Изобретение относится к области искусственного интеллекта, а именно к человеко-машинному взаимодействию. Оно может быть использовано в любой ситуации, где необходимо бесконтактное взаимодействие различных групп пользователей, включая людей с ограниченными возможностями по слуху и зрению, с мобильными информационными роботами посредством автоматического распознавания жестовой и речевой информации.
Заявленное изобретение способно обрабатывать как естественные управляющие жесты рук, так и элементы жестового языка глухих людей, а также управляющие речевые команды пользователя.
Для решения задач человеко-машинного взаимодействия возможно использовать интерактивные информационные системы на базе естественных и универсальных способов обмена информацией (жесты, речь). Так, например, крупнейшая японская автомобильная компания Toyota начиная с 2004 года разрабатывает социальных роботов с искусственным интеллектом, в рамках проекта «Partner Robot Family» (https://www.toyota-global.com/innovation/partner_robot/) в июле 2015 года на выставке в Японии она представила робота Human Support Robot (HSR), ориентированного на помощь людям с инвалидностью в повседневной жизни и коммуникации («ассистивные технологии»). Робот HSR управляется голосовыми командами, жестами или графическим интерфейсом на базе мобильного устройства (смартфон, планшет) и направлен на решение таких задач, как открытие дверей, включение света, захват предметов или доставку (к примеру, бутылок с водой или таблеток) и т.д. Кроме того, робот снабжен функциями телеприсутствия и удаленного контроля, что облегчает стороннюю заботу о человеке с ограниченными возможностями здоровья. В свою очередь, Американское космическое Национальное управление по аэронавтике и исследованию космического пространства (NASA) ведет разработки управляемого жестами космонавтов космического робота-ассистента «Mars 2020 Rover» в рамках программы «Марс-2020», целью которой является исследование Марса (https://mars.nasa.gov/mars2020/). Также Европейское космическое агентство (ESA) в рамках проекта «MOONWALK» разработало технологии для будущих космических миссий на Луну и Марс, в том числе интеллектуальный жестовый/многомодальный интерфейс для бесконтактного управления мобильным роботом-ассистентом в имитируемых условиях лунного ландшафта с возможностью автоматизированного следования за космонавтом (режим «Follow Me») (http://www.projectmoonwalk.net/moonwalk/).
Кроме описанных решений также известен способ, содержащий систему распознавания жестов с распознаванием статической позы кисти руки, основанным на динамическом изменении масштаба времени (патент RU 2014101965 A), который состоит из следующих этапов: идентифицирует представляющую интерес область кисти руки на изображении; извлекает контур области кисти руки; вычисляет вектор признаков на основе извлеченного контура; распознает статическую позу, которая представляет интерес области кисти руки с помощью операции динамического изменения масштаба времени на основе вектора признаков. К числу недостатков данного решения следует отнести отсутствие распознавания динамических жестов.
Известен способ распознавания жестов в динамике для последовательности стереокадров (патент RU 2280894 С2), который позволяет интерпретировать жесты с высокой точностью. Данный результат достигается за счет получения стереоизображений объекта, по которым строится карта различий в глубинах. Автоматическая инициализация системы происходит с помощью вероятностной модели верхней части тела объекта (человека). Моделирование верхней части тела осуществляется через три плоскости (туловище и руки человека), а также три гауссовские компоненты (голова и кисти человека). Из недостатков данного решения следует заметить использование только оптических камер.
Известно устройство и способ для распознавания жестов с использованием радиочастотного датчика (патент RU 2641269 C1), который позволяет получить следующие преимущества: непрерывную обработку жестов во время перемещения пользователя; наличие возможности встраивания в различные носимые устройства; отсутствие необходимости фиксации устройства для распознавания жестов на теле пользователя, поскольку настоящее изобретение использует радиочастотные сигналы, имеющие длины волн, которые длиннее, чем возможные расстояния смещения устройства на части тела пользователя; удобное управление устройством с помощью жеста; использование небольшого числа датчиков (антенн). Таким образом, данное изобретение позволяет распознавать жесты с помощью радиочастотного датчика, который последовательно генерирует набор радиочастотных сигналов с помощью передатчика и последовательно испускает набор радиочастотных сигналов в ткани частей тела пользователя через антенны; прием наборов радиочастотных сигналов, отраженных и искаженных тканями частей тела пользователя осуществляется через приемник и антенну; разделение каждого принятого радиочастотного сигнала в каждом наборе сигналов на первый и второй радиочастотные сигналы с помощью приемника, при этом первый радиочастотный сигнал представляет амплитуду, а второй сигнал представляет фазовый сдвиг; преобразование радиочастотных сигналов в цифровые сигналы осуществляется при помощи аналого-цифрового преобразователя, чтобы получать наборы цифровых сигналов, причем каждый набор цифровых сигналов получается из соответствующего набора радиочастотных сигналов; обработку наборов цифровых сигналов в центральном процессоре посредством искусственной нейронной сети с использованием опорных наборов данных для распознавания жестов, причем каждый опорный набор данных соответствует конкретному жесту и получен обучением искусственной нейронной сети.
