Область техники
Изобретение относится к области анализа данных и машинного обучения, а более конкретно к системам и способам формирования индивидуального содержимого для пользователей сервисов.
Уровень техники
Бурное развитие компьютерных технологий в последнее десятилетие, а также широкое распространение разнообразных вычислительных устройств (персональных компьютеров, ноутбуков, планшетов, смартфонов и т.д.) стали мощным стимулом для использования упомянутых устройств в разнообразных сферах деятельности и для огромного количества задач (от интернет-сёрфинга до банковских переводов и ведения электронного документооборота). Параллельно с ростом количества вычислительных устройств и объёма программного обеспечения, работающего на этих устройствах, быстрыми темпами росло и количество вредоносных программ, а также способов несанкционированного доступа к данным, обрабатываемых указанными устройствами, и мошеннических способов использования этих данных.
Таким образом, особенно важными становятся вопросы информационной безопасности. При этом большое внимание начинает уделяться не только обеспечению информационной безопасности персональных данных пользователей, но и защите персональных данных пользователей от гипотетических (зачастую и маловероятных) угроз, таких как успешные целевые атаки на сервера, хранящие персональные данные пользователей и т.д., что приводит к решениям, основанным на концепции добровольного согласия (например, в Европейском Союзе для этой цели введен общий регламент по защите данных, GDPR), а также решениям, обеспечивающим максимально объёмное хранение персональных данных пользователей на вычислительных устройствах пользователей и минимально возможный анализ и использование упомянутых данных на внешних сервисах.
В настоящий момент большое распространение получило использование обученных моделей (и машинного обучения вообще) в разнообразных областях человеческой деятельности. Были сделаны и попытки использовать обученные модели для хранения персональных данных пользователей и использования персональных данных пользователей для разных задач. Например, обученные модели на основании персональных данных пользователей могут позволить предсказывать предпочтения пользователей в заданных областях коммерции или иных информационных технологиях, также указанные модели могут использоваться как некоторые идентификаторы пользователей и т.д. Основным преимуществом обученных моделей может стать невозможность выделения из них персональных данных, на основе которых они обучались, что позволяет использовать персональные данные пользователей без их раскрытия (или передачи от одного вычислительного устройства другому, что негативно влияет на информационную безопасность).
В публикации US20150039315A1 описана технология получения доступа к вычислительным ресурсам с использованием некоторого набора действий пользователя (по сути, параметров, характеризующих поведение пользователя). Пользователь, желающий получить доступ к вычислительным ресурсам, прослушивает звуковой фрагмент, после чего голосом проговаривает, что услышал, в зависимости от точности воспроизведения определяется, предоставлять ли ему доступ к вычислительным ресурсам или нет.
Хотя описанные технологии хорошо справляются с задачами идентификации пользователей по поведению (действиям) пользователя, сами действия пользователя никак не скрываются, эти данные, которые являются персональными данными пользователя, передаются для анализа (идентификации) иным средствам (в том числе расположенным удалённо) и могут быть уязвимы к несанкционированному доступу.
Настоящее изобретение позволяет решать задачу идентификации пользователя на основании его персональных данных, а также формирования индивидуального содержимого для пользователей сервисов на основании персональных данных пользователя без их передачи по сети.
Раскрытие изобретения
Изобретение предназначено для обеспечения информационной безопасности.
Технический результат настоящего изобретения заключается в повышении точности выбора модели описания пользователя за счёт использования корректирующей модели описания пользователя.
Ещё один технический результат настоящего изобретения заключается в повышении точности работы модели описания пользователя за счёт переобучения указанной модели.
Данный результат достигается с помощью использования системы выбора модели описания пользователя, которая содержит: средство формирования данных, предназначенное для формирования данных о предпочтениях пользователя (далее, предпочтения) на основании заранее собранных данных о поведении пользователя (далее, поведение) и заранее выбранной из базы моделей модели описания пользователя (далее, базовая модель), при этом база моделей содержит по меньшей мере одну базовую модель, представляющую собой по меньшей мере одно правило определения предпочтений пользователя, и по меньшей мере одну функционально связанную с ней модель описания пользователя (далее, корректирующая модель), представляющая собой по меньшей мере одно правило определения предпочтений пользователей, функционально связанных с предпочтениями пользователей, определяемых базовой моделью; средство анализа, предназначенное для определения точности сформированных предпочтений на основании наблюдаемого поведения пользователя; средство выбора, предназначенное для выборки корректирующей модели, связанной с базовой моделью в случае, если определённая точность ниже заранее заданного порогового значения.
В другом частном случае реализации системы данные о поведении пользователя описывают по меньшей мере: приложения, с которыми работает пользователь, время работы пользователя в указанных приложениях, выполняемые пользователем действия в указанных приложения; поисковые запросы пользователя; сайты, которые посещает пользователь, выполняемые пользователем действия на указанных сайтах; заполненные пользователем формы.
Ещё в одном частном случае реализации системы модель описания пользователя предварительно обучают таким образом, чтобы указанная модель идентифицировала пользователя с заданным уровнем достоверности.
В другом частном случае реализации системы базовая модель является корректирующей моделью для модели, являющейся корректирующей для указанной базовой модели.
Ещё в одном частном случае реализации системы базовая модель функционально связана с несколькими корректирующими моделями, при этом по меньшей мере одна из указанных корректирующих моделей функционально связана с по меньшей мере одной другой из указанных корректирующих моделей.
В другом частном случае реализации системы указанная система дополнительно содержит средство переобучения моделей, предназначенное для переобучения базовой модели таким образом, чтобы для собранного поведения точность предпочтений была выше заранее заданного порогового значения, в случае если точность предпочтений не выше заранее заданного порогового значения.
Данный результат достигается с помощью использования способа выбора модели описания пользователя, при этом способ содержит этапы, которые реализуются с помощью средств из системы выбора модели описания пользователя и на которых: формируют данные о предпочтениях пользователя (далее, предпочтения) на основании заранее собранных данных о поведении пользователя (далее, поведение) и заранее выбранной из базы моделей модели описания пользователя (далее, базовая модель), при этом база моделей содержит по меньшей мере одну базовую модель, представляющая собой по меньшей мере одно правило определения предпочтений пользователя, и по меньшей мере одну функционально связанную с ней модель описания пользователя (далее, корректирующая модель), представляющая собой по меньшей мере одно правило определения предпочтений пользователей, функционально связанных с предпочтениями пользователей, определяемых базовой моделью; определяют точность сформированных предпочтений на основании наблюдаемого поведения пользователя; в случае, если определённая точность ниже заранее заданного порогового значения, выбирают корректирующую модель, связанную с базовой моделью.
В другом частном случае реализации способа данные о поведении пользователя описывают по меньшей мере: приложения, с которыми работает пользователь, время работы пользователя в указанных приложениях, выполняемые пользователем действия в указанных приложения; поисковые запросы пользователя; сайты, которые посещает пользователь, выполняемые пользователем действия на указанных сайтах; заполненные пользователем формы.
Ещё в одном частном случае реализации способа модель описания пользователя предварительно обучают таким образом, чтобы указанная модель идентифицировала пользователя с заданным уровнем достоверности.
В другом частном случае реализации способа базовая модель является корректирующей моделью для модели, являющейся корректирующей для указанной базовой модели.
Ещё в одном частном случае реализации способа базовая модель функционально связана с несколькими корректирующими моделями, при этом по меньшей мере одна из указанных корректирующих моделей функционально связана с по меньшей мере одной другой из указанных корректирующих моделей.
В другом частном случае реализации способа дополнительно в случае если точность предпочтений не выше заранее заданного порогового значения, переобучают базовую модель таким образом, чтобы для собранного поведения точность предпочтений была выше заранее заданного порогового значения.
