ОБЛАСТЬ ИЗОБРЕТЕНИЯ
Настоящее изобретение относится к анализу генетических данных. Более конкретно, настоящее изобретение относится к анализу генетических данных в отношении конкретного заболевания или нарушения.
ПРЕДПОСЫЛКИ СОЗДАНИЯ ИЗОБРЕТЕНИЯ
В наши дни медицинские и имеющие отношение к здоровью данные пациентов собирают и используют для клинических биоинформационных исследований. Помимо клинических данных, данных визуализирующих исследований, данных биобанкинга пациентов, также собираются их генетические данные, и анализ генетических данных играет важную роль в медицинских исследованиях, а также в диагностике и анамнезе. Например, генетические данные пациентов анализируют для поиска или улучшения средств лечения различных заболеваний.
Однако анализ генетических данных пациентов может создавать опасность для пациентов, которые делятся своими генетическими данными, в плане, например, нарушения их конфиденциальности. Такое нарушение обусловлено тем, что геном субъекта содержит такие данные, как данные относительно цвета глаз, цвета кожи. Эти генетические данные, совместно с другими данными, содержащимися в геноме субъекта, могут привести к идентификации субъекта путем анализа генетических данных. Чтобы защитить конфиденциальность частных лиц (субъектов), некоторые части генома этого субъекта нужно анонимизировать (обезличить) при предоставлении генетических данных для медицинских биоинформационных исследований или анализа.
Некоторые существующие решения для анонимизации генома в биоинформационных исследованиях пытаются анонимизировать весь геном, не принимая во внимание исследуемое заболевание. Поскольку анонимизация означает потерю информации, эти существующие решения также приводят к потере информации относительно генов, напрямую связанных с исследуемым заболеванием, что нежелательно.
Другие решения для анонимизации генома учитывают криминалистический контекст, который представляет тип модели атаки, отличный того, с которым имеет дело настоящее изобретение.
Кроме того, учитывая распространение генетического анализа, согласие пациента ограничивает сбор его/ее геномной информации только подмножеством генов без гибкого решения для анонимизации. В ходе дальнейших исследований может оказаться, что это подмножество генов слишком ограничено, и что для анализа был бы полезен какой-либо связанный ген. Даже если лицо, возможно, дало согласие на применение связанного гена, при условии, что он связан с заболеванием, этот ген отсутствует в массиве данных по соображениям конфиденциальности.
Более того, при сокрытии части генетической информации пациента, методики анонимизации должны также обеспечивать возможность раскрытия в случае необходимости модификации множества генов, связанных с заболеванием, в частности, при необходимости расширения множества генов, связанных с заболеванием.
В документе US 2014/0236833 A1 раскрыт способ установления транзакции между лицом и третьей стороной, на основании генетической информации субъекта, где лицо разрешает третьей стороне доступ к и анализ только подмножества генетической информации субъекта, необходимой для предложения и установления транзакции.
В документе US 2010/0063843 A1 раскрыт компьютерный способ и система для доступа к записанным маскированным данным, в котором маски данных применяют к чувствительной личной информации таким образом, что немаскированные части этой информации можно применять в отборе продуктов, услуг и поставщиков услуг для потребителя.
КРАТКОЕ ОПИСАНИЕ ИЗОБРЕТЕНИЯ
Для решения описанной выше проблемы предложено решение, в котором генетические данные генома одного или нескольких субъектов делят на слои, на основании того, насколько близко эти генетические данные связаны с генами, связанными с исследуемым заболеванием. Эту связь устанавливают на основании сети путей генома. Затем применяют различные методики анонимизации слоев генетических данных, кроме генетических данных, напрямую связанных с исследуемым заболеванием. Методики анонимизации выбирают для каждого слоя генетических данных на основании его оцененной релевантности. Генетические данные, напрямую связанные с исследуемым заболеванием, остаются не анонимизированными и могут применяться для анализа.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
На чертежах:
Фиг. 1 представляет схематическое изображение разделения генетических данных на слои для ориентированной на заболевание анонимизации.
Фиг. 2 представляет схематическое изображение переразделение генетических данных на слои.
Фиг. 3 представляет собой блок-схему, иллюстрирующую этапы варианта реализации способа заболевание-ориентированной анонимизации с разделением на слои.
Фиг. 4 иллюстрирует пример машиночитаемого носителя для хранения исполняемого компьютером кода для осуществления способа анонимизации генетических данных.
Фиг. 5 иллюстрирует вариант реализации системы, выполненной с возможностью анонимизации генетических данных.
ПОДРОБНОЕ ОПИСАНИЕ ВАРИАНТОВ РЕАЛИЗАЦИИ
В первом аспекте настоящего изобретения предложен способ анонимизации генетических данных.
Во втором аспекте настоящего изобретения предложен компьютерный программный продукт, обеспечивающий анонимизацию генетических данных.
В третьем аспекте настоящего изобретения предложена система для анонимизации генетических данных.
В четвертом аспекте настоящего изобретения предложено применение способа и/или компьютерного программного продукта для биоинформационных исследований и/или для диагностики.
Настоящее изобретение будет описано в отношении конкретных вариантов реализации и со ссылкой на фигуры, но это изобретение не ограничено ими, а ограничено только формулой изобретения. Описанные чертежи представляют собой просто схемы и не являются ограничивающими. На чертежах размер некоторых элементов увеличен, а не изображен в масштабе, в иллюстративных целях.
В соответствии с первым аспектом настоящего изобретения предложен способ анонимизации генетических данных от по меньшей мере одного субъекта в отношении конкретного заболевания. Указанный способ анонимизации генетических данных включает следующие этапы:
берут генетические данные от по меньшей мере одного субъекта;
выбирают заболевание для исследования;
определяют подмножество (подмножества) генетических данных из указанных генетических данных по меньшей мере одного субъекта, которые напрямую связаны с исследуемым заболеванием;
разделяют подмножества генетических данных, которые не связаны напрямую с исследуемым заболеванием, на слои на основании расстояний этих подмножеств до генетических данных, напрямую связанных с исследуемым заболеванием; и
анонимизируют слои, которые не связаны напрямую с исследуемым заболеванием, или генетические данные, присутствующие в слоях, которые не связаны напрямую с исследуемым заболеванием.
В этом способе применяют генетические данные от по меньшей мере одного субъекта. Термин "генетические данные" относится к любому виду генетической информации. Термин "генетические данные" включает нуклеотидную последовательность генома субъекта или части генома субъекта. "Генетические данные" также включают генетическую информацию, отличную от нуклеотидной последовательности, такую как, например, информация о присутствии или отсутствии генетических маркеров, таких как, например, полиморфизмы длин продуктов амплификации (AFLP), случайно амплифицированная полиморфная ДНК (RAPD), полиморфизмы длин фрагментов рестрикции (RFLP), однонуклеотидные полиморфизмы (SNP), короткие тандемные повторы (STR) и варьирующие по числу тандемные повторы (VNTR). Термин "генетические данные" также включает информацию относительно РНК и белков. Так, термин "генетические данные" включает информацию относительно нуклеотидных последовательностей, аминокислотных последовательностей, структуры, активности, распространенности и/или функции молекул нуклеиновой кислоты и/или белков. Дополнительно, "генетические данные" включают данные о количестве копий, такие как данные по количеству копий генов или других участков нуклеотидной последовательности.
Термин "субъект" (лицо) относится к субъекту-человеку. Указанный субъект-человек может быть поражен исследуемым заболеванием/страдать от исследуемого заболевания. Соответственно, термины "субъект", "персона"(лицо) и "пациент" применяются в настоящем раскрытии как синонимы.
Выражение "берут (обеспечивают) генетические данные" следует понимать в том смысле, что нужно получить генетические данные по меньшей мере одного субъекта. Тем не менее, генетические данные по меньшей мере одного субъекта не обязательно должны быть получены на одной прямой со способом или для реализации этого способа. Обычно генетические данные по меньшей мере одного субъекта получают в более ранний момент или период времени и хранят в электронном виде в подходящем электронном устройстве для хранения и/или базе данных. Для реализации способа генетические данные могут быть извлечены из устройства хранения или базы данных и использованы.
Выражение "выбирают заболевание для исследования" обозначает, что способ можно применять для исследования или анализа любого заболевания, нарушения или медицинского состояния. Соответственно, нужно выбрать или определить конкретное заболевание, нарушение или медицинское состояние для последующего определения подмножеств генетических данных, напрямую связанных с указанным заболеванием, нарушением или медицинским состоянием, и генетических данных, не связанных напрямую с указанным заболеванием, нарушением или медицинским состоянием.
Термин "связанный напрямую" применительно к связи подмножества генетических данных и исследуемого заболевания, относится к генным локусам и/или генам, которые вызывают указанное заболевание или находятся на одной прямой с указанными генными локусами и/или генами, вызывающими заболевания. Генные локусы и/или гены включают области, кодирующие белок (открытые рамки считывания), а также области, не кодирующие белок, выше или ниже открытой рамки считывания. Указанные генные локусы и/или гены также включают локусы и/или гены, которые непосредственно участвуют в регуляции экспрессии генов, которые вызывают исследуемое заболевание. Соответственно, "связанный напрямую" включает структурные признаки областей, кодирующих белки, генов, кодирующих белки, а также элементы, напрямую участвующие в регуляции экспрессии генов, кодирующих белки или полипептиды, вызывающие заболевание.
