Область техники, к которой относится изобретение
Настоящее изобретение относится к области информационных технологий, а именно к способам автоматизированной обработки текста на естественном языке путем его семантической индексации, а также к машиночитаемым носителям, содержащим соответствующие программы, и может применяться для упорядочивания и накопления информации по конкретно заданным предметным областям с целью семантической навигации по документам и коллекциям документов, а также высокоточного и быстрого поиска релевантных информационным потребностям пользователя фактов и документов.
Уровень техники
В настоящее время известны различные способы автоматизированной индексации текстов на естественных языках.
Так, в патенте ЕАПВ №002016 (опубл. 22.01.2001) описан способ, в котором во фрагментах текстового документа определяют уникальные блоки информации и используют их для последующей обработки и поиска. В патенте РФ №2268488 (опубл. 20.01.2006), выданном на основе заявки РСТ WO 01/06414, раскрыт способ, в котором кодируют слова, фразы, идиомы, предложения и даже идеи для последующей числовой обработки. В патенте РФ №2273879 (опубл. 10.04.2006) приведен способ, в котором проводят морфологический и синтаксический анализ текста с последующей индексацией найденных единиц. В способе по патенту США №6871174 (опубл. 22.03.2005) определяют сходство текстов по текстовым фрагментам. Недостаток всех этих способов состоит в том, что в них не учитывается семантическая неоднозначность слов и выражений естественного языка.
В патенте США №6189002 (опубл. 13.02.2001) раскрыт способ, в котором текст разбивают на абзацы и слова, которые преобразуют в векторы упорядоченных элементов. Каждый элемент вектора соответствует абзацу, найденному применением заданной функции к числу появлений в этом абзаце слова, соответствующего этому элементу. Текстовый вектор рассматривается как семантический профиль документа. Однако, с учетом многообразия абзацев, данный способ требует огромного массива запомненных данных и не различает семантической неоднозначности слов и выражений.
Учет семантической неоднозначности осуществляется во многих известных способах. Например, в патенте РФ №2242048 (опубл. 10.12.2004), патентах США №№6871199 (опубл. 22.03.2005), 7024407 (опубл. 04.04.2006) и 7383169 (опубл. 03.06.2008), заявках на патент США №№2007/0005343 и 2007/0005344 (обе опубл. 04.01.2007), 2008/0097951 (опубл. 24.04.2008), выложенных заявках Японии №№05-128149 (опубл. 25.05.1993), 06-195374 (опубл. 15.07.1994), 10-171806 (опубл. 26.06.1998) и 2005-182438 (опубл. 07.07.2005), в заявке ЕПВ №0853286 (опубл. 15.07.1998) описаны способы, в которых тем или иным образом устраняется неоднозначность встречающихся в текстах слов и (или) выражений. Однако все эти способы имеют лишь частное применение и не затрагивают полноценной семантической индексации текста.
Наиболее близкий к заявленной группе изобретений способ семантической индексации текста или коллекции текстов на естественном языке раскрыт в заявке на патент США №2007/0073533 (опубл. 29.03.2007). В этом способе в сегментированном тексте определяют функциональную структуру для каждого участка текста и, в каждой функциональной структуре, находят триады, характеризующие предикатные члены, на основе правил переноса линеаризации. Затем выделяют из каждого участка текста такие признаки как: именованная сущность, тождество по референту, лексическая статья, семантико-структурное отношение, атрибутивная и меронимическая информация. Далее определяют для каждого участка текста, на основе найденных структур конституэнтов, канонизированные представления триад, характеризующих предикатные члены, и выявленных признаков, и определяют структурный индекс на основе канонизированного представления участка текста. Этот способ обеспечивает хорошие результаты, но все же несколько ограничен вследствие того, что в виде триад линеаризуют фрагменты предикатно-аргументной структуры, полученные при синтаксическом анализе. Кроме того, этот способ ориентирован только на поисковые задачи, а не на задачи навигации по массиву документов.
Сущность изобретения
Цель настоящего изобретения состоит в расширении арсенала способов автоматизированной обработки текста на естественном языке путем его семантической индексации за счет использования методов автоматизированного лингвистического анализа и последующего использования его результатов для построения семантических индексов, что обеспечивает семантическую навигацию по документам и коллекциям документов, а также высокоточный и быстрый поиск релевантных информационным потребностям пользователя фактов и документов, особенно в применении к текстам на высоко флективных языках.
Достижение этой цели и получение указанного технического результата обеспечиваются с помощью способа автоматизированной обработки текста на естественном языке путем его семантической индексации и способа автоматизированной обработки коллекции текстов на естественном языке путем их семантической индексации согласно признакам независимых пунктов, соответственно 1 и 6, приложенной формулы изобретения. Варианты обоих способов раскрываются в соответствующих зависимых пунктах этой формулы изобретения.
Краткое описание чертежей
Изобретение поясняется описанием конкретного примера его выполнения и прилагаемыми чертежами, где:
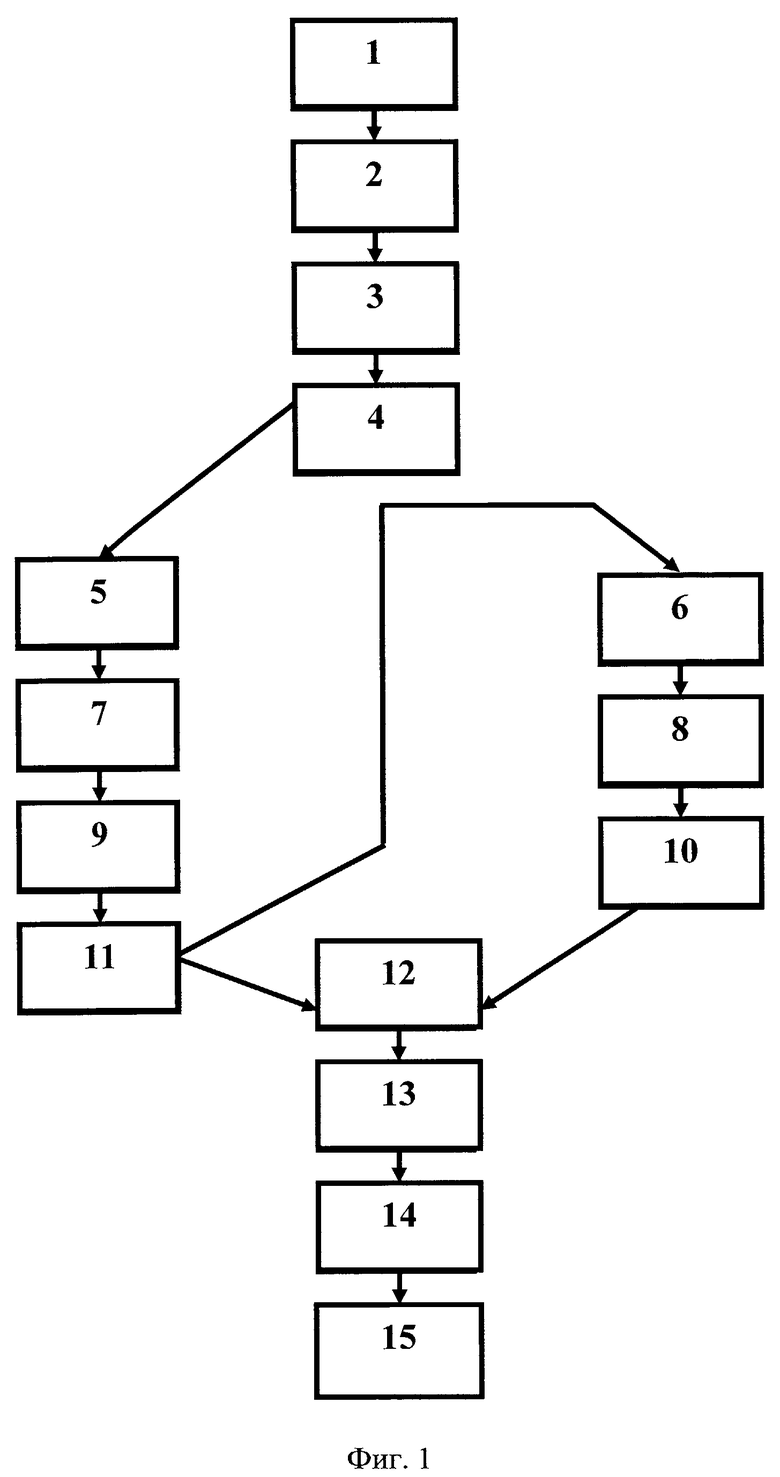
на фиг.1 приведена условная блок-схема, поясняющая заявленные способы;
на фиг.2 приведен фрагмент спецификации предметной области;
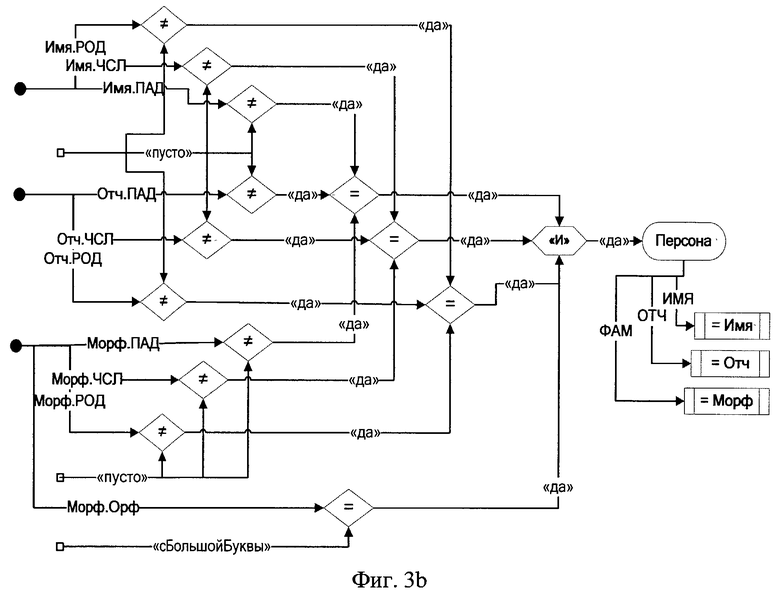
на фиг.3а, 3b приведены спецификация правила для выделения семантически значимых объектов типа «Персона» и соответствующая ей логическая схема обработки сигналов;
на фиг.4а, 4b приведены спецификация правила для выделения семантически значимых отношений типа «работать» и соответствующая ей логическая схема обработки сигналов;
