Область техники
Изобретение относится к области извлечения именованных сущностей из текстов на естественном языке с помощью вычислительных систем, в частности к процессам нормализации нормативно-справочной информации (НСИ), которые включают нахождение и дифференциацию контекстных атрибутов сущностей из частично структурированных источников текста. Атрибуты используются для характеристики именованной сущности, ее валидации, дифференциации, и окончательного принятия решения по их включению в НСИ.
Предшествующий уровень техники
Основные данные представляют собой общие бизнес-объекты, распределенные между операционными и аналитическими системами, включающие информацию о клиентах, поставщиках, организационных подразделениях, а также НСИ, необходимую для функционирования предприятия. В состав НСИ входят словари, справочники и классификаторы, данные из которых используются при формировании новых документов. Словари, справочники и классификаторы в процессе функционирования могут пополняться, консолидироваться. Пополнение НСИ часто осуществляется из частично структурированных источников - csv-таблиц, таблиц баз данных, прайс-листов из Интернет источников и т.п. Главная сложность в управлении основными данными состоит в обеспечении их полноты, согласованности и непротиворечивости. В НСИ это достигается нормализацией, “вычисткой” записей справочников и словарей НСИ, в результате которых:
- устраняются ошибки, неполнота и некорректность данных;
- уточняются ключевые атрибуты, и производится унификация наименований элементов справочников.
Известные системы управления основными данными - 1C MDM, SAP MDM, Oracle MDM и IBM InfoSphere MDM, базой которых является классификатор, представляющий собой иерархию классов, описывающих основные бизнес-объекты отрасли. Сопоставляя описания объектов НСИ и поля классификатора, эксперт может понять, какие характеристики имеет тот или иной объект, найти дубликаты и заполнить значения недостающих характеристик. Внедрение автоматизированных подсистем, использующих алгоритмы, обрабатывающие текст на естественном языке, и выполняющих две основные операции - классификацию объектов НСИ относительно заданного классификатора и атрибутизацию (выделение значений характеристик объектов НСИ), позволяет существенно понизить требования к квалификации экспертов, занимающихся нормализацией.
При классификации система должна получить от эксперта идентификаторы классификатора, относительно которого выполняется классификация, и объекта НСИ, и вернуть несколько наиболее вероятных классов с указанием степени уверенности системы в каждом ответе.
При выделении значений характеристик (атрибутизации) система должна получить от эксперта идентификаторы класса, значения характеристик которого требуется выделить, и объекта НСИ, и вернуть наиболее вероятные возможные значения каждой из характеристик с указанием степени уверенности системы.
Частные подзадачи нормализации решались в разных областях обработки текстовой информации. Так, задачу классификации можно рассматривать как задачу выделения именованных сущностей из неструктурированного текста на естественном языке. Задача выделения значений характеристик объектов также предполагает применение методов машинного обучения для анализа текста.
В настоящее время используются ряд подходов, каждый из которых обладает своими преимуществами и недостатками.
Известны система и процесс для анализа, квалифицирования и проглатывания источников неструктурированных данных посредством эмпирической атрибуции. В заявке описываются атрибуция источника данных в соответствии с правилами. Анализируют данные для идентификации характеристики запутанности в данных. Вычисляют качественную меру атрибута и, таким образом, выдают взвешенный атрибут. Вычисляют качественную меру характеристики запутанности и, таким образом, выдают взвешенную характеристику запутанности. Анализируют взвешенный атрибут и взвешенную характеристику запутанности, для создания диспозиции. Фильтруют данные в соответствии с диспозицией и, таким образом, выдают извлеченные данные (RU2674331, МПК G06F 17/22, G06F 17/30, опубл. 06.12.2018).
Известны способ и система обработки естественного языка, в части распознавания сущностей (ERDS). В заявке описывается автоматическое определение того, к каким объектам относится текст, используя методы обработки естественного языка и анализ информации, полученной из контекстуальных данных в тексте (US20090144609, МПК G06F 17/00, G06F 17/30, опубл. 04.06.2009).
Известен способ обработки текста на естественном языке и, более конкретно, к методам автоматической идентификации значимых объектов в документах. Этот способ описывает идентификацию набора упоминаний сущностей в каждом абстрактном и каждом соответствующем документе на основе их соответствующих частей речи (POS) и анализе зависимостей (US9619457, МПК G06F 17/27, G06K 9/00, опубл. 11.04.2017).
