Изобретение относится к способам производства средств идентификации изделий, которые могут быть использованы для защиты изделий от подделок и копирования, а также для полной идентификации товарных знаков.
Термин «идентификация» определяется как «отождествление, установление совпадения чего-либо с чем-либо». При идентификации товаров выявляют соответствие испытуемых товаров аналогам, характеризующимся той же совокупностью потребительских свойств, или описанию товара на маркировке, в товарно-сопроводительных и нормативных документах.
Согласно ГОСТ Р 51293-99, идентификация продукции – установление соответствия конкретной продукции образцу и (или) ее описанию.
Актуальность обусловлена следующими факторами:
- Существенная доля рынка в ряде отраслей занята нелегальными производителями и импортерами;
- Государственный бюджет недополучает налоговые отчисления из-за нелегального оборота товаров;
- Бренды производителей сложно защитить от подделок, что ведет к репутационным рискам;
- Есть угроза здоровью и жизни потребителей, создаваемая сфальсифицированными и некачественными товарами;
- Производителям сложно своевременно получить обратную связь от потребителей по легальным товарам с недостаточным качеством.
В настоящее время повсеместно ужесточились требования, предъявляемые потребителем к качеству товаров. В результате возникла необходимость постоянного обеспечения требуемого уровня качества продукции, так как без этого невозможна эффективная деятельность организаций.
Требования к качеству продукции, удовлетворяющие потребности покупателей, устанавливаются в стандартах, технических условиях и других нормативно-правовых актах. Однако эти нормативные документы не гарантируют того, что при проектировании, разработке, производстве, хранении и реализации товаров фактически достигнутый уровень качества будет соответствовать установленным требованиям.
Существующие способы идентификации либо не обеспечивают должный уровень идентификации продукции, либо требуют дорогостоящего оборудования для считывания информации, представленной на информационно-защитной этикетке каждой единицы продукции.
Ключевыми элементами информационно-защитной этикетки являются содержательная информация (товарный знак и иные данные, хранящиеся в информационной базе данных) и идентификационная информация (так называемый идентификационный код единицы продукции, предназначенный для отличия каждой единицы продукции).
Для упрощения вычислительных операций в содержательную информацию информационно-защитной этикетки добавляют информацию о партии продукции, то есть осуществляют сегментацию. Количество единиц в отдельной партии устанавливается исходя из технологических особенностей производства и вычислительной мощностью оборудования для обработки данных. Соответственно, важной является задача осуществления операций по расчету коэффициента уникальности kун, представляющего собой разность между 1 и коэффициентом сходства kсх∈[0;1]. В случае, если kун=1, то сравниваемые объекты обладают абсолютным несходством, если kун =0, то наоборот – сравниваемые объекты обладают абсолютным сходством.
Вследствие этого, возникла необходимость разработки способа формирования идентификационного кода продукции с заданной степенью уникальности.
Известен способ контролируемой реализации продукции и ее защиты от подделки [Патент RU 2144220 C1, МПК G09F 3/02, G06K 19/16, опубл. 10.01.2000], заключающийся в том, что каждую единицу продукции оснащают информационно-защитной этикеткой, на которую наносят штриховой код, содержащий идентификационную и содержательную информацию, при этом этикетку дополнительно оснащают дифракционным элементом защиты от копирования, имеющим поверхностный микрорельеф, создающий эффект оптической дифракции, а информацию, подлежащую внесению в штриховой код, первоначально заносят в центральный компьютер контрольного учреждения из сопроводительных документов, предоставленных поставщиком на каждую поставляемую партию товара, затем путем компьютерного преобразования этой информации по заранее введенному алгоритму, преобразующему данные из сопроводительных документов по определенному правилу, которое задает конкретное ответственное лицо региона путем ввода пароля, в наборе символов формируют штриховой код и производят печатание партии этикеток в заявленном поставщиком количестве для наклейки на каждую единицу продукции с нанесением на каждую из этикеток штрихового кода, а в торговом учреждении осуществляют проверку продукции путем визуального контроля наличия дифракционного элемента и считывания штрихового кода с этикетки проверяемой единицы продукции с одновременным обратным преобразованием по заранее введенному алгоритму занесенной в штриховой код информации и сравнения этой информации с информацией из сопроводительных документов, представленных поставщиком на каждую поставляемую партию товара.
