространственного распределения первого отображаемого (подвергнутого рендерингу) сигнала или второго отображаемого сигнала путем применения широкополосного амплитудного панорамирования. Другими словами, в соответствии с описанием фиг.1b, данным выше, вместо создания точечного источника, панорамированное местоположение источника может меняться во времени для того, чтобы создать аудио источник с определенным пространственным распределением. В решениях блок рендеринга 120 может быть выполнен с возможностью использования локально сформированного низкочастотного шума для амплитудного панорамирования, т.е. коэффициенты усиления амплитуды панорамирования, например, масштабируемых усилителей 121 и 122 на рис.1b соответствуют значению локально созданного шума, то есть меняются во времени в определенной полосе частот.
Решения могут быть выполнены с возможностью эксплуатации в управляемом или неуправляемом режимах. Например, при управляемом режиме, например, см. блок, обведенный пунктирной линией на рисунке 2, декорреляция может быть достигнута путем применения стандартной технологии декорреляционных фильтров, управляемых на грубый временной сетке только для, например, фона или атмосферы и обеспечить корреляцию путем перераспределения каждого отдельного события в, например, области переднего плана с использованием переменного во времени пространственного позиционирования с помощью широкополосного амплитудного панорамирования на гораздо более точной временной сетке. Другими словами в решении, блок рендеринга 120 может быть выполнен с возможностью работы декорреляторов различных компонент сигналов на разных временных сетках, т.е базирующихся на разных временных масштабах, которые могут выражаться в виде различных частот дискретизации или различных задержек для соответствующих декорреляторов. В одном решении разделения фона и переднего плана, для области на переднем плане может использоваться амплитудное панорамирование, где амплитуда меняется на гораздо более точной временной сетке, чем в операции декорреляции, связанной с обработкой фона.
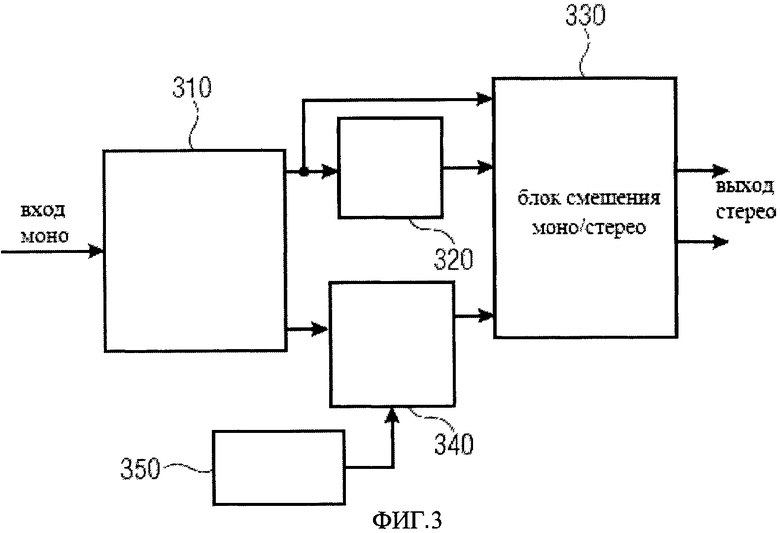
Кроме того отметим, что для декорреляции, например, сигналов похожих на аплодисменты, то есть квазистационарных случайных сигналов, точное пространственное положение каждого одиночного хлопка на переднем плане не может иметь такого значения, как восстановление общего распределения множества хлопков. Решение может иметь преимущество благодаря этому факту и может работать в неуправляемом режиме. В таком режиме, упомянутый выше фактор амплитудного панорамирования может контролироваться низкочастотным шумом. Фиг.3 иллюстрирует систему моно-стерео, осуществляющую этот сценарий. На фиг.3 изображен семантический блок разложения 310 соответствующего декомпозитора 110 для разложения входного моно сигнала на компоненту переднего плана и компоненту заднего плана.
