ОБЛАСТЬ ТЕХНИКИ
[01] Настоящая технология относится к области поисковых систем в общем смысле, и в частности к способу и устройству ранжирования результатов поиска.
УРОВЕНЬ ТЕХНИКИ
[02] Интернет предоставляет доступ к широкому спектру ресурсов, например, видеофайлам, файлам изображений, аудио-файлам или веб-страницам, содержащим контент по специфическим тематикам, референсные и новостные статьи. Типичный пользователь может выбирать конкретный веб-ресурс, доступ к которому он желает совершить, используя браузерное приложение, выполняемое на электронном устройстве: настольном компьютере, ноутбуке, планшете или смартфоне. Существует ряд коммерчески доступных браузеров для выполнения этой функции, например, браузер GOOGLE CHROME, браузер INTERNET EXPLORE, браузер YANDEX и так далее. Пользователь может ввести единый указатель ресурса (URL) для того веб-ресурса, который он желает посетить, или, альтернативно, пользователь может выбрать (щелкнуть или иным образом активировать) гиперссылку на URL веб-ресурса, который он желает посетить.
[03] Приведенный выше подход работает, когда пользователь заранее (apriori) знает, какой веб-ресурс он хочет посетить. Например, если пользователь заранее (apriori) знает, что он хочет получить доступ к веб-сайту Royal Bank of Canada, он может ввести в выбранный им браузер URL, связанный с Royal Bank of Canada, например, www.rbc.com.
[04] Однако, данный пользователь может не знать конкретного веб-ресурса, к которому он хочет получить доступ, но может знать тип информации, который ищет. При таких обстоятельствах пользователь может использовать так называемую поисковую систему, чтобы найти один или несколько веб-ресурсов, предоставляющие информацию, в которой заинтересован пользователь. Для этого пользователь может ввести «поисковый запрос», и поисковая система возвращает ранжированный список результатов поиска, которые отвечают на поисковый запрос, в виде страницы результатов поиска (или, сокращенно, SERP).
[05] На Фиг. 9 предоставлен снимок 9100 экрана типичной SERP, представляемой поисковой системой известного уровня техники, в данном случае, поисковая система представлена поисковой системой YANDEX, предоставленной ООО «Яндекс», Россия, 119021, Москва, улица Льва Толстого, 16. С иллюстративными целями поисковая система, с помощью которой был создан снимок 9100 экрана, реализуется на настольном компьютере.
[06] В рамках проиллюстрированного примера пользователь ввел в интерфейс 9102 поискового запроса поисковой системы поисковый запрос «ecuador», вероятно, интересуясь информацией, связанной с Эквадором. Как будет понятно, поисковый запрос «ecuador» не обладает четким поисковым намерением, поскольку пользователь, который ввел такой запрос, может интересоваться информацией о стране Эквадор, о песне «Ecuador» исполнителя Sash!, новостями об Эквадоре или изображениями эквадорской природы.
[07] Поисковый запрос, введенный в интерфейс поискового запроса, передается серверу поисковой системы (не изображен), и сервер поисковой системы выполняет поиск и возвращает данные для создания SERP 9104. SERP 9104 выполнена с возможностью передавать пользователю один или несколько результатов поиска. Эти результаты поиска, а также их представление, будут различаться, но в общем случае и исключительно в качестве примера они могут включать в себя: первый результат 9106 поиска, второй результат 9108 поиска, третий результат 9110 поиска и множество дополнительных результатов 9112 поиска. Некоторые из этих результатов поиска могут рассматриваться как «результаты веб-поиска», а некоторые их этих результатов поиска могут рассматриваться как «результаты вертикального поиска». Результаты вертикального поиска (например, первый результат 9106 поиска и третий результат 9110 поиска) являются поисковыми результатами, возвращенными модулем веб-поиска и, в общем случае, веб-ресурсами, доступными в сети интернет (в этих случаях, это русскоязычная статья об Эквадоре на WIKIPEDEA и статья об Эквадоре на Lonely Planet, соответственно). Результаты вертикального поиска (например, второй результат 9108 поиска) являются результатами поиска, возвращенными одним или несколькими модулями вертикального поиска поисковой системы (в этом случае второй результат 9108 поиска реализован как «виджет», представляющий результаты видео вертикали, т.е. одного или нескольких видео, которые отвечают на поисковый запрос «ecuador»).
[08] Опционально SERP 9104 может включать в себя карточку 9114 объекта. Карточка 9114 объекта обычно представлена тогда, когда поисковая система определила, что поисковый запрос связан с «объектом», причем объект обычно включает в себя или личность (актера, певца, политика и так далее), или достопримечательность (например, мост, музей, концертный зал, вокзал и так далее), или любое другое явление (например, кино, пьесу и так далее).
[09] SERP 9104 может также включать в себя активатор 9120 вертикального домена, причем этот активатор выполнен с возможностью позволять пользователю выбрать (или изменить) конкретный поисковый домен - в приведенном примере пользователь может инициировать переключение SERP 9104 с текущего «веб»-просмотра результатов поиска на один или несколько вертикальных доменов, включая: «карты», «изображения», «новости», «видео» и так далее. Число и конкретные типы вертикальных доменов могут различаться, но вертикальные домены позволяют пользователю переключаться на конкретный тип результатов поиска. Например, если пользователь был заинтересован в просмотре изображений Эквадора, пользователь может переключиться на вертикаль «изображений», что инициирует изменение SERP 9104 для представления пользователю результатов поиска из вертикали «изображений», причем результаты поиска являются изображениями, которые отвечают на результат поиска «ecuador».
[10] Очевидно, что результаты поиска, показанные как часть множества дополнительных результатов 9112 поиска, не являются всеми поисковыми результатами, которые создала поисковая система в ответ на поисковый запрос. Напротив, множество дополнительных результатов 9112 поиска включает в себя намного больше результатов поиска, которые не видны на снимке 9100 экрана из-за ограничений доступного пространства монитора электронного устройства. Кроме того, поисковые системы обычно «делят» результаты поиска на несколько экранов, и для этого предоставляется активатор 9116 прокручивания, чтобы переключаться на «следующую» часть SERP 9104. Активатор 9116 прокручивания может быть стрелочкой, цифровым указателем экранов в пределах SERP 9104 и так далее.
[11] Одной из технических сложностей в работе сервера поисковой системы является выбор и ранжирование результатов поиска для создания SERP 9104, которая потребует минимальных затрат времени пользователя. Это значит, что цель поисковых систем - поместить наиболее релевантные результаты поиска (т.е. результаты поиска, которые наиболее вероятно удовлетворят пользовательское поисковое намерение) ближе к «верху» SERP 9104. Другими словами, результаты поиска, представленные на более высоких позициях на SERP 9104 (т.е. первые N номеров результатов поиска, показанных на первой странице SERP 9104), должны удовлетворить поисковое намерение пользователя. В данной области техники существует общепринятое мнение, что, если пользователь должен «прокручивать» результаты поиска до второй, третьей и т.д. страницы SERP 9104, «качество» SERP 9104 расценивается как более низкое, чем желаемое.
[12] В поисковых системах используются различные техники и алгоритмы для ранжирования результатов поиска. Обычно для ранжирования результатов поиска SERP 9104 используется алгоритм машинного обучения. Для ранжирования результатов поиска доступны различные техники. Как пример, некоторые способы ранжирования результатов в соответствии с их релевантностью основаны на всех или некоторых из следующих критериев: (i) популярность данного поискового запроса или ответа на него в других предыдущих поисках (веб или вертикальных); (ii) число результатов, возвращенных модулями вертикального или веб-поиска; (iii) включает ли в себя поисковый запрос какие-либо ключевые термины (например, «изображения», «видео», «погода» или т.п.), (iv) насколько часто конкретный поисковый запрос включает в себя ключевые термины при вводе его другими пользователями; (v) насколько часто другие пользователи при выполнении аналогичного поиска выбирали конкретный ресурс или конкретные результаты вертикального поиска, когда результаты были представлены на SERP 9104.
[13] Одним из параметров, используемых для алгоритмов предварительного ранжирования, особенно для ранжирования результатов вертикального поиска относительно результатов веб-поиска, является «параметр полезности». Типичная система известного уровня техники может ранжировать результаты поиска на основе анализа показателя кликабельности (отношения количества щелчков (кликов) к количеству показов, CTR) первого результата поиска (наиболее высоко ранжированного результата поиска, который часто является результатом вертикального поиска), часто обозначаемого как "win", и второго результата поиска (следующего сразу после первого результата поиска, и который часто (но не обязательно) является результатом веб-поиска), часто обозначаемого как "loss". Типично используемая функция выглядит так: "S(ƒ, iw) - win - loss", где ƒ - факторы ранжирования, a iw - параметр, который указывает позицию данного результата поиска. Факторы ранжирования могут включать в себя одно или несколько из: вероятность встречаемости слова, поведенческие шаблоны, персонализированные параметры, соответственно связанные с первым результатом поиска и вторым результатом поиска. Параметр iw может включать в себя ранг первого результата поиска и второго результата поиска, связанный с ним вес намерения (т.е. параметр, указывающий необходимость потенциального пользователя в результате поиска конкретной категории - изображения, видео, карт, новостей, и т.д.).
[14] В рамках известного уровня техники алгоритм машинного обучения обучен прогнозировать параметр полезности. Алгоритм машинного обучения обучен использовать: (i) как параметры ввода, ранг результата поиска и связанные факторы ранжирования, причем связанные факторы ранжирования были определены на основе анализа предыдущих поисковых сессий (т.е. из истории), осуществляемых другими пользователями; (ii) как отмеченные ответы - значение CTR для данного положения на SERP.
[15] Как часть обучения алгоритма машинного обучения, алгоритм машинного обучения устанавливает взаимоотношения между (i) значением функции параметра полезности "S(ƒ, iw) - win - loss" с одной стороны и (ii) факторами ранжирования (включая фактор iw) с другой стороны. Формула параметра полезности затем используется для выбора конкретной позиции для данного результата вертикального поиска в пределах SERP, причем конкретная позиция выбирается таким образом, чтобы максимизировать параметр полезности для данного результата вертикального поиска.
[16] В патенте США 8,706,725 раскрыты способы переранжирования документов на основе факторов, специфичных для пользователя. Результаты поиска получения с помощью неконтекстуальной системы ранжирования таким образом, что результаты поиска не специфичны по отношению к конкретному пользователю, например, пользователю, который ввел поисковый запрос. Получают контекстуальные сигналы, предоставляющие специфичные для пользователя факторы, которые используются для переранжирования документов таким образом, что наиболее важные и релевантные документы перечислены сверху в списке результатов поиска. Каждый из факторов, специфичных для пользователя, оценивается и сравнивается для определения новой позиции каждого документа. Затем на основе новых позиций создается набор контектуальных результатов поиска.
[17] В патенте США 8,650,173 раскрыты технологии для размещения результатов поиска на странице результатов поиска (SERP). Может быть получен запрос. Запрос может быть передан множеству поставщиков результатов поиска. От поставщиков результатов поиска могут быть получены первый набор результатов поиска и второй набор результатов поиска. Из первого набора результатов поиска могут быть извлечены факторы намерения. На основе извлеченных факторов намерения можно сделать вывод о намерении пользователя во втором наборе результатов поиска. Первый набор результатов поиска и второй набор результатов поиска могут быть ранжированы на основе спрогнозированного пользовательского намерения. SERP может быть отображена в соответствии с ранжированными первым набором и вторым набором результатов поиска.
[18] В патенте США 7,698,331 раскрыта система создания списка результатов поиска в ответ на поисковый запрос от лица, проводящего поиск с использованием компьютерной сети. Ведется первая база данных, которая включает в себя первое множество поисковых позиций. Ведется вторая база данных, которая включает в себя документы, обладающие общим веб-контентом. От лица, производящего поиск, получают поисковый запрос. Из первой базы данных, обладающих документами, совпадающими с поисковым запросом, идентифицируется первый набор поисковых позиций, а из второй базы данных, обладающей документами, совпадающими с поисковым запросом, идентифицируется второй набор поисковых позиций. Определяется степень уверенности для каждой позиции из первого набора поисковых позиций, причем степень уверенности определяется в соответствии с релевантностью каждой позиции при сравнении с позициями второго набора поисковых позиций. Идентифицированные поисковые позиции из первого набора поисковых позиций расположены в соответствии, по меньшей мере частично, со степенью уверенности для каждой поисковой позиции.
РАСКРЫТИЕ
[19] Задачей предлагаемого изобретения является устранение по меньшей мере некоторых недостатков, присущих известному уровню техники.
[20] Варианты осуществления настоящей технологии были разработаны с учетом понимания разработчиками по меньшей мере одной технической проблемы, связанной с подходами известного уровня техники к ранжированию результатов вертикального поиска на основе параметра полезности. Разработчики выяснили, что при определенных обстоятельствах CTR двух соседних результатов поиска может быть очень схожим друг с другом, и, таким образом, разница в значениях CTR может зависеть от соответствующего ранга не напрямую. Разработчики также определили, что при этих обстоятельствах подходы известного уровня техники могут быть неэффективны (или менее эффективны) при определении для данного результата вертикального поиска позиции SERP, на которой параметр полезности данного результата вертикального поиска максимизирован. Это может привести к созданию SERP, которая не оптимизирована для намерения поиска пользователя. А это, в свою очередь, может привести к необходимости ввода пользователем множества поисковых запросов (с пояснительными и/или уточнительными и/или переформулированными поисковыми терминами) для получения информации, которую пользователь искал с самого начала. Это может привести к некоторым проблемам. Во-первых, это накладывает ограничения на вычислительные ресурсы поисковой системы из-за необходимости обработки множество поисковых запросов. Во-вторых, это накладывает ограничения на скорость соединения между пользовательским электронным устройством и сервером, связанным с поисковой системой. И, наконец, в-третьих, что не менее важно, для электронных устройств, питающихся от аккумулятора, это приводит к излишнему расходу ресурса аккумулятора.
[21] Чтобы проиллюстрировать корень проблемы, обнаруженной разработчиками, и не ограничиваясь какой-то конкретной теорией, будет описана Фиг. 10, на которой изображен график 10200. График 10200 изображает отношение конкретного значения 9202 CTR к конкретному значению 9204 iw. Предположим, что существуют определенные взаимоотношения (на основе анализа поисковых данных из истории) между CTR и позицией данного результата поиска (т.е. параметра iw). Следовательно, может быть составлено два графика - график первого результата поиска, изображенный на Фиг. 10 как 10206 и график второго результата поиска, изображенный на Фиг. 10 как 10208. График 10206 первого результата поиска и график 10208 второго результата поиска связаны, соответственно, с первым результатом поиска и со вторым результатом поиска, упомянутыми выше. Таким образом - можно сказать, что первый результат является результатом поиска, который был «оптимизирован» (т.е. первый результат является результатом вертикального поиска, для которого позиция на SERP была оптимизирована), а второй результат поиска является результатом поиска, следующим сразу после первого результата поиска.
[22] В пределах изображенной иллюстрации график 10210 параметра полезности (определенный с помощью формулы, использующейся на известном уровне техники, упомянутой выше) обладает нечетко выраженным максимумом на позициях 4-8 результатов поиска. При некоторых других обстоятельствах параметр полезности может быть определен с использованием другого алгоритма (на основе ряда компонентов в дополнение к CTR), например, S(iw, ƒ)=ΣikiTi, и при этих обстоятельствах может существовать корреляция не только между значениями CTR, но также и среди других параметров, что делает максимум еще более «размытым». Это может привести к тому, что определение позиции SERP с самой высокой полезностью становится еще более сложным.
[23] Варианты осуществления настоящей технологии, в широком смысле, решают приведенные выше технические проблемы с помощью специализированного (или, иными словами, независимого) алгоритма машинного обучения для создания (т.е. прогнозирования) каждого из компонентов (т.е. компонентов win и loss), которые затем используются в функции создания параметра полезности. В соответствии с вариантами осуществления настоящей технологи первый алгоритм машинного обучения обучен прогнозировать первый компонент, который используется для определения параметра полезности, причем первый алгоритм машинного обучения использует первый набор факторов обучения, и этот первый набор факторов обучения включает в себя по меньшей мере один фактор ƒ, который используется для обучения функции полезности. Аналогично, второй алгоритм машинного обучения обучен прогнозировать второй компонент, который используется для определения параметра полезности, причем второй алгоритм машинного обучения использует второй набор факторов обучения, и этот второй набор факторов обучения включает в себя по меньшей мере один другой фактор ƒ, который используется для обучения функции полезности.
[24] В результате соответствующего обучения первого алгоритма машинного обучения и второго алгоритма машинного обучения создается набор значений для данного компонента (т.е. либо компонента win, либо компонента loss). Каждое значение соответствует фактору из набора факторов (например, p(ƒ, iw)). Используют таким образом определенные значения компонентов (опционально вместе с фактором ƒ как параметрами обучения функции полезности). В результате таким образом обученная функция полезности дает возможность спрогнозировать значения параметра полезности на основе значений компонентов win и loss.
[25] Варианты осуществления настоящей технологии дают возможность при использовании таким образом созданного параметра полезности определять параметр полезности на основе независимо спрогнозированных компонентов win и loss.
[26] Например, компонент win (который представляет кликабельность данного результата поиска на данной позиции SERP) дает возможность прогнозировать, насколько может быть полезен (т.е. интересен) данный результат поиска, связанный с данной позицией SERP. Высокое значение win указывает на результат поиска с относительно высоким потенциальным интересом (и, таким образом, его параметр полезности должен быть увеличен). Низкое значение win указывает на относительно низкий потенциальный интерес (и, таким образом, значение функции S(ƒ, iw) должно быть понижено). Используя формулу параметра полезности, может быть определена «наиболее подходящая» позиция на SERP - что может включать в себя выбор таких значений как iw, что максимизирует значение параметра полезности. Таким образом определенное значение iw (т.е. позиция на SERP) используется для размещения данного результата поиска.
[27] Первым объектом настоящей технологии является способ создания страницы результатов поиска (SERP). Способ выполняется на сервере, реализующем поисковую систему, причем сервер доступен по сети передачи данных по меньшей мере одному электронному устройству. Способ включает в себя: получение по меньшей мере от одного электронного устройства поискового запроса; создание списка результатов поиска, причем список результатов поиска включает в себя первый результат поиска и второй результат поиска, оба отвечающие на поисковый запрос; ранжирование списка результатов поиска таким образом, что в результате ранжирования первый результат поиска и второй результат поиска находятся на первой позиции SERP и второй позиции SERP соответственно, причем первая позиция SERP и вторая позиция SERP являются соседними друг с другом; ранжирование дает ранжированный список результатов поиска; прогнозирование первого параметра интереса для первого результата поиска, причем прогнозирование осуществляется на основе первого алгоритма машинного обучения; прогнозирование второго параметра интереса для второго результата поиска, причем прогнозирование осуществляется на основе второго алгоритма машинного обучения, причем второй алгоритм машинного обучения отличается от первого алгоритма машинного обучения; прогнозирование параметра полезности для первого результата поиска, причем прогнозирование осуществляется на основе третьего алгоритма машинного обучения, и прогнозирование осуществляется по меньшей мере частично на основе первого параметра интереса и второго параметра интереса; корректировка позиции первого результата поиска в ранжированном списке результатов поиска на основе спрогнозированного параметра полезности, причем корректировка приводит к тому, что первый результат поиска оказывается на скорректированной позиции в ранжированном списке результатов поиска; создание SERP, включающей в себя первый результат поиска и второй результат поиска, причем первый результат поиска расположен на скорректированной позиции SERP.
[28] В некоторых вариантах осуществления способа первый результат поиска является результатом вертикального поиска.
