Область техники
[0001] Настоящее изобретение относится к устройству, способу и компьютерной программе для кодирования и декодирования видеоинформации.
Предпосылки создания изобретения
[0002] Масштабируемым видеокодированием называется такая структура кодирования, в которой один битовый поток может содержать несколько представлений видеоданных с различным битрейтом, разрешением или частотой смены кадров. В этих случаях приемник может извлекать требуемое представление в зависимости от своих характеристик. Альтернативно, сервер или сетевой элемент может извлекать части битового потока для передачи в приемник в зависимости, например, от характеристик сети или вычислительных возможностей приемника. Масштабируемый битовый поток состоит, как правило, из базового уровня кодирования, обеспечивающего наименьшее из доступных качество видеоинформации, а также из одного или более уточняющих уровней кодирования, которые повышают качество видеоинформации при их приеме и декодировании вместе с нижними уровнями. С целью повышения эффективности кодирования уточняющих уровней их кодированные представления, как правило, кодируют в зависимости от нижних уровней.
[0003] В стандарте или системе кодирования может упоминаться такое выражение как «рабочая точка» (operation point), или аналогичный термин, который может указывать на масштабируемые уровни и/или подуровни, для которых выполняется декодирование и/или которые могут быть связаны с битовым подпотоком, включающим декодируемые масштабируемые уровни и/или подуровни.
[0004] В стандарте SHVC (масштабируемое расширение H.265/HEVC) и MV-HEVC (многоракурсное расширение H.265/HEVC), определение рабочей точки может включать анализ набора целевых выходных уровней. В стандартах SHVC и MV-HEVC рабочая точка определена как битовый поток, который создан на основе другого битового потока при помощи процедуры извлечения битового подпотока, с поданными на ее вход упомянутым другим битовым потоком, целевым наивысшим временным уровнем и списком идентификаторов целевых уровней, и который связан с набором целевых выходных уровней.
[0005] Однако схемы масштабирования на современном уровне развития различных стандартов видеокодирования имеют некоторые ограничения. Например, в стандарте SHVC изображения блока доступа должны иметь одинаковый временной уровень. Это не позволяет определять различные иерархии предсказания для различных уровней в кодере, что ограничивает частоту передачи точек переключения на более высокий подуровень и/или не позволяет получить улучшенные показатели соотношения «битовая скорость - искажения». Еще одно ограничение связано с тем, что изображения переключения временного уровня не могут находиться в самом нижнем временном уровне. Это не позволяет указывать на изображение доступа, или точку доступа, для уровня, который обеспечивает возможность декодирования некоторых из временных уровней (однако не обязательно всех из них).
Сущность изобретения
[0006] Далее в настоящем документе будут рассмотрены способы кодирования и декодирования изображений ограниченного доступа к уровню, имеющие целью по меньшей мере частично решить описанные выше проблемы.
[0007] В соответствии с первым вариантом осуществления настоящего изобретения способ включает:
прием кодированных изображений первого уровня масштабирования;
декодирование кодированных изображений первого уровня масштабирования;
прием кодированных изображений второго уровня масштабирования, при этом второй уровень масштабирования зависит от первого уровня масштабирования;
выбор изображения доступа к уровню во втором уровне масштабирования из кодированных изображений второго уровня масштабирования, при этом выбранное изображение доступа к уровню является изображением пошагового доступа к временному подуровню в самом нижнем временном подуровне;
игнорирование кодированных изображений во втором уровне масштабирования, предшествующих в порядке декодирования выбранному изображению доступа к уровню;
декодирование выбранного изображения доступа к уровню.
[0008] В соответствии с одним из вариантов осуществления настоящего изобретения изображение пошагового доступа к временному подуровню обеспечивает точку доступа для поуровневой инициализации декодирования битового потока с одним или более временными подуровнями.
[0009] В соответствии с одним из вариантов осуществления настоящего изобретения изображение пошагового доступа к временному подуровню обеспечивает точку доступа для поуровневой адаптации битрейта (битовой скорости) битового потока с одним или более временными уровнями.
[0010] В соответствии с одним из вариантов осуществления настоящего изобретения способ дополнительно включает
прием указания об изображении пошагового доступа к временному подуровню в специальном типе NAL-блока, предоставленного вместе с битовым потоком.
[0011] В соответствии с одним из вариантов осуществления настоящего изобретения способ дополнительно включает
прием указания об изображении пошагового доступа к временному подуровню с использованием SEI-сообщения, определяющего количество декодируемых подуровней.
[0012] В соответствии с одним из вариантов осуществления настоящего изобретения способ дополнительно включает
начало декодирования битового потока в ответ на то, что базовый уровень содержит изображение внутренней точки произвольного доступа (intra random access point, IRAP) или изображение пошагового доступа к временному подуровню (step- wise temporal sub-layer access, STSA) в самом нижнем подуровне.
начало пошагового декодирования по меньшей мере одного уточняющего уровня в ответ на то, что упомянутый по меньшей мере один уточняющий уровень содержит IRAP-изображение или STSA-изображение в самом нижнем подуровне; и
постепенное увеличение количества декодируемых уровней и/или количества декодируемых временных подуровней.
[0013] В соответствии с одним из вариантов осуществления настоящего изобретения способ дополнительно включает формирование недоступных изображений для опорных изображений первого изображения, в порядке декодирования, в конкретном уточняющем уровне.
[0014] В соответствии с одним из вариантов осуществления настоящего изобретения способ дополнительно включает
пропуск декодирования изображений, предшествующих IRAP-изображению, с которого может начинаться декодирование конкретного уточняющего уровня.
[0015] В соответствии с одним из вариантов осуществления настоящего изобретения способ дополнительно включает
пометку упомянутых пропущенных изображений с использованием одного или более специальных типов NAL-блоков.
[0016] В соответствии с одним из вариантов осуществления настоящего изобретения способ дополнительно включает
поддержание информации о том, какие из подуровней каждого уровня были корректно декодированы.
[0017] В соответствии с одним из вариантов осуществления настоящего изобретения начало пошагового декодирования включает одно или более из следующих, выполняемых в зависимости от условий, операций:
- когда текущее изображение является IRAP-изображением, и декодирование всех опорных уровней этого IRAP-изображения было начато, декодируют данное IRAP-изображение и все изображения, следующие за ним в порядке декодирования.
- когда текущее изображение является STSA-изображением в самом нижнем подуровне, и декодирование самого нижнего подуровня всех опорных уровней этого STSA-изображения было начато, декодируют данное STSA-изображение и все изображения в самом нижнем подуровне, следующие за данным STSA-изображением в порядке декодирования.
- когда текущее изображение является TSA-изображением или STSA-изображением более высокого подуровня, по сравнению с самым нижним уровнем, и декодирование следующего, расположенного ниже, подуровня в том же уровне было начато, а также было начато декодирование того же подуровня во всех опорных уровнях упомянутого TSA-изображения или STSA-изображения, декодируют это TSA-изображение или STSA-изображение, а также все изображения в том же подуровне, следующие за данным TSA-изображением или STSA-изображением в порядке декодирования, в том же уровне.
[0018] В соответствии со вторым вариантом осуществления настоящего изобретения способ включает
прием кодированных изображений первого уровня масштабирования;
прием кодированных изображений второго уровня масштабирования, при этом второй уровень масштабирования зависит от первого уровня масштабирования;
выбор изображения доступа к уровню во втором уровне масштабирования из кодированных изображений второго уровня масштабирования, при этом выбранное изображение доступа к уровню является изображением пошагового доступа к временному подуровню в самом нижнем временном подуровне;
игнорирование кодированных изображений во втором уровне масштабирования, предшествующих в порядке декодирования выбранному изображению доступа к уровню;
передачу кодированных изображений первого уровня масштабирования и выбранного изображения доступа к уровню в битовом потоке.
[0019] В соответствии с третьим вариантом осуществления настоящего изобретения устройство включает: по меньшей мере один процессор и по меньшей мере одну память, при этом в упомянутой по меньшей мере одной памяти хранят код, который при исполнении упомянутым по меньшей мере одним процессором обеспечивает выполнение устройством по меньшей мере следующего:
прием кодированных изображений первого уровня масштабирования;
декодирование кодированных изображений первого уровня масштабирования;
прием кодированных изображений второго уровня масштабирования, при этом второй уровень масштабирования зависит от первого уровня масштабирования;
выбор изображения доступа к уровню во втором уровне масштабирования из кодированных изображений второго уровня масштабирования, при этом выбранное изображение доступа к уровню является изображением пошагового доступа к временному подуровню в самом нижнем временном подуровне;
игнорирование кодированных изображений во втором уровне масштабирования, предшествующих в порядке декодирования выбранному изображению доступа к уровню;
декодирование выбранного изображения доступа к уровню.
[0020] В соответствии с четвертым вариантом осуществления настоящего изобретения устройство включает:
по меньшей мере один процессор и по меньшей мере одну память, при этом в упомянутой по меньшей мере одной памяти хранят код, который при исполнении упомянутым по меньшей мере одним процессором обеспечивает выполнение устройством по меньшей мере следующего:
прием кодированных изображений первого уровня масштабирования;
прием кодированных изображений второго уровня масштабирования, при этом второй уровень масштабирования зависит от первого уровня масштабирования;
выбор изображения доступа к уровню во втором уровне масштабирования из кодированных изображений второго уровня масштабирования, при этом выбранное изображение доступа к уровню является изображением пошагового доступа к временному подуровню в самом нижнем временном подуровне;
игнорирование кодированных изображений во втором уровне масштабирования, предшествующих в порядке декодирования выбранному изображению доступа к уровню;
передачу кодированных изображений первого уровня масштабирования и выбранного изображения доступа к уровню в битовом потоке.
[0021] В соответствии с пятым вариантом осуществления настоящего изобретения предложен машиночитаемый носитель для хранения данных, на котором хранят код для использования устройством, который при исполнении процессором обеспечивает выполнение этим устройством следующего:
прием кодированных изображений первого уровня масштабирования;
декодирование кодированных изображений первого уровня масштабирования;
прием кодированных изображений второго уровня масштабирования, при этом второй уровень масштабирования зависит от первого уровня масштабирования; выбор изображения доступа к уровню во втором уровне масштабирования из кодированных изображений второго уровня масштабирования, при этом выбранное изображение доступа к уровню является изображением пошагового доступа к временному подуровню в самом нижнем временном подуровне;
игнорирование кодированных изображений во втором уровне масштабирования, предшествующих в порядке декодирования выбранному изображению доступа к уровню;
декодирование выбранного изображения доступа к уровню.
[0022] В соответствии с шестым вариантом осуществления настоящего изобретения предложено устройство, включающее видеодекодер, сконфигурированный для декодирования битового потока, включающего последовательность снимков, при этом видеодекодер включает
средства приема кодированных изображений первого уровня масштабирования;
средства декодирования кодированных изображений первого уровня масштабирования;
средства приема кодированных изображений второго уровня масштабирования, при этом второй уровень масштабирования зависит от первого уровня масштабирования;
средства выбора изображения доступа к уровню во втором уровне масштабирования из кодированных изображений второго уровня масштабирования, при этом выбранное изображение доступа к уровню является изображением пошагового доступа к временному подуровню в самом нижнем временном подуровне;
средства игнорирования кодированных изображений во втором уровне масштабирования, предшествующих в порядке декодирования выбранному изображению доступа к уровню;
средства декодирования выбранного изображения доступа к уровню.
[0023] В соответствии с седьмым вариантом осуществления настоящего изобретения предложен видеодекодер, сконфигурированный для декодирования битового потока, включающего последовательность снимков, при этом упомянутый видеодекодер сконфигурирован также для следующего:
прием кодированных изображений первого уровня масштабирования;
декодирование кодированных изображений первого уровня масштабирования;
прием кодированных изображений второго уровня масштабирования, при этом второй уровень масштабирования зависит от первого уровня масштабирования;
выбор изображения доступа к уровню во втором уровне масштабирования из кодированных изображений второго уровня масштабирования, при этом выбранное изображение доступа к уровню является изображением пошагового доступа к временному подуровню в самом нижнем временном подуровне;
игнорирование кодированных изображений во втором уровне масштабирования, предшествующих в порядке декодирования выбранному изображению доступа к уровню;
декодирование выбранного изображения доступа к уровню.
[0024] В соответствии с восьмым вариантом осуществления настоящего изобретения способ включает
кодирование первого изображения в первом уровне масштабирования и в самом нижнем временном подуровне;
кодирование второго изображения во втором уровне масштабирования и в самом нижнем временном подуровне, при этом первое изображение и второе изображение представляют один и тот же момент времени;
кодирование одного или более первых синтаксических элементов, связанных с упомянутым первым изображением, с использованием значения, указывающего на то, что типом первого изображения не является изображение пошагового доступа к временному подуровню;
кодирование одного или более вторых синтаксических элементов, связанных с упомянутым вторым изображением, с использованием значения, указывающего на то, что типом второго изображения не является изображение пошагового доступа к временному подуровню; и
кодирование по меньшей мере третьего изображения во второй уровень масштабирования и в более высокий временной подуровень, чем самый нижний временной подуровень.
[0025] В соответствии с одним из вариантов осуществления настоящего изобретения изображение пошагового доступа к временному подуровню обеспечивает точку доступа для поуровневой инициализации декодирования битового потока с одним или более временными подуровнями.
[0026] В соответствии с одним из вариантов осуществления настоящего изобретения изображение пошагового доступа к временному подуровню представляет собой STSA-изображение с Temporalld, равным 0.
[0027] В соответствии с одним из вариантов осуществления настоящего изобретения способ дополнительно включает
сигнализацию изображения пошагового доступа к временному подуровню при помощи специального типа NAL-блока.
[0028] В соответствии с одним из вариантов осуществления настоящего изобретения способ дополнительно включает
сигнализацию изображения пошагового доступа к временному подуровню в SEI-сообщении, определяющем количество декодируемых подуровней.
[0029] В соответствии с одним из вариантов осуществления настоящего изобретения способ дополнительно включает
кодирование упомянутого второго уровня масштабирования или любых последующих уровней масштабирования, с более частым включением в них TSA-изображений или STSA-изображений, по сравнению с первым уровнем масштабирования.
[0030] В соответствии с девятым вариантом осуществления настоящего изобретения устройство включает:
по меньшей мере один процессор и по меньшей мере одну память, при этом в упомянутой по меньшей мере одной памяти хранят код, который при исполнении упомянутым по меньшей мере одним процессором обеспечивает выполнение устройством по меньшей мере следующего:
кодирование первого изображения в первом уровне масштабирования и в самом нижнем временном подуровне;
кодирование второго изображения во втором уровне масштабирования и в самом нижнем временном подуровне, при этом первое изображение и второе изображение представляют один и тот же момент времени;
кодирование одного или более первых синтаксических элементов, связанных с упомянутым первым изображением, с использованием значения, указывающего на то, что типом первого изображения не является изображение пошагового доступа к временному подуровню;
кодирование одного или более вторых синтаксических элементов, связанных с упомянутым вторым изображением, с использованием значения, указывающего на то, что типом второго изображения не является изображение пошагового доступа к временному подуровню; и
кодирование по меньшей мере третьего изображения во второй уровень масштабирования и в более высокий временной подуровень, чем самый нижний временной подуровень.
[0031] В соответствии с десятым вариантом осуществления настоящего изобретения предложен машиночитаемый носитель для хранения данных, на котором хранят код для использования устройством, который при исполнении процессором обеспечивает выполнение этим устройством следующего:
кодирование первого изображения в первом уровне масштабирования и в самом нижнем временном подуровне;
кодирование второго изображения во втором уровне масштабирования и в самом нижнем временном подуровне, при этом первое изображение и второе изображение представляют один и тот же момент времени;
кодирование одного или более первых синтаксических элементов, связанных с упомянутым первым изображением, с использованием значения, указывающего на то, что типом первого изображения не является изображение пошагового доступа к временному подуровню;
кодирование одного или более вторых синтаксических элементов, связанных с упомянутым вторым изображением, с использованием значения, указывающего на то, что типом второго изображения не является изображение пошагового доступа к временному подуровню; и
кодирование по меньшей мере третьего изображения во второй уровень масштабирования и в более высокий временной подуровень, чем самый нижний временной подуровень.
[0032] В соответствии с одиннадцатым вариантом осуществления настоящего изобретения предложено устройство, включающее видеокодер, сконфигурированный для кодирования битового потока, включающего последовательность изображений, при этом видеокодер включает
средства кодирования первого изображения в первом уровне масштабирования и в самом нижнем временном подуровне;
средства кодирования второго изображения во втором уровне масштабирования и в самом нижнем временном подуровне, при этом первое изображение и второе изображение представляют один и тот же момент времени;
средства кодирования одного или более первых синтаксических элементов, связанных с упомянутым первым изображением, с использованием значения, указывающего на то, что типом первого изображения не является изображение пошагового доступа к временному подуровню;
средства кодирования одного или более вторых синтаксических элементов, связанных с упомянутым вторым изображением, с использованием значения, указывающего на то, что типом второго изображения не является изображение пошагового доступа к временному подуровню; и
средства кодирования по меньшей мере третьего изображения во второй уровень масштабирования и в более высокий временной подуровень, чем самый нижний временной подуровень.
[0033] В соответствии с двенадцатым вариантом осуществления настоящего изобретения предложен видеокодер, сконфигурированный для кодирования битового потока, включающего последовательность изображений, при этом упомянутый видеокодер дополнительно сконфигурирован для следующего:
кодирование первого изображения в первом уровне масштабирования и в самом нижнем временном подуровне;
кодирование второго изображения во втором уровне масштабирования и в самом нижнем временном подуровне, при этом первое изображение и второе изображение представляют один и тот же момент времени;
кодирование одного или более первых синтаксических элементов, связанных с упомянутым первым изображением, с использованием значения, указывающего на то, что типом первого изображения не является изображение пошагового доступа к временному подуровню;
кодирование одного или более вторых синтаксических элементов, связанных с упомянутым вторым изображением, с использованием значения, указывающего на то, что типом второго изображения не является изображение пошагового доступа к временному подуровню; и
кодирование по меньшей мере третьего изображения во второй уровень масштабирования и в более высокий временной подуровень, чем самый нижний временной подуровень.
[0034] В соответствии со тринадцатым вариантом осуществления настоящего изобретения способ включает
кодирование первого изображения в первом уровне масштабирования и в самом нижнем временном подуровне;
кодирование второго изображения во втором уровне масштабирования, при этом упомянутые первое изображение и второе изображение принадлежат одному блоку доступа;
кодирование одного или более синтаксических элементов, связанных с упомянутым блоком доступа, с использованием значения, указывающего на то, совпадают ли значения идентификаторов временного уровня кодированных первого и второго изображения внутри упомянутого блока доступа.
[0035] В соответствии с четырнадцатым вариантом осуществления настоящего изобретения способ включает
прием битового потока, включающего блок доступа, который имеет первое изображение, закодированное в первом уровне масштабирования и в самом нижнем временном подуровне, и второго изображение, закодированное во втором уровне масштабирования;
декодирование, из битового потока, одного или более синтаксических элементов, связанных с упомянутым блоком доступа, с использованием значения, указывающего на то, совпадают ли значения идентификаторов временного уровня кодированных первого и второго изображения внутри упомянутого блока доступа; и
выбор операции декодирования для упомянутых первого и второго изображения согласно упомянутому значению.
Краткое описание чертежей
[0036] Для более детального понимания настоящего изобретения оно будет описано далее с помощью примеров на приложенных чертежах, где:
[0037] на фиг. 1 эскизно проиллюстрировано электронное устройство, в котором применяются варианты осуществления настоящего изобретения;
[0038] на фиг. 2 эскизно проиллюстрировано абонентское оборудование, подходящее для применения в вариантах осуществления настоящего изобретения;
[0039] на фиг. 3 также эскизно проиллюстрированы электронные устройства, в которых применяются варианты осуществления настоящего изобретения и которые соединены при помощи проводных и беспроводных сетевых соединений;
[0040] на фиг. 4 эскизно проиллюстрирован кодер, подходящий для реализации некоторых из вариантов осуществления настоящего изобретения;
[0041] на фиг. 5 показан пример изображения, состоящего из двух тайлов (ячеек);
[0042] на фиг. 6 показан пример текущей группы (или блока) пикселей и пяти пространственно смежных с ним групп пикселей, которые могут быть использованы в качестве кандидатных предсказаний движения;
[0043] на фиг. 7 показана блок-схема алгоритма для способа кодирования в соответствии с одним из вариантов осуществления настоящего изобретения;
[0044] на фиг. 8 проиллюстрирован пример кодирования в соответствии с одним из вариантов осуществления настоящего изобретения;
[0045] на фиг. 9 проиллюстрирован пример кодирования в соответствии с другим вариантом осуществления настоящего изобретения;
[0046] на фиг. 10 проиллюстрирован пример кодирования в соответствии с еще одним из вариантов осуществления настоящего изобретения;
[0047] на фиг. 11 проиллюстрирован пример кодирования в соответствии с еще одним из вариантов осуществления настоящего изобретения;
[0048] на фиг. 12 показана блок-схема алгоритма для способа декодирования в соответствии с одним из вариантов осуществления настоящего изобретения;
[0049] на фиг. 13 показана блок-схема алгоритма для способа адаптации битрейта в соответствии с одним из вариантов осуществления настоящего изобретения;
[0050] на фиг. 14 проиллюстрирован пример адаптации битрейта в соответствии с одним из вариантов осуществления настоящего изобретения;
[0051] на фиг. 15 проиллюстрирован пример адаптации битрейта в соответствии с другим вариантом осуществления настоящего изобретения;
[0052] на фиг. 16 проиллюстрирован пример адаптации битрейта в соответствии с еще одним из вариантов осуществления настоящего изобретения;
[0053] на фиг. 17 проиллюстрирован пример адаптации битрейта в соответствии с еще одним из вариантов осуществления настоящего изобретения;
[0054] на фиг. 18 показана эскизная блок-схема декодера, подходящего для реализации некоторых из вариантов осуществления настоящего изобретения;
[0055] на фиг. 19а и 19b проиллюстрировано применение смещений масштабированного опорного уровня; и
[0056] на фиг. 20 показана эскизная блок-схема типовой мультимедийной системы связи, в которой могут быть реализованы различные варианты осуществления настоящего изобретения.
Подробное описание некоторых примеров осуществления изобретения
[0057] Ниже более подробно описаны устройства и возможные механизмы, подходящие для кодирования подизображений уточняющего уровня без значительного понижения эффективности кодирования. С этой целью обратимся сначала к фиг. 1 и 2. На фиг. 1 показана блок-схема системы видеокодирования в соответствии с одним из вариантов осуществления настоящего изобретения, в виде блок-схемы примера аппаратуры или электронного устройства 50, которое может включать кодек, соответствующий одному из вариантов осуществления настоящего изобретения. На фиг. 2 показана схема устройства в соответствии с одним из примеров осуществления настоящего изобретения. Далее будут описаны элементы фиг. 1 и 2.
[0058] Электронное устройство 50 может, например, быть мобильным терминалом или абонентским оборудованием системы беспроводной связи. Однако нужно понимать, что варианты осуществления настоящего изобретения могут быть реализованы в любом электронном устройстве или аппаратуре, где требуется кодирование и декодирование, или только кодирование, или же только декодирование видеоизображений.
[0059] Устройство 50 может иметь корпус 30 для размещения и защиты устройства. Устройство 50 может также включать дисплей 32 в форме дисплея на жидких кристаллах. В других вариантах осуществления настоящего изобретения упомянутый дисплей может быть выполнен по любой технологии, подходящей для отображения изображений или видеоинформации. Устройство 50 может также включать клавиатуру 34. В других вариантах осуществления настоящего изобретения может применяться любой подходящий интерфейс обмена данными или пользовательский интерфейс. К примеру, пользовательский интерфейс может быть реализован в виде виртуальной клавиатуры или системы ввода данных, являющейся частью сенсорного дисплея.
[0060] Устройство может включать микрофон 36 или любое другое подходящее устройство ввода аудиоинформации, которое может быть устройством ввода цифрового или аналогового сигнала. Устройство 50 может также включать устройство вывода аудиоинформации, которое в вариантах осуществления настоящего изобретения может представлять собой любое из следующего: головной телефон 38, громкоговоритель или же аналоговое или цифровое соединение для вывода аудиоинформации. Устройство 50 может также включать аккумулятор 40 (или в других вариантах осуществления настоящего изобретения устройство может снабжаться электроэнергией от любого подходящего мобильного энергетического устройства, например, солнечной батареи, топливной батареи или заводного генератора). Устройство может дополнительно включать камеру 42, способную записывать, или захватывать, изображения и/или видеоинформацию. Устройство может также включать инфракрасный порт 50 для связи с другими устройствами в ближней зоне прямой видимости. В других вариантах осуществления настоящего изобретения устройство 50 может включать любые подходящие решения связи малой дальности, например, беспроводное соединение Bluetooth или проводное соединение USB/Firewire.
[0061] Устройство 50 может включать контроллер 56 или процессор для управления устройством 50. Контроллер 56 может быть соединен с памятью 58, которая в различных вариантах осуществления настоящего изобретения может хранить данные, одновременно в форме видеоинформации и аудиоинформации, и/или может также хранить инструкции для исполнения в контроллере 56. Контроллер 56 может быть также соединен со схемами 54 кодека, способными осуществлять кодирование и декодирование аудио- и/или видеоданных или являться вспомогательным средством при кодировании и декодировании, выполняемом контроллером.
[0062] Устройство 50 может также включать устройство 48 чтения карт и смарт-карту 46, например, карту UICC и устройство чтения UICC-карт для предоставления информации об абоненте, и для обеспечения возможности предоставления аутентификационной информации с целью аутентификации и авторизации абонента в сети.
[0063] Устройство 50 может включать схемы 52 радиоинтерфейса, связанные с контроллером, которые могут использоваться для формирования сигналов беспроводной связи, например, для связи с сетью сотовой связи, системой беспроводной связи или беспроводной локальной вычислительной сетью. Устройство 50 может также включать антенну 44, связанную со схемами 52 радиоинтерфейса, для передачи радиочастотных сигналов, формируемых в схемах 52 радиоинтерфейса, в другое устройство (или устройства), а также для приема радиочастотных сигналов от другого устройства (или устройств).
[0064] Устройство 50 может включать камеру, способную записывать или регистрировать отдельные кадры, которые затем передают в кодек 54 или контроллер для обработки. Устройство может принимать от другого устройства данные видеоизображений для обработки перед их передачей и/или хранением. Устройство 50 может также принимать изображение для кодирования/декодирования либо беспроводным способом, либо по проводному соединению.
[0065] С помощью фиг. 3 проиллюстрирован один из примеров системы, в которой могут использоваться различные варианты осуществления настоящего изобретения. Система 10 включает несколько устройств связи, способных осуществлять связь при помощи одной или нескольких сетей. В состав системы 10 может входить любая комбинация проводных и беспроводных сетей, включая, без ограничения перечисленным, беспроводную сотовую телефонную сеть (например, сеть GSM, UMTS, CDMA и т.п.), беспроводную локальную вычислительную сеть (wireless local area network, WLAN), например, в соответствии с определением в любом из стандартов IEEE 802.x, персональную сеть Bluetooth, локальную вычислительную сеть Ethernet, локальную вычислительную сеть типа «маркерное кольцо» глобальную сеть и Интернет.
[0066] Система 10 может включать как проводные, так и беспроводные устройства связи, и/или устройство 50, подходящее для реализации вариантов осуществления настоящего изобретения.
[0067] В качестве примера на фиг. 3 показана мобильная телефонная сеть 11 и изображение сети Интернет 28. Соединение с Интернетом 28 может включать, без ограничения перечисленным, беспроводные соединения с большим радиусом действия, беспроводные соединения с малым радиусом действия, а также различные проводные соединения, включая, без ограничения перечисленным, телефонные линии, кабельные линии, линии электропередач и аналогичные каналы связи.
[0068] Примерами устройств связи в системе 10 могут служить, без ограничения перечисленным, электронная аппаратура или устройство 50, комбинация карманного персонального компьютера (personal digital assistant, PDA) и мобильного телефона 14, PDA 16, интегрированное устройство 18 обмена сообщениями (integrated messaging device, IMD), настольный компьютер 20, ноутбук 22. Устройства 50 связи могут быть как стационарными, так и мобильными, например, они могут переноситься лицами, находящимися в движении. Устройство 50 может также размещаться на транспортном средстве, включая, без ограничения перечисленным, автомобиль, грузовик, такси, автобус, поезд, судно, самолет, велосипед, мотоцикл или любое аналогичное подходящее транспортное средство.
[0069] Варианты осуществления настоящего изобретения могут также быть реализованы в абонентской телеприставке, т.е. в приемнике цифрового телевидения, который, опционально, может обладать функциональностью отображения видеоинформации и беспроводной связи, в планшетных или (портативных) персональных компьютерах (ПК), которые включают аппаратную или программную (или комбинированную) реализацию кодера и/или декодера, в различных операционных системах, в чипсетах (микросхемных наборах), процессорах, DSP-процессорах и/или во встраиваемых системах, обеспечивающих аппаратное и/или программное кодирование. [0070] Некоторые из подобных или других устройств могут как посылать, так и принимать вызовы и сообщения, а также осуществлять связь с операторами связи при помощи беспроводного соединения 25 с базовой станцией 24. Базовая станция 24 может быть соединена с сетевым сервером 26, обеспечивающим связь между средствами 11 связи и Интернетом 28. Система может включать дополнительные устройства связи, а также устройства связи других типов.
[0071] Устройства связи могут осуществлять связь с использованием различных технологий передачи данных, включая, без ограничения перечисленным, множественный доступ с кодовым разделением (Code Division Multiple Access, CDMA), глобальную систему мобильной связи (Global System for Mobile Communications, GSM), универсальную систему мобильной связи (Universal Mobile Telecommunication System, UMTS), множественный доступ с разделением по времени (Time Division Multiple Access, TDMA), множественный доступ с разделением по частоте (Frequency Division Multiple Access, FDMA), протокол управления передачей/протокол Интернета (Transmission Control Protocol/Internet Protocol, TCP-IP), службу коротких сообщений (Short Messaging Service, SMS), службу мультимедийных сообщений (Multimedia Messaging Service, MMS), электронную почту, сервис мгновенной передачи сообщений (Instant Messaging Service, IMS), Bluetooth, IEEE 802.11, и любые аналогичные технологии беспроводной связи. Устройство связи, используемое при реализации различных вариантов осуществления настоящего изобретения, может осуществлять связь с использованием различных сред передачи данных, включая, без ограничения, радиосоединения, инфракрасные, лазерные, кабельные соединения или любые другие подходящие соединения.
[0072] Видеокодек состоит из кодера, при помощи которого входные видеоданные преобразуют в сжатое представление, подходящее для хранения и передачи, а также декодера, при помощи которого сжатое представление видеоданных распаковывают, возвращая их к форме, пригодной для просмотра пользователем. Как правило, в кодере часть информации исходной видеопоследовательности отбрасывается с целью представления видеоинформации в более компактной форме (т.е. с меньшим битрейтом).
[0073] Типовые гибридные видеокодеки, например, многие из реализаций кодеров, соответствующие стандартам ITU-T Н.263 и Н.264, кодируют видеоинформацию в два этапа. Сначала предсказывают значения пикселей в определенной области изображения (или «блоке пикселей»), например, с использованием механизмов компенсации движения (нахождение области в одном из предварительно закодированных видеокадров, которая близко соответствует кодируемому в текущий момент блоку пикселей, и указание на эту область) или с использованием средств пространственного предсказания (использование, заданным образом, значений пикселей вокруг кодируемого блока пикселей). Затем кодируют ошибку предсказания, т.е. разность между предсказанным блоком пикселей и исходным блоком пикселей. Как правило, это выполняется при помощи преобразования разности пиксельных значений с использованием заданного преобразования (например, дискретного косинусного преобразования (Discrete Cosine Transform, DCT), или его варианта), квантования его коэффициентов и энтропийного кодирования квантованных коэффициентов. За счет регулировки степени детализации процесса квантования кодер может управлять балансом между точностью представления пикселей (качеством изображения) и размером результирующего кодированного представления видеоинформации (размером файла или битрейтом).
[0074] Внешнее предсказание, которое может также называться временным предсказанием, компенсацией движения или предсказанием с компенсацией движения, позволяет понизить временную избыточность. Источником информации для внешнего предсказания являются ранее декодированные изображения. Для внешнего предсказания используют тот факт, что смежные пиксели в одном изображении с большой вероятностью являются коррелированными. Внутреннее предсказание может выполняться в пространственном или во временном домене, т.е. могут предсказываться либо значения элементов изображения, либо коэффициенты преобразования. Внутреннее предсказание обычно применяют при внутреннем кодировании, когда внешнее предсказание не применяется.
[0075] Одним из результатов процедуры кодирования является набор параметров кодирования, таких как векторы движения и коэффициенты преобразования. Энтропийное кодирование многих параметров может быть более эффективным, если сначала выполняется их предсказание на основе пространственно-смежных или соседних по времени параметров Например, вектор движения может предсказываться на основе пространственно смежных векторов движения, при этом кодироваться может только разность относительно предсказания вектора движения. Предсказание параметров кодирования и внутреннее предсказание совместно могут называться внутрикадровым предсказанием.
[0076] На фиг. 4 проиллюстрирована блок-схема видеодекодера, подходящего для применения вариантов осуществления настоящего изобретения. На фиг. 4 проиллюстрирован кодер для двух уровней, однако нужно понимать, что проиллюстрированный кодер может быть расширен и выполнять кодирование более чем двух уровней. На фиг. 4 проиллюстрирован один вариантов осуществления видеокодера, включающий первый сегмент 500 кодера для базового уровня (кодирования) и второй сегмент 502 кодера для уточняющего уровня. Каждый из сегментов, первый сегмент 500 кодера и второй сегмент 502 кодера, могут включать аналогичные элементы для кодирования поступающих изображений. Сегменты 500, 502 кодера могут включать устройство 302, 402 предсказания пикселей, кодер 303, 403 ошибки предсказания и декодер 304, 404 ошибки предсказания. Также, на фиг. 4 показан один из вариантов осуществления устройства 302, 402 предсказания пикселей, включающего устройство 306, 406 внешнего предсказания, устройство 308, 408 внутреннего предсказания, селектор 310, 410 режима, фильтр 316, 416 и память 318, 418 опорных кадров. Устройство 302 предсказания пикселей в первом сегменте 500 кодера принимает изображения 300 базового уровня кодируемого видеопотока одновременно в устройстве 306 внешнего предсказания (которое определяет разницу между этим изображением и опорным кадром 318 компенсации движения) и в устройстве 308 внутреннего предсказания (которое определяет предсказание для блока пикселей изображения, исходя только из уже обработанных частей текущего кадра или изображения). Выходные данные из устройства внешнего предсказания и из устройства внутреннего предсказания передают в селектор 310 режима. Устройство 308 внутреннего предсказания может иметь более одного режима внутреннего предсказания. Следовательно, в каждом из режимов может выполняться внутреннее предсказание, и предсказанный сигнал может быть предоставлен в селектор 310 режима. В селектор 310 режима передается также копия изображения 300 базового уровня. Соответственно, устройство 402 предсказания пикселей во втором сегменте 502 кодера принимает изображения 400 уточняющего уровня кодируемого видеопотока одновременно в устройстве 406 внешнего предсказания (которое определяет разницу между этим изображением и опорным кадром 418 компенсации движения) и в устройстве 408 внутреннего предсказания (которое определяет предсказание для блока пикселей изображения, исходя только из уже обработанных частей текущего кадра или изображения). Выходные данные из устройства внешнего предсказания и из устройства внутреннего предсказания передают в селектор 410 режима. Устройство 408 внутреннего предсказания может иметь более одного режима внутреннего предсказания. Следовательно, в каждом из режимов может выполняться внутреннее предсказание, и предсказанный сигнал может быть предоставлен в селектор 410 режима. В селектор 410 режима передается также копия изображения 400 уточняющего уровня.
[0077] В зависимости от режима кодирования выбранного для кодирования текущего блока пикселей, на выход селектора 310, 410 режима передают выходные данные устройства 306, 406 внешнего предсказания, выходные данные одного из опциональных режимов внутреннего предсказания или выходные данные поверхностного кодера из состава селектора режима. Выходные данные селектора режима передают в первое суммирующее устройство 321, 421. Первое суммирующее устройство может вычитать выходные данные устройства 302, 402 предсказания пикселей из изображения 300 базового уровня, или изображения 400 уточняющего уровня, соответственно, с формированием первого сигнала 320, 420 ошибки предсказания, который подают на вход кодера 303, 403 ошибки предсказания.
[0078] Также, устройство 302, 402 предсказания пикселей принимает от устройства 339, 439 предварительного восстановления комбинацию предсказанного представления блока 312, 418 изображения и выходные данные 338, 438 кодера 304, 404 ошибки предсказания. Предварительно восстановленное изображение 314, 414 может быть передано в устройство 308, 408 внутреннего предсказания и фильтр 316, 416. В фильтре 316, 416 где принимается это предварительное представление, может выполняться его фильтрация и вывод окончательного восстановленного изображения 340, 440, которое может быть сохранено в память 318, 418 опорных кадров. Память 318 опорных кадров может иметь соединение с устройством 306 внешнего предсказания и использоваться в качестве опорного изображения, с которым сравнивают будущее изображение 300 базового уровня при выполнении операций внешнего предсказания. При условии, что базовый уровень выбран в качестве источника для межуровневого предсказания сэмплов и/или для межуровневого предсказания информации о движении уточняющего уровня, и если на это также выполнено соответствующее указание, в соответствии с некоторыми из вариантов осуществления настоящего изобретения, память 318 опорных кадров может иметь соединение с устройством 406 внешнего предсказания и может использоваться в качестве опорного изображения, с которым сравнивают будущее изображение 400 уточняющего уровня при выполнении операций внешнего предсказания. При этом память 418 опорных кадров может иметь соединение с устройством 406 внешнего предсказания и использоваться в качестве опорного изображения, с которым сравнивают будущее изображение 400 уточняющего уровня при выполнении операций внешнего предсказания.
[0079] При условии, что базовый уровень выбран в качестве источника для предсказания параметров фильтрации уточняющего уровня, и на это выполнено соответствующее указание, в соответствии с некоторыми из вариантов осуществления настоящего изобретения, параметры фильтрации из фильтра 316 первого сегмента 500 кодера могут передаваться во второй сегмент 502 кодера.
[0080] Кодер 303, 403 ошибки предсказания включает блок 342, 442 преобразования и квантователь 344, 444. Блок 342 преобразования преобразует первый сигнал 320, 420 ошибки предсказания в домен преобразования. Таким преобразованием является, к примеру, преобразование DCT. Квантователь 344, 444 квантует сигнал, например, коэффициенты DCT, в домене преобразования и формирует квантованные коэффициенты.
[0081] Декодер 304, 404 ошибки предсказания принимает выходные данные из кодера 303, 403 ошибки предсказания и выполняет процедуры, обратные процедурам кодера 303, 403 ошибки предсказания, в результате чего получают декодированный сигнал 338, 438 ошибки предсказания, который при комбинировании с предсказанным представлением блока 312, 412 изображения во втором суммирующем устройстве 339, 439 дает предварительное восстановленное изображение 314, 414. Декодер ошибки предсказания можно рассматривать как имеющий в своем составе деквантователь 361, 461 который деквантует квантованные значения коэффициентов, например, коэффициентов DCT, и восстанавливает преобразованный сигнал, а также как включающий блок 363, 463 обратного преобразования, который выполняет обратное преобразование над восстановленным сигналом преобразования, при этом выходные данные блока 363, 463 обратного преобразования содержат восстановленный блок (или блоки). Декодер ошибки предсказания может также включать фильтр блоков, который может выполнять фильтрацию восстановленного блока (или блоков) в соответствии с дополнительной декодированной информацией и параметрами фильтрации.
[0082] Энтропийный кодер 330, 430 принимает выходные данные из кодера 303, 403 ошибки предсказания и может выполнять соответствующее кодирование переменной длины и/или энтропийное кодирование сигнала для обеспечения возможности обнаружения и исправления ошибок. Выходные данные энтропийных кодеров 330,430 могут быть введены в битовый поток, например, при помощи мультиплексора 508.
[0083] Стандарт H.264/AVC был разработан объединенной командой по видео (Joint Video Team, JVT) из состава группы экспертов по видеокодированию (Video Coding Experts Group (VCEG) сектора стандартизации телекоммуникаций Международного союза электросвязи (International Telecommunication Union, ITU-T) и группой экспертов по движущемуся изображению (Moving Picture Experts Group, MPEG) Международной организации по стандартизации (International Organization for Standardization, ISO) / Международной электротехнической комиссии (International Electrotechnical Commission, IEC). Стандарт H.264/AVC был опубликован обеими родительскими организациями по стандартизации и получил наименование Рекомендации Н.264 ITU-T и Международного стандарта ISO/IEC 14496-10, известного также как улучшенное видеокодирование (Advanced Video Coding, AVC), 10-ая часть MPEG-4. Были выпущены несколько версий стандарта H.264/AVC, в спецификацию каждой из которых добавлялись новые расширения или элементы. В число этих расширений вошли масштабируемое видеокодирование (Scalable Video Coding, SVC) и многоракурсное видекодирование (Multiview Video Coding, MVC).
[0084] Объединенной командой по видеокодированию (Joint Collaborative Team - Video Coding, JCT-VC) группы VCEG и MPEG был создан разработан высокоэффективного видеокодирования (High Efficiency Video Coding, HEVC), H.265. Стандарт опубликован, или будет опубликован, обеими родительскими организациями по стандартизации и имеет наименование Рекомендации H.265 ITU-T и Международного стандарта ISO/IEC 23008-2, известного также как высокоэффективное видеокодирование (HEVC), 2-ая часть MPEG-H. В настоящее время продолжаются работы по стандартизации, имеющие целью определить расширения стандарта H.265/HEVC, включая расширения масштабируемого, многоракурсного, трехмерного кодирования и расширение диапазона точности, которые, соответственно, могут быт сокращенно обозначены SHVC, MV-HEVC, HEVC и REXT.
[0085] В настоящем разделе приведены ключевые определения, описана структура битового потока и кодирования, а также основные понятия стандартов H.264/AVC и HEVC, - в качестве примера видеокодера, декодера, способа кодирования, способа декодирования и структуры битового потока, в которых могут быть реализованы варианты осуществления настоящего изобретения. Часть ключевых определений, структур битового потока и кодирования, а также основных понятий стандарта H.264/AVC совпадают с проектом стандарта HEVC, в этом случае они описаны ниже совместно. Аспекты настоящего изобретения не ограничены стандартами H.264/AVC или HEVC, напротив, данное описание приведено в качестве одного из примеров базы для частичной или полной реализации настоящего изобретения.
[0086] Аналогично многим предшествующим стандартам видеокодирования, в стандартах H.264/AVC и HEVC определены синтаксис и семантика битового потока, а также процесс декодирования безошибочных битовых потоков. Процесс кодирования не определен, однако кодеры должны формировать битовые потоки, соответствующие стандарту. Соответствие битового потока и декодера стандарту может быть проверено с помощью гипотетического опорного декодера (Hypothetical Reference Decoder (HRD). Стандарт включает в себя инструменты кодирования, помогающие справиться с ошибками и потерями при передаче, однако использование этих инструментов при кодировании не является обязательным, а процесс декодирования для битовых потоков с ошибками не определен.
[0087] В описании существующих стандартов, а также в описании примеров осуществления настоящего изобретения, синтаксическим элементом называется элемент данных, представленных в битовом потоке. Синтаксической структурой может быть назван ноль или более синтаксических элементов, совместно находящихся в битовом потоке в заданном порядке. В описании существующих стандартов, а также в описании примеров осуществления настоящего изобретения может применяться выражение «при помощи внешних средств» или «с использованием внешних средств». Например, «при помощи внешних средств» в процедуру декодирования может предоставляться некоторый элемент, такой как синтаксическая структура или значение переменной, используемые в процедуре декодирования. Выражение «при помощи внешних средств» может указывать на то, что подобный элемент не включен в битовый поток, формируемый кодером, но вместо этого передается вне битового потока, например, с использованием управляющего протокола. Альтернативно или дополнительно, это может означать, что такой элемент не формируется кодером, однако может быть создан, например, в проигрывателе или в логике управления декодированием, или аналогичном устройстве, которое использует декодер. Декодер может иметь интерфейс для ввода данных из внешних средств, например, значения переменных.
[0088] Профилем может быть названо подмножество всего синтаксиса битового потока, определенного стандартом или спецификацией декодирования/кодирования. В рамках ограничений, налагаемых синтаксисом заданного профиля, может сохраняться очень большой разброс требований к производительности кодеров и декодеров, в зависимости от значений, принимаемых синтаксическими элементами в битовом потоке, например, заданного размера декодируемых изображений. Во многих применениях реализация декодера, способного обрабатывать все гипотетически возможные синтаксические конструкции определенного профиля, не представляется ни практичной, ни экономичной. Для решения данной проблемы могут применяться уровни стандарта. Уровнем стандарта может быть назван заданный набор ограничений, налагаемых на значения синтаксических элементов в битовом потоке и переменных, определенных в стандарте или спецификации декодирования/кодирования. Такие ограничениями могут быть простыми ограничениями, накладываемыми на значения. Альтернативно или в дополнение они могут принимать форму ограничений на арифметические комбинации значений (например, ширина изображения, умноженная на высоту изображения, умноженные на количество декодируемых в секунду изображений). Для уровней стандарта могут также использоваться другие средства определения ограничений. Некоторые из ограничений, заданных для уровня стандарта, могут, например, относиться к максимальному размеру изображения, максимальному битрейту и максимальной скорости передачи данных в блоках кодирования, например, макроблоках, за единицу времени, например, секунду. Для всех профилей могут быть определены одинаковые наборы уровней стандарта. Например, в целях повышения совместимости терминалов, в которых реализованы различные профили, может быть предпочтительным, чтобы большинство или все параметры, определяющие каждый из уровней, были общими для всех профилей.
[0089] Элементарной единицей для ввода в декодер H.264/AVC или HEVC и вывода из декодера H.264/AVC или HEVC, соответственно, является изображение. Изображение, поданное в качестве входных данных в кодер может называться исходным изображением, а изображение, декодированное декодером, может называться декодированным изображением. [0090] Исходное и декодированное изображения, каждое, состоят из одного или более массивов отсчетов (элементов изображения), например, одного или более наборов массивов отсчетов:
- Только составляющая яркости (Y) (монохромное изображение).
- Составляющая яркости и две составляющие цветности (YCbCr или YCgCo).
- Составляющие зеленого, синего и красного (GBR или RGB).
- Массивы, представляющие другие неопределенные монохромные или трехкомпонентные цветовые отсчеты (например, YZX, которые также называют XYZ).
[0091] Далее в настоящем описании такие массивы называются компонентами яркости (или L, или Y) и компонентами цветности, при этом два массива цветности могут обозначаться Cb и Cr; независимо от реально используемого метода представления информации о цвете. Реально используемый способ представления цветовой информации может, например, указываться в битовом потоке, например, с использованием синтаксиса информации об используемости видео (Video Usability Information, VUI) в стандарте H.264/AVC и/или HEVC. Составляющая может быть определена как массив отсчетов или одиночный отсчет из одного из трех массивов отчетов (одного яркости и двух цветности), или как массив отсчетов или одиночный отсчет из массива, составляющего изображение в монохромном формате.
[0092] В случае стандартов H.264/AVC и HEVC изображение может представлять собой кадр или поле. Кадр включает в себя матрицу отсчетов яркости, и возможно также, соответствующих отсчетов цветности. Поле представляет собой множество чередующихся строк элементов изображения в кадре и может использоваться в качестве входных данных для кодера в случае, когда исходный сигнал является чересстрочным. Массивы отсчетов цветности могут отсутствовать (и следовательно, могут применяться монохромные значения) или массивы отсчетов цветности могут иметь пониженное разрешение по сравнению с массивами отсчетов яркости. Форматы представления цветности могут быть, в общем, описаны следующим образом:
- При дискретизации в монохромном формате имеется только один массив отсчетов, который, по определению, считают массивом яркости.
- При дискретизации с форматом 4:2:0 каждый из двух массивов цветности имеет половину высоты массива яркости и половину его ширины.
- При дискретизации с форматом 4:2:2 каждый из двух массивов цветности имеет одинаковую высоту с массивом яркости, но половину ширины.
- При дискретизации с форматом 4:4:4, если не используются отдельных цветовых плоскостей, каждый из двух массивов цветности ту же высоту и ширину, что и массив яркости.
[0093] В стандартах H.264/AVC и HEVC массивы отсчетов могут кодироваться в виде отдельных цветовых плоскостей в битовом потоке, и соответственно, может выполняться декодирование отдельно кодированных цветовых плоскостей из битового потока. Если применяются отдельные цветовые плоскости, каждую из них обрабатывают отдельно (в кодере и/или декодере) как изображение с монохромным представлением.
[0094]
[0095] Если для составляющих цветности применяют меньшую частоту дискретизации (например, формат 4:2:0 или 4:2:2 представления цветовой информации), то местоположение отсчетов цветности относительно отсчетов яркости может определяться на стороне кодера (например, в качестве шага предварительной обработки или в качестве части процедуры кодирования). Положения отсчетов яркости относительно отсчетов цветности могут быть заранее заданы, например, в стандарте кодирования, в случае H.264/AVC или HEVC, или могут быть указаны в битовом потоке, например, как часть информации VUI в стандартах H.264/AVC или HEVC.
[0096] Разбиением называют такое разделение множества на подмножества, при котором каждый из элементов множества находится только в одном из подмножеств.
[0097] В стандарте H.264/AVC макроблок представляет собой блок отсчетов яркости размером 16×16 и соответствующие блоки отсчетов цветности. Например, при схеме дискретизации 4:2:0 макроблок будет содержать один блок отсчетов размером 8×8 для каждого компонента цветности. В стандарте H.264/AVC изображение разбивается на одну или более групп слайсов, при этом каждая группа слайсов содержит один или более слайсов. В стандарте H.264/AVC слайс состоит из целого числа макроблоков, упорядоченных в порядке сканирования растра в данной группе слайсов.
[0098] При описании операций кодирования и/или декодирования в стандарте HEVC могут использоваться термины, описанные ниже. Блок для кодирования (coding block) может быть определен как блок отсчетов размером N×N, для некоторого значения N, такого, что разделение блока отсчетов с древообразной структурой кодирования на блоки отсчетов для кодирования является разбиением. Блок с древообразной структурой кодирования (coding tree block, СТВ) может быть определен как блок отсчетов размером N×N, для некоторого значения N, такого, что разделение составляющей изображения на блоки с древообразной структурой кодирования представляет собой разбиение. Блок с древообразной структурой кодирования (coding tree unit, CTU) может быть определен как блок отсчетов яркости с древообразной структурой кодирования, два соответствующих блока отсчетов цветности с древообразной структурой кодирования изображения, имеющего три массива отсчетов, или блок отсчетов с древообразной структурой кодирования монохромного изображений, или изображения, которое кодируют с использованием трех отдельных цветовых плоскостей и синтаксических структур, применяемых для кодирования отсчетов. Блок кодирования (coding unit, CU) может быть определен как блок отсчетов яркости, два соответствующих блока отсчетов цветности для кодирования изображения, имеющего три массива значений, или блок отсчетов для кодирования монохромного изображения, или изображения, которое кодируют с использованием трех отдельных цветовых плоскостей и синтаксических структур, применяемых для кодирования отсчетов.
[0099] В некоторых видеокодеках, например, соответствующих стандарту высокоэффективного видеокодирования (HEVC), видеоизображения разделяют на блоки кодирования (CU), покрывающие область изображения. Каждый из блоков кодирования состоит из одного или более блоков предсказания (prediction unit, PU), определяющих процедуру предсказания элементов изображения в блоке кодирования, а также одного или более блоков преобразования (transform units, TU), определяющих процедуру кодирования ошибки предсказания для элементов изображения в блоке кодирования. Как правило, блок кодирования состоит из квадратного массива отсчетов, размер которого выбирается из заранее заданного множества допустимых размеров блока кодирования. Блок кодирования максимально допустимого размера, как правило, называется LCU (largest coding unit, наибольший блок кодирования) или блоком с древовидной структурой кодирования (coding tree unit, (CTU), при этом изображение в видео разбивается на неперекрывающиеся блоки LCU. Блок LCU может быть разбит на комбинацию менее крупных блоков кодирования, например, при помощи рекурсивного разбиения LCU и результирующих блоков кодирования. Каждый из результирующих блоков кодирования, как правило, имеет связанными с ним по меньшей мере один блок предсказания и один блок преобразования. Каждый блок предсказания и блок преобразования могут быть разбиты на менее крупные блоки предсказания и блоки преобразования с целью повышения точности процедур предсказания и кодирования ошибки предсказания соответственно. Каждый блок предсказания имеет связанную с ним информацию предсказания, которая определяет, предсказание какого типа должно применяться к пикселям данного блока предсказания (например, информацию вектора движения в случае блока предсказания с внешним предсказанием, или информацию направления внутреннего предсказания в случае внутренне предсказываемого блока предсказания).
[0100] Например, направленность режима предсказания в случае внутреннего предсказания (т.е. направление предсказания, применяемого в конкретном режиме предсказания) может быть вертикальной, горизонтальной, диагональной. Например, в стандарте HEVC, унифицированное внутреннее предсказание может обеспечиваться во вплоть до 33 режимах направленного предсказания, в зависимости от размера блоков предсказания, при этом каждый из режимов предсказания имеет присвоенное ему направление предсказания.
[0101] Аналогично, каждый блок преобразования связан с информацией, описывающей процедуру декодирования ошибки предсказания для значений в данном блоке преобразования (включая, например, информацию о коэффициентах DCT-преобразования). Информация о необходимости применения кодирования ошибки предсказания для каждого блока кодирования, как правило, сигнализируется на уровне блока кодирования. Если остатка или ошибки предсказания, связанного с блоком кодирования нет, то можно считать, что для данного блока кодирования блоки преобразования отсутствуют. Информация о разделении изображения на блоки кодирования, и разделение блоков кодирования на блоки предсказания и блоки преобразования, сигнализируемая, как правило, в битовом потоке, позволяет декодеру воспроизводить заданную структуру этих блоков.
[0102] В стандарте HEVC изображение может быть разбито на тайлы (ячейки), которые имеют прямоугольную форму и содержат целое число блоков LCU. В стандарте HEVC разбиение на тайлы дает регулярную сетку, в которой максимальная разность между высотой и шириной тайлов равна одному LCU. В проекте стандарта HEVC слайс определен как целое количество блоков с древообразной структурой кодирования, содержащихся в одном независимом сегмента слайса и во всех последующих зависимых сегментах слайса (если они присутствуют), которые предшествуют следующему независимому сегменту слайса (если он существует) внутри одного блока доступа. В стандарте HEVC сегмента слайса определен как целое количество блоков с древообразной структурой кодирования, последовательно упорядоченных в порядке сканирования ячейки и содержащихся в одном блоке NAL. Разделение каждого из изображений на сегменты слайса является разбиением. В стандарте HEVC независимый сегмент слайса определен как сегмент слайса, для которого значения синтаксических элементов в заголовке сегмента слайса не получают на основе значений предыдущего сегмента слайса, а зависимый сегмент слайса определен как сегмент слайса, для которого значения некоторых из синтаксических элементов в заголовке сегмента слайса получают на основе значений для предыдущего независимого сегмента слайса в порядке декодирования. В стандарте HEVC заголовок слайса определен как заголовок независимого сегмента слайса, который является текущим, или как заголовок независимого сегмента слайса, который предшествует текущему зависимому сегменту слайса, и при этом заголовок сегмента слайса определен как часть кодированного сегмента слайса, включающего элементы данных, которые относятся к первому блоку (или ко всем блокам) с древообразной структурой кодирования, представленному (или представленным) в сегменте слайса. Блоки кодирования сканируются в порядке сканирования растра LCU в тайлах или в изображении в целом, если тайлы не используются. В LCU блоки кодирования могут иметь заданный порядок сканирования. На фиг. 5 показан пример изображения, состоящего из двух тайлов и разделенного на квадратные блоки кодирования (показаны сплошными линиями), которые также были дополнительно разделены на прямоугольные блоки предсказания (показаны штриховыми линиями).
[0103] Декодер восстанавливает выходную видеоинформацию, применяя средства предсказания, аналогично кодеру, для формирования предсказанного представления блоков пикселей (с использованием информации о движении или пространственной информации, созданной кодером и хранимой в сжатом представлении) и декодирования ошибки предсказания (операция, обратная кодированию ошибки предсказания, для восстановления квантованного сигнала ошибки предсказания в пространственном домене пикселей). После применения средств декодирования предсказания и ошибки предсказания пикселей в декодере выполняется суммирование сигналов (пиксельных значений) предсказания и ошибки предсказания с формированием выходного видеокадра. В декодере (и кодере) могут также применяться дополнительные средства фильтрации, имеющие целью повышение качества выходного видеоизображения перед передачей его на отображение и/или хранение в качестве опорного для предсказания последующих кадров видеопоследовательности.
[0104] Фильтрация может включать, например, одно или более из следующего: деблокирующую фильтрацию, адаптивное смещение элементов изображения (sample adaptive offset, SAO), и/или адаптивную петлевую фильтрацию (adaptive loop filtering, ALF).
[0105] При выполнении SAO-фильтрации изображения разделяют на области, в которых, независимо для каждой области, принимают решение о необходимости выполнения SAO-фильтрации. Информацию о SAO-фильтрации в области инкапсулируют в блок параметров адаптации SAO (блок SAO), при этом в стандарте HEVC базовым блоком для размещения параметров SAO является блок CTU (соответственно, областью SAO является блок пикселей, охватываемый соответствующим CTU-блоком).
[0106] В алгоритме SAO-фильтрации элементы изображения в CTU-блоках классифицируют согласно определенному набору правил, при этом каждый набор отсчетов, отнесенный к своему классу, уточняют при помощи добавления значений смещения. Значения смещения сигнализируют в битовом потоке. Существуют два типа смещений: 1) Полосовое смещение; 2) Краевое смещение. Для CTU-блоков либо не применяют SAO-фильтрацию, либо применяют или полосовое смещение, или краевое смещение. Выбор: не применять SAO-фильтрацию, применять полосовое смещение или применять краевое смещение, может осуществляться кодером, например, исходя из требуемого значения показателя «битовая скорость - искажения» (rate distortion optimization, RDO), из затем информацию о выборе сигнализируют в декодер.
[0107] При полосовом смещении весь диапазон значений отсчетов, в некоторых случаях, разделяют на 32 полосы равной ширины. Например, в случае 8-битных отсчетов, ширина полосы будет равна 8 (=256/32). Из этих 32 полос выбирают 4 и для каждой из выбранных полос сигнализируют различные смещения. Решение по выбору принимается кодером и может быть сигнализировано следующим образом: Сигнализируют порядковый номер первой полосы, и затем делают вывод, что выбранными являются четыре полосы, следующие за ней. Полосовое смещение может быть полезным для исправления ошибок в однородных областях.
[0108] При краевом смещении тип краевого смещения (edge offset, ЕО) может быть выбран из четырех возможных типов (или категорий края), каждый из которых связан с определенным направлением: 1) вертикальный; 2) горизонтальный; 3) диагональный с углом 135 градусов; и 4) диагональный с углом 45 градусов. Выбор направления осуществляется кодером и сигнализируется в декодер. Каждый из типов определяет местоположение двух смежных отсчетов для заданного элемента изображения в зависимости от угла. Затем каждый элемент изображения в блоке CTU относят к одной из пяти категорий, на основе сравнения значения элемента изображения со значениями двух смежных с ним отсчетов. Эти пять категорий заданы следующим образом:
1. Значение текущего отсчета меньше, чем значение двух смежных с ним отсчетов.
2. Значение текущего отсчета меньше, чем значение одного из смежных с ним, и равно второму смежному с ним отсчету.
3. Значение текущего отсчета больше, чем значение одного из смежных с ним, и равно второму смежному с ним отсчету.
4. Значение текущего отсчета больше, чем значение двух смежных с ним отсчетов.
5. Ничто из перечисленного выше.
[0109] Сигнализация этих пяти категорий в декодер не является обязательной, поскольку классификация основана только на восстановленных элементах изображения, и может выполняться, идентичным образом, как в кодере, так и в декодере. После того, как каждый из отсчетов в CTU-блоке, имеющем краевой тип смещения, будет отнесен к одной из пяти категорий, определяют значение смещения для каждой из первых четырех категорий и передают их в декодер. Смещение для каждой категории складывают со значениями отсчетов, относящихся к соответствующей категории. Краевые смещения могут быть эффективными для исправления ложного оконтуривания в изображениях.
[0110] Параметры SAO-фильтрации в данных CTU-блоков могут сигнализироваться с интерливингом (т.е. с чередованием). На более высоком уровне, над CTU-блоком, заголовок слайса содержит синтаксический элемент, который определяет, применяется ли в данном слайсе SAO-фильтрация. Если SAO-фильтрация используется, то два дополнительных синтаксических элемента определяют, применяется ли SAO-фильтрация к составляющим Cb и Cr. Для каждого CTU-блока возможны три варианта: 1) копирование параметров SAO-фильтрации из CTU-блока, расположенного слева, 2) копирование параметров SAO-фильтрации из CTU-блока, расположенного сверху; или 3) сигнализация новых параметров SAO-фильтрации.
[0111] Адаптивный петлевой фильтр (adaptive loop filter, ALF) - это еще один способ повышения качества восстановленных отсчетов. Оно может достигаться при помощи циклической фильтрации отсчетов. Кодер может определять, например, исходя из информации RDO, какие из областей изображения подлежат фильтрации, а также коэффициенты фильтрации, и сигнализировать эту информацию в декодер.
[0112] В типовых видеокодеках на информацию о движении указывают при помощи векторов движения, связанных с каждой из групп пикселей изображения, для которых используется компенсация движения. Каждый из таких векторов движения является представлением смещения блока пикселей в кодируемом изображении (в кодере) или декодируемом изображении (в декодере) и блока пикселей, являющегося исходным для предсказания, в одном из ранее кодированных иди декодированных изображениях. С целью эффективного представления векторов движения, как правило, применяют их разностное кодирование относительно вектора движения, предсказанного для конкретного блока пикселей. В типовых видеокодеках предсказанные векторы движения формируются заранее заданным способом, например, при помощи вычисления среднего вектора движения двух смежных кодируемых или декодируемых блоков пикселей. Другим способом создания предсказаний векторов движения является формирование списка кандидатных предсказаний на основе соседних блоков пикселей и/или сорасположенных блоков пикселей в опорных изображения временного предсказания и сигнализация выбранного кандидата в качестве предсказания вектора движения. В дополнение к предсказанию значений векторов движения может также выполняться предсказание, какое опорное изображение (или изображения) будут применяться для предсказания с компенсацией движения, и такая информация предсказания может быть представлена, например, указателем на опорное изображение, которое указывает на ранее кодированное или декодированное изображение. Указатель на опорное изображение, как правило, предсказывается на основе соседних блоков пикселей и/или сорасположенных блоков пикселей в опорном изображении временного предсказания. При этом, обычно, в кодеках стандарта высокоэффективного видеокодирования применяют дополнительный механизм кодирования/декодирования информации о движении, часто называемый режимом слияния, в котором вся информация поля движения, включающая вектор движения и указатель на соответствующее опорное изображение для каждого имеющегося списка опорных изображений, является предсказываемой и применяется без какого-либо изменения или коррекции. Аналогично, предсказание информации поля движения выполняют с использованием информации поля движения соседних блоков и/или сорасположенных блоков в опорных изображениях временного предсказания, а использованную информацию поля движения сигнализируют в списке кандидатных полей движения вместе с информацией поля движения имеющихся смежных и/или сорасположенных блоков.
[0113] В типовых видеокодеках имеется возможность применения однонаправленного предсказания, при котором для кодируемого (или декодируемого) блока пикселей используют один блок пикселей предсказания, а также двунаправленного предсказания, при котором для формирования предсказания для кодируемого (или декодируемого) блока пикселей комбинируют два блока пикселей предсказания. В некоторых из видеокодеков обеспечивается возможность взвешенного предсказания, при котором значения элементов изображения из блоков пикселей предсказания взвешивают перед сложением с информацией ошибки. Например, могут применяться весовой коэффициент-множитель и добавочное смещение. При явном взвешенном предсказании, обеспечиваемом некоторыми из видеокодеков, весовой коэффициент и смещение могут быть закодированы, например, в заголовке слайса для каждого возможного указателя на опорное изображение. При неявном взвешенном предсказании, обеспечиваемом некоторыми из видеокодеков, весовые коэффициенты и/или смещения не кодируют, а вычисляют, например, на основе взаимного расстояния между порядковыми номерами изображений (picture order count, РОС) для опорных изображений.
[0114] В типовых видеокодеках остаток предсказания после компенсации движения сначала преобразуют с помощью ядра преобразования (например, DCT), и только затем кодируют. Причиной тому является частое наличие остаточной корреляции в остатке предсказания, а преобразование во многих случаях позволяет снизить эту корреляцию и дает в результате более эффективное кодирование.
[0115] В типовых видекодерах для поиска режимов кодирования с оптимальным соотношением битовой скорости/потери качества, например, необходимого режима макроблоков и связанных с ними векторов движения, используется целевая функция Лагранжа. В целевой функции такого типа используется весовой коэффициент, или λ, связывающий (точное или предполагаемое) значение искажения изображения в результате кодирования с потерями и (точное или предполагаемое) количество информации, необходимое для представления значений пикселей или элементов изображения в некоторой области изображения:

