Область техники
[0001] Настоящее изобретение относится к устройству, способу и компьютерной программе для кодирования и декодирования видеоинформации.
Предпосылки создания изобретения
[0002] В настоящее время высокими темпами продолжается развитие приложений для потоковой передачи медиаданных, и в особенности приложений 360-градусного видео или виртуальной реальности (virtual reality, VR). Потоковая передача с адаптацией к окну просмотра позволяет снизить битрейт, например, за счет того, что данные для основного окна просмотра (т.е. текущей ориентации взгляда) передают с наивысшим качеством, или разрешением, тогда как остальную часть 360-градусного видео передают с пониженным качеством, или разрешением. Когда направление взгляда меняется, например, если пользователь просматривает контент с помощью устанавливаемого на голове дисплея и поворачивает голову, должна стартовать передача другой версии контента, отвечающей новой ориентации взгляда.
[0003] Для доставки всенаправленного видео, зависящего от окна просмотра, возможны несколько альтернативных вариантов. Например, для его доставки могут применяться битовые потоки HEVC (высокоэффективное видеокодирование, High Efficiency Video Coding) с одинаковым разрешением, имеющие ограниченные по движению наборы тайлов (motion-constrained tile sets, MCTS). To есть, несколько битовых потоков HEVC, относящихся к одному и тому же всенаправленному исходному контенту, кодируют с одинаковым разрешением, однако с разным качеством и битрейтом, используя ограниченные по движению наборы тайлов. Еще один вариант доставки всенаправленного видео, зависящего от окна просмотра, - применение масштабируемого кодирования для области интереса при помощи расширения масштабируемости HEVC (Scalable Extension HEVC, SHVC). При таком подходе базовый уровень кодируют обычным образом, а уточняющие уровни для области интереса (region-of-interest, ROI) кодируют с использованием профиля Scalable Main (основной масштабируемый). Однако ограниченная поддержка межуровневого предсказания, в частности, SHVC-расширения HEVC, в имеющихся на рынке аппаратных декодерах не позволяет в полной мере применять кодирование ROI-областей при помощи SHVC (SHVC-ROI).
[0004] Еще один из возможных подходов называют ограниченным межуровневым предсказанием (constrained inter-layer prediction, CILP). При CILP-предсказании выбирают часть входных изображений, и каждое из них кодируют в два кодированных изображения в одном битовом потоке. Первое из этих кодированных изображений называют общим кодированным изображением (shared coded picture). Общее кодированное изображение в первом битовом потоке идентично соответствующему общему кодированному изображению во втором битовом потоке. Такой способ кодирования позволяет декодировать первый битовый поток вплоть до (но не включая) выбранного общего кодированного изображения, и затем декодировать второй битовый поток, начиная с соответствующего общего кодированного изображения. Для того, чтобы начать декодировать второй битовый поток, не требуются никакие внутренне кодированные изображения, и, следовательно, достигается повышенная, по сравнению с традиционными подходами, эффективность сжатия.
[0005] CILP-предсказание позволяет применять кодер и декодер, соответствующие профилю Main HEVC (основной профиль HEVC), и, следовательно, обеспечивает лучшую совместимость при практической реализации, чем подход SHVC-ROI. При этом CILP-предсказание также выгодно отличается пониженной частотой появления внутренне-предсказываемых изображений (аналогично подходу SHVC-ROI). Однако, по сравнению с SHVC-ROI, CILP-предсказание проигрывает из-за необходимости использования наборов MCTS для тайлов базового качества, и также имеет худшее соотношение «битовая скорость/искажения», если используются сетки из мелких тайлов. Соответственно, в различных ситуациях подходы SHVC-ROI и CILP-предсказания могут иметь преимущества друг перед другом, однако ни один из них не является однозначно более эффективным для всех возможных ситуаций.
Сущность изобретения
[0006] Далее в настоящем документе будет рассмотрен улучшенный способ кодирования, имеющий целью по меньшей мере частично решить описанные выше проблемы.
[0007] Способ, в соответствии с первым аспектом настоящего изобретения, включает кодирование входного изображения в кодированное составляющее изображение; восстановление, в качестве части упомянутого кодирования, декодированного составляющего изображения, соответствующего кодированному составляющему изображению; кодирование пространственной области в кодированный тайл, включающее: определение горизонтального смещения и вертикального смещения, указывающих, для области, якорную позицию пространственной области внутри декодированного составляющего изображения; кодирование горизонтального смещения и вертикального смещения; определение того, что пакет предсказания в позиции первой горизонтальной координаты и первой вертикальной координаты упомянутого кодированного таила предсказывают относительно якорной позиции области, при этом первая горизонтальная координата и первая вертикальная координата являются горизонтальной и вертикальной координатой, соответственно, внутри упомянутой пространственной области; указание на то, что упомянутый пакет предсказания предсказывают относительно якорной позиции пакета предсказания, то есть, относительно упомянутых горизонтального и вертикального смещений; вычисление якорной позиции пакета предсказания, равной сумме упомянутых первой горизонтальной координаты и горизонтального смещения, и упомянутых первой вертикальной координаты и вертикального смещения, соответственно; определение вектора движения для упомянутого пакета предсказания; и применение упомянутого вектора движения относительно якорной позиции пакета предсказания, с получением блока предсказания.
[0008] В соответствии с одним из вариантов осуществления настоящего изобретения способ дополнительно включает извлечение упомянутой пространственной области из входного изображения; и определение горизонтального смещения и вертикального смещения на основе местоположения этой пространственной области во входном изображении.
[0009] В соответствии с одним из вариантов осуществления настоящего изобретения входное изображение представляет собой первый ракурс, при этом способ дополнительно включает получение пространственной области из второго входного изображения, которое представляет собой второй ракурс, отличающийся от первого ракурса.
[0010] В соответствии с одним из вариантов осуществления настоящего изобретения первое кодированное изображение включает упомянутые составляющее изображение и кодированный тайл, при этом способ дополнительно включает определение того, что вектор движения является нулевым; и указание на то, что первое кодированное изображение является опорным изображением для упомянутого вектора движения.
[0011] В соответствии с одним из вариантов осуществления настоящего изобретения первое кодированное изображение включает составляющее изображение, а второе кодированное изображение включает кодированный тайл, при этом способ включает указание на то, что первое кодированное изображение является опорным изображением для упомянутого вектора движения.
[0012] В соответствии с одним из вариантов осуществления настоящего изобретения упомянутое указание включает определение вектора движения таким образом, что применение упомянутого вектора движения относительно позиции пакета предсказания вызывает, при вычислении блока предсказания, использование по меньшей мере одного отсчета извне упомянутого кодированного таила.
[0013] Второй и третий аспекты настоящего изобретения относятся к устройству и машиночитаемому носителю данных, на котором хранится код, при этом устройство и машиночитаемый носитель сконфигурированы для реализации описанного выше способа, а также одного или более связанных с ним вариантов осуществления настоящего изобретения.
[0014] Четвертый аспект настоящего изобретения относится к способу, включающему декодирование кодированного таила в декодированный тайл, при этом декодирование включает: декодирование горизонтального смещения и вертикального смещения; декодирование указания на то, что пакет предсказания в позиции первой горизонтальной координаты и первой вертикальной координаты кодированного таила предсказывают относительно якорной позиции пакета предсказания, то есть, относительно упомянутых горизонтального смещения и вертикального смещения; вычисление якорной позиции пакета предсказания, равной сумме упомянутых первой горизонтальной координаты и горизонтального смещения, и упомянутых первой вертикальной координаты и вертикального смещения, соответственно; определение вектора движения для упомянутого пакета предсказания; и применение упомянутого вектора движения относительно якорной позиции пакета предсказания, с получением блока предсказания.
[0015] Пятый и шестой аспекты настоящего изобретения относятся к устройству и к машиночитаемому носителю данных, на котором хранится код, при этом устройство и машиночитаемый носитель сконфигурированы для реализации описанного выше способа, а также одного или более связанных с ним вариантов осуществления настоящего изобретения.
Краткое описание чертежей
[0016] Для более детального понимания настоящего изобретения оно будет описано далее с помощью примеров, показанных на приложенных чертежах, где:
[0017] на фиг. 1 эскизно проиллюстрировано электронное устройство, в котором применяются варианты осуществления настоящего изобретения;
[0018] на фиг. 2 эскизно проиллюстрировано абонентское оборудование, подходящее для применения в вариантах осуществления настоящего изобретения;
[0019] на фиг. 3 также эскизно проиллюстрированы электронные устройства, в которых применяются варианты осуществления настоящего изобретения и которые соединены при помощи проводных и беспроводных сетевых соединений;
[0020] на фиг. 4 эскизно проиллюстрирован кодер, подходящий для реализации некоторых из вариантов осуществления настоящего изобретения;
[0021] на фиг. 5 проиллюстрирован пример сшивки, проецирования и мэппинга изображений, соответствующих одному моменту времени, в упакованный кадр виртуальной реальности;
[0022] на фиг. 6 проиллюстрирована процедура формирования моноскопического равнопрямоугольного панорамного изображения;
[0023] на фиг. 7 показан пример иерархической модели данных, применяемой в протоколе DASH;
[0024] на фиг. 8 показан пример мэппинга фронтальной грани кубической карты, имеющей повышенное разрешение, в один упакованный кадр виртуальной реальности вместе с остальными гранями куба;
[0025] на фиг. 9а показан пример доставки битовых потоков HEVC одинакового разрешения с ограниченными по движению наборами тайлов;
[0026] на фиг. 9b показан один из примеров масштабируемого кодирования SHVC-ROI;
[0027] на фиг. 10 показан пример кодирования с ограниченным внутриуровневым предсказанием (CILP);
[0028] на фиг. 11а и 11b показан пример кодирования двух битовых потоков и переключение между ними в соответствии с кодированием SP-CILP;
[0029] на фиг. 12 показана блок-схема алгоритма для способа кодирования в соответствии с одним из вариантов осуществления настоящего изобретения;
[0030] на фиг. 13 показан пример способа кодирования в соответствии с одним из вариантов осуществления настоящего изобретения;
[0031] на фиг. 14 проиллюстрированы различия в плотностях отсчетов в общем составляющем изображении и в тайлах, в соответствии с одним из вариантов осуществления настоящего изобретения;
[0032] на фиг. 15 показан один из примеров структуры контейнерного файла, в соответствии с одним из вариантов осуществления настоящего изобретения;
[0033] на фиг. 16 показан один из примеров создания контейнерного файла, в соответствии с одним из вариантов осуществления настоящего изобретения;
[0034] на фиг. 17 показан еще один пример создания контейнерного файла, в соответствии с одним из вариантов осуществления настоящего изобретения;
[0035] на фиг. 18 показан один из примеров кодирования стереоскопического видео в соответствии с одним из вариантов осуществления настоящего изобретения;
[0036] на фиг. 19 показан другой пример кодирования стереоскопического видео, в соответствии с одним из вариантов осуществления настоящего изобретения;
[0037] на фиг. 20 показана эскизная блок-схема декодера, подходящего для реализации некоторых из вариантов осуществления настоящего изобретения;
[0038] на фиг. 21 показана блок-схема алгоритма для способа декодирования в соответствии с одним из вариантов осуществления настоящего изобретения; и
[0039] на фиг. 22 показана эскизная блок-схема типовой мультимедийной системы связи, в которой могут быть реализованы различные варианты осуществления настоящего изобретения.
Подробное описание некоторых примеров осуществления изобретения
[0040] Ниже будут более подробно рассмотрены соответствующее устройство и возможные механизмы для инициирования переключения точки просмотра. С этой целью обратимся сначала к фиг. 1 и 2. На фиг. 1 показана блок-схема системы видеокодирования в соответствии с одним из вариантов осуществления настоящего изобретения, имеющая вид блок-схемы примера аппаратуры или электронного устройства 50, которое может включать в свой состав кодек, соответствующий одному из вариантов осуществления настоящего изобретения. На фиг. 2 показана схема устройства в соответствии с одним из примеров осуществления настоящего изобретения. Далее будут описаны элементы, показанные на фиг. 1 и 2.
[0041] Электронное устройство 50 может, например, быть мобильным терминалом или абонентским оборудованием системы беспроводной связи. Однако нужно понимать, что варианты осуществления настоящего изобретения могут быть реализованы в любом электронном устройстве или аппаратуре, где требуется кодирование и декодирование, или только кодирование, или же только декодирование видеоизображений.
[0042] Устройство 50 может иметь корпус 30 для размещения и защиты устройства. Устройство 50 может также включать дисплей 32 в форме дисплея на жидких кристаллах. В других вариантах осуществления настоящего изобретения упомянутый дисплей может быть выполнен по любой технологии, подходящей для отображения изображений или видеоинформации. Устройство 50 может также включать клавиатуру 34. В других вариантах осуществления настоящего изобретения может применяться любой подходящий интерфейс обмена данными или пользовательский интерфейс. К примеру, пользовательский интерфейс может быть реализован в виде виртуальной клавиатуры или системы ввода данных, являющейся частью сенсорного дисплея.
[0043] Устройство может включать микрофон 36 или любое другое подходящее устройство ввода аудиоинформации, которое может быть устройством ввода цифрового или аналогового сигнала. Устройство 50 может также включать устройство вывода аудиоинформации, которое в вариантах осуществления настоящего изобретения может представлять собой любое из следующего: головной телефон 38, громкоговоритель, или же аналоговое или цифровое соединение для вывода аудиоинформации. Устройство 50 может также иметь в своем составе аккумулятор (или, в других вариантах осуществления настоящего изобретения, устройство может снабжаться электроэнергией от любого подходящего мобильного энергетического устройства, например, солнечной батареи, топливной батареи или заводного генератора). Устройство может дополнительно включать камеру, способную записывать, или захватывать, изображения и/или видеоинформацию. Устройство 50 может также включать инфракрасный порт для связи с другими устройствами в ближней зоне прямой видимости. В других вариантах осуществления настоящего изобретения устройство 50 может включать любые подходящие решения связи малой дальности, например, беспроводное соединение Bluetooth или проводное соединение USB/Firewire.
[0044] Устройство 50 может включать контроллер 56, процессор или схемы обработки данных для управления устройством 50. Контроллер 56 может быть соединен с памятью 58, которая в различных вариантах осуществления настоящего изобретения может хранить данные, одновременно в форме видеоинформации и аудиоинформации, и/или может также хранить инструкции для исполнения в контроллере 56. Контроллер 56 может быть также соединен со схемами 54 кодека, способными осуществлять кодирование и декодирование аудио- и/или видеоданных или являться вспомогательным средством при кодировании и декодировании, выполняемом контроллером.
[0045] Устройство 50 может также включать устройство 48 чтения карт и смарт-карту 46, например, карту UICC и устройство чтения UICC-карт для предоставления информации об абоненте, и для обеспечения возможности предоставления аутентификационной информации с целью аутентификации и авторизации абонента в сети.
[0046] Устройство 50 может включать схемы 52 радиоинтерфейса, связанные с контроллером, которые могут использоваться для формирования сигналов беспроводной связи, например, для связи с сетью сотовой связи, системой беспроводной связи или беспроводной локальной вычислительной сетью. Устройство 50 может также включать антенну 44, связанную со схемами 52 радиоинтерфейса, для передачи радиочастотных сигналов, формируемых в схемах 52 радиоинтерфейса, в другое устройство (или устройства), а также для приема радиочастотных сигналов от другого устройства (или устройств).
[0047] Устройство 50 может включать камеру, способную записывать или регистрировать отдельные кадры, которые затем передают в кодек 54 или контроллер для обработки. Устройство может принимать от другого устройства данные видеоизображений для обработки перед их передачей и/или хранением. Устройство 50 может также принимать изображение для кодирования/декодирования либо беспроводным способом, либо по проводному соединению. Структурные элементы устройства 50, описанные выше, представляют собой примеры средств выполнения соответствующих функций.
[0048] С помощью фиг.3 проиллюстрирован один из примеров системы, в которой могут использоваться различные варианты осуществления настоящего изобретения. Система 10 включает несколько устройств связи, способных осуществлять связь при помощи одной или нескольких сетей. В состав системы 10 может входить любая комбинация проводных и беспроводных сетей, включая, без ограничения перечисленным, беспроводную сотовую телефонную сеть (например, сеть GSM, UMTS, CDMA и т.п.), беспроводную локальную вычислительную сеть (wireless local area network, WLAN), например, в соответствии с определением в любом из стандартов IEEE 802.x, персональную сеть Bluetooth, локальную вычислительную сеть Ethernet, локальную вычислительную сеть типа «маркерное кольцо» глобальную сеть и Интернет.
[0049] Система 10 может включать как проводные, так и беспроводные устройства связи, и/или устройство 50, подходящее для реализации вариантов осуществления настоящего изобретения.
[0050] В качестве примера, на фиг. 3 показана мобильная телефонная сеть 11 и сеть Интернет 28. Соединение с Интернетом 28 может включать, без ограничения перечисленным, беспроводные соединения с большим радиусом действия, беспроводные соединения с малым радиусом действия, а также различные проводные соединения, включая, без ограничения перечисленным, телефонные линии, кабельные линии, линии электропередач и аналогичные каналы связи.
[0051] Примерами устройств связи в системе 10 могут служить, без ограничения перечисленным, электронная аппаратура или устройство 50, комбинация карманного персонального компьютера (personal digital assistant, PDA) и мобильного телефона 14, PDA 16, интегрированное устройство 18 обмена сообщениями (integrated messaging device, IMD), настольный компьютер 20, ноутбук 22. Устройство 50 может также размещаться на транспортном средстве, включая, без ограничения перечисленным, автомобиль, грузовик, такси, автобус, поезд, судно, самолет, велосипед, мотоцикл или любое аналогичное подходящее транспортное средство.
[0052] Варианты осуществления настоящего изобретения могут также быть реализованы в абонентской телеприставке, т.е. в приемнике цифрового телевидения, который, опционально, может обладать функциональностью отображения видеоинформации и беспроводной связи, в планшетных или (портативных) персональных компьютерах (ПК), которые включают аппаратную или программную (или комбинированную) реализацию кодера и/или декодера, в различных операционных системах, в чипсетах (микросхемных наборах), процессорах, DSP-процессорах и/или во встраиваемых системах, обеспечивающих аппаратное и/или программное кодирование.
[0053] Некоторые из подобных или других устройств могут как посылать, так и принимать вызовы и сообщения, а также осуществлять связь с операторами связи при помощи беспроводного соединения 25 с базовой станцией 24. Базовая станция 24 может быть соединена с сетевым сервером 26, обеспечивающим связь между средствами 11 связи и Интернетом 28. Система может включать дополнительные устройства связи, а также устройства связи других типов.
[0054] Устройства связи могут осуществлять связь с использованием различных технологий передачи данных, включая, без ограничения перечисленным, множественный доступ с кодовым разделением (Code Division Multiple Access, CDMA), глобальную систему мобильной связи (Global System for Mobile Communications, GSM), универсальную систему мобильной связи (Universal Mobile Telecommunication System, UMTS), множественный доступ с разделением по времени (Time Division Multiple Access, TDMA), множественный доступ с разделением по частоте (Frequency Division Multiple Access, FDMA), протокол управления передачей/протокол Интернета (Transmission Control Protocol/Internet Protocol, TCP-IP), службу коротких сообщений (Short Messaging Service, SMS), службу мультимедийных сообщений (Multimedia Messaging Service, MMS), электронную почту, сервис мгновенной передачи сообщений (Instant Messaging Service, IMS), Bluetooth, IEEE 802.11, и любые аналогичные технологии беспроводной связи. Устройство связи, используемое при реализации различных вариантов осуществления настоящего изобретения, может осуществлять связь с использованием различных сред передачи данных, включая, без ограничения, радиосоединения, инфракрасные, лазерные, кабельные соединения или любые другие подходящие соединения.
[0055] В телекоммуникационных сетях и в сетях передачи данных под «каналом» может пониматься как физический, так логический канал. Физическим каналом может быть любая физическая среда передачи, например, провод, тогда как логическим каналом может быть логическое соединение по мультиплексируемой среде передачи, способной обеспечивать передачу нескольких логических каналов. Канал может применяться для передачи информационного сигнала, например, битового потока, от одного или нескольких отправителей (или передатчиков) на один или несколько приемников.
[0056] Транспортный поток (transport stream, TS) MPEG-2, определенный стандартом ISO/IEC 13818-1, или, эквивалентно, в Рекомендации Н.222.0 ITU-T, представляет собой формат для передачи аудио-, видео- и других медиаданных, а также метаданных программ или иных метаданных, в мультиплексированном потоке. Для идентификации элементарных потоков (также называемых, пакетированными элементарными потоками) используются идентификаторы пакетов (packet identifier, PID). Следовательно, можно считать, что каждый логический канал в потоке MPEG-2 TS соответствует конкретному значению PID.
[0057] Существующие стандарты форматов медиафайлов включают базовый формат медиафайлов ISO (ISO/IEC 14496-12, сокращенно обозначаемый ISOBMFF) и формат файлов для видеоданных, структурированных NAL-пакетами (ISO/IEC 14496-15), являющийся производным от ISOBMFF.
[0058] Ниже будут описаны некоторые из понятий, структур и спецификаций ISOBMFF, в качестве примера формата контейнерного файла, на основе которого могут быть реализованы варианты осуществления настоящего изобретения. Аспекты настоящего изобретения не ограничены форматом ISOBMFF, напротив, данное описание приведено лишь в качестве одной из возможностей, на которых может быть полностью или частично основана реализация настоящего изобретения.
[0059] Элементарная единица построения базового формата медиафайлов ISO называется «боксом» (box). Каждый бокс имеет заголовок и полезную нагрузку. В заголовке бокса указывают тип бокса и размер бокса, выраженный в байтах. Бокс может включать внутри себя другие боксы, при этом в формате файлов ISO определены типы боксов, которые могут находиться внутри бокса каждого типа. При этом, также, некоторые боксы должны присутствовать в каждом файле обязательно, тогда как другие боксы могут быть опциональными. В дополнение, для боксов некоторого типа, допустимо наличие нескольких экземпляров бокса в одном файле. Таким образом, в базовом формате медиафайлов ISO по существу определена иерархическая структура боксов.
[0060] В соответствии с форматом файлов семейства ISO файл включает мультимедийные данные и метаданные, инкапсулированные в боксах. Каждый бокс идентифицируют при помощи четырехсимвольного кода (4СС), и при этом каждый бокс начинается с заголовка, который несет информацию о типе и размере бокса.
[0061] В файлах, соответствующих базовому формату медиафайлов ISO медиаданные могут располагаться в боксе медиаданных mdat, а для размещения метаданных может использоваться бокс фильма moov. В некоторых случаях для того, чтобы файл мог быть обработан, обязательно должны присутствовать оба указанных бокса, бокс mdat и бокс moov. Бокс фильма ('moov') может содержать один или несколько треков («дорожек»), при этом каждый трек занимает один соответствующий бокс трека ('trak'). Трек может относиться к одному из множеству различных типов, включая мультимедийные треки, которые представляют собой отсчеты, отформатированные согласно формату сжатия медиаданных (и правилам его инкапсуляции в базовый формат медиафайлов ISO).
[0062] Фрагменты фильма могут использоваться, например, при записи содержимого в файлы ISO, к примеру, чтобы исключить потери данных в случае сбоя в приложении записи, нехватки объема памяти или возникновения других аварийных ситуаций. Если не использовать фрагменты фильма, возможны потери данных, поскольку форматы файлов, как правило, требуют, чтобы все метаданные, например, бокс фильма, были записаны в одной непрерывной области файла. Также, при записи файла, может не хватить памяти (например, памяти с произвольным доступом, RAM) для буферизации бокса фильма в доступном объеме хранилища, а повторное вычисление содержимого бокса фильма при закрытии фильма может быть слишком медленным. Также, при этом, фрагменты фильма позволяют обеспечить одновременную запись и воспроизведение файла с использованием обычного анализатора файлов ISO. Также, при применении фрагментов фильма может требоваться меньшая длительность начальной буферизации при постепенной подгрузке файла, например, при одновременном приеме и воспроизведении файла, и при этом первый бокс фильма может быть меньше, по сравнению с файлом с тем же мультимедийными данными, но структурированным без использования фрагментов фильма.
[0063] Функциональность фрагментов фильма может обеспечивать возможность удобного разбиения метаданных, которые в противном случае размещались в боксе фильма с разбиением на несколько частей. Каждая часть может соответствовать определенному периоду времени трека. Другими словами, функциональность фрагментов фильма позволяет чередовать метаданные и медиаданные в файле. Следовательно, размер бокса фильма может быть сокращен и могут быть реализованы описанные выше сценарии применения.
[0064] В некоторых из примеров отсчеты медиаданных для фрагментов фильма могут располагаться в боксе mdat, если они находятся в том же файле, что и бокс moov. Однако для метаданных фрагментов фильма может присутствовать бокс moof. Бокс moof может включать информацию для определенного интервала времени воспроизведения, который ранее был в боксе moov. Бокс moov может при этом сам являться полноценным «фильмом», однако при этом он может включать в дополнение бокс mvex, который указывает на то, какие фрагменты фильма следуют за ним в этом файле. Фрагменты фильма позволяют увеличить временную длительность презентации, связанной с боксом moov.
[0065] Внутри фрагмента фильма может присутствовать набор сегментов трека, включающий любое количество (ноль и более) треков. Фрагменты трека, в свою очередь, могут включать в себя любое количество (ноль и более) отрезков трека, каждый из которых представляет собой непрерывную последовательность смежных отсчетов в этом треке. Внутри этих структур присутствует множество опциональных полей, которые могут иметь заданные по умолчанию значения. Метаданные, размещаемые в боксе moof, могут быть ограничены подмножеством метаданных, допускающих включение в бокс moov, и в некоторых случаях могут кодироваться отличающимся образом. Подробная информация о боксах, которые могут входить в состав бокса moof приведена в спецификации базового формата медиафайлов ISO. Автономный (self-contained) фрагмент фильма может - это фрагмент, состоящий из бокса moof и бокса mdat, которые следуют друг за другом в порядке файла, и в котором бокс mdat содержит отсчеты фрагмента фильма (метаданные для которого содержит бокс moof) и не содержит отсчетов каких-либо других фрагментов фильма (т.е. никаких других боксов moof).
[0066] Для связи треков друг с другом может использоваться механизм ссылок на треки. Бокс TrackReferenceBox содержит боксы, каждый из которых дает ссылку из содержащегося в нем трека на набор других треков. Такие ссылки могут помечаться типом включенного бокса (т.е. четырехсимвольным кодом бокса).
[0067] Базовый формат медиафайлов ISO предполагает три механизма для синхронизированных метаданных, которые могут быть связаны с отдельными отсчетами: группы отсчетов, треки синхронизированных метаданных и вспомогательная информация о отсчетах. В производных стандартах может также обеспечиваться аналогичная функциональность, с использованием одного или более из этих трех механизмов.
[0068] Группирование отсчетов в базовом формате медиафайлов ISO и в производных от него форматах, таких как формат файлов AVC или формат файлов SVC, может быть определено как назначение каждого отсчета в треке в качестве члена одной из групп отсчетов на основе некоторого критерия группирования. Группа отсчетов при группировании отсчетов не ограничена непрерывной последовательностью смежных отсчетов и может включать содержать отсчеты, не являющиеся соседними друг с другом. Поскольку отсчеты в треке могут группироваться более чем одним способом, каждая группа отсчетов может иметь поле типа, в котором указывают тип группирования. Группы отсчетов могут представлены двумя взаимосвязанными структурами данных: (1) бокс SampleToGroupBox (соответствия отсчет-группа) (sgpd), который отражает распределение отсчетов по группам отсчетов; и (2) бокс SampleGroupDescriptionBox (описание группы отсчетов) (sgpd), который содержит запись группы отсчетов, описывающую свойства группы, для каждой группы отсчетов. Могут присутствовать несколько экземпляров боксов SampleToGroupBox и SampleGroupDescriptionBox для различных критериев группирования. Они могут отличаться полем типа, которое используют для указания на тип группирования.
SampleToGroupBox может включать поле grouping_type_parameter (параметр типа группирования), который может использоваться, например, для указания подтипа группирования.
[0069] Формат файлов Matroska позволяет хранить (без ограничения перечисленным) любые видео-, аудиотреки, треки изображений или субтитров в одном файле. Формат Matroska может быть использован как основа для производных форматов файлов, таких как WebM. В качестве базы для формата Matroska использован расширяемый двоичный метаязык (Extensible Binary Meta Language, EBML). Язык EBML представляет собой двоичный формат с выравниванием по октетам (байтам), вдохновленный принципами языка XML. Язык EBML - это обобщенное описание метода разметки двоичных данных. Файл Matroska состоит из «элементов» (Elements), которые составляют «документ» на языке EBML. Элементы содержат идентификатор элемента, дескриптор размера элемента и собственно двоичные данные. Элементы могут быть вложенными. Сегментный элемент (Segment Element) в формате Matroska - это контейнер для других элементов верхнего уровня (уровня 1). Файл Matroska может содержать как минимум один сегмент (Segment), но не обязательно только один. Мультимедийные данные в файлах Matroska организованы в «кластеры» (Clusters) или «кластерные элементы» (Cluster Elements), каждый из которых, как правило, содержит несколько секунд медиаданных. Каждый кластер содержит элементы BlockGroup («группа блоков»), которые, в свою очередь, содержат «блочные элементы» (Block Elements). Элементы-подсказки (Cues Element) содержат метаданные, которые могут быть вспомогательным средством при произвольном доступе или поиске и могут содержать файловые указатели на местоположение в файле или соответствующие временные метки для точек поиска.
[0070] Видеокодек состоит из кодера, при помощи которого входные видеоданные преобразуют в сжатое представление, подходящее для хранения и передачи, а также декодера, при помощи которого сжатое представление видеоданных распаковывают, возвращая их к форме, пригодной для просмотра пользователем. Видеокодер и/или видеодекодер могут быть также независимыми друг от друга, т.е. не обязательно образовывать кодек. Как правило, в кодере часть информации исходной видеопоследовательности отбрасывается с целью представления видеоинформации в более компактной форме (т.е. с меньшим битрейтом).
[0071] Типовые гибридные видеокодеры, например, многие из реализаций кодеров, соответствующие стандартам ITU-T Н.263 и Н.264, кодируют видеоинформацию в два этапа. Сначала предсказывают значения пикселей в определенной области изображения (или «блоке пикселей»), например, с использованием механизмов компенсации движения (нахождение области в одном из предварительно закодированных видеокадров, которая близко соответствует кодируемому в текущий момент блоку пикселей, и указание на эту область) или с использованием средств пространственного предсказания (использование, заданным образом, значений пикселей вокруг кодируемого блока пикселей). Затем кодируют ошибку предсказания, т.е. разность между предсказанным блоком пикселей и исходным блоком пикселей. Как правило, это выполняется при помощи преобразования разности пиксельных значений с использованием заданного преобразования (например, дискретного косинусного преобразования (Discrete Cosine Transform, DCT), или его варианта), квантования его коэффициентов и энтропийного кодирования квантованных коэффициентов. Регулируя степень детализации в процедуре квантования, кодер может управлять балансом между точностью представления пикселей (качеством изображения) и размером результирующей кодированной видеорепрезентации (размером файла или битрейтом).
[0072] Источником информации для внешнего предсказания являются ранее декодированные изображения (называемые опорными изображениями). При внутреннем копировании блоков (intra block сору, IBC), которое также называют «предсказанием на основе внутреннего копирования блоков», предсказание выполняют аналогично временному предсказанию, однако опорным изображением в таком случае является само текущее изображение, при этом в процессе декодирования ссылки допускаются только на уже декодированные ранее отсчеты. Межуровневое или межракурсное предсказание может выполняться аналогично временному предсказанию, однако в этом случае опорным будет, соответственно, декодированное изображение из другого масштабируемого уровня или из другого ракурса. В некоторых случаях под внешним предсказанием понимают исключительно временное предсказание, однако в других случаях внешнее предсказание может обобщенно обозначать как временное предсказание, так и любые другие типы предсказания, а именно, внутреннее копирование блоков, межуровневое и межракурсное предсказание, если их выполняют с помощью той же процедуры, что и временное предсказание, или аналогичной процедуры. Внешнее предсказание или временное предсказание иногда называют компенсацией движения или предсказанием с компенсацией движения.
[0073] Внешнее предсказание, которое может также называться временным предсказанием, компенсацией движения или предсказанием с компенсацией движения, позволяет понизить временную избыточность. Источником информации для внешнего предсказания являются ранее декодированные изображения. Для внешнего предсказания используют тот факт, что смежные пиксели в одном изображении с большой вероятностью являются коррелированными. Внутреннее предсказание быть либо пространственным, либо относиться собственно к преобразованию, т.е. могут предсказываться либо значения элементов изображения, либо коэффициенты преобразования. Внутреннее предсказание обычно применяют при внутреннем кодировании, когда внешнее предсказание не применяется.
[0074] Одним из результатов процедуры кодирования является набор параметров кодирования, таких как векторы движения и коэффициенты преобразования. Энтропийное кодирование множества параметров может быть более эффективным, если сначала выполнить их предсказание, на основе пространственно-смежных или соседних по времени параметров. Например, вектор движения может предсказываться на основе пространственно смежных векторов движения, при этом кодироваться может только разность относительно предсказания вектора движения. Предсказание параметров кодирования и внутреннее предсказание совместно могут называться внутрикадровым предсказанием.
[0075] На фиг. 4 проиллюстрирована блок-схема видеодекодера, подходящего для применения вариантов осуществления настоящего изобретения. На фиг. 4 проиллюстрирован кодер для двух уровней, однако нужно понимать, что проиллюстрированный кодер может быть расширен и выполнять кодирование более чем двух уровней. На фиг. 4 проиллюстрирован один вариантов осуществления видеокодера, включающий первый сегмент 500 кодера для базового уровня (кодирования) и второй сегмент 502 кодера для уточняющего уровня. Каждый из сегментов, первый сегмент 500 кодера и второй сегмент 502 кодера, могут включать аналогичные элементы для кодирования поступающих изображений. Сегменты 500, 502 кодера могут включать устройство 302, 402 предсказания пикселей, кодер 303, 403 ошибки предсказания и декодер 304, 404 ошибки предсказания. Также, на фиг.4 показан один из вариантов осуществления устройства 302, 402 предсказания пикселей, включающего устройство 306, 406 внешнего предсказания, устройство 308, 408 внутреннего предсказания, селектор 310, 410 режима, фильтр 316, 416 и память 318, 418 опорных кадров. Устройство 302 предсказания пикселей в первом сегменте 500 кодера принимает изображения 300 базового уровня кодируемого видеопотока одновременно в устройстве 306 внешнего предсказания (которое определяет разницу между этим изображением и опорным кадром 318 компенсации движения) и в устройстве 308 внутреннего предсказания (которое определяет предсказание для блока пикселей изображения, исходя только из уже обработанных частей текущего кадра или изображения). Выходные данные из устройства внешнего предсказания и из устройства внутреннего предсказания передают в селектор 310 режима. Устройство 308 внутреннего предсказания может иметь более одного режима внутреннего предсказания. Следовательно, в каждом из режимов может выполняться внутреннее предсказание, и предсказанный сигнал может быть предоставлен в селектор 310 режима. В селектор 310 режима передается также копия изображения 300 базового уровня. Соответственно, устройство 402 предсказания пикселей во втором сегменте 502 кодера принимает изображения 400 уточняющего уровня кодируемого видеопотока одновременно в устройстве 406 внешнего предсказания (которое определяет разницу между этим изображением и опорным кадром 418 компенсации движения) и в устройстве 408 внутреннего предсказания (которое определяет предсказание для блока пикселей изображения, исходя только из уже обработанных частей текущего кадра или изображения). Выходные данные из устройства внешнего предсказания и из устройства внутреннего предсказания передают в селектор 410 режима. Устройство 408 внутреннего предсказания может иметь более одного режима внутреннего предсказания. Следовательно, в каждом из режимов может выполняться внутреннее предсказание, и предсказанный сигнал может быть предоставлен в селектор 410 режима. В селектор 410 режима передается также копия изображения 400 уточняющего уровня.
[0076] В зависимости от режима кодирования выбранного для кодирования текущего блока пикселей, на выход селектора 310, 410 режима передают выходные данные устройства 306, 406 внешнего предсказания, выходные данные одного из опциональных режимов внутреннего предсказания или выходные данные поверхностного кодера из состава селектора режима. Выходные данные селектора режима передают в первое суммирующее устройство 321, 421. Первое суммирующее устройство может вычитать выходные данные устройства 302, 402 предсказания пикселей из изображения 300 базового уровня, или изображения 400 уточняющего уровня, соответственно, с формированием первого сигнала 320, 420 ошибки предсказания, который подают на вход кодера 303, 403 ошибки предсказания.
