ОБЛАСТЬ ТЕХНИКИ
Настоящее изобретение относится к способам кодирования звукового содержимого в битовый поток и к способам декодирования звукового содержимого из битового потока. В частности, настоящее изобретение относится к таким способам, в которых в битовом потоке передают классификационную информацию, указывающую тип содержимого звукового содержимого.
ПРЕДПОСЫЛКИ ИЗОБРЕТЕНИЯ
Воспринимаемые выгоды постобработки звуковых сигналов можно повысить, если алгоритмам обработки звуковых сигналов известно обрабатываемое содержимое. Например, точное обнаружение диалога усилителем диалога улучшается, если в текущем аудиокадре есть измеренная высокая уверенность в наличии диалога. Кроме того, в присутствии музыкального содержимого виртуализатор может отключаться для сохранения музыкального тембра, или в присутствии диалога в фильме динамический эквалайзер, предназначенной для подгонки музыкального тембра (такой как интеллектуальный эквалайзер громкости Dolby®), может отключаться для сохранения тембра речи.
Обычно для получения лучших настроек на своем устройстве воспроизведения от пользователей может требоваться переключать профили, такие как «фильм» или «музыка», но для этого часто требуется доступ к продвинутым настройкам или пользовательским интерфейсам, о которых многие пользователи могут не знать или с которыми им неудобно работать.
Одним из подходов к решению этой проблемы было бы использование инструмента анализа содержимого (такого как, например, инструмент Dolby’s Media Intelligence) для обнаружения признаков в звуковом сигнале, чтобы определять, какова вероятность того, что в аудиопотоке присутствуют определенные типы содержимого.
Современное устройство воспроизведения, такое как мобильный телефон, которое может воспроизводить разнообразное содержимое, включая фильмы и музыку, может использовать инструмент анализа содержимого (такой как, например, Dolby’s Media Intelligence) для определения значений уверенности в присутствии в аудиопотоке определенных типов содержимого. Инструмент анализа содержимого может возвращать значения уверенности (показатели уверенности) о присутствии «музыки», «речи» или «фоновых эффектов». Значения уверенности могут затем быть использованы в комбинациях для возврата весов управления алгоритмами, которые в свою очередь могут быть использованы для регулирования некоторых признаков постобработки (например, их интенсивностью).
Способ, описанный выше, представляет собой «одностороннее» решение, которое можно было бы выполнять в декодере или в отдельной библиотеке постобработки, включающей аудиоданные ИКМ. Эта односторонняя реализация может быть эффективной при управлении алгоритмами постобработки, но привносит в устройство воспроизведения значительную вычислительную сложность, и поэтому характер анализа содержимого, касающийся реального времени, может быть ограничен доступными возможностями в устройстве воспроизведения.
Таким образом, существует необходимость в улучшенных способах и устройствах для обработки звукового содержимого при известном содержимом.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
В настоящем изобретении предлагаются способы кодирования звукового содержимого и способы декодирования звукового содержимого, имеющие признаки соответствующих независимых пунктов формулы изобретения.
В одном аспекте настоящее изобретение относится к способу кодирования звукового содержимого. Способ может включать выполнение анализа содержимого звукового содержимого. Анализ содержимого может быть выполнен с использованием инструмента Dolby’s Media Intelligence, например. Кроме того, анализ содержимого может быть выполнен для каждого из множества последовательных окон, причем каждое окно включает предопределенное количество последовательных (аудио) кадров. При этом анализ содержимого может быть основан на одном или более расчетах вероятности/уверенности, основанных на поддающихся определению признаках в звуковом содержимом. Эти расчеты могут быть динамическими и могут корректироваться для увеличения или уменьшения конкретной вероятности. В более общих терминах анализ содержимого может быть адаптивным и/или может быть обучен заранее с использованием предопределенного звукового содержимого. При анализе содержимого для уменьшения задержки может использоваться буфер упреждающей выборки. В дополнение или в качестве альтернативы, для обеспечения времени обработки, необходимого для анализа содержимого, может вводиться задержка кодирования. Также анализ содержимого может быть выполнен в несколько проходов. Способ может дополнительно включать генерирование классификационной информации, указывающей тип содержимого звукового содержимого, на основании (результата) анализа содержимого. Генерирование классификационной информации может также быть основано на обнаружении переходов сцены в звуковом содержимом (или на выставляемом вручную указании перехода сцены). Например, скорость изменения значений уверенности, включенных в классификационную информацию, может быть выше, если обнаружен/указан переход сцены (т. е. выше, чем в устойчивом состоянии). Способ может дополнительно включать кодирование звукового содержимого и классификационной информации, например, значений уверенности, в битовый поток. Кодированный звуковое содержимое и кодированная классификационная информация могут быть мультиплексированы. Способ может еще дополнительно включать выдачу битового потока.
В контексте настоящего описания «тип содержимого» звукового содержимого означает тип содержимого, который может быть воспроизведен в устройстве воспроизведения и который может отличить человеческое ухо по одной или более характеристикам типа содержимого. Например, музыка может быть отличимой от речи или шума, поскольку включает отличающуюся полосу звуковых частот, отличающееся распределение мощности звукового сигнала по разным частотам, отличающуюся тональную длительность, отличающиеся тип и число основных и доминантных частот и т. д.
Благодаря выполнению анализа содержимого на стороне кодера и кодированию получаемой в результате классификационной информации в битовый поток вычислительную нагрузку на кодер можно значительно облегчить. Дополнительно превосходящие вычислительные возможности кодера могут быть использованы для выполнения более сложного и более точного анализа содержимого. Помимо обеспечения разных вычислительных возможностей кодера и декодера, предлагаемый способ предоставляет стороне декодера дополнительную гибкость в постобработке звука декодированного звука. Например, постобработка может быть настроена в соответствии с типом устройства у устройства, реализующего декодер, и/или личными предпочтениями пользователя.
В некоторых вариантах осуществления анализ содержимого может быть основан, по меньшей мере частично, на метаданных для звукового содержимого. Тем самым обеспечивается дополнительное управление над анализом содержимого, например, со стороны создателя содержимого. В то же время точность анализа содержимого можно повысить путем предоставления соответствующих метаданных.
В еще одном аспекте настоящее изобретение относится к дополнительному способу кодирования звукового содержимого. Способ может включать прием пользовательского ввода, относящегося к типу содержимого звукового содержимого. Пользовательский ввод может включать выставляемые вручную метки или выставляемые вручную значения уверенности, например. Способ может дополнительно включать генерирование классификационной информации, указывающей тип содержимого звукового содержимого, на основании пользовательского ввода. Способ может дополнительно включать кодирование звукового содержимого и классификационной информации в битовый поток. Например, в битовом потоке могут быть закодированы метки или значения уверенности. Способ может еще дополнительно включать выдачу битового потока. Благодаря этому способу обеспечивается дополнительное управление над анализом содержимого, например, со стороны создателя содержимого.
В некоторых вариантах осуществления пользовательский ввод может содержать одно или более из метки, указывающей, что звуковое содержимое будет относиться к данному типу содержимого, и одного или более значений уверенности, причем каждое значение уверенности связывают с соответствующим типом содержимого и оно дает указание вероятности того, что звуковое содержимое относится к соответствующему типу содержимого. Тем самым пользователю кодера может быть дан дополнительный контроль над постобработкой, выполняемой на стороне декодера. Это позволяет, например, гарантировать, что постобработка сохранит художественное намерение создателя содержимого.
В еще одном аспекте настоящее изобретение относится к дополнительному способу кодирования звукового содержимого. Звуковое содержимое может быть предоставлено в потоке звукового содержимого как часть звуковой программы. Способ может включать прием указания типа сервиса, указывающего тип сервиса (например, тип звуковой программы) звукового содержимого. Типом сервиса могут быть музыкальный сервис или сервис/канал новостей (последних известий), например. Способ может дополнительно включать выполнение анализа содержимого звукового содержимого на основании, по меньшей мере частично, указания типа сервиса. Способ может дополнительно включать генерирование классификационной информации, указывающей тип содержимого звукового содержимого, на основании (результата) анализа содержимого. Значения уверенности как примеры классификационной информации могут также быть непосредственно предоставлены создателем содержимого вместе со звуковым содержимым. Учитывать или не учитывать значения уверенности и т. д., предоставленные, например, создателем содержимого, может зависеть от указания типа сервиса. Способ может дополнительно включать кодирование звукового содержимого и классификационной информации в битовый поток. Способ может еще дополнительно включать выдачу битового потока.
Учитывая указание типа сервиса, можно оказывать помощь кодеру при выполнении анализа содержимого. Более того, пользователю на стороне кодера может быть дано дополнительное управление над постобработкой звука, выполняемой на стороне декодера, что позволяет, например, гарантировать, что постобработка сохранит художественное намерение создателя содержимого.
В некоторых вариантах осуществления способ может дополнительно включать определение, на основании указания типа сервиса, того, является ли тип сервиса звукового содержимого музыкальным сервисом. Способ может еще дополнительно включать, в ответ на определение того, что тип сервиса звукового содержимого является музыкальным сервисом, генерирование классификационной информации для указания того, что тип содержимого звукового содержимого является музыкальным содержимым (тип содержимого «музыка»). Это может быть равносильным установке значения уверенности для типа содержимого «музыка» в наибольшее возможное значение (например, 1) с установкой любых других значений уверенности в ноль.
В некоторых вариантах осуществления способ может дополнительно включать определение, на основании указания типа сервиса, того, является ли тип сервиса звукового содержимого сервисом последних известий. Способ может еще дополнительно включать, в ответ на определение того, что тип сервиса звукового содержимого является сервисом последних известий, адаптирование анализа содержимого так, чтобы иметь более высокую вероятность указания того, что звуковое содержимое будет речевым содержимым. Это может быть достигнуто путем адаптирования одного или более расчетов (алгоритмов расчета) анализа содержимого для увеличения вероятности/уверенности для речевого содержимого (тип содержимого «речь») в результате анализа содержимого и/или адаптирования одного или более расчетов анализа содержимого для уменьшения вероятностей/уверенности для типов содержимого, отличных от речевого содержимого.
В некоторых вариантах осуществления указание типа сервиса может предоставляться на покадровой основе.
В еще одном аспекте настоящее изобретение относится к дополнительному способу кодирования звукового содержимого. Звуковое содержимое может предоставляться на файловой основе. Способ может быть выполнен на файловой основе. Файлы могут содержать метаданные для своего соответствующего звукового содержимого. Метаданные могут включать маркеры, метки, тэги и т. д. Способ может включать выполнение анализа содержимого звукового содержимого на основании, по меньшей мере частично, метаданных для звукового содержимого. Способ может дополнительно включать генерирование классификационной информации, указывающей тип содержимого звукового содержимого, на основании (результата) анализа содержимого. Способ может дополнительно включать кодирование звукового содержимого и классификационной информации в битовый поток. Способ может еще дополнительно включать выдачу битового потока.
Учитывая файловые метаданные, можно оказывать помощь кодеру при выполнении анализа содержимого. Более того, пользователю на стороне кодера может быть дано дополнительное управление над постобработкой звука, выполняемой на стороне декодера, что позволяет, например, гарантировать, что постобработка сохранит художественное намерение создателя содержимого.
В некоторых вариантах осуществления метаданные могут включать указание типа содержимого файла, указывающее тип содержимого файла для файла. Типом содержимого файла может быть музыкальный файл (тип содержимого файла «музыкальный файл»), файл/клип последних известий (тип содержимого файла «файл последних известий») или файл, содержащий динамическое (нестатическое или смешанный источник) содержимое (такое как, например, кинофильм музыкального жанра, который часто переходит, например через каждые несколько минут, между разговорными сценами и музыкальными/песенными сценами; тип содержимого файла «динамическое содержимое»). Тип содержимого файла может быть одним и тем же (единообразным) для всего файла или может отличаться для разных частей файла. Тогда анализ содержимого может быть основан, по меньшей мере частично, на указании типа содержимого файла.
В некоторых вариантах осуществления способ может дополнительно включать определение, на основании указания типа содержимого файла, является ли тип содержимого файла для файла музыкальным файлом. Способ может еще дополнительно включать, в ответ на определение того, что тип содержимого файла для файла является музыкальным файлом, генерирование классификационной информации для указания того, что тип содержимого звукового содержимого является музыкальным содержимым.
В некоторых вариантах осуществления способ может дополнительно включать определение, на основании указания типа содержимого файла, является ли тип содержимого файла для файла файлом последних известий. Способ может еще дополнительно включать, в ответ на определение того, что тип содержимого файла для файла является файлом последних известий, адаптирование анализа содержимого так, чтобы иметь более высокую вероятность указания того, что звуковое содержимое будет речевым содержимым. Этого можно добиться путем адаптирования одного или более расчетов (алгоритмов расчета) анализа содержимого для повышения вероятности/уверенности для речевого содержимого при анализе содержимого и/или путем адаптирования одного или более расчетов для снижения вероятностей/уверенности для типов содержимого, отличающихся от речевого содержимого.
В некоторых вариантах осуществления способ может дополнительно включать определение, на основании указания типа содержимого файла, является ли тип содержимого файла для файла динамическим содержимым. Способ может еще дополнительно включать, в ответ на определение того, что тип содержимого файла для файла является динамическим содержимым, адаптирование анализа содержимого так, чтобы обеспечивать возможность более высокой скорости перехода между разными типами содержимого. Например, для типа содержимого может быть разрешен более частый переход между типами содержимого, например между музыкой и не музыкой (т. е. чаще, чем для устойчивого состояния). Более того, сглаживание классификационной информации (временное сглаживание) может быть отключено для динамического содержимого (т. е. динамического содержимого файла).
В некоторых вариантах осуществления в способе в соответствии с любым из вышеупомянутых аспектов или вариантов осуществления классификационная информация может содержать одно или более значений уверенности. Каждое значение уверенности может быть связано с соответствующим типом содержимого и может давать указание вероятности того, что звуковое содержимое относится к соответствующему типу содержимого.
В некоторых вариантах осуществления в способе в соответствии с любым из вышеупомянутых аспектов или вариантов осуществления типы содержимого могут включать одно или более из музыкального содержимого, речевого содержимого или содержимого с эффектами (например, фоновые эффекты). Типы содержимого могут дополнительно включать шум / одобрительные возгласы толпы.
В некоторых вариантах осуществления способ в соответствии с любым из вышеупомянутых аспектов или вариантов осуществления может дополнительно включать кодирование указания переходов сцены в звуковом содержимом в битовый поток. Указание переходов сцены может содержать один или более флагов сброса сцены, каждый из которых указывает соответствующий переход сцены. Переходы сцены могут обнаруживаться в кодере или могут предоставляться извне, например создателем содержимого. В первом случае способ включал бы этап обнаружения переходов сцены в звуковом содержимом, а в последнем случае – этап приема (выставляемого вручную) указания переходов сцены в звуковом содержимом. Благодаря указанию переходов сцены в битовом потоке можно избежать слышимых артефактов на стороне декодера, которые могут возникать в результате несоответствующей постобработки по переходам сцены.
В некоторых вариантах осуществления способ в соответствии с любым из вышеупомянутых аспектов или вариантов осуществления может дополнительно включать сглаживание (временное сглаживание) классификационной информации перед кодированием. Например, значения уверенности могут сглаживаться во времени. Сглаживание может быть отключено в зависимости от обстоятельств, например, при переходах сцены, для звукового содержимого, помеченного флагом как динамическое (нестатическое), в соответствии с управляющим входным сигналом/метаданными и т. д. Путем сглаживания классификационной информации можно повысить устойчивость/непрерывность постобработки звука на стороне декодера.
В некоторых вариантах осуществления способ в соответствии с любым из вышеупомянутых аспектов или вариантов осуществления может дополнительно включать квантование классификационной информации перед кодированием. Например, могут квантоваться значения уверенности. Тем самым пропускная способность, требуемая для передачи классификационной информации в битовом потоке, может быть уменьшена.
В некоторых вариантах осуществления способ в соответствии с любым из вышеупомянутых аспектов или вариантов осуществления может дополнительно включать кодирование классификационной информации в специальное поле данных в пакете битового потока. Битовый поток может представлять собой битовый поток AC-4 (Dolby® AC-4), например. Специальное поле данных может представлять собой поле данных Media Intelligence (MI). Поле данных MI может содержать любое, некоторые или все из следующих полей: b_mi_data_present, music_confidence, speech_confidence, effects_confidence, b_prog_switch, b_more_mi_data_present, more_mi_data.
В еще одном аспекте настоящее изобретение относится к способу декодирования звукового содержимого из битового потока, содержащего звуковое содержимое и классификационную информацию для этого звукового содержимого. Классификационная информация может указывать классификацию содержимого звукового содержимого. Классификация содержимого может быть основана на анализе содержимого и необязательно на пользовательском вводе, относящемся к типу содержимого звукового содержимого (когда и анализ содержимого, и предоставление ввода пользователем выполняются в кодере), например. Способ может включать прием битового потока. Способ может дополнительно включать декодирование звукового содержимого и классификационной информации. Способ может еще дополнительно включать выбор, на основании классификационной информации, режима постобработки для выполнения постобработки декодированного звукового содержимого. Иными словами, способ декодирования может выбирать постобработку декодированного звукового содержимого на основании классификационной информации.
Предоставление декодеру классификационной информации позволяет декодеру отказаться от анализа содержимого, что значительно облегчает вычислительную нагрузку на декодер. Кроме того, декодеру придается дополнительная гибкость: на основании классификационной информации он может принимать решения относительно подходящего режима постобработки. При этом может учитываться дополнительная информация, такая как тип устройства и предпочтения пользователя.
В некоторых вариантах осуществления способ декодирования может дополнительно включать расчет одного или более управляющих весов для постобработки декодированного звукового содержимого на основании классификационной информации.
В некоторых вариантах осуществления выбор режима постобработки может быть дополнительно основан на пользовательском вводе.
В некоторых вариантах осуществления звуковое содержимое основано на каналах. Например, звуковое содержимое может быть двухканальным звуковым содержимым или звуковым содержимым с большим числом каналов. Постобработка декодированного звукового содержимого может включать повышающее микширование основанного на каналах звукового содержимого в подвергнутое повышающему микшированию основанное на каналах звуковое содержимое. Например, звуковое содержимое на основе двух каналов может быть подвергнуто повышающему микшированию в 5.1-канальное, 7.1- канальное или 9.1- канальное звуковое содержимое. Способ может дополнительно включать применение виртуализатора к подвергнутому повышающему микшированию основанному на каналах звуковому содержимому для получения виртуализированного подвергнутого повышающему микшированию основанного на каналах звукового содержимого для виртуализация для массива динамиков необходимого количества каналов. Например, виртуализация может предоставлять подвергнутое повышающему микшированию 5.1-канальное, 7.1-канальное или 9.1-канальное звуковое содержимое в двухканальный массив динамиков, например наушники. Однако виртуализация может также предоставлять подвергнутое повышающему микшированию 5.1-канальное звуковое содержимое на двухканальный или 5.1-канальный массив динамиков, подвергнутое повышающему микшированию 7.1-канальное звуковое содержимое в двухканальный, 5.1 или 7.1-канальный массив динамиков и подвергнутое повышающему микшированию 9.1-канальное звуковое содержимое в двухканальный, 5.1, 7.1 или 9.1-канальный массив динамиков.
