ОБЛАСТЬ ТЕХНИКИ
Данное техническое решение относится к области вычислительной техники, а именно к способам и системам кластеризации исполняемых файлов, что может быть необходимо при определении принадлежности программного обеспечения (ПО) к известному семейству ПО, а также принадлежности ПО той или иной группе авторов ПО.
УРОВЕНЬ ТЕХНИКИ
Данное техническое решение относится к области вычислительной техники, а именно к способам и системам кластеризации исполняемых файлов, что может быть необходимо при определении принадлежности программного обеспечения (ПО). Под определением принадлежности в данном случае можно понимать, как принадлежность ПО к известному семейству ПО, так и принадлежность ПО той или иной группе авторов ПО.
Известно, что профессиональные киберпреступники тщательно разрабатывают стратегию атаки и редко ее меняют, притом обычно они длительное время используют одни и те же вредоносные программы, лишь незначительно модифицируя их.
С другой стороны, разработчики вредоносного ПО (ВПО), создающие инструментарий для киберпреступников, могут на протяжении длительного времени использовать одно и то же программное решение, например, функцию, реализующую алгоритм шифрования, в различных образцах ВПО, притом создаваемого для разных киберпреступных группировок и относящихся к разным семействам ВПО.
Поэтому в области кибербезопасности знание о том, что данный образец вредоносного ПО (ВПО) принадлежит к определенному семейству ВПО, как и знание о том, что данный образец ВПО создан определенным автором или группой авторов, может быть весьма важно.
Хорошо известен такой метод обнаружения вредоносного ПО, как сигнатурный анализ. Этот метод основан на поиске в файлах уникальной последовательности байтов, то есть сигнатуры, которая характерна для данного конкретного вредоносного ПО. Для каждого нового образца ВПО специалисты антивирусной лаборатории выполняют анализ кода, на основании которого определяют сигнатуру этого нового ВПО. Полученную сигнатуру помещают в базу данных вирусных сигнатур, с которой работает антивирусная программа, и это впоследствии помогает антивирусу обнаруживать данное ВПО.
Данный метод хорошо известен и киберпреступникам. Поэтому почти все современные вредоносные программы так или иначе постоянно модифицируются, притом целью подобной модификации не является изменение основной функциональности ВПО. В результате модификации файлы очередной версии ВПО должны приобрести, с точки зрения антивирусных сигнатурных анализаторов, новые свойства. Тогда они перестанут "опознаваться" как вредоносные при помощи существующих баз сигнатур, что повысит скрытность действий киберпреступников.
Помимо модификации также широко используется прием, называемый обфускацией. Он представляет собой приведение исходного текста или исполняемого кода программы к виду, сохраняющему ее функциональность, но затрудняющему анализ и понимание алгоритмов работы. Перечисленные изменения ВПО могут осуществляться как человеком, так и автоматически, например, так называемым полиморфным генератором, входящим в состав вредоносной программы.
При этом важно, что основные функции ВПО, как правило, не подвергаются существенным изменениям. После модификации вредоносная программа будет "выглядеть" иначе для сигнатурных анализаторов, ее код может быть обфусцирован и непригоден для анализа человеком, но набор функций, который эта программа исполняла до модификации, с большой вероятностью после модификации останется прежним.
Из уровня техники известен патент RU2728497A1 (Слипенчук П.В., Померанцев И.С., СПОСОБ И СИСТЕМА ОПРЕДЕЛЕНИЯ ПРИНАДЛЕЖНОСТИ ПРОГРАММНОГО ОБЕСПЕЧЕНИЯ ПО ЕГО МАШИННОМУ КОДУ, опубл. 29.07.2020. кл. G06F 8/74). В нем описан способ определения принадлежности ПО к определенному семейству программ по его машинному коду, в котором получают файл, содержащий машинный код ПО; определяют формат полученного файла; извлекают и сохраняют код функций, присутствующих в полученном файле; удаляют из сохраненного кода функции, которые являются библиотечными; выделяют в каждой функции команды; выделяют в каждой команде пару «действие, аргумент»; преобразуют каждую пару «действие, аргумент» в число; сохраняют, отдельно для каждой выделенной функции, полученные упорядоченные последовательности чисел; накапливают заранее заданное количество результатов анализа машинного кода и выявляют в них повторяющиеся последовательности чисел (паттерны); для каждого выявленного паттерна вычисляют параметр, характеризующий его частотность; на основе вычисленного набора параметров обучают классификатор определять принадлежность ПО по последовательности пар «действие, аргумент»; применяют обученный классификатор для последующего определения принадлежности ПО к определенному семейству программ.
Как легко видеть, для работы описанного способа необходим значительный массив файлов, содержащих машинный код, причем в этом массиве должны находиться представители всех семейств ПО, определению принадлежности к которым предполагается обучить классификатор. Соответственно, образцы ПО, которые относятся к семействам, не представленным в массиве файлов к моменту начала его использования, классификатор идентифицировать не сможет. А для того, чтобы обучить его этому, понадобится добавлять в массив несколько представителей нового семейства и повторять описанные процедуры заново, с нуля. В то же время формирование вручную такого массива файлов, содержащего достаточный для обучения классификатора ассортимент ПО, является чрезвычайно трудоемкой задачей.
По существу, именно проблема быстрого, автоматического формирования подобных массивов файлов, кластеризованных по принадлежности к определенным семействам, и сдерживает сегодня активное развитие решений, подобных описанному в RU2728497A1.
В то же время, из уровня техники известно решение US20150178306A1 (YI YANG et al., Method and apparatus for clustering portable executable files, опубл. 06.25.2015. кл. G06F 7/30), в котором описан способ кластеризации «переносимых исполняемых» (Portable Executable, РЕ) файлов. Способ подразумевает извлечение из РЕ-файла характеристик РЕ-файла; генерацию для РЕ-файла идентификатора РЕ-файла на основе характеристик РЕ-файла; и кластеризацию базы РЕ-файлов по идентификаторам РЕ-файла.
Прежде всего, следует отметить, что данный способ исходно ориентирован на анализ исполняемых файлов формата РЕ, используемых в основном в операционной системе Microsoft Windows. Соответственно, исполняемые файлы других форматов, не имеющие характеристик РЕ-файла, анализу описанным способом не подлежат. Тогда как вредоносное ПО весьма разнообразно; оно существует для множества операционных систем, таких как *nix-системы, Android, операционные системы Apple и т.д.
Из уровня техники также известно решение ЕР 2743854 В1 (TAO YU, Clustering processing method and device for virus files, опубл. 25.03.2015. кл. G06F 21/56), раскрывающее способ кластеризации переносимых исполняемых (РЕ) файлов, в том числе вирусных файлов, включающий: статический анализ двоичных данных вирусных файлов, которые необходимо классифицировать, для получения переносимых данных исполняемой структуры вирусных файлов; сравнение данных переносимой исполняемой структуры вирусных файлов, которые необходимо классифицировать, и классификация вирусных файлов, которые имеют данные РЕ-структуры, удовлетворяющие заданному условию сходства, в одну и ту же категорию; и выполнение вторичной кластеризации вирусных файлов в каждой из категорий, классифицированных на предыдущем этапе.
Несложно видеть, что данное решение обладает теми же недостатками, что и предыдущее, то есть не предназначено для работы с исполняемыми файлами, не имеющими формата РЕ.
