Перекрестная ссылка на родственные заявки
Настоящая заявка притязает на приоритет PCT заявки на патент № PCT/CN2019/083173, поданной 18 апреля 2019 года, предварительной заявки на патент США № 62/840,839, поданной 30 апреля 2019 года, и заявки на европейский патент № 19192553.6, поданной 20 августа 2019 года, каждая из которых ссылкой полностью включается в настоящий документ.
Область техники, к которой относится изобретение
Настоящее изобретение относится в общем к обработке звуковых сигналов, и в частности к детектору диалогов.
Предпосылки изобретения
Детектор диалогов – это ключевой компонент во многих алгоритмах обработки звуковых сигналов, таких как усиление диалога, шумоподавление и измеритель громкости. Как правило, в существующем детекторе диалогов входной звуковой сигнал вначале в компоненте предварительной обработки преобразуется в однородный формат посредством преобразования частоты дискретизации или понижающего микширования и т. д. Например, в качестве предварительной обработки, входной звуковой сигнал может быть подвергнут понижающему микшированию в монофонический звуковой сигнал. Затем обработанный звуковой сигнал разбивают на кратковременные кадры и из контекстного окна, включающего фиксированное количество кадров, извлекают звуковые признаки для описания характеристик каждого кадра. Затем применяется классификатор, построенный с использованием методов машинного обучения, для автоматического придания звуковым признакам показателя достоверности, представляющего вероятность наличия диалога. Наконец, для устранения или сглаживания нежелательной флуктуации полученных показателей достоверности может применяться постобработка, например медианный или средний фильтр. В случае если показатель достоверности высокий, сигнал будет классифицирован как диалог. Тогда сигнал диалога может быть отправлен в устройство улучшения звука, такое как устройство усиления диалога.
Краткое описание изобретения
Первый аспект настоящего изобретения относится к способу извлечения звуковых признаков в детекторе диалогов в ответ на входной звуковой сигнал, способ включает разделение входного звукового сигнала на множество кадров, извлечение кадровых звуковых признаков из каждого кадра, определение набора контекстных окон, где каждое контекстное окно содержит некоторое количество кадров, окружающих текущий кадр, выведение для каждого контекстного окна соответствующего контекстного звукового признака для текущего кадра на основании кадровых звуковых признаков кадров в каждом соответствующем контексте и выполнение конкатенации над каждым контекстным звуковым признаком с формированием комбинированного вектора признаков для представления текущего кадра.
Таким образом, в настоящем изобретении предлагается использование нескольких контекстных окон, каждое из которых содержит разное количество кадров, для представления кадра в разных контекстах, причем контекстные окна разной длины будут играть разные роли в представлении звукового свойства целевого кадра. Контекстные окна разной длины могут улучшать скорость реагирования и улучшать надежность. С этой целью в соответствии с настоящим изобретением вводится новый процесс – определение комбинированного временного контекста – для определения множества, например трех, контекстных окон разной длины или диапазона, например кратковременного контекста, средневременного контекста и долговременного контекста; затем звуковые признаки в контекстах извлекают в компоненте для извлечения звуковых признаков.
В некоторых вариантах осуществления компонент для извлечения кадровых признаков извлекает кадровые звуковые признаки (т. е. звуковые признаки кадра) из каждого из множества кадров, выделенных из входного звукового сигнала, а компонент для определения комбинированного временного контекста определяет длину или диапазон каждого контекстного окна. Затем соответствующий контекстный звуковой признак выводят на основании кадровых звуковых признаков в каждом определенном контексте. Каждый контекстный звуковой признак затем подвергают конкатенации и формируют комбинированный вектор признаков для представления текущего кадра.
В некоторых вариантах осуществления контекстные окна содержат кратковременный контекст, средневременный контекст и долговременный контекст. Кратковременный контекст представляет локальную информацию вокруг текущего кадра. Средневременный контекст дополнительно содержит множество кадров ретроспективного просмотра. Долговременный контекст дополнительно содержит множество кадров долговременной истории.
В некоторых вариантах осуществления длину или диапазон одного или более контекстов (т. е. количество кадров в соответствующих контекстных окнах) могут определять предварительно. Например, если доступен буфер опережающего просмотра, кратковременный контекст может содержать текущий кадр и кадры опережающего просмотра. Средневременный контекст может содержать текущий кадр, кадры опережающего просмотра и кадры ретроспективного просмотра. Долговременный контекст может содержать текущий кадр, кадры опережающего просмотра, кадры ретроспективного просмотра и кадры долговременной истории. В одном варианте осуществления длина или диапазон кадров опережающего просмотра могут предварительно определять размером до 23 кадров, а длину или диапазон кадров ретроспективного просмотра могут предварительно определять размером до 24 кадров, а также длину или диапазон кадров долговременной истории могут предварительно определяться размером от 48 до 96 кадров. В другом примере, если буфер опережающего просмотра недоступен, кратковременный контекст может содержать текущий кадр и первую часть кадров ретроспективного просмотра. Средневременный контекст может содержать текущий кадр, первую часть кадров ретроспективного просмотра и вторую часть кадров ретроспективного просмотра. Долговременный контекст может содержать текущий кадр, первую часть кадров ретроспективного просмотра, вторую часть кадров ретроспективного просмотра и кадры долговременной истории. Следовательно, длину или диапазон первой части кадров ретроспективного просмотра могут предварительно определять размером до 23 кадров, и длину или диапазон второй части кадров ретроспективного просмотра могут предварительно определять размером до 24 кадров, а также длину или диапазон кадров долговременной истории могут предварительно определять размером от 48 до 96 кадров.
В некоторых вариантах осуществления длину или диапазон одного или более контекстов могут определять адаптивно путем анализа стационарности признака кадрового уровня. Например, адаптивное определение основано на информации, относящейся к амплитуде входного звукового сигнала. В частности, один из способов адаптивного определения длины или диапазона кратковременного контекста основан на обнаружении мощного начала или перехода. В другом примере адаптивное определение основано на информации, относящейся к спектру входного звукового сигнала. В частности, один из способов адаптивного определения длины или диапазона кратковременного контекста основан на идентификации наибольшей спектральной несогласованности с использованием байесовских информационных критериев. Кроме того, в реализациях адаптивного определения кратковременный контекст может распространяться в направлениях как опережающего просмотра, так и ретроспективного просмотра, или распространяться только в одном направлении. В некоторых вариантах осуществления длину или диапазон контекстов могут предварительно определять в комбинации с адаптивным определением.
В дополнение в настоящем изобретении предлагается способ предварительной очистки для устранения некоррелируемых помех в сигнале с целью повышения точности обнаружения в диалоге с низким отношением сигнал/шум. С этой целью в настоящем изобретении используют понижающее микширование с зависимыми от времени и частоты коэффициентами усиления с большим упором на коррелированный сигнал.
В некоторых вариантах осуществления входной звуковой сигнал сначала разделяют на множество кадров, а затем кадры в левом канале и правом канале преобразуют в спектральное представление кадров. Некоррелированные сигналы в левом канале и правом канале удаляют путем применения частотно-зависимых коэффициентов усиления к спектру в левом канале и правом канале соответственно, чтобы получать сигнал после понижающего микширования. В некоторых вариантах осуществления частотно-зависимые коэффициенты усиления могут вычислять из ковариационной матрицы.
Кроме того, в настоящем изобретении предусмотрен детектор музыкального содержимого так, что как показатель достоверности музыки, так и показатель достоверности речи можно совместно учитывать для коррекции исходного показателя достоверности диалога и получения окончательного откорректированного показателя достоверности диалога, чтобы значительно уменьшать ложные срабатывания в музыке.
В некоторых вариантах осуществления детектор речевого содержимого принимает признаки, извлеченные с использованием контекстных окон, а затем детектор речевого содержимого определяет показатель достоверности речи. Затем детектор музыкального содержимого принимает признаки, извлеченные с использованием контекстных окон, а затем детектор музыкального содержимого определяет показатель достоверности музыки. Показатель достоверности речи и показатель достоверности музыки комбинируют для получения окончательного показателя достоверности диалога. В некоторых вариантах осуществления окончательный показатель достоверности диалога могут уточнять посредством контекстно-зависимого параметра, который могут вычислять на основании доли кадров, идентифицированных как речь или музыка в историческом контексте. В некоторых вариантах осуществления исторический контекст может иметь продолжительность десять секунд или более.
Краткое описание графических материалов
Прилагаемые фигуры даны в целях иллюстрации и служат лишь для представления примеров возможных операций для раскрытых новаторских способов, системы и машиночитаемого носителя. Эти фигуры никоим образом не ограничивают любые изменения формы и деталей, которые может внести специалист в данной области техники в пределах сущности и объема раскрытых вариантов осуществления.
