Область техники, к которой относится изобретение
Изобретение относится к области обработки цифровых данных с помощью электрических устройств, в частности к обработке данных на естественном языке, а именно анализу естественного языка, семантическому, морфологическому и лексическому.
Глоссарий
С целью обеспечения достаточности раскрытия изобретения и обеспечения возможности проведения информационного поиска в отношении заявляемого технического решения ниже приведен перечень терминов, используемых в описании заявляемого изобретения.
Четкий поиск — способ поиска информации, при котором выполняется точное сопоставление информации заданному образцу поиска.
Нечеткий поиск — поиск информации, при котором выполняется сопоставление информации заданному образцу поиска или близкому к нему значению.
Лингвистический токен — объект, описывающий элемент предложения на естественном языке с точки зрения наличия морфологических и других лингвистических характеристик, включая, но не ограничиваясь характеристику части речи, падеж, род, число, лицо, время и другие характеристики, а также содержащий начальную форму слова.
Регулярные выражения — формальный язык поиска и осуществления манипуляций с подстроками в тексте, основанный на использовании метасимволов. Для поиска используется строка-образец, состоящая из символов и метасимволов и задающая правило поиска.
Суперрегулярные выражения (лингвистические регулярные выражения) — формальный язык описания цепочек лингвистических токенов, а также механизм осуществления поиска данных цепочек, основанный на использовании языка описания характеристик отдельных лингвистических токенов, а также языка задания цепочек лингвистических токенов.
АПИ (API) — программный интерфейс приложения, (набор классов, процедур, функций, структур или констант), которыми одна компьютерная система может взаимодействовать с другой системой, а также способ использования данных элементов с помощью какого-либо протокола.
Аффиксы — морфемы, которые присоединяется к корню слова и служат для образования слов.
Словоформы — обладающая признаками слова цепочка фонем, образованные от одной лексемы.
Стоп-слова — фрагменты текста, которые с высокой долей вероятности не несут для читателя смысла относительно цели конкретного текста, либо подлежат переформулировке или дополнению посредством проведения анализа исходного текста
К стоп-словам, как правило, относятся слова и словосочетания из следующих условных категорий: рекламные, газетные и бытовые штампы, клише, устойчивые выражения, канцелярит, неточные формулировки, необъективные оценки, качественные прилагательные, фразы с отглагольными существительными, чрезмерные обобщения, плеоназмы, неопределенные формулировки, избыточные указания времени, неправильно используемые заимствования, матерные выражения и эвфемизмы.
Также к стоп-словам относится ряд неоправданных синтаксических оборотов, затрудняющих понимание текста, в частности повторы, страдательный залог, вводные конструкции, модальность и другие обороты, устранение которых не повлияет на смысл предложения, но сделает текст более простым для чтения. К стоп-словам можно отнести любые слова или словосочетания, которые могут быть удалены из текста без потери смысла.
Также к стоп-словам относятся обобщающие и оценочные понятия, которые необходимо раскрывать более подробно для того, чтобы читателю стала понятнее мысль автора.
Редактор — человек, который занимается написанием, проверкой и исправлением (редактурой) текста. В процессе редактуры текста редактор прорабатывает стоп-слова: удаляет их, раскрывает понятия, скрытые стоп-словами, или осознанно оставляет стоп-слова в тех местах, где их употребление оправдано, а удаление приведет к потере смысла. После такой обработки текст становится понятнее, короче, информативнее и проще для чтения — повышается читабельность текста. Благодаря этому читатель тратит меньше времени на прочтение текста и быстрее усваивает смысл написанного.
Читабельность текста — мера доступности для понимания письменного текста, определяемая анализом ряда факторов, включая синтаксическую сложность, лексику, выраженность темы, связность тем и т.п. (https://psychology_dictionary.academic.ru/9253). В англоязычной литературе для данного понятия используется термин «readability». Чтобы повысить читабельность текста, редакторы используют приемы редактирования, которые помогают очистить текст от стоп-слов и наполнить его полезной информацией.
Формант — морфема, которая присоединяется к корню и служит для образования слов.
Флексия — комплекс грамматических категорий, выражающихся в словоизменении, совокупность морфем, осуществляющих словоизменение.
Словоизменение — изменение слов по их грамматическим формам.
Уровень техники
В 1920 г. в США вышла книга профессора Уильяма Странка мл. «Элементы стиля». Странк привел правила, как писать понятно и избегать распространённых ошибок:
«Чтобы текст был энергичным, он должен быть ёмким. В предложении не должно быть ненужных слов, в абзаце — ненужных предложений, так же, как и на картине не должно быть ненужных штрихов, а в механизме — ненужных частей. Это не значит, что автор должен делать каждое предложение максимально короткими, избегать подробностей или описывать свой предмет лишь общими чертами. Это значит, что каждое слово должно нести смысл».
1972 году в СССР вышла книга редактора и переводчика Норы Галь «Слово живое и мёртвое». Галь также советует избегать канцеляризмов, использовать глаголы вместо отглагольных существительных, сменить официальный тон на простой, использовать русские слова вместо заимствованных, писать по делу и быстро приходить к сути.
Так, на протяжении последнего столетия в редактуре постепенно формировались приемы, которые помогали очищать текст от лишних слов и наполнять текст полезной информацией.
С развитием компьютерных технологий стали появляться системы и способы автоматизированного анализа и обработки текста, предназначенные для повышения читабельности обрабатываемого текста.
Заявляемое техническое решение производит семантический, лексический, морфологический и синтаксический анализ текста. При этом под семантическим анализом следует понимать анализ с целью определения смысла определенной части текста, лексический анализ — анализ лексем с целью поиска слов, анализ морфологический анализ — анализ частей речи, синтаксический анализ — анализ знаков препинания.
