Заявленное изобретение относится к области искусственного интеллекта, в частности, к цифровым методам автоматического мониторинга уровня безопасности людей, а также к человеко-машинному взаимодействию. Оно может использоваться в ситуациях, когда необходимо эффективно предотвращать вспышки различных эпидемий (COVID-19 и др.) и дальнейшего их распространения или же в случаях, когда возникает потребность в автоматической проверке наличия средств индивидуальной защиты на лицах медицинских работников и лиц других профессий, которые должны перемещаться по территориям различных учреждений (медицинских, промышленных, торговых, банковских, страховых и т.д.) и контактировать с другими людьми исключительно в различных вариациях защитных масок (медицинские, тканевые и т.д.), экранов, респираторов.
Данное изобретение способно производить как интеллектуальный анализ голосовых характеристик людей по их речи для определения наличия средств индивидуальной защиты в процессе говорения, так и интеллектуальный анализ лицевых характеристик людей по видеоданным для локализации и детекции наличия средств индивидуальной защиты в процессе выполнения каких-либо действий в определенный момент времени. Поддержка одновременной обработки обоих модальностей (аудио и видео) позволяет достичь более точных аудиовизуальных предсказаний для итоговых действий в зависимости от определенной степени индивидуальной защиты на лице человека.
Для решения задач автоматического мониторинга уровня безопасности людей возможно использовать передовые цифровые системы на базе универсальных способов обработки информации (аудио, видео). Так, например, компания «ВижнЛабс» (VisionLabs), является официальным резидентом инновационного центра «Сколково», входит в экосистему «Сбер» и осуществляет научно-исследовательскую деятельность в сферах компьютерного зрения, машинного обучения, анализа визуальных данных и робототехники. К основным программно-аппаратным решениям и цифровым сервисам данной компании можно отнести биометрический терминал контроля и управления доступом LUNA АСЕ (https://www.visionlabs.ru/ru/products/luna-ace), который способен решать множество задача связанных с увеличением пропускной способности на различных проходных с соблюдением всех обязательных мер безопасности (например, распознавание лиц под воздействием внешних факторов: борода, очки, изменение прически головные уборы, медицинские маски и др.). Кроме того, используемая технология Liveness позволяет защищать систему от различных спуфинг-атак, что приводит к исключению использования распечатанных фотографий или видео, которое воспроизводится на экране мобильного или иного устройства.
В свою очередь, Голландская компания «Aerialtronics», специализирующаяся на разработке комплексных решений, на базе визуального искусственного интеллекта и данных получаемых от Интернет вещей представила программное обеспечение (ПО) для локализации и идентификации различных вариантов защитных масок на лицах людей (https://www.aerialtromcs.com/en/products/face-mask-detection-software#featuresfacemask). К основным отличительным характеристикам ПО компания относит: 1) точную локализацию и идентификацию защитных масок на лицах людей; 2) масштабируемость ПО (можно использовать любой тип IP камер); конфиденциальность анализируемых визуальных данных; 4) мобильность (получение уведомления на мобильные устройства в режиме реального времени, в случаях когда люди не носят защитных масок или носят их неверно).
Другая Европейская компания «Grekkom Technologies)) из Испании разрабатывает интеллектуальные решения, направленные на анализ визуальных данных. Так, была представлена система обнаружения защитных масок на лицах людей (https://grekkom.com/en/products/our-analytics/facial-recognition/face-mask-detection/), которая способна функционировать в условиях плохого освещения и при необходимости отправлять оповещения или сигналы тревоги в режиме реального времени.
Компания «Asura Technologies)) головной офис которой расположен в Венгрии ведет активные разработки систем видеоаналитики нового поколения и ПО для обнаружения защитных масок на лицах людей в режиме реального времени (https://asuratechnologies.com/mask-detection/). По заявлениям данной компании ПО способно обнаруживать различные вариации защитных масок независимо от рисунков или иллюстраций, которые нанесены поверх них и даже в условиях большого скопления людей. Также имеется утверждение, о том, что ПО может быть интегрировано в системы наблюдения и идеально подходит для таких областей применения, как автоматический контроль доступа в торговых помещениях, гостиничном секторе или общественном транспорте, с высокой точностью определяя людей без защитных масок и присылая уведомления или другие автоматические оповещения на мобильные устройства людей, отвечающих за общую безопасность.
Стоит выделить ведущего мирового поставщика инновационных продуктов и систем безопасности, а именно Китайскую компанию «Hikvision». Разработчики данной компании предлагают комплексное решение для обнаружения защитных масок на лицах людей (https://www.hikvision.com/pt/solutions/solutions-by-application/mask-detection/). Их отличительная особенность заключается в предоставлении не только ПО для решения поставленных задач связанных с обнаружением защитных масок на лицах людей, но и аппаратного обеспечения, которое в связке с их ПО работает как единый механизм.
Американские компании «Milestone» и «6SS» в тесном сотрудничестве разработали модуль обнаружения различных защитных масок на лицах людей (https://www.milestonesys.com/marketplace/6ss/6ss-iva---face-mask-detection/), для определения ситуаций, когда ношение масок не соблюдается. Данный модуль позволяет осуществлять захват видеоинформации и в режиме реального времени производить визуальный анализ контролируемой среды для определения находится ли человек в маске или он без нее. Ключевая особенность заявленного модуля состоит в его возможной интеграции с системой контроля доступа или другими системами сторонних разработчиков ПО, а также производителей аппаратных средств (IP камеры и т.д.).