Термин "слой" относится к подгруппе генетических данных, которые не связаны напрямую с исследуемым заболеванием. Слой может содержать несколько подмножеств генетических данных. Например, слой представляет собой подмножество генов, имеющих одинаковое расстояние до какого-либо из основных генов, напрямую связанных с заболеванием, причем два разных слоя характеризуются двумя различными расстояниями. Для каждого слоя назначают способ анонимизации, причем для нескольких слоев может быть назначен один и тот же способ анонимизации.
В одном варианте реализации способ анонимизации генетических данных предназначен для исследования конкретного заболевания биоинформатическими средствами, т.е. путем применения программных средств для in silico анализа биологических вопросов с применением математических и статистических методик для интерпретации биологических данных относительно их связи с конкретным заболеванием. Этот вариант реализации обычно требует применения генетической информации от множества субъектов.
В другом варианте реализации способа для анонимизации генетических данных способ предназначен для применения в диагностике, причем генетическую информацию субъекта анализируют для определения генетической предрасположенности и/или присутствия конкретного заболевания или нарушения у указанного субъекта.
Способ можно применять для любого заболевания, нарушения или медицинского состояния. Исследуемое заболевание представляет собой конкретное заболевание, которое выбирают с какой-либо целью. В одном варианте реализации исследуемое заболевание представляет собой заболевание, о котором известно, что оно связано с конкретным генотипом. Примерами таких заболеваний являются различные виды рака, заболевания иммунной системы, заболевания нервной системы, сердечно-сосудистые заболевания, респираторные заболевания, эндокринные и метаболические заболевания, заболевания мочевыделительной системы, заболевания репродуктивной системы, скелетно-мышечные заболевания, врожденные нарушения метаболизма и другие врожденные заболевания, такие как рак простаты, диабет, нарушения метаболизма и психиатрические нарушения (расстройства).
В этом способе генетические данные указанного по меньшей мере одного субъекта группируют в подмножества или слои генетической информации на основе связи генетических данных с исследуемым заболеванием. Соответственно, те генетические данные, о которых известно, что они напрямую связаны с исследуемым заболеванием (гены основного заболевания) группируют в подмножество, которое не анонимизируют.
"Генетические данные", напрямую связанные с исследуемым заболеванием, включают ген(ы), маркеры, РНК и белки, которые связаны с исследуемым заболеванием, В предпочтительном варианте последовательность, структура, активность, распространенность и/или функция объекта указанных генетических данных либо вызывает исследуемое заболевание, или является прямым следствием исследуемого заболевания. Генетические данные могут учитывать нуклеотидные последовательности одного или более генов, либо с участком, кодирующим белок, и/или вне участка, кодирующего белок. Генетические данные могут также учитывать регуляторные гены. Генетические данные, напрямую связанные с исследуемым заболеванием, помещают в подгруппу, которая может быть обозначена как "основа" (ядро).
Генетические данные, которые не связаны напрямую с исследуемым заболеванием, группируют в по меньшей мере одно подмножество или слой. Теоретически, количество слоев может достигать x - 1, где x представляет собой число генов в данном геноме. В предпочтительном варианте генетические данные, которые не связаны напрямую с исследуемым заболеванием, группируют в два или более слоев, на основании степени их удаления (расстояния) от одного или более генов основного заболевания, причем если данное подмножество генетических данных имеет различные расстояния до разных генов основного заболевания, выбирают самое близкое расстояние. В одном варианте реализации число подмножеств или слоев равно или меньше 10, В предпочтительном варианте число подмножеств/слоев составляет 2, 3, 4, 5, 6, 7, 8, 9 или 10. Соответственно, в примере реализации, где число слоев равно 1, генетические данные разбивают на данные, напрямую связанные с заболеванием, и данные не связанные с заболеванием. В альтернативных вариантах реализации, где число слоев равно 2 или более, генетические данные разбивают на подмножество данных, напрямую связанных с заболеванием, и несколько подмножеств данных, не связанных напрямую с заболеванием.
Для определения связи подмножества генетических данных с исследуемым заболеванием и/или относительного расстояния до подмножества генетических данных, напрямую связанных с исследуемым заболеванием, применяют сети геномных путей.
Сети геномных путей доступны и к ним может быть получен доступ через базы данных в интернете, а также они могут быть созданы, например, для конкретного заболевания, такого как рак простаты (http://www.genome.jp/dbget-bin/www_bget?pathway:map05215), сахарный диабет II типа (http://www.genome.jp/dbget-bin/www_bget?pathway:map04930) или болезнь Паркинсона (http://www.genome.jp/dbget-bin/www_bget?pathway:map05012).
В дополнительном и/или альтернативном варианте реализации сети геномных путей не ограничены конкретным заболеванием. Примерами баз данных таких более общих сетей геномных путей является открытая база данных путей с отбором и c отбором и экспертной проверкой (www.reactome.org), подборка баз данных путей/геномных баз данных BioCyc (www.biocyc.org), и информационная база данных для путей Pathway Commons (www.pathwaycommons.org), а также базы данных Консорциума онтологии генов (Gene Ontology Consortium, www.geneontology.org).
В дополнительном и/или альтернативном варианте реализации применяют базу данных STRING (https://www.string-db.org). STRING представляет собой базу данных известных и предсказанных белок-белковых взаимодействий. Взаимодействия включают прямые (физические) и непрямые (функциональные) связи; они получены на основании вычислительных предсказаний, передачи знаний между организмами и взаимодействий, собранных из других (первичных) баз данных. Взаимодействия в базе данных STRING получены из предсказаний на основе геномного контекста, высокопроизводительных лабораторных экспериментов, (консервативной) коэкспрессии генов, автоматизированного анализа текстов и предшествующей информации в базах данных. База данных STRING охватывала 9643763 белков из 2031 организмов на конец июня 2016 г. База данных STRING управляется консорциумом STRING Consortium, который включает Швейцарский институт биоинформатики, Центр исследований белков CPR-NNF и Европейскую библиотеку молекулярной биологии.
Генетические данные, напрямую связанные с исследуемым заболеванием и присутствующие в основном слое, не анонимизируются и, соответственно, доступны для анализа без ограничений.
Генетические данные и/или слои генетических данных, не связанные напрямую с исследуемым заболеванием, анонимизируют с применением методик, которые выбирают из группы, состоящей из статистической анонимизации, шифрования и защищенной многосторонней анонимизации и вычислений.
Эти методики анонимизации допускают анализ данных, но этот анализ ограничен их свойствами. Статистическая анонимизация подразумевает потерю информации, но сохраняет остальную информацию в формате, который может быть прочитан человеком. Это позволяет проводить анализ данных, но результаты изначально ограничиваются потерей информации. Методики шифрования не связаны с потерей информации, но эта информация недоступна. Однако, если существует какое-либо указание на то, что зашифрованная информация необходима для исследования, уполномоченный по конфиденциальности может расширить информацию об основном заболевании путем дешифровки этого множества. Существует промежуточное решение, в котором применяются современные методики, такие как гомоморфное шифрование, многосторонние вычисления и/или другие действия с зашифрованными данными, для объединения основного множества болезни с зашифрованными слоями. В этих случаях чувствительная к конфиденциальности информация останется секретной, а результаты этих операций могут быть раскрыты специалистом по конфиденциальности. Эти методики обуславливают задержку в анализе, и, соответственно, ограничивают виды анализа, которые можно осуществлять с данными.
В одном варианте реализации статистическую анонимизацию выбирают из группы, состоящей из k-анонимности, l-разнообразия, t-близости и δ-присутствия.
K-анонимность представляет собой формальную модель конфиденциальности, созданную L. Sweeney (Л. Свини). Задача заключается в том, чтобы сделать каждую запись неотличимой от определенного числа (k) других записей в случае попытки идентифицировать данные. Набор данных k-анонимизировано, если для любой записи данных с заданным набором параметров, существует по меньшей мере k-1 других записей, соответствующих этим параметрам [J. Sedayao, "Enhancing Cloud Security Using Data Anonymization," June 2012. [онлайн]. Доступно: http://www.intel.nl/content/dam/www/public/us/en/documents/best-practices/enhancing-cloud-security-using-data-anonymization.pdf. (просмотрено 26 января 2015 г.).], [L. Sweeney, "K-anonymity: A Model for Protecting Privacy," Int. J. Uncertain. Fuzziness Knowl.-Based Syst., vol. 10, no. 5, pp. 557-570, 2002.]. Типичное значение k составляет 3 [M. Templ, B. Meindl, A. Kowarik and S. Chen, "Introduction to Statistical Disclosure Control (SDC)", август 2014 г. [онлайн]. Доступно: http://www.ihsn.org/HOME/sites/default/ files/resources/ihsn-working-paper-007-Oct27.pdf. (просмотрено 26 января 2015 г.)].
