[1] Данная заявка испрашивает приоритет:
Предварительной заявки на патент (США) № 62/020348, озаглавленной "REDUCING CORRELATION BETWEEN HOA BACKGROUND CHANNELS", поданной 2 июля 2014 года; и
Предварительной заявки на патент (США) № 62/060,512, озаглавленной "REDUCING CORRELATION BETWEEN HOA BACKGROUND CHANNELS", поданной 6 октября 2014 года,
содержимое каждой из которых полностью содержится в данном документе по ссылке.
Область техники, к которой относится изобретение
[2] Данное раскрытие сущности относится к аудиоданным, а более конкретно, к кодированию амбиофонических аудиоданных высшего порядка.
Уровень техники
[3] Сигнал на основе амбиофонии высшего порядка (HOA) (зачастую представленный посредством множества коэффициентов сферических гармоник (SHC) или других иерархических элементов) является трехмерным представлением звукового поля. HOA- или SHC-представление может представлять звуковое поле таким способом, который является независимым от геометрии локальных динамиков, используемой для того, чтобы воспроизводить многоканальный аудиосигнал, преобразованный посредством рендеринга из SHC-сигнала. SHC-сигнал также может упрощать обратную совместимость, поскольку SHC-сигнал может преобразовываться посредством рендеринга в известные и широко используемые многоканальные форматы, к примеру, в формат 5.1-аудиоканала или формат 7.1-аудиоканала. Следовательно, SHC-представление позволяет обеспечивать лучшее представление звукового поля, которое также обеспечивает обратную совместимость.
Сущность изобретения
[4] В общем, описываются технологии для кодирования аудиоданных амбиофонии высшего порядка. Аудиоданные амбиофонии высшего порядка могут содержать, по меньшей мере, один коэффициент амбиофонии высшего порядка (HOA), соответствующий базисной функции сферических гармоник, имеющей порядок больше первого. Описываются технологии для уменьшения корреляции между фоновыми каналами амбиофонии высшего порядка (HOA).
[5] В одном аспекте, способ включает в себя получение декоррелированного представления коэффициентов амбиофонии окружающего пространства, имеющих, по меньшей мере, левый сигнал и правый сигнал, причем коэффициенты амбиофонии окружающего пространства извлекаются из множества коэффициентов амбиофонии высшего порядка и представляют фоновый компонент звукового поля, описанного посредством множества коэффициентов амбиофонии высшего порядка, при этом, по меньшей мере, один из множества коэффициентов амбиофонии высшего порядка ассоциирован со сферической базисной функцией, имеющей порядок больше первого; и формирование сигнала для подачи в динамик на основе декоррелированного представления коэффициентов амбиофонии окружающего пространства.
[6] В другом аспекте, способ включает в себя применение преобразования с декорреляцией к коэффициентам амбиофонии окружающего пространства, чтобы получать декоррелированное представление коэффициентов амбиофонии окружающего пространства, причем HOA-коэффициенты окружающего пространства извлекаются из множества коэффициентов амбиофонии высшего порядка и представляют фоновый компонент звукового поля, описанного посредством множества коэффициентов амбиофонии высшего порядка, при этом, по меньшей мере, один из множества коэффициентов амбиофонии высшего порядка ассоциирован со сферической базисной функцией, имеющей порядок больше первого.
[7] В другом аспекте, устройство для сжатия аудиоданных включает в себя один или более процессоров, сконфигурированных с возможностью получать декоррелированное представление коэффициентов амбиофонии окружающего пространства, имеющих, по меньшей мере, левый сигнал и правый сигнал, причем коэффициенты амбиофонии окружающего пространства извлекаются из множества коэффициентов амбиофонии высшего порядка и представляют фоновый компонент звукового поля, описанного посредством множества коэффициентов амбиофонии высшего порядка, при этом, по меньшей мере, один из множества коэффициентов амбиофонии высшего порядка ассоциирован со сферической базисной функцией, имеющей порядок больше первого; и формировать сигнал для подачи в динамик на основе декоррелированного представления коэффициентов амбиофонии окружающего пространства.
[8] В другом аспекте, устройство для сжатия аудиоданных включает в себя один или более процессоров, сконфигурированных с возможностью применять преобразование с декорреляцией к коэффициентам амбиофонии окружающего пространства, чтобы получать декоррелированное представление коэффициентов амбиофонии окружающего пространства, причем HOA-коэффициенты окружающего пространства извлекаются из множества коэффициентов амбиофонии высшего порядка и представляют фоновый компонент звукового поля, описанного посредством множества коэффициентов амбиофонии высшего порядка, при этом, по меньшей мере, один из множества коэффициентов амбиофонии высшего порядка ассоциирован со сферической базисной функцией, имеющей порядок больше первого.
[9] В другом аспекте, устройство для сжатия аудиоданных включает в себя средство для получения декоррелированного представления коэффициентов амбиофонии окружающего пространства, имеющих, по меньшей мере, левый сигнал и правый сигнал, причем коэффициенты амбиофонии окружающего пространства извлекаются из множества коэффициентов амбиофонии высшего порядка и представляют фоновый компонент звукового поля, описанного посредством множества коэффициентов амбиофонии высшего порядка, при этом, по меньшей мере, один из множества коэффициентов амбиофонии высшего порядка ассоциирован со сферической базисной функцией, имеющей порядок больше первого; и средство для формирования сигнала для подачи в динамик на основе декоррелированного представления коэффициентов амбиофонии окружающего пространства.
[10] В другом аспекте, устройство для сжатия аудиоданных включает в себя средство для применения преобразования с декорреляцией к коэффициентам амбиофонии окружающего пространства, чтобы получать декоррелированное представление коэффициентов амбиофонии окружающего пространства, причем HOA-коэффициенты окружающего пространства извлекаются из множества коэффициентов амбиофонии высшего порядка и представляют фоновый компонент звукового поля, описанного посредством множества коэффициентов амбиофонии высшего порядка, при этом, по меньшей мере, один из множества коэффициентов амбиофонии высшего порядка ассоциирован со сферической базисной функцией, имеющей порядок больше первого; и средство для сохранения декоррелированного представления коэффициентов амбиофонии окружающего пространства.
[11] В другом аспекте, машиночитаемый носитель хранения данных кодируется с инструкциями, которые при выполнении инструктируют одному или более процессоров устройства сжатия аудио получать декоррелированное представление коэффициентов амбиофонии окружающего пространства, имеющих, по меньшей мере, левый сигнал и правый сигнал, причем коэффициенты амбиофонии окружающего пространства извлекаются из множества коэффициентов амбиофонии высшего порядка и представляют фоновый компонент звукового поля, описанного посредством множества коэффициентов амбиофонии высшего порядка, при этом, по меньшей мере, один из множества коэффициентов амбиофонии высшего порядка ассоциирован со сферической базисной функцией, имеющей порядок больше первого; и формировать сигнал для подачи в динамик на основе декоррелированного представления коэффициентов амбиофонии окружающего пространства.
[12] В другом аспекте, машиночитаемый носитель хранения данных кодируется с инструкциями, которые при выполнении инструктируют одному или более процессоров устройства сжатия аудио применять преобразование с декорреляцией к коэффициентам амбиофонии окружающего пространства, чтобы получать декоррелированное представление коэффициентов амбиофонии окружающего пространства, причем HOA-коэффициенты окружающего пространства извлекаются из множества коэффициентов амбиофонии высшего порядка и представляют фоновый компонент звукового поля, описанного посредством множества коэффициентов амбиофонии высшего порядка, при этом, по меньшей мере, один из множества коэффициентов амбиофонии высшего порядка ассоциирован со сферической базисной функцией, имеющей порядок больше первого.
[13] Подробности одного или более аспектов технологий изложены на прилагаемых чертежах и в нижеприведенном описании. Другие признаки, цели и преимущества технологий должны становиться очевидными из описания и чертежей, а также из формулы изобретения.
Краткое описание чертежей
[14] Фиг. 1 является схемой, иллюстрирующей базисные функции сферических гармоник различных порядков и подпорядков.
[15] Фиг. 2 является схемой, иллюстрирующей систему, которая может выполнять различные аспекты технологийй, описанных в этом раскрытии сущности.
[16] Фиг. 3 является блок-схемой, подробнее иллюстрирующей один пример устройства кодирования аудио, показанного в примере по фиг. 2, которое может выполнять различные аспекты технологий, описанных в этом раскрытии сущности.
[17] Фиг. 4 является блок-схемой, подробнее иллюстрирующей устройство декодирования аудио по фиг. 2.
[18] Фиг. 5 является блок-схемой последовательности операций способа, иллюстрирующей примерную работу устройства кодирования аудио при выполнении различных аспектов осуществления векторного синтеза, описанных в этом раскрытии сущности.
[19] Фиг. 6A является блок-схемой последовательности операций способа, иллюстрирующей примерную работу устройства декодирования аудио при выполнении различных аспектов технологий, описанных в этом раскрытии сущности.
[20] Фиг. 6B является блок-схемой последовательности операций способа, иллюстрирующей примерную работу устройства кодирования аудио и устройства декодирования аудио при выполнении различных аспектов способов кодирования, описанных в этом раскрытии сущности.
Подробное описание изобретения
[21] Развитие объемного звука в наше время обеспечивает доступность множества выходных форматов для развлечений. Примеры таких потребительских форматов объемного звука являются главным образом "канально"-ориентированными в том, что они неявно указывают сигналы подачи звука в громкоговорители в определенных геометрических координатах. Потребительские форматы объемного звука включают в себя популярный 5.1-формат (который включает в себя следующие шесть каналов: передний левый (FL), передний правый (FR), центральный или передний центральный, задний левый или левый объемного звучания, задний правый или правый объемного звучания и канал низкочастотных эффектов (LFE)), развивающийся 7.1-формат, различные форматы, которые включают в себя высотные динамики, такие как 7.1.4-формат и 22.2-формат (например, для использования со стандартом телевидения сверхвысокой четкости). Непотребительские форматы могут охватывать любое число динамиков (в симметричных и несимметричных геометриях), зачастую называемых "массивами объемного звучания". Один пример такого массива включает в себя 32 громкоговорителя, позиционированные в координатах по углам усеченного икосаэдра.
[22] Входные данные для будущего MPEG-кодера необязательно представляют собой один из трех возможных форматов: (i) традиционное канально-ориентированное аудио (как пояснено выше), которое предназначено для воспроизведения через громкоговорители в заранее указываемых позициях; (ii) объектно-ориентированное аудио, которое заключает в себе дискретные данные импульсно-кодовой модуляции (PCM) для одних аудиообъектов с ассоциированными метаданными, содержащими их координаты местоположения (в числе другой информации); и (iii) сцено-ориентированное аудио, которое заключает в себе представление звукового поля с использованием коэффициентов базисных функций сферических гармоник (также называемых "коэффициентами сферических гармоник" или SHC, "амбиофонией высшего порядка" или HOA, и "HOA-коэффициентами"). Будущий MPEG-кодер подробнее описан в документе, озаглавленном "Call for Proposals for 3D Audio", от Международной организации по Стандартизации/Международной электротехнической комиссии (ISO)/(IEC) JTC1/SC29/WG11/N13411, выпущенном в январе 2013 года в Женеве, Швейцария и доступном по адресу http://mpeg.chiariglione.org/sites/default/files/files/standards/parts/does/w13411.zip.
[23] На рынке предусмотрены различные канально-ориентированные форматы "объемного звука". Они варьируются, например, от 5.1-системы домашнего кинотеатра (которая является наиболее успешной с точки зрения проникновения в гостиные, если не учитывать стерео) до 22.2-системы, разработанной посредством NHK (Nippon Hoso Kyokai или Японской вещательной корпорации). Создатели контента (например, голливудские студии) хотят производить звуковую дорожку для фильма один раз и не тратить усилия на ее повторное сведение для каждой конфигурации динамиков. В последнее время, организации по разработке стандартов рассматривают способы, которыми можно предоставлять кодирование в стандартизированный поток битов и последующее декодирование, которое является адаптируемым и независимым от геометрии (и числа) динамиков и акустических условий в местоположении воспроизведения (предусматривающих модуль рендеринга).
[24] Чтобы предоставлять такую гибкость для создателей контента, иерархический набор элементов может использоваться для того, чтобы представлять звуковое поле. Иерархический набор элементов может означать набор элементов, в котором элементы упорядочиваются таким образом, что базовый набор элементов более низкого порядка предоставляет полное представление моделируемого звукового поля. По мере того, как набор расширяется, так что он включает в себя элементы высшего порядка, представление становится более подробным, повышая разрешение.
[25] Один пример иерархического набора элементов представляет собой набор коэффициентов сферических гармоник (SHC). Следующее выражение демонстрирует описание или представление звукового поля с использованием SHC:
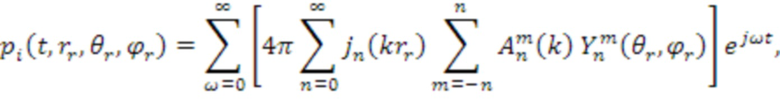
[26] Выражение показывает то, что давление 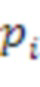 в любой точке
в любой точке 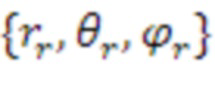 звукового поля, во время t, может быть представлено уникально посредством SHC,
звукового поля, во время t, может быть представлено уникально посредством SHC, 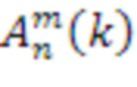 . Здесь,
. Здесь, 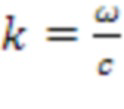 , c является скоростью звука (~343 м/с), является опорной точкой (или точкой наблюдения),
, c является скоростью звука (~343 м/с), является опорной точкой (или точкой наблюдения), 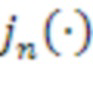 является сферической функцией Бесселя порядка n, и
является сферической функцией Бесселя порядка n, и 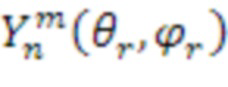 являются базисными функциями сферических гармоник порядка n и подпорядка m. Можно распознавать, что член в квадратных скобках является представлением в частотной области сигнала (т.е.
являются базисными функциями сферических гармоник порядка n и подпорядка m. Можно распознавать, что член в квадратных скобках является представлением в частотной области сигнала (т.е. 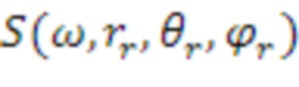 ), которое может быть аппроксимировано посредством различных частотно-временных преобразований, таких как дискретное преобразование Фурье (DFT), дискретное косинусное преобразование (DCT) или вейвлет-преобразование. Другие примеры иерархических наборов включают в себя наборы коэффициентов вейвлет-преобразования и другие наборы коэффициентов базисных функций с переменным разрешением. Сигналы амбиофонии высшего порядка обрабатываются посредством усечения высших порядков таким образом, что остаются только нулевой и первый порядок. Обычно выполняется некоторая энергетическая компенсация оставшихся сигналов вследствие потерь энергии в коэффициенте высшего порядка.
), которое может быть аппроксимировано посредством различных частотно-временных преобразований, таких как дискретное преобразование Фурье (DFT), дискретное косинусное преобразование (DCT) или вейвлет-преобразование. Другие примеры иерархических наборов включают в себя наборы коэффициентов вейвлет-преобразования и другие наборы коэффициентов базисных функций с переменным разрешением. Сигналы амбиофонии высшего порядка обрабатываются посредством усечения высших порядков таким образом, что остаются только нулевой и первый порядок. Обычно выполняется некоторая энергетическая компенсация оставшихся сигналов вследствие потерь энергии в коэффициенте высшего порядка.
[27] Различные аспекты этого раскрытия сущности направлены на уменьшение корреляции между фоновыми сигналами. Например, технологии этого раскрытия сущности могут уменьшать или возможно исключать корреляцию между фоновыми сигналами, выражаемыми в HOA-области. Потенциальное преимущество уменьшения корреляции между фоновыми HOA-сигналами заключается в сокращении демаскирования шумом. При использовании в данном документе, выражение "демаскирование шумом" может означать приписывание аудиообъектов местоположениям, которые не соответствуют аудиообъекту в пространственной области. В дополнение к снижению остроты потенциальных проблем, связанных с демаскированием шумом, способы кодирования, описанные в данном документе, могут формировать выходные сигналы, которые представляют левый и правый аудиосигналы, к примеру, сигналы, которые вместе формируют стереовывод. В свою очередь, устройство декодирования может декодировать левый и правый аудиосигналы для того, чтобы получать стереовывод, или может смешивать левый и правый сигналы для того, чтобы получать моновывод. Дополнительно, в сценариях, в которых кодированный поток битов представляет чисто горизонтальную схему размещения, устройство декодирования может реализовывать различные технологии этого раскрытия сущности для того, чтобы декодировать только фоновые HOA-сигналы с декоррелированными горизонтальными компонентами. Посредством ограничения процесса декодирования фоновыми HOA-сигналами с декоррелированными горизонтальными компонентами декодер может реализовывать технологии для того, чтобы экономить вычислительные ресурсы и уменьшать потребление полосы пропускания.
[28] Фиг. 1 является схемой, иллюстрирующей базисные функции сферических гармоник от нулевого порядка (n=0) до четвертого порядка (n=4). Как можно видеть, для каждого порядка, предусмотрено расширение подпорядков m, которые показаны, но не отмечены явно в примере по фиг. 1, для упрощения иллюстрации.
[29] SHC могут физически получаться (например, записываться) посредством различных конфигураций массивов микрофонов, либо альтернативно, они могут извлекаться из канально-ориентированных или объектно-ориентированных описаний звукового поля. SHC представляет сцено-ориентированное аудио, при котором SHC может вводиться в аудиокодер для того, чтобы получать кодированный SHC, что может способствовать более эффективной передаче или хранению. Например, может использоваться представление четвертого порядка, предусматривающее (1+4)2 (25 и, следовательно, четвертого порядка) коэффициентов.
[30] Как отмечено выше, SHC может извлекаться из записи с микрофона с использованием массива микрофонов. Различные примеры того, как SHC может извлекаться из массивов микрофонов, описываются в работе автора Poletti, M. "Three-Dimensional Surround Sound Systems Based on Spherical Harmonics", J. Audio Eng. Soc., издание 53, № 11, ноябрь 2005 года, стр. 1004-1025.
[31] Чтобы иллюстрировать то, как SHC могут извлекаться из объектно-ориентированного описания, рассмотрим следующее уравнение. Коэффициенты 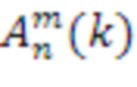 для звукового поля, соответствующего отдельному аудиообъекту, могут выражаться следующим образом:
для звукового поля, соответствующего отдельному аудиообъекту, могут выражаться следующим образом:
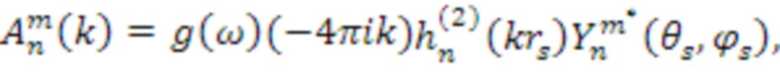 ,
,
где i является 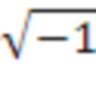 ,
, 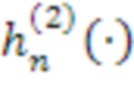 является сферической функцией Ганкеля (второго вида) порядка n, и
является сферической функцией Ганкеля (второго вида) порядка n, и 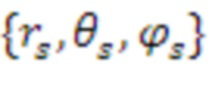 является местоположением объекта. Знание энергии
является местоположением объекта. Знание энергии 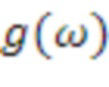 источника объектов в качестве функции от частоты (например, с использованием технологий частотно-временного анализа, таких как выполнение быстрого преобразования Фурье для PCM-потока) обеспечивает возможность преобразовывать каждый PCM-объект и соответствующее местоположение в SHC . Дополнительно, можно показывать (поскольку выше приведено линейное и ортогональное разложение) то, что коэффициентов для каждого объекта являются дополнением. Таким образом, множество PCM-объектов может быть представлено посредством коэффициентов (например, в качестве суммы векторов коэффициентов для отдельных объектов). По существу, коэффициенты содержат информацию относительно звукового поля (давления в качестве функции от трехмерных координат), и выше представлено преобразование из отдельных объектов в представление полного звукового поля около точки наблюдения. Оставшиеся чертежи описываются ниже в контексте объектно-ориентированного и SHC-ориентированного кодирования аудио.
источника объектов в качестве функции от частоты (например, с использованием технологий частотно-временного анализа, таких как выполнение быстрого преобразования Фурье для PCM-потока) обеспечивает возможность преобразовывать каждый PCM-объект и соответствующее местоположение в SHC . Дополнительно, можно показывать (поскольку выше приведено линейное и ортогональное разложение) то, что коэффициентов для каждого объекта являются дополнением. Таким образом, множество PCM-объектов может быть представлено посредством коэффициентов (например, в качестве суммы векторов коэффициентов для отдельных объектов). По существу, коэффициенты содержат информацию относительно звукового поля (давления в качестве функции от трехмерных координат), и выше представлено преобразование из отдельных объектов в представление полного звукового поля около точки наблюдения. Оставшиеся чертежи описываются ниже в контексте объектно-ориентированного и SHC-ориентированного кодирования аудио.
[32] Фиг. 2 является схемой, иллюстрирующей систему 10, которая может выполнять различные аспекты технологий, описанных в этом раскрытии сущности. Как показано в примере по фиг. 2, система 10 включает в себя устройство 12 создателя контента и устройство 14 потребителя контента. Хотя описаны в контексте устройства 12 создателя контента и устройства 14 потребителя контента, технологии могут реализовываться в любом контексте, в котором SHC (которые также могут упоминаться в качестве HOA-коэффициентов) или любое другое иерархическое представление звукового поля кодируются для того, чтобы формировать поток битов, представляющий аудиоданные. Кроме того, устройство 12 создателя контента может представлять любую форму вычислительного устройства, допускающего реализацию технологий, описанных в этом раскрытии сущности, включающего в себя переносной телефон (или сотовый телефон), планшетный компьютер, смартфон или настольный компьютер в качестве нескольких примеров. Аналогично, устройство 14 потребителя контента может представлять любую форму вычислительного устройства, допускающего реализацию технологий, описанных в этом раскрытии сущности, включающего в себя переносной телефон (или сотовый телефон), планшетный компьютер, смартфон, абонентскую приставку или настольный компьютер в качестве нескольких примеров.
[33] Устройство 12 создателя контента может управляться посредством киностудии или другого объекта, который может формировать многоканальный аудиоконтент для потребления операторами устройств потребителя контента, таких как устройство 14 потребителя контента. В некоторых примерах, устройство 12 создателя контента может управляться отдельным пользователем, который хочет сжимать HOA-коэффициенты 11. Зачастую, создатель контента формирует аудиоконтент в сочетании с видеоконтентом. Устройство 14 потребителя контента может управляться человеком. Устройство 14 потребителя контента может включать в себя систему 16 воспроизведения аудио, которая может означать любую форму системы воспроизведения аудио, допускающей рендеринг SHC для воспроизведения в качестве многоканального аудиоконтента.
[34] Устройство 12 создателя контента включает в себя систему 18 редактирования аудио. Устройство 12 создателя контента получает записи 7 вживую в различных форматах (в том числе непосредственно в качестве HOA-коэффициентов) и аудиообъекты 9, которые устройство 12 создателя контента может редактировать с использованием системы 18 редактирования аудио. Микрофон 5 может захватывать записи 7 вживую. Создатель контента, в ходе процесса редактирования, может преобразовывать посредством рендеринга HOA-коэффициенты 11 из аудиообъектов 9, прослушивая преобразованные посредством рендеринга сигналы подачи в динамики в попытке идентифицировать различные аспекты звукового поля, которые требуют дополнительного редактирования. Устройство 12 создателя контента затем может редактировать HOA-коэффициенты 11 (потенциально косвенно посредством манипулирования различными аудиообъектами 9, из которых исходные HOA-коэффициенты могут извлекаться способом, описанным выше). Устройство 12 создателя контента может использовать систему 18 редактирования аудио для того, чтобы формировать HOA-коэффициенты 11. Система 18 редактирования аудио представляет любую систему, допускающую редактирование аудиоданных и вывод аудиоданных в качестве одного или более исходных коэффициентов сферических гармоник.
