Область техники
[0001] Настоящая заявка относится к области компьютерных технологий и, в частности, к способу и устройству определения состояния базы данных и к способу и устройству верификации согласованности базы данных.
Предшествующий уровень техники
[0002] При хранении данных компьютер иногда сохраняет один и тот же фрагмент данных во множестве разных баз данных. Данные, хранящиеся в этих разных базах данных, обычно необходимо синхронизировать на основе требования услуги, то есть, данные, хранящиеся в базах данных, обычно должны быть согласованными. Технология блокчейна (цепочки блоков) используется в качестве примера. После того, как верификация выполнена, множество записей транзакции записываются во все узлы (базы данных, соответствующие узлам), которые хранят данные блокчейна. Чтобы гарантировать, что новый блок, который принимается всеми узлами, сгенерирован, данные, сохраненные во всех базах данных, соответствующих всем узлам, должны быть согласованными. В качестве другого примера, в случае первичной/вторичной базы данных в распределенном хранилище, чтобы способствовать восстановлению данных из другой базы данных (вторичной базы данных), когда возникает ошибка в данных в первичной базе данных, данные, сохраненные в первичной базе данных, и данные, сохраненные во вторичной базе данных, обычно также должны быть согласованными.
[0003] Чтобы гарантировать, что данные, сохраненные во множестве баз данных, являются согласованными, проверка согласованности может выполняться в отношении данных во множестве баз данных, и восстановительная мера может предприниматься своевременно, когда обнаружено, что данные не согласованы. Поскольку база данных обычно включает в себя много данных, проверка согласованности базы данных обычно выполняется путем сравнения значения состояния, которое используется, чтобы представлять состояние данных в базе данных, вместо сравнения всех данных во множестве баз данных поочередно. Для простоты описания состояние данных в базе данных может упоминаться как состояние базы данных.
[0004] В существующей технологии после того, как данные в базе данных изменяются каждый раз, значение состояния базы данных необходимо определить повторно. Когда значение состояния определено, значение состояния обычно вычисляется с использованием всех данных в базе данных. Например, значение состояния может представлять собой значение хэша данных в базе данных. В этом случае, когда значение хэша определено, все данные в базе данных необходимо состыковать, чтобы получить строку. Затем эта строка используется в качестве ввода хэш-функции, и значение хэша вычисляется с использованием хэш-функции. В этом случае, когда база данных включает в себя относительно большое количество данных, потребляется относительно большое количество вычислительных ресурсов, когда определяется значение состояния базы данных.
Краткое описание сущности изобретения
[0005] Реализации настоящей заявки обеспечивают способ определения состояния базы данных, чтобы смягчить проблему существующей технологии, состоящую в том, что потребляется относительно большое количество вычислительных ресурсов, когда определяется значение состояния базы данных.
[0006] Следующие технические решения используются в реализациях настоящей заявки.
[0007] Обеспечен способ определения состояния базы данных, включающий в себя: определение операции перехода состояния, выполняемой на целевой базе данных; и определение, на основе определенной операции перехода состояния и значения состояния, которое относится к целевой базе данных и которое существует перед выполнением операции перехода состояния, значения состояния, которое относится к целевой базе данных и которое существует после выполнения операции перехода состояния, причем значение состояния используется, чтобы представлять состояние целевой базы данных.
[0008] Реализации настоящей заявки дополнительно обеспечивают устройство определения состояния базы данных, чтобы смягчить проблему существующей технологии, состоящую в том, что потребляется относительно большое количество вычислительных ресурсов, когда определяется значение состояния базы данных.
[0009] Обеспечено устройство определения состояния базы данных, включающее в себя: первый модуль определения, сконфигурированный, чтобы определять операцию перехода состояния, выполняемую на целевой базе данных; и второй модуль определения, сконфигурированный, чтобы определять, на основе определенной операции перехода состояния и значения состояния, которое относится к целевой базе данных и которое существует перед выполнением операции перехода состояния, значение состояния, которое относится к целевой базе данных и которое существует после выполнения операции перехода состояния, причем значение состояния используется, чтобы представлять состояние целевой базы данных.
[0010] Обеспечен способ верификации согласованности базы данных, включающий в себя: определение, являются ли одними и теми же значение состояния первой базы данных, подлежащей проверке, и значение состояния второй базы данных, подлежащей проверке, причем значение состояния первой базы данных и значение состояния второй базы данных определяются с использованием способа определения состояния базы данных, обеспеченного в настоящей заявке; и если значение состояния первой базы данных и значение состояния второй базы данных являются одними и теми же, определение, что состояние первой базы данных и состояние второй базы данных являются согласованными.
[0011] Обеспечено устройство верификации согласованности базы данных, включающее в себя: модуль определения состояния, сконфигурированный, чтобы определять, являются ли одними и теми же значение состояния первой базы данных, подлежащей проверке, и значение состояния второй базы данных, подлежащей проверке, причем значение состояния первой базы данных и значение состояния второй базы данных определяются с использованием устройства определения состояния базы данных, обеспеченного в настоящей заявке; и модуль определения согласованности, сконфигурированный, чтобы: когда определено, что значение состояния первой базы данных и значение состояния второй базы данных являются одними и теми же, определять, что состояние первой базы данных и состояние второй базы данных являются согласованными.
[0012] По меньшей мере одно из предыдущих технических решений, используемых в реализациях настоящей заявки, может достигать следующих полезных результатов:
[0013] Когда значение состояния базы данных, в которой данные изменяются вследствие операции перехода состояния, определено, определяется операция перехода состояния, выполняемая на целевой базе данных, и затем значение состояния, которое относится к базе данных и которое существует после выполнения операции перехода состояния, определяется на основе определенной операции перехода состояния и значения состояния, которое относится к базе данных и которое существует перед выполнением операции перехода состояния. По сравнению с существующей технологией, нет необходимости выполнять операцию на всех данных в полной базе данных, тем самым уменьшая потребление излишних вычислительных ресурсов.
