Область техники, к которой относится изобретение
Изобретение относится к способу прогнозирования характера движения в дорожной системе на основе набора профилей движения, каждый из которых представляет собой показатель движения транспортных средств в дорожной системе, записанный в течение определенного периода времени, в котором один или более заданных тегов, связанных с временем записи специфического профиля движения, присваиваются упомянутому профилю движения.
Уровень техники
Таким образом, изобретение относится к области измерения и оценки характера движения транспортных средств, например, характера движения на главной улице города. После того, как характер движения на этой улице был проанализирован в течение длительного периода времени, как правило, в течение года или дольше, цель состоит в том, чтобы оценить характер движения в определенный день или временной промежуток в будущем. Это можно использовать для прогнозирования того, какая дорога будет перегружена или заблокирована в определенное время, например, для грузовых перевозок, планирующих перевозку груза, или семей, планирующих свой отпуск. Затем в зависимости от спрогнозированного характера движения могут быть выбраны различные маршруты или время, в которое можно проехать по этой улице, посредством чего в любом случае можно будет уменьшить продолжительность проезда транспортного средства от начала до конца.
Для этой цели в известных способах прогнозирования интенсивности дорожного движения используется кластеризация сходности записанных профилей и назначение характеристических векторов ("меток") тегов кластерам, которые можно запрашивать для идентификации кластера профилей движения в качестве прогнозируемого характера движения в течение определенного дня, например, определенного буднего дня, "дождливого" дня и т.д.
В работе Weijermars, van Berkom: "Analyzing highway flow patterns using cluster analysis", IEEE Conference on Intelligence Transportation Systems, September 13 - 16, 2005 раскрыт способ анализа порядка движения транспортных средств. В этой работе представлена запись 118 профилей движения для автомобильной магистрали, каждый из которых был записан в течение промежутка времени, равного 24 часам. После этого профили движения были сгруппированы с помощью стандартного алгоритма кластеризации. После ручной маркировки кластеров были оценены отклонения внутри кластеров.
Из уровня техники также известно, что вместо ручной маркировки кластеров можно найти подходящую метку для кластера посредством рандомизированного алгоритма. Такой алгоритм занимает много вычислительных ресурсов и имеет недостаток, связанный с тем, что некоторые метки, которые могли бы точно описать содержимое кластера, не могут быть найдены из-за нескольких соответствующих профилей движения в этом кластере.
Задача изобретения состоит в том, чтобы создать более надежный и быстрый способ определения меток кластеров, которые можно в дальнейшем использовать для поиска прогнозируемого характера движения для конкретного запроса.
Сущность изобретения
Для этой цели настоящее изобретение обеспечивает способ прогнозирования характера движения в дорожной системе, содержащий следующие этапы, выполняемые по меньшей мере одним процессором, подключенным к базе данных, содержащей набор профилей движения, причем каждый профиль движения представляет собой интенсивность движения или различные показатели движения транспортных средств в дорожной системе, записанные в течение продолжительного периода времени, при этом один или более заданных тегов, связанных с временем записи соответствующего профиля движения, присваиваются упомянутому профилю движения:
кластеризацию профилей движения с их тегами по меньшей мере в один кластер, предпочтительно по меньшей мере в два кластера при несходстве профилей движения;
по меньшей мере для одного тега в каждом кластере, вычисление уровня значимости посредством статистического анализа;
если уровень значимости тега выше порогового значения, назначение этого тега в качестве характеристического вектора этому кластеру;
в механизме прогнозирования, прием запроса, имеющего один или более тегов запроса для определения соответствующего кластера;
определение кластера посредством сопоставления тега(ов) запроса с характеристическими векторами кластеров; и
вывод спрогнозированного характера движения на основании определенного кластера.
Множество всех характеристических векторов одного кластера в дальнейшем упоминается как "метка" этого кластера. Используя предлагаемый способ, метки кластеров можно определить эффективным и систематическим образом. Оценивая уровень значимости для тега профиля движения в кластере, можно проверить, является ли этот тег действительным представлением этого кластера. Этот частичный статистический анализ кластера может использоваться для определения характеристических векторов "первого уровня", которые содержат только один тег.
В примерном варианте осуществления изобретения имеются по меньшей мере две переменные, и каждый тег назначается переменной, причем способ содержит дополнительные этапы:
по меньшей мере для одной переменной в каждом кластере, вычисления уровня значимости; и
для тега, назначенного переменной с самым высоким уровнем значимости каждого кластера, вычисления уровня значимости.
Это преимущество состоит в том, что имеет место "предварительная сортировка", которая ускоряет алгоритм в целом. Уровень значимости для переменных можно определить так же, как и для тегов.
В данном примерном варианте осуществления дополнительное преимущество состоит в том, что способ содержит дополнительные этапы:
группирования всех профилей движения, которые не содержат тег, уровень значимости которого превышает упомянутое пороговое значение, в подкластер;
по меньшей мере для одной переменной в подкластере, вычисления уровня значимости; и
по меньшей мере для одного тега, назначенного переменной с самым высоким уровнем значимости подкластера, вычисления уровня значимости.
Таким образом, подкластер используется для "повторного использования" порядка движения транспортных средств, которые не содержат теги с уровнем значимости выше порогового уровня в первой итерации.
Кроме того, предпочтительно в данном примерном варианте осуществления этапы группирования, вычисления уровня значимости для переменной и вычисления уровня значимости для тега повторяются до тех пор, пока не будут доступны профили движения для группирования. В данном случае подкластер после подкластера создается и оценивается для каждой переменной для того, чтобы получить все теги значимости кластера. Кроме того, все вышеупомянутые этапы могут повторяться для каждой переменной, встречающейся в кластере для того, чтобы получить самый широкий набор тегов значимости.
Можно также определить характеристические векторы "второго уровня" кластера. Характеристический вектор второго уровня представляет собой комбинацию двух тегов, которые вместе представляют кластер. Поэтому в предпочтительном варианте осуществления предлагаемого способа, по меньшей мере для одного тега, уровень значимости которого находится ниже упомянутого порогового значения, вычисляется уровень значимости комбинации упомянутого тега с дополнительным тегом, и, если упомянутый уровень значимости упомянутой комбинации тегов превышает пороговое значение, упомянутая комбинация тегов назначается в качестве дополнительного характеристического вектора кластеру упомянутого тега.
Таким образом, можно провести поуровневый анализ репрезентативных характеристических векторов кластера. Например, кластер может содержать профили движения, которые были записаны по пятницам в июле. Хотя ни "пятница", ни "июль" не являются репрезентативными характеристическими векторами этого кластера, комбинация тегов "пятница в июле" точно описывает содержание этого кластера и является характеристическим вектором для этого кластера.
Предпочтительно уровень значимости комбинации тегов вычисляется для тега, который имел самый высокий уровень значимости во время оценки "первого уровня", в то время как его уровень значимости был все еще ниже порогового значения, но предпочтительно выше дополнительного порогового уровня "нижней границы". Для этого тега уровень значимости определяется в сочетании со всеми оставшимися тегами или просто в сочетании с наиболее распространенным из этих оставшихся тегов. Тег, который использовался в качестве характеристического вектора при оценке "первого уровня", не считается оставшимся тегом.
Кроме того, предпочтительно, чтобы оценки "третьего уровня", "четвертого уровня" и т.д. могли выполняться до тех пор, пока уровень значимости комбинации тегов все еще превышает упомянутый дополнительный пороговый уровень нижней границы. Пороговые уровни могут изменяться в зависимости от количества комбинированных тегов.
В предпочтительном варианте осуществления изобретения для каждого кластера вычисляются уровни значимости для всех тегов этого кластера. Таким образом, невозможно пропустить характеристические векторы, чьи базовые теги не очень распространены в этом кластере, но все еще описывают точно содержание этого кластера. Например, если тег "Рождество" является единственным тегом в кластере, характеристическое значение "Рождество" все еще имеет значение для этого кластера, когда тег "Рождество" является уникальным тегом среди всего набора профилей движения. Альтернативно оцениваются только самые распространенные или только произвольные теги. Таким образом, кластеру может быть назначена метка, которая выводится быстрым, систематическим и надежным способом.
