Предшествующий уровень техники
[0001] Различные пользовательские рабочие приложения создают возможность ввода данных и анализа пользовательского контента. Эти приложения могут обеспечивать возможность создания, редактирования и анализа контента с использованием электронных таблиц, презентаций, текстовых документов, мультимедийных документов, форматов передачи сообщений или других форматов пользовательского контента. Среди этого пользовательского контента, различная текстовая, буквенно–числовая или другая информация на основе символов может включать в себя конфиденциальные данные, которые пользователи или организации могут не желать включать в публикуемые или распределяемые работы. Например, электронная таблица может включать в себя номера социального страхования (SSN), информацию кредитной карты, идентификаторы медицинского обеспечения или другую информацию. Хотя пользователь, вводящий эти данные или пользовательский контент, может иметь авторизацию, чтобы просматривать конфиденциальные данные, другие объекты или конечные точки распределения могут не иметь такой авторизации.
[0002] Методы защиты и администрирования информации могут упоминаться как защита от потери данных (DLP), которая пытается избежать незаконного присвоения и ошибочного распределения этих конфиденциальных данных. В определенных форматах контента или типах контента, таких как форматы или типы, включенные в электронные таблицы, слайдовые презентации и графические приложения разработки диаграмм, пользовательский контент может быть включен в различные ячейки, объекты или другие структурированные или полу–структурированные объекты данных. Более того, конфиденциальные данные могут быть разделены среди более чем одного объекта данных. Трудности могут возникать при попытке идентифицировать и защитить от потери конфиденциальных данных, когда такие документы включают в себя конфиденциальные данные.
Краткий обзор
[0003] В настоящем документе обеспечены системы, способы и программное обеспечение для инфраструктур обфускации данных для пользовательских приложений. Примерный способ включает в себя предоставление пользовательского контента в службу классификации, сконфигурированную, чтобы обрабатывать пользовательский контент, чтобы классифицировать части пользовательского контента как содержащие конфиденциальный контент, и прием от службы классификации указаний пользовательского контента, который содержит конфиденциальный контент. Способ включает в себя представление графических указаний в пользовательском интерфейсе на пользовательское приложение, которые аннотируют пользовательский контент как содержащий конфиденциальный контент, и представление опций обфускации в пользовательском интерфейсе для маскирования конфиденциального контента в пределах по меньшей мере выбранной части среди пользовательского контента. В ответ на выбор пользователем по меньшей мере одной из опций обфускации, способ включает в себя замену ассоциированного пользовательского контента обфусцированным контентом, который поддерживает схему данных ассоциированного пользовательского контента.
[0004] Настоящий краткий обзор обеспечен, чтобы представить в упрощенной форме выбор понятий, которые дополнительно описаны ниже в подробном описании. Может быть понятно, что настоящий краткий обзор не предназначен, чтобы идентифицировать ключевые признаки или существенные признаки заявленного предмета, и не предназначен, чтобы использоваться для ограничения объема заявленного предмета.
Краткое описание чертежей
[0005] Множество аспектов раскрытия могут быть лучше поняты со ссылкой на следующие чертежи. В то время как несколько реализаций описаны в связи с этими чертежами, раскрытие не ограничено реализациями, раскрытыми в настоящем документе. Напротив, предусматривается, что оно должно охватывать все альтернативы, модификации и эквиваленты.
[0006] Фиг. 1 иллюстрирует среду защиты от потери данных на примере.
[0007] Фиг. 2 иллюстрирует элементы среды защиты от потери данных на примере.
[0008] Фиг. 3 иллюстрирует элементы среды защиты от потери данных на примере.
[0009] Фиг. 4 иллюстрирует операции сред защиты от потери данных на примере.
[0010] Фиг. 5 иллюстрирует операции сред защиты от потери данных на примере.
[0011] Фиг. 6 иллюстрирует операции сред защиты от потери данных на примере.
[0012] Фиг. 7 иллюстрирует операции сред защиты от потери данных на примере.
[0013] Фиг. 8 иллюстрирует пороговые операции с данными сред защиты от потери данных на примере.
[0014] Фиг. 9 иллюстрирует вычислительную систему, подходящую для реализации любой из архитектур, процессов, платформ, служб и операционных сценариев, раскрытых в настоящем документе.
Подробное описание
[0015] Пользовательские рабочие приложения (приложения продуктивности) обеспечивают возможность создания, редактирования и анализа пользовательских данных и контента с использованием электронных таблиц, слайдов, элементов векторной графики, документов, электронной почты, контента передачи сообщений, баз данных или других форматов и типов данных приложений. Среди пользовательского контента может быть включена различная текстовая, буквенно–числовая или другая информация на основе символов. Например, электронная таблица может включать в себя номера социального страхования (SSN), информацию кредитной карты, идентификаторы медицинского обеспечения, номера паспортов или другую информацию. Хотя пользователь, вводящий эти данные или пользовательский контент, может иметь авторизацию, чтобы просматривать конфиденциальные данные, другие объекты или конечные точки распределения могут не иметь такой авторизации. Могут быть установлены различные политики конфиденциальности или правила конфиденциальности данных, которые указывают, какие типы данных или пользовательского контента являются конфиденциальными по своей природе. Расширенные меры защиты от потери данных (DLP), обсуждаемые в настоящем документе, могут быть включены, чтобы пытаться избежать незаконного присвоения и ошибочного использования этих конфиденциальных данных.
[0016] В определенных форматах контента или типах контента, таких как форматы и типы, включенные в электронные таблицы, слайдовые презентации и графические приложения разработки диаграмм, пользовательский контент может быть включен в различные ячейки, объекты или другие структурированные или полу–структурированные объекты данных. Более того, конфиденциальные данные могут быть разделены среди более чем одного элемента или записи данных. Примеры в настоящем документе обеспечивают возможность усовершенствованной идентификации конфиденциальных данных в файлах пользовательских данных, которые включают в себя структурированные элементы данных. Более того, примеры в настоящем документе обеспечивают возможность усовершенствованных пользовательских интерфейсов для оповещения пользователей о конфиденциальных данных. Эти элементы пользовательского интерфейса могут включать в себя как маркировку отдельных элементов данных, содержащих конфиденциальные данные, так и пороги для оповещения во время редактирования контента.
[0017] В одном примерном приложении, которое использует структурированные элементы данных, такое как приложение электронных таблиц, данные могут вводиться в ячейки, которые организованы в столбцы и строки. Каждая ячейка может содержать пользовательские данные или пользовательский контент и может также включать в себя одно или несколько выражений, которые используются, чтобы выполнять вычисления, которые могут ссылаться на введенные пользователем данные в одной или нескольких других ячейках. Другие пользовательские приложения, такие как приложения презентации слайд–шоу, могут включать в себя пользовательский контент на более чем одном слайде, а также в пределах объектов, включенных на этих слайдах.
[0018] Предпочтительно, примеры и реализации в настоящем документе обеспечены для усовершенствованных операций и структур для служб защиты от потери данных. Эти усовершенствованные операции и структуры имеют технические эффекты более быстрой идентификации конфиденциального контента в пределах документов и особенно для структурированных документов, таких как электронные таблицы, презентации, графические рисунки и тому подобное. Более того, множество приложений могут совместно использовать одну службу классификации, которая обеспечивает обнаружение и идентификацию конфиденциального контента в файлах пользовательских данных по множеству разных приложений и платформ конечного пользователя. Процессы аннотирования и обфускации на уровне конечного пользователя также обеспечивают значительные преимущества и технические эффекты в пользовательских интерфейсах для приложений. Например, пользователям могут быть представлены графические аннотации конфиденциального контента и всплывающие диалоговые окна, которые представляют различные опции обфускации или маскирования. Различные усовершенствованные пороги аннотации могут также быть установлены, чтобы динамически указывать конфиденциальный контент пользователям, чтобы сделать редактирование пользовательского контента и обфускацию конфиденциальных данных более эффективными и отвечающими требованиям различных политик и правил защиты от потери данных.
[0019] В качестве первого примера среды защиты от потери данных для пользовательского приложения, обеспечена фиг. 1. Фиг. 1 иллюстрирует среду 100 защиты от потери данных в примере. Среда 100 включает в себя пользовательскую платформу 110 и платформу 120 защиты от потери данных. Элементы на фиг. 1 могут осуществлять связь по одной или нескольким физическим или логическим линиям связи. На фиг. 1, показаны линии 160–161 связи. Однако следует понимать, что эти линии связи являются только примерными, и могут быть включены одна или несколько дополнительных линий связи, которые могут включать в себя беспроводные, проводные, оптические или логические части.
[0020] Инфраструктура защиты от потери данных может включать в себя часть, локальную для конкретного пользовательского приложения, и совместно используемую часть, применяемую по множеству приложений. Пользовательская платформа 110 обеспечивает среду приложения для пользователя, чтобы взаимодействовать с элементами пользовательского приложения 111 посредством пользовательского интерфейса 112. Во время взаимодействия пользователя с приложением 111, могут выполняться ввод контента и манипуляция с контентом. Модуль 113 защиты от потери данных (DLP) приложения может обеспечивать части функциональности для аннотации и замены конфиденциальных данных в приложении 111. Модуль 113 DLP приложения является локальным для пользовательской платформы 110 в этом примере, но может вместо этого быть отдельным от приложения 111 или интегрированным в него. Модуль 113 DLP приложения может обеспечивать возможность аннотации и замены конфиденциальных данных для пользователей и приложения 111. Платформа 120 защиты от потери данных обеспечивает совместно используемую часть инфраструктуры защиты от потери данных и обеспечивает совместно используемую службу 121 DLP для совместного использования множеством приложений, таких как приложения 190 с ассоциированной локальной частью 193 DLP.
[0021] В операции, приложение 111 обеспечивает пользовательский интерфейс 112, через который пользователи могут взаимодействовать с приложением 111, например, чтобы вводить, редактировать и иным образом обращаться с пользовательским контентом, который может быть загружен посредством одного или нескольких файлов данных или введен посредством пользовательского интерфейса 112. На фиг. 1, рабочая книга электронной таблицы показана с ячейками, организованными в строки и столбцы. В качестве части приложения 111, обеспечена служба защиты от потери данных, которая идентифицирует конфиденциальный пользовательский контент и позволяет пользователям заменять конфиденциальный пользовательский контент безопасным текстом или данными. Конфиденциальный контент содержит контент, который может иметь вопросы касательно конфиденциальности, политики/правила конфиденциальности или другие свойства, для которых распространение было бы нежелательным или ненужным. Потеря данных в этом контексте относится к распространению частных или конфиденциальных данных к неавторизованным пользователям или конечным точкам.
[0022] Чтобы идентифицировать конфиденциальный контент, приложение 111 обеспечивает (соразмерные распределения) разделения пользовательского контента на части или порции пользовательского контента на службе защиты от потери данных. На фиг. 1, части 140 контента показаны при помощи отдельных частей 141–145 контента, предоставляемых во времени в службу 121 DLP. Обычно, приложение 111 может обрабатывать пользовательский контент, чтобы разделять пользовательский контент на части во время периодов бездействия, например, когда один или несколько тредов обработки, связанных с приложением 111, бездействуют или находятся ниже порогов активности. Как будет рассмотрено в настоящем документе, структурированный пользовательский контент преобразуется в 'выровненную' или неструктурированную компоновку во время процесса разделения. Эта неструктурированная компоновка имеет несколько преимуществ для обработки посредством службы 121 DLP.
[0023] Служба 121 DLP затем обрабатывает каждую часть или 'порцию' пользовательского контента отдельно, чтобы определить, содержат ли части конфиденциальный контент. Различные правила 125 классификации, такие как схемы данных, шаблоны данных или политики/правила конфиденциальности могут быть введены, чтобы служба 121 DLP идентифицировала конфиденциальные данные. После того, как служба 121 DLP синтаксически анализирует каждую отдельную порцию пользовательского контента, смещения местоположений конфиденциальных данных в файле пользовательских данных определяются и указываются в службу 113 DLP приложения. Функция модуля отображения в службе 113 DLP приложения определяет структурное отношение между смещениями порций и структурой документа. Указания смещений местоположений, длины конфиденциальных данных и типы конфиденциальных данных могут быть предоставлены на приложение 111, как видно для примерных указаний 150 конфиденциальных данных. Смещения местоположений, указанные посредством службы 121 DLP, могут не создавать точное или конкретное местоположение среди структурных элементов файла пользовательских данных для конфиденциального контента. В этих случаях, процесс отображения может использоваться службой 113 DLP приложения в приложении 111, чтобы определять конкретные структурные элементы, которые содержат конфиденциальные данные.
[0024] Когда конкретные местоположения определены, приложение 111 может аннотировать конфиденциальные данные в пределах пользовательского интерфейса 112. Эта аннотация может включать в себя глобальную или индивидуальную отметку или маркировку конфиденциальных данных. Аннотации могут содержать 'подсказки политики', представленные в пользовательском интерфейсе. Затем пользователям могут быть представлены одна или несколько опций, чтобы обфусцировать или иным образом делать пользовательский контент неидентифицируемым как исходный конфиденциальный контент. Могут быть установлены различные пороги на уведомление конфиденциального контента, которые запускают отсчеты или количества конфиденциальных данных, присутствующих в файле пользовательских данных.
[0025] В одном примере, файл 114 пользовательских данных включает в себя контент 115, 116 и 117 в конкретных ячейках файла 114 пользовательских данных, который может быть ассоциирован с конкретным рабочим листом или страницей рабочей книги электронной таблицы. Различный контент может быть включен в ассоциированные ячейки, и этот контент может содержать потенциально конфиденциальные данные, такие как примеры, показанные на фиг. 1 для SSN, телефонных номеров и адресов. Некоторое из этого контента может пересекать структурные границы в файле пользовательских данных, например, охватывая несколько ячеек или охватывая несколько графических объектов. Если 'порция' разделяет данные на строки или группы строк, то выровненные представления (т.е. выделенные из какого–либо структурного контента) могут все еще идентифицировать конфиденциальные данные в пределах одной или нескольких ячеек.
[0026] Элементы каждой из пользовательской платформы 110 и платформы 120 DLP могут включать в себя интерфейсы связи, сетевые интерфейсы, системы обработки, компьютерные системы, микропроцессоры, системы хранения, носители хранения или некоторые другие устройства обработки или системы программного обеспечения и могут быть распределены среди множества устройств или по множеству географических местоположений. Примеры элементов каждой из пользовательской платформы 110 и платформы 120 DLP могут включать в себя программное обеспечение, такое как операционная система, приложения, журналы регистрации, интерфейсы, базы данных, утилиты, драйверы, сетевое программное обеспечение и другое программное обеспечение, хранящееся на считываемом компьютером носителе. Элементы каждой из пользовательской платформы 110 и платформы 120 DLP могут содержать одну или несколько платформ, которые хостируются распределенной вычислительной системой или службой облачных вычислений. Элементы каждой из пользовательской платформы 110 и платформы 120 DLP могут содержать логические элементы интерфейса, такие как интерфейсы, определенные программным обеспечением, и программные интерфейсы приложений (API).
[0027] Элементы пользовательской платформы 110 включают в себя приложение 111, пользовательский интерфейс 112 и модуль 113 DLP приложения. В этом примере, приложение 111 содержит приложение электронных таблиц. Следует понимать, что пользовательское приложение 111 может содержать любое пользовательское приложение, такое как рабочие приложения, приложения связи, приложения социальных сетей, игровые приложения, мобильные приложения или другие приложения. Пользовательский интерфейс 112 содержит элементы графического пользовательского интерфейса, которые могут формировать вывод для отображения пользователю и принимать ввод от пользователя. Пользовательский интерфейс 112 может содержать элементы, описанные ниже со ссылкой на фиг. 9 для системы 908 пользовательского интерфейса. Модуль 113 DLP приложения содержит один или несколько элементов программного обеспечения, сконфигурированных, чтобы соразмерно распределять контент для доставки в службу классификации, аннотировать данные, указанные как конфиденциальные, и обфусцировать конфиденциальные данные, среди прочих операций.
