Изобретение относится к системам ограничения доступа к защищаемой информации с криптографической аутентификацией пользователя по его нечетким неоднозначным биометрическим данным. Изобретение может быть использовано при анонимном электронном голосовании, при анонимной электронной торговле, при обеспечении анонимных электронных сделок, при обеспечении анонимности и конфиденциальности проведения операций с электронными банковскими счетами.
Известен способ безопасной аутентификации пользователя по его паролю, который состоит в вычислении необратимой хэш-функции пароля и запоминании значения этой хэш-функции [1, стр.30, рис.1.6] вместо самого пароля. Положительным эффектом от хранения хэш-функции пароля является то, что злоумышленник, похитивший базу хэш-функции паролей пользователей системы, не сможет восстановить сами пароли, чтобы воспользоваться ими, из-за необратимости хэширующего преобразования.
Основным недостатком способа [1] является то, что он не применим к биометрической идентификации и аутентификации. В отличие от пароля биометрические данные неоднозначны и изменение даже одного бита оцифрованных биометрических данных приводит к очень сильному изменению значения их хэш-функции. Пользователь при каждой попытке аутентифицироваться будет получать разные значения хэш-функции для своих оцифрованных биометрических данных, что эквивалентно отрицательному результату аутентификации.
Известен способ, по которому реализуется система биометрической аутентификации [2], способный работать с биометрическими данными, шифровать и/или хэшировать их, сохраняя свою работоспособность. Суть способа [2] состоит в переводе «сырых» биометрических параметров в цифровую бинарную форму с помощью системы компараторов блока-6 с последующим их хэшированием и кодированием специальным кодом, способным обнаруживать и исправлять ошибки. Сопряжение хэширования с кодированием, исправляющим часть ошибок, позволяет системе [2] работать с нестабильными биометрическими данными.
Основным недостатком [2] является необходимость обеспечения достаточно высокой стабильности бинарного биометрического кода. Выполнить это условие технически сложно, и попытки получить достаточно стабильную бинарную последовательность биометрических данных не для всех биометрических данных оказываются успешными. Условия, при которых подобное кодирование осуществимо на практике, в описании к изобретению [2] не приведены. Можно предположить, что при формировании системой компараторов биометрических параметров в двоичной форме не выполняется дополнительное условие равной вероятности состояний «0» и «1» разрядов биометрических кодов при откликах на биометрических данных «Чужие», накладываемое национальным российским стандартом [3], что приводит к неоправданному ослаблению стойкости биометрических кодов к атакам подбора. Кроме того, при описании инициализации устройства [2] авторы изобретения не учитывают распределение вероятности биометрических данных множества «Чужие», что не позволяет им выполнить дополнительные условия [3].
Наиболее близким к предлагаемому способу является способ [4], состоящий в выделении области биометрических данных «Свой» специальным нелинейным преобразованием и создании рядом с выделенной областью других похожих областей, дающих другой выходной код нелинейного преобразования.
Недостатком способа [4] является то, что он не может обеспечить равную вероятность состояний «0» и «1» кодов биометрических данных. Биометрические данные пользователя имеют разное положение области «Свой» и разную ее ширину. Способ [4] неспособен учитывать одновременно оба этих параметра при анализе исходных сырых биометрических данных, не подвергнутых предварительному нейросетевому обогащению. В случае предварительного нейросетевого обогащения способ [4] неспособен полностью извлечь всю полезную биометрическую информацию и дает недостаточно высокое качество нейросетевого решения.
Наиболее важным недостатком способа [4] является то, что он выполняет низкокачественное хэширование биометрических данных «Чужие», то есть устройства, выполненные по способу [4], для биометрических данных «Свой» дают однозначный выходной код, но выходные коды «Чужие» этих устройств оказываются слабо перемешанными и имеют значительные неоднородности заполнения поля выходных кодов. В поле выходных кодов имеются области с повышенной плотностью кодов-откликов «Чужой» и области с низкой плотностью кодов-откликов «Чужой», тогда как у идеальных хэш-функций поле выходных кодов должно быть равномерно заполнено независимо от статистик входной хэшируемой информации. Даже незначительные изменения входной информации должны приводить к действительно случайному (непредсказуемому) необратимому изменению выходного кода отклика идеальной хэш-функции.
Задачей данного изобретения по п.1 формулы является создание специализированной хэш-функции, предназначенной для хэширования неоднозначных биометрических данных. Технический результат, достигаемый при выполнении поставленной задачи, заключается в обеспечении равномерности выходных кодов хэширования при воздействии биометрическими данными «Чужие» и однозначности выходного кода при воздействии биометрическими данными «Свой».
Указанный технический результат достигается за счет того, что неоднозначные биометрические данные рассматриваются последовательно. При рассмотрении первого биометрического параметра выделяют первый интервал «Свой», далее по каждому из следующих контролируемых биометрических параметров выделяют также первый интервал «Свой». После чего на основании знания закона распределения значений множества биометрических данных «Чужие» по каждому контролируемому биометрическому параметру осуществляют дополнение выделенного первого интервала «Свой» похожими соседними интервалами. При этом дополнительные соседние интервалы выбирают так, чтобы внешний наблюдатель не мог указать какой из них является первым интервалом «Свой» и чтобы все эти интервалы покрывали интервал данных «Чужие». Далее присваивают каждому выделенному интервалу свой код. Далее запоминают параметры выделенных интервалов и их кодов и формируют общий выходной код проверяемых биометрических данных как последовательность кодов, соответствующих интервалам, в которые попали проверяемые биометрические параметры. Все перечисленные выше операции по своей сути воспроизводят операции способа-прототипа.
Новой отличительной особенностью предложенного способа является то, что для выделенного первого интервала «Свой» по каждому контролируемому биометрическому параметру определяют вероятность, с которой «Чужие» попадают в этот интервал. Далее все соседние дополнительные интервалы формируют таким образом, чтобы они давали близкую вероятность попадания данных «Чужой» в первый интервал «Свой». Формирование всех интервалов ведут итерационно, постепенно увеличивая интервал первой области «Свой» до момента заданного сближения контролируемых вероятностей попадания биометрических данных «Чужой» в выделенные дополнительные интервалы, а также до максимума вероятности попадания в большинство интервалов заданного диапазона значений правдоподобных вероятностей. Расширяя границы выделенных интервалов, стараются избавиться от неправдоподобных ситуаций: слишком узких интервалов, редко встречающихся в реальных данных и выдающих присутствие интервала «Свой» далеко за пределами распределения значений данных «Чужие».
