ОБЛАСТЬ ТЕХНИКИ, К КОТОРОЙ ОТНОСИТСЯ ИЗОБРЕТЕНИЕ
[001] Данное изобретение относится к сетевому компьютеризированному приложению для получения, обработки, анализа и приема видео медиаконтента, так что к контенту может быть осуществлен доступ посредством платформы визуального поиска.
УРОВЕНЬ ТЕХНИКИ ИЗОБРЕТЕНИЯ
[002] Электронная торговля - это транзакция покупки или продажи по сети. Электронная торговля стала важным инструментом для малого и крупного бизнеса по всему миру, не только, чтобы продавать покупателям, но также, чтобы привлекать их. В 2012, продажи электронной торговли превысили 1 триллион долларов США.
[003] Интернет-маркетинг относится к рекламной и маркетинговой деятельности, которая использует веб-сервисы и электронную почту, чтобы побуждать продажи посредством электронной торговли. Она включает в себя маркетинг с использованием электронной почты, маркетинг с использованием поисковых механизмов (SEM), маркетинг с использованием социальных медиа, множество типов рекламы на дисплеях (например, баннерная реклама) и рекламу на мобильных устройствах. Метаданные являются крайне важным компонентом Интернет-маркетинга.
[004] Бизнес обычным образом сохраняет метаданные о поисках и транзакциях, которые обеспечивают им возможность анализа тенденций продаж, разработки маркетинговых планов и совершения предсказаний. Эти же метаданные могут обеспечить бизнесу возможность обеспечения более персонализированного восприятия совершения покупок с помощью таких функциональных возможностей, как история покупок, адресные книги для многочисленный местоположений доставки и рекомендации по продуктам.
[005] Сегодня, большинство веб-страниц имеют встроенные в них метаданные. Механизмы веб-поиска осуществляют построение огромного числа указателей, которые используют текст со страницы и их сопутствующие метаданные, чтобы предоставить пользователям релевантные результаты поиска. Метаданные могут быть использованы для таргетированной рекламы. Рекламодатели могут использовать более сложные способы для таргетирования наиболее восприимчивых аудиторий с определенными особенностями, на основе продукта, который продвигает рекламодатель.
[006] Так как онлайн-покупатели не имеют возможности просмотра товаров лично, они обычно осуществляют поиск по критериям, таким как ключевое слово. Например, человек может использовать веб-браузер, чтобы искать авиарейсы до Новой Зеландии. Метаданные в форме данных типа "cookie" от веб-сайтов, посещенных им/ею, сохраняются на компьютере веб-браузером пользователя. Данные типа cookie отправляются туда и обратно между Интернет-сервером и браузером, что обеспечивает пользователю возможность идентификации и/или слежения за его/ее действиями. В дальнейшем, человек может принимать рекламные объявления, такие как баннерные рекламные объявления, относящиеся к путешествию в Новую Зеландию, с отелем, арендой автомобиля, информацией о турах и рейсах.
[007] К тому же, метаданные могут быть использованы для таргетирования пользователей на основе демографических данных. Бизнес может понять, что продукт привлекателен для определенной демографической группы, и маркетинг может быть направлен на эту демографическую группу. Например, баннерная реклама для безопасности инвестиций может быть неэффективной для подростковой аудитории. Таргетирование рекламы для более старшей демографической группы, и более конкретно для тех, кто готовится к пенсии, будет более эффективным. Метаданные могут быть скомпилированы пользователем для идентификации его/ее демографической группы и вероятности, что он/она может быть заинтересована в защите инвестиций.
[008] С появлением рынка, демонстрирующего возрастающий уровень использования визуального поиска, совершенствование демографического профилирования представляет огромный интерес и пользу для потребителей, так же как и для бизнеса. Организации могут использовать такие модели для предоставления персонализированных предложений, оценки шаблонов использования (на основе сезонности, например) и помощи в определении будущего направления продукта.
[009] Поиск на основе визуальных данных является обычным явлением, особенно при повсеместности смартфонов и планшетных компьютеров. Например, пользователь в примере выше может искать изображения, относящиеся к пешему туризму в Новой Зеландии. Так как он/она щелкает по изображениям, браузер не имеет возможности записи метаданных на основе ключевых слов, набираемых в браузере. Аналогично, он/она может смотреть видео, относящееся к достопримечательностям в Новой Зеландии. При обыкновенной технологии, ни изображения, ни видео не будут отдавать метаданные для таргетированного маркетинга.
[0010] Имея быстрое распространение и популярность платформ распространения Интернет-видео с различными архитектурами, визуальный поиск по видеоконтенту имеет потенциал использования многомиллионной пользовательской базы, состоящей из создателей контента, покупателей и коммерческих партнеров. Если конкретные сегменты видео могут быть идентифицированы, заинтересованные стороны приобретают способность дополнения и/или кооперации этих секций с дополнительным контентом. Это может принимать вид усовершенствования информации для таких секций. Коммерческие партнеры могут захотеть таргетировать релевантные секции в качестве пути для распространения предложений продуктов.
[0011] В настоящее время нет средств для эффективного создания и извлечения метаданных на основе изображений, просматриваемых пользователем. Таким образом, изображения, просмотренные/которые искали, не могут соотноситься со своим профилем для целевого маркетинга. Также, нет средства для поиска, основанного на захваченном изображении без описания его в текстовом запросе. Таким образом, для наблюдателя нет возможности выразить заинтересованность в объекте или продукте, который он/она просматривает в шоу или сцене. Например, наблюдатель может видеть знаменитость с сумочкой. Однако, может быть не ясно, где купить данную сумочку. Единственным вариантом для наблюдателя является описание атрибутов сумочки в запросе визуального поиска.
[0012] Были сделаны попытки для связывания видео и/или печати с веб-сайтом. Используя текущую технологию, поставщик или рекламодатель может добавить QR-код (код быстрого ответа) на печатном рекламном объявлении или рекламном видеообъявлении. Наблюдатель может использовать смартфон для сканирования QR-кода, который направит его/ее к веб-сайту и/или веб-контенту. Однако, это требует помещения видимого блока кода вблизи наблюдателя. Кроме того, для каждого объекта, представляющего интерес, должен быть добавлен отдельный QR-код. Для видео, QR-код должен представляться в течение всей его продолжительности.
[0013] При использовании QR-кода есть явные ограничения. Кроме того, маркетологи ищут улучшенные способы для привлечения более молодой аудитории, привыкшую пропускать рекламу и использовать медиа по запросу. Размещение скрытой рекламы и фирменные развлекательные материалы предоставляют "омниканальные" возможности для более эффективного привлечения более молодых и/или технологически подкованных потребителей. Соответственно, есть потребность в способе обеспечения наблюдателю возможности выражения интереса и/или получения дополнительной информации, относящейся к объектам на изображениях и/или видео. Система должна обеспечивать пользователю возможность получения сведений и дополнительной информации о предмете без проведения поиска по ключевым словам или сканирования QR-кода. Она должна быть способна использоваться с печатными медиа (например, рекламными объявлениями в журналах), так же как и видеомедиа (например, телевидении.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
[0014] Первым аспектом данного изобретения является средство приема изображений из печатных медиа в базу данных.
[0015] Вторым аспектом данного изобретения является средство приема изображений из печатных медиа в базу данных, так что объекты на изображениях могут быть идентифицированы и сопоставлены с продуктами.
[0016] Третьим аспектом данного изобретения является средство приема изображений из печатных медиа в базу данных, при этом текстовый и посторонний контент удаляется.
[0017] Четвертым аспектом данного изобретения является средство приема сегментов видеомедиа в базу данных.
[0018] Пятым аспектом данного изобретения является средство приема сегментов видео в базу данных, при этом видеосегменты идентифицируются посредством сравнения одинаковых или схожих сцен, так что схожие сегменты могут быть сгруппированы, и дублирующиеся сегменты удалены.
[0019] Шестым аспектом данного изобретения является средство для приема сегментов видео в базу данных, при этом разрешение и/или частота смены кадров видео понижается.
[0020] Седьмым аспектом данного изобретения является средство для приема сегментов видео в базу данных, так что объекты в видеосегментах могут быть идентифицированы и сопоставлены с продуктами.
ВВЕДЕНИЕ
[0021] Данное изобретение включает в себя способ компилирования изображений из печатных медиа в базу данных, содержащий этапы (a) получения печатных медиа, (b) преобразования печатных медиа в цифровые медиа, (c) обнаружения текста в цифровых медиа на основе соединенных контуров краев, (e) удаление областей с текстом из цифровых медиа, (f) обнаружения одного или более изображений в цифровых медиа, (g) определения того, достаточно ли признаков присутствует для категорирования одного или более изображений, (h) категорирования одного или более изображений и (i) вставки одного или более изображений в базу данных. Способ может включать в себя дополнительные этапы осуществления доступа к базе данных, когда пользователь подает запрос, и сопоставления запроса с одним или более изображениями в базе данных посредством сравнения признаков.
[0022] Данное изобретение также включает в себя способ компилирования кадров из видео, сохранения и индексирования кадров в базе данных, содержащий этапы (a) получения видео, (b) анализа видео на предмет признаков в кадрах, (c) разделения видео на сегменты на основе признаков, (d) анализа признаков сегментов для группирования сегментов, которые совместно используют эти признаки, (e) снабжение аннотациями одного или более кадров сегментов с использованием метаданных и (f) сохранение одного или более кадров сегментов в базе данных. Способ может включать в себя дополнительный этап уменьшения частоты смены кадров и/или разрешения видео. Он может также включать в себя дополнительные этапы осуществления доступа к базе данных, когда пользователь подает запрос, и сопоставления запроса с одним или более кадров сегментов в базе данных на основе совместно используемых признаков. Дублирующиеся кадры могут быть идентифицированы на основе совместно используемого контента, так что один или более дублирующихся кадров могут быть отброшены.
