Изобретение относится к области технологий компьютерной лингвистики по обработке естественно-язычных текстов, а именно - к автоматизированному извлечению смысловых компонентов из текстов любого уровня сложности в системах межъязыкового машинного перевода [G06F 16/00, G06F 17/00, G06F 17/21, G06F 17/27, G06F 17/30, G06F 40/00].
Из уровня техники известен СПОСОБ ИЗВЛЕЧЕНИЯ ФАКТОВ ИЗ ТЕКСТОВ НА ЕСТЕСТВЕННОМ ЯЗЫКЕ [RU 2637992 (C1), опубл. 08.12.2017 г.], отличающийся тем, что при извлечении фактов из текстов на естественном языке получают идентификатор первого токена, содержащегося в тексте и включающего слово естественного языка, ссылающееся на первый информационный объект, представленный первой именованной сущностью. Далее получают идентификаторы первого множества слов, представляющего первый факт определенной категории фактов, связанный с первым информационным объектом некоторой категории информационных объектов. После чего определяют в тексте второе множество слов, включающее второй токен, ссылающийся на второй информационный объект, ассоциирующийся с указанной категорией информационных объектов. В ответ на получение подтверждения того, что второе множество слов представляет второй факт, связанный со вторым информационным объектом той же категории информационных объектов, извлекают второй факт и сохраняют его в форме RDF-графа. А в конце изменяют параметр функции классификатора, которая дает значение, отражающее степень ассоциации данной семантической структуры с фактом из определенной категории фактов.
Недостатками аналога являются:
- данное техническое решение не позволяет эффективно осуществлять машинный перевод для текстов на флективных языках;
- при извлечении текста система не реагирует на члены предложений, образующих смысловые конструкции, которые разделены различного рода описательно-уточняющими оборотами.
Также из уровня техники известен CПОСОБ ИЗВЛЕЧЕНИЯ ИНФОРМАЦИИ ИЗ СМЫСЛОВЫХ БЛОКОВ ДОКУМЕНТОВ С ИСПОЛЬЗОВАНИЕМ МИКРОМОДЕЛЕЙ НА БАЗЕ ОНТОЛОГИИ [RU 2662688 (C1), опубл. 26.07.2018], отличающийся тем, что извлечение информации из документов, содержащих текст на естественном языке, производится на основе идентификации в тексте смысловых блоков, относящихся к заданной категории. Далее выполняется лексический анализ множества слов смыслового блока с целью построения множества лексических структур, содержащих информацию о лексических значениях слов и соответствующих семантических классах, представляющих смысловой блок. Затем идентифицируется микромодель для извлечения информации, относящейся к заданной категории, причем микромодель включает множество продукционных правил, связанных с онтологией. Впоследствии применяются продукционные правила микромодели с целью извлечения информационных объектов, связанных с соответствующим семантическим классом, соответствующим концепту онтологии.
Недостатками данного аналога являются:
- данный способ не позволяет оптимально качественно производить машинный перевод текстов на флективных языках;
- при проведении семантико-синтаксического анализа текста на флективных языках технические решения данного способа способны выявлять смысловые компоненты только в рамках одного простого предложения или в одном из фрагментов сложносочиненного предложения.
Наиболее близкой по технической сущности является АВТОМАТИЧЕСКОЕ ИЗВЛЕЧЕНИЕ ИМЕНОВАННЫХ СУЩНОСТЕЙ ИЗ ТЕКСТА [RU 2665239 (C2), опубл. 28.08.2018 г.], отличающийся тем, что извлечение именованных сущностей из неразмеченного текстового корпуса производится путем выделения обучающего набора текстов на естественном языке, после чего процессором соответствующего набора признаков извлекают именованные сущности для каждой категории. Далее производится обучение процессором модели классификации с использованием обучающего набора текстов и наборов признаков для каждой категории именованных сущностей. После чего процессором извлекаются токены из неразмеченного текста и формируются наборы атрибутов для каждого токена неразмеченного текста на основании по меньшей мере глубокого семантико-синтаксического анализа. Далее определяются возможные синтаксические связи по меньшей мере в одном предложении неразмеченного текста, включающее получение множества синтаксических атрибутов, и производится формирование независимой от языка семантической структуры, включающее определение семантических связей и соответствующих семантических атрибутов каждого токена. Затем процессором классифицируется каждый токен по меньшей мере в одну из категорий на основании модели классификатора и набора атрибутов токена и формируется размеченное представление по меньшей мере части текста на основании по меньшей мере одного из токенов, классифицированных по категориям.
Основной технической проблемой прототипа является то, что в данном решении автоматизированная обработка естественно-язычных текстов, в части извлечения смысловых компонентов из сложно-сочиненных предложений с многочисленным составом словоформ для флективных языков, осуществляется с неудовлетворительном качеством, что впоследствии негативно сказывается на эффективности грамматически-правильного машинного перевода всего текста в целом.
Задачей изобретения является устранение недостатков прототипа.
Техническим результатом изобретения является повышение качества автоматизированного извлечения смысловых компонентов из текстов любого уровня сложности в системах межъязыкового машинного перевода.