[29] В некоторых вариантах осуществления способа второй результат поиска является результатом веб-поиска.
[30] В некоторых вариантах осуществления способа первый алгоритм машинного обучения и второй алгоритм машинного обучения обучены независимо друг от друга.
[31] В некоторых вариантах осуществления способа третий алгоритм машинного обучения был обучен с использованием параметров, спрогнозированных первым алгоритмом машинного обучения и вторым алгоритмом машинного обучения.
[32] В некоторых вариантах осуществления способа параметры, спрогнозированные первым алгоритмом машинного обучения и вторым алгоритмом машинного обучения, включают в себя первый фактор, указывающий отношение количества щелчков (кликов) к количеству показов данного результата поиска, и второй фактор, указывающий отношение количества щелчков (кликов) к количеству показов другого результата поиска, следующего по порядку ранжирования за данных результатом поиска.
[33] В некоторых вариантах осуществления способа третий алгоритм машинного обучения основан по меньшей мере частично на модифицированном алгоритме "win-loss".
[34] В некоторых вариантах осуществления способа корректировка позиции первого результата поиска также включает в себя дополнительную корректировку позиции второго результата поиска в соответствии со скорректированной позицией первого результата поиска.
[35] В некоторых вариантах осуществления способа список результатов поиска дополнительно включает в себя третий результат поиска, ранжированный на третьей позиции SERP, причем третья позиция SERP является соседней со второй позицией SERP, и способ дополнительно включает в себя: прогнозирование третьего параметра интереса для первого результата поиска для второй позиции SERP, причем прогнозирование осуществляется на основе первого алгоритма машинного обучения; прогнозирование четвертого параметра интереса для третьего результата поиска, причем прогнозирование осуществляется на основе второго алгоритма машинного обучения; а также прогнозирование параметра полезности для первого результата поиска дополнительно включает в себя прогнозирование второго параметра полезности для первого результата поиска, причем прогнозирование осуществляется на основе третьего алгоритма машинного обучения и по меньшей мере частично на основе третьего параметра интереса и четвертого параметра интереса; а также корректировка позиции первого результата поиска дополнительно включает в себя выбор одной из: первой позиции SERP и второй позиции SERP для размещения первого результата поиска на основе сравнения параметра полезности и второго параметра полезности.
[36] В некоторых вариантах осуществления способа прогнозирование параметра полезности и прогнозирование второго параметра полезности выполняются, в основном, одновременно.
[37] В некоторых вариантах осуществления способа и первый параметр интереса, и второй параметр интереса являются соответствующим спрогнозированным отношением количества щелчков (кликов) к количеству показов данного результата поиска.
[38] Другим объектом настоящей технологии является способ создания страницы результатов поиска (SERP). Способ выполняется на сервере, реализующем поисковую систему, причем сервер доступен по сети передачи данных по меньшей мере одному электронному устройству; способ включает в себя: получение по меньшей мере от одного электронного устройства поискового запроса; создание списка результатов поиска, причем список результатов поиска включает в себя первый результат поиска, второй результат поиска и третий результат поиска, первый результат поиска является результатом вертикального поиска, а второй результат поиска и третий результат поиска являются результатами веб-поиска, а также и первый результат поиска, и второй результат поиска, и третий результат поиска отвечают на поисковый запрос; ранжирование второго результата поиска и третьего результата поиска в порядке ранжирования таким образом, что второй результат поиска находится на первой позиции ранжирования, а третий результат поиска находится на второй позиции ранжирования; первая позиция ранжирования и вторая позиция ранжирования являются соседними друг с другом; определение и для первой позиции ранжирования, и для второй позиции ранжирования соответствующего параметра полезности для первого результата поиска, причем определение выполняется с помощью: прогнозирования первого параметра интереса для первого результата поиска для соответствующей позиции: и для первой позиции ранжирования, и для второй позиции ранжирования, прогнозирование осуществляется на основе первого алгоритма машинного обучения; прогнозирование второго параметра интереса для следующего результата поиска, прогнозирование осуществляется на основе второго алгоритма машинного обучения, причем второй алгоритм машинного обучения отличается от первого алгоритма машинного обучения; следующий результат поиска является соответствующим результатом из второго результата поиска и третьего результата поиска; прогнозирование соответствующего параметра полезности для первого результата поиска, прогнозирование осуществляется на основе третьего алгоритма машинного обучения, причем прогнозирование осуществляется по меньшей мере частично на основе первого параметра интереса и второго параметра интереса; выбор данной позиции из первой позиции ранжирования и второй позиции ранжирования для размещения первого результата поиска, причем данная позиция из первой позиции ранжирования и второй позиции ранжирования связана с наивысшим значением параметра полезности; создание SERP, включающей в себя первый результат поиска, размещенный на данной позиции из первой позиции ранжирования и второй позиции ранжирования.
[39] В некоторых вариантах осуществления способа первый алгоритм машинного обучения и второй алгоритм машинного обучения обучены независимо друг от друга.
[40] В некоторых вариантах осуществления способа третий алгоритм машинного обучения был обучен с использованием параметров, спрогнозированных первым алгоритмом машинного обучения и вторым алгоритмом машинного обучения.
[41] В некоторых вариантах осуществления способа параметры, спрогнозированные первым алгоритмом машинного обучения и вторым алгоритмом машинного обучения, включают в себя первый фактор, указывающий отношение количества щелчков (кликов) к количеству показов данного результата поиска, и второй фактор, указывающий отношение количества щелчков (кликов) к количеству показов другого результата поиска, следующего по порядку ранжирования за данных результатом поиска.
[42] В некоторых вариантах осуществления способа третий алгоритм машинного обучения основан по меньшей мере частично на модифицированном алгоритме "win-loss".
[43] В некоторых вариантах осуществления способа список результатов поиска дополнительно включает в себя четвертый результат поиска, который является еще одним результатом вертикального поиска, и в этом случае способ дополнительно включает в себя: и для первой позиции ранжирования и для второй позиции ранжирования определение соответствующего второго параметра полезности для четвертого результата поиска, причем при определении выполняется: прогнозирование первого параметра интереса для четвертого результата поиска на соответствующей позиции: и первой позиции ранжирования, и второй позиции ранжирования, причем прогнозирование осуществляется на основе первого алгоритма машинного обучения; прогнозирование второго параметра интереса для следующего результата поиска, причем прогнозирование осуществляется на основе второго алгоритма машинного обучения, причем второй алгоритм машинного обучения отличается от первого алгоритма машинного обучения, а следующий результат поиска является соответствующим результатом из второго результата поиска и третьего результата поиска; прогнозирование соответствующего второго параметра полезности для четвертого результата поиска, причем прогнозирование осуществляется на основе третьего алгоритма машинного обучения и осуществляется по меньшей мере частично на основе первого параметра интереса и второго параметра интереса; а также выбор данной позиции из первой позиции ранжирования и второй позиции ранжирования включает в себя: выбор данной позиции из первой позиции ранжирования и второй позиции ранжирования для размещения первого результата поиска, причем данная позиция из первой позиции ранжирования и второй позиции ранжирования связана с наивысшим значением параметра полезности; выбор другой позиции из первой позиции ранжирования и второй позиции ранжирования для размещения четвертого результата поиска, причем другая позиция из первой позиции ранжирования и второй позиции ранжирования связана с наивысшим значением второго параметра полезности; а также создание SERP включает в себя: размещение первого результата поиска на данной позиции из первой позиции ранжирования и второй позиции ранжирования; размещение четвертого результата поиска на другой позиции из первой позиции ранжирования и второй позиции ранжирования.
[44] Другим объектом настоящей технологии является сервер, включающий в себя: носитель информации; сетевой интерфейс, выполненный с возможностью передачи данных по сети передачи данных; процессор, функционально подключенный к носителю информации и сетевому интерфейсу, процессор выполнен с возможностью осуществлять: получение по меньшей мере от одного электронного устройства поискового запроса; создание списка результатов поиска, причем список результатов поиска включает в себя первый результат поиска и второй результат поиска, оба отвечающие на поисковый запрос; ранжирование результатов поиска таким образом, что в результате ранжирования первый результат поиска и второй результат поиска находятся на первой позиции SERP и второй позиции SERP соответственно, причем первая позиция SERP и вторая позиция SERP являются соседними друг с другом; ранжирование, дающее ранжированный список результатов поиска; прогнозирование первого параметра интереса для первого результата поиска, причем прогнозирование осуществляется на основе первого алгоритма машинного обучения; прогнозирование второго параметра интереса для второго результата поиска, причем прогнозирование осуществляется на основе второго алгоритма машинного обучения, причем второй алгоритм машинного обучения отличается от первого алгоритма машинного обучения; прогнозирование параметра полезности для первого результата поиска, причем прогнозирование осуществляется на основе третьего алгоритма машинного обучения, и прогнозирование осуществляется по меньшей мере частично на основе первого параметра интереса и второго параметра интереса; корректировка позиции первого результата поиска в ранжированном списке результатов поиска на основе спрогнозированного параметра полезности, причем корректировка приводит к тому, что первый результат поиска оказывается на скорректированного позиции в ранжированном списке результатов поиска; создание SERP, включающей в себя первый результат поиска и второй результат поиска, причем первый результат поиска расположен на скорректированной позиции на SERP.
[45] В некоторых вариантах осуществления сервера первый результат поиска является результатом вертикального поиска.
[46] В некоторых вариантах осуществления сервера второй результат поиска является результатом веб-поиска.
[47] В некоторых вариантах осуществления сервера первый алгоритм машинного обучения и второй алгоритм машинного обучения обучены независимо друг от друга.
[48] В некоторых вариантах осуществления сервера третий алгоритм машинного обучения был обучен с использованием параметров, спрогнозированных первым алгоритмом машинного обучения и вторым алгоритмом машинного обучения.
[49] В некоторых вариантах осуществления сервера параметры, спрогнозированные первым алгоритмом машинного обучения и вторым алгоритмом машинного обучения, включают в себя первый фактор, указывающий отношение количества щелчков (кликов) к количеству показов данного результата поиска, и второй фактор, указывающий отношение количества щелчков (кликов) к количеству показов другого результата поиска, следующего по порядку ранжирования за данных результатом поиска.
[50] В некоторых вариантах осуществления сервера третий алгоритм машинного обучения основан по меньшей мере частично на модифицированном алгоритме "win-loss".
[51] В некоторых вариантах осуществления сервера для корректировки позиции первого результата поиска процессор выполнен с возможностью дополнительно корректировать позицию второго результата поиска в соответствии со скорректированной позицией первого результата поиска.
[52] В некоторых вариантах осуществления сервера список результатов поиска дополнительно включает в себя третий результат поиска, ранжированный на третьей позиции SERP, причем третья позиция SERP является соседней со второй позицией SERP, и процессор выполнен с дополнительной возможностью осуществлять: прогнозирование третьего параметра интереса для первого результата поиска для второй позиции SERP, причем прогнозирование осуществляется на основе первого алгоритма машинного обучения; прогнозирование четвертого параметра интереса для третьего результата поиска, причем прогнозирование осуществляется на основе второго алгоритма машинного обучения; а также для прогнозирования параметра полезности для первого результата поиска процессор выполнен с дополнительной возможностью осуществлять прогнозирование второго параметра полезности для первого результата поиска, причем прогнозирование осуществляется на основе третьего алгоритма машинного обучения и по меньшей мере частично на основе третьего параметра интереса и четвертого параметра интереса; а для корректировки позиции первого результата поиска процессор выполнен с дополнительной возможностью осуществлять выбор одной из: первой позиции SERP и второй позиции SERP для размещения первого результата поиска на основе сравнения параметра полезности и второго параметра полезности.
[53] В некоторых вариантах осуществления сервера процессор выполнен с возможностью осуществлять прогнозирование параметра полезности и прогнозирование второго параметра полезности, в основном, одновременно.
[54] В некоторых вариантах осуществления сервера и первый параметр интереса, и второй параметр интереса являются соответствующим спрогнозированным отношением количества щелчков (кликов) к количеству показов данного результата поиска.
[55] Другим объектом настоящей технологии является сервер, включающий в себя: носитель информации; сетевой интерфейс, выполненный с возможностью передачи данных по сети передачи данных; процессор, функционально подключенный к носителю информации и сетевому интерфейсу, процессор выполнен с возможностью осуществлять: получение по меньшей мере от одного электронного устройства поискового запроса; создание списка результатов поиска, причем список результатов поиска включает в себя первый результат поиска, второй результат поиска и третий результат поиска, первый результат поиска является результатом вертикального поиска, а второй результат поиска и третий результат поиска являются результатами веб-поиска, а также и первый результат поиска, и второй результат поиска, и третий результат поиска отвечают на поисковый запрос; ранжирование второго результата поиска и третьего результата поиска в порядке ранжирования таким образом, что второй результат поиска находится на первой позиции ранжирования, а третий результат поиска находится на второй позиции ранжирования; первая позиция ранжирования и вторая позиция ранжирования являются соседними друг с другом; определение и для первой позиции ранжирования, и для второй позиции ранжирования соответствующего параметра полезности для первого результата поиска, причем определение выполняется с помощью: прогнозирования первого параметра интереса для первого результата поиска для соответствующей позиции: и для первой позиции ранжирования, и для второй позиции ранжирования, прогнозирование осуществляется на основе первого алгоритма машинного обучения; прогнозирование второго параметра интереса для следующего результата поиска, прогнозирование осуществляется на основе второго алгоритма машинного обучения, причем второй алгоритм машинного обучения отличается от первого алгоритма машинного обучения; следующий результат поиска является соответствующим результатом из второго результата поиска и третьего результата поиска; прогнозирование соответствующего параметра полезности для первого результата поиска, прогнозирование осуществляется на основе третьего алгоритма машинного обучения, причем прогнозирование осуществляется по меньшей мере частично на основе первого параметра интереса и второго параметра интереса; выбор данной позиции из первой позиции ранжирования и второй позиции ранжирования для размещения первого результата поиска, причем данная позиция из первой позиции ранжирования и второй позиции ранжирования связана с наивысшим значением параметра полезности; создание SERP, включающей в себя первый результат поиска, размещенный на данной позиции из первой позиции ранжирования и второй позиции ранжирования.
[56] В некоторых вариантах осуществления сервера первый алгоритм машинного обучения и второй алгоритм машинного обучения обучены независимо друг от друга.
[57] В некоторых вариантах осуществления сервера третий алгоритм машинного обучения был обучен с использованием параметров, спрогнозированных первым алгоритмом машинного обучения и вторым алгоритмом машинного обучения.
[58] В некоторых вариантах осуществления сервера параметры, спрогнозированные первым алгоритмом машинного обучения и вторым алгоритмом машинного обучения, включают в себя первый фактор, указывающий отношение количества щелчков (кликов) к количеству показов данного результата поиска, и второй фактор, указывающий отношение количества щелчков (кликов) к количеству показов другого результата поиска, следующего по порядку ранжирования за данных результатом поиска.
[59] В некоторых вариантах осуществления сервера третий алгоритм машинного обучения основан по меньшей мере частично на модифицированном алгоритме "win-loss".
[60] В некоторых вариантах осуществления сервера список результатов поиска дополнительно включает в себя четвертый результат поиска, который является еще одним результатом вертикального поиска, и в этом случае процессор выполнен с дополнительной возможностью осуществлять: и для первой позиции ранжирования и для второй позиции ранжирования определение соответствующего второго параметра полезности для четвертого результата поиска, причем при определении выполняется: прогнозирование первого параметра интереса для четвертого результата поиска на соответствующей позиции: и первой позиции ранжирования, и второй позиции ранжирования, причем прогнозирование осуществляется на основе первого алгоритма машинного обучения; прогнозирование второго параметра интереса для следующего результата поиска, причем прогнозирование осуществляется на основе второго алгоритма машинного обучения, причем второй алгоритм машинного обучения отличается от первого алгоритма машинного обучения, а следующий результат поиска является соответствующим результатом из второго результата поиска и третьего результата поиска; прогнозирование соответствующего второго параметра полезности для четвертого результата поиска, причем прогнозирование осуществляется на основе третьего алгоритма машинного обучения и осуществляется по меньшей мере частично на основе первого параметра интереса и второго параметра интереса; а также для выбора данной позиции из первой позиции ранжирования и второй позиции ранжирования процессор выполнен с возможностью осуществлять: выбор данной позиции из первой позиции ранжирования и второй позиции ранжирования для размещения первого результата поиска, причем данная позиция из первой позиции ранжирования и второй позиции ранжирования связана с наивысшим значением параметра полезности; выбор другой позиции из первой позиции ранжирования и второй позиции ранжирования для размещения четвертого результата поиска, причем другая позиция из первой позиции ранжирования и второй позиции ранжирования связана с наивысшим значением второго параметра полезности; а также для создания SERP процессор выполнен с возможностью осуществлять: размещение первого результата поиска на данной позиции из первой позиции ранжирования и второй позиции ранжирования; размещение четвертого результата поиска на другой позиции из первой позиции ранжирования и второй позиции ранжирования.
[61] В контексте настоящего описания «сервер» подразумевает под собой компьютерную программу, работающую на соответствующем оборудовании, которая способна получать запросы (например, от клиентских устройств) по сети и выполнять эти запросы или инициировать выполнение этих запросов. Оборудование может представлять собой один физический компьютер или одну физическую компьютерную систему, но ни то, ни другое не является обязательным для данного технического решения. В контексте настоящей технологии использование выражения «сервер» не означает, что каждая задача (например, полученные команды или запросы, извлечение поисковых сессий из истории) или какая-либо конкретная задача будет получена, выполнена или инициирована к выполнению одним и тем же сервером (то есть одним и тем же программным обеспечением и/или аппаратным обеспечением); это означает, что любое количество элементов программного обеспечения или аппаратных устройств может быть вовлечено в прием/передачу, выполнение или инициирование выполнения любого запроса или последствия любого запроса, связанного с клиентским устройством, и все это программное и аппаратное обеспечение может быть одним сервером или несколькими серверами, оба варианта включены в выражение «сервер».
[62] В контексте настоящего описания «клиентское устройство» подразумевает под собой аппаратное устройство, способное работать с программным обеспечением, подходящим к решению соответствующей задачи. Таким образом, примерами клиентских устройств (среди прочего) могут служить персональные компьютеры (настольные компьютеры, ноутбуки, нетбуки и т.п.) смартфоны, планшеты, а также сетевое оборудование, такое как маршрутизаторы, коммутаторы и шлюзы. Следует иметь в виду, что устройство, ведущее себя как клиентское устройство в настоящем контексте, может вести себя как сервер по отношению к другим клиентским устройствам. Использование выражения «клиентское устройство» не исключает возможности использования множества клиентских устройств для получения/отправки, выполнения или инициирования выполнения любой задачи или запроса, или же последствий любой задачи или запроса, или же этапов любого вышеописанного способа.
[63] В контексте настоящего описания «база данных» подразумевает под собой любой структурированный набор данных, не зависящий от конкретной структуры, программного обеспечения по управлению базой данных, аппаратного обеспечения компьютера, на котором данные хранятся, используются или иным образом оказываются доступны для использования. База данных может находиться на том же оборудовании, выполняющем процесс, на котором хранится или используется информация, хранящаяся в базе данных, или же база данных может находиться на отдельном оборудовании, например, выделенном сервере или множестве серверов.
[64] В контексте настоящего описания «информация» включает в себя информацию любого рода или типа, которая может храниться в базе данных. Таким образом, информация включает в себя, среди прочего, аудиовизуальные произведения (изображения, видео, звукозаписи, презентации и т.д.), данные (данные о местоположении, цифровые данные и т.д.), текст (мнения, комментарии, вопросы, сообщения и т.д.), документы, таблицы и т.д.
