Изобретение относится к биометрической идентификации и аутентификации личности и может быть использовано в системах защиты информации и разграничения доступа.
Из уровня техники известен способ безопасной биометрической аутентификации по патенту на изобретение RU 2406143 C2 (патентообладатель: Иванов А.И., МПК: G06K 9/03, G07D 7/00, опубл. 10.12.2010). Способ биометрической аутентификации заключается в преобразовании данных биометрического образа человека в самокорректирующийся код биометрического образа, способный обнаруживать и исправлять ошибки, а также в индикации ошибки ввода биометрического образа при обнаружении в самокорректирующемся коде числа ошибок, которое код не может исправить. В способе вводят данные нескольких биометрических образов и преобразуют каждый из них в самокорректирующийся код. При аутентификации правильность ввода каждого из биометрических образов индицируют с помощью индикатора и отображают самокорректирующийся код биометрического образа с положительным результатом аутентификации. В итоге оценивают общее число обнаруженных неисправимых ошибок в каждом из анализируемых кодов и отображают индикатором коды биометрических образов, имеющие число ошибок, превышающее его корректирующую способность на несколько бит, которое самокорректирующийся код может исправить.
Известен также способ динамической биометрической аутентификации личности по особенностям почерка по патенту на изобретение RU 2541131 C2 (патентообладатель: ФГБОУ ВПО "Юго-Западный государственный университет", МПК: G06K 9/62, опубл. 10.02.2015). Способ заключается в дискретизации многокомпонентного аналогового сигнала, воспроизводящего динамику воспроизведения рукописного текста, квантовании дискретных отсчетов, формировании матрицы квантованных отсчетов, ее преобразовании к цифровому виду, по значениям ее элементов вычисления идентификационной матрицы. Определение индивидуальных особенностей почерка производят по идентификационной матрице, полученной путем двумерного дискретного преобразования Хаара. Для этого создают базу эталонных параметров образцов почерка пользователей, допущенных в компьютеризированную систему, в виде интервала изменения каждого идентификационного параметра. Вновь вводимого в систему пользователя идентифицируют по идентификационной матрице, полученной путем двумерного дискретного преобразования Хаара. Затем вычисляют максимальное и минимальное значения идентифицируемых параметров. Определяют расстояние Хемминга как общее число выпадений идентификационных параметров за интервалы допустимых значений эталонных параметров образцов почерка пользователей, допущенных в компьютеризированную систему. Решение о допуске произвольного пользователя в систему принимают, если расстояние Хемминга минимально, в противном случае формируют сообщение о несанкционированной попытке входа в систему.
Известен также способ биометрической аутентификации пользователя по патенту на изобретение RU 2552189 C1 (патентообладатель: ГКОУ ВПО Академия Федеральной службы охраны Российской Федерации, МПК: G06K 9/62, опубл. 10.06.2015), заключающийся в том, что предварительно создают базу идентификационных параметров образцов почерка пользователей, допущенных в компьютеризированную систему. Далее пользователю, входящему в систему контроля допуска, предлагают выполнить произвольную запись образца рукописного почерка. Полученный аналоговый сигнал преобразуют в цифровую форму, формируя матрицу квантованных отсчетов, по значениям ее элементов вычисляют матрицу коэффициентов. Элементы матрицы коэффициентов сравнивают с соответствующими элементами матриц зарегистрированных пользователей, и распознаваемый пользователь считается инцидентным эталонной записи, если эта разница минимальна. После того, как аналоговый сигнал преобразуют в цифровую форму, определяют джиттер аналогового сигнала, отношение числа значений джиттера аналогового сигнала, превышающих первое пороговое значение, к общему числу значений джиттера аналогового сигнала. Сравнивают рассчитанное отношение со вторым пороговым значением, в случае, если рассчитанное отношение не превышает второе пороговое значение, вычисляют с помощью двумерного дискретного косинусного преобразования матрицу коэффициентов, иначе вновь осуществляют запись образца почерка.
Наиболее близким аналогом заявляемого изобретения является способ идентификации человека по его биометрическому образу по патенту на изобретение RU 2292079 C2 (патентообладатель: ФГУП "Пензенский научно-исследовательский электротехнический институт", МПК: G06K 9/66, опубл. 20.01.2007). В известном способе с использованием заданного кода предварительно обучают искусственную нейронную сеть на примерах биометрических образов идентифицируемого человека, описание обученной искусственной нейросети в виде таблицы включают в состав документа, идентифицирующего личность человека, при идентификации человека его биометрический образ преобразуют в контролируемые параметры, которые преобразуют в выходной код с помощью нейронной сети, сравнивают выходной код с заданным кодом и при их совпадении принимают положительное решение об идентификации человека.
