Область техники, к которой относится изобретение
[1] Настоящее раскрытие сущности относится к технологии кодирования и декодирования изображения, а более конкретно к способу и оборудованию для выполнения кодирования/декодирования во внутреннем прогнозировании.
Уровень техники
[2] Наряду с широким применением Интернет-терминалов и портативных терминалов и развития информационно-коммуникационных технологий, мультимедийные данные используются все в большей степени. Соответственно, чтобы предоставлять различные услуги или выполнять различные задачи через прогнозирование изображений в различных системах, существует настоятельная необходимость в повышении производительности и эффективности системы обработки изображений. Тем не менее, научно-исследовательские достижения по-прежнему должны придерживаться трендов.
[3] В связи с этим, существующему способу и оборудованию для кодирования/декодирования изображение требуется повышение производительности в обработке изображений, в частности, при кодировании изображений или декодировании изображений.
Сущность изобретения
Техническая задача
[4] Цель настоящего раскрытия заключается в том, чтобы предоставлять способ и оборудование для выполнения внутреннего прогнозирования. Другая цель настоящего раскрытия заключается в том, чтобы предоставлять способ и оборудование для выполнения субблочного внутреннего прогнозирования. Другая цель настоящего раскрытия сущности заключается в том, чтобы предоставлять способ и оборудование для выполнения сегментации на субблоки и определения порядка кодирования субблоков.
Техническое решение
[5] В способе и оборудовании для кодирования/декодирования изображений согласно настоящему раскрытию сущности, кандидатная группа (группа возможных вариантов) типов сегментов для текущего блока сконфигурирована, и тип сегментации текущего блока на субблоки определяется на основе кандидатной группы и кандидатного индекса (индекса возможного варианта) , режим внутреннего прогнозирования извлекается в единицах текущего блока, и текущий блок внутренне прогнозируется на основе режима внутреннего прогнозирования текущего блока и типа сегмента.
Преимущества изобретения
[6] Согласно настоящему раскрытию, производительность кодирования/декодирования может повышаться через субблочное внутреннее прогнозирование. Дополнительно, согласно настоящему раскрытию, точность прогнозирования может увеличиваться посредством эффективного конфигурирования кандидатной группы типов субблочных сегментов. Дополнительно, согласно настоящему раскрытию, эффективность внутреннего прогнозирующего кодирования/декодирования может повышаться посредством адаптации порядка субблочного кодирования.
Краткое описание чертежей
[7] Фиг. 1 является концептуальной схемой, иллюстрирующей систему кодирования и декодирования изображений согласно варианту осуществления настоящего раскрытия сущности.
[8] Фиг. 2 является блок-схемой, иллюстрирующей оборудование кодирования изображений согласно варианту осуществления настоящего раскрытия сущности.
[9] Фиг. 3 является блок-схемой оборудования декодирования изображений согласно варианту осуществления настоящего изобретения.
[10] Фиг. 4 является примерной схемой, иллюстрирующей различные типы сегментов, которые могут получаться в модуле разбиения блоков настоящего раскрытия сущности.
[11] Фиг. 5 является примерной схемой, иллюстрирующей режимы внутреннего прогнозирования согласно варианту осуществления настоящего раскрытия сущности.
[12] Фиг. 6 является примерной схемой, иллюстрирующей конфигурация опорных пикселов, используемых для внутреннего прогнозирования согласно варианту осуществления настоящего раскрытия сущности.
[13] Фиг. 7 является концептуальной схемой, иллюстрирующей целевой блок для внутреннего прогнозирования, и блоки, соседние с целевым блоком, согласно варианту осуществления настоящего раскрытия сущности.
[14] Фиг. 8 является схемой, иллюстрирующей различные типы субблочных сегментов, которые могут получаться из блока кодирования.
[15] Фиг. 9 является примерной схемой, иллюстрирующей опорные пиксельные области, используемые для режимов внутреннего прогнозирования согласно варианту осуществления настоящего раскрытия сущности.
[16] Фиг. 10 является примерной схемой, иллюстрирующей порядки кодирования, доступные в режимах прогнозирования вверх и вправо по диагонали согласно варианту осуществления настоящего раскрытия сущности.
[17] Фиг. 11 является примерной схемой, иллюстрирующей порядки кодирования, доступные в горизонтальных режимах согласно варианту осуществления настоящего раскрытия сущности.
[18] Фиг. 12 является примерной схемой, иллюстрирующей порядки кодирования, доступные в режимах прогнозирования вниз и вправо по диагонали согласно варианту осуществления настоящего раскрытия сущности.
[19] Фиг. 13 является примерной схемой, иллюстрирующей порядки кодирования, доступные в вертикальных режимах согласно варианту осуществления настоящего раскрытия сущности.
[20] Фиг. 14 является примерной схемой, иллюстрирующей порядки кодирования, доступные в режимах прогнозирования вниз и влево по диагонали согласно варианту осуществления настоящего раскрытия сущности.
[21] Фиг. 15 является примерной схемой, иллюстрирующей порядки кодирования на основе режимов внутреннего прогнозирования и типов сегментов согласно варианту осуществления настоящего раскрытия сущности.
Оптимальный режим осуществления изобретения
[22] В способе и оборудовании для кодирования/декодирования изображений согласно настоящему раскрытию, кандидатная группа типов сегментов, доступных для текущего блока, может быть сконфигурирована, тип сегментации текущего блока на субблоки может определяться на основе кандидатной группы и кандидатного индекса, режим внутреннего прогнозирования может извлекаться в единицах текущего блока, и текущий блок может внутренне прогнозироваться на основе режима внутреннего прогнозирования и типа субблочного сегмента текущего блока.
Оптимальный режим осуществления изобретения
[23] Настоящее раскрытие может подвергаться различным модификациям и иметь различные варианты осуществления. Ниже описываются конкретные варианты осуществления настоящего раскрытия сущности со ссылкой на прилагаемые чертежи. Тем не менее, варианты осуществления не имеют намерение ограничивать объем настоящего раскрытия сущности, и следует понимать, что настоящее раскрытие охватывает различные модификации, эквиваленты и альтернативы в пределах объема и идеи настоящего раскрытия сущности.
[24] Термины, "первый", "второй", "A" и "B", при использовании в раскрытии сущности, могут использоваться , чтобы описывать различные компоненты, без ограничения компонентов. Эти выражения используются только , чтобы отличать один компонент из другого компонента. Например, первый компонент может упоминаться как второй компонент, и наоборот, без отступления от объема настоящего раскрытия сущности. Термин "и/или" охватывает комбинацию множества связанных пунктов или любой из множества связанных пунктов.
[25] Когда считается, что компонент "связывается (connected to)" или "соединяется (coupled with/to)" с другим компонентом, следует понимать, что один компонент соединяется с другим компонентом непосредственно либо через любой другой компонент. С другой стороны, когда считается, что компонент "непосредственно связывается (directly connected to)" или "непосредственно соединяется (directly coupled to)" с другим компонентом, следует понимать, что между компонентами отсутствуют другие компоненты.
[26] Термины, при использовании в настоящем раскрытии сущности, предоставляются , чтобы просто описывать конкретные варианты осуществления, и не предназначены , чтобы ограничивать настоящее раскрытие. Формы единственного числа включают в себя несколько объектов ссылки, если контекст явно не предписывает иное. В настоящем раскрытии сущности, термин "включать в себя" или "иметь" обозначает присутствие признака, числа, этапа, операции, компонента, части либо комбинации вышеозначенного, без исключения присутствия или добавления одного или более других признаков, чисел, этапов, операций, компонентов, частей либо комбинации вышеозначенного.
[27] Если не указано иное, термины, включающие в себя технические или научные термины, используемые в раскрытии сущности, могут иметь смысловые значения, такие же смысловые значения, как понятные для специалистов в данной области техники. Термины в общем, задаваемые в словарях, могут интерпретироваться как имеющие смысловые значения, такие же или аналогичные контекстным смысловым значениям технологии предшествующего уровня техники. Если не указано иное, термины не должны интерпретироваться как идеально или чрезмерно формальные смысловые значения.
[28] Типично, изображение может включать в себя одно или более цветовых пространств согласно своему цветовому формату. Изображение может включать в себя одно или более изображений одинакового размера или различных размеров. Например, цветовая YCbCr-конфигурация может поддерживать цветовые форматы, такие как 4:4:4, 4:2:2, 4:2:0, и монохромные (состоящие из только Y). Например, YCbCr 4:2:0 может состоять из одного компонента сигнала яркости (Y в этом примере) и двух компонентов сигнала цветности (Cb и Cr в этом примере). В этом случае, конфигурационное отношение компонента сигнала цветности и компонента сигнала яркости может иметь отношение ширины к высоте 1:2. Например, в случае 4:4:4, они могут иметь одинаковое конфигурационное отношение по ширине и высоте. Когда изображение включает в себя одно или более цветовых пространств, как указано в вышеприведенном примере, изображение может разделяться на цветовые пространства.
[29] Изображения могут классифицироваться на I, P и B согласно своим типам изображений (например, изображение, серия последовательных макроблоков, мозаичный фрагмент и т.д.). I-изображение может представлять собой изображение, которое кодируется/декодируется без опорного изображения. P-изображение может представлять собой изображение, которое кодируется/декодируется с использованием опорного изображения, с разрешением только прямого прогнозирования. B-изображение может представлять собой изображение, которое кодируется/декодируется с использованием опорного изображения, с разрешением двунаправленного прогнозирования. Тем не менее, некоторые (P и B) из типов могут комбинироваться, либо может поддерживаться тип изображения другой композиции, согласно конфигурации кодирования/декодирования.
[30] Различные фрагменты информации кодирования/декодирования, сформированной в настоящем раскрытии сущности, могут обрабатываться явно или неявно. Явная обработка может пониматься как процесс формирования информации выбора, указывающей один кандидат в кандидатной группе из множества кандидатов, связанных с информацией кодирования в последовательности, серии последовательных макроблоков, мозаичном фрагменте, блоке или субблоке, и включения информации выбора в поток битов посредством кодера, и восстановления связанной информации в качестве декодированной информации посредством синтаксического анализа связанной информации на таком же единичном уровне с кодером, посредством декодера. Неявная обработка может пониматься как обработка кодированной/декодированной информации в таком же процессе, правиле и т.п. как в кодере, так и в декодере.
[31] [32] Фиг. 1 является концептуальной схемой, иллюстрирующей систему кодирования и декодирования изображений согласно варианту осуществления настоящего раскрытия сущности.
[33] Ссылаясь на фиг. 1, каждое из оборудования 105 кодирования изображений и оборудования 100 декодирования изображений может представлять собой пользовательский терминал, такой как персональный компьютер (PC), переносной компьютер, персональное цифровое устройство (PDA), портативный мультимедийный проигрыватель (PMP), портативная PlayStation (PSP), терминал беспроводной связи, смартфон или телевизионный приемник (телевизор), либо серверный терминал, такой как сервер приложений или сервер предоставления услуг. Каждое из оборудования 105 кодирования изображений и оборудования 100 декодирования изображений может представлять собой любое из различных устройств, включающих в себя устройство связи, такое как модем связи, который обменивается данными с различными устройствами или сетью проводной/беспроводной связи, запоминающее устройство 120 или 125, которое сохраняет различные программы и данные для взаимного прогнозирования или внутреннего прогнозирования, чтобы кодировать или декодировать изображение, либо процессор 110 или 115, который выполняет операции вычисления и управления посредством выполнения программ.
[34] Дополнительно, оборудование 105 кодирования изображений может передавать изображение, кодированное в поток битов, в оборудование 100 декодирования изображений в реальном времени или не в реальном времени через сеть проводной/беспроводной связи, такую как Интернет, сеть ближней беспроводной связи, беспроводная локальная вычислительная сеть (WLAN), беспроводная широкополосная связь (WiBro) сеть или сеть мобильной связи, либо через различные интерфейсы связи, такие как кабель или универсальная последовательная шина (USB), и оборудование 100 декодирования изображений может восстанавливать принимаемый поток битов в изображение посредством декодирования потока битов и воспроизводить изображение. Дополнительно, оборудование 105 кодирования изображений может передавать изображение, кодированное в поток битов, в оборудование 100 декодирования изображений через машиночитаемый носитель записи.
[35] Хотя вышеописанные оборудование кодирования изображений и оборудование декодирования изображений могут представлять собой отдельное оборудование, они могут быть включены в одно оборудование кодирования/декодирования изображений в зависимости от реализации. В этом случае, некоторые компоненты оборудования кодирования изображений могут быть практически такими же как их аналоги оборудования декодирования изображений. Следовательно, эти компоненты могут быть выполнены с возможностью включать в себя такие же структуры или выполнять, по меньшей мере, такие же функции.
[36] В силу этого, избыточное описание соответствующего технического компонента должно исключаться в нижеприведенном подробном описании технического компонента и его принципов работы. Дополнительно, поскольку оборудование декодирования изображений представляет собой вычислительное устройство, которое применяет способ кодирования изображений, осуществляемый в оборудовании кодирования изображений, к декодированию, нижеприведенное описание акцентирует внимание на оборудовании кодирования изображений.
[37] Вычислительное устройство может включать в себя запоминающее устройство, сохраняющее программу или программный модуль, который осуществляет способ кодирования изображений и/или способ декодирования изображений, и процессор, соединенный с запоминающим устройством и выполняющий программу. Оборудование кодирования изображений может упоминаться как кодер, и оборудование декодирования изображений может упоминаться как декодер.
[38] [39] Фиг. 2 является блок-схемой, иллюстрирующей оборудование кодирования изображений согласно варианту осуществления настоящего раскрытия сущности.
[40] Ссылаясь на фиг. 2, оборудование 20 кодирования изображений может включать в себя модуль 200 прогнозирования, модуль 205 вычитания, модуль 210 преобразования, модуль 215 квантования, модуль 220 деквантования, модуль 225 обратного преобразования, модуль 230 суммирования, модуль 235 фильтрации, буфер 240 кодированных изображений и модуль 245 энтропийного кодирования.
[41] Модуль 200 прогнозирования может реализовываться с использованием модуля прогнозирования, который представляет собой программный модуль, и формировать прогнозный блок для блока, который должен кодироваться, посредством внутреннего прогнозирования или взаимного прогнозирования. Модуль 200 прогнозирования может формировать прогнозный блок посредством прогнозирования текущего блока, который должен кодироваться в изображении. Другими словами, модуль 200 прогнозирования может формировать прогнозный блок, имеющий прогнозированное пиксельное значение каждого пиксела, посредством прогнозирования пиксельного значения пиксела в текущем блоке согласно взаимному прогнозированию или внутреннему прогнозированию. Дополнительно, модуль 200 прогнозирования может предоставлять требуемую информацию для формирования прогнозного блока, такую как информация относительно режима прогнозирования, к примеру режим внутреннего прогнозирования или режим взаимного прогнозирования, в единицу кодирования таким образом, что единица кодирования может кодировать информацию относительно режима прогнозирования. Единица обработки, подвергнутая прогнозированию, способ прогнозирования и конкретный подробности относительно единицы обработки могут быть сконфигурированы согласно конфигурации кодирования/декодирования. Например, способ прогнозирования и режим прогнозирования могут определяться на основе единиц прогнозирования, и прогнозирование может выполняться на основе единиц преобразования.
[42] Модуль взаимного прогнозирования может отличать модель поступательного движения в пространстве и модель непоступательного движения в пространстве друг от друга согласно способу прогнозирования движения. Для модели поступательного движения в пространстве, прогнозирование выполняется только с учетом параллельного перемещения в пространстве, тогда как для модели непоступательного движения в пространстве, прогнозирование может выполняться с учетом движения, такого как вращение, перспектива и увеличение/уменьшение масштаба, помимо параллельного перемещения в пространстве. При предположении относительно однонаправленного прогнозирования, модель поступательного движения в пространстве может требовать одного вектора движения, тогда как модель непоступательного движения в пространстве может требовать одного или более векторов движения. В случае модели непоступательного движения в пространстве, каждый вектор движения может представлять собой информацию, применяемую к предварительно заданным позициям в текущем блоке, таким как левая верхняя вершина и правая верхняя вершина текущего блока, и позиция области, которая должна прогнозироваться в текущем блоке, может получаться на пиксельном уровне или уровне субблока на основе соответствующего вектора движения. Модуль взаимного прогнозирования может применять часть следующего процесса в общем и другую часть следующего процесса отдельно согласно модели движения.
[43] Модуль взаимного прогнозирования может включать в себя модуль конфигурирования опорных изображений, модуль оценки движения, модуль компенсации движения, модуль принятия решений по информации движения и кодер информации движения. Модуль конфигурирования опорных изображений может включать в себя кодированное изображение до или рядом с текущим изображением в списке L0 или L1 опорных изображений. Прогнозный блок может получаться из опорного изображения, включенного в список опорных изображений, и текущее изображение также может быть сконфигурировано как опорное изображение и включено, по меньшей мере, в один список опорных изображений согласно конфигурации кодирования.
[44] Модуль конфигурирования опорных изображений модуля взаимного прогнозирования может включать в себя интерполятор опорных изображений. Интерполятор опорных изображений может выполнять интерполяцию для дробного пиксела согласно точности интерполяции. Например, 8-отводный интерполяционный фильтр на основе дискретного косинусного преобразования (DCT) может применяться к компоненту сигнала яркости, и 4-отводный интерполяционный фильтр на основе DCT может применяться к компоненту сигнала цветности.
[45] Модуль оценки движения модуля взаимного прогнозирования может обнаруживать блок, имеющий высокую корреляцию с текущим блоком, с использованием опорного изображения. С этой целью, могут использоваться различные способы, такие как алгоритм поблочного сопоставления на основе полного поиска (FBMA), трехэтапный поиск (TSS) и т.д. Модуль компенсации движения может получать прогнозный блок в процессе оценки движения.
[46] Модуль принятия решений по информации движения модуля взаимного прогнозирования может выполнять процесс выбора наилучшей информации движения для текущего блока. Информация движения может кодироваться в режиме кодирования информации движения, таком как режим пропуска, режим объединения и режим конкуренции. Режим кодирования информации движения может быть сконфигурирован посредством комбинирования поддерживаемых режимов согласно модели движения. Такие примеры могут включать в себя режим пропуска (с поступательным перемещением в пространстве), режим пропуска (с непоступательным перемещением в пространстве), режим объединения (с поступательным перемещением в пространстве), режим объединения (с непоступательным перемещением в пространстве), режим конкуренции (с поступательным перемещением в пространстве) и режим конкуренции (с непоступательным перемещением в пространстве). В зависимости от конфигурации кодирования, часть режимов может быть включена в кандидатную группу.
[47] В режиме кодирования информации движения, прогнозное значение информации движения (вектора движения, опорного изображения, направления прогнозирования и т.д.) относительно текущего блока может получаться, по меньшей мере, из одного кандидатного блока. Когда два или более кандидатных блоков поддерживаются, может формироваться наилучшая кандидатная информация выбора. Прогнозное значение может использоваться без обработки в качестве информации движения относительно текущего блока в режиме пропуска (без остаточного сигнала) и в режиме объединения (с остаточным сигналом), тогда как информация разности между информацией движения относительно текущего блока и прогнозным значением может формироваться в режиме конкуренции.
[48] Кандидатная группа для прогнозного значения информации движения относительно текущего блока может быть сконфигурирована адаптивно различными способами согласно режиму кодирования информации движения. Информация движения относительно блоков, пространственно соседних с текущим блоком (например, левого, верхнего, левого верхнего, правого верхнего и левого нижнего блоков и т.д.), может быть включена в кандидатную группу, информация движения относительно блоков, временно соседних с текущим блоком, может быть включена в кандидатную группу, и информация смешанного движения относительно пространственных кандидатов и временных кандидатов может быть включена в кандидатную группу.
[49] Временные соседние блоки могут включать в себя блоки в других изображениях, соответствующие (совпадающие) с текущим блоком, и могут означать левый, правый, верхний, нижний, левый верхний, правый верхний, левый нижний и правый нижний блоки относительно блоков. Информация смешанного движения может означать информацию, полученную в качестве среднего значения, медианного значения и т.п. информации движения относительно пространственного соседнего блока и информации движения относительно временного соседнего блока.
[50] Информация движения может приоритезироваться с возможностью конфигурировать кандидатную группу прогнозных значений информации движения. Порядок информации движения, которая должна быть включена в кандидатную группу прогнозных значений, может задаваться согласно приоритетам. Когда столько фрагментов информации движения, сколько составляет число кандидатов в кандидатной группе (определенное согласно режиму кодирования информации движения), заполнены в кандидатной группе согласно приоритетам, кандидатная группа может быть полностью сконфигурирована. Информация движения может приоритезироваться в порядке информации движения относительно пространственного соседнего блока, информации движения относительно временного соседнего блока и информации смешанного движения относительно пространственных и временных соседних блоков. Тем не менее, приоритезация также может модифицироваться.