L-разнообразие улучшает анонимизацию по сравнению с обеспечиваемой k-анонимностью. Разница между этими двумя заключается в том, что хотя k-анонимность требует, чтобы каждая комбинация квази-идентификаторов имела k элементов, l-разнообразие требует присутствия l различных чувствительных значений для каждой комбинации квази-идентификаторов [J. Sedayao, "Enhancing Cloud Security Using Data Anonymization," июнь 2012 г. [онлайн]. Доступно: http://www.intel.nl/content/dam/www/ public /us/en/documents/best-practices/enhancing-cloud-security-using-data-anonymization.pdf. [Просмотрено 26 января 2015 г.]] [4].
T-близость требует, чтобы распределение чувствительного параметра в любом классе эквивалентности было близко к распределению в таблице в целом (т.е., чтобы расстояние между двумя распределениями не должно быть больше порога T) [N. Li, T. Li and S. Venkatasubramanian, "t-Closeness: Privacy Beyond k-Anonymity and l-Diversity," в Data Engineering, 2007. ICDE 2007. IEEE 23я Международная конференция, 2007 г.]. Требование L-разнообразия обеспечивает "разнообразие" чувствительных значений в каждой группе, но оно не учитывает семантическую близость этих значений. Это учитывает t-близость.
δ-присутствие является мерой оценки риска идентификации субъекта в таблице на основании обобщения общеизвестных данных. δ-присутствие является хорошей мерой для баз данных, в случае, когда "известность того, что субъект находится в базе данных ставит" под угрозу конфиденциальность. [M. E. Nergiz, M. Atzori, C. Clifton, "Hiding the Presence of Individuals from Shared Databases," в материалах конференции 2007 ACM SIGMOD International Conference on Management of Data, Пекин, Китай, 2007 г.]
Методики анонимизации "шифрование с возможностью поиска", "гомоморфное шифрование" и "защищенное многостороннее вычисление" обладают тем преимуществом, что фактически расшифровка зашифрованных данных не требуется, но возможно осуществлять обработку данных в зашифрованном домене. Основное различие между этими методиками заключается в выборе их компромиссных решений. Шифрование с возможностью поиска ограничивает обработку просто совпадением ключевых слов. Полностью гомоморфное шифрование позволяет осуществлять любую обработку, но оперирует с шифротекстами исключительно больших размеров и требует очень больших вычислительных усилий. Многостороннее вычисление лучше масштабируется, но требует совместной работы независимых компьютеров для обработки.
В дополнительном и/или альтернативном варианте реализации генетические данные и/или слои генетических данных, не связанные напрямую с исследуемым заболеванием, анонимизируют путем шифрования, в предпочтительном варианте, выбранного из группы, состоящей из гомоморфного шифрования, шифрования с возможностью поиска шифрования, не характеризующегося податливостью (non-malleable).
По сравнению с удалением генов не-податливое шифрование обладает преимуществом, заключающемся в том, что данные не теряются, и специалисты по статистической обработке могут отметить присутствие большего количества данных в определенной области генома. Кроме того, если будет замечено, что какой-либо конкретный ген должен быть отнесен к категории основных генов заболевания, можно заново осуществить разделение генома на слои и повторно анонимизировать геном в соответствии с новым множеством основных генов заболевания.
В дополнительном и/или альтернативном варианте реализации анонимизация учитывает близость генетических данных в пределах слоя к основе таким образом, что слои, содержащие генетические данные, более близкие к основе заболевания, анонимизируют с применением методик, при которых теряется меньше информации, и, таким образом, сохраняется возможность некоторой степени анализа.
В дополнительном и/или альтернативном варианте реализации различные слои анонимизируют с применением разных методик, в предпочтительном варианте в зависимости от расстояния подмножеств генетических данных в слоях до t подмножества генетических данных, напрямую связанных с исследуемым заболеванием. Анонимизация различных слоев с применением различных методик улучшает безопасность данных, поскольку при этом затрудняется непреднамеренное декодирование генетических данных.
Свойства генетической информации, анонимизированной способом, раскрытым в настоящем документе, поддаются определению, поскольку по меньшей мере одно подмножество – основной слой – может быть прочитано человеком. Подмножества генетических данных, которые представляют собой статистически анонимизированные данные, могут быть прочитаны человеком. Кроме того, статистически анонимизированные данные могут быть определены с применением инструментов, которые проверяют, обладают ли данные такими свойствами как 2-анонимность. В одном варианте реализации указанный инструмент выбирают из группы, состоящей из инструмента анонимизации ARX-Anonymization Tool, инструмента анонимизации UTD Anonymization Toolbox, µ-Argus, R-Package sdcMicro, Cornell Anonymization Toolkit, PARAT, платформы для удаления идентифицирующих данных CATS, IRI FieldShield, Gedis Studio Anonymization, SAFELINK, группы по добыче данных Австралийского национального университета (ANU Data Mining Group), пакета Data Swapping Toolkit, инструмента анонимизации данных Ruby и инструмента для обратимой анонимизации записей (Reversible log anonymization tool).
Инструмент анонимизации данных ARX Data Anonymization Tool (http://arx.deidentifier.org/ anonymization-tool/) можно использовать для проверки того, что данные корректно анонимизированы, путем сравнения входных данных с выходными, которые не должны отличаться при представлении данных в CSV-формате.
Набор инструментов для анонимизации данных UTD Anonymization Toolbox (http://cs.utdallas.edu/dspl/cgi-bin/toolbox/index.php) охватывает следующие модели анонимизации: k-анонисность, l-разнообразие, t-близость. Его можно использовать таким же образом, что и инструмент анонимизации данных ARX Data Anonymization Tool.
µ-Argus (Система против повторной идентификации общего применения) представляет собой программный пакет, разработанный в Statistics Netherlands (http://neon.vb.cbs.nl/casc/Software/MuManual4.2.pdf). Этот программный пакет реализует подход, основанный на рисках, пост-рандомизацию (PRAM), численное микроагрегирование, ранговые преобразование. Код доступен по адресу: http://neon.vb.cbs.nl/casc/mu.htm.
Пакет R-Package sdcMicro представляет собой инструмент из набора R. Его можно использовать для генерации анонимизированных микроданных. Этот инструмент можно скачать по адресу: http://cran.r-project.org/web/packages/sdcMicro/. sdcMicro содержит почти все популярные методы анонимизации как для категориальных (качественных), так и для непрерывных переменных. Этот документ использует открытую общественную лицензию (GPL).
Набор инструментов для анонимизации CAT (Cornell Anonymization) (http://sourceforge.net/projects/anony-toolkit/) реализует два критерия конфиденциальности: l-разнообразие и t-близость. Для каждого конкретного критерия конфиденциальности имеется ряд стратегий анонимизации, которые позволяют достичь этого критерия, такие как обобщение (генерализация) данных, замена данных, перемешивание данных и т.д. В настоящее время CAT поддерживает только механим обобщения данных.
PARAT (http://www.privacyanalytics.ca/software/) представляет собой интегральное П.О. для удаления идентифицирующей информации и маскирования, с упором на данные из области здравоохранения. Оно доступно на коммерческой основе. PARAT может оперировать со структурированными данным и неструктурированными данными и использует различные способы защиты: маскирование, удаление идентифицирующих данных для различных типов переменных: прямых идентификаторов, квази-идентификаторов.
Платформа для удаления идентифицирующих данных CATS (https://www.custodix.com/ index.php/cats, CATS = Custodix Anonymisation Services (Сервисы анонимизации Custodix)) представляет собой серивис-ориентированную платформу для удаления идентифицирующей информации из данных. CATS поддерживают анонимизацию различных типов данных (CSV, XML, HL7, DICOM), причем делают это общими и масштабируемыми способами. Ее можно интегрировать в автоматизированные потоки данных или использовать для ручного удаления персональных данных.
IRI FieldShield (http://www.iri.com/solutions/data-masking/de-identification/anonymize) обеспечивает функции для удаления персональных данных, кодирования, шифрования, маскирования, рандомизации и псевдонимизации данных.
Gedis Studio Anonymization (http://www.gedis-studio.com/ anonymization.html) обеспечивает анонимизацию путем шифрования и перемешивания, а также путем маскирования данных. Маскирование данных может быть выполнено с учетом распределения данных.
SAFELINK (https://www.uni-due.de/soziologie/schnell_forschung_safelink_ software.php) представляет собой описание и реализацию процедуры объединения данных с сохранением конфиденциальности, которая криптографическое хеширование (процедуры хеширования сообщений с использованием ключа (HMAC)).
Деятельность группы добычи данных Австралийского национального университета (http://datamining.anu.edu.au/ projects/linkage.html) направлена на разработку методик слепого объединения данных на основании одностороннего хеширования и/или шифрования.
Набор инструментов для замены данных Data Swapping Toolkit можно найти по ссылке: http://www.niss.org/sites/default/files/dstk-afk.pdf
Инструмент для анонимизации данных Ruby (https://www.ruby-toolbox.com/projects/ data-anonymization) использует понятия белого списка и черного списка для удаления прямых идентификаторов. Код можно найти по ссылке: https://github.com/sunitparekh/data-anonymization.
Инструмент для анонимизации записей Reversible (http://blog.cassidiancyber-security.com/post/2014/01/Reversible-log-anonymization-tool) представляет собой инструмент, предназначенный для замены чувствительных полей в записях (журналах) клиента анонимизированными значениями с генерацией таблицы соответствия.