[0077] Также, устройство 302, 402 предсказания пикселей принимает от устройства 339, 439 предварительного восстановления комбинацию предсказанного представления блока 312, 418 изображения и выходные данные 338, 438 кодера 304, 404 ошибки предсказания. Предварительно восстановленное изображение 314, 414 может быть передано в устройство 308, 408 внутреннего предсказания и фильтр 316, 416. В фильтре 316, 416, где принимается это предварительное представление, может выполняться его фильтрация и вывод окончательного восстановленного изображения 340, 440, которое может быть сохранено в память 318, 418 опорных кадров. Память 318 опорных кадров может иметь соединение с устройством 306 внешнего предсказания и использоваться в качестве опорного изображения, с которым сравнивают будущее изображение 300 базового уровня при выполнении операций внешнего предсказания. При условии, что базовый уровень выбран в качестве источника для межуровневого предсказания отсчетов и/или для межуровневого предсказания информации о движении уточняющего уровня, и если на это также выполнено соответствующее указание, в соответствии с некоторыми из вариантов осуществления настоящего изобретения, память 318 опорных кадров может иметь соединение с устройством 406 внешнего предсказания и может использоваться в качестве опорного изображения, с которым сравнивают будущее изображение 400 уточняющего уровня при выполнении операций внешнего предсказания. При этом память 418 опорных кадров может иметь соединение с устройством 406 внешнего предсказания и использоваться в качестве опорного изображения, с которым сравнивают будущее изображение 400 уточняющего уровня при выполнении операций внешнего предсказания.
[0078] При условии, что базовый уровень выбран в качестве источника для предсказания параметров фильтрации уточняющего уровня, и на это выполнено соответствующее указание, в соответствии с некоторыми из вариантов осуществления настоящего изобретения, параметры фильтрации из фильтра 316 первого сегмента 500 кодера могут передаваться во второй сегмент 502 кодера.
[0079] Кодер 303, 403 ошибки предсказания включает блок 342, 442 преобразования и квантователь 344, 444. Блок 342 преобразования преобразует первый сигнал 320, 420 ошибки предсказания в домен преобразования. Таким преобразованием является, к примеру, преобразование DCT. Квантователь 344, 444 квантует сигнал, например, коэффициенты DCT, в домене преобразования и формирует квантованные коэффициенты.
[0080] Декодер 304, 404 ошибки предсказания принимает выходные данные из кодера 303, 403 ошибки предсказания и выполняет процедуры, обратные процедурам кодера 303, 403 ошибки предсказания, в результате чего получают декодированный сигнал 338, 438 ошибки предсказания, который при комбинировании с предсказанным представлением блока 312, 412 изображения во втором суммирующем устройстве 339, 439 дает предварительное восстановленное изображение 314, 414. Декодер ошибки предсказания можно рассматривать как имеющий в своем составе деквантователь 361, 461 который деквантует квантованные значения коэффициентов, например, коэффициентов DCT, и восстанавливает преобразованный сигнал, а также как включающий блок 363, 463 обратного преобразования, который выполняет обратное преобразование над восстановленным сигналом преобразования, при этом выходные данные блока 363, 463 обратного преобразования содержат восстановленный блок (или блоки). Декодер ошибки предсказания может также включать фильтр блоков, который может выполнять фильтрацию восстановленного блока (или блоков) в соответствии с дополнительной декодированной информацией и параметрами фильтрации.
[0081] Энтропийный кодер 330, 430 принимает выходные данные из кодера 303, 403 ошибки предсказания и может выполнять соответствующее кодирование переменной длины и/или энтропийное кодирование сигнала для обеспечения возможности обнаружения и исправления ошибок. Выходные данные энтропийных кодеров 330, 430 могут быть введены в битовый поток, например, при помощи мультиплексора 508.
[0082] Энтропийное кодирование/декодирование может выполняться множеством различных способов. К примеру, может применяться контекстно-зависимое кодирование/декодирование, при котором и кодер, и декодер, меняют контекстное состояние параметров кодирования в зависимости от ранее кодированных/декодированных параметров кодирования. Примерами контекстно-зависимого кодирования являются контекстно-зависимое двоичное арифметическое кодирование (context adaptive binary arithmetic coding, С ABAC), контекстно-зависимое кодирование с переменной длиной кодового слова (context-based variable length coding, CAVLC) или любое аналогичное энтропийное кодирование. Энтропийное кодирование/декодирование, альтернативно или в дополнение, может выполняться при помощи схем кодирования с переменной длиной кодового слова, например, кодирования/декодирования методом Хаффмана или кодирования/декодирования методом экспоненциального кодирования Голомба.
Декодирование параметров кодирования из энтропийно-кодированного битового потока, или из кодовых слов, может называться синтаксическим анализом.
[0083] Стандарт H.264/AVC был разработан объединенной командой по видео (Joint Video Team, JVT) из состава группы экспертов по видеокодированию (Video Coding Experts Group (VCEG) сектора стандартизации телекоммуникаций Международного союза электросвязи (International Telecommunication Union, ITU-T) и группой экспертов по движущемуся изображению (Moving Picture Experts Group, MPEG) Международной организации по стандартизации (International Organization for Standardization, ISO) / Международной электротехнической комиссии (International Electrotechnical Commission, IEC). Стандарт H.264/AVC был опубликован обеими родительскими организациями по стандартизации и получил наименование Рекомендации Н.264 ITU-T и Международного стандарта ISO/IEC 14496-10, известного также как улучшенное видеокодирование (Advanced Video Coding, AVC), 10-ая часть MPEG-4. Были выпущены несколько версий стандарта H.264/AVC, в спецификацию каждой из которых добавлялись новые расширения или элементы. В число этих расширений вошли масштабируемое видеокодирование (Scalable Video Coding, SVC) и многоракурсное видекодирование (Multiview Video Coding, MVC).
[0084] Объединенной командой по видеокодированию (Joint Collaborative Team -Video Coding, JCT-VC) группы VCEG и MPEG была создана первая версия (version 1) стандарта высокоэффективного видеокодирования (High Efficiency Video Coding, HEVC), H.265. Стандарт будет опубликован обеими родительскими стандартизующими организациями и в текущий момент имеет наименование Рекомендации H.265 ITU-T и Международного стандарта ISO/IEC 23008-2, известного также как высокоэффективное видеокодирование (HEVC), 2-ая часть MPEG-H. В более поздние версии стандарта H.265/HEVC вошли расширения масштабируемого, многоракурсного кодирования, расширения диапазона точности, трехмерного кодирования и кодирования экранного контента, которые сокращенно обозначаются, соответственно, SHVC, MV-HEVC, REXT, 3D-HEVC и SCC.
[0085] Для расширений SHVC, MV-HEVC и 3D-HEVC используется общая базовая спецификация, описанная в приложении F второй версии стандарта HEVC. Эта общая база включает, например, высокоуровневые синтаксис и семантику, к примеру, определяющие часть характеристик уровней битового потока, такие как межуровневые зависимости, а также процедуры декодирования, такие как построение списка опорных изображений, включающего опорные изображения межуровневого предсказания, а также вычисление порядковых номеров изображений для многоуровневых потоков. Приложение F может применяться и в последующих многоуровневых расширениях HEVC, которые могут появиться позднее. В приведенном ниже описании видеокодер, видеодекодер, способы кодирования, способы декодирования, структуры битового потока и/или варианты осуществления настоящего изобретения могут быть рассмотрены на примере конкретных расширений, таких как SHVC и/или MV-HEVC, однако нужно понимать, что они, в общем случае, применимы также для многоуровневых расширений HEVC, а также, в еще более общем случае, к любой многоуровневой схеме видеокодирования.
[0086] В настоящем разделе приведены ключевые определения, описана структура битового потока и кодирования, а также основные понятия стандартов H.264/AVC и HEVC, - в качестве примера видеокодера, видеодекодера, способа кодирования, способа декодирования и структуры битового потока, в которых могут быть реализованы варианты осуществления настоящего изобретения. Часть ключевых определений, структур битового потока и кодирования, а также основных понятий стандарта H.264/AVC совпадают с проектом стандарта HEVC, в этом случае они описаны ниже совместно. Аспекты настоящего изобретения не ограничены стандартами H.264/AVC или HEVC, напротив, данное описание приведено в качестве одного из примеров базы для частичной или полной реализации настоящего изобретения.
[0087] Аналогично многим предшествующим стандартам видеокодирования, в стандартах H.264/AVC и HEVC определены синтаксис и семантика битового потока, а также процесс декодирования безошибочных битовых потоков. Процедура кодирования стандартом не определена, однако кодеры должны формировать битовые потоки, соответствующие стандарту. Соответствие битового потока и декодера стандарту может быть проверено с помощью гипотетического опорного декодера (Hypothetical Reference Decoder, HRD). Стандарт включает в себя инструменты кодирования, помогающие справиться с ошибками и потерями при передаче, однако использование этих инструментов при кодировании не является обязательным, а процесс декодирования для битовых потоков с ошибками не определен.
[0088] Элементарной единицей для ввода в декодер H.264/AVC или HEVC и вывода из декодера H.264/AVC или HEVC, соответственно, является изображение (picture). Изображение, передаваемое в качестве входных данных в кодер, может называться исходным изображением, а изображение, декодированное декодером, может называться декодированным изображением.
[0089] Исходное и декодированное изображения, каждое, состоят из одного или более массивов отсчетов (элементов изображения), например, одного или более наборов массивов отсчетов:
- Только составляющая яркости (Y) (монохромное изображение).
- Составляющая яркости и две составляющие цветности (YCbCr или YCgCo).
- Составляющие зеленого, синего и красного (GBR или RGB).
- Массивы, представляющие другие неопределенные монохромные или трехкомпонентные цветовые отсчеты (например, YZX, которые также называют XYZ).
[0090] Далее в настоящем описании такие массивы называются компонентами яркости (или L, или Y) и компонентами цветности, при этом два массива цветности могут обозначаться за Cb и Cr; независимо от реально используемого метода представления информации о цвете. Реально используемый способ представления цветовой информации может, например, указываться в битовом потоке, например, с использованием синтаксиса информации об используемости видео (Video Usability Information, VUI) в стандарте H.264/AVC и/или HEVC. Составляющая может быть определена как массив отсчетов, или одиночный отсчет, из одного из трех массивов отчетов (одного яркости и двух цветности), или как массив отсчетов, или одиночный отсчет, из массива, образующего изображение в монохромном формате.
[0091] В случае стандартов H.264/AVC и HEVC изображение может представлять собой кадр или поле. Кадр включает в себя матрицу отсчетов яркости, и возможно также, соответствующих отсчетов цветности. Поле представляет собой множество чередующихся строк отсчетов в кадре и может использоваться в качестве входных данных для кодера в случае, когда исходный сигнал является чересстрочным. Массивы отсчетов цветности могут отсутствовать (и, следовательно, могут применяться монохромные значения) или массивы отсчетов цветности могут иметь пониженное разрешение по сравнению с массивами отсчетов яркости. Форматы представления цветности могут быть, в общем, описаны следующим образом:
- При дискретизации в монохромном формате имеется только один массив отсчетов, который, по определению, считают массивом яркости.
- При дискретизации с форматом 4:2:0 каждый из двух массивов цветности имеет половину высоты массива яркости и половину его ширины.
- При дискретизации с форматом 4:2:2 каждый из двух массивов цветности имеет одинаковую высоту с массивом яркости, но половину ширины.
- При дискретизации с форматом 4:4:4, если не используются отдельных цветовых плоскостей, каждый из двух массивов цветности ту же высоту и ширину, что и массив яркости.
[0092] В стандартах H.264/AVC и HEVC массивы отсчетов могут кодироваться в виде отдельных цветовых плоскостей в битовом потоке, и соответственно, может выполняться декодирование отдельно кодированных цветовых плоскостей из битового потока. Если применяются отдельные цветовые плоскости, каждую из них обрабатывают отдельно (в кодере и/или декодере) как изображение с монохромным представлением.
[0093] Разбиением называют такое разделение множества на подмножества, при котором каждый из элементов множества находится только в одном из подмножеств.
[0094] При описании операций кодирования и/или декодирования в стандарте HEVC могут использоваться термины, описанные ниже. Кодовый блок (coding block) - это блок отсчетов размером N×N, для некоторого значения N, такого, что разделение блока отсчетов кодового дерева на блоки отсчетов для кодирования является разбиением. Блок кодового дерева (coding tree block, СТВ) - это блок отсчетов размером N×N, для некоторого значения N, такого, что разделение составляющей изображения на блоки кодового дерева будет разбиением. Пакет кодового дерева (coding tree unit, CTU) - это блок кодового дерева из отсчетов яркости, два соответствующих блока кодового дерева из отсчетов цветности в случае изображения, имеющего три массива отсчетов, или блок кодового дерева в монохромном изображении, или изображении, которое кодируют с использованием трех отдельных цветовых плоскостей и синтаксических структур, применяемых для кодирования отсчетов. Пакет кодирования (coding unit, CU) - это кодовый блок из отсчетов яркости, два соответствующих кодовых блока из отсчетов цветности для изображения, имеющего три массива значений, кодовый блок из отсчетов монохромного изображения, или изображения, которое кодируют с использованием трех отдельных цветовых плоскостей и синтаксических структур, применяемых для кодирования отсчетов. Пакет кодирования максимально допустимого размера, как правило, называется LCU (largest coding unit, наибольший пакет кодирования) или пакетом кодового дерева (coding tree unit, CTU), при этом изображение в видео разбивается на неперекрывающиеся блоки LCU.
[0095] Каждый из кодовых пакетов состоит из одного или более пакетов предсказания (prediction unit, PU), определяющих процедуру предсказания отсчетов в пакете кодирования, а также одного или более пакетов преобразования (transform units, TU), определяющих процедуру кодирования ошибки предсказания для отсчетов в пакете кодирования. Как правило, пакет кодирования состоит из квадратного блока отсчетов, размер которого выбирается из заранее заданного множества допустимых размеров кодового пакета. Каждый пакет предсказания и пакет преобразования могут быть разбиты на менее крупные пакеты предсказания и пакеты преобразования с целью повышения точности процедур предсказания и кодирования ошибки предсказания соответственно. Каждый пакет предсказания имеет связанную с ним информацию предсказания, которая определяет, предсказание какого типа должно применяться к пикселям данного пакета предсказания (например, информацию вектора движения в случае пакета предсказания с внешним предсказанием, или информацию направления внутреннего предсказания в случае внутренне предсказываемого пакета предсказания).
[0096] Аналогично, каждый пакет преобразования может быть связан с информацией, описывающей процедуру декодирования ошибки предсказания для значений в данном пакете преобразования (включая, например, информацию о коэффициентах DCT-преобразования). Информация о необходимости применения кодирования ошибки предсказания для каждого кодового пакета, как правило, сигнализируется в синтаксических элементах, относящихся к пакету кодирования. Если остатка или ошибки предсказания, связанного с кодовым пакетом нет, то можно считать, что для данного кодового пакета пакеты преобразования отсутствуют. Информация о разделении изображения на кодовые пакеты, и о разделении кодовых пакетов на пакеты предсказания и пакеты преобразования, сигнализируемая, как правило, в битовом потоке, позволяет декодеру воспроизводить заданную структуру этих пакетов.
[0097] В стандарте HEVC изображение может быть разбито на тайлы (tile), которые имеют прямоугольную форму и содержат целое число пакетов LCU. В стандарте HEVC разбиение на тайлы дает регулярную сетку, в которой максимальная разность между высотой и шириной тайлов равна одному LCU. В стандарте HEVC слайс определен как целое количество пакетов кодового дерева, содержащихся в одном независимом сегменте слайса и во всех последующих зависимых сегментах слайса (если они присутствуют), которые предшествуют следующему независимому сегменту слайса (если он существует) внутри одного пакета доступа. В стандарте HEVC сегмент слайса определяют как целое количество пакетов кодового дерева, организованных в виде последовательности, в порядке сканирования таила, и содержащихся в одном пакете NAL. Разделение каждого из изображений на сегменты слайса является разбиением. В стандарте HEVC независимый сегмент слайса определен как сегмент слайса, для которого значения синтаксических элементов в заголовке сегмента слайса не получают на основе значений предыдущего сегмента слайса, а зависимый сегмент слайса определен как сегмент слайса, для которого значения некоторых из синтаксических элементов в заголовке сегмента слайса получают на основе значений для предыдущего независимого сегмента слайса в порядке декодирования. В стандарте HEVC заголовок слайса определен как заголовок независимого сегмента слайса, который является текущим, или как заголовок независимого сегмента слайса, который предшествует текущему зависимому сегменту слайса, и при этом заголовок сегмента слайса определен как часть кодированного сегмента слайса, включающего элементы данных, которые относятся к первому пакету (или ко всем пакетам) кодового дерева, представленному (или представленным) в сегменте слайса. Кодовые пакеты сканируют в порядке сканирования растра LCU в тайлах или в изображении в целом, если тайлы не используются. В LCU кодовые пакеты могут иметь заданный порядок сканирования.
[0098] Ограниченный по движению набор тайлов (MCTS) - это набор, в котором процедура внешнего предсказания при кодировании ограничена таким образом, что ни одно значение отсчета извне данного набора тайлов, как и ни одно значение отсчета с дробно-пиксельной позицией, вычисленное с использованием одного или более значений отсчетов вне данного набора тайлов, не может использоваться для внешнего предсказания ни одного из отсчетов внутри ограниченного по движению набора тайлов. При этом на кодирование набора MCTS накладывается следующее ограничение: не формируют кандидатные вектора движения на основе блоков вне данного набора MCTS. Это может обеспечиваться при помощи отключения временного предсказания векторов движения в HEVC или запрета в кодере на использование TMVP-кандидатов или любых кандидатных предсказаний векторов движения, следующих за TMVP-кандидатом в списке слияния или списке AMVP-кандидатов, для пакетов предсказания, расположенных непосредственно слева и справа от границы тайлов в данном наборе MCTS, за исключением последнего таила в нижнем правом углу набора. В общем случае набор MCTS - это набор тайлов, который не зависит ни от каких значений отсчетов или кодированных данных, например, векторов движения, вне этого набора MCTS. В некоторых случаях может предъявляться требование, чтобы набор MCTS имел прямоугольную форму. Нужно понимать, что в зависимости от контекста набор MCTS может обозначать набор тайлов внутри изображения или соответствующий набор тайлов в последовательности изображений. Соответствующий набор тайлов может иметь идентичное местоположение в последовательности изображений, однако в общем случае это не обязательно.
[0099] Следует отметить, что местоположениям отсчетов, используемых для внешнего предсказания, процедурой кодирования и/или декодирования могут присваиваться значения насыщения, то есть, местоположению, которое могло бы оказаться вне изображения, присваивается значение насыщения, указывающее на соответствующий граничный отсчет изображения. Таким образом, если граница таила является также границей изображения, в некоторых сценариях применения кодер может разрешать фактическое пересечение этой границы векторами движения, поскольку местоположения отсчетов нормализованы до граничных, и значит возможна дробно-пиксельная интерполяция со ссылками на местоположения вне границ таила. В других сценариях применения, в частности, если кодированный тайл извлекают из битового потока, где он расположен в позиции, прилегающей к границе изображения, и помещают в другой битовый поток, где этот тайл не будет лежать вплотную к границе изображения, ограничения, кодер может ограничивать векторы движения на границах изображения аналогично границам MCTS.
[0100] Для указания на наличие ограниченных по движению наборов тайлов в битовом потоке могут применяться сообщения SEI о временные ограниченных по движению наборов тайлов, определенные стандартом HEVC.
[0101] Декодер восстанавливает выходную видеоинформацию, применяя средства предсказания, аналогично кодеру, для формирования предсказанного представления блоков пикселей (с использованием информации о движении или пространственной информации, созданной кодером и хранимой в сжатом представлении) и декодирования ошибки предсказания (операция, обратная кодированию ошибки предсказания, для восстановления квантованного сигнала ошибки предсказания, относящегося к пространственному расположению пикселей). После применения средств декодирования предсказания и ошибки предсказания пикселей в декодере выполняется суммирование сигналов (пиксельных значений) предсказания и ошибки предсказания с формированием выходного видеокадра. В декодере (и кодере) могут также применяться дополнительные средства фильтрации, имеющие целью повышение качества выходного видеоизображения перед передачей его на отображение и/или хранение в качестве опорного для предсказания последующих кадров видеопоследовательности.
[0102] Фильтрация, например, может включать одно или более из следующего: деблокирующую фильтрацию, адаптивное смещение отсчетов (sample adaptive offset, SAO), и/или адаптивную петлевую фильтрацию (adaptive loop filtering, ALF). Стандарт H.264/AVC включает деблокирование, тогда как стандарт HEVC включает и деблокирование, и SAO.
[0103] В типовых видеокодеках на информацию о движении указывают при помощи векторов движения, связанных с каждым из блоков пикселей изображения, для которых используется компенсация движения, например, это могут быть пакеты предсказания. Каждый из таких векторов движения является представлением смещения блока пикселей в кодируемом изображении (в кодере) или декодируемом изображении (в декодере) и блока пикселей, являющегося исходным для предсказания, в одном из ранее кодированных иди декодированных изображениях. С целью эффективного представления векторов движения, как правило, применяют их разностное кодирование относительно вектора движения, предсказанного для конкретного блока. Как правило, в видеокодеках предсказанные векторы движения формируются заранее заданным способом, например, при помощи вычисления среднего вектора движения двух смежных кодируемых или декодируемых пикселей. Другим способом создания предсказаний векторов движения является формирование списка кандидатных предсказаний на основе соседних блоков и/или сорасположенных блоков в опорных изображения временного предсказания и сигнализация выбранного кандидата в качестве предсказания вектора движения. В дополнение к предсказанию значений векторов движения может также выполняться предсказание, какое опорное изображение (или изображения) будет применяться для предсказания с компенсацией движения, и такая информация предсказания может быть представлена, например, порядковым номером опорного изображения, который указывает на ранее кодированное или декодированное изображение. Порядковый номер опорного изображения, как правило, предсказывается на основе соседних блоков и/или сорасположенных блоков в опорном изображении временного предсказания. При этом, обычно, в кодеках стандарта высокоэффективного видеокодирования применяют дополнительный механизм кодирования/декодирования информации о движении, часто называемый режимом слияния, в котором вся информация поля движения, включающая вектор движения и указатель на соответствующее опорное изображение для каждого имеющегося списка опорных изображений, является предсказываемой и применяется без какого-либо изменения или коррекции. Аналогично, предсказание информации поля движения выполняют с использованием информации поля движения соседних блоков и/или сорасположенных блоков в опорных изображениях временного предсказания, а использованную информацию поля движения сигнализируют в списке кандидатных полей движения вместе с информацией поля движения имеющихся смежных и/или сорасположенных блоков.
[0104] В типовых видеокодеках остаток предсказания после компенсации движения сначала преобразуют с помощью ядра преобразования (например, DCT), и только затем кодируют. Причиной тому является частое наличие остаточной корреляции в остатке предсказания, а преобразование во многих случаях позволяет снизить эту корреляцию и дает в результате более эффективное кодирование.
[0105] В типовых видекодерах для поиска оптимальных режимов кодирования, например, необходимого режима кодирования для блоков и связанных с ними векторов движения, используется целевая функция Лагранжа. В целевой функции такого типа используется весовой коэффициент, или λ, связывающий (точное или предполагаемое) значение искажения изображения в результате кодирования с потерями и (точное или предполагаемое) количество информации, необходимое для представления значений пикселей в некоторой области изображения:

где С - оптимизируемое значение функции Лагранжа, D - искажение изображения (например, среднеквадратическая ошибка) с учетом режима и его параметров, a R - количество битов, необходимое для представления данных, требуемых для восстановления блока изображения в декодере (включая количество данных для представления кандидатных векторов движения).
[0106] Стандарт и спецификации видеокодирования могут разрешать разделение, в кодере, кодированного изображения на кодированные слайсы или аналогичные элементы. Предсказание внутри изображения с пересечением границ слайсов, как правило, не допускается. Следовательно, слайсы можно считать способом разделения кодированного изображения на независимо декодируемые части. В стандартах H.264/AVC и HEVC предсказание внутри изображения с пересечением границ слайсов может быть запрещено. Соответственно, слайсы можно считать способом деления кодированного изображения на независимо декодируемые части, и, следовательно, слайсы часто считаются элементарными единицами передачи. Во многих случаях кодеры могут указывать в битовом потоке, какие типы внутреннего предсказания с переходом между границами слайсов запрещены, при этом декодер учитывает данную информацию при своей работе, например, делая вывод о доступных источниках предсказания. Например, отсчеты из смежных кодовых пакетов могут считаться недоступными для внутреннего предсказания, если эти кодовые пакеты расположены в различных слайсах.
[0107] Элементарной единицей для вывода из кодера Н.264/AVC или HEVC и ввода в декодер H.264/AVC или HEVC, соответственно, является пакет уровня сетевой абстракции (Network Abstraction Layer, NAL). С целью передачи по сетям пакетной передачи данных или хранения в структурированных файлах NAL-пакеты могут инкапсулироваться в пакеты или в аналогичные структуры. Формат битового потока определен в стандартах H.264/AVC и HEVC для сред передачи или хранения, не обеспечивающих структуру кадров. В формате битового потока NAL-пакеты отделяются друг от друга при помощи прикрепления стартового кода перед каждым NAL-пакетом. Чтобы исключить ложное обнаружение границ NAL-пакетов в кодерах исполняется байтовый алгоритм предотвращения эмуляции стартового кода, который добавляет байт предотвращения эмуляции к полезной нагрузке NAL-пакета, если в противном случае в ней будет присутствовать стартовый код. Для обеспечения прозрачного шлюзового взаимодействия между системами пакетной и потоковой передачи данных, предотвращение эмуляции стартового кода должно выполняться в любом случае, независимо от того, применяется формат битового потока или нет.NAL-пакет - это синтаксическая структура, содержащая указание на тип данных, следующих за ней, и байты, содержащие эти данные в форме RBSP, чередующиеся, при необходимости, с байтами предотвращения эмуляции. Последовательность исходных байтов полезной нагрузки (raw byte sequence payload, RBSP) может быть определена как синтаксическая структура, включающая целое число байт и инкапсулированная в NAL-пакете. Последовательность RBSP может быть либо пустой, либо иметь форму строки информационных бит, содержащих синтаксические элементы, за которыми следует стоп-бит RBSP и ноль или более последующих бит, равных 0.
[0108] NAL-пакеты состоят из заголовка и полезной нагрузки. В стандартах H.264/AVC и HEVC в заголовке NAL-пакета имеется указание на тип NAL-пакета.
[0109] В стандарта HEVC для всех определенных типов NAL-пакетов используется двухбайтный заголовок NAL-пакета. Заголовок NAL-пакета содержит один зарезервированный бит, шестибитный индикатор типа NAL-пакета, трехбитный индикатор nuh_temporal_id_plus1 временного уровня (может предъявляться требования, чтобы он был большим либо равным 1) и шестибитный синтаксический элемент nuh_layer_id. Синтаксический элемент temporal_id_plus1 можно считать временным идентификатором NAL-пакета, при этом отсчитываемая от нуля переменная Temporalid может быть вычислена следующим образом: Temporalld=temporal_id_plus1 - 1. Вместо переменной Temporalld может использоваться сокращенное обозначение TID. TemporalId, равный нулю, соответствует самому нижнему временному уровню. Значение temporal_id_plus1 должно быть ненулевым, чтобы не возникала эмуляция стартового кода, в который входит два байта заголовка NAL-пакета. Битовый поток, формируемый исключением всех NAL-пакетов VCL, чей temporal_id больше или равен выбранному значению, и включением всех остальных NAL-пакетов VCL, остается соответствующим стандарту. Следовательно, для изображений с temporal_id, равным некоторому значению tid_value, в качестве опорных для предсказания не используются изображения с temporal_id, большим tid_value. Подуровень или временной подуровень - это уровень временного масштабирования (или временной уровень TL (temporal layer) или битовый поток с временным масштабированием, состоящий из NAL-пакетов VCL с конкретным значением переменной TemporalId, а также из соответствующих NAL-пакетов, не относящихся к VCL, при этом nuh_layer_id может рассматриваться как идентификатор уровня масштабирования.
[0110] NAL-пакеты могут быть разделены на две категории: NAL-пакеты уровня видеокодирования (Video Coning Layer, VCL) и NAL-пакеты, не относящиеся к VCL. NAL-пакеты категории VCL представляют собой NAL-пакеты со стандартным кодированием слайсов. В стандарте HEVC NAL-пакеты VCL содержат синтаксические элементы, представляющие собой один или более кодовых пакетов.
[0111] Сокращения для типов изображений в стандарте HEVC могут быть определены следующим образом: запаздывающее изображение (trailing picture, TRAIL), изображение доступа к временному подуровню (Temporal Sub-layer Access, TSA), изображение пошагового доступа к временному подуровню (Step-wise Temporal Sub-layer Access, STSA), опережающее декодируемое изображение с произвольным доступом (Random Access Decodable Leading, RADL), опережающее пропускаемое изображение произвольного доступа (Random Access Skipped Leading, RASL), изображение разорванной цепи доступа (Broken Link Access, BLA), изображение мгновенного обновления декодирования (Instantaneous Decoding Refresh, IDR), изображение чистого произвольного доступа (Clean Random Access, CRA).
[0112] Изображения точки произвольного доступа (Random Access Point, RAP), которые могут, альтернативно, называться внутренне-предсказываемыми изображениями точки произвольного доступа (IRAP), в независимом уровне содержит только внутренне-кодированные слайсы. Для IRAP-изображения, принадлежащего некоторому предсказываемому уровню, которое может включать Р-, В- и I-слайсы, не может применяться внешнее предсказание на основе других изображений в этом же предсказываемом уровне, но может применяться межуровневое предсказание на основе его непосредственных опорных уровней. В текущей версии стандарта HEVC IRAP-изображение может быть BLA-изображением, CRA-изображением или IDR-изображением. Первым изображением в битовом потоке, включающем базовый уровень, является IRAP-изображение базового уровня. При условии, что нужные наборы параметров доступны, на момент необходимости их активации, изображение IRAP в независимом уровне и все следующие за ним в порядке декодирования изображения, не являющиеся RASL-изображениями, в независимом уровне могут быть корректно декодированы без выполнения процедуры декодирования каких-либо изображений, предшествующих этому IRAP-изображению в порядке декодирования. IRAP-изображение, которое принадлежит некоторому предсказываемому уровню, и все следующие за ним He-RASL-изображения в порядке декодирования в том же предсказываемом уровне могут быть декодированы корректно без декодирования каких-либо изображений в том же предсказываемом уровне, предшествующих упомянутому IRAP-изображению в порядке декодирования, если все необходимые наборы параметров доступны на момент необходимости их активации при запуске декодирования каждого непосредственного опорного уровня для упомянутого предсказываемого уровня. В битовом потоке могут присутствовать изображения, которые содержат только внутренне кодируемые слайсы, однако не являются IRAP-изображениями.
[0113] NAL-пакет, не относящийся к VCL, может, например, иметь один из следующих типов: набор параметров последовательности, набор параметров изображения, NAL-пакет дополнительной уточняющей информации (supplemental enhancement information, SEI), разделитель пакета доступа, конец последовательности NAL-пакетов, конец битового потока NAL-пакетов или NAL-пакет с данными фильтрации. Набор параметров может быть необходим для восстановления декодированных изображений, при этом многие из остальных типов NAL-пакетов, не относящихся к VCL, не являются необходимыми для восстановления декодированных изображений.
[0114] В набор параметров последовательности могут включаться параметры, которые остаются неизменными на протяжении всей кодированной видеопоследовательности. В дополнение к параметрам, которые могут быть необходимы в процессе декодирования, набор параметров последовательности опционально может включать информацию по используемости видео (video usability information, VUI), включающую параметры, важные для буферизации, синхронизации вывода изображения, отрисовки и резервирования ресурсов. В стандарте HEVC RBSP набора параметров последовательности включает в себя параметры, на которые могут выполняться ссылки в RBSP одного или более наборов параметров последовательности или в одном или более NAL-пакетов SEI, содержащих сообщение SEI с периодом буферизации. Набор параметров изображения содержит параметры, которые с большой вероятностью будут неизменными для нескольких кодированных изображений. RBSP набора параметров изображения может включать в себя параметры, на которые могут выполняться ссылки из NAL-пакетов кодированного слайса или из одного или более кодированных изображений.
[0115] В стандарте HEVC набор видеопараметров (video parameter set, VPS) определен как синтаксическая структура, содержащая синтаксические элементы, применимые к нулю или более полным кодированным видеопоследовательностям, в зависимости от содержимого синтаксического элемента, находящегося в наборе SPS, на который ссылается синтаксический элемент в наборе PPS, на который, в свою очередь, ссылается синтаксический элемент в заголовке сегмента слайса.
[0116] RBSP набора видеопараметров может включать в себя параметры, ссылки на которые могут осуществляться в RBSP одной или более наборов параметров последовательности.
[0117] Ниже описаны взаимоотношения и иерархия набора видеопараметров (VPS), набора параметров последовательности (SPS) и набора параметров изображения (SPS). Набор VPS располагается на один уровень выше набора SPS в иерархии наборов параметров и в контексте масштабируемости и/или 3D. Набор VPS может включать в себя параметры, являющиеся общими для всех слайсов во всех уровнях (масштабируемости или ракурсов) кодированной видеопоследовательности в целом. Набор SPS включает в себя параметры, являющиеся общими для всех слайсов в данном уровне (масштабируемости или ракурсов) кодированной видеопоследовательности в целом, которые при этом могут быть также общими для нескольких уровней (масштабируемости или ракурсов). Набор PPS включает в себя параметры, являющиеся общими для всех слайсов в данном уровне представления (представления уровня масштабируемости или ракурса в одном пакете доступа) и которые с большой вероятностью являются общими для всех слайсов в нескольких представлениях уровня кодирования.
[0118] Набор VPS может предоставлять информацию о отношениях зависимости уровней кодирования в битовом потоке, а также множество другой информации, применимой для всех слайсов во всех уровнях (масштабируемости или ракурсов) кодированной видеопоследовательности в целом. Набор VPS можно рассматривать как состоящий из двух частей, базовый VPS и VPS расширения при этом наличие VPS расширения может быть опциональным.
[0119] Передача, сигнализация или хранение данных вне основной полосы частот, в дополнение или альтернативно, может применяться в иных целях, а не только для повышения устойчивости к ошибкам передачи, например, для упрощения доступа или для установления сеанса. К примеру, наборы параметров в файле, отвечающем базовому формату медиафайлов ISO, могут быть включены в запись с информацией о отсчетах трека, тогда как кодированные данные битового потока хранят в другом месте этого файла или в другом файле. Выражение «параллельно битовому потоку» (например, «указание параллельно битовому потоку») или «параллельно пакету кодирования битового потока» (например, «указание параллельно кодированному тайлу») может пониматься, в пунктах формулы изобретения и в описании вариантов осуществления настоящего изобретения, как передача, сигнализация или хранение данных вне основной полосы частот, таким образом, чтобы данные, не принадлежащие основной полосе частот, оставались связанными с битовым потоком или кодовым пакетом, соответственно. Выражение «декодирование параллельно битовому потоку», или «параллельно пакету кодирования битового потока», или аналогичные выражения, могут обозначать декодирование данных, поступающих вне основной полосы частот, на которые осуществляют ссылки (и которые могут быть получены за счет передачи, сигнализации или хранения данных вне основной полосы частоты) и которые связаны с битовым потоком или кодовым пакетом, соответственно.
[0120] NAL-пакеты SEI могут содержать одно или более сообщений SEI, которые не требуются для декодирования выходных изображений, но могут быть полезными в связанных с этим процедурах, например, синхронизации вывода изображения, отрисовки, обнаружения ошибок, сокрытия ошибок и резервирования ресурсов. В стандартах H.264/AVC и HEVC определены несколько типов сообщений SEI, при этом сообщения SEI с пользовательскими данными (user data SEI messages) позволяют организациям и компаниям определять сообщения SEI для личного использования. В стандартах H.264/AVC и HEVC описаны синтаксис и семантика сообщений SEI, однако процедура обработки сообщений на стороне приемника не определена. Следовательно, кодер должен следовать стандарту H.264/AVC или HEVC при формировании сообщений, SEI при этом декодер, отвечающий стандарту H.264/AVC или HEVC соответственно, не обязательно должен обрабатывать сообщения SEI, соответствие выходной последовательности стандарту от этого не зависит. Одной из причин включения синтаксиса и семантики сообщений SEI в стандарты H.264/AVC и HEVC является возможность идентичной интерпретации дополнительной информации различными системами, и, следовательно, их взаимодействия. Предполагается, что системные спецификации могут требовать применения конкретных сообщений SEI как на стороне кодера, так и на стороне декодера, при этом процедура обработки конкретных сообщений SEI на стороне приемника может быть определена дополнительно.
[0121] В стандарте HEVC определены два типа NAL-пакетов SEI, а именно, суффиксные NAL-пакеты SEI и префиксные NAL-пакеты SEI, значение nalunittype в которых отличается друг от друга. Сообщения SEI, содержащиеся в суффиксных NAL-пакетах SEI относятся к NAL-пакету VCL, который предшествует, в порядке декодирования, суффиксному NAL-пакету SEI. Сообщения SEI, содержащиеся в префиксных NAL-пакетах SEI относятся к NAL-пакету VCL, который следует, в порядке декодирования, за префиксным NAL-пакетом SEI.
[0122] Кодированное изображение - это кодовое представление изображения.