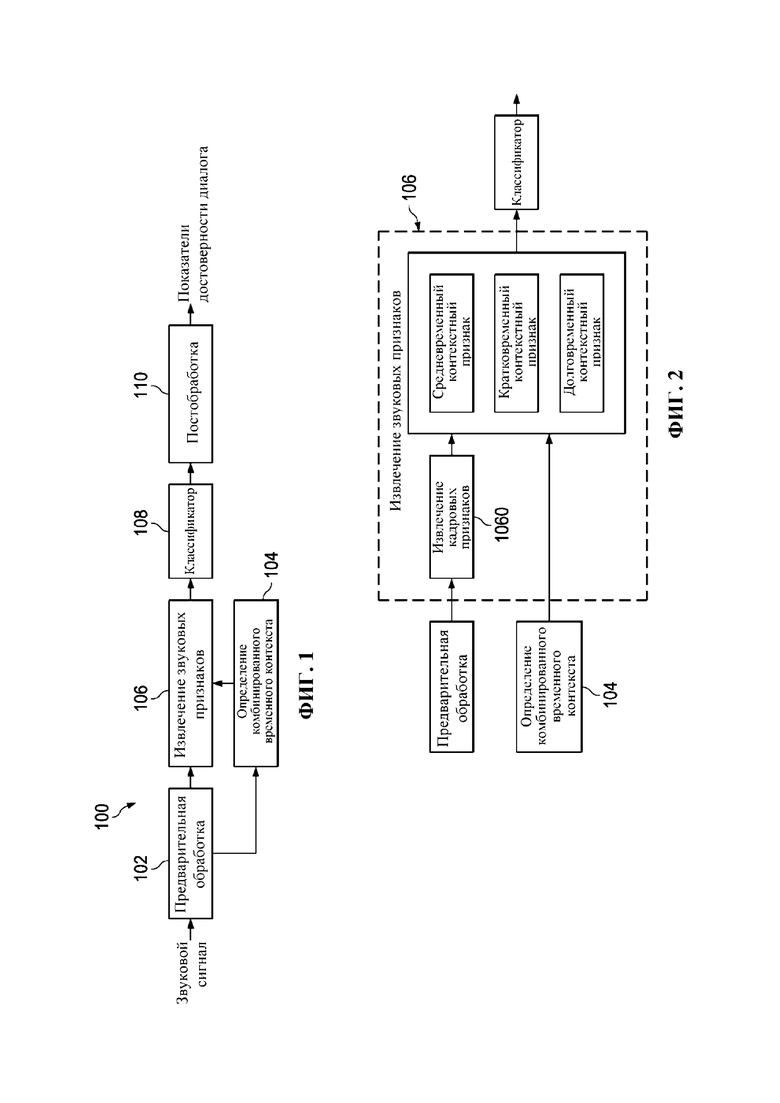
Фиг. 1 представляет собой структурную схему детектора 100 диалогов, содержащего компонент 104 определения комбинированного временного контекста в соответствии с некоторыми вариантами осуществления.
Фиг. 2 представляет собой структурную схему компонента 102 для извлечения звуковых признаков в детекторе 100 диалогов в соответствии с некоторыми вариантами осуществления.
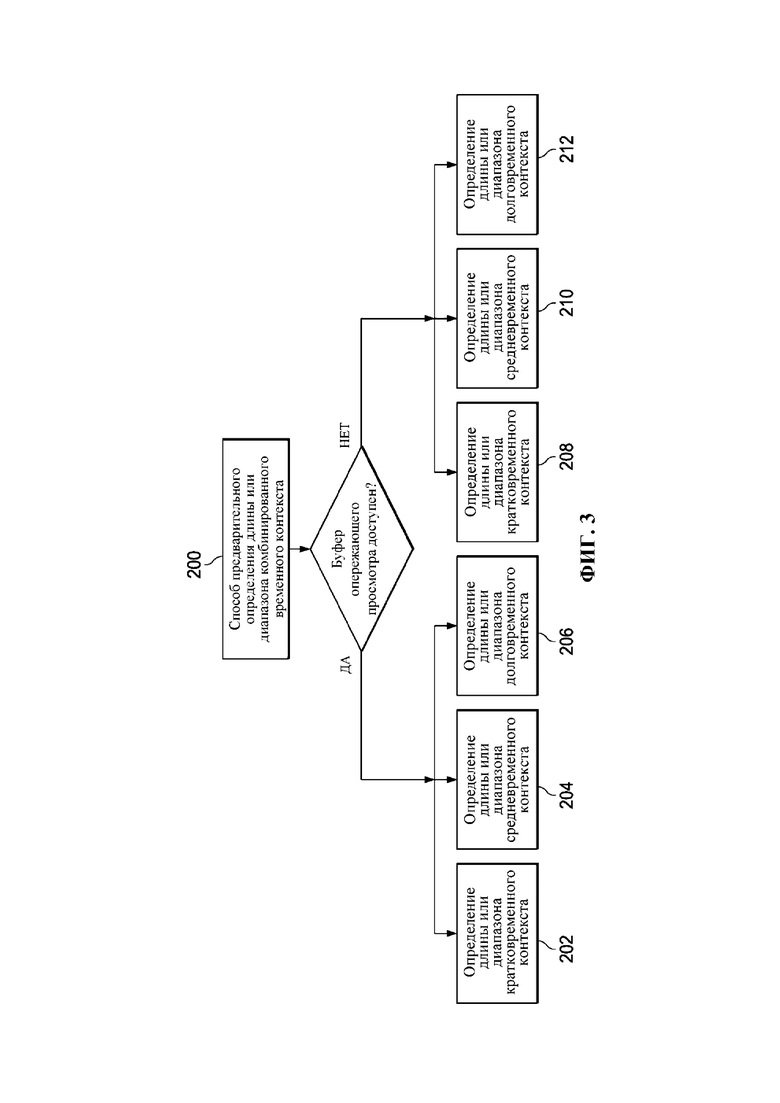
Фиг. 3 представляет собой блок-схему способа 200 в соответствии с некоторыми вариантами осуществления для предварительного определения длины или диапазона комбинированного временного контекста с использованием компонента 104 определения комбинированного временного контекста.
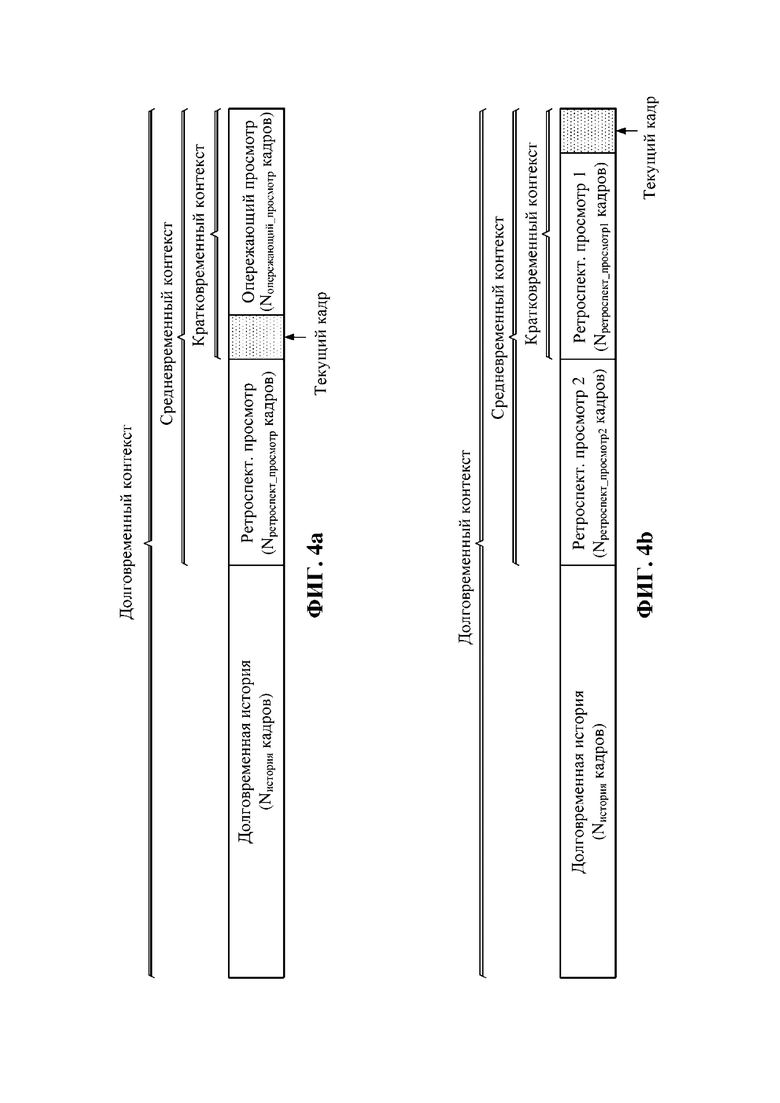
Фиг. 4a представляет собой пример предварительно определенной длины или диапазона комбинированного временного контекста, если доступен буфер опережающего просмотра, в соответствии с некоторыми вариантами осуществления.
Фиг. 4b представляет собой пример предварительно определенной длины или диапазона комбинированного временного контекста, если буфер опережающего просмотра недоступен, в соответствии с некоторыми вариантами осуществления.