Недостатки этого способа защиты товара:
- упреждающее формирование идентификационных кодов, что обуславливает их большую уязвимость от подделки на копировальной технике.
Известен способ генерирования кода о товаре [Патент RU 2678163, МПК G06K 5/00 (2006.01), опубл. 23.01.2019, бюл. №3], который включает следующие этапы: нанесение на товар N-значного номера, причем N-значные номера генерируются на основе трех постоянно изменяющихся параметров: GPS-координат предприятия, ГЛОНАСС-координат предприятия и текущего времени, при этом один из них меняется ежесекундно (время), а два других (координаты) - случайно изменяются относительно некоторого среднего положения в течение всего времени измерения, поскольку зависят от численности группировки космических аппаратов, обслуживающих ГЛОНАСС и GPS; расположения спутников ГЛОНАСС и GPS в момент определения координат; различия влияния атмосферы Земли при передаче сигналов из-за различных систем кодирования сигналов ГЛОНАСС и GPS; различных принципов вычисления координат приемником ГЛОНАСС и GPS; уникальной погрешности, характерной как для отдельно взятых ГЛОНАСС- и GPS-навигаторов, так и используемых для измерения времени часов.
Недостатки способа генерирования кода о товаре:
- невозможность определения степени уникальности сгенерированных кодов.
Известен способ автоматизированного учета движения товаров [Патент RU 2640749, МПК G06Q 10/00 (2012.01), опубл. 11.01.2018, бюл. №2], в котором используют электронную сетевую систему, включающую сервер, связанный с устройствами учета товара в торговых точках сетевого предприятия. Информацию о товарных операциях в месте их хранения и распределения осуществляют путем передачи на сервер информации о поступившем товаре. Сначала вводят идентификационные коды поставщика с носителя информации каждого поступившего товара, производят его идентификацию путем нахождения в электронной базе данных о товарах поставщиков информации о товаре, соответствующей коду. Затем определяют соответствующий товару идентификационный код товара сетевого предприятия. Идентификационные коды наносят на носитель информации каждого товара. На основании информации, полученной от устройств учета товара торговых точек, формируют перечень товара, предназначенного для направления в торговую точку. В случае наличия товара в торговых точках товар оставляют на временном складском хранении.
Недостатки способа автоматизированного учета движения товаров:
- упреждающее формирование идентификационных кодов, что обуславливает их высокую уязвимость от подделки на копировальной технике.
Известен способ определения подлинности товаров в режиме реального времени, контроля распространении, продажи товаров и стимулирования покупки товаров [Патент RU 2534430, МПК G06K 9/18 (2006.01), G06Q 30/02 (2012.01), опубл. 27.11.2014, бюл. №33], в котором идентификационный код генерируют в виде двух связанных уникальных символьно-цифровых кодов в формате штрих-кода, вторую метку со вторым уникальным символьно-цифровым кодом в формате штрих-кода и символьно-цифровой записи кода размещают так, что доступ к данной метке обеспечивается после продажи товара, подлинность товара проверяют последовательно сравнением уникальных символьно-цифровых кодов на товарных метках и уникальных символьно-цифровых кодов, зарегистрированных в базе данных оригинальных товаров.
Недостатки способа определения подлинности товаров в режиме реального времени, контроля распространении, продажи товаров и стимулирования покупки товаров:
- степень уникальности символьно-цифровых кодов не контролируется, что ведет к необходимости применения дорогостоящего элементов для создания системы идентификации с высокой вычислительной мощностью, а также к повышению вероятности возникновения конфликтных ситуаций;
- упреждающее формирование идентификационных кодов, что обуславливает их большую уязвимость от подделки на копировальной технике.