Как видно на фиг.3, компонента сигнала заднего плана обрабатывается фазовым фильтром D1 320. Декоррелированный сигнал, затем поступает вместе с необработанной компонентой заднего плана (фона) в блок смешения 330, соответствующий процессору 130. Компонента сигнала переднего плана поступает на стадию амплитудного панорамирования D2 340, которой соответствует блок рендеринга 120. Локально созданный низкочастотный шум 350 также поступает на стадию амплитудного панорамирования 340, которая формирует входной сигнал переднего плана блока смешения 330. Выходной сигнал стадии амплитудного панорамирования D2 340 может определяться, коэффициентом масштабирования k для выбора амплитуды из двух наборов стерео аудио каналов. Выбор коэффициента масштабирования k может быть основан на низкочастотном шуме.
Как видно из фиг.3, есть только одна стрелка между амплитудным панорамирование 340 и блоком смешения 330. Эта стрелка может также представлять амплитудно панорамированные сигналы, то есть в случае стерео блока смешения - левый и правый каналы. Как видно из фиг.3, блок смешения 330 соответствующий процессору 130 может быть выполнен с возможностью обработки или объединения компонент сигналов фона и переднего плана, чтобы получит выходной стерео сигнал.
Другие решения могут использовать естественную обработку для получения компонент фона и переднего плана, или входных параметров для разложения. Декомпозитор 110 может быть выполнен с возможностью определения первой компоненты сигнала и/или второй компоненты сигнала на основе метода анализа кратковременных особенностей. Другими словами декомпозитор 110 может быть выполнен с возможностью определения первой или второй компоненты сигнала, основываясь методе разделения и другой компоненте сигнала, основанной на разнице между определенной компонентой сигнала и полным аудио сигналом. В других решениях первая или вторая компоненты сигнала могут быть определены на основе метода анализа кратковременных особенностей и вычисление другой компоненты сигнала может быть основано на разнице между первой или второй компонентами сигнала и полного аудио сигнала.
Декомпозитор 110, и/или блок рендеринга 120, и/или процессор 130 может включать DirAC моно стадию, и/или стадию DirAC synthesis, и/или DirAC стадию слияния. В решении декомпозитор 110 может быть выполнен с возможностью разложения входного аудио сигнала, блок рендеринга 120 может быть выполнен с возможностью рендеринга первой и/или второй компоненты сигнала, и/или процессор 130 может быть выполнен с возможностью обработки первой и/или второй компоненты с блока рендеринга в различных частотных диапазонах.
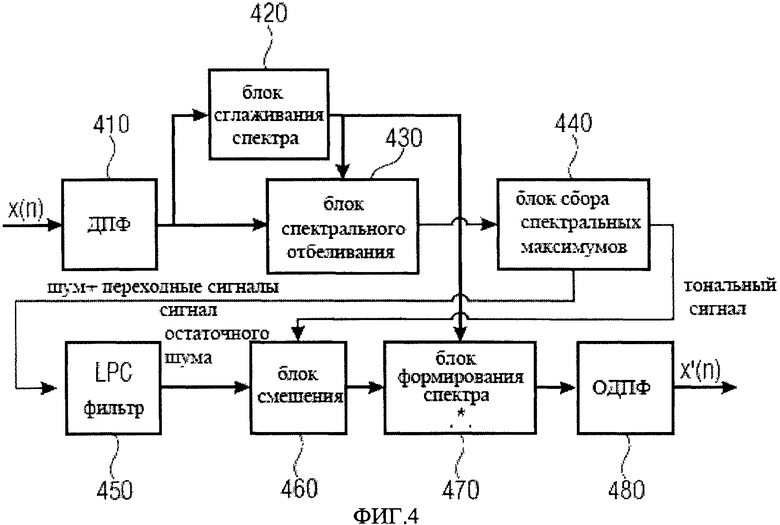
Решение может использовать следующее приближение для сигналов похожих на аплодисменты. В то время как компонента переднего плана может быть получена методами обнаружения или разделения кратковременных особенностей, см. Pulkki, Ville; "Spatial Sound Reproduction with Directional Audio Coding" in J. Audio Eng. Soc., Vol.55, No. 6, 2007, компонента фона может быть получена с использованием разностного сигнала. На фиг.4 изображен пример, где описан подходящий метод для получения компоненты фона х'(n), например, х(n) сигналов похожих на аплодисменты для реализации семантического разложения 310, см. фиг.3, то есть воплощение декомпозитора 120. На Фиг.4 изображен дискретизированный во времени входной сигнал х(n), который является входным для блока ДПФ 410 (DFT = дискретное преобразование Фурье). Выходной сигнал блока ДПФ 410 подается на блок сглаживания спектра 420 и блок спектрального отбеливания 430 для спектрального отбеливания на основе результатов ДПФ 410 и выходных данных стадии сглаживания спектра 430.