Из уровня техники также известно решение ЕР 2946331 В1 (SOURABH SATISH et al, Classifying samples using clustering, опубл. 17.08.2016. кл. G06F 21/56). В данном решении раскрыт способ классификации файла, включающий создание набора образцов, связанных с файлом, содержащим маркированные и немаркированные образцы; сбор значений признаков из маркированных и немаркированных образцов; выбор подмножества функций; кластеризацию вместе маркированных и немаркированных выборок, имеющих, по меньшей мере, пороговую меру сходства среди собранных значений выбранного подмножества признаков для создания набора кластеров, причем каждый кластер имеет подмножество выборок из набора выборок; рекурсивно повторяя этапы выбора и кластеризации на подмножестве выборок в каждом кластере в наборе кластеров, пока не будет достигнуто по крайней мере одно условие остановки, при этом существует множество итераций этапов выбора и кластеризации, первая итерация кластеризации использует первую пороговая мера сходства и последующие итерации кластеризации используют все более строгие пороги подобия, итерации создают кластер, имеющий по крайней мере одну маркированную выборку и по крайней мере одну немаркированную выборку, а на этапе выбора выбираются разные подмножества признаков для разных итераций множества итераций к определению величины отклонения в значениях признаков образцов в кластере из набора кластеров, созданных итерацией кластеризации; и выбор подмножества признаков для последующей итерации кластеризации в ответ на определенную величину отклонения в значениях признаков выборок в кластере из набора кластеров, созданных итерацией кластеризации; и после достижения хотя бы одного условия остановки, распространение метки от по меньшей мере одного маркированному образца в кластере к по меньшей мере одному немаркированному образцу в кластере для классификации файла, связанного по меньшей мере с одним немаркированным образцом.
Применительно к данному решению прежде всего нужно заметить, что оно требует наличия маркированных файлов, то есть таких, которые заранее помечены как вредоносные, соответственно, для работы с выборкой произвольного состава оно не подходит. Далее, решение подразумевает изучение данных, извлеченных из внутренней структуры файла, следовательно, непригодно для кластеризации стойко зашифрованных или обфусцированных исполняемых файлов.
Настоящее решение создано для решения проблем, выявленных при анализе уровня техники и создании улучшенного комплексного метода кластеризации исполняемых файлов.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
В рамках настоящего описания, если это не оговорено непосредственно по месту применения, нижеперечисленные специальные термины используются в следующих значениях:
Библиотечные функции - функции, реализующие наиболее распространенные, типовые действия. Библиотечные функции широко используются самыми разными программами, поэтому их наличие в коде или в рабочих процессах программы не специфично ни для какой-то одной программы, ни для какого-то определенного разработчика.
Длина секвенции - это количество команд, составляющих данную секвенцию. Важно, что эта величина не связана со способом записи команд (в машинном коде и в исходном коде программы применяются разные способы записи), и не зависит от того, сколько байт необходимо для записи команд, составляющих секвенцию. Иными словами, выражение «секвенция длиной 40» означает, что данная секвенция состоит из 40 команд. О том, сколько бит или байт нужно для ее записи, это выражение ничего не сообщает.
Кластеризация файлов - разделение неупорядоченного множества файлов на кластеры (подмножества), где каждый кластер или подмножество соответствует определенному семейству ПО. Задача идентификации семейства, то есть определение функционального назначения входящих в семейство программ, в данном случае не ставится. Основной задачей кластеризации является отнесение каждого файла, входящего в исходное неупорядоченное множество, к какому-либо из семейств, причем количество семейств, необходимое для кластеризации этого множества, перед началом кластеризации неизвестно.
Обфускация или запутывание кода - это приведение кода программы к виду, сохраняющему функциональность программы, но затрудняющему его статический анализ, понимание алгоритмов работы.
Семейство ПО - множество программ, объединенных одним функциональным назначением (например, шифровальщики, загрузчики и т.д.) и\или общим коллективом разработчиков, а также базовым алгоритмом исполнения. Программы, составляющие одно семейство, отличаются друг от друга разного рода модификациями, в результате чего их общеизвестные характеристики, такие как контрольная сумма, объем файла, имя файла, и т.д., различаются. Однако, все программы, входящие в одно семейство, предназначены для одной цели и все они для достижения этой цели совершают одни и те же основные шаги алгоритма. В рамках данного описания предполагается, что программы, имеющие идентичное функциональное назначение, но различные форматы, относятся к различным семействам, например, «шифровальщики формата РЕ» и «шифровальщики формата Mach-О» это не одно, а два различных семейства.
Секвенция - последовательность, «цепочка» команд, следующих одна за другой в коде исследуемого файла. При этом каждая команда сама по себе может иметь достаточно сложную структуру, состоять, скажем, из действия и одного или нескольких аргументов. Команды могут иметь различную длину, обычно выражаемую количеством байт, необходимых для их записи. Как уже упоминалось, длина секвенции не зависит от длины составляющих ее команд, и выражается не в битах или байтах, а в единицах. Говоря, например, о секвенции длиной 50, подразумевают, что эта секвенция представляет собой последовательность 50 следующих друг за другом команд.
Сэмпл (от англ. sample, «образец, экземпляр») - не функциональная, используемая только для исследования часть какого-либо файла, например, файла, содержащего код программы. Из исходного файла программы, готового к запуску и исполнению, сэмпл получают путем удаления из этого файла различных фрагментов кода, не представляющих интереса в рамках исследования. Например, сэмпл может быть получен из исходного файла путем удаления из него библиотечных функций и устойчивых конструкций.
Устойчивые конструкции - это фрагменты кода, которые можно найти в самых разных программах. Такие конструкции встречаются не только в ПО какого-то определенного назначения или определенного автора, а практически повсеместно. В качестве примера устойчивых конструкций могут быть названы, например, прологи функций.
Функция - фрагмент кода, к которому можно обратиться из другого места программы. В большинстве случаев с функцией связывается идентификатор (имя). С именем функции неразрывно связан адрес первой инструкции (оператора), входящей в функцию, которой передается управление при обращении к функции. После выполнения функции управление возвращается обратно в адрес возврата, то есть ту точку программы, где данная функция была вызвана.
Технической проблемой, на решение которой направлено заявленное техническое решение, является создание компьютерно-реализуемого способа и системы кластеризации исполняемых файлов, которые охарактеризованы в независимых пунктах формулы. Дополнительные варианты реализации настоящего решения представлены в зависимых пунктах формулы изобретения.
Технический результат заключается в обеспечении автоматической кластеризации исполняемых файлов.
В предпочтительном варианте реализации заявлен компьютерно-реализуемый способ кластеризации исполняемых файлов, заключающийся в выполнении шагов, на которых с помощью вычислительного устройства:
получают множество исполняемых файлов,
определяют формат каждого исполняемого файла,
по отдельности для каждого формата файлов:
находят в файлах повторяющиеся секвенции заданной длины,
определяют наиболее частотные секвенции,
файлы, которые содержат по меньшей мере одну наиболее частотную секвенцию, относят к одному семейству,
исключают все файлы, относящиеся к данному семейству, из дальнейшей обработки,
повторяют поиск наиболее частотных секвенций, отнесение файлов, содержащих по меньшей мере одну наиболее частотную секвенцию, к очередному семейству и исключение данных файлов из дальнейшей обработки до тех пор, пока все файлы не будут отнесены к какому-либо семейству, либо пока не останутся файлы, не содержащие повторяющихся секвенций,
в ответ на то, что остались файлы, не содержащие повторяющихся секвенций, каждый из этих файлов относят к отдельному семейству.
В частном варианте реализации способа длина секвенции выбирается в зависимости от количества файлов, в которых была найдена данная секвенция.
В другом частном варианте реализации способа длина секвенции является фиксированной, заранее заданной величиной.
Еще в одном частном варианте реализации способа рассматривают только секвенции, энтропия которых превышает заранее заданный порог.
В частном варианте реализации способа наиболее частотные секвенции находят посредством поиска по хеш-таблице.
В другом частном варианте реализации способа решение о принадлежности каждого файла к данному одному семейству принимается по результатам вычисления для этого файла значения взвешивающей функции, представляющей собой сумму коэффициентов по меньшей мере двух наиболее частотных секвенций, найденных в данном файле.
Еще в одном частном варианте реализации способа каждый коэффициент взвешивающей функции вычисляют как отношение количества файлов, в которых хотя бы один раз присутствует данная секвенция, к исходному количеству файлов.
В другом частном варианте реализации способа в ответ на то, что остались файлы, не содержащие повторяющихся секвенций, эти файлы не относят ни к одном семейству.