[65] В контексте настоящего описания «компонент» подразумевает под собой программное обеспечение (соответствующее конкретному аппаратному контексту), которое является необходимым и достаточным для выполнения конкретной(ых) указанной(ых) функции(й).
[66] В контексте настоящего описания «используемый компьютером носитель компьютерной информации» подразумевает под собой носитель абсолютно любого типа и характера, включая ОЗУ, ПЗУ, диски (компакт диски, DVD-диски, дискеты, жесткие диски и т.д.), USB флеш-накопители, твердотельные накопители, накопители на магнитной ленте и т.д.
[67] В контексте настоящего описания, как было описано ранее, «список словопозиций» для данного поискового термина - это обычно список ссылок на элементы данных в наборе данных, который включает в себя этот поисковый термин. В этом случае понятно, что чем более общим является поисковый термин, тем больше будет число ссылок в списке словопозиций. Для широко распространенных поисковых терминов, например, артикля "the" в английском языке, список словопозиций будет включать в себя ссылки на каждый элемент данных в наборе данных. Однако, почти для всех иных поисковых терминов такого не происходит, и для этих элементов существуют разрывы между элементами данных в наборе данных, содержащими данный поисковый термин, причем эти разрывы образованы элементами данных, которые не содержат этот термин. Так, например, принимая, что ссылки в списке словопозиций были на номера документов, будут присутствовать соответствующие разрывы в номерах документов в списке словопозиций.
[68] Список словопозиций для данного общего поискового термина (т.е. поисковый термин, который можно обнаружить в относительно большом числе документов, но не во всех) будет содержать ссылки в форме номеров документов, на те документы, в которых этот поисковый термин появляется. Ссылки в списках словопозиций сами по себе пронумерованы по порядку, но при отсутствии поискового термина в документах образуются разрывы между номерами документов из-за пропущенных документов. Длина списка словопозиций может быть различной в зависимости от числа элементов данных в наборе данных, которые включают в себя поисковый термин. Длина списка словопозиций может быть нулевой, при отсутствии в наборе данных документов, в которых встречается поисковый термин из запроса.
[69] В контексте настоящего описания, как было описано выше, «инвертированный индекс» содержит ряд списков словопозиций.
[70] В некоторых вариантах осуществления настоящей технологии каждый из множества списков словопозиций соответствует множеству ссылок поисковых терминов на множество индексированных элементов, причем проиндексированные элементы последовательно пронумерованы. Как было описано выше, такую схему используют поисковые интернет-системы, причем проиндексированные элементы последовательно пронумерованы номерами документов.
[71] В некоторых вариантах осуществления настоящей технологии каждый из множества списков словопозиций соответствует множеству ссылок поисковых терминов на множество индексированных элементов, причем проиндексированные элементы сгруппированы в порядке понижения их независимой от запроса релевантности. Эту схему обычно используют поисковые интернет-системы, в которых элементы данных не вносятся в набор данных бессистемно. Обычно элементы в наборе данных расположены в порядке понижения их независимой от запроса релевантности. Таким образом элементы данных, вероятность которых оказаться частью поисковых результатов любого данного поискового запроса статистически выше, будут расположены таким образом, чтобы их можно было найти в начале поиска. Поэтому более вероятно, что они будут найдены быстрее, чем данные в наборе данных, которые были введены бессистемно.
[72] В контексте настоящего описания слова «первый», «второй», «третий» и т.д. используются в виде прилагательных исключительно для того, чтобы отличать существительные, к которым они относятся, друг от друга, а не для целей описания какой-либо конкретной взаимосвязи между этими существительными. Так, например, следует иметь в виду, что использование терминов «первый сервер» и «третий сервер» не подразумевает какого-либо порядка, отнесения к определенному типу, хронологии, иерархии или ранжирования (например) серверов/между серверами, равно как и их использование (само по себе) не предполагает, что некий «второй сервер» обязательно должен существовать в той или иной ситуации. В дальнейшем, как указано здесь в других контекстах, упоминание «первого» элемента и «второго» элемента не исключает возможности того, что это один и тот же фактический реальный элемент. Так, например, в некоторых случаях, «первый» сервер и «второй» сервер могут являться одним и тем же программным и/или аппаратным обеспечением, а в других случаях они могут являться разным программным и/или аппаратным обеспечением.
[73] Каждый вариант осуществления настоящей технологии преследует по меньшей мере одну из вышеупомянутых целей и/или объектов, но наличие всех не является обязательным. Следует иметь в виду, что некоторые объекты данного технического решения, полученные в результате попыток достичь вышеупомянутой цели, могут не удовлетворять этой цели и/или могут удовлетворять другим целям, отдельно не указанным здесь.
[74] Дополнительные и/или альтернативные характеристики, аспекты и преимущества вариантов осуществления настоящего технического решения станут очевидными из последующего описания, прилагаемых чертежей и прилагаемой формулы изобретения.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[75] Для лучшего понимания настоящего изобретения, а также других его аспектов и характерных черт сделана ссылка на следующее описание, которое должно использоваться в сочетании с прилагаемыми чертежами, где:
[76] На Фиг. 1 представлена принципиальная схема системы, выполненной в соответствии с вариантами осуществления настоящей технологии, не ограничивающими ее объем.
[77] На Фиг. 2 представлена схема работы первого модуля системы, изображенной на Фиг. 1, причем первый модуль реализует первый алгоритм машинного обучения.
[78] На Фиг. 3 представлена схема работы второго модуля системы, изображенной на Фиг. 1, причем второй модуль реализует второй алгоритм машинного обучения.
[79] На Фиг. 4 представлена схема работы третьего модуля системы, изображенной на Фиг. 1, причем третий модуль реализует третий алгоритм машинного обучения.
[80] На Фиг. 5 представлена схема работы модуля поиска системы, изображенной на Фиг. 1, причем модуль поиска выполнен с возможностью ранжировать результаты поиска по меньшей мере частично на основе вывода третьего модуля, изображенного на Фиг. 4.
[81] На Фиг. 6 представлено схематическое изображение ранжированного списка результатов поиска и переранжированного списка результатов поиска, причем переранжированный список результатов поиска является выводом поискового модуля, изображенного на Фиг. 5.
[82] На Фиг. 7 представлено схематическое изображение модуля обучения, изображенного на Фиг. 1, причем модуль обучения отвечает за обучение алгоритмов машинного обучения первого модуля, второго модуля и третьего модуля.
[83] На Фиг. 8 представлена блок-схема способа, выполняемого в рамках системы, изображенной на Фиг. 1, и выполняемого в соответствии с вариантами осуществления настоящей технологии, не ограничивающими ее объем.
[84] На Фиг. 9 представлен снимок экрана с типичной SERP, предоставленной поисковой системой известного уровня техники.
[85] На Фиг. 9 представлен график отношения конкретного значения CTR к конкретному значению iw, причем подобный график используется в подходах известного уровня техники для определения параметра полезности.
[86] На Фиг. 11 представлена блок-схема способа, исполняемого в соответствии с другими вариантами осуществления настоящей технологии, не ограничивающими ее объем.
ОСУЩЕСТВЛЕНИЕ
[87] На Фиг. 1 представлена принципиальная схема системы 100, выполненной в соответствии с вариантами осуществления настоящей технологии, не ограничивающими ее объем. Важно иметь в виду, что нижеследующее описание системы 100 представляет собой описание показательных вариантов осуществления настоящей технологии. Таким образом, все последующее описание представлено только как описание показательного примера настоящей технологии. Это описание не предназначено для определения объема или установления границ настоящего технического решения. Некоторые полезные примеры модификаций системы 100 также могут быть охвачены нижеследующим описанием. Целью этого является также исключительно помощь в понимании, а не определение объема и границ настоящей технологии. Эти модификации не представляют собой исчерпывающий список, и специалистам в данной области техники будет понятно, что возможны и другие модификации. Кроме того, это не должно интерпретироваться так, что там, где это еще не было сделано, т.е. там, где не были изложены примеры модификаций, никакие модификации невозможны, и/или что то, что описано, является единственным вариантом осуществления этого элемента настоящей технологии. Как будет понятно специалисту в данной области техники, это, скорее всего, не так. Кроме того, следует иметь в виду, что система 100 представляет собой в некоторых конкретных проявлениях достаточно простой вариант осуществления настоящего технического решения, и в подобных случаях этот вариант представлен здесь с целью облегчения понимания. Как будет понятно специалисту в данной области техники, многие варианты осуществления настоящего технического решения будут обладать гораздо большей сложностью.
[88] В общем случае система 100 выполнена с возможностью получать поисковые запросы и проводить поиски (например, обычные и вертикальные поиски) в ответ на эти запросы, а также создавать аннотированные поисковые индексы в соответствии с вариантами осуществления настоящей технологии, не ограничивающими ее объем. Поэтому любой вариант системы, выполненный с возможностью обрабатывать поисковые запросы пользователя и создавать аннотированные поисковые индексы, может быть адаптирован специалистом к выполнению вариантов осуществления настоящей технологии после того, как специалистом было прочитано настоящее описание.
[89] Система 100 включает в себя электронное устройство 102. Электронное устройство 102 обычно связано с пользователем (не показан) и, таким образом, иногда может упоминаться как «клиентское устройство» или «клиентское электронное устройство». Следует отметить, что тот факт, что электронное устройство 102 связано с пользователем, не подразумевает какого-либо конкретного режима работы, равно как и необходимости входа в систему, регистрации, или чего-либо подобного.
[90] Варианты осуществления электронного устройства 102 конкретно не ограничены, но в качестве примера электронного устройства 102 могут использоваться персональные компьютеры (настольные компьютеры, ноутбуки, нетбуки и т.п.), устройства беспроводной связи (смартфоны, мобильные телефоны, планшеты и т.п.), а также сетевое оборудование (маршрутизаторы, коммутаторы или шлюзы). Электронное устройство 102 включает в себя аппаратное и/или прикладное программное, и/или системное программное обеспечение (или их комбинацию), как известно в данной области техники, для использования поискового приложения 104. В общем случае, целью поискового приложения 104 является предоставление возможности пользователю (не показан) выполнять поиск, например, сетевой поиск с помощью поисковой системы.
[91] Реализация поискового приложения 104 никак конкретно не ограничена. Одним из примеров выполнения поискового приложения 104 является доступ пользователем на вебсайт, соответствующий поисковой системе, для получения доступа к поисковому приложению 104. Например, поисковое приложение может быть вызвано путем ввода URL, связанного с поисковой системой Яндекс (Yandex™): www.yandex.ru. Важно иметь в виду, что поисковое приложение 104 может быть вызвано с помощью любой другой коммерчески доступной или собственной поисковой системы.
[92] В других вариантах осуществления настоящей технологии, не ограничивающих ее объем, поисковое приложение 104 может представлять собой браузерное приложение на портативном устройстве (например, беспроводном устройстве связи). Для тех случаев (но не только), когда электронное устройство 102 является портативным устройством, таким как, например, Samsung™ Galaxy™ Sin, электронное устройство 102 может использовать приложение Яндекс-браузер. Важно иметь в виду, что любое другое коммерчески доступное или собственное браузерное приложение может быть использовано для реализации вариантов осуществления настоящего технического решения, не ограничивающих ее объем.
[93] В общем случае, поисковое приложение 104 включает в себя интерфейс 106 поисковых запросов и интерфейс 108 результатов поиска. Основной задачей интерфейса 106 поисковых запросов является предоставление возможности пользователю (не показан) вводить свой запрос или «поисковый вопрос». Основной задачей интерфейса 108 результатов поиска является предоставление результатов поиска, отвечающих пользовательскому поисковому запросу, который был введен в интерфейс 106 поисковых запросов.
[94] К сети передачи данных также присоединен сервер 116. Сервер доступен для электронного устройства 102 по сети 110 передачи данных (электронное устройство 102 является всего лишь одним примеров из множества других электронных устройств, которые не изображены, но которые могут получить доступ к серверу 116 по сети 110 передачи данных).
[95] Сервер 116 может представлять собой обычный компьютерный сервер. В примере варианта осуществления настоящей технологии сервер 116 может представлять собой сервер Dell™ PowerEdge™, на котором используется операционная система Microsoft™ Windows Server™. Излишне говорить, что сервер 116 может представлять собой любое другое подходящее аппаратное и/или прикладное программное, и/или системное программное обеспечение. В представленном варианте осуществления настоящей технологии, не ограничивающем ее объем, сервер 116 является одиночным сервером. В других вариантах осуществления настоящего технического решения, не ограничивающих ее объем, функциональность сервера 116 может быть разделена и может выполняться с помощью нескольких серверов.
[96] Электронное устройство 102 выполнено с возможностью обмениваться данными с сервером 116 по сети 110 передачи данных и линии 112 передачи данных. В некоторых вариантах осуществления настоящей технологии, не ограничивающих ее объем, сеть 110 передачи данных может представлять собой Интернет. В других вариантах осуществления настоящей технологии сеть 110 передачи данных может быть реализована иначе - в виде глобальной сети передачи данных, локальной сети передачи данных, частной сети передачи данных и т.п.
[97] Реализация линии 112 передачи данных никак конкретно не ограничена, и будет зависеть от того, какое электронное устройство 102 используется. В качестве примера, но не ограничения, в данных вариантах осуществления настоящей технологии в случаях, когда электронное устройство 102 представляет собой беспроводное устройство связи (например, смартфон), линия 112 передачи данных представляет собой беспроводную сеть передачи данных (например, среди прочего, линия передачи данных 3G, линия передачи данных 4G, беспроводной интернет Wireless Fidelity или коротко WiFi®, Bluetooth® и т.п.). В тех примерах, где электронное устройство 102 представляет собой портативный компьютер, линия передачи данных может быть как беспроводной (беспроводной интернет Wireless Fidelity или коротко WiFi®, Bluetooth® и т.п) так и проводной (соединение на основе сети Ethernet).
[98] Сервер 116 функционально соединен с поисковым модулем 118 (или иным образом имеет к нему доступ). В соответствии с этими вариантами осуществления настоящей технологии, поисковый модуль 118 выполняет общий и/или вертикальный поиск в ответ на поисковый запрос пользователя, введенный с помощью интерфейса 106 поисковых запросов, и выводит результаты поиска для представления их пользователю с помощью интерфейса 108 результатов поиска.
[99] В рамках этих вариантов осуществления настоящей технологии, не ограничивающих ее объем, поисковый модуль 118 включает в себя базу данных 130 или имеет к ней доступ. Как известно специалистам в данной области техники, база данных 130 хранит информацию, связанную с множеством ресурсов, потенциально доступных через сеть передачи данных (например, эти ресурсы доступны по интернету).
[100] Процесс заполнения и ведения базы данных 130 общеизвестен как «сбор данных» («кроулинг» от англ. "crawling"). Осуществление базы данных 130 никак конкретно не ограничено. Следует понимать, что может быть использовано любое подходящее для хранения данных оборудование. В некоторых вариантах осуществления настоящей технологии база данных 130 может быть физически смежной с поисковым модулем 118, т.е. нет необходимости в том, чтобы они являлись отдельными частями аппаратного оборудования, как это изображено, хотя они могут являться отдельными частями аппаратного оборудования. В представленном варианте осуществления настоящей технологии, не ограничивающем ее объем, база данных 130 является одиночной базой данных. В альтернативных неограничивающих вариантах осуществления настоящей технологии база данных 130 может быть разделена на одну или несколько отдельных баз данных (не изображены). Эти отдельные базы данных могут являться частями той же самой физической базы данных или могут быть реализованы как самостоятельные физические единицы. Например, одна база данных в, допустим, базе данных 130 может хранить инвертированный индекс, а другая база данных в базе данных 130 может хранить доступные ресурсы, а еще одна база данных в базе данных 130 может хранить характеристики поисковых историй, относящихся к конкретным поисковым запросам (т.е. поисковым сессиям в истории). Излишне упоминать, что вышеприведенный пример является только иллюстрацией, и возможны другие дополнительные возможности для реализации вариантов осуществления настоящей технологии.
[101] База данных 130 также хранит информацию и данные, представляющие предыдущие поисковые запросы, например: что искал пользователь, какие результаты поиска были представлены, на каких позициях был представлен данный результат поиска, какие результаты были выбраны, был ли выбран данный результат поиска, сколько времени данный пользователь провел на данном результате прошлого поиска, сколько переформулировок ввел пользователь и так далее. В альтернативных вариантах осуществления технологии информация, представляющая предыдущие поисковые запросы, может быть сохранена в базе данных, отдельной от базы данных 130.
[102] Важно иметь в виду, что для упрощения нижеследующего описания конфигурация поискового модуля 118 и базы данных 130 была сильно упрощена. Считается, что специалисты в данной области техники смогут понять подробности реализации поискового модуля 118 и его компонентов и базы данных 130.
[103] В общем случае данный поисковый запрос, который данный пользователь может ввести, используя интерфейс 106 поисковых запросов, может быть рассмотрен как серии одного или нескольких поисковых терминов, а поисковые термины этих запросов могут быть представлены как T1, Т2, … Tn. Таким образом, поисковый запрос может пониматься как запрос поисковому приложению 104 определить каждый документ в наборе данных, индекс которого сохранен в базе данных 130, содержащей каждый поисковый термин T1, Т2, … Tn (логический эквивалент «и» между поисковыми терминами; т.е. в каждом документе, найденном в поиске, должно встречаться по меньшей мере один раз слово Ti, для каждого i от 1 до n. Альтернативно поисковый запрос может пониматься как запрос поисковому приложению 104 определить каждый документ в наборе данных, индекс которого сохранен в базе данных 130, содержащей по меньшей мере поисковые термины T1, Т2, … Tn, а также другие термины.
[104] В этих вариантах осуществления настоящей технологии сервер 116 выполнен с возможностью выполнять доступ к поисковому модулю 118 (чтобы осуществлять обычный веб-поиск и/или вертикальный поиск, например, в ответ на введенный поисковый запрос). В рамках варианта осуществления настоящей технологии, изображенного на Фиг. 1, сервер 116 выполнен с возможностью
[105] (i) получать от электронного устройства 102 поисковый запрос (например, поисковый запрос, введенный в интерфейс 106 поисковых запросов);
[106] (ii) проводить поиски (с помощью доступа к поисковому кластеру 118) для создания списка результатов поиска, причем список результатов поиска включает в себя первый результат поиска и второй результат поиска, оба отвечающие на поисковый запрос - в пределах некоторых вариантов осуществления настоящей технологии первый результат поиска является результатом вертикального поиска, и второй результат поиска является результатом веб-поиска;
[107] (iii) проводить анализ результатов поиска и ранжирование результатов поиска для создания ранжированного списка результатов поиска (процесс создания ранжированного списка результатов поиска будет описан подробнее ниже);
[108] (iv) группировать результаты для создания страницы результатов поиска (SERP) для вывода на электронное устройство 102 в ответ на поисковый запрос.
[109] Более конкретно, сервер 116 соединен с первым модулем 120, вторым модулем 122, третьим модулем 124 и модулем 126 обучения (причем модуль 126 обучения, в свою очередь, соединен и с первым модулем 120, и со вторым модулем 122, и с третьим модулем 124), или же имеет к ним доступ.