Известен способ автоматического извлечения и организации информации устройством обработки из множества источников данных. Для источников данных применяется конвейер для извлечения информации об обработке естественного языка, который включает автоматическое обнаружение объектов. Информация об обнаруженных объектах идентифицируется путем анализа продуктов конвейера обработки естественного языка. Идентифицированная информация сгруппирована в классы эквивалентности, содержащие эквивалентную информацию. Создается хотя бы одно отображаемое представление классов эквивалентности. Вычисляется порядок, в котором отображается хотя бы одно отображаемое представление. Производится комбинированное представление классов эквивалентности, которое соответствует порядку отображения отображаемого представления (US20140195884, МПК G06F 17/21, G06F 17/30, опубл. 10.07.2014).
Известен способ распознавания именованных сущностей в текстах на естественном языке, основанный на использовании морфологических и семантических признаков, включающий, лексико-морфологический анализ с помощью вычислительной системы текста на естественном языке, содержащего множество токенов, определение на основе лексико-морфологического анализа одного или более лексических значений и грамматических значений, связанных с каждым токеном в множестве токенов; вычисление для каждого токена в множестве токенов одной или более функций классификатора с использованием лексических и грамматических значений, ассоциированных с токеном, отличающихся тем, что значение каждой функции классификатора указывает на оценку степени ассоциации токена с категорией именованных сущностей; интерпретация семантических структур с использованием набора продукционных правил для определения для одного или более токенов, входящих в выбранную часть текста на естественном языке, оценки степени ассоциации токена с категорией именованных сущностей (RU2619193, МПК G06F 17/28, опубл. 12.05.2017).
Среди недостатков вышеуказанных аналогов можно отметить, что механизм поиска и определения токенов, ассоциированных с категорией именованных сущностей производится либо на основе анализа соответствующих частей речи (POS), либо на основе лексико-морфологического анализа текста на естественном языке, что исключает разметку и поиск численных характеристик, единиц измерений, аббревиатур, характерных для атрибутов НСИ.
Наиболее близким техническим решением к заявленному изобретению является средство распознавания именованных сущностей из неразмеченного текстового корпуса. Технический результат заключается в повышении эффективности распознавания и разметки именованных сущностей в текстах. Выбирают обучающий набор текстов на естественном языке. Извлекают процессором соответствующий набор признаков для каждой категории именованных сущностей. Обучают процессором модели классификации с использованием обучающего набора текстов и наборов признаков для каждой категории именованных сущностей. Извлекают процессором токены из неразмеченного текста. Формируют процессором набор атрибутов для каждого токена неразмеченного текста на основании, по меньшей мере, глубокого семантико-синтаксического анализа. Определяют возможные синтаксические связи, по меньшей мере, в одном предложении неразмеченного текста, включающее получение множества синтаксических атрибутов. Формируют независимую от языка семантическую структуру, включающую определение семантических связей и соответствующих семантических атрибутов каждого токена. Классифицируют процессором каждый токен, по меньшей мере, в одну из категорий на основании модели классификатора и набора атрибутов токена. Формируют процессором размеченное представление, по меньшей мере, части текста на основании, по меньшей мере, одного из токенов, классифицированных по категориям (RU 2665239, МПК G06F 17/27, опубл. 28.08.2018).
Недостатком прототипа является процедура выделения атрибутов именованных сущностей на основе семантических связей и синтаксического анализа, что является обоснованным для разметки неструктурированных тестов с высокой семантической нагрузкой и не подходит для частично-структурированных тестов - источников пополнения и консолидации НСИ, где атрибуты именованных сущностей очень часто являются комбинацией слов с численными характеристиками и единицами измерений.
Сущность изобретения
Техническим результатом, достигаемом при использовании заявленного изобретения, является повышение скорости, обеспечение масштабируемости, гибкости и согласованности процессов атрибутизации данных.
