Настоящая заявка испрашивает приоритет китайской патентной заявки № 201610447125.8, поданной 20 июня 2016 и озаглавленной ʺSTREAMING DATA DISTRIBUTED PROCESSING METHOD AND DEVICEʺ, все содержание которой полностью включено в настоящий документ посредством ссылки.
ОБЛАСТЬ ТЕХНИКИ
Настоящее изобретение относится к области обработки данных и, в частности, к способу и устройству распределенной обработки потоковых данных.
ПРЕДШЕСТВУЮЩИЙ УРОВЕНЬ ТЕХНИКИ
По мере того как различные сетевые приложения становятся все более глубоко укоренившимися в повседневной жизни людей, многие системы приложений будут генерировать сервисные данные в терабитах ежедневно. Анализ в реальном времени этого громадного количества данных может обеспечивать информацию, которая имеет большое значение для систем приложений. Например, анализ в реальном времени потоков видео данных, собранных системами мониторинга трафика, может способствовать направлению потока трафика, и анализ в реальном времени поведения доступа пользователей к сайтам социальных сетей может своевременно обнаруживать злободневные темы обсуждения и рассылать к многим пользователям.
Огромные количества сервисных данных реального времени обычно сохраняются в различных местоположениях, на различных программных и аппаратных платформах и/или в различных типах баз данных. Система сбора данных реального времени непрерывно собирает изменяющиеся в реальном времени сервисные данные в базе данных в форме потока, чтобы выполнять обработку данных реального времени. Система сбора данных реального времени может быть реализована с использованием одного потока (треда) или может быть реализована с использованием распределенной формы, с множеством потоков, одновременно выполняя сбор данных реального времени.
Поскольку сервисные данные системы приложения могут обновляться в любое время, особенно так, что один фрагмент сервисных данных может обновляться множество раз за очень короткий период времени, система сбора данных реального времени, реализованная с использованием одного потока, может гарантировать, что значение в реальном времени (оперативное значение) сервисных данных, которое было обновлено первым, поступит перед обновленным последним оперативным значением сервисных данных в потоковых данных. Однако, в большинстве ситуаций, низкая производительность одиночных потоков не может удовлетворить потребностям обработки данных реального времени для больших объемов данных. В распределенной системе сбора данных реального времени, становится возможным, что последовательность оперативных значений сервисных данных в сгенерированных ею распределенных потоковых данных отличается от последовательности, в которой происходят обновления.
В современных технологиях, обработка данных в отношении оперативных значений сервисных данных выполняется в соответствии с последовательностью сервисных данных в потоковых данных. Таким образом, когда последовательность оперативных значений сервисных данных в распределенных потоковых данных отличается от последовательности, в которой происходят обновления, ранее обновленные оперативные значения будут заменять обновленные позже оперативного значения, приводя к ошибкам в результатах обработки данных.
КРАТКОЕ ОПИСАНИЕ СУЩНОСТИ ИЗОБРЕТЕНИЯ
Ввиду вышеизложенного, настоящая заявка обеспечивает способ распределенной обработки потоковых данных, содержащий:
получение информации идентификатора сервисных данных для записи данных потоковых данных, подлежащего обработке значения в реальном времени (оперативного значения) этой записи данных и характеристики временной последовательности этого подлежащего обработке оперативного значения записи данных, причем информация идентификатора однозначно представляет один фрагмент или один набор сервисных данных;
получение характеристики временной последовательности обработанного оперативного значения сервисных данных на основе соотношения соответствия между сохраненной информацией идентификатора сервисных данных и характеристикой временной последовательности обработанного оперативного значения;
сравнение характеристики временной последовательности подлежащего обработке оперативного значения сервисных данных и характеристики временной последовательности обработанного оперативного значения сервисных данных, и если временная последовательность подлежащего обработке оперативного значения позже, чем временная последовательность обработанного оперативного значения, использование подлежащего обработке оперативного значения в выполнении сервисных вычислений и обновление сохраненной характеристики временной последовательности обработанного оперативного значения характеристикой временной последовательности подлежащего обработке оперативного значения.
Настоящая заявка также обеспечивает устройство распределенной обработки потоковых данных, содержащее:
блок получения подлежащей обработке информации, сконфигурированный получать информацию идентификатора сервисных данных для записи данных потоковых данных, подлежащее обработке оперативное значение этой записи данных и характеристику временной последовательности этого подлежащего обработке оперативного значения записи данных, причем информация идентификатора однозначно представляет один фрагмент или один набор сервисных данных;
блок получения обработанной информации, сконфигурированный получать характеристику временной последовательности обработанного оперативного значения сервисных данных на основе соотношения соответствия между сохраненной информацией идентификатора сервисных данных и характеристикой временной последовательности обработанного оперативного значения;
блок обработки данных, сконфигурированный сравнивать характеристику временной последовательности подлежащего обработке оперативного значения сервисных данных и характеристику временной последовательности обработанного оперативного значения сервисных данных и, когда временная последовательность подлежащего обработке оперативного значения позже, чем временная последовательность обработанного оперативного значения, использовать подлежащее обработке оперативное значение в выполнении сервисных вычислений и обновлять сохраненную характеристику временной последовательности обработанного оперативного значения характеристикой временной последовательности подлежащего обработке оперативного значения.
Как показано описанными выше техническими решениями, в вариантах осуществления настоящей заявки характеристика временной последовательности обработанного оперативного значения записи данных сохраняется во время обработки данных и сравнивается с характеристикой временной последовательности подлежащего обработке оперативного значения из той же записи данных в потоковых данных, и только подлежащее обработке оперативное значение с временной последовательностью позже, чем обработанное оперативное значение, подвергается сервисным вычислениям. Таким образом, реализуется обработка данных в соответствии с последовательностью обновления данных, предотвращая ошибки в результатах обработки, вызванные обработкой оперативного значения, которое было обновлено позже, и повышая точность обработки данных.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
Фиг. 1 является схематичным представлением сетевой структуры для сценария применения варианта осуществления настоящей заявки;
Фиг. 2 является блок-схемой последовательности действий способа распределенной обработки потоковых данных варианта осуществления настоящей заявки;
Фиг. 3 является структурной схемой аппаратных средств устройства, содержащего вариант осуществления настоящей заявки;
Фиг. 4 является структурной схемой логики устройства распределенной обработки потоковых данных варианта осуществления настоящей заявки.
ПОДРОБНОЕ ОПИСАНИЕ
Варианты осуществления настоящей заявки представляют новый способ распределенной обработки потоковых данных. Потоковые данные включают в себя характеристики временной последовательности подлежащих обработке значений в реальном времени (оперативных значений) записей данных, и характеристики временной последовательности обработанных оперативных значений для записей данных, которые уже подверглись обработке данных, сохраняются. Путем сравнения характеристик временной последовательности подлежащих обработке и обработанных оперативных значений, находится относительная временная последовательность подлежащих обработке и обработанных оперативных значений, и когда временная последовательность подлежащего обработке оперативного значения позже, временная последовательность подлежащего обработке оперативного значения подвергается обработке данных. Таким путем становится возможным предотвратить ошибки в результатах обработки данных, вызванные более поздней обработкой оперативных значений с более ранними временными последовательностями, таким образом преодолевая проблему, имеющуюся в существующей технологии.