В дополнительном и/или альтернативном варианте реализации подмножества зашифрованных данных допускают сравнение по шифротексту и, соответственно, раскрытие информации, которая может быть использована в анализе исследуемого заболевания. Анализ зашифрованных данных можно определить
- путем анализа с извлечением данных из базы данных, где зашифрованные данные из базы данных выбирают и применяют локально в других частях системы, которая осуществляет операции с зашифрованными данными; и/или
- путем анализа потока информации, который раскрывает многосторонние вычисления, осуществляемые на машинах, отличных от локальной.
Способ обеспечивает преимущество гибкой анонимизации. Способ обеспечивает возможность деанонимизации и реанонимизации генетических данных. На основании прогресса в исследованиях ранее анонимизированные генетические данные можно восстановить и перераспределить, либо задействовав те же способ и субъект, которые были задействован в первой анонимизации, либо с привлечением третьего субъекта.
В альтернативном и/или дополнительном варианте реализации способ дополнительно включает анализ генетических данных, напрямую связанных с исследуемым заболеванием. Обычно анализ генетических данных в отношении исследуемого заболевания необходимо выполнять в отношении исследуемого заболевания, должен был выполнен стороной, отличной от стороны, анонимизирующей генетические данные.
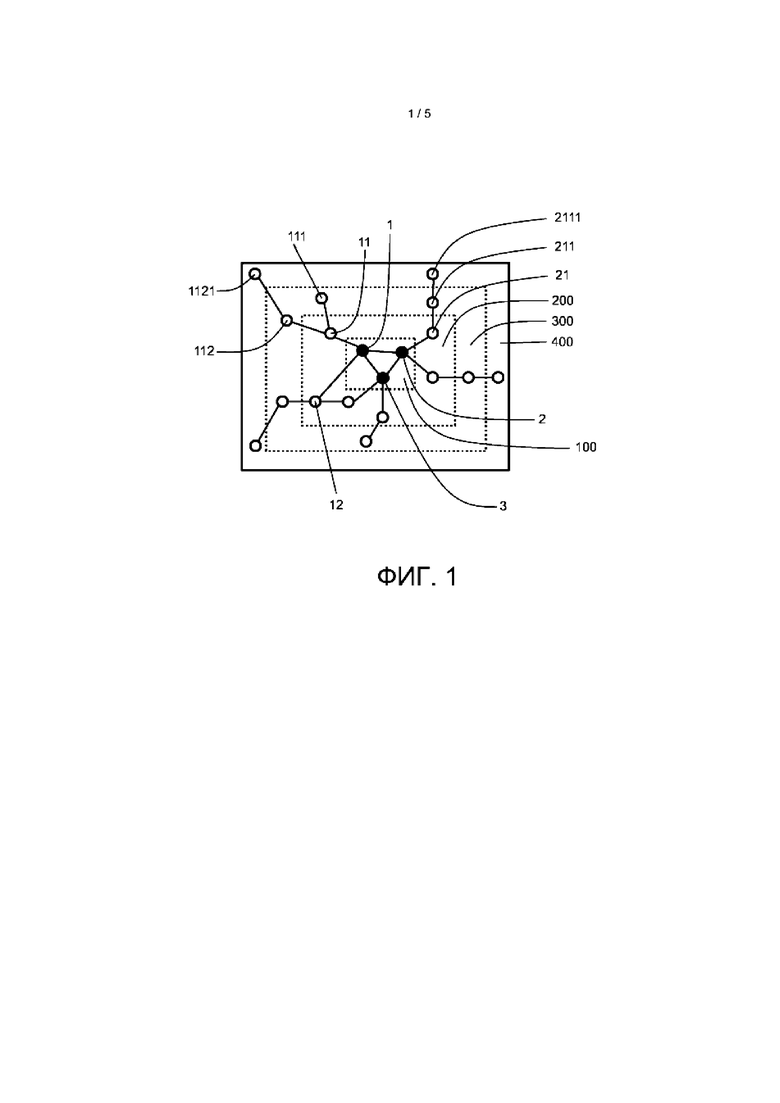
На Фиг. 1 показана анонимизация генетических данных с разделением на слои. В этом варианте реализации предполагается, что генетические данные представляют собой гены. Каждый ген представлен кружком. Гены, напрямую связанные с исследуемым заболеванием, являются основными генами (1, 2, 3) и находятся в основе (ядре) (100). Эти основные гены показаны кружками с заливкой. Представлены три слоя (200, 300, 400) для помещения генов, которые не связаны напрямую с исследуемым заболеванием. Гены, которые не связаны напрямую с исследуемым заболеванием, показаны кружками без заливки. Гены 11 и 12 находятся на одной прямой с основным геном 1, что показано сплошными линиями между кружками, представляющими соответствующими генами. Гены 11 и 12 группируют в слой 1 (200), который содержат гены, наиболее близкие к основным генам, которые не связаны напрямую с исследуемым заболеванием. Гены 111 и 112 находятся на одной прямой с геном 11, но менее близко связаны с основным геном 1. Соответственно, гены 111 и 112 помещают в слой 2, содержащий гены, которые более отдаленно связаны с основными генами, чем гены, напрямую связанные с основными генами. Слои 200, 300, 400 и гены, содержащиеся в указанных слоях, анонимизируют, причем основу 100 и основные гены заболевания 1, 2, 3 не анонимизируют.
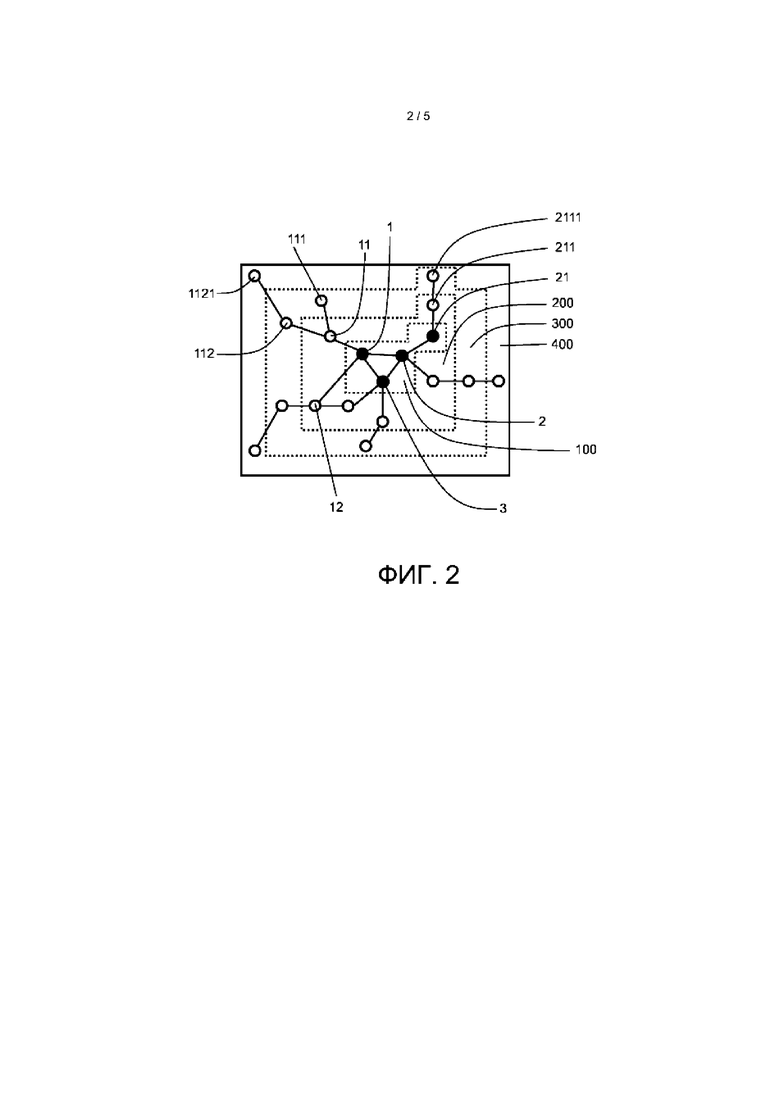
Фиг. 2 иллюстрирует ориентированную на заболевание анонимизацию с делением на слои как показано на Фиг. 1 после да-анонимизации и ре-анонимизации с геном 21 в качестве основного гена, напрямую связанного с исследуемым заболеванием. Как показано Фиг. 1, ген 21 изначально считали геном, напрямую связанным с основным геном 2, но не связанным напрямую с исследуемым заболеванием. Если в ходе прогресса в исследованиях и разработке станет понятно, что ген 21 напрямую связан с исследуемым заболеванием, его включают в основу 1 как показано на Фиг. 2. Кроме того, ген 211, находящийся на одной прямой с геном 21, также будет перенесен в следующий по близости к основе слой, а именно, перенесен из слоя 300 в слой 200, где слои 200, 300, 400 и гены, содержащиеся в этих слоях, анонимизируют, а основу 100 и основные гены заболевания 1, 2, 3, 21 не анонимизируют. Соответственно, любой ген, находящийся на одной прямой с данным геном, т.е. в случае, когда ген или полипептид, кодируемый этим геном, напрямую взаимодействует с другим геном или полипептидом, кодируемым указанным другим геном, распределяют в слой, который на один слой ближе к основе, если определяют, что указанный данный ген является основным геном заболевания. Распределение указанных других генов, находящихся на одной прямой с указанным данным геном, в слой, который на один слой ближе к основе, происходит на основе прямого взаимодействия генов и/или полипептидов, кодируемых указанными генами.