[51] Например, информация движения относительно пространственных соседних блоков может быть включена в кандидатную группу в порядке левого, верхнего, правого верхнего, левого нижнего и левого верхнего блоков, и информация движения относительно временных соседних блоков может быть включена в кандидатную группу в порядке правого нижнего, центрального, правого и нижнего блоков.
[52] Модуль 205 вычитания может формировать остаточный блок посредством вычитания прогнозного блока из текущего блока. Другими словами, модуль 205 вычитания может вычислять разность между пиксельным значением каждого пиксела в текущем блоке, который должен быть кодирован, и прогнозированным пиксельным значением соответствующего пиксела в прогнозном блоке, сформированном посредством модуля прогнозирования, чтобы формировать остаточный сигнал в форме блока, т.е. остаточный блок. Дополнительно, модуль 205 вычитания может формировать остаточный блок в единице, отличной от блока, полученного через нижеописанный модуль разбиения блоков.
[53] Модуль 210 преобразования может преобразовывать пространственный сигнал в частотный сигнал. Сигнал, получаемый посредством процесса преобразования, упоминается как коэффициенты преобразования. Например, остаточный блок с остаточным сигналом, принимаемым из модуля вычитания, может преобразовываться в блок преобразования с коэффициентами преобразования, и входной сигнал определяется согласно конфигурации кодирования, не ограниченной остаточным сигналом.
[54] Модуль преобразования может преобразовывать остаточный блок посредством, но не только, такой схемы преобразования, как преобразование Адамара, преобразование на основе дискретного синусного преобразования (DST) или преобразование на основе DCT. Эти схемы преобразования могут изменяться и модифицироваться различными способами.
[55] По меньшей мере, одна из схем преобразования может поддерживаться, и по меньшей мере одна подсхема преобразования из каждой схемы преобразования может поддерживаться. Подсхема преобразования может получаться посредством модификации части базового вектора в схеме преобразования.
[56] Например, в случае DCT, могут поддерживаться одна или более подсхем DCT-1-DCT-8 преобразования, и в случае DST, могут поддерживаться одна или более подсхем DST-1-DST-8 преобразования. Кандидатная группа схем преобразования может быть сконфигурирована с частью подсхем преобразования. Например, DCT-2, DCT-8 и DST-7 могут группироваться в кандидатную группу для преобразования.
[57] Преобразование может выполняться в горизонтальном/вертикальном направлении. Например, одномерное преобразование может выполняться в горизонтальном направлении посредством DCT-2, и одномерное преобразование может выполняться в вертикальном направлении посредством DST-7. При двумерном преобразовании, пиксельные значения могут преобразовываться из пространственной области в частотную область.
[58] Одна фиксированная схема преобразования может приспосабливаться, или схема преобразования может выбираться адаптивно согласно конфигурации кодирования/декодирования. Во втором случае, схема преобразования может выбираться явно или неявно. Когда схема преобразования выбирается явно, информация относительно схемы преобразования или набора схем преобразования, применяемого в каждом из горизонтального направления и вертикального направления, может формироваться, например, на уровне блока. Когда схема преобразования выбирается неявно, конфигурация кодирования может задаваться согласно типу изображения (I/P/B), цветовому компоненту, размеру блока, форме блока, режиму внутреннего прогнозирования и т.д., и предварительно заданная схема преобразования могут выбираться согласно конфигурации кодирования.
[59] Дополнительно, некоторое преобразование может пропускаться согласно конфигурации кодирования. Таким образом, одна или более горизонтальных и вертикальных единиц могут опускаться явно или неявно.
[60] Дополнительно, модуль преобразования может передавать информацию, требуемую для формирования блока преобразования, в единицу кодирования, так что единица кодирования кодирует информацию, включает кодированную информацию в поток битов и передает поток битов в декодер. Таким образом, единица декодирования декодера может синтаксически анализировать информацию из потока битов для использования в обратном преобразовании.
[61] Модуль 215 квантования может квантовать входной сигнал. Сигнал, получаемый из квантования, упоминается как квантованные коэффициенты. Например, модуль 215 квантования может получать квантованный блок с квантованными коэффициентами посредством квантования остаточного блока с остаточными коэффициентами преобразования, принимаемыми из модуля преобразования, и входной сигнал может определяться согласно конфигурации кодирования, не ограниченной остаточными коэффициентами преобразования.
[62] Модуль квантования может квантовать преобразованный остаточный блок посредством, но не только, такой схемы квантования, как равномерное квантование граничных значений с мертвыми зонами, взвешенная матрица квантования и т.п. Вышеуказанные схемы квантования могут изменяться и модифицироваться различными способами.
[63] Квантование может пропускаться согласно конфигурации кодирования. Например, квантование (и деквантование) может пропускаться согласно конфигурации кодирования (например, параметру квантования в 0, т.е. окружению сжатия без потерь). В другом примере, когда производительность сжатия на основе квантования не проявляется с учетом характеристик изображения, процесс квантования может опускаться. Квантование может пропускаться в полной или частичной области (M/2 x N/2, MxN/2 или M/2 x N) блока квантования (MXN), и информация выбора пропуска квантования может задаваться явно или неявно.
[64] Модуль квантования может передавать информацию, требуемую для формирования квантованного блока, в единицу кодирования, так что единица кодирования кодирует информацию, включает кодированную информацию в поток битов и передает поток битов в декодер. Таким образом, единица декодирования декодера может синтаксически анализировать информацию из потока битов для использования в деквантовании.
[65] Хотя вышеприведенный пример описывается при условии, что остаточный блок преобразуется и квантуется посредством модуля преобразования и модуля квантования, остаточный блок с коэффициентами преобразования может формироваться посредством преобразования остаточного сигнала и может не квантоваться. Остаточный блок может подвергаться только квантованию без преобразования. Дополнительно, остаточный блок может подвергаться как преобразованию, так и квантованию. Эти операции могут определяться в зависимости от конфигурации кодирования.
[66] Модуль 220 деквантования деквантует остаточный блок, квантованный посредством модуля 215 квантования. Таким образом, модуль 220 деквантования формирует остаточный блок с частотными коэффициентами посредством деквантования последовательности частотных коэффициентов квантования.
[67] Модуль 225 обратного преобразования обратно преобразует остаточный блок, деквантованный посредством модуля 220 деквантования. Таким образом, модуль 225 обратного преобразования обратно преобразует частотные коэффициенты деквантованного остаточного блока, чтобы формировать остаточный блок с пиксельными значениями, т.е. восстановленный остаточный блок. Модуль 225 обратного преобразования может выполнять обратное преобразование посредством обратного выполнения схемы преобразования, используемой посредством модуля 210 преобразования.
[68] Модуль 230 суммирования восстанавливает текущий блок посредством суммирования прогнозного блока, прогнозированного посредством модуля 200 прогнозирования, и остаточного блока, восстановленного посредством модуля 225 обратного преобразования. Восстановленный текущий блок сохраняется в качестве опорного изображения (или опорного блока) в буфере 240 кодированных изображений для использования в качестве опорного изображения, когда следующий блок относительно текущего блока, другого блока или другого изображения кодируется позднее.
[69] Модуль 235 фильтрации может включать в себя один или более постобрабатывающих фильтров, таких как фильтр удаления блочности, дискретизированное адаптивное смещение (SAO) и адаптивный контурный фильтр (ALF). Фильтр удаления блочности может удалять искажение в виде блочности, возникающее на границе между блоками в восстановленном изображении. ALF может выполнять фильтрацию на основе значения, полученного посредством сравнения восстановленного изображения и исходного изображения после того, как блок фильтруется через фильтр удаления блочности. SAO может восстанавливать разность смещения на пиксельном уровне между исходным изображением и остаточным блоком, к которому применяется фильтр удаления блочности. Эти постобрабатывающие фильтры могут применяться к восстановленному изображению или блоку.
[70] Буфер 240 кодированных изображений может сохранять блок или изображение, восстановленное посредством модуля 235 фильтрации. Восстановленный блок или изображение, сохраненное в буфере 240 кодированных изображений, может предоставляться в модуль 200 прогнозирования, который выполняет внутреннее прогнозирование или взаимное прогнозирование.
[71] Модуль 245 энтропийного кодирования сканирует сформированную последовательность квантованных частотных коэффициентов в различных способах сканирования, чтобы формировать последовательность квантованных коэффициентов, кодирует последовательность квантованных коэффициентов посредством энтропийного кодирования и выводит последовательность энтропийно кодированных коэффициентов. Шаблон сканирования может быть сконфигурирован как один из различных шаблонов, таких как зигзагообразный, диагональный и растровый. Дополнительно, кодированные данные, включающие в себя информацию кодирования, принимаемую из каждого компонента, могут формироваться и выводиться в потоке битов.
[72] [73] Фиг. 3 является блок-схемой оборудования декодирования изображений согласно варианту осуществления настоящего изобретения.
[74] Ссылаясь на фиг. 3, оборудование 30 декодирования изображений может быть выполнено с возможностью включать в себя энтропийный декодер 305, модуль 310 прогнозирования, модуль 315 деквантования, модуль 320 обратного преобразования, модуль 325 суммирования/модуль вычитания, фильтр 330 и буфер 335 декодированных изображений.
[75] Дополнительно, модуль 310 прогнозирования может быть выполнен с возможностью включать в себя модуль внутреннего прогнозирования и модуль взаимного прогнозирования.
[76] Когда поток битов изображения принимается из оборудования 20 кодирования изображений, поток битов изображения может передаваться в энтропийный декодер 305.
[77] Энтропийный декодер 305 может декодировать поток битов в декодированные данные, включающие в себя квантованные коэффициенты и информацию декодирования, которая должна передаваться в каждый компонент.
[78] Модуль 310 прогнозирования может формировать прогнозный блок на основе данных, принимаемых из энтропийного декодера 305. На основе опорного изображения, сохраненного в буфере 335 декодированных изображений, список опорных изображений может составляться с использованием конфигурационной схемы по умолчанию.
[79] Модуль взаимного прогнозирования может включать в себя модуль конфигурирования опорных изображений, модуль компенсации движения и декодер информации движения. Некоторые компоненты могут выполнять процессы, такие же как процессы в кодере, и другие могут обратно выполнять процессы кодера.
[80] Модуль 315 деквантования может деквантовать квантованные коэффициенты преобразования, которые предоставляются в потоке битов и декодируются посредством энтропийного декодера 305.
[81] Модуль 320 обратного преобразования может формировать остаточный блок посредством применения обратного DCT, обратного целочисленного преобразования или аналогичной технологии обратного преобразования к коэффициентам преобразования.
[82] Модуль 315 деквантования и модуль 320 обратного преобразования могут выполнять в обратном порядке процессы модуля 210 преобразования и модуля 215 квантования оборудования 20 кодирования изображений, описанного выше, и могут реализовываться различными способами. Например, модуль 315 деквантования и модуль 320 обратного преобразования могут использовать такие же процессы и обратное преобразование, совместно используемые с модулем 210 преобразования и модулем 215 квантования, и могут выполнять в обратном порядке преобразование и квантование с использованием информации относительно процессов преобразования и квантования, принимаемой из оборудования 20 кодирования изображений (например, размера преобразования, формы преобразования, типа квантования и т.д.).
[83] Остаточный блок, который деквантован и обратно преобразован, может суммироваться с прогнозным блоком, извлекаемый посредством модуля 310 прогнозирования, за счет этого формируя блок восстановленных изображений. Это суммирование может выполняться посредством модуля 325 суммирования/модуля вычитания.
[84] Относительно фильтра 330, фильтр удаления блочности может применяться, чтобы удалять явление блочности из блока восстановленных изображений, при необходимости. Чтобы повышать качество видео до и после процесса декодирования, дополнительно могут использоваться другие контурные фильтры.
[85] Блок восстановленных и фильтрованных изображений может сохраняться в буфере 335 декодированных изображений.
[86] [87] Хотя не показано на чертежах, оборудование кодирования/декодирования изображений дополнительно может включать в себя модуль разбиения изображений и модуль разбиения блоков.
[88] Модуль разбиения изображений может разбивать (или разделять) изображение, по меньшей мере, на одну единицу обработки, такую как цветовое пространство (например, YCbCr, RGB или XYZ), мозаичный фрагмент, серия последовательных макроблоков или базовая единица кодирования (максимальная единица кодирования или единица дерева кодирования (CTU)), и модуль разбиения блоков может разбивать базовую единицу кодирования, по меньшей мере, на одну единицу обработки (например, на единицу кодирования, единицу прогнозирования, единицу преобразования, единицу квантования, единицу энтропийного кодирования и единицу внутриконтурной фильтрации).
[89] Базовые единицы кодирования могут получаться посредством разбиения изображения с регулярными интервалами в горизонтальном направлении и вертикальном направлении. Таким образом, изображение может разбиваться, но не только, на мозаичные фрагменты, серии последовательных макроблоков и т.д. Хотя единица сегментации, такая как мозаичный фрагмент или серия последовательных макроблоков, может включать в себя целое кратное базовых блоков кодирования, единица сегментации, расположенная в крае изображения, может быть исключительной. В этом случае, размер базового блока кодирования может регулироваться.
[90] Например, изображение может разделяться на базовые единицы кодирования и затем разбиваться на вышеуказанные единицы, или изображение может разделяться на вышеуказанные единицы и затем разбиваться на базовые единицы кодирования. Порядок разделения и разбиения на единицы предположительно представляет собой первый в настоящем раскрытии сущности, что не должно истолковываться в качестве ограничения настоящего раскрытия сущности. Согласно конфигурации кодирования/декодирования, также может быть возможным второй случай. Во втором случае, размер базовой единицы кодирования может изменяться адаптивно согласно единице сегментации (например, мозаичному фрагменту). Таким образом, это означает, что базовый блок кодирования, имеющий другой размер, может поддерживаться в каждой единице сегментации.
[91] В настоящем раскрытии сущности, дальнейшее описание приводится с признанием, что разделение изображения на базовые единицы кодирования сконфигурировано как настройка по умолчанию. Настройка по умолчанию может означать, что изображение не разделяется на мозаичные фрагменты или серии последовательных макроблоков, или изображение представляет собой один мозаичный фрагмент либо одну серию последовательных макроблоков. Тем не менее, как описано выше, даже когда изображение сначала разделяется на единицы сегментации (мозаичные фрагменты, серии последовательных макроблоков и т.п.) и затем разбивается на базовые единицы кодирования на основе единиц сегментации (т.е. когда число каждой единицы сегментации не является целым кратным базовых единиц кодирования), следует понимать, что различные варианты осуществления, описанные ниже, могут применяться таким же образом или с некоторой модификацией.
[92] Из числа единиц сегментации, серия последовательных макроблоков может представлять собой группу, по меньшей мере, их одного последовательного блока согласно шаблону сканирования, и мозаичный фрагмент может представлять собой прямоугольную группу из пространственно соседних блоков. Другие единицы сегментации могут поддерживаться и конструироваться согласно своим определениям. Серия последовательных макроблоков и мозаичный фрагмент могут представлять собой единицы сегментации, поддерживаемые для целей параллелизации. С этой целью, обращение между единицами сегментации может быть ограничено (т.е. обращение не разрешается).
[93] Серия последовательных макроблоков может формировать информацию сегментации для каждой единицы с использованием информации относительно начальных позиций последовательных блоков, и в случае мозаичного фрагмента, она может формировать информацию относительно горизонтальных и вертикальных линий сегментации или формировать информацию позиции мозаичного фрагмента (например, левая верхняя, правая верхняя, левая нижняя и правая нижняя позиция).
[94] Каждое из серии последовательных макроблоков и мозаичного фрагмента может разбиваться на множество единиц согласно конфигурации кодирования/декодирования.
[95] Например, единица A может включать в себя конфигурационную информацию, которая затрагивает процесс кодирования/декодирования (т.е. заголовок мозаичного фрагмента или заголовок серии последовательных макроблоков), и единица B может не включать в себя конфигурационную информацию. Альтернативно, единица A может представлять собой единицу, которой не разрешается обращаться к другой единице во время кодирования/декодирования, и единица B может представлять собой единицу, которой разрешается обращаться к другой единице. Дополнительно, единица A может включать в себя другую единицу b в иерархической взаимосвязи с единицей B или может иметь равноправную взаимосвязь с единицей B.
[96] Единица A и единица B могут представлять собой серию последовательных макроблоков и мозаичный фрагмент (или мозаичный фрагмент и серию последовательных макроблоков), соответственно. Альтернативно, каждая из единицы A и единицы B может представлять собой серию последовательных макроблоков или мозаичный фрагмент. Например, единица A может представлять собой тип 1 серии последовательных макроблоков/мозаичного фрагмента, и единица B может представлять собой тип 2 серии последовательных макроблоков/мозаичного фрагмента.
[97] Каждый из типа 1 и типа 2 может представлять собой одну серию последовательных макроблоков или мозаичный фрагмент. Альтернативно, тип 1 может представлять собой множество серий последовательных макроблоков или мозаичных фрагментов (группу серий последовательных макроблоков или группу мозаичных фрагментов) (включающих в себя тип 2), и тип 2 может представлять собой одну серию последовательных макроблоков или мозаичный фрагмент.
[98] Как описано выше, настоящее раскрытие описывается при условии, что изображение состоит из одной серии последовательных макроблоков или мозаичного фрагмента. Тем не менее, если две или более единиц сегментации формируются, вышеприведенное описание может применяться и пониматься в вариантах осуществления, описанных ниже. Дополнительно, единица A и единица B представляют собой примеры с признаками, которые может иметь единица сегментации, и также является возможным пример комбинирования единицы A и единицы B в соответствующих примерах.
[99] Модуль разбиения блоков может получать информацию относительно базовой единицы кодирования из модуля разбиения изображений, и базовая единица кодирования может означать базовую (или начальную) единицу для прогнозирования, преобразования, квантования и т.д. в процессе кодирования/декодирования изображений. В этом случае, базовая единица кодирования может состоять из одного базового блока кодирования сигнала яркости (максимального блока кодирования, или CTB) и двух базовых блоков кодирования сигналов цветности согласно цветовому формату (YCbCr в этом примере), и размер каждого блока может определяться согласно цветовому формату. Блок кодирования (CB) может получаться согласно процессу сегментации. CB может пониматься как единица, которая дополнительно не подразделяется вследствие определенных ограничений, и может задаваться в качестве начальной единицы для сегментации на субъединицы. В настоящем раскрытии сущности, блок концептуально охватывает различные формы, такие как треугольник, окружность и т.д., без ограничения квадратом. Для удобства описания, предполагается, что блок является прямоугольным.
[100] Хотя дальнейшее описание приводится в контексте одного цветового компонента, оно также является применимым к другому цветовому компоненту с некоторой модификацией, пропорционально отношению согласно цветовому формату (например, в случае YCbCr 4:2:0, отношение длины касательно ширины к высоте компонента сигнала яркости и компонента сигнала цветности составляет 2:1). Дополнительно, хотя сегментация на блоки в зависимости от другого цветового компонента (например, в зависимости от результата сегментации на блоки Y в Cb/Cr), является возможной, следует понимать, что также является возможной независимая от блоков сегментация каждого цветового компонента. Дополнительно, хотя может использоваться одна общая конфигурация сегментации на блоки (с учетом пропорциональности отношению длины), также необходимо рассматривать и понимать, что отдельная конфигурация сегментации на блоки используется согласно цветовому компоненту.
[101] В модуле разбиения блоков, блок может выражаться как MxN, и максимальные и минимальные значения каждого блока могут получаться в диапазоне. Например, если максимальные и минимальные значения блока составляют 256×256 и 4×4, соответственно, могут получаться блок размера 2mx2n (m и n являются целыми числами 2-8 в этом примере), блок размера 2mx2n (m и n являются целыми числами 2-128 в этом примере) или блок размера mxm (m и n являются целыми числами 4-256 в этом примере). В данном документе, m и n могут быть равными или отличаться, и могут формироваться один или более диапазонов, в которых блоки поддерживаются, к примеру, максимальное значение и минимальное значение.
[102] Например, информация относительно максимального размера и минимального размера блока может формироваться, и информация относительно максимального размера и минимального размера блока может формироваться в некоторой конфигурации сегментации. В первом случае, информация может представлять собой информацию диапазона относительно максимальных и минимальных размеров, которые могут формироваться в изображении, тогда как во втором случае, информация может представлять собой информацию относительно максимальных и минимальных размеров, которые могут формироваться согласно некоторой конфигурации сегментации. Конфигурация сегментации может задаваться посредством типа изображения (I/P/B), цветового компонента (YCbCr и т.п.), типа блока (кодирования/прогнозирования/ преобразования/квантования), типа сегментации (индекса или типа) и схемы сегментации (дерево квадрантов (QT), двоичное дерево (BT) и троичное дерево (TT) в качестве способов на основе дерева и SI2, SI3 и SI4 в качестве способов на основе типа).