на фиг.5 приведен фрагмент графического представления результатов обработки текста;
на фиг.6 показана общая схема сохранения результатов обработки одного текста;
на фиг.7 приведены спецификация левой части правила для объединения семантически значимых объектов типа «Персона» и соответствующая ей логическая схема обработки сигналов.
Подробное описание изобретения
Предлагаемые способы позволяют эффективно осуществлять смысловую индексацию текстов на естественном языке, как для целей дальнейшей семантической навигации по документам и коллекциям документов, так и для поисковых целей.
Способ автоматизированной обработки текста на естественном языке путем его семантической индексации по первому объекту настоящего изобретения и способ автоматизированной обработки коллекции текстов на естественном языке путем их семантической индексации по второму объекту настоящего изобретения могут быть реализованы практически в любой вычислительной среде, к примеру на персональном компьютере, подключенном к внешним базам данных. Этапы осуществления этих способов иллюстрируются на фиг.1.
Все дальнейшие пояснения даются в применении к русскому языку, который является одним из самых высоко флективных языков, хотя заявляемые способы применимы к семантической индексации текстов на любых естественных языках.
Прежде всего подлежащий индексации текст необходимо представить в электронной форме для последующей автоматизированной обработки. Этот этап на фиг.1 условно обозначен ссылочной позицией 1 и может быть выполнен любым известным способом, например сканированием текста с последующим распознаванием с помощью общеизвестных средств типа ABBYY FineReader. Если же текст поступает на индексацию из электронной сети, к примеру из Интернета, то этап его представления в электронной форме выполняется заранее, до размещения этого текста в сети.
Преобразованный в электронную форму текст поступает на обработку, в процессе которой сначала этот текст сегментируется на элементарные единицы первого уровня, именуемые в общеизвестной литературе токенами (Token). Токеном может быть любой текстовый объект из следующего множества: слова, состоящие каждое из последовательности букв и, возможно, дефисов; последовательность пробелов; знаки препинания; числа. Иногда сюда же относят такие последовательности символов как A300, i150b и т.п. Выделение токенов всегда осуществляется по достаточно простым правилам, например, как в упомянутой заявке на патент США №2007/0073533. На фиг.1 этот этап условно обозначен ссылочной позицией 2.
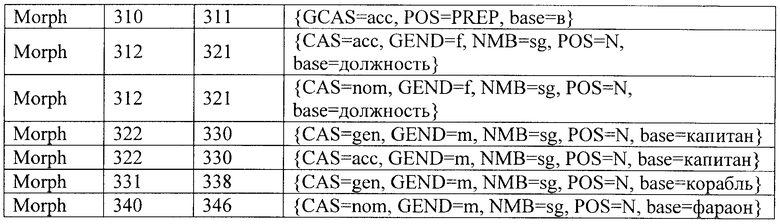
Кроме того, для каждого токена, представляющего собой слово, на основе морфологического анализа формируются соответствующие элементарные единицы второго уровня, именуемые в общеизвестной литературе и далее морфами. При этом для каждого слова выявляется его нормализованная словоформа. К примеру, для слова «иду» нормализованной словоформой будет «идти», для слова «красивого» нормализованной словоформой будет «красивый», а для слова «стеной» нормализованная словоформа - «стена». Кроме того, для каждой словоформы указывается часть речи, к которой относится данное слово, и его морфологические характеристики. Естественно, что для разных частей речи эти характеристики различны. К примеру, для существительных и прилагательных это род (мужской - женский - средний), число (единственное - множественное), падеж; для глаголов это вид (совершенный - несовершенный), лицо, число (единственное - множественное); и т.д. Таким образом, для заданного слова его морфом является нормализованная словоформа + морфологические характеристики, в том числе часть речи. Одно и то же слово может иметь несколько морфов. Например, слово «стекло» имеет два морфа - один для существительного среднего рода и один для глагола в прошедшем времени.
Специалистам должно быть понятно, что операции этого и последующих этапов осуществляются с запоминанием промежуточных результатов, например в оперативном запоминающем устройстве (ОЗУ).
Следующий этап, условно обозначенный на фиг.1 ссылочной позицией 3, состоит в том, что на множестве полученных элементарных единиц первых двух уровней (токенов и морфов) выявляют словосочетания. Это действие выполняется путем преобразования элементарных единиц, т.е. токенов и морфов, в последовательности, которые сопоставляются с последовательностями нормализованных слов и их характеристик в заранее запомненных в базе данных словарях, где слова приведены с указанием морфологических и синтаксических связей между ними. При совпадении очередной сопоставляемой последовательности с соответствующей словарной последовательностью эта очередная сопоставляемая последовательность считается словосочетанием и в таком качестве запоминается в базе данных как элементарная единица третьего уровня.
На следующем этапе, обозначенном на фиг.1 ссылочной позицией 4, формируют предложения, соответствующие участкам индексируемого текста. Обычно это реальные предложения, оканчивающиеся точкой, но в некоторых случаях бывает удобно трактовать в качестве предложения какие-то части обычных предложений, скажем, отдельные элементы при перечислении. Поэтому данная операция может дать на выходе предложения, не всегда совпадающие с предложениями индексируемого текста в традиционном понимании.
Указанная выше последовательность этапов определяется тем, что выявление устойчивых словосочетаний до формирования предложений позволяет в некоторых случаях снять определенные неоднозначности еще до этапов детального анализа текста. Так, например, фиксация устойчивого словосочетания «МГУ им. М.В.Ломоносова» в тексте «…С 1992 г. по 1997 г. Иванов учился в МГУ им. М.В.Ломоносова…» позволяет снять ложный конец предложения после слова «им», которое в общем случае является местоимением, а в данном - сокращением от слова «имени».