В некоторых вариантах осуществления способ может дополнительно включать расчет одного или более управляющих весов для постобработки декодированного звукового содержимого на основании классификационной информации.
В некоторых вариантах осуществления классификационная информация (закодированная в битовом потоке, принятом декодером) может содержать одно или более значений уверенности, причем каждое значение уверенности связывают с соответствующим типом содержимого и оно дает указание вероятности того, что звуковое содержимое относится к соответствующему типу содержимого. Управляющие веса могут быть рассчитаны на основании значений уверенности.
В некоторых вариантах осуществления способ может дополнительно включать направление выхода виртуализатора в массив динамиков и расчет соответствующих управляющих весов для повышающего микшера и виртуализатора на основании классификационной информации.
В некоторых вариантах осуществления способ может дополнительно включать после применения виртуализатора применение кроссфейдера к основанному на каналах звуковому содержимому и виртуализированному подвергнутому повышающему микшированию звуковому содержимому и направление выхода кроссфейдера в массив динамиков. В этом варианте осуществления способ может дополнительно включать расчет соответствующих управляющих весов для повышающего микшера и кроссфейдера на основании классификационной информации.
В некоторых вариантах осуществления управляющие веса могут быть предназначены для управляющих модулей, отличающихся от повышающего микшера, кроссфейдера или виртуализатора. Аналогично возможны несколько альтернативных способов расчета управляющих весов. Варианты осуществления, относящиеся к количеству и типам управляющих весов и способам их расчета, описаны ниже в связи со следующим другим аспектом настоящего изобретения. Однако эти варианты осуществления не ограничены следующим аспектом настоящего изобретения, а напротив могут быть применимы к любому способу декодирования звукового содержимого, раскрытому в настоящем документе.
В еще одном аспекте настоящее изобретение относится к дополнительному способу декодирования звукового содержимого из битового потока, содержащего звуковое содержимое и классификационную информацию для этого звукового содержимого. Классификационная информация может указывать классификацию содержимого звукового содержимого. Способ может включать прием битового потока. Способ может дополнительно включать декодирование звукового содержимого и классификационной информации. Способ может еще дополнительно включать расчет одного или более управляющих весов для постобработки декодированного звукового содержимого на основании классификационной информации. Управляющие веса могут представлять собой управляющие веса для алгоритмов/модулей постобработки и могут называться весами управления алгоритмами. Управляющие веса могут управлять стойкостью соответствующих алгоритмов постобработки.
В некоторых вариантах осуществления классификационная информация может содержать одно или более значений уверенности, причем каждое значение уверенности связывают с соответствующим типом содержимого и оно дает указание вероятности того, что звуковое содержимое относится к соответствующему типу содержимого. Управляющие веса могут быть рассчитаны на основании значений уверенности.
В некоторых вариантах осуществления управляющие веса могут представлять собой управляющие веса для соответствующих модулей (алгоритмов) для постобработки декодированного звукового содержимого. Модули (алгоритмы) для постобработки могут включать, например, одно или более из следующего: (интеллектуальный/динамический) эквалайзер, (адаптивный) виртуализатор, процессор объемного звучания, усилитель диалога, повышающий микшер и кроссфейдер.
В некоторых вариантах осуществления управляющие веса могут включать одно или более из управляющего веса для эквалайзера, управляющего веса для виртуализатора, управляющего веса для процессора объемного звучания, управляющего веса для усилителя диалога, управляющего веса для повышающего микшера и управляющего веса для кроссфейдера. Эквалайзер может представлять собой интеллектуальный эквалайзер, IEQ, например. Виртуализатор может представлять собой адаптивный виртуализатор, например.
В некоторых вариантах осуществления расчет управляющих весов может зависеть от типа устройства у устройства, выполняющего декодирование. Иными словами, расчет может быть зависящим от оконечной точки или персонализированным. Например, сторона декодера может реализовывать набор зависящих от оконечной точки процессов/модулей/алгоритмов для постобработки, а параметры (управляющие веса) для этих процессов/модулей/алгоритмов могут определяться на основании значений уверенности зависимым от оконечной точки способом. Тем самым при выполнении постобработки звука могут учитываться специфические возможности соответствующих устройств. Например, разная постобработка может применяться мобильным устройством и устройством саундбара.
В некоторых вариантах осуществления расчет управляющих весов может быть дополнительно основан на пользовательском вводе. Пользовательский ввод может замещать или частично замещать расчет, основанный на значении уверенности. Например, по желанию пользователя к речи может быть применена виртуализация, или по желанию пользователя стерео расширение, повышающее микширование и/или виртуализация могут быть применены для ПК пользователя.
В некоторых вариантах осуществления расчет управляющих весов может быть дополнительно основан на количестве каналов звукового содержимого. Также расчет управляющих весов может быть дополнительно основан на одном или более параметрах битового потока (например, параметрах, переносимых битовым потоком и извлекаемых из битового потока).
В некоторых вариантах осуществления способ может включать выполнение анализа содержимого звукового содержимого для определения одного или более дополнительных значений уверенности (например, для типов содержимого, не учтенных стороной кодера). Этот анализ содержимого может быть выполнен таким же образом, как описано выше в отношении стороны кодера. Тогда расчет управляющих весов может быть дополнительно основан на одном или более дополнительных значениях уверенности.
В некоторых вариантах осуществления управляющие веса могут включать управляющий вес для виртуализатора. Управляющий вес для виртуализатора может быть рассчитан так, что виртуализатор отключается, если классификационная информация указывает, что типом содержимого звукового содержимого является музыка или вероятно будет музыка. Так может быть, например, если значение уверенности для музыки выше заданного порога. Тем самым можно сохранить музыкальный тембр.
В некоторых вариантах осуществления управляющий вес для виртуализатора может быть рассчитан так, что коэффициенты виртуализатора масштабируются между пропусканием и полной виртуализацией. Например, управляющий вес для виртуализатора может быть рассчитан как 1 – music_confidence*{1 – max[effects_confidence,speech_confidence]^2}. В некоторых вариантах осуществления управляющий вес для виртуализатора может дополнительно зависеть от (например, определяться на основании) количества каналов в звуковом содержимом (т. е. подсчета каналов) или иного параметра (параметров) битового потока. Например, управляющий вес (весовой коэффициент) для виртуализации может только быть определен на основании значений уверенности для стереофонического содержимого, а фиксированный управляющий вес (например, равный 1) может применяться ко всему многоканальному содержимому, отличающемуся от стереофонического содержимого (т. е. для количества каналов выше 2).
В некоторых вариантах осуществления управляющие веса могут включать управляющий вес для усилителя диалога. Управляющий вес для усилителя диалога может быть рассчитан так, что усиление диалога усилителем диалога включается/усиливается, если классификационная информация указывает, что типом содержимого звукового содержимого является речь или вероятно будет речь. Так может быть, например, если значение уверенности для речи выше заданного порога. Тем самым усиление диалога может быть ограничено частями звукового содержимого, которые действительно выигрывают от этого, одновременно экономя вычислительную мощность.
В некоторых вариантах осуществления управляющие веса могут включать управляющий вес для динамического эквалайзера. Управляющий вес для динамического эквалайзера может быть рассчитан так, что динамический эквалайзер отключается, если классификационная информация указывает, что типом содержимого звукового содержимого является речь или вероятно будет речь. Так может быть, например, если значение уверенности для речи выше заданного порога. Тем самым можно избежать нежелательного изменения тембра речи.
В некоторых вариантах осуществления способ может дополнительно включать сглаживание (временное сглаживание) управляющих весов. Сглаживание может быть отключено в зависимости от обстоятельств, например, при переходах сцены, для звукового содержимого, помеченного флагом как динамическое (нестатическое), в соответствии с управляющим входным сигналом/метаданными и т. д. Сглаживание управляющих весов может повысить устойчивость/непрерывность постобработки звука.
В некоторых вариантах осуществления сглаживание управляющих весов может зависеть от конкретного управляющего веса, который сглаживают. То есть сглаживание может различаться между по меньшей мере двумя управляющими весами. Например, сглаживание для управляющего веса усилителя диалога может отсутствовать или оно может очень быть малым и/или сглаживание для управляющего веса виртуализатора может быть сильнее.
В некоторых вариантах осуществления сглаживание управляющих весов может зависеть от типа устройства у устройства, выполняющего декодирование. Например, сглаживание управляющего веса виртуализатора для мобильного телефона и телевизора может быть разным.
В некоторых вариантах осуществления способ может дополнительно включать применение нелинейной функции отображения к управляющим весам для повышения непрерывности (например, устойчивости) управляющих весов. Это может включать применение к управляющим весам функции отображения, отображающей значения, близкие к границам доменного диапазона управляющих весов, ближе к границам диапазона изображения, такой как сигмоидная функция, например. Тем самым можно дополнительно повысить устойчивость/непрерывность постобработки звука.
В еще одном аспекте настоящее изобретение относится к способу декодирования звукового содержимого из битового потока, содержащего двухканальное звуковое содержимое и классификационную информацию для этого двухканального звукового содержимого. Битовый поток может представлять собой битовый поток AC-4, например. Классификационная информация может указывать классификацию содержимого двухканального звукового содержимого. Способ может включать прием битового потока. Способ может дополнительно включать декодирование двухканального звукового содержимого и классификационной информации. Способ может дополнительно включать повышающее микширование двухканального звукового содержимого в подвергнутое повышающему микшированию 5.1-канальное звуковое содержимое. Способ может дополнительно включать применение виртуализатора к подвергнутому повышающему микшированию 5.1-канальному звуковому содержимому для 5.1 виртуализации для двухканального массива динамиков. Способ может дополнительно включать применение кроссфейдера к двухканальному звуковому содержимому и виртуализированному подвергнутому повышающему микшированию 5.1-канальному звуковому содержимому. Способ может еще дополнительно включать направление выхода кроссфейдера в двухканальный массив динамиков. При этом способ может включать расчет соответствующих управляющих весов для виртуализатора и/или кроссфейдера на основании классификационной информации. Виртуализатор и кроссфейдер могут работать под управлением их соответствующих управляющих весов.
В еще одном аспекте настоящее изобретение относится к дополнительному способу декодирования звукового содержимого из битового потока, содержащего двухканальное звуковое содержимое и классификационную информацию для этого двухканального звукового содержимого. Битовый поток может представлять собой битовый поток AC-4, например. Классификационная информация может указывать классификацию содержимого двухканального звукового содержимого. Способ может включать прием битового потока. Способ может дополнительно включать декодирование двухканального звукового содержимого и классификационной информации. Способ может дополнительно включать применение повышающего микшера к двухканальному звуковому содержимому для повышающего микширования двухканального звукового содержимого в подвергнутое повышающему микшированию 5.1-канальное звуковое содержимое. Способ может дополнительно включать применение виртуализатора к подвергнутому повышающему микшированию 5.1-канальному звуковому содержимому для 5.1 виртуализации для пятиканального массива динамиков. Способ может еще дополнительно включать направление выхода виртуализатора в пятиканальный массив динамиков. При этом способ может включать расчет соответствующих управляющих весов для повышающего микшера и/или виртуализатора на основании классификационной информации. Повышающий микшер и виртуализатор могут работать под управлением своих соответствующих управляющих весов. Управляющий вес для повышающего микшера может относиться к весу повышающего микширования.
Еще один аспект относится к устройству (например, кодеру или декодеру), содержащему процессор, подключенный к запоминающему устройству, хранящему команды для процессора. Процессор может быть приспособлен выполнять способы в соответствии с любым из вышеупомянутых аспектов и их вариантами осуществления.
Дополнительные аспекты относятся к компьютерным программам, содержащим команды для обеспечения выполнения процессором способов в соответствии с любым из вышеупомянутых аспектов и их вариантами осуществления, и к соответствующим машиночитаемым носителям данных, хранящим эти компьютерные программы.
КРАТКОЕ ОПИСАНИЕ ГРАФИЧЕСКИХ МАТЕРИАЛОВ
Иллюстративные варианты осуществления настоящего изобретения описаны ниже со ссылкой на сопроводительные графические материалы, на которых одинаковые ссылочные номера обозначают одинаковые или подобные элементы и на которых:
Фиг. 1 схематически иллюстрирует пример системы кодера-декодера в соответствии с вариантами осуществления настоящего изобретения.
Фиг. 2 схематически иллюстрирует пример битового потока, к которому могут быть применимы варианты осуществления настоящего изобретения.
Фиг. 3 схематически иллюстрирует пример поля данных для хранения классификационной информации звукового содержимого в соответствии с вариантами осуществления настоящего изобретения.
Фиг. 4 схематически иллюстрирует в виде блок-схемы пример способа кодирования звукового содержимого в соответствии с вариантами осуществления настоящего изобретения.
Фиг. 5 схематически иллюстрирует пример анализа содержимого звукового содержимого в соответствии с вариантами осуществления настоящего изобретения.
Фиг. 6 схематически иллюстрирует в виде блок-схемы другой пример способа кодирования звукового содержимого в соответствии с вариантами осуществления настоящего изобретения.
Фиг. 7 схематически иллюстрирует в виде блок-схемы другой пример способа кодирования звукового содержимого в соответствии с вариантами осуществления настоящего изобретения.
Фиг. 8 схематически иллюстрирует другой пример анализа содержимого звукового содержимого в соответствии с вариантами осуществления настоящего изобретения.
Фиг. 9 схематически иллюстрирует в виде блок-схемы еще другой пример способа кодирования звукового содержимого в соответствии с вариантами осуществления настоящего изобретения.
Фиг. 10 схематически иллюстрирует еще другой пример анализа содержимого звукового содержимого в соответствии с вариантами осуществления настоящего изобретения.
Фиг. 11 схематически иллюстрирует в виде блок-схемы пример способа декодирования звукового содержимого в соответствии с вариантами осуществления настоящего изобретения.
Фиг. 12 схематически иллюстрирует в виде блок-схемы другой пример способа декодирования звукового содержимого в соответствии с вариантами осуществления настоящего изобретения.
Фиг. 13 схематически иллюстрирует пример расчета управляющего веса в соответствии с вариантами осуществления настоящего изобретения.
Фиг. 14 схематически иллюстрирует в виде блок-схемы другой пример способа декодирования звукового содержимого в соответствии с вариантами осуществления настоящего изобретения.
Фиг. 15 схематически иллюстрирует пример использования управляющих весов в декодере в соответствии с вариантами осуществления настоящего изобретения.
Фиг. 16 схематически иллюстрирует в виде блок-схемы еще другой пример способа декодирования звукового содержимого в соответствии с вариантами осуществления настоящего изобретения.
Фиг. 17 схематически иллюстрирует другой пример использования управляющих весов в декодере в соответствии с вариантами осуществления настоящего изобретения.
ПОДРОБНОЕ ОПИСАНИЕ
Как указано выше, одинаковые или подобные ссылочные номера в описании обозначают одинаковые или подобные элементы, а повторное их описание может быть пропущено для краткости.
Говоря в общем, настоящее изобретение предлагает переход анализа содержимого от звукового декодера к звуковому декодеру, тем самым создавая двусторонний подход к постобработке звука. То есть по меньшей мере часть модуля анализа содержимого переходит из декодера в кодер, и аудиопоток (битовый поток) обновляется для переноса классификационной информации (например, значений уверенности, меток уверенности или оценок уверенности), генерируемой модулем анализа содержимого (его частью) в кодере. Расчет весов оставлен декодеру, где он работает на основании классификационной информации, принятой с аудиопотоком.
Пример системы 100 кодера-декодера, реализующей вышеуказанную схему, иллюстрируется в виде структурной схемы на фиг. 1. Система 100 кодера-декодера содержит (звуковой) кодер 105 и (звуковой) декодер 115. Понятно, что модули кодера 105 и декодера 115, описываемые ниже, могут быть реализованы соответствующими процессорами соответствующих вычислительных устройств, например.
Кодер 105 содержит модуль 120 анализа содержимого и мультиплексор 130. Таким образом, как отмечено выше, анализ содержимого теперь является частью стадии кодера. Кодер 105 принимает входное звуковое содержимое 101, которое необходимо кодировать, возможно в сочетании со связанными метаданными и/или пользовательским вводом. Входное звуковое содержимое 101 подается в модуль 120 анализа содержимого и в мультиплексор 130. Модуль 120 анализа содержимого выполняет анализ содержимого звукового содержимого 101 (например, с применением инструмента Dolby’s Media Intelligence) и получает классификационную информацию 125 для звукового содержимого. Классификационная информация 125 указывает тип содержимого входного звукового содержимого 101, согласно заключению по анализу содержимого. Как будет более подробно описано ниже, классификационная информация 125 может содержать одно или более значений уверенности, относящихся к соответствующим типам содержимого (например, значения уверенности «музыка», «речь» и «фоновый эффект»). В некоторых вариантах осуществления значения уверенности могут иметь более высокую глубину детализации, чем эта. Например, классификационная информация 125 вместо или в дополнение к значению уверенности для типа содержимого «музыка» может содержать значения уверенности для одного или более жанров музыки (такие как, например, значения уверенности для типов содержимого «классическая музыка», «рок/поп музыка», «акустическая музыка», «электронная музыка» и т. д.). В некоторых вариантах осуществления анализ содержимого может быть дополнительно основан на метаданных для звукового содержимого и/или на пользовательском вводе (например, на управляющем входном сигнале от создателя содержимого).
Мультиплексор 130 мультиплексирует звуковое содержимое и классификационную информацию 125 в битовый поток 110. Звуковое содержимое может быть закодировано в соответствии с известными способами кодирования звука, такими как кодирование по стандарту кодирования AC-4, например. Вследствие этого можно сказать, что звуковое содержимое 101 и классификационная информация 125 закодированы в битовый поток 110, и можно сказать, что битовый поток содержит звуковое содержимое и связанную классификационную информацию для звукового содержимого. Затем битовый поток 110 может быть передан в декодер 115.
В некоторых реализациях анализ содержимого в кодере 105 системы 100 кодера-декодера может быть выполнен для каждого из множества последовательных окон, где каждое окно содержит предопределенное число последовательных (аудио) кадров.
Анализ содержимого может быть основан на одном или более расчетах вероятности/уверенности соответствующих типов содержимого, основанных на поддающихся определению признаках в звуковом содержимом.