Краткое описание чертежей
[0014] Прилагаемые чертежи, описанные здесь, предназначены для обеспечения дополнительного понимания настоящей заявки и составляют часть настоящей заявки. Иллюстративные реализации настоящей заявки и описания реализаций предназначены для описания настоящей заявки и не налагают ограничений на настоящую заявку. На прилагаемых чертежах:
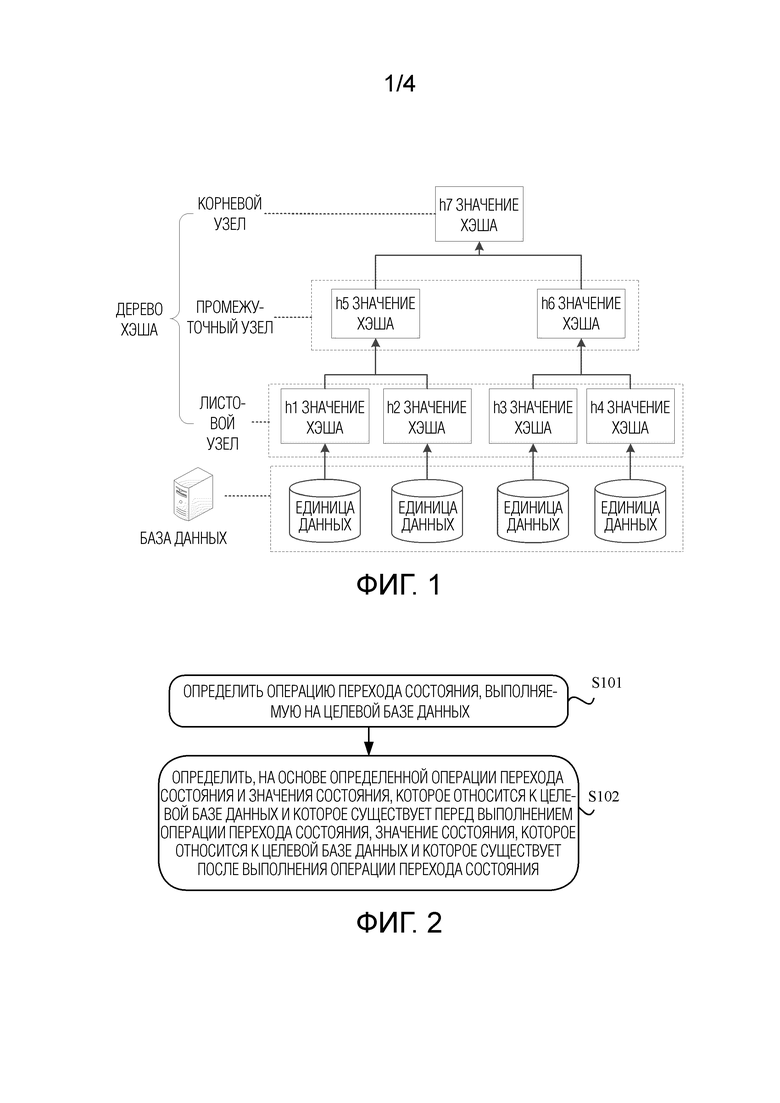
[0015] Фиг. 1 представляет собой схематичную диаграмму, иллюстрирующую структуру данных дерева хэша, в соответствии с настоящей заявкой;
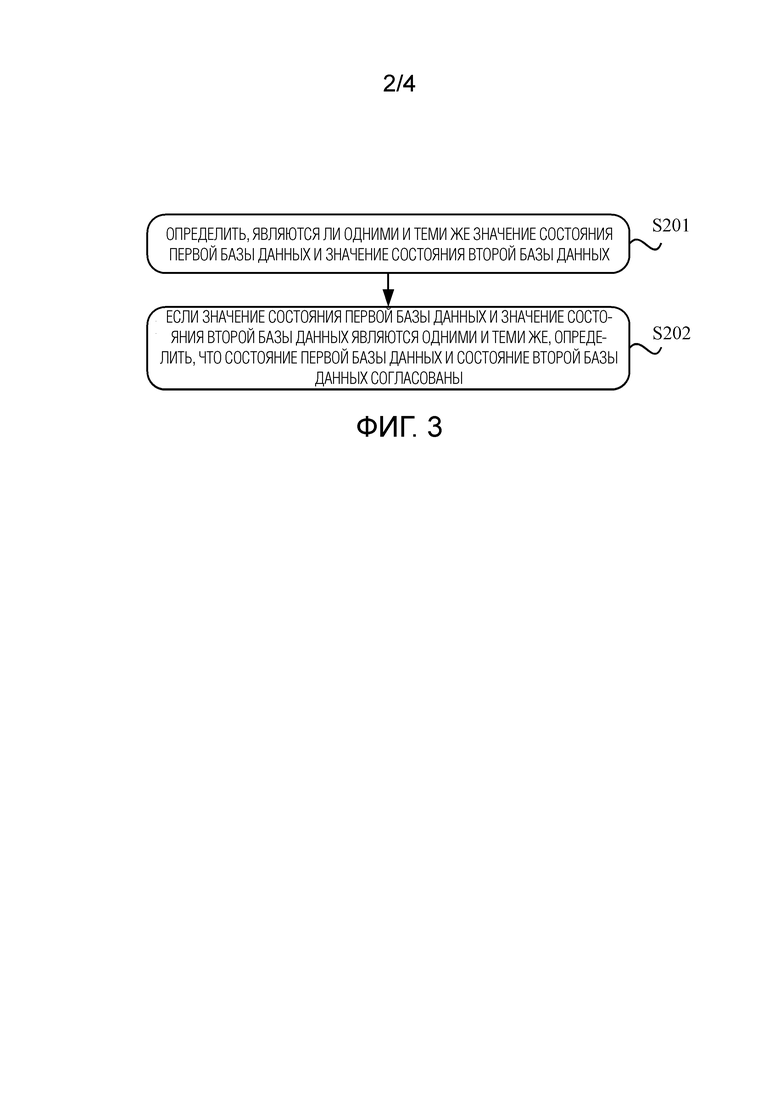
[0016] Фиг. 2 представляет собой блок-схему последовательности операций реализации, иллюстрирующую способ определения состояния базы данных, в соответствии с настоящей заявкой;
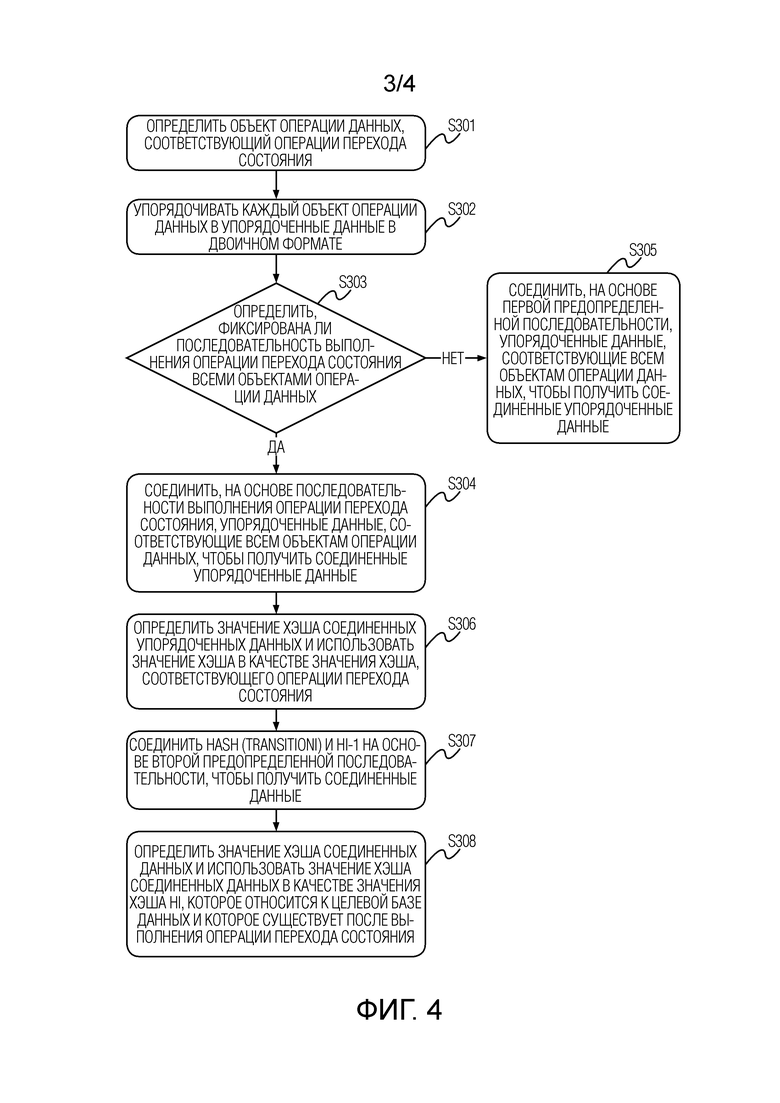
[0017] Фиг. 3 представляет собой блок-схему последовательности операций реализации, иллюстрирующую способ верификации согласованности базы данных, в соответствии с настоящей заявкой;
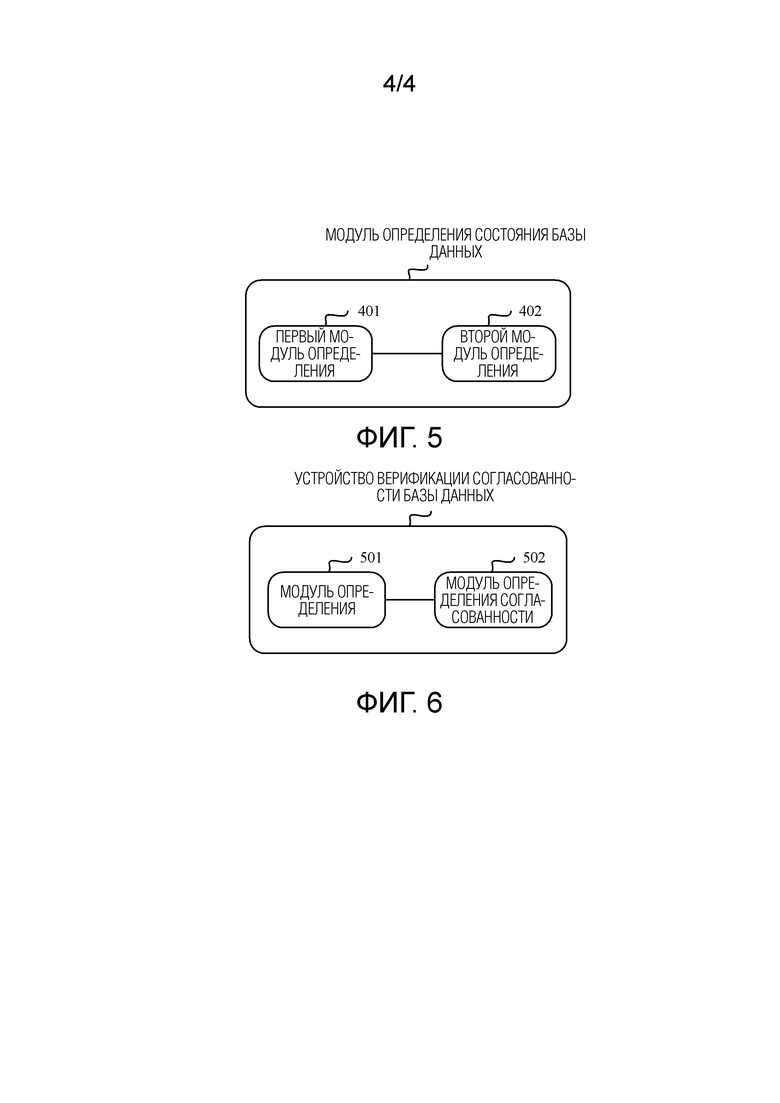
[0018] Фиг. 4 представляет собой блок-схему последовательности операций реализации, иллюстрирующую способ определения состояния базы данных, в соответствии с настоящей заявкой;
[0019] Фиг. 5 представляет собой схематичную диаграмму, иллюстрирующую конкретную структуру устройства определения состояния базы данных, в соответствии с настоящей заявкой; и
[0020] Фиг. 6 представляет собой схематичную диаграмму, иллюстрирующую конкретную структуру устройства верификации согласованности базы данных, в соответствии с настоящей заявкой.
