Изобретение касается способа прогнозирования динамики дорожного движения в системе дорог на основе набора профилей дорожного движения, каждый из которых представляет меру дорожного движения для транспортных средств в системе дорог и которые записаны в течение продолжительного времени, при этом один или несколько заранее определенных тегов, связанных со временем записи конкретного профиля дорожного движения, приписывают указанному профилю дорожного движения.
Таким образом, изобретение касается области измерения и оценки динамики дорожного движения, например, динамики дорожного движения на главной улице города. Когда динамика дорожного движения на этой улице проанализирована в течение длительного периода времени, обычно в течение года или больше, цель заключается в оценке динамики дорожного движения в определенный день или временное окно в будущем. Указанное может быть использовано для прогнозирования того, какая дорога будет перегружена или заблокирована в определенное время, например, чтобы отправители планировали перемещение грузов или чтобы семьи планировали свои выходные. В зависимости от прогноза динамики дорожного движения, могут быть выбраны разные маршруты или моменты времени для перемещения по этой улице, тем самым в любом случае может быть уменьшено время путешествия транспортного средства от начала до конца.
С этой целью, в известных способах прогнозирования дорожного движения используют объединение в кластеры записанных профилей по их сходству и снабжение кластеров характеристическими векторами («метками») из тегов, при этом указанные теги можно запросить для идентификации кластера из профилей дорожного движения в качестве прогноза динамики дорожного движения для определенного дня, например, конкретного дня недели, «дождливого» дня и так далее.
В документе Weijermars, van Berkom: «Analysing highurey patterns using cluster analysis» («Анализ шаблонов потока для шоссе с использованием кластерного анализа»), конференция IEEE по интеллектуальным транспортным системам, 13 - 16 сентября 2005 года, показан способ анализа шаблонов дорожного движения. В указанном документе было записано 118 профилей дорожного движения для шоссе, каждый для промежутка времени, равного 24 часам. Далее, профили дорожного движения были объединены в кластеры с помощью стандартного алгоритма объединения в кластеры. После ручного снабжения кластеров метками, были оценены отклонения в кластерах.
Далее, в соответствии с уровнем техники брали стандартную динамику дорожного движения и экстраполировали динамику дорожного движения для получения краткосрочного прогноза путем определения текущего отклонения от стандартной динамики дорожного движения. Этот способ известен как параметрическая регрессия и в результате получается 15 минутный прогноз.
Таким образом, существует потребность в надежном способе долгосрочного прогнозирования дорожного движения. Этот способ должен получать результаты даже с компьютерами, обладающими малыми вычислительными ресурсами, чтобы этот способ можно было использовать на мобильных телефонах и подобных перемещающихся устройствах.
Следовательно, цель изобретения заключается в создании улучшенного способа для прогнозирования динамики дорожного движения.
С этой целью, в изобретении предложен способ прогнозирования динамики дорожного движения в системе дорог, который включает в себя следующие этапы, выполняемые по меньшей мере одним процессором, который соединен с базой данных, содержащей набор профилей дорожного движения, при этом каждый профиль дорожного движения представляет поток транспорта или другую меру дорожного движения для транспортных средств в системе дорог, записанную в течении длительного времени, при этом указанному профилю дорожного движения приписывают один или несколько заранее определенных тегов, связанных со временем записи соответствующего профиля дорожного движения:
объединяют профили дорожного движения с их тегами по меньшей мере в два кластера по схожести профилей дорожного движения;
каждому кластеру приписывают по меньшей мере один характеристический вектор, что делают на основе тегов в этом кластере, при этом каждый характеристический вектор содержит тег или комбинацию тегов указанного кластера;
определяют, какой кластер содержит наибольшее количество профилей дорожного движения, и устанавливают этот кластер как эталонный кластер;
для каждого кластера, определяют меру несхожести этого кластера с эталонным кластером, и приписывают эту меру несхожести всем характеристическим векторам этого кластера, при этом мера несхожести представляет собой меру того, насколько профили дорожного движения кластера отличаются от профилей дорожного движения эталонного кластера;
принимают запрос, содержащий один или несколько тегов запроса;
проверяют, соответствуют ли все теги запроса одному из характеристических векторов кластеров, и
если указанное выполняется, подают на выход прогноз динамики дорожного движения, основанный на кластере с указанным соответствующим характеристическим вектором,
в противном случае, исключают один из тегов запроса из запроса, и возвращаются к началу указанного этапа проверки;
при этом тег запроса, подлежащий исключению, выбирают путем определения того, какие характеристические векторы соответствуют каждому тегу запроса, и выбора тега запроса, для которого соответствующий характеристический вектор обладает наименьшей мерой несхожести.
В способе, который соответствует изобретению, обрабатывают запрос, который может быть легко сформулирован, путем выбора надлежащих тегов. Например, если пользователь хочет спрогнозировать динамику дорожного движения для понедельника в июле, и он знает, что этот понедельник будет выходным днем, он может сформулировать запрос с помощью тегов «понедельник», «июль» и «выходной». Далее в способе используют алгоритм исключения, который предоставляет минимальное количество этапов для нахождения наиболее близкого соответствующего кластера для указанного запроса.
Способ прогнозирования, соответствующий изобретению, основан на той идее, что кластер с наибольшим количеством профилей дорожного движения представляет средний поток транспорта в системе дорог. Теги в запросе, которые являются очень специфическими, то есть соответствуют кластерам, которые очень непохожи на кластер с наибольшим количеством профилей дорожного движения, будут предпочтительными и, таким образом, скорее всего не будут исключены. На основе этого принципа, способ включает в себя цикл, в котором последовательно исключают наименее интересные теги до тех пор, пока запрос не станет соответствовать характеристическому вектору одного из кластеров, который далее могут использовать для прогнозирования динамики дорожного движения.
Способ может быть также дополнительно улучшен с помощью учета комбинаций тегов запроса. С этой целью, при выборе того, какой тег запроса исключать из запроса, также могут проверить, соответствует ли комбинация тегов запроса характеристическому вектору, и, если соответствует и, если этот характеристический вектор обладает наименьшей мерой несхожести среди характеристических векторов, соответствующих всем тегам запроса или комбинациям тегов запроса, указанную комбинацию тегов не рассматривают до тех пор, пока не исключат тег из запроса. С помощью указанного может быть улучшена точность прогнозирования, при этом вычислительные затраты существенно не увеличиваются. Даже хотя цикл может повторяться чаще, не может иметь место ситуация, выполнения одного цикла в другом, так что требования к вычислительным ресурсам остаются низкими.
Мера несхожести может быть получена разными путями. Предпочтительно, чтобы меру несхожести кластера получали путем сравнения среднего профиля дорожного движения указанного кластера со средним профилем дорожного движения эталонного кластера. Здесь термин «средний» также включает в себя взвешенные средние. В качестве альтернативы, вместо среднего также могут быть использовано наиболее вероятное или медианное значение. Таким образом, наиболее значимый (отклонившийся) профиль дорожного движения одного кластера будут сравнивать с наиболее значимым (отклонившимся) профилем дорожного движения эталонного кластера. Этап сравнения также может быть выполнен разными путями, например, путем вычисления норм L1 и L2 профилей для сравнения.
Существует два альтернативных варианта осуществления изобретения при определении того, какой характеристический вектор соответствует тегу или комбинации тегов запроса. В первом, «эквивалентность один-к-одному», варианте осуществления изобретения характеристический вектор соответствует тегу запроса или комбинации тегов запроса в том случае, когда характеристический вектор содержит только этот тег запроса или комбинацию тегов запроса. Указанное может обладать достоинством, которое заключается в том, что в качестве соответствующих характеристических векторов находят мало характеристических векторов, что улучшает скорость вычислений.