Далее все интервалы биометрических данных объединяют в одну последовательность, причем рядом в последовательности располагают биометрические данные с близкими вероятностями попадания данных «Чужие» в дополнительные интервалы. Последовательность объединения биометрических данных запоминают. После этого общую последовательность интервалов разбивают на группы с числом интервалов кратным двум, а номера выделенных интервалов в группе задают неповторяющимися, выбирая их из поля кодов, образующегося на выходе счетчика числа интервалов в выбранной группе. Далее для осуществления проверочного преобразования биометрических данных хэшируют последовательность кодов выделенных интервалов, в который попал тот или иной биометрический параметр проверяемых биометрических данных, и тем самым получают требуемый технический результат. Хэширование данных осуществляют любым из известных способов, например используют хэш-функцию MD5, выполненную по международному стандарту. Возможно использование хэш-функции, выполненной по национальному стандарту России.
Поставленный перед изобретением технический результат - однозначное хэширование неоднозначных нечетких биометрических данных «Свой» осуществляется благодаря тому, что при каждой обработке биометрических данных «Свой» на выходе получается одинаковый выходной код. Совпадение кодов обусловлено попаданием биометрических данных в одни и те же выделенные первые интервалы «Свой». Для биометрических данных «Чужие» в большей части интервалов происходит попадание обрабатываемых биометрических данных в дополнительные области с иными номерами, чем номера интервалов «Свой». Из-за этого последовательность кодов номеров интервалов изменяется, поэтому для кардинального изменения выходного кода в этом случае достаточно даже изменения одного бита в этой последовательности. Высокое качество хэширования биометрических кодов «Чужой» гарантировано тем, что разряды выходного биометрического кода имеют почти равновероятные состояния значений «0» и «1» (выполняется требование стандарта ГОСТ Р 52633-2006), поле выходных кодов «Чужие» равномерно заполнено, так как используется классическое хэширующее преобразование, описанное в соответствующем стандарте и протестированное на его стойкость к обращению.
Основным недостатком предложенного способа является то, что при его программной реализации злоумышленник может отключить операцию классического хэширования и наблюдать неравномерность выходных биометрических кодов. Это дает ему теоретическую возможность снизить вычислительную сложность подбора биометрических данных или поиска его кодового отклика.
Задачей изобретения, описанного во втором пункте формулы, является не дать злоумышленнику возможности наблюдать реальные выходные биометрические коды инициированной для работы заявленной биометрической хэш-функции и пользоваться остаточными неравномерностями появления вероятностей «0» и «1» в биометрических кодах.
Технический результат, достигаемый при выполнении этой задачи, заключается в том, что хэширование осуществляют через случайное задание кодов номеров случайной длины, выделенных интервалов. Если по способу п.1. коды номеров интервалов имеют одинаковую длину и могут быть получены путем простого подсчета номера интервала в его группе, то по п.2 формулы коды интервала могут иметь любую длину и образовывать конечный биометрический код произвольной длины. Предлагается осуществлять шифрование и расшифрование случайных кодов выделенных ранее интервалов, причем при настройке функции хэширования шифруют коды интервалов последующих биометрических параметров на кодах интервалов «Свой» предшествующих параметров с последующим замещением открыто записанных в памяти кодов на их шифрограммы. При проверочном преобразовании биометрических данных извлеченные из памяти коды выделенных интервалов расшифровывают уже восстановленными кодами ключа предшествующих и уже проверенных биометрических параметров. Шифрование и расшифровывание повторяют многократно для множества уже восстановленных предшествующих кодов-ключей.
Так как описанная выше последовательность приводит к конечной шифрограмме разной длины, а для классических хэш-функций принято выдавать код фиксированной длины, далее осуществляют трансформацию длины общего кода и/или приведение его к значению личного ключа пользователя через операции, осуществляемые с использованием стандартных функций хэширования полученного биометрического кода. В частности, после трансформации выходного кода произвольной длины с помощью классической хэш-функции MD5 длина выходного кода равна 128 бит. При необходимости полученный трансформированный выходной код фиксированной длины может быть безопасно связан с личным ключом пользователя через его дополнение до этого ключа и хранение этого дополнения.
Достижение технического результата по п.2 формулы обеспечивается также тем, что хэширование данных осуществляют их самошифрованием и саморасшифрованием. Если обрабатываются биометрические данные «Свой», то их расшифрование полностью обращает процесс шифрования, осуществленный при инициализации биометрической хэш-функции для заданных биометрических данных «Свой». В этом случае последовательности кодов номеров полностью повторяют последовательности, появляющиеся при реализации способа по п.1 формулы. Если появляются биометрические данные «Чужой», то происходит расхождение ключа шифрования с ключом расшифрования, далее происходит размножение ошибок при каждом вложенном цикле расшифрования. Фактически реализуется классическое хэширование с неизвестным ключом через шифрование с неизвестным ключом. Если процедура шифрования качественная, то реализованная функция хэширования будет качественной. При этом отключить эту функцию программно невозможно, так как для этого потребуется расшифровать многократно зашифрованные данные, хранящиеся вместо обычных открытых данных. Фактически способ, предложенный по п.2 формулы изобретения, осуществляет двойное хэширование биометрических данных, причем первое хэширование невозможно отключить, а второе хэширование делает выходной код первого хэширования стандартным по длине.
Еще одним важным преимуществом изобретения по п.2 формулы является то, что шифрующие свойства первого хэширования усиливаются за счет рассинхронизации схемы шифрования по длине ключа. То есть злоумышленник столкнется с тем, что он не знает не только ключи промежуточного циклического самошифрования, но и их длину. Последнее важно при программной реализации самых простых схем шифрования, которые часто нуждаются в дополнительном усилении.
Основным недостатком способа, реализованного по п.2 формулы, является то, что злоумышленник может наблюдать параметры структуры производимых операций над биометрическими данными. Так как он знает, что вероятности попадания в дополнительные интервалы соседних биометрических параметров близки, то он может оценить эту близость, сравнивая их между собой. Кроме того, злоумышленник может видеть несимметрию выделенных интервалов, открыто хранящихся в памяти. Ему также доступна побочная информация криптосхем, которой он может воспользоваться.
Задачей п.3. заявленной формулы изобретения является исключение возможности наблюдения злоумышленником параметров интервалов для каждого анализируемого биометрического параметра.
Технический результат, достигаемый при выполнении этой задачи, заключается в обеспечении хранения в памяти параметров интервалов в зашифрованном виде, благодаря чему оказывается перекрытым канал возможной утечки побочной информации о хэшируемых биометрических параметрах, что усиливает уровень обеспечиваемой информационной безопасности.