Известен способ проверки подлинности товаров или услуг [Патент RU 2643503, МПК G06Q 30/00 (2012.01), G06F 17/30 (2006.01), опубл. 01.02.2018, бюл. №4], в котором разбивают жизненный цикл товаров или услуг на этапы, на каждом этапе формируют уникальный код отслеживания, который наносят на товар или маркируют документ, соответствующий услуге, каждому такому уникальному коду отслеживания ставят в соответствие информацию в единой базе данных всех товаров и услуг, содержащую сведения о параметрах товара или услуги как на каждом следующем этапе жизненного цикла, так и на всех предыдущих, формируют список из параметров доступа пользователей, соответствующих различным правам доступа пользователей единой базы данных, которую разбивают на области, соответствующие разным параметрам доступа пользователей, для каждого пользователя формируют код идентификации пользователя, соответствующий его параметру доступа пользователя, который заносят в единую базу данных, при обращении к единой базе данных проверяют код идентификации пользователя, при соответствии проверяемого кода идентификации пользователя тому коду , который находится в единой базе данных, предоставляют пользователю доступ согласно его праву доступа к соответствующей области единой базы данных, при несоответствии – не предоставляют доступа.
Недостатки способа проверки подлинности товаров или услуг:
- степень уникальности кода не контролируется, что ведет к необходимости применения дорогостоящих элементов для создания системы идентификации с высокой вычислительной мощностью, а также к повышению вероятности возникновения конфликтных ситуаций;
- упреждающее формирование идентификационных кодов, что обуславливает их возможную уязвимость от подделки на копировальной технике.
Наиболее близким по технической сущности и принятым за прототип является способ формирования идентификационного кода продукции (варианты) [Патент RU 2263355 C1, МПК G09F 3/02 (2000.01), опубл. 27.10.2005, бюл. №30], заключающийся в том, что каждую единицу продукции оснащают информационно-защитной этикеткой, код в виде кодовых частиц, каждая из которых имеет случайное расположение, подмешивают в клей, с помощью которого этикетку, выполненную оптически прозрачной, приклеивают на единицу продукции, код этикетки, содержащий идентификационную информацию, заносят в информационную базу данных после приклеивания этикетки на единицу продукции и формируют содержательную информацию, которую вносят в информационную базу данных.