Описание реализаций
[0021] Для пояснения задач, технических решений и преимуществ настоящей заявки, последующее описание ясно и полностью описывает технические решения настоящей заявки со ссылкой на конкретные реализации и соответствующие прилагаемые чертежи настоящей заявки. Очевидно, описанные реализации представляют собой лишь некоторые, но не все, из реализаций настоящей заявки. Все другие реализации, полученные специалистом в данной области техники на основе реализаций настоящей заявки без творческих усилий, должны соответствовать объему защиты настоящей заявки.
[0022] Технические решения, обеспеченные в реализациях настоящей заявки, описаны подробно ниже со ссылкой на прилагаемые чертежи.
[0023] По мере развития компьютерных технологий все более распространенным становится выполнение верификации того, являются ли согласованными данные во всех базах данных. Блокчейн используется в качестве примера. Блокчейн представляет собой распределенную базу данных, изменение каждого фрагмента данных в блокчейне широковещательно передается на каждый узел блокчейна во всей сети, и все узлы должны иметь полные и согласованные данные. Данные обычно хранятся во множестве единиц данных на каждом узле. Единица данных может представлять собой блок в блокчейне или может представлять собой единицу данных, которая включает в себя множество блоков. Когда значение состояния узла определено, дерево хэша, такое как дерево Меркла, создается с использованием значения хэша данных в каждой единице данных как листового узла, и затем значение хэша корневого узла дерева хэша используется в качестве значения состояния базы данных, так что значение состояния используется, чтобы уникально представлять состояние базы данных.
[0024] Фиг. 1 представляет собой схематичную диаграмму, иллюстрирующую структуру данных дерева хэша, созданного для некоторой базы данных. Когда вычисляется значение хэша корневого узла дерева хэша, сначала вычисляется значение хэша данных в каждой единице данных, затем полученное значение хэша используется в качестве значения листового узла дерева хэша, и вычисляется значение хэша родительского узла каждого листового узла, так что в итоге получают значение хэша корневого узла дерева хэша. После того как данные в базе данных изменяются, значение состояния базы данных требуется повторно определить. Таким образом, предыдущий процесс вычисления значения хэша корневого узла дерева хэша должен повторяться. Если существует большое количество данных в базе данных, операция хэша должна выполняться на большом количестве данных. Это потребляет большое количество вычислительных ресурсов.
[0025] В некоторых аналогичных сценариях, когда определяется значение состояния базы данных, также потребляется относительно большое количество вычислительных ресурсов. Подробности опущены здесь для простоты. Чтобы смягчить эту проблему, настоящая заявка обеспечивает способ определения состояния базы данных, так что состояние целевой базы данных определяется на основе операции перехода состояния, выполняемой на целевой базе данных.
[0026] Последующее описание подробно описывает способ определения состояния базы данных, обеспеченный в настоящей заявке. Способ может выполняться вычислительным устройством, например, узлом базы данных в распределенной базе данных или узлом в блокчейне. Кроме того, способ может выполняться прикладной программой, которая реализует способ определения состояния базы данных, обеспеченный в настоящей заявке. Для простоты описания, реализация способа описана ниже с использованием примера, в котором способ выполняется вычислительным устройством. Может быть понятно, что то, что способ выполняется вычислительным устройством, является только примером для описания и не должно рассматриваться как ограничение способа.
[0027] Фиг. 2 представляет собой блок-схему последовательности операций реализации, иллюстрирующую способ определения состояния базы данных, в соответствии с настоящей заявкой. Способ включает в себя этапы, описанные ниже.
[0028] Этап S101: Определить операцию перехода состояния, выполняемую на целевой базе данных.
[0029] Операция перехода состояния здесь может представлять собой операцию базы данных, которая вызывает изменение состояния базы данных, и может, в частности, представлять собой операцию, такую как операция записи данных, операция обновления данных или операция удаления данных. Операция перехода состояния может включать в себя обработанные данные и способ для обработки данных. Например, операция записи данных включает в себя данные, подлежащие записи, и конкретное местоположение, куда требуется записать данные в базе данных. Целевая база данных здесь может представлять собой базу данных, на которой выполняется операция перехода состояния, и целевая база данных может представлять собой любую базу данных, значение состояния которой необходимо определить.
[0030] В действительных применениях может существовать много способов для определения операции перехода состояния. Например, в объектно-ориентированной прикладной программе, если операция перехода состояния реализуется объектом, операция перехода состояния может быть определена путем определения объекта операции данных, соответствующего операции перехода состояния; или операция перехода состояния может быть определена на основе оператора операции базы данных, соответствующего операции перехода состояния. Объект операции данных здесь представляет собой объект данных, который находится в объектно-ориентированной прикладной программе и используется, чтобы выполнять операцию базы данных. В объектно-ориентированной прикладной программе, "объект" обычно представляет собой экземпляр, класс которого загружен в память, и имеет связанные переменные элементов и функции элементов.
[0031] Поскольку операция перехода состояния вызывает изменение данных в базе данных после того, как операция перехода состояния определена, состояние, которое относится к базе данных и которое существует после выполнения операции перехода состояния, может быть определено.
[0032] Этап S102: Определить, на основе определенной операции перехода состояния и значения состояния, которое относится к целевой базе данных и которое существует перед выполнением операции перехода состояния, значение состояния, которое относится к целевой базе данных и которое существует после выполнения операции перехода состояния.
[0033] Значение состояния здесь используется, чтобы представлять состояние целевой базы данных. Поскольку значение состояния может использоваться, чтобы выполнять проверку согласованности на целевой базе данных, значение состояния может использоваться, чтобы уникально представлять характеристику данных, сохраненных в целевой базе данных. Например, значение состояния может представлять собой значение хэша или может представлять собой глобально уникальный идентификатор. Значение хэша получают путем выполнения операции хэша на параметре ввода с использованием хэш-функции. Глобально уникальный идентификатор может представлять собой идентификатор, который распределяется системой и который используется, чтобы уникально идентифицировать состояние базы данных в системе.
