ПРЕДПОСЫЛКИ СОЗДАНИЯ ИЗОБРЕТЕНИЯ
1. Область техники, к которой относится изобретение
Настоящее изобретение относится к дата-центру и, в частности, к способу анализа и сброса ненормального состояния стоек, применяемых в дата-центре.
2. Уровень техники
Вообще говоря, администратор дата-центра может удаленно администрировать несколько контроллеров управления стойкой (RMC) и контроллеров управления материнской платой (BMC) в их стойках и узлах в дата-центре посредством интеллектуального интерфейса администрирования платформы (IPMI).
Вне зависимости от того, какой способ применяется для процедуры выполнения удаленного администрирования, администратор дата-центра будет получать большое количество предупреждающих уведомлений, как только RMC/BMC какой-либо стойки или узла оказывается в ненормальном состоянии. Однако администратор едва ли может понять основную проблему ненормального состояния в тот момент, когда он или она получает предупреждающие уведомления. В частности, администратор должен быть уведомлен в нерабочее время и затем, в конечном счете, понимает, что RMC/BMC точно находится в некотором ненормальном состоянии, не раньше получения им или ей сотен или тысяч предупреждающих уведомлений или потере дата-центром соединения со стойкой/узлом.
Более того, часть платформ администрирования, представленных на рынке, могут собирать сообщения об ошибках в стойках/узлах посредством каналов мониторинга с возможностью объединения этих сообщений об ошибках и представления отчета по оценке сбоев администратору. Однако вышеописанный подход к мониторингу все еще нуждается в администраторе для вынесения суждения согласно отчету по оценке сбоев с целью вынесения окончательного решения в отношении ненормального состояния, поэтому при вмешательстве человека всегда будет присутствовать вероятность вынесения неверного суждения.
Согласно вышеуказанной претензии, в области техники необходима новая система/способ, способный автоматически выполнять процедуру восстановления RMC/BMC, находящегося в ненормальном состоянии, из удаленного пункта, с целью усиления способности к мониторингу дата-центра. Также администрирование стоек может быть высокоавтоматизированным с целью сокращения времени, которое тратится на человеческое решение, и также с целью предотвращения администрирования, основанного на неверном суждении из-за вмешательства человека.
Ближайшим аналогом к настоящей заявке является документ TW201714432, в котором описывается служебный контроллер, содержащий один или более сетевых интерфейсов, поддерживающих связь с другим устройством в сервере; процессор, соединенный с сетевыми интерфейсами и выполненный с возможностью исполнения одного или более процессов; запоминающее устройство, выполненное с возможностью хранения команд, исполняемых процессором. Команды, при их исполнении процессором, заставляют процессор выполнять операции включающие: мониторинг устройства физического уровня в сервере и по меньшей мере одного сетевого коннектора, соединенного с устройством физического уровня, причем устройство физического уровня обеспечивает обмен данными между по меньшей мере одним контроллером доступа к среде и по меньшей мере одним сетевым коннектором; определение состояния устройства физического уровня или состояния по меньшей мере одного сетевого коннектора, которое указывает по меньшей мере одно из предупреждения или сбоя; и передачу сигнала тревоги, соответствующего по меньшей мере одному из предупреждения или сбоя на контроллер управления стойкой.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
Целью настоящего изобретения является предоставление способа удаленного сброса ненормального состояния стоек, применяемых в дата-центре, который может автоматически выполнять процедуру удаленного аварийного восстановления BMC в стойке для сброса ненормального состояния BMC непосредственно из удаленного пункта каждый раз при определении того, что BMC утрачивает соединение с системой администрирования стоечного сервера.
В одном из иллюстративных вариантов осуществления способ согласно настоящему изобретению по меньшей мере включает следующие этапы: регулярное получение любой информации от RMC и нескольких BMC в стойке системой администрирования стоечного сервера из удаленного пункта; запись любого порядка действий, выполняемого администратором посредством системы администрирования стоечного сервера; анализ информации и порядка действий системой администрирования стоечного сервера для определения того, находится ли какой-либо из RMC и BMC в стойке в одном из нескольких определенных заранее состояний, требующих внимания.
При определении того, что один из BMC утратил сетевое соединение с системой администрирования стоечного сервера, система администрирования стоечного сервера автоматически выполняет процедуру удаленного аварийного восстановления такого BMC для сброса ненормального состояния, вызванного потерей соединения с таким BMC.
В сравнении с известным уровнем техники способ, раскрытый в настоящем изобретении, выполняет анализ и процедуры удаленного восстановления посредством системы администрирования стоечного сервера, соединенной и связанной со стойкой в дата-центре, поэтому отпадает необходимость в традиционном человеческом решении, принимаемом администратором для суждения о ненормальном состоянии. Таким образом, стоимость администрирования при мониторинге стойки может быть уменьшена. Также отсутствует вмешательство человека при мониторинге стойки, так что традиционное влияние расстояния и времени также может быть устранено.
КРАТКОЕ ОПИСАНИЕ ГРАФИЧЕСКИХ МАТЕРИАЛОВ
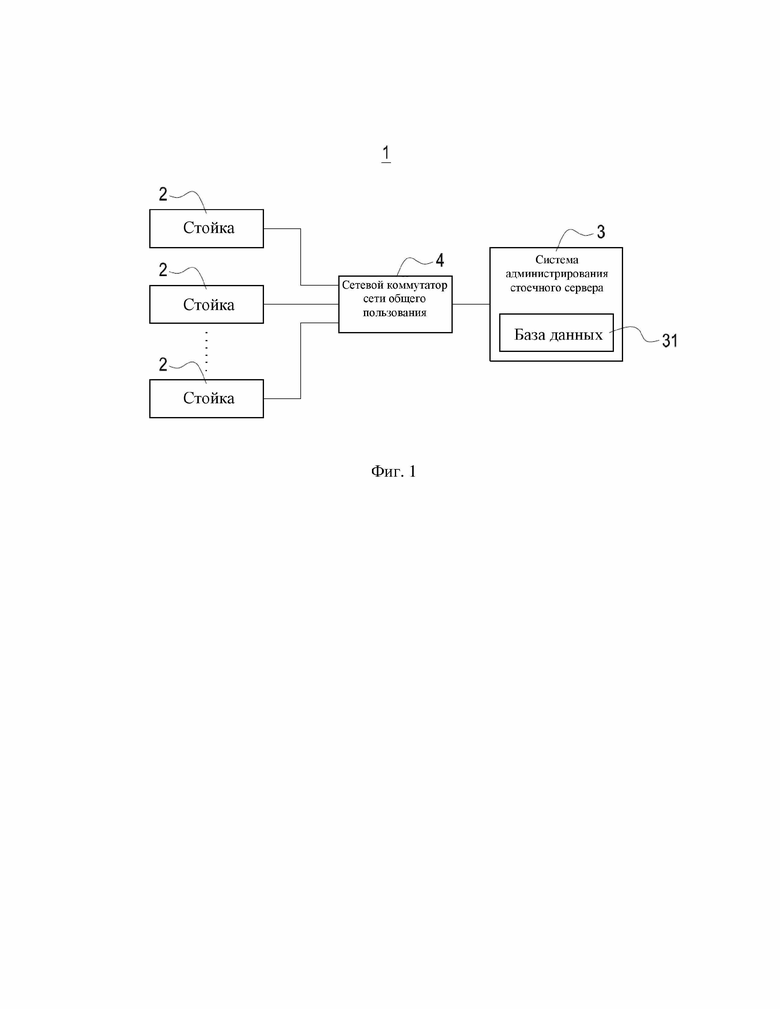
На фиг. 1 показана принципиальная схема, изображающая дата-центр согласно настоящему изобретению.
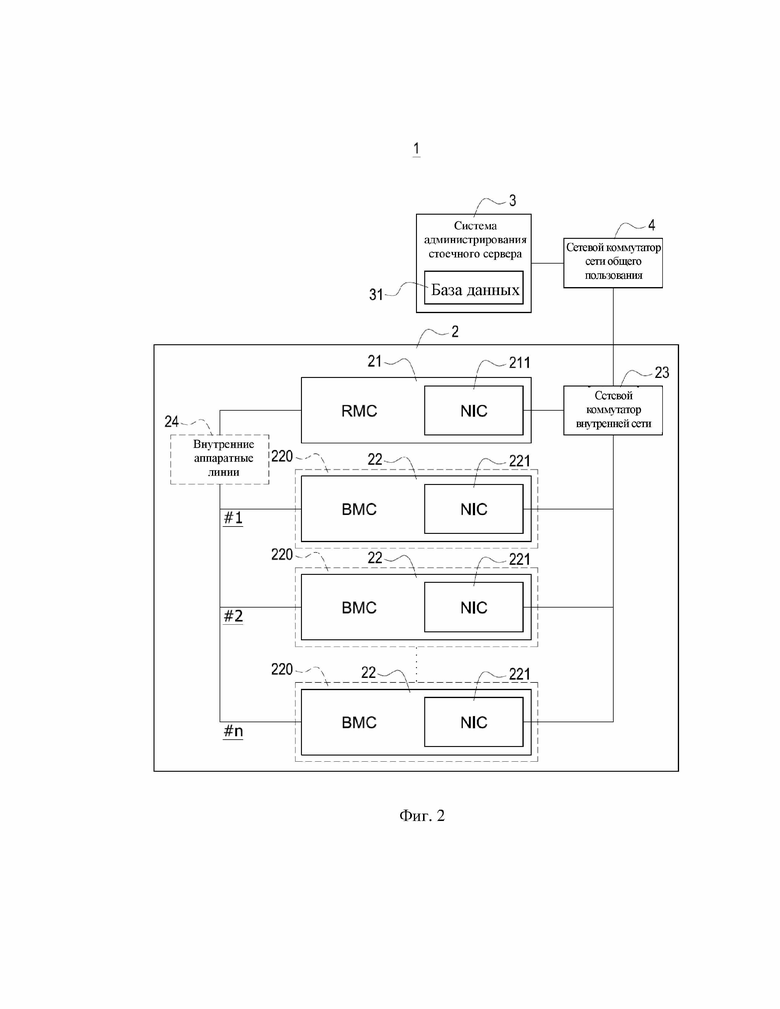
На фиг. 2 показана функциональная схема стойки согласно первому варианту осуществления настоящего изобретения.