[35] Когда процесс редактирования завершен, устройство 12 создателя контента может формировать поток 21 битов на основе HOA-коэффициентов 11. Иными словами, устройство 12 создателя контента включает в себя устройство 20 кодирования аудио, которое представляет устройство, сконфигурированное с возможностью кодировать или иным образом сжимать HOA-коэффициенты 11 в соответствии с различными аспектами технологий, описанных в этом раскрытии сущности для того, чтобы формировать поток 21 битов. Устройство 20 кодирования аудио может формировать поток 21 битов для передачи, в качестве одного примера, через канал передачи, который может представлять собой проводной или беспроводной канал, устройство хранения данных и т.п. Поток 21 битов может представлять кодированную версию HOA-коэффициентов 11 и может включать в себя первичный поток битов и другой боковой поток битов, который может упоминаться в качестве информации боковых каналов.
[36] Хотя показано на фиг. 2 в качестве непосредственной передачи в устройство 14 потребителя контента, устройство 12 создателя контента может выводить поток 21 битов в промежуточное устройство, позиционированное между устройством 12 создателя контента и устройством 14 потребителя контента. Промежуточное устройство может сохранять поток 21 битов для последующей доставки в устройство 14 потребителя контента, которое может запрашивать поток битов. Промежуточное устройство может содержать файловый сервер, веб-сервер, настольный компьютер, переносной компьютер, планшетный компьютер, мобильный телефон, смартфон или любое другое устройство, допускающее сохранение потока 21 битов для последующего извлечения посредством аудиодекодера. Промежуточное устройство может постоянно размещаться в сети доставки контента, допускающей потоковую передачу потока 21 битов (и возможно в сочетании с передачей соответствующего потока битов видеоданных) абонентам, таким как устройство 14 потребителя контента, запрашивающее поток 21 битов.
[37] Альтернативно, устройство 12 создателя контента может сохранять поток 21 битов на носитель хранения данных, такой как компакт-диск, цифровой видеодиск, диск по стандарту видео высокой четкости или другие носители хранения данных, большинство которых допускает считывание посредством компьютера и, следовательно, может упоминаться в качестве машиночитаемых носителей хранения данных или энергонезависимых машиночитаемых носителей хранения данных. В этом контексте, канал передачи может означать каналы, посредством которых передается контент, сохраненный на носителях (и может включать в себя розничные магазины и другой механизм доставки через магазины). В любом случае, технологии этого раскрытия сущности в силу этого не должны быть ограничены в этом отношении примером по фиг. 2.
[38] Как подробнее показано в примере по фиг. 2, устройство 14 потребителя контента включает в себя систему 16 воспроизведения аудио. Система 16 воспроизведения аудио может представлять любую систему воспроизведения аудио, допускающую воспроизведение многоканальных аудиоданных. Система 16 воспроизведения аудио может включать в себя определенное число различных модулей 22 рендеринга. Модули 22 рендеринга могут предоставлять различную форму рендеринга, причем различные формы рендеринга могут включать в себя один или более из различных способов выполнения векторного амплитудного панорамирования (VBAP) и/или один или более из различных способов выполнения синтеза звукового поля. При использовании в данном документе, "A и/или B" означает "A или B" или "как A, так и B".
[39] Система 16 воспроизведения аудио дополнительно может включать в себя устройство 24 декодирования аудио. Устройство 24 декодирования аудио может представлять устройство, сконфигурированное с возможностью декодировать HOA-коэффициенты 11' из потока 21 битов, причем HOA-коэффициенты 11' могут быть аналогичными HOA-коэффициентам 11, но отличаться вследствие операций с потерями (например, квантования) и/или передачи через канал передачи. Система 16 воспроизведения аудио, после декодирования потока 21 битов, может получать HOA-коэффициенты 11' и преобразовывать посредством рендеринга HOA-коэффициенты 11' с тем, чтобы выводить сигналы подачи 25 в громкоговорители. Сигналы подачи 25 в громкоговорители могут активировать один или более громкоговорителей (которые не показаны в примере по фиг. 2 для упрощения иллюстрации).
[40] Чтобы выбирать надлежащий модуль рендеринга или, в некоторых случаях, формировать надлежащий модуль рендеринга, система 16 воспроизведения аудио может получать информацию 13 громкоговорителей, указывающую число громкоговорителей и/или пространственную геометрию громкоговорителей. В некоторых случаях, система 16 воспроизведения аудио может получать информацию 13 громкоговорителей с использованием опорного микрофона и управления громкоговорителей таким образом, чтобы динамически определять информацию 13 громкоговорителей. В других случаях или в сочетании с динамическим определением информации 13 громкоговорителей, система 16 воспроизведения аудио может указывать пользователю взаимодействовать с системой 16 воспроизведения аудио и вводить информацию 13 громкоговорителей.
[41] Система 16 воспроизведения аудио затем может выбирать один из модулей 22 рендеринга аудио на основе информации 13 громкоговорителей. В некоторых случаях, система 16 воспроизведения аудио, когда ни один из модулей 22 рендеринга аудио не находится в пределах некоторого порогового показателя подобия (с точки зрения геометрии громкоговорителя) с геометрией громкоговорителя, указываемой в информации 13 громкоговорителей, может формировать один из модулей 22 рендеринга аудио на основе информации 13 громкоговорителей. Система 16 воспроизведения аудио, в некоторых случаях, может формировать один из модулей 22 рендеринга аудио на основе информации 13 громкоговорителей без попытки сначала выбирать существующий из модулей 22 рендеринга аудио. Один или более динамиков 3 затем могут воспроизводить преобразованные посредством рендеринга сигналы подачи 25 в громкоговорители.
[42] Фиг. 3 является блок-схемой, подробнее иллюстрирующей один пример устройства 20 кодирования аудио, показанного в примере по фиг. 2, которое может выполнять различные аспекты технологий, описанных в этом раскрытии сущности. Устройство 20 кодирования аудио включает в себя модуль 26 анализа контента, модуль 27 на основе осуществления векторного синтеза, модуль 28 на основе технологии направленного синтеза и модуль 40' декорреляции. Хотя кратко описывается ниже, более подробная информация относительно устройства 20 кодирования аудио и различных аспектов сжатия или иного кодирования HOA-коэффициентов доступна в публикации международной заявки на патент номер WO 2014/194099, озаглавленной "INTERPOLATION FOR DECOMPOSED REPRESENTATIONS OF A SOUND FIELD", поданной 29 мая 2014 года.
[43] Модуль 26 анализа контента представляет модуль, сконфигурированный с возможностью анализировать контент HOA-коэффициентов 11, чтобы идентифицировать то, представляют HOA-коэффициенты 11 контент, сформированный из записи вживую или аудиообъекта. Модуль 26 анализа контента может определять то, сформированы HOA-коэффициенты 11 из записи фактического звукового поля или из искусственного аудиообъекта. В некоторых случаях, когда кадрированные HOA-коэффициенты 11 сформированы из записи, модуль 26 анализа контента передает HOA-коэффициенты 11 в модуль 27 векторного разложения. В некоторых случаях, когда кадрированные HOA-коэффициенты 11 сформированы из синтетического аудиообъекта, модуль 26 анализа контента передает HOA-коэффициенты 11 в модуль 28 направленного синтеза. Модуль 28 направленного синтеза может представлять модуль, сконфигурированный с возможностью осуществлять направленный синтез HOA-коэффициентов 11, чтобы формировать направленный поток 21 битов.
[44] Как показано в примере по фиг. 3, модуль 27 векторного разложения может включать в себя модуль 30 линейного обратимого преобразования (LIT), модуль 32 вычисления параметров, модуль 34 переупорядочения, модуль 36 выбора переднего плана, модуль 38 энергетической компенсации, модуль 40 психоакустического аудиокодера, модуль 42 формирования потоков битов, модуль 44 анализа звукового поля, модуль 46 уменьшения числа коэффициентов, модуль 48 выбора фоновых компонентов (BG), модуль 50 пространственно-временной интерполяции и модуль 52 квантования.
[45] Модуль 30 линейного обратимого преобразования (LIT) принимает HOA-коэффициенты 11 в форме HOA-каналов, причем каждый канал представляет блок или кадр коэффициента, ассоциированного с данным порядком, подпорядком сферических базисных функций (которые могут обозначаться как HOA[k], где k может обозначать текущий кадр или блок выборок). Матрица HOA-коэффициентов 11 может иметь размеры D: M x (N+1)2.
[46] LIT-модуль 30 может представлять модуль, сконфигурированный с возможностью выполнять форму анализа, называемого в качестве разложения по сингулярным значениям. Хотя описаны относительно SVD, технологии, описанные в этом раскрытии сущности, могут выполняться относительно любого аналогичного преобразования или разложения, которое предоставляет наборы линейно некоррелированного, энергетического уплотненного вывода. Кроме того, ссылка на "наборы" в этом раскрытии сущности, в общем, имеет намерение ссылаться на ненулевые наборы, если прямо не указано обратное, и не имеет намерение ссылаться на классическое математическое определение наборов, которое включает в себя так называемый "пустой набор". Альтернативное преобразование может содержать анализ главных компонентов, который зачастую упоминается в качестве "PCA". В зависимости от контекста, PCA может упоминаться посредством ряда различных названий, таких как дискретное преобразование Карунена-Лоэва, преобразование Хотеллинга, собственное ортогональное разложение (POD) и разложение по собственным значениям (EVD), в качестве нескольких примеров. Свойства таких операций, которые способствуют базовой цели сжатия аудиоданных, представляют собой "энергетическое уплотнение" и "декорреляцию" многоканальных аудиоданных.
[47] В любом случае, при условии, что LIT-модуль 30 выполняет разложение по сингулярным значениям (которое, снова, может упоминаться в качестве "SVD") в целях примера, LIT-модуль 30 может преобразовывать HOA-коэффициенты 11 в два или более наборов преобразованных HOA-коэффициентов. "Наборы" преобразованных HOA-коэффициентов могут включать в себя векторы преобразованных HOA-коэффициентов. В примере по фиг. 3, LIT-модуль 30 может выполнять SVD относительно HOA-коэффициентов 11, чтобы формировать так называемую V-матрицу, S-матрицу и U-матрицу. SVD, в линейной алгебре, может представлять факторизацию действительной или комплексной матрицы X y на z (где X может представлять многоканальные аудиоданные, такие как HOA-коэффициенты 11) в следующей форме:
X=USV*
U может представлять действительную или комплексную унитарную матрицу y на y, где y столбцов U известны как левые сингулярные вектора многоканальных аудиоданных. S может представлять прямоугольную диагональную матрицу y на z с неотрицательными действительными числами на диагонали, где диагональные значения S известны как сингулярные значения многоканальных аудиоданных. V* (которая может обозначать сопряженную транспонированную матрицу относительно V) может представлять действительную или комплексную унитарную матрицу z на z, где z столбцов V* известны как правые сингулярные векторы многоканальных аудиоданных.
[48] В некоторых примерах, V*-матрица в математическом SVD-выражении, упомянутом выше, обозначается как сопряженная транспонированная матрица относительно V-матрицы, чтобы отражать то, что SVD может применяться к матрицам, содержащим комплексные числа. При применении к матрицам, содержащим только действительные числа, комплексно-сопряженная матрица относительно V-матрицы (или, другими словами, V*-матрица) может рассматриваться в качестве транспонированной матрицы относительно V-матрицы. Ниже предполагается, для упрощения иллюстрации, что HOA-коэффициенты 11 содержат действительные числа, так что в итоге V-матрица выводится через SVD, а не через V*-матрицу. Кроме того, хотя обозначается в качестве V-матрицы в этом раскрытии сущности, следует понимать, что ссылка на V-матрицу означает транспонированную матрицу относительно V-матрицы при необходимости. Хотя предполагается в качестве V-матрицы, технологии могут применяться аналогично HOA-коэффициентам 11, имеющим комплексные коэффициенты, причем вывод SVD представляет собой V*-матрицу. Соответственно, технологии не должны быть ограничены в том отношении, чтобы предоставлять применение SVD только для того, чтобы формировать V-матрицу, и могут включать в себя применение SVD к HOA-коэффициентам 11, имеющим комплексные компоненты, чтобы формировать V*-матрицу.
[49] Таким образом, LIT-модуль 30 может выполнять SVD относительно HOA-коэффициентов 11, чтобы выводить US[k]-векторы 33 (которые могут представлять комбинированную версию векторов S и векторов U), имеющие размеры D: M x (N+1)2, и V[k]-векторы 35, имеющие размеры D: (N+1)2 x (N+1)2. Отдельные векторные элементы в US[k]-матрице также могут называться 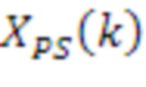 , тогда как отдельные векторы V[k]-матрицы также могут называться
, тогда как отдельные векторы V[k]-матрицы также могут называться 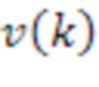 .
.
[50] Анализ U-, S- и V-матриц может раскрывать то, что матрицы переносят или представляют пространственные и временные характеристики базового звукового поля, представленного выше посредством X. Каждый из N-векторов в U (длины в M выборок) может представлять нормализованные разделенные аудиосигналы в качестве функции от времени (для периода времени, представленного посредством M выборок), которые являются ортогональными друг к другу и которые развязаны от пространственных характеристик (которые также могут упоминаться в качестве направленной информации). Пространственные характеристики, представляющие пространственную форму и позицию (r, theta, phi), вместо этого могут быть представлены посредством отдельных i-ых векторов, 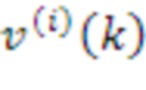 , в V-матрице (каждый с длиной (N+1)2). Отдельные элементы каждого из векторов могут представлять HOA-коэффициент, описывающий форму (включающую в себя ширину) и позицию звукового поля для ассоциированного аудиообъекта. Векторы в U-матрице и в V-матрице нормализуются таким образом, что их среднеквадратические энергии равны единице. Энергия аудиосигналов в U в силу этого представлена посредством диагональных элементов в S. Умножение U и S, чтобы формировать US[k] (с отдельными векторными элементами
, в V-матрице (каждый с длиной (N+1)2). Отдельные элементы каждого из векторов могут представлять HOA-коэффициент, описывающий форму (включающую в себя ширину) и позицию звукового поля для ассоциированного аудиообъекта. Векторы в U-матрице и в V-матрице нормализуются таким образом, что их среднеквадратические энергии равны единице. Энергия аудиосигналов в U в силу этого представлена посредством диагональных элементов в S. Умножение U и S, чтобы формировать US[k] (с отдельными векторными элементами 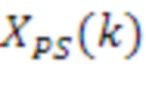 ), в силу этого представляет аудиосигнал с энергиями. Способность SVD-разложения развязывать временные аудиосигналы (в U), их энергии (в S) и их пространственные характеристики (в V) позволяет поддерживать различные аспекты технологий, описанных в этом раскрытии сущности. Дополнительно, модель синтезирования базовых HOA[k]-коэффициентов, X, посредством векторного умножения US[k] и V[k] дает начало термину "векторное разложение", который используется в этом документе.
), в силу этого представляет аудиосигнал с энергиями. Способность SVD-разложения развязывать временные аудиосигналы (в U), их энергии (в S) и их пространственные характеристики (в V) позволяет поддерживать различные аспекты технологий, описанных в этом раскрытии сущности. Дополнительно, модель синтезирования базовых HOA[k]-коэффициентов, X, посредством векторного умножения US[k] и V[k] дает начало термину "векторное разложение", который используется в этом документе.
[51] Хотя описывается в качестве выполнения непосредственно относительно HOA-коэффициентов 11, LIT-модуль 30 может применять линейное обратимое преобразование к производным HOA-коэффициентов 11. Например, LIT-модуль 30 может применять SVD относительно матрицы спектральной плотности мощности, извлекаемой из HOA-коэффициентов 11. Посредством выполнения SVD относительно спектральной плотности мощности (PSD) HOA-коэффициентов, а не самих коэффициентов, LIT-модуль 30 потенциально может уменьшать вычислительную сложность выполнения SVD с точки зрения одного или более циклов процессора и пространства для хранения при достижении идентичной исходной эффективности кодирования аудио, как если SVD применяется непосредственно к HOA-коэффициентам.
[52] Модуль 32 вычисления параметров представляет модуль, сконфигурированный с возможностью вычислять различные параметры, такие как параметр (R) корреляции, параметры (θ, ϕ, r) направленных свойств и энергетическое свойство (e). Каждый из параметров для текущего кадра может обозначаться как R[k], θ[k], ϕ[k], r[k] и e[k]. Модуль 32 вычисления параметров может выполнять энергетический анализ и/или корреляцию (или так называемую взаимную корреляцию) относительно US[k]-векторов 33, чтобы идентифицировать параметры. Модуль 32 вычисления параметров также может определять параметры для предыдущего кадра, причем параметры предыдущего кадра могут обозначаться как R[k-1], θ[k-1], ϕ[k-1], r[k-1] и e[k-1], на основе предыдущего кадра US[k-1]-вектора и V[k-1]-векторов. Модуль 32 вычисления параметров может выводить текущие параметры 37 и предыдущие параметры 39 в модуль 34 переупорядочения.
[53] Параметры, вычисленные посредством модуля 32 вычисления параметров, могут использоваться посредством модуля 34 переупорядочения для того, чтобы переупорядочивать аудиообъекты, чтобы представлять их естественную оценку или непрерывность во времени. Модуль 34 переупорядочения может сравнивать каждый из параметров 37 из первых US[k]-векторов 33 по перегибам с каждым из параметров 39 для вторых US[k-1]-векторов 33. Модуль 34 переупорядочения может переупорядочивать (с использованием, в качестве одного примера, венгерского алгоритма) различные векторы в US[k]-матрице 33 и V[k]-матрице 35 на основе текущих параметров 37 и предыдущих параметров 39, чтобы выводить переупорядоченную US[k]-матрицу 33' (которая может обозначаться математически в качестве 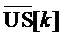 ) и переупорядоченную V[k]-матрицу 35' (которая может обозначаться математически в качестве
) и переупорядоченную V[k]-матрицу 35' (которая может обозначаться математически в качестве 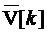 ) в модуль 36 выбора переднего плана (или преобладающего звука, PS) ("модуль 36 выбора переднего плана ") и модуль 38 энергетической компенсации.
) в модуль 36 выбора переднего плана (или преобладающего звука, PS) ("модуль 36 выбора переднего плана ") и модуль 38 энергетической компенсации.
[54] Модуль 44 анализа звукового поля может представлять модуль, сконфигурированный с возможностью осуществлять анализ звукового поля относительно HOA-коэффициентов 11, с тем чтобы потенциально достигать целевой скорости 41 передачи битов. Модуль 44 анализа звукового поля, на основе анализа и/или на основе принимаемой целевой скорости 41 передачи битов, может определять общее число экземпляров психоакустического кодера (которое может быть функцией от общего числа (BGTOT) каналов окружающего пространства или фоновых каналов и числа каналов переднего плана или, другими словами, преобладающих каналов). Общее число экземпляров психоакустического кодера может обозначаться как numHOATransportChannels.
[55] Модуль 44 анализа звукового поля, в свою очередь, также может определять, чтобы потенциально достигать целевой скорости 41 передачи битов, общее число (nFG) 45 каналов переднего плана, минимальный порядок фонового звукового поля (или, другими словами, окружающего пространства звукового поля) (NBG или, альтернативно, MinAmbHOAorder), соответствующее число фактических каналов, представляющих минимальный порядок фонового звукового поля (nBGa=(MinAmbHOAorder+1)2), и индексы (i) дополнительных BG HOA-каналов для отправки (что может совместно обозначаться как информация 43 фоновых каналов в примере по фиг. 3). Информация 42 фоновых каналов также может упоминаться в качестве информации 43 каналов окружающего пространства. Каждый из каналов, который остается от numHOATransportChannels-nBGa, может представлять собой "дополнительный фоновый/канал окружающего пространства", "активный векторный преобладающий канал", "активный направленный преобладающий сигнал" или "абсолютно неактивный". В одном аспекте, типы каналов могут указываться (в качестве синтаксического элемента ChannelType) посредством двух битов (например, 00: направленный сигнал; 01: векторный преобладающий сигнал; 10: дополнительный сигнал окружающего пространства; 11: неактивный сигнал). Общее число фоновых сигналов или сигналов окружающего пространства, nBGa, может задаваться посредством (MinAmbHOAorder+1)2+число раз, когда индекс 10 (в вышеприведенном примере) появляется в качестве типа канала в потоке битов для этого кадра.
[56] Модуль 44 анализа звукового поля может выбирать число фоновых каналов (или, другими словами, каналов окружающего пространства) и число каналов переднего плана (или, другими словами, преобладающих каналов) на основе целевой скорости 41 передачи битов, выбирая большее число фоновых и/или каналов переднего плана, когда целевая скорость 41 передачи битов является относительно более высокой (например, когда целевая скорость 41 передачи битов равна или превышает 512 Кбит/с). В одном аспекте, numHOATransportChannels может задаваться равным 8, тогда как MinAmbHOAorder может задаваться равным 1 в секции заголовка потока битов. В этом сценарии, в каждом кадре, четыре канала могут выделяться для того, чтобы представлять фоновую часть или часть окружающего пространства звукового поля, тогда как другие 4 канала могут, на покадровой основе, варьироваться по типу канала, например, использоваться либо в качестве дополнительного фонового канала/канала окружающего пространства, либо в качестве преобладающего канала/канала переднего плана. Преобладающие сигналы/сигналы переднего плана могут представлять собой одно из векторных или направленных сигналов, как описано выше.
[57] В некоторых случаях, общее число векторных преобладающих сигналов для кадра может задаваться посредством числа раз, когда индекс ChannelType равен 01 в потоке битов этого кадра. В вышеуказанном аспекте, для каждого дополнительного фонового канала/канала окружающего пространства (например, соответствующего ChannelType в 10), согласно информации того, какие из возможных HOA-коэффициентов (помимо первых четырех) могут быть представлены в этом канале. Информация, для HOA-контента четвертого порядка, может представлять собой индекс для того, чтобы указывать HOA-коэффициенты 5-25. Первые четыре HOA-коэффициента 1-4 окружающего пространства могут отправляться все время, когда minAmbHOAorder задается равным 1, следовательно, устройство кодирования аудио, возможно, должно только указывать один из дополнительного HOA-коэффициента окружающего пространства, имеющего индекс 5-25. Информация в силу этого может отправляться с использованием 5-битового синтаксического элемента (для контента четвертого порядка), который может обозначаться как CodedAmbCoeffIdx. В любом случае, модуль 44 анализа звукового поля выводит информацию 43 фоновых каналов и HOA-коэффициенты 11 в модуль 36 выбора фоновых компонентов (BG), информацию 43 фоновых каналов в модуль 46 уменьшения числа коэффициентов и модуль 42 формирования потоков битов и nFG 45 в модуль 36 выбора переднего плана.