[0034] Следует отметить, что специалисту в данной области техники должно быть известно, что "уникально представлять" следует понимать не как абсолютную уникальность, а как уникальность в пределах разрешенного диапазона ошибок. В настоящее время, для наиболее широко используемого алгоритма хэша, теоретически, разные данные ввода имеют одно и то же значение вывода хэша, то есть, существует конфликт хэша.
[0035] Состояние, существующее после того, как данные в базе данных изменяются, связано с состоянием, существующим перед изменением данных, и операцией перехода состояния. Например, после того, как операция перехода состояния, выполняемая на целевой базе данных, определена, значение состояния, которое относится к целевой базе данных и которое существует после того, как операция перехода состояния выполнена, может быть определено на основе определенной операции перехода состояния и значения состояния, которое относится к целевой базе данных и которое существует перед выполнением операции.
[0036] В действительных применениях, как описано на этапе S101, в объектно-ориентированной прикладной программе, операция перехода состояния может быть определена путем определения объекта операции данных, соответствующего операции перехода состояния. Затем, значение состояния, которое относится к целевой базе данных и которое существует после того, как операция перехода состояния выполнена, может быть определено на основе определенного объекта операции данных и значения состояния, которое относится к целевой базе данных и которое существует перед выполнением операции перехода состояния.
[0037] Чтобы способствовать различению между разными операциями перехода состояния с использованием короткого идентификатора, операция перехода состояния может также быть уникально представлена с использованием некоторого характеристического значения. Характеристическое значение операции перехода состояния может представлять собой значение хэша или может представлять собой глобально уникальный идентификатор, используемый, чтобы уникально идентифицировать операцию перехода состояния. Подробности опущены здесь для простоты. Чтобы способствовать вычислению характеристического значение операции перехода состояния и значения состояния целевой базы данных, чтобы получить значение состояния, которое относится к целевой базе данных и которое существует после того, как операция перехода состояния выполнена, формат данных характеристического значения может быть тем же самым или аналогичным формату данных значения состояния целевой базы данных.
[0038] В действительных применениях для объектно-ориентированной прикладной программы, значение хэша объекта операции данных может быть определено, и затем значение состояния, которое относится к целевой базе данных и которое существует после того, как операция перехода состояния выполнена, определяется на основе определенного значения хэша объекта операции данных и значения состояния, которое относится к целевой базе данных и которое существует перед выполнением операции перехода состояния.
[0039] Последующее описание конкретно описывает процесс определения значение хэша объекта операции данных в этой реализации настоящей заявки.
[0040] Когда значение хэша объекта операции данных определено, чтобы преобразовать формат данных объекта операции данных в формат, поддерживаемый вводом алгоритма хэша, операция преобразования в последовательную форму (упорядочивание) может выполняться на объекте операции данных. Операция упорядочивания может преобразовывать информацию состояния объекта в формат, который может быть сохранен или передан. После того, как операция упорядочивания выполнена на объекте операции данных, могут быть получены упорядочены данные, соответствующие объекту операции данных. Например, формат данных упорядоченных данных может представлять собой двоичный формат, и данные в двоичном формате могут использоваться в качестве ввода алгоритма хэша.
[0041] После того как получены упорядоченные данные, соответствующие объекту операции данных, операция хэша может выполняться на упорядоченных данных, чтобы получить значение хэша упорядоченных данных, и значение хэша упорядоченных данных может использоваться в качестве значения хэша объекта операции данных.
[0042] Следует отметить, что одна операция перехода состояния обычно соответствует более чем одному объекту операции данных, например, каждая операция перехода состояния, выполняемая для узла в блокчейне, обычно соответствует множеству объектов операции данных. По существу, когда объект операции данных, соответствующий операции перехода состояния, упорядочен, все объекты операции данных могут быть отдельно упорядочены; затем, все полученные упорядоченные данные соединяются (состыковываются) последовательно; и наконец, полученные соединенные (состыкованные) упорядоченные данные используются в качестве упорядоченных данных, соответствующих операции перехода состояния.
[0043] Когда все полученные упорядоченные данные соединены последовательно, если последовательность выполнения операции перехода состояния всеми объектами операции данных фиксирована, упорядоченные данные, соответствующие всем объектам операции данных, соединяются на основе последовательности выполнения операции перехода состояния, чтобы получить соединенные упорядоченные данные. Альтернативно, если последовательность выполнения операции перехода состояния всеми объектами операции данных не фиксирована, упорядоченные данные, соответствующие всем объектам операции данных, соединяются на основе первой предопределенной последовательности, чтобы получить соединенные упорядоченные данные. Затем, значение хэша соединенных упорядоченных данных может быть вычислено с использованием хэш-функции, и значение хэша соединенных упорядоченных данных используется в качестве значения хэша объекта операции данных, соответствующего операции перехода состояния.
[0044] Первая предопределенная последовательность может представлять собой предопределенную последовательность соединения (состыковки). Например, если формат данных в каждом объекте операции данных представляет собой формат 'ключ-значение', упорядоченные данные, соответствующие всем объектам операции данных, могут быть соединены в порядке убывания значений ключа.
[0045] После того, как значение хэша объекта операции данных, соответствующее операции перехода состояния, определено, значение состояния, которое относится к целевой базе данных и которое существует после выполнения операции перехода состояния, может быть определено на основе определенного значения хэша объекта операции данных и значения состояния, которое относится к целевой базе данных и которое существует перед выполнением операции перехода состояния. Конкретно, значение хэша объекта операции данных и значение состояния, которое относится к целевой базе данных и которое существует перед выполнением операции перехода состояния, могут быть соединены на основе второй предопределенной последовательности, чтобы получить соединенные данные. Значение хэша соединенных данных является определенным. Значение хэша соединенных данных используется в качестве значения состояния, которое относится к целевой базе данных и которое существует после выполнения операции перехода состояния.
[0046] Первая предопределенная последовательность и вторая предопределенная последовательность здесь, каждая, может представлять собой предопределенную последовательность соединения (состыковки). Когда значения состояния всех баз данных вычислены, одна и та же последовательность соединения должна использоваться, когда данные соединяются. В противном случае, даже если данные во всех базах данных согласованы, вычисленные значения состояния являются разными, и согласованность между базами данных не может быть точно проверена.
[0047] Следует отметить, что в некоторых случаях две группы разных данных, возможно, станут одними и теми же соединенными данными после того, как соединение выполнено. Например, данные "hello" и "world" могут быть соединены, чтобы получить соединенные данные "helloworld", и аналогично, данные "he" и "lloworld" соединяются, чтобы получить "helloworld". Очевидно, две группы данных представляют собой разные данные перед выполнением соединения. В этом случае, чтобы предотвратить то, что разные данные становятся теми же самыми данными после выполнения соединения, когда выполняется операция соединения, может использоваться разделитель, чтобы гарантировать уникальность соединенных данных. Конкретно, предопределенный разделитель может быть помещен в местоположении соединения данных. Предопределенный разделитель может быть предварительно определен разработчиком. Например, разделитель представляет собой 123. В этом случае данные "hello" и "world" могут быть соединены, чтобы получить "hello123world", и данные "he" и "lloworld" могут быть соединены, чтобы получить "he123lloworld". По существу, может гарантироваться, что два фрагмента данных являются разными данными после выполнения соединения.
[0048] На основе предыдущего способа для соединения данных с использованием разделителя, когда упорядоченные данные, соответствующие всем объектам операции данных, соединяются, предопределенный разделитель может быть помещен между по меньшей мере двумя фрагментами упорядоченных данных, которые следует соединить, и все фрагменты упорядоченных данных, полученные после того, как предопределенный разделитель помещен, соединяются, чтобы получить соединенные упорядоченные данные. Конечно, перед соединением данных с использованием разделителя, сначала может быть определено, являются ли различные группы данных теми же самыми данными после того, как выполнено соединение. Если результатом определения является то, что соединенные данные являются теми же самыми, каждая группа данных соединяется с использованием разделителя, чтобы получить соединенные упорядоченные данные.