Указанный технический результат достигается за счет того, что устройство автоматизированного извлечения смысловых компонент из сложносочиненных предложений естественно-язычных текстов в системах машинного перевода, содержащее последовательно соединенные лингвистический модуль сентенсизации, выполненный с возможностью первичной обработки текста с целью разделения его на отдельные абзацы и предложения по знаку «<.>точка» или символам «!»; «?», лингвистический модуль фрагментизации, выполненный с возможностью дальнейшего деления предложений на фрагменты по знакам «<,> - запятая» или «<;> - точка с запятой», лингвистический модуль графематизации, выполненный с возможностью реализации процесса дифференцирования входной информации до выделения из нее отдельных графем (словоформ) и знаков (символов), лингвистический модуль морфологизации, выполненный с возможностью распределения по разным морфологическим классам выявленных текстовых элементов, лингвистический модуль паттернизации, выполненный с возможностью связывания текстовых элементов друг с другом по синтаксическим правилам, образуя устойчивые синтаксические словосочетания (паттерны) и присвоения им индивидуальных маркеров, лингвистический модуль индексации, выполненный с возможностью осуществления модулем атрибутирования установления морфологических атрибутов для фрагментов текста, а модулем постиндексирования индексирования фрагментов текста, при котором атрибутированным фрагментам присваивают уникальные индексы, лингвистический модуль семантизации, выполненный с возможностью получения для словоформ и паттернов присущих им лексических значений - семантисов и лингвистический модуль экстракции, выполненный с возможностью извлечения искомых лингвистических объектов, при этом лингвистический модуль индексации образуют последовательно соединенные модуль атрибутирования, вход которого соединен с выходом лингвистического модуля паттернизации, и модуль постиндексирования, выход которого соединен с входом лингвистического модуля семантизации.
Указанный технический результат достигается за счет того, что способ автоматизированного извлечения смысловых компонент из сложносочиненных предложений естественно-язычных текстов в системах машинного перевода, характеризующийся тем, что на этапе сентенсизации производят первичную обработку текста с целью разделения его на отдельные абзацы и предложения по знаку «<.> точка» или символам «!»; «?», на этапе фрагментизации производят дальнейшее деление предложений на фрагменты по знакам «<,> - запятая» или «<;> - точка с запятой», на этапе графематизации производят процесс дифференцирования входной информации до выделения из нее отдельных графем (словоформ) и знаков (символов), на этапе морфологизации выявленные текстовые элементы распределяют по разным морфологическим классам, на этапе паттернизации текстовые элементы связывают друг с другом по синтаксическим правилам, образуя устойчивые синтаксические словосочетания (паттерны) и присваивают им индивидуальные маркеры, на этапе индексации осуществляют атрибутирование, при котором производят установление морфологических атрибутов для фрагментов текста, и индексирование фрагментов текста, при котором атрибутированным фрагментов присваивают уникальные индексы, на этапе семантизации получают для словоформ и паттернов присущие им лексические значения - семантисы и на этапе экстракции осуществляют извлечение искомых лингвистических объектов.
В частности, индексирование фрагментов текста осуществляют по классификации на основе закономерности для сложносочиненных предложений русского языка, заключающейся в том, что типология фрагментов предложений русского языка содержит ограниченное количество различных вариантов, равное восьмидесяти одному.
Краткое описание чертежей
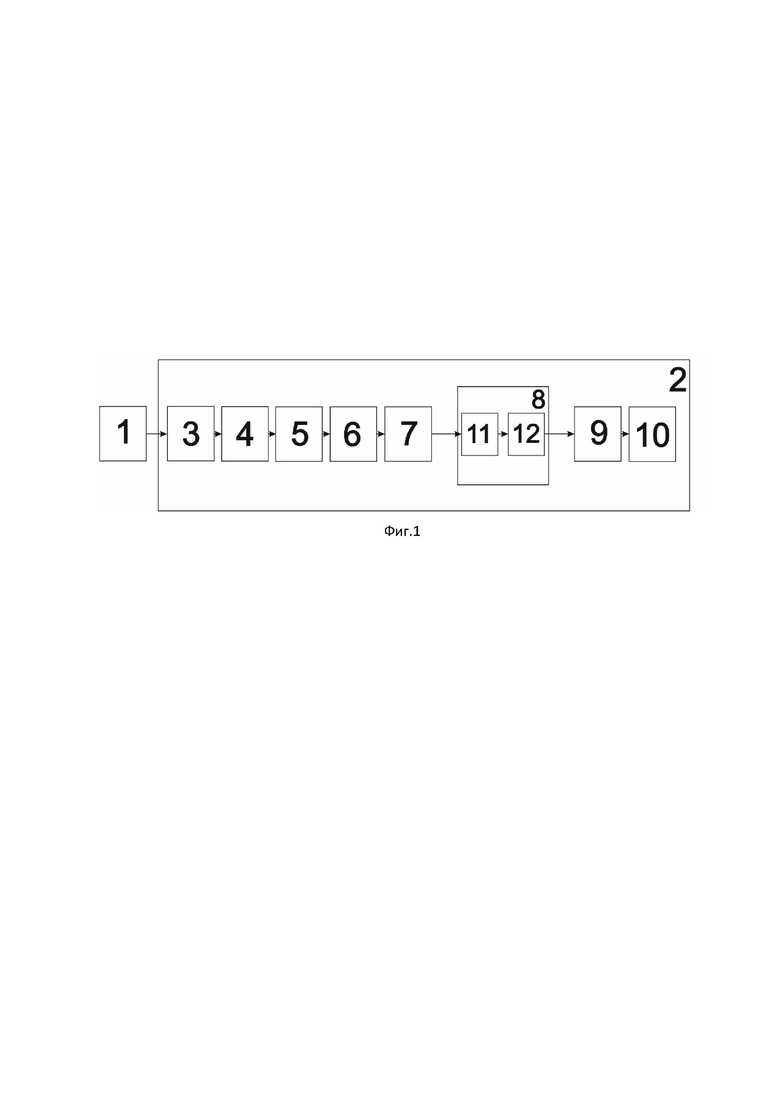
На фиг.1 показана блок-схема устройства автоматизированного извлечения смысловых компонент из сложносочиненных предложений естественно-язычных текстов в системах машинного перевода.