[0028] Элементы платформы 120 DLP включают в себя службу 121 DLP. Служба 121 DLP включает в себя внешний интерфейс в виде программного интерфейса приложения (API) 122, хотя могут применяться другие интерфейсы. Служба 121 DLP также включает в себя отслеживатель (трекер) 123 и службу 124 классификации, которые будут рассмотрены более подробно ниже. API 122 может включать в себя один или несколько пользовательских интерфейсов, таких как веб–интерфейсы, API, терминальные интерфейсы, консольные интерфейсы, интерфейсы оболочки командной строки, интерфейсы расширяемого языка разметки (XML), среди прочего. Трекер 123 поддерживает отсчеты или количества конфиденциальных данных, найденных для конкретного документа в пределах выровненных частей структурированного пользовательского контента, а также поддерживает запись смещений местоположений в пределах выровненных частей структурированного пользовательского контента, которые соответствуют местоположениям конфиденциальных данных в пределах структурированного пользовательского контента. Трекер 123 может также выполнять пороговый анализ, чтобы определить, когда пороговые количества конфиденциальных данных найдены и должны быть аннотированы модулем 113 DLP приложения. Однако в других примерах, части порога/отсчета службы 121 DLP могут быть включены в модуль 113 DLP. Служба 124 классификации синтаксически анализирует выровненный пользовательский контент, чтобы определить наличие конфиденциальных данных, и может использовать различные вводы, которые определяют правила и политики для идентификации конфиденциальных данных. Элементы модуля 113 DLP приложения и совместно используемой службы 121 DLP могут быть сконфигурированы в разных компоновках или распределениях, которые показаны на фиг. 1, например, когда части совместно используемой службы 121 DLP включены в модуль 113 DLP приложения или приложение 111, среди других конфигураций. В одном примере, части совместно используемой службы 121 DLP содержат динамически связанную библиотеку (DLL), включенную на пользовательскую платформу 110 для использования посредством приложения 111 и модуля 113 DLP приложения.
[0029] Линии 160–161 связи, вместе с другими линиями связи, не показанными среди элементов на фиг. 1 для ясности, могут содержать, каждая, одну или несколько линий связи, таких как одна или несколько сетевых линий связи, содержащих линии связи беспроводной или проводной сетей. Линии связи могут содержать различные логические, физические или прикладные программные интерфейсы. Примерные линии связи могут использовать металл, стекло, оптику, воздух, пространство или некоторый другой материал в качестве транспортного носителя. Линии связи могут использовать различные протоколы связи, такие как Интернет–протокол (IP), Ethernet, гибридный волоконно–коаксиальный кабель (HFC), синхронная оптическая сеть (SONET), асинхронный режим передачи (ATM), мультиплексирование с временным разделением (TDM), с коммутацией каналов, сигнализация связи, беспроводная связь или некоторый другой формат связи, включая их комбинации, усовершенствования или варианты. Линии связи могут представлять собой прямые линии связи или могут включать в себя промежуточные сети, системы или устройства и могут включать в себя логическую сетевую линию связи, транспортируемую по множеству физических линий связи.
[0030] Для дополнительного рассмотрения элементов и функционирования среды 100, представлена фиг. 2. Фиг. 2 представляет собой блок–схему, иллюстрирующую примерную конфигурацию 200 модуля 113 DLP приложения, которая выделяет примерные операции модуля 113 DLP приложения, среди прочих элементов. На фиг. 2, модуль 113 DLP приложения включает в себя разделитель 211 контента, модуль 212 аннотирования, модуль 213 отображения и обфускатор 214. Каждый из элементов 211–214 может содержать модули программного обеспечения, применяемые модулем 113 DLP приложения, чтобы работать, как описано ниже.
[0031] При функционировании, пользовательский контент предоставляется на модуль 113 DLP приложения, такой как файл или рабочая книга электронной таблицы, как показано на фиг. 1 для файла 114 пользовательских данных. Этот файл пользовательских данных может быть организован в структурированный или полу–структурированный формат, такой как ячейки, организованные в строки и столбцы для примера электронной таблицы. Вместо этого могут использоваться другие форматы данных, такие как слайд–шоу презентации, имеющие страницы/слайды и множество отдельных графических объектов, программы векторных рисунков с различными объектами на различных страницах, документы обработки слов с различными объектами (таблицами, текстовыми окнами, картинками), базы данных, контент веб–страниц или другие форматы, включая их комбинации. Файлы пользовательских данных могут содержать конфиденциальный контент или конфиденциальные данные. Эти конфиденциальные данные могут включать в себя любой пользовательский контент, который соответствует одному или нескольким шаблонам или схемам данных. Примерные типы конфиденциальных данных включают в себя номера социального страхования, номера кредитных карт, номера паспортов, адреса, телефонные номера или другую информацию.
[0032] Параллельно редактированию или просмотру файла пользовательских данных, разделитель 211 контента подразделяет пользовательский контент на одну или несколько частей или 'порций', которые находятся в выровненной форме из исходной/родной структурированной или иерархической формы. Разделитель 211 контента может затем предоставить эти порции контента на совместно используемую службу 121 DLP, вместе с метаданными порции для каждой порции. Метаданные порции могут указывать различные свойства порции, такие как смещение местоположения порции во всем контенте и длина порции. Смещение местоположения соответствует местоположению порции относительно всего пользовательского документа/файла, и длина порции соответствует размеру порции.
[0033] Совместно используемая служба 121 DLP отдельно синтаксически анализирует порции контента, чтобы идентифицировать конфиденциальные данные среди выровненного пользовательского контента порций, и предоставляет указания конфиденциальных данных обратно на модуль 113 DLP приложения. В некоторых примерах, рассматриваемых ниже, различные пороги применяются к отсчетам или количествам конфиденциальных данных перед тем, как указания предоставляются на модуль 113 DLP приложения. Указания содержат смещения для каждой из порций, которые содержат конфиденциальные данные, длины порций и опционально указатели типов данных или схем данных, ассоциированных с конфиденциальными данными. Указания конфиденциальных данных могут использоваться, чтобы определять действительные или конкретные местоположения конфиденциального контента среди структурированных данных файла пользовательских данных. Указатели типов данных могут представлять собой закодированные в символьном или числовом виде указатели, такие как целочисленные значения, на которые ссылаются при перечислении указателей, которые модуль 213 отображения может использовать, чтобы идентифицировать типы данных для аннотации.
[0034] Модуль 213 отображения может применяться, чтобы преобразовывать смещения и длины в конкретные местоположения в пределах документа или пользовательского файла. Смещения и длины соответствуют конкретным идентификаторам порций, которые поддерживаются посредством модуля 213 отображения и хранятся в ассоциации с идентификатором сеанса. Идентификатор сеанса может представлять собой уникальный идентификатор, который сохраняется по меньшей мере на протяжении сеанса, в течение которого пользователь открыл или просмотрел документ. Модуль 213 отображения может быть обеспечен метаданными порции из разделителя 211 контента, чтобы формировать отображенные отношения между смещениями, длинами порций и идентификаторами сеанса. В ответ на прием указаний конфиденциальных данных, модуль 213 отображения может использовать отображенные отношения, чтобы идентифицировать грубые местоположения, указанные для конфиденциальных данных в пределах документа, которые соответствуют смещению и длинам порций. Поскольку порции могут включать в себя более одного структурного или иерархического элемента файла пользовательских данных, модуль 213 отображения может выполнять дополнительные процессы местоположения, чтобы найти конкретные местоположения в файле пользовательских данных для конфиденциальных данных.
[0035] Например, смещения могут указывать грубые местоположения, такие как конкретный ряд или конкретный столбец в электронной таблице. Чтобы определить конкретное местоположение, такое как ячейка в пределах указанной строки или столбца, модуль 213 отображения может использовать смещения/длины вместе с локальным знанием структурированных данных и самого файла пользовательских данных, чтобы расположить конфиденциальный контент среди структурированных данных. Модуль 213 отображения определяет, откуда в файле пользовательских данных обеспечены порции, такие как ассоциированные строки, столбцы, рабочие листы для примеров электронной таблицы и ассоциированные слайды/страницы и объекты для примеров слайд–шоу. Другие примеры, такие как примеры обработки слов, могут не иметь такой структуры, и контент более легко выравнивается, и смещения могут быть основаны на отсчетах слов документа или аналогичном позиционировании.
[0036] В некоторых примерах, конкретные местоположения определены путем поиска конфиденциального контента в конкретном грубом местоположении. Когда множество структурных элементов или иерархических элементов подразумевается конкретным смещением, модуль 213 отображения может итеративно выполнять поиск или проходить через каждый из элементов, чтобы определить местоположение конфиденциальных данных. Например, если существуют 'n' уровней структуры/иерархии в документе, то модуль 213 отображения может сначала проходить более высокие иерархии, а затем более низкие иерархии. В примерах электронной таблицы, иерархия/структура может содержать рабочие листы, имеющие ассоциированные строки и столбцы. В примерах документа презентации, иерархия/структура может содержать слайды/страницы, имеющие ассоциированные формы/объекты. По каждому рабочему листу и слайду, указанному смещением, можно продвигаться, чтобы найти точные ячейки или объекты, которые содержат конфиденциальный контент. В других примерах, определение местоположения конфиденциальных данных может производиться путем повторного создания одной или нескольких порций, ассоциированных с грубым местоположением, и нахождения конфиденциальных данных в пределах этих повторно созданных порций, чтобы найти конкретное местоположение конфиденциальных данных.
[0037] Как только конкретные местоположения конфиденциальных данных были определены, модуль 212 аннотации может использоваться, чтобы маркировать или иным образом отмечать конфиденциальные данные для пользователя. Эта аннотация может принимать форму глобальной отметки или баннера, который указывает пользователю, что конфиденциальный контент представлен в файле пользовательских данных. Эта аннотация может принимать форму отдельных отметок, которые указывают маркеры, близкие к конфиденциальным данным. В одном примере, фиг. 2 показывает конфигурацию 201 с видом пользовательского интерфейса электронной таблицы, который имеет рабочую книгу, в настоящее время открытую для просмотра или редактирования. Показана аннотация 220 баннера, а также аннотации 221 отдельных ячеек. Аннотации 221 отдельных ячеек содержат графические указания, которые аннотируют одну или несколько частей пользовательского контента, и содержат указатели, расположенные близко к одной или нескольким частям, которые могут выбираться в пользовательском интерфейсе 112, чтобы представить опции обфускации.
[0038] Пользователю может быть представлена одна или несколько опций, когда выбрана конкретная аннотация. Может быть представлено всплывающее меню 202, которое включает в себя различные опции просмотра/редактирования, такие как вырезать, копировать, вставить, среди прочего. Всплывающее меню 202 может также включать в себя опции обфускации. Выбор одной из опций обфускации может формировать обфусцированный контент, который поддерживает схему данных ассоциированного пользовательского контента и содержит символы, выбранные, чтобы предотвратить идентификацию ассоциированного пользовательского контента, в то же время поддерживая схему данных ассоциированного пользовательского контента. В некоторых примерах, символы выбираются частично на основе схемы данных ассоциированного пользовательского контента, среди других соображений. Например, если схема данных включает в себя числовую схему данных, то буквы могут использоваться в качестве символов обфускации. Подобным образом, если схема данных включает в себя буквенную схему данных, то числа могут использоваться в качестве символов обфускации. Комбинации букв и чисел или других символов, могут выбираться в качестве символов обфускации в примерах буквенно–числового контента.
[0039] На фиг. 2, первая опция обфускации включает в себя замену конфиденциального контента маскированным или иным образом обфусцированным текстом, в то время как вторая опция обфускации включает в себя замену всего контента шаблоном или схемой данных, аналогичной контенту текущей выбранной аннотации. Например, если SSN включено в ячейку, пользователю могут быть представлены опции, чтобы заменить разряды в SSN на символы 'X', в то же время оставляя неизменную схему данных SSN, т.е. оставаясь в знакомой компоновке символов "3–2–4", разделенной символами тире. Более того, другая опция обфускации может включать в себя опцию, чтобы заменить все из SSN, которые совпадают с шаблоном выбранного SSN, на символы 'X'. Следует понимать, что могут быть представлены разные примерные опции обфускации, и разные символы могут использоваться в процессе замены. Однако, независимо от используемых символов обфускации, конфиденциальные данные делаются анонимными, деперсонифицированными, 'чистыми' или неидентифицируемыми как исходный контент.
[0040] Со ссылкой на фиг. 3, примерная конфигурация 300 показана, чтобы фокусироваться на аспектах службы 121 DLP. На фиг. 3, служба 121 DLP принимает части выровненного пользовательского контента, обеспеченные в одной или нескольких порциях контента посредством разделителя 211 контента, вместе с метаданными порции, которые по меньшей мере включают в себя смещения во всем контенте и длины порций. Два примерных типа структурированного пользовательского контента показаны на фиг. 3, а именно, контент 301 электронной таблицы и контент 302 слайд–шоу/презентации. Контент 301 электронной таблицы имеет структуру, отражающую строки 321 и столбцы 322, которые определяют отдельные ячейки. Более того, контент 301 электронной таблицы может иметь более одного рабочего листа 320, который ограничен метками табуляции ниже рабочего листа, и каждый рабочий лист может иметь отдельный набор строк/столбцов. Каждая ячейка может иметь пользовательский контент, такой как символы, буквенно–числовой контент, текстовый контент, числовой контент или другой контент. Контент 302 слайд–шоу может иметь один или несколько слайдов или страниц 323, которые включают в себя множество объектов 324. Каждый объект может иметь пользовательский контент, такой как символы, буквенно–числовой контент, текстовый контент, числовой контент или другой контент.
[0041] Разделитель 211 контента подразделяет пользовательский контент на элементы и удаляет любую ассоциированную структуру, например, посредством извлечения любого пользовательского контента, такого как текстовый или буквенно–числовой контент, из ячеек или объектов и затем упорядочивая извлеченный контент в выровненные или линейные порции для доставки в службу 121 DLP. Эти порции и метаданные порции предоставляются в службу 121 DLP для обнаружения потенциально конфиденциальных данных.
[0042] Когда отдельные порции пользовательского контента приняты службой 121 DLP, различная обработка выполняется на порциях посредством службы 124 классификации. Также, трекер 123 поддерживает записи 332 данных, содержащие одну или несколько структур данных, которые связывают смещения/длины и идентификатор сеанса с отсчетами обнаруженных конфиденциальных данных. Записи 332 данных сохраняются для службы 121 DLP, чтобы обеспечивать смещения/длины для порций, которые содержат конфиденциальные данные, обратно на запрашивающее приложение для дальнейшего определения местоположения и аннотации любого конфиденциального контента, обнаруженного в них.
[0043] Служба 124 классификации синтаксически анализирует каждую из порций с учетом различных правил 331 классификации, чтобы идентифицировать конфиденциальные данные или конфиденциальный контент. Правила 331 классификации могут устанавливать одну или несколько предопределенных схем данных, определенных одним или несколькими выражениями, используемыми, чтобы синтаксически анализировать выровненные порции/ представления данных, чтобы идентифицировать части порций как указывающие один или несколько предопределенных шаблонов контента или один или несколько предопределенных типов контента.
[0044] Конфиденциальный контент обычно идентифицируется на основе структурного шаблона данных или 'схемы' данных, которая ассоциирована с конфиденциальным контентом. Эти шаблоны или схемы могут идентифицировать, когда точные контенты порций могут отличаться, но данные могут соответствовать шаблону или компоновке, которая отражает типы конфиденциальных данных. Например, SSN может иметь определенную компоновку данных, имеющую предопределенное число разрядов, перемешанных и отделенных предопределенным числом тире. Правила 331 классификации могут включать в себя различные определения и политики, используемые в идентификации конфиденциальных данных. Эти правила классификации могут включать в себя политики конфиденциальности, шаблоны данных, схемы данных и пороговые политики. Политики конфиденциальности могут указывать, что определенные потенциально конфиденциальные данные могут не указываться как конфиденциальные на приложение, ввиду политик компании, организации или пользователя, среди других соображений. Пороговые политики могут устанавливать минимальные пороги для нахождения конфиденциальных данных в различных порциях перед тем, как наличие конфиденциальных данных сообщается на приложение. Правила 331 классификации могут быть установлены пользователями или создателями политики, такими как администраторы.
[0045] Дополнительно, служба 124 классификации может обрабатывать контент данных через одно или несколько регулярных выражений, обрабатываемых службой 333 регулярных выражений (regex). Служба 333 regex может включать в себя службы сопоставления и обработки регулярных выражений, вместе с различными регулярными выражениями, которые пользователь или создатель политики может развертывать для идентификации конфиденциальных данных. Дополнительные примеры службы 333 regex рассматриваются ниже на фиг. 7.