В другом предпочтительном варианте осуществления изобретения, когда двум кластерам будет назначен один и тот же характеристический вектор, пороговое значение уменьшается, и это снова осуществляется проверка того, превышает ли уровень значимости каждого тега (или комбинации тегов) пороговое значение для назначения этого тега (или комбинации тегов) в качестве характеристического вектора этому кластеру. Благодаря этому возможно добавление дополнительного тега к характеристическому вектору, который вызвал "двойное присвоение меток" для двух различных кластеров.
Альтернативно, характеристический вектор, чей тег или комбинация тегов, соответственно, имеет более низкий уровень значимости, не учитывается. Эта мера предотвращает проблемы коллизий при определении кластера путем сопоставления тегов запроса. Другими словами, характеристический вектор отбрасывается для кластера в том случае, когда другой кластер имеет один и тот же характеристический вектор с более высоким уровнем значимости.
Уровень значимости каждого тега или комбинации тегов может быть определен с помощью различных методов статистического анализа. В первом предпочтительном варианте осуществления уровень значимости каждого тега или комбинации тегов, соответственно, вычисляется посредством статистики хи-квадрата. В этом способе статистика хи-квадрата является особенно предпочтительной, так как она дает очень точное представление значимости тега или комбинации тегов в кластере, в то же время учитывая теги или комбинации тегов других кластеров. Предпочтительно, чтобы использовалась статистика хи-квадрат Пирсона.
Было замечено, что некоторые характеристические векторы всегда появляются в одних и тех же кластерах. Например, по понедельникам, вторникам, средам и четвергам может наблюдаться одинаковый характер движения, и таким образом характеристические векторы с тегами, относящимися к этим дням недели, могут быть сгруппированы вместе. В результате можно ускорить определение кластера посредством сопоставления тегов запроса, так как количество характеристических векторов для этого кластера было уменьшено, например, в этом случае с четырех дней недели до одной группы дней.
В некоторых вариантах осуществления уровни значимости тегов или комбинации тегов также используются при проверке того, соответствует ли тег запроса характеристическому вектору. Таким образом, определенный уровень значимости можно использовать в способе дважды, сначала при маркировке кластеров и затем при определении соответствующего кластера. Это является преимуществом, так как характеристические векторы с более высокими уровнями значимости с большей вероятностью соответствуют тегу запроса, чем характеристические векторы с более низкими уровнями значимости.
Во всех вариантах осуществления изобретения предпочтительно, чтобы каждый профиль движения представлял собой показатель движения транспортных средств в дорожной системе в течение промежутка времени, равного 24 часам. В качестве альтернативы, могут также использоваться промежутки времени, равные 6 часам, 12 часам или 18 часам, особенно когда характер движения в определенные часы суток, например, в ночные часы или часы пик, являются по существу одинаковыми для всех профилей движения.
Предпочтительно по меньшей мере один тег указывает день недели, месяц года, неделю месяца, индикатор школьных каникул или индикатор особого праздничного дня с упомянутым временем записи. Например, такие теги могут быть выработаны автоматически путем привязки атрибута календаря к профилю движения. Календарь можно определить заранее, в режиме реального времени или задним числом, а также можно в дальнейшем добавить теги в профили движения, когда они появляются в запросе в первый раз.
Альтернативно или дополнительно к этому, по меньшей мере один тег указывает состояние дороги или погодные условия в упомянутое время записи. Такие теги представляют собой физическое измерение с данными об окружающей среде, которые могут быть заранее закодированы с помощью тега в режиме реального времени или в ретроспективе.
Краткое описание чертежей
Теперь изобретение будет пояснено более подробно на основе его предпочтительных примерных вариантов осуществления со ссылкой на сопроводительные чертежи, на которых:
на фиг. 1 показано схематичное изображение дорожной системы;
на фиг. 2 показана блок-схема баз данных и механизмов обработки для выполнения способа изобретения;
на фиг. 3 показан пример кластеров и связанных с ними меток, встречающихся на стадиях кластеризации и присваивания меток согласно способу изобретения;
на фиг. 4 показано дерево решений, используемое для определения меток для кластеров во время выполнения способа согласно изобретению;
на фиг. 5 показана блок-схема последовательности операций на стадии прогнозирования согласно способу изобретения; и
на фиг. 6 показан пример исключения тегов из запроса на стадии прогнозирования, показанной на фиг. 5.
Подробное описание изобретения
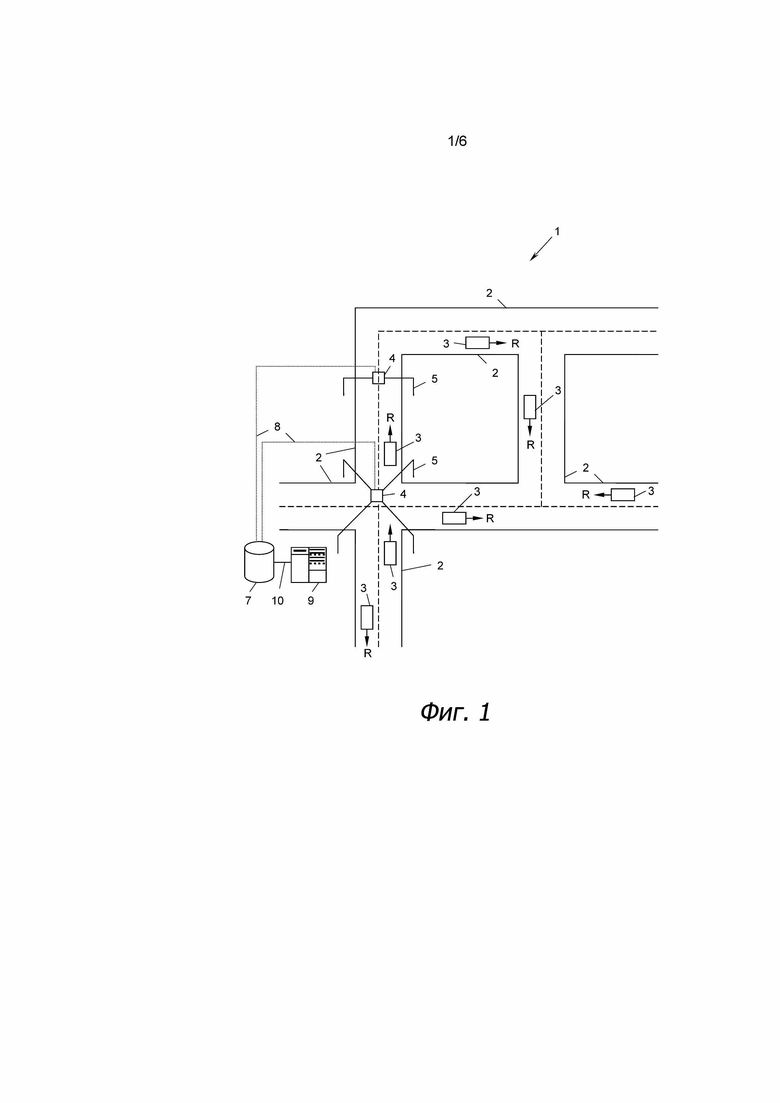
На фиг. 1 изображена дорожная система 1 с множеством дорог 2, по которым движутся транспортные средства 3 в направлениях R. Дорожная система 1 оснащена по меньшей мере одним устройством 4 для измерения интенсивности дорожного движения, которое может, например, использоваться для измерения транспортного потока на дороге 2 или на пересечении дорог 2. Устройство 4 для измерения интенсивности дорожного движения может быть установлено на опоре 5, охватывающей дорогу 2, или альтернативно может быть установлено на обочине дороги. Устройство 4 для измерения интенсивности дорожного движения может быть воплощено в виде любого типа, известного в данной области техники, например, в виде индуктивных петлевых датчиков, радарных устройств, световых защитных ограждений, камер для обработки видеоинформации, или в виде беспроводных считывающих устройств, которые считывают радиоотклик так называемых бортовых устройств (OBU), которые установлены на транспортных средствах 3.
