Перекрестные ссылки на родственные заявки
[0001] Данная заявка притязает на приоритет предварительной заявки на патент (США) № 61/754,882, поданной 21 января 2013 года; предварительной заявки на патент (США) № 61/809,250, поданной 5 апреля 2013 года; и предварительной заявки на патент (США) № 61/824,010, поданной 16 мая 2013 года, все из которых настоящим содержатся по ссылке.
Область техники, к которой относится изобретение
[0002] Один или более вариантов осуществления, в общем, относятся к обработке аудиосигналов, а более конкретно, к обработке потоков битов аудиоданных с метаданными, указывающими характеристики громкости и динамического диапазона аудиоконтента на основе окружений и устройств воспроизведения.
Уровень техники
[0003] Предмет изобретения, поясненный в разделе "Уровень техники", не должен предполагаться в качестве предшествующего уровня техники только в результате его упоминания в разделе "Уровень техники". Аналогично, проблема, упомянутая в разделе "Уровень техники" или ассоциированная с предметом изобретения раздела "Уровень техники", не должна предполагаться как ранее распознанная в предшествующем уровне техники. Предмет изобретения в разделе "Уровень техники" просто представляет разные подходы, которые сами также могут быть изобретениями.
[0004] Динамический диапазон аудиосигнала, в общем, является отношением между наибольшими и наименьшими возможными значениями звука, осуществленного в сигнале, и обычно измеряется в качестве значения в децибелах (по основанию 10). Во многих системах аудиообработки, управление динамическим диапазоном (или сжатие динамического диапазона, DRC) используется для того, чтобы уменьшать уровень громких звуков и/или усиливать уровень тихих звуков, чтобы вмещать исходный контент с широким динамическим диапазоном в более узкий записанный динамический диапазон, который может быть более легко сохранен и воспроизведен с использованием электронного оборудования. Для аудиовизуального (AV) контента опорный уровень диалога может использоваться для того, чтобы задавать "нулевую" точку для сжатия через DRC-механизм. DRC действует с возможностью усиливать контент ниже опорного уровня диалога и обрезать контент выше опорного уровня.
[0005] В известной системе кодирования аудио метаданные, ассоциированные с аудиосигналом, используются для того, чтобы задавать DRC-уровень на основе типа и предназначенного использования контента. DRC-режим задает объем сжатия, примененный к аудиосигналу, и задает выходной опорный уровень декодера. Такие системы могут быть ограничены двумя настройками DRC-уровня, которые программируются в кодере и выбираются пользователем. Например, значение диалнормы (нормализации диалога) в -31 дБ (линейный выход) традиционно использовано для контента, который воспроизводится на AVR или на устройствах с поддержкой полного динамического диапазона, и значение диалнормы в -20 дБ (RF) используется для контента, воспроизводимого на телевизионных приемниках или аналогичных устройствах. Этот тип системы предоставляет возможность использования одного потока аудиобитов в двух общих, но существенно отличающихся сценариях воспроизведения с помощью двух различных наборов DRC-метаданных. Тем не менее, такие системы ограничены предварительно установленными значениями диалнормы, а не оптимизированы для воспроизведения в широком спектре различных устройств воспроизведения и окружений прослушивания, которые теперь являются возможными в силу появления цифрового мультимедиа и технологии потоковой Интернет-передачи.
[0006] В современных системах кодирования аудио на основе метаданных, поток аудиоданных может включать в себя как аудиоконтент (например, один или более каналов аудиоконтента), так и метаданные, указывающие, по меньшей мере, одну характеристику аудиоконтента. Например, в AC-3-потоке битов предусмотрено несколько параметров аудиометаданных, которые специально предназначены для использования при изменении звука программы, доставляемой в окружение прослушивания. Один из параметров метаданных представляет собой параметр диалнормы, который указывает средний уровень громкости диалога (или среднюю громкость контента), возникающий в аудиопрограмме, и используется для того, чтобы определять уровень сигнала воспроизведения аудио.
[0007] Во время воспроизведения потока битов, содержащего последовательность различных сегментов аудиопрограммы (имеющих различный параметр диалнормы), AC-3-декодер использует параметр диалнормы каждого сегмента, чтобы выполнять тип обработки громкости, которая модифицирует уровень или громкость воспроизведения сегмента таким образом, что воспринимаемая громкость диалога сегмента имеет согласованный уровень. Каждый кодированный аудиосегмент (элемент) в последовательности кодированных аудиоэлементов (в общем) должен иметь различный параметр диалнормы, и декодер должен масштабировать уровень каждого из элементов таким образом, что уровень или громкость воспроизведения диалога для каждого элемента является идентичным или почти идентичным, хотя это может требовать применения различных коэффициентов усиления к различным элементов во время воспроизведения.
[0008] В некоторых вариантах осуществления, параметр диалнормы задается пользователем, а не формируется автоматически, хотя имеется значение диалнормы по умолчанию, если значение не задается пользователем. Например, создатель контента может проводить измерения громкости с помощью устройства, внешнего для AC-3-кодера, и затем передавать результат (указывающий громкость разговорного диалога аудиопрограммы) в кодер, чтобы задавать значение диалнормы. Таким образом, именно от создателя контента зависит корректное задание параметра диалнормы.
[0009] Существует несколько различных причин, по которым параметр диалнормы в AC-3-потоке битов может быть некорректным. Во-первых, каждый AC-3-кодер имеет значение диалнормы по умолчанию, которое используется во время формирования потока битов, если значение диалнормы не задается посредством создателя контента. Это значение по умолчанию может существенно отличаться от фактического уровня громкости диалога аудио. Во-вторых, даже если создатель контента измеряет громкость и задает значение диалнормы, соответственно, возможно, использован алгоритм или счетчик для измерения громкости, который не соответствует рекомендуемому способу измерения громкости, приводя к некорректному значению диалнормы. В-третьих, даже если AC-3-поток битов создан со значением диалнормы, измеренным и заданным корректно посредством создателя контента, оно, возможно, изменено на некорректное значение посредством промежуточного модуля в ходе передачи и/или хранения потока битов. Например, довольно часто в телевизионных широковещательных вариантах применения AC-3-потоки битов должны декодироваться, модифицироваться и затем повторно кодироваться с использованием некорректной информации метаданных диалнормы. Таким образом, значение диалнормы, включенное в AC-3-поток битов, может быть некорректным или неточным, и, следовательно, может оказывать негативное влияние на качество восприятия при прослушивании.
[0010] Дополнительно, параметр диалнормы не указывает состояние обработки громкости соответствующих аудиоданных (например, какой тип(ы) обработки громкости выполнен(ы) для аудиоданных). Дополнительно, текущие развернутые системы управления громкостью и DRC-системы, к примеру, системы Dolby Digital (DD) и системы Dolby Digital Plus (DD+), спроектированы с возможностью осуществлять рендеринг AV-контента в гостиной потребителя или кинотеатре. Чтобы адаптировать такое содержимое для воспроизведения в других окружениях и на аппаратуре прослушивания (например, на мобильном устройстве), постобработка должна применяться "вслепую" в устройстве воспроизведения, чтобы адаптировать AV-контент для этого окружения прослушивания. Другими словами, постпроцессор (или декодер) предполагает то, что уровень громкости принимаемого контента имеет конкретный уровень (например, -31 или-20 дБ), и постпроцессор задает уровень равным предварительно определенному фиксированному целевому уровню, подходящему для конкретного устройства. Если предполагаемый уровень громкости или предварительно определенный целевой уровень является некорректным, постобработка может приводить к противоположному от намеченного эффекта; т.е. постобработка может делать выходное аудио менее желательным для пользователя.
[0011] Раскрытые варианты осуществления не ограничены использованием с AC-3-потоком битов, E-AC-3-потоком битов или Dolby E-потоком битов, тем не менее, для удобства, такие потоки битов поясняются в сочетании с системой, которая включает в себя метаданные состояния обработки громкости. Dolby, Dolby Digital, Dolby Digital Plus и Dolby E являются торговыми марками Dolby Laboratories Licensing Corporation. Dolby Laboratories предоставляет собственные реализации AC-3 и E-AC-3, известные как Dolby Digital и Dolby Digital Plus, соответственно.
Сущность вариантов осуществления изобретения
[0012] Варианты осуществления направлены на способ для декодирования аудиоданных посредством приема потока битов, который содержит метаданные, ассоциированные с аудиоданными, и анализа метаданных в потоке битов, чтобы определять то, доступен или нет параметр громкости для первой группы устройств воспроизведения аудио в потоке битов. В ответ на определение того, что параметры присутствуют для первой группы, компонент обработки использует параметры и аудиоданные для того, чтобы осуществлять рендеринг аудио. В ответ на определение того, что параметры громкости не присутствуют для первой группы, компонент обработки анализирует одну или более характеристик первой группы и определяет параметр на основе одной или более характеристик. Способ дополнительно может использовать параметры и аудиоданные для того, чтобы осуществлять рендеринг аудио посредством передачи параметра и аудиоданных в нижележащий модуль, который осуществляет рендеринг аудио для воспроизведения. Параметр и аудиоданные также могут использоваться для того, чтобы осуществлять рендеринг аудио посредством рендеринга аудиоданных на основе параметра и аудиоданных.
[0013] В варианте осуществления, способ также содержит определение устройства вывода, которое должно осуществлять рендеринг принимаемого аудиопотока, и определение того, принадлежит или нет устройство вывода первой группе устройств воспроизведения аудио; при этом этап анализа метаданных в потоке, чтобы определять то, доступен или нет параметр громкости для первой группы устройств воспроизведения аудио, выполняется после этапа определения того, что устройство вывода принадлежит первой группе устройств воспроизведения аудио. В одном варианте осуществления, этап определения того, что устройство вывода принадлежит первой группе устройств воспроизведения аудио, содержит: прием индикатора из модуля, соединенного с устройством вывода, указывающего идентификационные данные устройства вывода или указывающее идентификационные данные группы устройств, которая включает в себя устройство вывода, и определение того, что устройство вывода принадлежит первой группе устройств воспроизведения аудио, на основе принимаемого индикатора.
[0014] Варианты осуществления дополнительно направлены на устройство или систему, которая включает в себя компоненты обработки, которые совершают действия, описанные в вышеуказанных вариантах осуществления способа кодирования.
[0015] Варианты осуществления еще дополнительно направлены на способ декодирования аудиоданных посредством приема аудиоданных и метаданных, ассоциированных с аудиоданными, анализа метаданных в потоке битов, чтобы определять то, доступна или нет информация громкости, ассоциированная с параметрами громкости для первой группы аудиоустройств, в потоке, и в ответ на определение того, что информация громкости присутствует для первой группы, определение информации громкости из потока и передачу аудиоданных и информации громкости для использования при рендеринге аудио, либо если информация громкости не присутствует для первой группы, определение информации громкости, ассоциированной с выходным профилем, и передачу определенной информации громкости для выходного профиля для использования при рендеринге аудио. В одном варианте осуществления, этап определения информации громкости, ассоциированной с выходным профилем, дополнительно может включать в себя анализ характеристик выходного профиля, определение параметров на основе характеристик, и передача определенной информации громкости содержит передачу определенных параметров. Информация громкости может включать в себя параметры громкости или характеристики выходного профиля. В варианте осуществления, способ дополнительно может содержать определение кодированного потока с низкой скоростью передачи битов, который должен передаваться, при этом информация громкости содержит характеристики для одного или более выходных профилей.
[0016] Варианты осуществления дополнительно направлены на устройство или систему, которая включает в себя компоненты обработки, которые совершают действия, описанные в вышеуказанных вариантах осуществления способа декодирования.
Краткое описание чертежей
[0017] На нижеприведенных чертежах аналогичные ссылки с номерами используются для того, чтобы означать аналогичные элементы. Хотя нижеприведенные чертежи иллюстрируют различные примеры, реализации, описанные в данном документе, не ограничены примерами, проиллюстрированными на чертежах.
[0018] Фиг. 1 является блок-схемой варианта осуществления системы аудиообработки, выполненной с возможностью осуществлять оптимизацию громкости и динамического диапазона в некоторых вариантах осуществления.
[0019] Фиг. 2 является блок-схемой кодера для использования в системе по фиг. 1, в некоторых вариантах осуществления.
[0020] Фиг. 3 является блок-схемой декодера для использования в системе по фиг. 1, в некоторых вариантах осуществления.
[0021] Фиг. 4 является схемой AC-3-кадра, включающего в себя сегменты, на которые он разделен.
[0022] Фиг. 5 является схемой сегмента информации синхронизации (SI) AC-3-кадра, включающего в себя сегменты, на которые он разделен.
[0023] Фиг. 6 является схемой сегмента информации потока битов (BSI) AC-3-кадра, включающего в себя сегменты, на которые он разделен.
[0024] Фиг. 7 является схемой E-AC-3-кадра, включающего в себя сегменты, на которые он разделен.
[0025] Фиг. 8 является таблицей, иллюстрирующей определенные кадры кодированного потока битов и формат метаданных в некоторых вариантах осуществления.
[0026] Фиг. 9 является таблицей, иллюстрирующей формат метаданных состояния обработки громкости в некоторых вариантах осуществления.
[0027] Фиг. 10 является более подробной блок-схемой системы аудиообработки по фиг. 1, которая может быть выполнена с возможностью осуществлять оптимизацию громкости и динамического диапазона в некоторых вариантах осуществления.
[0028] Фиг. 11 является таблицей, которая иллюстрирует различные требования по динамическому диапазону для множества устройств воспроизведения и фоновых окружений прослушивания в примерном случае использования.
[0029] Фиг. 12 является блок-схемой системы оптимизации динамического диапазона в варианте осуществления.
[0030] Фиг. 13 является блок-схемой, иллюстрирующей интерфейс между различными профилями для множества различных классов устройств воспроизведения в варианте осуществления.
[0031] Фиг. 14 является таблицей, которая иллюстрирует корреляцию между долговременной громкостью и кратковременным динамическим диапазоном для множества заданных профилей в варианте осуществления.
[0032] Фиг. 15 иллюстрирует примеры профилей громкости для различных типов аудиоконтента в варианте осуществления.
[0033] Фиг. 16 является блок-схемой последовательности операций способа, которая иллюстрирует способ оптимизации громкости и динамического диапазона через устройства и приложения для воспроизведения в варианте осуществления.
Подробное описание изобретения
Определения и терминология
[0034] В ходе этого раскрытия сущности, в том числе и в формуле изобретения, выражение "выполнение операции "над" сигналом или данными" (например, фильтрация, масштабирование, преобразование или применение усиления к сигналу или данным) используется в широком смысле для того, чтобы обозначать выполнение операции непосредственно над сигналом или данными, либо над обработанной версией сигнала или данных (например, над версией сигнала, который подвергнут предварительной фильтрации или предварительной обработке до выполнения операции). Выражение "система" используется в широком смысле для того, чтобы обозначать устройство, систему или подсистему. Например, подсистема, которая реализует декодер, может упоминаться в качестве системы декодера, а система, включающая в себя такую подсистему (например, система, которая формирует X выходных сигналов в ответ на несколько вводов, в которых подсистема формирует M вводов, и другие X-M вводов принимаются из внешнего источника), также может упоминаться в качестве системы декодера. Термин "процессор" используется в широком смысле для того, чтобы обозначать систему или устройство, запрограммированное или иным способом сконфигурированное (например, с помощью программного обеспечения или микропрограммного обеспечения) с возможностью осуществлять операции для данных (например, аудио или видео или других данных изображений). Примеры процессоров включают в себя программируемую пользователем вентильную матрицу (либо другую конфигурируемую интегральную схему или набор микросхем), процессор цифровых сигналов, запрограммированный и/или иным способом сконфигурированный с возможностью осуществлять конвейерную обработку для аудио или других звуковых данных, программируемый процессор общего назначения или компьютер и программируемую микропроцессорную интегральную схему или набор микросхем.
[0035] Выражения "аудиопроцессор" и "аудиопроцессорный блок" используются взаимозаменяемо и в широком смысле для того, чтобы обозначать систему, выполненную с возможностью обрабатывать аудиоданные. Примеры аудиопроцессоров включают в себя, но не только, кодеры (например, транскодеры), декодеры, кодеки, системы предварительной обработки, системы постобработки и системы обработки потоков битов (иногда называемые инструментальными средствами обработки потоков битов). Выражение "метаданные состояния обработки" (например, как в выражении "метаданные состояния обработки громкости") означает отдельные и различные данные из соответствующих аудиоданных (аудиоконтента потока аудиоданных, который также включает в себя метаданные состояния обработки). Метаданные состояния обработки ассоциированы с аудиоданными, указывает состояние обработки громкости соответствующих аудиоданных (например, какой тип(ы) обработки уже выполнены для аудиоданных), и необязательно также указывает, по меньшей мере, один признак или характеристику аудиоданных. В некотором варианте осуществления, ассоциирование метаданных состояния обработки с аудиоданными является синхронным во времени. Таким образом, текущие (последние принятые или обновленные) метаданные состояния обработки указывают то, что соответствующие аудиоданные одновременно содержат результаты указываемого типа(ов) обработки аудиоданных. В некоторых случаях, метаданные состояния обработки могут включать в себя предысторию обработки и/или некоторые или все параметры, которые используются в и/или извлекаются из указываемых типов обработки. Дополнительно, метаданные состояния обработки могут включать в себя, по меньшей мере, один признак или характеристику соответствующих аудиоданных, которая вычислена или извлечена из аудиоданных. Метаданные состояния обработки также могут включать в себя другие метаданные, которые не связаны или извлечены из обработки соответствующих аудиоданных. Например, сторонние данные, информация отслеживания, идентификаторы, внутренняя или стандартная информация, данные пользовательских примечаний, данные пользовательских настроек и т.д. могут добавляться посредством конкретного аудиопроцессора, чтобы передаваться в другие аудиопроцессоры.
[0036] Выражение "метаданные состояния обработки громкости" (или "LPSM") обозначает метаданные состояния обработки, указывающие состояние обработки громкости соответствующих аудиоданных (например, какой тип(ы) обработки громкости выполнены для аудиоданных), и необязательно также, по меньшей мере, один признак или характеристику (например, громкость) соответствующих аудиоданных. Метаданные состояния обработки громкости могут включать в себя данные (например, другие метаданные), которые не представляют собой (т.е. когда они рассматриваются отдельно) метаданные состояния обработки громкости. Термин "соединяется" или "соединенный" используется для того, чтобы означать прямое или косвенное соединение.