Краткое описание чертежей
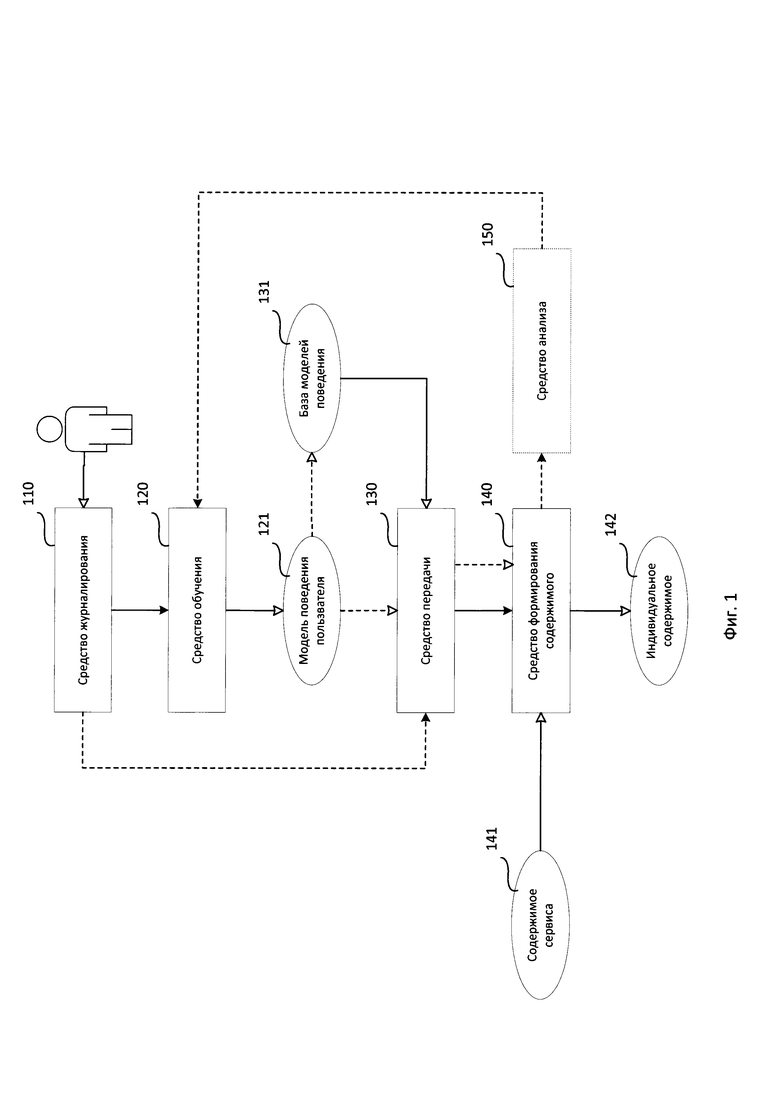
Фиг. 1 представляет структурную схему системы формирования индивидуального содержимого для пользователя сервиса.
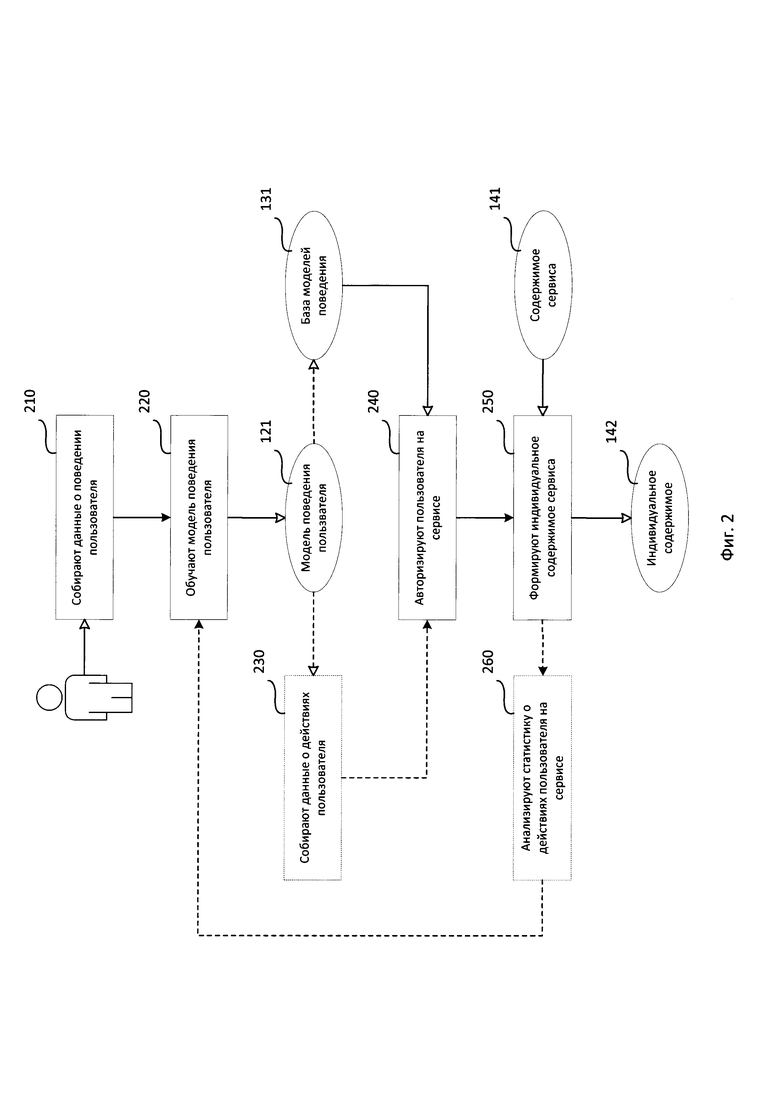
Фиг. 2 представляет структурную схему способа формирования индивидуального содержимого для пользователя сервиса.
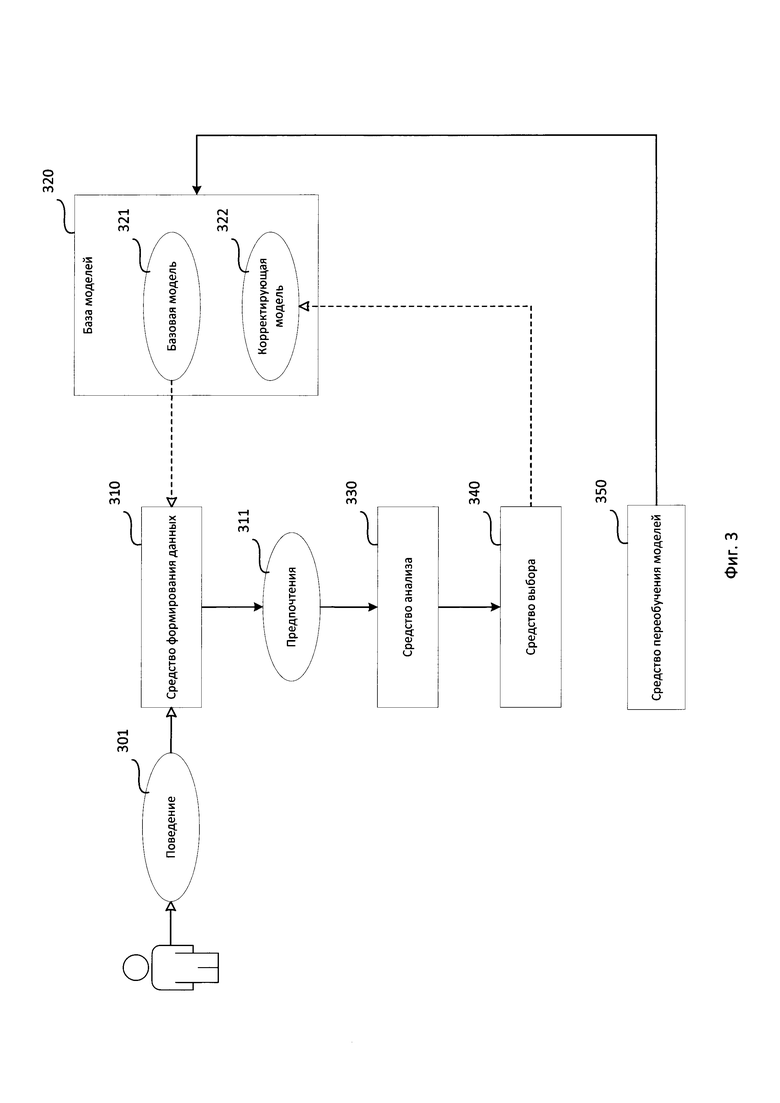
Фиг. 3 представляет структурную схему системы выбора модели описания пользователя.