Устройство 4 для измерения интенсивности дорожного движения может напрямую записывать поток движения на дороге 2, например, в виде количества v транспортных средств 3 в единицу времени t, или оно может записывать количество v/t транспортных средств 3, движущихся по заданному участку дороги 2 в данный момент времени, например, путем подсчета транспортных средств 3 на снимках с камеры указанного участка дороги, сделанных через регулярные промежутки времени.
Вместо измерения потока движения можно также измерять другие условия дорожного движения на дороге посредством различных значений измерения, например, путем записи средней скорости на дороге 2 в определенный момент вовремя t или путем измерения времени движения, в течение которого транспортное средство проезжает участок дороги 2.
Устройство 4 для измерения интенсивности дорожного движения записывает поток движения v/t или эквивалентное значение измерения, как описано выше, за время t в течение заданного промежутка времени, например, в течение 24 часов, в виде профиля 6 движения (фиг. 2). В качестве альтернативы, можно также использовать более короткие промежутки времени, например, только самые интересные промежутки времени, например, в 6, 12 или 18 часов дня.
Устройство 4 для измерения интенсивности дорожного движения записывает упомянутые профили 6 движения в течение продолжительного периода времени, например, каждый день в течение целого года или дольше. Профиль движения может состоять из дискретных выборок, например, одной выборки каждые 5 минут, 15 минут или каждый час, или может представлять собой, по меньшей мере частично, плавную кривую во времени. Таким образом, каждое устройство 4 для измерения интенсивности дорожного движения записывает набор профилей 6 движения для своей дороги 2 или пересечения дорог 2 и сохраняет его в базе 7 данных через информационное соединение 8. Процессор 9 подключен к базе 7 данных через соединение 10 для дальнейшей обработки профилей 6 движения, как будет описано ниже.
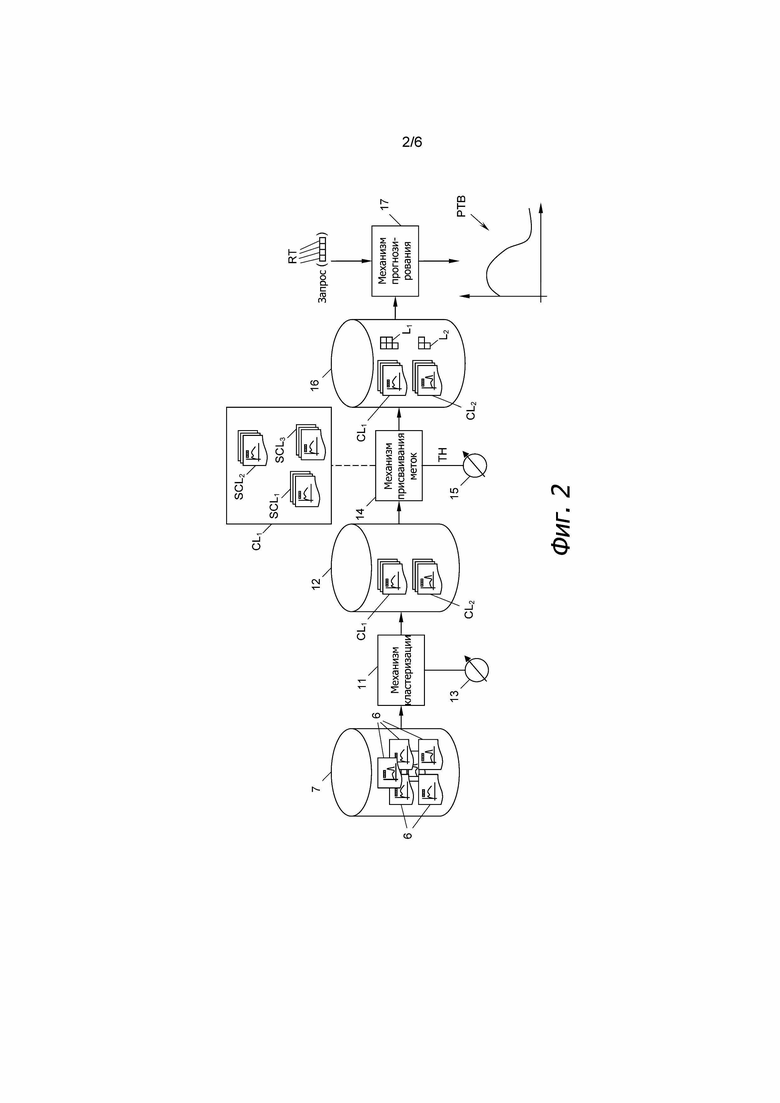
На фиг. 2 показан механизм RT запроса, который может быть частью вышеупомянутого процессора 9. Механизм RT запроса получает профили 6 движения из базы 7 данных и группирует эти профили 6 движения по меньшей мере в один или по меньшей мере в два кластера CL1, CL2 …, как правило, CLi. Алгоритм кластеризации, используемый в механизме RT запроса, может иметь любой вид, известный из уровня техники, например, может представлять собой агломерационный иерархический алгоритм кластеризации. Для этой цели возможно потребуется предварительная обработка профилей 6 движения с тем, чтобы они содержали, например, 96 временных выборок с интервалом между ними, равным 15 минутам. Кроме того, фильтры могут применяться для устранения локальных аномалий, возникающих в профилях 6 движения.
В результате механизм RT запроса кластеров выводит кластеры CLi, каждый из которых содержит несколько профилей 6 движения, которые аналогичны друг другу, в базу 12 данных. Эта база 12 данных может быть такой же, как и база 7 данных или представлять ее подмножество. Кроме того, механизмом RT запроса можно управлять посредством ввода 13 настроек управления для того, чтобы регулировать параметры кластеризации.
После того, как профили 6 движения были кластеризованы в кластеры CLi, механизм 14 присваивания меток используется для назначения меток L1, L2, …, как правило, Li, каждому кластеру CLi, при этом каждая метка Li состоит по меньшей мере из одного характеристического вектора CV1, CV2, …, как правило, CVj. Метки Li должны максимально точно отражать содержание кластеров CLi.