[0123] В стандарте HEVC кодированное изображение может быть определено как кодированное представление изображения, содержащее все блоки кодового дерева этого изображения. В стандарте HEVC пакет доступа (AU) - это набор NAL-пакетов, которые связаны друг с другом согласно определенному правилу классификации, следуют друг за другом в порядке декодирования и содержат максимум одно изображение с конкретным значением nuh_layer_id. Помимо NAL-пакетов VCL кодированного изображения, пакет доступа может содержать также NAL-пакеты, не относящиеся к VCL. Упомянутое заданное правило классификации, например, позволяет объединять в один пакет доступа изображения, имеющие идентичное время вывода, или идентичное значение счетчика вывода изображений.
[0124] Битовый поток - это последовательность битов, в форме потока NAL-пакетов или байтового потока, который позволяет получить представление кодированных изображений и связанных с ними данных в форме одной или более кодированных видеопоследовательностей. В одном логическом канале, например, в одном файле или по одному соединению протокола связи за первым битовым потоком может следовать второй битовый поток. Элементарный поток (в контексте видеокодирования) - это последовательность из одного или более битовых потоков. Конец первого битового потока может быть означен специальным NAL-пакетом, который может называться NAL-пакетом конца битового потока (end of bitstream, ЕОВ), и который является последним NAL-пакетом битового потока. В стандарте HEVC и в имеющихся на сегодняшний день проектах его расширений NAL-пакет ЕОВ должен иметь nuh_layer_id равный 0.
[0125] В стандарте H.264AVC кодированная видеопоследовательность определена как ряд последовательных пакетов доступа в порядке декодирования от пакета доступа ПЖ включительно до следующего пакета доступа ПЖ исключительно или до конца битового потока, - в зависимости от того, что появляется раньше.
[0126] В стандарте HEVC кодированная видеопоследовательность (coded video sequence, CVS) может быть определена, например, как последовательность пакетов доступа, которые состоят, в порядке декодирования: из пакета доступа IRAP-изображения с флагом NoRaslOutputFlag, равным 1, за которым следуют ноль или более пакетов доступа, не являющихся блоками доступа IRAP-изображения и имеющих флаг NoRaslOutputFlag, равный 1, включая все последующие пакеты доступа вплоть до (не включительно) первого последующего пакета доступа, который является блоком доступа IRAP-изображения с флагом NoRaslOutputFlag, равным 1. Пакет доступа IRAP-изображения - это пакет доступа, в котором изображение базового уровня является IRAP-изображением. Для всех IDR-изображений, всех BLA-изображений и всех IRAP-изображений, являющихся первыми изображениями в данном конкретном уровне битового потока, IRAP-изображений, идущих первым после окончания последовательности NAL-пакетов, имеющих такое же значение nuh_layer_id, в порядке декодирования, значение NoRaslOutputFlag равно 1. Возможна передача значения флага HandleCraAsBlaFlag в декодер из внешнего объекта, например, проигрывателя или приемника, осуществляющего управление декодером. Флаг HandleCraAsBlaFlag может быть установлен в 1, например, проигрывателем, который осуществляет поиск новой позиции в битовом потоке или подключается к трансляции и начинает декодирование, и в этом случае он будет начинать декодирование с CRA-изображения. Когда для CRA-изображения флаг HandleCraAsBlaFlag равен 1, это CRA-изображение обрабатывают и декодируют так, как если бы оно было BLA-изображением.
[0127] В стандарте HEVC, дополнительно или альтеративно (к описанной выше спецификации), может быть определено, что кодированная видеопоследовательность оканчивается, когда в битовом потоке встречается специальный NAL-пакет, который может называться NAL-пакетом конца последовательности (end of sequence, EOS) и имеет nuh_layer_id, равным 0.
[0128] Далее приведено определение и характеристики группы изображений (group of pictures, GOP). Группа GOP может быть декодирована независимо от того, были ли декодированы какие-либо предшествующие ей изображения или нет. Открытая группа изображений - это группа изображений, в которой изображения, предшествующие первому внутренне предсказываемому изображению в порядке вывода, могут не быть декодированы корректно, если декодирование начинается с упомянутого первого внутренне предсказываемого изображения открытой группы изображений. Другими словами, изображения в открытой GOP могут ссылаться (для внутреннего предсказания) на изображения из предшествующей GOP. Декодер, соответствующий стандарту HEVC, способен распознавать внутренне предсказываемое изображение в начале открытой GOP благодаря специальному типу NAL-пакетов, CRA, который может использоваться для кодируемых слайсов этого изображения. Закрытая группа изображений - это группа изображений, в которой все изображения могут быть декодированы корректно, если декодирование начинается с первого внутренне предсказываемого изображения закрытой группы изображений. Другими словами, ни одно из изображений в закрытой GOP не ссылается ни на одно изображение из предшествующих GOP. В стандартах H.264/AVC и HEVC закрытая группа GOP может начинаться с IDR-изображения. В стандарте HEVC закрытая группа изображений, GOP, может также начинаться с изображения BLA_W_RADL или BLA_N_LP. Структура кодирования с открытыми GOP дает потенциально более эффективное сжатие, по сравнению со структурой кодирования с закрытыми GOP, благодаря большей гибкости при выборе опорных изображений.
[0129] В кодере и/или декодере может применяться буфер декодированных изображений (Decoded Picture Buffer, DPB). Декодированные изображения буферизуют по двум причинам: для использования в качестве опорных при внешнем предсказании и для изменения порядка декодированных изображений в выходной последовательности. Стандарты H.264/AVC и HEVC дают значительную гибкость как для маркировки опорных изображений, так и для переупорядочивания выходной последовательности, однако содержание отдельных буферов для опорных изображений и для изображений выходной последовательности не является оптимальным с точки зрения расхода ресурсов памяти. Следовательно, буфер DPB может включать унифицированную процедуру буферизации опорных изображений и переупорядочивания выходной последовательности. Декодированное изображение может удаляться из буфера DPB, когда оно больше не используется в качестве опорного и не требуется для вывода.
[0130] Во многих режимах кодирования стандартов H.264/AVC и HEVC, на опорное изображение внешнего предсказания указывают с помощью указателя на список опорных изображений. Указатель может кодироваться с использованием кодирования переменной длины (неравномерного кодирования), что обычно дает более короткие значения указателей с меньшим числовым значением для соответствующих синтаксических элементов. В стандартах H.264/AVC и HEVC формируются два списка опорных изображений (список 0 опорных изображений и список 1 опорных изображений) для каждого двунаправленно предсказываемого слайса (В-слайса), и один список опорных изображений (список 0 опорных изображений) для каждого слайса, кодируемого с внешним предсказанием (Р-слайса).
[0131] Во многих стандартах кодирования, включая H.264/AVC и HEVC, процедура декодирования может давать на выходе указатель на опорное изображение в списке опорных изображений, который может применяться для указания, какое из нескольких опорных изображений необходимо использовать для внешнего предсказания определенного блока пикселей. Указатель на опорное изображение в некоторых режимах кодирования с внешним предсказанием может кодироваться кодером в битовый поток, или, в других режимах кодирования с внешним предсказанием, может вычисляться (например, кодером и декодером), например, с использованием соседних блоков.
[0132] Для одного пакета предсказания могут вычисляться несколько кандидатных векторов движения. Например, предсказание векторов движения в HEVC включает две схемы предсказания, а именно, улучшенное предсказание векторов движения (AMVP) и режим слияния. В режиме AMVP или в режиме слияния для каждого пакета предсказания вычисляют список кандидатных векторов движения. Кандидаты бывают двух видов: пространственные кандидаты и временные кандидаты, причем временные кандидаты могут также называться TMVP-кандидатами.
[0133] Ниже будет рассмотрен один из примеров вычисления списка кандидатов, однако нужно понимать, что оно может выполняться и иначе. Если список кандидатов не заполнен, сначала в список добавляют пространственных кандидатов, если они существуют, и если они еще не присутствуют в списке кандидатов. После этого, если список кандидатов еще не заполнен, в него добавляют временных кандидатов. Если количество кандидатов все еще не достигло максимально разрешенного, в список добавляют кандидатов комбинированного двунаправленного предсказания (для В-слайсов) и нулевой вектор движения. После формирования списка кандидатов кодер определяет окончательную информацию о движении, исходя из имеющихся кандидатов, например, исходя из оптимизации показателя «битовая скорость - искажения» (rate-distortion optimization, RDO), и кодирует порядковый номер выбранного кандидата в битовый поток. Аналогично, декодер декодирует порядковый номер выбранного кандидата из битового потока, строит список кандидатов, и использует декодированный порядковый номер для выбора предсказания вектора движения из списка кандидатов.
[0134] Ниже будут описаны характеристики AMVP-предсказания и режима слияния в HEVC. При AMVP-пред сказании кодер указывает, используется ли однонаправленное или двунаправленное предсказание, а также, какие опорные изображения используются, и кодирует разность векторов движения. В режиме слияния в битовый поток кодируют только кандидата, выбранного из списка, с указанием на то, что текущий пакет предсказания имеет такую же информацию о движении, что и переданное предсказание. То есть, в режиме слияния формируются области, состоящие из смежных блоков предсказания с одинаковой информацией о движении, которую передают только один раз для каждой области.
[0135] Улучшенное предсказание векторов движения может выполняться, например, описанным ниже образом, в то время как возможны и другие аналогичные реализации улучшенного предсказания векторов движения, например, с использованием различных наборов кандидатных позиций и кандидатных местоположений в наборах кандидатных позиций. Нужно при этом понимать, что аналогичным образом может функционировать и другой режим предсказания, например, режим слияния. Могут вычисляться два пространственных предсказания вектора движения (spatial motion vector predictors, MVP) и одно временное предсказание вектора движения (temporal motion vector predictor, TMVP). Они могут быть выбраны из следующих позиций: три позиции кандидатных пространственных предсказаний вектора движения, расположенные над текущим блоком предсказания (В0, B1, В2) и две позиции слева (А0, A1). В качестве представления направления предсказания (вверх или влево) для отбора кандидатных векторов движения может быть выбрано первое предсказание вектора движения, которое доступно (например, располагается в том же слайсе, кодировано с внешним предсказанием и т.п.) в заранее заданном порядке для каждого набора позиций кандидатов (В0, B1, В2) или (А0, A1). Указатель на опорное изображение для временного предсказания вектора движения может быть указан кодером в заголовке слайса (например, как сорасположенный с ним синтаксический элемента ref_idx). В качестве исходного значения для временного предсказания вектора движения может быть выбрано доступное (например, кодированное с внешним предсказанием) предсказание вектора движения, являющееся первым в заранее заданном порядке потенциальных кандидатных местоположений временного предсказания, например, в порядке (С0, C1). Вектор движения, полученный на основе первого доступного кандидатного местоположения в сорасположенном изображении, может масштабироваться пропорционально разности порядковых номеров изображений между опорным изображением для временного предсказания вектора движения, сорасположенного изображения и текущего изображения. При этом может также выполняться проверка на избыточность среди кандидатов, чтобы устранить идентичных кандидатов, что может привести к включению в список кандидатов нулевого вектора движения. Предсказание вектора движения может быть указано в битовом потоке, например, при помощи указания направления на пространственное предсказание вектора движения (вверх или влево) или при помощи указания на выбор кандидатного временного предсказания вектора движения. Сорасположенные изображения могут также называться опорными изображениями для предсказания векторов движения или исходными изображениями для предсказания векторов движения.
[0136] Информация о движении, может относиться, без ограничения перечисленным, к одному или более из следующих типов:
- указание на тип предсказания (например, внутреннее предсказание, однонаправленное предсказание, двунаправленное предсказание) и/или на количество опорных изображений;
- указание на направление предсказания, например, внешнее (также называемое временным) предсказание, межуровневое предсказание, межракурсное предсказание, предсказание на основе синтеза ракурсов (view synthesis prediction, VSP), межкомпонентное предсказание (указание на которое может быть выполнено для конкретного опорного изображения или для конкретного типа предсказания, и при этом в некоторых из вариантов осуществления настоящего изобретения межвидовое предсказание и предсказание на основе синтаксиса ракурсов может считаться одним направлением предсказания) и/или
- указание на тип опорных изображений, например, краткосрочное опорное изображение и/или долгосрочное опорное изображение, и/или опорное изображение межуровневого предсказания (при этом указание может выполняться, например, для каждого опорного изображения);
- указатель на список опорных изображений и/или любой другой идентификатор, указывающий на опорные изображения (при этом указание может выполняться, например, для каждого типа опорного изображения, тип которого может зависеть от направления предсказания и/или от типа опорного изображения, и которое при этом может сопровождаться другими соответствующими фрагментами информации, например, информацией о списке опорных изображений или аналогичной структуре, к которой относится указатель на опорные изображения);
- горизонтальная составляющая вектора движения (она может указываться для каждого блока предсказания, для каждого указателя на опорные изображения и т.п.);
- вертикальная составляющая вектора движения (она может указываться для каждого блока предсказания, для каждого указателя на опорные изображения и т.п.);
- один или более параметров, таких как разность порядковых номеров изображений и/или относительное расстояние между камерами, для изображений, содержащих параметры движения и соответствующее опорное изображение, или связанных с ними, которые могут применяться для масштабирования горизонтальной составляющей вектора движения и/или вертикальной составляющей вектора движения в процессе предсказания одного или более векторов движения (при этом упомянутые один или более параметров могут быть указаны, например, для каждого опорного изображения, для каждого указателя на опорные изображения и т.п.);
- координаты блока пикселей, к которому применимы параметры движения и/или информация о движении, например, координаты верхнего левого отсчета в блоке пикселей для блоков отсчетов яркости;
- размеры (например, ширина и длина) блока пикселей, к которому применимы параметры движения и/или информация о движении.
[0137] В общем случае механизмы предсказания векторов движения, например, такие как описанные выше механизмы, могут включать предсказание или наследование некоторых заранее заданных или указываемых параметров движения.
[0138] Поле движения, связанное с изображением, может рассматриваться как включающее набор информации о движении, сформированной для каждого кодированного блока изображения. Доступ к полю движения может, например, по координатам блока. Поле движения может применяться, например, при TMVP-предсказании или в любом другом механизме предсказания движения, где для предсказания, помимо текущего (де)кодируемого изображения, применяют также другие исходные, или опорные, изображения.
[0139] Для представления и/или хранения поля движения могут применяться различный уровень пространственной детализации, или различные элементы. К примеру, может применяться регулярная сетка из пространственных элементов. Например, изображение может быть разбито на прямоугольные блоки заданного размера (опционально, за исключением блоков на краях изображения, то есть, на правой и нижней границах изображения). К примеру, размер пространственных элементов может быть равен минимальному размеру, для которого кодером в битовом потоке может быть указано различимое движение, например, это может быть блок отсчетов яркости размера 4×4. К примеру, может применяться так называемое сжатое поле движения, в котором пространственные элементы могут быть равными заранее заданному или указанному размеру, к примеру, блок отсчетов яркости размером 16×16, при этом его размер должен превосходить минимальный размер для указания различимого движения. К примеру, кодер и/или декодер по стандарту HEVC может быть реализован таким образом, чтобы для каждого декодированного поля движения применялась процедура сжатия хранимых данных о движении (motion data storage reduction, MDSR) или сжатие поля движения, перед использованием поля движения для внешнего предсказания изображений. В одной из реализаций стандарта HEVC MDSR-сжатие обеспечивает возможность снижения детализации данных о движении до блоков отсчетов яркости размером 16×16 за счет хранения информации о движении, применимой к верхнему левому отсчету блока размером 16×16 в несжатом поле движения. Кодер может кодировать указание (или указания), относящиеся к пространственному элементу несжатого поля движения в виде одного или более синтаксических элементов и/или значений синтаксических элементов, к примеру, в синтаксической структуре на уровне последовательности, например, в наборе видеопараметров или в наборе параметров последовательности. В некоторых способах и/или устройствах (де)кодирования поле движения может быть представлено и/или может храниться согласно разбиению блока для предсказания движения (например, согласно пакетам предсказания в стандарте HEVC). В некоторых способах и/или устройствах (де)кодирования может применяться комбинация регулярной сетки и разбиения на блоки, так что информацию о движении, связанную с фрагментами, чей размер превышает заранее заданный или указанный размер пространственного элемента, представляют и/или хранят в связи с этими фрагментами, тогда как информацию о движении, связанную с фрагментами, меньшими, чем заранее заданный или указанный размер пространственного элемента, или с несовпадающими с ними фрагментами, представляют и/или хранят для заранее заданных или указанных элементов.
[0140] Масштабируемым видеокодированием может называться такая схема кодирования, в которой один битовый поток может содержать несколько представлений видеоданных (контента), например, с различным битрейтом, разрешением и/или частотой смены кадров. При такой схеме приемник может получать необходимое представление контента в зависимости от своих характеристик (например, разрешение, наиболее подходящее для дисплейного устройства). Альтернативно, сервер или сетевой элемент может извлекать части битового потока для передачи в приемник в зависимости, например, от характеристик сети или вычислительных возможностей приемника. Корректное декодированное представление может быть получено, даже если декодируются только определенные части масштабируемого битового потока. Масштабируемый битовый поток состоит, как правило, из «базового уровня», обеспечивающего наименьшее из доступных качество видеоинформации, а также из одного или более уточняющих уровней, которые повышают качество видео при их приеме и декодировании вместе с нижними уровнями. Чтобы повысить эффективность кодирования уточняющих уровней, их кодированные представления, как правило, зависят от нижних уровней. Например, информация о движении и режиме уточняющего уровня может предсказываться на основе нижележащих уровней. Аналогично, данные пикселей нижних уровней могут применяться для формирования предсказания уточняющего уровня.
[0141] В некоторых из схем масштабируемого видеокодирования видеосигнал может кодироваться в базовый уровень и в один или более уточняющих уровней. Уточняющий уровень, например, может повышать временное разрешение (т.е. частоту смены кадров), пространственное разрешение или просто качество видеоконтента, представленного в другом уровне, или его части. Каждый уровень вместе со всеми зависимыми уровнями является одним из представлений видеосигнала, например, с определенным пространственным разрешением, временным разрешением и уровнем качества. В данном документе масштабируемый уровень вместе со всеми зависимыми уровнями называется «репрезентацией масштабируемого уровня». Часть масштабируемого битового потока, соответствующая репрезентации масштабируемого уровня, может быть извлечена и декодирована, в результате чего получают представление исходного сигнала с определенной точностью.
[0142] Режимы масштабирования, или масштабируемые величины, могут включать, без ограничения перечисленным, описанные ниже режимы.
- Масштабируемость качества: изображения базового уровня кодируют с меньшим качеством, чем изображения уточняющих уровней, что может быть реализовано, например, за счет использования более высокого значения параметра квантования (т.е. большего размера шага квантования коэффициентов преобразования) в базовом уровне, по сравнению с уточняющим уровнем. Масштабируемость качества может, в свою очередь, подразделяться на мелкозернистую или мелкогранулярную масштабируемость (fine-grain или fine-granularity scalability, FGS), среднезернистую или среднегранулярную масштабируемость (medium-grain или medium-granularity scalability, MGS) и/или крупнозернистую или крупногранулярную масштабируемость (coarse-grain или coarse-granularity scalability, CGS) которые будут описаны ниже.
- Пространственная масштабируемость: изображения базового уровня кодируют с меньшим разрешением (т.е. имеют меньше количество отсчетов), чем изображения уточняющих уровней. Пространственную масштабируемость и масштабируемость качества, особенно ее крупногранулярный тип, иногда относят к одному типу масштабируемости.
- Масштабируемость битовой глубины: изображения базового уровня кодирования кодируют с меньшей битовой глубиной (например, 8 бит), чем изображения уточняющих уровней (например, 10 или 12 бит).
- Масштабируемость динамического диапазона: масштабируемые уровни представляют собой различные динамические диапазоны и/или изображения, полученные с использованием различных функций тональной компрессии и/или различных частотно-контрастных характеристик. Масштабируемость формата цветности: изображения базового уровня кодирования обеспечивают меньшее пространственное разрешение в массивах отсчетов цветности (например, кодированы в формате цветности 4:2:0), чем изображения уточняющих уровней (например, формат 4:4:4).
- Масштабируемость цветового охвата: изображения уточняющего уровня имеют более емкий, или широкий, диапазон представления цвета, чем изображения базового уровня, например, уточняющий уровень может иметь цветовой охват по стандарту UHDTV (ITU-R ВТ.2020), а базовый уровень может иметь цветовой охват по стандарту ITU-R ВТ.709.
- Масштабируемость ракурсов, которая может также называться многоракурсным кодированием. Базовый уровень представляет собой первый ракурс, тогда как уточняющий уровень является вторым ракурсом. Ракурс - это последовательность изображений, представляющих одну камеру или одну точку зрения. Можно считать, что при стереоскопическом, или двухракурсном, видео одну видеопоследовательность, или ракурс, отображают для левого глаза, тогда как параллельный ракурс отображают для правого глаза.
- Масштабируемость глубины, которая может также называться кодированием с уточнением глубины. Один или несколько уровней в битовом потоке могут представлять собой ракурс (или ракурсы) текстуры, тогда как другой уровень, или уровни, могут представлять собой ракурс (или ракурсы) глубины.
- Масштабируемость областей интереса (описана ниже).
- Чересстрочно-прогрессивная масштабируемость (также называемая масштабируемостью поле-кадр): исходные кодированные чересстрочные данные базового уровня уточняют с использованием уточняющего уровня, который представляет прогрессивные исходные данные. Кодированные чересстрочные видеоданные в базовом уровне могут содержать кодированные поля, кодированные кадры, представляющие пары полей, или их комбинацию. При чересстрочно-прогрессивной масштабируемости разрешение изображения базового уровня может быть изменено таким образом, чтобы оно подходило в качестве опорного изображения для одного или более изображений уточняющего уровня.
- Масштабируемость с гибридным кодеком (также называемая масштабируемостью стандартов кодирования): при масштабируемости с гибридным кодеком синтаксис, семантика и процедура декодирования для базового уровня и уточняющего уровня могут определяться различными стандартами видеокодирования. Таким образом, изображения базового уровня кодируют согласно стандарту или формату кодирования, отличающемуся от кодирования изображений уточняющего уровня. К примеру, базовый уровень может кодироваться с использованием стандарта H.264/AVC, а уточняющий уровень может быть закодирован с использованием многоуровневого расширения HEVC.
[0143] Нужно понимать, что многие из типов масштабируемости могут комбинироваться и применяться совместно. К примеру, могут совместно применяться масштабируемость цветового охвата и масштабируемость битовой глубины.
[0144] Термин «уровень» может использоваться в контексте любых типов масштабируемости, включая масштабируемость ракурсов и уточнение глубины. Уточняющий уровень может иметь отношение к любому типу уточнения, например, повышению соотношения сигнал-шум, уточнению пространственного разрешения, многоракурсному уточнению, уточнению глубины, битовой глубины, формата цветности и/или и/или увеличению цветового охвата. Базовый уровень может относиться к любому типу базовой видеопоследовательности, например, к базовому ракурсу, базовому уровню пространственной масштабируемости или масштабируемости отношения сигнал-шум, или к базовому ракурсу текстуры для видеокодирования с уточнением глубины.
[0145] В некоторых из схем видеокодирования может быть необходимо выравнивание ЖАР изображений в различных уровнях таким образом, чтобы либо все изображения в пакете доступа были IRAP-изображениями, либо ни одно изображение в пакете доступа не было IRAP-изображением. В других схемах масштабируемого видеокодирования, например, в многоуровневых расширениях HEVC, может допускаться, чтобы IRAP-изображения были не выровнены, т.е. одно или более изображений в пакете доступа могут быть IRAP-изображениями, тогда как остальные изображения в пакете доступа могут не быть IRAP-изображениями. Могут применяться масштабируемые битовые потоки с использованием IRAP-изображений, или аналогичных структур, местоположения которых не совпадают в различных уровнях, например, в базовом уровне могут присутствовать более часто встречающиеся IRAP-изображения, которые могут иметь меньший размер в кодированном виде, например, из-за меньшего пространственного расширения. В схему видеодекодирования может быть включена процедура, или механизм, поуровневого запуска декодирования. Соответственно, декодер может начинать декодирование битового потока, когда базовый уровень содержит IRAP-изображение, и пошагово начинать декодирование остальных слоев, когда они содержат IRAP-изображения. Другими словами, при использовании механизма, или процедуры, поуровневого запуска декодирования декодер постепенно увеличивает количество декодируемых уровней (причем эти уровни могут представлять собой уточнение пространственного разрешения, уровня качества, ракурсы, дополнительные компоненты, такие как глубина, или их комбинацию) по мере декодирования последующих изображений из дополнительных уточняющих уровней в процессе декодирования. Постепенное увеличение количества декодируемых уровней может восприниматься, например, как постепенное повышение качества изображения (в случае масштабируемости качества и пространственной масштабируемости).
[0146] В передатчике, шлюзе, клиентском или аналогичном объекте, могут выбираться передаваемые уровни и/или подуровни масштабируемого битового потока видеоинформации. «Извлечение», «извлечение уровней» или «переключение уровней с понижением качества» может означать передачу меньшего количества уровней, чем доступно в битовом потоке, принятом передатчиком, шлюзом, клиентским или аналогичным объектом. «Переключение уровней с повышением качества» можно понимать как передачу дополнительного уровня (или уровней), по сравнению с передаваемыми до переключения уровней с повышением передатчиком, шлюзом, клиентским или аналогичным объектом, т.е. перезапуск передачи одного или более уровней, передача которых была приостановлена ранее после переключения уровней с понижением. Аналогично переключению уровней с повышением и/или понижением качества передатчик, шлюз, клиентский или аналогичный объект может выполнять переключение временных подуровней с повышением и/или с понижением качества. Передатчик, шлюз, клиент или аналогичный объект, могут также выполнять одновременно переключение как уровней, так и подуровней с повышением и/или с понижением качества. Переключение уровней и подуровней с повышением и/или с понижением качества может выполняться в одном пакете доступа, или аналогичном элементе, (т.е. практически одновременно), или может выполняться в различных пакетах доступа, или аналогичных элементах (т.е. по существу в различные моменты времени).
[0147] Масштабируемость может обеспечиваться двумя основными способами: либо при помощи введения новых режимов кодирования для выполнения предсказания значения пикселей или синтаксических элементов на основе нижних уровней кодирования масштабируемого представления, либо при помощи помещения изображений нижнего уровня в буфер опорных изображений (например, буфер декодированных изображений (decoded picture buffer, DPB)) вышележащего уровня. Первый подход дает большую гибкость, и, следовательно, в большинстве случаев позволяет получить более эффективное кодирование. Однако второй подход, т.е. масштабируемость, основанная на опорных кадрах, очень удобен в реализации и требует лишь минимальных изменений в одноуровневых кодеках, с сохранением большинства преимуществ в эффективности кодирования. По существу, кодек с масштабируемостью на основе опорных кадров может быть реализован с применением одинаковых аппаратных или программных реализаций для всех уровней, необходимо лишь решить вопрос управления буфером DPB с помощью внешних средств.
[0148] Кодер масштабируемого видеокодирования с масштабируемостью качества (также называемой масштабируемостью соотношения сигнал/шум, или SNR (Signal -to-Noise)) и/или пространственной масштабируемостью, может быть реализован описанным ниже способом. Для базового уровня кодирования могут применяться традиционные видеокодер и видеодекодер без масштабируемости. Восстановленные или декодированные изображения базового уровня вносят в буфер опорных изображений и/или в список опорных изображений для уточняющего уровня. В случае пространственной масштабируемости может выполняться передискретизация (увеличение разрешения) восстановленного, или декодированного, изображения базового уровня перед его добавлением в список опорных изображений для изображения уточняющего уровня. Декодированные изображения базового уровня могут вноситься в список (или списки) опорных изображений для кодирования/декодирования изображения уточняющего уровня, аналогично декодированным опорным изображениям уточняющего уровня. Следовательно, в кодере опорное изображение базового уровня может выбираться в качестве опорного для внешнего предсказания, при этом указание на его использование, как правило, выполняют с помощью указателя на опорное изображение в кодированном битовом потоке. В декодере из битового потока, например, на основе указателя на опорное изображение декодируется информация о том, что в качестве опорного изображения внешнего предсказания для уточняющего уровня было использовано изображение базового уровня. При использовании декодированного изображения базового уровня в качестве опорного для предсказания уточняющего уровня, оно называется опорным изображением межуровневого предсказания.
[0149] В предыдущем абзаце было описан видеокодек с масштабируемостью, в котором применялись два масштабируемых уровня: уточняющий уровень и базовый уровень. Нужно понимать, что это описание может быть обобщено для любых двух уровней в иерархии масштабируемости с более чем двумя уровнями. В таком случае второй уточняющий уровень может зависеть от первого уточняющего уровня в процессе кодирования и/или декодирования, и соответственно, первый уточняющий уровень может считаться базовым уровнем для кодирования и/или декодирования второго уточняющего уровня. Также, нужно понимать, что в буфере опорных изображений или списках опорных изображений уточняющего уровня могут присутствовать опорные изображения межуровневого предсказания более чем из одного уровня кодирования, и при этом каждое из этих опорных изображений межуровневого предсказания может рассматриваться как располагающееся в базовом, или опорном, уровне для кодируемого и/или декодируемого уточняющего уровня. При этом нужно понимать, что помимо повышения разрешения изображений опорного уровня, или в дополнение к нему, могут иметь место и другие типы межуровневой обработки. Например, битовая глубина отчетов изображения опорного уровня может приводиться к битовой глубине уточняющего уровня, и/или значения отсчетов могут преобразовываться из цветового пространства опорного уровня в цветовое пространство уточняющего уровня.
[0150] Схема масштабируемого кодирования и/или декодирования может включать многопетлевое кодирование и/или декодирование, которые описаны ниже. При кодировании и декодировании изображение базового уровня может восстанавливаться, или декодироваться, с целью его использования в качестве опорного изображения компенсации движения для последующих изображений в порядке кодирования, или декодирования, в том же уровне кодирования, или в качестве опорного для межуровневого (или межракурсного, или межкомпонентного) предсказания. Восстановленное, или декодированное, изображение базового уровня может сохраняться в буфер DPB. Изображение уточняющего уровня, аналогично, может восстанавливаться, или декодироваться, с целью его использования в качестве опорного изображения компенсации движения для последующих изображений в порядке кодирования, или декодирования, в том же уровне кодирования, или в качестве опорного для межуровневого (или межракурсного или межкомпонентного) предсказания более высоких уточняющих уровней, если они присутствуют. В дополнение к восстановленным, или декодированным, значениям отсчетов, для межуровневого (или межкомпонентного, или межракурсного) предсказания могут также использоваться значения синтаксических элементов базового, или опорного, уровня или переменные, полученные на основе значений синтаксических элементов базового, или опорного, уровня.
[0151] Межуровневое предсказание - это метод, при котором предсказание зависит от элементов данных (например, значений отсчетов или векторов движения) в опорных изображениях других уровней, отличающихся от уровня текущего изображения (кодируемого или декодируемого). В кодерах/декодерах масштабируемого видео могут быть определены и выполняться множество различных типов межуровневого предсказания. То, какие из типов межуровневого предсказания доступны, может зависеть, например, от профиля кодирования, в соответствии с которым кодирован битовый поток или отдельный уровень в битовом потоке, или, при декодировании, от профиля кодирования, которому, в соответствии с указанием, отвечает битовый поток или отдельный уровень в битовом потоке. Альтернативно или в дополнение, доступные типы межуровневого предсказания могут зависеть от применяемых типов масштабируемости или от типа масштабируемого кодека, или от редакции стандарта видеокодирования (например, SHVC, MV-HEVC или 3D-HEVC).
[0152] Прямой опорный уровень - это уровень, который может быть использован для межуровневого предсказания другого уровня, для которого упомянутый уровень является прямым опорным уровнем. Прямой предсказываемый уровень - это уровень, для которого другой уровень является прямым опорным уровнем. Косвенный опорный уровень - это уровень, который не является прямым опорным уровнем для некоторого второго уровня, однако является прямым опорным уровнем для третьего уровня, являющегося прямым опорным уровнем или косвенным опорным уровнем для прямого опорного уровня второго уровня, для которого упомянутый уровень является косвенным опорным уровнем. Косвенный предсказываемый уровень - это уровень, для которого другой уровень является косвенным опорным уровнем. Независимый уровень -это уровень, который не имеет прямых опорных уровней. Другими словами, независимый уровень не предсказывают с помощью межуровневого предсказания. Небазовый уровень -это любой уровень, помимо базового, при этом базовый уровень - это самый нижний уровень в битовом потоке. Независимый небазовый уровень - это уровень, одновременно являющийся независимым уровнем и небазовым уровнем.
[0153] В некоторых случаях данные в уточняющем уровне могут отсекаться после определенного местоположения, или даже после произвольной позиции, при этом каждая позиция отсечения может включать дополнительные данные, представляющие все более высокое визуальное качество. Такая масштабируемость называется мелкозернистой (или мелкогранулярной) масштабируемостью (fine grained (granularity) scalability, FGS).
[0154] Аналогично стандарту MVC, в MV-HEVC опорные изображения межракурсного предсказания могут включаться в список (или списки) опорных изображений для текущего кодируемого или декодируемого изображения. В SHVC применяется многопетлевое декодирование (в отличие от расширения SVC стандарта H.264/AVC). В расширении SHVC применяется подход, основанный на указателях на опорные изображения, то есть опорное изображение межуровневого предсказания может включаться в один или более списков опорных изображений для текущего кодируемого или декодируемого изображения (в соответствии с предшествующим описанием).
[0155] Для кодирования уточняющего уровня в расширениях SHVC, MV-HEVC и/или SMV-HEVC могут применяться те же принципы и инструменты кодирования, что и для базового уровня HEVC. Однако в кодеки SHVC, MV-HEVC и/или SMV-HEVC, или аналогичные им, с целью эффективного кодирования уточняющего уровня, могут быть встроены дополнительные инструменты межуровневого предсказания, в которых применяются уже кодированные данные (включая восстановленные элементы изображений и параметры движения, которые также называют информацией о движении) из опорного уровня.
[0156] «Составляющим изображением» (constituent picture) называют часть (де)кодированного изображения, которая является представлением полного входного изображения. Помимо составляющего изображения содержащее его (де)кодированное изображение может содержать другие данные, например, другие составляющие изображения.
[0157] Упаковка кадров - это размещение, в одном выходном изображении, нескольких входных изображений, которые могут называться (входными) составляющими кадрами или составляющими и изображениями. В общем случае упаковка кадров не ограничена никаким конкретным типом составляющих кадров, а составляющие кадры не обязательно должны быть каким-либо образом связаны между собой. Во многих случаях упаковку кадров используют для организации составляющих кадров стереоскопического видеоролика в единую последовательность изображений. Такая организация может включать помещение входных изображений в пространственно неперекрывающиеся области в выходном изображении. Например, при расположении бок о бок, два входных изображения размещают в выходном изображении смежно друг с другом по горизонтали. Такая организация может также включать разбиение одного или более входных изображений на два или более разделов, или составляющих кадров, и расположение этих разделов в пространственно неперекрывающихся областях выходного изображения. Выходное изображение, или последовательность выходных изображений с упаковкой кадров, может кодироваться в битовый поток, например, видеокодером. Битовый поток может быть декодирован, например, при помощи видеодекодера. После декодирования, в декодере или в операции декодирования, может выполняться извлечение декодированных составляющих кадров из декодированных изображений, например, для их отображения.
[0158] При упаковке кадров возможно межракурсное предсказание значений отсчетов между упакованными составляющими кадрами, которое выполняют с помощью инструмента внутреннего копирования блоков, описанного ниже. В кадр упаковывают первый составляющий кадр, который является представлением первого ракурса, и второй составляющий кадр, который является представлением второго ракурса того же самого многоракурсного (например, стереоскопического) контента. При кодировании разрешено предсказание, с внутренним копированием блоков, для второго составляющего кадра на основе первого составляющего кадра, однако предсказание с внутренним копированием блоков для первого составляющего кадра на основе второго составляющего кадра не разрешено. Следовательно, межракурсное предсказание отсчетов по существу достигается применением предсказания с внутренним копированием блоков между составляющими кадрами различных ракурсов. Соответственно, повышается эффективность сжатия, по сравнению с кодированием упакованного в кадры многоракурсного контента без предсказания с внутренним копированием блоков.
[0159] Термины «360-градусное видео» и «видео виртуальной реальности (VR)» могут использоваться взаимозаменяемо. В самом общем смысле они относятся к видеоконтенту, имеющему такой широкий угол зрения, что в стандартных устройствах воспроизведения в каждый момент времени может отображаться только часть видео. К примеру, видео виртуальной реальности может отображаться при помощи устанавливаемого на голове дисплея (head-mounted display, HMD), который обеспечивает поле зрения шириной около 100 градусов. Отображаемое пространственное подмножество видеоконтента виртуальной реальности может выбираться в зависимости от ориентации HMD-дисплея. В другом примере, если используется стандартная система просмотра с плоским экраном, может отображаться поле зрения шириной вплоть до 40 градусов. При отображении контента с широким полем зрения (например, типа «рыбий глаз») предпочтительнее отображать некоторое пространственное подмножество, а не изображение целиком.