Раскрытое в наиболее близком аналоге изобретение позволяет сократить объем памяти баз данных для хранения указанных нейросетей, однако требует больших затрат времени на формирование обучающей выборки примеров образа «Свой», дообучения и тестирования нейросетевого преобразователя биометрия-код, т.к. по требованиям ГОСТ Р 52633.5-2011: при обучении необходимо использовать не менее 11 примеров образа «Свой». После обучения нейронной сети следует контролировать качество обучения не менее чем на трех примерах, не участвовавших в обучении, при этом при выявлении отказа в доступе не прошедший распознавание пример следует добавить в обучающую выборку. Увеличение обучающей выборки необходимо вести до устойчивого узнавания «Своего» в трех-четырех следующих подряд попытках. Кроме того, рекомендуется дообучение средства аутентификации на примерах биометрического образа «Свой», предъявленных пользователем через несколько часов (дней) после первоначального обучения. При необходимости последующего дообучения (переобучения) средства аутентификации, базу примеров образа «Свой» следует хранить в доверенной вычислительной среде, либо обеспечить ее защиту от компрометации. Все вышеперечисленные факторы приводят к необходимости ввода большого количества примеров естественного рукописного слова-пароля, на что пользователю необходимо затратить продолжительное время.
Задачей заявляемого изобретения является преодоление необходимости ввода большого количества максимально близких примеров рукописного слова-пароля при формировании обучающей и тестовой базы биометрических образов «Свой», размер которых должен гарантировать подтверждение заданных характеристик тестируемых средств высоконадежной биометрико-нейросетевой аутентификации личности.
Техническим результатом изобретения, достигаемым при его осуществлении, является снижение времени ввода естественных рукописных образов для обучения, дообучения и тестирования базы биометрических образов «Свой».
Указанная задача решается, а технический результат достигается за счет того, что способ автоматического формирования эмбриона базы биометрических образов «Свой» для обучения и тестирования средств высоконадежной биометрико-нейросетевой аутентификации личности заключается в том, что он включает этапы, на которых осуществляют ввод естественного рукописного биометрического образа «Свой», состоящего из Nест примеров, где Nест – четное число, преобразование каждого из Nест примеров естественного рукописного биометрического образа «Свой» в электронный биометрический нечеткий образ «Свой», их нормирование, выполнение преобразования Фурье нормированных образов и формирование вектора биометрических параметров образа «Свой» на основе вычисленных коэффициентов Фурье, классификацию первого из Nест примеров векторов биометрических параметров образа «Свой» по заданным критериям, анализ остальных Nест-1 примеров векторов биометрических параметров образа «Свой» по заданным критериям относительно параметров первого введенного образа, принятого за эталонный, выбор Nест/2 пар примеров-родителей из Nест примеров векторов биометрических параметров образа «Свой», задание необходимого числа синтетических примеров векторов биометрических параметров образа «Свой» Nсинт для обучения и для тестирования, где Nсинт> Nест, расчет для каждой пары примеров-родителей расстояния между их биометрическими параметрами, выбор количества примеров-потомков k для пары примеров-родителей в зависимости от вероятности появления расстояния между их биометрическими параметрами из множества всех возможных расстояний между биометрическими параметрами, формирование синтетических примеров векторов биометрических параметров образа «Свой» путем морфинга биометрических параметров примеров-потомков для каждого из биометрических параметров пары примеров-родителей посредством линейной интерполяции биометрических параметров примеров-родителей таким образом, чтобы обеспечить сохранение естественных корреляционных связей биометрических параметров, присутствующих у примеров-родителей, формирование эмбриона базы биометрических параметров образа «Свой» на основе введенных естественных и сформированных синтетических примеров векторов биометрических параметров образа «Свой», деление эмбриона базы биометрических параметров образа «Свой» на обучающую Nобуч и тестовую Nтест части таким образом, что Nобуч > Nтест, нейросетевое преобразование вектора нечетких биометрических параметров "Свой" в четкий однозначный код ключа доступа для аутентификации личности.