[103] Дополнительно, может быть предусмотрено ограничение на отношение ширины к высоте, доступное для блока (формы блока), и в этом отношении, может задаваться граничное значение. Могут поддерживаться только блоки, меньшие или равные/меньшие граничного значения k, где k может задаваться согласно отношению ширины к высоте, A/B (A является большим или равным значением между шириной и высотой, и B является другим значением). k может быть действительным числом, равным или большим 1, к примеру, 1,5, 2, 3, 4 и т.п. Как указано в вышеприведенном примере, ограничение на форму одного блока в изображении может поддерживаться, или одно или более ограничений могут поддерживаться согласно конфигурации сегментации.
[104] В общих словах, может определяться, поддерживается или нет сегментация на блоки, на основе вышеописанного диапазона и ограничения и нижеописанной конфигурации сегментации. Например, когда кандидат (дочерний блок), разбиваемый из блока (родительского блока), удовлетворяет условию поддерживаемых блоков, сегментация может поддерживаться, а в противном случае, сегментация не может поддерживаться.
[105] Модуль разбиения блоков может быть сконфигурирован относительно каждого компонента оборудования кодирования изображений и оборудования декодирования изображений, и размер и форма блока может определяться в этом процессе. Различные блоки могут быть сконфигурированы согласно компонентам. Блоки могут включать в себя прогнозный блок для единицы прогнозирования, блок преобразования для единицы преобразования и блок квантования для единицы квантования. Тем не менее, настоящее раскрытие не ограничено этим, и единицы блоков дополнительно могут задаваться для других компонентов. Хотя форма каждого ввода и вывода описывается как квадрат в каждом компоненте в настоящем раскрытии сущности, ввод и вывод некоторого компонента могут иметь любую другую форму (например, треугольник).
[106] Размер и форма первоначального (или начального) блока в модуле разбиения блоков могут определяться из верхней единицы. Первоначальный блок может разбиваться на меньшие блоки. После того как оптимальный размер и форма определяются согласно сегментации на блоки, блок может определяться в качестве первоначального блока для нижней единицы. Верхняя единица может представлять собой блок кодирования, и нижняя единица может представлять собой прогнозный блок или блок преобразования, причем этим настоящее раскрытие не ограничено. Наоборот, возможны различные примеры модификаций. После того как первоначальный блок нижней единицы определяется, как указано в вышеприведенном примере, процесс сегментации может выполняться, чтобы обнаруживать блок оптимального размера и формы, такой как верхняя единица.
[107] В общих словах, модуль разбиения блоков может разбивать базовый блок кодирования (или максимальный блок кодирования), по меньшей мере, на один блок кодирования, и блок кодирования может разбиваться, по меньшей мере, на один прогнозный блок/блок преобразования/блок квантования. Дополнительно, прогнозный блок может разбиваться, по меньшей мере, на один блок преобразования/блок квантования, и блок преобразования может разбиваться, по меньшей мере, на один блок квантования. Некоторые блоки могут иметь зависимую взаимосвязь с другими блоками (т.е. задаваться посредством верхней единицы и нижней единицы) или могут иметь независимую взаимосвязь с другими блоками. Например, прогнозный блок может представлять собой верхнюю единицу выше блока преобразования или может представлять собой единицу, независимую от блока преобразования. Различные взаимосвязи могут устанавливаться согласно типам блоков.
[108] В зависимости от конфигурации кодирования/декодирования, может определяться, следует комбинировать или нет верхнюю единицу и нижнюю единицу. Комбинация между единицами означает, что блок верхней единицы подвергается процессу кодирования/декодирования нижней единицы (например, в единице прогнозирования, единице преобразования, единице обратного преобразования и т.д.) без разбиения на нижние единицы. Таким образом, она может означать, что процесс сегментации совместно используется множеством единиц, и информация сегментации формируется в одной (например, верхней единице) из единиц.
[109] Например (когда блок кодирования комбинируется с прогнозным блоком или блоком преобразования), блок кодирования может подвергаться прогнозированию, преобразованию и обратному преобразованию.
[110] Например (когда блок кодирования комбинируется с прогнозным блоком), блок кодирования может подвергаться прогнозированию, и блок преобразования, равный или меньший блока кодирования по размеру, может подвергаться преобразованию и обратному преобразованию.
[111] Например (когда блок кодирования комбинируется с блоком преобразования), прогнозный блок, равный или меньший блока кодирования по размеру, может подвергаться прогнозированию, и блок кодирования может подвергаться преобразованию и обратному преобразованию.
[112] Например (когда прогнозный блок комбинируется с блоком преобразования), прогнозный блок, равный или меньший блока кодирования по размеру, может подвергаться прогнозированию, преобразованию и обратному преобразованию.
[113] Например (когда отсутствует комбинирование блоков), прогнозный блок, равный или меньший блока кодирования по размеру, может подвергаться прогнозированию, и блок преобразования, равный или меньший блока кодирования по размеру, может подвергаться преобразованию и обратному преобразованию.
[114] Хотя различные случаи блока кодирования, прогнозного блока и блока преобразования описываются в вышеприведенных примерах, настоящее раскрытие не ограничено этим.
[115] Для комбинации между единицами, фиксированная конфигурация может поддерживаться в изображении, или адаптивная конфигурация может поддерживаться с учетом различных факторов кодирования/декодирования. Факторы кодирования/декодирования включают в себя тип изображения, цветовой компонент, режим кодирования (внутреннего/взаимного), конфигурацию сегментации, размер/форму/позицию блока, отношение ширины к высоте, связанную с прогнозированием информацию (например, режим внутреннего прогнозирования, режим взаимного прогнозирования и т.п.), связанную с преобразованием информацию (например, информацию выбора схемы преобразования и т.п.), связанную с квантованием информацию (например, информацию выбора области квантования и информацию кодирования квантованных коэффициентов преобразования) и т.д.
[116] Когда блок оптимального размера и формы обнаружен, как описано выше, информация режима (например, информация сегментации) для блока может формироваться. Информация режима может быть включена в поток битов наряду с информацией, сформированной из компонента, которому принадлежит блок (например, связанной с прогнозированием информацией и связанной с преобразованием информацией), и передаваться в декодер и может синтаксически анализироваться на таком же единичном уровне посредством декодера, для использования в процессе декодирования видео.
[117] Далее описывается схема сегментации. Хотя предполагается, что первоначальный блок формируется в квадрат, для удобства описания, настоящее раскрытие не ограничено этим, и описание является применимым так же или аналогично к случаю, в котором первоначальный блок является прямоугольным.
[118] Модуль разбиения блоков может поддерживать различные типы сегментации. Например, может поддерживаться сегментация на основе дерева или сегментация на основе индексов, и также могут поддерживаться другие способы. В сегментации на основе дерева, тип сегмента может определяться на основе различных типов информации (например, информации, указывающей, выполняется или нет сегментация, типа дерева, направления сегментации и т.д.), тогда как в сегментации на основе индексов, тип сегментации может определяться с использованием конкретной информации индекса.
[119] [120] Фиг. 4 является примерной схемой, иллюстрирующей различные типы сегментов, которые могут получаться в модуле разбиения блоков настоящего раскрытия сущности. В этом примере, предполагается, что типы сегментации, проиллюстрированные на фиг. 4, получаются посредством одной операции (или процесса) сегментации, что не должно истолковываться в качестве ограничения настоящего раскрытия сущности. Типы сегментов также могут получаться во множестве операций сегментации. Дополнительно, также может быть доступным дополнительный тип сегмента, который не проиллюстрирован на фиг. 4.
[121] Сегментация на основе дерева
[122] В сегментации на основе дерева настоящего раскрытия сущности, могут поддерживаться QT, BT и TT. Если один способ на основе дерева поддерживается, это может упоминаться как "сегментация на основе одиночного дерева" а если два или более способов на основе дерева поддерживаются, это может упоминаться как "сегментация на основе мультидерева".
[123] В QT, блок разбивается на два сегмента в каждом из горизонтального и вертикального направлений (n), тогда как в BT, блок разбивается на два сегмента в горизонтальном направлении или в вертикальном направлении (b-g). В TT, блок разбивается на три сегмента в горизонтальном направлении или в вертикальном направлении (h-m).
[124] В QT, блок может разбиваться на четыре сегмента посредством ограничения направления сегментации одним из горизонтального и вертикального направлений (o и p). Дополнительно, в BT, может поддерживаться только разбиение блока на сегменты одинакового размера (b и c), только разбиение блока на сегменты различных размеров (d-g) либо на оба типа сегментов. Дополнительно, в TT, могут поддерживаться разбиение блока на сегменты, сконцентрированные только в конкретном направлении (1:1:2 или 2:1:1 в направлении слева -> направо или сверху -> вниз) (h, j, k и m), разбиение блока на сегменты, сконцентрированные в центре (1:2:1) (i и l) либо на оба типа сегментов. Дополнительно, может поддерживаться разбиение блока на четыре сегмента в каждом из горизонтального и вертикального направлений (т.е. всего на 16 сегментов) (q).
[125] Из числа способов на основе дерева, может поддерживаться разбиение блока на z сегментов только в горизонтальном направлении (b, d, e, h, i, j, o), разбиение блока на z сегментов только в вертикальном направлении (c, f, g, k, l, m, p) либо на оба типа сегментов. В данном документе, z может быть целым числом, равным или большим 2, к примеру, 2, 3 или 4.
[126] В настоящем раскрытии сущности, предполагается, что тип n сегмента поддерживается в качестве QT, типы b и c сегментов поддерживаются в качестве BT, и типы i и l сегментов поддерживаются в качестве TT.
[127] Одна или более схем древовидной сегментации могут поддерживаться согласно конфигурации кодирования/декодирования. Например, могут поддерживаться QT, QT/BT или QT/BT/TT.
[128] В вышеприведенном примере, базовая схема древовидной сегментации представляет собой QT, и BT и TT включаются в качестве дополнительных схем сегментации в зависимости от того, поддерживаются или нет другие деревья. Тем не менее, различные модификации могут вноситься. Информация, указывающая, поддерживаются или нет другие деревья (bt_enabled_flag, tt_enabled_flag и bt_tt_enabled_flag, где 0 указывает отсутствие поддержки, а 1 указывает поддержку), может неявно определяться согласно настройке кодирования/декодирования либо явно определяться в таких единицах, как последовательность, изображение, серия последовательных макроблоков мозаичный фрагмент.
[129] Информация сегментации может включать в себя информацию, указывающую, выполняется или нет сегментация (tree_part_flag или qt_part_flag, bt_part_flag, tt_part_flag и bt_tt_part_flag, которые могут иметь значение 0 или 1, где 0 указывает отсутствие сегментации, и 1 указывает сегментацию). Дополнительно, в зависимости от схем сегментации (BT и TT), может добавляться информация относительно направления сегментации (dir_part_flag или bt_dir_part_flag, tt_dir_part_flag и bt_tt_dir_part_flag, которые имеют значение 0 или 1, где 0 указывает <ширина/горизонтальный>, и 1 указывает <высота/вертикальный>). Она может представлять собой информацию, которая может формироваться, когда выполняется сегментация.
[130] Когда сегментация на основе мультидерева поддерживается, различные фрагменты информации сегментации могут быть сконфигурированы. Ниже приводится описание примера, как информация сегментации сконфигурирована на одном уровне глубины (т.е. хотя рекурсивная сегментация является возможной посредством задания одной или более поддерживаемых глубин сегментации), для удобства описания.
[131] В примере 1, проверяется информация, указывающая, выполняется или нет сегментация. Если сегментация не выполняется, сегментация завершается.
[132] Если сегментация выполняется, информация выбора относительно типа сегмента (например, tree_idx 0 для QT, 1 для BT и 2 для TT) проверяется. Информация направления сегментации дополнительно проверяется согласно выбранному типу сегмента, и процедура переходит к следующему этапу (если дополнительная сегментация является возможной по таким причинам, как когда глубина сегментации не достигает максимального значения, процедура начинается снова с начала, и если дополнительная сегментация является невозможной, процедура сегментации завершается).
[133] В примере 2, проверяется информация, указывающая, выполняется или нет сегментация в определенной древовидной схеме (QT), и процедура переходит к следующему этапу. Если сегментация не выполняется в древовидной схеме (QT), проверяется информация, указывающая, выполняется или нет сегментация в другой древовидной схеме (BT). В том случае, если сегментация не выполняется в древовидной схеме, проверяется информация, указывающая, выполняется или нет сегментация в третьей древовидной схеме (TT). Если сегментация не выполняется в третьей древовидной схеме (TT), процедура сегментации завершается.
[134] Если сегментация выполняется в древовидной схеме (QT), процедура переходит к следующему этапу. Дополнительно, сегментация выполняется во второй древовидной схеме (BT), проверяется информация направления сегментации, и процедура переходит к следующему этапу. Если сегментация выполняется в третьей древовидной схеме (TT), проверяется информация направления сегментации, и процедура переходит к следующему этапу.
[135] В примере 3, проверяется информация, указывающая, выполняется или нет сегментация в древовидной схеме (QT). Если сегментация не выполняется в древовидной схеме (QT), проверяется информация, указывающая, выполняется или нет сегментация в других древовидных схемах (BT и TT). Если сегментация не выполняется, процедура сегментации завершается.
[136] Если сегментация выполняется в древовидной схеме (QT), процедура переходит к следующему этапу. Дополнительно, сегментация выполняется в других древовидных схемах (BT и TT), проверяется информация направления сегментации, и процедура переходит к следующему этапу.
[137] Хотя схемы древовидной сегментации приоритезируются (пример 2 и пример 3), либо приоритеты не назначаются схемам древовидной сегментации (пример 1) в вышеприведенных примерах, также могут быть доступными различные примеры модификаций. Дополнительно, сегментация на текущем этапе не связана с результатом сегментации предыдущего этапа в вышеприведенном примере. Тем не менее, также можно конфигурировать сегментацию на текущем этапе таким образом, что она зависит от результата сегментации предыдущего этапа.
[138] В примерах 1-3, если некоторая схема древовидной сегментации (QT) выполняется на предыдущем этапе, и в силу этого процедура переходит к текущему этапу, такая же схема древовидной сегментации (QT) также может поддерживаться на текущем этапе.
[139] С другой стороны, если определенная схема древовидной сегментации (QT) не выполнена, и в силу этого другая схема древовидной сегментации (BT или TT) выполнена на предыдущем этапе, и затем процедура переходит к текущему этапу, может быть предусмотрена такая конфигурация, в которой другие схемы древовидной сегментации (BT и TT), за исключением определенной схемы древовидной сегментации (QT) поддерживаются на текущем этапе и следующих этапах.
[140] В вышеописанном случае, древовидная конфигурация, поддерживаемая для сегментации на блоки, может быть адаптивной, и в силу этого вышеуказанная информация сегментации также может быть сконфигурирована по-другому. (Пример, который описывается ниже, предположительно представляет собой пример 3). Таким образом, если сегментация не выполняется в определенной древовидной схеме (QT) на предыдущем этапе, процедура сегментации может выполняться безотносительно древовидной схемы (QT) на текущем этапе. Дополнительно, информация сегментации, связанная с определенной древовидной схемой (например, информация, указывающая, выполняется или нет сегментация, информация относительно направления сегментации и т.д.; в этом примере <QT>, информация, указывающая, выполняется или нет сегментация), может удаляться.
[141] Вышеприведенный пример связан с адаптивной конфигурацией информации сегментации для случая, в котором сегментация на блоки разрешается (например, размер блока находится в пределах диапазона между максимальным и минимальным значениями, глубина сегментации каждой древовидной схемы не достигает максимальной глубины (разрешенной глубины) и т.п.). Даже когда сегментация на блоки ограничивается (например, размер блока не существует в диапазоне между максимальным и минимальным значениями, глубина сегментации каждой древовидной схемы достигает максимальной глубины и т.п.), информация сегментации может быть сконфигурирована адаптивно.
[142] Как уже упомянуто, сегментация на основе дерева может выполняться рекурсивным способом в настоящем раскрытии сущности. Например, если флаг сегмента блока кодирования с глубиной k сегментации задается равным 0, кодирование на основе блоков кодирования выполняется в блоке кодирования с глубиной k сегментации. Если флаг сегмента блока кодирования с глубиной k сегментации задается равным 1, кодирование на основе блоков кодирования выполняется в N субблоков кодирования с глубиной k+1 сегментации согласно схеме сегментации (где N является целым числом, равным или большим 2, к примеру, 2, 3 и 4).
[143] Субблок кодирования может задаваться в качестве блока (k+1) кодирования и сегментироваться на субблоки (k+2) кодирования в вышеуказанной процедуре. Эта схема иерархической сегментации может определяться согласно конфигурации сегментации, такой как диапазон сегментации и разрешенная глубина сегментации.
[144] В этом случае, структура потока битов, представляющая информацию сегментации, может выбираться из одного или более способов сканирования. Например, поток битов информации сегментации может быть сконфигурирован на основе порядка глубин сегментации или на основе того, выполняется или нет сегментация.
[145] Например, в случае на основе порядка глубины сегментации, информация сегментации получается на текущем уровне глубины на основе первоначального блока, и затем информация сегментации получается на следующем уровне глубины. В случае на основе того, выполняется или нет сегментация, дополнительная информация сегментации сначала получается в блоке, разбитом из первоначального блока, и могут рассматриваться другие дополнительные способы сканирования.
[146] [147] Сегментация на основе индексов
[148] В сегментации на основе индексов настоящего раскрытия сущности, могут поддерживаться схема с постоянным индексом разбиения (CSI) и схема с переменным индексом разбиения (VSI).
[149] В CSI-схеме, k субблоков могут получаться посредством сегментации в предварительно определенном направлении, и k может быть целым числом, равным или большим 2, к примеру, 2, 3 или 4. В частности, размер и форма субблока могут определяться на основе k независимо от размера и формы блока. Предварительно определенное направление может представлять собой одно из либо комбинацию двух или более из горизонтального, вертикального и диагонального направлений (направление слева и снизу -> вниз и вправо или направление слева и снизу -> вверх и вправо).
[150] В схеме CSI-сегментации на основе индексов настоящего раскрытия сущности, z кандидатов может получаться посредством сегментации в горизонтальном направлении или в вертикальном направлении. В этом случае, z может быть целым числом, равным или большим 2, к примеру, 2, 3 или 4, и субблоки могут быть равными согласно одному из ширины и высоты и могут быть равными или отличаться согласно другому из ширины и высоты. Отношение длины касательно ширины или высоты субблоков представляет собой A1:A2:…:AZ, и каждое из A1-AZ может быть целым числом, равным или большим 1, к примеру, 1, 2 или 3.
[151] Дополнительно, кандидат может получаться посредством сегментации на сегменты x и сегменты y вдоль горизонтального и вертикального направлений, соответственно. Каждое из x и y может быть целым числом, равным или большим 1, к примеру, 1, 2, 3 или 4. Тем не менее, кандидат, где x и y равны единице, может ограничиваться (поскольку a уже существует). Хотя фиг. 4 иллюстрирует случаи, в которых субблоки имеют такое же отношение ширины или высоты, также могут быть включены кандидаты, имеющие другое отношение ширины или отношение высоты.
[152] Дополнительно, кандидат может разбиваться на w сегментов в одном из диагональных направлений, сверху слева -> вниз и вправо и снизу слева -> вверх и вправо. В данном документе, w может быть целым числом, равным или большим 2, к примеру, 2 или 3.
[153] Ссылаясь на фиг. 4, типы сегментов могут классифицироваться на тип симметричного сегмента (b) и тип асимметричного сегмента (d и e) согласно отношению длины каждого субблока. Дополнительно, типы сегментов могут классифицироваться на тип сегмента, сконцентрированный в конкретном направлении (k и m), и тип сегментации в центре (k). Типы сегментов могут задаваться посредством различных факторов кодирования/декодирования, включающих в себя форму субблока, а также отношение длины субблоков, и поддерживаемый тип сегмента может неявно или явно определяться согласно конфигурации кодирования/декодирования. Таким образом, кандидатная группа может определяться на основе поддерживаемого типа сегмента в схеме сегментации на основе индексов.
[154] В VSI-схеме, при фиксированной ширине w или высоте h каждого субблока, один или более субблоков могут получаться посредством сегментации в предварительно определенном направлении. В данном документе, каждый из w и h может быть целым числом, равным или большим 1, к примеру, 1, 2, 4 или 8. В частности, число субблоков может определяться на основе размера и формы блока и значения h или w.