После этапа 4 выполняют многоступенчатый семантико-синтаксический анализ. Условно на фиг.1 этот анализ разбит на этапы, обозначенные ссылочными позициями 5-11. Упомянутый многоступенчатый семантико-синтаксический анализ выполняют путем обращения к сформированным в базе данных лингвистическим и эвристическим правилам в заранее заданной лингвистической среде. Такой средой может быть, например, лингвистическая среда, упомянутая в вышеуказанном патенте РФ №2242048, или среда, раскрытая в упомянутой заявке на патент США №2007/0073533, либо любая иная лингвистическая среда, определяющая соответствующие правила, которые позволяют устранять синтаксические и семантические неоднозначности слов и выражений реального текста. Лингвистические и эвристические правила в выбранной среде именуются далее правилами. В процессе упомянутого многоступенчатого семантико-синтаксического анализа выявляют семантически значимые объекты (ссылочная позиция 5 на фиг.1) и их атрибуты (ссылочные позиции 7 и 9 на фиг.1).
Выявление семантически значимых объектов, которые считаются элементарными единицами четвертого уровня, производится в предложении на множестве элементарных единиц первого, второго и (или) третьего уровней. При этом для каждого семантически значимого объекта с помощью упомянутых правил формируют морфологические атрибуты из морфологических атрибутов тех элементарных единиц второго и/или третьего уровней (т.е. морфов и/или словосочетаний), которые составляют данный семантически значимый объект. Кроме того, для каждого семантически значимого объекта с помощью упомянутых правил формируют семантические атрибуты из семантических атрибутов элементарных единиц второго и/или третьего уровней, которые составляют данный семантически значимый объект. Этап формирования указанных атрибутов условно обозначен на фиг.1 ссылочной позицией 7. А на этапе, обозначенном на фиг.1 ссылочной позицией 9, каждому семантически значимому объекту присваивают соответствующий тип из предметной онтологии по тематике той предметной области, к которой относится индексируемый текст. Под онтологией в данном случае понимается спецификация конкретной предметной области, которая хранится в соответствующей базе данных.
Для каждого семантически значимого объекта, т.е. элементарной единицы четвертого уровня, с присвоенным ему типом находят соответствующую ему анафорическую ссылку (если она есть), считающуюся элементарной единицей пятого уровня. Например, в предложении «Капитану Леклеру не суждено было ступить на родную землю: он умер от горячки в открытом море.» анафорической ссылкой к семантически значимому объекту «Леклер» (слово «Леклеру» в тексте) будет местоимение «он», тогда как объект «Леклер» будет антецедентом для этой анафоры. Этот этап нахождения анафорической ссылки условно обозначен на фиг.1 ссылочной позицией 11.
После этого каждый выявленный семантически значимый объект сохраняют в соответствующей памяти вместе с присвоенным ему типом и найденными для него морфологическими и семантическими атрибутами. Анафорическую ссылку запоминают вместе с типом и атрибутами семантически значимого объекта, который является антецедентом этой анафорической ссылки, а также с указанием тождества по референции между этим семантически значимым объектом и его анафорической ссылкой.
После выполнения этапов, обозначенных на фиг.1 ссылочными позициями 5-7-9-11, на основе элементарных единиц первого, второго, третьего, четвертого и/или пятого уровней находят с помощью упомянутых правил семантически значимые отношения между семантически значимыми объектами (этап 6). Семантически значимые отношения могут связывать семантически значимые объекты как внутри одного предложения, так и в пределах всего индексируемого текста.
Для каждого семантически значимого отношения на этапе, обозначенном на фиг.1 ссылочной позицией 8, с помощью упомянутых правил находят морфологические атрибуты из элементарных единиц второго уровня (т.е. морфов), составляющих данное отношение, а также семантические атрибуты из составляющих данное семантически значимое отношение элементарных единиц первого, второго, третьего и/или четвертого уровней.
На этапе, обозначенном на фиг.1 ссылочной позицией 10, каждому семантически значимому отношению присваивают соответствующий тип из хранящейся в базе данных предметной онтологии по тематике той предметной области, к которой относится индексируемый текст. После этого каждое семантически значимое отношение сохраняют в соответствующей памяти вместе с присвоенным ему типом и найденными для него морфологическими и семантическими атрибутами.
На этапе, обозначенном на фиг.1 ссылочной позицией 12, сохраненные семантически значимые объекты и семантически значимые отношения используют для формирования триад. При этом в пределах индексируемого текста для каждого из выявленных семантически значимых отношений, связывающих определенные семантически значимые объекты, формируют множество триад трех типов. Единственная триада первого типа соответствует связи, устанавливаемой семантически значимым отношением между двумя семантически значимыми объектами. Каждая из множества триад второго типа соответствует значению конкретного атрибута одного из этих семантически значимых объектов, а каждая из множества триад третьего типа соответствует значению конкретного атрибута самого семантически значимого отношения. Если обозначить два семантически значимых объекта через Oi и Oj, а связывающее их семантически значимое отношение через Rij, то триаду первого типа можно условно представить (изобразить) как Oi→Rij→Oj. Каждая из триад второго типа может быть представлена как Oi→Aim→Vim или Oj→Ajn→Vjn, где Aim и Ajn являются соответствующими атрибутами, a Vim или Vjn являются соответственно значениями этих атрибутов. Аналогично, каждую из множества триад третьего типа можно представить как Rij→Aijk→Vijk, где Aijk является соответствующим атрибутом, a Vijp является значением этого атрибута. В этих записях индексы i, j, k, m, n и р представляют собой целые числа.
Затем на этапе, обозначенном на фиг.1 ссылочной позицией 13, выполняют индексацию текста. Для этого на множестве сформированных триад индексируют все связанные семантически значимыми отношениями семантически значимые объекты по отдельности, все пары вида «семантически значимый объект - семантически значимое отношение» и все триады вида «семантически значимый объект - семантически значимое отношение - семантически значимый объект» с учетом атрибутов соответствующих семантически значимых объектов и/или семантически значимых отношений. Сформированные на этапе 12 триады и полученные на этапе 13 индексы вместе со ссылкой на исходный текст, из которого сформированы эти триады, сохраняют в базе данных (этап 15 на фиг.1; этап 14 при этом пропускается). Перед этим сначала выполняют (не показано на фиг.1) свертку объектов, которые связаны отношениями тождества по референции, в единый объект, множество атрибутов которого является объединением атрибутов всех объектов, связанных друг с другом отношениями тождества по референции. Это делается для того, чтобы сократить объем памяти в базе данных, требуемый для сохранения таких объектов, а также для того, чтобы интегрировать в рамках одного объекта информацию, полученную из всего текста.
Способ автоматизированной обработки коллекции текстов на естественном языке путем их семантической индексации согласно второму объекту настоящего изобретения выполняется точно так же, как и уже рассмотренный способ автоматизированной обработки текста на естественном языке путем его семантической индексации согласно первому объекту настоящего изобретения, но в этом случае после этапа 13 индексации и перед этапом 15 сохранения в базе данных осуществляют еще один этап. На этом этапе, обозначенном на фиг.1 ссылочной позицией 14 и выполняемом по существу одновременно с этапом 15, при сохранении в базе данных сформированных триад и полученных семантических индексов очередного текста из коллекции текстов выполняют следующее. С помощью сформированных в базе данных лингвистических и эвристических правил в заранее заданной лингвистической среде сравнивают вновь выявленные семантически значимые объекты и семантически значимые отношения с уже имеющимися в базе данных семантически значимыми объектами и семантически значимыми отношениями. В случае идентификации одинаковых семантически значимых объектов и/или семантически значимых отношений дублирующую информацию в базе данных не запоминают, а к соответствующим семантически значимым объектам и/или семантически значимым отношениям добавляют ссылки на очередные тексты, в которых они присутствуют, и ссылки на текстовые фрагменты в пределах каждого из очередных текстов, из которых они выделены. Благодаря этому индексация коллекции текстов происходит практически так же, как и индексация первого текста этой коллекции (или первого текста, проиндексированного данным способом), что позволяет существенно упростить всю процедуру индексации, сократить требуемый объем памяти и интегрировать в рамках одного объекта информацию, полученную из разных текстов.
Для специалистов очевидно, что упоминавшиеся на отдельных этапах запоминающие устройства могут на деле быть как разными устройствами, так и одним запоминающим устройством достаточного объема. Точно так же отдельные базы данных, упоминавшиеся на соответствующих этапах, могут быть не только физически раздельными базами данных, но и единственной базой данных. Более того, упомянутые запоминающие устройства (памяти) могут быть выполнены на той же самой единственной базе данных, либо объединяться с одной из упомянутых баз данных. Специалистам также понятно, что заявленные в настоящем изобретении способы выполняются в соответствующей вычислительной среде под управлением соответствующих программ, которые записаны на машиночитаемых носителях, предназначенных для непосредственного участия в работе компьютера. Поэтому объектами настоящего изобретения являются также и машиночитаемые носители с такими программами.