[0037] Системы и способы описываются для аудиокодера/декодера, который недеструктивно нормализует громкость и динамический диапазон аудио через различные устройства, которые требуют или используют различные целевые значения громкости и имеют отличающиеся характеристики динамического диапазона. Способы и функциональные компоненты согласно некоторым вариантам осуществления отправляют информацию относительно аудиоконтента из кодера в декодер для одного или более профилей устройств. Профиль устройства указывает требуемую целевую громкость и динамический диапазон для одного или более устройств. Система является наращиваемой, так что могут поддерживаться новые профили устройств с различными "номинальными" целевыми показателями громкости.
[0038] В варианте осуществления, система формирует надлежащие усиления на основе требований по управления громкостью и динамическому диапазону в кодере или формирует усиления в декодере, под управлением из кодера через параметризацию исходных усилений, чтобы уменьшать скорость передачи данных. Система регулирования динамического диапазона включает в себя два механизма для реализации управления громкостью: профиль художественного динамического диапазона, который предоставляет создателям контента управление касательно того, как должно воспроизводиться аудио, и отдельный механизм защиты, чтобы обеспечивать то, что перегрузка не возникает для различных профилей воспроизведения. Система также выполнена с возможностью давать возможность использования других параметров метаданных (внутренних или внешних) для того, чтобы надлежащим образом управлять усилениями и/или профилями громкости и динамического диапазона. Декодер выполнен с возможностью поддерживать n-канальный вспомогательный ввод, который использует настройки/обработку громкости и динамического диапазона на стороне декодера.
[0039] В некоторых вариантах осуществления, метаданные состояния обработки громкости (LPSM) встраиваются в одно или более зарезервированных полей (или квантов) сегментов метаданных потока аудиобитов, который также включает в себя аудиоданные в других сегментах (сегментах аудиоданных). Например, по меньшей мере, один сегмент каждого кадра потока битов включает в себя LPSM, и, по меньшей мере, один другой сегмент кадра включает в себя соответствующие аудиоданные (т.е. аудиоданные, состояние обработки громкости и громкость которых указываются посредством LPSM). В некоторых вариантах осуществления, объем данных LPSM может быть достаточно небольшим для переноса без влияния на скорость передачи битов, выделяемую для того, чтобы переносить аудиоданные.
[0040] Передача метаданных состояния обработки громкости в цепочке обработки аудиоданных является, в частности, полезной, когда два или более аудиопроцессоров должны работать совместно друг с другом во всей цепочке обработки (или в жизненном цикле контента). Без включения метаданных состояния обработки громкости в поток аудиобитов могут возникать проблемы обработки мультимедиа, такие как ухудшение качества, уровня и пространственных характеристик, например, когда два или более аудиокодеков используются в цепочке, и несимметричная авторегулировка громкости применяется несколько раз в ходе перемещения потока битов в устройство потребления мультимедиа (или в точку рендеринга аудиоконтента потока битов).
Система обработки метаданных громкости и динамического диапазона
[0041] Фиг. 1 является блок-схемой варианта осуществления системы аудиообработки, которая может быть выполнена с возможностью осуществлять оптимизацию громкости и динамического диапазона, в некоторых вариантах осуществления с использованием определенных компонентов обработки метаданных (например, предварительной обработка и постобработки). Фиг. 1 иллюстрирует примерную цепочку аудиообработки (систему обработки аудиоданных), в которой один или более элементов системы могут быть сконфигурированы в соответствии с вариантом осуществления настоящего изобретения. Система 10 по фиг. 1 включает в себя следующие элементы, соединенные между собой так, как показано: препроцессор 12, кодер 14, узел 16 анализа сигналов и коррекции метаданных, транскодер 18, декодер 20 и постпроцессор 24. В изменениях показанной системы, один или более элементов опускаются, либо дополнительные процессоры аудиоданных включаются. Например, в одном варианте осуществления, постпроцессор 22 является частью декодера 20, а не отдельным узлом.
[0042] В некоторых реализациях, препроцессор по фиг. 1 выполнен с возможностью принимать выборки PCM (временной области), содержащие аудиоконтент, в качестве ввода 11 и выводить обработанные PCM-выборки. Кодер 14 может быть выполнен с возможностью принимать PCM-выборки в качестве ввода и выводить кодированный (например, сжатый) поток аудиобитов, указывающий аудиоконтент. Данные потока битов, которые служат признаком аудиоконтента, иногда упоминаются в данном документе в качестве "аудиоданных". В одном варианте осуществления, поток аудиобитов, выводимый из кодера, включает в себя метаданные состояния обработки громкости (и необязательно также другие метаданные), а также аудиоданные.
[0043] Узел 16 анализа сигналов и коррекции метаданных может принимать один или более кодированных потоков аудиобитов в качестве ввода и определять (например, проверять допустимость) то, являются или нет метаданные состояния обработки в каждом кодированном потоке аудиобитов корректными, посредством выполнения анализа сигналов. В некоторых вариантах осуществления, проверка допустимости может выполняться посредством компонента узла проверки допустимости состояния, к примеру, элемента 102, показанного на фиг. 2, и одна такая технология проверки допустимости описывается ниже в контексте узла 102 проверки допустимости состояния. В некоторых вариантах осуществления, узел 16 включен в кодер, и проверка допустимости выполняется либо посредством узла 16, либо посредством узла 102 проверки допустимости. Если узел анализа сигналов и коррекции метаданных обнаруживает то, что включенные метаданные являются недопустимыми, узел 16 коррекции метаданных выполняет анализ сигналов, чтобы определять корректное значение(я), и заменяет некорректное значение(я) определенным корректным значением(ями). Таким образом, каждый кодированный поток аудиобитов, выводимый из узла анализа сигналов и коррекции метаданных может включать в себя скорректированные метаданные состояния обработки, а также кодированные аудиоданные. Узел 16 анализа сигналов и коррекции метаданных может быть частью препроцессора 12, кодера 14, транскодера 18, декодера 20 или постпроцессора 22. Альтернативно, узел 16 анализа сигналов и коррекции метаданных может быть отдельным узлом или частью другого узла в цепочке аудиообработки.
[0044] Транскодер 18 может принимать кодированные потоки аудиобитов в качестве модифицированного ввода и выводить (например, по-другому кодированные) потоки аудиобитов в ответ (например, посредством декодирования входного потока и повторного кодирования декодированного потока в другом формате кодирования). Поток аудиобитов, выводимый из транскодера, включает в себя метаданные состояния обработки громкости (и необязательно также другие метаданные), а также кодированные аудиоданные. Метаданные, возможно, включены в поток битов.
[0045] Декодер 20 по фиг. 1 может принимать кодированные (например, сжатые) потоки аудиобитов в качестве ввода и выводить (в ответ) потоки декодированных PCM-аудиовыборок. В одном варианте осуществления, выход декодера представляет собой или включает в себя любое одно из следующего: поток аудиовыборок и соответствующий поток метаданных состояния обработки громкости (и необязательно также других метаданных), извлеченных из входного кодированного потока битов; поток аудиовыборок и соответствующий поток управляющих битов, определенных из метаданных состояния обработки громкости (и необязательно также других метаданных), извлеченных из входного кодированного потока битов; или поток аудиовыборок, без соответствующего потока метаданных состояния обработки или управляющих битов, определенных из метаданных состояния обработки. В этом последнем случае, декодер может извлекать метаданные состояния обработки громкости (и/или другие метаданные) из входного кодированного потока битов и выполнять, по меньшей мере, одну операцию для извлеченных метаданных (например, проверку допустимости), даже если он не выводит извлеченные метаданные или управляющие биты, определенные из них.
[0046] Посредством конфигурирования постпроцессора по фиг. 1 в соответствии с вариантом осуществления настоящего изобретения, постпроцессор 22 выполнен с возможностью принимать поток декодированных PCM-аудиовыборок и выполнять постобработку для них (например, авторегулировку громкости аудиоконтента) с использованием метаданных состояния обработки громкости (и необязательно также других метаданных), принимаемых с выборками, или управляющих битов (определенных посредством декодера из метаданных состояния обработки громкости и необязательно также других метаданных), принимаемых с выборками. Постпроцессор 22 необязательно также выполнен с возможностью осуществлять рендеринг постобработанного аудиоконтенто для воспроизведения посредством одного или более динамиков. Эти динамики могут быть осуществлены в любом из множества различных устройств прослушивания или элементов оборудования для воспроизведения, таких как компьютеры, телевизионные приемники, стереосистемы (домашние или кино-), мобильные телефоны и другие портативные устройства воспроизведения. Динамики могут иметь любой надлежащий размер и номинальную мощность и могут предоставляться в форме автономных головок громкоговорителя, акустических экранов динамиков, систем объемного звучания, звуковых панелей, наушников, наушников-вкладышей и т.д.
[0047] Некоторые варианты осуществления предоставляют усовершенствованную цепочку аудиообработки, в которой аудиопроцессоры (например, кодеры, декодеры, транскодеры и пре- и постпроцессоры) адаптируют свою соответствующую обработку, которая должна применяться к аудиоданным согласно текущему состоянию мультимедийных данных, как указано посредством метаданных состояния обработки громкости, соответственно, принимаемых посредством аудиопроцессоров. Ввод 11 аудиоданных в любой аудиопроцессор системы 100 (например, кодер или транскодер по фиг. 1) может включать в себя метаданные состояния обработки громкости (и необязательно также другие метаданные), а также аудиоданные (например, кодированные аудиоданные). Эти метаданные, возможно, включены во входное аудио посредством другого элемента или другого источника в соответствии с некоторыми вариантами осуществления. Процессор, который принимает входное аудио (с метаданными), может быть выполнен с возможностью осуществлять, по меньшей мере, одну операцию для метаданных (например, проверку допустимости) или в ответ на метаданные (например, адаптивную обработку входного аудио), и необязательно также включать в свое выходное аудио метаданные, обработанную версию метаданных или управляющие биты, определенные из метаданных.
[0048] Вариант осуществления аудиопроцессора (audio processing unit) (или аудиопроцессора (audio processor)) выполнен с возможностью осуществлять адаптивную обработку аудиоданных на основе состояния аудиоданных, как указано посредством метаданных состояния обработки громкости, соответствующих аудиоданным. В некоторых вариантах осуществления, адаптивная обработка представляет собой (или включает в себя) обработку громкости (если метаданные указывают то, что обработка громкости или обработка, аналогичная ей, уже не выполнена для аудиоданных, но не представляет собой (и не включает в себя) обработку громкости (если метаданные указывают то, что такая обработка громкости или обработка, аналогичная ей, уже выполнена для аудиоданных). В некоторых вариантах осуществления, адаптивная обработка представляет собой или включает в себя проверку допустимости метаданных (например, выполняемую в подузле проверки допустимости метаданных), чтобы обеспечивать то, что аудиопроцессор выполняет другую адаптивную обработку аудиоданных на основе состояния аудиоданных, как указано посредством метаданных состояния обработки громкости. В некоторых вариантах осуществления, проверка допустимости определяет надежность метаданных состояния обработки громкости, ассоциированных (например, включенных в поток битов) с аудиоданными. Например, если подтверждено то, что метаданные являются надежными, то результаты из типа ранее выполняемой аудиообработки могут быть многократно использованы, и может исключаться дополнительное выполнение идентичного типа аудиообработки. С другой стороны, если обнаружено то, что метаданные подделаны (либо являются ненадежными в иных отношениях), то тип обработки мультимедиа, предположительно ранее выполняемой (как указано посредством ненадежных метаданных), может повторяться посредством аудиопроцессора, и/или другая обработка может выполняться посредством аудиопроцессора для метаданных и/или аудиоданных. Аудиопроцессор также может быть выполнен с возможностью передавать в служебных сигналах в другие аудиопроцессоры ниже в усовершенствованной цепочке обработки мультимедиа то, что метаданные состояния обработки громкости (например, присутствующие в потоке мультимедийных битов) являются допустимыми, если узел определяет то, что метаданные состояния обработки являются допустимыми (например, на основе соответствия извлеченного криптографического значения и опорного криптографического значения).
[0049] Для варианта осуществления по фиг. 1, компонент 12 предварительной обработки может быть частью кодера 14, и компонент 22 постобработки может быть частью декодера 22.
Альтернативно, компонент 12 предварительной обработки может быть осуществлен в функциональном компоненте, который является отдельным от кодера 14. Аналогично, компонент 22 постобработки может быть осуществлен в функциональном компоненте, который является отдельным от декодера 20.
[0050] Фиг. 2 является блок-схемой кодера 100, который может использоваться в сочетании с системой 10 по фиг. 1. Любые из компонентов или элементов кодера 100 могут быть реализованы как один или более процессов и/или одна или более схем (например, ASIC, FPGA или другие интегральные схемы), в аппаратных средствах, в программном обеспечении либо в комбинации аппаратных средств и программного обеспечения. Кодер 100 содержит буфер 110 кадров, синтаксический анализатор 111, декодер 101, узел 102 проверки допустимости состояния аудио, каскад 103 обработки громкости, каскад 104 выбора аудиопотока, кодер 105, каскад 107 узла форматирования/согласования скорости передачи данных, каскад 106 формирования метаданных, подсистему 108 измерения громкости диалога и буфер 109 кадров, соединенные так, как показано. Необязательно также кодер 100 включает в себя другие элементы обработки (не показаны). Кодер 100 (который представляет собой транскодер) выполнен с возможностью преобразовывать входной поток аудиобитов (который, например, может представлять собой одно из AC-3-потока битов, E-AC-3-потока битов или Dolby E-потока битов) в кодированный выходной поток аудиобитов (который, например, может представлять собой другое из AC-3-потока битов, E-AC-3-потока битов или Dolby E-потока битов), в том числе посредством выполнения адаптивной и автоматизированной обработки громкости с использованием метаданных состояния обработки громкости, включенных во входной поток битов. Например, кодер 100 может быть выполнен с возможностью преобразовывать входной Dolby E-поток битов (формат, типично используемый в оборудовании для производства и широковещательной передачи телевизионных программ, но не в бытовых устройствах, которые принимают аудиопрограммы, которые переданы в широковещательном режиме в них) в кодированный выходной поток аудиобитов (подходящий для широковещательной передачи в бытовые устройства) в AC-3- или E-AC-3-формате.
[0051] Система по фиг. 2 также включает в себя подсистему 150 доставки кодированного аудио (которая сохраняет и/или доставляет кодированные потоки битов, выводимые из кодера 100) и декодер 152. Кодированный поток аудиобитов, выводимый из кодера 100, может сохраняться посредством подсистемы 150 (например, в форме DVD или BluRay-диска) или передаваться посредством подсистемы 150 (которая может реализовывать линию или сеть передачи) либо может как сохраняться, так и передаваться посредством подсистемы 150. Декодер 152 выполнен с возможностью декодировать кодированный поток аудиобитов (сформированный посредством кодера 100), который он принимает через подсистему 150, в том числе посредством извлечения метаданных состояния обработки громкости (LPSM) из каждого кадра потока битов и формирования декодированных аудиоданных. В одном варианте осуществления, декодер 152 выполнен с возможностью осуществлять адаптивную обработку громкости для декодированных аудиоданных с использованием LPSM и/или перенаправлять декодированные аудиоданные и LPSM в постпроцессор, выполненный с возможностью осуществлять адаптивную обработку громкости для декодированных аудиоданных с использованием LPSM. Необязательно, декодер 152 включает в себя буфер, который сохраняет (например, энергонезависимым способом) кодированный поток аудиобитов, принимаемый из подсистемы 150.
[0052] Различные реализации кодера 100 и декодера 152 выполнены с возможностью осуществлять различные варианты осуществления, описанные в данном документе. Буфер 110 кадров представляет собой буферное запоминающее устройство, соединенное с возможностью принимать кодированный входной поток аудиобитов. При работе, буфер 110 сохраняет (например, энергонезависимым способом), по меньшей мере, один кадр кодированного потока аудиобитов, и последовательность кадров кодированного потока аудиобитов предъявляется из буфера 110 через синтаксический анализатор 111. Синтаксический анализатор 111 соединяется и сконфигурирован с возможностью извлекать метаданные состояния обработки громкости (LPSM) и другие метаданные из каждого кадра кодированного входного аудио, предъявлять, по меньшей мере, LPSM в узел 102 проверки допустимости состояния аудио, каскад 103 обработки громкости, каскад 106 и подсистему 108, чтобы извлекать аудиоданные из кодированного входного аудио, и предъявлять аудиоданные в декодер 101. Декодер 101 кодера 100 выполнен с возможностью декодировать аудиоданные для того, чтобы формировать декодированные аудиоданные, и предъявлять декодированные аудиоданные в каскад 103 обработки громкости, каскад 104 выбора аудиопотока, подсистему 108 и необязательно также в узел 102 проверки допустимости состояния.
[0053] Узел 102 проверки допустимости состояния выполнен с возможностью аутентифицировать и проверять допустимость LPSM (и необязательно других метаданных), предъявленных в него. В некоторых вариантах осуществления, LPSM представляет собой (или включен в) блок данных, который включен во входной поток битов (например, в соответствии с вариантом осуществления настоящего изобретения). Блок может содержать криптографический хэш (хэш-код аутентификации сообщений, или "HMAC") для обработки LPSM (и необязательно также других метаданных) и/или базовых аудиоданных (предоставленных из декодера 101 в узел 102 проверки допустимости). Блок данных может иметь цифровую подпись в этих вариантах осуществления, так что нижележащий аудиопроцессор может относительно легко аутентифицировать и проверять допустимость метаданных состояния обработки.
[0054] Например, HMAC используется для того, чтобы формировать дайджест, и защитное значение(я), включенное в изобретаемый поток битов, может включать в себя дайджест. Дайджест может формироваться следующим образом для AC-3 кадра: (1) После того, как AC-3-данные и LPSM кодируются, байты данных кадра (конкатенированные frame_data #1 и frame_data #2) и байты LPSM-данных используются в качестве ввода для HMAC хэш-функции. Другие данные, которые могут присутствовать в поле auxdata, не учитываются для вычисления дайджеста. Такие другие данные могут представлять собой байты, не принадлежащие ни AC-3-данным, ни LSPSM-данным. Защитные биты, включенные в LPSM, не могут учитываться для вычисления HMAC-дайджеста. (2) После того, как дайджест вычисляется, он записывается в поток битов в поле, зарезервированном для защитных битов. (3) Последний этап формирования полного AC-3-кадра представляет собой вычисление CRC-проверки. Она записывается в самом конце кадра, и учитываются все данные, принадлежащие этому кадру, включающие в себя LPSM-биты.