Во втором, «содержащая эквивалентность», варианте осуществления изобретения характеристический вектор соответствует тегу запроса или комбинации тегов запроса в том случае, когда характеристический вектор содержит отдельно этот тег запроса или комбинацию тегов запроса или содержит в комбинации по меньшей мере с одним дополнительным тегом. Указанное может обладать достоинством, которое заключается в том, что доступно больше вариантов, что увеличивает надежность способа и предотвращает слишком раннее исключение «редких», важных тегов, когда они не содержат точного эквивалентного характеристического вектора.
Для дополнительного улучшения надежности способа, вычисляют уровень значимости каждого характеристического вектора каждого кластера и, когда два или более характеристических векторов соответствуют тегу запроса или комбинации тегов запроса, исключают характеристический вектор с меньшим уровнем значимости. Указанное доступно для обоих упомянутых выше альтернативных вариантов осуществления изобретения и это предотвращает проблемы с возможными коллизиями, а также увеличивает точность благодаря дополнительному уровню значимости.
Для дополнительного исключения проблем с коллизиями для двух или более соответствующих векторов, то есть если два характеристических вектора соответствуют тегу запроса или комбинации тегов запроса и оба обладают одним и тем же уровнем значимости, если это применимо, то не рассматривается характеристический вектор кластера с меньшим количеством профилей дорожного движения. Указанное является более безопасным вариантом, но также возможно использовать характеристический вектор кластера с меньшим количеством профилей дорожного движения, чтобы не отбрасывать слишком быстро соответствующие теги или комбинации тегов.
Иногда могут иметь место ситуации, когда тег запроса не соответствует точно какому-либо из характеристических векторов кластеров. Указанное может означать, что накоплено недостаточно данных для получения результата для этого запроса. Если все же нужно получить наибольшее соответствие с доступными данными, если на этапе исключения не найдено характеристического вектора для тега запроса, то для этого тега предполагается наименьшая мера несхожести. Тем не менее, указанное также означает, что этот тег запроса с большой вероятностью будет рано исключен в цикле.
Во всех вариантах осуществления изобретения предпочтительно, чтобы каждый профиль дорожного движения представлял меру дорожного движения транспортных средств в системе дорог для промежутка времени, равного 24 часам. В качестве альтернативы, также могут быть использованы промежутки времени, равные 6 часам, 12 часам или 18 часам, особенно когда динамика дорожного движения в определенные часы дня, например, в ночные часы или в часы пик, по существу, совпадает для всех профилей дорожного движения.
Предпочтительно, чтобы по меньшей мере один тег указывал день недели, месяц года, неделю месяца, содержал указание на школьные каникулы, указание на специальный праздник для указанного времени записи. Такие теги могут быть, например, выработаны автоматически, путем присоединения к профилю дорожного движения атрибута календаря. Календарь может быть определен заранее, в режиме реального времени, или ретроспективно и также возможно последовательно добавлять теги к профилям дорожного движения, когда они появляются в запросе первый раз.
В качестве альтернативы или дополнительно, по меньшей мере один тег указывает дорожные условия или погодные условия в указанное время записи. Такие теги представляют физическое значение для данных окружающей среды, которые могут быть закодированы с помощью тега заранее, в режиме реального времени, или ретроспективно.
Далее изобретение будет описано более подробно на основе предпочтительных примеров вариантов осуществления изобретения со ссылками на приложенные чертежи, на которых:
фиг. 1 - вид, схематично показывающий систему дорог;
фиг. 2 - вид, показывающий структурную схему баз данных и модулей обработки для осуществления способа, соответствующего изобретению;
фиг. 3 - вид, показывающий пример кластеров и соответствующих меток, появляющихся на этапах объединения в кластеры и снабжения метками из способа, соответствующего изобретению;
фиг. 4 - вид, показывающий дерево решений, которое используют для определения меток для кластеров в ходе осуществления способа, соответствующего изобретению;
фиг. 5 - вид, показывающий блок-схему этапа прогнозирования из способа, соответствующего изобретению; и
фиг. 6 - вид, показывающий пример исключения тегов из запроса в ходе этапа прогнозирования с фиг. 5.
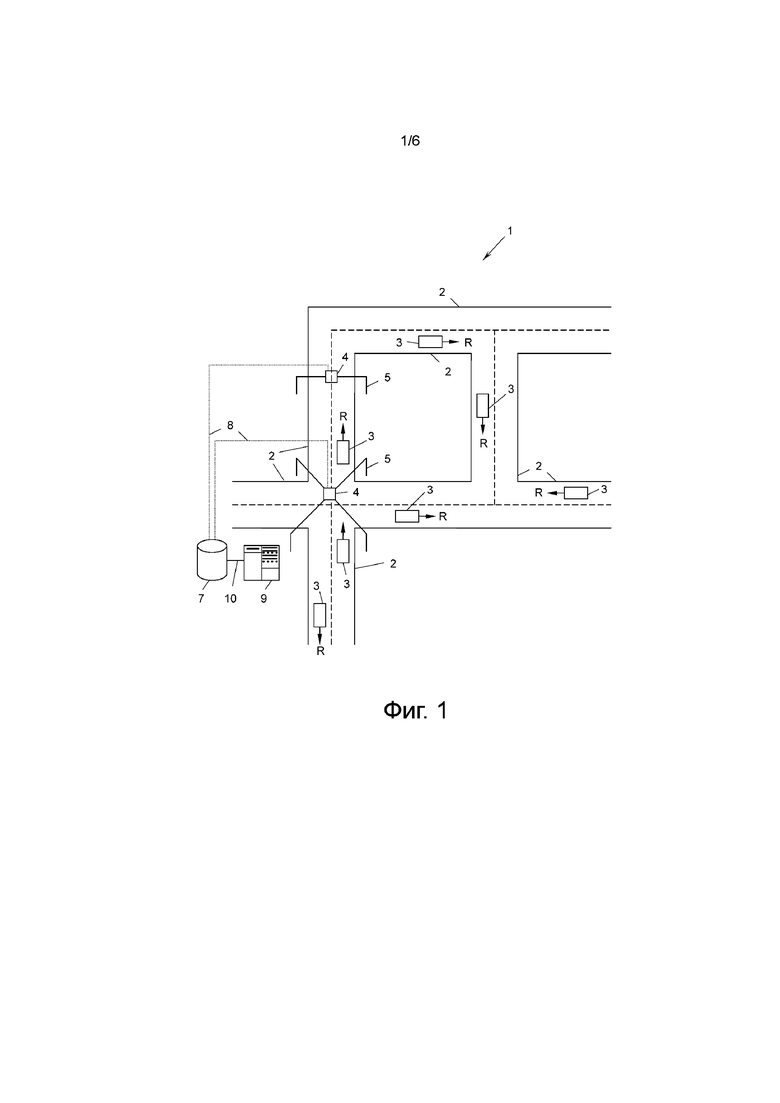
На фиг. 1 показана система 1 дорог с несколькими дорогами 2, на которых транспортные средства 3 перемещаются в направлениях R. Система 1 дорог снабжена по меньшей мере одним устройством 4 измерения дорожного движения, которое, например, может быть использовано для измерения потока транспорта на дороге 2 или на пересечении дорог 2. Устройство 4 измерения дорожного движения может быть установлено на стойке 5, перекинутой над дорогой 2, или, в качестве альтернативы, может быть установлено на краю дороги. Устройство 4 измерения дорожного движения может быть реализовано любым известным в технике образом, например, как индуктивные петлевые датчики, радиолокационные устройства, световые защитные устройства, камеры с видеообработкой данных, или беспроводные устройства считывания, которые считывают радиоответ так называемых бортовых устройств (OBU), расположенных на транспортных средствах 3.
Устройство 4 измерения дорожного движения может непосредственно записывать поток транспорта на дороге 2, например, как количество v транспортных средств 3 за единицу t времени, или оно может записывать количество v/t транспортных средств 3, перемещающихся по заданной секции дороги 2 в заданный момент времени, например, путем подсчета транспортных средств 3 на картинках с камер заданной секции дороги, которые формируются с регулярными временными интервалами.
