Изобретение относится к вычислительной технике, а именно к тестированию программного обеспечения и, в особенности, к автоматизированному тестированию программного обеспечения и опытного приложения.
Из уровня техники известны решения, направленные на тестирование программного обеспечения, в частности, на автоматизированное тестирование программ и опытных приложений.
В современных интернет-сервисах для обеспечения высокого качества программных решений широко применяются многоуровневые методики тестирования, одной из которых является сквозное (end-to-end) тестирование - метод тестирования программного обеспечения. Данный метод тестирования программного обеспечения предусматривает проверку функциональности и надежности работы приложения от начального этапа до конечного, охватывая всю систему и все связанные подсистемы, а также сквозной поток процессов. Этот подход позволяет имитировать реальные сценарии использования, моделируя поведение пользователя при взаимодействии с приложением. В процессе сквозного тестирования проверяется выполнение ключевых операций, чтобы убедиться, что весь процесс работы приложения для конечного пользователя функционирует согласно ожиданиям и требованиям.
В контексте тестирования облачных сервисов, сквозное тестирование имитирует действия пользователей, такие как выполнение действий на веб-странице, переходы между страницами, редактирование полей и другие аналогичные операции. Данный подход позволяет выявить возможные неисправности в работе приложения на различных уровнях его взаимодействия с пользователем.
Сквозное тестирование предоставляет возможность уменьшить объем работы инженеров-тестировщиков, связанный с регрессионным и иными видами тестирования, поскольку оно охватывает работу всей системы и быстрее выявляет проблемные области, в отличие от методов, сосредоточенных на отдельных участках или подсистемах. Однако сквозное тестирование сталкивается с проблемами из-за своей сложности и высокой стоимости. Это связано с необходимостью использования мощных программно-аппаратных ресурсов для разработки и поддержания полноценных автоматизированных тестов и их сценариев, которые охватывают все ключевые функциональные возможности системы. Автоматизация тестирования целевых систем и опытных приложений может быть затруднена ввиду сложной структуры функциональности и множественных вариантов поведения в зависимости от выбранного сценария.
В настоящее время для упрощения создания е2е тестов существуют тестовые системы, основанные на low-code решениях - платформах для разработки программного обеспечения, которые позволяют создавать приложения с минимальным ручным кодированием. Одним из примеров такого решения является «Selenium IDE» (https://www.selenium.dev/), расширение для браузера Firefox. Selenium IDE входит в экосистему инструментов автоматизации Selenium и основано на среде Selenium Core, разработанной на языке JavaScript. Этот инструмент позволяет записывать, редактировать, отлаживать и выполнять тесты практически без навыков программирования, имитируя действия пользователя, такие как нажатие клавиш и использование мыши. Selenium IDE оснащен функцией записи и воспроизведения автотестов, что делает его подходящим для «легкой» автоматизации: чтобы записать автотест, пользователю нужно лишь раз кликнуть все действия в браузере, описанные в тестовом сценарии, после чего Selenium автоматически сгенерирует необходимый код. Далее тестировщик сможет автоматизированно воспроизвести этот сценарий простым нажатием кнопки. Однако, несмотря на возможность записи и воспроизведения е2е тестов, этот инструмент не обеспечивает автоматическую генерацию описаний тестовых сценариев, что требует ручного создания сценариев и их дальнейшей записи для воспроизведения.
Известны патентные заявки, такие как RU 2013126869 A, опубликованная 2014.12.20, RU 2012127581 A, опубликованная 2003.07.20, и патент RU 2390830 C2, опубликованный 2010.05.27, которые раскрывают методы и системы автоматизации тестирования программного обеспечения. Однако данные решения страдают от отсутствия единообразных и четко сформулированных требований к программным интерфейсам для взаимодействия систем е2е тестирования с тестируемым программным обеспечением. Это значительно усложняет реализацию программных комплексов таких систем и ограничивает возможность их дальнейшего расширения.
Существуют также другие решения, применяющие различные подходы к созданию и автоматизации тестов E2E, которые отличаются степенью участия тестировщика в процессе формирования тест-кейсов. Так, источник https://www.functionize.com/testgpt предлагает решение, которое сначала изучает поведение пользователей и их взаимодействие с веб-сайтом (опытным приложением), анализирует поисковые запросы, формы взаимодействия и другие аспекты для создания тестовых примеров, отражающих реальные сценарии. Только после этого генерируются тестовые сценарии.
Из источника https://sofy.ai/blog/automatic-test-case-generation-using-machine-learning/ известно о решении, в котором создание тестовых сценариев осуществляется с помощью модели машинного обучения на основании заранее подготовленных пользовательских сценариев, что аналогично описанию е2е тестов. Это также требует активного участия пользователя на этапе их изначального создания.
Несмотря на то, что в этих решениях применяется машинное обучение для автоматизации создания тестовых сценариев, освобождая тестировщика от необходимости ручного создания и записи пользовательских действий, они обладают существенным недостатком. Данные решения не поддерживают возможность анализа работы опытного приложения «изнутри» на уровне кода. Весь процесс взаимодействия и анализа работы системы основан на взаимодействии с элементами интерфейса через браузер (поля ввода, кнопки и другие элементы) и не включает анализ и тестирование кода приложения. Это затрудняет выявление проблем на ранних стадиях разработки, когда приложение еще не является завершенным продуктом или функционал которого может изменяться динамически в процессе разработки.
Таким образом, предложенное изобретение направлено на решение вышеуказанных проблем уровня техники и техническим результатом изобретения является создание способа и системы автоматизации e2e тестирования, реализующей новый способ тестирования опытного приложения, в котором реализуется автоматизация и повышается точность сгенерированных тест-кейсов и тестовых сценариев, в сравнении с предыдущим уровнем техники, не за счет рутинной обработки - работы по созданию сценариев или накопления и анализа данных от пользователей при работе с опытным приложением, а за счет анализа кода моделью машинного обучения и генерации тест-кейсов и тестовых сценариев. Интеграция работы на уровне кода позволяет сократить этап обучения модели, а более точная генерация тест-кейсов и тестовых сценариев позволяет сократить время и затраты или временные затраты на поддержку их актуальности и обновление, применять заявленный способ и систему, его реализующую, еще на этапе разработки опытного приложения, не дожидаясь его финального релиза. Таким образом, предлагаемый способ и система позволяют снизить усилия и автоматизировать процесс создания тест-кейсов и тестовых сценариев для веб сервисов, а разработчик тестов в этом случае может получить заготовки тестов для выбранных им элементов интерфейса сервисов или страниц целиком.
Таким образом, для достижения нового технического результата необходимо было решить несколько задач: более эффективно задействовать машинное обучение для большего сокращения времени обучения и создания тестовых сценариев и тест-кейсов; повысить точность создания тестовых сценариев, как на ранних этапах создания опытного приложения, так и в целом, для сокращения времени на выявление проблемных мест в работе опытного приложения; сократить время и затраты на поддержку актуальности и обновление тестовой документации, описывающей поведение пользователя и используемой инженерами тестирования для проверки работоспособности приложения, корректности его поведения.
Понимание этих задач приводит к реализации этапов (задач) и требований в предложенном решении:
1. Сбор и подготовка обучающего набора данных (обучающей выборки): необходимо собрать достаточное количество тест-кейсов - документированных последовательностей шагов и условий, предназначенных для a) выполнения и проверки определенных функций в коде опытного приложения, b) выявления функциональных возможностей внутри целевой системы на основе кода и c) проверки функциональности на предмет соответствия заданным требованиям, с точки зрения возможности создания машиночитаемых пользовательских сценариев использования и их работоспособности.