[0046] В качестве конкретного примера, процесс 341 классификации иллюстрирует несколько порций C1–C8 контента, которые представляют собой линеаризованные версии контента первоначально в структурной или иерархической компоновке в документе или файле пользовательских данных. Служба 124 классификации обрабатывает эти порции, чтобы идентифицировать те из порций, которые содержат конфиденциальные данные. Если найдены какие–либо конфиденциальные данные, указания могут быть предоставлены на приложение. Указания могут содержать смещения и длины для конфиденциальных данных и обеспечиваются для модуля 213 отображения, чтобы определять местоположение конфиденциальных данных в структуре файла пользовательских данных. Сами порции могут отбрасываться службой 124 классификации после того, как каждая порция обработана для идентификации конфиденциальных данных. Поскольку смещения и длины позволяют находить конфиденциальные данные в исходном файле данных, и исходный контент остается в файле данных (если не произошли промежуточные правки), то действительные порции не требуется сохранять после обработки.
[0047] Чтобы сформировать порции, разделитель 211 контента связывает буквенно–числовой контент, такой как текст, в одну или несколько линейных структур данных, таких как строки или BSTR (базовые строки или двоичные строки). Служба 124 классификации обрабатывает линейные структуры данных и определяет список результатов. Порции проверяются на конфиденциальные данные, и части линейных структур данных могут определяться как имеющие конфиденциальный контент. Служба 124 классификации во взаимосвязи с трекером 123 определяют смещения/длины, соответствующие порциям, которые содержат конфиденциальные данные среди линейных структур данных. Эти смещения могут указывать грубые местоположения, которые могут переводиться обратно в конкретные местоположения в исходном документе (например, файле пользовательских данных), содержащем пользовательский контент. Когда порции приняты, трекер 123 может коррелировать каждую порцию с информацией смещения/длины, указанной в метаданных порции. Эта информация смещения/длины может использоваться, чтобы обратно отображаться на структуру или иерархию исходного документа посредством модуля 213 отображения.
[0048] Однако, служба 121 DLP обычно имеет только частичный контекст обратно на исходный документ или файл пользовательских данных, например, указанный смещениями в исходно сгенерированные линейные структуры данных. Более того, линейные структуры данных и сам пользовательский контент могут быть освобождены/удалены службой 124 классификации в конце процесса классификации. Это может означать, что служба 124 классификации может не иметь возможности непосредственно выполнять поиск конфиденциального контента, чтобы конкретно локализовать конфиденциальный контент в исходном документе, и даже если служба 124 классификации могла бы выполнять поиск точного конфиденциального контента, служба 124 классификации может не иметь возможности находить конфиденциальный контент, поскольку алгоритм 'разбиения на порции' может пересекать границы иерархических конструктов или структур в исходном документе или файле данных. В качестве конкретного примера, рабочий лист 320 в документе электронной таблицы может иметь текст "SSN 123 45 6789", охватывающий четыре смежные ячейки. Предпочтительно, служба 124 классификации может находить этот текст как содержащий конфиденциальный контент. Однако, из–за анализа пересечения границ службой 124 классификации, в конце оценки правила политики, служба 124 классификации обычно не имеет достаточно данных, чтобы найти конфиденциальный контент в исходном документе для представления пользователю. Пользователь может остаться с неверным впечатлением, что конфиденциальный контент не присутствовал.
[0049] Чтобы эффективно сканировать пользовательский контент на наличие конфиденциального контента, служба 124 классификации считывает одну порцию пользовательского контента за раз во время бездействия приложения, производит частичный анализ и продолжает процесс. Когда служба 124 классификации заканчивает считывание всего контента, служба 124 классификации имеет только грубые положения для конфиденциального контента в исходном контенте, такие как только начало/смещение и длина. Чтобы эффективным образом выполнить отображение обратно на структурированный или полу–структурированный документ, комбинация методов может применяться модулем 213 отображения. Следует отметить, что эти методы отличаются от того, как может работать проверка правописания или проверка грамматики, отчасти потому, что может потребоваться полный контент, а не просто слово/предложение/абзац, чтобы понять, превысил ли контент порог.
[0050] Для каждого уровня физической иерархии или структуры, присутствующей в исходном документе (т.е. рабочих листах в рабочей книге или слайдах в презентации), модуль 213 отображения использует идентификатор, чтобы указывать существование в структуре данных отображения и дополнительно подразделять на разумное число уровней иерархии (т.е. строк в рабочем листе, форм на слайде) контент, так что каждая часть обрабатывается, модуль 213 отображения отслеживает длину исходного контента и, на основе порядка вставки в отображение, неявное начало этого элемента. Идентификатор может представлять собой идентификатор на длительность процесса, который сохраняется между моментами открытия конкретного документа или может отличаться в каждом экземпляре конкретного документа. В некоторых примерах, вычисления для объединения наличия/отсутствия конфиденциального контента удерживается, пока не останется ни необработанного контента, ни любых ожидающих правок, которые могут дополнительно изменить контент.
[0051] Полагая, что существует конфиденциальный контент, модуль 213 отображения принимает от службы 121 DLP начало и длину каждого фрагмента конфиденциального контента, и модуль 213 отображения выполняет поиск в структуре данных отображения идентификаторов и вкладок конфиденциального контента в пределах наиболее точно отображенной области, чтобы найти точное местоположение. По причинам производительности, может отслеживаться только определенное число уровней иерархии, так что таблица внутри формы внутри слайда или ячейка внутри строки внутри рабочего листа не может отдельно отслеживаться. Поэтому, частичный повторный проход может выполняться после выполнения обратного отображения, чтобы найти точное местоположение.
[0052] В конкретном примере, рабочая книга может иметь 20 рабочих листов, но миллионы строк, и каждая из миллионов строк может иметь 50 столбцов пользовательских данных. Для относительно малого числа элементов конфиденциальных данных в этом (т.е. один лист имеет только один столбец с конфиденциальными данными), процесс классификации может становиться чрезвычайно затратным в отношении памяти, чтобы иметь 20 * 1 миллион * 50 запомненных элементов 'длина+смещение' данных. Удаление последнего измерения представляет собой 50x сохранений в памяти, для малых вычислительных затрат, во время, когда конфиденциальные данные действительно идентифицируются в исходном документе. Предпочтительно, занимаемая площадь памяти может поддерживаться, чтобы обратно отображать начало/длины на исходный контент.
[0053] Чтобы дополнительно проиллюстрировать функционирование элементов согласно фиг. 1–3, на фиг. 4 представлена блок–схема последовательности операций (потоков). Два основных потока представлены на фиг. 4, а именно, первый поток 400 для идентификации конфиденциальных данных и второй поток 401 для аннотации и обфускации конфиденциальных данных. Первый поток 400 может вводиться во второй поток 401, хотя возможны другие конфигурации.
[0054] На фиг. 4, служба 121 DLP принимает (410) поднаборы структурированного пользовательского контента, консолидированного в ассоциированные выровненные представления, каждое из ассоциированных выровненных представлений имеет отображение на соответствующий поднабор структурированного пользовательского контента. Как упомянуто выше, структурированный контент может содержать контент электронной таблицы, организованный в листы/строки/столбцы, или может вместо этого включать в себя другие структуры, такие как контент слайд–шоу, организованный в слайды/объекты, контент программ рисования, организованный в страницы/объекты, или текстовый контент, организованный в страницы, среди других структур. Эти поднаборы структурированного пользовательского контента могут включать в себя 'порции' 141–146, показанные на фиг. 1, или порции C1–C8 на фиг. 3, среди прочего. Структура основного пользовательского контента выравнивается или удаляется в этих поднаборах, чтобы формировать порции, и каждый поднабор может отображаться обратно на исходную структуру путем обращения к структурным идентификаторам или локализаторам, таким как листы/строки/столбцы или слайды/объекты, например.
[0055] Служба 121 DLP принимает эти порции и метаданные порции, например, по линии 160 связи или API 122 на фиг. 1, и отдельно синтаксически анализирует (411) выровненные представления, чтобы классифицировать части как содержащие конфиденциальный контент, соответствующий одной или нескольким предопределенным схемам данных. Правила 125 классификации могут устанавливать одну или несколько предопределенных схем данных, определенных одним или несколькими выражениями, используемыми, чтобы синтаксически анализировать представления выровненных порций/данных, чтобы идентифицировать части порций как указатели одного или нескольких предопределенных шаблонов контента или одного или нескольких предопределенных типов контента.
[0056] Если конфиденциальные данные найдены (412), то для каждой из частей, служба 121 DLP определяет (413) ассоциированное смещение/длину, относящееся к структурированному пользовательскому контенту, указанному как поддерживаемый в трекере 123 в записях 332 данных. Служба 121 DLP затем указывает (414) по меньшей мере ассоциированное смещение/длину для частей на пользовательское приложение 111 для маркировки конфиденциального контента в пользовательском интерфейсе 112 к пользовательскому приложению 111. Если конфиденциальные данные не найдены или если какие–либо ассоциированные пороги не удовлетворены, то может продолжаться дополнительная обработка порций или дополнительный контроль дополнительных порций, как обеспечено пользовательским приложением 111. Более того, редактирование или изменение пользовательского контента может предлагать дополнительные или повторяемые процессы классификации для любого измененного или отредактированного пользовательского контента.
[0057] Модуль 113 DLP приложения принимает (415) от службы классификации службы 121 DLP указания одной или нескольких частей пользовательского контента, которые содержат конфиденциальный контент, где указания содержат смещения/длины, ассоциированные с конфиденциальным контентом. Модуль 113 DLP приложения представляет (416) графические указания в пользовательском интерфейсе 112 на пользовательское приложение 111, которые аннотируют одну или несколько частей пользовательского контента как содержащие конфиденциальный контент. Модуль 113 DLP приложения может затем представить (417) опции обфускации в пользовательском интерфейсе 112 для маскирования конфиденциального контента в пределах по меньшей мере выбранной части среди одной или нескольких частей пользовательского контента. В ответ на выбор пользователем по меньшей мере одной из опций обфускации, модуль 113 DLP приложения заменяет (418) ассоциированный пользовательский контент обфусцированным контентом, который поддерживает схему данных ассоциированного пользовательского контента.
[0058] Фиг. 5 иллюстрирует диаграмму 500 последовательности, чтобы дополнительно проиллюстрировать функционирование элементов согласно фиг. 1–3. Более того, фиг. 5 включает в себя подробную примерную структуру 510 для некоторых из этапов процесса на фиг. 5. На фиг. 5, приложение 111 может открывать документ для просмотра или редактирования пользователем. Этот документ может быть обнаружен модулем 113 DLP приложения. Любые ассоциированные правила политики или классификации могут предоставляться в службу 121 DLP, чтобы определять соответствующие политики классификации. Служба 121 DLP может затем поддерживать экземпляр обработки открытого документа в записи 332, которая может включать в себя перечисление нескольких открытых документов. Когда временные кадры обработки бездействия приложения 111 обнаруживаются модулем 113 DLP, указатель бездействия может быть представлен в службу 121 DLP, которая в ответ запрашивает порции пользовательского контента для классификации. Альтернативно, модуль 113 DLP может предоставлять порции пользовательского контента в службу 121 DLP во время периодов бездействия приложения 111. Модуль 113 DLP разделяет пользовательский контент на порции, и эти порции могут определяться на основе текста или другого контента, включенного в структуры или иерархические объекты документа. Когда порции определены, модуль 113 DLP переносит порции в службу 121 DLP для классификации. Служба 121 DLP классифицирует каждую порцию отдельно и применяет правила классификации к порциям, чтобы идентифицировать потенциально конфиденциальный пользовательский контент среди порций. Этот процесс классификации может представлять собой итеративный процесс, чтобы гарантировать, что все порции, перенесенные модулем 113 DLP, были обработаны. Если конфиденциальные данные или контент обнаруживаются среди порций, то служба 121 DLP указывает наличие конфиденциальных данных на модуль 113 DLP для дальнейшей обработки. Как упомянуто в настоящем документе, конфиденциальные данные могут быть указаны путем смещений, грубых местоположений или другой информации местоположения, а также информации длины. Модуль 113 DLP может затем выполнить один или несколько процессов аннотации и процессов обфускации на конфиденциальных данных в документе.
[0059] Правила классификации могут быть установлены до процесса классификации, например, пользователями, администраторами, специалистами политики или другими объектами. Как видно в структуре 510, различные правила 511 и 512 могут быть основаны на одном или нескольких утверждениях. Утверждения, показанные в двух категориях на фиг. 5, представляют собой связанные с контентом утверждения 511 и связанные с доступом утверждения 512. Связанные с контентом утверждения 511 могут содержать схемы данных, которые указывают конфиденциальные данные, такие как шаблоны данных, структурная информация данных или регулярные выражения, которые определяют схемы данных. Связанные с доступом утверждения 512 содержат правила уровня пользователя, уровня организации или другие правила на основе доступа, такие как правила совместного использования контента, которые определяют, когда конфиденциальные данные нежелательны для распространения или выпускаются конкретными пользователями, организациями, или другие факторы.
[0060] Правила 513 политики могут быть установлены, чтобы комбинировать одно или несколько из связанных с контентом утверждений и связанных с доступом утверждений в политики 551–554. Каждое правило политики также имеет приоритет и ассоциированное действие. В общем, приоритет согласуется с важностью действия. Например, правило политики может определить, что свойства 'сохранить' приложения следует заблокировать. В другом примерном правиле политики, пользовательский контент может содержать SSN, которые определяются в соответствии со связанным с контентом утверждением, но в соответствии со связанным с доступом утверждением, эти SSN могут быть допустимыми для распространения. Большинство правил политики содержат по меньшей мере одно утверждение классификации среди утверждений 511–512. Эти политики могут влиять на одно или несколько действий 514. Действия могут включать в себя различные операции аннотации, которые приложение может предпринимать в ответ на идентификацию, или конфиденциальный контент, такой как уведомление пользователя, уведомление, позволяющее осуществлять пользовательское переопределение, блокирование свойств/функций (т.е. свойств 'сохранить' или 'копировать') и обоснованные переопределения, среди прочего.
[0061] Фиг. 6 иллюстрирует блок–схему 600 последовательности операций, чтобы дополнительно иллюстрировать работу элементов согласно фиг. 1–3. Фиг. 6 фокусируется на одном примерном полном процессе из процессов идентификации, аннотации и обфускации конфиденциальных данных. Под–процесс 601 содержит установление, хранение и извлечение политик и правил. Эти политики и правила могут представлять собой правила аннотации, правила классификации, регулярные выражения, организационные/пользовательские политики, среди прочей информации, рассматриваемой в настоящем документе. В операции 611 на фиг. 6, различные правила 630 обнаружения и правила 631 замены могут вводиться посредством пользовательского интерфейса или API для конфигурирования политик обнаружения. Правила 630 обнаружения и правила 631 замещения могут содержать различные утверждения и правила, как показано на фиг. 5, среди прочего. Пользователи, администраторы, специалисты политики или другие объекты могут вводить правила 630 обнаружения и правила 631 замены, например, путем установления политик для пользователей, организаций или использования приложений, среди прочих объектов и действий. Правила 630 обнаружения и правила 631 замены могут сохраняться на одной или нескольких системах хранения в операции 612 для дальнейшего использования. Когда один или несколько клиентов желают использовать политики, установленные правилами 630 обнаружения и правилами 631 замены, эти политики могут загружаться или извлекаться в операции 613. Например, правила аннотации могут загружаться приложением для использования в аннотировании конфиденциального контента в пользовательском интерфейсе, при этом правила классификации могут загружаться совместно используемой службой DLP для классифицирования пользовательского контента как конфиденциального контента.
[0062] Под–процесс 602 содержит действия приложения стороны клиента, такие как загрузка документов для редактирования или просмотра в пользовательском интерфейсе и предоставления порций этих документов для классификации. В операции 614, клиентское приложение может обеспечивать один или несколько опытов конечного пользователя, чтобы обработать пользовательский контент, редактировать пользовательский контент или просматривать пользовательский контент, среди прочих операций. Операция 614 может также обеспечивать процессы аннотации и обфускации, которые описаны ниже. Операция 615 обеспечивает части этого пользовательского контента на совместно используемую службу DLP для классификации пользовательского контента. В некоторых примерах, части содержат выровненные порции пользовательского контента, который выделен из ассоциированной структуры или иерархии из исходного документа.