Недостатком способа-прототипа является:
- контроль степени уникальности не обеспечивается, что ведет к необходимости применения дорогостоящего элементов для создания системы идентификации с высокой вычислительной мощностью.
Предлагаемый способ направлен на решение технической проблемы, сущность которой заключается в необходимости создания информационно-защитных этикеток с заданным уровнем уникальности для последующей оптимизации технических возможностей системы идентификации.
Технический результат изобретения заключается в формировании идентификационного кода продукции с заданным уровнем уникальности, что позволит оптимизировать технические возможности системы идентификации.
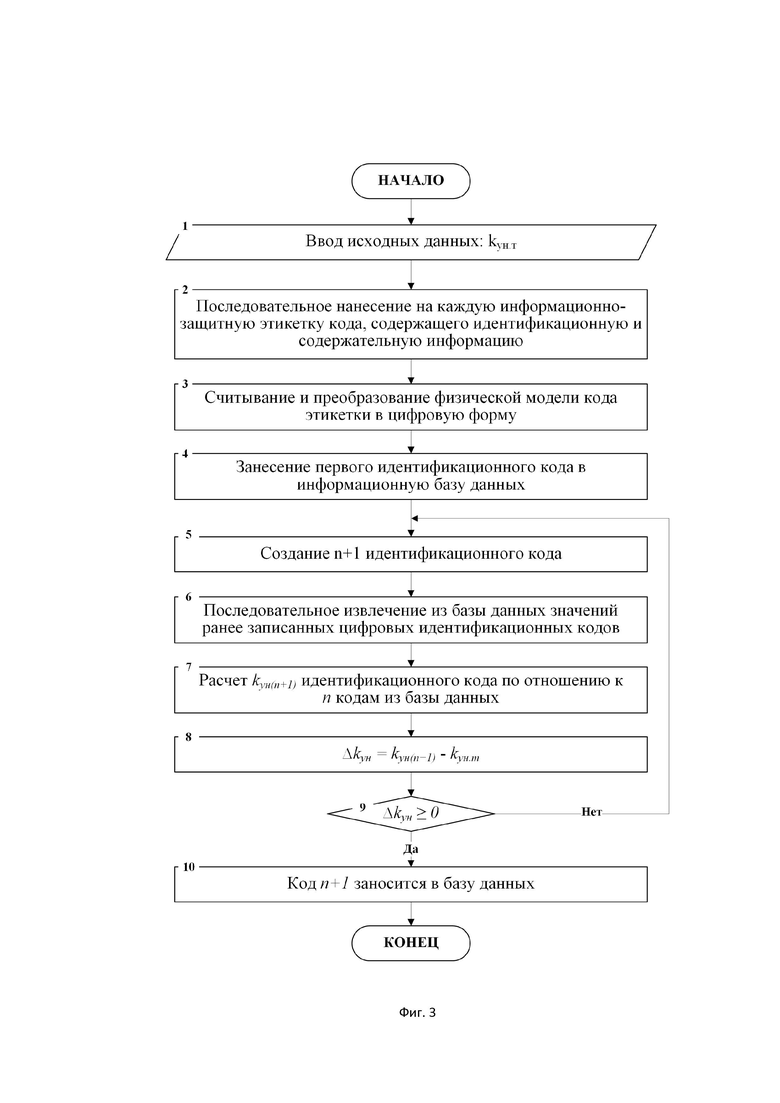
Технический результат достигается следующей последовательностью действий: вводят исходные данные: kун.т - количественное значение требуемого коэффициента уникальности идентификационных кодов; на информационно-защитную этикетку наносят код, содержащий идентификационную и содержательную информацию; считывают код этикетки, содержащий идентификационную и содержательную информацию; заносят первый идентификационный код в информационную базу данных; преобразуют физическую модель идентификационного кода в цифровую форму; создают n+1 идентификационный код; последовательно извлекают из базы данных значения ранее записанных цифровых идентификационных кодов; рассчитывают kун(n+1) – коэффициент уникальности созданного n+1 идентификационного кода по отношению к n кодам из базы данных; рассчитывают Δkун – разницу между результатами оценки kун(n+1) – коэффициента уникальности и kун.т – требуемого коэффициента уникальности; если Δkун > 0 , то код n+1 заносится в базу данных; если Δkун < 0 , то : код n+1 не заносится в базу данных, переходят к созданию нового идентификационного кода n+i.
Изобретение поясняется чертежами:
Фиг. 1 – пример содержания информационно-защитной этикетки.
Фиг. 2 – послойное представление информационно-защитной этикетки.
Фиг. 3 – блок-схема способа формирования идентификационного кода продукции с заданным уровнем уникальности.
Фиг. 4 – блок-схема способа формирования идентификационного кода продукции с заданным уровнем уникальности с учетом числа повторений нанесения кодовых частиц.