Пример
Для иллюстрации осуществления заявленного способа автоматизированной обработки текстов на естественном языке путем их семантической индексации рассмотрим следующий пример. Пусть имеется совокупность русских текстов из электронной коллекции литературной классики, представленной на Интернет-сайте http://www.litra.ru. Таким образом, можно считать, что преобразование текстов в электронную форму, обозначенное на фиг.1 ссылочной позицией 1, уже выполнено.
Типичным примером таких текстов является следующий фрагмент из романа А. Дюма «Граф Монте-Кристо»:
27 февраля 1815 г. Марсель из очередного плавания возвращается трехмачтовый корабль «Фараон». Капитану Леклеру не суждено было ступить на родную землю: он умер от горячки в открытом море. Молодой моряк Эдмон Дантес принял на себя командование. Владелец корабля Моррель предлагает Дантесу официально вступить в должность капитана корабля «Фараон»…
В соответствии с заявленным способом автоматизированной обработки текстов на естественном языке путем их семантической индексации используют предварительно созданную спецификацию предметной области, в рамках которой будет осуществляться обработка коллекции документов и построение семантического индекса. Фрагмент такой спецификации представлен на фиг.2. Подобные спецификации готовятся людьми-экспертами, которые на основании своего опыта и знаний фиксируют перечень типов объектов и перечень типовых отношений между ними, существенных для данной предметной области.
В приведенном примере основными типами объектов являются «ФизЛицо», «Организация», «Местоположение» и некоторые другие. Типовые отношения между ними делятся на два класса - общие, характерные для любых предметных областей, например отношение «БЫТЬ_ПРИМЕРОМ» (is_a), фиксирующее иерархию объектов типа «потомок-предок», и специальные - специфичные для выбранной предметной области, например в приведенном примере это типовые отношения «работать_в», «владеть», «высказывания_заявления» и тому подобные.