Вместо измерения потока транспорта, с помощью разных измеряемых значений также могут быть измерены другие условия дорожного движения на дороге, например, путем записи средней скорости на дороге 2 в определенный момент времени t или путем измерения времени, которое нужно транспортным средствам для проезда секции дороги 2.
Устройство 4 измерения дорожного движения записывает в качестве профиля 6 дорожного движения (фиг. 2) поток v/t транспорта - или эквивалентные значения измерений, как описано выше, - за время t в течении заранее определенного промежутка времени, например, 24 часов. В качестве альтернативы, могут быть использованы более короткие промежутки времени, например, только наиболее интересные промежутки времени дня, например, 6, 12 или 18 часов.
Устройство 4 измерения дорожного движения записывает указанные профили 6 дорожного движения за длительный период времени, например, день за днем в течение целого года или дольше. Профиль дорожного движения может состоять из дискретных отсчетов, например, один отсчет каждые 5 минут, 15 минут или каждый час, или может быть по меньшей мере гладкой кривой, зависящей от времени. Таким образом, каждое устройство 4 измерения дорожного движения записывает набор профилей 6 дорожного движения для своей дороги 2 или пересечения дорог 2 и сохраняет его в базе 7 данных с помощью соединения 8 для данных. Процессор 9 соединен с базой 7 данных с помощью соединения 10 с целью дополнительной обработки профилей 6 дорожного движения, что будет описано ниже.
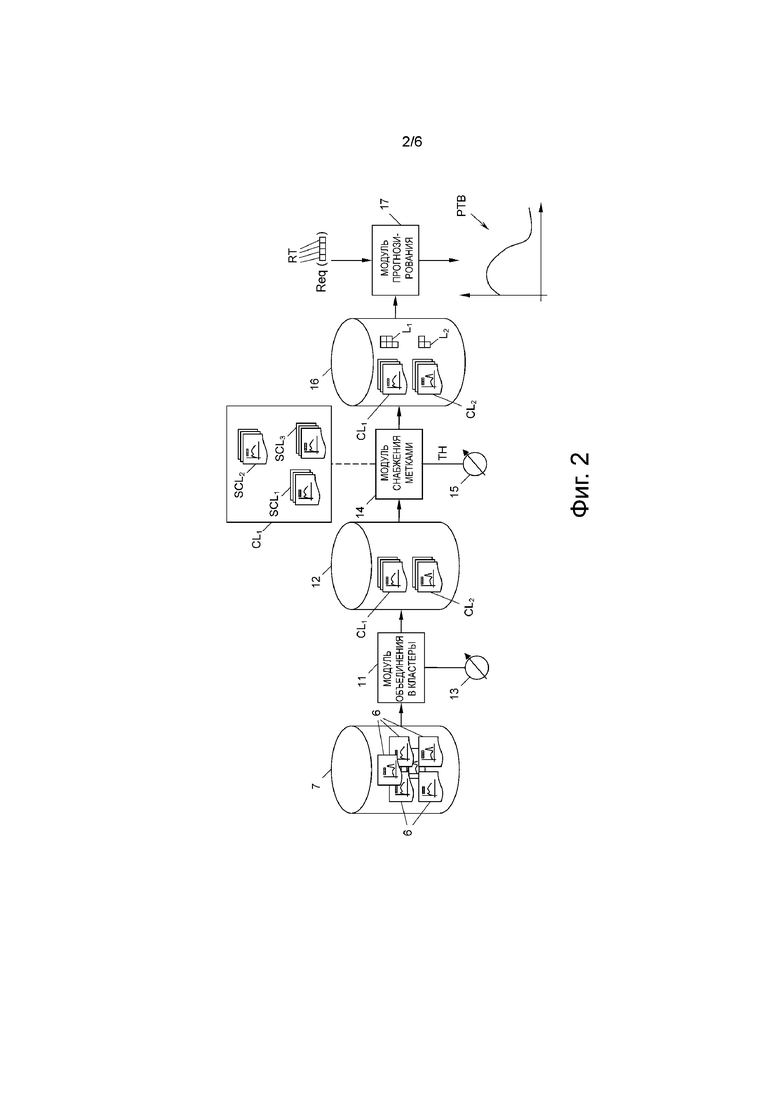
На фиг. 2 показан модуль 11 объединения в кластеры, который может быть частью упомянутого выше процессора 9. Модуль 11 объединения в кластеры получает профили 6 дорожного движения из базы 7 данных и объединяет эти профили 6 дорожного движения по меньшей мере в один или по меньшей мере в два кластера CL1, CL2 …, в общем, CLi. Алгоритм объединения в кластеры, который используют в модуле 11 объединения в кластеры, может быть алгоритмом любого типа, который известен в технике, например, иерархический агломеративный алгоритм объединения в кластеры. С этой целью, может понадобиться предварительно обработать профили 6 дорожного движения, чтобы они содержали, например, 96 временных отсчетов каждый с интервалами, равными 15 минутам. Более того, для решения проблемы локальных аномалий, имеющих место в профилях 6 дорожного движения, могут быть использованы фильтры.
В результате, модуль 11 объединения в кластеры подает на выход на базу 12 данных кластеры CLi, каждый из которых содержит несколько профилей 6 дорожного движения, которые похожи друг на друга. Эта база 12 данных может совпадать с базой 7 данных или ее подмножеством. Более того, модулем 11 объединения в кластеры можно управлять с помощью средства 13 ввода настроек управления путем регулировки параметров объединения в кластеры.
После того, как профили 6 дорожного движения объединили в кластеры CLi, применяют модуль 14 снабжения метками для снабжения метками L1, L2, …, в общем, Li, каждого кластера CLi, при этом каждая метка Li состоит по меньшей мере из одного характеристического вектора CV1, CV2, …, в общем, CVj. Метки Li должны отражать содержимое кластеров CLi, настолько точно, насколько это возможно.
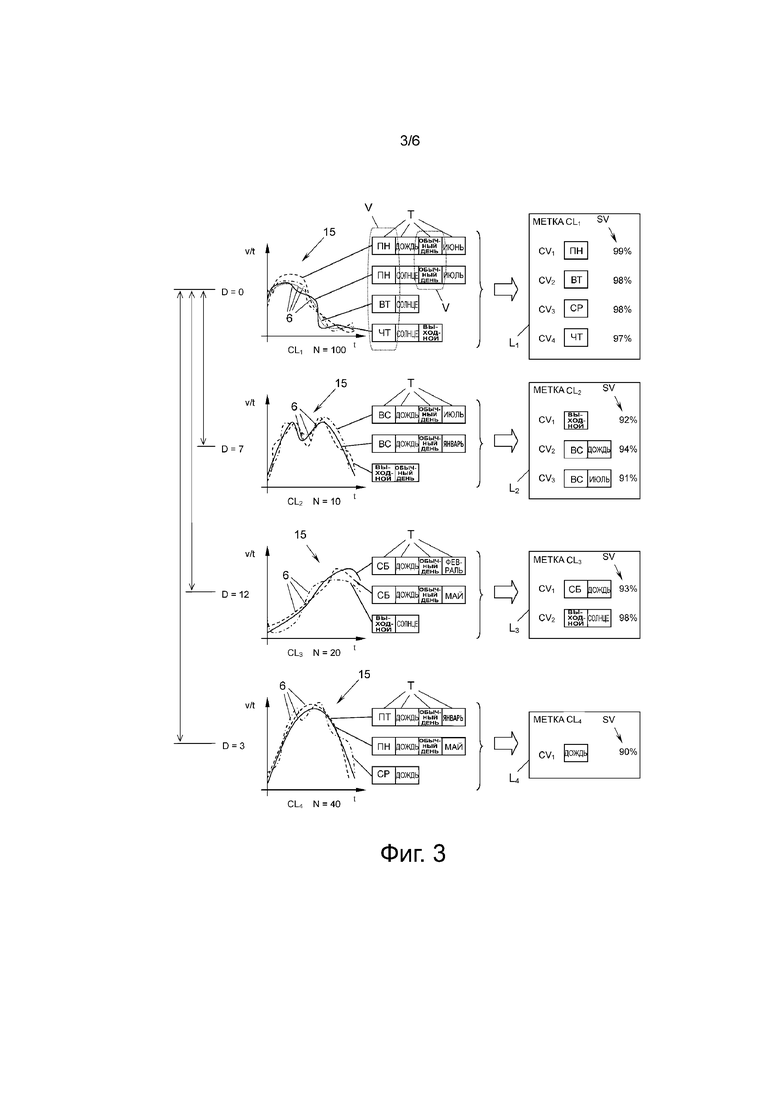
Далее будут подробно описаны этапы способа, осуществляемые модулем 14 снабжения метками, при этом в описании будет опираться на фиг. 3, на которой описано четыре примера кластеров CL1, CL2, CL3, CL4, которые были выданы модулем 11 объединения в кластеры. Первый кластер CL1 содержит N = 100 похожих профилей 6 дорожного движения, из которых только четыре показаны на схеме 15, для легкости представления. На схеме 15 время t откладывают по горизонтальной оси и поток v/t транспортных средств за единицу времени откладывают по вертикальной оси. Дополнительно ясно, что каждый из четырех примеров профилей 6 дорожного движения может содержать один или несколько, в настоящем примере от двух до четырех, заранее определенных тегов Т, которые приписаны указанным профилям.