[0055] Другие криптографические способы, включающие в себя, но не только, любые из одного или более криптографических не-HMAC-способов, могут использоваться для проверки допустимости LPSM (например, в узле 102 проверки допустимости), чтобы обеспечивать защищенную передачу и прием LPSM и/или базовых аудиоданных. Например, проверка допустимости (с использованием такого криптографического способа) может выполняться в каждом аудиопроцессоре, который принимает вариант осуществления потока аудиобитов, чтобы определять то, подвергнуты (и/или получены в результате) или нет метаданные состояния обработки громкости и соответствующие аудиоданные, включенные в поток битов, конкретной обработке громкости (как указано посредством метаданных), и не модифицированы после выполнения такой конкретной обработки громкости.
[0056] Узел 102 проверки допустимости состояния предъявляет управляющие данные в каскад 104 выбора аудиопотока, узел 106 формирования метаданных и подсистему 108 измерения громкости диалога, чтобы указывать результаты операции проверки допустимости. В ответ на управляющие данные каскад 104 может выбирать (и пропускать через кодер 105) либо: (1) адаптивно обработанный вывод каскада 103 обработки громкости (например, когда LPSM указывают то, что аудиоданные, выводимые из декодера 101, не подвергнуты конкретному типу обработки громкости, и управляющие биты из узла 102 проверки допустимости указывают то, что LPSM являются допустимыми); либо (2) аудиоданные, выводимые из декодера 101 (например, когда LPSM указывают то, что аудиоданные, выводимые из декодера 101, уже подвергнуты конкретному типу обработки громкости, которая должны выполняться посредством каскада 103, и управляющие биты из узла 102 проверки допустимости указывают то, что LPSM являются допустимыми). В варианте осуществления, каскад 103 обработки громкости корректирует громкость до указанного целевого показателя и диапазона громкости.
[0057] Каскад 103 кодера 100 выполнен с возможностью осуществлять адаптивную обработку громкости для декодированных аудиоданных, выводимых из декодера 101, на основе одной или более характеристик аудиоданных, указываемых посредством LPSM, извлеченных посредством декодера 101. Каскад 103 может представлять собой процессор адаптивного управления громкостью и динамическим диапазоном в реальном времени в области преобразования. Каскад 103 может принимать пользовательский ввод (например, пользовательские целевые значения громкости/динамического диапазона или значения диалнормы) или ввод других метаданных (например, один или более типов сторонних данных, информации отслеживания, идентификаторов, внутренней или стандартной информации, данных пользовательских примечаний, данные пользовательских настроек и т.д.) и/или другой ввод (например, из процесса получения контрольной суммы) и использовать такой ввод, чтобы обрабатывать декодированные аудиоданные, выводимые из декодера 101.
[0058] Подсистема 108 измерения громкости диалога может работать, чтобы определять громкость сегментов декодированного аудио (из декодера 101), которые служат признаком диалога (или другой речи), например, с использованием LPSM (и/или других метаданных), извлеченных посредством декодера 101, когда управляющие биты из узла 102 проверки допустимости указывают то, что LPSM являются недопустимыми. Работа подсистемы 108 измерения громкости диалога может деактивироваться, когда LPSM указывают ранее определенную громкость сегментов диалога (или другой речи) декодированного аудио (из декодера 101), когда управляющие биты из узла 102 проверки допустимости указывают то, что LPSM являются допустимыми.
[0059] Существуют полезные инструментальные средства (например, счетчик громкости Dolby LM100) для удобного и простого измерения уровня диалога в аудиоконтенте. Некоторые варианты осуществления APU (например, каскад 108 кодера 100) реализуются с возможностью включать в себя (или выполнять функции) такое инструментальное средство, чтобы измерять среднюю громкость диалога аудиоконтента потока аудиобитов (например, декодированного AC-3-потока битов, предъявленного в каскад 108 из декодера 101 кодера 100). Если каскад 108 реализуется с возможностью измерять истинную среднюю громкость диалога аудиоданных, измерение может включать в себя этап изоляции сегментов аудиоконтента, которые преимущественно содержат речь. Аудиосегменты, которые преимущественно представляют собой речь, затем обрабатываются в соответствии с алгоритмом измерения громкости. Для аудиоданных, декодированных из AC-3-потока битов, этот алгоритм может представлять собой стандартную K-взвешенную меру громкости (в соответствии с международным стандартом ITU-R BS.1770). Альтернативно, могут использоваться другие меры громкости (например, меры громкости на основе психоакустических моделей громкости).
[0060] Изоляция речевых сегментов не является существенной для того, чтобы измерять среднюю громкость диалога аудиоданных. Тем не менее, она повышает точность меры и предоставляет более удовлетворительные результаты с точки зрения слушателя сообщений. Поскольку не весь аудиоконтент содержит диалог (речь), мера громкости всего аудиоконтента может предоставлять достаточную аппроксимацию уровня диалога аудио, если присутствует речь.
[0061] Узел 106 формирования метаданных формирует метаданные, которые должны быть включены посредством каскада 107 в кодированный поток битов, который должен выводиться из кодера 100. Узел 106 формирования метаданных может пропускать в каскад 107 LPSM (и/или другие метаданные), извлеченные посредством кодера 101 (например, когда управляющие биты из узла 102 проверки допустимости указывают то, что LPSM и/или другие метаданные являются допустимыми), или формировать новые LPSM (и/или другие метаданные) и предъявлять новые метаданные в каскад 107 (например, когда управляющие биты из узла 102 проверки допустимости указывают то, что LPSM и/или другие метаданные, извлеченные посредством декодера 101, являются недопустимыми), либо он может предъявлять в каскад 107 комбинацию метаданных, извлеченных посредством декодера 101, и заново сформированных метаданных. Узел 106 формирования метаданных может включать в себя данные громкости, сформированные посредством подсистемы 108, и, по меньшей мере, одно значение, указывающее тип обработки громкости, выполняемой посредством подсистемы 108, в LPSM, которые он предъявляет в каскад 107 для включения в кодированный поток битов, который должен выводиться из кодера 100. Узел 106 формирования метаданных может формировать защитные биты (которые могут состоять или включать в себя хэш-код аутентификации сообщений или "HMAC"), полезные, по меньшей мере, для одного из дешифрования, аутентификации или проверки допустимости LPSM (и необязательно также другие метаданные), которые должны быть включены в кодированный поток битов, и/или базовые аудиоданные, которые должны быть включены в кодированный поток битов. Узел 106 формирования метаданных может предоставлять такие защитные биты в каскад 107 для включения в кодированный поток битов.
[0062] В одном варианте осуществления, подсистема 108 измерения громкости диалога обрабатывает аудиоданные, выводимые из декодера 101, чтобы формировать в ответ на это значения громкости (например, стробированные и нестробированные значения громкости диалога) и значения динамического диапазона. В ответ на эти значения, узел 106 формирования метаданных может формировать метаданные состояния обработки громкости (LPSM) для включения (посредством узла 107 форматирования/согласования скорости передачи данных) в кодированный поток битов, который должен выводиться из кодера 100. В варианте осуществления, громкость может вычисляться на основе технологий, указываемых посредством стандартов ITU-R BS.1770-1 и ITU-R BS.1770-2, либо других аналогичных стандартов измерения громкости. Стробированная громкость может представлять собой стробированную диалогом громкость или относительную стробированную громкость, или комбинацию этих типов стробированной громкости, и система может использовать надлежащие блоки стробирования в зависимости от требований к приложениям и системных ограничений.
[0063] Дополнительно, необязательно или альтернативно, подсистемы 106 и/или 108 кодера 100 могут выполнять дополнительный анализ аудиоданных для того, чтобы формировать метаданные, указывающие, по меньшей мере, одну характеристику аудиоданных для включения в кодированный поток битов, который должен выводиться из каскада 107. Кодер 105 кодирует (например, посредством выполнения их сжатия) аудиоданные, выводимые из каскада 104 выбора, и предъявляет кодированное аудио в каскад 107 для включения в кодированный поток битов, который должен выводиться из каскада 107.
[0064] Каскад 107 мультиплексирует кодированное аудио из кодера 105 и метаданные (включающие в себя LPSM) из узла 106 формирования, чтобы формировать кодированный поток битов, который должен выводиться из каскада 107, так что кодированный поток битов имеет формат, как указано посредством варианта осуществления. Буфер 109 кадров представляет собой буферное запоминающее устройство, которое сохраняет (например, энергонезависимым способом), по меньшей мере, один кадр кодированного потока аудиобитов, выводимого из каскада 107, и последовательность кадров кодированного потока аудиобитов затем предъявляется из буфера 109 в качестве вывода из кодера 100 в систему 150 доставки.
[0065] LPSM, сформированные посредством узла 106 формирования метаданных и включенные в кодированный поток битов посредством каскада 107, служат признаком состояния обработки громкости соответствующих аудиоданных (например, какой тип(ы) обработки громкости выполнены для аудиоданных) и громкости (например, измеренной громкости диалога, стробированной и/или нестробированной громкости и/или динамического диапазона) соответствующих аудиоданных. В данном документе, "стробирование" измерений громкости и/или уровня, выполняемых для аудиоданных, означает конкретное пороговое значение уровня или громкости, при котором вычисленное значение(я), которые превышают пороговое значение, включены в конечное измерение (например, при игнорировании значений кратковременной громкости ниже -60 dBFS в конечных измеренных значениях). Стробирование абсолютного значения означает фиксированный уровень или громкость, тогда как стробирование относительного значения означает значение, которое зависит от текущего "нестробированного" значения измерения.
[0066] В некоторых реализациях кодера 100, кодированный поток битов, буферизованный в запоминающем устройстве 109 (и выводимый в систему 150 доставки), представляет собой AC-3-поток битов или E-AC-3-поток битов и содержит сегменты аудиоданных (например, сегменты AB0-AB5 кадра, показанного на фиг. 4) и сегменты метаданных, при этом сегменты аудиоданных служат признаком аудиоданных, и каждый, по меньшей мере, из некоторых сегментов метаданных включает в себя метаданные состояния обработки громкости (LPSM). Каскад 107 вставляет LPSM в поток битов в следующем формате. Каждый из сегментов метаданных, который включает в себя LPSM, включен в поле addbsi сегмента информации потока битов (BSI) кадра потока битов или в поле auxdata (например, сегмента AUX, показанного на фиг. 4) в конце кадра потока битов.
[0067] Кадр потока битов может включать в себя один или два сегмента метаданных, каждый из которых включает в себя LPSM, и если кадр включает в себя два сегмента метаданных, один присутствует в поле addbsi кадра, а другой – в поле AUX кадра. Каждый сегмент метаданных, включающих в себя LPSM, включает в себя сегмент рабочих LPSM-данных (или контейнера), имеющий следующий формат: заголовок (например, включающий в себя синхрослово, идентифицирующее начало рабочих LPSM-данных, после которого идет, по меньшей мере, одно идентификационное значение, например, значения версии, длины, периода LPSM-формата, числа и ассоциирования субпотоков, указываемые в таблице 2 ниже); и после заголовка, по меньшей мере, одно значение индикатора диалога (например, параметр "канал диалога" таблицы 2), указывающее то, указывают соответствующие аудиоданные диалог или не указывают диалог (например, какие каналы соответствующих аудиоданных указывают диалог); по меньшей мере, одно значение соответствия правилам регулирования громкости (например, параметр "Тип правил регулирования громкости" таблицы 2), указывающее то, соответствуют или нет соответствующие аудиоданные указываемому набору правил регулирования громкости; по меньшей мере, одно значение обработки громкости (например, один или более параметров "флаг коррекции стробированной диалогом громкости", "тип коррекции громкости", таблицы 2), указывающее, по меньшей мере, один тип обработки громкости, которая выполнена для соответствующих аудиоданных; и, по меньшей мере, одно значение громкости (например, один или более параметров "относительная стробированная громкость по стандарту ITU", "стробированная речью громкость по стандарту ITU", "кратковременная 3-секундная громкость по стандарту ITU (EBU 3341)" и "истинная пиковая" таблицы 2), указывающее, по меньшей мере, одну характеристику громкости (например, пиковую или среднюю громкость) соответствующих аудиоданных.
[0068] В некоторых реализациях, каждый из сегментов метаданных, вставленных посредством каскада 107 в поле addbsi или поле auxdata кадра потока битов, имеет следующий формат: базовый заголовок (например, включающий в себя синхрослово, идентифицирующее начало сегмента метаданных, после которого идут идентификационные значения, например, значения версии, длины и периода базового элемента, числа расширенных элементов и ассоциирования субпотоков, указываемые в таблице 1 ниже); и после базового заголовка, по меньшей мере, одно защитное значение (например, значения HMAC-дайджеста и контрольной суммы аудио таблицы 1), полезное, по меньшей мере, для одного из дешифрования, аутентификации или проверки допустимости, по меньшей мере, одних из метаданных состояния обработки громкости или соответствующих аудиоданных); и также после базового заголовка, если сегмент метаданных включает в себя LPSM, значения идентификации ("идентификатора") рабочих LPSM-данных и размера рабочих LPSM-данных, которые идентифицируют следующие метаданные в качестве рабочих LPSM-данных и указывают размер рабочих LPSM-данных.
[0069] Сегмент рабочих LPSM-данных (или контейнера) (например, имеющий вышеуказанный формат) идет после значений идентификатора рабочих LPSM-данных и размера рабочих LPSM-данных.
[0070] В некоторых вариантах осуществления, каждый из сегментов метаданных в поле auxdata (или поле addbsi) кадра имеет три уровня структуры: высокоуровневую структуру, включающую в себя флаг, указывающий то, включает или нет поле auxdata (или addbsi) в себя метаданные, по меньшей мере, одно значение идентификатора, указывающее то, какой тип(ы) метаданных присутствует, и необязательно также значение, указывающее то, сколько битов метаданных (например, каждого типа) присутствует (если метаданные присутствуют). Один тип метаданных, которые могут присутствовать, представляет собой LSPM, а другой тип метаданных, которые могут присутствовать, представляет собой метаданные медиаисследований (например, метаданные медиаисследований Нильсена); структуру промежуточного уровня, содержащую базовый элемент для каждого идентифицированного типа метаданных (например, базовый заголовок, защитные значения и значения идентификатора рабочих LPSM-данных и размера рабочих LPSM-данных, как упомянуто выше, для каждого идентифицированного типа метаданных); и низкоуровневую структуру, содержащую каждые рабочие данные для одного базового элемента (например, рабочие LPSM-данные, если они идентифицированы посредством базового элемента как присутствующие, и/или рабочие данные метаданных другого типа, если они идентифицированы посредством базового элемента как присутствующие).
[0071] Значения данных в таких трех структурах уровня могут быть вложены. Например, защитное значение(я) для рабочих LPSM-данных и/или других рабочих данных метаданных, идентифицированных посредством базового элемента, может быть включено после каждых рабочих данных, идентифицированных посредством базового элемента (и в силу этого после базового заголовка базового элемента). В одном примере, базовый заголовок может идентифицировать рабочие LPSM-данные и другие рабочие данные метаданных, значения идентификатора рабочих данных и размера рабочих данных для первых рабочих данных (например, рабочие LPSM-данные) могут идти после базового заголовка, сами первые рабочие данные могут идти после значений идентификатора и размера, значение идентификатора рабочих данных и размера рабочих данных для вторых рабочих данных может идти после первых рабочих данных, сами вторые рабочие данные могут идти после этих значений идентификатора и размера, и защитные биты для обоих рабочих данных (или для значений базового элемента и обоих рабочих данных) могут идти после последних рабочих данных.
[0072] В некоторых вариантах осуществления, если декодер 101 принимает поток аудиобитов, сформированный в соответствии с вариантом осуществления изобретения с криптографическим хэшем, декодер выполнен с возможностью синтаксически анализировать и извлекать криптографический хэш из блока данных, определенного из потока битов, причем упомянутый блок содержит метаданные состояния обработки громкости (LPSM). Узел 102 проверки допустимости может использовать криптографический хэш, чтобы проверять допустимость принимаемого потока битов и/или ассоциированных метаданных. Например, узел 102 проверки допустимости обнаруживает то, что LPSM являются допустимыми, на основе соответствия между опорным криптографическим хэшем и криптографическим хэшем, извлеченным из блока данных, затем он может отключать операцию процессора 103 для соответствующих аудиоданных и инструктировать каскаду 104 выбора пропускать (неизменными) аудиоданные. Дополнительно, необязательно или альтернативно, другие типы криптографических технологий могут использоваться вместо способа на основе криптографического хэша.
[0073] Кодер 100 по фиг. 2 может определять (в ответ на LPSM, извлеченные посредством декодера 101) то, что пост/препроцессор выполняет тип обработки громкости для аудиоданных, которые должны кодироваться (в элементах 105, 106 и 107), и, следовательно, может создавать (в узле 106 формирования) метаданные состояния обработки громкости, которые включают в себя конкретные параметры, используемые в и/или извлекаемые из ранее выполняемой обработки громкости. В некоторых реализациях, кодер 100 может создавать (и включать в кодированный поток битов, выводимый из него) метаданные состояния обработки, указывающие обработку предыстории для аудиоконтента, до тех пор, пока кодер имеет сведения по типам обработки, которые выполнены для аудиоконтента.
[0074] Фиг. 3 является блок-схемой декодера, который может использоваться в сочетании с системой 10 по фиг. 1. Любые из компонентов или элементов декодера 200 и постпроцессора 300 могут быть реализованы как один или более процессов и/или одна или более схем (например, ASIC, FPGA или другие интегральные схемы), в аппаратных средствах, в программном обеспечении либо в комбинации аппаратных средств и программного обеспечения. Декодер 200 содержит буфер 201 кадров, синтаксический анализатор 205, аудиодекодер 202, каскад 203 (узел) проверки допустимости состояния аудио и каскад 204 формирования управляющих битов, соединенные так, как показано. Декодер 200 может включать в себя другие элементы обработки (не показаны). Буфер 201 кадров (буферное запоминающее устройство) сохраняет (например, энергонезависимым способом), по меньшей мере, один кадр кодированного потока аудиобитов, принимаемого посредством декодера 200. Последовательность кадров кодированного потока аудиобитов предъявлена из буфера 201 в синтаксический анализатор 205. Синтаксический анализатор 205 соединяется и сконфигурирован с возможностью извлекать метаданные состояния обработки громкости (LPSM) и другие метаданные из каждого кадра кодированного входного аудио, предъявлять, по меньшей мере, LPSM в узел 203 проверки допустимости состояния аудио и каскад 204, предъявлять LPSM в качестве вывода (например, в постпроцессор 300), извлекать аудиоданные из кодированного входного аудио и предъявлять извлеченные аудиоданные в декодер 202. Кодированный поток аудиобитов, вводимый в декодер 200, может представлять собой одно из AC-3-потока битов, E-AC-3-потока битов или Dolby E-потока битов.