На рисунке обозначено: 1 - модуль подачи текста на естественном языке, 2 - лингвистический процессор, 3 - лингвистический модуль сентенсизации, 4 - лингвистический модуль фрагментизации, 5 - лингвистический модуль графематизации, 6 - лингвистический модуль морфологизации, 7 - лингвистический модуль паттернизации, 8 - модуль индексации, 9 - лингвистический модуль семантизации, 10 - лингвистический модуль экстракции, 11 - модуль атрибутирования, 12 - модуль постиндексирования.
Осуществление изобретения
Устройство автоматизированного извлечения смысловых компонент из сложносочиненных предложений естественно-язычных текстов в системах машинного перевода состоит из модуля подачи текста на естественном языке 1, выход которого соединен с лингвистическим процессором 2 непосредственно через вход лингвистического модуля сентенсизации 3, к которому последовательно присоединены лингвистический модуль фрагментизации 4, лингвистический модуль графематизации 5, лингвистический модуль морфологизации 6, лингвистический модуль паттернизации 7, модуль индексации 8, лингвистический модуль семантизации 9 и лингвистический модуль экстракции 10. При этом модуль индексации 8 включает в себя последовательно соединенные модуль атрибутирования 11, вход которого соединен с выходом модуля паттернизации 7 и модуль постиндексирования 12, выход которого соединен с входом лингвистического модуля семантизации 9.
Автоматизированное извлечение смысловых компонент из сложносочиненных предложений естественно-язычных текстов в системах машинного перевода осуществляется следующим образом.
В общем случае, извлечение смысловых компонентов в естественно-язычных текстах производят с использованием лингвистических процессоров, которые используют в разнообразных компьютерных приложениях для смысловой обработки естественно-язычных текстов, включая машинный перевод, целевой информационный поиск по заданным смыслам, реферирование и аннотирование текстов, категоризацию и классификацию документов и др.
Смысловыми компонентами в заявляемом изобретении являются субъектно-предикатные конструкции словоформ, несущие в себе смысловую нагрузку, к таковым относятся: смысловые ядра, смысловые блоки и смысловые кластеры.
Под смысловыми ядрами понимается связка слов в виде субъектно-предикатных конструкций, определяющих смыслы в виде переходных процессов, происходящих с субъектами, как в целом предложении, так и в его фрагментах. Примерами смысловых ядер в русскоязычных текстах могут быть следующие словосочетания: «Петя пошел»; «Дерево было спилено»; «Он должен быть»; «Татьяна хотела научиться стрелять» и др.
Под смысловыми блоками понимаются несколько смысловых ядер, объединенных союзами или разделенные знаками пунктуации. Например: «Кот ел, ел и объелся»; «Дерево было спилено и сожжено».
Смысловые ядра и смысловые блоки подразделяются на главные и второстепенные лингвистические объекты, различие между которыми заключается в том, что второстепенные лингвистические объекты, например, в предложениях русского языка всегда входят в состав какого-либо оборота, описывающего главные лингвистические объекты, а сам главный лингвистический компонент, соответственно, никогда в такой роли не выступает. Например, в предложении «Велосипедист, который все время шел вторым в пелетоне, пришел к финишу первым» главным лингвистическим объектом является «Велосипедист пришел», а второстепенным - «который шел».
Под смысловым кластером понимаются главные или второстепенные лингвистические объекты, дополненные сабжем - пакетом описаний субъект-объектных предикатных отношений. Например: «…человеческое сознание точно также имеет свой вход и тоже обладает выходом…».
Под системой машинного перевода понимается автоматизированная трансформация на программном уровне оригинального текста, составленного на одном исходном языке, в другой иноязычный текст, например, перевод с русского на английский. В известных системах машинного перевода используются четыре основных технологии - это подстрочный, статистический, семантический и смысловой анализ, которые можно охарактеризовать, соответственно, как: «неудовлетворительный», «удовлетворительный», «хороший» и «отличный».
Для систем машинного перевода, особенно для случаев автоматизированного преобразования текста на аналитические языки (английский, голландский и др.), характеризующиеся четким грамматическим строем, требуется выявление в оригинальном тексте, представленного на языке иной грамматико-строевой типологии, например, на флективном русском языке, смысловых компонент текста, к которым относятся: смысловые ядра, блоки и кластеры, то есть, несущие смысловую нагрузку словесные конструкции предложений - главные и второстепенные лингвистические объекты.