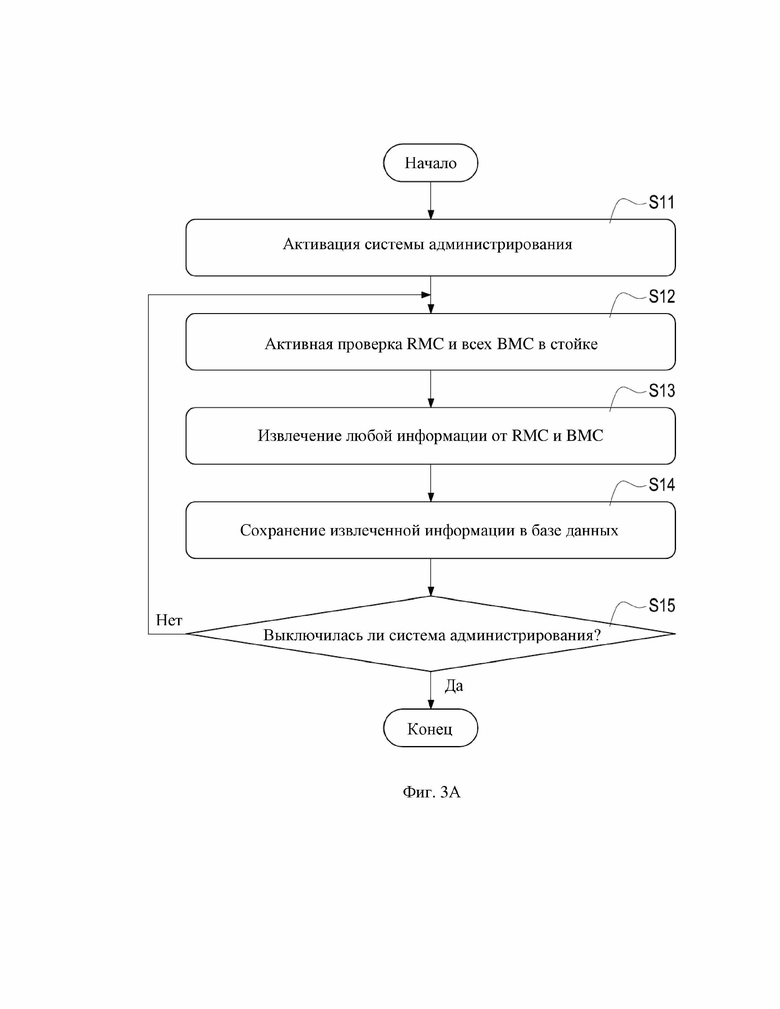
На фиг. 3A показана блок-схема сбора данных согласно первому варианту осуществления настоящего изобретения.
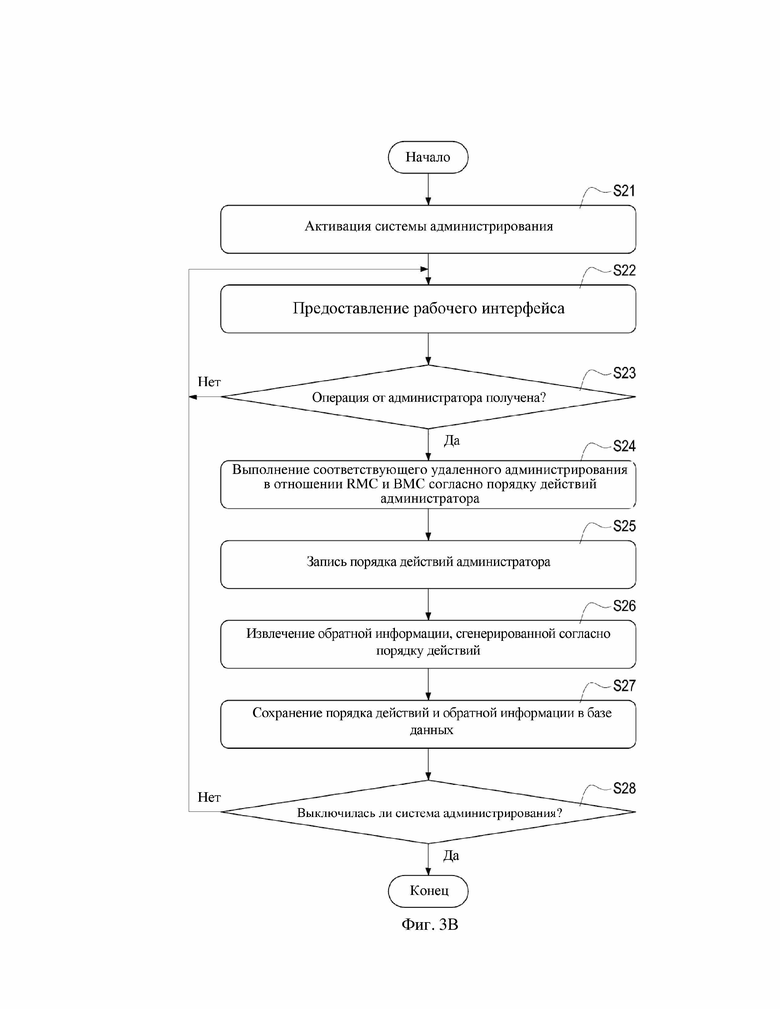
На фиг. 3B показана блок-схема сбора данных согласно второму варианту осуществления настоящего изобретения.
На фиг. 4 показана блок-схема анализа и сброса согласно первому варианту осуществления настоящего изобретения.
На фиг. 5 показана блок-схема для сброса первого типа состояния, требующего внимания, согласно первому варианту осуществления настоящего изобретения.
На фиг. 6 показана блок-схема для сброса первого типа состояния, требующего внимания, согласно второму варианту осуществления настоящего изобретения.
На фиг. 7 показана блок-схема для сброса второго типа состояния, требующего внимания, согласно первому варианту осуществления настоящего изобретения.
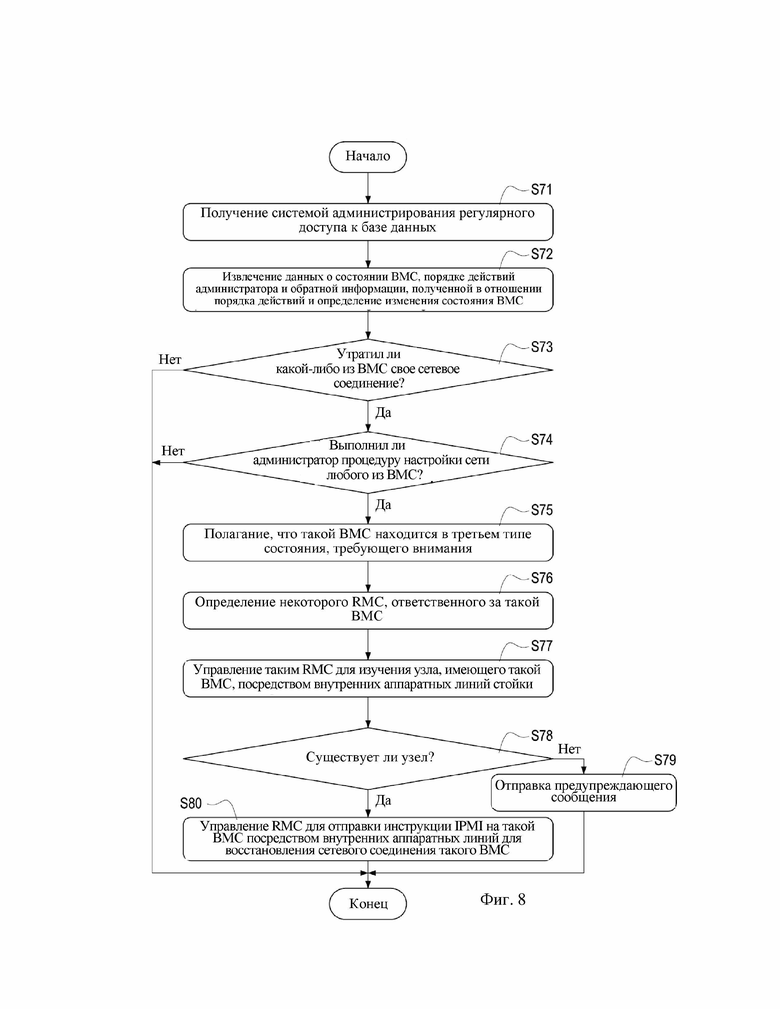
На фиг. 8 показана блок-схема для сброса третьего типа состояния, требующего внимания, согласно первому варианту осуществления настоящего изобретения.
ПОДРОБНОЕ ОПИСАНИЕ ИЗОБРЕТЕНИЯ
Здесь и далее в сочетании с прилагаемыми графическими материалами описывается техническое содержание и приводится подробное описание настоящего изобретения согласно предпочтительному варианту осуществления, не используемому с целью ограничения его объема правовой охраны. Любые эквивалентные варианты и модификации, выполненные согласно прилагаемой формуле изобретения, попадают под объем правовой охраны формулы, заявленной в настоящем изобретении.
Настоящее изобретение раскрывает способ удаленного сброса ненормального состояния стоек (именуемый далее способом сброса), причем способ сброса в основном применяют в отношении дата-центра для помощи администратору дата-центра в мониторинге, анализе и сбросе разных видов ненормальных состояний в пределах дата-центра.
На фиг. 1 показана принципиальная схема, изображающая дата-центр согласно настоящему изобретению. Как показано на фиг. 1, дата-центр 1 в настоящем изобретении содержит несколько стоек 2, а также содержит систему 3 администрирования стоечного сервера (именуемую далее системой 3 администрирования), удаленно соединенную и связанную с несколькими стойками 2. Система 3 администрирования может быть расположена непосредственно в дата-центре 1. Однако система 3 администрирования может также быть расположена в удаленном пункте вне дата-центра 1. В этом сценарии система 3 администрирования может быть соединена с сетевым коммутатором 4 сети общего пользования посредством сети Интернет и соединена с несколькими стойками 2 в дата-центре 1 посредством сетевого коммутатора 4 сети общего пользования.
Система 3 администрирования в настоящем изобретении может осуществлять мониторинг нескольких стоек 2 в дата-центре 1, извлекать любую информацию из нескольких стоек 2 и анализировать извлеченную информацию в режиме реального времени. Каждый раз, когда система 3 администрирования замечает, что одна из стоек 2 находится в ненормальном состоянии или ненормальное состояние скоро возникнет в какой-либо из стоек 2, она может автоматически выполнять одну из нескольких заранее заданных исполнительных процедур, соответствующих ненормальному состоянию, для сброса такого ненормального состояния стойки 2. Таким образом, благодаря техническому решению, предложенному в настоящем изобретении, можно сбросить существующее ненормальное состояние стоек 2 или предотвратить наступление ненормального состояния стоек 2 без какого-либо вмешательства человека, с целью устранения неверного человеческого суждения и ускорения всей исполнительной процедуры.