2. Разработка системы автоматизации e2e тестирования на базе модели машинного обучения: a) разработка последовательности действий, на основе собранных данных (обучающей выборки) - создание, обучение и тестирование алгоритма, способного анализировать данные и делать на их основе предсказания или принимать решения без явного программирования для каждой возможной ситуации, способного генерировать новые тест-кейсы, при этом модель должна уметь анализировать входные данные и предполагать возможные действия пользователя с разными элементами опытного приложения (например, кнопками и полями ввода), b) обучение и валидация модели: после разработки модели необходимо показать системе, какие действия с какими элементами опытного приложения возможны. Затем следует этап валидации, чтобы проверить, что система может правильно описывать действия пользователя исходя из найденных в опытном приложении элементов взаимодействия, с) интеграция модели в систему тестирования: после успешной валидации модель необходимо интегрировать в общепринятые (test managment system) системы для управления процессами тестирования, d) поддержка и обновление модели: после интеграции модели важно поддерживать ее актуальность и эффективность, что может включать регулярное обновление модели на основе новых данных, а также мониторинг и анализ ее производительности.
Поставленный технический результат достигается тем, что предложен способ автоматизации end-to-end тестирования с помощью модели машинного обучения, реализуемый системой автоматизированного тестирования, включающий этапы, на которых:
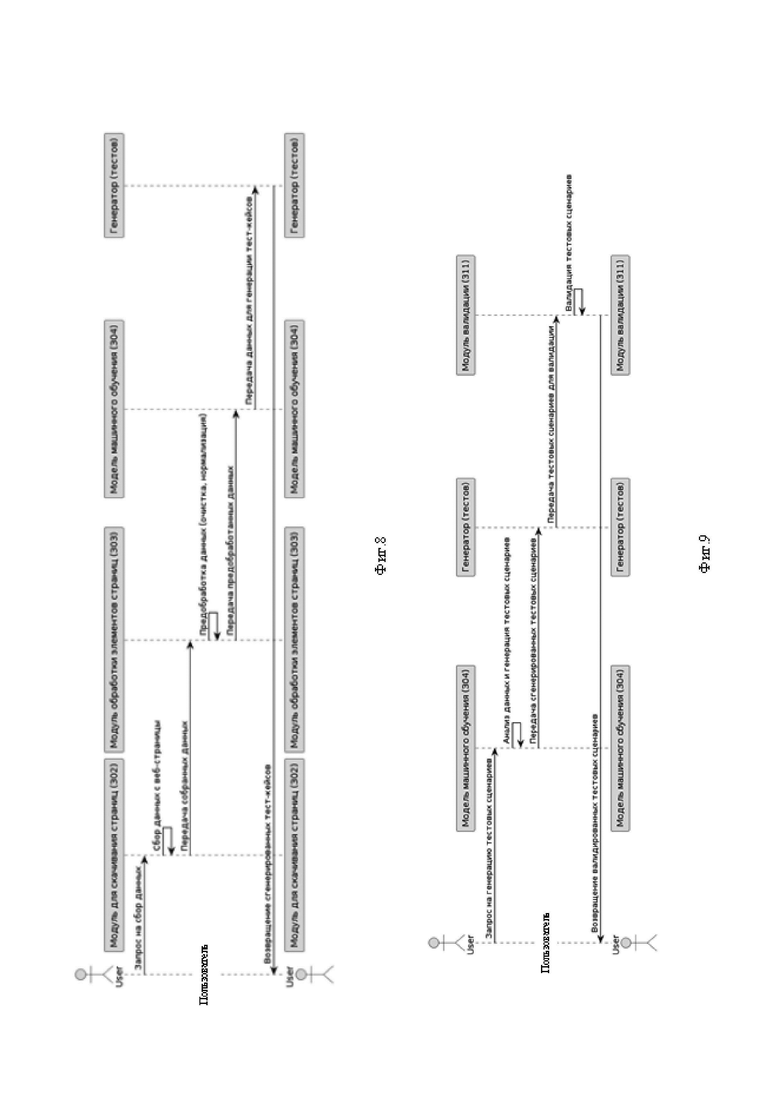
посредством модуля скачивания и хранения страниц 302 собирают данные с выбранных страниц веб сервиса;
посредством модуля обработки элементов страниц 303, который соединен с упомянутым модулем скачивания и хранения страниц 302, обрабатывают собранные данные, включая очистку от шума, в виде неиспользуемых элементов разметки страницы, нормализацию и преобразование данных страницы в формат обработки;
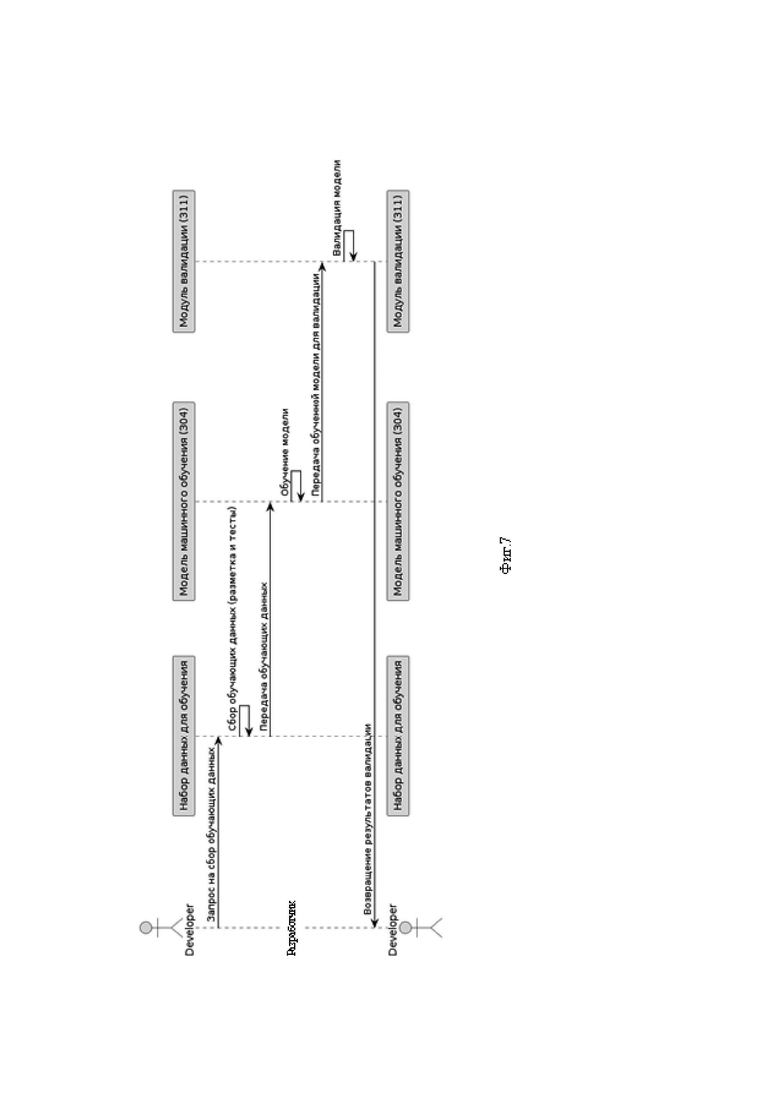
посредством модуля памяти 300 для хранения обучающей выборки, соединённого с модулем обработки элементов страниц 303, который соединен с модулем валидации 311, который в свою очередь соединен входом/выходом с модулем модели машинного обучения 304 обучают модель машинного обучения на основе заранее сохраненного набора данных и обучающей выборки;
посредством модулей текст-кейсов 305 и тестовых сценариев 306, соединенных с упомянутым модулем модели машинного обучения 304 с генератором 310, генерируют тест-кейсы на основе результатов работы модели машинного обучения и формируют тестовые сценарии, включая последовательность действий, требуемые результаты и проверку соответствия фактического и требуемого состояния страницы, и выполняют сгенерированные тест-кейсы и тестовые сценарии системой автоматизированного тестирования,
при этом процесс обучения и валидации модели машинного обучения, осуществляют с использованием трансформеров и для генерации тест-кейсов осуществляют следующие шаги: предобработка данных, разделение данных на обучающую и тестовую выборки, валидация гиперпараметров для трансформеров, обучение модели машинного обучения на основе указанного выбора гиперпараметров, после обучения модель машинного обучения тестируется на тестовой выборке, с последующим анализом результатов, чтобы определить как модель машинного обучения справляется с задачей генерации тест-кейсов по проценту успешных и неуспешных тестов, и если результаты неудовлетворительные, то процесс повторяют с изменением гиперпараметров или модели машинного обучения.