В ходе патентного поиска были обнаружены документы, определяющие уровень техники и не считающиеся особо релевантным по отношению к заявленному изобретению, а именно:
«Способ автоматизированного анализа текстовых документов» (патент на изобретение №474870 RU, Заявка: 2011146888/08, 18.11.2011, Патентообладатель: Общество с ограниченной ответственностью «Центр Инноваций Натальи Касперской» (RU));
«Автоматическое извлечение именованных сущностей из текста» (патент на изобретение №2665239 RU, Заявка: 2014101126 от 15.01.2014, Патентообладатель: Общество с ограниченной ответственностью «Аби Продакшн» (RU));
«Извлечение сущностей из текстов на естественном языке» (патент на изобретение №2626555 RU, Заявка: 2015151699, 02.12.2015, Патентообладатель: Общество с ограниченной ответственностью «Аби Продакшн» (RU));
«Сентиментный анализ на уровне аспектов с использованием методов машинного обучения» (патент на изобретение № RU 2 657 173, Заявка: 2016131180, 28.07.2016, Патентообладатель: Общество с ограниченной ответственностью «Аби Продакшн» (RU));
«Метод анализа тональности текстовых данных» (патент на изобретение №2571373 RU, Заявка: 2014112242/08, 31.03.2014, Патентообладатель: Общество с ограниченной ответственностью «Аби ИнфоПоиск» (RU));
«Предложение релевантных терминов во время ввода текста» (патент на изобретение №2589727 RU, Конвенционный приоритет: 01.11.2010 US 61/408,699, Патентообладатель: Конинклейке Филипс Электроникс н.в. (NL));
«Readability evaluation method, readability evaluation device and readability evaluation program» (Метод оценки читабельности, устройство оценки читабельности и программа оценки читабельности), (JP2012230652, ISUZU MOTORS LTD, Ведомство Япония, Номер заявки 2011100191, Дата подачи 27.04.2011, Номер публикации 2012230652, Дата публикации 22.11.2012, Номер предоставления патента 5733617, Дата выдачи патента 24.04.2015);
«Text normalization method, device and equipment and storage medium» (Метод нормализации текста, устройство, оборудование и носитель информации), (CN110765733, IFLYTEK CO., LTD., Ведомство Китай, Номер заявки 201911017291.4, Дата подачи 24.10.2019, Номер публикации 110765733, Дата публикации 07.02.2020);
«System and method for enhancing comprehension and readability of text» (Система и метод улучшения понимания и читабельности текста), (GB2514725, QUILLSOFT LTD, Ведомство Соединённое Королевство, Номер заявки 201416621, Дата подачи 22.02.2013, Номер публикации 2514725, Дата публикации 05.11.2014).
Также были обнаружены и исследованы технические решения, содержащие отдельные признаки или их эквиваленты, используемые в заявленном изобретении.
«Способ выявления незначащих лексических единиц в текстовом сообщении и компьютер» (патент на изобретение №2580424RU, Заявка: 2014147903/08, 28.11.2014, Патентообладатель: Общество с ограниченной ответственностью «Яндекс») Данный способ относится к системам обработки предназначенного пользователю входящего сообщения электронной почты. Технический результат заключается в обеспечении возможности выявления незначащих лексических единиц в тексте сообщения электронной почты. Такой результат достигается тем, что осуществляют синтаксический анализ сообщения электронной почты для определения лексической единицы в качестве кандидата в незначащие лексические единицы; осуществляют первую и вторую проверки кандидата в незначащие лексические единицы путем сопоставления с незначащими лексическими единицами из первой и из второй базы данных лексических единиц, где первая база данных сформирована в результате синтаксического анализа предыдущих сообщений электронной почты, предназначенных пользователю, а вторая база данных сформирована в результате синтаксического анализа предыдущих сообщений электронной почты, предназначенных группе пользователей из множества пользователей. В ответ на положительный результат любой из первой проверки и второй проверки определяют кандидата в незначащие лексические единицы в качестве незначащей лексической единицы.
Вышеуказанный способ отличается от заявленного изобретения и имеет иное назначение, но в целом данный способ в той или иной мере позволяет выявлять незначащие лексические единицы в тексте, как и заявляемое изобретение. В отличие от заявляемого технического решения в данном способе используется только семантический анализ текста и не используется лексический и морфологический анализ. Также данный способ предназначен для достижения иного технического результата.
«Method for displaying degree of difficulty of readability of text in word processor, involves comparing numerical readability subscripts in overview of text, so that readability assessments of passages are compared with each other» (Метод отображения степени сложности читабельности текста в текстовом процессоре включает сравнение числовых индексов читабельности в обзоре текста, так что оценки читабельности отрывков сравниваются друг с другом), (DE102010027146, Ramps Ullrich, Ведомство Германия, Номер заявки 102010027146, Дата подачи 09.07.2010, Номер публикации 102010027146, Дата публикации 12.01.2012) включает определение степени трудности чтения текста в текстовом процессоре приложением в зависимости от количественных лингвистических единиц, например букв, слогов и слов в тексте в узких отрывках. Индексы числовой читабельности одновременно и отдельно представлены для отдельных отрывков анализируемого текста как аналогичные замкнутые языковые единицы. Индексы представлены в обзоре текста, так что оценки читабельности отдельных отрывков сравниваются друг с другом.
Вышеуказанный метод, как и заявляемое изобретение, позволяет дать автоматическую оценку читабельности текста. Однако, в отличие от заявляемого изобретения данный метод оценивает читабельность текста только в части семантической сложности текста, и не предназначен для дальнейшего редактирования текста.
Компьютерная система представленная в «Detecting document text that is hard to read» (Обнаружение трудночитаемого текста документа), (US08990224, Google Inc., Ведомство Соединенные Штаты Америки, Номер заявки 13674320, Дата подачи 12.11.2012, Номер публикации 08990224, Дата публикации 24.03.2015) сконфигурирована для определения частей текста, извлеченных из соответствующей группы документов; предоставляет возможность обрабатывать конкретную часть текста с помощью набора фильтров, где конкретная часть текста может соответствовать конкретному документу, и где каждый из фильтров может генерировать соответствующую оценку на основе обработки конкретной части текста; вычислить оценку удобочитабельности на основе соответствующих оценок, сгенерированных фильтрами; определить, что оценка удобочитабельности соответствует пороговой оценке; и сгенерировать или выбрать новую часть текста для конкретного документа на основе определения того, что оценка читабельности соответствует пороговой оценке. Данное техническое решение в отличие от заявляемого изобретения предназначено исключительно для анализа заголовков текста и поддержке пользователя в их исправлении для повышения их соответствия содержанию и упрощению восприятия.