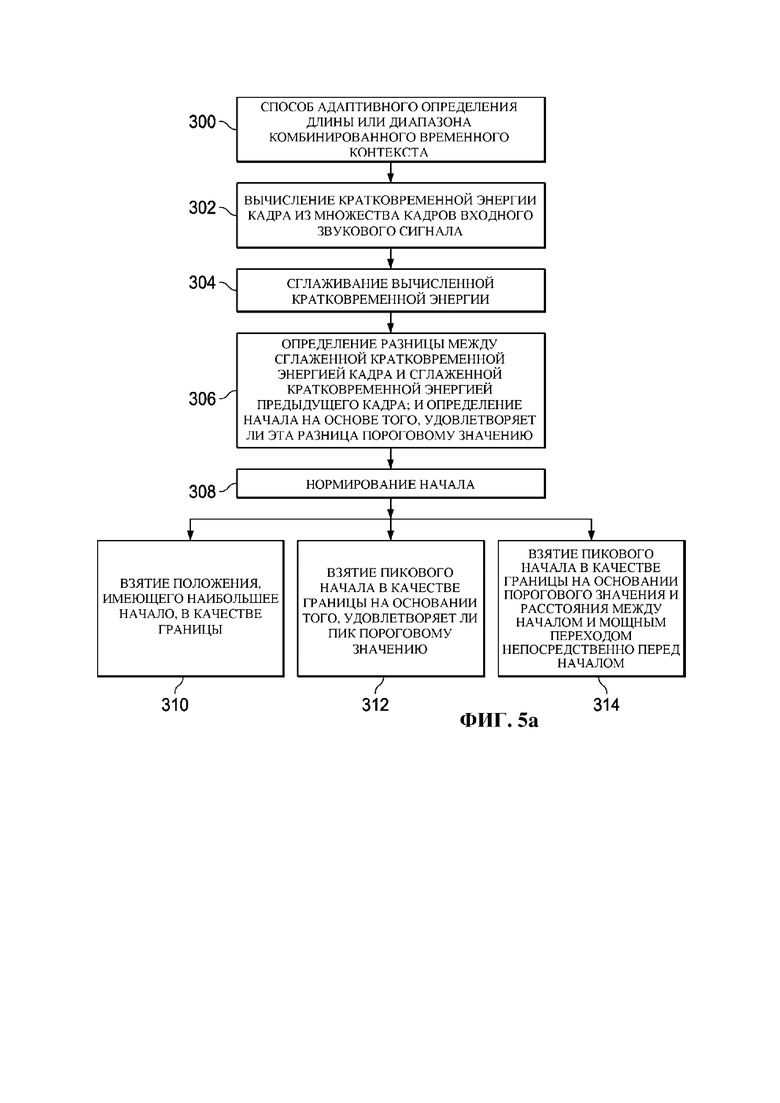
Фиг. 5a представляет собой блок-схему примера способа 300 в соответствии с некоторыми вариантами осуществления для адаптивного определения длины или диапазона комбинированного временного контекста с использованием компонента 104 определения комбинированного временного контекста.
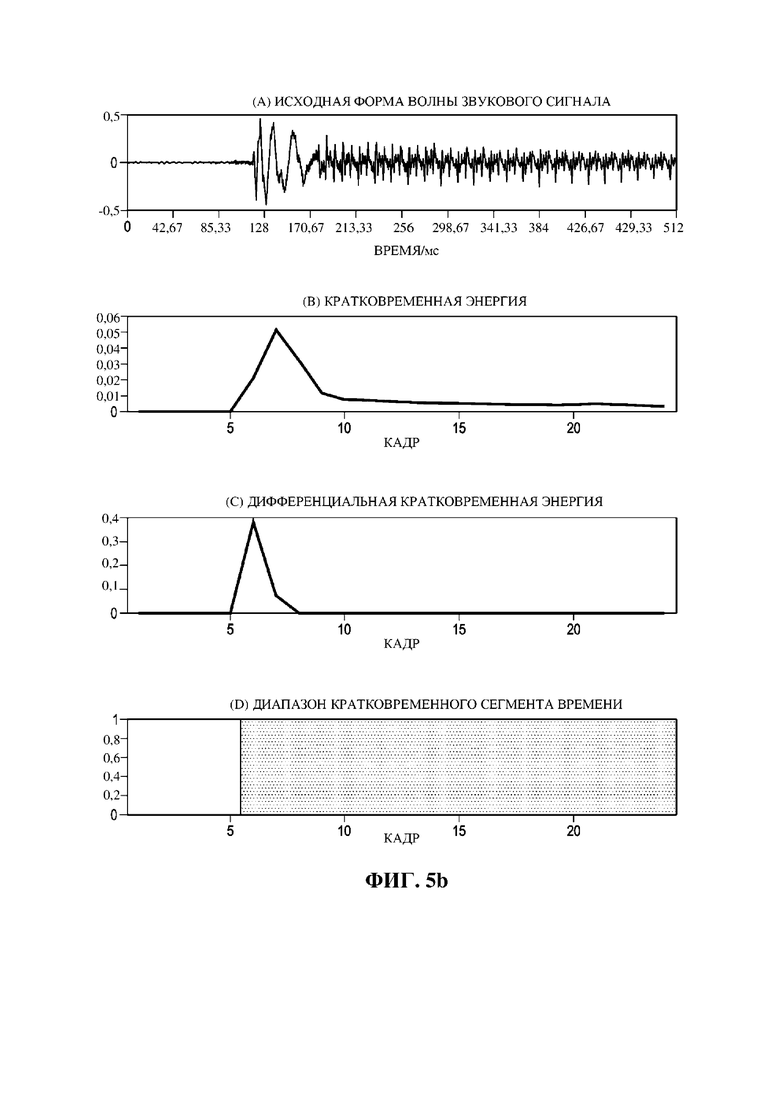
Фиг. 5b представляет собой схематический вид способа 300, проиллюстрированного в диапазоне поиска границ контекста.
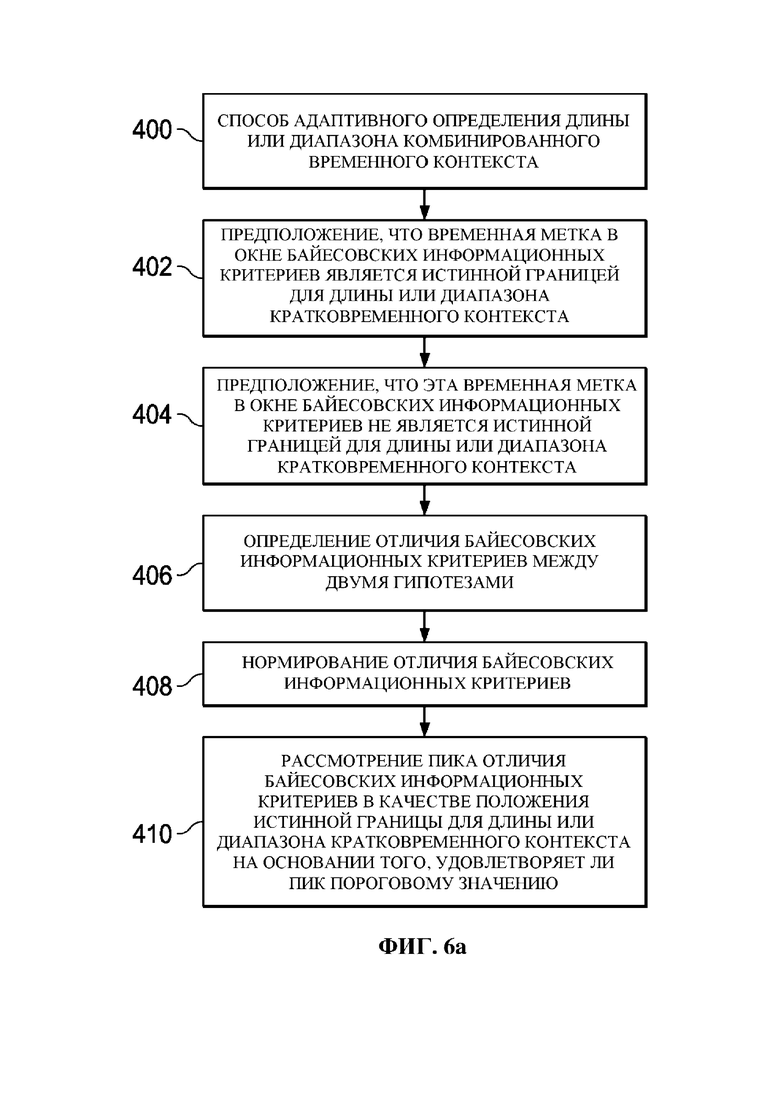
Фиг. 6a представляет собой блок-схему другого примера способа 400 в соответствии с некоторыми вариантами осуществления для адаптивного определения длины или диапазона комбинированного временного контекста с использованием компонента 104 определения комбинированного временного контекста.