Дополнительная особенность заключается в том, что обучение модели машинного обучения использует метод машинного перевода.
Дополнительная особенность заключается в том, что способ выполнен с возможностью вносить разработчику изменения в сгенерированные тест-кейсы и тестовые сценарии.
Дополнительная особенность заключается в том, что сгенерированные тест-кейсы используют для дообучения модели машинного обучения.
Дополнительная особенность заключается в том, что в качестве гиперпараметров модели машинного обучения используют размер буфера, количество слоев и размерность скрытого слоя.
Проведенный анализ уровня техники позволяет определить, что предложенное техническое решение является новым и имеет изобретательский уровень, а возможность его использования в промышленности определяет его как промышленно применимое.
Эти и другие аспекты станут очевидными и будут объяснены со ссылками на чертежи и варианты осуществления, описанные в дальнейшем.
Изобретение поясняется следующими графическими материалами.
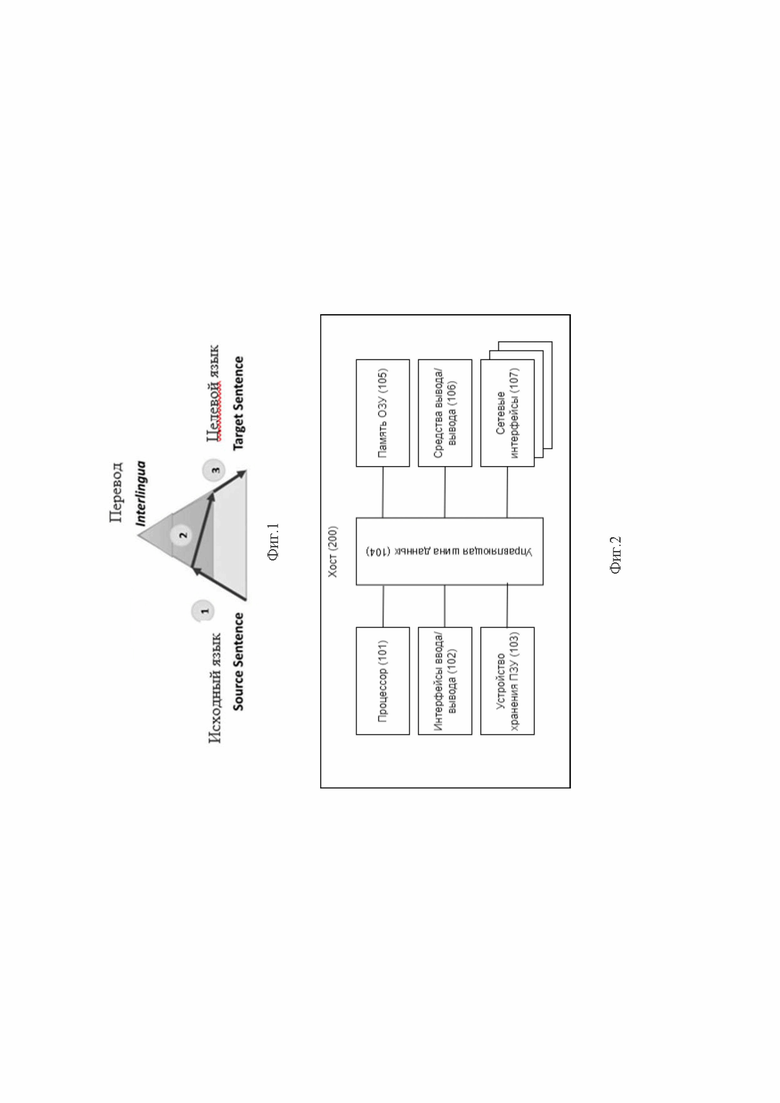
Фиг.1 - представлен принцип автоматизированного лингвистического перевода в виде треугольника Вокуа.
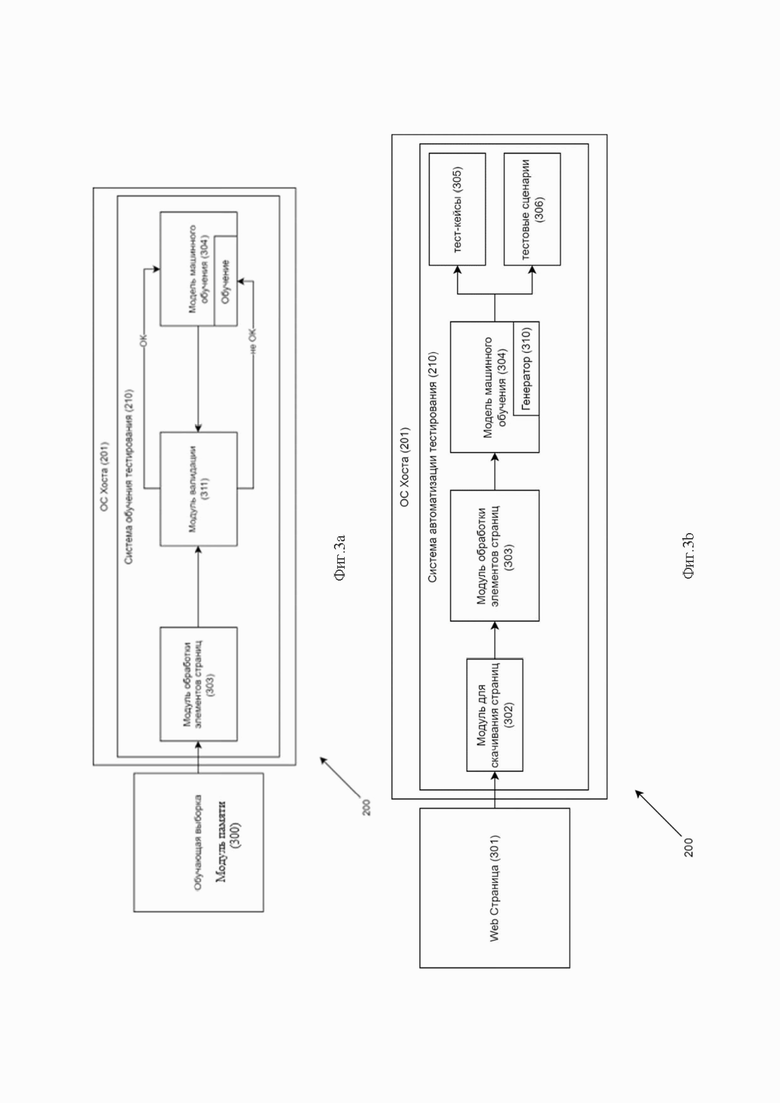
Фиг. 2 - представлен пример архитектуры узла вычислительной системы - хоста 200.