Известен способ, содержащий систему распознавания жестов для управления телевизором (патент US 9213890 B2). Данная система использует метод на основе определения цвета кожи в сочетании с информацией о движении для выполнения сегментации в режиме реального времени. Фильтр Калмана используется для отслеживания центров тяжести рук. Вычисляются центры ладоней и их нижняя координата, а также наибольшее расстояние от центра ладоней до их контуров, которые вычисляются на основе извлеченных масок рук. Вычисленные расстояния затем сравнивается с заданным порогом, чтобы определить, являются ли текущие положения «открытыми» или «закрытыми». В предпочтительном варианте осуществления переход между положением «открыто» и «закрыто» позволяет определить, находится ли текущий жест в состоянии «выбрать» или «захватить». К минусам данного способа можно отнести возможность распознавания только жестов, когда руки закрыты или открыты.
Известен способ распознавания жестов на основе карты глубины и компьютерного зрения (патент WO 2019/091491 Al), который использует систему устройств из цветной камеры и карты глубины для идентификации переднего плана видеоинформации на основе информации полученной от карты глубины и определение того, соответствует ли она заранее заданному жесту в базе данных. В случае совпадения определяется дальнейшие совпадения видеокадров с предопределенными жестами. К числу недостатков данного подхода следует отнести распознавание только одноручных статических жестов.
Известен способ распознавания речи на основе двухуровнего морфофонетического префиксного графа (патент RU 2597498 C1), который позволяет распознавать слитную непрерывную речь вне зависимости от индивидуальных особенностей говорящего на основе определения групп фонем по характеризующим их признакам и метода последовательного декодирования последовательностей символов, обозначающих группы фонем, на основе двухуровнего морфофонемного префиксного графа в цепочку слов, составляющих высказывание (текст). К числу недостатков данного подхода следует отнести: вариативность морфем в русском языке из-за чередования звуков, затрудняющую правильное формирование слов; короткий размер единиц словаря (морфем), приводящий к появлению большого числа омонимов, что затрудняет построение модели языка.
Наиболее близким по технической сущности к заявляемому способу и выбранным в качестве прототипа является способ управления устройством с помощью жестов (патент RU 2455676 C2), включающий подачу жеста пользователем, захват трехмерного изображения, распознавание жеста и выдачу на управляемое устройство соответствующей жесту команды, отличающийся тем, что в окружающем пользователя пространстве выделяют, по меньшей мере, одну сенсорную область, с каждой сенсорной областью ассоциируют, по меньшей мере, один ожидаемый жест и с каждой комбинацией сенсорной области и жеста ассоциируют одну команду, определяют положение глаз пользователя, положение его головы и положение его руки, определяют условную линию взгляда, исходящую из органа зрения пользователя и направленную в видимую пользователем точку окружающего пространства, проверяют, направлена ли условная линия взгляда на сенсорную область, анализируют подаваемый рукой пользователя жест и в случае, если жест подают одновременно с наведением условной линии взгляда на сенсорную область, то на управляемое устройство выдают команду, ассоциированную с данной комбинацией сенсорной области и поданного жеста.
Основными недостатками существующих аналогов в предметной области является их узкая функциональная направленность, выраженная в решении задач с использованием только одной модальности (аудио или видео).
Техническая проблема, решение которой обеспечивается настоящим изобретением, заключается в необходимости расширения функциональности мобильного информационного робота за счет использования многомодального человеко-машинного взаимодействия, под которым понимается управление мобильным информационным роботом через комбинирование аудио и видео модальностей.
Технический результат достигается за счет того, что способ многомодального бесконтактного управления мобильным информационным роботом, заключающийся в комбинированной обработке видео- и аудиоинформации от пользователя.
Кроме того, комбинированная обработка видео- и аудиоинформации от пользователя заключается в последовательной обработке видеоинформации от пользователя, включающей прием цветных видеоданных и карты глубины; формировании областей с людьми на каждом трехмерном (3D) кадре карты глубины; вычислении 3D 25-точечных моделей скелетов людей; слежении за ближайшим человеком; преобразовании 3D 25-точечной скелетной модели ближайшего человека в 2D 25-точечную скелетную модель; определении графической области лица и форм рук в пределах сформированных прямоугольной области с человеком; вычислении визуальных признаков жеста в определенный момент времени; распознавании жеста; последовательной обработке аудиоинформации от пользователя, включающей определение границ речи; вычислении акустических признаков; распознавании речевых команд. Действие мобильного информационного робота происходит на основании полученных результатов распознанных аудио и видео модальностей.