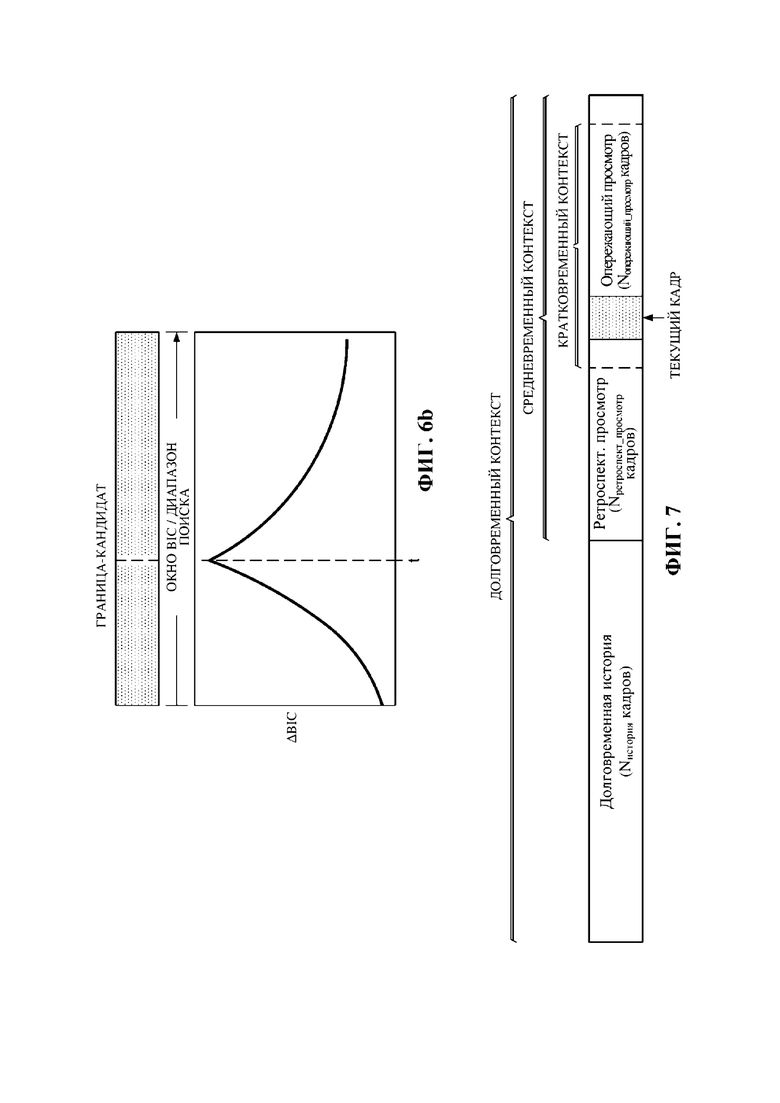
Фиг. 6b представляет собой схематический вид способа 400, проиллюстрированного в окне байесовских информационных критериев.
На фиг. 7 показан пример адаптивно определенной длины или диапазона комбинированного временного контекста, если доступен буфер опережающего просмотра, в соответствии с некоторыми вариантами осуществления.
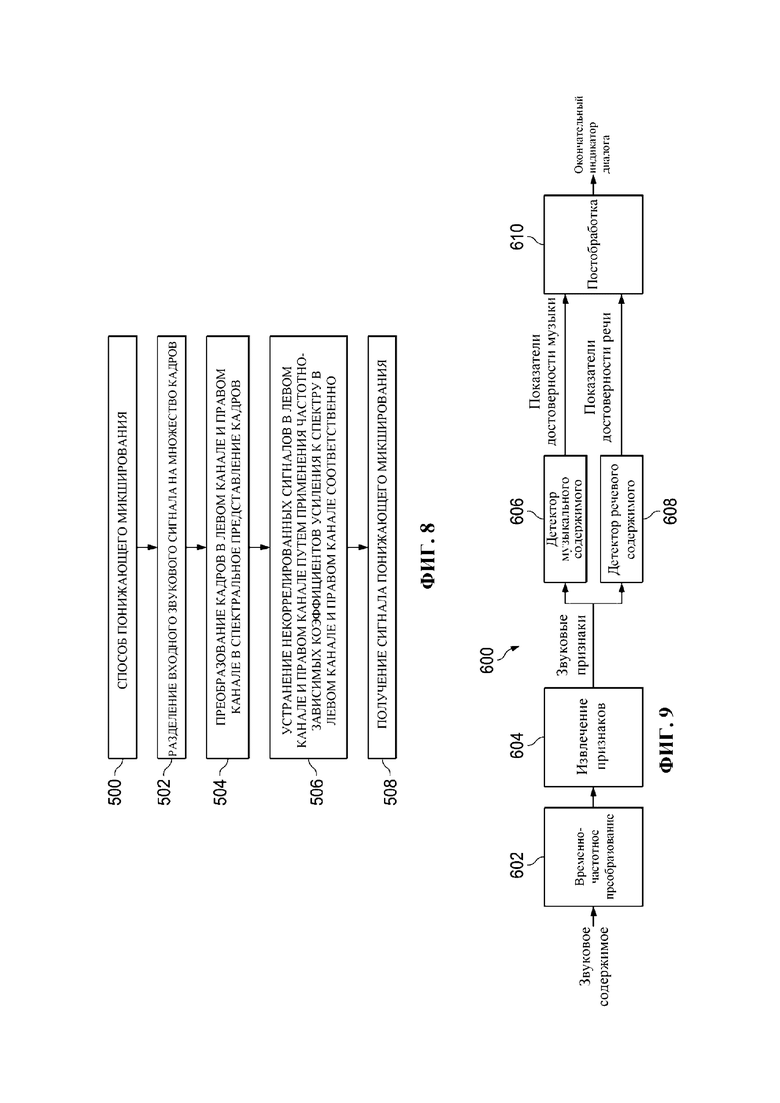
Фиг. 8 представляет собой блок-схему примера способа 500 понижающего микширования входного звукового сигнала детектора диалогов, который выполняют в соответствии с некоторыми вариантами осуществления.
Фиг. 9 представляет собой структурную схему детектора 600 диалогов, дополнительно содержащего детектор 606 музыкального содержимого, в соответствии с некоторыми вариантами осуществления.
Подробное описание
Как уже отмечалось, в обычном известном детекторе диалогов каждый кадр представлен контекстом, а именно окном, содержащим ряд кадров (например, 32 или 48 кадров), и классифицируется по звуковым признакам, извлеченным из кадров в этом контекстном окне. Однако проблема, связанная с этим обычным детектором диалогов, заключается в том, что он иногда может вносить в обнаружение большую задержку, поскольку детектор может определять, присутствует ли диалог, только после идентификации нескольких кадров диалога, что может отрицательно сказываться на применении в реальном времени. Кроме того, он не может извлекать более надежные ритмические признаки, которые могут способствовать распознаванию речи из поющего голоса или речитатива, и, соответственно, это может отрицательно сказываться на надежности обнаружения диалога.
Для решения этих проблем в настоящем изобретении предлагаются методы, предусматривающие использование набора контекстных окон разной длины для представления кадра в нескольких масштабах, причем контекстные окна разной длины будут играть разные роли в представлении звукового свойства целевого кадра. Далее приводится описание некоторых примеров способов, систем и машиночитаемого носителя, реализующих эти методы для извлечения звукового признака детектора диалогов с учетом входного звукового сигнала.
Фиг. 1 представляет собой структурную схему детектора 100 диалогов, содержащего компонент 104 определения окна комбинированного временного контекста в соответствии с некоторыми вариантами осуществления. На фиг. 1 компонент 102 предварительной обработки принимает входной звуковой сигнал. В компоненте 102 предварительной обработки входной звуковой сигнал может быть подвергнут понижающему микшированию в монофонический звуковой сигнал. Затем его разбивают на кадры. Затем компонент 104 определения комбинированного временного контекста и компонент 106 извлечения звуковых признаков принимают кадры из компонента 102 предварительной обработки соответственно. Затем из каждого кадра в компоненте 106 извлечения звуковых признаков извлекают кадровые звуковые признаки. Кроме того, в компоненте 104 определения комбинированного временного контекста определяют длину или диапазон каждого контекстного окна. Затем компонент 106 извлечения звуковых признаков принимает результат определения из компонента 104 комбинированного временного определения. Затем в компоненте 106 извлечения звуковых признаков кадровые звуковые признаки в каждом контекстном окне используют для выведения каждого контекстного признака в зависимости от определенного контекстного окна. Каждый набор контекстных признаков затем подвергают конкатенации или комбинируют и формируют совместный вектор признаков. Затем классификатор 108 принимает вектор извлеченных признаков из компонента 106 извлечения звуковых признаков. В классификаторе 108 получают показатель достоверности, представляющий вероятность наличия диалога. Наконец, в компоненте 110 постобработки полученные показатели достоверности могут сглаживаться, например, медианным или средним фильтром, для устранения их нежелательной флуктуации.
Фиг. 2 представляет структурную схему компонента 106 извлечения звуковых признаков в детекторе 100 диалогов в соответствии с некоторыми вариантами осуществления. В частности, на этой фигуре описываются извлечение и комбинирование признаков комбинированного временного контекста. На фиг. 2 в компоненте 106 извлечения звуковых признаков из каждого принятого кадра извлекают кадровые звуковые признаки посредством компонента 1060 для извлечения кадровых признаков. Затем в компоненте 104 определения комбинированного временного контекста определяют длину или диапазон каждого контекстного окна, в данном случае кратковременного контекстного окна, средневременного контекстного окна и долговременного контекстного окна. Затем на основании кадровых звуковых признаков в кратковременном контекстном окне, средневременном контекстном окне и долговременном контекстном окне выводят соответственно кратковременный контекстный звуковой признак, средневременный контекстный звуковой признак и долговременный контекстный звуковой признак. Наконец, эти три набора контекстных признаков подвергают конкатенации и формируют вектор признаков большой размерности. Например, если, предположим, каждый контекстный признак является 100-мерным, то полученный конкатенацией признак будет 300-мерным.