[110] И первый модуль 120, и второй модуль 122, и третий модуль 124 выполнены с возможностью осуществлять свои соответствующие алгоритмы машинного обучения. Конкретная реализация соответствующего алгоритма машинного обучения никак конкретно не ограничивается и может включать в себя, в широком смысле, алгоритм обучения с учителем (контролируемый) или алгоритм машинного обучения с учителем. Примеры алгоритмов обучения с учителем включают в себя, без установления ограничений: искусственные нейронные сети (Artificial neural network); алгоритмы на основе байесовой статистики (Bayesian statistics); обучающие алгоритмы, основанные на прецедентах (Case-based reasoning); алгоритмы регрессий на основе гауссовских процессов (Gaussian process regression); алгоритм генетического программирования (Gene expression programming); алгоритм метода группового учета аргументов (МГУА) (Group method of data handling (GMDH)); алгоритм индуктивного логического программирования (Inductive logic programming); алгоритм обучения на основе экземпляров выборки (Instance-based learning); «ленивое» обучение (Lazy learning); алгоритм конечных автоматов (Learning Automata); алгоритмы сетей векторного квантования (Learning Vector Quantization); логистические модели с деревьями решений (Logistic Model Tree) и так далее.
[111] Работа первого модуля 120, второго модуля 122 и третьего модуля 124, а также модуля 126 обучения теперь будет описана подробнее.
[112] На Фиг. 2 представлена схема работы первого модуля 120. Первый модуль 120 выполнен с возможностью реализовать первый алгоритм 208 машинного обучения. Первый алгоритм 208 машинного обучения выполнен с возможностью прогнозировать спрогнозированный первый параметр 210. В некоторых вариантах осуществления настоящей технологии спрогнозированный первый параметр 210 является параметром win, т.е. параметром, указывающим вероятность клика (щелчка) для данного результата поиска (в некоторых вариантах осуществления настоящей технологии данный результат поиска является результатом вертикального поиска), причем данный результат поиска размещен на конкретной позиции SERP. Другими словами, спрогнозированный первый параметр 210 указывает потенциальную заинтересованность пользователя в данном результате поиска относительно поискового запроса пользователя (предполагается, что чем более вероятно пользователь заинтересован в данном результате поиска, тем более вероятно пользователь щелкнет на данный результат поиска).
[113] Более конкретно, первый алгоритм 208 машинного обучения выполнен с возможностью прогнозировать спрогнозированный первый параметр 210 на основе множества факторов, включая в качестве примеров: первый фактор 202, второй фактор 204 и третий фактор 206. В соответствии с вариантами осуществления настоящей технологии первый фактор 202 является позицией SERP, использованной для прогнозирования (т.е. позицией, на которой размещен первый результат поиска на SERP). Природа второго фактора 204 и третьего фактора 206 (а также ряда дополнительных факторов, используемых первым алгоритмом 208 машинного обучения) никак конкретно не ограничена. В общем случае второй фактор 204 и третий фактор 206 могут включать в себя некоторые или все пункты из перечисленных: число результатов поиска в пределах конкретного результата вертикального поиска (например, в случае, когда конкретный результат вертикального поиска является результатом вертикального поиска по изображениям, представленным виджетом изображений - сколько изображений включает в себя виджет изображений); качество индивидуальных результатов в пределах конкретного результата вертикального поиска (например, в случае, когда конкретный результат вертикального поиска является результатом вертикального поиска по изображениям, представленным виджетом изображений - качество изображений виджета изображений); предварительно определенную вероятность щелчка пользователя на виджет на основе одного или нескольких поисковых терминов, входящих в состав поискового запроса, до взаимодействия пользователя с данным результатом поиска; данные, представляющие факторы данного результата поиска и так далее.
[114] В течение фазы обучения первого алгоритма 208 машинного обучения, первому алгоритму 208 машинного обучения предоставляется набор обучающих объектов, причем для каждого обучающего объекта предоставляется: соответствующий набор из первого фактора 202, второго фактора 204 и третьего фактора 206 (а также потенциально ряд дополнительных факторов, связанных с данным объектом обучения) и соответствующая «цель». В рамках вариантов осуществления настоящей технологии цель может быть реальными предыдущими данными по щелчкам данного обучающего объекта (например, «1» означает щелчок, а «0» - его отсутствие). В рамках вариантов осуществления настоящей технологии данный объект обучения может быть предыдущим результатом вертикального поиска, первый фактор 202 может быть позицией предыдущего результата вертикального поиска на данной предыдущей SERP, второй фактор 204 и третий фактор 206 могут быть извлечены из базы данных 130.
[115] Число обучающих объектов, используемых для обучения первого алгоритма 208 машинного обучения, никак конкретно не ограничено и может быть выбрано специалистами в данной области техники, обладающими доступом к описанию настоящей технологии. На основе обучающих объектов первый алгоритм 208 машинного обучения создает формулу алгоритма машинного обучения для прогнозирования спрогнозированого первого параметра 210 для нового первого результата поиска (т.е. нового результата вертикального поиска) для данной новой позиции на новой SERP.
[116] На Фиг. 3 представлена схема работы второго модуля 122. Второй модуль 122 выполнен с возможностью реализовать второй алгоритм 308 машинного обучения. Второй алгоритм 308 машинного обучения выполнен с возможностью прогнозировать спрогнозированный второй параметр 310. В некоторых вариантах осуществления настоящей технологии спрогнозированный второй параметр 310 является параметром loss, т.е. параметром, указывающим вероятность клика (щелчка) для следующего результата поиска, следующего сразу после данного результата поиска, упомянутого выше (в некоторых вариантах осуществления настоящей технологии следующий результат поиска является результатом веб-поиска, но следует понимать, что следующий результат поиска может быть еще одним результатом вертикального поиска). В рамках вариантов осуществления настоящей технологии «следующий сразу после» (или соседний) означает, что следующий результат поиска является тем результатом поиска, который ранжирован ниже данного результата поиска, упомянутого выше, и следует непосредственно за ним. Однако следует понимать, что в альтернативных вариантах осуществления настоящей технологии «следующий сразу после» или «соседний» может означать, что такой результат поиска может быть разделен с данным результатом поиска одним или несколькими промежуточными результатами поиска.
[117] Другими словами, спрогнозированный второй параметр 310 указывает потенциальную заинтересованность пользователя в следующем результате поиска относительно поискового запроса пользователя (предполагается, что чем более вероятно пользователь заинтересован в данном результате поиска, тем более вероятно пользователь щелкнет на данный результат поиска). Таким образом, спрогнозированный второй параметр 310 в известной мере указывает щелчок пользователя на следующий результата поиска (а не на данный результат поиска).
[118] Более конкретно, второй алгоритм 308 машинного обучения выполнен с возможностью прогнозировать спрогнозированный второй параметр 310 на основе множества факторов, включая в качестве примеров: первый фактор 302, второй фактор 304 и третий фактор 306. В соответствии с вариантами осуществления настоящей технологии первый фактор 302 является позицией SERP, использованной для прогнозирования (т.е. позицией, на которой размещен следующий результат поиска на SERP).
[119] Природа второго фактора 304 и третьего фактора 306 (а также ряда дополнительных факторов, используемых вторым алгоритмом 308 машинного обучения) никак конкретно не ограничена. В общем случае, второй фактор 304 и третий фактор 306 могут включать в себя некоторые или все пункты из перечисленных: предварительно определенная вероятность щелчка пользователя на следующий результат поиска на основе одного или нескольких поисковых терминов, входящих в состав поискового запроса, до взаимодействия пользователя со следующим результатом поиска; данные, представляющие факторы данного результата поиска и так далее.
[120] В течение фазы обучения второго алгоритма 308 машинного обучения, второму алгоритму 308 машинного обучения предоставляется набор обучающих объектов, причем для каждого обучающего объекта предоставляется: соответствующий набор из первого фактора 302, второго фактора 304 и третьего фактора 306 (а также потенциально ряд дополнительных факторов, связанных с данным объектом обучения) и соответствующая «цель». В рамках вариантов осуществления настоящей технологии цель может быть реальными предыдущими данными по щелчкам данного обучающего объекта (например, «1» означает щелчок, а «0» - его отсутствие). В рамках вариантов осуществления настоящей технологии данный объект обучения может быть предыдущим результатом веб-поиска, первый фактор 302 может быть позицией предыдущего результата веб-поиска на данной предыдущей SERP, второй фактор 304 и третий фактор 306 могут быть извлечены из базы данных 130.
[121] Число обучающих объектов, используемых для обучения второго алгоритма 308 машинного обучения, никак конкретно не ограничено и может быть выбрано специалистами в данной области техники, обладающими доступом к описанию настоящей технологии. На основе обучающих объектов второй алгоритм 308 машинного обучения создает формулу алгоритма машинного обучения для прогнозирования спрогнозированого второго параметра 310 для нового следующего результата поиска (т.е. нового результата веб-поиска) для данной новой позиции на новой SERP, причем данная новая позиция следует за данным результатом вертикального поиска.
[122] На Фиг. 4 представлена схема работы третьего модуля 124. Третий модуль 124 выполнен с возможностью реализовать третий алгоритм 406 машинного обучения. Третий алгоритм 406 машинного обучения выполнен с возможностью прогнозировать спрогнозированный параметр 402 полезности. В некоторых вариантах осуществления настоящей технологии спрогнозированный параметр 402 полезности указывает вероятность клика (щелчка) пользователя на данный результат поиска (т.е. результат вертикального поиска), а не на следующий сразу за данным результат поиска (т.е. следующий сразу результат веб-поиска или следующий сразу другой результат вертикального поиска). Спрогнозированный параметр 402 полезности определен для данного результата поиска на данной позиции SERP. Например, данная «страница» SERP может иметь 10 позиций, потенциально на ней отображаемых - и, таким образом, данный результат поиска будет обладать разными спрогнозированными параметрами 402 полезности для каждой из 10 позиций данной страницы SERP, причем одна из позиции SERP будет обладать максимальным спрогнозированным параметром 402 полезности из 10 позиций на данной странице SERP. Позиция SERP с наивысшим спрогнозированным параметром 402 полезности может быть использована для размещения данного результата поиска (таким образом, повышая его потенциальную вероятность на щелчок от пользователя).
[123] Более конкретно, третий алгоритм 406 машинного обучения выполнен с возможностью прогнозировать спрогнозированный параметр 402 полезности на основе спрогнозированного первого параметра 210 и спрогнозированного второго параметра 310. Следует отметить, что спрогнозированный параметр 402 полезности определяется для данного результата поиска (т.е. того, который связан со спрогнозированным первым параметром 210) на основе спрогнозированного первого параметра и спрогнозированного второго параметра 310 (т.е. параметра, связанного со следующим результатом поиска относительно данного результата поиска). Следует отметить, что в рамках этих вариантов осуществления настоящей технологии спрогнозированный первый параметр 210 и спрогнозированный второй параметр 310 были независимо спрогнозированы в том смысле, что спрогнозированный первый параметр 210 был спрогнозирован первым алгоритмом 208 машинного обучения, а спрогнозированный второй параметр 310 был спрогнозирован вторым алгоритмом 308 машинного обучения.
[124] Хотя в проиллюстрированном на Фиг. 4 примере третий алгоритм 406 машинного обучения выполнен с возможностью использовать спрогнозированный первый параметр 210 и спрогнозированный второй параметр 310, следует отметить, что в альтернативных вариантах осуществления настоящей технологии третий алгоритм 406 машинного обучения может быть выполнен с возможностью рассматривать ряд дополнительных параметров.
[125] В течение фазы обучения третьего алгоритма 406 машинного обучения, третьему алгоритму 406 машинного обучения предоставляется набор обучающих объектов, причем для каждого обучающего объекта предоставляется: соответствующий набор из спрогнозированного первого параметра 202 и спрогнозированного второго параметра 310, а также соответствующая «цель». В пределах вариантов осуществления настоящей технологии цель может быть «вертикальным параметром предпочтения», основанным на актуальных предыдущих данных по кликам (щелчкам) данного обучающего объекта или других обучающих объектов, которые были соседними для данного обучающего объекта в предыдущих поисках. Исключительно как пример и без введения конкретных ограничений, вертикальный параметр предпочтения может быть назначен следующим образом: (i) «вертикальный параметр предпочтения» может составлять «1», если по результату вертикального поиска щелкнули; (ii) «вертикальный параметр предпочтения» может составлять «0», если не щелкнули ни по результату вертикального поиска, ни по следующему результату поиска; и (iii) «вертикальный параметр предпочтения» может составлять «-2,5», если по результату вертикального поиска не щелкнули, но щелкнули по следующему результату поиска. Следует отметить, что значение «-2,5» может быть другим в других вариантах осуществления настоящей технологии. Значение «-2,5» может быть фиксированным, или может различаться на основе позиции SERP результата вертикального поиска. «Вертикальный параметр предпочтения», представленный в (iii), используется для «снижения» значения результата вертикального поиска в тех обучающих объектах, где пользователь щелкнул на следующий результат поиска, на основе предположения, что пользователь видел результат вертикального поиска, но щелкнул на следующий результат поиска, в том смысле, что предлагается более низкое значение, связанное с результатом вертикального поиска (т.е. пользователь не заинтересовался результатом вертикального поиска).
[126] Число обучающих объектов, используемых для обучения третьего алгоритма 406 машинного обучения, никак конкретно не ограничено и может быть выбрано специалистами в данной области техники, обладающими доступом к описанию настоящей технологии. На основе обучающих объектов третий алгоритм 406 машинного обучения создает формулу алгоритма машинного обучения для прогнозирования спрогнозированного параметра 402 полезности для нового первого результата поиска (т.е. нового результата вертикального поиска) для данной новой позиции на новой SERP.
[127] На Фиг. 7 представлена схема модуля 126 обучения. В некоторых вариантах осуществления настоящей технологии модуль 126 обучения может отвечать за координацию обучения соответствующих алгоритмов машинного обучения первого модуля 120, второго модуля 122 и третьего модуля 124. Следует понимать, что функциональность модуля 126 обучения может входить в функциональность одного из модулей: первого модуля 120, второго модуля 122 и третьего модуля 124. Альтернативно, функциональность модуля 126 обучения может быть распределена между одним или несколькими модулями: первым модулем 120, вторым модулем 122 и третьим модулем 124.
[128] В некоторых вариантах осуществления настоящей технологии модуль 126 обучения инициирует независимое между собой обучение первого модуля 120 и второго модуля 122. В некоторых вариантах осуществления настоящей технологии модуль 126 обучения инициирует независимое между собой обучение первого модуля 120 и второго модуля 122 с помощью возможности использовать разные обучающие объекты и различные цели. В некоторых других вариантах осуществления настоящей технологии модуль 126 обучения инициирует независимое между собой обучение первого модуля 120 и второго модуля 122 с помощью возможности использовать по меньшей мере частично перекрывающиеся обучающие объекты и различные цели. В некоторых других вариантах осуществления настоящей технологии модуль 126 обучения инициирует независимое между собой обучение первого модуля 120 и второго модуля 122 с помощью возможности проводить обучение в различные моменты времени. В некоторых других вариантах осуществления настоящей технологии модуль 126 обучения инициирует независимое между собой обучение первого модуля 120 и второго модуля 122 с помощью возможности проводить обучение по меньшей мере в частично перекрывающиеся моменты времени.
[129] В соответствии с вариантом осуществления настоящей технологи модуль 126 обучения инициирует обучение третьего модуля 124 на основе первых предсказанных данных 702 от первого модуля 120 и вторых предсказанных данных от второго модуля 122. Первые предсказанные данные 702 представляют спрогнозированный первый параметр 210, а вторые предсказанные данные представляют спрогнозированный второй параметр 310.
[130] На Фиг. 5 представлена схема работы поискового модуля 118. В соответствии с вариантами осуществления настоящей технологии поисковый модуль 118 выполнен с возможностью осуществления процедуры 502 ранжирования. Работа процедуры 502 ранжирования теперь будет описана также с учетом Фиг. 6.
[131] На Фиг. 6 представлено схематическое изображение ранжированного списка 600 результатов поиска и переранжированного списка 600' результатов поиска, причем переранжированный список 600' результатов поиска является выводом процедуры 502 ранжирования, выполненной в соответствии с вариантами осуществления настоящей технологии. Ранжированный список 600 результатов поиска включает в себя первый результат 602 поиска, второй результат 604 поиска, третий результат 606 поиска и четвертый результат 608 поиска. Следует понимать, что первый результат 602 поиска, второй результат 604 поиска, третий результат 606 поиска и четвертый результат 608 поиска являются всего лишь некоторыми примерами результатов поиска, которые могут потенциально присутствовать в ранжированном списке 600 результатов поиска. Также следует понимать, что первый результат 602 поиска, второй результат 604 поиска, третий результат 606 поиска и четвертый результат 608 поиска являются всего лишь некоторыми примерами результатов поиска, которые могут потенциально присутствовать в ранжированном списке 600 результатов поиска, созданном поисковым модулем 118 в ответ на пользовательский поисковый запрос, полученный от электронного устройства 102.
[132] Некоторые из первого результата 602 поиска, второго результата 604 поиска, третьего результата 606 поиска и четвертого результата 608 поиска являются результатами веб-поиска, и некоторые из первого результата 602 поиска, второго результата 604 поиска, третьего результата 606 поиска и четвертого результата 608 поиска являются результатами вертикального поиска. В рамках проиллюстрированного варианта осуществления настоящей технологии первый результат 602 поиска и третий результат 606 поиска являются результатами вертикального поиска (для простоты понимания изображены заштрихованными), а второй результат 604 поиска и четвертый результат 608 поиска являются результатами веб-поиска.
[133] В некоторых вариантах осуществления настоящей технологии ранжированный список 600 результатов поиска ранжирован алгоритмом предварительного ранжирования процедуры 502 ранжирования. В некоторых вариантах осуществления настоящей технологии алгоритм предварительного ранжирования процедуры 502 ранжирования ранжирует результаты веб-поиска (т.е. второй результат 604 поиска и четвертый результат 608 поиска). В других вариантах осуществления настоящей технологии алгоритм предварительного ранжирования процедуры 502 ранжирования ранжирует результаты веб-поиска (т.е. второй результат 604 поиска и четвертый результат 608 поиска), а также результаты вертикального поиска (т.е. первый результат 602 поиска и третий результат 606 поиска).
[134] В соответствии с вариантами осуществления настоящей технологии процедура 502 ранжирования выполнена с возможностью выполнения алгоритма выбора расположения вертикального результата. В соответствии с вариантами осуществления настоящей технологии процедура 502 ранжирования выполнена с возможностью выполнения для каждого потенциального расположения на SERP определения спрогнозированного параметра 402 полезности любого данного результата вертикального поиска (т.е. первый результат 602 поиска и третий результат 606 поиска). Более конкретно, процедура 502 ранжирования выполнена с возможностью определять для данного результата вертикального поиска для данной позиции SERP из потенциальных позиций SERP спрогнозированный параметр 402 полезности с помощью (i) инициации определения первым модулем 120 спрогнозированного первого параметра 210 для данного результата вертикального поиска для данной позиции SERP; (ii) инициации определения вторым модулем 122 спрогнозированного второго параметра 310 для данного результата вертикального поиска, т.е. результата поиска на позиции, следующей за данной позицией SERP; (iii) инициации прогнозирования третьим модулем спрогнозированного параметра 402 полезности для данного результата вертикального поиска для данной позиции SERP на основе спрогнозированного первого параметра 210 и спрогнозированного второго параметра 310. Процедура 502 ранжирования дополнительно выполнена с возможностью повторять процесс для данного результата вертикального поиска по отношению к другой потенциальной данной позиции SERP. Для каждой итерации процедура 502 ранжирования определяет соответствующий спрогнозированный параметр 402 полезности. Процедура 502 ранжирования может затем выбрать данную позицию SERP с максимальным значением спрогнозированного параметра 402 полезности для размещения данного результата вертикального поиска.