Например, анализ содержимого может включать этапы предобработки звукового содержимого, извлечения признаков и расчета значений уверенности. Предобработка, которая может быть необязательной, может включать понижающее микширование, рефрейминг, вычисление амплитудного спектра и т. д. На этапе извлечения признаков из звукового содержимого могут извлекать/рассчитывать множество признаков (например, несколько сотен признаков). Эти признаки могут включать любое из коэффициентов косинусного преобразования Фурье для частот чистых тонов (MFCC), потока MFCC, частоты переходов через нуль, насыщенности, автокорреляции и т. д. Расчеты, окончательно дающие значения уверенности, могут выполняться обученными сетями машинного обучения, например.
Расчеты, выполняемые в контексте анализа содержимого (например, сетями машинного обучения), могут быть вариабельными/адаптивными. Если расчеты являются вариабельными, их подгонка позволит получить классификационную информацию в соответствии с предпочтениями для определенных типов содержимого. Например, анализ (по умолчанию) содержимого может вернуть значение уверенности 0,7 для типа содержимого «музыка», значение уверенности 0,15 для типа содержимого «речь» и значение уверенности 0,15 для типа содержимого «эффекты» для данной части звукового содержимого (следует заметить, что значения уверенности в этом примере в сумме дают единицу). Если анализ содержимого адаптирован так, чтобы иметь некоторое предпочтение для типа содержимого «музыка» (т. е. если его расчеты адаптированы с этой целью), адаптированный анализ/расчеты содержимого могут дать, например, значение уверенности 0,8 для типа содержимого «музыка», значение уверенности 0,1 для типа содержимого «речь» и значение уверенности 0,1 для типа содержимого «эффекты». Ниже будут описаны дополнительные неограничительные примеры, в которых расчеты являются адаптированными.
Кроме того, анализ содержимого (например, сетью (сетями) машинного обучения) может быть адаптивным и/или может быть обученным заранее с использованием предопределенного звукового содержимого. Например, в двусторонней системе, такой как система 100 кодера-декодера, анализ содержимого может дополнительно развиваться во времени для повышения точности обозначения признаков. Усовершенствования могли бы быть достигнуты благодаря повышенной сложности, позволительной за счет увеличенной вычислительной мощности в сервере кодирования и/или расширений возможностей процессора компьютера. Кроме того, анализ содержимого может быть улучшен с течением времени посредством обозначения конкретного типа содержимого вручную.
При анализе содержимого на стороне кодера могут использовать буфер упреждающей выборки или подобное устройство для уменьшения задержки при принятии решения о типе содержимого. Это устранило бы известный недостаток односторонней реализации, требующей для принятия твердого решения аудиокадра весьма значительного размера. Например, для принятия решения о наличии диалога может потребоваться аудиокадр 700 мс, при этом оценка уверенности диалога составляет 700 мс после начала речи и начало сказанной фразы может быть упущено. В дополнение или в качестве альтернативы для обеспечения времени обработки, необходимого для анализа содержимого, может вводиться задержка кодирования.
В некоторых реализациях для повышения точности принятия решения о типе содержимого анализ содержимого может быть выполнен в несколько проходов.
В целом, генерирование классификационной информации может также быть основано на обнаружении переходов сцены в звуковом содержимом (или на указании перехода сцены вручную). С этой целью кодер 105 может содержать дополнительный детектор сброса для обнаружения этих переходов/сбросов сцены в звуковом содержимом. Ручное обозначение или дополнительное обнаружение сброшенных сцен может быть использовано для оказания влияния на скорость изменения значений уверенности анализа содержимого. Например, скорость изменения значений уверенности, включенных в классификационную информацию, может быть выше, если обнаружен/указан переход сцены (т. е. выше, чем в устойчивом состоянии). Иными словами, когда звуковая программа изменяется, значениям уверенности может быть разрешено адаптироваться быстрее, чем в устойчивом состоянии звуковой программы, чтобы гарантировать, что слышимые переходы между эффектами постобработки сведены к минимуму. В соответствии с обнаружением сцены указание переходов сцены (например, один или более флагов сброса (флагов перехода сцены), каждый из которых указывает на соответствующий переход сцены) может быть закодировано/мультиплексировано в битовый поток 110 вместе с классификационной информацией 125 (например, со значениями уверенности).
Декодер 115 в системе 100 кодера-декодера содержит демультиплексор 160, модуль 170 расчета весов и модуль 180 постобработки. Битовый поток 110, принятый декодером 115, демультиплексируется в демультиплексоре 160, и классификационная информация 125 и звуковое содержимое, возможно после декодирования в соответствии с известными способами декодирования звука, такими как декодирование в соответствии со стандартом кодирования AC-4, например, извлекаются. Следовательно, можно сказать, что звуковое содержимое и классификационная информация 125 будут декодированы из битового потока 110. Декодированное звуковое содержимое передают в модуль 180 постобработки, выполняющий постобработку декодированного звукового содержимого. С этой целью декодер 115 выбирает режим постобработки для модуля 180 постобработки на основании классификационной информации 125, извлеченной из битового потока 110. Более подробно, классификационная информация 125, извлеченная из битового потока 110, передается в модуль 170 расчета весов, который рассчитывает один или более управляющих весов 175 для постобработки декодированного звукового содержимого на основании классификационной информации 125. Каждый управляющий вес может представлять собой число между 0 и 1, например, и может определять интенсивность соответствующего процесса/модуля/алгоритма для постобработки. Один или более управляющих весов 175 передаются в модуль 180 постобработки. Модуль 180 постобработки может выбирать/применять режим постобработки в соответствии с управляющими весами 175 для постобработки декодированного звукового содержимого. В некоторых вариантах осуществления выбор режима постобработки может дополнительно основываться на пользовательском вводе. Постобработка декодированного звукового содержимого модулем 180 постобработки с использованием выбранного режима постобработки может давать выходной звуковой сигнал 102, выдаваемый декодером 115.
Рассчитанные один или более управляющих весов 175 могут представлять собой управляющие веса для алгоритмов постобработки, выполняемых модулем 180 постобработки, и поэтому также могут быть названы весами управления алгоритмами. По существу, один или более управляющих весов 175 могут обеспечивать управление для алгоритмов постобработки в модуле 180 постобработки. В этом смысле управляющие веса 175 могут представлять собой управляющие веса для соответствующих (под)модулей для постобработки декодированного звукового содержимого. Например, модуль 180 постобработки может содержать один или более соответствующих (под-) модулей, таких как (интеллектуальный/динамический) эквалайзер, (адаптивный) виртуализатор, процессор объемного звучания, усилитель диалога, повышающий микшер и/или кроссфейдер. Управляющие веса 175 могут представлять собой управляющие веса для этих (под-)модулей, которые могут работать под управлением их соответствующих управляющих весов. Соответственно, управляющие веса 175 могут включать одно или более из управляющего веса для эквалайзера (такого как интеллектуальный эквалайзер (IEQ), например), управляющего веса для виртуализатора (такого как адаптивный виртуализатор, например), управляющего веса для процессора объемного звучания, управляющего веса для усилителя диалога, управляющего веса для повышающего микшера и/или управляющего веса для кроссфейдера. Здесь интеллектуальный эквалайзер понимается как регулирующий множество полос частот с использованием целевого спектрального профиля. Кривая усиления адаптируется в зависимости от звукового содержимого, к которому применяется интеллектуальный эквалайзер.
Определение классификационной информации 125 в кодере 105 и передача ее в декодер 115 как части битового потока 110 может облегчить вычислительную нагрузку в декодере 115. Более того, благодаря более высоким вычислительным возможностям кодера анализ содержимого можно сделать более мощным (например, более точным).
Фиг. 2 схематически иллюстрирует битовый поток AC-4 как примерную реализацию битового потока 110. Битовый поток 110 содержит множество кадров (кадров AC-4) 205. Каждый кадр 205 содержит слово синхронизации, слово кадра, необработанный кадр 210 (кадр AC-4) и слово CRC. Необработанный кадр 210 содержит поле таблицы содержимого (TOC) и множество подпотоков, как показано в поле TOC. Каждый подпоток содержит поле 211 аудиоданных и поле 212 метаданных. Поле 211 аудиоданных может содержать кодированное звуковое содержимое, а поле 212 метаданных может содержать классификационную информацию 125.
Принимая во внимание такую структуру битового потока, классификационная информация 125 может быть закодирована в специальном поле данных в пакете битового потока. Фиг. 3 схематически иллюстрирует пример поля данных в битовом потоке (его кадре) для переноса классификационной информации 125. Это поле данных может называться полем данных MI. Поле данных может содержать множество подполей 310–370. Например, поле данных может содержать любое, некоторые или все из: поля 310 b_mi_data_present, которое указывает, присутствует ли в кадре классификационная информация (медийная информация, или медийная аналитика); поля 320 music_confidence, которое содержит значение уверенности для типа содержимого «музыка»; поля 330 speech_confidence, которое содержит значение уверенности для типа содержимого «речь»; поля 340 effects_confidence, которое содержит значение уверенности для типа содержимого «эффекты»; поля 350 b_prog_switch; поля 360 b_more_mi_data_present, которое указывает, присутствует ли больше классификационной информации (медийной информации); и поля 370 more_mi_data, содержащего больше классификационной информации (например, значение уверенности для шума толпы). Поскольку классификационную информацию (например, значения уверенности) определяют долгосрочным анализом (анализом содержимого), она может изменяться сравнительно медленно. Таким образом, классификационная информация может не быть закодирована для каждого пакета/кадра, но может быть закодирована в, например, один из N кадров, где N ≥ 2.
Альтернативно классификационная информация 125 (например, значения уверенности) может быть закодирована в подпоток представления битового потока АС-4.
Кроме того, для звукового содержимого на файловой основе классификационная информация 125 (например, значения уверенности) может не быть закодирована для каждого кадра, но может быть закодирована в соответствующее поле данных битового потока, будучи при этом действительной для всех кадров в файле.
Фиг. 4 представляет собой блок-схему, иллюстрирующую пример способа 400 кодирования звукового содержимого. Способ 400 может быть выполнен кодером 105 в системе 100 кодера-декодера, представленной на фиг. 1, например.
На этапе S410 выполняют анализ содержимого звукового содержимого.
На этапе S420 генерируют классификационную информацию, указывающую тип содержимого звукового содержимого, на основании анализа содержимого (его результата).
На этапе S430 звуковое содержимое и классификационную информацию кодируют в битовый поток.
Наконец, на этапе S440 выдают битовый поток.
Следует отметить, что этапы способа 400 могут выполняться так, как описано выше для системы 100 кодера-декодера.
Как было отмечено выше, генерирование классификационной информации может быть дополнительно основано на обнаружении переходов сцены в звуковом содержимом (или указании перехода сцены вручную). Соответственно, способ 400 (или любой из способов 600, 700, или 900, описанных ниже) может дополнительно включать обнаружение переходов сцены в звуковом содержимом (или прием входного сигнала с указаниями вручную переходов сцены в звуковом содержимом) и кодирование указания переходов сцены в звуковом содержимом в битовый поток.
Подробности анализа содержимого (например, анализа содержимого, выполняемого модулем 120 анализа содержимого кодера 105, или анализа содержимого, выполняемого на этапе S410 способа 400) будут описаны далее со ссылкой на фиг. 5.
Как отмечено выше, анализ содержимого выдает классификационную информацию 125, указывающую тип содержимого звукового содержимого 101. В некоторых вариантах осуществления настоящего изобретения классификационная информация 125 содержит одно или более значений уверенности (значения уверенности признаков, оценки уверенности). Каждое из этих значений уверенности связано с соответствующим типом содержимого и дает указание вероятности того, что звуковое содержимое относится к соответствующему типу содержимого. Эти типы содержимого могут включать одно или более из музыкального содержимого, речевого содержимого и содержимого эффектов (например, фоновые эффекты). В некоторых реализациях типы содержимого могут дополнительно включать содержимое шума толпы (например, одобрительные возгласы). То есть, классификационная информация 125 может включать одно или более из значения уверенности для музыки, указывающего уверенность в том (вероятность того), что звуковое содержимое относится к типу содержимого «музыка»; значения уверенности для речи, указывающего уверенность в том (вероятность того), что звуковое содержимое 101 относится к типу содержимого «речь»; и значения уверенности для эффектов, указывающего уверенность в том (вероятность того), что звуковое содержимое 101 относится к типу содержимого «эффекты»; а также, возможно, значения уверенности для шума толпы, указывающего уверенность в том (вероятность того), что звуковое содержимое 101 относится к типу содержимого «шум толпы».
В последующем будет предполагаться, что значения уверенности нормализованы так, чтобы попадать в диапазон от 0 до 1, где 0 указывает нулевую вероятность (0%) того, что звуковое содержимое относится к соответствующему типу содержимого, а 1 указывает определенность (полную вероятность, 100%) того, что звуковое содержимое относится к соответствующему типу содержимого. Понятно, что значение «0» служит неограничительным примером для величины значения уверенности, указывающего нулевую вероятность, и что значение «1» служит неограничительным примером для величины значения уверенности, указывающего полную вероятность.
В примере на фиг. 5 анализ содержимого звукового содержимого 101 возвращает (необработанное) значение 125a уверенности для музыки, (необработанное) значение 125b уверенности для речи и (необработанное) значение 125c уверенности для эффектов. В принципе, эти необработанные значения 125a, 125b, 125c уверенности могли бы непосредственно использоваться для их кодирования как (части) классификационной информации 125 в битовый поток 110. Альтернативно классификационная информация 125 (т. е. необработанные значения 125a, 125b, 125c уверенности) может перед кодированием подвергаться сглаживанию (например, временному сглаживанию) для получения по существу непрерывных значений уверенности. Это может осуществляться соответствующими модулями 140a, 140b, 140c сглаживания, выдающими сглаженные значения 145a, 145b, 145c уверенности соответственно. При этом разные модули сглаживания могут применять разное сглаживание, например используя для сглаживания разные параметры/коэффициенты.
В соответствии с вышеизложенным, перед мультиплексированием/кодированием способ 400 (или любой из способов 600, 700 и 900, описанных ниже) может дополнительно включать сглаживание классификационной информации (например, значений уверенности).
Сглаживание классификационной информации (например, значений уверенности) может при определенных обстоятельствах, например, если сглаживание выполняется по переходам сцены, вызвать слышимые искажения. Таким образом, в зависимости от обстоятельств, например при переходах сцены, сглаживание может отключаться. Кроме того, как будет подробнее описано ниже, сглаживание может также отключаться для динамического (нестатического) звукового содержимого или в соответствии с управляющим входным сигналом или метаданными.
В некоторых реализациях сглаженное значение 145a уверенности для музыки, сглаженное значение 145b уверенности для речи и сглаженное значение 145c уверенности для эффектов перед кодированием могут дополнительно быть подвергнуты квантованию. Это может осуществляться в соответствующих квантователях 150a, 150b, 150c, выдающих квантованные значения 155a, 155b, 155c уверенности соответственно. При этом разные квантователи могут применять разное квантование, например используя для квантования разные параметры.
В соответствии с вышеизложенным, перед мультиплексированием/ кодированием способ 400 (или любой из способов 600, 700 и 900, описанных ниже) может дополнительно включать квантование классификационной информации (например, значений уверенности).
Сглаживание классификационной информации 125 может давать в результате повышенные непрерывность и устойчивость постобработки в декодере, а значит и впечатления от прослушивания. Квантование классификационной информации 125 может повысить эффективность пропускной способности битового потока 110.
Как уже отмечалось, определение классификационной информации 125 в кодере 105 и передача ее в декодер 115 как части битового потока 110 могут быть преимущественными с точки зрения вычислительных возможностей. Дополнительно это может обеспечить некоторое управление на стороне кодера над постобработкой звука на стороне декодера путем задания значений уверенности, передаваемых в аудиопотоке, равными определенным желаемым значениям. Например, пользователю на стороне кодера (например, создателю содержимого) может быть дано управление над постобработкой звука на стороне декодера путем постановки классификационной информации (по меньшей мере, частично) в зависимость от пользовательского ввода на стороне кодера. Далее описываются некоторые примерные реализации, обеспечивающие дополнительное управление на стороне кодера над постобработкой звука на стороне декодера.
Фиг. 6 схематически иллюстрирует в виде блок-схемы пример способа 600 кодирования звукового содержимого, обеспечивающего такое управление на стороне кодера, основанное на пользовательском вводе, над постобработкой звка на стороне декодера. Способ 600 может быть выполнен кодером 105 в системе 100 кодера-декодера, представленной на фиг. 1, например.
На этапе S610 принимают пользовательский ввод. Пользователем может быть, например, создатель содержимого. Пользовательский ввод может включать выставление вручную меток для обозначения звукового содержимого как относящегося к определенному типу содержимого, или он может относиться, например, к выставляемым вручную значениям уверенности.
На этапе S620 генерируют классификационную информацию, указывающую тип содержимого звукового содержимого, по меньшей мере частично основанную на пользовательском вводе. Например, выставляемые вручную метки и/или выставляемые вручную значения уверенности могут непосредственно использоваться как классификационная информация. Если звуковое содержимое помечено вручную как относящееся к определенному типу содержимого, значение уверенности для этого определенного типа содержимого может быть установлено в 1 (полагая, что значения уверенности находятся в пределах между 0 и 1), а другие значения уверенности могут быть установлены в ноль. В этом случае анализ содержимого будет обойден. В альтернативных реализациях для получения классификационной информации результат анализа содержимого может использоваться вместе с пользовательским вводом. Например, окончательные значения уверенности могут быть рассчитаны на основании значений уверенности, сгенерированных при анализе содержимого, и выставляемых вручную значений уверенности. Это можно выполнить усреднением или любым иным подходящим комбинированием этих значений уверенности.
На этапе S630 звуковое содержимое и классификационную информацию кодируют в битовый поток.
Наконец, на этапе S640 выдают битовый поток.