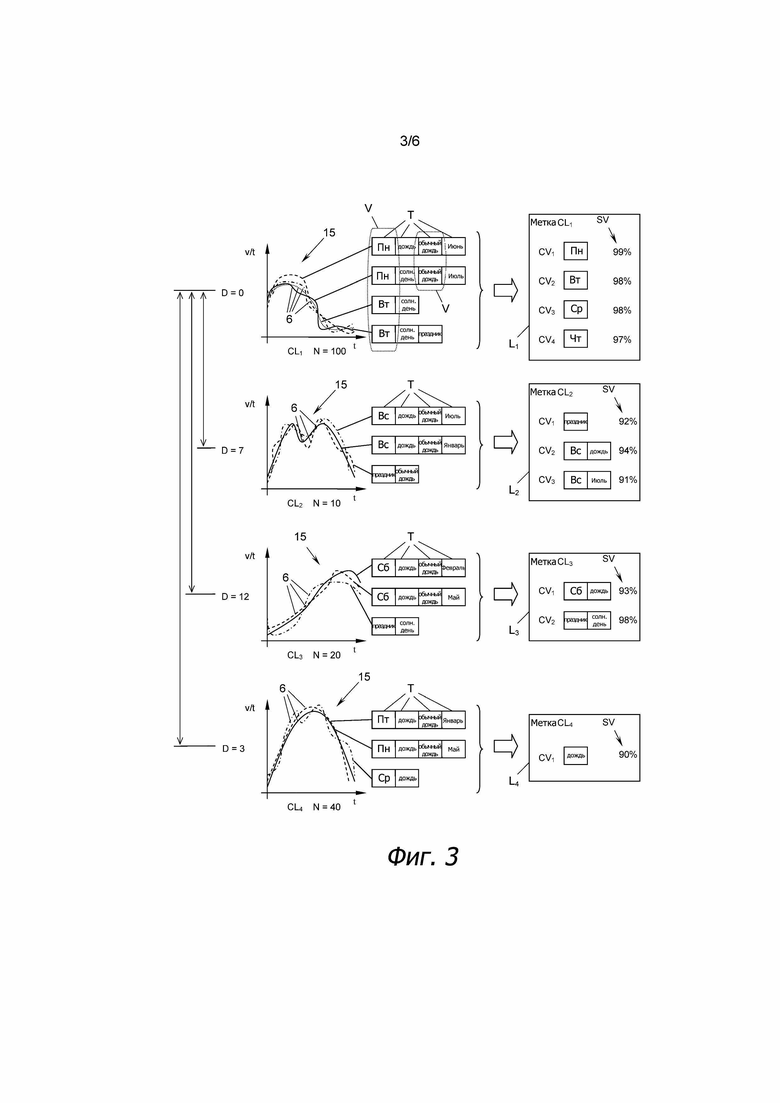
Этапы способа, выполняемые механизмом 14 присваивания меток, будут теперь подробно описаны посредством фиг. 3, на которой показаны четыре примерных кластера CL1, CL2, CL3, CL4, выведенных механизмом RT запроса. Первый кластер CL1 содержит N = 100 аналогичных профилей 6 движения, из которых только четыре показаны на диаграмме 15 для простоты представления. Диаграмма 15 отображает время t по горизонтальной оси и поток движения транспортных средств в единицу времени v/t по вертикальной оси. Кроме того, можно видеть, что каждый из четырех примерных профилей 6 движения может иметь один или более, в настоящем примере от двух до четырех, предварительно определенных тегов T, присвоенных ему.
Теги T, присвоенные профилю 6 движения, связаны отчасти со временем записи упомянутого профиля 6 движения. Например, тег T может указывать день недели, месяц года, неделю месяца, индикатор школьных каникул, индикатор особого праздничного дня, состояние дороги или погодные условия за промежуток времени, в течение которого был записан их профиль 6 движения.
Теги T могут быть присвоены профилю 6 движения непосредственно во время записи посредством устройства 4 для измерения интенсивности дорожного движения в базу 7 данных или даже после кластеризации в базе 12 данных. Для этой цели, каждое соответствующее устройство 4, 7, 12 может содержать часы, календарь, метеостанцию или любое средство для приема данных об окружающей среде или состоянии дороги. В качестве альтернативы, теги T могут быть присвоены профилям 6 движения ретроспективно, например, посредством календарей баз 7, 12 данных. Информация о календаре, погоде, состоянии окружающей среды или состоянии дороги может быть присвоена ретроспективно, например, если через неделю или месяц появляется информация о том, что дорога, на которой производится запись транспортного потока, была повреждена или находилась в процессе строительства. Теги T могут даже быть присвоены профилям 6 движения во время выполнения этапа присваивания меток посредством механизма 14 присваивания меток, который может иметь свой собственный календарь или ввод данных для этой цели.
Возвращаясь снова к конкретному примеру, показанному на фиг. 3, видно, что первый профиль 6 движения первого кластера CL1 имеет теги "понедельник", "дождь", "обычный день (без праздника)" и "июнь". Второй профиль 6 движения этого кластера имеет различные теги T, в данном случае "понедельник", "солнечная погода", "обычный день (без праздника)", "июль" и т.д.
Чтобы извлечь метку Li, которая наиболее точно описывает кластер CLi из всех тегов T этого кластера CLi, механизм 14 присваивания меток сначала вычисляет уровень SV значимости по меньшей мере для некоторых тегов T в этом кластере CLi. В некоторых вариантах осуществления вычисляются уровни SV значимости всех тегов T всех профилей 6 движения кластера CLi, в то время как в других вариантах осуществления вычисляются уровни SV значимости только для наиболее распространенных тегов T профилей 6 движения кластера CLi.
Уровень SV значимости можно рассчитать с помощью статистики хи-квадрата. Например, статистику хи-квадрата Пирсона можно использовать в том случае, если имеются 5 или более профилей 6 движения, и точный комбинаторный метод, такой как точный тест Фишера, можно использовать в том случае, если имеются менее 5 профилей 6 движения. Это дает наиболее точное описание значимости отдельного тега T.
Чтобы оценить, является или нет тег T фактически значимым, механизм 14 присваивания меток получает пороговое значение TH из средства 15 ввода порогового значения. Средство 15 ввода порогового значения можно регулировать вручную или в цифровой форме, если оно подключено к компьютеру. Если уровень SV значимости тега T в кластере CLi превышает пороговое значение TH, характеристический вектор CVj, содержащий этот тег T, назначается этому кластеру CLi (смотри правую часть фиг. 3).
Для первого кластера CL1, показанного на фиг. 3, видно, что четыре тега T в пределах этого кластера имеют уровень SV значимости, превышающий пороговое значение TH, поэтому они были сохранены как характеристические векторы CV1, CV2, CV3, CV4. Соответствующими тегами T были "понедельник", "вторник", "среда" и "четверг". Таким образом, метка L1 этого кластера CL1 состоит из четырех характеристических векторов CVj, каждый из которых содержит один тег T.
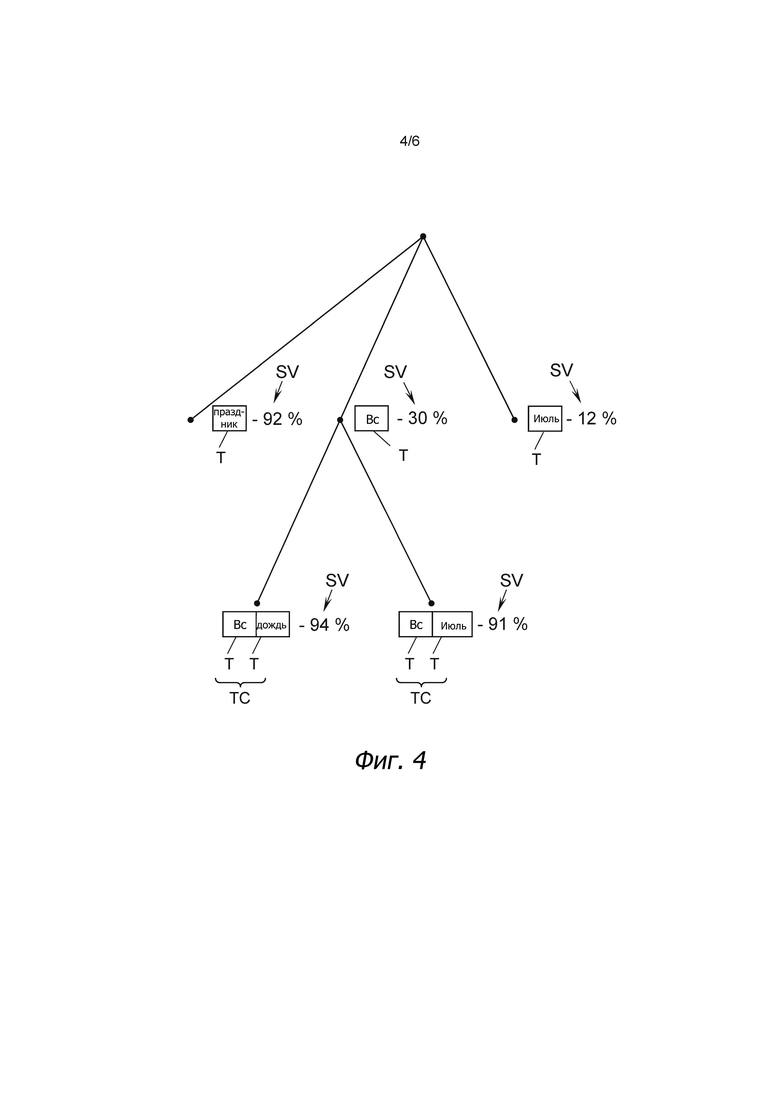
На фиг. 4 показан пример того, как выработать первую метку Li, соответствующую второму кластеру CL2, и вторую метку L2, показанную на фиг. 3. В данном случае, сначала были вычислены уровень SV значимости трех тегов "праздник", "воскресенье" и "июль". Предполагая, что пороговое значение TH составляет 90%, можно видеть, что только тег "праздник" с уровнем SV значимости 92% квалифицируется как характеристический вектор CVj.