[0049] В соответствии со способом определения состояния базы данных, обеспеченным в этой реализации настоящей заявки, когда значение состояния базы данных, данные которой изменяются, определено, определяется операция перехода состояния, выполняемая на целевой базе данных, и затем значение состояния, которое относится к базе данных и которое существует после выполнения операции перехода состояния, может быть определено на основе определенной операции перехода состояния и значения состояния, которое относится к базе данных и которое существует перед выполнением операции перехода состояния. По сравнению с существующей технологией, не требуется выполнять операцию на всех данных в полной базе данных, тем самым уменьшая потребление излишних вычислительных ресурсов. Кроме того, по сравнению с тем, что в существующей технологии блокчейна значение хэша узла вычисляется с использованием структуры дерева, такого как дерево хэша, в этой реализации настоящей заявки не требуется создавать структуру дерева и не требуется вычислять значение хэша каждого узла в структуре дерева, тем самым уменьшая потребление излишних вычислительных ресурсов за счет проверки согласованности.
[0050] В некоторых предпочтительных решениях, обеспеченных в этой реализации настоящей заявки, операция упорядочивания выполняется на объекте операции данных, и операция хэша выполняется на упорядоченных данных, и это потребляет некоторое количество вычислительных ресурсов. Однако, в распределенной базе данных, в частности, в блокчейне, база данных обычно хранит очень большое количество данных, и вычислительные ресурсы, потребляемые выполнением операции хэша на данных в базе данных, являются гораздо большими, чем вычислительные ресурсы, потребляемые вышеописанной операцией в этой реализации настоящей заявки.
[0051] В соответствии с вышеописанным способом определения состояния базы данных может быть определено значение состояния базы данных. Далее проверка согласованности может выполняться на базе данных на основе определенного значения состояния. Последующее описание подробно описывает способ верификации согласованности базы данных, обеспеченный в настоящей заявке.
[0052] Фиг. 3 представляет собой блок-схему последовательности операций реализации, иллюстрирующую способ верификации согласованности базы данных. Способ включает в себя этапы, описанные ниже.
[0053] Этап S201: Определить, являются ли одними и теми же значение состояния первой базы данных, подлежащей проверке, и значение состояния второй базы данных, подлежащей проверке.
[0054] Первая база данных и вторая база данных здесь представляют собой базы данных, подлежащие проверке. В этом случае значение состояния первой базы данных и значение состояния второй базы данных могут отдельно определяться на основе способа определения состояния базы данных, обеспеченного в этой реализации настоящей заявки. Для конкретного процесса определения можно сослаться на связанные описания в настоящей заявке. Подробности опущены здесь для простоты.
[0055] Этап S202: Если значение состояния первой базы данных и значение состояния второй базы данных являются одними и теми же, определить, что состояние первой базы данных и состояние второй базы данных являются согласованными.
[0056] Если значение состояния первой базы данных и значение состояния второй базы данных являются разными, определяется, что состояние первой базы данных и состояние второй базы данных являются несогласованными.
[0057] На основе вышеописанного принципа изобретения в настоящей заявке, чтобы способствовать лучшему пониманию технических признаков, средств и результатов настоящей заявки, последующее описание использует пример, в котором целевая база данных используется в качестве базы данных узла в технологии блокчейна, чтобы дополнительно описать способ определения состояния базы данных в настоящей заявке.
[0058] В этой реализации настоящей заявки для описания используется пример, в котором приложение блокчейна представляет собой приложение распределенной блокчейн-цепи (fabric blockchain), целевая база данных представляет собой базу данных LevelDB, и значение состояния базы данных представляет собой значение хэша. Операция перехода состояния может выполняться на базе данных LevelDB с использованием объекта операции данных. Объект операции данных может записывать данные в формате ключ-значение в базу данных LevelDB. Когда операция перехода состояния выполняется в блокчейне, используется алгоритм консенсуса, чтобы гарантировать, что операции перехода состояния являются согласованными между всеми узлами, и переход состояния выполняется в том же самом порядке.
[0059] Для каждого узла блокчейна, когда никакие данные не записаны в базу данных, исходное состояние Sinit каждой базы данных является пустым. В этом случае, значение хэша может быть задано. Здесь, значение хэша исходного состояния базы данных обозначено как Hinit.
[0060] В этом случае, когда определено, что i-ая операция перехода состояния Transitioni выполняется на целевой базе данных, значение хэша целевой базы данных может быть повторно вычислено на основе операции. Фиг. 4 представляет собой блок-схему последовательности операций реализации процесса, и процесс включает в себя этапы, описанные ниже.
[0061] Этап S301: Определить объект операции данных, соответствующий операции перехода состояния.
[0062] Одна операция перехода состояния обычно соответствует множеству объектов операции данных, и i-ая операция перехода состояния Transitioni для узла может быть обозначена как набор {op1, op2… opN}, где op представляет собой сокращение "операции", указывает один объект операции данных и обозначает одну операцию записи для одной пары ключ-значение. Формат каждой op представляет собой Key:= NewVal. Например, {op1, op2… opN} указывает операции записи для N пар ключ-значение во время i-ой операции перехода состояния.
[0063] Этап S302: Упорядочивать каждый объект операции данных в упорядоченные данные в двоичном формате.
[0064] Этап S303: Определить, фиксирована ли последовательность выполнения операции перехода состояния всеми объектами операции данных; и если да, выполнить этап S304; или если нет, выполнить этап S305.
[0065] Этап S304: Если последовательность выполнения операции перехода состояния всеми объектами операции данных фиксирована, соединить (состыковать), на основе последовательности выполнения операции перехода состояния, упорядоченные данные, соответствующие всем объектам операции данных, чтобы получить соединенные упорядоченные данные; и выполнить этап S306.
[0066] Этап S305: Если последовательность выполнения операции перехода состояния всеми объектами операции данных не фиксирована, соединить, на основе первой предопределенной последовательности, упорядоченные данные, соответствующие всем объектам операции данных, чтобы получить соединенные упорядоченные данные.
[0067] Первая предопределенная последовательность здесь может представлять собой порядок по убыванию значений ключа.
[0068] Этап S306: Определить значение хэша соединенных упорядоченных данных и использовать значение хэша в качестве значения хэша, соответствующего операции перехода состояния.
[0069] Соединенные упорядоченные данные используются в качестве ввода алгоритма хэша для выполнения операции хэша, чтобы получить значение хэша соединенных упорядоченных данных, то есть, значение хэша Hash(Transitioni) операции перехода состояния Transitioni.
[0070] Этап S307: Соединить, на основе второй предопределенной последовательности, значение хэша, соответствующее операции перехода состояния, и значение хэша Hi-1, которое относится к целевой базе данных и которое существует перед выполнением операции перехода состояния, чтобы получить соединенные данные.
[0071] Этап S308: Определить значение хэша соединенных данных и использовать значение хэша соединенных данных в качестве значения хэша Hi, которое относится к целевой базе данных и которое существует после того, как операция перехода состояния Transitioni выполнена.
[0072] Наконец, полученное значение хэша Hi, которое относится к целевой базе данных и которое существует после выполнения операции перехода состояния Transitioni, может быть представлено следующим уравнением: Hi:= Hash(Hi-1 || Hash (Transitioni)).
[0073] H0=Hinit, где || указывает операцию соединения, Hash(x) представляет собой хэш-функцию и указывает, что операция хэша выполняется на данных ввода x, и хэш-функция может представлять собой, например, SHA3.
[0074] В соответствии со способом определения состояния базы данных, обеспеченным в этой реализации настоящей заявки, когда определяется значение хэша базы данных, данные которой изменяются, определяется операция перехода состояния Transitioni, выполняемая на целевой базе данных; затем определяется значение хэша Hash (Transitioni), соответствующее операции перехода состояния; и значение состояния Hi, которое относится к базе данных и которое существует после выполнения операции перехода состояния, может быть определено на основе значения хэша Hi-1, которое относится к базе данных и которое существует перед выполнением операции перехода состояния. По сравнению с существующей технологией не требуется выполнять операцию на всех данных в базе данных целого узла, чтобы получить значение хэша, тем самым уменьшая потребление излишних вычислительных ресурсов. Кроме того, по сравнению с тем, что в существующей технологии блокчейна значение хэша узла вычисляется с использованием структуры дерева, такого как дерево хэша, в этой реализации настоящей заявки не требуется создавать структуру дерева и не требуется вычислять значение хэша каждого узла в структуре дерева, так что потребление вычислительных ресурсов дополнительно уменьшается.
