Уровень техники
[0001] Различные офисные пользовательские приложения предоставляют возможность ввода данных и анализа пользовательского контента. Эти приложения могут предоставлять создание, редактирование и анализ контента с использованием электронных таблиц, презентаций, текстовых документов, мультимедийных документов, форматов обмена сообщениями или других форматов пользовательского контента. В числе этого пользовательского контента, различная текстовая, буквенно–цифровая или другая символьно–ориентированная информация может включать в себя конфиденциальные данные, которые пользователи или организации могут не хотеть включать в опубликованные или распределенные работы. Например, электронная таблица может включать в себя номера социального страхования (SSN), информацию кредитных карт, идентификаторы субъектов медицинской помощи или другую информацию. Хотя пользователь, вводящий эти данные или пользовательский контент, может иметь авторизацию на то, чтобы просматривать конфиденциальные данные, другие субъекты или конечные точки распределения могут не иметь такой авторизации.
[0002] Технологии защиты и управления информацией могут упоминаться как защита от потерь данных (DLP), которая пытается не допускать неправомерного присвоения и нерационального выделения этих конфиденциальных данных. В определенных форматах контента или типах контента, к примеру, включенных в электронные таблицы, презентации на основе слайдов и приложения для создания графических диаграмм, пользовательский контент может быть включен в различные ячейки, объекты или другие структурированные или полуструктурированные объекты данных. Кроме того, конфиденциальные данные могут разбиваться более чем между одним объектом данных. Трудности могут возникать при попытке идентифицировать и защищать от потерь конфиденциальных данных, когда такие документы включают в себя конфиденциальные данные.
Сущность изобретения
[0003] В данном документе предоставляются системы, способы и программное обеспечение для инфраструктур снабжения примечаниями (аннотирования) для обеспечения конфиденциальности данных для пользовательских приложений. Примерный способ включает в себя идентификацию, по меньшей мере, первой пороговой величины, коэффициента эластичности для изменения первой пороговой величины на вторую пороговую величину и указание свойства пороговой устойчивости, указывающее то, когда вторая пороговая величина переопределяет (замещает) первую пороговую величину. Способ включает в себя отслеживание процесса редактирования контента пользовательского контента таким образом, чтобы идентифицировать количество элементов пользовательского контента, которые содержат конфиденциальные данные, соответствующие одной или более предварительно определенным схемам данных, и в ходе процесса редактирования контента, активацию и деактивацию представления индикаторов примечаний для элементов контента, по меньшей мере, отчасти на основе текущего количества относительно первой пороговой величины, коэффициента эластичности для первой пороговой величины при его применении и указания свойства пороговой устойчивости.
[0004] Это краткое изложение сущности изобретения приведено для представления в упрощенной форме подборки концепций, которые дополнительно описаны ниже в подробном описании. Следует понимать, что данное краткое изложение сущности изобретения не имеет намерением ни для идентификации ключевых признаков или важнейших признаков заявленного изобретения, ни для использования в целях ограничения объема заявленного изобретения.
Краткое описание чертежей
[0005] Множество аспектов раскрытия могут лучше пониматься в отношении нижеприведенных чертежей. Хотя несколько реализаций описываются в связи с этими чертежами, раскрытие не ограничено реализациями, раскрытыми в данном документе. Наоборот, намерение состоит в том, чтобы охватывать все альтернативы, модификации и эквиваленты.
[0006] Фиг. 1 иллюстрирует окружение защиты от потерь данных в примере.
[0007] Фиг. 2 иллюстрирует элементы окружения защиты от потерь данных в примере.
[0008] Фиг. 3 иллюстрирует элементы окружения защиты от потерь данных в примере.
[0009] Фиг. 4 иллюстрирует операции окружений защиты от потерь данных в примере.
[0010] Фиг. 5 иллюстрирует операции окружений защиты от потерь данных в примере.
[0011] Фиг. 6 иллюстрирует операции окружений защиты от потерь данных в примере.
[0012] Фиг. 7 иллюстрирует операции окружений защиты от потерь данных в примере.
[0013] Фиг. 8 иллюстрирует операции с пороговыми значениями данных окружений защиты от потерь данных в примере.
[0014] Фиг. 9 иллюстрирует вычислительную систему, подходящую для реализации любой из архитектур, процессов, платформ, служб и рабочих сценариев, раскрытых в данном документе.
Подробное описание изобретения
[0015] Офисные пользовательские приложения предоставляют создание, редактирование и анализ пользовательских данных и контента с использованием электронных таблиц, слайдов, элементов векторной графики, документов, почтовых сообщений, контента обмена сообщениями, баз данных или других форматов и типов данных приложений. В пользовательский контент может быть включена различная текстовая, буквенно–цифровая или другая символьно–ориентированная информация. Например, электронная таблица может включать в себя номера социального страхования (SSN), информацию кредитных карт, идентификаторы субъектов медицинской помощи, номера паспорта или другую информацию. Хотя пользователь, вводящий эти данные или пользовательский контент, может иметь авторизацию на то, чтобы просматривать конфиденциальные данные, другие субъекты или конечные точки распределения могут не иметь такой авторизации. Могут устанавливаться различные политики конфиденциальности или правила конфиденциальности данных, которые указывают то, какие типы данных или пользовательского контента являются конфиденциальными по своему характеру. Улучшенные показатели защиты от потерь данных (DLP), поясненные в данном документе, могут быть включены для того, чтобы пытаться не допускать неправомерного присвоения и нерационального выделения этих конфиденциальных данных.
[0016] В определенных форматах контента или типах контента, к примеру, включенных в электронные таблицы, презентации на основе слайдов и приложения для создания графических диаграмм, пользовательский контент может быть включен в различные ячейки, объекты или другие структурированные или полуструктурированные объекты данных. Кроме того, конфиденциальные данные могут разбиваться более чем между одним элементом или записью данных. Примеры в данном документе предоставляют улучшенную идентификацию конфиденциальных данных в файлах пользовательских данных, которые включают в себя структурированные элементы данных. Кроме того, примеры в данном документе предоставляют улучшенные пользовательские интерфейсов для предупреждения пользователей относительно конфиденциальных данных. Эти элементы пользовательского интерфейса могут включать в себя отметку отдельных содержащих конфиденциальные данные элементов данных, а также пороговые значения для предупреждения во время редактирования контента.
[0017] В одном примерном приложении, которое использует структурированные элементы данных, к примеру, в приложении для обработки электронных таблиц, данные могут вводиться в ячейки, которые размещаются в столбцах и строках. Каждая ячейка может содержать пользовательские данные или пользовательский контент и также может включать в себя одно или более выражений, которые используются для того, чтобы выполнять вычисления, которые могут ссылаться на вводимые пользователем данные в одной или более других ячеек. Другие пользовательские приложения, такие как приложения создания презентаций в форме слайд–шоу, могут включать в себя пользовательский контент более чем на одном слайде, а также в объектах, включенных в эти слайды.
[0018] Преимущественно, примеры и реализации предоставляются в данном документе для улучшенных операций и структур для служб защиты от потерь данных. Эти улучшенные операции и структуры имеют технические эффекты более быстрой идентификации конфиденциального контента в пределах документов, в частности, для структурированных документов, таких как электронные таблицы, презентации, графические чертежи и т.п. Кроме того, несколько приложений могут совместно использовать одну службу классификации, которая предоставляет обнаружение и идентификацию конфиденциального контента в файлах пользовательских данных во множестве различных приложений и конечных пользовательских платформ. Процессы снабжения примечаниями и запутывания на конечном пользовательском уровне также предоставляют значительные преимущества и технические эффекты в пользовательских интерфейсах для приложений. Например, пользователям могут представляться графические примечания конфиденциального контента и раскрывающиеся диалоговые окна, которые представляют различные опции запутывания или маскирования. Различные улучшенные пороговые значения по примечаниям также могут устанавливаться с возможностью динамически указывать конфиденциальный контент пользователям, чтобы задавать редактирование пользовательского контента и запутывание конфиденциальных данных более эффективным и совместимым с различными политиками и правилами защиты от потерь данных.
[0019] В качестве первого примера окружения защиты от потерь данных для пользовательского приложения, предоставляется фиг. 1. Фиг. 1 иллюстрирует окружение 100 защиты от потерь данных в примере. Окружение 100 включает в себя пользовательскую платформу 110 и платформу 120 для защиты от потерь данных. Элементы по фиг. 1 могут обмениваться данными по одной или более физических или логических линий связи. На фиг. 1, показаны линии 160–161 связи. Тем не менее, следует понимать, что эти линии связи являются только примерными, и могут быть включены одна или более дополнительных линий связи, которые могут включать в себя беспроводные, проводные, оптические или логические части.
[0020] Инфраструктура защиты от потерь данных может включать в себя часть, локальную для конкретного пользовательского приложения, и совместно используемую часть, используемую во множестве приложений. Пользовательская платформа 110 предоставляет окружение приложений для пользователя, чтобы взаимодействовать с элементами пользовательского приложения 111 через пользовательский интерфейс 112. Во время пользовательского взаимодействия с приложением 111, могут выполняться ввод контента и манипулирование контентом. Модуль 113 защиты от потерь данных (DLP) приложений может предоставлять части функциональности для снабжения примечаниями и замены конфиденциальных данных в приложении 111. DLP–модуль 113 приложений является локальным для пользовательской платформы 110 в этом примере, но вместо этого может быть отдельным или интегрированным в приложение 111. DLP–модуль 113 приложений может предоставлять снабжение примечаниями и замену конфиденциальных данных пользователей и приложение 111. Платформа 120 для защиты от потерь данных предоставляет совместно используемую инфраструктуру защиты потерь части данных и предоставляет совместно используемую DLP–службу 121 для совместного использования множеством приложений, к примеру, приложений 190 с ассоциированной DLP–частью 193 местоположений.
[0021] При работе, приложение 111 предоставляет пользовательский интерфейс 112, через который пользователи могут взаимодействовать с приложением 111, к примеру, чтобы вводить, редактировать и иным образом манипулировать пользовательским контентом, который может загружаться через один или более файлов данных или вводиться через пользовательский интерфейс 112. На фиг. 1, рабочая книга электронной таблицы показана с ячейками, размещаемыми в строках и столбцах. В качестве части приложения 111, предоставляется служба защиты от потерь данных, которая идентифицирует конфиденциальный пользовательский контент и обеспечивает возможность пользователям заменять конфиденциальный пользовательский контент безопасным текстом или данными. Конфиденциальный контент содержит контент, который может иметь проблемы конфиденциальности, политики/правила конфиденциальности или другие свойства, для которых распределение является нежелательным или нежелательным. Потери данных в этом контексте означают распределение конфиденциальных или чувствительных данных неавторизованным пользователям или конечным точкам.
[0022] Чтобы идентифицировать конфиденциальный контент, приложение 111 предоставляет разделение пользовательского контента на фрагменты или порции пользовательского контента в службу защиты от потерь данных. На фиг. 1, показаны части 140 контента с предоставлением отдельных частей 141–145 контента во времени в DLP–службу 121. Типично, приложение 111 может обрабатывать пользовательский контент, чтобы разделять пользовательский контент на части в течение периодов бездействующего режима, к примеру, когда один или более подпроцессов обработки, связанных с приложением 111, являются бездействующими или ниже пороговых значений операций. Как пояснено в данном документе, структурированный пользовательский контент преобразуется в "сглаженную" или неструктурированную компоновку в ходе процесса разделения. Эта неструктурированная компоновка имеет несколько преимуществ для обработки посредством DLP–службы 121.
[0023] DLP–служба 121 затем обрабатывает каждую часть или "порцию" пользовательского контента отдельно, чтобы определять то, содержат или нет части конфиденциальный контент. Различные правила 125 классификации, такие как схемы данных, шаблоны данных или политики/правила конфиденциальности, могут вводиться в DLP–службу 121 для идентификации конфиденциальных данных. После того, как DLP–служба 121 синтаксически анализирует (разбирает) каждую отдельную порцию пользовательского контента, смещения местоположения конфиденциальных данных в файле пользовательских данных определяются и указываются для DLP–службы 113 приложений. Функция модуля привязки в DLP–службе 113 приложений определяет структурную взаимосвязь между смещениями порций и структурой документа. Индикаторы относительно смещений местоположения, длин конфиденциальных данных и типов конфиденциальных данных могут предоставляться в приложение 111, как видно, например, индикаторы 150 конфиденциальных данных. Смещения местоположения, указываемые DLP–службой 121, не могут формировать точное или конкретное местоположение из структурных элементов файла пользовательских данных для конфиденциального контента. В этих случаях, процесс привязки может использоваться DLP–службой 113 приложений приложения 111 для того, чтобы определять конкретные структурные элементы, которые содержат конфиденциальные данные.
[0024] После того, как конкретные местоположения определяются, в таком случае приложение 111 может снабжать примечаниями конфиденциальные данные в пользовательском интерфейсе 112. Это снабжение примечаниями может включать в себя глобальную или отдельную пометку флагами или отметку конфиденциальных данных. Примечания могут содержать "подсказки по политике", представленные в пользовательском интерфейсе. Пользователям в таком случае могут представляться одна или более опций для запутывания или иного обеспечения неидентифицируемость пользовательского контента в качестве исходного конфиденциального контента. Могут устанавливаться различные пороговые значения по уведомлению относительно конфиденциального контента, которые инициируются по количествам или величинам конфиденциальных данных, присутствующих в файле пользовательских данных.
[0025] В одном примере, файл 114 пользовательских данных включает в себя контент 115, 116 и 117 в конкретных ячейках файла 114 пользовательских данных, который может быть ассоциирован с конкретным рабочим листом или страницей рабочей книги электронной таблицы. Различный контент может быть включен в ассоциированные ячейки, и этот контент может содержать потенциально конфиденциальные данные, такие как примеры, приведенные на фиг. 1, для SSN, телефонных номеров и адресов. Часть этого контента может пересекать структурные границы в файле пользовательских данных, к примеру, с охватом нескольких ячеек или с охватом нескольких графических объектов. Если "порция" разделяет данные на строки или группировки строк, то сглаженные представления (т.е. не содержащие структурный контент) по–прежнему могут идентифицировать конфиденциальные данные в одной или более ячеек.
[0026] Элементы каждой из пользовательской платформы 110 и DLP–платформы 120 могут включать в себя интерфейсы связи, сетевые интерфейсы, системы обработки, компьютерные системы, микропроцессоры, системы хранения данных, носители хранения данных либо некоторые другие обрабатывающие устройства или программные системы и могут быть распределены по нескольким устройствам или по нескольким географическим местоположениям. Примеры элементов каждой из пользовательской платформы 110 и DLP–платформы 120 могут включать в себя программное обеспечение, такое как операционная система, приложения, журналы регистрации, интерфейсы, базы данных, утилиты, драйверы, сетевое программное обеспечение и другое программное обеспечение, сохраненное на машиночитаемом носителе. Элементы каждой из пользовательской платформы 110 и DLP–платформы 120 могут содержать одну или более платформ, которые размещаются посредством распределенной вычислительной системы или облачной вычислительной службы. Элементы каждой из пользовательской платформы 110 и DLP–платформы 120 могут содержать элементы логического интерфейса, такие как программно–определяемые интерфейсы и интерфейсы прикладного программирования (API).
[0027] Элементы пользовательской платформы 110 включают в себя приложение 111, пользовательский интерфейс 112 и DLP–модуль 113 приложений. В этом примере, приложение 111 содержит приложение для обработки электронных таблиц. Следует понимать, что пользовательское приложение 111 может содержать любое пользовательское приложение, к примеру, офисные приложения, приложения связи, приложения для средств социального общения, игровые приложения, мобильные приложения или другие приложения. Пользовательский интерфейс 112 содержит элементы графического пользовательского интерфейса, которые могут формировать вывод для отображения пользователю и принимать ввод от пользователя. Пользовательский интерфейс 112 может содержать элементы, поясненные ниже на фиг. 9 для пользовательской интерфейсной системы 908. DLP–модуль 113 приложений содержит один или более программных элементов, выполненных с возможностью разделять контент для доставки в службу классификации, снабжать примечаниями данные, указываемые как конфиденциальные, и запутывать конфиденциальные данные, в числе других операций.
[0028] Элементы DLP–платформы 120 включают в себя DLP–службу 121. DLP–служба 121 включает в себя внешний интерфейс в форме интерфейса 122 прикладного программирования (API), хотя могут использоваться другие интерфейсы. DLP–служба 121 также включает в себя модуль 123 отслеживания и службу 124 классификации, которые подробнее поясняются ниже. API 122 может включать в себя один или более пользовательских интерфейсов, таких как веб–интерфейсы, API, терминальные интерфейсы, консольные интерфейсы, интерфейсы командной оболочки, интерфейсы расширяемого языка разметки (XML), в числе других. Модуль 123 отслеживания поддерживает количества или величины конфиденциальных данных, обнаруженных для конкретного документа в сглаженных частях структурированного пользовательского контента, а также поддерживает запись смещений местоположения в сглаженных частях структурированного пользовательского контента, которые соответствуют местоположениям конфиденциальных данных в структурированном пользовательском контенте. Модуль 123 отслеживания также может выполнять анализ пороговых значений, чтобы определять то, когда пороговые величины конфиденциальных данных обнаружены и должны снабжаться примечаниями посредством DLP–модуля 113 приложений. Тем не менее, в других примерах, части пороговых значений/количеств DLP–службы 121 могут быть включены в DLP–модуль 113. Служба 124 классификации синтаксически анализирует сглаженный пользовательский контент, чтобы определять присутствие конфиденциальных данных, и может использовать различные вводы, которые задают правила и политики для идентификации конфиденциальных данных. Элементы DLP–модуля 113 приложений и совместно используемой DLP–службы 121 могут быть сконфигурированы в различных компоновках или распределениях, которые показаны на фиг. 1, к примеру, когда части совместно используемой DLP–службы 121 включены в DLP–модуль 113 приложений или приложение 111, в числе других конфигураций. В одном примере, части совместно используемой DLP–службы 121 содержат динамически подключаемую библиотеку (DLL), включенную в пользовательскую платформу 110 для использования посредством приложения 111 и DLP–модуля 113 приложений.