Следовательно, вместо представления текущего кадра одним контекстным окном в настоящем изобретении предлагается использование нескольких контекстных окон. В одном варианте осуществления для представления текущего кадра используются три контекстных окна, а именно: кратковременное контекстное окно, средневременное контекстное окно и долговременное контекстное окно разной длины или диапазона. В частности, кратковременный контекст представляет локальную информацию вокруг целевого кадра, чтобы при появлении диалога детектор мог быстрее отреагировать. Средневременный контекст – это элемент, используемый в существующем детекторе, поскольку он может обеспечить соответствующий временной интервал для анализа звукового содержимого. Долговременное контекстное окно представляет более глобальную информацию, в которой извлекаются лишь ритмические признаки, поскольку кратковременный контекст или средневременное контекстное окно, как правило, не являются достаточно долгими для того, чтобы можно было извлечь надежные ритмические признаки. То есть в настоящем изобретении предлагается добавление кратковременного контекстного окна для повышения быстродействия и долговременного контекста для повышения надежности. Таким образом, длину этих трех контекстных окон следует определять при извлечении признаков. С этой целью в настоящем изобретении предлагается компонент комбинированного временного определения для определения длины кратковременного контекстного окна, средневременного контекстного окна и долговременного контекстного окна.
В одном примере кадровый звуковой признак может содержать по меньшей мере один из признаков поддиапазона или признаков полного диапазона. Примеры признаков поддиапазона включают: спектральное распределение энергии поддиапазона, спектральный контраст поддиапазона, частичный выброс поддиапазона, коэффициенты косинусного преобразования Фурье для частот чистых тонов (MFCC), MFCC-поток и энергия нижних частот. Примеры признаков полного диапазона включают: спектральный поток, спектральная остаточная и кратковременная энергия.
В одном примере контекстный звуковой признак может быть выведен из одного или более кадровых звуковых признаков. Например, контекстный звуковой признак может включать статистику кадровых звуковых признаков, такую как среднее, мода, медиана, дисперсия или стандартное отклонение.
Дополнительно или альтернативно контекстный звуковой признак может включать признак, связанный с ритмом, такой как признак 2D модуляции, мощность ритма, чистота ритма, регулярность ритма, средний темп и/или корреляция на уровне окна (т. е. корреляция на уровне контекста).
Вышеприведенные примеры кадровых звуковых признаков и контекстных звуковых признаков не являются исчерпывающими, и вместо перечисленных признаков или в дополнение к ним могут использоваться различные другие кадровые звуковые признаки и контекстные звуковые признаки.
Фиг. 3 представляет собой блок-схему способа 200 в соответствии с некоторыми вариантами осуществления для предварительного определения длины или диапазона комбинированного временного контекста с использованием компонента 104 определения комбинированного временного контекста. В этом примерном варианте осуществления длина или диапазон комбинированных временных контекстов могут быть определены предварительно. В одном примере, если доступен буфер опережающего просмотра, на этапе 202 могут определять, что кратковременный контекст содержит лишь текущий кадр и несколько кадров опережающего просмотра, причем длину или диапазон кадров опережающего просмотра могут предварительно определять как 23 кадра, таким образом, общая длина или диапазон кратковременного контекста составляет 24 кадра, так чтобы анализировать самое последнее поступающее содержимое. На этапе 204 могут определять, что средневременный контекст содержит текущий кадр, несколько кадров опережающего просмотра и несколько кадров ретроспективного просмотра, причем длину или диапазон кадров ретроспективного просмотра могут предварительно определять как 24 кадра, таким образом, общая длина или диапазон средневременного контекста составляет 48 кадров. Затем на этапе 206 могут определять, что долговременный контекст содержит текущий кадр, несколько кадров опережающего просмотра, несколько кадров ретроспективного просмотра и еще кадры истории, причем длину или диапазон кадров долговременной истории могут предварительно определять как 48–96 кадров; таким образом, общая длина или диапазон долговременного контекста составляет от 96 до 144 кадров, так чтобы иметь анализ стабильных ритмических признаков. На фиг. 4a показан этот пример предварительно определенной длины или диапазона комбинированного временного контекста. В другом примере, если буфер опережающего просмотра отсутствует, на этапе 208 могут определять, что кратковременный контекст содержит лишь текущий кадр и часть кадров ретроспективного просмотра, причем длину или диапазон части кадров ретроспективного просмотра могут предварительно определять как 23 кадра, таким образом, общая длина или диапазон кратковременного контекста составляет 24 кадра. На этапе 210 могут определять, что средневременный контекст содержит текущий кадр, часть кадров ретроспективного просмотра и дополнительные кадры ретроспективного просмотра, причем длину или диапазон дополнительных кадров ретроспективного просмотра могут предварительно определять как 24 кадра, таким образом, общая длина или диапазон средневременного контекста составляет 48 кадров. Затем на этапе 212 могут определять, что долговременный контекст содержит текущий кадр, часть кадров ретроспективного просмотра, дополнительные кадры ретроспективного просмотра и еще кадры истории, причем длину или диапазон кадров долговременной истории могут предварительно определить как 48–96 кадров; таким образом, общая длина или диапазон долговременного контекста составляет от 96 до 144 кадров. На фиг. 4b показан этот пример предварительно определенной длины или диапазона комбинированного временного контекста. В способе 200 длина или диапазон буфера опережающего просмотра, буфера ретроспективного просмотра и долговременной истории все могут быть предварительно определены. Альтернативно, помимо вышеуказанного числа кадров, могут использовать и другое число кадров, пока оно обеспечивает, что кратковременный контекст содержит лишь кадры со свойством, подобным текущему кадру, а долговременный контекст содержит достаточно кадров истории для извлечения надежных ритмических признаков.
Альтернативно длину или диапазон одного или более контекстных окон могут адаптивно определять в компоненте 104 определения комбинированного временного контекста путем анализа стационарности признаков уровня кадра и соответственного группирования звуковых кадров. Фиг. 5a представляет блок-схему примера способа 300 в соответствии с некоторыми вариантами осуществления для адаптивного определения длины или диапазона окна комбинированного временного контекста с использованием компонента 104 определения комбинированного временного контекста. В частности, в качестве примера для описания способа 300 берется кратковременный контекст. Способ 300 основан на обнаружении мощного переходного процесса. Вначале на этапе 302 рассчитывают кратковременную энергию 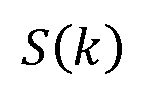 кадра k по следующей формуле (1):
кадра k по следующей формуле (1):

Здесь [xk,0, …, xk, N-1] представляют PCM-выборки кадра k. Перед вычислением энергии выборки могут также быть обработаны методом окна / взвешены, и энергию могут выводить из сигнала либо полного диапазона, либо поддиапазона.
Затем на этапе 304 энергию кадра асимметрично сглаживают с коэффициентом ускоренного продвижения при повышении энергии и медленным затуханием при уменьшении энергии, как представлено в формуле (2):
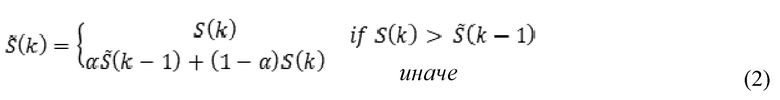
где – сглаженная кратковременная энергия в k-м звуковом кадре. Параметр α является коэффициентом сглаживания.
Затем на этапе 306 на огибающей сглаженной энергии применяют разностный фильтр, и значения, превышающие заданный порог δ, могут рассматривать как начало 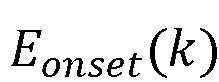 , как представлено в формуле (3):
, как представлено в формуле (3):
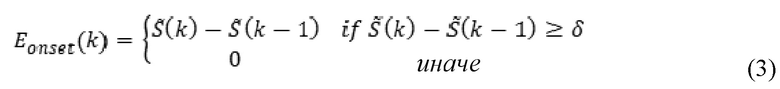
Затем на этапе 308 могут дополнительно нормировать средним значением кратковременной энергии в диапазоне поиска. Затем на любом из этапов 310, 312 или 314 могут определять границу для длины или диапазона кратковременного контекста. На этапе 310 положение с наибольшим берут как границу контекста. На этапе 312 пиковое выше некоторого порогового значения, например 0,3 (его могут настраивать между 0 и 1), могут брать как границу контекста. Вместо порогового значения на этапе 314 могут учитывать расстояние между и ранее идентифицированным мощным пиком. Иными словами, лишь в том случае, если он будет иметь определенную продолжительность, например одну секунду, от предыдущего мощного переходного процесса, его определят как мощный переходной процесс и выберут границей контекста. Кроме того, на этапе 314, если мощный переходной процесс в диапазоне поиска не обнаруживают, то используют полные кадры ретроспективного просмотра и/или кадры опережающего просмотра. Фиг. 5b представляет схематический вид способа 300, проиллюстрированного в диапазоне поиска границ контекста. В частности, она иллюстрирует исходную форму волны звуковых сигналов, кратковременную энергию, дифференциальную кратковременную энергию после нормирования и диапазон определенного кратковременного контекста.