[0160] Ниже рассмотрен один из примеров получения и подготовки 360-градусных изображений или видеоконтента. Изображения или видео может захватываться при помощи набора камер или при помощи съемочного устройства с множеством объективов и датчиков. В результате получают набор цифровых сигналов изображения или видеосигналов. Камеры и/или объективы, как правило, охватывают все направления вокруг центральной точки набора камер или съемочного устройства. Для изображений, соответствующих одному моменту времени, выполняют сшивку, проецирование и мэппинг в упакованный кадр виртуальной реальности. Ниже будут пошагово описаны процедуры сшивки, проецирования и мэппинга изображений, проиллюстрированные на фиг. 5. Входные изображения сшивают и проецируют на трехмерную структуру проекции, например, сферу или куб. Структуру проекции можно рассматривать как имеющую одну или более поверхностей, например, плоскостей или их фрагментов. Структура проекции представляет собой трехмерную фигуру, состоящую из одной или более поверхностей, на которые проецируют захваченный видеоконтент или контент изображений виртуальной реальности. При помощи структуры проекции может быть сформирован соответствующий кадр проекции. Данные изображений, спроецированные на структуру проекции, помещают в двумерный кадр проекции. Под «проекцией» может пониматься процедура, при помощи которой набор входных изображений проецируют в кадр проекции. Для кадра проекции может быть заранее задан набор форматов представления, которые могут включать, например, такие форматы представления, как равнопрямоугольная панорама или кубическая карта.
[0161] Для мэппинга кадра проекции в один или более упакованных кадров виртуальной реальности (или «упакованных изображений») может применяться мэппинг областей (region-wise mapping), который также называют упаковкой областей (region-wise packing). В некоторых случаях мэппинг областей можно считать эквивалентным извлечению двух или более областей из кадра проекции, опционально, с применением к ним геометрической трансформации (например, поворот, зеркальное отображение и/или передискретизация), и размещение преобразованных областей в пространственно неперекрывающихся местоположениях внутри упакованного кадра виртуальной реальности. Если мэппинг областей не применяют, упакованный кадр виртуальной реальности идентичен кадру проекции. В противном случае выполняют мэппинг кадра проекции в упакованный кадр виртуальной реальности с указанием местоположения, формы и размера каждой области в упакованном кадре виртуальной реальности. Под «мэппингом» понимают процедуру, при помощи которой кадр проекции переносят в упакованный кадр виртуальной реальности. Под «упакованным кадром виртуальной реальности» может пониматься кадр, полученный в результате мэппинга кадров проекции. На практике преобразование входных изображений в упакованный кадр виртуальной реальности может выполняться в ходе единой процедуры, без промежуточных шагов.
[0162] Информация об упаковке областей может кодироваться в виде метаданных внутри битового потока или параллельно, например, в виде сообщений SEI упаковки областей и/или в виде боксов упаковки областей в файле, содержащем битовый поток. К примеру, информация об упаковке может включать информацию о мэппинге областей из заранее заданного или указанного исходного формата в формат упакованного кадра, например, из кадра проекции в упакованный кадр виртуальной реальности, в соответствии с предшествующим описанием. Информация о мэппинге областей может включать, например, для каждой области мэппинга, исходный прямоугольник в кадре проекции и целевой прямоугольник в упакованном кадре виртуальной реальности, при этом отсчеты в исходном прямоугольнике преобразуют в отсчеты целевого прямоугольника, а сами прямоугольники могут быть представлены, например, координатами левого верхнего и правого нижнего углов. Мэппинг может включать изменение частоты дискретизации отсчетов. В дополнение или альтернативно, информация об упаковке может включать одно или более из следующего: ориентация трехмерной структуры проекции относительно системы координат, указание на используемый формат проекции виртуальной реальности, ранг качества для каждый области, указывающий на ранг качества изображения в различных областях и/или в первой и второй пространственных последовательностях областей, одна или более операций трансформации, например, поворот на 90, 180 или 270 градусов, зеркальное отображение по горизонтали или по вертикали. Семантика информации об упаковке может быть определена таким образом, чтобы указывать, для каждой координаты отсчета внутри упакованных областей декодируемого изображения, соответствующее местоположение в сферической системе координат.
[0163] Метаданные ранжирования областей по качеству могут быть включены в битовый поток или передаваться параллельно битовому потоку. Значения рангов качества для областей могут задаваться относительно других областей в том же битовом потоке или в том же треке, или относительно значений ранга других треков. Метаданные ранжирования областей по качеству могут указываться, например, при помощи боксов SphereRegionQualityRankingBox или 2DRegionQualityRankingBox, которые определены как часть формата всенаправленных медиаданных MPEG. В боксе SphereRegionQualityRankingBox содержатся значения ранга качества для областей сферы, т.е. областей, заданных в сферических координатах, тогда как в боксе 2DRegionQualityRankingBox содержатся значения ранга качества для прямоугольных областей в декодированных изображениях (а также, потенциально, для остаточной области, которая включает все области, не охваченные прямоугольными областями). Значения ранга качества указывают на относительный порядок качества для ранжированных областей. Если ранжированная по качеству область А имеет ненулевое значение ранга качества, меньшее, чем у ранжированной по качеству области В, ранжированная по качеству область А имеет более высокое качество, чем ранжированная по качеству область В. Если значение ранга качества ненулевое, качество изображения во всей области, для которой указан ранг, может считаться приблизительно постоянным. В общем случае границы ранжирования по качеству сферических или двумерных областей не обязательно должны совпадать с границами областей упаковки или с границами областей проекции, указанными в метаданных упаковки областей.
[0164] Панорамный 360-градусный контент (изображения или видео) по горизонтали охватывает полное 360-градусное поле зрения вокруг точки съемки устройства формирования изображений. Вертикальное поле зрения может быть различным и может составлять, например, 180 градусов. Панорамное изображение, охватывающее 360-градусное поле зрения по горизонтали и 180-градусное поле зрения по вертикали может быть представлено сферой. Сфера может быть спроецирована на ограничивающий ее цилиндр, который может быть рассечен по вертикали, с получением двумерного изображения (такой тип проекции называют равнопрямоугольной). Процедура формирования моноскопического равнопрямоугольного панорамного изображения проиллюстрирована на фиг. 6. Набор входных изображений, например, изображений типа "рыбий глаз" с камерного массива или со съемочного устройства с множеством объективов и датчиков, сшивают, и получают единое сферическое изображение. Сферическое изображение затем проецируют на цилиндр (без верхней и нижней граней). Цилиндр развертывают, получая двумерный кадр проекции. На практике один или более из описанных шагов могут быть скомбинированы, например, входные изображения могут сразу проецироваться на цилиндр, без промежуточной проекции на сферу. Структурой проекции для равнопрямоугольной панорамы может считаться цилиндр, имеющий одну поверхность.
[0165] В общем случае 360-градусный контент может отображаться на геометрические структуры различных типов, например, многогранник (т.е. трехмерный монолитный объект, имеющий плоские многоугольные грани, прямолинейные ребра и острые углы, или вершины, например, куб или пирамида), цилиндр (проецирование сферического изображения на цилиндр, как описано выше в примере с равнопрямоугольной проекцией), цилиндр без предварительной проекции на сферу, конус или другие тела, и - затем развертываться в двумерную плоскость изображения.
[0166] В некоторых случаях панорамный контент с 360-градусным полем зрения по горизонтали и менее чем 180-градусным полем зрения по вертикали может трактоваться как специальный случай панорамной проекции, где области полюсов сферы не отображаются на двумерную плоскость изображения. В некоторых случаях панорамное изображение может иметь менее чем 360-градусное горизонтальное поле зрения и вертикальное поле зрения, составляющее вплоть до 180 градусов, и при этом иметь характеристики панорамного формата проекции.
[0167] Человеческий глаз не способ охватывать все 360-градусное пространство сразу, его поле зрения (FoV) ограничено максимальными горизонтальным и вертикальным значениями (HHFoV, HVFoV). HMD-дисплеи также имеют технические ограничения, которые позволяют видеть лишь подмножество всего 360-градусного пространства в горизонтальном и вертикальном направлениях.
[0168] В любой момент времени видео, отображаемое каким-либо приложением на HMD-дисплее, представляет собой лишь часть 360-градусного видео. Эта часть называется в настоящем документе «окном просмотра» (Viewport). Окно просмотра - это окно в 360-градусное пространство, которое представлено всенаправленным видео, отображаемым при помощи визуализирующего дисплея. Окно просмотра характеризуется горизонтальным и вертикальным полями зрения, FoVs (VHFoV, WFoV). Далее VHFoV и WFoV будут сокращенно обозначаться HFoV и VFoV.
[0169] В зависимости от конкретного применения, размер окна просмотра может соответствовать полю зрения HMD-дисплея или иметь меньший размер. Для простоты определим основное окно просмотра как часть 360-градусного пространства, видимую для пользователя в любой заданный момент времени.
[0170] Когда многоуровневый битовый поток, например, многоуровневый битовый поток HEVC, хранят в файле, например в файле ISOBMFF, в каждом треке допускается хранение одного или более уровней. К примеру, если поставщик контент собирается передавать многоуровневый поток, не подразумевающий извлечения из него подмножеств, или если битовый поток создают для нескольких заранее заданных наборов выходных уровней, где каждый уровень соответствует отдельному ракурсу (например, 1, 2, 5 или 9 ракурсов), треки могут формироваться соответствующим образом.
[0171] Если битовый поток с множеством подуровней, например, битовый поток HEVC с множеством подуровней, хранят в файле, например, файле ISOBMFF, в одном треке допускается хранение одного или более подуровней, при этом битовый поток может содержаться более чем в одном треке. К примеру, каждый трек может содержать только конкретные подуровни и не должен содержать самый нижний подуровень (например, в HEVC, подуровень с Temporalld, равным 0).
[0172] Экстракторы, определенные в документе ISOIEC 14496-15 для H.264/AVC и HEVC, позволяют создавать компактные треки, которые извлекают данные NAL-пакетов при помощи ссылок. Экстрактор имеет структуру, аналогичную NAL-пакету. Такая структура может быть определена как включающая заголовок NAL-пакета и полезную нагрузку NAL-пакета, как и в любом NAL-пакете, однако в ней не обязательно должны присутствовать данные предотвращения эмуляции стартового кода (обязательные для обычного NAL-пакета). В случае HEVC экстрактор содержит один или более конструкторов. Конструктор отсчетов получает, при помощи ссылки, данные NAL-пакета из отсчетов другого трека. Поточный конструктор содержит данные NAL-пакета. При обработке экстрактора соответствующей считывающей файл программой экстрактор логически заменяется на байты, полученные в результате разрешения содержащихся в нем конструкторов в порядке их появления. Вложенное извлечение может быть запрещено, например, байты, на которые ссылается конструктор отсчетов, сами не должны содержать экстракторов; и никакой экстрактор не должен ссылаться, прямо или косвенно, на какой-либо другой экстрактор. Экстрактор может содержать один или более конструкторов для извлечения данных из текущего трека или из другого трека, связанного с треком размещения данного экстрактора при помощи ссылки на трек типа 'seal'. Байты экстрактора после выполнения процедуры его разрешения могут представлять собой один или несколько полных NAL-пакетов. Разрешенный таким образом экстрактор начинается с корректного поля длины и заголовка NAL-пакета. Байты конструктора отсчетов копируют только из одного заданного отсчета в треке, на который ведет указанная ссылка типа 'seal'. Выравнивание выполняют по времени декодирования, т.е. используют только таблицу time-to-sample (соответствие «время-отсчет»), следуя учитываемому смещению номера отсчета. Экстракторный трек - это трек, содержащий один или более экстракторов.
[0173] Трек тайлов, определенный в документе ISO/ГЕС 14496-15, позволяет хранить один или более ограниченных по движению наборов тайлов в виде единого трека. Если трек тайлов содержит тайлы базового уровня HEVC, применяют тип 'hvtT записи с информацией о отсчетах. Если трек тайлов содержит тайлы небазового уровня, применяют тип 'lhtl' записи с информацией о отсчетах. Каждый сэмпл в треке тайлов состоит из одного или более полных тайлов в одном или более полных сегментах слайса. Трек тайлов не зависит ни от какого другого трека тайлов, включающего NAL-пакеты VCL того же уровня, что и данный трек тайлов. Трек тайлов имеет ссылку типа 'tbas' на базовый трек тайлов. Трек тайлов не содержит NAL-пакетов VCL. Базовый трек тайлов определяет порядок тайлов при помощи ссылок на остальные треки тайлов, имеющей тип 'sabt'. В стандарте HEVC кодированное изображение, соответствующее отсчетам в базовом треке тайлов, может быть восстановлено при помощи сбора кодированных данных из выровненных по времени отсчетов треков, на которые указывает трековая ссылка 'sabt', в порядке выполнения ссылок на треки.
[0174] {Трек | битовый поток} с набором тайлов, соответствующим полному изображению, - это {трек | битовый поток} с набором тайлов, который отвечает формату {трека | битового потока} полного изображения. Здесь нотация вида {опция А | опция В} обозначает альтернативы, т.е. во всех случаях выбора выбирают или опцию А, или опцию В. Трек с набором тайлов, соответствующим полному изображению, может быть воспроизведен как любой трек полного изображения, с использованием процедур синтаксического анализа и декодирования треков полных изображений. Битовый поток, соответствующий полному изображению, может декодироваться как любой битовый поток полного изображения с использованием процедуры декодирования битовых потоков полного изображения. Трек полного изображения - это трек, представляющий собой исходный битовый поток (включающий все его тайлы). Битовый поток набора тайлов - это битовый поток, который содержит набор тайлов исходного битового потока, но не является при этом исходным битовым потоком. Трек набора тайлов - это трек, который представляет собой набор тайлов из исходного битового потока, однако не является исходным битовым потоком.
[0175] Трек набора тайлов, соответствующий полному изображению, может включать экстракторы, отвечающие спецификации HEVC. Экстрактор, например, может включать поточный конструктор, включающий заголовок сегмента слайса и конструктор отсчетов, который извлекает кодированные данные для набора тайлов из указанного трека полного изображения.
[0176] Подизображение может быть определено как область, например, тайл или прямоугольник из тайлов, в полном изображении. Трек подизображений - это трек, представляющий собой последовательность подизображений, т.е. последовательность областей изображений, при этом от соответствует формату традиционных треков, например, 'hvcl' или 'hevl' в HEVC, описанных в документе ISO/ГЕС 14496-15. В одном из подходов для формирования треков подизображений последовательность исходных изображений разбивают на последовательности подизображений перед кодированием. Затем последовательности подизображений кодируют независимо друг от друга в виде одноуровневых битовых потоков, например, битовых потоков основного (Main) профиля HEVC. Каждый кодированный одноуровневый битовый поток инкапсулируются в отдельный трек подизображений. Битовый поток для трека подизображений может быть кодирован с использованием ограниченных по движению изображений, которые будут описаны ниже. В другом подходе для формирования треков подизображений исходную последовательность изображений кодируют в битовый поток с использованием ограниченных по движению наборов тайлов. Затем на основе этого битового потока формируют битовый поток наборов тайлов, соответствующий полному изображению. И наконец формируют трек подизображений, инкапсулируя в него битовый поток наборов тайлов, соответствующий полному изображению. Сформированные таки образом треки подизображений содержат ограниченные по движению изображения.
[0177] Коллекторный трек (collector track) - это трек, который извлекает, явно или неявно, MCTS-наборы, или подизображения, из других треков. Коллекторный трек может иметь формат, соответствующий треку полных изображений. Коллекторный трек, например, может извлекать MCTS-наборы или подизображения, в результате чего получают последовательность кодированных изображений, в которой MCTS-наборы или подизображения упорядочены в виде сетки. К примеру, когда коллекторный трек извлекает два MCTS-набора или подизображения, они могут упорядочиваться в виде сетки 2x1 MCTS-наборов или подизображений. Базовый трек тайлов можно рассматривать как коллекторный трек, при этом экстракторный трек, который извлекает MCTS-наборы или подизображения из других треков, также может рассматриваться как коллекторный трек. Коллекторный трек может также называться треком коллекции (collection track). Трек, который является источником для извлечения в коллекторный трек, может называться треком объектов коллекции (collection item track).
[0178] Межракурсное предсказание позволяет значительно повысить степень сжатия при кодировании стереоскопического и многоракурсного видео, однако на существующем уровне техники оно поддерживается лишь в некоторых из профилей стандартов видеокодирования, например, в профиле Multiview Main (основной многоракурсный) стандарта HEVC. При ограниченном межракурсном предсказании кодирование стереоскопического или многоракурсного видео ограничивают таким образом, что кодированный контент может быть перезаписан в форме, позволяющей применять один или более одноуровневых и одноракурсных декодеров, например, соответствующих профилю Main (основной) стандарта HEVC. В качестве опорных изображений для кодирования предсказываемого ракурса может применяться лишь ограниченное подмножество изображений независимого ракурса, например, IRAP-изображения в HEVC. Одноуровневый и одноракурсный битовый поток может формироваться для предсказываемого ракурса при помощи включения упомянутого ограниченного подмножества изображений независимого ракурса в битовый поток предсказываемого ракурса. При формировании одноуровневого и одноракурсного битового потока для предсказываемого ракурса может требоваться перезапись синтаксических структур высокого уровня, таких как наборы параметров и заголовки слайсов. Треки, соответствующие полному изображению, могут формироваться для управления перезаписью, при этом они могут включать экстракторы для подстановки кодированных данных изображения из ограниченного подмножества независимого ракурса, а также могут включать поточные конструкторы для перезаписи высокоуровневых синтаксических структур. Перезапись битового потока предсказываемого ракурса может выполняться при помощи процедуры разрешения треков, соответствующих полному изображению, т.е. при помощи процедуры разрешения содержащихся в них экстракторов и поточных конструкторов.
[0179] Уникальный идентификатор ресурса (uniform resource identifier, URI) - это строка символов, используемая для идентификации имени ресурса. Такой идентификатор дает возможность взаимодействовать с представлениями ресурса по сети при помощи специальных протоколов. Указатель URI определяют при помощи схемы, которая задает конкретный синтаксис и соответствующий для URI протокол. Унифицированный локатор ресурса (uniform resource locator, URL) и унифицированное имя ресурса (uniform resource name, URN) являются частными случаями идентификатора URI. URL-локатор -это идентификатор URI, который идентифицирует веб-ресурс и описывает средства для работы с представлением ресурса или средства его получения, описывая при этом как основной механизм доступа, так и местоположение в сети. Имя URN - это URI-идентификатор, который идентифицирует ресурс по имени в конкретном пространстве имен. Имя URN может применяться для идентификации ресурсов, без указания на его местоположения или способ доступа к нему.
[0180] Во многих системах обмена видеоинформацией или передачи видеоинформации, транспортных механизмах и форматах мультимедийных контейнерных фалов имеются механизмы для передачи или хранения одного из масштабируемых уровней отдельно от других масштабируемых уровней того же битового потока, например, для передачи или хранения базового уровня отдельно от уточняющих. Можно считать, что уровни хранят или передают по отдельным логическим каналам. К примеру, в ISOBMFF базовый уровень может храниться в виде одного трека, а все уточняющие уровни - в отдельных треках, связанных с треком базового уровня при помощи так называемой трековых ссылок.
[0181] Во многих системах обмена или передачи видеоинформации, транспортных механизмах и форматах контейнерных медиафайлов имеются средства для связывания кодированных данных различных логических каналов, например, различных треков или сеансов, друг с другом. Например, существуют механизмы для связывания друг с другом кодированных данных одного пакета доступа. К примеру, в формате контейнерного файла или в транспортном механизме могут предоставляться времена декодирования или вывода, и при этом кодированные данные с одинаковыми временами декодирования или вывода могут рассматриваться как образующие пакет доступа.
[0182] В последнее время для доставки мультимедийного контента в реальном времени по сети Интернет, например, в приложениях потоковой передачи видеоданных, широко используется протокол передачи гипертекста (Hypertext Transfer Protocol, HTTP). В отличие от применения транспортного протокола реального времени (Real-time Transport Protocol, RTP), надстроенного над протоколом пользовательских датаграмм (User Datagram Protocol, UDP), протокол HTTP более прост в конфигурировании и, как правило, разрешен для пропускания через брандмауэры и трансляторы сетевых адресов (network address translators, NAT), что делает его привлекательным для использования в приложениях потоковой передачи медиаданных.
[0183] Для адаптивной потоковой передачи по протоколу HTTP на рынке предложены несколько готовых решений, например, технология плавной потоковой передачи от Microsoft (Microsoft® Smooth Streaming, Apple®), технология прямой потоковой передачи по протоколу HTTP от Apple (HTTP Live Streaming) и технология динамической потоковой передачи от Adobe (Adobe® Dynamic Streaming). Также созданы соответствующие проекты стандартов. Адаптивная потоковая передача по протоколу HTTP (Adaptive HTTP streaming, AHS) была впервые стандартизована в 9-й редакции стандарта Консорциума третьего поколения (3GPP) для службы потоковой передачи с коммутацией пакетов (packet-switched streaming, PSS) (документ 3GPP TS 26.234 Release 9: "Transparent end-to-end packet-switched streaming service (PSS); protocols and codecs" («Служба прозрачной межузловой потоковой передачи с коммутацией пакетов (PSS); протоколы и кодеки», редакция 9). Группа MPEG взяла редакцию 9 стандарта AHS 3GPP за отправную точку для стандарта MPEG DASH (международный стандарт ISO/ГЕС 23009-1: "Dynamic adaptive streaming over HTTP (DASH)-Part 1: Media presentation description and segment formats" (Динамическая адаптивная потоковая передача по протоколу HTTP (DASH) - часть 1: описание представления медиаданных и форматы сегментов», редакция 2, 2014 год). Консорциум 3GPP продолжил работу над адаптивной потоковой передачей по HTTP, во взаимодействии с группой MPEG, и опубликовал стандарт 3GP-DASH (Динамическая адаптивная потоковая передача по протоколу HTTP; 3GPP TS 26.247 «Служба прозрачной потоковой передачи с коммутацией пакетов (packet-switched streaming Service, PSS)2; прогрессивная загрузка и динамическая адаптивная потоковая передача по HTTP (3GP-DASH))». Стандарты MPEG DASH и 3GP-DASH технически близки друг другу, и соответственно, обозначаются совместно как просто DASH. Ниже будут представлены некоторые из понятий, форматов и операций технологии DASH, в качестве примера системы потоковой передачи видео, в которой могут быть реализованы варианты осуществления настоящего изобретения. Аспекты настоящего изобретения не ограничены технологией DASH, а данное описание приведено исключительно в качестве базы для частичной или полной реализации настоящего изобретения.
[0184] При динамической адаптивной потоковой передаче видео по протоколу HTTP (DASH), мультимедийный контент может захватываться и храниться на HTTP-сервере, и может доставляться при помощи протокола HTTP. Контент может храниться на сервере в виде двух частей: описание медиапрезентации (Media Presentation Description, MPD), которое описывает манифест имеющегося контента, различные его альтернативы, их URL-адреса и другие характеристики; и сегменты, которые содержат фактические битовые потоки медиаданных, в форме чанков (chunks), в одном или нескольких файлов. MPD-описание содержит информацию, необходимую клиентам для установления сеанса динамической адаптивной потоковой передачи видео по протоколу HTTP. MPD содержит информацию, описывающую медиапрезентацию, например, унифицированные локаторы ресурсов (URL) протокола HTTP для каждого сегмента, позволяющие выполнять запросы GET для получения этих сегментов. Для воспроизведения контента клиент DASH может получать MPD-описание, например, с использованием протокола HTTP, электронной почты, флэш-накопителя, широковещательной передачи или других методов передачи данных. При помощи синтаксического анализа MPD-описания клиент DASH может получить информацию о синхронизации программ, доступности медиаконтента, типах медиаданных, разрешении, минимальной и максимальной полосах пропускания, а также о наличии различных кодированных альтернатив для мультимедийных компонентов, функциях доступности и требованиях по управлению цифровыми правами (digital rights management, DRM), расположении медиакомпонентов в сети и других характеристиках контента. При помощи этой информации клиент DASH может выбрать подходящую кодированную альтернативу и запустить потоковую передачу контента, получая сегменты, например, с помощью запросов GET протокола HTTP. После соответствующей буферизации, для компенсации флуктуации в пропускной способности сети, клиент может продолжить получение последующих сегментов, с одновременным контролем колебаний пропускной способности. Клиент может выбрать, каким образом адаптироваться к доступной полосе пропускания, получая различные альтернативные сегменты (с более или менее высоким битрейтом), которые позволяют поддерживать приемлемое заполнение буфера.
[0185] В технологии DASH для структурирования медиапрезентаций может использоваться иерархическая модель данных, показанная на фиг. 7. Медиапрезентация включает в себя последовательность из одного или более периодов (Period), причем каждый период содержит одну или более групп (Group), каждая группа содержит один или более наборов адаптации (Adaptation Set), каждый набор адаптации содержит одну или более репрезентаций (Representation), а каждая репрезентация состоит из одного или более сегментов (Segment). Каждая репрезентация представляет собой одну из альтернатив выбора медиаконтента или его подмножества, которая обычно отличается выбранным кодированием, например, битрейтом, разрешением, языком, кодеком и т.п. Сегмент содержит медиаданные некоторой длительности, а также метаданные для декодирования и отображения содержащегося в нем медиаконтента. Сегмент идентифицируется URI-идентификатором и, как правило, может быть запрошен при помощи запроса HTTP GET. Сегмент - это блок данных, связанных с локатором HTTP-URL, и опционально, байтовым диапазоном, заданным в описании MPD.
[0186] Описание MPD в технологии DASH соответствует спецификации расширяемого языка разметки (Extensible Markup Language, XML), и соответственно, задается при помощи элементов и атрибутов, определенных в языке XML. Описание MPD может быть сформировано с использованием описанных ниже условных обозначений. Элементы в XML-документе могут идентифицироваться первой прописной буквой и могут отображаться жирным шрифтом, например, «Element». Выражение, указывающее на то, что элемент Elementl содержится в другом элементе, Element2, может быть записано как Element2.Elementl. Если имя элемента состоит из двух или более слов, объединенных друг с другом, может применяться так называемый «горбатый регистр», например, ImportantElement. Элементы могут встречаться либо ровно один раз, либо может быть определено минимальное и максимальное количество экземпляров, при помощи, соответственно, <minOccurs> … <maxOccurs>. Атрибуты в XML-документе идентифицируются первой строчной буквой, а также им может предшествовать знак '@', например, @attribute. Для указания на конкретный атрибут, @attribute, содержащий в элементе Element может применяться запись вида Element@attribute. Если имя атрибута состоит из двух или более слов, объединенных друг с другом, после первого слова может применяться «горбатый регистр», например, @veryImportantAttribute. В XML атрибуты могут иметь различный статус: обязательный (mandatory, М), опциональный (optional, О), опциональный с заданным по умолчанию значением (optional with default value, OD) и условно обязательный (conditionally mandatory, CM).
[0187] Услуга DASH может предоставляться по запросу или в режиме прямого вещания. В первом случае MPD-описание является статическими, а все сегменты медиапрезентации уже доступны на момент публикации MPD-описания поставщиком контента. Однако во втором случае MPD-описание может быть как статическим, так и динамическим, в зависимости от способа построения URL-локаторов сегментов, применяемого в MPD-описании, при этом сегменты создаются непрерывно, а контент - формироваться и публиковаться для DASH-клиентов поставщиком контента. Могут применяться два способа построения URL-локаторов: способ построения URL-локаторов сегментов на базе шаблонов или способ с формированием списка сегментов. При первом из них DASH-клиент может формировать URL-локаторы сегментов без обновления MPD перед запросом сегмента. Во втором способе DASH-клиенту для получения URL сегментов необходима периодическая загрузка обновленных MPD-описаний. Соответственно, для службы прямого вещания способ построения URL сегментов на базе шаблонов является более эффективным, чем способ с формированием списка сегментов.
[0188] Ниже будут рассмотрены определения, которые могут использоваться в контексте технологии DASH. Компонент медиаконента, или медиакомпонент, - это один непрерывный компонент медиаконтента с присвоенным ему типом медиакомпонента, который может быть закодирован в медиапоток независимо. Медиаконтент - это один период медиаконтента или как последовательность из смежных периодов медиаконтента. Тип компонента медиаконтента - это один из типов медиаконтента, например, аудио, видео или текст. Медиапоток - это закодированный вариант компонента медиаконтента.
[0189] Инициализационный сегмент (Initialization Segment) - это сегмент, который содержит метаданные, необходимые для воспроизведения медиапотоков, инкапсулированных в медиасегментах. В форматах сегментов, основанных на ISOBMFF, инициализационный сегмент может включать бокс фильма ('moov'), который может не содержать метаданных отсчетов, т.е. все метаданные для отсчетов могут находиться в боксах 'moof'.
[0190] Медиасегмент (Media Segment) содержит некоторый временной интервал медиаданных для воспроизведения с нормальной скоростью, и такой интервал называют длительностью медиасегмента или длительностью сегмента. Создатель контента, или поставщик услуги, может выбирать длительность сегмента согласно требуемым характеристикам услуги. Например, для услуг прямого вещания может применяться сравнительно короткая длительность сегмента, что позволяет обеспечить минимальное время запаздывания между оконечными узлами. Так поступают, поскольку длительность сегмента обычно является минимальным значением запаздывания между узлами, регистрируемой клиентом DASH, т.к. в технологии DASH сегмент является элементарным блоком формирования медиаданных. Контент обычно формируют таким образом, чтобы медиаданные были доступны серверу в виде целых сегментов (Segment).
При этом, также, во многих реализациях клиентских программ сегменты могут использоваться в качестве минимальной единицы запросов GET. Таким образом, в типовых системах для прямого вещания сегмент может быть запрошен DASH-клиентами, только когда вся длительность медиасегмента целиком доступна, а также закодирована и инкапсулирована в сегмент. В случае услуг, предоставляемых по запросу, могут применяться различные стратегии выбора длительности сегмента.
[0191] Сегмент может быть дополнительно разбит на подсегменты (Sub segments), чтобы, например, загрузка сегментов могла выполняться по частям. Может предъявляться требование, чтобы подсегменты содержали только целые пакеты доступа. Подсегменты могут быть проиндексированы в боксе индексного указателя сегментов (Segment Index box), который содержит информацию о соответствии между интервалом времени презентации и байтовым диапазоном для каждого подсегмента. В боксе индексного указателя подсегментов могут быть также описаны подсегменты и точки доступа к потоку в сегментах, при помощи указания их длительности и байтовых смещений. Клиент DASH может использовать информацию, полученную из бокса индексного указателя подсегментов для формирования запроса HTTP GET на конкретный подсегмент с использованием подсегментов с использованием HTTP-запроса байтового диапазона. Если применяют относительно большую длительность сегментов, то подсегменты могут применяться для сохранения подходящего размера HTTP-ответов, дающего достаточно гибкости для адаптации битрейта. Индексная информация сегмента может быть помещена в один бокс в начале соответствующего сегмента или распределена по множеству индексирующих боксов в сегменте. Возможны различные способы распределения, например, иерархическое, гирляндное и гибридное. Такой подход позволяет не добавлять большой бокс в начале сегмента, и соответственно, избежать потенциальной длительной задержки в начале загрузки.
[0192] Выражение «(под)сегмент» обозначает сегмент или подсегмент. Если боксы индексного указателя сегментов (Segment Index) отсутствуют, то «(под)сегмент» означает просто сегмент (Segment). Если боксы индексного указателя сегментов присутствуют, выражение «(под)сегмент» может обозначать как сегмент, так и подсегмент, в зависимости, например, от того, присылает ли клиентская сторона запросы на сегменты или подсегменты.
[0193] Неперекрывающиеся сегменты (или соответственно, подсегменты) могут быть определены описанным ниже образом. Пусть TE(S,i) - самое раннее время презентации для всех пакетов доступа в потоке i сегмента или подсегмента S, a TL(S,i) - самое позднее время презентации всех пакетов доступа в потоке i сегмента или подсегмента S. Два сегмента (и соответственно, подсегмента) А и В, которые могут относиться к различным репрезентациям (однако это не является обязательным), могут быть названы неперекрывающимися, когда TL(A,i) < TE(В,i) для всех медиапотоков i в А и В, или если TL(В,i) < TE(A,i) для всех потоков i в А и В, где i относится к одному и тому же медиакомпоненту.
[0194] Стандарт MPEG-DASH определяет контейнерные форматы сегментов как для базового формата медиафайлов ISO, так и для транспортных потоков MPEG-2. В других стандартах форматы сегментов могут быть определены на основе других контейнерных форматов. Например, был предложен формат, основанный на формате контейнерных файлов Matroska, основные свойства которого описаны ниже. Когда файлы Matroska передают в виде DASH-сегментов, или аналогичных структур, соответствие блоков DASH и блоков Matroska может быть задано описанным ниже образом. Подсегмент (DASH) - это один или более последовательных кластеров (Clusters) контента, инкапсулированного в файле Matroska. Может предъявляться требование, чтобы инициализационный сегмент DASH содержал заголовок EBML, заголовок сегмента (Matroska), информацию о сегменте (Matroska) и треки (Tracks), а также, опционально, содержал другие элементы первого уровня (1) и заполняющие данные. Индексный указатель сегмента DASH может включать элементы указаний (Cues Element) Matroska.
[0195] В DASH определены различные временные шкалы (timeline), включающие временную шкалу медиапрезентации и времена доступности сегмента. Временная шкала указывает на время презентации пакета доступа с медиаконтентом, которое отображено (наложено) на глобальную временную шкалу общей презентации. Временная шкала медиапрезентации в технологии DASH дает возможность «бесшовной» синхронизации различных медиакомпонентов, закодированных при помощи различных методов кодирования и имеющих общую временную шкалу. Времена доступности сегмента указывают на абсолютное время (время суток), при этом их применяют для сообщения клиентам информации о временах доступности сегментов, которые идентифицируются URL-локаторами протокола HTTP. DASH-клиент способен определять время доступности конкретного сегмента за счет сравнения текущего абсолютного времени с временем доступности сегмента, присвоенного этому сегменту. Время доступности сегментов играет ключевую роль при доставке медиасегментов в режиме прямого вещания, что может именоваться «услугой прямого вещания». В случае услуги прямого вещания время доступности различных сегментов будет различным, при этом время доступности каждого сегмента зависит от позиции сегмента на временной шкале медиапрезентации. В случае услуги вещания по запросу время доступности сегмента, как правило, одинаково для всех сегментов.
[0196] Технология DASH поддерживает адаптацию скорости передачи путем адаптации, с целью подстройки к вариациям пропускной способности сети. Переключение между репрезентациями с различным битрейтом может использоваться, например, для согласования битовой скорости передачи с расчетной пропускной способностью сети и/или для исключения перегрузки сети. Когда DASH-клиент переключается на репрезентации с пониженным/повышенным качеством, учет зависимостей кодирования внутри репрезентации не является обязательным. На существующем уровне техники переключение репрезентации выполняют только в точке произвольного доступа (RAP), применяемой, например, в таких методах видеокодирования, как H.264/AVC. В технологии DASH введено более общее понятие «точки доступа к потоку» (Stream Access Point, SAP), являющееся независимым от применяемых кодеков решением для доступа к репрезентации и переключения между репрезентациями. В технологии DASH точка SAP определена как позиция в репрезентации, которая позволяет запустить воспроизведение медиапотока с использованием информации, содержащейся в данных репрезентации, начиная с этой позиции и далее (которым предшествуют данные инициализации в инициализационном сегменте, если таковой присутствует). Соответственно, переключение репрезентации может выполняться в точке SAP.
[0197] Определены несколько типов SAP, которые будут описаны ниже. SAP первого типа (type 1) соответствует понятию, носящему в различных схемах кодирования имя «точки произвольного доступа к закрытой группе GOP» (в которой все изображения, в порядке декодирования, могут быть корректно декодированы и позволяют получить непрерывную временную последовательность корректно декодированных изображений без пропусков), для которой первое изображение в порядке декодирования является также первым изображением в порядке воспроизведения. SAP второго типа (type 2) соответствует понятию, носящему в различных схемах кодирования имя «точки произвольного доступа к закрытой группе GOP» (в которой все изображения, в порядке декодирования, могут быть корректно декодированы и позволяют получить непрерывную временную последовательность корректно декодированных изображений без пропусков) для которой первое изображение в порядке декодирования не обязательно является также первым изображением в порядке воспроизведения. SAP третьего типа (type 3) соответствует понятию, носящему в различных схемах кодирования имя «точкой произвольного доступа к открытой группе GOP», где могут присутствовать некоторые изображения, в порядке декодирования, которые не могут быть декодированы корректно и имеют времена презентации, меньшие, чем внутренне-кодируемое изображение, связанное с этой SAP.