Кроме описанных решений также имеются другие способы и устройства для визуального анализа лицевых характеристик человека для определения различных средств индивидуальной защиты на его лице. Известен способ многоклассового распознавания объектов на изображениях с помощью глубоких сверточных нейросетей (патент RU 2710942 С1), относящийся к интеллектуальным автоматизированным системам и направлен на повышение точности при различных уровнях освещенности и окклюзиях. Представленный способ делит весь процесс многоклассового распознавания на связанные между собой этапы которые позволяют: 1) извлекать векторы признаков из объектов на изображениях; 2) применять преобразование главных компонентов к извлеченных векторам и упорядочивать их по собственным значениям; 3) делить полученное количество главных компонентов на последовательности таким образом, чтобы они отличались друг от друга; 4) сопоставлять объекты из входного изображения с обучающим подмножеством изображений для классификации. Такой способ может быть полезен, например при задачах более детального извлечения признаков из объектов на изображениях. В роли интересующих объектов могут выступать лица людей в различных вариациях защитных масок. К довольно значительному недостатку данного способа следует отнести его сложность обработки входных данных (изображений), что сказывается на невозможности реализации различных мобильных автоматизированных систем, которые должны функционировать в режиме реального времени с меньшим количеством затрачиваемых ресурсов для различных вычислений.
Известны способ и система для создания мимики на основе текста (патент RU 2723454 С1). Изобретение относится к процессу создания видеопоследовательности с анимированными изображениями 3D-модели головы с размещенной на ней динамической текстурой защитной маски на основе данных, которые получены от речевого сигнала. Речевой сигнал генерируется с помощью средств синтеза речи (например, система преобразования текста в речь) эмитирующих человеческий голос, который соответствует акустическим параметрам голоса диктора. Технический результат представленного способа и системы состоит из таких этапов, как: 1) получение данных минимум от одного речевого сигнала; 2) разделение участков полученного речевого сигнала на временные последовательности (окна); 3) формирование для каждого временного окна частотного изображения; 4) образование лицевой маски на основе частотных наборов изображений; 5) размещение лицевой маски на 3D-модель головы для формирования видеопоследовательности. Такой способ и система являются полезными, например для генерации искусственного набора данных с лицами людей с дальнейшим наложением на них различных вариаций защитных масок.
Известны способ и устройство для систем детектирования/распознавания лица (патент RU 2741768 С2), предназначенные для повышения безопасности при попытках осуществить спуфинг-атаку путем предъявления системе поддельного биометрического параметра (лица). Устройство приема информации позволяет получать последовательности видеокадров для дальнейшей идентификации области лица на основе участков кожи в области лица и извлечения сердечных сокращений из каждого сигнала сердцебиения. Способ направлен на извлечение и анализ пространственных признаков из множества отдельных областей лица, которые не перекрыты другим видимым объектом (например, защитной маской).
Известны способ и устройство распознавания лица с частичным его перекрытием на основе извлечения основных лицевых характеристик (патент KR 101998112 В1, Корея, от англ. Method for Recognizing Partial Obscured Face by Specifying Partial Area based on Facial Feature Point, Recording Medium and Apparatus for Performing the Method). Изобретение относится к области биометрических технологий и направлено на получение изображений, которые содержат минимум одно лицо человека; установку множества областей интереса (лиц) на входном изображении; формирование векторов признаков путем соответствующего извлечения локальных признаков из области с лицом; произведение анализа и определения сходства между извлеченными признаками и оригинальными признаками из имеющего набора данных (эталоны). Реализация данного изобретения актуально при задачах идентификации человека в условиях, когда лица подвержено частичному перекрытию (например, на лице присутствует защитная маска).
Известен двухрежимный способ автоматического обнаружения человека в защитной маске на основе статистических характеристик, получаемых от видеосигнала (патент CN 105678213 А, Китай, от англ. Dual-Mode Masked Man Event Automatic Detection Method based on Video Characteristic Statistics). Изобретение направлено на устранение недостатков современных систем интеллектуального видеонаблюдения, которые должны обнаруживать и распознавать лица людей в различных вариациях защитных масок в режиме реального времени. Процесс автоматического обнаружения человека в защитной маске состоит из следующих этапов: 1) считывание исходного цветного видеокадра с последующим масштабированием и преобразованием его в градацию оттенков серого; 2) нахождение лиц людей; 2) обнаружение контуров лиц людей; 3) сохранение информации о количестве людей и их местоположении; 4) оценивание местоположения и положения лица для каждого найденного человека; 5) обнаружение лиц людей в защитных масках. Таким образом реализация предложенного изобретения позволит в режиме реального времени автоматически обнаруживать лица людей в различных вариациях защитных масок, который также робастен к различным сценам и углам захвата видеоинформации.
Известны способ и устройство для определения температуры тела человека в защитной маске (патент CN 211904417 U, Китай, от англ. Face Mask Wearing Recognition and Body Temperature Detection System), относящиеся к биометрическим технологиям. Основная идея изобретения заключается в определении корректно надетой защитной маски на лицо человека и текущей температуры тела, что позволит контролировать и предотвращать различные эпидемические ситуации (например, коронавирусную инфекцию), а также обезопасить их распространение на промышленных производствах. Устройство состоит из множества связанных между собой таких модулей, как: модуль получения изображения, модуль определения температуры тела, модуль анализа процесса распознавания наличия защитной маски на лице человека и голосовой модуль для передачи информационных сообщений пользователю в случаях, когда маска надета не полностью или вовсе отсутствует. К недостаткам данного изобретения следует отнести обязательное наличие устройства с довольно большими габаритами и сложной системой обмена информации между модулями.