[0063] Под–процесс 603 содержит классификацию пользовательского контента, чтобы обнаруживать конфиденциальные данные среди пользовательского контента, а также аннотацию этих конфиденциальных данных для пользователя. В операции 616, применяются различные правила обнаружения, такие как регулярные выражения, описанные ниже со ссылкой на фиг. 7, среди прочих правил и процессов обнаружения. Если конфиденциальные данные найдены, то операция 617 определяет, следует ли уведомить пользователя. Уведомление может не происходить, если количество конфиденциальных данных падает ниже порогового количества для предупреждения. Однако если пользователь должен быть предупрежден, то операция 619 может вычислять местоположения конфиденциальных данных в обнаруженных областях структурированных данных. Как описано в настоящем документе, процесс отображения может использоваться, чтобы определять конкретные местоположения конфиденциальных данных в пределах структурированных элементов или иерархических элементов из смещений выровненных данных и длин строк или частей конфиденциальных данных. После того как эти конкретные местоположения определены, затем операция 618 может отобразить местоположения пользователю. Аннотации или другие элементы выделения пользовательского интерфейса используются, чтобы сигнализировать пользователю, что конфиденциальные данные присутствуют среди пользовательского контента.
[0064] Под–процесс 604 содержит обфускацию конфиденциальных данных в пределах пользовательского контента, содержащего структурированные или иерархические элементы. В операции 621, пользовательский ввод может приниматься, чтобы заменить по меньшей мере один элемент конфиденциальных данных 'безопасными' или обфусцированными данными/текстом. Когда пользователю показана выделенная область, демонстрирующая фрагмент конфиденциальных данных, который вызвал появление аннотации или 'подсказки политики', пользователю может быть представлена опция заменить конфиденциальные данные 'безопасным текстом', который обфусцирует конфиденциальные данные. В зависимости от вариантов выбора, выполненных объектами, первоначально устанавливающими политики в операции 611, операции 622 и 624 определяют и генерируют одно или несколько правил замены или обфускации. Правила обфускации могут использоваться для замены внутреннего кодового имени на маркетинговое название, используемое, чтобы обфусцировать персонально идентифицируемую информацию (PII) шаблонными названиями, могут использоваться, чтобы заменить числовые конфиденциальные данные набором символов, которые указывают будущим пользователям, просматривающим документ, на соответствующий тип конфиденциальных данных (т.е. номера кредитных карт, номера социального страхования, номера идентификации транспортных средств, среди прочего) без раскрытия действительных конфиденциальных данных. Операция 623 заменяет конфиденциальные данные обфусцированными данными. Обфусцированные данные могут использоваться, чтобы заменять числовые конфиденциальные данные набором символов, которые могут использоваться, чтобы подтверждать схему данных или тип контента, но остаются недостаточными для извлечения исходных данных даже определенным человеком (т.е. чтобы определить, что фрагмент контента представляет собой SSN, но не раскрыть действительный SSN). Пользователи могут выполнять отдельную или единичную замену конфиденциального контента на обфусцированный текст или массовую замену из пользовательского интерфейса, который показывает множество образцов конфиденциального контента.
[0065] Замена конфиденциального контента, такого как текстовый или буквенно–числовой контент, может производиться при помощи регулярных выражений или альтернативно посредством недетерминированных конечных автоматов (NFA), детерминированных конечных автоматов (DFA), автоматов магазинного типа (PDA), машин Тьюринга, произвольного функционального кода или других процессов. Замена конфиденциального контента обычно содержит сопоставление шаблона среди текста или контента. Это сопоставление шаблона может оставлять незамаскированные символы или контент с учетом того, имеет ли целевой шаблон возможность для множества символов существовать в заданном местоположении в строке, и эти символы не требуется маскировать, например, как для символов–разделителей. Например, строка "123–12–1234" может стать "xxx–xx–xxxx", и строка "123 12 1234" может стать "xxx xx xxxx" после процесса маскирования. Это согласование шаблона может также оставлять определенные части различимыми в целях уникальности, например, при помощи последнего предопределенного числа разрядов номера кредитной карты или SSN. Например, "1234–1234–1234–1234" может стать "xxxx–xxxx–xxxx–1234" после процесса маскирования. Для маскирования/замены кодового имени, не все аспекты представляют собой шаблоны и могут в действительности представлять собой внутренние кодовые имена или другие ключевые слова. Например, кодовое имя "Whistler" может стать "Windows XP" после процесса маскирования. Более того, шаблонам, которые заменяют переменное число символов безопасным текстом, может быть разрешено сохранять согласованную длину или устанавливать длину на известную постоянную. Например, одно и то же правило может превратить "1234–1234–1234–1234" в "xxxx–xxxx–xxxx–1234" и "xxxxx–xxxxx–x1234" после процесса маскирования. Это может потребовать шаблона, который содержит достаточные данные, чтобы обрабатывать любой из этих случаев. Регулярные выражения могут обрабатывать такие сценарии путем увеличения регулярного выражения путем окружения каждого элементарного (атомного) совпадающего выражения скобками и отслеживания, какие увеличенные утверждения 'совпадения' парны каким утверждениям 'замены'. Дополнительные примеры согласования регулярных выражений показаны на фиг. 7 ниже.
[0066] Чтобы поддерживать целостность процессов аннотации и классификации среди более чем одного документа/файла, могут быть установлены различные процессы. Правила и политики обнаружения/классификации, аннотации и обфускации обычно не включены в файлы документов. Это обеспечивает возможность изменения в политиках и препятствует обратному инжинирингу методов обфускации. Например, если пользователь сохраняет документ, затем закрывает и загружает тот же самый документ, то правила того, какие части документа содержат конфиденциальные данные, которые необходимо учитывать, вопрос политики наличия конфиденциальных данных, могли измениться. К тому же отметки аннотации не должны быть включены в операции буфера обмена, такие как вырезать, копировать или вставить. Если пользователь должен был скопировать контент из одного документа и вставить его в другой, то второй документ мог применять другие правила обнаружения/классификации, аннотации и обфускации. Если пользователь должен был ограничиться текстом из первого документа и вставить во второй документ, то аннотации первого документа должны рассматриваться нерелевантными, пока не будет повторной классификации. Даже если пользователь должен был копировать контент из одного документа в тот же самый документ, любые отсчеты конфиденциального контента могут сдвигаться, и то, что требуется выделить в документе, может изменяться.
[0067] Фиг. 7 иллюстрирует блок–схему 700 последовательности операций, чтобы дополнительно проиллюстрировать работу элементов согласно фиг. 1–3. Фиг. 7 фокусируется на операциях регулярных выражений во время процессов обфускации конфиденциальных данных. На фиг. 7, если имеется регулярное выражение (regex), такое примерное регулярное выражение 730 вымышленных водительских прав, и строка, которая совпадает с ней, то может генерироваться полное совпадение путем по меньшей мере увеличения регулярного выражения путем окружения каждого отделяемого совпадающего по символам выражения скобками (например, каждого атома (элементарного объекта в языке), как указано в операции 711. Увеличенное регулярное выражение может затем повторно применяться или исполняться в операции 712, чтобы выполнить процесс обфускации или маскирования. Для каждого сопоставления, операции 713–714 определяют самый широкий и самый узкий наборы действительно совпадающих символов. Например, когда совпадающий символ представляет собой "–", символ является узким, поскольку он представляет собой одиночный символ. Когда совпадающий символ представляет собой набор всех буквенных символов, он является широким. Абсолютный отсчет символов, которые могли бы находиться в любой области, является ключевым определителем. Процесс обфускации в операции 715 может заменять символы в соответствии с шириной совпадения. Для тех совпадающих символов, которые представляют собой одиночные символы, процесс обфускации может не отличаться. Для тех совпавших символов, которые находятся в широких группах, процесс обфускации заменяет символы на ‘безопасный’ символ, который не является членом набора. Например, набор всех букв становится "0", набор всех чисел становится "X", а смешанный буквенно–числовой контент становится "?", с резервным списком символов для использования, пока он не будет истощен. Когда текст или контент подвергся процессу обфускации или маскирования, операция 716 подтверждает, что текст или контент был успешно сделан обфусцированным, когда новая строка текста/контента больше не совпадает с исходным regex.
[0068] Фиг. 8 иллюстрирует диаграмму 800 графа, чтобы дополнительно проиллюстрировать работу элементов согласно фиг. 1–3. Фиг. 8 фокусируется на усовершенствованных пороговых процессах, используемых в аннотировании конфиденциальных данных в пользовательских интерфейсах. Операции согласно фиг. 8 могут содержать усовершенствованные операции гистерезиса для аннотирования конфиденциальных данных, и различные пороги или правила аннотации могут быть установлены администраторами политики или пользователями, среди прочих объектов.
[0069] Фиг. 8 включает в себя граф 800, который включает в себя вертикальную ось, указывающую количество конфиденциальных данных/элементов контента, представленных в документе, и горизонтальную ось, указывающую время. Установлен первый порог 820, который может инициировать представление или удаление аннотаций конфиденциального контента в пользовательском интерфейсе. Может быть установлен второй порог 822, который может также инициировать представление или удаление аннотаций конфиденциального контента. Фактор эластичности 821 и свойство устойчивости 823 могут быть установлены, чтобы модифицировать поведение первого и второго порогов.
[0070] Когда конфиденциальные данные были аннотированы в пользовательском интерфейсе, например, флагами, маркировками или выделением, пользователь может редактировать конфиденциальный контент, чтобы решить проблемы конфиденциального контента (например, путем выбора одной или нескольких опций обфускации). Однако после того как пороговое число вопросов (пунктов) конфиденциального контента решено, может иметься недостаточно оставшихся примеров (конкретных случаев) некоторого вопроса, чтобы гарантировать аннотацию документа как находящегося полностью в противоречии с правилами конфиденциального контента для организации или местоположения хранения. Подобным образом, когда новый конфиденциальный контент вводится в документ, может иметься достаточно примеров, чтобы гарантировать аннотирование документа для указания конфиденциального контента пользователю.
[0071] Во время процессов редактирования контента пользователями, задействование или блокирование указателей аннотации для одного или нескольких элементов контента может основываться по меньшей мере частично на текущем количестве элементов контента в отношении правил аннотации. Правила аннотации могут содержать по меньшей мере первое пороговое количество 820, фактор эластичности 821 для модифицирования первого порогового количества 820 во второе пороговое количество 822 при задействовании, и указание устойчивости порога или свойства 'негибкости' 823, указывающего, когда второе пороговое количество 822 переопределяет первое пороговое количество 820. Служба аннотации, например, модуль 212 аннотации, может определять или идентифицировать правила аннотации, такие как правила 513 политики и действия 514, описанные со ссылкой на фиг. 5, которые установлены для целевых объектов, ассоциированных с редактированием контента. Целевые объекты могут включать в себя пользователей, выполняющих редактирование контента, организацию, которая содержит пользователя, выполняющего редактирование контента, или тип приложения пользовательского приложения, среди прочего. Во время редактирования пользователем документа, который содержит конфиденциальный контент или потенциально может содержать конфиденциальный контент, модуль 212 аннотации контролирует пользовательский контент в ассоциированном файле пользовательских данных, представленном для редактирования контента в пользовательском интерфейсе на пользовательское приложение. Модуль 212 аннотации идентифицирует количество элементов контента, содержащих конфиденциальный контент, среди пользовательского контента, соответственно одной или нескольким предопределенным схемам данных, описанным в настоящем документе. Элементы контента могут включать в себя ячейки, объекты, формы, слова или другие структурные или иерархические элементы данных.
[0072] Во время редактирования, и на основе по меньшей мере количества элементов контента, превосходящего первое пороговое количество, модуль 212 аннотации инициирует представление по меньшей мере одного указателя аннотации в пользовательском интерфейсе, который отмечает пользовательский контент в пользовательском интерфейсе как содержащий по меньшей мере первый конфиденциальный контент. На фиг. 8 (начиная с аннотаций в 'выключенном' состоянии), первый порог 820 указывает примерное количество '8' в точке 830 перехода как запускающее представление указателей аннотации в пользовательском интерфейсе. Количество элементов контента с конфиденциальным контентом может увеличиваться, например, посредством пользовательского редактирования, и затем может снижаться после того, как пользователь видит, что конфиденциальный контент представлен, и начинает выбор опций обфускации, чтобы замаскировать этот конфиденциальный контент.
[0073] На основе по меньшей мере количества элементов контента, первоначально превышающего первое пороговое количество 820 и затем спадающего ниже первого порогового количества 820, когда фактор эластичности 821 применяется к первому пороговому количеству 820, модуль 212 аннотации устанавливает второе пороговое количество 822 на основе по меньшей мере фактора эластичности. Когда второе пороговое количество 822 активно (т.е. когда фактор эластичности 821 применяется к первому пороговому количеству 820), второе пороговое количество 822 используется, чтобы инициировать удаление представления по меньшей мере одного указателя аннотации, когда количество падает ниже второго порогового количества 822, как видно в точке 832 перехода. Однако, на основе по меньшей мере количества элементов контента, первоначально превышающего первое пороговое количество 820 и затем спадающего ниже первого порогового количества 820, когда фактор эластичности не применяется к первому пороговому количеству 820, представление по меньшей мере одного указателя аннотации удаляется, как указано точкой 831 перехода.
[0074] Фактор эластичности 821 может содержать процент в диапазоне 0–100 процентов или другую метрику. В конкретном примере, может быть установлено правило аннотации, которое определяет, что включение более 100 SSN в документ нарушает корпоративную политику. Во время редактирования документа, который превышает 100 SSN, правило аннотации для первого порогового количества может вызывать выделение всех из SSN в документе. Когда пользователь начинает обфускацию SSN, количество оставшихся необфусцированных SSN будет уменьшаться. Фактор эластичности может поддерживать аннотацию или выделение SSN, даже если первое пороговое количество 820, которое запустило аннотацию, больше не удовлетворяется, например, когда 99 SSN остаются необфусцированными. Фактор эластичности 100 будет соответствовать немодифицированному первому пороговому количеству, и эластичность 0 будет соответствовать аннотациям, никогда не удаляющимся, пока все SSN не будут обфусцированы. Промежуточное значение 50 для фактора эластичности будет соответствовать удалению аннотаций, как только зафиксирована 50–ая запись, после того как аннотации были первоначально запущены для представления. Таким образом, в примере на фиг. 8, фактор эластичности устанавливает второе пороговое количество для удаления аннотаций, после того как аннотации были представлены пользователю. В этом примере, второе пороговое количество 822 составляет '2', и, таким образом, когда оставшиеся части конфиденциального контента спадают ниже остающихся '2', аннотации будут удалены, как указано точкой 832 перехода.
[0075] Если второе пороговое количество 822 упало ниже, и затем дополнительные проблемы конфиденциального контента возникают во время редактирования контента, то модуль 212 аннотации должен принять решение, когда следует предупредить пользователя путем представления аннотаций снова. На основе по меньшей мере количества элементов контента, сначала спадающего ниже второго порогового количества 822 и затем превышающего второе пороговое количество 822, когда свойство устойчивости 823 порога применяется к второму пороговому количеству 822, модуль 212 аннотации инициирует представление дополнительных аннотаций в пользовательском интерфейсе, что отмечает пользовательский контент в пользовательском интерфейсе как содержащий конфиденциальный контент, как указано точкой 833 перехода.
[0076] Свойство устойчивости 823 содержит свойство 'негибкости' для второго порогового количества 822 и определяется путем включения/отключения или булевым условием. При отключении, второе пороговое количество 822 не используется для повторного представления аннотаций при превышении. При включении, второе пороговое количество 822 используется для повторного представления аннотаций при превышении. Поэтому, на основе по меньшей мере количества элементов контента, первоначально спадающего ниже второго порогового количества 822 и затем превышающего второе пороговое количество 822, когда способность устойчивости не применяется к второму пороговому количеству 822, модуль 212 аннотации воздерживается от представления аннотаций, что отмечает пользовательский контент в пользовательском интерфейсе как содержащий по меньшей мере конфиденциальный контент, пока количество элементов контента не превысит первое пороговое количество 820 снова.