[0198] Поставщик контента может формировать сегменты и подсегменты различных репрезентаций таким образом, чтобы упростить переключение. В одном из простейших случаев, каждый сегмент и подсегмент начинается с точки SAP, а границы сегментов и подсегментов совпадают в каждой репрезентаций некоторого набора адаптации. Тогда DASH-клиент может переключать репрезентации без дрейфа ошибки, запрашивая сегменты или подсегменты из исходной репрезентации для новой репрезентации. В технологии DASH ограничения на формирование подсегментов определены в MPD-описании и указателе сегментов таким образом, чтобы обеспечивать возможность для DASH-клиентов переключаться между репрезентациями без внесения дрейфа ошибки. Одним из применений профиля, описанного в DASH, является наложение различных уровней ограничений на формирование сегментов и подсегментов.
[0199] В проект стандарта MPEG-DASH включена функциональность сегментно-независимой сигнализации SAP (Segment Independent SAP Signaling, SIS SI), которая позволяет передавать сегменты, начинающиеся с точек SAP, различной длительности. В проекте стандарта MPEG-DASH определена сигнализация SISSI для переключения внутри наборов адаптации и между различными наборами адаптации.
[0200] Переключение внутри одного набора адаптации подразумевает переключение с отображения декодированных данных из одной репрезентации до заданного момента t времени на отображение декодированных данных из другой репрезентации после упомянутого момента t времени. Если репрезентации находятся в одном наборе адаптации, и клиент корректно выполнит переключение, в процессе переключения медиапрезентация будет восприниматься неразрывной («бесшовной»). Клиенты могут игнорировать репрезентации, зависящие от неподдерживаемых или неподходящих кодеков, или от других технологий визуализации.
[0201] Элемент Switching (переключение), описанный в таблице 1, содержит инструкции о точках переключения внутри набора адаптации, при этом допустимые опции переключения определены в таблице 2. Этот элемент может использоваться вместо атрибутов @segmentAlignment или @bitstreamSwitching.
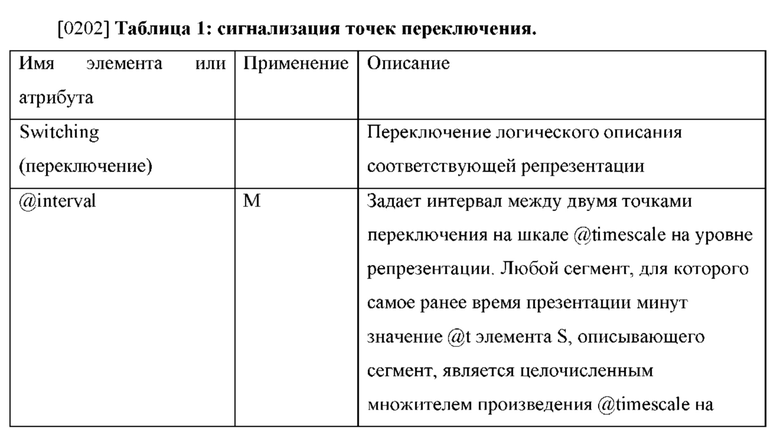
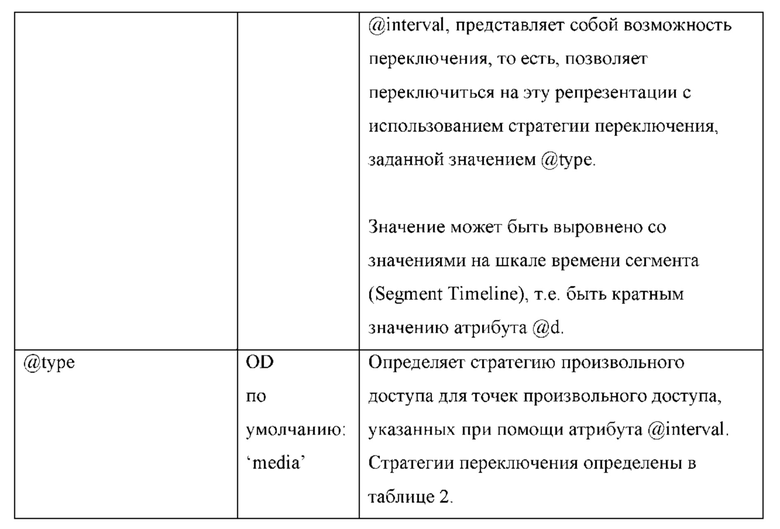
[0203] В таблице 2 определены различные стратегии переключения, которые
инструктируют клиента о процедурах корректного переключения внутри набора адаптации.


[0205] Под произвольным доступом (Random Access) может пониматься запуск обработки, декодирования и отображения репрезентации, начиная с точки произвольного доступа, с момента t времени и далее, с инициализацией репрезентации, с использованием сегмента инициализации, если таковой имеется, и декодирование и отображение репрезентации, начиная с сигнализированного сегмента и далее, т.е., начиная с самого раннего времени презентации в сигнализированном сегменте. Точка произвольного доступа может сигнализироваться с помощью элемента RandomAccess (произвольный доступ), описанного в таблице 3.
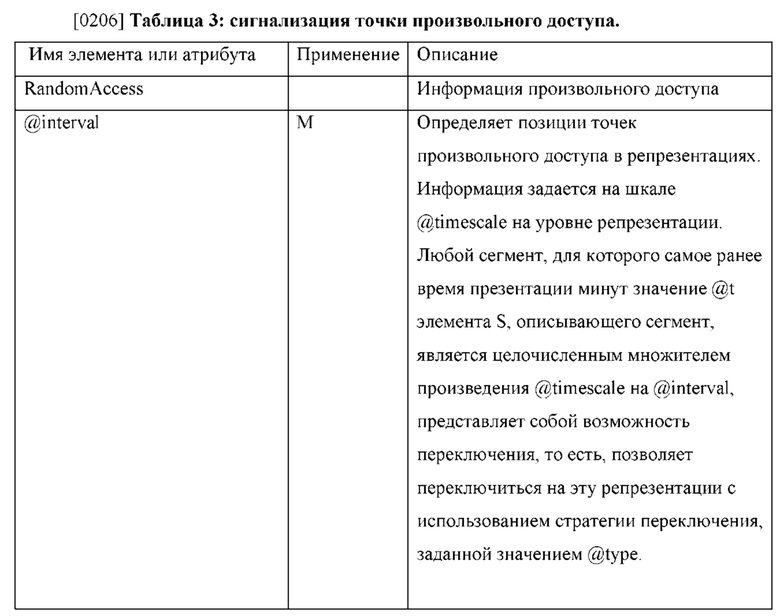
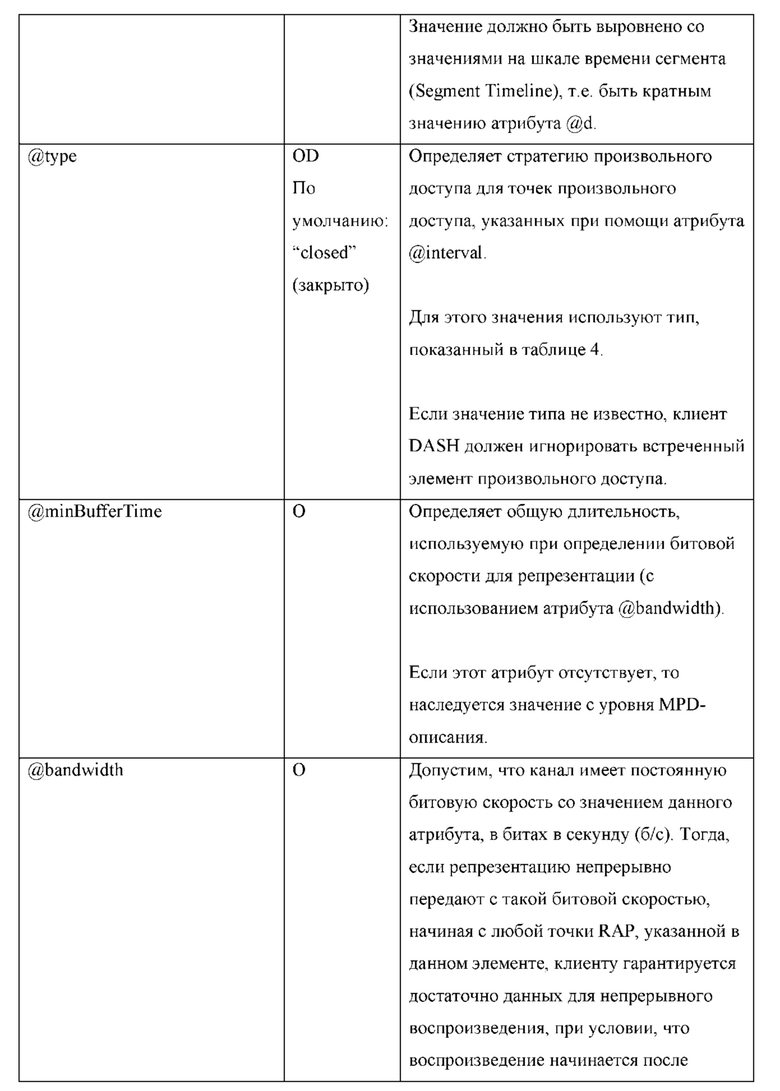


[0208] Стандарт DASH включает механизмы обеспечения быстрого запуска медиасеанса. К примеру, в MPD-описании, в одном наборе адаптации могут быть объявлены несколько репрезентаций с разным битрейтом. При этом каждый сегмент и/или подсегмент может начинаться с точки доступа к потоку, а изображения внутри сегмента и/или подсегмента закодированы без ссылок на какие-либо другие изображения в других сегментах. Таким образом клиент DASH может начинать с репрезентации, имеющей меньший битрейт, чтобы быстро повысить уровень заполнения буфера. Затем клиент может переключиться и запрашивать сегменты и/или подсегменты репрезентации с более высоким битрейтом (которая, например, может иметь большее пространственное разрешение, чем ранее принимаемая репрезентация). При быстром запуске клиент может пытаться достичь заданного уровня заполнения уровня, например, относительно длительности всей медиапрезентации, и в ходе дальнейшей работы, после фазы быстрого запуска, может стараться поддерживать уровень заполнения буфера приблизительно на том же уровне. Клиент, после запуска сеанса потоковой передачи медиаданных и/или после операции произвольного доступа, может начинать воспроизведение медиапрезентации, только после буферизации заданного объема медиаданных. Этот объем медиаданных может быть равным целевому уровню занятости буфера при быстром запуске, однако это не обязательно. В любом случае быстрый запуск позволяет клиенту начинать воспроизведение быстрее, чем в случае, когда только одну репрезентацию с высоким битрейтом всегда принимают после запуска сеанса потоковой передачи медиаданных и/или после операции произвольного доступа.
[0209] В соответствии с предшествующим описанием, клиент, или проигрыватель, может запрашивать сегменты и подсегменты для передачи из различных репрезентаций, аналогичному тому, как могут быть определены передаваемые уровни и/или подуровни масштабируемого битового потока видеоданных. Выражения «переключение репрезентации с понижением качества» или «переключение битового потока с понижением качества» могут означать запрос или передачу репрезентации с меньшим битрейтом, чем запрашивалось или передавалось (соответственно) ранее. Выражения «переключение репрезентации с повышением качества» или «переключение битового потока с повышением качества» могут означать запрос или передачу репрезентации с большим битрейтом, чем запрашивали или передавали (соответственно) ранее. Выражения «переключение репрезентации» или «переключение битового потока» могут означать, в совокупности, переключение репрезентации или битового потока как с повышением, так и с понижением качества, а также, альтернативно, означать также и переключение между репрезентациями или битовыми потоками различных точек зрения.
[0210] В технологии DASH все дескрипторные элементы имеют сходную структуру, а именно, они содержат атрибут @schemeIdUri, включающий URI-идентификатор, который указывает на схему, опциональный атрибут @value и опциональный атрибут @id. Семантика элементов зависит от конкретной применяемой схемы. URI-идентификатор, определяющий схему, может быть именем, URN, или локатором, URL. Часть дескрипторов определены стандартом MPEG-DASH (ISO/IEC 23009-1), тогда как другие могут быть определены, дополнительно или альтернативно, в других стандартах. Если используется не MPEG-DASH, а другой стандарт, описание MPD не дает никакой конкретной информации о том, как использовать дескрипторные элементы. Выбор значений дескрипторных элементов и подходящей информации о схеме зависит от конкретного приложения или стандарта, в которых применяют форматы DASH. В приложении или стандарте, где задействованы один из таких элементов, может быть определен идентификатор схемы (Scheme Identifier), имеющий форму URI-идентификатора, и пространство имен для элементов в случае использования такого идентификатора схемы. Идентификатор схемы располагается в атрибуте @schemeIdUri. Когда требуется простой набор пронумерованных значений, для каждого значения может быть определена текстовая строка, и это строка может быть включена в атрибут @value. Если нужны структурированные данные, то в отдельном пространстве имен может быть определен любой элемент или атрибут расширения. Значение @id может использоваться для указания на уникальный дескриптор или на группу дескрипторов. В последнем случае может предъявляться требование, чтобы дескрипторы с одинаковыми значениями атрибута @id были синонимичны, то есть, в этом случае достаточно обработать только один из множества дескрипторов с идентичными значениями @id.
[0211] В DASH независимая репрезентация может быть определена как репрезентация, которая может быть обработана независимо от всех других репрезентаций. Независимая репрезентация может рассматриваться как включающая независимый битовый поток или независимый уровень битового потока. Зависимая репрезентация может быть определена как репрезентация, для отображения и/или декодирования медиаконтента которой необходимы сегменты из дополняющих ее репрезентаций. Зависимая репрезентация может рассматриваться, например, как включающая предсказываемый уровень масштабируемого битового потока. Дополняющая репрезентация может быть определена как репрезентация, которая дополняет по меньшей мере одну зависимую репрезентацию. Дополняющая репрезентация может быть как зависимой, так и независимой репрезентацией. Зависимые репрезентации могут быть описаны при помощи элемента Representation (репрезентация), который содержит атрибут @dependencyld. Зависимые репрезентации можно считать обычными репрезентациями, с тем отличием, что они зависят от набор дополняющих репрезентаций для их декодирования и/или отображения. Атрибут @dependencyld содержит значения атрибутов @id всех дополняющих репрезентаций, т.е. репрезентаций, которые необходимы для отображения и/или декодирования компонентов медиаконтента, содержащихся в зависимой репрезентации.
[0212] Преселекция (Preselection) в DASH определяет подмножество медиакомпонентов в MPD-описании, которые предназначены для совместного «потребления» в одном экземпляре декодера, при этом под «потреблением» понимают декодирование и визуализацию. Набор адаптации, который содержит главный медиакомпонент преселекции, называется главным набором адаптации (Main Adaptation Set). При этом каждая преселекция может включать как один, так и несколько частичных наборов адаптации. Обработка частичных наборов адаптации должна выполняться в комбинации с главным набором адаптации. Главный набор адаптации и частичные наборы адаптации могут указываться при помощи одного из двух: дескриптор преселекции или элемент преселекции.
[0213] Системы потоковой передачи, аналогичные MPEG-DASH, включают, например, прямую потоковую передачу по протоколу HTTP (HTTP Live Streaming, HLS), которая определена в документе IETF RFC 8216. В качестве формата манифеста, соответствующего описанию MPD, в HLS применяют расширенный формат M3U. M3U -это формат файла для мультимедийных списков воспроизведения («плейлистов»), исходно разработанный для аудиофайлов. Список воспроизведения, M3U, представляет собой текстовый файл, состоящий из отдельных строк, при этом каждая строка может быть URI-идентификатором, пустой строкой, или начинаться с символа '#', указывающего на тег или комментарий. Строка с URI-идентификатором определяет медиасегмент или файл списка воспроизведения (Playlist). Теги начинаются с символов #ЕХТ. В спецификации HLS определено несколько тегов, которые можно рассматривать как пары из ключа и соответствующего значения. Часть тега, относящаяся к значению, может содержать список атрибутов, представляющий собой список с разделителями-запятыми из пар атрибут-значение, при этом каждая пара атрибут-значение может рассматриваться как имеющая следующий синтаксис: ИмяАтрибута=ЗначениеАтрибута. Соответственно, теги в файлах M3U8 HLS могут трактоваться аналогично элементам в описании MPD или XML, а атрибуты в файлах M3U8 HLS могут трактоваться аналогично атрибутам в описании MPD или XML. Формат медиасегментов в HLS может соответствовать потоку MPEG-2 и содержать одну программу (Program) MPEG-2. Рекомендуется, чтобы каждый медиасегмент начинался с таблицы ассоциаций программ (Program Association Table, PAT) и таблицы карты программ (Program Map Table, РМТ). Медиасегменты в более поздних версиях HLS могут быть совместимы с форматом ISOBMFF.
[0214] Инкапсулированный битовый поток -это битовый поток медиаданных, например, битовый поток видео (напр., битовый поток HEVC), который хранят в контейнерном файле или в (под)сегментах, и который может включать метаданные некоторого файлового формата, например, боксы формата ISOBMFF.
[0215] Как отмечалось выше, DASH, или аналогичные системы потоковой передачи, предоставляют протокол и/или форматы для приложений потоковой передачи медиаданных, и, в частности, для многоракурсных кодированных видеопотоков. В последнее время в протоколах потоковой передачи все чаще применяют следующие решения, которые позволяют понизить битрейт передачи видео виртуальной реальности: передача некоторого подмножества 360-градусного видеоконтента, охватывающего основную (текущую) ориентацию просмотра с наилучшим качеством/разрешением, и передача остальных частей 306-градусного видео с пониженным качеством/разрешением. Фактически, существуют два подхода к потоковой передаче с адаптацией к окну просмотра:
1. Кодирование и передача, зависящие от окна просмотра, (Viewport-specific encoding and streaming или viewport-dependent encoding and streaming), также называемые асимметрической проекцией.
[0216] При таком подходе 360-градусный визуальный контент упаковывают в один кадр с акцентом (например, с большей пространственной областью) на основное окно просмотра. Упакованные кадры виртуальной реальности кодируют в один битовый поток.
[0217] К примеру, фронтальная грань кубической карты может иметь более высокое разрешение, чем остальные грани куба, при этом все грани куба могут проецироваться (отображаться) в один упакованный кадр виртуальной реальности, в соответствии с иллюстрацией фиг. 8, где фронтальная грань куба имеет удвоенное по сравнению с другими гранями разрешение.
2. Кодирование и потоковая передача на основе тайлов
[0218] При таком подходе 360-градусный контент кодируют и доставляют таким образом, чтобы была возможной выборочная потоковая передача по-разному кодированных окон просмотра.
[0219] Метод кодирования и потоковой передачи на основе тайлов, который может называться «кодированием и потоковой передачей на основе прямоугольников тайлов», или «кодированием или потоковой передачей на основе подизображений», может применяться в любых видеокодеках, даже если тайлы, аналогичные стандарту HEVC, не доступны в кодеке, и даже если в кодере не применялись ограниченные по движению наборы тайлов или аналогичные механизмы. При кодировании на основе прямоугольника тайлов исходный контент, перед кодированием, разбивают на последовательности прямоугольников тайлов (также называемые последовательностями подизображений). Каждая последовательность прямоугольников тайлов охватывает подмножество пространственной области исходного контента, например, полнопанорамного контента, который, к примеру, может иметь формат равнопрямоугольной проекции. Каждую последовательность прямоугольников тайлов затем кодируют независимо друг от друга в виде одноуровневых битовых потоков. На основе одной последовательности прямоугольников тайлов могут быть закодированы несколько битовых потоков, например, с различным битрейтом. Каждый битовый поток прямоугольников тайлов может инкапсулироваться в файл как отдельный трек (или аналогичная структура) и предоставляться для потоковой передачи. На стороне приемника передаваемые треки могут выбираться в зависимости от ориентации просмотра. Клиент может принимать треки, охватывающие весь всенаправленный контент. При этом для текущего окна просмотра могут приниматься треки с лучшим качеством, или более высоким разрешением, по сравнению с качеством или разрешением для остальных, в текущий момент невидимых окон просмотра. В одном из примеров каждый трек может декодироваться при помощи отдельного экземпляра декодера.
[0220] В одном из примеров кодирования и потоковой передачи на основе прямоугольников тайлов каждая грань куба может кодироваться в отдельности и инкапсулироваться в собственный трек (и репрезентацию). Для каждой грани может создаваться более одного кодированного битового потока, например, каждый из них может иметь отличающееся пространственное разрешение. Проигрыватели могут выбирать треки (или репрезентации) для декодирования и воспроизведения на основе текущей ориентации просмотра. Треки (или репрезентации) высокого разрешения могут выбираться для граней куба, используемых для визуализации текущей ориентации просмотра, тогда как остальные грани куба могут извлекаться из соответствующих треков (или репрезентаций) низкого разрешения.
[0221] В подходе с кодированием и потоковой передачей на основе тайлов кодирование выполняют таким образом, чтобы результирующий битовый поток включал ограниченные по движению наборы тайлов. Для одного исходного контента с использованием ограниченных по движению наборов тайлов кодируют несколько битовых потоков.
[0222] В одном из подходов из битового потока извлекают одну или более последовательностей ограниченных по движению наборов тайлов, и каждую такую последовательность сохраняют в виде трека набора тайлов (например, трека тайлов или трека набора тайлов, соответствующих полным изображениям). Может быть сформирован базовый трек тайлов (например, базовый трек тайлов в HEVC или трек полных изображений, включающий экстракторы для извлечения данных из треков наборов тайлов), который затем сохраняют в файл. Базовый трек тайлов представляет битовый поток путем неявного сбора ограниченных по движению наборов тайлов из треков наборов тайлов или путем явного извлечения (например, при помощи экстракторов в HEVC) ограниченных по движению наборов тайлов из треков наборов тайлов. Треки наборов тайлов и базовый трек тайлов в каждом битовом потоке могут быть инкапсулированы в отдельный файл, при этом во всех файлах могут использоваться одинаковые идентификаторы треков. На стороне приемника треки наборов тайлов для потоковой передачи могут выбираться в зависимости от ориентации просмотра. Клиент может принимать треки наборов тайлов, полностью охватывающие всенаправленный контент. При этом для текущего окна просмотра могут приниматься треки наборов с лучшим качеством, или более высоким разрешением, по сравнению с качеством или разрешением для остальных, в текущий момент невидимых окон просмотра.
[0223] Рассмотрим пример кодирования равнопрямоугольного панорамного контента с помощью ограниченных по движению наборов тайлов. Формируют несколько кодированных битовых потоков, например, каждый из которых имеет отличающееся пространственное разрешение и/или качество изображения. Каждый ограниченный по движению набор тайлов располагается в собственном треке (и репрезентации). Проигрыватели могут выбирать треки (или репрезентации) для декодирования и воспроизведения на основе текущей ориентации просмотра. Треки (или репрезентации) с высоким разрешением или высоким качеством могут выбираться для наборов тайлов, охватывающих текущее основное окно просмотра, тогда как оставшаяся область 360-градусного контента может приниматься из треков (или репрезентаций) с пониженным разрешением или пониженным качеством.
[0224] В одном из подходов каждый принятый трек наборов тайлов декодируют с помощью отдельного декодера или экземпляра декодера.
[0225] В другом подходе базовый трек тайлов используют при декодировании описанным ниже образом. Если все принятые треки тайлов происходят из битовых потоков одного разрешения (или, в общем случае, если базовые треки тайлов этих битовых потоков идентичны или эквивалентны, или если инициализационные сегменты, или иные инициализационные данные, например, наборы параметров всех этих битовых потоков одинаковы), то базовый трек тайлов может быть принят и использован для формирования битового потока. Сформированный битовый поток может декодироваться одиночным декодером.
[0226] При другом подходе первый набор треков с прямоугольниками тайлов и/или треков наборов тайлов может внедряться в первый битовый поток, соответствующий полным изображениями, а второй набор треков с прямоугольниками тайлов и/или треков наборов тайлов может внедряться во второй битовый поток, соответствующий полным изображениям. Упомянутый первый битовый поток, соответствующий полным изображениям, может быть декодирован при помощи первого декодера или экземпляра декодера, а упомянутый второй битовый поток, соответствующий полным изображениям, может быть декодирован при помощи второго первого декодера или экземпляра декодера. В общем случае такой подход не ограничен ни двумя наборами треков прямоугольников тайлов или треков наборов тайлов, ни двумя битовыми потоками, соответствующими полным изображениям, ни двумя декодерами или экземплярами декодера, и остается действенным для любого их числа. При таком подходе клиент может управлять количеством параллельных декодеров или экземпляров декодера. При этом клиенты, которые не могут декодировать треки тайлов (например, треки тайлов HEVC) и способны декодировать только битовые потоки, соответствующие полным изображениям, выполняют операцию слияния таким образом, чтобы получить битовые потоки, соответствующие полным изображениям. Такое слияние может выполняться полностью на стороне клиента, или, альтернативно, могут формироваться треки наборов тайлов, соответствующие полным изображениям, чтобы упростить слияние, выполняемое клиентом.
[0227] Описанные выше подходы 1 (кодирование и потоковая передача, зависящие от окна просмотра) и 2 (кодирование и потоковая передача на основе тайлов) могут сочетаться друг с другом.
[0228] Нужно понимать, что кодирование и потоковая передача на основе тайлов могут быть реализованы путем разбиения исходного изображения на последовательности прямоугольников из тайлов, которые частично перекрывают друга. Альтернативно или в дополнение, битовые потоки с ограниченными по движению наборами тайлов могут формироваться, на основе одного и того исходного контента, но с различными сетками тайлов или сетками наборов тайлов. Допустим, все 360-гдрадусное пространство разбито на отдельные наборы окон просмотра, отстоящих друг от друга на заданное расстояние (измеряемое, например, в градусах), в таком случае всенаправленное пространство может быть представлено как карта из накладывающихся друг на друга окон просмотра, при этом основное окно просмотра, если пользователь меняет свою ориентацию при просмотре контента на HMD-дисплее, переключается дискретно. Если перекрытие окон просмотра уменьшить до нулевого, окна просмотра можно считать смежными неперекрывающимися тайлами в 360-градусном пространстве.
[0229] Как отмечалось выше, при потоковой передаче с адаптацией к окну просмотра достигается снижение битрейта, например, за счет того, что данные для основного окна просмотра (т.е. текущей ориентации взгляда) передают с наилучшим качеством, или разрешением, тогда как остальное 360-градусное видео передают с пониженным качеством, или разрешением. Когда направление взгляда меняется, например, пользователь поворачивает голову, просматривая контент при помощи устанавливаемого на голове дисплея, необходимо передавать другую версию контента, отвечающую новой ориентации взгляда. В общем случае новая версия может запрашиваться, начиная с точки доступа к потоку (SAP), которая, как правило, совпадает с началом (под)сегмента. В одноуровневых видеопотоках точки SAP кодируют с внутренним предсказанием, и значит, они существенно сказываются на отношении «битовая скорость/искажения». Поэтому традиционно используют сравнительно большие интервалы между точками SAP, и значит, сравнительно высокую длительность (под)сегментов, порядка нескольких секунд. Соответственно, задержка (называемая здесь задержкой повышения качества окна просмотра) при повышении качества после смены ориентации просмотра (например, поворота головы) также обычно составляет порядка нескольких секунд, и соответственно, явно заметна и неприятна.
[0230] Для доставки всенаправленного видео, зависящего от окна просмотра, возможны несколько альтернативных вариантов. Например, для его доставки могут применяться битовые потоки HEVC равного разрешения, имеющие ограниченные по движению наборы тайлов (motion-constrained tile sets, MCTS). To есть, несколько битовых потоков HEVC одного всенаправленного исходного контента кодируют с одинаковым разрешением, однако с различным качеством и битрейтом, используя ограниченные по движению наборы тайлов. Сетка MCTS во всех битовых потоках одинакова. Чтобы клиент мог использовать тот же базовый трек тайлов для восстановления битового потока на основе набора MCTS, принятого из других исходных битовых потоков, каждый битовый поток инкапсулируют в отдельный файл, и для всех треков тайлов с одинаковым местоположением в сетке тайлов используют один и тот же идентификатор во всех файлах. На основе каждой последовательности ограниченных по движению наборов тайлов формируют треки тайлов HEVC, а также дополнительно формируют базовый трек тайлов. Клиент выполняет синтаксический анализ базового трека тайлов, чтобы неявно восстановить битовый поток на основе треков тайлов. Восстановленный битовый поток может быть декодирован декодером, поддерживающим формат HEVC.
[0231] Клиент может выбирать, какая из версий для каждого набора MCTS будет доставлена. Одного базового трека тайлов достаточно для комбинирования наборов MCTS из различных битовых потоков, поскольку во всех соответствующих треках тайлов используют одинаковые идентификаторы.
[0232] На фиг. 9а проиллюстрирован пример использования треков тайлов одинакового разрешения для потоковой передачи всенаправленного видео на основе тайлов. При формировании ограниченных по движению наборов тайлов использована сетка тайлов размера 4×2. Два битового потока HEVC, полученных из одинакового исходного контента, кодируют с различным качеством изображения и битрейтом. Каждый битовый поток инкапсулируют в отдельный файл, при этом каждую последовательность ограниченных по движению наборов тайлов включают в собственный трек тайлов, и в файл также добавляют базовый трек тайлов. Клиент выбирает качество, с которым принимает каждый трек тайлов, в зависимости от ориентации просмотра. В данном примере клиент принимает треки 1, 2, 5 и 6 тайлов с одним уровнем качества, и треки 3, 4, 7 и 8 тайлов с другим уровнем качества. Базовый трек тайлов используют для размещения принятых данных треков тайлов в битовый поток, который может быть декодирован декодером HEVC.
[0233] Еще один вариант доставки всенаправленного видео, зависящего от окна просмотра, - применение масштабируемого кодирования области интереса при помощи расширения масштабируемости HEVC (SHVC). При таком подходе базовый уровень кодируют обычным образом. Дополнительно кодируют уточняющие уровне области интереса (ROI), с использованием профиля Scalable Main (основной масштабированный) SHVC. К примеру, для каждой позиции таила может кодироваться несколько уровней, каждый из которых соответствует отличающемуся битрейту или разрешению. Уточняющие уровни ROI могут быть уровнями пространственного масштабирования или масштабирования качества. Могут быть закодированы несколько битовых потоков SHVC, со значительно отличающимися битрейтами, поскольку можно ожидать что уже только для уточняющих уровней потребуется интенсивная адаптация битрейта. Такой подход к кодированию проиллюстрирован на фиг. 9b.
[0234] Базовый уровень принимают и декодируют всегда. В дополнение, принимают и декодируют уточняющие уровни (ELl, …, ELN), выбранные в зависимости от текущей ориентации просмотра.
[0235] Точки доступа к потоку (SAP) для уточняющих уровней предсказывают при помощи межуровневого предсказания на основе базового уровня, и, следовательно, они более компактны, чем в случае реализации точек SAP с помощью внутренне-предсказываемых изображений. Поскольку базовый уровень принимают и декодируют непрерывно, интервал между точками SAP в базовом уровне может быть длиннее, чем в уточняющих уровнях.
[0236] Подход, основанный на областях ROI в SHVC, может быть реализован без межуровневого предсказания (inter-layer prediction, ILP), в таком случае он называется не-ILP подходом.
[0237] При сравнении эффективности подхода на основе тайлов (см. фиг. 9а) и подхода на основе ROI SHVC (см. фиг. 9b) было выявлено, что битрейт при подходе ROI SHVC значительно ниже (в среднем более чем на 20%) по сравнению с битрейтом при подходе на основе тайлов. Соответственно, подход на основе ROI SHVC значительно более эффективен, чем доставка на основе наборов MCTS, зависимая от окна просмотра, в целях снижения битрейта, при этом реализация межуровневого предсказания позволяет повысить степень сжатия, по сравнению с отсутствием межуровневого предсказания.
[0238] Однако подход ROI SHVC обладает рядом недостатков. Межуровневое предсказание поддерживается только расширениями кодеков, например, расширением SHVC стандарта HEVC. Поддержка таких расширений кодеков в декодерах может быть не повсеместной, особенно в случае аппаратно-реализованных декодеров. При этом подход ROI SHVC, как и не-ILP подход, значительно повышают сложность декодирования, по сравнению с подходом на основе наборов MCTS. К примеру, если используют сетку размера 4×2, уточняющий уровень в подходе ROI SHVC, или в подходе без ILP, охватывает, как правило 2×2 тайлов сетки, т.е. поднимает сложность декодирования на 50%.
[0239] Еще один метод доставки всенаправленного видео в зависимости от окна просмотра называют ограниченным межуровневым предсказанием (CILP). CILP-предсказание проиллюстрировано на фиг. 10, где показано, каким образом входную последовательность изображений кодируют в два или более битовых потоков, каждый из которых является представлением всей входной последовательности изображений, т.е. в эти битовые потоки кодируют одни и те же входные изображения, или подмножество одних и тех же входных изображений, потенциально, с пониженной частотой смены кадров.
[0240] Выбирают часть входных изображений и кодируют каждое из них в два кодированных изображения в одном битовом потоке, первое из которых называют общим кодированным изображением (shared coded picture), а оба кодированных изображения могут называться общей парой кодированных изображений. Общее кодированное изображение кодируют либо с внутренним предсказанием, либо в качестве опорных для его предсказания используют только другие общие кодированные изображения (или соответствующие восстановленные изображения). Общее кодированное изображение в первом битовом потоке (из двух или более кодированных битовых потоков) идентично соответствующем общему кодированному изображению во втором битовом потоке (из двух или более кодированных битовых потоков), при этом «идентично» понимается как идентичность кодированного представления, возможно, не включая некоторые высокоуровневые синтаксические структуры, такие как сообщения SEI, и/или как идентичность восстановленных изображений. Любое изображение, следующее за каким-либо общим кодированным изображением в порядке декодирования не предсказывают на основе никаких изображений, предшествующих этому общему кодированному изображению и не являющихся общими кодированными изображениями.
[0241] Общие кодированные изображения могут помечаться как не выводимые (non-output) изображения. В ответ на декодирование указания на не выводимое изображение, декодер не выводит восстановленное общее кодированное изображение. Такой способ кодирования позволяет декодировать первый битовый поток вплоть до (не включая) выбранного общего кодированного изображения, и декодировать второй битовый поток, начиная с соответствующего общего кодированного изображения. Для того, чтобы начать декодировать второй битовый поток, не нужны никакие внутренне кодируемые изображения, и, следовательно, достигается повышенная, по сравнению с традиционными подходами, эффективность сжатия.
[0242] CILP-предсказание позволяют применять кодер и декодер, соответствующие профилю Main HEVC (основной профиль HEVC), и, следовательно, обеспечивает лучшую совместимость при практической реализации, чем подход с SHVC-кодированием ROI-областей. При этом CILP-предсказание также имеет дополнительное преимущество, заключающееся в пониженной частоте внутренне-предсказываемых изображений (аналогично подходу SHVC-кодирования ROI-областей). Однако по сравнению с подходом ROI SHVC, CILP-предсказание менее эффективно из-за применения MCTS-наборов для тайлов базового качества. Отношение «битовая скорость/искажения» для потоковой передачи при помощи CILP близко по значению SHVC-ROI при сравнительно грубых сетках тайлов (вплоть до 6×3). Однако при использовании более мелких сеток показатель «битовая скорость/искажения» становится хуже, чем у SHVC-ROI, предположительно из-за применения наборов MCTS для базового качества.
[0243] Соответственно, в различных ситуациях подходы SHVC-ROI и CILP-предсказания могут иметь преимущества друг перед другом, однако ни один из них не является однозначно более эффективным для всех возможных ситуаций.
[0244] Чтобы объединить преимущества обоих подходов, SHVC-ROI и CILP, был предложен способ кодирования, который называют ограниченным межуровневым предсказанием с пространственной упаковкой (spatially packed constrained inter-layer prediction, SP-CILP).
[0245] При SP-CILP-предсказании входную последовательность изображений кодируют в битовый поток таким образом, что область изображения оказывается разделенной на область первого составляющего изображения и первую область тайлов, которая не пересекается с областью изображения. Область составляющего изображения используют для размещения кодированных данных базового качества, а область тайлов используют для размещения тайлов повышенного качества. Чтобы было возможным предсказание тайлов повышенного качества на основе составляющего изображения базового качества, совпадающего с ними по времени, аналогично подходам SHVC-ROI и CILP, некоторые из входных изображений могут кодироваться в виде двух кодированных изображений. В первом из этих двух кодированных изображений область тайлов может быть пустой. Во втором из этих двух кодированных изображений область тайлов может быть предсказанной на основе составляющего изображения базового качества из первого кодированного изображения. Область составляющего изображения во втором кодированном изображении может быть либо пустой, либо кодироваться с использованием, в качестве опорного, первого кодированного изображения с нулевым движением и без ошибки предсказания («кодированный пропуск»).
[0246] На практике могут кодироваться несколько (по меньшей мере два) битовых потоков с различными выбранными тайлами повышенного качества, но с одинаковыми составляющими изображениями базового качества. К примеру, если используют сетку тайлов размером 4×2, и для кодирования с повышенным качеством выбраны четыре таила, соответствующие ориентации просмотра, может быть необходимо кодирование около 40 битовых потоков для различных выборок тайлов повышенного качества. Интервал между IRAP-изображениями может быть выбран более длительным, чем интервал при кодировании входного изображения в виде двух кодированных изображений, описанном выше. НА фиг. 11а показан пример, где кодируют два битовых потока. На иллюстрации 'b' обозначает пустой тайл, например, в соответствии с предшествующим описанием, а «В-слайсы» включают по мере один В- или Р-слайс, но могут дополнительно включать и любые другие слайсы, например, I-, Р- или В-слайсы.