Одной из основных задач систем машинного перевода является нахождение главных лингвистических объектов в любом месте предложения на оригинальном тексте, и вынесение их в начало переведенного варианта предложения. Например, если в русском тексте допустимо выражение: «В школу шел Петя.», то в его английском выражении обязательно должно быть: «Petya was going to school.»
Смысловые ядра главных и второстепенных лингвистических объектов не всегда образуются линейкой рядом расположенных слов в рамках одного фрагмента или простого предложения. В сложносочиненных предложениях элементы субъектно-предикатных конструкций могут быть разнесены по разным фрагментам, и тогда это становится проблемой для всех известных систем машинного перевода, поскольку они сталкиваются с затруднениями в выявлении главных лингвистических объектов.
Например, в предложении: «А ведь, и человеческое сознание, подобно той курице, которая на входе клюет зерна и щиплет зелень, а на выходе производит яйцо, точно также имеет свой вход, где поступающая информация осмысляется, и тоже обладает выходом, из которого подается уже готовый смысловой продукт.» - имеются следующие смысловые компоненты: [сознание имеет… и обладает] (главный лингвистический объект); [которая клюет…, щиплет…, а производит], [информация осмысляется], [продукт подается] (второстепенные лингвистические объекты).
Нахождение лингвистических объектов в естественно-язычных текстах возлагают на системы автоматизированной обработки текстов, под которыми в настоящем документе понимаются технологии лингвистического анализа естественно-язычного текста на машинно-программном уровне. Известные системы автоматизированной обработки текстов включают в себя, как правило, морфологические, синтаксические и семантические языковые исследования анализируемых текстов. В общем виде автоматизированная обработка данных строится на основе четырех процедурных принципов: дифференциации, дивергенции, конвергенции и интеграции. Сначала текст дифференцируется, разбиваясь на элементы - слова и знаки, затем дивергенируется, разводя элементы по морфологическим признакам в разные группы, далее эти элементы подвергаются конвергенции, сводя их друг с другом по синтаксическим критериям, и, наконец, они интегрируются в конечный семантико-синтаксический граф.
Выполнение процедур автоматизированной обработки текстов возлагаются на лингвистические модули - это программные блоки, исполняющие одну или несколько родственных алгоритмических процедур в ходе выполнения одного шага обработки естественно-язычного текста с целью получения какого-либо одного искомого промежуточного результата, например, в ходе морфологического или синтаксического анализа входного текста.
Из набора лингвистических модулей при выполнении конкретной задачи автоматизированной обработки текстов составляется лингвистический процессор, который может быть многошаговым и целью которого является уже получение каких-либо искомых конечных результатов, например, извлечение именованных сущностей из заданного на входе естественно-язычного текста, выявление главных или второстепенных лингвистических объектов, построение семантико-синтаксического графа предложения или текста или осуществление межъязыкового перевода.
Как правило, для типовых лингвистических процессоров анализ и перевод предложений текста на русском языке (обладающих повышенной категорией сложности, то есть включают в себя несколько единиц придаточных, причастных, деепричастных, указательных и прочих оборотов речи, отделенных знаками препинания и имеющих строгий упорядоченный грамматический строй) на другие языки становится непреодолимой проблемой.
В заявляемом изобретении для решения указанных выше проблем по автоматизированной обработке текстов на вход лингвистического процессора 2, а именно на лингвистический модуль сентенсизации 3, подают машинно-читаемый текст с модуля подачи текста на естественном языке 1, производящий первичную обработку текста с целью разделения его на отдельные абзацы и предложения для дальнейшего исследования. Дифференциация текста в модуле сентенсизации 3 на первом этапе осуществляют по пунктуационным критериям, в частности, по знаку «<.> точка» или символам «!»; «?». Например, текст: - <Петя, который утром пошел в школу, к обеду не вернулся. Вечером он также еще не появлялся дома> - получает разбивку на два следующих предложения: <Петя, который утром пошел в школу, к обеду не вернулся> и <Вечером он также еще не появлялся дома>.
Полученные по результатам первого этапа предложения поступают из лингвистического модуля сентенсизации 3 на вход лингвистического модуля фрагментизации 4, где происходит дальнейшее деление предложений на фрагменты, но уже по другим пунктуационным критериям, в частности, по знакам «<,> - запятая» или «<;> - точка с запятой». Например, вышеприведенные предложения будут разбиты на следующие фрагменты: - <Петя>, <который утром пошел в школу>, <к обеду не вернулся>. <Вечером он также еще не появлялся дома>.
Далее, выделенные на втором этапе фрагменты в лингвистическом модуле фрагментизации 4 поступают на вход лингвистического модуля графематизации 5, где процесс дифференцирования входной информации продолжают до выделения из нее отдельных графем (словоформ) и знаков (символов), которые являются элементарными единицами текста.
Затем, эти выходные данные из лингвистического модуля графематизации 5 поступают на четвертом этапе в лингвистический модуль морфологизации 6, в котором всем текстовым элементам - и графемам, и знакам - присваивают «пометы», как морфологические признаки или характеристики, дивергенируя (разводя) выявленные элементы текста по разным морфологическим группам.
