Область техники, к которой относится изобретение
Настоящее изобретение относится к определению и уточнению вектора движения, которые могут использоваться во время кодирования и декодирования видео.
Уровень техники
Современные гибридные видеокодеки используют кодирование с предсказанием. Изображение видеопоследовательности подразделяется на блоки пикселей, и эти блоки затем кодируются. Вместо кодирования блока пиксель за пикселем весь блок предсказывают с использованием уже закодированных пикселей в пространственной или временной близости блока. Кодер дополнительно обрабатывает только различия между блоком и его предсказанием. Дальнейшая обработка обычно включает в себя преобразование пикселей блока в коэффициенты в области преобразования. Коэффициенты могут затем дополнительно сжиматься посредством квантования и дополнительно сжиматься посредством энтропийного кодирования для формирования битового потока. Битовый поток дополнительно включает в себя любую информацию сигнализации, которая позволяет декодеру декодировать кодированное видео. Например, сигнализация может включать в себя настройки, касающиеся настроек кодера, таких как размер входного изображения, частота кадров, индикация шага квантования, предсказание, примененное к блокам изображений, или тому подобное.
Временное предсказание использует временную корреляцию между изображениями, также называемыми кадрами, видео. Временное предсказание также называется межкадровым предсказанием, так как это предсказание, использующее зависимости между (меж) различными видеокадрами. Соответственно, кодируемый блок, также называемый текущим блоком, предсказывается из одного или нескольких ранее кодированного(-ы_х изображения(-й), называемого(-ых) опорным(и) изображением(-ями). Опорное изображение не обязательно является изображением, предшествующим текущему изображению, в котором текущий блок расположен в порядке отображения видеопоследовательности. Кодер может кодировать изображения в порядке кодирования, отличном от порядка отображения. В качестве предсказания текущего блока, в опорном изображении может быть определен совместно расположенный блок. Совместно расположенный блок представляет собой блок, который расположен в опорном изображении в том же самом положении, в котором находится текущий блок в текущем изображении. Такое предсказание является точным для областей неподвижного изображения, то есть областей изображения без перемещения от одного изображения к другому.
Чтобы получить предиктор, который учитывает движение, то есть предиктор с компенсацией движения, оценка движения обычно используется при определении предсказания текущего блока. Соответственно, текущий блок предсказывают посредством блока в опорном изображении, который находится на расстоянии, заданном посредством вектора движения из положения совместно расположенного блока. Чтобы дать возможность декодеру определять то же самое предсказание текущего блока, вектор движения может сигнализироваться в битовом потоке. Чтобы дополнительно уменьшить издержки сигнализации, вызванные сигнализацией вектора движения для каждого из блоков, сам вектор движения может быть оценен. Оценка вектора движения может быть выполнена на основе векторов движения соседних блоков в пространственной и/или временной области.
Предсказание текущего блока может быть вычислено с использованием одного опорного изображения или посредством взвешивания предсказания, полученного из двух или более опорных изображений. Опорное изображение может быть смежным изображением, т.е. изображением, непосредственно предшествующим и/или изображением непосредственно следующим за текущим изображением в порядке отображения, так как смежные изображения, скорее всего, будут схожи с текущим изображением. Однако, в общем, опорное изображение может быть также любым другим изображением предшествующим или следующим за текущим изображением в порядке отображения и предшествующим текущему изображению в битовом потоке (порядке декодирования). Это может обеспечить преимущества, например, в случае окклюзий и/или нелинейного движения в видеоконтенте. Идентификация опорного изображения, таким образом, может также сигнализироваться в битовом потоке.
Специальный режим межкадрового предсказания представляет собой так называемое двунаправленное предсказание, в котором два опорных изображения используются при формировании предсказания текущего блока. В частности, два предсказания, определенные в соответствующих двух опорных изображениях, объединяют в сигнал предсказания текущего блока. Двунаправленное предсказание может привести к более точному предсказанию текущего блока, чем однонаправленное предсказание, то есть предсказания только с использованием одного опорного изображения. Более точное предсказание приводит к меньшим различиям между пикселями текущего блока и предсказания (также называемым «остатками»), которые могут кодироваться более эффективно, то есть сжиматься в более короткий битовый поток. В общем, более двух опорных изображений можно использовать для нахождения соответствующих более двух опорных блоков для предсказания текущего блока, то есть можно применять многонаправленное межкадровое предсказание. Таким образом, термин многонаправленное предсказание включает в себя двунаправленное предсказание, а также предсказания с использованием более двух опорных изображений.
Для того, чтобы обеспечить более точную оценку движения, разрешение опорного изображения может быть улучшено посредством интерполяции сэмплов между пикселами. Интерполяция дробных пикселей может быть выполнена посредством взвешенного усреднения ближайших пикселей. В случае разрешения в полпикселя, например, обычно используется билинейная интерполяция. Другие дробные пиксели вычисляются как среднее значение ближайших пикселей, взвешенных посредством величины, обратной расстоянию между соответствующими ближайшими пикселями к предсказываемому пикселю.
Оценка вектора движения является вычислительно сложной задачей, в которой вычисляется сходство между текущим блоком и соответствующими блоками предсказания, на которые направлены возможные векторы движения в опорном изображении. Как правило, область поиска включает в себя M x M сэмплов изображения, и проверяется каждое из положений сэмплов в M x M положениях. Проверка включает в себя вычисление меры сходства между N × N опорным блоком С и блоком R, расположенным в проверенном возможном положении в области поиска. Для простоты сумма абсолютных разностей (SAD - sum of absolute differences) является мерой, часто используемой для этой цели и определяемой как:
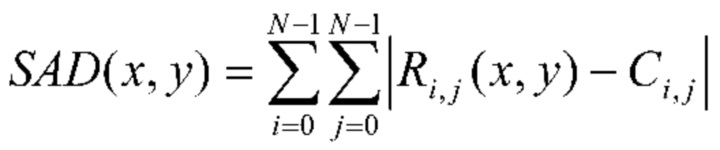
В приведенной выше формуле, х и у определяют возможное положение в пределах области поиска, в то время как индексы I и J обозначают сэмплы (sample) в пределах опорного блока C и возможного блока R. Возможное положение часто упоминается как перемещение блока или смещение, которое отражает представление соответствия блока как смещение опорного блока в пределах зоны поиска и вычисления сходства между опорным блоком C и перекрытой частью области поиска. Чтобы уменьшить сложность, число возможных векторов движения обычно уменьшают, ограничивая возможные векторы движения определенным пространством поиска. Пространство поиска может быть, например, определено посредством числа и/или положений пикселей, окружающих положение в опорном изображении, соответствующее положению текущего блока в текущем изображении. После вычисления SAD для всех M x M возможных положений x и y наиболее соответствующим блоком R является блок в положении, приводящем к наименьшему SAD, соответствующем наибольшему сходству с опорным блоком C. С другой стороны, возможные векторы движения могут быть определены посредством перечня возможных векторов движения, образованного посредством векторов движения соседних блоков.
Векторы движения обычно по меньшей мере частично определяются на стороне кодера и передаются в декодер в кодированном битовом потоке. Однако векторы движения также могут быть получены в декодере. В таком случае, текущий блок не доступен в декодере, и не может быть использован для вычисления сходства с блоками, на которые возможные векторы движения направлены в опорном изображении. Следовательно, вместо текущего блока используется шаблон, который состоит из пикселей уже декодированных блоков. Например, могут использоваться уже декодированные пиксели, смежные с текущим блоком. Такая оценка движения обеспечивает преимущество уменьшения сигнализации: вектор движения получают одинаково как в кодере, так и в декодере, и, таким образом, не требуется никакой сигнализации. С другой стороны, точность такой оценки движения может быть ниже.
Чтобы обеспечить компромисс между точностью и издержками сигнализации, оценка вектора движения может быть разделена на два этапа: получение вектора движения и уточнение вектора движения. Например, получение вектора движения может включать в себя выбор вектора движения из перечня возможных. Такой выбранный вектор движения может быть дополнительно уточнен, например, посредством поиска в пространстве поиска. Поиск в пространстве поиска основан на вычислении функции затрат для каждого возможного вектора движения, то есть для каждого возможного положения блока, на который указывает возможный вектор движения.
Документ JVET-D0029: Уточнение вектора движения на стороне декодера на основе двустороннего сопоставления с шаблоном, X. Chen, J. An, J. Zheng (документ можно найти на сайте: http://phenix.it-sudparis.eu/jvet/ site) показывает уточнение вектора движения, в котором первый вектор движения в целочисленном пиксельном разрешении находят и дополнительно уточняют посредством поиска с полупиксельным разрешением в пространстве поиска вокруг первого вектора движения.
Чтобы выполнить уточнение вектора движения, необходимо сохранить в памяти по меньшей мере те сэмплы, которые необходимы текущему блоку для выполнения уточнения, то есть сэмплы, которые соответствуют пространству поиска, и сэмплы, к которым можно получить доступ при выполнении сопоставления с шаблоном в пространстве поиска.
Доступ к внешней памяти является важным параметром проектирования в современных аппаратных и/или программных реализациях. Это связано с тем, что доступ к внешней памяти замедляет обработку по сравнению с использованием внутренней памяти. С другой стороны, внутренняя память на микросхеме ограничена, например, из-за реализации размера микросхемы.
Сущность изобретения
Настоящее раскрытие основано на наблюдении, что для уточнения вектора движения при реализации в сочетании с дробной интерполяцией может потребоваться дополнительное увеличение объема памяти на микросхеме или даже доступ к внешней памяти. Оба варианта могут быть нежелательны.
Ввиду вышеупомянутой проблемы настоящее раскрытие обеспечивает предсказание вектора движения, которое позволяет учитывать количество обращений к внешней памяти и количество точек, которые необходимы для того, чтобы быть доступными для уточнения вектора движения вектора движения для блока кодирования.
Это достигается посредством ограничения количества сэмплов до тех, которые необходимы для сопоставления с шаблоном целочисленных сэмплов, и обеспечением только тех положений, которые можно получить с помощью предварительно определенного интерполяционного фильтра, без необходимости дополнительных целочисленных сэмплов.
Согласно аспекту изобретения обеспечено устройство для определения вектора движения для блока предсказания, включающее в себя схему обработки, выполненную с возможностью: получения начального вектора движения и шаблона для блока предсказания; и определения уточнения начального вектора движения посредством сопоставления с упомянутым шаблоном в пространстве поиска. Упомянутое пространство поиска расположено в положении, заданном посредством начального вектора движения, и включает в себя одно или несколько дробных положений сэмплов, причем каждое из дробных положений сэмплов, принадлежащих пространству поиска, получается посредством интерполяционной фильтрации фильтром c предварительно заданным коэффициентом отвода фильтра, оценивающим целочисленные сэмплы только в пределах окна, причем упомянутое окно образовано посредством целочисленных сэмплов, доступных для сопоставления с шаблоном в упомянутом пространстве поиска.
Одним из преимуществ такого определения вектора движения является ограниченное количество сэмплов, которые должны быть доступны для выполнения уточнения вектора движения для блока предсказания, в то же время ограничивая количество обращений к внешней памяти или, как правило, к памяти/запоминающему устройству/кэшу, хранящему все опорные изображения.
В одном примере окно определяется как N столбцов целочисленных сэмплов и M строк целочисленных сэмплов относительно начального вектора движения блока предсказания, причем N и M являются ненулевыми целочисленными значениями. Такое определение может обеспечить простое средство для указания, какие сэмплы должны быть уточнены с целью определения и/или уточнения вектора движения. Оно также может быть легко конфигурируемым, например, в битовом потоке или стандарте.
В одном варианте осуществления схема обработки выполнена с возможностью определения уточнения начального вектора движения посредством сопоставления с упомянутым шаблоном в пространстве поиска, которое итеративно расширяется в направлении, заданном посредством одного из нескольких положений наилучшего соответствия пространства поиска в самой последней итерации, и окно определяется посредством предварительно заданного максимального количества итераций.
Пространство поиска может включать в себя прямоугольное подокно окна, так что все целочисленные сэмплы, к которым осуществляется доступ для интерполяционной фильтрации каждого дробного сэмпла в подокне, расположены в упомянутом окне для интерполяционного фильтра с предварительно заданным коэффициентом отвода фильтра.
Пространство поиска может включать в себя прямоугольное подокно поиска для окна, при этом уточнение начального вектора движения определяется посредством сопоставления с упомянутым шаблоном в прямоугольном подокне поиска, так что целочисленные сэмплы, к которым осуществляется доступ для интерполяционной фильтрации каждого дробного сэмпла в подокне поиска, расположены в упомянутом окне для интерполяционного фильтра с предварительно заданным коэффициентом отвода фильтра.
В одной реализации схема обработки может быть выполнена с возможностью определения уточнения начального вектора движения посредством сопоставления с упомянутым шаблоном в пространстве поиска, которое итеративно расширяется в направлении, заданном посредством одного из нескольких положений наилучшего соответствия пространства поиска в самой последней итерации, при этом итерация заканчивается, когда по меньшей мере один сэмпл в пространстве поиска самой последней итерации находится вне подокна поиска.
В частности, в качестве конкретного примера, интерполяционный фильтр является одномерным фильтром, оценивающим K горизонтальных или вертикальных целочисленных сэмплов, когда дробное положение расположено на соответствующей горизонтальной или вертикальной линии целочисленных сэмплов.
Кроме того, например, пространство поиска дополнительно включает в себя дробные положения, расположенные вне подокна, которые являются:
смежными сверху или снизу от подокна и расположенными на горизонтальной линии целочисленных сэмплов, или
смежными слева или справа от подокна и расположенными на вертикальной линии целочисленных сэмплов.
В соответствии с другим аспектом изобретения обеспечено устройство кодирования для кодирования видеоизображений, разделенных на блоки предсказания, в битовый поток, причем устройство кодирования содержит: устройство для определения вектора движения для блока предсказания, как описано выше; и схему кодирования для кодирования разницы между блоком предсказания и предиктором, заданным посредством блока предсказания в положении на основе определенного вектора движения, и для формирования битового потока, включающего в себя кодированную разницу и начальный вектор движения.
Согласно другому аспекту изобретения обеспечено устройство декодирования для декодирования из битового потока видеоизображений, разделенных на блоки предсказания, причем устройство декодирования содержит: модуль синтаксического анализа для выявления из битового потока начального вектора движения и кодированной разницы между блоком предсказания и предиктором, заданным посредством блока предсказания в положении, заданном посредством уточненного вектора движения; устройство для определения уточненного вектора движения для блока предсказания, как описано выше; а также схему декодирования для восстановления блока предсказания как функции от выявленной разницы и предиктора, заданного посредством блока предсказания в положении, заданном посредством уточненного вектора движения. Функция может быть суммой или включать таковую. Функция может дополнительно содержать отсечение, округление, масштабирование или дополнительные операции.
В соответствии с другим аспектом изобретения обеспечен способ для определения вектора движения для блока предсказания, включающий в себя этапы, на которых: получают начальный вектор движения и шаблон для блока предсказания; определяют уточнение начального вектора движения посредством сопоставления с упомянутым шаблоном в пространстве поиска, причем упомянутое пространство поиска расположено в положении, заданном посредством начального вектора движения, и включает в себя одно или несколько дробных положений сэмплов, причем каждое из дробных положений сэмплов, принадлежащих пространству поиска, получается посредством интерполяционной фильтрации фильтром с предварительно заданным коэффициентом отвода фильтра, оценивающим целочисленные сэмплы только в пределах окна, причем упомянутое окно формируется посредством целочисленных сэмплов, доступных для сопоставления с шаблоном в упомянутом пространстве поиска.
Например, окно определено как N столбцов целочисленных сэмплов и M строк целочисленных сэмплов относительно начального вектора движения блока предсказания, причем N и M являются ненулевыми целочисленными значениями.
В варианте осуществления уточнение начального вектора движения определяется посредством сопоставления с упомянутым шаблоном в пространстве поиска, которое итеративно расширяется в направлении, заданном посредством одного из нескольких положений наилучшего соответствия пространства поиска в самой последней итерации, причем окно определяется посредством предварительно заданного максимального количества итераций.
В примерной реализации пространство поиска включает в себя прямоугольное подокно окна, так что все целочисленные сэмплы, к которым осуществляется доступ для интерполяционной фильтрации каждого дробного сэмпла в подокне, расположены в упомянутом окне для интерполяционного фильтра с предварительно заданным коэффициентом отвода фильтра.
Пространство поиска может включать в себя прямоугольное подокно поиска для окна, при этом уточнение первоначального вектора движения определяется посредством сопоставления с упомянутым шаблоном в прямоугольном подокне поиска, так что целочисленные сэмплы, к которым осуществляют доступ для интерполяционной фильтрации каждого дробного сэмпла в подокне поиска, расположены в упомянутом окне для интерполяционного фильтра с предварительно заданным коэффициентом отвода фильтра.