[0077] На фиг. 9 представлена вычислительная система 901. Вычислительная система 901 является представлением любой системы или совокупности систем, в которых могут быть реализованы различные операционные архитектуры, сценарии и процессы, раскрытые в настоящем документе. Например, вычислительная система 901 может использоваться, чтобы реализовывать любую из пользовательской платформы 110 или платформы 120 DLP согласно фиг. 1. Примеры вычислительной системы 901 включают в себя, но без ограничения, серверные компьютеры, облачные вычислительные системы, распределенные вычислительные системы, определяемые программным обеспечением сетевые системы, компьютеры, настольные компьютеры, гибридные компьютеры, стоечные серверы, веб–серверы, платформы облачных вычислений и оборудование центров обработки данных, а также любой другой тип физической или виртуальной серверной машины, и другие вычислительные системы и устройства, а также любую другую их вариацию или комбинацию. Когда части вычислительной системы 901 реализуются на пользовательских устройствах, примерные устройства включают в себя смартфоны, ноутбуки, планшеты, настольные компьютеры, игровые системы, развлекательные системы и тому подобное.
[0078] Вычислительная система 901 может быть реализована как одиночное устройство, система или прибор или может быть реализована распределенным образом как множество устройств, систем или приборов. Вычислительная система 901 включает в себя, но без ограничения, систему 902 обработки, систему 903 хранения, программное обеспечение 905, систему 907 интерфейса связи и систему 908 пользовательского интерфейса. Система 902 обработки функционально соединена с системой 903 хранения, системой 907 интерфейса связи и системой 908 пользовательского интерфейса.
[0079] Система 902 обработки загружает и исполняет программное обеспечение 905 из системы 903 хранения. Программное обеспечение 905 включает в себя среду 906 DLP приложения и/или среду 909 совместно используемой DLP, что является репрезентативным для процессов, рассматриваемых со ссылками на предыдущие чертежи. При исполнении системой 902 обработки для обработки пользовательского контента для идентификации, аннотации и обфускации конфиденциального контента, программное обеспечение 905 направляет систему 902 обработки, чтобы работать, как описано в настоящем документе для по меньшей мере различных процессов, операционных сценариев и сред, описанных в предыдущих реализациях. Вычислительная система 901 может опционально включать в себя дополнительные устройства, признаки или функциональность, не описанную в целях краткости.
[0080] Все еще со ссылкой на фиг. 9, система 902 обработки может содержать микропроцессор и схему обработки, которая извлекает и исполняет программное обеспечение 905 из системы 903 хранения. Система 902 обработки может быть реализована в пределах одного устройства обработки, но может также быть распределена по множеству устройств обработки или подсистем, которые взаимодействуют при исполнении программных инструкций. Примеры системы 902 обработки включают в себя универсальные центральные процессоры, специализированные процессоры приложений и логические устройства, а также любой другой тип устройства обработки, их комбинации или вариации.
[0081] Система 903 хранения может содержать любые считываемые компьютером носители хранения, считываемые системой 902 обработки и способные сохранять программное обеспечение 905. Система 903 хранения может включать в себя энергозависимые и энергонезависимые, съемные и несъемные носители, реализуемые посредством любого способа или технологии для хранения информации, такой как считываемые компьютером инструкции, структуры данных, программные модули или другие данные. Примеры носителей хранения включают в себя память с произвольным доступом, постоянную память, магнитные диски, резистивную память, оптические диски, флэш–память, виртуальную память и не–виртуальную память, магнитные кассеты, магнитную ленту, хранилище на магнитном диске или другие магнитные устройства хранения или любые другие подходящие носители хранения. Ни в каком случае считываемые компьютером носители хранения не представляют собой распространяющийся сигнал.
[0082] В дополнение к считываемым компьютером носителям хранения, в некоторых реализациях система 903 хранения может также включать в себя считываемые компьютером носители связи, по которым по меньшей мере некоторое из программного обеспечения 905 может сообщаться внутренним или внешним образом. Система 903 хранения может быть реализована как единое устройство хранения, но может также быть реализована на множестве устройств хранения или подсистем, совместно расположенных или распределенных относительно друг друга. Система 903 хранения может содержать дополнительные элементы, такие как контроллер, способный осуществлять связь с системой 902 обработки или, возможно, другими системами.
[0083] Программное обеспечение 905 может быть реализовано в программных инструкциях и помимо прочих функций может, при исполнении системой 902 обработки, направлять систему 902 обработки, чтобы работать, как описано в отношении различных операционных сценариев, последовательностей и процессов, проиллюстрированных в настоящем документе. Например, программное обеспечение 905 может включать в себя программные инструкции для реализации сред и платформ обработки наборов данных, рассматриваемых в настоящем документе.
[0084] В частности, программные инструкции могут включать в себя различные компоненты или модули, которые работают совместно или иным образом взаимодействуют, чтобы выполнять различные процессы и операционные сценарии, описанные в настоящем документе. Различные компоненты или модули могут быть воплощены в компилируемых или интерпретируемых инструкциях или в некоторой другой вариации или комбинации инструкций. Различные компоненты или модули могут исполняться синхронным или асинхронным образом, последовательно или параллельно, в однопотоковой или мультипотоковой среде или в соответствии с любой другой подходящей парадигмой исполнения, их вариацией или комбинацией. Программное обеспечение 905 может включать в себя дополнительные процессы, программы или компоненты, такие как программное обеспечение операционной системы или другое прикладное программное обеспечение, в дополнение к среде 906 DLP приложения или среде 909 совместно используемой DLP или включающее их в себя. Программное обеспечение 905 может также содержать прошивку или некоторый другой вид машиночитаемых инструкций обработки, исполняемых системой 902 обработки.
[0085] В общем, программное обеспечение 905 может, когда загружается в систему 902 обработки и исполняется, преобразовывать подходящее устройство, систему или прибор (представлением которых является вычислительная система 901) полностью из универсальной вычислительной системы в специализированную вычислительную систему, приспособленную, чтобы облегчать усовершенствованную обработку пользовательского контента для идентификации, аннотации и обфускации конфиденциального контента. Фактически кодирующее программное обеспечение 905 на системе 903 хранения может преобразовывать физическую структуру системы 903 хранения. Конкретное преобразование физической структуры может зависеть от различных факторов в разных реализациях настоящего описания. Примеры таких факторов могут включают в себя, но без ограничения, технологию, используемую, чтобы реализовывать носители хранения системы 903 хранения, и то, характеризуются ли компьютерные носители хранения как первичное или вторичное хранилище, а также другие факторы.
[0086] Например, если считываемые компьютером носители хранения реализованы как память на полупроводниковой основе, программное обеспечение 905 может преобразовывать физическое состояние полупроводниковой памяти, когда программные инструкции закодированы в ней, например, путем преобразования состояния транзисторов, конденсаторов или других дискретных схемных элементов, составляющих полупроводниковую память. Аналогичное преобразование может происходить в отношении магнитных или оптических носителей. Другие преобразования физических носителей возможны без отклонения от объема настоящего описания, причем предыдущие примеры обеспечены, только чтобы облегчить настоящее обсуждение.
[0087] Среда 906 DLP приложения или среда 909 совместно используемой DLP, каждая, включает в себя один или несколько элементов программного обеспечения, такие как OS 921/931 и приложения 922/932. Эти элементы могут описывать различные части вычислительной системы 901, с которой взаимодействуют пользователи, источники данных, службы данных или другие элементы. Например, OS 921/931 может обеспечивать платформу программного обеспечения, на которой исполняется приложение 922/932 и которая обеспечивает возможность обработки пользовательского контента для идентификации, аннотации и обфускации конфиденциального контента, помимо прочих функций.
[0088] В одном примере, служба 932 DLP включает в себя разделитель 924 контента, модуль 925 аннотации, модуль 926 отображения и обфускатор 927. Разделитель 924 контента выравнивает структурированные или иерархические элементы пользовательского контента в линейные порции для обработки посредством службы классификации. Модуль 925 аннотации графически выделяет конфиденциальные данные или контент в пользовательском интерфейсе, так что пользователи могут предупреждаться о наличии порогового количества конфиденциальных данных. Модуль 926 отображения может получать конкретные местоположения среди документов для аннотаций конфиденциальных данных, например, когда только смещения/длины/ID обеспечиваются службой классификации для локализации конфиденциальных данных в различных структурных или иерархических элементах документа. Обфускатор 927 представляет опции обфускации для маскирования/замены пользовательского контента, который был идентифицирован как конфиденциальные данные. Обфускатор 927 также заменяет конфиденциальный контент в ответ на варианты выбора пользователями опций обфускации.
[0089] В другом примере, служба 933 DLP включает в себя службу 934 классификации, трекер 935, модуль 936 политики/правил и службу 937 regex. Служба 934 классификации синтаксически анализирует линейные порции данных или контент, чтобы идентифицировать конфиденциальные данные. Трекер 935 поддерживает отсчеты или количества элементов конфиденциальных данных, найденных службой 934 классификации, и указывает смещения и длины конфиденциальных данных на модуль отображения для аннотации в документе (такой как модуль 926 отображения и модуль 925 аннотации). Модуль 936 политики/правил может принимать и поддерживать различные политики и правила для аннотации, классификации, обнаружения, обфускации или других операций на пользовательском контенте. Служба 937 Regex содержит один примерный метод классификации с использованием сопоставления с регулярными выражениями, чтобы идентифицировать конфиденциальные данные с использованием шаблонов данных или схем данных и чтобы заменить текст сопоставляемого контента на обфусцированный контент.
[0090] Система 907 интерфейса связи может включать в себя соединения и устройства связи, которые обеспечивают возможность связи с другими вычислительными системами (не показаны) по сетям связи (не показаны). Примеры соединений и устройств, которые вместе создают возможность связи между системами, могут включать в себя карты сетевого интерфейса, антенны, усилители мощности, RF схемы, приемопередатчики и другие схемы связи. Соединения и устройства могут осуществлять связь по средам связи, чтобы обмениваться сообщениями с другими вычислительными системами или сетями систем, таким как металлические, стеклянные, воздушные или любые другие подходящие среды связи. Физические или логические элементы системы 907 интерфейса связи могут принимать наборы данных от источников телеметрии, переносить наборы данных и информацию управления между одним или несколькими распределенными элементами хранения данных и взаимодействовать с пользователем, чтобы принимать варианты выбора данных и обеспечивать визуализированные наборы данных, среди других признаков.
[0091] Система 908 пользовательского интерфейса является опциональной и может включать в себя клавиатуру, мышь, устройство голосового ввода, устройство сенсорного ввода для приема ввода от пользователя. Устройства вывода, такие как дисплей, динамики, веб–интерфейсы, терминальные интерфейсы и другие типы устройств вывода, могут также быть включены в систему 908 пользовательского интерфейса. Система 908 пользовательского интерфейса может обеспечивать вывод и принимать ввод по сетевому интерфейсу, такому как система 907 интерфейса связи. В примерах сети, система 908 пользовательского интерфейса может пакетировать данные отображения или графики для удаленного отображения посредством системы отображения или вычислительной системы, связанных по одному или нескольким сетевым интерфейсам. Физические или логические элементы системы 908 пользовательского интерфейса могут принимать правила или политики классификации от пользователей или специалистов политики, принимать действия редактирования данных от пользователей, представлять аннотации конфиденциального контента пользователям, обеспечивать опции обфускации пользователям и представлять обфусцированный пользовательский контент пользователям, среди прочих операций. Система 908 пользовательского интерфейса может также включать в себя ассоциированное программное обеспечение пользовательского интерфейса, исполняемое системой 902 обработки при поддержке различных устройств пользовательского ввода и вывода, описанных выше. Отдельно или во взаимосвязи друг с другом и другими элементами аппаратных средств и программного обеспечения, программное обеспечение пользовательского интерфейса и устройства пользовательского интерфейса могут поддерживать графический пользовательский интерфейс, естественный пользовательский интерфейс или любой другой тип пользовательского интерфейса.
[0092] Связь между вычислительной системой 901 и другими вычислительными системами (не показаны) может происходить по сети или сетям связи и в соответствии с различными протоколами связи, комбинациями протоколов или их вариациями. Примеры включают в себя интрасети, интерсети, Интернет, локальные сети, глобальные сети, беспроводные сети, проводные сети, виртуальные сети, определяемые программным обеспечением сети, шины центров обработки данных, вычислительные соединительные панели или любой другой тип сети, комбинацию сетей или их вариацию. Вышеупомянутые сети и протоколы связи хорошо известны и не требуют подробного описания. Однако, некоторые протоколы связи, которые могут использоваться, включают в себя, но без ограничения, Интернет–протокол (IP, IPv4, IPv6, и т.д.), протокол управления передачей данных (TCP) и протокол пользовательских дейтаграмм (UDP), а также любой другой подходящий протокол связи, их вариацию или комбинацию.
[0093] Определенные аспекты изобретения могут быть поняты из предшествующего раскрытия, различными примерами которого являются следующие.
[0094] Пример 1: Способ обеспечения инфраструктуры обфускации данных для пользовательского приложения, способ содержит предоставление пользовательского контента в службу классификации, сконфигурированную, чтобы обрабатывать пользовательский контент, чтобы классифицировать части пользовательского контента как содержащие конфиденциальный контент, соответствующий одной или нескольким предопределенным схемам данных, и прием от службы классификации указаний одной или нескольких частей пользовательского контента, которые содержат конфиденциальный контент. Способ включает в себя представление графических указаний в пользовательском интерфейсе на пользовательское приложение, которые аннотируют одну или несколько частей пользовательского контента как содержащие конфиденциальный контент, и представление опций обфускации в пользовательском интерфейсе для маскирования конфиденциального контента в пределах по меньшей мере выбранной части среди одной или нескольких частей пользовательского контента. В ответ на выбор пользователем по меньшей мере одной из опций обфускации, способ включает в себя замену ассоциированного пользовательского контента обфусцированным контентом, который поддерживает схему данных ассоциированного пользовательского контента.
[0095] Пример 2: Способ в соответствии с Примером 1, дополнительно содержащий представление опций обфускации как содержащих первую опцию, чтобы маскировать конфиденциальный контент в пределах выбранной части, и вторую опцию, чтобы маскировать конфиденциальный контент в пределах выбранной части и дополнительных частей пользовательского контента, содержащих дополнительный конфиденциальный контент, имеющий аналогичную схему данных, что и выбранная часть.
[0096] Пример 3: Способ в соответствии с Примерами 1–2, дополнительно содержащий представление опций обфускации как указывающих по меньшей мере примерную обфусцированную версию целевого пользовательского контента в пределах выбранной части.
[0097] Пример 4: Способ в соответствии с Примерами 1–3, где графические указания, которые аннотируют одну или несколько частей пользовательского контента, содержат указатели, расположенные вблизи одной или нескольких частей, которые доступны для выбора в пользовательском интерфейсе, чтобы представить опции обфускации.
[0098] Пример 5: Способ в соответствии с Примерами 1–4, где обфусцированный контент, который поддерживает схему данных ассоциированного пользовательского контента, содержит символы, выбранные частично на основе схемы данных ассоциированного пользовательского контента, чтобы предотвратить идентификацию ассоциированного пользовательского контента во время поддержания схемы данных ассоциированного пользовательского контента.
[0099] Пример 6: Способ в соответствии с Примерами 1–5, дополнительно содержащий в ответ на замену ассоциированного пользовательского контента обфусцированным контентом, предоставление обфусцированного контента в службу классификации, чтобы подтвердить, что обфусцированный контент не содержит дополнительный конфиденциальный контент.
[0100] Пример 7: Способ в соответствии с Примерами 1–6, где одна или несколько предопределенных схем данных определяются посредством одного или нескольких регулярных выражений, используемых, чтобы синтаксически анализировать пользовательский контент, чтобы идентифицировать части как указывающие один или несколько предопределенных шаблонов контента или один или несколько предопределенных типов контента.
[0101] Пример 8: Способ в соответствии с Примерами 1–7, где одна или несколько предопределенных схем данных содержат, каждая, первые части, подлежащие обфускации, и вторые части, которые должны остаться необфусцированными, первые части, подлежащие обфускации, соответствуют местоположениям, имеющим более одного разрешенного символа, и вторые части, которые должны остаться необфусцированными, имеют только один разрешенный символ, содержащий символ–разделитель. Способ дополнительно содержит идентификацию, назначена ли часть первых частей, чтобы остаться различимой для уникальности после обфускации, и назначение части, чтобы остаться необфусцированной.