[0075] Система по фиг. 3 также включает в себя постпроцессор 300. Постпроцессор 300 содержит буфер 301 кадров и другие элементы обработки (не показаны), включающие в себя, по меньшей мере, один элемент обработки, соединенный с буфером 301. Буфер 301 кадров сохраняет (например, энергонезависимым способом), по меньшей мере, один кадр декодированного потока аудиобитов, принимаемого посредством постпроцессора 300 из декодера 200. Элементы обработки постпроцессора 300 соединяются и сконфигурированы с возможностью принимать и адаптивно обрабатывать последовательность кадров декодированного потока аудиобитов, выводимого из буфера 301, с использованием метаданных (включающих в себя LPSM-значения), выводимых из декодера 202, и/или управляющих битов, выводимых из каскада 204 декодера 200. В одном варианте осуществления, постпроцессор 300 выполнен с возможностью осуществлять адаптивную обработку громкости для декодированных аудиоданных с использованием LPSM-значений (например, на основе состояния обработки громкости и/или одной или более характеристик аудиоданных, указываемых посредством LPSM). Различные реализации декодера 200 и постпроцессора 300 выполнены с возможностью осуществлять различные варианты осуществления способов согласно вариантам осуществления, описанным в данном документе.
[0076] Аудиодекодер 202 декодера 200 выполнен с возможностью декодировать аудиоданные, извлеченные посредством синтаксического анализатора 205, чтобы формировать декодированные аудиоданные и предъявлять декодированные аудиоданные в качестве вывода (например, в постпроцессор 300). Узел 203 проверки допустимости состояния выполнен с возможностью аутентифицировать и проверять допустимость LPSM (и необязательно других метаданных), предъявленных в него. В некоторых вариантах осуществления, LPSM представляет собой (или включен в) блок данных, который включен во входной поток битов (например, в соответствии с вариантом осуществления настоящего изобретения). Блок может содержать криптографический хэш (хэш-код аутентификации сообщений или "HMAC") для обработки LPSM (и необязательно также другие метаданные) и/или базовые аудиоданные (предоставленные из синтаксического анализатора 205 и/или декодера 202 в узел 203 проверки допустимости). Блок данных может иметь цифровую подпись в этих вариантах осуществления, так что нижележащий аудиопроцессор может относительно легко аутентифицировать и проверять допустимость метаданных состояния обработки.
[0077] Другие криптографические способы, включающие в себя, но не только, любые из одного или более криптографических не-HMAC-способов, могут использоваться для проверки допустимости LPSM (например, в узле 203 проверки допустимости), чтобы обеспечивать защищенную передачу и прием LPSM и/или базовых аудиоданных. Например, проверка допустимости (с использованием такого криптографического способа) может выполняться в каждом аудиопроцессоре, который принимает вариант осуществления изобретаемого потока аудиобитов, чтобы определять то, подвергнуты (и/или получены в результате) или нет метаданные состояния обработки громкости и соответствующие аудиоданные, включенные в поток битов, конкретной обработке громкости (как указано посредством метаданных), и не модифицированы после выполнения такой конкретной обработки громкости.
[0078] Узел 203 проверки допустимости состояния предъявляет управляющие данные в узел 204 формирования управляющих битов и/или предъявляет управляющие данные в качестве вывода (например, в постпроцессор 300), чтобы указывать результаты операции проверки допустимости. В ответ на управляющие данные (и необязательно также другие метаданные, извлеченные из входного потока битов), каскад 204 может формировать (и предъявлять в постпроцессор 300) либо: управляющие биты, указывающие то, что декодированные аудиоданные, выводимые из декодера 202, подвергнуты конкретному типу обработки громкости (когда LPSM указывают то, что аудиоданные, выводимые из декодера 202, подвергнуты конкретному типу обработки громкости, и управляющие биты из узла 203 проверки допустимости указывают то, что LPSM являются допустимыми); либо управляющие биты, указывающие то, что декодированные аудиоданные, выводимые из декодера 202, должны подвергаться конкретному типу обработки громкости (например, когда LPSM указывают то, что аудиоданные, выводимые из декодера 202, не подвергнуты конкретному типу обработки громкости, или когда LPSM указывают то, что аудиоданные, выводимые из декодера 202, подвергнуты конкретному типу обработки громкости, но управляющие биты из узла 203 проверки допустимости указывают то, что LPSM не являются допустимыми).
[0079] Альтернативно, декодер 200 предъявляет LPSM (и любые другие метаданные), извлеченные посредством декодера 202 из входного потока битов, в постпроцессор 300, и постпроцессор 300 выполняет обработку громкости для декодированных аудиоданных с использованием LPSM или выполняет проверку допустимости LPSM и затем выполняет обработку громкости для декодированных аудиоданных с использованием LPSM, если проверка допустимости указывает то, что LPSM являются допустимыми.
[0080] В некоторых вариантах осуществления, если декодер 201 принимает поток аудиобитов, сформированный в соответствии с вариантом осуществления изобретения с криптографическим хэшем, декодер выполнен с возможностью синтаксически анализировать и извлекать криптографический хэш из блока данных, определенного из потока битов, причем упомянутый блок содержит метаданные состояния обработки громкости (LPSM). Узел 203 проверки допустимости может использовать криптографический хэш, чтобы проверять допустимость принимаемого потока битов и/или ассоциированных метаданных. Например, если узел 203 проверки допустимости обнаруживает то, что LPSM являются допустимыми, на основе соответствия между опорным криптографическим хэшем и криптографическим хэшем, извлеченным из блока данных, то он может передавать в служебных сигналах в нижележащий аудиопроцессор (например, в постпроцессор 300, который может быть или включать в себя узел авторегулировки громкости) пропускать (неизменными) аудиоданные потока битов. Дополнительно, необязательно или альтернативно, другие типы криптографических технологий могут использоваться вместо способа на основе криптографического хэша.
[0081] В некоторых реализациях декодера 100, кодированный поток битов, принимаемый (и буферизованный в запоминающем устройстве 201), представляет собой AC-3-поток битов или E-AC-3-поток битов и содержит сегменты аудиоданных (например, сегменты AB0-AB5 кадра, показанного на фиг. 4) и сегменты метаданных, при этом сегменты аудиоданных служат признаком аудиоданных, и каждый, по меньшей мере, из некоторых сегментов метаданных включает в себя метаданные состояния обработки громкости (LPSM).
Каскад 202 декодера выполнен с возможностью извлекать из потока битов LPSM, имеющие следующий формат. Каждый из сегментов метаданных, который включает в себя LPSM, включен в поле addbsi сегмента информации потока битов (BSI) кадра потока битов или в поле auxdata (например, сегмента AUX, показанного на фиг. 4) в конце кадра потока битов. Кадр потока битов может включать в себя один или два сегмента метаданных, каждый из которых включает в себя LPSM, и если кадр включает в себя два сегмента метаданных, один присутствует в поле addbsi кадра, а другой – в поле AUX кадра. Каждый сегмент метаданных, включающих в себя LPSM, включает в себя сегмент рабочих LPSM-данных (или контейнера), имеющий следующий формат: заголовок (например, включающий в себя синхрослово, идентифицирующее начало рабочих LPSM-данных, после которого идут идентификационные значения, например, значения версии, длины, периода LPSM-формата, числа и ассоциирования субпотоков, указываемые в таблице 2 ниже); и после заголовка, по меньшей мере, одно значение индикатора диалога (например, параметр "канал диалога" таблицы 2), указывающее то, указывают соответствующие аудиоданные диалог или не указывают диалог (например, какие каналы соответствующих аудиоданных указывают диалог); по меньшей мере, одно значение соответствия правилам регулирования громкости (например, параметр "Тип правил регулирования громкости" таблицы 2), указывающее то, соответствуют или нет соответствующие аудиоданные указываемому набору правил регулирования громкости; по меньшей мере, одно значение обработки громкости (например, один или более параметров "флаг коррекции стробированной диалогом громкости", "тип коррекции громкости", таблицы 2), указывающее, по меньшей мере, один тип обработки громкости, которая выполнена для соответствующих аудиоданных; и, по меньшей мере, одно значение громкости (например, один или более параметров "относительная стробированная громкость по стандарту ITU", "стробированная речью громкость по стандарту ITU", "кратковременная 3-секундная громкость по стандарту ITU (EBU 3341)" и "истинная пиковая" таблицы 2), указывающее, по меньшей мере, одну характеристику громкости (например, пиковую или среднюю громкость) соответствующих аудиоданных.
[0082] В некоторых реализациях, каскад 202 декодера выполнен с возможностью извлекать, из поля addbsi или поля auxdata кадра потока битов, каждый сегмент метаданных, имеющий следующий формат: базовый заголовок (например, включающий в себя синхрослово, идентифицирующее начало сегмента метаданных, после которого идет, по меньшей мере, одно идентификационное значение, например, значения версии, длины и периода базового элемента, числа расширенных элементов и ассоциирования субпотоков, указываемые в таблице 1 ниже); и после базового заголовка, по меньшей мере, одно защитное значение (например, значения HMAC-дайджеста и контрольной суммы аудио таблицы 1), полезное, по меньшей мере, для одного из дешифрования, аутентификации или проверки допустимости, по меньшей мере, одних из метаданных состояния обработки громкости или соответствующих аудиоданных); и также после базового заголовка, если сегмент метаданных включает в себя LPSM, значения идентификации ("идентификатора") рабочих LPSM-данных и размера рабочих LPSM-данных, которые идентифицируют следующие метаданные в качестве рабочих LPSM-данных и указывают размер рабочих LPSM-данных. Сегмент рабочих LPSM-данных (или контейнера) (например, имеющий вышеуказанный формат) идет после значений идентификатора рабочих LPSM-данных и размера рабочих LPSM-данных.
[0083] Если обобщать, кодированный поток аудиобитов, сформированный посредством варианта осуществления, имеет структуру, которая предоставляет механизм для того, чтобы помечать элементы метаданных и субэлементы в качестве базовых (обязательных) или расширенных (необязательных) элементов. Это дает возможность масштабирования скорости передачи данных потока битов (включающего в себя его метаданные) через множество вариантов применения. Базовые (обязательные) элементы синтаксиса потока битов должны также допускать передачу в служебных сигналах того, что расширенные (необязательные) элементы, ассоциированные с аудиоконтентом, присутствуют (внутриполосно) и/или в удаленном местоположении (внеполосно).
[0084] В некотором варианте осуществления, базовый элемент(ы) должен присутствовать в каждом кадре потока битов. Некоторые субэлементы базовых элементов являются необязательными и могут присутствовать в любой комбинации. Расширенные элементы не должны присутствовать в каждом кадре (чтобы ограничивать объем служебной информации в скорости передачи битов). Таким образом, расширенные элементы могут присутствовать в некоторых кадрах, и не присутствовать в других. Некоторые субэлементы расширенного элемента являются необязательными и могут присутствовать в любой комбинации, тогда как некоторые субэлементы расширенного элемента могут быть обязательными (т.е. если расширенный элемент присутствует в кадре потока битов).
[0085] В некоторых вариантах осуществления, кодированный поток аудиобитов, содержащий последовательность сегментов аудиоданных и сегментов метаданных, формируется (например, посредством аудиопроцессора, который осуществляет изобретение). Сегменты аудиоданных служат признаком аудиоданных, каждый, по меньшей мере, из некоторых сегментов метаданных включает в себя метаданные состояния обработки громкости (LPSM), и сегменты аудиоданных мультиплексируются с временным разделением каналов с сегментами метаданных. В некоторых вариантах осуществления в этом классе, каждый из сегментов метаданных имеет формат, который описывается в данном документе. В одном формате, кодированный поток битов представляет собой AC-3-поток битов или E-AC-3-поток битов, и каждый из сегментов метаданных, который включает в себя LPSM, включен (например, посредством каскада 107 кодера 100) в качестве дополнительной информации потока битов в поле addbsi (показано на фиг. 6) сегмента информации потока битов (BSI) кадра потока битов или в поле auxdata кадра потока битов. Каждый из кадров включает в себя базовый элемент в поле addbsi кадра, имеющего формат, показанный в таблице 1 по фиг. 8.
[0086] В одном формате, каждое из полей addbsi (или auxdata), которое содержит LPSM, содержит базовый заголовок (и необязательно также дополнительные базовые элементы), и после базового заголовка (или базового заголовка и других базовых элементов) следующие LPSM-значения (параметры): идентификатор рабочих данных (идентифицирующий метаданные в качестве LPSM), идущий после значений базового элемента (например, как указано в таблице 1); размер рабочих данных (указывающий размер рабочих LPSM-данных), идущий после идентификатора рабочих данных; и LPSM-данные (идущие после значения идентификатора рабочих данных и размера рабочих данных), имеющие формат, как указано в таблице 2 по фиг. 9.
[0087] Во втором формате кодированного потока битов, поток битов представляет собой AC-3-поток битов или E-AC-3-поток битов, и каждый из сегментов метаданных, который включает в себя LPSM, включен (например, посредством каскада 107 кодера 100) либо: в поле addbsi (показано на фиг. 6) сегмента информации потока битов (BSI) кадра потока битов; либо в поле auxdata (например, сегмент AUX, показанный на фиг. 4) в конце кадра потока битов. Кадр может включать в себя один или два сегмента метаданных, каждый из которых включает в себя LPSM, и если кадр включает в себя два сегмента метаданных, один присутствует в поле addbsi кадра, а другой – в поле AUX кадра. Каждый сегмент метаданных, включающий в себя LPSM, имеет формат, указанный выше в отношении вышеприведенных таблиц 1 и 2 (т.е. он включает в себя базовые элементы, указываемые в таблице 1, после которых идут значения идентификатора рабочих данных (идентифицирующего метаданные в качестве LPSM) и размера рабочих данных, указываемые выше, после которых идут рабочие данные (LPSM-данные, которые имеют формат, как указано в таблице 2).
[0088] В другом, кодированный поток битов представляет собой Dolby E-поток битов, и каждый из сегментов метаданных, которые включают в себя LPSM, являются первыми N местоположений выборок интервала защитной полосы частот Dolby E. Dolby E-поток битов, включающий в себя такой сегмент метаданных, который включает в себя LPSM, например, включает в себя значение, указывающее длину рабочих LPSM-данных, передаваемую в служебных сигналах в Pd-слове преамбулы SMPTE 337M (частота повторения Pa-слова согласно SMPTE 337M может оставаться идентичной ассоциированной частоте видеокадров).
[0089] В формате, в котором кодированный поток битов представляет собой E-AC-3-поток битов, каждый из сегментов метаданных, который включает в себя LPSM, включен (например, посредством каскада 107 кодера 100) в качестве дополнительной информации потока битов в поле addbsi сегмента информации потока битов (BSI) кадра потока битов. Дополнительные аспекты кодирования E-AC-3-потока битов с LPSM в этом формате описываются следующим образом: (1) во время формирования E-AC-3-потока битов, в то время как E-AC-3-кодер (который вставляет LPSM-значения в поток битов) является "активным" для каждого сформированного кадра (синхрокадра), поток битов должен включать в себя блок метаданных (включающий в себя LPSM), переносимый в поле addbsi кадра. Биты, требуемые для того, чтобы переносить блок метаданных, не должны увеличивать скорость передачи битов кодера (длину кадра); (2) каждый блок метаданных (содержащий LPSM) должен содержать следующую информацию:
- loudness_correction_type_flag: где T указывает то, что громкость соответствующих аудиоданных скорректирована выше кодера, и 0 указывает то, что громкость скорректирована посредством корректора громкости, встраиваемого в кодер (например, процессор 103 громкости кодера 100 по фиг. 2); speech_channel: указывает то, какой исходный канал(ы) содержит речь (за предыдущие 0,5 секунды). Если речь не обнаруживается, то это должно указываться как таковое; speech_loudness: указывает интегрированную речевую громкость соответствующего аудиоканала, который содержит речь (за предыдущие 0,5 секунды); ITU_loudness: указывает интегрированную громкость ITU BS.1770-2 соответствующего аудиоканала; gain: составное усиление(я) громкости для обратной обработки в декодере (чтобы демонстрировать обратимость).
[0090] Хотя E-AC-3-кодер (который вставляет LPSM-значения в поток битов) является "активным" и принимает AC-3-кадр с флагом "доверия", контроллер громкости в кодере (например, процессоре 103 громкости кодера 100 по фиг. 2) обходится. "Доверенные" исходные значения диалнормы и DRC проходят (например, посредством узла 106 формирования кодера 100) в компонент E-AC-3-кодера (например, каскад 107 кодера 100). Формирование LPSM-блоков продолжается, и loudness_correction_type_flag задается равным 1. Последовательность обхода контроллера громкости синхронизируется с началом декодированного AC-3-кадра, в котором возникает флаг "доверия". Последовательность обхода контроллера громкости реализована следующим образом: элемент leveler_amount управления постепенно уменьшается со значения 9 до значения 0, за 10 периодов аудиоблока (т.е. 53,3 мс), и элемент leveler_back_end_meter управления переведен в обходной режим (эта операция должна приводить к прозрачному переходу). Термин "доверенный обход узла авторегулироваки" подразумевает, что значение диалнормы исходного потока битов также повторно используется в выводе кодера (например, если "доверенный" исходный поток битов имеет значение диалнормы -30, то вывод кодера должен использовать -30 для исходящего значения диалнормы).