[58] Модуль 48 выбора фоновых компонентов может представлять модуль, сконфигурированный с возможностью определять фоновые или HOA-коэффициенты окружающего пространства 47 на основе информации фоновых каналов (например, фонового звукового поля (NBG) и числа (nBGa) и индексов (i) дополнительных BG HOA-каналов для отправки). Например, когда NBG равен единице, модуль 48 выбора фоновых компонентов может выбирать HOA-коэффициенты 11 для каждой выборки аудиокадра, имеющего порядок, равный или меньший единицы. Модуль 48 выбора фоновых компонентов, в этом примере, затем может выбирать HOA-коэффициенты 11, имеющие индекс, идентифицированный посредством одного из индексов (i), в качестве дополнительных BG HOA-коэффициентов, причем nBGa предоставляется в модуль 42 формирования потоков битов для того, чтобы указываться в потоке 21 битов, с тем чтобы обеспечивать возможность устройству декодирования аудио, к примеру, устройству 24 декодирования аудио, показанному в примере фиг. 2 и 4, синтаксически анализировать фоновые HOA-коэффициенты 47 из потока 21 битов. Модуль 48 выбора фоновых компонентов затем может выводить HOA-коэффициенты окружающего пространства 47 в модуль 38 энергетической компенсации. HOA-коэффициенты окружающего пространства 47 могут иметь размеры D: M x [(NBG+1)2+nBGa]. HOA-коэффициенты окружающего пространства 47 также могут упоминаться в качестве "HOA-коэффициентов 47 окружающего пространства ", причем каждый из HOA-коэффициентов 47 окружающего пространства соответствует отдельному HOA-каналу 47 окружающего пространства, который должен кодироваться посредством модуля 40 психоакустического аудиокодера.
[59] Модуль 36 выбора переднего плана может представлять модуль, сконфигурированный с возможностью выбирать переупорядоченную US[k]-матрицу 33' и переупорядоченную V[k]-матрицу 35', которые представляют компоненты переднего плана или отличительные компоненты звукового поля на основе nFG 45 (которые могут представлять один или более индексов, идентифицирующих векторы переднего плана). Модуль 36 выбора переднего плана может выводить nFG-сигналы 49 (которые могут обозначаться как переупорядоченные US[k]1,..., nFG 49, FG1,..., nfG[k] 49 или 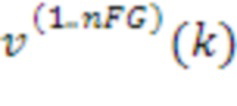 49) в модуль 40 психоакустического аудиокодера, причем nFG-сигналы 49 могут иметь размеры D: M x nFG и представлять моноаудиообъекты. Модуль 36 выбора переднего плана также может выводить переупорядоченную V[k]-матрицу 35' (или 35'), соответствующую компонентам переднего плана звукового поля, в модуль 50 пространственно-временной интерполяции, причем поднабор переупорядоченной V[k]-матрицы 35', соответствующей компонентам переднего плана, может обозначаться как V[k]-матрица 51k переднего плана (которая может математически обозначаться в качестве
49) в модуль 40 психоакустического аудиокодера, причем nFG-сигналы 49 могут иметь размеры D: M x nFG и представлять моноаудиообъекты. Модуль 36 выбора переднего плана также может выводить переупорядоченную V[k]-матрицу 35' (или 35'), соответствующую компонентам переднего плана звукового поля, в модуль 50 пространственно-временной интерполяции, причем поднабор переупорядоченной V[k]-матрицы 35', соответствующей компонентам переднего плана, может обозначаться как V[k]-матрица 51k переднего плана (которая может математически обозначаться в качестве 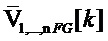 ), имеющая размеры D: (N+1)2 x nFG.
), имеющая размеры D: (N+1)2 x nFG.
[60] Модуль 38 энергетической компенсации может представлять модуль, сконфигурированный с возможностью осуществлять энергетическую компенсацию относительно HOA-коэффициентов 47 окружающего пространства, чтобы компенсировать энергетические потери вследствие удаления различных HOA-каналов посредством модуля 48 выбора фоновых компонентов. Модуль 38 энергетической компенсации может выполнять энергетический анализ относительно одного или более из переупорядоченной US[k]-матрицы 33', переупорядоченной V[k]-матрицы 35', nFG-сигналов 49, V[k]-векторов 51k переднего плана и HOA-коэффициентов 47 окружающего пространства и затем выполнять энергетическую компенсацию на основе энергетического анализа, чтобы формировать HOA-коэффициенты 47' окружающего пространства после энергетической компенсации. Модуль 38 энергетической компенсации может выводить HOA-коэффициенты 47' окружающего пространства после энергетической компенсации в модуль 40' декорреляции. В свою очередь, модуль 40' декорреляции может реализовывать технологии этого раскрытия сущности для того, чтобы уменьшать или исключать корреляцию между фоновыми сигналами HOA-коэффициентов 47', чтобы формировать один или более декоррелированных HOA-коэффициентов 47''. Модуль 40' декорреляции может выводить декоррелированные HOA-коэффициенты 47'' в модуль 40 психоакустического аудиокодера.
[61] Модуль 50 пространственно-временной интерполяции может представлять модуль, сконфигурированный с возможностью принимать V[k]-векторы 51k переднего плана для k-ого кадра и V[k-1]-векторы 51k-1 переднего плана для предыдущего кадра (отсюда и обозначение k-1) и выполнять пространственно-временную интерполяцию, чтобы формировать интерполированные V[k]-векторы переднего плана. Модуль 50 пространственно-временной интерполяции может рекомбинировать nFG-сигналы 49 с V[k]-векторами 51k переднего плана, чтобы восстанавливать переупорядоченные HOA-коэффициенты переднего плана. Модуль 50 пространственно-временной интерполяции затем может делить переупорядоченные HOA-коэффициенты переднего плана на интерполированные V[k]-векторы, чтобы формировать интерполированные nFG-сигналы 49'. Модуль 50 пространственно-временной интерполяции также может выводить V[k]-векторы 51k переднего плана, которые использованы для того, чтобы формировать интерполированные V[k]-векторы переднего плана, так что устройство декодирования аудио, к примеру, устройство 24 декодирования аудио, может формировать интерполированные V[k]-векторы переднего плана и за счет этого восстанавливать V[k]-векторы 51k переднего плана. V[k]-векторы 51k переднего плана, используемые для того, чтобы формировать интерполированные V[k]-векторы переднего плана, обозначаются как оставшиеся V[k]-векторы 53 переднего плана. Чтобы обеспечивать то, что идентичные V[k] и V[k-1] используются в кодере и декодере (чтобы создавать интерполированные векторы V[k]), квантованные/деквантованные версии векторов могут использоваться в кодере и декодере. Модуль 50 пространственно-временной интерполяции может выводить интерполированные nFG-сигналы 49' в модуль 46 психоакустического аудиокодера и интерполированные V[k]-векторы 51k переднего плана в модуль 46 уменьшения числа коэффициентов.
[62] Модуль 46 уменьшения числа коэффициентов может представлять модуль, сконфигурированный с возможностью осуществлять уменьшение числа коэффициентов относительно оставшихся V[k]-векторов переднего плана 53 на основе информации 43 фоновых каналов, чтобы выводить уменьшенные V[k]-векторы 55 переднего плана в модуль 52 квантования. Уменьшенные V[k]-векторы 55 переднего плана могут иметь размеры D: [(N+1)2-(NBG+1)2-BGTOT] x nFG. Модуль 46 уменьшения числа коэффициентов, в этом отношении, может представлять модуль, сконфигурированный с возможностью уменьшать число коэффициентов в оставшихся V[k]-векторах 53 переднего плана. Другими словами, модуль 46 уменьшения числа коэффициентов может представлять модуль, сконфигурированный с возможностью исключать коэффициенты в V[k]-векторах переднего плана (которые формируют оставшиеся V[k]-векторы 53 переднего плана), практически не имеющие направленной информации. В некоторых примерах, коэффициенты отличительных или, другими словами, V[k]-векторов переднего плана, соответствующих базисным функциям первого и нулевого порядка (которые могут обозначаться как NBG), предоставляют небольшой объем направленной информации и, следовательно, могут удаляться из V-векторов переднего плана (посредством процесса, который может упоминаться в качестве "уменьшения числа коэффициентов"). В этом примере, большая гибкость может предоставляться не только для того, чтобы идентифицировать коэффициенты, которые соответствуют NBG, но и для того, чтобы идентифицировать дополнительные HOA-каналы (которые могут обозначаться посредством переменной TotalOfAddAmbHOAChan) из набора [(NBG+1)2+1, (N+1)2].
[63] Модуль 52 квантования может представлять модуль, сконфигурированный с возможностью осуществлять любую форму квантования, чтобы сжимать уменьшенные V[k]-векторы 55 переднего плана, чтобы формировать кодированные V[k]-векторы 57 переднего плана, выводя кодированные V[k]-векторы 57 переднего плана в модуль 42 формирования потоков битов. При работе, модуль 52 квантования может представлять модуль, сконфигурированный с возможностью сжимать пространственный компонент звукового поля, т.е. один или более уменьшенных V[k]-векторов 55 переднего плана в этом примере. Модуль 52 квантования может выполнять любой из следующих 12 режимов квантования, как указано посредством синтаксического элемента режима квантования, обозначаемого как NbitsQ:
Тип значения NbitsQ режима квантования
0-3: зарезервировано
4: векторное квантование
5: скалярное квантование без кодирования Хаффмана
6: 6-битовое скалярное квантование с кодированием Хаффмана
7: 7-битовое скалярное квантование с кодированием Хаффмана
8: 8-битовое скалярное квантование с кодированием Хаффмана
......
16: 16-битовое скалярное квантование с кодированием Хаффмана
Модуль 52 квантования также может выполнять прогнозные версии любого из вышеприведенных типов режимов квантования, причем разность определяется между элементом (или весовым коэффициентом, когда выполняется векторное квантование) V-вектора предыдущего кадра и элементом (или весовым коэффициентом, когда выполняется векторное квантование) V-вектора текущего кадра, определяется. Модуль 52 квантования затем может квантовать разность между элементами или весовыми коэффициентами текущего кадра и предыдущего кадра, а не значение элемента V-вектора самого текущего кадра.
[64] Модуль 52 квантования может выполнять несколько форм квантования относительно каждого из уменьшенных V[k]-векторов 55 переднего плана, чтобы получать несколько кодированных версий уменьшенных V[k]-векторов 55 переднего плана. Модуль 52 квантования может выбирать одну из кодированных версий уменьшенных V[k]-векторов 55 переднего плана в качестве кодированного V[k]-вектора 57 переднего плана. Модуль 52 квантования, другими словами, может выбирать одно из непрогнозированного векторно квантованного V-вектора, прогнозированного векторно квантованного V-вектора, некодированного по Хаффману скалярно квантованного V-вектора и кодированного по Хаффману скалярно квантованного V-вектора, для использования в качестве выходного переключаемого квантованного V-вектора на основе любой комбинации критериев, поясненных в этом раскрытии сущности. В некоторых примерах, модуль 52 квантования может выбирать режим квантования из набора режимов квантования, который включает в себя режим векторного квантования и один или более режимов скалярного квантования, и квантовать входной V-вектор на основе (или согласно) выбранного режима. Модуль 52 квантования затем может предоставлять выбранный один из непрогнозированного векторно квантованного V-вектора (например, с точки зрения значений весовых коэффициентов или битов, указывающих их), прогнозированного векторно квантованного V-вектора (например, с точки зрения значений ошибки или битов, указывающих их), некодированного по Хаффману скалярно квантованного V-вектора и кодированного по Хаффману скалярно квантованного V-вектора в модуль 52 формирования потоков битов в качестве кодированных V[k]-векторов 57 переднего плана. Модуль 52 квантования также может предоставлять синтаксические элементы, указывающие режим квантования (например, синтаксический элемент NbitsQ), и любые другие синтаксические элементы, используемые для того, чтобы деквантовать или иным образом восстанавливать V-вектор.
[65] Модуль 40' декорреляции, включенный в устройство 20 кодирования аудио, может представлять одни или более экземпляров модуля, сконфигурированного с возможностью применять одно или более преобразований с декорреляцией к HOA-коэффициентам 47', с тем чтобы получать декоррелированные HOA-коэффициенты 47''. В некоторых примерах, модуль 40' декорреляции может применять UHJ-матрицу к HOA-коэффициентам 47'. В различных примерах этого раскрытия сущности, UHJ-матрица также может упоминаться в качестве "фазового преобразования". Применение фазового преобразования также может упоминаться в данном документе как "декорреляция со сдвигом фаз".
[66] Амбиофонический UHJ-формат является разработкой системы амбиофонического объемного звучания, спроектированной с возможностью быть совместимой с моно- и стереомультимедиа. UHJ-формат включает в себя иерархию систем, в которых записанное звуковое поле должно воспроизводиться со степенью точности, которая варьируется согласно доступным каналам. В различных случаях, UHJ также упоминается как "C-формат". Начальные буквы указывают некоторые источники, включенные в систему: U от Universal (универсальный) (UD-4); H от матрицы H; и J от системы 45J.
[67] UHJ является иерархической системой кодирования и декодирования направленной звуковой информации в технологии на основе амбиофонии. В зависимости от доступного числа каналов, система может переносить больший или меньший объем информации. UHJ является полностью стерео- и моносовместимым. Могут использоваться до четырех каналов (L, R, T, Q).
[68] В одной форме, двухканальном (L, R) UHJ, информация горизонтального (или "планарного") объемного звучания может переноситься посредством нормальных каналов передачи стереосигналов (CD, FM или цифровых радиоканалов и т.д.) которые могут восстанавливаться посредством использования UHJ-декодера на прослушивающей стороне. Суммирование двух каналов может давать в результате совместимый моносигнал, который может быть более точным представлением двухканальной версии, чем суммирование традиционного "панорамированного моно-" источника. Если третий канал (T) доступен, третий канал может использоваться для того, чтобы давать в результате повышенную точность локализации для эффекта планарного объемного звучания при декодировании через 3-канальный UHJ-декодер. Третий канал не обязательно должен иметь полную полосу пропускания аудиосигнала для этой цели, что приводит к вероятности так называемых "2½-канальных" систем, в которых третий канал имеет ограниченную полосу пропускания. В одном примере, предел может составлять 5 кГц. Третий канал может передаваться в широковещательном режиме через FM-радиомодуль, например, посредством фазовой квадратурной модуляции. Добавление четвертого канала (Q) в UHJ-систему может обеспечивать возможность кодирования полного объемного звука с высотой, иногда называемой в качестве перифонии, с уровнем точности, идентичным 4-канальному B-формату.
[69] Двухканальный UHJ представляет собой формат, обычно используемый для распределения амбиофонических записей. Двухканальные UHJ-записи могут передаваться через все нормальные стереоканалы, и любое нормальное двухканальное мультимедиа может использоваться без изменения. UHJ является стереосовместимым в том, что без декодирования слушатель может воспринимать стереоизображение, но стереоизображение, которое является значительно более широким по сравнению с традиционным стерео (например, так называемое "суперстерео"). Левый и правый каналы также могут быть суммированы для очень высокой степени моносовместимости. При воспроизведении через UHJ-декодер, характеристики объемного звучания могут быть раскрыты.
[70] Примерное математическое представление модуля 40' декорреляции, применяющего UHJ-матрицу (или фазовое преобразование), заключается в следующем:
UHJ-кодирование:
S=(0,9397*W)+(0,1856*X);
D=imag(hilbert((-0,3420*W)+(0,5099*X)))+(0,6555*Y);
T=imag(hilbert((-0,1432*W)+(0,6512*X)))-(0,7071*Y);
Q=0,9772*Z;
преобразование S и D в Left и Right:
Left=(S+D)/2
Right=(S-D)/2
[71] Согласно некоторым реализациям вышеприведенных вычислений, допущения относительно вышеприведенных вычислений могут включать в себя следующее: фоновый HOA-канал является амбиофоническим первого порядка, FuMa-нормализованным, в порядке нумерации каналов на основе амбиофонии W(a00), X(a11), Y(a11-), Z(a10).
[72] В вышеуказанных вычислениях, модуль 40' декорреляции может выполнять скалярное умножение различных матриц на постоянные значения. Например, чтобы получать S-сигнал, модуль 40' декорреляции может выполнять скалярное умножение W-матрицы на постоянное значение 0,9397 (например, посредством скалярного умножения) и X-матрицы на постоянное значение 0,1856. Как также проиллюстрировано в вышеуказанных вычислениях, модуль 40' декорреляции может применять преобразование Гильберта (обозначаемое посредством функции "Hilbert ()" при вышеуказанном UHJ-кодировании) при получении каждого из D- и T-сигналов. Функция "imag" при вышеуказанном UHJ-кодировании указывает то, что получается мнимое число (в математическом смысле) результата преобразования Гильберта.
[73] Другое примерное математическое представление модуля 40' декорреляции, применяющего UHJ-матрицу (или фазовое преобразование), заключается в следующем:
UHJ-кодирование:
S=(0,9396926*W)+(0,151520536509082*X);
D=imag(hilbert((-0,3420201*W)+(0,416299273350443*X)))+(0,535173990363608*Y);
T=0,940604061228740*(imag(hilbert((-0,1432*W)+(0,531702573500135*X)))-(0,577350269189626*Y));
Q=Z;
преобразование S и D в Left и Right:
Left=(S+D)/2;
Right=(S-D)/2;
[74] В некоторых примерных реализациях вышеприведенных вычислений, допущения относительно вышеприведенных вычислений могут включать в себя следующее: фоновый HOA-канал является амбиофоническим первого порядка, N3D-(или "полное три D") нормализованным, в порядке нумерации каналов на основе амбиофонии W(a00), X(a11), Y(a11-), Z(a10). Хотя описывается в данном документе относительно N3D-нормализации, следует принимать во внимание, что примерные вычисления также могут применяться к фоновым HOA-каналам, которые являются SN3D-нормализованными (или "полунормализованными по Шмидту"). N3D- и SN3D-нормализация может различаться с точки зрения используемых коэффициентов масштабирования. Примерное представление N3D-нормализации, относительно SN3D-нормализации, выражается ниже:
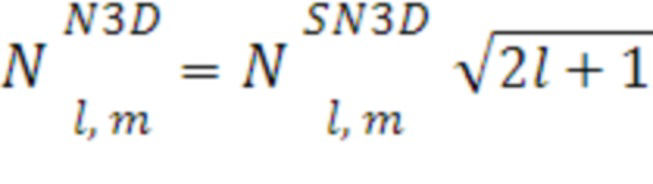
[75] Пример весовых коэффициентов, используемых в SN3D-нормализации, выражается ниже:
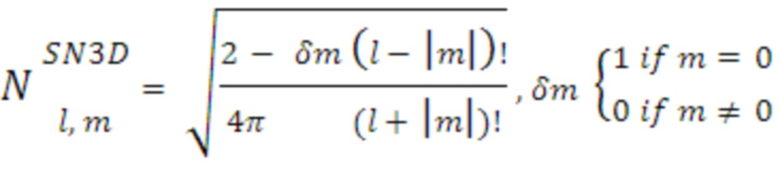
[76] В вышеуказанных вычислениях, модуль 40' декорреляции может выполнять скалярное умножение различных матриц на постоянные значения. Например, чтобы получать S-сигнал, модуль 40' декорреляции может выполнять скалярное умножение W-матрицы на постоянное значение 0,9396926 (например, посредством скалярного умножения) и X-матрицы на постоянное значение 0,151520536509082. Как также проиллюстрировано в вышеуказанных вычислениях, модуль 40' декорреляции может применять преобразование Гильберта (обозначаемое посредством функции "Hilbert ()" при вышеуказанном UHJ-кодировании или декорреляции со сдвигом фаз) при получении каждого из D- и T-сигналов. Функция "imag" при вышеуказанном UHJ-кодировании указывает то, что получается мнимое число (в математическом смысле) результата преобразования Гильберта.
[77] Модуль 40' декорреляции может выполнять вышеупомянутые вычисления, так что результирующие S- и D-сигналы представляют левый и правый аудиосигналы (или другими словами, стереоаудиосигналы). В некоторых таких сценариях, модуль 40' декорреляции может выводить T- и Q-сигналы в качестве части декоррелированных HOA-коэффициентов 47'', но устройство декодирования, которое принимает поток 21 битов, не может обрабатывать T- и Q-сигналы при рендеринге в геометрию стереодинамиков (или, другими словами, конфигурацию стереодинамиков). В примерах, HOA-коэффициенты 47' могут представлять звуковое поле, которое должно преобразовываться посредством рендеринга в системе воспроизведения монофонического аудио. Модуль 40' декорреляции может выводить S- и D-сигналы в качестве части декоррелированных HOA-коэффициентов 47'', и устройство декодирования, которое принимает поток 21 битов, может комбинировать (или "смешивать") S- и D-сигналы для того, чтобы формировать аудиосигнал, который должен преобразовываться посредством рендеринга и/или выводиться в моноаудиоформате. В этих примерах, устройство декодирования и/или устройство воспроизведения могут восстанавливать моноаудиосигнал различными способами. Один пример заключается в сведении левого и правого сигналов (представленных посредством S- и D-сигналов). Другой пример заключается в применении UHJ-матрицы (или фазового преобразования), чтобы декодировать W-сигнал (подробнее поясняется ниже относительно фиг. 5). Посредством формирования естественного левого сигнала и естественного правого сигнала в форме S- и D-сигналов посредством применения UHJ-матрицы (или фазового преобразования), модуль 40' декорреляции может реализовывать технологии этого раскрытия сущности для того, чтобы предоставлять потенциальные преимущества и/или потенциальные улучшения по сравнению с технологиями, которые применяют другие преобразования с декорреляцией (к примеру, матрицу мод, описанной в стандарте MPEG-H).
[78] В различных примерах, модуль 40' декорреляции может применять различные преобразования с декорреляцией, на основе скорости передачи битов принимаемых HOA-коэффициентов 47'. Например, модуль 40' декорреляции может применяться UHJ-матрицу (или фазовое преобразование), описанную выше, в сценариях, в которых HOA-коэффициенты 47' представляют четырехканальный ввод. Более конкретно, на основе HOA-коэффициентов 47', представляющих четырехканальный ввод, модуль 40' декорреляции может применять UHJ-матрицу (или фазовое преобразование) 4×4. Например, матрица 4×4 может быть ортогональной к четырехканальному вводу HOA-коэффициентов 47'. Другими словами, в случаях, когда HOA-коэффициенты 47' представляют меньшее число каналов (например, четыре), модуль 40' декорреляции может применять UHJ-матрицу в качестве выбранного преобразования с декорреляцией, чтобы декоррелировать фоновые сигналы HOA-сигналов 47', чтобы получать декоррелированные HOA-коэффициенты 47''.
[79] Согласно этому примеру, если HOA-коэффициенты 47' представляют большее число каналов (например, девять), модуль 40' декорреляции может применять преобразование с декорреляцией, отличающееся от UHJ-матрицы (или фазового преобразования). Например, в сценарии, в котором HOA-коэффициенты 47' представляют девятиканальный ввод, модуль 40' декорреляции может применять матрицу мод (например, как описано в стандарте MPEG-H), чтобы декоррелировать HOA-коэффициенты 47'. В примерах, в которых HOA-коэффициенты 47' представляют девятиканальный ввод, модуль 40' декорреляции может применять матрицу мод 9×9, чтобы получать декоррелированные HOA-коэффициенты 47''.