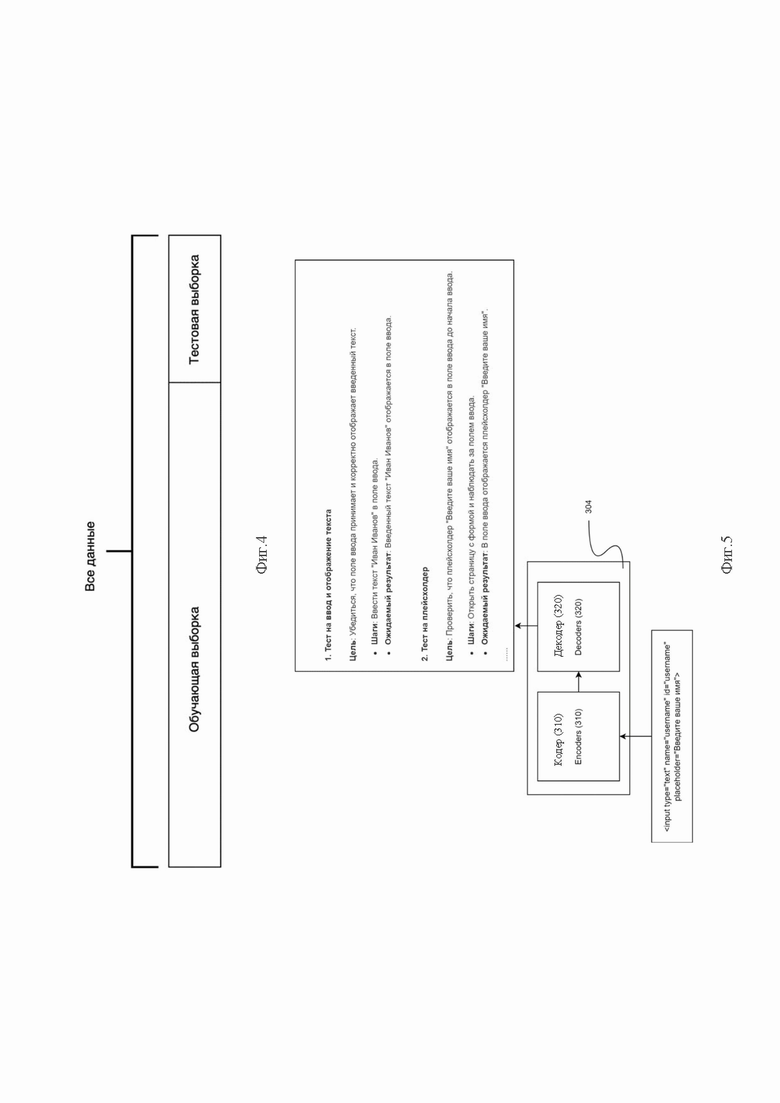
Фиг.3a - представлена структурно-функциональная схема системы e2e тестирования (режим обучения).
Фиг.3b - представлена структурно-функциональная схема системы e2e тестирования (рабочий режим).
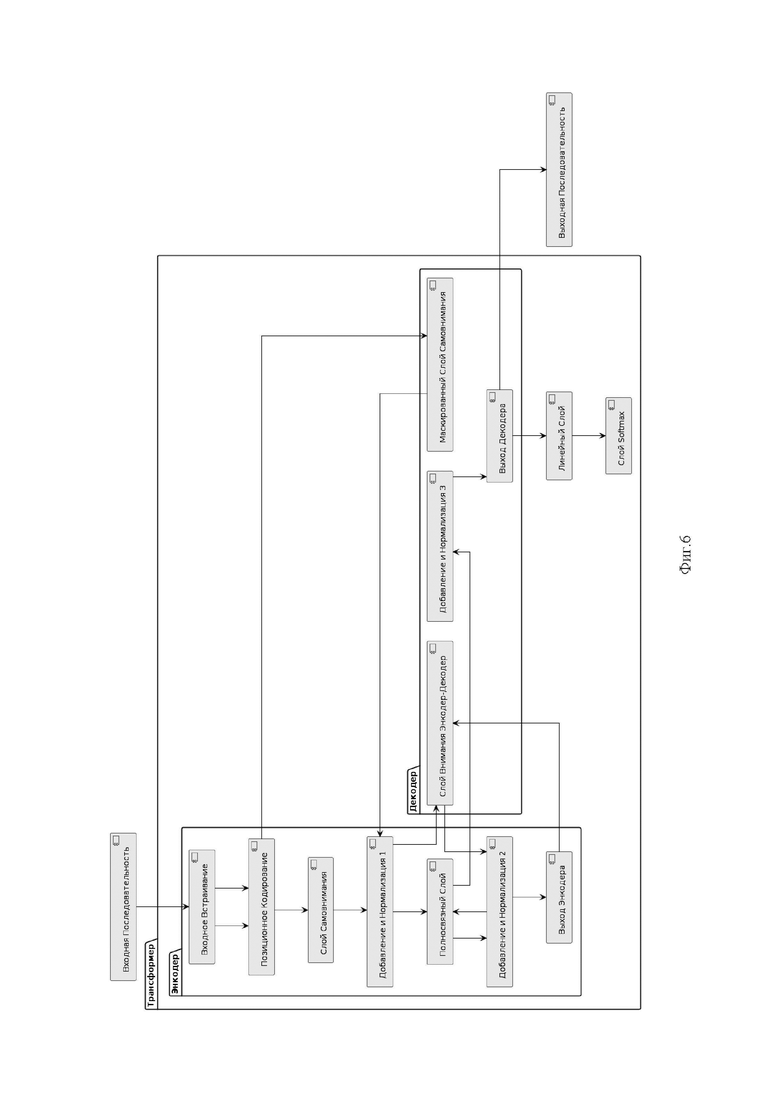
Фиг.4 - представлена модель данных (обучающая + тестовая выборки).
Фиг.5 - представлен пример генерации тестового сценария.
Фиг.6 - представлена внутренняя структура построения трансформера.
Фиг.7 - представлена сиквенс диаграмма обучения модели.
Фиг.8 - представлена сиквенс диаграмма генерации тест-кейсов.
Фиг.9 - представлена сиквенс диаграмма генерации тестовых сценариев.
Введем ряд определений и понятий, которые будут использоваться при описании осуществления заявленного изобретения.
Обучающая выборка (обучающий датасет) - набор примеров, который содержит примеры входных данных и соответствующие выходные данные. На примерах система обучается восстанавливать неявную зависимость между входными данными и ожидаемыми результатами для новых входных данных.
Тестовая выборка (тестовый датасет) - набор данных, на котором модель не обучалась. Используется для оценки качества модели после ее обучения, позволяет оценить, насколько хорошо модель работает (обеспечивает требуемые параметры) на новых данных.
Элементы разметки - основная структурная единица веб-страницы, написанная на языке HTML (гипертекст) - стандартизированный язык гипертекстовой разметки документов для просмотра веб-страниц в браузере.
Набор тестов для элемента разметки - необходимый и достаточный общий набор тестов, состоящий из общей + обучающей выборки, для проверки функционала конкретного элемента разметки.
Результирующая модель - обученная модель машинного обучения которую можно использовать для генерации тестов по исходным элементам разметки.
Векторное представление (векторное вложение слов, вложение слов, эмбеддинги) - общее название для различных подходов к моделированию языка и обучению представлений в обработке естественного языка, направленных на сопоставление словам (фразам) из некоторого словаря векторов, значительно меньшего количества слов в словаре.
Кодировщик (encoder) - часть модели, которая преобразует входные данные в более компактную форму. Кодировщик может использовать различные алгоритмы и методы для достижения этой цели, например, получать на вход векторизованую последовательность с позиционной информацией для подготовки данных к последующим этапам обработки. Декодировщик (decoder) - это часть модели, которая преобразует закодированные данные обратно в исходную форму и для этого он принимает закодированный признак, получая на вход часть этой последовательности, или представление и восстанавливает исходные данные.
Слой - кодировщик и декодировщик состоят из слоев. Слои кодировщика последовательно передают результат следующему слою в качестве его входа, выполняющего определенные функции в процессе обработки данных.
Пользовательские сценарии - поведение реального пользователя при работе с приложением, выполнение основных операций с приложением. При автоматизации такого поведения и подменой его на программную эмуляцию такого поведения это можно назвать e2e-тестом.
E2e-тесты (сквозное тестирование) - тесты, в которых происходит подробная эмуляция пользовательской среды. В данных тестах имитируют действия пользователя: щелчки мышью, нажатия на кнопки, заполнение форм, переходы по страницам и ссылкам, и другие поведенческие факторы.