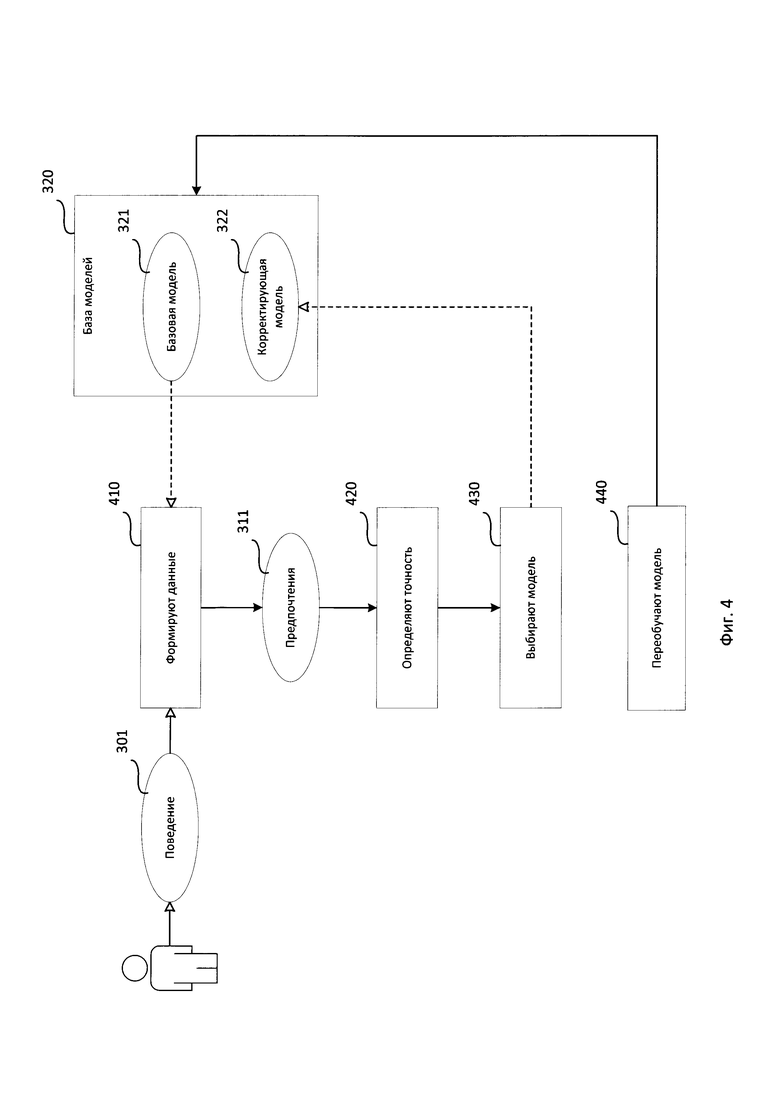
Фиг. 4 представляет структурную схему способа выбора модели описания пользователя.
Фиг. 5 представляет пример компьютерной системы общего назначения, персональный компьютер или сервер.
Хотя изобретение может иметь различные модификации и альтернативные формы, характерные признаки, показанные в качестве примера на чертежах, будут описаны подробно. Следует понимать, однако, что цель описания заключается не в ограничении изобретения конкретным его воплощением. Наоборот, целью описания является охват всех изменений, модификаций, входящих в рамки данного изобретения, как это определено приложенной формуле.
Описание вариантов осуществления изобретения
Объекты и признаки настоящего изобретения, способы для достижения этих объектов и признаков станут очевидными посредством отсылки к примерным вариантам осуществления. Однако настоящее изобретение не ограничивается примерными вариантами осуществления, раскрытыми ниже, оно может воплощаться в различных видах. Сущность, приведённая в описании, является ничем иным, как конкретными деталями, необходимыми для помощи специалисту в области техники в исчерпывающем понимании изобретения, и настоящее изобретение определяется в объёме приложенной формулы.
Фиг. 1 представляет структурную схему системы формирования индивидуального содержимого для пользователя сервиса.
Структурная схема системы формирования индивидуального содержимого для пользователя сервиса состоит из средства журналирования 110, средства обучения 120, модели поведения пользователя 121, средства передачи 130, базы моделей поведения 131, средства формирования содержимого 140, содержимого сервиса 141, индивидуального содержимого 142, средства анализа 150.
Основным назначением системы формирования индивидуального содержимого для пользователя сервиса является формирование из заранее заданного содержимого удалённого сервиса индивидуального содержимого пользователя на основании анализа его работы на своём вычислительном устройстве.
При этом по меньшей мере выступают:
• в качестве удалённого сервиса - онлайн-магазин, в качестве содержимого сервиса - совокупность товаров (включающих информацию о товаре), доступную в указанном онлайн-магазине;
• в качестве удалённого сервиса - рекламная площадка
(предоставляющая рекламу пользователям, к примеру, помещающим информационные сайты), в качестве содержимого сервиса -
рекламные блоки (медиа-данные рекламы товаров и услуг, к примеру баннеры);
• в качестве удалённого сервиса - ресурс, предоставляющий информационные услуги, в качестве содержимого сервиса - информационные, новостные и т.д. блоки данных, передаваемых пользователям (по аналогии с RSS-каналами).
Средство журналирования 110 предназначено для сбора данных (журналирования, англ. logging) об использовании пользователем вычислительного устройства и передачи собранных данных средству обучения 120.
В одном из вариантов реализации системы в качестве вычислительного устройства пользователя выступает по меньшей мере:
• персональный компьютер;
• ноутбук;
• планшет;
• мобильный телефон или смартфон.
Ещё в одном из вариантов реализации системы в качестве вычислительного устройства выступает совокупность вычислительных устройств на которых работает программное обеспечение, связанных между собой единым аккаунтом пользователя.
Например, в качестве вычислительного устройства может рассматриваться персональный компьютер пользователя, iPhone пользователя и планшет iPad, на которых работает ПО, подключённое к удалённым сервисам под единым аккаунтом (к примеру, к YouTube под одним аккаунтом) или к единому облачному сервису (к примеру, на основе технологии Handoff), т.е. вычислительное устройство, на котором используется технология единого входа (англ. Single Sign-On, SSO).
Ещё в одном из вариантов реализации системы данные о поведении пользователя включают по меньшей мере:
• названия приложений, с которыми работает пользователь, время работы пользователя в указанных приложениях, выполняемые пользователем действия в указанных приложения;
• поисковые запросы пользователях;
• адреса сайтов, которые посещает пользователь, выполняемые пользователем действия на указанных сайтах (по каким ссылкам переходил пользователь, выделял и копировал текст со страниц сайтов и т.д.);
• данные из заполненных пользователем форм;
• информацию о движениях курсора мыши, тачпада и иных устройств ввода;
• переходы на другие страницы с целевой страницы;
• идентификаторы устройств или средств ввода (англ, hardware ID);
• идентификаторы приложения-клиента.
Например, в качестве данных о поведении пользователя собирают запросы к голосовым помощникам, таким как Alisa, Alexa, Siri и т.д.
Ещё в одном примере в качестве данных о поведении пользователя собирают поисковые запросы Google и адреса сайтов, на которые переходил пользователь после каждого поискового запроса.
Ещё в одном из вариантов реализации системы, собранные данные с помощью средства журналирования 110 дополнительно анализируют с целью по меньшей мере:
• не журналировать данные, имеющие низкий приоритет при формировании индивидуального 142 содержимого для пользователя сервиса средством формирования содержимого 140;
• не журналировать дублирующие данные;
• корректировать ошибочные данные.
Средство обучения 120 предназначено для обучения модели поведения пользователя 121 на основании собранных данных и передачи обученной модели поведения пользователя 121 средству передачи 130.
В одном из вариантов реализации системы модель поведения пользователя 121 представляет собой нейронную сеть с весами, которая используется для предсказания последующего поведения пользователя.
Например, обученная модель поведения пользователя 121 формируется на основании данных о поисковых запросах пользователя таким образом, чтобы при использовании указанной модели 121 было возможным определить, какой из известных поисковых запросов (в том числе и модифицированных известных поисковых запросов, т.е. запросов, составленных на основании комбинации нескольких известных запросов) с наибольшей вероятностью будет выполнен пользователем в будущем.
Ещё в одном из вариантов реализации системы модель поведения пользователя 121 обучают таким образом, чтобы указанная модель 121 идентифицировала пользователя с заданным уровнем достоверности.
Ещё в одном из вариантов реализации системы обучение модели поведения пользователя 121 производится следующим образом:
• полученные данные поведения пользователя параметризируют в виде вектора (к примеру, производится лексический анализ, в результате которого речь переводится в слова, слова в вектор слов);
• полученный вектор очищают от низкоприоритетной информации, устраняют шумы и т.д.;
• очищенный вектор подают на вход обучающего алгоритма.
Например, для двух пользователей, которые работали на одном и том же
вычислительном устройстве, но выполняли разные действия (работая с разными приложениями, выполняя разные поисковые запросы, заполняя разные формы и т.д.), будут сформированы разные обученные модели поведения пользователя 121, при этом указанные модели будут однозначно отличаться друг от друга, а степень их отличия будет характеризовать уровень достоверности идентификации пользователя для заданной обученной модели поведения пользователя 121. При этом для сравнения указанных обученных моделей поведения пользователя 121 могут использоваться разные метрики (см. ниже). Кроме того, для одного пользователя, который работал в разное время на вычислительном устройстве, будут сформированы схожие обученные модели поведения пользователя 121, такие что с заданным уровнем достоверности будут идентифицировать только одного пользователя.
Ещё в одном из вариантов реализации системы модель поведения пользователя 121 обучается предварительно таким образом, чтобы характеризовать поведение большой группы пользователей. При этом для разных групп пользователей могут быть обучены несколько разных моделей поведения пользователя 121, чтобы характеризовать разные группы пользователей.