Теги Т, приписанные профилю 6 дорожного движения, связаны некоторым образом со временем записи указанного профиля 6 дорожного движения. Например, тег Т может указывать день недели, месяц года, неделю месяца, указание на школьные каникулы, указание на специальный праздник, дорожные условия или погодные условия в промежутке времени, за который был записан профиль 6 дорожного движения.
Теги Т могут быть приписаны профилю 6 дорожного движения непосредственно во время записи с помощью устройства 4 измерения дорожного движения, в базе 7 данных или даже после объединения в кластеры в базе 12 данных. С этой целью, каждое из соответствующих устройств 4, 7, 12 может содержать часы, календарь, метеорологическую станцию или любое средство для приема данных об условиях окружающей среды или дорожных условиях. В качестве альтернативы, теги Т могут быть приписаны профилям 6 дорожного движения ретроспективно, например, с помощью календарей из баз 7, 12 данных. Информация о календаре, погодных условиях, условиях окружающей среды или дорожных условиях может быть приписана ретроспективно, например, если на неделю или месяц позже появляется информация о том, что дорога, на которой был записан поток транспорта, была повреждена или находится в процессе строительства. Теги Т даже могут быть приписаны профилям 6 дорожного движения в ходе этапа снабжения метками с помощью модуля 14 снабжения метками, который для этой цели может содержать свой собственный календарь или введенные данные.
Возвращаясь к конкретному примеру с фиг. 3, ясно, что первый профиль 6 дорожного движения первого кластера CL1 содержит теги «понедельник», «дождь», «обычный день (не выходной)» и «июнь». Второй профиль 6 дорожного движения этого кластера обладает другими тегами Т, а именно «понедельник», «солнечно», «обычный день (не выходной)» и «июль» и так далее.
Для выделения метки Li, которая наиболее точно описывает кластер CLi из всех тегов Т этого кластера CLi, модуль 14 снабжения метками сначала вычисляет уровень SV значимости по меньшей мере для некоторых тегов Т в этом кластере CLi. В некоторых вариантах осуществления изобретения вычисляют уровни SV значимости всех тегов Т всех профилей 6 дорожного движения кластера CLi, а в других вариантах осуществления изобретения уровни SV значимости вычисляют только для наиболее типовых тегов Т профилей 6 дорожного движения кластера CLi.
Уровни SV значимости могут быть вычислены с помощью статистики хи-квадрат. Например, если присутствует 5 или более профилей 6 дорожного движения, то может быть использована статистика хи-квадрат Пирсона, а если присутствует менее 5 профилей 6 дорожного движения, то может быть использован точный комбинаторный способ, такой как точный критерий Фишера. Указанное позволяет получить наиболее точное описание значимости отдельного тега Т.
Для вычисления, является ли тег Т значимым или не является, модуль 14 снабжения метками получает пороговое значение ТН из средства 15 ввода порогового значения. Средство 15 ввода порогового значения можно устанавливать вручную или цифровым образом, если он соединен с компьютером. Если уровень SV значимости тега Т в кластере CLi находится выше порогового значения TH, то характеристический вектор CVj, содержащий этот тег T, приписывают этому кластеру CLi, смотри фиг. 3 справа.
Для первого кластера CL1 с фиг. 3 ясно, что четыре тега T в этом кластере обладают уровнем SV значимости, который находится выше порогового значения TH, так что их сохраняют как характеристические векторы CV1, CV2, CV3, CV4. Соответствующие теги Т представляли собой «понедельник», «вторник», «среда» и «четверг». Таким образом, метка L1 этого кластера CL1 состоит из четырех характеристических векторов CVj, каждый из которых содержит один тег T.
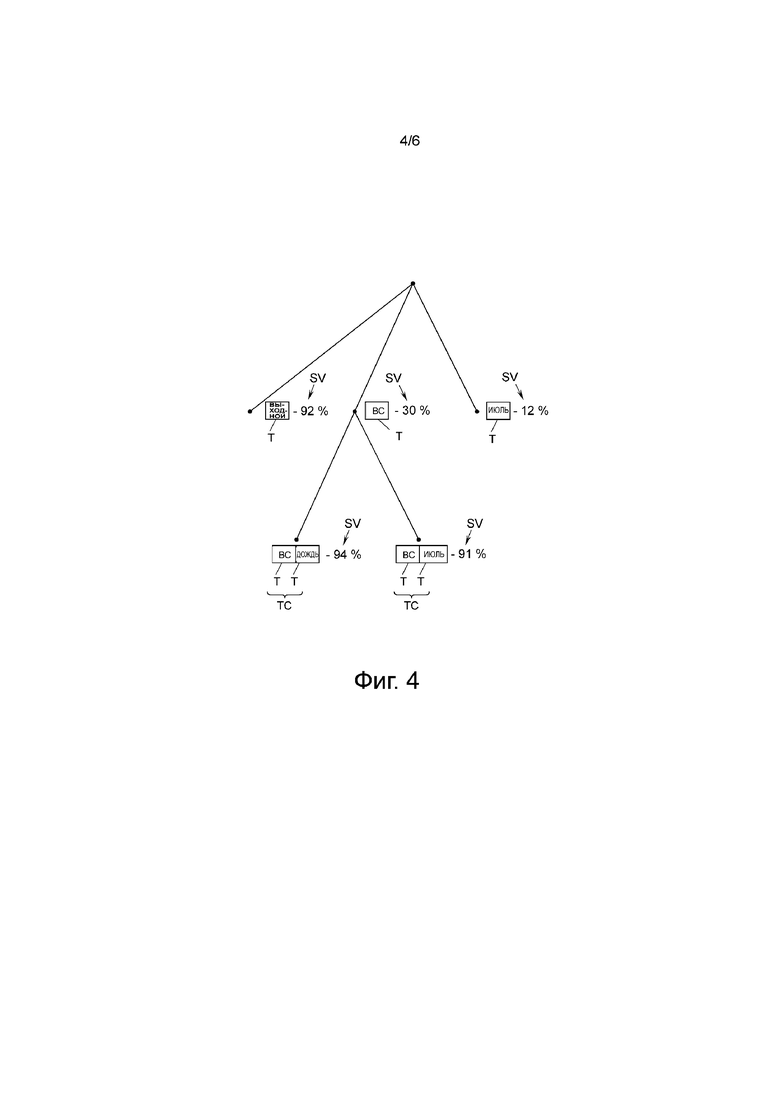
На фиг. 4 показан пример того, как вырабатывают метку Li, которая соответствует второму кластеру CL2 и вторую метку L2 с фиг. 3. Здесь сначала вычисляют уровни SV значимости трех тегов «выходной», «воскресенье» и «июль». В предположении, что пороговое значение TH составляет 90%, ясно, что только тег «выходной» с уровнем SV значимости, равным 92%, подходит в качестве характеристического вектора CVj.