Кроме того, людьми-экспертами предварительно строится и множество правил, причем каждое правило содержит в левой части шаблон поиска примеров объектов и/или примеров отношений между ними, а в правой части - операторы фиксации в тексте найденных по шаблону примеров объектов и/или примеров отношений между ними. В дальнейшем с помощью таких правил, подготовленных людьми-лингвистами, в обрабатываемых текстах автоматически выявляют конкретные сведения, соответствующие спецификации предметной области.
Кроме спецификации предметной области и правил в соответствии с изложенными выше способами используются словари общей и специальной лексики.
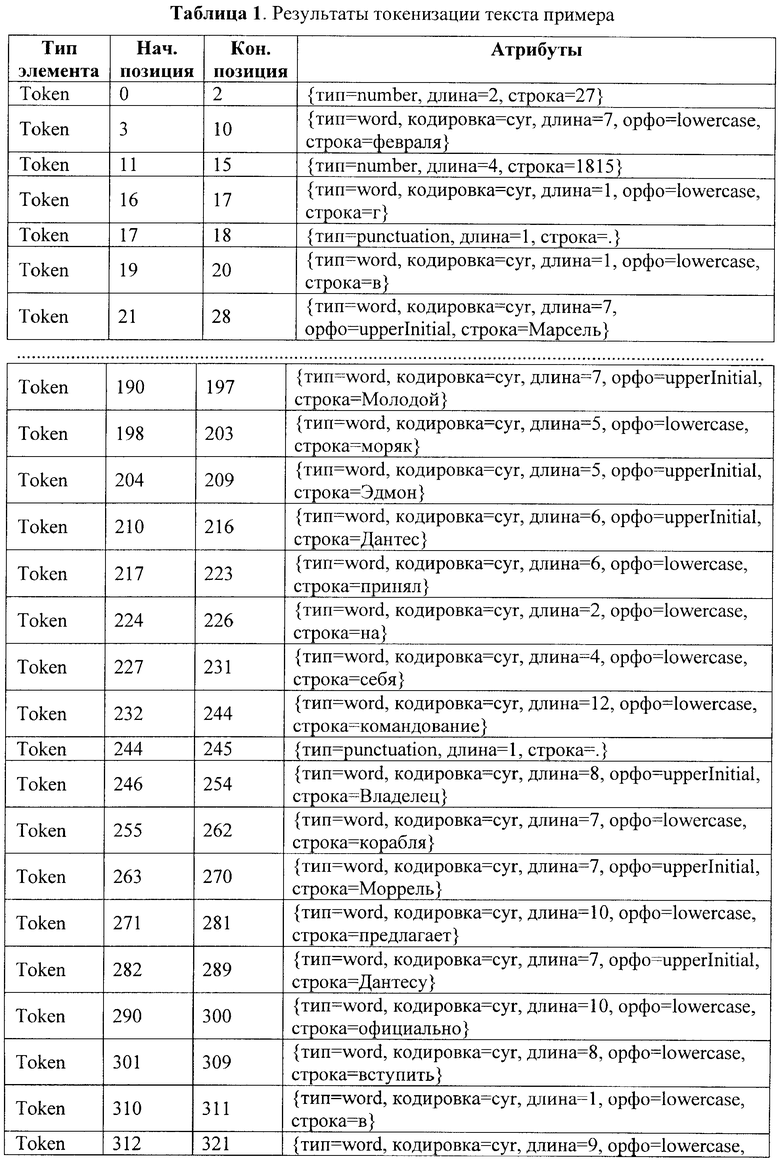
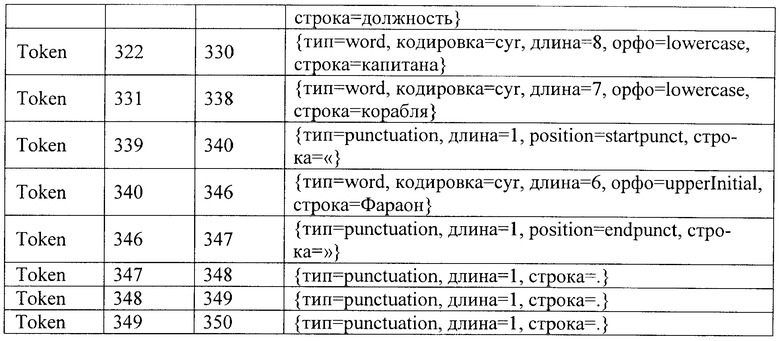
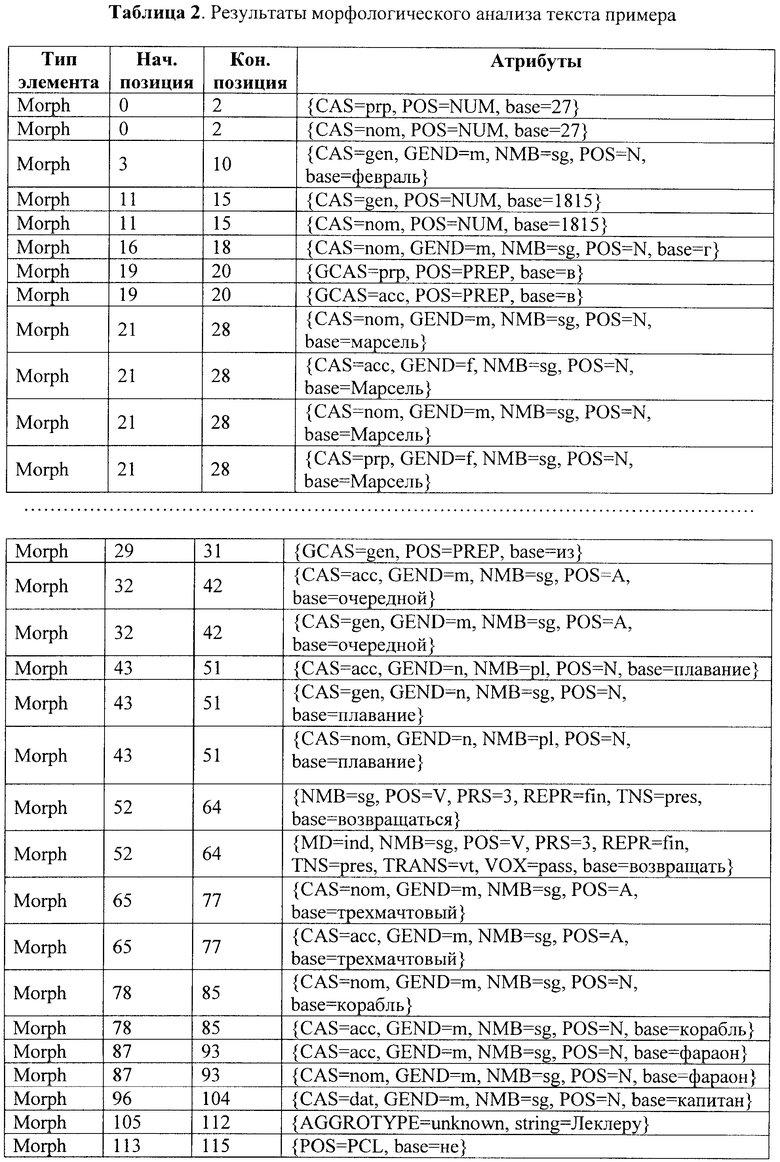
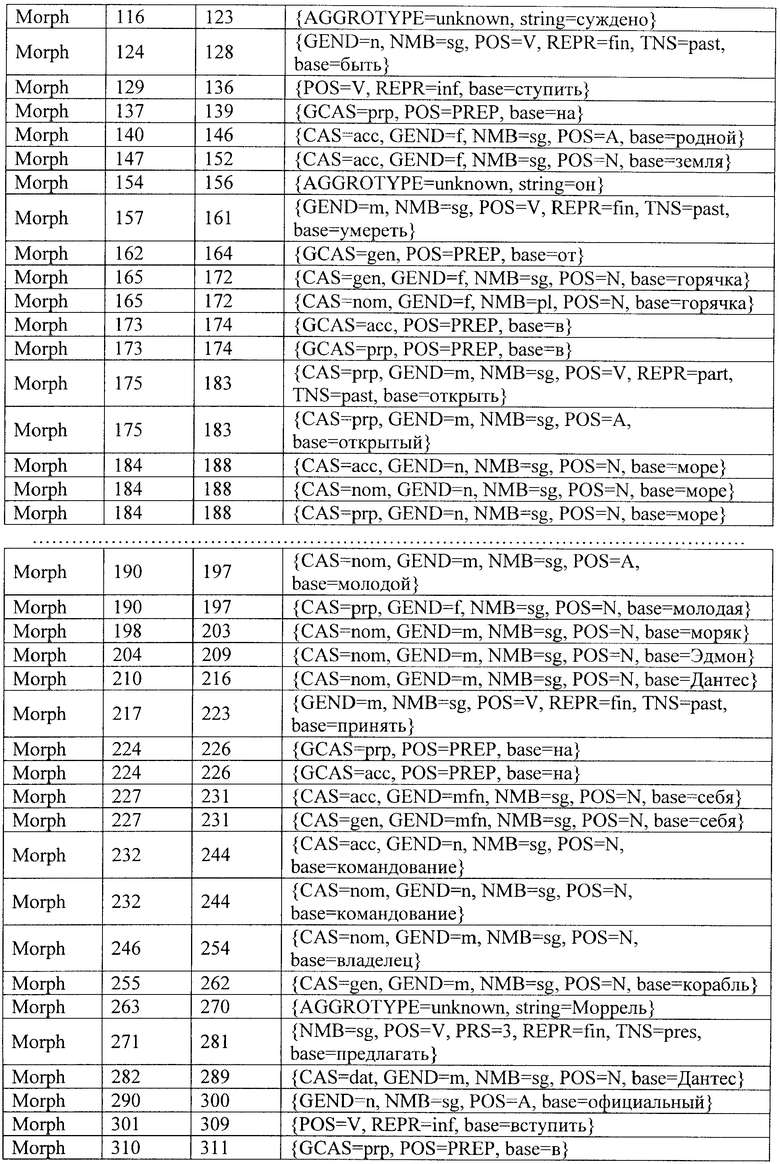
В соответствии с заявленным способом автоматизированной обработки текстов на естественном языке путем их семантической индексации сначала осуществляют сегментацию текста на элементарные единицы - токены и морфологический анализ токенов-слов (ссылочная позиция 2 на фиг.1). В результате выполнения этого этапа исходный текст трансформируется во множество токенов и морфов, которые представлены в Таблице 1 и Таблице 2, соответственно.
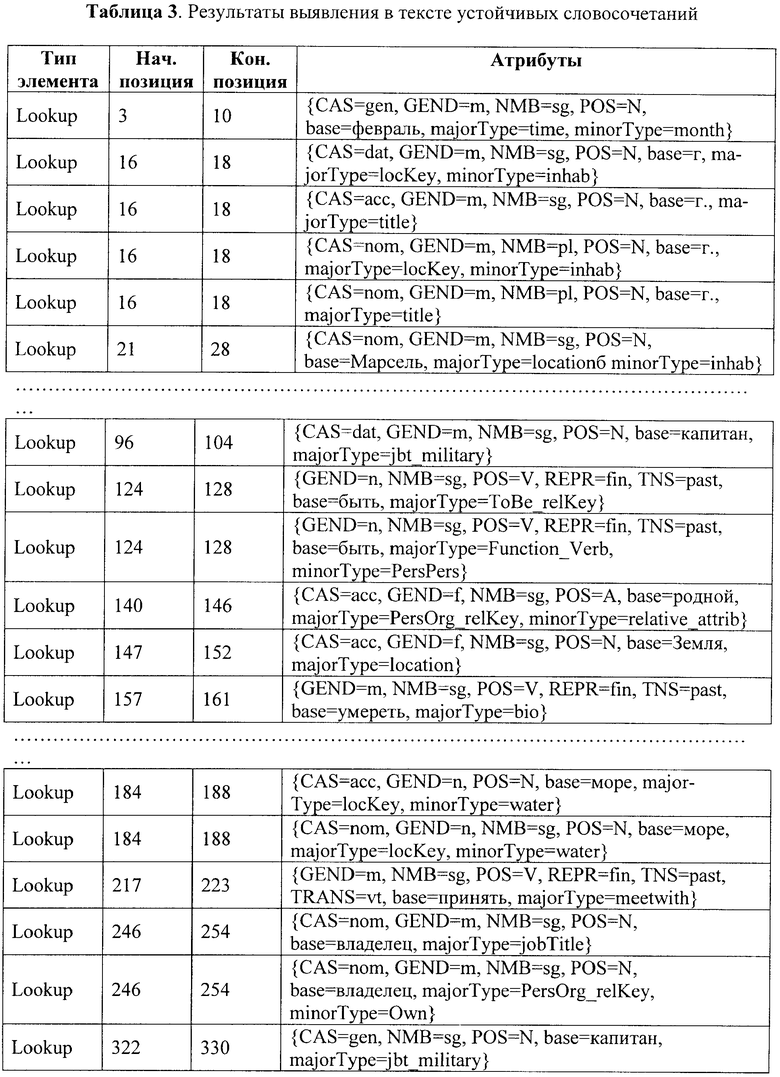
Далее после сегментации текста на токены и морфологического анализа токенов-слов осуществляют выделение устойчивых словосочетаний с помощью общих и специальных словарей (ссылочная позиция 3 на фиг.1). В результате выполнения этого этапа исходный текст, кроме элементарных единиц первого и второго уровней, дополняется множеством единиц третьего уровня - устойчивыми словосочетаниями. Фрагмент этого множества для нашего примера представлен в Таблице 3.
После выполнения вышеуказанных этапов осуществляют фрагментацию обрабатываемого текста на предложения (ссылочная позиция 4 на фиг.1). В результате выполнения этого этапа сформированные выше множества дополняются множеством предложений, представленным в Таблице 4.
Таким образом, после выполнения всех рассмотренных выше этапов обрабатываемый текст будет сегментирован на предложения, каждое из которых размечено множествами аннотаций элементарных единиц первого, второго и третьего уровней.