[80] В свою очередь, различные компоненты устройства 20 кодирования аудио (к примеру, психоакустический аудиокодер 40) могут перцепционно кодировать декоррелированные HOA-коэффициенты 47'' согласно AAC или USAC. Модуль 40' декорреляции может применять преобразование с декорреляцией со сдвигом фаз (например, UHJ-матрицу или фазовое преобразование в случае четырехканального ввода), чтобы оптимизировать AAC/USAC-кодирование для HOA. В примерах, в которых HOA-коэффициенты 47' (и в силу этого декоррелированные HOA-коэффициенты 47'') представляют аудиоданные, которые должны преобразовываться посредством рендеринга в системе стереовоспроизведения, модуль 40' декорреляции может применять технологии этого раскрытия сущности для того, чтобы улучшать или оптимизировать сжатие, на основе относительной ориентации (или оптимизации) AAC и USAC для стереоаудиоданных.
[81] Следует понимать, что модуль 40' декорреляции может применять технологии, описанные в данном документе, в случаях, когда HOA-коэффициенты 47' после энергетической компенсации включают в себя каналы переднего плана, а также в случаях, когда HOA-коэффициенты 47' после энергетической компенсации не включают в себя каналы переднего плана. В качестве одного примера, модуль 40' декорреляции может применять технологии и/или вычисления, описанные выше, в сценарии, в котором HOA-коэффициенты 47' после энергетической компенсации включают в себя нуль (0) каналов переднего плана и четыре (4) фоновых канала (например, в сценарии более низкой/меньшей скорости передачи битов).
[82] В некоторых примерах, модуль 40' декорреляции может инструктировать модулю 42 формирования потоков битов сигнализировать, в качестве части векторного потока 21 битов, один или более синтаксических элементов, которые указывают то, что модуль 40' декорреляции применяет преобразование с декорреляцией к HOA-коэффициентам 47'. Посредством предоставления такого индикатора в устройство декодирования, модуль 40' декорреляции может обеспечивать возможность устройству декодирования выполнять взаимно-обратные преобразования с декорреляцией для аудиоданных в HOA-области. В некоторых примерах, модуль 40' декорреляции может инструктировать модулю 42 формирования потоков битов сигнализировать синтаксические элементы, которые указывают то, какое преобразование с декорреляцией применяется, к примеру, UHJ-матрица (или другое фазовое преобразование) либо матрица мод.
[83] Модуль 40' декорреляции может применять фазовое преобразование к HOA-коэффициенту 47’ окружающего пространства после энергетической компенсации. Фазовое преобразование для первых 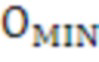 последовательностей HOA-коэффициентов
последовательностей HOA-коэффициентов 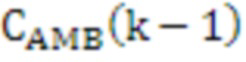 задается следующим образом:
задается следующим образом:
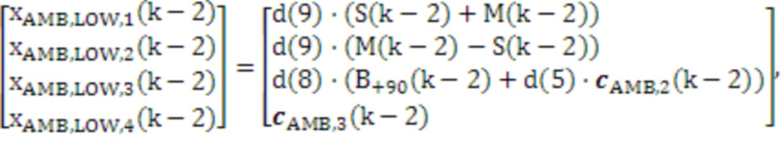 ,
,
с коэффициентами  , как задано в таблице 1, кадрами
, как задано в таблице 1, кадрами 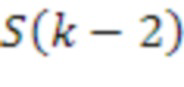 и
и 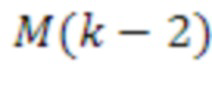 сигналов, заданными следующим образом:
сигналов, заданными следующим образом:
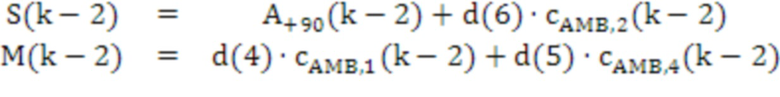 ,
,
и 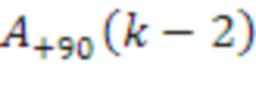
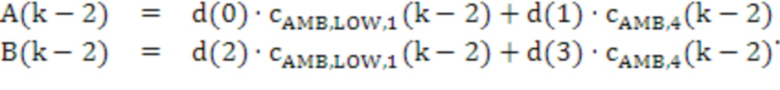
Фазовое преобразование для первых 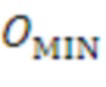 последовательностей HOA-коэффициентов
последовательностей HOA-коэффициентов 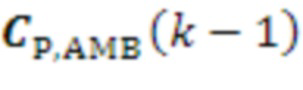 задается соответствующим образом. Описанное преобразование может вводить задержку в один кадр.
задается соответствующим образом. Описанное преобразование может вводить задержку в один кадр.
[84] В вышеприведенном описании,  -
- могут соответствовать декоррелированным HOA-коэффициентам 47'' окружающего пространства. В вышеприведенном уравнении, переменная
могут соответствовать декоррелированным HOA-коэффициентам 47'' окружающего пространства. В вышеприведенном уравнении, переменная  обозначает HOA-коэффициенты для k-ого кадра, соответствующие сферическим базисным функциям, имеющим (порядок:подпорядок) (0:0), который также может упоминаться в качестве W-канала или компонента. Переменная
обозначает HOA-коэффициенты для k-ого кадра, соответствующие сферическим базисным функциям, имеющим (порядок:подпорядок) (0:0), который также может упоминаться в качестве W-канала или компонента. Переменная 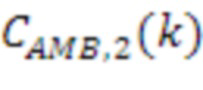 обозначает HOA-коэффициенты для k-ого кадра, соответствующие сферическим базисным функциям, имеющим (порядок:подпорядок) (1:-1), который также может упоминаться в качестве Y-канала или компонента. Переменная
обозначает HOA-коэффициенты для k-ого кадра, соответствующие сферическим базисным функциям, имеющим (порядок:подпорядок) (1:-1), который также может упоминаться в качестве Y-канала или компонента. Переменная  обозначает HOA-коэффициенты для k-ого кадра, соответствующие сферическим базисным функциям, имеющим (порядок:подпорядок) (1:0), которые также могут быть коэффициентами для k-ого кадра, соответствующего сферическим базисным функциям, имеющим (порядок:подпорядок) (1:1), который также может упоминаться в качестве X, называемого в качестве Z-канала или компонента. Переменная
обозначает HOA-коэффициенты для k-ого кадра, соответствующие сферическим базисным функциям, имеющим (порядок:подпорядок) (1:0), которые также могут быть коэффициентами для k-ого кадра, соответствующего сферическим базисным функциям, имеющим (порядок:подпорядок) (1:1), который также может упоминаться в качестве X, называемого в качестве Z-канала или компонента. Переменная  обозначает HOA-канал или компонент. - могут соответствовать HOA-коэффициентам 47' окружающего пространства.
обозначает HOA-канал или компонент. - могут соответствовать HOA-коэффициентам 47' окружающего пространства.
[85] Нижеприведенная таблица 1 иллюстрирует пример коэффициентов, которые модуль 40 декорреляции может использовать для выполнения фазового преобразования.
Табл. 1. Коэффициенты для фазового преобразования
[86] В некоторых примерах, различные компоненты устройства 20 кодирования аудио (к примеру, модуль 42 формирования потоков битов) могут быть сконфигурированы с возможностью передавать только HOA-представления первого порядка для более низких целевых скоростей передачи битов (например, целевой скорости передачи битов в 128 Кбит/с или 256 Кбит/с). Согласно некоторым таким примерам, устройство 20 кодирования аудио (либо его компоненты, такие как модуль 42 формирования потоков битов) может быть сконфигурировано с возможностью отбрасывать HOA-коэффициенты высшего порядка (например, коэффициенты с большим порядком, чем первый порядок, или другими словами, N>1). Тем не менее, в примерах, в которых устройство 20 кодирования аудио определяет то, что целевая скорость передачи битов является относительно высокой, устройство 20 кодирования аудио (например, модуль 42 формирования потоков битов) может разделять каналы переднего плана и фоновые каналы и может назначать биты (например, в больших количествах) каналам переднего плана.
[87] Модуль 40 психоакустического аудиокодера, включенный в устройство 20 кодирования аудио, может представлять несколько экземпляров психоакустического аудиокодера, каждый из которых используется для того, чтобы кодировать различный аудиообъект или HOA-канал каждого из HOA-коэффициентов 47' окружающего пространства после энергетической компенсации и интерполированных nFG-сигналов 49', чтобы формировать кодированные HOA-коэффициенты окружающего пространства 59 и кодированные nFG-сигналы 61. Модуль 40 психоакустического аудиокодера может выводить кодированные HOA-коэффициенты окружающего пространства 59 и кодированные nFG-сигналы 61 в модуль 42 формирования потоков битов.
[88] Модуль 42 формирования потоков битов, включенный в устройство 20 кодирования аудио, представляет модуль, который форматирует данные таким образом, что они соответствуют известному формату (который может означать формат, известный посредством устройства декодирования), за счет этого формируя векторный поток 21 битов. Поток 21 битов, другими словами, может представлять кодированные аудиоданные, кодированные способом, описанным выше. Модуль 42 формирования потоков битов в некоторых примерах может представлять мультиплексор, который может принимать кодированные V[k]-векторы 57 переднего плана, кодированные HOA-коэффициенты окружающего пространства 59, кодированные nFG-сигналы 61 и информацию 43 фоновых каналов. Модуль 42 формирования потоков битов затем может формировать поток 21 битов на основе кодированных V[k]-векторов 57 переднего плана, кодированных HOA-коэффициентов 59 окружающего пространства, кодированных nFG-сигналов 61 и информации 43 фоновых каналов. Таким образом, модуль 42 формирования потоков битов в силу этого может указывать векторы 57 в потоке 21 битов, чтобы получать поток 21 битов. Поток 21 битов может включать в себя первичный или основной поток битов и один или более потоков битов боковых каналов.
[89] Хотя не показано в примере по фиг. 3, устройство 20 кодирования аудио также может включать в себя модуль вывода потоков битов, который переключает поток битов, выводимый из устройства 20 кодирования аудио (например, между направленным потоком 21 битов и векторным потоком 21 битов), на основе того, должен текущий кадр кодироваться с использованием направленного синтеза или векторного синтеза. Модуль вывода потоков битов может выполнять переключение на основе синтаксического элемента, выводимого посредством модуля 26 анализа контента, указывающего того, выполнен направленный синтез (в качестве результата обнаружения того, что HOA-коэффициенты 11 сформированы из синтетического аудиообъекта) или выполнен векторный синтез (в качестве результата обнаружения того, что HOA-коэффициентов записаны). Модуль вывода потоков битов может указывать корректный синтаксис заголовка, чтобы указывать переключение или текущее кодирование, используемое для текущего кадра, вместе с соответствующим одним из потоков 21 битов.
[90] Кроме того, как отмечено выше, модуль 44 анализа звукового поля может идентифицировать BGTOT HOA-коэффициентов 47 окружающего пространства, которые могут изменяться на покадровой основе (хотя время от времени BGTOT может оставаться постоянным или идентичным через два или более смежных (во времени) кадров). Изменение BGTOT может приводить к изменениям коэффициентов, выражаемым в уменьшенных V[k]-векторах 55 переднего плана. Изменение BGTOT может приводить к фоновым HOA-коэффициентам (которые также могут упоминаться в качестве "HOA-коэффициентов окружающего пространства"), которые изменяются на покадровой основе (хотя, снова, время от времени BGTOT может оставаться постоянным или идентичным через два или более смежных (во времени) кадров). Изменения зачастую приводят к изменению энергии для аспектов звукового поля, представленных посредством добавления или удаления дополнительных HOA-коэффициентов окружающего пространства и соответствующего удаления коэффициентов из или добавления коэффициентов в уменьшенные V[k]-векторы 55 переднего плана.
[91] Как результат, модуль 44 анализа звукового поля дополнительно может определять то, когда HOA-коэффициенты окружающего пространства изменяются между кадрами, и формировать флаг или другой синтаксический элемент, указывающий изменение HOA-коэффициента окружающего пространства с точки зрения использования для того, чтобы представлять компоненты окружающего пространства звукового поля (при этом изменение также может упоминаться в качестве "перехода" HOA-коэффициента окружающего пространства или в качестве "перехода" HOA-коэффициента окружающего пространства). В частности, модуль 46 уменьшения числа коэффициентов может формировать флаг (который может обозначаться как флаг AmbCoeffTransition или флаг AmbCoeffIdxTransition), предоставлять флаг в модуль 42 формирования потоков битов, так что флаг может быть включен в поток 21 битов (возможно в качестве части информации боковых каналов).
[92] Модуль 46 уменьшения числа коэффициентов, в дополнение к указанию флага перехода коэффициента окружающего пространства, также может модифицировать то, как формируются уменьшенные V[k]-векторы 55 переднего плана. В одном примере, после определения того, что один из HOA-коэффициентов окружающего пространства находятся в переходном режиме в ходе текущего кадра, модуль 46 уменьшения числа коэффициентов может указывать векторный коэффициент (который также может упоминаться в качестве "векторного элемента" или "элемента") для каждого из V-векторов уменьшенных V[k]-векторов 55 переднего плана, который соответствует HOA-коэффициенту окружающего пространства в переходном режиме. С другой стороны, HOA-коэффициент окружающего пространства в переходном режиме может добавляться или удаляться из общего числа BGTOT фоновых коэффициентов. Следовательно, результирующее изменение общего числа фоновых коэффициентов влияет на то, включен или не включен HOA-коэффициент окружающего пространства в поток битов, и на то, включен или нет соответствующий элемент V-векторов для V-векторов, указываемых в потоке битов во втором и третьем режимах конфигурирования, описанных выше. Более подробная информация относительно того, как модуль 46 уменьшения числа коэффициентов может указывать уменьшенные V[k]-векторы 55 переднего плана, чтобы преодолевать изменения энергии, предоставляется в заявке на патент (США) порядковый номер 14/594533, озаглавленной "TRANSITIONING OF AMBIENT HIGHER-ORDER AMBISONIC COEFFICIENTS", поданной 12 января 2015 года.
[93] Таким образом, устройство 20 кодирования аудио может представлять пример устройства для сжатия аудио, сконфигурированного с возможностью применять преобразование с декорреляцией к коэффициентам амбиофонии окружающего пространства, чтобы получать декоррелированное представление коэффициентов амбиофонии окружающего пространства, причем HOA-коэффициенты окружающего пространства извлекаются из множества коэффициентов амбиофонии высшего порядка и представляют фоновый компонент звукового поля, описанного посредством множества коэффициентов амбиофонии высшего порядка, при этом, по меньшей мере, один из множества коэффициентов амбиофонии высшего порядка ассоциирован со сферической базисной функцией, имеющей порядок больше первого. В некоторых примерах, для того чтобы применять преобразование с декорреляцией, устройство сконфигурировано с возможностью применять UHJ-матрицу к коэффициентам амбиофонии окружающего пространства.
[94] В некоторых примерах, устройство дополнительно сконфигурировано с возможностью нормализовать UHJ-матрицу согласно N3D-("полное три D") нормализации. В некоторых примерах, устройство дополнительно сконфигурировано с возможностью нормализовать UHJ-матрицу согласно SN3D-нормализации (полунормализации Шмидта). В некоторых примерах, коэффициенты амбиофонии окружающего пространства ассоциированы со сферическими базисными функциями, имеющими нулевой порядок или первый порядок, и для того чтобы применять UHJ-матрицу к коэффициентам амбиофонии окружающего пространства, устройство сконфигурировано с возможностью осуществлять скалярное умножение UHJ-матрицы относительно, по меньшей мере, поднабора коэффициентов амбиофонии окружающего пространства. В некоторых примерах, для того чтобы применять преобразование с декорреляцией, устройство сконфигурировано с возможностью применять матрицу мод к коэффициентам амбиофонии окружающего пространства.
[95] Согласно некоторым примерам, для того чтобы применять преобразование с декорреляцией, устройство сконфигурировано с возможностью получать левый сигнал и правый сигнал из декоррелированных коэффициентов амбиофонии окружающего пространства. Согласно некоторым примерам, устройство дополнительно сконфигурировано с возможностью сигнализировать декоррелированные коэффициенты амбиофонии окружающего пространства вместе с одним или более каналов переднего плана. Согласно некоторым примерам, для того чтобы сигнализировать декоррелированные коэффициенты амбиофонии окружающего пространства вместе с одним или более каналов переднего плана, устройство сконфигурировано с возможностью сигнализировать декоррелированные коэффициенты амбиофонии окружающего пространства вместе с одним или более каналов переднего плана в ответ на определение того, что целевая скорость передачи битов удовлетворяет или превышает предварительно определенное пороговое значение.
[96] В некоторых примерах, устройство дополнительно сконфигурировано с возможностью сигнализировать декоррелированные коэффициенты амбиофонии окружающего пространства без сигнализации каналов переднего плана. В некоторых примерах, для того чтобы сигнализировать декоррелированные коэффициенты амбиофонии окружающего пространства без сигнализации каналов переднего плана, устройство сконфигурировано с возможностью сигнализировать декоррелированные коэффициенты амбиофонии окружающего пространства без сигнализации каналов переднего плана в ответ на определение того, что целевая скорость передачи битов ниже предварительно определенного порогового значения. В некоторых примерах, устройство дополнительно сконфигурировано с возможностью сигнализировать указание о преобразовании с декорреляцией, применяемом к коэффициентам амбиофонии окружающего пространства. В некоторых примерах, устройство дополнительно включает в себя массив микрофонов, сконфигурированный с возможностью захватывать аудиоданные, которые должны сжиматься.
[97] Фиг. 4 является блок-схемой, подробнее иллюстрирующей устройство 24 декодирования аудио по фиг. 2. Как показано в примере по фиг. 4 устройство 24 декодирования аудио может включать в себя модуль 72 извлечения, модуль 90 восстановления на основе направленности, модуль 92 векторного восстановления и модуль 81 повторной корреляции.
[98] Хотя описывается ниже, более подробная информация относительно устройства 24 декодирования аудио и различных аспектов распаковки или иного декодирования HOA-коэффициентов доступна в публикации международной заявки на патент номер WO 2014/194099, озаглавленной "INTERPOLATION FOR DECOMPOSED REPRESENTATIONS OF A SOUND FIELD", поданной 29 мая 2014 года.
[99] Модуль 72 извлечения может представлять модуль, сконфигурированный с возможностью принимать поток 21 битов и извлекать различные кодированные версии (например, направленную кодированную версию или векторную кодированную версию) HOA-коэффициентов 11. Модуль 72 извлечения может определять из вышеуказанного синтаксического элемента, указывающего то, кодированы HOA-коэффициенты 11 через различные направленные или кодированные версии. Когда выполняется направленное кодирование, модуль 72 извлечения может извлекать направленную версию HOA-коэффициентов 11 и синтаксические элементы, ассоциированные с кодированной версией (что обозначается как направленная информация 91 в примере по фиг. 4), передавая направленную информацию 91 в модуль 90 направленного восстановления. Модуль 90 направленного восстановления может представлять модуль, сконфигурированный с возможностью восстанавливать HOA-коэффициенты в форме HOA-коэффициентов 11' на основе направленной информации 91. Ниже описываются поток битов и компоновка синтаксических элементов в потоке битов.
[100] Когда синтаксический элемент указывает то, что HOA-коэффициенты 11 кодированы с использованием векторного синтеза, модуль 72 извлечения может извлекать кодированные V[k]-векторы 57 переднего плана (которые могут включать в себя кодированные весовые коэффициенты 57 и/или индексы 63 либо скалярно квантованные V-векторы), кодированные HOA-коэффициенты окружающего пространства 59 и соответствующие аудиообъекты 61 (которые также могут упоминаться в качестве кодированных nFG-сигналов 61). Аудиообъекты 61 соответствуют одному из векторов 57. Модуль 72 извлечения может передавать кодированные V[k]-векторы 57 переднего плана в модуль 74 восстановления V-векторов и кодированные HOA-коэффициенты окружающего пространства 59 вместе с кодированными nFG-сигналами 61 в модуль 80 психоакустического декодирования.
[101] Модуль 74 восстановления V-векторов может представлять модуль, сконфигурированный с возможностью восстанавливать V-векторы из кодированных V[k]-векторов 57 переднего плана. Модуль 74 восстановления V-векторов может работать способом, обратным относительно способа работы модуля 52 квантования.
[102] Модуль 80 психоакустического декодирования может работать способом, обратным относительно модуля 40 психоакустического аудиокодера, показанного в примере по фиг. 3, с тем чтобы декодировать кодированные HOA-коэффициенты окружающего пространства 59 и кодированные nFG-сигналы 61 и за счет этого формировать HOA-коэффициенты 47' окружающего пространства после энергетической компенсации и интерполированные nFG-сигналы 49' (которые также могут упоминаться в качестве интерполированных nFG-аудиообъектов 49'). Модуль 80 психоакустического декодирования может передавать HOA-коэффициенты 47' окружающего пространства после энергетической компенсации в модуль 81 повторной корреляции и nFG-сигналы 49' в модуль 78 формулирования компонентов переднего плана. В свою очередь, модуль 81 повторной корреляции может применять одно или более преобразований с повторной корреляцией к HOA-коэффициентам 47' окружающего пространства после энергетической компенсации, чтобы получать один или более повторно коррелированных HOA-коэффициентов 47'' (или коррелированных HOA-коэффициентов 47''), и может передавать коррелированные HOA-коэффициенты 47'' в модуль 82 формулирования HOA-коэффициентов (необязательно через модуль 770 постепенного нарастания/затухания).
[103] Аналогично вышеприведенным описаниям, относительно модуля 40' декорреляции устройства 20 кодирования аудио, модуль 81 повторной корреляции может реализовывать технологии этого раскрытия сущности для того, чтобы уменьшать корреляцию между фоновыми каналами HOA-коэффициентов 47’ окружающего пространства после энергетической компенсации, чтобы уменьшать или сокращать демаскирование шумом. В примерах, в которых модуль 81 повторной корреляции применяет UHJ-матрицу (например, обратную UHJ-матрицу) в качестве выбранного преобразования с повторной корреляцией, модуль 81 повторной корреляции может улучшать коэффициенты сжатия и экономить вычислительные ресурсы посредством уменьшения числа операций обработки данных. В некоторых примерах, векторный поток 21 битов может включать в себя один или более синтаксических элементов, которые указывают то, что преобразование с декорреляцией применяется во время кодирования. Включение таких синтаксических элементов в векторном потоке 21 битов может обеспечивать возможность модулю 81 повторной корреляции выполнять взаимно-обратные преобразования с декорреляцией (например, с корреляцией или повторной корреляцией) для HOA-коэффициентов 47' после энергетической компенсации. В некоторых примерах, сигнальные синтаксические элементы могут указывать то, какое преобразование с декорреляцией применяется, к примеру, UHJ-матрица или матрица мод, за счет этого обеспечивая возможность модулю 81 повторной корреляции выбирать надлежащее преобразование с повторной корреляцией для применения к HOA-коэффициентам 47' после энергетической компенсации.