[0023] Данное изобретение также включает в себя компьютеризированную систему для приема документов, состоящую из (a) пользовательского интерфейса для выгрузки документа на сервер, (b) модуля, состоящего из логики для обработки документа и извлечения секций из документа в качестве изображений, (c) модуля, состоящего из логики для удаления текста с изображений, (d) модуля, состоящего из логики для обнаружения признаков на изображениях и (e) модуля, состоящего из логики для прикрепления уникального идентификатора к изображениям. Компьютеризированная система может также включать в себя средство для приема запроса и модуль для сопоставления запроса с одним или более изображениями в базе данных на основе совместно используемых признаков.
[0024] Кроме того, данное изобретение включает в себя компьютеризированную систему для приема видео, состоящую из (a) пользовательского интерфейса для выгрузки видео на сервер, (b) компьютерной программы для обработки видео и извлечения секций из видео в качестве изображений и (c) базы данных для хранения извлеченных секций. Извлеченные секции могут быть проанализированы на предмет соответствия параметрам пригодности, включая признаки изображения и разрешение изображения. Уникальный идентификатор может быть прикреплен к каждой извлеченной секции видео. Компьютеризированная система может также включать в себя средство для приема запроса и модуль для сопоставления запроса с одной или более секциями видео в базе данных на основе совместно используемых признаков.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[0025] Фиг. 1 изображает примерный общий вид фреймворка приема изображения.
[0026] Фиг. 2 изображает этапы, используемые алгоритмом обрезки изображения.
[0027] Фиг. 3 изображает примерный общий вид фреймворка приема видео.
[0028] Фиг. 4 изображает общий вид программы обработки видеосегмента.
[0029] Фиг. 5 изображает программу приема видеосегмента.
ПОДРОБНОЕ ОПИСАНИЕ ИЗОБРЕТЕНИЯ
Определения
[0030] Указание в этом описании на "один вариант осуществления/аспект" или "вариант осуществления/аспект" означает, что конкретный признак, структура или характеристика, описанная применительно к варианту осуществления/аспекту, включена по меньшей мере в вариант осуществления/аспект данного раскрытия. Использование фразы "в одном варианте осуществления/аспекте" или "в другом варианте осуществления/аспекте" в различных местах в данном описании не везде обязательно относится к одному и тому же варианту осуществления/аспекту, также не все являются отдельными или альтернативными вариантами осуществления/аспектами, взаимоисключающими другие варианты осуществления/аспекты. Более того, описаны различные признаки, которые могут быть продемонстрированы некоторыми вариантами осуществления/аспектами, и не могут остальными. Аналогично, описаны различные требования, которые могут быть требованиями для некоторых вариантов осуществления/аспектов, но не для остальных вариантов осуществления/аспектов. Вариант осуществления и аспект могут быть в некоторых случаях использованы взаимозаменяемо.
[0031] Термины, используемые в этом описании, обычно имеют свои обычные значения в данной области техники, в рамках контекста данного раскрытия, и в конкретном контексте, где используется каждый термин. Некоторые термины, которые используются для описания данного раскрытия, рассмотрены ниже, или где-либо еще в описании, для предоставления дополнительного указания для специалиста-практика, касательно описания данного раскрытия. Для удобства, некоторые термины могут быть выделены, например, с использованием курсива и/или кавычек. Использование выделения не имеет влияния на объем и значение термина; объем и значение термина являются одинаковыми, в одном и том же контексте, выделен он или нет. Будет понятно, что одни и те же вещи могут быть сказаны более, чем одним образом.
[0032] Следовательно, альтернативный язык и синонимы могут быть использованы для любого одного или более терминов, рассмотренных в настоящем документе. Какое-либо специальное значение также не должно помещаться на основании того, объяснен ли или рассмотрен ли термин в настоящем документе или нет. Для некоторых терминов предоставлены синонимы. Указание одного или более синонимов не исключает использования других синонимов. Использование примеров где-либо в этом описании, в том числе примеров любых терминов, рассмотренных в настоящем документе, является только иллюстративным, и не предназначено для дополнительного ограничения объема и значения данного раскрытия или какого-либо приведенного в качестве примера термина. Аналогично, данное раскрытие не ограничивается различными вариантами осуществления, приведенными в этом описании.
[0033] Без намерения дополнительно ограничивать объем данного раскрытия ниже приведены примеры инструментов, устройства, способов и их соответствующих результатов согласно вариантам осуществления настоящего раскрытия. Следует отметить, что заголовки или подзаголовки могут быть использованы в примерах для удобства читателя, что никаким образом не должно ограничивать объем данного раскрытия. Пока не задано иначе, все технические и научные термины, здесь используемые, имеют такое же значение, которое в общем понятно специалисту в области техники, к которой имеет отношение это раскрытие. В случае конфликта силу будет иметь настоящий документ, включая определения.
[0034] Термин "приложение" относится к самодостаточной программе или части программного обеспечения, спроектированной удовлетворять конкретным целям, особенно после загрузки на мобильное устройство.
[0035] Термин "cookie", "Интернет-cookie" или "HTTP cookie" относится к небольшой порции данных, отправленных от веб-сайта и хранящихся на компьютере пользователя веб-браузером пользователя. Данные типа cookie отправляются туда и обратно между Интернет-сервером и браузером, что обеспечивает пользователю возможность идентификации или слежения за его/ее продвижением. Данные типа cookie предоставляют сведения о том, какие страницы посещает потребитель, количество времени, потраченного на просмотр каждой страницы, ссылки, по которым был осуществлен щелчок, сделанные поисковые запросы и взаимодействия. Из этой информации, эмитент данных типа cookie получает понимание тенденций пользовательских просмотров в браузере и интересов, генерируя профиль. Анализируя профиль, рекламодатели имеют возможность создания сегментов заданной аудитории на основе пользователей с аналогичной возвращенной информацией, а именно профилями.
[0036] Термин "кластеризация" или "кластерный анализ" относятся к задаче группирования набора объектов таким образом, что объекты в одной и той же группе (называемой кластером) больше похожи (в том или ином смысле) друг на друга, чем объекты в других группах (кластерах). Это является главной задачей исследовательской добычи данных, и основным методом для статистического анализа данных, используемым во многих областях, включая машинное обучение, распознавание образов, анализ изображений, извлечение информации, биоинформатику, сжатие данных и компьютерную графику.
[0037] Термин "глубокое обучение" относится к приложению для обучения задач искусственных нейронных сетей (ANN), которые содержат более, чем один скрытый слой. Глубокое обучение является частью более широкого семейства способов машинного обучения на основе представлений данных обучения, в противоположность алгоритмов, характерных для задачи.
[0038] Термин "вектор признаков", в распознавании образов и машинном обучении, относится к вектору признаков, который является n-мерным вектором числовых признаков, которые представляют некоторый объект. Многие алгоритмы в машинном обучении требуют числовое представление объектов, так как такие представления способствуют обработке и статистическому анализу. При представлении изображений, значения признаков могут соответствовать пикселям изображения, при представлении текстов, возможно частотам встречаемости терминов.
[0039] Термин "инвертированный индекс" (“inverted index”, "postings file") или "инвертированный файл" относится к индексной структуре данных, сохраняющей отображение из контента, такого как слова или числа, в его размещение в файле базы данных, или в документе или наборе документов (названный в противоположность прямому индексу, который осуществляет отображение из документов в контент). Целью инвертированного индекса является обеспечение возможности быстрых полнотекстовых поисков, ценой повышенной обработки, когда документ добавляется в базу данных.
[0040] Термин "k-ближайших соседей" или "k-NN" относится к объекту классификации по методу ближайших соседей, где и показатель расстояния ("ближайший"), и число соседей могут быть изменены. Объект классифицирует новые наблюдения с использованием способа предсказания. Объект содержит данные, используемые для обучения, таким образом можно вычислить предсказания повторных подстановок.
Анализ связей
[0041] Термин "модуль" относится к самодостаточной единице, такой как узел в сборе из электронных компонентов и соответствующих проводных соединений или сегмент компьютерного программного обеспечения, который сам выполняет заданную задачу и может быть связан с другими такими блоками для образования большей системы.
[0042] Термин "Многослойная перцептронная нейронная сеть" или "MLP" относится к нейронной сети прямого распространения с одним или более слоями между входным и выходным слоями. Прямое распространение означает, что данные движутся в одном направлении от входного к выходному слою (вперед). MLP широко используются для классификации, распознавания, предсказания и аппроксимации образов. Многослойный перцептрон может решать проблемы, которые линейно неразделимы.
[0043] Термин "метаданные" относятся к данным, которые описывают остальные данные. Они предоставляют информацию о контенте некоторого товара. Изображение может включать в себя метаданные, которые описывают, насколько большим является изображение, глубину цвета, разрешение изображения, и когда изображение было создано. Метаданные текстового документа могут содержать информацию о том, насколько длинным является документ, кто автор, когда документ был написан и краткое изложение документа.
[0044] Термин "метатег" относится к метаданным, которые включены в веб-страницы. Метатеги "описание" и "ключевые слова" обычно используются для описания контента веб-страницы. Большинство поисковых механизмов используют эти данные при добавлении страниц к их поисковому индексу.
[0045] Термин "QR-код" или "код быстрого ответа" относится к матричному штрих-коду (или двухмерному штрих-коду), который содержит информацию о товаре, к которому он прикреплен. QR-код включает в себя черные квадраты, размещенные в квадратной сетке на белом фоне, которые могут быть считаны устройством формирования изображения, таким как камера, и обработаны с использованием коррекции ошибок Рид-Соломона пока изображение не будет интерпретировано соответствующим образом. Требуемые данные затем извлекаются из образов, которые они представляют как в горизонтальных, так и вертикальных компонентах изображения.