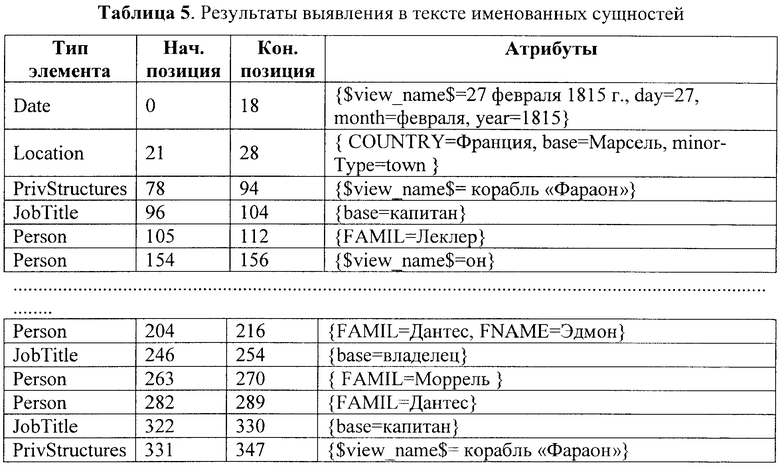
Вслед за этим в соответствии с заявленным способом автоматизированной обработки текстов на естественном языке путем их семантической индексации выявление семантически значимых объектов (элементарных единиц четвертого уровня) производится в каждом предложении на множестве элементарных единиц первого, второго и (или) третьего уровней с помощью упомянутых правил. Так, например, в предложении «Молодой моряк Эдмон Дантес принял на себя командование.» рассматриваемого текста с помощью правила, спецификация которого представлена на фиг.3а, а соответствующая ей схема обработки сигналов - на фиг.3b, выделяется семантически значимый объект «Эдмон Дантес». Другие семантически значимые объекты выделяются с помощью правил, аналогичных представленному на фиг.3a, b. В результате выполнения этапов, обозначенных на фиг.1 ссылочными позициями 5-7-9, в исходном тексте выделяют элементарные единицы четвертого уровня (семантически значимые объекты с их атрибутами). Фрагмент множества таких единиц для рассматриваемого примера представлен в Таблице 5.
После этого в пределах всего обрабатываемого текста в процессе выполнения этапа, обозначенного на фиг.1 ссылочной позицией 11, находят местоимения, которые могут быть анафорическими ссылками на соответствующие семантически значимые объекты, и для местоимений, которые действительно таковыми являются, фиксируют тождество по референции между соответствующим семантически значимым объектом и его анафорической ссылкой (элементарной единицей пятого уровня). Для рассматриваемого примера полученное множество кореференций анафорических ссылок представлено в Таблице 6.
После выполнения предыдущих этапов на множестве выделенных элементарных единиц первого, второго, третьего, четвертого и пятого уровней с помощью упомянутых правил находят семантически значимые отношения между семантически значимыми объектами. Так, например, в предложении «Владелец корабля Моррель предлагает Дантесу официально вступить в должность капитана корабля «Фараон»…» рассматриваемого текста с помощью правила, спецификация которого представлена на фиг.4а, а соответствующая схема обработки сигналов - на фиг.4b, выделяют именованное отношение «работать». В результате выполнения этапов, обозначенных на фиг.1 ссылочными позициями 6-8-10, в исходном тексте выделяют множество семантически значимых отношений между семантически значимыми объектами, фрагмент которого для нашего примера представлен в Таблице 7.
Таким образом, после выполнения всех рассмотренных выше этапов обработки исходный текст будет размечен множеством аннотаций, соответствующих семантически значимым объектам с их атрибутами и семантически значимым отношениям с их атрибутами между семантически значимьми объектами. Для нашего примера графическое представление фрагмента результата обработки текста показано на фиг.5.
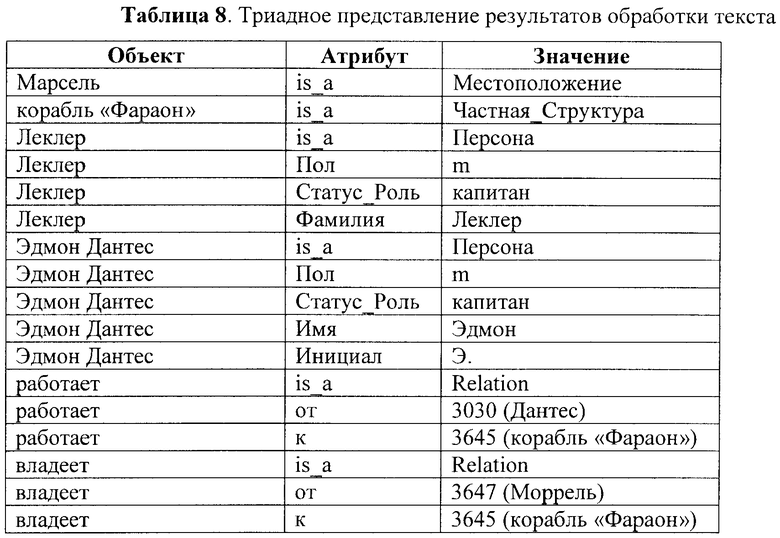
Следующий этап, обозначенный на фиг.1 ссылочной позицией 12, является техническим и выполняется для формирования триад, соответствующих сохраненным семантически значимым объектам и семантически значимым отношениям. Фрагмент множества таких триад для нашего примера представлен в Таблице 8. По сути дела, сформированное множество триад составляет исходные данные для построения семантического индекса обработанного на предыдущих этапах текста.
На этапе, обозначенном на фиг.1 ссылочной позицией 13, строят семантический индекс следующим образом: сначала из множества триад, полученных на предыдущем этапе, формируют подмножества триад, каждое из которых соответствует одному семантически значимому объекту с его атрибутами, и каждое полученное подмножество триад используют как вход для одного из стандартных индексаторов, например широко известного свободно распространяемого индексатора Lucene, индексатора поисковой машины Яндекс, индексатора Google или любого другого индексатора, с выхода которого получают уникальный для заданного подмножества триад индекс. Аналогичную последовательность действий выполняют для всех подмножеств триад, соответствующих парам вида «семантически значимый объект - семантически значимое отношение» и триадам вида «семантически значимый объект - семантически значимое отношение - семантически значимый объект» с учетом атрибутов соответствующих семантически значимых объектов и/или семантически значимых отношений, получая множество соответствующих уникальных индексов, которые в совокупности и составляют семантический индекс текста. Фрагмент семантического индекса для рассматриваемого примера представлен в Таблицах 9-11.
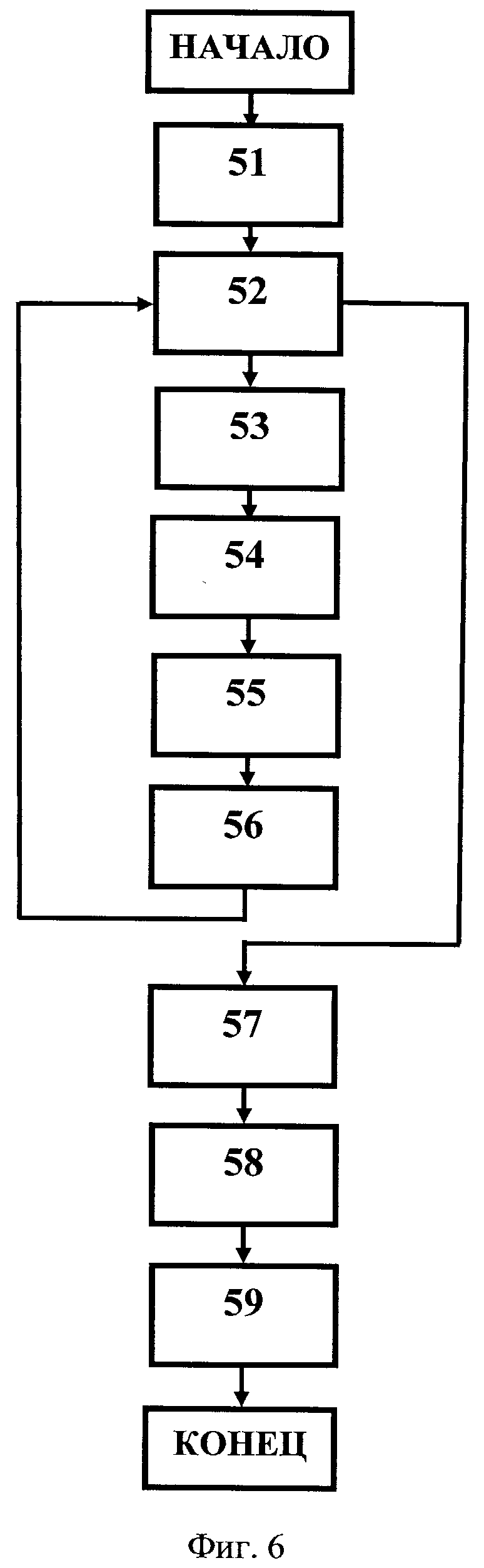
На этапе, обозначенном на фиг.1 ссылочной позицией 15, сформированные на этапе 12 триады и полученные на этапе 13 индексы вместе со ссылкой на исходный текст, из которого сформированы эти триады, сохраняют в базе данных, а этап 14, в случае обработки одного текста, пропускают. Общая схема сохранения всех полученных на предыдущих этапах результатов представлена на фиг.6.