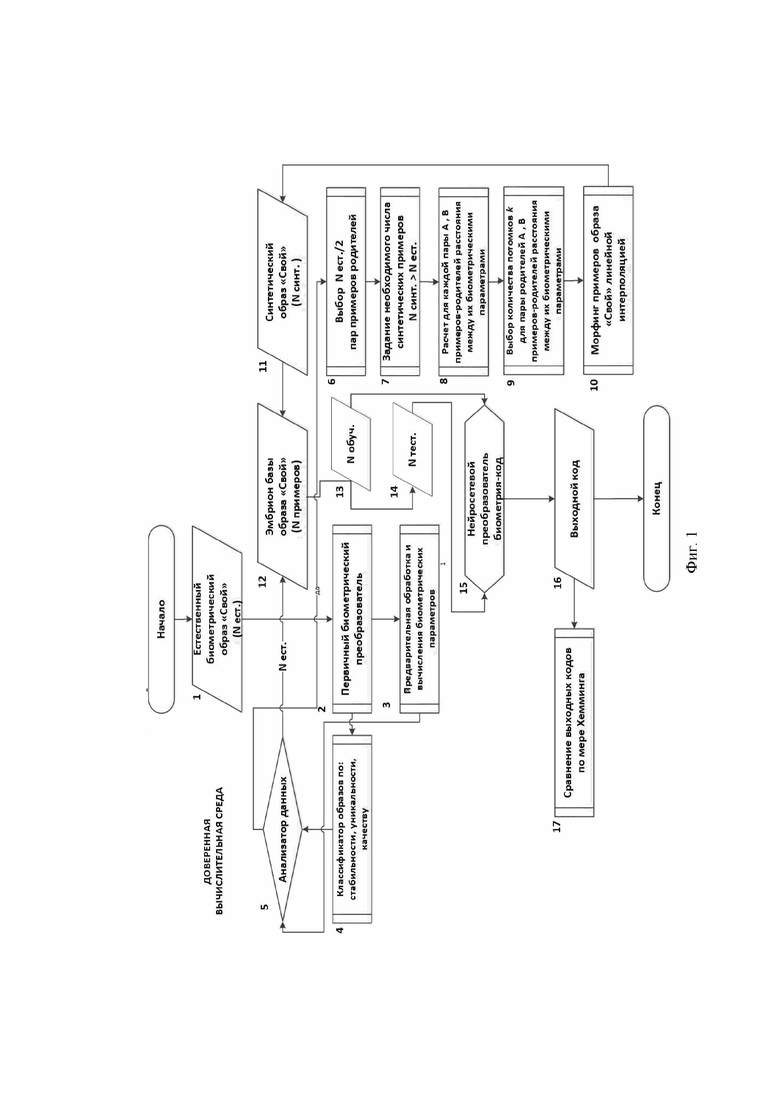
Заявленное изобретение поясняется чертежом (фигура 1), на котором изображен алгоритм автоматического формирования эмбриона базы биометрических образов «Свой» для обучения и тестирования средств высоконадежной биометрико-нейросетевой аутентификации личности, и позициями обозначены:
1 - естественный биометрический образ «Свой»;
2 - первичный биометрический преобразователь;
3 - предварительная обработка и вычисление биометрических параметров;
4 - классификатор образов по заданным критериям;
5 - анализатор данных;
6 - выбор пар примеров-родителей;
7 - задание необходимого числа синтетических примеров-потомков;
8 - расчет для каждой пары примеров-родителей расстояния между их биометрическими параметрами;
9 - выбор количества примеров-потомков для пары примеров-родителей;
10 - морфинг примеров образа «Свой»;
11 - синтетический образ «Свой»;
12 - эмбрион базы образа «Свой»;
13 - разделение эмбриона базы образа «Свой» на обучающую и тестовую части;
14 - нейросетевой преобразователь биометрия-код;
15 - выходной код ключа доступа;
16 - сравнение выходных кодов ключа доступа по мере Хемминга.
Все более широкое использование мобильных средств обработки и хранения различного рода информации, например, планшетных компьютеров, ставит задачу как безопасного доступа к ним, так и хранения на них данных. Единственным способом сохранения мобильности пользователя и обеспечения ему достаточно высоких гарантий защиты его личного ключа является применение нейросетевых биометрических контейнеров – структурированных блоков данных, содержащих параметры обученного нейросетевого преобразователя биометрия-код, реализованных программно в доверенной вычислительной среде. В этом случае стойкость нейросетевого хранителя к атакам подбора может быть сделана сопоставимой со стойкостью растворенного в параметрах нейросети ключа. Для исключения атак на стык ключа и его нейросетевого хранителя целесообразно размещать их в одной доверенной вычислительной среде физически выполненной в виде не вскрываемого малогабаритного модуля со средствами самоуничтожения информации при попытках взлома.