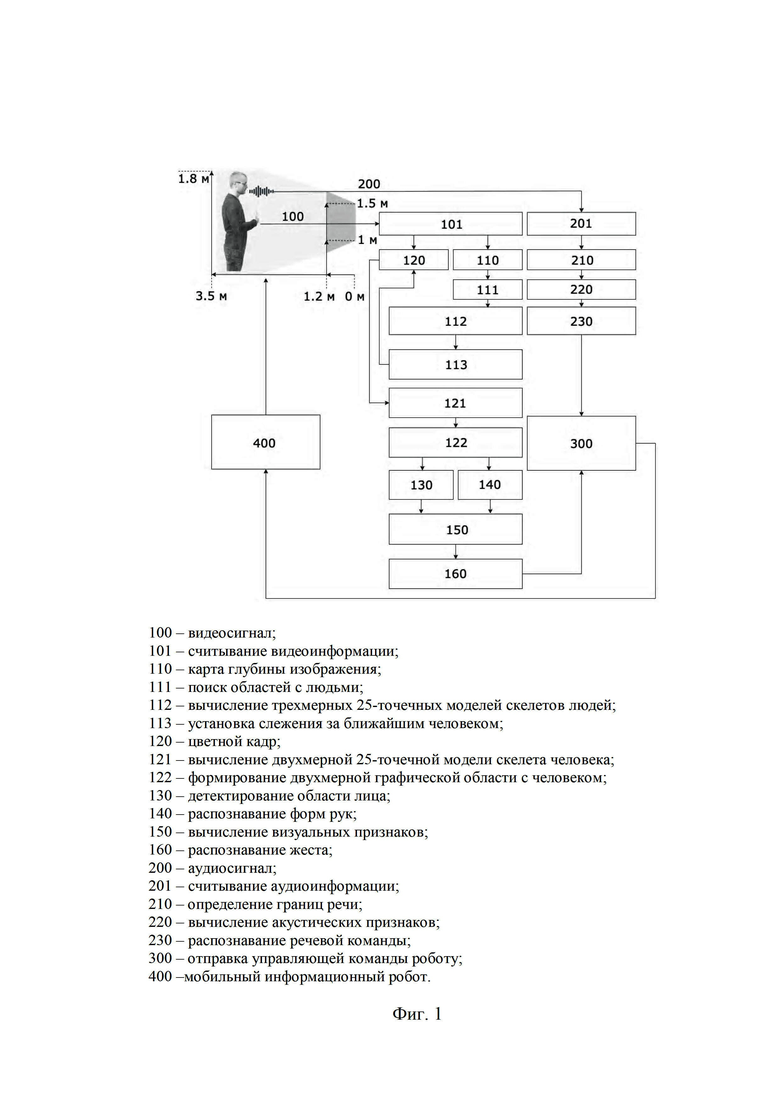
Сущность изобретения поясняется фиг. 1, на которой отображена функциональная схема способа многомодального бесконтактного управления мобильным информационным роботом.
В способе многомодального бесконтактного управления мобильным информационным роботом (фиг. 1) входные данные представляют в виде видеосигнала (100) и аудиосигнала (200). В роли приемника видеосигнала (101) выступает устройство, способное получать цветные видеоданные и карту глубины (например, сенсор Kinect v2). Качество цветопередачи цветного (120) видеопотока составляет 8 бит с разрешением видеопотока 1920×1080 (FullHD) пикселей и частотой 30 кадров в секунду, а для карты глубины (110) 16 бит с разрешением видеопотока 512×424 пикселей и такой же частотой кадров, как у цветного видеопотока. В роли приемника аудиосигнала (201) выступает устройство, способное получать аудиоданные с частотой дискретизации 16 КГц, 16 бит на цифровой отсчет и отношением аудиосигнал/шум - не менее 20 дБ (например, смартфон на базе операционной системы Android версии 7.0 и выше). Данные устройства получения сигналов устанавливают на мобильный информационный робот на высоту от 1 до 1.5 метра, также способ предполагает соблюдение расстояния от человека, который выполняет бесконтактное управление до робота в диапазоне от 1.2 до 3.5 метров.
Формирование областей с людьми (111) на каждом 3D кадре карты глубины (110) и вычисление 3D 25-ти точечных моделей скелетов людей (112) осуществляют с помощью набора средств разработки приемника, который формирует карту глубины (например, набор средств разработки сенсора Kinect v2 [https://docs.microsoft.com/en-us/previous-versions/windows/kinect/dn758675(v=ieb.10)]).
Слежение за ближайшим человеком (113) производят на основании определения ближайшей 3D скелетной модели по оси Z трехмерного пространства путем вычисления минимального значения из всех средних значений оси Z 25-ти точечных моделей скелетов людей.
Преобразование 3D 25-ти скелетной модели ближайшего человека в 2D 25-ти скелетную модель (121) осуществляют, например, с помощью набора средств разработки приемника, что позволяет формировать 2D области (122) с ближайшим человеком.