[104] В примерах, в которых модуль 92 векторного восстановления выводит HOA-коэффициенты 11' в систему воспроизведения, содержащую стереосистему, модуль 81 повторной корреляции может обрабатывать S- и D-сигналы (например, естественный левый сигнал и естественный правый сигнал), чтобы формировать повторно коррелированные HOA-коэффициенты 47''. Например, поскольку S- и D-сигналы представляют естественный левый сигнал и естественный правый сигнал, система воспроизведения может использовать S- и D-сигналы в качестве двух выходных стереопотоков. В примерах, в которых модуль 92 восстановления выводит HOA-коэффициенты 11' в систему воспроизведения, содержащую моноаудиосистему, система воспроизведения может комбинировать или смешивать S- и D-сигналы (как представлено в HOA-коэффициентах 11'), чтобы получать моноаудиовывод для воспроизведения. В примере моноаудиосистемы, система воспроизведения может добавлять сведенный моноаудиовывод в один или более каналов переднего плана (если существуют какие-либо каналы переднего плана) с тем, чтобы формировать аудиовывод.
[105] Относительно некоторых существующих кодеров с поддержкой UHJ, сигналы обрабатываются в матрице фазных амплитуд, чтобы восстанавливать набор сигналов, который напоминает B-формат. В большинстве случаев, сигнал фактически представляет собой B-формат, но в случае двухканального UHJ, доступно недостаточно информации для того, чтобы иметь возможность восстанавливать истинный сигнал в B-формате, а вместо этого, сигнал, который демонстрирует аналогичные характеристики сигналу в B-формате. Информация затем передается в амплитудную матрицу, которая развертывает сигналы подачи в динамики через набор обрезных фильтров, которые повышают точность и производительность декодера в меньших окружениях прослушивания (они могут опускаться в более крупномасштабных вариантах применения). Амбиофония спроектирована с возможностью подходить к фактическим помещениям (например, гостиным) и практическим позициям динамиков: множество таких помещений являются прямоугольными, и как результат, базовая система спроектирована с возможностью декодировать в четыре громкоговорителя в прямоугольнике, со сторонами между 1:2 (ширина в два раз превышает длину) и 2:1 (длина в два раз превышает ширину) по длине, в силу этого подходя к большинству таких помещений. Управление схемой размещения, в общем, предоставляется, чтобы обеспечивать возможность конфигурирования декодера для позиций громкоговорителей. Управление схемой размещения является аспектом амбиофонического воспроизведения, который отличается от других систем объемного звучания: декодер может быть сконфигурирован, в частности, для размера и схемы размещения массива динамиков. Управление схемой размещения может принимать форму поворотной ручки, 2-стороннего (1:2,2:1) или 3-стороннего (1:2,1:1,2:1) переключателя. Четыре динамика являются минимумом, требуемым для горизонтального декодирования объемного звучания, и хотя схема размещения с четырьмя динамиками может быть подходящей для нескольких окружений прослушивания, большие пространства могут требовать большего числа динамиков для того, чтобы обеспечивать полную локализацию объемного звучания.
[106] Пример вычислений, которые модуль 81 повторной корреляции может выполнять относительно применения UHJ-матрицы (например, обратной UHJ-матрицы или обратного фазового преобразования) в качестве преобразования с повторной корреляцией, упоминается ниже:
[107] UHJ-декодирование:
преобразование Left и Right в S и D:
S=Left+Right
D=Left-Right
W=(0,982*S)+0,197*imag(hilbert((0,828*D)+(0,768*T)));
X=(0,419*S)-imag(hilbert((0,828*D)+(0,768*T)));
Y=(0,796*D)-0,676*T+imag(hilbert(0,187*S));
Z=(1,023*Q);
[108] В некоторых примерных реализациях вышеприведенных вычислений, допущения относительно вышеприведенных вычислений могут включать в себя следующее: фоновый HOA-канал является амбиофоническим первого порядка, FuMa-нормализованным, в порядке нумерации каналов на основе амбиофонии W(a00), X(a11), Y(a11-), Z(a10).
[109] Пример вычислений, которые модуль 81 повторной корреляции может выполнять относительно применения UHJ-матрицы (или обратного фазового преобразования) в качестве преобразования с повторной корреляцией, упоминается ниже:
[110] UHJ-декодирование:
преобразование Left и Right в S и D:
преобразование Left и Right в S и D:
S=Left+Right;
D=Left-Right;
h1=imag(hilbert(1,014088753512236*D+T));
h2=imag(hilbert(0,229027290950227*S));
W=0,982*S+0,160849826442762*h1;
X=0,513168101113076*S-h1;
Y=0,974896917627705*D-0,880208333333333*T+h2;
Z=Q;
[111] В некоторых реализациях вышеприведенных вычислений, допущения относительно вышеприведенных вычислений могут включать в себя следующее: фоновый HOA-канал является амбиофоническим первого порядка, N3D-(или "полное три D") нормализованным, в порядке нумерации каналов на основе амбиофонии W(a00), X(a11), Y(a11-), Z(a10). Хотя описывается в данном документе относительно N3D-нормализации, следует принимать во внимание, что примерные вычисления также могут применяться к фоновым HOA-каналам, которые являются SN3D-нормализованными (или "полунормализованными по Шмидту"). Как описано выше относительно фиг. 4, N3D- и SN3D-нормализация может различаться с точки зрения используемых коэффициентов масштабирования. Примерное представление коэффициентов масштабирования, используемых в N3D-нормализации, описывается выше относительно фиг. 4. Примерное представление весовых коэффициентов, используемых в SN3D-нормализации, описывается выше относительно фиг. 4.
[112] В некоторых примерах, HOA-коэффициенты 47' после энергетической компенсации могут представлять только горизонтальную схему размещения, к примеру, аудиоданные, которые не включают в себя вертикальные каналы. В этих примерах, модуль 81 повторной корреляции не может выполнять вышеприведенные вычисления относительно Z-сигнала, поскольку Z-сигнал представляет вертикальные направленные аудиоданные. Вместо этого, в этих примерах, модуль 81 повторной корреляции может выполнять вышеприведенные вычисления только относительно W-, X- и Y-сигналов, поскольку W-, X- и Y-сигналы представляют горизонтальные направленные данные. В некоторых примерах, в которых HOA-коэффициенты 47' после энергетической компенсации представляют аудиоданные, которые должны преобразовываться посредством рендеринга в системе воспроизведения монофонического аудио, модуль 81 повторной корреляции может только извлекать W-сигнал из вышеприведенных вычислений. Более конкретно, поскольку результирующий W-сигнал представляет моноаудиоданные, W-сигнал может предоставлять все данные, требуемые, когда HOA-коэффициенты 47' после энергетической компенсации представляют данные, которые должны преобразовываться посредством рендеринга в моноаудиоформате, либо когда система воспроизведения содержит моноаудиосистему.
[113] Аналогично тому, что описано выше относительно модуля 40' декорреляции устройства 20 кодирования аудио, модуль 81 повторной корреляции, в примерах, может применять UHJ-матрицу (обратную UHJ-матрицу или обратное фазовое преобразование) в сценариях, в которых HOA-коэффициенты 47' после энергетической компенсации включают в себя меньшее число фоновых каналов, но может применять матрицу мод или обратную матрицу мод (например, как описано в стандарте MPEG-H) в сценариях, в которых HOA-коэффициенты 47' после энергетической компенсации включают в себя большее число фоновых каналов.
[114] Следует понимать, что модуль 81 повторной корреляции может применять технологии, описанные в данном документе, в случаях, когда HOA-коэффициенты 47' после энергетической компенсации включают в себя каналы переднего плана, а также в случаях, когда HOA-коэффициенты 47' после энергетической компенсации не включают в себя каналы переднего плана. В качестве одного примера, модуль 81 повторной корреляции может применять технологии и/или вычисления, описанные выше, в сценарии, в котором HOA-коэффициенты 47' после энергетической компенсации включают в себя нуль (0) каналов переднего плана и восемь (8) фоновых каналов (например, в сценарии более низкой/меньшей скорости передачи битов).
[115] Устройство может дополнительно содержать интерфейс, связанный с запоминающим устройством и сконфигурированный с возможностью принимать поток битов, содержащий по меньшей мере часть амбиофонических аудиоданных, и принимать флаг UsePhaseShiftDecorr. Различные компоненты устройства 24 декодирования аудио, такие как модуль 81 повторной корреляции, могут определять синтаксический элемент, к примеру, флаг UsePhaseShiftDecorr, чтобы определять то, какой из двух способов обработки применяется для декорреляции. В случаях, когда модуль 40' декорреляции использует пространственное преобразование для декорреляции, модуль 81 повторной корреляции может определять то, что флаг UsePhaseShiftDecorr задается равным нулю.
[116] В случаях, если модуль 81 повторной корреляции определяет то, что флаг UsePhaseShiftDecorr задается равным единице, модуль 81 повторной корреляции может определять то, что повторная корреляция должна выполняться с использованием фазового преобразования. Если флаг UsePhaseShiftDecorr имеет значение 1, следующая обработка применяется, чтобы восстанавливать первые четыре последовательности коэффициентов HOA-компонента окружающего пространства следующим образом:
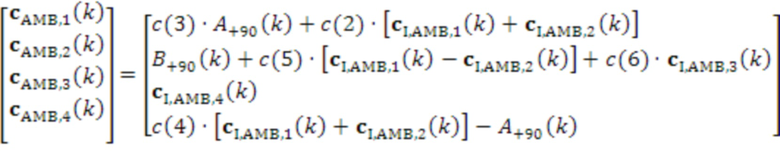 ,
,
с коэффициентами  , как задано в нижеприведенной таблице 1, и
, как задано в нижеприведенной таблице 1, и 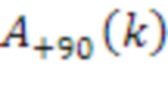 и
и 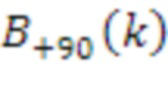 являются кадрами сигналов
являются кадрами сигналов  и
и  со сдвигом фаз на +90 градусов, заданными следующим образом:
со сдвигом фаз на +90 градусов, заданными следующим образом:
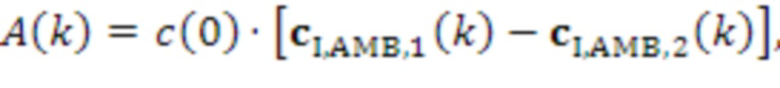
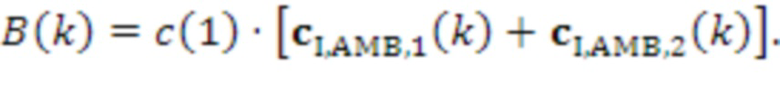
[117] Нижеприведенная таблица 2 иллюстрирует примерные коэффициенты, которые модуль 40' декорреляции может использовать для того, чтобы реализовывать фазовое преобразование.
Таблица 2. Коэффициенты для фазового преобразования
[118] В вышеприведенном уравнении, переменная обозначает HOA-коэффициенты для k-ого кадра, соответствующие сферическим базисным функциям, имеющим (порядок:подпорядок) (0:0), который также может упоминаться в качестве W-канала или компонента. Переменная обозначает HOA-коэффициенты для k-ого кадра, соответствующие сферическим базисным функциям, имеющим (порядок:подпорядок) (1:-1), который также может упоминаться в качестве Y-канала или компонента. Переменная обозначает HOA-коэффициенты для k-ого кадра, соответствующие сферическим базисным функциям, имеющим (порядок:подпорядок) (1:0), который также может упоминаться в качестве Z-канала или компонента. Переменная обозначает HOA-коэффициенты для k-ого кадра, соответствующие сферическим базисным функциям, имеющим (порядок:подпорядок) (1:1), который также может упоминаться в качестве X-канала или компонента. - могут соответствовать HOA-коэффициентам 47’ окружающего пространства.
[119] Вышеприведенное обозначение [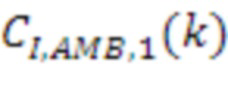 +
+ указывает то, что альтернативно упоминается в качестве S, который является эквивалентным левому каналу плюс правый канал. Переменная обозначает левый канал, сформированный в качестве результата UHJ-кодирования, в то время как переменная
указывает то, что альтернативно упоминается в качестве S, который является эквивалентным левому каналу плюс правый канал. Переменная обозначает левый канал, сформированный в качестве результата UHJ-кодирования, в то время как переменная 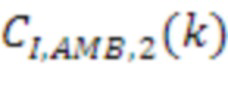 обозначает правый канал, сформированный в качестве результата UHJ-кодирования. Обозначение I в подстрочном индексе указывает то, что соответствующий канал декоррелирован (например, через применение UHJ-матрицы или фазового преобразования) от других каналов окружающего пространства. Обозначение [- указывает то, что упоминается в качестве D в ходе этого раскрытия сущности, который представляет левый канал минус правый канал. Переменная
обозначает правый канал, сформированный в качестве результата UHJ-кодирования. Обозначение I в подстрочном индексе указывает то, что соответствующий канал декоррелирован (например, через применение UHJ-матрицы или фазового преобразования) от других каналов окружающего пространства. Обозначение [- указывает то, что упоминается в качестве D в ходе этого раскрытия сущности, который представляет левый канал минус правый канал. Переменная  указывает то, что упоминается в качестве переменной T в ходе этого раскрытия сущности. Переменная
указывает то, что упоминается в качестве переменной T в ходе этого раскрытия сущности. Переменная  указывает то, что упоминается в качестве переменной Q в ходе этого раскрытия сущности
указывает то, что упоминается в качестве переменной Q в ходе этого раскрытия сущности
[120] Обозначение 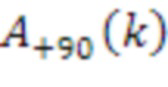 указывает положительный сдвиг
указывает положительный сдвиг 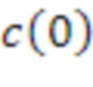 фаз на 90 градусов, умноженный на S (который также обозначается посредством переменной h1 в ходе этого раскрытия сущности). Обозначение
фаз на 90 градусов, умноженный на S (который также обозначается посредством переменной h1 в ходе этого раскрытия сущности). Обозначение 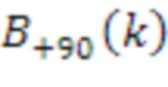 указывает положительный сдвиг
указывает положительный сдвиг 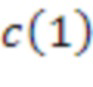 фаз на 90 градусов, умноженный на D (который также обозначается посредством переменной h2 в ходе этого раскрытия сущности).
фаз на 90 градусов, умноженный на D (который также обозначается посредством переменной h2 в ходе этого раскрытия сущности).
[121] Модуль 76 пространственно-временной интерполяции может работать способом, аналогичным способу, описанному выше относительно модуля 50 пространственно-временной интерполяции. Модуль 76 пространственно-временной интерполяции может принимать уменьшенные V[k]-векторы 55k переднего плана и выполнять пространственно-временную интерполяцию относительно V[k]-векторов 55k переднего плана и уменьшенных V[k-1]-векторов 55k-1 переднего плана, чтобы формировать интерполированные V[k]-векторы 55k'' переднего плана. Модуль 76 пространственно-временной интерполяции может перенаправлять интерполированные V[k]-векторы 55k'' переднего плана в модуль 770 постепенного нарастания/затухания.
[122] Модуль 72 извлечения также может выводить сигнал 757, указывающий то, когда один из HOA-коэффициентов окружающего пространства находится в переходном режиме в модуль 770 постепенного нарастания/затухания, который затем может определять то, какие из SHCBG 47' (причем SHCBG 47' также могут обозначаться "как HOA-каналы 47 окружающего пространства" или "HOA-коэффициенты окружающего пространства 47") и элементов интерполированных V[k]-векторов 55k'' переднего плана должны постепенно нарастать или постепенно затухать. В некоторых примерах, модуль 770 постепенного нарастания/затухания может работать противоположным образом относительно каждого из HOA-коэффициентов 47’ окружающего пространства и элементов интерполированных V[k]-векторов 55k'' переднего плана. Иными словами, модуль 770 постепенного нарастания/затухания может выполнять постепенное нарастание или постепенное затухание либо как постепенное нарастание, так и постепенное затухание относительно соответствующего одного из HOA-коэффициентов 47’ окружающего пространства, при выполнении постепенного нарастания или постепенного затухания либо как постепенного нарастания, так и постепенного затухания относительно соответствующего одного из элементов интерполированных V[k]-векторов 55k'' переднего плана. Модуль 770 постепенного нарастания/затухания может выводить отрегулированные HOA-коэффициенты 47'’ окружающего пространства в модуль 82 формулирования HOA-коэффициентов и отрегулированные V[k]-векторы 55k''' переднего плана в модуль 78 формулирования компонентов переднего плана. В этом отношении, модуль 770 постепенного нарастания/затухания представляет модуль, сконфигурированный с возможностью осуществлять операцию постепенного нарастания/затухания относительно различных аспектов HOA-коэффициентов или их производных, например, в форме HOA-коэффициентов 47’ окружающего пространства и элементов интерполированных V[k]-векторов 55k'' переднего плана.
[123] Модуль 78 формулирования компонентов переднего плана может представлять модуль, сконфигурированный с возможностью осуществлять умножение матриц относительно отрегулированных V[k]-векторов 55k''' переднего плана и интерполированных nFG-сигналов 49', чтобы формировать HOA-коэффициенты переднего плана 65. В этом отношении, модуль 78 формулирования компонентов переднего плана может комбинировать аудиообъекты 49' (что представляет собой другой способ, посредством которого можно обозначать интерполированные nFG-сигналы 49') с векторами 55k''', чтобы восстанавливать аспекты переднего плана или, другими словами, преобладающие аспекты HOA-коэффициентов 11'. Модуль 78 формулирования компонентов переднего плана может выполнять умножение матриц интерполированных nFG-сигналов 49' на отрегулированные V[k]-векторы 55k''' переднего плана.
[124] Модуль 82 формулирования HOA-коэффициентов может представлять модуль, сконфигурированный с возможностью комбинировать HOA-коэффициенты переднего плана 65 с отрегулированными HOA-коэффициентами 47’’ окружающего пространства, с тем чтобы получать HOA-коэффициенты 11'. Простое обозначение отражает то, что HOA-коэффициенты 11' могут быть аналогичными, но не идентичными HOA-коэффициентам 11. Разности между HOA-коэффициентами 11 и 11' могут получаться в результате потерь вследствие передачи по среде передачи с потерями, квантования или других операций с потерями.
[125] UHJ является способом матричного преобразования, который использован для того, чтобы создавать двухканальный стереопоток из контента на основе амбиофонии первого порядка. UHJ использован ранее для того, чтобы передавать стерео- или только горизонтальный контент объемного звучания через передающее FM-устройство. Тем не менее, следует принимать во внимание, что UHJ не ограничен использованием в передающих FM-устройствах. В схеме MPEG-H HOA-кодирования, фоновые HOA-каналы могут предварительно обрабатываться с матрицей мод, чтобы преобразовывать фоновые HOA-каналы в ортогональные точки в пространственной области. Преобразованные каналы затем перцепционно кодируются через USAC или AAC.
[126] Технологии этого раскрытия сущности, в общем, направлены на использование UHJ-преобразования (или фазового преобразования) при применении кодирования фоновых HOA-каналов вместо использования этой матрицы мод. Оба способа ((1) преобразование в пространственную область через матрицу мод, (2) UHJ-преобразование), в общем, направлены на уменьшение корреляции между фоновыми HOA-каналами, которая может приводить к (потенциально нежелательному) эффекту демаскирования шумом в декодированном звуковом поле.
[127] Таким образом, устройство 24 декодирования аудио, в примерах, может представлять устройство, сконфигурированное с возможностью получать декоррелированное представление коэффициентов амбиофонии окружающего пространства, имеющих, по меньшей мере, левый сигнал и правый сигнал, причем коэффициенты амбиофонии окружающего пространства извлекаются из множества коэффициентов амбиофонии высшего порядка и представляют фоновый компонент звукового поля, описанного посредством множества коэффициентов амбиофонии высшего порядка, при этом, по меньшей мере, один из множества коэффициентов амбиофонии высшего порядка ассоциирован со сферической базисной функцией, имеющей порядок больше первого, и формировать сигнал для подачи в динамик на основе декоррелированного представления коэффициентов амбиофонии окружающего пространства. В некоторых примерах, устройство дополнительно сконфигурировано с возможностью применять преобразование с повторной корреляцией к декоррелированному представлению коэффициентов амбиофонии окружающего пространства, чтобы получать множество коррелированных коэффициентов амбиофонии окружающего пространства.
[128] В некоторых примерах, для того чтобы применять преобразование с повторной корреляцией, устройство сконфигурировано с возможностью применять обратную UHJ-матрицу (или фазовое преобразование) к коэффициентам амбиофонии окружающего пространства. Согласно некоторым примерам, обратная UHJ-матрица (или обратное фазовое преобразование) нормализована согласно N3D-("полное три D") нормализации. Согласно некоторым примерам, обратная UHJ-матрица (или обратное фазовое преобразование) нормализована согласно SN3D-нормализации (полунормализации Шмидта).
[129] Согласно некоторым примерам, коэффициенты амбиофонии окружающего пространства ассоциированы со сферическими базисными функциями, имеющими нулевой порядок или первый порядок, и применять обратную UHJ-матрицу (или обратное фазовое преобразование), устройство сконфигурировано с возможностью осуществлять скалярное умножение UHJ-матрицы относительно декоррелированного представления коэффициентов амбиофонии окружающего пространства. В некоторых примерах, для того чтобы применять преобразование с повторной корреляцией, устройство сконфигурировано с возможностью применять обратную матрицу мод к декоррелированному представлению коэффициентов амбиофонии окружающего пространства. В некоторых примерах, для того чтобы формировать сигнал для подачи в динамик, устройство сконфигурировано с возможностью формировать, для вывода посредством системы стереовоспроизведения, сигнал для подачи в левый динамик на основе левого сигнала и сигнал для подачи в правый динамик на основе правого сигнала.
[130] В некоторых примерах, для того чтобы формировать сигнал для подачи в динамик, устройство сконфигурировано с возможностью использовать левый сигнал в качестве сигнала для подачи в левый динамик и правый сигнал в качестве сигнала для подачи в правый динамик без применения преобразования с повторной корреляцией к правому и левому сигналам. Согласно некоторым примерам, для того чтобы формировать сигнал для подачи в динамик, устройство сконфигурировано с возможностью смешивать левый сигнал и правый сигнал для вывода посредством моноаудиосистемы. Согласно некоторым примерам, для того чтобы формировать сигнал для подачи в динамик, устройство сконфигурировано с возможностью комбинировать коррелированные коэффициенты амбиофонии окружающего пространства с одним или более каналов переднего плана. При этом способ может содержать этап, на котором комбинируют посредством устройства декодирования аудио повторно коррелированные коэффициенты амбиофонии окружающего пространства с одним или более каналов переднего плана, полученными на основе одного или более пространственных компонентов.
[131] Согласно некоторым примерам, устройство дополнительно сконфигурировано с возможностью определять то, что нет доступных каналов переднего плана, с которыми можно комбинировать коррелированные коэффициенты амбиофонии окружающего пространства. В некоторых примерах, устройство дополнительно сконфигурировано с возможностью определять то, что звуковое поле должно выводиться через систему воспроизведения монофонического аудио, и декодировать, по меньшей мере, поднабор декоррелированных коэффициентов амбиофонии высшего порядка, которые включают данные для вывода посредством системы воспроизведения монофонического аудио. В некоторых примерах, устройство дополнительно сконфигурировано с возможностью получать индикатор того, что декоррелированное представление коэффициентов амбиофонии окружающего пространства декоррелировано с преобразованием с декорреляцией. Согласно некоторым примерам, устройство дополнительно включает в себя массив громкоговорителей, сконфигурированный с возможностью выводить сигнал для подачи в динамик, сформированный на основе декоррелированного представления коэффициентов амбиофонии окружающего пространства.
