Область техники, к которой относится изобретение
[001] Настоящая технология в целом относится к определению аномального поведения при поиске в Интернете и, в частности, к способу и системе для определения веб-хостов с аномальными посещениями веб-сайтов.
Уровень техники
[002] Объем информации, доступной на различных интернет-ресурсах, в течение последних десятилетий растет экспоненциально. Для помощи типичному пользователю в поиске необходимой информации было разработано несколько решений. Одним из таких решений является поисковая система. В качестве примера можно привести поисковые системы GOOGLE™, YANDEX™, YAHOO!™ и т.п. Пользователь может получать доступ к интерфейсу поисковой системы и отправлять поисковый запрос, связанный с информацией, которую требуется найти в сети Интернет. В ответ на поисковый запрос поисковая система выдает ранжированный список результатов поиска. Ранжированный список результатов поиска формируется на основе различных алгоритмов ранжирования, используемых конкретной поисковой системой, применяемой пользователем для поиска. Общая цель таких алгоритмов ранжирования заключается в представлении наиболее релевантных результатов поиска в верхней части ранжированного списка, тогда как менее релевантные результаты поиска могут располагаться в ранжированном списке на менее заметных местах (наименее релевантные результаты поиска находятся в нижней части ранжированного списка).
[001] Поисковые системы обычно обеспечивают хороший инструментарий для обработки поискового запроса, когда пользователь заранее знает, что требуется найти. Иными словами, если пользователь заинтересован в получении информации о наиболее популярных местах в Италии (т.е. если известна тема поиска), он может отправить поисковый запрос «Наиболее популярные места в Италии?». В ответ поисковая система выдает ранжированный список Интернет-ресурсов, потенциально релевантных поисковому запросу. Пользователь может просмотреть ранжированный список результатов поиска для получения требуемой информации, касающейся мест для посещения в Италии. Если пользователь по какой-либо причине не удовлетворен полученными результатами поиска, он может выполнить повторный поиск, например, с более точным поисковым запросом, таким как «Наиболее популярные места в Италии летом?», «Наиболее популярные места на юге Италии?», «Наиболее популярные места для романтического отпуска в Италии?».
[002] Когда пользователь отправляет поисковый запрос, поисковая система формирует список релевантных веб-ресурсов (на основе анализа просмотренных обходчиком веб-ресурсов, указания на которые хранятся в базе данных обходчика в виде списков вхождений (posting lists) и т.п.). Затем поисковая система ранжирует сформированный таким образом список результатов поиска. Формирование списка и/или ранжирование результатов поиска может выполняться с использованием различных средств, например, путем выполнения алгоритма машинного обучения (MLA, Machine Learning Algorithm). Алгоритм MLA ранжирует список результатов поиска на основе их релевантности поисковому запросу. Алгоритм MLA «обучен» прогнозировать релевантность результата поиска поисковому запросу на основе большого количества «признаков», связанных с результатом поиска, и указаний на прошлые действия пользователей с результатами поиска при отправке подобных поисковых запросов в прошлом.
[003] При ранжировании списка результатов поиска принимаются во внимание различные факторы, например, зафиксированная история веб-поиска. История веб-поиска указывает на то, какие результаты поиска выбирались пользователями, ранее отправлявшими тот же или подобный поисковый запрос. Предполагается, что веб-хосты, ранее выбиравшиеся пользователями, отправлявшими подобные запросы, представляют собой наиболее релевантные этому поисковому запросу веб-хосты. Для предоставления пользователю наиболее полезной информации целесообразно присваивать веб-хостам, ранее выбиравшимся пользователями, более высокий ранг.
[004] Промоутерам веб-сайтов известно, что история веб-поиска влияет на ранжирование результатов поиска. Некоторые недобросовестные акторы пытаются повысить ранг веб-сайта, предлагая пользователям отправлять определенные запросы и после получения ранжированного списка результатов поиска выбирать определенные результаты. Недобросовестные акторы могут платить пользователям за выполнение поисков. В результате этих аномальных посещений веб-сайтов, соответствующим веб-хостам может присваиваться более высокий ранг в ответах на запрос даже в случае низкой релевантности этих веб-хостов. Но если пользователю выдаются нерелевантные результаты, удовлетворенность пользователя поисковой системой снижается.
[005] В патенте US9092510 (Google Inc., выдан 28 июля 2015 г.) описана система ранжирования результатов поиска, которая может содержать средство защиты от спамеров, формирующих мошеннические «клики», направленные на повышение ранга конкретных результатов поиска. Средство защиты может быть реализовано с использованием модели пользователя, описывающей корректное поведение пользователя с течением времени так, чтобы в процессе ранжирования можно было игнорировать такие мошеннические «клики». Мошеннические «клики» также могут быть обнаружены на основе аномального распределения позиций «кликов», продолжительности «кликов» или количества кликов в минуту, в час или в сутки.
[006] В патенте US2008/0172271 (NHN Corporation, выдан 15 января 2008 г.) описано отслеживание действий пользователя после выбора веб-сайта с целью определения недопустимого «клика». Недопустимый «клик» - это «клик», выполняемый пользователем со злым умыслом либо с применением автоматизированного сценария (script) или компьютерной программы. Действия, выполняемые пользователем после выбора поискового рекламного объявления, собираются, сохраняются и сравниваются с усредненной моделью поведения на данном веб-сайте. На основе этих результатов сравнения определяется недопустимый «клик», выполненный пользователем.
[007] В работе «Search Engine Click Spam Detection Based on Bipartite Graph Propagation» (опубликована в трудах конференции WSDM ’14, The 7th ACM International Conference on Web Search and Data Mining, 24 февраля 2014 г.) описаны система и способ, которые могут использоваться для определения «клик-спама», формируемого в поисковых системах или подобных средствах с целью повышения ранга веб-страницы при поисковой оптимизации. Способ включает в себя моделирование действий пользователей с учетом интервалов времени, в течение которых они выполняются, с целью определения возможных пользователей-мошенников, а также использование алгоритма формирования графа для отображения характеристик сеанса предполагаемого пользователя-мошенника, чтобы способствовать лучшему определению других пользователей-мошенников.
Раскрытие изобретения
[008] Разработчики настоящей технологии обнаружили по меньшей мере одну техническую проблему, связанную с известными решениями.
[009] Настоящая технология относится к определению аномального поведения при поиске в Интернете в целом, и, в частности, к способам и системам для определения веб-хостов с аномальными посещениями веб-сайтов. Как описано выше, различные недобросовестные акторы могут стремиться повлиять на позицию веб-хоста на странице результатов поисковой системы (SERP, Search Engine Results Page) Например, пользователю может быть предложено вводить определенный запрос в поисковой системе и после получения страницы SERP выбирать определенный веб-хост на странице SERP. Разработанные способы предназначены для определения аномального поведения при поиске в Интернете.
[0010] Операторам поисковых систем, таких как Google™, Yandex™, Bing™, Yahoo™ и т.д., доступно большое количество данных истории веб-поиска с результатами поиска, полученными в ответ на пользовательские запросы. История веб-поиска содержит записи с информацией о веб-хостах на странице SERP, выбранных пользователем. История веб-поиска может быть использована для определения аномального поведения при поиске в Интернете.
[0011] При просмотре сети Интернет пользователи обычно посещают последовательность естественным образом связанных веб-хостов. Естественным образом связанные веб-хосты могут иметь общую тему. Например, если пользователь посещает первый веб-хост, предоставляющий новости о футболе, то этот пользователь может затем посетить второй веб-хост, предоставляющий домашнюю страницу футбольного клуба. В этом примере тема обоих веб-хостов касается футбола, и поэтому они связаны естественным образом. Пользователи, получающие инструкции от недобросовестного актора, могут посещать веб-хосты, не связанные естественным образом. Для обнаружения аномальных посещений веб-сайтов может анализироваться история веб-поиска с целью определения пользователей, посещавших не связанные естественным образом веб-хосты.
[0012] При этом могут собираться данные о действиях пользователей, описывающие историю просмотра пользователей. Веб-хосты, не связанные естественным образом общей темой, могут быть связаны на основе данных о действиях пользователей. Даже если веб-хосты тематически не связаны, похожие группы пользователей могут посещать оба веб-хоста. Тематически не связанные веб-хосты могут быть связаны тем, что к этим веб-хостам обращается группа пользователей. Для определения связи веб-хостов могут анализироваться данные о действиях пользователей. Для определения веб-хостов с аномальными посещениями веб-сайтов веб-хосты сначала могут фильтроваться на основе их естественной связи на основе общей темы, а затем эти веб-хосты могут дополнительно фильтроваться с учетом их связи на основе данных о действиях пользователей.
[0013] Согласно не имеющим ограничительного характера вариантам осуществления настоящей технологии, может быть сформирован граф истории веб-поиска или части истории веб-поиска. Граф содержит вершины и ребра, соединяющие вершины. Каждое ребро соединено с двумя вершинами. Каждая вершина представляет собой веб-хост в истории веб-поиска. Каждому ребру в графе назначается вес ребра. Вес ребра определяется для каждого ребра на основе количества пользователей, посетивших и веб-хост первой вершины, соединенной с этим ребром, и веб-хост второй вершины, соединенной с этим ребром.
[0014] Согласно ее имеющим ограничительного характера вариантам осуществления настоящей технологии, после формирования графа определяется одна или несколько тем для каждой вершины графа. Темы основаны на контенте веб-хоста вершины. Затем темы связанных друг с другом вершин сравниваются для определения связанных естественным образом веб-хостов вершин. Если ребро соединяет две вершины со связанными естественным образом хостами, то такое ребро удаляется из графа.
[0015] После формирования графа выполняется кластеризация вершин графа на основе веса ребра. В результате определяются кластеры вершин, в которых отдельные пользователи посетили несколько хостов. Хосты в каждом кластере анализируются для определения того, связаны ли хосты в кластере на основе данных о действиях пользователей. Данные о действиях пользователей описывают историю просмотра веб-страниц пользователей, такую как посещенные пользователями веб-хосты и/или поведение пользователя при посещении веб-хостов. Если хосты в кластере определяются как связанные на основе данных о действиях пользователей, то такой кластер удаляется. Считается, что в оставшихся кластерах, в которых веб-хосты не связаны на основе данных о действиях пользователей, выполнялись аномальные посещения веб-сайтов. Ранг веб-хостов, связанных с аномальными посещениями веб-сайтов, на страницах SERP может быть снижен. Аномальные посещения веб-сайтов могут быть удалены из истории веб-поиска.
[0016] В соответствии с первым аспектом настоящей технологии реализован способ определения веб-хостов с аномальными посещениями веб-сайтов. Способ выполняется сервером и включает в себя: получение истории веб-поиска для множества пользователей; формирование графа истории веб-поиска, в котором каждая вершина представляет собой веб-хост в истории веб-поиска, при этом вершины соединены с другими вершинами ребрами, каждое из которых имеет вес ребра, определенный на основе количества пользователей, посетивших оба хоста, соединенных этим ребром; кластеризацию вершин графа на основе весов ребер и формирование таким образом множества кластеров вершин; получение данных о действиях пользователей, соответствующих этим кластерам вершин и связанных с множеством пользователей, посетивших веб-хосты, связанные с этими кластерами вершин; определение для каждого кластера вершин связанных веб-хостов в этом кластере на основе данных о действиях пользователей; удаление из графа каждого кластера вершин, содержащего веб-хосты, связанные на основе данных о действиях пользователей; и сохранение для каждого веб-хоста, связанного с кластером, оставшимся в графе, индикатора того, что этот веб-хост связан с аномальными посещениями веб-сайтов.
[0017] В некоторых вариантах осуществления способа он перед кластеризацией вершин графа дополнительно включает в себя определение для каждой вершины графа одной или нескольких тем, соответствующих этой вершине, и удаление из графа ребер, соединяющих две вершины со связанными темами.
[0018] В некоторых вариантах осуществления способа определение одной или нескольких тем для каждой вершины графа включает в себя запрашивание в базе данных тем, связанных с веб-хостом, соответствующим этой вершине.
[0019] В некоторых вариантах осуществления способа он дополнительно включает в себя: получение поискового запроса; формирование на основе этого поискового запроса страницы результатов поисковой системы с ранжированным множеством веб-хостов, соответствующих этому поисковому запросу; и снижение на странице результатов поисковой системы ранга веб-хоста, связанного с аномальными посещениями веб-сайтов.
[0020] В некоторых вариантах осуществления способа он дополнительно включает в себя: получение поискового запроса; формирование на основе этого поискового запроса страницы результатов поисковой системы с ранжированным множеством веб-хостов, соответствующих этому поисковому запросу; и удаление со страницы результатов поисковой системы веб-хоста, связанного с аномальными посещениями веб-сайтов.
[0021] В некоторых вариантах осуществления способ дополнительно включает в себя удаление из истории веб-поиска данных, соответствующих веб-хостам, связанным с аномальными посещениями веб-сайтов.
[0022] В некоторых вариантах осуществления способа он дополнительно включает в себя определение множества идентификаторов пользователей, соответствующих аномальным посещениям веб-сайтов, и сохранение для каждого из них индикатора того, что этот идентификатор пользователя связан с аномальными посещениями веб-сайтов.
[0023] В некоторых вариантах осуществления способа данные о действиях пользователей содержат историю веб-поиска.
[0024] В некоторых вариантах осуществления способа данные о действиях пользователей содержат данные об использовании веб-браузера.
[0025] В некоторых вариантах осуществления способа данные о действиях пользователей содержат данные веб-сценария (web script data).
[0026] В некоторых вариантах осуществления способа он дополнительно включает в себя определение веса каждого ребра на основе количества совпадающих поисковых запросов, введенных пользователями, посетившими оба хоста, соединенные этим ребром.
[0027] В соответствии с другим аспектом настоящей технологии реализована система для определения веб-хостов с аномальными посещениями веб-сайтов. Система содержит процессор и машиночитаемый физический носитель информации, содержащий команды. Процессор при исполнении команд способен: получать историю веб-поиска, соответствующую множеству пользователей; формировать граф истории веб-поиска, в котором каждая вершина представляет собой веб-хост в истории веб-поиска, при этом вершины соединены с другими вершинами ребрами, каждое из которых имеет вес ребра, определенный на основе количества пользователей, посетивших оба хоста, соединенных этим ребром; выполнять кластеризацию вершин графа на основе весов ребер и формировать таким образом множество кластеров вершин; получать данные о действиях пользователей, соответствующие этим кластерам вершин и связанные с множеством пользователей, посетивших веб-хосты, связанные с этими кластерами вершин; определять для каждого кластера вершин связанные веб-хосты в этом кластере на основе данных о действиях пользователей; удалять из графа каждый кластер вершин, содержащий веб-хосты, связанные на основе данных о действиях пользователей; и сохранять для каждого веб-хоста, связанного с кластером, оставшимся в графе, индикатор того, что этот веб-хост связан с аномальными посещениями веб-сайтов.
[0028] В некоторых вариантах осуществления системы процессор при исполнении команд дополнительно способен определять для каждой вершины графа одну или несколько тем, соответствующих этой вершине, и удалять из графа ребра, соединяющие две вершины со связанными темами.