Сущность изобретения заключается в том, что способ атрибутизации частично структурированных текстов для формирования нормативно-справочной информации, включающий выбор обучающего набора текстов на естественном языке, извлечение процессором соответствующего набора признаков для каждой категории именованных сущностей, обучение процессором модели классификации с использованием обучающего набора текстов и наборов признаков для каждой категории именованных сущностей, извлечение процессором токенов из неразмеченного текста, формирование процессором размеченного представления, по меньшей мере, части текста на основании, по меньшей мере, одного из токенов, классифицированных по категориям. Для обучения модели классификации именованных сущностей выбраны частично структурированные тексты и выполнена их предобработка - лемматизация, стемминг, удаление стоп-слов, знаков пунктуации, а также векторизация слов с присвоением веса каждому слову наименования сущности в соответствии с оценкой важности слова в контексте документа. Для извлечения токенов неразмеченный текст размечается на обученной модели классификатора наименований, а наименования разбиваются на токены по заданному набору разделителей, после чего составляются все возможные комбинации из 1-5 последовательных токенов. Для извлечения атрибутов полученные комбинации токенов обрабатываются обученной на заданном наборе атрибутов класса моделью классификатора атрибутов, который возвращает для каждой комбинации вероятность того, что данная комбинация является тем или иным атрибутом из набора атрибутов заданного класса или не является атрибутом вообще, для каждого атрибута в качестве основного значения выбирается комбинация с наибольшей вероятностью и превышающей заданный порог.
Краткое описание чертежей изобретения
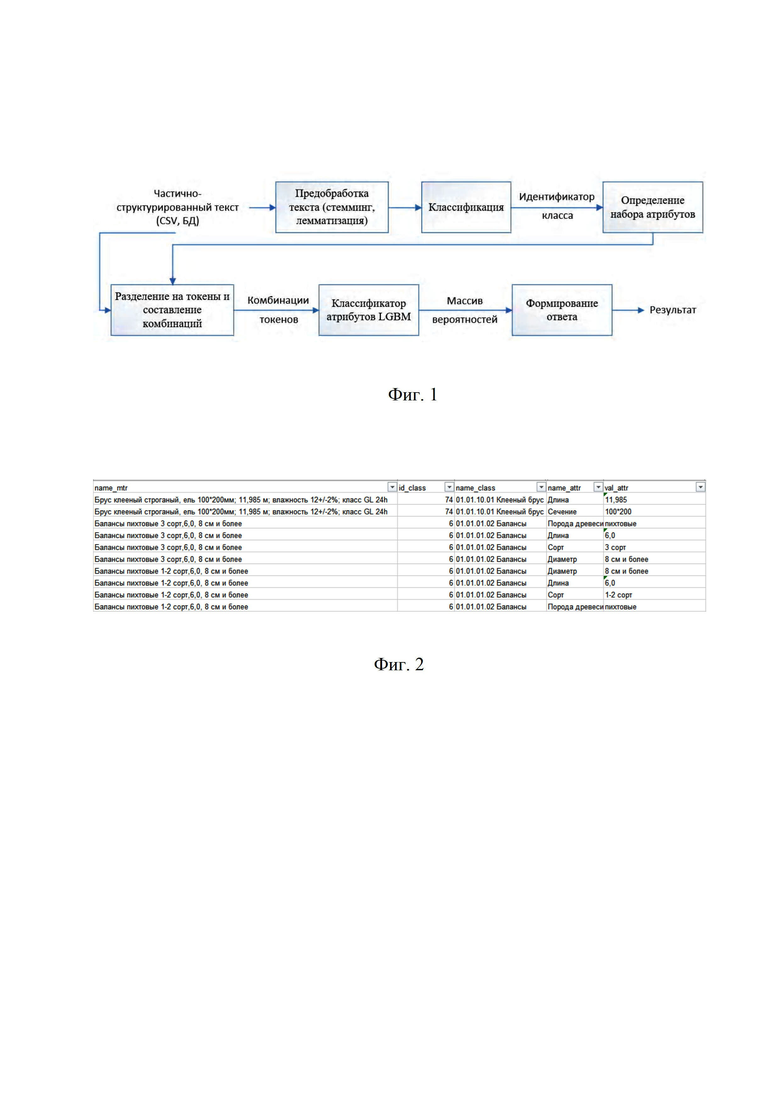
На фиг. 1 представлена схема процесса атрибутизации частично структурированных текстов, на фиг. 2 представлен прайс-лист в CSV-формате, как пример - частично структурированного текста. В табл. 1 показан пример распределения вероятностей отнесения комбинаций токенов к заданным атрибутам.
Осуществление изобретения
Частично структурированный текст (фиг. 1) после лемматизации и стеминга классифицируется обученным на размеченных наименованиях сущностей классификатором. Под наименованием сущности подразумевается собственно имя сущности (например, «доска пола») и контекст, который возможно содержит набор атрибутов. Для каждого наименования сущности классификатор выдает вероятность принадлежности некоторому классу. Каждому классу ставится в соответствие конкретный набор атрибутов.