Потом эти графемы и знаки вместе с полученными на четвертом этапе морфемными пометами направляют в синтаксический синтезатор - лингвистический модуль паттернизации 7, где конвергенируют, то есть, связывают друг с другом по синтаксическим правилам, образуя устойчивые синтаксические словосочетания - паттерны, которым присваивают индивидуальные маркеры. При этом под паттерном понимается простейшая двухэлементная синтаксическая связка двух графем. Примерами паттернов в русском языке могут служить следующие словосочетания: [в школе], [красивая одежда], [все равно], [Петя пошел], [выпить воду] и другие. Морфологически паттерны для русского языка подразделяются на 256 видов, каждый из которых имеет свое уникальное наименование. Примерами таких наименований для различных видов паттернов могут служить следующие обозначения: «Онтологотив»; «Актоид»; «Пактоид» и т.д. Каждое подобное видовое наименование паттерна имеет свой уникальный трехбуквенный маркер, который представляет собою краткое (сокращенное) обозначение паттерна. Примерами такого сокращенного обозначения паттернов могут служить, соответственно, следующие маркеры: «Отв», «Атд», «Птд» и т.д.
Полученные на пятом этапе промаркированные паттерны на шестом этапе проходят индексацию с помощью дополнительно введенного модуля индексации 8, а именно производят установление морфологических атрибутов для фрагментов текста с помощью модуля атрибутирования 11 и присвоение атрибутированным фрагментов уникальных индексов в модуле постиндексирования 12. Уникальность индексов определяется особенностями присвоения фрагментам текста (фрагмент - часть предложения, ограниченная знаками пунктуации и символов.) индексов с использованием классификации, построенной на основе закономерности для сложносочиненных предложений русского языка, заключающейся в том, что типология фрагментов предложений русского языка содержит ограниченное количество различных вариантов - восемьдесят один. Поясняя, необходимо сказать, что современные технологии компьютерной лингвистики (ТКЛ), используемые для обработки текстов на естественных языках, например, на русском языке, применяют морфологическую индексацию, в основном, для словоформ языка, как для отдельных частей речи, но не дифференцируют фрагменты сентенций, как обороты речи, выделяемые в тексте знаками пунктуации, например, запятыми. Данное положение не позволяет известным ТКЛ устанавливать семантическую связь (коннекцию) между фрагментами в анализируемых предложениях, особенно, в сложносочиненных сентенциях, изобилующих знаками пунктуации, что, практически, всегда вызывает трудность для систем автоматизированного перевода с русского (флективного) языка на аналитические и агглютинативные языки. Для примера приведем следующее предложение: «Не заметив, что на мосту, где было совершенно темно, шоссе, давно требующее починки, о которой некому было позаботиться, размыто дождями, в этих местах почти не прекращающимися, покрыто выбоинами, заполненными, о чем было нетрудно догадаться, густой грязью, завалено мусором, велосипедист, как мешок с картошкой, со всего маху свалился в яму.» В данном тексте 15 запятых, поэтому для установления коннекции между фрагментами применяют морфологическую индексацию фрагментов для сложносочиненных предложений, которая разработана в рамках данного технического решения и является уникальной. К примеру, вышеприведенное предложение разбивается на 17 фрагментов:
1) Не заметив; 2) , что на мосту; 3) , где было совершенно темно 4) , шоссе 5) , давно требующее починки; 6) , о которой некому было позаботиться 7) , размыто дождями 8) , в этих местах почти не прекращающимися; 9) , покрыто выбоинами; 10) , заполненными; 11) , о чем было нетрудно догадаться; 12) , густой грязью; 13) , завалено мусором; 14) , велосипедист; 15) , как мешок с картошкой; 16) , со всего маху свалился в яму; 17) . (точка).
Для этого используется три класса, согласно разработанной классификации:
А) Класс I => по двум признакам наличия или отсутствия в начале каждого фрагмента знака пунктуации. Соответственно, класс I имеет только два маркера.
Б) Класс II => по четырем признакам наличия и конкретного вида паттернов во фрагментах. Соответственно, класс II имеет только четыре маркера.
В) Класс III => по десяти признакам наличия и конкретного вида оборотов и кластеров во фрагментах. Соответственно, класс III имеет только десять маркеров.
Эти три класса образуют трехпозиционный индекс, состоящий из трех маркеров для каждого фрагмента в виде: I~II~III. Иначе говоря, 2 маркера группы I ~4 маркера группы II ~10 маркеров группы III, которые дают в сумме 80 различных перестановочных вариантов, к которым добавляется один индекс, обозначающий окончание предложения. Всего в итоге получается 81 индекс. Ниже приведена таблица индексов.
Класс I. Классификация фрагментов по общепунктерным признакам:
1.1 Наличие в начале фрагмента Пунктера «Запятая», находящегося ВНЕ паттерновых конструкций, присутствующих в данном Фрагменте. Описание критерия: «Если фрагмент начинается с запятой, расположенной вне паттерновых конструкций этого фрагмента, то данный фрагмент обозначается Атрибутом => «Зп». Пример: Fr N => , [густой грязью] (пдф) => Зп. Здесь запятая вынесена за пределы Паттерна.
1.2 Отсутствие во фрагменте Пунктера «Запятая», находящегося ВНЕ паттерновых конструкций, присутствующих в данном Фрагменте. Описание критерия: «Если фрагмент не начинается с запятой, то такой фрагмент обозначается Атрибутом => «Бз».
Пример: => [Не заметив] => Бз. В данном Фрагменте вообще отсутствует запятая.