Выходные данные блока спектрального отбеливания 430 затем подаются на блок сбора спектральных максимумов 440, который разделяет спектр и формирует два выходных сигнала, т.е. шум, переходные сигналы и тональный сигнал. Шум и переходные сигналы подаются на LPC фильтр 450 (LPC = Linear Prediction Coding), выходной сигнал остаточного шума которого подается на блок смешения 460 вместе с выходным тональным сигналом блока сбора спектральных максимумов 440. Выходные данные блока смешения 460 затем подаются на блок формирования спектра 470, который формирует спектр на основе сглаженного спектра, формируемого в блоке сглаживания спектра 420. Выходные данные блока формирования спектра 470 затем предоставляется на фильтр синтеза 480, то есть на блок обратного дискретного преобразования Фурье для получения сигнала х'(n), представляющего компонент фона. Основной компонент, затем может быть получен как разница входного сигнала и выходного сигнала, то есть как х(n)-х'(n).
Настоящее изобретение может использоваться в приложениях виртуальной реальности, как, например, 3D играх. В таких приложениях синтез источников звука с большой пространственной протяженностью на основе известных решений может быть составным и сложным. Источниками звука могут быть, например, море, стая птиц, скачущая лошадь, подразделение солдат на марше или приветствия аудитории. Как правило, такие звуковые события пространственно формируются, как большая группа точечных источников, что приводит к вычислительно сложным реализациям, см. Wagner, Andreas; Walther, Andreas; Melchoir, Frank; Strauβ, Michael; "Generation of Highly Immersive Atmospheres for Wave Field Synthesis Reproduction" at 116th International EAS Convention, Berlin, 2004.
Предложенное решение может дать метод, который правдоподобно осуществляет синтез протяженных источников звука, но, в то же время, имеет меньшую структурную и вычислительную сложность. Решение может основываться на DirAC (DirAC = Directional Audio Coding),CM. Pulkki, Ville; "Spatial Sound Reproduction with Directional Audio Coding” / J. Audio Eng. Soc., Vol.55, No. 6, 2007. Другими словами решение, декомпозитора 110 и/или средств рендеринга 120 и/или процессора 130 могут быть выполнены с возможностью обработки сигналов DirAC. Другими словами декомпозитор 110 может включать стадию DirAC моно, блок рендеринга 120 может включать стадии DirAC синтеза и/или процессор может включать стадию DirAC слияния.
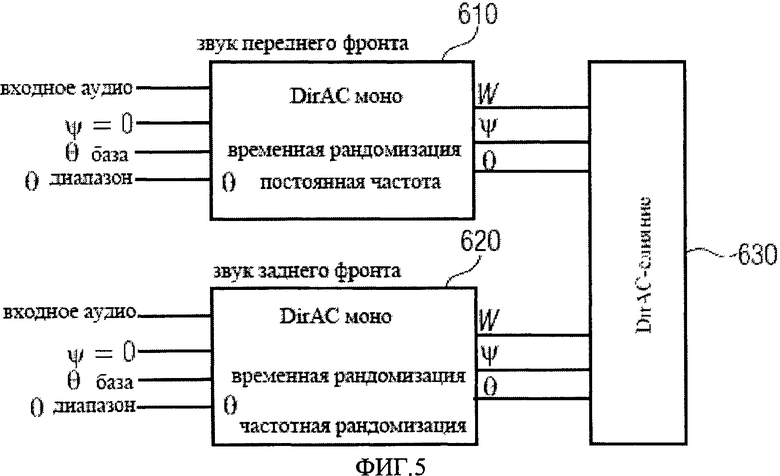
Решение может основываться на DirAC обработке, например, используя только две структуры синтеза, например, один для источников звука переднего плана и один для источников звука фона. Звук переднего плана может быть использован в одном DirAC потоке с данными контроля направления, что приводит к восприятию расположенных вблизи точечных источников. Фоновый звук, также может быть воспроизведен с помощью одного потока с данными дифференциального контроля направления, что приводит к восприятию пространственно распределенных звуковых объектов. Два потока DirAC могут быть объединены и декодированы, например, для произвольной установки громкоговорителей или для наушников.