где С - оптимизируемое значение функции Лагранжа, D - искажение изображения (например, среднеквадратическая ошибка) с учетом режима и его параметров, a R - количество бит, необходимое для представления данных, требуемых для восстановления блока изображения в декодере (включая количество данных для представления кандидатных векторов движения).
[0116] Стандарт и спецификации видеокодирования могут разрешать разделение в кодере кодированного изображения на кодированные слайсы или аналогичные элементы. Предсказание внутри изображения с пересечением границ слайсов, как правило, не допускается. Следовательно, слайсы можно считать способом разделения кодированного изображения на независимо декодируемые части. В стандартах H.264/AVC и HEVC предсказание внутри изображения с пересечением границ слайсов может быть запрещено. Соответственно, слайсы можно считать способом деления кодированного изображения на независимо декодируемые части, и следовательно, слайсы часто считаются элементарными единицами передачи. Во многих случаях кодеры могут указывать в битовом потоке, какие типы внутреннего предсказания с переходом между границами слайсов запрещены, при этом декодер учитывает данную информацию при своей работе, например, делая вывод о доступных источниках предсказания. Например, элементы изображения из соседних макроблоков, или блоков кодирования, могут считаться недоступными для внутреннего предсказания, если эти соседние макроблоки, или блоки кодирования, расположены в различных слайсах.
[0117] Элементарной единицей для вывода из кодера H.264/AVC или HEVC и ввода в декодер H.264/AVC или HEVC, соответственно, является блок уровня сетевой абстракции (Network Abstraction Layer, NAL). С целью передачи по сетям пакетной передачи данных или хранения в структурированных файлах NAL-блоки могут инкапсулироваться в пакеты или в аналогичные структуры. Формат битового потока определен в стандартах H.264/AVC и HEVC для сред передачи или хранения, не обеспечивающих структуру кадров. В формате битового потока NAL-блоки отделяются друг от друга при помощи прикрепления стартового кода перед каждым NAL-блоком. Чтобы исключить ложное обнаружение границ NAL-блоков в кодерах исполняется байтовый алгоритм предотвращения эмуляции стартового кода, который добавляет байт предотвращения эмуляции к полезной нагрузке NAL-блока, если в противном случае в ней будет присутствовать стартовый код. Для обеспечения прозрачного шлюзового взаимодействия между системами пакетной и потоковой передачи данных, предотвращение эмуляции стартового кода должно выполняться в любом случае, независимо от того, применяется формат битового потока или нет. NAL-блок может быть определен как синтаксическая структура, содержащая указание на тип данных, следующих за ней, и байты, содержащие эти данные в форме RBSP, чередующиеся, при необходимости, с байтами предотвращения эмуляции. Последовательность исходных байтов полезной нагрузки (raw byte sequence payload, RBSP) может быть определена как синтаксическая структура, включающая целое число байт и инкапсулированная в NAL-блоке. Последовательность RBSP может быть либо пустой, либо иметь форму строки информационных бит, содержащих синтаксические элементы, за которыми следует стоп-бит RBSP и ноль или более последующих бит, равных 0.
[0118] NAL-блоки состоят из заголовка и полезной нагрузки. В стандартах H.264/AVC и HEVC в заголовке NAL-блока имеется указание на тип NAL-блока. В стандарте H.264/AVC заголовок NAL-блока указывает также на то, является ли кодированный слайс, содержащийся в данном NAL-блоке, частью опорного изображения или неопорного изображения.
[0119] NAL-блок в стандарте H264/AVC включает 2-битный синтаксический элемент nal_ref_idc, который, если он равен 0, указывает на то, что кодированный слайс, содержащийся в данном NAL-блоке, является частью неопорного изображения, и если он больше 0, указывает на то, что кодированный слайс, содержащийся в данном NAL-блоке, является частью опорного изображения. Заголовок NAL-блоков расширений SVC и MVC может дополнительно содержать различные указания, связанные с масштабированием и многоракурсной иерархией.
[0120] В стандарте HEVC для всех определенных типов NAL-блоков используется двухбайтный заголовок NAL-блока. Заголовок NAL-блока содержит один зарезервированный бит, шестибитный индикатор типа NAL-блока, трехбитный индикатор nal_temporal_id_plus1 временного уровня (может предъявляться требования, чтобы он был большим либо равным 1) и шестибитное зарезервированное поле (имеющее наименование nuh_layer_id). Синтаксический элемент temporal_id_plus1 можно считать временным идентификатором NAL-блока, при этом отсчитываемая от нуля переменная Temporalld может быть вычислена следующим образом: Temporalld = temporal_id_plus1 - 1. Случай, в котором Temporalld равна нулю, соответствует наименьшему временному уровню. Значение temporal_id_plus1 должно быть ненулевым, чтобы не возникала эмуляция стартового кода, в который входит два байта заголовка NAL-блока. Битовый поток, формируемый исключением всех NAL-блоков VCL, чей temporal_id больше или равен выбранному значению, и включением всех остальных NAL-блоков VCL, остается соответствующим стандарту. Следовательно, для изображений с temporal_id, равным TID, в качестве опорных для предсказания не используются изображения с temporal_id, большим ТID. Подуровень или временной подуровень может быть определен как уровень временного масштабирования или битовый поток с временным масштабированием, состоящий из NAL-блоков VCL с конкретным значением переменной Temporalld, а также из соответствующих NAL-блоков, не являющихся блоками VCL.
[0121] Шестибитное зарезервированное поле (nuh_layer_id) предназначено для использования расширениями, например, будущими расширениями масштабирования или трехмерного видеокодирования. Подразумевается, что эти шесть бит будут нети информацию о иерархии масштабирования. Без потери общности в некоторых примерах осуществления настоящего изобретения переменную Layerld вычисляют на основе значения nuh_layer_id, например, следующим образом: Layerld = nuh_layer_id. В дальнейшем описании идентификатор уровня, Layerld, nuh_layer_id и layer_id могут использоваться взаимозаменяемо, если только не будет указано на обратное.
[0122] NAL-блоки могут быть разделены на две категории: NAL-блоки уровня видеокодирования (Video Coning Layer, VCL) и NAL-блоки, не являющиеся блоками VCL. NAL-блоки категории VCL представляют собой NAL-блоки со стандартным кодированием слайсов. В стандарте H.264/AVC кодированные NAL-блоки слайса содержат синтаксические элементы, представляющие собой один или более кодированных макроблоков, каждый из которых соответствует блоку значений несжатого изображения. В стандарте HEVC кодированные NAL-блоки слайса содержат синтаксические элементы, представляющие собой один или более блоков кодирования.
[0123] В стандарте H.264/AVC может осуществляться указание на то, что кодированный NAL-блок слайса является кодированным слайсом изображения мгновенного обновления декодирования (Instantaneous Decoding Refresh, IDR) или кодированным слайсом изображения, не являющегося IDR-изображением.
[0124] В стандарте HEVC может выполняться указание на то, что NAL-блок кодированного слайса имеет один из следующих типов:


[0125] Сокращения для типов изображений в стандарте HEVC могут быть определены следующим образом: запаздывающее изображение (trailing picture, TRAIL), изображение доступа к временному подуровню (Temporal Sub-layer Access, TSA), изображение пошагового доступа к временному подуровню (Step-wise Temporal Sub-layer Access, STSA), опережающее декодируемое изображение с произвольным доступом (Random Access Decodable Leading, RADL), опережающее пропускаемое изображение с произвольным доступом (Random Access Skipped Leading, RASL), изображение разорванной цепи доступа (Broken Link Access, BLA), изображение мгновенного обновления декодирования (Instantaneous Decoding Refresh, IDR), изображение с чистым произвольным доступом (Clean Random Access, CRA).
[0126] Изображение точки произвольного доступа (Random Access Point, RAP), которое может, альтернативно, называться изображением внутренней точки произвольного доступа (IRAP), - это изображение, в котором каждый слайс или сегмент слайса имеет параметр nal_unit_type в диапазоне от 16 до 23 включительно. RAP-изображение содержит слайсы только с внутренним кодированием, и может являться BLA-изображением, CRA-изображением или IDR-изображением. Первое изображение в битовом потоке является RAP-изображением. При условии, что нужные наборы параметров доступны, когда они должны быть активированы, изображение RAP и следующие за ним в порядке декодирования изображения, не являющиеся RASL-изображениями, могут быть корректно декодированы без выполнения процедуры декодирования каких-либо изображений, предшествующих этому RAP-изображению в порядке декодирования. В битовом потоке могут присутствовать изображения, которые содержат только внутренне кодируемые слайсы, однако не являются RAP-изображениями.
[0127] В стандарте HEVC CRA-изображение может быть первым изображением в битовом потоке в порядке декодирования, или может появляться в битовом потоке позднее. CRA-изображения в стандарте HEVC позволяют иметь так называемые опережающие изображения, которые следуют за CRA-изображением в порядке декодирования, однако предшествуют ему в порядке вывода. Для некоторых из опережающих изображений, так называемых RASL-изображений, в качестве опорных могут использоваться изображения, декодированные перед CRA-изображением. Изображения, которые следуют за CRA-изображением и в порядке декодирования, и в порядке вывода, являются декодируемыми при осуществлении произвольного доступа в точке CRA-изображения, и следовательно, может осуществляться чистый произвольный доступ, аналогично функциональности чистого произвольного доступа IDR-изображения.
[0128] CRA-изображение может иметь связанные с ним RADL- или RASL-изображения. Когда CRA-изображение является первым изображением в битовом потоке в порядке декодирования, это CRA-изображение является первым изображением кодированной видеопоследовательности в порядке декодирования, и все связанные с ним RASL-изображения не выводятся декодером и могут не быть декодируемыми, поскольку могут содержать отсылки к изображениям, которых нет в битовом потоке.
[0129] Опережающее изображение, это изображение, которое предшествует связанному с ним RAP-изображению в порядке вывода. Связанное с ним RAP-изображение - это предыдущее RAP-изображение в порядке декодирования (если оно имеется). Опережающее изображение представляет собой либо RADL-изображение, либо RASL-изображение.
[0130] Все RASL-изображения являются опережающими изображениями для связанных с ними BLA-изображений или CRA-изображений. Когда RAP-изображение, связанное с RASL-изображением, является BLA-изображением или является первым кодированным изображением в битовом потоке, это RASL-изображение не выводят и оно при этом может не быть корректно декодируемым, поскольку RASL-изображение может содержать ссылки на изображения, которых нет в битовом потоке. Однако RASL-изображение может быть корректно декодируемым, если декодирование начато с RAP-изображения, которое предшествует RAP-изображению, связанному с данным RASL-изображением. RASL-изображения не используются в качестве опорных в процессе декодирования изображений других типов (не являющихся RASL-изображениями). Если они присутствуют, все RASL-изображения предшествуют, в порядке декодирования, всем запаздывающим изображениям для одного связанного с ним RAP-изображения. В некоторых из проектов стандарта HEVC RASL-изображения назывались изображениями, помеченными для отбрасывания (Tagged for Discard, TFD).
[0131] Все RADL-изображения являются опережающими изображениями. RADL-изображения не используются в качестве опорных в процессе декодирования запаздывающих изображений для связанного с ними RAP-изображения. Если они присутствуют, все RADL-изображения предшествуют, в порядке декодирования, всем запаздывающим изображениям для одного связанного с ним RAP-изображения. RADL-изображение не ссылается ни на какое изображение, предшествующее связанному с ним RAP-изображению в порядке декодирования, и следовательно, может быть корректно декодировано, если декодирование начинается со связанного с ним RAP-изображения. В некоторых из проектов стандарта HEVC RADL-изображения назывались декодируемыми опережающими изображениями (Decodable Leading Picture, DLP).
[0132] Если часть битового потока, начинающуюся с CRA-изображения, включают в другой битовый поток, то RASL-изображения, связанные с этим CRA-изображением, могут не быть корректно декодируемыми, поскольку некоторые из их опорных изображений могут отсутствовать в комбинированном битовом потоке. Чтобы сделать операцию «склеивания» потоков более простой, тип NAL-блока в случае CRA-изображения может быть изменен и указывать на то, что оно является BLA-изображением. RASL-изображения, связанные с BLA-изображением, могут не быть корректно декодируемыми, их не выводят и/или не отображают. При этом RASL-изображения, связанные с BLA-изображением, могут быть пропущены при декодировании.
[0133] BLA-изображение может быть первым изображением в битовом потоке, в порядке декодирования, или может появляться в битовом потоке позднее. Каждое BLA-изображение начинает новую кодированную видеопоследовательность, и оказывает влияние на процесс декодирования, аналогичное IDR-изображению. Однако BLA-изображение содержит синтаксические элементы, определяющие непустой набор опорных изображений. Если BLA изображение имеет тип (nal_unit_type), равный BLA_W_LP, оно может иметь связанные с ним RASL-изображения, которые не выводятся декодером и могут не быть декодируемыми, поскольку могут содержать ссылки на изображения, отсутствующие в битовом потоке. Если BLA изображение имеет тип (nal_unit_type), равный BLA_W_LP, оно может иметь связанные с ним RADL-изображения, которые определены как декодируемые. Если BLA изображение имеет тип (nal_unit_type), равный BLA_W_DLP, оно не имеет связанных с ним RASL-изображений, однако может иметь связанные с ним RADL-изображения, которые определены как декодируемые. Если BLA изображение имеет тип (nal_unit_type), равный BLA_W_LP, то оно не имеет никаких связанных с ним опережающих сообщений.
[0134] IDR-изображение, имеющее значение параметра nal_unit_type, равное IDR_N_LP не имеет связанных с ним опережающих сообщений в битовом потоке. IDR-изображение, имеющее значение параметра nal_unit_type, равное IDR_W_LP, не имеет связанных с ним RASL-сообщений в битовом потоке, Однако может иметь связанные с ним RADL-изображения в битовом потоке.
[0135] Когда значение параметра nal_unit_type равно TRAIL_N, TSA_N, STSA_N, RADL_N, RASL_N, RSV_VCL_N10, RSV_VCL_N12 или RSV_VCL_N14, декодированное изображение не используют в качестве опорного ни для какого другого изображения с тем же nuh_layer_id и в том же временном подуровне. То есть, в проекте стандарта HEVC, если значение параметра nal_unit_type равно TRAIL_N, TSA_N, STSA_N, RADL_N, RASL_N, RSV_VCL_N10, RSV_VCL_N12 или RSV_VCL_N14, декодированное изображение не включают в значения RefPicSetStCurrBefore, RefPicSetStCurrAfter или RefPicSetLtCurr никакого изображения с тем же значением Temporalld. Кодированное изображение со значением параметра, равным TRAIL_N, TSA_N, STSA_N, RADL_N, RASL_N, RSV_VCL_N10, RSV_VCL_N12 или RSV_VCL_N14 может быть отброшено без влияния на декодируемость остальных изображений с тем же значением Temporalld.
[0136] Запаздывающее изображение может быть определено как изображение, следующее за связанным с ним RAP-изображением в порядке вывода. Никакое изображение, являющееся запаздывающим, не может иметь параметр nal_unit_type равным RADL_N, RADL_R, RASL_N или RASL_R. Любое изображение, являющееся опережающим, в порядке декодирования должно предшествовать всем запаздывающим изображением, связанным с тем же RAP-изображением. В битовом потоке не могут присутствовать RASL-изображения, которые связаны с BLA-изображением, параметр nal_unit_type которого равен BLA_W_DLP или BLA_N_LP. В битовом потоке не могут присутствовать RADL-изображения, связанные с BLA-изображением, параметр nal_unit_type которого равен BLA_N_LP, или связанные с IDR-изображением, параметр nal_unit_type которого равен IDR_N_LP. Любое RASL-изображение, связанное с CRA-изображением или BLA-изображением, должно предшествовать в порядке вывода всем RADL-изображением, связанным с данными CRA-изображением или BLA-изображением. Любое RASL-изображение, связанное с CRA-изображением, должно следовать в порядке вывода за всем другими RAP-изображениями, которые предшествуют данному CRA-изображению в порядке декодирования.
[0137] В стандарте HEVC имеются два типа изображений, TSA-изображения и STSA-изображения, которые могут использоваться для указания на точки переключения временных подуровней. Если временные подуровни со значениями Temporalld вплоть до N были декодированы до появления TSA-изображения или STSA-изображения (исключительно), и данное TSA-изображение или STSA-изображение имеет значение Temporalld, равное N+1, то данное TSA-изображение или STSA-изображение указывает на возможность декодирования всех последующих (в порядке декодирования) изображений, имеющих значение Temporalld равным N+1. Тип TSA-изображения может налагать ограничения на само TSA-изображение, а также на все изображения в том же подуровне, которые следуют за этим TSA-изображением в порядке декодирования. Ни для одного из этих изображений не допускается применение внешнего предсказания на основе изображений в том же подуровне, предшествующих данному TSA-изображению в порядке декодирования. Определение TSA-изображения может также налагать ограничения на изображения в верхних подуровнях, которые следуют за данным TSA-изображением в порядке декодирования. Ни одно из этих изображений, если оно принадлежит тому же подуровню, что и TSA-изображение, или более высокому подуровню, не должно ссылаться на изображения, предшествующие данному TSA-изображению в порядке декодирования. TSA-изображения имеют значение Temporalld больше 0. STSA-изображение аналогично TSA-изображению, однако не налагает ограничений на изображения в более высоких подуровнях, следующие за STSA-изображением в порядке декодирования, и следовательно, позволяют выполнять переключение только на тот подуровень, в котором находится STSA-изображение.
[0138] NAL-блок, не являющийся блоком VCL, может, например, иметь один из следующих типов: набор параметров последовательности, набор параметров изображения, NAL-блок дополнительной уточняющей информации (supplemental enhancement information, SEI), разделитель блока доступа, конец последовательности NAL-блоков, конец потока NAL-блоков или NAL-блок с данными фильтрации. Набор параметров может быть необходим для восстановления декодированных изображений, при этом многие из остальных типов NAL-блоков, не являющихся блоками VCL, не являются необходимыми для восстановления декодированных изображений.
[0139] В набор параметров последовательности могут включаться параметры, которые остаются неизменными на протяжении всей кодированной видеопоследовательности. В дополнение к параметрам, которые могут быть необходимы в процессе декодирования, набор параметров последовательности опционально может включать информацию по используемости видео (video usability information, VUI), включающую параметры, важные для буферизации, синхронизации вывода изображения, отрисовки и резервирования ресурсов. В стандарте H.264/AVC определены три типа NAL-блоков, несущих наборы параметров последовательности: NAL-блоки с параметрами последовательности, содержащие все данные для NAL-блоков VCL стандарта H.264/AVC в последовательности, расширенные NAL-блоки набора параметров последовательности, содержащие данные внешне кодируемых изображений и блоки, содержащие подмножество набора параметров для NAL-блоков MVC и SVC VCL. В стандарте HEVC RBSP набора параметров последовательности включает в себя параметры, на которые могут выполняться ссылки в RBSP одного или более наборов параметров последовательности или в одном или более NAL-блоков SEI, содержащих сообщение SEI с периодом буферизации. Набор параметров изображения содержит параметры, которые с большой вероятностью будут неизменными для нескольких кодированных изображений. RBSP набора параметров изображения может включать в себя параметры, на которые могут выполняться ссылки из NAL-блоков кодированного слайса или из одного или более кодированных изображений.
[0140] В проекте стандарта HEVC присутствовал также третий тип набора параметров, который в настоящим документе называется набором параметров адаптации (Adaptation Parameter Set, APS) и включает параметры, с большой вероятностью остающиеся неизменными для нескольких кодированных слайсов, но которые могут при этом изменяться, например, в каждом изображении или в каждых нескольких изображениях. В проекте стандарта HEVC синтаксическая структура набора APS содержит параметры или синтаксические элементы, относящиеся к матрицам квантования (quantization matrices, QM), смещению значений адаптации (adaptive sample offset, SAO), адаптивной петлевой фильтрации (adaptive loop filtering, ALF) и деблокирующей фильтрации. В проекте стандарта HEVC APS-набор представляет собой NAL-блок и кодируется без ссылок на другие NAL-блоки и без предсказания на основе других NAL-блоков. В каждый NAL-блок набора APS включают идентификатор, имеющий наименование синтаксического элемента aps_id, который также включается в состав заголовка слайса для указания на конкретный набор APS. В другом варианте проекта стандарта HEVC синтаксическая структура набора APS содержит только параметры ALF. В проекте стандарта HEVC RBSP набора параметров адаптации включает в себя параметры, которые могут быть названы NAL-блоками кодированного слайса одного или более изображений, если флаг sample_adaptive_offset_enabled_flag и/или флаг adaptive_loop_filter enabled_flag равен 1. В окончательно, опубликованном стандарте HEVC синтаксическая структура набора APS была удалена из текста спецификации.
[0141] В стандарте HEVC набор видеопараметров (video parameter set, VPS) может быть определен как синтаксическая структура, содержащая синтаксические элементы, применимые к нулю или более полных кодированных видеопоследовательностей, в зависимости от содержимого синтаксического элемента, находящегося в наборе SPS, на который ссылается синтаксический элемент в наборе PPS, на который, в свою очередь, ссылается синтаксический элемент в заголовке сегмента слайса.
[0142] RBSP набора видеопараметров может включать в себя параметры, ссылки на которые могут осуществляться в RBSP одной или более наборов параметров последовательности.
[0143] Ниже описаны взаимоотношения и иерархия набора видеопараметров (VPS), набора параметров последовательности (SPS) и набора параметров изображения (SPS). Набор VPS располагается на один уровень выше набора SPS в иерархии наборов параметров и в контексте масштабируемости и/или 3D. Набор VPS может включать в себя параметры, являющиеся общими для всех слайсов во всех уровнях (масштабируемости или ракурсов) кодированной видеопоследовательности в целом. Набор SPS включает в себя параметры, являющиеся общими для всех слайсов в данном уровне (масштабируемости или ракурсов) кодированной видеопоследовательности в целом, которые при этом могут быть также общими для нескольких уровней (масштабируемости или ракурсов). Набор PPS включает в себя параметры, являющиеся общими для всех слайсов в данном уровне представления (представления уровня масштабируемости или ракурса в одном блоке доступа) и которые с большой вероятностью являются общими для всех слайсов в нескольких представлениях уровня кодирования.
[0144] Набор VPS может предоставлять информацию о отношениях зависимости уровней кодирования в битовом потоке, а также множество другой информации, применимой для всех слайсов во всех уровнях (масштабируемости или ракурсов) кодированной видеопоследовательности в целом.
[0145] Синтаксис стандартов H.264/AVC и HEVC допускает наличие множественных экземпляров наборов параметров, при этом каждый экземпляр имеет уникальный идентификатор. Чтобы ограничить использование памяти, необходимой для наборов параметров, был ограничен диапазон значений для идентификаторов наборов параметров. В стандартах H.264/AVC и HEVC каждый заголовок слайса включает идентификатор набора параметров изображения, который является активным для декодирования изображения, содержащего этот слайс, при этом каждый набор параметров изображения содержит идентификатор активного набора параметра последовательности. В проекте стандарта HEVC заголовок слайса дополнительно включает идентификатор набора APS, однако в опубликованном стандарте HEVC идентификатор набора APS был удален из заголовка слайса. Следовательно, передача наборов параметров изображения и последовательности не обязательно должна быть точно синхронизирована с передачей слайсов. Напротив, достаточно, чтобы активные наборы параметров последовательности и изображения были приняты до момента осуществления ссылки на них, что позволяет передавать наборы параметров с использованием более надежных механизмов передачи, по сравнению с протоколами, применяемыми для передачи данных слайсов. Например, наборы параметров могут включаться в качестве параметров в описание сеанса для сеансов транспортного протокола реального времени (Real-time Transport Protocol, RTP). Если наборы параметров передаются в основной полосе, то в целях повышения устойчивости к ошибкам они могут повторяться.
[0146] Наборы параметров могут активироваться при помощи ссылки из слайса или из другого активного набора параметров, или, в некоторых случаях, из других синтаксических структур, например, из сообщения SEI с периодом буферизации.
[0147] NAL-блоки SEI могут содержать одно или более сообщений SEI, которые не требуются для декодирования выходных изображений, но могут быть полезными в связанных с этим процедурах, например, синхронизации вывода изображения, отрисовки, обнаружения ошибок, сокрытия ошибок и резервирования ресурсов. В стандартах H.264/AVC и HEVC определены несколько типов сообщений SEI, при этом сообщения SEI с пользовательскими данными позволяют организациям и компаниям определять сообщения SEI для личного использования. В стандартах H.264/AVC и HEVC описаны синтаксис и семантика сообщений SEI, однако процедура обработки сообщений на стороне приемника не определена. Следовательно, кодер должен следовать стандарту H.264/AVC или HEVC при формирований сообщений, SEI при этом декодер, отвечающий стандарту H.264/AVC или HEVC соответственно, не обязательно должен обрабатывать сообщения SEI, соответствие выходной последовательности стандарту от этого не зависит. Одной из причин включения синтаксиса и семантики сообщений SEI в стандарты H.264/AVC и HEVC является возможность идентичной интерпретации дополнительной информации различными системами, и следовательно, их взаимодействия. Предполагается, что системные спецификации могут требовать применения конкретных сообщений SEI как на стороне кодера, так и на стороне декодера, при этом процедура обработки конкретных сообщений SEI на стороне приемника может быть определена дополнительно.
[0148] В стандартах AVC и HEVC были определены, а также предложены независимо, несколько типов контейнерных сообщений SEI. Принцип контейнеризации сообщений SEI заключается в помещении одного или более сообщений SEI внутри контейнерного сообщения SEI и в обеспечении механизма для связывания вложенных сообщений SEI с подмножеством битового потока и/или подмножеством декодированных данных. Может предъявляться требование, чтобы контейнерное сообщение SEI содержало одно или более сообщений SEI, которые сами не являются контейнерными сообщениями SEI. Сообщение SEI, содержащееся в контейнерном сообщении SEI называется вложенным сообщением SEI. Сообщение SEI, не содержащееся в контейнерном сообщении SEI называется невложенным сообщением SEI. Сообщения SEI с масштабируемой вложенностью в стандарте HEVC позволяют указывать либо на подмножество битового потока (полученное при помощи процедуры извлечения битового подпотока), либо на набор уровней, к которому применимы вложенные сообщения SEI. Подмножество битового потока может также называться битовым подпотоком.
[0149] Кодированное изображение - это кодовое представление изображения. Кодированное изображение в стандарте H.264/AVC включает NAL-блоки VCL, которые необходимы для декодирования изображения. В стандарте H.264/AVC кодированное изображение может быть либо первично кодированным изображением, либо избыточно кодированным изображением. Первично кодированное изображение используется в процедуре декодирования безошибочных битовых потоков, тогда как избыточно кодированное изображение является представлением с избыточностью и декодируется, только если первично кодированное изображение не может быть успешно декодировано. В стандарте HEVC избыточное кодированное изображение не определено.
[0150] В стандарте H.264/AVC блок доступа (AU) включает первично кодированное изображение и связанные с ним NAL-блоки. В стандарте H.264/AVC порядок появления NAL-блоков внутри блока доступа задан следующим образом. На начало блока доступа может указывать опциональный NAL-блок, являющийся разделителем блоков доступа. За ним следует ноль или более NAL-блоков SEI. Далее идут кодированные слайсы первично кодированного изображения. В стандарте H.264/AVC после кодированных слайсов первично кодированного изображения могут следовать кодированные слайсы нуля или более избыточно кодированных изображений. Избыточно кодированное изображение - это кодовое представление изображения или части изображения. Избыточно кодированное изображение может декодироваться, если первично кодированное изображение не принято в декодере, например, в результате потерь при передаче или в результате ошибки в физическом носителе.
[0151] В стандарте H.264/AVC блок доступа может также включать внешне кодированное изображение, которое дополняет первично кодированное изображение и может использоваться, например, в процедуре отображения. Внешне кодированное изображение может, например, использоваться в качестве альфа-канала или альфа-слоя, задающего уровень прозрачности пикселей декодированных изображений. Альфа-канал, или альфа-слой, может использоваться в многоуровневой системе формирования или отрисовки изображений, где выходное изображение образуется накладывающимися друг поверх друга частично прозрачными изображениями. Внешне кодированное изображение имеет те же синтаксические и семантические ограничения, что и монохромное избыточно кодированное изображение. В стандарте H.264/AVC внешне кодированное изображение содержит то же количество макроблоков, что и первично кодированное изображение.
[0152] В стандарте HEVC кодированное изображение может быть определено как кодированное представление изображения, содержащее все блоки с древообразной структурой кодирования для этого изображения. В стандарте HEVC блок доступа (AU) может быть определен как набор NAL-блоков, которые связаны друг с другом согласно определенному правилу классификации, следуют друг за другом в порядке декодирования и содержат одно или более кодированных изображений с различными значениями nuh_layer_id. Помимо NAL-блоков VCL кодированного изображения, блок доступа может содержать также NAL-блоки, не являющиеся блоками VCL.
[0153] В стандарте H.264/AVC кодированная видеопоследовательность определена как ряд последовательных блоков доступа в порядке декодирования от блока доступа IDR включительно до следующего блока доступа IDR исключительно или до конца битового потока, - в зависимости от того, что появляется раньше.
[0154] В стандарте HEVC кодированная видеопоследовательность (coded video sequence, CVS) может быть определена, например, как последовательность блоков доступа, которые состоят, в порядке декодирования, из блока доступа IRAP-изображения с флагом NoRaslOutputFlag, равным 1, за которым следуют ноль или более блоков доступа, не являющихся блоками доступа IRAP-изображения и имеющих флаг NoRaslOutputFlag, равный 1, включая все последующие блоки доступа вплоть до (но не включая) первого последующего блока доступа, который является блоком доступа IRAP-изображения с флагом NoRaslOutputFlag, равным 1. Блок доступа IRAP-изображения может быть блоком доступа IDR-изображения, блоком доступа BLA-изображения или блоком доступа CRA-изображения. Значение флага NoRaslOutputFlag равно 1 для любого блока доступа IDR-изображения, любого блока доступа BLA-изображения и любого блока доступа CRA-изображения, который является первым блоком доступа, в порядке декодирования, в битовом потоке, является первым блоком доступа после конца NAL-блока последовательности, в порядке декодирования, или имеет флаг HandleCraAsBlaFlag равным 1. Если флаг NoRaslOutputFlag равен 1, это означает, что RASL-изображения, связанные с IRAP-изображением, для которых установлено такое значение флага NoRaslOutputFlag, не выводятся декодером. Могут иметься средства для предоставления значения флага HandleCraAsBlaFlag в декодер из внешнего элемента, например, проигрывателя или приемника, осуществляющего управление декодером. Флаг HandleCraAsBlaFlag может быть установлен равным 1, например, проигрывателем, который осуществляет поиск новой позиции в битовом потоке или подключается к трансляции и начинает декодирование, и в этом случае он будет начинать декодирование с CRA-изображения. Когда для CRA-изображения флаг HandleCraAsBlaFlag равен 1, это CRA-изображение обрабатывают и декодируют так, как если бы оно было BLA-изображением.
[0155] Структура изображений (Structure of Pictures, SOP) может быть определена как одно или более кодированных изображений, следующих друг за другом в порядке декодирования, при этом первое кодированное изображение в порядке декодирования является опорным изображением в самом нижнем временном подуровне, и ни одно кодированное изображение, кроме, потенциально, первого кодированного изображения в порядке декодирования, не является RAP-изображением. Все изображения в предыдущей структуре SOP предшествуют, в порядке декодирования, всем изображениям в текущей структуре SOP, а все изображения в следующей структуре SOP, расположены позднее, в порядке декодирования, чем все изображения в текущей структуре SOP. Структура SOP может представлять иерархическую и повторяющуюся структуру внешнего предсказания. Термин группа изображений (GOP) в некоторых случаях может использоваться взаимозаменяемо с термином SOP и имеет тот же значение.
[0156] В синтаксисе битового потока стандартов H.264/AVC и HEVC присутствуют указания на то, является ли изображение опорным для внутреннего предсказания какого-либо иного изображения. Изображения с любым типом кодирования (I, Р, В) в стандартах H.264/AVC и HEVC могут быть как опорными изображениями, так и неопорными изображениями.
[0157] В стандарте H.264/AVC определена процедура маркировки декодированного опорного изображения с целью управления потреблением памяти в декодере. Максимальное количество опорных изображений для внешнего предсказания обозначается М и определяется в наборе параметров последовательности. При декодировании опорного изображения оно маркируется как «используемое в качестве опорного». Если в результате декодирования опорного изображения более М изображений были помечены как «используемые в качестве опорного», то по меньшей мере одно из этих изображений помечают как «не используемое в качестве опорного». Имеются два типа операций маркировки декодированного опорного изображения: адаптивное управление памятью и скользящее окно. Режим маркировки декодированного опорного изображения может выбираться для каждого изображения в отдельности. Адаптивное управление памятью обеспечивает явную сигнализацию, при которой изображения помечаются как «не используемые в качестве памяти», причем также возможно назначение долгосрочных указателей на краткосрочные опорные изображения. Адаптивное управление памятью может требовать наличия в битовом потоке параметров операций управления памятью (memory management control operation, MMCO). Параметры ММСО могут быть включены в синтаксическую структуру, маркирующую декодированное опорное изображение. Если применяется режим работы со скользящим окном, и М изображений помечены как «используемые в качестве опорных», то краткосрочное опорное изображение, являвшееся первым декодированным изображением среди краткосрочных опорных изображений, помеченных «используемыми в качестве опорных», помечается как «не используемое в качестве опорного». Другими словами, режим работы со скользящим окном обеспечивает работу с краткосрочными опорными изображениями по типу буфера «первый вошел, первый вышел».
[0158] Одна из операций управления памятью в стандарте H.264/AVC обеспечивает маркировку всех опорных изображений, кроме текущего изображения, как «не используемых в качестве опорных». Изображение мгновенного обновления декодирования (IDR) содержит только слайсы с внутренним предсказанием и вызывает аналогичный «сброс» опорных изображений.
[0159] В стандарте HEVC синтаксические структуры для маркировки опорных изображений и соответствующие процедуры декодирования не применяются. Вместо этого, с аналогичными целями, используется синтаксическая структура и процедура декодирования набора опорных изображений (reference picture set, RPS). Набор опорных изображений, являющийся действительным или активным для изображения, включает все опорные изображения для данного изображения и все опорные изображения, которые остаются помеченными как «используемые в качестве опорных» для последующих изображений в порядке декодирования. В наборе опорных изображений существует шесть подмножеств, которые обозначаются RefPicSetStCurr0 (или, альтернативно, RefPicSetStCurrBefore), RefPicSetStCurr1 (или, альтернативно, RefPicSetStCurrAfter), RefPicSetStFoll0, RefPicSetStFoll1, RefPicSetLtCurr и RefPicSetLtFoll. Подмножества RefPicSetStFollO и RefPicSetStFolll иногда трактуют как одно объединенное подмножество, RefPicSetStFoll. Нотация обозначений этих шести подмножеств имеет следующее значение. "Curr" обозначает опорное изображение, которое включено в список опорных изображения для текущего изображения, и следовательно, может быть использовано как опорное изображение при внешнем предсказании текущего изображения. "Foll" обозначает опорное изображение, которое не включено в список опорных изображений для текущего изображения, но может быть использовано как опорное изображение для последующих изображений в порядке декодирования. "St" обозначает краткосрочные опорные изображения, которые в общем случае могут идентифицироваться при помощи определенного количества младших бит в их значении РОС (порядкового номера). "Lt" обозначает долгосрочные опорные изображения, которые идентифицируются специальным образом и, как правило, имеют большее отличие в значениях РОС от текущего изображения, чем это может быть отражено с помощью упомянутого определенного количества младших бит. "0" обозначает те опорные изображения, которые имеют меньшее значение РОС, тем текущее изображение. "1" обозначает те опорные изображения, которые имеют большее значение РОС, чем текущее изображение. RefPicSetStCurr0, RefPicSetStCurr1, RefPicSetStFoll0 и RefPicSetStFoll1 совместно называют краткосрочным подмножеством набора опорных изображений. RefPicSetLtCurr и RefPicSetLtFoll совместно называют долгосрочным подмножеством набора опорных изображений.
[0160] В проекте стандарта HEVC набор опорных изображений может быть задан в наборе параметров последовательности и использоваться в заголовке слайса при помощи указателя на конкретный набор опорных изображений. Набор опорных изображений может также задаваться в заголовке слайса. Долгосрочное подмножество набора опорных изображений, как правило, задается только в заголовке слайса, тогда как краткосрочные подмножества того же самого набора опорных изображений могут задаваться в наборе параметров изображения или в заголовке слайса. Набор опорных изображений может кодироваться независимо или может предсказываться на основе другого набора опорных изображений (это называется внешним предсказанием RPS). При независимом кодировании набора опорных изображений синтаксическая структура включает вплоть до трех циклически определяемых элементов с итерацией по различным типам опорных изображений: краткосрочные опорные изображения со значениями РОС, меньшими текущего изображения, краткосрочные опорные изображения со значениями РОС, большими текущего изображения, и долгосрочные опорные изображения. Каждая такая циклическая запись определяет, что изображение должно быть помечено как «используемое в качестве опорного». В большинстве случаев изображение задается с использованием дифференциального значения РОС. При внешнем предсказании набора RPS используется тот факт, что набор опорных изображений для текущего изображения может быть предсказан на основе набора опорных изображений ранее декодированного изображения. Это возможно, поскольку все опорные изображения для текущего изображения являются либо опорными изображениями для предыдущего изображения, либо непосредственно декодированным изображением. Необходимо только указать, какие из этих изображений должны быть опорными и использоваться для предсказания текущего изображения. В обоих типах кодирования опорных изображений для каждого опорного изображения дополнительно устанавливают флаг (used_by_curr_pic_X_flag), который указывает, используется ли данное изображение в качестве опорного для текущего изображения (т.е. входит в список *Curr) или нет (т.е. входит в список *Foll). Изображения из набора опорных изображений, используемых для текущего слайса, помечают как «используемые в качестве опорных», а изображения, не входящие в набор опорных изображений, используемых для текущего слайса, помечают как «не используемые в качестве опорных». Если текущее изображение является IDR-изображением, то RefPicSetStCurr0, RefPicSetStCurr1, RefPicSetStFoll0, RefPicSetStFoll1, RefPicSetLtCurr и RefPicSetLtFoll назначаются равным пустому множеству.
[0161] В кодере и/или декодере может применяться буфер декодированных изображений (Decoded Picture Buffer, DPB). Имеются две причины для буферизации декодированных изображений: для использования в качестве опорных при внешнем предсказании и для изменения порядка декодированных изображений в выходной последовательности. Стандарты H.264/AVC и HEVC дают значительную гибкость как для маркировки опорных изображений, так и для переупорядочивания выходной последовательности, однако отдельные буферы для опорных изображений и изображений выходной последовательности могут приводить к нерациональному расходованию ресурсов памяти. Следовательно, буфер DPB может включать унифицированную процедуру буферизации опорных изображений и переупорядочивания выходной последовательности. Декодированное изображение может удаляться из буфера DPB, когда оно больше не используется в качестве опорного и не требуется для вывода.
[0162] Во многих режимах кодирования стандартов H.264/AVC и HEVC, на опорное изображение внешнего предсказания указывают с помощью указателя на список опорных изображений. Указатель может кодироваться с использованием кодирования переменной длины (неравномерного кодирования), что обычно дает более короткие значения указателей с меньшим числовым значением для соответствующих синтаксических элементов. В стандартах H.264/AVC и HEVC формируются два списка опорных изображений (список 0 опорных изображений и список 1 опорных изображений) для каждого двунаправленно предсказываемого слайса (В-слайса), и один список опорных изображений (список 0 опорных изображений) для каждого слайса, кодируемого с внешним предсказанием (Р-слайса).
[0163] Список опорных изображений, например список 0 или список 1, как правило, формируется в два шага. Сначала формируют первичный список опорных изображений. Первичный список опорных изображений может формироваться, например, на основе параметров frame_num, РОС, temporal_id (или Temporalld, или аналогичного параметра), или информации об иерархии предсказания, например, из структуры GOP, или на основе какой-либо комбинации перечисленного. На втором шаге первичный список опорных изображений может быть переупорядочен с помощью команд переупорядочения списка опорных изображений (reference picture list reordering, RPLR), также называемых синтаксической структурой модификации списка опорных изображений, которая может содержаться в заголовках слайсов. В стандарте H.264/AVC команды RPLR указывают на изображения, которые упорядочены в направлении к началу соответствующего списка опорных изображений. Этот второй шаг может также быть назван процедурой модификации списка опорных изображений, а команды RPLR могут включаться в синтаксическую структуру модификации списка опорных изображений. Если используются наборы опорных изображений, то список 0 опорных изображений может инициализироваться включением в него сначала RefPicSetStCurr0, за которым следует RefPicSetStCurr1 и затем RefPicSetLtCurr. Список 1 опорных изображений может инициализироваться включением в него сначала RefPicSetStCurr1 и затем RefPicSetStCulr0. В стандарте HEVC первичные списки опорных изображений могут модифицироваться при помощи синтаксической структуры модификации списка опорных изображений, в которой изображения в первичных списках опорных изображений могут идентифицироваться при помощи записи-указателя на список. Другими словами, в стандарте HEVC модификацию списка опорных изображений кодируют в синтаксической структуре, которая содержит циклическое определение по всем записям в окончательном списке опорных изображений, при этом каждая запись циклической структуры представляет собой кодированный указатель фиксированный длины на исходный список опорных изображений, который указывает, с возрастающим порядком расположения, на изображение в окончательном списке опорных изображений.
[0164] Во многих стандартах кодирования, включая H.264/AVC и HEVC, процедура декодирования может давать на выходе указатель на опорное изображение в списке опорных изображений, который может применяться для указания, какое из нескольких опорных изображений необходимо использовать для внешнего предсказания определенного блока пикселей. Указатель на опорное изображение в некоторых режимах кодирования с внешним предсказанием может кодироваться кодером в битовый поток, или, в других режимах кодирования с внешним предсказанием, может вычисляться (например, кодером и декодером), например, с использованием соседних блоков.
[0165] С целью эффективного представления векторов движения в битовом потоке может выполняться их разностное кодирование относительно вектора движения, предсказанного для конкретного блока. Во многих видеокодеках предсказанные векторы движения формируются заранее заданным способом, например, при помощи вычисления среднего вектора движения двух смежных кодируемых или декодируемых блоков. Другим способом создания предсказаний векторов движения, который иногда называют улучшенным предсказанием векторов движение (advanced motion vector prediction, AMVP) является формирование списка кандидатных предсказаний на основе соседних блоков пикселей и/или сорасположенных блоков пикселей в опорных изображения временного предсказания и сигнализация выбранного кандидата в качестве предсказания вектора движения. В дополнение к предсказанию значений векторов движения может также выполняться предсказание указателя на опорное изображение ранее кодированного или декодированного изображения. Указатель на опорное изображение, как правило, предсказывается на основе соседних блоков и/или сорасположенных блоков в опорном изображении временного предсказания. Разностное кодирование векторов движения с переходом границы слайса, как правило, не разрешено.
[0166] Улучшенное предсказание векторов движения (AMVP) или сходная с ним процедура может выполняться, например, описанным ниже образом, в то время как возможны и другие аналогичные реализации улучшенного предсказания векторов движения, например, с использованием различных наборов кандидатных позиций и кандидатных местоположений в наборах кандидатных позиций. Могут вычисляться два пространственных предсказания вектора движения (spatial motion vector predictors, MVP) и одно временное предсказание вектора движения (temporal motion vector predictor, TMVP). Они могут быть выбраны из позиций, проиллюстрированных на фиг. 6: три позиции 603, 604, 605 кандидатных пространственных предсказаний вектора движения, расположенные над текущим блоком 600 предсказания (В0, В1, В2) и две позиции 601, 602 - слева (АО, А1). В качестве представления направления предсказания (вверх или влево) для отбора кандидатных векторов движения может быть выбрано первое предсказание вектора движения, которое доступно (например, располагается в том же слайсе, кодировано с внешним предсказанием и т.п.) в заранее заданном порядке для каждого набора позиций кандидатов (В0, В1, В2) или (АО, А1). Указатель на опорное изображение для временного предсказания вектора движения может быть указан кодером в заголовке слайса (например, как сорасположенный с ним синтаксический элемента ref_idx). Вектор движения, полученный на основе сорасположенного изображения, может масштабироваться пропорционально разности порядковых номеров изображений между опорным изображением для временного предсказания вектора движения, сорасположенного изображения и текущего изображения. При этом может также выполняться контроль по избыточности для всех кандидатов, что позволяет устранить дублирование кандидатов, в результате которого в списке кандидатов может оказаться нулевой вектор движения. Предсказание вектора движения может быть указано в битовом потоке, например, при помощи указания направления на пространственное предсказание вектора движения (вверх или влево) или при помощи указания на выбор кандидатного временного предсказания вектора движения.
[0167] Во многих кодеках эффективного видеокодирования, например, в кодеках, соответствующих стандарту HEVC, применяют дополнительный механизм кодирования и декодирования информации, часто называемый режимом (или процессом, или механизмом) слияния, в котором информация о движении блока пикселей или блока предсказания предсказывается и используется без какой-либо модификации или коррекции. Упомянутая выше информация о движении блока предсказания может включать одно или более из следующего: 1) информация о том, является ли «данный блок предсказания однонаправленно предсказываемым с использованием только списка 0 опорных изображений», или «данный блок предсказания является однонаправленно предсказываемым с использованием только списка 1 опорных изображений», или «данный блок предсказания является двунаправленно предсказываемым с использованием обоих списков опорных изображений, списка 0 и списка 1»; 2) значение вектора движения, соответствующее списку 0 опорных изображений, которое может включать горизонтальную и вертикальную составляющую вектора движения; 3) указатель на опорное изображение в списке 0 опорных изображений и/или идентификатор опорного изображения, на которое указывает вектор движения, соответствующий списку 0 опорных изображений, при этом идентификатор опорного изображения может представлять собой, например, значение порядкового номера изображения, значение идентификатора уровня кодирования (для межуровневого предсказания), или пару из значения порядкового номера изображения и значения идентификатора уровня кодирования; 4) информация маркировки опорного изображения, например, информация о том, было ли опорное изображение помечено как «используемое в качестве краткосрочного опорного изображения» или как «используемое в качестве долгосрочного опорного изображения»; 5)-7) аналогично 2)-4), соответственно, но для списка 1 опорных изображений. Аналогично, предсказание информации о движении выполняют с использованием информации о движении соседних блоков пикселей и/или сорасположенных блоков пикселей в опорных изображениях временного предсказания. Список, часто называемый списком слияния, формируют при помощи включения кандидатных предсказаний движения, связанных с доступными смежными/сорасположенными группами пикселей, при этом сигнализируется указатель на выбранное кандидатное предсказание движения в списке, а информация о движении выбранного кандидата копируется в информацию о движении текущего блока предсказания. Если применяется механизм слияния для всего блока кодирования, и при этом сигнал предсказания для блока кодирования используется в качестве сигнала восстановления, т.е. остаток предсказания не обрабатывается, то такой тип кодирования и декодирования блока кодирования называется, как правило, режимом пропуска или режимом пропуска, основанным на слиянии. В дополнение к режиму пропуска для отдельных блоков предсказания применятся также механизм слияния (не обязательно для всего блока кодирования, как в режиме пропуска) и в этом случае остаток предсказания может использоваться для повышения качества предсказания. Такой тип режима предсказания, называют, как правило, режимом внешнего слияния.
[0168] Одним из кандидатов в списке слияния может быть TMVP-кандидат, который может быть получен на основе сорасположенного блока пикселей внутри опорного изображения, на которое было указано, или которое было вычислено, например, внутри опорного изображения, на которое было выполнено указание, например, в заголовке слайса, к примеру, с использованием синтаксического элемента ref_idx сорасположенного изображения или аналогичного ему элемента.
[0169] В стандарте HEVC, когда режимом кодирования является режим слияния, указатель на так называемое целевое опорное изображение для временного предсказания вектора движения в списке слияния назначают равным 0. Когда режимом кодирования движения в стандарте HEVC, при использовании временного предсказания векторов движения, является режим улучшенного предсказания векторов движения, значение указателя на целевое опорное изображение указывают явно (например, для каждого блока кодирования).
[0170] После определения значения указателя на целевое опорное изображение значение вектора движения, основанное на временном предсказании вектора движения, может быть получено следующим образом: вычисляют вектор движения в группе пикселей, которая сорасположена с соседним, справа-снизу, блоком кодирования для текущего блока кодирования. Изображение, в котором находится этот сорасположенный блок, может быть определено, например, согласно указателю на опорное изображение, сигнализированному в заголовке слайса в соответствии с предшествующим описанием. Найденный вектор движения для сорасположенного блока пикселей масштабируют пропорционально первой разности порядковых номеров изображений и второй разности порядковых номеров изображений. Первую разность порядковых номеров изображений вычисляют между изображением, содержащим данный сорасположенный блок, и опорным изображением вектора движения этого сорасположенного блока пикселей. Вторую разность порядковых номеров изображений вычисляют между текущим изображением и целевым опорным изображением. Если одно (но не оба) из изображений, целевого опорного изображения и опорного изображение вектора движения сорасположенного блока пикселей, является долгосрочным опорным изображением (то есть, второе является краткосрочным опорным изображением), то кандидатное TMVP-предсказание может считаться недоступным. Если оба изображения, целевое опорное изображение и опорное изображение вектора движения сорасположенного блока пикселей, являются долгосрочными опорными изображениями, то масштабирование вектора движения на основе РОС неприменимо.
[0171] Масштабируемым видеокодированием может называться такая структура кодирования, в которой один битовый поток может содержать несколько представлений контента, например, с различным битрейтом, разрешением и/или частотой смены кадров. В этих случаях приемник может извлекать требуемое представление в зависимости от своих характеристик (например, разрешение, наиболее подходящее для дисплейного устройства). Альтернативно, сервер или сетевой элемент может извлекать части битового потока для передачи в приемник в зависимости, например, от характеристик сети или вычислительных возможностей приемника. Масштабируемый битовый поток состоит, как правило, из «базового уровня кодирования», обеспечивающего наименьшее из доступных качество видеоинформации, а также из одного или более уточняющих уровней кодирования, которые повышают качество видеоинформации при их приеме и декодировании вместе с нижними уровнями. С целью повышения эффективности кодирования уточняющих уровней их кодированные представления, как правило, кодируют в зависимости от нижних уровней. Например, информация о движении и режиме уточняющего уровня может предсказываться на основе низлежащих уровней. Аналогично, данные пикселей нижних уровней могут применяться для формирования предсказания уточняющего уровня.
[0172] В некоторых из схем масштабируемого видеокодирования видеосигнал может кодироваться в базовый уровень и в один или более уточняющих уровней. Уточняющий уровень, например, может повышать временное разрешение (т.е. частоту смены кадров), пространственное разрешение или просто качество видеоконтента, представленного в другом уровне, или его части. Каждый уровень вместе со всеми зависимыми уровнями является одним из представлений видеосигнала, например, с определенным пространственным разрешением, временным разрешением и уровнем качества. В данном документе уровень масштабирования вместе со всеми зависимыми уровнями называется «представлением уровня масштабирования». Часть масштабируемого битового потока, соответствующая представлению уровня масштабирования, может быть извлечена и декодирована, в результате чего получают представление исходного сигнала с определенной точностью.
[0173] Режимы масштабирования, или масштабируемые величины, могут включать, без ограничения перечисленным, описанные ниже режимы.
- Масштабирование качества: изображения базового уровня кодируют с меньшим качеством, чем изображения уточняющих уровней, что может быть реализовано, например, за счет использования более высокого значения параметра квантования (т.е. большего размера шага квантования для квантования коэффициентов преобразования) в базовом уровне, по сравнению с уточняющим уровнем. Масштабируемость качества может, в свою очередь, подразделяться на мелкозернистую или мелкогранулярную масштабируемость (fine-grain или fine-granularity scalability, FGS), среднезернистую или среднегранулярную масштабируемость (medium-grain или medium-granularity scalability, MGS) и/или крупнозернистую или крупногранулярную масштабируемость (coarse-grain или coarse-granularity scalability, CGS) которые будут описаны ниже.
- Пространственная масштабируемость: изображения базового уровня кодируют с меньшим разрешением (т.е. имеют меньше количество отсчетов), чем изображения уточняющих уровней. Пространственная масштабируемость и масштабируемость качества, особенно ее крупногранулярный тип, иногда относят к одному типу масштабируемости.
- Масштабируемость битовой глубины: изображения базового уровня кодирования кодируют с меньшей битовой глубиной (например, 8 бит), чем изображения уточняющих уровней (например, 10 или 12 бит).
- Масштабируемость формата цветности: изображения базового уровня кодирования обеспечивают меньшее пространственное разрешение в массивах отсчетов цветности (например, кодированы в формате цветности 4:2:0), чем изображения уточняющих уровней (например, формат 4:4:4).
- Масштабируемость цветового охвата: изображения уточняющего уровня имеют более емкий, или широкий, диапазон представления цвета, чем изображения базового уровня, например, уточняющий уровень может иметь цветовой охват по стандарту UHDTV (ITU-R ВТ.2020), а базовый уровень может иметь цветовой охват по стандарту ITU-R ВТ.709.
- Масштабируемость ракурсов, которая может также называться многоракурсным кодированием. Базовый уровень представляет собой первый ракурс, тогда как уточняющий уровень является вторым ракурсом.
- Масштабируемость глубины, которая может также называться кодированием с уточнением глубины. Один или несколько уровней в битовом потоке могут представлять собой ракурс (или ракурсы) текстуры, тогда как другой уровень, или уровни, могут представлять собой ракурс (или ракурсы) глубины.
- Масштабируемость областей интереса (описана ниже).
- Чересстрочно-прогрессивная масштабируемость (также называемая масштабируемостью поле-кадр): исходные кодированные чересстрочные данные базового уровня уточняют с использованием уточняющего уровня, который представляет прогрессивные исходные данные. Кодированные чересстрочные видеоданные в базовом уровне могут содержать кодированные поля, кодированные кадры, представляющие пары полей, или их комбинацию. При чересстрочно-прогрессивной масштабируемости разрешение изображения базового уровня может быть изменено таким образом, чтобы оно подходило в качестве опорного изображения для одного или более изображений уточняющего уровня.
