Область техники, к которой относится изобретение
[1] Настоящая технология относится в целом к компьютерной кластеризации документов и, в частности, к способу и системе для кластеризации документов с использованием обобщенного параметра метрики.
Уровень техники
[2] По мере увеличения количества пользователей, имеющих доступ к сети Интернет, возникает огромное количество интернет-сервисов. В качестве примера таких сервисов можно привести поисковые системы (такие как Yandex™, Google™ и т.п.), социальные сети (такие как Facebook™), мультимедийные сервисы (такие как Instagram™ и YouTube™) и сервисы агрегаторов новостей (такие как Yandex.News™). В частности, последний сервис полезен тем, что позволяет пользователям легко просматривать новостные статьи на одной платформе.
[3] Интерес к технологиям в сфере агрегирования цифровых новостей постоянно растет. Новости представляют собой очень важную часть повседневной жизни биржевого брокера, научного работника или юриста. Благодаря сервису агрегирования новостей пользователь может быть в курсе самых свежих новостей без частого посещения большого количества отдельных веб-сайтов (например, связанных с отдельными новостными агентствами или с отдельными газетами) для проверки возможных обновлений контента.
[4] В общем случае, сервисы агрегирования новостей могут выполнять алгоритмы кластеризации для группировки связанных друг с другом новостных документов с целью их представления пользователям. Например, новостные документы могут быть сгруппированы по темам, таким как политика, бизнес, спорт, музыка и т.п. Поскольку в настоящее время доступно большое количество источников новостей, конкретная новость может быть освещена множеством источников новостей и содержать сходную или незначительно отличающуюся информацию. Например, статья о новом научном достижении, таком как открытие новой субатомной частицы, может быть представлена различными источниками новостей с разными уровнями сложности контента: специализированный источник новостей (такой как журнал, предназначенный для энтузиастов науки) может более подробно изложить новость, чем популярный источник новостей (такой как таблоид, ориентированный на широкую публику).
[5] В патенте US 8312049 B2 «News group clustering based on cross-post graph» (Microsoft, выдан 13 ноября 2012 г.) описано построение взвешенного графа с использованием подмножества групп новостей, представленных в виде вершин графа, и перекрестных связей между двумя группами новостей из подмножества групп новостей, представленных в виде ребер между вершинами, соответствующими двум группам новостей.
[6] В патенте US 7797265 B2 ((Document clustering that applies a locality sensitive hashing function to a feature vector to obtain a limited set of candidate clusters» (Siemens, выдан 14 сентября 20101 г.) описана кластеризация документов из потока данных путем первоначального формирования вектора признаков для каждого документа. Набор центроидов кластера (например, векторов признаков соответствующих кластеров) извлекается из памяти на основе вектора признаков документа с использованием локально-чувствительной хеш-функции. Центроиды могут быть получены из таблицы кластеров путем извлечения набора идентификаторов кластеров, каждый из которых указывает на соответствующий центроид кластера, и могут быть получены из памяти путем извлечения центроидов кластеров, соответствующих полученным идентификаторам кластеров. Затем возможна кластеризация документов в один или несколько возможных кластеров с использованием расстояний от вектора признаков документа до центроидов кластеров.
Раскрытие изобретения
[7] Целью настоящего изобретения является устранение по меньшей мере некоторых недостатков известных решений. Варианты осуществления настоящей технологии позволяют реализовать и/или расширить арсенал подходов и/или способов достижения целей в настоящей технологии.
[8] Разработчики настоящей технологии обнаружили по меньшей мере одну техническую проблему, связанную с известными решениями.
[9] Разработчики настоящей технологии обнаружили, что для кластеризации статей, поступивших из множества источников новостей и касающихся одного события, согласно некоторым известным подходам требуется анализ контента всех статей, определение подобия контента, определение количества статей, которые должны быть объединены в один кластер, и определение имени кластера.
[10] Разработчики настоящей технологии также обнаружили, что кластер, содержащий документы, касающиеся некоторой темы или некоторого события, может содержать избыточную информацию, поскольку два или более документов в кластере могут поступать из различных источников и могут описывать эту тему или это событие сходным образом без предоставления какой-либо дополнительной полезной информации, что приводит к бесполезным затратам времени пользователя, а также к перерасходу пропускной способности канала связи и заряда аккумулятора в клиентском устройстве, поскольку путем прочтения двух или более статей пользователь может не получить больше информации, чем путем прочтения одной из этих статей.
[11] Безотносительно какой-либо конкретной теории, варианты осуществления настоящей технологии разработаны на основе понимания разработчиками того, что алгоритм кластеризации может быть способным выполнять объединение документов в кластеры на основе оценочной метрики, объединяющей две другие оценочные метрики. Алгоритм кластеризации, способный выполнять кластеризацию документов на основе такой обобщенной метрики (или обобщенной оценочной метрики) может автоматически формировать кластеры из множества документов и группировать в одном кластере документы, относящиеся к одному событию и/или теме. Такая обобщенная оценочная метрика позволяет измерять, насколько контент документов в кластере сходен или взаимно дополняет друг друга, а также учитывать степень разбавления информации в кластере. Обобщенная оценочная метрика, определенная для потенциального кластера, содержащего документы кластера и новый документ, позволяет измерять влияние добавления нового документа в кластер на взаимное дополнение контента этих документов и на разбавление контента этих документов, т.е. насколько информация из нового документа, добавляемого в кластер, разбавляет или уменьшает точность информации, относящейся к теме и/или событию, которому посвящены другие документы в кластере, с учетом влияния на избыточность информации, представленной в кластере. Например, такой подход позволяет формировать кластеры так, чтобы информация, предоставляемая каждым документом в кластере, была дополняющей, таким образом максимизируя «полную» информацию, представленную в кластере, с учетом избыточности или разбавления информации в кластере, при этом минимизируя количество документов в кластере. В результате пользователю может потребоваться чтение меньшего количества документов в каждом кластере для получения достаточной части информации, содержащейся во всем множестве документов этого кластера.
[12] Кроме того, разработчики настоящей технологии обнаружили, что такой подход может сокращать потребность в ручном определении окончательного количества кластеров и позволять автоматически останавливать процесс кластеризации.
[13] Такая технология позволяет экономить ресурсы на сервере путем более эффективной кластеризации документов, а также сокращать потери пропускной способности каналов связи и ресурсов, таких как заряд аккумулятора, в клиентских устройствах путем предоставления пользователям более «репрезентативных» документов для некоторой темы или некоторого события. В результате пользователям не требуется просматривать все документы для получения информации относительно этой темы или этого события.
[14] Несмотря на то, что настоящая технология описана в контексте сервисов агрегирования новостей, предоставляющих новостные документы, специалисту в данной области должно быть понятно, что она может применяться для цифровых документов других видов, допускающих объединение, таких как музыка, видеоматериалы и т.д., без выхода за границы настоящей технологии.
[15] Согласно первому аспекту настоящей технологии реализован выполняемый сервером, реализующим алгоритм кластеризации, компьютерный способ формирования кластеров документов с использованием алгоритма кластеризации, при этом каждый кластер документов содержит документы, имеющие по меньшей мере одну общую тему. Способ включает в себя получение первого документа и второго документа, содержащих контент документа. Способ определяет для потенциального кластера, содержащего первый и второй документ: обновленный первый параметр метрики, указывающий на степень взаимного дополнения контента документов в потенциальном кластере, если первый документ и второй документ объединяются в этом потенциальном кластере; обновленный второй параметр метрики, указывающий на степень разбавления контента документов в потенциальном кластере, если первый документ и второй документ объединяются в этом потенциальном кластере; и обновленный обобщенный параметр метрики на основе обновленного первого параметра метрики и обновленного1 (1 В тексте источника пропущено выделенное слово. В переводе исправлено.) второго параметра метрики. Затем способ на основе обновленного обобщенного параметра метрики формирует кластер, содержащий первый документ и второй документ.
[16] В некоторых вариантах осуществления способ перед определением обновленного первого параметра метрики для потенциального кластера дополнительно включает в себя определение для первого документа и для второго документа первого параметра метрики, второго параметра метрики и обобщенного параметра метрики на основе первого параметра метрики и второго параметра метрики, при этом кластер формируется, если обновленный обобщенный параметр метрики потенциального кластера превышает обобщенный параметр метрики первого документа и/или второго документа.
[17] В некоторых вариантах осуществления способа он дополнительно включает в себя сохранение сервером обновленного обобщенного параметра метрики в качестве обобщенного параметра метрики кластера.
[18] В некоторых вариантах осуществления способа кластер представляет собой первый кластер; получение включает в себя получение множества документов, каждый из которых содержит контент документа, при этом множество документов содержит первый документ и второй документ; определение включает в себя определение первого параметра метрики, второго параметра метрики и обновленного обобщенного параметра метрики для каждого возможного потенциального кластера, содержащего пару документов из множества документов; а формирование первого кластера, содержащего первый документ и второй документ, на основе обобщенного параметра метрики дополнительно основано на превышении обновленным обобщенным параметром метрики потенциального кластера, содержащего первый документ и второй документ, обновленных обобщенных параметров метрики оставшихся потенциальных кластеров, содержащих пару документов из множества документов.
[19] В некоторых вариантах осуществления способа он дополнительно включает в себя: определение сервером для каждого потенциального кластера, содержащего документы из первого кластера и оставшийся документ из множества документов обновленного первого параметра метрики, указывающего на степень взаимного дополнения контента документов в потенциальном кластере, если оставшийся документ объединяется с документами первого кластера в этом потенциальном кластере; обновленного второго параметра метрики, указывающего на степень разбавления контента документов в потенциальном кластере, если оставшийся документ объединяется с документами первого кластера в этом потенциальном кластере; и обновленного обобщенного параметра метрики на основе обновленного первого параметра метрики и обновленного второго параметра метрики; добавление третьего документа в первый кластер, если один из обновленных обобщенных параметров метрики превышает обобщенный параметр метрики первого кластера, при этом третий документ представляет собой оставшийся документ из множества документов, который в случае его объединения с документами первого кластера имеет один из обновленных обобщенных параметров метрики, превышающий обобщенный параметр метрики первого кластера; и сохранение сервером этого одного из обновленных обобщенных параметров метрики в качестве обобщенного параметра метрики первого кластера.
[20] В некоторых вариантах осуществления способа он дополнительно включает в себя закрытие первого кластера без добавления третьего документа, если все обновленные обобщенные параметры метрики оказываются меньшими обобщенного параметра метрики первого кластера.
[21] В некоторых вариантах осуществления способа он дополнительно включает в себя повторение способа для оставшихся документов из множества документов до тех пор, пока все обновленные обобщенные параметры метрики не окажутся меньшими обобщенного параметра метрики первого кластера, и закрытие первого кластера, когда все обновленные обобщенные параметры метрики оказываются меньшими обобщенного параметра метрики первого кластера.
[22] В некоторых вариантах осуществления способа он дополнительно включает в себя: определение сервером для каждого потенциального кластера, содержащего пару оставшихся документов из множества документов, не содержащих документов из первого кластера, обновленного2 (2 В тексте источника пропущено выделенное слово. В переводе исправлено.) первого параметра метрики, указывающего на степень взаимного дополнения контента документов из пары оставшихся документов, если они объединяются в этом потенциальном кластере, обновленного второго параметра метрики, при этом обновленный второй параметр метрики указывает на степень разбавления контента документов в потенциальном кластере, если пара оставшихся документов объединяется в этом потенциальном кластере, и обновленного обобщенного параметра метрики на основе обновленного первого параметра метрики и обновленного второго параметра метрики; при превышении одним из обновленных обобщенных параметров метрики обновленных обобщенных параметров метрики оставшихся потенциальных кластеров формирование сервером второго кластера, содержащего пару документов, имеющих в случае их объединения этот один из обновленных обобщенных параметров метрики; и сохранение сервером этого одного из обновленных обобщенных параметров метрики в качестве обобщенного параметра метрики второго кластера.
[23] В некоторых вариантах осуществления способа он дополнительно включает в себя: определение сервером для каждого потенциального кластера, содержащего документы из второго кластера и оставшийся документ из множества документов, обновленного первого параметра метрики, указывающего на степень взаимного дополнения контента документов в потенциальном кластере, если оставшийся документ объединяется с документами второго кластера, обновленного второго параметра метрики, указывающего на степень разбавления контента документов в потенциальном кластере, если оставшийся документ объединяется с документами второго кластера, и обновленного обобщенного параметра метрики на основе обновленного первого параметра метрики и обновленного второго параметра метрики; добавление сервером четвертого документа во второй кластер, если один из обновленных обобщенных параметров метрики превышает обобщенный параметр метрики второго кластера, при этом четвертый документ представляет собой оставшийся документ из множества документов, который в случае его объединения с документами второго кластера имеет один из обновленных обобщенных параметров метрики, превышающий обобщенный параметр метрики второго кластера; сохранение сервером этого одного из обновленных обобщенных параметров метрики в качестве обобщенного параметра метрики второго кластера.
[24] В некоторых вариантах осуществления способа он дополнительно включает в себя повторение способа для оставшихся документов из множества документов с целью получения набора кластеров, содержащего по меньшей мере первый кластер и второй кластер.
[25] В некоторых вариантах осуществления способа он после получения множества документов дополнительно включает в себя формирование сервером вектора документа для каждого документа из множества документов на основе по меньшей мере части контента соответствующего документа, при этом определение обновленного первого параметра метрики для потенциального кластера основано на расстояниях между векторами документов в потенциальном кластере, а определение обновленного второго параметра метрики для потенциального кластера основано на расстояниях между векторами документов в потенциальном кластере и на размере этого потенциального кластера.
[26] В некоторых вариантах осуществления способа первый документ представляет собой первый кластер, содержащий множество документов первого кластера, а второй документ представляет собой второй кластер, содержащий множество документов второго кластера.
[27] В некоторых вариантах осуществления способа первый кластер и второй кластер имеют обобщенный параметр метрики, а кластер формируется, если этот обновленный обобщенный параметр метрики превышает обобщенный параметр метрики первого кластера и обобщенный параметр метрики второго кластера.
[28] В некоторых вариантах осуществления способа он дополнительно включает в себя сохранение первого кластера и второго кластера в качестве отдельных кластеров, если обобщенный параметр метрики оказывается меньшим обобщенного параметра метрики первого кластера и обобщенного параметра метрики второго кластера.
[29] В некоторых вариантах осуществления способа определение обновленного первого параметра метрики дополнительно основано на расстояниях между векторами документов первого кластера, расстояниях между векторами документов второго кластера и расстояниях между векторами документов первого кластера и второго кластера, а определение обновленного второго параметра метрики для потенциального кластера дополнительно основано на расстояниях между векторами документов первого кластера, расстояниях между векторами документов второго кластера, расстояниях между векторами документов первого кластера и второго кластера и размере этого потенциального кластера, который представляет собой сумму размеров первого кластера и второго кластера.
[30] В некоторых вариантах осуществления способа контент документа включает в себя заголовок документа и контент тела документа.
[31] Согласно другому аспекту настоящей технологии реализована система для формирования с использованием алгоритма кластеризации кластеров документов, каждый из которых содержит документы, имеющие по меньшей мере одну общую тему. Система содержит процессор и машиночитаемый физический носитель информации, содержащий команды. Процессор при исполнении команд способен получать первый документ и второй документ, содержащие контент документа. Процессор способен определять для потенциального кластера, содержащего первый и второй документ, обновленный первый параметр метрики, указывающий на степень взаимного дополнения контента документов в потенциальном кластере, если первый документ и второй документ объединяются в этом потенциальном кластере, обновленный второй параметр метрики, указывающий на степень разбавления контента документов в потенциальном кластере, если первый документ и второй документ объединяются в этом потенциальном кластере, и обновленный обобщенный параметр метрики на основе обновленного первого параметра метрики и обновленного второго параметра метрики. Процессор способен на основе обновленного обобщенного параметра метрики формировать кластер, содержащий первый документ и второй документ.
[32] В некоторых вариантах осуществления системы процессор перед определением обновленного первого параметра метрики для потенциального кластера дополнительно способен определять для первого документа и для второго документа первый параметр метрики, второй параметр метрики и обобщенный параметр метрики на основе первого параметра метрики и второго параметра метрики, при этом кластер формируется, если обобщенный параметр метрики потенциального кластера превышает обобщенные параметры метрики первого документа и второго документа.
[33] В некоторых вариантах осуществления системы процессор дополнительно способен сохранять обновленный обобщенный параметр метрики в качестве обобщенного параметра метрики кластера.