[0029] В некоторых вариантах осуществления системы процессор при исполнении команд дополнительно способен: получать поисковый запрос; формировать на основе этого поискового запроса страницу результатов поисковой системы с ранжированным множеством веб-хостов, соответствующих этому поисковому запросу; и снижать на странице результатов поисковой системы ранг веб-хоста, связанного с аномальными посещениями веб-сайтов.
[0030] В некоторых вариантах осуществления системы процессор при исполнении команд дополнительно способен: получать поисковый запрос; формировать на основе этого поискового запроса страницу результатов поисковой системы с ранжированным множеством веб-хостов, соответствующих этому поисковому запросу; и удалять со страницы результатов поисковой системы веб-хост, связанный с аномальными посещениями веб-сайтов.
[0031] В некоторых вариантах осуществления системы процессор при исполнении команд дополнительно способен удалять из истории веб-поиска данные, соответствующие веб-хостам, связанным с аномальными посещениями веб-сайтов.
[0032] В некоторых вариантах осуществления системы процессор при исполнении команд дополнительно способен: определять множество идентификаторов пользователей, соответствующих аномальным посещениям веб-сайтов, и сохранять для каждого из них индикатор того, что этот идентификатор пользователя связан с аномальными посещениями веб-сайтов.
[0033] В некоторых вариантах осуществления системы процессор при исполнении команд дополнительно способен определять вес ребра на основе количества совпадающих запросов, введенных пользователями, посетившими оба веб-хоста, соединенные этим ребром.
[0034] В соответствии с еще одним аспектом настоящей технологии реализован способ определения веб-хостов с аномальными посещениями веб-сайтов. Способ выполняется на сервере и включает в себя: получение истории веб-поиска для множества пользователей; для каждого веб-хоста в истории поиска: определение на основе истории веб-поиска списка других веб-хостов, посещенных пользователями, посетивших данный веб-хост, и удаление других веб-хостов, имеющих естественную связь с данным веб-хостом, из списка других веб-хостов; основанную на списках других веб-хостов кластеризацию не связанных естественным образом веб-хостов и формирование таким образом множества кластеров вершин; получение данных о действиях пользователей, соответствующих этим кластерам вершин и связанных с множеством пользователей, посетивших веб-хосты, связанные с этими кластерами вершин; удаление кластеров, содержащих веб-хосты, связанные друг с другом на основе данных о действиях пользователей; и сохранение для каждого веб-хоста, связанного с оставшимися кластерами, индикатора того, что этот веб-хост связан с аномальными посещениями веб-сайтов.
[0035] В некоторых вариантах осуществления способа удаление других веб-хостов, имеющих естественную связь с данным веб-хостом, включает в себя выполнение для каждого другого веб-хоста из списка других веб-хостов сравнения одной или нескольких тем, соответствующих данному веб-хосту, с одной или несколькими темами, соответствующими другому веб-хосту.
[0036] В некоторых вариантах осуществления способа он дополнительно включает в себя: получение поискового запроса; формирование на основе этого поискового запроса страницы результатов поисковой системы с ранжированным множеством веб-хостов, соответствующих этому поисковому запросу; и снижение на странице результатов поисковой системы ранга веб-хоста, связанного с аномальными посещениями веб-сайтов.
[0037] В контексте настоящего описания термин «сервер» означает компьютерную программу, выполняемую соответствующими аппаратными средствами и способную принимать запросы (например, от электронных устройств) через сеть и выполнять эти запросы или инициировать их выполнение. Аппаратные средства могут представлять собой один физический компьютер или одну компьютерную систему, что не существенно для настоящей технологии. В настоящем контексте выражение «сервер» не означает, что каждая задача (например, принятая команда или запрос) или некоторая определенная задача принимается, выполняется или запускается одним и тем же сервером (т.е. одними и теми же программными и/или аппаратными средствами). Это выражение означает, что любое количество программных средств или аппаратных средств может принимать, отправлять, выполнять или инициировать выполнение любой задачи или запроса либо результатов любых задач или запросов. Все эти программные и аппаратные средства могут представлять собой один сервер или несколько серверов, причем оба эти случая подразумеваются в выражении «по меньшей мере один сервер».
[0038] В контексте настоящего описания термин «электронное устройство» означает любое компьютерное аппаратное средство, способное выполнять программы, подходящие для решения поставленной задачи. Таким образом, некоторые (не имеющие ограничительного характера) примеры электронных устройств включают в себя персональные компьютеры (настольные, ноутбуки, нетбуки и т.п.), смартфоны и планшеты, а также сетевое оборудование, такое как маршрутизаторы, коммутаторы и шлюзы. Следует отметить, что в данном контексте устройство, функционирующее как электронное устройство, также может функционировать как сервер в отношении других электронных устройств. Использование выражения «электронное устройство» не исключает использования нескольких электронных устройств для приема, отправки, выполнения или инициирования выполнения любой задачи или запроса либо результатов любых задач или запросов либо шагов любого описанного здесь способа.
[0039] В контексте настоящего описания термин «база данных» означает любой структурированный набор данных, независимо от его конкретной структуры, программного обеспечения для управления базой данных или компьютерных аппаратных средств для хранения этих данных, их применения или обеспечения их использования иным способом. База данных может располагаться в тех же аппаратных средствах, где реализован процесс, обеспечивающий хранение или использование информации, хранящейся в базе данных, либо база данных может располагаться в отдельных аппаратных средствах, таких как специализированный сервер или множество серверов.
[0040] В контексте настоящего описания выражение «информация» включает в себя информацию любого рода или вида, допускающую хранение в базе данных. Таким образом, информация включает в себя аудиовизуальные произведения (изображения, фильмы, звукозаписи, презентации и т.д.), данные (данные о местоположении, числовые данные и т.д.), текст (мнения, комментарии, вопросы, сообщения и т.д.), документы, электронные таблицы и т.д., но не ограничивается ими.
[0041] В контексте настоящего описания выражение «пригодный для использования в компьютере носитель информации» означает носители любого рода и вида, включая ОЗУ, ПЗУ, диски (CD-ROM, DVD, гибкие диски, жесткие диски и т.д.), USB-накопители, твердотельные накопители, накопители на магнитных лентах и т.д.
[0042] В контексте настоящего описания, если явно не указано другое, в качестве указания на информационный элемент может выступать сам информационный элемент, а также указатель, ссылка, гиперссылка или другое косвенное средство, с помощью которого получатель данных может найти место в сети, памяти, базе данных или на другом машиночитаемом носителе информации, откуда можно извлечь этот информационный элемент. Например, указание на документ может включать в себя сам документ (т.е. его содержимое) или это указание может представлять собой уникальный дескриптор документа, указывающий на файл в определенной файловой системе, или какие-либо другие средства для указания получателю данных места в сети, адреса памяти, таблицы в базе данных или другого места, где можно получить доступ к файлу. Специалисту в данной области должно быть очевидно, что степень детализации, требуемая для такого указания, зависит от объема предварительных пояснений относительно интерпретации информации, которой обмениваются отправитель и получатель данных. Например, если перед началом обмена данными между отправителем и получателем известно, что указание на информационный элемент представляет собой ключ базы данных для элемента в определенной таблице заранее заданной базы данных, содержащей этот информационный элемент, то для эффективной передачи этого информационного элемента получателю достаточно оправить ключ базы данных, даже если сам информационный элемент не передается между отправителем и получателем данных.
[0043] В контексте настоящего описания числительные «первый», «второй», «третий», и т.д. используются лишь для указания различия между существительными, к которым они относятся, но не для описания каких-либо определенных взаимосвязей между этими существительными. Например, должно быть понятно, что использование терминов «первый сервер» и «третий сервер» не подразумевает какого-либо определенного порядка, типа, хронологии, иерархии или классификации, в данном случае, серверов, а также что их использование (само по себе) не подразумевает наличие «второго сервера» в любой ситуации. Кроме того, как встречается в настоящем описании в другом контексте, ссылка на «первый» элемент и «второй» элемент не исключает того, что эти два элемента в действительности могут быть одним и тем же элементом. Таким образом, например, в некоторых случаях «первый» сервер и «второй» сервер могут представлять собой одно и то же программное и/или аппаратное средство, а в других случаях - разные программные и/или аппаратные средства.
[0044] Каждый вариант осуществления настоящей технологии относится к по меньшей мере одной из вышеупомянутых целей и/или аспектов, но не обязательно ко всем ним. Должно быть понятно, что некоторые аспекты настоящей технологии, связанные с попыткой достижения вышеупомянутой цели, могут не соответствовать этой цели и/или могут соответствовать другим целям, явным образом здесь не упомянутым.
[0045] Дополнительные и/или альтернативные признаки, аспекты и преимущества вариантов осуществления настоящей технологии содержатся в дальнейшем описании, в приложенных чертежах и в формуле изобретения.
Краткое описание чертежей
[0046] Дальнейшее описание приведено для лучшего понимания настоящей технологии, а также других аспектов и их признаков, и должно использоваться совместно с приложенными чертежами.
[0047] На фиг. 1 представлены элементы и признаки вычислительного устройства согласно вариантам осуществления настоящей технологии.
[0048] На фиг. 2 представлена схема системы, реализованной согласно вариантам осуществления настоящей технологии, не имеющим ограничительного характера.
[0049] На фиг. 3 представлена схема обычного обмена данными между пользователями и поисковым сервером согласно вариантам осуществления настоящей технологии.
[0050] На фиг. 4 представлена схема аномального обмена данными между пользователями и поисковым сервером согласно вариантам осуществления настоящей технологии.
[0051] На фиг. 5 и 6 приведена блок-схема способа определения веб-хостов с аномальными посещениями веб-сайтов, выполняемого в представленной на фиг. 2 системе согласно некоторым вариантам осуществления настоящей технологии, не имеющим ограничительного характера.
[0052] На фиг. 7 приведена история веб-поиска согласно вариантам осуществления настоящей технологии.
[0053] На фиг. 8 изображен граф истории веб-поиска, представленной на фиг. 7, согласно вариантам осуществления настоящей технологии.
[0054] На фиг. 9 изображен граф, представленный на фиг. 8, после фильтрации согласно вариантам осуществления настоящей технологии.
[0055] На фиг. 10 приведены кластеры, сформированные с использованием графа, представленного на фиг. 9, согласно вариантам осуществления настоящей технологии.
Осуществление изобретения
[0056] Представленные в данном описании примеры и условный язык предназначены для обеспечения лучшего понимания принципов настоящей технологии, а не для ограничения ее объема до таких специально приведенных примеров и условий. Очевидно, что специалисты в данной области техники способны разработать различные способы и устройства, которые явно не описаны и не показаны, но реализуют принципы настоящей технологии в пределах ее существа и объема.
[0057] Кроме того, чтобы способствовать лучшему пониманию, последующее описание может содержать упрощенные варианты реализации настоящей технологии. Специалистам в данной области должно быть понятно, что различные варианты осуществления настоящей технологии могут быть значительно сложнее.
[0058] В некоторых случаях также приводятся полезные примеры модификаций настоящей технологии. Они способствуют пониманию, но также не определяют объем или границы настоящей технологии. Представленный перечень модификаций не является исчерпывающим и специалист в данной области может разработать другие модификации в пределах объема настоящей технологии. Кроме того, если в некоторых случаях модификации не описаны, это не означает, что они невозможны и/или что описание содержит единственно возможный вариант реализации того или иного элемента настоящей технологии.
[0059] Более того, описание принципов, аспектов и вариантов реализации настоящей технологии, а также их конкретные примеры предназначены для охвата их структурных и функциональных эквивалентов, независимо от того, известны они в настоящее время или будут разработаны в будущем. Например, специалистам в данной области техники должно быть очевидно, что любые описанные здесь структурные схемы соответствуют концептуальным представлениям иллюстративных принципиальных схем, реализующих принципы настоящей технологии. Также должно быть очевидно, что любые блок-схемы, схемы процессов, диаграммы изменения состояния, псевдокоды и т.п. соответствуют различным процессам, которые могут быть представлены на машиночитаемом физическом носителе информации и могут выполняться компьютером или процессором, независимо от того, показан такой компьютер или процессор явно или нет.
[0060] Функции различных элементов, показанных на чертежах, включая любой функциональный блок, обозначенный как «процессор» или «графический процессор», могут быть реализованы с использованием специализированных аппаратных средств, а также с использованием аппаратных средств, способных выполнять соответствующее программное обеспечение. Если используется процессор, эти функции могут выполняться одним выделенным процессором, одним совместно используемым процессором или множеством отдельных процессоров, некоторые из которых могут использоваться совместно. В некоторых вариантах осуществления настоящей технологии процессор может представлять собой процессор общего назначения, такой как центральный процессор (CPU), или специализированный процессор, такой как графический процессор (GPU). Кроме того, явное использование термина «процессор» или «контроллер» не должно трактоваться как указание исключительно на аппаратные средства, способные выполнять программное обеспечение, и может подразумевать, помимо прочего, аппаратные средства цифрового сигнального процессора (DSP), сетевой процессор, специализированную интегральную схему (ASIC), программируемую вентильную матрицу (FPGA), ПЗУ для хранения программного обеспечения, ОЗУ и энергонезависимое ЗУ. Также могут подразумеваться другие аппаратные средства, общего назначения и/или заказные.
[0061] Программные модули или просто модули, реализация которых предполагается в виде программных средств, могут быть представлены здесь как любое сочетание элементов блок-схемы или других элементов, указывающих на выполнение шагов процесса и/или содержащих текстовое описание. Такие модули могут выполняться аппаратными средствами, показанными явно или подразумеваемыми.
[0062] Далее с учетом вышеизложенных принципов рассмотрены некоторые не имеющие ограничительного характера примеры, иллюстрирующие различные варианты реализации аспектов настоящей технологии.
[0063] На фиг. 1 представлено вычислительное устройство 100, пригодное для использования с некоторыми вариантами осуществления настоящей технологии. Вычислительное устройство 100 содержит различные аппаратные элементы, включая один или несколько одноядерных или многоядерных процессоров, коллективно представленные процессором 110, графический процессор 111, твердотельный накопитель120, ОЗУ 130, дисплейный интерфейс 140 и интерфейс 150 ввода-вывода.
[0064] Связь между различными элементами вычислительного устройства 100 может осуществляться через одну или несколько внутренних и/или внешних шин 160 (таких как шина PCI, универсальная последовательная шина, шина FireWire стандарта IEEE 1394, шина SCSI, шина Serial-ATA и т.д.), с которыми различные аппаратные элементы соединены электронными средствами.
[0065] Интерфейс 150 ввода-вывода может соединяться с сенсорным экраном 190 и/или с одной или несколькими внутренними и/или внешними шинами 160. Сенсорный экран 190 может входить в состав дисплея. В некоторых вариантах реализации сенсорный экран 190 представляет собой дисплей. Сенсорный экран 190 может также называться экраном 190. В представленных на фиг. 1 вариантах осуществления изобретения сенсорный экран 190 содержит сенсорное оборудование 194 (например, чувствительные к нажатию ячейки, встроенные в экран дисплея и позволяющие обнаруживать физическое взаимодействие между пользователем и дисплеем) и контроллер 192 ввода-вывода для сенсорного оборудования, обеспечивающий связь с дисплейным интерфейсом 140 и/или одной или несколькими внутренними и/или внешними шинами 160. В некоторых вариантах осуществления изобретения интерфейс 150 ввода-вывода может соединяться с клавиатурой (не показана), мышью (не показана) или сенсорной площадкой (не показана), которые обеспечивают взаимодействие пользователя с вычислительным устройством 100 в дополнение к сенсорному экрану 190 или вместо него.