Средство высоконадежной биометрико-нейросетевой аутентификации личности (согласно ГОСТ Р 52633.0-2006) – это средство биометрической аутентификации, способное принимать аутентификационное решение высокой надежности, имеющее в своем составе: биометрические механизмы преобразования биометрических данных в векторы биометрических параметров большой размерности, преобразователь биометрия-код ключа (пароля), механизм криптографической аутентификации. Для повышения качества средств высоконадежной биометрико-нейросетевой аутентификации необходимо проводить процедуру тестирования. Для этого необходимо сформировать базы биометрических образов, размеры которых должны гарантировать подтверждение заданных характеристик тестируемых средств. При проведении тестирования на вероятность ошибочного отказа «Своему» пользователю в биометрической аутентификации после обучения нейронной сети следует контролировать качество обучения не менее чем на трех примерах, не участвовавших в обучении. В связи с этим при внедрении высоконадежных мобильных средств биометрико-нейросетевой аутентификации возникает определенная трудность ввода максимально похожих друг на друга нескольких десятков примеров образа рукописного слова-пароля (образ «Свой») на планшете либо ином мобильном устройстве, на экране которого с помощью стилуса можно ввести рукописные примеры образа слова-пароля, состоящего обычно из 5 – 7 знаков.
При этом качество ввода рукописных данных напрямую связано с качеством обучения нейросетевого преобразователя биометрия-код и, соответственно, с вероятностями возникновению ошибочной аутентификации: ошибок первого рода – вероятности ошибочного отказа пользователю из группы «Свой» в доступе при биометрической аутентификации, и ошибок второго рода – вероятности ошибочной аутентификации пользователя из группы «Чужой» как пользователя из группы «Свой».
С целью устранения указанных выше недостатков предлагается способ автоматического формирования образов «Свой» для обучения и тестирования на ошибки первого рода средств высоконадежной биометрико-нейросетевой аутентификации с использованием эмбриона базы образов «Свой» (фиг.1).
Под термином «Эмбрион базы образов «Свой»» для целей настоящего изобретения понимается полноценные обучающая и тестовая базы образов «Свой», созданные из нескольких примеров образа «Свой», полученных введением биометрических данных человека в «чистую», изолированную (доверенную) среду. Эмбрион базы образов «Свой» предназначен для экспресс-формирования обучающей и тестовой выборки для средств высоконадежной биометрико-нейросетевой аутентификации, состоящей из N примеров образа «Свой». При этом минимальным количеством примеров образа «Свой» в соответствии с требованиями ГОСТ Р 52633.5-2011 является N=14 примеров: 11 примеров для обучения базы образов «Свой» и 3 дополнительных примера, не участвовавших в обучении, для контролирования качества обучения. С целью повышения качества обучения нейросети, напрямую связанной с распознаванием и стойкостью к атакам подбора кода ключа своего пользователя, обучающая и тестовая выборки базы образов «Свой» должны содержать большее количество примеров образа «Свой» (от 20 и от 10 примеров соответственно). Использованные после обучения и тестирования примеры образа «Свой» удаляются из памяти эмбриона, в которой остаются только параметры обученного нейросетевого преобразователя биометрия-код.
Для определения вероятности ошибки первого рода для целей настоящего изобретения может быть использована мера Хемминга, позволяющая определить количество не совпавших разрядов кодовых откликов преобразователя биометрия-код на образы «Свой».
После процедуры обучения средства высоконадежной биометрико-нейросетевой аутентификации потребитель или администратор безопасности должны оценить качество обучения. В случае осуществления настоящего изобретения может быть оценена вероятность ошибки первого рода – ошибочного отказа в аутентификации «Своему». Это необходимо в силу того, что пользователи на практике стараются облегчить себе процедуру биометрической аутентификации, например, необоснованно сократить длину своего рукописного пароля. При этом пользователи имеют разную стабильность воспроизведения их биометрического образа. Кроме того, уникальность и информативность биометрических образов разных людей также различна. Стойкость конкретного биометрического образа пользователя является функцией его длины, стабильности, уникальности. Для оценки реальной стойкости к атакам подбора конкретной реализации биометрической защиты после ее обучения, построенной на воспроизведении конкретного тайного биометрического образа, осуществляют тестирование в соответствии с ГОСТ Р 52633.0-2006 «Защита информации. Техника защиты информации. Требования к средствам высоконадежной биометрической аутентификации». Причем примеры векторов образов «Свой», используемые для тестирования системы, не должны использоваться ранее при ее обучении.