[0029] Линии 160–161 связи, наряду с другими линиями связи, не показанными в числе элементов по фиг. 1 для ясности, могут содержать одну или более линий связи, к примеру, одну или более сетевых линий связи, содержащих беспроводные или проводные сетевые линии связи. Линии связи могут содержать различные логические интерфейсы, физические интерфейсы или интерфейсы прикладного программирования. Примерные линии связи могут использовать металл, стекло, оптику, воздух, пространство либо некоторый другой материал в качестве транспортных сред. Линии связи могут использовать различные протоколы связи, такие как Интернет–протокол (IP), Ethernet, гибридная волоконно–оптическая/коаксиальная линия (HFC), синхронные оптические сети (SONET), режим асинхронной передачи (ATM), мультиплексирование с временным разделением каналов (TDM), режим с коммутацией каналов, передача служебных сигналов связи, беспроводная связь либо некоторый другой формат связи, включающий в себя комбинации, улучшения или варьирования означенного. Линии связи могут представлять собой прямые линии связи или могут включать в себя промежуточные сети, системы или устройства и могут включать в себя логическую сетевую линию связи, транспортируемую по нескольким физическим линиям связи.
[0030] Для дополнительного пояснения элементов и работы окружения 100, представляется фиг. 2. Фиг. 2 является конфигурацией иллюстративного примера блок–схемы 200 из DLP–модуля 113 приложений, который выделяет яркостью примерные операции DLP–модуля 113 приложений, в числе других элементов. На фиг. 2, DLP–модуль 113 приложений включает в себя модуль 211 разделения контента, модуль 212 снабжения примечаниями, модуль 213 привязки и модуль 214 запутывания. Каждый из элементов 211–214 может содержать программные модули, используемые посредством DLP–модуля 113 приложений для того, чтобы работать так, как пояснено ниже.
[0031] При работе, пользовательский контент предоставляется в DLP–модуль 113 приложений, такой как файл электронной таблицы или рабочая книга, как видно на фиг. 1 для файла 114 пользовательских данных. Этот файл пользовательских данных может организовываться в структурированный или полуструктурированный формат, такой как ячейки, организованные посредством строк и столбцов для примера на основе электронных таблиц. Вместо этого могут использоваться другие форматы данных, такие как презентации в форме слайд–шоу, имеющие страницы/слайды и множество отдельных графических объектов, векторные чертежные программы с различными объектами на различных страницах, документы, создаваемые в текстовом процессоре с различными объектами (таблицами, текстовыми полями, изображениями), базы данных, контент веб–страниц или другие форматы, включающие в себя комбинации вышеозначенного. Файлы пользовательских данных могут содержать конфиденциальный контент или конфиденциальные данные. Эти конфиденциальные данные могут включать в себя любой пользовательский контент, который соответствует одному или более шаблонам или схемам данных. Примерные типы конфиденциальных данных включают в себя номера социального страхования, номера кредитных карт, номера паспорта, адреса, телефонные номера или другую информацию.
[0032] Параллельно с редактированием или просмотром файла пользовательских данных, модуль 211 разделения контента подразделяет пользовательский контент на одну или более частей или "порций", которые имеют сглаженную форму относительно исходной/собственной структурированной или иерархической формы. Модуль 211 разделения контента затем может предоставлять эти порции контента в совместно используемую DLP–службу 121, наряду с метаданными порций для каждой порции. Метаданные порций могут указывать различные свойства порций, такие как смещение местоположения порции в полном контенте и длина порции. Смещение местоположения соответствует местоположению порции относительно полного пользовательского документа/файла, и длина порции соответствует размеру порции.
[0033] Совместно используемая DLP–служба 121 отдельно синтаксически анализирует порции контента таким образом, чтобы идентифицировать конфиденциальные данные для сглаженного пользовательского контента порций и предоставляет индикаторы относительно конфиденциальных данных обратно в DLP–модуль 113 приложений. В некоторых примерах, поясненных ниже, различные пороговые значения применяются к количествам или величинам конфиденциальных данных до того, как индикаторы предоставляются в DLP–модуль 113 приложений. Индикаторы содержат смещения для каждой из порций, которые содержат конфиденциальные данные, длины порций и необязательно индикаторы типов данных или схем данных, ассоциированных с конфиденциальными данными. Индикаторы конфиденциальных данных могут использоваться для того, чтобы определять фактические или конкретные местоположения конфиденциального контента из структурированных данных файла пользовательских данных. Индикаторы типов данных могут представлять собой символически или численно кодированные индикаторы, такие как целочисленные значения, которые ссылаются на перечень индикаторов, которые модуль 213 привязки может использовать для того, чтобы идентифицировать типы данных для снабжения примечаниями.
[0034] Модуль 213 привязки может использоваться для того, чтобы преобразовывать смещения и длины в конкретные местоположения в документе или пользовательском файле. Смещения и длины соответствуют конкретным идентификационным данным порции, которые поддерживаются посредством модуля 213 привязки и сохраняются в ассоциации с идентификатором сеанса. Идентификатор сеанса может представлять собой уникальный идентификатор, который сохраняется, по меньшей мере, в течение сеанса, в ходе которого пользователь имеет открытый или просматриваемый документ. Модуль 213 привязки может содержать метаданные порций из модуля 211 разделения контента таким образом, чтобы формировать взаимосвязи привязки между смещениями, длинами порций и идентификаторами сеансов. В ответ на прием индикаторов относительно конфиденциальных данных, модуль 213 привязки может использовать взаимосвязи привязки, чтобы идентифицировать приблизительные местоположения, указываемые для конфиденциальных данных в пределах документа, которые соответствуют смещению порции и длинам. Поскольку порции могут охватывать более одного структурного или иерархического элемента файла пользовательских данных, модуль 213 привязки может выполнять дополнительные процессы определения местоположения, чтобы обнаруживать конкретные местоположения в файле пользовательских данных для конфиденциальных данных.
[0035] Например, смещения могут указывать приблизительные местоположения, такие как конкретная строка или конкретный столбец в электронной таблице. Чтобы определять конкретное местоположение, такое как ячейка в указываемой строке или столбце, модуль 213 привязки может использовать смещения/длины наряду с локальным знанием структурированных данных и непосредственно файла пользовательских данных, чтобы находить конфиденциальный контент из структурированных данных. Модуль 213 привязки определяет то, из какого места в файле пользовательских данных предоставляются порции, к примеру, ассоциированные строки, столбцы, рабочие листы для примеров на основе электронных таблиц и ассоциированные слайды/страницы и объекты для примеров на основе слайд–шоу. Другие примеры, к примеру, примеры на основе обработки текстов, могут не иметь крупной структуры, и контент проще сглаживается, и смещения могут быть основаны на количествах слов в документе или аналогичном позиционировании.
[0036] В некоторых примерах, конкретные местоположения определяются посредством поиска конфиденциального контента в конкретном приблизительном местоположении. Когда несколько структурных элементов или иерархических элементов вовлечены посредством конкретного смещения, модуль 213 привязки может итеративно выполнять поиск или обходить через каждый из элементов, чтобы находить конфиденциальные данные. Например, если существуют n уровней структуры/иерархии в документе, то модуль 213 привязки может осуществлять навигацию по верхним иерархиям сначала и затем нижним иерархиям впоследствии. В примерах на основе электронных таблиц, иерархия/структура может содержать рабочие листы, имеющие ассоциированные строки и столбцы. В примерах на основе документов в форме презентации, иерархия/структура может содержать слайды/страницы, имеющие ассоциированные формы/объекты. Каждый рабочий лист и слайд, указываемые посредством смещения, могут проходиться, чтобы обнаруживать ячейки или объекты, которые содержат конфиденциальный контент. В дополнительных примерах, нахождение конфиденциальных данных может выполняться посредством воссоздания одной или более порций, ассоциированных с приблизительным местоположением, и обнаружения конфиденциальных данных в этих воссозданных порциях, чтобы обнаруживать конкретное местоположение конфиденциальных данных.
[0037] После того, как конкретные местоположения конфиденциальных данных определены, в таком случае модуль 212 снабжения примечаниями может использоваться для того, чтобы отмечать или иным образом помечать флагом конфиденциальные данные пользователю. Это снабжение примечаниями может принимать форму глобального флага или баннера, который указывает пользователю т, что конфиденциальный контент присутствует в файле пользовательских данных. Это снабжение примечаниями может принимать форму отдельных флагов, которые указывают метки рядом с конфиденциальными данными. В одном примере, фиг. 2 показывает конфигурацию 201 с видом пользовательского интерфейса в форме электронной таблицы, который имеет рабочую книгу, открытую в данный момент для просмотра или редактирования. Показано примечание 220 в виде баннера, а также примечания 221 к отдельным ячейкам. Примечания 221 к отдельным ячейкам содержат графические индикаторы, которые снабжают примечаниями одну или более частей пользовательского контента и содержат индикаторы, позиционированные рядом с одной или более частей, которые могут выбираться в пользовательском интерфейсе 112, чтобы представлять опции запутывания.
[0038] Пользователю могут представляться одну или более опций, когда выбирается конкретное примечание. Может представляться всплывающее меню 202, которое включает в себя различные опции просмотра/редактирования, такие как вырезание, копирование, вставка, в числе других. Всплывающее меню 202 также может включать в себя опции запутывания. Выбор одной из опций запутывания может формировать запутанный контент, который поддерживает схему данных ассоциированного пользовательского контента и содержит символы, выбранные для того, чтобы предотвращать идентификацию ассоциированного пользовательского контента при поддержании схемы данных ассоциированного пользовательского контента. В некоторых примерах, символы выбираются отчасти на основе схемы данных ассоциированного пользовательского контента, в числе других факторов. Например, если схема данных включает в себя схему числовых данных, то буквы могут использоваться в качестве символов запутывания. Аналогично, если схема данных включает в себя схему буквенных данных, то числа могут использоваться в качестве символов запутывания. Комбинации букв и чисел или других символов могут выбираться в качестве символов запутывания в примерах на основе буквенно–цифрового контента.
[0039] На фиг. 2, первая опция запутывания включает в себя замену конфиденциального контента маскированным или иным образом запутанным текстом, в то время как вторая опция запутывания включает в себя замену всего контента шаблоном или схемой данных, аналогично контенту текущего выбранного примечания. Например, если SSN включен в ячейку, пользователю могут представляться опции для замены цифры в SSN символами "X" при оставлении нетронутой схемы данных SSN, т.е. при оставлении знакомой компоновки символов "3–2–4", разделенной символами тире. Кроме того, дополнительная опция запутывания может включать в себя опцию для замены всех SSN, которые соответствуют шаблону выбранного SSN, символами "X". Следует понимать, что могут представляться другие примерные опции запутывания, и различные символы могут использоваться в процессе замены. Тем не менее, независимо от используемых символов запутывания, конфиденциальные данные становятся анонимизированными, санированными, "чистыми" или неидентифицируемыми в качестве исходного контента.
[0040] Обращаясь теперь к фиг. 3, показана примерная конфигурация 300, чтобы акцентировать внимание на аспектах DLP–службы 121. На фиг. 3, DLP–служба 121 принимает части сглаженного пользовательского контента, предоставленного в одной или более порциях контента посредством модуля 211 разделения контента, наряду с метаданными порций, которые, по меньшей мере, включают в себя смещения в полном контенте и длины порций. Два примерных типа структурированного пользовательского контента показаны на фиг 3, а именно, контент 301 в форме электронных таблиц и контент 302 в форме слайд–шоу/презентаций. Контент 301 в форме электронных таблиц имеет структуру, отражающую строки 321 и столбцы 322, которые задают отдельные ячейки. Кроме того, контент 301 в форме электронных таблиц может иметь более одного рабочего листа 320, которые разграничиваются посредством вкладок ниже рабочего листа, и каждый рабочий лист может иметь отдельный набор строк/столбцов. Каждая ячейка может иметь пользовательский контент, такой как символы, буквенно–цифровой контент, текстовый контент, числовой контент или другой контент. Контент 302 в форме слайд–шоу может иметь один или более слайдов или страниц 323, которые включают в себя множество объектов 324. Каждый объект может иметь пользовательский контент, такой как символы, буквенно–цифровой контент, текстовый контент, числовой контент или другой контент.
[0041] Модуль 211 разделения контента подразделяет пользовательский контент на фрагменты и удаляет любую ассоциированную структуру, к примеру, посредством извлечения любого пользовательского контента, такого как текст или буквенно–цифровой контент, из ячеек или объектов, и затем размещения извлеченного контента в сглаженные или линейные порции для доставки в DLP–службу 121. Эти порции и метаданные порций предоставляются в DLP–службу 121 для обнаружения потенциальных конфиденциальных данных.
[0042] После того, как отдельные порции пользовательского контента принимаются DLP–службой 121, различная обработка выполняется в отношении этих порций службой 124 классификации. Кроме того, модуль 123 отслеживания поддерживает записи 332 данных, содержащие одну или более структур данных, которые связывают смещения/длины и идентификатор сеанса с обнаруженными количествами конфиденциальных данных. Записи 332 данных сохраняются для этой DLP–службы 121, чтобы предоставлять смещения/длины для порций, которые содержат конфиденциальные данные, обратно в запрашивающее приложение для нахождения и снабжения примечаниями любого конфиденциального контента, обнаруженного в них.
[0043] Служба 124 классификации синтаксически анализирует каждую из порций на предмет различных правил 331 классификации для того, чтобы идентифицировать конфиденциальные данные или конфиденциальный контент. Правила 331 классификации могут устанавливать одну или более предварительно определенных схем данных, заданных посредством одного или более выражений, используемых для того, чтобы синтаксически анализировать сглаженные порции/представления данных, чтобы идентифицировать части порций как указывающие один или более предварительно определенных шаблонов контента или один или более предварительно определенных типов контента.
[0044] Конфиденциальный контент типично идентифицируется на основе структурного шаблона данных или "схемы" данных, которая ассоциирована с конфиденциальным контентом. Эти шаблоны или схемы могут идентифицировать то, когда точный контент порций может отличаться, но данные могут соответствовать шаблону или компоновке, которая отражает типы конфиденциальных данных. Например, SSN может иметь определенную компоновку данных, имеющую предварительно определенное число цифр, смешанных и разделенных посредством предварительно определенного числа тире. Правила 331 классификации могут включать в себя различные определения и политики, используемые в идентификации конфиденциальных данных. Эти правила классификации могут включать в себя политики конфиденциальности, шаблоны данных, схемы данных и политики задания пороговых значений. Политики конфиденциальности могут указывать то, что определенные потенциально конфиденциальные данные могут не указываться как конфиденциальные для приложения вследствие политик компании, организации или пользовательских политик, в числе других факторов. Политики задания пороговых значений могут устанавливать минимальные пороговые значения для нахождения конфиденциальных данных в различных порциях до того, как присутствие конфиденциальных данных сообщается в приложение. Правила 331 классификации могут устанавливаться пользователями или создателями политики, такими как администраторы.
[0045] Дополнительно, служба 124 классификации может обрабатывать контент данных через одно или более регулярных выражений, обрабатываемых посредством службы 333 управления регулярными выражениями (рег–выраж.). Служба 333 управления рег–выраж. может включать в себя службы сопоставления обработки регулярных выражений, наряду с различными регулярными выражениями, которые пользователь или политик может развертывать для идентификации конфиденциальных данных. Ниже поясняются дополнительные примеры службы 333 управления рег–выраж. на фиг. 7.
[0046] В качестве конкретного примера, процесс 341 классификации иллюстрирует несколько порций C1–C8 контента, которые представляют собой линеаризованные версии контента первоначально в структурной или иерархической компоновке в документе или файле пользовательских данных. Служба 124 классификации обрабатывает эти порции, чтобы идентифицировать порций, которые содержат конфиденциальные данные. Если какие–либо конфиденциальные данные обнаружены, индикаторы могут предоставляться в приложение. Индикаторы могут содержать смещения и длины для конфиденциальных данных и предоставляются для модуля 213 привязки, чтобы находить конфиденциальные данные в структуре файла пользовательских данных. Непосредственно порции могут отбрасываться посредством службы 124 классификации после того, как каждая порция обрабатывается для идентификации конфиденциальных данных. Поскольку смещения и длины обеспечивают возможность нахождения конфиденциальных данных в файле исходных данных, и исходный контент остается в файле данных (если промежуточные редактирования не возникают), то фактические порции не должны обязательно сохраняться после обработки.
[0047] Чтобы формировать порции, модуль 211 разделения контента пакетирует буквенно–цифровой контент, такой как текст, в одну или более линейных структур данных, таких как строки или BSTR (базовые строки или двоичные строки). Служба 124 классификации обрабатывает линейные структуры данных и определяет список результатов. Порции проверяются на предмет конфиденциальных данных, и части линейных структур данных могут определяться как имеющие конфиденциальный контент. Служба 124 классификации в сочетании с модулем 123 отслеживания определяет смещения/длины, соответствующие порциям, которые содержат конфиденциальные данные из линейных структур данных. Эти смещения могут указывать приблизительные местоположения, которые могут преобразовываться обратно в конкретные местоположения в исходном документе (например, в файле пользовательских данных), содержащем пользовательский контент. Когда порции принимаются, модуль 123 отслеживания может коррелировать каждую порцию с информацией смещения/длины, указываемой в метаданных порций. Эта информация смещения/длины может использоваться для обратной привязки к структуре или иерархии исходного документа посредством модуля 213 привязки.