Фиг.5 иллюстрирует синтез пространственно протяженных источников звука. На фиг.5 показан верхний моно блок 610, который создает DirAC моно поток, ведущих к восприятию близлежащих точечных источников звука, таких как ближайшие хлопки аплодисментов аудитории. Нижний моно блок 620 используется для создания DirAC моно потока, ведущего к восприятию пространственно распределенного звука, который подходит, например, для создания фонового звука аплодисментов от аудитории. Выходные сигналы двух DirAC моно блоков 610 и 620 затем объединяются на этапе DirAC слияния 630. фиг.5 показывает, что в этом решении используются только два блока DirAC синтеза 610 и 620. Один из них используется для создания звуковых событий, которые находятся на переднем плане, такие, как звуки ближайших или расположенных поблизости птиц или ближайших или расположенных поблизости лиц аплодирующей аудитории и другой создает фоновый звук, непрерывный звук стаи птиц, и т.д.
Звук переднего плана преобразуется в DirAC моно поток DirAC моно блоком 610 способом, при котором азимутальные данные остаются неизменными с частотой, однако, изменяются случайно или под контролем внешнего процесса во времени. Параметр диффузии ψ имеет значение 0, то есть представляет точечный источник. Предполагается, что аудио входные данные блока 610 являются неперекрывающимся во времени звуками, такими как звуки криков отдельных птиц или хлопки аплодисментов, что создает восприятие близлежащих звуков таких источников, как птицы или аплодирующих персон. Пространственно распределенные звуковые события на переднем плане контролируется подстройкой θ и θrange_foreground, что означает, что отдельные звуковые события будет восприниматься в направлениях θ±θrange_foreground, в то время как, одно событие может быть воспринято как точечное. Другими словами, точечные источники звука создаются в возможных позициях в диапазоне θ±θrange_foreground.
Блок фона 620 принимает входной поток аудио сигналов, который содержит все остальные звуковые события, которые не представлены в аудио потоке переднего плана, которые включают множество дублированных во времени звуковых событий, например, сотни птиц или большое количество далеких аплодисментов. Прилагаемые значения азимута устанавливаются случайно, как во времени, так и по частоте, в пределах, учитывающих ограничение значений азимута θ±θrange_background. Пространственно протяженные фоновые звуки, таким образом, могут быть синтезированы с низкой сложностью вычислений. Параметром диффузии ψ также можно управлять. Если он был добавлен, DirAC декодер будет применять звук на всех направлениях, которые могут быть использованы, когда источник звука полностью окружает слушателя. Если этого окружения нет, диффузия в решении может оставаться низкой или близкой к 0, или нулевой.
Решение настоящего изобретения может предоставить преимущество, заключающееся в том, что отличное качество восприятия обработанных звуков может быть достигнуто при умеренных вычислительных затратах. Решение допускает модульную реализацию пространственного представления звука, как, например, показано на фиг.5.
В зависимости от определенных требований осуществления изобретения предложенные методы могут осуществляться в виде аппаратуры или программного обеспечения. Осуществление изобретения может быть выполнено с использованием цифрового носителя и, в частности, флэш-памяти, диска, DVD или CD, с которых могут быть считаны в электронной форме записанные управляющие сигналы, которые с программируемой компьютерной системой обеспечивают выполнение методов предлагаемого изобретения. Таким образом, как правило, настоящее изобретение является компьютерной программой с программным кодом, хранящемся на машиночитаемых носителях. Программный код осуществляет предложенные в изобретении методы, когда программа выполняется на компьютере. Другими словами, предложенные в изобретении методы являются, таким образом, компьютерной программой, имеющей код для выполнения, по крайней мере, одного из предложенных методов, когда программа выполняется на компьютере.