Известен способ распознавания наличия/отсутствия защитной маски на лице (патент CN 112115818 А, Китай, от англ. Mask Wearing Recognition Method), состоящий из: 1) обучения модели детектирования лиц на основе сверточной нейронной сети MTCNN (от англ. Multi-task Cascaded Convolutional Networks); 2) обучения модели распознавания наличия/отсутствия защитной маски на лице на основе метода опорных векторов. Изобретение направлено на использование в различных общественных местах с большим скоплением людей, где необходимо соблюдать правила социального дистанцирования и масочного режима. Из преимуществ данного способа стоит отметить высокую скорость обработки входных видеоданных. К недостаткам относятся естественные проблемы с производительностью при обнаружении и распознавании лиц людей в условиях со слабой освещенностью.
Известен способ распознавания лиц в защитной маске с помощью алгоритма YOLOv3 (патент CN 111414887 А, Китай, от англ. Secondary Detection Mask Face Recognition Method based on YOLOV3 Algorithm). Изобретение относится к области распознавания лиц и включает в себя следующие этапы: сбор видео в общественных местах и сохранение их в виде изображений в качестве базового набора данных для распознавания лиц в маске; использование изображений из базового набора данных в качестве обучающих данных и выполнение их аннотации по областям «голова», «маска», а также обучение алгоритма YOLOv3 на обнаружение области «голова»; повторное обучение алгоритма YOLOv3 для задачи распознавания лиц в маске; вывод результата распознавания лиц в маске, при этом алгоритм распознавания способен выводить один из двух возможных классов «лицо в маске», «лицо без маски», а также ограничительные рамки для головы в целом. Таким образом изобретение выполняет обнаружение областей головы и распознавание наличия/отсутствия маски на лице. Такое изобретение способно работать как по одному изображению, так и по видеопоследовательности и может быть применимо в местах, где возникает необходимость в ношении защитной маски на лице.
Известны способ и устройство построения 3D маски для лица при антиспуфинге с дистанционной фотоплетизмографией (патент US 10380444 В2 США, от англ. 3D Mask Face Anti-Spoofing with Remote Photoplethysmography), относящиеся к области обнаружения частей тела человека. Изобретение выполняет следующие задачи: захват в видеопотоке лица интересующего человека (камера спроектирована таким образом, чтобы захватывать изменения цвета кожи лица); извлечение сигналов с дистащионной фотоплетизмографией; моделирование извлеченных сигналов посредством взаимной корреляции для создания надежной модели антиспуфинга лица при наличии 3D маски; формирование прогнозов на основе извлеченных сигналов с дистанционной фотоплетизмографией; классификация лица на предмет наличия или отсутствия 3D маски. С помощью встроенных технологий оценивания состояния сосудов (фотоплетизмография и спроектированная камера) способ способен обнаружить области лица, при которых цвет кожи остается неизменным, что позволяет не только предотвратить спуфинг, но и зафиксировать присутствие посторонних атрибутов на лице, в том числе защитной маски.
Известны способ и устройство распознавания лица в маске (патент US 10984225 В1 США, от англ. Masked Face Recognition). Изобретение относится к системам и методам распознавания лиц в маске, включающее вычислительное устройство, которое имеет по крайней мере один центральный процессор. Технический результат достигается за счет таких компонентов, как: 1) вычислительное устройство для получения видеопоследовательностей; 2) алгоритм обнаружения лица в маске, т.е. определение наличия на изображении лица в маске; 3) сопоставление областей лица без маски или маской с эталонами, хранящимися в исходном наборе данных, при совпадении как минимум с одним эталоном для каждой области лица, выполняется идентификация пользователя на основе взвешенного набора совпадающих визуальных лицевых признаков. Такое изобретение является полезным, например, для отслеживания людей без маски. Так при распознавании человека без маски, этому человеку или организации может быть сформировано и отправлено сообщение о нарушении режима обязательного ношения масок.
Известны способ и устройство для систем распознавания лиц со значительным перекрытием (патент WO 2019011165 А1, от англ. Facial Recognition Method and Apparatus, Electronic Device, and Storage Medium), предназначенные для проверки личности в контрольно-пропускных пунктах при окклюзии лица различными предметами, включая защитные маски. Технический результат представленного способа и устройства состоит из таких этапов, как: 1) получение изображения лица; 2) нахождение перекрытой и не перекрытой областей на лице путем сегментации входного изображения; 3) расчет весов найденных областей интереса; 4) извлечение векторов признаков из найденных областей интереса; 5) объединение весов каждой области с соответствующими ими векторами признаков; 6) выполнение сравнения объединенных векторов с оригинальными векторами из набора данных. Сходство между изображениями фиксируется в том случае, если оно больше или равно установленному пороговому значению. Также из особенностей стоит отметить, что способ включает в себя этап нахождения перекрытой и не перекрытой областей на лице, что также говорит о том, что помимо задачи распознавания лиц, метод способен надежно детектировать наличие/отсутствие различных атрибутов на лице, включая защитные маски.
Наиболее близким по технической сущности к заявляемому способу и выбранным в качестве прототипа является система и способ идентификации средств индивидуальной защиты на человеке (патент RU 2724785 С1), относящиеся к области применения искусственных нейронных сетей в различных задачах компьютерного зрения, а именно к системам и способам обработки визуальной информации, которая может быть получена от различных камер видеонаблюдения, для обеспечения необходимых мер безопасности на рабочем месте. Технический результат в данном патенте обеспечивается за счет локализации и идентификации средств индивидуальной защиты на человеке в режиме реального времени путем программной обработки входной визуальной информации, получаемой минимум от одного устройства захвата видеоданных. Непосредственный процесс сегментации изображений выполняется по цвету, форме или текстуре интересующих объектов (различные вариации защитных масок, респираторов и других средств индивидуальной защиты области лица).