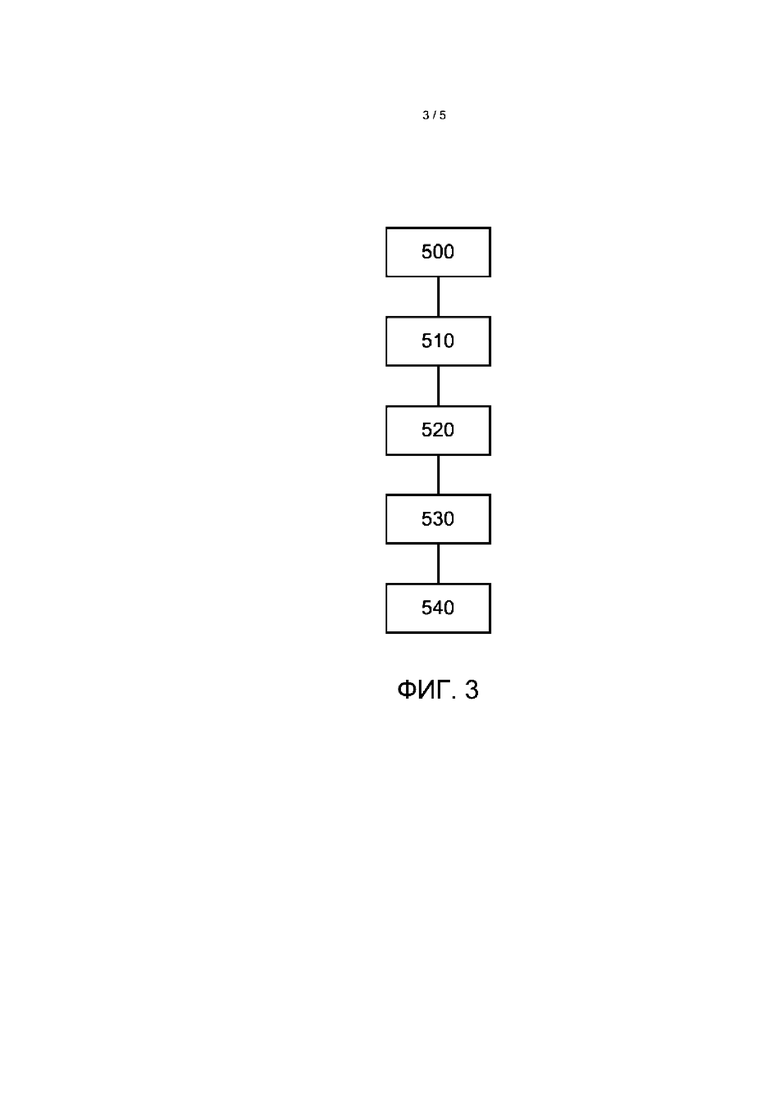
Фиг. 3 представляет схематическую блок-схему, иллюстрирующую вариант реализации способа заболевание-ориентированной анонимизации генетических данных, где этап 500 представляет сбор и хранение генетических данных одного или нескольких субъектов. На этапе 510 выбирают заболевание для исследования. Затем определяют гены основного заболевания на этапе 520 и распределяют гены на слои на основании сеть геномных путей и близости этих генов к генам основного заболевания. На этапе 540, генетические данные, находящиеся в слоях, отличных от основного слоя, анонимизируют.
В соответствии со вторым аспектом настоящего изобретения предложен компьютерный программный продукт для анонимизации генетических данных. Этот компьютерный программный продукт содержит инструкции, которые, при их исполнении на компьютере, приводят к выполнению компьютером по меньшей мере одного этапа способа анонимизации генетических данных по меньшей мере одного субъекта, где способ включает следующие этапы:
берут генетические данные от по меньшей мере одного субъекта;
выбирают заболевание для исследования;
определяют по меньшей мере одно подмножество генетических данных, где указанное подмножество генетических данных напрямую связано с исследуемым заболеванием;
распределяют остальные генетические данные, которые не связаны напрямую с исследуемым заболеванием, на ряд подмножеств, сгруппированных в более, чем один слой на основании близости этих подмножеств к генетическим данным, которые напрямую связаны с исследуемым заболеванием, причем близость в предпочтительном варианте определяют на основании сети геномных путей, которая соответствует этим генетическим данным;
анонимизируют указанные более одного слоя, содержащие подмножества генетических данных, не связанных напрямую с исследуемым заболеванием.
В одном варианте реализации компьютерный программный продукт содержит инструкции, которые при исполнении анонимизируют указанные более одного слоя, содержащие подмножества генетических данных, не связанных напрямую с исследуемым заболеванием. Анонимизацию указанных более одного слоев осуществляют с применением по меньшей мере одной методики, выбранной из группы, состоящей из статистической анонимизации, шифрования и защищенной многосторонней анонимизации и вычислений, как описано выше в настоящем документе в отношении первого аспекта изобретения.
В дополнительном и/или альтернативном варианте реализации компьютерный программный продукт содержит инструкции, которые, при их исполнении распределяют остальные генетические данные, которые не связаны напрямую с исследуемым заболеванием, на одно или более подмножеств и на один или более слоев на основании близости этих подмножеств к генетическим данным, которые напрямую связаны с исследуемым заболеванием.
В дополнительном и/или альтернативном варианте реализации компьютерный программный продукт содержит инструкции, которые, при их исполнении, определяют по меньшей мере одно подмножество генетических данных, где указанное подмножество генетических данных напрямую связано с исследуемым заболеванием.
В одном варианте реализации способ, описанный на Фиг. 3, может быть реализован на компьютере как способ, реализуемый на компьютере, в форме специализированного устройства или в виде комбинации обоих вариантов. Как показано на той же Фиг. 4, инструкции для компьютера, например, исполняемый код, может храниться на машиночитаемом носителе 470, например, в форме ряда 480 машиночитаемых физических отметок и/или ряда элементов с различными электрическими, например, магнитными или оптическими свойствами или значениями. Исполняемый код можно хранить временно или постоянно. Примеры машиночитаемых носителей включают запоминающие устройства, интегральные схемы, серверы, онлайн-программы и т.д. На Фиг. 4 показан оптический диск 470.
Понятно, что настоящее изобретение относится к компьютерным программам, в частности, к компьютерным программам на носителе или в носителе, обеспечивающим возможность осуществления настоящего изобретения. Программа может быть представлена в форме исходного кода, объектного (машинного) кода, кода, промежуточного между исходным и объектным, например, в частично скомпилированной форме, или в любой другой форме, подходящей для реализации способа согласно изобретению. Также понятно, что такая программа может иметь различную архитектуру. Например, программный код, реализующий функционал способа или системы согласно изобретению, может быть подразделен на одну или более подпрограмм. Существует много различных способов распределения функциональности между этими подпрограммами, которые будут ясны специалисту. Подпрограммы можно хранить вместе в одном исполняемом файле с получением независимой программы. Такой исполняемый файл может содержать инструкции, исполняемые компьютером, например, инструкции процессора и/или инструкции интерпретатора (например, инструкции интерпретатора Java). В альтернативном варианте, одна или более, или все подпрограммы, могут храниться в по меньшей мере одном файле внешней библиотеки, и быть статически или динамически связаны с основной программой, например, во время исполнения. Основная программа содержит по меньшей мере один вызов по меньшей мере одной из подпрограмм. Подпрограммы могут вызывать друг друга в виде функций. Вариант реализации, относящийся к компьютерному программному продукту, включает исполняемые компьютером инструкции, соответствующие каждому этапу обработки по меньшей мере одного из способов, представленных в настоящем тексте. Эти инструкции могут быть подразделены на насколько подпрограмм и/или храниться в одном или более файлах, которые могут быть статистически или динамически связаны. Другой вариант реализации, относящийся к компьютерному программному продукту, включает исполняемые компьютером инструкции, соответствующие каждому средству по меньшей мере одной из систем и/или продуктов, представленных в настоящем документе. Эти инструкции могут быть подразделены на насколько подпрограмм и/или храниться в одном или более файлах, которые могут быть статистически или динамически связаны.
Носитель компьютерной программы может представлять собой любой объект или устройство, способные выполнять функцию носителя программы. Например, носитель может включать хранилище данных, такое как постоянное запоминающее устройство (ПЗУ, ROM), например, CD ROM или полупроводниковое ПЗУ, или магнитный записывающий носитель, например, жесткий диск. Кроме того, носитель может представлять собой передаваемый носитель, такой как электрический или оптический сигнал, который может передаваться по электрическому или оптическому кабелю, или по радио или другими средствами. Когда программа реализована в виде такого сигнала, носитель может состоять из такого кабеля, или другого устройства или средства. В альтернативном варианте носитель может представлять собой интегральную схему, реализующую программу, где интегральная схема выполнена с возможностью осуществлять, или применяться в осуществлении соответствующего способа.