[34] В некоторых вариантах осуществления системы кластер представляет собой первый кластер; получение включает в себя получение множества документов, каждый из которых содержит контент документа, при этом множество документов содержит первый документ и второй документ; определение включает в себя определение первого параметра метрики, второго параметра метрики и обновленного обобщенного параметра метрики для каждого возможного потенциального кластера, содержащего пару документов из множества документов; формирование на основе обобщенного параметра метрики первого кластера, содержащего первый документ и второй документ, дополнительно основано на превышении обновленным обобщенным параметром метрики потенциального кластера, содержащего первый документ и второй документ, обновленных обобщенных параметров метрики оставшихся потенциальных кластеров, содержащих пару документов из множества документов.
[35] В некоторых вариантах осуществления системы процессор дополнительно способен: определять для каждого потенциального кластера, содержащего документы из первого кластера и оставшийся документ из множества документов обновленный первый параметр метрики, указывающий на степень взаимного дополнения контента документов в потенциальном кластере, если оставшийся документ объединяется с документами первого кластера в этом потенциальном кластере, обновленный второй параметр метрики, указывающий на степень разбавления контента документов в потенциальном кластере, если оставшийся документ объединяется с документами первого кластера в этом потенциальном кластере, и обновленный обобщенный параметр метрики на основе обновленного первого параметра метрики и обновленного второго параметра метрики;
[36] добавлять третий документ в первый кластер, если один из обновленных обобщенных параметров метрики превышает обобщенный параметр метрики первого кластера, при этом третий документ представляет собой оставшийся документ из множества документов, который в случае его объединения с документами первого кластера имеет один из обновленных обобщенных параметров метрики, превышающий обобщенный параметр метрики первого кластера; и сохранять этот один из обновленных обобщенных параметров метрики в качестве обобщенного параметра метрики первого кластера.
[37] В некоторых вариантах осуществления системы процессор дополнительно способен закрывать первый кластер без добавления третьего документа, если все обновленные обобщенные параметры метрики оказываются меньшими обобщенного параметра метрики первого кластера.
[38] В некоторых вариантах осуществления системы процессор дополнительно способен повторять выполнение команд для оставшихся документов из множества документов до тех пор, пока все обновленные обобщенные параметры метрики не окажутся меньшими обобщенного параметра метрики первого кластера, и закрывать первый кластер, если все обновленные обобщенные параметры метрики оказываются меньшими обобщенного параметра метрики первого кластера.
[39] В некоторых вариантах осуществления системы процессор дополнительно способен: определять для каждого потенциального кластера, содержащего пару оставшихся документов из множества документов, не содержащих документов из первого кластера, обновленный первый параметр метрики, указывающий на степень взаимного дополнения контента документов из пары оставшихся документов, если они объединяются в потенциальном кластере, обновленный второй параметр метрики, при этом обновленный второй параметр метрики указывает на степень разбавления контента документов в потенциальном кластере, если пара оставшихся документов объединяется в этом потенциальном кластере, и обновленный обобщенный параметр метрики на основе обновленного первого параметра метрики и обновленного второго параметра метрики; при превышении одним из обновленных обобщенных параметров метрики обновленных обобщенных параметров метрики оставшихся потенциальных кластеров формировать второй кластер, содержащий пару документов, имеющих в случае их объединения этот один из обобщенных параметров метрики; сохранять этот один из обобщенных параметров метрики в качестве обобщенного параметра метрики второго кластера.
[40] В некоторых вариантах осуществления системы процессор дополнительно способен: определять для каждого потенциального кластера, содержащего документы из второго кластера и оставшийся документ из множества документов обновленный первый параметр метрики, указывающий на степень взаимного дополнения контента документов в потенциальном кластере, если оставшийся документ объединяется с документами второго кластера, обновленный второй параметр метрики, указывающий на степень разбавления контента документов в потенциальном кластере, если оставшийся документ объединяется с документами второго кластера, и обновленный обобщенный параметр метрики на основе обновленного первого параметра метрики и обновленного второго параметра метрики; добавлять четвертый документ во второй кластер, если один из обновленных обобщенных параметров метрики превышает обобщенный параметр метрики второго кластера, при этом четвертый документ представляет собой оставшийся документ из множества документов, который в случае его объединения с документами второго кластера имеет один из обновленных обобщенных параметров метрики, превышающий обобщенный параметр метрики второго кластера; сохранять этот один из обновленных обобщенных параметров метрики в качестве обобщенного параметра метрики второго кластера.
[41] В некоторых вариантах осуществления системы процессор дополнительно способен повторять выполнение команд для оставшихся документов из множества документов с целью получения набора кластеров, содержащего по меньшей мере первый кластер и второй кластер.
[42] В некоторых вариантах осуществления системы после получения множества документов процессор дополнительно способен формировать вектор документа для каждого документа из множества документов на основе по меньшей мере части контента соответствующего документа, при этом определение обновленного первого параметра метрики для потенциального кластера основано на расстояниях между векторами документов в потенциальном кластере, а определение обновленного второго параметра метрики для потенциального кластера основано на расстояниях между векторами документов в потенциальном кластере и на размере этого потенциального кластера.
[43] В некоторых вариантах осуществления системы первый документ представляет собой первый кластер, содержащий множество документов первого кластера, а второй документ представляет собой второй кластер, содержащий множество документов второго кластера.
[44] В некоторых вариантах осуществления системы первый кластер и второй кластер имеют обобщенный параметр метрики, а кластер формируется, если обновленный обобщенный параметр метрики превышает обобщенный параметр метрики первого кластера и обобщенный параметр метрики второго кластера.
[45] В некоторых вариантах осуществления системы процессор дополнительно способен сохранять первый кластер и второй кластер в качестве отдельных кластеров, если обновленный обобщенный параметр метрики оказывается меньшим обобщенного параметра метрики первого кластера и обобщенного параметра метрики второго кластера.
[46] В некоторых вариантах осуществления системы определение обновленного первого параметра метрики дополнительно основано на расстояниях между векторами документов первого кластера, расстояниях между векторами документов второго кластера и расстояниях между векторами документов первого кластера и второго кластера, а определение обновленного второго параметра метрики для потенциального кластера дополнительно основано на расстояниях между векторами документов первого кластера, расстояниях между векторами документов второго кластера, расстояниях между векторами документов первого кластера и второго кластера и размере этого потенциального кластера, который представляет собой сумму размеров первого кластера и второго кластера.
[47] В некоторых вариантах осуществления системы контент документа включает в себя заголовок документа и контент тела документа.
[48] В контексте настоящего описания термин «сервер» означает компьютерную программу, выполняемую соответствующими аппаратными средствами и способную принимать запросы (например, из электронных устройств) через сеть и выполнять эти запросы или инициировать их выполнение. Аппаратные средства могут представлять собой один физический компьютер или одну компьютерную систему, что не существенно для настоящей технологии. В настоящем контексте выражение «по меньшей мере один сервер» не означает, что каждая задача (например, принятая команда или запрос) или некоторая определенная задача принимается, выполняется или запускается одним сервером (т.е. одними и теми же программными и/или аппаратными средствами). Это выражение означает, что любое количество программных средств или аппаратных средств может принимать, отправлять, выполнять или инициировать выполнение любой задачи или запроса либо результатов любых задач или запросов. Все эти программные и аппаратные средства могут представлять собой один сервер или несколько серверов, причем оба эти случая подразумеваются в выражении «по меньшей мере один сервер».
[49] В контексте настоящего описания, если явно не указано другое, числительные «первый», «второй», «третий» и т.д. используются лишь для указания различия между существительными, к которым они относятся, но не для описания каких-либо определенных взаимосвязей между этими существительными. Например, должно быть понятно, что использование терминов «первый сервер» и «третий сервер» не подразумевает какого-либо определенного порядка, типа, хронологии, иерархии или классификации, в данном случае, серверов, а также что их использование (само по себе) не подразумевает обязательного наличия «второго сервера» в любой ситуации. Кроме того, как встречается в настоящем описании в другом контексте, ссылка на «первый» элемент и «второй» элемент не исключает того, что эти два элемента в действительности могут быть одним и тем же элементом. Таким образом, например, в некоторых случаях «первый» сервер и «второй» сервер могут представлять собой одно и то же программное и/или аппаратное средство, а в других случаях - различные программные и/или аппаратные средства.
[50] В контексте настоящего описания, если явно не указано другое, термин «база данных» означает любой структурированный набор данных, независимо от его конкретной структуры, программного обеспечения для управления базой данных или компьютерных аппаратных средства для хранения этих данных, их применения или обеспечения их использования иным способом. База данных может располагаться в тех же аппаратных средствах, где реализован процесс, обеспечивающий хранение или использование информации, хранящейся в базе данных, либо база данных может располагаться в отдельных аппаратных средствах, таких как специализированный сервер или множество серверов.
Краткое описание чертежей
[51] Дальнейшее описание приведено для лучшего понимания настоящей технологии, а также других аспектов и их признаков, и должно использоваться совместно с приложенными чертежами.
[52] На фиг. 1 представлена схема системы, реализованной согласно вариантам осуществления настоящей технологии, не имеющим ограничительного характера.
[53] На фиг. 2 приведена схема процедуры кластеризации, выполняемой приложением кластеризации в представленной на фиг. 1 системе, реализованной согласно вариантам осуществления данной технологии, не имеющим ограничительного характера.
[54] На фиг. 3-5 приведена блок-схема способа кластеризации документов в набор кластеров на основе обобщенного параметра метрики, выполняемого в представленной на фиг. 1 системе в соответствии с не имеющими ограничительного характера вариантами осуществления настоящей технологии.
[55] На фиг. 6 приведена блок-схема способа кластеризации первого кластера и второго кластера в единый кластер на основе обобщенного параметра метрики, выполняемого в представленной на фиг. 1 системе в соответствии с не имеющими ограничительного характера вариантами осуществления настоящей технологии.
Осуществление изобретения
[56] На фиг. 1 представлена схема системы 100, пригодной для реализации вариантов осуществления настоящей технологии, не имеющих ограничительного характера. Очевидно, что система 100 приведена лишь для демонстрации варианта реализации настоящей технологии. Таким образом, дальнейшее описание системы представляет собой описание примеров, иллюстрирующих настоящую технологию. Это описание не предназначено для определения объема или границ настоящей технологии. В некоторых случаях приводятся полезные примеры модификаций системы 100. Они способствуют пониманию, но также не определяют объем или границы настоящей технологии. Эти модификации не составляют исчерпывающего перечня. Как должно быть понятно специалисту в данной области возможны и другие модификации. Кроме того, если в некоторых случаях модификации не описаны (т.е. примеры модификаций отсутствуют), это не означает, что они невозможны и/или что это описание содержит единственно возможный вариант реализации того или иного элемента настоящей технологии. Специалисту в данной области должно быть понятно, что это не так. Кроме того, следует понимать, что система 100 в некоторых случаях может представлять собой упрощенную реализацию настоящей технологии и что такие варианты представлены для того, чтобы способствовать лучшему ее пониманию. Специалистам в данной области должно быть понятно, что различные варианты осуществления настоящей технологии могут быть значительно сложнее.
[57] Представленные в данном описании примеры и условный язык предназначены для обеспечения лучшего понимания принципов настоящей технологии, а не для ограничения ее объема до таких специально приведенных примеров и условий. Очевидно, что специалисты в данной области техники способны разработать различные способы и устройства, которые явно не описаны и не показаны, но реализуют принципы настоящей технологии в пределах ее существа и объема. Кроме того, чтобы способствовать лучшему пониманию, следующее описание может содержать упрощенные варианты реализации настоящей технологии. Специалисту в данной области должно быть понятно, что различные варианты осуществления данной технологии могут быть значительно сложнее.
[58] Более того, описание принципов, аспектов и вариантов реализации настоящей технологии, а также их конкретные примеры предназначены для охвата их структурных и функциональных эквивалентов, независимо от того, известны они в настоящее время или будут разработаны в будущем. Например, специалистам в данной области техники должно быть очевидно, что любые описанные структурные схемы соответствуют концептуальным представлениям иллюстративных принципиальных схем, реализующих принципы настоящей технологии. Также должно быть очевидно, что любые блок-схемы, схемы процессов, диаграммы изменения состояния, псевдокоды и т.п. соответствуют различным процессам, которые могут быть представлены на машиночитаемом физическом носителе информации и могут выполняться компьютером или процессором, независимо от того, показан такой компьютер или процессор явно или нет.
[59] Функции различных элементов, показанных на чертежах, включая любой функциональный блок, обозначенный как «процессор», могут быть реализованы с использованием специализированных аппаратных средств, а также аппаратных средств, способных выполнять соответствующее программное обеспечение. Если используется процессор, эти функции могут выполняться одним выделенным процессором, одним совместно используемым процессором или множеством отдельных процессоров, некоторые из которых могут использоваться совместно. В некоторых вариантах осуществления настоящей технологии процессор может представлять собой процессор общего назначения, такой как центральный процессор (CPU), или специализированный процессор, такой как графический процессор (GPU). Кроме того, явное использование термина «процессор» или «контроллер» не должно трактоваться как указание исключительно на аппаратные средства, способные выполнять программное обеспечение, и может подразумевать, помимо прочего, аппаратные средства цифрового сигнального процессора (DSP), сетевой процессор, специализированную интегральную схему (ASIC), программируемую вентильную матрицу (FPGA), ПЗУ для хранения программного обеспечения, ОЗУ и энергонезависимое ЗУ. Также могут подразумеваться и другие аппаратные средства, общего назначения и/или заказные.
[60] С учетом вышеизложенных принципов далее рассмотрены некоторые не имеющие ограничительного характера примеры, иллюстрирующие различные варианты реализации аспектов настоящей технологии.
[61] Система 100 содержит электронное устройство 102. Электронное устройство 102 обычно взаимодействует с пользователем (не показан) и иногда может называться «клиентским устройством». Следует отметить, что связь электронного устройства 102 с пользователем не означает необходимости указывать или предполагать какой-либо режим работы, например, вход в систему, регистрацию и т.п.
[62] В контексте настоящего описания, если явно не указано другое, термин «электронное устройство» означает любое компьютерное аппаратное средство, способное выполнять программы, подходящие для решения поставленной задачи. Таким образом, некоторые (не имеющие ограничительного характера) примеры электронных устройств включают в себя персональные компьютеры (настольные, ноутбуки, нетбуки и т.п.), смартфоны и планшеты, а также сетевое оборудование, такое как маршрутизаторы, коммутаторы и шлюзы. Следует отметить, что в данном контексте устройство, функционирующее как электронное устройство, может функционировать как сервер в отношении других электронных устройств. Использование выражения «электронное устройство» не исключает использования нескольких электронных устройств для приема, отправки, выполнения или инициирования выполнения любой задачи или запроса либо результатов любых задач или запросов либо шагов любого описанного здесь способа.
[63] Электронное устройство 102 содержит энергонезависимое запоминающее устройство (ЗУ) 104. Энергонезависимое ЗУ 104 может содержать один или несколько носителей информации и в общем случае обеспечивает пространство для хранения компьютерных команд, исполняемых процессором 106. Например, энергонезависимое ЗУ 104 может быть реализовано в виде машиночитаемого физического носителя информации, включая ПЗУ, жесткие диски (HDD), твердотельные накопители (SSD) и карты флэш-памяти.
[64] Электронное устройство 102 содержит известные в данной области техники аппаратные средства и/или программное обеспечение и/или встроенное программное обеспечение (либо их сочетание) для выполнения браузерного приложения 108. В общем случае браузерное приложение 108 обеспечивает пользователю (не показан) доступ к одному или нескольким веб-ресурсам. Способ реализации браузерного приложения 108 известен в данной области техники и здесь не описан. Достаточно сказать, что в качестве браузерного приложения 108 может использоваться приложение Google™ Chrome™, Yandex.Browser™ или другой коммерчески доступный или проприетарный браузер.
[65] Независимо от способа реализации браузерное приложение 108 обычно имеет командный интерфейс 110. В общем случае пользователь (не показан) может получать доступ к веб-ресурсу через сеть связи двумя основными способами. Пользователь может получать доступ к конкретному веб-ресурсу непосредственно, введя адрес этого веб-ресурса (обычно универсальный указатель ресурсов (URL, Uniform Resource Locator), такой как www.example.com) в командном интерфейсе 110, либо перейдя по ссылке в сообщении электронной почты или в другом веб-ресурсе (это действие эквивалентно копированию и вставке в командный интерфейс 110 URL-адреса, связанного со ссылкой).
[66] В качестве альтернативы, пользователь согласно своей цели может выполнять поиск интересующего ресурса с использованием поисковой системы (не показана). Последний вариант особенно удобен, если пользователю известна интересующая его тема, но не известен URL-адрес веб-ресурса. Поисковая система обычно формирует страницу результатов поисковой системы (SERP, Search Engine Result Page), содержащую ссылки на один или несколько веб-ресурсов, соответствующих запросу пользователя. Путем перехода по одной или нескольким ссылкам на странице SERP пользователь может открыть требуемый веб-ресурс.