Дополнительно, могут быть вычислены уровни SV значимости для комбинаций, то есть, «и»-комбинаций, тегов Т, или для всех тегов T, уровни SV значимости которых находятся ниже порогового значения TH, или для тегов T, уровни SV значимости которых находятся ниже порогового значения TH, но выше дополнительного порогового значения, равного, например, 25%. Для этих тегов T, уровень SV значимости вычисляют в комбинации с дополнительным тегом T, и, если уровень SV значимости такой комбинации ТС тегов находится выше порогового значения TH (или другого порогового значения), эту комбинацию ТС тегов приписывают в качестве характеристического вектора CVj этому кластеру CLi.
В зависимости от способа вычисления уровня SV значимости, может быть полезно также рассмотреть «или»-комбинации, так как их до сих пор не находили в форме нескольких отдельных тегов Т, уровни SV значимости которых находятся выше порогового уровня в том же кластере CLi. С этой целью, вычисляют уровень SV значимости «или»-комбинации из двух тегов, уровни SV значимости которых находятся ниже порогового уровня TH, чтобы увидеть, нужно ли поместить каждый из тегов в качестве характеристического вектора CVj для кластера CLi.
В общем, этот способ также может быть осуществлен для комбинаций ТС тегов, которые содержат три или более тегов Т, например, когда уровень SV значимости комбинации ТС из двух тегов снова находится в конкретном диапазоне пороговых значений. С помощью указанного, кластеру CLi могут быть приписаны комбинации из любого количества тегов в качестве характеристических векторов CVj.
Один пример алгоритма идентификации значимых тегов Т кластера CLi приведен ниже. Для начала, теги Т представляют собой конкретные значения так называемых переменных V, например, переменными V могут быть «день недели», «специальный день», «выходной день в школе», «месяц», «неделя месяца» и/или «погодные условия». В свою очередь, теги Т приписывают каждой переменной V, например, теги «понедельник», «вторник», «среда», ... приписывают переменной «день недели», теги «выходной», «день перед выходным» приписывают переменной «специальный день», теги «да», «нет» приписывают переменной «выходной день в школе» и так далее.
На первом этапе примера алгоритма, определяют, с помощью одного из указанных статистических критериев (критерий хи-квадрат Пирсона, точный критерий Фишера, ...), значима ли переменная V для кластера CLi, например, является ли распределение дня недели априори значимым в кластере CLi.
На втором этапе для наиболее значимой переменной V определяют теги Т, которые появляются чаще, чем ожидается.
На третьем этапе определяют уровень SV значимости для каждого тега Т относительно оставшихся тегов Т для одной и той же переменной V и сравнивают с заранее определенным пороговым значением ТН, как подробно описано выше. Таким образом, может быть определено указанное выше, например, значимо ли распределение «субботы» относительно оставшихся дней недели в этом кластере. Более того, вырабатывают дополнительный «подкластер» SCLi, который содержит только оставшиеся профили 6 дорожного движения, которые не соответствуют значимым тегам Т, определенным ранее.
На четвертом этапе повторяют второй и третий этапы для подкластера SCLi до тех пор, пока больше не будет больше переменных V или профилей 6 дорожного движения для анализа.
На пятом этапе выполняют критерий значимости для тегов Т, начиная с наименее значимой переменной V, в соответствии с первым этапом, но только для элементов из указанного подкластера SCLi и не с полным размером кластера. Если уровень SV значимости находится выше указанного порогового значения ТН, то эти теги Т будут добавлены в метку кластера.
На шестом этапе повторяют пятый этап для следующего подкластера SCLi в порядке увеличения значимости. В этом случае рассматривают не только собственные профили 6 дорожного движения, но также элементы ранее проанализированных подкластеров SCLi, которые не были значимыми. Таким образом, могут быть вычислены все «значимые» подкластеры SCLi для первого уровня, и соответствующие теги Т добавляют в качестве метки к начальному кластеру CLi.
Если присутствует один или несколько значимых подкластеров SCLi в первом уровне, на седьмом этапе процесс повторяют для каждого подкластера SCLi в следующем уровне для определения новых «дочерних подкластеров», при этом рассматривают только характеристики или переменные, которые не были проанализированы ранее.
Далее указанные этапы повторяют до тех пор, пока есть что анализировать в какой-либо ветке, и все «объединенные» теги Т могут быть добавлены в метку для дочерних подкластеров SCLi.
Более того, если подкластер SCLi содержит более одного значимого тега Т для переменной V, то каждый тег Т будет проанализирован в отдельной ветке. Только если после анализа всех этих веток, они не содержат подветок, то все теги Т группируют вместе.
Также для вычисления уровня SV значимости тега Т в каждой ветке, рассматривают только профили 6 дорожного движения, которые соответствуют переменным всех уровней, расположенных выше проанализированной ветки. Например, когда анализируют тег «дождливо» в подкластере «пятницы», ожидаемое значение для «дождливо» будет вычислено с учетом только погодных условий для всех «пятниц» генеральной совокупности.
Возвращаясь ко второму кластеру CL2 с фиг. 3, который подробно показан на фиг. 4, ясно, что комбинации тегов «воскресенье и дождь» и «воскресенье и июль» обладают уровнями SV значимости, который находится выше порогового значения TH. Таким образом, эти две комбинации ТС тегов приписывают в качестве характеристических векторов CV1, CV2 второму кластеру CL2.
В этом примере, ясно, что, хотя второй кластер CL2 не представляет отдельно воскресенья, дождливые дни или дни в июле, этот кластер CL2 представляет дождливые воскресенья и воскресенья в июле.
Более того, если двум кластерам приписаны одинаковые характеристические векторы CVj, характеристический вектор CVj, тег Т которого или комбинация ТС тегов обладает меньшим уровнем SV значимости, может быть удален из метки Li этого кластера CLi.
С помощью указанного всем кластерам CLi могут быть приписаны метки Li, содержащие любое количество характеристических векторов CVj, которые представляют этот кластер CLi. В свою очередь модуль 14 снабжения метками сохраняет эти снабженные метками кластеры CLi в базе 16 данных, которая снова может быть реализована как база 7 данных или ее подмножество, как база 12 данных или ее подмножество, или может быть реализована как отдельная база данных.
Из первого кластера CL1 с фиг. 3 также ясно, что, так как каждый из характеристических векторов CV1, CV2, CV3, CV4 содержит только один тег Т, при желании, они могут быть сгруппированы вместе, например, как дни недели. Указанное может быть сделано для уменьшения количества характеристических векторов CVj, что, в свою очередь, уменьшает вычислительные затраты при попытке найти определенный кластер.
Далее снабженные метками кластеры CLi в базе 16 данных могут быть использованы для прогнозирования прошлой, настоящей или будущей динамики РТВ дорожного движения (фиг. 2) в системе 1 дорог. С этой целью, запрос Req может быть загружен в модуль 17 прогнозирования, который для этой цели получает снабженные метками кластеры CLi из базы 16 данных. Запрос Req содержит один или несколько тегов RT запроса, которые могут быть сформулированы пользователем. Далее модуль 17 прогнозирования сопоставляет теги RT запроса с характеристическими векторами CVj снабженных метками кластеров CLi для определения «соответствующего» кластера CLi. Далее этот соответствующий кластер CLi, или любые полученные из него данные, подают на выход с помощью модуля 17 прогнозирования в качестве прогноза РТВ динамики дорожного движения.