В другом предпочтительном варианте реализации заявлен компьютерно-реализуемый способ кластеризации исполняемых файлов, заключающийся в выполнении шагов, на которых с помощью вычислительного устройства:
получают множество исполняемых файлов,
определяют формат каждого исполняемого файла,
запускают каждый исполняемый файл в виртуальной среде, соответствующей его формату,
из каждого исполняемого файла создают сэмпл, в котором из кода исключены библиотечные функции и устойчивые конструкции, и сохраняют полученный сэмпл,
после получения сэмплов, соответствующих всем полученным файлам:
находят в сэмплах повторяющиеся секвенции заданной длины,
определяют наиболее частотные секвенции,
файлы, соответствующие сэмплам, которые содержат по меньшей мере одну наиболее частотную секвенцию, относят к одному семейству,
исключают файлы и сэмплы, соответствующие данному семейству, из дальнейшей обработки.
повторяют поиск наиболее частотных секвенций, отнесение файлов, соответствующих сэмплам, содержащим по меньшей мере одну наиболее частотную секвенцию, к очередному семейству и исключение данных файлов и сэмплов из дальнейшей обработки до тех пор, пока все файлы не будут отнесены к какому-либо семейству, либо пока не останутся сэмплы, не содержащие повторяющихся секвенций,
в ответ на то, что остались сэмплы, не содержащие повторяющихся секвенций, каждый из файлов, соответствующих этим сэмплам, относят к отдельному семейству.
В частном варианте реализации способа длина секвенции выбирается в зависимости от количества сэмплов, в которых была найдена данная секвенция.
В другом частном варианте реализации способа длина секвенции является фиксированной, заранее заданной величиной.
В другом возможном частном варианте реализации способа рассматривают только секвенции, энтропия которых превышает заранее заданный порог.
Еще в одном возможном частном варианте реализации способа наиболее частотные секвенции находят посредством поиска по хеш-таблице.
Возможен также частный вариант реализации способа, при котором решение о принадлежности каждого файла к данному семейству принимается по результатам вычисления для этого файла значения взвешивающей функции, представляющей собой сумму коэффициентов по меньшей мере двух наиболее частотных секвенций, найденных в сэмпле, соответствующем данному файлу.
В другом частном варианте реализации способа каждый коэффициент взвешивающей функции вычисляют как отношение количества сэмплов, в которых хотя бы один раз присутствует данная секвенция, к исходному количеству сэмплов.
В еще одном частном варианте реализации способа в ответ на то, что остались сэмплы, не содержащие повторяющихся секвенций, файлы, соответствующие этим сэмплам, не относят ни к одном семейству.
Заявленное решение также осуществляется за счет системы кластеризации исполняемых файлов, содержащей:
- долговременную память, выполненную с возможностью хранения используемых файлов и данных;
- вычислительное устройство, выполненное с возможностью выполнения описанного способа.
ОПИСАНИЕ ЧЕРТЕЖЕЙ
Реализация изобретения будет описана в дальнейшем в соответствии с прилагаемыми чертежами, которые представлены для пояснения сути изобретения и никоим образом не ограничивают область изобретения. К заявке прилагаются следующие чертежи:
Фиг. 1А-Б иллюстрируют предпочтительный вариант реализации компьютерно-реализуемого способа кластеризации исполняемых файлов.
Фиг. 2А-В иллюстрируют другой предпочтительный вариант реализации компьютерно-реализуемого способа кластеризации исполняемых файлов.
Фиг. 3 иллюстрирует шаги изготовления вспомогательной программы, используемой в одном из предпочтительных вариантов реализации способа.
Фиг. 4 иллюстрирует пример общей схемы компьютерного устройства.
ДЕТАЛЬНОЕ ОПИСАНИЕ ИЗОБРЕТЕНИЯ
В приведенном ниже подробном описании реализации изобретения приведены многочисленные детали реализации, призванные обеспечить отчетливое понимание настоящего изобретения. Однако, квалифицированному в предметной области специалисту, будет очевидно каким образом можно использовать настоящее изобретение, как с данными деталями реализации, так и без них. В других случаях хорошо известные методы, процедуры и компоненты не были описаны подробно, чтобы не затруднять понимание особенностей настоящего изобретения.
Кроме того, из приведенного изложения будет ясно, что изобретение не ограничивается приведенной реализацией. Многочисленные возможные модификации, изменения, вариации и замены, сохраняющие суть и форму настоящего изобретения, будут очевидными для квалифицированных в предметной области специалистов.
Настоящее изобретение направлено на обеспечение реализации компьютерно-реализуемого способа и системы кластеризации исполняемых файлов.
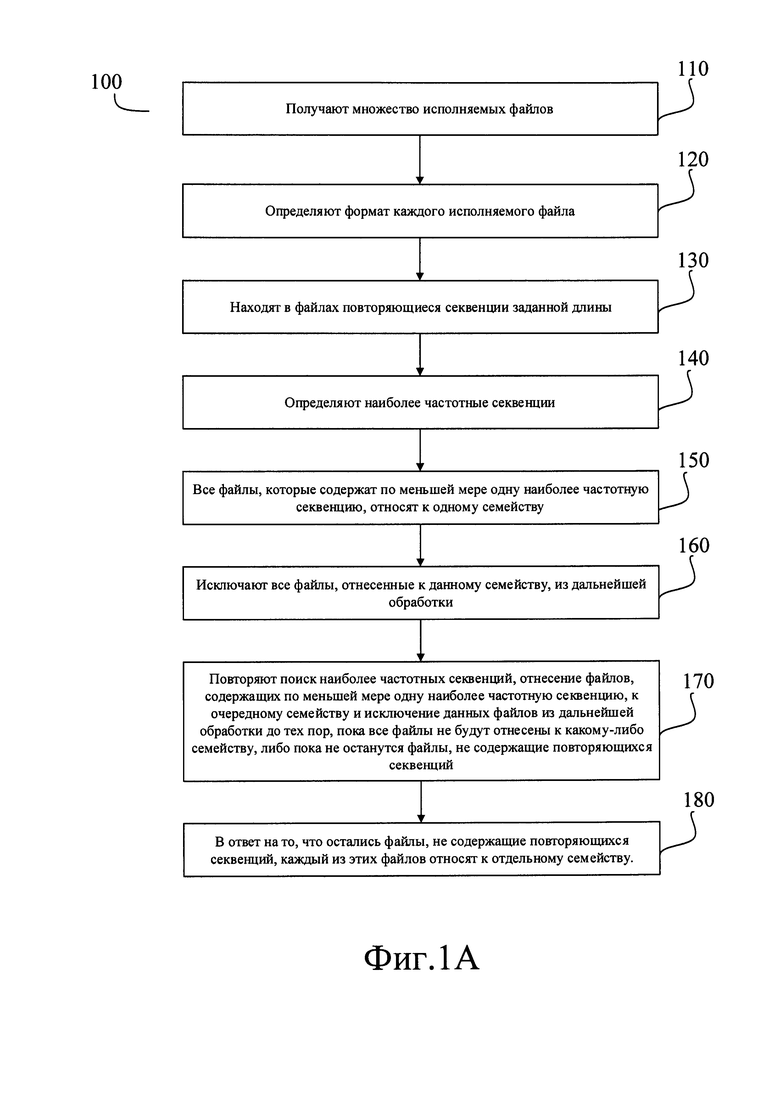
Как представлено на Фиг. 1А, заявленный компьютерно-реализуемый способ кластеризации исполняемых файлов (100) может быть реализован следующим образом:
Способ начинается на шаге (ПО), на котором получают множество исполняемых файлов, подлежащих анализу. Это могут быть уже откомпилированные файлы, наподобие ЕХЕ или DLL, содержащие программу или динамическую библиотеку, файлы электронных документов со встроенным языком сценариев (например, языком VBA), такие как файлы DOC или XLS, а также файлы, содержащие исходный код программ на любых интерпретируемых языках программирования, например, таких как JavaScript, Python и т.д. Во всех этих файлах или в некоторой их части также могут быть дополнительно зашифрованы фрагменты кода или данных, все эти файлы или их часть также могут быть обфусцированы, в том числе с использованием стойких к раскрытию алгоритмов.
Исполняемые файлы могут относиться к любому известному формату, не ограничиваясь только форматом РЕ; например, это также могут быть, без ограничений, исполняемые файлы форматов Mach-O, ELF, COM, COFF и других.