[0066] Согласно вариантам осуществления настоящей технологии, твердотельный накопитель 120 хранит программные команды, пригодные для загрузки в ОЗУ 130 и исполнения процессором 110 и/или графическим процессором 111. Программные команды могут, например, входить в состав библиотеки или приложения.
[0067] Вычислительное устройство 100 может представлять собой сервер, настольный компьютер, планшет, смартфон, персональный цифровой помощник (personal digital assistant) или любое устройство, позволяющее реализовать настоящую технологию, как должно быть понятно специалисту в данной области.
[0068] На фиг. 2 представлена система 200, реализованная согласно не имеющим ограничительного характера вариантам осуществления настоящей технологии. Система 200 содержит первое клиентское устройство 210, второе клиентское устройство 215, третье клиентское устройство 220 и четвертое клиентское устройство 225, соединенные с сетью 205 связи соответствующими линиями 245 связи. Система 200 содержит сервер 230 поисковой системы, сервер 235 анализа и сервер 240 обнаружения аномальных посещений веб-сайтов, соединенные с сетью 205 связи соответствующими линиями 245 связи.
[0069] Первое клиентское устройство 210, второе клиентское устройство 215, третье клиентское устройство 220, четвертое клиентское устройство 225, сервер 230 поисковой системы, сервер 235 анализа и/или сервер 240 обнаружения аномальных посещений веб-сайтов могут представлять собой вычислительные устройства 100 и/или содержать элементы вычислительных устройств 100. Например, первое клиентское устройство 210 может быть реализовано в виде смартфона, второе клиентское устройство 215 может быть реализовано в виде ноутбука, третье клиентское устройство 220 может быть реализовано в виде смартфона, четвертое клиентское устройство 225 может быть реализовано в виде планшета. В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии сеть 205 связи может представлять собой сеть Интернет. В других вариантах осуществления настоящей технологии сеть 205 связи может быть реализована иначе, например, в виде произвольной глобальной сети связи, локальной сети связи, частной сети связи и т.д.
[0070] На реализацию линии 245 связи не накладывается каких-либо особых ограничений, она зависит от реализации первого клиентского устройства 210, второго клиентского устройства 215, третьего клиентского устройства 220 и четвертого клиентского устройства 225. В качестве примера, не имеющего ограничительного характера, в тех вариантах реализации настоящей технологии, где по меньшей мере одно из клиентских устройств, таких как первое клиентское устройство 210, второе клиентское устройство 215, третье клиентское устройство 220 и четвертое клиентское устройство 225, реализовано в виде беспроводного устройства связи (такого как смартфон), линия 245 связи может быть реализована в виде беспроводной линии связи (такой как канал сети связи 3G, канал сети связи 4G, Wireless Fidelity или сокращенно WiFi®, Bluetooth® и т.п.). В тех примерах, где по меньшей мере одно из клиентских устройств, таких как первое клиентское устройство 210, второе клиентское устройство 215, третье клиентское устройство 220 и четвертое клиентское устройство 225, реализовано в виде ноутбука, смартфона или планшетного компьютера, линия 245 связи может быть как беспроводной (такой как Wireless Fidelity или кратко WiFi®, Bluetooth® т.п.), так и проводной (такой как соединение на основе Ethernet).
[0071] Должно быть очевидно, что варианты реализации первого клиентского устройства 210, второго клиентского устройства 215, третьего клиентского устройства 220, четвертого клиентского устройства 225, лини 245 связи и сети 205 связи приведены лишь для иллюстрации. Специалистам в данной области должны быть очевидными и другие конкретные детали реализации первого клиентского устройства 210, второго клиентского устройства 215, третьего клиентского устройства 220, четвертого клиентского устройства 225, лини 245 связи и сети 205 связи. Представленные выше примеры никак не ограничивают объем настоящей технологии.
[0072] Несмотря на то, что на фиг. 2 показаны лишь четыре клиентских устройства 210, 215, 220 и 225, предполагается, что к системе 200 может быть подключено любое количество клиентских устройств 210, 215, 220 и 225. Также предполагается, что в некоторых вариантах осуществления изобретения к системе 200 могут быть подключены десятки или сотни тысяч клиентских устройств 210, 215, 220 и 225.
[0073] К сети 205 связи также подключен вышеупомянутый сервер 230 поисковой системы. Сервер 230 поисковой системы может быть реализован в виде традиционного компьютерного сервера. В одном примере осуществления настоящей технологии сервер 230 поисковой системы может быть реализован в виде сервера Dell™ PowerEdge™, работающего под управлением операционной системы Microsoft™ Windows Server™. Сервер 230 поисковой системы может быть реализован с применением любых других подходящих аппаратных средств и/или программного обеспечения, и/или встроенного программного обеспечения либо их сочетания. В представленном не имеющем ограничительного характера варианте осуществления настоящей технологии сервер 230 поисковой системы представляет собой один сервер. В других не имеющих ограничительного характера вариантах осуществления настоящей технологии функции сервера 230 поисковой системы могут быть распределены между несколькими серверами. В некоторых вариантах осуществления настоящей технологии сервер 230 поисковой системы управляется и/или администрируется оператором поисковой системы. В качестве альтернативы, сервер 230 поисковой системы может управляться и/или администрироваться поставщиком услуг.
[0074] В целом сервер 230 поисковой системы (а) осуществляет поиск, (б) анализирует и ранжирует результаты поиска, (в) группирует результаты и формирует страницу SERP для отправки электронному устройству (такому как первое клиентское устройство 210, второе клиентское устройство 215, третье клиентское устройство 220 и четвертое клиентское устройство 225).
[0075] На сервер 230 поисковой системы, предназначенный для выполнения поиска, не накладывается каких-либо особых ограничений. Специалистам в данной области известен ряд способов и средств для выполнения поиска с использованием сервера 230 поисковой системы, поэтому структурные элементы сервера 230 поисковой системы описаны в лишь общем виде. Сервер 230 поисковой системы может поддерживать базу 250 данных журналов поиска.
[0076] В некоторых вариантах осуществления настоящей технологии сервер 230 поисковой системы может выполнять несколько поисков, включая общий поиск и вертикальный поиск, но не ограничиваясь ими.
[0077] Как известно специалистам в данной области, сервер 230 поисковой системы способен выполнять общие веб-поиски. Сервер 230 поисковой системы также способен выполнять один или несколько вертикальных поисков, таких как вертикальный поиск изображений, вертикальный поиск музыкальных произведений, вертикальный поиск видеоматериалов, вертикальный поиск новостей, вертикальный поиск карт и т.д. Как известно специалистам в данной области, сервер 230 поисковой системы также способен выполнять алгоритм обходчика, согласно которому сервер 230 поисковой системы выполняет обход сети Интернет и индексирует посещенные веб-сайты в одной или нескольких индексных базах данных, таких как база 250 данных журналов поиска.
[0078] Сервер 230 поисковой системы способен формировать ранжированный список результатов поиска, включающий в себя результаты общего веб-поиска и вертикального веб-поиска. Известно множество алгоритмов ранжирования результатов поиска, которые могут быть реализованы сервером 230 поисковой системы.
[0079] В качестве примера, не имеющего ограничительного характера, некоторые известные способы ранжирования результатов поиска по степени соответствия сделанному пользователем поисковому запросу основаны на некоторых или на всех из следующих критериев: (а) популярность данного поискового запроса или соответствующего ответа при выполнении поисков, (б) количество предоставляемых результатов, (в) наличие определяющих терминов (таких как «изображения», «фильмы», «погода» и т.п.) в запросе, (г) частота использования другими пользователями данного поискового запроса с определяющими терминами, (д) частота выбора другими пользователями, выполняющими аналогичный поиск, определенного ресурса или определенных результатов вертикального поиска, при представлении результатов с использованием страницы SERP. Сервер 230 поисковой системы может рассчитывать и назначать коэффициент релевантности (основанный на различных представленных выше критериях) для каждого результата поиска, полученного по сделанному пользователем поисковому запросу, а также формировать страницу SERP, где результаты поиска ранжированы согласно их коэффициентам релевантности. В данном варианте осуществления изобретения сервер 230 поисковой системы может выполнять множество алгоритмов машинного обучения для ранжирования документов и/или формировать признаки для ранжирования документов.
[0080] Сервер поисковой системы обычно поддерживает базу 250 данных журналов поиска. В общем случае база 250 журнала поиска может поддерживать индекс 255, журнал 260 запросов и журнал 265 действий пользователей.
[0081] Индекс 255 предназначен для индексирования документов, таких как веб-страницы, изображения, файлы в формате PDF, документы Word™, документы PowerPoint™, просмотренные (или обнаруженные) обходчиком сервера 230 поисковой системы. Когда пользователь первого клиентского устройства 210, второго клиентского устройства 215, третьего клиентского устройства 220 или четвертого клиентского устройства 225 вводит запрос и выполняет поиск на сервере 230 поисковой системы, сервер 230 поисковой системы анализирует индекс 255 и извлекает документы, содержащие термины запроса, а затем ранжирует их согласно алгоритму ранжирования.
[0082] Журнал 260 запросов предназначен для регистрации поисков, выполненных с использованием сервера 230 поисковой системы. В частности, в журнале 260 запросов хранятся термины поисковых запросов (т.е. искомые слова) и соответствующие им результаты поиска. Следует отметить, что журнал 260 запросов может поддерживаться в обезличенной форме, при этом поисковые запросы невозможно соотнести с пользователями, отправившими эти поисковые запросы.
[0083] В частности, журнал 260 запросов может содержать список запросов с терминами, с информацией о документах, указанных сервером 230 поисковой системы в списке в ответ на запрос, и с отметкой времени, а также он может содержать список пользователей, идентифицируемых с использованием анонимных идентификаторов (или вовсе без идентификаторов), и соответствующие документы, выбранные ими после отправки запроса. В некоторых вариантах осуществления изобретения журнал 260 запросов может обновляться при каждом выполнении нового поиска на сервере 230 поисковой системы. В других вариантах осуществления изобретения журнал 260 запросов может обновляться в заранее заданные моменты времени. В некоторых вариантах осуществления изобретения может существовать множество копий журнала 260 запросов, каждая из которых соответствует журналу 260 запросов в различные моменты времени.
[0084] Журнал 265 действий пользователей может быть связан с журналом 260 запросов и содержать параметры действий пользователей, отслеживаемые сервером 235 анализа после того, как пользователь отправил запрос и выбрал один или несколько документов на странице SERP на сервере 230 поисковой системы. В не имеющем ограничительного характера примере журнал 265 действий пользователей может содержать ссылку на документ, который может быть идентифицирован с использованием идентификационного номера или универсального указателя ресурсов (URL, Uniform Resource Locator), и список запросов, каждый из которых связан с множеством параметров действий пользователей, как более подробно описано ниже. В общем случае может отслеживаться и объединяться сервером 235 анализа множество параметров действий пользователей и, в некоторых вариантах осуществления изобретения, они могут фиксироваться для каждого отдельного пользователя.
[0085] Не имеющие ограничительного характера примеры действий пользователей, отслеживаемых с использованием журнала 265 действий пользователей, включают в себя (в числе прочего) следующее:
- успех/неудача: был или не был выбран документ из ответа на поисковый запрос;
- время пребывания: время, затраченное пользователем на документ до возврата на страницу SERP;
- длинный/короткий «клик»: было ли действие пользователя с документом длинным или коротким по сравнению с действием пользователя с другими документами на странице SERP.
[0086] Разумеется, что представленный выше список не является исчерпывающим и что он может включать в себя другие виды действий пользователей без выхода за границы настоящей технологии. В некоторых вариантах осуществления изобретения сервер 235 анализа может объединять данные о действиях пользователей (которые в не имеющем ограничительного характера примере могут включать в себя действия пользователей для каждого часа) и формировать действия пользователей для сохранения в журнале 265 действий пользователя в подходящем для реализации настоящей технологии формате (которые в не имеющем ограничительного характера примере могут представлять собой действия пользователей для заранее заданного периода времени длительностью 3 месяца). В других вариантах осуществления изобретения в журнале 265 действий пользователей могут храниться данные о действиях пользователей в необработанном виде так, чтобы они могли извлекаться и объединяться сервером 230 поисковой системы и/или сервером 235 анализа и/или сервером 240 обнаружения аномальных посещений веб-сайтов и/или другим сервером (не показан) в формате, подходящем для реализации настоящей технологии.
[0087] В некоторых вариантах осуществления изобретения журнал 260 запросов и журнал 265 действий пользователей могут быть реализованы в виде единого журнала. Информация, хранящаяся в журнале 260 запросов и в журнале 265 действий пользователей, реализованных в виде одного журнала или нескольких журналов, образует историю 270 веб-поиска.
[0088] К сети 205 связи также подключен вышеупомянутый сервер 235 анализа. Сервер 235 анализа может быть реализован в виде традиционного компьютерного сервера. В одном примере осуществления настоящей технологии сервер 235 анализа может быть реализован в виде сервера Dell™ PowerEdge™, работающего под управлением операционной системы Microsoft™ Windows Server™. Очевидно, что сервер 235 анализа может быть реализован с использованием любых других подходящих аппаратных средств и/или прикладного программного обеспечения и/или встроенного программного обеспечения либо их сочетания. В представленном не имеющем ограничительного характера варианте осуществления настоящей технологии сервер 235 анализа представляет собой один сервер. В других не имеющих ограничительного характера вариантах осуществления настоящей технологии функции сервера 235 анализа могут быть распределены между несколькими серверами. В других вариантах осуществления изобретения функции сервера 235 анализа могут полностью или частично выполняться сервером 230 поисковой системы. В некоторых вариантах осуществления настоящей технологии сервер 235 анализа управляется и/или администрируется оператором поисковой системы. В качестве альтернативы, сервер 235 анализа может управляться и/или администрироваться другим поставщиком услуг.
[0089] В общем случае сервер 235 анализа предназначен для отслеживания действий пользователей с результатами поиска, предоставленными сервером 230 поисковой системы по запросам пользователей (например, сделанным пользователями первого клиентского устройства 210, второго клиентского устройства 215, третьего клиентского устройства 220 или четвертого клиентского устройства 225), на основе данных, хранящихся в журнале 265 действий пользователей.