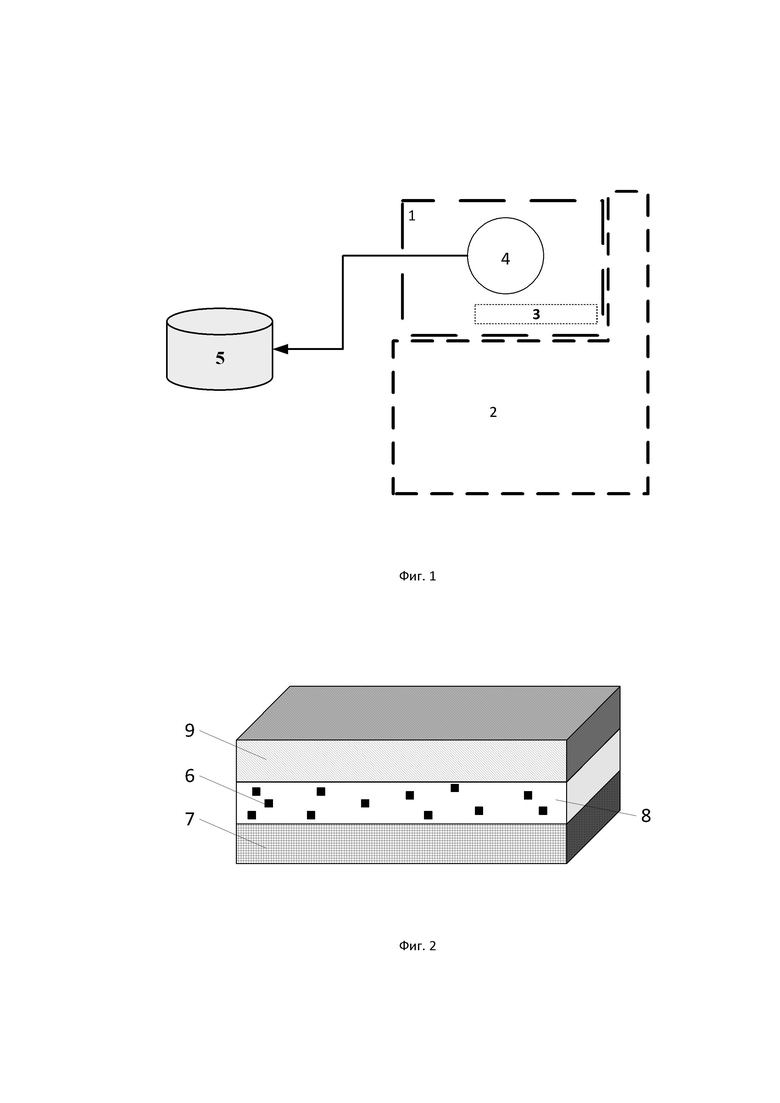
Информационно-защитная этикетка представлена на фиг. 1 и содержит следующие элементы: содержательная информация 1, идентификационная информация 2, номер партии 3, товарный знак 4, база данных 5.
Идентификационная информация – это так называемый идентификационный код единицы продукции, предназначенный для отличия каждой единицы продукции. Идентификационный код единицы продукции не несет в себе содержательной информации, а представляет собой ссылку на данные, хранящиеся в информационной базе данных.
Содержательная информация единицы продукции – товарный знак и иные данные, хранящиеся в информационной базе данных.
Для упрощения вычислительных операций в содержательную информацию этикетки добавляют информацию о партии продукции. Количество единиц в партии устанавливается исходя из технологических особенностей производства и мощностью оборудования для обработки данных. Соответственно, вычислительные операции по расчету коэффициента уникальности проводят в рамках одной определенной партии.
Послойное представление информационно-защитной этикетки представлено на фиг. 2 и содержит поверхность единицы продукции (упаковки) 7, кодовые частицы 6, клей 8, оптически прозрачную этикетку 9.
Заявленный способ может быть реализован следующим образом (фиг. 3).
Фиг. 3. Блок 1. Вводят исходные данные: kун.т - количественное значение требуемого коэффициента уникальности идентификационных кодов.
Фиг. 3. Блок 2. Последовательно на каждую информационно-защитную этикетку наносят код, содержащий идентификационную и содержательную информацию (фиг. 1).
Каждую единицу продукции последовательно оснащают информационно-защитной этикеткой 9, на которую наносят код, содержащий идентификационную и содержательную информацию. При этом код в виде кодовых частиц 6, каждая из которых имеет случайное расположение, подмешивают в клей 8, с помощью которого этикетку 9, выполненную оптически прозрачной приклеивают на единицу продукции 7.
Подмешивание кодовых частиц 6 в клей 8 может быть технологически реализовано различным образом. Во-первых, путем распыления порции пыли, изготовленной из любых непрозрачных материалов с помощью сжатого воздуха. Во-вторых, распыление ферромагнитных материалов может осуществляться с помощью магнитного поля, создаваемого электромагнитом. Перемещение заготовок для этикеток может осуществляться с помощью шаговых электродвигателей.