Далее на шаге (120) определяют формат каждого исполняемого файла и выбирают соответствующее формату средство анализа кода. Определение формата файла выполняют любым известным способом, например, посредством скрипта, который поочередно сравнивает сигнатуру проверяемого файла с известными сигнатурами различных форматов файлов и при совпадении сигнатур выдает сообщение о фактическом формате файла (который в общем случае может отличаться от формата, ассоциированного в используемой операционной системе с данным расширением файла). Для файлов, содержащих исходный код на одном из интерпретируемых языков программирования, на этом же шаге определяют язык программирования на котором написан код, и выбирают соответствующее языку средство анализа кода. Определение языка программирования также может быть выполнено любым известным способом, например, посредством программы Linguist (https://github.corn/github/linguist) или посредством программы Ohcount (https://github.com/blackducksoftware/ohcount).
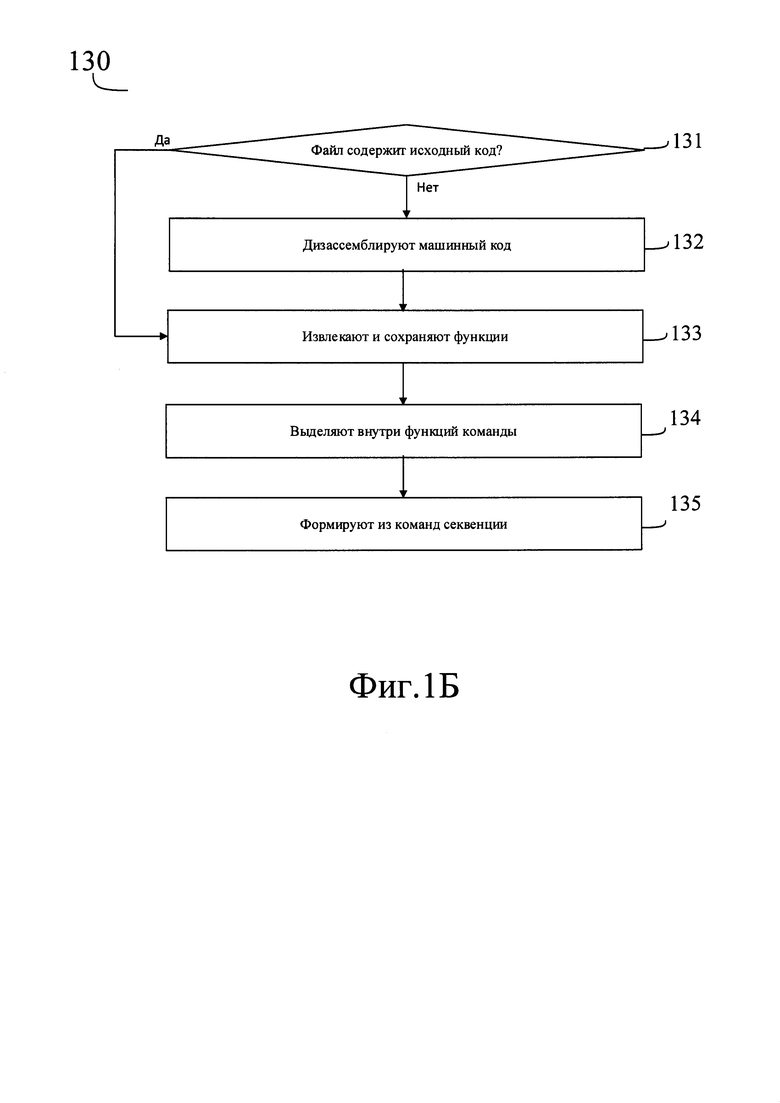
Затем способ переходит к шагу (130) на котором в файлах находят повторяющиеся секвенции заданной длины. Данный шаг далее будет подробно описан применительно к Фиг. 1Б.
Шаг начинается с этапа выбора (131), на котором в зависимости от того, содержит ли данный файл исходный код или нет, выбирают последовательность дальнейших действий.
В ответ на то, что файл содержит исходный код, далее способ переходит к этапу (133).
В ответ на то, что файл не содержит исходного кода (то есть файл содержит машинный или операционный код), способ переходит к этапу (132), на котором дизассемблируют содержащийся в файле код. Дизассемблирование выполняют специализированной программой-дизассемблером, которая преобразует машинный или операционный код в набор инструкций на языке ассемблер или языке IL. Программа-дизассемблер может быть любой известной, например, IDA Pro, Sourcer или другой. В результате работы данной программы машинный код оказывается размечен: в нем явным образом выделены границы функций.
Затем способ переходит к этапу (133), на котором извлекают и сохраняют в виде списка функции. Это выполняют выбранным ранее на шаге (120) средством анализа кода, выбранным для данного формата файла. Это средство представляет собой программу-парсер, алгоритм действия которой в случае исходного кода основан на синтаксисе того языка программирования, на котором написан данный код. В случае машинного кода используют программу-парсер, алгоритм действия которой основан на спецификации используемой вычислительной архитектуры.
Весь код, находящийся в выделенных дизассемблером границах функций, сохраняют, например, в виде отдельного файла, имеющего текстовый формат.Весь остальной (оставшийся за пределами этих границ) код в описываемом способе считается данными программы и не используется.
Аналогично поступают при анализе исходного кода. Парсером находят в анализируемом исходном коде границы, фрагменты кода внутри которых являются функциями. Для этого может использоваться, например, тот общеизвестный факт, что в большинстве языков программирования высокого уровня тело функции заключается в блочный оператор. Соответственно, одним из возможных алгоритмов работы парсера может быть выявление в коде пар слов или символов, которыми в синтаксисе данного языка обозначается блочный оператор, дополнительная проверка того факта, что найденный блочный оператор содержит именно тело функции, а также перемещение кода, составляющего тела найденной функции, в файл, где сохраняют результаты обработки. Проверка того факта, что блочный оператор содержит именно тело функции может выполняться, например, путем поиска в строке, предшествующей открытию блочного оператора, символьного выражения, соответствующего в синтаксисе данного языка программирования имени функции.
Альтернативно, если исходный код написан на С-подобном языке программирования, например, на JavaScript, то каждая функция будет начинаться с заголовка функции, имеющего известный формат. Например, в коде следующего примера, написанном на языке JavaScript, заголовок каждой из двух функций может быть идентифицирован по наличию ключевого слова function. За заголовком в таком коде будет следовать тело функции, также заключенное в блочный оператор, в данном случае обозначаемый парой фигурных скобок, {и}:
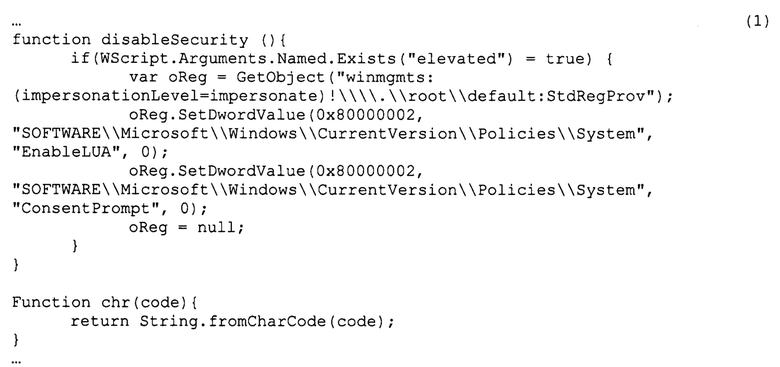
Действия над исходным кодом, оставшимся за пределами блочных операторов (то есть границ функций), выполняют в зависимости от того, позволяет ли синтаксис данного языка программирования исполнение кода за пределами функций. Например, для исходного кода, написанного на языке С или С#, такой код игнорируют. В рассматриваемом примере, для кода, написанного на языке JavaScript, такой код считают относящимся еще к одной функции, отдельной от всех уже выделенных. Код этой функции также переносят в список функций и в дальнейшем обрабатывают аналогично всему остальному коду, помещенному в этот список. Таким образом на этапе (133) получают и сохраняют в виде отдельного файла код всех функций, имеющихся в анализируемом файле.