[135] В тех вариантах осуществления настоящей технологии, где алгоритм предварительного ранжирования процедуры 502 ранжирования ранжирует результаты веб-поиска (т.е. второй результат 604 поиска и четвертый результат 608 поиска), параметр loss (т.е. спрогнозированный второй параметр 310) определяется на основе следующего результата, который является результатом веб-поиска. В тех вариантах осуществления настоящей технологии, где алгоритм предварительного ранжирования процедуры 502 ранжирования ранжирует результаты веб-поиска (т.е. второй результат 604 поиска и четвертый результат 608 поиска), а также результаты вертикального поиска (т.е. первый результат 602 поиска и третий результат 606 поиска) параметр loss (т.е. спрогнозированный второй параметр 310) может быть определен на основе следующего результата, который является либо результатом веб-поиска, либо другим результатом вертикального поиска, в зависимости от обстоятельств.
[136] Вышеприведенное будет проиллюстрировано с использованием первого результата поиска 602, изображенного на Фиг. 6. С целью иллюстрации - предположим, что в ранжированном списке 600 результатов поиска есть только три результата поиска: первый результат 602 поиска, второй результат 604 поиска, третий результат 606 поиска и четвертый результат 608 поиска.
[137] Процедура 502 ранжирования сначала «размещает» первый результат поиска 602 на верхней позиции SERP (как изображено в ранжированном списке 600 результатов поиска).
[138] Процедура ранжирования затем определяет спрогнозированный параметр 402 полезности для первого результата 602 поиска, размещенного на верхней позиции SERP. Более конкретно, процедура 502 ранжирования выполнена с возможностью определять спрогнозированный параметр 402 полезности с помощью (i) инициации определения первым модулем 120 спрогнозированного первого параметра 210 для первого результата поиска для верхней позиции SERP; (ii) инициации определения вторым модулем 122 спрогнозированного второго параметра 310 для данного результата вертикального поиска, т.е. второго результата поиска; (iii) инициации прогнозирования третьим модулем спрогнозированного параметра 402 полезности для первого результата 601 вертикального поиска для данной позиции SERP на основе спрогнозированного первого параметра 210 и спрогнозированного второго параметра 310. Таким образом процедура 502 ранжирования определила первый вариант спрогнозированного параметра 402 полезности для первого результата поиска 602 для верхней позиции SERP, изображенной в ранжированном списке 600 результатов поиска.
[139] Процедура 502 ранжирования дополнительно выполнена с возможностью повторять процесс для первого результата 602 поиска для другой позиции SERP. С учетом переранжированного списка 600' результатов поиска процедура 502 ранжирования теперь может разместить первый результат 602 поиска на второй позиции SERP (где ранее был расположен второй результат 604 поиска). В варианте осуществления переранжированного списка 600' результатов поиска процедура 502 ранжирования размещает третий результат 606 поиска на третью позицию, в то время как второй результат 604 поиска размещается на верхней позиции SERP. В альтернативных вариантах осуществления технологии процедура 502 ранжирования может «сместить» оставшиеся результаты ниже, фактически помещая второй результат 604 поиска на третье положение SERP. В других вариантах осуществления настоящей технологии процедура 502 ранжирования может итерационно осуществлять оба варианта, определяя соответствующее значение спрогнозированного параметра 402 полезности для первого результата 602 поиска, расположенного на второй позиции SERP относительно (i) второго результата 604 поиска, расположенного на третьей позиции SERP и (ii) третьего результата 606 поиска, расположенного на третьей позиции SERP.
[140] Процедура 502 ранжирования может повторять процесс, описанный выше, для любой данной позиции SERP первого результата 602 поиска. Процедура 502 ранжирования может также повторять процесс для любого другого результата вертикального поиска, потенциально присутствующего в ранжированном списке 600 результатов поиска, например, для четвертого результат 608 поиска.
[141] Процедура 502 ранжирования выполнена с дополнительной возможностью выбирать расположение данного результата вертикального поиска для каждого результата вертикального поиска. Более конкретно, процедура ранжирования выбирает расположение, которое максимизирует спрогнозированный параметр 402 полезности данного результата вертикального поиска. Например, в варианте осуществления технологии, изображенном на Фиг. 6, с учетом переранжированного списка 600' результатов поиска может быть определено, что для первого результата 602 поиска вторая позиция SERP максимизирует спрогнозированный параметр 402 полезности для первого результата 602 поиска.
[142] Когда в ранжированном списке 600 результатов поиска присутствует больше одного результата вертикального поиска, и когда два (или более) данных результата вертикального поиска обладают одинаковой позицией SERP, связанной с их соответствующим максимальным спрогнозированным параметром 402 полезности, процедура 502 ранжирования может выбирать позицию для результата поиска с наивысшим абсолютным значением спрогнозированным параметром 402 полезности. Альтернативно (или когда значения совпадают), процедура 502 ранжирования может выбирать предварительно определенный тип результата вертикального поиска (например, процедура 502 ранжирования может приоритизировать вертикаль изображений перед вертикалью видео и т.д.).
[143] С учетом Фиг. 5, процедура 50 ранжирования выполнена с возможностью получать (i) результаты 504 поиска (например, ранжированный список 600 результатов поиска и (ii) спрогнозированный параметр 402 полезности (или множество спрогнозированных параметров 402 полезности) и выводить SERP 510, на которой один или несколько результатов вертикального поиска (например, первый результат 602 вертикального поиска и четвертый результат 608 поиска, а также другой результат вертикального поиска, потенциально присутствующий в ранжированном списке 600 результатов поиска) помещены в соответствии с их соответствующим спрогнозированным параметром 402 полезности, как было описано выше.
[144] Следовательно, SERP 510 может быть переранжирована в соответствии со спрогнозированным параметром 410 полезности, который был определен в соответствии с вариантами осуществления настоящей технологии.
[145] Предполагается, что специалисты в данной области техники, изучив настоящее описание, смогут реализовать первый алгоритм машинного обучения, второй алгоритм машинного обучения и третий алгоритм машинного обучения, описанные выше. Однако, с целью иллюстрации (и без введения ограничений), ниже будут описаны некоторые примеры формул, созданные алгоритмом машинного обучения.
[146] В некоторых вариантах осуществления настоящей технологии первый модуль 120, выполняющий первый алгоритм 208 машинного обучения может создавать формулу алгоритма машинного обучения, представленную следующим образом: p(ƒ, iw), где ƒ является одним или несколькими факторами (такими как те, что описаны выше по отношению ко второму фактору 204 и третьему фактору 206), и где iw является данной позицией SERP или, альтернативно, параметром, определяющим данную позицию SERP (например, вес намерения), т.е. первый фактор 202.
[147] В некоторых вариантах осуществления настоящей технологии второй модуль 122, выполняющий второй алгоритм 308 машинного обучения может создавать формулу алгоритма машинного обучения, представленную следующим образом: p(ƒ, iw), где ƒ является одним или несколькими факторами (такими как те, что описаны выше по отношению ко второму фактору 304 и третьему фактору 306), и где iw является данной позицией SERP или, альтернативно, параметром, определяющим данную позицию SERP (например, вес намерения) следующего результата поиска, т.е. первый фактор 302.
[148] В некоторых вариантах осуществления настоящей технологии третий модуль 124, выполняющий третий алгоритм 406 машинного обучения, может создавать формулу алгоритма машинного обучения, представленную следующим образом: S(ƒ, iw)=[win, loss], где win является спрогнозированным значением, созданным первым модулем 120, a loss является спрогнозированным значением, созданным вторым модулем 122. В дополнительных вариантах осуществления настоящей технологии третий алгоритм машинного обучения 406, в дополнение к таким образом созданным параметрам win и loss, может рассматривать дополнительные факторы, связанные с данным результатом вертикального поиска и/или данной позицией SERP.
[149] С учетом описанной архитектуры возможно выполнить способ создания страницы результатов поиска (SERP). На Фиг. 8 представлена блок-схема способа 800, который выполняется в соответствии с вариантами осуществления настоящей технологии, не ограничивающими ее объем. Способ 800 может выполняться 116.
[150] 802 - получение по меньшей мере от одного электронного устройства поискового запроса
[151] Способ 800 начинается на этапе 802, на котором сервер 116 получает по меньшей мере от одного электронного устройства (т.е. электронного устройства 102) поисковый запрос. Поисковый запрос может быть введен пользователем электронного устройства 102 с использованием интерфейса 106 поисковых запросов.
[152] 804 - создание списка результатов поиска, причем список результатов поиска включает в себя первый результат поиска и второй результат поиска, оба отвечающие на поисковый запрос
[153] Далее, на этапе 804 сервер 116 создает список результатов поиска, причем список результатов поиска включает в себя первый результат поиска и второй результат поиска, оба отвечающие на поисковый запрос.
[154] Сервер 116 может инициировать создание поисковым модулем 118 списка результатов поиска с использованием базы данных 130, как было описано подробно выше.
[155] 806 - ранжирование списка результатов поиска таким образом, что в результате ранжирования первый результат поиска и второй результат поиска находятся на первой позиции SERP и второй позиции SERP соответственно, причем первая позиция SERP и вторая позиция SERP являются соседними друг с другом; ранжирование дает ранжированный список результатов поиска
[156] На этапе 806 сервер 116 ранжирует список результатов поиска. В результате этапа ранжирования первый результат поиска и второй результат поиска находятся на первой позиции SERP и второй позиции SERP соответственно, причем первая позиция SERP и вторая позиция SERP являются соседними друг с другом. Этап ранжирования дает ранжированный список результатов поиска.
[157] Как уже упоминалось, поисковый модуль 118 может выполнять процедуру 502 ранжирования. В некоторых вариантах осуществления настоящей технологии сервер 116 инициирует выполнение поисковым модулем 118 алгоритма предварительного ранжирования процедуры 502 ранжирования для ранжирования списка результатов поиска.
[158] В некоторых вариантах осуществления настоящей технологии алгоритм предварительного ранжирования процедуры 502 ранжирования ранжирует результаты веб-поиска. В других вариантах осуществления настоящей технологии алгоритм предварительного ранжирования процедуры 502 ранжирования ранжирует результаты веб-поиска, а также результаты вертикального поиска.
[159] 808 - прогнозирование первого параметра интереса для первого результата поиска, причем прогнозирование осуществляется на основе первого алгоритма машинного обучения
[160] На этапе 808 сервер 116 прогнозирует первый параметр интереса для первого результата поиска. Прогнозирование на этапе 808 осуществляется на основе первого алгоритма машинного обучения.
[161] В некоторых вариантах осуществления настоящей технологии сервер 116 инициирует создание первым модулем 120 спрогнозированного первого параметра 210.
[162] 810 - прогнозирование второго параметра интереса для второго результата поиска, причем прогнозирование осуществляется на основе второго алгоритма машинного обучения, причем второй алгоритм машинного обучения отличается от первого алгоритма машинного обучения
[163] На этапе 810 сервер 116 прогнозирует второй параметр интереса для второго результата поиска. Этап прогнозирования на этапе 810 осуществляется на основе второго алгоритма машинного обучения, причем второй алгоритм машинного обучения отличается от первого алгоритма машинного обучения.
[164] В некоторых вариантах осуществления настоящей технологии сервер 116 инициирует создание вторым модулем 122 спрогнозированного второго параметра 310.
[165] 812 - прогнозирование параметра полезности для первого результата поиска, причем прогнозирование осуществляется на основе третьего алгоритма машинного обучения, и прогнозирование осуществляется по меньшей мере частично на основе первого параметра интереса и второго параметра интереса
[166] На этапе 812 сервер 116 прогнозирует параметр полезности для первого результата поиска. Этап прогнозирования на этапе 812 осуществляется на основе третьего алгоритма машинного обучения, и по меньшей мере частично на основе первого параметра интереса и второго параметра интереса.
[167] В некоторых вариантах осуществления настоящей технологии сервер 116 инициирует создание третьим модулем 124 спрогнозированного параметра 402 полезности.
[168] 814 - корректировка позиции первого результата поиска в ранжированном списке результатов поиска на основе спрогнозированного параметра полезности, причем корректировка приводит к тому, что первый результат поиска оказывается на скорректированной позиции в ранжированном списке результатов поиска
[169] На этапе 814 сервер 116 корректирует позицию первого результата поиска в ранжированном списке результатов поиска на основе спрогнозированного параметра полезности. Этап корректировки приводит к тому, что первый результат поиска оказывается на скорректированной позиции в ранжированном списке результатов поиска.
[170] Сервер 116 может инициировать корректировку поисковым модулем 118 позиции первого результата поисков в соответствии с параметром полезности.
[171] 816 - создание SERF, включающей в себя первый результат поиска и второй результат поиска, причем первый результат поиска расположен на скорректированной позиции SERP
[172] Далее, на этапе 816, сервер 116 создает SERP, включающую в себя первый результат поиска и второй результат поиска, причем первый результат поиска расположен на скорректированной позиции SERP.
[173] Сервер 116 инициирует создание поисковым модулем 118 SERP 510. Сервер 116 может также передавать данные, связанные с SERP 510, электронному устройству 102, чтобы инициировать отображение электронным устройством 102 SERP 510 в интерфейсе 108 результатов поиска.
[174] Способ 800 может затем завершиться.
[175] В некоторых вариантах осуществления способа 800 первый результат поиска является результатом вертикального поиска. В некоторых вариантах осуществления способа 800 второй результат поиска является результатом веб-поиска. Однако следует понимать, что в некоторых вариантах осуществления настоящей технологии способ 800 может быть применен к первому результату поиска, который является либо результатом вертикального поиска, либо результатом веб-поиска. Аналогично, в некоторых вариантах осуществления настоящей технологии способ 800 может быть применен ко второму результату поиска, который является либо результатом вертикального поиска, либо результатом веб-поиска.
[176] В некоторых вариантах осуществления способа 800 первый алгоритм машинного обучения и второй алгоритм машинного обучения обучены независимо друг от друга.
[177] В некоторых вариантах осуществления способа 800 третий алгоритм машинного обучения был обучен с использованием параметров, спрогнозированных первым алгоритмом машинного обучения и вторым алгоритмом машинного обучения.
[178] В некоторых вариантах осуществления способа 800 параметры, спрогнозированные первым алгоритмом машинного обучения и вторым алгоритмом машинного обучения, включают в себя первый фактор, указывающий отношение количества щелчков (кликов) к количеству показов данного результата поиска, и второй фактор, указывающий отношение количества щелчков (кликов) к количеству показов другого результата поиска, следующего по порядку ранжирования за данным результатом поиска.
[179] В некоторых вариантах осуществления способа 800 третий алгоритм машинного обучения основан по меньшей мере частично на модифицированном алгоритме "win-loss".
[180] В некоторых вариантах осуществления способа 800 этап корректировки позиции первого результата поиска также включает в себя дополнительную корректировку позиции второго результата поиска в соответствии со скорректированной позицией первого результата поиска.
[181] В некоторых вариантах осуществления способа 800 список результатов поиска дополнительно включает в себя третий результат поиска, ранжированный на третьей позиции SERP, причем третья позиция SERP является соседней со второй позицией SERP, и способ дополнительно включает в себя: прогнозирование третьего параметра интереса для первого результата поиска для второй позиции SERP, причем прогнозирование осуществляется на основе первого алгоритма машинного обучения; прогнозирование четвертого параметра интереса для третьего результата поиска, причем прогнозирование осуществляется на основе второго алгоритма машинного обучения; а также прогнозирование параметра полезности для первого результата поиска дополнительно включает в себя прогнозирование второго параметра полезности для первого результата поиска, причем прогнозирование осуществляется на основе третьего алгоритма машинного обучения и по меньшей мере частично на основе третьего параметра интереса и четвертого параметра интереса; а также корректировка позиции первого результата поиска дополнительно включает в себя выбор одной из: первой позиции SERP и второй позиции SERP для размещения первого результата поиска на основе сравнения параметра полезности и второго параметра полезности.
[182] В некоторых вариантах осуществления способа 800 этап прогнозирования параметра полезности и этап прогнозирования второго параметра полезности выполняются, в основном, одновременно.
[183] В некоторых вариантах осуществления способа 800 и первый параметр интереса, и второй параметр интереса являются соответствующим спрогнозированным отношением количества щелчков (кликов) к количеству показов данного результата поиска.
[184] На Фиг. 11 представлена блок-схема способа 1100, реализованного в соответствии с вариантами осуществления настоящей технологии, не ограничивающими ее объем. Способ 1100 также может выполняться сервером 116.
[185] Этап 1102 - получение по меньшей мере от одного электронного устройства поискового запроса
[186] Способ 1100 начинается на этапе 1102, на котором сервер 116 получает по меньшей мере от одного электронного устройства (т.е. электронного устройства 102) поисковый запрос. Поисковый запрос может быть введен пользователем электронного устройства 102 с использованием интерфейса 106 поисковых запросов.
[187] Этап 1104 - создание списка результатов поиска, причем список результатов поиска включает в себя первый результат поиска, второй результат поиска и третий результат поиска, первый результат поиска является результатом вертикального поиска, а второй результат поиска и третий результат поиска являются результатами веб-поиска, а также и первый результат поиска, и второй результат поиска, и третий результат поиска отвечают на поисковый запрос
[188] Далее, на этапе 1104, сервер 116 создает списка результатов поиска, причем список результатов поиска включает в себя первый результат поиска, второй результат поиска и третий результат поиска, первый результат поиска является результатом вертикального поиска, а второй результат поиска и третий результат поиска являются результатами веб-поиска, а также и первый результат поиска, и второй результат поиска, и третий результат поиска отвечают на поисковый запрос.
[189] Этап 1106 - ранжирование второго результата поиска и третьего результата поиска в порядке ранжирования таким образом, что второй результат поиска находится на первой позиции ранжирования, а третий результат поиска находится на второй позиции ранжирования; первая позиция ранжирования и вторая позиция ранжирования являются соседними друг с другом
[190] Далее, на этапе 1106 сервер 116 ранжирует второй результат поиска и третий результат поиска в порядке ранжирования таким образом, что второй результат поиска находится на первой позиции ранжирования, а третий результат поиска находится на второй позиции ранжирования; первая позиция ранжирования и вторая позиция ранжирования являются соседними друг с другом.
[191] Этап 1108 - определение и для первой позиции ранжирования, и для второй позиции ранжирования соответствующего параметра полезности для первого результата поиска, причем определение выполняется с помощью: прогнозирования первого параметра интереса для первого результата поиска для соответствующей позиции: и для первой позиции ранжирования, и для второй позиции ранжирования, прогнозирование осуществляется на основе первого алгоритма машинного обучения; прогнозирование второго параметра интереса для следующего результата поиска, прогнозирование осуществляется на основе второго алгоритма машинного обучения, причем второй алгоритм машинного обучения отличается от первого алгоритма машинного обучения; следующий результат поиска является соответствующим результатом из второго результата поиска и третьего результата поиска; прогнозирование соответствующего параметра полезности для первого результата поиска, прогнозирование осуществляется на основе третьего алгоритма машинного обучения, причем прогнозирование осуществляется по меньшей мере частично на основе первого параметра интереса и второго параметра интереса
[192] Далее, на этапе 1108, сервер 116 определяет и для первой позиции ранжирования, и для второй позиции ранжирования соответствующий параметр полезности для первого результата поиска, причем определение выполняется с помощью: (i) прогнозирования первого параметра интереса для первого результата поиска для соответствующей позиции: и для первой позиции ранжирования, и для второй позиции ранжирования, прогнозирование осуществляется на основе первого алгоритма машинного обучения; (ii) прогнозирования второго параметра интереса для следующего результата поиска, прогнозирование осуществляется на основе второго алгоритма машинного обучения, причем второй алгоритм машинного обучения отличается от первого алгоритма машинного обучения; следующий результат поиска является соответствующим результатом из второго результата поиска и третьего результата поиска; (iii) прогнозирования соответствующего параметра полезности для первого результата поиска, прогнозирование осуществляется на основе третьего алгоритма машинного обучения, причем прогнозирование осуществляется по меньшей мере частично на основе первого параметра интереса и второго параметра интереса.
