Область техники, к которой относится изобретение
Данная технология относится к системам распределенных баз данных и, в частности, к способу и системе для маршрутизации и выполнения транзакций системой распределенной базы данных.
Уровень техники
Требования к запоминающим устройствам для хранения цифровых данных постоянно растут, поскольку большие объемы цифровых данных создаются ежедневно. Например, хранения могут требовать различные виды пользовательских данных, данных организаций и/или данных приложений. Это повышает требования к емкости хранилищ данных. Растущие потребности пользователей и/или организаций способны удовлетворить «облачные» системы удаленного хранения данных.
В общем случае «облачное» хранилище данных представляет собой вид компьютерного запоминающего устройства, в котором цифровые данные хранятся в логических пулах. Физическая память, в которой фактически хранятся цифровые данные, распределена между несколькими серверами, возможно, расположенными в различных местах (т.е. в различных центрах обработки данных), и обычно управляется компанией, предоставляющей услуги «облачного» хранения данных. Пользователи и/или организации обычно покупают или арендуют некоторый объем памяти у поставщиков услуг «облачного» хранения данных, чтобы хранить свои цифровые данные. Со своей стороны, поставщики услуг «облачного» хранения данных отвечают за доступность цифровых данных и защиту физической памяти с целью предотвращения утраты данных.
В некоторых случаях физическая память поставщиков услуг «облачного» хранения данных содержит распределенную базу данных, способную получать транзакции для ввода/вывода цифровых данных. Транзакция может представлять собой единицу работы (т.е. задачу), которая должна выполняться распределенной базой данных и потенциально представляет собой изменение состояния распределенной базы данных. Например, транзакция может представлять собой преднамеренный запуск компьютерной программы, осуществляющей доступ к базе данных и обеспечивающей операторам распределенной базы данных возможности извлечения и/или обновления данных.
Известно, что в некоторых конкретных случаях может требоваться выполнение транзакций в некотором порядке (например, последовательно), чтобы обеспечить надлежащую работу систем распределенных баз данных. Чтобы обеспечить этот порядок, система распределенной базы данных обычно содержит систему управления транзакциями, которая управляет транзакциями, предназначенными для этой базы данных.
Раскрытие изобретения
Разработчики настоящей технологии обнаружили некоторые технические недостатки, связанные с управлением транзакциями в системах распределенных баз данных.
Например, в некоторых традиционных системах распределенных баз данных реализована единая система управления транзакциями или сокращенно «единый менеджер транзакций». В этом случае имеется единая «точка входа» транзакций в систему распределенной базы данных. Иными словами, этот единый менеджер транзакций способен принимать все транзакции, предназначенные для системы распределенной базы данных. Разработчики данной технологии обнаружили, что реализация такого менеджера транзакций с единой «точкой входа» может затруднять масштабирование систем распределенных баз данных. Иными словами, менеджер транзакций с единой «точкой входа» может создавать проблемы, когда система распределенной базы данных содержит большое количество сегментов базы данных.
Когда система распределенной базы данных содержит небольшое количество сегментов, использование менеджера транзакций с единой «точкой входа» может быть приемлемым решением. Тем не менее, когда система распределенной базы данных содержит большое количество сегментов, использование менеджера транзакций с единой «точкой входа» становится менее эффективным, поскольку глобальная схема транзакций, используемая для глобального упорядочивания транзакций в системе распределенной базы данных, может приводить к необходимости обмена информацией между ее сегментами. Поэтому в случае большого количества сегментов в системе распределенной базы данных обмен информацией между сегментами увеличивается, что, в свою очередь, может увеличивать задержку в этой системе распределенной базы данных.
Разработчики данной технологии также обнаружили, что менеджер транзакций с «единой точкой входа» приводит к возникновению «узкого места» в системах распределенных баз данных. В этом случае возможно возникновение проблем, когда в эту единую «точку входа» для упорядочивания направляется большое количество транзакций.
Кроме того, разработчики данной технологии обнаружили, что реализация нескольких традиционных менеджеров транзакций для управления транзакциями, предназначенными для системы распределенной базы данных, с целью устранения «узкого места» также может быть неидеальным решением. Если для системы распределенной базы данных используется несколько традиционных менеджеров транзакций, может потребоваться их взаимная синхронизация для обеспечения глобальной схемы транзакций. Взаимная синхронизация менеджеров транзакций требует большого количества вычислений и выделения дополнительных вычислительных ресурсов.
Целью настоящего изобретения является устранение по меньшей мере некоторых недостатков известных решений.
В некоторых вариантах осуществления данной технологии разработчики данной технологии разработали, среди прочего, «многовходовую» систему маршрутизации транзакций. Эта «многовходовая» система маршрутизации транзакций может быть реализована как часть распределенной программной системы, способной маршрутизировать и выполнять транзакции в системе распределенной базы данных.
Согласно некоторым вариантам осуществления данной технологии, «многовходовая» система маршрутизации транзакций содержит (а) уровень «портов-координаторов», в целом, способных обеспечивать несколько «точек входа» для транзакций, предназначенных для системы распределенной базы данных, и (б) уровень «портов-посредников», способных обеспечивать упорядочение надлежащим образом транзакций, предназначенных для соответствующих сегментов системы распределенной базы данных, для их выполнения.
В некоторых вариантах осуществления эта «многовходовая» система маршрутизации транзакций может упрощать масштабирование систем распределенных баз данных и поэтому может быть разработана для систем распределенных баз данных, содержащих большое количество сегментов, с целью снижения задержки в системе распределенной базы данных по сравнению с некоторыми традиционными системами управления транзакциями.
В других вариантах осуществления для этой «многовходовой» системы маршрутизации транзакций может не требоваться взаимная синхронизация (а) портов-координаторов и (б) портов-посредников. В результате реализация этой «многовходовой» системы маршрутизации транзакций позволяет сократить потребности в вычислительных ресурсах по сравнению с некоторыми традиционными системами управления транзакциями, в которых требуется синхронизация.
Предполагается, что в некоторых вариантах осуществления данной технологии использование этой «многовходовой» системы маршрутизации транзакций может быть полезным по меньшей мере по одной из следующих причин:
- каждый порт-координатор принимает соответствующий набор транзакций, и, следовательно, можно избежать проблемы «узкого места», присущей некоторым традиционным системам управления транзакциями;
- может не требоваться обмен информацией между портами-координаторами или их взаимная синхронизация, что позволяет снизить потребности в вычислительных ресурсах системы маршрутизации транзакций;
- принятые и упорядоченные соответствующими портами-координаторами транзакции передаются в конкретные порты-посредники, для которых также может не требоваться взаимный обмен информацией или синхронизация, что позволяет снизить потребности в вычислительных ресурсах системы маршрутизации транзакций;
- принятые и упорядоченные соответствующими портами-посредниками транзакции передаются только в те сегменты, для которых транзакции фактически предназначены, и поэтому:
- не требуются расчеты глобальной схемы для всех транзакций;
- не требуется отправка этой глобальной схемы транзакций в каждый сегмент системы распределенной базы данных;
- требуется доступ только к части сегментов системы распределенной базы данных; и/или
- сегменты, к которым осуществляется доступ, принимают порядок только предназначенных для них транзакций и, следовательно, не должны принимать глобальную схему транзакций с порядком всех транзакций, предназначенных для системы распределенной базы данных.
Таким образом, предполагается, что в некоторых вариантах осуществления данной технологии использование такой «многовходовой» системы маршрутизации транзакций может, например, позволить сократить до минимума обмен информацией в распределенной программной системе, которая маршрутизирует и выполняет транзакции; сократить до минимума использование центрального процессора для поддержки такой распределенной программной системы; избежать ненужного доступа к сегментам системы распределенной базы данных, для которых эти транзакции не предназначены.
Согласно первому аспекту данной технологии реализована распределенная программная система для маршрутизации транзакций с целью их выполнения. Транзакции формируются из запроса, предоставленного источником запросов. Распределенная программная система содержит подсистему базы данных, содержащую множество мест назначения транзакции и разделенную на множество сегментов. Каждый сегмент из множества сегментов содержит соответствующую часть множества мест назначения транзакции. Распределенная программная система также содержит подсистему маршрутизации транзакций для упорядочивания множества транзакций. Каждая транзакция из множества транзакций имеет соответствующий уникальный идентификатор транзакции (TUID, Transaction Unique Identifier) и предназначена для по меньшей мере одного соответствующего места назначения транзакции для ее выполнения. Подсистема маршрутизации транзакций содержит множество портов-координаторов. Каждый порт из множества портов-координаторов связан с соответствующим счетчиком. Порт из множества портов-координаторов способен принимать соответствующий набор транзакций. Каждая транзакция из набора транзакций имеет соответствующий идентификатор TUID и связана с по меньшей мере одним соответствующим местом назначения транзакции для ее выполнения. Каждый порт из множества портов-координаторов также способен для сегмента, содержащего по меньшей мере одно место назначения транзакции, связанное с соответствующим набором транзакций, определять локальный посегментный порядок транзакций из подмножества этого набора транзакций. Транзакции из этого подмножества предназначены для по меньшей мере одного места назначения транзакции в этом сегменте. Локальный посегментный порядок основан на соответствующих идентификаторах TUID транзакций из подмножества набора транзакций. Локальный посегментный порядок для подмножества набора транзакций указывает порядок, в котором транзакции из этого подмножества набора транзакций должны выполняться сегментом. Подсистема маршрутизации транзакций также содержит множество портов-посредников. Каждый порт из множества портов-посредников заранее сопоставлен с по меньшей мере одним сегментом. Порт из множества портов-посредников способен принимать локальные посегментные порядки от множества портов-координаторов. Принятые локальные посегментные порядки связаны с по меньшей мере одним сегментом, с которым заранее сопоставлен некоторый порт из множества портов-посредников. Порт из множества портов-посредников также способен определить централизованный посегментный порядок для по меньшей мере одного заранее сопоставленного сегмента путем упорядочивания соответствующих локальных посегментных порядков, связанных с по меньшей мере одним заранее сопоставленным сегментом, на основе связанных с множеством портов-координаторов счетчиков принятых соответствующих локальных посегментных порядков. Централизованный посегментный порядок указывает порядок, в котором все транзакции, предназначенные для мест назначения транзакции соответствующего сегмента и принятые соответствующим портом-посредником, должны выполняться соответствующим сегментом.
В некоторых вариантах осуществления данной технологии каждый порт из множества портов-координаторов и каждый порт из множества портов-посредников реализован в виде программного модуля.
В некоторых вариантах осуществления данной технологии программный модуль реализован как конечный автомат (SM, State Machine).
В некоторых вариантах осуществления данной технологии каждый сегмент из множества сегментов заранее сопоставлен с одним портом-посредником из множества портов-посредников.
В некоторых вариантах осуществления данной технологии порт-посредник из множества портов-посредников заранее сопоставлен с несколькими сегментами из множества сегментов.
В некоторых вариантах осуществления данной технологии порт-посредник из множества портов-посредников реализован в виде части соответствующего заранее сопоставленного сегмента.
В некоторых вариантах осуществления данной технологии порт из множества портов-координаторов способен отправлять пустой пакет координатора в те порты из множества портов-посредников, для которых этот порт из множества портов-координаторов не принял транзакции.
В некоторых вариантах осуществления данной технологии количество портов во множестве портов-координаторов меньше количества портов во множестве портов-посредников.
В некоторых вариантах осуществления данной технологии количество портов во множестве портов-посредников меньше количества сегментов во множестве сегментов.
В некоторых вариантах осуществления данной технологии подсистема базы данных содержит базу данных.
В некоторых вариантах осуществления данной технологии база данных представляет собой распределенную базу данных и хранится в подсистеме распределенного хранения данных.
В некоторых вариантах осуществления данной технологии база данных содержит одну или несколько таблиц базы данных.
В некоторых вариантах осуществления данной технологии одна или несколько таблиц базы данных разделены между множеством сегментов.
Согласно второму аспекту данной технологии реализован способ маршрутизации транзакций с целью их выполнения. Способ выполняется распределенной программной системой. Распределенная программная система содержит подсистему базы данных, содержащую множество мест назначения транзакции и разделенную на множество сегментов. Каждый сегмент из множества сегментов содержит соответствующую часть множества мест назначения транзакции. Распределенная программная система также содержит подсистему маршрутизации транзакций для упорядочивания множества транзакций. Каждая транзакция из множества транзакций имеет соответствующий уникальный идентификатор транзакции (TUID) и предназначена для по меньшей мере одного соответствующего места назначения транзакции для ее выполнения. Подсистема маршрутизации транзакций содержит множество портов-координаторов и множество портов-посредников. Каждый порт из множества портов-посредников заранее сопоставлен с по меньшей мере одним соответствующим сегментом из множества сегментов. Способ включает в себя прием портом-координатором соответствующего набора транзакций. Каждая транзакция имеет соответствующий идентификатор TUID и связана с по меньшей мере одним соответствующим местом назначения транзакции для ее выполнения. Способ включает в себя формирование портом-координатором по меньшей мере одного локального посегментного порядка на основе идентификаторов TUID и по меньшей мере одного соответствующего места назначения транзакции для транзакций из соответствующего набора транзакций. Некоторый порядок из по меньшей мере одного локального посегментного порядка содержит транзакции из соответствующего набора транзакций, предназначенных для мест назначения транзакции некоторого сегмента из множества сегментов. Способ включает в себя передачу портом-координатором по меньшей мере одного локального посегментного порядка в соответствующий порт-посредник, заранее сопоставленный с некоторым сегментом из множества сегментов. Способ включает в себя прием портом-посредником по меньшей мере одного локального посегментного порядка от множества портов-координаторов. Каждый порядок из по меньшей мере одного локального посегментного порядка, принятого портом-посредником, связан с идентификатором координатора (CID) соответствующего порта-координатора и со счетчиком соответствующего порта-координатора. Способ включает в себя формирование портом-посредником по меньшей мере одного централизованного посегментного порядка выполнения из по меньшей мере одного локального посегментного порядка, принятого от множества портов-координаторов, на основе соответствующих идентификаторов CID и соответствующих счетчиков, при этом по меньшей мере один централизованный посегментный порядок выполнения предназначен для соответствующего заранее сопоставленного сегмента этого порта-посредника.
В некоторых вариантах осуществления данной технологии способ дополнительно включает в себя выполнение соответствующим заранее сопоставленным сегментом порта-посредника транзакций, указанных в соответствующем централизованным посегментном порядке выполнения.
В некоторых вариантах осуществления данной технологии перед формированием по меньшей мере одного централизованного посегментного порядка выполнения способ дополнительно включает в себя проверку портом-посредником получения пакета координатора от каждого порта из множества портов-координаторов.
В некоторых вариантах осуществления данной технологии формирование портом-координатором по меньшей мере одного локального посегментного порядка включает в себя упорядочивание этим портом-координатором соответствующего набора транзакций с целью формирования соответствующего упорядоченного набора транзакций.
В некоторых вариантах осуществления данной технологии упорядочивание включает в себя применение алгоритма упорядочивания в отношении соответствующих идентификаторов TUID.
В некоторых вариантах осуществления данной технологии количество портов во множестве портов-координаторов меньше количества портов во множестве портов-посредников.
В некоторых вариантах осуществления данной технологии количество портов во множестве портов-посредников меньше количества сегментов во множестве сегментов.
В некоторых вариантах осуществления данной технологии подсистема базы данных содержит базу данных.
В некоторых вариантах осуществления данной технологии база данных представляет собой распределенную базу данных и хранится в подсистеме распределенного хранения данных.
В некоторых вариантах осуществления данной технологии база данных содержит одну или несколько таблиц базы данных.
В некоторых вариантах осуществления данной технологии одна или несколько таблиц базы данных разделены между множеством сегментов.
В контексте настоящего описания термин «сервер» означает компьютерную программу, выполняемую соответствующими аппаратными средствами и способную принимать запросы (например, от клиентских устройств) через сеть и выполнять эти запросы или инициировать их выполнение. Аппаратные средства могут представлять собой один физический компьютер или одну компьютерную систему и это не существенно для данной технологии. В настоящем контексте выражение «сервер» не означает, что каждая задача (например, принятая команда или запрос) или некоторая задача принимается, выполняется или запускается одним и тем же сервером (т.е. одними и теми же программными и/или аппаратными средствами). Это выражение означает, что любое количество программных средств или аппаратных средств может принимать, отправлять, выполнять или запускать выполнение любой задачи или запроса либо результатов любых задач или запросов; все эти программные и аппаратные средства могут представлять собой один сервер или несколько серверов, при этом оба эти случая подразумеваются в выражении «по меньшей мере один сервер».
В контексте настоящего описания термин «клиентское устройство» означает любое компьютерное аппаратное средство, способное выполнять программы, подходящие для решения данной задачи. Таким образом, некоторые (не имеющие ограничительного характера) примеры клиентских устройств включают в себя персональные компьютеры (настольные, ноутбуки, нетбуки и т.п.), смартфоны и планшеты, а также сетевое оборудование, такое как маршрутизаторы, коммутаторы и шлюзы. Следует отметить, что в данном контексте устройство, функционирующее как клиентское устройство, также может функционировать как сервер для других клиентских устройств. Использование выражения «клиентское устройство» не исключает использования нескольких клиентских устройств для приема, отправки, выполнения или инициирования выполнения любой задачи или запроса, либо результатов любых задач или запросов, либо шагов любого описанного здесь способа.