Устройство и способ «Apparatus and method for improving line-to-line word positioning of text for easier reading» (Устройство и способ улучшения построчного позиционирования слов текста для облегчения чтения), (US6766495, International Business Machines Corporation, Ведомство Соединенные Штаты Америки, Номер заявки 09406188, Дата подачи 27.09.1999, Номер публикации 6766495, Дата публикации 20.07.2004) улучшают читабельность текста в компьютерной системе, изменяя расположение одного или нескольких слов, чтобы устранить потенциальные проблемы в удобочитабельности, которые можно идентифицировать, исследуя текст. Когда потенциальная проблема идентифицирована, позиционирование текста слово в слово может быть скорректировано для сжатия одной или нескольких строк и / или расширения одной или нескольких строк для перемещения одного или нескольких слов в другую строку. Например, если две соседние строки начинаются с одного и того же слова, первая строка может быть сжата, чтобы первое слово второй строки было перемещено в конец первой строки. В качестве альтернативы, первая строка может быть расширена так, чтобы последнее слово первой строки было перемещено в первое слово второй строки. Выборочно изменяя расположение слов, можно значительно улучшить читабельность текста.
Вышеуказанное техническое решение, как и заявляемое изобретение, позволяет анализировать текст на предмет наличия повторов, однако, в отличие от заявляемого изобретения, функционал данного технического решения ограничивается выявлением повторов и не проводит анализ текста на предмет наличия иных возможностей для улучшения читабельности текста.
Система обработки естественного языка «Readability awareness in natural language processing systems» (Обеспечение читабельности в системах обработки естественного языка), (US20170193093 - International Business Machines Corporation, Ведомство Соединенные Штаты Америки, Номер заявки 15162641, Дата подачи 24.05.2016, Номер публикации 20170193093, Дата публикации 06.07.2017, Номер предоставления патента 09875300, Дата выдачи патента 23.01.2018) и развивающая ее технология «Readability awareness in natural language processing systems» (Обеспечение читабельности в системах обработки естественного языка), (US20190179840, International Business Machines Corporation,Ведомство Соединенные Штаты Америки, Номер заявки 16274663, Дата подачи 13.02.2019, Номер публикации 20190179840, Дата публикации 13.06.2019, Номер предоставления патента 10534803, Дата выдачи патента 14.01.2020) предназначены для определения уровня читабельности текста на основе индикатора уровня читабельности. В отличие от заявляемого изобретения, данные системы рассчитывают уровень читабельности в зависимости от наличия в тексте грамматических и орфографических ошибок, жаргонных терминов и не учитывает иных морфологических, лексических и синтаксических критериев.
Также можно выделить ряд технических решений, направленных на анализ текста на естественном языке: «Многоэтапное распознавание именованных сущностей в текстах на естественном языке на основе морфологических и семантических признаков (патент на изобретение №2619193 RU, Заявка: 2016124139, 17.06.2016, Патентообладатель: Общество с ограниченной ответственностью «Аби ИнфоПоиск» (RU)), «Выявление словосочетаний в текстах на естественном языке» (патент на изобретение №2618374 RU, Заявка: 2015147536, 05.11.2015, Патентообладатель: Общество с ограниченной ответственностью «Аби ИнфоПоиск» (RU)), «Способ суммаризации текста и используемые для его реализации устройство и машиночитаемый носитель информации» (патент на изобретение № RU 2 635 213, Заявка: 2016138082, 26.09.2016, Патентообладатель: Самсунг Электроникс КО., ЛТД. (KR)), «Обнаружение языковой неоднозначности в тексте», (патент на изобретение № RU 2 643 438, Заявка: 2013157757, 25.12.2013, Патентообладатель: Общество с ограниченной ответственностью «Аби Продакшн» (RU)).
Вышеуказанные технические решения, как и заявляемое изобретение, позволяют так или иначе проводить анализ текста, однако принцип и порядок работы анализа существенно отличается от реализованного в настоящем изобретении.
В качестве прототипа заявляемого изобретения можно рассматривать техническое решение, раскрытое в публикации US20160306787 «Сomputer processes for analyzing and suggesting improvements for text readability» («Компьютерные процессы для анализа и предложения улучшений для читабельности текста») (Правообладатель: Wordrake Holdings, LLC, Ведомство Соединенные Штаты Америки, Номер заявки 15191418, Дата подачи 23.06.2016, Номер публикации 20160306787, Дата публикации 20.10.2016, Номер предоставления патента 09953026).
Техническое решение, представленное в публикации US20160306787, описывает компьютерный процесс для анализа и улучшения читабельности документов. Читабельность документа улучшается за счет использования правил и соответствующей логики для автоматического обнаружения различных типов проблем с записью и внесения и / или предложения изменений для устранения таких проблем. Многие правила направлены на создание более лаконичных формулировок анализируемых предложений, например, путем исключения ненужных слов, перестановки слов и фраз и внесения различных других типов редактирования. Предлагаемые изменения могут быть переданы, например, через платформу обработки текста, путем изменения внешнего вида текста, чтобы указать, как текст будет выглядеть с (или с и без) редактированием.
Основным недостатком технического решения, представленного в публикации US20160306787, является то, что данная система предназначена для анализа английского языка и не может быть эффективно использована для анализа славянских языков, в том числе русского языка. Это обусловлено различиями между самими языками и их правилами словообразования, что в свою очередь предполагает использование различных подходов к анализу текстов на этих языках.