[0090] Не имеющие ограничительного характера примеры параметров действий пользователей, сформированных сервером 235 анализа, включают в себя (в числе прочего) следующее:
- коэффициент «кликов» (CTR, Click-Through Rate): отношение количества случаев выбора элемента к количеству показов (демонстраций) элемента;
- длительность сеанса: средняя продолжительность сеанса в секундах;
- логарифмическая длительность сеанса: среднее логарифмическое значение продолжительности сеанса;
- запросы: количество запросов, отправленных пользователем;
- «клики»: количество переходов, выполненных пользователем;
- количество «кликов» на запрос: среднее количество переходов в расчете на один запрос для пользователя;
- суточное количество активных пользователей (DAU, Daily Active Users): количество уникальных пользователей, взаимодействующих с сервисом в течение суток;
- среднее количество сеансов в сутки на пользователя (S/U): u S(u) |u|, где S(u) - количество сеансов пользователя u в сутки, |u| - общее количество пользователей за эти сутки;
- среднее количество уникальных запросов за сеанс (UQ/S): s UQ(s) |s|, где UQ(s) - количество уникальных запросов в сеансе s, |s| - общее количество сеансов за эти сутки;
- средняя длина сеанса на пользователя (SL/U): общее количество запросов в сеансе, усредненное по каждому пользователю;
- доля в процентах навигационных запросов на пользователя (%-Nav-Q/U): позиции переходов: если свыше n% всех переходов для запроса концентрируются на трех первых URL-адресах, этот запрос рассматривается как навигационный. В противном случае он обрабатывается как информационный. Значение n может быть установлено равным 80;
- средняя длина запроса на пользователя (QL/U): количество слов в запросе пользователя;
- средняя доля успешных попыток на пользователя (QSuccess/U): запрос пользователя считается успешным, если пользователь выбирает один или несколько результатов и остается на любом из них более 30 секунд;
- средний интервал между запросами на пользователя (QI/U): средний интервал времени между двумя последовательными запросами пользователя в течение сеанса пользователя;
- время пребывания: время, затраченное пользователем на документ до возврата на страницу SERP.
[0091] Разумеется, что представленный выше список не является исчерпывающим и он может включать в себя параметры действий пользователей других видов без выхода за границы настоящей технологии.
[0092] Сервер 235 анализа может отправлять отслеженные параметры действий пользователей серверу 230 поисковой системы для сохранения в журнале 265 действий пользователей. В некоторых вариантах осуществления изобретения сервер 235 анализа может сохранять параметры действий пользователей и соответствующие результаты поиска локально в журнале действий пользователей (не показан). В других не имеющих ограничительного характера вариантах осуществления настоящей технологии функции сервера 235 анализа и сервера 230 поисковой системы могут выполняться одним сервером.
[0093] К сети 205 связи также подключен вышеупомянутый сервер 240 обнаружения аномальных посещений веб-сайтов. Сервер 240 обнаружения аномальных посещений веб-сайтов может быть реализован в виде традиционного компьютерного сервера. В одном примере осуществления настоящей технологии сервер 240 обнаружения аномальных посещений веб-сайтов может быть реализован в виде сервера Dell™ PowerEdge™, работающего под управлением операционной системы Microsoft™ Windows Server™. Очевидно, что сервер 240 обнаружения аномальных посещений веб-сайтов может быть реализован с использованием любых других подходящих аппаратных средств и/или прикладного программного обеспечения и/или встроенного программного обеспечения либо их сочетания. В представленном не имеющем ограничительного характера варианте осуществления настоящей технологии сервер 240 обнаружения аномальных посещений веб-сайтов представляет собой один сервер. В других не имеющих ограничительного характера вариантах осуществления настоящей технологии функции сервера 240 обнаружения аномальных посещений веб-сайтов могут быть распределены между несколькими серверами. В контексте настоящей технологии описанные здесь способы и система могут быть частично реализованы на сервере 240 обнаружения аномальных посещений веб-сайтов. В некоторых вариантах осуществления настоящей технологии сервер 240 обнаружения аномальных посещений веб-сайтов управляется и/или администрируется оператором поисковой системы. В качестве альтернативы, сервер 240 обнаружения аномальных посещений веб-сайтов может управляться и/или администрироваться другим поставщиком услуг.
[0094] В общем случае сервер 240 обнаружения аномальных посещений веб-сайтов предназначен для определения аномальных посещений веб-сайтов. Как более подробно описано ниже, сервер 240 обнаружения аномальных посещений веб-сайтов может, например, анализировать историю 270 веб-поиска (хранящуюся в журнале 260 запросов и/или в журнале 265 действий пользователей) с целью определения запросов и/или посещений веб-сайтов, которые подверглись влиянию вредоносного актора.
[0095] На фиг. 3 представлена схема обычного обмена данными между пользователями и сервером 230 поисковой системы. Как описано выше, сервер 230 поисковой системы формирует страницу SERP в ответ на запрос, полученный от пользователя. На страницу SERP может влиять предыдущее поведение пользователей, например, данные, хранящиеся в истории 270 веб-поиска.
[0096] Как показано на фиг. 3, пользователь 310 отправляет запрос путем передачи 341 серверу 230 поисковой системы. Затем сервер 230 поисковой системы выдает страницу SERP путем передачи 342 пользователю 310. Как описано выше, сервер 230 поисковой системы хранит различную информацию о взаимодействии между пользователем 310 и сервером 230 поисковой системы, такую как веб-хосты на странице SERP, ранее выбиравшиеся пользователем 310.
[0097] Затем пользователь 320 отправляет тот же запрос, что и пользователь 310, путем передачи 343 серверу 230 поисковой системы. После получения запроса сервер 230 поисковой системы отправляет страницу SERP пользователю 320 путем передачи 344. На страницу SERP, отправленную пользователю 320, могут влиять предыдущие действия пользователя 310. Например, ранг последнего веб-хоста, выбранного пользователем 310, может быть повышен на странице SERP, отправленной пользователю 320. Предполагается, что последний веб-хост, выбранный пользователем 310, рассматривался пользователем 310 как наиболее релевантный веб-хост на странице SERP.
[0098] Затем пользователь 330 отправляет тот же запрос, что и пользователи 310 и 320, серверу 230 поисковой системы путем передачи 345. В ответ на запрос сервер 230 поисковой системы формирует и выдает страницу SERP пользователю 330 путем передачи 346. На страницу SERP, предоставленную пользователю 330, может влиять поведение пользователей 310 и 320. Таким образом, сервер 230 поисковой системы может непрерывно уточнять ранг результатов поиска на основе зафиксированного поведения пользователей. Поведение пользователей может анализироваться с целью определения веб-хостов на странице SERP, которые рассматривались пользователями как наиболее релевантные. Затем этим веб-хостам может присваиваться более высокий ранг на будущих страницах SERP, что позволяет повысить удовлетворенность пользователей, поскольку наиболее релевантные результаты представляются пользователям с высоким рангом на страницах SERP.
[0099] На фиг. 3 представлена схема естественного поведения при поиске. На фиг. 4 показано, как недобросовестный актор может влиять на страницы SERP, предоставляемые сервером 230 поисковой системы. На схеме аномального обмена данными, представленной на фиг. 4, сервер 450 фальсификации результатов поиска влияет на поведение пользователей 410 и 420. Сервер 450 фальсификации результатов поиска может предоставлять инструкции пользователям 410 и 420. Инструкции могут указывать на то, какие поисковые запросы должны вводиться и какие результаты поиска должны выбираться на страницах SERP. Пользователи 410 и 420 могут вознаграждаться за выполнение инструкций, выданных сервером 450 фальсификации результатов поиска.
[00100] Пользователь 410 отправляет запрос согласно указаниям сервера 450 фальсификации результатов поиска серверу 230 поисковой системы путем передачи 441. В ответ на этот запрос сервер 230 поисковой системы отправляет страницу SERP пользователю 410 путем передачи 442. Затем пользователь 410 на основе указаний сервера 450 фальсификации результатов поиска посещает один или несколько веб-хостов путем выбора ссылок на странице SERP. Таким образом, сервер 450 фальсификации результатов поиска влияет на историю 270 веб-поиска путем предоставления инструкций относительно поведения пользователя 410. Посещения веб-сайтов, выполненные пользователем 410, здесь называются аномальными посещениями веб-сайтов. В отличие от естественного поведения человека, такие аномальные посещения веб-сайтов выполнены согласно указаниям недобросовестного актора, т.е. сервера 450 фальсификации результатов поиска в данном случае.
[00101] Пользователь 420 отправляет тот же запрос, что и пользователь 410, серверу 230 поисковой системы путем передачи 443. Сервер 230 поисковой системы отвечает на запрос отправкой страницы SERP пользователю 420 путем передачи 444. На ранжирование на странице SERP, отправленной пользователю 420, может влиять поведение пользователя 410, зависящее от сервера 450 фальсификации результатов поиска. Подобно пользователю 410, пользователь 420 взаимодействует со страницей SERP согласно указаниям сервера 450 фальсификации результатов поиска. Сервер 450 фальсификации результатов поиска может предложить пользователю 420 выбрать веб-хост, владелец которого заплатил лицу, управляющему сервером 450 фальсификации результатов поиска, чтобы повысить ранг результата поиска для этого веб-хоста.
[00102] Пользователь 430, не получавший указаний от сервера 450 фальсификации результатов поиска, отправляет тот же запрос, что и пользователи 410 и 420, серверу 230 поисковой системы путем передачи 445. Затем сервер 230 поисковой системы отправляет страницу SERP пользователю 430 путем передачи 446. На страницу SERP, отправленную пользователю 430, влияет предыдущее поведение пользователей 410 и 420. Веб-хост, который согласно указаниям сервера 450 фальсификации результатов поиска выбрали пользователи 410 и 420, имеет более высокий ранг на странице SERP, предоставленной пользователю 430, вследствие аномальных посещений веб-сайтов пользователями 410 и 420. Путем управления поведением пользователей 410 и 420 сервер 450 фальсификации результатов поиска повлиял на страницу SERP, полученную пользователем 430. Теперь пользователь 430 с большей вероятностью выберет веб-хост, продвигаемый сервером 450 фальсификации результатов поиска, поскольку этот веб-хост имеет более высокий ранг на странице SERP, полученной пользователем 430. Способ 500, более подробно описанный ниже и на фиг. 5, предназначен для анализа истории веб-поиска с целью определения аномального поведения пользователей, такого как поведение пользователей 410 и 420.
[00103] Способ (не имеющий ограничительного характера вариант осуществления)
[00104] На фиг. 5 и 6 представлена блок-схема способа 500, реализованного согласно вариантам осуществления настоящей технологии, не имеющим ограничительного характера.
[00105] Шаг 505: получение истории веб-поиска.
[00106] Способ 500 начинается с шага 505. На нем могут быть получены данные, описывающие предыдущие запросы и действия пользователей, например, история 270 веб-поиска. История веб-поиска может храниться в журнале 260 запросов, в журнале 265 действий пользователей и/или других хранилищах зафиксированных данных. На фиг. 7, более подробно описанной ниже, представлен пример получаемой истории веб-поиска. История веб-поиска может содержать идентификаторы пользователей (UID, User Identifier), отправленные каждым пользователем запросы и веб-хосты, выбранные пользователями после получения страниц SERP в ответ на их запросы.
[00107] История 270 веб-поиска может быть получена из одной или нескольких баз данных. Например, как описано на фиг. 2, история 270 веб-поиска может быть получена из базы 250 данных журналов поиска, которая может поддерживаться сервером 230 поисковой системы. Полученная история веб-поиска может соответствовать указанному временному окну. Например, может быть получена история 270 веб-поиска за предыдущие шесть месяцев. Полученная история 270 веб-поиска может соответствовать указанному местоположению или региону. Например, может быть получена история веб-поиска, соответствующая Северной Америке. Для получения истории веб-поиска могут быть использованы один или несколько запросов к базе данных. Запрос может указывать период времени, регион и/или другие фильтры, которые должны применяться к истории веб-поиска.
[00108] Шаг 510: формирование графа истории веб-поиска.
[00109] После получения истории 270 веб-поиска на шаге 510 может быть сформирован граф. На фиг. 8, более подробно описанной ниже, представлен пример графа истории веб-поиска. Каждый веб-хост из истории 270 веб-поиска может быть включен в состав графа в качестве вершины. Для фильтрации веб-хостов, включенных в состав графа, может использоваться пороговое количество посещений. Например, веб-хосты, имеющие менее 500 уникальных посетителей, могут не включаться в состав графа в качестве вершин. Граф может содержать ребра, каждое из которых соединяет две вершины. Ребром могут быть соединены две вершины, посещенные пользователем с одним идентификатором UID. Например, если история веб-поиска указывает на то, что пользователь посетил веб-сайты engadget.com и gizmodo.com, то ребро, соединяющее эти две вершины, должно быть включено в состав графа.
[00110] Несмотря на то, что здесь описан граф, должно быть понятно, что для анализа истории веб-поиска могут быть использованы и другие структуры данных. Для каждого веб-хоста в истории веб-поиска может быть сформирован список других веб-хостов, посещенных пользователями с теми же идентификаторами UID, что и у пользователей, посетивших этот веб-хост.
[00111] Шаг 515: назначение веса ребра каждому ребру в графе.
[00112] Каждому ребру в сформированном на шаге 510 графе на шаге 515 может быть назначен вес ребра. Вес ребра может указывать количество идентификаторов UID пользователей, посетивших оба веб-хоста, соединенных этим ребром. Например, если 50 пользователей посетили оба хоста, соединенных этим ребром, весу этого ребра может быть назначено значение 50. Вес ребра может назначаться на основе количества совпадающих поисковых запросов, введенных пользователями, посетивших оба хоста, соединенные этим ребром. Например, если два пользователя с идентификаторами UID ввели один и тот же поисковый запрос, а затем выбрали оба веб-хоста на странице SERP, сформированной в ответ на этот запрос, то вес ребра, соединяющего эти два веб-хоста, может быть увеличен.
[00113] Вес ребра с большим значением указывает на то, что оба веб-хоста, соединенных этим ребром, посещало большее количество одних и тех же посетителей. Связанные веб-хосты, такие как веб-хосты с близкими темами, должны иметь большие веса ребер, соединяющих их. Обычно предполагается, что пользователи посещают несколько тематически связанных веб-хостов. Например, веб-хосты newyorker.com и nytimes.com, вероятно, будут иметь относительно большой вес ребра, соединяющего их, поскольку оба веб-сайта связаны с городом Нью-Йорк и с новостями.
[00114] Шаг 520: получение темы для каждой вершины в графе.
[00115] На шаге 520 для каждой вершины в графе может быть получена и/или определена одна или несколько тем. Для определения одной или нескольких тем для каждой вершины в графе может быть использован алгоритм MLA. Алгоритм MLA может быть обучен определению одной или нескольких тем на основе информации, соответствующей веб-хосту, такой как метаданные, контент страницы и/или другая информация. В обученный алгоритм MLA могут быть введены адрес веб-хоста, метаданные, контент страницы и/или другая информация, соответствующая веб-хосту. Алгоритм MLA может выдавать одну или несколько тем. Алгоритм MLA может представлять собой модель обработки естественного языка (NLP, Natural Language Processing), такую как модель на основе латентно-семантического анализа (LSA, Latent Semantic Analysis), вероятностного латентно-семантического анализа (pLSA, Probabilistic Latent Semantic Analysis), модели Word2vec, алгоритма глобальных векторов для представления слов (GloVe, Global Vectors for Word Representation) или латентное размещение Дирихле (LDA, Latent Dirichlet Allocation).