[132] Фиг. 5 является блок-схемой последовательности операций способа, иллюстрирующей примерную работу устройства кодирования аудио, такого как устройство 20 кодирования аудио, показанное в примере по фиг. 3, при выполнении различных аспектов осуществления векторного синтеза, описанных в этом раскрытии сущности. Первоначально, устройство 20 кодирования аудио принимает HOA-коэффициенты 11 (106). Устройство 20 кодирования аудио может активировать LIT-модуль 30, который может применять LIT относительно HOA-коэффициентов для того, чтобы выводить преобразованные HOA-коэффициенты (например, в случае SVD, преобразованные HOA-коэффициенты могут содержать US[k]-векторы 33 и V[k]-векторы 35) (107).
[133] Устройство 20 кодирования аудио затем может активировать модуль 32 вычисления параметров, чтобы выполнять вышеописанный анализ относительно любой комбинации US[k]-векторов 33, US[k-1]-векторов 33, V[k]- и/или V[k-1]-векторов 35, чтобы идентифицировать различные параметры способом, описанным выше. Иными словами, модуль 32 вычисления параметров может определять, по меньшей мере, один параметр на основе анализа преобразованных HOA-коэффициентов 33/35 (108).
[134] Устройство 20 кодирования аудио затем может активировать модуль 34 переупорядочения, который может переупорядочивать преобразованные HOA-коэффициенты (которые, снова в контексте SVD, могут означать US[k]-векторы 33 и V[k]-векторы 35) на основе параметра, чтобы формировать переупорядоченные преобразованные HOA-коэффициенты 33'/35' (или, другими словами, US[k]-векторы 33' и V[k]-векторы 35'), как описано выше (109). Устройство 20 кодирования аудио, в ходе любой из вышеприведенных операций или последующих операций, также может активировать модуль 44 анализа звукового поля. Модуль 44 анализа звукового поля, как описано выше, может выполнять анализ звукового поля относительно HOA-коэффициентов 11 и/или преобразованных HOA-коэффициентов 33/35, чтобы определять общее число (nFG) 45 каналов переднего плана, порядок (NBG) фонового звукового поля и число (nBGa) и индексы (i) дополнительных BG HOA-каналов для отправки (что может совместно обозначаться как информация 43 фоновых каналов в примере по фиг. 3) (109).
[135] Устройство 20 кодирования аудио также может активировать модуль 48 выбора фоновых компонентов. Модуль 48 выбора фоновых компонентов может определять фоновые или HOA-коэффициенты окружающего пространства 47 на основе информации 43 фоновых каналов (110). Устройство 20 кодирования аудио дополнительно может активировать модуль 36 выбора переднего плана, который может выбирать переупорядоченные US[k]-векторы 33' и переупорядоченные V[k]-векторы 35', которые представляют компоненты переднего плана или отличительные компоненты звукового поля на основе nFG 45 (которые могут представлять один или более индексов, идентифицирующих векторы переднего плана) (112).
[136] Устройство 20 кодирования аудио может активировать модуль 38 энергетической компенсации. Модуль 38 энергетической компенсации может выполнять энергетическую компенсацию относительно HOA-коэффициентов 47 окружающего пространства, чтобы компенсировать энергетические потери вследствие удаления различных HOA-коэффициентов посредством модуля 48 выбора фоновых компонентов (114) и за счет этого формировать HOA-коэффициенты 47' окружающего пространства после энергетической компенсации.
[137] Устройство 20 кодирования аудио также может активировать модуль 50 пространственно-временной интерполяции. Модуль 50 пространственно-временной интерполяции может выполнять пространственно-временную интерполяцию относительно переупорядоченных преобразованных HOA-коэффициентов 33'/35', чтобы получать интерполированные сигналы 49' переднего плана (которые также могут упоминаться в качестве "интерполированных nFG-сигналов 49'") и оставшуюся направленную информацию 53 переднего плана (которая также может упоминаться в качестве "V[k]-векторов 53") (116). Устройство 20 кодирования аудио затем может активировать модуль 46 уменьшения числа коэффициентов. Модуль 46 уменьшения числа коэффициентов может выполнять уменьшение числа коэффициентов относительно оставшихся V[k]-векторов переднего плана 53 на основе информации 43 фоновых каналов, чтобы получать уменьшенную направленную информацию 55 переднего плана (которая также может упоминаться в качестве уменьшенных V[k]-векторов 55 переднего плана) (118).
[138] Устройство 20 кодирования аудио затем может активировать модуль 52 квантования для того, чтобы сжимать, способом, описанным выше, уменьшенные V[k]-векторы 55 переднего плана и формировать кодированные V[k]-векторы 57 переднего плана (120). Устройство 20 кодирования аудио также может активировать модуль 40' декорреляции для того, чтобы применять декорреляцию со сдвигом фаз, чтобы уменьшать или исключать корреляцию между фоновыми сигналами HOA-коэффициентов 47', чтобы формировать один или более декоррелированных HOA-коэффициентов 47'' (121).
[139] Устройство 20 кодирования аудио также может активировать модуль 40 психоакустического аудиокодера. Модуль 40 психоакустического аудиокодера может психоакустически кодировать каждый вектор HOA-коэффициентов 47’ окружающего пространства после энергетической компенсации и интерполированных nFG-сигналов 49', чтобы формировать кодированные HOA-коэффициенты окружающего пространства 59 и кодированные nFG-сигналы 61. Устройство кодирования аудио затем может активировать модуль 42 формирования потоков битов. Модуль 42 формирования потоков битов может формировать поток 21 битов на основе кодированной направленной информации 57 переднего плана, кодированных HOA-коэффициентов 59 окружающего пространства, кодированных nFG-сигналов 61 и информации 43 фоновых каналов.
[140] Фиг. 6 является блок-схемой последовательности операций способа, иллюстрирующей примерную работу устройства декодирования аудио, такого как устройство 24 декодирования аудио, показанное на фиг. 4, при выполнении различных аспектов технологий, описанных в этом раскрытии сущности. Первоначально, устройство 24 декодирования аудио может принимать поток 21 битов (130). При приеме потока битов, устройство 24 декодирования аудио может активировать модуль 72 извлечения. При условии, для целей пояснения, что поток 21 битов указывает то, что должно выполняться векторное восстановление, модуль 72 извлечения может синтаксически анализировать поток битов, чтобы извлекать вышеуказанную информацию, передавая информацию в модуль 92 векторного восстановления.
[141] Другими словами, модуль 72 извлечения может извлекать кодированную направленную информацию 57 переднего плана (которая, снова, также может упоминаться в качестве кодированных V[k]-векторов 57 переднего плана), кодированные HOA-коэффициенты окружающего пространства 59 и кодированные сигналы переднего плана (которые также могут упоминаться в качестве кодированных nFG-сигналов 59 переднего плана или кодированных аудиообъектов 59 переднего плана) из потока 21 битов способом, описанным выше (132).
[142] Устройство 24 декодирования аудио дополнительно может активировать модуль 74 деквантования. Модуль 74 деквантования может энтропийно декодировать и деквантовать кодированную направленную информацию 57 переднего плана, чтобы получать уменьшенную направленную информацию 55k переднего плана (136). Устройство 24 декодирования аудио может активировать модуль 81 повторной корреляции. Модуль 81 повторной корреляции может применять одно или более преобразований с повторной корреляцией к HOA-коэффициентам 47’ окружающего пространства после энергетической компенсации, чтобы получать один или более повторно коррелированных HOA-коэффициентов 47'' (или коррелированных HOA-коэффициентов 47''), и может передавать коррелированные HOA-коэффициенты 47'' в модуль 82 формулирования HOA-коэффициентов (необязательно через модуль 770 постепенного нарастания/затухания) (137). Устройство 24 декодирования аудио также может активировать модуль 80 психоакустического декодирования. Модуль 80 психоакустического декодирования аудио может декодировать кодированные HOA-коэффициенты окружающего пространства 59 и кодированные сигналы 61 переднего плана, чтобы получать HOA-коэффициенты 47' окружающего пространства после энергетической компенсации и интерполированные сигналы 49' переднего плана (138). Модуль 80 психоакустического декодирования может передавать HOA-коэффициенты 47' окружающего пространства после энергетической компенсации в модуль 770 постепенного нарастания/затухания и nFG-сигналы 49' в модуль 78 формулирования компонентов переднего плана.
[143] Устройство 24 декодирования аудио затем может активировать модуль 76 пространственно-временной интерполяции. Модуль 76 пространственно-временной интерполяции может принимать переупорядоченную направленную информацию 55k' переднего плана и выполнять пространственно-временную интерполяцию относительно уменьшенной направленной информации 55k/55k-1 переднего плана, чтобы формировать интерполированную направленную информацию 55k'' переднего плана (140). Модуль 76 пространственно-временной интерполяции может перенаправлять интерполированные V[k]-векторы 55k'' переднего плана в модуль 770 постепенного нарастания/затухания.
[144] Устройство 24 декодирования аудио может активировать модуль 770 постепенного нарастания/затухания. Модуль 770 постепенного нарастания/затухания может принимать или иным образом получать синтаксические элементы (например, из модуля 72 извлечения), указывающие то, когда HOA-коэффициенты 47' окружающего пространства после энергетической компенсации находится в переходном режиме (например, синтаксический элемент AmbCoeffTransition). Модуль 770 постепенного нарастания/затухания, на основе синтаксических элементов перехода и поддерживаемой информации переходного состояния, может обеспечивать постепенное нарастание или постепенное затухание HOA-коэффициентов 47’ окружающего пространства после энергетической компенсации, выводя отрегулированные HOA-коэффициенты 47'’ окружающего пространства в модуль 82 формулирования HOA-коэффициентов. Модуль 770 постепенного нарастания/затухания также может, на основе синтаксических элементов и поддерживаемой информации переходного состояния, обеспечивать постепенное затухание или постепенное нарастание соответствующего одного или более элементов интерполированных V[k]-векторов 55k'' переднего плана, выводя отрегулированные V[k]-векторы 55k''' переднего плана в модуль 78 формулирования компонентов переднего плана (142).
[145] Устройство 24 декодирования аудио может активировать модуль 78 формулирования компонентов переднего плана. Модуль 78 формулирования компонентов переднего плана может выполнять умножение матриц nFG-сигналов 49' на отрегулированную направленную информацию 55k''' переднего плана, чтобы получать HOA-коэффициенты переднего плана 65 (144). Устройство 24 декодирования аудио также может активировать модуль 82 формулирования HOA-коэффициентов. Модуль 82 формулирования HOA-коэффициентов может суммировать HOA-коэффициенты переднего плана 65 с отрегулированными HOA-коэффициентами 47’’ окружающего пространства, с тем чтобы получать HOA-коэффициенты 11' (146).
[146] Фиг. 6B является блок-схемой последовательности операций способа, иллюстрирующей примерную работу устройства кодирования аудио и устройства декодирования аудио в технологиях выполнения кодирования, описанных в этом раскрытии сущности. Фиг. 6B является процессом 160 кодирования и декодирования блок-схемы последовательности операций способа, иллюстрирующей пример, в соответствии с одним или более аспектов этого раскрытия сущности. Хотя процесс 160 может выполняться посредством множества устройств, для простоты пояснения, процесс 160 описывается в данном документе относительно устройства 20 кодирования аудио и устройства 24 декодирования аудио, описанных выше. Секции кодирования и декодирования процесса 160 разграничены с использованием пунктирной линии на фиг. 6B. Процесс 160 может начинаться с одного или более компонентов устройства 20 кодирования аудио (например, модуля 36 выбора переднего плана и модуля 48 выбора фоновых компонентов), формирующих каналы переднего плана 164 и фоновые HOA-каналы 166 первого порядка из HOA-ввода с использованием пространственного HOA-кодирования (162). В свою очередь, модуль 40' декорреляции может применять преобразование с декорреляцией (например, в форме фазового преобразования с декорреляцией или матрицы) в HOA-коэффициенты 47' окружающего пространства после энергетической компенсации. Более конкретно, устройство 20 кодирования аудио может применять UHJ-матрицу или фазовое преобразование с декорреляцией (например, посредством скалярного умножения) в HOA-коэффициенты 47' окружающего пространства после энергетической компенсации (168).
[147] В некоторых примерах, модуль 40' декорреляции может применять UHJ-матрицу (или фазовое преобразование), если модуль 40' декорреляции, в случаях, когда модуль 40' декорреляции определяет то, что фоновые HOA-каналы включают в себя меньшее число каналов (например, четыре). С другой стороны, в этих примерах, если модуль 40' декорреляции определяет то, что фоновые HOA-каналы включают в себя большее число каналов (например, девять), устройство 20 кодирования аудио может выбирать и применять преобразование с декорреляцией, отличающееся от UHJ-матрицы (к примеру, матрицы мод, описанной в стандарте MPEG-H), к фоновым HOA-каналам. Посредством применения преобразования с декорреляцией (например, UHJ-матрица) к фоновым HOA-каналам, устройство 20 кодирования аудио может получать декоррелированные фоновые HOA-каналы.
[148] Как показано на фиг. 6B, устройство 20 кодирования аудио (например, посредством активации модуля 40 психоакустического аудиокодера) может применять временное кодирование (например, посредством применения AAC и/или USAC) к декоррелированным фоновым HOA-сигналам (170) и к любым каналам переднего плана (166). Следует принимать во внимание, что в некоторых сценариях, модуль 40 психоакустического аудиокодера может определять то, что число каналов переднего плана может составлять нуль (т.е. в этих сценариях, модуль 40 психоакустического аудиокодера не может получать каналы переднего плана из HOA-ввода). Поскольку AAC и/или USAC может не быть оптимизирован или не подходить в других отношениях к стереоаудиоданным, модуль 40' декорреляции может применять матрицу декорреляции для того, чтобы уменьшать или исключать корреляцию между фоновыми HOA-каналами. Уменьшенная корреляция, показанная в декоррелированных фоновых HOA-каналах, предоставляет потенциальное преимущество сокращения или исключения демаскирования шумом на стадии временного AAC/USAC-кодирования, поскольку AAC и USAC не может быть оптимизирован для стереоаудиоданных.
[149] В свою очередь, устройство 24 декодирования аудио может выполнять временное декодирование кодированного потока битов, выводимого посредством устройства 20 кодирования аудио. В примере процесса 160, один или более компонентов устройства 24 декодирования аудио (например, модуль 80 психоакустического декодирования) могут выполнять временное декодирование отдельно относительно каналов переднего плана (если какие-либо каналы переднего плана включены в поток битов) (172) и фоновых каналов (174). Дополнительно, модуль 81 повторной корреляции может применять преобразование с повторной корреляцией к временно декодированным фоновым HOA-каналам. В качестве примера, модуль 81 повторной корреляции может применять преобразование с декорреляцией взаимно-обратным способом к модулю 40' декорреляции. Например, как описано в конкретном примере процесса 160, модуль 81 повторной корреляции может применять UHJ-матрицу или фазовое преобразование ко временно декодированным фоновым HOA-сигналам (176).
[150] В некоторых примерах, модуль 81 повторной корреляции может применять UHJ-матрицу или фазовое преобразование, если модуль 81 повторной корреляции определяет то, что временно декодированные фоновые HOA-каналы включают в себя меньшее число каналов (например, четыре). С другой стороны, в этих примерах, если модуль 81 повторной корреляции определяет то, что временно декодированные фоновые HOA-каналы включают в себя большее число каналов (например, девять), модуль 81 повторной корреляции может выбирать и применять преобразование с декорреляцией, отличающееся от UHJ-матрицы (к примеру, матрицу мод, описанную в стандарте MPEG-H), к фоновым HOA-каналам.
[151] Дополнительно, модуль 82 формулирования HOA-коэффициентов может выполнять пространственное декодирование HOA коррелированных фоновых HOA-каналов и любых доступных декодированных каналов переднего плана (178). В свою очередь, модуль 82 формулирования HOA-коэффициентов может преобразовывать посредством рендеринга декодированные аудиосигналы в одно или более устройств вывода (180), таких как громкоговорители и/или наушники (включающих в себя, но только, устройства вывода со стереохарактеристиками или характеристиками объемного звука).
[152] Вышеприведенные технологии могут выполняться относительно любого числа различных контекстов и аудиоэкосистем. Ниже описывается ряд примерных контекстов, хотя технологии должны быть ограничены примерными контекстами. Одна примерная аудиоэкосистема может включать в себя аудиоконтент, киностудии, музыкальные студии, игровые студии звукозаписи, канально-ориентированный аудиоконтент, механизмы кодирования, игровые аудиостемы, механизмы кодирования/рендеринга игрового аудио и системы доставки.
[153] Киностудии, музыкальные студии и игровые студии звукозаписи могут принимать аудиоконтент. В некоторых примерах, аудиоконтент может представлять вывод получения. Киностудии могут выводить канально-ориентированный аудиоконтент (например, в 2.0, 5.1 и 7.1), к примеру, посредством использования цифровой звуковой рабочей станции (DAW). Музыкальные студии могут выводить канально-ориентированный аудиоконтент (например, в 2.0 и 5.1), к примеру, посредством использования DAW. В любом случае, механизмы кодирования могут принимать и кодировать канально-ориентированный аудиоконтент на основе одного или более кодеков (например, AAC, AC3, Dolby True HD, Dolby Digital Plus и DTS Master Audio) для вывода посредством систем доставки. Игровые студии звукозаписи могут выводить один или более игровых аудиостемов, к примеру, посредством использования DAW. Механизмы кодирования/рендеринга игрового аудио могут кодировать и/или преобразовывать посредством рендеринга аудиостемы в канально-ориентированный аудиоконтент для вывода посредством систем доставки. Другой примерный контекст, в котором могут выполняться технологии, содержит аудиоэкосистему, которая может включать в себя аудиообъекты для широковещательной записи, профессиональные аудиосистемы, потребительскую реализованную на устройстве систему захвата, HOA-аудиоформат, реализованную на устройстве систему рендеринга, потребительское аудиооборудование, телевизоры и вспомогательные средства и автомобильные аудиосистемы.
[154] Аудиообъекты для широковещательной записи, профессиональные аудиосистемы и потребительские реализованные на устройстве системы захвата могут кодировать свой вывод с использованием HOA-аудиоформата. Таким образом, аудиоконтент может кодироваться с использованием HOA-аудиоформата в одно представление, которое может воспроизводиться с использованием реализованной на устройстве системы рендеринга, потребительского аудиооборудования, телевизоров и вспомогательных средств и автомобильных аудиосистем. Другими словами, одно представление аудиоконтента может воспроизводиться в общей системе воспроизведения аудио (т.е. в противоположность необходимости конкретной конфигурации, к примеру, 5.1, 7.1 и т.д.), к примеру, в системе 16 воспроизведения аудио.
[155] Другие примеры контекста, в котором могут выполняться технологии, включают в себя аудиоэкосистему, которая может включать в себя элементы получения и элементы воспроизведения. Элементы получения могут включать в себя устройства проводного и/или беспроводного получения (например, собственные микрофоны), реализованные на устройстве системы захвата объемного звука и мобильные устройства (например, смартфоны и планшеты). В некоторых примерах, устройства проводного и/или беспроводного получения могут соединяться с мобильным устройством через канал(ы) проводной и/или беспроводной связи.
[156] В соответствии с одной или более технологий этого раскрытия сущности, мобильное устройство может использоваться для того, чтобы получать звуковое поле. Например, мобильное устройство может получать звуковое поле через устройства проводного и/или беспроводного получения и/или реализованную на устройстве систему захвата объемного звука (например, множество микрофонов, интегрированных в мобильное устройство). Мобильное устройство затем может кодировать полученное звуковое поле в HOA-коэффициенты для воспроизведения посредством одного или более элементов воспроизведения. Например, пользователь мобильного устройства может записывать (получать звуковое поле) передаваемое вживую событие (например, встречу, конференцию, матч, концерт и т.д.) и кодировать запись в HOA-коэффициенты.
[157] Мобильное устройство также может использовать один или более элементов воспроизведения для того, чтобы воспроизводить HOA-кодированное звуковое поле. Например, мобильное устройство может декодировать HOA-кодированное звуковое поле и выводить в один или более элементов воспроизведения сигнал, который инструктирует одному или более элементов воспроизведения воссоздавать звуковое поле. В качестве одного примера, мобильное устройство может использовать каналы беспроводной и/или беспроводной связи для того, чтобы выводить сигнал в один или более динамиков (например, в массивы динамиков, в звуковые панели и т.д.). В качестве другого примера, мобильное устройство может использовать решения на основе пристыковки, чтобы выводить сигнал в одну или более стыковочных станций и/или в один или более пристыкованных динамиков (например, в аудиосистемы в интеллектуальных автомобилях и/или домах). В качестве другого примера, мобильное устройство может использовать рендеринг для наушников, чтобы выводить сигнал в набор наушников, например, с тем чтобы создавать реалистичный бинауральный звук.
[158] В некоторых примерах, конкретное мобильное устройство может как получать трехмерное звуковое поле, так и воспроизводить идентичное трехмерное звуковое поле позднее. В некоторых примерах, мобильное устройство может получать трехмерное звуковое поле, кодировать трехмерное звуковое поле в HOA и передавать кодированное трехмерное звуковое поле в одно или более других устройств (например, в другие мобильные устройства и/или другие немобильные устройства) для воспроизведения.
[159] Еще один другой контекст, в котором могут выполняться технологии, включает в себя аудиоэкосистему, которая может включать в себя аудиоконтент, игровые студии, кодированный аудиоконтент, механизмы рендеринга и системы доставки. В некоторых примерах, игровые студии могут включать в себя одну или более DAW, которые могут поддерживать редактирование HOA-сигналов. Например, одна или более DAW могут включать в себя подключаемые HOA-модули и/или инструментальные средства, которые могут быть сконфигурированы с возможностью работать (например, взаимодействовать) с одной или более игровых аудиосистем. В некоторых примерах, игровые студии могут выводить новые форматы стемов, которые поддерживают HOA. В любом случае, игровые студии могут выводить кодированный аудиоконтент в механизмы рендеринга, которые могут преобразовывать посредством рендеринга звуковое поле для воспроизведения посредством систем доставки.
[160] Технологии также могут выполняться относительно примерных устройств получения аудио. Например, технологии могут выполняться относительно собственного микрофона, который может включать в себя множество микрофонов, которые совместно сконфигурированы с возможностью записывать трехмерное звуковое поле. В некоторых примерах, множество микрофонов из собственного микрофона может быть расположено на поверхности практически сферического шара с радиусом приблизительно в 4 см. В некоторых примерах, устройство 20 кодирования аудио может быть интегрировано в собственный микрофон, с тем чтобы выводить поток 21 битов непосредственно из микрофона.
[161] Другой примерный контекст получения аудио может включать в себя производственную станцию, которая может быть сконфигурирована с возможностью принимать сигнал из одного или более микрофонов, к примеру, одного или более собственных микрофонов. Производственная станция также может включать в себя аудиокодер, к примеру, аудиокодер 20 по фиг. 3.
[162] Мобильное устройство, в некоторых случаях, также может включать в себя множество микрофонов, которые совместно сконфигурированы с возможностью записывать трехмерное звуковое поле. Другими словами, множество микрофона может иметь разнесение X, Y, Z. В некоторых примерах, мобильное устройство может включать в себя микрофон, который может поворачиваться, чтобы предоставлять разнесение X, Y, Z относительно одного или более других микрофонов мобильного устройства. Мобильное устройство также может включать в себя аудиокодер, к примеру, аудиокодер 20 по фиг. 3.