В одной реализации уточнение начального вектора движения может быть определено посредством сопоставления с упомянутым шаблоном в пространстве поиска, которое итеративно расширяется в направлении, заданном посредством одного из нескольких положений наилучшего соответствия пространства поиска в самой последней итерации, причем итерация заканчивается, когда по меньшей мере один сэмпл в пространстве поиска в самой последней итерации находится за пределами подокна поиска.
Кроме того, например, интерполяционный фильтр представляет собой одномерный фильтр, оценивающий K либо горизонтальных, либо вертикальных целочисленных сэмплов, когда дробное положение расположено на соответствующей горизонтальной или вертикальной линии целочисленных сэмплов.
В качестве преимущества, пространство поиска также включает в себя дробные положения, расположенные вне подокна, которые являются: смежными сверху или снизу от подокна и расположенными на горизонтальной линии целочисленных сэмплов, либо смежными слева или справа от подокна и расположенными на вертикальной линии целочисленных сэмплов.
Согласно другому аспекту изобретения, для кодирования видеоизображений, разделенных на блоки предсказания в битовый поток, обеспечен способ кодирования, содержащий этапы, на которых определяют вектор движения для блока предсказания в соответствии с любым из описанных выше способов; а также кодируют разницу между блоком предсказания и предиктором, заданным посредством блока предсказания в положении, основанном на определенном векторе движения и для формирования битового потока, включающего закодированную разницу и первоначальный вектор движения.
Согласно другому аспекту изобретения обеспечен способ декодирования из битового потока видеоизображений, разделенных на блоки предсказания, причем способ декодирования содержит этапы, на которых: выявляют из битового потока первоначальный вектор движения и кодированную разницу между блоком предсказания и предиктором, заданным посредством блока предсказания в положении, указанном посредством уточненного вектора движения; определяют уточненный вектор движения для блока предсказания в соответствии с любым из упомянутых выше способов; и восстанавливают блок предсказания как сумму выявленной разницы и предиктора, заданного посредством блока предсказания в положении, указанном посредством уточненного вектора движения.
В соответствии с аспектом изобретения постоянное считываемое компьютером средство хранения обеспечено для хранения инструкций, которые при выполнении посредством процессора/схемы обработки выполняет этапы в соответствии с любым из вышеперечисленных аспектов или вариантов осуществления или их комбинаций.
Далее иллюстративные варианты осуществления более подробно описаны со ссылкой на сопровождающие фигуры и чертежи, на которых:
Фигура 1 представляет собой блок-схему, показывающую иллюстративное строение кодера, в котором могут быть использованы получение и уточнение вектора движения;
Фигура 2 представляет собой блок-схему, показывающую иллюстративное строение декодера, в котором могут использоваться получение и уточнение вектора движения;
Фигура 3 представляет собой схематический чертеж, иллюстрирующий иллюстративный шаблон, подходящий для двунаправленного предсказания;
Фигура 4 представляет собой схематический чертеж, иллюстрирующий иллюстративный шаблон, подходящий для одно- и двунаправленного предсказания;
Фигура 5 представляет собой блок-схему, иллюстрирующую этапы получения вектора движения, без обеспечения первоначальных векторов движения, которые должны быть уточнены в битовом потоке;
Фигура 6 представляет собой блок-схему, иллюстрирующую иллюстративное оборудование для реализации варианта осущестления изобретения;
Фигура 7 представляет собой схематический чертеж, иллюстрирующий для блока кодирования иллюстративное окно с сэмплами, которые должны быть доступны для доступа;
Фигура 8 представляет собой схематический чертеж, иллюстрирующий пространство итеративного поиска;
Фигура 9 представляет собой схематический чертеж, иллюстрирующий расширение окна доступа к памяти в горизонтальном направлении из-за интерполяционной фильтрации;
Фигура 10 представляет собой схематический чертеж, иллюстрирующий определение подокна для дробных положений сэмплов;
Фигура 11 представляет собой схематический чертеж, иллюстрирующий иллюстративное определение окна доступа к памяти;
Фигура 12 - схематический чертеж, иллюстрирующий иллюстративные положения, включающие в себя дробные положения, которым разрешено формировать положения пространства поиска для уточнения вектора движения;
Фигура 13 - схематический чертеж, иллюстрирующий иллюстративные дробные положения, которым не разрешено формировать положения пространства поиска для уточнения вектора движения;
На фигуре 14 показана блок-схема последовательности операций, иллюстрирующая способ определения того, какое положение пространства поиска разрешено проверять посредством сопоставления с шаблоном для уточнения вектора движения;
Фигура 15 - схематичный чертеж, иллюстрирующий иллюстративные положения, включающие в себя дробные положения, которым разрешено формировать положения пространства поиска для уточнения вектора движения;
Фигура 16 - блок-схема, иллюстрирующая процесс итеративного уточнения в окне доступа к памяти; и
На фиг.17 показана блок-схема, иллюстрирующая процесс итеративного уточнения в подокне поиска.
ПОДРОБНОЕ ОПИСАНИЕ
Настоящее изобретение относится к регулировке количества сэмплов, которые должны быть доступны для выполнения уточнения вектора движения и интерполяции для получения дробных положений в опорном изображении.
Как упоминалось выше, доступ к внешней памяти является одним из наиболее важных конструктивных соображений в современных аппаратных и программных архитектурах. Оценка вектора движения, особенно при включении сопоставления с шаблоном, например, в случае уточнения вектора движения, также может использоваться с интерполяционной фильтрацией для получения дробных положений пространства поиска. Использование интерполяционной фильтрации может потребовать увеличения количества сэмплов, к которым необходимо обращаться из памяти. Однако это может привести либо к увеличению дорогостоящей памяти на микросхеме, либо к увеличению количества обращений к внешней памяти, что, с другой стороны, замедляет реализацию. Особенно на стороне декодера, эти проблемы могут привести к более дорогостоящим или более медленным применениям, что нежелательно.
Для предотвращения такой ситуации настоящее раскрытие обеспечивает ограничение доступа к внешней памяти. Согласно варианту осуществления изобретения окно сэмплов, которые должны быть доступны для уточнения вектора движения, определяется вокруг положения, на которое указывает неуточненный вектор движения, то есть начальный вектор движения. Окно определяет максимальное количество сэмплов, к которым необходимо получить доступ из памяти, чтобы выполнить уточнение вектора движения. Как правило, сэмплы, которые должны быть доступны, включают в себя сэмплы в положениях пространства поиска, в которых должно выполняться сопоставление с шаблоном, и сэмплы, которые должны сопоставляться с шаблоном для всех положений в пространстве поиска. Последние обычно превышают пространство поиска. По причинам простоты окно доступа к памяти может быть определено как расширение вокруг блока кодирования (текущего блока, для которого должен быть найден вектор движения). Например, R сэмплов слева и справа и R сэмплов сверху и снизу от границ текущего блока могут определять окно. Другими словами, когда текущий блок имеет размер N x N сэмплов, окно доступа может иметь размер (R+N+R) x (R+N+R), т.е. (N+2R) x (N+2R) сэмплов. Например, R может быть равно 4. Однако текущий блок может иметь размер N по вертикали, отличный от размера N по горизонтали, и количество сэмплов расширения в верхнем, нижнем, левом и правом направлениях также может отличаться.
Согласно настоящему раскрытию, чтобы ограничить окно доступа к памяти, дробные пиксельные координаты доступны посредством уточнения вектора движения, только если сэмплы, необходимые для интерполяции, находятся внутри окна доступа к памяти для уточнения вектора движения, как определено для целочисленных сэмплов.
На фиг.1 показан кодер 100, который содержит вход для приема сэмплов входных изображений кадров или изображений видеопотока и выход для формирования кодированного битового потока видео. Термин «кадр» в этом раскрытии используется в качестве синонима для изображения. Однако следует отметить, что настоящее раскрытие также применимо к полям в случае применения чередования. В общем, изображение включает в себя m раз n пикселей. Это соответствует сэмплам изображения и может содержать один или несколько цветовых компонентов. Для простоты нижеследующее описание относится к пикселям, означающим сэмплы яркости. Тем не менее, следует отметить, что поиск вектора движения согласно изобретению может применяться к любому цветовому компоненту, включая цветность или компоненты пространства поиска, такие как RGB или тому подобное. С другой стороны, может быть выгодно выполнять оценку вектора движения только для одного компонента и применять определенный вектор движения к большему количеству (или ко всем) компонентам.
Кодируемые входные блоки не обязательно имеют одинаковый размер. Одно изображение может включать в себя блоки разных размеров, и растр блоков разных изображений также может отличаться.
В объяснительной реализации кодер 100 выполнен с возможностью применения предсказания, преобразования, квантования и энтропийного кодирования к видеопотоку. Преобразование, квантование и энтропийное кодирование выполняются соответственно посредством модуля 106 преобразования, модуля 108 квантования и модуля 170 энтропийного кодирования для формирования на выходе кодированного бытового потока видео.
Видеопоток может включать в себя множество кадров, причем каждый кадр делится на блоки определенного размера, которые кодируются с использованием внутрикадрового или межкадрового кодирования. Блоки, например, первого кадра видеопотока подвергаются внутрикадровому кодированию посредством модуля 154 внутрикадрового предсказания. Кадр, кодируемый с использованием внутрикадрового кодирования, кодируется с использованием только информации в одном и том же кадре, так что он может быть независимо декодирован и может обеспечивать точку входа в битовый поток для произвольного доступа. Блоки других кадров видеопотока могут быть кодированы с использованием межкадрового кодирования посредством модуля 144 межкадрового предсказания: информация из ранее кодированных кадров (опорных кадров) используется для уменьшения временной избыточности, так что каждый блок кадра, кодированного с использованием межкадрового кодирования, предсказывается из блока в опорном кадре. Модуль 160 выбора режима выполнен с возможностью выбора, должен ли блок кадра обрабатываться посредством модуля 154 внутрикадрового предсказания или модуля 144 межкадрового предсказания. Этот модуль 160 выбора режима также управляет параметрами внутрикадрового или межкадрового предсказания. Чтобы обеспечить возможность обновления информации изображения, блоки, кодированные с использованием внутрикадрового кодирования, могут быть обеспечены в кодированных кадрах, кодированных с использованием межкадрового кодирования. Кроме того, кадры, кодированные с использованием внутрикадрового кодирования, которые содержат только блоки, кодированные с использованием внутрикадрового кодирования, могут быть регулярно вставлены в видеопоследовательность в обеспечение точек входа для декодирования, то есть точек, где декодер может начать декодирование, не имея информации из ранее кодированных кадров.
Модуль 152 внутрикадровой оценки и модуль 154 внутрикадрового предсказания являются модулями, которые выполняют внутрикадровое предсказание. В частности, модуль 152 внутрикадровой оценки может получать режим предсказания на основе также знания исходного изображения, в то время как модуль 154 внутрикадрового предсказания обеспечивает соответствующий предиктор, то есть сэмплы, предсказываемые с использованием выбранного режима предсказания, для кодирования разницы. Для выполнения пространственного или временного предсказания кодированные блоки могут быть дополнительно обработаны посредством модуля 110 обратного квантования и модуля 112 обратного преобразования. После восстановления блока применяется модуль 120 циклической фильтрации для дальнейшего улучшения качества декодированного изображения. Затем отфильтрованные блоки формируют опорные кадры, которые затем сохраняются в буфере 130 декодированного изображения. Такой цикл декодирования (декодер) на стороне кодера обеспечивает преимущество создания опорных кадров, которые являются такими же, как опорные изображения, восстановленные на стороне декодера. Соответственно, сторона кодера и декодера работает соответствующим образом. Термин «восстановление» здесь относится к получению восстановленного блока посредством добавления к декодированному остаточному блоку блока предсказания.
Модуль 142 межкадровой оценки принимает в качестве входных данных блок текущего кадра или изображения, подлежащего межкадровому кодированию, и один или несколько опорных кадров из буфера 130 декодированного изображения. Оценка движения выполняется посредством модуля 142 межкадровой оценки, тогда как компенсация движения применяется посредством модуля 144 межкадрового предсказания. Оценка движения используется для получения вектора движения и опорного кадра на основании определенной функции затрат, например, с использованием также исходного изображения, подлежащего кодированию. Например, модуль 142 оценки движения может обеспечивать начальную оценку вектора движения. Начальный вектор движения может быть затем сигнализирован в битовом потоке в форме вектора непосредственно или в качестве индекса, относящегося к возможному вектору движения в перечне возможных векторов движения, построенном на основе предварительно определенного правила одинаковым образом в кодере и декодере. Компенсации движения затем получает предиктор текущего блока как перевод блока совместно расположенного с текущим блоком в опорном кадре для опорного блока в опорном кадре, т.е. посредством вектора движения. Модуль 144 межкадрового предсказания выводит блок предсказания для текущего блока, причем указанный блок предсказания минимизирует функцию затрат. Например, функция затрат может быть разницей между текущим кодируемым блоком и его блоком предсказания, то есть функция затрат минимизирует остаточный блок. Сведение к минимуму остаточного блока основано, например, на вычислении суммы абсолютных разностей (SAD) между всеми пикселями (сэмплами) из текущего блока и возможным блоком в возможном опорном кадре. Однако, как правило, может использоваться любая другая метрика сходства, такая как среднеквадратическая ошибка (MSE - mean square error) или метрика структурного сходства (SSIM - structural similarity metric).
Однако функция затрат также может быть количеством битов, необходимых для кодирования такого блока, кодируемого с использованием межкадрового кодирования, и/или искажения, возникающего в результате такого кодирования. Таким образом, процедура оптимизации искажения скорости может использоваться для осуществления выбора вектора движения и/или в целом параметров кодирования, таких как использование внутрикадрового или межкадрового предсказания для блока и с какими настройками.
Модуль 152 внутрикадровой оценки и модуль 154 внутрикадрового предсказания принимают в качестве входных данных блок текущего кадра или изображения, подлежащего внутрикадровому кодированию, и один или несколько опорных сэмплов из уже восстановленной области текущего кадра. Внутрикадровое предсказание затем описывает пиксели текущего блока текущего кадра в форме функции от опорных сэмплов текущего кадра. Модуль 154 внутрикадрового предсказания выводит блок предсказания для текущего блока, причем указанный блок предсказания преимущественно минимизирует разницу между текущим блоком, который должен быть кодирован, и его блоком предсказания, то есть он минимизирует остаточный блок. Минимизация остаточного блока может быть основана, например, на процедуре оптимизации искажения скорости. В частности, блок предсказания получается как направленная интерполяция опорных сэмплов. Направление может быть определено посредством оптимизации искажения скорости и/или посредством вычисления меры сходства, как упомянуто выше в связи с межкадровым предсказанием.
Модуль 142 межкадровой оценки принимает в качестве входных данных блок или более универсально образованный сэмпл изображения текущего кадра или изображения, подлежащего межкадровому кодированию, и два или более уже декодированных изображений 231. Затем межкадровое предсказание описывает текущий сэмпл изображения текущего кадра в форме векторов движения для обращения к сэмплам изображений опорных изображений. Модуль 142 межкадрового предсказания выводит один или более векторов движения для текущего сэмпла изображения, причем указанные сэмплы опорного изображения, на которые указывает вектор движения, предпочтительно сводят к минимуму разницу между сэмплом текущего изображения, подлежащего кодированию, и его сэмплами опорного изображения, то есть, это сводит к минимуму сэмпл остаточного изображения. Предиктор для текущего блока затем обеспечивается посредством модуля 144 межкадрового предсказания для кодирования разницы.
Разница между текущим блоком и его предсказанием, то есть остаточным блоком 105, затем преобразуется посредством модуля 106 преобразования. Коэффициенты 107 преобразования квантуются посредством модуля 108 квантования и энтропийно кодируются посредством модуля 170 энтропийного кодирования. Сформированные таким образом данные 171 кодированного изображения, то есть битовый поток кодированного видео, содержат блоки, кодированные с использованием внутрикадрового кодирования, и блоки, кодированные с использованием межкадрового кодирования, и соответствующую сигнализацию (такую как индикация режима, индикация вектора движения и/или направление внутреннего предсказания). Модуль 106 преобразования может применять линейное преобразование, такое как преобразование Фурье или дискретное косинусное преобразование (DFT/FFT - Discrete Fourier Transformation или DCT - Discrete Cosine Transformation). Такое преобразование в пространственную частотную область обеспечивает то преимущество, что результирующие коэффициенты 107 обычно имеют более высокие значения на более низких частотах. Таким образом, после эффективного сканирования коэффициентов (такого как зигзаг) и квантования результирующая последовательность значений обычно имеет несколько больших значений в начале и заканчивается серией нулей. Это обеспечивает дальнейшее эффективное кодирование. Модуль 108 квантования выполняет фактическое сжатие с потерями посредством уменьшения разрешения значений коэффициентов. Модуль 170 энтропийного кодирования затем назначает значениям коэффициентов двоичные кодовые слова для создания битового потока. Модуль 170 энтропийного кодирования также кодирует информацию сигнализации (не показана на фиг.1).