Дополнительное управление на стороне кодера может быть достигнуто путем принятия решения относительно классификации содержимого на стороне кодера по меньшей мере частично в зависимости от метаданных, связанных со звуковым содержимым. Ниже будут описаны два примера такой обработки на стороне кодера. Первый пример будет описан со ссылкой на фиг. 7 и фиг. 8. В первом примере звуковое содержимое предоставляется в потоке (например, в линейном непрерывном потоке) звукового содержимого как часть звуковой программы. Метаданные для звукового содержимого включают по меньшей мере указание типа сервиса звукового содержимого (т. е. звуковой программы). По существу тип сервиса может также быть назван типом звуковой программы. Примеры типа сервиса могут включать музыкальный сервис (например, сервис потоковой передачи музыки или трансляции музыки и т. д.) или новостной (последние известия) сервис (например, звуковой компонент информационного канала и т. д.). Указание типа сервиса может предоставляться на покадровой основе или может быть одинаковым (единообразным/статическим) для всего аудиопотока. Второй пример будет описан со ссылкой на фиг. 9 и фиг. 10. Во втором примере звуковое содержимое предоставляется на файловой основе. Каждый файл может содержать метаданные для его соответствующего звукового содержимого. Метаданные могут включать тип содержимого (звукового содержимого) файла. Метаданные могут дополнительно включать маркеры, метки, тэги и т. д. Примеры типа содержимого файла могут включать указание о том, что файл является музыкальным файлом, указание о том, что файл является новостным файлом/файлом последних известий (новостным клипом), указание о том, что файл содержит динамическое (нестатическое) содержимое (такое как, например, музыкальный жанр кинофильма с частыми переходами между разговорными и музыкальными/песенными сценами). Тип содержимого файла может быть одним и тем же (единообразным/статическим) для всего файла или может отличаться для разных частей файла. Обработка во втором примере может быть на файловой основе. Можно сказать, что «снабжение тэгами» файлов с помощью метаданных, указывающих тип содержимого файла, помогает кодеру в получении классификационной информации (в дополнение к предоставлению для стороны кодера дополнительного управления над постобработкой звука на стороне декодера).
Теперь производится ссылка на фиг. 7, иллюстрирующую в виде блок-схемы способ 700 кодирования звукового содержимого, предоставленного в потоке звукового содержимого как часть звуковой программы. В этом способе 700 при получении классификационной информации учитывают метаданные звукового содержимого. Способ 700 может быть выполнен кодером 105 в системе 100 кодера-декодера, показанной на фиг. 1, например.
На этапе S710 принимают указание типа сервиса. Как отмечено выше, указание типа сервиса указывает тип сервиса звукового содержимого.
На этапе S720 выполняют анализ содержимого звукового содержимого на основании, по меньшей мере частично, указания типа сервиса. Неограничительные примеры такого анализа содержимого будут описаны ниже со ссылкой на фиг. 8.
На этапе S730 генерируют классификационную информацию, указывающую тип содержимого звукового содержимого, на основании (результата) анализа содержимого.
На этапе S740 звуковое содержимое и классификационную информацию кодируют в битовый поток.
Наконец, на этапе S750 выдают битовый поток.
Фиг. 8 схематически иллюстрирует примеры анализа содержимого звукового содержимого на этапе S720 способа 700. Верхний ряд 810 на фиг. 8 относится к примеру музыкального сервиса, т. е. к указанию типа сервиса, указывающему, что звуковое содержимое относится к типу сервиса «музыкальный сервис». В этом случае значение уверенности для «музыки» может быть установлено в 1, тогда как значения уверенности для других типов содержимого (например, «речь», «эффекты» и, возможно, «шум толпы») устанавливают в 0. Иными словами, тип содержимого «музыка» может быть жестко закодирован в классификационную информацию. По существу, способ 700 может включать определение, на основании указания типа сервиса, является ли тип сервиса звукового содержимого музыкальным сервисом. Затем, в ответ на определение того, что тип сервиса звукового содержимого является музыкальным сервисом, может генерироваться классификационная информация для указания того, что тип содержимого звукового содержимого является музыкальным содержимым.
Нижний ряд 820 на фиг. 8 относится к примеру новостного сервиса, т. е. к указанию типа сервиса, указывающему, что звуковое содержимое относится к типу сервиса «новостной сервис» (или сервис последних известий, новостной канал). В этом случае расчеты, используемые при анализе содержимого, могут быть адаптированы так, чтобы имело место явное предпочтение для речи и меньшее предпочтение для, например, музыки (например, значение уверенности для речевого содержимого (тип содержимого «речь»), выданное анализом содержимого, может быть повышено, тогда как значение уверенности для музыкального содержимого (тип содержимого «музыка») и, возможно, для любых остальных типов содержимого может быть уменьшено). Это означает, что, например, тип содержимого «музыка» будет указываться только в том случае, если вполне определенно, что типом содержимого является музыка. Иными словами, путем адаптации расчетов шансы ложного указания типа содержимого «музыка» уменьшаются. По существу, способ 700 может включать определение, на основании указания типа сервиса, является ли тип сервиса звукового содержимого сервисом последних известий. Затем, в ответ на определение того, что тип сервиса звукового содержимого является сервисом последних известий, анализ содержимого на этапе S720 может быть адаптирован так, чтобы иметь большую вероятность указания того, что звуковое содержимое будет речевым содержимым. Дополнительно анализ содержимого на этапе S720 может быть адаптирован так, чтобы иметь меньшую вероятность указания того, что звуковое содержимое относится к любому иному типу содержимого.
В некоторых реализациях одно или более значений уверенности для звукового содержимого могут быть непосредственно предоставлены пользовательским вводом (например, создателем содержимого) или как часть метаданных. Затем от указания типа сервиса может зависеть, учитываются ли эти значения уверенности. Например, значения уверенности, предоставленные пользовательским вводом или метаданными, могут быть использованы для кодирования как классификационная информация, если (и только если) тип сервиса звукового содержимого относится к определенному типу. В некоторых альтернативных реализациях значения уверенности, предоставленные пользовательским вводом или метаданными, могут использоваться как часть классификационной информации, если только тип сервиса звукового содержимого не относится к определенному типу. Например, значения уверенности, предоставленные пользовательским вводом или метаданными, могут использоваться, если только указание типа сервиса не указывает, что тип сервиса звукового содержимого является музыкальным сервисом. В последнем случае значение уверенности для музыкального содержимого может быть установлено в 1 независимо от того, какие значения уверенности предоставлены пользовательским вводом или метаданными.
Теперь производится ссылка на фиг. 9, иллюстрирующую в виде блок-схемы способ 900 кодирования звукового содержимого, выполняемый на файловой основе. Соответственно, способ 900 может быть выполнен на файловой основе. В этом способе 900 при получении классификационной информации учитывают метаданные файла звукового содержимого. Способ 900 может быть выполнен кодером 105 в системе 100 кодера-декодера, показанной на фиг. 1, например.
На этапе S910 выполняют анализ содержимого звукового содержимого на основании, по меньшей мере частично, метаданных (файла) для звукового содержимого. Например, метаданные могут включать указание типа содержимого файла, указывающее тип содержимого файла для файла. Тогда анализ содержимого может быть основан, по меньшей мере частично, на указании типа содержимого файла. Неограничительные примеры такого анализа содержимого на основании, по меньшей мере частично, типа содержимого файла будут описаны ниже со ссылкой на фиг. 10.
На этапе S920 генерируют классификационную информацию, указывающую тип содержимого звукового содержимого, на основании анализа (результата) содержимого.
На этапе S930 звуковое содержимое и классификационную информацию кодируют в битовый поток.
Наконец, на этапе S940 выдают битовый поток.
Фиг. 10 схематически иллюстрирует пример анализа содержимого звукового содержимого на этапе S910 способа 900. Верхний ряд 1010 на фиг. 10 относится к примеру музыкального файла, т. е. к указанию типа содержимого файла, указывающему, что содержимое файла относится к типу содержимого файла «музыка». В этом случае тип содержимого “музыка” может быть жестко закодирован в классификационную информацию. Кроме того, классификационная информация может быть сделана единообразной (статической) для всего файла. Соответственно, способ 900 может дополнительно включать определение, на основании указания типа содержимого файла, является ли тип содержимого файла для файла музыкальным файлом. Затем в ответ на определение того, что тип содержимого файла для файла является музыкальным файлом, классификационная информация может быть сгенерирована так, чтобы указывать, что тип содержимого звукового содержимого относится к музыкальному содержимому.
Средний ряд 1020 на фиг. 10 относится к примеру новостного файла, т. е. к указанию типа содержимого файла, указывающему, что содержимое файла относится к типу содержимого файла «новости». В этом случае способ 900 может дополнительно включать определение, на основании указания типа содержимого файла, является ли тип содержимого файла для файла файлом последних известий. Затем, в ответ на определение того, что тип содержимого файла для файла является файлом последних известий, анализ содержимого может быть адаптирован так, чтобы иметь более высокую вероятность указания того, что звуковое содержимое будет речевым содержимым. Этого можно добиться путем адаптирования одного или более расчетов (алгоритмов расчета) анализа содержимого для повышения вероятности/уверенности для речевого содержимого при анализе содержимого и/или путем адаптирования одного или более расчетов для снижения вероятностей/уверенности для типов содержимого, отличающихся от речевого содержимого. Опять-таки, классификационная информация может быть сделана единообразной (статической) для всего файла.
Нижний ряд 1030 на фиг. 10 относится к примеру динамического (нестатического) файла (например, к музыкальному жанру кинофильма с частыми переходами между разговорными и музыкальными/песенными сценами), т. е. к указанию типа содержимого файла, указывающему, что содержимое файла относится к «динамическому» типу содержимого файла. В этом случае способ 900 может дополнительно включать определение, на основании указания типа содержимого файла, является ли тип содержимого файла для файла динамическим содержимым (т. е. динамическим содержимым файла). Затем, в ответ на определение того, что тип содержимого файла для файла является динамическим содержимым (т. е. динамическим содержимым файла), анализ содержимого может быть адаптирован для обеспечения более высокой скорости перехода между разными типами содержимого. Например, для типа содержимого может быть разрешен более частый переход между типами содержимого, например между музыкой и не музыкой (т. е. чаще, чем для устойчивого состояния). Соответственно, классификационной информации может быть разрешено переключаться между, например, музыкальными и немузыкальными участками файла. В отличие от первых двух рядов 1010 и 1020 на фиг. 10 это означает, что классификационная информация не поддерживается единообразной (статической) для всего файла.
Понятно также, что динамическое содержимое (т. е. динамическое содержимое файла) может иметь резкие переходы между участками с разным типом содержимого в файле. Например, могут быть резкие переходы между музыкальными участками и немузыкальными участками. В таких случаях применять к классификационной информации (например, к значениям уверенности) временное сглаживание может не иметь смысла. В некоторых реализациях, таким образом, сглаживание классификационной информации (временное сглаживание) для динамического содержимого (т. е. для динамического содержимого файла) может быть отключено.
Далее будут описаны варианты осуществления и реализации, относящиеся к декодированию звукового содержимого из битового потока, содержащего звуковое содержимое и классификационную информацию для этого звукового содержимого. Понятно, что классификационная информация указывает классификацию содержимого (в отношении типа содержимого) звукового содержимого. Понятно также, что классификация содержимого может быть основана на анализе содержимого, проведенном на стороне кодера.
Фиг. 11 иллюстрирует в виде блок-схемы обобщенный способ 1100 декодирования звукового содержимого из битового потока. Способ 1100 может быть выполнен декодером 115 в системе 100 кодера-декодера, показанной на фиг. 1, например.
На этапе S1110 принимают битовый поток, например по беспроводной или проводной передачи или посредством запоминающей среды, на которой хранится битовый поток.
На этапе S1120 звуковое содержимое и классификационную информацию декодируют из битового потока.
На этапе S1130 выбирают режим постобработки для выполнения (звуковой) постобработки декодированного звукового содержимого на основании классификационной информации, полученной на этапе S1120. В некоторых реализациях выбор режима постобработки может быть дополнительно основан на пользовательском вводе.
Дополнительно способ 1100 может также включать выполнение анализа содержимого звукового содержимого для определения одного или более дополнительных значений уверенности (например, для типов содержимого, не учтенных на стороне кодера). Этот анализ содержимого может быть выполнен таким же образом, как описано выше со ссылкой на этап S410 в способе 400. Тогда выбор режима постобработки может быть дополнительно основан на одном или более дополнительных значениях уверенности. Например, если декодер содержит детектор для типа содержимого, который не был учтен (старым) кодером, декодер может рассчитать значение уверенности для этого типа содержимого и использовать это значение уверенности вместе с любыми значениями уверенности, переданными в классификационной информации, для выбора режима постобработки.
Как описано выше в контексте фиг. 1, постобработка может быть выполнена с использованием алгоритмов постобработки, таких, как соответствующие алгоритмы, реализующие (интеллектуальный/динамический) эквалайзер, (адаптивный) виртуализатор, процессор объемного звучания, усилитель диалога, повышающий микшер или кроссфейдер, например. Соответственно, можно сказать, что выбор режима для выполнения постобработки соответствует определению (например, расчету) одного или более управляющих весов (весов управления, весов управления алгоритмами, управляющих весов алгоритмов) для соответствующих процессов/модулей/алгоритмов для постобработки.
Соответствующий способ 1200 проиллюстрирован блок-схемой на фиг. 12. Опять-таки, этот способ 1200 может быть выполнен декодером 115 в системе 100 кодера-декодера, показанной на фиг. 1, например.
Этап S1210 и этап S1220 идентичны этапу S1110 и этапу S1120 способа 1100 соответственно.
На этапе S1230 определяют (например рассчитывают) один или более управляющих весов для постобработки декодированного звукового содержимого на основании классификационной информации, полученной на этапе S1220.
Передача значений уверенности вместо управляющих весов (весов управления), т. е. оставление модуля расчета весов в декодере вместо перемещения его кодер, не только обеспечивает экономию вычислительных ресурсов в декодере, но и может позволить получить настраиваемый и гибкий декодер, в котором расчет весов может быть персонализирован. Например, расчет весов может зависеть от типа устройства и/или личных предпочтений пользователя. В этом заключается отличие от обычных подходов, в которых декодер принимает с кодера конкретные команды относительно того, какую постобработку звука необходимо выполнять для декодированного звукового содержимого.
А именно, требования относительно постобработки звука могут зависеть от типа устройства у устройства, посредством которого воспроизводится декодированное звуковое содержимое. Например, воспроизведение декодированного звукового содержимого динамиками мобильного устройства (такого как, например, мобильный телефон) лишь с двумя динамиками может потребовать другой постобработки звука, чем воспроизведение декодированного звукового содержимого устройством саундбара с пятью или более динамиками. Соответственно, в некоторых реализациях расчет управляющих весов зависит от типа устройства у устройства, выполняющего декодирование. Иными словами, расчет может быть зависящим от оконечной точки или персонализированным. Например, сторона декодера может реализовывать набор зависящих от оконечной точки процессов/модулей/алгоритмов для постобработки, а параметры (управляющие веса) для этих процессов/модулей/алгоритмов могут определяться на основании значений уверенности зависимым от оконечной точки способом.
Кроме того, разные пользователи могут иметь разные предпочтения относительно постобработки аудио. Например, речь обычно не виртуализируется, но могло бы быть принято решение на основании предпочтений пользователя виртуализировать насыщенное речью звуковое содержимое (т. е. виртуализация может быть применена к речи по желанию пользователя). Как еще один пример, для воспроизведения звука на персональном компьютере обычно отсутствуют стереофонические расширение, повышающее микширование и виртуализация. Однако в зависимости от предпочтений пользователя стереофонические расширение, повышающее микширование, и/или виртуализация могли бы быть применены и в этом случае (т. е. стереофонические расширение, повышающее микширование и/или виртуализация могут быть применены для пользователя ПК по желанию пользователя). Соответственно, в некоторых реализациях расчет управляющих весов дополнительно основан на предпочтении пользователя или пользовательском вводе (например, пользовательском вводе, указывающем предпочтение пользователя). По существу, пользовательский ввод может замещать или частично замещать расчет, основанный на классификационной информации.
Если классификационная информация содержит значения уверенности (оценки уверенности), каждое из которых связано с соответствующим типом содержимого и дает указание вероятности того, что звуковое содержимое относится к соответствующему типу содержимого, как описано выше, управляющие веса могут быть рассчитаны на основании этих значений уверенности. Неограничительные примеры таких расчетов будут описаны ниже.
Дополнительно способ 1200 может также включать выполнение анализа содержимого звукового содержимого для определения одного или более дополнительных значений уверенности (например, для типов содержимого, не учтенных на стороне кодера). Этот анализ содержимого может быть выполнен таким же образом, как описано выше со ссылкой на этап S410 в способе 400. Тогда расчет режима управляющих весов может быть дополнительно основан на одном или более дополнительных значениях уверенности. Например, если декодер содержит детектор для типа содержимого, который не был учтен (старым) кодером, декодер может рассчитать значение уверенности для этого типа содержимого и использовать это значение уверенности вместе с любыми значениями уверенности, переданными в классификационной информации, для расчета управляющих весов.
Как отмечено выше, значения уверенности могут сглаживаться на стороне кодера в двусторонней системе кодера-декодера для точного и стабильного отражения кодируемого содержимого. Альтернативно или дополнительно при определении управляющих весов (весов управления алгоритмами) расчет весов на стороне декодера может предусматривать дополнительное сглаживание. Тем самым можно гарантировать, что каждый алгоритм постобработки имеет соответствующий уровень непрерывности во избежание слышимых искажений. Например, во избежание нежелательного изменения в пространственной картине виртуализатору могут потребоваться медленные изменения, в то время как усилителю диалога могут потребоваться быстрые изменения, чтобы гарантировать, что диалоговые кадры получают реакцию, а недиалоговые кадры минимизируют любое ошибочное усиление диалога. Соответственно, способ 1200 может дополнительно включать этап сглаживания (временного сглаживания) управляющих весов.
Сглаживание может зависеть от типа устройства, выполняющего декодирование. Например, сглаживание может различаться между управляющим весом виртуализатора для мобильного устройства (например, мобильного телефона) и управляющим весом виртуализатора для телевизионного приемника или устройства саундбара. При этом сглаживание может быть разным в отношении набора коэффициентов сглаживания, определяющих сглаживание, таких как постоянная времени сглаживания, например.
Кроме того, сглаживание может также зависеть от конкретного управляющего веса, который сглаживается. То есть сглаживание может различаться между по меньшей мере двумя управляющими весами. Например, сглаживание для управляющего веса усилителя диалога может отсутствовать или оно может быть малым и/или сглаживание для управляющего веса виртуализатора может быть сильнее.
Наконец, следует отметить, что в зависимости от обстоятельств сглаживание может быть отключено. Как отмечено выше, сглаживание может быть контрпродуктивным для звукового содержимого, помеченного флагом как динамическое (нестатическое), или при переходах сцены. Кроме того, сглаживание может быть отключено в соответствии с управляющим входным сигналом и/или метаданными.
Другой подход к повышению непрерывности/устойчивости управляющих весов (а значит и постобработки звука) заключается в применении нелинейного отображения Φ к управляющим весам. Значения управляющих весов могут быть в диапазоне от 0 до 1. Нелинейное отображение Φ может представлять собой отображение Φ: [0,1] → [0,1]. Предпочтительно нелинейное отображение Φ отображает значения управляющих значений, близкие к границам диапазона значений управляющих весов (т. е. доменного диапазона, такого как [0,1]), ближе к соответствующим границам диапазона значений отображенных значений (т. е. диапазона отображения, такого как [0,1]). То есть Φ может отображать значение 0 + ε (ε << 1) ближе к 0, т. е. Φ(0 + ε) < (0 + ε) и может отображать значение 1 – ε ближе к 1, т. е. Φ(1 – ε) > (1 – ε). Примером такого нелинейного отображения Φ является сигмоидная функция.