Основными недостатками существующих аналогов в предметной области является их узкая функциональная направленность, выраженная в решении задач распознавания различных средств индивидуальной защиты на лицах людей посредствам исключительно одной модальности (визуальной).
Техническая проблема, решение которой обеспечивается настоящим изобретением, заключается в необходимости расширения функциональности различных способов путем использования интеллектуального анализа аудиовизуальной информации для более точного распознавания различных средств индивидуальной защиты на лицах людей через объединение аудио и видео модальностей.
В свою очередь, технический результат достигается за счет того, что способ аудиовизуального распознавания средств индивидуальной защиты на лице человека объединяет обработку аудио- и видеоинформации получаемых от каких-либо устройств захвата данных информаций.
Также стоит заметить, что процесс объединения видео- и аудиоинформации базируется на последовательной обработке аудиоинформации, получаемой от микрофона устройства захвата данной акустической информации, а именно: считывание аудиоданных; определение границ речи; определение речи целевого диктора; вычисление акустических признаков; предсказание типа индивидуальной защиты на лице человека на основе акустических признаков. В свою очередь последовательная обработка видеоинформации, получаемая от цветной камеры устройства захвата данной визуальной информации выполняется благодаря считыванию видеоданных; процессу разделения видеоданных на цветные кадры; обработке цветных кадров; вычислению визуальных признаков; поиску графических областей лиц; поиску ближайшей графической области лица; цифровой обработке ближайшей графической области лица; предсказанию типа индивидуальной защиты на лице человека на основе визуальных признаков. Итоговое принятие решения в зависимости от определенной степени индивидуальной защиты на лице человека происходит на основании полученных результатов от синхронных между собой аудио и видео модальностей.
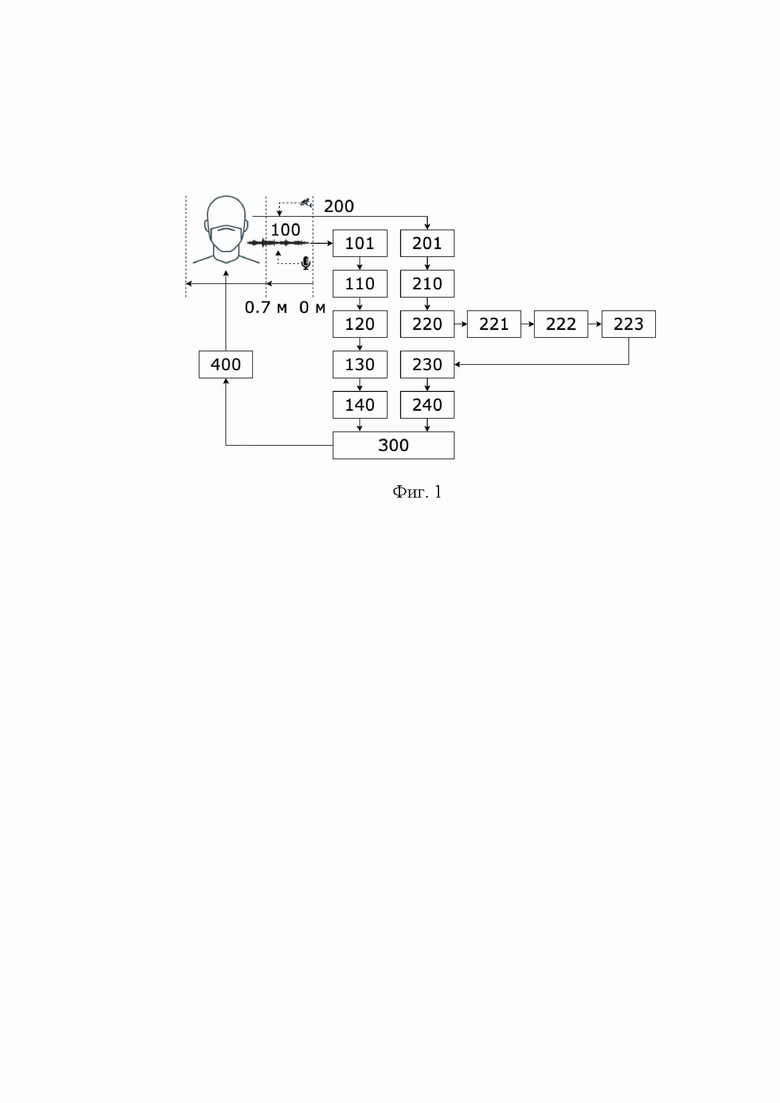
Сущность изобретения поясняется фиг. 1, на которой отображена функциональная схема способа аудиовизуального распознавания средств индивидуальной защиты на лице человека. Позициями на фиг. 1 обозначены: 100 - аудиосигнал; 101 - считывание аудиоданных; 110 - определение границ речи; 120 - определения речи целевого диктора; 130 - вычисление акустических признаков; 140 - предсказание средств индивидуальной защиты на лице человека; 200 - видеосигнал; 201 - считывание видеоданных; 210 - разделение видеоданных на цветные кадры; 220 - обработка цветных кадров; 221 - вычисление визуальных признаков; 222 - поиск графических областей лиц; 223 - поиск ближайшей графической области лица; 230 - цифровая обработка ближайшей графической области лица; 240 - предсказание средств индивидуальной защиты на лице человека; 300 - объединение предсказаний для итогового определения средств индивидуальной защиты на лице человека; 400 - вывод текстовой гипотезы предсказания о распознанном средстве индивидуальной защиты на лице человека.