[67] Электронное устройство 102 содержит интерфейс связи (не показан) для двухсторонней связи с сетью 114 связи по линии 112 связи. В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии в качестве сети 114 связи может использоваться сеть Интернет. В других вариантах осуществления настоящей технологии сеть 114 связи может быть реализована иначе, например, в виде любой глобальной сети связи, локальной сети связи, частной сети связи и т.п.
[68] На реализацию линии 112 связи не накладывается каких-либо особых ограничений, она зависит от реализации электронного устройства 102. Лишь в качестве примера, не имеющего ограничительного характера, в тех вариантах осуществления настоящей технологии, где электронное устройство 102 реализовано в виде беспроводного устройства связи (такого как смартфон), линия 112 связи может быть реализована в виде беспроводной линии связи (такой как канал сети связи 3G, канал сети связи 4G, Wireless Fidelity или сокращенно WiFi®, Bluetooth® и т.п.) или проводной линии связи (такой как соединение на основе Ethernet).
[69] Должно быть очевидно, что варианты реализации электронного устройства 102, линии 112 связи и сети 114 связи приведены лишь для иллюстрации. Специалисту в данной области должны быть понятными и другие конкретные детали реализации электронного устройства 102, линии 112 связи и сети 114 связи. Представленные выше примеры никак не ограничивают объем настоящей технологии.
[70] Сервер
[71] Система 100 также содержит сервер 116, соединенный с сетью 114 связи. Сервер 116 может быть реализован в виде традиционного компьютерного сервера. В примере осуществления настоящей технологии сервер 116 может быть реализован в виде сервера Dell™ PowerEdge™, работающего под управлением операционной системы Microsoft™ Windows Server™. Очевидно, что сервер 116 может быть реализован с использованием любых других подходящих аппаратных средств и/или прикладного программного обеспечения и/или встроенного программного обеспечения либо их сочетания. В представленном не имеющем ограничительного характера варианте осуществления настоящей технологии сервер 116 реализован в виде одного сервера. В других не имеющих ограничительного характера вариантах осуществления настоящей технологии функции сервера 116 могут быть распределены между несколькими серверами.
[72] Сервер 116 содержит интерфейс связи (не показан), структура и настройки которого позволяют осуществлять связь с различными элементами (такими как электронное устройство 102 и другие устройства, которые могут быть соединены с сетью 114 связи) через сеть 114 связи. Подобно электронному устройству 102, сервер 116 содержит память 118 сервера, которая содержит один или несколько носителей информации и в общем случае обеспечивает пространство для хранения компьютерных программных команд, исполняемых процессором 120 сервера. Например, память 118 сервера может быть реализована в виде машиночитаемого физического носителя информации, включая ПЗУ и/или ОЗУ. Память 118 сервера также может содержать одно или несколько устройств постоянного хранения, таких как жесткие диски (HDD), твердотельные накопители (SSD) и карты флэш-памяти.
[73] В некоторых вариантах осуществления изобретения сервер 116 может управляться организацией, предоставляющей описанное выше браузерное приложение 108. Например, если браузерное приложение 108 представляет собой приложение Yandex.Browser™, сервер 116 может управляться компанией Yandex LLC (ул. Льва Толстого, 16, Москва, 119021, Россия). В других вариантах осуществления изобретения сервер 116 может управляться организацией, отличной от той, что предоставляет описанное выше браузерное приложение 108.
[74] В соответствии с настоящей технологией сервер 116 способен выполнять приложение 122 агрегатора новостей, такое как Yandex.News™. Приложение 122 агрегатора новостей способно предоставлять сервис агрегатора новостей, доступный электронному устройству 102 через сеть 114 связи, обеспечивая новостной контент из нескольких источников (не показаны).
[75] Согласно не имеющим ограничительного характера вариантам осуществления настоящей технологии, сервер 116 способен (например, путем использования программного кода, прикладного программного обеспечения, аппаратных средств, встроенного программного обеспечения или их сочетания) выполнять приложение 126 кластеризации. Реализация приложения 126 кластеризации подробно описана ниже. Здесь достаточно сказать, что приложение 126 кластеризации способно группировать цифровые документы (или сокращенно «документы») в кластеры так, чтобы документы в кластере имели общую тему и/или событие. Приложение 126 кластеризации способно предоставлять указание на кластеры приложению 122 агрегатора новостей так, чтобы приложение 122 агрегатора новостей группировало документы, входящие в состав одного кластера, в сервисе агрегатора новостей, доступном электронному устройству 102 через сеть 114 связи.
[76] С этой целью сервер 116 соединен с базой 124 данных новостей с использованием выделенной линии связи (без позиционного обозначения). В других вариантах осуществления изобретения база 124 данных новостей может быть соединена с сервером 116 с использованием сети 114 связи без выхода за границы настоящей технологии. Несмотря на то, что база 124 данных новостей схематично показана здесь в виде одного элемента, предполагается, что база 124 данных новостей может быть распределенной.
[77] Множество цифровых документов
[78] База 124 данных новостей наполнена множеством 160 цифровых документов. На характер каждого документа из множества 160 цифровых документов не накладывается каких-либо особых ограничений. В общем случае документ из числа одного или нескольких цифровых документов содержит одно или несколько предложений, изображений, видеоматериалов и т.д. Цифровой документ может, например, представлять собой доступный в сети Интернет новостной документ, такой как статья CNN™ о современной мировой политике.
[79] На способ наполнения базы 124 данных новостей не накладывается каких-либо ограничений. Например, база 124 данных новостей может выполнять (или осуществлять доступ к ней) функцию обхода (не показана), способную собирать множество 160 цифровых документов из выбранных источников новостей, таких как веб-сайты газет, интернет-журналы, научные журналы, социальные медиа, другие электронные новостные ресурсы и т.п. В качестве альтернативы, база 124 данных новостей может получать множество 160 цифровых документов непосредственно из различных источников без использования функции обхода.
[80] В общем случае каждый документ 162 из множества 160 цифровых документов содержит контент 164 документа, включая заголовок 166 и контент 168 тела. Заголовок 166 обычно содержит одно или несколько слов, указывающих на контент 168 тела соответствующего документа 162. Контент 168 тела обычно содержит текстовый контент тела, но также может содержать по меньшей мере одно из следующего: текстовый контент тела, видеоконтент тела, аудиоконтент тела, игровой контент тела и т.п. Например, возможен заголовок цифрового документа «Physicists discover new charming particle at the Large Hadron Collider» («Физики открыли новую очаровательную частицу в Большом адронном коллайдере»), контент тела которого может содержать текстовый контент, описывающий открытие новой частицы, и одну или несколько фотографий физиков, открывших новую частицу.
[81] После выполнения процедуры кластеризации приложением 126 кластеризации (более подробно описано ниже) каждый документ 162 из множества 160 цифровых документов может быть связан с соответствующим кластером 195 из набора 190 кластеров, в котором каждый кластер 195 содержит подмножество документов 167 из множества 160 цифровых документов и указывает на тему и/или событие, определенное приложением 126 кластеризации. На способ сопоставления множества 160 цифровых документов с кластером из набора 190 кластеров в базе 124 данных новостей не накладывается каких-либо ограничений. Например, каждый документ 162 может быть связан с идентификатором кластера (не показан) так, чтобы приложение 122 агрегатора новостей группировало части множества 160 цифровых документов с одним идентификатором кластера в сервисе агрегатора новостей для представления пользователю электронного устройства 102.
[82] На фиг. 2 представлена схема процедуры 200 кластеризации, выполняемой приложением 126 кластеризации в соответствии с не имеющими ограничительного характера вариантами осуществления настоящей технологии.
[83] Приложение кластеризации
[84] В общем случае приложение 126 кластеризации способно выполнять процедуру 200 кластеризации для кластеризации множества 160 цифровых документов в набор 190 кластеров, в котором каждый кластер 195 содержит один или несколько документов из множества 160 документов и указывает на событие и/или тему. После выполнения процедуры 200 кластеризации приложение 126 кластеризации способно отправлять указание на множество 160 цифровых документов (где каждый документ 162 связан с кластером из набора 190 кластеров) приложению 122 агрегатора новостей, которое, в свою очередь, может предоставлять один или несколько документов из множества 160 цифровых документов, отсортированных по кластерам, сервису агрегатора новостей для показа пользователю электронного устройства 102, которому сервис агрегатора новостей доступен через сеть 114 связи.
[85] Приложение 126 кластеризации может выполнять процедуру 200 кластеризации после получения указания на кластеризацию множества 160 цифровых документов и/или может выполнять процедуру 200 кластеризации через заранее заданные интервалы времени. В некоторых вариантах осуществления изобретения приложение 126 кластеризации может выполнять процедуру 200 кластеризации после получения заранее заданного количества документов в базе 124 данных новостей.
[86] Для выполнения процедуры 200 кластеризации приложение 126 кластеризации способно выполнять процедуру 210 формирования векторов и алгоритм 215 кластеризации.
[87] Процедура векторизации
[88] Приложение 126 кластеризации выполняет процедуру 210 формирования векторов, чтобы сформировать множество 220 векторов документов, в котором каждый вектор 225 документа представляет по меньшей мере часть контента 164 документа соответствующего документа 162 из множества 160 цифровых документов.
[89] В общем случае процедура 210 формирования векторов предназначена для представления документа в виде вектора действительных чисел в многомерном пространстве с использованием набора способов языкового моделирования и формирования признаков, применяемых для обработки естественного языка (NLP, Natural Language Processing), так, чтобы документы можно было сопоставлять и сравнивать друг с другом с использованием их векторов, например, путем определения расстояния между векторами, которое может указывать на степень сходства или связанности.
[90] На способ представления процедурой 210 формирования векторов документа 162 в виде вектора 225 документа не накладывается каких-либо ограничений. Например, процедура 210 формирования векторов может выполнять следующие алгоритмы: word2vec, doc2vec, GloVe, sense2vec, wang2vec, латентное размещение Дирихле (LDA, Latent Dirichlet Allocation) и т.д. В некоторых вариантах осуществления изобретения процедура 210 формирования векторов может выполнять алгоритм машинного обучения (MLA, Machine Learning Algorithm), обученный формировать множество 220 векторов, например, с использованием нейронной сети (NN, Neural Network), но не ограничиваясь этим.
[91] Процедура 210 формирования векторов определяет вектор 225 документа для каждого документа 162 из множества 160 цифровых документов на основе по меньшей мере части контента 164 документа соответствующего документа 162. В представленном варианте осуществления изобретения процедура 210 формирования векторов определяет вектор 225 документа на основе заголовка 166 документа 162. Дополнительно или в качестве альтернативы предполагается, что процедура 210 формирования векторов способна формировать вектор 225 документа на основе по меньшей мере части контента 168 тела документа 162.
[92] Приложение 126 кластеризации может хранить каждый вектор 225 документа в сочетании с указанием на документ 162, который он представляет, например, в памяти 118 сервера, в базе 124 данных новостей либо в другой энергозависимой или энергонезависимой памяти (не показана).
[93] После формирования вектора 225 документа для каждого документа 162 из множества 160 цифровых документов множество 220 векторов 225 документов принимается в качестве входных данных алгоритмом 215 кластеризации приложения 126 кластеризации для кластеризации множества 160 цифровых документов.
[94] Алгоритм кластеризации
[95] В общем случае алгоритм 215 кластеризации предназначен для формирования на основе множества 220 векторов документов набора 190 кластеров, в котором каждый кластер 195 содержит один или несколько документов из множества 160 цифровых документов. Для достижения этой цели алгоритм 215 кластеризации способен формировать: (а) первый параметр метрики, (б) второй параметр метрики и (в) обобщенный параметр метрики на основе первого параметра метрики и второго параметра метрики.
[96] Следует отметить, что в контексте настоящей технологии алгоритм 215 кластеризации способен группировать документы и/или кластеры в один кластер на основе обобщенного параметра метрики. Таким образом, можно сказать, что алгоритм 215 кластеризации не различает кластеризацию двух документов в один кластер, кластеризацию документа и кластера в один кластер и кластеризацию двух кластеров в один кластер, где каждый кластер содержит два или более документов, т.е. кластеризация основана на обобщенном параметре метрики, который может быть сформирован как для документов, так и для кластеров.
[97] Первый параметр метрики
[98] Алгоритм 215 кластеризации способен формировать первый параметр метрики. Первый параметр метрики для кластера обычно представляет собой степень взаимного дополнения документов в кластере, измеренную на основе векторов 225 документов в кластере. Таким образом, первый параметр метрики представляет собой оценочную метрику, которая на основе векторов 225 документов оценивает для кластера: (а) насколько схожи документы в кластере и (б) насколько данные различных документов кластера дополняют друг друга. Иными словами, можно сказать, что первый параметр метрики позволяет измерять «широту» охвата темы контентом документов кластера.
[99] В общем случае алгоритм 215 кластеризации способен формировать:
[100] (1) первый параметр метрики для первого объекта (не показан) и для второго объекта (не показан), которые потенциально могут быть объединены в один кластер, где (а) первый объект может представлять собой кластер, содержащий документы кластера, или отдельный документ, и (б) второй объект может представлять собой другой кластер, содержащий другие документы, или другой отдельный документ, при этом первый параметр метрики указывает на степень взаимного дополнения контента документов в первом объекте и во втором объекте; и
[101] (2) обновленный первый параметр метрики для потенциального кластера, содержащего первый объект и второй объект, указывающий на степень взаимного дополнения контента документов в потенциальном кластере, содержащем первый объект и второй объект.
[102] Иными словами, обновленный первый параметр метрики представляет собой «новое» или «обновленное» значение первого параметра метрики первого объекта, если второй объект добавляется в кластер или объединяется в кластере с первым объектом (или наоборот), при этом первые параметры метрики представляют собой текущие значения первого параметра метрики первого объекта и второго объекта. Таким образом, увеличение первого параметра метрики (когда обновленный первый параметр метрики превышает первый параметр метрики) указывает на увеличение степени взаимного дополнения контента документов первого объекта, когда второй объект добавляется к первому объекту (или наоборот), что может указывать на то, что документ (или документы) первого объекта и документ (или документы) второго объекта дополняют друг друга с точки зрения их контента и что в случае их объединения они могут предоставить дополнительную информацию, относящуюся к теме или к событию. Чем больше первый параметр метрики для кластера, тем проще пользователю понять контент документов кластера, прочтя документ из этого кластера. Таким образом, чем больше обновленный первый параметр метрики двух документов, объединенных в кластере, тем «богаче» объединенный контент двух документов применительно к теме этого кластера.
[103] И наоборот, уменьшение первого параметра метрики (когда обновленный первый параметр метрики меньше первого параметра метрики) указывает на уменьшение степени взаимного дополнения контента документов первого объекта, когда второй объект добавляется в кластер или объединяется в кластере с первым объектом (или наоборот), что может указывать на то, что документ (или документы) первого объекта и документ (или документы) второго объекта меньше дополняют друг друга с точки зрения их контента и что в случае их объединения они могут не обеспечивать дополнительную информацию, относящуюся к теме или к событию. Чем меньше обновленный первый параметр метрики для кластера, тем сложнее пользователю понять контент документов кластера, прочтя документ кластера.
[104] Алгоритм 215 кластеризации может назначить заранее заданное значение для первого параметра метрики отдельного документа, которое может быть равно 1, т.е. отдельный документ имеет степень взаимного дополнения 100%.
[105] На способ определения алгоритмом 215 кластеризации первого параметра метрики для кластера на основе векторов документов, представляющих документы кластера, не накладывается каких-либо ограничений. В не имеющем ограничительного характера примере алгоритм 215 кластеризации может определять для потенциального кластера, содержащего документы кластера и новый документ, обновленный первый параметр метрики на основе расстояний между векторами каждой пары документов в потенциальном кластере (которые включают в себя вектор документа, представляющий другой документ, и векторы документов, представляющие документы кластера). В некоторых вариантах осуществления настоящей технологии для определения обновленного первого параметра метрики алгоритм 215 кластеризации может объединять векторы документов, представляющие документы кластера, с целью получения объединенного вектора документов и может определять обновленный первый параметр метрики на основе расстояния между объединенным вектором документов и вектором документа, представляющим другой документ.
[106] В некоторых вариантах осуществления настоящей технологии первый параметр метрики для документа из подмножества документов может быть определен по формуле (1):
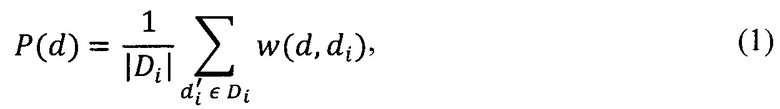
где P(d) - первый параметр метрики вектора d документа (представляющего документ) из подмножества векторов Di∈D документов, w(d, di) - функция расстояния между вектором d документа и вектором di другого документа из подмножества Di векторов документов. В не имеющем ограничительного характера примере значение w(d, di) может изменяться от 0 до 1.