Фиг. 2 показывает видеодекодер 200. Видеодекодер 200 содержит, в частности, буфер 230 декодированного изображения, модуль 244 межкадрового предсказания и модуль 254 внутрикадрового предсказания, который является модулем предсказания блоков. Буфер 230 декодированного изображения выполнен с возможностью хранения по меньшей мере одного (для однонаправленного предсказания) или по меньшей мере двух (для двунаправленного предсказания) опорных кадров, восстановленных из битового потока кодированного видео, причем упомянутые опорные кадры отличаются от текущего кадра (текущего декодированного кадра) закодированного битового потока видео. Модуль 254 внутрикадрового предсказания выполнен с возможностью формирования блока предсказания, который является оценкой блока, который должен быть декодирован. Модуль 254 внутрикадрового предсказания выполнен с возможностью формирования этого предсказание на основе опорных сэмплов, которые получены из восстановленного блока 215 или буфера 216.
Декодер 200 выполнен с возможностью декодирования кодированного битового потока видео, сформированного посредством видеокодера 100, и предпочтительно как декодер 200, так и кодер 100 формируют идентичные предсказания для соответствующего блока, который должен быть кодирован/декодирован. Характеристики буфера 230 декодированного изображения, восстановленного блока 215, буфера 216 и модуля 254 внутрикадрового предсказания аналогичны признакам буфера 130 декодированного изображения, восстановленного блока 115, буфера 116 и модуля 154 внутрикадрового предсказания по фиг.1.
Видеодекодер 200 содержит дополнительные модули, которые также присутствуют в видеокодере 100, например, модуль 210 обратного квантования, модуль 212 обратного преобразования и модуль 220 циклической фильтрации, которые соответственно соответствуют модулю 110 обратного квантования, модулю 112 обратного преобразования и модулю 120 циклической фильтрации видеокодера 100.
Модуль 204 энтропийного декодирования выполнен с возможностью декодирования принятого кодированного битового потока видео и соответственно получения квантованных остаточных коэффициентов 209 преобразования и информации сигнализации. Квантованные остаточные коэффициенты 209 преобразования подают в модуль 210 обратного квантования и модуль 212 обратного преобразования для формирования остаточного блока. Остаточный блок добавляют в блок 265 предсказания, и добавление подают в модуль 220 циклической фильтрации для получения декодированного видео. Кадры декодированного видео могут быть сохранены в буфере 230 декодированного изображения и служить в качестве декодированного изображения 231 для межкадрового предсказания.
Обычно модули 154 и 254 внутрикадрового предсказания на фиг. 1 и 2 могут использовать опорные сэмплы из уже кодированной области для формирования сигналов предсказания для блоков, которые должны быть кодированы или должны быть декодированы.
Модуль 204 энтропийного декодирования принимает на входе кодированный битовый поток 171. В общем, битовый поток сначала выявляют, то есть параметры сигнализации и остатки извлекают из битового потока. Как правило, синтаксис и семантика битового потока определяются посредством стандарта, так что кодеры и декодеры могут работать совместимым образом. Как описано в приведенном выше разделе «Уровень техники», кодированный битовый поток включает в себя не только остатки предсказания. В случае предсказания с компенсацией движения индикацию вектора движения также кодируют в битовом потоке и выявляют из него в декодере. Индикация вектора движения может быть задана посредством опорного изображения, в котором обеспечен вектор движения и с использованием координат вектора движения. До сих пор рассматривалось кодирование полных векторов движения. Однако также может быть закодирована только разница между текущим вектором движения и предыдущим вектором движения в битовом потоке. Этот подход позволяет использовать избыточность между векторами движения соседних блоков.
Для того, чтобы эффективно закодировать опорное изображение, кодек H.265 (ITU-T, H265, серия H: аудиовизуальные и мультимедийные системы: высокоэффективное кодирование видео) обеспечивает перечень опорных изображений, назначаемых для перечня индексов соответствующих опорных кадров. Опорный кадр затем сигнализируют в битовом потоке посредством включения в него соответствующего назначенного индекса из перечня. Такой перечень может быть определен в стандарте или сигнализироваться в начале видео или набора нескольких кадров. Следует отметить, что в H.265 определены два перечня опорных изображений, называемые L0 и L1. Опорное изображение затем сигнализируют в битовом потоке посредством указания перечня (L0 или L1) и указания индекса в этом перечне, связанного с требуемым опорным изображением. Обеспечение двух или более перечней может иметь преимущества для лучшего сжатия. Например, L0 может использоваться как для слайсов с однонаправленным межкадровым предсказанием, так и для слайсов с двунаправленным межкадровым предсказанием, в то время как L1 может использоваться только для слайсов с двунаправленным межкадровым предсказанием. Однако в целом настоящее раскрытие не ограничено каким-либо содержанием перечней L0 и L1.
Перечни L0 и L1 могут быть определены в стандарте и фиксированы. Однако большая гибкость в кодировании/декодировании может быть достигнута посредством сигнализации их в начале видеопоследовательности. Соответственно, кодер может конфигурировать перечни L0 и L1 с конкретными опорными изображениями, упорядоченными в соответствии с индексом. Перечни L0 и L1 могут иметь одинаковый фиксированный размер. В целом может быть более двух перечней. Вектор движения может быть сигнализирован непосредственно посредством координат в опорном изображении. В качестве альтернативы, как также указано в H.265, может быть создан перечень возможных векторов движения и может быть передан индекс, связанный в перечне с конкретным вектором движения.
Векторы движения текущего блока обычно коррелируют с векторами движения соседних блоков в текущем изображении или в ранее кодированных изображениях. Это связано с тем, что соседние блоки, вероятно, соответствуют одному и тому же движущемуся объекту с аналогичным движением, а движение объекта с большой вероятностью не изменится со временем. Следовательно, использование векторов движения в соседних блоках в качестве предикторов уменьшает размер сигнализируемой разницы векторов движения. Предикторы вектора движения (MVPs - Motion Vector Predictors), как правило, получают из уже кодированных/декодированных векторов движения пространственных соседних блоков или из соседних по времени или совместно расположенных блоков в опорном кадре. В H.264/AVC это осуществляется посредством составления медианной составляющей трех пространственно смежных векторов движения. Используя этот подход, никакая сигнализация предиктора не требуется. Временные MVPs из совместно расположенного блока в опорном кадре рассматриваются только в так называемом временном прямом режиме H.264/AVC. Прямые режимы H.264/AVC также используются для получения данных движения, отличных от векторов движения. Следовательно, они больше связаны с концепцией объединения блоков в HEVC. В HEVC подход неявного получения MVP был заменен способом, известным как конкуренция вектора движения, который явно сигнализирует, какой MVP из списка MVP используется для получения вектора движения. Блочная структура дерева квадрантов с переменным кодированием в HEVC может привести к тому, что один блок будет иметь несколько соседних блоков с векторами движения в качестве потенциально возможных MVP. Взяв левого соседа в качестве примера, получим, что в наихудшем случае блок предсказания яркости 64×64 может иметь 16 блоков предсказания яркости 4×4 слева, когда блок дерева кодирования яркости 64×64 дополнительно не разделен, а левый - разделен на максимальную глубину.
Усовершенствованное предсказание вектора движения (AMVP - Advanced Motion Vector Prediction) было введена для изменения конкуренции векторов движения с учетом такой гибкой структуры блоков. Во время разработки HEVC первоначальный дизайн AMVP был значительно упрощен, чтобы обеспечить хороший компромисс между эффективностью кодирования и дружественным к реализации дизайном. Первоначальный проект AMVP включал пять MVP из трех разных классов предикторов: три вектора движения от пространственных соседей, медиана трех пространственных предикторов и масштабированный вектор движения от совместно расположенного, временно соседнего блока. Кроме того, перечень предикторов был изменен посредством переупорядочения, чтобы поместить наиболее вероятный предиктор движения в первое положение, и посредством удаления избыточных возможных предикторов в обеспечение минимальных издержек сигнализации. Окончательный вариант построения перечня возможных предикторов AMVP включает в себя следующие два возможных MVP: а) до двух пространственных возможных MVP, которые получены из пяти пространственных соседних блоков; b) один временной возможный MVP, полученный из двух временных, совместно расположенных блоков, когда оба пространственных возможных MVP недоступны или они идентичны; и c) нулевые векторы движения, когда пространственный, временной или оба возможных предиктора недоступны. Подробности определения вектора движения можно найти в книге В. Се и др. (Ред.), Высокоэффективное кодирование видео (HEVC): Алгоритмы и архитектуры, Спрингер, 2014, в частности, в главе 5, включенной в настоящий документ посредством ссылки.
Чтобы дополнительно улучшить оценку вектора движения без дальнейшего увеличения издержек сигнализаци, может быть полезным дополнительное уточнение векторов движения, полученных на стороне кодера и обеспеченных в битовом потоке. Уточнение вектора движения можно выполнять в декодере без помощи кодера. Кодер в его цикле декодера может использовать то же уточнение для получения соответствующих векторов движения. Уточнение вектора движения выполняется в пространстве поиска, которое включает в себя целочисленные положения пикселей и дробные положения пикселей опорного изображения. Например, дробные положения пикселей могут быть полупиксельными положениями или четвертьпиксельными или дополнительными дробными положениями. Дробные положения пикселей могут быть получены из целочисленных (полнопиксельных) положений посредством интерполяции, такой как билинейная интерполяция.
При двунаправленном предсказании текущего блока два блока предсказания, полученные с использованием соответствующего первого вектора движения из перечня L0 и второго вектора движения из перечня L1, объединяют в один сигнал предсказания, который может обеспечить лучшую адаптацию к исходному сигналу, чем однонаправленное предсказание, что приводит к уменьшению остаточной информации и, возможно, к более эффективному сжатию.
Поскольку в декодере текущий блок недоступен, так как он декодируется, для уточнения вектора движения используется шаблон, который является оценкой текущего блока и который построен на основе уже обработанной (то есть закодированной на стороне кодера и декодированной на стороне декодера) части изображения.
Сначала оценка первого вектора MV0 движения и оценка второго вектора MV1 движения принимаются в качестве входных данных в декодере 200. На стороне 100 кодера оценки вектора движения MV0 и MV1 могут быть получены посредством сопоставления блоков и/или посредством поиска в перечне возможных векторов движения (таком как перечень объединения), образованном посредством векторов движения блоков, соседних с текущим блоком (на том же изображении или на соседних изображениях). MV0 и MV1 затем преимущественно сигнализируются стороне декодера в битовом потоке. Тем не менее, следует отметить, что, в общем, также первый этап определения в кодере может быть выполнен посредством сопоставления с шаблоном, что обеспечит преимущество уменьшения издержек сигнализации.
На стороне 200 декодера векторы движения MV0 и MV1 преимущественно получают на основе информации в битовом потоке. MV0 и MV1 передают либо напрямую, либо дифференциально, и/или указывают индекс в перечне векторов движения (перечне объединения). Однако настоящее раскрытие не ограничено сигнализацией векторов движения в битовом потоке. Скорее, вектор движения может быть определен посредством сопоставления с шаблоном уже на первом этапе, в соответствии с работой кодера. Сопоставление с шаблоном первого этапа (получение вектора движения) может выполняться на основе пространства поиска, отличного от пространства поиска второго этапа уточнения. В частности, уточнение может быть выполнено в пространстве поиска с более высоким разрешением (то есть с более коротким расстоянием между положениями поиска).
Указание двух опорных изображений RefPic0 и RefPic1, на которые указывают соответствующие MV0 и MV1, также обеспечивается для декодера. Опорные изображения сохраняются в буфере декодированного изображения на стороне кодера и декодера в результате предыдущей обработки, то есть соответствующего кодирования и декодирования. Одно из этих опорных изображений выбирается для уточнения вектора движения посредством поиска. Модуль выбора опорного изображения устройства для определения векторов движения выполнен с возможностью выбора первого опорного изображения, на которое MV0 указывает, и второго опорного изображения, на которое MV1 указывает. После выбора, модуль выбора опорного изображения определяет, используется ли первое опорное изображение или второе опорное изображение для выполнения уточнения вектора движения. Для выполнения уточнения вектора движения область поиска в первом опорном изображении определяется вокруг возможного положения, на которое вектор MV0 движения указывает. Возможные положения пространства поиска в области поиска анализируются, чтобы найти блок, наиболее схожий с блоком шаблона, посредством выполнения сопоставления с шаблоном в пространстве поиска и определения метрики сходства, такой как сумма абсолютных разностей (SAD). Положения пространства поиска обозначают положения, с которыми совпадает верхний левый угол шаблона. Как уже упоминалось выше, верхний левый угол является простым соглашением, и любая точка пространства поиска, такая как центральная точка, может в общем случае использоваться для обозначения положения сопоставления.
Согласно вышеупомянутому документу JVET-D0029, уточнение вектора движения на стороне декодера (DMVR) имеет в качестве входных данных начальные векторы движения MV0 и MV1, которые указывают на два соответствующих опорных изображения RefPict0 и RefPict1. Эти начальные векторы движения используются для определения соответствующих пространств поиска в RefPict0 и RefPict1. Кроме того, используя векторы движения MV0 и MV1, шаблон строится на основе соответствующих блоков (сэмплов) A и B, на которые указывают MV0 и MV1, следующим образом:
Шаблон = функция((Блок A, Блок B)).
Функция может быть операцией отсечения сэмплов в сочетании с взвешенным по сэмплу суммированием. Затем шаблон используется для выполнения сопоставления с шаблоном в пространствах поиска, определенных на основе MV0 и MV1 в соответствующих опорных изображениях 0 и 1. Функция затрат для определения наилучшего совпадения с шаблоном в соответствующих пространствах поиска представляет собой SAD (Template, Block candA’), где block CandA’ является возможным блоком кодирования, на который указывает возможный MV в пространстве поиска, расположенном в положении, заданной посредством MV0. На фигуре 3 показано определение наиболее подходящего блока A’ и результирующего уточненного вектора движения MV0’. Соответственно, один и тот же шаблон используется для поиска наиболее подходящего блока B’ и соответствующего вектора движения MV1’, который указывает на блок B’, как показано на фигуре 3. Другими словами, после того, как шаблон построен на основе блока A и B, на который указывают начальные векторы движения MV0 и MV1, уточненные векторы движения MV0’ и MV1’ находят через поиск по RefPic0 и RefPic1 с шаблоном.
Способы получения вектора движения иногда также называют повышением частоты кадров (FRUC - frame rate up-conversion). Начальные векторы движения MV0 и MV1 могут обычно указываться в битовом потоке, чтобы гарантировать, что кодер и декодер могут использовать одну и ту же начальную точку для уточнения вектора движения. Альтернативно, начальные векторы движения могут быть получены посредством обеспечения перечня начальных возможных векторов движения, включающего в себя один или более начальных возможных векторов движения. Для каждого из них определяется уточненный вектор движения, и в конце выбирается уточненный вектор движения, минимизирующий функцию затрат.
Кроме того, следует отметить, что настоящее изобретение не ограничивается сопоставлением с шаблоном, как описано выше со ссылкой на фиг.3. Фигура 4 иллюстрирует альтернативное сопоставление с шаблоном, которое также применимо для однонаправленного предсказания. Подробности можно найти в документе JVET-A1001, в частности, в разделе «2.4.6. Полшучение вектора движения по согласованному шаблону» документа JVET-A1001 под названием «Описание алгоритма объединённой модели 1 исследовательных испытаний», автор Джанл Чен и др. и который доступен на сайте: http://phenix.it-sudparis.eu/jvet/. Шаблон в этом подходе сопоставления с шаблоном определяется как сэмплы, смежные с текущим боком в текущем кадре. Как показано на фигуре 1, могут быть взяты уже восстановленные сэмплы, смежные с верхней и левой границами текущего блока, называемые «L-образным шаблоном».