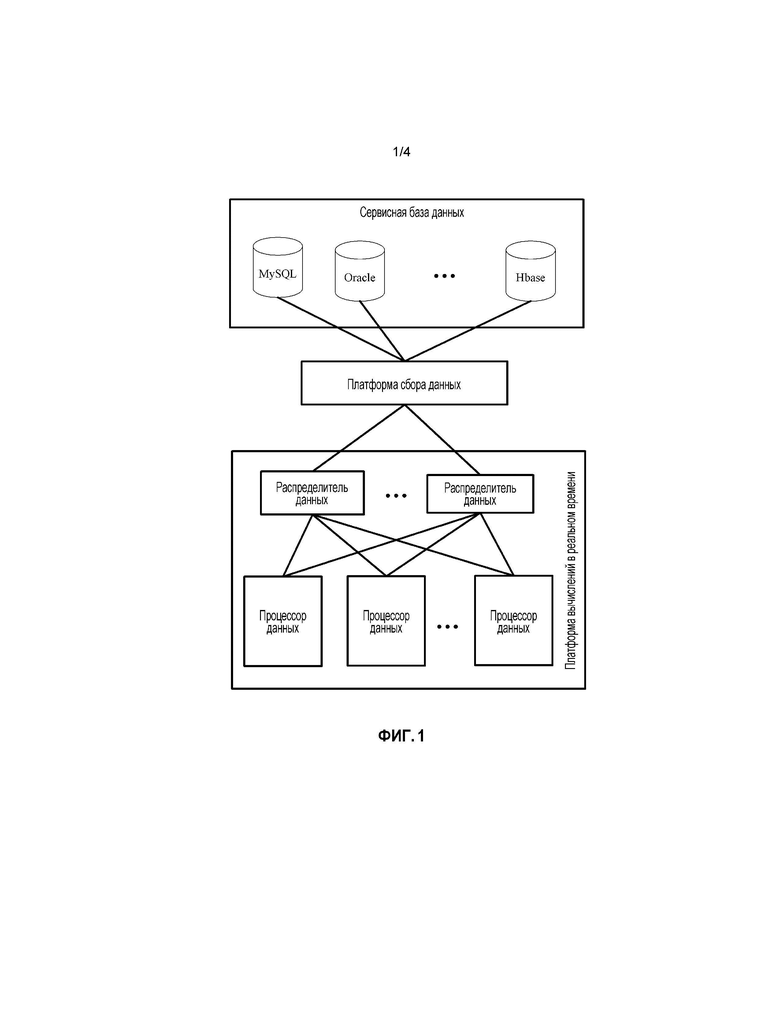
Сетевая структура сценария применения варианта осуществления настоящей заявки показана на фиг. 1: сервисные данные, генерируемые и обновляемые различными сервисными системами во время исполняющегося операционного процесса, могут сохраняться в ряде различных типов (например, MySQL, Oracle, HBase и т.д.) сервисных баз данных. Когда сервисные данные, удовлетворяющие предопределенным условиям, добавляются или обновляются в сервисной базе данных, платформа сбора данных генерирует запись данных на основе заново добавленных или обновленных сервисных данных, комбинирует постоянно генерируемые записи данных как потоковые данные и предоставляет потоковые данные в вычислительную платформу в реальном времени. Платформа сбора данных может быть реализована с использованием ориентированного на сообщения межплатформенного (промежуточного) программного обеспечения (например, kafka, TimeTunel и т.д.), записывающего сгенерированную запись данных как сообщение в очередь сообщений, чтобы предоставлять вычислительной платформе в реальном времени для считывания. Вычислительная платформа в реальном времени может использовать распределенные вычисления (например, Jstorm, storm и т.д.) и может также использовать централизованные вычисления. Фиг. 1 может соответствовать структуре, когда используются распределенные вычисления. Один или несколько распределителей данных (например, ʺворонокʺ (spouts) storm-платформы) распределяют записи данных для потоковых данных на по меньшей мере два процессора данных (например, ʺситаʺ (bolts) storm-платформы), и процессор данных обеспечивает то, что изменения в реальном времени в сервисных данных отражаются в результатах обработки.
В связи с этим, на фиг. 1, если платформа сбора данных использует многопотоковое параллельное получение и/или вычислительная платформа в реальном времени использует распределенные вычисления, когда фрагмент сервисных данных непрерывно обновляется, запись данных, несущая оперативное значение сервисных данных, которые были обновлены ранее, может поступать на процессор данных вычислительной платформы в реальном времени позже, чем запись данных, несущая оперативное значение сервисных данных, которые были обновлены позже. Варианты осуществления настоящей заявки могут работать на вычислительной платформе в реальном времени (работать на каждом процессоре данных, когда используются распределенные вычисления) и могут предотвращать ошибки, состоящие в том, что результаты обработки позже обновленных сервисных данных покрываются результатами обработки ранее обновленных сервисных данных в вышеупомянутой ситуации.
Варианты осуществления настоящей заявки могут применяться к любому физическому или логическому устройству с возможностями вычисления и хранения, например, мобильным телефонам, планшетным компьютерам, PC (персональным компьютерам), ноутбукам, серверам и виртуальным машинам. Устройство может альтернативно быть двумя или более физическими или логическими устройствами с совместно используемыми различными рабочими циклами, координирующимися друг с другом для реализации различных функций в вариантах осуществления настоящей заявки.