В одном варианте осуществления система 3 администрирования представляет собой персональный компьютер (PC) или облачный сервер со встроенным одним или более центральными процессорами (CPU). После активации система 3 администрирования может соединяться с несколькими стойками 2 в дата-центре 1 посредством сетевого коммутатора 4 сети общего пользования и осуществлять по меньшей мере процедуру мониторинга, процедуру анализа данных и процедуру сброса ненормального состояния этих стоек 2 путем выполнения специфичных прикладных программ или алгоритмов посредством одного или более CPU.
Система 3 администрирования может также содержать базу 31 данных, выполненную с возможностью временного или постоянного хранения информации, извлеченной из нескольких стоек 2 в дата-центре 1. В варианте осуществления, показанном на фиг. 1, база 31 данных встроена в систему 3 администрирования. Однако система 3 администрирования в другом варианте осуществления может также быть соединенной с одной или более базами 31 данных, не ограничиваясь этим.
На фиг. 2 показана функциональная схема стойки согласно первому варианту осуществления настоящего изобретения. В варианте осуществления, показанном на фиг. 2, для простоты описания в качестве примера взята одна единственная стойка 2 в дата-центре 1, соединенная с вышеуказанной системой 3 администрирования. Однако дата-центр 1 может быть выполнен с использованием нескольких стоек 2 в соответствии с реальными потребностями, без ограничения тем, что раскрыто на фиг. 2.
Как раскрыто на фиг. 2, стойка 2 в основном содержит по меньшей мере один контроллер 21 управления стойкой (RMC), и также содержит несколько узлов 220, соединенных с RMC 21, причем каждый из узлов 220 соответственно содержит по меньшей мере один контроллер 22 управления материнской платой (BMC). То есть, стойка 2 по меньшей мере содержит один RMC 21 и множество BMC 22.
Вышеуказанный RMC 21 является встроенной системой и размещен внутри стойки 2. RMC 21 может помогать внутренним аппаратным устройствам внутри стойки 2, таким как вентиляторы охлаждения, датчики, источники питания и т. д. поддерживать связь с внешними устройствами посредством разных аппаратных линий, и также поддерживать связь с BMC 22 каждого узла 220 в стойке 2. Вышеуказанный BMC 22 также является встроенной системой, размещенной в каждом узле 220 для помощи внутренним аппаратным устройствам в узле 220, таким как датчики, при связи с другими внешними аппаратами.
В данном варианте осуществления RMC 21 соединен со всеми BMC 22 в узлах 220 стойки 2 посредством внутренних аппаратных линий 24 с целью связи с каждым из BMC 22 и управления каждым узлом 220 и извлечения информации с BMC 22 и узлов 220. В этом варианте осуществления эти узлы 220 могут представлять собой, например, серверы башенной модели, блейд-серверы, и т. д., но не ограничиваясь этим.
Как раскрыто на фиг. 2, каждый узел 220, размещенный в стойке 2, имеет закрепленный номер места соответственно (как, например, №1, №2, №n как показано на фиг. 2). Если функция внешней сети узла 220 или BMC 22 повреждена, RMC 21 может соединиться с указанным местом стойки 2 (таким, как №1, №2, №n, как указано выше) посредством внутренних аппаратных линий 24 с целью связи с узлом 220 или BMC 22, размещенным в указанном месте. Таким образом, даже при потере узлом 220 или BMC 22 своего сетевого соединения, он по-прежнему может подвергаться мониторингу посредством RMC 21 в той же стойке 2, так что ненормальное состояние узла 220 или BMC 22 может также быть проанализировано и сброшено посредством RMC 21.
Кроме того, RMC 21 в настоящем изобретении выполнен с контроллером 211 сетевого интерфейса (NIC), и каждый из BMC 22 также выполнен с сетевым внутренним контроллером 221. RMC 21 соединен с сетевым коммутатором 23 внутренней сети в стойке 2 посредством NIC 211, и каждый из BMC 22 соответственно соединен с сетевым коммутатором 23 внутренней сети посредством каждого из NIC 221. Стойка 2 соединена с сетевым коммутатором 4 сети общего пользования посредством сетевого коммутатора 23 внутренней сети и устанавливает сетевое соединение с системой 3 администрирования посредством сетевого коммутатора 4 сети общего пользования. Таким образом, система 3 администрирования может проверять стойку 2 в дата-центре 1 из удаленного пункта посредством сети Интернет и система 3 администрирования может запрашивать и извлекать любую информацию их RMC21 и всех BMC 22 в стойке 2 и хранить информацию в базе 31 данных.
Одним из технических отличий настоящего изобретения является то, что система 3 администрирования может регулярно проверять стойку 2 для извлечения любой информации, такой как данные о состоянии, журнал событий, степень использования системных ресурсов, показание внутренних датчиков в узлах 220 и т. д., в отношении RMC 21 и BMC 22 в стойке 2 с активным анализом того, находятся ли RMC 21 и BMC 22 в ненормальном состоянии или возникнет ли ненормальное состояние согласно извлеченной информации. Если система 3 администрирования определяет, что необходимо проведение процедуры после анализа вышеуказанной информации, она может активно выполнять соответствующую процедуру удаленно для сброса существующего ненормального состояния RMC 21 или BMC 22 из удаленного пункта или для предотвращения возникновения спрогнозированного ненормального состояния в RMC 21 или BMC 22.
Благодаря техническому решению, предложенному в настоящем изобретении, можно разобраться с ненормальными состояниями без вмешательства человека с целью уменьшения возможности неверного человеческого суждения и с возможностью создания высокоавтоматизированной процедуры мониторинга стойки 2.
Рассмотрим фиг. 3A, которая представляет собой блок-схему сбора данных согласно первому варианту осуществления настоящего изобретения.
Как показано на фиг. 3A, если администратор желает произвести мониторинг стойки 2 в дата-центре 1, он или она может непосредственно активировать систему 3 администрирования, расположенную в удаленном пункте (этап S11). После активации система 3 администрирования может выполнять процедуру удаленной проверки для активной проверки RMC 21 и всех BMC 22 в стойке 2 (единственная стойка 2, как проиллюстрировано на фиг. 2) в дата-центре 1 из удаленного пункта (этап S12). Также система 3 администрирования может выполнять процедуру извлечения информации для извлечения любой информации из RMC 21 и всех BMC 22 в стойке 2 посредством процедуры удаленной проверки (этап S13). Система 3 администрирования может дополнительно выполнять процедуру сохранения для сохранения извлеченной информации в базу 31 данных (этап S14).
В частности, система 3 администрирования в этом варианте осуществления может регулярно и активно проверять стойку 2 после активации, что делает процедуру удаленной проверки, процедуру извлечения информации и процедуру сохранения, как показано на этапе S12, этапе S13 и этапе S14, плановой последовательностью после активации системы 3 администрирования. При исполнении плановой последовательности система 3 администрирования продолжает определять, включена ли она или выключена (этап S15), и система 3 администрирования может продолжать исполнение этапов S12–S14 для непрерывного мониторинга RMC21 и BMC 22 в стойке 2 перед выключением.
Рассмотрим фиг. 3B, которая представляет собой блок-схему сбора данных согласно второму варианту осуществления настоящего изобретения.
После активации системы 3 администрирования администратором (этап S21) система 3 администрирования может предоставить рабочий интерфейс (этап S22). Администратор может войти в систему 3 администрирования посредством рабочего интерфейса с целью мониторинга информации в каждой стойке 2 в дата-центре 1 и управления ею посредством системы 3 администрирования из удаленного пункта. В данном варианте осуществления рабочий интерфейс может представлять собой физический интерфейс или веб-интерфейс, но не ограничиваясь этим.
После предоставления рабочего интерфейса система 3 администрирования продолжает определение того, получена ли выполняемая операция от администратора посредством рабочего интерфейса или нет (этап S23). Если система 3 администрирования получает операцию, выполненную администратором, система 3 администрирования может выполнять соответствующее удаленное администрирование в отношении стойки 2 и также RMC 21 и BMC 22 в стойке 2 из удаленного пункта согласно порядку действий администратора (этап S24). Далее система 3 администрирования может записывать вышеуказанный порядок действий, выполняемый администратором (этап S25). Также система 3 администрирования может извлекать и записывать обратную информацию, сгенерированную и полученную в ответ от системы 3 администрирования, стойки 2, каждого узла 220, RMC 21 и любого BMC 22 в соответствии с удаленным администрированием (т. е. согласно порядку действий администратора) (этап S26). Наконец, система 3 администрирования сохраняет вышеуказанный порядок действий и обратную информацию в базу 31 данных (этап S27) с целью анализа в отношении ненормального состояния в последующих процедурах.
Схожим образом система 3 администрирования в данном варианте осуществления полагает действия на этапах S22–S27 плановой последовательностью после активации. При исполнении плановой последовательности система 3 администрирования продолжает определять, включена ли она или выключена (этап S28), и система 3 администрирования продолжает исполнение этапов S22–S27 перед выключением для непрерывного мониторинга и анализа влияния, вызванного порядком действий, выполняемым администратором, на RMC 21 и BMC 22 в стойке 2.
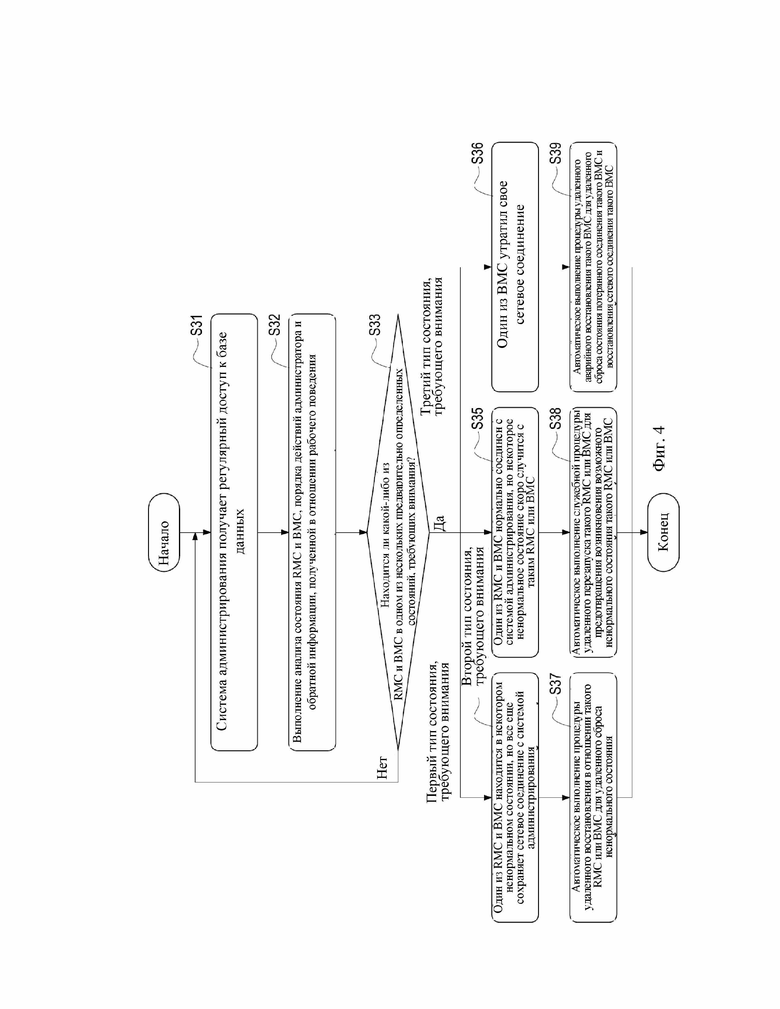
Рассмотрим фиг. 4, которая представляет собой блок-схему анализа и сброса согласно первому варианту осуществления настоящего изобретения.