На фигуре 5 показан другой тип получения вектора движения, который также может быть использован. Входными данными для процесса получения вектора движения является маркер, который указывает, применяется ли получение вектора движения. Неявно, другими входными данными в процесс получения является вектор движения соседнего (во времени или пространстве) ранее кодированного/восстановленного блока. Векторы движения множества соседних блоков используются в качестве возможных векторов движения для начального этапа поиска при получении вектора движения. Результатом процесса является MV0’ (возможно, также MV1’, если используется двунаправленное предсказание) и соответствующие индексы опорного изображения refPict0 и, возможно, refPict1 соответственно. Этап уточнения вектора движения затем включает в себя сопоставление с шаблоном, как описано выше. После нахождения уточненного одного (однонаправленное предсказание) или более (двунаправленное предсказание/многокадровое предсказание) векторов движения создается предиктор текущего блока (для двунаправленного/многонаправленного предсказания посредством взвешенного по сэмплу предсказания, в противном случае - посредством обращения к сэмплам, указанным посредством уточненного MV).
Настоящее изобретение не ограничивается двумя способами сопоставления с шаблоном, описанными выше. В качестве примера третий способ сопоставления с шаблоном, который называется двусторонним сопоставлением (также описанный в документе JVET-A1001), также может использоваться для уточнения вектора движения, и изобретение применяется аналогично. В соответствии с двусторонним сопоставлением выполняется поиск наилучшего совпадения между двумя блоками вдоль траектории движения текущего блока в двух разных опорных изображениях. В предположении непрерывной траектории движения векторы движения MV0 и MV1, указывающие на два опорных блока, должны быть пропорциональны временным расстояниям, то есть TD0 и TD1, между текущим изображением и двумя опорными изображениями. При двустороннем сопоставлении можно использовать функцию затрат, такую как SAD (Block cand0‘, Block cand1’), где Block cand0‘ указывается посредством MV0, а Block cand1’ указывается посредством MV1.
В соответствии с вариантом осуществления изобретения обеспечено устройство для определения вектора движения для блока предсказания, причем устройство включает в себя схему обработки. Схема обработки выполнена с возможностью получения начального вектора движения и шаблона для блока предсказания и определения уточнения начального вектора движения посредством сопоставления с упомянутым шаблоном в пространстве поиска. Упомянутое пространство поиска расположено в положении, заданном посредством начального вектором движения, и включает в себя одно или несколько дробных положений сэмплов, причем каждое из дробных положений сэмплов, принадлежащих пространству поиска, получают псоредством интерполяционной фильтрации фильтром с предварительно заданным коэффициентом отвода фильтра, оценивающим целочисленные сэмплы только в пределах окна, причем упомянутое окно образовано посредством целочисленных сэмплов, доступных для сопоставления с шаблоном в упомянутом пространстве поиска.
Схема 600 обработки показана на фиг.6. Схема обработки может включать в себя любое аппаратное обеспечение, и конфигурация может быть реализована посредством любого вида программирования или аппаратного обеспечения комбинации обоих. Например, схема обработки может быть сформирована посредством одного процессора, такого как процессор общего назначения, с соответствующим программным обеспечением, реализующим вышеуказанные этапы. С другой стороны, схема обработки может быть реализована посредством специализированного аппаратного обеспечения, такого как ASIC (Application-Specific Integrated Circuit - специализированная интегральная схема) или FPGA (Field-Programmable Gate Array - программируемая пользователем вентильная матрица) DSP (Digital Signal Processor - процессор цифровых сигналов) или тому подобного.
Схема обработки может включать в себя один или несколько из вышеупомянутых аппаратных компонентов, соединенных для выполнения вышеупомянутого получения вектора движения. Схема 600 обработки включает в себя вычислительную логику, которая реализует две функциональные возможности: получение начального вектора движения (или множества начальных векторов движения, если используется дву-/многонаправленное предсказание) и шаблона 610 и уточнения 620 вектора движения. Эти две функциональные возможности могут быть реализованы на одном и том же элементе аппаратного обеспечения или могут быть выполнены посредством отдельных модулей аппаратного обеспечения, таких как начальный вектор движения и модуль 610 определения шаблона и модуль 620 уточнения вектора движения. Схема 600 обработки может быть коммуникативно соединена с внешней памятью 650, в которой хранятся восстановленные сэмплы опорных изображений. Кроме того, схема 600 обработки может дополнительно включать в себя внутреннюю память 640, которая буферизует сэмплы в окне, переданном из внешней памяти и используемом для определения вектора движения для текущего обрабатываемого блока. Схема обработки может быть реализована на одной микросхеме в виде интегральной схемы.
Следует отметить, что схема обработки может реализовывать дополнительные функции кодера и/или декодера, описанные со ссылкой на фиг.1 и 2. Внутренняя память может быть памятью на микросхеме, такой как кэш или линейная память. Память микросхемы преимущественно реализована на микросхеме кодера/декодера для ускорения вычислений. Поскольку размер микросхемы ограничен, объем памяти на микросхеме обычно невелик. С другой стороны, внешняя память может быть очень большой по размеру, однако доступ к внешней памяти потребляет больше энергии, и доступ намного медленнее. Обычно вся необходимая информация извлекается из внешней памяти в память на микросхеме перед выполнением вычислений. В худшем случае доступ к внешней памяти (или полоса пропускания, которую необходимо выделить при проектировании шины памяти), обозначает максимально возможный объем передачи памяти между внешней памятью и микросхемой при декодировании кадра или блока кодирования. Доступ к памяти (особенно к внешней памяти) обычно возможен только в предварительно заданных блоках. Другими словами, как правило, невозможно получить доступ к одному пикселю, вместо этого необходимо получить доступ к наименьшему блоку (например, 8×8). Размер памяти на микросхеме также является важным фактором при проектировании, поскольку увеличение объема памяти на микросхеме увеличивает стоимость.
Другими словами, вышеупомянутое устройство может быть интегральной схемой, дополнительно содержащей: внутреннюю память, встроенную в интегральную схему, и модуль доступа к памяти (интерфейс) для извлечения целочисленных сэмплов, расположенных в упомянутом окне, из внешней памяти во внутреннюю память.
Используемый выше термин «блок предсказания» относится к текущему блоку, который должен быть предсказан. Это блок в изображении, который может быть получен посредством разделения изображения на блоки одинакового или разного размера (например, посредством иерархического разбиения блока дерева кодирования, CTU (coding tree unit) на более мелкие блоки). Блок может быть квадратным или, в более общем смысле, прямоугольным, поскольку это типичные формы, также используемые в современных кодерах/декодерах. Однако настоящее раскрытие не ограничено каким-либо размером/формой блока.
Устройство, включающее в себя схему обработки, может представлять собой кодер или декодер или даже устройство, включающее в себя такой кодер или декодер, например устройство записи и/или устройство воспроизведения.
Дробные положения сэмплов представляют собой положения между положениями сэмплов реального изображения, полученных посредством восстановления опорного изображения, которое было закодировано, как показано на фигуре 1. Таким образом, дробные положения должны быть получены посредством интерполяции на основе ближайших целочисленных положений. Подробности иллюстративной интерполяционной фильтрации, которая используется посредством H.265, можно найти в разделе «5.3. Интерполяция дробных сэмплов» книги Высокоэффективное видеокодирование (HEVC) автор В. Се и др., Спрингер, 2014.
Интерполяционная фильтрация обычно применяет разные фильтры для формирования разных (сэмплов). В качестве примера следующие разделительные фильтры 1D применяются для формирования положений в четверть пикселя и в полпикселя в стандарте сжатия видео H.265:
Как видно из приведенной выше таблицы, интерполяционная фильтрация требует нескольких сэмплов вокруг положения дробного пикселя, соответствующего отводам фильтра (количество коэффициентов в таблице). Используя приведенные выше примеры фильтров, для формирования положения требуется 4 целочисленных сэмпла слева/сверху и справа/снизу. Следует отметить, что длина интерполяционного фильтра отличается для положений сэмплов в четверть пикселя (7 отводов) от положений сэмплов в полпикселя (8 отводов).
В некоторых вариантах осуществления изобретения интерполяционный фильтр с предварительно заданным коэффициентом отвода фильтра оценивает целочисленные сэмплы только в пределах окна, заданного посредством целочисленных сэмплов, доступных для сопоставления с шаблоном в упомянутом пространстве поиска. Окно может содержать гораздо больше сэмплов, чем фактически используемые в вычислениях определенного блока предсказания. Это связано с тем, что операция уточняющего поиска обычно реализуется с использованием способа быстрого поиска (в отличие от способа поиска грубой силы), в соответствии с которым некоторые из сэмплов не оцениваются в зависимости от постепенного продвижения операции поиска. В результате число итераций сопоставления с шаблоном, а также сэмплов, которые используются в вычислениях для операции уточняющего поиска, может изменяться для каждого блока предсказания.
Настоящее раскрытие устанавливает верхние пределы (территориальную границу) для целочисленных сэмплов, которые могут использоваться во время операции уточняющего поиска, учитывая, что интерполяционная фильтрация должна применяться для дробных положений сэмплов. Это соответствует термину «целочисленные сэмплы, доступные для сопоставления с шаблоном». Какие сэмплы действительно доступны, зависит от способа формирования пространства поиска, что будет проиллюстрировано ниже.
Фиг.7 иллюстрирует блок кодирования (блок предсказания) и соответствующие сэмплы окна. Следует отметить, что сэмплы, показанные на фигуре 7 являются сэмплами опорного изображения и блок кодирования здесь на самом деле является блоком, соответствующим по размеру и положению текущему блоку в текущем кадре, для которого вектор движения должен быть получен на опорном изображении. Таким образом, фактически, блок кодирования на фиг.7 фактически является блоком, совместно расположенным с блоком, для которого ищется предиктор. Однако по причине простоты этот блок далее называется «блоком кодирования».
В этом примере неуточненный вектор движения MV0 указывает на целочисленное положение сэмпла (начальный вектор движения может указывать на дробное положение сэмпла, целочисленное положение сэмпла выбирается только для простоты описания). Степень детализации поиска уточнения вектора движения составляет 1 целочисленный сэмпл, что означает, что, поскольку начальная точка является целочисленным сэмплом, выполняется поиск только целочисленных точек сэмплов. Поиск осуществляется, в этом примере, в постепенно развивающемся пространстве поиска. Это означает, что пространство поиска в каждой итерации улучшается посредством добавления новых положений поиска в зависимости от наилучшего направления с точки зрения функции затрат для ранее проверенных положений.
Такой подход упрощенно проиллюстрирован на фигуре 8. На фиг.8 начальный вектор движения указывал на центральную точку 810. Пространство поиска постепенно строится вокруг положения начального вектора движения. На первом этапе проверяются четыре положения, непосредственно примыкающие сверху, снизу, слева и справа к положению 810, на которое указывает начальный вектор движения, а также положение 810, на которое указывает начальный вектор движения. На основе направления, которое приводит к функции наименьших затрат среди проверенных пяти точек, в область поиска добавляются дополнительные положения для проверки. В этом примере функцию наименьших затрат можно было увидеть в правой точке, и поэтому пространство поиска было расширено еще на три точки в горизонтальном правом направлении на втором этапе. На втором этапе функция наименьших затрат может быть видна в правой точке (по отношению к точке наименьших затрат первого этапа), что приводит к дальнейшему расширению пространства поиска на три точки в горизонтальном правом направлении. На третьем этапе функция наименьших затрат снова наблюдается в правой точке относительно точки наименьших затрат на этапе 2 и приводит к расширению пространства поиска еще на три точки в горизонтальном правом направлении. В соответствии с примером на фигуре 8, еще три этапа выполняются в верхнем, верхнем и правом направлениях в этом порядке. В этом примере ромбовидный шаблон (состоящий из 5 точек поиска) используется для каждой итерации, и пространство поиска расширяется для заполнения недостающих точки поиска на каждом этапе.
В каждой итерации определения пространства поиска пространство поиска может увеличиваться на одно или несколько целочисленных положений сэмплов. Возвращаясь теперь к фигуре 7, в примере которой максимальное количество итераций поиска равно 4. Поскольку возможно максимальное число 4 итераций, все сэмплы, изображенные слева, должны быть извлечены из памяти для выполнения операции поиска, в случае если постепенное развитие пространства поиска идет влево. Точно так же необходимо расширение до 4 сэмплов. Таким образом, пространство поиска расширяется в обоих направлениях (слева направо и сверху вниз), поскольку уточненный MV может перемещаться в любом направлении, а аппаратные реализации требуют, чтобы все сэмплы, которые могут потребоваться, извлекались из внешней памяти перед применением уточняющего поиска. Если пространство поиска развивается в нижнем или правом направлении, необходимо расширение еще на 4 сэмпла, поскольку шаблон, соответствующий шаблону, соответствующему размеру блока кодирования (блока предсказания), должен будет получить доступ к некоторым из этих сэмплов. Кроме того, угловые сэмплы (например, в верхнем правом углу) также должны выбираться из памяти, поскольку аппаратные реализации обычно не могут извлекать неправильные формы (прямоугольный доступ более осуществим).
Следует отметить, что вышеописанное развитие пространства итеративного поиска является только иллюстративным, и правила и количество точек для расширения пространства поиска в каждой итерации могут отличаться, то есть указываться по-разному.
На фигуре 8 также показан сценарий, который может возникнуть из-за правил доступа к внешней памяти, описанных выше. Количество сэмплов, извлекаемых из внешней памяти, намного выше, чем сэмплов, которые фактически используются на этапе вычислений. Предполагая, что шаблон здесь имеет размер только одного сэмпла (по причине простоты), белые кружки представляют сэмплы, которые извлекаются из внешней памяти, а закрашенные сэмплы - которые фактически используются. Однако такая избыточность необходима, если количество обращений к внешней памяти должно поддерживаться на низком уровне, поскольку, когда начинается обработка текущего блока, фактически необходимые сэмплы еще не известны.
Следует отметить, что пространство поиска также может быть определено другим способом, например, как стабильная форма, расположенная в положении, на которое указывает начальный вектор движения. Форма может быть любой формы, такой как квадрат, прямоугольник, ромб или тому подобное.
Фиг.9 иллюстрирует пример, в котором пространство поиска также может включать в себя дробные сэмплы. На фигурах 7 и 8 поиск вектора движения был выполнен на целочисленных сэмплах, в результате чего положения, обозначенные большими точками сплошной линии, были включены в окно доступа. Если теперь поиск выполняется для сэмпла с разрешением в полпикселя (точка меньшего размера сплошной линией), чтобы сформировать дробный сэмпл, изображенный справа, необходимо извлечь еще три столбца сэмплов из памяти также, предполагая, что интерполяционный фильтр является симметричным и имеет восемь отводов. Более того, то же самое должно применяться с левой стороны (расширение на 3 столбца пикселей) из-за того, что операция поиска является симметричной (может перемещаться итеративно влево и вправо), так что дробный пиксель может быть расположен на левой стороне окна.
В результате из-за интерполяционной фильтрации количество сэмплов, необходимых для извлечения из памяти, дополнительно увеличивается, обозначенные пунктирной линией, теперь также включаются пунктирные кружки, представляющие положения, добавленные из-за дробной интерполяции. Точно так же, если также разрешить поиск половинных положений в вертикальном направлении, то окно сэмплов, к которым осуществляется доступ из памяти, необходимо также расширить в вертикальном направлении (не показано в примере на фигуре 9), сверху и снизу.
Окно доступа к памяти определяется как прямоугольник, который охватывает все сэмплы, которые необходимо извлечь из памяти для выполнения поиска вектора движения для блока предсказания (блока кодирования). Окно доступа к памяти включает в себя не только фактически необходимые сэмплы, но также и все оставшиеся сэмплы, к которым есть возможность доступа во время операции поиска вектора движения. В примере на фиг. 9 поиск вектора движения сместился вправо. Но его можно было бы перенести и в левую сторону, что предварительно неизвестно. Соответственно, чтобы не обращаться к внешней памяти несколько раз, окно доступа к памяти (или окно доступа) включает в себя все сэмплы, доступные посредством соответствующей обработки.
На фигуре 10 показано окно доступа к памяти для уточнения вектора движения. Центральная точка 1010 - это положение, на которое указывает неуточненный входной вектор движения (начальный вектор движения, полученный либо из битового потока, либо посредством ранее выполненного сопоставления с шаблоном или проверки возможых векторов движения, как описано выше). Во избежание дальнейшего увеличения размера окна из-за добавления дробных положений в пространство поиска, уточнение вектора движения выполняется согласно следующим правилам:
A) Окно доступа к памяти для уточнения определяется вокруг неуточненной координаты начального вектора движения (то есть положения, на которое указывает начальный вектор движения). Окно идентифицирует максимальное количество сэмплов пикселей, к которым необходимо получить доступ из памяти для выполнения уточнения вектора движения посредством сопоставления с шаблоном в пространстве поиска.