[0102] Пример 9: Инфраструктура обфускации данных для пользовательского приложения, содержащая один или несколько считываемых компьютером носителей хранения, систему обработки, функционально связанную с одним или несколькими считываемыми компьютером носителями хранения, и программные инструкции, хранящиеся на одном или нескольких считываемых компьютером носителях хранения. На основе по меньшей мере считывания и исполнения системой обработки, программные инструкции направляют систему обработки, чтобы по меньшей мере предоставлять пользовательский контент в службу классификации, сконфигурированную, чтобы обрабатывать пользовательский контент, чтобы классифицировать части пользовательского контента как содержащие конфиденциальный контент, соответствующий одной или нескольким предопределенным схемам данных, и принимать от службы классификации указания одной или нескольких частей пользовательского контента, которые содержат конфиденциальный контент. На основе по меньшей мере считывания и исполнения системой обработки, программные инструкции дополнительно направляют систему обработки, чтобы по меньшей мере представлять графические указания в пользовательском интерфейсе на пользовательское приложение, которые аннотируют одну или несколько частей пользовательского контента как содержащие конфиденциальный контент, представлять опции обфускации в пользовательском интерфейсе для маскирования конфиденциального контента в пределах по меньшей мере выбранной части среди одной или нескольких частей пользовательского контента, и в ответ на выбор пользователем по меньшей мере одной из опций обфускации, заменять ассоциированный пользовательский контент на обфусцированный контент, который поддерживает схему данных ассоциированного пользовательского контента.
[0103] Пример 10: Инфраструктура обфускации данных в соответствии с Примером 9, содержащая дополнительные программные инструкции, которые, на основе по меньшей мере считывания и исполнения системой обработки, направляют систему обработки, чтобы по меньшей мере представлять опции обфускации как содержащие первую опцию, чтобы маскировать конфиденциальный контент в пределах выбранной части, и вторую опцию, чтобы маскировать конфиденциальный контент в пределах выбранной части и дополнительных частей пользовательского контента, содержащих дополнительный конфиденциальный контент, имеющий аналогичную схему данных, что и выбранная часть.
[0104] Пример 11: Инфраструктура обфускации данных в соответствии с Примерами 9–10, содержащая дополнительные программные инструкции, которые, на основе по меньшей мере считывания и исполнения системой обработки, направляют систему обработки, чтобы по меньшей мере представлять опции обфускации как указывающие по меньшей мере примерную обфусцированную версию целевого пользовательского контента в пределах выбранной части.
[0105] Пример 12: Инфраструктура обфускации данных в соответствии с Примерами 9–11, где графические указания, которые аннотируют одну или несколько частей пользовательского контента, содержат указатели, расположенные вблизи одной или нескольких частей, которые доступны для выбора в пользовательском интерфейсе, чтобы представить опции обфускации.
[0106] Пример 13: Инфраструктура обфускации данных в соответствии с Примерами 9–12, где обфусцированный контент, который поддерживает схему данных ассоциированного пользовательского контента, содержит символы, выбранные частично на основе схемы данных ассоциированного пользовательского контента, чтобы предотвратить идентификацию ассоциированного пользовательского контента при поддержании схемы данных ассоциированного пользовательского контента.
[0107] Пример 14: Инфраструктура обфускации данных в соответствии с Примерами 9–13, содержащая дополнительные программные инструкции, которые, на основе по меньшей мере считывания и исполнения системой обработки, направляют систему обработки, чтобы по меньшей мере, в ответ на замену ассоциированного пользовательского контента обфусцированным контентом, предоставлять обфусцированный контент в службу классификации, чтобы подтвердить, что обфусцированный контент не содержит дополнительный конфиденциальный контент.
[0108] Пример 15: Инфраструктура обфускации данных в соответствии с Примерами 9–14, где одна или несколько предопределенных схем данных определяются посредством одного или нескольких регулярных выражений, используемых, чтобы синтаксически анализировать пользовательский контент, чтобы идентифицировать части как указывающие один или несколько предопределенных шаблонов контента или один или несколько предопределенных типов контента.
[0109] Пример 16: Инфраструктура обфускации данных в соответствии с Примерами 9–15, где одна или несколько предопределенных схем данных содержат, каждая, первые части, подлежащие обфускации, и вторые части, которые должны остаться необфусцированными, первые части, подлежащие обфускации, соответствуют местоположениям, имеющим более одного разрешенного символа, и вторые части, которые должны остаться необфусцированными, имеют только один разрешенный символ, содержащий символ–разделитель. Инфраструктура обфускации данных, содержит дополнительные программные инструкции, которые, на основе по меньшей мере считывания и исполнения системой обработки, направляют систему обработки, чтобы по меньшей мере идентифицировать, назначена ли часть первых частей, чтобы остаться различимой для уникальности после обфускации, и назначать часть, чтобы остаться необфусцированной.
[0110] Пример 17: Способ работы пользовательского приложения, способ содержит предоставление пользовательского контента файла пользовательских данных в службу классификации, сконфигурированную, чтобы обрабатывать пользовательский контент, чтобы классифицировать одну или несколько частей пользовательского контента как содержащие конфиденциальный контент, соответствующий одной или нескольким схемам данных, и представление указателей в пользовательском интерфейсе, которые отмечают одну или несколько частей пользовательского контента как содержащие конфиденциальный контент, где указатели расположены вблизи одной или нескольких частей и доступны для выбора в пользовательском интерфейсе, чтобы представить опции обфускации. В ответ на выбор первого из указателей, способ включает в себя представление первых опций обфускации в пользовательском интерфейсе для замены ассоциированного конфиденциального контента в пределах первой части пользовательского контента, отмеченного первым из указателей. В ответ на выбор пользователем по меньшей мере одной из первых опций обфускации, способ включает в себя замену ассоциированного конфиденциального контента обфусцированным контентом, который поддерживает схему данных ассоциированного конфиденциального контента.
[0111] Пример 18: Способ в соответствии с Примером 17, дополнительно содержащий представление первых опций обфускации как содержащих первую опцию, чтобы замещать ассоциированный конфиденциальный контент обфусцированным контентом, и вторую опцию, чтобы заменять ассоциированный конфиденциальный контент и дополнительный конфиденциальный контент файла пользовательских данных, имеющего аналогичную схему данных, что и ассоциированный конфиденциальный контент.
[0112] Пример 19: Способ в соответствии с Примерами 17–18, где обфусцированный контент, который поддерживает схему данных ассоциированного конфиденциального контента, содержит один или несколько символов, выбранных, чтобы предотвратить идентификацию ассоциированного конфиденциального контента во время поддержания схемы данных ассоциированного пользовательского контента, где один или несколько символов выбираются частично на основе схемы данных ассоциированного конфиденциального контента.
[0113] Пример 20: Способ в соответствии с Примерами 17–19, где одна или несколько схем данных содержат, каждая, первые части, подлежащие обфускации, и вторые части, которые должны остаться необфусцированными, первые части, подлежащие обфускации, соответствуют местоположениям, имеющим более одного разрешенного символа, и вторые части, которые должны остаться необфусцированными, имеют только один разрешенный символ, содержащий символ–разделитель. Способ дополнительно содержит идентификацию, назначена ли часть первых частей, чтобы остаться различимой для уникальности после обфускации, и назначение части, чтобы остаться необфусцированной.