Основным недостатком способов, предложенных по п.1, п.2, п.3 формулы изобретения, является то, что они рассчитаны на работу с биометрическими данными, обладающими высокой стабильностью. То есть данными, для которых дисперсия каждого параметра «Свой» как минимум в 2 раза меньше дисперсии распределения биометрических данных множества «Чужие» для этих же параметров. Если выявляются биометрические параметры данных «Свой» с плохой стабильностью, их нельзя применять в предложенном способе по п.п.1, 2, 3, формулы. Исключение нестабильных данных ослабляет биометрическую защиту.
Задачей п.4 формулы изобретения является усиление биометрической защиты.
Технический результат, достигаемый по п.4 формулы изобретения, заключается в использовании для решения этой задачи всех биометрических данных, в том числе обладающих плохой стабильностью. Указанный технический результат достигается за счет того, что предварительно осуществляют нейросетевое улучшение качества используемых биометрических данных. При этом используют нейронные сети, предварительно обученные уменьшать дисперсию выходных биометрических данных «Свой» по отношению к дисперсии выходных биометрических данных «Чужие». Таблицы связей и параметров обученных нейронных сетей размещаются в памяти и используются при проверочном преобразовании биометрических данных. Предварительное обучение нейронных сетей может осуществляться быстрыми алгоритмами обучения, подробно описанными в монографии [5], однако использование только этих алгоритмов не выгодно, так как эти алгоритмы при обучении нейронов обязательно выталкивают биометрические данные «Свой» на периферию области распределения биометрических данных все «Чужие». В предложенном по п.1 способе это не обязательно. Он работает с распределениями данных «Свой», находящимися в любом месте распределения данных «Чужие». Это означает, что при обучении нейросети можно смягчить условия контроля и добиваться только относительного сужения ширины области «Свой» без контроля ее положения, что сильно упрощает и ускоряет обучение нейронов.
В сравнении с ранее использованными алгоритмами обучения [5] их упрощение приводит к снижению затрат вычислительных ресурсов на обучение при одновременном увеличении энтропии нейросетевого преобразователя (число хороших нейросетевых решений резко увеличивается из-за снижения требований к ним). Последнее увеличивает стойкость нейросетевых решений по отношению к известным ранее [6] нейросетевым преобразователям биометрия-код.
Таким образом, при использовании способа по п.4 формулы изобретения удается повысить стойкость нейросетевых преобразователей биометрия-код к атакам подбора за счет вовлечения в обработку плохих нестабильных биометрических данных «Свой» по сравнению с алгоритмами, выполненными по п.1 формулы. По сравнению с известными нейросетевыми преобразователями [6] уровень защищенности увеличивается за счет упрощения обучения нейронов и роста числа их возможных состояний.
Основным недостатком реализации способа по п.4 формулы является то, что в отличие от аналога [6] и способа по п.2, 3 злоумышленник может исследовать нейросетевой преобразователь биометрия-код, отключив вычисление классической хэш-функции.
Задачей изобретения по п.5 формулы является предотвращение возможности исследования злоумышленником нейросетевого преобразователя биометрия-код.
Технический результат, достигаемый при решении этой задачи, заключается в обеспечении хранения параметров нейросетевого преобразователя в зашифрованном виде.
Указанный технический результат достигается тем, что таблицы связей нейронов и/или таблицы весовых коэффициентов нейронов обученных нейронных сетей шифруют на последовательностях кодов интервалов «Свой», предшествующих биометрических данных, а затем заменяют памяти открытые таблицы связей и параметров обученных нейронных сетей на их шифрограммы. При осуществлении проверочных преобразований биометрических данных шифрограммы таблиц связей и/или параметров расшифровывают на кодах интервалов, выявленных в предшествующих биометрических данных. Такое решение оказывается возможным благодаря тому, что для биометрических данных «Свой» процедуры шифрования параметров и их расшифровывания оказываются абсолютно симметричными. То есть распознаванию биометрических данных «Свои» они не мешают. Однако если обрабатываются биометрические данные «Чужой», то восстанавливаемые кодовые комбинации оказываются другими и правильного расшифровывания таблицы связей нейронов и/или таблицы весовых коэффициентов нейронов не происходит. Отключается режим обогащения биометрических данных, и, более того, включается режим размножения ошибок из-за многократного вложения процедур расшифровывания. Возникает эффект дополнительного нейросетевого хэширования обрабатываемых данных, совершенно такой же, как и у способа [6]. То есть п.5 формулы отражает использование независимого п.1 формулы совместно с дополнительным нейросетевым хэшированием. При реализации п.5 формулы изобретения достигается результат двойного хэширования биометрических данных, причем первое нейросетевое хэширование отключить невозможно, не расшифровав таблицы связей и таблицы весовых коэффициентов, обученных нейронов.
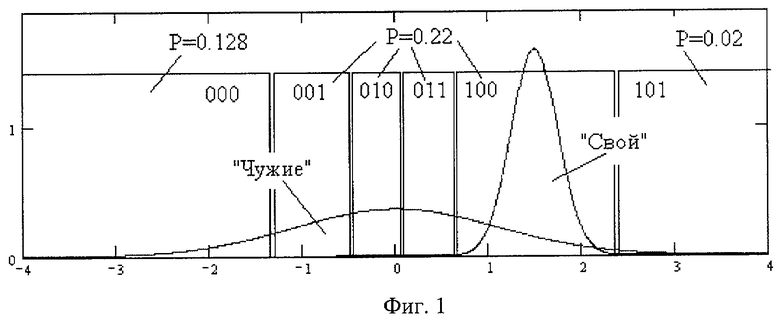
На фиг.1 представлен первый пример разбиения множества биометрических данных на первый интервал «Свой» (он помечен двоичным кодом 100) и 5 дополнительных интервалов (они помечены номерами 000, 001, 010, 011, 101). Выделенные интервалы с номерами 001, 010, 011, 100 имеют равную вероятность попадания в них биометрических данных «Чужие» P=0,22. Крайние интервалы 000 и 101 имеют отличающиеся от других интервалов вероятности попадания в них биометрических данных «Чужие». Средняя вероятность попадания на один из 6 интервалов составляет 0,171.
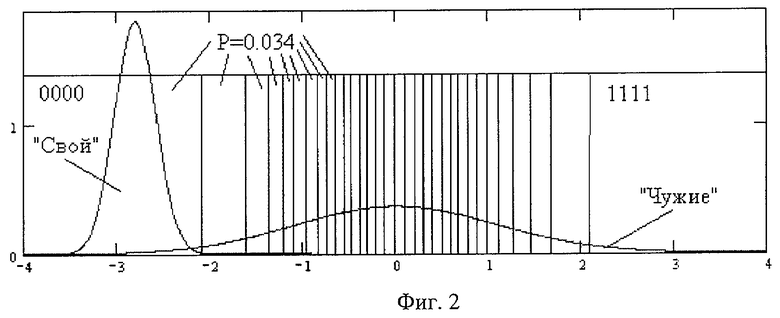
На фиг.2 приведен второй пример разбиения второго биометрического параметра на 32 интервала: первый интервал «Свой» (номер 00000) и 31 дополнительные интервалы. Вероятности попадания данных «Чужие» в первые 31 интервалы одинаковы и составляют P=0,034. Вероятность попадания данных «Чужие» в последние 32 интервала с двоичным номером 11111 составляет 0,031. Средняя вероятность попадания на один из 32 интервалов составляет 0,034.