Каждое наименование сущности разбивается на токены. Под токеном подразумевается часть наименования сущности между некоторыми символами-разделителями. Из полученных токенов составляются комбинации. Комбинации токенов подаются на обученный на размеченных атрибутах класса классификатор LightGBM [1]. Классификатор выдает массив вероятностей для каждой комбинации. Каждое значение вероятности определяет степень принадлежности комбинации к валидированным атрибутам. Эксперт на основе полученного массива вероятностей и значения комбинации токенов задает порог и принимает решение об отнесении комбинации к тому или иному атрибуту заданного класса.
Более подробно процесс атрибутизации частично структурированных текстов для формирования НСИ выглядит следующим образом.
1. Отнесение наименований сущностей из текста на естественном языке к классам по заданному классификатору.
1.1 Выполнение предобработки текста: лемматизации, стемминг, удаление стоп-слов и знаков пунктуации, векторизация.
1.1.1 При выполнении этапа лемматизации осуществляется приведение слов в тексте к их первоначальной словарной форме (например, «пихтовые» - «пихтовый»). Данный этап реализуется с использованием словарей. При этом удаляются стоп-слова (предлоги и вспомогательные части речи, а также стоп-слова из специальных баз стоп-слов).
1.1.2 В процессе стэмминга происходит приведение слов к основе, а именно, отрезание окончания и формообразующего суффикса.
1.1.3 Векторизация слов со схожим смысловым значением осуществляется с использованием метода word2vec. Обученный на поисковых запросах Word2Vec осуществляет кластеризацию слов на основе контекста и метода SKIP-грамм. Для присвоения веса каждому слову используется функция TF-IDF. Функция TF-IDF (TF — частота слова, IDF — обратная частота документа) - статистическая мера, используемая для оценки важности слова в контексте документа, являющегося частью коллекции документов или корпуса. Вес некоторого слова пропорционален частоте употребления этого слова в документе и обратно пропорционален частоте употребления слова во всех документах коллекции.
1.2 Отнесение сущностей к конкретной категории (классу) осуществляется на основе алгоритмов машинного обучения с применением библиотек c открытым исходным кодом (Keras). В частности, используется сверточная искусственная нейронная сеть (Conovolution Neural Network, CNN) с одним Embedding- и двумя Convolution-слоями. Обучение нейронной сети осуществляется на наборе текстов, полученном из валидированной НСИ. Для обучения используются только наименования сущностей.
2. Выделение значений атрибутов наименований сущностей
Второй этап атрибутизации показан на следующем примере:
Имеется некоторый прайс-лист в CSV-формате (фиг. 2), в котором столбцы имеют следующие значения:
- name_mtr - наименование товара (сущности)
- id_class - идентификатор класса
- name_atr - наименование атрибута
- val_atr - значение атрибута
Дальнейшая обработка осуществляется следующим образом.
2.1 По значению класса, полученному на предыдущем этапе, определяется, какие атрибуты встречаются внутри этого класса, и далее выделяются только эти атрибуты.
2.2 Для каждого возможного атрибута находится часть наименования, которая вероятнее всего является значением рассматриваемого атрибута. Для этого наименование разбивается на токены. Набор разделителей, разграничивающих токены, можно задавать. Для примера выбраны следующие разделители: « », «,», «;».
2.3 Далее составляются комбинации из подряд идущих токенов - все комбинации, которые состоят из 1-5 последовательных токенов, объединенных через заданные разделители. Для примера рассмотрим наименование «Брус клееный строганый, ель 100*200мм; 11,985 м; влажность 12+/-2%; класс GL 24h».
Данное наименование разобьется на следующие токены: «Брус», «клееный», «строганый», «ель», «100*200мм», «11» и т. д. Из них будут составлены следующие комбинации: «Брус», «Брус клееный», «Брус, клееный», «Брус; клееный», «Брус клееный строганый», «Брус, клееный, строганый» и т. д.
2.4 Каждая из полученных комбинаций обрабатывается обученным классификатором атрибутов. Данный классификатор возвращает для каждой комбинации вероятность того, что данная комбинация является тем или иным атрибутом из набора атрибутов заданного класса или не является атрибутом вообще. Другими словами, получают распределение вероятностей между атрибутами для рассматриваемой комбинации.
Так как для каждого класса наименований есть свой набор атрибутов, то потребуется обучить отдельную модель для каждого класса. Для обучения классификатору требуются пары вида {значение атрибута, имя атрибута}, которые имеются в прайс-листе. Для каждой модели выбираются пары из соответствующего класса наименований. Перед подачей на вход классификатору значение атрибута нужно векторизовать. Для векторизации выбран метод на основе N-грамм CountVectorizer из библиотеки scikit-learn, так как смысловую нагрузку несут именно сочетания слов с учетом их последовательности.