Фиг. 3. Блок 3. Считывают код этикетки, содержащий идентификационную и содержательную информацию и преобразуют физическую модель идентификационного кода в цифровую форму.
Считывание кода этикетки может быть осуществлено посредством применения сканера, подключенного к портативному компьютеру или цифрового фотоаппарата.
Аналоговая информация, которая образуется в результате измерения электрического заряда на фотосенсорах, поступает с матрицы в фотоаппарат. Далее с помощью аналого-цифрового преобразователя она преобразуется в цифровую форму – двоичный код.
Ключевые факторы, влияющие на считывание кода:
- Ширина поля сканирования;
- Расстояние считывания;
- Угол наклона считывающего устройства;
- Криволинейность поверхности;
- Качество изображения идентификационного кода;
- Разрешающая способность считывающего устройства.
Существует множество запатентованных способов считывания идентификационных кодов различного типа. Например, Патент RU 2439701 «Способ считывания, по меньшей мере, одного штрих-кода и система считывания штрих-кода», опубл. 10.01.2012, патентообладатели: АРЖОВИГЖЕН (FR), АРЖОВИГЖЕН СИКЬЮРИТИ (FR), Патент RU 2543569 «Устройство и способ для автоматического распознавания QR-кода», опубл. 10.03.2015, патентообладатель: ЕВОН КОММЬЮНИКЕЙШЕН КО., ЛТД. (KR) и др.
Изначальное задание требуемого уровня уникальности идентификационного кода позволяет осуществлять оптимальный выбор считывающего оборудования, ввиду подбора оборудования, обладающего определенным набором технических характеристик.
Фиг. 3. Блок 4. Заносят первый идентификационный код в информационную базу данных.
Фиг. 3. Блок 5. Создают n+1 идентификационный код.
Фиг. 3. Блок 6. Последовательно извлекают из базы данных значения ранее записанных цифровых идентификационных кодов.
Фиг. 3. Блок 7. Рассчитывают коэффициент уникальности созданного n+1 идентификационного кода по отношению к n кодам из базы данных.
Коэффициент уникальности kун представляет собой разность между 1 и коэффициентом сходства kсх∈[0;1].
В случае, если kсх=1, то сравниваемые объекты обладают абсолютным сходством, если kсх=0, то наоборот – сравниваемые объекты обладают абсолютным несходством.
Следовательно, если kун=1, то сравниваемые объекты обладают абсолютным несходством, если kун =0, то наоборот – сравниваемые объекты обладают абсолютным сходством.
Для вычисления kун целесообразно производить расчет по формуле Рассела и Рао [Жамбю М. Иерархический кластер-анализ и соответствия / М. Жамбю,: Пер. с фр. - М.: «Финансы и статистика», 1988, С. 94]:
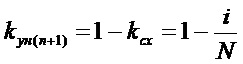 , где
, где
i – число совпадений параметров n+1 идентификационного кода по отношению к n кодам из базы данных; N – общее число сравниваемых параметров.
Далее составляется вариационный ряд из значений коэффициентов уникальности.
Фиг. 3. Блок 8. Рассчитывают разницу между результатами оценки коэффициента уникальности и требуемого коэффициента уникальности.
∆kун = kун(n+1) - kун.т , где
kун(n+1) – коэффициент уникальности созданного n+1 идентификационного кода по отношению к n кодам из базы данных; kун.т - требуемый коэффициент уникальности.
Фиг. 3. Блок 9. Блок сравнения: ∆kун ≥ 0
Фиг. 3. Блок 10. Если ∆kун ≥ 0 , то код n+1 заносится в базу данных.
В противном случае, код n+1 не заносится в базу данных, переходят к созданию нового идентификационного кода n+i (Фиг. 3. Блок 5).
Таким образом формируется идентификационный код информационно-защитной этикетки с заданным уровнем уникальности. Технический результат достигнут.
Рассмотрим второй вариант реализации способа формирования идентификационного кода информационно-защитной этикетки с заданным уровнем уникальности с учетом числа повторений нанесения кодовых частиц (фиг. 4).