Как показано на фиг. 4, система 3 администрирования может регулярно получать доступ к базе 31 данных (этап S31), извлекать любую информацию из RMC 21 и BMC 22 в стойке 2, порядок действий, выполняемый администратором, и любую обратную информацию из базы 31 данных (этап S32), и выполнять анализ вышеуказанных извлеченных данных. Путем анализа вышеуказанных данных система 3 администрирования может анализировать, находится ли RMC 21 или каждый из BMC 22 в стойке 2 в одном или более предварительно определенных состояниях, требующих внимания (этап S33).
В одном варианте осуществления система 3 администрирования может в режиме реального времени получать всю информацию от RMC 21 и BMC 22 в стойке 2, в режиме реального времени получать порядок действий, выполняемый посредством рабочего интерфейса, и затем выполнять анализ полученных данных. В другом варианте осуществления система 3 администрирования может регулярно сохранять вышеуказанные данные в базу 31 данных посредством этапа S14, как показано на фиг. 3A, и этапа S27, как показано на фиг. 3B, с регулярным извлечением вышеуказанных данных из базы 31 данных для анализа, но не ограничиваясь этим.
В одном варианте осуществления вышеуказанная информация из RMC 21 и BMC 22 может представлять собой, например, данные о состоянии (как, например, нахождение в рабочем режиме или в режиме обновления, IP-адрес, MAC-адрес, маска подсети, IP-адрес шлюза, текущая длительность сеанса IPMI и т. д.), журнал событий и т. д., и вышеуказанный порядок действий может представлять собой, например, процедуру запроса данных, процедуру обновления, процедуру сброса и т. д., выполняемые администратором в отношении конкретной стойки 2, узла 220, RMC 21 или BMC 22, но не ограничиваясь этим. Учитывая вышеуказанные данные, система 3 администрирования может анализировать, есть ли в стойке 2 в данный момент RMC 21 или BMC 22, нуждающийся в немедленном аварийном восстановлении посредством выполнения соответствующего алгоритма.
В варианте осуществления, показанном на фиг. 4, система 3 администрирования может предварительно определять три типа состояния, требующего внимания, включая первый тип состояния, требующего внимания, второй тип состояния, требующего внимания, и третий тип состояния, требующего внимания, причем эти три типа состояний, требующих внимания, соответствуют в указанном порядке разным ненормальным состояниям RMC 21/BMC 22 и требуют от системы 3 администрирования выполнения разных процедур по сбросу или предотвращению ненормальных состояний непосредственно из удаленного пункта.
Как показано на фиг. 4, если система 3 администрирования «понимает», что какой-либо из RMC 21 и BMC 22 находится в некотором ненормальном состоянии, но поддерживает соединение с системой 3 администрирования после анализа вышеуказанных данных (таких как данные о состоянии, журнал событий и порядок действий администратора), она будет полагать, что RMC 21/BMC 22 находится в вышеуказанном первом типе состояния, требующего внимания (этап S34). При «понимании», что один из RMC 21 и BMC 22 находится в первом типе состояния, требующего внимания, система 3 администрирования может автоматически выполнять процедуру удаленного восстановления RMC 21/BMC 22, находящегося в первом типе состояния, требующего внимания, с целью удаленного сброса ненормального состояния RMC 21/BMC 22 (этап S37).
Если система 3 администрирования «понимает», что какой-либо из RMC 21 и BMC 22 нормально соединен с системой 3 администрирования, но некоторое ненормальное состояние скоро возникнет в RMC 21/BMC 22, после анализа вышеуказанных данных (таких как данные о состоянии RMC 21 и BMC 22), она будет полагать, что RMC 21/BMC 22 находится в вышеуказанном втором типе состояния, требующего внимания (этап S35). При «понимании», что один из RMC 21 и BMC 22 находится во втором типе состояния, требующего внимания, система 3 администрирования может автоматически выполнять служебную процедуру удаленного перезапуска RMC 21/BMC 22, находящегося во втором типе состояния, требующего внимания, с целью предотвращения возникновения возможного ненормального состояния в RMC 21/BMC 22 (этап S38).
Если система 3 администрирования «понимает», что какой-либо из BMC 22 утратил сетевое соединение после анализа вышеуказанных данных (таких как данные о состоянии, порядок действий администратора и любая обратная информации), она будет полагать, что BMC 22 находится в вышеуказанном третьем типе состояния, требующего внимания (этап S36). При «понимании», что один из BMC 22 находится в третьем типе состояния, требующего внимания, система 3 администрирования может автоматически выполнять процедуру удаленного аварийного восстановления BMC 22, находящегося в третьем типе состояния, требующего внимания, с целью удаленного сброса состояния утраченного соединения BMC 22 для восстановления сетевого соединения BMC 22 (этап S39).
Ниже будет описан вышеуказанный первый тип состояния, требующего внимания.
Поскольку часть RMC 21/BMC 22 не имеет базовой системы ввода/вывода (BIOS), она должна устанавливать свое время посредством службы протокола сетевого времени (NTP), предоставляемого внешним сервером, или посредством генератора импульсов времени (RTC), предоставленным аппаратно (например, микросхемой генератора импульсов), чтобы осуществить синхронизацию времени с другими аппаратами.
Как описано выше, если системное событие происходит перед завершением RMC 21 или BMC 22 процедуры синхронизации времени, это системное событие может по-прежнему быть записано в журнал событий RMC 21/BMC 22, но в колонку «время» журнала событий, соответствующую этому системному событию, будет записана лишь текстовая информация, такая как «Предшествует инициализации», вместо точного времени возникновения события, указывающего на возникновение системного события. Без точного времени возникновения системного события администратор может вынести неверное суждение о системном событии из-за того, что журнал событий не может полагаться значимым указателем системного события. Кроме того, если RMC 21 или BMC 22 нуждается в выполнении процедуры сброса, он может также стать причиной такой же или похожей ситуации, при которой время возникновения системного события было записано неверно или ненормально.
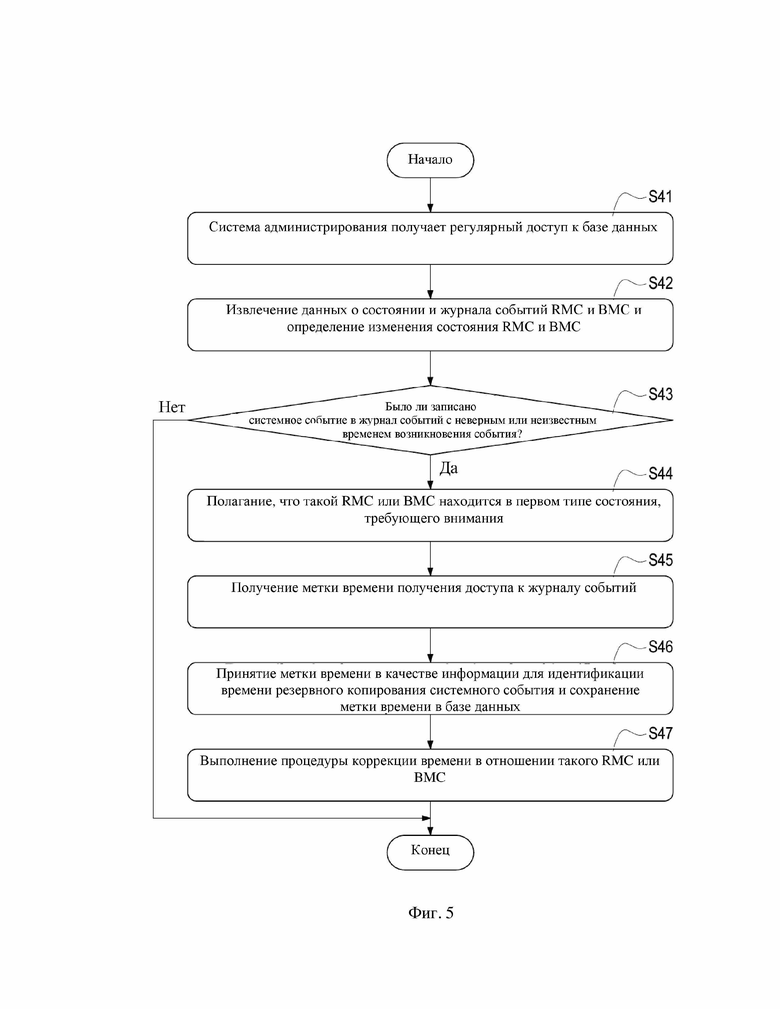
Рассмотрим фиг. 5, которая представляет собой блок-схему для сброса первого типа состояния, требующего внимания, согласно первому варианту осуществления настоящего изобретения. В данном варианте осуществления система 3 администрирования может регулярно получать доступ к базе 31 данных (этап S41), извлекать данные о состоянии и журнал событий RMC 21 и всех BMC 22 в стойке 2 из базы 31 данных с целью определения изменения состояния RMC 21 и BMC 22 (этап S42).
В этом варианте осуществления система 3 администрирования определяет, было ли записано системное событие в извлеченный журнал событий с неверным или неизвестным временем возникновения события (этап S43). Если все системные события в журнал событий записаны с верным временем возникновения события, система 3 администрирования не будет активно выполнять какую-либо процедуру.
Если система 3 администрирования «понимает» после анализа извлеченных данных, что какой-либо из RMC 21 и BMC 22 имеет по меньшей мере одно системное событие, записанное в журнал событий с неверным или неизвестным временем возникновения события, она может полагать, что RMC 21/BMC 22 находится в первом типе состояния, требующего внимания (этап S44), т. е. система 3 администрирования может полагать, что некоторое ненормальное состояние возникает в RMC 21/BMC 22, но RMC 21/BMC 22 по-прежнему поддерживает сетевое соединение с системой 3 администрирования.