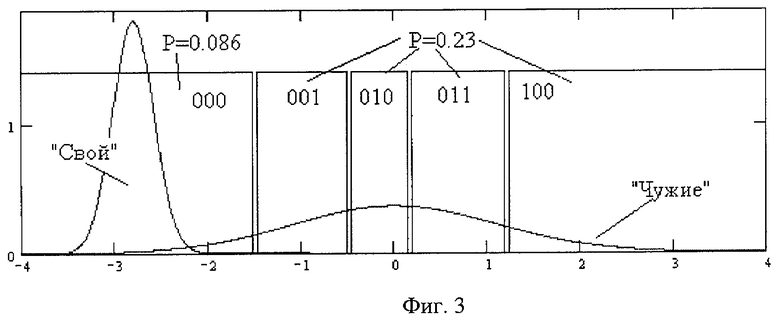
На фиг.3 приведен результат операции расширения первого интервала «Свой» (номер 000) при модификации процедуры дробления динамического диапазона изменения биометрических параметров второго биометрического параметра (того же, что и на фиг.2). Первый интервал «Свой» расширен таким образом, что вероятность попадания в него данных «Чужие» выросла с величины 0,034 до величины 0,086. Подобное расширение первого интервала «Свой» привело к появлению только 4 дополнительных интервалов с равной вероятностью попадания в них данных «Чужие», составляющей 0,23. При этом средняя вероятность попадания в интервалы фиг.3 данных «Чужие» составляет 0,201.
На фиг.4 приведен пример последовательного объединения интервалов разбиения первого параметра (фиг.1) и второго параметра (фиг.3). При таком объединении образована группа из 8 интервалов (все 6 интервалов разбиения первого параметра и первых 2 интервала разбиения второго параметра). Восьми интервалам первой группы параметров присвоены двоичные номера, сформированные простым перебором состояний двоичного счетчика (без случайных перестановок). Три оставшихся участка второго параметра отнесены к следующей второй группе из 8 следующих интервалов разбиения второго контролируемого биометрического параметра и третьего контролируемого биометрического параметра.
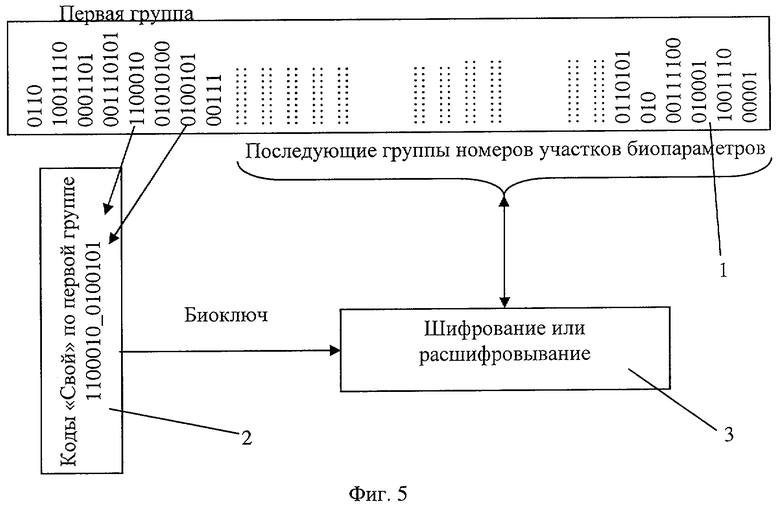
На фиг.5 приведена блок-схема шифрования и расшифровывания последовательности случайных номеров соседних интервалов разбиения биометрических параметров, где 1 - память, в которой размещена последовательность случайных номеров интервалов, 2 - блок формирования биоключа, 3 - блок шифровании и расшифровывания. Выход чтения памяти 1 соединен с блоком формирования ключа 2, выход блока формирования ключа 2 соединен с входом блока шифрования и расшифровывания 3. Выход блока шифрования и расшифровывания соединен с входами чтения и записи в память 1. Пример последовательности случайных номеров, присвоенных последовательности смежных интервалов разбиения соседних биометрических параметров, отображен в памяти 1. В первой части последовательности отражены номера, присвоенные 8 интервалам из первой группы, которые порождают биоключ для шифрования или расшифровывания всех последующих номеров интервалов. Значение биоключа составляет 1100010_0100101 при обработке данных «Свой», так как они дают попадание в 5 интервал «Свой» с номером 1100010 на первом параметре и попадание в 7 интервал первой группы при попадании в область «Свой» при анализе второго биометрического параметра, имеющего номер интервала 0100101.
Рассмотрим пример реализации предложенного способа по п.1 формулы изобретения. На фигуре 1 приведен пример распределения данных «Свой» и «Чужие» для первого из анализируемых параметров. По предложенному способу выделяют первый участок биометрических данных «Свой», находящихся в интервале от 0,8 до 2,2 контролируемого первого биометрического параметра. Далее по заранее известному распределению значений «Чужие» вычисляют вероятность попадания в первый выделенный интервал данных «Чужие», которая составляет 0,22. Далее выделяют с левой стороны четыре ложных интервала. Из четырех ложных интервалов три удается построить таким образом, что вероятность попадания в них данных «Чужие» составляет 0,22, как и вероятность первого выделенного интервала «Свой». Четвертый крайний левый интервал оказывается открыт слева, но вероятность попадания в него данных «Чужие» оказывается несколько меньше необходимой и составляет 0,128. С правой стороны от первого выделенного интервала «Свой» формирую еще один полуоткрытый интервал с вероятностью попадания в него данных «Чужие» 0,02. Получается, что динамический диапазон изменения биометрических данных первого параметра оказывается разбит на 6 интервалов. Усредненная вероятность попадания в один из этих интервалов составляет 0,171.