Тестовые сценарии - в тестовом сценарии подробно расписана последовательность действий, которую выполняет тестировщик для проверки и подтверждения работоспособности ПО. Он состоит из нескольких пунктов, в которых описано, что именно следует сделать с разработанной программой и какой должен быть ожидаемый результат.
Тест-кейсы - документированная последовательность шагов и условий, предназначенных для выполнения и проверки определенных функций в коде опытного приложения, выявления функциональных возможностей внутри целевой системы на основе кода, проверки функциональности на предмет соответствия заданным требованиям, с точки зрения возможности создания машиночитаемых пользовательских сценариев использования и их работоспособности.
Модель данных - обучающая выборка + тестовая выборка.
Трансформер - архитектура DNN, представленная в 2017г. В модели трансформера, например, слои кодировщика последовательно передают результат следующему слою в качестве его входа, в то время как слои декодировщика передают результат следующему слою вместе с результатом кодировщика в качестве его входа.
Веса модели - каждое соединение между нейронами в сети имеет свой вес или коэффициент. Веса могут быть положительными или отрицательными, что определяет, активируют они или подавляют передачу сигнала между нейронами. В начале обучения веса обычно инициализируются случайными значениями.
Валидация модели - проверка правильности работы (предсказательной способности) аналитической модели, построенной на основе машинного обучения на соответствие требованиям решаемой задачи.
Машинный перевод - комплекс алгоритмических подходов и технологий, используемых для автоматического перевода текста или речи с одного естественного языка на другой с помощью компьютерных программ.
Нормализация данных - этап предварительной обработки данных в области машинного обучения и обработки данных с целью улучшения качества данных и повышения эффективности последующего анализа или обучения моделей.
Дообучение модели - процесс адаптации предварительно обученной модели под конкретную задачу или набор данных путём дополнительного обучения.
Улучшение качества модели - процесс оптимизации и повышения точности, надёжности и валидности тестовых результатов в контексте оценки, анализа или исследования.
Переобучение модели (overfitting) - явление, когда построенная модель хорошо объясняет примеры из обучающей выборки, но относительно плохо работает на примерах, не участвовавших в обучении (на примерах из тестовой выборки).
Опытное приложение - веб-приложение, которое используется для опытного тестирования, для которого производится генерация тестовых сценариев, e2e-тестов, тест-кейсов.
На фиг.1 показан принцип автоматизированного лингвистического перевода, который сформулирован исследователем Бернаром Вокуа в 1968 году и был визуализирован в виде Треугольника Вокуа. Левая часть треугольника характеризует исходный язык, когда как правая - целевой. Уровни внутри треугольника представляют собой визуализацию глубины процесса анализа исходных данных, например, синтаксического, семантического и т.д. Так из исходного предложения, которое является просто последовательностью слов, мы сможем получить представление о его внутренней структуре и степени возможного применения глубины анализа. Идея применения принципа Треугольника Вокуа заключается в том, что чем выше (глубже) анализируется исходное предложение, тем проще проходит фаза переноса в целевой язык.
Таким образом, процесс генерации тестовых сценариев в предложенном решении аналогичен процессу перевода с одного языка на другой, где исходным языком является код системы и далее разметка, а целевым - тест-кейсы.
На фиг.2 показан пример архитектуры узла вычислительной системы хоста 200, которая обеспечивает реализацию заявленного способа автоматизированного тестирования и является частью компьютерной системы автоматизированного тестирования, например, модулем, узлом хранения, частью вычислительного кластера, обрабатывающим необходимые данные для осуществления заявленного технического решения. Хост 200 - устройство (например, компьютерная система общего назначения), на котором функционирует, например, клиент гипервизора и операционная система (ОС) хоста 201, под управлением которой исполняются виртуальные машины, с развернутой внутри виртуальной машины (ВМ) компонентов системы автоматизированного тестирования 210.
В общем случае система 200 содержит такие компоненты, как: один или более процессоров 101, по меньшей мере одну память 105, средство хранения данных 103, интерфейсы ввода/вывода 102, средство ввода/вывода 106, средство сетевого взаимодействия 107, которые объединяются посредством универсальной шины 104.
Процессор 101 выполняет основные вычислительные операции, необходимые для обработки данных при выполнении способа. Процессор 101 исполняет необходимые машиночитаемые команды, содержащиеся в оперативной памяти 105.
Память 105, как правило, выполнена в виде ОЗУ и содержит необходимую программную логику, обеспечивающую требуемый функционал.
Средство хранения данных 103 может выполняться в виде HDD, SSD дисков, рейд массива, флэш-памяти, оптических накопителей информации (CD, DVD, MD, Blue-Ray дисков). Средства 103 позволяют выполнять долгосрочное хранение различного вида информации, например, блоков данных, структур данных, метаданных, тестовых сценариев и тест-кейсов.
Для организации работы компонентов системы 200 и организации работы внешних подключаемых устройств применяются различные виды интерфейсов ввода/вывода 102. Выбор соответствующих интерфейсов зависит от конкретного исполнения вычислительных устройств, которые могут представлять собой, не ограничиваясь: PCI, AGP, PS/2, IrDa, FireWire, LPT, COM, SATA, IDE, Lightning, USB, TRS/Audio jack, HDMI, DVI, VGA, Display Port, RJ45, RS232.
Выбор интерфейсов 102 зависит от конкретного исполнения системы 201, которая может быть реализована на базе широкого класса устройств, например, персонального компьютера, ноутбука, серверного кластера, тонкого клиента, смартфона, сервера.
В качестве средств ввода/вывода данных 106 может использоваться: клавиатура, джойстик, дисплей (сенсорный дисплей), монитор, сенсорный дисплей, тачпад, манипулятор мышь, световое перо, стилус, сенсорная панель, трекбол, динамики, микрофон, средства дополненной реальности, оптические сенсоры, планшет, световые индикаторы, проектор, камера, средства биометрической идентификации.
Средства сетевого взаимодействия 107 выбираются из устройств, обеспечивающих сетевой прием и передачу данных, например, Ethernet карту, WLAN/Wi-Fi модуль, Bluetooth модуль, BLE модуль, NFC модуль, IrDa, RFID модуль, GSM модем. С помощью средств 106 обеспечивается организация обмена данными между, например, системой 200, представленной в виде сервера и вычислительным устройством пользователя, на котором могут отображаться полученные данные по проводному или беспроводному каналу передачи данных, например, WAN, PAN, ЛВС (LAN), Интранет, Интернет, WLAN, WMAN или GSM.
Конкретный выбор элементов системы 200 для реализации различных программно-аппаратных архитектурных решений может варьироваться с сохранением обеспечиваемого требуемого функционала.
Верхнеуровнево применение принципа Треугольника Вокуа в предложенном изобретении реализуется в несколько этапов. Входными данными для обучения являются элементы разметки и сопоставленные им тестовые сценарии и тест-кейсы. Система собирает данные с выбранных страниц веб сервиса, включая текст, изображения, элементы пользовательского интерфейса и другую информацию, инициируя по запросу или периодическим заданием запуск работы модуля 302. Затем системой в модуле 303 осуществляется предобработка данных, включающая очистку от шума в виде неиспользуемых элементов разметки, нормализацию и преобразование в удобный для обработки формат. Системой производится анализ исходной разметки на исходном языке для этого предобработанные данные передаются в модуль 304, обученный на основе заранее заготовленного набора данных. Предварительное обучение модели использует методику машинного перевода: заранее заготовленные элементы разметки сопоставляются с набором соответствующих сохраненных в памяти тестов, аналогично тому, как слово одного языка соответствует слову или наборам слов в другом языке. Результирующая модель анализирует контекст страницы и генерирует соответствующие тест-кейсы. Когда анализ завершен, предложение «переносится» вторым процессом с равной или меньшей глубиной анализа на целевой язык. Далее процесс, называемый «генерацией», формирует фактическое целевое предложение из этой интерпретации, то есть создает последовательность слов на целевом языке.