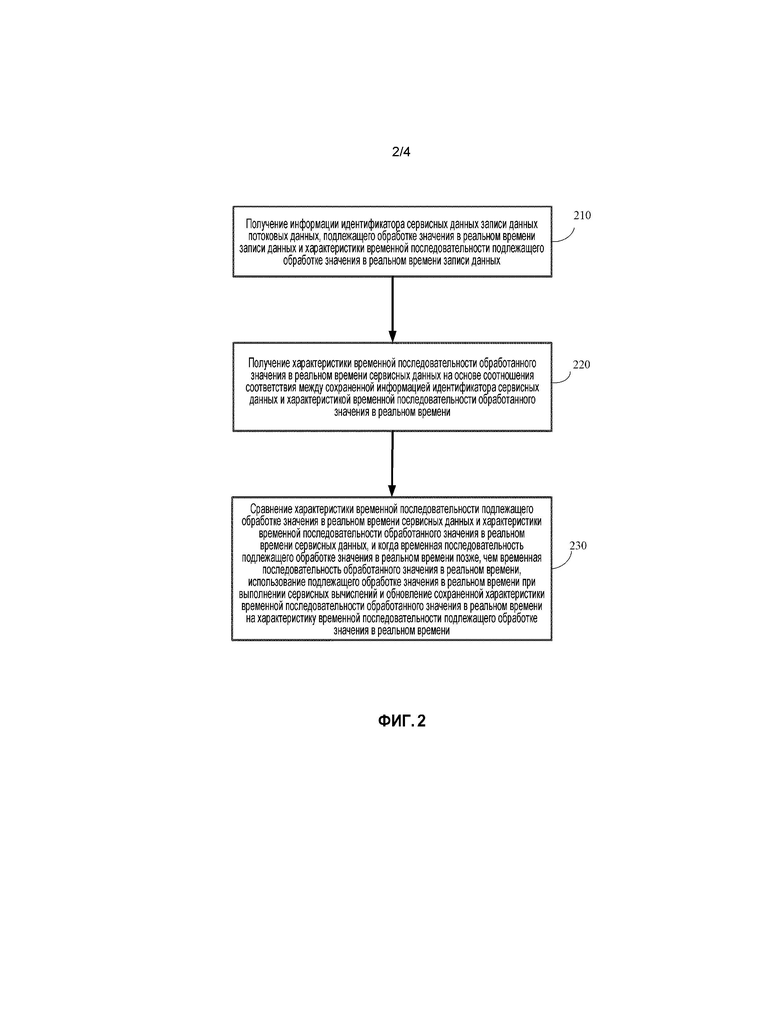
В некоторых вариантах осуществления настоящей заявки, поток способа распределенной обработки потоковых данных является таким, как показано на фиг. 2.
Этап 210, получение информации идентификатора сервисных данных для записи данных потоковых данных, подлежащего обработке оперативного значения этой записи данных и характеристики временной последовательности этого подлежащего обработке оперативного значения записи данных.
В некоторых вариантах осуществления настоящей заявки, запись данных является наименьшей составной единицей потоковых данных. Каждая запись данных генерируется на основе изменения (добавления или обновления) фрагмента сервисных данных (например, баланса счета) или одновременного изменения набора (двух или несколько фрагментов) сервисных данных (например, числа переводов, общей переведенной суммы) в сервисной базе данных. Запись данных содержит информацию идентификатора сервисных данных или набор сервисных данных и оперативное значение сервисных данных или набор сервисных данных; обычно, запись данных также содержит время, в которое оперативное значение было сгенерировано в сервисной базе данных.
Здесь, информация идентификатора однозначно представляет сервисные данные или набор сервисных данных, например, в объеме, в котором выполняются варианты осуществления настоящей заявки, существует однозначное соответствие между информацией идентификатора и сервисными данными или набором сервисных данных. Например, вариант осуществления настоящей заявки выполняется на каждом процессоре данных вычислительной платформы в реальном времени, так что для каждой записи данных, обработанной процессором данных, существует однозначное соответствие между информацией идентификатора и фрагментом сервисных данных или набором сервисных данных. В действительном сценарии применения, идентификаторы поля и таблицы в сервисной базе данных и/или идентификаторы сервисных данных в сервисной системе могут использоваться как ссылки для определения информации идентификатора сервисных данных. Например, комбинация основного ключа, имени таблицы и имени базы данных таблицы, в которой расположены сервисные данные, может использоваться как информация идентификатора сервисных данных. Также, главный идентификатор основного ключа сервиса для сервиса, которому принадлежат сервисные данные, вторичный идентификатор основного ключа сервиса и подпись (сигнатура) приложения могут использоваться как информация идентификатора сервисных данных.
Оперативное значение сервисных данных является значением сервисных данных или набором сервисных данных после самого недавнего изменения. Время генерации оперативного значения является временем, в которое сервисные данные изменяются в сервисной базе данных.
Характеристика временной последовательности оперативного значения содержит информацию, ассоциированную с временем, в которое сервисные данные или набор сервисных данных изменились. Когда сервисные данные или набор сервисных данных испытывают изменения в количестве N, будут сгенерированы N записей данных. В этих N записях данных, информация идентификатора сервисных данных является той же самой, оперативного значения сервисных данных являются разными, и в подавляющем большинстве ситуаций характеристики временной последовательности оперативного значения также являются различными. Путем сравнения характеристик временной последовательности оперативных значений, обычно можно узнать, какое оперативное значение или значения этих сервисных данные или набора сервисных данных произошло раньше, и какое произошло позже.
Переменные, которые используются в качестве характеристики временной последовательности оперативного значения, могут быть выбраны на основе факторов в действительном сценарии применения, таких как скорость, с которой изменяются сервисные данные, и требуемая точность для обработки потоковых данных. Например, время генерации оперативного значения в записи данных может быть использовано в качестве характеристики временной последовательности оперативного значения. Для сервисных данных, имеющих идентичную информацию идентификатора, временная последовательность оперативного значения может быть определена на основе времени генерации оперативного значения. Однако, поскольку сохранение времен генерации оперативного значения обычно ограничено точностью (например, до миллисекунд), два изменения одного и того же фрагмента или одного и того же набора сервисных данных, происходящих очень близко одно к другому (например, в пределах десятков микросекунд), могут иметь одно и то же время генерации оперативного значения.
В дополнение к повышению точности времен генерации оперативного значения, в сценариях применения с ориентированным на сообщения межплатформенным программным обеспечением, действующим как платформа сбора данных, также можно использовать время генерации оперативного значения и идентификатор сообщения для сообщения, содержащего оперативное значение, в качестве характеристики временной последовательности оперативного значения. В этом типе сценария применения, ориентированное на сообщения межплатформенное программное обеспечение компонует одну или несколько записей данных в сообщении, идентификатор сообщения назначается для каждого сообщения в соответствии с временной последовательностью генерации сообщения, и сообщения, несущие идентификаторы сообщений, составляют поток сообщений (т.е. данные потоковой передачи). Поскольку записи данных, сгенерированные для двух следующих друг за другом изменений одного и того же фрагмента или одного и того же набора сервисных данных, обычно не появятся в одном и том же сообщении, идентификатор сообщения, отражающий временную последовательность генерации сообщений, также отражает временную информацию оперативного значения сервисных данных. Для двух записей данных с той же самой информацией идентификатора сервисных данных, если времена генерации оперативного значения сервисных данных различны, временная последовательность оперативных значений определяется на основе времен генерации оперативных значений. Если времена генерации оперативных значений сервисных данных те же самые, временная последовательность оперативных значений может быть определена на основе идентификаторов сообщения для сообщений, содержащих записи данных.
В связи с этим, запись данных извлекается из потоковых данных, и из записи данных можно получить информацию идентификатора сервисных данных и подлежащее обработке оперативное значение сервисных данных (поскольку оперативное значение сервисных данных в записи данных не подверглось обработке данных, то оперативное значение сервисных данных в записи данных может упоминаться как подлежащее обработке оперативное значение), и характеристика временной последовательности подлежащего обработке оперативного значения может быть получена из записи данных или из записи данных и сообщения, несущего запись данных.