При этом средству обучения 120 передаётся одна из указанных моделей поведения пользователя 121 в зависимости от собранных средством журналирования 110 данных. Подобный подход позволяет снизить требования к ресурсам вычислительного устройства пользователя, поскольку выполняется не полное обучение модели поведения пользователя, а лишь дообучение.
Ещё в одном из вариантов реализации системы предобученные модели поведения пользователя 121 формируют на стороне удалённого сервиса, индивидуальное содержимое 142 которого будет формироваться в зависимости от обученной модели поведения пользователя 121 для каждого конкретного пользователя.
Например, сервис предоставляющий рекламные материалы (в виде баннеров на новостных сайтах и онлайн-магазинах), формирует разные обученные модели поведения пользователя 121, характеризующие разные группы пользователей (спортсмены, домохозяйки, студенты и т.д.). В зависимости от того, какой из сайтов-партнёров указанного сервиса посещает тот или иной пользователь, его средству формирования индивидуального содержимого для пользователя сервиса передаётся соответствующая предварительно обученная модель поведения пользователя (к примеру, для пользователей, посещающих онлайн-магазин спортивных товаров, будет передана обученная модель поведения пользователя 121, предварительно обученная под поведение спортсменов). Такая предварительно обученная модель поведения пользователя 121 настроена (обучена) так, чтобы учитывать поисковые запросы пользователя на сайтах со спортивной тематикой, использование спортивных приложений (трекеров, пульсометров и т.д.), и игнорирует остальные данные, собираемые средством журналирования 110 (т.е. остальные данные вносят незначительный или нулевой вклад в результат работы обученной модели поведения пользователя).
Средство передачи 130 предназначено для передачи обученной модели 121 средству формирования содержимого 140.
При этом средство передачи 130 также производит проверку выполнения условий, при которых требуется передача обученной модели 121, авторизацию пользователя и т.д. (см. ниже).
База моделей поведения 131 содержит модели поведения пользователя, собранные при регистрации пользователя на сервисе.
Например, сервис по продаже книг онлайн может содержать базу зарегистрированных пользователей, при этом в качестве регистрационной информации передают не логин и пароль пользователя, а обученную модель 121 своего поведения, при этом сама упомянутая модель 121 строилась с использованием предоставленного сервисом ПО, включающего в себя по меньшей мере средство журналирования 110, средство обучения 120 и средство передачи 130. Таким образом, после первого посещения пользователем сервиса, после того как формируется обученная модель 121 и передаётся сервису, она размещается в базе моделей поведения 131. И при повторных посещениях сервиса пользователем передают (а точнее, передаёт средство передачи 130) дообученную модель поведения пользователя 121, которая может отличаться от переданной ранее модели поведения пользователя 121, но не более той меры, которая позволяет однозначно идентифицировать пользователя на указанном сервисе (см. выше).
В одном из вариантов реализации системы средство передачи 130 представляет собой по меньшей мере:
• отдельное приложение, перехватывающее запросы сервисов на предоставление им обученной модели поведения пользователя 121 в качестве идентификатора пользователя;
• плагин, установленный в браузере и автоматически предоставляющий обученную модель поведения пользователя 121 сервису при переходе пользователя на сайт указанного сервиса;
• сценарий (например, в виде JS-кода), содержащий элементы обученной модели поведения пользователя 121 и внедряемый на сайт сервиса.
Например, средство передачи 130 представляет собой плагин к браузеру Google Chrome, устанавливаемый на вычислительной системе пользователя по запросу сайта онлайн-магазина продажи книг при первом посещении указанного сайта. Данный плагин передаёт сформированную модель поведения пользователя 121 в качестве идентификатора пользователя каждый раз при посещении указанного сайта.
Ещё в одном из вариантов реализации системы средство передачи 130 передаёт обученную модель поведения пользователя 121 средству формирования содержимого 140 по меньшей мере:
• с заранее заданной периодичностью;
• по запросу средства формирования содержимого 140.
Например, если пользователь пользуется некоторым ПО, предоставленным сервисом, данное ПО (описанное выше) может передавать сервису обновленные (дообученные) модели поведения пользователя 121 с периодичностью один раз в сутки. В результате пользователь при посещении сервиса по меньшей мере: 1) всегда авторизирован на сервисе; 2) получает релевантную и свежую информацию, т.е. индивидуальное содержимое 142 сервиса (см. ниже).
Ещё в одном из вариантов реализации системы средство передачи 130 дополнительно предназначено для авторизации пользователя на сервисе на основании результата сравнения переданной средству формирования содержимого модели поведения пользователя 121 с моделями из базы моделей поведения 131.
Например, если на одном вычислительном устройстве работает два пользователя, то обученная модель поведения пользователя №1 должна отличаться от обученной модели пользователя №2 настолько, чтобы с заданным уровнем достоверности можно было различать указанных пользователей. При этом, если на разных вычислительных устройствах в разное время работал один и тот же пользователь, то обученная модель пользователя, сформированная на основании данных с вычислительного устройства №1, должна быть схожа с обученной моделью пользователя, сформированная на основании данных с вычислительного устройства №2.
Ещё в одном из вариантов реализации системы для сравнения двух моделей поведения применяют по меньшей мере:
• матрицы диаграмм рассеяния;
• индивидуальные диаграммы рассеяния;
• тесты статистической значимости.
Например, в качестве диаграммы рассеяния выступают параметры нейронной сети.
В качестве способа сравнения двух обученных моделей поведения может выступать анализ результата работы двух обученных моделей поведения над заранее подготовленной тестовой выборкой данных. При этом тестовая выборка может подготавливаться из расчёта, какие действия пользователи могут (или должны) выполнять на указанном сервисе. К примеру, в тестовую выборку могут входить поисковые запросы по товарам онлайн-магазина, на который зашли пользователи, или поисковые запросы по товарам и услугам, по показанной пользователям рекламе и т.д.
Например, для пользователя №1 модель поведения обучалась на поисковых запросах пользователя №1 и некоторой группы иных пользователей, а для пользователя №2 модель поведения обучалась на поисковых запросах пользователя №2 и некоторой (не обязательно такой же, как при обучении модели поведения пользователя №1) группы иных пользователей. В качестве проверки, насколько обученные модели поведения пользователей № 1 и №2 схожи, моделям на вход подаётся заранее подготовленная тестовая выборка поисковых запросов, а на выходе вычисляются вероятности того, что тот или иной запрос принадлежит соответствующему пользователю (для обученной модели поведения пользователя №1 - пользователю №1, для обученной модели поведения пользователя №2 - пользователю №2). Сравнение полученных результатов (любым известным из уровня техники способом) определяет то, являются ли указанные модели поведения пользователей схожими или отличными.
Средство формирования содержимого 140 предназначено для формирования индивидуального содержимого для пользователя сервиса 142 на основании заранее заданного содержимого сервиса 141 с учётом предоставленной средством передачи 130 модели поведения 121.
В одном из вариантов реализации системы в качестве заданного содержимого сервиса 141 выступает по меньшей мере:
• список товаров и услуг, доступ к которым может быть предоставлен пользователю, при этом в качестве доступа к товару понимается предоставление пользователю информации о товаре или услуге и возможности совершить заказ товара или услуги, в том числе и произвести покупку (оплату) заказанного товара или услуги;
• данные, на доступ к которым пользователю выдано разрешение на основании анализа предоставленной средством передачи 130 модели поведения 121.
Например, пользователь заходит на сервис онлайн-продаж бытовой техники, после чего средство передачи 130 передаёт сервису модель поведения пользователя 121, обученную на поисковых запросах пользователя. Предоставленная обученная модель поведения пользователя 121 будет впоследствии использоваться для идентификации пользователя и авторизации его на данном сервисе. На основании предоставленной обученной модели пользователя 121 и заранее подготовленных поисковых запросов по товарам, предоставляемых сервисом онлайн-продаж, определяется, какие из товаров более приоритетны указанному пользователю (в первую очередь, товары, на которые ведут поисковые запросы, сопутствующие товары и т.д.), и на основании определённых товаров для указанного пользователя формируются каталоги и ценники.
Таким образом, пользователю предоставляется некоторая заранее подготовленная информация на основании его персональных данных (к примеру, поисковых запросов) без предоставления сервису самих поисковых запросов, а только модели поведения пользователя 121, обученной на указанных поисковых запросах, что в свою очередь повышает информационную безопасность персональных данных пользователя.