[163] Устройство видеозахвата повышенной прочности дополнительно может быть сконфигурировано с возможностью записывать трехмерное звуковое поле. В некоторых примерах, устройство видеозахвата повышенной прочности может присоединяться к шлему пользователя, занимающегося активным отдыхом. Например, устройство видеозахвата повышенной прочности может присоединяться к шлему пользователя, участвующего в рафтинге на реке с порогами. Таким образом, устройство видеозахвата повышенной прочности может захватывать трехмерное звуковое поле, которое представляет все действия вокруг пользователя (например, вода, грохочущая позади пользователя, другой рафтер, говорящий перед пользователем, и т.д.).
[164] Технологии также могут выполняться относительно мобильного устройства с улучшенными вспомогательными средствами, которое может быть сконфигурировано с возможностью записывать трехмерное звуковое поле. В некоторых примерах, мобильное устройство может быть аналогичным мобильным устройствам, поясненным выше, с добавлением одного или более вспомогательных средств. Например, собственный микрофон может присоединяться к вышеуказанному мобильному устройству, чтобы формировать мобильное устройство с улучшенными вспомогательными средствами. Таким образом, мобильное устройство с улучшенными вспомогательными средствами может захватывать более высококачественную версию трехмерного звукового поля, чем при использовании только компонентов захвата звука, неразъемно установленных в мобильном устройстве с улучшенными вспомогательными средствами.
[165] Примерные устройства воспроизведения аудио, которые могут выполнять различные аспекты технологий, описанных в этом раскрытии сущности, дополнительно пояснены ниже. В соответствии с одной или более технологий этого раскрытия сущности, динамики и/или звуковые панели могут размещаться в любой произвольной конфигурации при одновременном воспроизведении трехмерного звукового поля. Кроме того, в некоторых примерах, устройства воспроизведения с наушниками могут соединяться с декодером 24 через проводное или через беспроводное соединение. В соответствии с одной или более технологий этого раскрытия сущности, одно общее представление звукового поля может быть использовано для того, чтобы преобразовывать посредством рендеринга звуковое поле для любой комбинации динамиков, звуковых панелей и устройств воспроизведения с наушниками.
[166] Ряд других примерных окружений воспроизведения аудио также могут быть подходящими для выполнения различных аспектов технологий, описанных в этом раскрытии сущности. Например, окружение воспроизведения с помощью 5.1-динамиков, окружение воспроизведения с помощью 2,0-(например, стерео-) динамиков, окружение воспроизведения с помощью 9.1-динамиков с полновысотными передними громкоговорителями, окружение воспроизведения с помощью 22.2-динамиков, окружение воспроизведения с помощью 16.0-динамиков, окружение воспроизведения с помощью автомобильных динамиков и мобильное устройство с окружением воспроизведения с помощью наушников-вкладышей могут представлять собой подходящие окружения для выполнения различных аспектов технологий, описанных в этом раскрытии сущности.
[167] В соответствии с одной или более технологий этого раскрытия сущности, одно общее представление звукового поля может быть использовано для того, чтобы преобразовывать посредством рендеринга звуковое поле в любом из вышеприведенных окружений воспроизведения. Дополнительно, технологии этого раскрытия сущности обеспечивают возможность модулю рендеринга преобразовывать посредством рендеринга звуковое поле из общего представления для воспроизведения в окружениях воспроизведения, отличных от окружений воспроизведения, описанных выше. Например, если конструктивные соображения запрещают надлежащее размещение динамиков согласно окружению воспроизведения с помощью 7.1-динамиков (например, если невозможно размещать правый динамик объемного звучания), технологии этого раскрытия сущности обеспечивают возможность модулю рендеринга выполнять компенсацию с использованием других 6 динамиков, так что воспроизведение может достигаться в окружении воспроизведения с помощью 6.1-динамиков.
[168] Кроме того, пользователь может смотреть спортивную игру с надетыми наушниками. В соответствии с одной или более технологий этого раскрытия сущности, может получаться трехмерное звуковое поле спортивной игры (например, один или более собственных микрофонов могут быть размещены в и/или вокруг бейсбольного стадиона), HOA-коэффициенты, соответствующие трехмерному звуковому полю, могут получаться и передаваться в декодер, декодер может восстанавливать трехмерное звуковое поле на основе HOA-коэффициентов и выводить восстановленное трехмерное звуковое поле в модуль рендеринга, модуль рендеринга может получать индикатор в отношении типа окружения воспроизведения (например, наушники) и преобразовывать посредством рендеринга восстановленное трехмерное звуковое поле в сигналы, которые инструктируют наушникам выводить представление трехмерного звукового поля спортивной игры.
[169] В каждом из различных случаев, описанных выше, следует понимать, что устройство 20 кодирования аудио может осуществлять способ или в ином случае содержать средство для того, чтобы выполнять каждый этап способа, который устройство 20 кодирования аудио сконфигурировано с возможностью осуществлять. В некоторых случаях, средство может содержать один или более процессоров. В некоторых случаях, один или более процессоров могут представлять процессор специального назначения, сконфигурированный посредством инструкций, сохраненных на энергонезависимом машиночитаемом носителе хранения данных. Другими словами, различные аспекты технологий в каждом из наборов примеров кодирования могут предоставлять энергонезависимый машиночитаемый носитель хранения данных, имеющий сохраненные инструкции, которые при выполнении инструктируют одному или более процессоров осуществлять способ, который устройство 20 кодирования аудио сконфигурировано с возможностью осуществлять.
[170] В одном или более примеров, описанные функции могут быть реализованы в аппаратных средствах, программном обеспечении, микропрограммном обеспечении или любой комбинации вышеозначенного. При реализации в программном обеспечении, функции могут быть сохранены или переданы, в качестве одной или более инструкций или кода, по машиночитаемому носителю и выполнены посредством аппаратного модуля обработки. Машиночитаемые носители могут включать в себя машиночитаемые носители хранения данных, которые соответствуют материальному носителю, к примеру, носители хранения данных. Носители хранения данных могут представлять собой любые доступные носители, к которым может осуществляться доступ посредством одного или более компьютеров или одного или более процессоров, с тем чтобы извлекать инструкции, код и/или структуры данных для реализации технологий, описанных в этом раскрытии сущности. Компьютерный программный продукт может включать в себя машиночитаемый носитель.
[171] Аналогично, в каждом из различных случаев, описанных выше, следует понимать, что устройство 24 декодирования аудио может осуществлять способ или в ином случае содержать средство выполнять каждый этап способа, который устройство 24 декодирования аудио сконфигурировано с возможностью осуществлять. В некоторых случаях, средство может содержать один или более процессоров. В некоторых случаях, один или более процессоров могут представлять процессор специального назначения, сконфигурированный посредством инструкций, сохраненных на энергонезависимом машиночитаемом носителе хранения данных. Другими словами, различные аспекты технологий в каждом из наборов примеров кодирования могут предоставлять энергонезависимый машиночитаемый носитель хранения данных, имеющий сохраненные инструкции, которые при выполнении инструктируют одному или более процессоров осуществлять способ, который устройство 24 декодирования аудио сконфигурировано с возможностью осуществлять.
[172] В качестве примера, а не ограничения, эти машиночитаемые носители хранения данных могут содержать RAM, ROM, EEPROM, CD-ROM или другое устройство хранения на оптических дисках, устройство хранения на магнитных дисках или другие магнитные устройства хранения, флэш-память либо любой другой носитель, который может быть использован для того, чтобы сохранять требуемый программный код в форме инструкций или структур данных, и к которому можно осуществлять доступ посредством компьютера. Тем не менее, следует понимать, что машиночитаемые носители хранения данных и носители хранения данных не включают в себя соединения, несущие, сигналы или другие энергозависимые носители, а вместо этого направлены на энергонезависимые материальные носители хранения данных. Диск (disk) и диск (disc) при использовании в данном документе включают в себя компакт-диск (CD), лазерный диск, оптический диск, универсальный цифровой диск (DVD), гибкий диск и диск Blu-Ray, при этом диски (disk) обычно воспроизводят данные магнитно, тогда как диски (disc) обычно воспроизводят данные оптически с помощью лазеров. Комбинации вышеперечисленного также следует включать в число машиночитаемых носителей.
[173] Инструкции могут выполняться посредством одного или более процессоров, например, одного или более процессоров цифровых сигналов (DSP), микропроцессоров общего назначения, специализированных интегральных схем (ASIC), программируемых пользователем вентильных матриц (FPGA) либо других эквивалентных интегральных или дискретных логических схем. Соответственно, термин "процессор" при использовании в данном документе может означать любую вышеуказанную структуру или другую структуру, подходящую для реализации технологий, описанных в данном документе. Помимо этого, в некоторых аспектах функциональность, описанная в данном документе, может быть предоставлена в рамках специализированных программных и/или аппаратных модулей, сконфигурированных с возможностью кодирования или декодирования либо встроенных в комбинированный кодек. Кроме того, технологии могут быть полностью реализованы в одной или более схем или логических элементов.
[174] Технологии этого раскрытия сущности могут быть реализованы в широком спектре устройств или приборов, в том числе в беспроводном переносном телефоне, в интегральной схеме (IC) или в наборе IC (к примеру, в наборе микросхем). Различные компоненты, модули или блоки описываются в этом раскрытии сущности для того, чтобы подчеркивать функциональные аспекты устройств, сконфигурированных с возможностью осуществлять раскрытые технологии, но необязательно требуют реализации посредством различных аппаратных модулей. Наоборот, как описано выше, различные блоки могут быть комбинированы в аппаратный модуль кодека или предоставлены посредством набора взаимодействующих аппаратных модулей, включающих в себя один или более процессоров, как описано выше, в сочетании с надлежащим программным обеспечением и/или микропрограммным обеспечением.
[175] Описаны различные аспекты технологий. Эти и другие аспекты технологий находятся в пределах объема прилагаемой формулы изобретения.
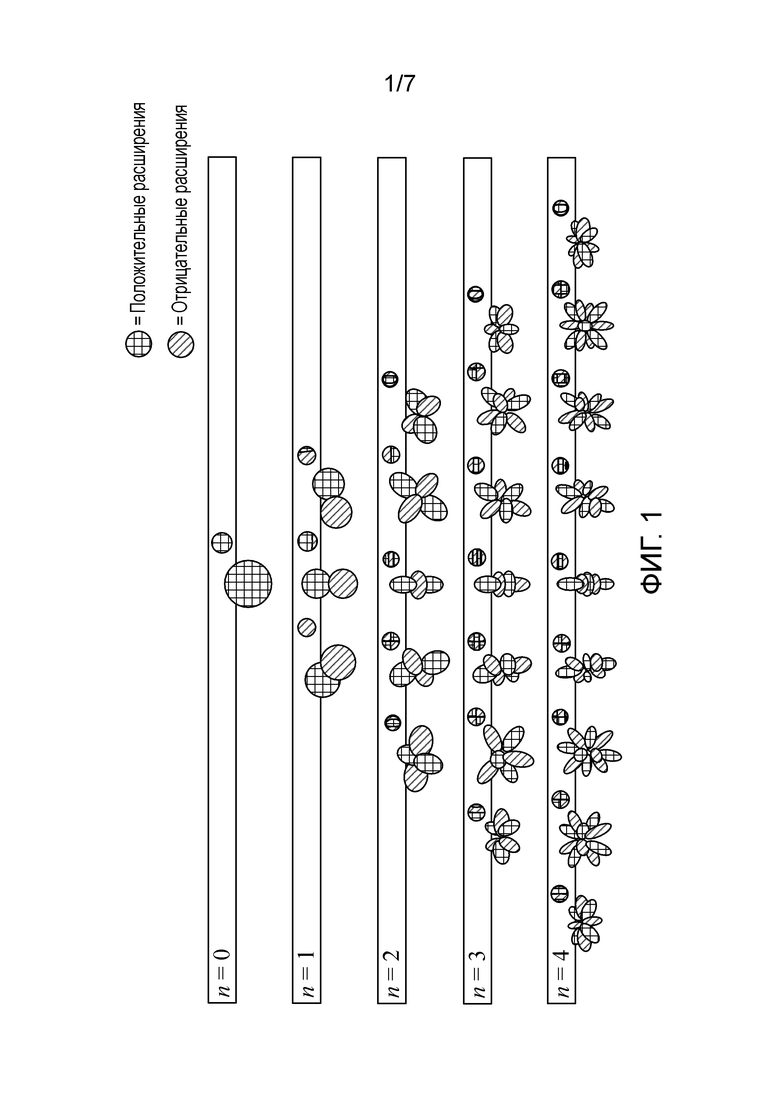

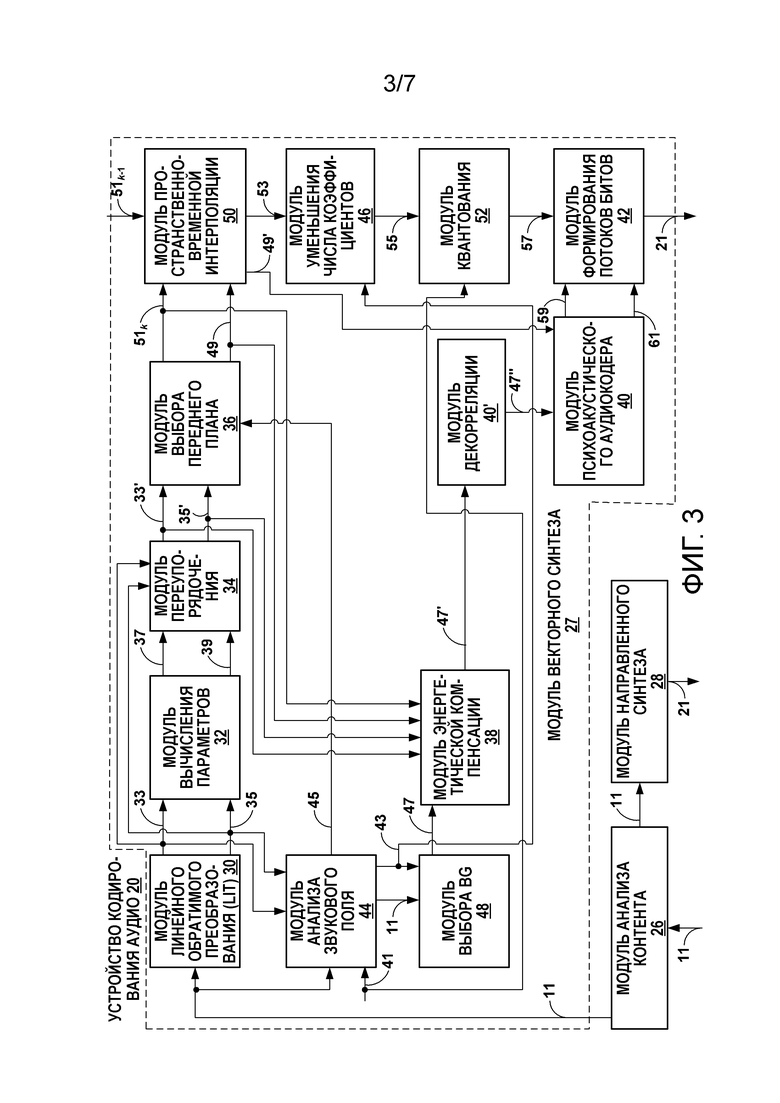
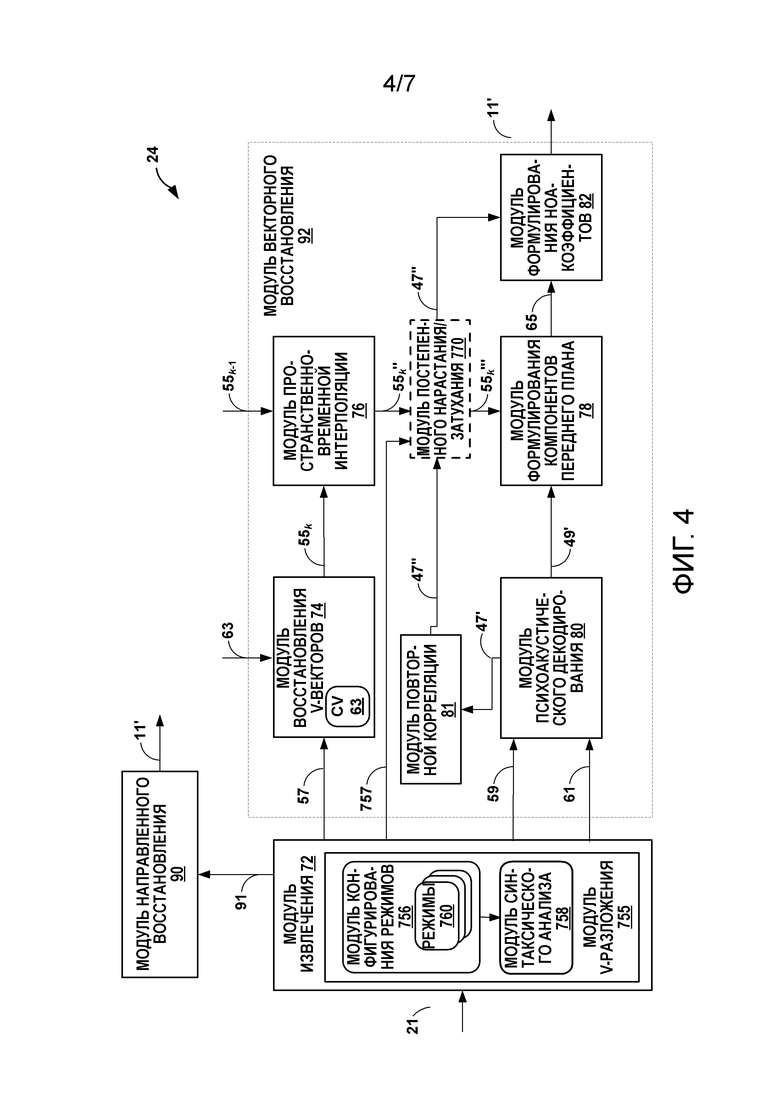
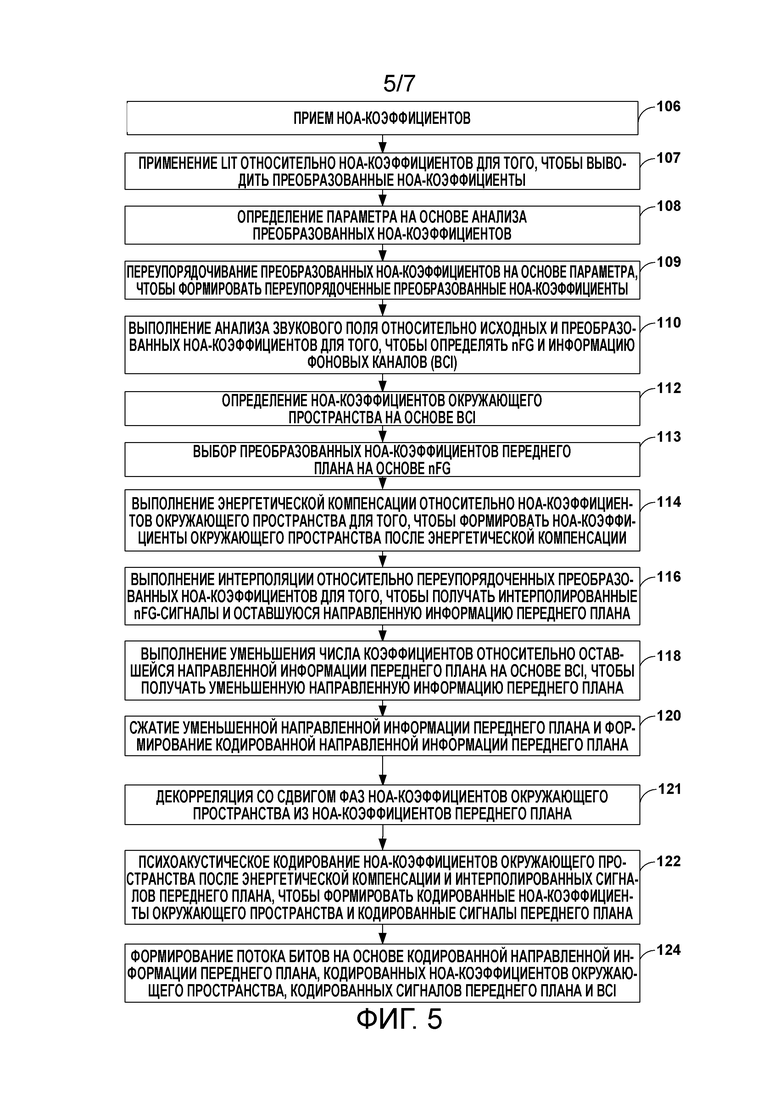
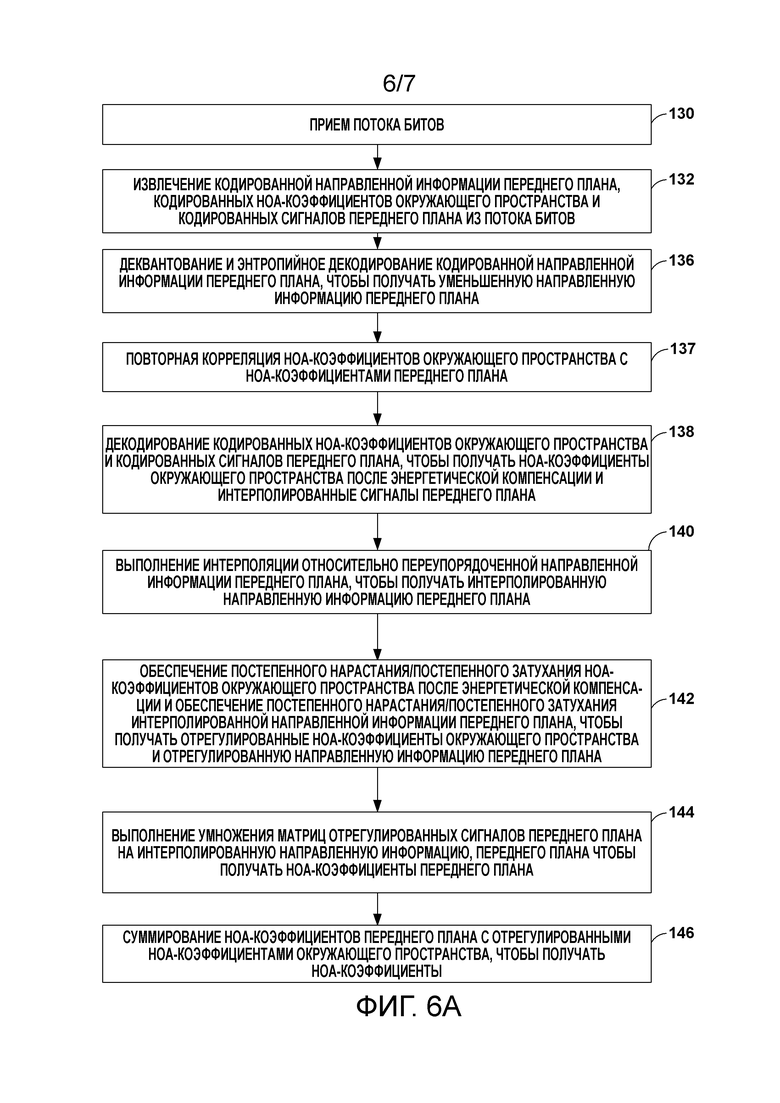
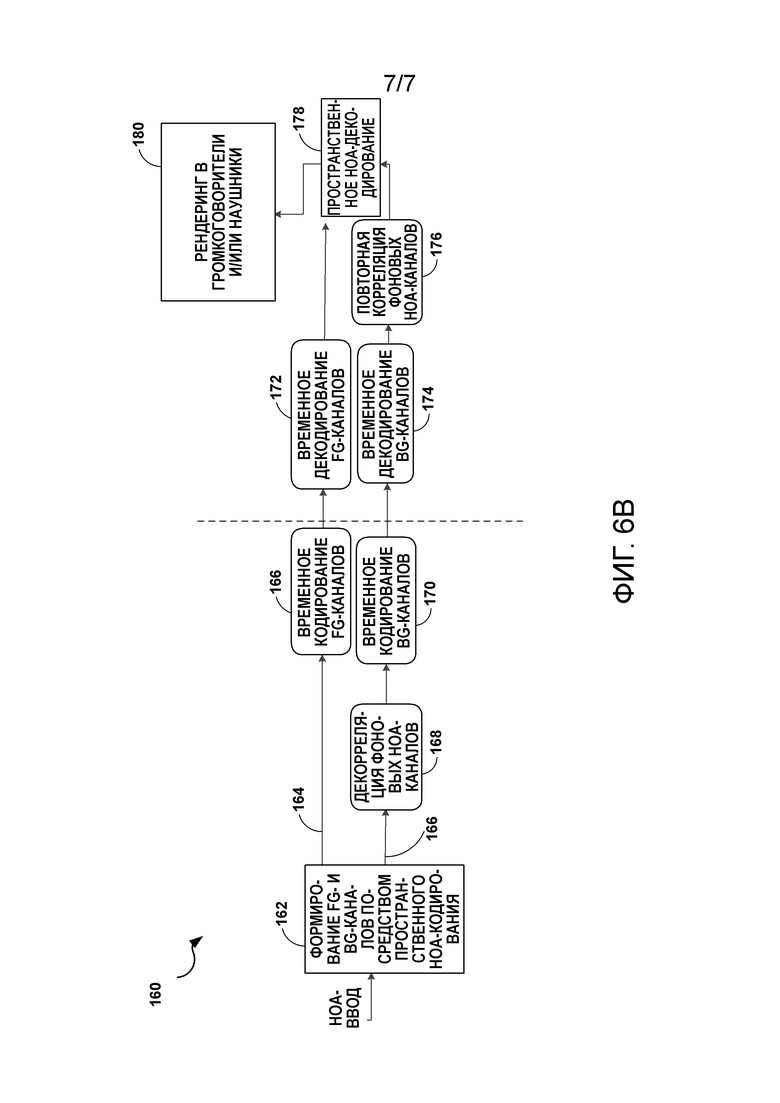
Группа изобретений относится к акустике. Способ декодирования амбиофонических аудиоданных, содержащий этапы, на которых получают посредством устройства декодирования аудиодекоррелированное представление коэффициентов амбиофонии окружающего пространства, которые представляют фоновый компонент звукового поля, описанного посредством множества коэффициентов амбиофонии высшего порядка. Декоррелированное представление коэффициентов амбиофонии окружающего пространства декоррелируется с использованием фазового преобразования, при этом, по меньшей мере, один из множества коэффициентов амбиофонии высшего порядка, описывающих звуковое поле, ассоциирован со сферической базисной функцией, имеющей нулевой или первый порядок. Применяют посредством устройства декодирования аудиопреобразование с повторной корреляцией к декоррелированному представлению коэффициентов амбиофонии окружающего пространства, чтобы получать множество повторно коррелированных коэффициентов амбиофонии окружающего пространства. Технический результат – улучшенное представление звука. 5 н. и 33 з.п. ф-лы, 2 табл., 7 ил.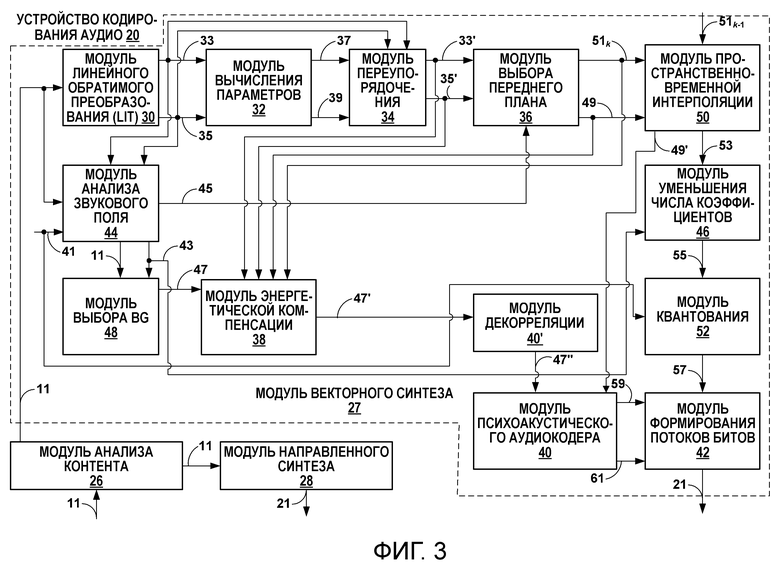
1. Способ декодирования амбиофонических аудиоданных, содержащий этапы, на которых:
- получают посредством устройства декодирования аудиодекоррелированное представление коэффициентов амбиофонии окружающего пространства, которые представляют фоновый компонент звукового поля, описанного посредством множества коэффициентов амбиофонии высшего порядка, причем декоррелированное представление коэффициентов амбиофонии окружающего пространства декоррелируется с использованием фазового преобразования, при этом, по меньшей мере, один из множества коэффициентов амбиофонии высшего порядка, описывающих звуковое поле, ассоциирован со сферической базисной функцией, имеющей нулевой или первый порядок;
- и применяют посредством устройства декодирования аудиопреобразование с повторной корреляцией к декоррелированному представлению коэффициентов амбиофонии окружающего пространства, чтобы получать множество повторно коррелированных коэффициентов амбиофонии окружающего пространства.