В контексте настоящего описания выражение «информация» включает в себя информацию любого рода или вида, допускающую хранение в базе данных. Таким образом, информация включает в себя аудиовизуальные произведения (изображения, фильмы, звукозаписи, презентации и т.д.), данные (данные о местоположении, числовые данные и т.д.), текст (мнения, комментарии, вопросы, сообщения и т.д.), документы, электронные таблицы, списки слов и т.д., но не ограничивается ими.
В контексте настоящего описания выражение «компонент» включает в себя программное обеспечение (подходящее для определенных аппаратных средств), необходимое и достаточное для выполнения соответствующей определенной функции (или функций).
В контексте настоящего описания выражение «пригодный для использования в компьютере носитель информации» означает носители любого типа и вида, включая ОЗУ, ПЗУ, диски (CD-ROM, DVD, гибкие диски, жесткие диски и т.д.), USB-накопители, твердотельные накопители, накопители на магнитных лентах и т.д.
В контексте настоящего описания числительные «первый» «второй», «третий» и т.д. используются лишь для указания различия между существительными, к которым они относятся, но не для описания каких-либо определенных взаимосвязей между этими существительными. Например, должно быть понятно, что использование терминов «первый сервер» и «третий сервер» не подразумевает какого-либо определенного порядка, вида, хронологии, иерархии или классификации, в данном случае, серверов, и что их использование (само по себе) не подразумевает обязательного наличия «второго сервера» в любой ситуации. Кроме того, как встречается в настоящем описании в другом контексте, ссылка на «первый» элемент и «второй» элемент не исключает того, что эти два элемента могут быть одним и тем же реальным элементом. Таким образом, например, в некоторых случаях «первый» сервер и «второй» сервер могут представлять собой одно и то же программное и/или аппаратное средство, а в других случаях - различные программные и/или аппаратные средства.
Каждый вариант осуществления данной технологии имеет отношение к по меньшей мере одной из вышеупомянутых целей и/или одному из вышеупомянутых аспектов, но не обязательно ко всем ним. Должно быть понятно, что некоторые аспекты данной технологии, связанные с попыткой достижения вышеупомянутой цели, могут не соответствовать этой цели и/или могут соответствовать другим целям, явным образом здесь не упомянутым.
Дополнительные и/или альтернативные признаки, аспекты и преимущества вариантов осуществления данной технологии содержатся в дальнейшем описании, в приложенных чертежах и в формуле изобретения.
Краткое описание чертежей
Дальнейшее описание приведено для лучшего понимания данной технологии, а также других аспектов и их признаков, и должно использоваться совместно с приложенными чертежами.
На фиг. 1 представлена схема системы, пригодной для реализации вариантов осуществления данной технологии, не имеющих ограничительного характера.
На фиг. 2 представлено соответствующее некоторым вариантам осуществления настоящей технологии устройство хранения данных подсистемы распределенного хранения данных системы, представленной на фиг. 1.
На фиг. 3 представлена схема распределенной программной системы для маршрутизации транзакций в соответствии с некоторыми вариантами осуществления данной технологии.
На фиг. 4 представлена схема обработки, выполняемой портами-координаторами распределенной программной системы, представленной на фиг. 3, в соответствии с некоторыми вариантами осуществления данной технологии.
На фиг. 5 представлена схема обработки, выполняемой портами-посредниками распределенной программной системы, представленной на фиг. 3, в соответствии с некоторыми вариантами осуществления данной технологии.
На фиг. 6 представлена схема распределенной программной системы для маршрутизации транзакций в соответствии с другими вариантами осуществления данной технологии.
На фиг. 7 представлена блок-схема способа, который выполняется в представленной на фиг. 3 распределенной программной системе и реализован согласно вариантам осуществления данной технологии, не имеющим ограничительного характера.
Осуществление изобретения
Дальнейшее подробное описание представляет собой лишь описание примеров, иллюстрирующих данную технологию. Это описание не предназначено для определения объема или границ данной технологии. В некоторых случаях приводятся полезные примеры модификаций, способствующие пониманию, но не определяющие объема или границ настоящей технологии. Эти модификации не составляют исчерпывающего списка, возможны и другие модификации.
Кроме того, если в некоторых случаях примеры модификаций не описаны, это не означает, что модификации невозможны и/или что описание содержит единственный вариант осуществления определенного аспекта данной технологии. Кроме того, следует понимать, что настоящее подробное описание в некоторых случаях касается упрощенных вариантов осуществления данной технологии, и что такие варианты представлены для того, чтобы способствовать лучшему ее пониманию. Различные варианты осуществления данной технологии могут быть значительно сложнее.
На фиг. 1 представлена система 100 распределенной компьютерной обработки информации или сокращенно система 100 распределенной обработки информации. Система 100 распределенной обработки информации позволяет реализовать не имеющие ограничительного характера варианты осуществления данной технологии. Очевидно, что система 100 распределенной обработки информации приведена лишь в качестве иллюстративного варианта осуществления данной технологии. Таким образом, дальнейшее описание системы представляет собой описание примеров, иллюстрирующих данную технологию. Это описание не предназначено для определения объема или границ данной технологии.
В некоторых случаях также приводятся полезные примеры модификаций системы 100 распределенной обработки информации. Они способствуют пониманию, но также не определяют объема или границ данной технологии. Эти модификации не составляют исчерпывающего списка. Специалисту в данной области должно быть понятно, что возможны и другие модификации. Кроме того, если в некоторых случаях примеры модификаций не описаны, это не означает, что модификации невозможны и/или что описание содержит единственный вариант осуществления определенного элемента данной технологии. Специалисту в данной области должно быть понятно, что это не так. Кроме того, следует понимать, что система 100 распределенной обработки информации в некоторых случаях может представлять собой упрощенную реализацию данной технологии, и что такие варианты представлены, чтобы способствовать лучшему ее пониманию. Специалисту в данной области должно быть понятно, что различные варианты осуществления данной технологии могут быть значительно сложнее.
Система 100 распределенной обработки информации содержит источник 102 запросов, сеть 103 связи, подсистему 104 предварительной обработки запросов, подсистему 105 обработки транзакций, подсистему 106 маршрутизации транзакций, подсистему 108 распределенного хранения данных, подсистему 110 базы данных и операционную подсистему 111.
Далее описана реализация указанных выше компонентов системы 100 распределенной обработки информации в соответствии с различными не имеющими ограничительного характера вариантами осуществления данной технологии.
Источник запросов
Источник 102 запросов может представлять собой электронное устройство, связанное с конечным пользователем (например, клиентское устройство), или любую другую подсистему системы 100 распределенной обработки информации, способную обеспечивать пользовательские запросы к системе 100 распределенной обработки информации. Несмотря на то, что на фиг. 1 показан лишь один источник 102 запросов, система 100 распределенной обработки информации может содержать несколько источников 102 запросов. Как показано в данном документе, источник 102 запросов входит в состав системы 100 распределенной обработки информации. Тем не менее, в некоторых вариантах осуществления данной технологии источник 102 запросов может быть внешним по отношению к системе 100 распределенной обработки информации и может подключаться с использованием линии и связи (не обозначена).
На практике типичный вариант осуществления системы 100 распределенной обработки информации может включать в себя большое количество источников 102 запросов (сотни, тысячи, миллионы и т.д.).
В некоторых вариантах осуществления данной технологии, когда система 100 распределенной обработки информации используется в среде бизнес-потребитель (В2С, Business-to-Customer), источник 102 запросов может представлять собой клиентское устройство, такое как смартфон, связанное с пользователем системы 100 распределенной обработки информации. Например, система 100 распределенной обработки информации может обеспечивать услуги «облачного» хранения данных для клиентского устройства определенного пользователя.
В некоторых вариантах осуществления данной технологии, когда система 100 распределенной обработки информации используется в среде бизнес-бизнес (В2В, Business-to-Business), источник 102 запросов может представлять собой подсистему, такую как удаленный сервер, обеспечивающую пользовательские запросы к системе 100 распределенной обработки информации. Например, в некоторых вариантах осуществления данной технологии система 100 распределенной обработки информации может обеспечивать услуги отказоустойчивой обработки и/или хранения данных для оператора такой подсистемы.
В целом, независимо от реализации системы 100 распределенной обработки данных в виде системы В2С или В2В (или любого другого варианта системы), источник 102 запросов может представлять собой клиентское устройство или другую подсистему, которые могут быть внутренними или внешними по отношению к системе 100 распределенной обработки информации.
Как указано выше, источник 102 запросов способен выдавать множество запросов 180, каждый из которых далее называется запросом 180. Характер запроса 180 зависит от вида источника 102 запросов. В частности, один из примеров запроса 180 представляет собой запрос, сформированный на языке структурированных запросов (SQL, Structured Query Language). Поэтому предполагается, что в некоторых вариантах осуществления данной технологии запрос 180 может быть сформирован на языке декларативного программирования, т.е. запрос 180 может представлять собой запрос декларативного вида.
В общем случае декларативное программирование относится к формированию структуры и элементов компьютерных программ, отражая логику вычислений без описания потока управления. Распространенные языки декларативного программирования включают в себя SQL, XQuery и другие языки запросов к базам данных. В целом, запрос декларативного типа определяет действие в выражениях «что требуется выполнить», а не «как это требуется выполнить».
Это означает, что запрос декларативного типа может быть связан с условием выполнения определенного действия. В качестве условия, например, может быть указано, в каком элементе должно выполняться это действие или где следует получать значения для выполнения этого действия.
В качестве не имеющих ограничительного характера примеров можно привести следующие запросы декларативного вида: «Вставить значение 5 в ячейку, связанную с ключом, который равен значению ячейки, связанной с ключом А» и «Для всех ключей, связанных с ячейкой, имеющей значение 5, изменить это значение на значение 10». Тем не менее, должно быть понятно, что представленные выше примеры декларативных языков и примеры запросов декларативного вида приведены исключительно для лучшего понимания, и что другие декларативные языки и другие запросы декларативного вида могут использоваться источником 102 запросов в пределах объема данной технологии.
В некоторых вариантах осуществления данной технологии источник 102 запросов также способен принимать множество ответов 181, каждый из которых далее называется ответом 181. В общем случае в ответ на запрос 180, обработанный или не обработанный системой 100 распределенной обработки информации, система 100 распределенной обработки информации может формировать ответ 181, предназначенный для источника 102 запросов, связанного с соответствующим запросом 180. Характер ответа 181, среди прочего, зависит от вида источника 102 запросов, вида соответствующего запроса 180 и от того, обработала или не обработала система 100 распределенной обработки информации соответствующий запрос 180. В некоторых вариантах осуществления данной технологии система 100 распределенной обработки информации может формировать ответ 181, только если не удалось обработать запрос, или только в случае успешной обработки запроса, или в обоих случаях.
Например, во время обработки запроса 180 система 100 распределенной обработки информации может быть способна запрашивать дополнительные данные от источника 102 запросов для продолжения или завершения обработки запроса 180. В этом случае система 100 распределенной обработки информации может быть способна формировать ответ 181 в виде сообщения с запросом данных, в котором указываются дополнительные данные, запрашиваемые системой 100 распределенной обработки информации для продолжения или завершения обработки запроса 180.
В другом примере, если система 100 распределенной обработки информации успешно обработала соответствующий запрос 180, система 100 распределенной обработки информации может быть способна формировать ответ 181 в виде сообщения об успешном завершении, оповещающего об успешной обработке соответствующего запроса 180.
В другом примере, если системе 100 распределенной обработки информации не удалось успешно обработать соответствующий запрос 180, система 100 распределенной обработки информации может быть способна формировать ответ 181 в виде сообщения о неудачном завершении, оповещающий о том, что соответствующий запрос 180 обработать не удалось. В этом случае источник 102 запроса может быть способен выполнять дополнительные действия, такие как повторное направление запроса 180, выполнение диагностического контроля для определения причины неудачного завершения обработки запроса 180 системой 100 распределенной обработки информации, направление нового запроса, предназначенного для системы 100 распределенной обработки информации, и т.д.
Сеть связи
Источник 102 запросов связан с сетью 103 связи для направления запроса 180 в систему 100 распределенной обработки информации и для приема ответа 181 от системы 100 распределенной обработки информации. В некоторых не имеющих ограничительного характера вариантах осуществления данной технологии в качестве сети 103 связи может использоваться сеть Интернет. В других не имеющих ограничительного характера вариантах осуществления данной технологии сеть 103 связи может быть реализована иначе, например, в виде любой глобальной сети связи, локальной сети связи, частной сети связи и т.п.Реализация линии и связи (отдельно не обозначена) между источником 102 запросов и сетью 103 связи зависит, среди прочего, от реализации источника 102 запросов.
Лишь в качестве примера, не имеющего ограничительного характера, в тех вариантах осуществления данной технологии, где источник 102 запросов реализован как беспроводное устройство связи (такое как смартфон), линии я связи может быть реализована как беспроводная линии я связи (такая как канал сети связи 3G, канал сети связи 4G, Wireless Fidelity или сокращенно WiFi®, Bluetooth® и т.п.). В тех примерах, где источник 102 запросов реализован как удаленный сервер, линии я связи может быть беспроводной (такой как Wireless Fidelity или сокращенно WiFi®, Bluetooth® и т.д.) или проводной (такой как соединение по сети Ethernet).
Следует отметить, что сеть 103 связи, среди прочего, способна передавать пакет данных запроса, содержащий запрос 180, от источника 102 запросов к подсистеме 104 предварительной обработки запросов системы 100 распределенной обработки информации. Например, этот пакет данных запроса может содержать выполняемые компьютером команды, составленные на языке программирования декларативного типа, на котором представлен запрос 180. Сеть 103 связи, среди прочего, также способна передавать пакет данных ответа, содержащий ответ 181, от системы 100 распределенной обработки информации к источнику 102 запросов. Например, этот пакет данных ответа может содержать выполняемые компьютером команды, представляющие ответ 181.
Тем не менее, предполагается, что в некоторых вариантах осуществления данной технологии, где источник 102 запросов представляет собой, например, подсистему системы 100 распределенной обработки информации, сеть 103 связи может быть реализована способом, отличным от описанного выше, или в некоторых случаях может вовсе отсутствовать в пределах объема данной технологии.
Операционная подсистема (улей)
Как указано выше, система 100 распределенной обработки информации содержит операционную подсистему 111 или, сокращенно, улей. В общем случае улей 111 представляет собой программное приложение (например, конечный автомат), способное управлять по меньшей мере некоторыми подсистемами системы 100 распределенной обработки информации, такими как подсистема 104 предварительной обработки запросов и подсистема 105 обработки транзакций. Можно сказать, что улей 111 может быть реализован как конечный автомат (SM, State Machine), способный формировать, удалять и/или выравнивать нагрузку других автоматов SM, образующих по меньшей мере некоторые подсистемы системы 100 распределенной обработки информации.
Должно быть понятно, что автомат SM представляет собой вычислительную модель, реализованную в виде компьютерной системы и определяемую списком состояний. Автомат SM может изменять свое текущее состояние в ответ на некоторые внешние входные данные и может в конкретный момент времени находиться лишь в одном состоянии. Переход автомата SM из одного состояния в другое состояние называется изменением состояния.
Следует отметить, что в контексте данной технологии автоматы SM, образующие по меньшей мере некоторые подсистемы системы 100 распределенной обработки информации, являются детерминированными по свое природе, т.е. каждое изменение состояния каждого автомата SM однозначно определено (а) текущим состоянием соответствующего автомата SM и (б) внешними входными данными соответствующего автомата SM. Иными словами, для текущего состояния автомата SM и для некоторых внешних входных данных существует единственное следующее состояние этого автомата SM. Этот детерминированный характер изменения состояния не зависит от того, у какого именно автомата SM системы 100 распределенной обработки информации происходит изменение состояния.
Поэтому, как описано ниже, в некоторых вариантах осуществления данной технологии система 100 распределенной обработки информации должна принимать внешние входные данные определенного вида, соответствующие свойству детерминированности автоматов SM, от по меньшей мере некоторых подсистем системы 100 распределенной обработки информации.
Подсистема распределенного хранения данных
Как упомянуто ранее, система 100 распределенной обработки информации также содержит подсистему 108 распределенного хранения данных. В общем случае подсистема 108 распределенного хранения данных способна, среди прочего, хранить системные данные, указывающие состояния, изменения состояний, внешние входные и/или выходные данные по меньшей мере некоторых автоматов SM системы 100 распределенной обработки информации. Например, системные данные, связанные с автоматом SM системы 100 распределенной обработки информации, могут храниться в форме журнала, содержащего хронологический список состояний, изменений состояний, внешних входных и/или выходных данных данного автомата SM.
Подсистема 108 распределенного хранения данных также способна хранить клиентские данные, т.е. данные, связанные с внешними входными данными, обрабатываемыми системой 100 распределенной обработки информации. Например, в некоторых вариантах осуществления данной технологии клиентские данные могут храниться как часть системных данных в подсистеме 108 распределенного хранения данных в пределах объема данной технологии.
Для хранения системных и/или клиентских данных подсистема 108 распределенного хранения данных содержит множество устройств 112 хранения данных, каждое из которых далее называется устройством 112 хранения данных. Согласно различным вариантам осуществления данной технологии некоторые или все устройства из множества устройств 112 хранения данных могут располагаться в одном или в различных местах. Например, некоторые или все устройства из множества устройств 112 хранения данных могут располагаться в одной серверной стойке, и/или в одном центре обработки данных, и/или могут быть распределены среди множества серверных стоек в одном или нескольких центрах обработки данных.