[0048] Тем не менее, DLP–служба 121 типично имеет только частичный контекст обратно в исходный документ или файл пользовательских данных, к примеру, указываемый посредством смещений в первоначально сформированных линейных структурах данных. Кроме того, непосредственно линейные структуры данных и пользовательский контент могут раскрываться/удаляться посредством службы 124 классификации в конце процесса классификации. Это может означать то, что служба 124 классификации может не иметь возможность непосредственно выполнять поиск конфиденциального контента таким образом, чтобы, в частности, локализовать конфиденциальный контент в пределах исходного документа, и даже если служба 124 классификации может выполнять поиск, служба 124 точной классификации конфиденциального контента может не иметь возможность обнаруживать конфиденциальный контент, поскольку алгоритм "разделения на порции" может пересекать границы иерархических конструкций или структур в исходном документе или файле данных. В качестве конкретного примера, рабочий лист 320 в документе в форме электронной таблицы может иметь текст "SSN 123 45 6789" с охватом четырех смежных ячеек. Преимущественно, служба 124 классификации может обнаруживать этот текст как содержащий конфиденциальный контент. Тем не менее, вследствие анализа на основе пересечения границ посредством службы 124 классификации, в конце оценки правил политик, служба 124 классификации типично не имеет достаточного количества данных, чтобы обнаруживать конфиденциальный контент в исходном документе для представления пользователю. У пользователя может оставаться такое некорректное впечатление, что конфиденциальный контент не присутствует.
[0049] Чтобы эффективно сканировать пользовательский контент на предмет конфиденциального контента, служба 124 классификации считывает порцию пользовательского контента во время бездействия приложения, проводит частичный анализ и продолжает процесс. Когда служба 124 классификации заканчивает считывание всего контента, служба 124 классификации имеет только приблизительные позиции для конфиденциального контента в исходном контенте, к примеру, только начало/смещение и длину. Для эффективной обратной привязки к структурированному или полуструктурированному документу, модулем 213 привязки может использоваться комбинация технологий. Следует отметить, что эти технологии отличаются от того, как может работать проверка написания или проверка грамматики, в частности, поскольку может требоваться полный контент, а не просто слово/предложение/параграф, чтобы понимать то, превышает или нет контент пороговое значение.
[0050] Для каждого уровня физической иерархии или структуры, присутствующего в исходном документе (т.е. для рабочих листов в рабочей книге или слайдов в презентации) модуль 213 привязки использует идентификатор для того, чтобы указывать существование в структуре данных привязки, и дополнительно подразделять, на обоснованное число уровней иерархии (т.е. строк в рабочем листе, форм в слайде), контент, так что по мере того, как каждый из них обрабатывается, модуль 213 привязки отслеживает длину исходного контента и, на основе порядка вставки в привязку, неявное начало этого элемента. Идентификатор может представлять собой процессостойкий идентификатор, который сохраняется между открытыми экземплярами конкретного документа или может отличаться в каждом экземпляре конкретного документа. В некоторых примерах, предусмотрен отказ от вычислений для того, чтобы укрупнять присутствие/отсутствие конфиденциального контента до тех пор, пока не закончится ни необработанный контент, ни ожидающие редактирования, которые должны дополнительно изменять контент.
[0051] При условии, что предусмотрен конфиденциальный контент, модуль 213 привязки принимает из DLP–службы 121 начало и длину каждого фрагмента конфиденциального контента, и модуль 213 привязки выполняет поиск в структуре данных привязки идентификаторов и вставок конфиденциального контента в самой точной области привязки, чтобы обнаруживать точное местоположение. По причинам производительности, может отслеживаться только определенное число уровней иерархии, так что таблица в форме в слайде или ячейка в строке в рабочем листе не может отдельно отслеживаться. Следовательно, частичный повторный обход может выполняться после выполнения обратной привязки, чтобы обнаруживать точное местоположение.
[0052] В конкретном примере, рабочая книга может иметь 20 рабочих листов, но миллионы строк, и каждая из миллионов строк может иметь 50 столбцов пользовательских данных. Для относительно небольшого числа фрагментов конфиденциальных данных в ней (т.е. один лист имеет только один столбец с конфиденциальными данными), процесс классификации может чрезвычайно интенсивно использовать запоминающее устройство, так что он имеет 20 * 1 миллион * 50 запомненных фрагментов данных "длина+смещение". Удаление последней размерности обеспечивает 50–кратную экономию в запоминающем устройстве для небольших вычислительных затрат в то время, когда конфиденциальные данные фактически идентифицируются в исходном документе. Преимущественно, небольшой объем потребляемого запоминающего устройства может поддерживаться для обратной привязки начала/длины к исходному контенту.
[0053] Чтобы дополнительно иллюстрировать работу элементов по фиг. 1–3, блок–схема последовательности операций способа представляется на фиг. 4. Две основных последовательности операций представляются на фиг. 4, а именно, первая последовательность 400 операций для идентификации конфиденциальных данных и вторая последовательность 401 операций для снабжения примечаниями и запутывания конфиденциальных данных. Первая последовательность 400 операций может подаваться во вторую последовательность 400 операций, хотя возможны другие конфигурации.
[0054] На фиг. 4, DLP–служба 121 принимает (410) поднаборы структурированного пользовательского контента, консолидированного в ассоциированные сглаженные представления, причем каждое из ассоциированных сглаженных представлений имеет привязку к соответствующему поднабору структурированного пользовательского контента.
Как упомянуто выше, структурированный контент может содержать контент в форме электронных таблиц, организованный в листы/строки/столбцы, или вместо этого может включать в себя другие структуры, такие как контент в форме слайд–шоу, организованный в слайды/объекты, контент чертежной программы, организованный в страницы/объекты, или текстовый контент, организованный в страницы, в числе других структур. Эти поднаборы структурированного пользовательского контента могут включать в себя "порции" 141–146, показанные на фиг. 1, или порции Ci–Cs на фиг. 3, в числе других. Структура базового пользовательского контента сглаживается или удаляется в этих поднаборах, чтобы формировать порции, и каждый поднабор может привязываться обратно к исходной структуре посредством обращения к структурным идентификаторам или локализаторам, таким как, например, листы/строки/столбцы или слайды/объекты.
[0055] DLP–служба 121 принимает эти порции и метаданные порций, к примеру, по линии 160 связи или API 122 на фиг. 1 и отдельно синтаксически анализирует (411) сглаженные представления, чтобы классифицировать части как содержащие конфиденциальный контент, соответствующий одной или более предварительно определенных схем данных. Правила 125 классификации могут устанавливать одну или более предварительно определенных схем данных, заданных посредством одного или более выражений, используемых для того, чтобы синтаксически анализировать сглаженные порции/представления данных, чтобы идентифицировать части порций как указывающие один или более предварительно определенных шаблонов контента или один или более предварительно определенных типов контента.
[0056] Если конфиденциальные данные обнаружены (412), то для каждой из частей, DLP–служба 121 определяет (413) ассоциированные смещение/длину, связанные со структурированным пользовательским контентом, указываемым как поддерживаемый в модуле 123 отслеживания в записях 332 данных. DLP–служба 121 затем указывает (414), по меньшей мере, ассоциированные смещение/длину для частей в пользовательское приложение 111 для отметки конфиденциального контента в пользовательском интерфейсе 112 для пользовательского приложения 111. Если конфиденциальные данные не обнаружены, либо если какие–либо ассоциированные пороговые значения не удовлетворяются, то последующая обработка порций может продолжаться или дополнительно отслеживаться на предмет дополнительных порций в соответствии с пользовательским приложением 111. Кроме того, редактирование или изменение пользовательского контента может указывать дополнительные или повторные процессы классификации для любого измененного или отредактированного пользовательского контента.
[0057] DLP–модуль 113 приложений принимает (415), из службы классификации DLP–службы 121, индикаторы относительно одной или более частей пользовательского контента, которые содержат конфиденциальный контент, причем индикаторы содержат смещения/длины, ассоциированные с конфиденциальным контентом. DLP–модуль 113 приложений представляет (416) графические индикаторы в пользовательском интерфейсе 112 для пользовательского приложения 111, которые снабжают примечаниями одну или более частей пользовательского контента как содержащие конфиденциальный контент. DLP–модуль 113 приложений затем может представлять (417) опции запутывания в пользовательском интерфейсе 112 для маскирования конфиденциального контента, по меньшей мере, в выбранной части из одной или более частей пользовательского контента.
В ответ на пользовательский выбор, по меньшей мере, одной из опций запутывания, DLP–модуль 113 приложений заменяет (418) ассоциированный пользовательский контент запутанным контентом, который поддерживает схему данных ассоциированного пользовательского контента.
[0058] Фиг. 5 иллюстрирует схему 500 последовательности операций, чтобы дополнительно иллюстрировать работу элементов по фиг. 1–3. Кроме того, фиг. 5 включает в себя подробную примерную структуру 510 для некоторых этапов процесса на фиг. 5. На фиг. 5, приложение 111 может открывать документ для просмотра или редактирования пользователем. Этот документ может обнаруживаться посредством DLP–модуля 113 приложений. Все ассоциированные политики или правила классификации могут проталкиваться в DLP–службу 121, чтобы задавать политики классификации. DLP–служба 121 затем может поддерживать экземпляр обработки открытого документа в записи 332, который может включать в себя перечень нескольких открытых документов. При обработке в режиме бездействия, временные кадры приложения 111 обнаруживаются посредством DLP–модуля 113, индикатор бездействующего режима может представляться в DLP–службу 121, которая в ответ запрашивает порции пользовательского контента для классификации. Альтернативно, DLP–модуль 113 может проталкивать порции пользовательского контента в DLP–службу 121 в течение периодов бездействующего режима приложения 111. DLP–модуль 113 разделяет пользовательский контент на порции, и эти порции могут определяться на основе текста или другого контента, включенного в структуры или иерархические объекты документа. После того, как порции определены, DLP–модуль 113 передает порции в DLP–службу 121 для классификации. DLP–служба 121 классифицирует каждую порцию отдельно и применяет правила классификации к порциям, чтобы идентифицировать потенциально конфиденциальный пользовательский контент из порций. Этот процесс классификации может представлять собой итеративный процесс для того, чтобы обеспечивать то, что все порции, передаваемые посредством DLP–модуля 113, обработаны. Если конфиденциальные данные или контент обнаружены из порций, то DLP–служба 121 указывает присутствие конфиденциальных данных в DLP–модуль 113 для дополнительной обработки. Как упомянуто в данном документе, конфиденциальные данные могут указываться посредством смещений, приблизительных местоположений или другой информации местоположения, а также информации длины. DLP–модуль 113 затем может выполнять один или более процессов снабжения примечаниями и процессов запутывания для конфиденциальных данных в документе.
[0059] Правила классификации могут устанавливаться перед процессом классификации, к примеру, пользователями, администраторов, персоналом управления политиками или другими объектами. Как видно в структуре 510, различные правила 511 и 512 могут быть основаны на одном или более предикатов. Предикаты показаны в двух категориях на фиг. 5, как связанные с контентом предикаты 511 и связанные с доступом предикаты 512. Связанные с контентом предикаты 511 могут содержать схемы данных, которые указывают конфиденциальные данные, к примеру, шаблоны данных, структурную информацию в виде данных или регулярные выражения, которые задают схемы данных. Связанные с доступом предикаты 512 содержат пользовательский уровень, организационный уровень или другие основанные на доступе правила, такие как правила совместного использования контента, которые задают то, когда конфиденциальные данные не требуются для распределения или раскрытия посредством конкретных пользователей, организаций или других факторов.
[0060] Могут устанавливаться правила 513 политик, которые комбинируют один или более связанных с контентом предикатов и связанных с доступом предикатов в политики 551–554. Каждое правило политики также имеет приоритет и ассоциированное действие. В общем, приоритет совпадает с серьезностью действия. Например, правило политики может задавать то, что признаки "сохранения" приложения должны блокироваться. В другом примерном правиле политики, пользовательский контент может содержать SSN, которые задаются согласно связанному с контентом предикату, но согласно связанному с доступом предикату, эти SSN могут быть приемлемыми для распределения. Большинство правил политик содержит, по меньшей мере, один предикат классификации из числа предикатов 511–512. Эти политики могут осуществлять одно или более действий 514. Действия могут включать в себя различные операции снабжения примечаниями, которые приложение может осуществлять в ответ на идентификацию или конфиденциальный контент, такие как уведомление пользователя, уведомление, но разрешение на пользовательское переопределение, блокирование признаков/функций (т.е. признаков "сохранения" или "копирования") и оправданные переопределения, в числе других.
[0061] Фиг. 6 иллюстрирует блок–схему 600 последовательности операций способа, чтобы дополнительно иллюстрировать работу элементов по фиг. 1–3. Фиг. 6 акцентирует внимание на одном примерном полном процессе процессов идентификации, снабжения примечаниями и запутывания конфиденциальных данных. Подпроцесс 601 содержит установление, хранение и извлечение политик и правил. Эти политики и правила могут представлять собой правила снабжения примечаниями, правила классификации, регулярные выражения, организационные/пользовательские политики, в числе другой информации, поясненной в данном документе. На этапе 611 по фиг. 6, различные правила 630 обнаружения и правила 631 замены могут вводиться через пользовательский интерфейс или API для конфигурирования политик обнаружения. Правила 630 обнаружения и правила 631 замены могут содержать различные предикаты и правила, обнаруженные на фиг. 5, в числе других. Пользователи, администраторы, персонал управления политиками или другие субъекты могут вводить правила 630 обнаружения и правила 631 замены, к примеру, посредством установления политик для пользователей, организаций или использования приложений, в числе других субъектов и действий. Правила 630 обнаружения и правила 631 замены могут сохраняться в одной или более системах хранения данных на этапе 612 для последующего использования. Когда один или более клиентов хотят использовать политики, устанавливаемые посредством правил 630 обнаружения и правил 631 замены, эти политики могут загружаться или извлекаться на этапе 613. Например, правила снабжения примечаниями могут загружаться посредством приложения для использования в снабжении примечаниями конфиденциального контента в пользовательском интерфейсе, тогда как правила классификации могут загружаться посредством совместно используемой DLP–службы для классификации пользовательского контента в качестве конфиденциального контента.
[0062] Подпроцесс 602 содержит действия клиентских приложений, такие как загрузка документов для редактирования или просмотра в пользовательском интерфейсе и предоставление порций этих документов для классификации. На этапе 614, клиентское приложение может предоставлять одну или более возможностей работы конечных пользователей, чтобы обрабатывать пользовательский контент, редактировать пользовательский контент или просматривать пользовательский контент, в числе других операций. Этап 614 также может предоставлять процессы снабжения примечаниями и запутывания, которые пояснены далее. Этап 615 предоставляет части этого пользовательского контента в совместно используемую DLP–службу для классификации пользовательского контента. В некоторых примерах, части содержат сглаженные порции пользовательского контента, который не содержит ассоциированную структуру или иерархию из исходного документа.
[0063] Подпроцесс 603 содержит классификацию пользовательского контента таким образом, чтобы обнаруживать конфиденциальные данные в числе пользовательского контента, а также снабжение примечаниями этих конфиденциальных данных пользователю. На этапе 616, применяются различные правила обнаружения, к примеру, регулярные выражения, поясненные ниже на фиг. 7, в числе других правил и процессов обнаружения. Если конфиденциальные данные обнаружены, то этап 617 определяет то, должен или нет уведомляться пользователь. Уведомление может не возникать, если величина конфиденциальных данных опускается ниже аварийной пороговой величины. Тем не менее, если пользователь должен предупреждаться, то этап 619 может вычислять местоположения конфиденциальных данных в обнаруженных областях структурированных данных. Как пояснено в данном документе, процесс привязки может использоваться для того, чтобы определять конкретные местоположения конфиденциальных данных в структурированных элементах или иерархических элементах из сглаженных смещений данных и длин строк или частей конфиденциальных данных. После того, как эти конкретные местоположения определяются, далее этап 618 может отображать местоположения пользователю. Примечания или другое выделение яркостью элементов пользовательского интерфейса используются для того, чтобы передавать в служебных сигналах пользователю то, что конфиденциальные данные присутствуют в числе пользовательского контента.