Фиг. 13 схематически иллюстрирует пример модуля 170 расчета весов, действующего в соответствии с вышеприведенными соображениями. Понятно, что модуль 170 расчета весов, описанный ниже, может быть реализован, например, процессором вычислительного устройства.
Безо всякого намеренного ограничения, модуль 170 расчета весов в этом примере определяет управляющий вес для интеллектуального/динамического эквалайзера и управляющий вес для виртуализатора. Понятно, что модулем 170 расчета весов могут быть рассчитаны и другие управляющие веса.
Модуль 170 расчета весов принимает значения уверенности (т. е. классификационную информацию 125) в качестве входного сигнала. На основании значений уверенности управляющий вес для интеллектуального/динамического эквалайзера рассчитывается в блоке 1310. Поскольку выравнивание может изменять тембр речи и поэтому обычно нежелательно для речи, в некоторых реализациях управляющий вес для интеллектуального/динамического эквалайзера (управляющий вес эквалайзера) может быть рассчитан так, что выравнивание отключается, если классификационная информация (например, значения уверенности) указывает, что типом содержимого декодированного звукового содержимого является речь или вероятно будет речь (например, если значение уверенности для речи выше определенного порога). Необязательно управляющий вес эквалайзера может быть сглажен в блоке 1330. Сглаживание может зависеть от коэффициентов 1335 сглаживания управляющего веса эквалайзера, которые могут быть особыми для сглаживания управляющего веса эквалайзера. Наконец, (сглаженный) управляющий вес 175a эквалайзера выдается модулем 170 расчета весов.
Значения уверенности также используются для расчета управляющего веса для виртуализатора (управляющего веса виртуализатора) в блоке 1320. Поскольку виртуализация может изменять музыкальный тембр и поэтому обычно нежелательна для музыки, в некоторых реализациях управляющий вес для виртуализатора может быть рассчитан так, что виртуализация (виртуализация динамика) отключается, если классификационная информация (например, значения уверенности) указывает, что типом содержимого декодированного звукового содержимого является музыка или вероятно будет музыка (например, если значение уверенности для музыки выше определенного порога). Также управляющий вес для виртуализатора может быть рассчитан так, что коэффициенты виртуализатора масштабируются между пропусканием (отсутствие обработки) и полной виртуализацией. Как пример, управляющий вес для виртуализатора может быть рассчитан на основании значения уверенности для музыки music_confidence, значения уверенности для речи speech_confidence и значения уверенности для эффектов effects_confidence по формуле
1 – music_confidence*{1 – max[effects_confidence, speech_confidence]^2}.
(формула 1)
Необязательно управляющий вес виртуализатора может быть сглажен в блоке 1340. Сглаживание может зависеть от коэффициентов 1345 сглаживания управляющего веса виртуализатора, которые могут быть особыми для сглаживания управляющего веса виртуализатора.
Кроме того, необязательно (сглаженный) управляющий вес виртуализатора может быть усилен, например сигмоидной функцией, в блоке 1350 для повышения устойчивости/непрерывности управляющего веса виртуализатора. Тем самым можно ослабить слышимые артефакты в выдаваемом представлении прошедшего постобработку звукового содержимого. Усиление может быть выполнено в соответствии с нелинейным отображением, описанным выше.
В конечном итоге (сглаженный и/или усиленный) управляющий вес 175b виртуализатора выдается модулем 170 расчета весов.
Значения уверенности также могут быть использованы для расчета управляющего веса для усилителя диалога (управляющего веса усилителя диалога, на этой фигуре не показан). Усилитель диалога может обнаруживать в частотной области временно-частотные тайлы, содержащие диалог. Эти временно-частотные тайлы могут затем избирательно усиливаться, тем самым усиливая диалог. Поскольку основной задачей усилителя диалога является усиление диалога, а применение усиления диалога к содержимому, не содержащему диалогов, представляет собой в лучшем случае напрасный расход вычислительных ресурсов, управляющий вес усилителя диалога может быть рассчитан так, что усиление диалога усилителем диалога включается тогда (и только тогда), когда классификационная информация указывает, что типом содержимого звукового содержимого является речь или вероятно будет речь. Так может быть, например, если значение уверенности для речи выше заданного порога. Подобно управляющему весу эквалайзера и управляющему весу виртуализатора управляющий вес усилителя диалога также может быть подвергнут сглаживанию и/или усилению.
Кроме того, значения уверенности могут использоваться для расчета управляющего веса для процессора объемного звучания (управляющего веса процессора объемного звучания, на этой фигуре не показан), повышающего микшера и/или кроссфейдера.
Фиг. 14 иллюстрирует в виде блок-схемы способ 1400 декодирования звукового содержимого из битового потока в особом случае двухканального (например, стереофонического) звукового содержимого для воспроизведения мобильным устройством (например, мобильным телефоном) с двумя динамиками в соответствии с вариантами осуществления настоящего изобретения. Понятно, что битовый поток содержит классификационную информацию или двухканальное звуковое содержимое и что классификационная информация указывает классификацию содержимого (например, в части типа содержимого) двухканального звукового содержимого. Способ 1400 может быть выполнен декодером мобильного устройства с двумя динамиками. Этот декодер может иметь такое же базовое исполнение, как и декодер 115 в системе 100 кодера-декодера на фиг. 1, например, с особыми реализациями расчета весов и постобработки.
На этапе S1410 принимают битовый поток АС-4.
На этапе S1420 выполняют декодирование/демультиплексирование двухканального звукового содержимого и классификационной информации из битового потока.
На этапе S1430 двухканальное звуковое содержимое, декодированное на этапе S1420, подвергают повышающему микшированию в подвергнутое повышающему микшированию 5.1-канальное звуковое содержимое.
На этапе S1440 к подвергнутому повышающему микшированию 5.1-канальному звуковому содержимому применяют виртуализатор для 5.1 виртуализации для двухканального массива динамиков. Виртуализатор действует под управлением соответствующего управляющего веса. Управляющий вес для виртуализатора рассчитывают на основании классификационной информации (например, значений уверенности). Это может быть выполнено, например, так, как описано выше со ссылкой на фиг. 13.
На этапе S1450 к двухканальному звуковому содержимому и виртуализированному подвергнутому повышающему микшированию 5.1-канальному звуковому содержимому применяют кроссфейдер. Кроссфейдер действует под управлением соответствующего управляющего веса. Управляющий вес для кроссфейдера рассчитывают на основании классификационной информации (например, значений уверенности).
Наконец, на этапе S1460 выход кроссфейдера направляют в двухканальный массив динамиков.
Фиг. 15 схематически иллюстрирует пример декодера 1500 мобильного устройства 1505 с двумя динамиками, которое может выполнять способ 1400, в соответствии с вариантами осуществления настоящего изобретения. Понятно, что модули декодера 1500, описанные ниже, могут быть реализованы процессором вычислительного устройства, например.
Декодер 1500 принимает битовый поток 110 (например, битовый поток AC-4), который затем декодируется/демультиплексируется модулем 1510 (мобильного) декодера AC-4. Модуль 1510 (мобильного) декодера AC-4 выдает декодированное двухканальное звуковое содержимое 1515 и декодированную классификационную информацию 125. Декодированная классификационная информация 125 подается в модуль 1570 расчета весов перекрестного затухания виртуализатора, который рассчитывает управляющий вес 1575 перекрестного затухания на основании классификационной информации 125 (например, значений уверенности). Управляющий вес 1575 перекрестного затухания может представлять собой параметр, определяющий относительный вес двух сигналов, объединяемых модулем 1540 кроссфейда. Декодированное двухканальное звуковое содержимое 1515 подвергается повышающему микшированию с 2.0 каналов до 5.1 каналов модулем 1520 повышающего микширования, выдающим подвергнутое повышающему микшированию 5.1-канальное звуковое содержимое 1625. Затем к подвергнутому повышающему микшированию 5.1-канальному звуковому содержимому 1525 модулем 1530 виртуализации (виртуализатором) применяется 5.1 виртуализация для стерео динамиков. Модуль виртуализации выдает виртуализированное подвергнутое повышающему микшированию 5.1-канальное звуковое содержимое 1535, которое затем модулем 1540 перекрестного затухания объединяется с первоначальным декодированным двухканальным звуковым содержимым. Модуль 1540 перекрестного затухания действует под управлением управляющего веса 1575 перекрестного затухания и в конечном итоге выдает прошедшее постобработку двухканальное звуковое содержимое 102 для направления в динамики мобильного устройства 1505.
Хотя на этой фигуре и не показано, декодер 1500 может также содержать модуль для расчета управляющего веса виртуализатора для модуля 1530 виртуализации на основании классификационной информации 125 (например, значений уверенности). Кроме того, декодер 1500 может содержать модуль для расчета управляющего веса повышающего микширования для модуля 1520 повышающего микширования на основании классификационной информации 125 (например, значений уверенности).
Фиг. 16 иллюстрирует в виде блок-схемы способ 1600 декодирования звукового содержимого из битового потока в особом случае двухканального (например, стереофонического) звукового содержимого для воспроизведения массивом из пяти (или более) динамиков, например устройства саундбара, в соответствии с вариантами осуществления настоящего изобретения. И снова понятно, что битовый поток содержит классификационную информацию или двухканальное звуковое содержимое и что классификационная информация указывает классификацию содержимого (например, в части типа содержимого) двухканального звукового содержимого. Способ 1600 может быть выполнен декодером устройства с массивом из пяти (или более) динамиков, таким как устройство саундбара, например. Этот декодер может иметь такое же базовое исполнение, как и декодер 115 в системе 100 кодера-декодера на фиг. 1, например, с конкретными реализациями расчета весов и постобработки.
На этапе S1610 принимают битовый поток АС-4.
На этапе S1620 двухканальное звуковое содержимое и классификационную информацию декодируют/демультиплексируют из битового потока.
На этапе S1630 к двухканальному звуковому содержимому применяют повышающий микшер для повышающего микширования двухканального звукового содержимого в подвергнутое повышающему микшированию 5.1-канальное звуковое содержимое. Повышающий микшер действует под управлением соответствующего управляющего веса. Управляющий вес для повышающего микшера рассчитывают на основании классификационной информации (например, значений уверенности). Управляющий вес для повышающего микшера может относиться к весу повышающего микширования, например.
На этапе S1640 к подвергнутому повышающему микшированию 5.1-канальному звуковому содержимому применяют виртуализатор для 5.1 виртуализации для пятиканального массива динамиков. Виртуализатор действует под управлением соответствующего управляющего веса. Управляющий вес для виртуализатора рассчитывают на основании классификационной информации (например, значений уверенности). Это может быть выполнено, например, так, как описано выше со ссылкой на фиг. 13.
Наконец, на этапе S1650 выход кроссфейдера направляют в пятиканальный массив динамиков.
Фиг. 17 схематически иллюстрирует пример декодера 1700 устройства 1705 саундбара, которое может выполнять способ 1600, в соответствии с вариантами осуществления настоящего изобретения. Понятно, что модули декодера 1700, описанные ниже, могут быть реализованы процессором вычислительного устройства, например.
Декодер 1700 принимает битовый поток 110 (например, AC-4 битовый поток), который затем декодируется/демультиплексируется модулем 1710 декодера (саундбара) AC-4. Модуль 1710 декодера (саундбара) AC-4 выдает декодированное двухканальное звуковое содержимое 1715 и декодированную классификационную информацию 125. Декодированная классификационная информация 125 подается в модуль 1770 расчета весов повышающего микширования, рассчитывающий управляющий вес 1775 повышающего микширования на основании классификационной информации 125 (например, значений уверенности). Управляющий вес 1775 повышающего микширования может представлять собой вес повышающего микширования, например. Декодированное двухканальное звуковое содержимое 1715 подвергается повышающему микшированию с 2.0 каналов до 5.1 каналов модулем 1720 повышающего микширования, выдающим подвергнутое повышающему микшированию 5.1-канальное звуковое содержимое. Модуль 1720 повышающего микширования действует под управлением управляющего веса 1775 повышающего микширования. Например, для музыки и речи может быть выполнено разное повышающее микширование (с разными управляющими весами повышающего микширования). Затем модуль 1730 виртуализации (виртуализатор) применяет 5.1 виртуализацию для пятиканального массива динамиков к подвергнутому повышающему микшированию 5.1-канальному звуковому содержимому 1725 и выдает виртуализированное подвергнутое повышающему микшированию 5.1-канальное звуковое содержимое. Виртуализированное подвергнутое повышающему микшированию 5.1-канальное звуковое содержимое в конечном итоге выдается как прошедшее постобработку 5.1-канальное звуковое содержимое 102 для направления в динамики устройства 1705 саундбара.
Хотя на этой фигуре и не показано, декодер 1700 может также содержать модуль для расчета управляющего веса виртуализатора для модуля 1730 виртуализации на основании классификационной информации 125 (например, значений уверенности), например так, как описано выше со ссылкой на фиг. 13.
Следует отметить, что способы 1400 и 1600, а также соответствующие декодеры 1500 и 1700, являются примерами зависящей от оконечной точки постобработки звука.
Различные аспекты настоящего изобретения можно понять из следующих пронумерованных примерных вариантов осуществления (ППВО).
1. Способ кодирования звукового содержимого, включающий:
выполнение анализа содержимого звукового содержимого;
генерирование классификационной информации, указывающей тип содержимого звукового содержимого, на основании анализа содержимого;
кодирование звукового содержимого и классификационной информации в битовом потоке; и
выдачу битового потока.
2. Способ по ППВО 1, в котором анализ содержимого основан, по меньшей мере частично, на метаданных для звукового содержимого.
3. Способ кодирования звукового содержимого, включающий:
прием пользовательского ввода, относящегося к типу содержимого звукового содержимого;
генерирование классификационной информации, указывающей тип содержимого звукового содержимого, на основании пользовательского ввода;
кодирование звукового содержимого и классификационной информации в битовом потоке; и
выдачу битового потока.
4. Способ по ППВО 3, в котором пользовательский ввод включает одно или более из следующего:
метку, указывающую, что звуковое содержимое относится к данному типу содержимого; и
одно или более значений уверенности, причем каждое значение уверенности связано с соответствующим типом содержимого и дает указание вероятности того, что звуковое содержимое относится к соответствующему типу содержимого.
5. Способ кодирования звукового содержимого, в котором звуковое содержимое предоставляют в потоке звукового содержимого как часть звуковой программы, причем способ включает:
прием указания типа сервиса, указывающего тип сервиса звукового содержимого;
выполнение анализа содержимого звукового содержимого на основании, по меньшей мере частично, указания типа сервиса;
генерирование классификационной информации, указывающей тип содержимого звукового содержимого, на основании анализа содержимого;
кодирование звукового содержимого и классификационной информации в битовом потоке; и
выдачу битового потока.
6. Способ по ППВО 5, который дополнительно включает:
определение, на основании указания типа сервиса, является ли тип сервиса звукового содержимого музыкальным сервисом; и
в ответ на определение того, что тип сервиса звукового содержимого является музыкальным сервисом, генерирование классификационной информации для указания того, что тип содержимого звукового содержимого является музыкальным содержимым.
7. Способ по ППВО 5 или 6, который дополнительно включает:
определение, на основании указания типа сервиса, является ли тип сервиса звукового содержимого сервисом последних известий; и
в ответ на определение того, что тип сервиса звукового содержимого является сервисом последних известий, адаптирование анализа содержимого так, чтобы иметь более высокую вероятность указания того, что звуковое содержимое будет речевым содержимым.
8. Способ по любому из ППВО 5–7, в котором указание типа сервиса предоставляют на покадровой основе.
9. Способ кодирования звукового содержимого, в котором звуковое содержимое предоставляют на файловой основе, и при этом файлы включают метаданные для своего соответствующего звукового содержимого, причем этот способ включает:
выполнение анализа содержимого звукового содержимого на основании, по меньшей мере частично, метаданных для звукового содержимого;
генерирование классификационной информации, указывающей тип содержимого звукового содержимого, на основании анализа содержимого;
кодирование звукового содержимого и классификационной информации в битовом потоке; и
выдачу битового потока.
10. Способ по ППВО 9,
в котором метаданные включают указание типа содержимого файла, указывающее тип содержимого файла; и
при этом анализ содержимого основан, по меньшей мере частично, на указании типа содержимого файла.
11. Способ по ППВО 10, который дополнительно включает:
определение, на основании указания типа содержимого файла, является ли тип содержимого файла для файла музыкальным файлом; и
в ответ на определение того, что тип содержимого файла для файла является музыкальным файлом, генерирование классификационной информации для указания того, что тип содержимого звукового содержимого является музыкальным содержимым.
12. Способ по ППВО 10 или 11, который дополнительно включает:
определение, на основании указания типа содержимого файла, является ли тип содержимого файла для файла файлом последних известий; и
в ответ на определение того, что тип содержимого файла для файла является файлом последних известий, адаптирование анализа содержимого так, чтобы иметь более высокую вероятность указания того, что звуковое содержимое будет речевым содержимым.
13. Способ по любому из ППВО 10–12, который дополнительно включает:
определение, на основании указания типа содержимого файла, является ли тип содержимого файла для файла динамическим; и
в ответ на определение того, что тип содержимого файла для файла является динамическим содержимым, адаптирование анализа содержимого так, чтобы обеспечивать возможность более высокой скорости перехода между разными типами содержимого.
14. Способ по любому из ППВО 1–13, в котором классификационная информация содержит одно или более значений уверенности, причем каждое значение уверенности связывают с соответствующим типом содержимого и оно дает указание вероятности того, что звуковое содержимое относится к соответствующему типу содержимого.
15. Способ по любому из ППВО 1–14, в котором типы содержимого включают одно или более из музыкального содержимого, речевого содержимого или содержимого с эффектами.
16. Способ по любому из ППВО 1–15, дополнительно включающий:
кодирование указания переходов сцены в звуковом содержимом в битовый поток.
17. Способ по любому из ППВО 1–16, дополнительно включающий:
сглаживание классификационной информации перед кодированием.
18. Способ по любому из ППВО 1–17, дополнительно включающий:
квантование классификационной информации перед кодированием.
19. Способ по любому из ППВО 1–18, дополнительно включающий:
кодирование классификационной информации в специальное поле данных в пакете битового потока.
20. Способ декодирования звукового содержимого из битового потока, содержащего звуковое содержимое и классификационную информацию для этого звукового содержимого, в котором классификационная информация указывает классификацию содержимого звукового содержимого, при этом способ включает:
прием битового потока;
декодирование звукового содержимого и классификационной информации; и
выбор, на основании классификационной информации, режима постобработки для выполнения постобработки декодированного звукового содержимого.