[0247] Кодирование входного изображения в виде двух кодированных изображений, в соответствии с приведенным выше описанием, позволяет сформировать точку переключения, в которой возможно переключение с одного битового потока на другой. Поскольку во всех битовых потоках составляющие изображения базового качества идентичны, то составляющее изображение базового качества в точке переключения может быть предсказано на основе предшествующего изображения (или изображений). В продолжение примера фиг. 11а, на фиг. 11b показан пример переключения с тайлов 1, 2, 5, 6 на тайлы 3, 4, 7, 8 повышенного качества в первой точке переключения, не являющейся IRAP-изображением.
[0248] В результате обеспечивается зависящая от окна просмотра доставка всенаправленного видео, при которой кодирование и декодирование может выполняться одноуровневым кодером/декодером, например, кодером/декодером, поддерживающим основной профиль (Main) стандарта HEVC. Соответственно, достигаются все преимущества, свойственные технологии CILP. При этом изображения с внутренним предсказанием для базового качества кодируют нечасто, с обеспечением, однако, достаточно частых возможностей переключения окна просмотра, сохраняя преимущества обоих подходов, SHVC-ROI и CILP. С другой стороны, удается избежать применения MCTS-наборов для базового качества, что повышает эффективность сжатия при кодировании базового качества, аналогично SHVC-ROI. Также, аналогично SHVC-ROI, обеспечивается повышенное отношение «битовая скорость/искажения».
[0249] Однако, при подходе SP-CILP, величины пространственно смежных и/или совпадающих по времени векторов движения в тайлах повышенного качества могут значительно отличаться друг от друга. При предсказании на основе векторов движения предпочтительно более плавное поле движения. При этом количество кодируемых битовых потоков, необходимых для SP-CILP, пропорционально количеству различных комбинаций выбора тайлов высокого разрешения или высокого качества, соответственно. Для последовательности составляющих изображений базового качества необходимо хранить только один файл, однако для каждой пары из позиции таила в исходном изображении и позиции таила в экстракторном треке необходим свой трек тайлов. Также, тайлы повышенного качества для кодирования SP-CILP выбирают на основе прогнозируемого (максимального) поля зрения, которое должно поддерживаться в устройствах, отображающих окна просмотра. Если поля зрения для поддерживаемых окон просмотра услуги допускают большие вариации, необходимо формировать дополнительные кодированные данные для полей зрения различных окон просмотра.
[0250] Ниже описан улучшенный способ обеспечения доставки всенаправленного видео, зависящей от окна просмотра, и/или обеспечения многоракурсного видеокодирования.
[0251] Способ, проиллюстрированный на фиг. 12, включает кодирование (1200) входной последовательности с получением кодированного составляющего изображения; восстановление (1202), в качестве части упомянутого кодирования, декодированного составляющего изображения, соответствующего кодированному составляющему изображению; кодирование (1204) пространственной области в кодированный тайл, включающее: определение (1204а) горизонтального смещения и вертикального смещения, указывающих, для областей, якорную позицию пространственной области внутри декодированного составляющего изображения; кодирование (1204b) горизонтального смещения и вертикального смещения; определение (1204с) того, что пакет предсказания в позиции первой горизонтальной координаты и первой вертикальной координаты упомянутого кодированного таила предсказывают относительно якорной позиции области, при этом первая горизонтальная координата и первая вертикальная координата являются горизонтальной и вертикальной координатой, соответственно, внутри упомянутой пространственной области; указание (1204d) на то, что упомянутый пакет предсказания предсказывают относительно якорной позиции пакета предсказания, то есть относительно якорной позиции области; вычисление (1204е) якорной позиции пакета предсказания, равной сумме упомянутых первой горизонтальной координаты и горизонтального смещения, и упомянутых первой вертикальной координаты и вертикального смещения, соответственно; определение (1204f) вектора движения упомянутого пакета предсказания; и применение (1204g) упомянутого вектора движения относительно якорной позиции пакета предсказания с получением блока предсказания.
[0252] В одном из вариантов осуществления настоящего изобретения, которое применимо для доставки всенаправленного видео, зависящей от окна просмотра, упомянутая пространственная область происходит из входного изображения, при этом якорная позиция области соответствует позиции пространственной области внутри входного изображения.
[0253] В результате кодируют одну или более версий одного и того же контента, которые отличаются, например, битрейтом. Кодированные изображения содержат составляющее изображение, представляющее собой все поле зрения в контенте. Составляющее изображение может, например, включать изображение равнопрямоугольной проекции, представляющее собой целую сферу. В этом контексте составляющее изображение может называться составляющим изображением базового качества или общим составляющим изображением, поскольку имеются несколько версий одного и того же контента. Во всех версиях общее составляющее изображение может иметь идентичное кодовое представление, и, следовательно, общее составляющее изображение будет идентичным, независимо от того, какую из кодированных версий декодируют.
[0254] Кодированные изображения дополнительно содержат тайлы одного и того же контента, которые могут присутствовать, но не являются необходимыми для отображения всего поля зрения в контенте. Тайлы имеют, как правило, повышенное по сравнению с соответствующим общим составляющим изображением качество.
[0255] В одном из вариантов осуществления настоящего изобретения, который может применяться для многоракурсного видеокодирования, упомянутая пространственная область происходит из второго входного изображения, которое представляет собой ракурс, отличающийся от упомянутого входного изображения. Эта пространственная область, например, может включать второе входное изображение полностью. Якорная позиция области может быть определена, например, на основе среднего или глобального расхождения между упомянутым входным изображением и вторым входным изображением. Якорная позиция области может, например, соответствовать позиции упомянутой пространственной области во входном изображении, если контент пространственной области находится на дистанции фона или на средней дистанции сцены. Такой вариант осуществления настоящего изобретения позволяет повысить эффективность сжатия, когда межракурсное предсказание многоракурсного видео с упаковкой кадров реализуют при помощи предсказания с внутренним копированием блоков. В частности, если в текущем блоке предсказания, выбрано межракурсное предсказание, и нет ни одного смежного блока, для которого бы применялось межракурсное предсказание (и во всех из них используют временное предсказание или внутреннее предсказание), предложенный вариант осуществления настоящего изобретения с большой вероятностью позволяет снизить разность необходимых векторов движения, а значит, повысить степень сжатия.
[0256] В одном из вариантов осуществления настоящего изобретения, который может применяться для любого видеокодирования, упомянутая пространственная область является вторым входным изображением, которое представляет собой другой момент времени, отличающийся от упомянутого исходного изображения. Упомянутое составляющее изображение может кодироваться в виде первого кодированного изображения, а упомянутая пространственная область может кодироваться в виде второго кодированного изображения. Якорная позиция области может быть определена, например, на основе среднего или глобального перемещения между упомянутым входным изображением и вторым входным изображением. К примеру, в случае панорамирования камеры, якорная позиция области может соответствовать, например, амплитуде и направлению панорамирования между входными изображениями. Такой вариант осуществления настоящего изобретения позволяет повысить эффективность сжатия. Следует отметить, что упомянутые горизонтальное смещение и/или вертикальное смещение могут лежать вне границ составляющего изображения, при этом якорные позиции пакетов предсказания также могут лежать вне границ составляющего изображения.
[0257] Ниже будут описаны некоторые из вариантов осуществления настоящего изобретения с применением таких терминов как общее составляющее изображение и/или тайлы повышенного качества. Эти термины относится к варианту осуществления настоящего изобретения, связанному с доставкой, зависящей от окна просмотра, однако при этом нужно понимать, что рассмотренные варианты осуществления настоящего изобретения могут с равной эффективностью использоваться и в других сценариях применения, например, в вариантах осуществления настоящего изобретения, относящихся к многоуровневому кодированию, если эти термины заменить на более общие (например, «составляющее изображение» вместо «общего составляющего изображения» и/или «кодированный тайл» вместо таила повышенного качества). Нужно также понимать, что варианты осуществления настоящего изобретения могут подходить и для других сценариев применения, не описанных в данном документе.
[0258] Определим якорную позицию вектора движения как позицию (например, координаты по горизонтали и вертикали) внутри области изображения, относительно которой применяют вектор движения. Традиционно якорная позиция вектора движения совпадает с позицией пакета предсказания, для которого сформирован этот вектор движения.
[0259] В одном из вариантов осуществления настоящего изобретения кодирование составляющего изображения ограничено, то есть не допускается, чтобы векторы движения отсылали к отсчетам вне кодированного составляющего изображения (или соответствующего декодированного составляющего изображения) в процедура предсказания. В остальном кодирование и декодирования кодированных составляющих изображений может выполняться обычным образом.
[0260] В одном из вариантов осуществления настоящего изобретения ссылки при кодировании составляющего изображения могут вести вовне границ изображения, однако при этом они ограничены так, чтобы векторы движения не отсылали к отсчетам внутри границ изображения, но вне границ составляющего изображения. В остальном кодирование и декодирования кодированных составляющих изображений может выполняться обычным образом.
[0261] На фиг. 13 проиллюстрирована одна из возможных схем кодирования, в которой кодирование и декодирование тайлов (пронумерованных с 1 по 8 в описанном выше чертеже) выполняют описанным ниже образом.
[0262] Когда разрешено использование смещения якорной позиции, горизонтальное смещение и вертикальное смещение для якорной позиции (tile_ref_x, tile_ref_y) задают в заголовке слайса, в наборе параметров слайса, в заголовке таила, в наборе параметров таила или в подобной структуре, при этом tile_ref_x и tile_ref_y указывают на верхний левый угол таила внутри общего составляющего изображения. В общем случае tile_ref_x и tile_ref_y могут указывать на любое заранее заданное или указываемое опорное местоположение, например, на центральную точку таила внутри общего составляющего изображения, при этом tile_ref_x, tile_ref_y могут быть ограничены так, чтобы указывать на местоположение внутри общего составляющего изображения, однако в общем случае, они могут указывать и на местоположение вне границ общего составляющего изображения.
[0263] То, что tile_ref_x и tile_ref_y заданы относительно верхнего левого угла изображения, включающего общее составляющее изображение, может быть заранее определено, например, в стандарте кодирования, или кодироваться кодером в битовый поток и/или декодироваться декодером из битового потока. В этом случае кодер может выбирать значения tile_ref_x, tile_ref_y, и возможно, других параметров, таким образом, что tile_ref_x и tile_ref_y указывают на левый верхний угол таила, внутри общего составляющего изображения. Альтернативно, tile_ref_x, tile_ref_y могут задаваться относительно опорного местоположения для общего составляющего изображения, при этом опорное местоположение может указываться кодером в битовом потоке и/или декодироваться декодером из битового потока, или вычисляться в кодере и/или декодере.
[0264] Для указания местоположений и/или протяженностей внутри общего составляющего изображения или в изображениях, содержащих общее составляющее изображение, может быть заранее задана, или указываться, некоторая система координат. В данном примере подразумевается, что система координат имеет начало в левом верхнем углу общего составляющего изображения или изображения, содержащего общее составляющее изображение, то есть, координаты увеличиваются по горизонтали вправо, а по вертикали - вниз. Следует понимать, что варианты осуществления настоящего изобретения может быть с той же эффективностью быть реализованы с системами координат других типов.
[0265] Допустим левый верхний угол таила в изображении имеет позицию (tile_x, tile_у). Пусть левый верхний угол текущего пакета предсказания имеет первую горизонтальную координату и первую вертикальную координату (rel_x, rel_y) относительно левого верхнего угла текущего таила. Следовательно, якорная позиция вектора движения при традиционном подходе будет следующей: (tile_x + rel_x, tile_y + rel_y). Кодер может указывать, например, в кодированном блоке предсказания, и/или декодер может декодировать, например, из кодированного пакета предсказания, что якорная позиция вектора движения для данного пакета предсказания задана равной (tile_ref_x + rel_x, tile_ref_y + rel_y).
[0266] Сигнализация горизонтального и вертикального смещений позволяет размещать тайлы в любых местоположениях внутри кодированных изображений, декодирование которых выполняют. Другими словами, тайлы в кодированных изображениях не обязательно должны находиться в тех же позициях, что и в кодированных изображениях, которые декодируют. Это позволяет избирательно восстанавливать битовые потоки из тайлов в соответствии с описанием в дополнениях к файловому формату. Таким образом, количество кодируемых битовых потоков и хранимых треков тайлов повышенного качества может быть снижено по сравнению с SP-CILP.
[0267] В соответствии с одним из вариантов осуществления настоящего изобретения, когда опорным изображением является текущее изображение (т.е., когда используют внутреннее копирование блоков) и вектор движения равен (0, 0), якорную позицию вектора движения задают равной (tile_ref_x + rel_x, tile_ref_y + rel_y). Следовательно, блоком предсказания будет блок в общем составляющем изображении, который пространственно совпадает с текущим блоком. Можно сказать, что это аналогично межуровневому предсказанию отсчетов в масштабируемом видеокодировании.
[0268] Указание на то, что следует использовать якорную позицию вектора движения, равную (tile_ref_x + rel_x, tile_ref у + rel_y), может выполняться различными способами. В соответствии с одним из вариантов осуществления настоящего изобретения, кодер указывает, например, с помощью флага, для слайса или таила, что механизм смещения якорной позиции векторов движения должен применяться для всех векторов движения в слайсе или в тайле, соответственно. Аналогично, в соответствии с одним из вариантов осуществления настоящего изобретения, декодер декодирует, например, из флага для слайса или таила, что механизм смещения якорной позиции векторов движения должен применяться для всех векторов движения в слайсе или в тайле, соответственно.
[0269] В соответствии с одним из вариантов осуществления настоящего изобретения, кодер указывает, например, с помощью флага, для слайса или таила, что механизм смещения якорной позиции векторов движения должен применяться для всех векторов движения, используемых для внутреннего копирования блоков, в слайсе или в тайле соответственно. В соответствии с одним из вариантов осуществления настоящего изобретения декодер декодирует, например, из флага для слайса или таила, что механизм смещения якорной позиции векторов движения должен применяться для всех векторов движения, используемых для внутреннего копирования блоков, в слайсе или в тайле, соответственно.
[0270] В соответствии с одним из вариантов осуществления настоящего изобретения, кодер указывает, например, с помощью флага, для слайса или таила, что механизм смещения якорной позиции векторов движения должен применяться для всех векторов движения, используемых для временного предсказания, в слайсе или в тайле, соответственно. В соответствии с одним из вариантов осуществления настоящего изобретения, декодер декодирует, например, из флага для слайса или таила, что механизм смещения якорной позиции векторов движения должен применяться для всех векторов движения, используемых для временного предсказания, в слайсе или в тайле, соответственно.
[0271] В соответствии с одним из вариантов осуществления настоящего изобретения, кодер указывает на то, что механизм смещения якорной позиции векторов движения активирован, например, на уровне слайса или таила. Определение, применяется ли смещение якорной позиции векторов движения, при этом может выполняться, например, для каждого пакета предсказания. Аналогично, в соответствии с одним из вариантов осуществления настоящего изобретения, декодер декодирует, например, из заголовка слайса или таила, что механизм смещения якорной позиции векторов движения активирован. Декодер может декодировать, например, для каждого пакета предсказания, применяется ли смещение якорной позиции векторов движения.
[0272] В соответствии с одним из вариантов осуществления настоящего изобретения, кодер указывает, применяется ли смещение якорной позиции векторов движения, например, в пакете кодирования или в блоке предсказания. Это указание может быть, например, флагом, кодированным при помощи С ABAC. Аналогично, в соответствии с одним из вариантов осуществления настоящего изобретения, декодер декодирует, например, из кодового пакета и/или пакета предсказания, применяется ли смещение якорной позиции векторов движения.
[0273] В соответствии с одним из вариантов осуществления настоящего изобретения, кодер указывает на то, что пакет предсказания должен предсказываться относительно якорной позиции, которая задана относительно горизонтального и вертикального смещения, с определением вектора движения таким образом, чтобы он вызывал использование, для вычисления блока предсказания, по меньшей мере одного отчета вне таила. В соответствии с одним из вариантов осуществления настоящего изобретения декодер при декодировании определяет, что вектор движения вызывает использование, при вычислении блока предсказания, по меньшей мере одного отсчета вне таила, и в результате определяет, что пакет предсказания должен предсказываться относительно якорной позиции, которая задана относительно горизонтального и вертикального смещений. Применение таких вариантов осуществления настоящего изобретения позволяет векторам движения ссылаться за пределы границ таила, что повышает степень сжатия.
[0274] В соответствии с одним из вариантов осуществления настоящего изобретения, когда упомянутое указание указывает на то, что смещение якорной позиции активировано, и опорным изображением является текущее изображение (т.е., когда используют внутреннее копирование блоков), и при этом вектор движения таков, что при вычислении блока предсказания ссылки осуществляются на еще не кодированные или не декодированные отсчеты, якорную позицию вектора движения задают равной (tile_ref_x+rel_x, tile_ref_y+rel_y).
[0275] На существующем уровни техники тайлы могут кодироваться параллельно (например, различными ядрами процессора), а во многих случаях - и декодироваться параллельно. В вариантах осуществления настоящего изобретения (в особенности в тех, где применяют внутреннее копирование блоков), где используют вектора движения, ссылающиеся на общее составляющее изображение из таила повышенного качества, общее составляющее изображение и тайл должны кодироваться и декодироваться в заданной последовательности. При этом, однако, может требоваться параллельное кодирование или декодирование нескольких тайлов повышенного качества.
[0276] В соответствии с одним из вариантов осуществления настоящего изобретения кодер указывает на то, что требуется последовательное декодирование тайлов, например, в наборе параметров изображения и/или в наборе параметров последовательности. В соответствии с одним из вариантов осуществления настоящего изобретения, декодер декодирует, что требуется последовательное декодирование тайлов, например, из набора параметров изображения и/или из набора параметров последовательности.
[0277] В соответствии с одним из вариантов осуществления настоящего изобретения, каждый тайл ассоциирован с одним кластером тайлов из двух или более кластеров тайлов. Тайлы внутри одного кластера тайлов могут декодироваться параллельно. Порядок декодирования кластеров тайлов является заданным.
[0278] В соответствии с одним из вариантов осуществления настоящего изобретения тайлы ассоциируют с кластерами тайлов заранее заданным образом. К примеру, крайний левый тайл в каждой строке тайлов может относиться к первому кластеру тайлов, а все остальные тайлы - ко втором кластеру. Первый кластер файлов должен декодироваться перед вторым кластером тайлов.
[0279] В соответствии с одним из вариантов осуществления настоящего изобретения, кодер кодирует указание, например, флаг или указатель, для каждого таила, при этом упомянутое указание указывает на кластер тайлов, к которому относится тайл. В одном из вариантов осуществления настоящего изобретения, декодер декодирует указание, например, флаг или указатель, в каждом тайле, при этом упомянутое указание указывает на кластер тайлов, к которому относится тайл. Такое указание может располагаться, например, в заголовке слайса, в заголовке таила, в наборе параметров изображения и/или в наборе параметров последовательности.
[0280] В соответствии с одним из вариантов осуществления настоящего изобретения, общее составляющее изображение может иметь плотность дискретизации, отличающуюся от плотности дискретизации тайлов. То есть, при получении блока предсказания может быть необходимо изменение частоты дискретизации. Один из примеров показан на фиг. 14, где тайлы являются частями первого 360-градусного равнопрямоугольного изображения, а общее составляющее изображение является вторым 360-градусным равнопрямоугольным изображением, разрешение которого по горизонтали и по вертикали в два раза меньше, чем у первого равнопрямоугольного изображения.
[0281] В соответствии с одним из вариантов осуществления настоящего изобретения кодер кодирует в битовый поток информацию, указывающую на отношение разрешений дискретизации между общим составляющим изображением и тайлом (или тайлами). Аналогично, в соответствии с одним из вариантов осуществления настоящего изобретения, декодер декодирует из битового потока информацию, указывающую на отношение разрешений дискретизации между общим составляющим изображением и тайлом (или тайлами).
[0282] В соответствии с одним из вариантов осуществления настоящего изобретения позицию (rel_x, rel_y) пакета предсказания, для получения якорной позиции, масштабируют в соответствии с отношением разрешений дискретизации.
[0283] В соответствии с одним из вариантов осуществления настоящего изобретения кодированный или декодированный вектор движения, чтобы получить блок предсказания, затем масштабируют в соответствии с отношением разрешений дискретизации. Однако вектор движения без подобного масштабирования хранят в поле движения, которое используют для ссылок. Это позволяет сохранить единое поле движения, и, следовательно, повысить вероятность наличия подходящих кандидатных предсказаний.
[0284] В соответствии с одним из вариантов осуществления настоящего изобретения, исходный блок для получения блока предсказания определяют путем применения вектора движения относительно якорной позиции. В данном примере вектор движения и якорная позиция могут быть масштабированы в соответствии с приведенным выше описанием. Пропорции размера исходного блока относительно размера блока предсказания могут быть выбраны равными отношению разрешений дискретизации. Для получения блока предсказания исходный блок может быть передискретизирован в соответствии с отношением разрешений дискретизации.
[0285] В соответствии с одним из вариантов осуществления настоящего изобретения, пакет предсказания разбивают на пакеты движения, которые, например, могут содержать 4x4 отсчетов. Вектор движения для каждого пакета движения может быть вычислен на основе вектора движения пакета предсказания в соответствии с отношением разрешений дискретизации. К примеру, если отношение разрешений указывает на то, что интервал между отсчетами в общем составляющем изображении в два раза меньше, чем в тайлах, как по горизонтали, так и по вертикали, а вектор движения равен (4, 4) в блоках отсчетов, векторы движения для блоков движения могут быть вычислены как равные (2, 2). Для каждого пакета движения отдельно получают якорную позицию и блок предсказания. Якорная позиция может быть вычислена как равная (tile_x+rel_x * 0.5, tile_y + rel_y * 0.5), где 0,5 - отношение разрешений, а (rel_x, rel_y) - позиция пакета движения в файле.
[0286] В соответствии с одним из вариантов осуществления настоящего изобретения, кодер указывает на трансформацию или определяет трансформацию, которая должна быть применена к исходному блоку для получения блока предсказания, и затем применяет эту трансформацию. Аналогично, в соответствии с одним из вариантов осуществления настоящего изобретения декодер декодирует указание на трансформацию или определяет трансформацию, которая должна быть применена к исходному блоку для получения блока предсказания, и затем применяет эту трансформацию. Такой трансформацией может быть, например, поворот на 90, 180 или 270 градусов и/или зеркальное отображение по горизонтали и/или по вертикали. Например, в кодируемых и/или декодируемых изображениях общее составляющее изображение может быть повернуто на 90 градусов по сравнению с тайлами.
[0287] Термин «параметры движения области» может обозначать следующий набор: горизонтальное и вертикальное смещения для якорной позиции (tile_ref_x, tile_ref_y), отношение разрешений дискретизации между общим составляющим изображением и тайлом, если оно применимо, и трансформация, если таковая имеется, которую необходимо применить для исходного блока, происходящего из общего составляющего изображения, чтобы получить блок предсказания для кодирования/декодирования пакетов предсказания в файле.
[0288] В соответствии с одним из вариантов осуществления настоящего изобретения, пакет предсказания разбивают на пакеты движения, при этом вектор движения, применяемый для первого пакета движения, отсылает только к отсчетам внутри таила, а второй блок движения предсказывают относительно якорной позиции, которую задают относительно горизонтального и вертикального смещений. Для каждого пакета движения отдельно получают якорную позицию и блок предсказания. Якорную позицию для первого пакета движения получают обычным образом, т.е. якорная позиция вектора движения остается позицией первого пакета движения. Якорную позицию для второго пакета движения назначают равной (tile_x + rel_x, tile_y + rel_y), где (rel_x, rel_y) - позиция пакета движения относительно текущего таила.
[0289] В соответствии с одним из вариантов осуществления настоящего изобретения кодер и/или декодер определяет, что используют нулевой вектор движения, когда применяют внутреннее копирование блоков, при помощи любого из описанного ниже.
- Кодер может предоставлять в битовом потоке, или декодер может декодировать из битового потока, указание на то, что механизм смещения якорной позиции векторов движения применяется для всех вектора движения при внутреннем копировании блоков в слайсе таила. В данном примере слайс может содержать кодированный тайл (как упоминалось в других вариантах осуществления настоящего изобретения) или слайс может содержаться в кодированным тайле (как упоминалось в других вариантах осуществления настоящего изобретения). Такое указание может располагаться, например, в заголовке таила в наборе параметров таила, в заголовке слайса, в наборе параметров слайса, в заголовке изображения, в наборе параметров изображения, в заголовке последовательности и/или в наборе параметров последовательности, которые применимы к слайсу или к тайлу.
- Кодер указывает на использование смещения якорной позиции векторов движения, например, в пакете кодирования или в блоке предсказания, и на то, что для этого кодового пакета или пакета предсказания должно использоваться внутреннее копирование блоков, соответственно, например, при помощи указателя на опорное изображение для текущего изображения. Аналогично, декодер декодирует указание на использование смещения якорной позиции векторов движения, например, из кодового пакета или пакета предсказания, и то, что для этого кодового пакета или пакета предсказания должно использоваться внутреннее копирование блоков, соответственно, например, если при декодировании определено, что указатель на опорное изображение для текущего изображения используют для упомянутого кодового пакета или пакета предсказания, соответственно.
[0290] В соответствии с одним из вариантов осуществления настоящего изобретения, в результате определения того, что при использовании внутреннего копирования блоков должен использоваться нулевой вектор движения, кодер не выполняет указания и/или декодер не выполняет декодирование синтаксических элементов, указывающих на выбранные кандидатные предсказания векторов движения или на разность векторов движения. Таким образом, предложенный вариант осуществления настоящего изобретения позволяет повысить эффективность сжатия.
[0291] В соответствии с одним из вариантов осуществления настоящего изобретения, когда кандидатным предсказанием является вектор движения при внутреннем копировании блоков, и для текущего пакета предсказания текущее изображение не используют в качестве опорного, кодер и/или декодер исключает кандидатное предсказание из списка кандидатных предсказаний. В данном примере режим предсказания и/или тип списка кандидатов не ограничен никаким конкретным режимом или типом, например, могут применяться режим AMVP или режим слияния HEVC, или аналогичный режим. Несмотря на описанное выше исключение векторов движения при внутреннем копировании блоков, список кандидатов, альтернативно, может быть получен в соответствии с приведенным ниже описанием.
[0292] В соответствии с одним из вариантов осуществления настоящего изобретения, когда кандидатным предсказанием является вектор движения при внутреннем копировании блоков, и для текущего пакета предсказания текущее изображение не используют в качестве опорного, кодер и/или декодер рассматривает кандидатное предсказание как недоступное для формирования списка кандидатных предсказаний. К примеру, если кандидатная пространственная позиция В0 среди потенциальных позиций сверху от текущего пакета предсказания содержит вектор движения для внутреннего копирования блоков, и для текущего пакета предсказания текущее изображение не используют в качестве опорного, Во считают недоступной и проверяют следующую потенциальную кандидатную позицию среди потенциальных позиций над текущим блоком предсказания, в соответствии с заранее заданным порядком.
[0293] В соответствии с одним из вариантов осуществления настоящего изобретения, описанное выше исключение или рассмотрение кандидатов в качестве недоступных при формировании списка кандидатных предсказаний применяют, только когда кодер и/или декодер определяет, что при внутреннем копировании блоков используют нулевой вектор движения, в соответствии с предшествующим описанием.
[0294] В таких вариантах осуществления изобретения маловероятные кандидатные предсказания не попадают в список кандидатных предсказаний, и следовательно, повышается вероятность того, что в список кандидатных предсказаний войдет подходящий кандидат для выбора кодером. Следовательно, такие варианты осуществления настоящего изобретения позволяют повысить эффективность сжатия.
[0295] В соответствии с одним из вариантов осуществления настоящего изобретения параметры движения области, например, tile_ref_x и tile_ref_y, могут указываться отдельно для различных типов предсказания или различных типов опорных изображений предсказания. К примеру, один набор параметров движения области может указываться для предсказания с внутренним копированием блоков, а другой набор параметров движения области может указываться для (временного) внешнего предсказания. В другом примере один набор параметров движения области может указываться для опорных изображений временного предсказания, а другой набор параметров движения области может указываться для опорных изображений межракурсного предсказания.
[0296] В соответствии с одним из вариантов осуществления настоящего изобретения параметры движения области, например, tile_ref_x и tile_ref_y, могут указываться отдельно для каждого опорного изображения. Кодер может, например, оценивать глобальный пространственный сдвиг между текущим изображением и опорным изображением, и компенсировать этот сдвиг, задавая соответствующие значения tile_ref_x и tile_ref_y. Кодер и декодер выбирают, какая пара значений tile_ref_x и tile_ref_y, будет использоваться, в зависимости от применяемого опорного изображения.
[0297] Варианты осуществления настоящего изобретения были описаны на примере тайлов, однако нужно понимать, что они могут применяться и для наборов тайлов. В таком случае тайлы внутри набора тайлов могут использоваться в обычных целях, например, для обеспечения параллельной обработки. Кодер может указывать, в битовом потоке, информацию о кластеризации тайлов в наборы тайлов и/или о разбиении изображений на наборы тайлов, а декодер может декодировать из битового потока информацию о кластеризации тайлов в наборы тайлов или о разбиение изображений на наборы тайлов.
[0298] В общем случае варианты осуществления настоящего изобретения могут применяться для любых блоков или областей, используемых для разбиения изображений, например, для одного или более из следующего: тайлы, слайсы, сегменты слайса или любые комбинации перечисленного. То есть, если в каком-либо варианте осуществления настоящего изобретения упоминается термин «тайл» или «тайл повышенного качества», такой вариант осуществления настоящего изобретения может быть применим и для других пространственных блоков. Аналогично, если в варианте осуществления настоящего изобретения упоминается термин «общее составляющее изображение» или «составляющее изображение», они также могут применяться и к другим пространственным блокам. Кодер может указывать в битовом потоке, какой пространственный блок ограничивает собой зону действия указанных и/или вычисляемых параметров движения области, и/или декодер может декодировать из битового потока, какой пространственный блок ограничивает собой действие указанных и/или вычисляемых параметров движения области.
[0299] В одном из вариантов осуществления настоящего изобретения зону действия параметров движения области определяют на основе синтаксической структуры, которая содержит параметры движения области. К примеру, если параметры движения области содержатся в заголовке слайса или в наборе параметров слайса, может быть определено, что зоной действия параметров движения области является соответствующий слайс.
[0300] В одном из вариантов осуществления настоящего изобретения, зону действия параметров движения области явно указывают в битовом потоке и/или декодируют из битового потока. К примеру, кодер, вместе с параметрами движения области, может указывать на прямоугольник, который определяет зону действия параметров движения области. Прямоугольник может быть указан, например, при помощи левого верхнего угла, ширины и высоты, или при помощи верхнего левого и нижнего правого углов. Координаты и длины сторон прямоугольника могут указываться с использованием заданной сетки разбиения, например, сетки тайлов или сетки CTU-блоков. Может предъявляться требование, чтобы прямоугольник состоял из целого числа пространственных блоков, например, целого числа тайлов и слайсов.
[0301] На фиг. 15 проиллюстрирован один из примеров организации контейнерного файла. Кодированный битовый поток может храниться в виде одного трека подизображений базового качества, который содержит общие составляющие изображения, и одного трека подизображений или тайлов для каждого таила повышенного качества. Для комбинирования тайлов повышенного качества может быть создан один экстракторный трек, охватывающий заданный диапазон ориентации просмотра. Экстракторный трек содержит ссылки на треки, отсылающие к треку подизображений базового качества и к выбранным трекам тайлов или подизображений повышенного качества. Отсчеты в экстракторном треке включают экстракторы, которые содержат конструкторы для извлечения данных из соответствующих треков. В другом примере экстракторный трек может содержать кодированные видеоданные общих составляющих изображения, а также экстракторы, которые включают конструкторы для извлечения данных из треков подизображений, или тайлов, содержащих тайлы повышенного качества.
[0302] В файл, например на уровне трека, могут быть включены метаданные для указания на характеристики экстракторных треков. Например, для описания отношений между областями в (де)кодированных изображениях и в изображениях, спроецированных на заданный формат проекции, например, равнопрямоугольной проекции, могут применяться метаданные упаковки областей.
[0303] Еще один набор экстракторных треков может быть сформирован для другого целевого поля зрения, включающего в себя максимальное количество окон просмотра; в данном примере он может обеспечивать экстракцию данных из шести тайлов повышенного качества (т.е. тайлов 1, 2, 5, 6, 7, 8).
[0304] В соответствии с одним из вариантов осуществления настоящего изобретения для множества версий битового потока создают собственные контейнерные файлы, в соответствии с иллюстрацией фиг. 16. Кодированные битовые потоки хранят в файле в виде треков тайлов или подизображений. Указывают на группы треков тайлов, или подизображений, которые являются альтернативами для экстракции. В каждой альтернативной группе экстракции (alternative-for-extraction group), треки тайлов, или подизображений, не обязательно представляют собой одну и ту же область упаковки, однако они имеют одинаковые размеры по высоте и ширине в пикселях. При этом идентификатор группы треков должен отличаться от всех идентификаторов треков. В данном примере для каждого файла формируют одну альтернативную группу экстракции, при этом указывают, что все треки тайлов повышенного качества являются членами этой альтернативной группы экстракции.
[0305] В файле создают экстракторный трек. Экстракторы конфигурируют так, чтобы они ссылались на трек базового качества и на альтернативную группу экстракции. Каждый отсчет в этом примере содержит шесть экстракторов, из которых два используют для извлечения данных из трека базового качества, а остальные четыре экстрактора ссылаются на данные из трека тайлов, или подизображений, повышенного качества, и могут быть обозначены а, b, с, d.
[0306] В одном из вариантов осуществления настоящего изобретения вместо хранения информации об упаковке областей в экстракторном треке, информацию об упаковке областей разбивают на две части, причем первая часть не содержит местоположения области упаковки, и ее хранят в треках тайлов или подизображений, а вторая часть содержит местоположение области упаковки, и ее хранят в экстракторном треке.
[0307] В соответствии с одним из вариантов осуществления настоящего изобретения, вместо хранения информации об упаковке областей в экстракторном треке, информацию об упаковке областей хранят в треках тайлов или подизображений, при этом местоположение и размер треков тайлов или подизображений в экстракторном треке, после разрешения (подстановки в него данных), указывают при помощи отдельного бокса, например, как некоторую группу треков. К примеру, может использоваться группа треков композиции подизображений. Если трек включает бокс TrackGroupTypeBox с треком типа композиции подизображений (т.е. (i.e., а SubPictureCompositionBox), значит этот трек относится к композиции треков, пространственная комбинация которых образует композиционные изображения. Визуальные треки, совместно помеченные как относящиеся к такой группе, представляют собой визуальный контент, который может быть отображен. Визуальные треки, помеченные как относящиеся к этой группе, не обязательно подходят для отображения отдельно, без наличия других треков, тогда как композиционные изображения могут быть отображены всегда. Композиционное изображение может быть получено путем пространственного упорядочивания выходных декодированных данных отчетов, выровненных по композиции, во всех треках, принадлежащей одной группе треков композиции подизображений. Бокс SubPictureCompositionBox содержит пространственное местоположение, ширину и высоту трека внутри композиционного изображения.
[0308] В соответствии с одним из вариантов осуществления настоящего изобретения в бокс SubPictureCompositionBox, например, при помощи функции записи в файл, включают следующую информацию: максимальный порядковый номер (max_index) и порядковый номер трека (track_index). Параметр max_index может иметь нулевое значение, это указывает, что композиционное изображение может быть получено на основе любого количества треков подизображений, max_index большее нуля означает, что композиционное изображение получают на основе треков подизображений, при этом порядковые номера треков находятся в диапазоне от 0 до max_index включительно. Значение max_index одинаково для всех треков в одной группе треков композиции подизображений, при этом track_index задает порядковый номер трека подизображений в группе треков композиции подизображений. Все треки, относящиеся к одной группе альтернатив (т.е. имеющие одинаковые ненулевое значение alternate_group) имеют одинаковое значение track_index. Значение track_index для трека А не может быть равно значению track_index для трека В, если трек А и трек В не принадлежат одной группе альтернатив. В соответствии с одним из вариантов осуществления настоящего изобретения синтаксический анализатор файлов, или аналогичная функция, определяет, имеются ли пропуски в значениях track_index в диапазоне от 0 до max_index Если они обнаружены, значит, что часть треков подизображений не была принята, и может быть сделан вывод о том, что композитные изображения не смогут быть восстановлены корректно.
[0309] В соответствии с одним из вариантов осуществления настоящего изобретения, преселекции (preselections) всенаправленного видео могут указываться в контейнерном файле и/или в описании MPD, например, с использованием функций преселекции стандарта DASH, при этом каждая преселекция задает комбинацию треков тайлов или подизображений. Каждая преселекция указывает, из каких отдельных треков подизображений или тайлов должны извлекаться данные. Могут указываться характеристики преселекции, например, в число которых может входить сегмент сферы, в котором обеспечивается повышенное качество.