Этап 220, получение характеристики временной последовательности обработанного оперативного значения сервисных данных на основе соотношения соответствия между сохраненной информацией идентификатора сервисных данных и характеристикой временной последовательности обработанного оперативного значения.
Этап 230, сравнение характеристики временной последовательности подлежащего обработке оперативного значения сервисных данных и характеристики временной последовательности обработанного оперативного значения сервисных данных, и когда временная последовательность подлежащего обработке оперативного значения позже, чем временная последовательность обработанного оперативного значения, использование подлежащего обработке оперативного значения при выполнении сервисных вычислений и обновление сохраненной характеристики временной последовательности обработанного оперативного значения характеристикой временной последовательности подлежащего обработке оперативного значения.
В некоторых вариантах осуществления настоящей заявки, поддерживается таблица соотношений соответствия между информацией идентификатора сервисных данных и характеристикой временной последовательности обработанных оперативных значений, причем характеристика временной последовательности обработанного оперативного значения является характеристикой временной последовательности оперативного значения сервисных данных, которое совсем недавно подверглось обработке данных. Запись данных, содержащая это оперативное значение, помещается перед исходной записью данных в потоковых данных.
После получения информации идентификатора сервисных данных из новой записи данных, обращаются к таблице соотношений соответствия между информацией идентификатора и характеристикой временной последовательности обработанных оперативных значений. Если эта информация идентификатора представлена, может быть получена характеристика временной последовательности обработанного оперативного значения сервисных данных при помощи этой информации идентификатора. Характеристики временной последовательности подлежащего обработке и обработанного оперативного значения этих сервисных данных сравниваются. Если временная последовательность подлежащего обработке оперативного значения позже, чем обработанное оперативное значение, то подлежащее обработке оперативное значение используется в сервисных вычислениях (т.е. подлежащее обработке оперативное значение подвергается обработке данных), и в таблице соотношений соответствия между информацией идентификатора и характеристикой временной последовательности обработанных оперативных значений, характеристика временной последовательности обработанного оперативного значения, соответствующая информации идентификатора в записи данных, обновляется как значение характеристики временной последовательности подлежащего обработке оперативного значения записи данных. В ином случае, подлежащее обработке оперативное значение в записи данных не подвергается обработке, т.е. подлежащее обработке оперативное значение в записи данных не используется в сервисных вычислениях, чтобы избежать того, что оперативное значение, которое было обновлено раньше, заменяет оперативное значение, которое было обновлено позже, что приводит к ошибкам в результатах обработки данных.
Для ситуации, в которой время генерации оперативного значения действует как характеристика временной последовательности оперативного значения, когда время генерации подлежащего обработке оперативного значения больше, чем время генерации обработанного оперативного значения, временная последовательность подлежащего обработке оперативного значения является более поздней, чем временная последовательность обработанного оперативного значения. Для ситуации, в которой время генерации оперативного значения и идентификатор сообщения для сообщения, содержащего оперативное значение, используются в качестве характеристики временной последовательности оперативного значения, когда время генерации подлежащего обработке оперативного значения позже, чем время генерации обработанного оперативного значения, и когда времена генерации подлежащего обработке и обработанного оперативных значений являются одними и теми же, причем временная последовательность, отражаемая идентификатором сообщения для сообщения, содержащего подлежащее обработке оперативное значение, является более поздней, чем временная последовательность, отражаемая идентификатором сообщения для сообщения, содержащего обработанное оперативное значение, временная последовательность подлежащего обработке оперативного значения позже, чем временная последовательность обработанного оперативного значения.
Если таблица соотношений соответствия между информацией идентификатора и характеристикой временной последовательности обработанных оперативных значений не имеет характеристику временной последовательности обработанного оперативного значения, соответствующую информации идентификатора сервисных данных в записи данных, это означает, что это может быть первым приемом оперативного значения для этих сервисных данных или этого набора сервисных данных. Поэтому подлежащее обработке оперативное значение сервисных данных в записи данных используется в сервисных вычислениях, характеристика временной последовательности подлежащего обработке оперативного значения сервисных данных действует как характеристика временной последовательности обработанного оперативного значения, и соотношение соответствия между информацией идентификатора сервисных данных и характеристикой временной последовательности обработанного оперативного значения сохраняется в таблице соотношения соответствия.
Конкретный алгоритм для использования подлежащего обработке оперативного значения для выполнения сервисных вычислений может быть основан на требованиях действительного сценария применения, получаемых путем обращения к режимам обработки данных современных технологий. Дополнительные подробности здесь не приводятся.
В сценариях применения, использующих информацию идентификатора с большими числами байтов или многочисленными элементами таблицы в таблице соотношений соответствия между информацией идентификатора и характеристикой временной последовательности обработанных оперативных значений, поиск в таблице соотношений соответствия может потребовать значительного количества времени. Чтобы сократить влияние времени поиска на качество в реальном времени обработки данных, информация идентификатора может быть создана так, чтобы содержать характеристику идентификатора и по меньшей мере одно поле идентификатора, причем комбинация всех полей идентификатора однозначно представляет один фрагмент или один набор сервисных данных; ввод характеристики идентификатора является предопределенным сегментом комбинации всех полей идентификатора и генерируется с использованием алгоритма (например, алгоритма дайджеста). Во время поиска в таблице соотношений соответствия, характеристика идентификатора в информации идентификатора может быть использована в качестве индекса для выполнения поиска элемента таблицы, тем самым ускоряя скорости поиска.
В сценарии применения, в котором вычислительная платформа в реальном времени использует распределенные вычисления, способ вариантов осуществления настоящей заявки работает параллельно и независимо на двух или нескольких функциональных модулях программного обеспечения, ответственных за обработку данных (например, процессорах данных в сетевой структуре, показанной на фиг. 1). Перед поступлением потоковых данных на эти функциональные модули программного обеспечения, распределители данных обычно распределят различные записи данных на эти функциональные модули программного обеспечения. Распределители данных могут распределять записи данных на функциональные модули программного обеспечения в соответствии со всеми или предопределенным сегментом информации идентификатора сервисных данных в записях данных, так что записи данных с одной и той же информацией идентификатора сервисных данных могут быть распределены на один и тот же функциональный модуль программного обеспечения. Таким образом, таблица соотношений соответствия между информацией идентификатора и характеристикой временной последовательности обработанных оперативных значений может быть реализована на одном функциональном модуле программного обеспечения, а не на всей вычислительной платформе в реальном времени, тем самым сокращая объем таблицы соотношений соответствия и ускоряя скорости поиска.