- Масштабируемость с гибридным кодеком (также называемая масштабируемостью стандартов кодирования): при масштабируемости с гибридным кодеком синтаксис, семантика и процедура декодирования для базового уровня и уточняющего уровня определены различными стандартами видеокодирования. Таким образом, изображения базового уровня кодируют согласно стандарту или формату кодирования, отличающего от кодирования изображений уточняющего уровня. К примеру, базовый уровень может быть кодирован с использованием стандарта H.264/AVC, а уточняющий уровень может быть закодирован с использованием расширения HEVC.
[0174] Нужно понимать, что многие из типов масштабируемости могут комбинироваться и применяться совместно. К примеру, могут совместно применяться масштабируемость цветового охвата и масштабируемость битовой глубины.
[0175] Термин «уровень» может использоваться в контексте любых типов масштабируемости, включая масштабируемость ракурсов и уточнение глубины. Уточняющий уровень может иметь отношение к любому типу уточнения, например, повышению соотношения сигнал-шум, уточнению пространственного разрешения, многоракурсному уточнению, уточнению глубины, битовой глубины, формата цветности и/или и/или увеличению цветового охвата. Базовый уровень может иметь отношение к любому типу базовой видеопоследовательности, например, к базовому ракурсу, базовому уровню для пространственной масштабируемости или масштабируемости отношения сигнал-шум, или к базовому ракурсу текстуры для видеокодирования с уточнением глубины.
[0176] В настоящее время ведутся исследования и разработки технологий предоставления трехмерных (3D) видеоданных. Можно считать, что при стереоскопическом, или двухракурсном, видео одну видеопоследовательность, или ракурс, отображают для левого глаза, тогда как параллельный ракурс отображают для правого глаза. Для приложений, допускающих переключение точки съемки, а также для автостереоскопических дисплеев, которые могут отображать большое количество ракурсов одновременно и давать зрителю возможность просматривать контент с различных точек, может требоваться более двух параллельных ракурсов. Интенсивные исследования направлены на разработку видеокодирования для автостереоскопических дисплеев, и другие подобные применения многоракурсных видеоизображений, в которых зритель может наблюдать только одну пару стереоскопических видеоизображений с определенной точки и еще одну пару стереоскопических видеоизображений с другой точки. Одним из наиболее целесообразных подходов для практической реализации таких многоракурсных технологий стал подход, в котором на сторону декодера передают только ограниченное количество ракурсов, например моно- или стереоскопическое видеоизображение плюс некоторые вспомогательные данные, а все необходимые ракурсы для отображения на дисплее затем отрисовываются (т.е. синтезируются) локально в декодере.
[0177] Ракурс может быть определен как последовательность изображений, представляющих одну камеру или одну точку зрения. Изображения, представляющие ракурс, могут при этом называться компонентами ракурса. Другими словами, «компонент ракурса» может быть определен как кодированное представление ракурса в одном блоке доступа. При многоракурсном видеокодировании в битовый поток кодируют более одного ракурса. Поскольку ракурсы, как правило, предназначены для отображения на стереоскопическом или многоракурсном автостереоскопическом дисплее, или предназначены для использования в других 3D-системах, они чаще всего относятся к одной и той же сцене и при этом их содержимое частично перекрывается, несмотря на то, что они являются представлением различных точек наблюдения за объектом съемки. Следовательно, при многоракурсном видеокодировании может применяться межракурсное предсказание, что позволяет использовать корреляцию между ракурсами для повышения эффективности сжатия. Один из методов реализации межракурсного предсказания - включение одного или более из декодированных изображений одного или более из других ракурсов в список (или списки) опорных изображений для кодируемого или декодируемого изображения в первом ракурсе. Понятие масштабируемости ракурсов может относиться к таким битовым потокам многоракурсного видеокодирования, или многоракурсного видео, которые допускают удаление, или отбрасывание, одного или более из кодированных ракурсов, в результате чего сохраняется соответствие стандарту, а видеоинформация оказывается представленной с помощью меньшего количества ракурсов, чем исходная информация.
[0178] Под кодированием на основе области интереса (Region of Interest, ROI) может пониматься кодирование некоторой области в видеоизображении с более высокой детализацией. Для определения ROI-областей во входных кодируемых изображениях существуют несколько различных методах, применяемых в кодерах и/или других узлах. К примеру, может применяться распознавание лиц, и лица могут быть определены в качестве ROI-областей. Дополнительно или альтернативно, в другом примере объекты, находящиеся в фокусе, могут выявляться и определяться в качестве ROI-областей, а объекты не в фокусе могут быть определены, как находящиеся вне ROI-областей. Дополнительно или альтернативно, в другом примере, может оцениваться, или быть известным, расстояние до объектов, например, на основе показаний датчика глубины, и при этом ROI-области могут быть определены как соответствующие объектам, расположенным ближе к камере относительно фона.
[0179] ROI-масштабируемость может быть определена как тип масштабируемости, в котором уточняющий уровень уточняет только часть изображения опорного уровня, например, по пространственному разрешению, по качеству, по битовой глубине и/или в отношении других масштабируемых величин. ROI-масштабируемость может применяться совместно с другими типами масштабируемости, при этом можно сказать, что она создает другую классификацию типов масштабируемости. Существуют несколько различных применений ROI-кодирования с различными требованиями, которые могут быть реализованы с использованием ROI-масштабируемости. К примеру, уточняющий уровень может передаваться с целью повышения качества и/или разрешения некоторой области в базовом уровне. Декодер, который принимает одновременно битовые потоки уточняющего и базового уровней, может декодировать оба уровня и накладывать декодированные изображения друг на друга, отображая результирующее изображение.
[0180] Пространственное соотношение между изображением уточняющего уровня и областью опорного уровня, или, что аналогично, областью опорного уровня, и изображением базового уровня, может быть указано кодером и/или декодировано декодером с помощью, например, так называемых смещений масштабированного опорного уровня. Смещения масштабированного опорного уровня можно трактовать как элементы, определяющие положение угловых отсчетов опорного уровня, имеющего повышенное разрешение, относительно соответствующих угловых элементов изображения уточняющего уровня. Значения смещений могут иметь знак, что позволяет применять значения смещения для обоих типов расширенной пространственной масштабируемости, в соответствии с иллюстрацией фиг. 19а и фиг. 19b. В случае масштабируемости областей интереса (фиг. 19а) изображение 110 уточняющего уровня соответствует области 112 изображения 116 опорного уровня, а смещения масштабированного опорного уровня указывают на углы изображения опорного уровня, имеющего повышенное разрешение, которое занимает область масштабированного опорного уровня. Смещения масштабированного опорного уровня могут быть указаны при помощи четырех синтаксических элементов (например, для каждой пары из уточняющего уровня и его опорного уровня), которые могут иметь наименования scaled_ref_layer_top_offset 118, scaled_ref_layer_bottom_offset 120, scaled_ref_layer_right_offset 122 и scaled_ref_layer_left_offset 124. Имеющая повышенное разрешение область опорного уровня может быть определена кодером и/или декодером путем пропорционального уменьшения смещений масштабированного опорного уровня согласно отношению между высотой или шириной изображения уточняющего уровня и высотой или шириной изображения опорного уровня с повышенным разрешением соответственно. Пропорционально уменьшенное смещение масштабированного опорного уровня может затем использоваться для получения области опорного уровня, которая имеет повышенное разрешение, и/или для определения того, какие из отсчетов опорного уровня сорасположены с заданными элементами изображения опорного уровня. В случае, когда изображение опорного уровня соответствует области изображения уточняющего уровня (фиг. 19b), смещения масштабированного опорного уровня указывают на углы изображения опорного уровня, имеющего повышенное разрешение, которое расположено внутри этой области изображения уточняющего уровня. Смещение масштабированного опорного уровня может использоваться для определения, какие из отсчетов опорного уровня, имеющего повышенное разрешение, сорасположены с заданными элементами изображения уточняющего уровня. Возможно также комбинированное применение расширенной пространственной масштабируемости, то есть, один из типов может применяться в горизонтальном направлении, а второй - в вертикальном. Смещения масштабированного опорного уровня могут указываться кодером и/или декодироваться кодером, например, в синтаксической структуре, относящейся к последовательности, такой как набор SPS и/или VPS. Точность смещения масштабированного опорного уровня может быть заранее заданной, например, в стандарте кодирования, и/или задана кодером и/или декодирована декодером из битового потока. К примеру, может применяться точность, равная 1/16 от размера отсчета цветности в уточняющем уровне. Смещения масштабированного опорного уровня могут указываться, декодироваться и/или применяться в процессе кодирования, декодирования и/или отображения, только когда между двумя уровнями не выполняется межуровневое предсказание.
[0181] Некоторые из стандартов кодирования допускают также создание масштабируемых битовых потоков. Корректное декодированное представление может быть получено, даже если декодируются только определенные части масштабируемого битового потока. Масштабируемые битовые потоки могут применяться, например, для адаптации битовых скоростей заранее кодированных потоков одноадресного вещания в сервере потоковой передачи или для передачи одного битового потока в оконечные устройства, имеющие различные возможности и/или находящиеся в различных сетевых условиях. Список других случаев применения масштабируемого видеокодирования приведен в выходном документе N5540 ISO/IEC JTC1 SC29 WG11 (MPEG), озаглавленном «Приложения и требования масштабируемого видеокодирования» ("Applications and Requirements for Scalable Video Coding"), 64-ая встреча группы MPEG, 10-14 марта 2003 года, Паттайя, Таиланд.
[0182] В стандарт кодирования могут входить процедуры извлечения битовых подпотоков, например, такие процедуры определены в стандартах SVC, MVC и HEVC. Под процедурой извлечения битового подтопотка понимается преобразование битового потока, как правило при помощи удаления NAL-блоков, с получением битового подпотока. Такой битовый подпоток остается соответствующим стандарту. Например, в проекте стандарта HEVC битовый поток, формируемый исключением всех NAL-блоков VCL, чей temporal_id больше выбранного значения, и включением всех остальных NAL-блоков VCL, остается соответствующим стандарту. В стандарте HEVC процедура извлечения битового подпотока принимает в качестве входных данных Temporalld и/или список значений nuh_layer_id и выдает битовый подпоток (называемый также подмножеством битового потока), полученный при помощи удаления из битового потока всех NAL-блоков с Temporalld большим, чем значение поданного на вход Temporalld, или значение nuh_layer_id которых не находится среди значений во входном списке значений nuh_layer_id.
[0183] В стандарте или системе кодирования может упоминаться такое выражение как «рабочая точка» (operation point), или аналогичный термин, который может указывать на масштабируемые уровни и/или подуровни, для которых выполняется декодирование и/или которые могут быть связаны с битовым подпотоком, включающим декодируемые масштабируемые уровни и/или подуровни. Ниже приведены несколько неограничивающих определений рабочей точки.
[0184] В стандарте HEVC рабочая точка определена как битовый поток, созданный на основе другого битового потока при помощи процедуры извлечения битового подпотока, входными данными которой являются упомянутый другой битовый поток, целевой наивысший Temporalld, и список идентификаторов целевых уровней.
[0185] Для этих наборов уровней в наборе VPS стандарта HEVC определены наборы уровней и HRD-параметры. Набор уровней может использоваться в качестве списка идентификаторов целевых уровней в процедуре извлечения подпотока.
[0186] В стандартах SHVC и MV-HEVC определение рабочей точки может включать анализ набора целевых выходных уровней. В стандарте SHVC и MV-HEVC рабочая точка определена как битовый поток, созданный на основе другого битового потока при помощи процедуры извлечения битового подпотока, входными данными которой являются упомянутый другой битовый поток, целевой наивысший Temporalld, и список идентификаторов целевых уровней, и который связан с набором целевых выходных уровней.
[0187] Набор выходных уровней может быть определен как набор уровней, состоящий из уровней из одного или более заданных наборов уровней, при этом для одного или более уровней в этом наборе уровней указано, что они являются выходными уровнями. Выходной уровень может быть определен как уровень из набора выходных уровней, который выводят при работе декодера и/или HRD-декодера с использованием данного набора выходных уровней в качестве целевого набора выходных уровней. В стандарте MV-HEVC/SHVC переменная TargetOptLayerSetldx может определять, какой из наборов выходных уровней является целевым, при помощи назначения TargetOptLayerSetldx равной порядковому номеру набора выходных уровней, который является целевым набором выходных уровней. Значение TargetOptLayerSetldx может назначаться, например, HRD-декодером, и/или может назначаться при помощи внешних средств, к примеру, проигрывателем или аналогичным элементом, при помощи интерфейса, обеспеченного декодером. В стандарте MV-HEVC/SHVC целевой выходной уровень может быть определен как уровень, который подлежит выводу и является одним из выходных уровней в наборе выходных уровней с порядковым номером olsldx, то есть, TargetOptLayerSetldx для которого равен olsldx.
[0188] В MV-HEVC/SHVC возможно вычисление «заданного по умолчанию» набора выходных уровней для каждого из наборов уровней, определенных в наборе VPS, с использованием специального механизма или при помощи явного указания на выходные уровни. Могут быть определены два специальных механизма: в наборе VPS может быть определено, что каждый уровень является выходным уровнем, или что только наивысший уровень является выходным уровнем в «заданном по умолчанию» наборе выходных уровней.
Если используются упомянутые специальные механизмы, то уровни вспомогательных изображений могут быть исключены из рассмотрения при определении, является ли уровень выходным. При этом для «заданных по умолчанию» наборов выходных уровней расширение VPS позволяет задать дополнительные наборы выходных уровней, в для выбранных выходных уровней указывают на то, что они являются выходными.
[0189] В стандарте MV-HEVC/SHVC с каждым из наборов выходных уровней связана синтаксическая структура profile_tier_level(). Точнее, в расширении VPS присутствует список из синтаксических структур profile_tier_level(), при этом порядковый номер применимого profile_tier_level() внутри списка задают для каждого набора выходных уровней. Другими словами, для каждого набора выходных уровней указывают комбинацию из профиля, яруса и уровня стандарта.
[0190] Постоянный набор выходных уровней хорошо подходит для сценариев применения и битовых потоков, в которых, в каждом блоке доступа, наивысший уровень остается неизменным, однако при этом не поддерживаются сценарии применения в которых наивысший уровень меняется при переходе между блоками доступа. Соответственно, было предложено, чтобы кодеры могли определять использование альтернативных выходных уровней внутри битового потока, и при этом, если будет указано на необходимость применения альтернативных выходных уровней, декодеры должны выводить декодированное изображение из альтернативного выходного уровня, когда отсутствует изображение в выходном уровне внутри того же блока доступа. Существуют несколько возможных способов указания на альтернативные выходные уровни. Например, каждый из выходных уровней в наборе выходных уровней может быть связан с минимальным альтернативным выходным уровнем, и специальный синтаксический элемент (или элементы), относящийся к выходному уровню, может использоваться для указания на альтернативный выходной уровень (или уровни) для всех выходных уровней. Альтернативно, применение механизма альтернативных выходных уровней может быть ограничено только наборами выходных уровней, содержащих ровно один выходной уровень, и при этом специальный синтаксический элемент (или элементы), относящийся к выходному уровню, может использоваться для указания на альтернативный выходного уровень (или уровни) для этого набора выходных уровней. Альтернативно, применение механизма альтернативных выходных уровней может быть ограничено только битовыми потоками или последовательностями CVS, в которых все указанные наборы выходных уровней содержат ровно один выходной уровень, и при этом указание на альтернативный выходной уровень (или уровни) может выполняться при помощи синтаксического элемента (или элементов), относящихся к битовому потоку или к CVS-последовательности. Указание на альтернативный выходной уровень (или уровни) может быть выполнено, например, при помощи перечисления, к примеру, в наборе VPS, альтернативных выходных уровней (к примеру, с помощью их идентификаторов уровней или порядковых номеров в списке непосредственных или косвенных опорных уровней), при помощи указания на минимальный альтернативный выходной уровень (к примеру, с помощью его идентификатора уровня или порядкового номера в списке непосредственных или косвенных опорных уровней) или при помощи флага, указывающего на то, что какой-либо из непосредственных или косвенных опорных уровней является альтернативным выходным уровнем. Если разрешено использование более чем одного альтернативного выходного уровня, может быть указано на то, что выводу подлежит первое прямое или косвенное опорное изображение межуровневого предсказания в блоке доступа, в порядке убывания идентификаторов уровней, вплоть до указанного минимального альтернативного выходного уровня.
[0191] Ниже приведен один из вариантов определения рабочей точки в расширении MVC. Операционную точку идентифицируют при помощи значения temporal_id, представляющего целевой временной уровень, и набора значений view_id, представляющего целевые выходные ракурсы. С каждым подмножеством битового потока связана одна рабочая точка, при этом подмножество битового потока состоит из целевых выходных ракурсов и всех остальных ракурсов, от которых зависят целевые выходные ракурсы, и его получают при помощи процедуры извлечения битового подпотока с использованием, в качестве входных данных процедуры, tldTarget, равного значению temporal_id, и списка viewldTargetList, состоящего из набора значений view_id. С одним и тем же подмножеством битового потока может быть связано более одной рабочей точки. Когда «операционная точка декодирована», может быть декодировано подмножество битового потока, соответствующее этой операционной точке, и затем, могут быть выведены целевые выходные ракурсы.
[0192] Как отмечалось выше, MVC является одним из расширений стандарта H.264/AVC. Многие из определений, понятий, синтаксических структур, часть семантики и процедур декодирования H.264/AVC применимы также к MVC полностью или с некоторыми обобщениями, или с ограничениями. Далее описаны некоторые и определений, понятий, синтаксических структур, семантики и процедур декодирования MVC.
[0193] Блок доступа в MVC определен как набор NAL-блоков, следующих друг за другом в порядке декодирования и содержащих в точности одно первично кодированное изображение, состоящее из одного или более компонентов ракурса. В дополнение к первично кодированному изображению блок доступа может также включать одно или более избыточно кодированных изображений, одно внешне кодированное изображение или другие NAL-блоки, не содержащие слайсов или разбиений данных слайсов кодированного изображения. В результате декодирования блока доступа получается одно декодированное изображение, состоящее из одного или более декодированных компонентов ракурса, если не происходит ошибок декодирования, т.е. ошибок битового потока или других ошибок, которые могут повлиять на декодирование. Другими словами блок доступа в MVC содержит компоненты ракурса для ракурсов в одном моменте времени вывода.
[0194] Под компонентом ракурса в может пониматься кодированное представление ракурса в одном блоке доступа.
[0195] В MVC может использоваться межракурсное предсказание, под которым может пониматься предсказание компонента ракурса на основе декодированных значений различных компонентов ракурса того же блока доступа. В MVC межракурсное предсказание реализуется аналогично внешнему предсказанию. К примеру, опорные изображения межракурсного предсказания помещаются в тот же список (или списки) опорных изображений, что и опорные изображения для внешнего предсказания, а указатель на опорное изображение, как и на вектор движения, кодируются или вычисляются аналогично для опорных изображений межракурсного предсказания и внешнего предсказания.
[0196] Якорное изображение в MVC - это кодированное изображение, для всех слайсов которого в качестве опорных могут использоваться только слайсы в том же блоке кодирования, т.е. межракурсное предсказание может использоваться, но внешнее предсказание не используется, при этом для всех последующих изображений в порядке вывода не используется внешнее предсказание на основе изображений, предшествующих этому кодированному изображению в порядке декодирования. Межракурсное предсказание может использоваться для компонентов ракурса IDR, являющихся частью не-базового ракурса. Базовый ракурс в MVC - это ракурс, который имеет минимальное значение порядкового номера ракурса в кодированной видеопоследовательности. Базовый ракурс может быть декодирован независимо от остальных видов, при этом для него не используется межракурсное предсказание. Базовый ракурс может декодироваться при помощи декодеров, соответствующих стандарту H.264/AVC, которые поддерживают только одноракурсные профили стандарта, например, базовый профиль (Baseline Profile) или верхний профиль (High Profile) стандарта H.264/AVC.
[0197] В стандарте MVC во многих из подпроцедур процедуры декодирования MVC используются соответствующие подпроцедуры стандарта H.264/AVC с заменой терминов «изображение», «кадр» и «поле» в спецификации этих процедур стандарта H.264/AVC на «компонент ракурса», «компонент ракурса кадра» и компонент ракурса поля» соответственно. Аналогично, термины «изображение», «кадр» и «поле» далее часто используются как обозначающие «компонент ракурса», «компонент ракурса кадра» и «компонент ракурса поля» соответственно.
[0198] В контексте многоракурсного видеокодирования порядковый номер ракурса может быть определен, как порядковый номер, который указывает на порядок декодирования или порядок битового потока для компонентов ракурса в блоке доступа. В стандарте MVC на отношения зависимости между ракурсами указывают в MVC-расширении набора параметров последовательности, которое включают в набор параметров последовательности. Согласно стандарту MVC все MVC-расширения набора параметров последовательности, на которые ссылается кодированная видеопоследовательности, должны быть идентичными.
[0199] Ракурсом текстуры называется ракурс, который является представлением обычного видеоконтента, например, записанного с использованием обычной камеры, и как правило подходит для отрисовки на дисплее. Ракурс текстуры как правило включает изображения, имеющие три составляющие, одну составляющую яркости и две составляющие цветности. В дальнейшем, как правило, под изображением текстуры понимаются все его составляющие, или составляющие цветности, если не указано обратное, например, с использованием таких терминов как изображение яркости текстуры и изображение цветности текстуры.
[0200] Под ракурсом глубины понимают ракурс, который является представлением информации о расстоянии отсчетов текстуры от датчика камеры, информации о диспарантности, или параллаксе, между одним отсчетом текстуры и соответствующим отсчетом текстуры в другом ракурсе, или аналогичной информации. Ракурс текстуры может включать изображения текстуры (также называемые «картами тестуры»), составляющая которых аналогична составляющей яркости для ракурсов текстуры. Карта глубины - это изображение с информацией глубины, или аналогичной информацией, для каждого пикселя. Например, каждый отсчет в карте глубины отражает расстояние соответствующего отсчета (или отсчетов) текстуры от плоскости расположения камеры. Другими словами, если ось z лежит на оси съемки камер (и следовательно, перпендикулярно плоскости расположения камер), то каждый элемент карты глубины представляет собой координату на оси z. Семантика значений глубины может, например, включать описанное ниже.
1. Каждое значение отсчета яркости в кодированном компоненте ракурса глубины представляет собой значение, обратное реальной дистанции (Z), т.е. 1/Z, нормализованное в динамическом диапазоне отсчетов яркости, то есть, в диапазоне от 0 до 255 включительно для 8-битного представления яркости. Нормализация может выполняться таким образом, чтобы значения 1/Z были одинаковыми для каждого значения диспарантности.
2. Каждое значение отсчета яркости в кодированном компоненте ракурса глубины представляет собой значение, обратное реальной дистанции (Z), т.е. 1/Z, которое отображают на динамический диапазон отсчетов яркости, например, диапазон от 0 до 255 включительно для 8-битного представления яркости, с использованием функции f(1/Z) отображения, например, кусочно-линейного отображения. Другими словами, значения карты глубины имеют своим результатом применение функции f(1/Z).
3. Каждое значение отсчета яркости в кодированном компоненте ракурса глубины представляет собой значение реальной дистанции (Z), нормализованное в динамическом диапазоне отсчетов яркости, то есть, в диапазоне от 0 до 255 включительно для 8-битного представления яркости.
4. Каждое значение отсчета яркости в кодированном компоненте глубины является представлением значения диспарантности или глубины между текущим ракурсом глубины и другим, указанным или найденным ракурсом глубины или местоположением глубины.
[0201] Семантика значений карты глубины может быть указана в битовом потоке, например, в синтаксической структуре набора видеопараметров, синтаксической структуре набора параметров последовательности, синтаксической структуре информации об используемости видео, синтаксической структуре набора параметров изображения, синтаксической структуре набора параметров камеры/глубины/адаптации, сообщении дополнительной уточняющей информации и т.п.
[0202] Под видеоинформацией с уточнением глубины понимается видеоинформация текстуры, имеющая один или более ракурсов, связанных с видеоинформацией глубины (имеющим одно или более ракурсов глубины). Для отображения видеоинформации с уточнением глубины может использоваться несколько различных подходов, которые включают использованием технологий «видео плюс глубина» (video plus depth, V+D), «многоракурсное видео плюс глубина» (multiview video plus depth, MVD) и видео с многоуровневой глубиной (layered depth video, LDV). При представлении типа «видео плюс глубина» (V+D) один ракурс текстуры и соответствующий ракурс глубины представлены как последовательность из изображения текстуры и изображений глубины соответственно. Представление типа MVD содержит набор ракурсов текстуры и соответствующие ракурсы глубины. В представлении типа LDV текстура и глубина центрального ракурса представлены традиционным образом, тогда как текстура и глубина других ракурсов частично представлена и охватывается только неперекрытыми областями, требуемыми для корректного построения промежуточных ракурсов.
[0203] «Компонент текстуры» может быть определен как кодированное представление текстуры некоторого ракурса в одном блоке доступа. Компоненты ракурса текстуры в битовом потоке видео с утонением глубины могут кодироваться методом, совместимым с одноракурсным битовым потоком текстуры или многоракурсным битовым потоком текстуры, благодаря чему одноракурсный или многоракурсный декодер может декодировать ракурсы текстуры, даже если он не способен декодировать ракурсы глубины. К примеру, декодер H.264/AVC может декодировать один ракурс текстуры из битового потока H.264/AVC с уточнением глубины. Альтернативно, компоненты ракурса текстуры могут кодироваться таким образом, чтобы декодер, способный декодировать одноракурсную или многоракурсную текстуру, например, декодер H.264/AVC или MVC, не был способен декодировать компоненты ракурса текстуры, например, по той причине, что для них применяют инструменты кодирования глубины. «Компонент глубины» может быть определен как кодированное представление глубины некоторого ракурса в одном блоке доступа. Парой компонентов ракурса могут быть названы компонент ракурса текстуры и компонент ракурса глубины для одного ракурса в одном блоке доступа.
[0204] Видео с уточнением глубины может кодироваться таким образом, что текстура и глубина кодируются независимо друг от друга. Например, ракурсы текстуры могут кодироваться как один битовый поток MVC, а ракурсы глубины могут кодироваться как другой поток MVC. Видео с уточнением глубины может также кодироваться методом, при котором текстура и глубина кодируются совместно. При применении совместного кодирования ракурсов текстуры и ракурсов глубины, часть декодируемых отсчетов изображения текстуры или элементов данных для декодирования изображения текстуры предсказывается или вычисляется на основе части декодированных значений изображения глубины или элементов данных, полученных в процессе декодирования изображения глубины. Альтернативно или дополнительно, часть декодируемых значений изображения глубины или элементов данных для декодирования изображения глубины, предсказывается или вычисляется на основе части декодированных значений изображения текстуры или элементов данных, полученных в процессе декодирования изображения текстуры. В другом варианте, кодированные видеоданные текстуры и кодированные видеоданные глубины не предсказывают на основе друг друга или не кодируют/декодируют на основе друг друга, однако кодированные ракурсы текстуры и глубины могут мультиплексироваться в один битовый поток при кодировании и демультиплексироваться из битового потока при декодировании. В еще одном из вариантов, несмотря на то, что кодированные видеоданные текстуры не предсказывают на основе кодированных видеоданных глубины, например, в нижележащем уровне слайса, некоторые из высокоуровневых структур кодирования ракурсов текстуры и ракурсов глубины могут быть использоваться совместно или предсказываться на основе друг друга. К примеру, заголовок кодированного слайса глубины может предсказываться на основе заголовка кодированного слайса текстуры. При этом некоторые из наборов параметров могут применяться одновременно как для кодированных ракурсов текстуры, так и для кодированных ракурсов глубины.
[0205] Масштабируемость может обеспечиваться двумя основными способами: либо при помощи введения новых режимов кодирования для выполнения предсказания значения пикселей или синтаксических элементов на основе нижних уровней кодирования масштабируемого представления, либо при помощи помещения изображений нижнего уровня в буфер опорных изображений (например, буфер декодированных изображений (decoded picture buffer, DPB)) вышележащего уровня. Первый подход может дать большую гибкость, и следовательно, в большинстве случаев позволяет получить более эффективное кодирование. Однако второй подход, т.е. масштабируемость, основанная на опорных кадрах, может быть очень эффективно реализована, лишь с минимальными изменениями в одноуровневых кодеках и с сохранением большинства преимуществ в эффективности кодирования. По существу, кодек с масштабируемостью на основе опорных кадров может быть реализован с применением одинаковых аппаратных или программных реализаций для всех уровней, необходимо лишь решить вопрос управления буфером DPB с помощью внешних средств.
[0206] Кодер масштабируемого видеокодирования с масштабируемостью качества (также называемой масштабируемостью соотношения сигнал/шум, или SNR (Signal-to-Noise)) и/или пространственной масштабируемостью, может быть реализован описанным ниже способом. Для базового уровня кодирования могут применяться традиционные видеокодер и видеодекодер без масштабируемости. Восстановленные или декодированные изображения базового уровня вносят в буфер опорных изображений и/или в список опорных изображений для уточняющего уровня. В случае пространственной масштабируемости может выполняться передискретизация (увеличение разрешения) восстановленного, или декодированного, изображения базового уровня перед его добавлением в список опорных изображений для изображения уточняющего уровня. Декодированные изображения базового уровня могут вноситься в список (или списки) опорных изображений для кодирования/декодирования изображения уточняющего уровня, аналогично декодированным опорным изображениям уточняющего уровня. Следовательно, в кодере опорное изображение базового уровня может выбираться в качестве опорного для внешнего предсказания, при этом указание на его использование, как правило, выполняют с помощью указателя на опорное изображение в кодированном битовом потоке. В декодере из битового потока, например, на основе указателя на опорное изображение декодируется информация о том, что в качестве опорного изображения внешнего предсказания для уточняющего уровня было использовано изображение базового уровня. При использовании декодированного изображения базового уровня в качестве опорного для предсказания уточняющего уровня, оно называется опорным изображением межуровнего предсказания.
[0207] В предыдущем абзаце было описан видеокодек с масштабируемостью, в котором применялись два масштабируемых уровня: уточняющий уровень и базовый уровень. Нужно понимать, что это описание может быть обобщено для любых двух уровней в иерархии масштабируемости с более чем двумя уровнями. В таком случае второй уточняющий уровень может зависеть от первого уточняющего уровня в процессе кодирования и/или декодирования, и соответственно, первый уточняющий уровень может считаться базовым уровнем для кодирования и/или декодирования второго уточняющего уровня. Также, нужно понимать, что в буфере опорных изображений или списках опорных изображений уточняющего уровня могут присутствовать опорные изображения межуровневого предсказания более чем из одного уровня кодирования, и при этом каждое из этих опорных изображений межуровневого предсказания может рассматриваться как располагающееся в базовом, или опорном, уровне для кодируемого и/или декодируемого уточняющего уровня.
[0208] Схема масштабируемого кодирования и/или декодирования может включать многопроходное кодирование и/или декодирование, которые описаны ниже. При кодировании и декодировании изображение базового уровня может восстанавливаться, или декодироваться, с целью его использования в качестве опорного изображения компенсации движения для последующих изображений в порядке кодирования, или декодирования, в том уровне кодирования, или в качестве опорного для межуровневого (или межракурсного, или межкомпонентного) предсказания. Восстановленное, или декодированное, изображение базового уровня может сохраняться в буфер DPB. Изображение уточняющего уровня, аналогично, может восстанавливаться, или декодироваться, с целью его использования в качестве опорного изображения компенсации движения для последующих изображений в порядке кодирования, или декодирования, в том же уровне кодирования, или в качестве опорного для межуровневого (или межракурсного или межкомпонентного) предсказания более высоких уточняющих уровней, если они присутствуют. В дополнение к восстановленным, или декодированным, значениям отсчетов, для межуровневого (или межкомпонентного, или межракурсного) предсказания могут также использоваться значения синтаксических элементов базового, или опорного, уровня или переменные, полученные на основе значений синтаксических элементов базового, или опорного, уровня.
[0209] В некоторых случаях данные в уточняющем уровне могут отсекаться после определенного местоположения, или даже после произвольной позиции, при этом каждая позиция отсечения может включать дополнительные данные, представляющие все более высокое визуальное качество. Такая масштабируемость называется мелкозернистой (или мелкогранулярной) масштабируемостью (fine grained (granularity) scalability, FGS).
[0210] В стандарте SVC используется механизм межуровнего предсказания, в котором часть информации может предсказываться на основе других уровней кодирования, не являющихся текущим восстанавливаемым уровнем, или следующим за ним нижним уровнем. Информация, предсказываемая с помощью механизма межуровневого предсказания включает внутреннюю текстуру, информацию о движении и данные остатка. Межуровневое предсказание движения включает предсказание режима кодирования блока, информации заголовка и т.п., при этом движение нижних уровней кодирования может использоваться для предсказания движения верхних уровней. В случае внутреннего кодирования возможно предсказание на основе соседних или сорасположенных макроблоков нижних уровней. В таких методах предсказания не применяется информация из ранее закодированных блоков доступа и следовательно, они называются методами внутреннего предсказания. Кроме того, данные остатка предсказания нижних уровней кодирования также могут применяться для предсказания текущего уровня.
[0211] Масштабируемое видео(де)кодирование может быть реализовано на основе принципа, получившего название однопроходного декодирования, при котором декодируемые опорные изображения восстанавливают только для наивысшего декодируемого уровня, тогда как изображения в нижележащих уровнях могут не декодироваться полностью или могут отбрасываться после их использования для межуровневого предсказания. При однопроходном декодировании декодер выполняет компенсацию движения и восстановление изображения полностью только для уровня масштабирования, необходимого для воспроизведения (который называют «требуемым уровнем» или «целевым уровнем»), за счет чего значительно снижается сложность декодирования, по сравнению с многопроходным декодированием. Все уровни кодирования, помимо требуемого, не обязательно должны быть декодированы полностью, поскольку для восстановления требуемого уровня кодирования не нужны все данные кодированного изображения, или не нужна как минимум часть этих данных. Однако нижележащие уровни (по сравнению с целевым уровнем) могут использоваться для межуровневого предсказания синтаксиса или параметров, например, для межуровневого предсказания движения. В дополнение или альтернативно, нижележащие уровни могут использоваться для межуровневого внутреннего предсказания, и следовательно, может быть необходимо декодирование внутренне-кодируемых блоков нижележащих уровней. Дополнительно или альтернативно, может применяться межуровневое предсказание остатка, при котором информация остатка нижележащих уровней может использоваться для декодирования целевого уровня, и при этом может требоваться декодирование или восстановление информации остатка. В некоторых схемах кодирования для кодирования большинства изображений достаточно одной петли декодирования, тогда как вторая петля декодирования может применяться, избирательно, для восстановления так называемых базовых представлений (т.е. декодированных изображений базового уровня), которые могут быть необходимы в качестве опорных для предсказания, но не для вывода или отображения.
[0212] В стандарте SVC допускается применение однопроходного декодирования. Возможность его обеспечивается с помощью режима внутреннего предсказания текстуры, за счет чего межуровневое предсказание внутренней текстуры может применяться к макроблокам, для которых соответствующая группа пикселей базового уровня расположена внутри макроблоков, предсказываемых внутренне. В то же время для этих внутренне предсказываемых макроблоков в базовом уровне кодирования используется ограниченное внутреннее предсказание (например, они имеют синтаксический элемент '"constrained_intra_pred_flag", равный 1). При однопроходном декодировании декодер выполняет компенсацию движения и восстановление изображения полностью только для уровня масштабирования, необходимого для воспроизведения (который называют «требуемым уровнем» или «целевым уровнем»), за счет чего значительно снижается сложность декодирования. Все уровни кодирования, помимо требуемого, не обязательно должны быть декодированы полностью, поскольку часть данных, или все данные их макроблоков не используются для межуровнего предсказания (будь это межуровневое предсказание внутренней текстуры, межуровневое предсказание движения или межуровневое предсказание остатка) и не являются необходимыми для восстановления требуемого уровня.
[0213] Одна петля декодирования необходима для декодирования большинства изображений, тогда как вторая петля декодирования выборочно применяется для восстановления базовых представлений, необходимых как опорных для предсказания, но не для вывода или отображения, при этом они восстанавливаются только для так называемых ключевых изображений (для которых флаг "store_ref_base_pic_flag" установлен в значение 1).
[0214] Масштабирование FGS входило в некоторые из проектов стандарта SVC, но в конечном итоге не было включено в принятый стандарт. Затем масштабируемость FGS обсуждалась далее в контексте некоторых версий проекта стандарта SVC. Масштабируемость, обеспечиваемая уточняющими уровнями, которые не могут быть отсечены, называется грубозернистой (или грубогранулярной) масштабируемостью (coarse-grained (granularity) scalability, CGS). Оно включает в себя одновременно традиционное масштабирование качества (SNR) и пространственное масштабирование. Стандарт SVC поддерживает также так называемое среднезернистое масштабирование (medium-grained scalability, MGS), при котором изображения, повышающие качество, кодируются аналогично масштабируемым изображениям уровней SNR, но указания на них выполняют с помощью высокоуровневых синтаксических элементов, аналогичных изображениям уровней FGS, при помощи назначения синтаксическому элементу quality_id значения, большего 0.
[0215] Структура масштабирования в стандарте SVC может быть охарактеризована тремя синтаксическими элементами: "temporal_id," "dependency_id" и "quality_id." Синтаксический элемент "temporal_id" используется для указания иерархии временной масштабируемости, или, косвенно, частоты смены кадров. Представление уровня масштабирования, включающее изображения с меньшим максимальным значением '"temporal_id" будет иметь меньшую частоту смену кадров, чем представление уровня масштабирования, включающее изображение с большим максимальным значением "temporal_id". Каждый временной уровень зависит, как правило, от нижних временных уровней (т.е. временных уровней с меньшими значениями "temporal_id"), но не зависит от вышележащих временных уровней. Синтаксический элемент "dependency_id" используется для указания иерархии зависимости межуровневого кодирования CGS (которая, как отмечалось ранее, включает и SNR, и пространственную масштабируемость). В любом местоположении временного слоя изображение с меньшим значением '"dependency_id" может использоваться для межуровневого предсказания при кодировании изображения с большим значением '"dependency_id". Синтаксический элемент "quality_id" используется для указания позиции уровня FGS или MGS в иерархии качества. В любой момент времени видеопоследовательности, при идентичном значением '"dependency_id", для межуровневого предсказания изображения с '"quality_id", равным QL, может быть использовано изображение с "quality_id", равным QL-1. Кодированный слайс с "quality_id", большим 0, может кодироваться либо как отсекаемый FGS-слайс, либо как неотсекаемый MGS-слайс.
[0216] Для простоты все блоки данных (например, в контексте SVC - блоки сетевой абстракции, NAL-блоки) в одном блоке доступа, имеющие одинаковое значение "dependency_id", называются блоком зависимости или представлением зависимости. В одном блоке зависимости все блоки данных с одинаковыми значениями "quality_id" называются блоком качества или представлением уровня кодирования.
[0217] Базовое представление, также называемое декодированным базовым изображением, представляет собой декодированное изображение, полученное в результате декодирования NAL-блоков уровня видеокодирования (Video Coding Layer, VCL) блока зависимости, чей '"quality_id" равен 0 и для которого флаг "store_ref_basepic_flag" установлен равным 1. Уточняющее представление, также называемое декодированным изображением, получают в результате обычного процесса декодирования, при котором декодируются все представления уровней, присутствующие для самого верхнего представления зависимости.
[0218] Как отмечалось выше, масштабируемость CGS включает и пространственную масштабируемость, и SNR-масштабируемость. Пространственная масштабируемость исходно предназначена для поддержки представлений видеоинформации с различным разрешением. NAL-блоки VCL для каждого момента времени кодируются в одном блоке доступа, причем эти NAL-блоки VCL могут соответствовать различным разрешениям. В процессе декодирования NAL-блоки VCL низкого разрешения дают поле движения и остаток, который опционально может наследоваться при окончательном декодировании и восстановлении изображения высокого разрешения. По сравнению с предшествующими стандартами сжатия видеоинформации пространственная масштабируемость в стандарте SVC была обобщена и позволяет базовому уроню быть кадрированной, или зуммированной, версией уточняющего уровня.
[0219] Уровни качества MGS указываются с помощью "quality_id", аналогично уровням качества FGS. Для каждого блока зависимости (с одинаковыми "dependency_id") имеется уровень с "quality_id", равным 0, и также могут присутствовать другие уровни, с "quality_id", большим 0. Эти уровни, имеющие "quality_id", больший 0, являются либом уровнями MGS, либо уровнями FGS, в зависимости оттого, являются ли слайсы кодируемыми как отсекаемые слайсы.
[0220] В базовой форме уточняющих уровней FGS используется только межуровневое предсказание. Следовательно, уточняющие уровни FGS могут свободно отсекаться, без риска распространения ошибок в декодированной последовательности. Однако такая базовая форма FGS страдает низкой эффективностью сжатия. Это проблема возникает по причине использования изображений с низким качеством как опорных при внешнем предсказании. Соответственно, было предложено, чтобы в качестве опорных изображений внешнего предсказания использовались уточняемые с помощью FGS изображения. Однако при отбросе части данных FGS, это может приводить к несовпадению кодирования-декодирования, которое называется дрейфом.
[0221] Одна из особенностей проекта стандарта SVC заключается в том, что NAL-блоки FGS могут свободно отсекаться или отбрасываться, а особенность стандарта SVCV - NAL-блоки могут свободно отбрасываться MGS (но не могут отсекаться), без нарушения соответствия битового потока стандарту. Как обсуждалось выше, если эти данные FGS или MGS использовались как опорные для внешнего предсказания при кодировании, то отбрасывание или отсечение этих данных приведет к несовпадению декодированных изображений на стороне кодера и декодера. Такое несовпадение также называют дрейфом.
[0222] Для контроля дрейфа, возникающего вследствие отбрасывания или отсечения данных FGS или MGS, в стандарте SVC применяется следующее решение: В каждом блоке зависимости базовое представление (при помощи декодирования только изображения CGS с "quality_id", равным 0, и всех данных, зависящих от нижних уровней) восстанавливается в буфере декодированных изображений. При декодировании последующего блока зависимости с таким же значением "dependency_id" для внешнего предсказания всех NAL-блоков, включающих NAL-блоки FGS или NAL, в качестве опорного используется базовое представление. Следовательно, любой дрейф, возникающий в результате отбрасывания или отсечения NAL-блоков FGS или MGS, прекращается на данном блоке доступа. В целях обеспечения высокой эффективности кодирования в других блоках зависимости с тем же значением "dependency_id" для всех NAL-блоков в качестве опорных изображений внешнего предсказания используются декодированные изображения.
[0223] Каждый NAL-блок включает в своем заголовке синтаксический элемент "use_ref_basepic_flag". Когда значение этого элемента равно 1, при декодировании NAL-блока в процессе внешнего предсказания используются базовые представления опорных изображений. Синтаксический элемент "store_ref_basepic_flag" определяет, следует ли (если он равен 1) сохранять базовое представление текущего изображения для будущих изображений с целью использования при внешнем предсказании или нет (если он равен 0).
[0224] NAL-блоки с "quality_id", большим 0, не содержат синтаксических элементов, связанных с построением списков опорных изображений и взвешенным предсказанием, т.е. отсутствуют синтаксические элементы '"num_ref_active_x_minus1" (х=0 или 1), синтаксическая таблица переупорядочивания списка опорных изображений и синтаксическая таблица взвешенного предсказания. Следовательно, при необходимости, уровни MGS или FGS должны наследовать эти синтаксические элементы от NAL-блоков с "quality_id", равным 0, в том же блоке зависимости.
[0225] В стандарте SVC список опорных изображений состоит либо только из базовых представлений (когда флаг "use_ref_base_pic_flag" равен 1) или только из декодированных изображений, не помеченных как «базовое представление» (когда флаг "use_ref_base_pic_flag" равен 0), но никогда из обоих одновременно.
[0226] Еще один тип классификации масштабируемого видеокодирования основан на том, используются ли, в качестве основы для базового уровня и уточняющего уровня, одинаковые или различные стандарты, или технологии кодирования.
Термин «масштабируемость с гибридным кодеком» или «масштабируемость стандартов» может применяться для указания на ситуацию, в которой для части уровней применяют один стандарт или систему кодирования, тогда как для остальных уровней применяют другие стандарты или системы кодирования. К примеру, для базового уровня может применяться AVC-кодирование, тогда как один или более уточняющих уровней могут кодироваться с применением такого расширения HEVC, как SHVC или MV-HEVC.
[0227] В настоящее время ведутся работы по спецификации расширения масштабируемости и многоракурсного расширения стандарта HEVC. Многоракурсное расширение стандарта HEVC, которое обозначается MV-HEVC, аналогично расширению MVC стандарта H.264/AVC. Аналогично стандарту MVC, в MV-HEVC опорные изображения межракурсного предсказания могут включаться в список (или списки) опорных изображений для текущего кодируемого или декодируемого изображения. Расширение масштабирования стандарта HEVC, обозначаемое SHVC, планируют определить таким образом, чтобы в нем применялась операция многопроходного декодирования (в отличие от расширения SVC стандарта H.264/AVC). Расширение SHVC основано на указателях на опорные изображения, то есть опорное изображение межуровневого предсказания может включаться в один или более списков опорных изображений для текущего кодируемого или декодируемого изображения (в соответствии с предшествующим описанием).
[0228] Для расширений MV-HEVC и SHVC могут использоваться множество одинаковых синтаксических структур, семантики и процедур декодирования. Другие типы масштабируемости, например, видео с уточнением глубины, могут также быть реализованы с использованием таких же, как в расширениях MV-HEVC и SHVC, или аналогичных синтаксических структур, семантики и процедур декодирования.
[0229] Для кодирования уточняющего уровня в расширениях SHVC, MV-HEVC и/или SMV-HEVC могут применяться те же самые принципы и инструменты кодирования, что и в HEVC. Однако в кодеки SHVC, MV-HEVC и/или SMV-HEVC, или аналогичные кодеки, с целью эффективного кодирования уточняющего уровня, могут быть встроены дополнительные инструменты межуровневого предсказания, в которых применяются уже кодированные данные (включая восстановленные элементы изображений и параметры движения, которые также называют информацией о движении) из опорного уровня.
[0230] В расширениях MV-HEVC, SHVC и/или аналогичных расширениях, набор VPS может включать, например, указание на соответствие значения Layerld, полученного из заголовка NAL-блока, одному или более значениям масштабируемой величины например, соответствующим параметрам dependency_id, quality_id, view_id и depth_flag для уровня, определенным аналогично расширениям SVC и MVC.
[0231] В расширениях MV-HEVC/SHVC, в наборе VPS, может выполняться указание на то, что уровень, значение идентификатора которого больше 0, не имеет прямых (непосредственных) опорных уровней, т.е. межуровневое предсказание для этого уровня на основе каких-либо других уровней не выполняется. Другими словами, битовый поток в расширениях MV-HEVC/SHVC может содержать независимые друг от друга уровни, которые могут называться уровнями одновременной передачи (simulcast).
[0232] Часть набора VPS, которая определяет масштабируемые величины, которые могут присутствовать в битовом потоке, соответствие между значениями nuh_layer_id и значениями масштабируемых величин, а также зависимости между уровнями могут быть заданы при помощи следующих синтаксических элементов:


[0233] В последующих абзацах описаны возможные определения семантики, проиллюстрированной выше части набора VPS.
[0234] Флаг splitting_flag, равный 1, указывает на то, что синтаксические элементы dimension_id [i][j] отсутствуют, и на то, что двоичное представление значения nuh_layer_id в заголовке NAL-блока разбито на NumScalabilityTypes сегментов, длина которых в битах соответствует значениям dimension_id_len_minus_1 [j], а также на то, что значения dimension_id[LayerldxInVpsf [nuh_layer_id][j] вычисляют на основе NumScalabilityTypes сегментов, а флаг splitting_flag, равный 0, указывает на то, что синтаксические элементы dimension_id[i][j] присутствуют. В приведенном ниже примере семантики, без потери общности, допущено, что флаг splitting_flag равен 0.
[0235] Флаг scalability_mask_flag[i], равный 1, указывает на то, что присутствуют синтаксические элементы масштабирования, соответствующие i-ой масштабируемой величине в приведенной ниже таблице.
Флаг scalability_mask_flag[i], равный 0, указывает на то, что синтаксические элементы масштабирования, соответствующие i-ой масштабируемой величине в приведенной ниже таблице, отсутствуют.


[0236] В будущих трехмерных расширениях стандарта HEVC, синтаксический элемент scalability_mask_index_0 может использоваться для указания на карты глубины.
[0237] Синтаксический элемент dimension_id_len_minus1[j] плюс 1 определяет длину, в битах, синтаксического элемента dimension_id[i][j].
[0238] Флаг vps_nuh_layer_id_present_flag, равный 1, определяет, что присутствуют layer_id_in_nuh[i], для i от 0 до MaxLayersMinus_1 (который равен максимальному количеству уровней в битовом потоке минус 1), включительно. Флаг vps_nuh_layer_id_present_flag, равный 0, определяет, что layer_id_in_nuh[i], для i от 0 до MaxLayersMinusI, включительно, отсутствуют.
[0239] Синтаксический элемент layer_id_in_nuh[i] определяет значение синтаксического элемента nuh_layer_id в NAL-блоках VCL i-го уровня. Для i в диапазоне от 0 до MaxLayersMinusI включительно, когда layer_id[i] отсутствует, значение принимают равным i. Когда i больше 1, layer_id_in_nuh[i] больше, чем layer_id_in_nuh[i-1]. Для i в диапазоне от 0 до MaxLayersMinus1 включительно переменную LayerldxInVps[layer_id_in_nuh[i]] назначают равной i.
[0240] Синтаксический элемент dimension_id[i][j] определяет идентификатор j-го присутствующего типа масштабируемой величины для i-го уровня. Количество бит, используемых для представления dimension_id[i][j] равно dimension_id_len_minus1 [j] + 1 бит. Когда флаг splitting_flag равен 0, для j от 0 до NumScalabilityTypes - 1 включительно, dimension_id[0][j] принимают равным 0.
[0241] Переменную Scalability Id [i][smldx], определяющую идентификатор smldx-го типа масштабируемой величины для i-го уровня, переменную ViewOrderldx[layer_id_in_nuh[i]], определяющую порядковый номер в порядке ракурсов для i-го уровня, переменную Dependencyld[layer_id_in_nuh[i]], определяющую идентификатор пространственной масштабируемости / масштабируемости качества для i-го уровня и переменную ViewScalExtLayerFlag[layer_id_in_nuh[i]], определяющую, является ли i-ый уровень уровнем расширения с масштабированием ракурсов, вычисляют следующим образом:


[0242] Для уточняющих уровней, или уровней, значение идентификатора уровня которых больше 0, может быть указано на то, что они содержат вспомогательные видеоданные, дополняющие базовый уровень или другие уровни. К примеру, в текущем проекте MV-HEVC вспомогательные изображения могут кодироваться в битовый поток с использованием уровней вспомогательных изображений. Уровень вспомогательных изображений связан с собственным значением масштабируемой величины, Auxld (аналогично, например, порядковому номеру ракурса). Уровни с Auxld большим 0 содержат вспомогательные изображения. Каждый уровень может содержать только один тип вспомогательных изображений, при этом тип вспомогательных изображений, включенных в уровень, может быть указан при помощи значения Auxld. Другими словами, значения Auxld могут быть поставлены во взаимно однозначное соответствие со вспомогательными изображениями. К примеру, Auxld, равный 1, может указывать на альфа-слои, a Auxld, равный 2, может указывать на изображения глубины. Вспомогательное изображение может быть определено как изображение, не обязательно влияющее на процедуру декодирования основных изображений. Другими словами, для основных изображений (Auxld которых равен 0) может быть введено ограничение, запрещающее их предсказание на основе вспомогательных изображений. Вспомогательное изображение может предсказываться с использованием основного изображения, но при этом могут присутствовать ограничения, запрещающие подобное предсказание, например, в зависимости от значения Auxld. Сообщения SEI могут применяться для передачи более детализированных характеристик уровней вспомогательных изображений, например, диапазона глубины, представленного вспомогательным уровнем глубины. Текущий проект расширения MV-HEVC включает поддержку вспомогательных уровней глубины.
[0243] Могут применяться различные типы вспомогательных изображений включая, без ограничения перечисленным: изображений глубины, альфа-изображения, оверлейные изображения и маркерные изображения. В изображениях глубины значение каждого отсчета представляет собой диспарантность между точкой зрения (или положением камеры) изображения глубины, или глубину (дистанцию). В альфа-изображениях (которые также называют альфа-слоями или матирующими альфа-изображениями) значение каждого отсчета является представлением прозрачности или непрозрачности. Альфа-изображения могут указывать, для каждого пикселя, степень прозрачности, или, что эквивалентно, степень непрозрачности. Альфа-изображения могут быть монохромными, или составляющие цветности в альфа-изображениях могут быть назначены таким образом, чтобы указывать на отсутствие цветности (например, равны 0, когда значения отсчетов цветности интерпретируют как имеющие знак, или 128, когда значения пикселей цветности являются 8-битными без знака). Оверлейные изображения могут накладываться поверх основных изображений при их отображении. Оверлейные изображения могут содержать несколько областей и фон, при этом все области, или их подмножество, могут иметь наложение при отображении, а для фона наложение не выполняется. Маркерные изображения содержат различные маркеры для различных областей наложения, которые могут применяться для идентификации отдельных областей наложения.
[0244] Продолжим рассмотрение одного из примеров спецификации семантики фрагмента набора VPS, предложенного в настоящем изобретении.
Синтаксический элемент view_id_len определяет длину синтаксического элемента view_id_val[i] в битах. Синтаксический элемент view_id_val[i] определяет идентификатор i-го ракурса, заданного набором VPS. Длина синтаксического элемента view_id_val[i] равна view_idjen бит. Если синтаксический элемент view_id_val[i] отсутствует, его значение принимают равным 0. Для каждого уровня, nuh_layer_id которого равен nuhLayerld, значение Viewld[nuhLayerld] назначают равным view_id_val[ViewOrderldx[nuhLayerld]].
Флаг direct_dependency_flag[i][j], равный 0, определяет, что уровень с порядковым номером j не является прямым опорным уровнем для уровня с порядковым номером i. Флаг direct_dependency_flag[i] [j], равный 1, определяет, что уровень с индексом j может быть прямым опорным уровнем для уровня с индексом i. Когда флаг direct_dependency_flag[i][j] отсутствует, для i и j в диапазоне от 0 до MaxLayersMinusI, его значение принимают равным 0.
[0245] Переменная NumDirectRefLayers[iNuhLld] может быть определена как количество прямых опорных уровней для уровня с nuh_layer_id, равным iNuhLld, на основе информации о зависимостях уровней. Переменная RefLayerld[iNuhLld] [j] может быть определена как список значений nuh_layer_id прямых опорных уровней для уровня с nuh_layer_id, равным iNuhLld, где j лежит в диапазоне от 0 до NumDirectRefLayers[iNuhLld] - 1 включительно, и каждый элемент j в списке соответствует одному прямому опорному уровню. Переменные NumDirectRefLayers[iNuhLld] и RefLayerld[iNuhLld][j] могут быть определены в соответствии с приведенным ниже описанием, где MaxLayersMinusI равен максимальному количеству уровней, заданному в наборе VPS, уменьшенному на 1:

[0246] Набор VPS может также включать информацию о временных подуровнях, ограничения по Temporalld для межуровневого предсказания и другие ограничения межуровневого предсказания, например, с использованием следующего синтаксиса:

[0247] В последующих абзацах описаны возможные определения семантики для проиллюстрированного выше фрагмента набора VPS.
[0248] vps_sub_layers_max_minusl_present_flag, равный 1, указывает на то, что присутствуют синтаксические элементы sub_layers_vps_max_minus1 [i], флаг vps_sub_layers_max_minus1_present_flag, равный 0, указывает на то, что синтаксические элементы sub_layers_vps_max_minus1 [i] отсутствуют.
[0249] Значение sub_layers_vps_max_minus1[i] плюс 1 определяет максимальное количество временных подуровней, который могут присутствовать в CVS-последовательности для уровня с nuh_layer_id, равным layer_id_in_nuh[i]. Если он отсутствует, sub_layers_vps_max_minus1[i] принимают равным vps_max_sub_layers_minus1 (описан ранее в синтаксисе набора VPS).
[0250] Флаг max_tid_ref_present_flag, равный 1, определяет, что присутствует синтаксический элемент max_tid_il_ref_pics_plus1 [i][j]. Флаг max_id_ref_present_flag, равный 0, определяет, что синтаксический элемент max_tid_il_ref_pics_plus1 [i][j] отсутствует.
[0251] Синтаксический элемент max_tid_il_ref_pics_plus1 [i][j], равный 0, определяет, что внутри данной CVS-последовательности не-IRAP изображения с nuh_layer_id, равными layer_id_in_nuh[i], не используют в качестве опорных для межуровневого предсказания изображений с nuh_layer_ld, равными layer_id_in_nuh[j]. Синтаксический элемент max_tid_il_ref_pics_plus1 [i][j], больший 0, определяет, что в данной CVS-последовательности с nuh_layer_id, равными layer_id_in_nuh[i], и Temporalld, большими max_tid_il_ref_pics_plus1 [i][j] - 1, не используют в качестве опорных для межуровневого предсказания изображений с nuh_layer_ld, равными layer_id_in_nuh[j]. Когда элемент max_tid_il_ref_pics _plus1 [i][j] отсутствует, его принимают равным 7.
[0252] Флаг all_ref_layers_active_flag, равный 1, определяет, что для каждого изображения, ссылающегося на набор VPS, изображения опорного уровня, которые принадлежат всем прямым опорным уровням для уровне, содержащего этого изображение, и которые могут быть использованы для межуровневого предсказания, соответственно значениями sub_layers_vps_max_minus1 [i] и max_tid_il_ref_pics_plus1 [i][j], присутствуют в том же блоке доступа, что и данное изображение, и включены в набор опорных изображений межуровневого предсказания для данного изображения. Флаг all_ref_layers_active_flag, равный 0, определяет, что описанные выше ограничения могут быть применимы, однако не являются обязательными.
[0253] Флаг max_one_active_ref_layer_flag, равный 1, определяет, что максимум одно изображение используется для межуровневого предсказания каждого изображения в данной CVS-последовательности. Флаг max_one_active_ref_layer_flag, равный 0, определяет, что более одно изображения может использоваться для межуровневого предсказания каждого изображения в данной CVS-последовательности.
[0254] Дерево уровней может быть определено как набор уровней, в котором каждый уровень является прямо или косвенно предсказываемым или является прямым или косвенным опорным уровнем для по меньшей мере одного другого уровня в том же наборе, и при этом ни один уровень вне данного набора уровней не уровень является прямо или косвенно предсказываемым и не является прямым или косвенным опорным уровнем для какого-либо уровня в данном наборе уровней. Прямо предсказываемый уровень может быть определен как уровень, для которого другой уровень является прямым опорным уровнем. Прямой опорный уровень может быть определен как уровень, который может быть использован для межуровневого предсказания другого уровня, для которого этот уровень является прямым опорным уровнем. Косвенно предсказываемый уровень может быть определен как уровень, для которого другой уровень является косвенным опорным уровнем. Косвенный опорный уровень может быть определен как уровень, который не является прямым опорным уровнем для некоторого второго уровня, однако является прямым опорным уровнем для третьего уровня, являющегося прямым опорным уровнем или косвенным опорным уровнем для прямого опорного уровня второго уровня, для которого упомянутый уровень является косвенным опорным уровнем.
[0255] Альтернативно, дерево уровней может быть определено как набор уровней, в котором каждый уровень входит в отношение межуровневого предсказания по меньшей мере с одним другим уровнем в этом же дереве уровней, и при этом ни один уровень вне дерева уровней не входит в отношение межуровневого предсказания с каким-либо уровнем в дереве подуровней.
[0256] В расширениях SHEVC, MV-HEVC и/или аналогичных разрешениях для поддержки межуровневого предсказания текстуры, не требуется изменений синтаксиса и процедур декодирования на уровне блоков. Необходима модификация (по сравнению со стандартом HEVC) только более высокоуровневого синтаксиса, что, в общем, означает синтаксические структуры, включающие заголовок слайса, наборы PPS SPS и VPS, чтобы восстановленные изображения (при необходимости, с повышением разрешения) из опорного уровня в одном блоке доступа могли использоваться в качестве опорных изображений для кодирования текущего изображения уточняющего уровня. Опорные изображения межуровневого предсказания, также как и опорные изображения временного предсказания, включают в списки опорных изображений. Сигнализируемый указатель на опорное изображение применяют для указания на то, что текущий блок предсказания (PU) может быть предсказан на основе опорного изображения временного предсказания или опорного изображения межуровневого предсказания. Применение такой функциональности может осуществляться под управлением декодера, а указания могут выполняться, например, в наборе видеопараметров, в наборе параметров последовательности, в одном из параметров изображения и/или в заголовке слайса. Указание (или указания) могут относиться, например, к конкретному уточняющему уровню, опорному уровню, к паре из уточняющего уровня и опорного уровня, к конкретным значениям Temporalld, к конкретным типам изображений (например, RAP-изображениям), к конкретным типам слайсов (например, Р-слайсы или В-слайсы, но не 1-слайсы), изображения с конкретными значениями РОС и/или к конкретным блокам доступа. Область действия и/или длительность действия указания (или указаний), могут быть указаны вместе с самими указаниями и/или могут быть вычислены.
[0257] В расширениях SHVC, MV-HEVC и/или аналогичных разрешениях, список (или списки) опорных изображений могут инициализироваться с использованием специальной процедуры, в которой опорное изображение (или изображения) межуровневого предсказания, если таковое имеется, может быть включено в исходный список (или списки) опорных изображений, которые формируют описанным ниже образом. Например, опорные изображения временного предсказания могут сначала добавляться в списки (список 0, список 1) опорных изображений тем же образом, что и при построении списка опорных изображений в стандарте HEVC. После того, как добавлены опорные изображения временного предсказания, могут быть добавлены опорные изображения межуровневого предсказания. Опорные изображения межуровневого предсказания могут быть найдены, например, на основе информации о зависимостях уровней, предоставленной в расширении VPS. Опорные изображения межуровневого предсказания могут быть добавлены в исходный список 0 опорных изображений, если текущий слайс уточняющего уровня является Р-слайсом, и могут быть добавлены в оба исходных списка 0 и 1 опорных изображений, если слайс текущего уточняющего уровня является В-слайсом. Опорные изображения межуровневого предсказания могут добавляться в списки опорных изображений в определенном порядке, который не обязательно должен быть одинаковым в обоих списках опорных изображений. Например, в исходном списке 1 опорных изображений, по сравнению с исходным списком 0 опорных изображений, может применяться обратный порядок добавления опорных изображений межуровневого предсказания. К примеру, опорные изображения межуровневого предсказания могут вноситься в исходный список 0 опорных изображений в порядке возрастания идентификатора nuh_layer_id, тогда как для инициализации исходного списка 1 опорных изображений может использоваться обратный порядок.
[0258] Ниже приведен второй пример построения списка (или списков) опорных изображений. Кандидатные изображения межуровневого предсказания могут быть определены, например, на основе информации о зависимостях уровней, которая может быть включена, к примеру, в набор VPS. Кодер может включать в битовый поток информацию уровней-изображений, а декодер может декодировать из битового потока изображений эту информацию о том, какие кандидатные изображения межуровневого предсказания могут использоваться в качестве опорных для межуровневого предсказания. Информация, размещаемая в синтаксических элементах изображения, может находиться, например, в заголовке слайса, и может называться набором опорных изображений межуровневого предсказания. К примеру, кандидатные опорные изображения межуровневого предсказания могут быть пронумерованы в заданном порядке, и в набор опорных изображений межуровневого предсказания могут быть включены один или более их порядковых номеров. В другом примере для каждого кандидатного опорного изображения межуровневого предсказания применяют флаг, который указывают, может ли оно быть использовано в качестве опорного изображения межуровневого предсказания. Как было отмечено выше, опорные изображения межуровневого предсказания могут быть добавлены в исходный список 0 опорных изображений, если текущий слайс уточняющего уровня является Р-слайсом, и могут быть добавлены в оба исходных списка 0 и 1 опорных изображений, если слайс текущего уточняющего уровня является В-слайсом. Опорные изображения межуровневого предсказания могут добавляться в списки опорных изображений в определенном порядке, который не обязательно должен быть одинаковым в обоих списках опорных изображений.
[0259] Ниже приведен третий пример построения списка (или списков) опорных изображений. В данном, третьем примере набор опорных изображений межуровневого предсказания задают в синтаксической структуре заголовка сегмента слайса следующим образом:


[0260] Переменная NumDirectRefLayers[iNuhLld] может быть была принята равной количеству прямых опорных уровней для уровня с nuh_layer_id, равным iNuhLld, на основе информации о зависимостях уровней. В контексте MV-HEVC, SHVC или аналогичных стандартов, NumDirectRefLayers[layerld] может быть найдено на основе синтаксических элементов direct_dependency_flag[i][j] в наборе VPS.
[0261] В последующих абзацах описаны возможные определения семантики для проиллюстрированного выше фрагмента синтаксической структуры заголовка сегмента слайса.
[0262] Флаг inter_layer_pred_enabled_flag, равный 1, определяет, что при декодировании текущего изображения может применяться межуровневое предсказание, inter_layer_pred_enabled_flag, равный 0, определяет что при декодировании текущего изображения межуровневое предсказание не применяют.
[0263] Значение num_inter_layer_ref_pics_minus1 + 1 определяет количество изображений, которые могут использоваться при декодировании текущего изображения для межуровневого предсказания. Длина синтаксического элемента num_inter_layer_ref_pics_minus1 равна Ceil(Log2(NumDirectRefLayers[nuh_layer_id])) битов. Значение num_inter_layer_ref_pics_minus1 должно лежать в диапазоне от 0 до NumDirectRefLayers[nuh_layer_id] -1 включительно.
[0264] Переменные numRefLayerPics и refLayerPicldc[j] могут быть вычислены следующим образом:

[0265] Список refLayerPicldc[j] может трактоваться как указывающий на кандидатные опорные изображения межуровневого предсказания, которые рассмотрены в приведенном выше втором примере.
[0266] Переменная NumActiveRefLayerPics может быть вычислена следующим образом:

[0267] Значение inter_layer_pred_layer_idc[i] определяет значение переменной RefPicLayerld[i], представляющей собой значение nuh_layer_id i-го изображения, которое может быть использовано для межуровневого предсказания текущего изображения. Длина синтаксического элемента inter_layer_pred_layer_idc[i] равна Ceil(Log2(NumDirectRefLayers[nuh_layer_id])) бит. Значение inter_layer_pred_layer_idc[i] должно лежать в диапазоне от 0 до NumDirectRefLayers[nuh_layer_id] - 1 включительно. Если этот синтаксический элемент отсутствует, значение inter_layer_pred_layer_idc[i] принимают равным refLayerPicldc[i].
[0268] Переменные RefPicLayerld[i] для всех значений i в диапазоне от 0 до NumActiveRefLayerPics -1 включительно вычисляют следующим образом:

[0269] Синтаксический элемент inter_layer_pred_layer_idc[i] может трактоваться как относящаяся к изображению информация о том, какие из кандидатных изображений межуровневого предсказания могут быть использованы в качестве опорных для межуровневого предсказания, в соответствии с рассмотренным выше вторым примером.
[0270] В исходный список опорных изображений могут быть включены изображения, на которые указывают переменные RefPicLayerld[i] для всех значений i от 0 до NumActiveRefLayerPics - 1 включительно. Как было отмечено выше, изображения, идентифицированные переменными RefPicLayerld[i], могут быть добавлены в исходный список 0 опорных изображений, если текущий слайс уточняющего уровня является Р-слайсом, и могут быть добавлены в оба исходных списка 0 и 1 опорных изображений, если слайс текущего уточняющего уровня является В-слайсом. Изображения, идентифицированные переменными RefPicLayerld[i], могут добавляться в списки опорных изображений в определенном порядке, который не обязательно должен быть одинаковым в обоих списках опорных изображений. Например, вычисленные значения Viewld могут влиять на порядок добавления изображений, идентифицированных переменными RefPicLayerld[i], в исходные списки опорных изображений.
[0271] В процессе кодирования и/или декодирования опорные изображения межуровневого предсказания могут рассматриваться как долгосрочные опорные изображения.
[0272] Один из типов межуровневого предсказания, который может называться межуровневым предсказанием движения, может быть реализован описанным ниже образом. Процедура предсказания временного вектора движения, например, TMVP в стандарте H.265/HEVC, может применяться с целью эксплуатации избыточности данных о движении между различными уровнями. Это может быть реализовано следующим образом: когда декодированное изображение базового уровня имеет повышенное разрешение, данные движения базового изображения также преобразуют к разрешению уточняющего уровня. Если для изображения уточняющего уровня применяют предсказание векторов движения на основе изображения базового уровня, например, с использованием такого механизма предсказания векторов движения, как TMVP в стандарте H.265/HEVC, соответствующее предсказание вектора движения получают на основе согласованного по разрешению поля движения базового уровня. Благодаря этому корреляция между данными о движении различных уровней может быть использована для повышения эффективности кодирования в масштабируемом видеокодере.
[0273] В расширении SHVC и/или аналогичных расширениях межуровневое предсказание параметров движения может выполняться при помощи назначения опорного изображения межуровневого предсказания в качестве сорасположенного опорного изображения для вычисления TMVP-предсказания. Может выполняться процедура согласования полей движения между двумя уровнями, например, чтобы исключить необходимость модификации процедуры декодирования на уровне блока пикселей при вычислении TMVP. Применение функции согласования полей движения может осуществляться под управлением декодера, а указания в битовом потоке могут размещаться, например, в наборе видеопараметров, в наборе параметров последовательности, в одном из параметров изображения и/или в заголовке слайса. Указание (или указания) могут относиться, например, к конкретному уточняющему уровню, опорному уровню, к паре из уточняющего уровня и опорного уровня, к конкретным значениям Temporalld, к конкретным типам изображений (например, RAP-изображениям), к конкретным типам слайсов (например, Р-слайсы или В-слайсы, но не I-слайсы), изображения с конкретными значениями РОС и/или к конкретным блокам доступа. Область действия и/или длительность действия указания (или указаний), могут быть указаны вместе с самими указаниями и/или могут быть вычислены.
[0274] В процедуре согласования (mapping) полей движения для пространственной масштабируемости на основе поля движения соответствующего изображения опорного уровня может быть получено поле движения опорного изображения межуровневого предсказания, имеющее повышенное разрешение. Параметры движения (которые могут включать, например, значение горизонтальной и/или вертикальной составляющей вектора движения и указатель на опорное изображение) и/или режим предсказания для каждого блока пикселей в имеющем повышенное разрешение опорном изображении межуровневого предсказания могут быть получены на основе соответствующих параметров движения и/или режима предсказания сорасположенного блока пикселей в изображении опорного уровня. Размер блока пикселей, применяемого для вычисления параметров движения и/или режима предсказания в передискретизированном опорном изображении межуровневого предсказания, может составлять, например, 16×16. Тот же размер блока пикселей, 16×16, применяется в процедуре вычисления TMVP-предсказания в стандарте HEVC, где используется сжатое поле движение опорного изображения.
[0275] Как упоминалось выше, в стандарте HEVC для всех определенных типов NAL-блоков используется двухбайтный заголовок NAL-блока. Заголовок NAL-блока содержит один зарезервированный бит, шестибитный индикатор типа NAL-блока (именуемый nal_unit_type), шестибитное зарезервированное поле (имеющее наименование nuh_layer_id) и трехбитный индикатор nal_temporal_id_plus1 временного уровня. Синтаксический элемент temporal_id_plus1 можно считать временным идентификатором NAL-блока, при этом отсчитываемая от нуля переменная Temporalld может быть вычислена следующим образом: Temporalld = temporal_id_plus1 - 1. Случай, в котором Temporalld равен нулю, соответствует наименьшему временному уровню. Значение temporal_id_plus1 должно быть ненулевым, чтобы не возникала эмуляция стартового кода, в который входит два байта заголовка NAL-блока. Битовый поток, формируемый исключением всех NAL-блоков VCL, чей temporal_id больше или равен выбранному значению, и включением всех остальных NAL-блоков VCL, остается соответствующим стандарту. Следовательно, для изображений с temporal_id, равным TID, в качестве опорных для предсказания не используются изображения с temporal_id, большим TID. Подуровень или временной подуровень может быть определен как уровень временного масштабирования или битовый поток с временным масштабированием, состоящий из NAL-блоков VCL с конкретным значением переменной Temporalld, а также из соответствующих NAL-блоков, не являющихся блоками VCL.
[0276] В расширениях стандарта HEVC элемент nuh_layer_id и/или аналогичные синтаксические элементы в заголовке NAL-блока содержат информацию уровня масштабирования. К примеру, значения layer_id, nuh_layer_id, и/или аналогичных синтаксических элементов могут быть отображены на значения переменных и/или других синтаксических элементов, описывающих различные масштабируемые величины.
[0277] При масштабируемом и/или многоракурсном видеокодировании могут поддерживаться по меньшей мере два описанных ниже принципа кодирования изображений и/или блоков доступа, обладающих свойством произвольного доступа.
[0278] - IRAP-изображение внутри уровня может быть внутренне-кодируемым изображением без межуровневого/межракурсного предсказания. Такое изображение обеспечивает возможность произвольного доступа к уровню, или ракурсу, в котором оно расположено.
- IRAP-изображение в уточняющем уровне может быть изображением без внешнего предсказания (т.е. временного предсказания), но может быть разрешено его межуровневое/межракурсное предсказание. Такое изображение обеспечивает возможность начала декодирования уровня/ракурса, в котором это изображение расположено, при условии, что доступны все опорные уровни/ракурсы. При однопроходном декодировании может быть достаточно, чтобы были доступны опорные кодированные уровни/ракурсы (это условие выполнено в SVC, например, в случае IDR-изображений, dependency_id которых больше 0). При многопроходном декодировании может требоваться, чтобы опорные уровни/ракурсы были декодированы. Такие изображения могут, например, называться изображениями пошагового доступа к уровню (stepwise layer access, STLA) или IRAP-изображениями уточняющего уровня.
- Под якорным блоком доступа или полным блоком доступа IRAP может пониматься блок доступа, который включает, во всех уровнях, только внутренне предсказываемое изображения (или изображение) и STLA-изображения. При многопроходном декодировании такие блоки доступа обеспечивают возможность произвольного доступа ко всем уровням, или ракурсам. Одним из примеров подобных блоков доступа является якорный блок доступа в MVC (специальным случаем которого является блок доступа IDR).
- Пошаговый блок доступа IRAP может быть определен как блок доступа, включающий IRAP-изображение в базовом уровне, однако не обязательно содержащий IRAP-изображение во всех уточняющих уровнях. Пошаговый блок доступа IRAP позволяет запускать декодирование базового уровня, причем декодирование уточняющего уровня может начинаться тогда, когда уточняющий уровень содержит IRAP-изображение, и (в случае многопроходного декодирования) на этот момент декодированы все его опорные уровни/ракурсы.
[0279] В расширении масштабируемого кодирования HEVC или любом другом расширении масштабируемого кодирования для одноуровневой схемы кодирования, аналогичной HEVC, IRAP-изображения могут быть определены как имеющие один или более параметров, описанных ниже.
- Для указания на точки произвольного доступа уточняющего уровня могут использоваться значения типа NAL-блока IRAP-изображений, имеющих nuh_layer_id больше 0.
- IRAP-изображение уточняющего уровня может быть определено как изображение, которое обеспечивает возможность запуска декодирования уточняющего уровня, когда декодированы все его опорные уровни, предшествующие данному IRAP-изображению уточняющего уровня.
- Межуровневое предсказание может быть разрешено для NAL-блоков IRAP-изображения, имеющих nuh_layer_id больше 0, тогда как внешнее предсказание может быть запрещено.
- NAL-блоки IRAP-изображения не обязательно должны совпадать друг с другом в различных уровнях. Другими словами, блок доступа может содержать как IRAP изображения, так и изображения других типов. После BLA-изображения в базовом уровне декодирование уточняющего уровня начинают, когда уточняющий уровень содержит IRAP-изображение и началось декодирование всех его опорных уровней. Другими словами, BLA-изображение в базовом уровне является триггером для процедуры поуровневого запуска.
- Когда декодирование уточняющего уровня начинается с CRA-изображения, его RASL-изображения обрабатывают аналогично RASL-изображениям BLA-изображения (в версии 1 HEVC).
[0280] Масштабируемые битовые потоки могут применяться с использованием IRAP-изображений, или аналогичных структур, которые не совпадают в различных уровнях, например, в базовом уровне могут присутствовать более часто встречающиеся IRAP-изображения, которые могут иметь меньший размер в кодированном виде, например, из-за меньшего пространственного расширения. Процедура, или механизм, поуровневого запуска декодирования может быть включен в схему видеокодирования. Соответственно, декодер может начинать декодирование битового потока, когда базовый уровень содержит IRAP, и пошагово начинать декодирование остальных слоев, когда они содержат IRAP-изображения. Другими словами, при поуровневом запуске процедуры декодирования декодер постепенно увеличивает количество декодируемых уровней (причем эти уровни могут представлять собой уточнение пространственного разрешения, уровня качества, ракурсы, дополнительные компоненты, такие как глубина, или их комбинацию) по мере декодирования последующих изображений из дополнительных уточняющих уровней в процессе декодирования. Постепенное увеличение количества декодируемых уровней может восприниматься, например, как постепенное повышение качества изображения (в случае масштабируемости качества и пространственной масштабируемости).
[0281] Механизм поуровневого запуска позволяет формировать недоступные изображения для опорных изображений первого изображения, в порядке декодирования, в конкретном уточняющем уровне. Альтернативно, декодер может не выполнять декодирование изображений, предшествующих IRAP-изображению в порядке декодирования, с которого может начинаться декодирование уровня. Эти изображения, которые могут быть отброшены, могут быть явно помечены кодером, или другим элементом, в битовом потоке. Например, для них могут применяться одно или более специальных значений типа NAL-блока. Такие изображения, независимо от того, маркированы ли они явно при помощи типа NAL-блока или выявлены декодером, могут называться межуровневыми пропускаемыми изображениями произвольного доступа. Декодер может не выполнять вывод сформированных недоступных изображений и декодированных CL-RAS-изображений.
[0282] Механизм поуровневого запуска может обеспечивать начало вывода изображений уточняющего уровня с IRAP-изображения в этом уточняющем уровне, когда все опорные уровни для этого уточняющего уровня были инициализированы аналогичным образом, с появлением IRAP-изображений в опорных уровнях. Другими словами, никакое изображение (внутри одного уровня), предшествующее упомянутому IRAP-изображению в порядке вывода, не может быть выведено из декодера и/или не может быть отображено. В некоторых случаях декодируемые опережающие сообщения, связанные с подобным IRAP-изображением, могут быть выведены, однако остальные изображения, предшествующие этому IRAP-изображению, не подлежат выводу.
[0283] Конкатенация кодированных видеоданных, которая может также называться «сплайсингом» (или стыковкой), может выполняться, например, когда кодированные видеопоследовательности объединяют в битовом потоке, подлежащем вещанию или потоковой передаче, или сохранению в запоминающее устройство (большой емкости). К примеру, кодированные видеопоследовательности, представляющие собой рекламу, могут объединяться с кинофильмами или иным, «главным» содержимым.
[0284] Масштабируемые битовые потоки видеоданных могут содержать IRAP-изображения, не выровненные в различных уровнях. Однако представляется удобным иметь возможность конкатенации кодированных видеопоследовательностей, содержащих IRAP-изображение в базовом уровне, в первом блоке доступа, даже если оно не присутствует во всех уровнях. Вторая кодированная видеопоследовательность, которую помещают в стык с первой кодированной последовательностью, должна инициировать процедуру пошагового запуска декодирования. Это необходимо, поскольку первый блок доступа в упомянутой второй кодированной видеопоследовательности может не содержать IRAP-изображения во всех уровнях, и следовательно, некоторые из опорных изображений для не-IRAP-изображений в этом блоке доступа могут быть недоступны (в объединенном битовом потоке), и соответственно, не могут быть декодированы. Элемент, выполняющий конкатенацию кодированных видеопоследовательностей (который далее будет именоваться «сплайсером»), должен, следовательно, изменить первый блок доступа второй кодированной видеопоследовательности таким образом, чтобы он запускал процедуру поуровневого запуска в декодере (или декодерах).
[0285] В синтаксисе битового потока может иметься указание (или указания), которые указывают на инициирование процедуры поуровневого запуска. Такое указание (или указания) может формироваться кодером или сплайсером, и может исполняться декодером. Такие указания могут применяться исключительно для конкретного типа (или типов) изображений или конкретных типов NAL-блоков, например, только для IDR-изображений, тогда как в других вариантах осуществления настоящего изобретения эти указания могут применяться для изображений любых типов. Без потери общности, ниже рассмотрен пример, в котором в заголовок сегмента слайса включено указание, имеющее наименование cross_layer_bla_flag. Нужно понимать, что дополнительно или альтернативно может применяться аналогичное указание, с любым другим наименованием или включенное в любую другую синтаксическую структуру.
[0286] Независимо от указаний, инициирующих процедуру поуровневого запуска, определенные типы NAL-блоков и/или типы изображений также могут инициировать эту процедуру. К примеру, BLA-изображение в базовом уровне может быть триггером для процедуры поуровневого запуска.
[0287] Механизм поуровневого запуска может быть активирован в одном или более из описанных ниже случаев.
- В начале битового потока.
- В начале кодированной видеопоследовательности, с явным управлением, например, когда выполняется запуск или перезапуск процедуры декодирования, например, в ответ на переключение канала вещания или на поиск позиции в файле или в потоке. В качестве входных данных процедура декодирования может принимать переменную, например, имеющую наименование NoClrasOutputFlag, которая может управляться при помощи внешних средств, таких как видеопроигрыватель или аналогичный элемент.
- BLA-изображение базового уровня.
- IDR-изображение базового уровня, которое имеет cross_layer_bla_flag, равный 1. (или IRAP-изображение базового уровня с cross_layer_bla_flag, равным 1).
[0288] Когда механизм поуровневого запуска активирован, все изображения в буфере DPB могут быть помечены как «не используемые в качестве опорных». Другими словами, все изображения во всех уровнях могут быть помещены как «не используемые в качестве опорных» и не будут использоваться в качестве опорных для предсказания изображения, инициировавшего механизм поуровневого запуска, а также для всех последующих изображений в порядке декодирования.
[0289] Межуровневые пропускаемые изображения произвольного доступа (CL-RAS) могут обладать следующим свойством: когда происходит вызов механизма поуровневого запуска (например, когда флаг NoClrasOutputFlag равен 1), изображения CL-RAS не выводят, и они не могут быть корректно декодированы, поскольку CL-RAS-изображения могут содержать ссылки на изображения, отсутствующие в битовом потоке. В стандарте может быть определено, что CL-RAS-изображения не могут использоваться в качестве опорных в процедуре декодирования He-CL-RAS-изображений.
[0290] Может выполняться явное указание на CL-RAS-изображения, например, с использованием одного или более типов NAL-блоков или флагов в заголовке слайса (например, при помощи переименования cross_layer_bla_flag в cross_layer_constraint_flag и переопределения семантики cross_layer_bla_flag для не-IRAP-изображений. Изображение может считаться CL-RAS-изображением, когда оно не является IRAP изображением (что определяют, например, по его nal_unit_type), расположено в уточняющем уровне и имеет cross_layer_constraint_flag (или аналогичный), равным 1. В противном случае изображение может быть классифицировано как не-CL-RAS-изображение, флаг cross_layer_bla_flag может быть принят равным 1 (или соответствующая переменная может быть назначена равной 1), и если данное изображение является IRAP-изображением (что определяют, например, при помощи его nal_unit_type), оно расположено в базовом уровне и его cross_layer_constraint_flag равен 1. В противном случае cross_layer_bla_flag может быть принят равным 0 (или соответствующая переменная может быть назначена равной 0). Альтернативно, CL-RAS изображения могут вычисляться. Например, если изображение имеет nuh_layer_id равный layer_id, то может быть сделан решение о том, что оно является CL-RAS-изображением, когда флаг LayerInitializedFlag [layerld] равен 0.CL-RAS-изображение может быть определено как изображение с nuh_layer_id, равным layer_id, то есть, для которого LayerInitializedFlag[layerld] равен 0, когда началось декодирование кодированного изображения с nuh_layer_id, большим 0.
[0291] Процедура декодирования может быть определена таким образом, чтобы необходимость применения процедуры поуровневого запуска управлялась при помощи некоторой переменной. К примеру, может применяться переменная NoClrasOutputFlag, которая, когда она равна 0, указывает нормальную операцию декодирования, а когда она равна 1, указывает на операцию поуровневого запуска. Флаг NoClrasOutputFlag может быть назначен, например, при помощи одного или более из описанных ниже шагов.
1) Если текущее изображение является IRAP-изображением, которое представляет собой первое изображение в битовом потоке, NoClrasOutputFlag назначают равным 1.
2) В противном случае, если имеются внешние средства для назначения переменной NoClrasOutputFlag равной значению для IRAP-изображения базового уровня, переменную NoClrasOutputFlag назначают равным значению, предоставленному внешними средствами.
3) В противном случае, если текущее изображение является BLA-изображением, которое представляет собой первое изображение в кодированной видеопоследовательности (CVS), NoClrasOutputFlag назначают равным 1.
4) В противном случае, если текущее изображение является IDR-изображением, которое представляет собой первое изображение в кодированной видеопоследовательности (CVS) и флаг cross_layer_bla_flag равен 1, NoClrasOutputFlag назначают равным 1.
5) В противном случае NoClrasOutputFlag назначают равным 0.
[0292] Описанный выше шаг 4 может, альтернативно, быть описан в более общем виде, например: «В противном случае, если текущее изображение является IRAP-изображением, которое представляет собой первое изображение в CVS-последовательности, и с данным IRAP-изображением связано указание на процедуру поуровневого запуска, флаг NoClrasOutputFlag назначают равным 1». Описанный выше шаг 3 может быть опущен, при этом может быть определено, что BLA-изображение инициирует процедуру поуровневого запуска (т.е. NoClrasOutputFlag назначают равным 1), когда его cross_layer_bla_flag равен 1. Нужно понимать, что могут существовать и другие, равноприменимые способы определения этих условий.
[0293] Процедура декодирования для поуровневого запуска может управляться, например, при помощи двух переменных-массивов LayerInitializedFlag[i] и FirstPiclnLayerDecodedFlag [i], которые могут иметь записи для каждого из уровней (возможно, включая базовый уровень, а также другие независимые уровни). Когда вызвана процедура поуровневого запуска, например, в ответ на флаг NoClrasOutputFlag, равный 1, эти переменные-массивы могут быть сброшены в заданные по умолчанию значения. К примеру, когда доступны 64 уровня (например, при 6-битном nuh_layer_id), эти переменные могут быть реинициализированы следующим образом: переменную LayerInitializedFlag[i] назначают равной 0 для всех значений i от 0 до 63 включительно, и переменную FirstPiclnLayerDecodedFlagf i] назначают равной 0 для всех значений i от 1 до 63 включительно.
[0294] Процедура декодирования может включать описанный ниже (или аналогичный) способ управления выводом RASL-изображений. Когда текущее изображение является IRAP-изображением, применимы описанные ниже условия.
- Если флаг LayerInitializedFlag [nuh_layer_id] равен 0, переменную NoRaslOutputFlag назначают равной 1.
- В противном случае, если имеются внешние средства для назначения HandleCraAsBlaFlag равным значению для текущего изображения, переменную HandleCraAsBlaFlag назначают равной значению, предоставленному внешними средствами, а переменную NoRaslOutputFlag назначают равной HandleCraAsBlaFlag.
- В противном случае переменную HandleCraAsBlaFlag назначают равной 0, и переменную NoRaslOutputFlag также назначают равной 0.
[0295] Процедура декодирования может включать описанные ниже шаги обновления флага LayerInitializedFlag в каждом уровне. Когда текущее изображение является IRAP-изображением и выполнено одно из приведенных ниже условий, LayerInitializedFlag [nuh_layer_id] назначают равным 1.
- nuh_layer_id равен 0.
- Флаг LayerInitializedFlag [nuh_layer_id] равен 0 и LayerInitializedFlag [refLayerld] равен 1 для всех значений refLayerld, равных RefLayerld [nuh_layer_id] [j], где j - значение в диапазоне от 0 до NumDirectRefLayers[nuh_layer_id] - 1 включительно.
[0296] Когда флаг FirstPiclnLayerDecodedFlag [nuh_layer_id] равен 0, перед декодированием текущего изображения может быть вызвана процедура декодирования для формирования отсутствующих опорных изображений. Процедура декодирования для формирования отсутствующих опорных изображений позволяет сформировать изображения для каждого из изображений в наборе опорных изображений с заданными по умолчанию значениями. Процедура формирования отсутствующих опорных изображений может быть определена, главным образом, для определения синтаксических ограничений по CL-RAS-изображениям, при этом CL-RAS-изображение может быть определено как изображение с nuh_layer_id, равным layer_id, и LayerInitializedFlag [layerld], равным 0. В операциях HRD-декодирования CL-RAS-изображения может быть необходим учет CL-RAS-изображений при вычислении моментов времени поступления и удаления в буфере СРВ. Декодеры могут игнорировать все CL-RAS, поскольку эти изображения не предназначены для вывода и не влияют на процесс декодирования каких-либо иных изображений, предназначенных для вывода.
[0297] Управление выводом изображений при масштабируемом кодировании может выполняться, например, описанным ниже образом. Для каждого изображения в процедуре декодирования сначала вычисляют PicOutputFlag, аналогично битовому потоку с единственным уровнем. Например, при вычислении PicOutputFlag может учитываться pic_output_flag, включенный в битовый поток для изображения. После декодирования блока доступа выходные уровни и возможные альтернативные выходные уровни используют для обновления PicOutputFlag для каждого изображения в блоке доступа, например, в соответствии с приведенным ниже описанием.
- Если было активировано использование альтернативного выходного уровня (например, в проекте MV-HEVC/SHVC, AltOptLayerFlag[TargetOptLayerSetldx] равен 1) и блок доступа либо не содержит изображения в целевом выходном уровне, или содержит в целевом выходном уровне изображение, имеющее флаг PicOutputFlag равным 0, выполняют следующую последовательность шагов:
- список nonOutputlayerPictures - это список изображений блока доступа с PicOutputFlag, равным 1, и со значениями nuh_layer_id, находящимися среди значений nuh_layer_id прямых и косвенных опорных уровней для целевого выходного уровня;
- изображение с наивысшим значением nuh_layer_id в списке nonOutputLayerPictures удаляют из списка nonOutputLayerPictures;
- флаг PicOutputFlag для каждого изображения, включенного в список nonOutputLayerPictures, назначают равным 0.
- В противном случае флаг PicOutputFlag для изображений, не включенных в целевой выходной уровень назначают равным 0.
[0298] Альтернативно, описанное выше условие, вызывающее вывод изображения из альтернативного выходного уровня, может быть ограничено рассмотрением только CL-RAS изображений, а не всех изображений с флагом PicOutputFlag, равным 0. Иными словами, это условие может быть сформулировано следующим образом:
- «Если было активировано использование альтернативного выходного уровня (например, в проекте MV-HEVC/SHVC, AltOptLayerFlag[TargetOptLayerSetldx] равен 1) и блок доступа либо не содержит изображений в целевом выходном уровне, или содержит в целевом выходном уровне CL-RAS изображение, имеющее флаг PicOutputFlag равным 0, выполняют следующую последовательность шагов:»
[0299] Альтернативно, это условие может быть сформулировано следующим образом:
- «если было активировано использование альтернативного выходного уровня (например, в проекте стандарта MV-HEVC/SHVC флаг AltOptLayerFlag[TargetOptLayerSetldx] равен 1) и блок доступа либо не содержит изображений в целевом выходном уровне, или содержит в целевом выходном уровне изображение, имеющее флаг PicOutputFlag равным 0, так что флаг LayerInitializedFlag[lid] равен, применяют следующую последовательность шагов:»
[0300] Однако схемы масштабирования на современном уровне развития описанных выше стандартов видеокодирования имеют некоторые ограничения. К примеру, в стандартах SVC и SHVC изображения (или аналогичные структуры) в блоке доступа должны иметь одинаковые временные уровни (например, значение Temporalld в HEVC и его расширениях). Следовательно, кодеры не способны определять иерархию предсказания различным образом для различных уровней. Различная иерархия предсказаний для различных уровней может быть полезной при кодировании некоторых уровней с большим количеством значений Temporalld, а также для более частого кодирования точек переключения на более высокие подуровни, а также некоторых уровней в иерархии предсказания, с целью получения улучшенных показателей «битовая скорость - искажения». При этом кодеры не способны также кодировать деревья уровней одного битового потока независимо друг от друга. К примеру, базовый уровень и уровень вспомогательных изображений мог быть кодироваться различными уровнями, и/или кодирование различных деревьев уровней могло бы выполняться в различные моменты времени. Однако на текущий момент уровни должны иметь одинаковый порядок (де)кодирования и Temporalld соответствующих изображений.
[0301] Еще одно ограничение, например, в стандартах SVC и SHVC заключается в том, что изображения переключения временного уровня, такие как TSA- и STSA-изображения в стандарте HEVC и его расширениях, не могут появляться на самом нижнем временном уровне, например, при Temporalld равном 0 в стандарте HEVC и его расширениях. Это, следовательно, не позволяет указывать изображение доступа, или точку доступа, для уровня, который обеспечивает возможность декодирования некоторых из временных уровней (однако не обязательно всех из них). Однако подобные точки доступа могли бы применяться, например, для пошагового запуска декодирования уровня при подуровневом подходе и/или для адаптации битрейта.
[0302] Далее в настоящем документе будут представлены способы кодирования и декодирования изображений ограниченного доступа к уровню, имеющие целью по меньшей мере частично решить описанные выше проблемы.
[0303] В способе кодирования, который показан на фиг. 7, первое изображение кодируют (750) в первом уровне масштабирования и в самом нижнем временном подуровне, а второе изображение кодируют (752) во втором уровне масштабирования и самом нижнем временном подуровне, при этом первое изображение и второе изображение представляют один и тот же момент времени. Один или более первых синтаксических элементов, связанных с упомянутым первым изображением, кодируют (754), с использованием значения, указывающего на то, что типом первого изображения не является изображение пошагового доступа к временному подуровню. Аналогично, одно или более вторых синтаксических элементов, связанных с упомянутым вторым изображением, кодируют (756), с использованием значения, указывающего на то, что типом второго изображения не является изображение пошагового доступа к временному подуровню. Затем по меньшей мере третье изображение кодируют (758) во второй уровень масштабирования и в более высокий временной подуровень, чем самый нижний временной подуровень.
[0304] В соответствии с одним из вариантов осуществления настоящего изобретения изображение пошагового доступа к временному подуровню обеспечивает точку доступа для поуровневой инициализации декодирования битового потока с одним или более временными подуровнями.
[0305] Таким образом, кодер кодирует, в уровень, изображение доступа, или точку доступа, при этом изображение доступа, или точка доступа, обеспечивает возможность декодирования некоторых из временных подуровней (но не обязательно всех из них). Подобные точки доступа могут применяться, например, для пошагового запуска декодирования уровня, при подходе с постепенным запуском подуровней (например, декодером), и/или для адаптации битрейта (например, передатчиком), в соответствии с последующим более подробным описанием.
[0306] В соответствии с одним из вариантов осуществления настоящего изобретения изображение пошагового доступа к временному подуровню представляет собой STSA-изображение с Temporalld, равным 0.
[0307] На фиг. 8 показан пример, в котором STSA-изображение с Temporalld, равным 0, используют для указания на изображение ограниченного доступа к уровню. На фиг. 8 как базовый уровень (BL), так и уточняющий уровень (EL)), содержат изображения четырех временных подуровней (Temporalld (TID) = 0, 1, 2, 3). Порядок декодирования изображений следующий: 0, 1, …, 9, А, В, С, …, при этом порядок вывода изображений представлен порядком изображений на фиг. 8 слева направо, Состояние буфера декодированных изображений (decoded picture buffer, DPB), или данные загрузки буфера («дамп»), для каждого изображения на фиг. 8 и последующих чертежах иллюстрируют декодированные изображения, которые помечены как «используемые в качестве опорных». Другими словами дамп буфера DPB содержит изображения, помеченные как «используемые в качестве опорных», однако не содержит изображения, помеченные как «необходимые для вывода» (которые могут быть уже помечены как «не используемые в качестве опорных»). Состояние буфера DPB может включать следующие изображения:
- анализируемое кодируемое или декодируемое изображение (самый нижний элемент в проиллюстрированном на фиг. 8 и последующих чертежах состоянии буфера DPB);
- изображения, которые не используют в качестве опорных для кодирования (и декодирования) анализируемого изображения, однако могут использоваться в качестве опорных для кодирования (и декодирования) последующих изображений в порядке декодирования (элементы, показанные курсивом и подчеркиванием в состоянии буфера DPB, проиллюстрированного на фиг. 8 и последующих чертежах); и
- изображения, которые могут использоваться в качестве опорных для кодирования (и декодирования) анализируемого изображений (все остальные элементы, показанные в состоянии буфера DPB, проиллюстрированного на фиг. 8 и последующих чертежах).
[0308] Изображение 1 уточняющего уровня представляет собой изображение доступа к уровню, которое обеспечивает доступ к подуровням с Temporalld 0, 1 и 2, однако не предоставляет доступа к подуровню с Temporalld, равным 3. В данном примере среди представленных изображений (5, 7, 8, С, D, F, G) для TID 3 уточняющего уровня нет TSA- или STSA-изображений.
[0309] В соответствии с одним из вариантов осуществления настоящего изобретения способ дополнительно включает сигнализацию изображения пошагового доступа к временному подуровню при помощи специального типа NAL-блока. Таким образом, вместо повторного использования типа NAL-блока для STSA, может быть применен специальный тип NAL-блока, который может называться изображением доступа к уровню, ограниченным подуровнем.
[0310] В соответствии с одним из вариантов осуществления настоящего изобретения способ дополнительно включает сигнализацию изображения пошагового доступа к временному подуровню при помощи SEI-изображения. SEI-сообщение может также определять количество декодируемых подуровней. SEI-сообщение может применяться в дополнение к применению типа NAL-блока, указывающего на изображение ограниченного доступа к уровню с ограничением подуровня или STSA-изображения с Temporalld, равным 0, или применяться вместо такого типа NAL-блока. SEI-сообщение может также включать количество подуровней, которые могут быть декодированы (при полной частоте смены кадров), когда декодирование уровня начинают с соответствующего изображения доступа к уровню. К примеру, в соответствии с иллюстрацией фиг. 8, может быть указано, что изображение 1 уточняющего уровня, которое является изображением доступа к уровню, обеспечивает доступ к трем подуровням (TID 0, 1, 2).
[0311] В соответствии с одним из вариантов осуществления настоящего изобретения способ дополнительно включает кодирование упомянутого второго уровня масштабирования или любых последующих уровней масштабирования, с более частым включением в них TSA-изображений или STSA-изображений, по сравнению с первым уровнем масштабирования. Таким образом, передатчик, декодер или аналогичный элемент может динамически определять, для каждого уровня, сколько подуровней передают или декодируют. Когда уточняющий уровень содержит более частые TSA- или STSA-изображения, чем базовый уровень, возможна более тонкая подстройка битрейта, что может быть реализовано при помощи определения количества уровней и/или количества подуровней ортогонально.
[0312] Следует отметить, что когда применяют механизм альтернативных выходных уровней, и в текущем выходном уровне нет изображений, будет выведено изображение из нижнего уровня. Следовательно, если изображения из целевого выходного уровня будут потеряны при передаче, выходная частота смены кадров (в декодере) может поддерживаться неизменной.
[0313] На фиг. 9 проиллюстрирован пример, в котором базовый уровень, BL, имеет меньше TSA-изображений (изображения 2, 3, 4), чем уточняющий уровень, EL, (изображения 2, 3, 4, 5, 7, 8, А, В, С, D, F, G) Необходимо отметить, что часть стрелок, указывающих на предсказание на основе изображений TID0, не отражены на иллюстрации (однако их можно выявить на основе данных загрузки DPB-буфера).
[0314] В соответствии с одним из вариантов осуществления настоящего изобретения возможно кодирование несовпадающих изображений доступа к временному подуровню, когда лишь некоторые из временных уровней используют для межуровневого предсказания.
[0315] В таком сценарии применения предполагается, что в качестве опорных для межуровневого предсказания используют лишь часть значений Temporalld, которые могут быть указаны в синтаксической структуре, относящейся к последовательности, например, с использованием синтаксического элемента max_tid_il_ref_pics_plus1 расширения набора VPS в стандарте MV-HEVC, SHVC или аналогичном им. Также предполагается, что передатчик имеет информацию о том, что в приемнике используют набор выходных уровней, из которого выводят только уточняющий уровень. Соответственно, передатчик не выполняет передачу изображений базового уровня со значением Temporalld, для которых указано, что их не следует использовать в качестве опорных для межуровневого предсказания. Также предполагается, что передатчик выполняет коррекцию или адаптацию битрейта при помощи адаптивного выбора максимального Temporalld, передаваемого из уточняющего уровня.
[0316] На фиг. 10 показан пример, который аналогичен примеру фиг. 9, однако в котором изображения базового уровня с Temporalld, большим или равным 2, не используют в качестве опорных для межуровневого предсказания, а именно, в стандартах MV-HEVC, SHVC или аналогичных им, на это может быть выполнено указание при помощи назначения синтаксического элемента max_tid_il_ref_pics_plus1, между базовым и уточняющим уровнем, равным 2.
[0317] В соответствии с одним из вариантов осуществления настоящего изобретения, который может применяться независимо или совместно с другими вариантами осуществления настоящего изобретения, возможно кодирование несовпадающих изображений доступа к временному подуровню, когда Temporalld не должны быть одинаковыми в различных уровнях в одном блоке доступа. Это может применяться, например, в схемах масштабируемого видеокодирования, которые допускают наличие изображений с различными значениями Temporalld (или аналогичного идентификатора) в одном блоке доступа.
[0318] Наличие разных значений Temporalld для изображений в одном блоке доступа может обеспечивать в кодере гибкость, позволяя различным образом определять иерархию предсказаний для различных уровней, что дает возможность кодировать некоторые из уровней с большим количеством значений Temporalld и частыми точками переключения на повышенный подуровень, а также кодировать некоторые уровни с иерархией предсказания, нацеленной на лучший показатель «битовая скорость - искажения». Также, это дает возможность кодировать деревья уровней одного битового потока независимо друг от друга. К примеру, базовый уровень и уровень вспомогательных изображений может кодироваться различными кодерами, и/или кодирование различных деревьев уровней может выполняться в различные моменты времени. Возможность работы кодеров независимо друг от друга, дает им гибкость при определении иерархии предсказания и количества значений Temporalld, в зависимости от конкретного входного сигнала.
[0319] Кодер может указывать, например, в синтаксических структурах, относящихся к последовательности, например, в наборе VPS, являются ли значения Temporalld, или аналогичного идентификатора, совпадающими (т.е. одинаковыми) для кодированных изображений внутри блока доступа. Декодер может декодировать, например, из синтаксической структуры, относящейся к последовательности, например, из набора VPS, являются ли значения Temporalld, или аналогичного идентификатора, совпадающими для кодированных изображений внутри блока доступа. Если значения Temporalld, или аналогичных идентификаторов, совпадают для кодированных изображений в блоке доступа, кодер и/или декодер, может выбирать отличающиеся синтаксис, семантику и/или операции, по сравнению с ситуацией, когда значения Temporalld, или аналогичных идентификаторов, для кодированных изображений в блоке доступа могут не совпадать. К примеру, когда значения Temporalld, или аналогичных идентификаторов, совпадают для кодированных изображений в блоке доступа, в синтаксисе, семантике и/или процедурах вычисления переменных RPS-набора межуровневого предсказания при кодировании и/или декодировании может использоваться информация о том, какие значения Temporalld могут иметь изображения, используемые в качестве опорных для межуровневого предсказания между опорным уровнем и предсказываемым уровнем, и/или какие из значений Temporald изображения, используемые в качестве опорных для межуровневого предсказания между опорным уровнем и предсказываемым уровнем, иметь не могут. К примеру, в набор VPS может быть включен синтаксический элемент, именуемый tid_aligned_flag, семантика которого может быть определена следующим образом: tid_aligned_flag, равный О, определяет, что Temporalld могут быть одинаковыми для различных кодированных изображений одного блока доступа, однако это не является обязательным; tid_aligned_flag, равный 1, определяет, что Temporalld обязательно являются одинаковыми для всех кодированных изображений в одном блоке доступа. Флаг tid_aligned_flag может учитываться при вычислении списка кандидатных опорных изображений межуровневого предсказания. К примеру, в соответствии с рассмотренным выше третьим примером построения списка (или списков) опорных изображений, псевдокод для определения списка, который указывает на кандидатные опорные изображения межуровневого предсказания, refLayerPicldc[], может быть определен следующим образом:

[0320] Когда указано, что значения Temporalld совпадают для всех изображений в блоке доступа, то указанное значение Temporalld, которое может быть использовано для межуровневого предсказания, влияет на вычисление списка кандидатных опорных изображений межуровневого предсказания, т.е. только изображения со значением Temporalld, меньшим или равным указанному максимальному значению Temporalld, включают в список кандидатных опорных изображений межуровневого предсказания. Когда значения Temporalld не являются обязательно совпадающими для всех изображений в блоке доступа, в список кандидатных опорных изображений межуровневого предсказания включают изображения с любыми значениями Temporalld.
[0321] На фиг. 11 показан пример, в котором иерархии предсказания определяют различным образом для различных уровней. В данном примере базовый уровень (BL) кодируют с иерархической иерархией предсказания, подразумевающей кодирование всех изображений с Temporalld (всех изобаржний), равных 0. Иерархия предсказаний для базового уровня была выбрана с целью получения высокого показателя «битовая скорость - искажения» в базовом уровне. Уточняющий уровень (EL) имеет четыре подуровня и частые TSA-изображения, которые обеспечивают возможность динамического выбора, сколько подуровней будут передаваться для уточняющего уровня.
[0322] Как и для фиг. 9, необходимо отметить, что часть стрелок, указывающих на предсказание на основе изображений TID0 уточняющего уровня, не отражены на иллюстрации фиг. 11 (однако их можно выявить на основе данных загрузки DPB-буфера).
Аналогично, не показаны стрелки для предсказания базового уровня, и соответствующая информация может быть получена из данных загрузки DPB-буфера.
[0323] Ниже будет описан один из вариантов осуществления настоящего изобретения, который может применяться совместно с другими вариантами осуществления настоящего изобретения или независимо. В свете рассмотрения примеров синтаксиса и семантики набора VPS, а также приведенного выше третьего примера построения списка (или списков) опорных изображений, были найдены описанные далее недостатки.
- Когда вычисляют список, указывающий на кандидатные опорные изображения межуровневого предсказания, refLayerPicldc[], условие «max_tid_il_ref_pics _plus1 [refLayerldx][LayerldxlnVps[nuh_layer_id]] > Temporalld» имеет своим следствием то, что когда max_tid_il_ref_pics_plus1 [refLayerldx][LayerldxInVps[nuh_layer_id]] равно 0 (т.е. когда только IRAP-изображения опорного уровня могут использоваться в качестве опорных для межуровневого предсказания), порядковый номер данного опорного уровня не включают в refLayerPicldc[]. Синтаксический элемент max_tid_il_ref_pics_plus1 [][] применяют в синтаксисе и семантике RPS-набора межуровневого предсказания не оптимально, по перечисленным ниже причинам.
- Синтаксические элементы RPS-набора межуровневого предсказания включают в заголовок слайса, даже если значение Temporalld таково, что межуровневое предсказание не разрешено согласно значениям max_tid_il_ref_pics_plus1 [][].
- Длину синтаксических элементов num_inter_layer_ref_pics_minus1 и inter_layer_pred_layer_idc[i] определяют на основе NumDirectRefLayers[nuh_layer_id]. Однако, если бы учитывались max_tid_il_ref_pics _plus1 [][] и Temporalld текущего изображения, потенциально могла бы быть получена меньшая длина, и соответственно, порядковый номер inter_layer_pred_layer_idc[i] мог быть оказаться среди опорных уровней, которые могут быть использованы для межуровневого предсказания для текущего Temporalld.
[0324] Для обеспечения корректного функционирования в ситуации, когда только IRAP-изображения опорного уровня могут использоваться в качестве опорных для межуровневого предсказания, псевдокод для определения списка, указывающего на кандидатные опорные изображения межуровневого предсказания, refLayerPicldc[], может быть задан следующим образом:

[0325] Как уже отмечалось, описанный выше вариант осуществления настоящего изобретения может применяться совместно с другими вариантами его осуществления. Рассмотренный вариант осуществления настоящего изобретения может применяться совместно с другим вариантом его осуществления, в котором кодер может кодировать в синтаксическую структуру, относящуюся к последовательности, например, набор VPS (и/или декодер может декодировать из такой структуры), указание на то, совпадают ли значения Temporalld, или аналогичного идентификатора, для кодированных изображений в блоке доступа, в соответствии с последующим более подробным описанием. Для обеспечения корректного функционирования в ситуации, когда только IRAP-изображения опорного уровня могут использоваться в качестве опорных для межуровневого предсказания, псевдокод для определения списка, указывающего на кандидатные опорные изображения межуровневого предсказания, refLayerPicldc[], может быть задан следующим образом:

[0326] Альтернативно, при более оптимальном использовании max_tid_il_ref_pics_plus1 [][], этот вариант осуществления настоящего изобретения может быть реализован в соответствии с описанием в приведенных ниже абзацах.
[0327] Кодер может кодировать или декодер может декодировать синтаксические элементы, относящиеся к RPS-набору межуровневого предсказания, с использованием кодирования фиксированной длины, например, u(v), при этом длина синтаксических элементов может выбираться согласно количеству потенциальных опорных уровней, разрешенному значением nuh_layer_id, и значению Temporalld текущего кодируемого или декодируемого изображения. Значения этих синтаксических элементов могут указывать на опорные изображения среди потенциальных опорных уровней, разрешенных значением nuh_layer_id и Temporalld. Указание на потенциальные опорные уровни может выполняться в синтаксической структуре, относящейся к последовательности, например, в наборе VPS. Указание на прямые опорные уровни для каждого из уровней может выполняться отдельно от подуровней, которые могут использоваться в качестве опорных для межуровневого предсказания. К примеру, в MV-HEVC, SHVC или аналогичных стандартах синтаксические элементы direct_dependency_flag[i][j] могут применяться для указания на потенциальные опорные уровни, а синтаксические элементы max_tid_il_ref_pics_plus1 [i][j] могут применяться для указания на то, может ли межуровневое предсказание выполняться исключительно на основе IRAP-изображений, и если это не так, на максимальный подуровень, на основе которого может выполняться межуровневое предсказание.
[0328] В контексте стандартов MV-HEVC, SHVC и/или аналогичных стандартов, переменные NumDirectRefLayersForTid[lid] [tld] и RefLayerldListForTid[lld] [tld] [k] вычисляют на основе информации расширения набоар VPS. Переменная NumDirectRefLayersForTid[lld][tld] указывает на количество прямых опорных уровней, которые могут применяться для межуровневого предсказания изображения с nuh_layer_id, равным lld, и Temporalld, равным tld. Переменная NumDirectRefLayersForTid[lld][tld] указывает на количество прямых опорных уровней, которые могут применяться для межуровневого предсказания изображения с nuh_layer_id, равным lld, и Temporalld, равным tld. Например, для вычисления NumDirectRefLayersForTid[lld] [tld] и RefLayerldListForTid[lld][tld][k] может быть использован приведенный ниже псевдокод, в котором MaxLayersMinus1 - это количество уровней, указанное в наборе VPS, минус 1, a LayerldxlnVps[layerld] определяет порядковый номер уровня (в диапазоне от 0 до MaxLayersMinus1 включительно) в некоторых структурах и циклах, заданных в наборе VPS.

[0329] Как уже отмечалось, описанный выше вариант осуществления настоящего изобретения может применяться совместно с другими вариантами его осуществления. Рассмотренный вариант осуществления настоящего изобретения может применяться совместно с другим вариантом его осуществления, в котором кодер может кодировать в синтаксическую структуру, относящуюся к последовательности, например, набор VPS (и/или декодер может декодировать из такой структуры), указание на то, совпадают ли значения Temporalld, или аналогичного идентификатора, для кодированных изображений в блоке доступа, в соответствии с последующим более подробным описанием. Для обеспечения корректного функционирования в ситуации, когда только IRAP-изображения опорного уровня могут использоваться в качестве опорных для межуровневого предсказания, псевдокод для вычисления NumDirectRefLayersForTid[lld] [tld] и RefLayerldListForTid[lld][tld][k] может быть задан следующим образом:

[0330] В синтаксисе и семантике RPS-набора межуровневого предсказания вместо NumDirectRefLayers[nuh_layer_id] используют NumDirectRefLayersForTid[nuh_layer_id] [Temporalld]. При этом inter_layer_pred_layer_idc[i] - это порядковый номер k для RefLayerldListForTid[nuh_layer_id] [Temporalld] [k] (а не порядковый номер k для RefLayerld[nuh_layer_id] [k]). В результате синтаксические элементы RPS-набора межуровневого предсказания включают в заголовок слайса, даже если значение Temporalld таково, что межуровневое предсказание не разрешено согласно значениям max_tid_il_ref_pics_plus1 [][]. При этом, также, длину синтаксических элементов num_inter_layer_ref_pics_minus1 и inter_layer_pred_layer_idc[i] определяют на основе NumDirectRefLayersForTid[nuh_layer_id][Temporalld], и следовательно, она может быть меньшей, чем если бы длину определяли на основе NumDirectRefLayers[nuh_layer_id].
[0331] К примеру, в синтаксической структуре заголовка сегмента слайса может применяться следующий синтаксис:


[0332] В последующих абзацах описаны возможные определения семантики для проиллюстрированного выше фрагмента синтаксической структуры заголовка сегмента слайса.
[0333] Синтаксический элемент num_inter_layer_ref_pics_minus1 + 1 определяет количество изображений, которые могут использоваться при декодировании текущего изображения для межуровневого предсказания. Длина синтаксического элемента num_inter_layer_ref_pics_minus1 равна Ceil(Log2(NumDirectRefLayersForTid[nuh_layer_id][Temporalld])) бит. Значение num_inter_layer_ref_pics_minus1 должно лежать в диапазоне от 0 до NumDirectRefLayersForTid[nuh_layer_id] [Temporalld] - 1 включительно.
[0334] Переменная NumActiveRefLayerPics может быть вычислена следующим образом:

[0335] Значение inter_layer_pred_layer_idc[i] определяет значение переменной RefPicLayerld[i], которая представляет собой значение nuh_layer_id i-го изображения, которое может быть использовано для межуровневого предсказания текущего изображения. Длина синтаксического элемента inter_layer_pred_layer_idc[i] равна Ceil(Log2(NumDirectRefLayersForTid[nuh_layer_id][Temporalld])) бит. Значение inter_layer_pred_layer_idc[i] должно лежать в диапазоне от 0 до NumDirectRefLayersForTid[nuh_layer_id] [Temporalld] - 1 включительно. Если этот синтаксический элемент отсутствует, значение inter_layer_pred_layer_idc[i] принимают равным refLayerPicldc[i].
[0336] Переменные RefPicLayerld[i] для всех значений i в диапазоне от 0 до NumActiveRefLayerPics - 1 включительно могут быть вычислены следующим образом:

[0337] В случае масштабируемости с гибридным кодеком декодированное изображение базового уровня может предоставляться для кодирования и/или декодирования уточняющих уровней, например, чтобы быть использовано в качестве опорного для межуровневого предсказания. В некоторых из вариантов осуществления настоящего изобретения может предъявляться требование, например, в стандарте кодирования, о том, что значения Temporalld кодированных изображений в одном блоке доступа должны быть одинаковыми, при этом значение Temporalld для изображения внешнего базового уровня может быть принято равным значению Temporalld изображений в блоке доступа, с которым связано изображение внешнего базового уровня. В некоторых из вариантов осуществления настоящего изобретения может выполняться указание, например, и использованием флага tid_aligned_flag или аналогичного элемента, на то, должны ли быть одинаковыми значения Temporalld кодированных изображений в блоке доступа. Когда флаг tid_aligned_flag или аналогичный элемент указывает на то, что значения Temporalld кодированных изображений в одном блоке доступа должны быть одинаковыми, значение Temporalld для изображения внешнего базового уровня принимают равными значению Temporalld изображений в блоке доступа, с которым связано изображение внешнего базового уровня. В противном случае значение Temporalld изображения внешнего базового уровня могут не влиять на кодирование или декодирование изображений в блоке доступа, с которым связан внешний базовый уровень, и следовательно, значение Temporalld для изображения внешнего базового уровня получать не требуется. В некоторых из вариантов осуществления настоящего изобретения значение Temporalld для изображения внешнего базового уровня может приниматься равным значению Temporalld выбранного изображения в блоке доступа, с которым связано данное внешнее изображение базового уровня. Упомянутое изображение может быть выбрано согласно ограничениям и/или алгоритму, которые могут быть определены, например, в стандарте кодирования. К примеру, выбрано может быть изображения, для которого изображение внешнего базового уровня является прямым опорным изображением. Если будут присутствовать несколько изображений, для которых изображение внешнего базового уровня является прямым изображением, то может быть выбрано, например, изображение с наименьшим значением nuh_layer_id. Могут накладываться дополнительные ограничения на значения Temporalld изображений в блоке доступа, который имеет связанное с ним изображение внешнего базового уровня. К примеру может предъявляться требование, например, в стандарте кодирования, о том, что значения Temporalld всех изображений, для которых внешний базовый уровень используют или могут использовать в качестве опорного изображения межуровневого предсказания, должны быть одинаковыми. Следовательно, значение Consequently изображения внешнего базового уровня может быть принято равным Temporalld любого изображения, для которого это изображение внешнего базового уровня является прямым опорным изображением.
[0338] В способе декодирования, который проиллюстрирован на фиг. 12, примеряют битовый поток, который закодирован согласно любому из описанных выше вариантов осуществления настоящего изобретения. В соответствии с иллюстрацией фиг. 12 кодированные изображения первого уровня масштабирования принимают (1200) и декодируют (1202). Принимают (1204) кодированные изображения второго уровня масштабирования, при этом второй уровень масштабирования зависит от первого уровня масштабирования. Затем изображение доступа к уровню во втором уровне масштабирования выбирают (1206) из кодированных изображений второго уровня масштабирования, при этом выбранное изображение доступа к уровню является изображением пошагового доступа к временному подуровню в самом нижнем временном подуровне. Кодированные изображения во втором уровне масштабирования, предшествующих в порядке декодирования выбранному изображению доступа к уровню, игнорируют (1208), и выбранное изображение доступа к уровню декодируют (1210).
[0339] В одном из вариантов осуществления настоящего изобретения способ по фиг. 13 может быть дополнен рассмотренными ниже шагами, которые выполняют после шагов, показанных на фиг. 13. Может быть определено количество подуровней, декодирование которых разрешено выбранным изображением доступа к уровню. Затем передают изображения, следующие в порядке декодирования за выбранным изображением доступа к уровню, в тех подуровнях, декодирование которых разрешено, при этом изображения, следующие в порядке декодирования за выбранным изображением доступа к уровню в тех подуровнях, декодирование которых не разрешено, игнорируют до тех пор, пока не будет встречено соответствующее изображение доступа к подуровню.
[0340] В дополнение к декодированию или вместо него кодер битового потока согласно любому из описанных выше вариантов осуществления настоящего изобретения может применяться для адаптации битрейта, передающим устройством (например, сервером потоковой передачи) и/или шлюзовым устройством. В способе адаптации битрейта, который проиллюстрирован на фиг. 13, принимают (1300) кодированные изображения первого уровня масштабирования. Также принимают (1302) кодированные изображения второго уровня масштабирования, при этом второй уровень масштабирования зависит от первого уровня масштабирования. Изображение доступа к уровню во втором уровне масштабирования выбирают (1304) из кодированных изображений второго уровня масштабирования, при этом выбранное изображение доступа к уровню является изображением пошагового доступа к временному подуровню в самом нижнем временном подуровне. Кодированные изображения во втором уровне масштабирования, предшествующие в порядке декодирования выбранному изображению доступа к уровню, игнорируют (1306), а кодированные изображения первого уровня масштабирования и выбранное изображение доступа к уровню передают (1308) в битовом потоке.
[0341] В одном из вариантов осуществления настоящего изобретения способ декодирования по фиг. 12 может быть дополнен рассмотренными ниже шагами, которые выполняют после шагов, показанных на фиг. 12. Может быть определено количество подуровней, декодирование которых разрешено выбранным изображением доступа к уровню. Затем декодируют изображения, следующие в порядке декодирования за выбранным изображением доступа к уровню, в тех подуровнях, декодирование которых разрешено, при этом изображения, следующие в порядке декодирования за выбранным изображением доступа к уровню в тех подуровнях, декодирование которых не разрешено, игнорируют до тех пор, пока не будет встречено соответствующее изображение доступа к подуровню.
[0342] В соответствии с одним из вариантов осуществления настоящего изобретения упомянутое изображение доступа к уровню представляет собой изображение пошагового доступа к временному подуровню, которое, в зависимости от сценария применения, обеспечивает точку доступа либо для поуровневой инициализации декодирования битового потока с одним или более временными подуровнями, либо для поуровневой адаптации битрейта битового потока с одним или более временными подуровнями.
[0343] Рассмотренная процедура декодирования может выполняться в виде объединенной процедуры запуска по уровням и по подуровням. Такая процедура запуска декодирования обеспечивает поуровневую инициализацию декодирования битового потока с одним или более уровнями.
[0344] Таким образом, в соответствии с одним из вариантов осуществления настоящего изобретения способ дополнительно включает начало декодирования битового потока в ответ на то, что базовый уровень содержит изображение IRAP-изображение STSA-изображение в самом нижнем подуровне; начало пошагового декодирования по меньшей мере одного уточняющего уровня в ответ на то, что упомянутый по меньшей мере один уточняющий уровень содержит IRAP-изображения; и постепенное увеличение количества декодируемых уровней и/или количества декодируемых временных подуровней. В данном случае уровни могут представлять собой уточнение в отношении любой масштабируемой величины, или величин, описанных выше, например, уточнение пространственного разрешения, показателя качества, ракурсы, такие дополнительные компоненты, как глубина, или любую комбинацию из перечисленного.
[0345] В соответствии с одним из вариантов осуществления настоящего изобретения способ дополнительно включает формирование недоступных изображений для опорных изображений первого изображения, в порядке декодирования, в конкретном уточняющем уровне.
[0346] В соответствии с одним из альтернативных вариантов осуществления настоящего изобретения способ дополнительно включает пропуск декодирования изображений, предшествующих в порядке декодирования IRAP-изображению, с которого может начинаться декодирование конкретного уточняющего уровня. В соответствии с одним из вариантов осуществления настоящего изобретения упомянутые пропущенные изображения могут быть помечены с использованием одного или более специальных типов NAL-блоков. Такие изображения, независимо от того, маркированы ли они явно при помощи типа NAL-блока или выявлены декодером, могут называться межуровневыми пропускаемыми изображениями произвольного доступа.
[0347] Декодер может не выполнять вывод сформированных недоступных изображений и/или декодированных CL-RAS-изображений.
[0348] В соответствии с одним из вариантов осуществления настоящего изобретения способ дополнительно включает поддержание информации о том, какие из подуровней каждого уровня были корректно декодированы (т.е. были инициализированы). Например, вместо переменной LayerInitializedFlag[i], которая использовалась в рассмотренной выше процедуре поуровневого запуска, для каждого идентификатора i уровня может поддерживаться переменная HighestTidPlus1InitializedForLayer[i]. Переменная HighestTidPlus1InitializedForLayer[i], равная 0, может указывать на то, что в уровне с идентификатором i не было корректно декодировано ни одного изображения, с момента последней активации механизма запуска. Значение HighestTidPlus1InitializedForLayer[i] - 1, большее или равное 0, может указывать на наивысшее значение Temporalld изображений, которые были корректно декодированы с момента последней активации механизма запуска.
[0349] Механизм запуска может быть активирован идентично или аналогично приведенному выше описанию для механизма поуровневого запуска. Когда механизм поуровневого запуска активирован, все изображения в буфере DPB могут быть помечены как «не используемые в качестве опорных». Другими словами, все изображения во всех уровнях могут быть помещены как «не используемые в качестве опорных» и не будут использоваться в качестве опорных для предсказания изображения, инициировавшего механизм поуровневого запуска, а также для всех последующих изображений в порядке декодирования.
[0350] Процедура декодирования для поуровневого запуска может управляться, например, при помощи двух переменных-массивов HighestTidPlus1InitializedForLayer[i] and FirstPiclnLayerDecodedFlag[i], которые могут иметь записи для каждого из уровней (возможно, включая базовый уровень, а также другие независимые уровни).
Когда вызвана процедура поуровневого запуска, например, в ответ на флаг NoClrasOutputFlag, равный 1, эти переменные-массивы могут быть сброшены в заданные по умолчанию значения. К примеру, когда доступны 64 уровня (например, при 6-битном nuh_layer_id), эти переменные могут быть реинициализированы следующим образом: переменную HighestTidPlus1InitializedForLayer[i Назначают равной 0 для всех значений i от 0 до 63 включительно, и переменную FirstPiclnLayerDecodedFlag[i] назначают равной 0 для всех значений i от 1 до 63 включительно.
[0351] Процедура декодирования может включать описанный ниже (или аналогичный) способ управления выводом RASL-изображений. Когда текущее изображение является IRAP-изображением, применимы описанные ниже условия.
- Если флаг HighestTidPlus1InitializedForLayer[nuh_layer_id] равно 0, переменную NoRaslOutputFlag назначают равной 1.
- В противном случае, если имеются внешние средства для назначения HandleCraAsBlaFlag равным значению для текущего изображения, переменную HandleCraAsBlaFlag назначают равной значению, предоставленному внешними средствами, а переменную NoRaslOutputFlag назначают равной HandleCraAsBlaFlag.
- В противном случае переменную HandleCraAsBlaFlag назначают равно 0, и переменную NoRaslOutputFlag также назначают равной 0.
[0352] В соответствии с одним из вариантов осуществления настоящего изобретения начало пошагового декодирования включает одно или более из следующих, выполняемых в зависимости от заданных условий, операций:
- когда текущее изображение является IRAP-изображением, и декодирование всех опорных уровней этого IRAP-изображения было начато, декодируют данное IRAP-изображение и все изображения, следующие за ним в порядке декодирования;
- когда текущее изображение является STSA-изображением в самом нижнем подуровне, и декодирование всех опорных уровней этого STSA-изображения было начато, декодируют данное STSA-изображение и все изображения в самом нижнем подуровне, следующие за данным STSA-изображением в порядке декодирования;
- когда текущее изображение является TSA-изображением или STSA-изображением более высокого подуровня, по сравнению с самым нижним уровнем, и декодирование следующего, расположенного ниже, подуровня в том же уровне было начато, а также было начато декодирование того же подуровня во всех опорных уровнях упомянутого TSA-изображения или STSA-изображения, декодируют это TSA-изображение или STSA-изображение, а также все изображения в том же подуровне, следующие за данным TSA-изображением или STSA-изображением в порядке декодирования, в том же уровне.
[0353] Эти операции, выполняемые в зависимости от заданных условий, могут быть описаны более подробно, например, в соответствии с приведенным ниже описанием. Процедура декодирования может включать описанные ниже шаги обновления значения HighestTidPlus1InitializedForLayer в каждом уровне. Когда текущее изображение является IRAP-изображением и выполнено любое из перечисленных ниже условий, HighestTidPlus1InitializedForLayer[nuh_layer_id] назначают равным максимальному значению Temporalld + 1 (при этом максимальное значение Temporalld может быть задано, например, в наборе VPS или заранее задано в стандарте кодирования).
- Идентификатор nuh_layer_id равен 0.
- Значение HighestTidPlus1InitializedForLayer[nuh_layer_ld] равно 0 и HighestTidPlus1InitializedForLayer[refLayerld] равен максимальному значению Temporalld + 1 для всех значений refLayerld, равных RefLayerld [nuh_layer_id] [j], где j - значение в диапазоне от 0 до NumDirectRefLayers[nuh_layer_id] - 1 включительно.
[0354] Когда текущее изображение является STSA-изображением с Temporalld, равным 0, и выполнено одно из приведенных ниже условий, HighestTidPlus1InitializedForLayer[nuh_layer_id] назначают равным 1.
- Идентификатор nuh_layer_id равен 0.
- Значение HighestTidPlus1InitializedForLayer[nuh_layer_id] равно 0 и HighestTidPlus1InitializedForLayer[refLayerld] больше 0 для всех значений refLayerld, равных RefLayerld[nuh_layer_id][j], где j - значение в диапазоне от 0 до NumDirectRefLayers[nuh_layer_id] - 1 включительно.
[0355] Когда текущее изображение является TSA-изображение или STSA-изображением с Temporalld больше 0 и выполнены оба из перечисленных ниже условий, HighestTidPlus1InitializedForLayer[nuh_layer_id] назнают равным Temporalld + 1.
- Значение HighestTidPlus1InitializedForLayer[nuh_layer_id] равно Temporalld.
- Значение HighestTidPlus1InitializedForLayer[refLayerld] больше или равно Temporalld + 1 refLayerld, равных RefLayerld [nuh_layer_id][j], где j - значение в диапазоне от 0 до NumDirectRefLayers[nuh_layer_id] - 1 включительно.
[0356] Когда флаг FirstPiclnLayerDecodedFlag [nuh_layer_id] равен 0, перед декодированием текущего изображения может быть вызвана процедура декодирования для формирования отсутствующих опорных изображений. Процедура декодирования для формирования отсутствующих опорных изображений позволяет сформировать изображения для каждого из изображений в наборе опорных изображений с заданными по умолчанию значениями. Процедура формирования отсутствующих опорных изображений может быть определена, главным образом, для определения синтаксических ограничений по CL-RAS-изображениям, при этом CL-RAS-изображение может быть определено как изображение с nuh_layer_id, равным layer_id, и LayerInitializedFlag [layerld], равным 0. В операциях HRD-декодирования CL-RAS-изображения может быть необходим учет CL-RAS-изображений при вычислении моментов времени поступления и удаления в буфере СРВ. Декодеры могут игнорировать все CL-RAS-изображения, поскольку эти изображения не предназначены для вывода и не влияют на процесс декодирования каких-либо иных изображений, предназначенных для вывода.
[0357] Изображения, имеющие такие значения nuh_layer_id (или аналогичных идентификаторов) и Temporalld (или аналогичных идентификаторов), для которых декодирование еще не было инициализировано, могут быть трактоваться декодером как не подлежащие выводу при декодировании. Декодирование nuh_layer_id (или аналогичного идентификатора) с любым значением Temporalld (или аналогичного идентификатора) может считаться инициализированным, когда для этого значения nuh_layer_id присутствует IRAP-изображение, и когда были инициализированы все прямые опорные уровни для уровня с этим значением nuh_layer_id. Декодирование nuh_layer_id (или аналогичного идентификатора) с любым значением Temporalld (или аналогичного идентификатора) может считаться инициализированным, когда присутствует TSA- или STSA-изображение (или аналогичное изображение) с таким значением nuh_layer_id и таким значением Temporalld, и было инициализировано декодирование всех прямых опорных уровней для уровней с этим значением nuh_layer_id и этим значением Temporal, и (когда Temporalld больше 0) было инициализировано декодирование уровня с этим nuh_layer_id значением nuh_layer_id и значением Temporalld - 1. В контексте MV-HEVC, SHVC и/или аналогичного стандарта, управление выводом изображения может быть определено в соответствии с приведенным ниже описанием или аналогичным образом. Декодером может быть определено, что изображение с Temporalld равным subLayerld, и nuh_layer_id, равным layerld, подлежит выводу (например, при помощи назначения флага PicOutputFlag равным 1), если HighestTidPlus1InitializedForLayerf layerld] больше subLayerld в начале декодирования этого изображения. В противном случае декодером может быть определено, что изображение не подлежит выводу (например, при помощи назначения флага PicOutputFlag равным 0). На определение, подлежит ли изображение выводу, может также влиять факт нахождения layerld среди выходных уровней целевого набора выходных уровней, и/или нахождение выводимого изображения среди альтернативных выходных уровней, если изображение в соответствующем выходном уровне отсутствует или не подлежит выводу.
[0358] Межуровневые пропускаемые изображения произвольного доступа (CL-RAS) могут быть определены как изображения со значениями Temporalld, равными subLayerld, и nuh_layer_id, равными layerld, для которых HighestTidPlus1InitializedForLayerf layerld] больше, чем subLayerld на момент начала декодирования изображения. CL-RAS-изображения могут обладать тем свойством, что они не подлежат выводу и не могут быть корректно декодированы, поскольку CL-RAS-изображения могут содержать ссылки на изображения, отсутствующие в битовом потоке. В стандарте может быть определено, что CL-RAS-изображения не могут использоваться в качестве опорных в процедуре декодирования нe-CL-RAS-изображений.
[0359] В соответствии с одним из вариантов осуществления настоящего изобретения изображение доступа к уровню может кодироваться кодером в битовый поток, который содержит только один уровень. Например, изображение доступа к уровню может быть STSA-изображением с nuh_layer_id, равным 0, и Temporalld, равным 0.
[0360] В соответствии с одним из вариантов осуществления настоящего изобретения декодер может начинать декодирование с изображение доступа к уровню в самом нижнем уровне. К примеру, декодер может начинать декодирование с STSA-изображения с nuh_layer_id, равным 0, и Temporalld, равным 0. Декодирование может включать запуск по подуровням, например, в соответствии с приведенным выше описанием. К примеру, декодирование может включать поддержание информации о том, какие из подуровней каждого уровня были корректно декодированы (т.е. были инициализированы), и переключение на следующий доступный подуровень или уровень, когда в порядке декодирования становится доступным соответствующее изображение доступа к уровню, изображение доступа к подуровню или IRAP-изображение. Декодируемый битовый поток может содержать только один уровень или может содержать несколько уровней.
[0361] Далее на нескольких примерах будет рассмотрено применение вариантов осуществления настоящего изобретения, относящихся к адаптации битрейта.
[0362] На фиг. 14 подразумевается, что закодирован битовый поток в соответствии с иллюстрацией фиг. 8, и передатчик выполняет адаптацию битрейта, адаптивно выбирая максимальный Temporalld, переданный из уточняющего уровня. Для первой группы GOP не передают изображений уточняющего уровня. Для второй группы GOP передатчик определяет, что необходимо повысить битрейт видеоданных и передают максимально возможное число подуровней уточняющего уровня. Поскольку для TID 0, 1 и 2 доступны STSA-изображения (т.е. изображения 1, А и В соответственно) передатчик переключается на передачу подуровней с TID 0-2, начиная со второй группы GOP уточняющего уровня. Переключение на TID 3 уточняющего уровня может быть выполнено позднее, когда появится IRAP-изображение уточняющего уровня или TSA-, или STSA-изображение уточняющего уровня с TID, равным 3. Следует отметить, что если разрешено использование альтернативных выходных уровней, в данном примере изображения будут выводиться постоянно с «полной» частотой смены кадров.
[0363] Если битовый поток был кодирован так, что по меньшей мере один уточняющий уровень содержит более частые TSA- или STSA-изображения, чем базовый уровень, например, в соответствии с иллюстрацией фиг. 9, передатчик может динамически адаптировать битрейт передачи поуровнево, при помощи определения, сколько подуровней будут передаваться.
[0364] Коррекция битрейта или адаптация битрейта может применяться, например, для обеспечения так называемого быстрого запуска в сервисах потоковой передачи данных, где битрейт передаваемого потока ниже, чем битрейт канала после запуска или произвольного доступа к потоку, что позволяет мгновенно запустить воспроизведение и обеспечить лучший уровень заполнения буфера, допускающего случайные задержки и/или повторные передачи пакетов. Коррекция битрейта может также использоваться при согласовании битрейта передаваемого потока с наличным битрейтом, обусловленным пропускной способностью канала. В этом сценарии применения может применяться большее число опорных изображений в базовом уровней, что позволяет достичь лучшего показателя «битовая скорость - искажения».
[0365] В примере на фиг. 15 предполагается, что битовый поток был кодирован в соответствии с иллюстрацией фиг. 9, и необходимо понизить битрейт первой группы GOP при передаче битового потока. В этом примере для первой группы GOP передают только изображения с Temporalld (TID), равным 0. Также предполагается, что битовый поток может быть передан с полным битрейтом, начиная со второй GOP. Поскольку вторая группа GOP в уточняющем уровне начинается с TSA-изображений, может быть начата передача изображений уточняющего уровня со всеми значениями TID.
[0366] В примере фиг. 16 предполагается, что битовый поток кодирован так, что в нем кодированы несовпадающие изображения доступа к временному подуровню, когда только некоторые временные уровни используются для межуровневого предсказания, в соответствии с иллюстрацией фиг. 10. Также предполагается, что передатчик осведомлен о том, что приемник использует набор выходных уровней, в котором выходным уровнем является только уточняющий уровень, и следовательно, передачу подуровней базового уровня, которые не используются в качестве опорных для межуровневого предсказания, не выполняют. Также предполагается, что необходимо понизить битрейт первой группы GOP при передаче битового потока. В данном примере для первой группы GOP передают изображения уточняющего уровня с Temporalld в диапазоне от 0 до 2 включительно. Также предполагается, что битовый поток может быть передан с полным битрейтом, начиная со второй GOP. Поскольку вторая группа GOP в уточняющем уровней начинается с TSA-изображений, может быть начата передача изображений уточняющего уровня со всеми значениями TID.
[0367] В примере на фиг. 17 предполагается, что битовый поток был кодирован так, что иерархии предсказания определены различным образом для различных уровней, в соответствии с иллюстрацией фиг. 11. Также предполагается, что передатчик корректирует битрейт передаваемого битового потока, вследствие чего передатчик выбирает для передачи только три подуровня (TID 0, 1 и 2) уточняющего уровня. Следует отметить, что если разрешено использование альтернативных выходных уровней, то в данном примере изображения будут выводиться постоянно с «полной» частотой смены кадров.
[0368] На фиг. 18 проиллюстрирована блок-схема видеодекодера, подходящего для применения вариантов осуществления настоящего изобретения. На фиг. 18 показана структура двухуровневого декодера, однако нужно понимать, что те же операции декодирования могут аналогичным образом применяться в одноуровневом декодере.
[0369] Видеодекодер 550 включает первый сегмент 552 декодера для компонентов базового ракурса и второй сегмент 554 декодера для компонентов небазового ракурса. Блок 556 иллюстрирует демультиплексор, предназначенный для предоставления информации о компонентах базового ракурса в первый сегмент 552 декодера, а также для предоставления информации о компонентах небазового ракурса во второй сегмент 554 декодера. Обозначение Р'n означает предсказанное представление блока пикселей изображения. D'n - это восстановленные сигналы ошибки предсказания. Блоки 704, 804 иллюстрируют предварительно восстановленные изображения (I'n). R'n - это окончательное восстановленное изображение. Блоками 703, 803 проиллюстрировано обратное преобразование (Т1). Блоками 702, 802 проиллюстрировано обратное преобразование (Q1). Блоками 701, 801 проиллюстрировано энтропийное декодирование (Е1). Блоками 705, 805 проиллюстрирована память опорных кадров (reference frame memory, RFM). Блоками 706, 806 проиллюстрировано предсказание (Р) (либо внутреннее, либо внешнее предсказание). Блоками 707, 807 проиллюстрирована фильтрация (F). Блоки 708, 808 могут использоваться для комбинирования декодированной информации ошибки предсказания с предсказанными компонентами базового или небазового ракурса, в результате чего получают предварительно восстановленные изображения (I'n). Предварительно восстановленные и прошедшие фильтрацию изображения базового ракурса могут выводиться (709) из первого сегмента 552 декодера, а предварительно восстановленные и прошедшие фильтрацию изображения базового ракурса могут выводиться (809) из первого сегмента 554 декодера.
[0370] Фиг. 20 является графическим представлением типовой системы мультимедийной связи, в которой могут быть реализованы различные варианты осуществления настоящего изобретения. В соответствии с иллюстрацией фиг. 8, источник 1510 данных предоставляет исходный сигнал в аналоговом, несжатом цифровом или сжатом цифровом формате, или в любой комбинации из этих форматов. Кодер 1520 может иметь в своем составе средства предварительной обработки, например, средства преобразования формата данных и/или средства фильтрации исходного сигнала, или может иметь соединение с таким средствами. Кодер 1520 кодирует исходный сигнал в кодированный битовый поток мультимедийных данных. Следует отметить, что кодируемый битовый поток может приниматься, напрямую или опосредованно, от удаленного устройства, расположенного в сети практически любого типа. Также, битовый поток может приниматься от локального аппаратного или программного обеспечения. Кодер 1520 может быть способен кодировать более одного типа мультимедийных данных, например, аудио- и видеоданные, или могут требоваться более одного кодера 1520 для кодирования различных типов исходного сигнала. Кодер 1520 может также получать входные данные, полученные при помощи синтеза, такие как графику или текст, или может быть способен формировать кодированные битовые потоки синтезированных мультимедийных данных. Ниже, для простоты описания, будет рассмотрена обработка только одного кодированного битового потока, содержащего однотипные мультимедийные данные. Однако нужно отметить, что обычно сервисы вещания реального времени включают несколько потоков (как правило, по меньшей мере один аудиопоток, видеопоток и текстовый поток субтитров). Также, нужно отметить, что система может включать множество кодеров, однако на фиг. 8, для простоты описания, без потери общности, показан только один кодер 1520. Описание и примеры в настоящем документы описывают именно процедура кодирования, однако при этом специалисты в данной области техники должны понимать, что те же самые принципы и идеи применимы и для соответствующей процедуры декодирования, и наоборот.
[0371] Кодированный битовый поток мультимедийных данных может быть передан в хранилище 1530. Хранилище 1530 может включать любой тип запоминающего устройства большой емкости для хранения кодированного битового потока мультимедийных данных. Формат кодированного битового потока мультимедийных данных в хранилище 1530 может быть элементарным автономным форматом битового потока, или один или более кодированных битовых потоков мультимедийных данных могут быть инкапсулированы в контейнерный файл. Если один или более битовых потоков мультимедийных данных инкапсулируют в контейнерный файл, может применяться формирователь файлов (не показан на чертежа) для сохранения одного или более битовых потоков мультимедийных данных в файл и для формирования метаданных формата файла, которые также сохраняют в файл. Кодер 1520 и/или хранилище 1530 могут включать формирователь файлов, или же формирователь файлов может быть функционально связан кодером 1520 и/или хранилищем 1530. Некоторые системы работают «на лету», то есть не используют память и передают кодированный битовый поток мультимедийных данных из кодера 1520 непосредственно в передатчик 1540. Затем кодированный битовый поток мультимедийных данных передают, когда это необходимо, в передатчик 1540, также именуемый сервером. Формат, используемый при передаче, может быть элементарным автономным форматом битового потока, или один или более кодированных битовых потоков мультимедийных данных могут быть инкапсулированы в контейнерный файл. Кодер 1520, хранилище 1530 и передатчик 1540 могут располагаться в одном и том же физическом устройстве, или же они могут входить в состав отдельных устройств. Кодер 1520 и сервер 1540 могут работать с данными реального времени, и в этом случае кодированный битовый поток мультимедийных данных, как правило, не хранят на постоянной основе, а буферизуют в течение небольших промежутков времени в кодере 1520 видеоданных и/или на сервере 1540 для сглаживания колебаний задержек на обработку, задержек на передачу и битрейта кодированных мультимедийных данных.
[0372] Сервер 1540 передает кодированный битовый поток мультимедийных данных с использованием стека протоколов связи. Стек может включать, без ограничения перечисленным, одно или более из следующего: протокол передачи в реальном времени (RTP), протокол пользовательских датаграмм (UDP), протокол передачи гипертекста (Hypertext Transfer Protocol, HTTP), протокол управления передачей (Transmission Control Protocol, TCP) и протокол Интернета (IP). Когда стек протоколов связи является пакетным, сервер 1540 инкапсулирует кодированный битовый поток мультимедийных данных в пакеты. Например, когда используется протокол RTP, сервер 1540 инкапсулирует кодированный битовый поток мультимедийных данных в пакеты RTP согласно формату полезной нагрузки протокола RTP. Как правило, каждый тип мультимедийных данных имеет отдельный формат полезной нагрузки RTP. Следует еще раз отметить, что система может содержать более одного сервера 1540, но для простоты в последующем описании рассмотрен только один сервер 1540.
[0373] Если мультимедийные данные инкапсулированы в контейнерный файл для хранилища 1530 или для ввода данных в передатчик 1540, передатчик 1540 может иметь в своем составе «анализатор передаваемого файла» (не показан на чертеже) или может быть функционально связан с подобным элементом. В частности, если контейнерный файл сам по себе не передают, но по меньшей мере один содержащийся в нем кодированный битовый поток мультимедийных данных инкапсулируют для передачи по протоколу связи, анализатор передаваемого файла находит соответствующие фрагменты кодированного битового потока мультимедийных данных, подлежащие передаче по протоколу связи. Анализатор передаваемого файла может также быть полезен при создании корректного формата для протокола связи, например, заголовков и полезной нагрузки пакетов. Мультимедийный контейнерный файл может содержать инструкции по инкапсуляции, такие как треки указаний в базовом формате медиафайлов ISO, используемые для инкапсуляции по меньшей мере одного кодированного битового потока мультимедийных данных в протокол связи.
[0374] Сервер 540 может быть связан со шлюзом 1550 через по сети связи, однако это не является обязательным. Следует отметить, что в общем случае система может включать любое количество шлюзов или аналогичных элементов, однако для простоты в приведенном ниже описании рассмотрен только один шлюз 1550. Шлюз 1550 может выполнять функции различных типов, например трансляцию потока пакетов, соответствующую одному стеку протоколов связи, в другой стек протоколов связи, слияние и разветвление потоков данных и манипуляцию потоками данных согласно возможностям нисходящей линии связи и/или приемника, например, управление битовой скоростью передачи данных перенаправляемого потока согласно превалирующим сетевым условиям в нисходящей линии связи. Примеры шлюзов 1550 включают устройство управления многоточечной конференцсвязью (multipoint conference control unit, MCU,), шлюзы между устройствами видеотелефонии с коммутацией каналов и с коммутацией пакетов, серверы сервиса «нажми и говори в сотовой сети» (Push-to-talk over Cellular, РОС), IP-инкапсуляторы в системах цифрового телевизионного вещания на портативные устройства (стандарт DVB-H), телевизионные приставки или другие устройства, которые перенаправляют вещание локально в домашние беспроводные сети. При использовании протокола RTP шлюз 1550 называют RTP-микшером или RTP-транслятором, при этом он может выступать в роли конечной точки соединения RTP.
[0375] Система включает один или более приемников 1560, которые, в общем случае, способны принимать, демодулировать и/или декапсулировать переданный сигнал с получением кодированного битового потока мультимедийных данных. Кодированный битовый поток мультимедийных данных может быть передан в записывающее хранилище 1570. Записывающее хранилище 1570 может включать любой тип запоминающего устройства большой емкости для хранения кодированного битового потока мультимедийных данных. Записывающие хранилище 1570 может, дополнительно или альтернативно, включать вычислительную память, например, память с произвольным доступом. Формат кодированного битового потока мультимедийных данных в записывающем хранилище 1570 может быть элементарным автономным форматом битового потока, или один или более кодированных битовых потоков мультимедийных данных могут быть инкапсулированы в контейнерный файл. Если имеются несколько кодированных битовых потоков мультимедийных данных, например, аудиопоток и видеопоток, связанные друг с другом, то, как правило, применяют контейнерный файл, и при этом приемник 1560 содержит формирователь контейнерного файла (или связан с подобным формирователем), формирующий контейнерный файл на основе входных потоков. Некоторые системы работают «на лету», то есть передают кодированный битовый поток мультимедийных данных из приемника 1560 непосредственно в декодер 1580, без задействования записывающего хранилища 1570. В некоторых системах в записывающем хранилище 1570 хранят только последнюю по времени часть записанного потока, например, последний 10-минутный фрагмент записанного потока, тогда как все ранее записанные данные удаляют из записывающего хранилища 1570.
[0376] Кодированный битовый поток мультимедийных данных из записывающего хранилища 1570 может быть передан в декодер 1580. Если имеются несколько кодированных битовых потоков мультимедийных данных, например, аудиопоток и видеопоток, связанные друг с другом и инкапсулированные в контейнерный файл, или один битовый поток, который инкапсулирован в контейнерный файл, например, для более простого доступа, то применяют анализатор файлов (не показан на чертеже) для декапсуляции всех кодированных битовых потоков мультимедийных данных из контейнерного файла. Записывающее хранилище 1570 или декодер 1580 могут иметь анализатор файлов в своем составе, или анализатор файлов может быть связан с записывающим хранилищем 1570, или с декодером 1580. Также, нужно отметить, что система может включать множество декодеров, однако в данном документе, для простоты описания, без потери общности, показан только один кодер 1570.
[0377] Кодированный битовый поток мультимедийных данных может далее обрабатываться декодером 1570, на выходе которого получают один или более несжатых потоков мультимедийных данных. Наконец, устройство 1590 воспроизведения может воспроизводить несжатые потоки мультимедийных данных, например, с помощью громкоговорителя или дисплея. Приемник 1560, записывающее хранилище 1570, декодер 1570 и устройство 1590 воспроизведения могут располагаться в одном и том же физическом устройстве, или же они могут входить в состав отдельных устройств.
[0378] Передатчик 1540 и/или шлюз 1550 могут быть сконфигурированы для выполнения адаптации битрейта согласно различным рассмотренным вариантам осуществления настоящего изобретения, и/или передатчик 1540, и/или шлюз 1550 могут быть сконфигурированы для выбора передаваемых уровней и/или подуровней масштабируемого видеопотока согласно различным вариантам осуществления настоящего изобретения. Адаптация битрейта и/или выбор передаваемых уровней, и/или подуровней, может выполняться по множеству различных пример, например, в ответ на запрос от приемника 1560 или в ответ на превалирующие условия в сети, по которой передают битовый поток, к примеру, в зависимости от ее пропускной способности. Запросом от приемника может быть, например, запрос на изменение передаваемых уровней масштабирования и/или подуровней, или переключение на устройство воспроизведения, которое имеет отличающиеся, по сравнению с предыдущим, возможности.
[0379] Декодер 1580 может быть сконфигурирован для выполнения адаптации битрейта согласно различным рассмотренным вариантам осуществления настоящего изобретения, и/или декодер 1580 может быть сконфигурирован для выбора передаваемых уровней и/или подуровней масштабируемого видеопотока согласно различным вариантам осуществления настоящего изобретения. Адаптация битрейта и/или выбор передаваемых уровней, и/или подуровней, может выполняться по множеству различных причин, например, для повышения быстродействия операции декодирования. Повышение быстродействия операции декодирования может быть необходимо, например, если устройство, в состав которого входит декодер 580, является многозадачным, и использует вычислительные ресурсы для других целей, а не только для декодирования масштабируемого битового потока видеоданных. В другом примере, повышение быстродействия операции декодирования может быть необходимо, когда воспроизведение видеоданных выполняют с увеличенной скоростью по сравнению с нормальной скоростью воспроизведения, например, в два или три раза быстрее, чем обычная скорость воспроизведения.
[0380] Существующие стандарты для форматов медиафайлов включают базовый формат медиафайла стандарта ISO (ISO/IEC 14496-12, который имеет аббревиатуру ISOBMFF), формат файлов MPEG-4 (ISO/IEC 14496-14, также называемый форматом МР4), формат файлов для видеоданных, структурированных NAL-блоками (ISO/IEC 14496-15) и формат файлов 3 GPP (3 GPP TS 26.244, также известный под называнием формата 3GP). Файлы форматов SVC и MVC определены как дополнения к формату файлов AVC. Формат файлов ISO является базовым для получения всех упомянутых выше форматов файла (за исключением собственно формата файлов ISO). Эти форматы файлов (включая собственно формат файлов ISO) называют семейством форматов файлов ISO.
[0381] Элементарная единица построения базового формата медиафайлов ISO называется «боксом» (box). Каждый бокс имеет заголовок и полезную нагрузку. В заголовке бокса указывают тип бокса и размер бокса, выраженный в байтах. Бокс может включать внутри себя другие боксы, при этом в формате файлов ISO определены типы боксов, которые могут находиться внутри бокса каждого типа. При этом, также, некоторые боксы должны присутствовать в каждом файле обязательно, тогда как другие боксы могут быть опциональными. В дополнение, для боксов некоторого типа, допустимо наличие нескольких экземпляров бокса в одном файле. Таким образом, в базовом формате медиафайлов ISO по существу определена иерархическая структура боксов.
[0382] В соответствии с форматом файлов семейства ISO файл включает мультимедийные данные и метаданные, размещенные в различных боксах. В одном из примеров реализации мультимедийные данные могут размещаться в боксе метаданных (mdat), а для размещения метаданных может использоваться бокс фильма (moov). В некоторых случаях для того, чтобы файл мог быть обработан, обязательно должны присутствовать оба указанных бокса, бокс mdat и бокс moov. Бокс фильма (moov) может содержать один или несколько треков («дорожек»), при этом каждый трек занимает один соответствующий бокс трека. Трек может иметь один из следующих типов: мультимедийный трек, трек указаний или трек синхронизированных метаданных. Мультимедийный трек представляет собой сэмплы (фрагменты видеоинформации), отформатированные согласно формату сжатия мультимедийных данных (и правилам его инкапсуляции в базовый формат медиафайлов ISO). Мультимедийный трек представляет собой сэмплы указаний, содержащие инструкции по формированию пакетов для передачи по указанному протоколу связи. Такие инструкции могут содержать указания по формированию заголовка пакета и указания по формированию полезной нагрузки пакета. При формировании полезной нагрузки пакета могут осуществляться ссылки на данные, расположенные в других треках или в других элементах. То есть, например, могут выполняться указания на данные, размещенные в других треках или элементах, при помощи ссылки, указывающей, какой фрагмент данных в конкретном треке или в конкретном элементе должен, согласно инструкциям, быть скопирован в пакет в ходе процедуры формирования пакета. Трек синхронизированных метаданных может ссылаться на сэмплы, описывающие мультимедийные сэмплы или сэмплы указаний, на которые осуществлена ссылка. Для представления одного типа мультимедийных данных выбирают, как правило, один мультимедийный трек. Сэмплы в треке быть явным образом связаны с номерами сэмплов, которые увеличиваются с единичным шагом в указанном порядке декодирования сэмплов. Первый сэмпл трека может быть связан номером сэмпла, равным 1.
[0383] Один из примеров упрощенной структуры файла, соответствующей базовому формату мультимедийных файлов ISO, может быть описан следующим образом: файл может включать бокс moov и бокс mdat, и при этом бокс moov может, соответственно, включать один или более треков, соответствующих видеоинформации или аудиоинформации.
[0384] Базовый формат медиафайлов ISO не ограничивает презентацию одним файлом. Фактически, презентация может храниться в нескольких файлах. В качестве примера, один из файлов может включать метаданные всей презентации, и соответственно, содержать также и все мультимедийные данные, в результате чего презентация становится автономной (самодостаточной). При использовании (если требуется) других файлов им не обязательно иметь базовый формат медиафайлов ISO. Другие файлы используются для хранения мультимедийных данных, при этом они могут также содержать неиспользуемые мультимедийные данные или другую информацию. Базовый формат медиафайлов ISO определяет только структуру файла презентации. Базовый формат медиафайлов ISO и его производные ограничивают формат файлов с мультимедийными данными только в том отношении, что форматирование мультимедийных данных в этих файлах должно соответствовать спецификации базового формата медиафайлов ISO или производных от него форматов.
[0385] Возможность ссылки на внешние файлы может быть реализована при помощи ссылок на данные. В некоторых из примеров в состав каждого трека включают бокс с описанием сэмпла, в котором может присутствовать список записей с информацией о сэмплах, каждая из которых предоставляет информацию об используемом типе кодирования, а также всю информацию об инициализации, необходимой для такого кодирования. Для всех сэмплов так называемого «чанка» и для всех сэмплов фрагмента трека может использоваться одна запись с информацией о сэмплах. Чанк может быть определен как непрерывный набор смежных сэмплов в одном треке. Бокс ссылок на данные (Data Reference, dref), который также входит в каждый трек, может определять пронумерованный список унифицированных локаторов ресурсов (uniform resource locators, URL), унифицированных имен ресурсов (uniform resource names, URN) и/или рекурсивные ссылки на файл, содержащий метаданные. Запись с информацией о сэмплах может указывать на один из порядковых номеров в боксе ссылок на данные, благодаря чему осуществляется указание на файл, содержащий сэмплы соответствующего чанка, или фрагмента трека.
[0386] Фрагменты фильма могут использоваться при записи содержимого в файлы ISO как средство, позволяющее исключить потери данных в случае сбоя в приложении записи, нехватки объема памяти или возникновения других аварийных ситуаций. Без фрагментов фильма могут происходить потери данных, поскольку форматы файлов, как правило, требуют, чтобы все метаданные, например, бокс фильма, были записаны в одной непрерывной области файла. Также, при записи файла, может возникать нехватка объема памяти (например, (e.g., RAM) для буферизации бокса фильма под доступный размер хранилища, а повторное вычисление содержимого бокса фильма при закрытии фильма может быть слишком медленным. Также, при этом, фрагменты фильма позволяют обеспечить одновременную запись и воспроизведение файла с использованием обычного анализатора файлов ISO. Наконец, при применении фрагментов фильма может требоваться меньшая длительность начальной буферизации при постепенной подгрузке файла, например, при одновременном приеме и воспроизведении файла, и при этом первый бокс фильма может быть меньше, по сравнению с файлом с тем же мультимедийным контентом, но структурированным без использования фрагментов фильма.
[0387] Функциональность фрагментов фильма может обеспечивать возможность удобного разбиения метаданных, при которых они размещаются в боксе фильма с разбиением на несколько частей. Каждая часть может соответствовать определенному периоду времени для трека. Другими словами, функциональность фрагментов фильма может давать возможность чередования метаданных и мультимедийных данных в файле. Следовательно, размер бокса фильма может быть ограничен и могут быть реализованы описанные выше сценарии применения.
[0388] В некоторых из примеров мультимедийные сэмплы для фрагментов фильма могут располагаться в боксе mdat, как обычно, если они находятся в том же файле, что и бокс moov. Однако для метаданных фрагментов фильма может присутствовать бокс moof. Бокс moof может включать информацию для определенного интервала времени воспроизведения, который ранее был в боксе moov. Бокс moov может при этом сам являться полноценным «фильмом», однако при этом он может включать в дополнение бокс mvex, который указывает на то, какие фрагменты фильма следуют за ним в этом файле. Фрагменты фильма позволяют увеличить временную длительность презентации, связанной с боксом moov.
[0389] Внутри фрагмента фильма может присутствовать набор сегментов трека, включающий в себя любое количество (ноль и более) треков. Фрагменты трека, в свою очередь, могут включать в себя любое количество (ноль и более) отрезков (run) трека, каждый из которых (document) представляет собой непрерывную последовательность смежных сэмплов в этом треке. Внутри эти структур присутствует множество опциональных полей, которые могут иметь заданные по умолчанию значения. Метаданные, которые могут входить в бокс moof, могут быть ограничены подмножеством метаданных, допускающих включение в бокс moov, и в некоторых случаях могут кодироваться отличающимся образом. Подробная информация о боксах, которые могут входить в состав бокса moof приведена в спецификации базового формата медиафайлов ISO.
[0390] Группирование сэмплов в базовом формате медиафайлов ISO и в производных от него форматах, таких как формат файлов AVC или формат файлов SVC, может быть определено как назначение каждого сэмпла в треке в качестве члена одной из групп сэмплов на основе критерия группирования. Группа сэмплов при группировании сэмплов не ограничена непрерывной последовательностью смежных сэмплов и может включать содержать сэмплы, не являющиеся соседними друг с другом. Поскольку сэмплы в треке могут группироваться более чем одним способом, каждая группа сэмплов может иметь поле типа, в котором указывают тип группирования. Группы сэмплов представлены двумя взаимосвязанными структурами данных: (1) бокс SampleToGroup (соответствия сэмпл-группа) (sgpd), который отражает назначения сэмплов в группы сэмплов; и (2) бокс SampleGroupDescription (описание группы сэмплов) (sgpd), который содержит запись группы сэмплов, описывающую свойства группы, для каждой группы сэмплов. Могут присутствовать несколько экземпляров боксов SampleToGroup и SampleGroupDescription для различных критериев группирования. Они могут отличаться полем типа, которое используют для указания на тип группирования.
[0391] Боксы групп сэмплов (бокс SampleGroupDescription и бокс SampleToGroup) размещаются внутри бокса таблицы сэмплов (stbl), которую включают в состав боксов мультимедийной инсрормации (mint), мультимедийных данных (mdia) и трека (trak), входящих, в свою очередь, в бокс фильма (moov). Разрешается помещение бокса SampleToGroup внутри фрагмента фильма. Следовательно, группирование сэмплов может осуществляться независимо для различных фрагментов.
[0392] В одном из вариантов осуществления настоящего изобретения, который может применяться независимо или совместно с другими вариантами осуществления настоящего изобретения, кодер или другой элемент, например, формирователь файлов, кодирует или вставляет указание на одно или более изображений доступа к уровню в контейнерный файл, который, например, может отвечать формату базового медиафайлов ISO, и возможно, некоторым производным от него форматам файлов. Может быть определено группирование сэмплов для изображений доступа к уровню, или на изображения доступа к уровню могут указывать другие, более общие, группирования сэмплов, например, используемые для указания на точки произвольного доступа.
[0393] В некоторых из вариантов осуществления настоящего изобретения, декодер или другой элемент, например, медиапроигрыватель или анализатор файла, декодирует или извлекает указание на одно или более изображений доступа к уровню из контейнерного файла, который, например, может отвечать формату базового медиафайлов ISO, и возможно, некоторым производным от него форматам файлов. Например, указание может быть получено из информации о группировании сэмплов для изображений доступа к уровню, или из более общей информации группирования сэмплов, например, используемой для указания на точки произвольного доступа, при помощи которой также могут выполняться указания на изображения доступа к уровню. Такое указание могут использоваться для запуска декодирования или другой обработки уровня, с которым связано указание.
[0394] Нужно понимать, что блок доступа для масштабируемого видеокодирования может быть определен различными способами, включая приведенное выше определение блока доступа HEVC, однако без ограничения им. В различных вариантах осуществления настоящего изобретения могут применяться различные определения блока доступа. К примеру, определение блока доступа в HEVC может быть менее строгим, то есть, блок доступа может включать кодированные изображения, связанные с одним моментом времени вывода и принадлежащие одному дереву кодирования. Когда битовый поток имеет несколько деревьев кодирования, блок доступа может (но не обязательно должен) включать кодированные изображения, связанные с одним моментом времени вывода и принадлежащие различным деревьям кодирования.
[0395] Выше некоторые из вариантов осуществления настоящего изобретения были описаны на примере MV-HEVC, SHVC и/или аналогичных стандартов, и соответственно, использовалась терминология, переменные, синтаксические элементы, типы изображений и т.п., относящиеся к MV-HEVC, SHVC и/или аналогичным стандартам. Нужно понимать, что варианты осуществления настоящего изобретения могут быть реализованы с использованием аналогичной соответствующей терминологии, переменных, синтаксических элементов, типов изображений и т.п., относящихся к другим стандартам и/или способам кодирования. Например, в приведенном выше описании некоторые из вариантов осуществления настоящего изобретения были описаны с упоминанием идентификаторов nuh_layer_id и/или Temporalld. Нужно понимать, что варианты осуществления настоящего изобретения могут быть реализованы с использованием любых других указателей, синтаксических элементов и/или переменных для идентификатора уровня и/или идентификатора подуровня соответственно.
[0396] В приведенном выше описания некоторые из вариантов осуществления настоящего изобретения были описаны на примере изображения пошагового доступа к временному подуровню в самом нижнем временном подуровне. Нужно понимать, что варианты осуществления настоящего изобретения могут быть реализованы аналогичным образом с использованием изображения доступа к уровню любого типа, которое обеспечивает возможность корректного декодирования подмножества изображений в уровнях, например, для некоторых подуровней уровня, но не обязательно всех его подуровней.
[0397] В предшествующем описании некоторые из вариантов осуществления настоящего изобретения были рассмотрены на примере кодирования указаний, синтаксических элементов и/или синтаксических структур в битовом потоке или в кодированной видеопоследовательности, и/или на примере декодирования указаний, синтаксических элементов и/или синтаксических структур из битового потока или из кодированной видеопоследовательности. Однако нужно понимать, что варианты осуществления настоящего изобретения могут быть реализованы при кодировании указаний, синтаксических элементов и/или синтаксических структур, в синтаксическую структуру или блок данных, который является внешним по отношению к битовому потоку или кодированной видеопоследовательности, содержащий данные уровней видеокодирования, например, кодированные слайсы, и/или при декодировании указаний, синтаксических элементов и/или синтаксических структур, из синтаксической структуры или блока данных, который является внешним по отношению к битовому потоку или кодированной видеопоследовательности, содержащей данные уровней видеокодирования, например, кодированных слайсов.
[0398] В приведенном выше описании, там, где примеры осуществления настоящего изобретения были описаны со ссылками на кодер, нужно понимать, что результирующий поток и декодер также могут включают соответствующие элементы. Аналогично, там, где примеры осуществления настоящего изобретения были описаны со ссылками на декодер, нужно понимать, что кодер может иметь структуру и/или компьютерную программу для формирования битового потока, декодируемого декодером.
[0399] В рассмотренных выше вариантах осуществления настоящего изобретения кодек описан на примере отдельных устройств кодирования и декодирования - для упрощения понимания применяемых процедур. Однако нужно понимать, что аппаратура, структуры и операции могут быть реализованы в виде единого устройства/структуры/операции кодирования-декодирования. Также допускается, что кодер и декодер могут совместно использовать часть общих элементов, или что всех элементы могут быть общими.
[0400] Рассмотренные выше примеры описывают работу вариантов осуществления настоящего изобретения в кодеке из состава электронного устройства, однако нужно понимать, что настоящее изобретение, определенное приложенной формулой изобретения, может быть реализовано как часть любого видеокодека. Так, например, варианты осуществления настоящего изобретения могут быть реализованы в видеокодеке, в котором видеокодирование может быть реализовано по фиксированным, или проводным, каналам связи.
[0401] Соответственно, абонентское оборудование может включать в свой состав видеокодек, например, аналогичный рассмотренным в приведенном выше описании настоящего изобретения. Нужно понимать, что выражение «абонентское оборудование» используется как охватывающие любые подходящие типы беспроводного абонентского оборудования, например, мобильные телефоны, портативные устройства обработки данных или портативные веб-браузеры.
[0402] При этом элементы наземной сети мобильной связи общего пользования (public land mobile network, PLMN) также могут включать видеокодеки в соответствии с предшествующим описанием.
[0403] В общем случае различные варианты осуществления настоящего изобретения могут быть реализованы в виде аппаратного обеспечения или схем специального назначения, программного обеспечения, логики или какой-либо их комбинации. К примеру, некоторые из аспектов могут быть реализованы в виде аппаратного обеспечения, тогда как другие аспекты могут быть реализованы в виде микропрограммного или программного обеспечения, которое может исполняться контроллером, микропроцессором или иным вычислительным устройством, без ограничения настоящего изобретения перечисленным. Различные аспекты настоящего изобретения допускают иллюстрацию и описание в виде блок-схем, блок-схем алгоритмов или с помощью некоторых других наглядных представлений, но при этом нужно понимать, что блоки, устройства, системы, методы или способы, описанные в настоящем документе, могут быть реализованы, в качестве неограничивающих примеров, в виде аппаратного обеспечения, программного обеспечения, микропрограммного обеспечения, схем или логики специального назначения, аппаратного обеспечения или контроллера общего назначения, или же иных вычислительных устройств, или некоторой их комбинации.
[0404] Варианты осуществления настоящего изобретения могут быть реализованы с помощью программного обеспечения, исполняемого процессором данных мобильного устройства, например, процессорным элементом, или с помощью аппаратного обеспечения, или с помощью комбинации программного и аппаратного обеспечения. Также в этом отношении следует отметить, что любые блоки последовательностей логических операций, проиллюстрированные на чертежах, могут представлять собой шаги программы или взаимосвязанные логические схемы, блоки и функции, или комбинацию программных шагов и логических схем, блоков и функций. Программное обеспечение может храниться на таких физических носителях, как микросхемы памяти или блоки памяти, реализованные внутри процессора, магнитные носители, например, жесткий диск или гибкий диск, и оптические носители, например, DVD и их варианты для хранения данных, CD.
[0405] Память может относиться к любому типу, соответствующему локальному техническому окружению, при этом она может быть реализована с использованием любой подходящей технологии хранения данных, например, запоминающие устройства на полупроводниках, магнитные запоминающие устройства и системы, оптические запоминающие устройства и системы, несъемная или съемная память. Процессоры данных могут относиться к любому типу, соответствующему локальному техническому окружению и могут включать одно или более из следующего: компьютеры общего назначения, компьютеры специального назначения, микропроцессоры, цифровые сигнальные процессоры (digital signal processors, DSP), процессоры на основе многоядерной архитектуры - в качестве неограничивающих примеров.
[0406] Варианты осуществления настоящего изобретения могут применяться на практике в различных компонентах, например, в модулях интегральных схем. Процесс разработки интегральных схем, в целом, в высокой степени автоматизирован. Существуют сложные и мощные программные инструменты для преобразования проектов логического уровня в конструкции полупроводниковых схем, готовые для вытравливания и формовки на полупроводниковой подложке.
[0407] Программы, подобные поставляемой фирмой Synopsys, Inc (Маунтин-Вью, Калифорния) или фирмой Cadence Design (Сан-Хосе, Калифорния), осуществляют автоматическую разводку проводников и позиционирование компонентов на полупроводниковом кристалле с использованием общепринятых правил разработки, а также с использованием библиотек заранее сохраненных модулей проектов. По завершении разработки полупроводниковой схемы результирующая конструкция, в стандартизированном электронном формате (например, Opus, GDSII и т.п.) может быть передана на полупроводниковое производство для изготовления микросхемы.
[0408] В предшествующем изложении с помощью иллюстративных и неограничивающих примеров было обеспечено полное и информативное описание одного из примеров осуществления настоящего изобретения. Однако в свете предшествующего описания, рассматриваемого в сочетании с приложенными чертежами, специалистам в соответствующих областях техники могут быть очевидны различные модификации и доработки. Тем не менее, настоящее изобретение охватывает любые такие или аналогичные им модификации изобретения.