[0310] В другой схеме, показанной на фиг. 17, группы треков-альтернатив для экстракции формируют из групп альтернатив, а не из треков. Другими словами, для групп альтернатив в целом указывают, что они являются членами альтернативной группы для экстракции.
[0311] При помощи рассмотренных выше вариантов осуществления настоящего изобретения, относящихся к созданию контейнерного файла, приемник может выбирать любую комбинацию из треков тайлов или подизображений для приема и декодирования совместно с соответствующим экстракторным треком. Таким образом, количество кодируемых битовых потоков и хранимых треков тайлов повышенного качества может быть значительно снижено по сравнению с SP-CILP.
[0312] Ниже будут более подробно описаны варианты осуществления настоящего изобретения, относящиеся к стереоскопическому контенту.
[0313] В соответствии с одним из вариантов осуществления настоящего изобретения векторы движения при внутреннем копировании блоков для блоков предсказания в тайлах предсказываемого ракурса могут ссылаться на соответствующий тайл независимого ракурса. Якорную позицию вектора движения для таких векторов движения вычисляют обычным образом, т.е. она остается равной позиции текущего пакета предсказания.
[0314] В соответствии с одним из вариантов осуществления настоящего изобретения, кодер указывает в битовом потоке на то, что кодированные изображения содержат контент из более чем одного ракурса, и указывает на структуру упаковки контента из различных ракурсов в декодированных изображениях. Когда вектор движения пакета предсказания во втором ракурсе ссылается только на отсчеты в первом ракурсе, кодер вычисляет якорную позицию вектора движения обычным образом, т.е. якорная позиция вектора движения остается равной позиции текущего пакета предсказания. В противном случае применяют описанные выше варианты осуществления настоящего изобретения.
[0315] В соответствии с одним из вариантов осуществления настоящего изобретения декодер декодирует из битового потока указание на то, что кодированные изображения содержат контент из более чем одного ракурса и указывает на структуру упаковки контента из различных ракурсов в декодированных изображениях. Когда вектор движения пакета предсказания во втором ракурсе ссылается только на отсчеты в первом ракурсе, декодер вычисляет якорную позицию вектора движения обычным образом, т.е. якорная позиция вектора движения остается равной позиции текущего пакета предсказания. В противном случае применяют описанные выше варианты осуществления настоящего изобретения.
[0316] В соответствии с одним из вариантов осуществления настоящего изобретения кодер указывает в битовом потоке, или декодер декодирует из битового потока, допустимую исходную область, или допустимый исходный тайл, или аналогичную информацию, для каждого из тайлов предсказываемого ракурса. Когда вектор движения ссылается только на отсчеты в разрешенной исходной области или в разрешенном исходном тайле, или в аналогичном элементе, тогда кодер или декодер вычисляют якорную позицию вектора движения традиционным образом, т.е. якорная позиция вектора движения остается равной позиции текущего пакета предсказания. В противном случае применяют описанные выше варианты осуществления настоящего изобретения.
[0317] На фиг. 18 проиллюстрирован один из примеров схемы стереоскопического кодирования. Стрелкой показан вектор движения для пакета предсказания в тайле R1 правого ракурса. Вектор движения ссылается только на тайл L1 левого ракурса, соответствующий тайлу R1. Допустим, что при декодировании стереоскопического контента, получают оба таила, L1 и R1, и значит зависимость их друг от друга при предсказании является допустимой. Такое предсказание можно рассматривать как аналогичное межракурсному. Кодер задает горизонтальное смещение и вертикальное смещение для якорной позиции (tile_ref_x, tile_ref_y), указывая на левый верхний угол таила внутри соответствующего общего составляющего изображения. К примеру, (tile_ref_x, tile_ref_y) для таила R1 указывает на относительную позицию R1 внутри правого составляющего изображения базового качества.
[0318] На фиг. 19 проиллюстрирован другой пример схемы стереоскопического кодирования. Здесь предполагается, что передаваемые тайлы повышенного качества охватывают окно просмотра, и, следовательно, предсказываемый ракурс базового качества (правый в данном примере) не нужен для отображения и негативно сказывается на отношении «битовая скорость/искажения». Этот пример аналогичен предыдущему, с тем отличием, что при задании горизонтального смещения и вертикального смещения якорной позиции (tile_ref_x, tile_ref_y) для тайлов предсказываемого ракурса кодер может, например, использовать глобальное, или среднее, значение различия между ракурсами для указания на относительную позицию таила внутри общего составляющего изображения.
[0319] На фиг. 20 проиллюстрирована блок-схема видеодекодера, подходящего для применения вариантов осуществления настоящего изобретения. На фиг. 20 показана структура двухуровневого декодера, однако нужно понимать, что те же операции декодирования могут аналогичным образом применяться в одноуровневом декодере.
[0320] Видеодекодер 550 включает первую секцию 552 декодера для базового уровня и вторую секцию 554 декодера для предсказываемого уровня. Блок 556 иллюстрирует демультиплексор, предназначенный для предоставления информации об изображениях базового уровня в первую секцию 552 декодера, а также для предоставления информации об изображениях предсказываемого уровня во вторую секцию 554 декодера. Р'n обозначены предсказанные представления блока пикселей изображения. D'n обозначены восстановленные сигналы ошибки предсказания. Блоки 705, 805 иллюстрируют предварительно восстановленные изображения (I'n). R'n обозначено окончательное восстановленное изображение. Блоками 703, 803 проиллюстрировано обратное преобразование (Т-1). Блоками 702, 802 проиллюстрированное обратное преобразование (Q-1). Блоками 700, 800 проиллюстрировано энтропийное декодирование (Е-1). Блоками 706, 806 проиллюстрирована память опорных кадров (reference frame memory, REM). Блоками 707, 807 проиллюстрировано предсказание (Р) (либо внутреннее, либо внешнее предсказание). Блоками 708, 808 проиллюстрирована фильтрация (F). Блоки 709, 809 могут использоваться для комбинирования декодированной информации ошибки предсказания с предсказанными изображениями базового или предсказываемого уровня, в результате чего получают предварительно восстановленные изображения (I'n). Предварительно восстановленные и прошедшие фильтрацию изображения базового уровня могут выводиться (710) из первой секции 552 декодера, а предварительно восстановленные и прошедшие фильтрацию изображения предсказываемого уровня могут выводиться (810) из второй секции 554 декодера.
[0321] Декодер может быть сконфигурирован для выполнения способа декодирования, соответствующего одному из аспектов настоящего изобретения. Способ декодирования, в соответствии с иллюстрацией фиг. 21, включает декодирование кодированного таила в декодированный тайл, при этом декодирование включает: декодирование (2100) горизонтального смещения и вертикального смещения; декодирование (2102) указания на то, что пакет предсказания в позиции первой горизонтальной координаты и первой вертикальной координаты кодированного таила предсказывают относительно якорной позиции пакета предсказания, то есть относительно упомянутых горизонтального смещения и вертикального смещения; вычисление (2104) якорной позиции пакета предсказания, равной сумме упомянутых первой горизонтальной координаты и горизонтального смещения, и упомянутых первой вертикальной координаты и вертикального смещения, соответственно; определение (2106) вектора движения упомянутого пакета предсказания; и применение (2108) упомянутого вектора движения относительно якорной позиции пакета предсказания, с получением блока предсказания.
[0322] Упомянутые горизонтальное смещение и/или вертикальное смещение могут указывать на местоположение вне декодируемого таила. Определение (2106) вектора движения для пакета предсказания может выполняться, например, при помощи декодирования вектора движения из кодированного таила.
[0323] В одном из вариантов осуществления настоящего изобретения способ декодирования дополнительно включает декодирование кодированного составляющего изображения в декодированное составляющее изображение, при этом вектор движения указывает на местоположение внутри декодированного составляющего изображения.
[0324] В одном из вариантов осуществления настоящего изобретения декодируемый тайл представляет собой подмножество контента, представленного в декодированном составляющем изображении. Декодируемый тайл может, например, иметь повышенную точность по сравнению с декодированным составляющим изображением. Упомянутые горизонтальное смещение и/или вертикальное смещение могут указывать на соответствие местоположения декодируемого таила относительно декодированного составляющего изображения.
[0325] В одном из вариантов осуществления настоящего изобретения способ декодирования дополнительно включает декодирование метаданных упаковки областей из кодированного таила и/или из кодированного составляющего изображения или вместе с ними, например, из файла, содержащего кодированный тайл и/или кодированное составляющее изображение, и определение, на основе метаданных упаковки областей, соответствия местоположения декодируемого таила относительно декодированного составляющего изображения. Соответствие местоположения, например, может определяться, на спроецированном изображении с заданным форматом проекции всенаправленного видео, или на сфере, на которую могут быть спроецированы декодированное составляющее изображение и декодируемый тайл.
[0326] В одном из вариантов осуществления настоящего изобретения способ декодирования дополнительно включает определение того, что декодируемый тайл используют при отображении, всякий раз, когда декодируемый тайл и декодированное изображение перекрываются, на основе соответствия их местоположений. Способ декодирования может, например, включать декодирование информации ранжирования качества областей, в которой содержится информация о ранжировании качества для областей декодируемых изображений, при этом области входят в декодируемый тайл и в декодированное составляющее изображение. Информация ранжирования качества областей может быть доступной в кодированном тайле и/или в кодированном составляющем изображении, или представляться вместе с ними, например, в файле, содержащем кодированный тайл и/или кодированное составляющее изображение. На основе декодированной информации ранжирования качества областей в способе декодирования может быть определено, что декодируемый тайл имеет более высокое качество, чем декодированное составляющее изображение, и следовательно декодируемый тайл используют при отображении всякий раз, когда декодируемый тайл и декодированное составляющее изображение перекрываются, на основе соответствия их местоположений.
[0327] В одном из вариантов осуществления настоящего изобретения декодируемый тайл представляет собой другой ракурс многоракурсного видео/изображения, отличающийся от декодированного составляющего изображения. Способ декодирования может включать декодирование информации, из кодированного таила и/или кодированного составляющего изображения, или сопровождающей их информации, о том, какие ракурсы они собой представляют, например, порядкового номера ракурса или указания на левый или правый ракурс в случае стереоскопического контента. К примеру, может декодироваться SEI-сообщение со схемой упаковки кадров в стандартах H.264/AVC или HEVC, и/или может декодироваться информация о ракурсе из метаданных упаковки областей.
[0328] В данном описании под декодером понимают любой функциональный блок, способный выполнять операции декодирования, например, это может быть проигрыватель, приемник, шлюз, демультиплексор и/или декодер.
[0329] Описанные операции декодирования могут выполняться с использованием одноуровневого кодека, например, кодека основного профиля (Main) HEVC, т.е. не требуются никакие расширения масштабирования. Применение общих составляющих изображений, описанных выше, позволяет получить ту же функциональность, что и при подходе SHVC-ROI, но с невысокой частотой IRAP-изображений в базовом уровне и сравнительно частыми IRAP-изображениями в уточняющих уровнях. Эта функциональность может применяться для обеспечения возможности частых переключений без значительного снижения отношения «битовая скорость/искажения».
[0330] Фиг. 22 является графическим представлением типовой системы мультимедийной связи, в которой могут быть реализованы различные варианты осуществления настоящего изобретения. В соответствии с иллюстрацией фиг. 8, источник 1510 данных предоставляет исходный сигнал в аналоговом, несжатом цифровом или сжатом цифровом формате, или в любой комбинации из этих форматов. Кодер 1520 может иметь в своем составе средства предварительной обработки, например, средства преобразования формата данных и/или средства фильтрации исходного сигнала, или может иметь соединение с таким средствами. Кодер 1520 кодирует исходный сигнал в кодированный битовый поток медиаданных. Следует отметить, что кодируемый битовый поток может приниматься, напрямую или опосредованно, от удаленного устройства, расположенного в сети практически любого типа. Также, битовый поток может приниматься от локального аппаратного или программного обеспечения. Кодер 1520 может быть способен кодировать более одного типа медиаданных, например, аудио- и видеоданные, или могут требоваться более одного кодера 1520 для кодирования различных типов исходного сигнала. Кодер 1520 может также получать входные данные, полученные при помощи синтеза, такие как графику или текст, или может быть способен формировать кодированные битовые потоки синтезированных медиаданных. Ниже, для простоты описания, будет рассмотрена обработка только одного кодированного битового потока, содержащего однотипные мультимедийные данные. Однако нужно отметить, что обычно сервисы вещания реального времени включают несколько потоков (как правило, по меньшей мере один аудиопоток, видеопоток и текстовый поток субтитров). Также, нужно отметить, что система может включать множество кодеров, однако на фиг. 8, для простоты описания, без потери общности, показан только один кодер 1520. Описание и примеры в настоящем документы описывают именно процедуру кодирования, однако при этом специалисты в данной области техники должны понимать, что те же самые принципы и идеи применимы и для соответствующей процедуры декодирования, и наоборот.
[0331] Кодированный битовый поток медиаданных может быть передан в хранилище 1530. Хранилище 1530 может включать любой тип запоминающего устройства большой емкости для хранения кодированного битового потока медиаданных. Формат кодированного битового потока медиаданных в хранилище 1530 может быть элементарным автономным форматом битового потока, или один или более кодированных битовых потоков медиаданных могут быть инкапсулированы в контейнерный файл, или кодированные медиаданные могут быть инкапсулированы в формат сегмента (Segment), подходящего для DASH или аналогичной системы потоковой передачи), и храниться в виде последовательности сегментов. Если один или более битовых потоков медиаданных инкапсулируют в контейнерный файл, может применяться формирователь файлов (не показан на чертеже) для сохранения одного или более битовых потоков медиаданных в файл и для формирования метаданных формата файла, которые также сохраняют в файл. Кодер 1520 и/или хранилище 1530 могут включать формирователь файлов, или же формирователь файлов может быть функционально связан кодером 1520 и/или хранилищем 1530. Некоторые системы работают «на лету», то есть не используют память и передают кодированный битовый поток медиаданных из кодера 1520 непосредственно в передатчик 1540. Затем кодированный битовый поток медиаданных передают, когда это необходимо, в передатчик 1540, также именуемый сервером. Формат, используемый при передаче, может быть элементарным автономным форматом битового потока, пакетным форматом потока, форматом сегментов (Segment), подходящих для DASH или аналогичной системы потоковой передачи, или один или более кодированных битовых потоков медиаданных могут быть инкапсулированы в контейнерный файл. Кодер 1520, хранилище 1530 и передатчик 1540 могут располагаться в одном и том же физическом устройстве, или же они могут входить в состав отдельных устройств. Кодер 1520 и сервер 1540 могут работать с данными реального времени, и в этом случае кодированный битовый поток медиаданных, как правило, не хранят на постоянной основе, а буферизуют в течение небольших промежутков времени в кодере 1520 видеоданных и/или на сервере 230 для сглаживания колебаний задержек на обработку, задержек на передачу и битрейта кодированных медиаданных.
[0332] Сервер 1540 передает кодированный битовый поток медиаданных с использованием стека протоколов связи. Стек может включать, без ограничения перечисленным, одно или более из следующего: протокол передачи в реальном времени (RTP), протокол пользовательских датаграмм (UDP), протокол передачи гипертекста (Hypertext Transfer Protocol, HTTP), протокол управления передачей (Transmission Control Protocol, TCP) и протокол Интернета (ГР). Когда стек протоколов связи является пакетным, сервер 1540 инкапсулирует кодированный битовый поток медиаданных в пакеты. Например, когда используется протокол RTP, сервер 1540 инкапсулирует кодированный битовый поток медиаданных в пакеты RTP согласно формату полезной нагрузки протокола RTP. Как правило, каждый тип медиаданных имеет отдельный формат полезной нагрузки RTP. Следует еще раз отметить, что система может содержать более одного сервера 1540, но для простоты в последующем описании рассмотрен только один сервер 1540.
[0333] Если мультимедийные данные инкапсулированы в контейнерный файл для хранилища 1530 или для ввода данных в передатчик 1540, передатчик 1540 может иметь в своем составе «анализатор передаваемого файла» (не показан на чертеже) или может быть функционально связан с подобным элементом. В частности, если контейнерный файл сам по себе не передают, но по меньшей мере один содержащийся в нем кодированный битовый поток медиаданных инкапсулируют для передачи по протоколу связи, анализатор передаваемого файла находит соответствующие фрагменты кодированного битового потока медиаданных, подлежащие передаче по протоколу связи. Анализатор передаваемого файла может также быть полезен при создании корректного формата для протокола связи, например, заголовков и полезной нагрузки пакетов. Мультимедийный контейнерный файл может содержать инструкции по инкапсуляции, такие как треки указаний в ISOBMFF, используемые для инкапсуляции по меньшей мере одного кодированного битового потока медиаданных в протокол связи.
[0334] Сервер 1540, опционально, может быть соединен со шлюзом 1550 по сети связи, которая может представлять собой, например, комбинацию из CDN, Интернета и/или одной или более сетей доступа. В дополнение или альтернативно, шлюз может называться промежуточным узлом. В случае DASH шлюз может быть пограничным сервером (сети CDN) или веб-прокси-сервером. Следует отметить, что в общем случае система может включать любое количество шлюзов или аналогичных элементов, однако для простоты в приведенном ниже описании рассмотрен только один шлюз 1550. Шлюз 1550 может выполнять функции различных типов, например трансляцию потока пакетов, соответствующую одному стеку протоколов связи, в другой стек протоколов связи, слияние и разветвление потоков данных и манипуляцию потоками данных согласно возможностям нисходящей линии связи и/или приемника, например, управление битовой скоростью передачи данных перенаправляемого потока согласно превалирующим сетевым условиям в нисходящей линии связи. Шлюз 1550 в различных вариантах осуществления настоящего изобретения может быть серверным объектом.
[0335] Система включает один или более приемников 1560, которые, в общем случае, способны принимать, демодулировать и/или декапсулировать переданный сигнал с получением кодированного битового потока медиаданных. Кодированный битовый поток медиаданных может быть передан в записывающее хранилище 1570. Записывающее хранилище 1570 может включать любой тип запоминающего устройства большой емкости для хранения кодированного битового потока медиаданных. Записывающие хранилище 1570 может, дополнительно или альтернативно, включать вычислительную память, например, память с произвольным доступом. Формат кодированного битового потока медиаданных в записывающем хранилище 1570 может быть элементарным автономны форматом битового потока, или один или более кодированных битовых потоков медиаданных могут быть инкапсулированы в контейнерный файл. Если имеются несколько кодированных битовых потоков медиаданных, например, аудиопоток и видеопоток, связанные друг с другом, то, как правило, применяют контейнерный файл, и при этом приемник 1560 содержит формирователь контейнерного файла (или связан с подобным формирователем), формирующий контейнерный файл на основе входных потоков. Некоторые системы работают «на лету», то есть передают кодированный битовый поток медиаданных из приемника 1560 непосредственно в декодер 1580, без задействования записывающего хранилища 1570. В некоторых системах в записывающем хранилище 1570 хранят только последнюю по времени часть записанного потока, например, последний 10-минутный фрагмент записанного потока, тогда как все ранее записанные данные удаляют из записывающего хранилища 1570.
[0336] Кодированный битовый поток медиаданных из записывающего хранилища 1570 может быть передан в декодер 1580. Если имеются несколько кодированных битовых потоков медиаданных, например, аудиопоток и видеопоток, связанные друг с другом и инкапсулированные в контейнерный файл, или один битовый поток, который инкапсулирован в контейнерный файл, например, для более простого доступа, то применяют анализатор файлов (не показан на чертеже) для декапсуляции всех кодированных битовых потоков медиаданных из контейнерного файла. Записывающее хранилище 1570 или декодер 1580 могут иметь анализатор файлов в своем составе, или анализатор файлов может быть связан с записывающим хранилищем 1570, или с декодером 1580. Также, нужно отметить, что система может включать множество декодеров, однако в данном документе, для простоты описания, без потери общности, показан только один кодер 1570.
[0337] Кодированный битовый поток медиаданных может далее обрабатываться декодером 1570, на выходе которого получают один или более несжатых потоков медиаданных. Наконец, устройство 1590 воспроизведения может воспроизводить несжатые потоки медиаданных, например, с помощью громкоговорителя или дисплея. Приемник 1560, записывающее хранилище 1570, декодер 1570 и устройство 1590 воспроизведения могут располагаться в одном и том же физическом устройстве, или же они могут входить в состав отдельных устройств.
[0338] Передатчик 1540 и/или шлюз 1550 могут быть сконфигурированы для выполнения переключения между различными репрезентациями, например, для переключения между различными окнами просмотра 360-градусного видеоконтента, переключения ракурсов, сшивки ракурсов, адаптации битрейта и/или быстрого запуска, и/или передатчик и/или шлюз 1550 могут быть сконфигурирован для выбора передаваемых репрезентаций. Переключение между различными репрезентациями может выполняться по множеству различных причин, например, в ответ на запрос от приемника 1560 или в зависимости от превалирующих условий в сети, по которой передают битовый поток, к примеру, ее пропускной способности. Другими словами, переключение между репрезентациями может быть инициировано приемником 1560. Запросом от приемника может быть, например, запрос сегмента или подсегмента из другой репрезентации, отличающейся от предыдущей, запрос на изменение передаваемых масштабируемых уровней и/или подуровней, или переключение на устройство воспроизведения, которое имеет отличающиеся, по сравнению с предыдущим, возможности. Запросом сегмента может быть запрос GET протокола HTTP. Запросом подсегмента может быть запрос GET протокола HTTP с некоторым байтовым диапазоном. В дополнение или альтернативно, коррекция битрейта или адаптация битрейта может применяться, например, для обеспечения так называемого быстрого запуска в сервисах потоковой передачи данных, где битрейт передаваемого потока ниже, чем битрейт канала после запуска или произвольного доступа к потоку, что позволяет мгновенно запустить воспроизведение и обеспечить лучший уровень заполнения буфера, допускающего случайные задержки и/или повторные передачи пакетов. Адаптация битрейта может включать операции переключения между различными репрезентациями или уровнями с повышением качества или переключения между различными репрезентациями или уровнями с понижением качества, выполняемые в различном порядке.
[0339] Декодер 1540 может быть сконфигурирован для выполнения переключения между различными репрезентациями, например, для переключения между различными окнами просмотра 360-градусного видеоконтента, переключения ракурсов, сшивки ракурсов, адаптации битрейта и/или быстрого запуска, и/или декодер 1580 могут быть сконфигурирован для выбора передаваемых репрезентаций. Переключение между различными репрезентациями может выполняться по множеству различных причин, например, для ускорение операции декодирования или для адаптации передаваемого битового потока, например, по битрейту, в зависимости от превалирующих условий в сети, по которой передают битовый поток, к примеру, ее пропускной способности. Повышение быстродействия операции декодирования может быть необходимо, например, если устройство, в состав которого входит декодер 1580, является многозадачным, и использует вычислительные ресурсы для других целей, а не только для декодирования битового потока видеоданных. В другом примере повышение быстродействия операции декодирования может быть необходимо, когда воспроизведение видеоданных выполняют с увеличенной скоростью (по сравнению с нормальной скоростью воспроизведения), например, в два или три раза быстрее, чем обычная скорость воспроизведения.
[0340] Выше часть вариантов осуществления настоящего изобретения была описана на примере стандарта HEVC и/или с использованием соответствующей терминологии. Нужно понимать, что варианты осуществления настоящего изобретения могут быть аналогичным образом реализованы с любым видеокодерами и/или видеодекодерами.
[0341] Выше часть вариантов осуществления настоящего изобретения была описана в терминах сегментов, например, определенные в MPEG-DASH. Нужно понимать, что варианты осуществления настоящего изобретения могут быть аналогичным образом реализованы с использованием подсегментов, например, также определенных в MPEG-DASH.
[0342] Выше некоторые из вариантов осуществления настоящего изобретения были описаны в отношении DASH или MPEG-DASH. Нужно понимать, что варианты осуществления настоящего изобретения могут быть аналогичным образом реализованы с использованием любой другой подобной системы потоковой передачи, и/или с использованием протоколов, аналогичных применяемым в DASH, и/или с использованием форматов сегментов и/или манифестов, аналогичным DASH, и/или клиентских операций, аналогичных операциям клиента DASH. К примеру, некоторые из вариантов осуществления настоящего изобретения могут быть реализованы с использованием формата манифеста M3U.
[0343] Выше некоторые из вариантов осуществления настоящего изобретения были описаны в отношении ISOBMFF, например, в том, что касается формата сегмента. Нужно понимать, что варианты осуществления настоящего изобретения могут быть аналогичным образом реализованы с использованием любых других форматов файлов, например, Matroska, имеющих возможности и/или структуры, сходные с ISOBMFF.
[0344] В приведенном выше описании, там, где примеры осуществления настоящего изобретения были описаны со ссылками на кодер, нужно понимать, что результирующий поток и декодер также могут включают соответствующие элементы. Аналогично, там, где примеры осуществления настоящего изобретения были описаны со ссылками на декодер, нужно понимать, что кодер может иметь структуру и/или компьютерную программу для формирования битового потока, декодируемого декодером. К примеру, часть вариантов осуществления настоящего изобретения была описана в связи с формированием пакета предсказания как части кодирования. Варианты осуществления настоящего изобретения могут быть аналогичным образом реализованы с формированием блока предсказания как части декодирования, с той разницей, что параметры кодирования, такие как горизонтальное смещение и вертикальное смещение, декодируют из битового потока, а не определяются кодером.
[0345] В рассмотренных выше вариантах осуществления настоящего изобретения кодек описан на примере отдельных устройств кодирования и декодирования - для упрощения понимания применяемых процедур. Однако нужно понимать, что аппаратура, структуры и операции могут быть реализованы в виде единого устройства/структуры/операции кодирования-декодирования. Также допускается, что кодер и декодер могут совместно использовать часть общих элементов, или что всех элементы могут быть общими.
[0346] Рассмотренные выше примеры описывают работу вариантов осуществления настоящего изобретения в кодеке из состава электронного устройства, однако нужно понимать, что настоящее изобретение, определенное приложенной формулой изобретения, может быть реализовано как часть любого видеокодека. Так, например, варианты осуществления настоящего изобретения могут быть реализованы в видеокодеке, в котором видеокодирование может быть реализовано по фиксированным, или проводным, каналам связи.
[0347] Соответственно, абонентское оборудование может включать в свой состав видеокодек, например, аналогичный рассмотренным в приведенном выше описании настоящего изобретения. Нужно понимать, что выражение «абонентское оборудование» используется как охватывающие любые подходящие типы беспроводного абонентского оборудования, например, мобильные телефоны, портативные устройства обработки данных или портативные веб-браузеры.
[0348] При этом элементы наземной сети мобильной связи общего пользования (public land mobile network, PLMN) также могут включать видеокодеки в соответствии с предшествующим описанием.
[0349] В общем случае различные варианты осуществления настоящего изобретения могут быть реализованы в виде аппаратного обеспечения или схем специального назначения, программного обеспечения, логики или какой-либо их комбинации. К примеру, некоторые из аспектов могут быть реализованы в виде аппаратного обеспечения, тогда как другие аспекты могут быть реализованы в виде микропрограммного или программного обеспечения, которое может исполняться контроллером, микропроцессором или иным вычислительным устройством, без ограничения настоящего изобретения перечисленным. Различные аспекты настоящего изобретения допускают иллюстрацию и описание в виде блок-схем, блок-схем алгоритмов или с помощью некоторых других наглядных представлений, но при этом нужно понимать, что блоки, устройства, системы, методы или способы, описанные в настоящем документе, могут быть реализованы, в качестве неограничивающих примеров, в виде аппаратного обеспечения, программного обеспечения, микропрограммного обеспечения, схем или логики специального назначения, аппаратного обеспечения или контроллера общего назначения, или же иных вычислительных устройств, или некоторой их комбинации.
[0350] Варианты осуществления настоящего изобретения могут быть реализованы с помощью программного обеспечения, исполняемого процессором данных мобильного устройства, например, процессорным элементом, или с помощью аппаратного обеспечения, или с помощью комбинации программного и аппаратного обеспечения. Также в этом отношении следует отметить, что любые блоки последовательностей логических операций, проиллюстрированные на чертежах, могут представлять собой шаги программы или взаимосвязанные логические схемы, блоки и функции, или комбинацию программных шагов и логических схем, блоков и функций. Программное обеспечение может храниться на таких физических носителях, как микросхемы памяти или блоки памяти, реализованные внутри процессора, магнитные носители, например, жесткий диск или гибкий диск, и оптические носители, например, DVD и их варианты для хранения данных, CD.
[0351] Память может относиться к любому типу, соответствующему локальному техническому окружению, при этом она может быть реализована с использованием любой подходящей технологии хранения данных, например, запоминающие устройства на полупроводниках, магнитные запоминающие устройства и системы, оптические запоминающие устройства и системы, несъемная или съемная память. Процессоры данных могут относиться к любому типу, соответствующему локальному техническому окружению и могут включать одно или более из следующего: компьютеры общего назначения, компьютеры специального назначения, микропроцессоры, цифровые сигнальные процессоры (digital signal processors, DSP), процессоры на основе многоядерной архитектуры - в качестве неограничивающих примеров.
[0352] Варианты осуществления настоящего изобретения могут применяться на практике в различных компонентах, например, в модулях интегральных схем. Процесс разработки интегральных схем, в целом, в высокой степени автоматизирован. Существуют сложные и мощные программные инструменты для преобразования проектов логического уровня в конструкции полупроводниковых схем, готовые для вытравливания и формовки на полупроводниковой подложке.
[0353] Программы, подобные поставляемой фирмой Synopsys, Inc (Маунтин-Вью, Калифорния) или фирмой Cadence Design (Сан-Хосе, Калифорния), осуществляют автоматическую разводку проводников и позиционирование компонентов на полупроводниковом кристалле с использованием общепринятых правил разработки, а также с использованием библиотек заранее сохраненных модулей проектов. По завершении разработки полупроводниковой схемы результирующая конструкция, в стандартизированном электронном формате (например, Opus, GDSII и т.п.) может быть передана на полупроводниковое производство для изготовления микросхемы.
[0354] В предшествующем изложении с помощью иллюстративных и неограничивающих примеров было обеспечено полное и информативное описание одного из примеров осуществления настоящего изобретения. Однако в свете предшествующего описания, рассматриваемого в сочетании с приложенными чертежами, специалистам в соответствующей области техники могут быть очевидны различные модификации и доработки. Тем не менее, любые такие или аналогичные им модификации концепции настоящего изобретения попадают в его рамки.