[0046] Термин "синтетические данные" относятся к любому воспроизведению данных применимых к заданной ситуации, которые не получены посредством прямого измерения.
[0047] Термин "метод опорных векторов" или "SVM" относится к контролируемым обучающим моделям с ассоциированными алгоритмами обучения, которые анализируют данные, используемые для классификации и регрессивного анализа. Дан набор обучающих примеров, каждый отмечен как принадлежащий одной или другой из двух категорий, алгоритм обучения SVM строит модель, которая присваивает новые примеры одной категории или другой, получая невероятностный двоичный линейный классификатор.
[0048] Термин "таргетированная реклама" относится к форме рекламы, где онлайн-рекламодатели могут использовать более сложные способы для таргетирования наиболее восприимчивых аудиторий с определенными особенностями, на основе продукта или человека, которого продвигает рекламодатель. Эти особенности могут быть либо демографическими, которые сфокусированы на расе, экономическом статусе, поле, возрасте, уровне образования, уровне дохода и занятости, или они могут быть сфокусированы психологически, которые основываются на ценностях потребителя, личности, менталитете, мнениях, стилях жизни и интересах. Они могут также быть поведенческими переменными, такими как история просмотра, история покупок и другая недавняя активность.
[0049] Другие технические термины, используемые в настоящем документе, имеют свое обычное значение в области техники, в которой они используются, как приведено в качестве примера в разнообразных технических словарях.
Описание предпочтительных вариантов осуществления
[0050] Конкретные значения и конфигурации, рассмотренные в этих неограничивающих примерах, могут варьироваться и приведены лишь для иллюстрации по меньшей мере одного варианта осуществления и не предназначены для ограничения их объема.
[0051] Данное изобретение относится к внедрению видеоконтента в платформу визуального поиска, так чтобы каждый уникально отличимый кадр можно было искать с использованием изображения запроса релевантного видеосегмента из компьютерной системы датчиков. Оно включает в себя средство приема изображений и видеокадров в базу данных. Потребительские продукты могут быть сопоставлены с изображениями и/или объектами на изображениях. Потребитель может осуществить доступ к базе данных посредством подачи цифрового изображения, снятого на мобильное устройство. Один или более объектов на поданном пользователем изображении могут быть сопоставлены с продуктами и/или коммерческими/рекламными материалами.
[0052] Одним из преимуществ визуального поиска (в противоположность обыкновенного текстового поиска) для демографического профилирования является по сути большее количество информации о запросе, который может быть выявлен. Например, пользователь может искать коричневые ботинки в поисковом механизме (или веб-сайте электронной торговли). В случае использования визуального поиска, само изображение запроса может раскрыть гораздо больше о природе запроса пользователя. Пользователь может разузнать об очень специфичном виде коричневого ботинка (форма, стиль, материал, бренд, лоферы, со шнурками, и т.д.) посредством подачи или осуществления щелчка на изображении конкретного ботинка. Имея доступ только к текстовому поиску, невозможно извлечь большую детализацию об объекте поиска без какой-либо дополнительной информации.
[0053] В последнее время визуальный поиск как вид пользовательского взаимодействия приобрел огромную популярность благодаря улучшениям в области машинного зрения. Теперь возможно осуществлять запросы к базам данных, содержащим миллионы изображений с высокой степенью точности. Это открывает возможности взаимодействия "человек-контент". В одном таком варианте осуществления, возможно усовершенствовать статические медиаресурсы помечая их с помощью случаев использования дополненной реальности. Для того чтобы осуществить доступ к более содержательному контенту, пользователь может указать устройство камеры в статическом контенте и, с использованием механизма визуального сопоставления, извлечь и отобразить слой наложения контента.
Конкретные сегменты видео могут быть идентифицированы, так что заинтересованные стороны приобретают способность дополнения и/или кооперации этих секций с дополнительным контентом. Это может принимать вид усовершенствования информации для таких секций. Коммерческие партнеры могут таргетировать релевантные секции в качестве пути для распространения предложений продуктов.
[0055] Для того чтобы извлечь метаданные о запросе визуального поиска, могут быть использованы усовершенствованные алгоритмы классификации, включая, но не ограничиваясь ими, глубокое обучение, контролируемое обучение и неконтролируемое обучение. Таким образом, из входного изображения может быть получен список описательных метаданных (например, ботинок, коричневый, шнурки, полуботинок, контекст, размещение производства, материал и любая такая информация, которая обеспечивает ясность касательно статуса контентов внутри изображения).
[0056] В одном варианте осуществления данного изобретения, список объектов, которые составляют изображение или видео, может быть извлечен и связан с последовательностью кадров, которые анализируются на соответствие семантически отличимой "тематике". Например, данные из печатных изображений (например, журналов) могут быть введены в систему. Пользователь может подать цифровое изображение ботинка со страницы журнала. Система может ретранслировать информацию о продукте по тематике ботинок. В другом варианте осуществления, данные из видео (например, телевидения) вводятся в систему. Пользователь может подать снимок видео, при этом ботинок является одним из предметов на экране. Система может ретранслировать информацию о продукте пользователю по тематике ботинок.
[0057] Для того чтобы построить и проиндексировать контент в системе, визуально содержательные цифровые документы, такие как журналы, комиксы или другие документы, которые передают информацию в основном нетекстовым образом (т.е. документы, которые включают в себя изображения), могут быть использованы, как описано ниже.
Прием документов
[0058] Пользовательский интерфейс приема документов предоставляет шлюз для выгрузки главного документа в базу данных контента. Этот интерфейс может предоставить средство заполнения аннотаций и метаданных. Выгруженные документы могут быть проиндексированы и сохранены в базе данных 180 контента. Метаданные могут соотноситься с каждым документом.
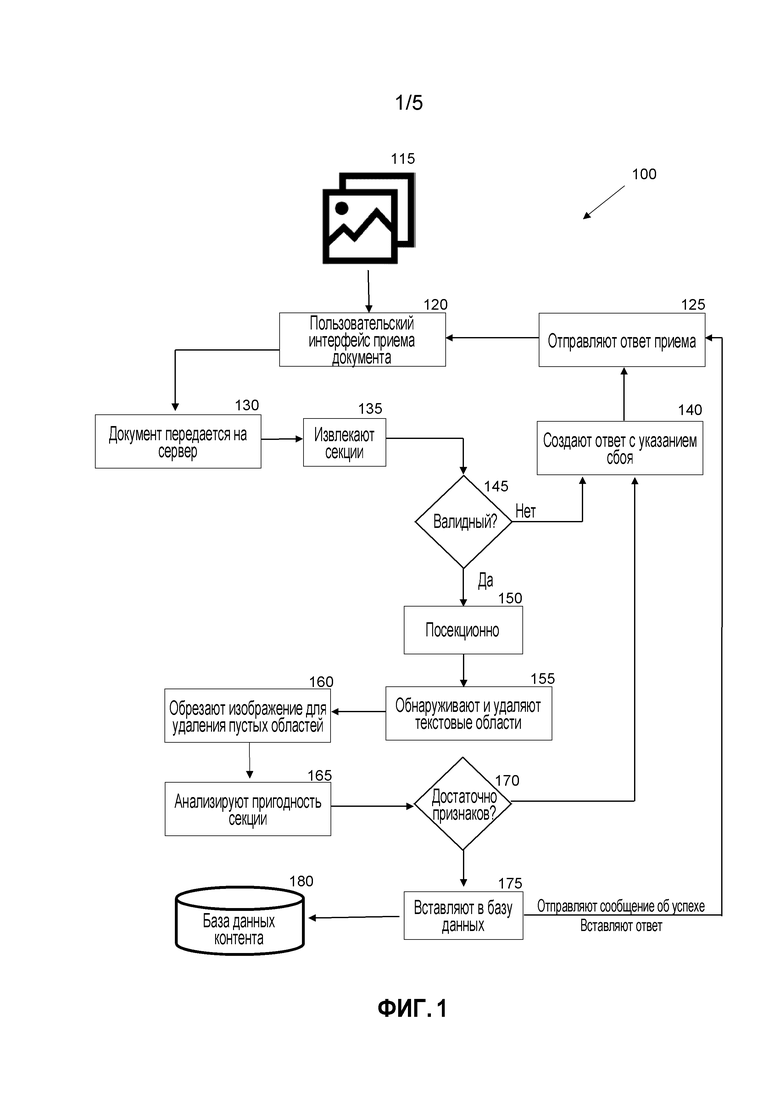
[0059] Этапы приема 100 документов подробно приведены на Фиг. 1. Фреймворк приема документов обеспечивает возможность идентификации конкретных сегментов документа, такого как журнал или газета, посредством использования изображения визуального запроса для приведения в действие этой идентификации.
[0060] Документы (например, отсканированные страницы из журнала) 115 могут быть выгружены или "приняты" с использованием пользовательского интерфейса 120. Например, страницы журнала могут быть отсканированы и выгружены в формате переносимых документов (PDF) или другом формате. Документы пересылаются на сервер 130 и секции (например, отдельные изображения) извлекаются 135. Система затем определяет, является ли документ валидным 145. Например, документ с неузнаваемыми изображениями не может считаться валидным. Алгоритм может быть использован для определения, соответствует ли документ критериям в пределах определенного допуска. Если он невалидный, система может создать ответ 140 с указанием сбоя. Ответ на прием может быть отправлен в пользовательский интерфейс 125, чтобы отправить оповещение или уведомление.