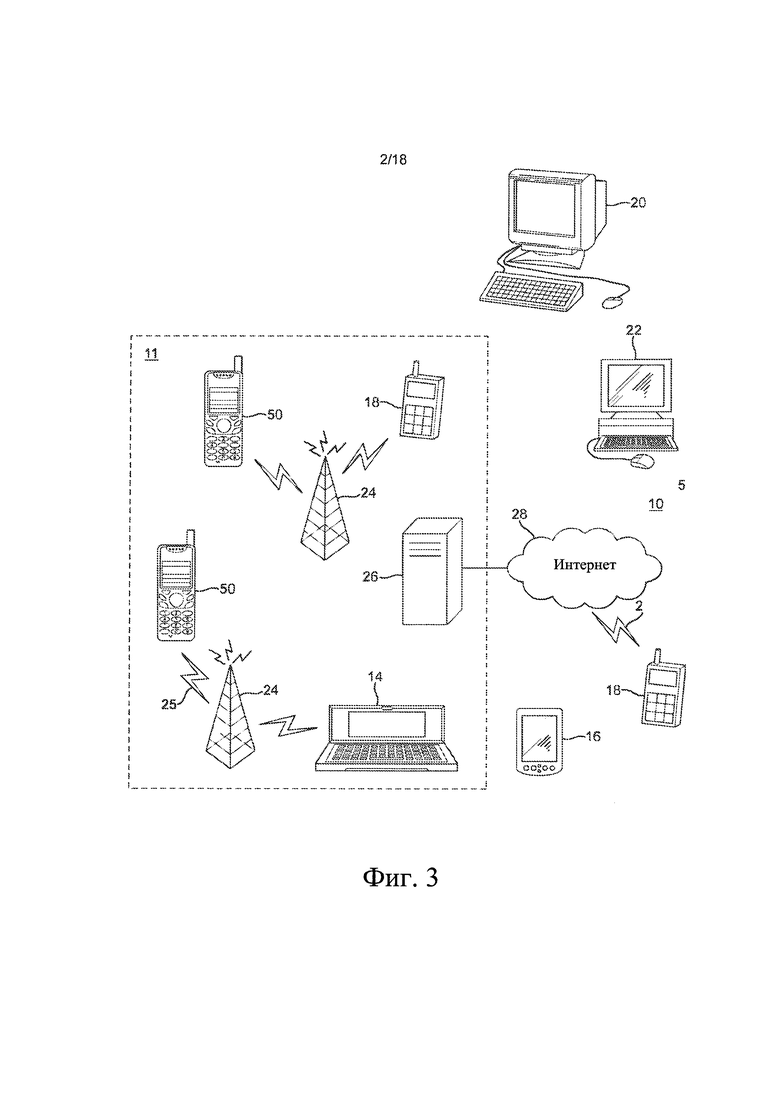
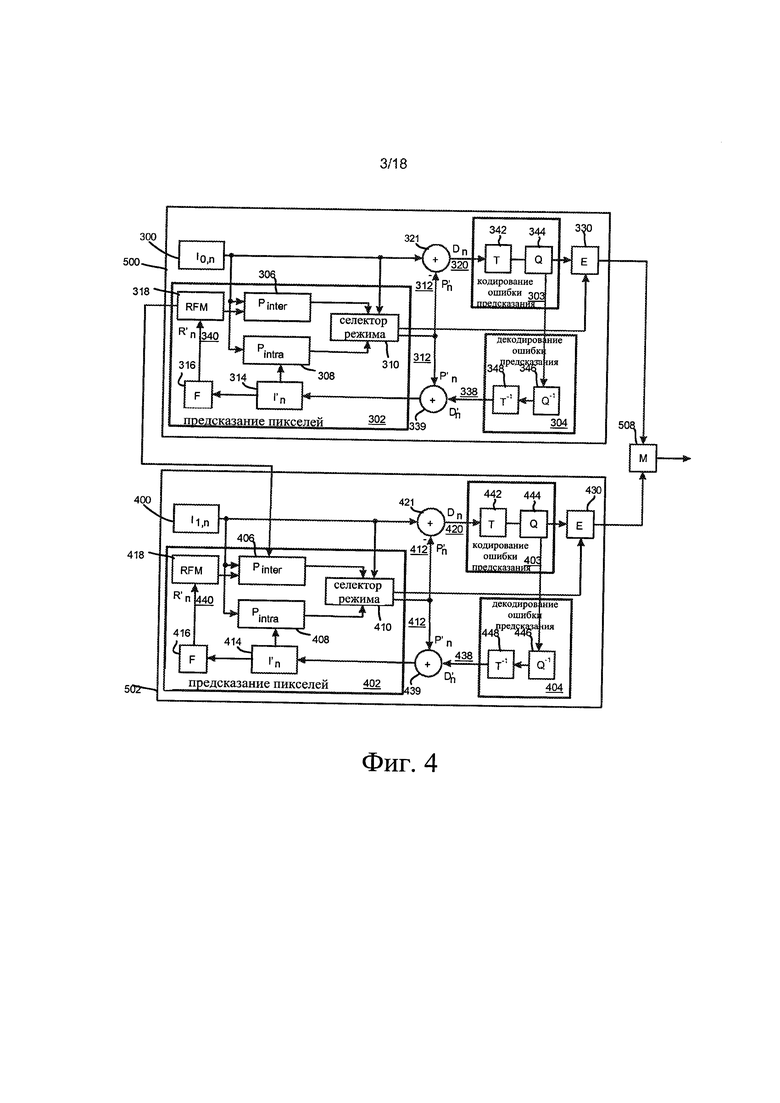
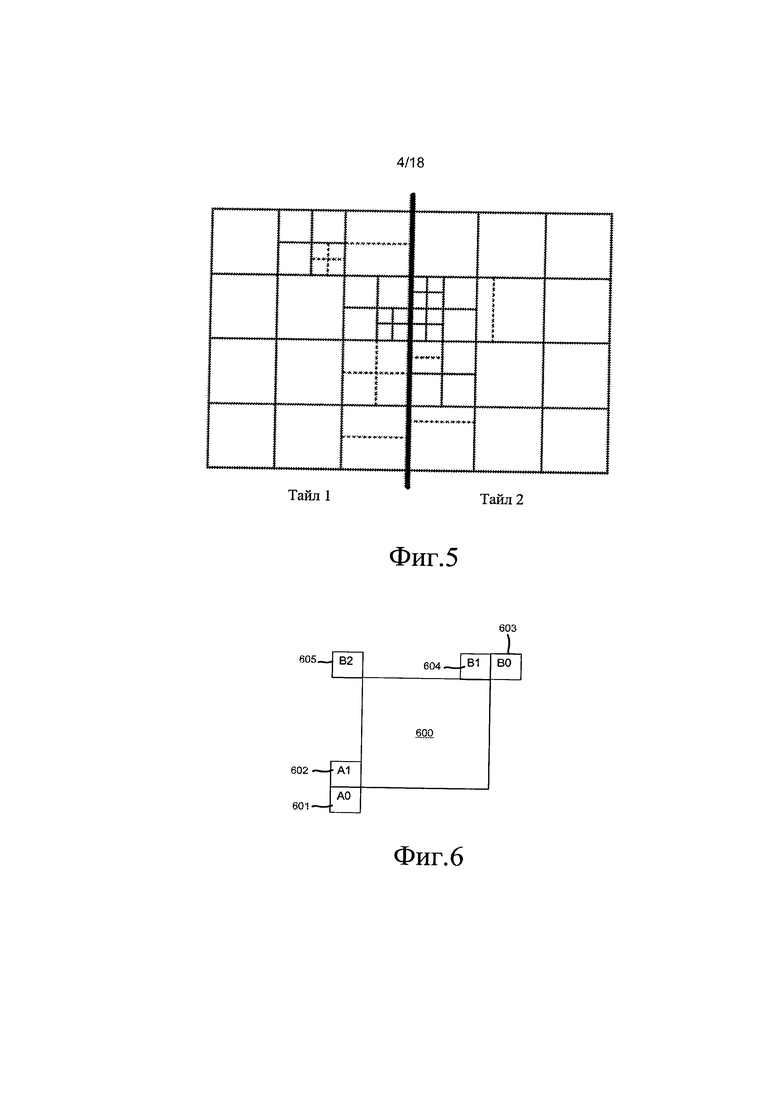





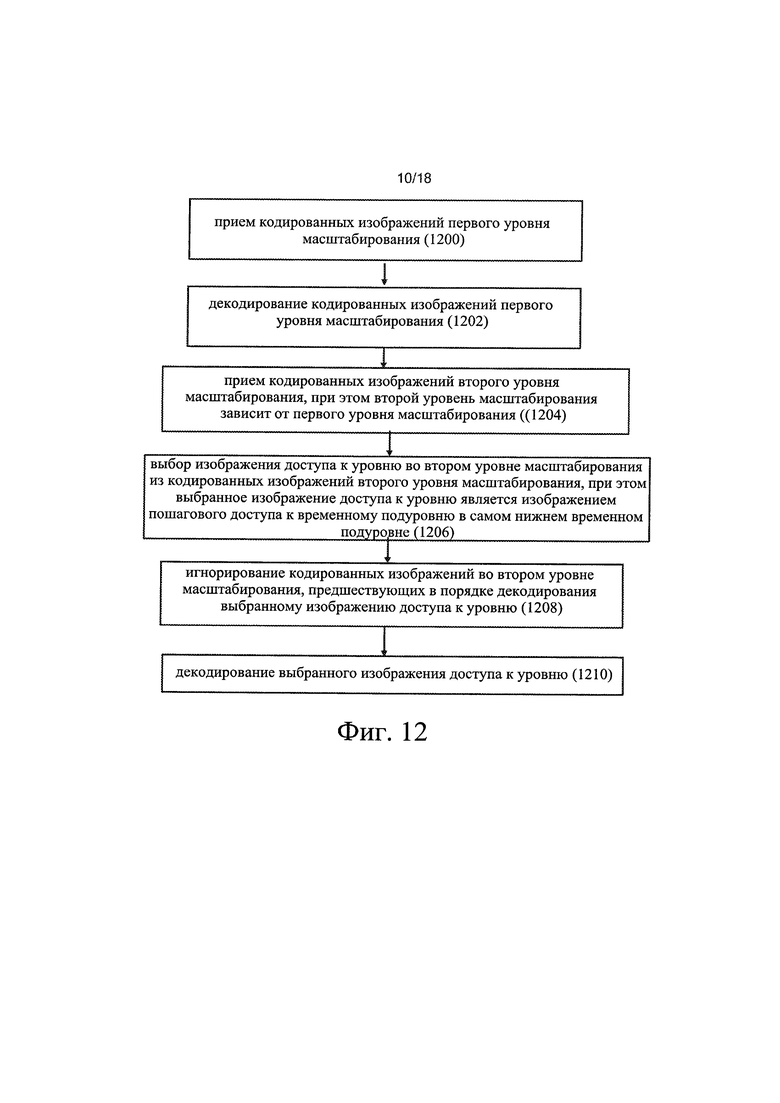




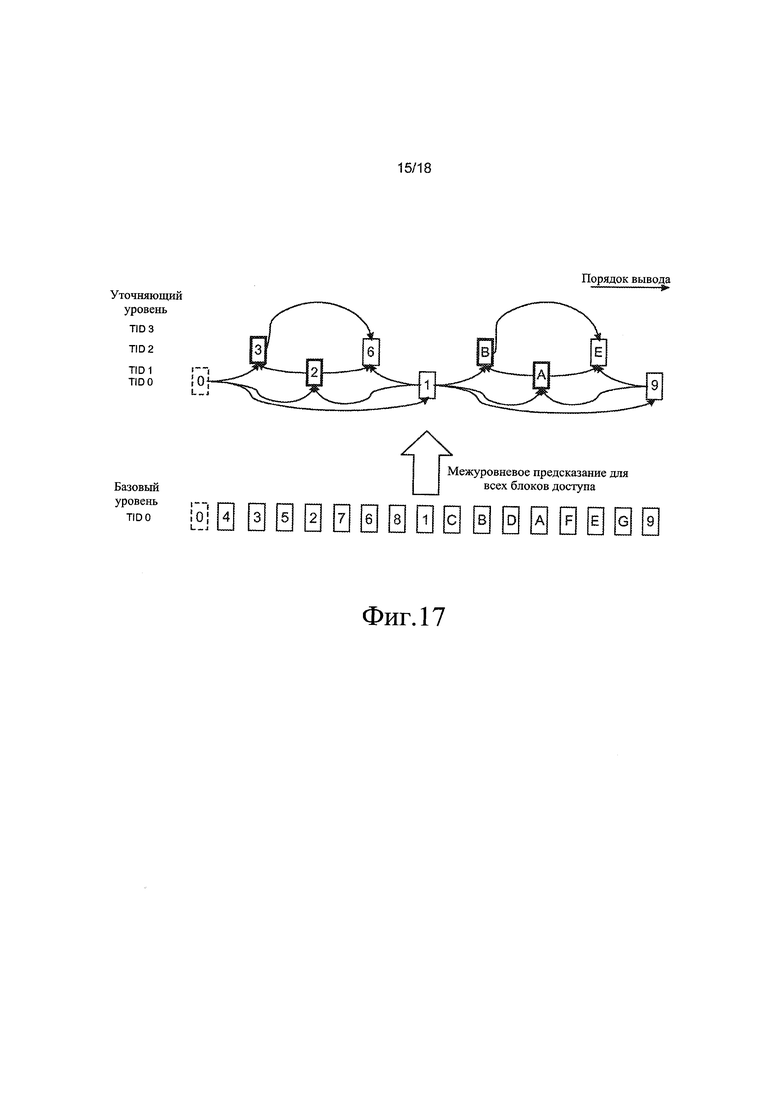



Изобретение относится к вычислительной технике. Технический результат заключается в обеспечении возможности указывать изображение доступа, или точку доступа, для уровня, который обеспечивает возможность декодирования некоторых из временных уровней. Способ декодирования кодированной видеоинформации включает прием кодированных изображений первого уровня масштабирования, включающего один или более временных подуровней; декодирование кодированных изображений первого уровня масштабирования; прием кодированных изображений второго уровня масштабирования, включающего один или более временных подуровней, при этом второй уровень масштабирования зависит от первого уровня масштабирования; выбор изображения доступа к уровню во втором уровне масштабирования из кодированных изображений второго уровня масштабирования, при этом выбранное изображение доступа к уровню является изображением пошагового доступа к временному подуровню (STSA) в самом нижнем временном подуровне; игнорирование кодированных изображений во втором уровне масштабирования, предшествующих в порядке декодирования выбранному изображению доступа к уровню; и декодирование или выбор выбранного изображения доступа к уровню. 14 н. и 32 з.п. ф-лы, 21 ил.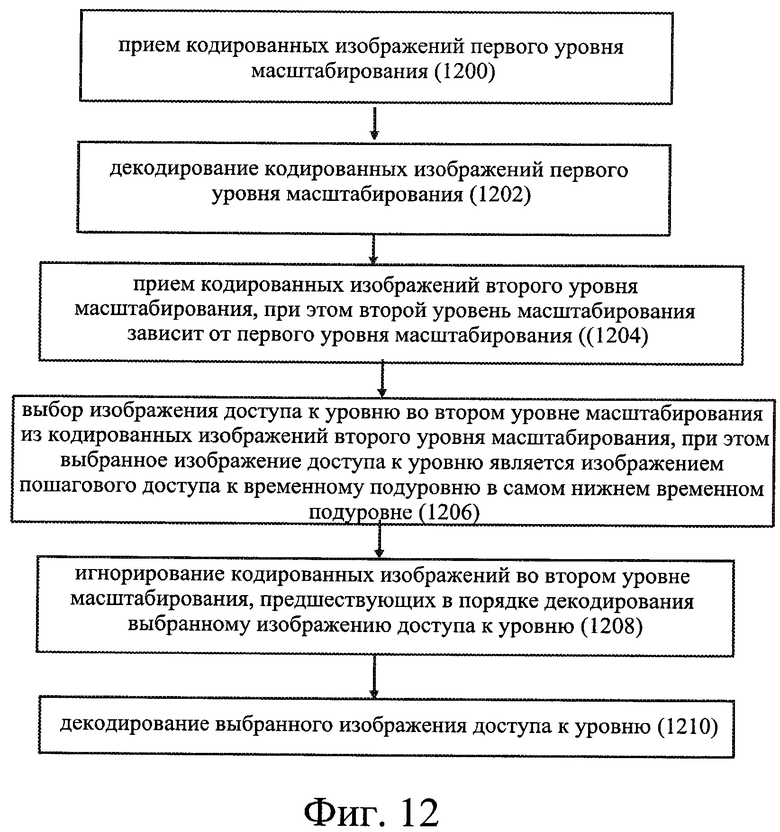
1. Способ декодирования кодированной видеоинформации, включающий:
прием (1200) кодированных изображений первого уровня масштабирования, включающего один или более временных подуровней;
декодирование (1202) кодированных изображений первого уровня масштабирования;
прием (1204) кодированных изображений второго уровня масштабирования, включающего один или более временных подуровней, при этом второй уровень масштабирования зависит от первого уровня масштабирования;
выбор (1206) изображения доступа к уровню во втором уровне масштабирования из кодированных изображений второго уровня масштабирования, при этом выбранное изображение доступа к уровню является изображением пошагового доступа к временному подуровню (STSA) в самом нижнем временном подуровне;
игнорирование (1208) кодированных изображений во втором уровне масштабирования, предшествующих в порядке декодирования выбранному изображению доступа к уровню; и
декодирование (1210) или выбор выбранного изображения доступа к уровню.
2. Способ по п. 1, в котором изображение пошагового доступа к временному подуровню обеспечивает точку доступа для поуровневой инициализации декодирования битового потока с одним или более временными подуровнями.
3. Способ по п. 1, в котором изображение пошагового доступа к временному подуровню обеспечивает точку доступа для поуровневой адаптации битрейта битового потока с одним или более временными подуровнями.
4. Способ по любому из пп. 1-3, в котором упомянутый выбор включает решение о том, что изображение является изображением пошагового доступа к временному подуровню, на основе того, что его тип блока уровня доступа к сети (NAL) указывает на изображение пошагового доступа к временному подуровню, а его идентификатор временного подуровня указывает на самый нижний временной подуровень.
5. Способ по любому из пп. 1-3, также включающий
прием указания об изображении пошагового доступа к временному подуровню в специальном типе NAL-блока, предоставленного вместе с битовым потоком.
6. Способ по любому из пп. 1-3, также включающий
прием указания об изображении пошагового доступа к временному подуровню с SEI-сообщением, определяющем количество декодируемых подуровней.
7. Способ по любому из пп. 1-3, также включающий:
начало декодирования битового потока в ответ на то, что базовый уровень содержит изображение внутренней точки произвольного доступа (IRAP) или изображение пошагового доступа к временному подуровню (STSA) в самом нижнем подуровне;
начало пошагового декодирования по меньшей мере одного уточняющего уровня в ответ на то, что упомянутый по меньшей мере один уточняющий уровень содержит IRAP-изображение или STSA-изображение в самом нижнем подуровне; и
постепенное увеличение количества декодируемых уровней и/или количества декодируемых временных подуровней.
8. Способ по п. 7, также включающий
формирование недоступных изображений для опорных изображений первого изображения, в порядке декодирования, в конкретном уточняющем уровне.
9. Способ по п. 7, также включающий
пропуск декодирования изображений, предшествующих IRAP-изображению, с которого может быть начато декодирование конкретного уточняющего уровня.
10. Способ по п. 9, также включающий
пометку упомянутых пропущенных изображений с использованием одного или более специальных типов NAL-блоков.
11. Способ по п. 7, также включающий
хранение информации о том, какие из подуровней каждого уровня были корректно декодированы.
12. Способ по п. 7, в котором начало пошагового декодирования включает одну или более из следующих операций, выполняемых в зависимости от выполнения условий:
- когда текущее изображение является IRAP-изображением и декодирование всех опорных уровней этого IRAP-изображения было начато, декодируют данное IRAP-изображение и все изображения, следующие за ним в порядке декодирования, в том же уровне;
- когда текущее изображение является STSA-изображением на самом нижнем подуровне и декодирование самого нижнего подуровня всех опорных уровней этого STSA-изображения было начато, декодируют данное STSA-изображение и все изображения на самом нижнем подуровне, следующие за данным STSA-изображением в порядке декодирования, в том же уровне;
- когда текущее изображение является TSA- или STSA-изображением более высокого подуровня, по сравнению с самым нижним подуровнем, и декодирование следующего, расположенного ниже, подуровня в том же уровне было начато, а также было начато декодирование того же подуровня во всех опорных уровнях упомянутого TSA-изображения или STSA-изображения, декодируют это TSA-изображение или STSA-изображение, а также все изображения в том же подуровне, следующие за данным TSA-изображением или STSA-изображением в порядке декодирования, в том же уровне.
13. Способ декодирования кодированной видеоинформации, включающий:
прием кодированных изображений первого уровня масштабирования, включающего один или более временных подуровней;
прием кодированных изображений второго уровня масштабирования, включающего один или более временных подуровней, при этом второй уровень масштабирования зависит от первого уровня масштабирования;
выбор изображения доступа к уровню во втором уровне масштабирования из кодированных изображений второго уровня масштабирования, при этом выбранное изображение доступа к уровню является изображением пошагового доступа к временному подуровню в самом нижнем временном подуровне;
игнорирование кодированных изображений во втором уровне масштабирования, предшествующих в порядке декодирования выбранному изображению доступа к уровню; и
передачу кодированных изображений первого уровня масштабирования и выбранного изображения доступа к уровню в битовом потоке.
14. Устройство для декодирования кодированной видеоинформации, включающее:
по меньшей мере один процессор и по меньшей мере одну память, в которой хранят код, который при исполнении упомянутым по меньшей мере одним процессором обеспечивает выполнение устройством по меньшей мере следующего:
прием кодированных изображений первого уровня масштабирования, включающего один или более временных подуровней;
декодирование кодированных изображений первого уровня масштабирования;
прием кодированных изображений второго уровня масштабирования, включающего один или более временных подуровней, при этом второй уровень масштабирования зависит от первого уровня масштабирования;
выбор изображения доступа к уровню во втором уровне масштабирования из кодированных изображений второго уровня масштабирования, при этом выбранное изображение доступа к уровню является изображением пошагового доступа к временному подуровню в самом нижнем временном подуровне;
игнорирование кодированных изображений во втором уровне масштабирования, предшествующих в порядке декодирования выбранному изображению доступа к уровню; и
декодирование выбранного изображения доступа к уровню.
15. Устройство по п. 14, в котором изображение пошагового доступа к временному подуровню обеспечивает точку доступа для поуровневой инициализации декодирования битового потока с одним или более временными подуровнями.
16. Устройство по п. 14, в котором изображение пошагового доступа к временному подуровню обеспечивает точку доступа для поуровневой адаптации битрейта битового потока с одним или более временными подуровнями.
17. Устройство по любому из пп. 14-16, дополнительно включающее код для обеспечения выполнения устройством упомянутого выбора путем принятия решения о том, что изображение является изображением пошагового доступа к временному подуровню, на основе того, что его тип блока уровня доступа к сети (NAL) указывает на изображение пошагового доступа к временному подуровню, а его идентификатор временного подуровня указывает на самый нижний временной подуровень.
18. Устройство по любому из пп. 14-16, дополнительно включающее код для обеспечения выполнения устройством
приема указания об изображении пошагового доступа к временному подуровню в специальном типе NAL-блока, предоставленного вместе с битовым потоком.
19. Устройство по любому из пп. 14-16, дополнительно включающее код для обеспечения выполнения устройством
приема указания об изображении пошагового доступа к временному подуровню с SEI-сообщением, определяющим количество декодируемых подуровней.
20. Устройство по любому из пп. 14-16, дополнительно включающее код для обеспечения выполнения устройством следующего:
начало декодирования битового потока в ответ на то, что базовый уровень содержит изображение внутренней точки произвольного доступа (IRAP) или изображение пошагового доступа к временному подуровню (STSA) в самом нижнем подуровне;
начало пошагового декодирования по меньшей мере одного уточняющего уровня в ответ на то, что упомянутый по меньшей мере один уточняющий уровень содержит IRAP-изображение или STSA-изображение в самом нижнем подуровне; и
постепенное увеличение количества декодируемых уровней и/или количества декодируемых временных подуровней.
21. Устройство по п. 20, дополнительно включающее код для обеспечения выполнения устройством
формирования недоступных изображений для опорных изображений первого изображения в порядке декодирования в конкретном уточняющем уровне.
22. Устройство по п. 20, дополнительно включающее код для обеспечения выполнения устройством
пропуска декодирования изображений, предшествующих IRAP-изображению, с которого может быть начато декодирование конкретного уточняющего уровня.
23. Устройство по п. 22, дополнительно включающее код для обеспечения выполнения устройством
пометки упомянутых пропущенных изображений с использованием одного или более специальных типов NAL-блоков.
24. Устройство по п. 20, дополнительно включающее код для обеспечения выполнения устройством
хранения информации о том, какие из подуровней каждого уровня были корректно декодированы.
25. Устройство по п. 20, в котором начало пошагового декодирования включает одну или более из следующих операций, выполняемых в зависимости от выполнения условий:
- когда текущее изображение является IRAP-изображением и декодирование всех опорных уровней этого IRAP-изображения было начато, декодируют данное IRAP-изображение и все изображения, следующие за ним в порядке декодирования, в том же уровне;
- когда текущее изображение является STSA-изображением в самом нижнем подуровне и декодирование самого нижнего подуровня всех опорных уровней этого STSA-изображения было начато, декодируют данное STSA-изображение и все изображения на самом нижнем подуровне, следующие за данным STSA-изображением в порядке декодирования, в том же уровне;
- когда текущее изображение является TSA- или STSA-изображением более высокого подуровня, по сравнению с самым нижним подуровнем, и декодирование следующего, расположенного ниже, подуровня в том же уровне было начато, а также было начато декодирование того же подуровня во всех опорных уровнях упомянутого TSA-изображения или STSA-изображения, декодируют это TSA-изображение или STSA-изображение, а также все изображения в том же подуровне, следующие за данным TSA-изображением или STSA-изображением в порядке декодирования, в том же уровне.
26. Устройство для декодирования кодированной видеоинформации, включающее:
по меньшей мере один процессор и по меньшей мере одну память, при этом в упомянутой по меньшей мере одной памяти хранят код, который при исполнении упомянутым по меньшей мере одним процессором обеспечивает выполнение устройством по меньшей мере следующего:
прием кодированных изображений первого уровня масштабирования, включающего один или более временных подуровней;
прием кодированных изображений второго уровня масштабирования, включающего один или более временных подуровней, при этом второй уровень масштабирования зависит от первого уровня масштабирования;
выбор изображения доступа к уровню во втором уровне масштабирования из кодированных изображений второго уровня масштабирования, при этом выбранное изображение доступа к уровню является изображением пошагового доступа к временному подуровню в самом нижнем временном подуровне;
игнорирование кодированных изображений во втором уровне масштабирования, предшествующих в порядке декодирования выбранному изображению доступа к уровню; и
передачу кодированных изображений первого уровня масштабирования и выбранного изображения доступа к уровню в битовом потоке.
27. Машиночитаемый носитель для хранения данных, на котором хранят код для использования устройством, который при исполнении процессором обеспечивает выполнение этим устройством следующего:
прием кодированных изображений первого уровня масштабирования, включающего один или более временных подуровней;
декодирование кодированных изображений первого уровня масштабирования;
прием кодированных изображений второго уровня масштабирования, включающего один или более временных подуровней, при этом второй уровень масштабирования зависит от первого уровня масштабирования;
выбор изображения доступа к уровню во втором уровне масштабирования из кодированных изображений второго уровня масштабирования, при этом выбранное изображение доступа к уровню является изображением пошагового доступа к временному подуровню в самом нижнем временном подуровне;
игнорирование кодированных изображений во втором уровне масштабирования, предшествующих в порядке декодирования выбранному изображению доступа к уровню; и
декодирование выбранного изображения доступа к уровню.
28. Видеодекодер, сконфигурированный для декодирования битового потока, включающего последовательность изображений, при этом видеодекодер включает
средства приема кодированных изображений первого уровня масштабирования, включающего один или более временных подуровней;
средства декодирования кодированных изображений первого уровня масштабирования;
средства приема кодированных изображений второго уровня масштабирования, включающего один или более временных подуровней, при этом второй уровень масштабирования зависит от первого уровня масштабирования;
средства выбора изображения доступа к уровню во втором уровне масштабирования из кодированных изображений второго уровня масштабирования, при этом выбранное изображение доступа к уровню является изображением пошагового доступа к временному подуровню в самом нижнем временном подуровне;
средства игнорирования кодированных изображений во втором уровне масштабирования, предшествующих в порядке декодирования выбранному изображению доступа к уровню; и
средства декодирования выбранного изображения доступа к уровню.
29. Видеодекодер, сконфигурированный для декодирования битового потока, включающего последовательность изображений, при этом упомянутый видеодекодер сконфигурирован также для следующего:
прием кодированных изображений первого уровня масштабирования, включающего один или более временных подуровней;
декодирование кодированных изображений первого уровня масштабирования;
прием кодированных изображений второго уровня масштабирования, включающего один или более временных подуровней, при этом второй уровень масштабирования зависит от первого уровня масштабирования;
выбор изображения доступа к уровню во втором уровне масштабирования из кодированных изображений второго уровня масштабирования, при этом выбранное изображение доступа к уровню является изображением пошагового доступа к временному подуровню в самом нижнем временном подуровне;
игнорирование кодированных изображений во втором уровне масштабирования, предшествующих в порядке декодирования выбранному изображению доступа к уровню; и
декодирование выбранного изображения доступа к уровню.
30. Способ кодирования видеоинформации, включающий:
кодирование (750) первого изображения в самом нижнем временном подуровне первого уровня масштабирования, включающего один или более временных подуровней;
кодирование (752) второго изображения в самом нижнем временном подуровне второго уровня масштабирования, включающего один или более временных подуровней, при этом первое изображение и второе изображение представляют один и тот же момент времени,
кодирование (754) одного или более первых синтаксических элементов, связанных с упомянутым первым изображением, с использованием значения, указывающего на то, что тип первого изображения отличается от изображения пошагового доступа к временному подуровню (STSA);
кодирование (756) одного или более вторых синтаксических элементов, связанных с упомянутым вторым изображением, с использованием значения, указывающего на то, что тип второго изображения отличается от изображения пошагового доступа к временному подуровню; и
кодирование (758) по меньшей мере третьего изображения во второй уровень масштабирования и в более высокий временной подуровень, чем самый нижний временной подуровень.
31. Способ по п. 30, в котором изображение пошагового доступа к временному подуровню обеспечивает точку доступа для поуровневой инициализации декодирования битового потока с одним или более временными подуровнями.
32. Способ по п. 30 или 31, в котором изображение пошагового доступа к временному подуровню представляет собой изображение пошагового доступа к временному подуровню в самом нижнем временном подуровне.
33. Способ по п. 30 или 31, также включающий
сигнализацию об изображении пошагового доступа к временному подуровню в битовом потоке при помощи специального типа NAL-блока.
34. Способ по п. 30 или 31, также включающий
сигнализацию об изображении пошагового доступа к временному подуровню в SEI-сообщении, определяющем количество декодируемых подуровней.
35. Способ по п. 30 или 31, также включающий
кодирование упомянутого второго уровня масштабирования или любых последующих уровней масштабирования с более частым включением в них TSA-изображений или STSA-изображений по сравнению с первым уровнем масштабирования.
36. Устройство для кодирования видеоинформации, включающее:
по меньшей мере один процессор и по меньшей мере одну память, при этом в упомянутой по меньшей мере одной памяти хранят код, который при исполнении упомянутым по меньшей мере одним процессором обеспечивает выполнение устройством по меньшей мере следующего:
кодирование первого изображения в самом нижнем временном подуровне первого уровня масштабирования, включающего один или более временных подуровней;
кодирование второго изображения в самом нижнем временном подуровне второго уровня масштабирования, включающего один или более временных подуровней, при этом первое изображение и второе изображение представляют один и тот же момент времени;
кодирование одного или более первых синтаксических элементов, связанных с упомянутым первым изображением, с использованием значения, указывающего на то, что тип первого изображения отличается от изображения пошагового доступа к временному подуровню;
кодирование одного или более вторых синтаксических элементов, связанных с упомянутым вторым изображением, с использованием значения, указывающего на то, что тип второго изображения отличается от изображения пошагового доступа к временному подуровню; и
кодирование по меньшей мере третьего изображения во второй уровень масштабирования и в более высокий временной подуровень, чем самый нижний временной подуровень.
37. Устройство по п. 36, в котором изображение пошагового доступа к временному подуровню обеспечивает точку доступа для поуровневой инициализации декодирования битового потока с одним или более временными подуровнями.
38. Устройство по п. 36 или 37, в котором изображение пошагового доступа к временному подуровню представляет собой изображение пошагового доступа к временному подуровню в самом нижнем временном подуровне.
39. Устройство по п. 36 или 37, дополнительно включающее код для обеспечения выполнения устройством
сигнализации об изображении пошагового доступа к временному подуровню в битовом потоке при помощи специального типа NAL-блока.
40. Устройство по п. 36 или 37, дополнительно включающее код для обеспечения выполнения устройством
сигнализации об изображении пошагового доступа к временному подуровню в SEI-сообщении, определяющем количество декодируемых подуровней.
41. Устройство по п. 36 или 37, дополнительно включающее код для обеспечения выполнения устройством
кодирования упомянутого второго уровня масштабирования или любых последующих уровней масштабирования с более частым включением в них TSA-изображений или STSA-изображений по сравнению с первым уровнем масштабирования.
42. Машиночитаемый носитель для хранения данных, на котором хранят код для использования устройством, который при исполнении процессором обеспечивает выполнение этим устройством следующего:
кодирование первого изображения в самом нижнем временном подуровне первого уровня масштабирования, включающего один или более временных подуровней;
кодирование второго изображения в самом нижнем временном подуровне второго уровня масштабирования, включающего один или более временных подуровней, при этом первое изображение и второе изображение представляют один и тот же момент времени,
кодирование одного или более первых синтаксических элементов, связанных с упомянутым первым изображением, с использованием значения, указывающего на то, что тип первого изображения отличается от изображения пошагового доступа к временному подуровню;
кодирование одного или более вторых синтаксических элементов, связанных с упомянутым вторым изображением, с использованием значения, указывающего на то, что тип второго изображения отличается от изображения пошагового доступа к временному подуровню; и
кодирование по меньшей мере третьего изображения во второй уровень масштабирования и в более высокий временной подуровень, чем самый нижний временной подуровень.
43. Видеокодер, сконфигурированный для кодирования битового потока, включающего последовательность изображений, при этом видеокодер включает
средства кодирования первого изображения в самом нижнем временном подуровне первого уровня масштабирования, включающего один или более временных подуровней;
средства кодирования второго изображения в самом нижнем временном подуровне второго уровня масштабирования, включающего один или более временных подуровней, при этом первое изображение и второе изображение представляют один и тот же момент времени;
средства кодирования одного или более первых синтаксических элементов, связанных с упомянутым первым изображением, с использованием значения, указывающего на то, что тип первого изображения отличается от изображения пошагового доступа к временному подуровню;
средства кодирования одного или более вторых синтаксических элементов, связанных с упомянутым вторым изображением, с использованием значения, указывающего на то, что тип второго изображения отличается от изображения пошагового доступа к временному подуровню; и
средства кодирования по меньшей мере третьего изображения во второй уровень масштабирования и в более высокий временной подуровень, чем самый нижний временной подуровень.
44. Видеокодер, сконфигурированный для кодирования битового потока, включающего последовательность изображений, при этом упомянутый видеокодер также сконфигурирован для следующего:
кодирование первого изображения в самом нижнем временном подуровне первого уровня масштабирования, включающего один или более временных подуровней;
кодирование второго изображения в самом нижнем временном подуровне второго уровня масштабирования, включающего один или более временных подуровней, при этом первое изображение и второе изображение представляют один и тот же момент времени;
кодирование одного или более первых синтаксических элементов, связанных с упомянутым первым изображением, с использованием значения, указывающего на то, что тип первого изображения отличается от изображения пошагового доступа к временному подуровню;
кодирование одного или более вторых синтаксических элементов, связанных с упомянутым вторым изображением, с использованием значения, указывающего на то, что тип второго изображения отличается от изображения пошагового доступа к временному подуровню; и
кодирование по меньшей мере третьего изображения во второй уровень масштабирования и в более высокий временной подуровень, чем самый нижний временной подуровень.
45. Способ кодирования видеоинформации, включающий:
кодирование первого изображения в самом нижнем временном подуровне первого уровня масштабирования, включающего один или более временных подуровней;
кодирование второго изображения во втором уровне масштабирования, включающего один или более временных подуровней, при этом упомянутые первое изображение и второе изображение принадлежат одному блоку доступа; и
кодирование одного или более синтаксических элементов, связанных с упомянутым блоком доступа, с использованием значения, указывающего на то, совпадают ли значения идентификаторов временного уровня кодированных первого и второго изображения внутри упомянутого блока доступа.
46. Способ декодирования видеоинформации, включающий:
прием битового потока, включающего блок доступа, который имеет первое изображение, кодированное в самом нижнем временном подуровне первого уровня масштабирования, включающего один или более временных подуровней, и второе изображение, кодированное во втором уровне масштабирования, включающего один или более временных подуровней;
декодирование, из битового потока, одного или более синтаксических элементов, связанных с упомянутым блоком доступа, с использованием значения, указывающего на то, совпадают ли значения идентификаторов временного уровня кодированных первого и второго изображений внутри упомянутого блока доступа; и
выбор операции декодирования для упомянутых первого и второго изображения согласно упомянутому значению.
| Способ защиты переносных электрических установок от опасностей, связанных с заземлением одной из фаз | 1924 |
|
SU2014A1 |
| T | |||
| IKAI et al | |||
| "MV-HEVC/SHVC HLS: TemporalID alignment and inter-layer prediction restriction", JCTVC-N0060 (version 2), опубл | |||
| Видоизменение пишущей машины для тюркско-арабского шрифта | 1923 |
|
SU25A1 |
| S | |||
| Разборный с внутренней печью кипятильник | 1922 |
|
SU9A1 |