[155] В схеме VSI-сегментации на основе индексов настоящего раскрытия сущности, кандидат может сегментироваться на субблоки, каждый из которых является фиксированным по одному из ширины и длины. Альтернативно, кандидат может сегментироваться на субблоки, каждый из которых является фиксированным как по ширине, так и по длине. Поскольку ширина или высота субблока является фиксированной, равная сегментация в горизонтальном или вертикальном направлении может разрешаться. Тем не менее, настоящее раскрытие не ограничено этим.
[156] В случае если блок имеет размер MxN до сегментации, если ширина w каждого субблока является фиксированной, высота h каждого субблока является фиксированной, либо как ширина w, так и высота h каждого субблока являются фиксированными, число полученных субблоков может составлять (MxN)/w, (MxN)/h или (MxN)/w/h.
[157] В зависимости от конфигурации кодирования/декодирования, могут поддерживаться только одна или обе из CSI-схемы и VSI-схемы, и информация относительно поддерживаемой схемы может неявно или явно определяться.
[158] В дальнейшем описывается настоящее раскрытие в контексте поддерживаемой CSI-схемы.
[159] Кандидатная группа может быть выполнена с возможностью включать в себя два или более кандидатов в схеме сегментации на основе индексов согласно настройке кодирования/декодирования.
[160] Например, может формироваться кандидатная группа, к примеру, {a, b, c}, {a, b, c, n} или {в g и n}. Кандидатная группа может представлять собой пример включения типов блоков, которые прогнозируются как возникающие много раз на основе общих статистических характеристик, такие как блок, разделенный на два сегмента в горизонтальном или вертикальном направлении либо в каждом из горизонтального и вертикального направлений.
[161] Альтернативно, может быть сконфигурирована кандидатная группа, к примеру, {a, b}, {a, o} или {a, b, o} или кандидатная группа, к примеру, {a, c}, {a, p} или {a, c, p}. Кандидатная группа может представлять собой пример включения кандидатов, сегментируемых на сегменты, и четырех сегментов в горизонтальном и вертикальном направлениях, соответственно. Это может представлять собой пример конфигурирования типов блоков, которые прогнозируются как сегментируемые главным образом в конкретном направлении, в качестве кандидатной группы.
[162] Альтернативно, может быть сконфигурирована кандидатная группа, к примеру, {a, o, p} или {a, n, q}. Это может представлять собой пример конфигурирования кандидатной группы с возможностью включать в себя типы блоков, которые прогнозируются как сегментируемые на множество сегментов, меньших блока до сегментации.
[163] Альтернативно, может быть сконфигурирована кандидатная группа, к примеру, {a, r, s}, и это может представлять собой пример определения оптимального результата сегментирования, который может получаться в прямоугольной форме через другой способ (способ на основе дерева) из блока до разбиения, и конфигурирования непрямоугольной формы в качестве кандидатной группы.
[164] Из вышеприведенных примеров следует отметить, что могут быть доступными различные конфигурации кандидатных групп, и одна или более конфигураций кандидатных групп могут поддерживаться с учетом различных факторов кодирования/декодирования.
[165] После того как кандидатная группа полностью сконфигурирована, могут быть доступными различные конфигурации информации сегментации.
[166] Например, относительно кандидатной группы, включающей в себя кандидат a, который не сегментируется, и кандидаты b-s, которые сегментируются, может формироваться информация выбора индекса.
[167] Альтернативно, может формироваться информация, указывающая, выполняется или нет сегментация (информация, указывающая, представляет собой тип сегментации a или нет). Если сегментация выполняется (если тип сегментации не представляет собой a), информация выбора индекса может формироваться относительно кандидатной группы, включающей в себя кандидатов b-s, которые сегментируются.
[168] Информация сегментации может быть сконфигурирована множеством способов, отличающихся от способов, описанных выше. За исключением информации, указывающей, выполняется или нет сегментация, двоичные биты могут назначаться индексу каждого кандидата в кандидатной группе различными способами, такими как преобразование в двоичную форму фиксированной длины, преобразование в двоичную форму переменной длины и т.д. Если число кандидатов равно 2, 1 бит может назначаться информации выбора индекса, и если число кандидатов равно 3, один или более битов могут назначаться информации выбора индекса.
[169] По сравнению со схемой сегментации на основе дерева, типы сегментов, которые прогнозируются как возникающие много раз, могут включаться в кандидатную группу в схеме сегментации на основе индексов.
[170] Поскольку число битов, используемых, чтобы представлять информацию индекса, может увеличиваться согласно числу поддерживаемых кандидатных групп, эта схема может быть подходящей для однослойной сегментации (например, глубина сегментации ограничена 0), вместо иерархической сегментации на основе дерева (рекурсивной сегментации). Таким образом, одна операция сегментации может поддерживаться, и субблок, полученный через сегментацию на основе индексов, может не разбиваться дополнительно.
[171] Это может означать, что дополнительно сегментация на меньшие блоки такого же типа является невозможной (например, блок кодирования, полученный через сегментацию на основе индексов, может не разбиваться дополнительно на блоки кодирования), а также означать, что дополнительная сегментация на различные типы блоков также может быть невозможной (например, сегментация блока кодирования на прогнозные блоки, а также блоки кодирования является невозможной). Очевидно, настоящее раскрытие не ограничено вышеприведенным примером, и также могут быть доступными другие примеры модификаций.
[172] [173] Далее приводится описание определения конфигурации сегментации на блоки главным образом на основе типа блока из числа факторов кодирования/декодирования.
[174] Во-первых, блок кодирования может получаться в процессе сегментации. Схема сегментации на основе дерева может приспосабливаться для процесса сегментации, и тип сегмента, такой как a (без разбиения), n (QT), b, c (BT), i или l (TT) по фиг. 4, может получаться в результате согласно типу дерева. Различные комбинации типов деревьев, такие как QT/QT+BT/QT+BT+TT, могут быть доступными согласно конфигурации кодирования/декодирования.
[175] Нижеприведенные примеры представляют собой процессы конечного разделения блока кодирования, полученного в вышеуказанной процедуре, на прогнозные блоки и блоки преобразования. Предполагается, что прогнозирование, преобразование и обратное преобразование выполняется на основе размера каждого сегмента.
[176] В примере 1, прогнозирование может выполняться посредством задания размера прогнозного блока равным размеру блока кодирования, и преобразование и обратное преобразование могут выполняться посредством задания размера блока преобразования равным размеру блока кодирования (или прогнозного блока).
[177] В примере 2, прогнозирование может выполняться посредством задания размера прогнозного блока равным размеру блока кодирования. Блок преобразования может получаться посредством сегментации блока кодирования (или прогнозного блока), и преобразование и обратное преобразование могут выполняться на основе размера полученного блока преобразования.
[178] Здесь, схема сегментации на основе дерева может приспосабливаться для процесса сегментации, и тип сегмента, такой как a (без разбиения), n (QT), b, c (BT), i или l (TT) по фиг. 4, может получаться в результате согласно типу дерева. Различные комбинации типов деревьев, такие как QT/QT+BT/QT+BT+TT, могут быть доступными согласно конфигурации кодирования/декодирования.
[179] Здесь, процесс сегментации может представлять собой схему сегментации на основе индексов. Тип сегмента, такой как a (без разбиения), b, c или d по фиг. 4, может получаться согласно типу индекса. В зависимости от конфигурации кодирования/декодирования, могут быть сконфигурированы различные кандидатной группы, к примеру, {a, b, c} и {a, b, c, d}.
[180] В примере 3, прогнозный блок может получаться посредством сегментации блока кодирования и подвергаться прогнозированию на основе размера полученного прогнозного блока. Для блока преобразования, его размер задается равным размеру блока кодирования, и преобразование и обратное преобразование могут выполняться для блока преобразования. В этом примере, прогнозный блок и блок преобразования могут иметь независимую взаимосвязь.
[181] Схема сегментации на основе индексов может использоваться для процесса сегментации, и тип сегмента, такой как a (без разбиения), b-g, n, r или s по фиг. 4, может получаться согласно типу индекса. Различные кандидатной группы, к примеру, {a, b, c, n}, {в g, n} и {a, r, s}, могут быть сконфигурированы согласно конфигурации кодирования/декодирования.
[182] В примере 4, прогнозный блок может получаться посредством сегментации блока кодирования и подвергаться прогнозированию на основе размера полученного прогнозного блока. Для блока преобразования, его размер задается равным размеру прогнозного блока, и преобразование и обратное преобразование могут выполняться для блока преобразования. В этом примере, блок преобразования может иметь размер, равный размеру полученного прогнозного блока, или наоборот (размер блока преобразования задается в качестве размера прогнозного блока).
[183] Схема сегментации на основе дерева может использоваться для процесса сегментации, и тип сегмента, такой как a (без разбиения), b, c (BT), i, l (TT) или n (QT) по фиг. 4, может формироваться согласно типу дерева. В зависимости от конфигурации кодирования/декодирования, могут быть доступными различные комбинации типов деревьев, такие как QT/BT/QT+BT.
[184] Здесь, схема сегментации на основе индексов может использоваться для процесса сегментации, и тип сегмента, такой как a (без разбиения), b, c, n, o или p по фиг. 4, может получаться в результате согласно типу индекса. Различные кандидатной группы, к примеру, {a, b}, {a, c}, {a, n}, {a, o}, {a, p}, {a, b, c}, {a, o, p}, {a, b, c, n} и {a, b, c, n, p} могут быть сконфигурированы в зависимости от конфигурации кодирования/дешифрования. Дополнительно, кандидатная группа может быть сконфигурирована только в VSI-схеме либо в CSI-схеме и VSI-схеме в комбинации, в качестве схем сегментации на основе индексов.
[185] В примере 5, прогнозный блок может получаться посредством сегментации блока кодирования и подвергаться прогнозированию на основе размера полученного прогнозного блока. Блок преобразования также может получаться посредством сегментации блока кодирования и подвергаться преобразованию и обратному преобразованию на основе размера полученного блока преобразования. В этом примере, каждый из прогнозного блока и блока преобразования может получаться в результате сегментации блока кодирования.
[186] Здесь, схема сегментации на основе дерева и схема сегментации на основе индексов могут использоваться для процесса сегментации, и кандидатная группа может иметь конфигурацию, такую же или аналогичную конфигурации в примере 4.
[187] В этом случае, вышеприведенные примеры представляют собой случаи, которые могут возникать в зависимости от того, используется совместно или нет процесс сегментации каждого типа блока, что не должно истолковываться в качестве ограничения настоящего раскрытия сущности. Также могут быть доступными различные примеры модификаций. Дополнительно, конфигурация сегментации на блоки может определяться с учетом различных факторов кодирования/декодирования, а также типа блока.
[188] Факторы кодирования/декодирования могут включать в себя тип изображения (I/P/B), цветовой компонент (YCbCr), размер/форму/позицию блока, отношение ширины к высоте блока, тип блока (блок кодирования, прогнозный блок, блок преобразования или блок квантования), состояние сегментации, режим кодирования (внутреннего/взаимного), связанную с прогнозированием информацию (режим внутреннего прогнозирования или режим взаимного прогнозирования), связанную с преобразованием информацию (информацию выбора схемы преобразования), связанную с квантованием информацию (информацию выбора области квантования и информацию кодирования квантованных коэффициентов преобразования).
[189] [190] В способе кодирования изображений согласно варианту осуществления настоящего раскрытия сущности, внутреннее прогнозирование может иметь следующую конфигурацию. Внутреннее прогнозирование в модуле прогнозирования может включать в себя этап конфигурирования опорных пикселов, этап формирования прогнозных блоков, этап определения режима прогнозирования и этап кодирования в режиме прогнозирования. Дополнительно, оборудование кодирования изображений может быть выполнено с возможностью включать в себя модуль конфигурирования опорных пикселов, формирователь прогнозных блоков и кодер в режиме прогнозирования, чтобы выполнять этап конфигурирования опорных пикселов, этап формирования прогнозных блоков, этап определения режима прогнозирования и этап кодирования в режиме прогнозирования. Часть вышеописанных этапов может опускаться, или другие этапы могут добавляться. Этапы могут выполняться в порядке, отличающемся от порядка, описанного выше.
[191] Фиг. 5 является примерной схемой, иллюстрирующей режимы внутреннего прогнозирования согласно варианту осуществления настоящего раскрытия сущности.
[192] Ссылаясь на фиг. 5, 67 режимов прогнозирования группируются в кандидатную группу режима прогнозирования для внутреннего прогнозирования. Хотя дальнейшее описание приводится с признанием того, что из числа этих 67 режимов прогнозирования 65 режимов прогнозирования представляют собой направленные режимы, а 2 режима прогнозирования представляют собой ненаправленные режимы (DC- и плоский), настоящее раскрытие не ограничено этим, и различные конфигурации являются доступными. Направленные режимы могут отличаться друг от друга посредством информации наклона (например, dy/dx) или информации угла (градусы). Все или часть режимов прогнозирования могут быть включены в кандидатную группу режима прогнозирования компонента сигнала яркости или компонента сигнала цветности, и другие дополнительные режимы могут быть включены в кандидатную группу режима прогнозирования.
[193] В настоящем раскрытии сущности, направленные режимы могут направляться в прямых линиях, и кривой направленный режим может быть дополнительно сконфигурирован в качестве режима прогнозирования. Дополнительно, ненаправленные режимы могут включать в себя DC-режим, в котором прогнозный блок получается посредством усреднения (или усреднения со взвешиванием) пикселов блоков, соседних с текущим блоком (например, верхнего, левого верхнего, правого верхнего и правого нижнего блоков), и планарный режим, в котором прогнозный блок получается посредством линейной интерполяции пикселов соседних блоков.
[194] В DC-режиме, опорные пикселы, используемые , чтобы формировать прогнозный блок, могут получаться из любой из различных комбинаций блоков, таких как левый, верхний, левый+верхний, левый+нижний-левый, верхний+верхний-правый, левый+верхний+нижний-левый+верхний-правый и т.д. Позиция блоков, из которых получаются опорные пикселы, может определяться согласно конфигурации кодирования/декодирования, заданной посредством типа изображения, цветового компонента, размера/типа/позиции блока и т.д.
[195] В планарном режиме, пикселы, используемые , чтобы формировать прогнозный блок, могут получаться из области с опорными пикселами (например, из левой, верхней, левой верхней, правой верхней и левой нижней областей) и области без опорных пикселов (например, из правой, нижней и правой нижней областей). Область без опорных пикселов (т.е. не кодированная) может получаться неявно посредством использования одного или более пикселов области с опорными пикселами (например, посредством копирования или усреднения со взвешиванием), либо информация, по меньшей мере, относительно одного пиксела в области, не состоящей из опорных пикселов, может явно формироваться. Соответственно, прогнозный блок может формироваться с использованием области с опорными пикселами и области без опорных пикселов, как описано выше.
[196] Дополнительно могут быть включены ненаправленные режимы, отличные от ненаправленных режимов, описанных выше. В настоящем раскрытии сущности, главным образом описаны линейные направленные режимы и ненаправленные режимы, DC- и плоский. Тем не менее, модификации могут вноситься в режимы.
[197] Режимы прогнозирования, проиллюстрированные фиг. 5, могут фиксированно поддерживаться независимо от размеров блоков. Дополнительно, режимы прогнозирования, поддерживаемые согласно размерам блоков, могут отличаться от режимов прогнозирования по фиг. 5.
[198] Например, число кандидатных групп режимов прогнозирования может быть адаптивным (например, хотя угол между каждыми смежными двумя режимами прогнозирования равен, угол может задаваться по-разному, к примеру, 9, 17, 33, 65 или 129 направленных режимов). Альтернативно, число кандидатных групп режима прогнозирования может быть фиксированным, но с другой конфигурацией (например, угол направленного режима и тип ненаправленного режима).
[199] Дополнительно, режимы прогнозирования по фиг. 5 могут фиксированно поддерживаться независимо от типов блоков. Дополнительно, режимы прогнозирования, поддерживаемые согласно типам блоков, могут отличаться от режимов прогнозирования по фиг. 5.
[200] Например, число кандидатов режимов прогнозирования может быть адаптивным (например, большее или меньшее число режимов прогнозирования может извлекаться в горизонтальном или вертикальном направлении согласно отношениям ширины к высоте блоков). Альтернативно, число кандидатов режимов прогнозирования может быть фиксированным, но с различными конфигурациями (например, режимы прогнозирования могут извлекаться более тщательно вдоль горизонтального или вертикального направления согласно отношениям ширины к высоте блоков).
[201] Альтернативно, большее число режимов прогнозирования может поддерживаться для большей стороны блока, тогда как меньшее число режимов прогнозирования может поддерживаться для меньшей стороны блока. Относительно интервала режима прогнозирования на более длинной стороне блока, могут поддерживаться режимы, расположенные справа от режима 66 (например, режимы под углами +45 градусов или более от режима 50, к примеру, режимы 67-80) или режимы, расположенные слева от режима 2 (например, режимы под углами в -45 градусов или меньше от режима 18, к примеру, режимы -1 - -14). Это может определяться согласно отношению ширины к высоте блока, и противоположная ситуация также может быть возможной.
[202] Хотя фиксированно поддерживаемые режимы прогнозирования (независимо от любого фактора кодирования/декодирования), такие ка режимы прогнозирования по фиг. 5, главным образом описываются в настоящем раскрытии сущности, режимы прогнозирования, поддерживаемые адаптивно согласно конфигурации кодирования, также могут быть сконфигурированы.
[203] Режимы прогнозирования могут классифицироваться на основе горизонтального и вертикального режимов (режимов 18 и 50) и некоторых диагональных режимов (режима 2 вверх и вправо по диагонали, режима 34 вниз и вправо по диагонали, режима 66 прогнозирования вниз и влево по диагонали и т.д.). Эта классификация может быть основана на некоторых направленностях (или углах, к примеру, 45 градусов, 90 градусов и т.д.).
[204] Режимы, расположенные на обоих концах направленных режимов (режимы 2 и 66), могут служить в качестве опорных режимов для классификации режимов прогнозирования, которая является возможной, когда режимы внутреннего прогнозирования сконфигурированы так, как проиллюстрировано на фиг. 5. Таким образом, когда режимы прогнозирования сконфигурированы адаптивно, опорные режимы могут изменяться. Например, режим 2 может заменяться режимом с индексом, меньшим или большим 2 (например, -2, -1, 3, 4 и т.п.), либо режим 66 может заменяться режимом с индексом меньшим или большим 66 (например, 64, 66, 67, 68 и т.п.).
[205] Дополнительно, дополнительные режимы прогнозирования, связанные с цветовым компонентом (цветовой режим копирования и цветовой режим), могут быть включены в кандидатную группу режима прогнозирования. Цветовой режим копирования может означать режим прогнозирования, относящийся к способу получения данных для формирования прогнозного блока из области, расположенной в другом цветовом пространстве, и цветовой режим может означать режим прогнозирования, относящийся к способу получения режима прогнозирования из области, расположенной в другом цветовом пространстве.
[206] [207] Фиг. 6 является примерной схемой, иллюстрирующей конфигурацию опорных пикселов, используемую для внутреннего прогнозирования согласно варианту осуществления настоящего раскрытия сущности. Размер и форма MxN прогнозного блока могут получаться через модуль разбиения блоков.
[208] Хотя может быть типичным выполнение внутреннего прогнозирования на основе прогнозных блоков, внутреннее прогнозирование также может выполняться на основе блоков кодирования или блоков преобразования согласно конфигурации модуля разбиения блоков. После проверки информации блоков, модуль конфигурирования опорных пикселов может конфигурировать опорные пикселы для использования в прогнозировании текущего блока. Опорные пикселы могут управляться во временном запоминающем устройстве (например, в массиве, первичном массиве, вторичном массиве и т.п.). Опорные пикселы могут формироваться и удаляться в каждом процессе внутреннего прогнозирования для блока, и емкость временного запоминающего устройства может определяться согласно конфигурации опорных пикселов.
[209] В этом примере, предполагается, что левый, верхний, левый верхний, правый верхний и левый нижний блоки относительно текущего блока используются для прогнозирования текущего блока. Тем не менее, настоящее раскрытие не ограничено этим, и кандидатная группа блока другой конфигурации может использоваться для прогнозирования текущего блока. Например, кандидатная группа соседних блоков для опорных пикселов может определяться на основе растрового или Z-сканирования, и некоторые кандидаты могут удаляться из кандидатной группы согласно порядку сканирования, либо дополнительно может быть включена другая кандидатная группа блоков (например, правый, нижний и правый нижний блоки).
[210] Дополнительно, если режим прогнозирования, такой как цветовой режим копирования поддерживается, некоторая область различного цветового пространства может использоваться для прогнозирования текущего блока. Следовательно, область также может рассматриваться для опорных пикселов.