[0061] Если документ валидный, система может разбить документ на секции 150. Например, схожие секции могут быть сгруппированы вместе. Инструмент аннотаций может быть использован для обеспечения возможности сегментирования документа. Журнал может быть разделен на статьи, рекламные объявления и рекламные акции. Если информация сегментации не предоставлена, весь документ может быть обработан как единая сущность. После сегментации, каждый сегмент может быть обработан для приема в базу данных контента.
[0062] Текстовые области могут быть обнаружены и удалены 155. Изображения могут быть обрезаны для отделения их от пустых областей и/или границ на страницах 160. Каждая секция может быть проанализирована, чтобы гарантировать ее пригодность 165. Например, система может обнаружить и идентифицировать признаки. Низкое разрешение, размытое или абстрактное изображение (или изображение с неидентифицируемыми признаками) может считаться непригодным. Если присутствуют 170 достаточно признаков, оно может быть вставлено в базу данных 175.
[0063] Метаданные могут быть связаны с каждым обработанным изображением. Поля метаданных могут включать в себя связанный контент, язык документа, так же как и информацию об авторе/издателе документа.
Вставка в базу данных
[0064] Сохранение сегмента в базу данных 180 изображений/контента может включать в себя нижеследующие этапы:
1) Извлечение визуальных признаков из изображения сегмента;
2) Создание ответа вставки, содержащего:
- Вектор визуальных признаков
- Уникальный ID сегмента
- ID связанного контента
3) Оборачивание ответа вставки в соответствующий формат пересылки (например, JSON);
4) Отправку ответа вставки в базу данных;
5) Прием статуса вставки; и
6) Передачу ответа статуса вставки в пользовательский интерфейс.
Извлечение секции документа
[0065] Как только документ был выгружен на сервер, компьютерная программа может обработать этот документ и разбить его на последовательность сегментов.
[0066] Например, цифровая копия журнала может быть первоначально выгруженным документом, таким как PDF. Сегменты могут быть обозначены как каждая страница PDF-файла. Стадия извлечения может также оценивать пригодность каждой секция документа для дальнейшей обработки. Это может принимать форму проверки целостности, которая оценивает, имеет ли файл соответствующий формат для приема, или попадает ли каждая секция в пределы параметров безопасности (таких как минимальное разрешение).
Анализ документа
[0067] Для каждого сегмента, который извлекается из первоначально выгруженного документа, фреймворк является необходимым для обработки и валидации качества изображения, которое должно быть вставлено в систему технического зрения. Фреймворк включает в себя удаление текста на основе соединенных контуров краев.
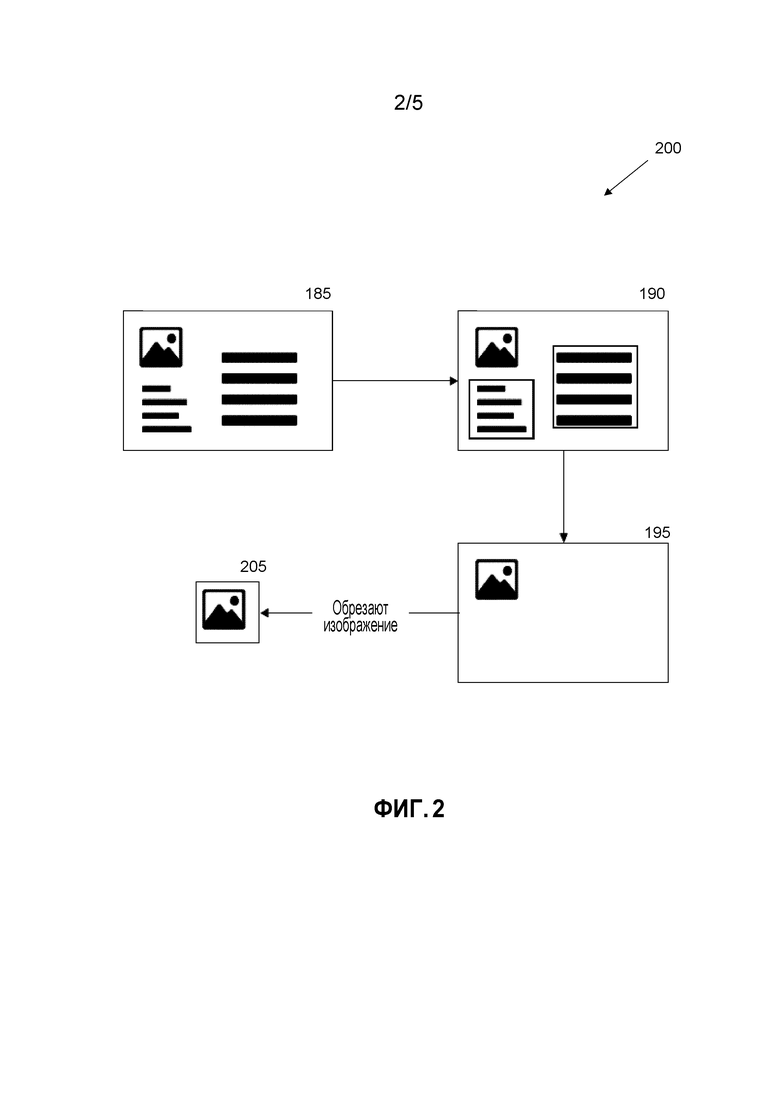
[0068] Одна проблема с приемом изображений из документов состоит в свойстве текста или текстовых признаков, которые должны быть встроены внутри изображения. Во многих системах визуального поиска, это может вызвать проблему при гарантировании уникальности внутри изображений с большой текстовой нагрузкой. Соответственно, важно обнаружить, изолировать и удалить области с большим количеством текста из составного изображения, которое включает в себя рисунок и текст.
[0069] Фиг. 2 изображает этапы с учетом обнаружения текста и алгоритма обрезки, который может быть использован для изолирования областей изображения сегмента, которое содержит текст. Изображение может быть обрезано так, что субоптимальные текстовые области удаляются до вставки. Обычное изображение 185 из журнала или газеты будет содержать секции текста. Компьютер может идентифицировать секции текста 190 на основе, например, распознавания символов и упорядоченного размещения букв в линии и параграфы (описанные ниже). Области с большим количеством текста удаляются, чтобы оставить изолированное изображение 195. В дальнейшем, изображение может быть обрезано 205 для удаления лишних областей.
[0070] Текст может также быть идентифицирован на основе соединенных контуров краев. Текст, подготовленный для печати, имеет сильно выраженные края, обычно более выраженные, чем обычное изображение. Края высокого уровня могут быть сохранены и подготовлены для обработки контуров. Обнаружение контуров будет изолировать слова, линии и ближайший текст. Если контуры содержат больше линий, они могут быть разделены на одиночные линии, и после этого, фильтрация завершается. Одиночные линии и слова соединяются и помечаются в параграфы или большие длинные линии. Нижеследующие принципы могут быть применены для обработки идентифицируемого текста.
• Края могут быть обнаружены на полутоновом изображении с использованием операции морфологического градиента.
• Преобразование в двоичную форму может быть достигнуто с использованием определения порога для изображения обнаруженных краев с использованием метода Отцу (определения порога изображения на основе кластеризации).
• Морфологическое замыкание может быть достигнуто для соединения небольших объектов (букв или слов).
• Контуры могут быть найдены с использованием анализа соединенных компонентов.
• Сначала фильтрация может быть достигнута с использованием ширины, высоты и соотношения ненулевых пикселей в области контуров.
• Вертикальная проекция области контуров может быть использована для обнаружения, содержит ли найденный контур более, чем одну линию. В случае нескольких линий, порог вертикальной проекции может быть использован для определения, где разделить линии.
• Области контуров могут быть валидированы и отфильтрованы с использованием площади области, размера, соотношения ненулевых пикселей в области контуров и некоторых настраиваемых признаков относительно произведения соотношения размеров и площади (RARA) и относительно произведения соотношения размеров и среднего размера стороны области (RARAS).
Соединение и пометка слов и линий в параграфы может проводиться в отношении прямоугольников, которые представляют собой обрамляющие блоки для области контуров. Сначала прямоугольники связываются слева и справа, так и линии, которые определены. Затем удаляются невозможные прямоугольники. В конце может быть выполнено связывание и отвязывание. Итоговый результат состоит из определенных больших прямоугольников, которые содержат области, считающиеся содержащими текст параграфа.
Прием видео
[0071] Аналогично, видеоконтент может быть скомпилирован и принят в базу данных контента. Эта секция вкратце освещает систему, которая обеспечивает пользователю возможность выгрузки видеоконтента в компьютерную программу, спроектированную для предварительной обработки видео в формат, пригодный для дальнейшего анализа и внедрения в платформу визуального поиска. Пользовательский интерфейс (UI) обеспечивает возможность выбора видеоисточника, который пользователь хочет внести в платформу. Источником может быть файл, который доступен удаленно или локально с компьютерного устройства пользователя.
[0072] Интерфейс может также обеспечить возможность снабжения аннотациями сегментов видеофайла с помощью настраиваемых метаданных, которые должны быть связаны с сегментом. Интерфейс может также предоставить обзор статуса для каждого сегмента, идентифицированного внутри видео, и показатели, относящиеся ко всему анализу и всем проверкам, выполняемым в отношении сегмента, тем самым, предоставляя незамедлительную обратную связь по статусам всех стадий для этого сегмента. Фиг. 3 изображает, как такой интерфейс может способствовать аннотации и пересылке видео и видеосегментов в платформу визуального поиска.