[0064] Подпроцесс 604 содержит запутывание конфиденциальных данных в пользовательском контенте, содержащем структурированные или иерархические элементы. На этапе 621, пользовательский ввод может приниматься, чтобы заменять по меньшей мере один экземпляр конфиденциальных данных "безопасными" или запутанными данными/текстом. Когда пользователю показана выделенная яркостью область, демонстрирующая фрагмент конфиденциальных данных, которые вызывают появление примечания или "подсказки по политике", пользователю может представляться опция, чтобы заменять конфиденциальные данные "безопасным текстом", который запутывает конфиденциальные данные. В зависимости от выбора, выполненного субъектами, изначально задавших политики на этапе 611, этапы 622 и 624 определяют и формируют одно или более правил запутывания или замены. Правила запутывания могут использоваться для замены внутреннего кодового названия утвержденным маркетинговым названием, используемым для того, чтобы запутывать идентифицирующую персональную информацию (PII) со стереотипными названиями, могут использоваться для того, чтобы заменять числовые конфиденциальные данные набором символов, которые указывают будущим просматривающим документ тип конфиденциальных данных (т.е. номера кредитных карт, номера социального страхования, идентификационные номера транспортных средств, в числе других), без раскрытия фактических конфиденциальных данных. Этап 623 заменяет конфиденциальные данные запутанными данными. Запутанные данные могут использоваться для того, чтобы заменять числовые конфиденциальные данные набором символов, которые могут использоваться для того, чтобы подтверждать схему данных или тип контента, но оставаться недостаточным для извлечения исходных данных даже определенным человеком (т.е. чтобы определять то, что фрагмент контента представлять собой SSN, но не раскрывать фактический SSN). Пользователи могут выполнять отдельную или одноэкземплярную замену конфиденциального контента запутанным текстом или массовую замену из пользовательского интерфейса, который показывает несколько экземпляров конфиденциального контента.
[0065] Замена конфиденциального контента, такого как текст или буквенно–цифровой контент, может проводиться с регулярными выражениями или альтернативно через недетерминированные конечные автоматы (NFA), детерминированные конечные автоматы (DFA), автомат с магазинной памятью (PDA), машины Тьюринга, произвольный функциональный код или другие процессы. Замена конфиденциального контента типично содержит сопоставление с шаблоном между текстом или контентом. Это сопоставление с шаблоном может оставлять демаскированные символы или контент посредством рассмотрения того, имеет или нет целевой шаблон способность к существованию нескольких символов в указанном местоположении в строке, и эти символы не должны маскироваться, к примеру, для символов–разделителей. Например, строка "123–12–1234" может становиться "xxx–xx–xxxx", и строка "123 12 1234" может становиться "xxxxxxxxx" после процесса маскирования. Это сопоставление с шаблоном также может сохранять определенные части различимыми для целей уникальности, к примеру, с последним предварительно определенным числом цифр номера кредитной карты или SSN. Например, "1234–1234–1234–1234" может становиться "xxxx–xxxx–xxxx–1234" после процесса маскирования. Для маскирования/замены кодовых названий, не все аспекты представляют собой шаблоны и фактически могут представлять собой внутренние кодовые названия или другие ключевые слова. Например, кодовое название "Whistler" может становиться "Windows XP" после процесса маскирования. Кроме того, шаблоны, которые заменяют варьирующееся число символов безопасным текстом, могут разрешаться для того, чтобы сохранять длину согласованной или задавать длину равной известной константе. Например, идентичное правило может превращать "1234–1234–1234–1234" в "xxxx–xxxx–xxxx–1234" и "xxxxx–xxxxx–xl234" после процесса маскирования. Это может требовать шаблона, который содержит достаточный объем данных для того, чтобы обрабатывать любой из этих случаев. Регулярные выражения могут обрабатывать такие сценарии посредством дополнения регулярного выражения посредством помещения каждого атомарного выражения для сопоставления в круглую скобку и отслеживания того, какие дополненные операторы "сопоставления" спариваются с какими операторами "замены". Ниже приведены дополнительные примеры сопоставления с регулярными выражениями на фиг. 7.
[0066] Чтобы поддерживать целостность процессов снабжения примечаниями и классификации более чем между одним документом/файлом, могут устанавливаться различные процессы. Правила и политики обнаружения/классификации, снабжения примечаниями и запутывания типично не включаются в файлы с документами. Это предоставляет возможность изменений политик и предотвращает декомпиляцию на исходные коды технологий запутывания. Например, если пользователь сохраняет документ, затем закрывает и загружает идентичный документ, то правила для того, какие части документа содержат конфиденциальные данные, необходимые для того, чтобы рассматривать присутствие конфиденциальных данных как проблему политики, могут изменяться. Помимо этого, флаги снабжения примечаниями не должны быть включены в операции буфера обмена, такие как вырезание, копирование или вставка. Если пользователь должен копировать контент из одного документа и вставлять в другой, то второй документ может иметь различные применяемые правила обнаружения/классификации, снабжения примечаниями и запутывания. Если пользователь должен в текст с контентом из первого документа и вставлять во второй документ, то примечания первого документа должны считаться нерелевантными до тех пор, пока они не будут повторно классифицированы. Даже если пользователь должен копировать контент из одного документа в идентичный документ, любые количества конфиденциального контента могут сдвигаться, и то, что должно выделяться яркостью во всем документе, может изменяться.
[0067] Фиг. 7 иллюстрирует блок–схему 700 последовательности операций способа, чтобы дополнительно иллюстрировать работу элементов по фиг. 1–3. Фиг. 7 акцентирует внимание на операциях с регулярными выражениями в ходе процессов запутывания конфиденциальных данных. На фиг. 7, с учетом регулярного выражения (рег–выраж.), к примеру, вымышленное примерное регулярное выражение 730 водительских прав, и строки, которая совпадает с ним, полное совпадение может формироваться посредством, по меньшей мере, дополнения регулярного выражения посредством помещения каждого разделимого посимвольного выражения для сопоставления в круглую скобку (например, каждого атома), как указано на этапе 711. Дополненное регулярное выражение затем может повторно применяться или выполняться на этапе 712, чтобы выполнять процесс запутывания или маскирования. Для каждого совпадения, этапы 713–714 определяют самые широкие и самые узкие фактически совпадающие наборы символов. Например, когда совпадающий символ представляет собой "–", символ является узким, поскольку он представляет собой отдельный символ. Когда совпадающий символ представляет собой набор всех буквенных символов, он является широким. Абсолютное количество символов, которые могут находиться в любой области, представлять собой ключевой детерминатор. Процесс запутывания на этапе 715 может заменять символы согласно ширине совпадения. Для совпадающих символов, которые представляют собой отдельные символы, процесс запутывания может не вносить изменение. Для совпадающих символов, которые находятся в широких группах, процесс запутывания заменяет символы "безопасным" символом, который не представляет собой члена набора. Например, набор всех букв становится "0", набор всех чисел становятся "X", и смешанный буквенно–цифровой контент становится"?", со списком отката символов, которые использовать до полного исчерпания. После того, как текст или контент проходит через процесс запутывания или маскирования, этап 716 подтверждает то, что текст или контент успешно становится запутанным, когда новая строка текста/контента более не совпадает с исходным рег–выраж.
[0068] Фиг. 8 иллюстрирует график 800, чтобы дополнительно иллюстрировать работу элементов по фиг. 1–3. Фиг. 8 акцентирует внимание на улучшенных процессах задания пороговых значений, используемых в снабжении примечаниями конфиденциальных данных в пользовательских интерфейсах. Операции по фиг. 8 могут содержать улучшенные гистерезисные операции для снабжения примечаниями конфиденциальных данных, и различные пороговые значения или правила снабжения примечаниями могут устанавливаться посредством администраторов политики или пользователей, в числе других объектов.
[0069] Фиг. 8 включает в себя график 800, который включает в себя вертикальную ось, указывающую величину элементов конфиденциальных данных/контента, присутствующих в документе, и горизонтальную ось, указывающую время. Устанавливается первое пороговое значение 820, которое может инициировать представление или удаление примечаний конфиденциального контента в пользовательском интерфейсе. Может устанавливаться второе пороговое значение 822, которое также может инициировать представление или удаление примечаний конфиденциального контента. Могут устанавливаться коэффициент 821 эластичности и свойство 823 устойчивости, чтобы модифицировать поведение первого и второго пороговых значений.
[0070] Когда конфиденциальные данные снабжаются примечаниями в пользовательском интерфейсе, к примеру, посредством флагов, отметок или выделения яркостью, пользователь может редактировать конфиденциальный контент, чтобы решать проблемы, связанные с конфиденциальным контентом (к примеру, посредством выбора одной или более опций запутывания). Тем не менее, после того, как решено пороговое число проблем, связанных с конфиденциальным контентом, может не быть предусмотрено достаточного числа оставшихся экземпляров проблемы для того, чтобы гарантировать снабжение примечаниями документа как полного в нарушение правил обработки конфиденциального контента для организации или местоположения сохранения. Аналогично, когда новый конфиденциальный контент вводится в документ, может быть предусмотрено достаточное число экземпляров для того, чтобы гарантировать снабжение примечаниями документа, чтобы указывать конфиденциальный контент пользователю.
[0071] В ходе процессов редактирования контента пользователями, активация и деактивация индикаторов примечаний для одного или более элементов контента может быть основана, по меньшей мере, частично на текущей величине элементов контента относительно правил снабжения примечаниями. Правила снабжения примечаниями могут содержать, по меньшей мере, первую пороговую величину 820, коэффициент 821 эластичности для модификации первой пороговой величины 820 на вторую пороговую величину 822 при активации и индикатор относительно свойства 823 пороговой устойчивости или "негибкости", указывающий то, когда вторая пороговая величина 822 переопределяет первую пороговую величину 820. Служба снабжения примечаниями, такая как модуль 212 снабжения примечаниями, может определять или идентифицировать правила снабжения примечаниями, к примеру, правила 513 политик и действия 514 поясненных на фиг. 5, которые устанавливаются для целевых объектов, ассоциированных с редактированием контента. Целевые объекты могут включать в себя пользователей, выполняющих редактирование контента, организацию, которая содержит пользователя, выполняющего редактирование контента, или тип приложения для пользовательского приложения, в числе других. Во время пользовательского редактирования документа, который содержит конфиденциальный контент или потенциально может содержать конфиденциальный контент, модуль 212 снабжения примечаниями отслеживает пользовательский контент в ассоциированном файле пользовательских данных, представленном для редактирования контента в пользовательском интерфейсе для пользовательского приложения. Модуль 212 снабжения примечаниями идентифицирует величину элементов контента, содержащих конфиденциальный контент, в числе пользовательского контента, соответствующего одной или более предварительно определенных схем данных, поясненных в данном документе. Элементы контента могут включать в себя ячейки, объекты, формы, слова или другие структурные элементы данных или иерархические элементы данных.
[0072] Во время редактирования и, по меньшей мере, на основе величины элементов контента, превышающей первую пороговую величину, модуль 212 снабжения примечаниями инициирует представление, по меньшей мере, одного индикатора примечания в пользовательском интерфейсе, который помечает флагом пользовательский контент в пользовательском интерфейсе как содержащий, по меньшей мере, первый конфиденциальный контент. На фиг. 8 (начиная с примечаний в деактивированном состоянии), первое пороговое значение 820 указывает примерную величину 8 в точке 830 перехода в качестве инициирования представления индикаторов примечаний в пользовательском интерфейсе. Величина элементов контента с конфиденциальным контентом может увеличиваться, к примеру, посредством пользовательского редактирования и затем может снижаться после того, как пользователь видит, что конфиденциальный контент присутствует, и начинает выбор опций запутывания, чтобы маскировать этот конфиденциальный контент.
[0073] По меньшей мере, на основе величины элементов контента, первоначально превышающей первую пороговую величину 820 и затем опускающейся ниже первой пороговой величины 820, когда коэффициент 821 эластичности применяется к первой пороговой величине 820, модуль 212 снабжения примечаниями устанавливает вторую пороговую величину 822, по меньшей мере, на основе коэффициента эластичности. Когда вторая пороговая величина 822 является активной (т.е. когда коэффициент 821 эластичности применяется к первой пороговой величине 820), затем вторая пороговая величина 822 используется для того, чтобы инициировать удаление представления, по меньшей мере, одного индикатора примечания, когда величина опускается ниже второй пороговой величины 822, как видно в точке 832 перехода. Тем не менее, по меньшей мере, на основе величины элементов контента, первоначально превышающей первую пороговую величину 820 и затем опускающейся ниже первой пороговой величины 820, когда коэффициент эластичности не применяется к первой пороговой величине 820, представление по меньшей мере одного индикатора примечания удаляется, как указано посредством точки перехода 831.
[0074] Коэффициент 821 эластичности может содержать процент в пределах от 0–100 процентов или другой показатель. В конкретном примере, может устанавливаться правило снабжения примечаниями, которое задает включение более 100 SSN в документ, что нарушает корпоративную политику. Во время редактирования документа, который превышает 100 SSN, в таком случае правило снабжения примечаниями для первой пороговой величины может указывать выделение яркостью всех SSN в документе. Когда пользователь начинает запутывание SSN, величина оставшихся незапутанных SSN должна уменьшаться. Коэффициент эластичности может поддерживать снабжение примечаниями или выделение яркостью SSN, даже если первая пороговая величина 820, которая инициирует снабжение примечаниями, более не удовлетворяется, к примеру, когда 99 SSN остаются незапутанными. Коэффициент эластичности в 100 должен соответствовать немодифицированной первой пороговой величине, и эластичность в 0 должна соответствовать тому, что примечания никогда не удаляются до тех пор, пока не будут запутаны все SSN. Промежуточное значение в 50 для коэффициента эластичности должно соответствовать удалению примечаний после фиксации 50–ой записи после того, как примечания первоначально инициированы для представления. Таким образом, в примере на фиг. 8, коэффициент эластичности устанавливает вторую пороговую величину для удаления примечаний, как только примечания представлены пользователю. В этом примере, вторая пороговая величина 822 равна 2, и в силу этого, когда оставшиеся проблемы, связанные с конфиденциальным контентом, опускаются ниже 2, оставшиеся примечания должны удаляться, как указано посредством точки 832 перехода.
[0075] Если вторая пороговая величина 822 опущена ниже, и затем дополнительные проблемы, связанные с конфиденциальным контентом, возникают во время редактирования контента, то модуль 212 снабжения примечаниями должен определять, когда предупреждать пользователя посредством представления примечаний снова. По меньшей мере, на основе величины элементов контента, первоначально опускающейся ниже второй пороговой величины 822 и затем превышающей вторую пороговую величину 822, когда свойство 823 пороговой устойчивости применяется ко второй пороговой величине 822, модуль 212 снабжения примечаниями инициирует представление дополнительных примечаний в пользовательском интерфейсе, которые помечают флагом пользовательский контент в пользовательском интерфейсе как содержащий конфиденциальный контент, как указано посредством точки 833 перехода.
[0076] Свойство 823 устойчивости содержит свойство "негибкости" для второй пороговой величины 822 и задается посредством условия включения/выключения или булева условия. При деактивации, вторая пороговая величина 822 не используется для повторного представления примечаний в случае превышения. При активации, вторая пороговая величина 822 используется для повторного представления примечаний в случае превышения. Следовательно, по меньшей мере, на основе величины элементов контента, первоначально опускающейся ниже второй пороговой величины 822 и затем превышающей вторую пороговую величину 822, когда свойство устойчивости не применяется ко второй пороговой величине 822, модуль 212 снабжения примечаниями отказывается от представления примечаний которые, помечают флагом пользовательский контент в пользовательском интерфейсе как содержащий, по меньшей мере, конфиденциальный контент, до тех пор, пока величина элементов контента не превысит первую пороговую величину 820 снова.
[0077] Обращаясь теперь к фиг. 9, представляется вычислительная система 901. Вычислительная система 901, которая представляет любую систему или совокупность систем, в которых могут реализовываться различные функциональные архитектуры, сценарии и процессы, раскрытые в данном документе. Например, вычислительная система 901 может использоваться для того, чтобы реализовывать любую из пользовательской платформы 110 или DLP–платформы 120 по фиг. 1. Примеры вычислительной системы 901 включают в себя, но не только, серверные компьютеры, облачные вычислительные системы, распределенные вычислительные системы, программно–определяемые сетевые системы, компьютеры, настольные компьютеры, аналого–цифровые компьютеры, стоечные серверы, веб–серверы, облачные вычислительные платформы и оборудование центра обработки и хранения данных, а также любой другой тип физической или виртуальной серверной машины и других вычислительных систем и устройств, а также любого варьирования или комбинации вышеозначенного. Когда части вычислительной системы 901 реализуются на пользовательских устройствах, примерные устройства включают в себя смартфоны, переносные компьютеры, планшетные компьютеры, настольные компьютеры, игровые системы, развлекательные системы и т.п.
[0078] Вычислительная система 901 может реализовываться как одно оборудование, система или устройство либо может реализовываться распределенно в качестве нескольких элементов оборудования, систем или устройств. Вычислительная система 901 включает в себя, но не только, систему 902 обработки, систему 903 хранения данных, программное обеспечение 905, интерфейсную систему 907 связи и пользовательскую интерфейсную систему 908. Система 902 обработки функционально соединяется с системой 903 хранения данных, интерфейсной системой 907 связи и пользовательской интерфейсной системой 908.
[0079] Система 902 обработки загружает и выполняет программное обеспечение 905 из системы 903 хранения данных. Программное обеспечение 905 включает в себя DLP–окружение 906 приложений и/или совместно используемое DLP–окружение 909, которое представляет процессы, поясненные относительно предыдущих чертежей. При выполнении посредством системы 902 обработки, чтобы обрабатывать пользовательский контент для идентификации, снабжения примечаниями и запутывания конфиденциального контента, программное обеспечение 905 направляет систему 902 обработки с возможностью работать, как описано в данном документе, по меньшей мере, для различных процессов, рабочих сценариев и окружений, поясненных в вышеприведенных реализациях. Вычислительная система 901 в необязательном порядке может включать в себя дополнительные устройства, признаки или функциональность, не поясненную в целях краткости.
[0080] По–прежнему ссылаясь на фиг. 9, система 902 обработки может содержать микропроцессор и схему обработки, которая извлекает и выполняет программное обеспечение 905 из системы 903 хранения данных. Система 902 обработки может реализовываться в одном обрабатывающем устройстве, но также может быть распределена по нескольким обрабатывающим устройствам или подсистемам, которые совместно работают при выполнении программных инструкций. Примеры системы 902 обработки включают в себя центральные процессоры общего назначения, специализированные процессоры и логические устройства, а также любой другой тип обрабатывающего устройства, комбинации или варьирования означенного.