Английский язык относится к аналитическим языкам с агглютинативным строем, в которых грамматические значения выражаются преимущественно при помощи служебных слов. Форманты в английском языке, как правило, не образуют неделимых структур и не изменяются под влиянием других формантов. В связи с этим обработка текста на естественном английском языке возможна путем применения фиксированного словаря, содержащего конкретные словоформы, как и предусмотрено в вышеуказанном техническом решении US20160306787.
Русский язык относится к синтетическим языкам с флективным строем, где доминирует словоизменение при помощи флексий — формантов, сочетающих сразу несколько значений. В связи с этим системы для обработки текста на естественном русском языке должны не только использовать фиксированный словарь, но и учитывать морфологию слов и их возможные окончания. Учитывая, что вышеуказанное техническое решение US20160306787 предусматривает применение фиксированного словаря, можно сделать вывод о том, что применение этого технического решения для обработки текста на русском языке не может быть полноценным, т.к. данная система основывается исключительно на алгоритме четкого поиска и не будет учитывать возможные все возможные словоформы, образующиеся при помощи флексий, и, как следствие, не будет реагировать на данные словоформы.
В заявляемом изобретении данная техническая задача решается за счет применения использования нечеткого поиска, когда слова указываются с возможными вариантами (например, «моё|его|её|... », которое соответствует притяжательным местоимениям в разных родах, лицах и падежах), с нечёткими окончаниями (например, «\bярки\w{1,2} +впечатлени\w{1,3}\b», которое соответствует фразам «яркие впечатления» или «ярких впечатлений»). Также в заявляемом изобретении используется механизм поиска по начальным формам слов (например, «<%на%><><%заря|восход|исход%>», которое соответствует «на заре», «на исходе» и др.) и механизм поиска по грамматическим признакам (например, «<деепр>» соответствует деепричастиям, а «(<A|S, им><>){5,10}» задаёт цепочку из 5–10 имён прилагательных или существительных в именительном падеже.). Данные технические признаки обуславливают возможность полноценного анализа текста на русском языке, когда система анализа текста учитывает не только конкретные словоформы, зафиксированные в словаре, но и все их возможные вариации.
Также заявляемое изобретение в сравнении с прототипом имеет ряд и других технических отличий. В отличие от прототипа, заявляемое изобретение выполнено с возможностью автоматической оценки качества текста, возможностью оптимизации обработки текста для автоматической оценки качества текста после его редактирования, а также с возможностью предоставления АПИ для подключения сторонних систем (например, систем управления содержимым (Content Management System, CMS) и других информационных систем. Таким образом, заявляемое техническое решение существенно отличается от технического решения, представленного в прототипе.
Техническая задача, на решение которой направлено настоящее изобретение, заключается в создании способа, использование которого позволит редактору увеличить скорость и эффективность редактирования текста с целью улучшения его читабельности.
Технический результат настоящего изобретения заключается в обеспечении возможности автоматизированного подбора релевантных рекомендаций по улучшению читабельности текста.
Указанный технический результат при использовании заявляемого изобретения достигается за счет автоматизированного морфологического, лексического и синтаксического анализа исходного текста, выполняемого с учетом особенностей славянских языков как синтетических языков с флективным строем, и направленного на выявление стоп-слов в анализируемом тексте, оценке читабельности текста, подбора и отображению релевантных рекомендаций по улучшению читабельности текста, а также повторному анализу отредактированных пользователем предложений и перерасчету оценке читабельности текста после редактирования.
Раскрытие изобретения
Способ автоматизированного анализа текста и подбора релевантных рекомендаций по улучшению его читабельности, выполняемый на ЭВМ, включающий
- получение исходного текста;
- выявление стоп-слов в исходном тексте в соответствии с заданными правилами определения стоп-слов посредством проведения морфологического, лексического, семантического и синтаксического анализа исходного текста на основе применения нечеткого поиска, поиска по начальным формам слов, поиска по грамматическим признакам и поиска по пунктуации;
- оценку читабельности исходного текста на основе расчета соотношения количества всех слов в исходном тексте и количества выявленных в исходном тексте стоп-слов;
- отображение релевантных рекомендаций по улучшению читабельности текста, включающих по меньшей мере указание на правило определения стоп-слов, в соответствии с которыми слова в исходном тексте были определены как стоп-слова.
Получение исходного текста при реализации заявляемого на регистрацию способа может осуществляться путем введения исходного текста пользователем, копирования или загрузки текста из файла. Также исходный текст может быть получен от иных компьютерных систем посредством АПИ.
Такие АПИ могут иметь ряд заданных ограничений в зависимости от заданных параметров доступа конкретного пользователя. Так, в зависимости от параметров доступа для конкретного пользователя может быть установлен допустимый объем исходного текста и/или доступный набор правил в соответствии с которыми осуществляется анализ исходного текста и/или содержание отображаемых пользователю рекомендаций по улучшению читабельности текста и/или доступное количество запросов в определенный период времени.
Выявление стоп-слов в исходном тексте производится в соответствии с заданными правилами определения стоп-слов посредством проведения морфологического, лексического, семантического и синтаксического анализа исходного текста на основе применения нечеткого поиска, поиска по начальным формам слов, поиска по грамматическим признакам и поиска по пунктуации;
Правила определения стоп-слов задаются по методу регулярных и суперрегулярных выражений.
Метод задания правил определения стоп-слов посредством регулярных выражений заключается в составлении шаблона на языке регулярных выражений (используется диалект, предоставляемый стандартной библиотекой языка Python), которое определяет одну или множество цепочек символов.
Примеры:
Шаблон задаёт строку «нередко», обрамлённую границами слов, т. е. фрагментами, где стыкуются буквенные и небуквенные символы, или же границы предложения.
разного рода
разного рода
немножко
{1,4} опредеяет повторение символа от 1 до 4 раз.
актуального
актуальному
Метод задания правил определения стоп-слов посредством суперрегулярных выражений заключается в составлении шаблона на языке суперрегулярных выражений, созданном в рамках данного изобретения. Данные шаблоны определяют множество цепочек лингвистических токенов, получаемых из проверяемого текста.