Вместо использования для определения диапазона контекста информации об амплитуде, адаптивное определение диапазона контекста может также быть основано на спектральной информации. Например, для определения диапазона контекста с использованием байесовских информационных критериев (BIC) могут находить наибольшую спектральную несогласованность. Фиг. 6a представляет способ 400 определения границ с использованием BIC. В качестве примера для описания способа 400 также берется кратковременный контекст. Сначала на этапе 402 предполагают, что временная метка t в окне BIC является истинной границей и что это окно лучше представить двумя отдельными моделями нормального распределения, разделенными в момент времени t. Затем на этапе 404 предполагают, что временная метка t в окне BIC не является истинной границей и что это окно лучше представить лишь одной моделью нормального распределения. Затем на этапе 406 рассчитывают дельта BIC по следующей формуле (4):
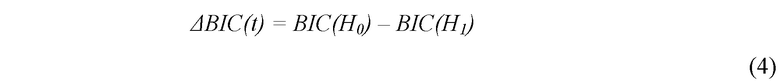
Здесь H0 является гипотезой на этапе 402 и H1 является гипотезой на этапе 404. На фиг. 6b показан пример кривой ΔBIC(t) в окне BIC, которая представляет собой разность логарифмического правдоподобия между двумя гипотезами. Затем на этапе 408 дельта BIC могут нормировать. Затем на этапе 410, если пик ΔBIC(t) больше порогового значения (его могут настраивать между 0 и 1), этот пик могут выбирать как наиболее возможное положение границы контекста.
На фиг. 7 показан пример адаптивного определения длины или диапазона окна комбинированного временного контекста, если доступен буфер опережающего просмотра, в соответствии с некоторыми вариантами осуществления. В частности, длина или диапазон кратковременного контекстного окна адаптивно определены способом 300 или способом 400, а длина или диапазон средневременного контекста и долговременного контекста предварительно определены способом 200. Как показано на фиг. 7, если доступен буфер опережающего просмотра, кратковременный контекст может распространяться как в направлении опережающего просмотра, так и в направлении ретроспективного просмотра. Альтернативно кратковременный контекст может распространяться только в одном направлении, например, если буфер опережающего просмотра отсутствует (не показано). В способе 300 или способе 400 в соответствии с настоящим изобретением как пример для описания адаптивного определения взят кратковременный контекст, однако длину или диапазон средневременного контекста также можно адаптивно определять методами, подобными описанным выше способам 300 или 400.
Как отмечено выше, современный детектор диалогов применяют для понижающего микширования в монофонический сигнал в каналах L/R для стереофонического сигнала или в каналах L/R/C для сигнала 5.1 с целью уменьшения сложности вычислений. Однако микширование всех каналов вместе может уменьшить отношение сигнал/шум диалога и снизить точность обнаружения диалога. Например, диалог с большими помехами (например, в спортивных играх) или диалог в сценах с интенсивным действием при обнаружении может быть упущен. Для решения этой проблемы применяется преобладающее понижающее микширование центрального канала, как представлено формулой (5), для уменьшения «смазывания» диалога, поскольку большая часть диалога находится в канале C в сигнале 5.1.

Здесь C, L, R означают комплексный спектр для каждого временно-спектрального «тайла» (то есть для каждого кадра и каждого интервала/полосы) в центральном, левом и правом каналах соответственно, а g – параметр между 0 и 1 для уменьшения «вклада» из L и R каналов. Однако вышеуказанный способ работает на сигнале 5.1, но неприменим для стереофонического сигнала, поскольку диалог обычно рассматривается как панорамированный сигнал, а значит коррелированный в L и R, в стереофоническом сигнале.
Для решения этой проблемы в настоящем изобретении предлагается новый способ понижающего микширования для устранения некоррелированного шума в сигнале, чтобы сделать диалог более четко выраженным после понижающего микширования. Фиг. 8 представляет пример способа 500 понижающего микширования входного звукового сигнала детектора диалогов, который выполняют в соответствии с некоторыми вариантами осуществления. Сначала на этапе 502 входной звуковой сигнал разделяют на множество кадров. Затем на этапе 504 кадры в левом канале и правом канале преобразуют в спектральное представление кадров. Затем на этапе 506 некоррелированные сигналы устраняют по формуле (6) следующим образом:

Здесь L – спектральное представление кадров в левом канале, R – спектральное представление кадров в правом канале, а g1 и g2 представляют два частотно-зависимых коэффициента усиления, а не широкополосные коэффициенты усиления, применяемые к L и R соответственно. Для простоты характеристика полосы частот в формуле упущена. В одном варианте осуществления g1 и g2 могут быть вычислены из ковариационной матрицы, которую рассчитывают для каждой полосы в определенном промежутке времени (причем учитывают только реальную часть, а характеристику полосы частот также упускают), как представлено в формуле (7):
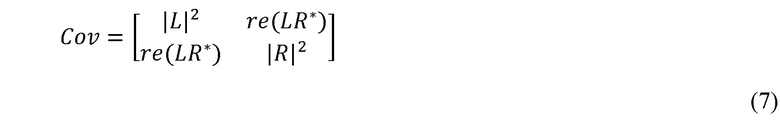
Затем после анализа собственных векторов и идеи выделения окружения в NGCS, g1 и g2 можно представить следующим образом.
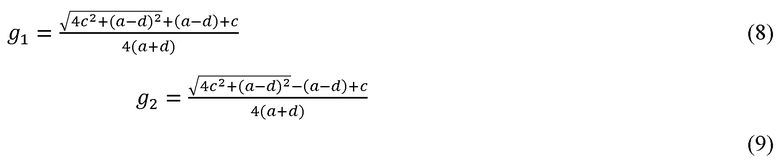
Здесь a, c и d являются альтернативным представлением коэффициентов ковариации 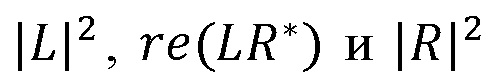 соответственно для упрощения представления формул (8) и (9). После этапа 506 на этапе 508 получают сигнал после понижающего микширования M.
соответственно для упрощения представления формул (8) и (9). После этапа 506 на этапе 508 получают сигнал после понижающего микширования M.
Хотя вышеупомянутый способ 500 описан и разработан на основании стереофонического сигнала, он мог бы быть применен и к сигналу 5.1. В одном варианте осуществления сигнал 5.1 может сначала быть преобразован в стереофонический сигнал (Lc и Rc) с преобладающим понижающим микшированием центрального канала, как представлено в формулах (10) и (11):

Затем Lc и Rc будут следовать способу 500 для устранения некоррелированного шума.
В дополнение к способу 500 устранения некоррелированного сигнала или вместо него также могут применяться и некоторые другие способы. В некоторых вариантах осуществления для снижения шума в центральном канале C с использованием (L+R)/2 как сигнала эталонного шума могут применять способ, подобный подавлению эхо-сигналов. Альтернативно могут строить спектральный базис НМР для либо диалога, либо как диалога, так и шума, и их могут применять для извлечения чистой диалоговой составляющей.
Кроме того, в современном детекторе музыкальный сигнал, особенно поющий голос в а капелла (без существенного инструментального сопровождения) или речитатив, имеющие много схожих свойств с диалогом, может ошибочно быть классифицирован как диалог, поэтому ложные срабатывания могут значительно возрасти. Заявитель установил, что показатель достоверности музыки также высок и для тех же ошибочно классифицированных кадров. Исходя из этого, параллельно детектору диалогов заявитель вводит классификатор музыки, чтобы показатель достоверности музыки мог использоваться как эталон для уточнения или корректировки исходного показателя достоверности диалога, чтобы значительно уменьшить ложные срабатывания в музыке.