В соответствии с третьим аспектом настоящее изобретение обеспечивает систему для анонимизации генетических данных. Указанная система содержит
интерфейс данных, выполненный с возможностью получения генетических данных по меньшей мере одного субъекта;
интерфейс для ввода данных пользователем, выполненный с возможностью получения вводимых пользователем команд от пользовательского устройства ввода для выбора заболевания для исследования; и
процессор, выполненный с возможностью (сконфигурированный для):
определения подмножества (подмножества) генетических данных из генетических данных по меньшей мере одного субъекта, которые непосредственно связаны с исследуемым заболеванием;
распределения подмножеств генетических данных, которые не связаны напрямую с исследуемым заболеванием, на слои на основании расстояний этих подмножеств до генетических данных, напрямую связанных с исследуемым заболеванием, причем расстояние в предпочтительном варианте определяют на основании сети геномных путей, которая соответствует этим генетическим данным; и
анонимизации слоев, которые не связаны напрямую с исследуемым заболеванием, или генетических данных, присутствующих в слоях, которые не связаны напрямую с исследуемым заболеванием.
На Фиг. 5 показана система 600, предназначенная (выполненная с возможностью) анонимизации генетических данных. Система 600 содержит интерфейс данных 620, обеспечивающий возможность доступа к генетическим данным 624 по меньшей мере одного субъекта. Далее, интерфейс данных 620 выполнен с возможностью взаимодействия с базой данных 634 сети геномных путей 632. В примере, показанном на Фиг. 6, интерфейс данных 620 показан соединенным с внешним хранилищем данных 622, таким как подходящее электронное устройство хранения, которое содержит генетические данные 624 по меньшей мере одного субъекта. Интерфейс данных 620 далее связан с сетью геномных путей 632. В альтернативном варианте доступ к генетическим данным 624 по меньшей мере одного субъекта, а также базе данных 634, может осуществляться через внутреннюю систему хранения данных системы 600. В целом интерфейс данных 620 может принимать различные формы, такие как сетевой интерфейс с локальной или сеть широкого охвата (WAN), например, Интернет, интерфейс хранилища с внутренним или внешним хранилищем данных и т.д.
Кроме того, показано, что система 600 содержит интерфейс для ввода данных пользователем 640, обеспечивающий возможность получения вводимых пользователем команд 742 от пользовательского устройства ввода 740, обеспечивая возможность ввода данных пользователем, например, выбора или задания конкретного заболевания , нарушения или медицинского состояния для последующего определения подмножества генетических данных, напрямую связанных с указанным заболеванием, нарушением или медицинским состоянием, и генетических данных, которые не связаны напрямую с этим заболеванием, нарушением или медицинским состоянием, выбора или отбора сети геномных путей 632, которые соответствуют выбранным генетическим данным. Пользовательское устройство вводя 740 может быть представлено в разных формах, включая компьютерную мышь, тачскрин, клавиатуру и т.д., но не ограничиваясь перечисленным. На Фиг. 5 показано пользовательское устройство ввода, представляющее собой компьютерную мышь 740. В общем случае, интерфейс для ввода данных пользователем 640 может принадлежать к типу, соответствующему типу пользовательского устройства ввода 740, т.е. может представлять собой интерфейс, прилагающийся к соответствующему пользовательскому устройству ввода.
Дополнительно показано, что система 600 содержит процессор 660 сконфигурированный (выполненный с возможностью, реализующий функцию) для определения по меньшей мере одного подмножества 100 генетических данных 624, где указанное подмножество 100 генетических данных 624 напрямую связано с исследуемым заболеванием; распределения оставшихся генетических данных, которые не связаны напрямую с исследуемым заболеванием, на одно или более подмножеств и на один или более слоев (200, 300, 400) на основании близости этих подмножеств к генетическим данным, которые напрямую связаны с исследуемым заболеванием; и анонимизации указанных одного или более слоев, содержащих подмножества генетических данных , не связанных напрямую с исследуемым заболеванием.
Процессор 660 реализует функцию определения связи подмножества генетических данных с исследуемым заболеванием и/или или относительного расстояния этого подмножества до подмножества генетических данных, напрямую связанных с исследуемым заболеванием, с применением сети геномных путей 632.
Сети геномных путей 632 существуют и к ним можно получить доступ через базы данных или интернет, и они могут быть установлены, например, для конкретного заболевания, такого как рак предстательной железы, сахарный диабет II типа или болезнь Паркинсона.
В одном из примеров на основании получаемых вводимых пользователем команд 742, процессор 660 может передать генетические данные 624 по меньшей мере одного субъекта в выбранную сеть геномных путей 632 через интерфейс данных 620. В ответ процессор 660 может получить результат, указывающий на связь подмножества генетических данных с исследуемым заболеванием и/или относительное расстояние до подмножества генетических данных, напрямую связанных с исследуемым заболеванием, от сети геномных путей 632. Затем процессор 660 может далее группировать генетические данные указанного по меньшей мере одного субъекта в подмножества или слои генетических данных на основании полученного результата, указывающего на связь генетических данных с исследуемым заболеванием. Так, генетические данные, о которых известно, что они напрямую связаны с исследуемым заболеванием (гены основного заболевания) процессор 660 группирует в подмножество 100. Генетические данные и/или слои (200, 300, 400) генетических данных, не связанные напрямую с исследуемым заболеванием, затем группируют на основании относительного расстояния до подмножества генетических данных, напрямую связанных с исследуемым заболеванием. Здесь 'расстояние' между двумя генами определяется по некоторым типам взаимодействий. Такие взаимодействия могут представлять собой коэкспрессию, совместную публикацию, белок-белковые взаимодействия и т.д., или любую их комбинацию. Например, несколько возможных взаимодействий перечислены в базе данных STRING (http://www.string-db.org/help/getting_started/#evidence). Далее процессор 600 реализует функцию анонимизации генетических данных и/или слоем (200, 300, 400) генетических данных, не связанных напрямую с исследуемым заболеванием, путем выбора одного или более алгоритмов из группы алгоритмов, состоящей из статистической анонимизации, шифрования и защищенных многосторонних анонимизации и вычислений. Эта группа алгоритмов хранится в памяти 670 (не показана на Фиг.5).
В предпочтительном примере в систему 600 может быть включена база данных 634. Соответственно, на основании получаемых вводимых пользователем команд 742, процессор 660 может получать генетические данные 624 по меньшей мере одного субъекта из внешнего хранилища 622. Процессор 660 может далее определять подмножество (подмножества) генетических данных совместно с базой данных 634. Затем, процессор разделять подмножества генетических данных, которые не связаны напрямую с исследуемым заболеванием, на слои на основании расстояний этих подмножеств до генетических данных, напрямую связанных с исследуемым заболеванием. После этого процессор 660 может анонимизировать слои, которые не связанные напрямую с исследуемым заболеванием, или генетические данные, присутствующие в слоях, которые не связаны напрямую с исследуемым заболеванием. Подробный пример, показывающий как разделяются и анонимизируются подмножества генетических данных, приведен ниже.
Процессор 600 также реализует функцию генерации анонимизированных генетических данных 662 на устройство вывода 760, такое как дисплей. В альтернативном варианте дисплей 760 может быть составляющей частью систему 600.
В альтернативном варианте процессор 600 может быть сконфигурирован для автоматического выбора или определения конкретного заболевания, нарушения или медицинского состояния для последующего определения подмножества генетических данных, напрямую связанных с указанным заболеванием, нарушением или медицинским состоянием, и генетических данных, не связанных напрямую с указанным заболеванием, нарушением или медицинским состоянием, а также выбора или отбора сети геномных путей 632, которые соответствуют выбранным генетическим данным.
Согласно четвертому аспекту изобретение относится к применению способа и/или компьютерного программного продукта в биоинформационных исследованиях и/или в диагностике.
В одном варианте реализации способ и/или компьютерный программный продукт применяют в биоинформационных исследованиях. Применение способа и/или компьютерного программного продукта в биоинформационных исследованиях включает получение генетических данных от множества субъектов. Примерами областей исследования в биоинформатике, в которых может быть использовано применение способа и/или компьютерного программного продукта в биоинформационных исследованиях и которые охватываются четвертым аспектом, являются геномика, транскриптомика, протеомика и системная биология.
В альтернативном варианте реализации способ и/или компьютерный программный продукт применяют в диагностике, при этом генетические данные субъекта используют для анализа того, страдает ли этот субъект конкретным заболеванием или подвержен риску приобретения указанного заболевания или поражения указанным заболеванием.
Настоящее изобретение можно применять в области диагностики и в области геномики, при этом генетические данные индивидуумов организуют в виде иерархии с основным массивом данных, которые полностью доступны для дальнейшего анализа, и слоями возрастающей чувствительности, которые могут быть раскрыты или применяться в вычислениях с зашифрованными данными. Настоящее изобретение позволяет улучшить процесс получения согласия у индивидуумов как для индивидуумов, так и для владельца данных. Индивидуумы уверены, что их генетические данные надлежащим образом анонимизируются, и при этом возможна ре-анонимизация, инициируемая прогрессом в исследованиях. Соответственно, становится легче установить согласие индивидуумов, разрешая доступ к "генетическим данным, значимым для проведения исследования изучаемого заболевания для их анализа или исследования ".