В связи с этим, в вариантах осуществления настоящей заявки, потоковые данные переносят характеристики временной последовательности подлежащих обработке оперативных значений записей данных. Во время обработки данных, характеристика временной последовательности обработанного оперативного значения записи данных сохраняется, и путем сравнения характеристик временной последовательности подлежащего обработке и обработанного оперативных значений, только подлежащее обработке оперативное значение с временной последовательностью позже, чем обработанное оперативное значение, подвергается сервисным вычислениям, избегая ошибок результатов обработки, вызванных обработкой оперативного значения, которое было обновлено позже, и повышая точность обработки данных.
В одном примере применения настоящей заявки, ориентированное на сообщение межплатформенное программное обеспечение собирает сервисные данные, которые были изменены, из сервисной базы данных и генерирует записи данных. Записи данных содержат информацию идентификатора сервисных данных, оперативного значения сервисных данных (подлежащие обработке оперативного значения) и времена генерации оперативных значений. Здесь, информация идентификатора сервисных данных содержит характеристику идентификатора и по меньшей мере два поля идентификатора, и поля идентификатора являются одним или несколькими идентификаторами основного ключа сервиса и подписью сервиса. Существует однозначное соотношение между комбинацией этих идентификаторов основного ключа сервиса и подписи сервиса и сервисными данными, используемыми для генерации записи данных (в пределах объема функционального модуля программного обеспечения, обрабатывающего запись данных). Идентификатор основного ключа сервиса содержит главный идентификатор основного ключа сервиса. Если существует больше, чем один идентификатор основного ключа сервиса, идентификатор основного ключа сервиса может также содержать вторичный идентификатор основного ключа сервиса и другие идентификаторы основного ключа сервиса. Характеристика идентификатора является первыми несколькими битами значения дайджеста главного основного ключа сервиса, причем значение дайджеста является значением, полученным из главного основного ключа сервиса после использования алгоритма дайджеста. Например, первые 5 битов значения MD5 (Message Digest Algorithm (алгоритма дайджеста сообщения) 5) главного основного ключа сервиса могут использоваться в качестве характеристики идентификатора. Характеристика идентификатора соединяется со всеми полями идентификатора (фиксированный символ может быть использован между соседними полями идентификатора в качестве оператора присоединения, такой как ʺ#ʺ), чтобы действовать как информация идентификатора сервисных данных. Примерные результаты показаны в Таблице 1.
Таблица 1
главного
идентификатора основного ключа сервиса
идентификатор основного ключа сервиса
идентификатор основного ключа сервиса
идентификатор основного ключа сервиса
Ориентированное на сообщения межплатформенное программное обеспечение компонует запись данных в сообщении, серийный номер следующего сообщения, отсортированный по возрастанию, используется в качестве идентификатора сообщения (аналогично скомпонованному в сообщении), и сгенерированное сообщение помещается в очередь сообщений.
Распределитель данных вычислительной платформы в реальном времени извлекает сообщение из очереди сообщений, синтаксически анализирует запись данных и отправляет запись данных и идентификатор сообщения для сообщения, содержащего запись данных, на один из процессоров данных в соответствии с характеристикой идентификатора информации идентификатора сервисных данных в записи данных. Поскольку характеристика идентификатора является первыми несколькими битами значения дайджеста главного основного ключа сервиса, записи данных с сервисными данными, порождающими тот же самый главный основной ключ сервиса, будут распределены на один и тот же процессор данных. Другими словами, одни и те же сервисные данные подвергнутся обработке данных на одном и том же процессоре данных.
Каждый процессор данных поддерживает таблицу соотношений соответствия между информацией идентификатора сервисных данных и характеристикой временной последовательности обработанных оперативных значений: DATA_CHECK. Поля таблицы DATA_CHECK являются такими, как показано в Таблице 2:
Таблица 2
После приема записи данных и идентификатора сообщения, где находится сообщения, в котором расположена запись данных, которые распределены распределителем данных, процессор данных извлекает информацию идентификатора сервисных данных из записи данных, использует оперативное значение сервисных данных записи данных и время генерации оперативного значения в качестве подлежащего обработке оперативного значения и времени генерации подлежащего обработке оперативного значения, и использует распределенный идентификатор сообщения в качестве идентификатора сообщения для сообщения, в котором находится подлежащее обработке оперативное значение.
С использованием характеристики идентификатора в информации идентификатора в качестве индекса, процессор данных ищет ROWKEY в таблице DATA_CHECK как элемент таблицы для этой информации идентификатора, получает LAST_VERSION характеристики временной последовательности обработанного оперативного значения, соответствующего информации идентификатора, и синтаксически анализирует время генерации обработанного оперативного значения и идентификатор сообщения, в котором находится обработанное оперативное значение.
Процессор данных сравнивает времена генерации подлежащего обработке и обработанного оперативных значений. Если время генерации подлежащего обработке оперативного значения позже, чем время генерации обработанного оперативного значения, или если времена генерации подлежащего обработке и обработанного оперативных значений одни и те же, и идентификатор сообщения, в котором находится подлежащее обработке оперативное значение, больше, чем идентификатор сообщения, в котором находится обработанное оперативное значение, подлежащее обработке оперативное значение подвергается обработке данных, и LAST_VERSION элемента таблицы с этой информацией идентификатора в таблице DATA_CHECK изменяется на время генерации подлежащего обработке оперативного значения и идентификатор сообщения, содержащего подлежащее обработке оперативное значение. В ином случае, подлежащее обработке оперативное значение записи данных отклоняется и не подвергается обработке данных.