[0091] Хотя E-AC-3-кодер (который вставляет LPSM-значения в поток битов) является "активным" и принимает AC-3-кадр без флага "доверия", контроллер громкости, встраиваемый в кодер (например, процессор 103 громкости кодера 100 по фиг. 2), является активным. Формирование LPSM-блоков продолжается, и loudness_correction_type_flag задается равным 0. Последовательность активации контроллера громкости синхронизируется с началом декодированного AC-3-кадра, в котором исчезает флаг "доверия". Последовательность активации контроллера громкости реализована следующим образом: элемент leveler_amount управления увеличивается со значения 0 на значение 9, за 1 период аудиоблока (т.е. 5,3 мс), и элемент leveler_back_end_meter управления переведен в "активный" режим (эта операция приводит к прозрачному переходу и включает в себя сброс интеграции back_end_meter); и во время кодирования, графический пользовательский интерфейс (GUI) указывает для пользователя следующие параметры: "входная аудиопрограмма: [доверенная/недоверенная]" – состояние этого параметра основано на присутствии флага "доверия" во входном сигнале; и "коррекция громкости в реальном времени: [активирована/деактивирована]" – состояние этого параметра основано на том, является или нет этот контроллер громкости, встраиваемый в кодер, активным.
[0092] При декодировании AC-3- или E-AC-3-потока битов, который имеет LPSM (в описанном формате), включенный в поле addbsi сегмента информации потока битов (BSI) каждого кадра потока битов, декодер синтаксически анализирует данные LPSM-блоков (в поле addbsi) и передает извлеченные LPSM-значения в графический пользовательский интерфейс (GUI). Набор извлеченных LPSM-значений обновляется каждый кадр.
[0093] В еще одном другом формате, кодированный поток битов представляет собой AC-3-поток битов или E-AC-3-поток битов, и каждый из сегментов метаданных, который включает в себя LPSM, включен (например, посредством каскада 107 кодера 100) в качестве дополнительной информации потока битов в поле addbsi (показано на фиг. 6) сегмента информации потока битов (BSI) (или в сегменте AUX) кадра потока битов. В этом формате (который является изменением формата, описанного выше со ссылками на таблицы 1 и 2), каждое из полей addbsi (или AUX), которое содержит LPSM, содержит следующие LPSM-значения: базовые элементы, указанные в таблице 1, после которых идут значения идентификатора рабочих данных (идентифицирующего метаданные в качестве LPSM) и размера рабочих данных, после которых идут рабочие данные (LPSM-данные), которые имеют следующий формат (аналогичный элементам, указываемым в вышеприведенной таблице 2): версия рабочих LPSM-данных: 2-битовое поле, которое указывает версию рабочих LPSM-данных; dialchan: 3-битовое поле, которое указывает то, содержат или нет левый, правый и/или центральный каналы соответствующих аудиоданных разговорный диалог. Выделение битов поля dialchan может заключаться в следующем: бит 0, который указывает присутствие диалога в левом канале, сохраняется в старшем бите поля dialchan; и бит 2, который указывает присутствие диалога в центральном канале, сохраняется в наименее значимом бите поля dialchan. Каждый бит поля dialchan задается равным 1, если соответствующий канал содержит разговорный диалог в течение предшествующих 0,5 секунд программы; loudregtyp: 3-битовое поле, которое указывает то, какому стандарту регулирования громкости соответствует громкость программы. Задание поля loudregtyp равным 000 указывает то, что LPSM не указывают соответствие правилам регулирования громкости. Например, одно значение этого поля (например, 000) может указывать то, что соответствие стандарту регулирования громкости не указывается, другое значение этого поля (например, 001) может указывать то, что аудиоданные программы соответствуют стандарту ATSC A/85, и другое значение этого поля (например, 010) может указывать то, что аудиоданные программы соответствуют стандарту EBU R128. В примере, если поле задается равным какому-либо значению, отличному от 000, поля loudcorrdialgat и loudcorrtyp должны идти далее в рабочих данных; loudcorrdialgat: однобитовое поле, которое указывает то, применена или нет коррекция стробированной диалогом громкости. Если громкость программы скорректирована с использованием стробирования диалога, значение поля loudcorrdialgat задается равным 1. В противном случае, оно задается равным 0; loudcorrtyp: однобитовое поле, которое указывает тип коррекции громкости, примененной к программе. Если громкость программы скорректирована с помощью процесса бесконечной упреждающей (на основе файлов) коррекции громкости, значение поля loudcorrtyp задается равным 0. Если громкость программы скорректирована с использованием комбинации измерения громкости и управления динамическим диапазоном в реальном времени, значение этого поля задается равным 1; loudrelgate: однобитовое поле, которое указывает то, существуют или нет данные относительной стробированной громкости (по стандарту ITU). Если поле loudrelgate задается равным 1, 7-битовое поле ituloudrelgat должно идти далее в рабочих данных; loudrelgat: 7-битовое поле, которое указывает относительную стробированную громкость программы (ITU). Это поле указывает интегрированную громкость аудиопрограммы, измеренной согласно ITU-R BS.1770-2 без регулировок усиления вследствие применения диалнормы и сжатия динамического диапазона. Значения от 0 до 127 интерпретируются в качестве от -58 LKFS до +5,5 LKFS с приращением в 0,5 LKFS; loudspchgate: однобитовое поле, которое указывает то, существуют или нет данные стробированной речью громкости (по стандарту ITU). Если поле loudspchgate задается равным 1, 7-битовое поле loudspchgat должно идти далее в рабочих данных; loudspchgat: 7-битовое поле, которое указывает стробированную речью громкость программы. Это поле указывает интегрированную громкость всей соответствующей аудиопрограммы, измеренной согласно формуле (2) ITU-R BS.1770-3 и без регулировок усиления вследствие применения диалнормы и сжатия динамического диапазона. Значения от 0 до 127 интерпретируются в качестве от -58 до +5,5 LKFS с приращением в 0,5 LKFS; loudstrm3se: однобитовое поле, которое указывает то, существуют или нет данные кратковременной (3-секундной) громкости. Если поле задается равным 1, 7-битовое поле loudstrm3s должно идти далее в рабочих данных; loudstrm3s: 7-битовое поле, которое указывает нестробированную громкость предшествующих 3 секунд соответствующей аудиопрограммы, измеренную согласно ITU-R BS.1771-1 и без регулировок усиления вследствие применения диалнормы и сжатия динамического диапазона. Значения от 0 до 256 интерпретируются в качестве от -116 LKFS до +11,5 LKFS с приращением в 0,5 LKFS; truepke: однобитовое поле, которое указывает то, существуют или нет данные истинной пиковой громкости. Если поле truepke задается равным 1, 8-битовое поле truepk должно идти далее в рабочих данных; и truepk: 8-битовое поле, которое указывает истинное пиковое выборочное значение программы, измеренное согласно приложению 2 из ITU-R BS.1770-3 и без регулировок усиления вследствие применения диалнормы и сжатия динамического диапазона. Значения от 0 до 256 интерпретируются как от -116 LKFS до +11,5 LKFS с приращением в 0,5 LKFS.
[0094] В некоторых вариантах осуществления, базовый элемент сегмента метаданных в поле auxdata (или поле addbsi) кадра AC-3-потока битов или E-AC-3-потока битов содержит базовый заголовок (необязательно включающий в себя идентификационные значения, например, версию базового элемента) и после базового заголовка: значения, указывающие то, включены или нет данные контрольной суммы (или другие защитные значения) для метаданных сегмента метаданных, значения, указывающие то, существуют или нет внешние данные (связанные с аудиоданными, соответствующими метаданным сегмента метаданных), значения идентификатора рабочих данных и размера рабочих данных для каждого типа метаданных (например, LPSM и/или метаданных типа, отличного от LPSM), идентифицированного посредством базового элемента, и защитные значения, по меньшей мере, для одного типа метаданных, идентифицированных посредством базового элемента. Рабочие данные метаданных сегмента метаданных идут после базового заголовка и (в некоторых случаях) вкладываются внутрь значений базового элемента.
Оптимизированная система регулирования громкости и динамического диапазона
[0095] Схема защищенного кодирования и транспортировки метаданных, описанная выше, используется в сочетании с масштабируемой и наращиваемой системой для оптимизации громкости и динамического диапазона через различные устройства, приложения для воспроизведения и окружения прослушивания, к примеру, как проиллюстрировано на фиг. 1. В варианте осуществления, система 10 выполнена с возможностью нормализовать уровни громкости и динамический диапазон входного аудио 11 через различные устройства, которые требуют различных целевых значений громкости и имеют отличающиеся характеристики динамического диапазона. Чтобы нормализовать уровни громкости и динамический диапазон, система 10 включает в себя различные профили устройств с аудиоконтентом, и нормализация выполняется на основе этих профилей. Профили могут быть включены посредством одного из аудиопроцессоров в цепочки аудиообработки, и включенные профили могут использоваться посредством нижележащего процессора в цепочке аудиообработки для того, чтобы определять требуемую целевую громкость и динамический диапазон для целевого устройства. Дополнительные компоненты обработки могут предоставлять или обрабатывать информацию для управления профилями устройств (включающими в себя (но не только) следующие параметры: диапазон нулевых полос частот, истинное пиковое пороговое значение, диапазон громкости, небольшую/большую постоянную времени (коэффициенты) и максимальное усиление), функции регулировки усиления и формирования широкополосного и/или многополосного усиления.
[0096] Фиг. 10 иллюстрирует более подробную схему системы по фиг 1 для системы, которая предоставляет оптимизированное управление громкостью и динамическим диапазоном в некоторых вариантах осуществления. Для системы 321 по фиг. 10, каскад кодера содержит компонент 304 базового кодера, который кодирует аудиоввод 303 в подходящем цифровом формате для передачи в декодер 312. Аудио обрабатывается таким образом, что оно может воспроизводиться во множестве различных окружений прослушивания, каждое из которых может требовать различных целевых настроек громкости и/или динамического диапазона. Таким образом, как показано на фиг. 10, декодер выводит цифровой сигнал, который преобразуется в аналоговый формат посредством цифро-аналогового преобразователя 316 для воспроизведения через множество различных типов головок громкоговорителя, включающих в себя полнодиапазонные динамики 320, миниатюрные динамики 322 и наушники 324. Эти головки громкоговорителя иллюстрируют просто некоторые примеры возможных головок громкоговорителя для воспроизведения, и может использоваться любой электроакустический преобразователь или головка громкоговорителя любого надлежащего размера и типа. Помимо этого, головки 320-324 громкоговорителя/электроакустические преобразователи по фиг. 10 могут быть осуществлены в любом надлежащем устройстве воспроизведения для использования в любом соответствующем окружении прослушивания. Типы устройств могут включать в себя, например, AVR, телевизионные приемники, стереофоническую аппаратуру, компьютеры, мобильные телефоны, планшетные компьютеры, MP3-проигрыватели и т.д.; и окружения прослушивания могут включать в себя, например, аудитории, дома, автомобили, кабинки для прослушивания и т.д.
[0097] Поскольку диапазон окружений воспроизведения и типов головок громкоговорителя может варьироваться от очень небольших частных контекстов до очень больших общедоступных концертных площадок, охват возможных и оптимальных конфигураций громкости и динамического диапазона воспроизведения может варьироваться значительно в зависимости от типа контента, уровней фонового шума и т.п. Например, в окружении домашнего кинотеатра, контент с широким динамическим диапазоном может воспроизводиться через оборудование для обеспечения объемного звука, и контент с более узким динамическим диапазоном может воспроизводиться через обычную телевизионную систему (к примеру, плоскопанельную светодиодную/жидкокристаллическую), в то время как режим с очень узким динамическим диапазоном может использоваться для определенных условий прослушивания (например, ночью или на устройстве с серьезными ограничениями по акустической выходной мощности, например, на внутренних динамиках или на выходе для наушников мобильного телефона/планшетного компьютера), когда большие изменения уровня не требуются. В портативных или мобильных контекстах прослушивания, к примеру, с использованием небольших компьютерных или пристыковываемых наушников или наушников, наушников-вкладышей, оптимальный динамический диапазон воспроизведения может варьироваться в зависимости от окружения. Например, в тихом окружении оптимальный динамический диапазон может быть большим по сравнению с зашумленным окружением. Варианты осуществления адаптивной системы аудиообработки по фиг. 10 должны варьировать динамический диапазон, чтобы осуществлять рендеринг аудиоконтента как более интеллектуальный в зависимости от параметров, таких как устройства прослушивания и тип устройства воспроизведения.
[0098] Фиг. 11 является таблицей, которая иллюстрирует различные требования по динамическому диапазону для множества устройств воспроизведения и фоновых окружений прослушивания в примерном случае использования. Аналогичные требования могут извлекаться для громкости. Различные требования по динамическому диапазону и громкости формируют различные профили, которые используются посредством системы 321 оптимизации.
Система 321 включает в себя компонент 302 измерения громкости и динамического диапазона, который анализирует и измеряет громкость и динамический диапазон входного аудио. В варианте осуществления, система анализирует общий контент программы, чтобы определять общий параметр громкости. В этом контексте, громкость означает долговременную громкость программы или среднюю громкость программы, в которой программа является одной единицей аудиоконтента, такой как контент фильмов, телешоу, коммерческих или аналогичных программ. Громкость используется для того, чтобы предоставлять индикатор относительно профиля художественного динамического диапазона, который используется посредством создателей контента, чтобы управлять тем, как должно воспроизводиться аудио. Громкость связана со значением метаданных диалнормы таким образом, что диалнорма представляет среднюю громкость диалога одной программы (например, фильма, шоу, коммерческой программы и т.д.). Кратковременный динамический диапазон количественно определяет изменения в сигналах за гораздо меньший период времени, чем громкость программы. Например, кратковременный динамический диапазон может измеряться в порядке секунд, тогда как громкость программы может измеряться за интервал в минуты или даже часы. Кратковременный динамический диапазон предоставляет механизм защиты, который является независимым от громкости программы, чтобы обеспечивать то, что перегрузка не возникает для различных профилей воспроизведения и типов устройств. В варианте осуществления, целевой показатель громкости (долговременной громкости программы) основан на громкости диалога, и кратковременный динамический диапазон основан на относительной стробированной и/или нестробированной громкости. В этом случае, определенные DRC-компоненты и компоненты громкости в системе являются контекстно-зависимыми относительно типа контента и/или типов и характеристик целевых устройств. В качестве части этой поддержки контекстно-зависимого режима система выполнена с возможностью анализировать одну или более характеристик устройства вывода, чтобы определять то, представляет собой устройство или нет элемент конкретных групп устройств, которые оптимизированы для определенных условий воспроизведения на основе DRC и громкости, таких как AVR-устройства, телевизионные приемники, компьютеры, портативные устройства и т.д.
[0099] Компонент предварительной обработки анализирует контент программы, чтобы определять громкость, пики, истинные пики и периоды молчания, чтобы создавать уникальные метаданные для каждого профиля из множества различных профилей. В варианте осуществления, громкость может представлять собой стробированную диалогом громкость и/или относительную стробированную громкость. Различные профили задают различные режимы DRC (управление динамическим диапазоном) и целевой громкости, в которых различные значения усиления формируются в кодере в зависимости от характеристик исходного аудиоконтента, требуемой целевой громкости и типа и/или окружения устройства воспроизведения. Декодер может предлагать различные DRC-режимы и целевые режимы громкости (предоставляемые посредством профилей, на которые ссылаются выше) и может включать в себя режим с отключением/деактивацией DRC и целевой громкости, который предоставляет возможность перечня в полном динамическом диапазоне без сжатия аудиосигнала и нормализации громкости, линейный режим с отключением/деактивацией DRC и нормализацией громкости с целевым показателем -31 LKFS для воспроизведения на системах домашнего кинотеатра, который обеспечивает умеренное сжатие динамического диапазона через сформированные значения усиления (в частности, для этого режима воспроизведения и/или профиля устройства) в кодере с нормализацией громкости с целевым показателем -31 LKFS; RF-режим для воспроизведения через телевизионные динамики, которое предоставляет существенную величину сжатия динамического диапазона с нормализацией громкости с целевым показателем в -24, -23 или -20 LKFS, промежуточный режим для воспроизведения на компьютерах или аналогичных устройствах, который предоставляет сжатие с нормализацией громкости при целевом показателе в -14 LKFS, и портативный режим, который предоставляет очень существенное сжатие динамического диапазона с целевым показателем нормализации громкости в -11 LKFS. Целевые значения громкости в -31, -23/-20, -14 и -11 LKFS служат в качестве примеров различных профилей устройств воспроизведения, которые могут задаваться для системы в некоторых вариантах осуществления, и любые другие надлежащие целевые значения громкости могут использоваться, и система формирует надлежащие значения усиления специально для этих режимов воспроизведения и/или профиля устройства.
Кроме того, система является наращиваемой и адаптируемой, так что различные устройства воспроизведения и окружения прослушивания могут приспосабливаться посредством задания нового профиля в кодере или в другом месте и загружаться в кодер. Таким образом, новые и уникальные профили устройств воспроизведения могут формироваться, чтобы поддерживать улучшенные или различные устройства воспроизведения для будущих вариантов применения.
[00100] В варианте осуществления, значения усиления могут вычисляться в любом надлежащем компоненте обработки системы 321, к примеру, в кодере 304, декодере 312 или транскодере 308, или любом ассоциированном компоненте предварительной обработки, ассоциированном с кодером, или в любом компоненте постобработки, ассоциированном с декодером.
[00101] Фиг. 13 является блок-схемой, иллюстрирующей интерфейс между различными профилями для множества различных классов устройств воспроизведения в варианте осуществления. Как показано на фиг. 13, кодер 502 принимает аудиоввод 501 и один из нескольких различных возможных профилей 506. Кодер комбинирует аудиоданные с выбранным профилем, чтобы формировать файл выходного потока битов, который обрабатывается в компонентах декодера, присутствующих или ассоциированных с целевым устройством воспроизведения. Для примера по фиг. 13, различные устройства воспроизведения могут представлять собой компьютер 510, мобильный телефон 512, AVR 514 и телевизионный приемник 516, хотя множество других устройств вывода также являются возможными. Каждое из устройств 510-516 включает в себя или соединяется с динамиками (включающими в себя головки громкоговорителя и/или электроакустические преобразователи), такими как головки 320-324 громкоговорителя. Комбинация обработки, номинальных мощностей и размеров устройств воспроизведения и ассоциированных динамиков, в общем, предписывает то, какой профиль является самым оптимальным для этого конкретного целевого показателя. Таким образом, профили 506 могут быть специально заданы для воспроизведения через AVR, телевизоры, мобильные динамики, мобильные наушники и т.д. Они также могут задаваться для конкретных рабочих режимов или состояний, таких как тихий режим, ночной режим, вне помещений, в помещениях и т.д. Профили, показанные на фиг. 13, представляют собой только примерные режимы, и может задаваться любой надлежащий профиль, включающий в себя пользовательские профили для конкретных целевых показателей и окружений.