Система формирует тест-кейсы на основе результатов работы модели, включая последовательность действий, ожидаемые результаты и проверку соответствия фактического и ожидаемого состояния страницы. При необходимости разработчик может вносить изменения в сгенерированные тест-кейсы. Аналогично формируется список планов тестирования для выбранных страниц или элементов веб сервисов, состоящий из набора тестовых сценариев.
Сформированные системой e2e тестирования тест-кейсы и планы тестирования не отличаются от реализованных разработчиком и запускаются уже в рамках существующей системы.
На фиг.3a и 3b показана верхнеуровневая структурно-функциональная схема системы автоматизированного тестирования 210, развернутая внутри хоста 200 и реализующая технический результат. Система в режиме обучения, содержит: модуль памяти 300 для хранения обучающей выборки, соединённый с модулем обработки элементов страниц 303, который соединен с модулем валидации 311, который в свою очередь соединен входом/выходом с модулем модели машинного обучения 304. Система в режиме работы, содержит: веб страницу 301, которая связана с модулем скачивания и хранения страниц 302, который соединен с модулем обработки элементов страниц 303, который в свою очередь соединен с модулем модели машинного обучения 304, содержащий генератор 310, где модуль модели машинного обучения 304, соединен с модулями текст-кейсов 305 и тестовых сценариев 306.
Одним из основных компонентов системы является модуль модели машинного обучения 304, в дальнейшем к которому применяется определение трансформера - одного из вариантов моделей машинного обучения.
Архитектурно трансформер 304, как показано на фиг.5, состоит из не менее чем одного кодировщика (encoder 310) и не менее чем одного декодировщика (decoder 320). Кодировщик 310 получает на вход векторизованную последовательность с позиционной информацией. Декодировщик 320 получает на вход часть этой последовательности и выход кодировщика. Кодировщик 310 и декодировщик 320, выполнены с возможностью реализации этапов (слоев) обработки получаемой и выдаваемой системой информации. Слои кодировщика 310 последовательно передают результат следующему слою вместе с результатом кодировщика в качестве его входа. На выходе декодера 320 получается готовый набор тест-кейсов и тестовых сценариев.
Сборка обучающей выборки.
При реализации любой модели машинного обучения существует задача сборки данных для обучающей и тестовой выборки. Под обучающей выборкой подразумевают набор данных примеров, на которых система обучается восстанавливать неявную зависимость между входными данными и ожидаемыми результатами. Обучающая выборка позволяет системе научиться строить алгоритмы, которые способны выдавать достаточно точные ответы для любых возможных входных объектов.
В предложенном решении используется модель машинного обучения с учителем - тип алгоритма машинного обучения, который обучается на заранее подготовленном наборе данных, содержащем входные данные и соответствующие им правильные ответы, поэтому требуется сформировать обучающую выборку требуемого состава, включающую в себя как элементы разметки страниц, так и получающиеся в результате готовые тест-кейсы и тестовые сценарии.
Основная проблема обучающей выборки заключается также в сборке для нее необходимого объема данных, для более качественного обучения модели. Для решения данной задачи и расширения собранной обучающей выборки в системе реализована генерация синтетических данных для обучения. Отдельный программный модуль (не показан) генерирует элементы разметки, при этом осуществляя варьирование параметров, которые встречаются в разметке документов, но при этом не влияют на результирующий тест. Более подробно раскрытие работы модуля генерации 310 будет дано ниже.
Для каждого элемента разметки также формируются описания возможных действий с выбранным элементом.
В результате мы получаем обучающую выборку, составленную, в основном, из синтетических тест-кейсов, и тестовую - составленную, преимущественно, из собранных вручную тестовых сценариев.
Под выборкой или датасетом понимается набор данных, используемый для сопоставления элементов опытного приложения и действий пользователя с этими элементами. Этот набор данных состоит из входных данных «признаков» и соответствующих им выходных данных «целевых переменных».
В результате, общую модель данных, включающую в себя обучающую и тестовую выборки (датасет), схематично можно представить, как показано на фиг.4.
В качестве наглядного примера входных данных для алгоритма обучения и обучающей выборки можно привести элемент разметки типа форма, в котором есть 1 поле для ввода типа пароль и 1 кнопка:

Примером выходных данных для обучающей выборки в этом случае может являться следующий набор тестовых сценариев и результирующих тест-кейсов.
Пример набора тестовых сценариев:
1. Проверка наличия поля ввода пароля (убедиться, что поле ввода пароля присутствует на странице)
2. Проверка возможности ввода текста в поле пароля (убедиться, что в поле ввода пароля можно ввести текст, и что введенный текст соответствует ожидаемому значению).
3. Проверка маскировки ввода пароля (убедиться, что введенный текст в поле пароля маскируется (не отображается в виде обычного текста).
4. Проверка наличия кнопки отправки формы (убедиться, что кнопка отправки формы присутствует на странице)
5. Проверка отправки формы с заполненным полем пароля (Убедиться, что форма отправляется корректно при заполненном поле пароля).
6. Проверка отправки формы с пустым полем пароля (убедиться, что форма не отправляется или отображается ошибка при попытке отправить форму с пустым полем пароля).
7. Проверка минимальной и максимальной длины пароля (убедиться, что поле пароля принимает пароли определенной длины (например, минимум 8 символов и максимум 20 символов).
8. Проверка ввода специальных символов в поле пароля (убедиться, что поле пароля корректно обрабатывает специальные символы).
9. Проверка ввода пробелов в поле пароля (убедиться, что поле пароля корректно обрабатывает пробелы (например, не допускает пробелы в начале и конце пароля).
10. Проверка отображения сообщений об ошибках (убедиться, что при некорректном вводе пароля отображаются соответствующие сообщения об ошибках).
Пример набора результирующих тест-кейсов:



Пример синтетической генерации данных для обучения.
Для расширения собранной обучающей выборки реализована генерация синтетических данных для обучения. Отдельный программный модуль генерирует элементы разметки (процесс аннотации или маркировки данных, который заключается в добавлении меток к данным, например, текстам, изображениям, аудио или видео, указывающих на определенные характеристики, категории, объекты или явления в этих данных), при этом осуществляя варьирование параметров, которые встречаются в разметке документов, но при этом не влияют на результирующий тест. Для каждого элемента разметки также формируются наборы тест-кейсов. В результате получается обучающая выборка, составленная в основном из синтетических тест-кейсов (метод тестирования производительности и функциональности веб-приложений, сервисов или инфраструктуры путём имитации действий пользователей или систем, работающий на уровне кода, без реального внешнего трафика) и тестовая - составленная преимущественно из собранных вручную тестовых сценариев. Иными словами, на примере формы авторизации, система генерирует различные варианты реализации форм для последующего использования данных, полученных на основе анализа работы других приложений, для которых тестовые сценарии уже были написаны и где определено правильное поведение пользователя с системой и ее объектами.
Приведем пример вариации генерации формы, с одинаковым результирующим функционалом и различными вариациями параметров, например идентификаторов, стилей, наличия отдельных дополнительных элементов разметки:


Для всех приведенных выше случаев мы также генерируем выходные тесты с учетом вариаций входных параметров (или их игнорированием).
В результате, для приведенного примера синтетической генерации обучающей выборки мы получаем набор выходных тестов для входного случая с id="user-password" :
Пример набора результирующих тест-кейсов (синтетика):

Как видно в данных выходных тестах поиск элемента ввода пароля осуществлялся уже по сгенерированному Id.
Алгоритм машинного обучения.