Кроме того, в пределах сформированной прямоугольной области с человеком производят определение графической области лица (130) и форм рук (140). Задачу по детектированию лиц (130) людей решают с помощью обученного детектора на основе сверточной нейронной сети, который, например, реализован в библиотеке компьютерного зрения и машинного обучения Dlib [https://www.dlib.net] и имеет следующие особенности: используется детектор для обнаружения объектов [D.E. King. Max-margin object detection // arXiv preprint arXiv:1502.00046, 2015] с функциями на основе сверточной нейронной сети; для обучения модели применяют такие наборы данных, как: ImageNet [J. Deng, W. Dong, R. Socher, L.J. Li, K. Li, L. Fei-Fei. Imagenet: A large-scale hierarchical image database // In 2009 IEEE conference on computer vision and pattern recognition, 2009, pp. 248–255; A. Krizhevsky, I. Sutskever, G.E. Hinton. Imagenet classification with deep convolutional neural networks // In Advances in neural information processing systems, 2012, pp. 1097–1105], PASCAL VOC [M. Everingham, L. Van Gool, C.K. Williams, J. Winn, A. Zisserman. The pascal visual object classes (voc) challenge // International journal of computer vision, Vol. 88, No. 2, 2010, pp. 303–338], VGG [O.M. Parkhi, A. Vedaldi, A. Zisserman. Deep face recognition // In BMVC, Vol. 1, No. 3, 2015, p. 6], WIDER [S. Yang, P. Luo, C.C. Loy, X. Tang. Wider face: A face detection benchmark // In Proceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 5525–5533], Face Scrub [H.W. Ng, S. Winkler. A data-driven approach to cleaning large face datasets // In 2014 IEEE International Conference on Image Processing, ICIP, 2014, pp. 343–347]. Обученный детектор лиц работает при разных ориентациях лица, устойчив к окклюзиям, а также работает в режиме реального времени как на центральном процессоре (CPU), так и на графическом процессоре (GPU).
Кроме того, в случае с определением графической области с формами рук (140) человека используют глубокую сверточную нейронную сеть с архитектурой MobileNetV2 [M. Sandler, A. Howard, M. Zhu, A. Zhmoginov, L.C. Chen. Mobilenetv2: Inverted residuals and linear bottlenecks // In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2018, pp. 4510–4520], которая, например, включена в платформу распознавания объектов с открытым исходным кодом TensorFlow Object Detection API [J. Huang, V. Rathod, Ch. Sun, M. Zhu, A. Korattikara, A. Fathi, I. Fischer, Z. Wojna, Y. Song, S. Guadarrama, K. Murphy. Speed/Accuracy Trade-Offs for Modern Convolutional Object Detectors // Proceedings of 30th IEEE Conference on Computer Vision and Pattern Recognition, CVPR-2017, 2017, pp. 3296–3297] и основана на инвертированной остаточной структуре. Непосредственное обучение глубокой сверточной нейронной сети производили с помощью размеченных данных с формами рук из базы данных Thesaurus of Russian Sign Language (мультимедийная база данных) [И.А. Кагиров, Д.А. Рюмин, А.А. Аксенов, А.А. Карпов. Мультимедийная база данных жестов русского жестового языка в трехмерном формате // Вопросы языкознания, 2020, №1: С. 104–123. DOI: 10.31857/S0373658X0008302-1]. Аннотированные области рук сохраняли в специальном формате PASCAL VOC [M. Everingham, L. Van Gool, C.K. Williams, J. Winn, A. Zisserman. The pascal visual object classes (voc) challenge // International journal of computer vision, Vol. 88, No. 2, 2010, pp. 303–338] в виде текстовых файлов XML при помощи, например, инструмента LabelImg [https://github.com/tzutalin/labelImg]. Распознавание форм рук осуществляли при следующих условиях: обученная модель глубокой сверточной нейронной сети определяет форму руки; центральная координата руки, полученная на этапе вычисления 2D 25-ти точечной модели скелета человека (121), находится в пределах распознанной области с формой руки.
Также вычисление визуальных признаков (150) направлено на извлечение отличительных характеристик жеста в определенный момент времени. При этом формируют следующие визуальные признаки: нормализованные 2D расстояния от лица до рук (зона артикуляции жеста); нормализованные 2D площади пересечения лица и рук; формы рук (представляются числовым значением); результат детектирования области рта (представлен числовым значением).