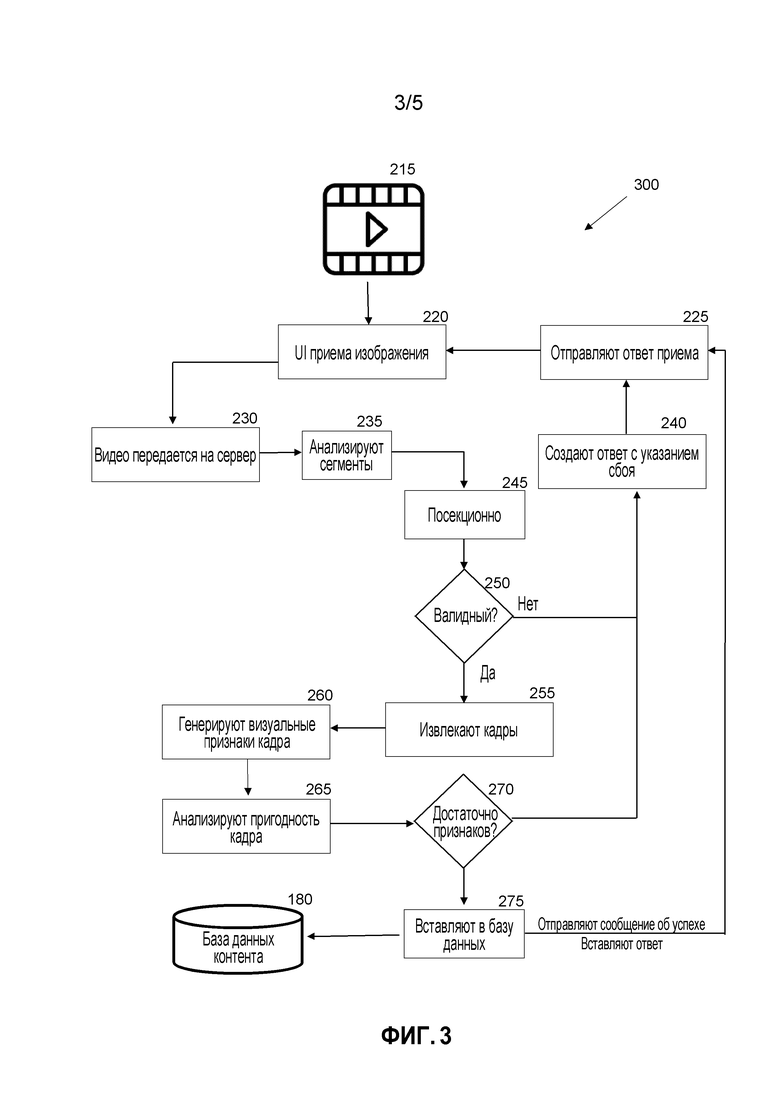
[0073] Этапы приема 300 видео подробно приведены на Фиг. 3. Фреймворк приема видео обеспечивает возможность идентификации конкретных сегментов видео посредством использования изображения визуального запроса.
[0074] Видеоконтент (например, телевизионные программы) 215 может быть выгружен или "принят" с использованием пользовательского интерфейса 220. Видео пересылается на сервер 230 и секции анализируются 235. Видео может быть дополнительно сегментировано 245. Например, разные объекты в сцене могут указывать изменение в обстановке. Система затем определяет, является ли видеосегмент валидным 250. Например, видео с неидентифицируемыми объектами может считаться невалидным. Алгоритм может быть использован для определения, соответствует ли документ критериям в пределах определенного допуска. Если он невалидный, система может создать ответ 240 с указанием сбоя. Ответ на прием может быть отправлен в пользовательский интерфейс 225, чтобы оповестить пользователя.
[0075] Если видеосегмент валидный, система может разбить видео на сегменты 245. Например, схожие секции (на основе контента сцены) могут быть сгруппированы вместе. Отдельные кадры могут быть извлечены 255. Визуальные признаки могут быть сгенерированы для каждого кадра 260. Каждый кадр может быть проанализирован, чтобы гарантировать его пригодность 265. Например, система может попытаться обнаружить и идентифицировать объекты и признаки в каждом кадре. Кадр с низким разрешением, или который размыт, может считаться непригодным. Если присутствуют 270 достаточно признаков, кадр может быть вставлен в базу данных (275, 180) контента.
Анализ сегмента
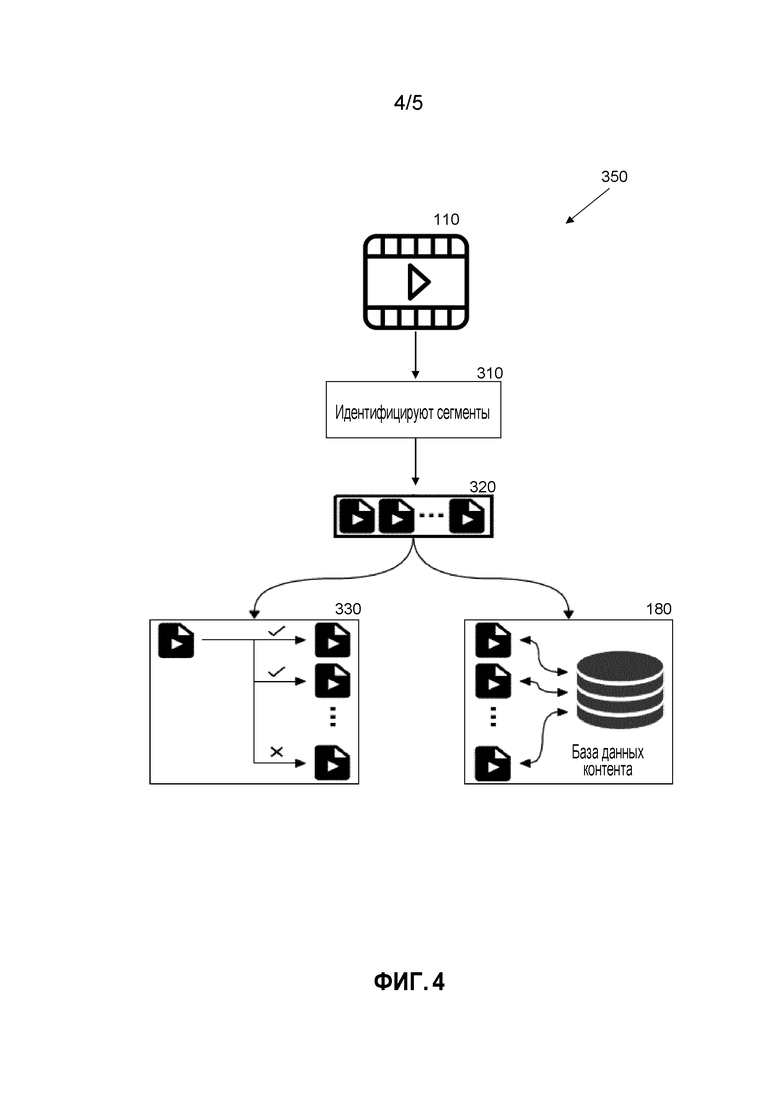
[0076] Анализ видеосегмента является компонентом фреймворка приема видео, который обеспечивает пользователю возможность изолирования и предоставления характерных для сегмента метаданных для идентифицированных сегментов.
[0077] Фиг. 4 показывает как может функционировать фреймворк 350 анализа сегмента. Выгруженное видео 110 делится на сегменты. Сегменты 310 могут быть идентифицированы и затем сгруппированы. Сегменты с внутрисегментной уникальностью могут быть объединены или сгруппированы вместе 330. Например, сегменты видео из схожей обстановки со схожими объектами вероятно находятся в схожей ситуации на видео. Кроме того, могут быть идентифицированы 180 дублирующиеся сегменты. Когда дублирующийся сегмент идентифицирован, он может быть отброшен/удален.
[0078] В предпочтительном варианте осуществления, видео обрабатывается всесторонним образом, чтобы идентифицировать нижеследующее:
1) Различимые сегменты или сцены внутри видео -> Это обрабатывает видео для обнаружения групп кадров, каждая из которых соответствует одиночному логическому событию.
2) Дублирующиеся сегменты представляются по всему видео -> Это сравнивает все обнаруженные сегменты из вышеуказанного процесса для идентификации какой-либо пары или группы сегментов, которые не могут быть отделены друг от друга (т.е. вероятно могут вызвать неоднозначность во время поиска изображения).
3) Дублирующиеся сегменты уже представляются внутри базы данных контента платформы визуального поиска -> Эта проверка оценивает, может ли уже сегмент или кадры внутри сегмента присутствовать внутри базы данных контента визуального поиска.
[0079] После успешной сегментации видео, каждый сегмент может быть дополнительно преобразован в формат, подходящий для вставки в базу данных 180 контента.
Извлечение признаков сегмента
[0080] После идентификации и изоляции валидных видеосегментов, необходимо упаковать каждый кадр внутри сегмента в запись вставки.
[0081] Это требует модуля, осуществленного компьютерной программой, функционирующей в системе для обработки каждого кадра внутри сегмента и извлечения данных, представляющих неизменяющиеся визуальные признаки масштаба и вращения в вектор (такой как ORB). Кроме того, каждый вектор признака может быть объединен с различными метаданными и идентификаторами для создания составной структуры данных для вставки в базу данных контента.
[0082] Образцовый вариант осуществления такой составной структуры данных может содержать нижеследующее:
- Уникальный идентификатор кадра
- Уникальный идентификатор сегмента
- Визуальные признаки кадра
- Метаданные (издатель, описательные теги, и т.д.)
Вставка в базу данных
[0083] Как только запись вставки кадра была сгенерирована, объект готов для вставки в базу данных контента. Перед вставкой записи кадра в базу данных контента, к базе данных контента осуществляется запрос с использованием предоставленного ID контента. Если контент не существует, может быть последовательность процессов для обеспечения возможности добавления контента соответствующим образом.