В некоторых вариантах осуществления данной технологии системные и/или клиентские данные, хранящиеся в одном устройстве 112 хранения данных, могут дублироваться и храниться в нескольких других устройствах 112 хранения данных. В некоторых вариантах осуществления такое дублирование и хранение системных и/или клиентских данных может обеспечивать отказоустойчивое хранение системных и/или клиентских данных в системе 100 распределенной обработки информации. Отказоустойчивое хранение системных и/или клиентских данных способно предотвратить утрату данных, когда устройство 112 хранения данных подсистемы 108 распределенного хранения данных становится временно или постоянно недоступным для хранения и извлечения данных. Такое отказоустойчивое хранение системных и/или клиентских данных также может предотвращать утрату данных, когда автомат SM системы 100 распределенной обработки информации становится временно или постоянно недоступным.
Предполагается, что устройство 112 хранения данных может быть реализовано в виде компьютерного сервера. Компьютерный сервер содержит по меньшей мере одно физическое запоминающее устройство (т.е. накопитель 126) и одно или несколько программных приложений, способных выполнять машиночитаемые команды. Накопитель 126 может представлять собой твердотельный накопитель (SSD, Solid State Drive), накопитель на жестких дисках (HDD, Hard Disk Drive) и т.п. Поэтому можно сказать, что по меньшей мере одно физическое запоминающее устройство может быть реализовано как устройство с подвижным или неподвижным диском.
Например, как показано на фиг. 1, данное устройство 112 хранения данных способно содержать, помимо прочего, следующие программные приложения: приложение 114 виртуального накопителя (Vdrive), приложение 116 физического накопителя (Pdrive), по меньшей мере одно приложение 118 моделирования накопителя, по меньшей мере одно приложение 120 планирования работы, приложение 122 обеспечения работы в реальном времени и по меньшей мере один прокси-сервер 124 автомата SM. Функции указанных выше программных приложений и накопителя 126, обеспечивающие хранение по меньшей мере некоторых системных и/или клиентских данных, более подробно описаны ниже со ссылками на фиг. 2.
Подсистема предварительной обработки запросов
Как указано выше, подсистема 105 обработки транзакций может содержать несколько детерминированных автоматов SM, которые должны получать входные данные определенного вида, соответствующие свойству детерминированности автоматов SM. Также следует еще раз отметить, что источник 102 запросов выдает запрос 180 в виде запроса декларативного типа.
Соответственно, подсистема 104 предварительной обработки запросов способна принимать запрос 180 декларативного типа от источника 102 запросов и предварительно обрабатывать или преобразовывать запрос 180 во множество детерминированных транзакций 182, которые соответствуют свойству детерминированности нескольких автоматов SM, образующих подсистему 105 обработки транзакций.
В целом, подсистема 104 предварительной обработки запросов предназначена для предварительной обработки или преобразования запроса 180 во множество детерминированных транзакций 182, которые могут быть обработаны детерминированными автоматами SM из подсистемы 105 обработки транзакций.
Следует отметить, что подсистема 104 предварительной обработки запросов также способна формировать ответ 181 для передачи в источник 102 запросов. Разумеется, что подсистема 104 предварительной обработки запросов связана с подсистемой 105 обработки транзакций не только для передачи множества детерминированных транзакций 182, но и для приема информации об обработке множества детерминированных транзакций 182. В некоторых не имеющих ограничительного характера вариантах осуществления данной технологии множество детерминированных транзакций 182 может содержать одну или несколько транзакций вида «считывание» или «запись».
В некоторых вариантах осуществления данной технологии подсистема 104 предварительной обработки запросов реализована в виде по меньшей мере одного автомата SM в пределах объема данной технологии.
В некоторых вариантах осуществления данной технологии предполагается, что представленная на фиг. 1 система 100 распределенной обработки информации способна поддерживать транзакции ACID (Atomicity, Consistency, Isolation and Durability). В целом, ACID - это аббревиатура для набора свойств транзакции (атомарность, согласованность, изолированность, долговечность), которые обеспечивают надежность базы данных при выполнении транзакций. Поэтому в некоторых вариантах осуществления данной технологии предполагается, что транзакции, предназначенные для подсистемы 105 обработки транзакций, могут быть атомарными, согласованными, изолированными и долговечными в пределах объема данной технологии.
Подсистема обработки транзакций
В общем случае подсистема 105 обработки транзакций способна принимать и обрабатывать множество детерминированных транзакций 182 и, таким образом, обрабатывать запрос 180 от источника 102 запросов. Подсистема 105 обработки транзакций содержит (а) подсистему 106 маршрутизации транзакций и (б) подсистему 110 базы данных, которые описаны далее.
Подсистема 110 базы данных содержит множество мест назначения транзакции (TDL, Transaction Destination Location) и разделена на множество сегментов 109, каждый из которых далее называется сегментом 109. В не имеющем ограничительного характера примере подсистема 110 базы данных может содержать базу данных, включающую в себя одну или несколько таблиц базы данных. Таблица базы данных может состоять из по меньшей мере двух столбцов, таких как первый столбец, содержащий ключи, и второй столбец, содержащий записи, в которых хранятся данные, связанные с соответствующими ключами. В этом не имеющем ограничительного характера примере место TDL может соответствовать строке таблицы базы данных, т.е. место TDL может соответствовать ключу и соответствующей ему записи в данной таблице базы данных.
В этом не имеющем ограничительного характера примере каждый сегмент 109 подсистемы 110 базы данных содержит часть таблицы базы данных. Следовательно, множество мест TDL, сопоставленных с соответствующими строками таблицы базы данных, разделено между множеством сегментов 109 так, чтобы каждый сегмент 109 содержал соответствующее подмножество (например, диапазон) множества мест TDL.
В некоторых вариантах осуществления данной технологии предполагается, что каждый сегмент из множества сегментов 109 может быть реализован с использованием соответствующего детерминированного автомата SM. Это означает, что после приема транзакции, предназначенной для места TDL сегмента 109, реализованного с использованием автомата SM, этот автомат SM может обработать транзакцию и перейти из текущего состояния в новое состояние в соответствии с транзакцией, как описано выше.
Подсистема 106 маршрутизации транзакций способна маршрутизировать транзакции из множества детерминированных транзакций 182 в соответствующие места TDL и, таким образом, направлять их в соответствующие сегменты 109 подсистемы 110 базы данных. С этой целью подсистема 106 маршрутизации транзакций может включать в себя множество портов, которые обычно способны (а) принимать множество детерминированных транзакций 182 из подсистемы 104 предварительной обработки запросов, (б) разделять множество детерминированных транзакций 182 на подмножества детерминированных транзакций, предназначенных для соответствующих сегментов 109, и (в) формировать для каждого сегмента централизованный порядок выполнения детерминированных транзакций соответствующими сегментами 109.
Следует отметить, что каждый порт из множества портов, образующих подсистему 106 маршрутизации транзакций, может быть реализован как соответствующий автомат SM. В некоторых вариантах осуществления изобретения предполагается, что множество портов может включать в себя порты двух различных видов для маршрутизации транзакций из множества детерминированных транзакций 182 в соответствующие сегменты 109. В других вариантах осуществления изобретения по меньшей мере некоторые функции множества портов могут выполняться автоматами SM, соответствующими множеству сегментов 109.
Кроме того, как показано на фиг. 1, по меньшей мере некоторые из автоматов SM подсистемы 105 обработки транзакций могут быть связаны с подсистемой 108 распределенного хранения данных с использованием соответствующей линии и 160 связи. В целом, линии я 160 связи предназначена для передачи системных данных, таких как данные о состояниях, изменениях состояний, внешние входные и/или выходные данные соответствующих автоматов SM и т.д., в подсистему 108 распределенного хранения данных для хранения. Далее со ссылками на фиг. 2 более подробно описана реализация линии й 160 связи и порядок конфигурирования подсистемы 108 распределенного хранения данных для хранения системных данных.
На фиг. 2 представлено устройство 112 хранения данных, входящее в состав подсистемы 108 распределенного хранения данных. Как описано выше, устройство 112 хранения данных содержит по меньшей мере один прокси-сервер 124 автомата SM. Прокси-сервер автомата SM предназначен для управления связью между автоматом SM и подсистемой 108 распределенного хранения данных. В некоторых вариантах осуществления данной технологии предполагается, что по меньшей мере один прокси-сервер 124 автомата SM устройства 112 хранения данных может представлять собой прикладной программный интерфейс (API, Application Programing Interface), управляющий связью между автоматом SM и устройством 112 хранения данных. В других вариантах осуществления данной технологии по меньшей мере один прокси-сервер 124 автомата SM сам может быть реализован в виде автомата SM. В других вариантах осуществления данной технологии по меньшей мере один прокси-сервер 124 автомата SM может быть реализован как программный модуль (не как автомат SM) для выполнения описанных выше функций.
В некоторых вариантах осуществления данной технологии прокси-сервер 124 автомата SM может быть способен (а) принимать системные данные обновления журнала этого автомата SM с использованием соответствующей линии и 160 связи, (б) обрабатывать системные данные и (в) передавать обработанные системные данные соответствующему приложению 114 Vdrive для дальнейшей обработки.
По меньшей мере один прокси-сервер 124 автомата SM может быть способен обрабатывать системные данные, например, для обеспечения целостности и отказоустойчивости системных данных. В некоторых вариантах осуществления данной технологии предполагается, что по меньшей мере один прокси-сервер 124 автомата SM может быть способен выполнять стойкое к потере кодирование (erasure coding) системных данных. В целом, стойкое к потере кодирование представляет собой способ кодирования, предусматривающий получение данных с избыточностью и разделение их на несколько фрагментов. Такие избыточность и фрагментация способствуют восстановлению данных в случае потери одного или нескольких фрагментов вследствие отказов в системе.
Предполагается, что обработанные таким образом по меньшей мере одним прокси-сервером 124 автомата SM системные данные принимаются по меньшей мере одним соответствующим приложением 114 Vdrive устройства 112 хранения данных. Приложение 114 Vdrive предназначено для обработки системных данных, полученных от по меньшей мере одного прокси-сервера 124 автомата SM, и для ответного формирования соответствующих операций ввода/вывода (I/O, Input/Output), которые должны выполняться накопителем 126 для сохранения системных данных в накопителе 126 устройства 112 хранения данных. После формирования по меньшей мере одним приложением 114 Vdrive операций I/O, соответствующих принятым системным данным, по меньшей мере одно приложение 114 Vdrive передает операции I/O приложению 116 Pdrive.
Иными словами, предполагается, что устройство 112 хранения данных может содержать несколько прокси-серверов 124 автомата SM для обработки и передачи системных данных нескольким соответствующим приложениям 114 Vdrive, которые обрабатывают системные данные, формируют соответствующие операции I/O и передают соответствующие операции I/O в единое приложение 116 Pdrive устройства 112 хранения данных.
В целом, приложение 116 Pdrive предназначено для управления работой накопителя 126. Например, приложение 116 Pdrive может быть способным выполнять кодирование операций I/O, которые должны выполняться в накопителе 126, и различные другие функции, способствующие надежному хранению данных в накопителе 126.
Приложение 116 Pdrive связано с приложением 120 планирования работы для передачи операции I/O. Приложение 120 планирования работы способно планировать передачу операций I/O в накопитель 126. Предполагается, что приложение 120 планирования работы (или сокращенно планировщик) может использовать различные схемы планирования для определения порядка передачи операций I/O в накопитель 126 для их дальнейшего выполнения.
Предполагается, что в некоторых вариантах осуществления настоящей технологии планировщик 120 может быть реализован как часть приложения 116 Pdrive. Иными словами, приложением 116 Pdrive могут выполняться различные схемы планирования в пределах объема данной технологии.
В одном случае планировщик 120 может обеспечивать схему «справедливого» планирования. Должно быть понятно, что для устройства 112 хранения данных может потребоваться хранение операций I/O, соответствующих системным данным, связанным с несколькими автоматами SM. Кроме того, каждый из нескольких автоматов SM связан с заранее заданной долей производительности накопителя, которую накопитель 126 может выделить для выполнения операций I/O, связанных с соответствующим автоматом SM. В целом, схемы «справедливого» планирования позволяют упорядочивать операции I/O, передаваемые в накопитель 126, так, чтобы производительность накопителя 126, предназначенная для выполнения упорядоченных операций I/O, использовалась согласно заранее заданным долям, связанным с несколькими автоматами SM.
В другом случае планировщик 120 может обеспечивать схему планирования «реального времени». Следует еще раз отметить, что система 100 распределенной обработки информации может использоваться для предоставления услуг «облачного» хранения данных. Во многих таких вариантах осуществления может быть желательным обрабатывать и сохранять системные данные в реальном времени, т.е. в течение очень короткого интервала времени. Чтобы обеспечить выполнение требования режима реального времени к системе 100 распределенной обработки информации, операции I/O могут быть связаны с соответствующими предельными сроками, указывающими момент времени, по прошествии которого соответствующие операции I/O уже не попадают в пределы допустимого времени, соответствующие требованиям режима реального времени к системе 100 распределенной обработки информации. В целом, схемы планирования реального времени способны упорядочивать операции I/O, передаваемые в накопитель 126, так, чтобы операции I/O выполнялись накопителем 126 с соблюдением соответствующих предельных сроков.
В другом случае планировщик 120 может обеспечивать гибридную схему планирования. Иными словами, планировщик 120 может обеспечить схему планирования, позволяющую упорядочить операции I/O, передаваемые для выполнения в накопитель 126, так, чтобы учитывались и заранее заданные доли производительности накопителя для каждого соответствующего SM, и соответствующие предельные сроки операций I/O.
Как было упомянуто ранее, накопитель 126 представляет собой носитель информации для выполнения операций I/O и, соответственно, для хранения системных данных, переданных в устройство 112 хранения данных. Например, накопитель 126 может быть реализован в виде накопителя HDD или накопителя SSD. Накопитель 126 включает в себя внутреннее логическое устройство 250 накопителя для выбора операции I/O среди всех переданных в накопитель операций I/O для выполнения в текущий момент времени.
Следует отметить, что операции I/O могут направляться для выполнения в накопитель 126 по одной, но это может приводить к увеличению задержек между накопителем 126 и другими компонентами устройства 112 хранения данных. Поэтому операции I/O могут предаваться в накопитель 126 пакетами или группами. После приема пакета или группы операций I/O накопителем 126 внутреннее логическое устройство 250 накопителя способно выбрать для выполнения наиболее эффективную операцию I/O среди имеющихся в пакете операций I/O.
Например, наиболее эффективная операция I/O может выбираться на основе различных критериев, таких как место выполнения предыдущей операции I/O в накопителе 126 и место выполнения операций I/O, имеющихся в накопителе 126. Иными словами, внутреннее логическое устройство 250 накопителя способно выбирать для текущего выполнения наиболее эффективную операцию (с точки зрения накопителя 126) среди всех операций I/O, имеющихся в накопителе 126 в текущий момент времени.
Поэтому в некоторых случаях, несмотря на то, что планировщик 120 упорядочил операции I/O для передачи определенным образом с учетом требований к режиму реального времени системы 100 распределенной обработки информации, внутреннее логическое устройство 250 накопителя 126 может выдавать в накопитель 126 команды формирования порядка выполнения операций I/O, отличного от порядка передачи, выбранного планировщиком 120. Поэтому порядок выполнения иногда может не соответствовать требованиям режима реального времени системы 100 распределенной обработки информации (в частности, когда от планировщика 120 принимаются дополнительные операции I/O, которые могут быть более «эффективными» с точки зрения накопителя 126 и могут выбираться среди еще не выполненных операций I/O).
Чтобы обеспечить работу устройства 112 хранения данных в реальном времени и предотвратить описанную выше проблему, также известную как «торможение работы» (operation stagnation), устройство 112 хранения данных может содержать приложение 122 обеспечения работы в реальном времени. Говоря упрощенно, приложение 122 обеспечения работы в реальном времени позволяет управлять тем, какие операции I/O из числа уже упорядоченных планировщиком 120 передаются в любой момент времени для выполнения в накопитель 126.
Предполагается, что в некоторых вариантах осуществления данной технологии приложение 122 обеспечения работы в реальном времени может быть реализовано как часть приложения 116 Pdrive. Иными словами, вышеупомянутые функции приложения 122 обеспечения работы в реальном времени могут выполняться приложением 116 Pdrive в пределах объема данной технологии.
Устройство 112 хранения данных также может содержать по меньшей мере одно соответствующее приложение 118 моделирования накопителя для каждого накопителя 126 в устройстве 112 хранения данных. В целом, приложение 118 моделирования накопителя способно эмулировать идеальную работу накопителя 126 для анализа накопителя 126 в диагностических целях. Тем не менее, в других вариантах осуществления планировщик 120 также может использовать приложение 118 моделирования накопителя, чтобы упорядочивать операции I/O для передачи в накопитель 126.
Предполагается, что в некоторых вариантах осуществления данной технологии по меньшей мере одно соответствующее приложение 118 моделирования накопителя может быть реализовано как часть приложения 116 Pdrive. Иными словами, вышеупомянутые функции по меньшей мере одного соответствующего приложения 118 моделирования накопителя могут выполняться приложением 116 Pdrive в пределах объема данной технологии.
Распределенная программная система
На фиг. 3 представлена схема распределенной программной системы 300 для маршрутизации и выполнения транзакций (например, детерминированных транзакций). Распределенная программная система 300 содержит (а) подсистему 302 базы данных и (б) подсистему 304 маршрутизации транзакций. В не имеющем ограничительного характера примере распределенная программная система 300 может быть реализована в виде представленной на фиг. 1 подсистемы 105 обработки транзакций. В частности, подсистема 304 маршрутизации транзакций может быть реализована как представленная на фиг. 1 подсистема 106 маршрутизации транзакций, а подсистема 302 базы данных может быть реализована в виде представленной на фиг. 1 подсистемы 110 базы данных.