При разбиении динамического диапазона второго контролируемого биометрического параметра вновь выделяют первый интервал данных «Свой» и подсчитывают вероятность попадания в этот интервал данных «Чужие». Как показано на фигуре 2, область данных «Свой» значительно смещена в левую сторону от центра распределения данных «Чужие». Это приводит к тому, что вероятность попадания данных «Чужие» в первый интервал «Свой» оказывается мала и составляет всего лишь 0,034. Далее по предложенному способу осуществляют разбиение оставшейся части динамического диапазона биометрических данных на дополнительные ложные интервалы, в которые с вероятностью 0,034 попадают данные «Чужие». Как показано на фигуре 2, таких дополнительных ложных интервалов оказывается 31. Общее число интервалов разбиения динамического диапазона второго параметра составляет 32. Среднее значение вероятности попадания в один их этих интервалов данных «Чужие» составляет 0,034.
Использовать разбиение динамического диапазона на неправдоподобно узкие интервалы, показанные на фиг.2, нельзя. Обнаружив неправдоподобную узость интервалов (неправдоподобную стабильность биометрических данных в центре распределения «Чужие»), злоумышленник сократит свой перебор, отбросив все неправдоподобно узкие интервалы. Вместо 32 возможных вариантов положения «Свой» злоумышленник будет рассматривать только правдоподобные крайние интервалы, обозначенные на фиг.2 двоичными номерами 00000, 11111.
Для того чтобы исключить возможность обнаружения неправдоподобно узких интервалов, предлагается расширение первого интервала «Свой» с состояния {-4; -2} до состояния {-4; -1,5}. При этом вероятность попадания «Чужих» в интервал «Свой» увеличивается почти в 3 раза с величины 0,034 до величины 0,086. Это приводит к тому, что ложные интервалы будут располагаться справа от истинного интервала «Свой» и вероятность попадания в них «Чужих» составит 0,23 (см. фиг.3). Таким образом, увеличение интервала «Свой» приводит к появлению 4 соседних ложных интервалов с одинаковой вероятностью попадания в них «Чужих». Дополнительные ложные интервалы на фигуре 3 обозначены двоичными номерами 001, 010, 011, 100. После того как информация о принадлежности интервалов «Свой» и «Чужой» будет удалена, злоумышленник по ширине интервалов фигуры 3 не сможет отбросить неправдоподобные и вынужден будет перебирать все возможные 5 состояний второго контролируемого биометрического параметра. Предложенная в способе операция по расширению интервала «Свой» при одновременном выполнении равенства вероятностей попадания «Чужих» в большинство интервалов лишает возможность злоумышленника сокращать перебор при атаках подбора биометрических данных.
По предложенному способу разбиение на интервалы проводят для всех контролируемых биометрических параметров, в частности анализатор рукописного почерка «Нейрокриптон 1.0» учитывает 416 биометрических параметров, то есть для него осуществляют операцию дробления каждого из 416 динамических диапазонов биометрических данных на несколько интервалов. Для рукописного почерка удается получать от 2 до 16 правдоподобных интервалов, в которых может находиться «Свой». Среднее число интервалов составляет 6,8, то есть сложность задачи прямого силового подбора биометрического данных составляет 6,8416, что является огромной величиной и лишает злоумышленника возможности использовать эту тактику атаки.
После того как все контролируемые биометрические параметры разбиты на правдоподобные интервалы, их сортируют по средней вероятности попадания данных «Чужие» в каждый из интервалов. Далее в соответствии с предложенным способом объединяют все интервалы в одну последовательность, причем рядом располагают интервалы с близкими вероятностями. Этот этап обработки биометрической информации отображен на фиг.4. На этой фигуре отображено объединение интервалов первого и второго биометрических параметров, которые оказались близки по средней вероятности попадания в их интервалы.
В соответствии с предложенным способом интервалы первого и второго биометрического параметра объединяют в одну последовательность и выбирают первую группу их 8 интервалов (число интервалов в группе кратно 2). В первую группу включены все 6 интервалов разбиения первого параметра и первые 2 интервала разбиения второго параметра. Восьми интервалам первой группы параметров присвоены двоичные номера, сформированные простым перебором состояний двоичного счетчика (без случайных перестановок), что отображено на фиг.4.
Три оставшихся интервала второго параметра отнесены ко второй группе из 8 следующих интервалов разбиения второго контролируемого биометрического параметра и третьего контролируемого биометрического параметра. Для идентификатора рукописного почерка «Нейрокриптон 1.0» вся группа из 416 анализируемых биометрических параметров дает около 2832 интервалов, объединяемых примерно в 354 группы по 8 соседних интервалов с близкими вероятностями попадания в них данных «Чужие».
Далее по предложенному способу по п.1 формулы при его практической реализации присваивают интервалам каждой группы номера, совпадающие с их двоичным номером в группе. Эта ситуация отображена на фигуре 4. После этого используют любой пример данных «Свой» и последовательно считывают номера интервалов, в которые попали данные «Свой» по каждому анализируемому параметру. Эту последовательность номеров хэшируют какой-либо из классических хэш-функций, например MD5, получая выходной код. Очевидно, что выходной код будет одинаковым для любых биометрических данных «Свой», поскольку получаемая для них последовательность номеров будет одной и той же. При этом после настройки параметров всех интервалов и присвоения им номеров данные о принадлежности части интервалов к данным «Свой» уничтожают.
При предъявлении описанному выше хэширующему преобразователю данных «Чужой» происходит выделение интервалов с другими номерами, характерными для биометрических данных, отличных от данных «Свой». Получается другая выходная кодовая последовательность, из которой получается другой выходной код. Так как используется классическая хэш-функция, достаточно изменения в последовательности из 2832 бит одного бита для необратимых непредсказуемых изменений отклика. На практике биометрические данные «Чужой» обычно дают расхождение примерно 50% бит кодовой последовательности, что удовлетворяет требованиям ГОСТ Р 52633-2006 по равновероятному состоянию значений «0» и «1» каждого бита биометрического кода, подлежащего последующему хэшированию.
Недостатком способа, выполненного по п.1. формулы изобретения, является то, что при его программной реализации злоумышленник может отключить вычисление классической хэш-функции и у него появится возможность наблюдать реальные значения биометрических кодов для данных «Чужие». Статистики этих биометрических кодов неравномерны, и возможен их криптоанализ, построенный на очевидных неравномерностях.
Противодействие наблюдению реальных значений биометрических кодов осуществляется при реализации способа по п.2 формулы изобретения. Для этой цели последовательность номеров интервалов перекодируют (заменяют) случайными числами разной длины, как это показано в поле памяти 1 на фиг.5, или одинаковой длины. Простая реализация использует случайные числа одинаковой длины по 8 разрядов в каждом числе. Далее создают из новой перекодированной последовательности биоключ, составляя его из кодов, соответствующих интервалам, в которые попадают данные «Свой». На фиг.5 это случайные коды 1100010 и 0100101, соответствующие пятому и седьмому интервалам фиг.4, в которые попали данные «Свой». Длина этого ключа при условии 8-разрядности случайных кодов составит 8×354=2832 бита. После этого выбирают 8 последних кодов в памяти 1 и шифруют их ключом из (2832-8) первых бит биоключа блока 2, например простым наложением гаммы, полученной из ключа (2832-8) бит. Зашифрованные таким образом 8 последних кодов интервалов размещают в памяти 1 на том месте, где были расположены незашифрованные эти комбинации.