Кроме того, уровни SV значимости для комбинаций, то есть комбинаций "и", тегов T могут быть рассчитаны либо для всех тегов T, чей уровень SV значимости находится ниже порогового значения TH, либо для тегов T, чей уровень SV значимости находится ниже порогового значения TH, но превышает дополнительное пороговое значение, например, 25%. Для этих тегов T уровень SV значимости вычисляется в сочетании с дополнительным тегом T, и если уровень SV значимости такой комбинации TC тегов превышает пороговое значение TH (или другое пороговое значение), эта комбинация TC тегов назначается в качестве характеристического вектора CVj этому кластеру CLi.
В зависимости от способа вычисления уровня SV значимости полезно также рассмотреть комбинации "или", поскольку они еще не были найдены в виде нескольких отдельных тегов T, чьи уровни SV значимости превышают пороговый уровень в пределах одного и того же кластера CLi. С этой целью вычисляется уровень SV значимости комбинации "или" двух тегов, чей уровень SV значимости находится ниже порогового уровня TH, чтобы увидеть, должен ли каждый из них быть включен в качестве характеристического вектора CVj для кластера CLi.
Как правило, этот способ может быть также выполнен для комбинаций TC тегов, содержащих три или более тегов T, например, когда уровень SV значимости комбинации TC из двух тегов снова находится в конкретном диапазоне пороговых значений. Посредством этого комбинации тегов любой длины могут быть назначены кластеру CLi в качестве характеристических векторов CVj.
Ниже приведен один примерный алгоритм идентификации значимых тегов T кластера CLi. Начнем с того, что теги T представляют собой конкретные значения так называемых переменных V, например, переменные V могут быть "будним днем", "особым днем", "днем школьных каникул", "месяцем", "неделей месяца" и/или "погодными условиями". В свою очередь, теги T назначаются каждой переменной V, например, теги переменной "день недели", теги "Mon" (понедельник), "Tue" (вторник), "Wed" (среда), теги "праздник", "предпраздничный день", … переменной "особый день", теги "Да", "Нет", переменной "день школьных каникул" и т.д.
На первом этапе примерного алгоритма определяется посредством одного из упомянутых статистических тестов (теста хи-квадрата Пирсона, точного теста Фишера …), является ли переменная V значимой для кластера CLi, например, является ли распределение по дням недели априорно значимым в этом кластере CLi.
На втором этапе для наиболее значимой переменной V определяются теги T, которые выглядят более чем ожидаемыми.
На третьем этапе определяется уровень SV значимости для каждого тега T по отношению к остальным тегам T для той же переменной V, и он сравнивается с заданным пороговым значением TH, как подробно описано выше. Таким образом, можно определить, например, является ли распределение "суббота" значимым по отношению к остальным дням недели в кластере. Кроме того, вырабатывается дополнительный "подкластер" SCLi, который содержит только остальные профили 6 движения, которые не соответствуют значимым тегам T, определенным ранее.
На четвертом этапе повторяются второй и третий этапы для подкластера SCLi до тех пор, пока не останется больше переменных V или профилей 6 движения для анализа.
На пятом этапе выполняется тест значимости для тегов T, начиная с наименее значимой переменной V в соответствии с первым этапом, но только для выборок внутри этого SCLi, а не с полного размера кластера. Если уровень SV значимости превышает упомянутое пороговое значение TH, эти теги T будут добавлены к метке кластера.
На шестом этапе повторяется пятый этап для следующего подкластера SCLi в порядке возрастания значимости. На этот раз рассматриваются не только его собственные профили 6 движения, но также и элементы ранее проанализированных подкластеров SCLi, которые не были значимыми. Таким образом, можно вычислить все "значимые" подкластеры SCLi для первого уровня, и соответствующие теги T добавляются в качестве метки в начальный кластер CLi.
Если на первом уровне имеется один или более значимых подкластеров SCLi на первом уровне, на седьмом этапе процесс повторяется для каждого подкластера SCLi на следующем уровне, чтобы определить новые "дочерние подкластеры" с учетом только характеристик или переменных, которые не были проанализированы ранее.
Затем эти этапы повторяются до тех пор, пока какой-либо ветви не нужно ничего анализировать, и все "объединенные" теги T могут быть добавлены к метке для дочерних подкластеров SCLi.
Кроме того, если подкластер SCLi включают в себя более одного значимого тега T для переменной V, то каждый тег T будет анализироваться в отдельной ветви. Только в том случае, если после анализа всех этих ветвей они не имеют подветвей, все теги T группируются вместе.
Кроме того, для вычисления уровня SV значимости тега T в каждой ветви учитываются только профили 6 движения, соответствующие переменным всех уровней выше анализируемой ветви. Например, при анализе тега "дождливый день" подкластера "пятница" будет рассчитываться ожидаемое значение "дождливый день" с учетом только погодных условий для всех "пятниц" из общей совокупности.
Возвращаясь ко второму кластеру CL2, показанному на фиг. 3 и подробно показанному на фиг. 4, видно, что комбинации тегов "воскресенье и дождь" и "воскресенье и июль" имеют уровня SV значимости, превышающие пороговое значение TH. Таким образом, эти две комбинации тегов TC назначаются как характеристические векторы CV1, CV2 второму кластеру CL2.
В этом примере видно, что хотя второй кластер CL2 не является репрезентативным только для воскресений, дождливых дней или дней только в июле, этот кластер CL2 является репрезентативным для дождливых воскресений и воскресений в июле.
Кроме того, если двум кластерам назначены одни и те же характеристические векторы CVj, характеристический вектор CVj, чей тег T или комбинация TC тегов имеет более низкий уровень SV значимости, может быть исключен из метки Li этого кластера CLi.
Посредством этого всем кластерам CLi может быть назначена метка Li, содержащая любое количество характеристических векторов CVj, которые представляют этот кластер CLi. В свою очередь, механизм 14 присваивания меток сохраняет эти помеченные кластеры CLi в базе 16 данных, которая может быть снова воплощена как база 7 данных или ее подмножество, как база 12 данных или ее подмножество, или воплощена как отдельная база данных.
Из первого кластера CL1, показанного на фиг. 3, можно также увидеть, что, так как каждый характеристический вектор CV1, CV2, CV3, CV4 содержит только один тег T, при необходимости они могут быть сгруппированы вместе, например, как дни недели. Это может быть выполнено с целью уменьшения количества характеристических векторов CVj, что, в свою очередь, позволяет снизить вычислительные затраты при попытке найти определенный кластер.
Помеченные кластеры CLi в базе 16 данных могут теперь использоваться для прогнозирования прошлого, настоящего или будущего характера движения PTB (фиг. 2) в дорожной системе 1. С этой целью запрос Req может подаваться в механизм 17 прогнозирования, который для этой цели получает помеченные кластеры CLi из базы 16 данных. Req запроса содержит один или более тегов RT запроса, которые могут быть сформулированы пользователем. Затем механизм 17 прогнозирования сопоставляет теги RT запроса с характеристическими векторами CVj помеченных кластеров CLi для определения "соответствующего" кластера CLi. Этот соответствующий кластер CLi или любые полученные из него данные затем выводятся механизмом 17 прогнозирования в виде спрогнозированного характера движения (PTB).
Одна примерная установка механизмов 11, 14, 17 может представлять собой следующее: хотя устройство 4 для измерения интенсивности дорожного движения получает данные в реальном времени и в полевых условиях, после продолжительного периода, например, одного года, механизм RT запроса и механизм 14 присваивания меток может создавать помеченные кластеры CLi в процессоре 9 центральной станции. С другой стороны, механизм 17 прогнозирования может быть воплощен в виде объекта, физически отличающегося от механизмов 11, 14 кластеризации и присваивания меток. В качестве альтернативы, механизм RT запроса, механизм 14 присваивания меток и механизм 17 прогнозирования могут быть реализованы с помощью одной и той же машины.