[107] Первый параметр метрики для подмножества документов может быть определен путем расчета среднего значения первых параметров метрики документов этого подмножества по формуле (2):
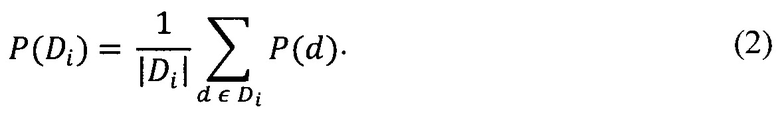
[108] Второй параметр метрики
[109] Алгоритм 215 кластеризации способен формировать второй параметр метрики. Второй параметр метрики для кластера обычно представляет собой степень разбавления контента документов кластера относительно контента всех оставшихся документов из множества документов, измеренную на основе векторов 225 документов. В общем случае, второй параметр метрики позволяет измерять зависимость первого параметра метрики (т.е. степени взаимного дополнения) от размера кластера. Иными словами второй параметр метрики указывает на то, как добавление нового документа в кластер (или к другому документу) разбавляет общий контент кластера относительно темы кластера.
[110] Чем больше документов содержит кластер, тем больше документов нужно прочесть пользователю, чтобы понять тему кластера, и тем сложнее алгоритму 215 кластеризации измерять первый параметр метрики, поскольку при этом требуется сравнивать друг с другом векторы документов из кластера. Второй параметр метрики позволяет измерять, насколько концентрирован (или разбавлен) контент документов в кластере, и можно сказать, что второй параметр метрики позволяет измерять, сколько информации «теряется» в кластере, если в него не добавлен документ.
[111] В общем случае алгоритм 215 кластеризации способен формировать:
[112] (1) второй параметр метрики для первого объекта (не показан) и для второго объекта (не показан), которые потенциально могут быть объединены в один кластер, при этом первый объект (не показан) может представлять собой (а) кластер, содержащий документы кластера, или отдельный документ, а второй объект (не показан) может представлять собой (б) другой кластер, содержащий другие документы, или другой отдельный документ, при этом второй параметр метрики указывает на степень разбавления контента документов в первом объекте и во втором объекте, соответственно; и
[113] (2) обновленный второй параметр метрики для потенциального кластера, содержащего первый объект и второй объект, указывающий на степень разбавления контента документов в кластере, содержащем первый объект и второй объект.
[114] Иными словами, обновленный второй параметр метрики представляет собой «новое» или «обновленное» значение второго параметра метрики первого объекта, если второй объект добавляется в кластер или объединяется в кластере с первым объектом (или наоборот), при этом вторые параметры метрики представляют собой текущие значения второго параметра метрики первого объекта и второго объекта. Таким образом, увеличение второго параметра метрики (когда обновленный второй параметр метрики превышает второй параметр метрики) указывает на уменьшение степени разбавления контента документов первого объекта, когда второй объект добавляется к первому объекту (или наоборот), что может указывать на то, что документ (или документы) первого объекта и документ (или документы) второго объекта в случае их объединения повышают точность информации, относящейся к теме или к событию (т.е. информация становится менее разбавленной или более концентрированной).
[115] И наоборот, уменьшение второго параметра метрики (когда обновленный второй параметр метрики меньше второго параметра метрики) указывает на увеличение степени разбавления контента документов первого объекта, когда второй объект добавляется в кластер или объединяется в кластере с первым объектом (или наоборот), что может указывать на то, что документ (или документы) первого объекта и документ (или документы) второго объекта в случае их объединения уменьшают точность информации, относящейся к теме или к событию (т.е. информация становится более разбавленной).
[116] Алгоритм 215 кластеризации может назначать заранее заданное значение для второго параметра метрики отдельного документа, которое может быть равно 0.
[117] На способ определения алгоритмом 215 кластеризации второго параметра метрики не накладывается каких-либо ограничений. Например, алгоритм 215 кластеризации может определять для потенциального кластера, содержащего документы кластера и новый документ, обновленный второй параметр метрики на основе расстояния между векторами каждой пары документов в потенциальном кластере (которые включают в себя вектор другого документа и векторы документов кластера), расстояния между векторами документов в потенциальном кластере и векторами оставшихся документов (которые могут входить или не входить в состав других кластеров) и размера потенциального кластера.
[118] В некоторых вариантах осуществления настоящей технологии второй параметр метрики для документа из подмножества документов может быть определен по формуле (3):
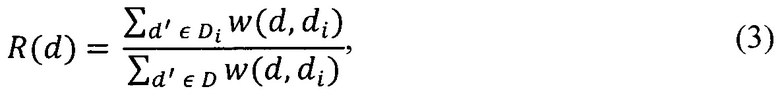
[119] где R(d) - второй параметр метрики вектора d документа из подмножества Dt векторов документов, w(d, di) - функция измерения расстояния между вектором d документа и вектором di другого документа из подмножества Di векторов документов, d' - вектор документа из набора всех векторов D документов, w(d, di) - функция расстояния между вектором d документа из подмножества Di векторов документов и вектором d' документа из множества всех векторов D документов.
[120] Второй параметр метрики для подмножества документов может быть рассчитан в виде среднего значения вторых параметров метрики документов из подмножества документов:
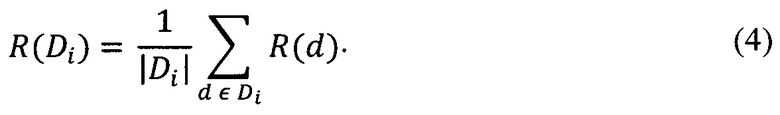
[121] Обобщенный параметр метрики
[122] Алгоритм 215 кластеризации способен формировать обобщенный параметр метрики для кластера на основе первого параметра метрики и второго параметра метрики. Обобщенный параметр метрики для кластера обычно одновременно позволяет измерять степень взаимного дополнения и степень разбавления контента документов кластера.
[123] В общем случае алгоритм 215 кластеризации способен формировать:
[124] (1) обобщенный параметр метрики для первого объекта (не показан) и второго объекта (не показан), которые потенциально могут быть объединены в один кластер, при этом (а) первый объект может представлять собой кластер, содержащий документы кластера, или отдельный документ, и (б) второй объект (не показан) может представлять собой другой кластер, содержащий другие документы, или другой отдельный документ, при этом обобщенный параметр метрики формируется на основе первого параметра метрики и второго параметра метрики; и
[125] (2) обновленный обобщенный параметр метрики для потенциального кластера, содержащего первый объект и второй объект, при этом обновленный обобщенный параметр метрики формируется на основе обновленного первого параметра метрики и обновленного второго параметра метрики.
[126] Иными словами, обновленный обобщенный параметр метрики представляет собой «новое» или «обновленное» значение обобщенного параметра метрики первого объекта, если второй объект добавляется в кластер или объединяется в кластере с первым объектом (или наоборот), при этом обобщенные параметры метрики представляют собой текущие значения обобщенного параметра метрики первого объекта и второго объекта.
[127] Таким образом, для определения того, следует ли объединять в одном кластере первый объект и второй объект, алгоритм 215 кластеризации способен сравнивать обобщенные параметры метрики (т.е. сравнивать обновленный обобщенный параметр метрики с обобщенными параметрами метрики).
[128] Увеличение обобщенного параметра метрики (когда обновленный обобщенный параметр метрики превышает обобщенный параметр метрики) одновременно указывает на увеличение степени взаимного дополнения контента документов и на уменьшение степени разбавления контента документов первого объекта, если второй объект добавляется к первому объекту (или наоборот). Обновленный обобщенный параметр метрики, превышающий обобщенные параметры метрики, может указывать на следующее.
[129] (1) Обновленный первый параметр метрики превышает первые параметры метрики, что указывает на то, что степень взаимного дополнения контента документов потенциального кластера превышает индивидуальные степени взаимного дополнения контента документов первого объекта и второго объекта, а обновленный второй параметр метрики превышает вторые параметры метрики, что указывает на то, что степень разбавления контента документов потенциального кластера меньше индивидуальных степеней разбавления контента документов первого объекта и второго объекта. Таким образом, алгоритму 215 кластеризации следует сформировать кластер, содержащий два объекта, поскольку данные документов в двух объектах дополняют друг друга без чрезмерных повторений (т.е. без разбавления).
[130] (2) Обновленный первый параметр метрики превышает первые параметры метрики, что указывает на то, что степень взаимного дополнения контента документов потенциального кластера превышает индивидуальные степени взаимного дополнения контента документов первого объекта и второго объекта, а обновленный второй параметр метрики меньше вторых параметров метрики, что означает, что степень разбавления контента документов потенциального кластера больше индивидуальных степеней разбавления контента документов первого объекта и второго объекта, но увеличение степени взаимного дополнения компенсирует увеличение степени разбавления. Таким образом, алгоритму 215 кластеризации следует сформировать кластер, содержащий два объекта.
[131] В некоторых вариантах осуществления настоящей технологии, если обновленный обобщенный параметр метрики для потенциального кластера двух объектов равен обоим параметрам метрики, алгоритм 215 кластеризации может не выполнять кластеризацию двух объектов. В других вариантах осуществления изобретения алгоритм 215 кластеризации может формировать кластер, содержащий два объекта.
[132] Уменьшение обобщенного параметра метрики (когда обновленный обобщенный параметр метрики меньше обобщенного параметра метрики) одновременно указывает на уменьшение степени взаимного дополнения контента документов и на увеличение степени разбавления контента документов первого объекта, если второй объект добавляется к первому объекту (или наоборот), что может указывать на следующее.
[133] (1) Обновленный первый параметр метрики меньше первых параметров метрики, что указывает на то, что степень взаимного дополнения контента документов потенциального кластера меньше индивидуальных степеней взаимного дополнения контента документов первого объекта и второго объекта, а обновленный второй параметр метрики меньше вторых параметров метрики, что указывает на то, что степень разбавления контента документов потенциального кластера больше индивидуальных степеней разбавления контента документов первого объекта и второго объекта. Таким образом, алгоритму 215 кластеризации не следует формировать кластер, содержащий два объекта, поскольку контент документов первого объекта и второго объекта не является взаимодополняющим и разбавляет тему кластера.
[134] (2) Обновленный первый параметр метрики превышает первые параметры метрики, что указывает на то, что степень взаимного дополнения контента документов потенциального кластера превышает индивидуальные степени взаимного дополнения контента документов первого объекта и второго объекта, а обновленный второй параметр метрики меньше вторых параметров метрики, что указывает на то, что степень разбавления контента документов потенциального кластера больше индивидуальных степеней разбавления контента документов первого объекта и второго объекта, но увеличение степени взаимного дополнения не компенсирует увеличения степени разбавления. Таким образом, алгоритму 215 кластеризации не следует формировать кластер, содержащий два объекта, поскольку, несмотря на то, что контент документов первого объекта и второго объекта является взаимодополняющим, контент документов кластера, содержащего первый объект и второй объект, разбавляет тему кластера.
[135] На способ формирования обобщенного параметра метрики на основе первого параметра метрики и второго параметра метрики не накладывается каких-либо ограничений. В некоторых вариантах осуществления изобретения обобщенный параметр метрики может быть сформирован путем перемножения первого параметра метрики и второго параметра метрики. В других вариантах осуществления изобретения обобщенный параметр метрики может представлять собой функцию, зависящую от первого параметра метрики и второго параметра метрики.
[136] В некоторых вариантах осуществления настоящей технологии обобщенный параметр метрики для подмножества документов (т.е. для потенциального кластера) может быть определен по формуле (5):
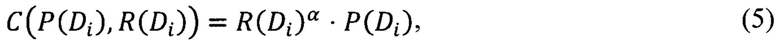
[137] где C(P(Di), R(Di)) - обобщенный параметр метрики, P(Di) - первый параметр метрики для подмножества Di векторов документов, R(Di) - второй параметр метрики для подмножества Di векторов документов, α - константа. Значение константы α определяет влияние второго параметра метрики на обобщенный параметр метрики, т.е. насколько важна степень разбавления контента документов в кластере.
[138] Например, если α=1, то первый параметр метрики и второй параметр метрики имеют равное влияние и обобщенный параметр метрики может быть рассчитан путем перемножения первого параметра метрики и второго параметра метрики.
[139] Выше писано, как приложение 126 кластеризации определяет обобщенный параметр метрики на основе первого параметра метрики и второго параметра метрики с использованием алгоритма 215 кластеризации. Ниже приведены три примера процедуры 200 кластеризации, не имеющие ограничительного характера.
[140] Кластеризация двух документов в один кластер
[141] В первом не имеющем ограничительного характера примере алгоритм 215 кластеризации определяет, должны ли документ (не показан) и другой документ (не показан) из множества 160 цифровых документов быть потенциально объединены с целью формирования одного кластера.
[142] Алгоритм 215 кластеризации определяет для вектора 232 документа, представляющего документ, первый параметр 234 метрики. Алгоритм 215 кластеризации определяет для вектора 232 документа, представляющего документ, второй параметр 236 метрики. В некоторых вариантах осуществления настоящей технологии алгоритм 215 кластеризации может назначить заранее заданное значение 1 первому параметру 234 метрики и заранее заданное значение 0 второму параметру 236 метрики, поскольку они определены для отдельных документов.
[143] Алгоритм 215 кластеризации определяет для вектора 232 документа, представляющего документ, обобщенный параметр 238 метрики на основе первого параметра 234 метрики и второго параметра 236 метрики. В некоторых вариантах осуществления настоящей технологии алгоритм 215 кластеризации может непосредственно назначить заранее заданное значение 0 обобщенному параметру 238 метрики вектора 232 документа, поскольку оно определено для отдельного документа.
[144] Алгоритм 215 кластеризации определяет для вектора 242 другого документа, представляющего другой документ, первый параметр 244 метрики. Алгоритм 215 кластеризации определяет для вектора 242 другого документа, представляющего другой документ, второй параметр 246 метрики. В некоторых вариантах осуществления настоящей технологии алгоритм 215 кластеризации может назначить заранее заданное значение 1 первому параметру 244 метрики и заранее заданное значение 0 второму параметру 246 метрики, поскольку они определены для отдельных документов.
[145] Алгоритм 215 кластеризации определяет для вектора 242 другого документа, представляющего другой документ, обобщенный параметр 248 метрики на основе первого параметра 244 метрики и второго параметра 246 метрики. В некоторых вариантах осуществления настоящей технологии алгоритм 215 кластеризации может непосредственно назначить заранее заданное значение 0 обобщенному параметру 248 метрики вектора 242 другого документа, поскольку оно определено для отдельного документа.
[146] Алгоритм 215 кластеризации определяет для потенциального кластера 252 на основе вектора 232 документа и вектора 242 другого документа обновленный первый параметр 254 метрики, указывающий на степень взаимного дополнения вектора 232 документа и вектора 242 другого документа. В некоторых вариантах осуществления настоящей технологии алгоритм 215 кластеризации может формировать обновленный первый параметр 254 метрики на основе расстояния между вектором 232 документа и вектором 242 другого документа.
[147] Затем алгоритм 215 кластеризации определяет для потенциального кластера 252, содержащего вектор 232 документа и вектор 242 другого документа, обновленный второй параметр 256 метрики, указывающий на степень разбавления контента потенциального кластера 252. В некоторых вариантах осуществления настоящей технологии алгоритм 215 кластеризации может формировать обновленный второй параметр 256 метрики на основе расстояния между вектором 232 документа и вектором 242 другого документа и размера потенциального кластера 252. Кроме того, алгоритм 215 кластеризации может рассчитывать обновленный второй параметр 256 метрики, дополнительно основываясь на расстояниях между вектором 232 документа и вектором каждого оставшегося документа (не показаны) из множества 220 векторов документов и на расстояниях между вектором 242 другого документа и вектором каждого оставшегося документа из множества 220 векторов документов.
[148] Затем алгоритм 215 кластеризации определяет для потенциального кластера 252, содержащего вектор 232 документа и вектор 242 другого документа, обновленный обобщенный параметр 258 метрики, указывающий на степень взаимного дополнения и разбавления контента потенциального кластера 252, на основе обновленного первого параметра 254 метрики и обновленного второго параметра 256 метрики. Если обновленный обобщенный параметр 258 метрики превышает обобщенный параметр 238 метрики и/или обобщенный параметр 248 метрики, это может указывать на то, что документ и другой документ (представленные вектором 232 документа и вектором 242 другого документа, соответственно) следует объединить в едином кластере, поскольку они предоставляют дополняющие друг друга данные и не разбавляют тему единого кластера (в отличие от случая, когда данный документ и другой документ не объединяются в едином кластере). И наоборот, если обновленный обобщенный параметр 258 оказывается меньшим параметра 238 метрики и/или обобщенного параметра 248 метрики, это может указывать на то, что данный документ и другой документ не должны входить в состав единого кластера и должны храниться отдельно, поскольку они не предоставляют дополняющие друг друга данные и/или разбавляют тему единого кластера, который они формируют (в отличие от случая, когда документ и другой документ объединяются в едином кластере).