21. Способ по ППВО 20, в котором выбор режима постобработки дополнительно основан на пользовательском вводе.
22. Способ декодирования звукового содержимого из битового потока, содержащего звуковое содержимое и классификационную информацию для этого звукового содержимого, в котором классификационная информация указывает классификацию содержимого звукового содержимого, при этом способ включает:
прием битового потока;
декодирование звукового содержимого и классификационной информации; и
расчет одного или более управляющих весов для постобработки декодированного звукового содержимого на основании классификационной информации.
23. Способ по ППВО 22,
в котором классификационная информация содержит одно или более значений уверенности, причем каждое значение уверенности связывают с соответствующим типом содержимого и оно дает указание вероятности того, что звуковое содержимое относится к соответствующему типу содержимого; и
при этом управляющие веса рассчитывают на основании значений уверенности.
24. Способ по ППВО 22 или 23, в котором управляющие веса представляют собой управляющие веса для соответствующих модулей для постобработки декодированного звукового содержимого.
25. Способ по любому из ППВО 22–24, в котором управляющие веса включают одно или более из управляющего веса для эквалайзера, управляющего веса для виртуализатора, управляющего веса для процессора объемного звучания и управляющего веса для усилителя диалога.
26. Способ по любому из ППВО 22–25, в котором расчет управляющих весов зависит от типа устройства у устройства, выполняющего декодирование.
27. Способ по любому из ППВО 22–26, в котором расчет управляющих весов дополнительно основан на пользовательском вводе.
28. Способ по любому из ППВО 22–27, в котором расчет управляющих весов дополнительно основан на количестве каналов звукового содержимого.
29. Способ по любому из ППВО 22–28,
в котором управляющие веса включают управляющий вес для виртуализатора; и
при этом управляющий вес для виртуализатора рассчитывают так, что виртуализатор отключается, если классификационная информация указывает, что типом содержимого звукового содержимого является музыка или вероятно будет музыка.
30. Способ по любому из ППВО 22–29,
в котором управляющие веса включают управляющий вес для виртуализатора; и
при этом управляющий вес для виртуализатора рассчитывают так, что коэффициенты виртуализатора масштабируются между пропусканием и полной виртуализацией.
31. Способ по любому из ППВО 22–30,
в котором управляющие веса включают управляющий вес для усилителя диалога; и
при этом управляющий вес для усилителя диалога рассчитывают так, что усиление диалога усилителем диалога усиливается, если классификационная информация указывает, что типом содержимого звукового содержимого является речь или вероятно будет речь.
32. Способ по любому из ППВО 22–31,
в котором управляющие веса включают управляющий вес для динамического эквалайзера; и
при этом управляющий вес для динамического эквалайзера рассчитывают так, что динамический эквалайзер отключается, если классификационная информация указывает, что типом содержимого звукового содержимого является речь или вероятно будет речь.
33. Способ по любому из ППВО 22–32, который дополнительно включает сглаживание управляющих весов.
34. Способ по ППВО 33, в котором сглаживание управляющих весов зависит от конкретного управляющего веса, который сглаживают.
35. Способ по ППВО 33 или 34, в котором сглаживание управляющих весов зависит от типа устройства у устройства, выполняющего декодирование.
36. Способ по любому из ППВО 33–35, который дополнительно включает применение нелинейной функции отображения к управляющим весам для повышения непрерывности управляющих весов.
37. Способ декодирования звукового содержимого из битового потока, содержащего двухканальное звуковое содержимое и классификационную информацию для этого двухканального звукового содержимого, в котором классификационная информация указывает классификацию содержимого двухканального звукового содержимого, при этом способ включает:
прием битового потока AC-4;
декодирование двухканального звукового содержимого и классификационной информации;
повышающее микширование двухканального звукового содержимого в подвергнутое повышающему микшированию 5.1-канальное звуковое содержимое;
применение виртуализатора к подвергнутому повышающему микшированию 5.1-канальному звуковому содержимому для 5.1 виртуализации для двухканального массива динамиков;
применение кроссфейдера к двухканальному звуковому содержимому и виртуализированному подвергнутому повышающему микшированию 5.1-канальному звуковому содержимому; и
направление выхода кроссфейдера в двухканальный массив динамиков,
при этом способ дополнительно включает расчет соответствующих управляющих весов для виртуализатора и кроссфейдера на основании классификационной информации.
38. Способ декодирования звукового содержимого из битового потока, содержащего двухканальное звуковое содержимое и классификационную информацию для этого двухканального звукового содержимого, в котором классификационная информация указывает классификацию содержимого двухканального звукового содержимого, при этом способ включает:
прием битового потока;
декодирование двухканального звукового содержимого и классификационной информации;
применение повышающего микшера к двухканальному звуковому содержимому для повышающего микширования двухканального звукового содержимого в подвергнутое повышающему микшированию 5.1-канальное звуковое содержимое;
применение виртуализатора к подвергнутому повышающему микшированию 5.1-канальному звуковому содержимому для 5.1 виртуализации для пятиканального массива динамиков; и
направление выхода виртуализатора в пятиканальный массив динамиков,
при этом способ дополнительно включает расчет соответствующих управляющих весов для повышающего микшера и виртуализатора на основании классификационной информации.
39. Кодер для кодирования звукового содержимого, содержащий процессор, подключенный к запоминающему устройству, хранящему команды для процессора, при этом процессор приспособлен выполнять способ по любому из ППВО 1–19.
40. Декодер для декодирования звукового содержимого, содержащий процессор, подключенный к запоминающему устройству, хранящему команды для процессора, при этом процессор приспособлен выполнять способ по любому из ППВО 20–38.
41. Компьютерная программа, содержащая команды для обеспечения выполнения процессором, который исполняет команды, способа по любому из ППВО 1–38.
42. Машиночитаемый носитель данных, на котором хранится компьютерная программа по ППВО 41.
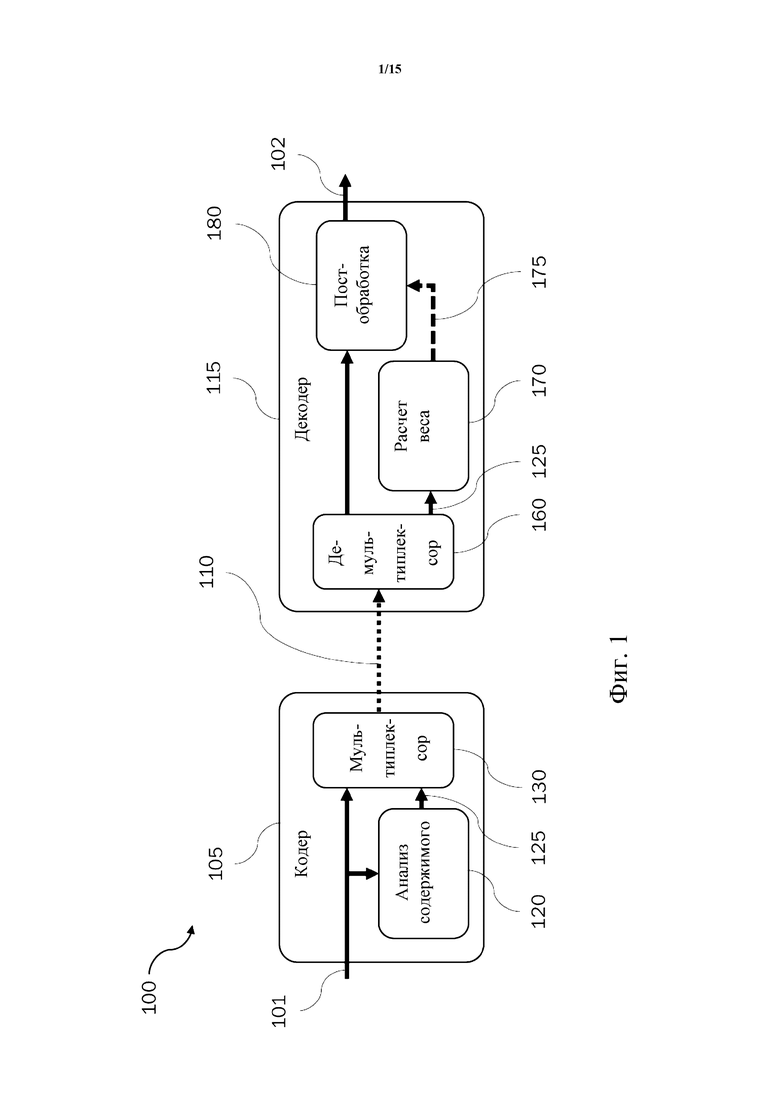
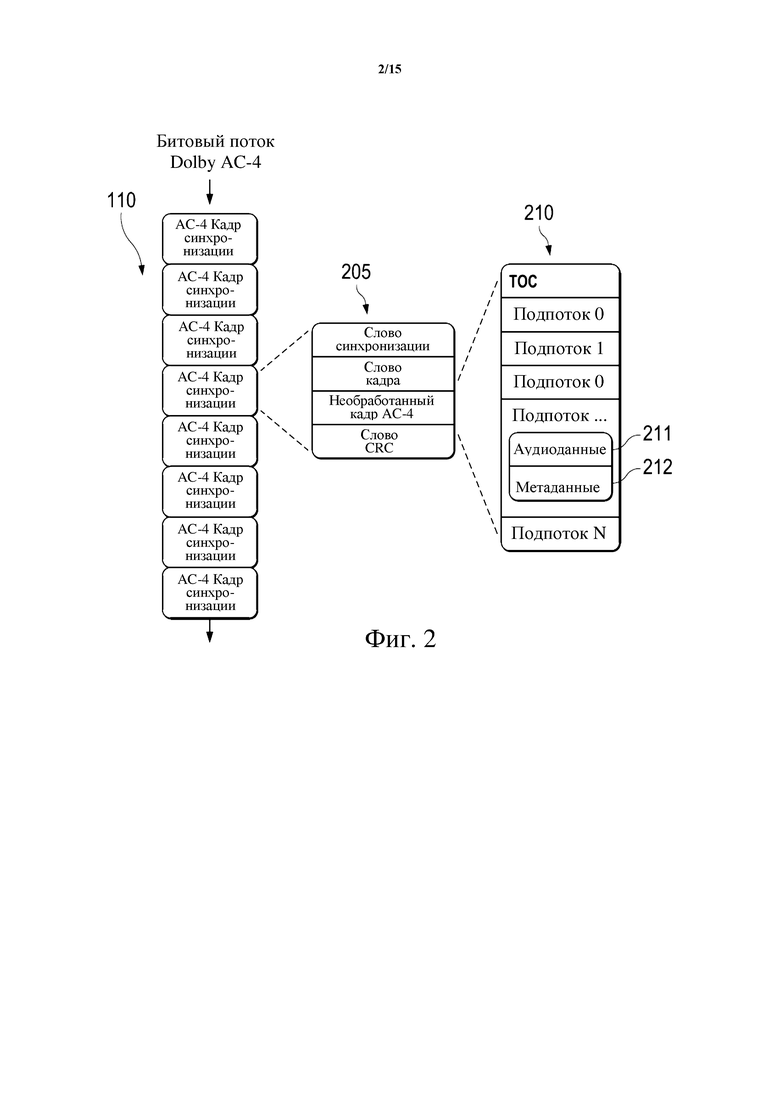
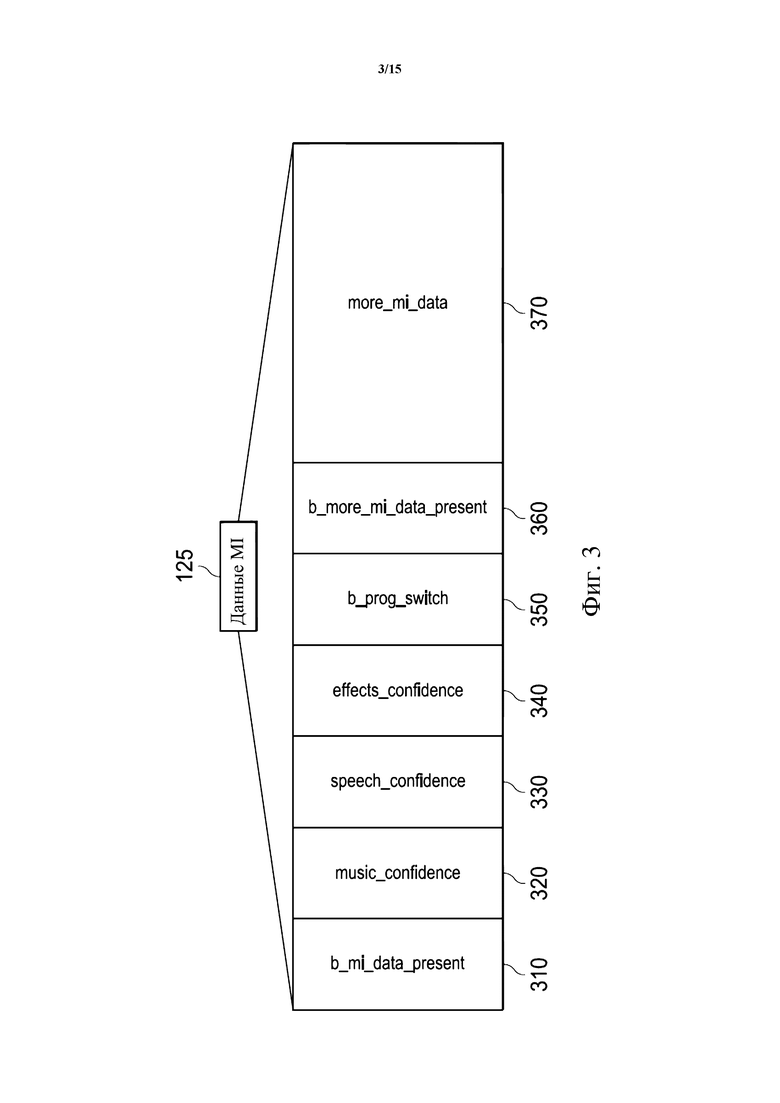
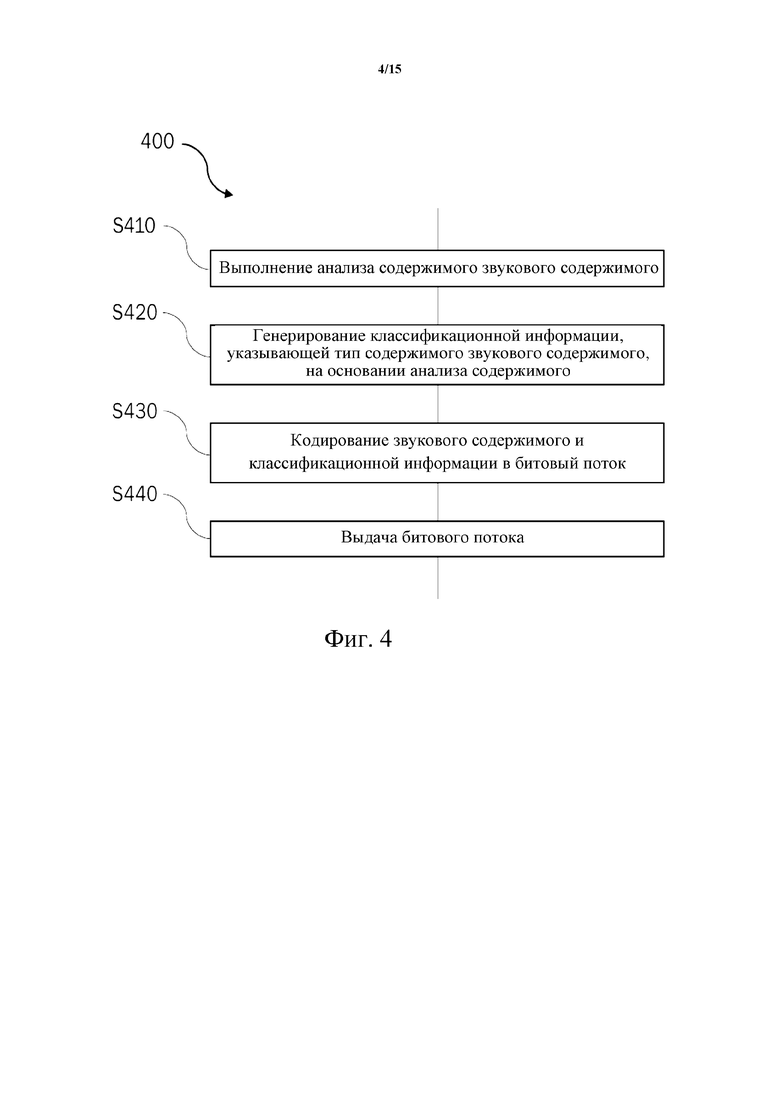
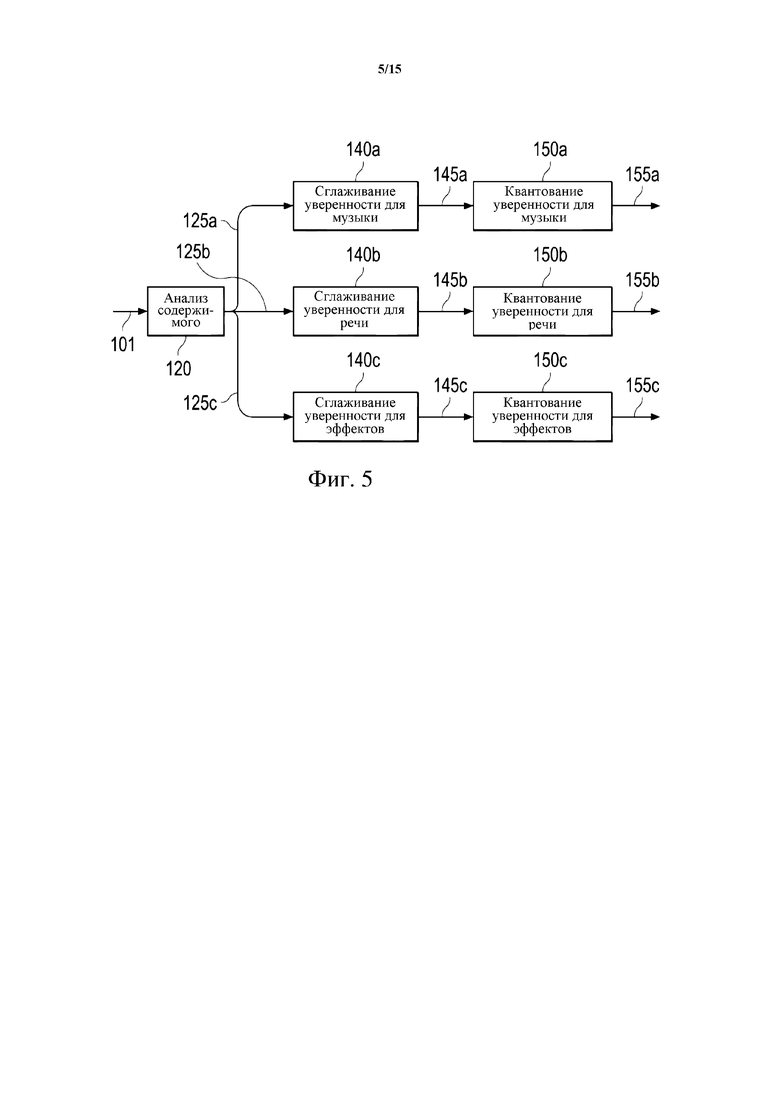
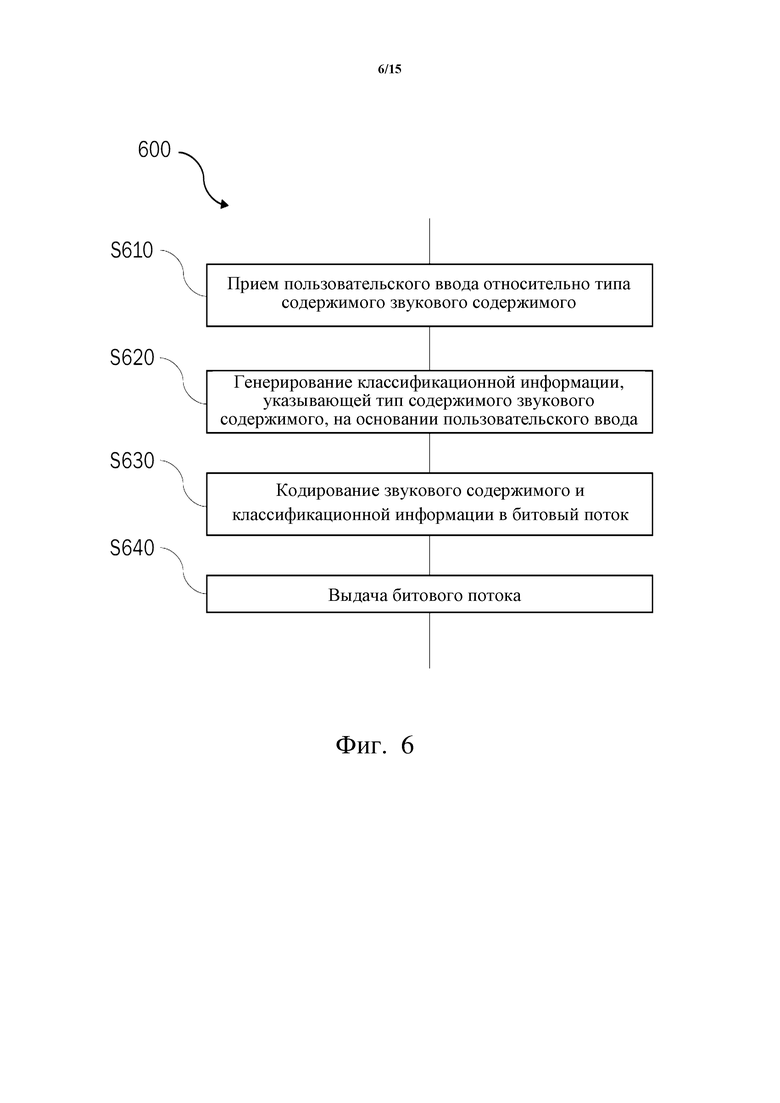
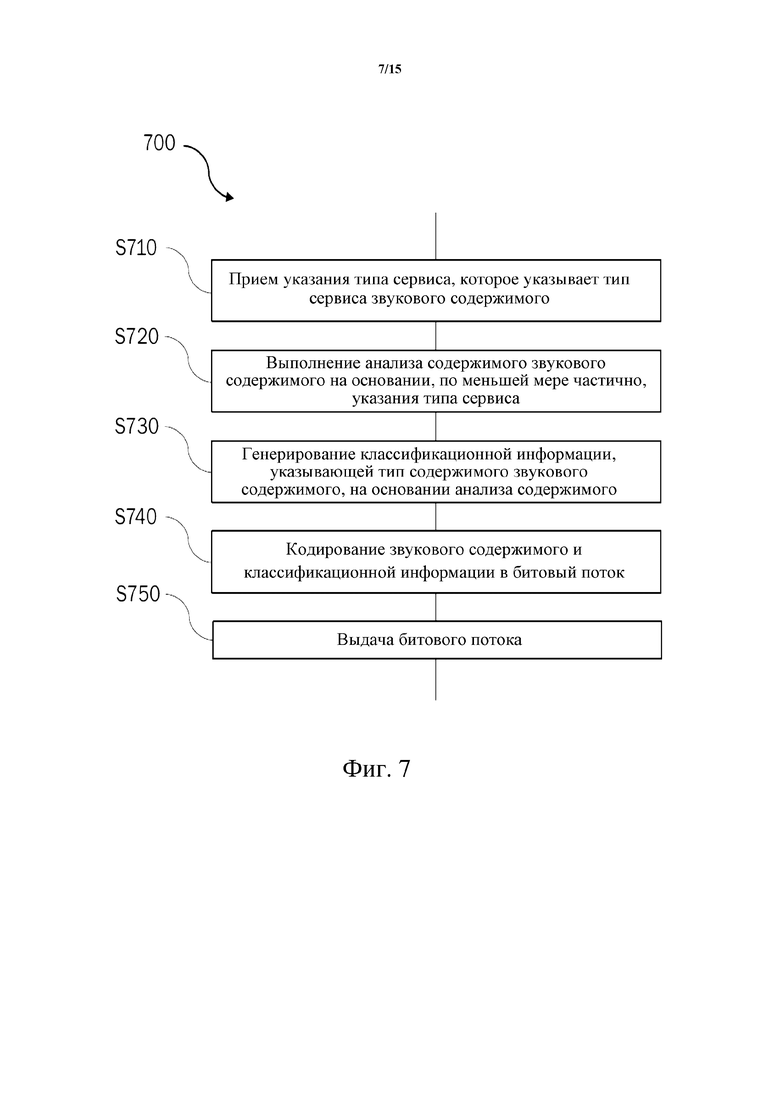
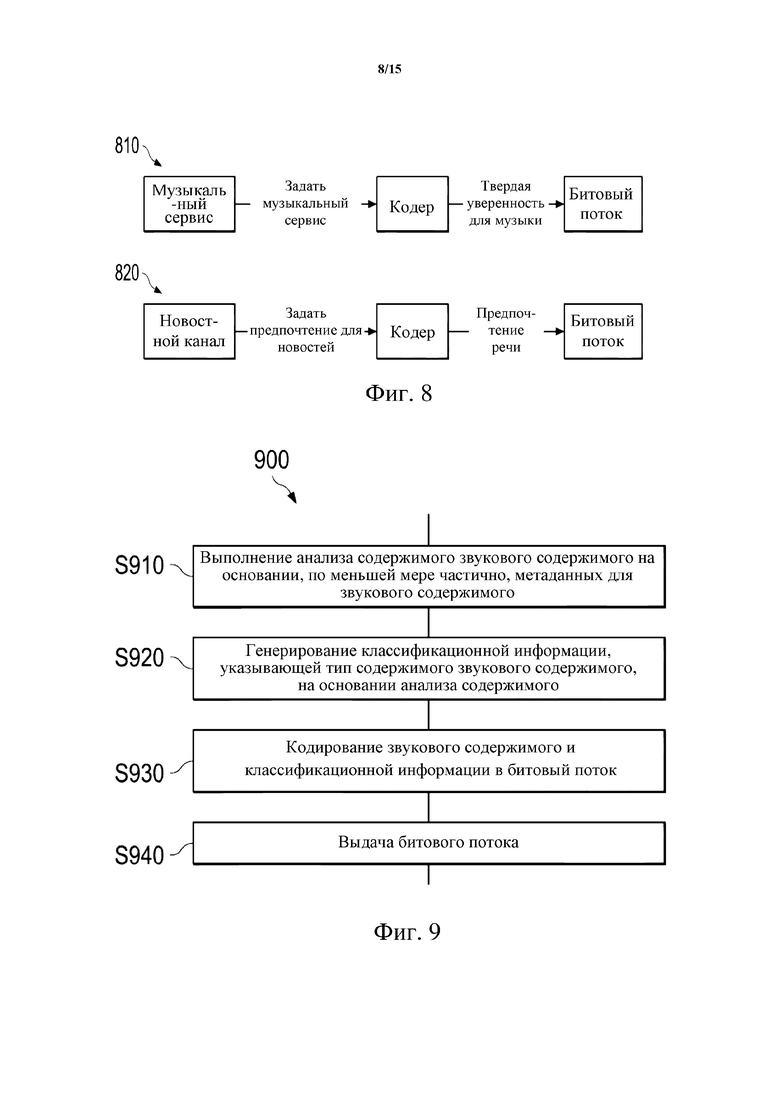
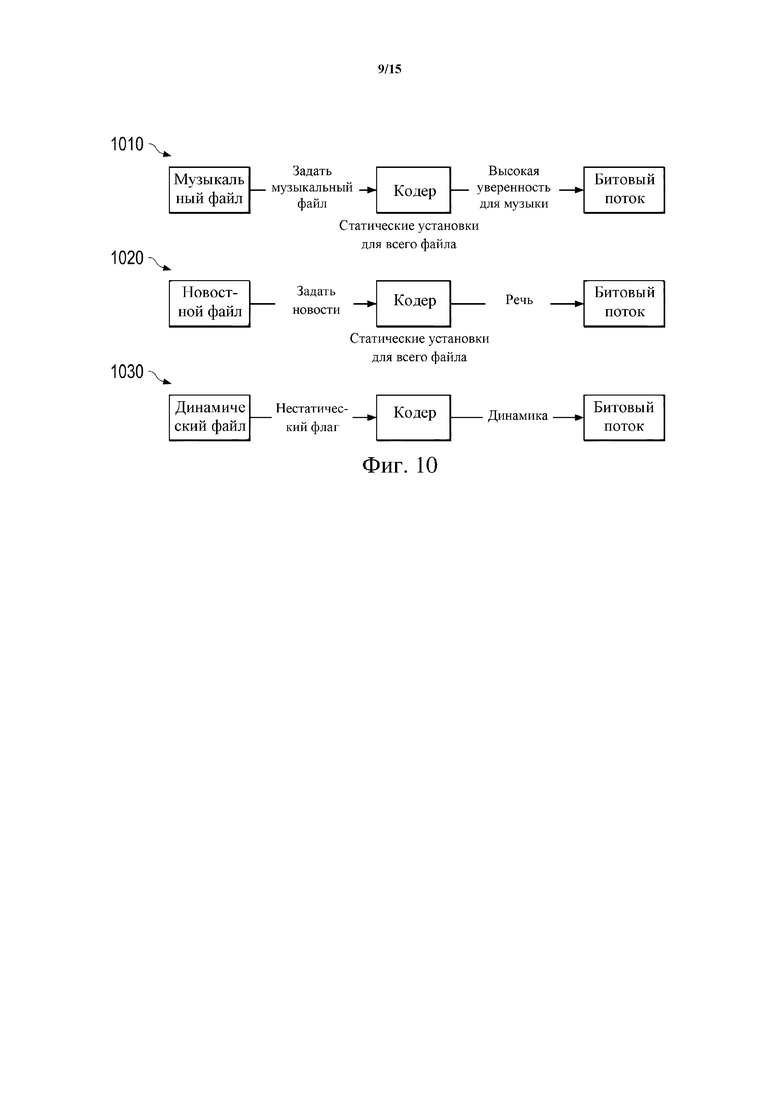
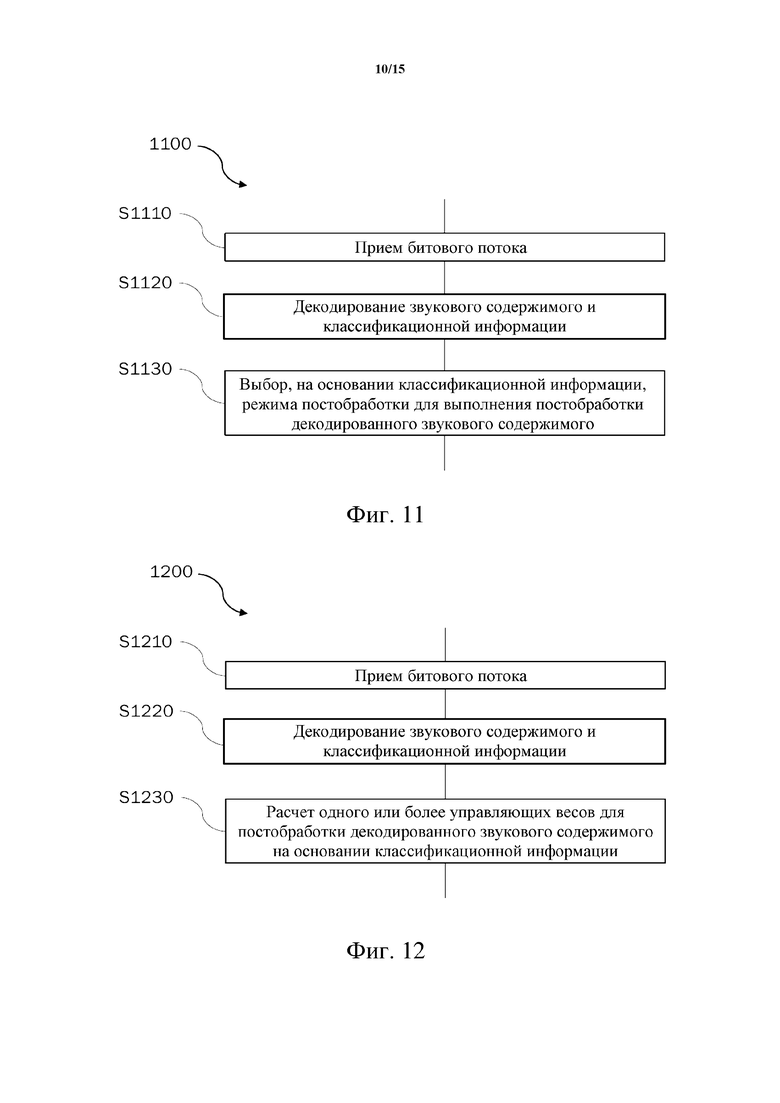
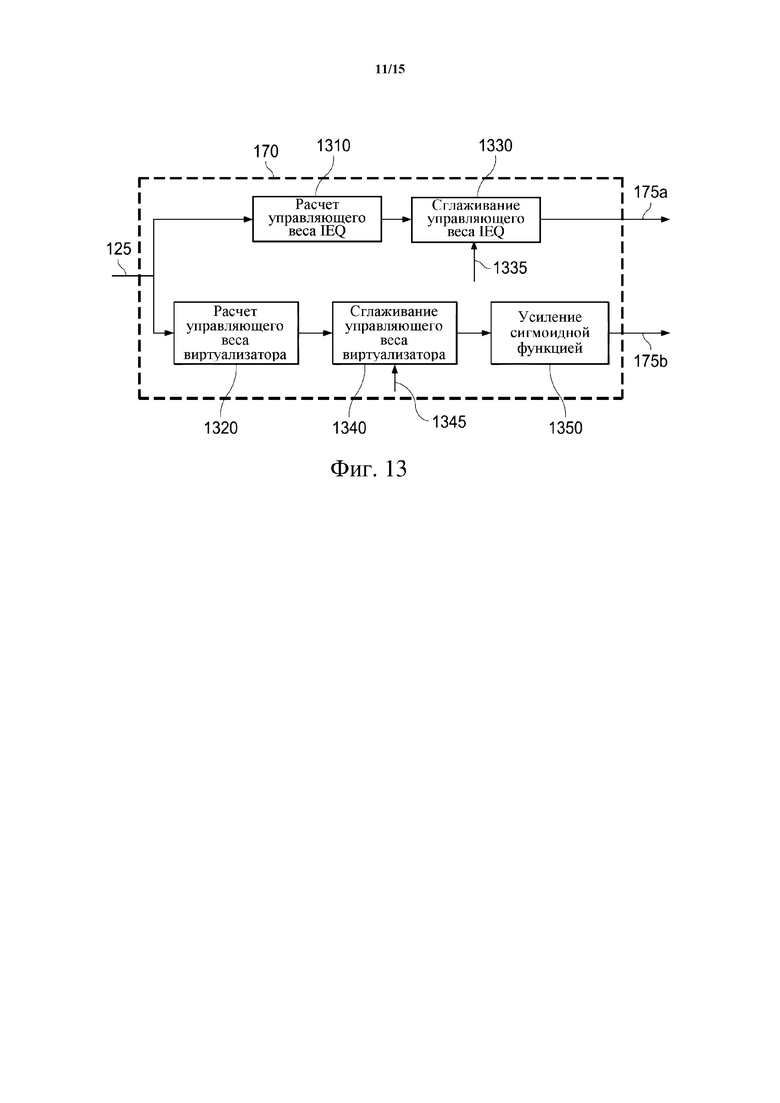

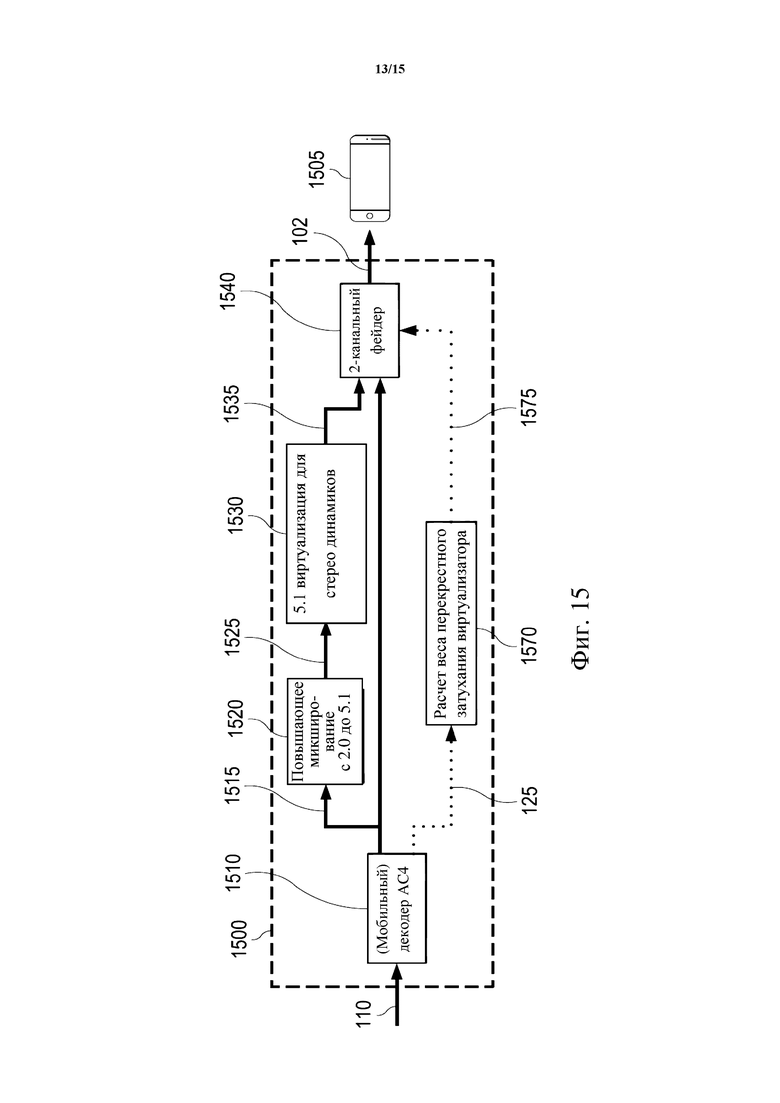

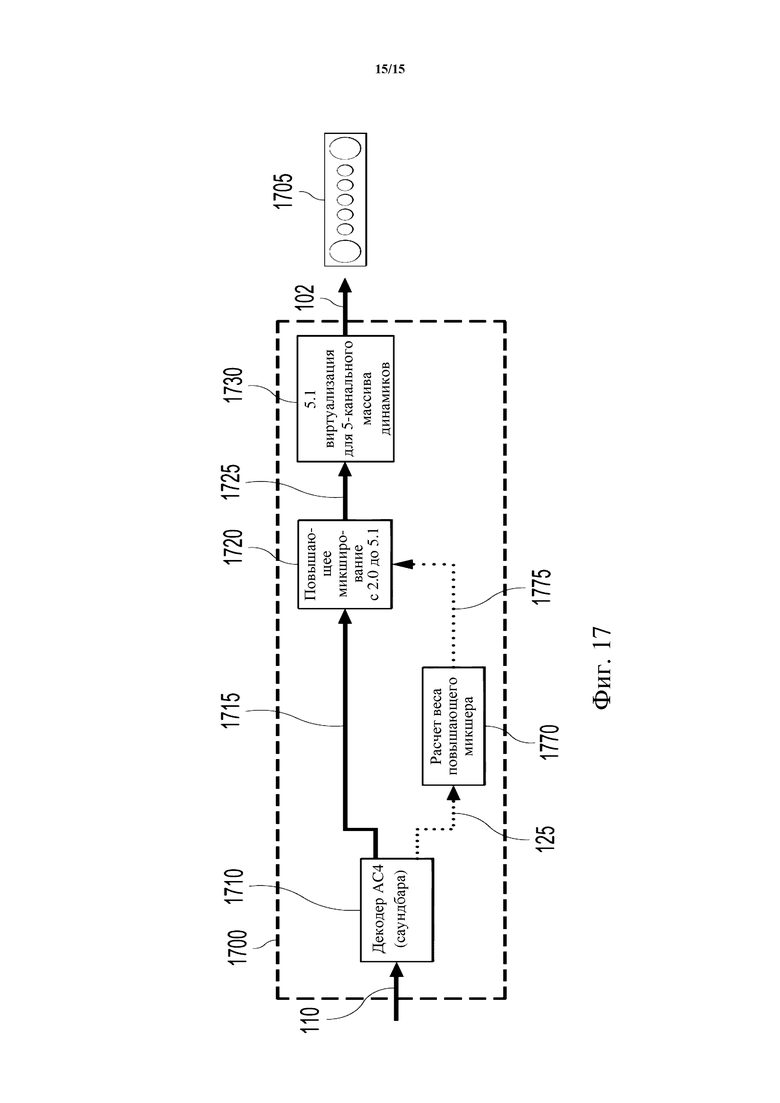