В одном варианте осуществления система 3 администрирования может определять, что одно системное событие записано с неверным или неизвестным временем возникновения события при записи времени возникновения системного события в журнал событий в виде «Предшествует инициализации» или схожей текстовой информации (т. е. то, что было записано в журнал событий по отношению к системному событию, не отвечает требованию верного указания точного времени возникновения системного события). В другом варианте осуществления система 3 администрирования может определять, что системное событие записано с неверным или неизвестным временем возникновения события, как только она «понимает», что один из RMC 21/BMC 22 имеет по меньшей мере одно системное событие, записанное в журнал событий с неизвестным временем возникновения события, после анализа журнала событий, и «понимает», что RMC 21/BMC 22 еще не завершил свою процедуру синхронизации времени или RMC 21/BMC 22 нуждается в выполнении процедуры сброса после анализа данных о состоянии.
Полагая, что RMC 21/BMC 22 находится в первом типе состояния, требующего внимания на этапе S44, система 3 администрирования сначала получает метку времени получения доступа к журналу событий (этап S45), затем она принимает метку времени в качестве информации для идентификации времени резервного копирования системного события и сохраняет метку времени в базе 31 данных (этап S46). В одном варианте осуществления система 3 администрирования записывает момент времени получения доступа к базе 31 данных для извлечения журнала событий и принимает этот момент времени в качестве вышеуказанной метки времени. В другом варианте осуществления система 3 администрирования записывает момент времени удаленной проверки стойки 2 для получения журнала событий непосредственно от RMC 21 и BMC 22 и принимает момент времени в качестве вышеуказанной метки времени, но не ограничиваясь этим.
Например, первоначальное содержимое журнала событий может быть похоже на следующую таблицу:
Если система 3 администрирования получила доступ к журналу событий в 23:32:23 22.12.2018 и «поняла», что время возникновения события 2 неверно или неизвестно, она может автоматически сгенерировать вышеуказанную информацию для идентификации времени резервного копирования для события 2 и исправить содержимое журнала событий или создать новый журнал событий согласно исправлению. В одном варианте осуществления исправленный журнал событий или новый журнал событий может быть похож на следующую таблицу:
Если администратор входит в систему 3 администрирования посредством рабочего интерфейса и запрашивает журнал событий системы 3 администрирования, система 3 администрирования может отобразить информацию для идентификации времени резервного копирования, как показано в вышеуказанной таблице в виде времени возникновения события 2. Таким образом, даже если системное событие возникает в RMC 21 или BMC 22 перед завершением им процедуры синхронизации времени, система 3 администрирования все еще может назначить идентифицируемое время резервного копирования для этого системного события. Таким образом, система 3 администрирования и администратор могут верно интерпретировать системное событие согласно времени резервного копирования с целью улучшения эффекта процедуры удаленного восстановления.
После этапа S46 система 3 администрирования может отправлять команду управления (такую как первая команда управления) посредством сети на RMC 21/BMC 22, находящийся в текущий момент в первом типе состояния, требующего внимания, с целью выполнения процедуры коррекции времени в RMC 21/BMC 22, функционирующего ненормально в отношении времени (этап S47). В одном варианте осуществления процедура коррекции времени выполняется для управления RMC 21/BMC 22 для выполнения коррекции времени в соответствии со службой NTP. В другом варианте осуществления процедура коррекции времени исполняется для того, чтобы заставить RMC 21/BMC 22 выполнить процедуру сброса, но не ограничиваясь этим.
Ниже будет описан другой вариант осуществления первого типа состояния, требующего внимания.
Если количество стоек 2 в дата-центре 1 слишком большое, для администратора дата-центра 1 может представлять сложность обновление каждой из стоек 1 вручную. Соответственно, когда администратор должен выполнять процедуру обновления RMC 21 и BMC 22 в стойках 2 (например, обновление прошивки), он или она может использовать систему 3 администрирования для доставки инструкции по обновлению и прошивки самой последней версии посредством исходного кода системы 3 администрирования с целью одновременного обновления всех RMC 21/BMC 22 нескольких стоек 2 в дата-центре 1.
Если во время процедуры обновления возникают проблемы, такие как разрывы сетевого соединения из-за сетевого трафика или неустойчивого сигнала, части RMC 21/BMC 22 могут быть неспособны завершить процедуру обновления в рамках стандартного процесса обновления, и это может привести к неудачной процедуре обновления. Однако части RMC 21/BMC 22 могут вызвать неправильную работу системы после неудачной процедуры обновления, но могут все еще поддерживать сетевое соединение (например, они вошли в режим обновления, но не могут выйти обратно в рабочий режим). В этом состоянии система 3 администрирования должна производить вмешательство из удаленного пункта для сброса такого ненормального состояния.
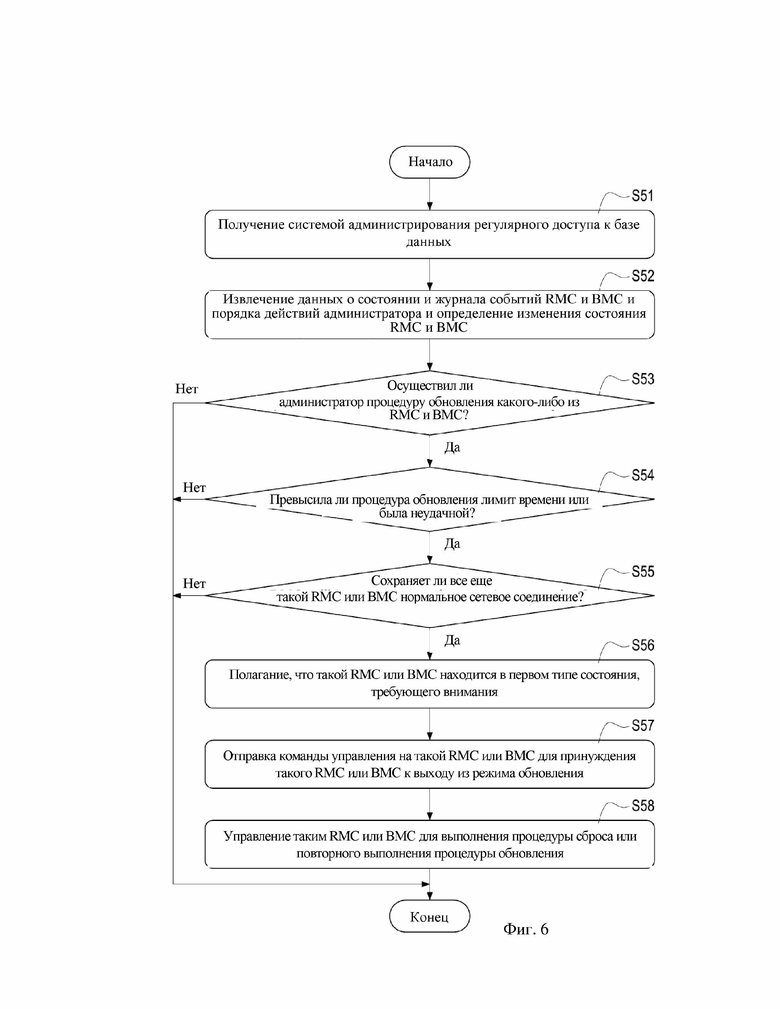
Рассмотрим фиг. 6, которая представляет собой блок-схему для сброса первого типа состояния, требующего внимания, согласно второму варианту осуществления настоящего изобретения. В этом варианте осуществления система 3 администрирования может регулярно получать доступ к базе 31 данных (этап S51) с целью извлечения данных о состоянии и журнала событий RMC 21 и BMC 22 в стойке 2 для извлечения порядка действий, выполняемого администратором посредством рабочего интерфейса, и определения изменения состояния RMC 21 и BMC 22 согласно данным о состоянии, журналу событий и порядку действий (этап S52).
В данном варианте осуществления система 3 администрирования может сначала анализировать данные о состоянии и журнал событий RMC 21 и BMC 22 для определения того, превысила ли процедура обновления какого-либо из RMC 21/BMC 22 лимит времени или была неудачной (этап S54), и также анализа данных о состоянии и журнала событий RMC 21 и BMC 22 для определения того, поддерживает ли все еще RMC 21/BMC 22 нормальное сетевое соединение (этап S55). Если система 3 администрирования определяет после анализа, что один из RMC 21/BMC 22 превысил лимит времени процедуры обновления или она была неудачной, но по-прежнему сохранил нормальное сетевое соединение, она может полагать, что такой RMC 21/BMC 22 находится в вышеуказанном первом типе состояния, требующего внимания (этап S56), т. е. система 3 администрирования может полагать, что определенное ненормальное состояние возникает в таком RMC 21/BMC 22, но RMC 21/BMC 22 по-прежнему поддерживает сетевое соединение с системой 3 администрирования.
Более конкретно, система 3 администрирования может определять, осуществил ли администратор процедуру обновления или нет в отношении какого-либо из RMC 21/BMC 22 в стойке 2 согласно порядку действий после этапа S52 (этап S53). После определения того, что администратор осуществил процедуру обновления, система 3 администрирования переходит к исполнению этапа S54 и этапа S55 с целью определения, превысили ли процедуры обновления RMC 21/BMC 22 лимит времени или были неудачными, и также определять, являются ли сетевые соединения RMC 21/BMC 22 нормальными.
После принятия RMC 21/BMC 22 процедуры обновления, осуществленной администратором, они могут автоматически войти в режим обновления. В то же время, каждый из RMC 21/BMC 22 может оставить метку в своих данных о состоянии для указания того, что на данный момент он находится в режиме обновления. Когда периферическое устройство поддерживает связь с каждым из RMC 21/BMC 22 и прочитывает метку, указывающую на режим обновления в данных о состоянии, оно может автоматически прекратить взаимодействовать с каждым из RMC 21/BMC 22. То есть, если один из RMC 21/BMC 22 осуществил неудачную процедуру обновления и не может выйти из режима обновления, этот RMC 21/BMC 22 будет неспособен нормально работать. Если система 3 администрирования обнаруживает, что один из RMC 21/BMC 22 принял процедуру обновления и процедура обновления превысила лимит времени или была неудачной, но этот RMC 21/BMC 22 не утратил сетевого соединения, то система 3 администрирования может полагать, что RMC 21/BMC 22 находится в вышеуказанном первом типе состояния, требующего внимания.
После этапа S56 система 3 администрирования может отправлять команду управления (такую как вторая команда управления) на такой RMC 21/BMC 22, находящийся в первом типе состояния, требующего внимания, посредством сети, с той целью, чтобы заставить RMC 21/BMC 22, который осуществил неудачную процедуру обновления, выйти из режима обновления (этап S57).