Затем способ переходит к этапу (134), на котором анализируют файл, содержащий найденные функции, и выделяют внутри функций команды. Для выделения команд используют результаты выполненного ранее дезассемблирования. Например, при дезассемблировании следующего фрагмента машинного кода
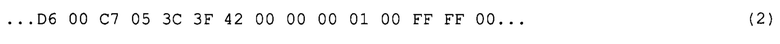
программой IDA Pro будет выделена следующая команда:

имеющая в машинном коде представление

Указанный анализ может выполняться любым известным способом, позволяющим получить данный результат, например, скриптом, специально написанном для этой цели. Алгоритм такого скрипта должен разбирать анализируемый фрагмент машинного кода в соответствии со спецификацией используемой архитектуры; в данном примере это архитектура х86.
Выявленные в машинном коде фрагменты, соответствующие отдельным командам, сохраняют, например, каждую на отдельной строке текстового файла. В одной из возможных реализаций описываемого способа аргументы, такие как аргумент 10000h, считают частью команды и сохраняют. В другой возможной реализации аргументы игнорируют, а сохраняют только команды, такие как команда mov dword_423F3C.
Что именно считают отдельной командой при анализе исходного кода, зависит от синтаксиса языка программирования, на котором написан исследуемый код. Так, в одном из возможных вариантов реализации началом команды может считаться начало строки, а окончанием - ближайший к началу строки символ, означающий в данном языке программирования окончание команды, как, например, символ «точка с запятой» (;) в языке С.
В альтернативном варианте реализации способа командой могут считать последовательность символов, расположенную на отдельной строке. Например, в рамках данного подхода в составе функции disabieSecurity из приведенного выше фрагмента исходного кода (1), написанного на языке JavaScript, будут выделены шесть команд, по числу строк:

Как и при анализе машинного кода, фрагменты, соответствующие отдельным командам, сохраняют, например, каждую команду на отдельной строке текстового файла. После этого способ переходит к этапу (135), на котором из выделенных команд формируют с заданным шагом секвенции заданной длины.
Секвенцией в рамках данного описания будем называть последовательность, «цепочку» команд, следующих одна за другой в коде исследуемого файла. Понятно, что в зависимости от того, исходный код анализируют или машинный, команды могут иметь достаточно сложную структуру и различную длину, содержать различные аргументы, модификаторы и так далее. Все эти обстоятельства при формированиии секвекций не учитывают.
Так, в одном из возможных вариантов реализации описываемого способа найденные команды могут быть для удобства предварительно преобразованы в числа. Это может быть выполнено, например, путем взятия хэш-функции от полного текста каждой команды, или любым другим общеизвестным способом преобразования строки в число. Понятно, что одинаковые команды при этом будут преобразованы в одинаковые числа. Кроме того, для данной цели может быть выбран такой алгоритм преобразования, при котором команды, текст которых различается незначительно, окажутся преобразованы в близкие по абсолютной величине числа, например, алгоритм нечеткого хэширования SSDeep.
Для простоты примера, поясняющего формирование секвенций, условно обозначим отдельные команды буквами алфавита, притом будем считать, что каждая команда обозначена одной буквой, а одинаковые команды обозначены одинаковыми буквами. Конечно, в действительности количество команд, которые могут быть извлечены из одного исполняемого файла, значительно превышает количество букв любого алфавита. Итак, в данном примере в результате выполнения вышеописанного этапа (134) для какого-то исполняемого файла получили следующий набор команд:
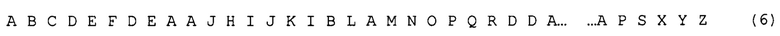
Допустим, в соответствии с предварительно заданными условиями обработки, из этого набора команд должны быть с шагом 1 сформированы секвенции длиной 5.
Важно подчеркнуть, что длина секвенции не зависит от длины или иных параметров составляющих ее команд; длина секвенции выражается не в битах или байтах, а в единицах. Говоря, например, о секвенции длиной 5, подразумевают, что эта секвенция представляет собой последовательность из пяти следующих друг за другом команд.
Параметр, названный шагом, в данном случае определяет, на сколько команд начало каждой следующей секвенции будет отстоять от начала предыдущей секвенции. В рамках примера (б), при шаге, равном 1, первая секвенция будет начинаться с команды А, а вторая с команды В. При шаге, равном 2, вторая секвенция будет начинаться с команды С, при шаге, равном 3, вторая секвенция будет начинаться с команды D, и так далее.
При заданных условиях (длина 5, шаг 1) из набора команд (б) будут сформированы и сохранены, например, в базе данных, следующие секвенции:

Условия формирования секвенций, длина и шаг, могут представлять собой фиксированные величины и быть заданы заранее, на этапе разработки системы, реализующей способ. В альтернативном варианте реализации описываемого способа длина секвенции и шаг ее формирования могут выбираться автоматически в зависимости от выполнения заранее заданных условий. Например, изначально была задана длина секвенции 100 команд, и в ходе анализа полученной выборки файлов установлено, что в полученной выборке файлов не оказалось ни одной повторяющейся секвенции, то есть нет ни одной секвенции, которая присутствовала бы по меньшей мере в двух различных файлах. Тогда длину секвенции уменьшают до 90 команд, заново формируют секвенции и проверяют, обнаружится ли хотя бы одна повторяющаяся в двух и более файлах секвенция.
Альтернативно, если изначально была задана длина секвенции 100 команд, и в ходе анализа полученной выборки исполнимых файлов было установлено, что одна из секвенций присутствует во всех файлах, длина секвенции может быть автоматически увеличена до 110 команд, после чего секвенции формируют заново и проверяют, что ни одна из секвенций не присутствует во всех файлах, составляющих полученную выборку.
Еще в одном возможном варианте реализации при невыполнении описанных требований к частотности секвенции может автоматически увеличиваться или уменьшаться шаг. Возможен также вариант при котором увеличивают одновременно шаг и длину секвенции, а также вариант, при котором увеличивают шаг и уменьшают длину секвенции.
В одном из возможных вариантов реализации описанного способа на этапе (135) дополнительно вычисляют энтропию каждой сформированной секвенции, и секвенцию сохраняют в базе данных только при условии, что ее энтропия превышает заранее заданный порог. Смысл подобной проверки с том, чтобы исключить из обработки секвенции, где слишком много повторяющихся команд. При этом энтропия может быть вычислена любым общеизвестным образом, например, как средняя энтропия сообщения, по формуле Шеннона:

где n - количество команд (длина) секвенции, a pi - вероятность присутствия определенной команды на i-й позиции внутри данной секвенции.
На примере секвенций (7) несложно видеть, что энтропия секвенций, в которых нет повтояющихся команд, например, секвенции а в с d е, будет выше, чем энтропия секвенций, в которых повторяющиеся команды присутствуют, как, например, в секвенции D Е F D Е.
В другом возможном варианте реализации описанного способа на этапе (135) сохраняют только те секвенции, энтропия которых оказывается больше первого заранее заданного порога, но меньше второго заданного порога. Таким образом отбирают и сохраняют секвенции, имеющие некоторое количество повторяющихся команд, но такие, где это количество не больше заданной величины.
Следует отметить, что на этапе (135) для каждой секвенции также сохраняют в базе данных указание на файл, из которого она получена, например, путем указания имени файла или полного пути к файлу, также включающего его имя и расширение.
В результате выполнения этапа (135) получают базу данных, в которой, отдельно для каждого файла исходного множества, полученного на шаге (110), сохранены все секвенции, обнаруженные в данном файле и обладающие заданным значением энтропии. Возможен также вариант реализации описываемого способа, при котором энтропию секвенций не вычисляют, а в базе данных сохраняют, отдельно для каждого файла исходного множества, все найденные в нем секвенции.
Указанная база данных может быть выполнена любым подходящим образом, например, она может представлять собой хеш-таблицу или любую другую известную структуру данных, реализующую интерфейс ассоциативного массива и позволяющую хранить пары «секвенция - значение», где поле «значение» подразумевает хранение численной величины.