[0075] Способ определения состояния базы данных, обеспеченный в реализациях настоящей заявки, описан выше. Как показано на фиг. 5, на основе той же самой идеи, реализация настоящей заявки дополнительно обеспечивает соответствующее устройство определения состояния базы данных. Устройство конкретно включает в себя: первый модуль 401 определения, сконфигурированный, чтобы определять операцию перехода состояния, выполняемую на целевой базе данных; и второй модуль 402 определения, сконфигурированный, чтобы определять, на основе определенной операции перехода состояния и значения состояния, которое относится к целевой базе данных и которое существует до выполнения операции перехода состояния, значение состояния, которое относится к целевой базе данных и которое существует после выполнения операции перехода состояния, причем значение состояния используется, чтобы представлять состояние целевой базы данных.
[0076] В этой реализации настоящей заявки существует также множество конкретных реализаций определения состояния базы данных. В одной реализации, первый модуль 401 определения сконфигурирован, чтобы определять объект операции данных, используемый, чтобы выполнять операцию перехода состояния на целевой базе данных.
[0077] Второй модуль 402 определения сконфигурирован, чтобы определять, на основе определенного объекта операции данных и значения состояния, которое относится к целевой базе данных и которое существует перед выполнением операции перехода состояния, значение состояния, которое относится к целевой базе данных и которое существует после выполнения операции перехода состояния.
[0078] В одной реализации второй модуль 402 определения конкретно включает в себя первый подмодуль 403 определения значения хэша и первый подмодуль 404 определения значения состояния.
[0079] Первый подмодуль 403 определения значения хэша сконфигурирован, чтобы определять значение хэша объекта операции данных.
[0080] Первый подмодуль 404 определения значения состояния сконфигурирован, чтобы определять, на основе определенного значения хэша объекта операции данных и значения состояния, которое относится к целевой базе данных и которое существует перед выполнением операции перехода состояния, значение состояния, которое относится к целевой базе данных и которое существует после выполнения операции перехода состояния.
[0081] В одной реализации первый подмодуль 403 определения значения хэша конкретно включает в себя подмодуль 405 определения упорядоченных данных и второй подмодуль 406 определения значения хэша.
[0082] Подмодуль 405 определения упорядоченных данных сконфигурирован, чтобы упорядочивать объект операции данных, чтобы получить упорядоченные данные.
[0083] Второй подмодуль 406 определения значения хэша сконфигурирован, чтобы: определять значение хэша упорядоченных данных и использовать значение хэша упорядоченных данных в качестве значения хэша объекта операции данных.
[0084] В одной реализации подмодуль 405 определения упорядоченных данных конкретно включает в себя первый подмодуль 407 соединения и второй подмодуль 408 соединения.
[0085] В одной реализации первый подмодуль 407 соединения сконфигурирован, чтобы: когда существует более одного объекта операции данных, используемого, чтобы выполнять операцию перехода состояния на целевой базе данных, и последовательность выполнения операции перехода состояния всеми объектами операции данных фиксирована, соединять, на основе последовательности выполнения операции перехода состояния, упорядоченные данные, соответствующие всем объектам операции данных, чтобы получить соединенные упорядоченные данные.
[0086] Второй подмодуль 408 соединения сконфигурирован, чтобы: когда существует более одного объекта операции данных, используемого, чтобы выполнять операцию перехода состояния на целевой базе данных, и последовательность выполнения операции перехода состояния всеми объектами операции данных не фиксирована, соединять, на основе первой предопределенной последовательности, упорядоченные данные, соответствующие всем объектам операции данных, чтобы получить соединенные упорядоченные данные.
[0087] Чтобы предотвратить то, что разные группы данных представляют собой те же самые данные после того, как соединение выполнено, в одной реализации, второй подмодуль 408 соединения сконфигурирован, чтобы: помещать предопределенный разделитель между по меньшей мере двумя фрагментами упорядоченных данных и соединять все фрагменты упорядоченных данных, полученные после помещения предопределенного разделителя, чтобы получить соединенные упорядоченные данные.
[0088] В одной реализации первый подмодуль 404 определения значения состояния сконфигурирован, чтобы: соединять, на основе второй предопределенной последовательности, значение хэша объекта операции данных и значение состояния, которое относится к целевой базе данных и которое существует перед выполнением операции перехода состояния, чтобы получить соединенные данные; и определять значение хэша соединенных данных и использовать значение хэша соединенных данных в качестве значения состояния, которое относится к целевой базе данных и которое существует после выполнения операции перехода состояния.
[0089] В одной реализации целевая база данных представляет собой базу данных, соответствующую любому узлу в блокчейне.
[0090] В одной реализации значение состояния используется, чтобы уникально представлять характеристику данных, сохраненных в целевой базе данных.
[0091] В соответствии с устройством определения состояния базы данных, обеспеченным в этой реализации настоящей заявки, когда определяется значение состояния базы данных, данные которой изменяются, определяется операция перехода состояния, выполняемая на целевой базе данных, причем операция перехода состояния представляет собой операцию перехода состояния, которая вызывает изменение данных. Затем значение состояния, которое относится к базе данных и которое существует после выполнения операции перехода состояния, определяется на основе определенной операции перехода состояния и значения состояния, которое относится к базе данных и которое существует перед выполнением операции перехода состояния. По сравнению с существующей технологией не требуется выполнять операцию на всех данных в полной базе данных, тем самым уменьшая потребление излишних вычислительных ресурсов.
[0092] Реализация настоящей заявки дополнительно обеспечивает соответствующее устройство верификации согласованности базы данных. Как показано на фиг. 6, устройство конкретно включает в себя: модуль 501 определения, сконфигурированный, чтобы определять, являются ли одними и теми же значение состояния первой базы данных, подлежащей проверке, и значение состояния второй базы данных, подлежащей проверке, причем значение состояния первой базы данных и значение состояния второй базы данных определяются с использованием устройства, обеспеченного в предыдущей реализации настоящей заявки; и модуль 502 определения согласованности, сконфигурированный, чтобы: когда определено, что значение состояния первой базы данных и значение состояния второй базы данных являются одними и теми же, определять, что состояние первой базы данных и состояние второй базы данных являются согласованными.
[0093] Следует отметить, что в 1990-х, может явно различаться то, является ли совершенствование технологии совершенствованием аппаратных средств (например, улучшением структуры схемы, такой как диод, транзистор или переключатель) или совершенствованием программного обеспечения (улучшением процедуры способа). Однако с развитием технологий современные улучшения многих процедур способа могут рассматриваться как непосредственные улучшения структур схем аппаратных средств. Разработчик обычно программирует усовершенствованную процедуру способа в схему аппаратных средств, чтобы получить соответствующую структуру схемы аппаратных средств. Поэтому процедура способа может быть усовершенствована с использованием модуля аппаратных средств. Например, программируемое логическое устройство (PLD) (например, программируемая вентильная матрица (FPGA)) является такой интегральной схемой, и логическая функция PLD определяется пользователем посредством программирования устройства. Разработчик выполняет программирование, чтобы ʺинтегрироватьʺ цифровую систему в PLD, без запрашивания производителя чипов проектировать и производить чип специализированной интегральной схемы. Кроме того, в настоящее время, такое программирование часто реализуется через программное обеспечение ʺлогического компилятораʺ, а не путем ручного производства чипа интегральной схемы. Программное обеспечение логического компилятора аналогично компилятору программного обеспечения, используемому для разработки и написания программы. Первоначальный код должен быть написан на конкретном языке программирования для компиляции. Этот язык упоминается как язык описания аппаратных средств (HDL). Существует множество HDL, таких как усовершенствованный язык булевых выражений (ABEL), язык описания аппаратных средств Altera (AHDL), Confluence, язык программирования Корнеллского университета (CUPL), HDCal, язык описания аппаратных средств Java (JHDL), Lava, Lola, MyHDL, PALASM и язык описания аппаратных средств Ruby (RHDL). Наиболее часто используются язык описания аппаратных средств на быстродействующих интегральных схемах (VHDL) и Verilog. Специалист в данной области техники должен также понимать, что аппаратная схема, которая реализует логическую процедуру способа, может быть легко получена, когда процедура способа логически запрограммирована с использованием нескольких описанных языков описания аппаратных средств и запрограммирована в интегральную схему.