[0081] Система 903 хранения данных может содержать любые машиночитаемые носители хранения данных, считываемые посредством системы 902 обработки и допускающие сохранение программного обеспечения 905. Система 903 хранения данных может включать в себя энергозависимые и энергонезависимые, съемные и стационарные носители, реализованные любым способом или технологией для хранения информации, такие как машиночитаемые инструкции, структуры данных, программные модули или другие данные. Примеры носителей хранения данных включают в себя оперативное запоминающее устройство, постоянное запоминающее устройство, магнитные диски, резистивное запоминающее устройство, оптические диски, флэш–память, виртуальное запоминающее устройство и невиртуальное запоминающее устройство, магнитные кассеты, магнитную ленту, устройство хранения данных на магнитных дисках или другие магнитные устройства хранения данных либо любые другие подходящие носители хранения данных. Машиночитаемые носители хранения данных ни при каких условиях не представляют собой распространяемый сигнал.
[0082] В дополнение к машиночитаемым носителям хранения данных, в некоторых реализациях система 903 хранения данных также может включать в себя машиночитаемые среды связи, по которым, по меньшей мере, часть программного обеспечения 905 может передаваться внутренне или внешне. Система 903 хранения данных может реализовываться как одно устройство хранения данных, но также может реализовываться в нескольких устройствах или подсистемах хранения данных, совместно размещаемых или распределенных относительно друг друга. Система 903 хранения данных может содержать дополнительные элементы, такие как контроллер, допускающий обмен данными с системой 902 обработки или возможно с другими системами.
[0083] Программное обеспечение 905 может реализовываться в программных инструкциях и, в числе других функций, при выполнении посредством системы 902 обработки, может направлять систему 902 обработки с возможностью работать, как описано относительно различных рабочих сценариев, последовательностей и процессов, проиллюстрированных в данном документе. Например, программное обеспечение 905 может включать в себя программные инструкции для реализации окружений и платформ обработки наборов данных, поясненных в данном документе.
[0084] В частности, программные инструкции могут включать в себя различные компоненты или модули, которые совместно работают или иным образом взаимодействуют, чтобы выполнять различные процессы и рабочие сценарии, описанные в данном документе. Различные компоненты или модули могут быть осуществлены в компилированных или интерпретируемых инструкциях либо в некотором другом варьировании или комбинации инструкций. Различные компоненты или модули могут выполняться синхронным или асинхронным способом, последовательно или параллельно, в однопоточном или многопоточном окружении либо в соответствии с любой другой подходящей парадигмой выполнения, варьированием или комбинацией вышеозначенного. Программное обеспечение 905 может включать в себя дополнительные процессы, программы или компоненты, такие как программное обеспечение операционной системы или другое прикладное программное обеспечение, помимо или которые включают в себя DLP–окружение 906 приложений или совместно используемое DLP–окружение 909. Программное обеспечение 905 также может содержать микропрограммное обеспечение или некоторую другую форму машиночитаемых инструкций по обработке, выполняемых посредством системы 902 обработки.
[0085] В общем, программное обеспечение 905, при загрузке в систему 902 обработки и выполнении, может преобразовывать подходящее оборудование, систему или устройство (которое представляет вычислительная система 901) в общем из вычислительной системы общего назначения в вычислительную систему специального назначения, индивидуально настроенную с возможностью упрощать улучшенную обработку пользовательского контента для идентификации, снабжения примечаниями и запутывания конфиденциального контента. Фактически, кодирование программного обеспечения 905 в системе 903 хранения данных может преобразовывать физическую структуру системы 903 хранения данных. Конкретное преобразование физической структуры может зависеть от различных факторов в различных реализациях этого описания. Примеры таких факторов могут включать в себя, но не только, технологию, используемую для того, чтобы реализовывать носители хранения данных системы 903 хранения данных, и то, характеризуются компьютерные носители хранения данных в качестве первичного устройства хранения данных или вторичного устройства хранения данных, а также другие факторы.
[0086] Например, если машиночитаемые носители хранения данных реализуются как полупроводниковое запоминающее устройство, программное обеспечение 905 может преобразовывать физическое состояние полупроводникового запоминающего устройства, когда программные инструкции кодируются в нем, к примеру, посредством преобразования состояния транзисторов, конденсаторов или других элементов дискретной схемы, составляющих полупроводниковое запоминающее устройство. Аналогичное преобразование может возникать относительно магнитных или оптических носителей. Другие преобразования физических носителей являются возможными без отступления от объема настоящего описания, при этом вышеприведенные примеры предоставляются только для того, чтобы упрощать настоящее пояснение.
[0087] DLP–окружение 906 приложений или совместно используемое DLP–окружение 909 включают в себя один или более программных элементов, таких как ОС 921/931 и приложения 922/932. Эти элементы могут описывать различные части вычислительной системы 901, с которыми взаимодействуют пользователи, источники данных, службы передачи данных или другие элементы. Например, ОС 921/931 может предоставлять программную платформу, на которой выполняется приложение 922/932, и предоставляет возможность обработки пользовательского контента для идентификации, снабжения примечаниями и запутывания конфиденциального контента, в числе других функций.
[0088] В одном примере, DLP–служба 932 включает в себя модуль 924 разделения контента, модуль 925 снабжения примечаниями, модуль 926 привязки и модуль 927 запутывания. Модуль 924 разделения контента сглаживает структурированные или иерархические элементы пользовательского контента в линейные порции для обработки посредством службы классификации. Модуль 925 снабжения примечаниями графически выделяет яркостью конфиденциальные данные или контент в пользовательском интерфейсе таким образом, что пользователи могут предупреждаться касательно присутствия порогового объема конфиденциальных данных. Модуль 926 привязки может извлекать конкретные местоположения из числа документов для примечаний конфиденциальных данных, к примеру, когда только смещения/длины/идентификаторы предоставляются посредством службы классификации для того, чтобы локализовать конфиденциальные данные в различных структурных или иерархических элементах документа. Модуль 927 запутывания представляет опции запутывания для маскирования/замены пользовательского контента, который идентифицирован в качестве конфиденциальных данных. Модуль 927 запутывания также заменяет конфиденциальный контент в ответ на пользовательский выбор опций запутывания.
[0089] В другом примере, DLP–служба 933 включает в себя службу 934 классификации, модуль 935 отслеживания, модуль 936 политик/правил и службу 937 управления рег–выраж. Служба 934 классификации синтаксически анализирует линейные порции данных или контента таким образом, чтобы идентифицировать конфиденциальные данные. Модуль 935 отслеживания поддерживает количества или величины элементов конфиденциальных данных, обнаруженных посредством службы 934 классификации, и указывает смещения и длины конфиденциальных данных в модуль преобразования для примечания в документе (к примеру, в модуль 926 привязки и модуль 925 снабжения примечаниями). Модуль 936 политик/правил может принимать и поддерживать различные политики и правила для снабжения примечаниями, классификации, обнаружения, запутывания или других операций для пользовательского контента. Служба 937 управления рег–выраж. содержит одну примерную технологию классификации с использованием сопоставления с регулярными выражениями, чтобы идентифицировать конфиденциальные данные с использованием шаблонов данных или схем данных и заменять текст совпадающего контента запутанным контентом.
[0090] Интерфейсная система 907 связи может включать в себя соединения связи и устройства, которые предоставляют возможность связи с другими вычислительными системами (не показаны) по сетям связи (не показаны). Примеры соединений и устройств, которые вместе предоставляют возможность межсистемной связи, могут включать в себя сетевые интерфейсные платы, антенны, усилители мощности, RF–схему, приемопередающие устройства и другую схему связи. Соединения и устройства могут обмениваться данными по средам связи, чтобы обмениваться связью с другими вычислительными системами или сетями систем, такими как металлические, стеклянные, воздушные или любые другие подходящие среды связи. Физические или логические элементы интерфейсной системы 907 связи могут принимать наборы данных из телеметрических источников, передавать наборы данных и управляющую информацию между одним или более распределенных элементов хранения данных и взаимодействовать с пользователем, чтобы принимать выборы данных и предоставлять визуализируемые наборы данных, в числе других признаков.
[0091] Пользовательская интерфейсная система 908 является необязательной и может включать в себя клавиатуру, мышь, устройство голосового ввода, устройство сенсорного ввода для приема ввода от пользователя. Устройства вывода, такие как дисплей, динамики, веб–интерфейсы, терминальные интерфейсы и другие типы устройств вывода, также могут быть включены в пользовательскую интерфейсную систему 908. Пользовательская интерфейсная система 908 может предоставлять вывод и принимать ввод по сетевому интерфейсу, такому как интерфейсная система 907 связи. В сетевых примерах, пользовательская интерфейсная система 908 может пакетизировать отображаемые или графические данные для удаленного отображения посредством системы отображения или вычислительной системы, соединенной по одному или более сетевых интерфейсов. Физические или логические элементы пользовательской интерфейсной системы 908 могут принимать правила или политики классификации от пользователей или персонала управления политиками, принимать операции редактирования данных от пользователей, представлять примечания конфиденциального контента пользователям, предоставлять опции запутывания пользователям и предоставлять запутанный пользовательский контент пользователям, в числе других операций. Пользовательская интерфейсная система 908 также может включать в себя ассоциированное программное обеспечение пользовательского интерфейса, выполняемое посредством системы 902 обработки при поддержке различных устройств пользовательского ввода и вывода, поясненных выше. Отдельно или друг в сочетании с другом и другими аппаратными и программными элементами, программное обеспечение пользовательского интерфейса и пользовательские интерфейсные устройства могут поддерживать графический пользовательский интерфейс, естественный пользовательский интерфейс или любой другой тип пользовательского интерфейса.
[0092] Связь между вычислительной системой 901 и другими вычислительными системами (не показаны) может возникать по сети или сетям связи и в соответствии с различными протоколами связи, комбинациями протоколов либо варьированиями означенного. Примеры включают в себя сети intranet, Интернет–сети, Интернет, локальные вычислительные сети, глобальные вычислительные сети, беспроводные сети, проводные сети, виртуальные сети, программно–определяемые сети, шины центра обработки и хранения данных, вычислительные основные платы или любой другой тип сети, комбинацию сети или варьирование означенного. Вышеуказанные сети и протоколы связи известны и не должны подробно поясняться здесь. Тем не менее, некоторые протоколы связи, которые могут использоваться, включают в себя, но не только, Интернет–протокол (IP, IPv4, IPv6 и т.д.), протокол управления передачей (TCP) и протокол пользовательских датаграмм (HDP), а также любой другой подходящий протокол связи, варьирование или комбинацию вышеозначенного.
[0093] Определенные изобретаемые аспекты могут приниматься во внимание из вышеприведенного раскрытия, для которого далее приводятся различные примеры.
[0094] Пример 1: Способ работы пользовательского приложения, при этом способ содержит идентификацию, по меньшей мере, первой пороговой величины, коэффициента эластичности для модификации первой пороговой величины на вторую пороговую величину при активации и индикатора относительно свойства пороговой устойчивости, указывающего то, когда вторая пороговая величина переопределяет первую пороговую величину, и отслеживание процесса редактирования контента пользовательского контента в файле пользовательских данных, чтобы идентифицировать величину элементов контента в числе пользовательского контента, которые содержат конфиденциальные данные, соответствующие одной или более предварительно определенных схем данных. Способ включает в себя, в ходе процесса редактирования контента, активацию и деактивацию представления индикаторов примечаний для одного или более элементов контента, по меньшей мере, отчасти на основе текущей величины элементов контента относительно первой пороговой величины, коэффициента эластичности для первой пороговой величины при активации и индикатора относительно свойства пороговой устойчивости.
[0095] Пример 2: Способ по примерам 1, в котором индикаторы примечаний содержат одно или более из глобального индикатора, представленного в пользовательском интерфейсе для пользовательского приложения, который применяется к файлу пользовательских данных, и отдельных индикаторов, представленных в пользовательском интерфейсе, позиционированных рядом с отдельными элементами контента, содержащими конфиденциальные данные.
[0096] Пример 3: Способ по примерам 1, дополнительно содержащий, в ходе процесса редактирования контента, по меньшей мере, на основе текущей величины элементов контента, превышающей первую пороговую величину, инициирование представления, по меньшей мере, одного индикатора примечания в пользовательском интерфейсе, который помечает флагом пользовательский контент в пользовательском интерфейсе как содержащий, по меньшей мере, первые конфиденциальные данные. Способ дополнительно включает в себя, в ходе процесса редактирования контента, по меньшей мере, на основе текущей величины элементов контента, первоначально превышающей первую пороговую величину и затем опускающейся ниже первой пороговой величины, когда коэффициент эластичности применяется к первой пороговой величине, установление второй пороговой величины, по меньшей мере, на основе коэффициента эластичности для удаления представления, по меньшей мере, одного индикатора примечания. Способ дополнительно включает в себя, в ходе процесса редактирования контента, по меньшей мере, на основе текущей величины элементов контента, опускающейся ниже второй пороговой величины, когда коэффициент эластичности применяется к первой пороговой величине, инициирование удаления представления, по меньшей мере, одного индикатора примечания. Способ дополнительно включает в себя, в ходе процесса редактирования контента, по меньшей мере, на основе текущей величины элементов контента, первоначально опускающейся ниже второй пороговой величины и затем превышающей вторую пороговую величину, когда свойство пороговой устойчивости применяется ко второй пороговой величине, инициирование представления, по меньшей мере, одного дополнительного индикатора примечания в пользовательском интерфейсе, который помечает флагом пользовательский контент в пользовательском интерфейсе как содержащий, по меньшей мере, вторые конфиденциальные данные.
[0097] Пример 4: Способ по примерам 3, дополнительно содержащий, в ходе процесса редактирования контента, по меньшей мере, на основе текущей величины элементов контента, первоначально превышающей первую пороговую величину и затем опускающейся ниже первой пороговой величины, когда коэффициент эластичности не применяется к первой пороговой величине, удаление представления, по меньшей мере, одного индикатора примечания. Способ дополнительно включает в себя, в ходе процесса редактирования контента, по меньшей мере, на основе текущей величины элементов контента, первоначально опускающейся ниже второй пороговой величины и затем превышающей второе пороговое значение, когда свойство устойчивости не применяется ко второй пороговой величине, отказ от представления, по меньшей мере, одного дополнительного индикатора примечания, который помечает флагом пользовательский контент в пользовательском интерфейсе как содержащий, по меньшей мере, вторые конфиденциальные данные, до тех пор, пока величина элементов контента не превысит первую пороговую величину.
[0098] Пример 5: Инфраструктура снабжения примечаниями для обеспечения конфиденциальности данных для пользовательского приложения, содержащая один или более машиночитаемых носителей хранения данных, систему обработки, функционально соединенную с одним или более машиночитаемых носителей хранения данных, и программные инструкции, сохраненные на одном или более машиночитаемых носителей хранения данных. По меньшей мере, на основе считывания и выполнения посредством системы обработки, программные инструкции направляют систему обработки с возможностью, по меньшей мере, идентифицировать одно или более из первой пороговой величины, коэффициента эластичности для первой пороговой величины и индикатора относительно свойства пороговой устойчивости и отслеживать пользовательский контент в файле пользовательских данных, представленном для редактирования контента в пользовательском интерфейсе для пользовательского приложения, чтобы идентифицировать величину элементов контента, содержащих конфиденциальные данные, в числе пользовательского контента, соответствующего одной или более предварительно определенных схем данных. Программные инструкции дополнительно направляют систему обработки, во время редактирования контента и, по меньшей мере, на основе величины элементов контента, превышающей первую пороговую величину, с возможностью инициировать представление, по меньшей мере, одного индикатора примечания в пользовательском интерфейсе, который помечает флагом пользовательский контент в пользовательском интерфейсе как содержащий, по меньшей мере, первые конфиденциальные данные. Программные инструкции дополнительно направляют систему обработки, во время редактирования контента и, по меньшей мере, на основе величины элементов контента, первоначально превышающей первую пороговую величину и затем опускающейся ниже первой пороговой величины, когда коэффициент эластичности применяется к первой пороговой величине, с возможностью устанавливать вторую пороговую величину, по меньшей мере, на основе коэффициента эластичности для удаления представления, по меньшей мере, одного индикатора примечания. Программные инструкции дополнительно направляют систему обработки, во время редактирования контента и, по меньшей мере, на основе величины элементов контента, первоначально опускающейся ниже второй пороговой величины и затем превышающей вторую пороговую величину, когда свойство пороговой устойчивости применяется ко второй пороговой величине, с возможностью инициировать представление, по меньшей мере, одного дополнительного индикатора примечания в пользовательском интерфейсе, который помечает флагом пользовательский контент в пользовательском интерфейсе как содержащий, по меньшей мере, вторые конфиденциальные данные.
[0099] Пример 6: Инфраструктура снабжения примечаниями для обеспечения конфиденциальности данных по примерам 5, содержащая дополнительные программные инструкции, которые, по меньшей мере, на основе считывания и выполнения посредством системы обработки, направляют систему обработки, по меньшей мере, во время редактирования контента, по меньшей мере, на основе величины элементов контента, опускающейся ниже второй пороговой величины, когда коэффициент эластичности применяется к первой пороговой величине, с возможностью инициировать удаление представления, по меньшей мере, одного индикатора примечания.