[149] В этом не имеющем ограничительного характера примере алгоритм 215 кластеризации определяет, что обновленный обобщенный параметр 258 метрики превышает обобщенный параметр 238 метрики, который равен 0, и формирует кластер 272. Алгоритм 215 кластеризации формирует из потенциального кластера 252 кластер 272, содержащий векторы 270 документов кластера (т.е. вектор 232 документа и вектор 242 другого документа), представляющие первый документ и второй документ, соответственно (т.е. документ и другой документ). Алгоритм 215 кластеризации сохраняет обновленный обобщенный параметр 258 метрики в качестве обобщенного параметра 278 метрики кластера 272. В некоторых вариантах осуществления изобретения алгоритм 215 кластеризации также может сохранять обновленный первый параметр 254 метрики и обновленный второй параметр 256 метрики в качестве первого параметра 274 метрики и второго параметра 276 метрики, соответственно, для кластера 272.
[150] Следует отметить, что алгоритм 215 кластеризации может выполнять эту процедуру для каждой возможной пары документов (представленной векторами 225 документов) из множества 160 цифровых документов.
[151] Кластеризация отдельного документа и кластера в один кластер
[152] Во втором не имеющем ограничительного характера примере алгоритм 215 кластеризации может определять, следует ли объединять третий документ (не показан) из множества 160 цифровых документов с первым документом и со вторым документом в кластере 272.
[153] Алгоритм 215 кластеризации определяет для вектора 262 третьего документа, представляющего третий документ, первый параметр 264 метрики, для которого может быть назначено заранее заданное значение 1. Алгоритм 215 кластеризации определяет второй параметр 266 метрики, для которого может быть назначено заранее заданное значение 0. Алгоритм 215 кластеризации определяет обобщенный параметр 268 метрики вектора 262 третьего документа на основе первого параметра 264 метрики и второго параметра 266 метрики. В некоторых вариантах осуществления настоящей технологии алгоритм 215 кластеризации может непосредственно назначить заранее заданное значение 0 обобщенному параметру 268 метрики, поскольку оно определено для отдельного документа.
[154] Приложение 126 кластеризации получает обобщенный параметр 278 метрики кластера 272 из памяти 118 сервера, из базы 124 данных новостей либо из другой энергозависимой или энергонезависимой памяти (не показана).
[155] Затем алгоритм 215 кластеризации определяет обновленный первый параметр 284 метрики для второго потенциального кластера 282 на основе векторов 270 документов кластера и вектора 262 третьего документа. В некоторых вариантах осуществления настоящей технологии алгоритм 215 кластеризации может определять обновленный первый параметр 284 метрики на основе расстояний между векторами 270 каждого документа кластера и расстояний между вектором 262 третьего документа и векторами 270 каждого документа из кластера.
[156] Алгоритм 215 кластеризации определяет обновленный второй параметр 286 метрики для второго потенциального кластера 282 на основе векторов 270 документов кластера и вектора 262 третьего документа. В некоторых вариантах осуществления настоящей технологии алгоритм 215 кластеризации может определять обновленный второй параметр 286 метрики на основе расстояний между векторами 270 каждого документа кластера, расстояний между вектором 262 третьего документа и векторами 270 каждого документа кластера и размера второго потенциального кластера 282. Кроме того, алгоритм 215 кластеризации может определять обновленный второй параметр 286 метрики, дополнительно основываясь на расстояниях между вектором 262 третьего документа и вектором каждого оставшегося документа из множества 220 векторов документов и на расстояниях между каждым вектором 270 документов кластера и вектором каждого оставшегося документа из множества 220 векторов документов.
[157] Затем алгоритм 215 кластеризации определяет для второго потенциального кластера 282, содержащего векторы 270 документов кластера и вектор 262 третьего документа, обновленный обобщенный параметр 288 метрики на основе обновленного первого параметра 284 метрики и обновленного второго параметра 286 метрики.
[158] Алгоритм 215 кластеризации сравнивает обновленный обобщенный параметр 288 метрики с обобщенным параметром 268 метрики вектора 262 третьего документа и с обобщенным параметром 278 метрики кластера 272.
[159] Если обновленный обобщенный параметр 288 метрики превышает обобщенный параметр 268 метрики и/или обобщенный параметр 278 метрики, это может указывать на то, что третий документ (представленный вектором 262 третьего документа) следует добавить в кластер 272, поскольку третий документ предоставляет информацию, дополняющую первый документ и второй документ из кластера 272, и не разбавляет тему кластера 272 (в отличие от случая, когда третий документ не добавляется в кластер 272). И наоборот, если обновленный обобщенный параметр 288 оказывается меньшим параметра 268 метрики и/или обобщенного параметра 278 метрики, это может указывать на то, что третий документ не следует добавлять в кластер 272, поскольку третий документ не предоставляет информацию, дополняющую первый документ и второй документ из кластера 272, и/или разбавляет информацию в кластере 272 (в отличие от случая, когда третий документ добавляется в кластер 272).
[160] В этом не имеющем ограничительного характера примере алгоритм 215 кластеризации определяет, что обновленный обобщенный параметр 288 метрики превышает обобщенный параметр 278 метрики кластера 272 и обобщенный параметр 268 метрики вектора 262 третьего документа, который равен 0. Алгоритм 215 кластеризации добавляет третий документ (представленный вектором 262 третьего документа) для формирования первого кластера 292.
[161] Алгоритм 215 кластеризации сохраняет обновленный обобщенный параметр 288 метрики в качестве обобщенного параметра 298 метрики первого кластера 292. В некоторых вариантах осуществления изобретения алгоритм 215 кластеризации также может сохранять обновленный первый параметр 284 метрики и обновленный второй параметр 286 метрики в качестве первого параметра 294 метрики и второго параметра 296 метрики, соответственно, для первого кластера 292.
[162] Кластеризация двух кластеров в один кластер
[163] В третьем не имеющем ограничительного характера примере алгоритм 215 кластеризации может определять, следует ли первый кластер 292, содержащий документы первого кластера (т.е. первый документ, второй документ и третий документ), представленные векторами 290 документов первого кластера (т.е. вектором 232 документа, вектором 242 другого документа и вектором 262 третьего документа), объединять со вторым кластером, содержащим векторы 300 документов второго кластера, представляющие документы второго кластера (не показаны). Второй кластер 302 может быть предварительно сформирован алгоритмом 215 кластеризации подобно формированию первого кластера 292. Второй кластер 302 содержит по меньшей мере два документа, представленные векторами 300 документов второго кластера.
[164] Приложение 126 кластеризации получает обобщенный параметр 298 метрики первого кластера 292 из памяти 118 сервера, из базы 124 данных новостей либо из другой энергозависимой или энергонезависимой памяти (не показана). В некоторых вариантах осуществления изобретения приложение 126 кластеризации может получать первый параметр 294 метрики и второй параметр 296 метрики и формировать обобщенный параметр 298 метрики на основе первого параметра 294 метрики и второго параметра 296 метрики.
[165] Приложение 126 кластеризации получает обобщенный параметр 308 метрики второго кластера 302 из памяти 118 сервера, из базы 124 данных новостей либо из другой энергозависимой или энергонезависимой памяти (не показана). В некоторых вариантах осуществления изобретения приложение 126 кластеризации может получать первый параметр 304 метрики и второй параметр 306 метрики и формировать обобщенный параметр 308 метрики второго кластера 302 на основе первого параметра 304 метрики и второго параметра 306 метрики.
[166] Затем алгоритм 215 кластеризации на основе векторов 290 документов первого кластера и векторов 300 документов второго кластера определяет для третьего потенциального кластера 312, содержащего первый кластер 292 и второй кластер 302, обновленный первый параметр 314 метрики, указывающий на степень взаимного дополнения документов первого кластера и документов второго кластера, если они объединяются в одном кластере. В некоторых вариантах осуществления настоящей технологии алгоритм 215 кластеризации может определять обновленный первый параметр 314 метрики на основе расстояний между векторами 290 каждого документа первого кластера, расстояний между векторами 300 каждого документа второго кластера и расстояний между векторами 290 каждого документа первого кластера и векторами 300 каждого документа второго кластера.
[167] Затем алгоритм 215 кластеризации на основе векторов 290 документов первого кластера и векторов 300 документов второго кластера определяет для третьего потенциального кластера 312, содержащего первый кластер 292 и второй кластер 302, обновленный второй параметр 316 метрики, указывающий на степень разбавления контента документов первого кластера и документов второго кластера, если они объединяются в одном кластере.
[168] В некоторых вариантах осуществления настоящей технологии алгоритм 215 кластеризации может формировать обновленный второй параметр 316 метрики на основе расстояний между векторами 290 каждого документа первого кластера, расстояний между векторами 300 каждого документа второго кластера, расстояний между векторами 290 каждого документа первого кластера и векторами 300 каждого документа второго кластера, а также размера третьего потенциального кластера 312. Кроме того, алгоритм 215 кластеризации может определять обновленный второй параметр 316 метрики, дополнительно основываясь на расстояниях между векторами 300 каждого документа второго кластера и векторами оставшихся документов из множества 220 векторов документов, а также на расстояниях между векторами 290 каждого документа первого кластера и векторами оставшихся документов из множества 220 векторов документов.
[169] Алгоритм 215 кластеризации определяет для третьего потенциального кластера 312, содержащего векторы 290 документов первого кластера и векторы 300 документов второго кластера, обновленный обобщенный параметр 318 метрики на основе обновленного первого параметра 314 метрики и обновленного второго параметра 316 метрики.
[170] Алгоритм 215 кластеризации сравнивает обновленный обобщенный параметр 318 метрики с обобщенным параметром 298 метрики первого кластера 292 и с обобщенным параметром 308 метрики второго кластера 302.
[171] Если обновленный обобщенный параметр 318 метрики превышает обобщенный параметр 298 метрики первого кластера 292 и обобщенный параметр 308 метрики второго кластера 302, это может указывать на то, что документы первого кластера и документы второго кластера предоставляют дополняющие друг друга данные и не разбавляют информацию, относящуюся к теме единого кластера, который они формируют (в отличие от случая, когда первый кластер 292 и второй кластер 302 хранятся отдельно). И наоборот, если обновленный обобщенный параметр 318 оказывается меньшим параметра 298 метрики и/или обобщенного параметра 308 метрики, это может указывать на то, что документы первого кластера и документы второго кластера не следует объединять в едином кластере, поскольку они не предоставляют дополняющие друг друга данные и/или разбавляют информацию в кластере, который они формируют (в отличие от случая, когда первый кластер 292 и второй кластер 302 объединяются в едином кластере).
[172] В этом не имеющем ограничительного характера примере алгоритм 215 кластеризации определяет, что обновленный обобщенный параметр 318 метрики превышает обобщенный параметр 298 метрики первого кластера 292 и обобщенный параметр 308 метрики второго кластера 302. Алгоритм 215 кластеризации объединяет первый кластер 292 и второй кластер 302 для формирования единого кластера.
[173] В общем случае приложение 126 кластеризации выполняет процедуру 200 кластеризации с целью продолжения добавления документов или объединения кластеров в уже существующем кластере до тех пор, пока обновленный обобщенный параметр метрики не окажется меньшим обобщенных параметров метрики существующих кластеров, что указывает на то, что документы для добавления или кластеры для объединения с уже существующим кластером не предоставляют дополняющих данных и/или разбавляют информацию, относящуюся к теме кластера, который они формируют. Затем алгоритм 215 кластеризации останавливает процедуру 200 кластеризации и закрывает уже существующий кластер. После этого алгоритм 215 кластеризации перезапускает процедуру для оставшихся пар документов из множества 160 цифровых документов.
[174] Следует отметить, что алгоритм 215 кластеризации способен запускать процедуру 200 кластеризации путем формирования обновленных обобщенных параметров метрики для всех возможных потенциальных кластеров, которые могут быть образованы двумя документами из множества 160 цифровых документов, и определяет первоначальный кластер, содержащий пару документов, имеющих обновленный обобщенный параметр метрики, превышающий другие обновленные обобщенные параметры метрики (т.е. наибольший обновленный обобщенный параметр метрики). Затем приложение 216 кластеризации может продолжать добавлять документы в первоначальный кластер, как описано выше, до тех пор, пока обновленный обобщенный параметр метрики не окажется меньшим обобщенного параметра метрики первого кластера. После этого приложение 216 кластеризации может сформировать второй кластер из числа всех возможных потенциальных кластеров, которые могут быть образованы двумя оставшимися документами из множества 160 цифровых документов, и продолжать процедуру для формирования набора 190 кластеров.
[175] Затем алгоритм 215 кластеризации выдает набор 190 кластеров, в котором каждый кластер 195 содержит подмножество векторов 197 документов из множества 220 векторов документов, представляющее подмножество документов 167 из множества 160 цифровых документов. Затем приложение 126 кластеризации сохраняет в базе 124 данных новостей для каждого документа 162 связанный с ним кластер и/или отправляет информацию приложению 122 агрегатора новостей, которое может показать по меньшей мере часть множества 160 документов, которые, например, могут быть отсортированы по кластерам 195.
[176] Выше со ссылками на фиг. 2 описано формирование приложением 126 кластеризации обобщенного параметра метрики на основе первого параметра метрики и второго параметра метрики в соответствии с не имеющими ограничительного характера вариантами осуществления настоящей технологии. Ниже со ссылками на фиг. 3-5 описаны способы кластеризации документов на основе обобщенного параметра метрики.
[177] На фиг. 3-5 приведена блок-схема способа 400 кластеризации документов в набор кластеров на основе обобщенного параметра метрики, выполняемого в соответствии с не имеющими ограничительного характера вариантами осуществления настоящей технологии.
[178] Способ 400 выполняется приложением 126 кластеризации сервера 116.
[179] Способ 400 начинается с шага 402.
[180] Шаг 402: получение множества документов, каждый из которых содержит контент документа.
[181] На шаге 402 приложение 126 кластеризации получает из базы 124 данных новостей множество 160 цифровых документов 162, каждый из которых содержит контент 164 документа. Контент 164 документа включает в себя заголовок 166 и контент 168 тела.
[182] Затем способ 400 продолжается на шаге 404.
[183] Шаг 404: формирование для каждого документа вектора документа.
[184] На шаге 404 приложение 126 кластеризации определяет с использованием процедуры 210 формирования векторов вектор 225 документа для каждого документа 162 на основе по меньшей мере части контента 164 документа. В некоторых вариантах осуществления изобретения приложение 126 кластеризации определяет вектор 225 документа на основе заголовка 166 документа. В других вариантах осуществления изобретения приложение 126 кластеризации определяет вектор 225 документа на основе заголовка 166 документа и по меньшей мере части контента 168 тела документа.
[185] Затем способ 400 продолжается на шаге 406.
[186] Шаг 406: определение для каждого документа на основе вектора документа первого параметра метрики, второго параметра метрики и обобщенного параметра метрики на основе первого параметра метрики и второго параметра метрики.
[187] На шаге 406 приложение 126 кластеризации для каждого документа 162 из множества 160 цифровых документов определяет на основе вектора 225 документа первый параметр 234 метрики, второй параметр 236 метрики и обобщенный параметр 238 метрики на основе первого параметра 234 метрики и второго параметра 236 метрики. В некоторых вариантах осуществления изобретения первый параметр 234 метрики и второй параметр 236 метрики могут иметь заранее заданное значение.
[188] Затем способ 400 продолжается на шаге 408.
[189] Шаг 408: определение на основе вектора документа для каждого возможного кластера, содержащего пару документов из множества документов, обновленного первого параметра метрики, обновленного второго параметра метрики и обновленного обобщенного параметра метрики на основе обновленного первого параметра метрики и обновленного второго параметра метрики.
[190] На шаге 408 приложение 126 кластеризации определяет для каждого возможного потенциального кластера 252, содержащего пару документов из множества 160 цифровых документов, на основе вектора 232 документа и вектора 242 другого документа обновленный первый параметр 254 метрики, указывающий на степень взаимного дополнения контента документов из пары оставшихся документов, если они объединяются в потенциальный кластер. Приложение 126 кластеризации определяет для каждого возможного потенциального кластера 252, содержащего пару документов из множества 160 цифровых документов, на основе вектора 232 документа и вектора 242 другого документа обновленный второй параметр 256 метрики, указывающий на степень разбавления контента документов в потенциальном кластере. Приложение 126 кластеризации определяет обновленный обобщенный параметр 258 метрики на основе обновленного первого параметра 254 метрики и обновленного второго параметра 258 метрики.
[191] Затем способ 400 продолжается на шаге 410.
[192] Шаг 410: формирование кластера, содержащего первый документ и второй документ, при превышении обновленным обобщенным параметром метрики других обновленных обобщенных параметров метрики.