Данный язык имеет четыре компонента компонента: лингвистические токены, язык определения шаблонов наборов граммем, язык определения шаблонов лингвистических токенов, язык определения шаблонов цепочек шаблонов токенов.
1. Лингвистические токены
При подготовке проверяемого текста, он разделяется на слова и междусловные цепочки символов, каждому слову сопоставляется начальная форма и набор грамматических признаков (граммем). В случае неоднозначности слову может сопоставляться несколько комбинаций исходных форм и граммем.
Примеры:
2. Язык определения наборов граммем
Язык определения наборов граммем используется для составления шаблонов, на соответствие которым проверяются наборы граммем, полученных после разделения предложения на лексические токены. Язык позволяет находить токены с определёнными грамматическими характеристиками.
Грамматика языка в формате EBNF:
pattern = and_expr | or_expr "," and_expr
or_expr = not_expr | not_expr OR or_expr
not_expr = "~" simple_expr | simple_expr
simple_expr = string
string = letter | letter string
letter = "A" | ... | "Z" | "a" | ... "z" | "A" | ... | "я" | "-" | "_"
В соответствии с грамматикой приоритет операций определяется так: «AND», «OR», «NOT» .
Примеры:
(«другу»)
A,вин,ед,полн,муж,неод («примерный»)
3. Язык определения лингвистических токенов
Язык определения лингвистических токенов используется для составления шаблонов, с которым сопоставляются лингвистические токены, полученных после лингвистического анализа проверяемого текста.
Каждый шаблон состоит из трёх частей:
1. Подшаблон, которому должен соответствовать набор граммем токена.
2. Подшаблон, которому должна соответствовать начальная форма токена.
3. Подшаблон, которому должна соответствовать конкретная цепочка символов из проверяемого текста.
При этом каждая часть является необязательной.
Лингвистический токен считается соответствующим шаблону на языке определения лингвистических токенов тогда и только тогда, когда выполняется соответствие всем указанным подшаблонам.
Шаблон на языке токенов составляется в соответствии со следующей грамматикой:
pattern = subpatterns | "!" subpatterns
subpatterns = grammar_pattern | grammar_pattern "%" subppatterns_2
| "%" subppatterns_2
subpatterns_2 = lexeme_pattern | lexeme_pattern "%" form_pattern
| "%" form_patten
lexeme_pattern = regex
word_pattern = regex
При этом grammar_pattern — это шаблон на языке определения наборов граммем, а regex — язык регулярных выражений, используемый в языке Python.
В случае неоднозначности, если у данной словоформы определяется несколько наборов граммем и/или несколько начальных форм, лингвистический токен считается соответствующим шаблону в соответствии с наличием знака «!» в начале шаблона: если знак «!» указан, то токен считается соответствующим шаблону, если ему соовтетствую все варианты грамматического разбора. Если «!» не указан, то достаточно соответствия одного из вариантов.
Примеры:
восходе
исходом
4. Язык определения цепочек токенов (суперрегулярные выражения)
Язык определения шаблонов цепочек шаблонов токенов используется для составления шаблонов, на соответствие с которыми проверяется цепочка из одного или многих лингвистических токенов, полученный в результате анализа проверяемого текста.
Язык определяется следующей грамматикой
superegex = part
| part superegex
| superegex "|" superegex
part = predicate
| repeatable
| repeatable "+"
| repeatable "*"
| repeatable "?"
| repeatable "{" number comma number "}"
| repeatable "{" comma number "}"
| repeatable "{" number comma "}"
| repeatable "{" number "+" "}"
| repeatable "{" number "}"
| repeatable "{" "}"
| repeatable "{" comma "}"
| "^"
| "$"
repeatable = "(" superegex ")" | predicate
number = digit | digit number
digit = "0" | "1" | "2" | "3" | "4" | "5" | "6" | "7" | "8" | "9"
comma = "," | ";"
predicate = "<" token_pattern ">"
token_pattern в данном контексте — это шаблон лингвистического токена, описанный выше.
Шаблоны позволяют задавать последовательности лингвистических токенов с указанием опциональности вхождения токена, повторения токенов в определённом количестве, с указанием вариантов токенов, указанием места нахождения токена (начало или конец предложения).
<…> может задавать определённые характеристики слов, а <> между словами соответствует любому токену и таким образом может соответствовать знакам препинания или пробелам между словами.
<...>{n+}
<...>{0,1}
<...>{1, }
<...>{0, }
Примеры
Правила распределяются по категориям:
Открыточный штамп
Личное местоимение
Притяжательное местоимение
Усилитель
Обобщение
Неопределенность
Необъективная оценка
Канцеляризм
Современный журналистский штамп
Штамп информационного стиля
Бытовой штамп
Газетный штамп
Плеоназм
Паразит времени
Корпоративный штамп
Рекламный штамп
Скажите это по-русски
Политкорректность или эвфемизм
Составное сказуемое
Возможно, плохое подлежащее
Вводная конструкция
Сложный синтаксис
Лишнее подчинение
Фраза с отглагольным существительным
Фраза с модальным глаголом
Неопределенное
Предлоги
Слабый глагол
Цепочка слов в общем падеже
Возможно, проблема с синтаксисом
Тяжеловато читается
Подозрение на сложную подчиненную конструкцию
Подозрение на парцелляцию
Тяжелая вводная конструкция
Стилистические особенности
Фичеризм
Второстепенный синтаксис
Матерное выражение
Эвфемизм
Исходный текст разделяется на предложения, в каждом из которых осуществляется поиск стоп-слов. Поиск стоп-слов в исходном тексте осуществляется путем применения нечеткого поиска, поиска по начальным формам слов, поиска по грамматическим признакам и поиска по пунктуации.