[193] Этап 1110 - выбор данной позиции из первой позиции ранжирования и второй позиции ранжирования для размещения первого результата поиска, причем данная позиция из первой позиции ранжирования и второй позиции ранжирования связана с наивысшим значением параметра полезности
[194] Далее, на этапе 1110, сервер 116 выбирает данную позицию из первой позиции ранжирования и второй позиции ранжирования для размещения первого результата поиска, причем данная позиция из первой позиции ранжирования и второй позиции ранжирования связана с наивысшим значением параметра полезности.
[195] Этап 1112 - создание SERP, включающей в себя первый результат поиска, размещенный на данной позиции из первой позиции ранжирования и второй позиции ранжирования
[196] Далее, на этапе 1112, сервер 116 создает SERP 510, включающей в себя первый результат поиска, размещенный на данной позиции из первой позиции ранжирования и второй позиции ранжирования
[197] Сервер 116 может также передавать данные, связанные с SERP 510, электронному устройству 102, чтобы инициировать отображение электронным устройством 102 SERP 510 в интерфейсе 108 результатов поиска.
[198] Способ 1100 может затем завершиться.
[199] В некоторых вариантах осуществления способа 1100 первый алгоритм машинного обучения и второй алгоритм машинного обучения обучены независимо друг от друга.
[200] В некоторых вариантах осуществления способа 1100 третий алгоритм машинного обучения был обучен с использованием параметров, спрогнозированных первым алгоритмом машинного обучения и вторым алгоритмом машинного обучения.
[201] В некоторых вариантах осуществления способа 1100 параметры, спрогнозированные первым алгоритмом машинного обучения и вторым алгоритмом машинного обучения, включают в себя первый фактор, указывающий отношение количества щелчков (кликов) к количеству показов данного результата поиска, и второй фактор, указывающий отношение количества щелчков (кликов) к количеству показов другого результата поиска, следующего по порядку ранжирования за данным результатом поиска.
[202] В некоторых вариантах осуществления способа 1100 третий алгоритм машинного обучения основан по меньшей мере частично на модифицированном алгоритме "win-loss".
[203] В некоторых вариантах осуществления способа 1100 список результатов поиска дополнительно включает в себя четвертый результат поиска, который является еще одним результатом вертикального поиска, и в этом случае способ 1100 дополнительно включает в себя: и для первой позиции ранжирования и для второй позиции ранжирования определение соответствующего второго параметра полезности для четвертого результата поиска, причем при определении выполняется: прогнозирование первого параметра интереса для четвертого результата поиска на соответствующей позиции: и первой позиции ранжирования, и второй позиции ранжирования, причем прогнозирование осуществляется на основе первого алгоритма машинного обучения; прогнозирование второго параметра интереса для следующего результата поиска, причем прогнозирование осуществляется на основе второго алгоритма машинного обучения, причем второй алгоритм машинного обучения отличается от первого алгоритма машинного обучения, а следующий результат поиска является соответствующим результатом из второго результата поиска и третьего результата поиска; прогнозирование соответствующего второго параметра полезности для четвертого результата поиска, причем прогнозирование осуществляется на основе третьего алгоритма машинного обучения и осуществляется по меньшей мере частично на основе первого параметра интереса и второго параметра интереса; а также выбор данной позиции из первой позиции ранжирования и второй позиции ранжирования включает в себя: выбор данной позиции из первой позиции ранжирования и второй позиции ранжирования для размещения первого результата поиска, причем данная позиция из первой позиции ранжирования и второй позиции ранжирования связана с наивысшим значением параметра полезности; выбор другой позиции из первой позиции ранжирования и второй позиции ранжирования для размещения четвертого результата поиска, причем другая позиция из первой позиции ранжирования и второй позиции ранжирования связана с наивысшим значением второго параметра полезности; а также создание SERP включает в себя: размещение первого результата поиска на данной позиции из первой позиции ранжирования и второй позиции ранжирования; размещение четвертого результата поиска на другой позиции из первой позиции ранжирования и второй позиции ранжирования.
[204] Следует понимать, что процедура, описанная выше, является просто иллюстративным вариантом осуществления настоящей технологии. Она не предназначена для определения или установления объема настоящей технологии.
[205] Важно иметь в виду, что не все упомянутые здесь технические результаты могут проявляться в каждом из вариантов осуществления настоящего технического решения. Например, варианты осуществления настоящего технического решения могут быть реализованы без проявления некоторых технических результатов, а другие варианты могут быть реализованы с проявлением других технических результатов или вовсе без них.
[206] Модификации и улучшения вышеописанных вариантов осуществления настоящей технологии будут ясны специалистам в данной области техники. Предшествующее описание представлено только в качестве примера и не несет никаких ограничений. Таким образом, объем настоящей технологии ограничен только объемом прилагаемой формулы изобретения.
[207] Соответственно, варианты осуществления настоящей технологии, описанные выше, могут быть кратко изложены в перечисленных ниже пунктах формулы изобретения.
[208] ПУНКТ 1. Способ (800) создания страницы результатов поиска (SERP), способ выполняется на сервере (116), реализующем поисковую систему, причем сервер (116) доступен по сети (ПО) передачи данных по меньшей мере одному электронному устройству (102), способ (800) включает в себя:
[209] получение (802) по меньшей мере от одного электронного устройства (102) поискового запроса;
[210] создание (804) списка (600) результатов поиска, причем список (600) результатов поиска включает в себя первый результат (602) поиска и второй результат (604) поиска, оба отвечающие на поисковый запрос,
[211] ранжирование (806) списка (600) результатов поиска таким образом, что в результате ранжирования первый результат (602) поиска и второй результат (604) поиска находятся на первой позиции SERP и второй позиции SERP соответственно, причем первая позиция SERP и вторая позиция SERP являются соседними друг с другом; ранжирование дает ранжированный список результатов поиска;
[212] прогнозирование (808) первого параметра (210) интереса для первого результата поиска, причем прогнозирование (808) осуществляется на основе первого алгоритма (208) машинного обучения;
[213] прогнозирование (810) второго параметра (310) интереса для второго результата (604) поиска, причем прогнозирование (810) осуществляется на основе второго алгоритма (308) машинного обучения, причем второй алгоритм (308) машинного обучения отличается от первого алгоритма (208) машинного обучения;
[214] прогнозирование (812) параметра (402) полезности для первого результата (602) поиска, причем прогнозирование (812) осуществляется на основе третьего алгоритма (406) машинного обучения, и прогнозирование (812) осуществляется по меньшей мере частично на основе первого параметра (210) интереса и второго параметра (310) интереса;
[215] корректировка (814) позиции первого результата (602) поиска в ранжированном списке (600) результатов поиска на основе спрогнозированного параметра (402) полезности, причем корректировка (814) приводит к тому, что первый результат (602) поиска оказывается на скорректированной позиции в ранжированном списке (600) результатов поиска;
[216] создание (816) SERP (510), включающей в себя первый результат (602) поиска и второй результат (604) поиска, причем первый результат (602) поиска расположен на скорректированной позиции SERP.
[217] ПУНКТ 2. Способ (800) по п. 1, в котором первый результат (602) поиска является результатом вертикального поиска.
[218] ПУНКТ 3. Способ (800) по любому из пп. 1 или 2, в котором второй результат (604) поиска является результатом веб-поиска.
[219] ПУНКТ 4. Способ по любому из пп. 1-3, в котором первый алгоритм машинного обучения и второй алгоритм машинного обучения обучены независимо друг от друга.
[220] ПУНКТ 5. Способ (800) по любому из пп. 1-4, в котором третий алгоритм (406) машинного обучения был обучен с использованием параметров, спрогнозированных первым алгоритмом (208) машинного обучения и вторым алгоритмом (308) машинного обучения.
[221] ПУНКТ 6. Способ (800) по п. 5, в котором параметры, спрогнозированные первым алгоритмом (208) машинного обучения и вторым алгоритмом (308) машинного обучения включают в себя первый фактор, указывающий отношение количества щелчков (кликов) к количеству показов данного результата поиска, и второй фактор, указывающий отношение количества щелчков (кликов) к количеству показов другого результата поиска, следующего по порядку ранжирования за данным результатом поиска.
[222] ПУНКТ 7. Способ (800) по п. 6, в котором третий алгоритм (406) машинного обучения основан по меньшей мере частично на модифицированном алгоритме "win-loss".
[223] ПУНКТ 8. Способ (800) по любому из пп. 1-7, в котором корректировка позиции первого результата (602) поиска также включает в себя дополнительную корректировку позиции второго результата (604) поиска в соответствии со скорректированной позицией первого результата (602) поиска.
[224] ПУНКТ 9. Способ (800) по любому из пп. 1-8, в котором список (600) результатов поиска дополнительно включает в себя третий результат (606) поиска, ранжированный на третьей позиции SERP, причем третья позиция SERP является соседней со второй позицией SERP, и способ (800) дополнительно включает в себя:
[225] прогнозирование третьего параметра (210) интереса для первого результата поиска для второй позиции SERP, причем прогнозирование осуществляется на основе первого алгоритма (208) машинного обучения;
[226] прогнозирование четвертого параметра (310) интереса для третьего результата поиска, причем прогнозирование осуществляется на основе второго алгоритма (308) машинного обучения; а также
[227] прогнозирование параметра (402) полезности для первого результата (602) поиска дополнительно включает в себя прогнозирование второго параметра (402) полезности для первого результата (602) поиска, причем прогнозирование осуществляется на основе третьего алгоритма (406) машинного обучения и по меньшей мере частично на основе третьего параметра (210) интереса и четвертого параметра (310) интереса; а
[228] корректировка позиции первого результата (602) поиска дополнительно включает в себя выбор одной из: первой позиции SERP и второй позиции SERP для размещения первого результата (602) поиска на основе сравнения параметра (402) полезности и второго параметра (402) полезности.
[229] ПУНКТ 10. Способ (800) по п. 9, в котором прогнозирование параметра (402) полезности и прогнозирование второго параметра (402) полезности выполняются, в основном, одновременно.
[230] ПУНКТ 11. Способ (800) по п. 10, в котором и первый параметр (210) интереса, и второй параметр (310) интереса являются соответствующим спрогнозированным отношением количества щелчков (кликов) к количеству показов данного результата поиска.
[231] ПУНКТ 12. Способ (1100) создания страницы результатов поиска (SERP), способ выполняется на сервере (116), реализующем поисковую систему, причем сервер (116) доступен по сети (ПО) передачи данных по меньшей мере одному электронному устройству (102), способ (1100) включает в себя:
[232] получение (1102) по меньшей мере от одного электронного устройства (102) поискового запроса;
[233] создание (1104) списка (600) результатов поиска, причем список (600) результатов поиска включает в себя первый результат (602) поиска, второй результат (604) поиска и третий результат (606) поиска, первый результат (602) поиска является результатом вертикального поиска, а второй результат (604) поиска и третий результат (606) поиска являются результатами веб-поиска, а также и первый результат поиска, и второй результат поиска, и третий результат поиска (602, 604, 606) отвечают на поисковый запрос;
[234] ранжирование (1106) второго результата (604) поиска и третьего результата (606) поиска в порядке ранжирования таким образом, что второй результат (604) поиска находится на первой позиции ранжирования, а третий результат (606) поиска находится на второй позиции ранжирования; первая позиция ранжирования и вторая позиция ранжирования являются соседними друг с другом;
[235] и для первой позиции ранжирования, и для второй позиции ранжирования определение (1108) соответствующего параметра (402) полезности для первого результата (602) поиска, причем определение (1108) выполняется с помощью:
[236] прогнозирования первого параметра (210) интереса для первого результата (602) поиска для соответствующей позиции: и для первой позиции ранжирования, и для второй позиции ранжирования, прогнозирование осуществляется на основе первого алгоритма (208) машинного обучения;
[237] прогнозирования второго параметра (310) интереса для следующего результата (604, 606) поиска, прогнозирование осуществляется на основе второго алгоритма (308) машинного обучения, причем второй алгоритм (308) машинного обучения отличается от первого алгоритма (208) машинного обучения; следующий результат поиска является соответствующим результатом из второго результата (604) поиска и третьего (606) результата поиска;
[238] прогнозирования соответствующего параметра (402) полезности для первого результата (602) поиска, прогнозирование осуществляется на основе третьего алгоритма (406) машинного обучения, причем прогнозирование осуществляется по меньшей мере частично на основе первого параметра (210) интереса и второго параметра (310) интереса;
[239] выбор (1110) данной позиции из первой позиции ранжирования и второй позиции ранжирования для размещения первого результата (602) поиска, причем данная позиция из первой позиции ранжирования и второй позиции ранжирования связана с наивысшим значением параметра (402) полезности;
[240] создание (1112) SERP (510), включающей в себя первый результат (602) поиска, размещенный на данной позиции из первой позиции ранжирования и второй позиции ранжирования.
[241] ПУНКТ 13. Способ (1100) по п. 12, в котором первый алгоритм (208) машинного обучения и второй алгоритм (308) машинного обучения обучены независимо друг от друга.
[242] ПУНКТ 14. Способ (1100) по любому из пп. 12 или 13, в котором третий алгоритм (406) машинного обучения был обучен с использованием параметров, спрогнозированных первым алгоритмом (208) машинного обучения и вторым алгоритмом (308) машинного обучения.
[243] ПУНКТ 15. Способ (1100) по любому из пп. 12-14, в котором параметры, спрогнозированные первым алгоритмом (208) машинного обучения и вторым алгоритмом (308) машинного обучения, включают в себя первый фактор, указывающий отношение количества щелчков (кликов) к количеству показов данного результата поиска, и второй фактор, указывающий отношение количества щелчков (кликов) к количеству показов другого результата поиска, следующего по порядку ранжирования за данным результатом поиска.
[244] ПУНКТ 16. Способ (1100) по любому из пп. 12-14, в котором третий алгоритм (406) машинного обучения основан по меньшей мере частично на модифицированном алгоритме "win-loss".
[245] ПУНКТ 17. Способ (1100) по любому из пп. 12-16, в котором список (600) результатов поиска дополнительно включает в себя четвертый результат (608) поиска, который является еще одним результатом вертикального поиска, и в этом случае способ (1100) дополнительно включает в себя:
[246] и для первой позиции ранжирования, и для второй позиции ранжирования определение соответствующего второго параметра полезности для четвертого результата поиска, причем при определении выполняется:
[247] прогнозирование первого параметра (210) интереса для четвертого результата (608) поиска на соответствующей позиции: и первой позиции ранжирования, и второй позиции ранжирования, причем прогнозирование осуществляется на основе первого алгоритма (208) машинного обучения;
[248] прогнозирование второго параметра (310) интереса для следующего результата поиска, причем прогнозирование осуществляется на основе второго алгоритма (308) машинного обучения, причем второй алгоритм (308) машинного обучения отличается от первого алгоритма (208) машинного обучения, а следующий результат поиска является соответствующим результатом из второго результата (604) поиска и третьего результата (606) поиска;
[249] прогнозирование соответствующего второго параметра (402) полезности для четвертого результата (608) поиска, причем прогнозирование осуществляется на основе третьего алгоритма (408) машинного обучения и осуществляется по меньшей мере частично на основе первого параметра (210) интереса и второго параметра (310) интереса;
[250] а также выбор данной позиции из первой позиции ранжирования и второй позиции ранжирования включает в себя:
[251] выбор данной позиции из первой позиции ранжирования и второй позиции ранжирования для размещения первого результата (602) поиска, причем данная позиция из первой позиции ранжирования и второй позиции ранжирования связана с наивысшим значением параметра (402) полезности;
[252] выбор другой позиции из первой позиции ранжирования и второй позиции ранжирования для размещения четвертого результата (608) поиска, причем другая позиция из первой позиции ранжирования и второй позиции ранжирования связана с наивысшим значением второго параметра (402) полезности;
[253] а также создание SERP (510) включает в себя:
[254] размещение первого результата (602) поиска на данной позиции из первой позиции ранжирования и второй позиции ранжирования;
[255] размещение четвертого результата (608) поиска на другой позиции из первой позиции ранжирования и второй позиции ранжирования.