На этом шаг (130), описанный применительно к Фиг. 1Б, завершается, и способ переходит, применительно к Фиг. 1 А, к шагу (140).
На шаге (140) определяют наиболее частотные секвенции, то есть такие секвенции, которые чаще всего встречаются в полученном на шаге (ПО) множестве исполняемых файлов. Это может быть выполнено любым общеизвестным способом. Например, сначала для каждой очередной секвенции из общего множества секвенций подсчитывают, сколько раз она встречается в исследуемом множестве исполняемых файлов; подсчитанное количество сохраняют в поле «значение», соответствующем данной секвенции. Затем, когда подсчет для всех секвенций завершен, вычисляют собственно частотность, то есть отношение количества вхождений данной секвенции L к общему количеству секвенций К. Этот параметр может быть, как меньше единицы, если секвенция встречается не в каждом исполняемом файле, так и больше, если секвенция в среднем встречается несколько раз на протяжении каждого файла:

Вычисленное для каждой секвенции значение частотности сохраняют в базе данных, в поле «значение», соответствующем данной секвенции. На этом шаг (140) завершается, и способ переходит к шагу (150).
На шаге (150) все файлы, которые содержат по меньшей мере одну наиболее частотную секвенцию, относят к одному семейству программ. Это может быть выполнено любым подходящим способом, например, поиском по хеш-таблице, применением методов машинного обучения и т.д.
На данном шаге выбирают одну или несколько секвенций, имеющих наибольшее численно значение частотности. Поскольку база данных хранит для каждой секвенции также указание на файл, из которого она получена, не составляет труда определить, в каких именно файлах полученного на шаге (ПО) множества исполняемых файлов встречается эта одна или эти несколько секвенций. Считают, что эти файлы составляют одно семейство семейство программ.
В альтернативном варианте реализации решение о принадлежности каждого файла к данному семейству принимается по результатам вычисления для этого файла значения взвешивающей функции вида F(A, Б, В, Г, Д, k1, k2, k3, k4, k5), где А…Д - пять наиболее частотных секвенций, a k1…k5 - коэффициенты, имеющий смысл частотности каждой из этих секвенций. Если значение F оказывается выше порогового значения, выбранного заранее, то считают, что данный файл относится к данному семейству. Возможны также варианты реализации описываемого способа, в которых учитывается другое количество наиболее частотных секвенций, например, без ограничения, две, три и так далее.
При этом собственно взвешивающая функция F может вычисляться, например, как
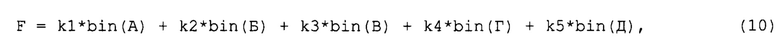
где bin(A) - бинарная величина, равная 1, если секвенция А найдена в данном файле, и равная 0, если не найдена, bin(Б) - аналогичная величина для секвенции Б, и т.д.
В одном варианте реализации способа коэффициенты k1…k5 могут быть вычислены как частотность данной секвенции (9). В другом возможном варианте реализации они могут быть вычислены как как отношение количества файлов, в которых данная секвенция хотя бы один раз присутствует, к общему количеству файлов. Также возможны любые другие варианты вычисления функции F, учитывающие вклад каждого из коэффициентов и наличие в данном файле конкретных секвенций.
Собственно отнесение файлов к одному семейству может означать, например, создание отдельной папки и копирование в эту папку соответствующих файлов. В альтернативном варианте реализации в текстовом файле, хранящем общий перечень имен файлов, полученных на шаге (110), напротив имен файлов, отнесенных к одному семейству, проставляется помета, например, «Семейство 1». Возможны также любые альтернативные варианты реализации данного шага, позволяющие указать на тот факт, что конкретные файлы, входившие в исходное множество исполнимых файлов, отнесены к одному семейству.
На этом шаг (150) завершается и способ переходит к шагу (160), на котором исключают все файлы, отнесенные к данному семейству, из дальнейшей обработки. На шаге (150) анализ ведут по базе данных, которая хранит созданные на шаге (140) секвенции и соответствующие им численные параметры, имеющие смысл частотности. Поэтому исключение из дальнейшей обработки файлов, отнесенных к одному семейству, технически может означать, например, исключение из базы данных тех секвенций, для которых в базе хранятся указания на эти файлы.
В альтернативном варианте реализации для тех секвенций, которые относятся к подлежащим исключению файлам, в базе данных могут быть обнулены численные значения, имеющие смысл частотности. Вследствие этого, в силу особенностей алгоритма, используемого на шаге (150), данные секвенции и соответствующие им файлы окажутся исключены из дальнейшего анализа.
На этом шаг (160) завершается и способ переходит к шагу (170). На данном шаге повторяют поиск наиболее частотных секвенций, отнесение файлов, содержащих по меньшей мере одну наиболее частотную секвенцию, к очередному семейству и исключение данных файлов из дальнейшей обработки до тех пор, пока все файлы не будут отнесены к какому-либо семейству, либо пока не останутся файлы, не содержащие повторяющихся секвенций.
Иными словами, шаг (170) представляет собой совокупность последовательно выполняемых описанных выше шагов (150) и (160), причем они выполняются циклически до тех пор, пока все файлы из множества, полученного на шаге (110), не окажутся отнесены к какому-либо семейству.
В том случае, если по окончании шага (170) в исходном множестве исполняемых файлов не осталось ни одного файла, не содержащего повторяющихся секвенций, на этом описываемый способ (100) завершается.
Возможна ситуация, при которой по окончании шага (170) в исходном множестве исполняемых файлов осталось какое-то количество файлов, причем они не содержат ни одной повторяющейся секвенции. В этом случае способ переходит к шагу (180).
На шаге (180) каждый из оставшихся файлов, в которых нет ни одной повторяющейся секвенции, относят к отдельному семейству. Иными словами, на шаге (180) создают столько новых семейств программ, сколько осталось файлов, не содержащих повторяющихся секвенций, и к каждому из этих новых семейств относят один из оставшихся файлов. На этом описываемый способ (100) завершается.
Альтернативно способу (100), описанному выше со ссылками на Фиг. 1А-Б, также возможна реализация заявленного компьютерно-реализуемого способа кластеризации исполняемых файлов, как это описано далее со ссылками на Фиг. 2А-В.