В способе аудиовизуального распознавания средств индивидуальной защиты на лице человека (фиг. 1) входные данные представляют в виде аудиосигнала (100) и видеосигнала (200). В роли устройства захвата аудиосигнала выступает приемник способный получать аудиоданные (101) с окном в 4 секунды, частотой дискретизации 16 кГц, 16 бит на цифровой отсчет и отношением аудиосигнал/шум - не менее 50 дБ (например, встроенные аудиосредства в веб-камере Logitech StreamCam). В роли устройства захвата видеосигнала выступает приемник способный получать цветные оптические видеоданные (например, встроенные видеосредства в веб-камере Logitech StreamCam). Качество цветопередачи цветного оптического (201) видеопотока составляет 8 бит с разрешением видеопотока 1920×1080 (FullHD) пикселей и частотой 30 кадров в секунду. Установка оборудования получения сигналов производят на высоту от 1,5 до 2,0 метров с обязательным соблюдением расстояния в диапазоне от 0,7 до 1,5 метров до как минимум одного человека, который выполняет какие-то статичные или динамичные действия (сидит, стоит, идет и т.д.) и на лице, которого может находиться/отсутствовать индивидуальные средства защиты (различные вариации защитных масок (медицинские, тканевые и т.д.), экраны, респираторы).
Определение границ речи (110) производят с помощью предварительно обученного детектора голосовой активности [https://github.com/snakers4/silero-vad/] с учетом таких важных параметров, как: порог вероятности речи (от 0,0 до 1,0); минимальная длительность речевого фрагмента (измеряется в миллисекундах); минимальная длительность тишины между речевыми фрагментами (измеряется в миллисекундах); количество временных отчетов в каждом окне (в роли окна выступает короткий речевой фрагмент установленной длины, измеряется в миллисекундах). Каждый формирующийся речевой сегмент подлежит проверки на наличие/отсутствие голосовой активности как минимум одного человека. Исходя из того, что как минимум один человек может воспроизводить голосовую активность за очень короткий промежуток времени, а также возможно наличие в речевых фрагментах определенных звуковых артефактов (щелчки, треск, смычки перед взрывными согласными и другие неречевые участки сигнала), приводящих к ошибочным восприятиям их в качестве речи, устанавливают минимальную длительность речевого фрагмента равную 250 миллисекундам. Также для исключения других специфических акустических активностей применяют порог вероятности речи в 0,56. Значение минимальной длительности тишины между речевыми фрагментами устанавливают в 50 миллисекунд, что позволяет объединять речевые фрагменты, состоящие из речи человека, произнесенной очень быстрым темпом говорения. Количество временных отчетов в каждом окне устанавливают в значение равное 1536, что является оптимальным для любых условий эксплуатации.
Задачу определения речи целевого диктора (120) решают путем вычисления значения энергии Е на каждом найденном речевом фрагменте следующим образом:
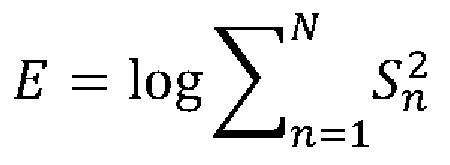 ,
,
где n∈N, N - длина кадра речевого фрагмента S.
В случаях, когда полученное значение Е больше заранее определенного порога T, то считается, что данный речевой фрагмент считается речевым фрагментом целевого диктора. Такой поиск выполняют для каждого сегмента акустического сигнала.
Вычисление акустических признаков (130) выполняют несколькими последовательными манипуляциями. В первую очередь, весь речевой сигнал делится на фрагменты с шириной окна в 1 секунду и шагом 0,5 секунды. Затем, для каждого анализируемого речевого сегмента строится спектрограмма (в виде 2D полутонового изображения), которая показывает зависимость спектральной плотности мощности сигнала по отношению к его времени. Процесс генерации спектрограмм производится с помощью специально разработанного программного модуля для анализа аудиоинформации torchaudio [https://pytorch.org/audio/stable/index.html] с шириной окна 22 миллисекунды и шагом 5 миллисекунд. После этого каждая отдельно взятая спектрограмма преобразуется в мел-шкалу с 64 мел-фильтрбанками (происходит преобразование частоты сигнала из Гц в мел), которая в свою очередь преобразуется в логарифмический масштаб (из мел в ДБ).
Предсказания средств индивидуальной защиты на лице человека (140) по акустической модальности производят на основе выбранной предварительно обученной сверточной нейросети с архитектурой CNN-14 из семейства архитектур сверточный нейросетей PANNs [Kong Q., Cao Y., Iqbal Т., Wang Y., Wang W., Plumbley M.D. PANNs: Large-Scale Pretrained Audio Neural Networks for Audio Pattern Recognition // IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2020, V. 28, pp. 2880-2894]. PANNs показывают высокую степень обобщения и точность распознавания при анализе акустических событий.
Процесс дообучения нейросетевой модели CNN-14 производили на аудиовизуальном корпусе русскоязычных данных людей в защитных масках BRAVE-MASKS [Маркитантов М.В., Рюмин Д.А., Рюмина Е.В., Карпов А.А. Корпус аудиовизуальных русскоязычных данных людей в защитных масках (BRAVE-MASKS - Biometric Russian Audio-Visual Ex-tended MASKS corpus) // Свидетельство о государственной регистрации Базы данных, №2021621094 от 26.05.2021]. Все предсказания для каждого речевого фрагмента, полученного на начальном этапе вычисления акустических признаков (130), объединялись с помощью мажоритарного голосования.