[0084] Запись вставки может быть затем передана в базу данных для сохранения. После успешного сохранения, база данных предоставит подтверждение этого запроса обновления и вернет ответ в компьютерную программу, ответственную за пересылку записи приема. Это обновление статуса может быть передано посредством фреймворка, указывая завершение цепочки процессов этого конкретного кадра
[0085] Фиг. 5 показывает примерный вариант осуществления того, как кадр может быть обработан и вставлен в базу данных 180 контента. Обработанный видеосегмент 410 анализируется для извлечения визуальных признаков 415 и создания записи 435 вставки сегмента.
[0086] Система может осуществить синтаксический анализ метаданных 420 и определить, существует ли 440 связанный контент. Например, схожий контент может уже быть в базе данных. Если так, система может идентифицировать ID 450 связанного контента для создания записи 435 вставки сегмента и вставки кадра в базу данных 180 контента. Если связанный контент не существует, система может создать контент 445 для вставки в базу данных 180 контента. Этот подход может быть использован для видеоконтента (т.е. обработанных кадров), так же как и для контента изображения (т.е. отсканированных изображений).
Случаи использования
Дополнение контента
[0087] Данное изобретение может быть использовано для усовершенствования и/или дополнения медиа в форме видео. Дополнительно, подвергая анализу и изоляции различимых сегментов внутри видео, возможно связать каждый сегмент с другим набором контента.
[0088] В качестве примера, создатель контента может выгрузить видеоконтент в платформу визуального поиска с использованием фреймворка. Из анализа видео идентифицируются несколько сегментов:
1) Последовательность вступительных заголовков. Она может быть связана с URL домашней страницы создателя или другими размещениями.
2) Несколько сегментов, представляющих каждого члена команды: Видеосегмент каждого члена может быть связан с URL их соответствующими биографическими страницами.
3) Сегмент, описывающий продукт. Этот сегмент может быть отображен в слой наложения дополненной реальности, который предоставляет механизм для виртуального взаимодействия с продуктом.
4) Заключительный сегмент преимуществ и недостатков продукта. Этот сегмент может быть отображен в список розничных продавцов в сети, из которого продукт может быть приобретен.
Таким образом, существующий видеоконтент может быть дополнен и усовершенствован посредством предоставления платформы для корреляции с дополнительным контентом на основе визуального поиска.
Операционное окружение:
[0089] Система обычно состоит из центрального сервера, который соединен сетью данных с пользовательским компьютером. Центральный сервер может состоять из одного или более компьютеров, соединенных с одним или более устройствами хранения большой емкости. Точная архитектура центрального сервера не ограничивает заявленное изобретение. Кроме того, пользовательским компьютером может быть персональный компьютер переносного или настольного типа. Им также может быть сотовый телефон, смартфон или другое карманное устройство, в том числе и планшет. Точный форм-фактор пользовательского компьютера не ограничивается заявленным изобретением. Примеры хорошо известных вычислительных систем, окружений и/или конфигураций, которые могут быть пригодны для использования с данным изобретением, включают в себя, но не ограничены этим, персональные компьютеры, серверные компьютеры, карманный, портативный или мобильный компьютер или устройства связи, такие как сотовые телефоны и PDA, микропроцессорные системы, системы на основе микропроцессоров, телеприставки, программируемую потребительскую электронику, сетевые ПК, миникомпьютеры, мэйнфреймы, распределенные вычислительные окружения, которые содержат любые из вышеуказанных систем или устройств, и тому подобные. Точный форм-фактор пользовательского компьютера не ограничивается заявленным изобретением. В одном варианте осуществления, пользовательский компьютер опускается, и вместо этого предоставляется вычислительная функциональность, которая работает с центральным сервером. В этом случае, пользователь будет осуществлять вход на сервер с другого компьютера и осуществлять доступ к системе через пользовательское окружение.
[0090] Пользовательское окружение может быть заключено в центральном сервере или оперативно соединено с ним. Кроме того, пользователь может принимать данные от центрального сервера и передавать их ему посредством Интернета, в силу чего пользователь осуществляет доступ к учетной записи с использованием Интернет-браузера, и браузер отображает интерактивную веб-страницу, оперативно соединенную с центральным сервером. Центральный сервер передает и принимает данные в ответ на данные и команды, переданные из браузера в ответ на приведение в действие покупателем пользовательского интерфейса браузера. Некоторые этапы данного изобретения могут быть выполнены на пользовательском компьютере и промежуточные результаты переданы на сервер. Эти промежуточные результаты могут быть обработаны сервером и итоговые результаты переданы обратно пользователю.
[0091] Способ, описанный в настоящем документе может выполняться на компьютерной системе, обычно состоящей из центрального процессора (CPU), который оперативно соединен с запоминающим устройством, схемы ввода и вывода данных (I/O) и схемы сетевого обмена компьютерными данными. Компьютерный код, исполняемый CPU может взять данные, принятые схемой обмена данными, и сохранить их в запоминающем устройстве. В дополнение, CPU может взять данные из схемы I/O и сохранить их в запоминающем устройстве. Кроме того, CPU может взять данные из запоминающего устройства и вывести их через схему I/O или схему обмена данными. Данные, хранящиеся в памяти, могут быть дополнительно вызваны из запоминающего устройства, дополнительно обработаны или модифицированы посредством CPU, описанным в настоящем документе образом, и повторно сохранены в том же запоминающем устройстве или другом запоминающем устройстве, оперативно соединенном с CPU, в том числе посредством сетевой схемы передачи данных. Запоминающее устройство может быть любого вида из схемы хранения данных или магнитного хранилища или оптического устройства, включающих в себя жесткий диск, оптический диск или твердотельную память. Устройства I/O могут включать в себя экран дисплея, громкоговорители, микрофон и подвижную мышь, которая указывает компьютеру относительное размещение положения курсора на дисплее, и одну или более кнопок, которые могут быть задействованы для указания команды.
[0092] Компьютер может отображать внешний вид пользовательского интерфейса на экране дисплея, оперативно соединенном со схемой I/O. Различные формы, текст и другие графические формы отображаются на экране как результат данных, сгенерированных компьютером, что обеспечивает, посредством пикселей, которые содержит экран дисплея, задействование покупателем пользовательского интерфейса браузера. Некоторые этапы данного изобретения могут быть выполнены на пользовательском компьютере и промежуточные результаты переданы на сервер. Эти промежуточные результаты могут быть обработаны сервером и итоговые результаты переданы обратно пользователю.
[0093] Способ, описанный в настоящем документе может выполняться на компьютерной системе, обычно состоящей из центрального процессора (CPU), который оперативно соединен с запоминающим устройством, схемы ввода и вывода данных (I/O) и схемы сетевого обмена компьютерными данными. Компьютерный код, исполняемый CPU может взять данные, принятые схемой обмена данными, и сохранить их в запоминающем устройстве. В дополнение, CPU может взять данные из схемы I/O и сохранить их в запоминающем устройстве. Кроме того, CPU может взять данные из запоминающего устройства и вывести их через схему I/O или схему обмена данными. Данные, хранящиеся в памяти, могут быть дополнительно вызваны из запоминающего устройства, дополнительно обработаны или модифицированы посредством CPU, описанным в настоящем документе образом, и повторно сохранены в том же запоминающем устройстве или другом запоминающем устройстве, оперативно соединенном с CPU, в том числе посредством сетевой схемы передачи данных. Запоминающее устройство может быть любого вида из схемы хранения данных или магнитного хранилища или оптического устройства, включающих в себя жесткий диск, оптический диск или твердотельную память. Устройства I/O могут включать в себя экран дисплея, громкоговорители, микрофон и подвижную мышь, которая указывает компьютеру относительное размещение положения курсора на дисплее, и одну или более кнопок, которые могут быть задействованы для указания команды.
[0094] Компьютер может отображать внешний вид пользовательского интерфейса на экране дисплея, оперативно соединенном со схемой I/O. Различные формы, текст и другие графические формы отображаются на экране как результат данных, сгенерированных компьютером, которые предписывают пикселям, которые содержит дисплей, принимать различные цвета и оттенки. Пользовательский интерфейс также отображает графический объект, называемый в данной области техники курсором. Размещение объекта на дисплее указывает пользователю выбор другого объекта на экране. Курсор может быть передвинут пользователем посредством другого устройства, соединенного схемой I/O с компьютером. Это устройство обнаруживает некоторые физические движения пользователя, например, положение руки на плоской поверхности или положение пальца на плоской поверхности. Такие устройства в данной области техники могут называться мышью или сенсорной панелью. В некоторых вариантах осуществления, сам экран дисплея может действовать как сенсорная панель посредством считывания присутствия и положения одного или более пальцев на поверхности экрана дисплея. Когда курсор размещается над графическим объектом, который выглядит кнопкой или переключателем, пользователь может задействовать кнопку или переключатель посредством контактирования с физическим переключателем на мыши или сенсорной панели или компьютерном устройстве, или постукивания по сенсорной панели или воспринимающему касания дисплею. Когда компьютер обнаруживает, что с физическим переключателем был осуществлен контакт (или что произошло постукивание по сенсорной панели или воспринимающему касания экрану), он берет видимое размещение курсора (или в случае воспринимающего касания экрана, обнаруженное положение пальца) на экране и исполняет процесс, ассоциированный с этим размещением. В качестве примера, не предназначенного для ограничения объема раскрытого изобретения, на экране может быть отображен графический объект, который выглядит как 2-мерная коробка со словом "ввести" внутри него. Если компьютер обнаруживает, что с переключателем был осуществлен контакт пока размещение курсора (или размещение пальца для воспринимающего касания экрана) было в пределах границ графического объекта, например, отображенной коробки, компьютер выполнит процесс, ассоциированный с командой "ввести". Таким образом, графические объекты на экране создают пользовательский интерфейс, который позволяет пользователю управлять процессами, функционирующими на компьютере.