Фиг. 9 представляет собой структурную схему детектора 600 диалогов, дополнительно содержащего детектор 606 музыкального содержимого, в соответствии с некоторыми вариантами осуществления. Сначала входной звуковой сигнал разделяют на множество кадров и преобразуют в спектральное представление с помощью дискретного преобразования Фурье (ДПФ) 602. Затем в компоненте 604 извлечения признаков извлекают признаки для представления каждого кадра согласно процедуре, проиллюстрированной на фиг. 2. Затем детектор 606 музыкального содержимого принимает извлеченные признаки для получения показателя Cm(t) достоверности музыки; тем временем детектор 608 речевого содержимого также принимает извлеченные признаки для получения показателя Cs(t) достоверности речи. Кроме того, показатель Cm(t) достоверности музыки и показатель Cs(t) достоверности речи могут быть дополнительно сглажены медианным фильтром или средним фильтром. Кроме того, в компоненте 610 постобработки показатель Cm(t) достоверности музыки и показатель Cs(t) достоверности речи объединяют для получения окончательного показателя 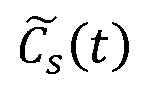 достоверности диалога. В частности, исходный показатель достоверности диалога уточняют для получения уточненного окончательного показателя достоверности диалога в компоненте 610 постобработки. Как правило, исходный показатель достоверности диалога может быть в некоторой степени уменьшен, если показатель Cm(t) достоверности музыки для такого же кадра также является высоким. Однако это может привести к чрезмерному уменьшению показателя Cs(t) достоверности речи, поскольку содержимое реального диалога может также генерировать как высокий показатель достоверности диалога, так и высокий показатель достоверности музыки, если диалог присутствует с музыкальным фоном. Для решения этой проблемы с целью определения того, можно ли показатель Cs(t) достоверности музыки уверенно использовать для уточнения показателя достоверности диалога, можно применять исторический контекст. Если исторический контекст является преобладающим в диалоге, более консервативным будет уточнение показателя достоверности диалога, то есть с намерением проигнорировать показатель достоверности музыки. Поэтому в некоторых вариантах осуществления окончательный показатель
достоверности диалога. В частности, исходный показатель достоверности диалога уточняют для получения уточненного окончательного показателя достоверности диалога в компоненте 610 постобработки. Как правило, исходный показатель достоверности диалога может быть в некоторой степени уменьшен, если показатель Cm(t) достоверности музыки для такого же кадра также является высоким. Однако это может привести к чрезмерному уменьшению показателя Cs(t) достоверности речи, поскольку содержимое реального диалога может также генерировать как высокий показатель достоверности диалога, так и высокий показатель достоверности музыки, если диалог присутствует с музыкальным фоном. Для решения этой проблемы с целью определения того, можно ли показатель Cs(t) достоверности музыки уверенно использовать для уточнения показателя достоверности диалога, можно применять исторический контекст. Если исторический контекст является преобладающим в диалоге, более консервативным будет уточнение показателя достоверности диалога, то есть с намерением проигнорировать показатель достоверности музыки. Поэтому в некоторых вариантах осуществления окончательный показатель  достоверности диалога уточняют по следующей формуле (12):
достоверности диалога уточняют по следующей формуле (12):
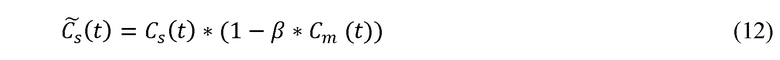
Здесь представляет уточненный показатель достоверности диалога в кадре t, Cs(t) – показатель достоверности речи, Cm(t) – показатель достоверности музыки и β – контекстно-зависимый параметр, определяющий, насколько показатель достоверности музыки влияет на окончательный показатель достоверности диалога. В одном варианте осуществления β рассчитывают по доле кадров, идентифицированных в историческом контексте как речь или музыка. Например, β могут задавать как отношение кадров, идентифицированных в историческом контексте как музыка простым двоичным методом. В частности, β могут задавать равным единице, если в контексте преобладает музыка, и β могут задавать равным нулю, если в контексте преобладает диалог, как представлено в формуле (13):

Здесь Nm представляет число музыкальных кадров, N – общее число кадров в историческом контексте; rth – пороговое значение, обычно задаваемое равным 0,5, хотя пороговое значение также может быть настроено между 0 и 1 в зависимости от того, насколько агрессивное влияние оказывают музыкальные кадры. Альтернативно β может быть представлен как непрерывная функция, например как линейная функция, как проиллюстрировано в формуле (14), или как сигмоидальная функция, как проиллюстрировано в формуле (15):

Здесь а представляет масштабный коэффициент, регулирующий форму сигмоидальной функции, и в настоящем изобретении может быть задан равным 5. Кроме того, исторический контекст, используемый при определении контекстно-зависимого параметра β, может быть намного длиннее, чем кадры истории, используемые для извлечения долговременных признаков, например, длину или диапазон исторического контекста могут задавать равными 10 секундам или даже более продолжительными.
Методы для детектора диалогов, описанные в настоящем документе, могли бы быть реализованы одним или более вычислительными устройствами. Например, контроллер вычислительного устройства специального назначения может быть аппаратно реализованным для выполнения описанных операций или обеспечения выполнения этих операций и может содержать цифровые электронные схемы, такие как одна или несколько специализированных интегральных схем (ASIC) или программируемых пользователем вентильных матриц (FPGA), постоянно запрограммированных для выполнения операций или обеспечения выполнения операций. В некоторых вариантах осуществления специальная аппаратно реализованная логика, устройства ASIC и/или FPGA с программированием по индивидуальному заказу комбинируют для выполнения указанных способов.
В некоторых других вариантах осуществления вычислительное устройство общего назначения могло бы содержать контроллер, содержащий центральный процессор (ЦП), запрограммированный для обеспечения выполнения одной или более из описанных операций в соответствии с программными командами в программно-аппаратных средствах, памяти, другом запоминающем устройстве или их комбинации.
Термин «машиночитаемый носитель» в значении, в котором он используется в настоящем описании, относится к любому носителю, хранящему команды и/или данные, вызывающие работу компьютера или машины иного типа конкретным образом. Любые из моделей, детектор и операции, описанные в настоящем документе , могут быть реализованы или их реализация может обеспечиваться кодом программного обеспечения, исполняемым процессором контроллера с использованием соответствующего компьютерного языка. Код программного обеспечения может храниться в виде последовательности команд на машиночитаемом запоминающем носителе. Примеры подходящего машиночитаемого запоминающего носителя включают оперативное запоминающее устройство (ОЗУ), постоянное запоминающее устройство (ПЗУ), магнитный носитель, оптический носитель, твердотельный накопитель, флэш-память и любой иной кристалл или картридж памяти. Машиночитаемый запоминающий носитель может представлять собой любую комбинацию указанных запоминающих устройств. Любой такой машиночитаемый запоминающий носитель может размещаться на или в одном вычислительном устройстве или в целой компьютерной системе и может находиться среди других машиночитаемых запоминающих носителей в системе или сети.
Хотя объект настоящего изобретения конкретно показан и описан со ссылками на его варианты осуществления, специалистам в данной области техники будет понятно, что в раскрытые варианты осуществления могут вноситься изменения формы и деталей в пределах сущности или объема настоящего изобретения. Примеры некоторых их этих вариантов осуществления проиллюстрированы на прилагаемых графических материалах, а для обеспечения их глубокого понимания изложены конкретные детали. Следует отметить, что варианты осуществления могут быть реализованы на практике без некоторых или всех из этих конкретных деталей. Кроме того, для ясности изложения хорошо известные признаки могли быть подробно не описаны. Наконец, хотя преимущества были рассмотрены в данном документе со ссылкой на некоторые варианты осуществления, будет понятно, что объем настоящего изобретения не следует ограничивать ссылкой на эти преимущества. Скорее, объем следует определять со ссылкой на прилагаемые пункты формулы изобретения.
Различные аспекты настоящего изобретения можно понять из следующих пронумерованных примерных вариантов осуществления (ППВО):
1. Способ извлечения звукового признака в детекторе диалогов в ответ на входной звуковой сигнал, включающий:
извлечение, компонентом извлечения кадровых признаков, кадровых признаков из каждого кадра из множества кадров, выделенных из входного звукового сигнала;
определение, компонентом определения комбинированного временного контекста, длины или диапазона каждого контекста;
выведение соответствующего контекстного признака на основании кадровых признаков в каждом определенном контексте; и
выполнение конкатенации над каждым контекстным признаком и формирование комбинированного вектора признаков для представления текущего кадра.
2. Способ по ППВО 1, отличающийся тем, что комбинированный временной контекст содержит:
кратковременный контекст, представляющий локальную информацию вокруг текущего кадра;
средневременный контекст, дополнительно содержащий множество кадров ретроспективного просмотра; и
долговременный контекст, дополнительно содержащий множество кадров долговременной истории.
3. Способ по ППВО 1 или 2, в котором длину или диапазон одного или более контекстов могут определять предварительно.
4. Способ по ППВО 2 или 3, в котором кратковременный контекст содержит текущий кадр и кадры опережающего просмотра, если доступен буфер опережающего просмотра; или кратковременный контекст содержит текущий кадр и первую часть кадров ретроспективного просмотра, если буфер опережающего просмотра недоступен.
5. Способ по ППВО 2 или 3, в котором средневременный контекст содержит текущий кадр, кадры опережающего просмотра и кадры ретроспективного просмотра, если доступен буфер опережающего просмотра; или средневременный контекст содержит текущий кадр, первую часть кадров ретроспективного просмотра и вторую часть кадров ретроспективного просмотра, если буфера опережающего просмотра недоступен.
6. Способ по ППВО 2 или 3, в котором долговременный контекст содержит текущий кадр, кадры опережающего просмотра, кадры ретроспективного просмотра и кадры долговременной истории, если доступен буфер опережающего просмотра; или долговременный контекст содержит текущий кадр, первую часть кадров ретроспективного просмотра, вторую часть кадров ретроспективного просмотра и кадры долговременной истории, если буфер опережающего просмотра недоступен.
7. Способ по ППВО 1 или 2, в котором длину или диапазон одного или более контекстов могут определять адаптивно.
8. Способ по ППВО 7, в котором длину или диапазон одного или более контекстов могут определять адаптивно путем анализа стационарности признаков кадрового уровня.
9. Способ по ППВО 8, в котором адаптивное определение длины или диапазона одного или более контекстов основано на информации, относящейся к амплитуде входного звукового сигнала.