Изобретение относится к области аудио обработки, особенно обработки пространственных свойств аудио. Сущность изобретения состоит в том, что устройство (100) для формирования выходного пространственного многоканального аудио сигнала на основе входного аудио сигнала и входного параметра. Устройство (100) включает в себя декомпозитор (110) для разложения входного аудио сигнала на основе входного параметра для получения первой компоненты сигнала и второй компоненты сигнала, отличающихся друг от друга. Кроме того, устройство (100) состоит из блока рендеринга (110) для рендеринга первой компоненты сигнала для получения первого подвергнутого рендерингу сигнала с первым семантическим свойством и для рендеринга второй компоненты сигнала для получения второго подвергнутому рендерингу сигнала с вторым семантическим свойством, отличающимся от первого семантического свойства. Устройство (100) включает в себя процессор (130) для обработки первого и второго подвергнутых рендерингу сигналов для получения выходного пространственного многоканального звукового сигнала. Технический результат - обеспечение высокого качества восприятия при обработке сигналов, создающих фон. 3. н. и 9 з.п. ф-лы, 8 ил.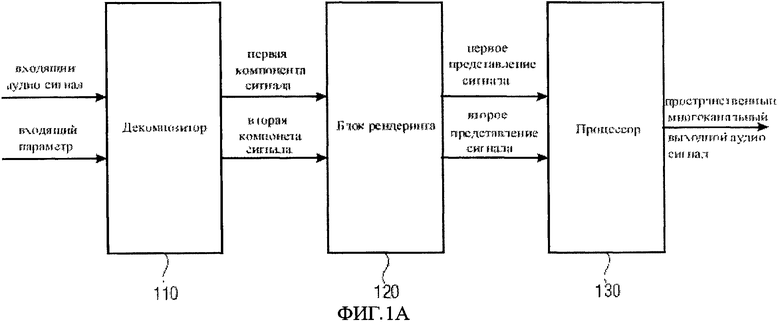
1. Устройство (100) для формирования выходного пространственного многоканального аудио сигнала на основе входного аудио сигнала, содержащее семантический декомпозитор (110), выполненный с возможностью разложения входного аудио сигнала для получения первой компоненты сигнала, имеющей первое семантическое свойство, первая компонента сигнала является сигналом области переднего плана, и второй компоненты сигнала, имеющей второе семантическое свойство, отличающееся от первого семантического свойства, вторая компонента сигнала является сигналом фона области заднего плана; блок рендеринга (120), выполненный с возможностью рендеринга сигнала области переднего плана, с использованием амплитудного панорамирования для получения первого подвергнутого рендерингу сигнала с первым семантическим свойством, блок рендеринга (120) включает уровень амплитудного панорамирования (221, 340) для обработки сигнала области переднего плана, где локально сформированный низкочастотный шум (350) поступает на уровень амплитудного панорамирования (340) для изменения во времени пространственной локализации аудио источника области переднего плана; и для рендеринга фонового сигнала области заднего плана путем декорреляции второй компоненты сигнала для получения второго подвергнутого рендерингу сигнала со вторым семантическим свойством; и процессор (130, 330), выполненный с возможностью обработки первого подвергнутого рендерингу сигнала и второго подвергнутого рендерингу сигнала, для получения пространственного выходного многоканального звукового сигнала.
2. Устройство (100) по п.1, в котором первая характеристика рендеринга основывается на первом семантическом свойстве и вторая характеристика рендеринга основывается на втором семантическом свойстве.
3. Устройство (100) по п.1, где блок рендеринга (120) выполнен с возможностью рендеринга первого и второго сигналов, каждый из которых имеет столько компонентов, сколько каналов в пространственном многоканальном звуковом сигнале, и где процессор (130) выполнен с возможностью объединения первого и второго, подвергнутых рендерингу, сигналов, чтобы получить выходной многоканальный аудио сигнал.