Разделение видеоданных на последовательности из кадров (210) осуществляют с помощью набора средств разработки используемого приемника, который способен формировать цветные оптические видеоданные. В случае если таких программных средств не предусмотрено для используемого приемника, то применяют сторонние инструментарии из библиотеки машинного обучения с открытым исходным кодом PyTorch [https://pytorch.org/vision/stable/io.html].
Обработку цветных кадров (220) выполняют циклически и подразумевается, что цветной кадр подлежит процессу преобразования в предварительный набор карт признаков разной размерности [Wang C.Y., Liao H.Y.M., Wu Y.H., Chen P.Y., Hsieh J.W., Yeh I.H. CSPNet: A New Backbone that can Enhance Learning Capability of CNN // IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) workshops, 2020, pp. 390-391]. Каждая предварительная карта признаков является 2D матрицей и содержит свое, характерное исключительно ей, синаптическое ядро (фильтр свертки).
Задачу вычисления визуальных признаков (221) решают путем многоразового масштабирования карт признаков с помощью пирамидального их объединения [Не K., Zhang X., Ren S., Sim J. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition // Transactions on Pattern Analysis and Machine Intelligence, 2015, V. 37, N. 9, pp. 1904-1916], что позволяет сохранить контекстную информацию о исходном кадре в процессе масштабирования, а также нормализовать сформированные визуальные признаки для последующей гипотезы относительно той или иной области.
Поиск графических областей лиц (222) на кадре производят на основе трех взаимосвязанных между собой архитектур глубоких нейросетей. В частности, архитектура пирамидальной нейросети [Kirillov A., Girshick R., Не K., Dollár P. Panoptic Feature Pyramid Networks // IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2019, pp. 6399-6408] направлена на формирование нейросетевых моделей таким образом, чтобы достигать максимальной производительности в задачах семантической сегментации объектов (в данном случае лиц). Вторая нейросеть с функцией агрегации пикселей [Wang W., Xie Е., Song X., Zang Y., Wang W., Lu Т., Shen C. Efficient and Accurate Arbitrary-Shaped Text Detection with Pixel Aggregation Network // IEEE/CVF International Conference on Computer Vision (CVPR), 2019, pp. 8440-8449] отвечает за группировку пикселей в сегментированных объектах. Сгруппированные пиксели образуют кластеры, на которых в дальнейшем должны быть локализованы объекты (области лиц). Процесс непосредственной локализации графических областей лиц на каждом цветном кадре видеопотока осуществляется с помощью алгоритма обнаружения объектов YOLOv5 [https://github.com/ultralytics/yolov5]. Данный алгоритм базируется на продуманной архитектуре глубокой нейросети, на основе которой производится обучение модели нейросети YOLOv5, что позволяет добиваться, как высокой точности обнаружения областей интересующих объектов (в данном случае лиц людей), так и скорости обработки кадров сопоставимой или превосходящей режим реальной времени (более 25 кадров в секунду).
Поиск ближайшей графической области лица (223) осуществляют с помощью вычисления 2D площадей из всех локализованных областей с лицами людей. Ближайшее лицо считается то, которое имеет наибольшую 2D площадь. Этот процесс необходим для дальнейшего объединения предсказаний средств индивидуальной защиты на лице человека (300) на уровне двух модальностей (аудио и видео).
Цифровую обработку ближайшей графической области лица (230) проводят множеством последовательных манипуляций. Так, манипуляция по выравниванию области лица решается посредством алгоритма, который реализован в библиотеке с открытым исходным кодом Face-Alignment [https://github.com/ladrianb/face-alignment; Bulat A., Tzimiropoulos G. How Far are we from Solving the 2D & 3D Face Alignment Problem? (and a Dataset of 230,000 3D Facial Landmarks) // IEEE/CVF International Conference on Computer Vision (CVPR), 2017, pp. 1021-1030]. Канальная нормализация (центрирование) пикселей выполняется по принципу того, что сперва из каждого пикселя канала Red отнимается значение равное 91,4953, затем из пикселей канала Green отнимается значение равное 103,8827, в заключении из всех пикселей канала Blue отнимается значение равное 131,0912. Данные значения стандартизированы и широко известны в цифровой обработке изображений. Цветное изображение графической области лица нормализуется до размера 224×224 пикселя. Реализация процесса нормализации присутствует в модуле трансформации и аугментации изображений библиотеки машинного обучения с открытым исходным кодом PyTorch [https://pytorch.org/vision/stable/transforms.html].
Предсказания средств индивидуальной защиты на лице человека (240) по визуальной модальности производят на основе предварительно обученной сверточной нейросети с архитектурой ResNet-50 [Не K., Zhang X., Ren S., Sun J. Deep Residual Learning for Image Recognition // IEEE/CVF International Conference on Computer Vision (CVPR), 2016, pp.770-778], которая, например, включена в коллекцию нейросетевых моделей, в том числе и для распознавания объектов с открытым исходным кодом PyTorch Image Models [https://github.com/rwightman/pytorch-image-models] и основана на инвертированной остаточной структуре. Непосредственное предварительное обучение нейросетевой модели ResNet-50 производили на визуальном корпусе VggFace2 [Cao Q., Shen L., Xie W., Parkhi О., Zisserman A. Vggface2: A Dataset for Recognising Faces Across Pose and Age // International Conference on Automatic Face and Gesture Recognition (FG), 2018, pp. 67-74]. Процесс дообучения нейросетевой модели ResNet-50 производили на аудиовизуальном корпусе русскоязычных данных людей в защитных масках BRAVE-MASKS [Маркитантов М.В., Рюмин Д.А., Рюмина Е.В., Карпов А.А. Корпус аудиовизуальных русскоязычных данных людей в защитных масках (BRAVE-MASKS - Biometric Russian Audio-Visual Ex-tended MASKS corpus) // Свидетельство о государственной регистрации Базы данных, №2021621094 от 26.05.2021].