10. Способ по ППВО 2 или 9, в котором адаптивное определение длины или диапазона кратковременного контекста включает:
вычисление кратковременной энергии одного кадра из множества кадров входного звукового сигнала;
сглаживание вычисленной кратковременной энергии;
определение разницы между сглаженной кратковременной энергией кадра и сглаженной кратковременной энергией предыдущего кадра;
определение начала на основании того, удовлетворяет ли эта разница пороговому значению;
нормирование начала;
определение границы для длины или диапазона кратковременного контекста одним из следующих этапов:
взятием положения, имеющего наибольшее начало, в качестве границы; или
взятием пикового начала в качестве границы, на основании того, удовлетворяет ли пик пороговому значению; или
взятием пикового начала в качестве границы на основании как порогового значения, так и расстояния между началом и мощным переходом непосредственно перед началом.
11. Способ по ППВО 8, в котором адаптивное определение длины или диапазона одного или более контекстов основано на информации, относящейся к спектру входного звукового сигнала.
12. Способ по ППВО 2 или 11, в котором адаптивное определение длины или диапазона кратковременного контекста включает:
предположение, что временная метка в окне байесовских информационных критериев является истинной границей для длины или диапазона кратковременного контекста;
предположение, что эта временная метка в окне байесовских информационных критериев не является истинной границей для длины или диапазона кратковременного контекста;
определение отличия байесовских информационных критериев между двумя гипотезами;
нормирование отличия байесовских информационных критериев; и
рассмотрение пика отличия байесовских информационных критериев в качестве положения истинной границы для длины или диапазона кратковременного контекста на основании того, удовлетворяет ли пик пороговому значению.
13. Способ по любому из предыдущих ППВО 2, 7–12, в котором кратковременный контекст может распространяться в направлениях как опережающего просмотра, так и ретроспективного просмотра, или распространяться только в одном направлении.
14. Способ по любому из предыдущих ППВО, в котором длину или диапазон контекстов могут определять предварительно в комбинации с адаптивным определением.
15. Способ понижающего микширования входного звукового сигнала детектора диалогов, включающий:
разделение входного звукового сигнала на множество кадров;
преобразование кадров в левом канале и правом канале в спектральное представление кадров;
устранение некоррелированных сигналов в левом канале и правом канале путем применения частотно-зависимых коэффициентов усиления к спектру в левом канале и правом канале соответственно;
получение сигнала понижающего микширования и
подачу сигнала понижающего микширования в детектор диалогов способом по любому из предыдущих ППВО 1–14.
16. Способ по ППВО 15, в котором частотно-зависимые коэффициенты усиления могут вычислять из ковариационной матрицы.
17. Способ классификации входного звукового сигнала детектора диалогов, включающий:
прием детектором речевого содержимого признаков, извлеченных способом по любому из предыдущих ППВО 1–14;
определение детектором речевого содержимого показателя достоверности речи; и
прием детектором музыкального содержимого признаков, извлеченных способом по любому из предыдущих ППВО 1–14;
определение детектором музыкального содержимого показателя достоверности музыки; и
комбинирование показателя достоверности речи и показателя достоверности музыки для получения окончательного показателя достоверности диалога.
18. Способ по ППВО 17, в котором окончательный показатель достоверности диалога могут уточнять посредством контекстно-зависимого параметра.
19. Способ по ППВО 18, в котором контекстно-зависимый параметр могут вычислять на основании доли кадров, идентифицированных как речь или музыка в историческом контексте.
20. Способ по ППВО 19, в котором исторический контекст может иметь продолжительность десять секунд или более.
Изобретение относится к области вычислительной техники для извлечения звуковых признаков в детекторе диалогов в ответ на входной звуковой сигнал. Технический результат заключается в повышении быстродействия извлечения звуковых признаков при использовании нескольких контекстных окон, каждое из которых содержит разное количество кадров для представления кадра в разных контекстах. Технический результат достигается за счет разделения входного звукового сигнала на множество кадров; извлечения кадровых звуковых признаков из каждого кадра I; определения набора контекстных окон, где каждое контекстное окно содержит некоторое количество кадров, окружающих текущий кадр; выведения для каждого контекстного окна соответствующего контекстного звукового признака для текущего кадра на основании кадровых звуковых признаков кадров в каждом соответствующем контексте; выполнения конкатенации над каждым контекстным звуковым признаком с формированием комбинированного вектора признаков для представления текущего кадра; и получения показателя достоверности речи, представляющего вероятность наличия диалога в текущем кадре, с использованием комбинированного вектора признаков, при этом количество кадров в одном или более контекстных окнах определяют адаптивно на основании извлеченных кадровых звуковых признаков. 4 н. и 8 з.п. ф-лы, 12 ил.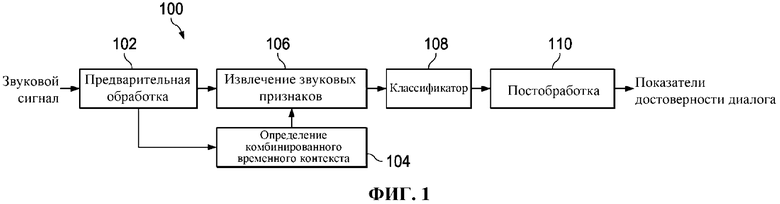
1. Способ получения показателя достоверности, представляющего вероятность наличия диалога в текущем кадре входного звукового сигнала, способ включает:
разделение входного звукового сигнала на множество кадров;
извлечение кадровых звуковых признаков из каждого кадра I;
определение набора контекстных окон, где каждое контекстное окно содержит некоторое количество кадров, окружающих текущий кадр;
выведение для каждого контекстного окна соответствующего контекстного звукового признака для текущего кадра на основании кадровых звуковых признаков кадров в каждом соответствующем контексте;
выполнение конкатенации над каждым контекстным звуковым признаком с формированием комбинированного вектора признаков для представления текущего кадра; и
получение показателя достоверности речи, представляющего вероятность наличия диалога в текущем кадре, с использованием комбинированного вектора признаков,
при этом количество кадров в одном или более контекстных окнах определяют адаптивно на основании извлеченных кадровых звуковых признаков.
2. Способ по п. 1, отличающийся тем, что набор контекстных окон содержит:
кратковременное контекстное окно, содержащее текущий кадр и некоторое количество кадров, предшествующих текущему кадру и/или следующих за ним;
средневременное контекстное окно, содержащее кадры кратковременного контекстного окна и множество кадров ретроспективного просмотра; и
долговременное контекстное окно, содержащее кадры средневременного контекстного окна и множество кадров долговременной истории.
3. Способ по п. 1 или п. 2, отличающийся тем, что количество кадров в одном или более контекстных окнах определяют адаптивно путем анализа стационарности звуковых признаков кадрового уровня.
4. Способ по п. 3, отличающийся тем, что адаптивное определение количества кадров в одном или более контекстных окнах основано на информации, относящейся к амплитуде входного звукового сигнала.
5. Способ по п. 4, отличающийся тем, что адаптивное определение количества кадров в одном или более контекстных окнах основано на информации, относящейся к спектру входного звукового сигнала.
6. Способ по любому из предыдущих пунктов, отличающийся тем, что дополнительно включает:
преобразование кадров в левом канале и правом канале в спектральное представление кадров;
устранение некоррелированных сигналов в левом канале и правом канале путем применения частотно-зависимых коэффициентов усиления к спектральному представлению в левом канале и правом канале соответственно;
получение сигнала понижающего микширования из левого и правого каналов; и
использование указанного сигнала после понижающего микширования в качестве указанного входного звукового сигнала.
7. Способ по п. 6, отличающийся тем, что частотно-зависимые коэффициенты усиления вычисляют из ковариационной матрицы.
8. Способ классификации входного звукового сигнала детектора диалогов, включающий:
получение показателя достоверности речи способом по любому из предыдущих пунктов 1-7;
определение показателя достоверности музыки на основе комбинированного вектора признаков; и
комбинирование показателя достоверности речи и показателя достоверности музыки для получения окончательного показателя достоверности диалога.
9. Способ по п. 8, отличающийся тем, что окончательный показатель достоверности диалога уточняют посредством контекстно-зависимого параметра.
10. Способ по п. 9, отличающийся тем, что контекстно-зависимый параметр вычисляют на основании доли кадров, идентифицированных как речь или музыка в контекстном окне истории, например, продолжительностью по меньшей мере десять секунд.
11. Детектор диалогов, содержащий средства для выполнения способа по любому из пунктов 1-7.
12. Машиночитаемый запоминающий носитель, на котором хранятся команды, которые при их исполнении вызывают выполнение компьютером способа по любому из пунктов 1-7.
| DIRK VON ZEDDELMANN AND FRANK KURTH "A construction of compact mfcc-type features using short-time statistics for applications in audio segmentation", 24.08.2009, стр | |||
| Радиоприемник с применением катодной лампы в качестве ограничивающего ток детектора | 1924 |
|
SU1504A1 |
| Изложница с суживающимся книзу сечением и с вертикально перемещающимся днищем | 1924 |
|
SU2012A1 |
| Способ приготовления лака | 1924 |
|
SU2011A1 |
| Способ приготовления мыла | 1923 |
|
SU2004A1 |
| RU 2016140453 A, 16.04.2018. | |||