Как указано выше, даже если процедура обновления была неудачной (т. е. не смогла выйти из режима обновления), RMC 21/BMC 22 все еще может получать и выполнять команды. Проблема заключается в том, что периферическое устройство будет автоматически прекращать взаимодействие с RMC 21/BMC 22 после прочтения метки, указывающей на режим обновления. В вышеуказанном варианте осуществления система 3 администрирования будет игнорировать метку, указывающую на режим обновления, и продолжать отправку второй команды управления непосредственно на RMC 21/BMC 22, чтобы заставить RMC 21/BMC 22 выйти из режима обновления, поскольку он определил возникновение некоторого ненормального состояния в RMC 21/BMC 22.
После этапа S57 система 3 администрирования может продолжать отправлять другую команду управления (такую как третья команда управления) на RMC 21/BMC 22, который уже вышел из режима обновления, посредством сети, с целью заставить такой RMC 21/BMC 22 выполнить процедуру сброса, или вновь выполнить процедуру обновления (этап S58). Таким образом, система 3 администрирования может удостовериться в том, что RMC 22/BMC 22 может восстановиться обратно к нормальному состоянию, и прошивка или программное обеспечение такого RMC 22/BMC 22 может быть обновлено до самой последней версии.
Ниже будет описан вышеуказанный второй тип состояния, требующего внимания.
RMC 21/BMC 22 в настоящем изобретении являются встроенными системами, даже если узлы 220 в стойке 2 еще не включены, система 3 администрирования все еще может выполнять процедуру удаленного администрирования, такую как удаленная загрузка, удаленное выключение, удаленный запрос и т. д., посредством связи с RMC 21/BMC 22 в стойке 2 и узлах 220.
Вообще говоря, при выполнении процедуры удаленного администрирования администратор дата-центра 1 может поддерживать связь с RMC 21/BMC 22 в стойке 2 путем отправки инструкций IPMI посредством сети с использованием средств IPMI (интеллектуального интерфейса администрирования платформой) на систему 3 администрирования. При использовании средств IPMI каждая инструкция IPMI, отправленная им, должна сначала установить сеанс IPMI с целевым RMC 21 или BMC 22, чтобы система 3 администрирования могла поддерживать связь с целевым RMC 21 или BMC 22 после установления сеанса IPMI. В частности, после установления сеанса IPMI системе 3 администрирования разрешается поддерживать связь с нижним аппаратным устройством RMC 21, BMC 22, стойкой 2 или узлом 220 посредством сети с целью получения результатов исполнения инструкции IPMI (такой как версия прошивки, показание всех датчиков в узле 220 и т. д.).
Вычислительный ресурс встроенной системы ограничен. Однако работа встроенной системы, связь с RMC 21, связь с каждым из BMC 22, ответ системе мониторинга дата-центра 1 и т. д., может целиком поглотить вычислительный ресурс встроенной системы (т. е. RMC 21 или BMC 22).
Кроме того, она может также поглотить вычислительный ресурс RMC 21/BMC 22 при выполнении системой 3 администрирования процедуры удаленного администрирования каждого из RMC 21/BMC 22. В частности, процедура удаленного администрирования, выполняемая системой удаленного 3 администрирования, может чрезвычайно увеличить длительность сеанса IPMI RMC 21/BMC 22 и привести к отсутствию ответа от RMC 21/BMC 22 или превышению лимита времени. В этом сценарии, хотя RMC 21/BMC 22 еще не находятся в ненормальном состоянии, но система 3 администрирования может быть вынуждена произвести вмешательство из удаленного пункта для ограждения RMC 21/BMC 22 от возможного ненормального состояния.
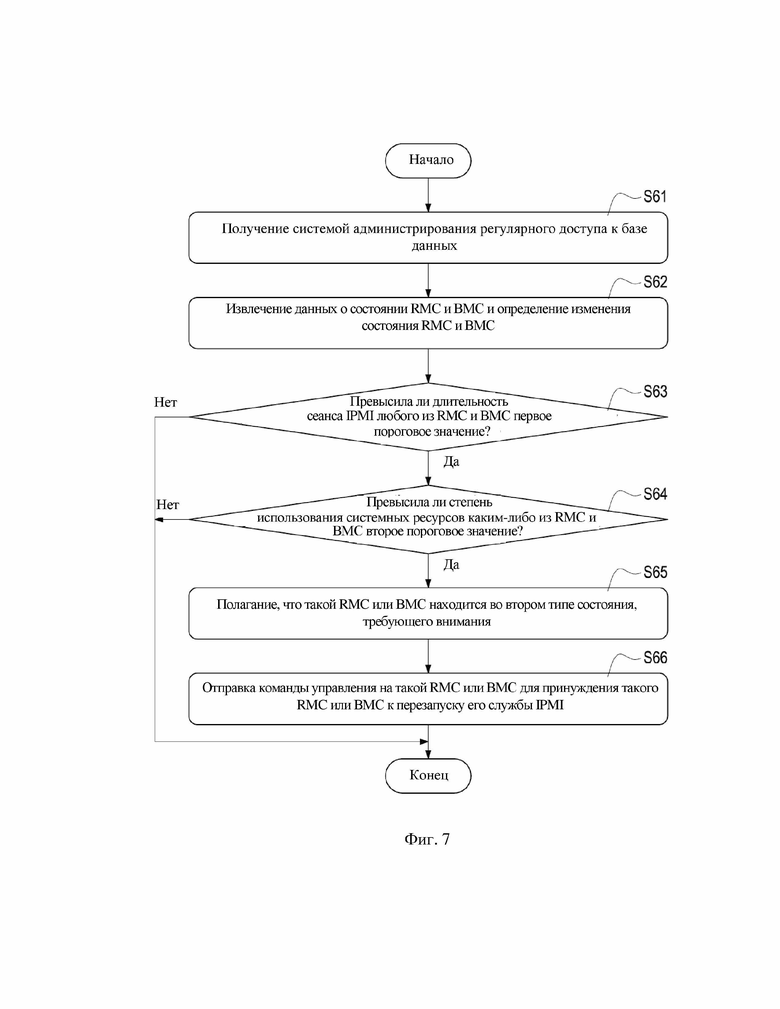
Рассмотрим фиг. 7, которая представляет собой блок-схему для сброса второго типа состояния, требующего внимания, согласно первому варианту осуществления настоящего изобретения. В данном варианте осуществления система 3 администрирования может регулярно получать доступ к базе 31 данных (этап S61), извлекать данные о состоянии RMC 21/BMC 22 в стойке 2 из базы 31 данных для определения изменения состояния RMC 21/BMC 22 (этап S62). В одном варианте осуществления система 3 администрирования на этапе S62 должна получать данные о текущей длительности сеанса IPMI RMC 21 и каждого из BMC 22. В другом варианте осуществления система 3 администрирования на этапе S62 также получает данные о текущей степени использования системных ресурсов RMC 21 и каждого из BMC 22.
После этапа S62 система 3 администрирования определяет, имеет ли RMC 21/BMC 22 длительность сеанса IPMI большую, чем первое пороговое значение (этап S63), и полагает, что RMC 21/BMC 22 находится в вышеуказанном втором типе состояния, требующего внимания, при определении, что длительность сеанса IPMI такого RMC 21/BMC 22 превышает первое пороговое значение (этап S65), т. е. система 3 администрирования может полагать, что такой RMC 21 или BMC 22 поддерживает нормальное сетевое соединение с системой 3 администрирования, но некоторое ненормальное состояние скоро возникнет в таком RMC 21/BMC 22.
Стоит заметить, что если система 3 администрирования получает степень использования системных ресурсов RMC 21 и каждого из BMC 22 на этапе S62, система 3 администрирования может одновременно определять, превышает ли степень использования RMC 21/BMC 22 системных ресурсов второе пороговое значение (этап S64). В этом сценарии система 3 администрирования может полагать, что RMC 21/BMC 22 находится во втором типе состояния, требующего внимания, при определении того, что текущая длительность сеанса IPMI такого RMC 21/BMC 22 превышает первое пороговое значение, и степень использования системных ресурсов такого RMC 21/BMC 22 превышает второе пороговое значение.
В одном варианте осуществления степень использования системных ресурсов включает степень использования CPU или памяти RMC 21/BMC 22. В другом варианте осуществления степень использования системных ресурсов может представлять собой степень использования некоторых системных ресурсов внутри RMC 21/BMC 22, используемых для предоставления любой службы, такой как служба протокола передачи гипертекста (HTTP), служба IPMI и т. д., но не ограничиваясь этим.
После подтверждения того, что RMC 21/BMC 22 находится во втором типе состояния, требующего внимания, система 3 администрирования может дополнительно отправить команду управления (такую как четвертая команда управления) на такой RMC 21/BMC 22, находящийся во втором типе состояния, требующего внимания, посредством сети, чтобы заставить RMC 21/BMC 22 перезапустить свою службу IPMI (этап S66). Таким образом, такой RMC 21/BMC 22 может выгрузить накопленные сеансы IPMI, чтобы оградить себя от возникновения ненормального состояния.
В одном варианте осуществления четвертая команда управления является командой сброса. Система 3 администрирования отправляет команду сброса на RMC 21/BMC 22, находящийся во втором типе состояния, требующего внимания, посредством сети, с целью принуждения RMC 21/BMC 22 к выполнению процедуры сброса. Таким образом, сброс RMC 21/BMC 22 может перезапустить его службу IPMI. Однако вышеуказанное описание представляет собой лишь один из иллюстративных вариантов осуществления настоящего изобретения, не ограничиваясь этим.
Путем выполнения вышеуказанного технического решения система 3 администрирования за счет анализа может заранее «понимать», что некоторое ненормальное состояние скоро возникнет в RMC 21/BMC 22, и активно выполнять служебную процедуру удаленного перезапуска RMC 21/BMC 22 для предотвращения возникновения ненормального состояния в таком RMC 21/BMC 22 и влияния на работу стойки 2.
Ниже будет описан вышеуказанный третий тип состояния, требующего внимания.
Как упомянуто выше, система 3 администрирования в настоящем изобретении может поддерживать связь с RMC 21/BMC 22 в стойке 2 в дата-центре 1 посредством сети, и администратор может выполнять процедуру удаленного администрирования этих RMC 21/BMC 22 также посредством сети. Таким образом, при потере BMC 22 стойки 2 своего сетевого соединения система 3 администрирования не сможет поддерживать связь с этими BMC 22, и администратор также не может администрировать эти BMC 22. В данном варианте осуществления ненормальное состояние BMC 22, выраженное в потере сетевого соединения, может быть вызвано ошибкой установки IP-адреса.