4. Устройство (100) по п.1, где блок рендеринга (120) выполнен с возможностью рендеринга первого и второго сигналов, каждый из которых имеет меньше компонентов, чем пространственный многоканальный аудио сигнал, и где процессор (130) выполнен с возможностью смешивания компонентов из первого и второго, подвергнутых рендерингу, сигналов для получения выходного пространственного многоканального аудио сигнала.
5. Устройство (100) по п.1, в котором декомпозитор (110) выполнен с возможностью определения из аудио сигнала входного параметра как параметра управления.
6. Устройство (100) по п.1, где блок рендеринга (120) выполнен с возможностью рендеринга первой и второй компоненты сигнала на основе различных временных сеток.
7. Устройство (100) по п.1, где декомпозитор (110) выполнен с возможностью определения первой компоненты сигнала и/или второй компоненты сигнала, основываясь на методе анализа кратковременных особенностей.
8. Устройство (100) по п.1, где декомпозитор (110) выполнен с возможностью определения первой или второй компоненты сигнала методом анализа кратковременных особенностей и другой компоненты методом, основанным на разнице между одной компонентой и аудио сигналом.
9. Устройство (100) по п.1, в котором декомпозитор (110) выполнен с возможностью разложения аудио сигнала, блок рендеринга (120) выполнен с возможностью рендеринга первой и/или второй компоненты сигнала, и/или процессор (130) выполнен с возможностью обработки первого и/или второго, подвергнутых рендерингу, сигналов в различных частотных диапазонах.
10. Устройство по п.1, в котором процессор выполнен с возможностью обработки первого подвергнутого рендерингу сигнала, второго подвергнутого рендерингу сигнала, второго подвергнутого рендерингу сигнала и сигнала области заднего плана, чтобы получить выходной пространственно распределенный многоканальный аудио сигнал.
11. Способ для формирования выходного пространственного многоканального аудио сигнала, основанный на входном аудио сигнале и входном параметре, включающий следующие шаги: семантическая декомпозиция входного аудио сигнала для получения первой компоненты сигнала с первым семантическим свойством, первая компонента сигнала является сигналом области переднего плана, и второй компоненты сигнала с вторым семантическим свойством, отличающимся от первого семантического свойства, вторая компонента сигнала является сигналом фона области заднего плана; рендеринг сигнала области переднего плана с использованием амплитудного панорамирования для получения первого подвергнутого рендерингу сигнала с первым семантическим свойством, путем обработки сигнала области переднего плана с использованием уровня амплитудного панорамирования (221, 340), где локально сформированный низкочастотный шум (350) поступает на уровень амплитудного панорамирования (340) для изменения во времени пространственной локализации аудио источника области переднего плана; рендеринг сигнала фона области заднего плана путем декорреляции декоррелируемой второй компоненты сигнала для получения второго подвергнутого рендерингу сигнала со вторым семантическим свойством; и обработка первого подвергнутого рендерингу сигнала и второго подвергнутого рендерингу сигнала для получения пространственного выходного многоканального звукового сигнала.
12. Машиночитаемый носитель информации, имеющий программный код для выполнения способа по п.11, когда программный код выполняется на компьютере или процессоре.
| УСТРОЙСТВО И СПОСОБ СОЗДАНИЯ МНОГОКАНАЛЬНОГО ВЫХОДНОГО СИГНАЛА ИЛИ ФОРМИРОВАНИЯ НИЗВЕДЕННОГО СИГНАЛА | 2005 |
|
RU2329548C2 |
| Пресс для выдавливания из деревянных дисков заготовок для ниточных катушек | 1923 |
|
SU2007A1 |
| Способ обработки целлюлозных материалов, с целью тонкого измельчения или переведения в коллоидальный раствор | 1923 |
|
SU2005A1 |
| GB 25353193 B, 25.08.2004 | |||
| RU 2006114742 A, 20.11.2007. | |||