Класс II. Классификация фрагментов по общепаттерным признакам:
2.1 Беспаттерный Фрагмент. Описание критерия: «Если во фрагменте не образовалось ни одной паттерновой конструкции, то такой фрагмент считается беспаттерным фрагментом и обозначается Атрибутом => «Бп». Пример: => , (велосипедист) ат => Бп
2.2 Фрагмент с единичной паттерновой конструкцией. Описание критерия: «Если во Фрагменте образовалась только одна паттерновая конструкция, будь то Паттерн, Валпаттерн, Субпаттерн или Экспаттерн, то такой фрагмент считается фрагментом с единичной паттерновой конструкцией, имеющим Атрибут => «Еп». Пример: => [Не заметив] (дцв) => Еп.
2.3 Фрагмент с разнородными мульти-паттерновыми конструкциями. Описание критерия: «Если во фрагменте образовалось несколько паттеновых конструкций с Маркерами разного рода, то такой фрагмент считается фрагментом с разнородными мульти-паттерновыми конструкциями, имеющим Атрибут => «Мп». Пример: => [, что] (отл) [на мосту] (отв) => Мп.
2.4 Фрагмент с однородными мульти-паттерновыми конструкциями. Описание критерия: «Если во фрагменте образовалось несколько и только однородных паттерновых конструкций с одинаковыми Маркерами, то такой фрагмент считается фрагментом с однородными мульти-паттерновыми конструкциями, имеющим Атрибут => «Оп». При этом между последовательно расположенными однородными Паттернами проставляется диез «#». Пример: => [размыто дождями] (нпд) # , [покрыто выбоинами] (нпд) => Оп.
Группа III. Классификация фрагментов по оборотным, кластерным и актантно-пактантным признакам:
3.1. Онтольный Оборот. Описание критерия: «Если во фрагменте наличествует паттерновая конструкция, в основе которой имеется Паттерн с Маркером Класса 1, вне зависимости от присутствия других Паттернов с Маркерами низшего класса, то данный фрагмент считается «Онтольным Оборотом» с Атрибутом «OO». Пример: => [, что] отл => OO.
3.2. Бактольный Оборот. Описание критерия: «Если во фрагменте наличествует паттерновая конструкция, в основе которой имеется Паттерн с Маркером Класса 2, при отсутствии других Паттернов с Маркерами более высшего Класса и вне зависимости от присутствия иных Паттернов с Маркерами низшего Класса, то данный фрагмент считается «Бактольным Оборотом» с Атрибутом «BO». Пример: => [, заполненными] бтл => BO.
3.3. Пояснительный Оборот. Описание критерия: «Если во фрагменте наличествует паттерновая конструкция, в основе которой имеется Паттерн с Маркером Класса 3, при отсутствии других Паттернов с Маркерами более высшего Класса и вне зависимости от присутствия иных Паттернов с Маркерами низшего Класса, то данный Фрагмент считается «Пояснительным Оборотом» с Атрибутом «PO». Пример: => [, как мешок с картошкой] пкг => PО.
3.4. Дакциальный Оборот. Описание критерия: «Если во фрагменте наличествует паттерновая конструкция, в основе которой имеется Паттерн с Маркером Класса 4, при отсутствии других Паттернов с Маркерами более высшего Класса и вне зависимости от присутствия иных Паттернов Маркерами низшего Класса, то данный фрагмент считается «Дакциальным Оборотом» с Атрибутом «DO». Пример: => [Не заметив] дтл => DO.
3.5. Смысловой Кластер. Описание критерия: «Если во фрагменте наличествует паттерновая конструкция, в основе которой имеется Паттерн с Маркером Класса 5, при отсутствии других Паттернов с Маркерами более высшего Класса и вне зависимости от присутствия иных Паттернов с Маркерами низшего Класса, то данный фрагмент считается «Акциальным Кластером» с Атрибутом «SK». Пример: => [Петя пошел домой] => SK.
3.6. Накциальный Кластер. Описание критерия: «Если во фрагменте наличествует паттерновая конструкция, в основе которой имеется Паттерн с Маркером Класса 6, при отсутствии других Паттернов с Маркерами более высшего Класса и вне зависимости от присутствия иных Маркеров низшего Класса, то данный фрагмент считается «Накциальным Кластером» с Атрибутом «NK». Пример: => [яма завалена мусором] => NK.
3.7. Акционное Ядро. Описание критерия: «Если во фрагменте наличествует паттерновая конструкция, в основе которой имеется Паттерн с Маркером Класса 7, при отсутствии других Паттернов с Маркерами более высшего Класса и вне зависимости от присутствия иных Маркеров низшего Класса, то данный фрагмент считается «Акционным Ядром» с Атрибутом «AY». Пример: => [зарабатывать деньги] => AY.
3.8. Накционное Ядро. Описание критерия: «Если во фрагменте наличествует паттерновая конструкция, в основе которой имеется Паттерн с Маркером Класса 8, при отсутствии других Паттернов с Маркерами более высшего Класса и вне зависимости от присутствия иных Маркеров низшего Класса, то данный фрагмент считается «Накционным Ядром» с Атрибутом «NY». Пример: => [завалена мусором] => NY.