[0094] Контроллер может быть реализован с использованием любого подходящего способа. Например, контроллер может представлять собой микропроцессор или процессор или считываемый компьютером носитель, который хранит считываемый компьютером программный код (такой как программное обеспечение или прошивка), который может исполняться микропроцессором или процессором, логической схемой, переключателем, специализированной интегральной схемой (ASIC), программируемым логическим контроллером или встроенным микропроцессором. Примеры контроллера включают в себя, но без ограничения, следующие микропроцессоры: ARC 625D, Atmel AT91SAM, Microchip PIC18F26K20 и Silicone Labs C8051F320. Контроллер памяти может также быть реализован как часть управляющей логики памяти. Специалист в данной области техники также знает, что, в дополнение к реализации контроллера с использованием считываемого компьютером программного кода, логическое программирование может выполняться на этапах способа, чтобы позволить контроллеру реализовывать ту же самую функцию в формах логической схемы, переключателя, специализированной интегральной схемы, программируемого логического контроллера и встроенного микроконтроллера. Поэтому, контроллер может рассматриваться как компонент аппаратных средств, и устройство, сконфигурированное, чтобы реализовывать различные функции в контроллере, может также рассматриваться как структура в компоненте аппаратных средств. Или устройство, сконфигурированное, чтобы реализовывать различные функции, может даже рассматриваться как модуль программного обеспечения, реализующий способ, и структура в компоненте аппаратных средств.
[0095] Система, устройство, модуль или блок, проиллюстрированные в вышеописанных реализациях, могут быть осуществлены с использованием компьютерного чипа или объекта или могут быть осуществлены с использованием продукта, имеющего некоторую функцию. Обычным устройством реализации является компьютер. Компьютер может быть, например, персональным компьютером, ноутбуком, сотовым телефоном, камерофоном, смартфоном, персональным цифровым ассистентом, медиа-плеером, устройством навигации, устройством электронной почты, игровой консолью, планшетным компьютером или носимым устройством, или комбинацией любых из этих устройств.
[0096] Для простоты описания устройство выше описано путем разделения функций на различные модули. Разумеется, при реализации настоящей заявки, функция каждого модуля может быть реализована в одном или нескольких фрагментах программного обеспечения и/или аппаратных средств.
[0097] Специалист в данной области техники должен понимать, что реализация настоящего раскрытия может быть обеспечена как способ, система или компьютерный программный продукт. Поэтому, настоящая заявка может использовать форму реализаций только в аппаратных средствах, реализаций только в программном обеспечении или реализаций с комбинацией программного обеспечения и аппаратных средств. Более того, настоящая заявка может использовать форму компьютерного программного продукта, который реализован на одном или нескольких используемых компьютером носителях хранения (включая, но без ограничения, память на диске, CD-ROM, оптическую память, и т.д.), которые включают в себя используемый компьютером программный код.
[0098] Настоящая заявка описана со ссылкой на блок-схемы последовательности операций и/или блок-схемы способа, устройства (системы) и компьютерного программного продукта на основе реализаций настоящего раскрытия. Следует отметить, что компьютерные программные инструкции могут использоваться для реализации каждого процесса и/или каждого блока в блок-схемах последовательности операций и/или блок-схемах устройства и комбинации процесса и/или блока в блок-схемах последовательности операций и/или блок-схемах устройства. Эти компьютерные программные инструкции могут быть обеспечены для универсального компьютера, специализированного компьютера, встроенного процессора или процессора другого программируемого устройства обработки данных, чтобы генерировать машину, так что инструкции, исполняемые компьютером или процессором другого программируемого устройства обработки данных, генерируют устройство для реализации конкретной функции в одном или нескольких процессах в блок-схемах последовательности операций и/или в одном или нескольких блоках в блок-схемах устройства.
[0099] Эти компьютерные программные инструкции могут также храниться в считываемой компьютером памяти, которая может инструктировать компьютер или другое программируемое устройство обработки данных работать конкретным образом, так что инструкции, хранящиеся в считываемой компьютером памяти, генерируют артефакт, который включает в себя устройство инструкций. Устройство инструкций реализует конкретную функцию в одном или нескольких процессах в блок-схемах последовательности операций и/или в одном или нескольких блоках в блок-схемах устройств.
[0100] Эти компьютерные программные инструкции могут быть загружены на компьютер или другое программируемое устройство обработки данных, так что последовательность операций и операции и этапы выполняются на компьютере или другом программируемом устройстве, тем самым генерируя реализуемую компьютером обработку. Поэтому, инструкции, исполняемые на компьютере или другом программируемом устройстве, обеспечивают этапы для реализации конкретной функции в одном или нескольких процессах в блок-схемах последовательности операций и/или в одном или нескольких блоках в блок-схемах устройств.
[0101] В типовой конфигурации вычислительное устройство включает в себя один или несколько процессоров (CPU), интерфейс ввода/вывода, сетевой интерфейс и память.
[0102] Память может включать в себя непостоянную память, память с произвольным доступом (RAM), энергонезависимую память и/или другую форму считываемого компьютером носителя, например, постоянную память (ROM) или флэш-память (флэш-RAM). Память представляет собой пример считываемого компьютером носителя.
[0103] Считываемый компьютером носитель включает в себя постоянные, непостоянные, перемещаемые и неперемещаемые носители, которые обеспечивают хранение информации с использованием любого способа или технологии. Информация может представлять собой считываемую компьютером инструкцию, структуру данных, программный модуль или другие данные. Примеры компьютерного носителя хранения включают в себя, но без ограничения, память с фазовым изменением (PRAM), статическую память с произвольным доступом (SRAM), динамическую память с произвольным доступом (DRAM), другой тип памяти с произвольным доступом (RAM), постоянную память (ROM), электрически стираемую программируемую постоянную память (EEPROM), флэш-память или другую технологию памяти, постоянную память на компакт-диске (CD-ROM), цифровой универсальный диск (DVD) или другое оптическое хранилище, кассетную магнитную ленту, хранилище на магнитной ленте/магнитном диске или другое магнитное устройство хранения. Компьютерный носитель хранения может использоваться для хранения информации, доступ к которой может осуществляться вычислительным устройством. В соответствии с определением в настоящей спецификации, считываемый компьютером носитель не включает в себя переходные носители (переходные среды), например, модулированный сигнал данных и несущую.
[0104] Следует дополнительно отметить, что термины ʺвключать в себяʺ, ʺсодержатьʺ или любой другой вариант этих терминов предназначены, чтобы охватывать не исключающее включение, так что процесс, способ, продукт или устройство, которые включают в себя перечень элементов, не только содержат эти элементы, но также содержат другие элементы, которые не перечислены явно, или дополнительно содержат элементы, которые являются присущими такому процессу, способу, продукту или устройству. Элемент, которому предшествует ʺвключает в себя …ʺ, не препятствует, без дополнительных ограничений, существованию дополнительных идентичных элементов в процессе, способе, продукте или устройстве, которые содержат этот элемент.
[0105] Настоящая заявка может быть описана в общем контексте компьютерно-исполняемых инструкций, исполняемых компьютером, например, программного модуля. Обычно, программный модуль включает в себя подпрограмму, программу, объект, компонент, структуру данных и т.д., исполняющую конкретную задачу или реализующую конкретный тип абстрактных данных. Настоящая заявка может также быть реализована в распределенных вычислительных средах. В распределенных вычислительных средах, задачи выполняются удаленными устройствами обработки, соединенными через сеть связи. В распределенной вычислительной среде, программный модуль может быть расположен как в локальных, так и в удаленных компьютерных носителях хранения, включающих в себя устройства хранения.
[0106] Реализации в настоящей спецификации описаны последовательным образом. Для одних и тех же или аналогичных частей реализаций могут даваться ссылки на реализации. Каждая реализация фокусируется на отличии от других реализаций. В частности, реализация системы в основном аналогична реализации способа и поэтому описана кратко. Для связанных частей ссылки могут даваться на связанные описания в реализации способа.