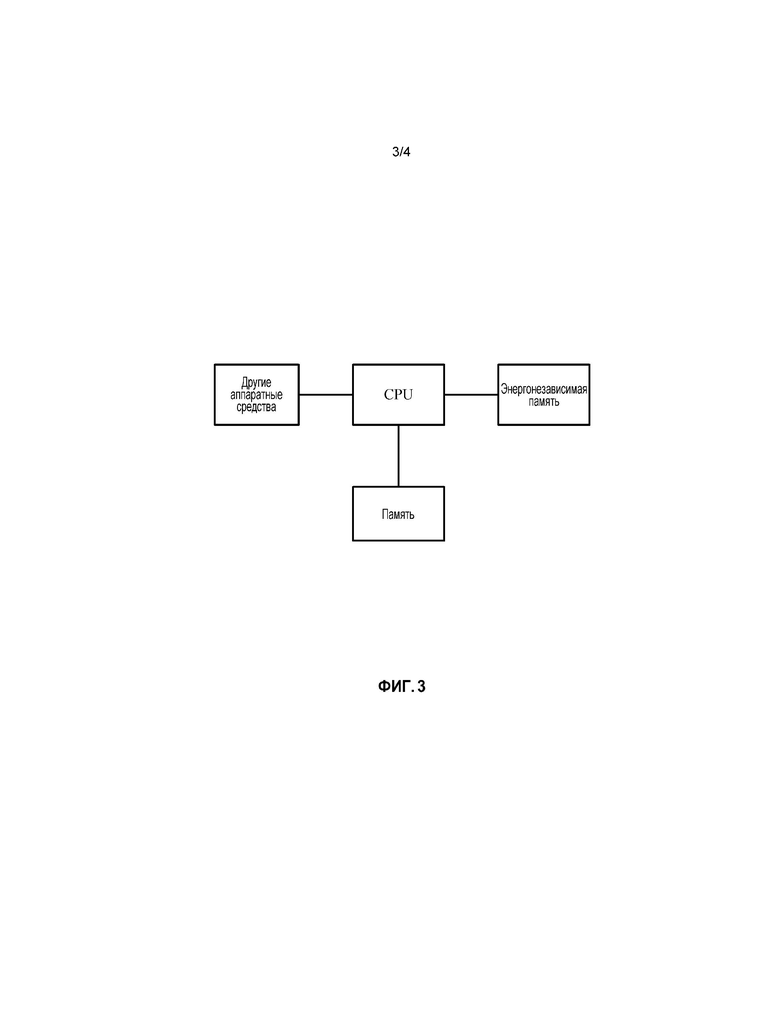
В соответствии с реализацией процессов, описанных выше, варианты осуществления настоящей заявки также обеспечивают устройство для распределенной обработки потоковых данных. Это устройство может быть реализовано посредством программного обеспечения, посредством аппаратных средств или комбинации программного обеспечения и аппаратных средств. С использованием реализации в программном обеспечении в качестве примера, в качестве логического устройства, устройство работает с помощью CPU (центрального процессора) устройства, в котором находится CPU, для считывания соответствующих компьютерных программных инструкций в память. Что касается аппаратных средств, в дополнение к CPU, памяти и энергонезависимой памяти, показанным на фиг. 3, устройство, в котором находится устройство для распределенной обработки потоковых данных, обычно также содержит другие аппаратные средства, такие как чип, используемый для выполнения беспроводной передачи и приема сигнала, и/или другие аппаратные средства, такие как карта, используемая для сетевой связи.
Фиг. 4 показывает устройство распределенной обработки потоковых данных, обеспечиваемое вариантами осуществления настоящей заявки, содержащее блок получения подлежащей обработке информации, блок получения обработанной информации и блок обработки данных, причем: блок получения подлежащей обработке информации сконфигурирован получать информацию идентификатора сервисных данных для записи данных потоковых данных, подлежащее обработке оперативное значение этой записи данных и характеристику временной последовательности этого подлежащего обработке оперативного значения записи данных, причем информация идентификатора однозначно представляет один фрагмент или один набор сервисных данных; блок получения обработанной информации сконфигурирован получать характеристику временной последовательности обработанного оперативного значения сервисных данных на основе соотношения соответствия между сохраненной информацией идентификатора сервисных данных и характеристикой временной последовательности обработанного оперативного значения; блок обработки данных сконфигурирован сравнивать характеристику временной последовательности подлежащего обработке оперативного значения сервисных данных и характеристику временной последовательности обработанного оперативного значения сервисных данных, и когда временная последовательность подлежащего обработке оперативного значения позже, чем временная последовательность обработанного оперативного значения, использовать подлежащее обработке оперативное значение при выполнении сервисных вычислений и обновлять сохраненную характеристику временной последовательности обработанного оперативного значения характеристикой временной последовательности подлежащего обработке оперативного значения.
В необязательном порядке, характеристика временной последовательности оперативного значения содержит: время генерации оперативного значения.
В необязательном порядке, потоковые данные содержат: поток сообщений из сообщений, несущих информацию идентификатора сервисных данных записи данных, подлежащее обработке оперативное значение записи данных и характеристику временной последовательности подлежащего обработке оперативного значения записи данных; характеристика временной последовательности оперативного значения содержит: время генерации оперативного значения и идентификатор сообщения для сообщения, содержащего оперативное значение, идентификатор сообщения приспособлен отражать временную последовательность генерации сообщения; временная последовательность подлежащего обработке оперативного значения, являющаяся более поздней, чем временная последовательность обработанного оперативного значения, соответствует тому, что: время генерации подлежащего обработке оперативного значения позже, чем время генерации обработанного оперативного значения, или времена генерации подлежащего обработке и обработанного оперативных значений являются одними и теми же и временная последовательность, отражаемая идентификатором сообщения для сообщения, содержащего подлежащее обработке оперативное значение, позже, чем временная последовательность, отражаемая идентификатором сообщения для сообщения, содержащего обработанное оперативное значение.
В необязательном порядке, устройство также содержит: блок добавления обработанной информации, сконфигурированный использовать подлежащее обработке оперативное значение сервисных данных в сервисных вычислениях, перед тем, как характеристика временной последовательности обработанного оперативного значения сервисных данных была сохранена, использовать характеристику временной последовательности подлежащего обработке значения сервисных данных в качестве характеристики временной последовательности обработанного оперативного значения и сохранять соотношение соответствия между информацией идентификатора сервисных данных и характеристикой временной последовательности обработанного оперативного значения.
В необязательном порядке, способ распределенной обработки потоковых данных работает параллельно и независимо на по меньшей мере двух функциональных модулях программного обеспечения, и запись данных, обработанная функциональным модулем программного обеспечения, определяется на основе информации идентификатора сервисных данных или части информации идентификатора сервисных данных записи данных.
В одном примере, информация идентификатора содержит: характеристику идентификатора и по меньшей мере одно поле идентификатора; комбинация всех полей идентификатора однозначно представляет один фрагмент или один набор сервисных данных, и характеристика идентификатора генерируется на основе предопределенного сегмента комбинации всех полей идентификатора.
В предшествующем примере, поле идентификатора может содержать: главный идентификатор основного ключа сервиса и подпись приложения; характеристика идентификатора является первыми несколькими битами значения дайджеста главного идентификатора основного ключа сервиса.
Описанное выше является только предпочтительными вариантами осуществления настоящей заявки и не ограничивает настоящую заявку. Все изменения, эквивалентные замещения и усовершенствования, выполненные в пределах сущности и принципов настоящей заявки, должны попадать в пределы объема защиты настоящей заявки.
В одной типичной конфигурации, вычислительное устройство содержит один или несколько процессоров (CPU), интерфейсы ввода/вывода, сетевые интерфейсы и внутреннюю память.
Внутренняя память может содержать формы энергозависимой памяти на считываемых компьютером носителях, памяти с произвольным доступом (RAM) и/или энергонезависимой RAM, такой как постоянная память (ROM) или флэш-RAM. Внутренняя память является примером считываемых компьютером носителей.