В тех случаях, когда [в исходном тексте на английском языке] используется неопределенный или определенный артикль применительно в существительному в форме единственного числа, например "a", "an", "the" (что в тексте на русском языке соответствует использованию существительного в единственном числе отдельно или со словами «указанный», «упомянутый», «этот» и т.п.), это включает множественное число этого существительного, если прямо не указано иное. Далее, термины «первый», «второй», «третий» и т.п. в описании и в формуле изобретения используются для того, чтобы различать схожие элементы, а не обязательно для описания последовательности или хронологического порядка. Следует понимать, что используемые таким образом термины являются взаимозаменяемыми в соответствующих условиях, и что варианты реализации изобретения, описанные в настоящем тексте, могут функционировать в последовательностях, отличающихся от описанных или проиллюстрированных в настоящем документе. Более того, термины «верх» (верхний), «низ» (нижний), «сверху», «под», «за» и т.п. в описании и формуле изобретения используются в описательных целях, а не обязательно для описания относительного положения. Следует понимать, что используемые таким образом термины являются взаимозаменяемыми в соответствующих обстоятельствах, и что варианты реализации изобретения, описанные в настоящем документе, могут функционировать в ориентациях, отличающихся от описанных в настоящем документе. Следует отметить, что термин "содержащий" (включающий), используемый в настоящем описании и формуле изобретения, не следует интерпретировать как ограниченный средствами, перечисленными после него; он не исключает другие элементы или этапы. Таким образом, объем выражения "устройство, содержащее средства A и B" не ограничивается устройствами, состоящими только из компонентов A и B. Применительно к настоящему изобретению оно означает, что значимыми компонентами являются только A и B.
Следует отметить, что указанные выше варианты реализации иллюстрируют изобретение, а не ограничивают его, и сто специалисты в соответствующей области смогут создать множество альтернативных вариантов реализации, не выходя за пределы объема прилагаемой описание формулы изобретения. В формуле изобретения любые ссылочные позиции, помещенные в скобках, не следует рассматривать как ограничения пункта формулы изобретения. Настоящее изобретение может быть реализовано посредством аппаратной части, состоящей из нескольких отдельных элементов, и посредством соответствующим образом запрограммированного компьютера. В пункте формулы, относящемся к устройству, где перечислено несколько средств, некоторые из этих средств могут быть реализованы одним и тем же аппаратным продуктом. Сам по себе тот факт, что некоторые признаки указаны в различных не связанных друг с другом независимых пунктах, не означает, что комбинацию этих признаков нельзя использовать для получения дополнительных преимуществ.
ПРИМЕР
Ориентированная на заболевание анонимизация генома в отношении рака предстательной железы
На первом этапе получали список основных генов рака предстательной железы путем поиска в базе данных путей KEGG (http://www.genome.jp/dbget-bin/www_bget?pathway:map05215) для пути рака предстательной железы.
В целом 70 генов, которые являются частью этого пути, получили с использованием базы KEGG Orthology, поскольку эта база данных группирует все гены, принадлежащие к нескольким видам в ортологичные группы, удаляя всё лишнее. Эти 70 генов представляют собой все гены, которые считают напрямую связанными с раком простаты. Эти 70 генов объединяли в “основу” (ядро). Это были следующие гены:
PIK3C = фосфатидилинозитол-4,5-бифосфат-3-киназа [EC:2.7.1.153] ;
PTEN = фосфатидилинозитол-3,4,5-трифосфат-3-фосфатаза и протеинфосфатаза двойной специфичности, KLK3 = семеногелаза [EC:3.4.21.77]; CTNNB1 = катенин-бета 1, BAD = Bcl-2-антагонист клеточной гибели, BCL2 = регулятор апоптоза Bcl-2, CDK2 = циклин-зависимая киназа 2 [EC:2.7.11.22]; NFKB1 = ядерный фактор NF-каппа-B, субъединица p105; TCF7 = фактор транскрипции 7; PIK3R = фосфоинозитид-3-киназа, регуляторная субъединица; HRAS = ГТФ-аза Hras; GSK3B = киназа гликогенсинтазы 3-бета [EC:2.7.11.26]; SOS = дочерний ген sevenless; htpG, HSP90A = молекулярный шаперон HtpG; EGF = эпидермальный фактор роста; PDGFA = тромбоцитарный фактор роста, субъединица A; EGFR, ERBB1 = рецептор эпидермального фактора роста [EC:2.7.10.1]; FGFR1 = рецептор 1 фактора роста фибробластов [EC:2.7.10.1]; PDGFRA = альфа-рецептор тромбоцитарного фактора роста [EC:2.7.10.1]; GRB2 = белок 2, связывающий фактор роста 2; BRAF = B-Raf протоонкогенная серин-треониновая протеинкиназа [EC:2.7.11.1]; RAF1 = протоонкогенная серин-треониновая протеинкиназа RAF [EC:2.7.11.1]; MAP2K1, MEK1 = киназа 1 митоген-активируемой протеинкиназы [EC:2.7.12.2]; MAP2K2, MEK2 = киназа 2 митоген-активируемой протеинкиназы [EC:2.7.12.2]; MAPK1_3 = киназа 1/3 митоген-активируемой протеинкиназы [EC:2.7.11.24]; ATF4, CREB2 = цАМФ-зависимый фактор транскрипции ATF-4; CASP9 = каспаза 9 [EC:3.4.22.62]; TP53, P53 = опухолевй белок p53; AKT = RAC серин-треониновая протеинкиназа [EC:2.7.11.1]; IKBKA, IKKA, CHUK = альфа-субъединица ингибитора киназы ядерного фактора-B [EC:2.7.11.10]; TCF7L1 = ген 1, подобный фактору транскрипции 7; TCF7L2 = ген 2, подобный фактору транскрипции 7; LEF1 = лимфоидный энхансер-связывающий фактор 1; EP300, CREBBP, KAT3 = E1A/CREB-связывающий белок [EC:2.3.1.48]; CCND1 = циклин D1; INS = инсулин; NFKBIA = ингибитор альфа NF-каппа-B; RELA = фактор транскрипции p65; ERBB2, HER2; = рецепторная тирозин-протеиновая киназа erbB-2 [EC:2.7.10.1]; INSRR = рецептор, связанный с рецептором инсулина [EC:2.7.10.1]; IGF1R = рецептор инсулиноподобного фактора роста 1 [EC:2.7.10.1]; PDGFRB = бета-рецептор тромбоцитарного роста [EC:2.7.10.1]; FGFR2 = рецептор 2 фактора роста фибробластов [EC:2.7.10.1]; PDGFC_D = тромбоцитарный фактор роста C/D; IGF1 = инсулиноподобный фактор роста 1; CREB1 = белок 1, связывающий цАМФ-чувствительный элемент; PDPK1 = 3-фосфоинозитид-зависимая протеинкиназа-1 [EC:2.7.11.1]; RB1 = белок, ассоциированный с ретинобластомой; E2F3 = фактор транскрипции E2F3; CDKN1B, P27, KIP1 = ингибитор 1B циклин-зависимой киназы; CDKN1A, P21, CIP1 = ингибитор 1А циклин-зависимой киназы; CCNE = циклин E; MDM2 = E3 убиквитин-протеинлигаза Mdm2 [EC:2.3.2.27]; FOXO1 = белок forkhead box O1; MTOR, FRAP, TOR = серин/треониновая протеикиназа mTOR [EC:2.7.11.1], IKBKB, IKKB = ингибитор ядерного фактора-B киназа subunit beta [EC:2.7.11.10]; IKBKG, IKKG, NEMO = субъединица гамма ингибитора киназы ядерного фактора-B киназа; KRAS, KRAS2 = ГТФаза Kras; NRAS = ГТФаза Nras; NR3C4, AR = рецептор андрогенов; TGFA = трансформирующий фактор роста альфа; ARAF, ARAF1 = прото-онкогенная серин-треониновая протеинкиназа A-Raf [EC:2.7.11.1]; CREB5, CREBPA = связывающий цАМФ-чувствительный элемент белок 5; CREB3; = связывающий цАМФ-чувствительный элемент белок 3; NKX3-1 = содержащий гомеобокс белок Nkx-3.1; E2F2 = фактор транскрипции E2F2; HSP90B, TRA1 = белок теплового шока массой 90КДа бета; SRD5A2 = 3-оксо-5-альфа-стероид-4-дегидрогеназа 2 [EC:1.3.1.22]; PDGFB = субъединица В тромбоцитарного фактора роста B и E2F1 = фактор транскрипции E2F1.
На следующем этапе создавали основную сеть рака предстательной железы, в которой список основных генов рака предстательной железы копируют в страницу поиска базы данных STRING (http://string-db.org/cgi/input.pl?input_page_active_form=multiple_identifiers), в результате чего получают сеть: http://bit.ly/28XP7HT (71 генов, опция ‘minimum required interaction score’ (минимальный необходимый балл взаимодействия): низкая достоверность (0,150), опция ‘disable structure previews inside network bubbles’ (отключить предпросмотр структур в сетевых пузырях) включена).
Затем создавали первый слой сети рака предстательной железы.