2. Способ по п. 1, в котором применение преобразования с повторной корреляцией содержит этап, на котором применяют посредством устройства декодирования аудио обратное фазовое преобразование к коэффициентам амбиофонии окружающего пространства.
3. Способ по п. 2, в котором обратное фазовое преобразование нормализовано согласно одной из N3D-("полное три D") нормализации.
4. Способ по п. 2, в котором обратное фазовое преобразование нормализовано согласно SN3D-нормализации (полунормализации Шмидта).
5. Способ по п. 2, в котором коэффициенты амбиофонии окружающего пространства ассоциированы со сферическими базисными функциями, имеющими нулевой порядок или первый порядок, при этом применение обратного фазового преобразования содержит этап, на котором выполняют посредством устройства декодирования аудио скалярное умножение матрицы HOA-коэффициентов на постоянное значение.
6. Способ по п. 1, дополнительно содержащий этап, на котором получают посредством устройства декодирования аудио один или более пространственных компонентов, задающих пространственные характеристики одного или более компонентов переднего плана звукового поля, описанного множеством коэффициентов амбиофонии высшего порядка, причем пространственные компоненты задаются в области сферических гармоник, и содержит этап, на котором комбинируют посредством устройства декодирования аудио повторно коррелированные коэффициенты амбиофонии окружающего пространства с одним или более каналов переднего плана, полученными на основе одного или более пространственных компонентов.
7. Способ по п. 1, дополнительно содержащий формирование посредством устройства декодирования аудиосигнала для подачи в динамик на основе множества повторно коррелированных коэффициентов амбиофонии окружающего пространства, полученных из применения преобразования с повторной корреляцией к декоррелированному представлению коэффициентов амбиофонии окружающего пространства.
8. Устройство для обработки амбиофонических аудиоданных, при этом устройство содержит:
- запоминающее устройство, сконфигурированное с возможностью хранить, по меньшей мере, часть амбиофонических аудиоданных, которые должны обрабатываться; и
- один или более процессоров, связанных с запоминающим устройством, при этом один или более процессоров сконфигурированы с возможностью:
- получать из части амбиофонических аудиоданных, хранящихся в запоминающем устройстве, декоррелированное представление коэффициентов амбиофонии окружающего пространства, которые представляют фоновый компонент звукового поля, описанного посредством множества коэффициентов амбиофонии высшего порядка, причем декоррелированное представление коэффициентов амбиофонии окружающего пространства декоррелируется из одного или более компонентов переднего плана звукового поля, описанного множеством коэффициентов амбиофонии высшего порядка, при этом, по меньшей мере, один из множества коэффициентов амбиофонии высшего порядка, описывающий звуковое поле, ассоциирован со сферической базисной функцией, имеющей нулевой или первый порядок;
и при этом декоррелированное представление коэффициентов амбиофонии окружающего пространства содержит четыре последовательности коэффициентов СAMB,1, СAMB,2, СAMB,3 и СAMB,4, и
применять преобразование с повторной корреляцией к декоррелированному представлению коэффициентов амбиофонии окружающего пространства, чтобы получать множество повторно коррелированных коэффициентов амбиофонии окружающего пространства.
9. Устройство по п. 8, в котором, чтобы формировать сигнал для подачи в динамик, один или более процессоров сконфигурированы с возможностью формировать, для вывода посредством системы стереовоспроизведения, сигнал для подачи в левый динамик на основе левого сигнала и сигнал для подачи в правый динамик на основе правого сигнала.
10. Устройство по п. 9, в котором один или более процессоров сконфигурированы с возможностью использовать левый сигнал в качестве сигнала для подачи в левый динамик и правый сигнал в качестве сигнала для подачи в правый динамик без применения преобразования с повторной корреляцией к правому и левому сигналам.
11. Устройство по п. 9, в котором один или более процессоров сконфигурированы с возможностью смешивать левый сигнал и правый сигнал для вывода посредством моноаудиосистемы.
12. Устройство по п. 8, в котором один или более процессоров сконфигурированы с возможностью комбинировать повторно коррелированные коэффициенты амбиофонии окружающего пространства с одним или более каналов переднего плана.
13. Устройство по п. 8, в котором один или более процессоров дополнительно сконфигурированы с возможностью определять то, что нет доступных каналов переднего плана, с которыми можно комбинировать повторно коррелированные коэффициенты амбиофонии окружающего пространства.
14. Устройство по п. 8, в котором один или более процессоров дополнительно сконфигурированы с возможностью:
- определять то, что звуковое поле, описанное множеством коэффициентов амбиофонии высшего порядка, должно выводиться через систему воспроизведения монофонического аудио; и
- декодировать, по меньшей мере, поднабор декоррелированных коэффициентов амбиофонии окружающего пространства, которые включают данные для вывода посредством системы воспроизведения монофонического аудио.
15. Устройство по п. 8, в котором один или более процессоров сконфигурированы с возможностью формировать сигнал для подачи в динамик на основе множества повторно коррелированных коэффициентов амбиофонии окружающего пространства, и устройство дополнительно содержит громкоговоритель, связанный с одним или более процессоров и сконфигурированный с возможностью выводить сигнал для подачи в динамик, сформированный на основе повторно коррелированных коэффициентов амбиофонии окружающего пространства.
16. Устройство по п. 8, в котором один или более процессоров дополнительно сконфигурированы с возможностью формирования аудиосигнала для подачи в динамик на основе множества повторно коррелированных коэффициентов амбиофонии окружающего пространства, полученных из применения преобразования с повторной корреляцией к декоррелированному представлению коэффициентов амбиофонии окружающего пространства.
17. Устройство по п. 9, в котором один или более процессоров сконфигурированы с возможностью формировать, для вывода посредством системы стереовоспроизведения, сигнал для подачи в левый динамик на основе левого сигнала и сигнал для подачи в правый динамик на основе правого сигнала.
18. Устройство для сжатия аудиоданных, причем устройство содержит:
- запоминающее устройство, сконфигурированное с возможностью хранить, по меньшей мере, часть аудиоданных, которые должны сжиматься; и
- один или более процессоров, связанных с запоминающим устройством, при этом один или более процессоров сконфигурированы с возможностью:
извлекать коэффициенты амбиофонии окружающего пространства, которые представляют фоновый компонент звукового поля, из множества коэффициентов амбиофонии высшего порядка, которые описывают звуковое поле и включены в аудиоданные, хранящиеся в запоминающем устройстве, при этом, по меньшей мере, один из множества коэффициентов амбиофонии высшего порядка ассоциирован со сферической базисной функцией, имеющей порядок, равный единице или нулю,
- применять фазовое преобразование к коэффициентам амбиофонии окружающего пространства, чтобы декоррелировать извлеченные коэффициенты амбиофонии окружающего пространства из одного или более компонентов переднего плана звукового поля, описанного множеством коэффициентов амбиофонии окружающего пространства высшего порядка, для получения декоррелированного представления коэффициентов амбиофонии окружающего пространства, и
сохранять в запоминающем устройстве аудиосигнал на основе декоррелированного представления коэффициентов амбиофонии окружающего пространства.
19. Устройство по п. 18, в котором один или более процессоров дополнительно сконфигурированы с возможностью включать в аудиосигнал c одним или более каналов переднего плана.
20. Устройство по п. 18, в котором один или более процессоров сконфигурированы с возможностью сигнализировать декоррелированные коэффициенты амбиофонии окружающего пространства вместе с одним или более каналов переднего плана в ответ на определение того, что целевая скорость передачи битов, ассоциированная с аудиосигналом, удовлетворяет или превышает предварительно определенное пороговое значение.
21. Устройство по п. 18, в котором один или более процессоров дополнительно сконфигурированы с возможностью сигнализировать декоррелированные коэффициенты амбиофонии окружающего пространства аудиосигнала, хранящегося в запоминающем устройстве, без сигнализации каналов переднего плана аудиосигнала, хранящегося в запоминающем устройстве.
22. Устройство по п. 21, в котором один или более процессоров сконфигурированы с возможностью сигнализировать декоррелированные коэффициенты амбиофонии окружающего пространства аудиосигнала, хранящегося в запоминающем устройстве, без сигнализации каналов переднего плана аудиосигнала, хранящегося в запоминающем устройстве, в ответ на определение того, что целевая скорость передачи битов, ассоциированная с аудиосигналом, ниже предварительно определенного порогового значения.
23. Устройство по п. 22, в котором один или более процессоров дополнительно сконфигурированы с возможностью включать в хранящийся аудиосигнал указание о преобразовании с декорреляцией, применяемом к коэффициентам амбиофонии окружающего пространства.
24. Устройство по п. 18, дополнительно содержащее микрофон, связанный с одним или более процессоров и сконфигурированный с возможностью захватывать аудиоданные, которые должны сжиматься.
25. Устройство для обработки амбиофонических аудиоданных, при этом устройство содержит:
запоминающее устройство, сконфигурированное с возможностью хранить, по меньшей мере, часть амбиофонических аудиоданных, которые должны обрабатываться, и флаг UsePhaseShiftDecorr; и
один или более процессоров, связанных с запоминающим устройством, при этом один или более процессоров сконфигурированы с возможностью:
определять, что значение флага UsePhaseShiftDecorr равно (1);
на основе значения флага UsePhaseShiftDecorr, равного (1), получать из части амбиофонических аудиоданных, хранящихся в запоминающем устройстве, декоррелированное представление коэффициентов амбиофонии окружающего пространства, которые представляют фоновый компонент звукового поля, описанного посредством множества коэффициентов амбиофонии высшего порядка, причем декоррелированное представление коэффициентов амбиофонии окружающего пространства декоррелируется из одного или более компонентов переднего плана звукового поля, описанного множеством коэффициентов амбиофонии высшего порядка, при этом, по меньшей мере, один из множества коэффициентов амбиофонии высшего порядка, описывающих звуковое поле, ассоциирован со сферической базисной функцией, имеющей нулевой или первый порядок;
применять преобразование с повторной корреляцией к декоррелированному представлению коэффициентов амбиофонии окружающего пространства, чтобы получать множество повторно коррелированных коэффициентов амбиофонии окружающего пространства.
26. Устройство по п. 25, дополнительно содержащее интерфейс, связанный с запоминающим устройством и сконфигурированный с возможностью принимать поток битов, содержащий, по меньшей мере, часть амбиофонических аудиоданных, и принимать флаг UsePhaseShiftDecorr.
27. Устройство по п. 25, в котором один или более процессоров сконфигурированы с возможностью формировать сигнал для подачи в динамик на основе множества повторно коррелированных коэффициентов амбиофонии окружающего пространства.
28. Устройство по п. 27, дополнительно содержащее громкоговоритель, связанный с одним или более процессоров и сконфигурированный с возможностью выводить сигнал для подачи в динамик, сформированный на основе повторно коррелированных коэффициентов амбиофонии окружающего пространства.
29. Устройство по п. 25, в котором один или более процессоров дополнительно сконфигурированы с возможностью реконструирования звукового поля с использованием множества коэффициентов амбиофонии окружающего пространства.
30. Устройство для обработки амбиофонических аудиоданных, при этом устройство содержит:
запоминающее устройство, сконфигурированное с возможностью хранить, по меньшей мере, часть амбиофонических аудиоданных, которые должны обрабатываться; и
один или более процессоров, связанных с запоминающим устройством, при этом один или более процессоров сконфигурированы с возможностью:
получать из части амбиофонических аудиоданных, хранящихся в запоминающем устройстве, декоррелированное представление коэффициентов амбиофонии окружающего пространства, которые представляют фоновый компонент звукового поля, описанного посредством множества коэффициентов амбиофонии высшего порядка, причем декоррелированное представление коэффициентов амбиофонии окружающего пространства декоррелируется из одного или более компонентов переднего плана звукового поля, описанного множеством коэффициентов амбиофонии высшего порядка, при этом, по меньшей мере, один из множества коэффициентов амбиофонии высшего порядка, описывающих звуковое поле, ассоциирован со сферической базисной функцией, имеющей нулевой или первый порядок;
причем декоррелированное представление коэффициентов амбиофонии окружающего пространства содержит четыре последовательности коэффициентов CI,AMB,1, CI,AMB,2, CI,AMB,3, и CI,AMB,4, и
применять преобразование с повторной корреляцией к декоррелированному представлению коэффициентов амбиофонии окружающего пространства, чтобы получать множество повторно коррелированных коэффициентов амбиофонии окружающего пространства,
причем для применения преобразования с повторной корреляцией один или более процессоров сконфигурированы с возможностью:
формировать первый сигнал со сдвигом фаз на основе первого результата умножнения коэффициента с(0) преобразования с повторной корреляцией и разницы между последовательностями коэффициентов CI,AMB,1 и CI,AMB,2 и формировать второй сигнал со сдвигом фаз на основе второго результата умножнения коэффициента с(1) преобразования с повторной корреляцией и суммы последовательностей коэффициентов CI,AMB,1 и CI,AMB,2.
31. Устройство по п. 30, в котором один или более процессоров дополнительно сконфигурированы с возможностью: формировать первую комбинацию на основе первого сигнала со сдвигом фаз, коэффициента с(3) преобразования с повторной корреляцией, коэффициента с(2) преобразования с повторной корреляцией и последовательностей коэффициентов CI,AMB,1 и CI,AMB,2; и формировать вторую комбинацию на основе второго сигнала со сдвигом фаз, коэффициента с(5) преобразования с повторной корреляцией и разницы между последовательностями коэффициентов CI,AMB,1 и CI,AMB,2, коэффициента с(6) преобразования с повторной корреляцией и последовательности коэффициентов CI,AMB,3; получать последовательность коэффициентов CI,AMB,4; и формировать третью комбинацию на основе коэффициента с(4) преобразования с повторной корреляцией, последовательностей коэффициентов CI,AMB,1 и CI,AMB,2 и первого сигнала со сдвигом фаз.
32. Устройство по п. 31, в котором преобразование с повторной корреляцией содержит обратное фазовое преобразование, которое основано по меньшей мера частично на наборе коэффициентов, включающих коэффициент с(0), коэффициент с(1), коэффициент с(2), коэффициент с(3), коэффициент с(4), коэффициент с(5) и коэффициент с(6), и при этом каждый из коэффициента с(0), коэффициента с(1), коэффициента с(2), коэффициента с(3), коэффициента с(4), коэффициента с(5) и коэффициента с(6) имеют различные зачения.
33. Устройство по п. 31, в котором первая комбинация основана на: третьем результате умножнения коэффициента с(3) и первого сигнала со сдвигом фаз, четвертом результате умножнения коэффициента с(2) и суммы последовательностей коэффициентов CI,AMB,1 и CI,AMB,2 и сумме третьего результата умножнения и четвертого результата умножения.
34. Устройство по п. 31, в котором вторая комбинация основана на: третьем результате умножнения коэффициента с(5) и разницы между последовательностями коэффициентов CI,AMB,1 и CI,AMB,2, четвертом результате умножнения коэффициента с(6) и последовательности коэффициентов CI,AMB,3 и сумме третьего результата умножнения и четвертого результата умножения, и втором сигнале со сдвигом фаз.
35. Устройство по п. 31, в котором третья комбинация основана на результате умножнения коэффициента с(4) и суммы последовательностей коэффициентов CI,AMB,1 и CI,AMB,2 и на первом сигнале со сдвигом фаз.
36. Устройство по п. 30, в котором один или более процессоров сконфигурированы с возможностью формировать сигнал для подачи в динамик на основе множества повторно коррелированных коэффициентов амбиофонии окружающего пространства.
37. Устройство по п. 36, дополнительно содержащее громкоговоритель, связанный с одним или более процессоров и сконфигурированный с возможностью выводить сигнал для подачи в динамик, сформированный на основе повторно коррелированных коэффициентов амбиофонии окружающего пространства.
38. Устройство по п. 30, в котором один или более процессоров дополнительно сконфигурированы с возможностью реконструирования звукового поля с использованием множества коэффициентов амбиофонии окружающего пространства.
| WO 2014014600 A1, 23.01.2014 | |||
| СНИЖЕНИЕ УРОВНЕЙ/АКТИВНОСТИ АРГИНАЗЫ | 2007 |
|
RU2469742C2 |
| CN 103313182 A, 18.09.2013 | |||
| US 20140086416 A1, 27.03.2014 | |||
| WO 2014014891 A1, 23.01.2014 | |||
| AU 2011325335 A1, 09.05.2013 | |||
| US 20120155653 A1, 21.06.2012 | |||
| РАБОЧЕЕ КОЛЕСО ДЛЯ ЦЕНТРОБЕЖНОГО НАСОСА, ЦЕНТРОБЕЖНЫЙ НАСОС, А ТАКЖЕ ЕГО ИСПОЛЬЗОВАНИЕ | 2015 |
|
RU2688066C2 |
| US 20140146970 A1, 29.05.2014 | |||
| УСТРОЙСТВО РОТАЦИОННОЙ ВЫТЯЖКИ | 2018 |
|
RU2688065C1 |
| СПОСОБ ЛИТЬЯ ПРОВОЛОКИ И УСТАНОВКА ДЛЯ ЕГО ОСУЩЕСТВЛЕНИЯ | 2013 |
|
RU2539892C1 |
| WO 2014090660 A1, 19.06.2014 | |||