[256] ПУНКТ 18. Сервер (116), включающий в себя:
[257] носитель информации;
[258] сетевой интерфейс, выполненный с возможностью передачи данных по сети (110) передачи данных;
[259] процессор, функционально соединенный с носителем информации и сетевым интерфейсом, причем процессор выполнен с возможностью выполнять способ (800, 1100) по любому из пп. 1-17.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ И СИСТЕМА ДЛЯ ОПРЕДЕЛЕНИЯ РАНЖИРОВАННЫХ ПОЗИЦИЙ ЭЛЕМЕНТОВ СИСТЕМОЙ РАНЖИРОВАНИЯ | 2020 |
|
RU2781621C2 |
| СПОСОБ И СИСТЕМА ОБРАБОТКИ ПОИСКОВОГО ЗАПРОСА | 2015 |
|
RU2640639C2 |
| СПОСОБ И СИСТЕМА ДЛЯ ОПРЕДЕЛЕНИЯ РАНЖИРОВАННЫХ ПОЗИЦИЙ НЕНАТИВНЫХ ЭЛЕМЕНТОВ С ПОМОЩЬЮ СИСТЕМЫ РАНЖИРОВАНИЯ | 2017 |
|
RU2689812C2 |
| СПОСОБ И СЕРВЕР ОБРАБОТКИ ПОИСКОВОГО ПРЕДЛОЖЕНИЯ | 2015 |
|
RU2609079C2 |
| СПОСОБ И СЕРВЕР ГЕНЕРИРОВАНИЯ МЕТА-ПРИЗНАКА ДЛЯ РАНЖИРОВАНИЯ ДОКУМЕНТОВ | 2018 |
|
RU2721159C1 |
| Система и способ для формирования обучающего набора для алгоритма машинного обучения | 2020 |
|
RU2790033C2 |
| СПОСОБ И СИСТЕМА РАНЖИРОВАНИЯ МНОЖЕСТВА ДОКУМЕНТОВ НА СТРАНИЦЕ РЕЗУЛЬТАТОВ ПОИСКА | 2017 |
|
RU2677380C2 |
| СПОСОБ И СИСТЕМА ГЕНЕРИРОВАНИЯ ПРИЗНАКА ДЛЯ РАНЖИРОВАНИЯ ДОКУМЕНТА | 2018 |
|
RU2733481C2 |
| СПОСОБ И СИСТЕМА ПОСТРОЕНИЯ ПОИСКОВОГО ИНДЕКСА С ИСПОЛЬЗОВАНИЕМ АЛГОРИТМА МАШИННОГО ОБУЧЕНИЯ | 2018 |
|
RU2720954C1 |
| СИСТЕМА И СПОСОБ РАНЖИРОВАНИЯ РЕЗУЛЬТАТОВ ПОИСКА В ПОИСКОВОЙ СИСТЕМЕ | 2024 |
|
RU2839310C1 |
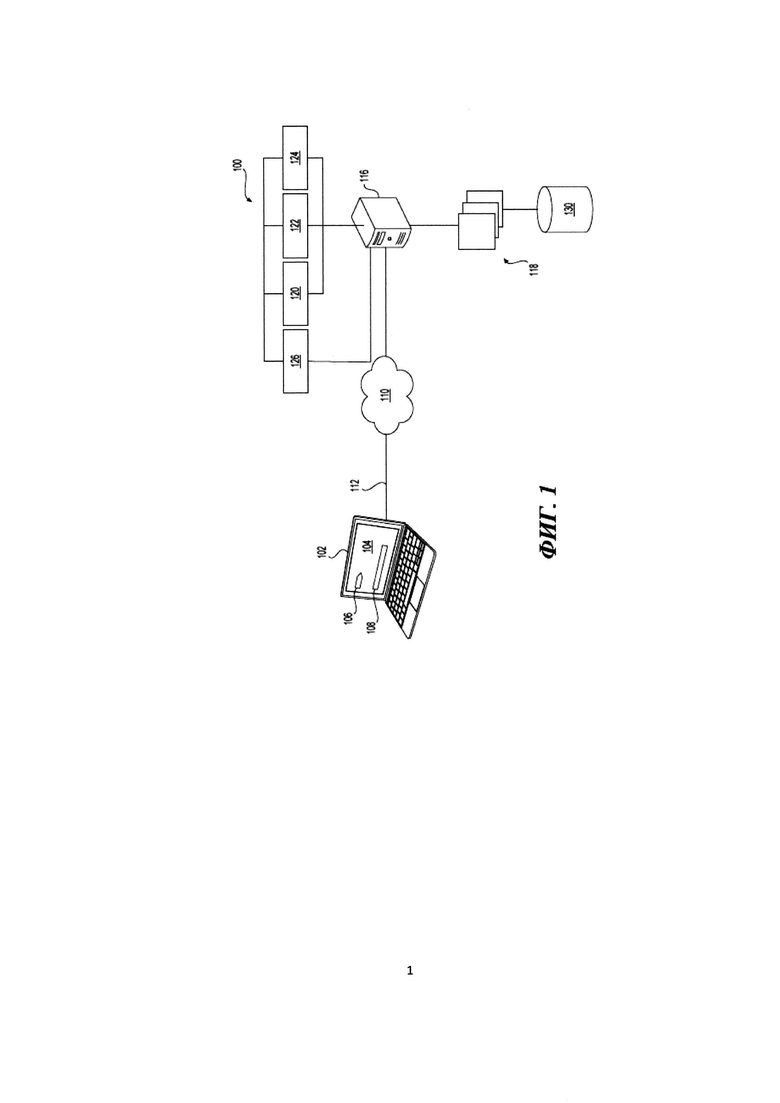
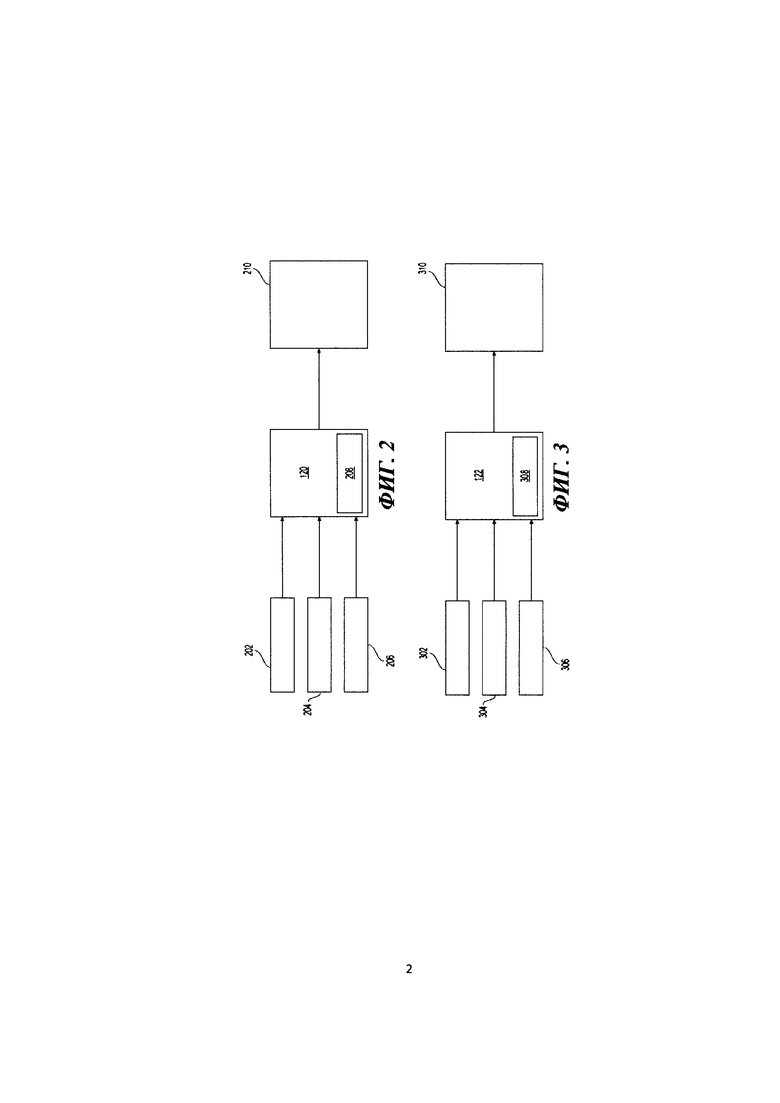
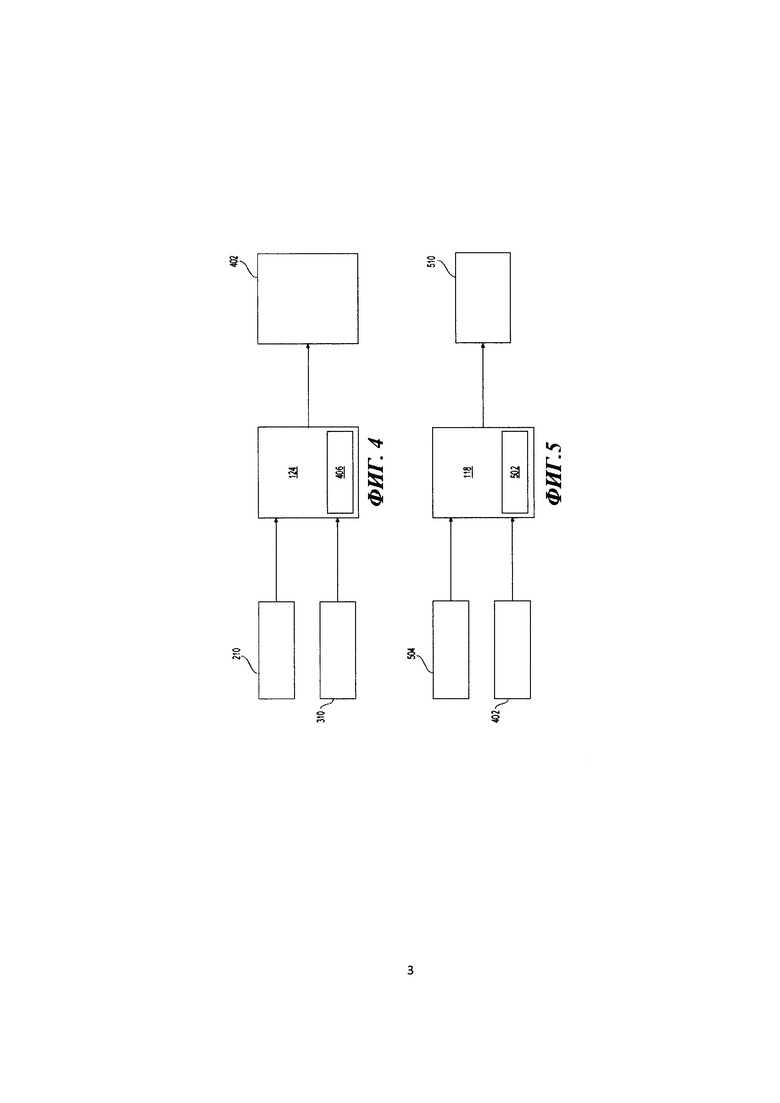
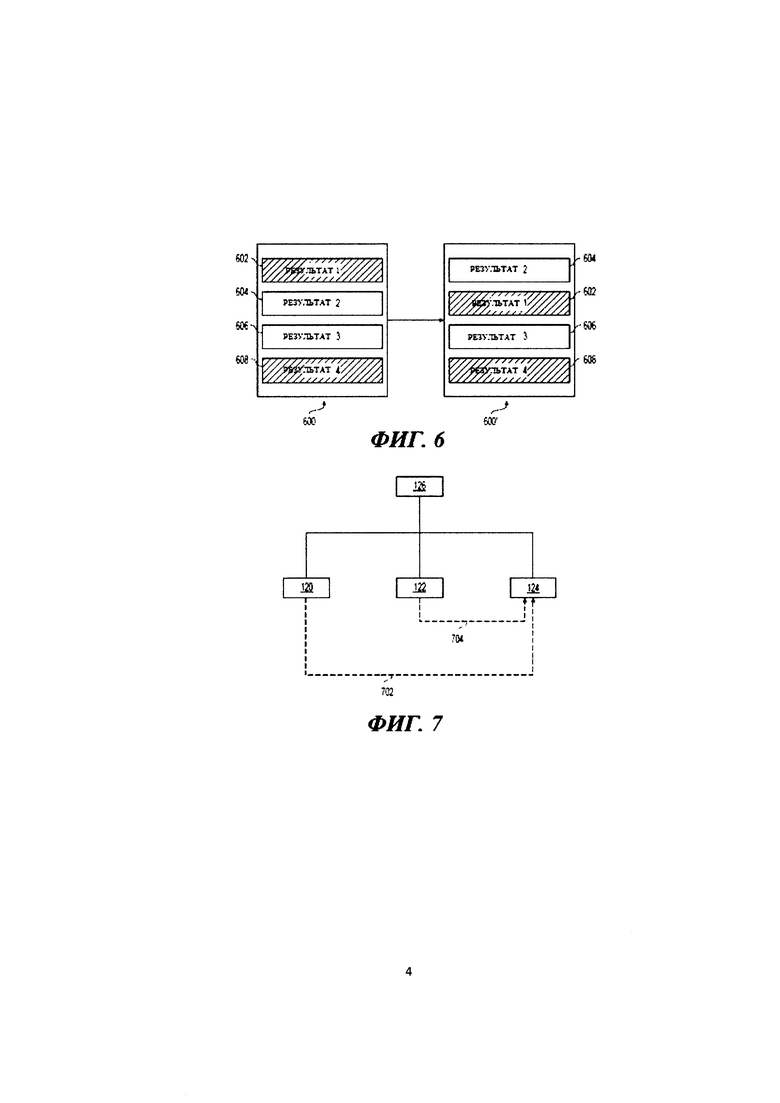
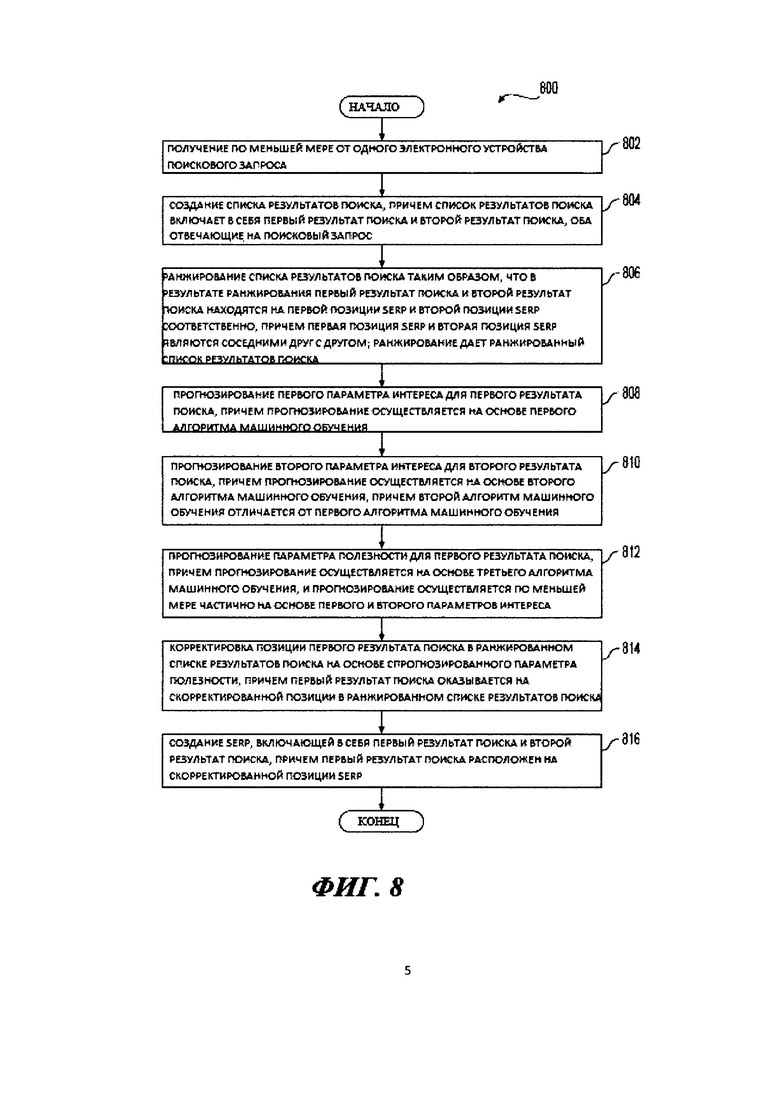

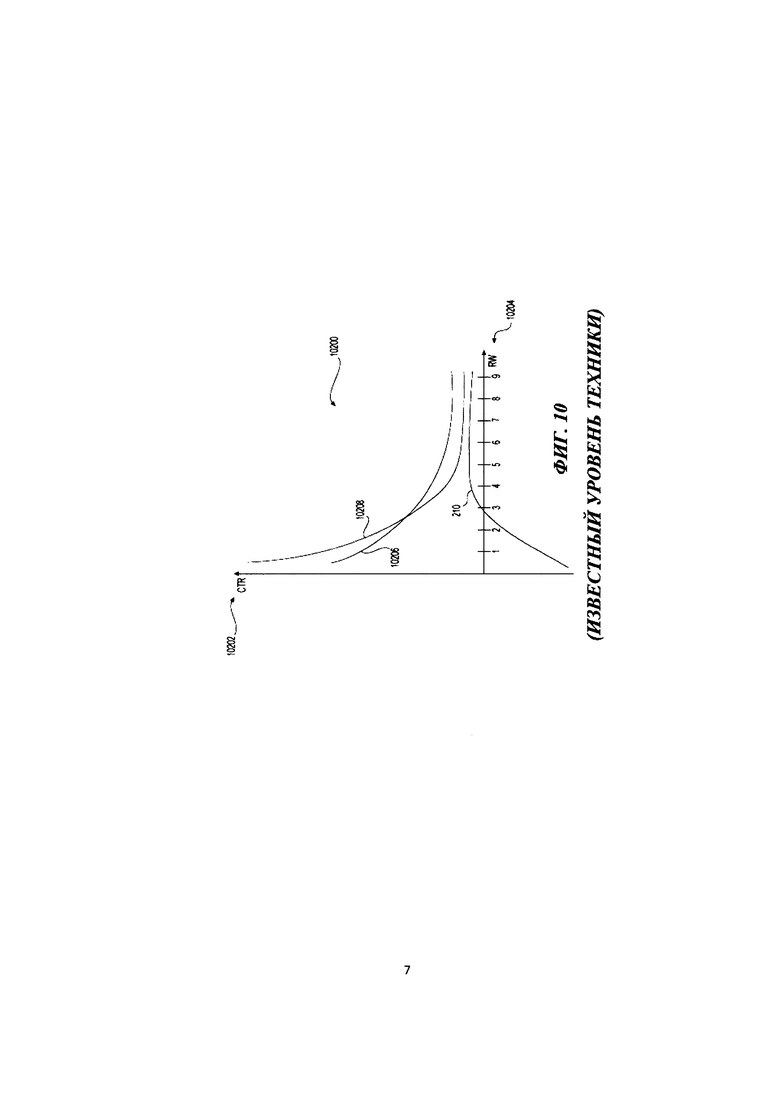

Изобретение относится к серверам и способам создания страницы результатов поиска (SERP). Технический результат заключается в повышении релевантности результатов поиска. В способе выполняют получение от электронного устройства поискового запроса, создание списка результатов поиска, включающего первый и второй результаты поиска, ранжирование списка результатов поиска так, что первый и второй результаты поиска находятся на первой и второй позициях SERP соответственно, прогнозирование первого параметра интереса для первого результата поиска на основе первого алгоритма машинного обучения, прогнозирование второго параметра интереса для второго результата поиска на основе второго алгоритма машинного обучения, отличного от первого алгоритма, прогнозирование параметра полезности для первого результата поиска на основе третьего алгоритма машинного обучения и первого и второго параметров интереса, корректировку позиции первого результата поиска в ранжированном списке результатов поиска на основе спрогнозированного параметра полезности так, что первый результат поиска оказывается на скорректированной позиции в ранжированном списке результатов поиска, создание SERP, включающей первый и второй результаты поиска, причем первый результат поиска расположен на скорректированной позиции SERP. 4 н. и 30 з.п. ф-лы, 11 ил.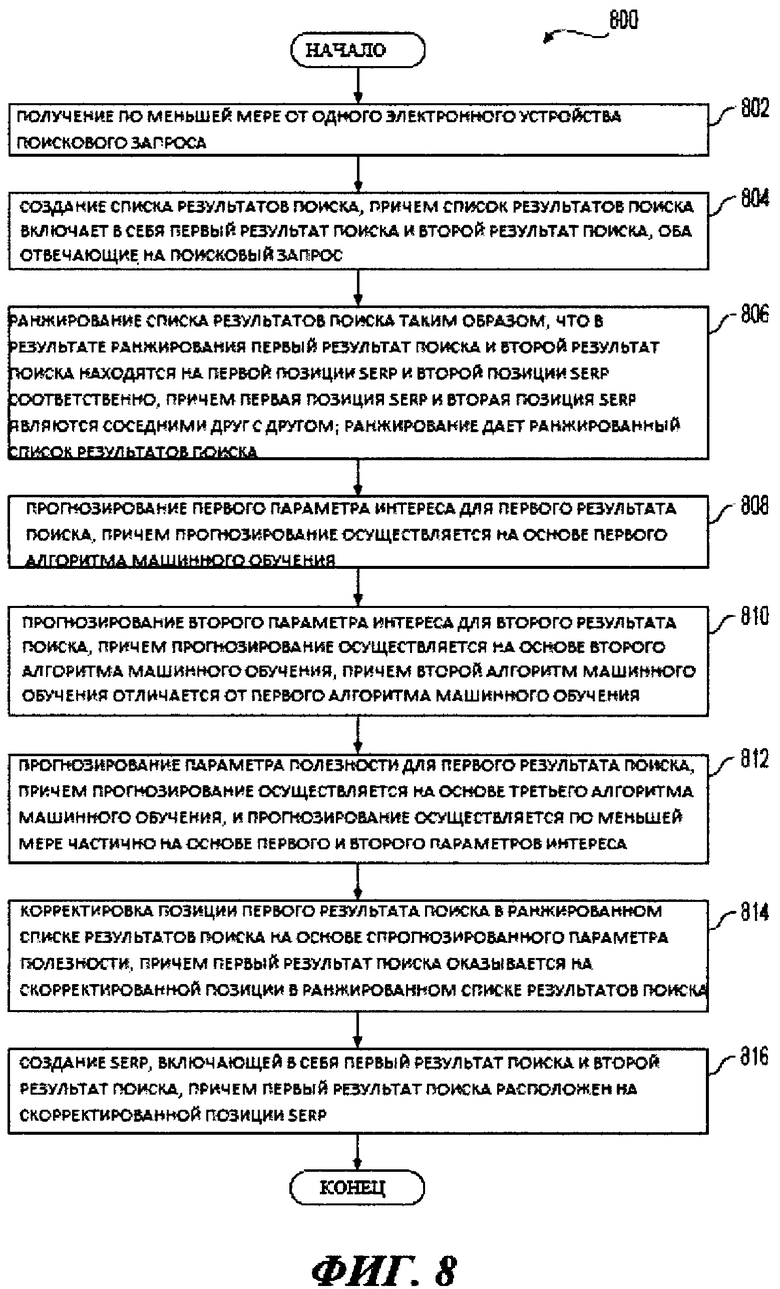
1. Способ создания страницы результатов поиска (SERP), способ выполняется на сервере, реализующем поисковую систему, причем сервер доступен по сети передачи данных по меньшей мере одному электронному устройству, способ включает в себя:
получение по меньшей мере от одного электронного устройства поискового запроса;
создание списка результатов поиска, причем список результатов поиска включает в себя первый результат поиска и второй результат поиска, оба отвечающие на поисковый запрос;
ранжирование списка результатов поиска таким образом, что в результате ранжирования первый результат поиска и второй результат поиска находятся на первой позиции SERP и второй позиции SERP соответственно, причем первая позиция SERP и вторая позиция SERP являются соседними друг с другом; ранжирование дает ранжированный список результатов поиска;
прогнозирование первого параметра интереса для первого результата поиска, причем прогнозирование осуществляется на основе первого алгоритма машинного обучения;
прогнозирование второго параметра интереса для второго результата поиска, причем прогнозирование осуществляется на основе второго алгоритма машинного обучения, причем второй алгоритм машинного обучения отличается от первого алгоритма машинного обучения;
прогнозирование параметра полезности для первого результата поиска, причем прогнозирование осуществляется на основе третьего алгоритма машинного обучения, и прогнозирование осуществляется по меньшей мере частично на основе первого параметра интереса и второго параметра интереса;
корректировку позиции первого результата поиска в ранжированном списке результатов поиска на основе спрогнозированного параметра полезности, причем корректировка приводит к тому, что первый результат поиска оказывается на скорректированной позиции в ранжированном списке результатов поиска;
создание SERP, включающей в себя первый результат поиска и второй результат поиска, причем первый результат поиска расположен на скорректированной позиции SERP.