[00116] Для получения тем может быть запрошена база данных тем (не показана). База данных тем может управляться сервером 230 поисковой системы. Веб-хост, соответствующий вершине, может быть сообщен базе данных тем в запросе, а база данных тем может предоставить одну или несколько тем, соответствующих этому веб-хосту.
[00117] Темы могут быть определены на основе контента веб-хоста, метаданных веб-хоста, истории 270 веб-поиска и/или других данных, относящихся к веб-хосту. Темы могут указывать на смысловое наполнение контента, отображаемого веб-хостом. Должно быть понятно, что темы могут быть получены из базы данных и/или сформированы в реальном времени.
[00118] Шаг 525: удаление ребер между вершинами со связанными темами.
[00119] На шаге 525 ребра, соединяющие два веб-хоста с одинаковыми или близкими темами, могут быть удалены из графа. Все ребра в графе, соединяющие пары веб-хостов с одинаковыми или близкими темами, могут быть удалены. Например, если для определения тем используется модель Word2vec, то для каждого из веб-хостов может быть определен вектор. Для векторов может быть определена близость косинусов их углов. Если близость косинусов удовлетворяет пороговому косинусному расстоянию, такому как заранее заданное пороговое косинусное расстояние, то темы могут считаться близкими. Ребра, определенные как имеющие одинаковые или близкие темы, соответствуют веб-хостам с естественной связью. После удаления этих ребер любые оставшиеся ребра в графе соединяют пары веб-хостов, не связанных естественным образом. На фиг. 9, более подробно описанной ниже, представлен граф после удаления ребер, соединяющих две вершины со связанными темами.
[00120] На шаге 510 вместо графа для каждого веб-хоста в истории веб-поиска могут быть сформированы списки других веб-хостов, посещенных пользователями с теми же идентификаторами UID. Если сформированы списки других веб-хостов, на шаге 525 могут быть удалены другие веб-хосты из списка, имеющие тему, связанную с данным веб-хостом.
[00121] Шаг 530: кластеризация вершин на основе весов ребер.
[00122] На шаге 530 может быть выполнена кластеризация вершин в графе. Кластеризация может быть выполнена на основе ребер и весов ребер. При этом может быть использован любой алгоритм кластеризации, такой как алгоритм на основе остовного k-дерева, алгоритм на основе минимального остовного дерева, алгоритм на основе общих ближайших соседей и/или любой другой подходящий алгоритм кластеризации. На фиг. 10, более подробно описанной ниже, представлен пример кластеров, сформированных из графа.
[00123] В некоторых случаях вершины могут быть включены в состав только одного кластера. В других случаях вершины могут быть включены в состав нескольких кластеров. Некоторые из вершин могут не быть объединены в кластер с другими вершинами. Например, если все ребра для некоторой вершины были удалены на шаге 525, то эта вершина может не включаться в состав ни одного из кластеров. Вершины, не объединенные в кластеры, могут не учитываться при дальнейшем анализе.
[00124] Шаг 535: получение данных о действиях пользователей.
[00125] На шаге 535 могут быть получены данные о действиях пользователей. Полученные данные о действиях пользователей могут соответствовать веб-хостам в кластере. Данные о действиях пользователей могут фильтроваться, чтобы свести полученные данные о действиях пользователей к данным, соответствующим веб-хостам в кластере. Для получения данных о действиях пользователей, соответствующих веб-хостам в кластере, могут быть использованы запросы.
[00126] Данные о действиях пользователей могут описывать поведение пользователей, соответствующее веб-хостам в кластере. Данные о действиях пользователей могут содержать данные из журнала 260 запросов и журнала 265 действий пользователей, зафиксированные веб-браузером данные, зафиксированные веб-сценариями данные, такие как куки-файлы, и/или другие данные, описывающие взаимодействие пользователей с веб-хостами. Данные о действиях пользователей могут указывать на посещенные пользователями веб-хосты, на действия, выполненные пользователями во время посещения веб-хостов, на порядок перехода пользователей к веб-хостам и/или на другие данные истории просмотра веб-страниц.
[00127] Полученные данные о действиях пользователей могут быть ограничены конкретным периодом времени, например, они могут представлять собой данные о действиях пользователей, зафиксированных в течение последних шести месяцев. Полученные данные о действиях пользователей могут быть ограничены географическим регионом, например, они могут представлять собой данные о действиях пользователей, соответствующие пользователям в Китае.
[00128] Шаг 540: выбор первого кластера.
[00129] На шаге 540 выбирается первый кластер вершин. При этом может быть выбран любой из кластеров. Может быть использован случайный выбор, упорядоченный выбор или любой другой подходящий способ выбора. Например, первым может выбираться наибольший кластер.
[00130] Шаг 545: определение связанных хостов в выбранном кластере.
[00131] На шаге 545 данные о действиях пользователей могут быть проанализированы, чтобы определить, связаны ли хосты в кластере. Несмотря на то, что хосты в кластере могут не иметь связанных тем, данные о действиях пользователей могут указывать на то, что соответствующая группа пользователей посещала веб-хосты в этом кластере. Если данные о действиях пользователей указывают на то, что веб-хосты в кластере связаны, посещения веб-хостов в этом кластере считаются обычными посещениями веб-сайтов.
[00132] Чтобы определить, связаны ли веб-сайты на основе данных о действиях пользователей, эти данные о действиях пользователей могут быть проанализированы для определения того, посещала ли соответствующая группа пользователей веб-хосты в этом кластере. Например, многие пользователи, интересующиеся гольфом, также могут интересоваться лодочным спортом. На шаге 530 мог быть сформирован кластер, содержащий веб-хосты, связанные с гольфом, и веб-хосты, связанные с лодочным спортом. Несмотря на то, что веб-хосты, связанные с гольфом, и веб-хосты, связанные с лодочным спортом, не связаны тематически, данные о действиях пользователей могут указывать на то, что значительная часть пользователей, просматривающих связанные с гольфом веб-хосты, посматривают и веб-хосты, связанные с лодочным спортом. В этом случае кластер может быть определен как связанный на основе данных о действиях пользователей.
[00133] Данные о действиях пользователей, анализируемые на шаге 545, могут представлять собой набор данных, описывающий действия тысяч пользователей, сотен тысяч пользователей и т.д. Размер набора данных может быть выбран так, чтобы аномальные посещения веб-сайтов составляли относительно небольшую часть данных о действиях пользователей, например, менее пяти процентов от данных о действиях пользователей.
[00134] Шаг 550: удаление кластера со связанными веб-хостами.
[00135] Если на шаге 545 было определено, что кластер содержит веб-хосты, связанные на основе данных о действиях пользователей, то на шаге 550 этот кластер может быть удален. Если веб-хосты в кластере связаны на основе данных о действиях пользователей, то предполагается, что веб-трафик, распределяемый между этими веб-хостами, соответствует естественным действиям пользователей, а не аномальным посещениям веб-сайтов. Если трафик, на основе которого сформирован кластер, считается естественным, то веб-хосты в этом кластере не связаны с аномальными посещениями веб-сайтов. Такой кластер может дальше не рассматриваться и/или может быть сохранен индикатор того, что этот кластер не связан с аномальными посещениями веб-сайтов.
[00136] На шаге 550 такой кластер может быть полностью или частично удален. Например, веб-хост без аномальных посещений веб-сайтов может оказаться в кластере с другими веб-хостами с аномальными посещениями веб-сайтов. Если определено, что веб-хост не имеет аномальных посещений веб-сайтов, этот веб-хост может быть отделен от остальной части кластера. Также возможно, что после реализации системы определения аномальных посещений веб-сайтов веб-хост может быть подвержен аномальным посещениям веб-сайтов с целью снижения ранга этого веб-хоста на странице SERP. Если предполагается такая ситуация, то веб-хост может быть удален из кластера, чтобы аномальные посещения веб-сайтов не приводили к снижению ранга этого веб-хоста.
[00137] Шаг 555: определение наличия оставшихся кластеров для анализа.
[00138] После удаления кластера на шаге 550 или если веб-хосты в кластере не были определены на шаге 545 как связанные на основе данных о действиях пользователей, на шаге 555 определяется, остались ли еще кластеры вершин для анализа. Если все кластеры вершин проанализированы на шаге 545, способ переходит к шагу 610, описанному ниже. Если имеется другой кластер для анализа, способ 500 переходит к шагу 560
[00139] Шаг 560: выбор следующего кластера для анализа.
[00140] На шаге 560 выбирается следующий кластер вершин для анализа. Как и на шаге 540, кластеры вершин могут выбираться в любом порядке. Выбранный следующий кластер вершин представляет собой кластер вершин, еще не анализированный на шаге 545. После выбора следующего кластера способ 500 переходит к шагу 545, на котором определяется, связаны ли веб-хосты в следующем кластере.
[00141] Шаг 610: сохранение индикатора аномальных посещений веб-сайтов для веб-хостов в оставшихся кластерах.
[00142] После удаления на шаге 550 кластеров, связанных на основе данных о действиях пользователей, оставшиеся кластеры считаются кластерами веб-хостов с аномальными посещениями веб-сайтов. Веб-хосты в оставшихся кластерах подвергнуты фильтрации дважды: сначала на шагах 520 и 525 путем определения естественной связи веб-хостов вследствие того, что они имеют близкие темы, а затем путем определения связи веб-хостов на основе данных о действиях пользователей. На посещения веб-хостов, подвергнутых фильтрации и оставшихся на шаге 610, вероятно, повлиял внешний источник, такой как сервер 540 фальсификации результатов поиска. Пользователям могли быть оплачены посещения веб-хостов в оставшихся кластерах. Для противодействия этим аномальным посещениям веб-сайтов могут быть выполнены различные действия, такие как действия, описанные на шагах 610, 620 и 630.
[00143] На шаге 610 для каждого веб-хоста в оставшихся кластерах может быть сохранен индикатор. Веб-хосты могут быть помечены как веб-хосты с аномальными посещениями веб-сайтов. Индикаторы могут быть сохранены в базе данных, такой как индекс 225. При этом могут быть определены связанные с аномальными посещениями веб-сайтов идентификаторы UID, для каждого из которых может быть сохранен индикатор, указывающий на то, что этот идентификатор UID связан с аномальными посещениями веб-сайтов.
[00144] Шаг 620: снижение ранга результатов поиска веб-хостов в оставшихся кластерах.
[00145] Поскольку веб-хосты в оставшихся кластерах имеют аномальные посещения веб-сайтов, они могут иметь высокий ранг на страницах SERP, чем в случае отсутствия у них аномальных посещений веб-сайтов. Чтобы скорректировать это, на шаге 610 ранг веб-хостов из оставшихся кластеров может быть снижен на страницах SERP либо эти веб-хосты могут вовсе не включаться в состав страниц SERP.
[00146] При формировании страницы SERP признаки, сохраненные на шаге 610, могут использоваться для определения того, имеет ли веб-хост аномальные посещения веб-сайтов. Если определено, что веб-хост имеет аномальные посещения веб-сайтов, ранг этого веб-хоста на странице SERP может быть снижен или этот веб-хост может быть удален со страницы SERP.
[00147] Шаг 630: удаление данных истории веб-поиска для веб-хостов в оставшихся кластерах.
[00148] На шаге 630 могут быть удалены данные истории веб-поиска и/или данные о действиях пользователей, соответствующие аномальным посещениям веб-сайтов. Для противодействия влиянию аномальных посещений веб-сайтов на результаты поиска действия, связанные с аномальными посещениями веб-сайтов, могут быть удалены из всех журналов. В качестве альтернативы, действия могут не удаляться, а помечаться как аномальные действия. Путем удаления действий, связанных с аномальными посещениями веб-сайтов, могут быть сформированы результаты для страниц SERP, на которые не влияют аномальные посещения веб-сайтов. Могут быть определены идентификаторы UID, связанные с аномальными посещениями веб-сайтов, и из журналов могут быть удалены все действия, связанные с этими идентификаторами UID. Затем способ 500 может быть завершен на шаге 640.
[00149] На фиг. 7-10 представлен не имеющий ограничительного характера пример применения способа 500. На фиг. 7 представлен пример истории 700 веб-поиска. История 700 веб-поиска представляет собой пример истории веб-поиска, которая может быть получена на шаге 505 способа 500. В истории 700 веб-поиска каждая запись содержит идентификатор UID, соответствующий пользователю, вводившему поисковый запрос, введенный этим пользователем запрос и веб-хосты, выбранные пользователем на странице SERP. Должно быть понятно, что история 700 веб-поиска представляет собой лишь пример и что, как описано выше в отношении журнала 260 запросов, в состав истории 700 веб-поиска может быть включена другая информация.
[00150] Как описано выше в отношении способа 500, на основе истории веб-поиска может быть сформирован граф. На фиг. 8 изображен граф 800, сформированный с использованием истории 700 веб-поиска, представленной на фиг. 7. Каждый веб-хост из истории 700 веб-поиска представляет собой вершину в графе 800. Ребра, соединяющие вершины, указывают на два веб-хоста, посещенные одним и тем же пользователем. Например, как показано в истории 700 веб-поиска, веб-сайты Newyorkbookranks.com и Freedoghairadvice.com посетил пользователь с идентификатором UID 855921. Поскольку эти два веб-хоста посетил один и тот же пользователь, они соединены ребром на графе 800.
[00151] Как описано на шагах 520 и 525 способа 500, ребра между веб-хостами, имеющими связанные темы, могут быть удалены. На фиг. 9 представлен подвергнутый фильтрации граф 900, представляющий собой граф 800 с удаленными ребрами, соединяющими вершины со связанными темами. Например, на графе 800 хосты Booklist.com и Constructionbooks.com соединены ребром. Оба эти веб-хоста связаны с темой «книги». Поскольку эти хосты имеют связанные темы, в графе 900 удалено ребро, соединяющее эти хосты.
[00152] Как описано на шаге 530 способа 500, вершины могут быть сгруппированы на основе веса ребра для формирования кластеров вершин. На фиг. 10 представлены кластеры, сформированные из графа 900. Из графа 900 сформированы три кластера: 1010, 1020 и 1030. Некоторые из вершин графа 900, такие как вершина, соответствующая веб-хосту Constructionbooks.com, не включены в состав какого-либо из кластеров 1010, 1020 и 1030, поскольку эти вершины не имеют ребер, оставшихся в графе 900.
[00153] Как описано на шагах 535-560 способа 500, кластеры могут фильтроваться на основе данных о действиях пользователей. Например, кластер 1030 может фильтроваться на основе данных о действиях пользователей. В представленном примере веб-хосты Mealreplacement.org и Workoutadvice.com тематически не связаны. Тем не менее, данные о действиях пользователей могут указывать на то, что пользователи, посещающие веб-хост Workoutadvice.com, также часто посещают веб-хост Mealreplacement.org. Поэтому эти веб-хосты оказываются связанными на основе данных о действиях пользователей. Кластер 1030 может быть удален, поскольку можно считать, что действия пользователей, связанные с этими веб-хостами, представляют собой обычные действия. Оставшиеся кластеры 1010 и 1020 могут содержать веб-хосты с аномальными посещениями веб-сайтов. Как описано на шагах 610-630 способа 500, для противодействия аномальным посещениям веб-сайтов этих хостов могут быть выполнены различные шаги, например, снижение ранга результатов поиска.