Пример. Возьмем наименование из пункта 2.3. Для класса данного наименования («01.01.10.01 Клееный брус непрофилированный») имеем два атрибута: сечение и длина.
Распределение вероятностей для некоторых комбинаций приведены в табл. 1.
Для каждого атрибута в качестве основного значения выбирается комбинация, которая имеет наибольшую вероятность и превышает заданный порог. Для рассматриваемого примера при значении порога 0.6 в качестве основных значений будут выбраны следующие: для атрибута «Длина» - «11,985», для атрибута «Сечение» - «100*200мм».
Источники информации
1. LightGBM - gradient boosting framework. Режим доступа: https://lightgbm.readthedocs.io/en/latest/. Дата доступа: 15.10.2020 г.
Изобретение относится к вычислительной технике. Технический результат заключается в повышении скорости процессов атрибутизации данных. Способ атрибутизации частично структурированных текстов для формирования нормативно-справочной информации включает выбор обучающего набора текстов на естественном языке частично структурированных текстов, извлечение соответствующего набора признаков для каждой категории именованных сущностей, обучение модели классификации с использованием обучающего набора текстов и наборов признаков для каждой категории именованных сущностей, осуществление обучения на атрибутах, получение модели для каждой именованной сущности и проверку атрибутов, извлечение процессором токенов из неразмеченного текста, формирование процессором размеченного представления, по меньшей мере, части текста на основании, по меньшей мере, одного из токенов, классифицированных по категориям. 2 ил., 1 табл.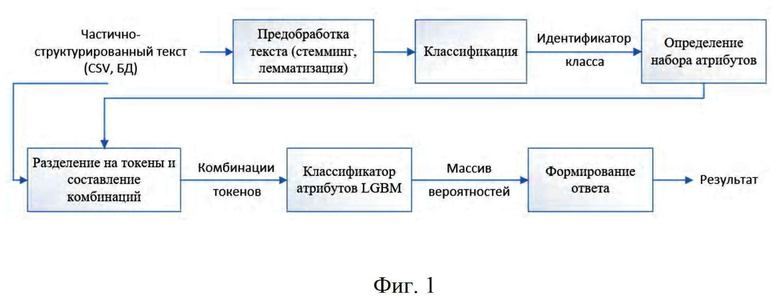
Способ атрибутизации частично структурированных текстов для формирования нормативно-справочной информации, включающий выбор обучающего набора текстов на естественном языке, извлечение процессором соответствующего набора признаков для каждой категории именованных сущностей, обучение процессором модели классификации с использованием обучающего набора текстов и наборов признаков для каждой категории именованных сущностей, извлечение процессором токенов из неразмеченного текста, формирование процессором размеченного представления, по меньшей мере, части текста на основании, по меньшей мере, одного из токенов, классифицированных по категориям, отличающийся тем, что для обучения модели классификации именованных сущностей выбраны частично структурированные тексты и выполнена их предобработка – лемматизация, стемминг, удаление стоп-слов, знаков пунктуации, а также векторизация слов с присвоением веса каждому слову наименования сущности в соответствии с оценкой важности слова в контексте документа, для извлечения токенов неразмеченный текст размечается на обученной модели классификатора наименований, а наименования разбиваются на токены по заданному набору разделителей, после чего составляются все возможные комбинации из 1-5 последовательных токенов, для извлечения атрибутов полученные комбинации токенов обрабатываются обученной на заданном наборе атрибутов класса моделью классификатора атрибутов, который возвращает для каждой комбинации вероятность того, что данная комбинация является тем или иным атрибутом из набора атрибутов заданного класса или не является атрибутом вообще, для каждого атрибута в качестве основного значения выбирается комбинация с наибольшей вероятностью и превышающей заданный порог.
| Способ защиты переносных электрических установок от опасностей, связанных с заземлением одной из фаз | 1924 |
|
SU2014A1 |
| Приспособление для суммирования отрезков прямых линий | 1923 |
|
SU2010A1 |
| Колосоуборка | 1923 |
|
SU2009A1 |
| Станок для изготовления деревянных ниточных катушек из цилиндрических, снабженных осевым отверстием, заготовок | 1923 |
|
SU2008A1 |
| Автоматическое извлечение именованных сущностей из текста | 2014 |
|
RU2665239C2 |