Эмбрион базы образов «Свой» представляет собой доверенную вычислительную среду, имеющую собственный процессор, элементы памяти, программный монитор. В частности, эмбрион может быть выполнен в виде не вскрываемого малогабаритного модуля со средствами самоуничтожения информации при попытках несанкционированного вскрытия. Поскольку процедуры тестирования и обучения нейросети предполагают использование конфиденциальных биометрических образов «Свой» и ключа (пароля) пользователя, они является потенциально опасными. В связи с этим тестирование и обучение проводится в условиях повышенных требований к чистоте вычислительной среды и малому времени вычислений при обучении. После обучения и тестирования информация в форме ключа (пароля), а также биометрических образов «Свой» должна быть гарантировано уничтожена. Для обеспечения защиты данных предусматриваются также организационно-технические мероприятия, исключающие перехват конфиденциальной информации через каналы визуального наблюдения, акустического прослушивания, побочных электромагнитных излучений и наводок. Такой эмбрион способен обеспечить функционирование программной среды формирования обучающей и тестовой базы по требованиям ГОСТ Р 52633.2-2010 «Защита информации. Техника защиты информации. Требования к формированию синтетических биометрических образов, предназначенных для тестирования средств высоконадежной биометрической аутентификации», и может быть сформирован из N образов «Свой», которые включают преобразованные данные Nест естественных рукописных примеров-родителей образа «Свой» и Nсинт синтетических образов «Свой», полученных морфингом биометрических параметров примеров одного биометрического образа «Свой».
Заявленный способ осуществляют следующим образом (фиг.1).
На первом этапе осуществляют ввод естественного рукописного биометрического образа «Свой», состоящего из Nест примеров, минимальное значение которых для целей настоящего изобретения составляет 8 примеров.
Далее посредством первичного биометрического преобразователя осуществляют преобразование физического нечеткого биометрического образа «Свой» в электронный нечеткий биометрический образ «Свой» через первичные преобразователи физических величин в электронные цифровые данные.
Затем в блоке предварительной обработки и вычисления биометрических параметров осуществляют нормирование, преобразование Фурье электронных нечетких биометрических образов «Свой», и вычисление вектора биометрических параметров в виде коэффициентов Фурье образа «Свой».
В блоке классификации полученных после предварительной обработки данных Nест векторов биометрических параметров образа «Свой» проводят их классификацию по заданным критериям, в качестве которых используют показатели стабильности, уникальности и качества биометрического параметра.
Далее в анализаторе данных производят оценку второго и последующих из оставшихся Nест-1 векторов биометрических параметров образа «Свой» по заданным критериям: стабильности, уникальности и качества, относительно данных первого введенного вектора, принимаемого в данном случае за эталонный. При выполнении условия, что последующий введенный образ по заданным критериям отличается от принятого эталонного не более чем на 30%, образ добавляется в базу. Затем данные примеров векторов биометрических параметров образа «Свой» подаются на блок выбора пар примеров-родителей и блок формирования эмбриона базы образа «Свой».
В блоке 6 осуществляют выбор Nест/2 пар примеров-родителей из Nест примеров векторов биометрических параметров образа «Свой».
Затем производят задание необходимого числа синтетических примеров Nсинт = N - Nест для обучения и тестирования, минимальное значение которых для целей настоящего изобретения составляет 22 примера.
Для каждой пары А, B примеров-родителей образа «Свой» производят расчет расстояния между их биометрическими параметрами по следующей формуле:
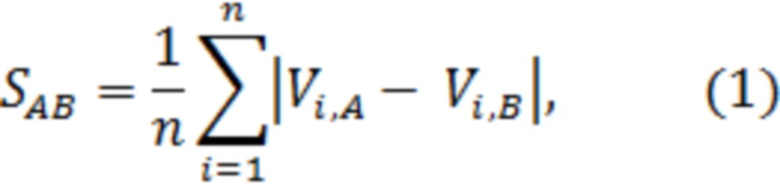
где  - i-й биометрический параметр примера А,
- i-й биометрический параметр примера А,
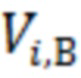 - i-й биометрический параметр примера В,
- i-й биометрический параметр примера В,
n - общее число биометрических параметров примеров.