[0095] Данное изобретение может также выполняться на одном или более серверах. Сервером может быть компьютер, состоящий из центрального процессора с устройством хранения большой емкости и сетевого соединения. В дополнение сервер может включать в себя несколько таких компьютеров, соединенных вместе сетью передачи данных или другим соединением передачи данных, или, несколько компьютеров в сети с хранилищем, доступным по сети, таким образом, который обеспечивает такую функциональность как группа. Обычный специалист-практик поймет, что функции, которые осуществляются на одном сервере, могут быть разбиты и осуществлены на нескольких серверах, которые оперативно соединены компьютерной сетью посредством соответствующего обмена данными между процессами. В дополнение, доступ к веб-сайту может быть посредством Интернет-браузера, осуществляющего доступ к защищенной или публичной странице, или посредством клиентской программы, выполняющейся на локальном компьютере, который соединен с сервером через компьютерную сеть. Сообщение данных и выгрузка или загрузка данных могут доставляться через Интернет с использованием обычных протоколов, включая TCP/IP, HTTP, TCP, UDP, SMTP, RPC, FTP или другие виды протоколов обмена данными, которые позволяют процессам, выполняющимся на двух удаленных компьютерах, обмениваться информацией посредством обмена данными по цифровой сети. В результате, сообщением данных может быть пакет данных, переданный компьютера и принятый им, содержащий сетевой адрес получателя, идентификатор процесса или приложения получателя, и значения данных, которые могут быть интерпретированы на компьютере получателя, размещенном по сетевому адресу получателя, посредством приложения получателя, для того, чтобы релевантные значения данных извлекались и использовались приложением получателя. Точная архитектура центрального сервера не ограничивает заявленное изобретение. В дополнение, сеть данных может функционировать на нескольких уровнях, так что пользовательский компьютер соединен через межсетевой экран с одним сервером, который маршрутизирует связь с другим сервером, который исполняет раскрытые способы.
[0096] Пользовательский компьютер может оперировать программой, которая принимает от удаленного сервера файл данных, который подается в программу, которая интерпретирует данные в файле данных, и дает команду устройству отображения представить конкретный текст, изображения, видео, аудио и другие объекты. Программа может обнаружить относительное размещение курсора, когда задействована кнопка мыши, и интерпретировать, что команда должна быть выполнена, на основе размещения указанного относительного размещения на дисплее, когда кнопка была нажата. Файлом данных может быть HTML-документ, программой - программа веб-браузера, и командой - гиперссылка, которая предписывает браузеру запросить новый HTML-документ от другого удаленного размещения адреса сети передачи данных. HTML может также иметь ссылки, которые приводят к вызову и выполнению других модулей кода, например, Flash или другого платформо-зависимого кода.
[0097] Специалисты в релевантной области техники поймут, что данное изобретение может быть применено на практике с другой связью, обработкой данных или конфигурациями компьютерной системы, включая: беспроводные устройства, Интернет-устройства, карманные устройства (включая персональные цифровые помощники (PDA)), носимые компьютеры, все виды сотовых или мобильных телефонов, многопроцессорные системы, микропроцессорная или программируемая потребительская электроника, телевизионные приставки, сетевые PC, миникомпьютеры, мейнфреймы и подобные. На самом деле, термины "компьютер", "сервер" и подобные используются здесь взаимозаменяемо, и могут относиться к любому из вышеуказанных устройств и систем.
[0098] В некоторых случаях, особенно где пользовательским компьютером является мобильное вычислительное устройство, используемое для осуществления доступа к данным через сеть, причем сеть может быть любого типа из сотовой, на основе протокола IP или конвергированной телекоммуникационной сети, включая, но не ограничиваясь этим, глобальную систему мобильной связи (GSM), множественный доступ с разделением по времени (TDMA), множественный доступ с кодовым разделением (CDMA), множественный доступ с ортогональным частотным разделением (OFDM), службу пакетной радиосвязи общего пользования (GPRS), усовершенствованную технологию передачи данных в среде GSM (EDGE), усовершенствованную систему мобильной связи (AMPS), технологию международного взаимодействия для микроволнового доступа (WiMAX), универсальную мобильную телекоммуникационную систему (UMTS), технологию оптимизированной развитой передачи данных (EVDO), проект долгосрочного развития (LTE), широкополосную сеть сверхмобильной связи (UMB), протокол передачи голоса по Интернету (VoIP) или нелицензируемый мобильный доступ (UMA).
[0099] Интернет является компьютерной сетью, которая позволяет покупателям, оперируя персональным компьютером, взаимодействовать с компьютерными серверами, размещенными удаленно, и просматривать контент, который доставляется от серверов на персональный компьютер по сети в виде файлов данных. При одном виде протокола, серверы представляют веб-страницы, которые воспроизводятся на персональном компьютере покупателя с использованием локальной программы, известной как браузер. Браузер принимает один или более файлов данных от сервера, которые отображаются на экране персонального компьютера покупателя. Браузер ищет эти файлы данных с конкретного адреса, который представлен буквенно-цифровой строкой, называемой универсальным указателем ресурсов (URL). Однако, веб-страница может содержать компоненты, которые загружаются с разнообразных URL или IP-адресов. Веб-сайт является коллекцией соответствующих URL, причем обычно все совместно используют одинаковый корневой адрес или управляются одной сущностью. В одном варианте осуществления разные области симулируемого пространства имеют разные URL. То есть, симулируемое пространство может быть унитарной структурой данных, но разные URL указывают разные размещения в структуре данных. Это делает возможным симулировать большую зону и заставить участников начать использовать ее внутри их виртуальной окрестности.
[00100] Логика компьютерной программы, реализующая всю или часть функциональности, ранее описанной в настоящем документе, может быть осуществлена в различных формах, включающих в себя, но ни каким образом не ограничиваемых этим, форму исходного кода, исполняемую компьютером форму, и различные промежуточные формы (например, формы, сгенерированные ассемблером, компилятором, редактором связей, или указателем.) Исходный код может включать в себя последовательность инструкций компьютерной программы, реализованных на любом из различных языков программирования (например, объектный код, язык ассемблера, или высокоуровневые языки, такие как C, C-HF, C#, Action Script, PHP, EcmaScript, JavaScript, JAVA или HTML 5) для использования с различными операционными системами или операционными окружениями. Исходный код может задавать и использовать различные структуры данных и сообщения связи. Исходный код может быть в исполняемой компьютером форме (например, посредством интерпретатора), или исходный код может быть преобразован (например, посредством транслятора, ассемблера или компилятора) в исполняемую компьютером форму.
[00101] Данное изобретение может быть описано в общем контексте исполняемых компьютером инструкций, таких как программные модули, исполняемые компьютером. Обычно, программные модули включают стандартные программы, программы, объекты, компоненты, структуры данных и так далее, которые выполняют конкретные задачи или реализуют конкретные абстрактные типы данных. Компьютерная программа и данные могут иметь любую фиксированную форму (например, форму исходного кода, исполняемую компьютером форму или промежуточную форму) либо постоянно, либо временно на материальном носителе информации, таком как полупроводниковое запоминающее устройство (например, RAM, ROM, PROM, EEPROM или программируемая Flash RAM), магнитное запоминающее устройство (например, дискета или стационарный жесткий диск), оптическое запоминающее устройство (например, CD-ROM или DVD), PC-карта (например, PCMCIA-карта), или другое запоминающее устройство. Компьютерная программа и данные могут быть фиксированными в любой форме в сигнале, который имеет возможность передачи на компьютер с использованием любой из разнообразных технологий связи, включающих в себя, но не ограничиваемых этим каким-либо образом, аналоговые технологии, цифровые технологии, оптические технологии, беспроводные технологии, сетевые технологии и межсетевые технологии. Компьютерная программа и данные могут распространятся в любой форме, такой как съемный носитель информации с прилагаемой печатной или электронной документацией (например, коробочное программное обеспечение или магнитная пленка), с предзагруженной компьютерной системой (например, в системной ROM или на стационарном диске), или распространяться с сервера или электронной доски объявлений через систему связи (например, Интернет или всемирную сеть.) Понятно, что любой из программных компонентов по настоящему изобретению может, если потребуется, быть реализован в форме ROM (постоянной памяти). Программные компоненты могут, в основном, быть реализованы в аппаратном обеспечении, если потребуется, с использованием обыкновенных способов.
[00102] Данное изобретение может быть также применено на практике в распределенных вычислительных окружениях, где задания выполняются устройствами удаленной обработки, которые сопряжены через сеть связи. В распределенном вычислительном окружении, программные модули могут быть размещены как на локальных, так и на удаленных компьютерных носителях информации, в том числе запоминающих устройствах. Специалисты-практики поймут, что данное изобретение может быть выполнено на одном или более компьютерных процессорах, которые связаны с использованием сети передачи данных, в том числе, например, Интернет. В другом варианте осуществления, разные этапы процесса могут быть выполнены одним или более компьютерами и устройствами хранения, географически разделенными, но соединенными сетью передачи данных таким образом, что они функционируют вместе для выполнения этапов процесса. В одном варианте осуществления, пользовательский компьютер может запустить приложение, которое предписывает пользовательскому компьютеру передать поток из одного или более пакетов данных через сеть передачи данных на второй компьютер, называемый здесь сервером. Сервер, в свою очередь, может быть соединен с одним или более устройствами хранения большой емкости, где хранится база данных. Сервер может выполнить программу, которая принимает переданный пакет и интерпретирует переданные пакеты данных, для того, чтобы извлечь информацию запроса к базе данных. Сервер может затем выполнить оставшиеся этапы данного изобретения посредством осуществления доступа к устройствам хранения большой емкости, чтобы получить желаемый результат для запроса. В качестве альтернативы, сервер может передать информацию запроса другому компьютеру, который соединен с устройствами хранения большой емкости, и этот компьютер может выполнить данное изобретение, чтобы получить желаемый результат. Может затем быть передан обратно на пользовательский компьютер посредством другого потока из одного или более пакетов данных, соответствующим образом адресованными пользовательскому компьютеру. В одном варианте осуществления, реляционная база данных может находится в одном или более оперативно соединенных серверах, оперативно соединенных с компьютерной памятью, например, дисковыми накопителями. В еще одном варианте осуществления, инициализация реляционной базы данных может быть подготовлена на группе серверов, и взаимодействие с пользовательским компьютером происходит в другом месте во всех процессах.