[0100] Пример 7: Инфраструктура снабжения примечаниями для обеспечения конфиденциальности данных по примерам 5, содержащая дополнительные программные инструкции, которые, по меньшей мере, на основе считывания и выполнения посредством системы обработки, направляют систему обработки, по меньшей мере, во время редактирования контента, по меньшей мере, на основе величины элементов контента, первоначально превышающей первую пороговую величину и затем опускающейся ниже первой пороговой величины, когда коэффициент эластичности не применяется к первой пороговой величине, с возможностью удалять представление, по меньшей мере, одного индикатора примечания.
[0101] Пример 8: Инфраструктура снабжения примечаниями для обеспечения конфиденциальности данных по примерам 5, содержащая дополнительные программные инструкции, которые, по меньшей мере, на основе считывания и выполнения посредством системы обработки, направляют систему обработки, по меньшей мере, во время редактирования контента, по меньшей мере, на основе величины элементов контента, первоначально опускающейся ниже второй пороговой величины и затем превышающей второе пороговое значение, когда свойство устойчивости не применяется ко второй пороговой величине, с возможностью отказываться от представления, по меньшей мере, одного дополнительного индикатора примечания, который помечает флагом пользовательский контент в пользовательском интерфейсе как содержащий, по меньшей мере, вторые конфиденциальные данные, до тех пор, пока величина элементов контента не превысит первую пороговую величину.
[0102] Пример 9: Инфраструктура снабжения примечаниями для обеспечения конфиденциальности данных по примерам 5, в которой идентификация одного или более из первой пороговой величины, коэффициента эластичности для первой пороговой величины и индикатора относительно свойства пороговой устойчивости содержит определение политики снабжения примечаниями, устанавливаемой для целевого объекта, ассоциированного с редактированием контента, причем политика снабжения примечаниями содержит одно или более из первой пороговой величины, коэффициента эластичности для первой пороговой величины и индикатора относительно свойства пороговой устойчивости.
[0103] Пример 10: Инфраструктура снабжения примечаниями для обеспечения конфиденциальности данных по примерам 9, в которой целевой объект содержит, по меньшей мере, одно из пользователя, выполняющего редактирование контента, организации, которая содержит пользователя, выполняющего редактирование контента, и типа приложения для пользовательского приложения.
[0104] Пример 11: Инфраструктура снабжения примечаниями для обеспечения конфиденциальности данных по примерам 5, в которой, по меньшей мере, один индикатор примечания и, по меньшей мере, один дополнительный индикатор примечания содержат одно или более из глобального индикатора, представленного в пользовательском интерфейсе, который применяется к файлу пользовательских данных, и отдельных индикаторов, представленных в пользовательском интерфейсе, позиционированных рядом с отдельными элементами контента, содержащими конфиденциальные данные.
[0105] Пример 12: Инфраструктура снабжения примечаниями для обеспечения конфиденциальности данных по примерам 5, в которой одна или более предварительно определенных схем данных задаются посредством одного или более выражений, используемых посредством службы классификации для того, чтобы синтаксически анализировать пользовательский контент и идентифицировать элементы контента, содержащие данные, указывающие один или более предварительно определенных шаблонов контента или один или более предварительно определенных типов контента.
[0106] Пример 13: Способ предоставления инфраструктуры снабжения примечаниями для обеспечения конфиденциальности данных для пользовательского приложения, при этом способ содержит идентификацию одного или более из первой пороговой величины, коэффициента эластичности для первой пороговой величины и индикатора относительно свойства пороговой устойчивости и отслеживание пользовательского контента в файле пользовательских данных, представленном для редактирования контента в пользовательском интерфейсе для пользовательского приложения, чтобы идентифицировать величину элементов контента, содержащих конфиденциальные данные, в числе пользовательского контента, соответствующего одной или более предварительно определенных схем данных. Способ включает в себя, в ходе процесса редактирования контента, по меньшей мере, на основе величины элементов контента, превышающей первую пороговую величину, инициирование представления, по меньшей мере, одного индикатора примечания в пользовательском интерфейсе, который помечает флагом пользовательский контент в пользовательском интерфейсе как содержащий, по меньшей мере, первые конфиденциальные данные. Способ включает в себя, в ходе процесса редактирования контента, по меньшей мере, на основе величины элементов контента, первоначально превышающей первую пороговую величину и затем опускающейся ниже первой пороговой величины, когда коэффициент эластичности применяется к первой пороговой величине, установление второй пороговой величины, по меньшей мере, на основе коэффициента эластичности для удаления представления, по меньшей мере, одного индикатора примечания. Способ включает в себя, в ходе процесса редактирования контента, по меньшей мере, на основе величины элементов контента, первоначально опускающейся ниже второй пороговой величины и затем превышающей вторую пороговую величину, когда свойство пороговой устойчивости применяется ко второй пороговой величине, инициирование представления, по меньшей мере, одного дополнительного индикатора примечания в пользовательском интерфейсе, который помечает флагом пользовательский контент в пользовательском интерфейсе как содержащий, по меньшей мере, вторые конфиденциальные данные.
[0107] Пример 14: Способ по примерам 13, дополнительно содержащий, во время редактирования контента, по меньшей мере, на основе величины элементов контента, опускающейся ниже второй пороговой величины, когда коэффициент эластичности применяется к первой пороговой величине, инициирование удаления представления, по меньшей мере, одного индикатора примечания.
[0108] Пример 15: Способ по примерам 13, дополнительно содержащий, во время редактирования контента, по меньшей мере, на основе величины элементов контента, первоначально превышающей первую пороговую величину и затем опускающейся ниже первой пороговой величины, когда коэффициент эластичности не применяется к первой пороговой величине, удаление представления, по меньшей мере, одного индикатора примечания.
[0109] Пример 16: Способ по примерам 13, дополнительно содержащий, во время редактирования контента, по меньшей мере, на основе величины элементов контента, первоначально опускающейся ниже второй пороговой величины и затем превышающей второе пороговое значение, когда свойство устойчивости не применяется ко второй пороговой величине, отказ от представления, по меньшей мере, одного дополнительного индикатора примечания, который помечает флагом пользовательский контент в пользовательском интерфейсе как содержащий, по меньшей мере, вторые конфиденциальные данные до тех пор, пока величина элементов контента не превысит первую пороговую величину.