Технический результат распознавания жестов (160) достигается за счет использования глубокой нейронной сети с длинной кратковременной памятью (LSTM [S. Hochreiter, J. Schmidhuber. Long short-term memory // Neural computation, Vol. 9, No. 8, 1997, pp.1735–1780]), которая в общем понимании – это своего рода рекуррентная нейронная сеть. В свою очередь, рекуррентная нейронная сеть – это нейронная сеть, которая пытается смоделировать некоторое поведение, зависящее от времени или последовательности, например, видеоанализ движений рук для распознавания жестов. Это выполняли при помощи обратной связи выхода уровня нейронной сети в момент времени t с входом того же уровня сети в момент времени t+1. Однако обычная рекуррентная нейронная сеть имеет недостаток, который заключается в исчезающем градиенте. Данная проблема возникает в случае, когда сеть пытается смоделировать зависимость внутри длинной последовательности обучающей выборки. Это связано с тем, что небольшие градиенты или веса (значения меньше 1) многократно умножаются на протяжении нескольких временных шагов, и следовательно градиенты сжимаются до нуля. Это означает, что веса более ранних шагов не будут существенно изменены, и, следовательно, сеть не будет изучать долгосрочные зависимости. Сеть LSTM позволяет решить данную проблему. Кроме того, на вход данной нейронной сети подавали функциональные ядра жестов, которые состоят из контекстно-независимых движений рук по отношению к другим жестам. В более расширенном понимании, LSTM нейронная сеть принимает последовательность N кадров × 8 значений из характеристик жеста, в частности: нормализованные 2D расстояния от лица до рук представляют собой число с плавающей точкой; нормализованные 2D площади пересечения лица и рук также представляют собой число с плавающей точкой; формы рук – целое число; результат детектирования области рта представлен числами 0 (область не найдена) и 1 (область найдена). Процесс обучения производили, например, с помощью библиотеки глубокого машинного обучения Keras [https://keras.io] и библиотеки с открытым исходным кодом TensorFlow [M. Abadi, P. Barham, J. Chen, Z. Chen, A. Davis, J. Dean, M. Devin, S. Ghemawat, G. Irving, M. Isard, M. Kudlur. Tensorflow: A system for large-scale machine learning // In 12th Symposium on Operating Systems Design and Implementation, 2016, pp. 265–283; https://www.tensorflow.org].
Кроме того, определение границ речи (210) в аудио модальности выполняют таким образом, что непрерывный цифровой аудиосигнал разделяется на короткие сегменты сигнала длительностью 10 миллисекунд, следующие с 50% перекрытием. Все поступающие сегменты звука сохраняют в буфер памяти аудиоданных и выполняют проверку каждого поступающего сегмента на наличие в нем речи человека. На каждом сегменте сигнала вычисляют значения энергии 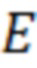 для каждого сегмента сигнала, которое состоит из цифровых отсчетов
для каждого сегмента сигнала, которое состоит из цифровых отсчетов  фиксированной длины, и выполняют его логарифмирование:
фиксированной длины, и выполняют его логарифмирование:
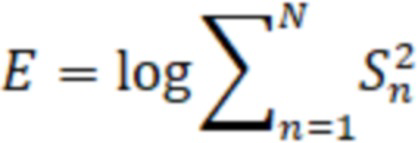
Кроме того, сравнивают логарифм энергии сегмента с заранее установленным пороговым значением 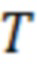 , которое зависит от окружающих акустических условий, и, если значение превосходит порог, то данный сегмент признается речью человека, в противном случае – считается тишиной (акустический фон). Такую проверку выполняют для каждого поступающего аудиосегмента.
, которое зависит от окружающих акустических условий, и, если значение превосходит порог, то данный сегмент признается речью человека, в противном случае – считается тишиной (акустический фон). Такую проверку выполняют для каждого поступающего аудиосегмента.
Кроме того, применяют логико-временную обработку функции значений энергии сегментов аудиосигнала, учитывающую допустимые на практике длительности речевых и неречевых фрагментов, определенных с применением заданного порога. Такая обработка требуется, так как во многих случаях такие звуковые артефакты, как щелканье или неречевые участки сигнала, ошибочно могут приниматься за речь, и наоборот, некоторые участки, содержащие речь, отбрасываются из-за специфических акустических характеристик. Применяя пороговое значение к функции , возможно определить чередующиеся речевые и неречевые участки на функции и применить для обработки 2 константы: 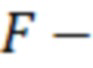 минимальная длительность речевого участка;
минимальная длительность речевого участка; 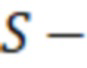 максимальная длительность безречевого участка между соседними речевыми сегментами.
максимальная длительность безречевого участка между соседними речевыми сегментами.