[00154] Как показано на фиг. 7-10 в отношении истории веб-поиска выполняется двухуровневая фильтрация. Во-первых, могут быть удалены ребра, соединяющие тематически связанные веб-хосты. Затем могут быть использованы данные о действиях пользователей, чтобы отфильтровать кластеры, сформированные из веб-хостов, связанных на основе действий пользователей. Выполнение фильтрации первого уровня, когда удаляются ребра, соединяющие тематически связанные вершины, может потребовать меньшего количества вычислений, чем выполнение фильтрации второго уровня, когда удаляются кластеры, связанные на основе данных о действиях пользователей.
[00155] Хотя описанные выше варианты реализации приведены со ссылкой на конкретные шаги, выполняемые в определенном порядке, должно быть понятно, что эти шаги могут быть объединены, разделены или что их порядок может быть изменен без выхода за границы настоящей технологии. По меньшей мере некоторые из этих шагов могут выполняться параллельно или последовательно. Соответственно, порядок и группировка шагов не носят ограничительного характера для настоящей технологии.
[00156] Очевидно, что не все упомянутые в данном описании технические эффекты должны присутствовать в каждом варианте осуществления настоящей технологии. Например, возможны варианты осуществления настоящей технологии, когда пользователь не получает некоторые из этих технических эффектов, или другие варианты реализации, когда пользователь получает другие технические эффекты либо технический эффект отсутствует.
[00157] Некоторые из шагов и передаваемых или принимаемых сигналов хорошо известны в данной области техники и по этой причине опущены в некоторых частях описания для упрощения. Сигналы могут передаваться или приниматься с использованием оптических средств (таких как волоконно-оптическое соединение), электронных средств (таких как проводное или беспроводное соединение) и механических средств (например, основанных на давлении, температуре или любом другом подходящем физическом параметре).
[00158] Для специалиста в данной области могут быть очевидными возможные изменения и усовершенствования описанных выше вариантов осуществления настоящей технологии. Предшествующее описание приведено лишь в иллюстративных целях, а не для ограничения объема изобретения. Объем охраны настоящей технологии определяется исключительно объемом приложенной формулы изобретения.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ И СИСТЕМА ДЛЯ ВЫЯВЛЕНИЯ АНОМАЛЬНОГО РЕЙТИНГОВАНИЯ | 2019 |
|
RU2776034C2 |
| СПОСОБ, ЭЛЕКТРОННОЕ УСТРОЙСТВО И СЕРВЕР ОРГАНИЗАЦИИ ИСТОРИИ БРАУЗЕРА | 2015 |
|
RU2640299C2 |
| СПОСОБ ОТОБРАЖЕНИЯ ВЕБ-РЕСУРСА ПОЛЬЗОВАТЕЛЮ (ВАРИАНТЫ) И ЭЛЕКТРОННОЕ УСТРОЙСТВО | 2014 |
|
RU2595497C2 |
| СПОСОБ СИНХРОНИЗАЦИИ ПЕРВОЙ И ВТОРОЙ СЕССИИ ПРОСМОТРА СТРАНИЦ ДЛЯ ПОЛЬЗОВАТЕЛЯ И СЕРВЕР | 2013 |
|
RU2580392C2 |
| СПОСОБ ПРЕДСТАВЛЕНИЯ РЕЗУЛЬТАТОВ ПОИСКА В СООТВЕТСТВИИ С ПОИСКОВЫМ ЗАПРОСОМ В СЕТИ ИНТЕРНЕТ | 2014 |
|
RU2598789C2 |
| СПОСОБ И СИСТЕМА ДЛЯ ФОРМИРОВАНИЯ ПОДСКАЗОК ПО РАСШИРЕНИЮ ПОИСКОВЫХ ЗАПРОСОВ В ПОИСКОВОЙ СИСТЕМЕ | 2019 |
|
RU2744111C2 |
| СИСТЕМА И СПОСОБ ВЫПОЛНЕНИЯ ПОИСКА | 2014 |
|
RU2597476C2 |
| СПОСОБ И СЕРВЕР ДЛЯ КЛАССИФИКАЦИИ ВЕБ-РЕСУРСА | 2017 |
|
RU2658878C1 |
| СПОСОБ И СИСТЕМА СОЗДАНИЯ ВЕКТОРОВ АННОТАЦИИ ДЛЯ ДОКУМЕНТА | 2017 |
|
RU2720074C2 |
| Способ и сервер прогнозирования популярности элемента содержимого | 2015 |
|
RU2635905C2 |
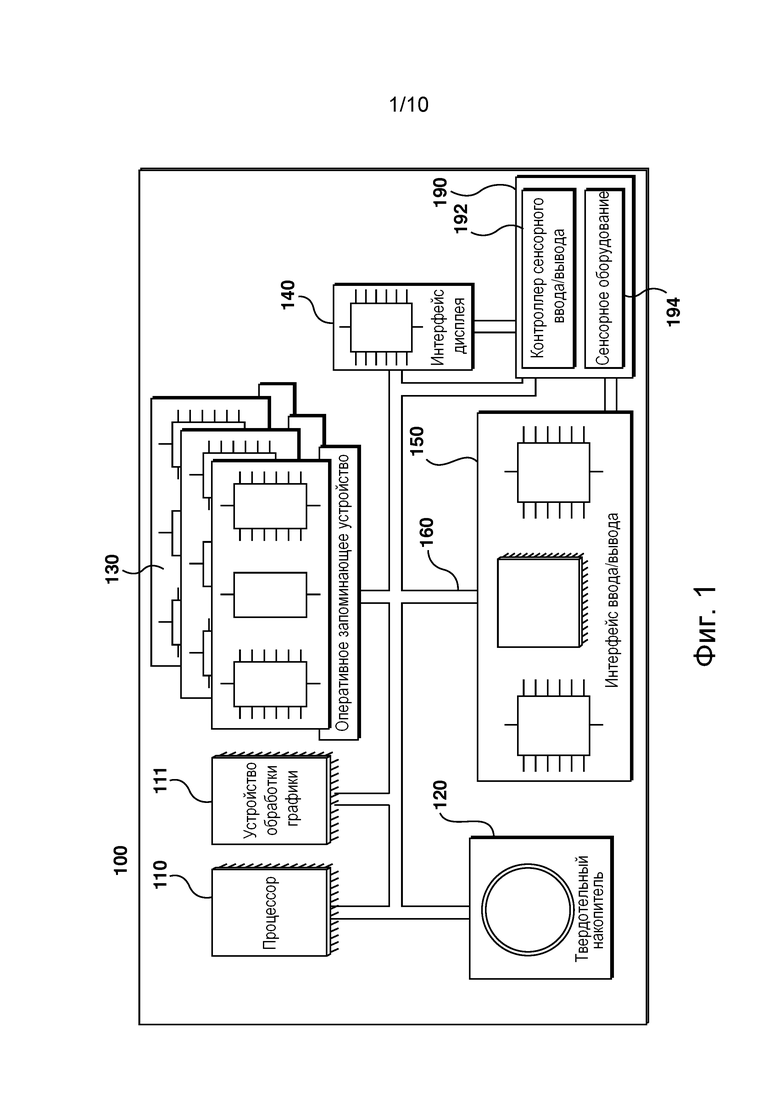
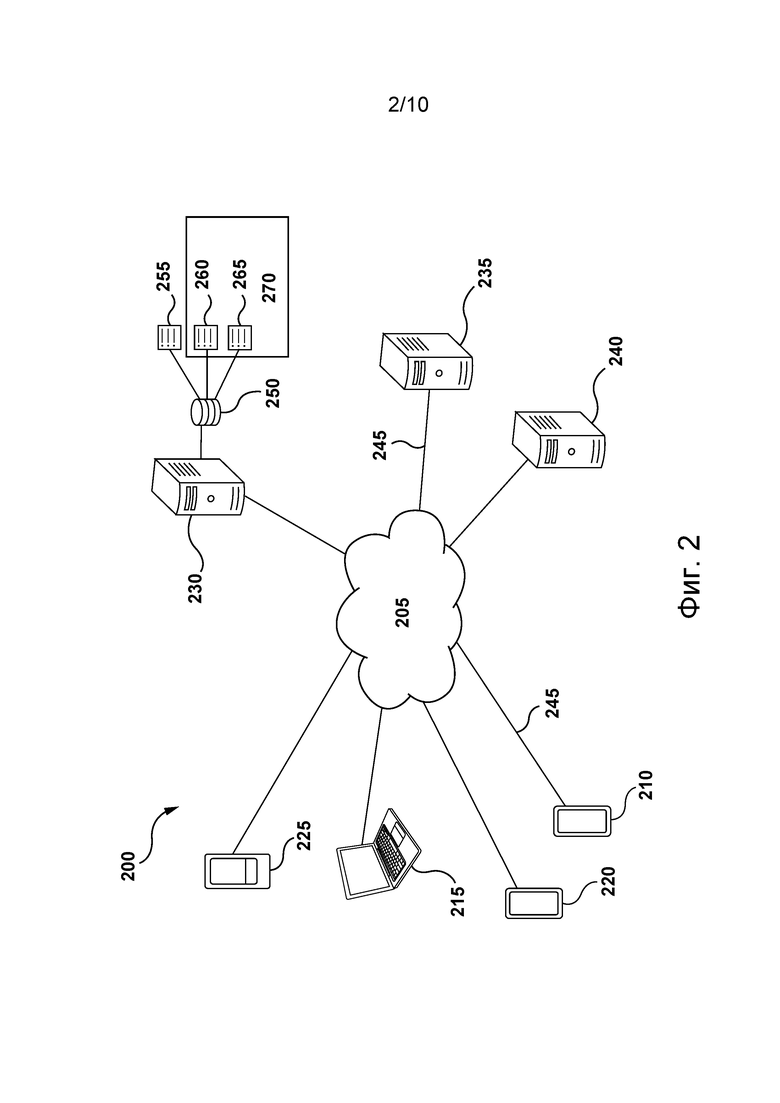
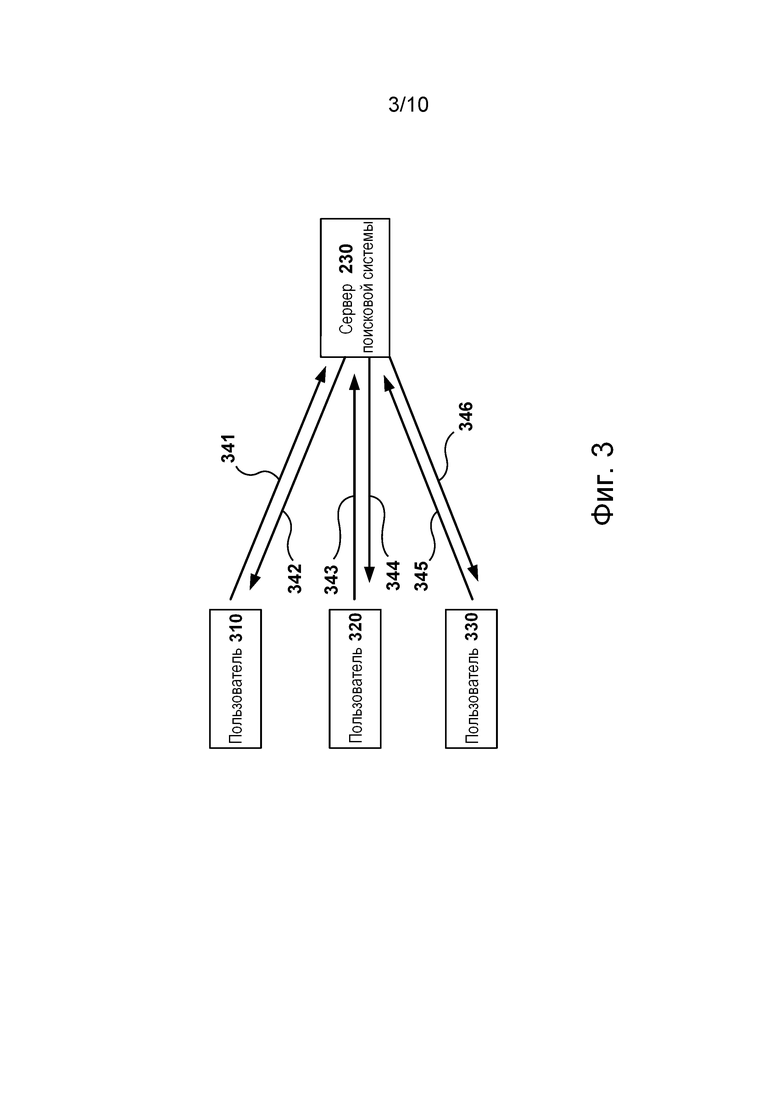
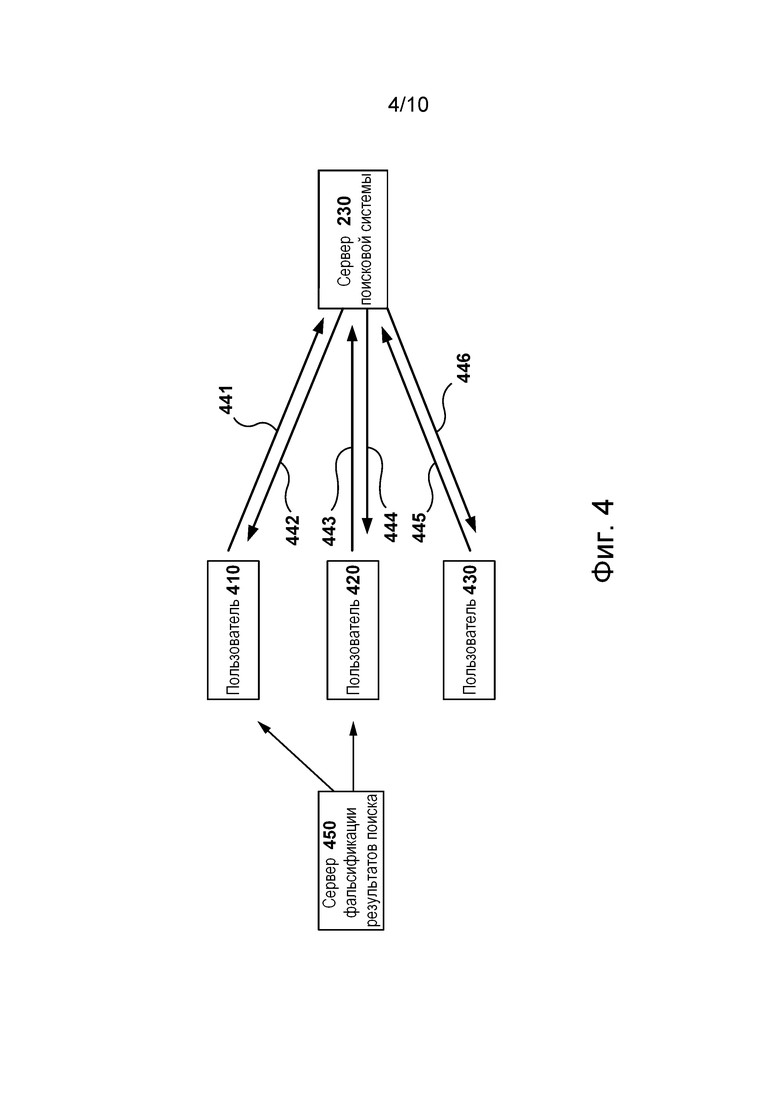
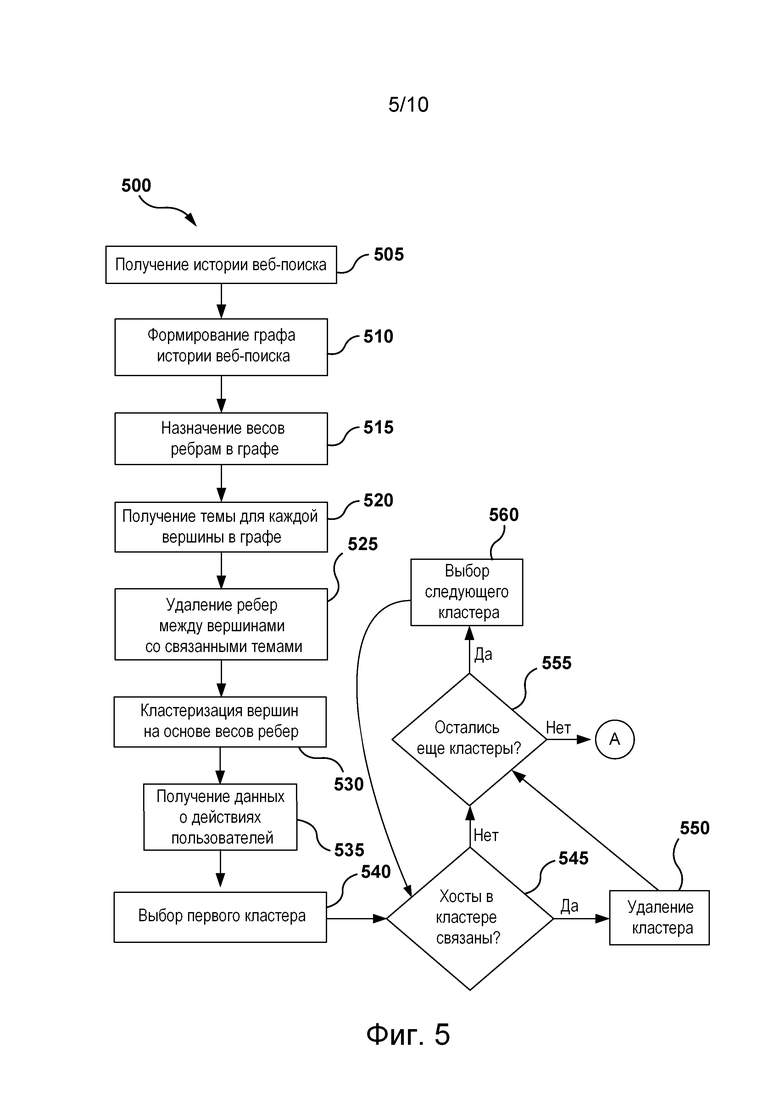
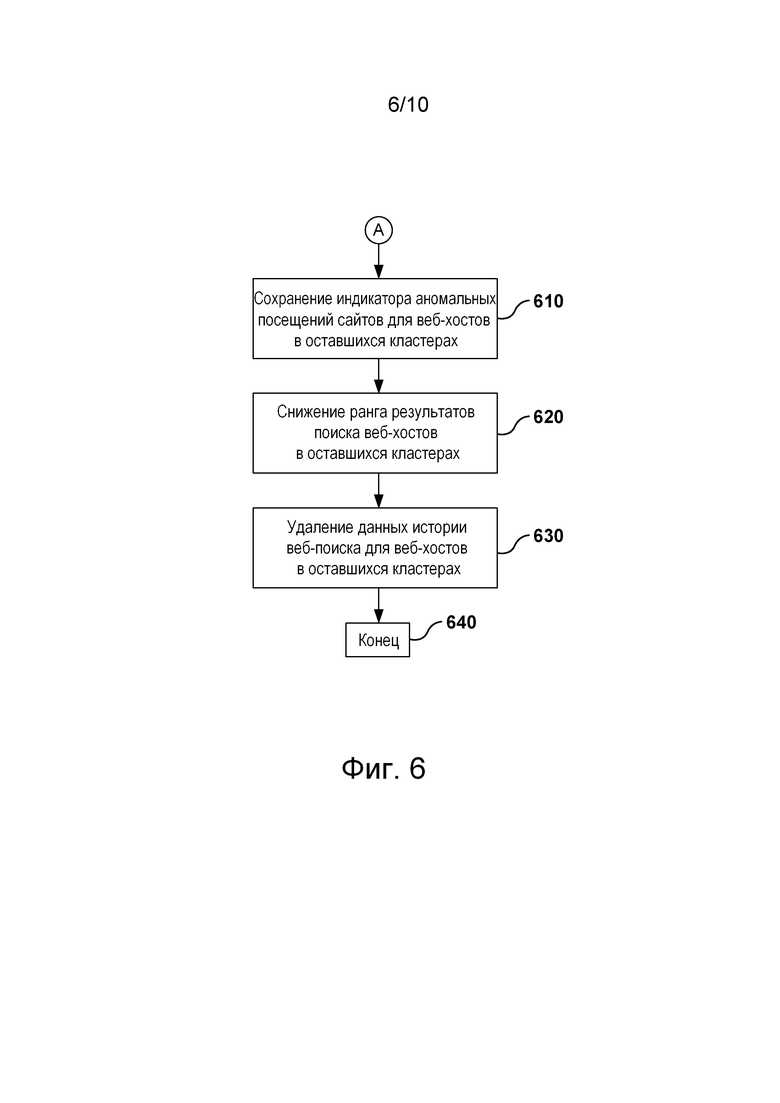
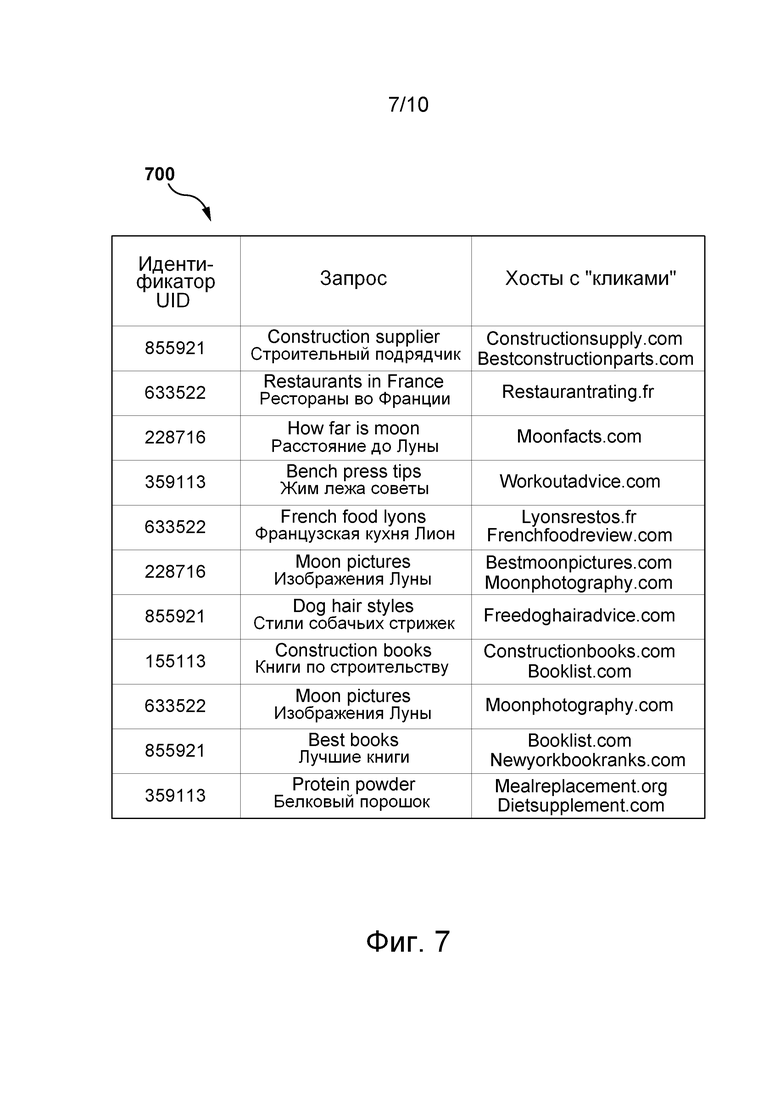
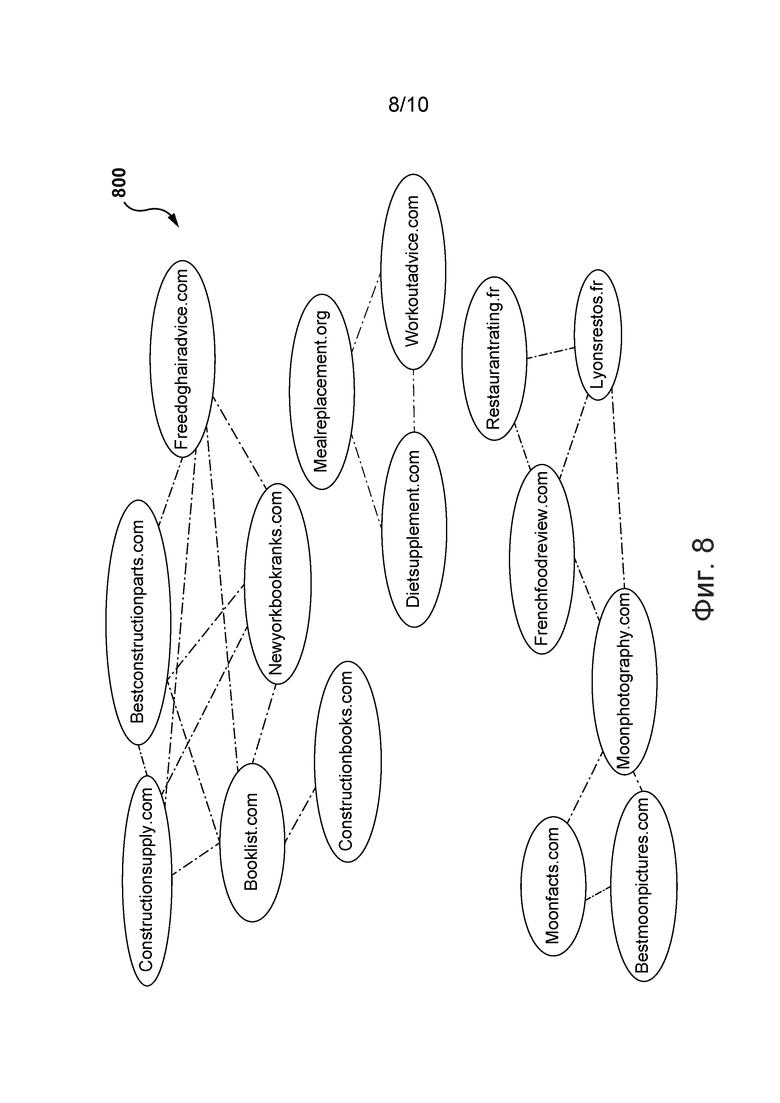
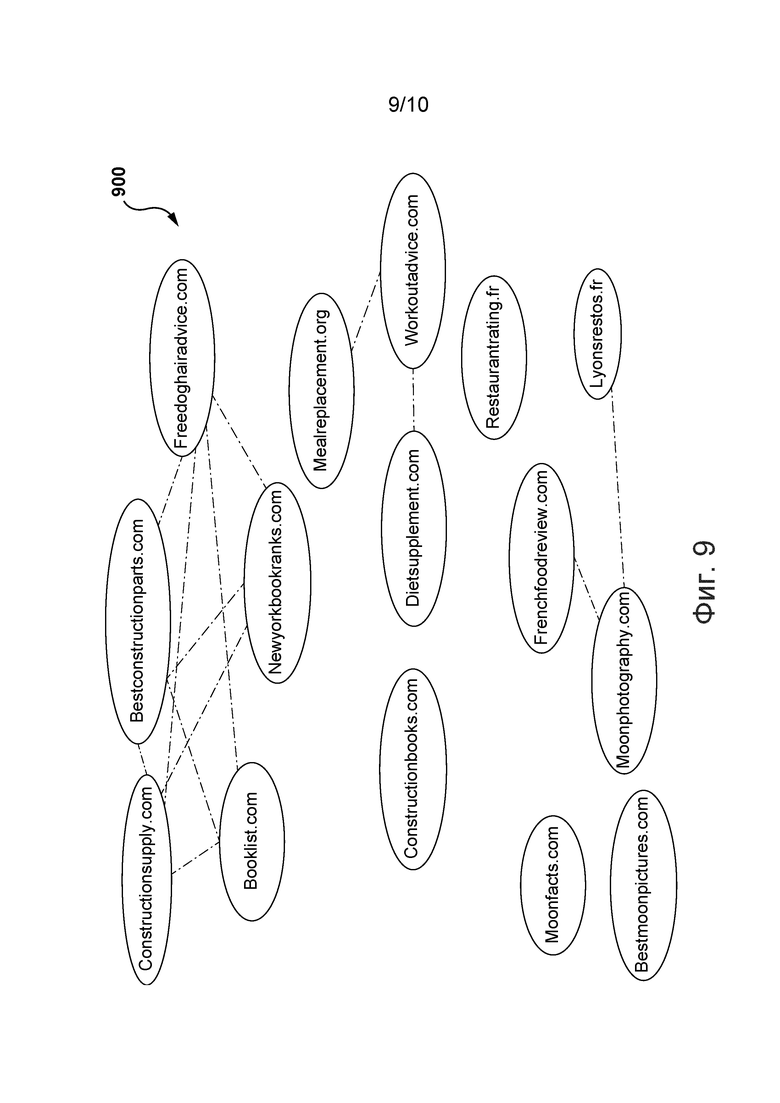
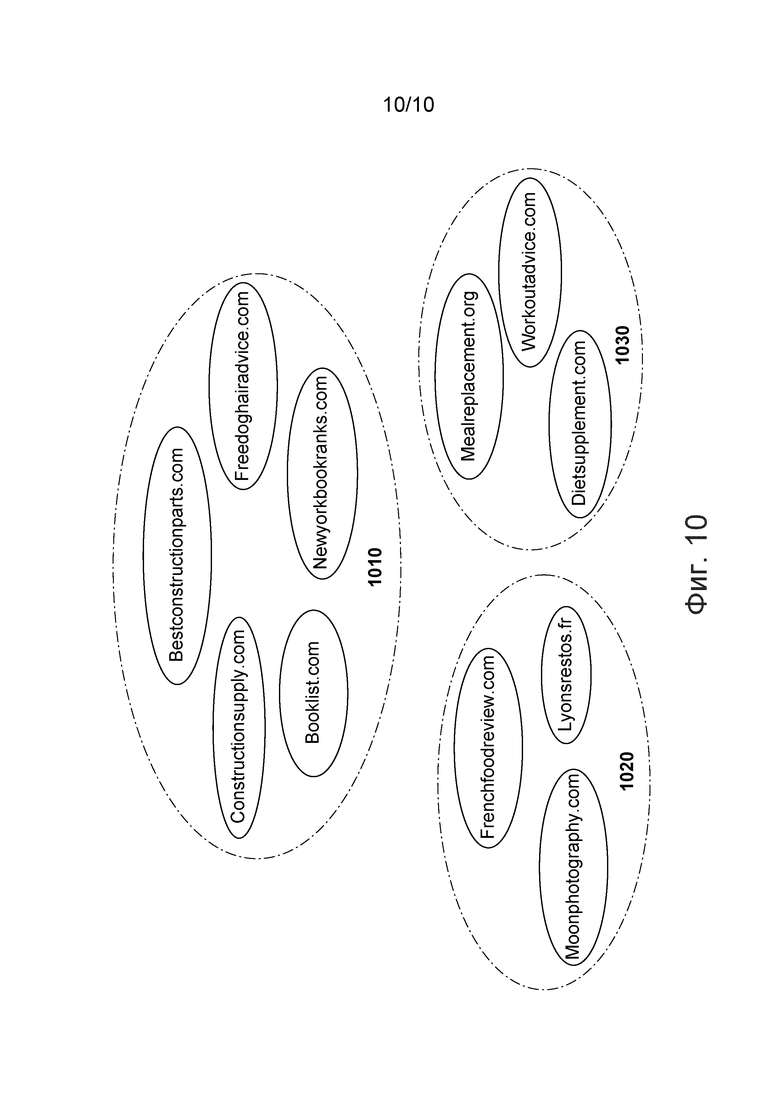
Группа изобретений относится к определению аномального поведения при поиске в Интернете и, в частности, к определению веб-хостов с аномальными посещениями веб-сайтов. Техническим результатом является повышение надежности работы поисковой системы за счет повышения достоверности результатов. Способ выполняется на сервере и содержит этапы получение истории веб-поиска для множества пользователей посредством сети связи на основании поисковых запросов от множества клиентских устройств; формирование графа истории веб-поиска, в котором каждая вершина представляет собой веб-хост из истории веб-поиска, при этом вершины соединены с другими вершинами ребрами, каждое из которых имеет вес ребра, определенный на основе количества пользователей, посетивших оба хоста, соединенных этим ребром; кластеризацию вершин графа на основе весов ребер и формирование множества кластеров вершин; получение данных о действиях пользователей, соответствующих этим кластерам вершин и связанных с множеством пользователей, посетивших веб-хосты, связанные с этими кластерами вершин; определение для каждого кластера вершин связанных веб-хостов в этом кластере на основе данных о действиях пользователей; удаление из графа каждого кластера вершин, содержащего веб-хосты, связанные на основе данных о действиях пользователей; и сохранение для каждого веб-хоста, связанного с кластером, оставшимся в графе, индикатора того, что этот веб-хост связан с аномальными посещениями веб-сайтов. 3 н. и 18 з.п. ф-лы, 10 ил.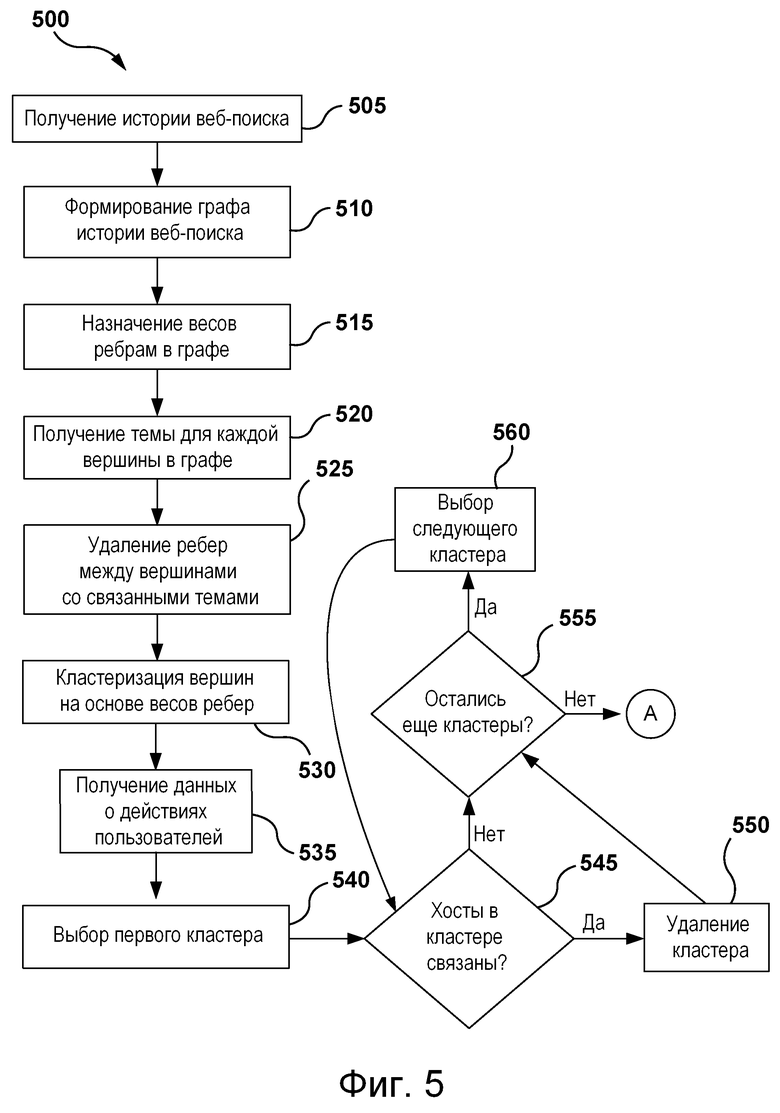