На фиг.6 в качестве первого этапа (51) формируют множество непрерывных цепочек триад для отношения «The same». На следующем этапе (52) проверяют, является ли полученное на предыдущем этапе множество цепочек триад пустым. Если это множество не пустое, то последовательно на следующих этапах (53-56) формируют множество объектов для очередной цепочки (53), свертывают это множество объектов в единый объект (54), имеющий объединенное множество атрибутов (без повторений), сохраняют полученный единый объект с его атрибутами (55) и удаляют множество обработанных объектов очередной цепочки (56). Если же множество цепочек триад на этапе 52 оказывается пустым (изначально или в результате выполнения этапов 53-55), далее на этапе 57 формируют общее множество триад, полученных на всех предыдущих этапах, на этапе 58 дополняют сформированное общее множество триад семантическими индексами и ссылками на исходный текст, после чего на этапе 59 и сохраняют дополненное множество триад в базе данных.
В соответствии с заявленным способом автоматизированной обработки коллекции текстов на естественном языке путем их семантической индексации обработка каждого следующего текста, включая построение его семантического индекса, осуществляется путем выполнения в точности тех же этапов, что и для одного текста. Однако в этом случае после этапа 13 индексации и перед этапом 15 сохранения в базе данных осуществляют еще один этап, обозначенный на фиг.1 ссылочной позицией 14 - этап объединения результатов обработки очередного текста с результатами обработки предыдущих текстов, уже сохраненных в базе данных, который выполняют следующим образом.
Вновь выявленные в очередном индексируемом тексте семантически значимые объекты и семантически значимые отношения сравнивают с уже имеющимися в базе данных семантически значимыми объектами и семантически значимыми отношениями путем проверки совпадения их семантических индексов и, в случае положительного результата такого сравнения, соответствующие объекты и отношения из дальнейшей обработки исключают, сохраняя при этом в уже присутствующем в базе данных объекте и/или отношении ссылку на тот текст и тот фрагмент этого текста, в котором выявлены объекты и/или отношения, исключенные из дальнейшей обработки. В случае отрицательного результата сравнения семантических индексов с помощью заранее сформированных в базе данных лингвистических и эвристических правил выявляют подобие между новыми объектами и/или отношениями и теми объектами и/или отношениями, которые уже присутствуют в базе данных и, в случае положительного результата, расширяют уже существующие в базе данных описания объектов и/или отношений новыми данными, после чего перестраивают соответствующие семантические индексы и добавляют новые семантические индексы в качестве вторичных к уже существующим и, кроме того, сохраняют в уже присутствующем в базе данных объекте и/или отношении ссылку на тот текст и тот фрагмент этого текста, в котором выявлены объекты и/или отношения, после чего соответствующие объекты и отношения из дальнейшей обработки исключают. В противном случае вновь выявленные именованные объекты и именованные отношения с их семантическими индексами добавляют в базу данных.
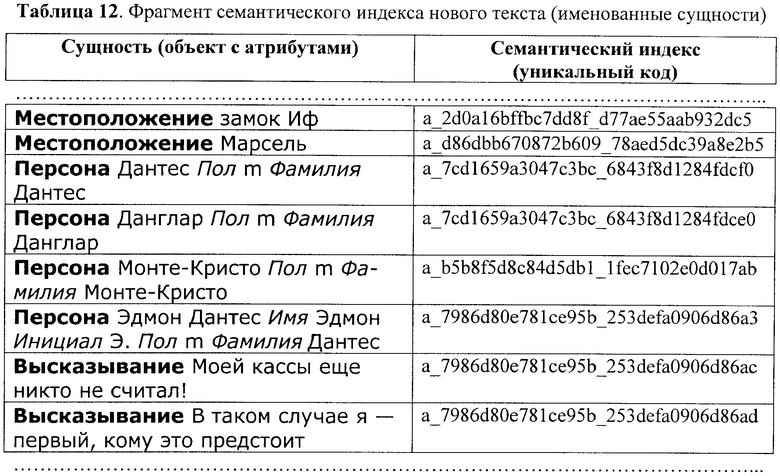
Так, например, если в качестве следующего, по отношению к уже рассмотренному примеру, обрабатывался текст «Дантес приговаривается к пожизненному заточению в замке Иф, политической тюрьме среди моря, неподалеку от Марселя… За долгие годы отсутствия Дантеса в судьбах тех, кто был повинен в его страданиях, тоже произошли значительные перемены. Данглар - богатый банкир. Де Вильфор - королевский прокурор… В банке Данглара граф Монте-Кристо открывает «неограниченный кредит». Данглар ставит под сомнение финансовые возможности графа. Граф иронизирует: «Для вас - может быть, но не для меня». «Моей кассы еще никто не считал!» - уязвлен Данглар. «В таком случае я - первый, кому это предстоит», - обещает ему Монте-Кристо. …Прежде чем испустить дух, аббат Бузони сообщает, что Монте-Кристо и Эдмон Дантес - одно лицо…», то после выполнения этапов 1-13 в нем будут выявлены, например, такие семантически значимые объекты и отношения между ними, как «замок Иф», «Марсель», «Дантес», «Де Вильфор», «Монте-Кристо», «высказывания_заявления» и др., а также будет сформирован его семантический индекс, фрагмент которого представлен в Таблицах 12-14.
Далее в соответствии с заявленным способом автоматизированной обработки коллекций текстов путем их семантической индексации на этапе 14 будет, в частности, выявлен объект «Марсель», семантический индекс которого полностью совпадает с семантическим индексом объекта «Марсель», уже присутствующего в базе данных, и, кроме того, будет выявлено (путем применения правила, спецификация которого приведена на фиг.7а, а соответствующая схема обработки сигналов - на фиг.7b) подобие между новым объектом «Эдмон Дантес» и объектом «Дантес», а также тождество по референции между объектом «Эдмон Дантес» и объектом «Монте-Кристо», уже присутствующими в базе данных, после чего существующее описание объекта «Эдмон Дантес» в базе данных будет расширено за счет новой информации и дополнительного семантического индекса, что показано в Таблицах 15 и 16.
Таким образом, настоящее изобретение обеспечивает расширение арсенала способов индексации текстов на естественных языках за счет использования методов их автоматизированного лингвистического анализа и последующего использования его результатов для построения семантических индексов, основное отличие которых от известных способов индексации в том, что индексируются не ключевые слова и словосочетания, а семантически значимые понятия и отношения между ними, что обеспечивает семантическую навигацию по документам и коллекциям документов, а также высокоточный и быстрый поиск релевантных информационным потребностям пользователя фактов и документов, особенно в применении к текстам на высоко флективных языках.










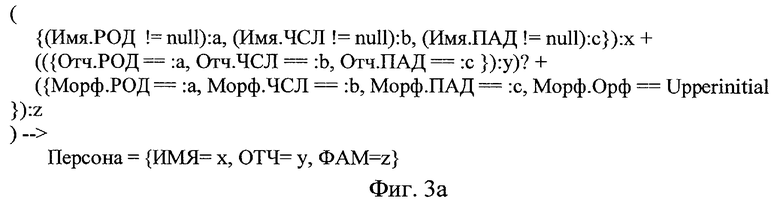




Изобретение относится к области информационных технологий. Текст сегментируют в электронной форме на элементарные единицы. Выявляют устойчивые словосочетания, формируют предложения. Выявляют семантически значимые объекты и семантически значимые отношения между ними. Формируют для каждого семантически значимого отношения множество триад, в которых единственная триада первого типа соответствует связи, устанавливаемой семантически значимым отношением между двумя семантически значимыми объектами. Каждая из триад второго типа соответствует значению конкретного атрибута одного из этих семантически значимых объектов. Каждая из триад третьего типа соответствует значению конкретного атрибута самого семантически значимого отношения. Индексируют на множестве сформированных триад все связанные семантически значимыми отношениями семантически значимые объекты по отдельности. Запоминают в базе данных сформированные триады и полученные индексы вместе со ссылкой на исходный текст, из которого сформированы эти триады. Техническим результатом изобретения является повышение точности и скорости поиска релевантных фактов и документов. 4 н. и 8 з.п. ф-лы, 16 табл., 7 ил.