Затем производят выбор количества примеров-потомков k для пары родителей А и B в зависимости от расстояния между их биометрическими параметрами по формуле:
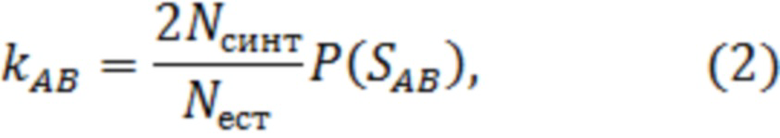
где 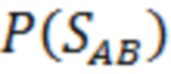 - вероятность появления расстояния между биометрическими параметрами
- вероятность появления расстояния между биометрическими параметрами 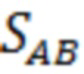 пары родителей А и В из множества всех возможных расстояний между параметрами. При этом значение
пары родителей А и В из множества всех возможных расстояний между параметрами. При этом значение 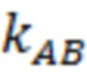 округляют до ближайшего целого числа.
округляют до ближайшего целого числа.
После произведенных операций выполняют формирование синтетических биометрических параметров примеров-потомков образа «Свой». Для этого осуществляют морфинг биометрических параметров каждого биометрического образа примера-потомка, который заключается в нахождении промежуточных значений биометрических параметров примеров-потомков для каждого из биометрических параметров пары примеров-родителей. Морфинг выбранной пары биометрических примеров родителей А и В производят с помощью линейной интерполяции биометрических параметров примеров-родителей. Значения каждого i-го биометрического параметра каждого из биометрических образов примеров-потомков определяют по формуле:
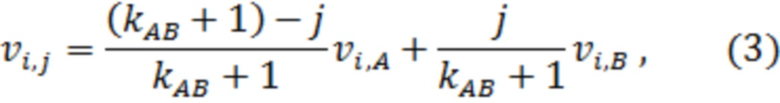
где 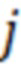 - порядковый номер примера-потомка (
- порядковый номер примера-потомка (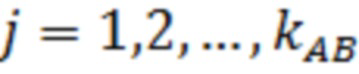 );
);
 - рассчитанное количество примеров-потомков для примеров-родителей А и В.
- рассчитанное количество примеров-потомков для примеров-родителей А и В.
Морфинг биометрических параметров примеров-потомков, выполненный вышеописанным способом посредством линейной интерполяции биометрических параметров примеров-родителей, позволяет сохранить естественные корреляционные связи, присутствующие у биометрических примеров-родителей, что позволяет использовать синтетическую базу, равноценную базе естественной, и в итоге делает достоверными результаты тестирования.
После завершения формирования всех Nсинт синтетических биометрических параметров примеров-потомков образа «Свой», они поступают в блок подсчета и накопления сгенерированных синтетических примеров образов «Свой».
Далее на основе данных Nест естественных и Nсинт синтетических примеров образа «Свой» производят формирование эмбриона базы образа «Свой».
Затем эмбрион базы образа «Свой» случайным образом делится на две части – обучающую Nобуч и тестовую Nтест, где Nобуч > Nтест, состоящих в предпочтительном варианте осуществления настоящего изобретения из Nобуч = 20 и Nтест = 10 примеров соответственно.
После чего при помощи преобразователя биометрия-код осуществляют преобразование вектора нечетких биометрических параметров образа «Свой» в четкий однозначный код ключа доступа для аутентификации пользователя. С выхода преобразователя биометрия-код выходной код ключа доступа подают на блок сравнения кодовых откликов преобразователя биометрия-код на образы «Свой» с использованием меры Хемминга и записи результатов.
После процедуры обучения и тестирования нейросетевого преобразователя биометрия-код данные примеров образа «Свой» гарантированно стирают из памяти эмбриона базы образов «Свой» в соответствии с требованиями ГОСТ Р 52633.0–2006 «Защита информации. Техника защиты информации. Требования к средствам высоконадежной биометрической аутентификации». Код ключа доступа и примеры образов «Свой» в процессе обучения размываются в параметрах обученной нейронной сети и остаются в виде таблиц связей нейронов и их весовых коэффициентов. При вводе нового рукописного образа слова-пароля все операции повторяются.