Изобретение относится к области вычислительной техники для обработки аудиоданных. Технический результат заключается в снижении вычислительной нагрузки на кодер и декодер аудиоданных. Технический результат достигается за счет генерирования классификационной информации, указывающей тип содержимого звукового содержимого, на основании анализа содержимого, причем анализ содержимого обучен с использованием предопределенного звукового содержимого, при этом классификационная информация содержит одно или более значений уверенности, каждое значение уверенности связывают с соответствующим типом содержимого и оно дает указание вероятности того, что звуковое содержимое относится к соответствующему типу содержимого. 5 н. и 38 з.п. ф-лы, 17 ил.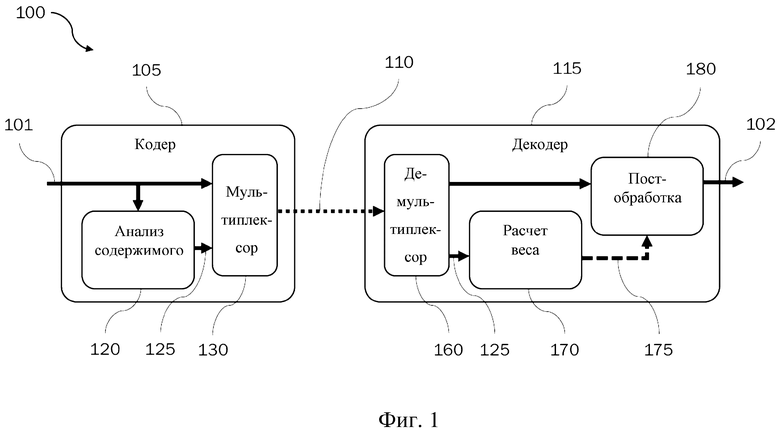
1. Способ кодирования звукового содержимого, включающий:
выполнение анализа содержимого звукового содержимого;
генерирование классификационной информации, указывающей тип содержимого звукового содержимого, на основании анализа содержимого, причем анализ содержимого обучен с использованием предопределенного звукового содержимого, при этом классификационная информация содержит одно или более значений уверенности, каждое значение уверенности связывают с соответствующим типом содержимого и оно дает указание вероятности того, что звуковое содержимое относится к соответствующему типу содержимого;
кодирование звукового содержимого и классификационной информации в битовом потоке; и
выдачу битового потока.
2. Способ по п. 1, отличающийся тем, что анализ содержимого основан, по меньшей мере частично, на метаданных для звукового содержимого.
3. Способ по любому из пп. 1, 2, отличающийся тем, что дополнительно включает:
прием пользовательского ввода, относящегося к типу содержимого звукового содержимого;
при этом генерирование информации основано на пользовательском вводе.
4. Способ по п. 3, отличающийся тем, что пользовательский ввод включает:
метку, указывающую, что звуковое содержимое относится к данному типу содержимого.
5. Способ по любому из пп. 1–4, отличающийся тем, что звуковое содержимое предоставляют в потоке звукового содержимого как часть звуковой программы, причем способ дополнительно включает:
прием указания типа сервиса, указывающего тип сервиса звукового содержимого;
выполнение анализа содержимого звукового содержимого на основании, по меньшей мере частично, указания типа сервиса;
при этом генерирование классификационной информации, указывающей тип содержимого звукового содержимого, основано на анализе содержимого.
6. Способ по п. 5, отличающийся тем, что дополнительно включает:
определение, на основании указания типа сервиса, является ли тип сервиса звукового содержимого музыкальным сервисом; и
в ответ на определение того, что тип сервиса звукового содержимого является музыкальным сервисом, генерирование классификационной информации для указания того, что тип содержимого звукового содержимого является музыкальным содержимым.
7. Способ по п. 5 или 6, отличающийся тем, что дополнительно включает:
определение, на основании указания типа сервиса, является ли тип сервиса звукового содержимого сервисом последних известий; и
в ответ на определение того, что тип сервиса звукового содержимого является сервисом последних известий, адаптирование анализа содержимого так, чтобы иметь значение вероятности более высокое, чем предопределенный порог, для указания того, что звуковое содержимое будет речевым содержимым.
8. Способ по любому из пп. 5–7, отличающийся тем, что указание типа сервиса предоставляют на покадровой основе.
9. Способ по любому из пп. 1–7, при зависимости от п. 2, отличающийся тем, что звуковое содержимое предоставляют на файловой основе и при этом файл включает метаданные для своего соответствующего звукового содержимого.
10. Способ по п. 9, отличающийся тем, что метаданные содержат указание типа содержимого файла, указывающее тип содержимого файла для файла; и при этом анализ содержимого основан, по меньшей мере частично, на указании типа содержимого файла.
11. Способ по п. 10, отличающийся тем, что дополнительно включает:
определение, на основании указания типа содержимого файла, является ли тип содержимого файла для файла музыкальным файлом; и
в ответ на определение того, что тип содержимого файла для файла является музыкальным файлом, генерирование классификационной информации для указания того, что тип содержимого звукового содержимого является музыкальным содержимым.
12. Способ по п. 10 или 11, отличающийся тем, что дополнительно включает:
определение, на основании указания типа содержимого файла, является ли тип содержимого файла для файла файлом последних известий; и
в ответ на определение того, что тип содержимого файла для файла является файлом последних известий, адаптирование анализа содержимого так, чтобы иметь значение вероятности более высокое, чем предопределенный порог, для указания того, что звуковое содержимое будет речевым содержимым.
13. Способ по любому из пп. 10–12, отличающийся тем, что дополнительно включает:
определение, на основании указания типа содержимого файла, является ли тип содержимого файла для файла динамическим; и
в ответ на определение того, что тип содержимого файла для файла является динамическим содержимым, адаптирование анализа содержимого так, чтобы обеспечивать возможность первой скорости перехода между разными типами содержимого, которая является более высокой, чем вторая скорость перехода между разными типами содержимого, файла, имеющего единообразную классификационную информацию.
14. Способ по любому из пп. 1–13, отличающийся тем, что типы содержимого включают одно или более из содержимого, выбранного из группы, состоящей из музыкального содержимого, речевого содержимого, содержимого с эффектами и шума толпы.
15. Способ по любому из пп. 1–14, отличающийся тем, что дополнительно включает:
кодирование указания переходов сцены в звуковом содержимом в битовый поток.
16. Способ по любому из пп. 1–15, отличающийся тем, что дополнительно включает:
сглаживание классификационной информации перед кодированием, при этом сглаживание классификационной информации включает сглаживание значений уверенности во времени.
17. Способ по любому из пп. 1–16, отличающийся тем, что дополнительно включает:
квантование классификационной информации перед кодированием.
18. Способ по любому из пп. 1–17, отличающийся тем, что дополнительно включает:
кодирование классификационной информации в специальное поле данных в пакете битового потока.
19. Способ по любому из предыдущих пунктов, отличающийся тем, что анализ содержимого адаптируют так, что классификационную информацию получают в соответствии с предпочтениями для определенных типов содержимого.
20. Способ по любому из предыдущих пунктов, отличающийся тем, что классификационная информация основана на обнаружении переходов сцены в звуковом содержимом.
21. Кодер для кодирования звукового содержимого, содержащий процессор, подключенный к запоминающему устройству, хранящему команды для процессора, при этом процессор приспособлен выполнять способ по любому из пп. 1–20.
22. Способ декодирования звукового содержимого из битового потока, закодированного в кодере, этот битовый поток содержит звуковое содержимое и классификационную информацию для этого звукового содержимого, отличающийся тем, что классификационная информация указывает тип содержимого звукового содержимого, при этом классификационная информация содержит одно или более значений уверенности, причем каждое значение уверенности связывают с соответствующим типом содержимого и оно дает указание вероятности того, что звуковое содержимое относится к соответствующему типу содержимого, при этом способ выполняется декодером и включает:
прием битового потока с кодера;