Один пример схемы модулей 11, 14, 17 может быть следующим. Пока устройство 4 измерения дорожного движения получает данные в режиме реального времени в месте эксплуатации, после длительного периода, например, одного года, модуль 11 объединения в кластеры и модуль 14 снабжения метками могут выработать снабженные метками кластеры CLi в процессоре 9 центральной станции. С другой стороны, модуль 17 прогнозирования может быть реализован как модуль, полностью физически отделенный от модуля 11 объединения в кластеры и модуля 14 снабжения метками. В качестве альтернативы, модуль 11 объединения в кластеры, модуль 14 снабжения метками и модуль 17 прогнозирования могут быть реализованы с помощью одной и той же машины.
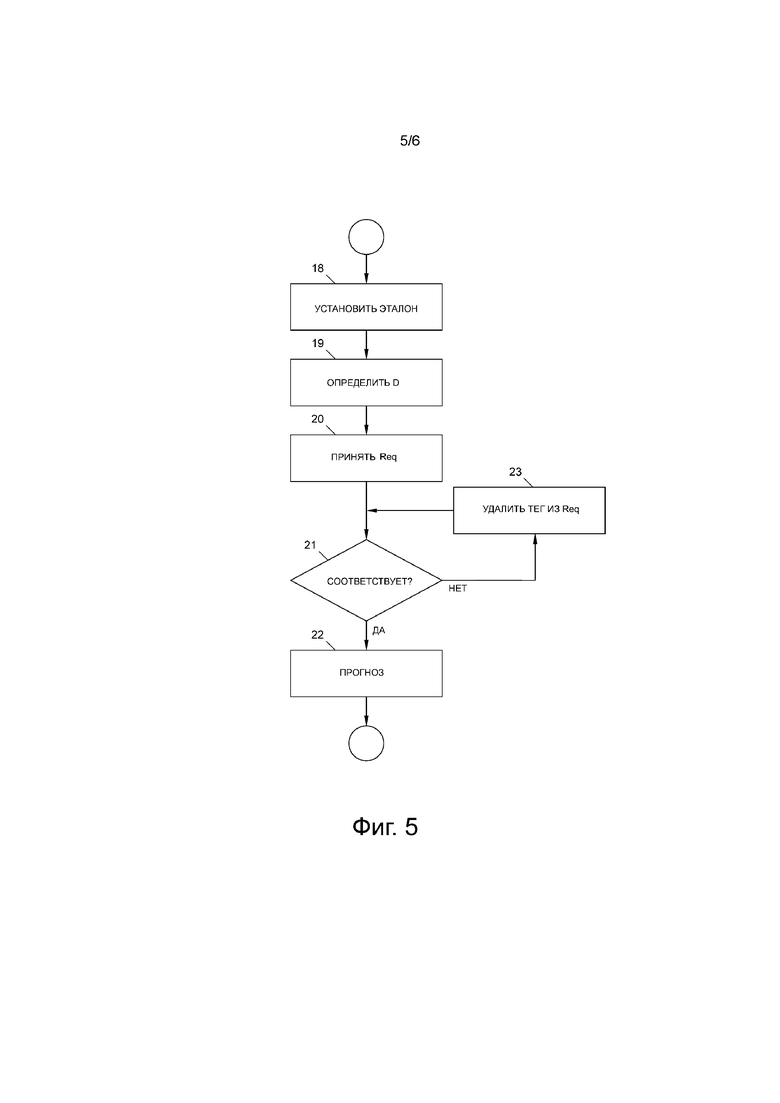
Далее со ссылкой на фиг. 5 и 6 будет подробно описана работа модуля 17 прогнозирования. После начала процесса прогнозирования на этапе 18 кластер CLi, который содержит наибольшее количество N профилей 6 дорожного движения, определяют и устанавливают в качестве эталонного кластера. В примере с фиг. 3, первый кластер CL1 содержит наибольшее количество (N = 100) профилей 6 дорожного движения.
На этапе 19, для каждого кластера CLi вычисляют меру D несхожести. Мера D несхожести является мерой того, насколько профили 6 дорожного движения конкретного кластера CLi отличаются от профилей 6 дорожного движения эталонного кластера (здесь: CL1). Когда вычислена мера D несхожести для кластера CLi, она может быть приписана всем характеристическим векторам CVj этого кластера CLi. По определению, эталонный кластер не отличается от самого себя и, таким образом, обладает наименьшей приписанной мерой несхожести, например, D = 0.
Для вычисления меры D несхожести для других кластеров, например, средний профиль дорожного движения кластера CLi сравнивают со средним профилем дорожного движения эталонного кластера. В некоторых вариантах осуществления изобретения указанное может быть выполнено с использованием такой же метрики расстояния, которая была использована для выработки кластеров. В примере с фиг. 3, третий кластер CL3 отклоняется наибольшим образом от эталонного кластера CL1 и обладает приписанной ему мерой D несхожести равной 12. Четвертый кластер CL4 только немного отклоняется от эталонного кластера и обладает приписанной ему мерой D несхожести равной 3, при этом второй кластер CL2 обладает приписанной ему мерой D несхожести равной 7. Подчеркнем, что мера D несхожести не зависит от количества N профилей 6 дорожного движения в кластере CLi и представляет только отличие среднего, наиболее вероятного или медианного значения или подобного для профилей 6 дорожного движения между кластерами CLi. В качестве меры D несхожести может быть использована любая мера (не)схожести между кривыми, известная в существующем уровне техники, например, норма L2, норма L1 или гибридные нормы. Этапы 19 и 20, например, могут быть осуществлены в процессоре 9 или в модуле 14 снабжения метками.
После загрузки запроса Req с тегами RT запроса в машину 17 прогнозирования на этапе 20, на этапе 21 проверяют, соответствуют ли все теги RT запроса Req одному из характеристических векторов CVj кластеров CLi. Для этой цели, теги RT запроса могут быть объединены для образования характеристического вектора CVj, чтобы понять совпадает ли он с каким-либо из характеристических векторов CVj кластеров. Если указанное имеет место (ветка «Да»), кластер CLi, который содержит соответствующий характеристический вектор CVj, определяют на этапе 22 как соответствующий кластер CLi.
После окончания этапа 22, или весь соответствующий кластер CLi или средний профиль дорожного движения или любые другие данные, полученные из этого соответствующего кластера CLi, могут быть поданы на выход с помощью модуля 17 прогнозирования в качестве прогноза РТВ динамики дорожного движения для запроса Req. В качестве альтернативы, если на этапе 21 не может быть найдено характеристического вектора CVj среди кластеров CLi (ветка «Нет»), то на этапе 23 из запроса Req исключают один из тегов RT запроса и повторяют этап 21.
Этап 23 исключения тега RT запроса из запроса Req подробно описан с помощью примера, который показан на фиг. 6 и в котором снова используют пример кластеров с фиг. 3. Здесь в начале запрос Req содержит теги запроса «среда», «выходной» и «дождь». Когда этап 21 осуществляют первый раз, проверяют, появляется ли комбинация из этих трех тегов RT запроса в любой из меток Li четырех кластеров CLi, смотри четыре метки L1, L2, L3, L4 на правой стороне фиг. 3. В этом примере невозможно найти характеристический вектор CVj, который содержит три тега RT запроса.
Для исключения из запроса Req одного из тегов RT запроса, в одном варианте осуществления настоящего способа для каждого тега RT запроса отдельно проверяют, существует ли характеристический вектор CVj, соответствующий этому тегу RT запроса, то есть не проверяют, появляется ли просто этот тег RT запроса в комбинации ТС тегов характеристического вектора CVj, а проверяют только, существует ли характеристический вектор CVj, который точно соответствует тегу RT запроса. С помощью фиг. 3 и 6, можно понять, что тег «среда» запроса Req появляется как характеристический вектор CV3 в метке L1 первого кластера CL1, тег «выходной» запроса Req появляется как характеристический вектор CV1 в метке L2 второго кластера CL2, и тег «дождь» запроса Req появляется как характеристический вектор CV1 в метке L4 четвертого кластера CL4.