Для создания первого слоя выбирали ‘data settings’ (установки данных) и ввод в поле ‘2nd shell’ (вторая оболочка): ‘no more than 20 interactors’ (не более 20 взаимодействующих объектов). Добавленные гены стали частью первого слоя (91 ген – 71 ген = 20 генов).
На следующем этапе создавали второй и внешний слои сети рака предстательной железы.
Для создания второго слоя эти гены вводили на странице поиска для создания второго слоя, эти гены вводили в страницу поиска базы данных STRING, и снова выбирали для опции ‘2nd shell’ (вторая оболочка): ‘no more than 50 interactors’ (не более 50 взаимодействующих объектов). Все новые всплывающие гены стали частью второго слоя (50 генов).
В этом примере третий слой (или, в данном случае, внешний слой) состоит из всех генов в геноме человека, которые не являются частью либо основного, либо первого слоя.
На следующем этапе геномные данные анонимизировали.
Для анонимизации использовали массив данных с геномными данными (например, данными об экспрессии) для полного генома (20457 генов согласно базе данных STRING) ста (100) субъектов.
Основу из 71 генов не анонимизировали, поскольку все гены не анонимизировали, поскольку необходима вся информация от этих генов рака предстательной железа.
Первый слой из 20 генов анонимизировали с применением анонимизировали с применением статистической анонимизации, поскольку информация из этих генов может быть важной. Точнее, это делали путем обобщения или подавления значений этих генов для достижения параметров k-анонимности и l-разнообразия для выбранных k (например, k=2) и l (например, l=3).
Второй слой из 50 генов анонимизировали с применением гомоморфного шифрования, поскольку информация из этих генов все же может быть важной. Этот способ может быть удобнее применять, когда слой содержит большее число генов (например, 50 генов или более).
Внешний слой из 20316 генов анонимизировали с применением шифрования, не отличающегося свойством податливости, поскольку информация из этих генов не важна для нашего конкретного исследования рака простаты.


Заявленная группа изобретений относится к биотехнологии. Предложены способ, система для анонимизации генетических данных от по меньшей мере одного субъекта, машиночитаемый носитель, на котором хранится компьютерный программный продукт для анонимизации генетических данных, и применение способа для анонимизации генетических данных от по меньшей мере одного субъекта. Способ для анонимизации генетических данных от по меньшей мере одного субъекта, осуществляемый с помощью машиночитаемого носителя, предусматривает отбор генетических данных, определение по меньшей мере одного подмножества генетических данных, напрямую связанных с исследуемым заболеванием, и анонимизирование слоев, содержащих подмножества генетических данных, не связанных напрямую с исследуемым заболеванием. Причем указанные этапы осуществляют с использованием системы, содержащей интерфейс данных, выполненный с возможностью получения генетических данных по меньшей мере одного субъекта, интерфейс для ввода данных пользователем, выполненный с возможностью получения вводимых пользователем команд от пользовательского устройства ввода для выбора заболевания для исследования, и процессор, выполненный с возможностью реализации этапов способа. Группа изобретений позволяет повысить точность диагностики заболевания и может быть использована в области геномики, генетики, биоинформационных исследований, транскриптомики, протеомики и системной биологии или диагностики. 4 н. и 11 з.п. ф-лы, 5 ил., 1 пр.
1. Способ анонимизации генетических данных от по меньшей мере одного субъекта, который включает следующие этапы:
- берут генетические данные от по меньшей мере одного субъекта;
- выбирают заболевание для исследования;
- определяют по меньшей мере одно подмножество генетических данных, причем указанное подмножество генетических данных напрямую связано с исследуемым заболеванием;
- распределяют оставшиеся генетические данные, которые не связаны напрямую с исследуемым заболеванием, на ряд подмножеств, сгруппированных в более чем один слой, на основании близости этих подмножеств к генетическим данным, которые напрямую связаны с исследуемым заболеванием, причем близость предпочтительно определяют на основании сети геномных путей, которая соответствует этим генетическим данным;
- анонимизируют указанные более одного слоя, содержащие подмножества генетических данных, не связанных напрямую с исследуемым заболеванием.
2. Способ по п. 1, в котором дополнительно анализируют генетические данные в отношении исследуемого заболевания.
3. Способ по п. 1 или 2, в котором генетические данные выбирают из группы, состоящей из нуклеотидных последовательностей, полиморфизмов длин продуктов амплификации (AFLP), случайно амплифицированных полиморфных ДНК (RAPD), полиморфизмов длин фрагментов рестрикции (RFLP), однонуклеотидных полиморфизмов (SNP), коротких тандемных повторов (STR) и варьирующих по числу тандемных повторов (VNTR), РНК, аминокислотных последовательностей, полипептидов, белков и данных о числе копий.
4. Способ по любому из пп. 1-3, характеризующийся тем, что число слоев составляет 2, 3, 4, 5, 6, 7, 8, 9 или 10.
5. Способ по любому из пп. 1-4, в котором анонимизацию осуществляют с применением по меньшей мере одной методики, выбранной из группы, состоящей из статистической анонимизации, шифрования и защищенных многосторонних анонимизации и вычислений.
6. Способ по п. 5, в котором статистическую анонимизацию выбирают из группы, состоящей из k-анонимности, l-разнообразия, t-близости и δ-присутствия.
7. Способ по п. 5, в котором шифрование выбирают из группы, состоящей из гомоморфного шифрования, шифрования с возможностью поиска и шифрования, не характеризующегося податливостью.
8. Способ по любому из пп. 1-7, в котором различные слои анонимизируют с применением различных методик, предпочтительно в зависимости от расстояния от подмножеств генетических данных в слоях до подмножества генетических данных, связанных напрямую с исследуемым заболеванием.
9. Способ по любому из пп. 1-8, в котором подмножество генетических данных, связанных напрямую с исследуемым заболеванием, выбирают из по меньшей мере одной базы данных, определяющей гены, кодирующие полипептиды, которые были определены как связанные напрямую с исследуемым заболеванием.
10. Способ по любому из пп. 1-9, в котором генетические данные из подмножеств генетических данных первого слоя выбирают из группы генов, кодирующих полипептиды, которые не связаны напрямую с исследуемым заболеванием, но о которых известно, что они напрямую взаимодействуют с одним из генов и/или полипептидов, кодируемых одним из генов из генетических данных, которые напрямую связаны с исследуемым заболеванием.
11. Способ по п. 10, в котором по меньшей мере одно из подмножеств генетических данных первого слоя включают в подмножество генетических данных, в отношении которых было определено, что они связаны напрямую с исследуемым заболеванием.
12. Способ по п. 11, в котором подмножество генетических данных, которые находятся на одной прямой с данным подмножеством генетических данных, распределяют в следующий слой, более близкий к генетическим данным, напрямую связанным с исследуемым заболеванием.
13. Компьютерный программный продукт для анонимизации генетических данных, содержащий инструкции, которые при исполнении их на компьютере приводят к выполнению компьютером по меньшей мере одного этапа способа анонимизации генетических данных по меньшей мере одного субъекта, где способ включает следующие этапы:
- берут генетические данные от по меньшей мере одного субъекта;
- выбирают заболевание для исследования;
- определяют по меньшей мере одно подмножество генетических данных, где указанное подмножество генетических данных напрямую связано с исследуемым заболеванием;
- распределяют остальные генетические данные, которые не связаны напрямую с исследуемым заболеванием, на ряд подмножеств, сгруппированных в более чем один слой, на основании близости этих подмножеств к генетическим данным, которые напрямую связаны с исследуемым заболеванием, причем близость в предпочтительном варианте определяют на основании сети геномных путей, которая соответствует этим генетическим данным;
- анонимизируют указанные более одного слоя, содержащие подмножества генетических данных, не связанных напрямую с исследуемым заболеванием.
14. Система для анонимизации генетических данных, содержащая:
интерфейс данных, выполненный с возможностью получения генетических данных по меньшей мере одного субъекта;
интерфейс для ввода данных пользователем, выполненный с возможностью получения вводимых пользователем команд от пользовательского устройства ввода для выбора заболевания для исследования;
- процессор, выполненный с возможностью
- определения подмножества (подмножеств) генетических данных из генетических данных по меньшей мере одного субъекта, которые напрямую связаны с исследуемым заболеванием;
- распределения подмножества генетических данных, которые не связаны напрямую с исследуемым заболеванием, на слои на основании расстояний этих подмножеств до генетических данных, напрямую связанных с исследуемым заболеванием, причем расстояние предпочтительно устанавливают на основании сети геномных путей, которая соответствует этим генетическим данным; и
- анонимизации слоев, которые не связаны напрямую с исследуемым заболеванием, или генетических данных, присутствующих в слоях, которые не связаны напрямую с исследуемым заболеванием.
15. Применение способа по любому из пп. 1 или 12, компьютерного программного продукта по п. 13 и/или системы по п. 14 в чем-либо для анонимизации генетических данных от по меньшей мере одного субъекта, в области геномики, генетики, биоинформационных исследований, транскриптомики, протеомики и системной биологии или диагностики.
| Способ защиты переносных электрических установок от опасностей, связанных с заземлением одной из фаз | 1924 |
|
SU2014A1 |
| Приспособление для суммирования отрезков прямых линий | 1923 |
|
SU2010A1 |