1. Способ коррекции работы поисковой системы путём определения веб-хостов с аномальными посещениями веб-сайтов в поисковой системе, выполняемый на сервере и включающий в себя:
- получение на сервере истории веб-поиска для множества пользователей посредством сети связи на основании поисковых запросов от множества клиентских устройств;
- формирование посредством сервера графа истории веб-поиска, в котором каждая вершина представляет собой веб-хост из истории веб-поиска, при этом вершины соединены с другими вершинами ребрами, каждое из которых имеет вес ребра, определенный на основе количества пользователей, посетивших оба хоста, соединенных этим ребром;
- кластеризацию посредством сервера вершин графа на основе весов ребер и формирование множества кластеров вершин;
- получение на сервере данных о действиях пользователей, соответствующих этим кластерам вершин и связанных с множеством пользователей, посетивших веб-хосты, связанные с этими кластерами вершин;
- определение посредством сервера для каждого кластера вершин связанных веб-хостов в этом кластере на основе данных о действиях пользователей;
- удаление посредством сервера из графа каждого кластера вершин, содержащего веб-хосты, связанные на основе данных о действиях пользователей; и
- сохранение посредством сервера для каждого веб-хоста, связанного с кластером, оставшимся в графе, индикатора того, что этот веб-хост связан с аномальными посещениями веб-сайтов.
2. Способ по п. 1, отличающийся тем, что перед кластеризацией вершин графа он дополнительно включает в себя:
- определение для каждой вершины графа одной или нескольких тем, соответствующих этой вершине; и
- удаление из графа ребер, соединяющих две вершины со связанными темами.
3. Способ по п. 2, отличающийся тем, что определение одной или нескольких тем для каждой вершины графа включает в себя запрашивание в базе данных тем, связанных с веб-хостом, соответствующим этой вершине.
4. Способ по п. 1, отличающийся тем, что он дополнительно включает в себя:
- получение поискового запроса;
- формирование на основе этого поискового запроса страницы результатов поисковой системы с ранжированным множеством веб-хостов, соответствующих этому поисковому запросу; и
- снижение на странице результатов поисковой системы ранга веб-хоста, связанного с аномальными посещениями веб-сайтов.
5. Способ по п. 1, отличающийся тем, что он дополнительно включает в себя:
- получение поискового запроса;
- формирование на основе этого поискового запроса страницы результатов поисковой системы с ранжированным множеством веб-хостов, соответствующих этому поисковому запросу; и
- удаление со страницы результатов поисковой системы веб-хоста, связанного с аномальными посещениями веб-сайтов.
6. Способ по п. 1, отличающийся тем, что он дополнительно включает в себя удаление из истории веб-поиска данных, соответствующих веб-хостам, связанным с аномальными посещениями веб-сайтов.
7. Способ по п. 1, отличающийся тем, что он дополнительно включает в себя:
- определение множества идентификаторов пользователей, соответствующих аномальным посещениям веб-сайтов; и
- сохранение для каждого из них индикатора того, что этот идентификатор пользователя связан с аномальными посещениями веб-сайтов.
8. Способ по п. 1, отличающийся тем, что данные о действиях пользователей содержат историю веб-поиска.
9. Способ по п. 1, отличающийся тем, что данные о действиях пользователей содержат данные об использовании веб-браузера.
10. Способ по п. 1, отличающийся тем, что данные о действиях пользователей содержат данные веб-сценария.
11. Способ по п. 1, отличающийся тем, что дополнительно включает в себя определение веса каждого ребра на основе количества совпадающих поисковых запросов, введенных пользователями, посетившими оба хоста, соединенные этим ребром.
12. Система для коррекции работы поисковой системы путём определения веб-хостов с аномальными посещениями веб-сайтов, содержащая процессор и машиночитаемый физический носитель информации, содержащий команды, при этом процессор выполнен с возможностью выполнения следующих действий при исполнении команд:
- получение истории веб-поиска для множества пользователей посредством сети связи на основании поисковых запросов от множества клиентских устройств;
- формирование графа истории веб-поиска, в котором каждая вершина представляет собой веб-хост из истории веб-поиска, при этом вершины соединены с другими вершинами ребрами, каждое из которых имеет вес ребра, определенный на основе количества пользователей, посетивших оба хоста, соединенных этим ребром;
- кластеризацию вершин графа на основе весов ребер и формирование множества кластеров вершин;
- получение посредством сети связи данных о действиях пользователей, соответствующих этим кластерам вершин и связанных с множеством пользователей, посетивших веб-хосты, связанные с этими кластерами вершин;