Таким образом, использование доверенной вычислительной среды эмбриона базы образов «Свой» позволяет снизить количество ошибок аутентификации первого рода – отказа пользователю из группы «Свой» в доступе при биометрической аутентификации, и тем самым повышает уровень защищенности мобильного средства аутентификации.
Техническим результатом изобретения, достигаемым при его осуществлении, является снижение времени ввода естественных рукописных образов для обучения базы биометрических образов «Свой» более чем в 3 раза по сравнению с прототипом, а также значительная экономия времени на возможные процедуры дообучения и тестирования базы.
| название | год | авторы | номер документа |
|---|---|---|---|
| Способ экспресс-тестирования средств высоконадежной биометрико-нейросетевой аутентификации личности с использованием базы биометрических образов "Свой" | 2020 |
|
RU2734906C1 |
| СПОСОБ ЗАЩИТЫ ПЕРСОНАЛЬНЫХ ДАННЫХ БИОМЕТРИЧЕСКОЙ ИДЕНТИФИКАЦИИ И АУТЕНТИФИКАЦИИ | 2007 |
|
RU2346397C1 |
| СПОСОБ БЕЗОПАСНОЙ БИОМЕТРИЧЕСКОЙ АУТЕНТИФИКАЦИИ | 2008 |
|
RU2406143C2 |
| СПОСОБ ФОРМИРОВАНИЯ АУДИТА ПЕРСОНАЛЬНОЙ БИОМЕТРИЧЕСКОЙ ИНФОРМАЦИИ | 2010 |
|
RU2427921C1 |
| СПОСОБ ФОРМИРОВАНИЯ ЭЛЕКТРОННОГО БИОМЕТРИЧЕСКОГО УДОСТОВЕРЕНИЯ ЛИЧНОСТИ | 2008 |
|
RU2391704C1 |
| СПОСОБ КОНТРОЛЯ ИСПОЛНЕНИЯ ДОМАШНЕГО АРЕСТА С БИОМЕТРИЧЕСКОЙ АУТЕНТИФИКАЦИЕЙ КОНТРОЛИРУЕМОГО | 2013 |
|
RU2543958C2 |
| СПОСОБ ОДНОЗНАЧНОГО ХЭШИРОВАНИЯ НЕОДНОЗНАЧНЫХ БИОМЕТРИЧЕСКИХ ДАННЫХ | 2010 |
|
RU2451409C2 |
| СПОСОБ БИОМЕТРИЧЕСКОЙ ЗАЩИТЫ АНОНИМНОСТИ СВИДЕТЕЛЕЙ ПРИ СУДЕБНОМ ДЕЛОПРОИЗВОДСТВЕ | 2012 |
|
RU2543956C2 |
| СПОСОБ ГОЛОСОВАНИЯ С ВЫСОКОНАДЕЖНОЙ БИОМЕТРИЧЕСКОЙ ЗАЩИТОЙ АНОНИМНОСТИ ГОЛОСУЮЩЕГО | 2010 |
|
RU2444063C1 |
| СПОСОБ ФОРМИРОВАНИЯ ЭЛЕКТРОННЫХ ДОКУМЕНТОВ И УСТРОЙСТВО ДЛЯ ЕГО ОСУЩЕСТВЛЕНИЯ | 2007 |
|
RU2365047C2 |
Изобретение относится к биометрической идентификации и аутентификации личности и может быть использовано в системах защиты информации и разграничения доступа. Технический результат заключается в снижении времени ввода естественных рукописных образов для обучения, дообучения и тестирования базы биометрических образов «Свой». В заявленном способе осуществляют ввод примеров естественного рукописного биометрического образа «Свой», их преобразование в электронный вид, нормирование, Фурье-преобразование, классификацию по заданным критериям, выбор пар примеров-родителей, расчет для каждой пары расстояния между их биометрическими параметрами, выбор количества примеров-потомков в зависимости от вероятности появления расстояния между параметрами пары примеров-родителей, формирование синтетических примеров векторов биометрических параметров образа «Свой» путем морфинга линейной интерполяцией биометрических параметров примеров-потомков таким образом, чтобы обеспечить сохранение естественных корреляционных связей биометрических параметров примеров-родителей, формирование эмбриона базы биометрических параметров образа «Свой» на основе естественных и синтетических примеров векторов биометрических параметров образа «Свой», деление эмбриона базы на обучающую и тестовую части, нейросетевое преобразование вектора нечетких биометрических параметров «Свой» в четкий однозначный код ключа доступа для аутентификации личности. 1 ил.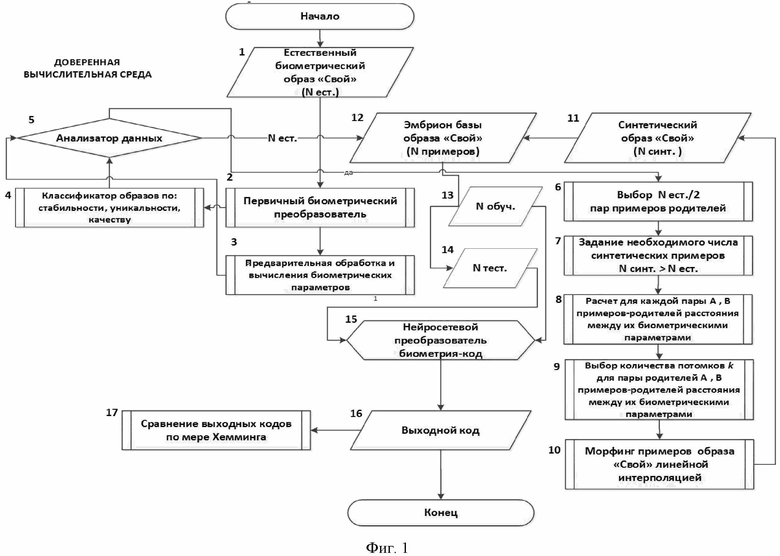