При проведении нечеткого поиска стоп-слов в исходном тексте, стоп-слова выявляются с учетом возможных вариантов (словоформ). Так, например, если правила определения стоп-слов устанавливают в качестве стоп-слова флективные местоимений «моё|его|её|... », которое соответствует притяжательным местоимениям в разных родах, лицах и падежах), в результате нечеткого поиска данные местоимения могут быть выявлены вне зависимости от их конкретной словоформы. с нечёткими окончаниями (например, «\bярки\w{1,2} +впечатлени\w{1,3}\b», которое соответствует фразам «яркие впечатления» или «ярких впечатлений»).
Проведение нечеткого поиска позволяет использовать заявляемый способ для обеспечения возможности автоматизированного подбора релевантных рекомендаций по улучшению читабельности текста на синтетических языках с флективным строем, в том числе на языках славянской языковой группы, например, на русском языке.
При проведении поиска по начальным формам слов стоп-слова могут быть обнаружены по их начальным формам. Например, если правила определения стоп-слов устанавливают в качестве стоп-слова газетный штамп «на заре», «на восходе» и «на исходе», такие слова могут быть выявлены путем поиска по их начальным формам по правилу «<%на%><><%заря|восход|исход%>», в результате которого в качестве стоп-слов в исходном тексте будут выявлены лексемы «на заре», «на восходе», «на исходе» вне зависимости от их конкретной словоформы, зависящей от падежа существительного.
При проведении поиска по грамматическим признакам стоп-слова в исходном тексте определяются в соответствии с их грамматическим признаком. Так, например, если правила определения стоп-слов устанавливают в качестве стоп-слов последовательность из трех идущих подряд существительных, то для поиска по грамматическим признакам устанавливается, что «<сущ>» соответствует существительным, а правило «(<A|S, им><>){3,…}» задает последовательность из трех имён существительных и прилагательных в именительном падеже, за счет чего обеспечивается поиск в исходном тексте последовательности из трех имён существительных в именительном падеже.
При проведении поиска по пунктуации речевые конструкции, ухудшающие читабельность, выявляются с помощью анализа знаков препинания. Например, чтобы выделить фрагменты с вопросительных предложений, оканчивающихся словами «что?»/«чем?»/«чём», может быть задано правило:
<% что %> <% \? % >
Все вышеуказанные методы поиска могут комбинироваться. Например, можем задать одно правило, которое будет определять:
1. Слово существительное или прилагательное
2. Слово — не в именительном падеже
3. Исходная форма слова начинается на «ден»
4. Конкретная словоформа заканчивается на «м».
Данное правило может быть представлено в форме:
<сущ|прил, ~им % ден\w+ % \w+м>
Использование данного правила даст возможность выявить в тексте слово «днём», у которого начальная форма — «день».
Также при использовании заявляемого способа правила можно задавать для нескольких идущих подряд слов. Например, мы можем задать правило, которое будет искать слово «днём», если до него стоит слово «но», а после него нет слова «это». В таком случае правило может быть представлено как:
< % но % > <> <сущ|прил, ~им % ден\w+ % \w+м> <> < % (?! это) % >
В результате проведения морфологического и семантического анализа исходного текста производится выявление стоп-слов в исходном тексте.
Далее осуществляется оценка читабельности текста и отображение оценки читабельности текста пользователю. Для оценки читабельности текста определяется количество слов в исходном тексте и количество выявленных стоп-слов. Оценка читабельности текста рассчитывается по соотношению количества всех слов в исходном тексте к количеству тех слов в исходном тексте, которые определены как стоп-слова.
В том случае если заявляемый способ применяется для дальнейшей автоматизированной публикации текста через компьютерные системы, такие системы могут предусматривать запрет публикации текста, показатель оценки читабельности которых меньше, чем установленный допустимый показатель оценки читабельности текста, допускаемого для публикации.
Далее производится отображение релевантных рекомендаций по улучшению читабельности текста.
Рекомендации по улучшению читабельности текста отображаются в отношении каждого выявленного стоп-слова и зависят от правила, в соответствии с которым слово в исходном тексте было определено как стоп-слово. Рекомендация по улучшению читаемости может содержать описание на естественном языке правила, по которому данное слово было определено как стоп-слово, указание категории правил выявленного стоп-слова, примеры редактуры стоп-слов указанной категории в формате «до-после», гиперссылки на публикацию, содержащую более подробные рекомендации по редактуре стоп-слов из указанной категории, а также иные рекомендации, которые будут полезны редактору для проработки стоп-слова с целью повышения читабельности и информативности текста.
Заявляемый способ может дополнительно включать отображение оценки читабельности текста пользователю ЭВМ на основе проведенного анализа исходного текста.
Оценка читабельности текста используется пользователем для того, чтобы принять решение о том, стоит ли производить дальнейшее редактирование исходного текста, или текст уже имеет достаточно высокую оценку читабельности, а значит будет квалифицирован читателем как удобочитаемый.
Заявляемый способ при оценке читабельности текста может дополнительно учитывать категории правил, в соответствии с которыми стоп-слова были выявлены в исходном тексте, при оценке читабельности исходного текста.
В таком случае для оценки читабельности текста определяется количество слов в исходном тексте и определяется сумма весов правил определения стоп-слов. Каждому правилу задается условный вес, выражаемый числом. В зависимости от категорий и количества обнаруженных в исходном тексте стоп-слов, а также соотношения количества слов в исходном тексте и количества тех слов в исходном тексте, которые определены как стоп-слова, рассчитывается оценка читабельности текста.
Например, читабельность текста может быть оценена по десятибалльной шкале по формуле:
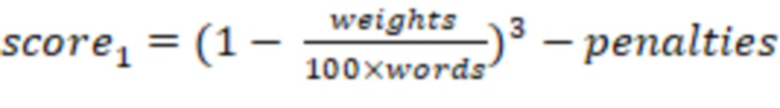 — количество баллов по шкале от 0 до 1 (при этом значение может выходить за границы диапазона).
— количество баллов по шкале от 0 до 1 (при этом значение может выходить за границы диапазона).