Далее отступают от длины биоключа на 16 бит и шифруют 8 последних открытых кодов последовательности в памяти 1 и 8 уже зашифрованных кодов в конце этой последовательности. Далее на биоключе длиной (2832-16) бит шифруют последние 16 кодов в памяти 1.
Эту операцию рекуррентного шифрования повторяют, пока все коды последовательности, кроме первых 8, не будут зашифрованы и возвращены в память 1. На этом этап инициализации биометрической хэш-функции заканчивают.
При процессе ее применения из памяти 1 извлекают 8 первых открытых кодов и по ним восстанавливают первые 8 разрядов биоключа, на этих 8 разрядах расшифровывают все (2832-8) следующих кодов. Из этих (2832-8) кодов полностью расшифрованными оказываются только первых 8 кодов. Используя их, восстанавливают следующую часть биоключа. Далее, используя уже восстановленную часть биоключа, расшифровывают (2832-16) кодов в памяти 1 и используют первые 8 из них для восстановления следующей части биоключа.
При хэшировании данных «Свой» процесс итерационного расшифровывания номеров интервалов в памяти 1 оказывается обратным процессу их зашифровывания и в итоге восстанавливается действительный длинный биоключ, соответствующий данным «Свой». Для данных «Свой» шифрование и расшифровывание не влияют на конечный результат.
В случае если используются коды номеров интервалов случайной длины, процесс шифрования и расшифровывания оказывается практически таким же, но ключ при этом используется разной длины, и для данных «Чужой» происходит не только неправильное расшифровывание, но и рассинхронизация расшифровывания. Например, возникают с вероятностью 0,5 ситуации, когда длины восстановленного ключа не хватает. Процесс хэширования прерывается не окончившись, что является дополнительной защитой от исследования.
Недостатком способа по п.п.1, 2 формулы изобретения является то, что злоумышленник может получить полную информацию о длинах выделенных интервалов, наблюдать их неравномерность и иные вариационные признаки. Последнее может быть использовано для организации атак.
Способ по п.3 формулы позволяет ликвидировать этот недостаток. Этот способ реализуется через одновременное рекуррентное шифрование (расшифровывание) области памяти с последовательностью, где хранится информация об интервалах разбиения биометрических данных. Этот процесс осуществляют параллельно процессу шифрования (расшифровывания) номеров интервалов, предусмотренному по п.2 формулы и описанному выше.
Недостатком способа, выполненного по п.п.1, 2, 3, является то, что он плохо работает с нестабильными биометрическими данными «Свой». Обычно до одной трети биометрических данных «Свой» имеют дисперсию больше одной второй дисперсии биометрических данных «Чужие» и находятся в центре распределения данных «Чужие». Эти нестабильные данные низкого качества приходится отбрасывать, что ослабляет защиту.
Этот недостаток устраняется по способу п.4 формулы изобретения. В соответствии с этим пунктом формулы изобретения нестабильные данные не отбрасывают, а подают на входы искусственных нейронов и обучают каждый нейрон таким образом, чтобы увеличилось выходное качество данных на выходе нейрона. Например, могут быть использованы алгоритмы быстрого обучения [5]. Этот тип алгоритмов построен на итерационном поиске максимума следующего функционала:

где mЧужие - математическое ожидание данных «Чужие» на выходе обучаемого нейрона, которое обычно близко к нулю;
mCвой - математическое ожидание данных «Свой» на выходе обучаемого нейрона, которое при обучении увеличивается;
σЧужие - дисперсия данных «Чужие» на выходе обучаемого нейрона, которая при обучении остается примерно одной той же;
σCвой - дисперсия данных «Свой» на выходе обучаемого нейрона, которая при обучении обычно уменьшается.
При обучении нейрона итерационно подбирают веса таким образом, чтобы функционал (1) увеличивался. Это эквивалентно выталкиванию распределения данных «Свой» из центра распределения данных «Чужие» на его периферию при одновременном снижении дисперсии данных «Свой». Как показал реальный опыт обучения нейронов с 24 входами программным продуктом «Нейрокриптон 1.0», из 24 плохих биометрических параметров всегда удается получить один выходной биометрический параметр хорошего качества (примеры распределения таких биометрических параметров приведены на фиг.1, 2.). Комбинируя различными способами входные плохие данные, удается получать несколько слабокоррелированных выходных данных хорошего качества на выходах нескольких нейронов. Коррелированность выходных данных оказывается допустимой по требованиям ГОСТ Р 52633-2006, если любая пара нейронов имеет не более 2 общих входов из 24.
В итоге предварительной нейросетевой обработкой удается поднять качество плохих биометрических данных, не уменьшая их количество. Удается использовать даже плохие биометрические данные, что усиливает биометрическую защиту.
Следует отметить, что очевидный эффект повышения уровня защищенности из-за возможности использования плохих биометрических данных не исчерпывает всех возможностей предложенного изобретения по п.4 формулы. Нейросетевая предобработка биометрических данных позволяет не только улучшать качество плохих данных, но она применима и для повышения качества и стабильности хороших биометрических данных. В связи с этим описанный выше пример реализации может быть усилен тем, что хорошие биометрические данные, так же как и плохие, подвергают нейросетевому обогащению.
Для этой цели хорошие биометрические данные подают на входы нейронов и обучают искусственные нейроны таким образом, чтобы качество и стабильность биометрических данных на выходе каждого нейрона возрастали. При обучении нейрона может быть использован алгоритм повышения качества (1), однако не все искусственные нейроны могут обучаться этим алгоритмом. Если допустить обучение всех нейронов алгоритмом повышения качества (1), то все биометрические данные на выходах нейронов окажутся в крайнем правом или крайнем левом интервале динамического диапазона контролируемого биометрического параметра. Пример попадания в крайний левый интервал отображен на фиг.2 и 3. Если злоумышленник будет знать, что данные «Свой» находятся в крайних интервалах, то он упростит подбор, не рассматривая комбинации, в которых происходит попадание данных «Свой» в центральные интервалы.