1. В этом примере, для простоты, размер текущего блока (размер блока кодирования) составляет 1×1 сэмплов, но он может быть больше и обычно будет больше.
2. Окно доступа к памяти определяется как расширение вокруг блока кодирования, например 4 сэмпла слева/справа и 4 сэмпла сверху/снизу, показанные на фигуре.
B) Дробные координаты пикселей доступны для уточнения MV, только если сэмплы, необходимые для интерполяции, находятся внутри окна доступа к памяти.
Требование B гарантирует, что окно доступа, определенное посредством сэмплов, необходимых для уточнения вектора движения на целочисленных сэмплах, не будет дополнительно расширено. Фактические дробные сэмплы, доступные в соответствии с этим правилом, определяются размером и формой интерполяционного фильтра. Соответственно, на фиг.10, предполагая интерполяционный фильтр с 6 отводами, пунктирная линия указывает область, в которой могут находиться дробные сэмплы. Тем не менее, следует отметить, что дополнительные положения дробных пикселей могут быть допустимы, как будет показано со ссылкой на фиг.12. В частности, все еще могут использоваться дробные положения, которые требуют только вертикальной или только горизонтальной фильтрации, которая не требует расширения за пределы окна доступа. Таким образом, ограничение дробных положений окном дробных сэмплов, показанным на фиг.10, может быть слишком ограничивающим для некоторых применений.
Другими словами, согласно варианту осуществления окно доступа к памяти включает в себя все сэмплы, которые доступны посредством уточнения вектора движения, выполненного для целочисленных сэмплов, и не включают в себя сэмплы, которые не доступны посредством уточнения вектора движения, выполненного для целочисленных сэмплов. Таким образом, если дробные сэмплы используются для уточнения вектора движения, они получаются способом, который не требует дополнительных сэмплов.
В примере, показанном на фиг.10, это достигается посредством разрешения только дробных сэмплов, которые для предварительно заданной формы и размера интерполяционного фильтра не требуют сэмплов из окна доступа. Пунктирное дробное окно сэмплов простирается в пределах окна доступа. Если T - количество отводов интерполяционного фильтра, то граница дробного окна сэмплов определяется посредством целочисленных сэмплов на расстоянии 1020 floor(T/2)-1 от граничных сэмплов окна доступа. В частности, в этом примере T=6, T/2=3, а расстояние от граничных сэмплов окна доступа до сэмпла дробного окна составляет T/2-1=2 целочисленных сэмплов.
Тем не менее, следует отметить, что это определение дробного окна является простым примером. В общем, окно может иметь различную форму и размер. Вертикальная и горизонтальная интерполяция могут выполняться фильтрами разных размеров. Кроме того, для некоторых дробных положений может потребоваться фильтр как в вертикальном, так и в горизонтальном направлении, который в общем случае может быть отделимым или неразделимым.
В качестве альтернативы, интерполяционный фильтр может быть изменен (например, уменьшено количество отводов по меньшей мере в одном направлении) для дробных положений за пределами пунктирного окна на фигуре 10. Однако для целей реализации и для обеспечения качества интерполяции такое решение может быть менее привлекательным.
Окно для доступа к памяти может быть определено различными способами. Фиг.11 иллюстрирует пример, в котором окно доступа к памяти определяется как расширения EXT слева/справа или сверху/снизу от блока кодирования (в соответствии с местоположением блока кодирования, заданным посредством начального вектора движения). Величины расширения могут зависеть от размера и формы блока кодирования или предсказания. На фигуре 11 расширение составляет 4 сэмпла в каждом направлении (сверху, снизу, слева, справа). Однако следует отметить, что EXT также может принимать разные значения для разных направлений в зависимости от размера блока (который может иметь разный размер в вертикальном и горизонтальном направлении) и/или формы и размера пространства поиска.
Например, согласно примеру, окно определяется как N столбцов целочисленных сэмплов и M строк целочисленных сэмплов относительно начального вектора движения блока предсказания, по меньшей мере одно из N и M являются ненулевыми целочисленными значениями (оба являются целыми числами, но одно из них может быть нулевым). На фигуре 11 указаны N и M, но они имеют одинаковый размер. Как упоминалось выше, N и M могут иметь разные размеры. N и M являются целыми числами, и по меньшей мере одно из них не равно нулю. Принимая параметры N и M, а также форму и размер шаблона, можно определить размер окна доступа. В частности, если шаблон имеет строки T1 и столбцы T2, размер окна доступа к памяти может быть рассчитан как (N+T2+N) строк и (M+T1+M) столбцов. Это связано с тем, что поиск можно выполнить по N сэмплов влево или вправо, что приведет к 2N сэмплов по горизонтали, и M сэмплов вверх или вниз, что приведет к 2M сэмплов по вертикали.
С другой стороны, для конкретных подходов конструкций пространства поиска, описанных со ссылкой на фиг.7 и 8, окно доступа к памяти может быть определено с точки зрения максимального количества итераций уточнения (итераций построения пространства поиска) и размера шага итерации (с учетом максимального расстояния сэмплов, достижимого в каждой итерации), которое впоследствии можно преобразовать в максимальное значение смещения влево, вправо, вверх и вниз. Поэтому окно доступа к памяти определяется как максимальное смещение в каждом направлении. Например, 4 итерации, в которых каждая итерация может продвигать пространство поиска не более чем на одно целочисленное положение сэмпла, приводят к EXT=4.
Другими словами, согласно этому примеру, схема обработки выполнена с возможностью определения уточнения начального вектора движения посредством сопоставления с упомянутым шаблоном в пространстве поиска, которое итеративно расширяется в направлении, заданном посредством одного (или более) из положений наилучшего соответствия пространства поиска в самой последней итерации, окно определяется посредством предварительно заданного максимального числа итераций.
Следует отметить, что в целом настоящее раскрытие не ограничено какой-либо конкретной формой или формой или видом определения пространства поиска. В другом примере пространство поиска представляет собой прямоугольное подокно окна, так что все целочисленные сэмплы, к которым осуществляется доступ для интерполяционной фильтрации каждого дробного сэмпла в подокне, расположены в упомянутом окне для интерполяционного фильтра с предварительно заданным коэффициентом отвода фильтра. Подобный пример уже обсуждался выше со ссылкой на фиг.10. На фигуре 10 пространство поиска задается посредством 9 × 9 целочисленных сэмплов и дробных сэмплов, расположенных в области, образованной посредством 5 × 5 целочисленных сэмплов с положением начального вектора движения в их центре.
Определение окна доступа к памяти может быть уместным, чтобы, возможно, включить соответствующий параметр сигнализации в битовый поток (например, параметр EXT или параметры N и M). Однако размер окна доступа к памяти также может быть определен в стандарте или может быть получен на основе других параметров кодирования (таких как размер шаблона, размер блока предсказания, разрешение изображения и т.д.).
На фигуре 12 показан пример с различными положениями дробного пикселя. Для этого примера предполагается, что размер шаблона составляет 1×1 сэмплов (для простоты), и для каждого положения полупикселя используется интерполяционный фильтр с 6 отводами. В этом примере координаты поиска, которые ищутся, обозначаются номерами 1-6, которые указывают порядок, в котором они проверяются, то есть порядок, в котором выполняется поиск по шаблону. Положения 1 и 2 представляют собой полупиксельное положение (это означает, что они расположены посередине между двумя целочисленными положениями сэмплов, pel - это аббревиатура для pixel (пиксель), а термин пиксель используется взаимозаменяемо с термином сэмпл в этой заявке). Положения 1 и 2 проверяются, поскольку необходимое расширение для интерполяционной фильтрации находится внутри окна доступа к памяти (3 целочисленных сэмпла по диагонали вверху слева и 3 целочисленных сэмпла внизу справа от положения 1; 3 целочисленных сэмпла справа и 3 целочисленных сэмпла слева от положения 2). Обратите внимание, что точка 1 дробного сэмпла требует расширения как в горизонтальном, так и в вертикальном направлении, оба из которых находятся внутри окна. Положение 2 требует расширения только вправо и влево.
Положения 3, 4 и 5 являются целочисленными положениями сэмплов (пикселей). Их можно искать, поскольку расширение интерполяционной фильтрации не требуется. К дробному (полупиксельному) сэмплу 6 также можно получить доступ, поскольку необходимо только расширение в вертикальном направлении (на три целочисленных положения вверх и вниз соответственно), которое все еще находится внутри окна. Никакого расширения в горизонтальном направлении не требуется. Тем не менее, в вышеупомянутой реализации к точкам дробных сэмплов обращаются, только если необходимое расширение интерполяции находится в пределах окна доступа к памяти.
Другими словами, согласно примеру, интерполяционный фильтр является одномерным фильтром, оценивающим K горизонтальных или вертикальных целочисленных сэмплов, когда дробное положение расположено на соответствующей горизонтальной или вертикальной линии целочисленных сэмплов.
Такие одномерные дробные положения (например, положения 2 и 6 на фигуре 12), расположенные на линии между двумя горизонтально или двумя вертикально смежными целочисленными положениями, требуют расширения для интерполяции только в горизонтальном направлении или только в вертикальном направлении, то есть должны фильтроваться только соответствующим горизонтальным или вертикальным интерполяционным фильтром. Чтобы иметь возможность использовать как можно больше дробных положений, в дополнение к дробным положениям, разрешенным в примере на фиг.10, может быть выгодно добавить дополнительные одномерные положения, такие как положение 6, показанное на фиг.12.
Другими словами, пространство поиска дополнительно включает в себя дробные положения, расположенные вне дробного подокна (см. пунктирное окно на фиг.10):
- смежные сверху или снизу от подокна и расположенные на горизонтальной линии целочисленных сэмплов или
- смежные слева или справа от подокна и расположенные на вертикальной линии целочисленных сэмплов.
Следует отметить, что для некоторых дробных сэмплов может потребоваться больше целочисленных сэмплов в заданном направлении, горизонтальном или вертикальном. Это может быть в том случае, если предварительно заданный размер фильтра отличается для формирования этого положения в соответствующих направлениях.
Фигура 13 иллюстрирует пример дробных положений 1 и 2 полупикселя, к которым нет доступа. Они расположены вне подокна, показанного на фиг. 10. Для этого примера предполагается, что 6 интерполяционный фильтр с 6 отводами используется для полупиксельных положений. Полупиксельные точки 1 и 2 поиска не разрешены для поиска, поскольку для горизонтальной или вертикальной интерполяционной фильтрации требуются сэмплы, которые находятся за пределами окна. Целочисленные положения сэмплов, необходимые горизонтальному фильтру для фильтрации положения 1 и вертикальному фильтру для фильтрации положения 2, обозначены пунктирной линией на фигуре 13. Как можно видеть, пунктирные кружки соответствуют целочисленным положениям, которые не находятся в окне доступа к памяти.
В вышеприведенных примерах окно доступа к памяти было определено таким образом, чтобы во время процесса уточнения вектора движения не осуществлялся доступ к сэмплу за пределами окна (даже для интерполяционной фильтрации). Другими словами, окно доступа к памяти является наименьшим окном, которое содержит сэмплы, к которым может потребоваться доступ для уточнения и интерполяции вектора движения. Кроме того, окно доступа к памяти было разработано в соответствии с сэмплами, необходимыми для уточнения вектора движения на основе целочисленных положений сэмплов. Затем допускаются только дробные положения, которые не требуют дальнейшего расширения такого окна доступа дополнительными целочисленными положениями.
Следует отметить, что приведенные выше примеры были обеспечены для полупиксельной интерполяции. Однако настоящее раскрытие не ограничено этим. В общем, можно использовать любое дробное положение, такое как 1/4, 1/8 или тому подобное, то есть интерполировать с использованием соответствующего интерполяционного фильтра.
Схема обработки, описанная со ссылкой на фиг.6, может быть использована в кодере и/или декодере, как показано на фиг.1 и 2.
В частности, устройство кодирования может быть обеспечено для кодирования видеоизображений, разделенных на блоки предсказания, в битовый поток, причем устройство кодирования содержит: устройство для определения вектора движения для блока предсказания, как описано выше, включая схему обработки; и схему кодирования для кодирования разницы между блоком предсказания и предиктором, заданным посредством блока предсказания в положении, заданном посредством определенного вектора движения, и для формирования битового потока, включающего в себя кодированную разницу и начальный вектор движения.
Дополнительные модули и функции кодера, описанные выше со ссылкой на фиг.1, также могут быть обеспечены или реализованы в схеме обработки.
Соответственно, устройство декодирования может быть обеспечено для декодирования из битового потока видеоизображений, разделенных на блоки предсказания, причем устройство декодирования содержит: модуль синтаксического анализа для выявления из битового потока начального вектора движения и кодированной разницы между блоком предсказания и предиктором, заданным посредством блока предсказания в положении, заданном посредством уточненного вектором движения; устройство для определения уточненного вектора движения для блока предсказания, как описано выше, включая схему обработки; и схему декодирования для восстановления блока предсказания в виде суммы выявленной разницы и предиктора, заданного посредством блока предсказания в положении на основе уточненного вектора движения. Например, предиктор может быть непосредственно задан посредством положения уточненного вектора движения. Однако могут быть дополнительные этапы обработки для получения вектора движения текущего блока предсказания, которые могут дополнительно изменять вектор движения (такие как фильтрация, отсечение, дополнительное уточнение или тому подобное).
Дополнительные модули и функции декодера, описанные выше со ссылкой на фиг.2, также могут быть обеспечены или реализованы в схеме обработки.
Кроме того, варианты осуществления изобретения были описаны с точки зрения устройства со схемой обработки для выполнения уточнения вектора движения. Однако настоящее раскрытие не ограничено этим, но также обеспечивает соответствующие способы, которые включают в себя этапы обработки, соответствующие тем, для выполнения которых сконфигурирована вышеописанная схема обработки.
В частности, обеспечен способ для определения вектора движения для блока предсказания, включающий в себя этапы, на которых: получают начальный вектор движения и шаблон для блока предсказания; определяют уточнение начального вектора движения посредством сопоставления с упомянутым шаблоном в пространстве поиска, причем упомянутое пространство поиска расположено в положении, заданном посредством начального вектора движения, и включает в себя одно или несколько дробных положений сэмплов, причем каждое из дробных положений сэмплов, принадлежащих пространству поиска получается посредством интерполяционной фильтрации фильтром с предварительно заданным коэффициентом отвода фильтра, оценивающим целочисленные сэмплы только в пределах окна, причем упомянутое окно формируется посредством целочисленных сэмплов, доступных для сопоставления с шаблоном в упомянутом пространстве поиска.
Отводы соответствуют коэффициентам фильтра. Коэффициент отвода фильтра соответствует порядку фильтра. Здесь предполагается, что фильтр является линейным фильтром. В некоторых примерах фильтр может быть симметричным, то есть иметь симметричные коэффициенты. Однако настоящее раскрытие не ограничено симметричными фильтрами или линейными фильтрами или фильтрами любого типа. Как правило, дробные положения могут быть получены любым способом на основе смежных сэмплов.
Кроме того, обеспечен способ кодирования для кодирования видеоизображений, разделенных на блоки предсказания, в битовый поток, причем способ кодирования содержит этапы, на которых определяют вектор движения для блока предсказания согласно любому из способов, описанных выше; а также разницу кодирования между блоком предсказания и предиктором, заданным посредством блока предсказания в положении на основе определенного вектора движения, и для формирования битового потока, включающего в себя кодированную разницу и начальный вектор движения.
Способ кодирования может дополнительно включать в себя этапы, описанные со ссылкой на функции блоков на фиг.1.
Кроме того, обеспечен способ декодирования для декодирования из битового потока видеоизображений, разделенных на блоки предсказания, причем способ декодирования содержит этапы, на которых: выявляют из битового потока начальный вектор движения и кодированную разницу между блоком предсказания и предиктором, заданным посредством блока предсказания в положении, заданном посредством уточненного вектора движения; определяют уточненный вектор движения для блока предсказания в соответствии с любым из упомянутых выше способов; и восстанавливают блок предсказания как сумму выявленной разницы и предиктора, заданного посредством блокв предсказания в положении, заданном посредством уточненного вектора движения.
Способ декодирования может дополнительно включать в себя этапы, описанные со ссылкой на функции блоков на фиг.2.
Однако следует отметить, что фиг.1 и 2 не предназначены для ограничения настоящего раскрытия. Они просто обеспечивают неограничивающий пример реализации настоящего изобретения в существующем кодере и/или декодере.
На фиг.14 показана иллюстративная реализация способа в соответствии с вариантом осуществления. Функция InterpolationFilterLength(C) возвращает количество дополнительных сэмплов, необходимых в горизонтальном и вертикальном направлениях для применения интерполяционной фильтрации. Количество необходимых сэмплов меняется в зависимости от:
- того, является ли координата поиска положением целого числа, половины или четверти пикселя.