[211] [212] Фиг. 7 является концептуальной схемой, иллюстрирующей блоки, соседние с целевым блоком для внутреннего прогнозирования согласно варианту осуществления настоящего раскрытия сущности. В частности, левый чертеж на фиг. 7 иллюстрирует блоки, соседние с текущим блоком в текущем цветовом пространстве, а правый чертеж на фиг. 7 иллюстрирует соответствующий блок в другом цветовом пространстве. Для удобства описания, дальнейшее описание приводится при условии, что блоки, соседние с текущим блоком в пространстве текущего цвета, представляют собой базовую конфигурацию опорных пикселов.
[213] Как проиллюстрировано на фиг. 6, соседние пикселы в левом, верхнем, левом верхнем, правом верхнем и левом нижнем блоках (Ref_L, Ref_T, Ref_TL, Ref_TR и Ref_BL на фиг. 6) могут быть сконфигурированы как опорные пикселы, используемые для прогнозирования текущего блока. Хотя опорные пикселы, в общем, представляют собой пикселы, ближайшие к текущему блоку в соседних блоках, как указано посредством ссылочного символа a на фиг. 6 (называется "опорной пиксельной линией"), другие пикселы (пикселы b на фиг. 6 и пикселы в других внешних линиях) также могут быть доступными в качестве опорных пикселов.
[214] Пикселы, соседние с текущим блоком, могут классифицироваться, по меньшей мере, на одну опорную пиксельную линию. Пикселы, ближайшие к текущему блоку, могут обозначаться посредством ref_0 (например, пикселы, разнесенные от граничных пикселов текущего блока на расстояние 1, p(-1,-1) - p(2m-1,-1) и p(-1,0) - p(-1,2n-1)), вторые ближайшие пикселы могут обозначаться посредством ref_1 (например, пикселы, разнесенные от граничных пикселов текущего блока на расстояние 2, p(-2,-2) - p(2m,-2) и p(-2,-1) - p(-2,2n)), и третьи ближайшие пикселы обозначаются посредством ref_2 (например, пикселы, разнесенные от граничных пикселов текущего блока на расстояние 3, p(-3,-3) - p(2m+1,-3) и p(-3,-2) - p(-3,2n+1)). Таким образом, опорные пиксельные линии могут задаваться согласно расстояниям между граничными пикселами текущего блока и соседних пикселов.
[215] N или более опорных пиксельных линий могут поддерживаться, и N может быть целым числом, равным или большим 1, к примеру, 1-5. Обычно, опорные пиксельные линии последовательно включаются в кандидатную группу опорных пиксельных линий в порядке по возрастанию расстояний. Тем не менее, настоящее раскрытие не ограничено этим. Например, когда N равно 3, кандидатная группа может включать в себя опорные пиксельные линии последовательно, к примеру,<ref_0, ref_1, ref_2>. Также можно конфигурировать кандидатную группу непоследовательно, к примеру,<ref_0, ref_1, ref_3>или<ref_0, ref_2, ref_3>, или конфигурировать кандидатную группу без ближайшей опорной пиксельной линии.
[216] Прогнозирование может выполняться с использованием всех или части (одной или более) опорных пиксельных линий в кандидатной группе.
[217] Например, одна из множества опорных пиксельных линий может выбираться согласно конфигурации кодирования/декодирования, и внутреннее прогнозирование может выполняться с использованием опорной пиксельной линии. Альтернативно, две или более из множества опорных пиксельных линий могут выбираться, и внутреннее прогнозирование может выполняться с использованием выбранных опорных пиксельных линий (например, посредством усреднения со взвешиванием данных опорных пиксельных линий).
[218] Опорная пиксельная линия может выбираться неявно или явно. Например, неявный выбор подразумевает, что эта опорная пиксельная линия выбирается согласно конфигурации кодирования/декодирования, заданной посредством одного или более факторов в комбинации, таких как тип изображения, цветовой компонент и размер/форма/позиция блока. Явный выбор подразумевает, что эта информация выбора опорной пиксельной линии может формироваться на уровне блока.
[219] Хотя настоящее раскрытие описывается в контексте выполнения внутреннего прогнозирования с использованием ближайшей опорной пиксельной линии, следует понимать, что нижеописанные различные варианты осуществления могут реализовываться так же или аналогично, когда используются множество опорных пиксельных линий.
[220] Например, конфигурация, в которой информация неявно определяется с учетом использования одной только ближайшей опорной пиксельной линии, может поддерживаться для субблочного внутреннего прогнозирования, как описано ниже. Таким образом, внутреннее прогнозирование может выполняться на основе субблоков, с использованием предварительно установленной опорной пиксельной линии, и опорная пиксельная линия может выбираться неявно. Опорная пиксельная линия может представлять собой, но не только, ближайшую опорную пиксельную линию.
[221] Альтернативно, опорная пиксельная линия может адаптивно выбираться для субблочного внутреннего прогнозирования, и различные опорные пиксельные линии, включающие в себя ближайшую опорную пиксельную линию, могут выбираться , чтобы выполнять субблочное внутреннее прогнозирование. Таким образом, внутреннее прогнозирование может выполняться на основе субблоков, с использованием опорной пиксельной линии, определенной с учетом различных факторов кодирования/декодирования, и опорная пиксельная линия может выбираться неявно или явно.
[222] Согласно настоящему раскрытию, модуль конфигурирования опорных пикселов для внутреннего прогнозирования может включать в себя формирователь опорных пикселов, интерполятор опорных пикселов и модуль фильтрации опорных пикселов. Модуль конфигурирования опорных пикселов может включать в себя все или часть вышеуказанных компонентов.
[223] Модуль конфигурирования опорных пикселов может отличать доступные пикселы от недоступных пикселов посредством проверки доступности опорных пикселов. Когда опорный пиксел удовлетворяет по меньшей мере одному из следующих условий, опорный пиксел определяется как недоступный.
[224] Например, если по меньшей мере одно из следующих условий удовлетворяется: опорный пиксел расположен за пределами границы изображения; опорный пиксел не принадлежит единице сегментации, такой же единице сегментации текущего блока (например, единице, которая разрешает взаимное обращение, такой как серия последовательных макроблоков или мозаичный фрагмент; тем не менее, единица, разрешающая взаимное обращение, является исключением, несмотря на серию последовательных макроблоков или мозаичный фрагмент); и опорный пиксел не полностью кодирован/декодирован, опорный пиксел может определяться как недоступный. Таким образом, если ни одно из вышеуказанных условий не удовлетворяется, опорный пиксел может определяться как доступный.
[225] Использование опорного пиксела может ограничиваться посредством конфигурации кодирования/декодирования. Например, даже если опорный пиксел определяется как доступный согласно вышеуказанным условиям, использование опорного пиксела может ограничиваться в зависимости от того, выполняется или нет ограниченное внутреннее прогнозирование (например, указывается посредством constrained_intra_pred_flag). Ограниченное внутреннее прогнозирование может выполняться, когда использование блока, восстановленного посредством обращения к другому изображению, запрещается для целей кодирования/декодирования, устойчивого к ошибкам, вследствие внешнего фактора, такого как окружение связи.
[226] Когда ограниченное внутреннее прогнозирование деактивируется (например, constrained_intra_pred_flag=0 для I-типа изображения или P- или B-типа изображения), могут быть доступными все кандидаты блоков опорных пикселов.
[227] Наоборот, когда ограниченное внутреннее прогнозирование активируется (например, constrained_intra_pred_flag=1 для P- или B-типа изображения), может определяться, следует или нет использовать кандидат блока опорных пикселов, согласно режиму кодирования (внутреннего или взаимного). Тем не менее, это условие может задаваться согласно различным другим факторам кодирования/декодирования.
[228] Поскольку опорные пикселы находятся в одном или более блоков, опорные пикселы могут классифицироваться на три типа согласно доступности опорных пикселов: полностью доступные, частично доступные и все недоступные. В других случаях за исключением полностью доступных, опорные пикселы могут заполняться или формироваться в позиции недоступного кандидатного блока.
[229] Когда кандидатный блока опорных пикселов является доступным, пикселы в соответствующих позициях могут быть включены в запоминающее устройство опорных пикселов для текущего блока. Пиксельные данные пикселов могут копироваться как есть, либо могут быть включены в запоминающее устройство опорных пикселов после таких процессов, как фильтрация опорных пикселов и интерполяция опорных пикселов. Наоборот, когда кандидат блока опорных пикселов является недоступным, пикселы, полученные посредством процесса формирования опорных пикселов, могут быть включены в запоминающее устройство опорных пикселов текущего блока.
[230] Ниже описываются примеры формирования опорных пикселов в позиции недоступного блока в различных способах.
[231] Например, опорный пиксел может формироваться с использованием произвольного пиксельного значения. Произвольное пиксельное значение может представлять собой одно из пиксельных значений в диапазоне пиксельных значений (например, в диапазоне пиксельных значений на основе битовой глубины или в диапазоне пиксельных значений на основе пиксельного распределения соответствующего изображения) (например, минимальное, максимальное или медианное значение диапазона пиксельных значений). В частности, этот пример может быть применимым, когда весь кандидатный блок опорных пикселов является недоступным.
[232] Альтернативно, опорный пиксел может формироваться из области, в которой завершено кодирование/декодирование изображений. В частности, опорный пиксел может формироваться, по меньшей мере, из одного доступного блока, соседнего с недоступным блоком. По меньшей мере, одно из экстраполяции, интерполяции или копирования может использоваться при формировании опорного пиксела.
[233] После того, как интерполятор опорных пикселов завершает конфигурирование опорных пикселов, интерполятор опорных пикселов может формировать дробный опорный пиксел посредством линейной интерполяции между опорными пикселами. Альтернативно, процесс интерполяции опорных пикселов может выполняться после процесса фильтрации опорных пикселов, описанного ниже.
[234] Интерполяция не выполняется в горизонтальных режимах, вертикальных режимах и некоторых диагональных режимах (например, режимах под углом 45 градусов от вертикальной/горизонтальной линии, таких как режимы вверх и вправо по диагонали, вниз и вправо по диагонали и вниз и влево по диагонали, соответствующие режимам 2, 34 и 66 на фиг. 5), ненаправленных режимах, цветовом режиме копирования и т.д. В других режимах (других диагональных режимах), процесс интерполяции может выполняться.
[235] В зависимости от режима прогнозирования (например, направленности режима прогнозирования, dy/dx и т.д.) и позиций опорного пиксела и прогнозного пиксела, может определяться позиция пиксела, который должен интерполироваться (т.е. дробной единицы, которая должна интерполироваться, в пределах от 1/2 в 1/64). В этом случае, может применяться один фильтр (например, такой же фильтр предполагается в уравнении, используемом, чтобы определять коэффициент фильтрации или длину отвода фильтра, но предполагается фильтр, для которого только коэффициент регулируется согласно дробной точности, к примеру, 1/32, 7/32 или 19/32,), либо один из множества фильтров (например, предполагаются фильтры, для которых различные уравнения используются , чтобы определять коэффициент фильтрации, или длину отвода фильтра) может выбираться и применяться согласно дробной единице.
[236] В первом случае, целочисленные пикселы могут использоваться в качестве вводов для интерполяции дробных пикселов, в то время как во втором случае, входной пиксел отличается на каждом этапе (например, целочисленный пиксел используется для 1/2 единицы, и целочисленный пиксел и пиксел в 1/2 единицы используются для 1/4 единицы). Тем не менее, настоящее раскрытие не ограничено этим и описывается в контексте первого случая.
[237] Фиксированная фильтрация или адаптивная фильтрация может выполняться для интерполяции опорных пикселов. Фиксированная фильтрация или адаптивная фильтрация может определяться согласно конфигурации кодирования/декодирования (например, одному или более из типа изображения, цветового компонента, позиции/размера/формы блока, отношения ширины к высоте блока и режима прогнозирования).
[238] В фиксированной фильтрации, интерполяция опорных пикселов может выполняться с использованием одного фильтра, тогда как в адаптивной фильтрации, интерполяция опорных пикселов может использоваться с использованием одного из множества фильтров.
[239] В адаптивной фильтрации, один из множества фильтров может неявно или явно определяться согласно конфигурации кодирования/декодирования. Фильтры могут включать в себя 4-отводный DCT-IF-фильтр, 4-отводный кубический фильтр, 4-отводный гауссов фильтр, 6-отводный фильтр Винера и 8-отводный фильтр Калмана. Поддерживаемая кандидатная группа фильтров может задаваться по-другому (например, типы фильтров являются частично такими же или отличающимися, и длины отводов фильтра являются небольшими или большими) согласно цветовому компоненту.
[240] Поскольку модуль фильтрации опорных пикселов уменьшает оставшееся ухудшение качества в процессе кодирования/декодирования, фильтрация может выполняться для опорных пикселов, для целей увеличения точности прогнозирования. Используемые фильтры могут представлять собой, но не только, фильтры нижних частот. Может определяться, следует или нет применять фильтрацию, согласно конфигурации кодирования/декодирования (извлекается из вышеприведенного описания). Дополнительно, когда фильтрация применяется, может использоваться фиксированная фильтрация или адаптивная фильтрация.
[241] Фиксированная фильтрация означает, что фильтрация опорных пикселов не выполняется, или фильтрация опорных пикселов применяется с использованием одного фильтра. Адаптивная фильтрация означает, следует или нет применять фильтрацию, определяется согласно конфигурации кодирования/декодирования, и когда два или более типов фильтров поддерживаются, один из типов фильтров может выбираться.
[242] Для типов фильтров, могут поддерживаться множество фильтров, отличаемых друг от друга посредством коэффициентов фильтрации, длины отвода фильтра и т.д., к примеру, 3-отводный фильтр [1, 2, 1]/4 и 5-отводный фильтр [2, 3, 6, 3, 2]/16.
[243] Интерполятор опорных пикселов и модуль фильтрации опорных пикселов, описанные относительно этапа конфигурирования опорных пикселов, могут представлять собой компоненты, требуемые, чтобы повышать точность прогнозирования. Два процесса могут выполняться независимо или в комбинации (т.е. в одной фильтрации).
[244] Формирователь прогнозных блоков может формировать прогнозный блок, по меньшей мере, в одном режиме прогнозирования, и опорные пикселы могут использоваться на основе режима прогнозирования. Опорные пикселы могут использоваться в таком способе (направленных режимах), как экстраполяция, или в таком способе (ненаправленных режимах), как интерполяция, усреднение (DC) или копирование.
[245] Модуль принятия решений по режиму прогнозирования выполняет процесс выбора оптимального режима из группы множества кандидатов режимов прогнозирования. В общем, оптимальный режим может определяться с точки зрения затрат на кодирование, с использованием схемы искажения в зависимости от скорости передачи, в которой учитываются искажение в виде блочности (например, искажение, сумма абсолютных разностей (SAD) и сумма квадратов разностей (SSD) текущего блока и восстановленного блока) и число сформированных битов согласно режиму. Прогнозный блок, сформированный на основе режима прогнозирования, определенного в вышеуказанном процессе, может передаваться в модуль вычитания и модуль суммирования.
[246] Во всех режимах прогнозирования из кандидатной группы режима прогнозирования можно выполнять поиск, чтобы определять наилучший режим прогнозирования, или наилучший режим прогнозирования может выбираться в другом процессе принятия решений, чтобы уменьшать объем/сложность вычислений. Например, некоторые режимы, имеющие хорошую производительность с точки зрения ухудшения качества изображений, выбираются из числа всех кандидатов режимов внутреннего прогнозирования на первом этапе, и наилучший режим прогнозирования может выбираться с учетом числа сформированных битов, а также ухудшения качества изображений режимов, выбранных на первом этапе, на втором этапе. Кроме этого способа, могут применяться различные другие способы определения наилучшего режима прогнозирования с уменьшенным объемом/сложностью вычислений.
[247] Дополнительно, хотя модуль принятия решений по режиму прогнозирования, в общем, может включаться только в кодер, он также может включаться в декодер согласно конфигурации кодирования/декодирования, например, когда сопоставление с шаблонами включается в качестве способа прогнозирования, или режим внутреннего прогнозирования извлекается из области, соседней с текущим блоком. Во втором случае, очевидно, что используется способ неявного получения режима прогнозирования в декодере.
[248] Кодер в режиме прогнозирования может кодировать режим прогнозирования, выбранный посредством модуля принятия решений по режиму прогнозирования. Информация относительно индекса режима прогнозирования в кандидатной группе режима прогнозирования может кодироваться, или режим прогнозирования может прогнозироваться, и информация относительно режима прогнозирования может кодироваться. Первый способ может применяться, но не только, к компоненту сигнала яркости, а второй способ может применяться, но не только, к компоненту сигнала цветности.
[249] Когда режим прогнозирования прогнозируется и затем кодируется, прогнозное значение (или информация прогнозирования) режима прогнозирования может упоминаться как наиболее вероятный режим (MPM). MPM могут включать в себя один или более режимов прогнозирования. Число k MPM может определяться согласно числу кандидатных групп режима прогнозирования (k является целым числом, равным или большим 1, к примеру, 1, 2, 3 или 6). Когда предусмотрено множество режимов прогнозирования в качестве MPM, они могут упоминаться как кандидатная группа MPM.
[250] Кандидатная группа MPM может поддерживаться согласно фиксированной конфигурации или согласно адаптивной конфигурации согласно различным факторам кодирования/декодирования. В примере адаптивной конфигурации, конфигурация кандидатных групп может определяться согласно тому, какой слой опорных пикселов используется из множества слоев опорных пикселов, и согласно тому, выполняется внутреннее прогнозирование на уровне блока или на уровне субблока. Для удобства описания, предполагается, что кандидатная группа MPM сконфигурирована согласно одной конфигурации, и следует понимать, что не только кандидатная группа MPM, но также и другие кандидатной группы внутреннего прогнозирования могут быть адаптивно сконфигурированы.
[251] MPM является понятием, поддерживаемым , чтобы эффективно кодировать режим прогнозирования, и кандидатная группа может быть сконфигурирована с режимами прогнозирования, имеющими высокую вероятность фактического использования в качестве режима прогнозирования для текущего блока.
[252] Например, кандидатная группа MPM может включать в себя предварительно установленные режимы прогнозирования (или статистически частые режимы прогнозирования, DC-режим, планарный режим, вертикальные режимы, горизонтальные режимы или некоторые диагональные режимы) и режимы прогнозирования соседних блоков (левого, верхнего, левого верхнего, правого верхнего, левого нижнего блоков и т.д.). Режимы прогнозирования соседних блоков могут получаться от L0 до L3 (левый блок), от T0 до T3 (верхний блок), TL (левый верхний блок), от R0 до R3 (правый верхний блок) и от B0 до B3 (левый нижний блок) на фиг. 7.
[253] Если кандидатная группа MPM может формироваться из двух или более позиций субблоков (например, L0 и L2) в соседнем блоке (например, левом блоке), режимы прогнозирования соответствующего блока могут быть сконфигурированы в кандидатной группе согласно предварительно заданным приоритетам (например, L0-L1-L2). Альтернативно, когда кандидатная группа MPM может не быть сконфигурирована из двух или более позиций субблоков, режим прогнозирования субблока в предварительно заданной позиции (например, L0) может быть сконфигурирован в кандидатной группе. В частности, режимы прогнозирования в позициях L3, T3, TL, R0 и B0 в соседних блоках могут выбираться в качестве режимов прогнозирования соседних блоков и включаться в кандидатную группу MPM. Вышеприведенное описание приводится для случая, в котором режимы прогнозирования соседних блоков сконфигурированы в кандидатной группе, что не должно истолковываться в качестве ограничения настоящего раскрытия сущности. Предполагается, что режим прогнозирования в предварительно заданной позиции сконфигурирован в кандидатной группе в следующем примере.
[254] Когда один или более режимов прогнозирования включаются в кандидатную группу MPM, режим, извлекаемый из ранее включенного одного более режимов прогнозирования, может быть дополнительно сконфигурирован в кандидатной группе MPM. В частности, когда k-ый режим (направленный режим) включается в кандидатную группу MPM, режим, извлекаемый из режима (режим, разнесенный от k-ого режима на расстояние в +a или -b, где каждое из a и b является целым числом, равным или большим 1, к примеру, 1, 2 или 3), может быть дополнительно включен в кандидатную группу MPM.
[255] Режимы могут приоритезироваться для конфигурирования кандидатных групп MPM. Кандидатная группа MPM может быть выполнена с возможностью включать в себя режимы прогнозирования в порядок режима прогнозирования соседнего блока, предварительно установленного режима прогнозирования и извлеченного режима прогнозирования. Процесс конфигурирования кандидатных групп MPM может завершаться посредством заполнения максимального числа кандидатов MPM согласно приоритетам. В вышеуказанном процессе, если режим прогнозирования является таким же как ранее включенный режим прогнозирования, режим прогнозирования может не быть включен в кандидатную группу MPM, и следующий по приоритету кандидат может извлекаться и подвергаться контролю по избыточности.