[00102] Хотя фиг. 13 иллюстрирует вариант осуществления, в котором кодер 502 принимает профили 506 и формирует надлежащие параметры для обработки громкости и DRC-обработки, следует отметить, что параметры, сформированные на основе профиля и аудиоконтента, могут выполняться для любого надлежащего аудиопроцессора, такого как кодер, декодер, транскодер, препроцессор, постпроцессор и т.д. Например, каждое устройство 510-516 вывода по фиг. 13 имеет или соединяется с компонентом декодера, который обрабатывает метаданные в потоке битов в файле 504, отправленном из кодера 502, чтобы предоставлять возможность адаптации громкости и динамического диапазона таким образом, что она совпадает с устройством или типом устройства для целевого устройства вывода.
[00103] В варианте осуществления, динамический диапазон и громкость аудиоконтента оптимизированы для каждого возможного устройства воспроизведения. Это достигается посредством поддержания долговременной громкости равной целевому значению и управления кратковременным динамическим диапазоном таким образом, чтобы оптимизировать звуковое восприятие (посредством управления динамикой, пиками выборок и/или истинными пиками сигналов) для каждого из целевых режимов воспроизведения. Различные элементы метаданных задаются для долговременной громкости и кратковременного динамического диапазона. Как показано на фиг. 10, компонент 302 анализирует весь входной аудиосигнал (или его части, такие как речевой компонент, если применимо), чтобы извлекать релевантные характеристики для обоих из этих отдельных DR-компонентов. Это дает возможность задания различных значений усиления для художественных усилений по сравнению с усеченными значениями усиления (для защиты от перегрузок).
[00104] Эти значения усиления для долговременной громкости и кратковременного динамического диапазона затем преобразуются в профиль 305, чтобы формировать параметры, описывающие значения усиления системы управления громкостью и динамическим диапазоном. Эти параметры комбинированы с кодированным аудиосигналом из кодера 304 в мультиплексоре 306 или аналогичном компоненте для создания потока битов, который передается через транскодер 308 в каскад декодера. Поток битов, вводимый в каскад декодера, демультиплексируется в демультиплексоре 310. Он затем декодируется в декодере 312. Компонент 314 усиления применяет усиления, соответствующие надлежащему профилю, чтобы формировать цифровые аудиоданные, которые затем обрабатываются через DACS-узел 416 для воспроизведения через надлежащие устройства воспроизведения и головки 320-324 громкоговорителя или электроакустические преобразователи.
[00105] Фиг. 14 является таблицей, которая иллюстрирует корреляцию между долговременной громкостью и кратковременным динамическим диапазоном для множества заданных профилей в варианте осуществления. Как показано в таблице 4 по фиг. 14, каждый профиль содержит набор значений усиления, которые предписывают величину сжатия динамического диапазона (DRC), применяемого в декодере системы или в каждом целевом устройстве. Каждые из N профилей, обозначаемых как профили 1-Ν, задают конкретные параметры долговременной громкости (например, диалнорму) и параметры сжатия для защиты от перегрузки посредством предписания соответствующих значений усиления, применяемых в каскаде декодера. Значения DRC-усиления для профилей могут задаваться посредством внешнего источника, который принят посредством кодера, или они могут формироваться внутренне в кодере в качестве значений усиления по умолчанию, если внешние значения не предоставляются.
[00106] В варианте осуществления, значения усиления для каждого профиля осуществлены в словах DRC-усиления, которые вычисляются на основе анализа определенных характеристик аудиосигнала, таких как пиковая, истинная пиковая, кратковременная громкость диалога или общая кратковременная громкость, либо в комбинации (гибридная схема) означенного, чтобы вычислять статические усиления на основе выбранного профиля (т.е. характеристики или кривой передачи), а также постоянные времени, необходимые для реализации быстрой/медленной атаки и быстрого/медленного высвобождения конечных DRC-усилений для каждого возможного профиля устройства и/или целевой громкости. Как указано выше, эти профили могут быть предварительно установлены в кодере, декодере или сформированы внешне и перенесены в кодер через внешние метаданные от создателя контента.
[00107] В варианте осуществления, значения усиления могут представлять собой широкополосное усиление, которое применяет идентичное усиление по всем частотам аудиоконтента. Альтернативно, усиление может состоять из значений многополосного усиления, так что различные значения усиления применяются к различным частотам или полосам частот аудиоконтента. В многоканальном случае, каждый профиль может составлять матрицу значений усиления, указывающих усиления для различных полос частот вместо одного значения усиления.
[00108] Со ссылкой на фиг. 10, в варианте осуществления, информация относительно свойств или характеристик окружения прослушивания и/или характеристик и конфигураций устройств воспроизведения предоставляется посредством каскада декодера в каскад кодера посредством линии 330 обратной связи. Информация 332 профиля также вводится в кодер 304. В варианте осуществления, декодер анализирует метаданные в потоке битов, чтобы определять то, доступен или нет параметр громкости для первой группы устройств воспроизведения аудио в потоке битов. Если да, он передает параметры в нисходящем направлении для использования при рендеринге аудио. В противном случае, кодер анализирует определенные характеристики устройств для того, чтобы извлекать параметры. Эти параметры затем отправляются в нижележащий компонент рендеринга для воспроизведения. Кодер также определяет устройство вывода (или группу устройств вывода, включающую в себя устройство вывода), которое должно осуществлять рендеринг принимаемого аудиопотока. Например, устройство вывода может определяться как сотовый телефон или принадлежащий такой группе, как портативные устройства. В варианте осуществления, декодер использует линию 330 обратной связи, чтобы указывать кодеру определенное устройство вывода или группу устройств вывода. Для этой обратной связи модуль, соединенный с устройством вывода (например, модуль в звуковой карте, соединенный с гарнитурой или соединенный с динамиками в переносном компьютере), может указывать декодеру идентификационные данные устройства вывода или идентификационные данные группы устройств, которая включает в себя устройство вывода. Декодер передает эту информацию в кодер через линию 330 обратной связи. В варианте осуществления, декодер выполняет, декодер определяет параметры громкости и DRC-параметры. В варианте осуществления, декодер определяет параметры громкости и DRC-параметры. В этом варианте осуществления, вместо передачи информации по линии 330 обратной связи, декодер использует информацию относительно определенного устройства или группы устройств вывода, чтобы определять параметры громкости и DRC-параметры. В другом варианте осуществления, другой аудиопроцессор определяет параметры громкости и DRC-параметры, и декодер передает информацию в этот аудиопроцессор вместо декодера.
[00109] Фиг. 12 является блок-схемой системы оптимизации динамического диапазона в варианте осуществления. Как показано на фиг. 12, кодер 402 принимает входное аудио 401. Кодированное аудио комбинировано в мультиплексоре 409 с параметрами 404, сформированными из выбранной кривой 422 сжатия и значения 424 диалнормы. Результирующий поток битов передается в демультиплексор 411, который формирует аудиосигналы, которые декодируются посредством декодера 406. Параметры и значения диалнормы используются посредством узла 408 вычисления усиления, чтобы формировать уровни усиления, которые возбуждают усилитель 410 для усиления вывода декодера. Фиг. 12 иллюстрирует, как управление динамическим диапазоном параметризовано и вставлено в поток битов. Громкость также может быть параметризована и вставлена в поток битов с использованием аналогичных компонентов. В варианте осуществления, управление выходным опорным уровнем (не показано) также может предоставляться в декодере. Хотя чертеж иллюстрирует параметры громкости и динамического диапазона как определенные и вставленные в кодере, аналогичное определение может выполняться в других аудиопроцессорах, таких как препроцессор, декодер и постпроцессор.
[00110] Фиг. 15 иллюстрирует примеры профилей громкости для различных типов аудиоконтента в варианте осуществления. Как показано на фиг. 15, примерные кривые 600 и 602 графически показывают входную громкость (в LKFS) в зависимости от усиления, центрированного приблизительно вокруг 0 LKFS. Различные типы контента демонстрируют различные кривые, как показано на фиг. 15, на котором кривая 600 может представлять речь, а кривая 602 может представлять стандартный киноконтент. Как показано на фиг. 15, речевой контент подвергается большему коэффициенту усиления относительно киноконтента. Фиг. 15 служит в качестве примера характерных кривых профиля для определенных типов аудиоконтента, и также могут использоваться другие кривые профиля. Конкретные аспекты характеристик профиля, к примеру, как показано на фиг. 15, используются для того, чтобы извлекать релевантные параметры для системы оптимизации. В варианте осуществления, эти параметры включают в себя: нулевую полосу пропускания, коэффициент обрезания, коэффициент усиления, максимальное усиление, FS-атаку, FS-затухание, удержание, пиковый предел и громкость целевого уровня. Другие параметры могут использоваться помимо этого или альтернативно, по меньшей мере, для некоторых из этих параметров в зависимости от требований к приложениям и системных ограничений.
[00111] Фиг. 16 является блок-схемой последовательности операций способа, которая иллюстрирует способ оптимизации громкости и динамического диапазона через устройства и приложения для воспроизведения в варианте осуществления. Хотя чертеж иллюстрирует оптимизацию громкости и динамического диапазона как выполняемую в кодере, аналогичная оптимизация может выполняться в других аудиопроцессорах, таких как препроцессор, декодер и постпроцессор. Как показано в процессе 620, способ начинается с приема входного сигнала посредством каскада кодера из источника (603). Кодер или компонент предварительной обработки затем определяет то, подвергнут или нет исходный сигнал процессу, который достигает целевой громкости и/или динамического диапазона (604). Целевая громкость соответствует долговременной громкости и может задаваться внешне или внутренне. Если исходный сигнал не подвергнут процессу для того, чтобы достигать целевой громкости и/или динамического диапазона, система выполняет надлежащую операцию управления громкостью и/или динамическим диапазоном (608); в противном случае, если исходный сигнал подвергнут этой операции управления громкостью и/или динамическим диапазоном, система переходит к обходному режиму, чтобы пропускать операции управления громкостью и/или динамическим диапазоном таким образом, чтобы давать возможность исходному процессу предписывать надлежащую долговременную громкость и/или динамический диапазон (606). Надлежащие значения усиления для обходного режима (606) или для режима выполнения (606) (которые могут представлять собой одиночные значения широкополосного усиления или частотно-зависимые значения многополосного усиления) затем применяются в декодере (612).
Формат потока битов
[00112] Как указано выше, система для оптимизации громкости и динамического диапазона использует защищенный наращиваемый формат метаданных, чтобы обеспечивать то, что метаданные и аудиоконтент, передаваемые в потоке битов между кодером и декодером либо между источником и рендерингом/устройствами воспроизведения, не отделены друг от друга или иным образом повреждены в ходе передачи по сетям или по другому собственному оборудованию, такому как интерфейсы поставщиков услуг и т.д. Этот поток битов предоставляет механизм для передачи в служебных сигналах в кодер и/или декодер компонентов для того, чтобы адаптировать громкость и динамический диапазон аудиосигнала, которые удовлетворяют аудиоконтенту и характеристикам устройства вывода, через надлежащую информацию профиля. В варианте осуществления, система выполнена с возможностью определять кодированный поток битов с низкой скоростью передачи битов, который должен передаваться между кодером и декодером, и информация громкости, кодированная через метаданные, содержит характеристики для одного или более выходных профилей. Далее приводится описание формата потока битов для использования с системой оптимизации громкости и динамического диапазона в варианте осуществления.
[00113] Кодированный AC-3-поток битов содержит метаданные и один-шесть каналов аудиоконтента. Аудиоконтент представляют собой аудиоданные, которые сжаты с использованием перцепционного кодирования аудио. Метаданные включают в себя несколько параметров аудиометаданных, которые предназначены для использования при изменении при изменении звука программы, доставляемой в окружение прослушивания. Каждый кадр кодированного AC-3-потока аудиобитов содержит аудиоконтент и метаданные для 1536 выборок цифрового аудио. Для частоты дискретизации в 48 кГц это представляет 32 миллисекунды цифрового аудио или скорость в 31,25 кадров в секунду аудио.
[00114] Каждый кадр кодированного E-AC-3-потока аудиобитов содержит аудиоконтент и метаданные для 256, 512, 768 или 1536 выборок цифрового аудио, в зависимости от того, содержит кадр один, два, три или шесть блоков аудиоданных, соответственно. Для частоты дискретизации в 48 кГц это представляет 5,333, 10,667, 16 или 32 миллисекунды цифрового аудио, соответственно, или скорости в 189,9, 93,75, 62,5 или 31,25 кадра в секунду аудио, соответственно.
[00115] Как указано на фиг. 4, каждый AC-3-кадр разделен на секции (сегменты), включающие в себя: секцию информации синхронизации (SI), которая содержит (как показано на фиг. 5) синхрослово (SW) и первое из двух слов коррекции ошибок (CRC1); секцию информации потока битов (BSI), которая содержит большинство метаданных; шесть аудиоблоков (AB0-AB5), которые содержат сжатый аудиоконтент данных (и также могут включать в себя метаданные); ненужные биты (W), которые содержат все неиспользуемые биты, остающиеся после аудиоконтента; секцию вспомогательной (AUX) информации, которая может содержать больше метаданных; и второе из двух слов коррекции ошибок (CRC2).
[00116] Как указано на фиг. 7, каждый E-AC-3-кадр разделен на секции (сегменты), включающие в себя: секцию информации синхронизации (SI), которая содержит (как показано на фиг. 5) синхрослово (SW); секцию информации потока битов (BSI), которая содержит большинство метаданных; между одним и шестью аудиоблоками (AB0-AB5), которые содержат сжатый аудиоконтент данных (и также могут включать в себя метаданные); ненужные биты (W), которые содержат все неиспользуемые биты, остающиеся после аудиоконтента; секцию вспомогательной (AUX) информации, которая может содержать больше метаданных; и слово коррекции ошибок (CRC).
[00117] В AC-3-(или E-AC-3-)потоке битов предусмотрено несколько параметров аудиометаданных, которые специально предназначены для использования при изменении звука программы, доставляемой в окружение прослушивания. Один из параметров метаданных представляет собой параметр диалнормы, который включен в BSI-сегмент.
[00118] Как показано на фиг. 6, BSI-сегмент AC-3-кадра включает в себя пятибитовый параметр ("dialnorm"), указывающий значение диалнормы для программы. Пятибитовый параметр ("dialnorm2"), указывающий значение диалнормы для второй аудиопрограммы, переносимой в идентичном AC-3-кадре, включен, если режим кодирования аудио ("acmod") AC-3-кадра равен 0, что указывает то, что используется сдвоенная моно- или "1+1"-канальная конфигурация.
[00119] BSI-сегмент также включает в себя флаг ("addbsie"), указывающий присутствие (или отсутствие) дополнительной информации потока битов, идущей после бита addbsie, параметр (addbsil), указывающий длину любой дополнительной информации потока битов, идущего после значения addbsil, и до 64 битов дополнительной информации потока битов (addbsi), идущей после значения addbsil. BSI-сегмент может включать в себя другие значения метаданных, не показанные конкретно на фиг. 6.
[00120] Аспекты одного или более вариантов осуществления, описанных в данном документе, могут реализовываться в аудиосистеме, которая обрабатывает аудиосигналы для передачи по сети, которая включает в себя один или более компьютеров или устройств обработки, выполняющих программные инструкции. Любой из описанных вариантов осуществления может использоваться автономно или совместно друг с другом в любой комбинации. Хотя различные варианты осуществления, возможно, обусловлены посредством различных недостатков предшествующего уровня техники, которые могут быть пояснены или упомянуты в одном или более мест в этом подробном описании, варианты осуществления не обязательно разрешают все эти недостатки. Другими словами, различные варианты осуществления могут разрешать различные недостатки, которые могут быть пояснены в подробном описании. Некоторые варианты осуществления могут только частично разрешать некоторые недостатки или только один недостаток, который может быть пояснен в подробном описании, и некоторые варианты осуществления не могут разрешать ни один из этих недостатков.
[00121] Аспекты систем, описанных в данном документе, могут реализовываться в надлежащем компьютерном сетевом окружении звуковой обработки для обработки цифровых или оцифрованных аудиофайлов. Части адаптивной аудиосистемы могут включать в себя одну или более сетей, которые содержат любое требуемое число отдельных машин, включающих в себя один или более маршрутизаторов (не показаны), которые служат для того, чтобы буферизовать и маршрутизировать данные, передаваемые между компьютерами. Эта сеть может быть основана на различных специальных сетевых протоколах и может представлять собой Интернет, глобальную вычислительную сеть (WAN), локальную вычислительную сеть (LAN) или любую комбинацию вышеозначенного.
[00122] Один или более компонентов, блоков, процессов или других функциональных компонентов могут реализовываться через компьютерную программу, которая управляет выполнением процессорного вычислительного устройства системы. Также следует отметить, что различные функции, раскрытые в данном документе, могут описываться с использованием любого числа комбинаций аппаратных средств, микропрограммного обеспечения и/или в качестве данных и/или инструкций, осуществленных на различных машиночитаемых или компьютерно-читаемых носителях, с точки зрения их поведенческих, межрегистровых пересылок, логических компонентов и/или других характеристик. Компьютерно-читаемые носители, на которых могут быть осуществлены такие отформатированные данные и/или инструкции, включают в себя, но не только, физические (энергонезависимые), энергонезависимые носители хранения данных в различных формах, такие как оптические, магнитные или полупроводниковые носители хранения данных.
[00123] Если контекст в явной форме не требует иного, во всем описании и в формуле изобретения слова "содержит", "содержащий" и т.п. должны быть истолкованы во включающем, в отличие от исключающего или исчерпывающего смысла; т.е. в смысле "включает в себя, но не только". Слова с использованием единственного или множественного числа также включают в себя множественное или единственное число, соответственно. Дополнительно, слова "в данном документе", "по настоящему документу", "выше", "ниже" и слова аналогичного смысла относятся к данной заявке в целом, а не к каким-либо конкретным частям этой заявки. Когда слово "или" используется в отношении списка из двух или более элементов, это слово охватывает все следующие интерпретации слова: любой из элементов в списке, все элементы в списке и любая комбинация элементов в списке.