Учитывая тот факт, что человек не может производить очень короткие речевые фрагменты, а также то, что в речи всегда присутствуют определенные паузы (например, смычки перед взрывными согласными), устанавливают пороговые значения минимальной длительности речевого участка 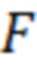 и максимальной длительности безречевого участка
и максимальной длительности безречевого участка 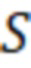 соответственно (их значения зависят от акустических условий). Анализ обнаруженных речевых фрагментов и неречевого фрагмента между ними производят следующим образом:
соответственно (их значения зависят от акустических условий). Анализ обнаруженных речевых фрагментов и неречевого фрагмента между ними производят следующим образом:
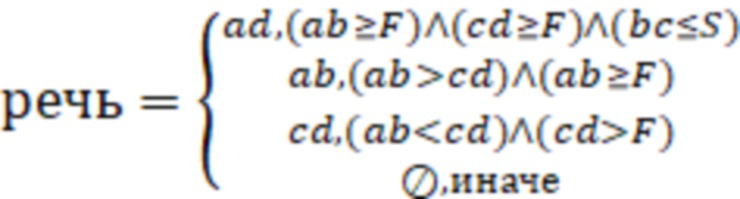
Данное правило итеративно применяют ко всем соседним размеченным фрагментам (участкам) анализируемой функции энергии сегментов аудиосигнала. Таким образом, если речевые участки в некотором сигнале имеют длительности не менее сегментов, а безречевой участок между ними – не более сегментов, то все данные участки объединяются в единый речевой фрагмент.
Вычисление акустических признаков (220) осуществляют, например, посредством спектрального анализа сегментов сигнала с вычислением мел-частотных кепстральных коэффициентов (Mel-Frequency Cepstral Coefficients, MFCC) с их первой и второй производными. Для этого выполняют кратковременный спектральный анализ сегментов аудиосигнала (для более точного описания сигнала речевые сегменты берут с перекрытием) и перемножают сигнал с некоторой функцией окна для того, чтобы разрывы на границах окна были ослаблены, в качестве функции окна обычно используют окно Хэмминга:
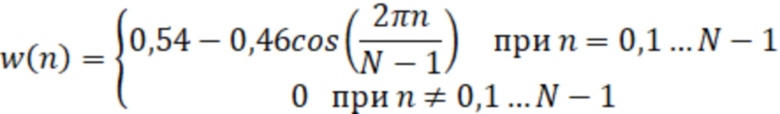
где 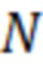 – ширина окна в цифровых отсчетах
– ширина окна в цифровых отсчетах 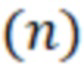 .
.
Вычисляют быстрое преобразование Фурье (БПФ) над перекрывающимися сегментами речи длительностью 10 миллисекунд. Полученный спектр сигнала преобразуют к мел-шкале путем применения набора перекрывающихся треугольных фильтров, расположенных в частотной области в соответствии с мел-шкалой частот, определяемой формулой:
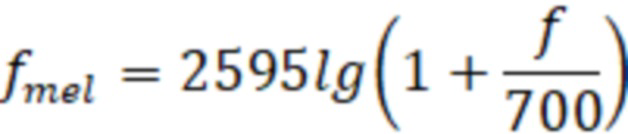
где 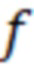 – значение частоты аудиосигнала.
– значение частоты аудиосигнала.
Значения БПФ, включенные в каждый фильтр, пересчитывают с учетом треугольного окна, определяют интегральную энергию на выходе каждого фильтра и производят логарифмирование выхода каждого фильтра. Этот набор векторов признаков подвергают дискретному косинусному преобразованию. В результате получают мел-частотные кепстральные коэффициенты, определяемые по следующей формуле:
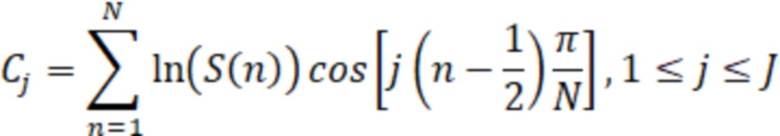
где 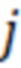 – номер кепстрального коэффициента, – количество треугольных фильтров,
– номер кепстрального коэффициента, – количество треугольных фильтров,  – энергия сигнала.
– энергия сигнала.
Распознавание речи (230) осуществляют посредством заранее обученных акустических моделей (например, скрытых марковских моделей (СММ) [L. Rabiner, B.-H. Juang. Fundamentals of Speech Recognition // Prentice Hall. 1993. 507 p.] или гибридных акустических моделей, объединяющих искусственные нейронные сети и СММ [D. Yu, L. Deng. Automatic Speech Recognition - A Deep Learning Approach // Springer. 2015. 322 p.]) и языковой модели или грамматики [Ф. Джелинек Распознавание непрерывной речи статистическими методами // ТИИЭР, 1976, Т. 64, № 4, С. 131–160]. Для распознавания слитной речи используют модифицированный алгоритм Витерби, называемый методом передачи маркеров (token passing method) [S. Young et al. The HTK Book (for HTK Version 3.4) // Cambridge, UK, 2009, 375 p.], который определяет прохождение возможных путей по состояниям объединенной СММ. В начало каждого слова из словаря ставится маркер и применяется итеративный алгоритм оптимизации Витерби, при этом на каждом шаге сдвигается маркер и для него вычисляется вероятностная оценка по акустической и языковой модели. После обработки всей последовательности векторов наблюдений выбирается маркер, имеющий наибольшую вероятность. Когда наилучший маркер (с наибольшей акустико-языковой вероятностью) достигает конца обрабатываемого сигнала (последовательности наблюдений), то путь, которым он проходит через сеть, известен в виде истории (хранящейся в маркере), и из маркера считывается последовательность пройденных слов, которая и является гипотезой распознавания фразы.