[193] На шаге 410 приложение 126 кластеризации выбирает первый документ и второй документ, представленные векторами 270 документов кластера, для формирования кластера 272 при превышении обновленным обобщенным параметром 258 метрики одного потенциального кластера 252 обновленных обобщенных параметров метрики других потенциальных кластеров 252.
[194] Шаг 412: сохранение обновленного обобщенного параметра метрики в качестве обобщенного параметра метрики кластера.
[195] На шаге 412 приложение 126 кластеризации сохраняет обновленный обобщенный параметр 258 метрики в качестве обобщенного параметра 278 метрики кластера 272.
[196] Затем способ 400 продолжается на шаге 414.
[197] Шаг 414: определение для каждого потенциального кластера, содержащего кластер и оставшийся документ из множества документов, обновленного первого параметра метрики, обновленного второго параметра метрики и обновленного обобщенного параметра метрики на основе обновленного первого параметра метрики и обновленного второго параметра метрики.
[198] На шаге 414 приложение 126 кластеризации определяет для каждого потенциального кластера 282, содержащего кластер 272 и оставшийся документ из множества 160 цифровых документов (т.е. из множества 160 цифровых документов за исключением первого документа и второго документа), на основе векторов 270 документов кластера и вектора оставшегося документа обновленный первый параметр 284 метрики, обновленный второй параметр 286 метрики и обновленный обобщенный параметр 288 метрики на основе обновленного первого параметра 284 метрики и обновленного второго параметра 286 метрики.
[199] Затем способ 400 продолжается на шаге 416.
[200] Шаг 416: при превышении одним из обновленных обобщенных параметров метрики обобщенного параметра метрики кластера добавление в кластер третьего документа, представляющего собой оставшийся документ из множества документов и при добавлении его в кластер имеющего обновленный обобщенный параметр метрики, превышающий обобщенный параметр метрики.
[201] На шаге 416 приложение 126 кластеризации для формирования первого кластера 292 добавляет в кластер 272 на основе одного из обновленных обобщенных параметров метрики, связанных с потенциальным кластером, содержащим кластер 272 и оставшийся документ, третий документ (представленный вектором 262 третьего документа), представляющий собой оставшийся документ из множества 160 цифровых документов (за исключением первого документа и второго документа), который имеет один из обновленных обобщенных параметров метрики, превышающий обобщенный параметр метрики кластера 272.
[202] В некоторых вариантах осуществления настоящей технологии несколько потенциальных кластеров могут иметь обновленный обобщенный параметр 288 метрики, превышающий обобщенный параметр 278 метрики кластера 272. В этом случае приложение 126 кластеризации может выбрать потенциальный кластер, имеющий обновленный обобщенный параметр метрики, превышающий другие обновленные обобщенные параметры метрики, которые также превышают обобщенный параметр метрики кластера 272. Затем алгоритм 126 кластеризации может добавить третий документ (представленный вектором 262 третьего документа) в кластер 272 для формирования первого кластера 292. Затем способ 400 продолжается на шаге 418.
[203] В других вариантах осуществления настоящей технологии все обновленные обобщенные параметры метрики могут не превышать обобщенного параметра метрики кластера 272. Приложение 126 кластеризации может рассматривать кластер 272 как полный и «закрыть» кластер 272. В этом случае способ 400 может продолжаться на шаге 422.
[204] Шаг 418: сохранение обновленного обобщенного параметра метрики в качестве обобщенного параметра метрики первого кластера.
[205] На шаге 418 приложение 126 кластеризации сохраняет обновленный обобщенный параметр 288 метрики в качестве обобщенного параметра 298 метрики первого кластера 292. В некоторых вариантах осуществления изобретения алгоритм кластеризации также может сохранять обновленный первый параметр 284 метрики и обновленный второй параметр 286 метрики в качестве первого параметра 294 метрики и второго параметра 296 метрики, соответственно, для первого кластера 292.
[206] Затем способ 400 продолжается на шаге 420.
[207] Шаг 420: повторение способа для оставшихся документов из множества документов до тех пор, пока все оставшиеся обновленные обобщенные параметры метрики не окажутся меньшими обобщенного параметра метрики первого кластера.
[208] На шаге 420 приложение 126 кластеризации может продолжать добавление оставшихся документов из множества 160 цифровых документов в кластер 272 путем повторения шагов 414 и 416 для первого кластера 292 до тех пор, пока все обновленные обобщенные параметры метрики потенциальных кластеров не окажутся меньшими обобщенного параметра метрики первого кластера 292. Затем приложение 126 кластеризации может рассматривать первый кластер 292 как полный и закрыть первый кластер 292.
[209] Затем способ 400 продолжается на шаге 422.
[210] Шаг 422: определение для каждого потенциального кластера, содержащего пару оставшихся документов из множества документов:
- обновленного первого параметра метрики, указывающего на степень взаимного дополнения контента документов для этой пары документов, если они объединяются в потенциальном кластере,
- обновленного второго параметра метрики, указывающего на степень разбавления контента документов для этой пары документов, если они объединяются в потенциальном кластере, и
- обновленного обобщенного параметра метрики на основе обновленного первого параметра метрики и обновленного второго параметра метрики.
[211] На шаге 422 приложение 126 кластеризации для каждого возможного потенциального кластера 252, содержащего пару оставшихся документов из множества 160 цифровых документов, определяет на основе векторов документов обновленный первый параметр 254 метрики, обновленный второй параметр 256 метрики и обновленный обобщенный параметр 258 метрики на основе обновленного первого параметра 254 метрики и обновленного второго параметра 2563 (3 В тексте источника опечатка. В переводе исправлено.) метрики. Оставшиеся документы из множества 160 цифровых документов не включают в себя документы кластера 272.
[212] Затем способ 400 продолжается на шаге 424.
[213] Шаг 424: формирование второго кластера, содержащего пару документов, при превышении одним из обновленных обобщенных параметров метрики этой пары документов других обновленных4 (4 В тексте источника пропущено выделенное слово. В переводе исправлено.) обобщенных параметров метрики.
[214] На шаге 424 приложение 126 кластеризации выбирает первый оставшийся документ и второй оставшийся документ для формирования второго кластера 302 при превышении обновленным обобщенным параметром 258 метрики одного из потенциальных кластеров 252 обновленных обобщенных параметров 258 метрики других потенциальных кластеров 252. Приложение 126 кластеризации сохраняет обновленный обобщенный параметр 258 метрики в качестве обобщенного параметра 308 метрики второго кластера 302.
[215] Затем способ 400 продолжается на шаге 426.
[216] Шаг 426: определение для каждого потенциального кластера, содержащего второй кластер и оставшийся документ из множества документов, обновленного первого параметра метрики, обновленного второго параметра метрики и обновленного обобщенного параметра метрики на основе обновленного первого параметра метрики и обновленного второго параметра метрики.
[217] На шаге 426 приложение 126 кластеризации на основе векторов 225 документов определяет для каждого потенциального кластера, содержащего второй кластер 302 и оставшийся документ из множества 160 цифровых документов (т.е. из множества 160 цифровых документов за исключением документов кластера 292), обновленный первый параметр метрики, обновленный второй параметр метрики и обновленный обобщенный параметр метрики на основе обновленного первого параметра метрики и обновленного второго параметра метрики.
[218] Затем способ 400 продолжается на шаге 428.
[219] Шаг 428: при превышении одним из обновленных обобщенных параметров метрики обобщенного параметра метрики второго кластера добавление во второй кластер третьего документа, представляющего собой оставшийся документ из множества документов и имеющего обновленный обобщенный параметр метрики, превышающий обобщенный параметр метрики второго кластера.
[220] На шаге 428 приложение 126 кластеризации добавляет во второй кластер на основе одного из обновленных обобщенных параметров метрики, превышающего обобщенный параметр метрики второго кластера, третий документ, представляющий собой оставшийся документ из множества 160 цифровых документов (за исключением первого документа и второго документа), который имеет этот один из обновленных обобщенных параметров метрики в потенциальном кластере, если он добавляется во второй кластер 302. В общем случае, один из обновленных обобщенных параметров превышает обобщенный параметр метрики второго кластера 302.
[221] В некоторых вариантах осуществления настоящей технологии несколько потенциальных кластеров могут иметь обновленный обобщенный параметр метрики, превышающий обобщенный параметр метрики второго кластера 302, и приложение 126 кластеризации может выбрать потенциальный кластер, имеющий обновленный обобщенный параметр метрики, превышающий другие обновленные обобщенные параметры метрики. Затем приложение 126 кластеризации может добавить третий оставшийся документ во второй кластер 302 и сохранить обновленный обобщенный параметр метрики в качестве обобщенного параметра 308 метрики второго кластера 302. После этого приложение 126 кластеризации повторяет шаги 406-426 для формирования набора 190 кластеров, содержащего по меньшей мере первый кластер 292 и второй кластер 302.
[222] В других вариантах осуществления настоящей технологии все обновленные обобщенные параметры метрики могут не превышать обобщенного параметра метрики второго кластера 302. Приложение 126 кластеризации может рассматривать второй кластер 302 как полный и закрыть второй кластер 302. Затем приложение 126 кластеризации повторяет шаги 406-428 для формирования набора 190 кластеров, содержащего по меньшей мере первый кластер 292 и второй кластер 302.
[223] На фиг. 6 приведена блок-схема способа 500 кластеризации первого кластера 292 и второго кластера 302.
[224] Способ 500 выполняется приложением 126 кластеризации сервера 116.
[225] Способ 500 начинается с шага 502.
[226] Шаг 502: получение первого кластера, содержащего документы первого кластера, и второго кластера, содержащего документы второго кластера.
[227] На шаге 502 приложение 126 кластеризации получает из базы 124 данных новостей первый кластер 292 и второй кластер 302. Первый кластер 292 содержит векторы 290 документов первого кластера, представляющие документы первого кластера, а второй кластер 302 содержит векторы 300 документов второго кластера, представляющие документы второго кластера.
[228] Затем способ 400 продолжается на шаге 504.
[229] Шаг 504: получение для первого кластера и для второго кластера обобщенного параметра метрики.
[230] Приложение 126 кластеризации получает обобщенный параметр 298 метрики первого кластера 292 из памяти 118 сервера, из базы 124 данных новостей либо из другой энергозависимой или энергонезависимой памяти (не показана). В некоторых вариантах осуществления изобретения приложение 126 кластеризации может получать первый параметр 294 метрики и второй параметр 296 метрики и формировать обобщенный параметр 298 метрики на основе первого параметра 294 метрики и второго параметра 296 метрики.
[231] Приложение 126 кластеризации получает обобщенный параметр 308 метрики второго кластера 302 из памяти 118 сервера, из базы 124 данных новостей либо из другой энергозависимой или энергонезависимой памяти (не показана). В некоторых вариантах осуществления изобретения приложение 126 кластеризации может получать первый параметр 304 метрики и второй параметр 306 метрики и формировать обобщенный параметр 308 метрики второго кластера 302 на основе первого параметра 304 метрики и второго параметра 306 метрики.
[232] Затем способ 500 продолжается на шаге 506.
[233] Шаг 506: определение для потенциального кластера, содержащего документы первого кластера и документы второго кластера:
- обновленного первого параметра метрики, указывающего на степень взаимного дополнения контента документов в потенциальном кластере, если документы первого кластера и документы второго кластера объединяются в этом потенциальном кластере;
- обновленного второго параметра метрики, указывающего на степень разбавления контента документов в потенциальном кластере, если документы первого кластера и документы второго кластера объединяются в этом потенциальном кластере; и
- обновленного обобщенного параметра метрики на основе обновленного первого параметра метрики и обновленного второго параметра метрики.
[234] На шаге 506 алгоритм 215 кластеризации на основе векторов 290 документов первого кластера и векторов 300 документов второго кластера определяет для третьего потенциального кластера 312, содержащего первый кластер 292 и второй кластер 302, обновленный первый параметр 314 метрики, указывающий на степень взаимного дополнения документов первого кластера и документов второго кластера, если они объединяются в одном кластере.
[235] Алгоритм 215 кластеризации на основе векторов 290 документов первого кластера и векторов 300 документов второго кластера определяет для третьего потенциального кластера 312, содержащего первый кластер 292 и второй кластер 302, обновленный второй параметр 316 метрики, указывающий на степень разбавления контента документов первого кластера и документов второго кластера, если они объединяются в одном кластере.
[236] Алгоритм 215 кластеризации определяет для третьего потенциального кластера 312, содержащего векторы 290 документов первого кластера и векторы 300 документов второго кластера, обновленный обобщенный параметр 318 метрики на основе обновленного первого параметра 314 метрики и обновленного второго параметра 316 метрики.
[237] Способ 500 продолжается на шаге 508.
[238] Шаг 508: формирование кластера, содержащего документы первого кластера и документы второго кластера, при превышении обновленным обобщенным параметром метрики обоих обобщенных параметров метрики.
[239] На шаге 508 приложение 126 кластеризации сравнивает обновленный обобщенный параметр 318 метрики с обобщенным параметром 298 метрики и с обобщенным параметром 308 метрики. Если обновленный обобщенный параметр 318 метрики превышает обобщенный параметр 298 метрики и обобщенный параметр 308 метрики, то приложение кластеризации формирует кластер, содержащий документы первого кластера и документы второго кластера.
[240] Если обновленный обобщенный параметр 318 оказывается меньшим параметра 298 метрики и/или обобщенного параметра 308 метрики, то приложение 126 кластеризации может сохранять первый кластер 292 и второй кластер 302 в виде отдельных кластеров.
[241] Приложение 126 кластеризации может повторять шаги 502-508 для множества кластеров (не показано) до тех пор, пока обновленный обобщенный параметр метрики не окажется меньшим по меньшей мере одного из параметров метрики.
[242] На этом способ 500 может быть завершен.
[243] Настоящая технология также может быть модифицирована и использована в сочетании с другими способами кластеризации, например, для оценки взаимного дополнения информации и разбавления информации в кластере (или кластерах), сформированных с использованием других способов.
[244] Специалистам в данной области техники должно быть очевидно, что по меньшей некоторые варианты осуществления настоящей технологии преследуют цель расширения арсенала технических решений определенной технической проблемы, а именно, улучшения использования ресурсов на сервере путем более эффективной кластеризации документов, а также сокращения потерь пропускной способности и ресурсов в клиентских устройствах путем предоставления пользователям более репрезентативных документов в отношении некоторой темы или события, в результате чего пользователям не требуется просматривать все документы для получения информации, относящейся к этой теме или к этому событию.
[245] Очевидно, что не все упомянутые в данном описании технические эффекты должны присутствовать в каждом варианте осуществления настоящей технологии. Например, возможны варианты осуществления настоящей технологии, когда пользователь не получает некоторые из этих технических эффектов, или другие варианты реализации, когда пользователь получает другие технические эффекты либо технический эффект отсутствует.
[246] Некоторые из этих шагов и передаваемых или принимаемых сигналов хорошо известны в данной области техники и по этой причине опущены в некоторых частях описания для упрощения. Сигналы могут передаваться или приниматься с использованием оптических средств (таких как волоконно-оптическое соединение), электронных средств (таких как проводное или беспроводное соединение) и механических средств (например, основанных на давлении, температуре или любом другом подходящем физическом параметре).