- того, нужно ли применять горизонтальный, вертикальный или оба интерполяционных фильтра для формирования сэмпла координат поиска.
Способ начинается на этапе 1430. В частности, положение начального вектора движения - это первое положение C(x,y) пространства поиска, подлежащее проверке. Функция InterpolationFilterLength(C) возвращает для этого положения количество сэмплов в горизонтальном и вертикальном направлениях для применения интерполяционной фильтрации. Если сумма C(x, y) и InterpolationFilterLength(C(x,y)) превышает размер окна доступа, определенный посредством MAX(max_x,max_y), то положение не используется как часть пространства поиска. Вместо этого на этапе 1440 для проверки выбирается следующая координата поиска C(x, y) (например, x или y или оба увеличиваются в зависимости от порядка, в котором выполняется поиск). Если проверенное положение на этапе 1430 не требует превышения окна доступа, на этапе 1410 сопоставление с шаблоном как часть уточнения вектора движения выполняется для этого положения C(x,y). Затем на этапе 1420 проверяется, остались ли еще места в пространстве поиска для сопоставления с шаблоном. Если нет, уточнение прекращается. Если да, следующая координата выбирается на этапе 1440, и условие этапа 1430 оценивается для этого нового положения. Эти этапы повторяются.
Как уже описано выше, существуют альтернативные возможности для определения допустимых дробных положений (таких как окно на фиг.10, возможно, расширенное посредством дополнительных дробных сэмплов, как показано на фиг.12). Основываясь на этом, более простое условие может быть сформулировано на этапе 1430, просто оценивая, принадлежит ли положение C(x,y) разрешенному окну. Например, поиск ограничен целочисленными точками поиска и дробными точками в окне дробного поиска, инкапсулированном в окне доступа к памяти, как показано на фиг.10.
Пространство поиска может включать в себя прямоугольное подокно поиска окна, и уточнение начального вектора движения может быть определено посредством сопоставления с упомянутым шаблоном в прямоугольном подокне поиска, так что целочисленные сэмплы, к которым осуществляется доступ для интерполяционной фильтрации каждого из дробных сэмплов в подокне поиска расположены в упомянутом окне для интерполяционного фильтра с предварительно заданным коэффициентом отвода фильтра.
Точнее, допустимые целочисленные и дробные положения могут быть определены на основе расстояния точки поиска от точки, связанной с начальным неуточненным вектором движения. В частности, разрешены положения поиска, которые находятся на расстоянии P в направлении x от начального неуточненного вектора движения и на расстоянии R в направлении y от начального неуточненного вектора движения. В частности, окно доступа к памяти определяется по отношению к точке опорного изображения, на которую указывает начальный неуточненный вектор движения. Это проиллюстрировано на фиг.15, где центральная точка окна доступа к памяти является полупиксельной точкой между двумя целочисленными точками вдоль горизонтальной оси. На фигуре окно доступа к памяти определено как расширения в направлении x (N) и в направлении y (M), где N и M - целые числа, по меньшей мере одно из которых не равно нулю. В соответствии с конкретной реализацией подокно, то есть подокно для точек поиска (или окна поиска), определяется в пределах окна доступа к памяти, определяемого как расширения в направлении x (P) и в направлении y (R), которые включают в себя все целопиксельные и дробнопиксельные точки поиска, которые можно искать посредством сопоставления с шаблоном. На фигуре 15 числа P и R равны 1 в целях иллюстрации. Соответственно, если расстояние от точки поиска до центральной точки больше, чем P или R, в направлении x и y соответственно точка поиска не включается в окно доступа к памяти. В этом конкретном примере, поскольку точки дробного поиска требуют доступа к дополнительным сэмплам, окно доступа к памяти, определенное посредством N и M, инкапсулирует или включает в себя вторичное окно. P и R могут быть действительными числами, описывающими расстояние в единицах расстояния между двумя точками целочисленных сэмплов в горизонтальном и вертикальном направлении. В качестве примера, если P и R определены как P=1,5 и R=1,5, то точку поиска (целой или дробной), которая находится на расстоянии 1,5 в направлении x к начальной центральной точке, разрешается искать посредством процесса уточнения вектора движения. Кроме того, на фигуре 15 удлинения в направлениях слева направо и сверху вниз определены равными P и R соответственно, которые в общем случае могут быть неравными. В общем, все 4 расширения слева, сверху, справа и снизу могут быть определены независимо.
На фигуре 16 описана возможная реализация процесса итеративного уточнения в окне доступа к памяти. Согласно фиг.16, уточняющий поиск применяется итеративным образом, что означает, что на каждой итерации выполняется поиск только до K точек поиска. Во-первых, K точек поиска определяются вокруг начальной стартовой точки или вокруг наилучшей точки поиска, выбранной в результате предыдущей итерации (1610). Во-вторых, если все K точек поиска находятся внутри окна доступа к памяти (1620), операция поиска уточнения применяется к K точкам поиска. Однако если любая из K точек находится за пределами окна доступа к памяти, итерации поиска завершаются. В-третьих, проверяется условие максимального количества итераций поиска (1630), и итерации прекращаются, если текущая итерация превышает максимально допустимое количество итераций поиска. Наконец, уточняющий поиск применяется к K точкам поиска (1640), и лучшая точка среди K точек поиска выбирается в соответствии с соответствующей функцией затрат (1650). Применение 1640 и 1650 увеличивает число итераций на 1. После 1650 процесс повторяется, используя лучшую точку, которая является выходом 1650 в качестве входа для 1610. Согласно фиг.16 число K, которое определяет количество точек поиска, которые ищут в течение одной итерации, определяет максимальное количество точек поиска для каждой итерации. Число K и шаблон точек, которые ищут для каждой итерации, могут отличаться в зависимости от используемой стратегии поиска. Например, в соответствии с иллюстративной стратегией поиска, K=5 точек поиска (в центре, слева, справа, снизу и сверху) можно искать в первой итерации, тогда как K=3 точек (в центре, внизу справа, внизу слева) можно искать во второй итерации. Число K - это число, которое меньше общего числа точек поиска в окне доступа к памяти.
В соответствии с конкретной реализацией, описанной на фиг.16, если одна точка поиска среди K точек поиска итерации находится за пределами окна доступа к памяти, итерации поиска завершаются. Могут быть и другие точки в K точках поиска, которые находятся внутри окна доступа к памяти, но поскольку итерации завершаются, эти точки внутри окна доступа к памяти также не ищутся. Цель конкретной реализации состоит в том, чтобы уменьшить количество итераций поиска и в то же время гарантировать, что точки поиска, которые выходят за пределы окна доступа к памяти, не ищутся.
Согласно 1620, проверка того, находится ли точка поиска внутри окна доступа к памяти, может быть выполнена посредством проверки расстояния точки поиска до начальной стартовой точки. Поэтому, если x-составляющая расстояния больше, чем N, или если y-составляющая расстояния больше, чем M, определяется, что точка поиска находится за пределами окна доступа к памяти. Обычно N и M являются целыми числами, по меньшей мере одно из которых больше 0.
Уточнение начального вектора движения может быть определено посредством сопоставления с упомянутым шаблоном в пространстве поиска, которое итеративно расширяется в направлении, заданном посредством одного из нескольких положений наилучшего соответствия соответствия пространства поиска в самой последней итерации, причем итерация заканчивается, когда по меньшей мере один сэмпл в пространстве поиска самой последней итерации находится вне подокна поиска.