[256] Дальнейшее описание приводится при условии, что кандидатная группа MPM включает в себя 6 режимов прогнозирования.
[257] Например, кандидатная группа MPM может формироваться в порядке L-T-TL-TR-BL-плоский-DC-вертикальный-горизонтальный-диагональный. Режим прогнозирования соседнего блока может быть включен с приоритетом в кандидатной группе MPM, и затем предварительно установленный режим прогнозирования может быть дополнительно сконфигурирован в этом случае.
[258] Альтернативно, кандидатная группа MPM может формироваться в порядке L-T-плоский-DC-<L+1>-<L-1>-<T+1>-<T-1>-вертикальный-горизонтальный-диагональный. В этом случае, режимы прогнозирования некоторых соседних блоков и некоторые предварительно установленные режимы прогнозирования могут быть включены с приоритетом, и режим, извлекаемый при условии, что режим прогнозирования в направлении, аналогичном направлению соседнего блока, формируется, и некоторые предварительно установленные режимы прогнозирования могут быть дополнительно включены.
[259] Вышеприведенные примеры представляют собой просто часть конфигураций кандидатных групп MPM. Настоящее раскрытие не ограничено этим, и могут быть доступными различные примеры модификаций.
[260] Кандидатная группа MPM может представляться посредством преобразования в двоичную форму, такого как унарное преобразование в двоичную форму или усеченное преобразование в двоичную форму Райса на основе индексов в кандидатной группе. Таким образом, короткие биты могут выделяться кандидату, имеющему небольшой индекс, и длинные биты могут выделяться кандидату, имеющему большой индекс, чтобы представлять биты режима.
[261] Режимы, которые не включаются в кандидатную группу MPM, могут классифицироваться в качестве кандидатной группы не-MPM. Две или более кандидатных групп не-MPM могут задаваться согласно конфигурации кодирования/декодирования.
[262] Дальнейшее описание приводится при условии, что 67 режимов, включающих в себя направленные режимы и ненаправленные режимы, включаются в кандидатную группу режима прогнозирования, 6 кандидатов MPM поддерживаются, и в силу этого кандидатная группа не-MPM включает в себя 61 режим прогнозирования.
[263] Если одна кандидатная группа не-MPM сконфигурирована, это подразумевает, что имеются оставшиеся режимы прогнозирования, которые не включаются в кандидатную группу MPM, и в силу этого дополнительный процесс конфигурации кандидатных групп не требуется. Следовательно, преобразование в двоичную форму, такое как преобразование в двоичную форму фиксированной длины и усеченное унарное преобразование в двоичную форму, может использоваться на основе индексов в кандидатной группе не-MPM.
[264] При условии, что две или более кандидатных групп не-MPM сконфигурированы, кандидатные группы не-MPM классифицируются на non-MPM_A (кандидатную группу A) и non-MPM_B (кандидатную группу B). Предполагается, что кандидатная группа A (p кандидатов, где p равно или выше числа кандидатов MPM) включает в себя режимы прогнозирования, имеющие более высокую вероятность режима прогнозирования текущего блока, чем кандидатная группа B (q кандидатов, где q равно или выше числа кандиатов в кандидатной группе A). В данном документе, может добавляться процесс конфигурирования кандидатной группы A.
[265] Например, некоторые равноотстоящие режимы прогнозирования (например, режимы 2, 4 и 6) из числа направленных режимов могут быть включены в кандидатную группу A, или предварительно установленный режим прогнозирования (например, режим, извлекаемый из режима прогнозирования, включенного в кандидатную группу MPM) может быть включен в кандидатную группу A. Оставшиеся режимы прогнозирования после конфигурации кандидатных групп MPM и конфигурации кандидатной группы A могут формировать кандидатную группу B, и дополнительный процесс конфигурации кандидатных групп не требуется. Преобразование в двоичную форму, такое как преобразование в двоичную форму фиксированной длины и усеченное унарное преобразование в двоичную форму может использоваться на основе индексов в кандидатной группе A и B кандидатной группы.
[266] Вышеприведенные примеры составляют часть случаев, в которых формируются две или более кандидатных групп не-MPM. Настоящее раскрытие не ограничено этим, и различные примеры модификаций являются доступными.
[267] Ниже описывается процесс прогнозирования и кодирования режима прогнозирования.
[268] Информация (mpm_flag), указывающая, совпадает или нет режим прогнозирования текущего блока с MPM (или режимом в кандидатной группе MPM), может проверяться.
[269] Когда режим прогнозирования текущего блока совпадает с MPM, информация MPM-индекса (mpm_idx) дополнительно может проверяться согласно MPM-конфигурации (одной или более конфигураций). После этого, процесс кодирования текущего блока завершается.
[270] Когда режим прогнозирования текущего блока не совпадает ни с одним MPM, если имеется одна сконфигурированная кандидатная группа не-MPM, информация не-MPM-индекса (remaining_idx) может проверяться. После этого, процесс кодирования текущего блока завершается.
[271] Если множество кандидатных групп не-MPM (две в этом примере) сконфигурированы, информация (non_mpm_flag), указывающая, совпадает или нет режим прогнозирования текущего блока с каким-либо режимом прогнозирования в кандидатной группе A, может проверяться.
[272] Если режим прогнозирования текущего блока совпадает с каким-либо кандидатом в кандидатной группе A, информация индекса относительно кандидатной группы A (non_mpm_A_idx) может проверяться, и если режим прогнозирования текущего блока не совпадает ни с одним кандидатом в кандидатной группе A, информация кандидатного индекса B (remaining_idx) может проверяться. После этого, процесс кодирования текущего блока завершается.
[273] Когда конфигурация кандидатной группы режима прогнозирования является фиксированной, режим прогнозирования, поддерживаемый посредством текущего блока, режим прогнозирования, поддерживаемый посредством соседнего блока, и предварительно установленный режим прогнозирования могут использовать такой же числовой индекс прогнозирования.
[274] Когда конфигурация кандидатной группы режима прогнозирования является адаптивной, режим прогнозирования, поддерживаемый посредством текущего блока, режим прогнозирования, поддерживаемый посредством соседнего блока, и предварительно установленный режим прогнозирования могут использовать такой же числовой индекс прогнозирования или различные числовые индексы прогнозирования. Со ссылкой на фиг. 5, приводится дальнейшее описание.
[275] В процессе кодирования в режиме прогнозирования, может выполняться процесс унификации (или регулирования) и т.п. кандидатной группы режима прогнозирования, чтобы конфигурировать кандидатную группу MPM. Например, режим прогнозирования текущего блока может представлять собой один режим прогнозирования из кандидатной группы режима прогнозирования с режимами -5-61, и режим прогнозирования соседнего блока может представлять собой один режим прогнозирования в кандидатной группе с режимами 2-66. В этом случае, поскольку часть (режим 66) режимов прогнозирования соседнего блока не может поддерживаться в качестве режима прогнозирования для текущего блока, процесс унификации режимов прогнозирования в процессе кодирования в режиме прогнозирования может выполняться. Таким образом, этот процесс не может требоваться, когда фиксированная конфигурация кандидатных групп режимов внутреннего прогнозирования поддерживается, и этот процесс может требоваться, когда адаптивная конфигурация кандидатных групп режимов внутреннего прогнозирования поддерживается, что подробно не описывается в данном документе.
[276] В отличие от способа на основе MPM, кодирование может выполняться посредством назначения индексов режимам прогнозирования из кандидатной группы режима прогнозирования.
[277] Например, режимы прогнозирования индексируются согласно предварительно заданным приоритетам. Когда режим прогнозирования выбирается в качестве режима прогнозирования текущего блока, индекс выбранного режима прогнозирования кодируется. Это означает случай, в котором кандидатная группа режима фиксированного прогнозирования сконфигурирована, и фиксированные индексы назначаются режимам прогнозирования.
[278] Альтернативно, когда кандидатная группа режима прогнозирования адаптивно сконфигурирована, способ фиксированного выделения индексов может не быть подходящим. Таким образом, режимы прогнозирования могут индексироваться согласно адаптивным приоритетам. Когда режим прогнозирования выбирается в качестве режима прогнозирования текущего блока, выбранный режим прогнозирования может кодироваться. Этот способ может обеспечивать эффективное кодирование режима прогнозирования, поскольку индексы режимов прогнозирования изменяются вследствие адаптивной конфигурации кандидатной группы режима прогнозирования. Таким образом, адаптивные приоритеты могут быть предназначены , чтобы назначать кандидат с высокой вероятностью выбора в качестве режима прогнозирования текущего блока, индексу, для которого формируются короткие биты режима.
[279] Нижеприведенное описание основано на таком допущении, что 8 режимов прогнозирования, включающих в себя предварительно установленные режимы прогнозирования (направленные режимы и ненаправленные режимы), цветовой режим копирования и цветовой режим, поддерживаются в кандидатной группе режима прогнозирования (случай компонента сигнала цветности).
[280] Например, предполагается, что поддерживаются предварительные установленные четыре режима из числа плоских, DC-, горизонтальных, вертикальных и диагональных режимов (вниз и влево по диагонали в этом примере), один цветовой режим C и три цветовых режима CP1, CP2 и CP3 копирования. Режимы прогнозирования могут индексироваться по существу в порядке предварительно установленного режима прогнозирования, цветового режима копирования и цветового режима.
[281] В этом случае, предварительно установленные режимы прогнозирования, которые представляют собой направленные режимы и ненаправленные режимы и цветовой режим копирования, представляют собой режимы прогнозирования, которые отличаются посредством способов прогнозирования, и в силу этого могут легко идентифицироваться. Тем не менее, цветовой режим может представлять собой направленный режим или ненаправленный режим, который с большой вероятностью должен перекрываться с предварительно установленным режимом прогнозирования. Например, когда цветовой режим представляет собой вертикальный режим, цветовой режим может перекрываться с вертикальным режимом, который представляет собой один из предварительно установленных режимов прогнозирования.
[282] В случае если число кандидатов режимов прогнозирования адаптивно регулируется согласно конфигурации кодирования/декодирования, когда возникает избыточный случай, число кандидатов может регулироваться (8->7). Альтернативно, в случае если число кандидатов режимов прогнозирования сохраняется фиксированным, когда имеется избыточный режим прогнозирования, индексы могут выделяться посредством добавления и рассмотрения другого кандидата. Дополнительно, кандидатная группа режима адаптивного прогнозирования может поддерживаться, даже когда включается переменный режим, такой как цветовой режим. Следовательно, адаптивный случай выделения индексов может рассматриваться в качестве примера конфигурирования кандидатной группы режима адаптивного прогнозирования.
[283] Далее приводится описание адаптивного выделения индексов согласно цветовому режиму. Предполагается, что индексы выделяются по существу в порядке "плоский(0)-вертикальный(1)-горизонтальный(2)-DC(3)-CP1(4)-CP2(5)-CP3(6)-C(7). Дополнительно, если цветовой режим не совпадает ни с одним предварительно установленным режимом прогнозирования, предполагается, что выделение индексов выполняется в вышеуказанном порядке.
[284] Например, если цветовой режим совпадает с одним из предварительно установленных режимов прогнозирования (плоскими, вертикальными, горизонтальными и DC-режимами), режим прогнозирования, совпадающий с индексом 7 цветового режима, заполняется. Предварительно установленный режим прогнозирования (вниз и влево по диагонали), заполняется в индексе (один из 0-3) совпадающего режима прогнозирования. В частности, когда цветовой режим представляет собой горизонтальный режим, индексы могут выделяться в порядке "плоский(0)-вертикальный(1)-вниз и влево по диагонали (2)-DC(3)-CP1(4)-CP2(5)-CP3(6)-горизонтальный (7)".
[285] Альтернативно, когда цветовой режим совпадает с одним из предварительно установленных режимов прогнозирования, совпадающий режим прогнозирования заполняется в индексе 0, и предварительно установленный режим прогнозирования (вниз и влево по диагонали), заполняется в индексе 7 цветового режима. В том случае, если заполненный режим прогнозирования не является существующим индексом 0 (т.е. это не планарный режим), существующая конфигурация индексов может регулироваться. В частности, когда цветовой режим представляет собой DC-режим, индексы могут выделяться в порядке "DC(0)-плоский(1)-вертикальный(2)-горизонтальный(3)-CP1(4)-CP2(5)-CP3(6)-вниз и влево по диагонали(7)".
[286] Вышеприведенный пример представляет собой просто часть адаптивных выделений индексов. Настоящее раскрытие не ограничено этим, и могут быть доступными различные примеры модификаций. Дополнительно, преобразование в двоичную форму, такое как преобразование в двоичную форму фиксированной длины, унарное преобразование в двоичную форму, усеченное унарное преобразование в двоичную форму и усеченное преобразование в двоичную форму Райса может использоваться на основе индексов в кандидатной группе.
[287] В дальнейшем описывается другой пример выполнения кодирования посредством назначения индексов режимам прогнозирования, принадлежащим кандидатной группе режима прогнозирования.
[288] Например, режимы прогнозирования и способы прогнозирования классифицируются на множество кандидатных групп режима прогнозирования, и индекс назначается режиму прогнозирования, принадлежащему соответствующей кандидатной группе, и затем кодируется. В этом случае, кодирование информации выбора кандидатной группы может предшествовать индексному кодированию. Например, направленный режим, ненаправленный режим и цветовой режим, которые представляют собой режимы прогнозирования, в которых прогнозирование выполняется в таком же цветовом пространстве, может принадлежать одной кандидатной группе (называемой "кандидатной группой S"), и цветовой режим копирования, который представляет собой режим прогнозирования, в котором прогнозирование выполняется в другом цветовом пространстве, может принадлежать другой кандидатной группе (называемой "кандидатной группой D").
[289] Нижеприведенное описание основано на таком допущении, что 9 режимов прогнозирования, включающих в себя предварительно установленные режимы прогнозирования, цветовой режим копирования и цветовой режим, поддерживаются в кандидатной группе режима прогнозирования (случай компонента сигнала цветности).
[290] Например, предполагается, что четыре предварительно установленных режима прогнозирования поддерживаются из числа плоских, DC-, горизонтальных, вертикальных и диагональных режимов, один цветовой режим C и четыре цветовых режима CP1, CP2, CP3 и CP4 копирования поддерживаются. Кандидатная группа S может включать в себя 5 кандидатов, представляющих собой предварительно установленные режимы прогнозирования и цветовой режим, и кандидатная группа D может включать в себя 4 кандидата, представляющих собой цветовые режимы копирования.
[291] Кандидатная группа S представляет собой пример адаптивно сконфигурированной кандидатной группы режима прогнозирования. Пример адаптивного выделения индексов описывается выше и в силу этого подробно не описывается в данном документе. Поскольку кандидатная группа D представляет собой пример кандидатной группы режима фиксированного прогнозирования, может использоваться способ фиксированного выделения индексов. Например, индексы могут назначаться в порядке "CP1(0)-CP2(1)-CP3(2)-CP4(3)".
[292] Преобразование в двоичную форму, такое как преобразование в двоичную форму фиксированной длины, унарное преобразование в двоичную форму, усеченное унарное преобразование в двоичную форму и усеченное преобразование в двоичную форму Райса может использоваться на основе индексов в кандидатной группе. Настоящее раскрытие не ограничено вышеприведенным примером, и также могут быть доступными различные примеры модификаций.
[293] Кандидатная группа, к примеру, кандидатная группа MPM для кодирования в режиме прогнозирования, может быть сконфигурирована на уровне блока. Альтернативно, процесс конфигурирования кандидатной группы может опускаться, и может использоваться предварительно определенная кандидатная группа или кандидатная группа, полученная в различных способах. Это может представлять собой конфигурацию, поддерживаемую для целей уменьшающейся сложности.
[294] В примере 1, может использоваться одна предварительно заданная кандидатная группа, либо может использоваться одна из множества предварительно заданных кандидатных групп согласно конфигурации кодирования/декодирования. Например, в случае кандидатных групп MPM, может использоваться предварительно заданная кандидатная группа, например, "плоский-DC-вертикальный-горизонтальный-вниз и влево по диагонали (66 на фиг. 5)-вниз и вправо по диагонали" (34 на фиг. 5). Альтернативно, может быть возможным применять кандидатную группу, сконфигурированную, когда все соседние блоки являются недоступными, из числа конфигураций кандидатных групп MPM.
[295] В примере 2, может использоваться кандидатная группа для блока, который полностью кодирован. Кодированный блок может выбираться на основе порядка кодирования (предварительно определенной схемы сканирования, такой как Z-сканирование, вертикальное сканирование, горизонтальное сканирование и т.п.), или из числа блоков, соседних с текущим блоком, таких как левый, верхний, левый верхний, правый верхний и левый нижний блоки. Тем не менее, соседние блоки могут быть ограничены блоками в позициях единиц сегментации, к которым можно взаимное обращаться с текущим блоком (например, единиц сегментации, имеющих свойства, к которым можно обращаться, даже если блоки принадлежат различным сериям последовательных макроблоков или мозаичным фрагментам, к примеру, различным мозаичным фрагментам, принадлежащим такой же группе мозаичных фрагментов). Если соседний блок принадлежит единице сегментации, которая не обеспечивает возможность обращения (например, когда каждый блок принадлежит различной серии последовательных макроблоков или мозаичному фрагменту и имеет свойства, к которым нельзя взаимно обращаться, например, когда каждый блок принадлежит различной группе этапов), блок в позиции может исключаться из кандидатов.
[296] В этом случае, соседние блоки могут определяться согласно состоянию текущего блока. Например, когда текущий блок является квадратным, кандидатная группа доступных блоков может заимствоваться (или совместно использоваться) из числа блоков, расположенных согласно предварительно определенному первому приоритету. Альтернативно, когда текущий блок является прямоугольным, кандидатная группа доступных блоков может заимствоваться из числа блоков, расположенных согласно предварительно определенному второму приоритету. Второй или третий приоритет может поддерживаться согласно отношению ширины к высоте блока. Для выбора кандидатных блоков, которые должны заимствоваться приоритеты могут задаваться в различных конфигурациях, таких как левый - верхний - правый верхний - левый нижний - левый верхний или верхний - левый - левый верхний - правый верхний - левый нижний. В этом случае, все из первого-третьего приоритетов могут иметь такую же конфигурацию или различные конфигурации, или часть приоритетов может иметь такую же конфигурацию.
[297] Кандидатная группа для текущего блока может заимствоваться из соседних блоков, только с равенством или выше/выше предварительно определенного граничного значения или только с равенством или ниже/ниже предварительно определенного граничного значения. Граничное значение может задаваться как минимальный или максимальный размер блока, который обеспечивает возможность заимствования кандидатной группы. Граничное значение может представляться как ширина (W) блока, высота (H) блока, WxH, W*H и т.п., где каждое из W и H может быть целым числом, равным или большим 4, 8, 16 или 32.
[298] В примере 3, общая кандидатная группа может формироваться из верхнего блока, представляющего собой предварительно определенную группу блоков. Общая кандидатная группа может использоваться для нижних блоков, принадлежащих верхнему блоку. Число нижних блоков может быть целым числом, равным или большим 1, к примеру, 1, 2, 3 или 4.
[299] В этом случае, верхний блок может представлять собой блок-предок (включающий в себя родительский блок) относительно нижних блоков или может представлять собой произвольную группу блоков. Блок-предок может означать блок предварительной сегментации на предыдущем этапе (разность глубины сегментации в 1 или больше) во время сегментации для получения нижних блоков. Например, родительский блок субблоков 0 и 1 для 4N x 2N в кандидате b по фиг. 4 может представлять собой 4N x 4N кандидата a на фиг. 4.
[300] Кандидатная группа для верхнего блока может заимствоваться (или совместно использоваться) из нижних блоков, только при равенстве или выше/выше предварительно определенного первого граничного значения или только при равенстве или ниже/ниже предварительно определенного второго граничного значения.
[301] Граничное значение может задаваться как минимальный размер или максимальный размер блока, для которого разрешается заимствование кандидатных групп. Только одно или оба из граничных значений могут поддерживаться, и граничное значение может выражаться как ширина W, высота H, WxH, W*H и т.п. блока, где каждое из W и H является целым числом 32, 8, 16, 64 или выше.
[302] С другой стороны, кандидатная группа для нижнего блока может заимствоваться из верхнего блока, только при равенстве или выше/выше предварительно определенного третьего граничного значения. Альтернативно, кандидатная группа для нижнего блока может заимствоваться из верхнего блока, только при равенстве или ниже/ниже предварительно определенного четвертого граничного значения.
[303] В этом случае, граничное значение может задаваться как минимальный размер или максимальный размер блока, для которого разрешается заимствование кандидатных групп. Только одно или оба из граничных значений могут поддерживаться, и граничное значение может выражаться как ширина W, высота H, WxH, W*H и т.п. блока, где каждое из W и H является целым числом 4, 8, 16, 32 или выше.