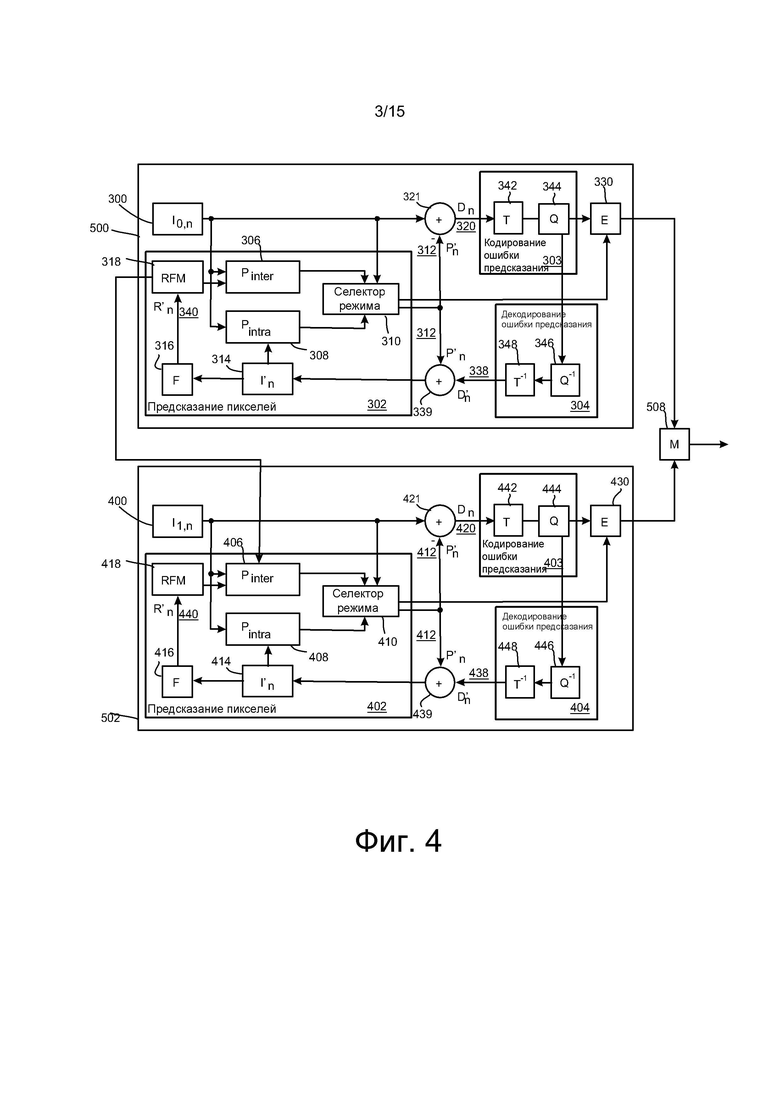
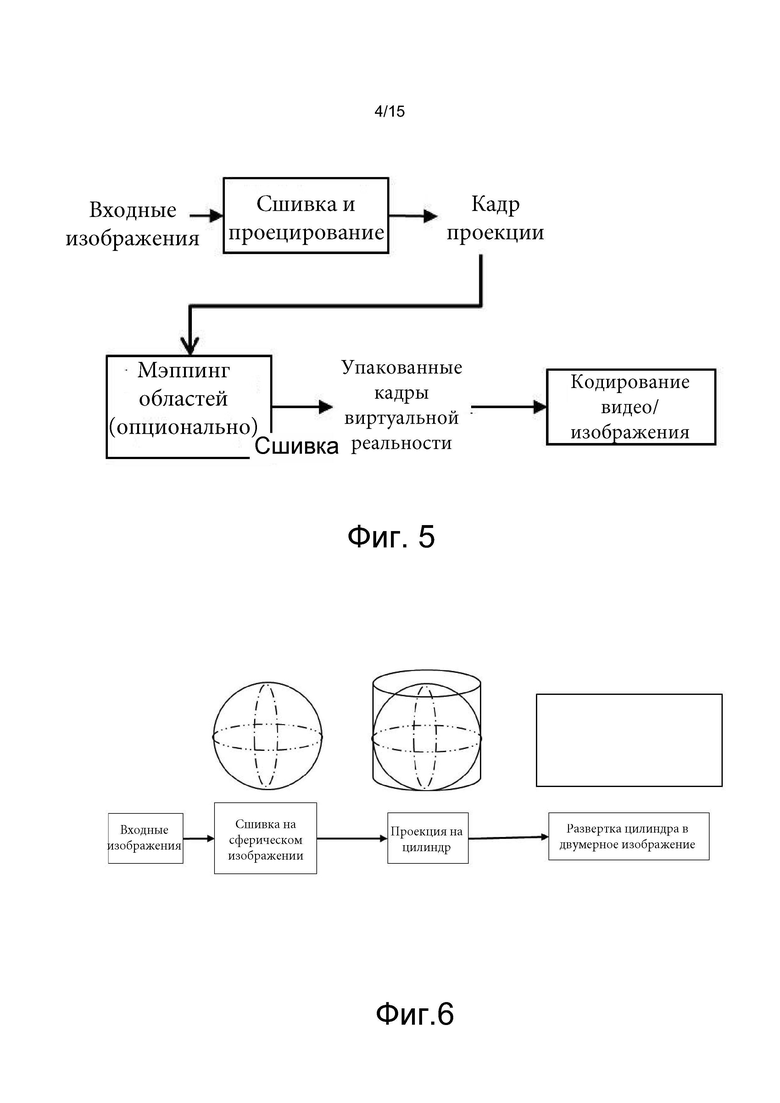
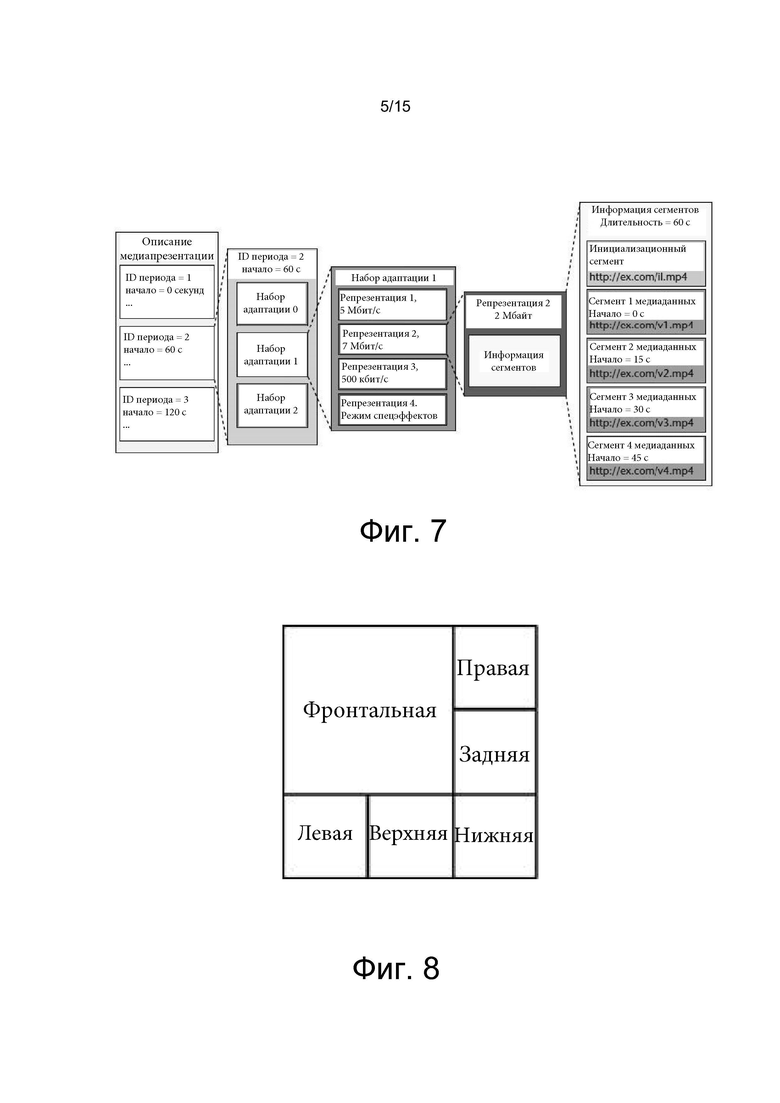
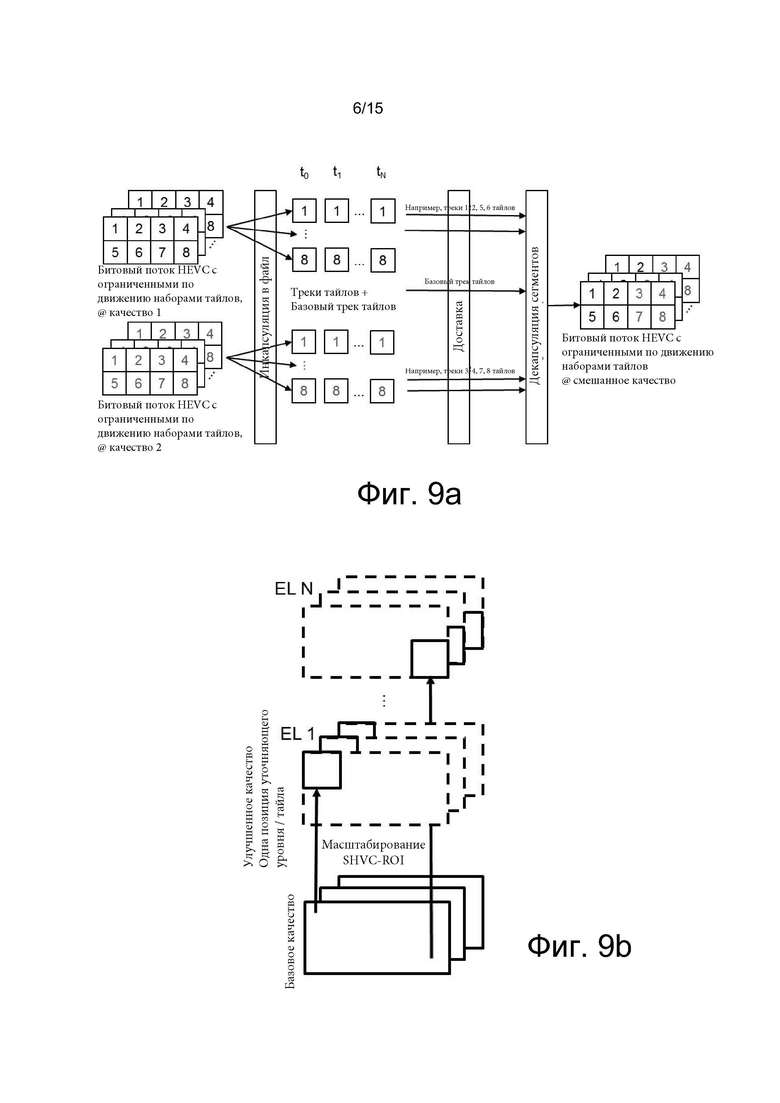
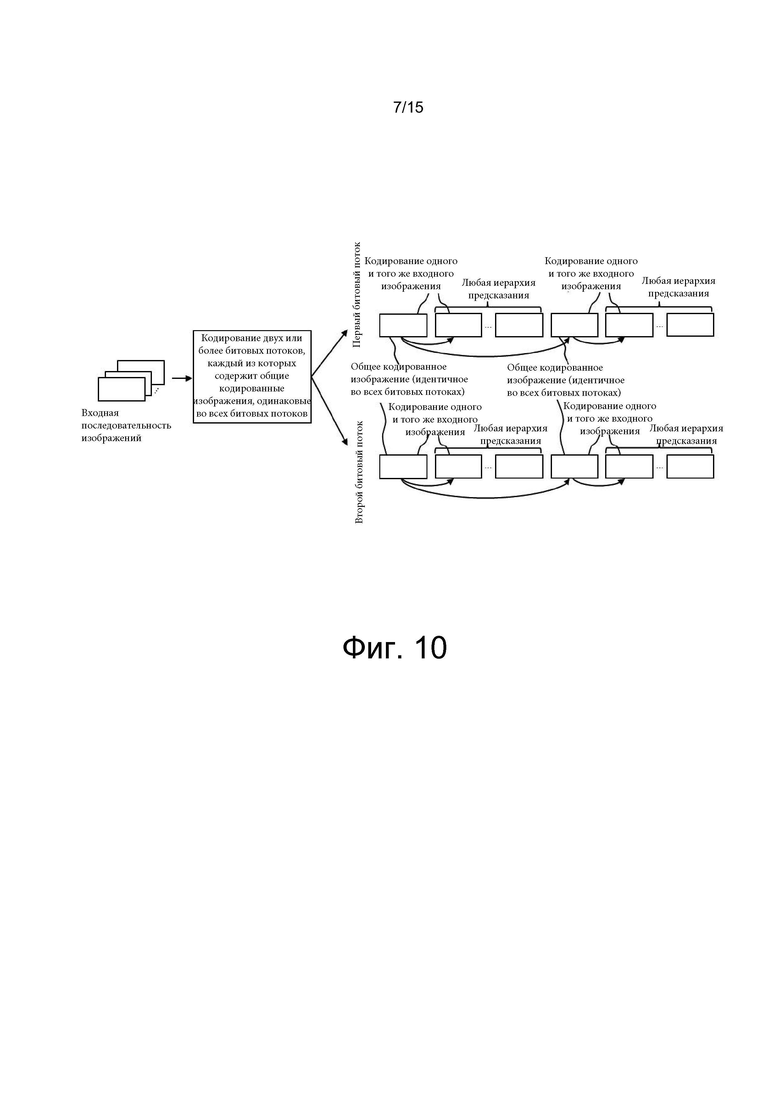
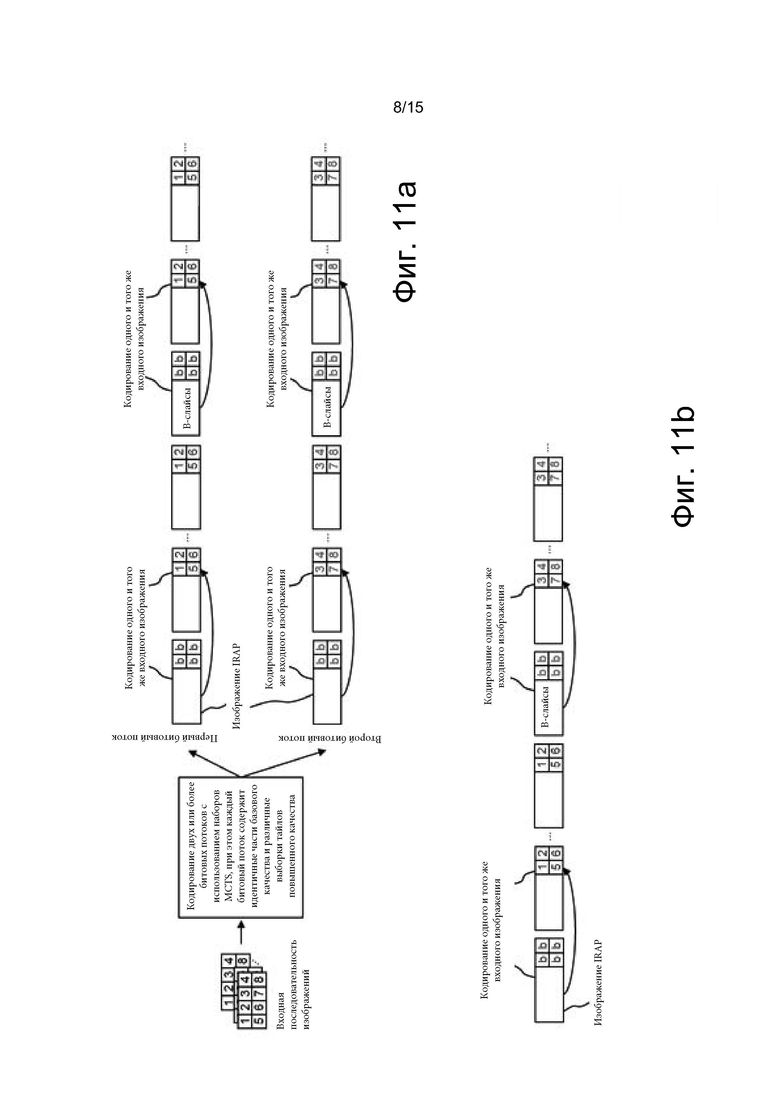
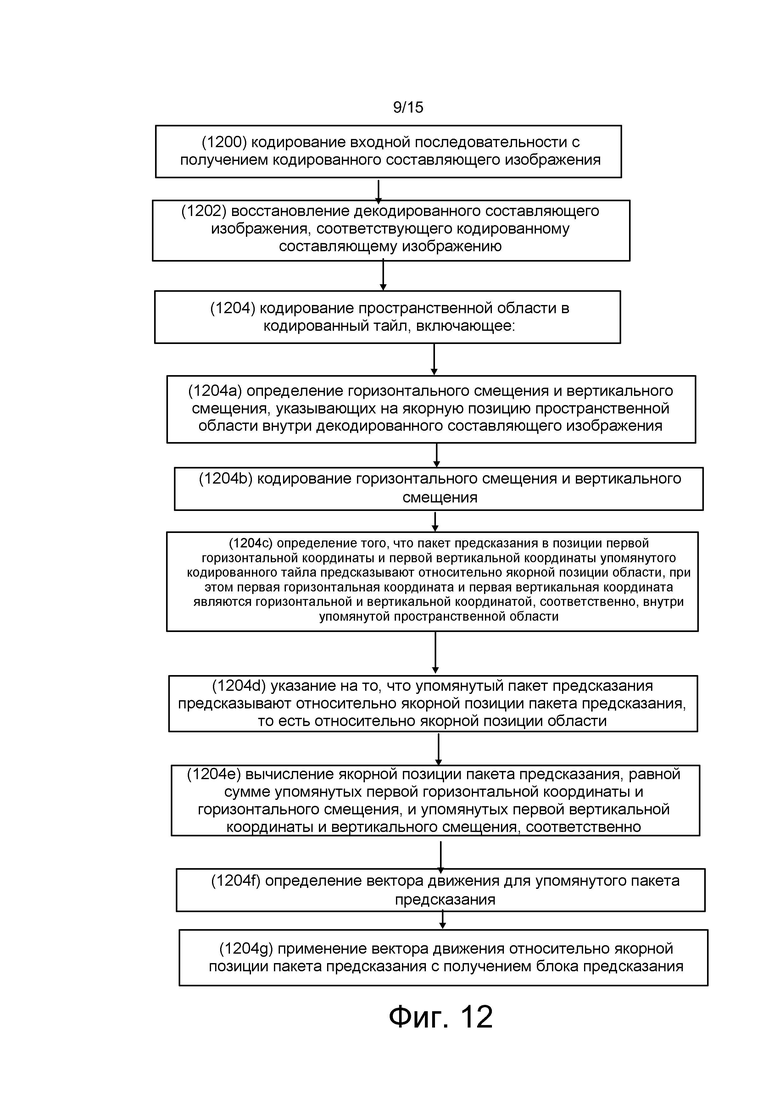
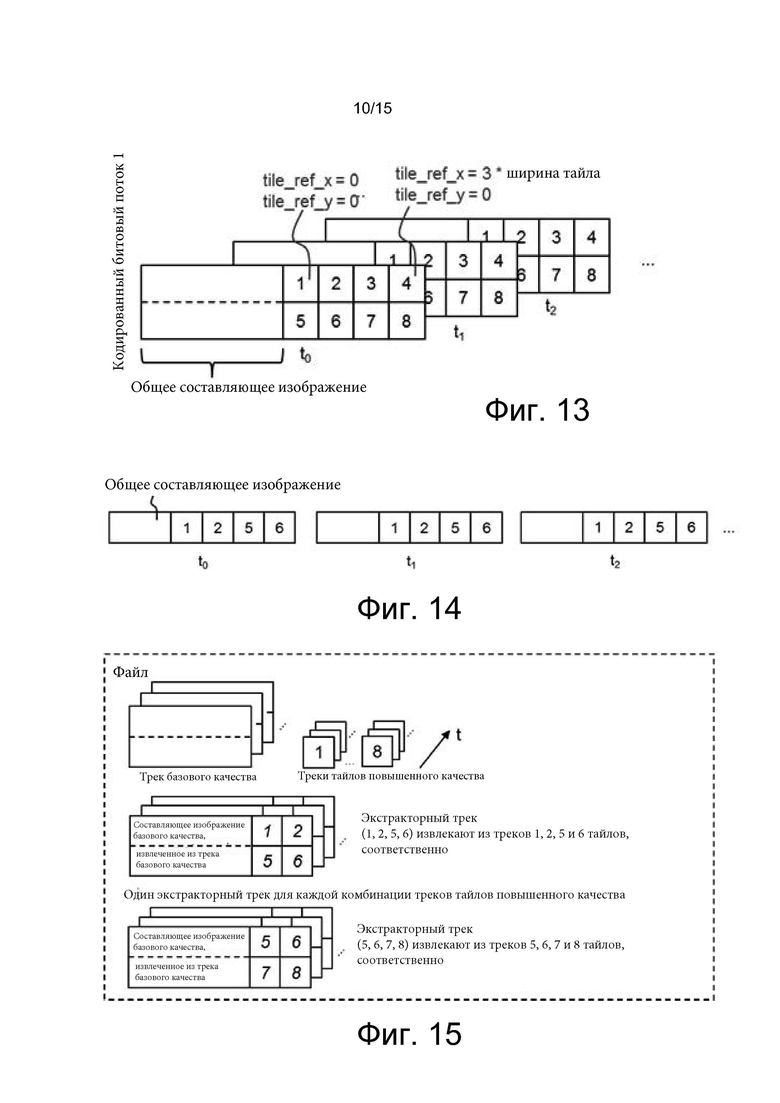
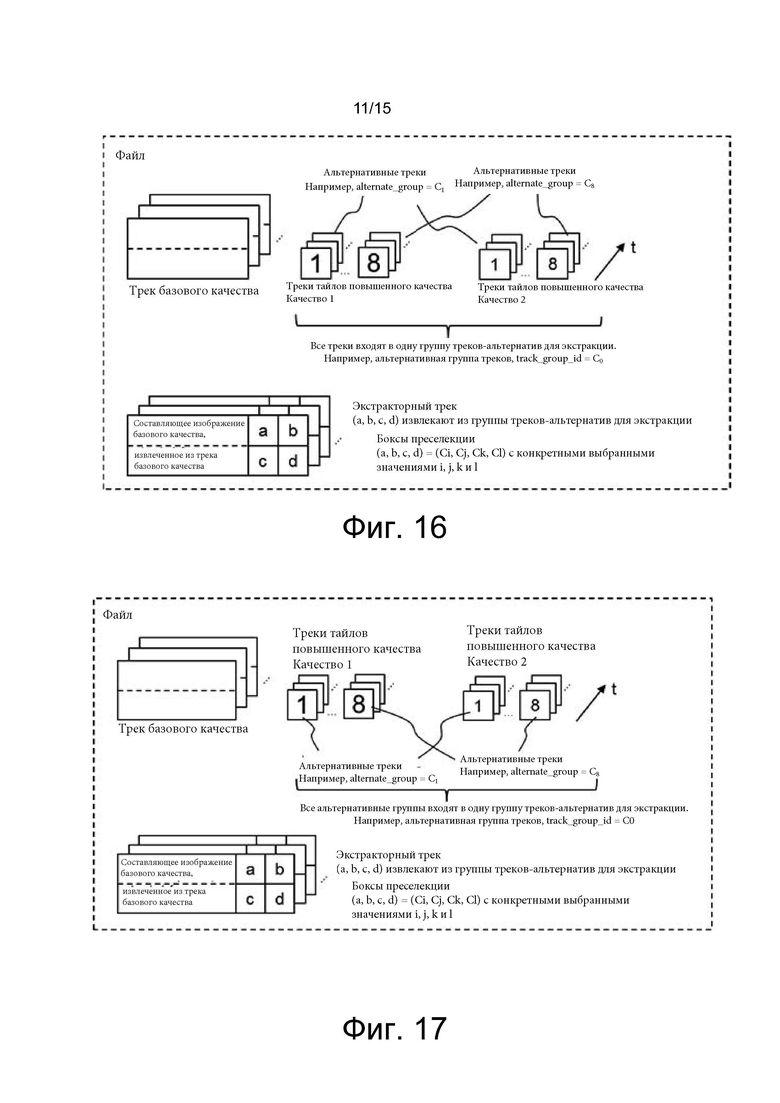
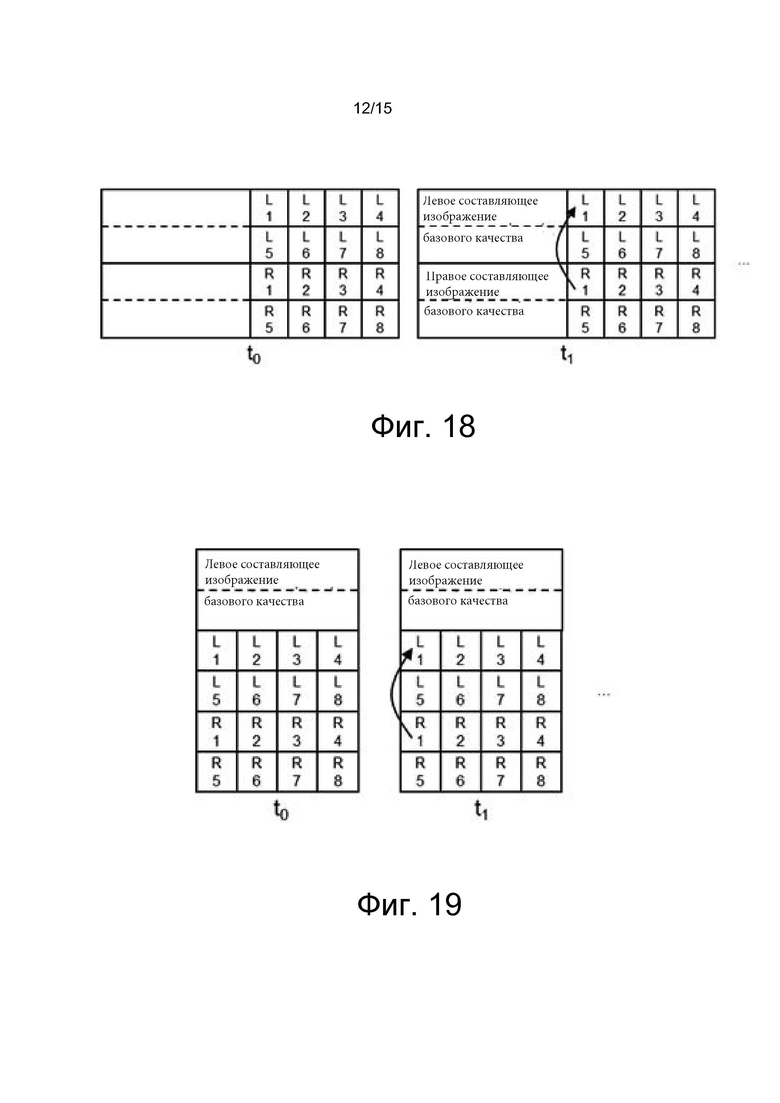
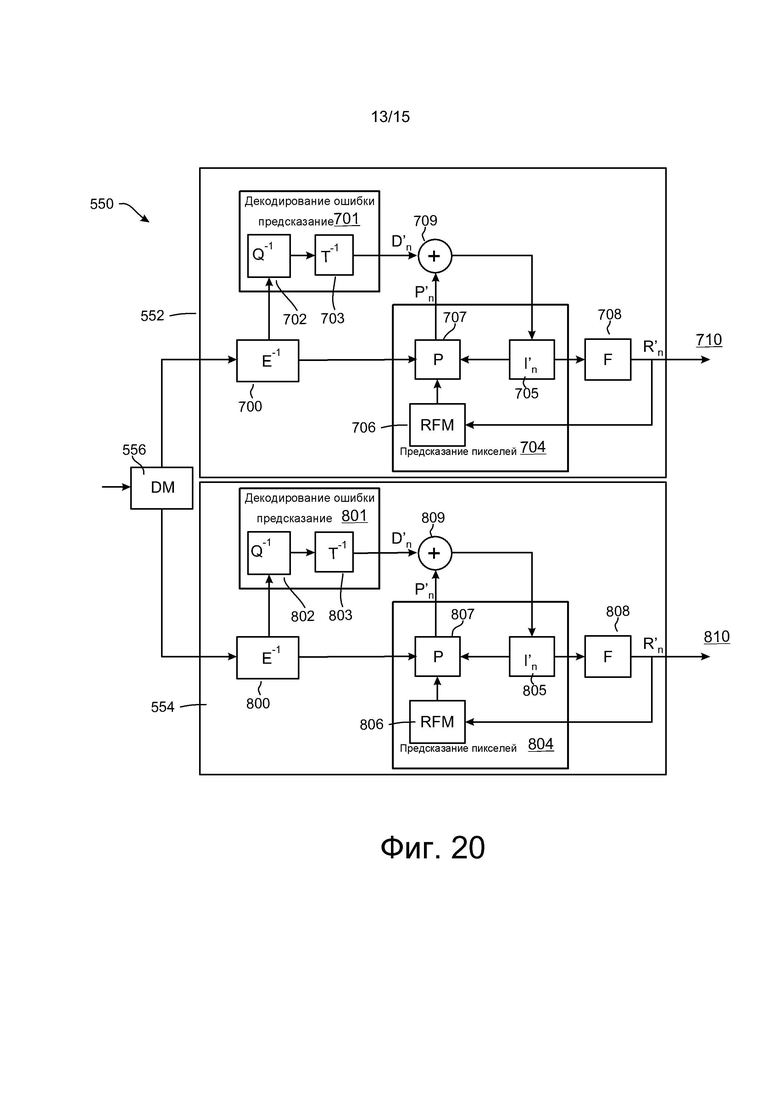
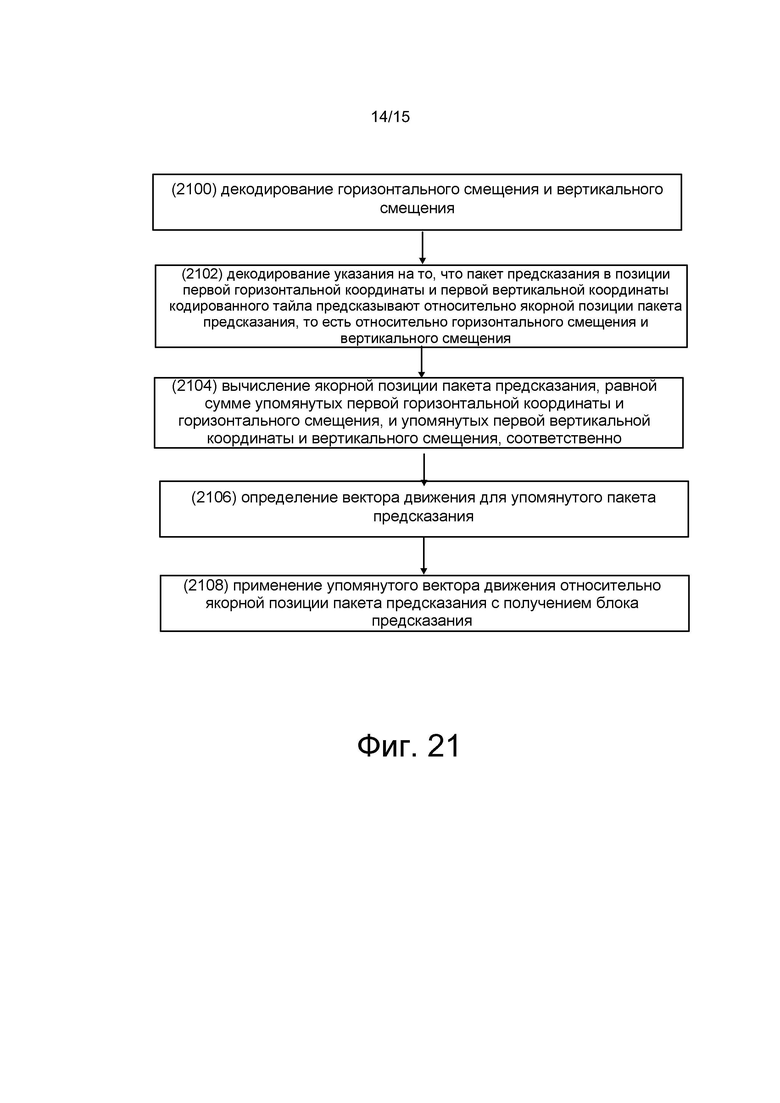
Изобретение относится к средствам для кодирования видео. Технический результат заключается в повышении эффективности кодирования видео. Способ включает: кодирование входного изображения в кодированное составляющее изображение; восстановление, в качестве части упомянутого кодирования, декодированного составляющего изображения, соответствующего кодированному составляющему изображению; кодирование пространственной области в кодированный тайл, включающее: определение горизонтального смещения и вертикального смещения, указывающих для области якорную позицию упомянутой пространственной области внутри декодированного составляющего изображения; кодирование горизонтального смещения и вертикального смещения; определение того, что пакет предсказания в позиции первой горизонтальной координаты и первой вертикальной координаты упомянутого кодированного тайла предсказывают относительно якорной позиции области, при этом первая горизонтальная координата и первая вертикальная координата являются горизонтальной и вертикальной координатой соответственно внутри упомянутой пространственной области; указание на то, что упомянутый пакет предсказания предсказывает относительно якорной позиции пакета предсказания, то есть относительно упомянутых горизонтального и вертикального смещений. 6 н. и 10 з.п. ф-лы, 24 ил., 4 табл.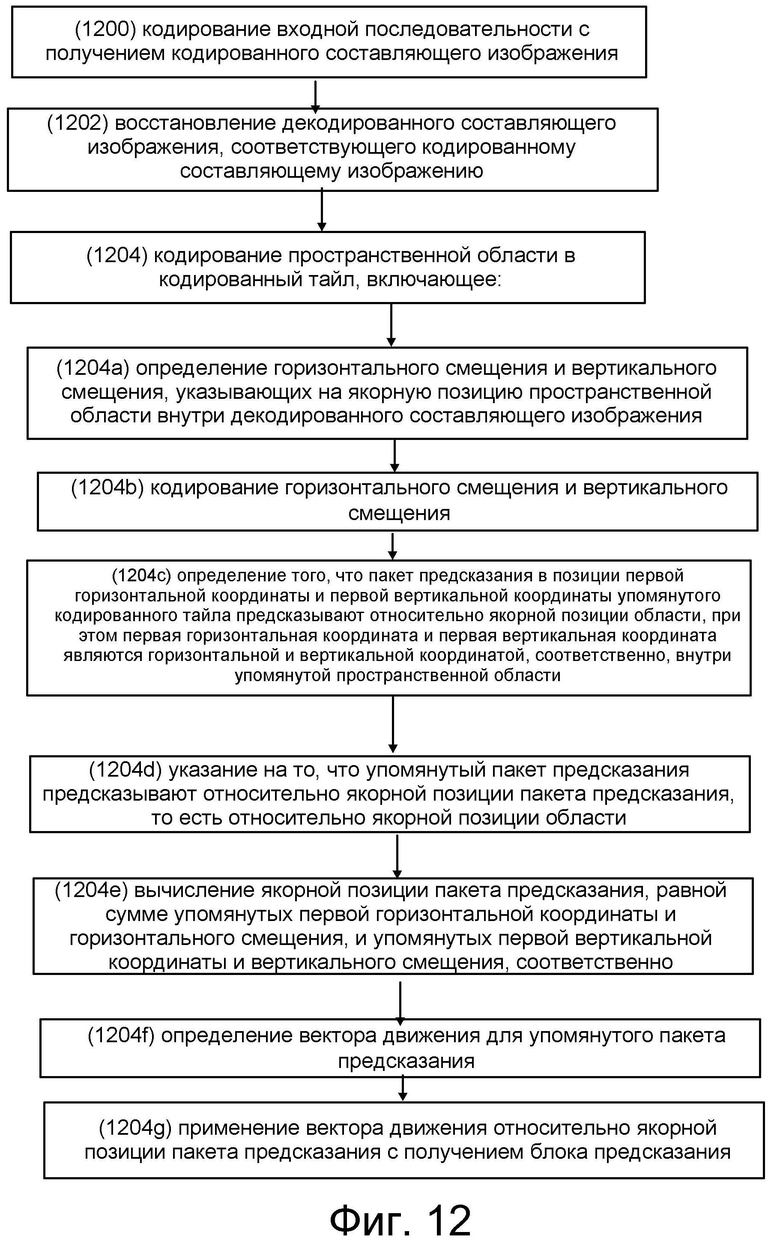
1. Способ кодирования, включающий:
кодирование входного изображения в кодированное составляющее изображение;
восстановление, в качестве части упомянутого кодирования, декодированного составляющего изображения, соответствующего кодированному составляющему изображению;
кодирование пространственной области в кодированный тайл, включающее:
определение горизонтального смещения и вертикального смещения, указывающих для области якорную позицию упомянутой пространственной области внутри декодированного составляющего изображения;
кодирование горизонтального смещения и вертикального смещения;
определение того, что пакет предсказания в позиции первой горизонтальной координаты и первой вертикальной координаты упомянутого кодированного тайла предсказывают относительно якорной позиции области, при этом первая горизонтальная координата и первая вертикальная координата являются горизонтальной и вертикальной координатой соответственно внутри упомянутой пространственной области;
указание на то, что упомянутый пакет предсказания предсказывают относительно якорной позиции пакета предсказания, то есть относительно упомянутых горизонтального и вертикального смещений;
вычисление якорной позиции пакета предсказания, равной сумме упомянутых первой горизонтальной координаты и горизонтального смещения, и упомянутых первой вертикальной координаты и вертикального смещения соответственно;
определение вектора движения для упомянутого пакета предсказания; и
применение упомянутого вектора движения относительно якорной позиции пакета предсказания с получением блока предсказания.
2. Способ по п. 1, дополнительно включающий:
извлечение пространственной области из входного изображения; и
определение горизонтального смещения и вертикального смещения на основе местоположения этой пространственной области во входном изображении.
3. Способ по п. 1, в котором входное изображение представляет собой первый ракурс, при этом способ дополнительно включает:
получение упомянутой пространственной области из второго входного изображения, представляющего собой второй ракурс, отличающийся от первого ракурса.
4. Способ по любому из предшествующих пунктов, в котором первое кодированное изображение содержит упомянутое составляющее изображение и кодированный тайл, при этом способ дополнительно включает
определение того, что вектор движения является нулевым; и
указание на то, что первое кодированное изображение является опорным изображением для упомянутого вектора движения.
5. Способ по любому из пп. 1-3, в котором первое кодированное изображение включает упомянутое составляющее изображение, а второе кодированное изображение включает кодированный тайл, при этом способ включает указание на то, что первое кодированное изображение является опорным изображением для упомянутого вектора движения.
6. Способ по любому из предшествующих пунктов, в котором упомянутое указание включает определение вектора движения таким образом, что применение этого вектора движения относительно позиции пакета предсказания вызывает вычисление блока предсказания с использованием по меньшей мере одного отсчета вне упомянутого кодированного тайла.
7. Способ по любому из предшествующих пунктов, также включающий определение, кодером, того, что при применении внутреннего копирования блоков используют нулевой вектор движения, путем указания в битовом потоке на то, что механизм смещения якорной позиции векторов движения применяется для всех векторов движения при внутреннем копировании блоков в кодированном тайле или в слайсе, содержащем этот кодированный тайл.
8. Способ по п. 7, также включающий, в ответ на определение того, что при применении внутреннего копирования блоков используют нулевой вектор движения, пропуск указания синтаксических элементов, указывающих выбранный кандидат вектора движения или разность векторов движения.
9. Устройство кодирования, включающее:
по меньшей мере один процессор и по меньшей мере одну память, при этом в упомянутой по меньшей мере одной памяти хранится код, который при исполнении упомянутым по меньшей мере одним процессором обеспечивает выполнение устройством способа в соответствии по меньшей мере с одним из пп. 1-8.
10. Машиночитаемый носитель для хранения данных, на котором хранится код для использования устройством, который при исполнении процессором обеспечивает выполнение этим устройством способа в соответствии по меньшей мере с одним из пп. 1-8.
11. Способ декодирования, включающий:
декодирование кодированного тайла в декодированный тайл, при этом декодирование включает:
декодирование горизонтального смещения и вертикального смещения;
декодирование указания на то, что пакет предсказания в позиции первой горизонтальной координаты и первой вертикальной координаты кодированного тайла предсказывают относительно якорной позиции пакета предсказания, то есть относительно упомянутых горизонтального смещения и вертикального смещения;
вычисление якорной позиции пакета предсказания, равной сумме упомянутых первой горизонтальной координаты и горизонтального смещения, и упомянутых первой вертикальной координаты и вертикального смещения соответственно;
определение вектора движения для упомянутого пакета предсказания; и
применение упомянутого вектора движения относительно якорной позиции пакета предсказания с получением блока предсказания.
12. Способ по п. 11, в котором упомянутое указание определяют на основе вектора движения, если применение вектора движения относительно позиции пакета предсказания вызывает, при вычислении блока предсказания, использование по меньшей мере одного отсчета вне упомянутого декодированного тайла.
13. Способ по п. 11 или 12, также включающий:
определение, декодером, того, что при применении внутреннего копирования блоков используют нулевой вектор движения, путем декодирования из битового потока указания на то, что механизм смещения якорной позиции векторов движения применяется для всех векторов движения при внутреннем предсказании блоков в кодированном тайле или в слайсе, содержащем этот кодированный тайл.
14. Способ по п. 13, также включающий, в ответ на определение того, что при применении внутреннего копирования блоков используют нулевой вектор движения, пропуск декодирования синтаксических элементов, указывающих выбранный кандидат вектора движения или разность векторов движения.
15. Устройство декодирования, включающее:
по меньшей мере один процессор и по меньшей мере одну память, при этом в упомянутой по меньшей мере одной памяти хранится код, который при исполнении упомянутым по меньшей мере одним процессором обеспечивает выполнение устройством способа по любому из пп. 11-14.
16. Машиночитаемый носитель для хранения данных, на котором хранится код для использования устройством, который при исполнении процессором обеспечивает выполнение этим устройством способа по любому из пп. 11-14.
| Автомобиль-сани, движущиеся на полозьях посредством устанавливающихся по высоте колес с шинами | 1924 |
|
SU2017A1 |
| Автомобиль-сани, движущиеся на полозьях посредством устанавливающихся по высоте колес с шинами | 1924 |
|
SU2017A1 |
| Автомобиль-сани, движущиеся на полозьях посредством устанавливающихся по высоте колес с шинами | 1924 |
|
SU2017A1 |
| Устройство для закрепления лыж на раме мотоциклов и велосипедов взамен переднего колеса | 1924 |
|
SU2015A1 |
| Автомобиль-сани, движущиеся на полозьях посредством устанавливающихся по высоте колес с шинами | 1924 |
|
SU2017A1 |
| Устройство для закрепления лыж на раме мотоциклов и велосипедов взамен переднего колеса | 1924 |
|
SU2015A1 |
| СПОСОБ И УСТРОЙСТВО КОДИРОВАНИЯ И ДЕКОДИРОВАНИЯ ИЗОБРАЖЕНИЙ | 2010 |
|
RU2537803C2 |
| ПОЛУЧЕНИЕ РЕЖИМА ВНУТРЕННЕГО ПРОГНОЗИРОВАНИЯ ДЛЯ ЦВЕТОРАЗНОСТНЫХ ЗНАЧЕНИЙ | 2013 |
|
RU2603548C2 |