Для исключения этой ситуации меняют алгоритм обучения, добиваясь не улучшения качества (1) биометрических данных, а улучшения только их стабильности:
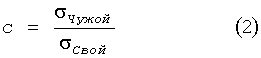
В этом случае при итерационном подборе весовых коэффициентов нейронов происходит только повышение стабильности данных «Свой» на выходе нейронов, эффект выталкивания распределения «Свой» на периферию распределения «Чужие» исчезает. Обученные искусственные нейроны по алгоритму максимизации показателя стабильности (2) могут иметь распределения биометрических данных «Свой» в любом из центральных интервалов. Это лишает возможности злоумышленника упростить атаку подбора.
Таким образом, использование обучения части нейронов по критерию повышения качества (1) и другой части нейронов по критерию повышения показателя стабильности (2) позволяет существенно увеличить стойкость биометрической защиты к атакам подбора за счет увеличения в несколько раз качества биометрических данных «Свой» или их стабильности.
Недостатком способа по п.4 является то, что таблицы связей и таблицы весовых коэффициентов обученных искусственных нейронов хранятся открыто. Это позволяет злоумышленнику наблюдать неравномерность статистических распределений биометрических кодов и пытаться организовать атаку подбора с использованием этой неравномерности.
Этот недостаток ликвидируется по п.5 формулы шифрованием хранимых таблиц связей и таблиц весовых коэффициентов обученных нейронов. Предложено вести шифрование таблиц по тому же алгоритму, что и шифрование номеров выделенных интервалов по п.2 формулы изобретения на фрагментах биоключа (подробно описано выше по тексту). Расшифровывание данных таблиц связей и весовых коэффициентов также осуществляется по аналогии с расшифровыванием номеров выделенных интервалов на тех же фрагментах выделенного ключа (подробно описано выше по тексту).
Положительным эффектом от применения способа по п.5 является недоступность для злоумышленника наблюдения неравномерности распределения биометрических данных, выраженных в параметрах обученной нейронной сети. Кроме того, при обработке данных «Чужие» параметры нейросети неверно расшифровываются, что приводит к эффекту дополнительного перемешивания данных (эффекту дополнительного нейросетевого хэширования данных). Эффект дополнительного хэширования нельзя отключить программно, не имея биометрических данных «Свой» и не расшифровав параметры обученной нейронной сети.
Литература
1. Смит Ричард Э. Аутентификация: от паролей до открытых ключей. М.: Вильямс. - 2002 г., 424 с.
2. Описание изобретения к патенту RU 2316120 C2 «Биометрическая система аутентификации», МПК H04L 9/28, H04L 9/32, G06F 12/14, опубликовано 27.01.2008, Бюл. №3, авторы Чморра А.Л., Уривский А.В., патентообладатель «Самсунг Электроникс» (KR).
3. ГОСТ Р 52633-2006 «Защита информации. Техника защиты информации. Требования к средствам высоконадежной биометрической аутентификации».
4. Заявка №99111404/09 от 1999.06.01. Способ криптографического обеспечения безопасности информационных технологий, G06F 12/14, опубликовано 2001.04.27, авторы: Иванов А.И., Волчихин В.И., Андрианов В.В., Каминский В.Г., заявитель Пензенский государственный университет.
5. Волчихин В.И., Иванов А.И., Фунтиков В.А. Быстрые алгоритмы обучения нейросетевых механизмов биометрико-криптографической защиты информации. Монография. Пенза. - 2005 г. Издательство Пензенского государственного университета, 273 с.
6. Описание изобретения к патенту RU 2346397, заявка №2007124112, приоритет от 26.06.2007. Способ защиты персональных данных биометрической идентификации и аутентификации. Авторы и владельцы патента: Иванов А.И., Фунтиков В.А., Ефимов О.В.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ ЗАЩИТЫ ПЕРСОНАЛЬНЫХ ДАННЫХ БИОМЕТРИЧЕСКОЙ ИДЕНТИФИКАЦИИ И АУТЕНТИФИКАЦИИ | 2007 |
|
RU2346397C1 |
| СПОСОБ БЕЗОПАСНОЙ БИОМЕТРИЧЕСКОЙ АУТЕНТИФИКАЦИИ | 2008 |
|
RU2406143C2 |
| СПОСОБ КЛАССИФИКАЦИИ РИСУНКОВ ОТПЕЧАТКА ПАЛЬЦА ПРИ АУТЕНТИФИКАЦИИ ЛИЧНОСТИ | 2011 |
|
RU2473125C1 |
| СПОСОБ БИОМЕТРИЧЕСКОЙ ЗАЩИТЫ АНОНИМНОСТИ СВИДЕТЕЛЕЙ ПРИ СУДЕБНОМ ДЕЛОПРОИЗВОДСТВЕ | 2012 |
|
RU2543956C2 |
| СПОСОБ АУТЕНТИФИКАЦИИ ЛИЧНОСТИ ПО РИСУНКУ ОТПЕЧАТКА ПАЛЬЦА И УСТРОЙСТВО ДЛЯ ЕГО РЕАЛИЗАЦИИ | 2007 |
|
RU2355307C2 |
| СПОСОБ ФОРМИРОВАНИЯ ЭЛЕКТРОННЫХ ДОКУМЕНТОВ И УСТРОЙСТВО ДЛЯ ЕГО ОСУЩЕСТВЛЕНИЯ | 2007 |
|
RU2365047C2 |
| Способ экспресс-тестирования средств высоконадежной биометрико-нейросетевой аутентификации личности с использованием базы биометрических образов "Свой" | 2020 |
|
RU2734906C1 |
| СПОСОБ РАСПРЕДЕЛЕНИЯ КЛЮЧЕЙ В БОЛЬШОЙ ТЕРРИТОРИАЛЬНО РАЗНЕСЕННОЙ СИСТЕМЕ | 2004 |
|
RU2273877C1 |
| СПОСОБ ФОРМИРОВАНИЯ ЭЛЕКТРОННОГО ДОКУМЕНТА | 2012 |
|
RU2527731C2 |
| СПОСОБ ФОРМИРОВАНИЯ ЭЛЕКТРОННОГО БИОМЕТРИЧЕСКОГО УДОСТОВЕРЕНИЯ ЛИЧНОСТИ | 2008 |
|
RU2391704C1 |