Технический результат итогового определения средств индивидуальной защиты на лице человека (300) достигают за счет объединения предсказаний, полученных на акустическом и визуальном уровнях, с помощью взвешенного усреднения предсказаний, следующим образом:
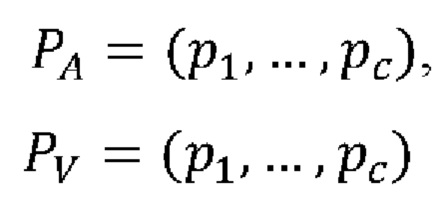 ,
,
где с ∈ С, С - количество классов; РА и Pv - векторы предсказаний для акустического и визуального сигналов соответственно, тогда предсказания по двум сигналам можно представить в виде общей матрицы:
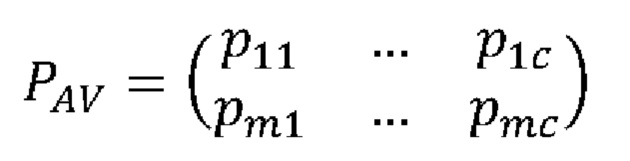 ,
,
где m ∈ М, М - количество векторов предсказаний, полученных от двух сигналов. В данном случае М=2. Затем для более точного итогового определения средств индивидуальной защиты на лице человека строится матрица весов, согласно:
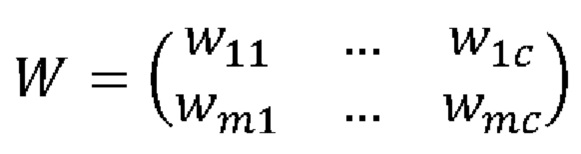 ,
,
где W - матрица весов, сгенерированная с помощью распределения Дирихле [Ryumina Е., Verkholyak О., Karpov A. Annotation Confidence vs. Training Sample Size: Trade-off Solution for Partially-Continuous Categorical Emotion Recognition // Proceedings of the Annual Conference of the International Speech Communication Association (INTERSPEECH), 2021, pp. 3690-3694]. Таким образом, все объединенные векторы предсказаний рассчитываются согласно:
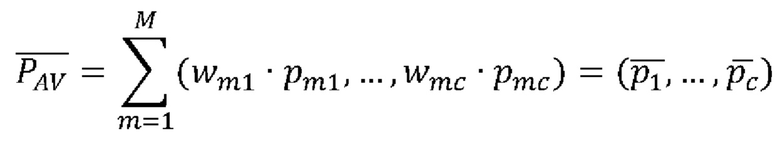 .
.
Финальное решение о наиболее подходящем средстве индивидуальной защиты (максимальная вероятность) из всех средств индивидуальной защиты на лице человека выносится согласно:
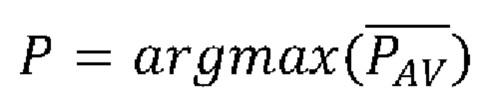 .
.
В заключении производят вывод текстовой гипотезы предсказания о распознанном средстве индивидуальной защиты на лице человека (400). При необходимости возможна отправка различных уведомлений на мобильные устройства в режиме реального времени, в случаях, когда люди не носят вовсе или носят неверно различные средства индивидуальной защиты на лице.
Таким образом, указанные отличительные особенности способа аудиовизуального распознавания средств индивидуальной защиты на лице человека позволяют производить автоматический мониторинг уровня безопасности людей, а также при необходимости осуществлять человеко-машинное взаимодействие и использоваться в случаях, когда необходимо максимально эффективно предотвращать вспышки различных эпидемий, а также дальнейшее их распространения.
Проведенный заявителем анализ уровня аналогов позволил установить, что способ аудиовизуального распознавания средств индивидуальной защиты на лице человека, характеризующийся совокупностями признаков, соответствует условию патентоспособности «Новизна».
Результаты поиска известных решений в данной и смежной областях техники с целью выявления признаков, совпадающих с отличительными от прототипов признаками заявляемого изобретения, показали, что они не следуют явным образом из уровня техники. Из определенного заявителем уровня техники не выявлена известность влияния предусматриваемых существенными признаками заявленного изобретения на достижение указанного технического результата. Следовательно, заявленное изобретение соответствует условию патентоспособности «Изобретательский уровень».