Процесс отправки управляющей команды (300), соответствующей распознанному управляющему жесту или речевой команды пользователя, в электронную систему управления мобильным информационным роботом осуществляют, например, через Wi-Fi 802.11 соединение по протоколу TPC/IP и специально выделенный порт.
Действие мобильного информационного робота (400) происходит на основании результата распознания аудио- или видеоинформации от пользователя.
Таким образом, указанные отличительные особенности способа многомодального бесконтактного управления мобильным информационным роботом позволяют бесконтактно взаимодействовать различным группам пользователей, включая людей с ограниченными возможностями по слуху и зрению, с мобильным информационным роботом посредством автоматического распознавания жестовой и речевой информации.
Проведенный заявителем анализ уровня аналогов позволил установить, что способ многомодального бесконтактного управления мобильным информационным роботом, характеризующийся совокупностями признаков, соответствует условию патентоспособности "Новизна".
Результаты поиска известных решений в данной и смежной областях техники с целью выявления признаков, совпадающих с отличительными от прототипов признаками заявляемого изобретения, показали, что они не следуют явным образом из уровня техники. Из определенного заявителем уровня техники не выявлена известность влияния предусматриваемых существенными признаками заявленного изобретения на достижение указанного технического результата. Следовательно, заявленное изобретение соответствует условию патентоспособности "Изобретательский уровень".
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ АУДИОВИЗУАЛЬНОГО РАСПОЗНАВАНИЯ СРЕДСТВ ИНДИВИДУАЛЬНОЙ ЗАЩИТЫ НА ЛИЦЕ ЧЕЛОВЕКА | 2022 |
|
RU2791415C1 |
| Операторный универсальный интеллектуальный 3-D интерфейс | 2017 |
|
RU2693197C2 |
| СПОСОБ ОТОБРАЖЕНИЯ ТРЕХМЕРНОГО ЛИЦА ОБЪЕКТА И УСТРОЙСТВО ДЛЯ НЕГО | 2017 |
|
RU2671990C1 |
| СПОСОБ РАСПРЕДЕЛЕНИЯ ЗАДАЧ МЕЖДУ СЕРВИСНЫМИ РОБОТАМИ И СРЕДСТВАМИ КИБЕРФИЗИЧЕСКОГО ИНТЕЛЛЕКТУАЛЬНОГО ПРОСТРАНСТВА ПРИ МНОГОМОДАЛЬНОМ ОБСЛУЖИВАНИИ ПОЛЬЗОВАТЕЛЕЙ | 2016 |
|
RU2638003C1 |
| Способ мониторинга профессиональной надёжности | 2022 |
|
RU2825116C2 |
| Способ передачи многомодальной информации на критически важных объектах | 2018 |
|
RU2696221C1 |
| СПОСОБ, ТЕРМИНАЛ И СИСТЕМА ДЛЯ БИОМЕТРИЧЕСКОЙ ИДЕНТИФИКАЦИИ | 2023 |
|
RU2815689C1 |
| СИСТЕМА ДЛЯ РАСПОЗНАВАНИЯ И ОТСЛЕЖИВАНИЯ ПАЛЬЦЕВ | 2012 |
|
RU2605370C2 |
| СПОСОБ УПРАВЛЕНИЯ УСТРОЙСТВОМ С ПОМОЩЬЮ ЖЕСТОВ И 3D-СЕНСОР ДЛЯ ЕГО ОСУЩЕСТВЛЕНИЯ | 2011 |
|
RU2455676C2 |