Следует отметить, что подсистема 304 маршрутизации транзакций и подсистема 302 базы данных могут быть реализованы распределенным образом на множестве устройств хранения данных (например, на множестве устройств 112 хранения данных, представленном на фиг. 1) в пределах объема данной технологии.
Множество сегментов
С правой стороны на фиг. 3 показана подсистема 302 базы данных, которая (а) содержит множество 320 мест назначения транзакции (TDL) и (б) разделена на множество 310 сегментов. Например, множество 310 сегментов содержит первый сегмент 312, второй сегмент 314, третий сегмент 316 и четвертый сегмент 318. В не имеющем ограничительного характера примере множество 310 сегментов может представлять собой представленное на фиг. 1 множество сегментов 109.
В не имеющем ограничительного характера примере подсистема 302 базы данных может содержать базу данных, включающую в себя одну или несколько таблиц базы данных. Таблица базы данных может состоять из по меньшей мере двух столбцов, таких как первый столбец, содержащий ключи, и второй столбец, содержащий записи, в которых хранятся данные, связанные с соответствующими ключами. В этом не имеющем ограничительного характера примере место TDL может соответствовать строке таблицы базы данных, т.е. место TDL может соответствовать ключу и соответствующей записи в таблице базы данных.
В этом не имеющем ограничительного характера примере каждый сегмент подсистемы 302 базы данных содержит часть таблицы базы данных. Следовательно, множество 320 мест TDL, сопоставленных с соответствующими строками таблицы базы данных, разделено между множеством 310 сегментов так, чтобы каждый сегмент из множества 310 сегментов содержал соответствующее подмножество (например, диапазон) множества 320 мест TDL.
Следует отметить, что, как описано выше со ссылкой на множество сегментов 109, каждый сегмент из множества 310 сегментов может быть реализован как соответствующий автомат SM. Несмотря на то, что множество 310 сегментов показано на фиг. 3 как содержащее четыре сегмента, в других вариантах осуществления данной технологии множество 310 сегментов может содержать большее количество сегментов, например, десятки, сотни, тысячи сегментов и т.д. в пределах объема данной технологии.
Также предполагается, что подсистема 302 базы данных может быть масштабируемой. Например, предполагается, что в состав множества 310 сегментов оператором распределенной программной системы 300 могут включаться дополнительные сегменты для увеличения размера подсистемы 302 базы данных. Как поясняется ниже, по меньшей мере некоторые варианты осуществления подсистемы 304 маршрутизации транзакций могут способствовать такой масштабируемости подсистемы 302 базы данных.
Множество 320 мест TDL разделено на соответствующие диапазоны множества 320 мест TDL, при этом каждый соответствующий диапазон связан с соответствующим сегментом из множества 310 сегментов. Иными словами, множество 320 мест TDL разделено на множество подмножеств мест TDL (например, диапазонов мест TDL), при этом каждое подмножество мест TDL связано с соответствующим сегментом из множества 310 сегментов. Например, (а) первый диапазон 322 (например, первое подмножество) множества 320 мест TDL связан с первым сегментом 312, (б) второй диапазон 324 (например, второе подмножество) множества 320 мест TDL связан со вторым сегментом 314, (в) третий диапазон 326 (например, третье подмножество) множества 320 мест TDL связан с третьим сегментом 316 и (г) четвертый диапазон 328 (например, четвертое подмножество) множества 320 мест TDL связан с четвертым сегментом 318.
Как описано выше, некоторое место из множества 320 мест TDL может соответствовать некоторому ключу в подсистеме 302 базы данных и соответствующей ячейке (связанной с этим ключом) для хранения данных в подсистеме 302 базы данных. Таким образом, предполагается, что каждый сегмент из множества 310 сегментов способен хранить данные в подсистеме 302 базы данных, связанные с местом TDL, входящим в состав соответствующего диапазона множества 320 мест TDL.
В не имеющем ограничительного характера примере осуществления данной технологии множество 320 мест TDL, разделенное на соответствующие диапазоны множества мест TDL, может соответствовать множеству строк таблицы (или нескольких таблиц) базы данных, разделенному на диапазоны строк таблицы базы данных. Диапазон строк может содержать подмножество строк с ключами из некоторого диапазона ключей.
В общем случае сегмент из множества 310 сегментов способен (а) принимать соответствующий централизованный посегментный порядок выполнения транзакций, предназначенных для мест TDL в соответствующем диапазоне данного сегмента, (б) принимать транзакции, указанные в соответствующем централизованном посегментном порядке выполнения, и (в) выполнять принятые транзакции согласно соответствующему централизованному посегментному порядку выполнения. Следовательно, сегмент предназначен для выполнения транзакций, предназначенных для мест TDL в соответствующем диапазоне множества 320 мест TDL, в соответствии с централизованным посегментным порядком выполнения. В некоторых альтернативных не имеющих ограничительного характера вариантах осуществления данной технологии на одном шаге из одного источника могут приниматься (а) соответствующий централизованный посегментный порядок выполнения транзакций, предназначенных для мест TDL в соответствующем диапазоне данного сегмента, и (б) транзакции, указанные в соответствующем централизованном посегментном порядке выполнения.
Должно быть понятно, что в контексте данной технологии централизованный посегментный порядок выполнения для некоторого сегмента соответствует порядку выполнения всех предназначенных для этого сегмента транзакций из числа транзакций, принятых в определенный момент времени соответствующим портом-посредником распределенной программной системы 300.
Например, централизованный посегментный порядок выполнения, предназначенный для первого сегмента 312, соответствует порядку выполнения всех предназначенных для первого диапазона 322 транзакций из числа транзакций, принятых в определенный момент времени первым портом-посредником 342 распределенной программной системы 300. В другом примере централизованный посегментный порядок выполнения, предназначенный для четвертого сегмента 318, соответствует порядку выполнения всех предназначенных для четвертого диапазона 328 транзакций из числа транзакций, принятых в определенный момент времени третьим портом-посредником 346 распределенной программной системы 300.
Поскольку подсистема 302 базы данных способна одновременно выполнять несколько транзакций (например, соответствующие транзакции могут одновременно выполняться каждым сегментом из множества 310 сегментов), каждый сегмент из множества 310 сегментов выполняет транзакции в соответствующем централизованном посегментном порядке выполнения, чтобы после выполнения подсистемой 302 базы данных всех транзакций, предназначенных для подсистемы 302 базы данных, получался тот же результат, что и после последовательного выполнения всех транзакций, предназначенных для подсистемы 302 базы данных.
Иными словами, обеспечение централизованного посегментного порядка выполнения для соответствующего сегмента из множества 310 сегментов позволяет множеству 310 сегментов выполнять несколько транзакций одновременно так, чтобы результат воздействия нескольких транзакций на подсистему 302 базы данных был тем же, что и после последовательного выполнения этих нескольких транзакций.
Следует отметить, что множество 310 сегментов подсистемы 302 базы данных принимает соответствующие централизованные посегментные порядки выполнения от подсистемы 304 маршрутизации транзакций. В частности, каждый сегмент из множества 310 сегментов принимает соответствующий централизованный посегментный порядок выполнения от соответствующего порта из множества 340 портов-посредников (показано на фиг. 3 в центре) подсистемы 304 маршрутизации транзакций.
Множество портов-посредников
Каждый порт из множества 340 портов-посредников подсистемы 304 маршрутизации транзакций может быть реализован в виде соответствующего автомата SM.
Согласно не имеющим ограничительного характера вариантам осуществления данной технологии, сегмент сопоставляется с портом из множества портов-посредников 340. Например, первый сегмент 312 заранее сопоставлен с первым портом-посредником 342 и поэтому способен принимать соответствующий централизованный посегментный порядок выполнения от первого порта-посредника 342 по первой линии и 332 связи. В другом примере второй сегмент 314 заранее сопоставлен со вторым портом-посредником 344 и поэтому способен принимать соответствующий централизованный посегментный порядок выполнения от второго порта-посредника 344 по второй линии и 334 связи. В другом примере третий сегмент 316 заранее сопоставлен со вторым портом-посредником 344 и поэтому способен принимать соответствующий централизованный посегментный порядок выполнения от второго порта-посредника 344 по третьей линии и 336 связи. В еще одном примере четвертый сегмент 318 заранее сопоставлен с третьим портом-посредником 346 и поэтому способен принимать соответствующий централизованный посегментный порядок выполнения от третьего порта-посредника 346 по четвертой линии и 338 связи.
Иными словами, соответствующие сегменты из множества 310 сегментов заранее сопоставлены с соответствующими портами из множества 340 портов-посредников согласно карте 330 сопоставления сегментов и посредников. Можно сказать, что карта 330 сопоставления сегментов и посредников указывает, какой сегмент из множества 310 сегментов способен принимать соответствующий централизованный посегментный порядок выполнения от какого порта-посредника из множества 340 портов-посредников. Также можно сказать, что карта 330 сопоставления сегментов и посредников указывает, какой сегмент из множества 310 сегментов связан с каким портом-посредником из множества 340 портов посредников с использованием первой линии и 332 связи, второй линии и 334 связи, третьей линии и 336 связи и четвертой линии и 338 связи.
Предполагается, что каждый сегмент из множества 310 сегментов мог быть сопоставлен оператором распределенной программной системы 300 с соответствующим портом-посредником из множества 340 портов-посредников. Иными словами, предполагается, что оператор распределенной программной системы 300 может определить карту 330 сопоставления сегментов и посредников и связать соответствующие сегменты из множества 310 сегментов и соответствующие порты из множества 340 портов-посредников с использованием первой линии и 332 связи, второй линии и 334 связи, третьей линии и 336 связи и четвертой линии и 338 связи, соответственно.
Каждый сегмент из множества 310 сегментов заранее сопоставлен с одним портом из множества 340 портов-посредников. Иными словами, некоторый сегмент из множества 310 сегментов способен принимать соответствующий централизованный посегментный порядок выполнения только от одного порта-посредника из множества 340 портов-посредников, с которым он сопоставлен. Таким образом, можно сказать, что взаимосвязь «сегмент-посредник» представляет собой взаимосвязь вида «один с одним».
По меньшей мере один сегмент из множества 310 сегментов может быть заранее сопоставлен с некоторым портом из множества 340 портов-посредников. Например, только первый сегмент 312 из множества 310 сегментов заранее сопоставлен с первым портом-посредником 342. Аналогично, только четвертый сегмент 318 из множества 310 сегментов заранее сопоставлен с третьим портом-посредником 346. Второй сегмент 314 и третий сегмент 316 заранее сопоставлены со вторым портом-посредником 344. Таким образом, можно сказать, что взаимосвязь «посредник-сегмент» представляет собой взаимосвязь вида «один с по меньшей мере одним». Иными словами, взаимосвязь «посредник-сегмент» может представлять собой взаимосвязь вида «один с одним» или «один с несколькими».
В соответствии с представленным на фиг. 3 не имеющим ограничительного характера примером, первый порт-посредник 342 способен формировать и передавать централизованный посегментный порядок выполнения только в первый сегмент 312. Аналогично, третий порт-посредник 346 способен формировать и передавать централизованный посегментный порядок выполнения только в четвертый сегмент 318. В отличие от первого порта-посредника 342 и третьего порта-посредника 346, второй порт-посредник 344 способен формировать и передавать соответствующие централизованные посегментные порядки выполнения во второй сегмент 314 и в третий сегмент 316.
Каждый порт из множества 340 портов-посредников способен формировать централизованный посегментный порядок выполнения для соответствующих заранее сопоставленных с ним сегментов, основываясь, среди прочего, на локальных посегментных порядках, полученных от показанного с левой стороны на фиг. 3 множества 360 портов-координаторов подсистемы 304 маршрутизации транзакций.
В общем случае, порт-посредник способен формировать централизованный посегментный порядок выполнения для сегмента, основываясь, среди прочего, на одном или нескольких локальных посегментных порядках, при этом локальный посегментный порядок представляет собой порядок транзакций, которые (а) предназначены для данного сегмента и (б) приняты распределенной программной системой 300 через общую точку входа распределенной программной системы 300.
Например, если распределенная программная система 300 содержит две точки входа, централизованный посегментный порядок выполнения для сегмента может быть сформирован портом-посредником на основе двух потенциальных локальных посегментных порядков. Первый из двух потенциальных локальных посегментных порядков представляет собой порядок транзакций, принятых через первую из двух точек входа распределенной программной системы 300 и предназначенных для этого сегмента. Второй из двух потенциальных локальных посегментных порядков представляет собой порядок транзакций, принятых через вторую из двух точек входа распределенной программной системы 300 и предназначенных для этого сегмента.
Далее более подробно описано формирование каждым портом из множества 340 портов-посредников централизованного посегментного порядка выполнения для соответствующих заранее сопоставленных сегментов на основе, среди прочего, локальных посегментных порядков.
Множество портов-координаторов
Множество 360 портов-координаторов подсистемы 304 маршрутизации транзакций, обеспечивающее локальные посегментные порядки для множества 340 портов-посредников, может быть реализовано в виде соответствующих автоматов SM.
Каждый порт из множества 360 портов-координаторов способен принимать соответствующий набор транзакций, подлежащих маршрутизации и выполнению в подсистеме 302 базы данных. Таким образом, можно сказать, что для транзакций каждый порт из множества 360 портов-координаторов представляет собой соответствующую точку входа в распределенную программную систему 300. Например, первый набор транзакций может приниматься первым портом-координатором 362 с использованием линии и 372 связи первой точки входа, а второй набор транзакций может приниматься вторым портом-координатором 364 с использованием линии и 374 связи второй точки входа.
Предполагается, что в некоторых вариантах осуществления данной технологии транзакция не может приниматься несколькими портами из множества 360 портов-координаторов. Иными словами, если данная транзакция принята первым портом-координатором 362, то второй порт-координатор 364 не может принять эту транзакцию. Аналогично, если данная транзакция принята вторым портом-координатором 364, то первый порт-координатор 362 не может принять эту транзакцию.
Следует отметить, что невозможность приема транзакции несколькими портами из множества 360 портов-координаторов не подразумевает, что данная транзакция должна приниматься определенным портом из множества 360 портов-координаторов, а означает, что наборы транзакций, принятые множеством 360 портов-координаторов, являются взаимоисключающими в некоторых вариантах осуществления данной технологии.
Каждый порт из множества 360 портов-координаторов локально хранит или иным образом имеет доступ к данным 366 координации, указывающим (а) на карту 330 сопоставления сегментов и посредников и (б) на соответствующий диапазон множества 320 мест TDL каждого сегмента из множества 310 сегментов. Данные 366 координации обеспечивают каждому порту из множества 360 портов-координаторов информацию (а) о том, какие места TDL связаны с каким сегментом из множества 310 сегментов, и (б) о том, какой сегмент заранее сопоставлен с каким портом из множества 340 портов-посредников.
В общем случае порт-координатор из множества 360 портов-координаторов способен (а) принимать соответствующий набор транзакций с использованием линии и связи соответствующей точки входа и (б) на основе транзакций из набора транзакций и данных 366 координации формировать соответствующие локальные посегментные порядки транзакций из соответствующего набора транзакций.
Каждая транзакция содержит соответствующий уникальный идентификатор транзакции (TUID) и указание на по меньшей мере одно место TDL в подсистеме 302 базы данных, для которого предназначена эта транзакция. Предполагается, что порт из множества 360 портов-координаторов способен упорядочивать транзакции в соответствующем наборе транзакций на основе соответствующих идентификаторов TUID. Порт-координатор также способен определять на основе данных 366 координации, какие транзакции предназначены для каких сегментов из множества сегментов. Следовательно, порт из множества 360 портов-координаторов способен для каждого сегмента, содержащего по меньшей мере одно место TDL, связанное с соответствующим набором транзакций, формировать соответствующий локальный посегментный порядок транзакций.
В целом, порт-координатор после упорядочивания набора транзакций на основе их соответствующих идентификаторов TUID определяет упорядоченные подмножества транзакций (например, локальные посегментные порядки) из упорядоченного набора транзакций, предназначенные для соответствующих сегментов из множества 310 сегментов.
Предполагается, что в контексте данной технологии локальный посегментный порядок для некоторого сегмента соответствует порядку транзакций, которые (а) приняты через общую точку входа (например, порт-координатор) распределенной программной системы 300 и (б) предназначены для этого сегмента. Иными словами, локальный посегментный порядок для некоторого сегмента соответствует порядку транзакций, принятых общим портом-координатором и предназначенных для этого сегмента.
В отличие от централизованного посегментного порядка выполнения, который представляет собой порядок выполнения всех предназначенных для некоторого сегмента транзакций из числа транзакций, маршрутизируемых распределенной программной системой 300, локальный посегментный порядок представляет собой порядок предназначенных для данного сегмента транзакций, принятых одним портом-координатором из множества 360 портов-координаторов.
Каждый порт из множества 360 портов-координаторов имеет соответствующий идентификатор координатора (CID, Coordinator IDentifier) и соответствующий счетчик (С, Counter). Например, первый порт-координатор 362 имеет первый идентификатор CID CID1 и первый счетчик С С1, а второй порт-координатор 364 имеет второй идентификатор CID CID2 и второй счетчик С С2.
Предполагается, что идентификаторы CID являются уникальными, т.е. два порта-координатора из множества 360 портов-координаторов не могут иметь одинаковый идентификатор CID и, следовательно, каждый порт-координатор из множества 360 портов-координаторов однозначно идентифицируется с использованием соответствующего идентификатора CID.