Изобретение относится к системам ограничения доступа к защищаемой информации, а именно к системам криптографической аутентификации пользователя по его неоднозначным биометрическим данным. Технический результат заключается в обеспечении равномерности выходных кодов хэширования при воздействии биометрическими данными «Чужой» и однозначности выходного кода при воздействии биометрическими данными «Свой». Технический результат достигается тем, что по каждому биометрическому параметру определяют вероятность попадания данных «Чужой» в первый интервал данных «Свой», далее все прилегающие дополнительные интервалы формируют таким образом, чтобы они давали близкую вероятность попадания данных «Чужой» к вероятности попадания в первый интервал «Свой». Предложено формирование всех интервалов вести итерационно, постепенно увеличивая первый интервал «Свой» до момента заданного сближения контролируемых вероятностей попадания данных «Чужой» во все выделенные интервалы, а также до момента приближения вероятности попадания в большинство выделенных интервалов к заданному диапазону значений правдоподобных вероятностей. Выделенные интервалы номеруют, формируют из номеров последовательность биометрического кода и хэшируют эту последовательность. 4 з.п. ф-лы, 5 ил.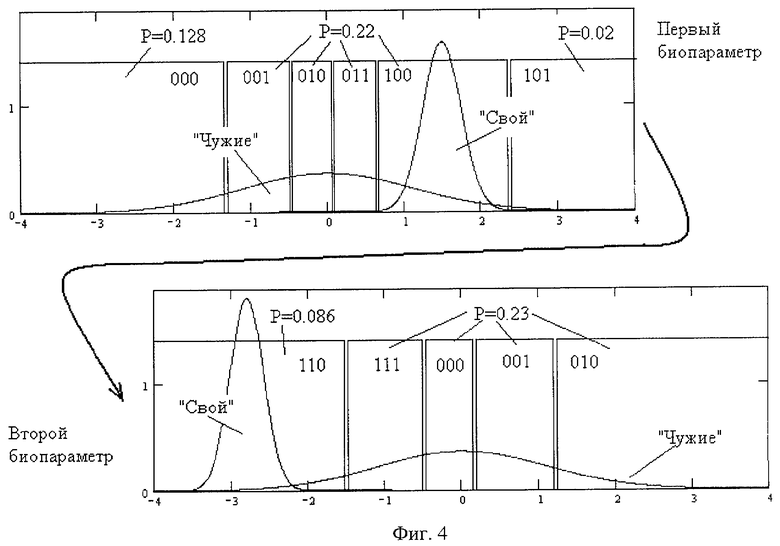
1. Способ однозначного хэширования неоднозначных биометрических данных, по которому выделяют первый интервал «Свой» по данным «Свой» в каждом из контролируемых биометрических параметров и знают закон распределения значений множества данных «Чужие» по каждому контролируемому биометрическому параметру, далее осуществляют дополнение выделенного первого интервала «Свой» похожими соседними интервалами, покрывающими интервал данных «Чужие», в котором присваивают каждому выделенному интервалу свой код, далее запоминают параметры выделенных интервалов и их коды и получают общий выходной код проверяемых биометрических данных как последовательность кодов, в которую отображаются проверяемые биометрические параметры, отличающийся тем, что по каждому биометрическому параметру определяют вероятность попадания данных «Чужой» в первый интервал данных «Свой», далее все прилегающие дополнительные интервалы формируют таким образом, чтобы они давали близкую вероятность попадания данных «Чужой» к вероятности попадания в первый интервал «Свой», формирование всех интервалов ведут итерационно, постепенно увеличивая первый интервал «Свой» до момента заданного сближения контролируемых вероятностей попадания данных «Чужой» во все выделенные интервалы, а также до момента приближения вероятности попадания в большинство выделенных интервалов к заданному диапазону значений правдоподобных вероятностей, все интервалы биометрических данных объединяют в одну последовательность, причем рядом в последовательности располагают биометрические данные с близкими вероятностями попадания данных «Чужие» в выделенные интервалы, принятую последовательность объединения биометрических данных запоминают, далее общую последовательность интервалов разбивают на группы с числом интервалов, кратным двум, а номера выделенных интервалов в группе задают неповторяющимися, выбирая их из поля кодов, образующегося на выходе счетчика числа интервалов в выбранной группе, далее при проверочном преобразовании биометрических данных хэшируют последовательность кодов выделенных интервалов, в который попал тот или иной биометрический параметр проверяемых биометрических данных.
2. Способ по п.1, отличающийся тем, что хэширование осуществляют через случайное задание кодов номеров случайной длины выделенных интервалов с последующим шифрованием и расшифровыванием случайных кодов выделенных ранее интервалов, причем при настройке функции хэширования шифруют коды участков последующих биометрических параметров на кодах интервалов «Свой» предшествующих параметров с последующим замещением открыто записанных в памяти кодов на их шифрограммы, а при проверочном преобразовании биометрических данных извлеченные из памяти коды выделенных интервалов расшифровывают восстановленными кодами предшествующих уже проверенных биометрических параметров, после чего осуществляют трансформацию длины общего кода и/или приведение его к значению личного ключа пользователя через операции, осуществляемые с использованием стандартных функций хэширования полученного биометрического кода.
3. Способ по п.2, отличающийся тем, что шифрование и расшифровывание на выделенных фрагментах восстановленного кода дополнительно применяют к параметрам, описывающим положение выделенных при инициализации первых интервалов «Свой» и дополняющих интервалов всех последующих биометрических данных.
4. Способ по п.1, отличающийся тем, что предварительно осуществляют нейросетевое улучшение качества используемых биометрических данных, причем используют нейронные сети, предварительно обученные уменьшать дисперсию выходных биометрических данных «Свой» по отношению к дисперсии выходных биометрических данных «Чужие», с размещением таблиц связей и параметров обученных нейронных сетей в памяти и последующим извлечением их из памяти при проверочном преобразовании биометрических данных.
5. Способ по п.4, отличающийся тем, что таблицы связей нейронов и/или таблицы весовых коэффициентов нейронов обученных нейронных сетей шифруют на последовательностях кодов участков «Свой» предшествующих биометрических данных, затем замещают в памяти открытые таблицы связей и параметров обученных нейронных сетей на их шифрограммы, при проверочных преобразованиях биометрических данных шифрограммы таблиц связей и/или параметров расшифровывают на кодах участков, выявленных в предшествующих биометрических данных.
| RU 99111404 А, 2001.04.27 | |||
| WO 03093923 A2, 2003.11.13 | |||
| СПОСОБ АУТЕНТИФИКАЦИИ ЛИЧНОСТИ ПО РИСУНКУ ОТПЕЧАТКА ПАЛЬЦА И УСТРОЙСТВО ДЛЯ ЕГО РЕАЛИЗАЦИИ | 2007 |
|
RU2355307C2 |
| БИОМЕТРИЧЕСКАЯ СИСТЕМА АУТЕНТИФИКАЦИИ | 2004 |
|
RU2316120C2 |
| Центральная жесткая автоматическая сцепка | 1934 |
|
SU42577A1 |
| ПРИБОР ДЛЯ ОПРЕДЕЛЕНИЯ ВЕСА ЖИДКОСТИ В БАКЕ ПО ПРОИЗВОДИМОМУ ЕЮ НА ДНО БАКА ДАВЛЕНИЮ | 1934 |
|
SU46710A1 |