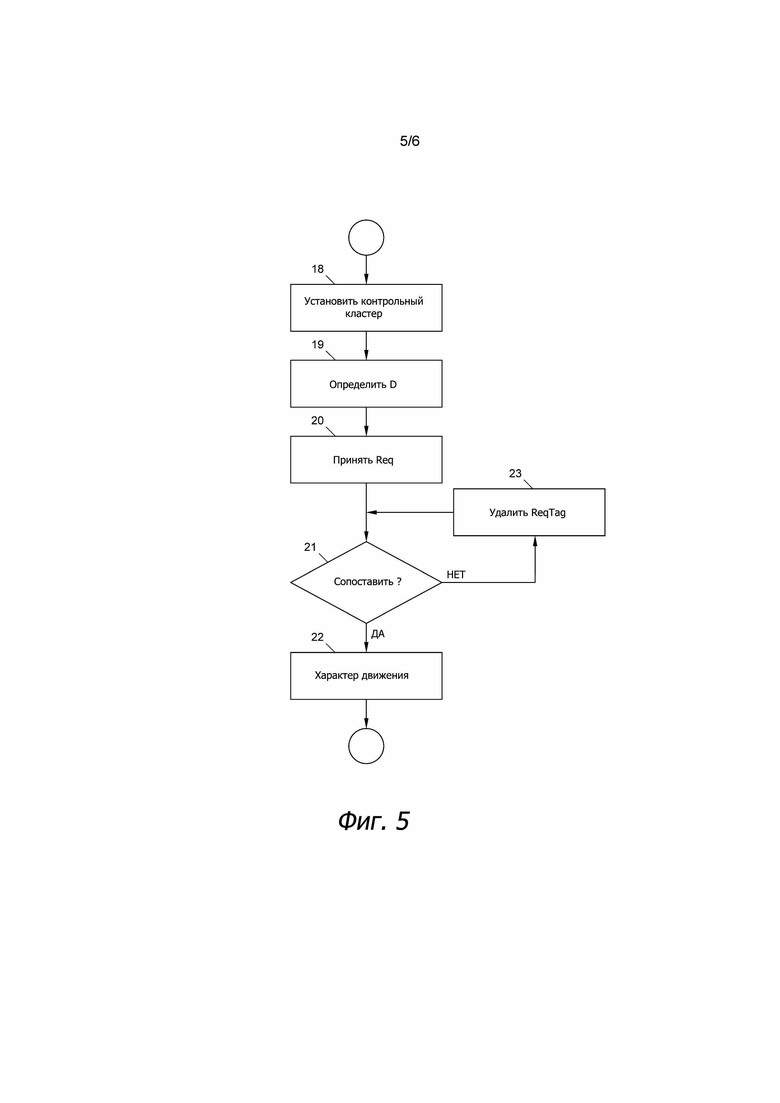
Ниже, со ссылкой на фиг. 5 и 6 будет подробно описана работа механизма 17 прогнозирования. После запуска процесса прогнозирования на этапе 18 кластер CLi, который содержит наибольшее число N профилей 6 движения, определяется и устанавливается в качестве контрольного кластера. В примере, показанном на фиг. 3, первый кластер CL1 содержит наибольшее число (N = 100) профилей 6 движения.
На этапе 19 мера D несходства вычисляется для каждого из кластеров CLi. Мера D несходства представляет собой меру того, насколько профили 6 движения конкретного кластера CLi отличаются от профилей 6 движения контрольного кластера (в данном случае CL1). После вычисления меры D несходства для кластера CLi ее можно назначить всем характеристическим векторам CVj этого кластера CLi. По определению контрольный кластер не отличается от самого себя и, таким образом, назначается наименьшей мерой несходства, например, D = 0.
Например, чтобы вычислить меру D несходства для других кластеров, усредненный профиль движения кластера CLi сравнивается с усредненным профилем движения контрольного кластера. В некоторых вариантах осуществления это можно выполнить, используя одну и ту же метрику расстояния, которая использовалась для выработки кластеров. В примере, показанном на фиг. 3, третий кластер CL3 больше всего отличается от контрольного кластера CL1 и имеет назначенную ему меру несходства D = 12. Четвертый кластер CL4 лишь незначительно отличается от контрольного кластера и имеет назначенную меру несходства D = 3, в то время как второй кластер CL2 имеет назначенную меру несходства D = 7. Подчеркивается, что мера D несходства не зависит от числа N профилей 6 движения в кластере CLi и представляет только разность между средним, наиболее вероятным или медианным значением или т.п. профилей 6 движения между кластерами CLi. Любую меру (не)сходства между кривыми, известными в данной области техники, можно использовать в качестве меры D несходства такой, например, как норма L2, норма L1 или гибридные нормы. Например, этапы 19 и 20 можно выполнить в процессоре 9 или в механизме 14 присваивания меток.
После подачи запроса Req с тегами RT запроса в машину 17 прогнозирования на этапе 20, на этапе 21 проверяется, соответствуют ли все теги RT запроса Req одному из характеристических векторов CVj кластеров CLi. Для этой цели теги RT запроса могут быть объединены в виде характеристического вектора CVj, чтобы увидеть, совпадают ли с ним характеристические векторы CVj кластеров. Если это так (ветвь "Y", "Да"), кластер CLi, который содержит соответствующий характеристический вектор CVj, определяется как соответствующий кластер CLi на этапе 22.
В конце этапа 22 весь соответствующий кластер CLi, или усредненный профиль движения или другие данные, полученные из этого соответствующего кластера CLi, могут выводиться механизмом 17 прогнозирования в качестве прогнозированного характера движения (PTB) для запроса Req. Альтернативно, если на этапе 21 не найден соответствующий характеристический вектор CVj среди кластеров, CLi (ветвь "N", "Нет"), один из тегов RT запроса исключается из запроса Req на этапе 23, и повторяется этап 21.
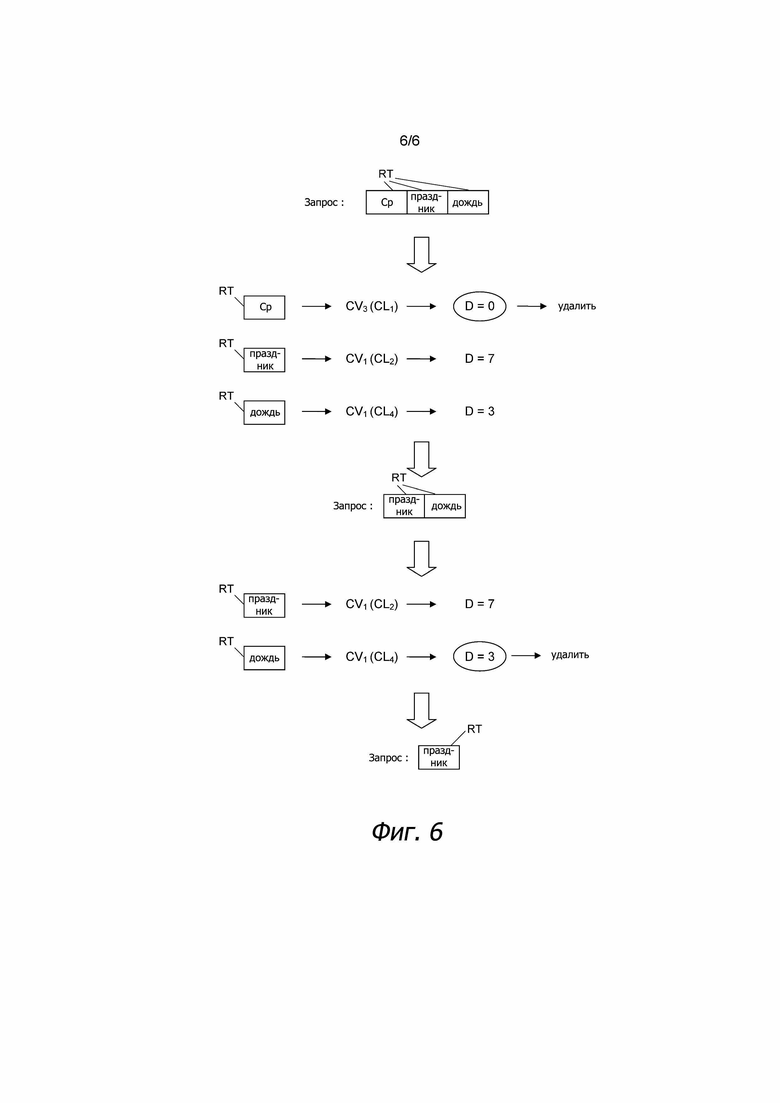
Этап 23 исключения тега RT запроса из запроса Req подробно описан посредством примера, показанного на фиг. 6, в котором снова используются примерные кластеры, показанные на фиг. 3. В данном документе, вначале запрос Req содержит теги запроса "среда", "праздник" и "дождь". Когда этап 21 выполняется в первый раз, проверяется, присутствует ли комбинация этих трех тегов RT в любой из меток Li четырех кластеров CLi (смотри четыре метки L1, L2, L3, L4 с правой стороны на фиг. 3). В этом примере нельзя найти характеристический вектор CVj, который содержит три тега RT запроса.