[00103] Следует отметить, что схемы последовательности операций используются здесь для демонстрации различных аспектов данного изобретения, и не должны толковаться как ограничивающие настоящее изобретение какой-либо логической последовательностью или реализацией логики. Описанная логика может быть разбита на разные логические блоки (например, программы, модули, функции или стандартные подпрограммы) без изменения общих результатов или иного отступления от истинного объема данного изобретения. Часто логические элементы могут добавляться, модифицироваться, опускаться, выполняться в разном порядке или реализовываться с использованием разных логических конструкций (например, логических вентилей, циклических примитивов, условной логики и других логических конструкций) без изменения общих результатов или иного отступления от истинного объема данного изобретения.
[00104] Описанные варианты осуществления данного изобретения предназначены, чтобы быть примерными, и многочисленные вариации и модификации будут понятны специалистам в данной области техники. Все такие вариации и модификации предназначены находится в рамках объема настоящего изобретения, который определяется прилагаемой формулой изобретения. Хотя настоящее изобретение было описано и проиллюстрировано подробно, следует четко понимать, что оно служит только в качестве иллюстрации и примера, и не должно считаться каким-либо ограничением. Понятно, что различные признаки данного изобретения, которые, для ясности, описаны в контексте отдельных вариантов осуществления, могут также быть предоставлены в комбинации в одном варианте осуществления.

Изобретение относится к сетевому компьютеризированному приложению для получения, обработки, анализа и приема видео медиаконтента. Технический результат заключается в обеспечении доступа к контенту посредством платформы визуального поиска. Такой результат достигается тем, что изобретение включает в себя фреймворк и способ для обеспечения возможности преобразования видеоконтента в формат, который обеспечивает возможность для отображения и отсюда идентификации отдельных секций (сегментов сцен или иного) медиаконтента. Оно включает в себя средство приема изображений и видеокадров в базу данных. Потребительские продукты могут быть сопоставлены с изображениями и/или объектами на изображениях. Потребитель может осуществить доступ к контенту посредством подачи цифрового изображения, снятого на мобильное устройство. Один или более объектов на поданном пользователем изображении могут быть сопоставлены с продуктами и/или коммерческими/рекламными материалами. 4 н. и 6 з.п. ф-лы, 5 ил.
1. Способ компилирования кадров из видео, сохранения и индексирования кадров в базе данных, содержащий этапы, на которых
a) получают видео;
b) анализируют видео на предмет признаков;
c) разделяют видео на сегменты на основе признаков, причем сегменты идентифицируются посредством группирования кадров, которые соответствуют одинаковым или схожим сценам, дублирующиеся сегменты на видео удаляются, при этом сегменты на видео, уже присутствующие в базе данных, удаляются, причем в сегментах извлекаются отдельные кадры и для каждого кадра генерируются визуальные признаки, при этом сегменты снабжаются аннотациями с использованием метаданных;
d) анализируют визуальные признаки сегментов для группирования сегментов, которые совместно используют эти визуальные признаки;
e) анализируют пригодность каждого кадра;
f) выдают оповещение, если определена непригодность;
g) снабжают один или более кадров сегментов аннотациями с использованием метаданных, если определена пригодность, при этом визуальные признаки извлекаются в вектор признаков, причем каждый вектор признаков объединяется с метаданными и уникальными идентификаторами для создания составной структуры данных, содержащей идентификатор кадра, идентификатор сегмента, визуальные признаки кадра и метаданные; и
h) сохраняют упомянутые один или более кадров сегментов в базу данных, при этом к базе данных осуществляется запрос с использованием упомянутой составной структуры данных для определения того, существует ли связанный с ней контент в базе данных, и либо i) создается запись вставки сегмента и вставляются кадры в базу данных, либо ii) создается контент для вставки в базу данных.
2. Способ по п. 1, включающий в себя дополнительный этап, на котором понижают частоту смены кадров и/или разрешение видео.
3. Способ по п. 1, включающий в себя два дополнительных этапа, на которых осуществляют доступ к базе данных, когда пользователь подает запрос, и сопоставляют запрос с одним или более кадрами сегментов в базе данных на основе совместно используемых признаков.
4. Компьютеризированная система для приема видео, состоящая из:
пользовательского интерфейса для выгрузки видео на сервер;
компьютерной программы для обработки видео и извлечения сегментов из видео в качестве кадров, при этом для каждого кадра генерируются визуальные признаки, причем извлеченные сегменты снабжаются аннотациями с использованием метаданных,
при этом сегменты идентифицируются посредством группирования кадров, которые соответствуют одинаковым или схожим сценам, причем дублирующиеся сегменты на видео удаляются, при этом сегменты на видео, уже присутствующие в базе данных, удаляются;
модуля для обработки каждого кадра в сегментах и извлечения визуальных признаков в вектор признаков, при этом каждый вектор признаков объединяется с метаданными и уникальными идентификаторами для создания составной структуры данных, содержащей идентификатор кадра, идентификатор сегмента, визуальные признаки кадра и метаданные;
базы данных для хранения извлеченных сегментов, при этом к базе данных осуществляется запрос с использованием упомянутой составной структуры данных для определения того, существует ли связанный с ней контент в базе данных, и либо i) создается запись вставки сегмента и вставляются кадры в базу данных, либо ii) создается контент для вставки в базу данных;
при этом извлеченные сегменты анализируются на предмет соответствия параметрам пригодности, включая признаки изображения и разрешение; и
при этом анализируется пригодность каждого кадра и создается ответ, обнаружена ли непригодность кадра.
5. Компьютеризированная система для приема видео по п. 4, включающая в себя средство для приема запроса и модуль для сопоставления запроса с одной или более секциями видео в базе данных на основе совместно используемых признаков.
6. Способ компилирования изображений из печатных медиа в базу данных, содержащий этапы, на которых
a) получают печатные медиа;
b) преобразовывают печатные медиа в цифровые медиа;
c) сегментируют цифровые медиа на один или более сегментов;
d) обнаруживают текст в одном или более сегментах на основе соединенных контуров краев, причем края обнаруживаются посредством операции морфологического градиента, при этом контуры обнаруживаются посредством анализа соединенных компонентов для изоляции слов, линий и ближайшего текста, причем вертикальной проекцией контуров обнаруживается, содержат ли контуры более чем одну линию, при этом одиночные линии и слова соединяются и помечаются в параграфы или большие одиночные линии в прямоугольниках, которые представляют собой обрамляющие блоки или области контуров;
e) удаляют области с текстом из одного или более сегментов;
f) обнаруживают одно или более изображений в одном или более сегментах;
g) определяют, достаточно ли признаков присутствует для категорирования одного или более изображений,
h) выдают оповещение, если признаков не достаточно;
i) категорируют одно или более изображений, если признаков достаточно; и
j) вставляют одно или более изображений в базу данных, при этом вставка содержит извлечение визуальных признаков из одного или более изображений, и создают ответ вставки, содержащий вектор визуальных признаков, ID сегмента и ID связанного контента.
7. Способ по п. 6, включающий в себя два дополнительных этапа, на которых осуществляют доступ к базе данных, когда пользователь подает запрос, и сопоставляют запрос с одним или более изображениями в базе данных посредством сравнения признаков.
8. Способ по п. 6, включающий в себя дополнительный этап, на котором снабжают одно или более изображений аннотациями с использованием метаданных.
9. Компьютеризированная система для приема документов в базу данных, состоящая из:
пользовательского интерфейса для выгрузки документа на сервер;
модуля, состоящего из логики для обработки документа и сегментации документа на одно или более изображений сегмента;
модуль, состоящий из логики для удаления текста из изображений на основе соединенных контуров краев, при этом края обнаруживаются посредством операции морфологического градиента, при этом контуры обнаруживаются посредством анализа соединенных компонентов для изоляции слов, линий и ближайшего текста, при этом вертикальной проекцией контуров обнаруживается, содержат ли контуры более чем одну линию, при этом одиночные линии и слова соединяются и помечаются в параграфы или большие одиночные линии в прямоугольниках, которые представляют собой обрамляющие блоки или области контуров;
модуля, состоящего из логики для обнаружения признаков на изображениях;
модуля, состоящего из логики для извлечения визуальных признаков из изображений и создания ответа вставки, содержащего вектор визуальных признаков, ID сегмента и ID связанного контента; и
базы данных для вставки изображений,
при этом обнаруженные признаки анализируются на предмет валидности изображений и
при этом создается ответ, если определена невалидность.
10. Компьютеризированная система для приема документов по п. 9, включающая в себя средство для приема запроса и модуль для сопоставления запроса с одним или более изображениями в базе данных на основе совместно используемых признаков.
| CN 103927387 A, 16.07.2014 | |||
| US 20110085739 A1, 14.04.2011 | |||
| US 20080317353 A1, 25.12.2008 | |||
| CN 103186538 A, 03.07.2013 | |||
| US 7246314 B2, 17.07.2007 | |||
| RU 2014119859 A, 27.11.2015. |