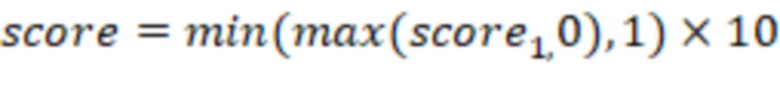 — итоговое количество баллов по шкале от 0 до 10
— итоговое количество баллов по шкале от 0 до 10
где переменная weights соответствует сумме весов правил определения стоп-слов, переменной words соответствует количество слов в исходном тексте, переменной penalties соответствует сумма оценочных штрафов по найденным стоп-словам, а показатель score является итоговым показателем оценки читабельности текста по десятибалльной шкале.
Например, анализируется следующий абзац:
«Кому не знакома боль в спине? Это, безусловно, одна из главных проблем современного человека. Доктора со всего мира ломают голову над вопросом, как избавить нас от этой напасти»
В таком тексте при использовании заявляемого способа будут выявлены следующие стоп-слова:
В 28 словах исходного текста обнаружено 9 стоп-слов (слов, словосочетаний, конструкций) из разных категорий. Таким образом:
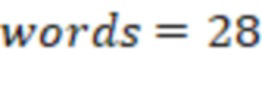
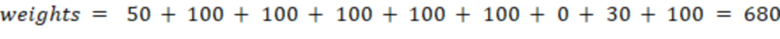
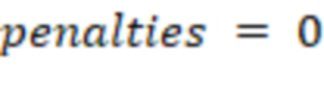


С учетом весов правил оценка по десятибалльной шкале рассчитывается как 4,3, что означает, что читабельность и информативность текста является низкой.
Заявляемый способ может дополнительно включать визуальное выделение в исходном тексте стоп-слов, определенных в результате проведенного анализа исходного текста. Визуальное выделение производится для того, чтобы пользователь быстрее мог определить, какие именно слова исходного текста определены в качестве стоп-слов. Например, визуальное выделение стоп-слов может быть произведено путем их подчеркивания и/или выделения выявленных стоп-слов цветом, отличающемся от цвета остальных слов исходного текста, не определенных в качестве стоп-слов.
Заявляемый способ может дополнительно обеспечивать возможность редактирования пользователем ЭВМ исходного текста и проведение анализа и подбора рекомендаций по улучшению читабельности отредактированного текста.
В таком случае, пользователь редактирует исходный текст в соответствии с рекомендациями по улучшению читабельности текста, затем производится повторный анализ текста. С целью оптимизации нагрузки на исполняющую ЭВМ повторный анализ может быть проведен не для всего текста, а только для отредактированной части. В таком случае отбираются те предложения, анализ которых до этого не проводился, в частности отбираются изменённые и добавленные предложения. Далее проводится анализ отредактированных пользователем предложений так же, как проводился анализ исходного текста.
Затем производится оценка читабельности текста с учетом отредактированных пользователем предложений и отображение оценки читабельности отредактированного текста пользователю. На основании оценки читабельности отредактированного текста пользователь может принять решение о продолжении редактирования текста или об окончании редактирования текста.
Пример осуществления изобретения
Заявляемый на регистрацию в качестве изобретения способ может быть осуществлен в автоматизированной компьютерно-реализуемой системе поддержки принятия решений для редактора (далее — СППР).
В таком случае система будет работать следующим образом.
Редактору на мониторе ЭВМ демонстрируется пользовательский интерфейс — веб-интерфейс системы или ее интерфейс в сторонних приложениях или плагинах, с которыми интегрирована система. Пользовательский интерфейс содержит два поля. Первое поле предназначено для введения и отображения исходного текста. Второе поле предназначено для отображения рекомендаций СППР, соответствующих стоп-слову, выбранному редактором в исходном тексте.
На первом этапе способа редактор вводит исходный текст в соответствующее поле СППР. Также текст может быть получен СППР через АПИ напрямую от других компьютерных систем. В результате выполнения этапа СППР получает исходный текст для дальнейшего анализа.
На втором этапе реализации способа внутренний контроллер СППР проводит морфологический и семантический анализ текста, взаимодействуя с базой правил и кэшем скомпилированных правил, содержащимся в системе или внешнем хранилище данных. Для анализа текста используется модуль лингвистического анализатора, модуль механизма поиска по регулярным выражениям, модуль механизма поиска по лингвистическим регулярным выражениям, а также модуль оптимизированных функций поиска. При этом СППР могут быть подключены и иные модули, направленные на решение задач пользователя.
В случае необходимости, СППР выделяет подчеркиванием и цветом стоп-слова в исходном тексте. Способ визуального выделения текста может зависеть от категории правил, по которой стоп-слово было определено.
На четвертом этапе реализации способа СППР выполняет функцию оценивания и рассчитывает оценку читабельности текста по десятибалльной шкале. Оценка может быть отражена редактору.
На четвертом этапе реализации способа СППР отображает редактору рекомендации по улучшению читабельности текста. Демонстрация рекомендаций по проработке стоп-слов может быть реализована следующим образом: редактор наводит курсор мыши или каретку на выделенное СППР стоп-слово, после чего СППР отображает редактору категорию данного стоп-слова, совет по его устранению, а также может отобразить примеры устранения аналогичных стоп-слов в формате «было-стало», и/или гиперссылку на публикацию, содержащую более подробные рекомендации по проработке стоп-слов из указанной категории. Такая публикация с более подробными рекомендациями может представлять собой статью, аудио или видеофайл, интерактивный обучающий тренажер.