Блоки 1-10 идентичны.
Добавляется дополнительный этап, заключающийся в следующем:
Фиг. 4. Блок 11. Если ∆kун < 0 , то : код n+1 не заносится в базу данных, сравнивают значение счетчика числа повторений нанесения кодовых частиц с максимальным значением (mмакс).
Если m ≤ mмакс, то процесс нанесения кода повторяется (Фиг. 4. Блок 2).
В противном случае, код n+1 уничтожается, переходят к созданию нового идентификационного кода n+i (Фиг. 4. Блок 5).
Таким образом формируется идентификационный код информационно-защитной этикетки с заданным уровнем уникальности. Технический результат достигнут.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ ИДЕНТИФИКАЦИИ ПРОДУКЦИИ | 2004 |
|
RU2263354C1 |
| СПОСОБ ФОРМИРОВАНИЯ ИДЕНТИФИКАЦИОННОГО КОДА ПРОДУКЦИИ (ВАРИАНТЫ) | 2004 |
|
RU2263355C1 |
| СПОСОБ КОНТРОЛЯ ПОДЛИННОСТИ И ПЕРЕМЕЩЕНИЯ АЛКОГОЛЬНОЙ ПРОДУКЦИИ (ВАРИАНТЫ) | 2005 |
|
RU2292587C1 |
| СПОСОБ ЗАЩИТЫ ПРОДУКЦИИ ОТ ПОДДЕЛКИ И КОНТРОЛЯ ПОДЛИННОСТИ ЗАЩИЩАЕМОЙ ОТ ПОДДЕЛКИ ПРОДУКЦИИ | 2015 |
|
RU2608240C2 |
| СПОСОБ КОНТРОЛЯ ПОДЛИННОСТИ И КАЧЕСТВА ПРОДУКЦИИ В ПРОЦЕССЕ ПРОИЗВОДСТВА И РЕАЛИЗАЦИИ | 2017 |
|
RU2639015C1 |
| СПОСОБ КОНТРОЛИРУЕМОЙ РЕАЛИЗАЦИИ ПРОДУКЦИИ И ЕЕ ЗАЩИТЫ ОТ ПОДДЕЛКИ | 1998 |
|
RU2144220C1 |
| Технология защиты от контрафакта и фальсификата путем кодирования, внутреннего размещения уникальных кодов и их распознания | 2020 |
|
RU2755969C1 |
| СПОСОБ КОНТРОЛЯ ПОДЛИННОСТИ ПРОДУКЦИИ И ЗАЩИТЫ ОТ КОНТРАФАКТА И ФАЛЬСИФИКАЦИИ | 2017 |
|
RU2733702C2 |
| СПОСОБ МАРКИРОВКИ ПРОДУКЦИИ ИЛИ ИЗДЕЛИЙ ДЛЯ ИХ ИДЕНТИФИКАЦИИ И ЗАЩИТЫ ОТ ПОДДЕЛКИ | 2013 |
|
RU2534952C1 |
| СПОСОБ УЧЕТА МАРКИРУЕМОЙ ПРОДУКЦИИ | 2018 |
|
RU2670727C9 |

Изобретение относится к способам производства средств идентификации изделий, которые могут быть использованы для защиты изделий от подделок и копирования, а также для полной идентификации товарных знаков. Технический результат изобретения заключается в формировании идентификационного кода продукции с заданным уровнем уникальности, что позволит оптимизировать технические возможности системы идентификации. Технический результат достигается следующей последовательностью действий: вводят исходные данные: kун.