[247] Для специалиста в данной области могут быть очевидными возможные изменения и усовершенствования описанных выше вариантов осуществления настоящей технологии. Предшествующее описание приведено лишь в иллюстративных целях, а не для ограничения объема изобретения. Объем охраны настоящей технологии определяется исключительно объемом приложенной формулы изобретения.
| название | год | авторы | номер документа |
|---|---|---|---|
| СИСТЕМА И СПОСОБ ФОРМИРОВАНИЯ ОБУЧАЮЩЕГО НАБОРА ДЛЯ АЛГОРИТМА МАШИННОГО ОБУЧЕНИЯ | 2017 |
|
RU2711125C2 |
| Способ и система для формирования карточки объекта | 2018 |
|
RU2739554C1 |
| Способ и система для создания пуш-уведомлений, связанных с цифровыми новостями | 2018 |
|
RU2731654C1 |
| СИСТЕМА И СПОСОБ УПРАВЛЕНИЯ И ОРГАНИЗАЦИИ КЭША ВЕБ-БРАУЗЕРА ДЛЯ ОБЕСПЕЧЕНИЯ АВТОНОМНОГО ПРОСМОТРА | 2014 |
|
RU2608668C2 |
| СПОСОБ И СИСТЕМА ДЛЯ ОПРЕДЕЛЕНИЯ АНОМАЛЬНЫХ ПОСЕЩЕНИЙ ВЕБ-САЙТОВ | 2019 |
|
RU2775824C2 |
| СПОСОБ И СИСТЕМА СОЗДАНИЯ ВЕКТОРОВ АННОТАЦИИ ДЛЯ ДОКУМЕНТА | 2017 |
|
RU2720074C2 |
| ОПТИМИЗИРОВАННЫЙ ПРОЦЕСС ВОСПРОИЗВЕДЕНИЯ БРАУЗЕРА | 2014 |
|
RU2638726C1 |
| СПОСОБ И СИСТЕМА ДЛЯ ОПРЕДЕЛЕНИЯ ФАКТА ПОСЕЩЕНИЯ ПОЛЬЗОВАТЕЛЕМ ТОЧКИ ИНТЕРЕСА | 2020 |
|
RU2767958C2 |
| СПОСОБ И СЕРВЕР ОПРЕДЕЛЕНИЯ ИСХОДНОЙ ССЫЛКИ НА ИСХОДНЫЙ ОБЪЕКТ | 2016 |
|
RU2660593C2 |
| ОПТИМИЗИРОВАННЫЙ ПРОЦЕСС ВОСПРОИЗВЕДЕНИЯ БРАУЗЕРА | 2017 |
|
RU2756482C2 |
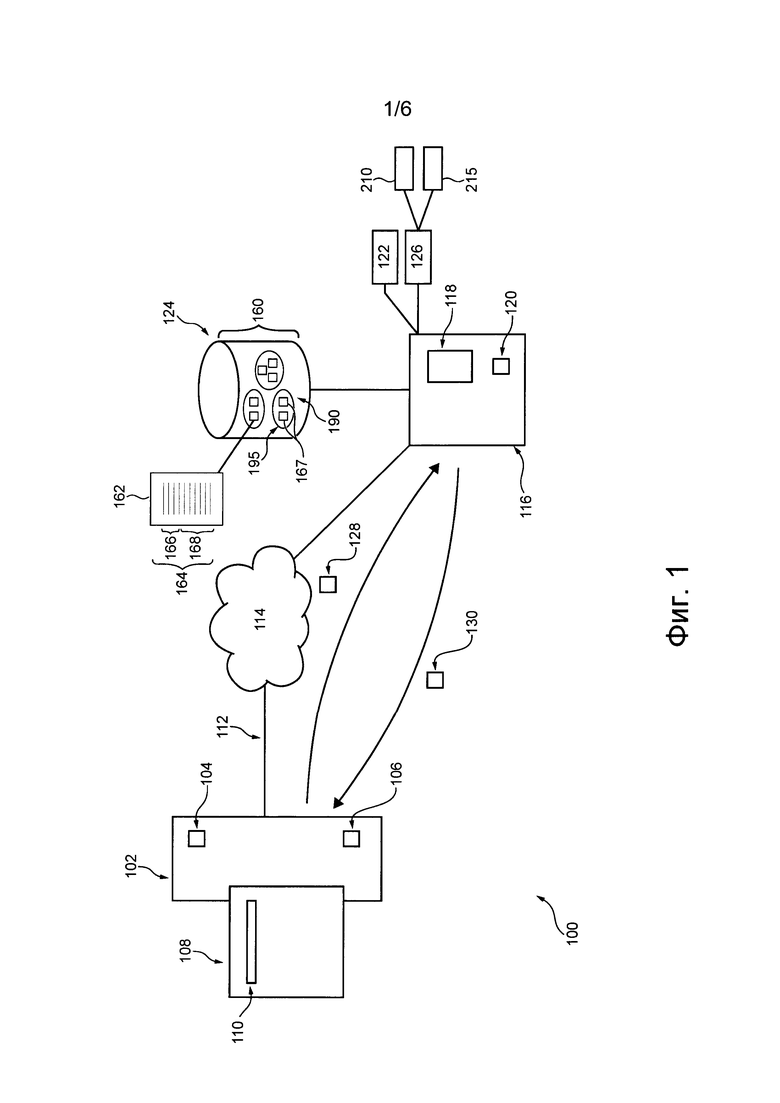
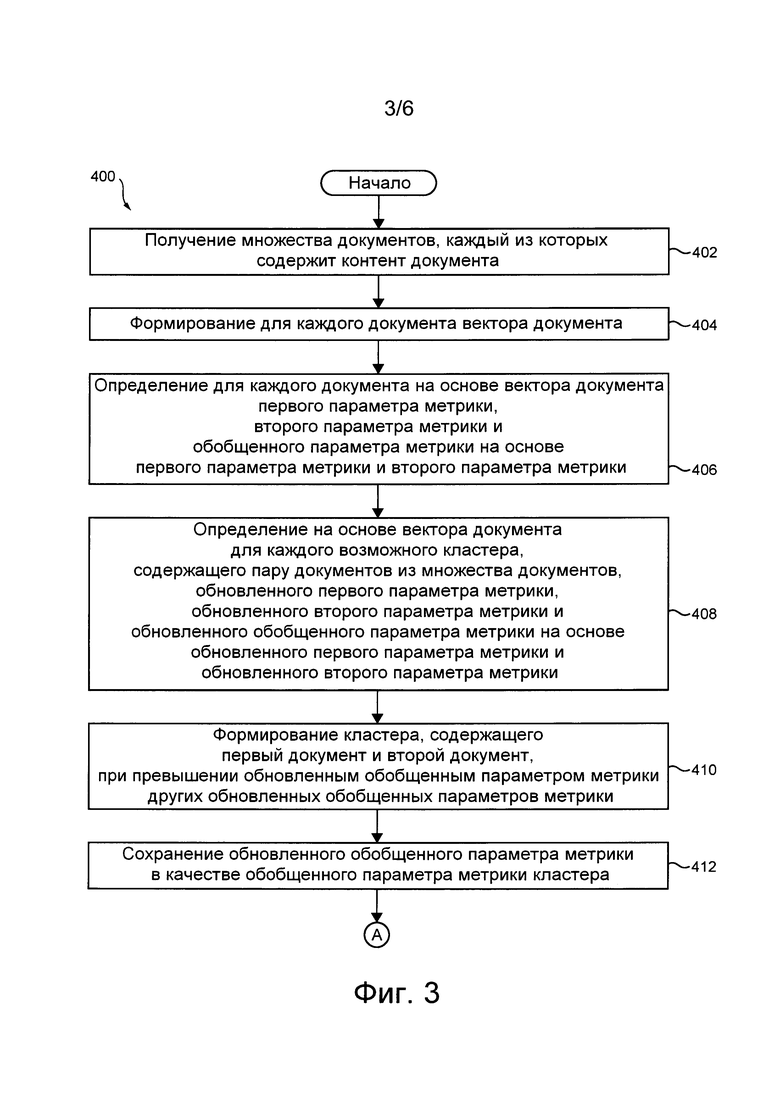
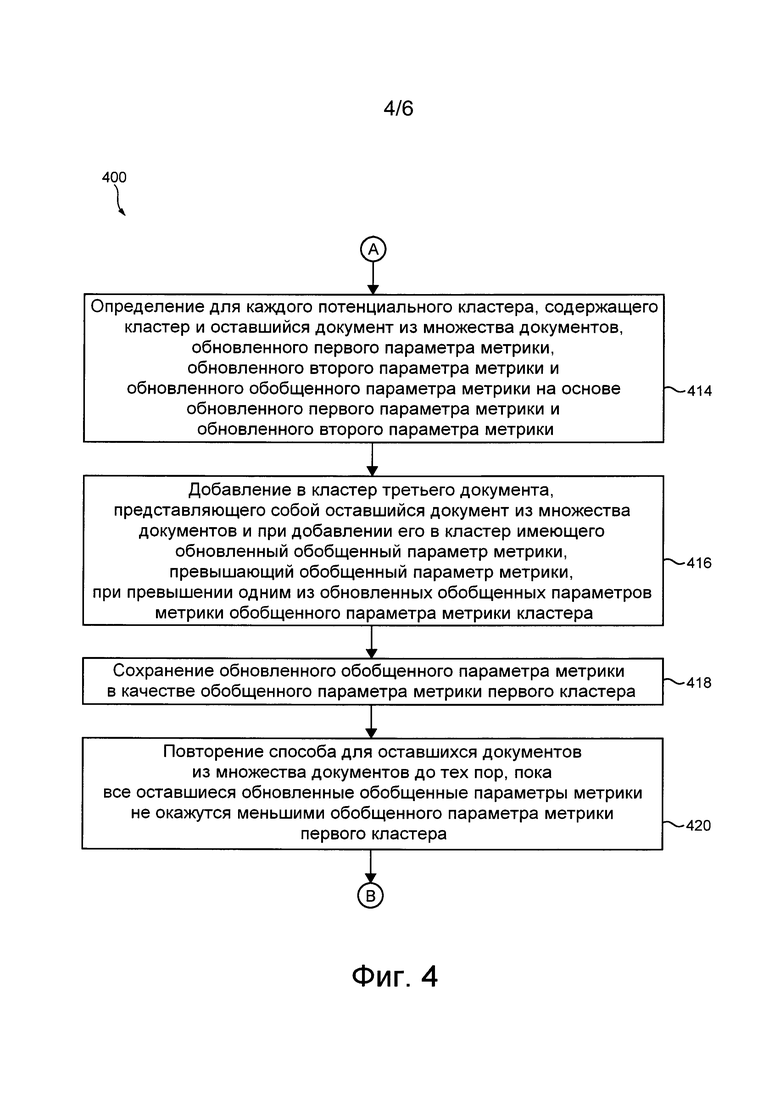
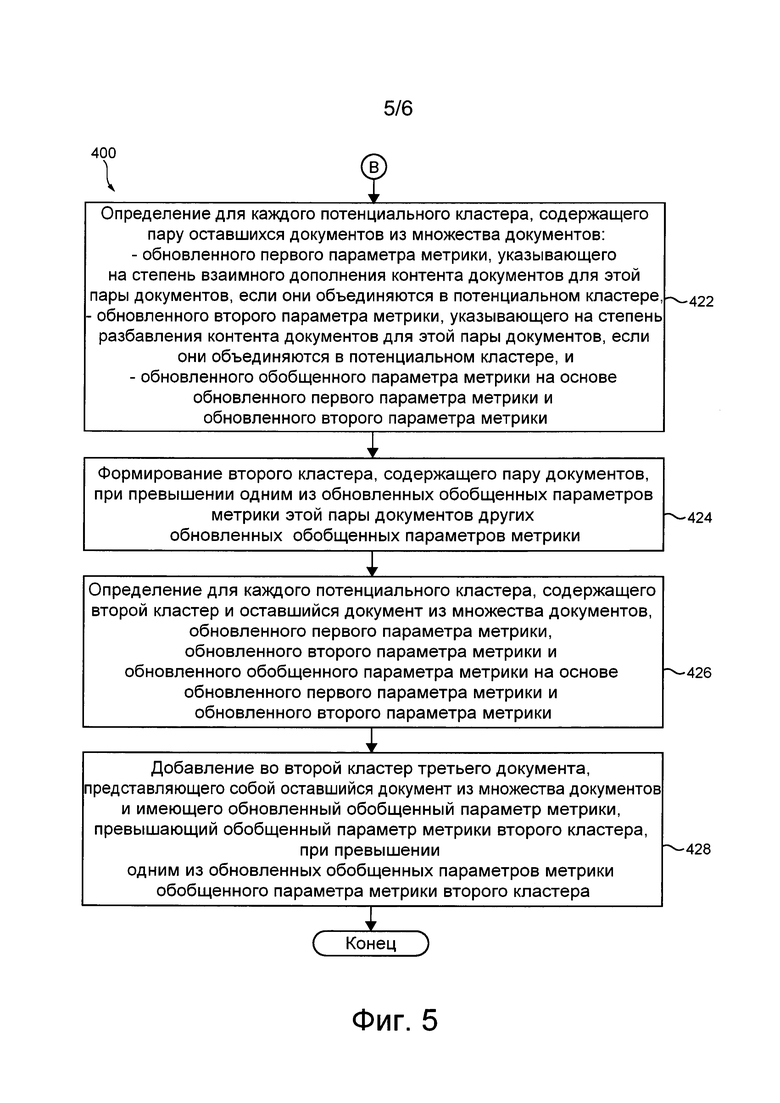
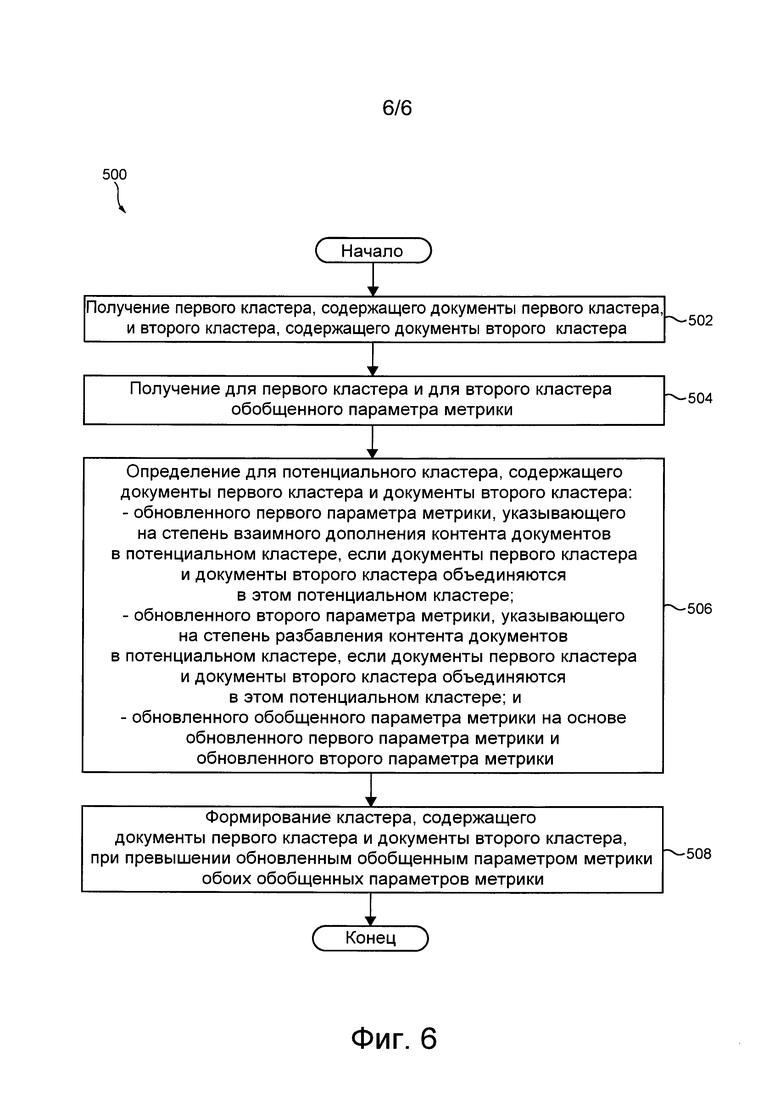
Изобретение относится к вычислительной технике. Технический результат заключается в повышении эффективности кластеризации документов и сокращении потери пропускной способности каналов связи. Реализованы способ и система для формирования кластеров документов с использованием обобщенного параметра метрики. Принимаются первый документ и второй документ и для потенциального кластера, содержащего первый документ и второй документ, и определяются первый параметр метрики, указывающий на степень взаимного дополнения контента документов в потенциальном кластере, и второй параметр метрики, указывающий на степень разбавления контента документов в этом потенциальном кластере. Обобщенный параметр метрики определяется на основе первого параметра метрики и второго параметра метрики. На основе обобщенного параметра метрики формируется кластер, содержащий первый и второй документ. Другой документ (или документы) или кластеры могут быть добавлены в кластер путем определения обновленного обобщенного параметра метрики для потенциального кластера и сравнения обновленного обобщенного параметра метрики с обобщенным параметром метрики. 2 н. и 30 з.п. ф-лы, 6 ил.
1. Компьютерный способ формирования кластеров документов с использованием алгоритма кластеризации, при этом каждый кластер документов содержит документы, имеющие по меньшей мере одну общую тему, выполняемый сервером, реализующим алгоритм кластеризации, и включающий в себя:
- получение сервером первого документа и второго документа, содержащих контент документа;
- определение сервером для потенциального кластера, содержащего первый документ и второй документ:
- обновленного первого параметра метрики, указывающего на степень взаимного дополнения контента документов в потенциальном кластере, если первый документ и второй документы объединяются в этом потенциальном кластере, и
- обновленного второго параметра метрики, указывающего на степень разбавления контента документов в потенциальном кластере, если первый документ и второй документ объединяются в этом потенциальном кластере, причем степень разбавления контента документов характеризуется уменьшением точности информации, относящейся к теме, которой посвящены другие документы в кластере, где
- обновленный первый параметр метрики представляет собой обновленное значение первого параметра метрики первого документа, если второй документ добавляется в кластер с первым документом, и обновленный второй параметр метрики представляет собой обновленное значение второго параметра метрики второго документа, если первый документ добавляется в кластер со вторым документом, и
- обновленного обобщенного параметра метрики на основе обновленного первого параметра метрики и обновленного второго параметра метрики; и
- формирование сервером кластера, содержащего первый документ и второй документ, на основе обновленного обобщенного параметра метрики.