- определение для каждого кластера вершин связанных веб-хостов в этом кластере на основе данных о действиях пользователей;
- удаление из графа каждого кластера вершин, содержащего веб-хосты, связанные на основе данных о действиях пользователей; и
- сохранение для каждого веб-хоста, связанного с кластером, оставшимся в графе, индикатора того, что этот веб-хост связан с аномальными посещениями веб-сайтов.
13. Система по п. 12, отличающаяся тем, что процессор дополнительно выполнен с возможностью выполнения следующих действий при исполнении команд:
- определение для каждой вершины графа одной или нескольких тем, соответствующих этой вершине; и
- удаление из графа ребер, соединяющих две вершины со связанными темами.
14. Система по п. 12, отличающаяся тем, что процессор дополнительно выполнен с возможностью выполнения следующих действий при исполнении команд:
- получение поискового запроса;
- формирование на основе этого поискового запроса страницы результатов поисковой системы с ранжированным множеством веб-хостов, соответствующих этому поисковому запросу; и
- снижение на странице результатов поисковой системы ранга веб-хоста, связанного с аномальными посещениями веб-сайтов.
15. Система по п. 12, отличающаяся тем, что процессор дополнительно выполнен с возможностью выполнения следующих действий при исполнении команд:
- получение поискового запроса;
- формирование на основе этого поискового запроса страницы результатов поисковой системы с ранжированным множеством веб-хостов, соответствующих этому поисковому запросу; и
- удаление со страницы результатов поисковой системы веб-хоста, связанного с аномальными посещениями веб-сайтов.
16. Система по п. 12, отличающаяся тем, что процессор дополнительно выполнен с возможностью выполнения следующего действия при исполнении команд: удаление из истории веб-поиска данных, соответствующих веб-хостам, связанным с аномальными посещениями веб-сайтов.
17. Система по п. 12, отличающаяся тем, что процессор дополнительно выполнен с возможностью выполнения следующих действий при исполнении команд:
- определение множества идентификаторов пользователей, соответствующих аномальным посещениям веб-сайтов, и
- сохранение для каждого из них признака того, что этот идентификатор пользователя связан с аномальными посещениями веб-сайтов.
18. Система по п. 12, отличающаяся тем, что процессор дополнительно выполнен с возможностью выполнения следующего действия при исполнении команд: определение веса ребра на основе количества совпадающих запросов, введенных пользователями, посетившими оба веб-хоста, соединенные этим ребром.
19. Способ коррекции работы поисковой системы путём определения веб-хостов с аномальными посещениями веб-сайтов, выполняемый на сервере и включающий в себя:
- получение на сервере истории веб-поиска для множества пользователей посредством сети связи на основании поисковых запросов от множества клиентских устройств;
- для каждого веб-хоста из истории поиска:
- определение посредством сервера на основе истории веб-поиска списка других веб-хостов, посещенных пользователями, посетившими данный веб-хост; и
- удаление посредством сервера других веб-хостов, имеющих естественную связь с данным веб-хостом, из списка других веб-хостов;
- кластеризацию посредством сервера не связанных естественным образом веб-хостов и формирование множества кластеров вершин на основе списков других веб-хостов;
- получение на сервере посредством сети связи данных о действиях пользователей, соответствующих этим кластерам вершин и связанных с множеством пользователей, посетивших веб-хосты, связанные с этими кластерами вершин;
- удаление посредством сервера кластеров, содержащих веб-хосты, связанные друг с другом на основе данных о действиях пользователей; и
- сохранение посредством сервера для каждого веб-хоста, связанного с оставшимися кластерами, индикатора того, что этот веб-хост связан с аномальными посещениями веб-сайтов.
20. Способ по п. 19, отличающийся тем, что удаление других веб-хостов, имеющих естественную связь с данным веб-хостом, включает в себя выполнение для каждого другого веб-хоста из списка других веб-хостов сравнения одной или нескольких тем, соответствующих данному веб-хосту, с одной или несколькими темами, соответствующими другому веб-хосту.
21. Способ по п. 19, отличающийся тем, что он дополнительно включает в себя:
- получение поискового запроса;
- формирование на основе этого поискового запроса страницы результатов поисковой системы с ранжированным множеством веб-хостов, соответствующих этому поисковому запросу; и
- снижение на странице результатов поисковой системы ранга веб-хоста, связанного с аномальными посещениями веб-сайтов.
| US 9092510 B1, 28.07.2015 | |||
| Пресс для выдавливания из деревянных дисков заготовок для ниточных катушек | 1923 |
|
SU2007A1 |
| Станок для изготовления деревянных ниточных катушек из цилиндрических, снабженных осевым отверстием, заготовок | 1923 |
|
SU2008A1 |
| CN 103605714 A, 26.02.2014 | |||
| Станок для придания концам круглых радиаторных трубок шестигранного сечения | 1924 |
|
SU2019A1 |
| СИСТЕМА И СПОСОБ РАНЖИРОВАНИЯ РЕЗУЛЬТАТОВ ПОИСКА | 2015 |
|
RU2632148C2 |