[304] В этом случае, первое граничное значение (или второе граничное значение) может быть равным или выше третьего граничного значения (или четвертого граничного значения).
[305] Заимствование (или совместно использование) кандидатов может избирательно использоваться на основе любого из вышеописанных вариантов осуществления, и заимствование кандидатных групп может избирательно использоваться на основе комбинации, по меньшей мере, двух из первого-третьего вариантов осуществления. Дополнительно, заимствование кандидатных групп может избирательно использоваться на основе любой из подробных конфигураций вариантов осуществления и может избирательно использоваться согласно комбинации одной или более подробных конфигураций.
[306] Дополнительно, может явно обрабатываться информация, указывающая, заимствуется или нет кандидатная группа, информация относительно атрибутов блока (размер/тип/позиция/отношение ширины к высоте), предусмотренных в заимствовании кандидатных групп, и информация относительно состояния сегментации (схема сегментации, тип сегмента, глубина сегментации и т.д.). Дополнительно, факторы кодирования, такие как тип изображения и цветовой компонент, могут выступать в качестве входных переменных в конфигурации заимствования кандидатных групп. Заимствование кандидатных групп может выполняться на основе информации и конфигурации кодирования/декодирования.
[307] Связанная с прогнозированием информация, сформированная посредством кодера в режиме прогнозирования, может передаваться в единицу кодирования и включаться в поток битов.
[308] [309] В способе декодирования видео согласно варианту осуществления настоящего раскрытия сущности, внутреннее прогнозирование может иметь следующую конфигурацию. Внутреннее прогнозирование в модуле прогнозирования может включать в себя этап декодирования в режиме прогнозирования, этап конфигурирования опорных пикселов и этап формирования прогнозных блоков. Дополнительно, оборудование декодирования изображений может быть выполнено с возможностью включать в себя декодер в режиме прогнозирования, модуль конфигурирования опорных пикселов и формирователь прогнозных блоков, которые выполняют этап декодирования в режиме прогнозирования, этап конфигурирования опорных пикселов и этап формирования прогнозных блоков. Часть вышеописанных этапов может опускаться, или другие этапы могут добавляться. Этапы могут выполняться в порядке, отличающемся от порядка, описанного выше.
[310] Поскольку модуль конфигурирования опорных пикселов и формирователь прогнозных блоков оборудования декодирования изображений играют такие же роли со своими аналогами оборудования кодирования изображений, подробное описание модуля конфигурирования опорных пикселов и формирователя прогнозных блоков не предоставляется в данном документе. Декодер в режиме прогнозирования может осуществлять в обратном порядке способ, используемый в кодере в режиме прогнозирования.
[311] [312] Субблочное внутреннее прогнозирование
[313] Фиг. 8 иллюстрирует различные типы субблочных сегментов, которые могут получаться из блока кодирования. Блок кодирования может упоминаться как родительский блок, и субблок может представлять собой дочерний блок. Субблок может представлять собой единицу прогнозирования или единицу преобразования. В этом примере, предполагается, что один фрагмент информации прогнозирования совместно используется субблоками. Другими словами, один режим прогнозирования может формироваться и использоваться в каждом субблоке.
[314] Ссылаясь на фиг. 8, порядок кодирования субблоков может определяться согласно различным комбинациям субблока a - субблока p по фиг. 8. Например, может использоваться одно из Z-сканирования (слева -> направо, сверху -> вниз), вертикального сканирования (сверху -> вниз), горизонтальное сканирование (слева -> направо), обратного вертикального сканирования (снизу -> вверх) и обратного горизонтального сканирования (справа -> налево).
[315] Порядок кодирования может быть предварительно согласован между кодером изображений и декодером изображений. Альтернативно, порядок кодирования субблоков может определяться с учетом направления сегментации родительского блока. Например, когда родительский блок разбивается в горизонтальном направлении, порядок кодирования субблоков может определяться в качестве вертикального сканирования. Когда родительский блок разбивается в вертикальном направлении, порядок кодирования субблоков может определяться в качестве горизонтального сканирования.
[316] Когда кодирование выполняется на основе субблоков, опорные данные, используемые для прогнозирования, могут получаться в более близкой позиции. Поскольку только один режим прогнозирования формируется и совместно используется субблоками, субблочное кодирование может быть эффективным.
[317] Например, ссылаясь на фиг. 8(b), когда кодирование выполняется на уровне родительского блока, правый нижний субблок может прогнозироваться с использованием пикселов, соседних с родительским блоком. С другой стороны, когда кодирование выполняется на уровне субблока, правый нижний субблок может прогнозироваться с использованием более близких пикселов, чем родительский блок, поскольку имеются левый верхний, правый верхний и левый нижний субблоки, восстановленные в предварительно определенном порядке кодирования (Z-сканирование в этом примере).
[318] Для внутреннего прогнозирования, посредством наилучшей сегментации на основе характеристик изображений кандидатная группа может быть сконфигурирована на основе одного или более типов сегментов с высокой вероятностью появления.
[319] В этом примере, предполагается, что информация сегментации формируется с использованием схемы сегментации на основе индексов. Кандидатная группа может формироваться с различными типами сегментов следующим образом.
[320] В частности, кандидатная группа может быть выполнена с возможностью включать в себя N типов сегментов. N может быть целым числом, равным или большим 2. Кандидатная группа может включать в себя комбинацию, по меньшей мере, двух из 7 типов сегментов, проиллюстрированных на фиг. 8.
[321] Родительский блок может разбиваться на предварительно определенные субблоки посредством избирательного использования любого из множества типов сегментов в кандидатной группе. Выбор может осуществляться на основе индекса, передаваемого в служебных сигналах посредством оборудования кодирования изображений. Индекс может означать информацию, указывающую тип сегмента родительского блока. Альтернативно, выбор может осуществляться с учетом атрибутов родительского блока в оборудовании декодирования изображений. Атрибуты могут включать в себя позицию, размер, форму, ширину, отношение ширины к высоте, одно из ширины и высоты, глубину сегментации, тип изображения (I/P/B), цветовой компонент (например, сигнал яркости или сигнал цветности), значение режима внутреннего прогнозирования, представляет ли собой режим внутреннего прогнозирования ненаправленный режим, угол режима внутреннего прогнозирования, позиции опорных пикселов и т.п. Блок может представлять собой блок кодирования или прогнозный блок и/или блок преобразования, соответствующий блоку кодирования. Позиция блока может означать, расположен или нет блок на границе предварительно определенного изображения (или фрагментарного изображения) родительского блока. Изображение (или фрагментарное изображение) может представлять собой по меньшей мере одно из изображения, группы серий последовательных макроблоков, группы мозаичных фрагментов, серии последовательных макроблоков, мозаичного фрагмента, CTU-строки или CTU, которой принадлежит родительский блок.
[322] В примере 1, может быть сконфигурирована кандидатная группа, к примеру, {a-d} или {a-g} по фиг. 8. Кандидатная группа может получаться с учетом различных типов сегментов. В случае кандидатной группы {a-d}, различные двоичные биты могут выделяться каждому индексу (при условии, что индексы выделяются в алфавитном порядке; такое же предположение также высказывается для нижеприведенного примера).
[323] Таблица 1
[324] В вышеприведенной таблице 1, тип 1 элемента разрешения может представлять собой пример преобразования в двоичную форму, в котором рассматриваются все возможные типы сегментов, и тип 2 элемента разрешения может представлять собой пример преобразования в двоичную форму, в котором бит, указывающий, выполняется или нет сегментация (первый бит), выделяется сначала, и когда сегментация выполняется (первый бит задается равным 1), только неразбитый кандидат исключается из доступных типов сегментов.
[325] В примере 2, может формироваться кандидатная группа, к примеру, {a, c, d} или {a, f, g} по фиг. 8, которая может получаться с учетом сегментации в конкретном направлении (горизонтальном или вертикальном направлении). В случае кандидатной группы {a, f, g}, различные двоичные биты могут выделяться каждому индексу.
[326] Таблица 2
[327] Вышеприведенная таблица 2 представляет собой пример преобразования в двоичную форму, выделяемого на основе атрибутов блока, в частности, пример преобразования в двоичную форму, выполняемого с учетом формы блока. В типе 1 элемента разрешения, когда родительский блок является квадратным, 1 бит выделяется, когда родительский блок не разбивается, и 2 бита выделяются, когда родительский блок разбивается на горизонтальное или вертикальное направление.
[328] В типе 2 элемента разрешения, когда родительский блок формируется в прямоугольник, удлиненный горизонтально, выделяется 1 бит, когда родительский блок разбивается в горизонтальном направлении, и 2 бита выделяются оставшимся случаям. Тип 3 элемента разрешения может представлять собой пример выделения 1 бита, когда родительский блок формируется в прямоугольник, удлиненный вертикально. В типе 3 элемента разрешения, 1 бит может выделяться, когда родительский блок разбивается в вертикальном направлении, и 2 бита могут выделяться в оставшихся случаях. Это может представлять собой пример выделения более коротких битов, когда определяется, что сегментация возникает с большой вероятностью дополнительно в форме родительского блока. Тем не менее, настоящее раскрытие не ограничено этим, и также могут быть доступными примеры модификаций, включающие в себя противоположный случай.
[329] В примере 3, может быть сконфигурирована кандидатная группа, к примеру, {a, c, d, f, g} по фиг. 8, которая может представлять собой другой пример конфигурации кандидатных групп, в которой рассматривается сегментация в конкретном направлении.
[330] Таблица 3
[331] В таблице 3 флаг (первый бит), указывающий, выполняется или нет сегментация, сначала выделяется, и после этого флаг, идентифицирующий число сегментаций, выделяется затем в типе 1 элемента разрешения. Если флаг (второй бит), идентифицирующий число сегментаций, задается равным 0, число сегментаций может быть равным 2, и если флаг (второй бит), идентифицирующий число сегментаций, задается равным 1, число сегментаций может быть равным 4. Дополнительно, последующий флаг может указывать направление сегментации. Если последующий флаг равен 0, это может указывать горизонтальную сегментацию, и если последующий флаг равен 1, это может указывать вертикальную сегментацию. Вышеприведенное описание представляет собой просто пример, и настоящее раскрытие не ограничено этим. Следовательно, могут быть доступными различные примеры модификаций, включающие в себя противоположную конфигурацию.
[332] Информация сегментации может поддерживаться в общей ситуации, но может модифицироваться на другую конфигурацию согласно окружению кодирования/декодирования. Таким образом, можно поддерживать исключительную конфигурацию для получения информации сегментации или заменять тип сегмента, представленный посредством информации сегментации, на другой тип сегмента.
[333] Например, может быть предусмотрен тип сегмента, который не поддерживается согласно атрибутам блока. Поскольку свойства блока упомянуты в предыдущем примере, их подробное описание не предоставляется в данном документе. Блок может представлять собой по меньшей мере один из родительского блока или субблока.
[334] Например, предполагается, что поддерживаемые типы сегментов представляют собой {a, f, g} на фиг. 8, и что размер родительского блока составляет 4Mx4N. Если некоторые типы сегментов не поддерживаются вследствие условия минимального значения блока в изображении и существования родительского блока на границе предварительно определенного изображения (или фрагментарного изображения), различные процессы могут выполняться. Для нижеприведенного примера предполагается, что минимальное значение ширины блока в изображении составляет 2M, и минимальное значение площади блока составляет 4*M*N.
[335] Во-первых, кандидатная группа может быть переконфигурирована посредством исключения недоступного типа сегмента. Кандидаты, доступные в существующей кандидатной группе, могут представлять собой 4Mx4N, 4MxN и Mx4N, и кандидатная группа, переконфигурированная без недоступного кандидата (4MxN), может включать в себя типы сегментов 4Mx4N и 4MxN. В этом случае, преобразование в двоичную форму может выполняться снова для кандидатов переконфигурированной кандидатной группы. В этом примере, 4Mx4N или 4MxN может выбираться посредством одного флага (1 бит).
[336] В другом примере, кандидатная группа может быть переконфигурирована посредством замены недоступного типа сегмента на другой. Недоступный тип сегмента может представлять собой тип сегментации в вертикальном направлении (4 сегмента). Тем не менее, можно переконфигурировать кандидатную группу посредством замены другой формы сегмента (например, 2Mx4N), который поддерживает тип сегментации в вертикальном направлении. Это позволяет поддерживать конфигурацию флагов на основе существующей информации сегментации.
[337] Как указано в вышеприведенном примере, кандидатная группа может быть переконфигурирована посредством регулирования числа кандидатов или замены существующего кандидата. Пример включает в себя описание некоторых случаев, и могут быть доступными различные примеры модификаций.
[338] [339] Порядок кодирования субблоков
[340] Можно задавать порядок кодирования для различных субблоков, как проиллюстрировано на фиг. 8. Порядок кодирования может неявно определяться согласно конфигурации кодирования/декодирования. Тип сегмента, тип изображения, цветовой компонент, размер/форма/позиция родительского блока, отношение ширины к высоте блока, информация, связанная с режимом прогнозирования (например, режим внутреннего прогнозирования, позиции используемых опорных пикселов и т.д.), состояние сегментации и т.д. могут быть включены в факторы кодирования/декодирования.
[341] Альтернативно, можно явно обрабатывать порядок кодирования субблоков. В частности, кандидатная группа может быть выполнена с возможностью включать в себя кандидатов с высокой вероятностью появления согласно типу сегмента, и информация выбора для одного из кандидатов может формироваться. Следовательно, кандидаты порядка кодирования, поддерживаемые согласно типу сегмента, могут быть адаптивно сконфигурированы.
[342] Как указано в вышеприведенном примере, субблоки могут кодироваться в одном фиксированном порядке кодирования. Тем не менее, также может применяться адаптивный порядок кодирования.
[343] Ссылаясь на фиг. 8, множество порядков кодирования могут получаться посредством упорядочения a-p различными способами. Поскольку позиции и число полученных субблоков могут варьироваться согласно типам сегментов, может быть важным задавать порядок кодирования, специализированный для каждого типа сегмента. Дополнительно, порядок кодирования не требуется для типа сегмента, проиллюстрированного на фиг. 8(a), в котором сегментация на субблоки не выполняется. Следовательно, когда информация относительно порядка кодирования явно обрабатывается, информация сегментации может сначала проверяться, и затем информация относительно порядка кодирования для субблоков может формироваться на основе выбранной информации относительно типа сегмента.
[344] Ссылаясь на фиг. 8(c), вертикальное сканирование, в котором 0 и 1 применяются к a и b, и обратное сканирование, в котором 1 и 0 применяются к a и b, соответственно, могут поддерживаться в качестве канждидатов, и может формироваться однобитовый флаг для выбора одного из сканирований.
[345] Альтернативно, ссылаясь на фиг. 8(b), могут поддерживаться Z-сканирование с 0-3, применяемыми к d, Z-сканирование, циклически сдвинутое на 90 градусов влево, с 1, 3, 0 и 2, применяемыми к d, обратное Z-сканирование с 3, 2, 1 и 0, применяемыми к d, Z-сканирование, циклически сдвинутое 90 градусов вправо, с 2, 0, 3 и 1, применяемыми к d, и флаг одного или более битов может формироваться, чтобы выбирать одно из сканирований.
[346] Ниже описывается случай, в котором который порядок кодирования субблоков неявно определяется. Для удобства описания, порядок кодирования описывается для случая, в котором типы сегментов (c) {или (f)} и (d) {или (g)} по фиг. 8 получаются (следует обратиться к фиг. 5 на предмет режимов прогнозирования).
[347] Например, когда режимы внутреннего прогнозирования задаются как вертикальные режимы, горизонтальные режимы, режимы вниз и вправо по диагонали (режимы 19-49), режимы вниз и влево по диагонали (режим 51 или выше) и режимы вверх и вправо по диагонали (режим 17 или ниже), могут задаваться вертикальное сканирование и горизонтальное сканирование.
[348] Альтернативно, когда режимы внутреннего прогнозирования представляют собой режимы вниз и влево по диагонали (режим 51 или больше), могут задаваться вертикальное сканирование и обратное горизонтальное сканирование.
[349] Альтернативно, когда режимы внутреннего прогнозирования представляют собой режимы вверх и вправо по диагонали (режим 17 или ниже), могут задаваться обратное вертикальное сканирование и горизонтальное сканирование.
[350] В вышеприведенных примерах, порядок кодирования может быть основан на предварительно определенном порядке сканирования. В этом случае, предварительно определенный порядок сканирования может представлять собой одно из Z-сканирования, вертикального сканирования и горизонтального сканирования. Альтернативно, порядок сканирования может определяться согласно позициям и расстояниям пикселов, к которым обращаются во время внутреннего прогнозирования. С этой целью, дополнительно может рассматриваться обратное сканирование.
[351] [352] Фиг. 9 является примерной схемой, иллюстрирующей опорные пиксельные области, используемые для режимов внутреннего прогнозирования согласно варианту осуществления настоящего раскрытия сущности. Ссылаясь на фиг. 9, можно отметить, что опорные области затеняются согласно направлениям режимов прогнозирования.
[353] Фиг. 9(a) иллюстрирует пример разделения области, соседней с родительским блоком, на левую, верхнюю, левую верхнюю, правую верхнюю и левую нижнюю области. Фиг. 9(b) иллюстрирует левую и левую нижнюю области, к которым обращаются в режиме вверх и вправо по диагонали, фиг. 9(c) иллюстрирует левую область, к которой обращаются в горизонтальном режиме, и фиг. 9(d) иллюстрирует левую, верхнюю и левую верхнюю области, к которым обращаются в режиме вниз и вправо по диагонали. Фиг. 9(e) иллюстрирует верхнюю область, к которой обращаются в вертикальном режиме, и фиг. 9 (f) иллюстрирует верхнюю и правую верхнюю области, к которым обращаются в режиме вниз и влево по диагонали.
[354] Когда прогнозирование выполняется с использованием соседних опорных пикселов (или восстановленных пикселов субблока), предварительное задание порядка кодирования субблоков может преимущественно исключать потребность в отдельной передаче в служебных сигналах связанной информации. Различные типы сегментов являются доступными, и в силу этого нижеприведенные примеры могут предоставляться на основе областей, к которым обращаются (или режимов прогнозирования), на основе типов сегментов.
[355] Фиг. 10 иллюстрирует пример порядков кодирования, доступных в режимах вверх и вправо по диагонали согласно варианту осуществления настоящего раскрытия сущности. Пример, в котором более высокий приоритет назначается левому нижнему соседнему субблоку, может предоставляться на фиг. 10(a)-(g).
[356] Фиг. 11 иллюстрирует пример порядков кодирования, доступных в горизонтальных режимах согласно варианту осуществления настоящего раскрытия сущности. Пример, в котором более высокий приоритет назначается левому соседнему субблоку, может предоставляться на фиг. 11(a)-(g).
[357] Фиг. 12 иллюстрирует пример порядков кодирования, доступных в режимах вниз и вправо по диагонали согласно варианту осуществления настоящего раскрытия сущности. Пример, в котором более высокий приоритет назначается левому верхнему соседнему субблоку, может предоставляться на фиг. 12(a)-(g).
[358] Фиг. 13 иллюстрирует пример порядков кодирования, доступных в вертикальных режимах согласно варианту осуществления настоящего раскрытия сущности. Пример, в котором более высокий приоритет назначается верхнему соседнему субблоку, может предоставляться на фиг. 13(a)-(g).
[359] Фиг. 14 иллюстрирует пример порядков кодирования, доступных в режимах вниз и влево по диагонали согласно варианту осуществления настоящего раскрытия сущности. Пример, в котором более высокий приоритет назначается правому верхнему соседнему субблоку, может предоставляться на фиг. 14(a)-(g).
[360] В вышеприведенных примерах, порядок кодирования задается из соседней области, полностью кодированной/декодированной, и другие примеры модификаций также являются доступными. Дополнительно, различные конфигурации, в которых порядок кодирования задается согласно другим факторам кодирования/декодирования, могут быть возможными.
[361] [362] Фиг. 15 является примерной схемой, иллюстрирующей порядки кодирования с учетом режимов внутреннего прогнозирования и типов сегментов согласно варианту осуществления настоящего раскрытия сущности. В частности, порядок кодирования субблоков может неявно определяться для каждого типа сегмента согласно режиму внутреннего прогнозирования. Дополнительно, описывается пример, при присутствии недоступного типа сегмента, переконфигурирования кандидатной группы посредством замены недоступного типа сегмента другим типом сегмента. Для удобства описания, предполагается, что родительский блок имеет размер 4Mx4N.