Ещё в одном примере в качестве сервиса выступает рекламное агентство, предоставляющее через разные площадки (сайты разной тематики: новостные сайты, форумы, онлайн-магазины и т.д.) контекстную рекламу пользователям. Для более точной работы сервиса, т.е. для подбора более релевантной рекламы для каждого конкретного пользователя требуется анализ данных пользователя: данных о поведении пользователя на вычислительном устройстве и в сети, о том, какими приложениями пользуется пользователь, какие запросы формирует, какие сайты посещает и т.д. Основная проблема работы сервиса заключается в сборе указанных данных, с одной стороны, сбор многих данных без согласия пользователя незаконен, с другой стороны, даже согласованный с пользователем сбор данных может привести к несанкционированному доступу к собранным данным, репутационным и финансовым рискам для пользователя. Поэтому для решения поставленной задачи хорошим решением является использование обученной на вычислительных устройствах пользователя модели поведения пользователя 121. Такая модель не содержит данных пользователя (в том числе и персональных данных), но при этом может использоваться для идентификации пользователя, предсказания его поведения, интересов и т.д.
Недостатком использования обученных моделей поведения пользователя 121 являются высокие требования к вычислительным ресурсам вычислительного устройства пользователя. Даже если обучение модели поведения пользователя на вычислительном устройстве пользователя осуществляется в реальном режиме времени, это может заметно для пользователя влиять на работу указанного вычислительного устройства как такового, а также на работу используемых пользователем приложений. К примеру, вычислительное устройство пользователя может работать медленнее, расход оперативной памяти быть выше, а время автономной работы для мобильных устройств ниже в случае, когда на вычислительном устройстве пользователя осуществляется обучение модели поведения пользователя 121.
В связи с указанными проблемами целесообразно использовать предварительно обученные модели поведения пользователя 121, для использования которых требуется лишь незначительное дообучение. Такой подход позволяет решить все упомянутые проблемы:
• пользователю предоставляется модель поведения пользователя 121, предназначенная для формирования индивидуального содержимого 142 для пользователя конкретного сервиса, что значительно улучшает точность формирования указанного индивидуального содержимого 142;
• обучение (дообучение) модели поведения пользователя 121 не приводит к передаче данных пользователя за пределы вычислительного устройства (например, по компьютерной сети на специализированный сервис), что повышает информационную безопасность данных пользователя;
• дообучение модели поведения пользователя 121, а не полноценное обучение модели поведения пользователя 121, снижает требования к вычислительным ресурсам вычислительного устройства пользователя.
В описанном выше примере рекламного агентства для разных площадок (сайтов) используются разные предобученные модели поведения пользователя 121. К примеру, для новостных сайтов предобучаются модели таким образом, чтобы учитывать поисковые запросы пользователей на интересующие их новости, определять, какие темы наиболее интересны пользователям и т.д., на спортивных сайтах - таким образом, чтобы учитывать используемые на вычислительных устройствах пользователей спортивные приложения и т.д. Такие модели поведения пользователя 121 выдаются пользователям в качестве идентификаторов для посещения соответствующих сайтов (например, для получения индивидуальных новостей, доступа к форумам, личным кабинетам и т.д.) и затем предоставляются от пользователей соответствующим сайтам (при заходе на сайты, например с помощью специальных плагинов, установленных в браузерах), а от сайтов - рекламному агентству (сервису). На основании уже полностью обученных моделей поведения пользователя 121 рекламное агентство определяет, какую именно рекламу требуется показывать для конкретного пользователя.
Дополнительно разные рекламные агентства (разные сервисы) могут обмениваться между собой указанными обученными и предобученными моделями поведения пользователя 121 для повышения точности формирования индивидуального содержимого для пользователя конкретного сайта.
Средство анализа 150 предназначено для сбора данных о действиях пользователя на сервисе, анализа статистики о действиях пользователя на сервисе на основании собранных данных и вынесения решения о необходимости переобучения модели поведения пользователя 121.
На основании того, какие именно действия выполняет пользователь (к примеру, какими товарами интересуется, какие покупки делает и т.д.), может быть вынесено решение о необходимости переобучения или дообучения модели поведения пользователя 121 с тем, чтобы при последующих посещениях сервиса для указанного пользователя формировалось более релевантное содержимое сервиса 142. Оценкой релевантности может служить как количественная характеристика времени, проведённого на сервисе, так и количество сделанных или отклонённых заказов, сообщений в службу поддержки и т.д.
В одном из вариантов реализации системы модель поведения пользователя 121 может формироваться (обучаться) не полностью, а дообучаться уже готовая, частично обученная модель поведения «универсального» пользователя. Например, в случае, когда обученная модель поведения пользователя 121 представляет собой нейронную сеть, дообучение заключается в корректировке весов слоёв указанной нейронной сети на основании данных, полученных от средства формирования содержимого 140.
Например, в случае, когда в качестве сервиса выступает онлайн-магазин, при первом посещении пользователем сайта онлайн-магазина в зависимости от тех действий, которые пользователя выполняет на сайте (например, какие каталоги просматривает, какие товары ищет и т.д.), для доступа к своему личному кабинету в данном онлайн-магазине пользователю предоставляется в качестве идентификатора уже предобученная модель поведения пользователя 121, учитывающая некоторые поисковые запросы, которые уже выполнял пользователь, и настроенная на более точное предсказание того, что в указанном онлайн-магазине требуется данному пользователю. При этом при предварительном обучении модели поведения пользователя 121 учитывалось поведение большой группы людей со схожими запросами, поэтому, с одной стороны, указанная модель поведения пользователя 121 подходит большому кол-ву пользователей, а с другой стороны использование такой модели поведения пользователя 121 при формировании индивидуального содержимого для пользователя данного онлайн-магазина может приводить к менее корректным результатам. Поэтому и требуется дообучать предоставленную модель поведения 121 пользователя на вычислительном устройстве пользователя. Таким образом частично снижаются требования к вычислительным ресурсам вычислительного устройства пользователя, и ускоряется обучение модели поведения пользователя за счёт того, что не требуется проходить весь цикл обучения с большими обучающими выборками и т.д. При этом, если одна и та же первоначально обученная модель поведения пользователя 121 будет предоставлена двум разным пользователям, то после дообучения на их вычислительных устройствах в зависимости от действий пользователей, указанные две модели будет отличаться (см. выше).
Фиг. 2 представляет структурную схему способа формирования индивидуального содержимого для пользователя сервиса.
Структурная схема способа формирования индивидуального содержимого для пользователя сервиса содержит этап 210, на котором собирают данные о поведении пользователя, этап 220, на котором, обучают модель поведения пользователя, этап 230, на котором собирают данные о действиях пользователя, этап 240, на котором авторизируют пользователя на сервисе, этап 250, на котором формируют индивидуальное содержимое пользователя, этап 260, на котором анализируют статистику о действиях пользователя на сервисе.
На этапе 210 с помощью средства журналирования 110 собирают данные об использовании пользователем вычислительного устройства.
На этапе 220 с помощью средства обучения 120 обучают модель поведения пользователя 121 на основании собранных на этапе 210 данных таким образом, чтобы модель идентифицировала пользователя с заданным уровнем достоверности.
На этапе 230 с помощью средства анализа 150 собирают данные о действиях пользователя на сервисе.
На этапе 240 с помощью средства передачи 130 авторизируют пользователя на сервисе на основании результата сравнения предоставленной на этапе 220 модели поведения пользователя 121с моделями из базы моделей поведения 131.
На этапе 250 с помощью средства формирования содержимого 140 формируют индивидуальное содержимое для пользователя сервиса 142 на основании заранее заданного содержимого сервиса 141 с учётом предоставленной средством передачи 130 модели поведения 121.
На этапе 260 с помощью средства анализа 150 анализируют статистику о действиях пользователя на сервисе на основании собранных на этапе 230 данных и выносят решение о необходимости переобучения модели поведения пользователя 121.
Фиг. 3 представляет структурную схему системы выбора модели описания пользователя.
Структурная схема системы выбора модели описания пользователя состоит из средства формирования данных 310, базы моделей 320, средства анализа 330, средства выбора 340, средства переобучения моделей 350.
Средство формирования данных 310 предназначено для формирования данных о предпочтениях пользователя (далее — предпочтения 311) на основании заранее собранных данных о поведении пользователя (далее — поведение 301) и заранее выбранной из базы моделей 320 модели описания пользователя (далее — базовая модель 321), при этом база моделей 320 содержит по меньшей мере одну базовую модель 321, представляющую собой по меньшей мере одно правило определения предпочтений пользователя, и по меньшей мере одну функционально связанную с ней модель описания пользователя (далее — корректирующая модель 322), представляющую собой по меньшей мере одно правило определения предпочтений пользователей, функционально связанных с предпочтениями пользователей, определяемых базовой моделью.
Модели описания пользователя 321 и 322 могут использоваться в качестве модели поведения пользователя 121, описанной на Фиг. 1. При этом в качестве базы моделей 320 выступает база моделей поведения 131. Такие модели описания пользователя 321 и 322 могут использоваться для формирования индивидуального содержимого для пользователя некоторого сервиса, что повышает точность (и, по сути, увеличивает эффективность) сформированного содержимого для конкретного пользователя.