[00124] Хотя одна или более реализаций описаны в качестве примера и с точки зрения конкретных вариантов осуществления, следует понимать, что одна или более реализаций не ограничены раскрытыми вариантами осуществления. Наоборот, они имеют намерение охватывать различные модификации и аналогичные компоновки, как должно быть очевидным для специалистов в данной области техники.
Следовательно, объем прилагаемой формулы изобретения должен соответствовать самой широкой интерпретации, так что он охватывает все такие модификации и аналогичные компоновки.
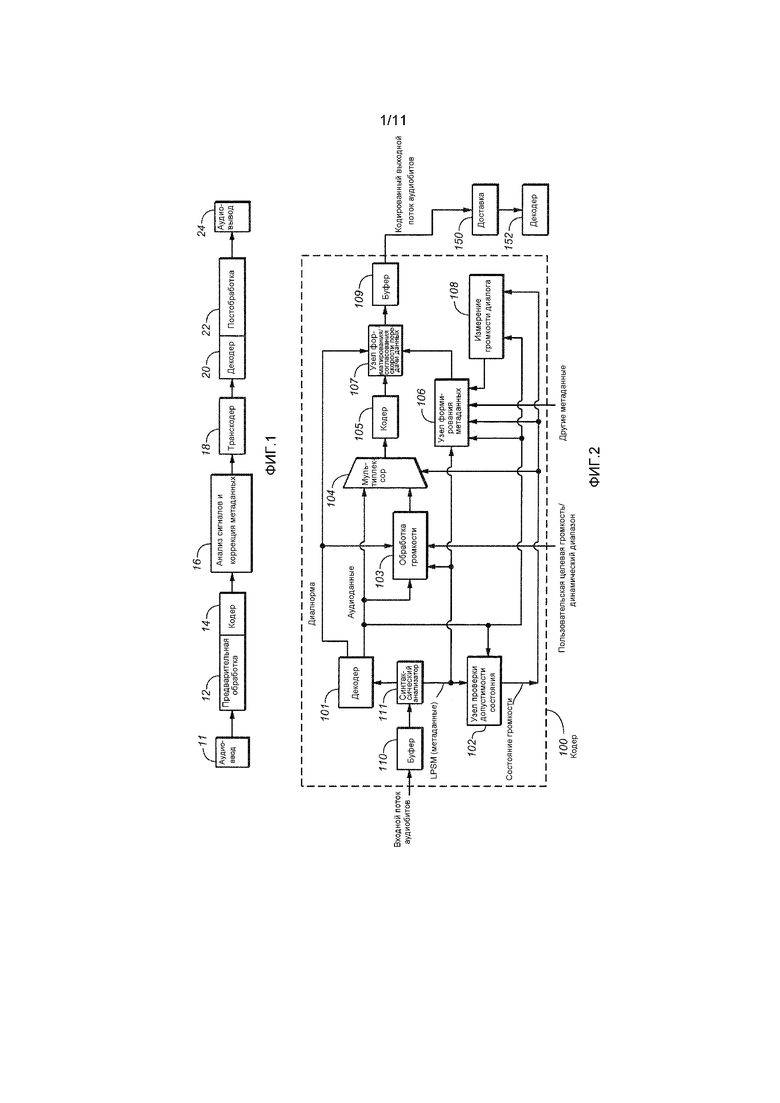
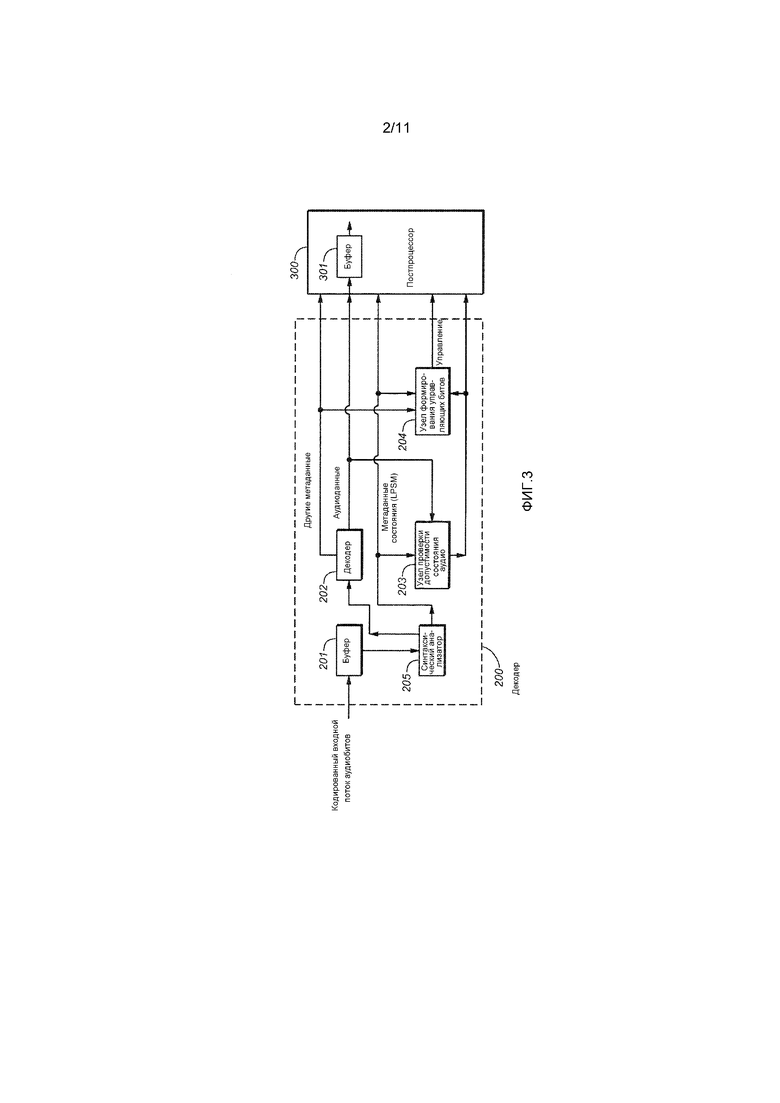
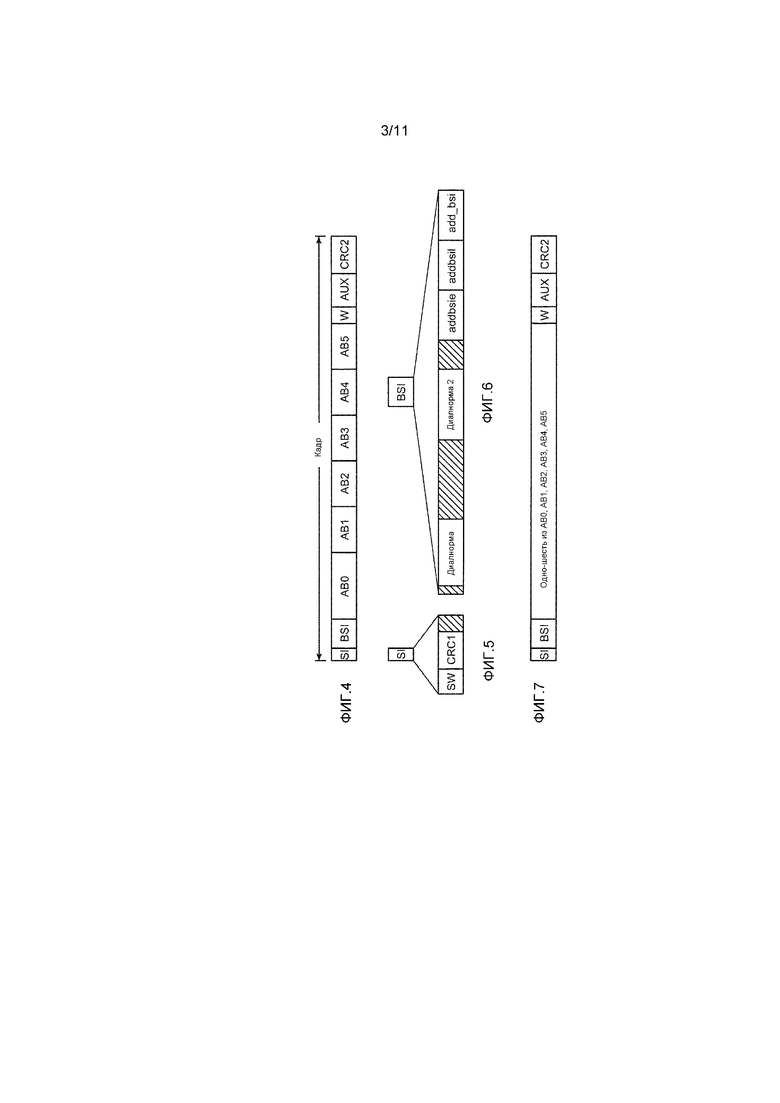
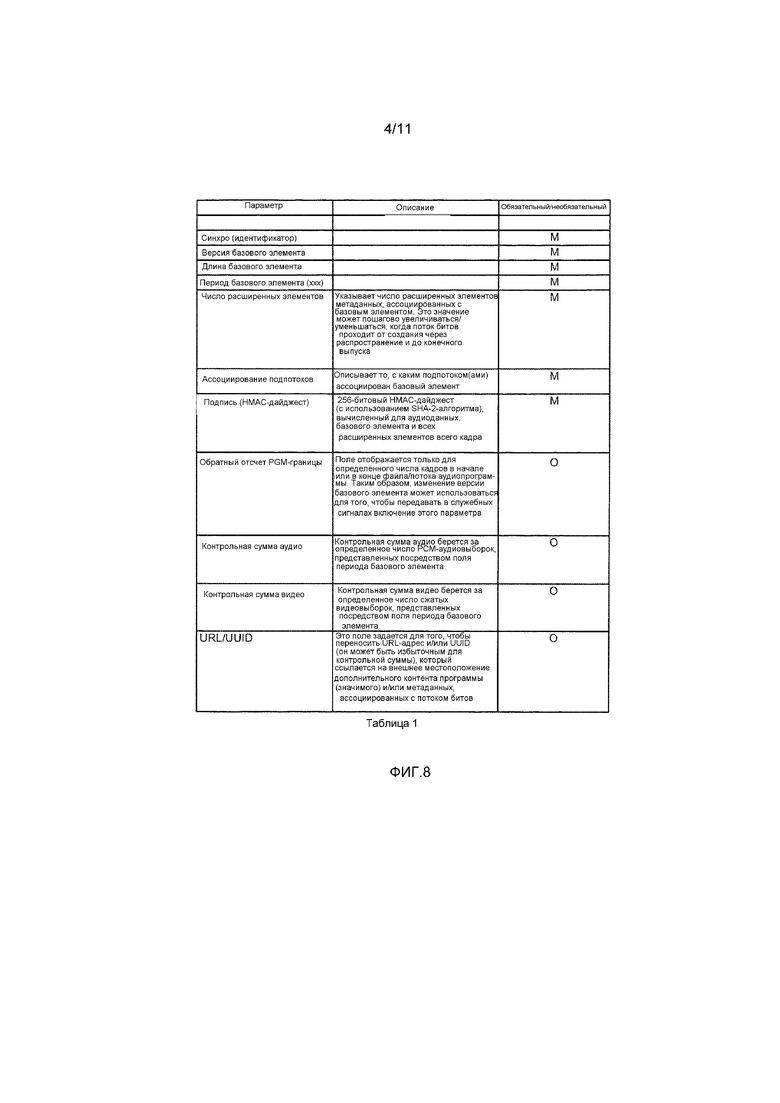
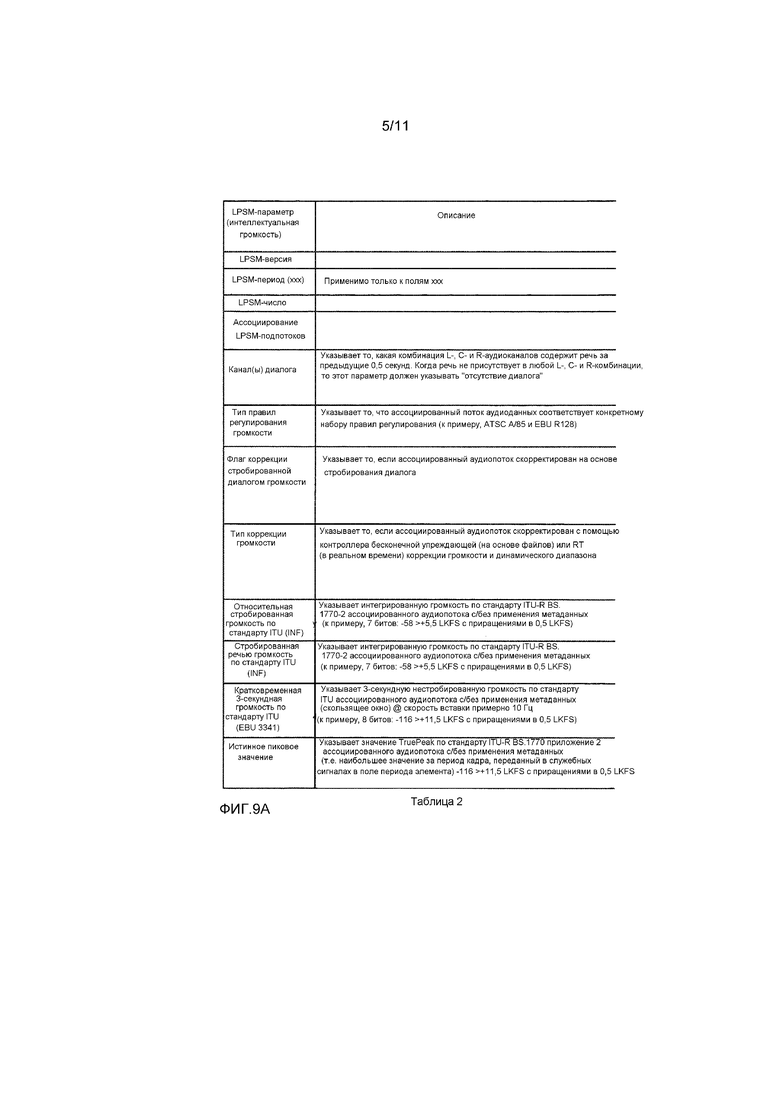
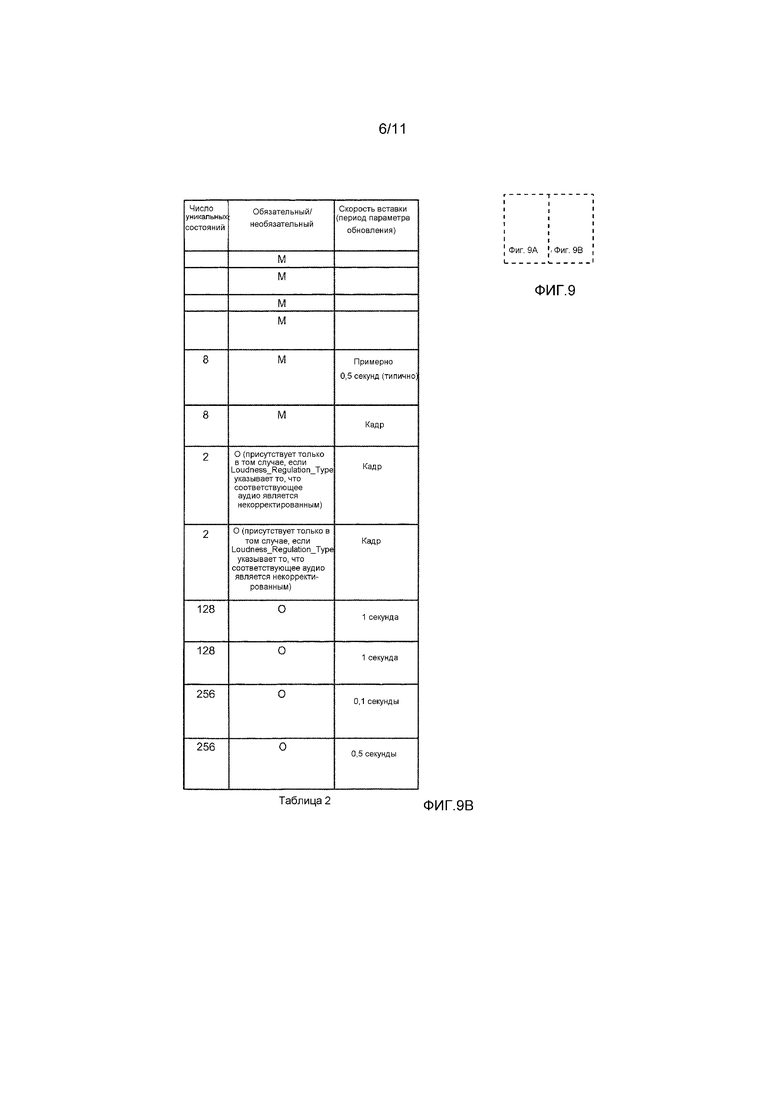
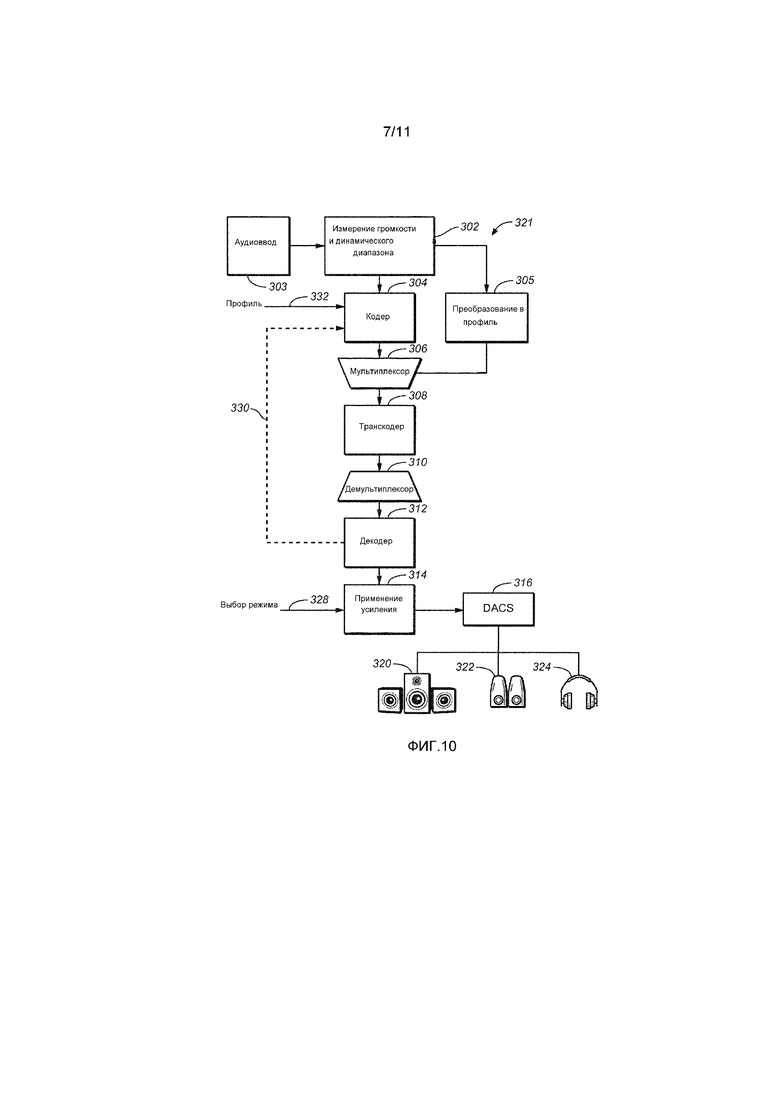
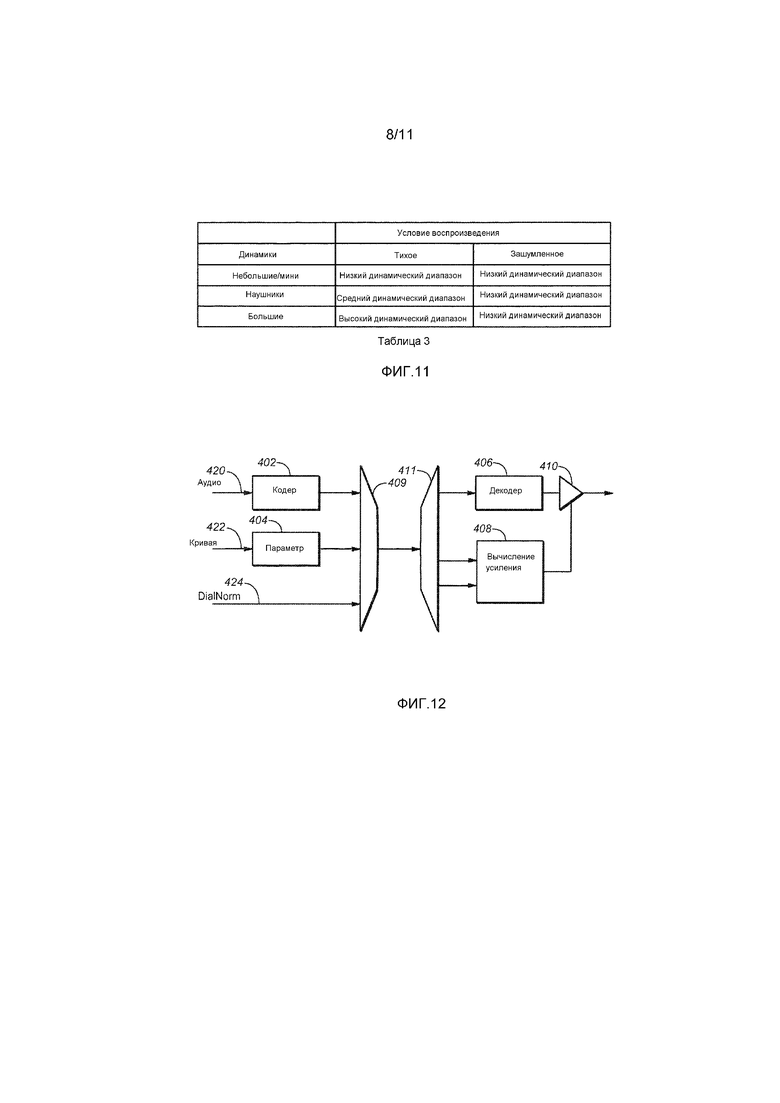
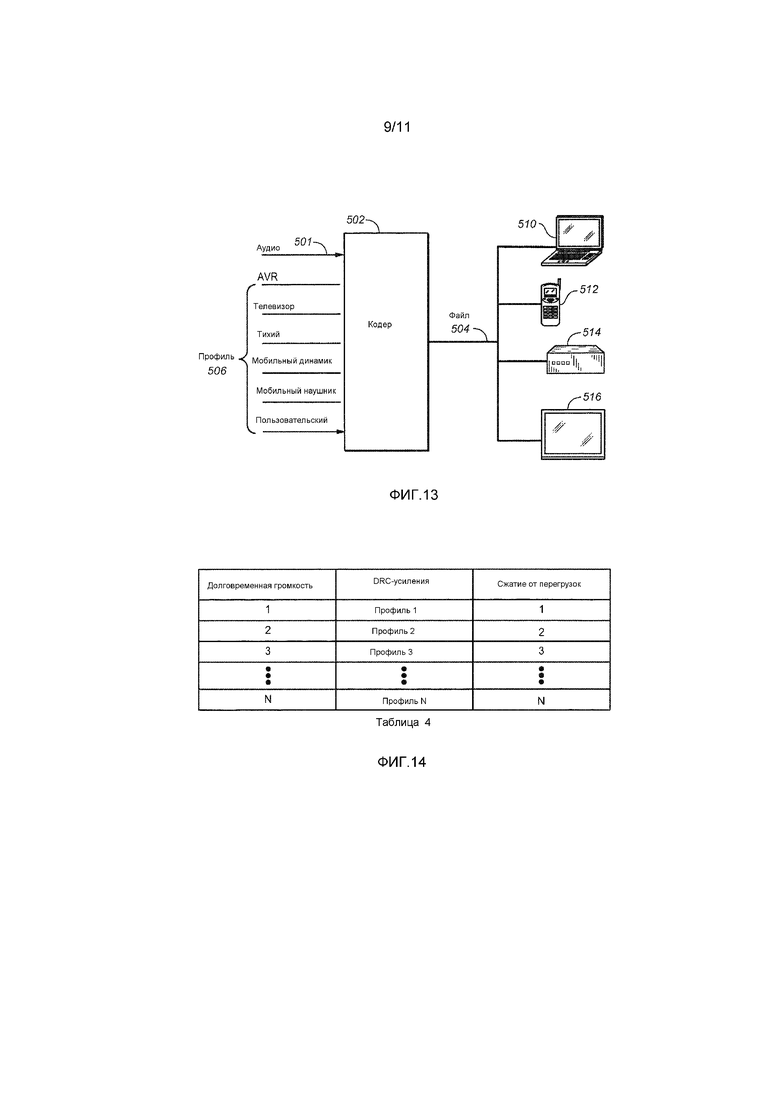
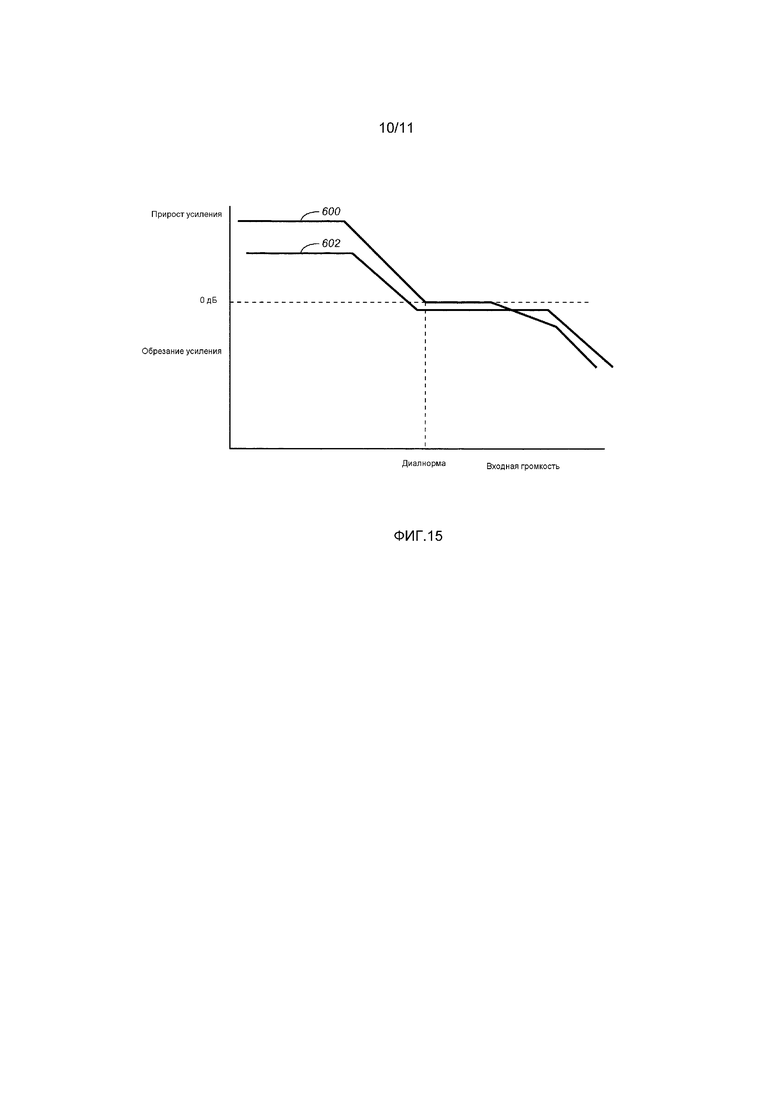
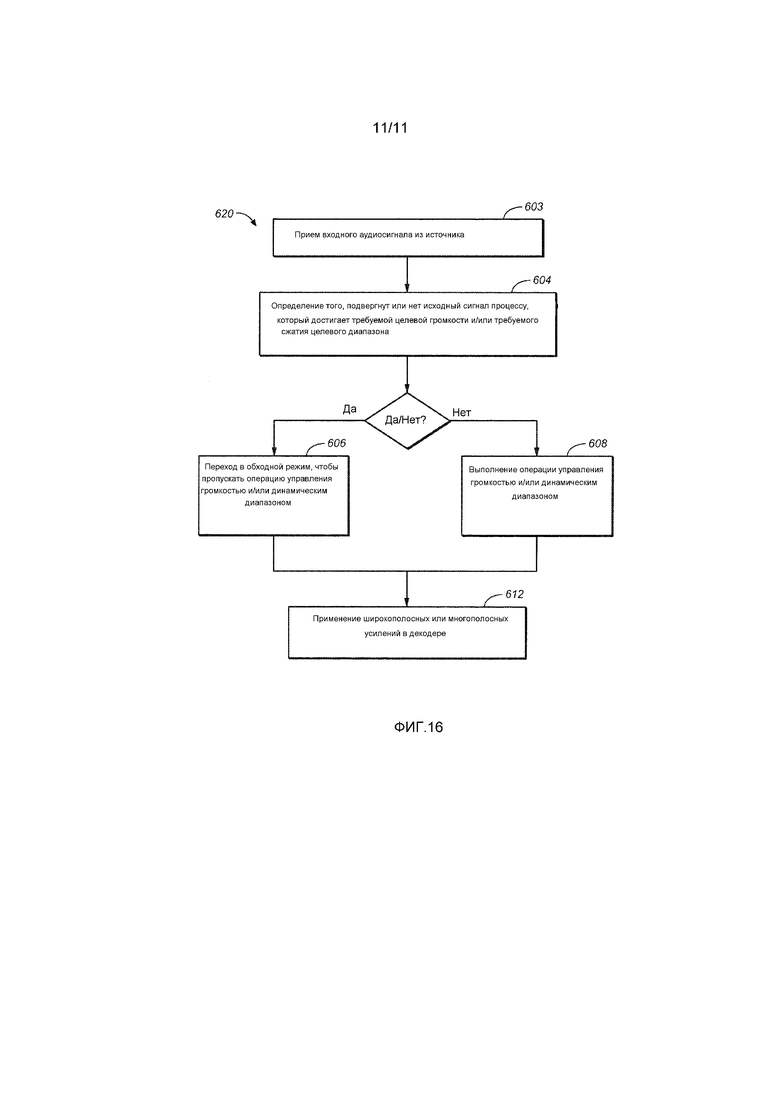
Настоящее техническое решение относится к области вычислительной техники для обработки аудиоданных. Технический результат заключается в оптимизации динамического диапазона за счёт возможности уменьшения уровня громких звуков и/или усиливания уровня тихих звуков, чтобы вмещать исходный контент с широким динамическим диапазоном в более узкий записанный динамический диапазон. Технический результат достигается за счёт устройства и способа, которые позволяют осуществлять синтаксический анализ кодированного потока аудиобитов и извлечение кодированных аудиоданных и метаданных для одного или более профилей DRC; декодировать кодированные аудиоданные и применять усиления DRC к декодированным аудиоданным, при этом каждый профиль DRC подходит по меньшей мере для одного типа устройства или окружения прослушивания; один или более профилей DRC выбираются в ответ на информацию об устройстве аудиообработки или окружении прослушивания и усиления DRC, применяемые к декодированным аудиоданным, соответствуют одному или более выбранным профилям DRC. 3 н.п. ф-лы, 16 ил.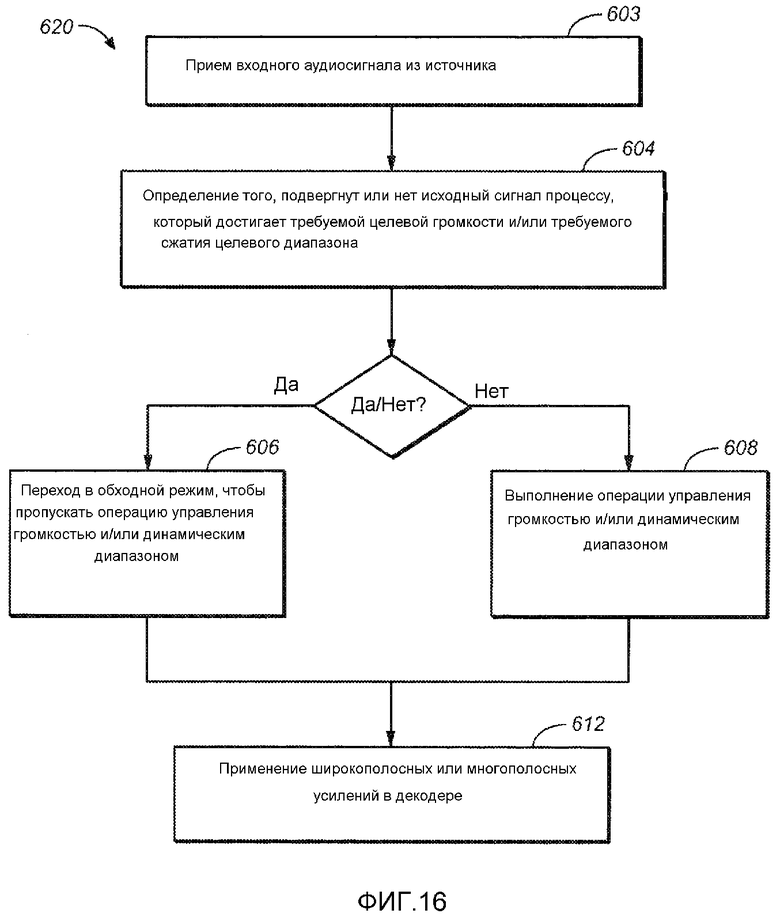
1. Устройство аудиообработки для декодирования одного или более кадров кодированного потока аудиобитов, причем кодированный поток аудиобитов включает в себя аудиоданные и метаданные для множества профилей управления динамическим диапазоном (DRC), причем устройство обработки звука содержит:
синтаксический анализатор потока битов, сконфигурированный для синтаксического анализа кодированного потока аудиобитов, а также для извлечения кодированных аудиоданных и метаданных для одного или более профилей DRC; и
аудиодекодер, сконфигурированный для декодирования кодированных аудиоданных и применения усилений DRC к декодированным аудиоданным, при этом:
каждый профиль DRC подходит по меньшей мере для одного типа устройства или окружения прослушивания;
аудиодекодер выбирает один или более профилей DRC в ответ на информацию об устройстве аудиообработки или окружении прослушивания; и
усиления DRC применяются к декодированным аудиоданным, соответствующим одному или более выбранным профилям DRC.
2. Способ, выполняемый устройством аудиообработки, для декодирования одного или более кадров кодированного потока аудиобитов, причем кодированный поток аудиобитов включает в себя аудиоданные и метаданные для множества профилей управления динамическим диапазоном (DRC), причем способ содержит этапы, на которых:
осуществляют синтаксический анализ кодированного потока аудиобитов и извлечение кодированных аудиоданных и метаданных для одного или более профилей DRC;
декодируют кодированные аудиоданные и применяют усиления DRC к декодированным аудиоданным, при этом:
каждый профиль DRC подходит по меньшей мере для одного типа устройства или окружения прослушивания;
один или более профилей DRC выбираются в ответ на информацию об устройстве аудиообработки или окружении прослушивания; и
усиления DRC, применяемые к декодированным аудиоданным, соответствуют одному или более выбранным профилям DRC.
3. Энергонезависимый компьютерно-читаемый носитель данных, содержащий последовательность инструкций, которые при выполнении устройством аудиодекодирования, вызывают выполнение устройством декодирования звука способа по п. 2.
| Колосоуборка | 1923 |
|
SU2009A1 |
| Изложница с суживающимся книзу сечением и с вертикально перемещающимся днищем | 1924 |
|
SU2012A1 |
| Приспособление для суммирования отрезков прямых линий | 1923 |
|
SU2010A1 |
| СПОСОБ ПОЛУЧЕНИЯ ТВОРОЖНОГО ПРОДУКТА | 1999 |
|
RU2143204C1 |
| СПОСОБЫ И УСТРОЙСТВА ДЛЯ КОДИРОВАНИЯ И ДЕКОДИРОВАНИЯ ОБЪЕКТНО-БАЗИРОВАННЫХ АУДИОСИГНАЛОВ | 2010 |
|
RU2449388C2 |