Далее проверяют, какой из этих соответствующих характеристических векторов CVj обладают наименьшей мерой D несхожести. Так как характеристический вектор CV3 находится в первом кластере CL1, который обладает наименьшей мерой D несхожести, равной 0, а другие два кластера CL2, CL4 обладают большими мерами D несхожести, равными, соответственно, 7 и 3, тег «среда» запроса исключают из запроса Req, так как этот тег RT запроса соответствует характеристическому вектору CVj кластера CLi с наименьшей мерой D несхожести, то есть наименее интересного кластера CLi, здесь: кластер CL1.
Далее, этап 21 повторяют и проверяют, существует ли характеристический вектор CVj, который содержит комбинацию оставшихся двух тегов «выходной» и «дождь» запроса. Снова, указанное не имеет место, и, следовательно, снова проверяют, какой из двух оставшихся тегов RT запроса соответствует кластеру CLi с наименьшей мерой D несхожести. В этом случае тег «дождь» запроса исключают из запроса Req, так как он обладает наименьшей мерой D несхожести.
Далее, снова проверяют, соответствует ли запрос Req, который теперь содержит только тег «выходной», любому из характеристических векторов CVj кластеров CLi. Указанное справедливо для второго кластера CL2, которому приписан характеристический вектор CV1. Следовательно, второй кластер CL2 является соответствующим кластером, из которого далее получают прогноз РТВ динамики дорожного движения.
Иногда теги RT запроса не появляются в характеристическом векторе CVj, который содержит только этот тег RT запроса в каком-либо из кластеров CLi, так как или этот тег запроса не присутствует в каком-либо из тегов T профилей 6 дорожного движения, которые используются для создания кластеров CLi или этот тег Т только используется в характеристическом векторе CVj в комбинации с дополнительным тегом T. В этом случае этому тегу RT запроса может быть приписана наименьшая мера D несхожести, например, равная 0.
В альтернативном варианте осуществления изобретения, когда проверяют, какие теги RT запроса нужно исключить, проверяют не только, существует ли характеристический вектор CVj, который только содержит этот тег RT запроса, но также проверяют, существует ли характеристический вектор CVj, содержащий этот тег RT запроса в комбинации с дополнительным тегом T. В этом случае, выбирают этот характеристический вектор CVj и, в свою очередь, лежащий в основе кластер CLi и его меру D несхожести, для которого больше, например, уровень SV значимости характеристического вектора CVj или который обладает большим или меньшим количеством N профилей 6 дорожного движения. Например, на фиг. 3 для тега «выходной» доступны характеристический вектор CV1 второго кластера CL2 и характеристический вектор CV2 третьего кластера CL3, который обладает комбинацией «выходной и солнечно» тегов. Так как уровень SV значимости характеристического вектора CV2 комбинации «выходной и воскресенье» тегов третьего кластера CL3 больше (98%) уровня SV значимости характеристического вектора CV1 во втором кластере CL2, то для тега «выходной» запроса выбирают меру D несхожести, равную 12, третьего кластера CL3 (а не D = 7 второго кластера CL2) и далее указанную меру используют для этапов сравнения с фиг. 6. Таким образом, в некоторых вариантах осуществления изобретения, в которых уровни SV значимости характеристических векторов CVj использовали для снабжения метками кластеров CLi, эти уровни SV значимости также могут быть использованы при определении кластера CLi, который соответствует запросу Req.
Во всех вариантах осуществления изобретения, при проверке, какой тег RT запроса соответствует характеристическому вектору CVj кластера CLi, и когда два кластера обладают одинаковыми характеристическими векторами CVj, для тега RT запроса может быть выбран характеристический вектор CVj с большим уровнем SV значимости.
Более того, когда на этапе 21 соответствия найдены два соответствующих кластера CLi, то кластер с большим количеством N профилей 6 дорожного движения может быть определен как соответствующий кластер, а другой кластер может быть отброшен.
Для дополнительного увеличения точности способа, можно проверять не только вхождения одиночных тегов RT запроса в характеристические векторы CVj кластеров CLi, но также, соответствуют ли комбинации тегов RT запроса характеристическому вектору CVj кластера CLi. В этом случае, если характеристический вектор CVj, соответствующий комбинации тегов RT запроса, обладает наименьшей мерой D несхожести среди характеристических векторов CVj, соответствующих всем тегам RT запроса или комбинациям тегов запроса, то указанную комбинацию тегов не рассматривают до тех пор, пока не исключат тег RT запроса из запроса Req.
Изобретение не ограничивается конкретными вариантами осуществления изобретения, которые подробно описаны в настоящем документе, а охватывает все их варианты, комбинации и изменения, которые находятся в рамках приложенной формулы изобретения.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ ПРОГНОЗИРОВАНИЯ ХАРАКТЕРА ДВИЖЕНИЯ В ДОРОЖНОЙ СИСТЕМЕ | 2018 |
|
RU2747317C2 |
| Способы обнаружения аномальных элементов веб-страниц на основании статистической значимости | 2017 |
|
RU2659741C1 |
| Способы обнаружения аномальных элементов веб-страниц | 2016 |
|
RU2652451C2 |
| Способ обнаружения связанных кластеров | 2019 |
|
RU2747451C2 |
| Способ отнесения неизвестного устройства кластеру | 2019 |
|
RU2747466C2 |
| Способы обнаружения вредоносных элементов веб-страниц | 2016 |
|
RU2638710C1 |
| Способ формирования кластеров устройств | 2019 |
|
RU2747452C2 |
| СПОСОБ И СИСТЕМА (ВАРИАНТЫ) КРУИЗ-КОНТРОЛЯ ТРАНСПОРТНОГО СРЕДСТВА | 2016 |
|
RU2719122C2 |
| СИСТЕМЫ И СПОСОБЫ ДЕТЕКТИРОВАНИЯ ПОВЕДЕНЧЕСКИХ УГРОЗ | 2019 |
|
RU2803399C2 |
| СИСТЕМЫ И СПОСОБЫ ДЕТЕКТИРОВАНИЯ ПОВЕДЕНЧЕСКИХ УГРОЗ | 2019 |
|
RU2778630C1 |