В одном из вариантов реализации системы данные о поведении пользователя 301 описывают по меньшей мере:
• приложения, с которыми работает пользователь, время работы
пользователя в указанных приложениях, выполняемые
пользователем действия в указанных приложениях;
• поисковые запросы пользователя;
• сайты, которые посещает пользователь, выполняемые
пользователем действия на указанных сайтах;
• заполненные пользователем формы.
Например, в качестве приложений могут выступать браузеры для интернет-сёрфинга, ПО электронного документооборота, такие как OpenOffice, приложения для фото и видеосъёмки и т.д.
Еще в одном примере в качестве поисковых запросов могут выступать данные, отправляемые браузером на заранее заданные поисковые сайты, такие как google.com.
Ещё в одном из вариантов реализации системы модель описания пользователя (по меньшей мере базовая модель 321 и/или корректирующая модель 322) предварительно обучают таким образом, чтобы указанная модель идентифицировала пользователя с заданным уровнем достоверности.
Ещё в одном из вариантов реализации системы модель описания пользователя (по меньшей мере базовая модель 321 и/или корректирующая модель 322) характеризуются предсказательной эффективность, т.е. показателем, характеризующим настолько указанная модель может точно предсказывать во времени по меньшей мере:
• действия пользователя на вычислительном устройстве пользователя, на котором функционирует описываемая система;
• используемые ресурсы на вычислительном устройстве пользователя;
• индивидуальное содержимое, формируемое сервисами на основании по меньшей мере:
о действиях пользователя (см. Фиг. 1); о предпочтения пользователя.
Ещё в одном из вариантов реализации системы предсказательная эффективность представляет собой численное значение от 0 (предсказания модели о действиях или предпочтениях пользователя носят случайных характер) до 1 (модель точно предсказывает любые действия или предпочтения пользователя).
Например, если действия пользователя заключаются в запуске приложения А или приложения Б, то нулевая предсказательная эффективность будет говорить о том, что приложение А или Б пользователь выбирает совершенно случайно.
Ещё в одном из вариантов реализации системы базовая модель 321 является корректирующей моделью 322 для модели, являющейся корректирующей для указанной базовой модели 321.
Например, базовая модель 321 и корректирующая модель 322 могут образовывать кольцо базовая модель —> корректирующая модель базовая модель —> ... В этом случае выбор модели описания пользователя может выполняться так: выбирается базовая модель 321, обучается базовая модель
1 ив результате выбирается корректирующая модель 322, обучается корректирующая модель 322 и выбирается базовая модель 321 и т.д. В случае, когда модели могут передаваться через вычислительный центр разным пользователям, один пользователь может использовать в таком кольце базовую 321 и корректирующую 322 модели, обученные другими пользователями, что в свою очередь увеличивает предсказательную эффективность таких моделей.
Ещё в одном из вариантов реализации системы базовая модель 321 функционально связана с несколькими корректирующими моделями 322, при этом по меньшей мере одна из указанных корректирующих моделей 322 функционально связана с по меньшей мере одной другой из указанных корректирующих моделей 322.
Например, базовая модель 321 и корректирующие модели 322 могут образовывать дерево, где корректирующие модели 322 представляют собой дочерние узлы, а базовая модель 321 - родительский узел. В этом случае выбор модели описания пользователя может выполняться так: выбирается базовая модель 321, обучается базовая модель 321 и в результате выбирается одна корректирующая модель 322, обучается указанная корректирующая модель
2 и выбирается следующая корректирующая модель 322 и т.д. В случае, когда модели могут передаваться через вычислительный центр разным пользователям, один пользователь может использовать в таком дереве базовую 321 и корректирующие 322 модели, обученные другими пользователями, что в свою очередь увеличивает предсказательную эффективность таких моделей.
Корректирующая модель 322 призвана исправлять неточности работы базовой модели 321, вызванные тем, что базовая модель 321 предназначена для предсказаний в более широкой области пользовательских интересов, чем корректирующая модель 322, но зато корректирующая модель 322 предназначена для более точных предсказаний в более узкой области пользовательских интересов.
Средство анализа 330 предназначено для определения точности сформированных предпочтений 311 на основании наблюдаемого поведения пользователя.
В одном из вариантов реализации системы точность сформированных предпочтений представляет собой численное значение от 0 (верно не определено ни одно из предпочтений пользователя) до 1 (все предпочтения пользователя определены верно).
Например, на основании поведения пользователя сервис предоставляет пользователю на выбор набор товаров, которые пользователь мог бы приобрести. Если какой-либо из предложенных товаров соответствует интересам пользователя и пользователь готов (даже если и не будет впоследствии этого делать) его приобрести, то это увеличивает точность сформированных предпочтений. Если пользователь готов приобрести все предложенные ему товары, то точность предпочтений равна 1, если пользователь не готов (т.е. полностью не заинтересован) в приобретении предложенных товаров, то точность предпочтений равна 0.
Ещё в одном из вариантов реализации системы точность предпочтений вычисляется на основании обратной связи с пользователем.
Например, в предыдущем примере пользователь мог бы отметить каждый предложенный товар как соответствующий или не соответствующий его предпочтениям и в зависимости от этого модель описания пользователя может быть переобучена (с помощью средства переобучения моделей 350), чтобы в следующий раз на основании те же данных сделать уже более точное предсказание о предпочтении пользователя.
Средство выбора 340 предназначено для выборки корректирующей модели 322, связанной с базовой моделью 321 в случае, если определённая точность ниже заранее заданного порогового значения.
В одном из случаев реализации системы может быть выбрана уже применяемая модель описания пользователя.
Например, если определённая точность будет выше заранее заданного порогового значения, то может при использовании базовой модели 321 может быть выбрана опять та же самая базовая модель 321 или при использовании одной из корректирующих моделей 322 может быть выбрана опять та же самая корректирующая модель 322.
Средство переобучения моделей 350 предназначено для переобучения базовой модели 321 таким образом, чтобы для собранного поведения 301 точность предпочтений 311 была выше заранее заданного порогового значения, в случае если точность предпочтений 311 не выше заранее заданного порогового значения.
В одном из случаев реализации системы в качестве средства переобучения 350 может выступать средство обучения 120, описанное на Фиг. 1.
В общем случае выбор модели описания пользователя приводит к тому, что оценка поведения пользователя (или оценка описания пользователя) выполняется более эффективно, а полученные результаты (выраженные в индивидуальном содержимом для пользователя сервиса) более подходят указанному пользователю.
В качестве примера работы системы выбора модели описания пользователя можно привести следующую ситуацию:
На мобильном устройстве пользователя установлено ПО, осуществляющее сбор данных о его поведении (т.е. о сетевой активности, действиях, выполняемых на мобильном устройстве и т.д.) и обучение (дообучение и переобучение) на основании собранных данных о поведении пользователя моделей описания пользователя. Указанное ПО использует единовременно одну из моделей описания пользователя, предоставляемых некоторым вычислительным центром - третьей стороной, обеспечивающей функционирование сервиса, используемого пользователем и описанного на Фиг. 1. Т.е. вычислительный центр в одном из случаев реализации системы содержит базу моделей поведения 131 (в частности, базу моделей 320), из которой предоставляет пользователям и сервисам модели, в том числе и заранее обученные модели, а также сохраняет в указанной базе обученные модели, полученные от пользователей и сервисов (см. ниже).
К примеру, изначально ПО на мобильном устройстве пользователя работает с моделью описания пользователя, предназначенной для определения, чем именно пользователь на мобильном устройстве активнее всего занимается (интернет-серфинг, работа с документами, звонки, съёмка фото или видео и т.д.), при этом при использовании пользователем мобильного устройства данная модель описания пользователя (далее — модель №1) постоянно обучается, повышая тем самым свою предсказательную эффективность (т.е. модель №1 более точно может описывать, чем пользователь будет заниматься в заданный период времени). Такая обученная модель №1 впоследствии будет передана вычислительному центру, от которого она может быть передана другому пользователю, обладающему схожими параметрами с указанным пользователем (см. Фиг. 1), или другому сервису (для последующей передачи ее пользователю, использующему указанный сервис). Таким образом следующий пользователь начнет работу с уже заранее подготовленной и, следовательно, более эффективной моделью описания пользователя. Возвращаясь к первому пользователю: после того как модель №1 достигла определённой предсказательной эффективности и стала показывать, что пользователь в основном занимается интернет-сёрфингом, пользователю взамен модели №1 (которая, по сути, являлась базовой моделью 321) предоставляется новая модель описания пользователя (далее — модель №2), предназначенная для определения интересов при осуществлении интернет-сёрфинга (которая, по сути, является корректирующей моделью 322). При этом модель №2 функционально связана с моделью №1, поскольку более подробно описывает одну из областей, в которых работает модель № 1.