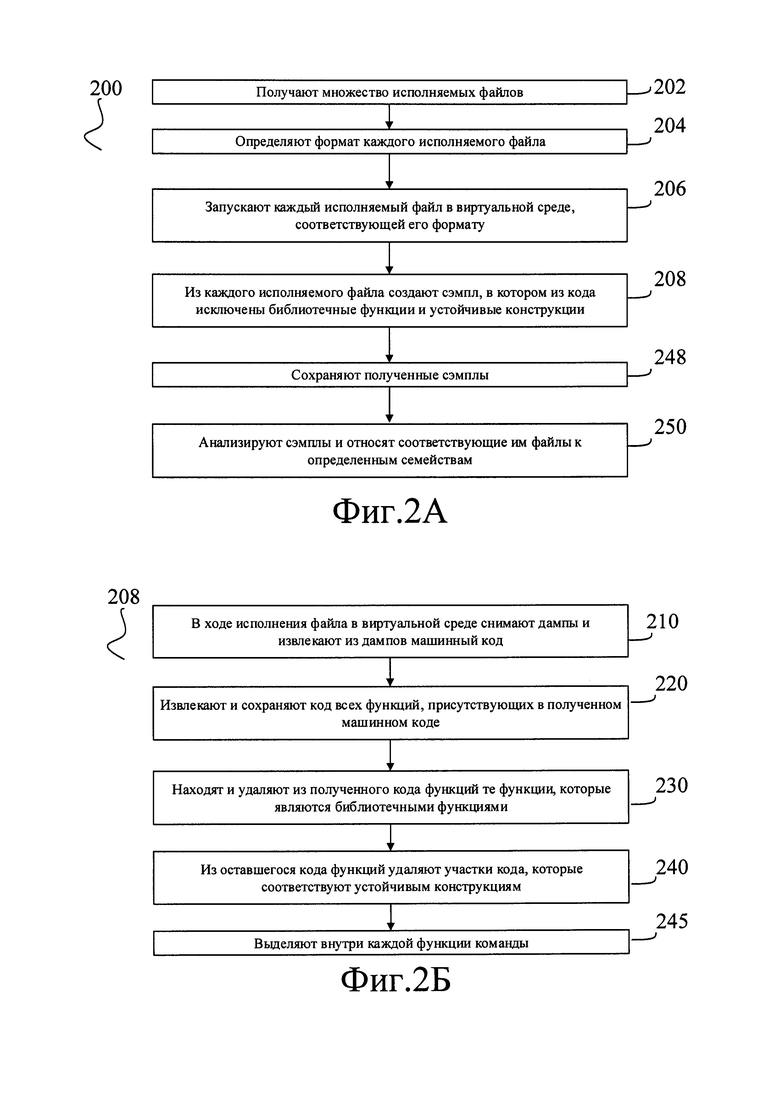
Как представлено на Фиг. 2А, заявленный компьютерно-реализуемый способ кластеризации исполняемых файлов (200) может быть реализован следующим образом:
Способ начинается на шаге (202), на котором получают множество исполняемых файлов, подлежащих анализу. Совершенно аналогично описанному выше шагу (НО), это могут быть уже откомпилированные файлы, наподобие ЕХЕ или DLL, содержащие программу или динамическую библиотеку, файлы электронных документов со встроенным языком сценариев (например, языком VBA), такие как файлы DOC или XLS, а также файлы, содержащие исходный код программ на любых интерпретируемых языках программирования, например, таких как JavaScript, Python и т.д. Во всех этих файлах или в некоторой их части также могут быть дополнительно зашифрованы фрагменты кода или данных, все эти файлы или их часть также могут быть обфусцированы, в том числе с использованием стойких к раскрытию алгоритмов. Исполнимые файлы могут относиться к любому известному формату, не ограничиваясь только форматом РЕ; например, это также могут быть, без ограничений, исполняемые файлы форматов Mach-O, ELF, COM, COFF и других.
Затем способ (200) переходит к шагу (204), на котором определяют формат каждого исполняемого файла и выбирают соответствующее формату средство анализа кода. Это выполняют полностью аналогично описанному выше шагу (120).
После завершения шага (204) способ (200) переходит к шагу (206), на котором каждый исполняемый файл запускают в изолированной среде, соответствующей его формату. Собственно изолированная среда может быть любой подходящей для запуска данного файла, выбор ее может осуществляться автоматически на основании сведений о формате файла, полученных на предыдущем шаге (204).
После этого способ переходит к шагу (208), на котором из исполняемого файла создают сэмпл. Сэмпл это не функциональная, используемая только для исследования часть исполняемого файла. Шаг (208) будет подробно описан ниже со ссылкой на Фиг. 2Б.
Как представлено на Фиг. 2Б, шаг (208) начинается на этапе (210), на котором снимают дампы и извлекают из дампов машинный код. В самом деле, любой исполняемый файл, запущенный в изолированной среде, порождает в рабочей памяти среды некоторое количество процессов. На данном этапе, обращаясь к рабочей памяти среды, получают дампы, то есть "отпечатки" рабочей памяти процессов, порожденных анализируемым файлом. При необходимости такие дампы могут делаться очень часто, буквально на каждый такт тактовой частоты основного процессора компьютерной системы, что позволяет детально изучить происходящие в памяти процессы. Снятие дампов может выполняться любым известным способом, например, при помощи утилиты ProcDump.
Поскольку каждый дамп памяти представляет собой текст машинного кода, располагающегося в памяти в момент снятия дампа, вышеописанным образом на этапе (210) получают машинный код программы, находящейся в исследуемом файле. При этом то обстоятельство, что источником данных выступает память рабочих процессов, позволяет получать "чистый", не зашифрованный и не обфусцированный машинный код даже в том случае, если исследуемый файл был стойко зашифрован, обфусцирован и т.д. Какой бы модификации ни был подвергнут ранее исследуемый файл, в тот момент, когда порожденные им процессы находятся в памяти, машинный код этих процессов характеризует именно те действия, для выполнения которых файл и был создан.
Извлеченный из дампов машинный код сохраняют, например, в виде файла текстового формата. На этом этап (210) завершается и способ переходит к этапу (220), на котором из полученного машинного кода извлекают и сохраняют код всех присутствующих в нем функций. Это выполняется программой-дизассемблером, а также программой-парсером, алгоритм действия которой основан на спецификации соответствующей данному файлу вычислительной архитектуры, такой, например, как архитектура х86.
На этапе (220) из машинного кода извлекают и сохраняют в виде списка функции. Это выполняют полностью аналогично описанному выше этапу (133). По окончании этапа (220) получают и сохраняют в виде отдельного файла код всех функций, имеющихся в анализируемом файле, после чего способ переходит к этапу (230).
На этапе (230) находят и удаляют из полученного кода функций те функции, которые являются библиотечными функциями. Для этого анализируют файл, полученный в ходе этапа (220) и содержащий найденные функции. При помощи сигнатурного анализа из списка исключают те функции, которые относятся к библиотечным. Библиотечные функции представляют собой стандартный инструментарий. Они широко используются самыми разными программами, поэтому их наличие в машинном коде или в рабочих процессах не специфично для какой-то одной определенной программы. Исключение библиотечных функций позволяет существенно упростить анализ и в то же время получить более качественный результат за счет того, что в коде останутся только те команды, которые наилучшим образом характеризуют конкретную программу.
Сигнатурный анализ и удаление библиотечных функций выполняют вспомогательной программой-скриптом. Алгоритм этого скрипта может представлять собой, например, поочередное сравнение каждой из функций с подготовленным заранее набором сигнатур (регулярных выражений). Каждая из этих сигнатур соответствует определенной, заранее описанной в виде сигнатуры библиотечной функции; при обнаружении функции, соответствующей какой-либо сигнатуре, весь код, составляющий тело и заголовок такой функции, из файла исключают.
По завершении обработки скриптом файл, содержащий оставшиеся функции, сохраняют и таким образом получают текст кода функций, присутствующих в анализируемом файле, и притом не являющихся библиотечными. На этом этап (230) завершается и способ переходит к этапу (240), на котором из оставшегося кода удаляют участки кода, которые соответствуют устойчивым конструкциям, то есть фрагменты кода, которые одинаково часто встречаются в любых программах, например, прологи функций. Это делают посредством заблаговременно изготовленной программы.
Изготовление названной программы (300) может быть выполнено, как это показано на Фиг. З, следующим образом.
На шаге (310) отбирают достаточное количество, например, 1000 экземпляров программ, относящихся к различным семействам. В состав данной вспомогательной подборки могут быть включены как заведомо вредоносные программы, например, датастилеры, загрузчики, «черви», так и заведомо легитимные, например, текстовые редакторы, программы просмотра изображений, архиваторы и так далее. В состав подборки также могут быть включены файлы электронных документов со встроенным языком сценариев (например, языком VBA), такие как файлы DOC или XLS, а также файлы, содержащие исходный код программ на любых интерпретируемых языках программирования, например, таких как JavaScript, Python и т.д.
На следующем шаге (320) обрабатывают указанную вспомогательную подборку алгоритмом, который выявляет повторяющиеся последовательности символов и подсчитывает количество вхождений данной последовательности символов в общем массиве кода. При этом задают минимальную длину последовательности, например, равной 20 символам, а максимальную длину последовательности не ограничивают. В альтернативном варианте воплощения задают как минимальную, так и максимальную длину последовательности, например, 15 и 250 символов соответственно.
Описанный алгоритм возвращает список найденных повторяющихся последовательностей символов, где каждой последовательности поставлено в соответствие количество ее вхождений во вспомогательной подборке файлов.
Затем на шаге (330) из списка устойчивых последовательностей, возвращенного алгоритмом, отбирают наиболее частотные последовательности. Например, отбирают те последовательности, которые встречаются в среднем не реже чем один раз в каждой программе, т.е. в данном примере, такие, которые встретились 1000 раз или больше.