Считываемые компьютером носители включают в себя постоянные, непостоянные, мобильные и немобильные носители, которые могут реализовывать хранилище информации посредством любого способа или технологии. Информация может быть считываемыми компьютером инструкциями, структурами данных, программными модулями или другими данными. Примеры компьютерных носителей хранения включают в себя, но без ограничения, RAM с фазовым переходом (PRAM), статическую RAM (SRAM), динамическую RAM (DRAM), другие типы памяти с произвольным доступом (RAM), постоянную память (ROM), электрически стираемую программируемую постоянную память (EEPROM), флэш-память или другие технологии внутренней памяти, постоянную память на компакт-диске (CD-ROM), цифровые универсальные диски (DVD) или другие устройства оптической памяти, кассеты, магнитную ленту и память на дисках или другие устройства магнитной памяти или любые другие носители, не являющиеся средами передачи, которые могут использоваться для хранения информации, доступ к которой может осуществляться вычислительным устройством. Согласно определениям в настоящей заявке, считываемые компьютером носители могут исключать переходные считываемые компьютером носители (переходные среды), такие как модулированные сигналы данных и несущие.
Следует также отметить, что термины ʺсодержатьʺ и ʺвключать в себяʺ или любые их варианты подразумеваются как не исключающее включение. Таким образом, процесс, способ, продукт или устройство, содержащее ряд элементов, может не только содержать эти элементы, но может также содержать другие элементы, не перечисленные явно, или элементы, присущие этому процессу, способу, продукту или устройству. Когда не существует других ограничений, элементы, определенные выражением ʺсодержащий один…ʺ, не исключают присутствие других аналогичных элементов в процессе, способе, продукте или устройстве, содержащем элемент.
Специалист в данной области техники должен понимать, что варианты осуществления настоящей заявки могут быть обеспечены как способы, системы или компьютерные программные продукты. Следовательно, эта заявка может использовать чисто аппаратную форму варианта осуществления, чисто программную форму варианта осуществления или форму варианта осуществления, которая комбинирует программное обеспечение и аппаратные средства. Также, эта заявка может использовать форму компьютерных программных продуктов, реализованных посредством одного или нескольких компьютерных носителей хранения (включая, но без ограничения, память на магнитных дисках, CD-ROM и оптическую память), содержащих исполняемый компьютером программный код.

Изобретение относится к области вычислительной техники для обработки потоковых данных. Технический результат заключается в повышении скорости обработки потоковых данных. Технический результат достигается за счет сравнения характеристики временной последовательности подлежащего обработке оперативного значения сервисных данных и характеристики временной последовательности обработанного оперативного значения сервисных данных, и когда временная последовательность подлежащего обработке оперативного значения позже, чем временная последовательность обработанного оперативного значения, используют подлежащее обработке оперативное значение при выполнении сервисных вычислений и обновляют сохраненную характеристику временной последовательности обработанного оперативного значения характеристикой временной последовательности подлежащего обработке оперативного значения. 2 н. и 12 з.п. ф-лы, 2 табл., 4 ил.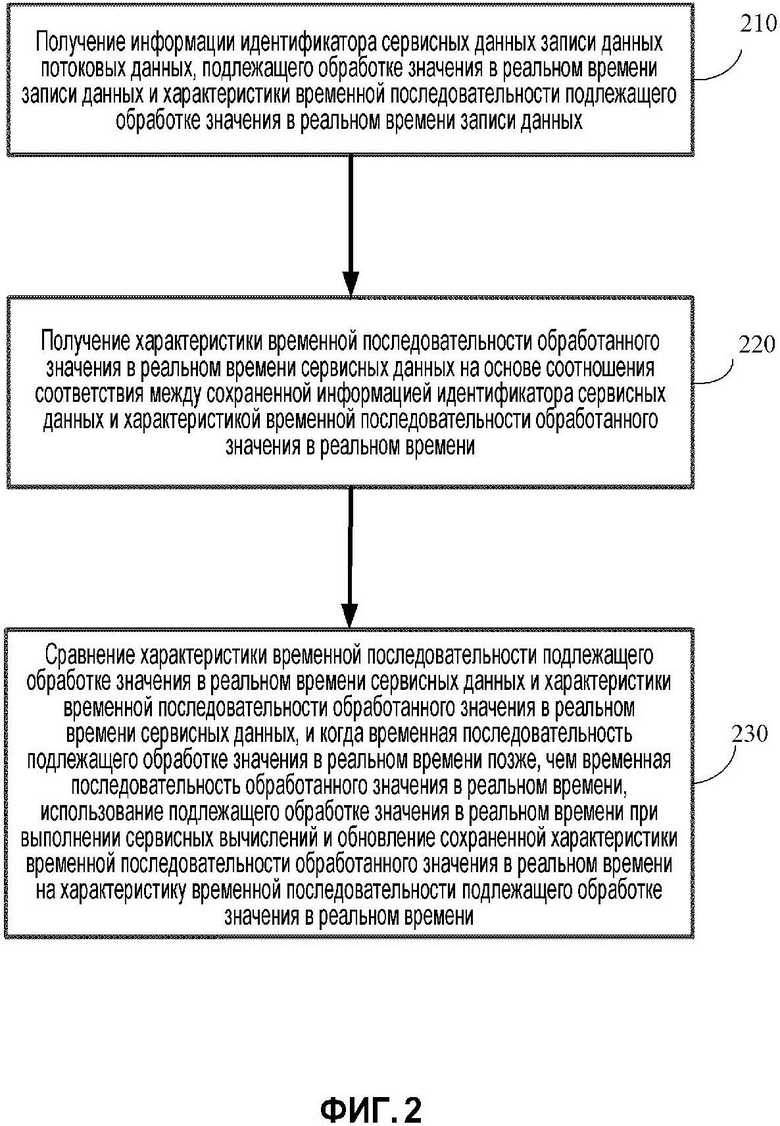
1. Способ распределенной обработки потоковых данных, содержащий этапы, на которых
получают информацию идентификатора сервисных данных для записи данных потоковых данных, подлежащее обработке оперативное значение этой записи данных и характеристику временной последовательности этого подлежащего обработке оперативного значения записи данных, причем информация идентификатора однозначно представляет один фрагмент или один набор сервисных данных;
получают характеристику временной последовательности обработанного оперативного значения сервисных данных на основе соотношения соответствия между сохраненной информацией идентификатора сервисных данных и характеристикой временной последовательности обработанного оперативного значения;
сравнивают характеристику временной последовательности подлежащего обработке оперативного значения сервисных данных и характеристику временной последовательности обработанного оперативного значения сервисных данных, и когда временная последовательность подлежащего обработке оперативного значения позже, чем временная последовательность обработанного оперативного значения, используют подлежащее обработке оперативное значение при выполнении сервисных вычислений и обновляют сохраненную характеристику временной последовательности обработанного оперативного значения характеристикой временной последовательности подлежащего обработке оперативного значения.
2. Способ по п.1, в котором характеристика временной последовательности оперативного значения содержит время генерации оперативного значения.