3.9. Актанто-Пактант. Описание критерия: «Если во фрагменте наличествует паттерновая конструкция, в основе которой имеется Паттерн с Маркером Класса 9, при отсутствии других Паттернов с Маркерами более высшего Класса и вне зависимости от присутствия иных Маркеров низшего Класса, то данный фрагмент считается «Актантно-пактантным Ядром» с Атрибутом «AP». Пример: => , (шоссе) ат/пт => AP.
3.10. Сабж. Описание критерия: «Если во фрагменте наличествует паттерновая конструкция, в основе которой имеется Паттерн с Маркером Класса 10, при отсутствии других Паттернов с Маркерами более высшего, то данный фрагмент считается «Сабжем» с Атрибутом «SJ». Пример: => [очень давно] => SJ.
Таким образом, вся морфологическая классификация фрагментов осуществляется исключительно по определению параметров Паттернов в паттерновых конструкциях фрагментов: их наличия или отсутствия, их качества и количества.
В итоге, благодаря процедурам атрибутирования и постиндексирования фрагментов текста с высоким качеством выявляют фрагменты, не имеющие в своем составе главные лингвистические объекты в виде смысловых компонентов. Полученные на шестом этапе перепаттернизированные проиндексирвоанные паттерны проходят на следующем этапе семантический анализ в лингвистическом модуле семантизации 9, в результате чего получают для словоформ и паттернов присущие им лексические значения - семантисы.
В конце, на восьмом этапе в лингвистическом модуле экстракции 10 происходит в зависимости от поставленной исходной задачи извлечение искомых лингвистических объектов, будь то, например, именованные сущности или главные лингвистические объекты.
Таким образом, использование исследуемого технического решения позволяет повысить качество автоматизированного извлечения смысловых компонент из текстов любого уровня сложности в системах межъязыкового машинного перевода.
Технический результат изобретения повышение качества автоматизированного извлечения смысловых компонент из текстов любого уровня сложности в системах межъязыкового машинного перевода достигается за счет того, что:
- модуль атрибутирования 11 позволяет установить морфологические атрибуты для фрагментов текста;
- модуль постиндексирования 12 осуществляет присвоение атрибутированным фрагментам специальных индексов, сформированных на основе выявленных закономерностей для сложносочиненных предложений русского языка
- в своей совокупности заявленное техническое решение позволяет с высоким качеством выявлять фрагменты, не имеющие в своем составе главные лингвистические объекты в виде смысловых компонентов, что впоследствии позволяет повысить качество перевода текстов на флективных языках, в том числе состоящих из предложений с повышенной категорией сложности, то есть включают в себя несколько единиц придаточных, причастных, деепричастных, указательных и прочих оборотов речи, отделенных знаками препинания и имеющих строгий упорядоченный грамматический строй.
Пример достижения технического результата:
К примеру, известные системы машинного перевода «Google» и «ProMT» для следующего русскоязычного предложения <Со всего маху свалился в яму, как мешок с картошкой, велосипедист из Сибири.> выдает неграмотный перевод <From all over the mahu fell into the pit, like a bag of potatoes, a cyclist from Siberia.> Здесь смысловым ядром является субъектно-предикатная конструкция словосочетания: «велосипедист свалился», которое в английском переводе должно быть перенесено в начало предложения. Однако, ввиду того, что слова «велосипедист» и «свалился» разнесены в разные фрагменты данного предложения, лингвистический процессор не справляется с выявлением указанного смыслового ядра.
А подобную систему перевода, улучшенная технологией статистической обработки двуязычных текстов, реализуют в лингвистическом процессоре языковой трансляции «Yandex», которая для вышеприведенного тестового предложения уже дает правильный перевод, а именно: <A cyclist from Siberia fell into the pit like a sack of potatoes.> Но для предложений повышенной сложности при численности слов более 20 и наличии двух и более смысловых компонентов, члены которых разнесены по различным фрагментам в предложениях с несколькими описательно-уточняющими оборотами, ограниченными пунктуационными знаками, например, запятой <,>, система машинного перевода «Yandex» уже переводит с нарушениями грамматики английского языка. Например, следующее допустимое в русском языке предложение:
<Не заметив, что на мосту, где было совершенно темно, шоссе, давно требующее починки, о которой некому было позаботиться, размыто дождями, в этих местах почти не прекращающимися, покрыто выбоинами, заполненными, о чем было нетрудно догадаться, густой грязью, завалено мусором, велосипедист, как мешок с картошкой, со всего маха свалился в яму.> система машинного перевода «Yandex» переводит с ошибками: <Without noticing that on the bridge, where it was completely dark, the highway, long in need of repair, which no one could take care of, was washed away by the rains, in these places almost non-stop, covered with potholes, filled, as it was easy to guess, with thick mud, littered with garbage, the cyclist, like a bag of potatoes, fell into the hole with all>.
А с помощью заявленного технического решения данное предложение переводиться безошибочно: <After all the human consciousness has the inlet where the arriving information is comprehended, and also possesses the outlet from which the readymade commonsense product is outgoing, likewise that chicken which pecks grains and nibbles greens on its inlet and makes egg to the outlet.>. В результате качество перевода сложносочиненных предложений текстов на флективных языках увеличилось на 20%.