Предполагается, что счетчики С соответствующих портов из множества 360 портов-координаторов могут иметь различные значения в определенный момент времени. Иными словами, предполагается, что в некоторых вариантах осуществления данной технологии может не требоваться взаимная синхронизация портов из множества 360 портов-координаторов, чтобы значения соответствующих счетчиков С были равны в любой момент времени.
Множество 360 портов-координаторов связано с множеством 340 портов-посредников с использованием множества 350 линии й связи координатор-посредник. Например, линии и 351, 353 и 356 связи координатор-посредник связывают первый порт-координатор 362 с соответствующими портами из множества 340 портов-посредников. В другом примере линии и 352, 354 и 358 связи координатор-посредник связывают второй порт-координатор 364 с соответствующими портами из множества 340 портов-посредников.
В некоторых вариантах осуществления данной технологии предполагается, что каждый порт из множества 360 портов-координаторов может быть способен передавать в соответствующие порты из множества 340 портов-посредников соответствующие локальные посегментные порядки с соответствующими идентификаторами CID, а затем значения соответствующих счетчиков С. Предполагается, что порт-посредник из множества 340 портов-посредников способен формировать централизованный посегментный порядок для некоторого сегмента на основе (а) принятых из множества 360 портов-координаторов соответствующих локальных посегментных порядков, предназначенных для этого сегмента, и (б) соответствующих идентификаторов CID и значений соответствующих счетчиков С множества 360 портов-координаторов, от которого этот порт-посредник принял соответствующие локальные посегментные порядки.
Далее со ссылками на фиг. 4 и 5 более подробно описано, как подсистема 304 маршрутизации транзакций принимает транзакции и маршрутизирует эти транзакции в подсистему 302 базы данных, как локальные посегментные порядки формируются множеством 360 портов-координаторов, как централизованные посегментные порядки формируются множеством 340 портов-посредников и как транзакции выполняются множеством 310 сегментов.
На фиг. 4 представлена схема 400 обработки транзакций первым портом-координатором 362 и вторым портом-координатором 364. Предполагается, что первый порт-координатор 362 принимает с использованием линии и 372 связи первой точки входа первый набор 402 транзакций, содержащий первую транзакцию Т1 и вторую транзакцию Т2, а второй порт-координатор 364 принимает с использованием линии и 374 связи второй точки входа второй набор 404 транзакций, содержащий третью транзакцию Т3 и четвертую транзакцию Т4.
В не имеющем ограничительного характера примере первый набор 402 транзакций и второй набор 404 транзакций могут представлять собой часть множества детерминированных транзакций 182 (см. фиг. 1). Предполагается, что в некоторых вариантах осуществления данной технологии транзакции с T1 по Т4 могут представлять собой детерминированные транзакции, предназначенные для подсистемы 302 базы данных (см. фиг. 3).
Как описано выше, каждая транзакция имеет соответствующий идентификатор TUID и указывает на по меньшей мере одно место TDL, для которого она предназначена. Например,
- транзакция Т1 имеет идентификатор TUID1 и предназначена для места TDL1 (содержит указание на него);
- транзакция Т2 имеет идентификатор TUID2 и предназначена для мест TDL2 и TDL3 (содержит указание на них);
- транзакция Т3 имеет идентификатор TUID3 и предназначена для мест TDL4 и TDL5 (содержит указание на них); и
- транзакция Т4 имеет идентификатор TUID4 и предназначена для мест TDL6 и TDL7 (содержит указание на них).
После приема первым портом-координатором 362 первого набора 402 транзакций он способен упорядочить транзакции в первом наборе 402 транзакций на основе соответствующих идентификаторов TUID. Иными словами, первый порт-координатор 362 может применить алгоритм упорядочивания для соответствующих идентификаторов TUID из первого набора транзакций 402. Предполагается, что идентификаторы TUID1 и TUID2 представляют собой алфавитно-цифровые идентификаторы, и что идентификатор TUID2 предшествует идентификатору TUID1 в случае размещения их в алфавитно-цифровом порядке. В этом примере первый порт-координатор 362 способен формировать упорядоченный набор 412 транзакций на основе идентификаторов TUID1 и TUID2 так, чтобы в упорядоченном наборе 412 транзакций после первой транзакции Т2 с идентификатором TUID2 располагалась транзакция Т1 с идентификатором TUID1.
После формирования первым портом-координатором 362 упорядоченного набора 412 транзакций он может быть способен формировать первый локальный посегментный порядок 422 и второй локальный посегментный порядок 432. Первый порт-координатор 362 способен формировать первый локальный посегментный порядок 422 и второй локальный посегментный порядок 432 на основе (а) соответствующих мест TDL транзакций Т1 и Т2 и (б) данных 366 координации.
Первый порт-координатор 362 способен определить, (а) что места TDL1 и TDL2 принадлежат первому диапазону 322 множества 320 мест TDL, связанному с первым сегментом 312 (см. фиг. 3), и (б) что место TDL3 принадлежит третьему диапазону 326 множества 320 мест TDL, связанному с третьим сегментом 316 (см. фиг. 3). Например, места TDL1 и TDL2 могут соответствовать строкам в таблице базы данных из диапазона строк первого сегмента 312. Первый порт-координатор 362 способен определить, что места TDL1 и TDL2 соответствуют строкам в диапазоне строк первого сегмента 312 на основе ключей строк в диапазоне строк первого сегмента 312. В результате первый порт-координатор 362 способен формировать (а) первый локальный посегментный порядок 422, указывающий на транзакцию Т2 и следующую за ней транзакцию Т1 и предназначенный для первого сегмента 312, и (б) второй локальный посегментный порядок 432, указывающий на транзакцию Т2 и предназначенный для третьего сегмента 316.
Кроме того, первый порт-координатор 362 способен на основе данных 366 координации передавать первый пакет 442 координатора, который содержит данные, указывающие на первый локальный посегментный порядок 422, по линии 351 связи координатор-посредник в первый порт-посредник 342, поскольку первый сегмент 312 (для которого предназначен первый локальный посегментный порядок 422) заранее сопоставлен с первым портом-посредником 342.
Аналогично, первый порт-координатор 362 способен на основе данных 366 координации передавать второй пакет 452 координатора, который содержит данные, указывающие на второй локальный посегментный порядок 432, по линии 353 связи координатор-посредник во второй порт-посредник 344, поскольку третий сегмент 316 (для которого предназначен второй локальный посегментный порядок 432) заранее сопоставлен со вторым портом-посредником 344.
Предполагается, что первый порт-координатор 362 также способен передавать пустой пакет 462 координатора по линии и 356 связи координатор-посредник в третий порт-посредник 346. Ниже со ссылками на фиг. 5 более подробно описано, как первый пакет 442 координатора, второй пакет 452 координатора и пустой пакет 462 координатора обрабатываются соответствующими портами из множества 340 портов-посредников.
Тем не менее, следует отметить, что первый пакет 442 координатора, второй пакет 452 координатора и пустой пакет 462 координатора указывают на идентификатор CID1 первого порта-координатора 362 и на значение счетчика С1 первого порта-координатора 362 в момент времени, когда первый порт-координатор 362 отправляет первый пакет 442 координатора, второй пакет 452 координатора и пустой пакет 462 координатора.
В других вариантах осуществления данной технологии первый пакет 442 координатора, второй пакет 452 координатора и пустой пакет 462 координатора указывают на идентификатор CID1 первого порта-координатора 362 и на значение счетчика С1 первого порта-координатора 362 в момент времени, когда первый порт-координатор 362 принимает первый набор 402 транзакций.
В дополнительных вариантах осуществления изобретения первый пакет 442 координатора, второй пакет 452 координатора и пустой пакет 462 координатора указывают на идентификатор CID1 первого порта-координатора 362 и на значение счетчика С1 первого порта-координатора 362 в любой момент времени между (а) моментом времени, когда первый порт-координатор 362 принимает первый набор 402 транзакций, и (б) моментом времени, когда первый порт-координатор 362 отправляет первый пакет 442 координатора, второй пакет 452 координатора и пустой пакет 462 координатора.
В некоторых вариантах осуществления данной технологии, где первый порт-координатор 362 реализован в виде автомата SM, предполагается, что первый порт-координатор 362 может быть способен передавать в подсистему 108 распределенного хранения данных системные данные 472, которые представляют собой обновление журнала, связанного с этим автоматом SM, и по меньшей мере частично указывают на первый локальный посегментный порядок 422 и на второй локальный посегментный порядок 432.
В некоторых вариантах осуществления данной технологии, когда первый порт-координатор 362 неправильно функционирует, неработоспособен или иным образом отключен от распределенной программной системы 300, для замены первого порта-координатора 362 может использоваться новый порт-координатор, а данные, указывающие на первый локальный посегментный порядок 422 и на второй локальный посегментный порядок 432, могут извлекаться из обновления журнала, представленного системными данными 472, хранящимися в подсистеме 108 распределенного хранения данных, в пределах объема данной технологии.
Аналогично представленному выше описанию для первого порта-координатора 362, второй порт-координатор 364 способен формировать упорядоченный набор 414 транзакций на основе идентификаторов TUID3 и TUID4 так, чтобы в упорядоченном наборе 414 транзакций после первой транзакции Т4 с идентификатором TUID4 располагалась транзакция Т3 с идентификатором TUID3. В этом примере предполагается, что идентификаторы TUID3 и TUID4 представляют собой алфавитно-цифровые идентификаторы, и что идентификатор TUID4 предшествует идентификатору TUID3 в случае их размещения в алфавитно-цифровом порядке.
После формирования вторым портом-координатором 364 упорядоченного набора 414 транзакций он может быть способен формировать третий локальный посегментный порядок 424 и четвертый локальный посегментный порядок 434. Как описано выше, второй порт-координатор 364 способен формировать третий локальный посегментный порядок 424 и четвертый локальный посегментный порядок 434 на основе (а) соответствующих мест TDL транзакций Т3 и Т4 и (б) данных 366 координации.
Второй порт-координатор 364 способен определить, (а) что места TDL6 и TDL4 принадлежат первому диапазону 322 множества 320 мест TDL, который связан с первым сегментом 312 (см. фиг. 3), и (б) что места TDL 7 и TDL5 принадлежат второму диапазону 324 множества 320 мест TDL, который связан со вторым сегментом 314 (см. фиг. 3). Например, места TDL6 и TDL4 могут соответствовать строкам в таблице базы данных из диапазона строк первого сегмента 312. Второй порт-координатор 364 на основе ключей строк в диапазоне строк первого сегмента 312 способен определить, что места TDL6 и TDL4 соответствуют строкам в диапазоне строк первого сегмента 312. Места TDL7 и TDL5 могут соответствовать строкам в таблице базы данных из диапазона строк второго сегмента 314. Второй порт-координатор 364 на основе ключей строк в диапазоне строк второго сегмента 314 способен определить, что места TDL7 и TDL5 соответствуют строкам в диапазоне строк второго сегмента 314. В результате второй порт-координатор 364 способен формировать (а) третий локальный посегментный порядок 424, указывающий на транзакцию Т4 и следующую за ней транзакцию Т3 и предназначенный для первого сегмента 312, и (б) четвертый локальный посегментный порядок 434, указывающий на транзакцию Т4 и следующую за ней транзакцию Т3 и предназначенный для второго сегмента 314.
Кроме того, второй порт-координатор 364 способен на основе данных 366 координации передавать третий пакет 444 координатора, который содержит данные, указывающие на третий локальный посегментный порядок 424, по линии 352 связи координатор-посредник в первый порт-посредник 342, поскольку первый сегмент 312 (для которого предназначен третий локальный посегментный порядок 424) заранее сопоставлен с первым портом-посредником 342.
Аналогично, второй порт-координатор 364 способен на основе данных 366 координации передавать четвертый пакет 454 координатора, который содержит данные, указывающие на четвертый локальный посегментный порядок 434, по линии 354 связи координатор-посредник во второй порт-посредник 344, поскольку второй сегмент 314 (для которого предназначен четвертый локальный посегментный порядок 434) заранее сопоставлен со вторым портом-посредником 344.
Предполагается, что второй порт-координатор 364 также способен передавать пустой пакет 464 координатора по линии и 358 связи координатор-посредник в третий порт-посредник 346. Ниже со ссылками на фиг. 5 более подробно описано, как третий пакет 444 координатора, четвертый пакет 454 координатора и пустой пакет 464 координатора обрабатываются соответствующими портами из множества 340 портов-посредников.
Тем не менее, следует отметить, что третий пакет 444 координатора, четвертый пакет 454 координатора и пустой пакет 464 координатора указывают на идентификатор CID2 второго порта-координатора 364 и на значение счетчика С2 второго порта-координатора 364 в момент времени, когда второй порт-координатор 364 отправляет третий пакет 444 координатора, четвертый пакет 454 координатора и пустой пакет 464 координатора.
В других вариантах осуществления данной технологии третий пакет 444 координатора, четвертый пакет 454 координатора и пустой пакет 464 координатора указывают на идентификатор CID2 второго порта-координатора 364 и на значение счетчика С2 второго порта-координатора 364 в момент времени, когда второй порт-координатор 364 принимает второй набор 404 транзакций.
В дополнительных вариантах осуществления изобретения третий пакет 444 координатора, четвертый пакет 454 координатора и пустой пакет 464 координатора указывают на идентификатор CID2 второго порта-координатора 364 и на значение счетчика С2 второго порта-координатора 364 в любой момент времени между (а) моментом времени, когда второй порт-координатор 364 принимает второй набор 404 транзакций, и (б) моментом времени, когда второй порт-координатор 364 отправляет третий пакет 444 координатора, четвертый пакет 454 координатора и пустой пакет 464 координатора.
В некоторых вариантах осуществления данной технологии, где второй порт-координатор 364 реализован в виде данного автомата SM, предполагается, что второй порт-координатор 364 может быть способен передавать в подсистему 108 распределенного хранения данных системные данные 474, представляющие собой обновление журнала, связанного с этим автоматом SM, и по меньшей мере частично указывающие на третий локальный посегментный порядок 424 и на четвертый локальный посегментный порядок 434. Второй порт-координатор 364 может передавать системные данные 474 в подсистему 108 распределенного хранения данных по меньшей мере по тем же причинам, по которым первый порт-координатор 362 может быть способен отправлять системные данные 472 в подсистему 108 распределенного хранения данных.
Вкратце, первый порт-координатор 362 формирует из первого набора 402 транзакций первый локальный посегментный порядок 422 и направляет его в первый сегмент 312, заранее сопоставленный с первым портом-посредником 342. Первый порт-координатор 362 также формирует из первого набора 402 транзакций второй локальный посегментный порядок 432 и направляет его в третий сегмент 316, заранее сопоставленный со вторым портом-посредником 344.
Также вкратце, второй порт-координатор 364 формирует из второго набора 404 транзакций третий локальный посегментный порядок 424 и направляет его в первый сегмент 312, заранее сопоставленный с первым портом-посредником 342. Второй порт-координатор 364 также формирует из второго набора 404 транзакций четвертый локальный посегментный порядок 434 и направляет его во второй сегмент 314, заранее сопоставленный со вторым портом-посредником 344.
Также вкратце, первый порт-координатор 362 и второй порт-координатор 364 передают в третий порт-посредник 346 пустой пакет 462 координатора и пустой пакет 464 координатора, соответственно.
Следует отметить, что в некоторых вариантах осуществления данной технологии предполагается, что количество портов во множестве 360 портов-координаторов может быть меньше количества портов во множестве 340 портов-посредников, например, как показано на фиг. 3. Также предполагается, что количество портов во множестве 340 портов-посредников может быть меньше количества сегментов во множестве 310 сегментов, например, как показано на фиг. 3.
На фиг. 5 представлена схема 500 обработки локальных посегментных порядков, принятых множеством 340 портов-посредников от первого порта-координатора 362 и от второго порта-координатора 364.
Как показано сверху на фиг. 5, первый порт-посредник 342 принимает первый пакет 442 координатора от первого порта-координатора 362 и третий пакет 444 координатора от второго порта-координатора 364.
Таким образом, первый порт-посредник 342 принимает (а) данные, указывающие на первый локальный посегментный порядок 422, предназначенный для первого сегмента 312 и связанный с идентификатором CID1 и значением счетчика С1 первого порта-координатора 362, и (б) данные, указывающие на третий локальный посегментный порядок 424, предназначенный для первого сегмента 312 и связанный с идентификатором CID2 и значением счетчика С2 второго порта-координатора 364. В некоторых вариантах осуществления данной технологии первый порт-посредник 342 может быть способен формировать первый централизованный посегментный порядок 502 выполнения для первого сегмента 312 на основе, среди прочего, первого локального посегментного порядка 422 и третьего локального посегментного порядка 424.
Предполагается, что в некоторых вариантах осуществления данной технологии порт-посредник перед формированием централизованного посегментного порядка выполнения для заранее сопоставленного сегмента может быть способен проверять, принят ли соответствующий пакет координатора от каждого порта из множества 360 портов-координаторов.
Например, если первый порт-посредник 342 принял первый пакет 442 координатора от первого порта-координатора 362, но не получил пакет координатора от второго порта-координатора 364, первый порт-посредник 342 может быть способен не начинать формирование первого централизованного посегментного порядка 502 выполнения, поскольку с точки зрения первого порта-посредника 342 не ясно: либо (а) второй порт-координатор 364 просто не сформировал локальный посегментный порядок для первого сегмента 312, либо (б) второй порт-координатор 364 неправильно функционирует, неработоспособен или иным образом отключен от первого порта-посредника 342.