Далее редактор производит редактирование текста, причем СППР может произвести кеширование текста и произвести анализ только отредактированных или новых предложений, не проводя повторный анализ неизмененных пользователем предложений. В результате СППР перерасчитывает оценку читабельности текста по десятибалльной шкале и отображает оценку читабельности отредактированного текста.
| название | год | авторы | номер документа |
|---|---|---|---|
| СИСТЕМА И МЕТОД АВТОМАТИЧЕСКОГО СОЗДАНИЯ ШАБЛОНОВ | 2018 |
|
RU2697647C1 |
| МНОГОЭТАПНОЕ РАСПОЗНАВАНИЕ ИМЕНОВАННЫХ СУЩНОСТЕЙ В ТЕКСТАХ НА ЕСТЕСТВЕННОМ ЯЗЫКЕ НА ОСНОВЕ МОРФОЛОГИЧЕСКИХ И СЕМАНТИЧЕСКИХ ПРИЗНАКОВ | 2016 |
|
RU2619193C1 |
| Автоматическое извлечение именованных сущностей из текста | 2014 |
|
RU2665239C2 |
| ИЗВЛЕЧЕНИЕ ИНФОРМАЦИИ ИЗ СМЫСЛОВЫХ БЛОКОВ ДОКУМЕНТОВ С ИСПОЛЬЗОВАНИЕМ МИКРОМОДЕЛЕЙ НА БАЗЕ ОНТОЛОГИИ | 2017 |
|
RU2662688C1 |
| ИСПОЛЬЗОВАНИЕ ГЛУБИННОГО СЕМАНТИЧЕСКОГО АНАЛИЗА ТЕКСТОВ НА ЕСТЕСТВЕННОМ ЯЗЫКЕ ДЛЯ СОЗДАНИЯ ОБУЧАЮЩИХ ВЫБОРОК В МЕТОДАХ МАШИННОГО ОБУЧЕНИЯ | 2016 |
|
RU2636098C1 |
| СПОСОБ ИЗВЛЕЧЕНИЯ ФАКТОВ ИЗ ТЕКСТОВ НА ЕСТЕСТВЕННОМ ЯЗЫКЕ | 2016 |
|
RU2637992C1 |
| ИСЧЕРПЫВАЮЩАЯ АВТОМАТИЧЕСКАЯ ОБРАБОТКА ТЕКСТОВОЙ ИНФОРМАЦИИ | 2014 |
|
RU2662699C2 |
| МЕТОД И СИСТЕМА ДЛЯ ГЕНЕРАЦИИ СТАТЕЙ В СЛОВАРЕ ЕСТЕСТВЕННОГО ЯЗЫКА | 2014 |
|
RU2639280C2 |
| ВОССТАНОВЛЕНИЕ ТЕКСТОВЫХ АННОТАЦИЙ, СВЯЗАННЫХ С ИНФОРМАЦИОННЫМИ ОБЪЕКТАМИ | 2017 |
|
RU2665261C1 |
| СПОСОБ УПРАВЛЕНИЯ АВТОМАТИЗИРОВАННОЙ СИСТЕМОЙ ПРАВОВЫХ КОНСУЛЬТАЦИЙ | 2019 |
|
RU2718978C1 |
Изобретение относится к способу автоматизированного анализа текста и подбора релевантных рекомендаций по улучшению его читабельности. Технический результат заключается в повышении точности формирования рекомендаций по улучшению читабельности текста. В способе выполняют получение исходного текста; выявление стоп-слов в исходном тексте в соответствии с заданными правилами определения стоп-слов посредством проведения морфологического, лексического, семантического и синтаксического анализа исходного текста на основе применения нечеткого поиска, поиска по начальным формам слов, поиска по грамматическим признакам и поиска по пунктуации; оценку читабельности исходного текста на основе расчета соотношения количества всех слов в исходном тексте и количества выявленных в исходном тексте стоп-слов; отображение релевантных рекомендаций по улучшению читабельности текста, включающих по меньшей мере указание на правило определения стоп-слов, в соответствии с которыми слова в исходном тексте были определены как стоп-слова. 4 з.п. ф-лы, 7 табл.
1. Способ автоматизированного анализа текста и подбора релевантных рекомендаций по улучшению его читабельности, выполняемый на ЭВМ, включающий:
получение исходного текста;
выявление стоп-слов в исходном тексте в соответствии с заданными правилами определения стоп-слов посредством проведения морфологического, лексического, семантического и синтаксического анализа исходного текста на основе применения нечеткого поиска, поиска по начальным формам слов, поиска по грамматическим признакам и поиска по пунктуации;
оценку читабельности исходного текста на основе расчета соотношения количества всех слов в исходном тексте и количества выявленных в исходном тексте стоп-слов;
отображение релевантных рекомендаций по улучшению читабельности текста, включающих по меньшей мере указание на правило определения стоп-слов, в соответствии с которыми слова в исходном тексте были определены как стоп-слова.
2. Способ по п.1, дополнительно включающий отображение оценки читабельности текста пользователю ЭВМ на основе проведенного анализа исходного текста.
3. Способ по п.1, в котором оценку читабельности исходного текста на основе расчета соотношения количества всех слов в исходном тексте и количества выявленных в исходном тексте стоп-слов производят с учетом категорий правил, в соответствии с которыми стоп-слова были выявлены в исходном тексте.
4. Способ по п.1, дополнительно включающий визуальное выделение в исходном тексте стоп-слов, определенных в результате проведенного анализа исходного текста.
5. Способ по п.1, дополнительно обеспечивающий возможность редактирования пользователем ЭВМ исходного текста и проведение последующего автоматизированного анализа отредактированных пользователем ЭВМ предложений исходного текста, оценку читабельности отредактированного текста и подбор релевантных рекомендаций по улучшению читабельности отредактированного текста.
| US 20160306787 A1, 20.10.2016 | |||
| US 20170193093 A1, 06.07.2017 | |||
| US 6766495 B1, 20.07.2004 | |||
| DE 102010027146 A1, 12.01.2012 | |||
| УСТРОЙСТВО И СПОСОБ ОПТИЧЕСКОЙ КОГЕРЕНТНОЙ ТОМОГРАФИИ | 2012 |
|
RU2514725C1 |
| CN 110765733 A, 07.02.2020 | |||
| JP 2012230652 A, 22.11.2012 | |||
| US 8794972 B2, 05.08.2014 | |||
| GB 201619813 D0, 04.01.2017 | |||
| KR 100916645 B1, 08.09.2009 | |||
| WO 2020069048 A1, 02.04.2020 | |||
| US 8990224 B1, 24.03.2015 | |||
| RU | |||