[363] Ссылаясь на фиг. 15(a), для субблочного внутреннего прогнозирования, родительский блок может разбиваться на форму 4MxN. В этом примере, может использоваться порядок обратного вертикального сканирования. Если тип сегментов 4MxN является недоступным, родительский блок может разбиваться на сегменты 2Mx2N согласно предварительно определенному приоритету. Поскольку порядок кодирования для этого случая проиллюстрирован на фиг. 15(a), его подробное описание не предоставляется в данном документе. Если тип сегментов 2Mx2N является недоступным, родительский блок может разбиваться на сегменты 4Mx2N следующего приоритета. В связи с этим, может поддерживаться тип сегмента на основе предварительно определенного приоритета, и родительский блок может сегментироваться на субблоки, соответственно. Если все предварительно заданные типы сегментов являются недоступными, можно отметить, что невозможно разбивать родительский блок на субблоки, и в силу этого родительский блок кодируется.
[364] Ссылаясь на фиг. 15(b), для субблочного внутреннего прогнозирования, родительский блок может разбиваться на форму Mx4N. Как показано на фиг. 15(a), предполагается, что порядок кодирования предварительно определяется на основе каждого типа сегмента. Этот пример может пониматься как случай замены в порядке 2Mx2N и 2Mx4N.
[365] Ссылаясь на фиг. 15(c), для субблочного внутреннего прогнозирования, родительский блок может разбиваться на сегменты 2Mx2N. Этот пример может пониматься как случай замены в порядке 4Mx2N и 2Mx4N.
[366] Ссылаясь на фиг. 15(d), для субблочного внутреннего прогнозирования, родительский блок может разбиваться на сегменты 4MxN. Этот пример может пониматься как случай замены в порядке 2Mx2N и 4Mx2N.
[367] Ссылаясь на фиг. 15(e), для субблочного внутреннего прогнозирования, родительский блок может разбиваться на сегменты Mx4N. Этот пример может пониматься как случай замены в порядке 2Mx2N и 2Mx4N.
[368] В вышеприведенных примерах, когда имеется доступный тип сегмента, сегментация на другой тип сегмента в предварительно определенном порядке поддерживается. Различные примеры модификаций являются доступными.
[369] Например, в случае если типы сегментов {4Mx4N, Mx4N, 4MxN} поддерживаются, когда тип сегментов Mx4N или 4MxN является недоступным, этот тип сегмента может заменяться на 2Mx4N или 4Mx2N.
[370] Аналогично вышеприведенным примерам, конфигурация сегментации на субблоки может определяться согласно различным факторам кодирования/декодирования. Поскольку факторы кодирования/декодирования могут извлекаться из вышеприведенного описания сегментации на субблоки, их подробное описание не предоставляется в данном документе.
[371] Дополнительно, когда сегментация на субблоки определяется, прогнозирование и преобразование могут выполняться как есть. Как описано выше, режим внутреннего прогнозирования может определяться на уровне родительского блока, и прогнозирование может выполняться, соответственно.
[372] Дополнительно, преобразование и обратное преобразование могут быть сконфигурированы на основе родительского блока, и преобразование и обратное преобразование могут выполняться на уровне субблока на основе конфигурации на основе родительского блока. Альтернативно, связанная конфигурация может определяться на основе субблоков, и преобразование и обратное преобразование могут выполняться на уровне субблока согласно конфигурации. Преобразование и обратное преобразование могут выполняться на основе одной из вышеуказанных конфигураций.
[373] [374] Способы настоящего раскрытия сущности могут реализовываться как программные инструкции, выполняемые посредством различных компьютерных средств и сохраненные на машиночитаемом носителе. Машиночитаемый носитель может включать в себя программные инструкции, файлы данных и структуры данных отдельно или в комбинации. Программные инструкции, записанные на машиночитаемом носителе, могут быть специально разработанными для настоящего раскрытия сущности или известными специалистам в области техники компьютерного программного обеспечения и в силу этого доступными.
[375] Машиночитаемый носитель может включать в себя аппаратное устройство, специально выполненное с возможностью сохранять и выполнять программные инструкции, к примеру, постоянное запоминающее устройство (ROM), оперативное запоминающее устройство (RAM), флэш-память и т.п. Программные инструкции могут включать в себя машинный код, который формируется посредством компилятора, или код высокоуровневого языка, который может выполняться в компьютере посредством интерпретатора. Вышеописанное аппаратное устройство может быть выполнено с возможностью работать в качестве одного или более программных модулей, чтобы выполнять операции согласно настоящему раскрытию, и наоборот.
[376] Дополнительно, вышеописанный способ или оборудование могут реализовываться при полной или частичной комбинации или разделении их конфигураций или функций.
[377] Хотя настоящее раскрытие описано выше со ссылкой на предпочтительные варианты осуществления настоящего раскрытия сущности, специалисты в данной области техники должны понимать, что различные модификации и варьирования могут вноситься в настоящее раскрытие без отступления от объема и сущности настоящего раскрытия сущности.
Промышленная применимость
[378] Настоящее раскрытие может использоваться при кодировании/декодировании изображений.
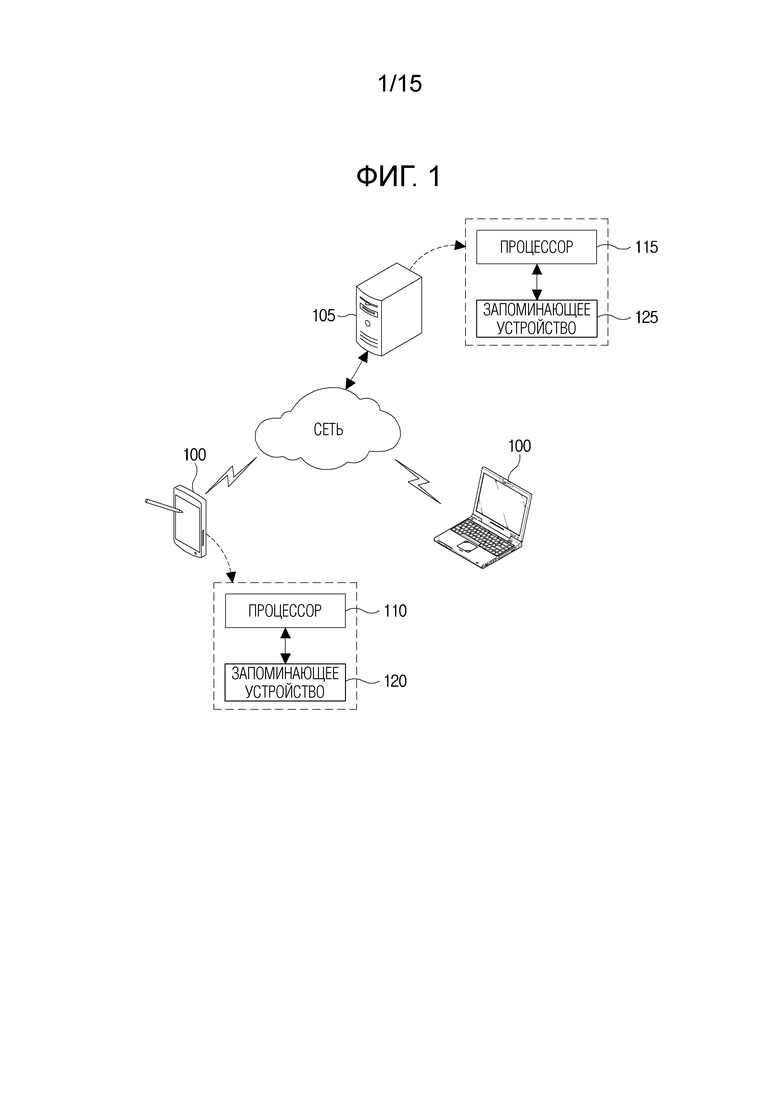


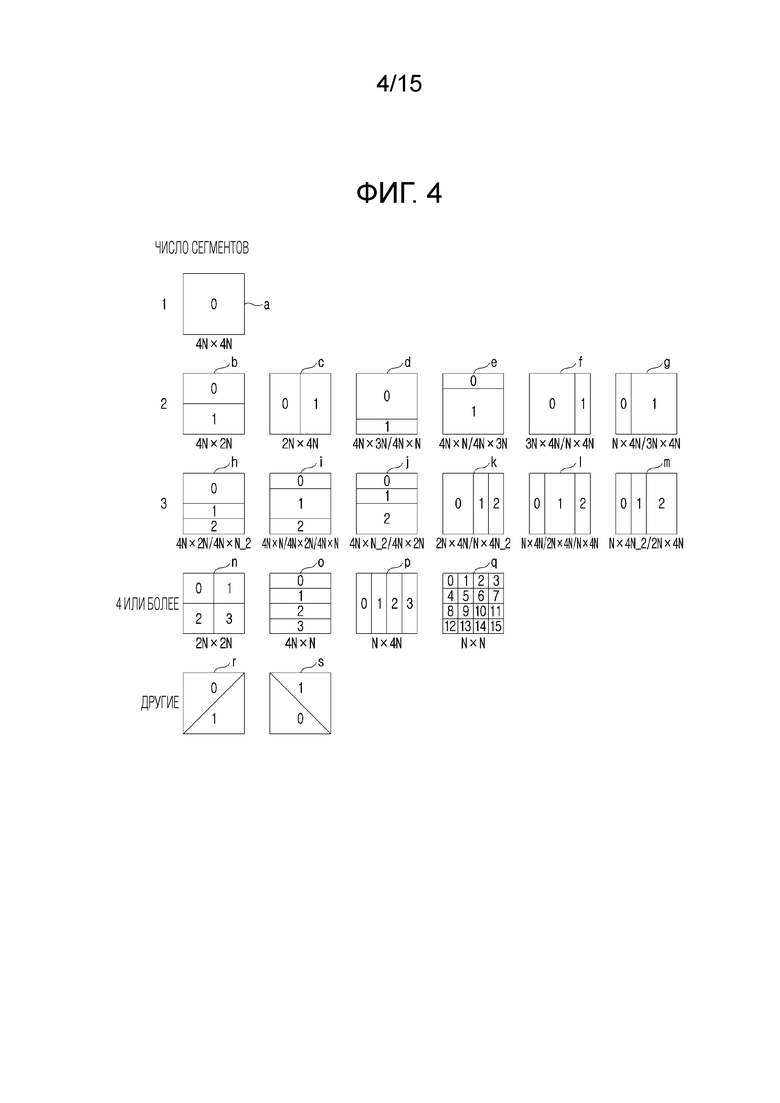





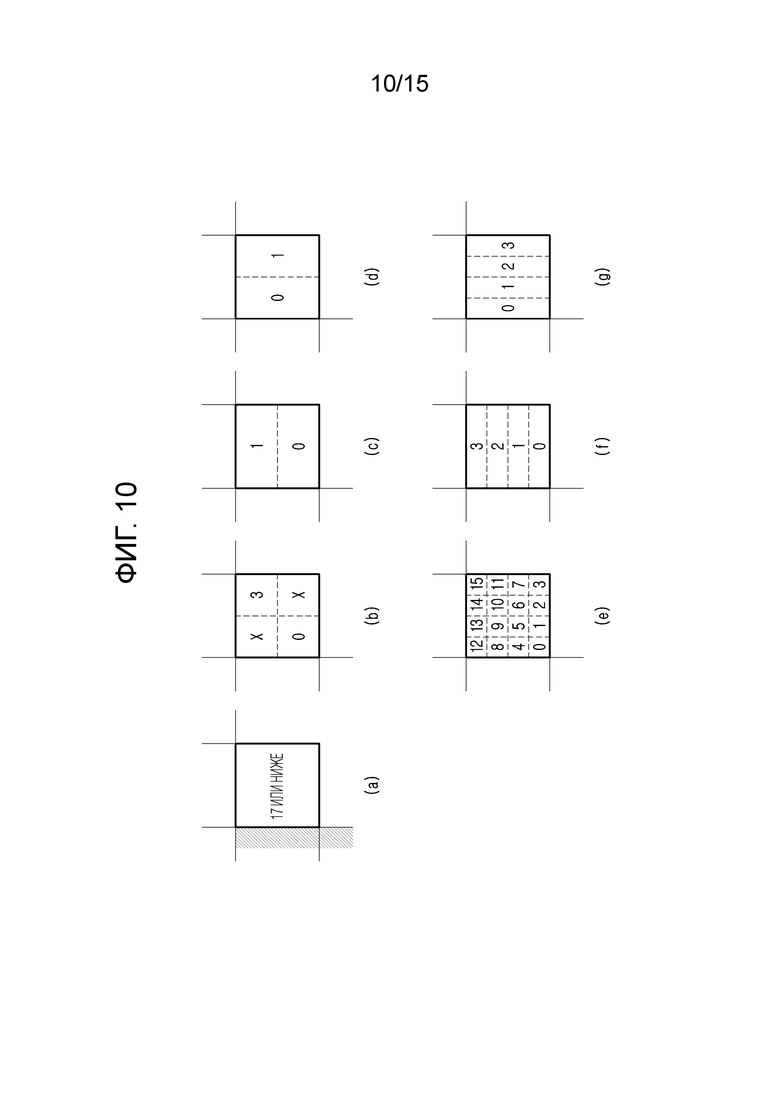

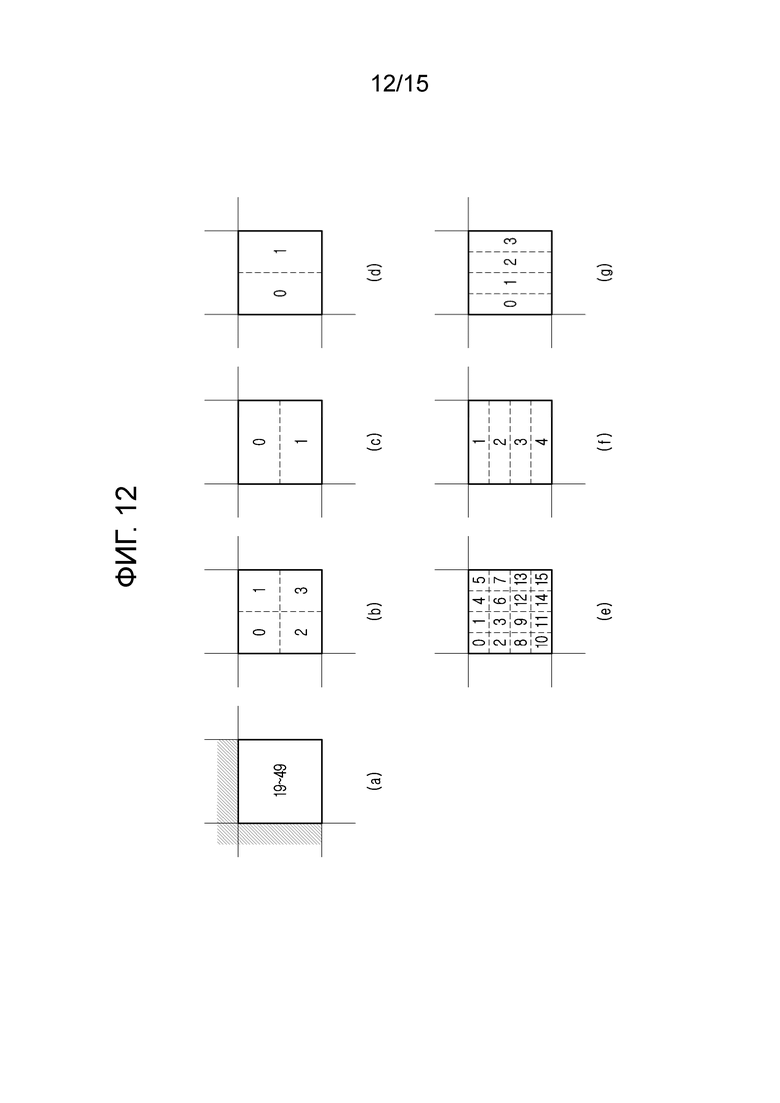


Группа изобретений относится к технологиям кодирования и декодирования изображений. Техническим результатом является повышение производительности обработки изображений за счет учета информации сегментации при внутреннем прогнозировании. Предложен способ внутреннего прогнозирования. Согласно способу, разделяют, на основе информации сегментации блока кодирования, блок кодирования на множество субблоков, причем информация сегментации включает в себя по меньшей мере одну из первой информации сегментации, указывающей следует или нет разделять на четыре субблока, второй информации сегментации, указывающей, следует или нет разделять на два субблока, или третьей информации сегментации, указывающей направление сегментации. Далее определяют порядок кодирования упомянутых субблоков на основе информации сегментации. 3 н. и 8 з.п. ф-лы, 3 табл., 15 ил.
1. Способ внутреннего прогнозирования, содержащий этапы, на которых:
- разделяют, на основе информации сегментации блока кодирования, блок кодирования на множество субблоков, причем информация сегментации включает в себя по меньшей мере одну из первой информации сегментации, указывающей следует или нет разделять на четыре субблока, второй информации сегментации, указывающей, следует или нет разделять на два субблока, или третьей информации сегментации, указывающей направление сегментации;
- определяют порядок кодирования упомянутых субблоков на основе информации сегментации; и
- формируют прогнозный блок каждого субблока на основе порядка кодирования субблоков и режима внутреннего прогнозирования каждого субблока.
2. Способ по п. 1, в котором порядок кодирования определяется на основе того, разделяется блок кодирования в вертикальном направлении или горизонтальном направлении, согласно третьей информации сегментации.
3. Способ по п. 2, в котором порядок кодирования определяется за счет дополнительного учета того, является или нет форма блока кодирования неквадратной, при этом ширина больше высоты.
4. Способ по п. 3, в котором порядок кодирования определяется за счет дополнительного учета размера блока кодирования.
5. Способ по п. 4, в котором определение порядка кодирования блока кодирования содержит этап, на котором получают, из потока битов, информацию выбора, указывающую один из предварительно заданных кандидатов порядка кодирования, и
- при этом порядок кодирования определяется посредством дополнительного учета полученной информации выбора.
6. Способ по п. 5, в котором предварительно заданные кандидаты порядка кодирования включают в себя горизонтальное сканирование и обратное горизонтальное сканирование.
7. Способ по п. 6, в котором прогнозный блок формируется посредством использования соседнего блока текущего блока,
- при этом текущий блок представляет один из субблоков, и
- при этом соседний блок включает в себя по меньшей мере одно из левого соседнего блока, верхнего соседнего блока, левого верхнего соседнего блока, левого нижнего соседнего блока или правого верхнего соседнего блока.
8. Способ по п. 7, в котором соседний блок дополнительно включает в себя по меньшей мере одно из правого соседнего блока или правого нижнего соседнего блока.
9. Способ по п. 8, в котором позиция соседнего блока для внутреннего прогнозирования текущего блока переменно определяется на основе определенного порядка кодирования.
10. Способ внутреннего прогнозирования, содержащий этапы, на которых:
- определяют информацию сегментации для разделения блока кодирования на множество субблоков, причем информация сегментации включает в себя по меньшей мере одну из первой информации сегментации, указывающей следует или нет разделять на четыре субблока, второй информации сегментации, указывающей следует или нет разделять на два субблока, или третьей информации сегментации, указывающей направление сегментации;
- определяют порядок кодирования субблоков на основе информации сегментации; и
- формируют прогнозный блок каждого субблока на основе порядка кодирования субблоков и режима внутреннего прогнозирования каждого субблока.
11. Машиночитаемый носитель, имеющий сохраненные на нем инструкции, которые, при выполнении посредством процессора, осуществляют способ, содержащий:
- разделение, на основе информации сегментации блока кодирования, блока кодирования на множество субблоков, причем информация сегментации включает в себя по меньшей мере одну из первой информации сегментации, указывающей следует или нет разделять на четыре субблока, второй информации сегментации, указывающей следует или нет разделять на два субблока, или третьей информации сегментации, указывающей направление сегментации;
- определение порядка кодирования субблоков на основе информации сегментации; и
- формирование прогнозного блока каждого субблока на основе порядка кодирования субблоков и режима внутреннего прогнозирования каждого субблока.
| WO 2017131233 A1, 03.08.2017 | |||
| US 20170118472 A1, 27.04.2017 | |||
| Многоступенчатая активно-реактивная турбина | 1924 |
|
SU2013A1 |
| Автомобиль-сани, движущиеся на полозьях посредством устанавливающихся по высоте колес с шинами | 1924 |
|
SU2017A1 |
| Токарный резец | 1924 |
|
SU2016A1 |
| СПОСОБ КОДИРОВАНИЯ ВИДЕОСИГНАЛА ПУТЕМ ПРЕДСКАЗАНИЯ РАЗБИЕНИЯ ТЕКУЩЕГО БЛОКА, СПОСОБ ДЕКОДИРОВАНИЯ И СООТВЕТСТВУЮЩИЕ УСТРОЙСТВА И КОМПЬЮТЕРНЫЕ ПРОГРАММЫ КОДИРОВАНИЯ И ДЕКОДИРОВАНИЯ | 2013 |
|
RU2648571C2 |