По этой причине в некоторых вариантах осуществления данной технологии порт-координатор из множества 360 портов-координаторов может быть способен формировать предназначенный для порта-посредника пустой пакет координатора, такой как пустой пакет 462 координатора или пустой пакет 464 координатора, связанный с соответствующим идентификатором CID и со значением счетчика С этого порта-координатора, чтобы оповещать порт-посредник о том, что порт-координатор по-прежнему подключен и просто не сформировал локальный посегментный порядок, предназначенный для данного сегмента, связанного с этим портом-посредником.
В результате в некоторых вариантах осуществления данной технологии формирование пустых пакетов координатора портами-координаторами позволяет обеспечивать, чтобы порт-посредник не начинал формирование централизованного посегментного порядка для заранее сопоставленного сегмента до приема от множества 360 портов-координаторов всех локальных посегментных порядков, предназначенных для данного сегмента.
Как описано выше, первый порт-посредник 342 может быть способен формировать первый централизованный посегментный порядок 502 выполнения на основе первого локального посегментного порядка 422 и третьего локального посегментного порядка 424. Например, первый порт-посредник 342 может быть способен сравнивать значение счетчика С1, связанное с первым локальным посегментным порядком 422, и значение счетчика С2, связанное с третьим локальным посегментным порядком 424.
В одном случае предполагается, что значение счетчика С1 меньше значения счетчика С2. В результате, как показано на фиг. 5, первый порт-посредник 342 может определить, что транзакции Т4 и Т3 из третьего локального посегментного порядка 424 должны выполняться позднее, чем транзакции Т2 и Т1 из первого локального посегментного порядка 422. Таким образом, первый порт-посредник 342 может сформировать первый централизованный посегментный порядок 502, указывающий, что после транзакции Т2 следует транзакция Т1, за которой следует транзакция Т4, за которой следует транзакция Т3.
В другом случае предполагается, что значение счетчика С1 больше значения счетчика С2. В результате в этом случае первый порт-посредник 342 может определить, что транзакции Т2 и Т1 из первого локального посегментного порядка 422 должны выполняться позднее, чем транзакции Т4 и Т3 из третьего локального посегментного порядка 424. Таким образом, в этом случае первый порт-посредник 342 может сформировать первый централизованный посегментный порядок, указывающий, что после транзакции Т4 следует транзакция Т3, за которой следует транзакция Т2, за которой следует транзакция Т1.
В еще одном случае предполагается, что значение счетчика С1 равно значению счетчика С2. В результате первый порт-посредник 342 в этом случае может быть способен изменить порядок взаимного расположения транзакций T1, Т2, Т3 и Т4 на основе соответствующих идентификаторов TUID. Предполагается, что в этом случае первый порт-посредник 342 может быть способен изменить порядок взаимного расположения транзакций T1, Т2, Т3 и Т4 на основе некоторых правил упорядочивания (например, алгоритма упорядочивания), которые используются множеством 360 портов-координаторов для упорядочивания транзакций.
Также предполагается, что в случае, когда значение счетчика С1 равно значению счетчика С2, первый порт-посредник 342 может быть заранее настроен так, чтобы назначать приоритеты транзакциям в централизованном посегментном порядке выполнения на основе заранее заданного порядка приоритетов портов-координаторов. Например, если первому порту-координатору 362 заранее задан более высокий приоритет, чем второму порту-координатору 364 (согласно порядку приоритетов портов-координаторов), и если определено, что значение счетчика С1 равно значению счетчика С2, то первый порт-посредник 342 может быть способен назначить транзакциям Т2 и Т1 более высокие приоритеты, чем транзакциям Т4 и Т3, в первом централизованном посегментном порядке, предназначенном для первого сегмента 312.
После формирования первым портом-посредником 342 первого централизованного посегментного порядка 502 выполнения, он может быть способен сформировать первый пакет 512 посредника, который содержит данные, указывающие на первый централизованный посегментный порядок 502. Первый порт-посредник 342 может быть способен передавать первый пакет 512 посредника по первой линии и 332 связи в первый сегмент 312, чтобы первый сегмент 312 выполнял транзакции T1, Т2, Т3 и Т4 в соответствии с первым централизованным посегментным порядком 502 выполнения.
Как показано в центре на фиг. 5, второй порт-посредник 344 принимает второй пакет 452 координатора от первого порта-координатора 362 и четвертый пакет 454 координатора от второго порта-координатора 364.
Таким образом, второй порт-посредник 344 принимает (а) данные, указывающие на второй локальный посегментный порядок 432, предназначенный для третьего сегмента 316 и связанный с идентификатором CID1 и значением счетчика С1 первого порта-координатора 362, и (б) данные, указывающие на четвертый локальный посегментный порядок 434, предназначенный для второго сегмента 314 и связанный с идентификатором CID2 и значением счетчика С2 второго порта-координатора 364. В некоторых вариантах осуществления данной технологии второй порт-посредник 344 может быть способен формировать (а) второй централизованный посегментный порядок 504 выполнения для второго сегмента 314 на основе четвертого локального посегментного порядка 434 и (б) третий централизованный посегментный порядок 506 выполнения для третьего сегмента 316 на основе второго локального посегментного порядка 432.
Предполагается, что в некоторых вариантах осуществления данной технологии порт-посредник перед формированием централизованного посегментного порядка выполнения для заранее сопоставленного сегмента может быть способен проверять, какие принятые пакеты координатора содержат данные, указывающие на локальные посегментные порядки, предназначенные для этого сегмента. Например, порт-посредник может быть способен анализировать принятые локальные посегментные порядки, чтобы определить, какой из принятых локальных посегментных порядков предназначен для соответствующих заранее сопоставленных сегментов.
В представленном на фиг. 5 не имеющем ограничительного характера примере второй порт-посредник 344 может быть способен анализировать второй локальный посегментный порядок 432 и четвертый локальный посегментный порядок 434, принятые вторым портом-посредником 344. В этом случае второй порт-посредник 344 может быть способен определить, что второй локальный посегментный порядок 432 и четвертый локальный посегментный порядок 434 предназначены для различных сегментов, заранее сопоставленных со вторым портом-посредником 344, а именно, для третьего сегмента 316 и для второго сегмента 314, соответственно.
В некоторых вариантах осуществления данной технологии второй порт-посредник 344 может быть способен определить, что второй централизованный посегментный порядок 504 выполнения должен быть сформирован на основе всех принятых локальных посегментных порядков, предназначенных для второго сегмента 314. В данном случае из всех принятых вторым портом-посредником 344 локальных посегментных порядков для второго сегмента 314 предназначен только четвертый локальный посегментный порядок 434. В некоторых вариантах осуществления данной технологии второй порт-посредник 344 также может быть способен определить, что третий централизованный посегментный порядок 506 выполнения должен быть сформирован на основе всех принятых локальных посегментных порядков, предназначенных для третьего сегмента 316. В данном случае из всех принятых вторым портом-посредником 344 локальных посегментных порядков для третьего сегмента 316 предназначен только второй локальный посегментный порядок 432.
Предполагается, что в некоторых вариантах осуществления данной технологии, если определено, что только один принятый портом-посредником локальный посегментный порядок предназначен для заранее сопоставленного сегмента, то этот порт-посредник может быть способен сформировать соответствующий централизованный посегментный порядок выполнения путем определения только одного локального посегментного порядка в качестве соответствующего централизованного посегментного порядка выполнения.
Например, если определено, что только четвертый локальный посегментный порядок 434, принятый вторым портом-посредником 344, предназначен для второго сегмента 314, то второй порт-посредник 344 может быть способен сформировать второй централизованный посегментный порядок 504 выполнения путем определения четвертого локального посегментного порядка 434 в качестве второго централизованного посегментного порядка 504 выполнения. Также, если определено, что только второй локальный посегментный порядок 432, принятый вторым портом-посредником 344, предназначен для третьего сегмента 316, то второй порт-посредник 344 может быть способен сформировать третий централизованный посегментный порядок 506 выполнения путем определения второго локального посегментного порядка 432 в качестве третьего централизованного посегментного порядка 506 выполнения.
После формирования вторым портом-посредником 344 второго централизованного посегментного порядка 504 выполнения он может быть способен сформировать второй пакет 514 посредника, который содержит данные, указывающие на второй централизованный посегментный порядок 504 выполнения. Второй порт-посредник 344 может быть способен передавать второй пакет 514 посредника по второй линии и 334 связи во второй сегмент 314, чтобы второй сегмент 314 выполнял транзакции Т4 и Т3 в соответствии со вторым централизованным посегментным порядком 504 выполнения.
После формирования вторым портом-посредником 344 третьего централизованного посегментного порядка 506 выполнения он может быть способен сформировать третий пакет 516 посредника, который содержит данные, указывающие на третий централизованный посегментный порядок 506 выполнения. Второй порт-посредник 344 может быть способен передавать третий пакет 516 посредника по третьей линии и 336 связи в третий сегмент 316, чтобы третий сегмент 316 выполнял транзакцию Т2 в соответствии с третьим централизованным посегментным порядком 506 выполнения.
Как показано снизу на фиг. 5, третий порт-посредник 346 принимает пустой пакет 462 координатора от первого порта-координатора 362 и пустой пакет 464 координатора от второго порта-координатора 364.
Предполагается, что третий порт-посредник 346 перед формированием централизованного посегментного порядка выполнения для заранее сопоставленного четвертого сегмента может быть способен проверять, принят ли соответствующий пакет координатора от каждого порта из множества 360 портов-координаторов.
В этом случае третий порт-посредник 346 может определить, что соответствующий пакет координатора принят от каждого порта из множества 360 портов-координаторов, а именно, что пустой пакет 462 координатора принят от первого порта-координатора 362 и пустой пакет 464 координатора принят от второго порта-координатора 364.
В этом случае предполагается, что третий порт-посредник 346 может быть способен не формировать централизованный посегментный порядок выполнения для заранее сопоставленного четвертого сегмента 318. Третий порт-посредник 346 способен не формировать централизованный посегментный порядок выполнения для четвертого сегмента 318, что может быть эквивалентно бездействию третьего порта-посредника 346.
Можно сказать, что, если третий порт-посредник 346 определяет, что (а) он принял соответствующий пакет координатора от каждого порта из множества 360 портов-координаторов, но (б) не принял локальный посегментный порядок, предназначенный для четвертого сегмента 318, то третий порт-посредник 346 может быть способен прекратить связь с четвертым сегментом 318 по четвертой линии и 338 связи (см. фиг. 3).
В некоторых вариантах осуществления данной технологии, где множество 340 портов-посредников реализовано в виде соответствующих автоматов SM, предполагается, что множество 340 портов-посредников может быть способно передавать системные данные, представляющие собой обновления журнала, в подсистему 108 распределенного хранения данных для их хранения в соответствующих журналах. Тем не менее, также предполагается, что в некоторых вариантах осуществления данной технологии множество 340 портов-посредников может не требовать или может быть способно не передавать системные данные для хранения в подсистему 108 распределенного хранения данных.
На фиг. 6 приведено схематическое представление соответствующей другому варианту осуществления данной технологии распределенной программной системы 600 для маршрутизации и выполнения транзакций. Распределенная программная система 600 содержит (а) подсистему 602 базы данных и (б) подсистему 604 маршрутизации транзакций.
Подсистема 602 базы данных содержит множество 610 сегментов, каждый из которых связан с соответствующим диапазоном множества 620 мест TDL. Подсистема 604 маршрутизации транзакций содержит множество 660 портов-координаторов и множество 640 портов-посредников.
Предполагается, что распределенная программная система 600 маршрутизирует и выполняет транзакции аналогично описанной выше распределенной программной системе 300. Тем не менее, в отличие от распределенной программной системы 300, множество 640 портов-посредников реализовано как часть множества 610 сегментов. Иными словами, в некоторых вариантах осуществления данной технологии предполагается, что функции порта-посредника могут выполняться сегментом.
Например, порт-посредник 642 может быть реализован как часть сегмента 612, порт-посредник 644 может быть реализован как часть сегмента 614, порт-посредник 646 может быть реализован как часть сегмента 616.
Предполагается, что в других вариантах осуществления данной технологии по меньшей мере некоторые порты из множества 640 портов-посредников могут быть реализованы как часть соответствующих сегментов из множества 610 сегментов, а по меньшей мере некоторые другие порты из множества 640 портов-посредников могут быть реализованы как элементы, отдельные от соответствующих сегментов из множества 610 сегментов, в пределах объема данной технологии.
В некоторых вариантах осуществления данной технологии представленная на фиг. 3 распределенная программная система 300 может быть способна выполнять представленный на фиг. 7 способ 700 для маршрутизации транзакций с целью их выполнения. Способ 700 описан далее.
Шаг 702: прием портом-координатором соответствующего набора транзакций
Способ 700 начинается на шаге 702, где порт-координатор принимает соответствующий набор транзакций. Например, как показано на фиг. 4, первый порт-координатор 362 принимает по линии и 372 связи первой точки входа первый набор 402 транзакций. В другом примере второй порт-координатор 364 принимает по линии и 374 связи второй точки входа второй набор 404 транзакций.
В некоторых вариантах осуществления данной технологии предполагается, что принятый портом-координатором набор транзакций может содержать детерминированные транзакции.
Предполагается, что принятый одним портом-координатором набор транзакций может быть взаимно исключающим с другими наборами транзакций, принятыми другими портами-координаторами распределенной программной системы 300 (или распределенной программной системы 600).
Следует отметить, что каждая принятая портом-координатором транзакция имеет соответствующий идентификатор TUID и связана с по меньшей мере одним соответствующим местом TDL для ее выполнения. Например, как показано на фиг. 4:
- транзакция Т1 имеет идентификатор TUID1 и предназначена для места TDL1 (содержит указание на него);
- транзакция Т2 имеет идентификатор TUID2 и предназначена для мест TDL2 и TDL3 (содержит указание на них);
- транзакция Т3 имеет идентификатор TUID3 и предназначена для мест TDL4 и TDL5 (содержит указание на них); и
- транзакция Т4 имеет идентификатор TUID4 и предназначена для мест TDL6 и TDL7 (содержит указание на них).
Предполагается, что принятая портом-координатором транзакция может иметь алфавитно-цифровой идентификатор TUID. Также предполагается, что принятая портом-координатором транзакция может содержать указание на соответствующее место TDL. Например, транзакция может содержать указание на строку таблицы базы данных, для которой эта транзакция предназначена. Например, указание на строку может представлять собой по меньшей мере ключ строки таблицы базы данных.
В некоторых вариантах осуществления изобретения предполагается, что транзакция, предназначенная для соответствующего места TDL, должна выполняться в этом месте. Например, если транзакция предназначена для некоторой строки таблицы базы данных, это может означать, что транзакция предусматривает считывание/запись данных в записи, связанной с ключом данной строки таблицы базы данных.
Шаг 704: формирование портом-координатором по меньшей мере одного локального посегментного порядка
Способ 700 продолжается на шаге 704, где упомянутый на шаге 702 порт-координатор формирует по меньшей мере один локальный посегментный порядок на основе идентификаторов TUID транзакций в соответствующем наборе транзакций.
Например, как показано на фиг. 4, первый порт-координатор 362 может быть способен формировать первый локальный посегментный порядок 422 и второй локальный посегментный порядок 432 на основе идентификаторов TUID и мест TDL каждой транзакции из первого набора 402 транзакций. В другом примере второй порт-координатор 364 может быть способен формировать третий локальный посегментный порядок 424 и четвертый локальный посегментный порядок 434 на основе идентификаторов TUID и мест TDL каждой транзакции из второго набора 404 транзакций.
Следует отметить, что некоторый порядок из по меньшей мере одного локального посегментного порядка содержит транзакции из соответствующего набора транзакций, предназначенных для мест TDL некоторого сегмента из множества 310 (или 610) сегментов.
Например, первый локальный посегментный порядок 422 содержит транзакции из первого набора 402 транзакций, предназначенные для мест TDL первого сегмента 312 из множества 310 сегментов. В другом примере третий локальный посегментный порядок 424 содержит транзакции из второго набора 404 транзакций, предназначенные для мест TDL первого сегмента 312 из множества 310 сегментов.
В некоторых вариантах осуществления данной технологии формирование портом-координатором по меньшей мере одного локального посегментного порядка может включать в себя упорядочивание транзакций в наборе транзакций и, следовательно, формирование упорядоченного набора транзакций.
Например, для формирования первого локального посегментного порядка 422 и второго локального посегментного порядка 432 первый порт-координатор 362 может быть способен упорядочивать первый набор 402 транзакций, таким образом, формируя первый упорядоченный набор 412 транзакций. В другом примере для формирования третьего локального посегментного порядка 424 и четвертого локального посегментного порядка 434, второй порт-координатор 364 может быть способен упорядочивать второй набор 404 транзакций, таким образом, формируя второй упорядоченный набор 414 транзакций.
Шаг 706: передача портом-координатором по меньшей мере одного локального посегментного порядка
Способ 700 продолжается на шаге 706, где упомянутый на шагах 702 и 704 порт-координатор передает по меньшей мере один локальный посегментный порядок в соответствующий порт-посредник, заранее сопоставленный с некоторым сегментом из множества сегментов.
Например, второй порт-координатор 364 способен на основе данных 366 координации передавать третий пакет 444 координатора, который содержит данные, указывающие на третий локальный посегментный порядок 424, по линии и 352 связи координатор-посредник в первый порт-посредник 342, поскольку первый сегмент 312 (для которого предназначен третий локальный посегментный порядок 424) заранее сопоставлен с первым портом-посредником 342. В другом примере второй порт-координатор 364 способен на основе данных 366 координации передавать четвертый пакет 454 координатора, который содержит данные, указывающие на четвертый локальный посегментный порядок 434, по линии 354 связи координатор-посредник во второй порт-посредник 344, поскольку второй сегмент 314 (для которого предназначен четвертый локальный посегментный порядок 434) заранее сопоставлен со вторым портом-посредником 344.