Работа с моделью №2 аналогична работе с моделью № 1, только в своей заданной области применения: она также постоянно обучается в зависимости от действий пользователя (т.е. в зависимости от того, какие он сайты посещает и какие поисковые запросы выполняет) и также может быть впоследствии передана вычислительному центру для передачи другому пользователю или сервису и получения следующей модели. После определённого момента пользователь вместо модели №2 от вычислительного центра получает новую модель, предназначенную для определения, какие товары пользователь чаще просматривает на самых посещаемых ресурсах (далее — модель №3), данная модель (аналогично модели №1 и модели №2) также постоянно обучается, повышая свою предсказательную эффективность.
И именно эта модель может использоваться в системе формирования индивидуального содержимого для пользователя сервиса (см. Фиг. 1). Впоследствии после модели №3 пользователю может быть передана опять модель №1, но уже переобученная на других пользователях и обладающая еще большей предсказательной эффективностью, чем та модель №1, которая была у пользователя изначально.
Ещё в одном примере обученные модели могут предоставляться вычислительным центром сервисам (например, сайтам для определения, какое содержимое формировать для конкретного пользователя). В этом случае весь описанный выше процесс может происходить по меньшей мере:
• целиком на стороне сервисов, при этом для каждого пользователя может использоваться как своя обученная модель, так и одна обученная модель может использоваться для нескольких пользователей;
• совместно на стороне пользователя (где происходит обучение модели) и на стороне сервиса, где происходит использование модели для формирования индивидуального содержимого сервиса.
Фиг. 4 представляет структурную схему способа выбора модели описания пользователя.
Структурная схема способа выбора модели описания пользователя содержит этап 410, на котором формируют данные, этап 420, на котором определяют точность, этап 430, на котором выбирают модель, этап 440, на котором переобучают модель.
На этапе 410 с помощью средства формирования данных 310 формируют данные о предпочтениях пользователя (далее — предпочтения 311) на основании заранее собранных данных о поведении пользователя (далее — поведение 301) и заранее выбранной из базы моделей 320 модели описания пользователя (далее, базовая модель 321), при этом база моделей 320 содержит по меньшей мере одну базовую модель 321, представляющую собой по меньшей мере одно правило определения предпочтений пользователя, и по меньшей мере одну функционально связанную с ней модель описания пользователя (далее, корректирующая модель 322), представляющую собой по меньшей мере одно правило определения предпочтений пользователей, функционально связанных с предпочтениями пользователей, определяемых базовой моделью 321.
На этапе 420 с помощью средства анализа 330 определяют точность сформированных предпочтений 311 на основании наблюдаемого поведения 301 пользователя.
На этапе 430 с помощью средства выбора 340 в случае, если определённая точность ниже заранее заданного порогового значения, выбирают корректирующую модель 322, связанную с базовой моделью 321.
На этапе 440 с помощью средства обучения моделей 350 в случае, если точность предпочтений не выше заранее заданного порогового значения, переобучают базовую модель 321 таким образом, чтобы для собранного поведения точность предпочтений была выше заранее заданного порогового значения.
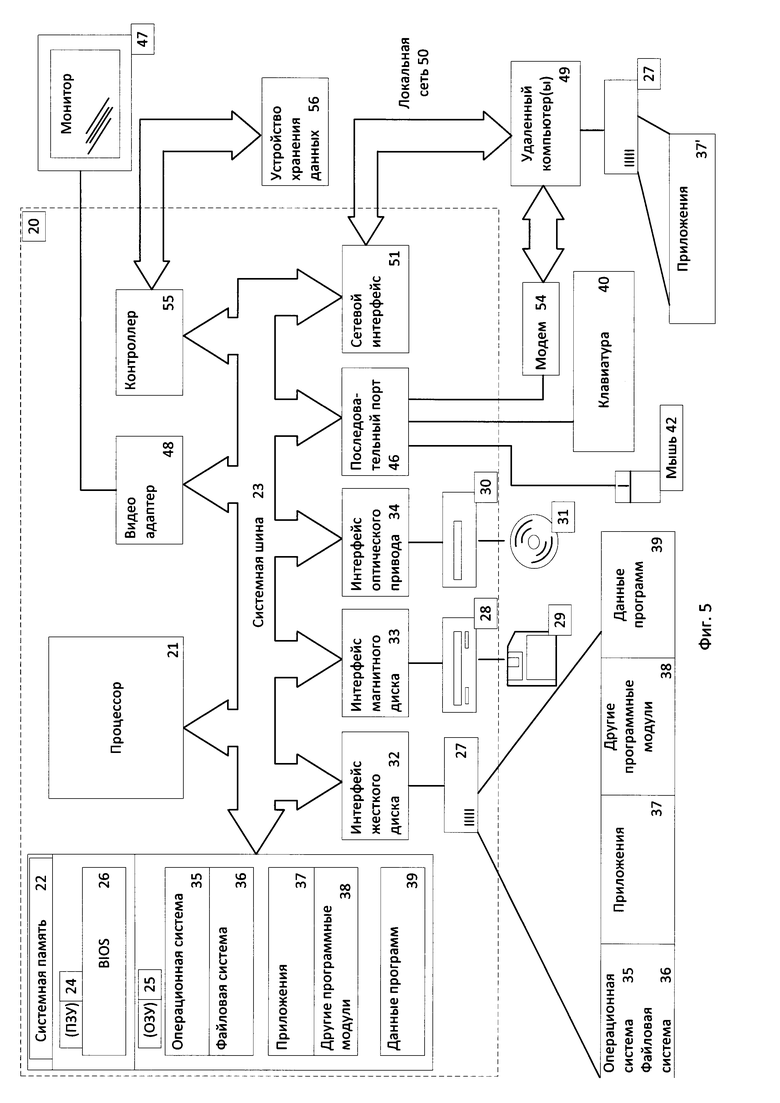
Фиг. 5 представляет пример компьютерной системы общего назначения, персональный компьютер или сервер 20, содержащий центральный процессор 21, системную память 22 и системную шину 23, которая содержит разные системные компоненты, в том числе память, связанную с центральным процессором 21. Системная шина 23 реализована, как любая известная из уровня техники шинная структура, содержащая в свою очередь память шины или контроллер памяти шины, периферийную шину и локальную шину, которая способна взаимодействовать с любой другой шинной архитектурой. Системная память содержит постоянное запоминающее устройство (ПЗУ) 24, память с произвольным доступом (ОЗУ) 25. Основная система ввода/вывода (BIOS) 26, содержит основные процедуры, которые обеспечивают передачу информации между элементами персонального компьютера 20, например, в момент загрузки операционной системы с использованием ПЗУ 24.
Персональный компьютер 20 в свою очередь содержит жёсткий диск 27
для чтения и записи данных, привод магнитных дисков 28 для чтения и записи
на сменные магнитные диски 29 и оптический привод 30 для чтения и записи на сменные оптические диски 31, такие как CD-ROM, DVD-ROM и иные оптические носители информации. Жёсткий диск 27, привод магнитных дисков 28, оптический привод 30 соединены с системной шиной 23 через интерфейс жёсткого диска 32, интерфейс магнитных дисков 33 и интерфейс оптического привода 34 соответственно. Приводы и соответствующие компьютерные носители информации представляют собой энергонезависимые средства хранения компьютерных инструкций, структур данных, программных модулей и прочих данных персонального компьютера 20.
Настоящее описание раскрывает реализацию системы, которая использует жёсткий диск 27, сменный магнитный диск 29 и сменный оптический диск 31, но следует понимать, что возможно применение иных типов компьютерных носителей информации 56, которые способны хранить данные в доступной для чтения компьютером форме (твердотельные накопители, флеш карты памяти, цифровые диски, память с произвольным доступом (ОЗУ) и т.п.), которые подключены к системной шине 23 через контроллер 55.
Компьютер 20 имеет файловую систему 36, где хранится записанная операционная система 35, а также дополнительные программные приложения 37, другие программные модули 38 и данные программ 39. Пользователь имеет возможность вводить команды и информацию в персональный компьютер 20 посредством устройств ввода (клавиатуры 40, манипулятора «мышь» 42).
Могут использоваться другие устройства ввода (не отображены): микрофон, джойстик, игровая консоль, сканер и т.п. Подобные устройства ввода по своему обычаю подключают к компьютерной системе 20 через последовательный порт 46, который в свою очередь подсоединён к системной шине, но могут быть подключены иным способом, например, при помощи параллельного порта, игрового порта или универсальной последовательной шины (USB). Монитор 47 или иной тип устройства отображения также подсоединён к системной шине 23 через интерфейс, такой как видеоадаптер 48. В дополнение к монитору 47, персональный компьютер может быть оснащён другими периферийными устройствами вывода (не отображены), например, колонками, принтером и т.п.