[0114] Функциональные блок–схемы, операционные сценарии и последовательности и блок–схемы последовательностей операций, показанные на чертежах, являются представлением примерных систем, сред и методологий для выполнения новых аспектов раскрытия. Хотя, в целях простоты объяснения, способы, включенные в настоящий документ, могут быть представлены в форме функциональной диаграммы, функционального сценария или последовательности или блок–схемы последовательности операций и могут быть описаны как последовательность действий, следует понимать, что способы не ограничены порядком действий, так как некоторые действия могут, в соответствии с этим, происходить в другом порядке и/или одновременно с другими действиями из тех, которые показаны и описаны в настоящем документе. Например, специалисты в данной области техники поймут, что способ может альтернативно быть представлен как последовательность взаимосвязанных состояний или событий, например, в диаграмме состояний. Более того, не все действия, проиллюстрированные в методологии, могут требоваться для новой реализации.
[0115] Описания и чертежи, включенные в настоящий документ, изображают конкретные реализации, чтобы показать специалистам в данной области техники, как должен осуществляться и использоваться лучший вариант. В целях раскрытия принципов, соответствующих изобретению, некоторые традиционные аспекты были упрощены или опущены. Специалистам в данной области техники будут поняты варианты этих реализаций, которые входят в объем раскрытия. Специалистам в данной области техники также будет понятно, что признаки, описанные выше, могут комбинироваться различными способами, чтобы формировать множество реализаций. В результате, изобретение не ограничено конкретными реализациями, описанными выше, а только пунктами формулы изобретения и их эквивалентами.
| название | год | авторы | номер документа |
|---|---|---|---|
| КОНФИГУРИРУЕМЫЕ ПРИМЕЧАНИЯ ДЛЯ ВЫСОКОКОНФИДЕНЦИАЛЬНОГО ПОЛЬЗОВАТЕЛЬСКОГО КОНТЕНТА | 2018 |
|
RU2764393C2 |
| Способ обработки данных пользователя | 2022 |
|
RU2785555C1 |
| ИНТЕРФЕЙСЫ ДЛЯ ПРИКЛАДНОГО ПРОГРАММИРОВАНИЯ ДЛЯ КУРИРОВАНИЯ КОНТЕНТА | 2014 |
|
RU2666302C2 |
| Способ и сервер для передачи персонализированного сообщения на пользовательское электронное устройство | 2017 |
|
RU2739720C2 |
| АССОЦИИРОВАНИЕ ИНФОРМАЦИИ С ЭЛЕКТРОННЫМ ДОКУМЕНТОМ | 2006 |
|
RU2406129C2 |
| ВИЗУАЛИЗАЦИЯ ПОЛЬЗОВАТЕЛЬСКОГО ИНТЕРФЕЙСА | 2005 |
|
RU2383919C2 |
| СЛУЖБА РЕПУТАЦИИ КОНТЕНТА НА ОСНОВЕ ДЕКЛАРАЦИИ | 2011 |
|
RU2573760C2 |
| Система предотвращения утечки информации и способ предотвращения утечки информации | 2024 |
|
RU2830388C1 |
| СИСТЕМА ПОСТАНОВКИ МЕТКИ КОНФИДЕНЦИАЛЬНОСТИ В ЭЛЕКТРОННОМ ДОКУМЕНТЕ, УЧЕТА И КОНТРОЛЯ РАБОТЫ С КОНФИДЕНЦИАЛЬНЫМИ ЭЛЕКТРОННЫМИ ДОКУМЕНТАМИ | 2017 |
|
RU2647643C1 |
| УСТРОЙСТВО БЕЗОПАСНОСТИ, СПОСОБ И СИСТЕМА ДЛЯ НЕПРЕРЫВНОЙ АУТЕНТИФИКАЦИИ | 2021 |
|
RU2786363C1 |
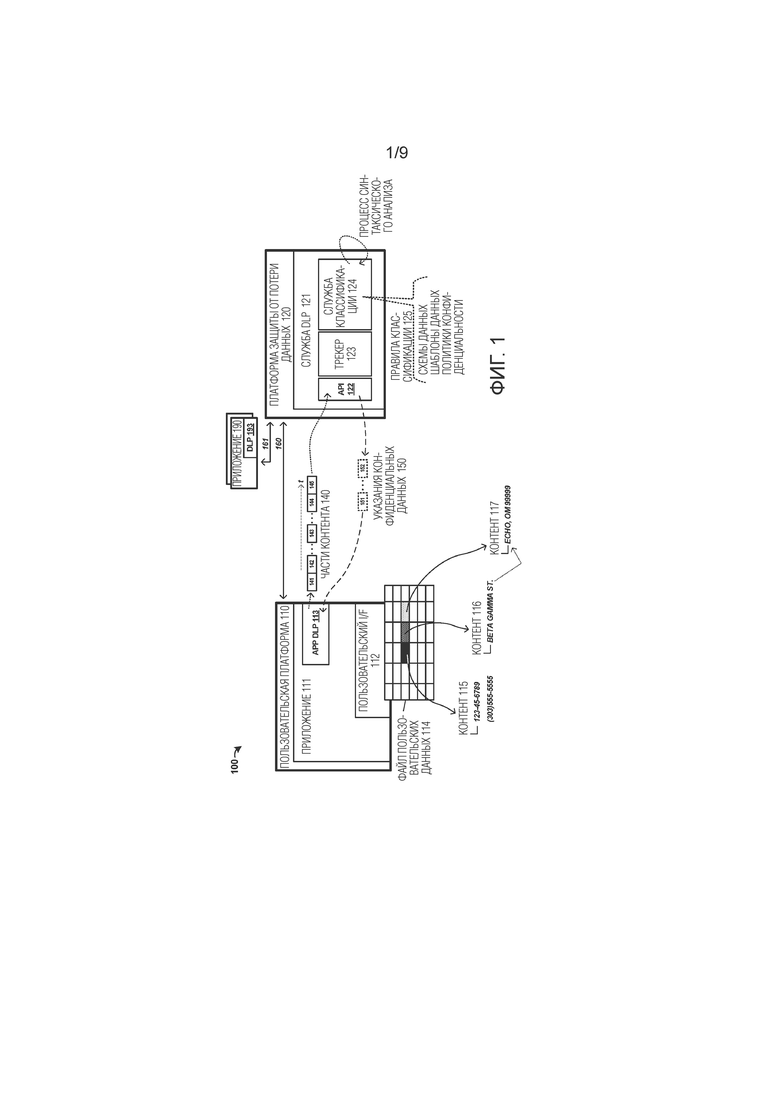
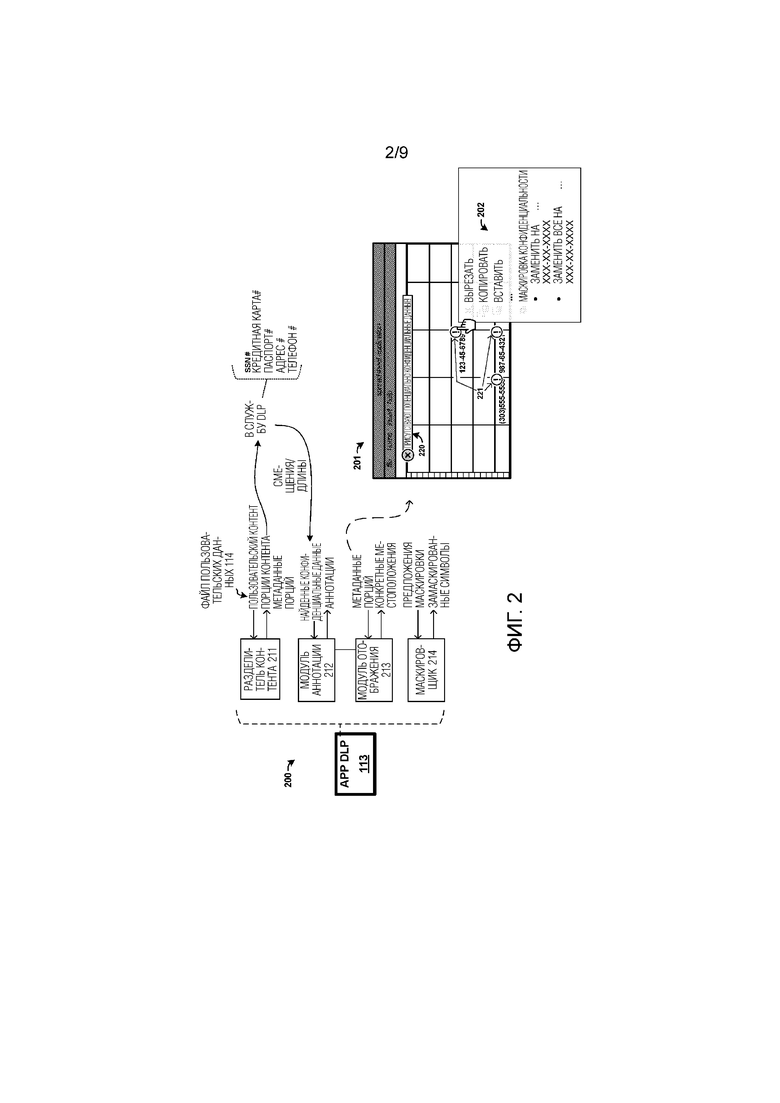
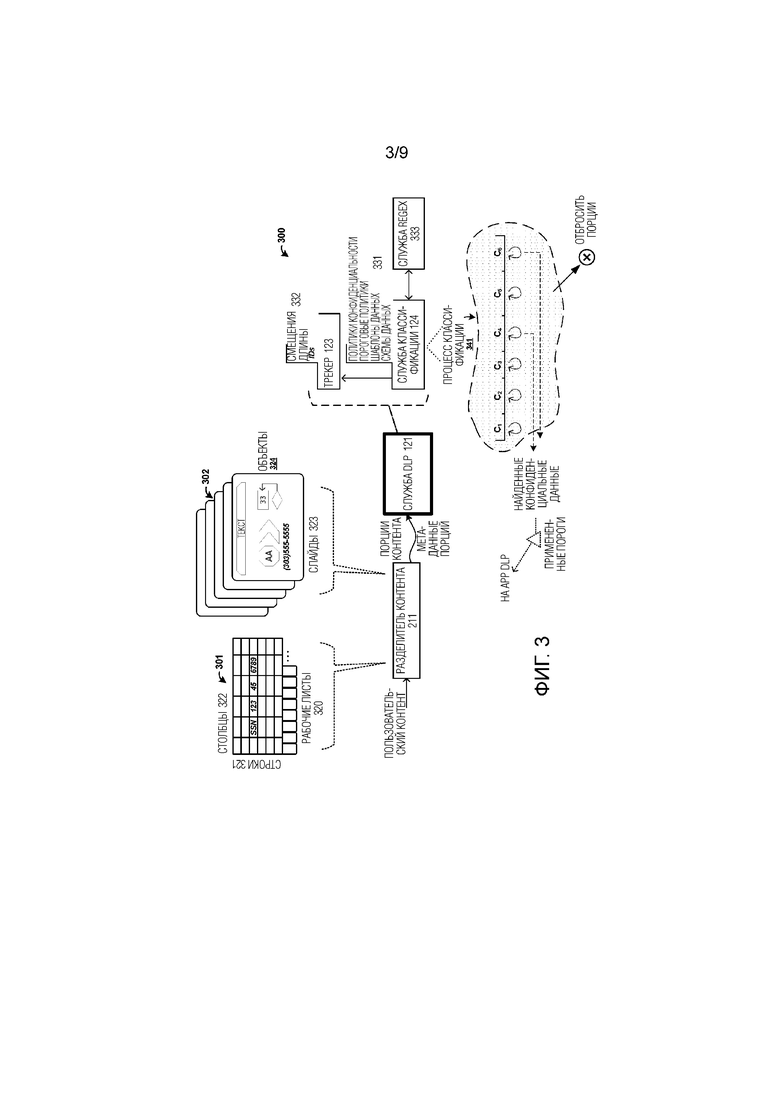
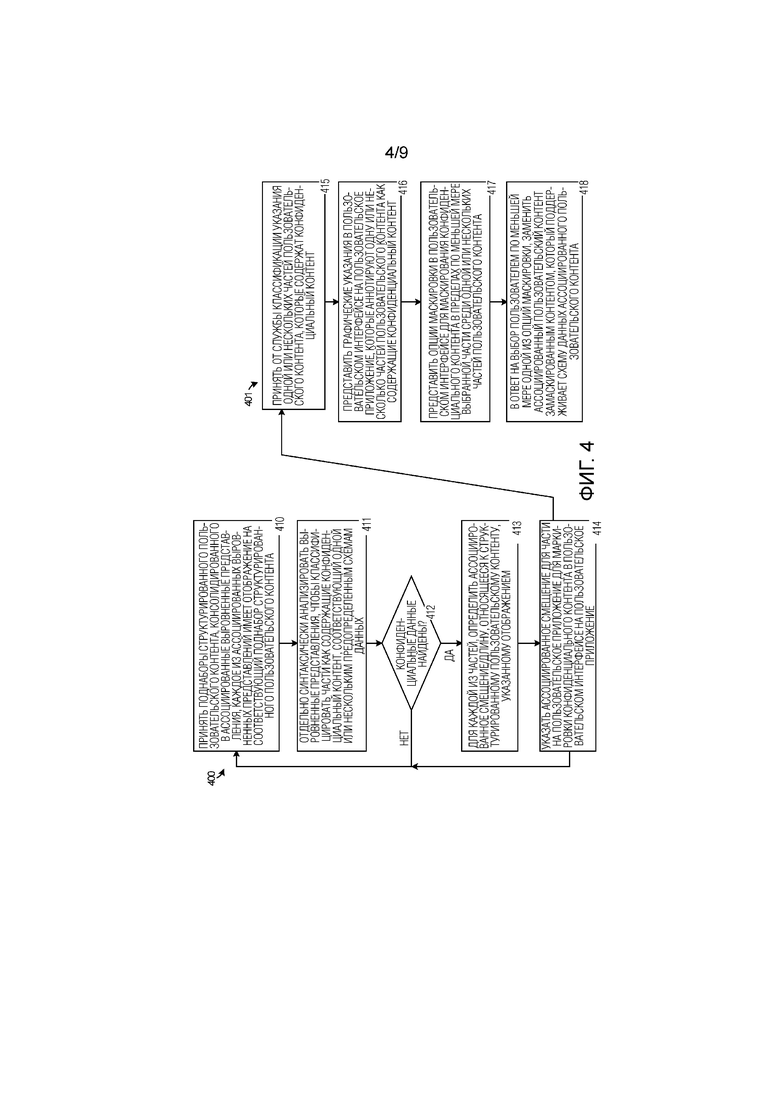
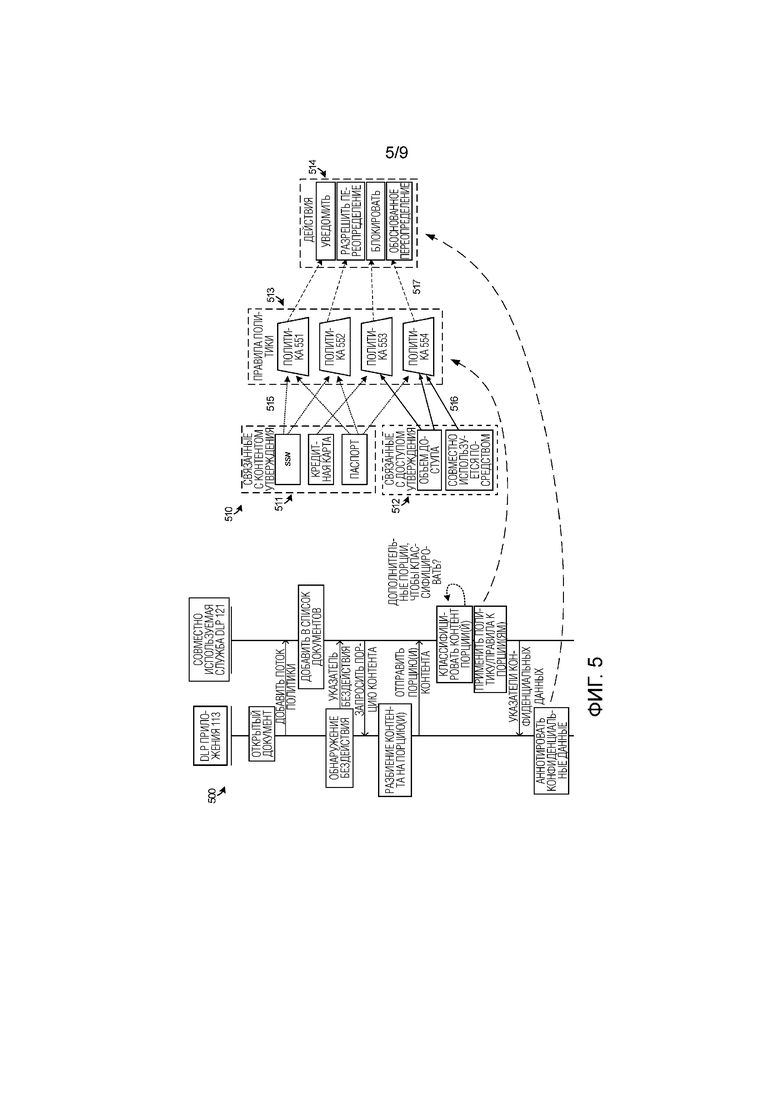
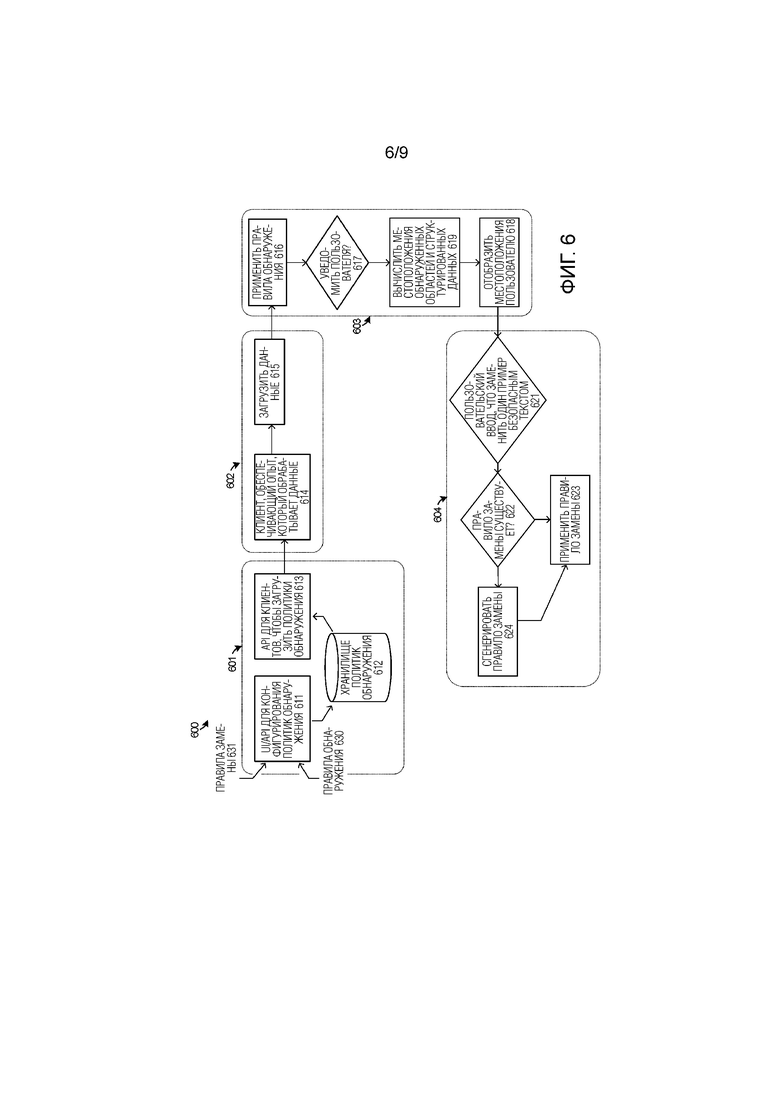
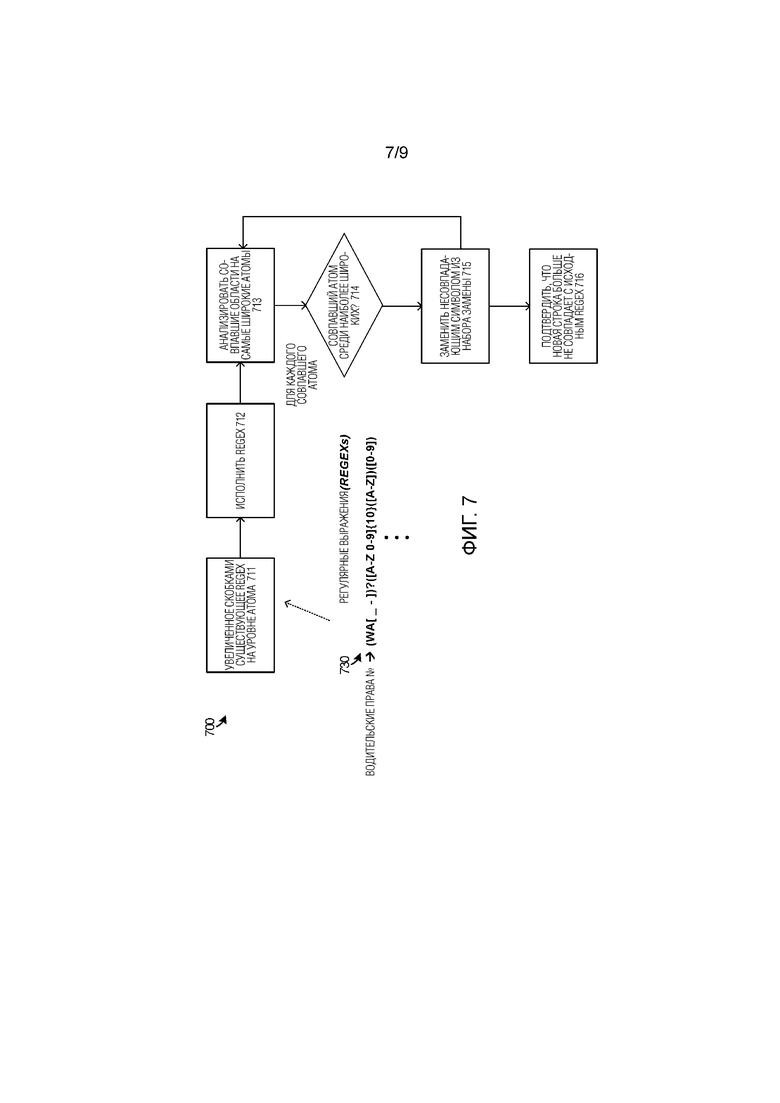
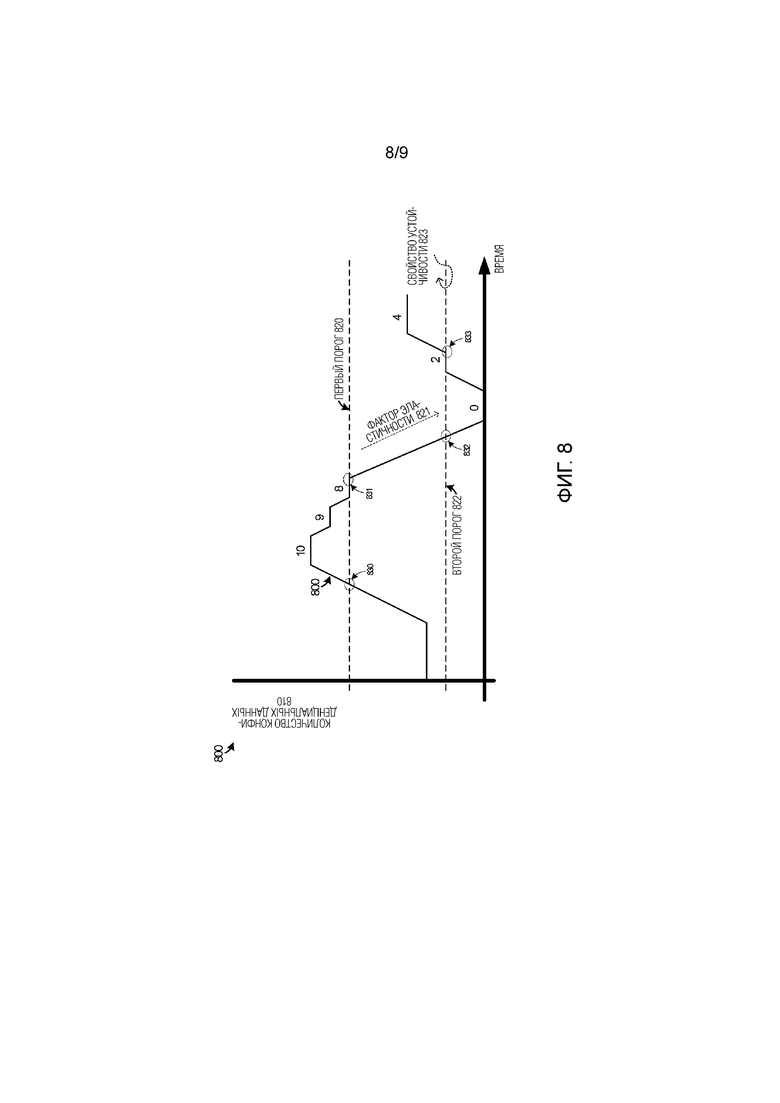
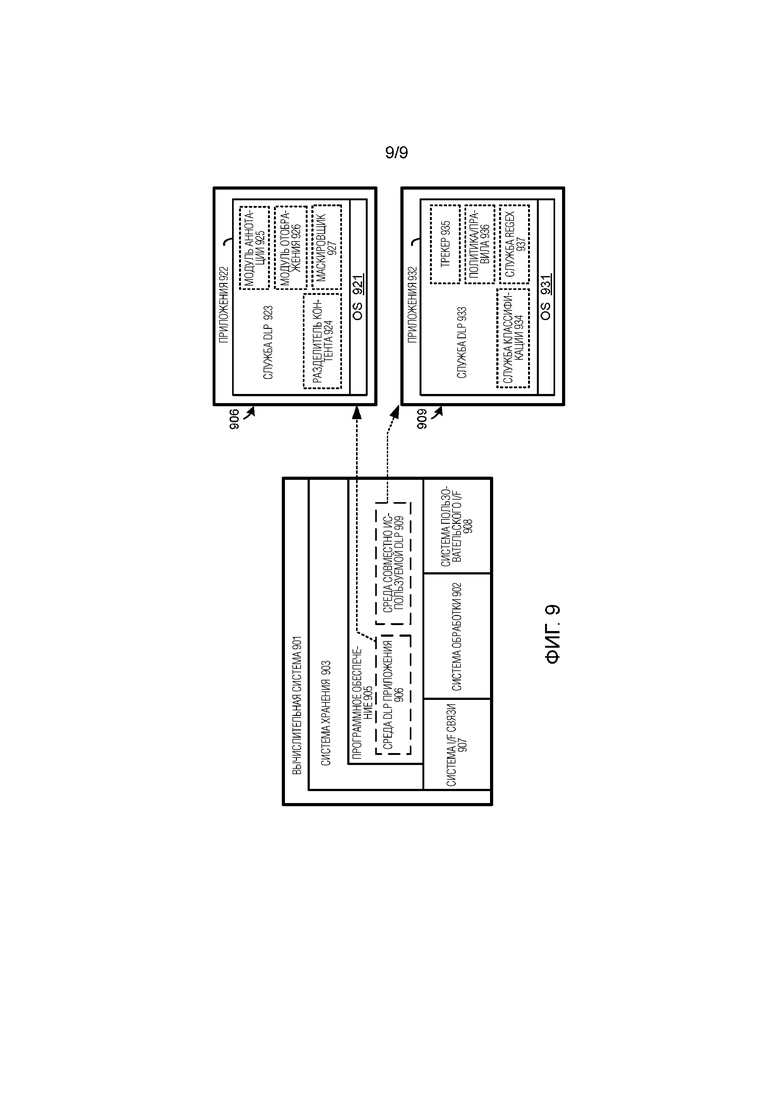
Изобретение относится к вычислительной технике. Технический результат заключается в обеспечении защиты от незаконного присвоения и ошибочного использования конфиденциальных данных пользователя. Способ обеспечения инфраструктуры обфускации данных для пользовательского приложения, содержащий: предоставление пользовательского контента в службу классификации, сконфигурированную, чтобы классифицировать части пользовательского контента как содержащие конфиденциальный контент; прием от службы классификации указаний местоположений в файле пользовательских данных частей пользовательского контента, которые содержат конфиденциальный контент; представление графических аннотаций, аннотирующих каждую из частей пользовательского контента в пользовательском интерфейсе как содержащую конфиденциальный контент; представление графических элементов выбора, которые указывают опции обфускации для маскирования конфиденциального контента; и в ответ на выбор пользователем опций обфускации, замену упомянутого ассоциированного пользовательского контента обфусцированным контентом. 3 н. и 17 з.п. ф-лы, 9 ил.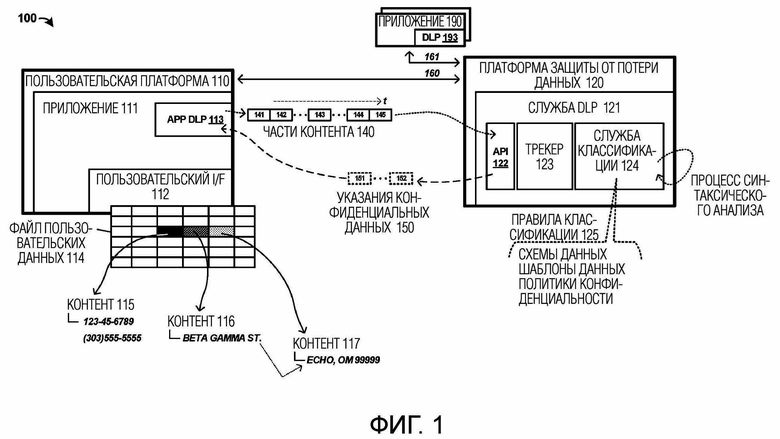
1. Способ обеспечения инфраструктуры обфускации данных для пользовательского приложения, причем способ содержит:
предоставление пользовательского контента, содержащего файл пользовательских данных, просматриваемый в пользовательском приложении, в службу классификации, сконфигурированную, чтобы обрабатывать пользовательский контент, чтобы классифицировать части пользовательского контента как содержащие конфиденциальный контент, соответствующий одной или нескольким предопределенным схемам данных;
прием от службы классификации указаний местоположений в файле пользовательских данных одной или нескольких частей пользовательского контента, которые содержат конфиденциальный контент;
перед маскированием конфиденциального контента, представление графических аннотаций, просматриваемых в пользовательском интерфейсе, в пользовательское приложение, которые аннотируют каждую из одной или нескольких частей пользовательского контента в пользовательском интерфейсе как содержащую конфиденциальный контент;
представление в пользовательском интерфейсе графических элементов выбора, которые соответствуют графическим аннотациям и указывают опции обфускации для маскирования конфиденциального контента; и
в ответ на выбор пользователем в пользовательском интерфейсе по меньшей мере одной из опций обфускации в графическом элементе выбора для ассоциированного пользовательского контента, замену по меньшей мере упомянутого ассоциированного пользовательского контента обфусцированным контентом, который поддерживает схему данных по меньшей мере упомянутого ассоциированного пользовательского контента.
2. Способ по п. 1, дополнительно содержащий:
представление опций обфускации как содержащих первую опцию, чтобы маскировать конфиденциальный контент в пределах выбранной части, и вторую опцию, чтобы маскировать конфиденциальный контент в пределах выбранной части и дополнительных частей пользовательского контента, содержащих дополнительный конфиденциальный контент, имеющий аналогичную схему данных, что и выбранная часть.
3. Способ по п. 1, дополнительно содержащий:
представление опций обфускации как указывающих по меньшей мере примерную обфусцированную версию целевого пользовательского контента в пределах выбранной части.
4. Способ по п. 1, причем графические аннотации, которые аннотируют каждую из одной или нескольких частей пользовательского контента, содержат указатели, расположенные вблизи каждой из одной или нескольких частей, которые доступны для выбора в пользовательском интерфейсе, чтобы представлять опции обфускации.
5. Способ по п. 1, причем обфусцированный контент, который поддерживает схему данных ассоциированного пользовательского контента, содержит символы, выбранные частично на основе схемы данных ассоциированного пользовательского контента, чтобы предотвратить идентификацию ассоциированного пользовательского контента при поддержании схемы данных ассоциированного пользовательского контента.
6. Способ по п. 1, дополнительно содержащий:
в ответ на замену ассоциированного пользовательского контента обфусцированным контентом, предоставление обфусцированного контента в службу классификации, чтобы подтвердить, что обфусцированный контент не содержит дополнительный конфиденциальный контент.
7. Способ по п. 1, причем одна или несколько предопределенных схем данных определяются посредством одного или нескольких регулярных выражений, используемых, чтобы синтаксически анализировать пользовательский контент, чтобы идентифицировать части как указывающие один или несколько предопределенных шаблонов контента или один или несколько предопределенных типов контента.
8. Способ по п. 1, причем одна или несколько предопределенных схем данных содержат, каждая, первые части, подлежащие обфускации, и вторые части, которые должны остаться необфусцированными, причем первые части, подлежащие обфускации, соответствуют местоположениям, имеющим более одного разрешенного символа, и вторые части, которые должны остаться необфусцированными, имеют только один разрешенный символ, содержащий символ–разделитель; и способ дополнительно содержит:
идентификацию, назначена ли некоторая часть первых частей, чтобы оставаться различимой для уникальности после обфускации, и назначение этой части оставаться необфусцированной.
9. Инфраструктура обфускации данных для пользовательского приложения, причем инфраструктура содержит:
один или несколько считываемых компьютером носителей хранения;