В общем, IP-адрес каждого из BMC 22 в стойке 2 может быть задан в виде динамического IP-адреса (т. е. режим сети BMC 22 задан в виде режима динамического IP) или статический IP-адрес (т. е. режим сети BMC 22 задан в виде режима статического IP). Если режим сети BMC 22 задан в виде режима динамического IP, сервер протокола динамической настройки узла (DHCP) (не показан) в дата-центре 1 может активно назначить динамический IP-адрес для BMC 22. Если режим сети BMC 22 задан в виде режима статического IP, администратор дата-центра 1 может вручную задать статический IP-адрес для BMC 22 посредством рабочего интерфейса, предоставленного системой 3 администрирования.
С целью выполнения процедуры задания сети в отношении каждого BMC 22 в стойке 2 для задания статического IP-адреса администратор должен отправить по меньшей мере четыре инструкции на BMC 22 посредством системы 3 администрирования (т. е. должны быть установлены по меньшей мере четыре сеанса IPMI), включая: (1) задание режима сети BMC 22 в виде режима статического IP; (2) задание статического IP-адреса для BMC 22; (3) задание маски подсети для BMC 22, и (4) задание IP-адреса шлюза для BMC 22.
Как указано выше, при задании администратором неверного статического IP-адреса для BMC 22 (например, статический IP-адрес, заданный администратором, является идентичным одному или более динамическим IP-адресам в назначенном сервере DHCP), или при задании администратором неверного IP-адреса шлюза для BMC 22, система 3 администрирования может быть неспособна соединиться с таким BMC 22 в некотором окружении, где сосуществуют несколько подсетей, или некотором окружении, где связь возможна только посредством шлюза. В этом сценарии, хотя узел 220, имеющий такой BMC 22, по-прежнему существует в стойке 2, но система 3 администрирования уже утратила соединение с BMC 22, так что она не может администрировать такой BMC 22 (и также узел 220, имеющий такой BMC 22). В результате система 3 администрирования может быть вынуждена вмешаться из удаленного пункта для помощи BMC 22 в восстановлении его сетевого соединения.
Рассмотрим фиг. 8, которая представляет собой блок-схему для сброса третьего типа состояния, требующего внимания, согласно первому варианту осуществления настоящего изобретения. В данном варианте осуществления система 3 администрирования может регулярно получать доступ к базе 31 данных (этап S71) и извлекать данные о состоянии каждого из BMC 22 в стойке 2, порядок действий, выполняемый администратором посредством системы 3 администрирования, и любую обратную информацию, полученной системой 3 администрирования на основании порядка действий из базы 31 данных, для определения изменения состояния BMC 22 (этап S72).
В одном варианте осуществления данные о состоянии, полученные системой 3 администрирования на этапе S72 по меньшей мере включают режим сети (режим статического IP или режим динамического IP) каждого из BMC 22, статический IP-адрес каждого из BMC 22, маску подсети каждого из BMC 22, шлюзовой IP-адрес каждого из BMC 22 и т. д., не ограничиваясь этим. Также обратная информация, полученная системой 3 администрирования на этапе S72, по меньшей мере содержит сигнал обратной связи, параметры системы и исполняемые данные, сгенерированные системой 3 администрирования, стойкой 2 и каждым из узлов 220 (и каждого из BMC 22), основанные на порядке действий при выполнении порядка действий, но не ограничиваясь этим.
После этапа S72 система 3 администрирования сначала определяет, потерял ли какой-либо из BMC 22 в стойке 2 свое сетевое соединение с системой 3 администрирования согласно данным о состоянии и обратной информации (этап S73). Также система 3 администрирования определяет, выполнил ли администратор процедуру настройки сети для какого-либо из BMC 22 в стойке 2 согласно порядку действий (этап S74). Если система 3 администрирования определяет, что администратор только что выполнил процедуру настройки сети в отношении одного из BMC 22 и такой BMC 22 потерял сетевое соединение с системой 3 администрирования после принятия процедуры задания сети, она может полагать, что такой BMC 22 находится в вышеуказанном третьем типе состояния, требующего внимания (этап S75), т. е. система 3 администрирования может полагать, что этот BMC 22 утратил сетевое соединение.
Стоит заметить, что на этапе S73 система 3 администрирования может определить, что один из BMC 22 утратил свое сетевое соединение (уже утратил свое сетевое соединение или вскоре утратит сетевое соединение) при определении, что режим сети такого BMC 22 находится в режиме статического IP и статический IP-адрес, использованный таким BMC 22, является идентичным одному или более динамическим IP-адресам, назначенным сервером DHCP.
В другом варианте осуществления система 3 администрирования на этапе S73 может также определять, что один из BMC 22 утратил свое сетевое соединение (уже утратил свое сетевое соединение или вскоре утратит сетевое соединение), когда режим сети такого BMC 22 находится в режиме статического IP и IP-адрес шлюза BMC 22 был задан неверно. Однако вышеуказанные описания представляют собой лишь несколько примеров иллюстративных вариантов осуществления настоящего изобретения, не ограничиваясь ими.
После этапа S75 система 3 администрирования может полагать, что конкретный BMC 22 находится в вышеуказанном третьем типе состояния, требующего внимания. После этого система 3 администрирования определяет некоторый RMC 21 в дата-центре 1, ответственный за такой BMC 22 (этап S76), и управляет этим RMC 21 для изучения узла 220, имеющего такой BMC 22, посредством внутренних аппаратных линий 24 (этап S77), с целью подтверждения того, существует ли узел 220 или нет (этап S78).
Как показано на фиг. 2, RMC 21 может физически соединяться со всеми BMC 22 всех узлов 220 в той же стойке 2 посредством внутренних аппаратных линий 24. Таким образом, даже при потере BMC 22 своего сетевого соединения RMC 21 в той же стойке 2 может все еще поддерживать связь с таким BMC 22 посредством внутренних аппаратных линий 24.
При определении того, что узел 220, имеющий такой BMC 22, утративший сетевое соединение, не существует на этапе S78 (например, узел 220 был удален из стойки 2 или поврежден), система 3 администрирования может отправлять соответствующее предупреждающее сообщение (этап S79). В одном варианте осуществления система 3 администрирования может отправлять предупреждающее сообщение, например, в виде слов, световых или звуковых сигналов, посредством рабочего интерфейса, с целью предупреждения администратора. В другом варианте осуществления система 3 администрирования может отправлять предупреждающее сообщение вовне к администратору, например, текстовые сообщения, электронные письма или сообщения программного обеспечения связи, посредством сети с целью предупреждения администратора.
При определении того, что узел 220, имеющий такой BMC 22, утративший сетевое соединение, действительно существует на этапе S78, система 3 администрирования управляет RMC 21, берущим ответственность за такой BMC 22, чтобы отправить набор инструкций IPMI на такой BMC 22 посредством внутренних аппаратных линий 24 для BMC 22 для восстановления его сетевого соединения (этап S80). В одном варианте осуществления система 3 администрирования может отправлять инструкции IPMI на такой BMC 22 посредством RMC 21 с целью исправления статичного IP адреса BMC 22 или IP-адреса шлюза BMC 22 и принуждает BMC 22 к восстановлению сетевого соединения (т. е. соединения с системой 3 администрирования).
Используя вышеуказанное техническое соединение, система 3 администрирования может активно выполнять процедуру аварийного восстановления с BMC 22 из удаленного пункта после потери BMC 22 его соединения с системой 3 администрирования, с целью помощи BMC 22 в восстановлении его сетевого соединения.
Способ, раскрытый в настоящем изобретении, может использовать систему 3 администрирования для автоматического сбора нужной информации и анализа состояния RMC 21 и BMC 22, и автоматически выполняет соответствующую процедуру для сброса ненормального состояния каждого из RMC 21/BMC 22 после определения того, что RMC 21/BMC 22 находится в одном из нескольких предварительно определенных состояний, требующих внимания. Таким образом, технические решения настоящего изобретения могут уменьшить стоимость администрирования с возможностью получения процедуры мониторинга дата-центра 1 без вмешательства человека и влияния расстояния и времени.