Для обучения модели и получения системы генерации тест-кейсов и тестовых сценариев использована модель на базе трансформеров - это передовой подход в области машинного перевода, использующий архитектуру трансформеров для обработки последовательностей текста. Трансформеры, впервые представленные в статье "Attention is All You Need" в 2017г., и отличаются от предыдущих моделей RNN, CNN, тем что они полагаются на механизмы внимания для моделирования зависимостей между словами в предложении без необходимости обрабатывать данные последовательно. Это позволяет моделям трансформеров эффективно обрабатывать целые предложения и даже абзацы текста за один шаг, что значительно ускоряет процесс перевода и повышает его качество. Пример выполнения трансформеров известен из https://habr.com/ru/articles/486358/.
В процессе обучения все данные должны быть разделены на тестовую и обучающую выборки, показанные на фиг.4. Обучающая выборка является набором примеров используемых для настройки параметров и используется в процессе обучения модели. Тестовая выборка - это набор данных, используемый для непредвзятой оценки окончательной модели, настроенной с помощью обучающего набора данных.
Обучающий набор данных - набор данных экземпляров, используемых во время обучающего процесса и используемых для настройки параметров (например, веса в классификаторе). В задачах классификации, алгоритм обучения с учителем изучает обучающий набор данных для обнаружения, или обучения, оптимальной комбинации переменных для генерирования хорошей прогнозной модели. Главной целью является создание обученной (настроенной) модели, которая хорошо делает общие выводы на новых, не использованных данных. Настроенная модель оценивается с помощью «новых» примеров из удержанных наборов данных (проверочного и тестового) для оценки аккуратности модели для классификации новых данных. Для уменьшения риска появления проблем, таких как переобучение, экземпляры в проверочном и тестовом наборе данных не должны быть использованы для обучения модели.
Модель трансформеров в модуле машинного обучения 304 для машинного обучения показана на фиг.5, который состоит из кодирующего компонента 310, декодирующего компонента 320 и связи между ними. В процессе обучения на вход подаются данные и проверяются на соответствие выходных результатов ответам из обучающей выборки.
Для обучения модели и получения модулем генерации тест-кейсов и тестовых сценариев использована модель машинного перевода на базе трансформеров. Внутренняя архитектура трансформеров показана на фиг.6.
Используется предварительно обученная модель (например, ruGpt3.5) и производится ее дообучение для проведения доменной адаптации. Полученная на предыдущем этапе обучающая выборка подается в модель и по окончании обучения проводится валидация полученной модели. Дообученная модель с весами используется для формирования результирующих тест-кейсов и тестовых сценариев.
Разработчик может вносить изменения в сгенерированные тест-кейсы. Аналогично формируется список планов тестирования с тестовыми сценариями для выбранных страниц или элементов веб сервисов. Сформированные таким образом тесты могут быть также дополнительно использованы для дообучения модели и улучшения качества результирующих тестов.
Процесс обучения и валидации модели.
Процесс обучения и валидации модели с использованием трансформеров для генерации тест-кейсов будет включать следующие шаги:
1) Предобработка данных: удаление ненужных символов, преобразование текста в нижний регистр, стемминг (процесс приведения слов к их корневой форме, с удалением окончаний и префиксов, чтобы оставить только основу слова, которая несет его основное семантическое значение) (приведение слов к их основной форме), лемматизацию (преобразование словоформ в их словарные формы, например, столы - стол) и т.д.
Примером может служить приведение к нижнему регистру полей в исходных данных:
Пример нормализации данных обучающей выборки:

В данном примере мы заменяем все буквы в верхнем регистре в нижний, например Password на password:

2) Разделение данных: данные разделяются на обучающую и тестовую выборки. Обучающая выборка используется для обучения модели, а тестовая - для оценки производительности модели (фиг.4)
3) Валидация гиперпараметров: для трансформеров, таких как BERT, GPT-2 или T5, важно правильно настроить гиперпараметры, такие как размер буфера, количество слоев и размерность скрытого слоя. Это делается с помощью валидационной выборки.
4) Обучение модели: после выбора оптимальных гиперпараметров (т. е. набора значений гиперпараметров модели машинного обучения, которые обеспечивают наилучшую производительность модели согласно выбранной метрике оценки на заданном наборе данных), модель обучается на обучающей выборке. Во время обучения модель пытается минимизировать потерю на обучающем наборе данных (фиг.7).
5) Тестирование модели: после обучения модель тестируется на тестовой выборке. Это позволяет оценить, насколько хорошо модель обобщает полученные знания и может ли она успешно применять их к новым данным.
6) Анализ результатов: результаты тестирования анализируются, чтобы определить, насколько хорошо модель справляется с задачей генерации тест-кейсов. Если результаты неудовлетворительные, процесс может быть повторен с изменением гиперпараметров или структуры модели. В качестве метрик выступают показатели процента успешных и неуспешных тестов.
Результатом является обученная модель, способная генерировать тест-кейсы и тестовые сценарии на основе подаваемой на вход разметки.
Процесс использования модели.
Интеграция модели в систему тестирования.
1. Обработка данных - парсинг страниц опытного приложения для создания тестовых сценариев. Собранные данные разметки обрабатываются и передаются в модель для генерации тест-кейсов.
Примеры использования парсинга HTML:
▪ Извлечение данных: например, парсинг веб-страницы новостного сайта для автоматического сбора заголовков новостей и их содержания. Это может быть полезно для агрегации новостей или мониторинга контента.
▪ Веб-скрапинг: автоматический сбор информации о продуктах с торговых платформ, таких как цены, описания и изображения, для анализа рынка или создания агрегаторов товаров.
▪ SEO-анализ: парсинг HTML-кода веб-страниц для анализа использования ключевых слов, структуры заголовков (теги H1, H2 и т.д.), наличия мета-тегов и других факторов, влияющих на поисковую оптимизацию.
▪ Тестирование опытных веб-приложений: автоматизация тестирования пользовательского интерфейса путём парсинга HTML для проверки наличия или отсутствия определённых элементов, их атрибутов и содержимого.
2. Загрузка предобработанных данных в обученную модель.
3. Генерация (фиг.8, 9) - модель генерирует тест-кейсы и тестовые сценарии.
4. Передача тест-кейсов и тестовых сценариев на ручное ревью (анализ) и автоматизированные проверки.
5. Исполнение тест-кейсов и тестовых сценариев.
6. Переиспользование результатов генерации для дообучения модели - результаты генерации тест-кейсов могут быть повторно использованы для дообучения системы тестирования.
В варианте осуществления изобретения вышеуказанные логические модули 101 - 311, в том числе кодировщик, декодировщик, трансформер могут быть реализованы на базе перепрограммируемой логической интегральной схемы (ПЛИС) или сверхбольшой интегральной схемы (СБИС). Также они могут быть реализованы конечным автоматом и несколькими регистрами с соответствующей внутренней логикой, которая реализуется автоматически, например, управляющим микрокодом, хранящимся во встроенной памяти. Специалисту очевидно, что вышеуказанные логические блоки, схемы обработки для автоматизации end-to-end тестирования могут быть выполнены с помощью элемента памяти, который записывает обрабатываемые данные и процессора обработки, в качестве которых могут применяться процессор общего назначения, конечный автомат или другое аппаратно-программируемое логическое устройство, дискретный логический элемент или транзисторная логика или любого их сочетания, чтобы выполнять описанные выше функции.
Предложенный способ может выполняться посредством одной или нескольких компьютерных программ на машиночитаемом носителе, которые исполняются на компьютере или процессоре, и которые побуждают компьютер выполнять способ автоматизации end-to-end тестирования с помощью модели машинного обучения используя алгоритмы, данные, хранимые значения и вычисления, описанные выше.