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ МНОГОМОДАЛЬНОГО БЕСКОНТАКТНОГО УПРАВЛЕНИЯ МОБИЛЬНЫМ ИНФОРМАЦИОННЫМ РОБОТОМ | 2020 |
|
RU2737231C1 |
| СПОСОБ ГЕНЕРАЦИИ ЦВЕТНЫХ ЗАЩИТНЫХ МАСОК НА ИЗОБРАЖЕНИЯХ ЛИЦ ЛЮДЕЙ | 2022 |
|
RU2790018C1 |
| ОДНОВРЕМЕННОЕ РАСПОЗНАВАНИЕ АТРИБУТОВ ЛИЦ И ИДЕНТИФИКАЦИИ ЛИЧНОСТИ ПРИ ОРГАНИЗАЦИИ ФОТОАЛЬБОМОВ | 2018 |
|
RU2710942C1 |
| Способ идентификации измененного лица человека | 2023 |
|
RU2804261C1 |
| Быстрый двухслойный нейросетевой синтез реалистичных изображений нейронного аватара по одному снимку | 2020 |
|
RU2764144C1 |
| Алгоритм комплексного дистанционного бесконтактного мультиканального анализа психоэмоционального и физиологического состояния объекта по аудио- и видеоконтенту | 2017 |
|
RU2708807C2 |
| СИСТЕМА И СПОСОБ РЕГИСТРАЦИИ ДВУХМЕРНЫХ ИЗОБРАЖЕНИЙ | 2005 |
|
RU2365995C2 |
| СПОСОБ ОПРЕДЕЛЕНИЯ ПОДЛИННОСТИ ЛИЦА ПО МАСКАМ СЕГМЕНТАЦИИ | 2021 |
|
RU2758966C1 |
| Способ 3D-реконструкции человеческой головы для получения рендера изображения человека | 2022 |
|
RU2786362C1 |
| СПОСОБ УПРАВЛЕНИЯ ТЕЛЕВИЗОРОМ С ПОМОЩЬЮ МУЛЬТИМОДАЛЬНОГО ИНТЕРФЕЙСА | 2010 |
|
RU2422878C1 |
Изобретение относится к области искусственного интеллекта, в частности, к цифровым методам автоматического мониторинга уровня безопасности людей, а также к человеко-машинному взаимодействию. Оно может использоваться в ситуациях, когда необходимо эффективно предотвращать вспышки различных эпидемий и дальнейшего их распространения или же в случаях, когда возникает потребность в автоматической проверке наличия средств индивидуальной защиты на лицах медицинских работников и лиц других профессий, которые должны перемещаться по территориям различных учреждений и контактировать с другими людьми исключительно в различных средствах индивидуальной защиты. Данное изобретение способно производить как интеллектуальный анализ голосовых характеристик людей по их речи для определения наличия средств индивидуальной защиты в процессе говорения, так и интеллектуальный анализ лицевых характеристик людей по видеоданным для локализации и детекции наличия средств индивидуальной защиты в процессе выполнения каких-либо действий в определенный момент времени. Поддержка одновременной обработки сигналов обеих модальностей позволяет достичь более точных аудиовизуальных предсказаний для итоговых действий в зависимости от определенной степени индивидуальной защиты на лице человека. В роли устройства захвата аудиосигнала выступает устройство, способное получать аудиоданные. В роли устройства захвата видеосигнала выступает устройство, способное получать цветные оптические видеоданные. Техническая проблема, решение которой обеспечивается настоящим изобретением, заключается в необходимости расширения функциональности различных способов путем использования интеллектуального анализа аудиовизуальной информации для более точного распознавания различных средств индивидуальной защиты на лицах людей через объединение информации от аудио- и видеомодальностей. 1 ил.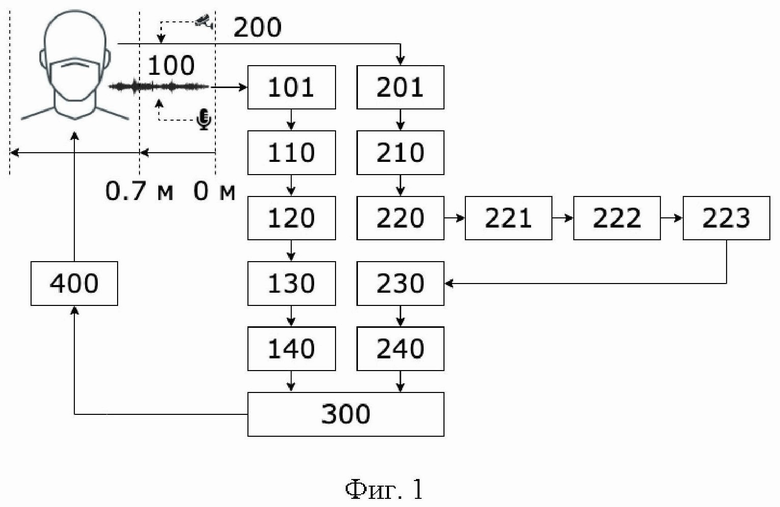
Способ аудиовизуального распознавания средств индивидуальной защиты на лице человека, состоящий из захвата аудио- и видеосигналов, отличающийся непрерывной и синхронной обработкой аудио- и видеоинформации, которые получены от микрофона и цветной видеокамеры как минимум одного устройства захвата данной акустической и визуальной информации, определением границ речи, определением речи целевого диктора, вычислением акустических признаков, предсказанием средств индивидуальной защиты на лице человека по акустической модальности посредством предварительно обученной сверточной нейросети, разделением видеоданных на цветные кадры, обработкой цветных кадров, вычислением визуальных признаков, поиском графических областей лиц, поиском ближайшей графической области лица, цифровой обработкой ближайшей графической области лица, предсказанием средств индивидуальной защиты на лице человека по визуальной модальности посредством предварительно обученной сверточной нейросети, объединением предсказаний, полученных на акустическом и визуальном уровнях с помощью матрицы весов, для итогового определения средств индивидуальной защиты на лице человека, выводом текстовой гипотезы предсказания о распознанном средстве индивидуальной защиты на лице человека.
| US 2022058381 A1, 24.02.2022 | |||
| WO 2019166952 A1, 06.09.2019 | |||
| US 2009161918 A1, 25.06.2009 | |||
| US 2011054909 A1, 03.03.2011 | |||
| Система формирования широкополосного гиперспектрального изображения на основе сжатого зондирования с нерегулярной дифракционной решеткой | 2014 |
|
RU2653772C1 |
| СИСТЕМА И СПОСОБ ИДЕНТИФИКАЦИИ СРЕДСТВ ИНДИВИДУАЛЬНОЙ ЗАЩИТЫ НА ЧЕЛОВЕКЕ | 2020 |
|
RU2724785C1 |