Предполагается, что порт-координатор может быть способен передавать пакет координатора в каждый порт-посредник. Например, если порт-координатор сформировал локальный посегментный порядок для некоторого порта-посредника, этот порт-координатор может передать пакет координатора, содержащий соответствующий локальный посегментный порядок, в этот порт-посредник. В другом примере, если порт-координатор не сформировал локальный посегментный порядок для другого порта-посредника, этот порт-координатор может передать пустой пакет координатора в другой порт-посредник.
Шаг 708: прием портом-посредником по меньшей мере одного локального посегментного порядка от множества портов-координаторов
Способ 700 продолжается на шаге 708, где порт-посредник принимает по меньшей мере один локальный посегментный порядок от множества портов-координаторов. Например, первый порт-посредник 342 принимает (а) данные, указывающие на первый локальный посегментный порядок 422, предназначенный для первого сегмента 312 и связанный с идентификатором CID 1 и значением счетчика С1 первого порта-координатора 362, и (б) данные, указывающие на третий локальный посегментный порядок 424, предназначенный для первого сегмента 312 и связанный с идентификатором CID2 и значением счетчика С2 второго порта-координатора 364.
Следует отметить, что каждый порядок из по меньшей мере одного локального посегментного порядка, принятого портом-посредником, может быть связан с идентификатором CID и счетчиком соответствующего порта-координатора, отправившего этот по меньшей мере один посегментный порядок.
Шаг 710: формирование портом-посредником по меньшей мере одного централизованного посегментного порядка выполнения
Способ 700 продолжается на шаге 710, где упомянутый на шаге 708 порт-посредник формирует по меньшей мере один централизованный посегментный порядок выполнения из по меньшей мере одного локального посегментного порядка, принятого от множества портов-координаторов. Например, первый порт-посредник 342 может быть способен формировать первый централизованный посегментный порядок 502 выполнения для первого сегмента 312 на основе, среди прочего, первого локального посегментного порядка 422 и третьего локального посегментного порядка 424.
В некоторых вариантах осуществления изобретения первый порт-посредник 342 может быть способен сравнивать значение счетчика С1, связанное с первым локальным посегментным порядком 422, и значение счетчика С2, связанное с третьим локальным посегментным порядком 424, для формирования первого централизованного посегментного порядка 502 выполнения.
В других вариантах осуществления изобретения порт-посредник перед формированием централизованного посегментного порядка выполнения для заранее сопоставленного сегмента может быть способен проверять, принят ли соответствующий пакет координатора от каждого порта из множества 360 портов-координаторов (см. фиг. 3).
В других вариантах осуществления изобретения централизованный посегментный порядок выполнения может передаваться в соответствующий заранее сопоставленный сегмент для выполнения этим заранее сопоставленным сегментом данного порта-посредника транзакций, указанных в соответствующем централизованном посегментном порядке выполнения.
Специалисту в данной области могут быть очевидны возможные изменения и усовершенствования описанных выше вариантов осуществления настоящей технологии. Предшествующее описание приведено лишь в качестве примера, но не для ограничения объема изобретения. Объем охраны данной технологии определяется исключительно объемом приложенной формулы изобретения.
| название | год | авторы | номер документа |
|---|---|---|---|
| Способ и система для обработки запросов в распределенной базе данных | 2018 |
|
RU2711348C1 |
| СИСТЕМА ОБРАБОТКИ ДАННЫХ И СПОСОБ ОБНАРУЖЕНИЯ ЗАТОРА В СИСТЕМЕ ОБРАБОТКИ ДАННЫХ | 2018 |
|
RU2718215C2 |
| СПОСОБ И СИСТЕМА ДЛЯ ОБРАБОТКИ ДАННЫХ | 2018 |
|
RU2714602C1 |
| СПОСОБ И СИСТЕМА ДЛЯ ПЕРЕДАЧИ СООБЩЕНИЯ | 2019 |
|
RU2746042C1 |
| СПОСОБ И СИСТЕМА ДЛЯ ПЛАНИРОВАНИЯ ПЕРЕДАЧИ ОПЕРАЦИЙ ВВОДА/ВЫВОДА | 2018 |
|
RU2714219C1 |
| Способ и система для планирования выполнения операций ввода/вывода | 2018 |
|
RU2714373C1 |
| СПОСОБ И СИСТЕМА ДЛЯ ПЛАНИРОВАНИЯ ОБРАБОТКИ ОПЕРАЦИЙ ВВОДА/ВЫВОДА | 2018 |
|
RU2749649C2 |
| Способ и распределенная компьютерная система для обработки данных | 2018 |
|
RU2720951C1 |
| СПОСОБ ОПРЕДЕЛЕНИЯ ПОТЕНЦИАЛЬНОЙ НЕИСПРАВНОСТИ ЗАПОМИНАЮЩЕГО УСТРОЙСТВА | 2018 |
|
RU2731321C2 |
| ПЛАТФОРМА СОСТАВНЫХ ПРИЛОЖЕНИЙ НА БАЗЕ МОДЕЛИ | 2008 |
|
RU2502127C2 |
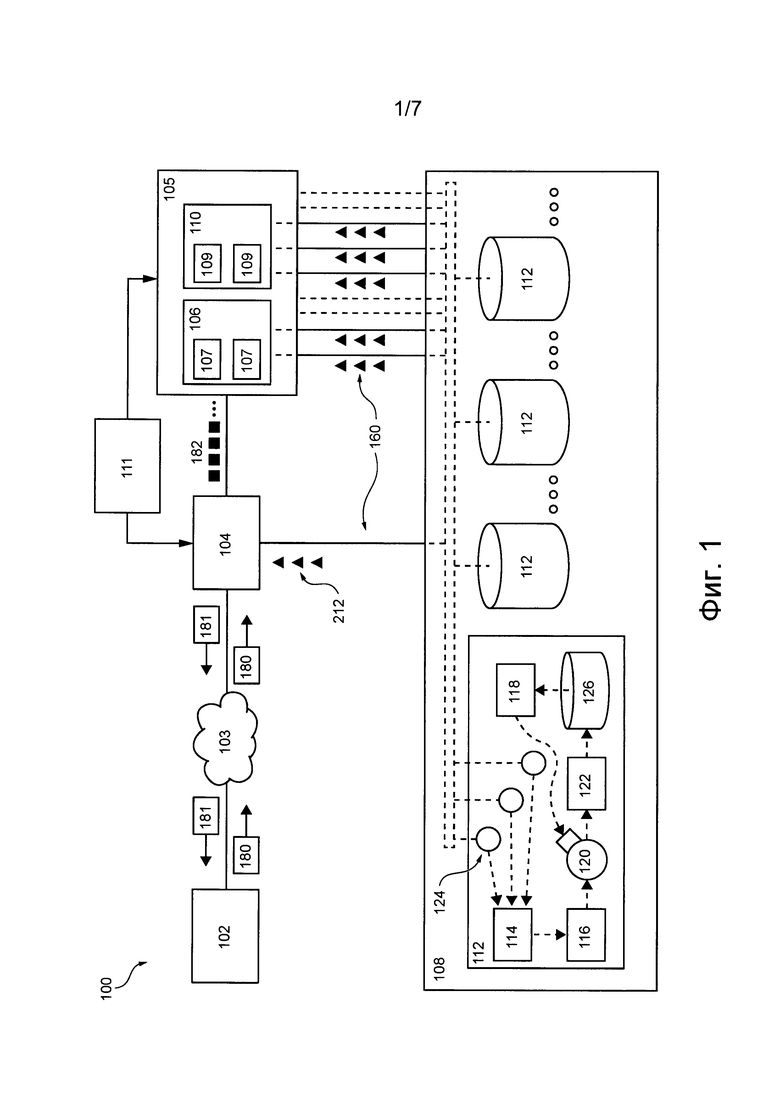
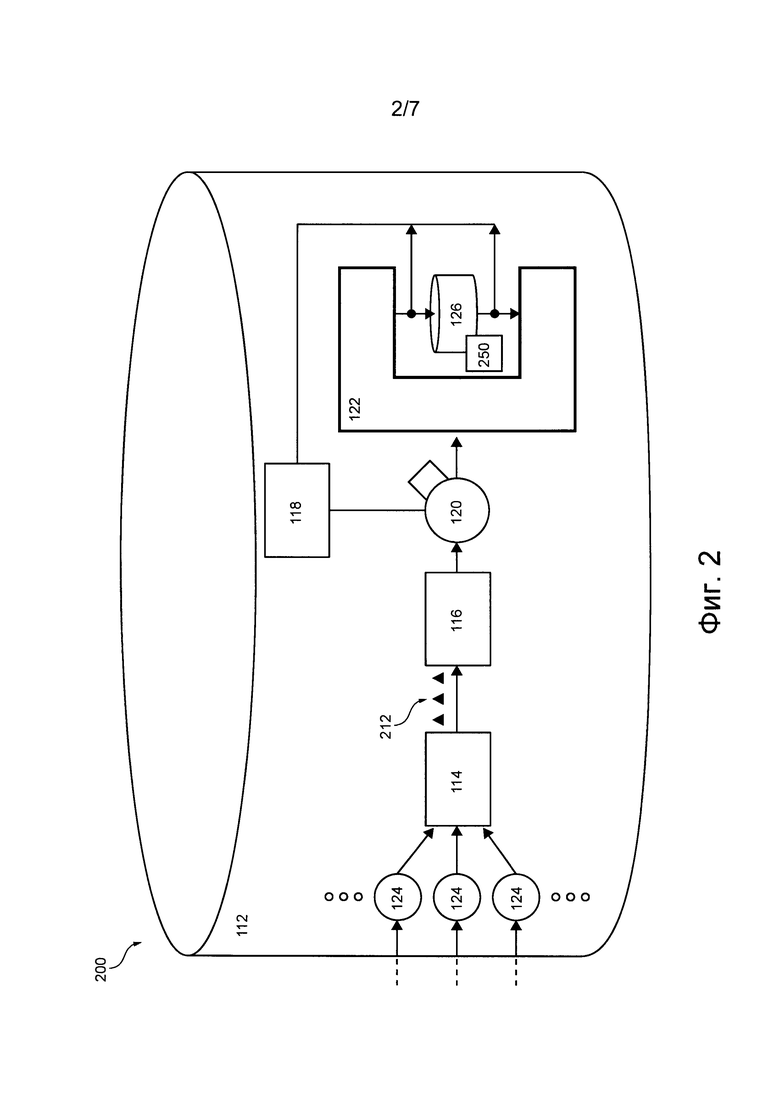
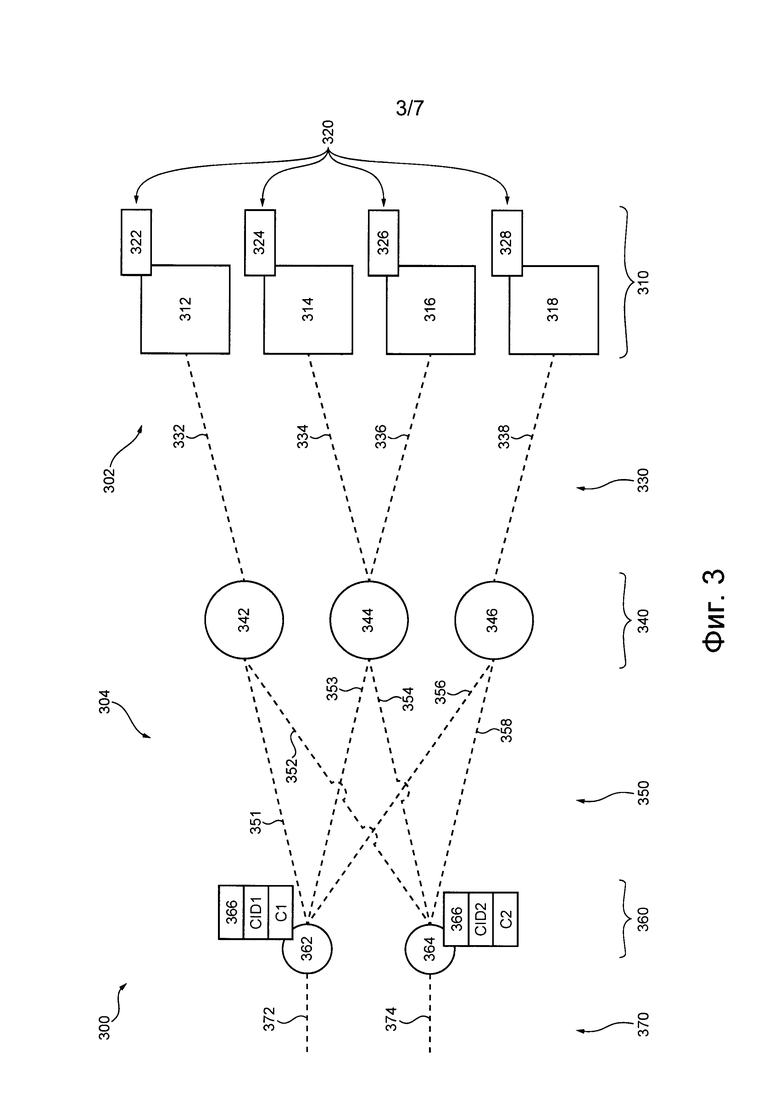
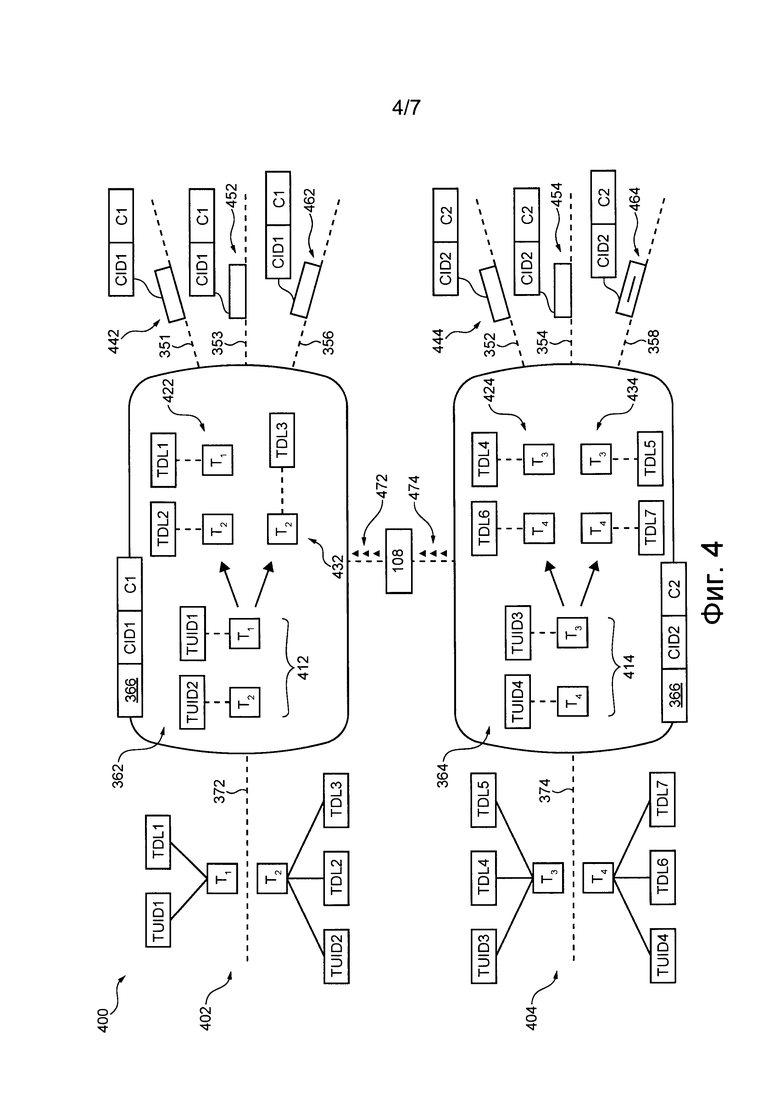
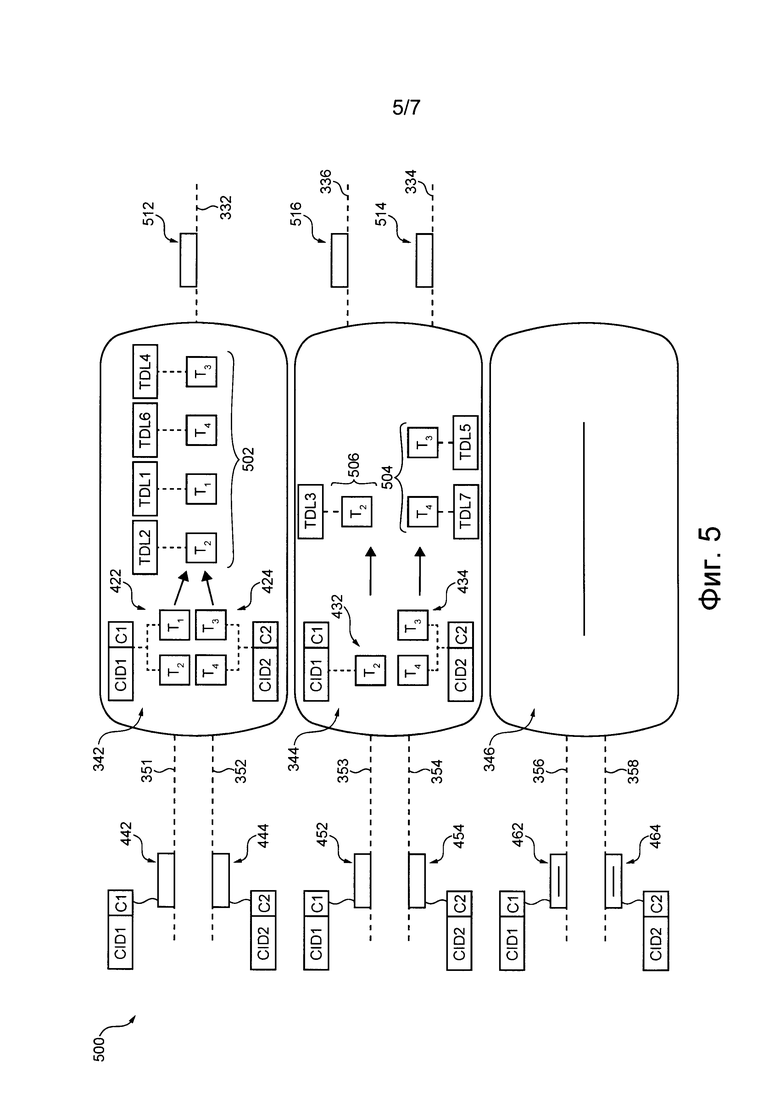
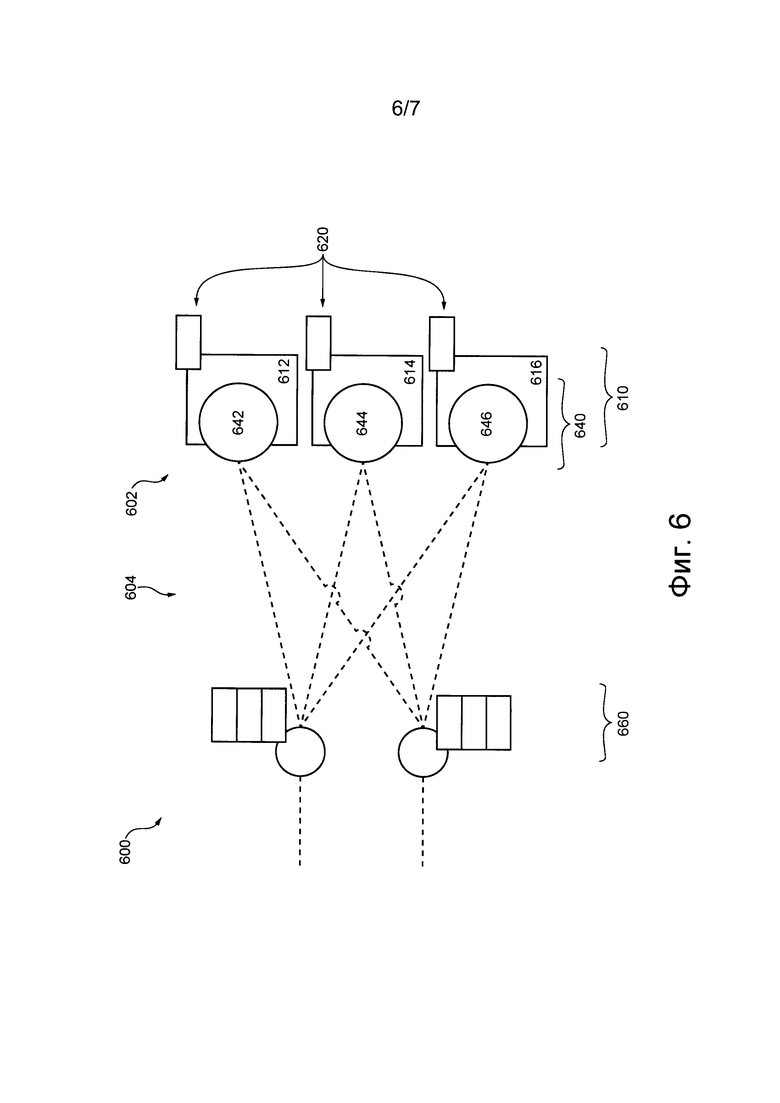
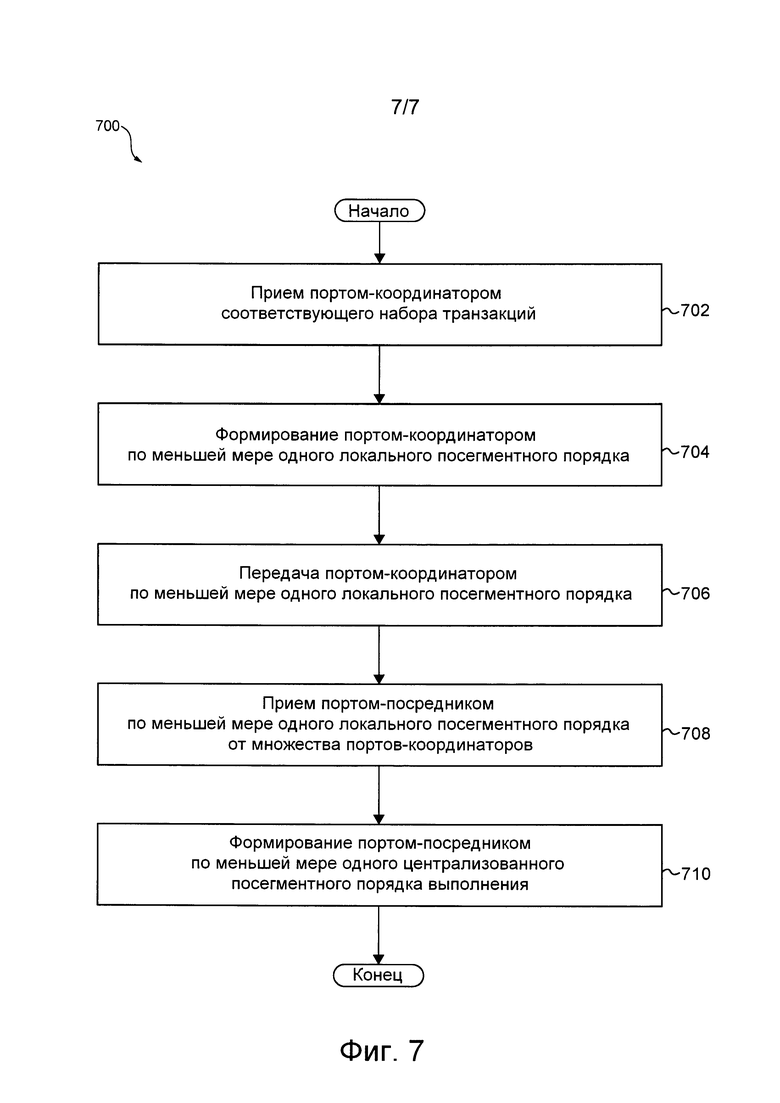
Изобретение относится к распределенной программной системе и способу для маршрутизации транзакций с целью их выполнения. Технический результат заключается в обеспечении возможности избежать ненужного доступа к сегментам системы распределенной базы данных, для которых эти транзакции не предназначены. Распределенная программная система для маршрутизации транзакций содержит подсистему базы данных, разделенную на сегменты, и подсистему маршрутизации транзакций для упорядочивания транзакций. Подсистема маршрутизации транзакций содержит множество портов-координаторов и множество портов-посредников. Порты-координаторы принимают транзакции, предназначенные для выполнения сегментами, и формируют локальные посегментные порядки для принятых транзакций. Локальные посегментные порядки принимаются множеством портов-посредников, заранее сопоставленных с соответствующими сегментами. Порты-посредники формируют централизованные посегментные порядки выполнения на основе принятых посегментных порядков. Централизованный посегментный порядок выполнения представляет собой порядок выполнения транзакций, принятых портом-посредником и предназначенных для выполнения сегментом, заранее сопоставленным с этим портом-посредником. 2 н. и 20 з.п. ф-лы, 7 ил.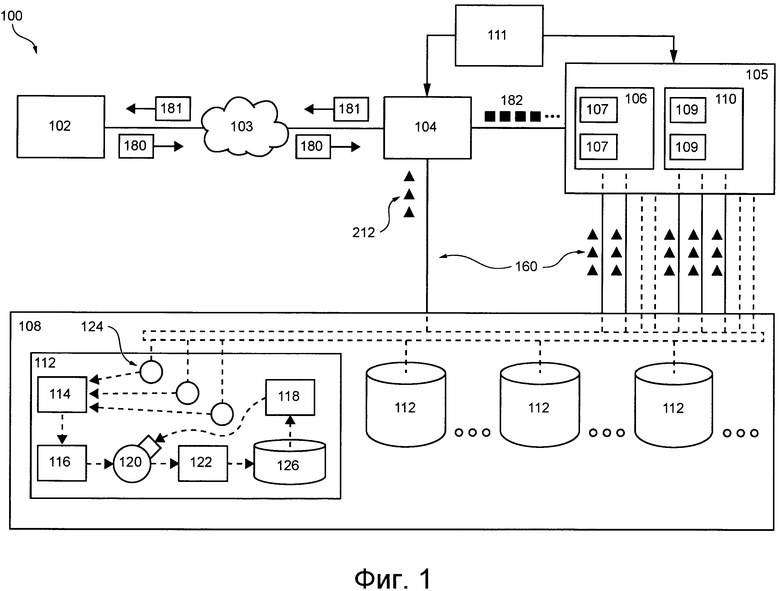
1. Распределенная программная система для маршрутизации транзакций с целью их выполнения, в которой транзакции формируются из запроса, предоставленного источником запросов, содержащая:
- подсистему базы данных, содержащую множество мест назначения транзакции и разделенную на множество сегментов, каждый из которых содержит соответствующую часть множества мест назначения транзакции; и
- подсистему маршрутизации транзакций для упорядочивания множества транзакций, каждая из которых имеет соответствующий уникальный идентификатор транзакции (TUID) и предназначена для по меньшей мере одного соответствующего места назначения транзакции для выполнения, содержащую:
- множество портов-координаторов, каждый из которых связан с соответствующим счетчиком и выполнен с возможностью:
- приема соответствующего набора транзакций, каждая из которых имеет соответствующий идентификатор TUID и связана с по меньшей мере одним соответствующим местом назначения транзакции для выполнения;
- определения для сегмента, содержащего по меньшей мере одно место назначения транзакции, связанное с соответствующим набором транзакций, локального посегментного порядка транзакций из подмножества набора транзакций, предназначенных для по меньшей мере одного места назначения транзакции из этого сегмента, при этом локальный посегментный порядок основан на соответствующих идентификаторах TUID транзакций из подмножества набора транзакций; при этом локальный посегментный порядок для подмножества набора транзакций указывает порядок, в котором транзакции из подмножества набора транзакций должны выполняться этим сегментом, и