2. Способ по п. 1, в котором первый результат поиска является результатом вертикального поиска.
3. Способ по п. 1, в котором второй результат поиска является результатом веб-поиска.
4. Способ по п. 1, в котором первый алгоритм машинного обучения и второй алгоритм машинного обучения обучены независимо друг от друга.
5. Способ по п. 4, в котором третий алгоритм машинного обучения был обучен с использованием параметров, спрогнозированных первым алгоритмом машинного обучения и вторым алгоритмом машинного обучения.
6. Способ по п. 5, в котором параметры, спрогнозированные первым алгоритмом машинного обучения и вторым алгоритмом машинного обучения, включают в себя первый фактор, указывающий отношение количества щелчков (кликов) к количеству показов данного результата поиска, и второй фактор, указывающий отношение количества щелчков (кликов) к количеству показов другого результата поиска, следующего по порядку ранжирования за данным результатом поиска.
7. Способ по п. 6, в котором третий алгоритм машинного обучения основан по меньшей мере частично на модифицированном алгоритме "win-loss".
8. Способ по п. 1, в котором корректировка позиции первого результата поиска также включает в себя дополнительную корректировку позиции второго результата поиска в соответствии со скорректированной позицией первого результата поиска.
9. Способ по п. 1, в котором список результатов поиска дополнительно включает в себя третий результат поиска, ранжированный на третьей позиции SERP, причем третья позиция SERP является соседней со второй позицией SERP, и способ дополнительно включает в себя:
прогнозирование третьего параметра интереса для первого результата поиска для второй позиции SERP, причем прогнозирование осуществляется на основе первого алгоритма машинного обучения;
прогнозирование четвертого параметра интереса для третьего результата поиска, причем прогнозирование осуществляется на основе второго алгоритма машинного обучения, а также
прогнозирование параметра полезности для первого результата поиска дополнительно включает в себя прогнозирование второго параметра полезности для первого результата поиска, причем прогнозирование осуществляется на основе третьего алгоритма машинного обучения и по меньшей мере частично на основе третьего параметра интереса и четвертого параметра интереса, а
корректировка позиции первого результата поиска дополнительно включает в себя выбор одной из первой позиции SERP и второй позиции SERP для размещения первого результата поиска на основе сравнения параметра полезности и второго параметра полезности.
10. Способ по п. 9, в котором прогнозирование параметра полезности и прогнозирование второго параметра полезности выполняются, в основном, одновременно.
11. Способ по п. 10, в котором и первый параметр интереса, и второй параметр интереса являются соответствующим спрогнозированным отношением количества щелчков (кликов) к количеству показов данного результата поиска.
12. Способ создания страницы результатов поиска (SERP), способ выполняется на сервере, реализующем поисковую систему, причем сервер доступен по сети передачи данных по меньшей мере одному электронному устройству, способ включает в себя:
получение по меньшей мере от одного электронного устройства поискового запроса;
создание списка результатов поиска, причем список результатов поиска включает в себя первый результат поиска, второй результат поиска и третий результат поиска, первый результат поиска является результатом вертикального поиска, а второй результат поиска и третий результат поиска являются результатами веб-поиска, а также и первый результат поиска, и второй результат поиска, и третий результат поиска отвечают на поисковый запрос;
ранжирование второго результата поиска и третьего результата поиска в порядке ранжирования таким образом, что второй результат поиска находится на первой позиции ранжирования, а третий результат поиска находится на второй позиции ранжирования; первая позиция ранжирования и вторая позиция ранжирования являются соседними друг с другом;
и для первой позиции ранжирования, и для второй позиции ранжирования определение соответствующего параметра полезности для первого результата поиска, причем при определении выполняется:
прогнозирование первого параметра интереса для первого результата поиска для соответствующей позиции: и для первой позиции ранжирования, и для второй позиции ранжирования прогнозирование осуществляется на основе первого алгоритма машинного обучения;
прогнозирование второго параметра интереса для следующего результата поиска, причем прогнозирование осуществляется на основе второго алгоритма машинного обучения, причем второй алгоритм машинного обучения отличается от первого алгоритма машинного обучения, а следующий результат поиска является соответствующим результатом из второго результата поиска и третьего результата поиска;
прогнозирование соответствующего параметра полезности для первого результата поиска, причем прогнозирование осуществляется на основе третьего алгоритма машинного обучения, и прогнозирование осуществляется по меньшей мере частично на основе первого параметра интереса и второго параметра интереса;
выбор данной позиции из первой позиции ранжирования и второй позиции ранжирования для размещения первого результата поиска, причем данная позиция из первой позиции ранжирования и второй позиции ранжирования связана с наивысшим значением параметра полезности;
создание SERP, включающей в себя первый результат поиска, размещенный на данной позиции из первой позиции ранжирования и второй позиции ранжирования.
13. Способ по п. 12, в котором первый алгоритм машинного обучения и второй алгоритм машинного обучения обучены независимо друг от друга.
14. Способ по п. 13, в котором третий алгоритм машинного обучения был обучен с использованием параметров, спрогнозированных первым алгоритмом машинного обучения и вторым алгоритмом машинного обучения.
15. Способ по п. 14, в котором параметры, спрогнозированные первым алгоритмом машинного обучения и вторым алгоритмом машинного обучения, включают в себя первый фактор, указывающий отношение количества щелчков (кликов) к количеству показов данного результата поиска, и второй фактор, указывающий отношение количества щелчков (кликов) к количеству показов другого результата поиска, следующего по порядку ранжирования за данным результатом поиска.
16. Способ по п. 14, в котором третий алгоритм машинного обучения основан по меньшей мере частично на модифицированном алгоритме "win-loss".
17. Способ по п. 12, в котором список результатов поиска дополнительно включает в себя четвертый результат поиска, который является еще одним результатом вертикального поиска, и в этом случае способ дополнительно включает в себя:
и для первой позиции ранжирования, и для второй позиции ранжирования определение соответствующего второго параметра полезности для четвертого результата поиска, причем при определении выполняется:
прогнозирование первого параметра интереса для четвертого результата поиска для соответствующей позиции: и для первой позиции ранжирования, и для второй позиции ранжирования прогнозирование осуществляется на основе первого алгоритма машинного обучения;
прогнозирование второго параметра интереса для следующего результата поиска, причем прогнозирование осуществляется на основе второго алгоритма машинного обучения, причем второй алгоритм машинного обучения отличается от первого алгоритма машинного обучения, а следующий результат поиска является соответствующим результатом из второго результата поиска и третьего результата поиска;
прогнозирование соответствующего второго параметра полезности для четвертого результата поиска, причем прогнозирование осуществляется на основе третьего алгоритма машинного обучения, и прогнозирование осуществляется по меньшей мере частично на основе первого параметра интереса и второго параметра интереса,
а также выбор данной позиции из первой позиции ранжирования и второй позиции ранжирования включает в себя:
выбор данной позиции из первой позиции ранжирования и второй позиции ранжирования для размещения первого результата поиска, причем данная позиция из первой позиции ранжирования и второй позиции ранжирования связана с наивысшим значением параметра полезности;
выбор другой позиции из первой позиции ранжирования и второй позиции ранжирования для размещения четвертого результата поиска, причем другая позиция из первой позиции ранжирования и второй позиции ранжирования связана с наивысшим значением второго параметра полезности;
а также создание SERP включает в себя:
размещение первого результата поиска на данной позиции из первой позиции ранжирования и второй позиции ранжирования;
размещение четвертого результата поиска на другой позиции из первой позиции ранжирования и второй позиции ранжирования.
18. Сервер включает в себя:
носитель информации;
сетевой интерфейс, выполненный с возможностью передачи данных по сети передачи данных;
процессор, функционально подключенный к носителю информации и сетевому интерфейсу, процессор выполнен с возможностью осуществлять:
получение по меньшей мере от одного электронного устройства поискового запроса;
создание списка результатов поиска, причем список результатов поиска включает в себя первый результат поиска и второй результат поиска, оба отвечающие на поисковый запрос;
ранжирование списка результатов поиска таким образом, что в результате ранжирования первый результат поиска и второй результат поиска находятся на первой позиции SERP и второй позиции SERP соответственно, причем первая позиция SERP и вторая позиция SERP являются соседними друг с другом; ранжирование дает ранжированный список результатов поиска;
прогнозирование первого параметра интереса для первого результата поиска, причем прогнозирование осуществляется на основе первого алгоритма машинного обучения;
прогнозирование второго параметра интереса для второго результата поиска, причем прогнозирование осуществляется на основе второго алгоритма машинного обучения, причем второй алгоритм машинного обучения отличается от первого алгоритма машинного обучения;
прогнозирование параметра полезности для первого результата поиска, причем прогнозирование осуществляется на основе третьего алгоритма машинного обучения, и прогнозирование осуществляется по меньшей мере частично на основе первого параметра интереса и второго параметра интереса;
корректировку позиции первого результата поиска в ранжированном списке результатов поиска на основе спрогнозированного параметра полезности, причем корректировка приводит к тому, что первый результат поиска оказывается на скорректированной позиции в ранжированном списке результатов поиска;
создание SERP, включающей в себя первый результат поиска и второй результат поиска, причем первый результат поиска расположен на скорректированной позиции SERP.
19. Сервер по п. 18, в котором первый результат поиска является результатом вертикального поиска.
20. Сервер по п. 18, в котором второй результат поиска является результатом веб-поиска.
21. Сервер по п. 18, в котором первый алгоритм машинного обучения и второй алгоритм машинного обучения обучены независимо друг от друга.
22. Сервер по п. 21, в котором третий алгоритм машинного обучения был обучен с использованием параметров, спрогнозированных первым алгоритмом машинного обучения и вторым алгоритмом машинного обучения.
23. Сервер по п. 22, в котором параметры, спрогнозированные первым алгоритмом машинного обучения и вторым алгоритмом машинного обучения, включают в себя первый фактор, указывающий отношение количества щелчков (кликов) к количеству показов данного результата поиска, и второй фактор, указывающий отношение количества щелчков (кликов) к количеству показов другого результата поиска, следующего по порядку ранжирования за данным результатом поиска.
24. Сервер по п. 22, в котором третий алгоритм машинного обучения основан по меньшей мере частично на модифицированном алгоритме "win-loss".
25. Сервер по п. 18, в котором для корректировки позиции первого результата поиска процессор выполнен с возможностью дополнительно корректировать позицию второго результата поиска в соответствии со скорректированной позицией первого результата поиска.
26. Сервер по п. 18, в котором список результатов поиска дополнительно включает в себя третий результат поиска, ранжированный на третьей позиции SERP, причем третья позиция SERP является соседней со второй позицией SERP, и процессор выполнен с дополнительной возможностью осуществлять:
прогнозирование третьего параметра интереса для первого результата поиска для второй позиции SERP, причем прогнозирование осуществляется на основе первого алгоритма машинного обучения;
прогнозирование четвертого параметра интереса для третьего результата поиска, причем прогнозирование осуществляется на основе второго алгоритма машинного обучения, а также
для прогнозирования параметра полезности для первого результата поиска процессор выполнен с дополнительной возможностью осуществлять прогнозирование второго параметра полезности для первого результата поиска, причем прогнозирование осуществляется на основе третьего алгоритма машинного обучения и по меньшей мере частично на основе третьего параметра интереса и четвертого параметра интереса, а
для корректировки позиции первого результата поиска процессор выполнен с возможностью осуществлять выбор одной из первой позиции SERP и второй позиции SERP для размещения первого результата поиска на основе сравнения параметра полезности и второго параметра полезности.
27. Сервер по п. 26, в котором процессор выполнен с возможностью осуществлять прогнозирование параметра полезности и прогнозирование второго параметра полезности, в основном, одновременно.
28. Сервер по п. 26, в котором и первый параметр интереса, и второй параметр интереса являются соответствующим спрогнозированным отношением количества щелчков (кликов) к количеству показов данного результата поиска.
29. Сервер включает в себя:
носитель информации;
сетевой интерфейс, выполненный с возможностью передачи данных по сети передачи данных;
процессор, функционально подключенный к носителю информации и сетевому интерфейсу, процессор выполнен с возможностью осуществлять:
получение по меньшей мере от одного электронного устройства поискового запроса;
создание списка результатов поиска, причем список результатов поиска включает в себя первый результат поиска, второй результат поиска и третий результат поиска, первый результат поиска является результатом вертикального поиска, а второй результат поиска и третий результат поиска являются результатами веб-поиска, а также и первый результат поиска, и второй результат поиска, и третий результат поиска отвечают на поисковый запрос;
ранжирование второго результата поиска и третьего результата поиска в порядке ранжирования таким образом, что второй результат поиска находится на первой позиции ранжирования, а третий результат поиска находится на второй позиции ранжирования; первая позиция ранжирования и вторая позиция ранжирования являются соседними друг с другом;
и для первой позиции ранжирования, и для второй позиции ранжирования определение соответствующего параметра полезности для первого результата поиска, причем при определении выполняется:
прогнозирование первого параметра интереса для первого результата поиска для соответствующей позиции: и для первой позиции ранжирования, и для второй позиции ранжирования прогнозирование осуществляется на основе первого алгоритма машинного обучения;
прогнозирование второго параметра интереса для следующего результата поиска, причем прогнозирование осуществляется на основе второго алгоритма машинного обучения, причем второй алгоритм машинного обучения отличается от первого алгоритма машинного обучения, а следующий результат поиска является соответствующим результатом из второго результата поиска и третьего результата поиска;
прогнозирование соответствующего параметра полезности для первого результата поиска, причем прогнозирование осуществляется на основе третьего алгоритма машинного обучения, и прогнозирование осуществляется по меньшей мере частично на основе первого параметра интереса и второго параметра интереса;
выбор данной позиции из первой позиции ранжирования и второй позиции ранжирования для размещения первого результата поиска, причем данная позиция из первой позиции ранжирования и второй позиции ранжирования связана с наивысшим значением параметра полезности;
создание SERP, включающей в себя первый результат поиска, размещенный на данной позиции из первой позиции ранжирования и второй позиции ранжирования.
30. Сервер по п. 29, в котором первый алгоритм машинного обучения и второй алгоритм машинного обучения обучены независимо друг от друга.
31. Сервер по п. 29, в котором третий алгоритм машинного обучения был обучен с использованием параметров, спрогнозированных первым алгоритмом машинного обучения и вторым алгоритмом машинного обучения.
32. Сервер по п. 31, в котором параметры, спрогнозированные первым алгоритмом машинного обучения и вторым алгоритмом машинного обучения, включают в себя первый фактор, указывающий отношение количества щелчков (кликов) к количеству показов данного результата поиска, и второй фактор, указывающий отношение количества щелчков (кликов) к количеству показов другого результата поиска, следующего по порядку ранжирования за данным результатом поиска.
33. Сервер по п. 31, в котором третий алгоритм машинного обучения основан по меньшей мере частично на модифицированном алгоритме "win-loss".
34. Сервер по п. 29, в котором список результатов поиска дополнительно включает в себя четвертый результат поиска, который является еще одним результатом вертикального поиска, и в этом случае процессор выполнен с дополнительной возможностью осуществлять:
и для первой позиции ранжирования, и для второй позиции ранжирования определение соответствующего второго параметра полезности для четвертого результата поиска, причем при определении выполняется:
прогнозирование первого параметра интереса для четвертого результата поиска для соответствующей позиции: и для первой позиции ранжирования, и для второй позиции ранжирования прогнозирование осуществляется на основе первого алгоритма машинного обучения;
прогнозирование второго параметра интереса для следующего результата поиска, причем прогнозирование осуществляется на основе второго алгоритма машинного обучения, причем второй алгоритм машинного обучения отличается от первого алгоритма машинного обучения, а следующий результат поиска является соответствующим результатом из второго результата поиска и третьего результата поиска;
прогнозирование соответствующего второго параметра полезности для четвертого результата поиска, причем прогнозирование осуществляется на основе третьего алгоритма машинного обучения, и прогнозирование осуществляется по меньшей мере частично на основе первого параметра интереса и второго параметра интереса,
а также для выбора данной позиции из первой позиции ранжирования и второй позиции ранжирования процессор выполнен с возможностью осуществлять:
выбор данной позиции из первой позиции ранжирования и второй позиции ранжирования для размещения первого результата поиска, причем данная позиция из первой позиции ранжирования и второй позиции ранжирования связана с наивысшим значением параметра полезности;
выбор другой позиции из первой позиции ранжирования и второй позиции ранжирования для размещения четвертого результата поиска, причем другая позиция из первой позиции ранжирования и второй позиции ранжирования связана с наивысшим значением второго параметра полезности;
и для создания SERP процессор выполнен с возможностью осуществлять:
размещение первого результата поиска на данной позиции из первой позиции ранжирования и второй позиции ранжирования;
размещение четвертого результата поиска на другой позиции из первой позиции ранжирования и второй позиции ранжирования.
| US 8924314 B2, 30.12.2014 | |||
| US 8886641 B2, 11.11.2014 | |||
| US 8370337 B2, 05.02.2013 | |||
| JP 2011232996 A, 17.11.2011 | |||
| СПОСОБ ОТБОРА ЭФФЕКТИВНЫХ ВАРИАНТОВ В ПОИСКОВЫХ И РЕКОМЕНДАТЕЛЬНЫХ СИСТЕМАХ (ВАРИАНТЫ) | 2013 |
|
RU2543315C2 |
| ОБЪДИНЕНИЕ РЕЗУЛЬТАТОВ ПОИСКА | 2010 |
|
RU2549121C2 |