Изобретение относится к способу прогнозирования динамики дорожного движения в системе дорог. Способ прогнозирования динамики дорожного движения в системе дорог, содержит этапы на которых объединяют профили дорожного движения с их тегами по меньшей мере в два кластера по схожести профилей дорожного движения, назначают по меньшей мере один характеристический вектор каждому кластеру на основе тегов в указанном кластере, при этом каждый характеристический вектор содержит тег или комбинацию тегов указанного кластера, определяют, какой кластер содержит наибольшее количество профилей дорожного движения, и устанавливают указанный кластер как эталонный кластер, для каждого кластера определяют меру несхожести указанного кластера с эталонным кластером и назначают указанную меру несхожести всем характеристическим векторам указанного кластера, при этом мера несхожести представляет собой меру того, насколько профили дорожного движения кластера отличаются от профилей дорожного движения эталонного кластера, принимают запрос, содержащий один или более тегов запроса, проверяют, соответствуют ли все теги запроса одному из характеристических векторов кластеров, и, если соответствуют, выводят прогноз динамики дорожного движения, основанный на кластере с указанным соответствующим характеристическим вектором, в противном случае исключают один из тегов запроса из запроса и возвращаются к началу указанного этапа проверки. Тег запроса, подлежащий исключению, выбирают путем определения того, какие характеристические векторы соответствуют каждому тегу запроса, и выбирают тег запроса, для которого соответствующий характеристический вектор обладает наименьшей мерой несхожести.</GipSegment> Достигается повышение безопасности дорожного движения. 9 з.п. ф-лы, 6 ил.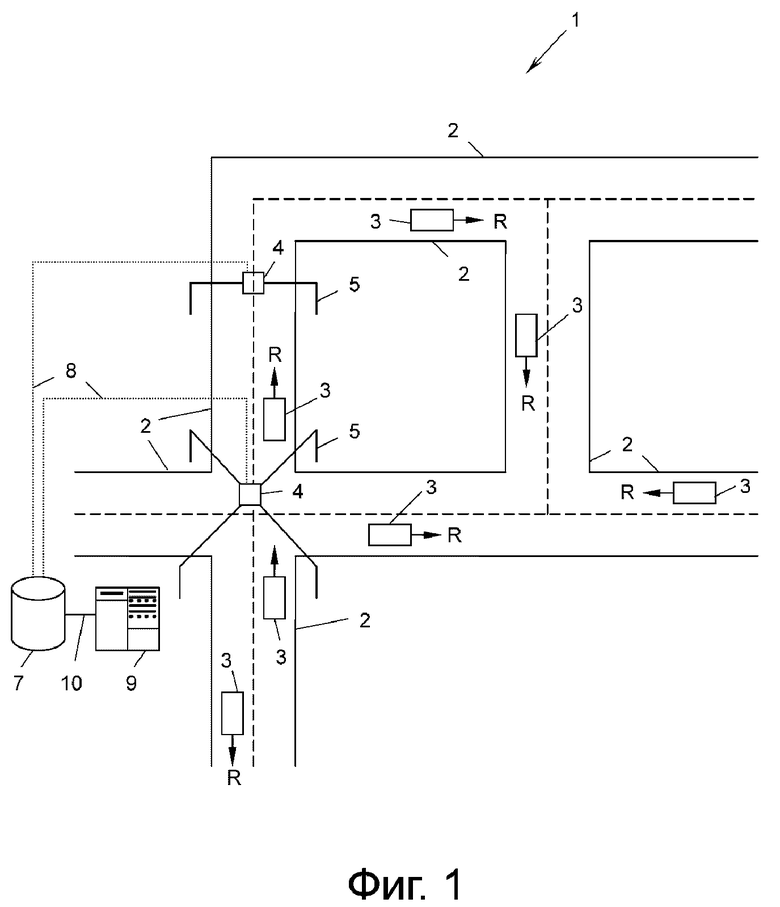
1. Способ прогнозирования динамики дорожного движения в системе дорог, содержащий следующие этапы, выполняемые по меньшей мере одним процессором (9, 11, 14, 17), соединенным с базой (7, 12, 16) данных, содержащей набор профилей (6) дорожного движения, при этом каждый профиль (6) дорожного движения представляет меру дорожного движения для транспортных средств (3) в системе (1) дорог, записанную в течении длительного времени (t), при этом указанному профилю (6) дорожного движения приписывают один или несколько заранее определенных тегов (Т), связанных со временем записи соответствующего профиля (6) дорожного движения:
объединяют профили (6) дорожного движения с их тегами (Т) по меньшей мере в два кластера (CLi) по схожести профилей (6) дорожного движения;
назначают по меньшей мере один характеристический вектор (CVj) каждому кластеру (CLi) на основе тегов (Т) в указанном кластере (CLi), при этом каждый характеристический вектор (CVj) содержит тег (T) или комбинацию тегов (TC) указанного кластера (CLi);
определяют, какой кластер (CLi) содержит наибольшее количество профилей (6) дорожного движения, и устанавливают указанный кластер (CLi) как эталонный кластер;
для каждого кластера (CLi) определяют меру (D) несхожести указанного кластера (CLi) с эталонным кластером и назначают указанную меру (D) несхожести всем характеристическим векторам (CVj) указанного кластера (CLi), при этом мера (D) несхожести представляет собой меру того, насколько профили (6) дорожного движения кластера (CLi) отличаются от профилей (6) дорожного движения эталонного кластера;
принимают запрос (Req), содержащий один или более тегов (RT) запроса;
проверяют, соответствуют ли все теги запроса одному из характеристических векторов (CVj) кластеров (CLi), и,
если соответствуют, выводят прогноз (РТВ) динамики дорожного движения, основанный на кластере (CLi) с указанным соответствующим характеристическим вектором (CVj),
в противном случае исключают один из тегов (RT) запроса из запроса (Req) и возвращаются к началу указанного этапа проверки;
при этом тег (RT) запроса, подлежащий исключению, выбирают путем определения того, какие характеристические векторы (CVj) соответствуют каждому тегу (RT) запроса, и выбирают тег (RT) запроса, для которого соответствующий характеристический вектор (CVj) обладает наименьшей мерой (D) несхожести.
2. Способ по п. 1, в котором на этапе выбора того, какой тег (RT) запроса исключить из запроса (Req), также проверяют, соответствует ли комбинация тегов (RT) запроса характеристическому вектору (CVj), и, если соответствует и если указанный характеристический вектор (CVj) обладает наименьшей мерой (D) несхожести среди характеристических векторов (CVj), соответствующих всем тегам (RT) запроса или комбинациям тегов запроса, указанную комбинацию тегов запроса не рассматривают до тех пор, пока тег (RT) запроса не исключен из запроса (Req).
3. Способ по п. 1 или 2, в котором меру (D) несхожести кластера (CLi) получают путем сравнения среднего профиля дорожного движения указанного кластера (CLi) со средним профилем дорожного движения эталонного кластера.
4. Способ по п. 1 или 2, в котором характеристический вектор соответствует тегу (RT) запроса или комбинации тегов запроса, если характеристический вектор (CVj) содержит только указанный тег (RT) запроса или указанную комбинацию тегов запроса.
5. Способ по п. 1 или 2, в котором характеристический вектор (CVj) соответствует тегу (RT) запроса или комбинации тегов запроса, если характеристический вектор (CVj) содержит указанный тег (RT) запроса или указанную комбинацию тегов запроса отдельно или в комбинации по меньшей мере с одним дополнительным тегом (T).
6. Способ по п. 1 или 2, в котором вычисляют уровень (SV) значимости каждого характеристического вектора (CVj) каждого кластера (CLi) и, когда два или более характеристических векторов (CVj) соответствуют тегу (RT) запроса или комбинации тегов запроса (Req), не рассматривают характеристический вектор (CVj) с меньшим уровнем (SV) значимости.
7. Способ по п. 1 или 2, в котором, если два характеристических вектора (CVj) соответствуют тегу (RT) запроса или комбинации тегов запроса и оба обладают одним и тем же уровнем (SV) значимости, если это применимо, не рассматривают характеристический вектор (CVj) кластера (CLi) с меньшим количеством (N) профилей (6) дорожного движения.
8. Способ по п. 1 или 2, в котором каждый профиль (6) дорожного движения представляет меру дорожного движения транспортных средств (3) в системе (1) дорог для промежутка времени, равного 24 часам.
9. Способ по п. 1 или 2, в котором по меньшей мере один тег (Т) указывает день недели, месяц года, неделю месяца, содержит указание на школьные каникулы, указание на специальный праздник для указанного времени записи.
10. Способ по п. 1 или 2, в котором по меньшей мере один тег (Т) указывает дорожные условия или погодные условия в указанное время записи.
| Устройство для закрепления лыж на раме мотоциклов и велосипедов взамен переднего колеса | 1924 |
|
SU2015A1 |
| Лигатура для чугуна | 1987 |
|
SU1532600A1 |
| СПОСОБЫ ПРЕДСКАЗАНИЯ ПУНКТОВ НАЗНАЧЕНИЯ ИЗ ЧАСТИЧНЫХ ТРАЕКТОРИЙ, ПРИМЕНЯЮЩИЕ СПОСОБЫ МОДЕЛИРОВАНИЯ ОТКРЫТОГО И ЗАМКНУТОГО МИРА | 2006 |
|
RU2406158C2 |