- множество портов-посредников, каждый из которых заранее сопоставлен с по меньшей мере одним сегментом и выполнен с возможностью приема от множества портов-координаторов локальных посегментных порядков, связанных с по меньшей мере одним сегментом, с которым заранее сопоставлен некоторый порт из множества портов-посредников, и определения централизованного посегментного порядка для по меньшей мере одного заранее сопоставленного сегмента путем упорядочивания соответствующих локальных посегментных порядков, связанных с этим по меньшей мере одним заранее сопоставленным сегментом, на основе связанных с множеством портов-координаторов счетчиков принятых соответствующих локальных посегментных порядков; при этом централизованный посегментный порядок указывает порядок, в котором все транзакции, предназначенные для мест назначения транзакции соответствующего сегмента и принятые соответствующим портом-посредником, должны выполняться соответствующим сегментом.
2. Система по п. 1, в которой каждый порт из множества портов-координаторов и каждый порт из множества портов-посредников реализован в виде программного модуля.
3. Система по п. 2, в которой программный модуль реализован как конечный автомат (SM).
4. Система по п. 1, в которой каждый сегмент из множества сегментов заранее сопоставлен с одним портом-посредником из множества портов-посредников.
5. Система по п. 4, в которой порт-посредник из множества портов-посредников заранее сопоставлен с несколькими сегментами из множества сегментов.
6. Система по п. 1, в которой порт-посредник из множества портов-посредников реализован в виде части соответствующего заранее сопоставленного сегмента.
7. Система по п. 1, в которой порт из множества портов-координаторов выполнен с возможностью отправки пустого пакета координатора в те порты из множества портов-посредников, для которых этот порт из множества портов-координаторов не принял транзакции.
8. Система по п. 1, в которой количество портов во множестве портов-координаторов меньше количества портов во множестве портов-посредников.
9. Система по п. 8, в которой количество портов во множестве портов-посредников меньше количества сегментов во множестве сегментов.
10. Система по п. 1, в которой подсистема базы данных содержит базу данных.
11. Система по п. 10, в которой база данных представляет собой распределенную базу данных и хранится в подсистеме распределенного хранения данных.
12. Система по п. 10, в которой база данных содержит одну или несколько таблиц базы данных.
13. Система по п. 12, в которой одна или несколько таблиц базы данных разделены между множеством сегментов.
14. Способ маршрутизации транзакций с целью их выполнения, выполняемый распределенной программной системой, содержащей подсистему базы данных, содержащую множество мест назначения транзакции и разделенную на множество сегментов, каждый из которых содержит соответствующую часть множества мест назначения транзакции, и подсистему маршрутизации транзакций для упорядочивания множества транзакций, каждая из которых имеет соответствующий уникальный идентификатор транзакции (TUID) и предназначена для по меньшей мере одного соответствующего места назначения транзакции для выполнения, при этом подсистема маршрутизации транзакций содержит множество портов-координаторов и множество портов-посредников и каждый порт из множества портов-посредников заранее сопоставлен с по меньшей мере одним сегментом из множества сегментов, включающий в себя:
- прием портом-координатором соответствующего набора транзакций, каждая из которых имеет соответствующий идентификатор TUID и связана с по меньшей мере одним соответствующим местом назначения транзакции для выполнения;
- формирование портом-координатором по меньшей мере одного локального посегментного порядка на основе идентификаторов TUID и по меньшей мере одного соответствующего места назначения транзакции для транзакций из соответствующего набора транзакций, при этом некоторый порядок из по меньшей мере одного локального посегментного порядка содержит транзакции из соответствующего набора транзакций, предназначенных для мест назначения транзакции некоторого сегмента из множества сегментов;
- передачу портом-координатором по меньшей мере одного локального посегментного порядка в соответствующий порт-посредник, заранее сопоставленный с некоторым сегментом из множества сегментов;
- прием портом-посредником по меньшей мере одного локального посегментного порядка от множества портов-координаторов, при этом каждый порядок из по меньшей мере одного локального посегментного порядка, принятого портом-посредником, связан с идентификатором координатора (CID) соответствующего порта-координатора и со счетчиком соответствующего порта-координатора; и
- формирование этим портом-посредником по меньшей мере одного централизованного посегментного порядка выполнения из по меньшей мере одного локального посегментного порядка, принятого от множества портов-координаторов, на основе соответствующих идентификаторов CID и соответствующих счетчиков, при этом такой по меньшей мере один централизованный посегментный порядок выполнения предназначен для соответствующего заранее сопоставленного сегмента этого порта-посредника.
15. Способ по п. 14, дополнительно включающий в себя выполнение соответствующим заранее сопоставленным сегментом порта-посредника транзакций, указанных в соответствующем централизованным посегментном порядке выполнения.
16. Способ по п. 14, в котором перед формированием по меньшей мере одного централизованного посегментного порядка выполнения способ дополнительно включает в себя проверку портом-посредником получения пакета координатора от каждого порта из множества портов-координаторов.
17. Способ по п. 14, в котором формирование портом-координатором по меньшей мере одного локального посегментного порядка включает в себя упорядочивание этим портом-координатором соответствующего набора транзакций с целью формирования соответствующего упорядоченного набора транзакций.
18. Способ по п. 17, в котором упорядочивание включает в себя применение алгоритма упорядочивания в отношении соответствующих идентификаторов TUID.
19. Способ по п. 14, в котором количество портов во множестве портов-координаторов меньше количества портов во множестве портов-посредников.
20. Способ по п. 19, в котором количество портов во множестве портов-посредников меньше количества сегментов во множестве сегментов.
21. Способ по п. 14, в котором подсистема базы данных содержит базу данных.
22. Способ по п. 21, в котором база данных представляет собой распределенную базу данных и хранится в подсистеме распределенного хранения данных.
23. Способ по п. 21, в котором база данных содержит одну или несколько таблиц базы данных.
24. Способ по п. 22, в котором одна или несколько таблиц базы данных разделены между множеством сегментов.
| СПОСОБ И УСРОЙСТВО МАРШРУТИЗАЦИИ ВВОДА-ВЫВОДА И КАРТА | 2010 |
|
RU2543558C2 |
| СПОСОБ И СИСТЕМА ПРОВЕДЕНИЯ ТРАНЗАКЦИЙ В СЕТИ С ИСПОЛЬЗОВАНИЕМ СЕТЕВЫХ ИДЕНТИФИКАТОРОВ | 2003 |
|
RU2376635C2 |
| US 6859931 B1, 22.02.2005 | |||
| СПОСОБ ЛЕЧЕНИЯ ПЕРЕЛОМОВ ТЕЛ ПОЗВОНКА | 2007 |
|
RU2351375C1 |
| US 6851115 B1, 01.02.2005. | |||