Представленные материалы заявки раскрывают предпочтительные примеры реализации технического решения и не должны трактоваться как ограничивающие иные, частные примеры его воплощения, не выходящие за пределы испрашиваемой правовой охраны, которые являются очевидными для специалистов в данной области техники.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ ПОЛУЧЕНИЯ НИЗКОРАЗМЕРНЫХ ЧИСЛОВЫХ ПРЕДСТАВЛЕНИЙ ПОСЛЕДОВАТЕЛЬНОСТЕЙ СОБЫТИЙ | 2020 |
|
RU2741742C1 |
| СИСТЕМА И СПОСОБ АВТОМАТИЧЕСКОГО МАШИННОГО ОБУЧЕНИЯ (AutoML) МОДЕЛЕЙ КОМПЬЮТЕРНОГО ЗРЕНИЯ ДЛЯ АНАЛИЗА БИОМЕДИЦИНСКИХ ИЗОБРАЖЕНИЙ | 2021 |
|
RU2787558C1 |
| Система и способ обнаружения фишинговых веб-страниц | 2024 |
|
RU2836604C1 |
| Способ управления бортовыми системами беспилотных транспортных средств при помощи нейронных сетей на основе архитектуры трансформеров | 2024 |
|
RU2841111C1 |
| АВТОМАТИЗИРОВАННАЯ СИСТЕМА ВЫЯВЛЕНИЯ И ПРОГНОЗИРОВАНИЯ ОСЛОЖНЕНИЙ В ПРОЦЕССЕ СТРОИТЕЛЬСТВА НЕФТЯНЫХ И ГАЗОВЫХ СКВАЖИН | 2020 |
|
RU2745137C1 |
| СПОСОБ И КОМПЬЮТЕРНАЯ СИСТЕМА ОБРАБОТКИ СКВАЖИННЫХ ДАННЫХ | 2020 |
|
RU2782505C2 |
| СПОСОБ ОПРЕДЕЛЕНИЯ ПРОФИЛЯ ПОЛЬЗОВАТЕЛЯ МОБИЛЬНОГО УСТРОЙСТВА НА САМОМ МОБИЛЬНОМ УСТРОЙСТВЕ И СИСТЕМА ДЕМОГРАФИЧЕСКОГО ПРОФИЛИРОВАНИЯ | 2016 |
|
RU2647661C1 |
| АВТОМАТИЗИРОВАННАЯ СИСТЕМА ВЫЯВЛЕНИЯ И ПРОГНОЗИРОВАНИЯ ОСЛОЖНЕНИЙ В ПРОЦЕССЕ СТРОИТЕЛЬСТВА НЕФТЯНЫХ И ГАЗОВЫХ СКВАЖИН | 2020 |
|
RU2745136C1 |
| МЕТОД ПОИСКА ТЕРАПЕВТИЧЕСКИ ЗНАЧИМЫХ МОЛЕКУЛЯРНЫХ МИШЕНЕЙ ДЛЯ ЗАБОЛЕВАНИЙ ПУТЕМ ПРИМЕНЕНИЯ МЕТОДОВ МАШИННОГО ОБУЧЕНИЯ К КОМБИНИРОВАННЫМ ДАННЫМ, ВКЛЮЧАЮЩИМ ГРАФЫ СИГНАЛЬНЫХ ПУТЕЙ, ОМИКСНЫЕ И ТЕКСТОВЫЕ ТИПЫ ДАННЫХ | 2022 |
|
RU2798897C1 |
| Система и способ защиты устройств пользователя | 2020 |
|
RU2770146C2 |
Изобретение относится к вычислительной технике, а именно к автоматизированному сквозному (end-to-end) тестированию программного обеспечения. Технический результат заключается в создании нового способа автоматизации end-to-end тестирования. Предложен способ автоматизации end-to-end тестирования с помощью модели машинного обучения методом машинного перевода, включающий этапы, на которых: собирают данные с выбранных страниц веб-сервиса; обрабатывают собранные данные, включая очистку от шума, в виде неиспользуемых элементов разметки, нормализацию и преобразование в соответствующий формат обработки; обучают модель машинного обучения на основе заранее заготовленного набора данных; генерируют тест-кейсы на основе результатов работы модели; формируют тестовые сценарии, включая последовательность действий, ожидаемые результаты и проверку соответствия фактического и ожидаемого состояния страницы; выполняют сгенерированные тест-кейсы и тестовые сценарии системой автоматизированного тестирования, причем упомянутые тест-кейсы дополнительно используют для дообучения модели машинного обучения. 4 з.п. ф-лы, 10 ил.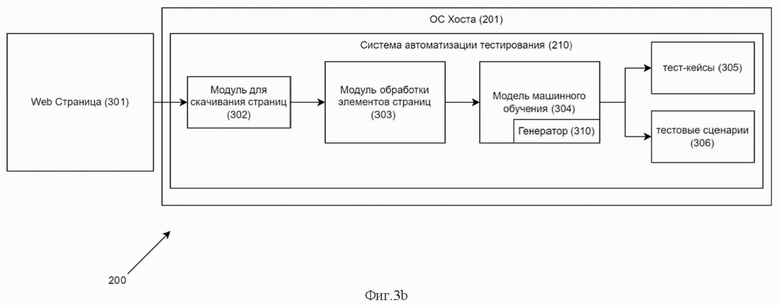
1. Способ автоматизации сквозного тестирования с помощью модели машинного обучения, реализуемый системой автоматизированного тестирования, включающий этапы, на которых:
посредством модуля скачивания и хранения страниц (302) собирают данные с выбранных страниц веб-сервиса;
посредством модуля обработки элементов страниц (303), который соединен с упомянутым модулем скачивания и хранения страниц (302), обрабатывают собранные данные, включая очистку от шума в виде неиспользуемых элементов разметки, нормализацию и преобразование в формат обработки;
посредством модуля памяти (300) для хранения обучающей выборки, соединённого с модулем обработки элементов страниц (303), который соединен с модулем валидации (311), который в свою очередь соединен входом/выходом с модулем модели машинного обучения (304), обучают модель машинного обучения на основе заранее сохраненного набора данных и обучающей выборки,
при этом процесс обучения и валидации модели машинного обучения осуществляют с использованием трансформеров для генерации тест-кейсов и осуществляют следующие шаги: предобработка данных, разделение данных на обучающую и тестовую выборки, валидация гиперпараметров модели машинного обучения для трансформеров, обучение модели машинного обучения на основе указанного выбора гиперпараметров, после обучения модель машинного обучения тестируется на тестовой выборке, анализ результатов, чтобы определить, как модель машинного обучения решает задачу генерации тест-кейсов по проценту успешных и неуспешных тестов, если результаты неудовлетворительные, процесс повторяют с изменением гиперпараметров или модели машинного обучения;
посредством модулей текст-кейсов (305) и тестовых сценариев (306), соединенных с упомянутым модулем модели машинного обучения (304), генерируют тест-кейсы на основе результатов работы модели машинного обучения и формируют тестовые сценарии, включая последовательность действий, требуемые результаты, и осуществляют проверку соответствия фактического и требуемого состояния страниц веб сервиса, и выполняют сгенерированные тест-кейсы и тестовые сценарии системой автоматизированного тестирования.
2. Способ по п. 1, характеризующийся тем, что обучение модели машинного обучения использует метод машинного перевода.
3. Способ по п. 1, характеризующийся тем, что способ выполнен с возможностью внесения изменений в сгенерированные данные тест-кейсов и тестовых сценариев.
4. Способ по п. 1, характеризующийся тем, что сгенерированные тест-кейсы дополнительно используют для обучения модели машинного обучения.
5. Способ по п. 1, характеризующийся тем, что в качестве гиперпараметров модели машинного обучения используют размер буфера, количество слоев и размерность скрытого слоя.
| Способ получения продуктов конденсации фенолов с формальдегидом | 1924 |
|
SU2022A1 |
| Многоступенчатая активно-реактивная турбина | 1924 |
|
SU2013A1 |
| сайт Geeksforgeeks.org, "How to handle Noise in Machine learning?", https://web.archive.org/web/20240706044155/https://www.geeksforgeeks.org/how-to-handle-noise-in-machine-learning/, "Data Transformation in Machine Learning", | |||