Способ автоматического формирования базы биометрических образов «Свой» для обучения и тестирования средств высоконадежной биометрико-нейросетевой аутентификации личности, заключающийся в том, что он включает этапы, на которых осуществляют:
- ввод естественного рукописного биометрического образа «Свой», состоящего из Nест примеров, где Nест - четное число;
- преобразование каждого из Nест примеров естественного рукописного биометрического образа «Свой» в электронный биометрический нечеткий образ «Свой», их нормирование, выполнение преобразования Фурье нормированных образов и формирование вектора биометрических параметров образа «Свой» на основе вычисленных коэффициентов Фурье;
- классификацию первого из Nест примеров векторов биометрических параметров образа «Свой» по заданным критериям;
- анализ остальных Nест-1 примеров векторов биометрических параметров образа «Свой» по заданным критериям относительно параметров первого введенного образа, принятого за эталонный;
- выбор Nест/2 пар примеров-родителей из Nест примеров векторов биометрических параметров образа «Свой»;
- задание необходимого числа синтетических примеров векторов биометрических параметров образа «Свой» Nсинт для обучения и для тестирования, где Nсинт > Nест;
- расчет для каждой пары примеров-родителей расстояния между их биометрическими параметрами;
- выбор количества примеров-потомков k для пары примеров-родителей в зависимости от вероятности появления расстояния между их биометрическими параметрами из множества всех возможных расстояний между биометрическими параметрами;
- формирование синтетических примеров векторов биометрических параметров образа «Свой» путем морфинга биометрических параметров примеров-потомков для каждого из биометрических параметров пары примеров-родителей посредством линейной интерполяции биометрических параметров примеров-родителей таким образом, чтобы обеспечить сохранение естественных корреляционных связей биометрических параметров, присутствующих у примеров-родителей;
- формирование базы биометрических параметров образа «Свой» на основе введенных естественных и сформированных синтетических примеров векторов биометрических параметров образа «Свой»;
- деление базы биометрических параметров образа «Свой» на обучающую Nобуч и тестовую Nтест части таким образом, что Nобуч > Nтест;
- нейросетевое преобразование вектора нечетких биометрических параметров "Свой" в четкий однозначный код ключа доступа для аутентификации личности.
| СПОСОБ БЕЗОПАСНОЙ БИОМЕТРИЧЕСКОЙ АУТЕНТИФИКАЦИИ | 2008 |
|
RU2406143C2 |
| Приспособление для суммирования отрезков прямых линий | 1923 |
|
SU2010A1 |
| Приспособление для суммирования отрезков прямых линий | 1923 |
|
SU2010A1 |
| Способ приготовления лака | 1924 |
|
SU2011A1 |
| Пломбировальные щипцы | 1923 |
|
SU2006A1 |