| СПОСОБ, ТЕРМИНАЛ И СИСТЕМА ДЛЯ БИОМЕТРИЧЕСКОЙ ИДЕНТИФИКАЦИИ | 2022 |
|
RU2798179C1 |
Изобретение относится к области искусственного интеллекта. Технический результат заключается в расширении функциональности мобильного информационного робота за счет использования многомодального человеко-машинного взаимодействия, под которым понимается управление мобильным информационным роботом через комбинирование аудио и видео модальностей. Изобретение содержит способ многомодального бесконтактного управления мобильным информационным роботом, состоящий из захвата трехмерного пространства, распознавания жеста, отличающийся тем, что происходит комбинированная обработка видео- и аудиоинформации от пользователя, последовательная обработка видеоинформации от пользователя, формирование областей с людьми на каждом трехмерном (3D) кадре карты глубины, вычисление 3D 25-точечных моделей скелетов людей, слежение за ближайшим человеком, преобразование 3D 25-точечной скелетной модели ближайшего человека в 2D 25-точечную скелетную модель, определение графической области лица и форм рук в пределах сформированной прямоугольной области с человеком, вычисление визуальных признаков жеста в определенный момент времени, последовательная обработка аудиоинформации от пользователя, вычисление акустических признаков, распознавание речевых команд. 1 ил.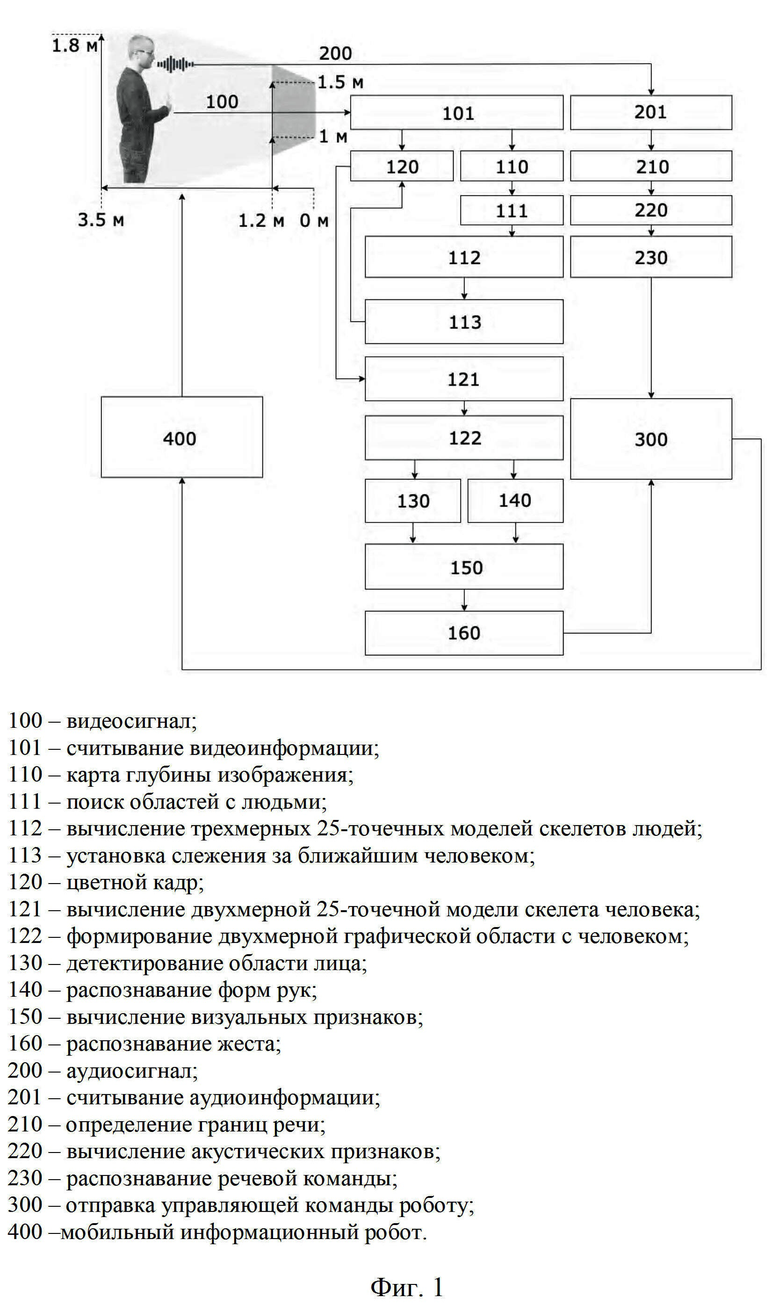
Способ многомодального бесконтактного управления мобильным информационным роботом, состоящий из захвата трехмерного пространства, распознавания жеста, отличающийся тем, что происходит комбинированная обработка видео- и аудиоинформации от пользователя, последовательная обработка видеоинформации от пользователя, формирование областей с людьми на каждом трехмерном (3D) кадре карты глубины, вычисление 3D 25-точечных моделей скелетов людей, слежение за ближайшим человеком, преобразование 3D 25-точечной скелетной модели ближайшего человека в 2D 25-точечную скелетную модель, определение графической области лица и форм рук в пределах сформированной прямоугольной области с человеком, вычисление визуальных признаков жеста в определенный момент времени, последовательная обработка аудиоинформации от пользователя, вычисление акустических признаков, распознавание речевых команд.
| RU 2011127116 A, 10.10.2011 | |||
| RU 2004104758 A, 10.07.2005 | |||
| Устройство и способ для распознавания жестов с использованием радиочастотного датчика | 2017 |
|
RU2641269C1 |
| Изложница с суживающимся книзу сечением и с вертикально перемещающимся днищем | 1924 |
|
SU2012A1 |
| JP 2011042011 A, 03.03.2011. | |||