[0110] Пример 17: Способ по примерам 13, в котором идентификация одного или более из первой пороговой величины, коэффициента эластичности для первой пороговой величины и индикатора относительно свойства пороговой устойчивости содержит определение политики снабжения примечаниями, устанавливаемой для целевого объекта, ассоциированного с редактированием контента, причем политика снабжения примечаниями содержит одно или более из первой пороговой величины, коэффициента эластичности для первой пороговой величины и индикатора относительно свойства пороговой устойчивости.
[0111] Пример 18: Способ по примерам 17, в котором целевой объект содержит, по меньшей мере, одно из пользователя, выполняющего редактирование контента, организации, которая содержит пользователя, выполняющего редактирование контента, и типа приложения для пользовательского приложения.
[0112] Пример 19: Способ по примерам 13, в котором, по меньшей мере, один индикатор примечания и, по меньшей мере, один дополнительный индикатор примечания содержат одно или более из глобального индикатора, представленного в пользовательском интерфейсе, который применяется к файлу пользовательских данных, и отдельных индикаторов, представленных в пользовательском интерфейсе, позиционированных рядом с отдельными элементами контента, содержащими конфиденциальные данные.
[0113] Пример 20: Способ по примерам 13, в котором одна или более предварительно определенных схем данных задаются посредством одного или более выражений, используемых посредством службы классификации для того, чтобы синтаксически анализировать пользовательский контент и идентифицировать элементы контента, содержащие данные, указывающие один или более предварительно определенных шаблонов контента или один или более предварительно определенных типов контента.
[0114] Функциональные блок–схемы, рабочие сценарии и последовательности и блок–схемы последовательности операций способа, предоставленные на чертежах, представляют примерные системы, окружения и технологии для выполнения новых аспектов раскрытия. Хотя, для простоты пояснения, способы, включенные в данный документ, могут иметь форму функциональной схемы, рабочего сценария либо последовательности или блок–схемы последовательности операций способа и могут описываться как последовательность этапов, следует понимать и принимать во внимание, что способы не ограничены посредством порядка действий, поскольку некоторые действия могут, в соответствии с ними, возникать в другом порядке и/или одновременно с действиями, отличным от действий, показанных и описанных в данном документе. Например, специалисты в данной области техники должны понимать и принимать во внимание, что способ альтернативно может представляться как последовательность взаимосвязанных состояний или событий, к примеру, на диаграмме состояний. Кроме того, не все действия, проиллюстрированные в технологии, могут требоваться для новой реализации.
[0115] Описания и чертежи, включенные в данный документ, иллюстрируют конкретные реализации для того, чтобы обучать специалистов в данной области техники тому, как осуществлять и использовать наилучший вариант. В целях изучения принципов изобретения, некоторые традиционные аспекты упрощены или опущены. Специалисты в данной области техники должны принимать во внимание варьирования этих реализаций, которые попадают в пределы объема раскрытия. Специалисты в данной области техники также должны принимать во внимание, что признаки, описанные выше, могут комбинироваться различными способами, чтобы формировать несколько реализаций. Как результат, изобретение ограничено не конкретными реализациями, описанными выше, а только формулой изобретения и ее эквивалентами.
| название | год | авторы | номер документа |
|---|---|---|---|
| ОБФУСКАЦИЯ ПОЛЬЗОВАТЕЛЬСКОГО КОНТЕНТА В СТРУКТУРИРОВАННЫХ ФАЙЛАХ ПОЛЬЗОВАТЕЛЬСКИХ ДАННЫХ | 2018 |
|
RU2772300C2 |
| СИСТЕМА ПОСТАНОВКИ МЕТКИ КОНФИДЕНЦИАЛЬНОСТИ В ЭЛЕКТРОННОМ ДОКУМЕНТЕ, УЧЕТА И КОНТРОЛЯ РАБОТЫ С КОНФИДЕНЦИАЛЬНЫМИ ЭЛЕКТРОННЫМИ ДОКУМЕНТАМИ | 2017 |
|
RU2647643C1 |
| УСТРОЙСТВО БЕЗОПАСНОСТИ, СПОСОБ И СИСТЕМА ДЛЯ НЕПРЕРЫВНОЙ АУТЕНТИФИКАЦИИ | 2021 |
|
RU2786363C1 |
| ОБУСЛОВЛЕННОЕ ОКРУЖАЮЩЕЙ СРЕДОЙ УПРАВЛЕНИЕ ДОСТУПОМ | 2014 |
|
RU2679983C2 |
| СРЕДСТВО ЗАПУСКА ДЛЯ КОНТЕКСТНЫХ МЕНЮ | 2012 |
|
RU2609070C2 |
| БЕСПРОВОДНОЕ СТЫКОВОЧНОЕ УСТРОЙСТВО | 2014 |
|
RU2667982C2 |
| НАСТРОЙКА КОНТЕНТА ВО ИЗБЕЖАНИЕ ЗАГОРАЖИВАНИЯ ВИРТУАЛЬНОЙ ПАНЕЛЬЮ ВВОДА | 2012 |
|
RU2609099C2 |
| Система и способ для идентификации и управления средствами связи | 2017 |
|
RU2691191C2 |
| ПРЕДОСТАВЛЕНИЕ ВОЗМОЖНОСТИ КЛАССИФИКАЦИИ И УПРАВЛЕНИЯ ПРАВАМИ ДОСТУПА К ИНФОРМАЦИИ В ПРОГРАММНЫХ ПРИЛОЖЕНИЯХ | 2015 |
|
RU2701111C2 |
| ГРАФИЧЕСКИЙ ПОЛЬЗОВАТЕЛЬСКИЙ ИНТЕРФЕЙС ДЛЯ РЕАЛИЗАЦИИ ЭЛЕМЕНТОВ УПРАВЛЕНИЯ ДЛЯ ГЕОГРАФИЧЕСКОЙ ПЕРЕВОЗКИ | 2016 |
|
RU2671249C2 |
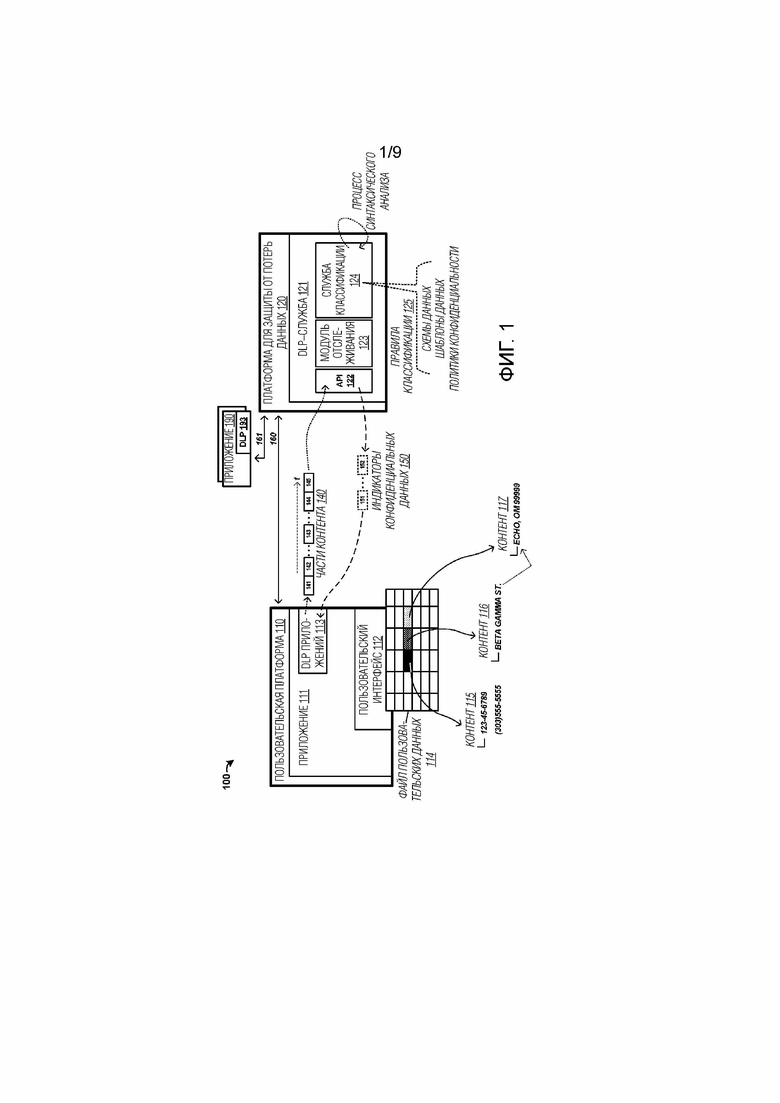
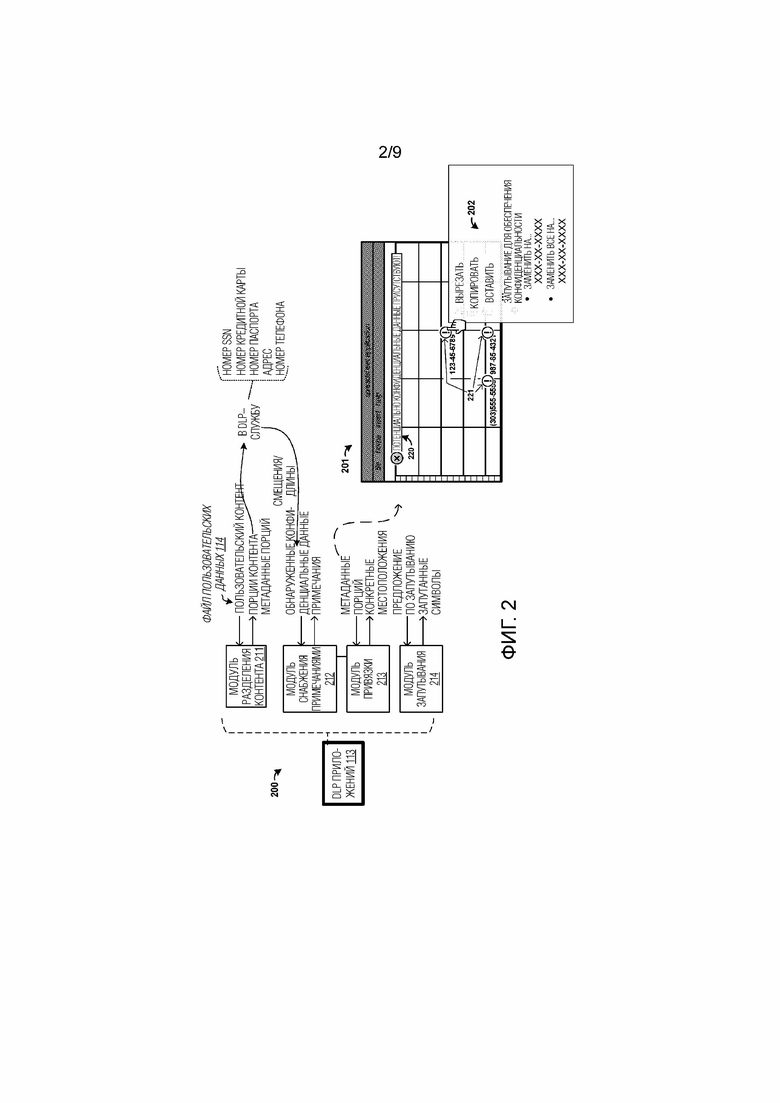
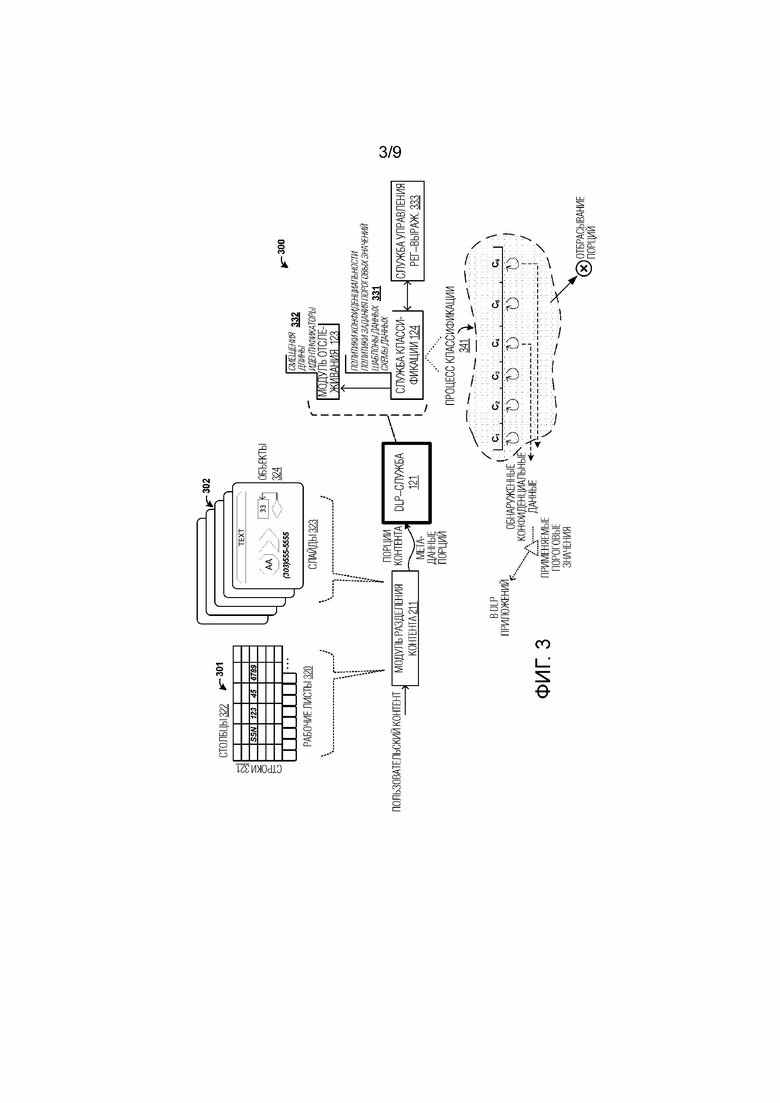
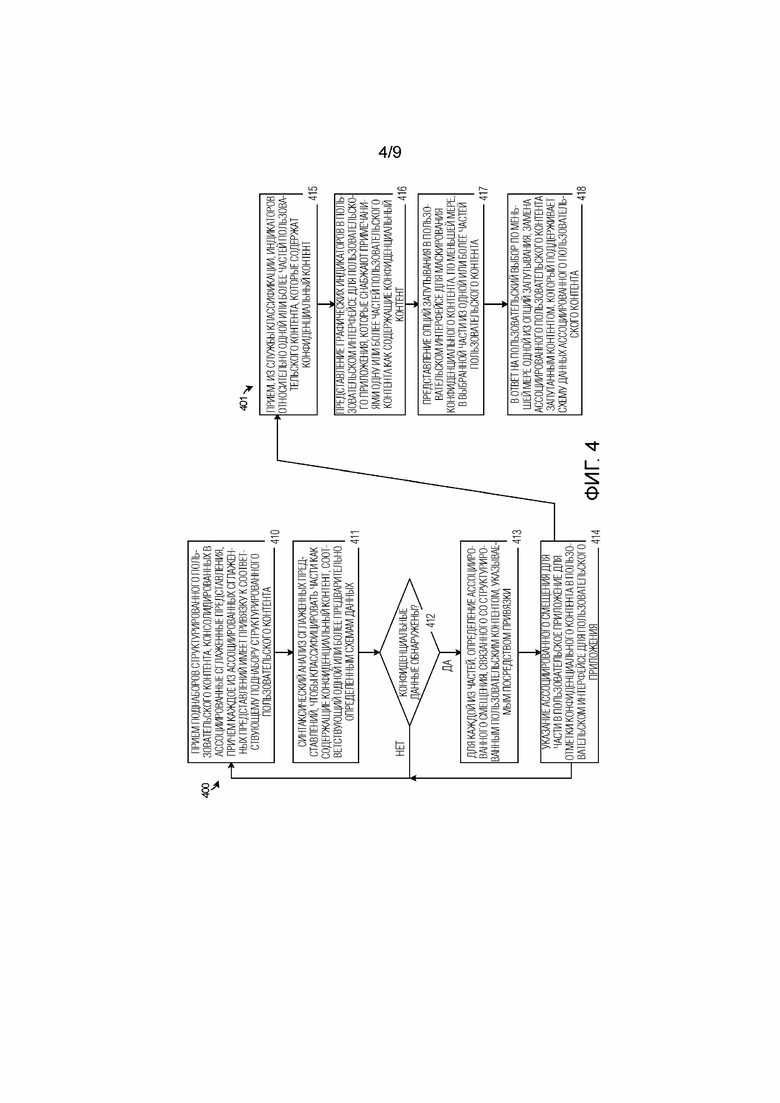
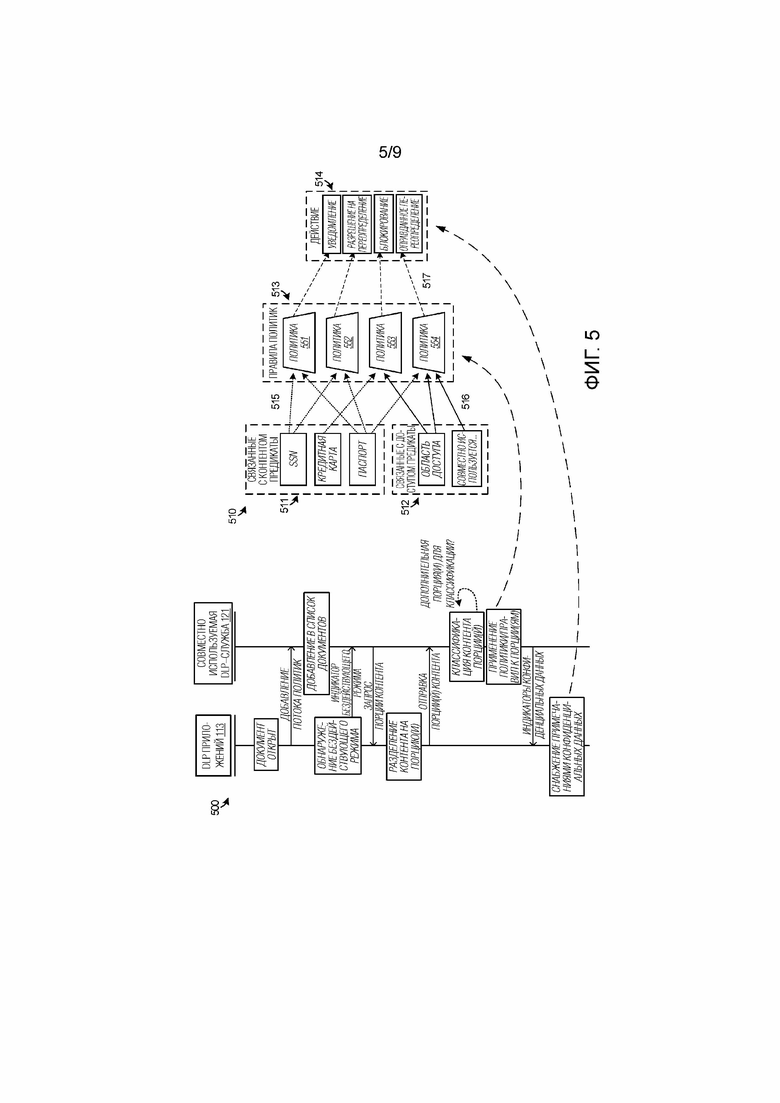
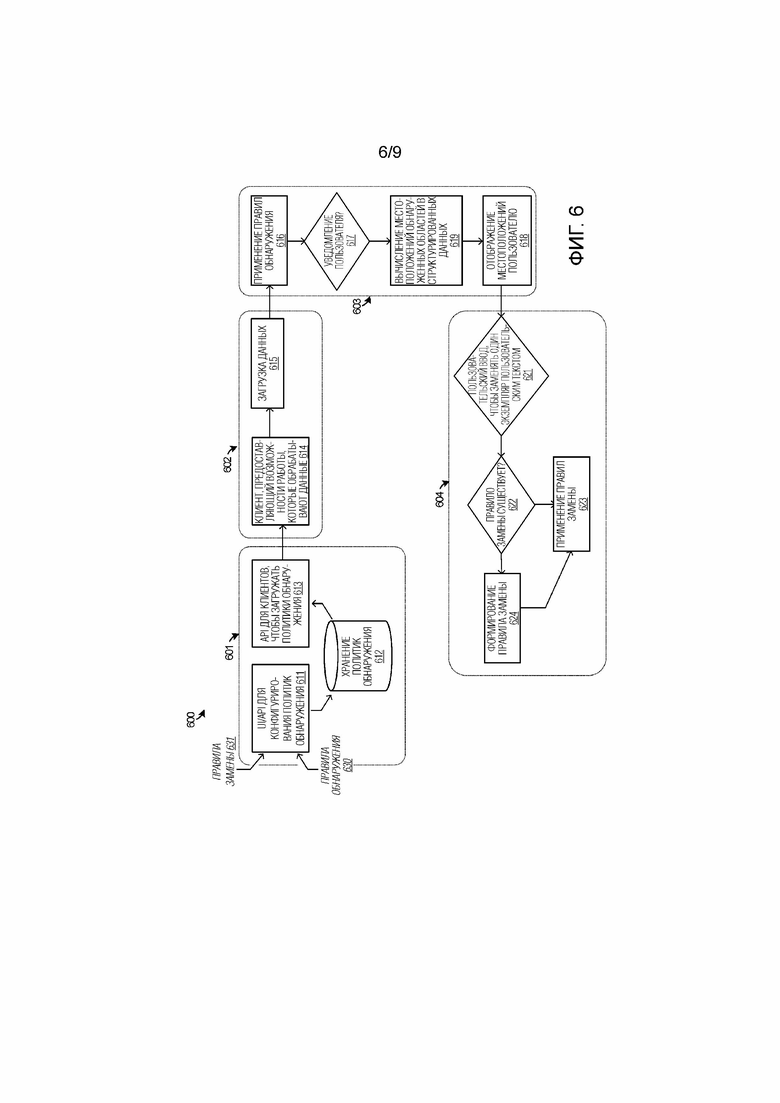
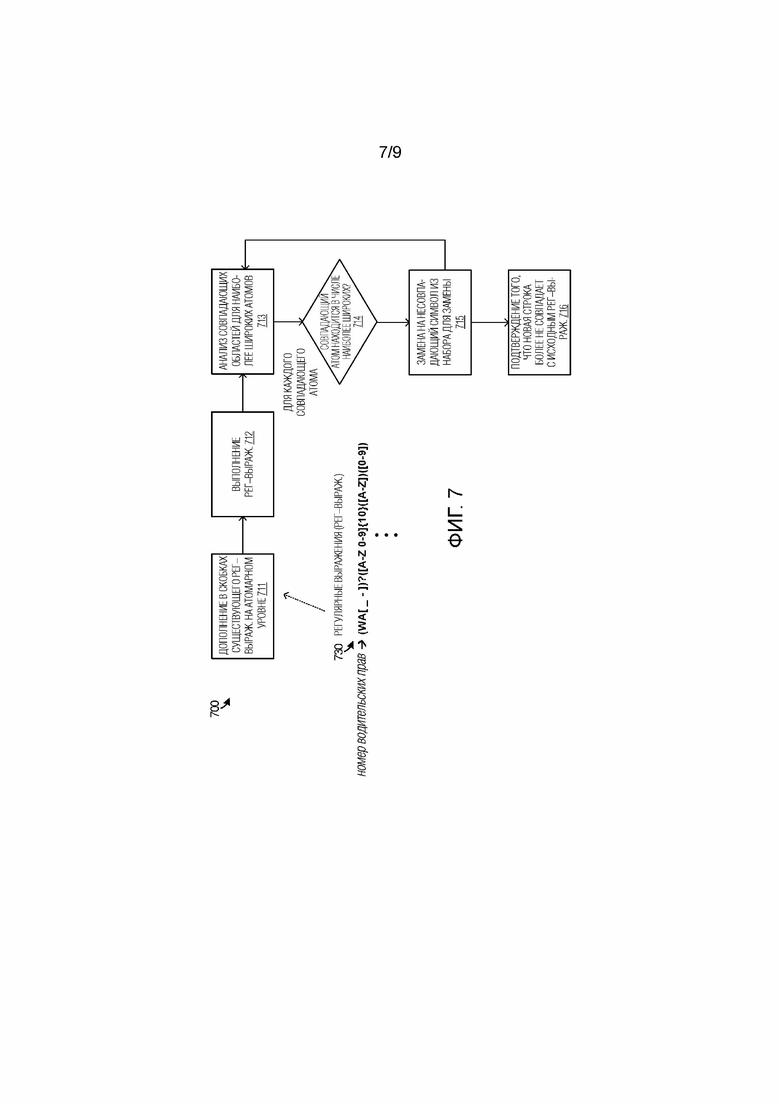
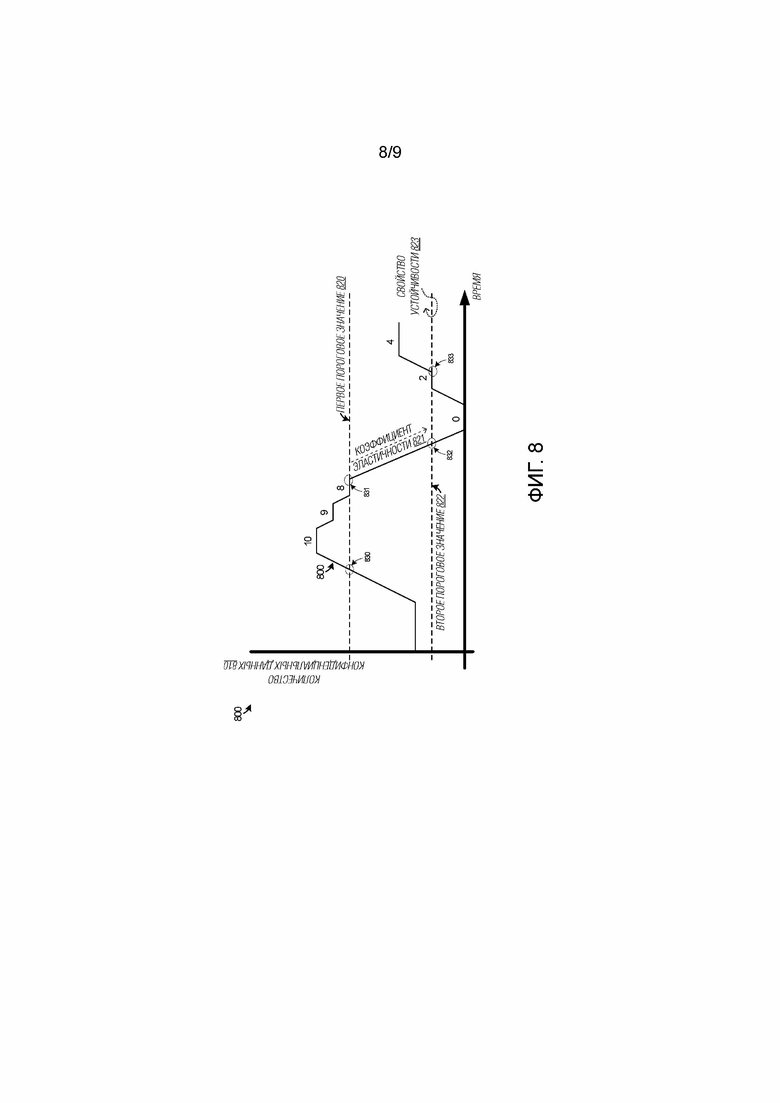
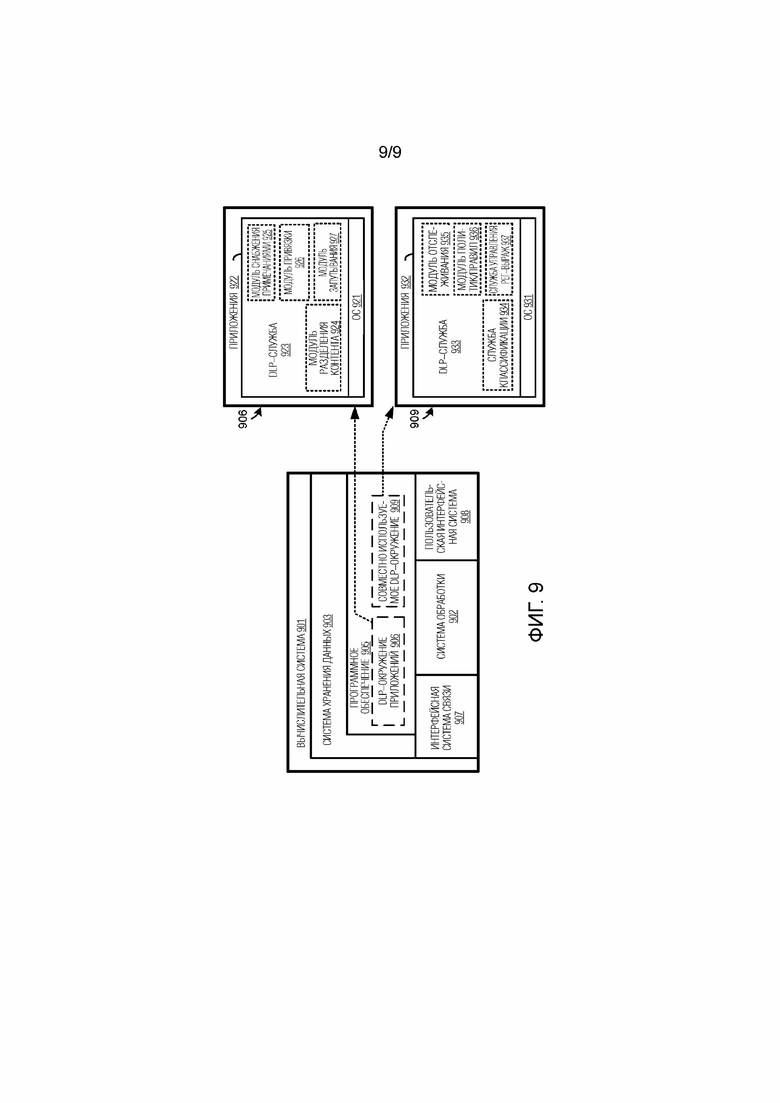
Изобретение относится к области информационных технологий. Техническим результатом является повышение эффективности защиты данных конфиденциального контента. Способ включает в себя идентификацию, по меньшей мере, первой пороговой величины, коэффициента эластичности для изменения первой пороговой величины на вторую пороговую величину и указание свойства пороговой устойчивости, указывающее то, когда вторая пороговая величина замещает первую пороговую величину. Способ включает в себя отслеживание процесса редактирования контента пользовательского контента таким образом, чтобы идентифицировать количество элементов пользовательского контента, которые содержат конфиденциальные данные, соответствующие одной или более предварительно определенным схемам данных, и в ходе процесса редактирования контента, активацию и деактивацию представления индикаторов примечаний для элементов контента, по меньшей мере, отчасти на основе текущего количества относительно первой пороговой величины, коэффициента эластичности для первой пороговой величины при активации и индикатора относительно свойства пороговой устойчивости. 3 н. и 17 з.п. ф-лы, 9 ил.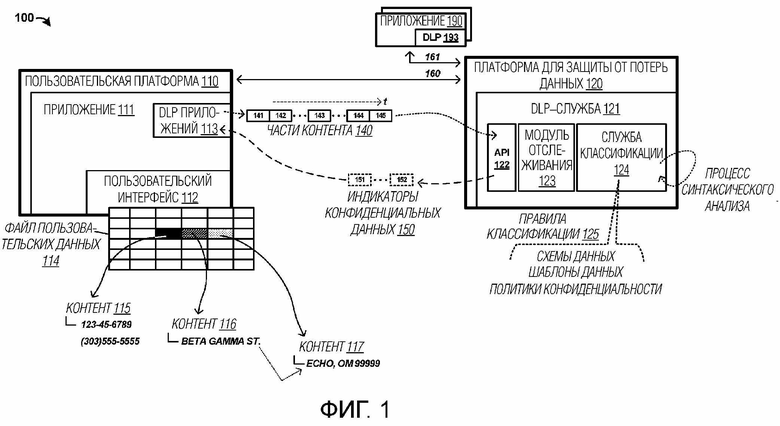
1. Способ работы пользовательского приложения, содержащий этапы, на которых:
идентифицируют, по меньшей мере, первую пороговую величину, коэффициент эластичности для изменения первой пороговой величины на вторую пороговую величину при его применении и указание свойства пороговой устойчивости, указывающее то, когда вторая пороговая величина замещает первую пороговую величину;
отслеживают процесс редактирования контента пользовательского контента в файле пользовательских данных, чтобы идентифицировать количество элементов контента среди пользовательского контента, которые содержат конфиденциальные данные, соответствующие одной или более предварительно определенным схемам данных; и
в ходе процесса редактирования контента, активируют и деактивируют представление индикаторов примечаний для одного или более из элементов контента на основе, по меньшей мере, отчасти текущего количества элементов контента относительно первой пороговой величины, коэффициента эластичности для первой пороговой величины при его применении и указания свойства пороговой устойчивости.