[0107] Предыдущие реализации представляют собой только реализации настоящей заявки и не предназначены для ограничения настоящей заявки. Специалист в данной области техники может осуществлять различные модификации и изменения в настоящей заявке. Любая модификация, эквивалентная замена или усовершенствование, выполненное без отклонения от сущности и принципа настоящей заявки, должно соответствовать объему формулы изобретения в настоящей заявке.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ И УСТРОЙСТВО ОБРАБОТКИ ДАННЫХ | 2018 |
|
RU2721402C1 |
| СПОСОБ И УСТРОЙСТВО УСТАНОВКИ КЛЮЧЕЙ И ОТПРАВКИ ДАННЫХ | 2018 |
|
RU2744494C2 |
| СПОСОБ И УСТРОЙСТВО ДЛЯ ОБРАБОТКИ ЗАПРОСА УСЛУГИ | 2018 |
|
RU2708952C1 |
| СПОСОБ И УСТРОЙСТВО ДЛЯ ОСНОВАННОЙ НА БЛОКЧЕЙНЕ ОБРАБОТКИ ДАННЫХ | 2018 |
|
RU2720641C1 |
| СПОСОБ И УСТРОЙСТВО УСТАНОВКИ КЛЮЧЕЙ И ОТПРАВКИ ДАННЫХ | 2018 |
|
RU2727098C1 |
| ДОСТИЖЕНИЕ КОНСЕНУСА МЕЖДУ СЕТЕВЫВЫМИ УЗЛАМИ В РАСПРЕДЕЛЕННОЙ СИСТЕМЕ | 2018 |
|
RU2723072C1 |
| СПОСОБ И УСТРОЙСТВО ОБРАБОТКИ ДАННЫХ НА ОСНОВЕ БЛОКЧЕЙНА | 2018 |
|
RU2728820C1 |
| БЕЛЫЕ СПИСКИ СМАРТ-КОНТРАКТОВ | 2018 |
|
RU2744827C2 |
| ИЗОЛЯЦИЯ ДАННЫХ В СЕТИ БЛОКЧЕЙН | 2018 |
|
RU2745518C2 |
| СПОСОБ И АППАРАТУРА ДЛЯ ВЕРИФИКАЦИИ СОГЛАСОВАННОСТИ | 2018 |
|
RU2733112C1 |
Изобретение относится к способу и устройству определения состояния базы данных. Технический результат заключается в сокращении вычислительных ресурсов за счет того, что операция перехода состояния целевой БД выполняется не на всех данных БД. Способ включает в себя определение операции перехода состояния, выполняемой на целевой базе данных, и определение, на основе определенной операции перехода состояния и значения состояния, которое относится к целевой базе данных и которое существует перед выполнением операции перехода состояния, значения состояния, которое относится к целевой базе данных и которое существует после выполнения операции перехода состояния, причем значение состояния используется, чтобы представлять состояние целевой базы данных. 2 н. и 12 з.п. ф-лы, 6 ил.
1. Способ определения состояния базы данных, причем способ содержит:
определение операции перехода состояния, выполняемой на объекте операции данных целевой базы данных; и
определение, на основе операции перехода состояния и значения предшествующего состояния, которое относится к целевой базе данных и которое существует перед выполнением операции перехода состояния, значения состояния, которое относится к целевой базе данных и которое существует после выполнения операции перехода состояния, причем значение состояния используется, чтобы представлять состояние целевой базы данных.
2. Способ по п. 1, причем объект операции данных содержит:
экземпляр, класс которого загружен в память целевой базы данных и имеет связанные переменные элементы и функции элементов.
3. Способ по п. 2, причем определение значения состояния, которое относится к целевой базе данных и которое существует после выполнения операции перехода состояния, содержит:
определение, на основе объекта операции данных и значения состояния, которое относится к целевой базе данных и которое существует перед выполнением операции перехода состояния, значения состояния, которое относится к целевой базе данных и которое существует после выполнения операции перехода состояния.
4. Способ по п. 3, причем целевая база данных представляет собой базу данных блокчейна.
5. Способ по п. 4, причем определение значения состояния, которое относится к целевой базе данных и которое существует после выполнения операции перехода состояния, содержит:
определение значения хэша объекта операции данных; и
определение, на основе значения хэша объекта операции данных и значения состояния, которое относится к целевой базе данных и которое существует перед выполнением операции перехода состояния, значения состояния, которое относится к целевой базе данных и которое существует после выполнения операции перехода состояния.
6. Способ по п. 5, причем определение значения хэша объекта операции данных содержит:
упорядочивание объекта операции данных, чтобы получить упорядоченные данные; и
определение значения хэша упорядоченных данных и использование значения хэша упорядоченных данных в качестве значения хэша объекта операции данных.
7. Способ по п. 6, причем упорядочивание объекта операции данных, чтобы получить упорядоченные данные, содержит:
определение, является ли фиксированной последовательность выполнения операции перехода состояния всеми объектами операции данных; и
если последовательность выполнения операции перехода состояния всеми объектами операции данных является фиксированной, соединение, на основе последовательности выполнения операции перехода состояния, упорядоченных данных, соответствующих всем объектам операции данных, чтобы получить соединенные упорядоченные данные.
8. Способ по п. 6, причем упорядочивание объекта операции данных, чтобы получить упорядоченные данные, содержит:
определение, является ли фиксированной последовательность выполнения операции перехода состояния всеми объектами операции данных; и
если последовательность выполнения операции перехода состояния всеми объектами операции данных является нефиксированной, соединение, на основе первой предопределенной последовательности, упорядоченных данных, соответствующих всем объектам операции данных, чтобы получить соединенные упорядоченные данные.
9. Способ по п. 7, причем получение соединенных упорядоченных данных содержит:
помещение предопределенного разделителя между по меньшей мере двумя фрагментами упорядоченных данных; и
соединение всех фрагментов упорядоченных данных, полученных после помещения предопределенного разделителя, чтобы получить соединенные упорядоченные данные.
10. Способ по п. 5, причем определение значения состояния, которое относится к целевой базе данных и которое существует после выполнения операции перехода состояния, содержит:
соединение, на основе второй предопределенной последовательности, значения хэша объекта операции данных и значения состояния, которое относится к целевой базе данных и которое существует перед выполнением операции перехода состояния, чтобы получить соединенные данные; и
определение значения хэша соединенных данных и использование значения хэша соединенных данных в качестве значения состояния, которое относится к целевой базе данных и которое существует после выполнения операции перехода состояния.
11. Способ по любому одному из пп. 1-7, причем целевая база данных представляет собой базу данных, соответствующую любому узлу в блокчейне.
12. Способ по п. 1, причем значение состояния используется, чтобы уникально представлять характеристику данных, хранящихся в целевой базе данных.
13. Способ по п. 1, дополнительно содержащий:
определение, является ли значение предшествующего состояния целевой базы данных, подлежащей проверке, тем же самым, что и значение состояния; и
в ответ на определение, что значение предшествующего состояния является тем же самым, что и значение состояния целевой базы данных, определение, что предшествующее состояние и состояние целевой базы данных являются согласованными.
14. Устройство для определения состояния базы данных, причем устройство содержит множество модулей, сконфигурированных, чтобы выполнять способ по любому одному из пп. 1-13.
| CA 2981511 A1, 06.10.2016 | |||
| Способ защиты переносных электрических установок от опасностей, связанных с заземлением одной из фаз | 1924 |
|
SU2014A1 |
| CN 102662946 B, 07.10.2015 | |||
| Автомобиль-сани, движущиеся на полозьях посредством устанавливающихся по высоте колес с шинами | 1924 |
|
SU2017A1 |
| ОТСЛЕЖИВАНИЕ ДАННЫХ ИЗМЕНЕНИЯ СОСТОЯНИЯ ДЛЯ ТОГО, ЧТОБЫ СОДЕЙСТВОВАТЬ БЕЗОПАСНОСТИ ВЫЧИСЛИТЕЛЬНОЙ СЕТИ | 2007 |
|
RU2425449C2 |