1. Способ автоматизированной обработки текста на естественном языке путем его семантической индексации, содержащий этапы, на которых:
представляют индексируемый текст в электронной форме для последующей автоматической и/или автоматизированной обработки;
сегментируют текст в электронной форме на элементарные единицы первого уровня, которые выбирают из группы, состоящей из слов в виде последовательностей букв или букв и дефисов, чисел, знаков препинания и последовательностей пробелов;
для каждой элементарной единицы текста, представляющей собой слово, на основе морфологического анализа формируют элементарные единицы второго уровня, включающие для заданного слова нормализованную словоформу и его морфологические характеристики;
на множестве полученных элементарных единиц первых двух уровней в процессе лингвистического анализа выявляют в тексте устойчивые словосочетания, которые являются элементарными единицами третьего уровня;
формируют предложения, соответствующие участкам индексируемого текста, каждое их которых размечено множествами аннотаций элементарных единиц первого, второго и третьего уровней;
выполняют многоступенчатый семантико-синтаксический анализ путем обращения к сформированным в базе данных лингвистическим и эвристическим правилам в заранее заданной лингвистической среде, в процессе которого выявляют в каждом предложении с выявленными словосочетаниями на множестве элементарных единиц первого, второго и/или третьего уровней семантически значимые объекты, которые являются элементарными единицами четвертого уровня, фиксируют тождество по референции между соответствующим семантически значимым объектом и его анафорической ссылкой, которая является элементарной единицей пятого уровня, после чего на множестве выделенных элементарных единиц первого, второго, третьего, четвертого и пятого уровней с помощью указанных правил определяют семантически значимые отношения между семантически значимыми объектами, являющимися элементарными единицами шестого уровня;
формируют в пределах индексируемого текста для каждого из выявленных семантически значимых отношений, связывающих соответствующие семантически значимые объекты, множество триад, причем единственная триада первого типа соответствует связи, устанавливаемой семантически значимым отношением между двумя семантически значимыми объектами, каждая из триад второго типа соответствует значению конкретного атрибута одного из этих объектов, а каждая из триад третьего типа соответствует значению конкретного атрибута самого семантически значимого отношения;
индексируют на множестве сформированных триад все связанные семантически значимыми отношениями семантически значимые объекты по отдельности, все пары вида "семантически значимый объект - семантически значимое отношение" и все триады вида "семантически значимый объект - семантически значимое отношение - семантически значимый объект" с учетом атрибутов соответствующих семантически значимых объектов и/или семантически значимых отношений;
сохраняют в базе данных сформированные триады и полученные индексы вместе со ссылкой на исходный текст, из которого сформированы эти триады.
2. Способ по п.1, в котором в процессе упомянутого лингвистического анализа при формировании словосочетаний преобразуют в каждом предложении последовательности элементарных единиц первого и/или второго уровней с помощью обращения к сохраненным в базе данных словарям и морфологическим связям в упомянутые словосочетания - элементарные единицы третьего уровня.
3. Способ по п.1, в котором в процессе упомянутого многоступенчатого семантико-синтаксического анализа выполняют этапы, на которых формируют с помощью упомянутых правил для каждого семантически значимого объекта семантические атрибуты из атрибутов элементарных единиц второго и/или третьего уровней, составляющих данный семантически значимый объект; присваивают каждому семантически значимому объекту соответствующий тип из хранящейся в базе данных предметной онтологии по тематике каждой предметной области, к которой относится индексируемый текст; сохраняют в памяти каждый семантически значимый объект вместе с присвоенным ему типом и найденными для него морфологическими и семантическими атрибутами.
4. Способ по п.1, в котором определяют с помощью упомянутых правил для каждого семантически значимого отношения морфологические атрибуты из составляющих данное семантически значимое отношение элементарных единиц второго уровня; находят с помощью упомянутых правил для каждого семантически значимого отношения семантические атрибуты из элементарных единиц первого, второго, третьего и/или четвертого уровней; присваивают каждому семантически значимому отношению соответствующий тип из хранящейся в базе данных предметной онтологии по тематике той предметной области, к которой относится индексируемый текст; сохраняют в памяти каждое семантически значимое отношение вместе с присвоенным ему типом и найденными для него морфологическими и семантическими атрибутами.
5. Способ по п.1, в котором перед сохранением в базе данных сформированных триад и полученных индексов осуществляют свертку каждой группы объектов, связанных отношениями тождества по референции, в единый объект, множество атрибутов которого является объединением атрибутов объектов данной группы, связанных отношениями тождества по референции.
6. Способ автоматизированной обработки коллекции текстов на естественном языке путем их семантической индексации, содержащий все этапы способа по п.1 в применении к очередному индексируемому тексту, после чего при запоминании в базе данных сформированных триад и полученных индексов очередного текста осуществляют сравнение с помощью сформированных в базе данных лингвистических и эвристических правил в заранее заданной лингвистической среде вновь выявленных семантически значимых объектов и семантически значимых отношений с уже имеющимися в базе данных семантически значимыми объектами и семантически значимыми отношениями и в случае идентификации одинаковых объектов и/или отношений дублирующую информацию в базе данных не запоминают, а к соответствующим семантически значимым объектам и/или семантически значимым отношениям добавляют ссылки на текстовые фрагменты в пределах каждого из очередных текстов, из которых они выделены.
7. Способ по п.6, в котором в процессе упомянутого лингвистического анализа при формировании словосочетаний преобразуют в каждом предложении последовательности элементарных единиц первого и/или второго уровней с помощью обращения к сохраненным в базе данных словарям и морфологическим связям в упомянутые словосочетания - элементарные единицы третьего уровня.
8. Способ по п.6, в котором в процессе упомянутого многоступенчатого семантико-синтаксического анализа выполняют этапы, на которых присваивают каждому семантически значимому объекту соответствующий тип из хранящейся в базе данных предметной онтологии по тематике каждой предметной области, к которой относится индексируемый текст; сохраняют в памяти каждый семантически значимый объект вместе с присвоенным ему типом и найденными для него морфологическими и семантическими атрибутами.
9. Способ по п.6, в котором с помощью упомянутых правил находят для каждого семантически значимого отношения морфологические атрибуты из составляющих данное семантически значимое отношение элементарных единиц второго уровня и семантические атрибуты из элементарных единиц первого, второго, третьего и/или четвертого уровней; присваивают каждому семантически значимому отношению соответствующий тип из хранящейся в базе данных предметной онтологии по тематике той предметной области, к которой относится индексируемый текст; сохраняют в памяти каждое семантически значимое отношение вместе с присвоенным ему типом и найденными для него морфологическими и семантическими атрибутами.
10. Способ по п.6, в котором перед сохранением в базе данных сформированных триад и полученных индексов осуществляют свертку каждой группы объектов, связанных отношениями тождества по референции, в единый объект, множество атрибутов которого является объединением атрибутов объектов данной группы, связанных отношениями тождества по референции.
11. Машиночитаемый носитель, предназначенный для непосредственного участия в работе компьютера и содержащий программу для осуществления способа по п.1.
12. Машиночитаемый носитель, предназначенный для непосредственного участия в работе компьютера и содержащий программу для осуществления способа по п.6.
| Пресс для выдавливания из деревянных дисков заготовок для ниточных катушек | 1923 |
|
SU2007A1 |
| СПОСОБ СИНТЕЗА САМООБУЧАЮЩЕЙСЯ СИСТЕМЫ ИЗВЛЕЧЕНИЯ ЗНАНИЙ ИЗ ТЕКСТОВЫХ ДОКУМЕНТОВ ДЛЯ ПОИСКОВЫХ СИСТЕМ | 2002 |
|
RU2273879C2 |
| US 7346493 B2, 18.03.2008 | |||
| US 7305336 В2, 04.12.2007 | |||
| US 7191115 B2, 13.03.2007. | |||