На фиг.17 представлена блок-схема последовательности операций, описывающая возможную итерационную схему, применимую к подокну поиска, как описано на фиг.15. Блок-схема последовательности операций на фиг.17 такая же, как схема, описанная на фиг.16, за исключением этапа 1720. В соответствии с этапом 1720 на фиг.17 решение выполнить уточняющий поиск по K точкам поиска принимают посредством проверки, все ли K точек находятся внутри подокна для точек поиска. Другими словами, как описано на фиг.15, если расстояние любой из K точек поиска до центральной точки, указанной посредством начального неуточненного вектора движения, больше, чем P или R, тогда условие, описанное в 1720, оценивают как ложное и итерации прекращаются.
Определение вектора движения с ограничением окна памяти, как описано выше, может быть реализовано как часть кодирования и/или декодирования видеосигнала (движущегося изображения). Однако определение вектора движения можно также использовать для других целей при обработке изображений, таких как обнаружение движения, анализ движения или тому подобное, без ограничения, для использования при кодировании/декодировании.
Определение вектора движения может быть реализовано как устройство. Такое устройство может быть комбинацией программного и аппаратного обеспечения. Например, определение вектора движения может выполняться посредством микросхемы, такой как процессор общего назначения, или процессор цифровых сигналов (DSP), или программируемая пользователем вентильная матрица (FPGA), или тому подобное. Однако настоящее изобретение не ограничено реализацией на программируемом оборудовании. Оно может быть реализовано на специализированной интегральной схеме (ASIC) или посредством комбинации вышеупомянутых аппаратных компонентов.
Определение вектора движения также может быть реализовано посредством программных инструкций, хранящихся на считываемом компьютером носителе. Программа, когда она выполняется, предписывает компьютеру выполнять этапы описанных выше способов. Считываемый компьютером носитель может быть любым носителем, на котором хранится программа, таким как DVD, CD, USB (флэш-накопитель), жесткий диск, серверное хранилище, доступное по сети, и т.д.
Кодер и/или декодер могут быть реализованы в различных устройствах, включая телевизор, телевизионную приставку, ПК, планшет, смартфон или тому подобное, то есть в любом устройстве записи, кодирования, транскодирования, декодирования или воспроизведения. Это может быть программное обеспечение или приложение, реализующее этапы способа и сохраненное/запущенное на процессоре, включенном в электронное устройство, как указано выше.
Подводя итог, настоящее раскрытие относится к уточнению вектора движения. В качестве первого этапа получают начальный вектор движения и шаблон для блока предсказания. Затем уточнение начального вектора движения определяют посредством сопоставления с упомянутым шаблоном в пространстве поиска. Пространство поиска находится в положении, заданном посредством начального вектора движения, и включает в себя одно или несколько дробных положений сэмплов, причем каждое из дробных положений сэмплов, принадлежащих пространству поиска, получают посредством интерполяционной фильтрации фильтром с предварительно заданным коэффициентом отвода фильтра, оценивающим целочисленные сэмплы только в пределах окна, причем упомянутое окно образовано посредством целочисленных сэмплов, доступных для сопоставления с шаблоном в упомянутом пространстве поиска.

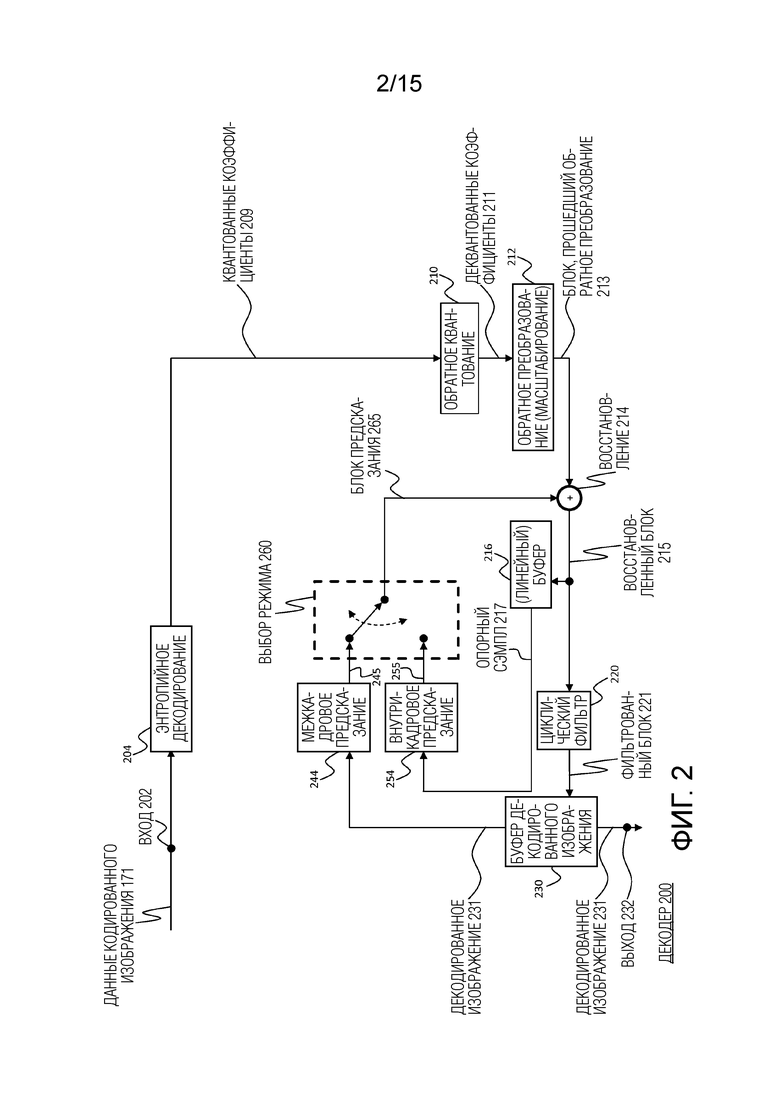


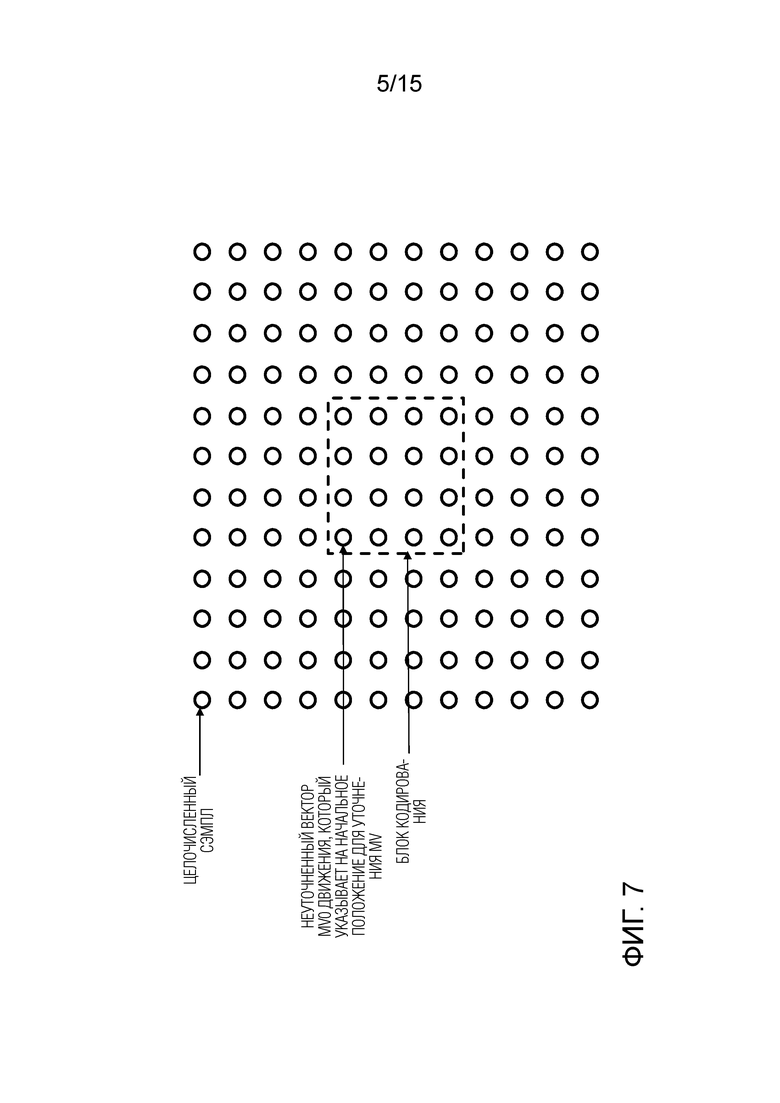

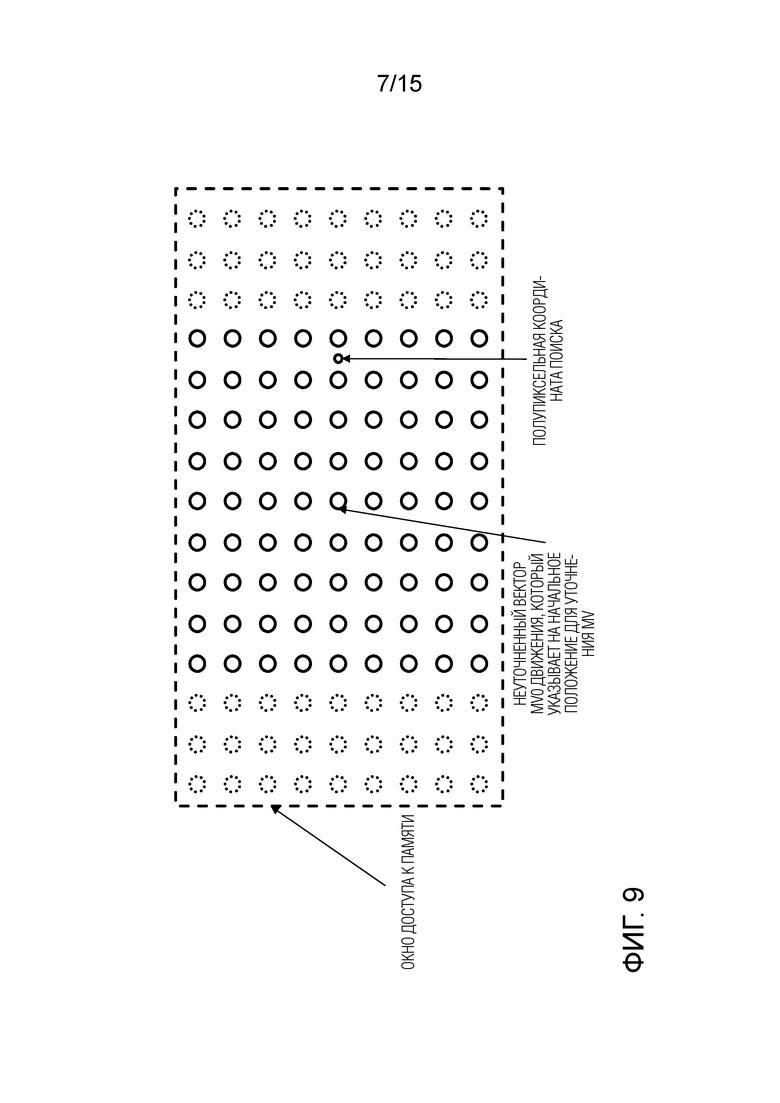
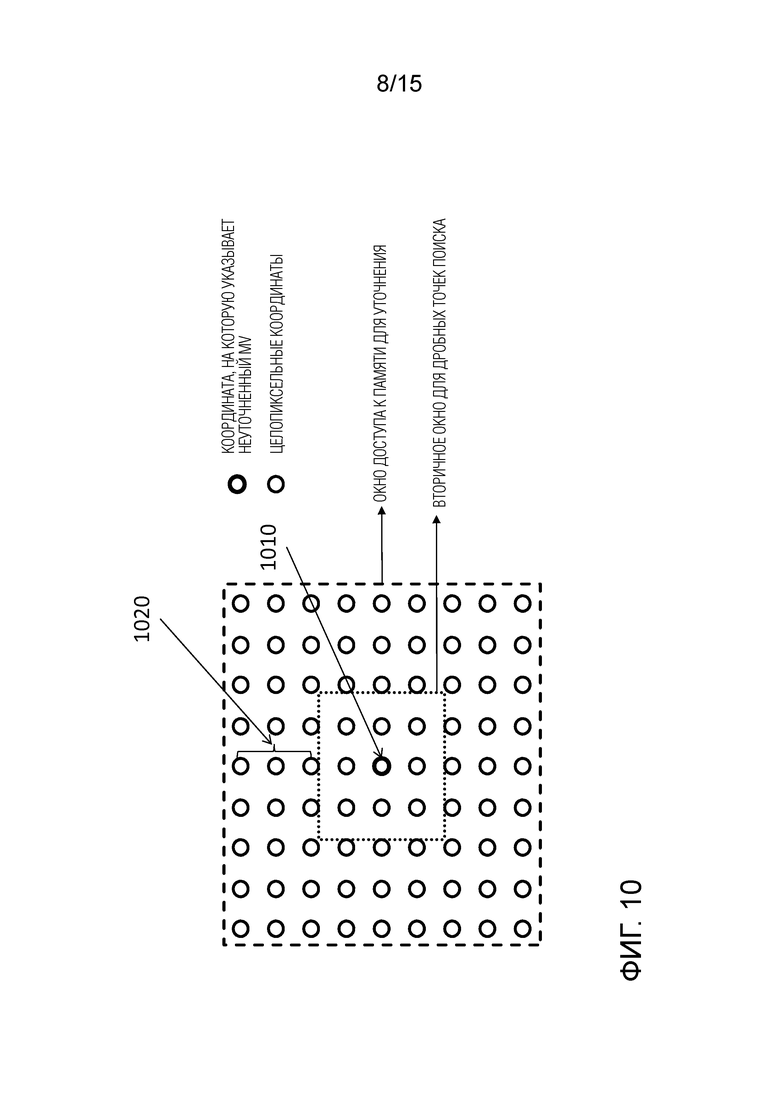
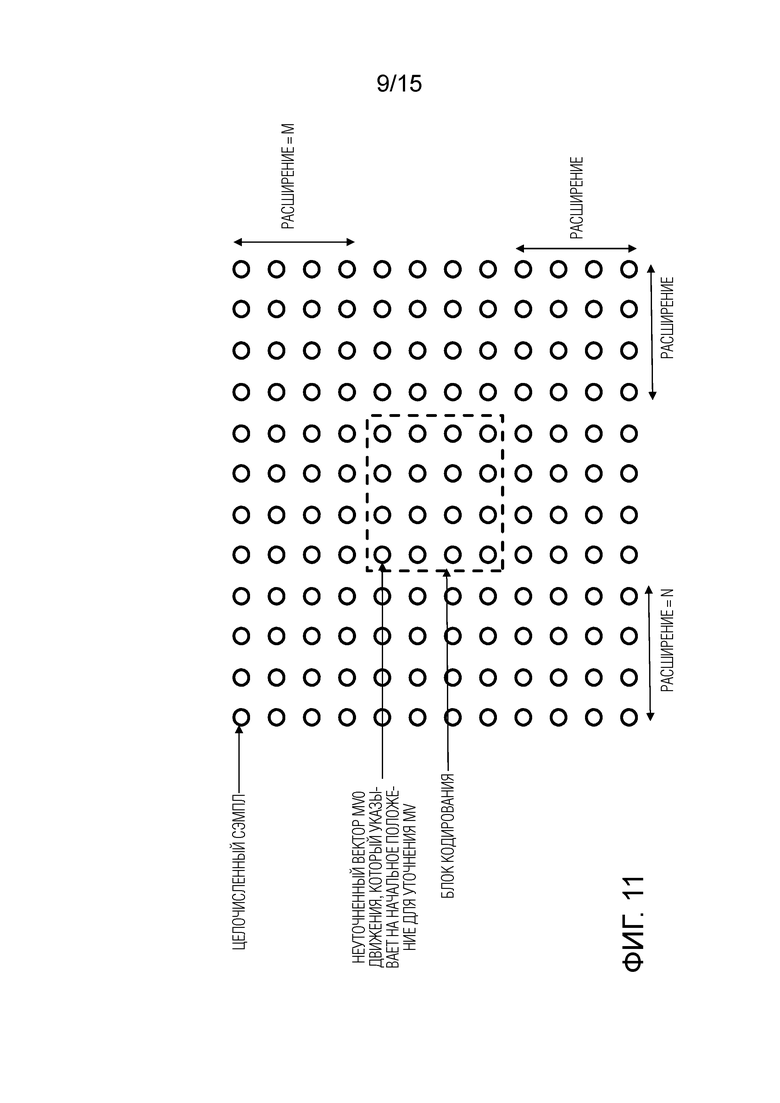
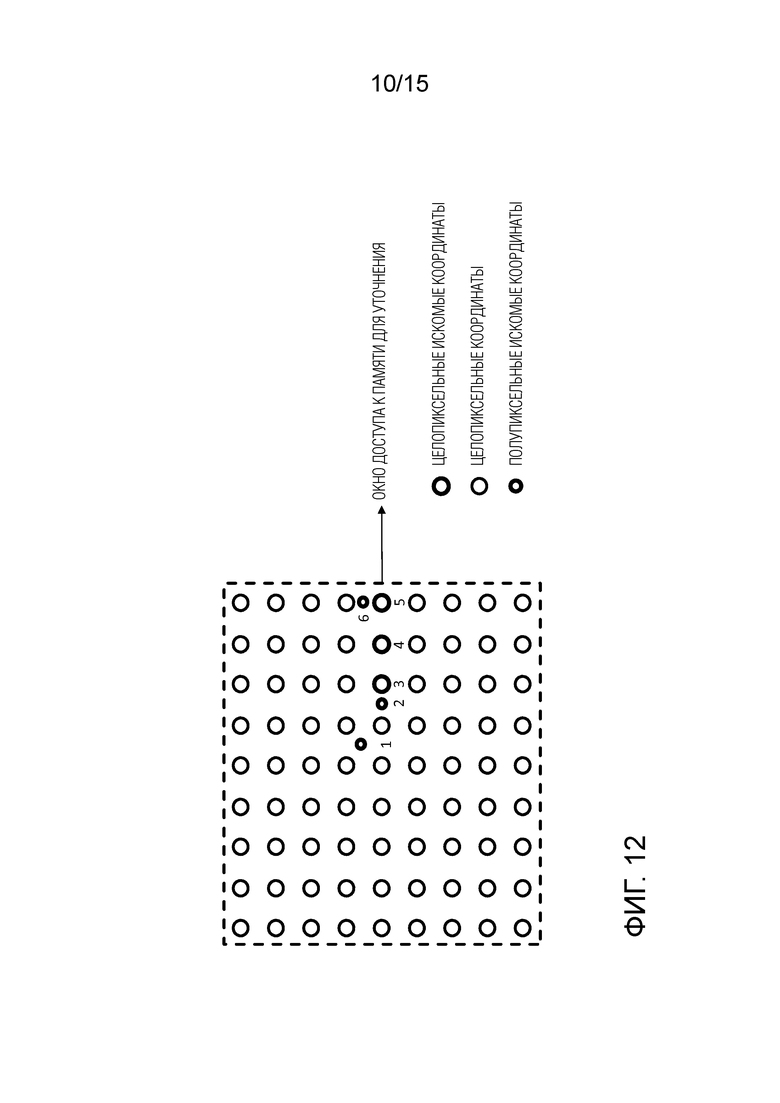

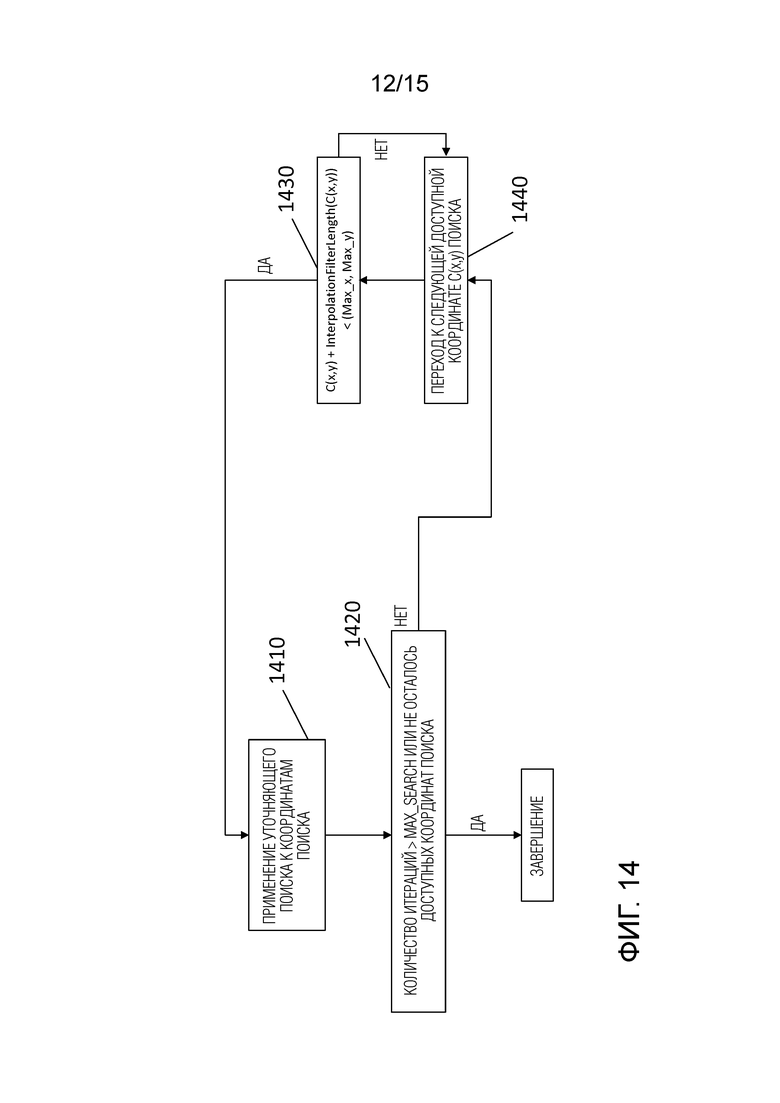
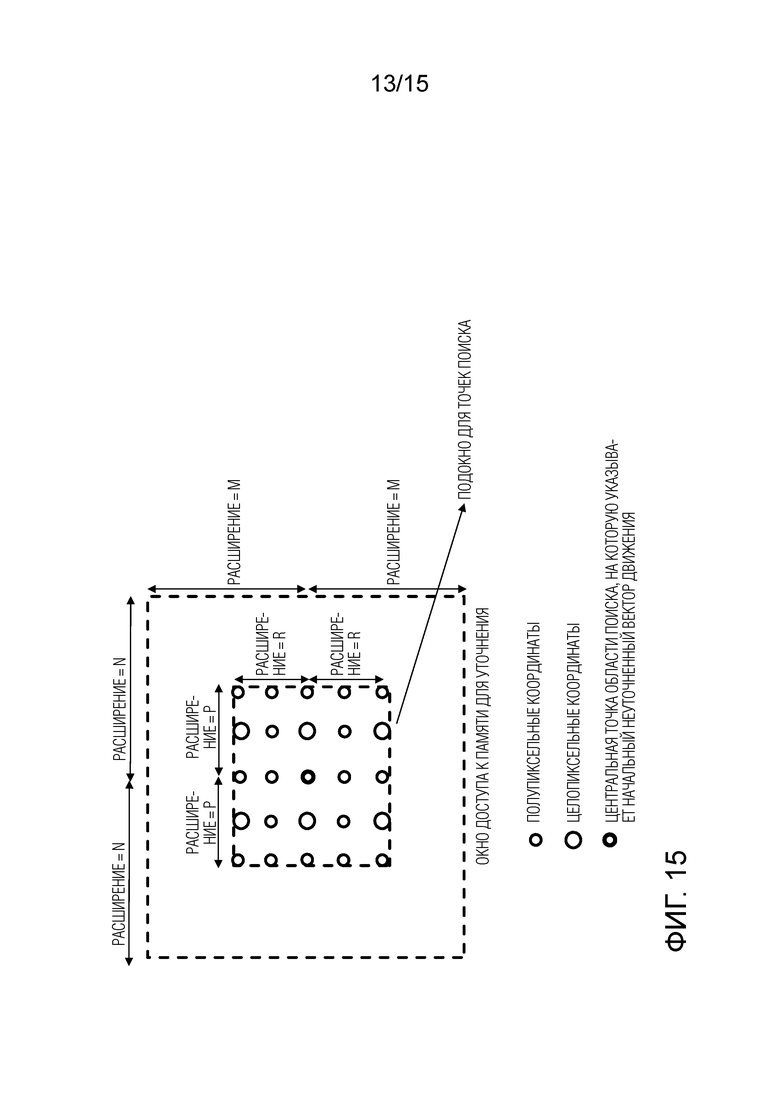
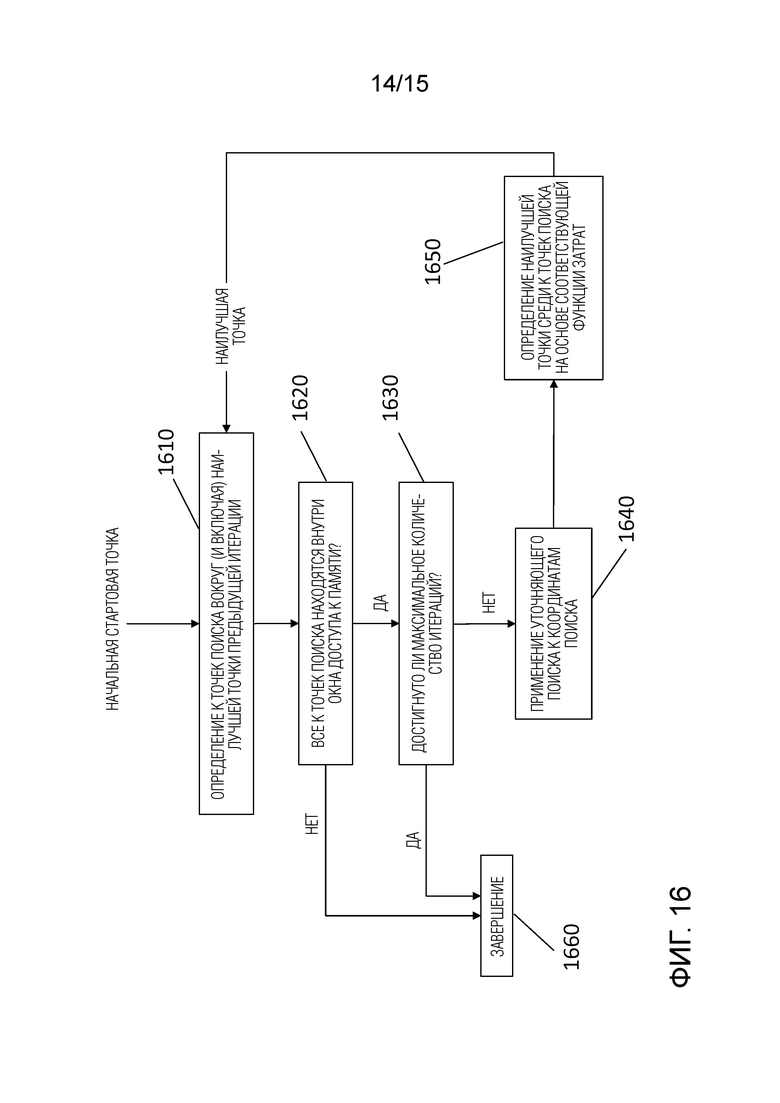
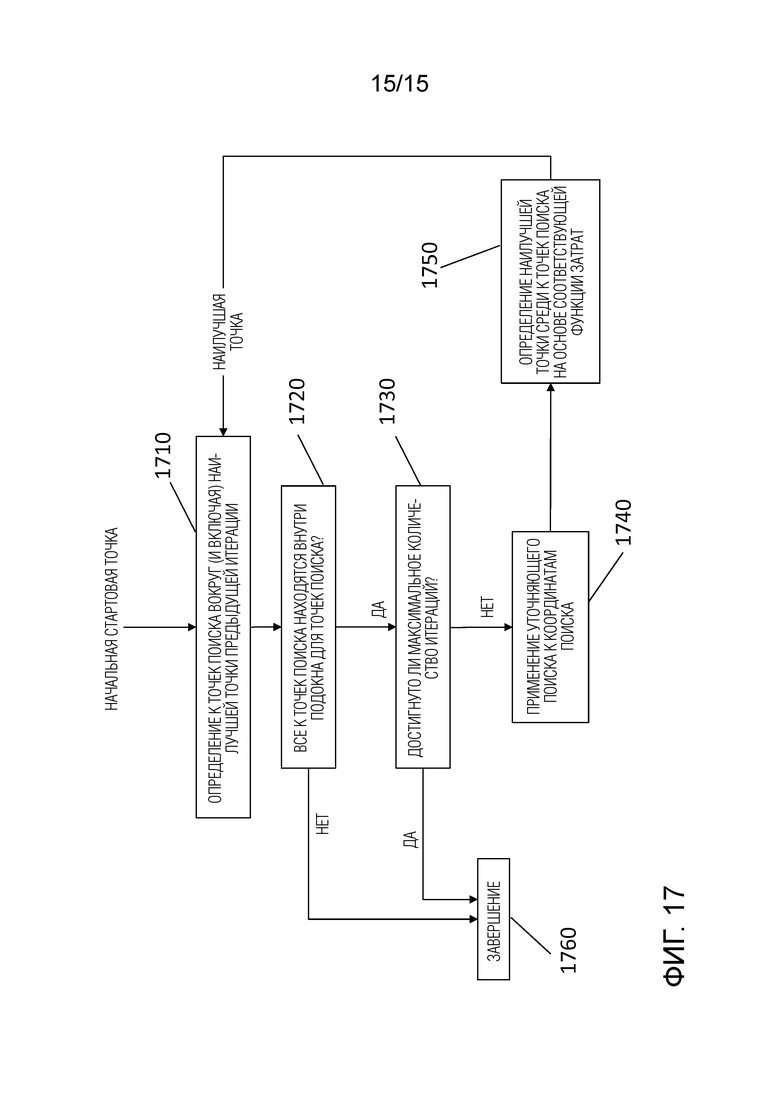
Изобретение относится к кодированию или декодированию, в частности к определению и уточнению вектора движения. Техническим результатом является обеспечение предсказания вектора движения, которое позволяет учитывать количество обращений к внешней памяти и количество точек, которые необходимы для того, чтобы быть доступными для уточнения вектора движения вектора движения для блока кодирования. Указанный технический результат достигается тем, что в качестве первого этапа получены начальный вектор движения и шаблон для блока. Затем уточнение начального вектора движения определяют посредством сопоставления с упомянутым шаблоном в пространстве поиска. Пространство поиска расположено в положении, заданном посредством начального вектора движения, и включает в себя одно или несколько дробных положений сэмплов, причем каждое из дробных положений сэмплов, принадлежащих пространству поиска, получено посредством интерполяционной фильтрации фильтром предварительно заданного размера метки, оценивающим целочисленные сэмплы только внутри окна, причем упомянутое окно сформировано посредством целочисленных сэмплов, доступных для сопоставления с шаблоном в упомянутом пространстве поиска. 9 н. и 16 з.п. ф-лы, 17 ил.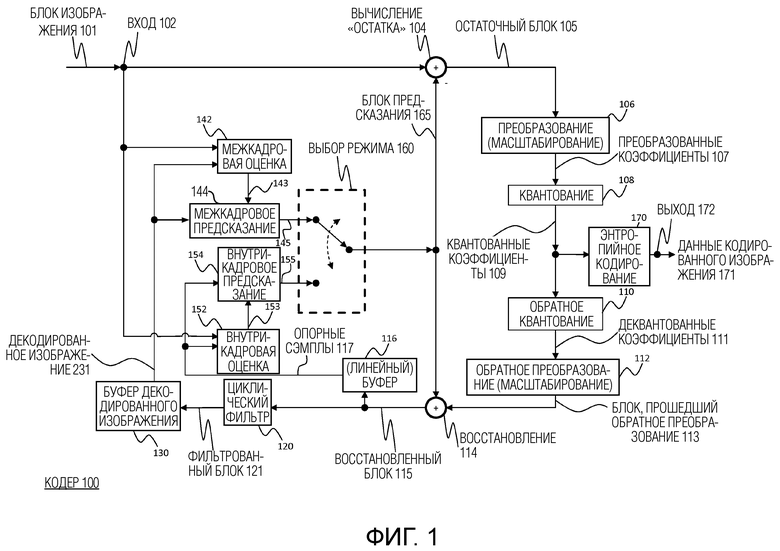
1. Устройство для определения вектора движения для блока, включающее в себя схему обработки, выполненную с возможностью:
получения начального вектора движения и шаблона для блока;
определения уточнения начального вектора движения посредством сопоставления с упомянутым шаблоном в пространстве поиска, причем
упомянутое пространство поиска расположено в положении, заданном посредством начального вектора движения, и включает в себя одно или несколько дробных положений сэмплов, причем каждое из дробных положений сэмплов, принадлежащих пространству поиска, получают посредством интерполяционной фильтрации фильтром с предварительно заданным коэффициентом отвода фильтра, оценивающим целочисленные сэмплы только в пределах окна, причем упомянутое окно образовано посредством целочисленных сэмплов, доступных для сопоставления с шаблоном в упомянутом пространстве поиска.
2. Устройство по п. 1, в котором окно определяется как расширение по меньшей мере в одном из направлений: слева и справа; и сверху и снизу от блока.
3. Устройство по п. 1 или 2, в котором окно определяется вокруг положения, указанного посредством начального вектора движения, и идентифицирует количество сэмплов, к которым должен осуществляться доступ для выполнения уточнения начального вектора движения.
4. Устройство по любому из предыдущих пунктов, в котором окно определено как N столбцов целочисленных сэмплов и M строк целочисленных сэмплов относительно начального вектора движения блока, причем по меньшей мере одно из N и M являются ненулевыми целочисленными значениями.
5. Устройство по любому из предыдущих пунктов, в котором схема обработки выполнена с возможностью определения уточнения начального вектора движения посредством сопоставления с упомянутым шаблоном в пространстве поиска, которое итеративно расширяется в направлении, заданном посредством одного из нескольких положений наилучшего соответствия пространства поиска в самой последней итерации, окно определено посредством предварительно заданного максимального количества итераций.
6. Устройство по любому из предыдущих пунктов, в котором пространство поиска включает в себя прямоугольное подокно окна, так что все целочисленные сэмплы, к которым осуществляется доступ для интерполяционной фильтрации каждого дробного сэмпла в подокне, расположены в упомянутом окне для интерполяционного фильтра с предварительно заданным коэффициентом отвода фильтра.