2. Способ по п.1, в котором индикаторы примечаний содержат одно или более из следующего:
глобальный индикатор, представленный в пользовательском интерфейсе для пользовательского приложения, который применяется к файлу пользовательских данных; и
отдельные индикаторы, представленные в пользовательском интерфейсе, позиционированные рядом с отдельными элементами контента, содержащими конфиденциальные данные.
3. Способ по п.1, дополнительно содержащий этапы, на которых, в ходе процесса редактирования контента:
на основе, по меньшей мере, того, что текущее количество элементов контента превышает первую пороговую величину, инициируют представление в пользовательском интерфейсе по меньшей мере одного индикатора примечания, который помечает пользовательский контент в пользовательском интерфейсе как содержащий, по меньшей мере, первые конфиденциальные данные;
на основе, по меньшей мере, того, что текущее количество элементов контента первоначально превышает первую пороговую величину и затем опускается ниже первой пороговой величины, когда коэффициент эластичности применяется к первой пороговой величине, устанавливают вторую пороговую величину на основе, по меньшей мере, коэффициента эластичности для удаления представления упомянутого по меньшей мере одного индикатора примечания;
на основе, по меньшей мере, того, что текущее количество элементов контента опускается ниже второй пороговой величины, когда коэффициент эластичности применяется к первой пороговой величине, инициируют удаление представления упомянутого по меньшей мере одного индикатора примечания; и
на основе, по меньшей мере, того, что текущее количество элементов контента первоначально опускается ниже второй пороговой величины и затем превышает вторую пороговую величину, когда свойство пороговой устойчивости применяется ко второй пороговой величине, инициируют представление по меньшей мере одного дополнительного индикатора примечания в пользовательском интерфейсе, который помечает пользовательский контент в пользовательском интерфейсе как содержащий, по меньшей мере, вторые конфиденциальные данные.
4. Способ по п.1, дополнительно содержащий этапы, на которых, в ходе процесса редактирования контента:
на основе, по меньшей мере, того, что текущее количество элементов контента первоначально превышает первую пороговую величину и затем опускается ниже первой пороговой величины, когда коэффициент эластичности не применяется к первой пороговой величине, удаляют представление упомянутого по меньшей мере одного индикатора примечания; и
на основе, по меньшей мере, того, что текущее количество элементов контента первоначально опускается ниже второй пороговой величины и затем превышает второе пороговое значение, когда свойство устойчивости не применяется ко второй пороговой величине, отказываются от представления упомянутого по меньшей мере одного дополнительного индикатора примечания, который помечает пользовательский контент в пользовательском интерфейсе как содержащий, по меньшей мере, вторые конфиденциальные данные, до тех пор, пока количество элементов контента не превысит первую пороговую величину.
5. Система снабжения примечаниями для обеспечения конфиденциальности данных для пользовательского приложения, содержащая:
один или более машиночитаемых носителей данных;
подсистему обработки, функционально соединенную с одним или более машиночитаемыми носителями данных; и
программные инструкции, сохраненные на одном или более машиночитаемых носителях данных, которые, по меньшей мере, на основе считывания и исполнения посредством подсистемы обработки, предписывают системе обработки, по меньшей мере:
идентифицировать одно или более из первой пороговой величины, коэффициента эластичности для первой пороговой величины и указания свойства пороговой устойчивости;
отслеживать пользовательский контент в файле пользовательских данных, представленном для редактирования контента в пользовательском интерфейсе для пользовательского приложения, чтобы идентифицировать среди пользовательского контента количество элементов контента, содержащих конфиденциальные данные, соответствующие одной или более предварительно определенным схемам данных; и
во время редактирования контента:
на основе, по меньшей мере, того, что количество элементов контента превышает первую пороговую величину, инициировать представление в пользовательском интерфейсе по меньшей мере одного индикатора примечания, который помечает пользовательский контент в пользовательском интерфейсе как содержащий, по меньшей мере, первые конфиденциальные данные;
на основе, по меньшей мере, того, что количество элементов контента первоначально превышает первую пороговую величину и затем опускается ниже первой пороговой величины, когда коэффициент эластичности применяется к первой пороговой величине, устанавливать вторую пороговую величину на основе, по меньшей мере, коэффициента эластичности для удаления представления упомянутого по меньшей мере одного индикатора примечания; и
на основе, по меньшей мере, того, что количество элементов контента первоначально опускается ниже второй пороговой величины и затем превышает вторую пороговую величину, когда свойство пороговой устойчивости применяется ко второй пороговой величине, инициировать представление в пользовательском интерфейсе по меньшей мере одного дополнительного индикатора примечания, который помечает пользовательский контент в пользовательском интерфейсе как содержащий, по меньшей мере, вторые конфиденциальные данные.
6. Система снабжения примечаниями для обеспечения конфиденциальности данных по п.5, содержащая дополнительные программные инструкции, которые, по меньшей мере, на основе считывания и исполнения подсистемой обработки, предписывают подсистеме обработки, по меньшей мере: во время редактирования контента, на основе, по меньшей мере, того, что количество элементов контента опускается ниже второй пороговой величины, когда коэффициент эластичности применяется к первой пороговой величине, инициировать удаление представления упомянутого по меньшей мере одного индикатора примечания.
7. Система снабжения примечаниями для обеспечения конфиденциальности данных по п.5, содержащая дополнительные программные инструкции, которые, по меньшей мере, на основе считывания и исполнения подсистемой обработки, предписывают подсистеме обработки, по меньшей мере: во время редактирования контента, на основе, по меньшей мере, того, что количество элементов контента первоначально превышает первую пороговую величину и затем опускается ниже первой пороговой величины, когда коэффициент эластичности не применяется к первой пороговой величине, удалять представление упомянутого по меньшей мере одного индикатора примечания;
8. Система снабжения примечаниями для обеспечения конфиденциальности данных по п.5, содержащая дополнительные программные инструкции, которые, по меньшей мере, на основе считывания и исполнения подсистемой обработки, предписывают подсистеме обработки, по меньшей мере: во время редактирования контента, на основе, по меньшей мере, того, что количество элементов контента первоначально опускается ниже второй пороговой величины и затем превышает второе пороговое значение, когда свойство устойчивости не применяется ко второй пороговой величине, отказываться от представления упомянутого по меньшей мере одного дополнительного индикатора примечания, который помечает пользовательский контент в пользовательском интерфейсе как содержащий, по меньшей мере, вторые конфиденциальные данные, до тех пор, пока количество элементов контента не превысит первую пороговую величину.
9. Система снабжения примечаниями для обеспечения конфиденциальности данных по п.5, в которой идентификация одного или более из первой пороговой величины, коэффициента эластичности для первой пороговой величины и указания свойства пороговой устойчивости содержит определение политики снабжения примечаниями, устанавливаемой для целевого субъекта, ассоциированного с редактированием контента, причем политика снабжения примечаниями содержит одно или более из первой пороговой величины, коэффициента эластичности для первой пороговой величины и указания свойства пороговой устойчивости.
10. Система снабжения примечаниями для обеспечения конфиденциальности данных по п.9, при этом целевой субъект представляет собой по меньшей мере одно из пользователя, выполняющего редактирование контента, организации, которая содержит пользователя, выполняющего редактирование контента, и типа приложения для пользовательского приложения.
11. Система снабжения примечаниями для обеспечения конфиденциальности данных по п.5, в которой упомянутые по меньшей мере один индикатор примечания и по меньшей мере один дополнительный индикатор примечания содержат одно или более из следующего:
глобальный индикатор, представленный в пользовательском интерфейсе, который применяется к файлу пользовательских данных; и
отдельные индикаторы, представленные в пользовательском интерфейсе, позиционированные рядом с отдельными элементами контента, содержащими конфиденциальные данные.
12. Система снабжения примечаниями для обеспечения конфиденциальности данных по п.5, в которой упомянутые одна или более предварительно определенных схем данных задаются посредством одного или более выражений, используемых службой классификации, чтобы синтаксически анализировать пользовательский контент и идентифицировать элементы контента, содержащие данные, указывающие один или более предварительно определенных шаблонов контента либо один или более предварительно определенных типов контента.
13. Способ предоставления инфраструктуры снабжения примечаниями для обеспечения конфиденциальности данных для пользовательского приложения, содержащий этапы, на которых:
идентифицируют одно или более из первой пороговой величины, коэффициента эластичности для первой пороговой величины и указания свойства пороговой устойчивости;
отслеживают пользовательский контент в файле пользовательских данных, представленном для редактирования контента в пользовательском интерфейсе для пользовательского приложения, чтобы идентифицировать среди пользовательского контента количество элементов контента, содержащих конфиденциальные данные, соответствующие одной или более предварительно определенным схемам данных; и
во время редактирования контента:
на основе, по меньшей мере, того, что количество элементов контента превышает первую пороговую величину, инициируют представление в пользовательском интерфейсе по меньшей мере одного индикатора примечания, который помечает пользовательский контент в пользовательском интерфейсе как содержащий, по меньшей мере, первые конфиденциальные данные;
на основе, по меньшей мере, того, что количество элементов контента первоначально превышает первую пороговую величину и затем опускается ниже первой пороговой величины, когда коэффициент эластичности применяется к первой пороговой величине, устанавливают вторую пороговую величину на основе, по меньшей мере, коэффициента эластичности для удаления представления упомянутого по меньшей мере одного индикатора примечания; и
на основе, по меньшей мере, того, что количество элементов контента первоначально опускается ниже второй пороговой величины и затем превышает вторую пороговую величину, когда свойство пороговой устойчивости применяется ко второй пороговой величине, инициируют представление по меньшей мере одного дополнительного индикатора примечания в пользовательском интерфейсе, который помечает пользовательский контент в пользовательском интерфейсе как содержащий, по меньшей мере, вторые конфиденциальные данные.
14. Способ по п.13, дополнительно содержащий этап, на котором: во время редактирования контента, на основе, по меньшей мере, того, что количество элементов контента опускается ниже второй пороговой величины, когда коэффициент эластичности применяется к первой пороговой величине, инициируют удаление представления упомянутого по меньшей мере одного индикатора примечания.
15. Способ по п.13, дополнительно содержащий этап, на котором: во время редактирования контента, на основе, по меньшей мере, того, что количество элементов контента первоначально превышает первую пороговую величину и затем опускается ниже первой пороговой величины, когда коэффициент эластичности не применяется к первой пороговой величине, удаляют представление упомянутого по меньшей мере одного индикатора примечания.
16. Способ по п.13, дополнительно содержащий этап, на котором: во время редактирования контента, на основе, по меньшей мере, того, что количество элементов контента первоначально опускается ниже второй пороговой величины и затем превышает второе пороговое значение, когда свойство устойчивости не применяется ко второй пороговой величине, отказываются от представления упомянутого по меньшей мере одного дополнительного индикатора примечания, который помечает пользовательский контент в пользовательском интерфейсе как содержащий, по меньшей мере, вторые конфиденциальные данные, до тех пор, пока количество элементов контента не превысит первую пороговую величину.
17. Способ по п.13, в котором идентификация одного или более из первой пороговой величины, коэффициента эластичности для первой пороговой величины и указания свойства пороговой устойчивости содержит этап, на котором определяют политику снабжения примечаниями, устанавливаемую для целевого субъекта, ассоциированного с редактированием контента, причем политика снабжения примечаниями содержит одно или более из первой пороговой величины, коэффициента эластичности для первой пороговой величины и указания свойства пороговой устойчивости.
18. Способ по п.17, в котором целевой субъект представляет собой, по меньшей мере, одно из пользователя, выполняющего редактирование контента, организации, которая содержит пользователя, выполняющего редактирование контента, и типа приложения для пользовательского приложения.
19. Способ по п.13, в котором упомянутые по меньшей мере один индикатор примечания и по меньшей мере один дополнительный индикатор примечания содержат одно или более из следующего:
глобальный индикатор, представленный в пользовательском интерфейсе, который применяется к файлу пользовательских данных; и
отдельные индикаторы, представленные в пользовательском интерфейсе, позиционированные рядом с отдельными элементами контента, содержащими конфиденциальные данные.
20. Способ по п.13, в котором упомянутые одна или более предварительно определенных схем данных задаются посредством одного или более выражений, используемых службой классификации, чтобы синтаксически анализировать пользовательский контент и идентифицировать элементы контента, содержащие данные, указывающие один или более предварительно определенных шаблонов контента либо один или более предварительно определенных типов контента.
| Многоступенчатая активно-реактивная турбина | 1924 |
|
SU2013A1 |
| Изложница с суживающимся книзу сечением и с вертикально перемещающимся днищем | 1924 |
|
SU2012A1 |
| US 9256727 B1, 09.02.2016 | |||
| СПОСОБ И УСТРОЙСТВО ДЛЯ ОБЕСПЕЧЕНИЯ ЗАЩИТЫ В СИСТЕМЕ ОБРАБОТКИ ДАННЫХ | 2002 |
|
RU2333608C2 |
| СИСТЕМА И СПОСОБ ПРЕДОСТАВЛЕНИЯ КОНТЕНТА АБОНЕНТУ | 2011 |
|
RU2604517C2 |