Изобретение относится к области технологий компьютерной лингвистики по обработке естественно-язычных текстов, а именно - к автоматизированному извлечению смысловых компонентов из текстов любого уровня сложности в системах межъязыкового машинного перевода. Техническим результатом изобретения является повышение качества машинного перевода текстов с любой степенью сложности. Способ автоматизированного извлечения смысловых компонент из сложносочиненных предложений естественно-язычных текстов в системах машинного перевода, характеризующийся тем, что содержит этапы: сентенсизации, фрагментизации, графематизации, морфологизации, паттернизации, индексации, семантизации и экстракции. 2 н. и 1 з.п. ф-лы, 1 ил.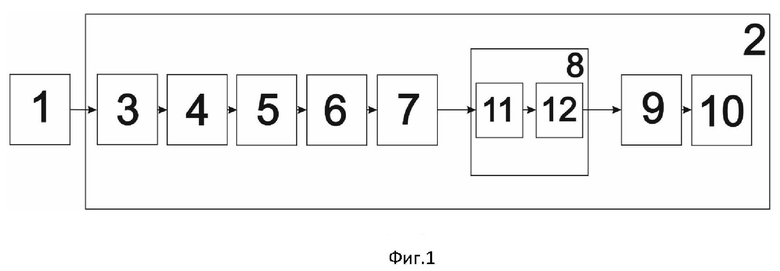
1. Устройство автоматизированного извлечения смысловых компонент из сложносочиненных предложений естественно-язычных текстов в системах машинного перевода, содержащее последовательно соединенные лингвистический модуль сентенсизации, выполненный с возможностью первичной обработки текста с целью разделения его на отдельные абзацы и предложения по знаку «<.> точка» или символам «!»; «?», лингвистический модуль фрагментизации, выполненный с возможностью дальнейшего деления предложений на фрагменты по знакам «<,> - запятая» или «<;> - точка с запятой», лингвистический модуль графематизации, выполненный с возможностью реализации процесса дифференцирования входной информации до выделения из нее отдельных графем (словоформ) и знаков (символов), лингвистический модуль морфологизации, выполненный с возможностью распределения по разным морфологическим классам выявленных текстовых элементов, лингвистический модуль паттернизации, выполненный с возможностью связывания текстовых элементов друг с другом по синтаксическим правилам, образуя устойчивые синтаксические словосочетания (паттерны), и присвоения им индивидуальных маркеров, лингвистический модуль индексации, выполненный с возможностью осуществления модулем атрибутирования установления морфологических атрибутов для фрагментов текста, а модулем постиндексирования индексирования фрагментов текста, при котором атрибутированным фрагментам присваивают уникальные индексы, лингвистический модуль семантизации, выполненный с возможностью получения для словоформ и паттернов присущих им лексических значений – семантисов, и лингвистический модуль экстракции, выполненный с возможностью извлечения искомых лингвистических объектов, при этом лингвистический модуль индексации образуют последовательно соединенные модуль атрибутирования, вход которого соединен с выходом лингвистического модуля паттернизации, и модуль постиндексирования, выход которого соединен с входом лингвистического модуля семантизации.
2. Способ автоматизированного извлечения смысловых компонент из сложносочиненных предложений естественно-язычных текстов в системах машинного перевода, характеризующийся тем, что на этапе сентенсизации производят первичную обработку текста с целью разделения его на отдельные абзацы и предложения по знаку «<.> точка» или символам «!»; «?», на этапе фрагментизации производят дальнейшее деление предложений на фрагменты по знакам «<,> - запятая» или «<;> - точка с запятой», на этапе графематизации производят процесс дифференцирования входной информации до выделения из нее отдельных графем (словоформ) и знаков (символов), на этапе морфологизации выявленные текстовые элементы распределяют по разным морфологическим классам, на этапе паттернизации текстовые элементы связывают друг с другом по синтаксическим правилам, образуя устойчивые синтаксические словосочетания (паттерны) и присваивают им индивидуальные маркеры, на этапе индексации осуществляют атрибутирование, при котором производят установление морфологических атрибутов для фрагментов текста, и индексирование фрагментов текста, при котором атрибутированным фрагментам присваивают уникальные индексы, на этапе семантизации получают для словоформ и паттернов присущие им лексические значения - семантисы и на этапе экстракции осуществляют извлечение искомых лингвистических объектов.
3. Способ по п. 2, отличающийся тем, что индексирование фрагментов текста осуществляют по классификации на основе закономерности для сложносочиненных предложений русского языка, заключающейся в том, что типология фрагментов предложений русского языка содержит ограниченное количество различных вариантов, равное восьмидесяти одному.
| Автоматическое извлечение именованных сущностей из текста | 2014 |
|
RU2665239C2 |
| СПОСОБ ИЗВЛЕЧЕНИЯ ФАКТОВ ИЗ ТЕКСТОВ НА ЕСТЕСТВЕННОМ ЯЗЫКЕ | 2016 |
|
RU2637992C1 |
| ИЗВЛЕЧЕНИЕ ИНФОРМАЦИИ ИЗ СМЫСЛОВЫХ БЛОКОВ ДОКУМЕНТОВ С ИСПОЛЬЗОВАНИЕМ МИКРОМОДЕЛЕЙ НА БАЗЕ ОНТОЛОГИИ | 2017 |
|
RU2662688C1 |
| JP 2004318344 A, 11.11.2004 | |||
| Приспособление для суммирования отрезков прямых линий | 1923 |
|
SU2010A1 |
| CN 103116578 A, 22.05.2013. | |||