Специалистам в данной области необходимо принять во внимание, что в описанном варианте осуществления могут быть выполнены различные изменения и модификации. Предполагается включение всех подобных вариантов, модификаций и эквивалентов, которые попадают под объем правовой охраны настоящего изобретения, который определен прилагаемой формулой изобретения.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ УДАЛЕННОГО СБРОСА НЕНОРМАЛЬНОГО СОСТОЯНИЯ СТОЕК, ПРИМЕНЯЕМЫХ В ДАТА-ЦЕНТРЕ | 2019 |
|
RU2711469C1 |
| СПОСОБ УДАЛЕННОГО СБРОСА НЕНОРМАЛЬНОГО СОСТОЯНИЯ СТОЕК, ПРИМЕНЯЕМЫХ В ДАТА-ЦЕНТРЕ | 2019 |
|
RU2709677C1 |
| ИНТЕЛЛЕКТУАЛЬНАЯ СТОЙКА И ПРИМЕНЯЕМЫЙ В НЕЙ СПОСОБ УПРАВЛЕНИЯ IP-АДРЕСАМИ | 2018 |
|
RU2697745C1 |
| СТОЙКА С МНОЖЕСТВОМ МОДУЛЕЙ УПРАВЛЕНИЯ СТОЙКОЙ И СПОСОБ ОБНОВЛЕНИЯ ВСТРОЕННОГО ПРОГРАММНОГО ОБЕСПЕЧЕНИЯ, ИСПОЛЬЗУЕМОГО ДЛЯ СТОЙКИ | 2015 |
|
RU2602378C9 |
| УСТРОЙСТВО JBOD, СОДЕРЖАЩЕЕ МОДУЛЬ BMC, И СПОСОБ УПРАВЛЕНИЯ ИМ | 2015 |
|
RU2602376C1 |
| СТОЙКА С ФУНКЦИЕЙ АВТОМАТИЧЕСКОГО ВОССТАНОВЛЕНИЯ И СПОСОБ АВТОМАТИЧЕСКОГО ВОССТАНОВЛЕНИЯ ДЛЯ ЭТОЙ СТОЙКИ | 2015 |
|
RU2614569C2 |
| Компьютерная система с удаленным управлением сервером и устройством создания доверенной среды | 2017 |
|
RU2690782C2 |
| Компьютерная система с удаленным управлением сервером и устройством создания доверенной среды и способ реализации удаленного управления | 2016 |
|
RU2633098C1 |
| СПОСОБ И СИСТЕМА ДЛЯ ОПРЕДЕЛЕНИЯ ФИЗИЧЕСКОГО МЕСТОПОЛОЖЕНИЯ ОБОРУДОВАНИЯ | 2008 |
|
RU2475976C2 |
| ПОЛЬЗОВАТЕЛЬСКИЙ ИНТЕРФЕЙС ДЛЯ ОБЕСПЕЧЕНИЯ БЕЗОПАСНОСТИ И УДАЛЕННОГО УПРАВЛЕНИЯ СЕТЕВЫМИ КОНЕЧНЫМИ ТОЧКАМИ | 2015 |
|
RU2697935C2 |
Изобретение относится к дата-центру и может быть использовано для анализа и сброса ненормального состояния стоек, применяемых в дата-центре. Технический результат – автоматическое выполнение процедуры удаленного аварийного восстановления ВМС в стойке для сброса ненормального состояния ВМС из удаленного пункта. Способ удаленного сброса ненормального состояния стоек включает следующие этапы: регулярное получение системой администрирования любой информации от контроллера управления стойкой (RMC) и нескольких контроллеров управления материнской платой (BMC); запись каждого рабочего действия, выполненного администратором посредством системы администрирования; анализ информации и рабочего действия системой администрирования для определения того, находится ли какой-либо из RMC или BMC в одном из нескольких установленных по умолчанию состояний, требующих внимания; и автоматическое выполнение процедуры удаленного аварийного восстановления одного из RMC и нескольких BMC для устранения ненормального состояния соединения RMC или BMC, при определении того, что RMC или BMC утрачивает соединение с системой администрирования. 9 з.п. ф-лы, 9 ил., 2 табл.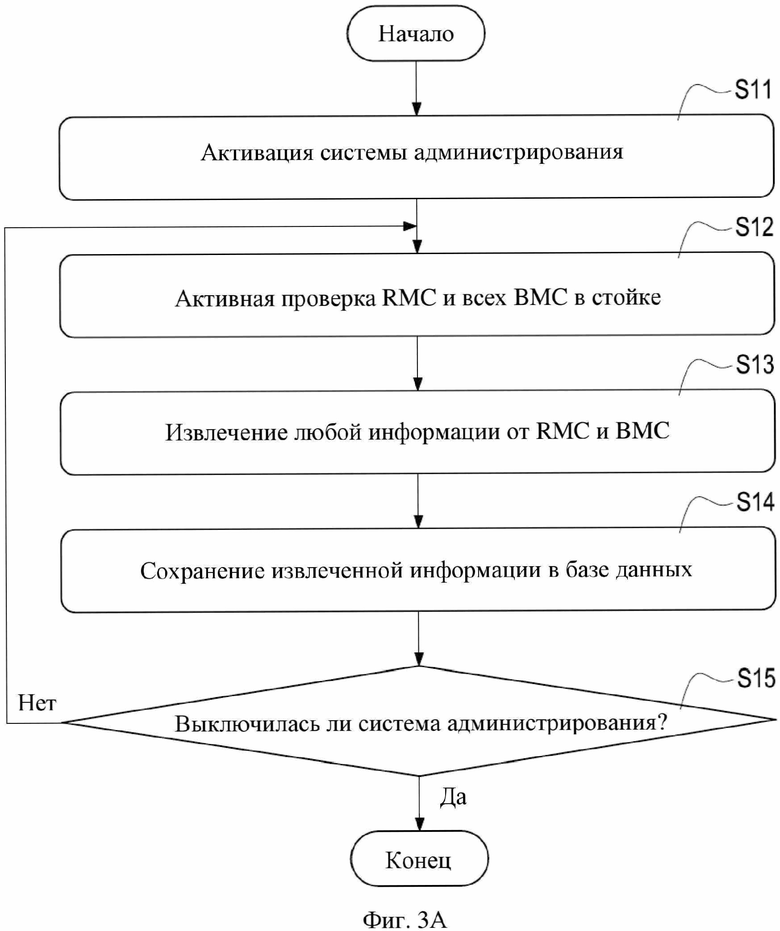
1. Способ удаленного сброса ненормального состояния стоек, применяемых в дата-центре, содержащем стойку и систему администрирования стоечного сервера, соединенную со стойкой из удаленного пункта, причем стойка содержит контроллер управления стойкой (RMC) и несколько узлов, при этом каждый из узлов содержит контроллер управления материнской платой (BMC), и при этом способ включает следующие этапы:
a) регулярное получение доступа к базе данных системой администрирования стоечного сервера для получения данных о состоянии каждого из BMC, порядке действий, выполняемом администратором в отношении стойки посредством системы администрирования стоечного сервера, и обратной информации, сгенерированной и полученной на основании порядка действий;
b) определение того, находится ли какой-либо из нескольких BMC в одном из нескольких предварительно определенных состояний, требующих внимания, согласно данным о состоянии, порядке действий и обратной информации; и
c) выполнение процедуры удаленного аварийного восстановления автоматически в отношении конкретного одного из нескольких BMC, находящегося в третьем типе состояния, требующего внимания, из нескольких предварительно определенных состояний, требующих внимания, посредством системы администрирования стоечного сервера после определения того, что конкретный один из нескольких BMC находится в третьем типе состояния, требующего внимания, причем процедуру удаленного восстановления выполняют для сброса ненормального состояния потери соединения конкретным одним из нескольких BMC, и третий тип состояния, требующего внимания, указывает, что конкретный один из BMC утратил соединение с системой администрирования стоечного сервера.
2. Способ по п. 1, отличающийся тем, что дополнительно включает следующие этапы:
a01) активация системы администрирования стоечного сервера;
a02) регулярная и активная проверка RMC и каждого из BMC в стойке системой администрирования стоечного сервера из удаленного пункта после этапа a01);
a03) получение данных о состоянии RMC и каждого из BMC;
a04) сохранение данных о состоянии в базе данных, и
a05) непрерывное исполнение этапов a02)–a04) перед выключением системы администрирования стоечного сервера.
3. Способ по п. 1, отличающийся тем, что дополнительно включает следующие этапы:
a11) активация системы администрирования стоечного сервера;
a12) предоставление рабочего интерфейса системой администрирования стоечного сервера после этапа a11);
a13) выполнение процедуры удаленного администрирования RMC и каждого из BMC согласно порядку действий, при получении порядка действий, выполненного администратором посредством рабочего интерфейса;
a14) получение обратной информации, сгенерированной на основании выполненной процедуры удаленного администрирования;
a15) сохранение порядка действий и обратной информации в базе данных, и
a16) непрерывное исполнение этапов a12)–a15) перед выключением системы администрирования стоечного сервера.
4. Способ по п. 1, отличающийся тем, что данные о состоянии по меньшей мере содержат режим сети, IP-адрес, маску подсети и IP-адрес шлюза каждого из BMC.
5. Способ по п. 1, отличающийся тем, что обратная информация по меньшей мере содержит сигнал обратной связи, параметры системы и исполняемые данные, сгенерированные системой администрирования стоечного сервера, стойкой, каждым из узлов, RMC и каждым из BMC на основании порядка действий при выполнении порядка действий.
6. Способ по п. 1, отличающийся тем, что этап b) содержит следующие этапы:
b1) определение того, утратил ли какой-либо из нескольких BMC свое соединение с системой администрирования стоечного сервера согласно данным о состоянии и обратной информации;
b2) определение того, проводится ли процедура настройки сети в отношении какого-либо из нескольких BMC согласно порядку действий; и
b3) принятие того, что конкретный один из нескольких BMC находится в третьем типе состояния, требующего внимания, если конкретный один из нескольких BMC выполнил процедуру настройки сети и утратил свое соединение с системой администрирования стоечного сервера после выполнения процедуры настройки сети.
7. Способ по п. 6, отличающийся тем, что этап b1) предназначен для определения того, что конкретный один из нескольких BMC утратил свое соединение, когда режим сети конкретного одного из нескольких BMC находится в режиме статического IP, и статический IP-адрес, используемый конкретным одним из BMC, идентичен одному из нескольких динамических IP-адресов, назначенных сервером протокола динамической настройки узла (DHCP) в дата-центре.
8. Способ по п. 6, отличающийся тем, что этап b1) предназначен для определения того, что конкретный один из нескольких BMC утратил свое соединение, когда режим сети конкретного одного из нескольких BMC находится в режиме статического IP и IP-адрес шлюза конкретного одного из нескольких BMC был задан неверно.
9. Способ по п. 6, отличающийся тем, что этап c) включает следующие этапы:
c1) подтверждение и соединение с некоторым RMC в дата-центре, который ответственен за конкретный один из нескольких BMC, при определении того, что конкретный один из BMC находится в третьем типе состояния, требующего внимания;
c2) управление некоторым RMC для изучения некоторого одного из узлов, имеющего конкретный один из нескольких BMC, посредством внутренних аппаратных линий стойки, причем некоторый RMC физически соединен со всеми BMС внутри стойки посредством внутренних аппаратных линий;
c3) отправка предупреждающего сообщения, если некоторый один из узлов, имеющий конкретный один из нескольких BMC, не существует; и
c4) управление некоторым RMC, чтобы отправить инструкцию интеллектуального интерфейса администрирования платформы (IPMI) на конкретный один из нескольких BMC посредством внутренних аппаратных линий, чтобы конкретный один из нескольких BMC восстановил свое сетевое соединение с системой администрирования стоечного сервера, если некоторый один из узлов, имеющий конкретный один из BMC, существует.
10. Способ по п. 9, отличающийся тем, что этап c4) предназначен для сброса статического IP-адреса или IP-адреса шлюза конкретного одного из нескольких BMC.
| TW 201714432 A, 16.04.2017 | |||
| US 9223394 B2, 29.12.2015 | |||
| СТОЙКА С ФУНКЦИЕЙ АВТОМАТИЧЕСКОГО ВОССТАНОВЛЕНИЯ И СПОСОБ АВТОМАТИЧЕСКОГО ВОССТАНОВЛЕНИЯ ДЛЯ ЭТОЙ СТОЙКИ | 2015 |
|
RU2614569C2 |
| СТОЙКА С МНОЖЕСТВОМ МОДУЛЕЙ УПРАВЛЕНИЯ СТОЙКОЙ И СПОСОБ ОБНОВЛЕНИЯ ВСТРОЕННОГО ПРОГРАММНОГО ОБЕСПЕЧЕНИЯ, ИСПОЛЬЗУЕМОГО ДЛЯ СТОЙКИ | 2015 |
|
RU2602378C9 |
| Измерительный трансформатор постоянного тока | 1958 |
|
SU120260A1 |
| СПОСОБ ИЗГОТОВЛЕНИЯ ЗЕРКАЛ | 0 |
|
SU178957A1 |
| US 7761622 B2, 20.07.2010 | |||
| US 9436249 B2, 06.09.2016 | |||
| US 8656003 B2, 18.02.2014. | |||