3. Способ по п.1, в котором потоковые данные содержат поток сообщений из сообщений, несущих информацию идентификатора сервисных данных для записи данных, подлежащее обработке оперативное значение записи данных и характеристику временной последовательности подлежащего обработке оперативного значения записи данных;
характеристика временной последовательности оперативного значения содержит время генерации оперативного значения и идентификатор сообщения для сообщения, содержащего оперативное значение, причем идентификатор сообщения приспособлен отражать временную последовательность генерации сообщений;
то, что временная последовательность подлежащего обработке оперативного значения является более поздней, чем временная последовательность обработанного оперативного значения, соответствует тому, что время генерации подлежащего обработке оперативного значения позже, чем время генерации обработанного оперативного значения, или времена генерации подлежащего обработке и обработанного оперативных значений являются одними и теми же и временная последовательность, отражаемая идентификатором сообщения для сообщения, содержащего подлежащее обработке оперативное значение, является более поздней, чем временная последовательность, отражаемая идентификатором сообщения для сообщения, содержащего обработанное оперативное значение.
4. Способ по п.1, дополнительно содержащий этапы, на которых
используют подлежащее обработке оперативное значение сервисных данных в сервисных вычислениях перед сохранением характеристики временной последовательности обработанного оперативного значения сервисных данных,
используют характеристику временной последовательности подлежащего обработке значения сервисных данных в качестве характеристики временной последовательности обработанного оперативного значения и
сохраняют соотношение соответствия между информацией идентификатора сервисных данных и характеристикой временной последовательности обработанного оперативного значения.
5. Способ по п.1, причем способ распределенной обработки потоковых данных выполняется параллельно и независимо на по меньшей мере двух функциональных модулях программного обеспечения, и запись данных, обработанная функциональным модулем программного обеспечения, определяется на основе информации идентификатора сервисных данных или части информации идентификатора сервисных данных для записи данных.
6. Способ по п.1 или 5, в котором информация идентификатора содержит характеристику идентификатора и по меньшей мере одно поле идентификатора; комбинация всех полей идентификатора однозначно представляет один фрагмент или один набор сервисных данных, и характеристика идентификатора генерируется на основе заранее определенного сегмента комбинации всех полей идентификатора.
7. Способ по п.6, в котором упомянутое поле идентификатора содержит главный идентификатор основного ключа сервиса и подпись приложения; характеристика идентификатора является первыми несколькими битами значения дайджеста главного идентификатора основного ключа сервиса.
8. Устройство распределенной обработки потоковых данных, содержащее:
блок получения подлежащей обработке информации, сконфигурированный получать информацию идентификатора сервисных данных для записи данных потоковых данных, подлежащее обработке оперативное значение этой записи данных и характеристику временной последовательности этого подлежащего обработке оперативного значения записи данных, причем информация идентификатора однозначно представляет один фрагмент или один набор сервисных данных;
блок получения обработанной информации, сконфигурированный получать характеристику временной последовательности обработанного оперативного значения сервисных данных на основе соотношения соответствия между сохраненной информацией идентификатора сервисных данных и характеристикой временной последовательности обработанного оперативного значения;
блок обработки данных, сконфигурированный сравнивать характеристику временной последовательности подлежащего обработке оперативного значения сервисных данных и характеристику временной последовательности обработанного оперативного значения сервисных данных, и когда временная последовательность подлежащего обработке оперативного значения является более поздней, чем временная последовательность обработанного оперативного значения, использовать подлежащее обработке оперативное значение в выполнении сервисных вычислений и обновлять сохраненную характеристику временной последовательности обработанного оперативного значения характеристикой временной последовательности подлежащего обработке оперативного значения.
9. Устройство по п.8, при этом характеристика временной последовательности оперативного значения содержит время генерации оперативного значения.
10. Устройство по п.8, при этом потоковые данные содержат поток сообщений из сообщений, несущих информацию идентификатора сервисных данных для записи данных, подлежащее обработке оперативное значение записи данных и характеристику временной последовательности подлежащего обработке оперативного значения записи данных;
характеристика временной последовательности оперативного значения содержит время генерации оперативного значения и идентификатор сообщения для сообщения, содержащего оперативное значение, причем идентификатор сообщения приспособлен отражать временную последовательность генерации сообщения;
то, что временная последовательность подлежащего обработке оперативного значения является более поздней, чем временная последовательность обработанного оперативного значения, соответствует тому, что время генерации подлежащего обработке оперативного значения позже, чем время генерации обработанного оперативного значения, или времена генерации подлежащего обработке и обработанного оперативных значений являются одними и теми же и временная последовательность, отражаемая идентификатором сообщения для сообщения, содержащего подлежащее обработке оперативное значение, позже, чем временная последовательность, отражаемая идентификатором сообщения для сообщения, содержащего обработанное оперативное значение.
11. Устройство по п.8, дополнительно содержащее блок добавления обработанной информации, сконфигурированный использовать подлежащее обработке оперативное значение сервисных данных в сервисных вычислениях перед сохранением характеристики временной последовательности обработанного оперативного значения сервисных данных, использовать характеристику временной последовательности подлежащего обработке значения сервисных данных в качестве характеристики временной последовательности обработанного оперативного значения и сохранять соотношение соответствия между информацией идентификатора сервисных данных и характеристикой временной последовательности обработанного оперативного значения.
12. Устройство по п.8, причем способ распределенной обработки потоковых данных выполняется параллельно и независимо на по меньшей мере двух функциональных модулях программного обеспечения, и запись данных, обработанная функциональным модулем программного обеспечения, определяется на основе информации идентификатора сервисных данных или части информации идентификатора сервисных данных для записи данных.
13. Устройство по п.8 или 12, при этом информация идентификатора содержит характеристику идентификатора и по меньшей мере одно поле идентификатора; комбинация всех полей идентификатора однозначно представляет один фрагмент или один набор сервисных данных, и характеристика идентификатора генерируется на основе заранее определенного сегмента комбинации всех полей идентификатора.
14. Устройство по п.13, при этом упомянутое поле идентификатора содержит главный идентификатор основного ключа сервиса и подпись приложения; характеристика идентификатора является первыми несколькими битами значения дайджеста главного идентификатора основного ключа сервиса.
| УСТРОЙСТВО ДЛЯ ПРИЕМА И ПЕРЕДАЧИ ДАННЫХ С ВОЗМОЖНОСТЬЮ ОСУЩЕСТВЛЕНИЯ ВЗАИМОДЕЙСТВИЯ С OpenFlow КОНТРОЛЛЕРОМ | 2014 |
|
RU2584471C1 |
| СПОСОБ РАСПРЕДЕЛЕННОГО ВЫПОЛНЕНИЯ ЗАДАЧ КОМПЬЮТЕРНОЙ БЕЗОПАСНОСТИ | 2011 |
|
RU2494453C2 |
| Устройство для закрепления лыж на раме мотоциклов и велосипедов взамен переднего колеса | 1924 |
|
SU2015A1 |
| US 8639625 B1, 28.01.2014 | |||
| US 8904181 B1, 02.12.2014. | |||