Персональный компьютер 20 способен работать в сетевом окружении, при этом используется сетевое соединение с другим или несколькими удалёнными компьютерами 49. Удалённый компьютер (или компьютеры) 49 являются такими же персональными компьютерами или серверами, которые имеют большинство или все упомянутые элементы, отмеченные ранее при описании существа персонального компьютера 20, представленного на Фиг. 5. В вычислительной сети могут присутствовать также и другие устройства, например, маршрутизаторы, сетевые станции, пиринговые устройства или иные сетевые узлы.
Сетевые соединения могут образовывать локальную вычислительную сеть (LAN) 50 и глобальную вычислительную сеть (WAN). Такие сети применяются в корпоративных компьютерных сетях, внутренних сетях компаний и, как правило, имеют доступ к сети Интернет. В LAN- или WAN- сетях персональный компьютер 20 подключён к локальной сети 50 через сетевой адаптер или сетевой интерфейс 51. При использовании сетей персональный компьютер 20 может использовать модем 54 или иные средства обеспечения связи с глобальной вычислительной сетью, такой как Интернет. Модем 54, который является внутренним или внешним устройством, подключён к системной шине 23 посредством последовательного порта 46. Следует уточнить, что сетевые соединения являются лишь примерными и не обязаны отображать точную конфигурацию сети, т.е. в действительности существуют иные способы установления соединения техническими средствами связи одного компьютера с другим.
В заключение следует отметить, что приведённые в описании сведения являются примерами, которые не ограничивают объём настоящего изобретения, определённого формулой.
Изобретение относится к области вычислительной техники. Технический результат заключается в повышении точности выбора модели описания пользователя. Технический результат достигается за счет формирования данных о предпочтениях пользователя (далее, предпочтения) на основании заранее собранных данные о поведении пользователя (далее, поведение) и заранее выбранной из базы моделей модели описания пользователя (далее, базовая модель), при этом база моделей содержит базовую модель, представляющую собой правило определения предпочтений пользователя, и функционально связанную с ней модель описания пользователя (далее, корректирующая модель), представляющую собой правило определения предпочтений пользователей, функционально связанных с предпочтениями пользователей, определяемых базовой моделью; определения точности сформированных предпочтений на основании наблюдаемого поведения пользователя; выбора корректирующей модели, связанной с базовой моделью, в случае если определенная точность ниже заранее заданного порогового значения. 2 н. и 8 з.п. ф-лы, 5 ил.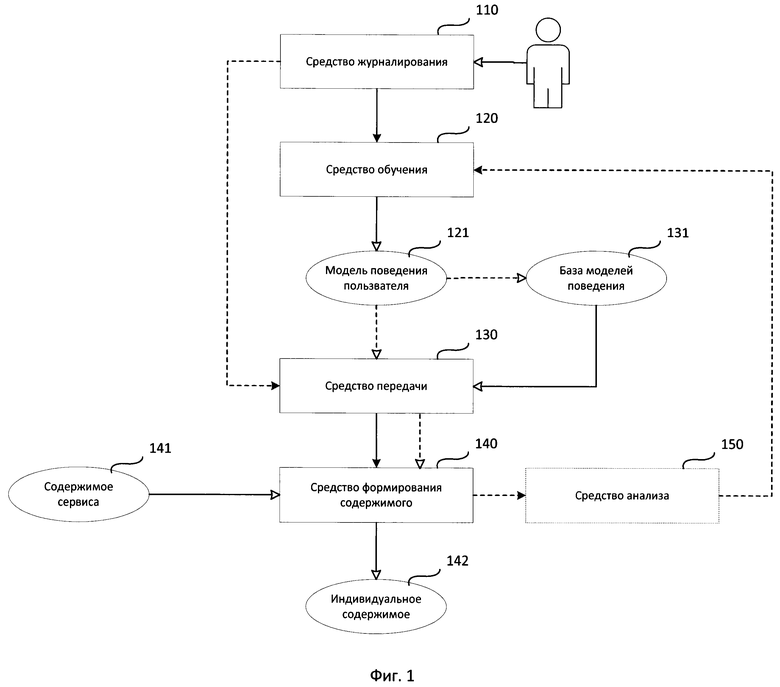
1. Система выбора модели описания пользователя, которая содержит:
а) средство формирования данных, предназначенное для формирования данных о предпочтениях пользователя (далее предпочтения) на основании заранее собранных данных о поведении пользователя (далее поведение) и заранее выбранной из базы моделей модели описания пользователя (далее базовая модель) и передаче сформированных данных средству анализа, при этом база моделей содержит по меньшей мере одну базовую модель, представляющую собой по меньшей мере одно правило определения предпочтений пользователя, и по меньшей мере одну функционально связанную с ней модель описания пользователя (далее корректирующая модель), представляющую собой по меньшей мере одно правило определения предпочтений пользователей, функционально связанных с предпочтениями пользователей, определяемых базовой моделью;
б) средство анализа, предназначенное для определения точности сформированных предпочтений на основании наблюдаемого поведения пользователя и передачи определённой точности средству выбора;
в) средство выбора, предназначенное для выборки корректирующей модели, связанной с базовой моделью, в случае если определённая точность ниже заранее заданного порогового значения, и передачи выбранной корректирующей модели средству переобучения моделей;
г) средство переобучения моделей, предназначенное для сбора данных о поведении пользователя и переобучения базовой модели таким образом, чтобы для собранных данных о поведении пользователя точность определённых предпочтений была выше заранее заданного порогового значения, в случае если точность предпочтений не выше заранее заданного порогового значения.
2. Система по п.1, в которой данные о поведении пользователя описывают по меньшей мере:
• приложения, с которыми работает пользователь, время работы пользователя в указанных приложениях, выполняемые пользователем действия в указанных приложениях;
• поисковые запросы пользователя;
• сайты, которые посещает пользователь, выполняемые пользователем действия на указанных сайтах;
• заполненные пользователем формы.
3. Система по п.1, в которой модель описания пользователя предварительно обучают таким образом, чтобы указанная модель идентифицировала пользователя с заданным уровнем достоверности.
4. Система по п.1, в которой базовая модель является корректирующей моделью для модели, являющейся корректирующей для указанной базовой модели.
5. Система по п.1, в которой базовая модель функционально связана с несколькими корректирующими моделями, при этом по меньшей мере одна из указанных корректирующих моделей функционально связана с по меньшей мере одной другой из указанных корректирующих моделей.
6. Способ выбора модели описания пользователя, при этом способ содержит этапы, которые реализуются с помощью средств из системы по п.1 и на которых:
а) формируют данные о предпочтениях пользователя (далее предпочтения) на основании заранее собранных данных о поведении пользователя (далее поведение) и заранее выбранной из базы моделей модели описания пользователя (далее базовая модель), при этом база моделей содержит по меньшей мере одну базовую модель, представляющую собой по меньшей мере одно правило определения предпочтений пользователя, и по меньшей мере одну функционально связанную с ней модель описания пользователя (далее корректирующая модель), представляющую собой по меньшей мере одно правило определения предпочтений пользователей, функционально связанных с предпочтениями пользователей, определяемых базовой моделью;
б) определяют точность сформированных предпочтений на основании наблюдаемого поведения пользователя;
в) в случае, если определённая точность ниже заранее заданного порогового значения, выбирают корректирующую модель, связанную с базовой моделью;
г) собирают данные о поведении пользователя и в случае, если для собранных данных о поведении пользователя точность предпочтений не выше заранее заданного порогового значения, переобучают базовую модель таким образом, чтобы для собранного поведения точность предпочтений была выше заранее заданного порогового значения.
7. Способ по п.6, по которому данные о поведении пользователя описывают по меньшей мере:
• приложения, с которыми работает пользователь, время работы пользователя в указанных приложениях, выполняемые пользователем действия в указанных приложениях;
• поисковые запросы пользователя;
• сайты, которые посещает пользователь, выполняемые пользователем действия на указанных сайтах;
• заполненные пользователем формы.
8. Способ по п.6, по которому модель описания пользователя предварительно обучают таким образом, чтобы указанная модель идентифицировала пользователя с заданным уровнем достоверности.
9. Способ по п.6, по которому базовая модель является корректирующей моделью для модели, являющейся корректирующей для указанной базовой модели.
10. Способ по п.6, по которому базовая модель функционально связана с несколькими корректирующими моделями, при этом по меньшей мере одна из указанных корректирующих моделей функционально связана с по меньшей мере одной другой из указанных корректирующих моделей.
| US 20110161308 A1, 30.06.2011 | |||
| US 20060156326 A1, 13.07.2006 | |||
| US 20110282954 A1, 17.11.2011 | |||
| US 20110078323 A1, 31.03.2011 | |||
| ОПРЕДЕЛЕНИЕ НАМЕРЕНИЯ ПОЛЬЗОВАТЕЛЯ | 2005 |
|
RU2378680C2 |