7. Устройство по любому из пп. 1-4, в котором пространство поиска включает в себя прямоугольное подокно поиска для окна, в котором уточнение начального вектора движения определяют посредством сопоставления с упомянутым шаблоном в прямоугольном подокне поиска, так что целочисленные сэмплы, к которым осуществляется доступ для интерполяционной фильтрации каждого дробного сэмпла в подокне поиска, расположены в упомянутом окне для интерполяционного фильтра с предварительно заданным коэффициентом отвода фильтра.
8. Устройство по п. 7, в котором: схема обработки выполнена с возможностью определения уточнения начального вектора движения посредством сопоставления с упомянутым шаблоном в пространстве поиска, которое итеративно расширяется в направлении, заданном посредством одного из нескольких положений наилучшего соответствия пространства поиска в самой последней итерации, причем итерация заканчивается, когда по меньшей мере один сэмпл в пространстве поиска самой последней итерации находится вне подокна поиска.
9. Устройство по п. 6, в котором интерполяционный фильтр является одномерным фильтром, оценивающим K горизонтальных или вертикальных целочисленных сэмплов, когда дробное положение расположено на соответствующей горизонтальной или вертикальной линии целочисленных сэмплов.
10. Устройство по п. 7, в котором пространство поиска дополнительно включает в себя дробные положения, расположенные вне подокна, которые являются: смежными сверху или снизу от подокна и расположенными на горизонтальной линии целочисленных сэмплов или смежными слева или справа от подокна и расположенными на вертикальной линии целочисленных сэмплов.
11. Устройство кодирования для кодирования видеоизображений, разделенных на блоки, в битовый поток, причем устройство кодирования содержит:
устройство для определения вектора движения для блока по любому из пп. 1-10;
схему кодирования для кодирования разницы между блоком и предиктором, заданным посредством блока в положении на основе определенного вектора движения, и для формирования битового потока, включающего в себя кодированную разницу и начальный вектор движения.
12. Устройство декодирования для декодирования из битового потока видеоизображений, разделенных на блоки, причем устройство декодирования содержит:
модуль синтаксического анализа для выявления из битового потока начального вектора движения и кодированной разницы между блоком и предиктором, заданным посредством блока в положении, заданном посредством уточненного вектора движения;
устройство для определения уточненного вектора движения для блока по любому из пп. 1-10;
схему декодирования для восстановления блока как суммы выявленной разницы и предиктора, заданного посредством блока в положении, заданном посредством уточненного вектора движения.
13. Способ определения вектора движения для блока, включающий в себя этапы, на которых:
получают начальный вектор движения и шаблон для блока;
определяют уточнение начального вектора движения посредством сопоставления с упомянутым шаблоном в пространстве поиска, причем
упомянутое пространство поиска расположено в положении, заданном посредством начального вектора движения, и включает в себя одно или несколько дробных положений сэмплов, причем каждое из дробных положений сэмплов, принадлежащих пространству поиска, получают посредством интерполяционной фильтрации фильтром с предварительно заданным коэффициентом отвода фильтра, оценивающим целочисленные сэмплы только в пределах окна, причем упомянутое окно образовано посредством целочисленных сэмплов, доступных для сопоставления с шаблоном в упомянутом пространстве поиска.
14. Способ по п. 13, в котором окно определено как N столбцов целочисленных сэмплов и M строк целочисленных сэмплов относительно начального вектора движения блока, причем N и M являются ненулевыми целочисленными значениями.
15. Способ по п. 13 или 14, в котором уточнение начального вектора движения определяют посредством сопоставления с упомянутым шаблоном в пространстве поиска, которое итеративно расширяется в направлении, заданном посредством одного из нескольких положений наилучшего соответствия пространства поиска в самой последней итерации, окно определяют посредством предварительно заданного максимального количества итераций.
16. Способ по любому из пп. 13-15, в котором пространство поиска включает в себя прямоугольное подокно окна, так что все целочисленные сэмплы, к которым осуществляется доступ для интерполяционной фильтрации каждого дробного сэмпла в подокне, расположены в упомянутом окне для интерполяционного фильтра с предварительно заданным коэффициентом отвода фильтра.
17. Способ по п. 13 или 16, в котором пространство поиска включает в себя прямоугольное подокно поиска для окна, в котором уточнение начального вектора движения определяют посредством сопоставления с упомянутым шаблоном в подокне прямоугольного поиска, так что целочисленные сэмплы, к которым осуществляется доступ для интерполяционной фильтрации каждого дробного сэмпла в подокне поиска, расположены в упомянутом окне для интерполяционного фильтра с предварительно заданным коэффициентом отвода фильтра.
18. Способ по п. 17, в котором: уточнение начального вектора движения определяют посредством сопоставления с упомянутым шаблоном в пространстве поиска, которое итеративно расширяется в направлении, заданном посредством одного из нескольких положений наилучшего соответствия пространства поиска в самой последней итерации, причем итерация заканчивается, когда по меньшей мере один сэмпл в пространстве поиска самой последней итерации находится вне подокна поиска.
19. Способ по п. 16, в котором интерполяционный фильтр представляет собой одномерный фильтр, оценивающий K горизонтальных или вертикальных целочисленных сэмплов, когда дробное положение находится на соответствующей горизонтальной или вертикальной линии целочисленных сэмплов.
20. Способ по п. 19, в котором пространство поиска дополнительно включает в себя дробные положения, расположенные вне подокна, которые являются: смежными сверху или снизу от подокна и расположенными на горизонтальной линии целочисленных сэмплов или смежными слева или справа от подокна и расположенными на вертикальной линии целочисленных сэмплов.
21. Способ кодирования для кодирования видеоизображений, разделенных на блоки, в битовый поток, причем способ кодирования содержит этапы, на которых:
определяют вектор движения для блока по любому из пп. 13-20;
кодируют разницу между блоком и предиктором, заданным посредством блока в положении на основе определенного вектора движения, и для формирования битового потока, включающего в себя кодированную разницу и начальный вектор движения.
22. Способ декодирования для декодирования из битового потока видеоизображений, разделенных на блоки, причем способ декодирования содержит этапы, на которых:
выявляют из битового потока начальный вектор движения и закодированную разницу между блоком и предиктором, заданным посредством блока в положении, заданном посредством уточненного вектора движения;
определяют уточненный вектор движения для блока по любому из пп. 13-20;
восстанавливают блок как сумму выявленной разницы и предиктора, заданного посредством блока в положении, заданном посредством уточненного вектора движения.
23. Считываемый компьютером носитель данных, хранящий инструкции, которые при исполнении на процессоре предписывают процессору выполнять способ по любому из пп. 13-20.
24. Считываемый компьютером носитель данных, хранящий инструкции, которые при исполнении на процессоре предписывают процессору выполнять способ по п. 21.
25. Считываемый компьютером носитель данных, хранящий инструкции, которые при исполнении на процессоре предписывают процессору выполнять способ по п. 22.
| WO 2017036414 A1, 09.03.2017 | |||
| US 2016286230 A1, 29.09.2016 | |||
| CHEN J | |||
| et al., Algorithm description of Joint Exploration Test Model 7 (JEM7), THE JOINT VIDEO EXPLORATION TEAM OF ISO/IEC JTC1/SC29/WG11 AND ITU-T SG.16, JVET-G1001, JVET MEETING; 13-7-2017 - 21-7-2017 | |||
| CHIU YI-JEN et al., Decoder-side Motion Estimation and Wiener filter for HEVC, |