систему обработки, функционально связанную с одним или несколькими считываемыми компьютером носителями хранения; и
программные инструкции, хранящиеся на одном или нескольких считываемых компьютером носителях хранения, которые, на основе по меньшей мере считывания и исполнения системой обработки, направляют систему обработки, чтобы по меньшей мере:
предоставлять пользовательский контент, содержащий файл пользовательских данных, просматриваемый в пользовательском приложении, в службу классификации, сконфигурированную, чтобы обрабатывать пользовательский контент, чтобы классифицировать части пользовательского контента как содержащие конфиденциальный контент, соответствующий одной или нескольким предопределенным схемам данных;
принимать от службы классификации указания местоположений в файле пользовательских данных одной или нескольких частей пользовательского контента, которые содержат конфиденциальный контент;
перед маскированием конфиденциального контента, представлять графические аннотации, просматриваемые в пользовательском интерфейсе, для пользовательского приложения, которые аннотируют каждую из одной или нескольких частей пользовательского контента в пользовательском интерфейсе как содержащую конфиденциальный контент;
представлять в пользовательском интерфейсе графические элементы выбора, которые соответствуют графическим аннотациям и указывают опции обфускации для маскирования конфиденциального контента; и
в ответ на выбор пользователем в пользовательском интерфейсе по меньшей мере одной из опций обфускации в графическом элементе выбора для ассоциированного пользовательского контента, заменять по меньшей мере упомянутый ассоциированный пользовательский контент обфусцированным контентом, который поддерживает схему данных по меньшей мере упомянутого ассоциированного пользовательского контента.
10. Инфраструктура обфускации данных по п. 9, содержащая дополнительные программные инструкции, которые, на основе по меньшей мере считывания и исполнения системой обработки, направляют систему обработки, чтобы по меньшей мере:
представлять опции обфускации как содержащие первую опцию, чтобы маскировать конфиденциальный контент в пределах выбранной части, и вторую опцию, чтобы маскировать конфиденциальный контент в пределах выбранной части и дополнительных частей пользовательского контента, содержащих дополнительный конфиденциальный контент, имеющий аналогичную схему данных, что и выбранная часть.
11. Инфраструктура обфускации данных по п. 9, содержащая дополнительные программные инструкции, которые, на основе по меньшей мере считывания и исполнения системой обработки, направляют систему обработки, чтобы по меньшей мере:
представлять опции обфускации как указывающие по меньшей мере примерную обфусцированную версию целевого пользовательского контента в пределах выбранной части.
12. Инфраструктура обфускации данных по п. 9, причем графические аннотации, которые аннотируют каждую из одной или нескольких частей пользовательского контента, содержат указатели, расположенные вблизи каждой из одной или нескольких частей, которые доступны для выбора в пользовательском интерфейсе, чтобы представить опции обфускации.
13. Инфраструктура обфускации данных по п. 9, причем обфусцированный контент, который поддерживает схему данных ассоциированного пользовательского контента, содержит символы, выбранные частично на основе схемы данных ассоциированного пользовательского контента, чтобы предотвратить идентификацию ассоциированного пользовательского контента при поддержании схемы данных ассоциированного пользовательского контента.
14. Инфраструктура обфускации данных по п. 9, содержащая дополнительные программные инструкции, которые, на основе по меньшей мере считывания и исполнения системой обработки, направляют систему обработки, чтобы по меньшей мере:
в ответ на замену ассоциированного пользовательского контента обфусцированным контентом, предоставлять обфусцированный контент в службу классификации, чтобы подтвердить, что обфусцированный контент не содержит дополнительный конфиденциальный контент.
15. Инфраструктура обфускации данных по п. 9, причем одна или несколько предопределенных схем данных определяются посредством одного или нескольких регулярных выражений, используемых, чтобы синтаксически анализировать пользовательский контент, чтобы идентифицировать части как указывающие один или несколько предопределенных шаблонов контента или один или несколько предопределенных типов контента.
16. Инфраструктура обфускации данных по п. 9, причем одна или несколько предопределенных схем данных содержат, каждая, первые части, подлежащие обфускации, и вторые части, которые должны остаться необфусцированными, причем упомянутые первые части, подлежащие обфускации, соответствуют местоположениям, имеющим более одного разрешенного символа, и упомянутые вторые части, которые должны остаться необфусцированными, имеют только один разрешенный символ, содержащий символ–разделитель; и содержит дополнительные программные инструкции, которые, на основе по меньшей мере считывания и исполнения системой обработки, направляют систему обработки, чтобы по меньшей мере:
идентифицировать, назначена ли некоторая часть первых частей, чтобы оставаться различимой для уникальности после обфускации, и назначать этой части оставаться необфусцированной.
17. Способ работы пользовательского приложения, содержащий:
предоставление пользовательского контента файла пользовательских данных в службу классификации, сконфигурированную, чтобы обрабатывать пользовательский контент, чтобы классифицировать одну или несколько частей пользовательского контента как содержащие конфиденциальный контент, соответствующий одной или нескольким схемам данных;
перед маскированием конфиденциального контента, представление аннотаций в пользовательском интерфейсе, которые отмечают каждую из одной или нескольких частей пользовательского контента в пользовательском интерфейсе как содержащую конфиденциальный контент, при этом аннотации расположены вблизи каждой из одной или нескольких частей и доступны для выбора в пользовательском интерфейсе, чтобы представить опции обфускации;
в ответ на выбор первой из аннотаций, представление в пользовательском интерфейсе графических элементов выбора, которые соответствуют аннотациям и указывают первые опции обфускации для замены ассоциированного конфиденциального контента; и
в ответ на выбор пользователем в пользовательском интерфейсе по меньшей мере одной из первых опций обфускации, замену по меньшей мере упомянутого ассоциированного конфиденциального контента обфусцированным контентом, который поддерживает схему данных по меньшей мере упомянутого ассоциированного конфиденциального контента.
18. Способ по п. 17, дополнительно содержащий:
представление первых опций обфускации как содержащих первую опцию, чтобы замещать ассоциированный конфиденциальный контент обфусцированным контентом, и вторую опцию, чтобы заменять ассоциированный конфиденциальный контент и дополнительный конфиденциальный контент файла пользовательских данных, имеющего аналогичную схему данных, что и ассоциированный конфиденциальный контент.
19. Способ по п. 17, в котором обфусцированный контент, который поддерживает схему данных ассоциированного конфиденциального контента, содержит один или несколько символов, выбранных, чтобы предотвратить идентификацию ассоциированного конфиденциального контента во время поддержания схемы данных ассоциированного пользовательского контента, при этом один или несколько символов выбираются частично на основе схемы данных ассоциированного конфиденциального контента.
20. Способ по п. 17, в котором одна или несколько схем данных содержат, каждая, первые части, подлежащие обфускации, и вторые части, которые должны остаться необфусцированными, причем упомянутые первые части, подлежащие обфускации, соответствуют местоположениям, имеющим более одного разрешенного символа, и упомянутые вторые части, которые должны остаться необфусцированными, имеют только один разрешенный символ, содержащий символ–разделитель; и дополнительно содержащий:
идентификацию, назначена ли некоторая часть первых частей, чтобы оставаться различимой для уникальности после обфускации, и назначение этой части оставаться необфусцированной.
| Колосоуборка | 1923 |
|
SU2009A1 |
| Приспособление для суммирования отрезков прямых линий | 1923 |
|
SU2010A1 |
| Изложница с суживающимся книзу сечением и с вертикально перемещающимся днищем | 1924 |
|
SU2012A1 |
| Изложница с суживающимся книзу сечением и с вертикально перемещающимся днищем | 1924 |
|
SU2012A1 |
| УПРАВЛЕНИЕ ОНЛАЙНОВОЙ КОНФИДЕНЦИАЛЬНОСТЬЮ | 2011 |
|
RU2550531C2 |