Чтобы исключить один из тегов RT запроса из запроса Req, в одном варианте осуществления настоящего способа для каждого тега RT запроса отдельно проверяется, существует ли характеристический вектор CVj, соответствующий этому тегу RT запроса, то есть не проверяется то, находится ли просто этот тег RT запроса в комбинации TC тегов характеристического вектора CVj, но только если существует характеристический вектор CVj, который точно соответствует тегу RT запроса. Как показано на фиг. 3 и 6, видно, что тег запроса "среда" запроса Req встречается в качестве характеристического вектора CV3 в метке L1 первого кластера CL1, тег запроса "праздник" запроса Req встречается в качестве характеристического вектора CV1 в метке L2 второго кластера CL2, и тег запроса "дождь" запроса Req встречается в качестве характеристического вектора CV1 в метке L4 четвертого кластера CL4.
Теперь проверяется, какой из этих соответствующих характеристических векторов CVj имеет наименьшую меру D несходства. Так как характеристический вектор CV3 находится в первом кластере CL1, который имеет наименьшую меру несходства D = 0, и два других кластера CL2, CL4 имеют более высокие меры несходства D = 7, 3, соответственно, тег запроса "среда" исключается из запроса Req, так как этот тег RT запроса соответствует характеристическому вектору CVj кластера CLi с наименьшей мерой D несходства, то есть наименее интересному кластеру CLi, в данном случае: кластеру CL1.
После этого повторяется этап 21 и проверяется, существует ли характеристический вектор CVj, который содержит комбинацию тегов из оставшихся двух тегов запроса "праздник" и "дождь". И снова, если результат проверки является отрицательным, то повторно проверяется, какой из двух остающихся тегов RT запроса соответствует кластеру CLi с наименьшей мерой D несходства. В этом случае тег запроса "дождь" исключается из запроса Req, так как он имеет наименьшую меру D несходства.
Поэтому снова проверяется, соответствует ли запросу Req, который только теперь содержит тег "праздник", любым характеристическим векторам CVj кластеров CLi. Это справедливо для второго кластера CL2, который имеет назначенный характеристический вектор CV1. Поэтому второй кластер CL2 является соответствующим кластером, из которого затем получается спрогнозированный характер движения (PTB).
Иногда теги RT запроса не встречаются в характеристическом векторе CVj, который содержит только этот тег RT запроса в любом из кластеров CLi, так как этот тег запроса не присутствует в каких-либо тегах T профилей 6 движения, которые используются для создания кластеров CLi или так как этот тег T используется только в характеристическом векторе CVj в комбинации с другим тегом T. В этом случае наименьшую меру несходства, например, D = 0, можно назначить этому тегу RT запроса.
В альтернативном варианте осуществления, при проверке, какой из тегов RT запроса должен быть исключен, проверяется не только, существует ли характеристический вектор CVj, который только содержит этот тег запроса RT, но также проверяется, существует ли характеристический вектор CVj, содержащий этот тег RT запроса в комбинации с другим тегом T. В этом случае выбирается этот характеристический вектор CVj и, в свою очередь, базовый кластер CLi и его мера D несходства, для которого, например, уровень SV значимости характеристического вектора CVj превышает или имеет более высокое или более низкое число N профилей 6 движения. Например, на фиг. 3 для тега "праздник" доступны характеристический вектор CV1 второго кластера CL2 и характеристический вектор CV2 третьего кластера CL3, который имеет комбинации тегов "праздник" и "солнечный день". Так как уровень SV значимости характеристического вектора CV2 комбинации тегов "праздник и воскресенье" третьего кластера CL3 выше (98%), чем уровень SV значимости (92%) характеристического вектора CV1 во втором кластере CL2, мера несходства D = 12 третьего кластера CL3 (и D ≠ 7 второго кластера CL2) выбрана для тега запроса "праздник" и дополнительно используется на этапах сравнения, показанных на фиг. 6. Таким образом, в некоторых вариантах осуществления, в которых уровни SV значимости характеристических векторов CVj использовались для присваивания меток кластеров CLi, эти уровни SV значимости можно также использовать при определении кластера CLi, соответствующего запросу Req.
Во всех вариантах осуществления при проверке того, какой тег запроса RT соответствует характеристическому вектору CVj кластера CLi, когда два кластера имеют одинаковые характеристические векторы CVj, характеристический вектор CVj с более высоким уровнем SV значимости может быть выбран для этого тега RT запроса.
Кроме того, когда на этапе 21 сопоставления обнаруживаются два соответствующих кластера CLi, один из них с более высоким числом N профилей 6 движения может быть определен как соответствующий кластер, и другой кластер отбрасывается.
Чтобы дополнительно повысить точность способа, можно не только проверить, встречаются ли единичные теги RT запроса в характеристических векторах CVj кластеров CLi, но также соответствуют ли комбинации тегов RT запроса характеристическому вектору CVj кластера CLi. В этом случае, если этот характеристический вектор, соответствующий CVj комбинации тегов RT запроса, имеет самую низкую меру D несходства среди характеристических векторов, CVj, соответствующий всем тегам RT запроса или комбинациям тегов запроса, упомянутая комбинация тегов запроса не учитывается до тех пор, пока тег RT запроса не будет исключен из запроса Req.