2. Способ по п. 1, отличающийся тем, что перед определением обновленного первого параметра метрики для потенциального кластера он дополнительно включает в себя определение для первого документа и для второго документа первого параметра метрики, второго параметра метрики и обобщенного параметра метрики на основе первого параметра метрики и второго параметра метрики, при этом кластер формируется, если обновленный обобщенный параметр метрики потенциального кластера превышает обобщенный параметр метрики первого документа и/или второго документа.
3. Способ по п. 1, отличающийся тем, что он дополнительно включает в себя сохранение сервером обновленного обобщенного параметра метрики в качестве обобщенного параметра метрики кластера.
4. Способ по п. 2, отличающийся тем, что:
- кластер представляет собой первый кластер;
- получение включает в себя получение множества документов, каждый из которых содержит контент документа, при этом множество документов содержит первый документ и второй документ;
- определение включает в себя определение обновленного первого параметра метрики, обновленного второго параметра метрики и обновленного обобщенного параметра метрики для каждого возможного потенциального кластера, содержащего пару документов из множества документов; и
- формирование первого кластера, содержащего первый документ и второй документ, на основе обновленного обобщенного параметра метрики дополнительно основано на превышении обновленным обобщенным параметром метрики потенциального кластера, содержащего первый документ и второй документ, обновленных обобщенных параметров метрики оставшихся потенциальных кластеров, содержащих пару документов из множества документов.
5. Способ по п. 4, отличающийся тем, что он дополнительно включает в себя:
- определение сервером для каждого потенциального кластера, содержащего документы из первого кластера и оставшийся документ из множества документов:
- обновленного первого параметра метрики, указывающего на степень взаимного дополнения контента документов в потенциальном кластере, если оставшийся документ объединяется с документами первого кластера в этом потенциальном кластере,
- обновленного второго параметра метрики, указывающего на степень разбавления контента документов в потенциальном кластере, если оставшийся документ объединяется с документами первого кластера в этом потенциальном кластере, и
- обновленного обобщенного параметра метрики на основе обновленного первого параметра метрики и обновленного второго параметра метрики;
- добавление третьего документа в первый кластер, если один из обновленных обобщенных параметров метрики превышает обобщенный параметр метрики первого кластера, при этом третий документ представляет собой оставшийся документ из множества документов, который в случае его объединения с документами первого кластера имеет один из обновленных обобщенных параметров метрики, превышающий обобщенный параметр метрики первого кластера; и
- сохранение сервером этого одного из обновленных обобщенных параметров метрики в качестве обобщенного параметра метрики первого кластера.
6. Способ по п. 4, отличающийся тем, что он дополнительно включает в себя закрытие первого кластера без добавления третьего документа, если все обновленные обобщенные параметры метрики оказываются меньшими обобщенного параметра метрики первого кластера.
7. Способ по п. 4, отличающийся тем, что он дополнительно включает в себя:
- повторение способа для оставшихся документов из множества документов до тех пор, пока все обновленные обобщенные параметры метрики не окажутся меньшими обобщенного параметра метрики первого кластера; и
- закрытие первого кластера, если все обновленные обобщенные параметры метрики оказываются меньшими обобщенного параметра метрики первого кластера.
8. Способ по п. 5, отличающийся тем, что он дополнительно включает в себя:
- определение сервером для каждого потенциального кластера, содержащего пару оставшихся документов из множества документов, не содержащих документов из первого кластера:
- обновленного первого параметра метрики, указывающего на степень взаимного дополнения контента документов из этой пары оставшихся документов, если они объединяются в этом потенциальном кластере,
- обновленного второго параметра метрики, при этом обновленный второй параметр метрики указывает на степень разбавления контента документов в потенциальном кластере, если эта пара оставшихся документов объединяется в этом потенциальном кластере, и
- обновленного обобщенного параметра метрики на основе обновленного первого параметра метрики и обновленного второго параметра метрики;
- при превышении одним из обновленных обобщенных параметров метрики обновленных обобщенных параметров метрики оставшихся потенциальных кластеров формирование сервером второго кластера, содержащего пару документов, имеющих в случае их объединения этот один из обновленных обобщенных параметров метрики; и
- сохранение сервером этого одного из обновленных обобщенных параметров метрики в качестве обобщенного параметра метрики второго кластера.
9. Способ по п. 5, отличающийся тем, что он дополнительно включает в себя:
- определение сервером для каждого потенциального кластера, содержащего документы из второго кластера и оставшийся документ из множества документов:
- обновленного первого параметра метрики, указывающего на степень взаимного дополнения контента документов в потенциальном кластере, если оставшийся документ объединяется с документами второго кластера,
- обновленного второго параметра метрики, указывающего на степень разбавления контента документов в потенциальном кластере, если оставшийся документ объединяется с документами второго кластера, и
- обновленного обобщенного параметра метрики на основе обновленного первого параметра метрики и обновленного второго параметра метрики;
- добавление сервером четвертого документа во второй кластер, если один из обновленных обобщенных параметров метрики превышает обобщенный параметр метрики второго кластера, при этом четвертый документ представляет собой оставшийся документ из множества документов, который в случае его объединения с документами второго кластера имеет один из обновленных обобщенных параметров метрики, превышающий обобщенный параметр метрики второго кластера; и
- сохранение сервером этого одного из обновленных обобщенных параметров метрики в качестве обобщенного параметра метрики второго кластера.
10. Способ по п. 8, отличающийся тем, что он дополнительно включает в себя повторение способа для оставшихся документов из множества документов с целью получения набора кластеров, содержащего по меньшей мере первый кластер и второй кластер.
11. Способ по п. 7, отличающийся тем, что после получения множества документов он дополнительно включает в себя формирование сервером вектора документа для каждого документа из множества документов на основе по меньшей мере части контента соответствующего документа, при этом определение обновленного первого параметра метрики для потенциального кластера основано на расстояниях между векторами документов в потенциальном кластере, а определение обновленного второго параметра метрики для потенциального кластера основано на расстояниях между векторами документов в потенциальном кластере и на размере этого потенциального кластера.
12. Способ по п. 1, отличающийся тем, что первый документ представляет собой первый кластер, содержащий множество документов первого кластера, а второй документ представляет собой второй кластер, содержащий множество документов второго кластера.
13. Способ по п. 12, отличающийся тем, что первый кластер и второй кластер имеют обобщенный параметр метрики, при этом кластер формируется, если обновленный обобщенный параметр метрики превышает обобщенный параметр метрики первого кластера и обобщенный параметр метрики второго кластера.
14. Способ по п. 12, отличающийся тем, что он дополнительно включает в себя сохранение первого кластера и второго кластера в качестве отдельных кластеров, если обобщенный параметр метрики оказывается меньшим обобщенного параметра метрики первого кластера и обобщенного параметра метрики второго кластера.
15. Способ по п. 12, отличающийся тем, что:
- определение обновленного первого параметра метрики дополнительно основано на расстояниях между векторами документов первого кластера, расстояниях между векторами документов второго кластера и расстояниях между векторами документов первого кластера и второго кластера; и
- определение обновленного второго параметра метрики для потенциального кластера основано на расстояниях между векторами документов первого кластера, расстояниях между векторами документов второго кластера, расстояниях между векторами документов первого кластера и второго кластера и размере этого потенциального кластера, который представляет собой сумму размеров первого кластера и второго кластера.
16. Способ по п. 9, отличающийся тем, что контент документа включает в себя заголовок документа и контент тела документа.
17. Система для формирования кластеров документов с использованием алгоритма кластеризации, при этом каждый кластер документов содержит документы, имеющие по меньшей мере одну общую тему, содержащая процессор и машиночитаемый физический носитель информации, содержащий команды, при этом процессор выполнен с возможностью выполнения следующих действий при исполнении команд:
- получение первого документа и второго документа, содержащих контент документа;
- определение для потенциального кластера, содержащего первый и второй документ:
- обновленного первого параметра метрики, указывающего на степень взаимного дополнения контента документов в потенциальном кластере, если первый документ и второй документ объединяются в этом в потенциальном кластере,
- обновленного второго параметра метрики, указывающего на степень разбавления контента документов в потенциальном кластере, если первый документ и второй документ объединяются в этом потенциальном кластере, причем степень разбавления контента документов характеризуется уменьшением точности информации, относящейся к теме, которой посвящены другие документы в кластере, где
- обновленный первый параметр метрики представляет собой обновленное значение первого параметра метрики первого документа, если второй документ добавляется в кластер с первым документом, и обновленный второй параметр метрики представляет собой обновленное значение второго параметра метрики второго документа, если первый документ добавляется в кластер со вторым документом, и
- обновленного обобщенного параметра метрики на основе обновленного первого параметра метрики и обновленного второго параметра метрики; и
- формирование кластера, содержащего первый документ и второй документ, на основе обновленного обобщенного параметра метрики.
18. Система по п. 17, отличающаяся тем, что процессор перед определением обновленного первого параметра метрики для потенциального кластера дополнительно выполнен с возможностью определения для первого документа и для второго документа первого параметра метрики, второго параметра метрики и обобщенного параметра метрики на основе первого параметра метрики и второго параметра метрики, при этом кластер формируется, если обновленный обобщенный параметр метрики потенциального кластера превышает обобщенный параметр метрики первого документа и/или второго документа.
19. Система по п. 17, отличающаяся тем, что процессор дополнительно выполнен с возможностью сохранения обновленного обобщенного параметра метрики в качестве обобщенного параметра метрики кластера.
20. Система по п. 18, отличающаяся тем, что:
- кластер представляет собой первый кластер;
- получение включает в себя получение множества документов, каждый из которых содержит контент документа, при этом множество документов содержит первый документ и второй документ;
- определение включает в себя определение обновленного первого параметра метрики, обновленного второго параметра метрики и обновленного обобщенного параметра метрики для каждого возможного потенциального кластера, содержащего пару документов из множества документов; и
- формирование первого кластера, содержащего первый документ и второй документ, на основе обновленного обобщенного параметра метрики дополнительно основано на превышении обновленным обобщенным параметром метрики потенциального кластера, содержащего первый документ и второй документ, обновленных обобщенных параметров метрики оставшихся потенциальных кластеров, содержащих пару документов из множества документов.
21. Система по п. 20, отличающаяся тем, что процессор дополнительно выполнен с возможностью:
- определения для каждого потенциального кластера, содержащего документы из первого кластера и оставшийся документ из множества документов:
- обновленного первого параметра метрики, указывающего на степень взаимного дополнения контента документов в потенциальном кластере, если оставшийся документ объединяется с документами первого кластера в этом потенциальном кластере,
- обновленного второго параметра метрики, указывающего на степень разбавления контента документов в потенциальном кластере, если оставшийся документ объединяется с документами первого кластера в этом потенциальном кластере, и
- обновленного обобщенного параметра метрики на основе обновленного первого параметра метрики и обновленного второго параметра метрики;
- добавления третьего документа в первый кластер, если один из обновленных обобщенных параметров метрики превышает обобщенный параметр метрики первого кластера, при этом третий документ представляет собой оставшийся документ из множества документов, который в случае его объединения с документами первого кластера имеет один из обновленных обобщенных параметров метрики, превышающий обобщенный параметр метрики первого кластера; и
- сохранения этого одного из обновленных обобщенных параметров метрики в качестве обобщенного параметра метрики первого кластера.
22. Система по п. 20, отличающаяся тем, что процессор дополнительно выполнен с возможностью закрытия первого кластера без добавления третьего документа, если все обновленные обобщенные параметры метрики оказываются меньшими обобщенного параметра метрики первого кластера.
23. Система по п. 21, отличающаяся тем, что процессор дополнительно выполнен с возможностью:
- повторения выполнения команд для оставшихся документов из множества документов до тех пор, пока все обновленные обобщенные параметры метрики не окажутся меньшими обобщенного параметра метрики первого кластера; и
- закрытия первого кластера, если все обновленные обобщенные параметры метрики оказываются меньшими обобщенного параметра метрики первого кластера.
24. Система по п. 21, отличающаяся тем, что процессор дополнительно выполнен с возможностью:
- определения для каждого потенциального кластера, содержащего пару оставшихся документов из множества документов, не содержащих документов из первого кластера:
- обновленного первого параметра метрики, указывающего на степень взаимного дополнения контента документов из пары оставшихся документов, если они объединяются в этом потенциальном кластере,
- обновленного второго параметра метрики, при этом обновленный второй параметр метрики указывает на степень разбавления контента документов в потенциальном кластере, если эта пара оставшихся документов объединяется в этом потенциальном кластере, и
- обновленного обобщенного параметра метрики на основе обновленного первого параметра метрики и обновленного второго параметра метрики;
- при превышении этим одним из обновленных обобщенных параметров метрики обновленных обобщенных параметров метрики оставшихся потенциальных кластеров формирования второго кластера, содержащего пару документов, имеющих в случае их объединения этот один из обновленных обобщенных параметров метрики; и
- сохранения этого одного из обобщенных параметров метрики в качестве обобщенного параметра метрики второго кластера.
25. Система по п. 21, отличающаяся тем, что процессор дополнительно выполнен с возможностью:
- определения для каждого потенциального кластера, содержащего документы из второго кластера и оставшийся документ из множества документов:
- обновленного первого параметра метрики, указывающего на степень взаимного дополнения контента документов в потенциальном кластере, если оставшийся документ объединяется с документами второго кластера,
- обновленного второго параметра метрики, указывающего на степень разбавления контента документов в потенциальном кластере, если оставшийся документ объединяется с документами второго кластера, и
- обновленного обобщенного параметра метрики на основе обновленного первого параметра метрики и обновленного второго параметра метрики;
- добавления четвертого документа во второй кластер, если один из обновленных обобщенных параметров метрики превышает обобщенный параметр метрики второго кластера, при этом четвертый документ представляет собой оставшийся документ из множества документов, который в случае его объединения с документами второго кластера имеет один из обновленных обобщенных параметров метрики, превышающий обобщенный параметр метрики второго кластера; и
- сохранения этого одного из обновленных обобщенных параметров метрики в качестве обобщенного параметра метрики второго кластера.
26. Система по п. 23, отличающаяся тем, что процессор дополнительно выполнен с возможностью повторения выполнения команд для оставшихся документов из множества документов с целью получения набора кластеров, содержащего по меньшей мере первый кластер и второй кластер.
27. Система по п. 23, отличающаяся тем, что процессор после получения множества документов дополнительно выполнен с возможностью формирования вектора документа для каждого документа из множества документов на основе по меньшей мере части контента соответствующего документа, при этом определение обновленного первого параметра метрики для потенциального кластера основано на расстояниях между векторами документов в потенциальном кластере, а определение обновленного второго параметра метрики для потенциального кластера основано на расстояниях между векторами документов в потенциальном кластере и на размере этого потенциального кластера.
28. Система по п. 17, отличающаяся тем, что первый документ представляет собой первый кластер, содержащий множество документов первого кластера, а второй документ представляет собой второй кластер, содержащий множество документов второго кластера.
29. Система по п. 28, отличающаяся тем, что первый кластер и второй кластер имеют обобщенный параметр метрики, при этом кластер формируется, если обновленный обобщенный параметр метрики превышает обобщенный параметр метрики первого кластера и обобщенный параметр метрики второго кластера.
30. Система по п. 28, отличающаяся тем, что процессор дополнительно выполнен с возможностью сохранения первого кластера и второго кластера в качестве отдельных кластеров, если обобщенный параметр метрики оказывается меньшим обобщенного параметра метрики первого кластера и обобщенного параметра метрики второго кластера.
31. Система по п. 28, отличающаяся тем, что:
- определение обновленного первого параметра метрики дополнительно основано на расстояниях между векторами документов первого кластера, расстояниях между векторами документов второго кластера и расстояниях между векторами документов первого кластера и второго кластера; и
- определение обновленного второго параметра метрики для потенциального кластера основано на расстояниях между векторами документов первого кластера, расстояниях между векторами документов второго кластера, расстояниях между векторами документов первого кластера и второго кластера и размере этого потенциального кластера, который представляет собой сумму размеров первого кластера и второго кластера.
32. Система по п. 31, отличающаяся тем, что контент документа включает в себя заголовок документа и контент тела документа.
| Токарный резец | 1924 |
|
SU2016A1 |
| US 7003519 B1, 21.02.2006 | |||
| US 7499923 B2, 03.03.2009 | |||
| US 8312049 B2, 13.11.2012 | |||
| Станок для изготовления деревянных ниточных катушек из цилиндрических, снабженных осевым отверстием, заготовок | 1923 |
|
SU2008A1 |