декодирование звукового содержимого и классификационной информации;
выбор, на основании классификационной информации, режима постобработки для выполнения постобработки декодированного звукового содержимого; и
расчет одного или более управляющих весов для постобработки декодированного звукового содержимого на основании классификационной информации, при этом управляющие веса рассчитывают на основании значений уверенности.
23. Способ по п. 22, отличающийся тем, что выбор режима постобработки дополнительно основан на пользовательском вводе.
24. Способ по п. 22 или 23, отличающийся тем, что битовый поток содержит основанное на каналах звуковое содержимое и постобработка включает:
повышающее микширование, посредством повышающего микшера, основанного на каналах звукового содержимого в подвергнутое повышающему микшированию основанное на каналах звуковое содержимое; и
применение виртуализатора к подвергнутому повышающему микшированию основанному на каналах звуковому содержимому для получения виртуализированного подвергнутого повышающему микшированию основанного на каналах звукового содержимого для виртуализации для массива динамиков необходимого количества каналов.
25. Способ по п. 24, отличающийся тем, что дополнительно включает:
направление выхода виртуализатора на массив динамиков и
расчет соответствующих управляющих весов для повышающего микшера и виртуализатора на основании классификационной информации.
26. Способ по любому из пп. 23, 24, отличающийся тем, что после применения виртуализатора способ дополнительно включает:
применение кроссфейдера к основанному на каналах звуковому содержимому и виртуализированному подвергнутому повышающему микшированию звуковому содержимому;
направление выхода кроссфейдера на массив динамиков; и
расчет соответствующих управляющих весов для повышающего микшера и кроссфейдера на основании классификационной информации.
27. Способ по любому из пп. 22–26, отличающийся тем, что управляющие веса представляют собой управляющие веса для соответствующих модулей для постобработки декодированного звукового содержимого.
28. Способ по любому из пп. 22–27, отличающийся тем, что управляющие веса включают одно или более из управляющего веса для эквалайзера, управляющего веса для виртуализатора, управляющего веса для процессора объемного звучания и управляющего веса для усилителя диалога.
29. Способ по любому из пп. 22–28, отличающийся тем, что расчет управляющих весов зависит от типа устройства у устройства, выполняющего декодирование.
30. Способ по любому из пп. 22–29, отличающийся тем, что расчет управляющих весов дополнительно основан на пользовательском вводе.
31. Способ по любому из пп. 22–30, отличающийся тем, что расчет управляющих весов дополнительно основан на количестве каналов звукового содержимого.
32. Способ по любому из пп. 22–31,
отличающийся тем, что управляющие веса включают управляющий вес для виртуализатора; и
при этом управляющий вес для виртуализатора рассчитывают так, что виртуализатор отключается, если классификационная информация указывает, что типом содержимого звукового содержимого является музыка или вероятно будет музыка.
33. Способ по любому из пп. 22–32,
отличающийся тем, что управляющие веса включают управляющий вес для виртуализатора; и
при этом управляющий вес для виртуализатора рассчитывают так, что коэффициенты виртуализатора масштабируются между пропусканием и полной виртуализацией.
34. Способ по любому из пп. 22–33,
отличающийся тем, что управляющие веса включают управляющий вес для усилителя диалога; и
при этом управляющий вес для усилителя диалога рассчитывают так, что усиление диалога усилителем диалога усиливается, если классификационная информация указывает, что типом содержимого звукового содержимого является речь или вероятно будет речь.
35. Способ по любому из пп. 22–34,
отличающийся тем, что управляющие веса включают управляющий вес для динамического эквалайзера; и
при этом управляющий вес для динамического эквалайзера рассчитывают так, что динамический эквалайзер отключается, если классификационная информация указывает, что типом содержимого звукового содержимого является речь или вероятно будет речь.
36. Способ по любому из пп. 22–35, отличающийся тем, что дополнительно включает сглаживание управляющих весов.
37. Способ по п. 36, отличающийся тем, что сглаживание управляющих весов зависит от конкретного управляющего веса, который сглаживают.
38. Способ по п. 36 или 37, отличающийся тем, что сглаживание управляющих весов зависит от типа устройства у устройства, выполняющего декодирование.
39. Способ по любому из пп. 35–38, отличающийся тем, что дополнительно включает применение нелинейной функции отображения к управляющим весам для повышения непрерывности управляющих весов.
40. Способ по любому из пп. 23–39, отличающийся тем, что битовый поток представляет собой битовый поток AC-4, при этом способ включает:
декодирование двухканального звукового содержимого и классификационной информации;
повышающее микширование двухканального звукового содержимого в подвергнутое повышающему микшированию 5.1-канальное звуковое содержимое;
применение виртуализатора к подвергнутому повышающему микшированию 5.1-канальному звуковому содержимому для 5.1 виртуализации для двухканального массива динамиков;
применение кроссфейдера к двухканальному звуковому содержимому и виртуализированному подвергнутому повышающему микшированию 5.1-канальному звуковому содержимому; и
направление выхода кроссфейдера в двухканальный массив динамиков,
при этом способ дополнительно включает расчет соответствующих управляющих весов для виртуализатора и кроссфейдера на основании классификационной информации.
41. Способ по любому из пп. 23–40, отличающийся тем, что битовый поток содержит двухканальное звуковое содержимое и классификационную информацию для этого двухканального звукового содержимого, причем классификационная информация указывает классификацию содержимого двухканального звукового содержимого, при этом способ включает:
декодирование двухканального звукового содержимого и классификационной информации;
применение повышающего микшера к двухканальному звуковому содержимому для повышающего микширования двухканального звукового содержимого в подвергнутое повышающему микшированию 5.1-канальное звуковое содержимое;
применение виртуализатора к подвергнутому повышающему микшированию 5.1-канальному звуковому содержимому для 5.1 виртуализации для пятиканального массива динамиков; и
направление выхода виртуализатора в пятиканальный массив динамиков,
при этом способ дополнительно включает расчет соответствующих управляющих весов для повышающего микшера и виртуализатора на основании классификационной информации.
42. Декодер для декодирования звукового содержимого, содержащий процессор, подключенный к запоминающему устройству, хранящему команды для процессора, при этом процессор приспособлен выполнять способ по любому из пп. 22–41.
43. Машиночитаемый носитель данных, содержащий компьютерную программу, включающую команды для обеспечения выполнения процессором, который исполняет команды, способа по любому из пп. 1–20.
| US 20170243596 A1, 24.08.2017 | |||
| US 20120084089 A1, 05.04.2012 | |||
| US 20180182394 A1, 28.06.2018 | |||
| US 20150088508 A1, 26.03.2015 | |||
| СПОСОБ И УСТРОЙСТВО ДЛЯ НОРМАЛИЗОВАННОГО ПРОИГРЫВАНИЯ АУДИО МЕДИАДАННЫХ С ВЛОЖЕННЫМИ МЕТАДАННЫМИ ГРОМКОСТИ И БЕЗ НИХ НА НОВЫХ МЕДИАУСТРОЙСТВАХ | 2014 |
|
RU2639663C2 |