т - количественное значение требуемого коэффициента уникальности идентификационных кодов; на информационно-защитную этикетку наносят код, содержащий идентификационную и содержательную информацию; считывают код этикетки, содержащий идентификационную и содержательную информацию; заносят первый идентификационный код в информационную базу данных; создают n+1 идентификационный код; преобразуют физическую модель идентификационного кода в цифровую форму; последовательно извлекают из базы данных значения ранее записанных цифровых идентификационных кодов; рассчитывают kун(n+1) - коэффициент уникальности созданного n+1 идентификационного кода по отношению к n кодам из базы данных; рассчитывают Δkун - разницу между результатами оценки kун(n+1) - коэффициента уникальности и kун.т - требуемого коэффициента уникальности; если Δkун > 0, то код n+1 заносится в базу данных; если Δkун < 0 , то код n+1 не заносится в базу данных, переходят к созданию нового идентификационного кода n+i. 1 з.п. ф-лы, 4 ил.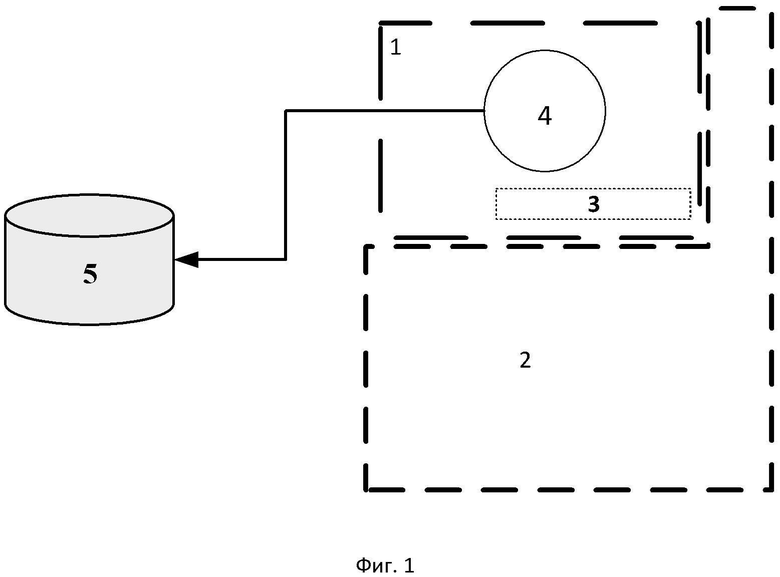
1. Способ формирования идентификационного кода информационно-защитной этикетки с заданным уровнем уникальности, заключающийся в том, что на информационно-защитную этикетку наносят код, содержащий идентификационную и содержательную информацию, считывают и заносят первый идентификационный код в информационную базу данных, код в виде кодовых частиц, каждая из которых имеет случайное расположение, отличающийся тем, что задают kун.т - количественное значение требуемого коэффициента уникальности идентификационных кодов, преобразуют физическую модель идентификационного кода в цифровую форму, создают n+1 идентификационный код, последовательно извлекают из базы данных значения ранее записанных цифровых идентификационных кодов, рассчитывают kун(n+1) - коэффициент уникальности созданного n+1 идентификационного кода по отношению к n кодам из базы данных, рассчитывают Δkун - разницу между результатами оценки kун(n+1) - коэффициента уникальности и kун.т - требуемого коэффициента уникальности, если Δkун ≥ 0 , то код n+1 заносится в базу данных, если Δkун<0, то код n+1 не заносится в базу данных, переходят к созданию нового идентификационного кода n+i.
2. Способ по п. 1, отличающийся тем, что дополнительно задают mмакс - число повторений нанесения кодовых частиц, в случае если Δkун < 0, то код n+1 не заносится в базу данных, сравнивают m - значение счетчика числа повторений нанесения кодовых частиц с mмакс - максимальным значением числа повторений нанесения кодовых частиц, если m ≤ mмакс, то процесс нанесения кода повторяется, в противном случае - код n+1 уничтожается, переходят к созданию нового идентификационного кода n+i.
| US 20110160576 A1, 30.06.2011 | |||
| US 5751835 A, 12.05.1998 | |||
| СПОСОБ ФОРМИРОВАНИЯ ИДЕНТИФИКАЦИОННОГО КОДА ПРОДУКЦИИ (ВАРИАНТЫ) | 2004 |
|
RU2263355C1 |
| US 2012212597 A1, 23.08.2012. | |||