Изобретение не ограничивается конкретными вариантами осуществления, подробно описанными в данном документе, но охватывает все их варианты, комбинации и модификации, которые попадают в рамки прилагаемой формулы изобретения.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ ПРОГНОЗИРОВАНИЯ ДИНАМИКИ ДОРОЖНОГО ДВИЖЕНИЯ В СИСТЕМЕ ДОРОГ | 2018 |
|
RU2751381C2 |
| Способы обнаружения аномальных элементов веб-страниц на основании статистической значимости | 2017 |
|
RU2659741C1 |
| Способы обнаружения аномальных элементов веб-страниц | 2016 |
|
RU2652451C2 |
| Способы обнаружения вредоносных элементов веб-страниц | 2016 |
|
RU2638710C1 |
| Способ обнаружения связанных кластеров | 2019 |
|
RU2747451C2 |
| Способ отнесения неизвестного устройства кластеру | 2019 |
|
RU2747466C2 |
| Способ формирования кластеров устройств | 2019 |
|
RU2747452C2 |
| СПОСОБ И МАШИНА ДЛЯ ГЕНЕРИРОВАНИЯ КАРТОГРАФИЧЕСКИХ ДАННЫХ И СПОСОБ И НАВИГАЦИОННОЕ УСТРОЙСТВО ДЛЯ ОПРЕДЕЛЕНИЯ МАРШРУТА, ИСПОЛЬЗУЯ КАРТОГРАФИЧЕСКИЕ ДАННЫЕ | 2008 |
|
RU2489681C2 |
| СПОСОБ ФИЛЬТРАЦИИ АТАКУЮЩИХ ПОТОКОВ, НАЦЕЛЕННЫХ НА МОДУЛЬ СВЯЗИ | 2019 |
|
RU2777839C2 |
| СПОСОБ И УСТРОЙСТВО ДЛЯ ГЕНЕРИРОВАНИЯ ОТСОРТИРОВАННОГО СПИСКА ЭЛЕМЕНТОВ | 2012 |
|
RU2617391C2 |
Изобретение относится к способу прогнозирования характера движения в дорожной системе. Способ прогнозирования характера движения транспортного средства в дорожной системе содержит этапы, выполняемые одним процессором, подключенным к базе данных, которая содержит ряд профилей движения. Каждый профиль движения представляет собой показатель движения транспортных средств в дорожной системе. При этом заданные теги, связанные со временем записи соответствующего профиля движения, присваиваются упомянутому профилю движения. Кластеризацию профилей движения с их тегами в один кластер при несходстве профилей движения, для одного тега в каждом кластере вычисление уровня значимости посредством статистического анализа, в котором уровень значимости каждого тега или комбинации тегов вычисляется посредством статистики хи-квадрата. Если уровень значимости тега выше порогового значения, назначение этого тега в качестве характеристического вектора этому кластеру, в механизме прогнозирования прием запроса, имеющего один или более тегов запроса для определения соответствующего кластера, определение кластера посредством сопоставления тега запроса с характеристическими векторами кластеров и вывод спрогнозированного характера движения на основании определенного кластера. Достигается уменьшение продолжительности проезда транспортного средства. 10 з.п. ф-лы, 6 ил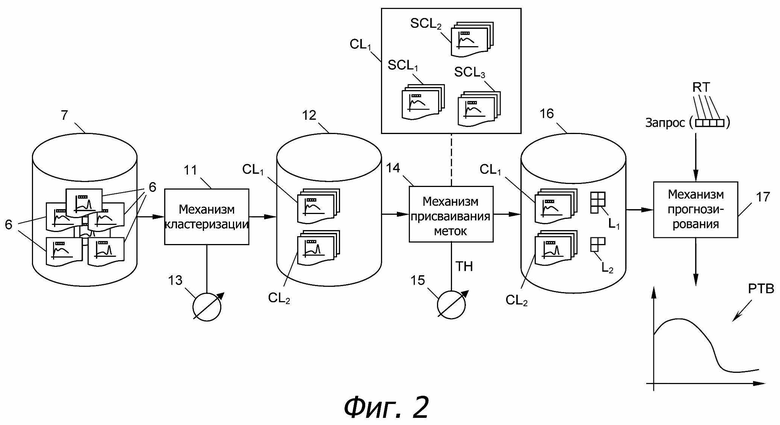
1. Способ прогнозирования характера движения транспортного средства в дорожной системе, содержащий следующие этапы, выполняемые по меньшей мере одним процессором (9, 11, 14, 17), подключенным к базе (7, 12, 16) данных, которая содержит ряд профилей (6) движения, причем каждый профиль (6) движения представляет собой показатель движения транспортных средств (3) в дорожной системе (1), записанный в течение продолжительного периода времени (t), при этом один или более заданных тегов (T), связанных с временем записи соответствующего профиля (6) движения, присваиваются упомянутому профилю (6) движения:
кластеризацию профилей (6) движения с их тегами (T) по меньшей мере в один кластер (CLi) при несходстве профилей (6) движения;
по меньшей мере для одного тега (T) в каждом кластере (CLi) вычисление уровня (SV) значимости посредством статистического анализа, в котором уровень (SV) значимости каждого тега (T) или комбинации (TC) тегов соответственно вычисляется посредством статистики хи-квадрата;
если уровень (SV) значимости тега (T) выше порогового значения (TH), назначение этого тега (T) в качестве характеристического вектора (CVj) этому кластеру (CLi);
в механизме прогнозирования прием запроса (Req), имеющего один или более тегов (RT) запроса для определения соответствующего кластера (CLi);
определение кластера (CLi) посредством сопоставления тега(ов) (RT) запроса с характеристическими векторами (CVj) кластеров (CLi) и
вывод спрогнозированного характера движения (PTB) на основании определенного кластера (CLi).
2. Способ по п. 1, в котором имеются по меньшей мере две переменные и каждый тег (T) назначается переменной (V), причем способ содержит дополнительные этапы:
по меньшей мере для одной переменной (V) в каждом кластере (CLi) вычисление уровня (SV) значимости и
по меньшей мере для одного тега (T), назначенного переменной (V) с самым высоким уровнем (SV) значимости каждого кластера (CLi), вычисление уровня (SV) значимости.
3. Способ по п. 2, в котором способ содержит дополнительные этапы:
группирование всех профилей (6) движения, которые не содержат тег (T), чей уровень (SV) значимости превышает упомянутое пороговое значение (TH), в подкластер (SCLi);
по меньшей мере для одной переменной в подкластере (SCLi) вычисление уровня (SV) значимости и
для тега (T), назначенного переменной (V) с самым высоким уровнем (SV) значимости подкластера (SCLi), вычисление уровня (SV) значимости.
4. Способ по п. 3, в котором этапы группирования, вычисления уровня (SV) значимости для переменной (V) и вычисления уровня (SV) значимости для тега (T) повторяются до тех пор, пока профили (6) движения станут не доступными для группирования.
5. Способ по любому из пп. 1-3, в котором по меньшей мере для одного тега (T), чей уровень (SV) значимости находится ниже упомянутого порогового значения (TH), вычисляется уровень (SV) значимости комбинации упомянутого тега (T) с дополнительным тегом (T) и, если упомянутый уровень (SV) значимости упомянутой комбинации (TC) тегов превышает пороговое значение (TH), упомянутая комбинация (TC) тегов назначается в качестве дополнительного характеристического вектора (CVj) кластеру (CLi) упомянутого тега (T).
6. Способ по любому из пп. 1-3, в котором для каждого кластера (CLi) вычисляются уровни (SV) значимости для всех меток (T) этого кластера (CLi).
7. Способ по любому из пп. 1-3, в котором, когда два кластера (CLi) будут назначены одному и тому же характеристическому вектору (CVj), пороговое значение уменьшается, и снова проверяется, превышает ли уровень (SV) значимости каждого тега (T) или комбинации (TC) тегов соответственно пороговое значение (TH), для того, чтобы назначить этот тег (T) или комбинацию (TC) тегов соответственно в качестве характеристического вектора (CVj) этому кластеру (CLi).
8. Способ по любому из пп. 1-3, в котором уровни (SV) значимости меток (T) или комбинации (TC) тегов используются при проверке того, соответствует ли тег (RT) запроса характеристическому вектору (CVj).
9. Способ по любому из пп. 1-3, в котором каждый профиль (6) движения представляет собой показатель движения транспортных средств (3) в дорожной системе (1) в течение промежутка времени, равного 24 часам.
10. Способ по любому из пп. 1-3, в котором по меньшей мере один тег (RT) указывает день недели, месяц года, неделю месяца, индикатор школьных каникул или индикатор праздничного дня с упомянутым временем записи.
11. Способ по любому из пп. 1-3, в котором по меньшей мере один тег (RT) указывает состояние дороги или погодные условия в упомянутое время записи.
| US 9368027 B2, 14.06.2016 | |||
| СПОСОБ ПРИГОТОВЛЕНИЯ СЫРОГО КОРМА ИЗ ПОБОЧНЫХ ПРОДУКТОВ КРАХМАЛО-ПАТОЧНОГО ПРОИЗВОДСТВА | 2007 |
|
RU2336722C1 |
| US 8160805 B2, 17.04.2012. | |||