На следующем шаге (340) создают программу или скрипт, который будет удалять из любого кода именно те последовательности, которые были отобраны на предыдущем шаге.
Таким образом получают программу, способную обрабатывать произвольные фрагменты кода, удаляя из них те последовательности символов, которые включены в "список удаления" как часто встречающиеся в разных программах.
Возвращаясь к Фиг. 2Б, после обработки программой (300) на этапе (240) получают файл, в котором из всех функций, выявленных в анализируемом файле, удалены устойчивые конструкции, то есть такие фрагменты кода, которые достаточно часто встречаются в любых, произвольно выбранных программах.
На этом этап (240) завершается и способ переходит к этапу (245). На этом этапе анализируют файл, полученный на предыдущем этапе, и выделяют внутри каждой функции команды. Этап (245) выполняется полностью аналогично описанному выше этапу (134), и в результате его для каждого файла исходного множества получают сэмпл, в котором из кода удалены как библиотечные функции, так и устойчивые конструкции.
После завершения этапа (245) способ переходит, применительно к Фиг. 2А, к этапу (248), на котором сохраняют полученные сэмплы. Следует отметить, что на этапе (248) для каждого сэмпла также сохраняют в базе данных указание на файл, из которого он получен, например, путем указания имени файла или полного пути к файлу, также включающего его имя и расширение, или как-либо иначе, любым известным способом. То есть тем или иным образом но для каждого сохраняемого сэмпла сохраняют также сведения о том, из какого именно файла данных сэмпл получен.
На этом этап (248) завершается и способ переходит к этапу (250), на котором анализируют сэмплы и относят соответствующие им файлы к определенным семействам. Выполнение этапа (250) подробно описано ниже со ссылкой на Фиг. 2В.
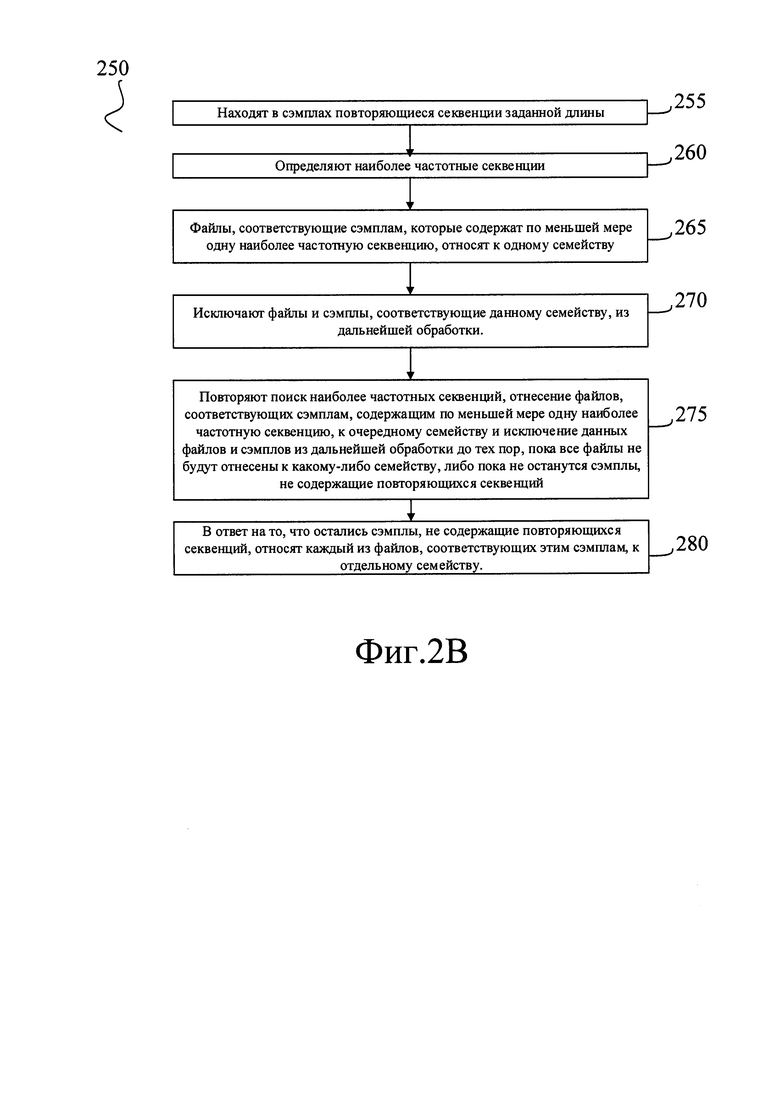
Как представлено на Фиг. 2В, выполнение этапа (250) начинается на шаге (255), на котором находят в полученных на предыдущем этапе сэмплах повторяющиеся секвенции заданной длины. Это выполняют аналогично описанному ранее со ссылкой на Фиг. 1Б этапу (135), с той лишь разницей, что секвенции в данном случае формируются из команд, следующих одна за другой в коде исследуемого сэмпла, а не в коде исследуемого файла. Иными словами, на шаге (255) выполняют те же самые действия, что были описаны ранее для этапа (135), но применительно к сэмплам, а не к файлам.
Полностью аналогично описанному выше, в результате выполнения шага (255) получают базу данных, в которой, отдельно для каждого сэмпла, сохранены все секвенции, обнаруженные в данном сэмпле и обладающие заданным значением энтропии. Возможен также вариант реализации описываемого способа, при котором энтропию секвенций не вычисляют, а в базе данных сохраняют, отдельно для каждого сэмпла, все найденные в нем секвенции. Понятно, что на основании этих сведений не составляет труда любым известным способом построить и обратную зависимость, то есть найти, в каких именно сэмплах присутствует данная секвенция. На этом шаг (255) завершается и способ переходит к шагу (260).
На шаге (260) определяют наиболее частотные секвенции, то есть такие секвенции, которые чаще всего встречаются в полученном множестве сэмплов. Это может быть выполнено аналогично описанному выше шагу (140). Вычисленное для каждой секвенции значение частотности сохраняют в базе данных, в поле «значение», соответствующем данной секвенции. На этом шаг (260) завершается, и способ переходит к шагу (265).
На шаге (265) файлы, соответствующие тем сэмплам, которые содержат по меньшей мере одну наиболее частотную секвенцию, относят к одному семейству. Это выполняют аналогично описанному выше шагу (150), с той лишь разницей, что по меньшей мере одну наиболее частотную секвенцию находят в сэмплах, а к одному семейству программ относят соответствующие этим сэмплам файлы.
Как и было описано выше, на данном шаге выбирают одну или несколько секвенций, имеющих наибольшее численно значение частотности. Поскольку база данных хранит для каждой секвенции также указание на сэмпл или сэмплы, где она встречается, а для каждого сэмпла на этапе (248) было сохранено указание на соответствующий ему файл, не составляет труда определить, каким именно файлам полученного на шаге (110) множества исполняемых файлов соответствуют эта одна или эти несколько секвенций. Считают, что эти файлы составляют одно семейство семейство программ.
На этом шаг (265) завершается и способ переходит к шагу (270), на котором исключают файлы и сэмплы, соответствующие данному семейству, из дальнейшей обработки. Поскольку анализ ведут по базе данных, которая хранит созданные секвенции и соответствующие им численные параметры, имеющие смысл частотности, исключение из дальнейшей обработки сэмплов, отнесенных к одному семейству, технически может означать, например, исключение из базы данных тех секвенций, для которых в базе хранятся указания на эти сэмплы.
В альтернативном варианте реализации для тех секвенций, которые относятся к подлежащим исключению сэмплам, в базе данных могут быть обнулены численные значения, имеющие смысл частотности. Вследствие этого, в силу особенностей используемого алгоритма, данные секвенции и соответствующие им сэмплы окажутся исключены из дальнейшего анализа. Понятно также, что после выполнения данной операции наиболее частотными секвенциями, оставшимися в базе данных, будут секвенции, имеющие показатели частотности, следующие за показателями только что исключенных секвенций
На этом шаг (270) завершается и способ переходит к шагу (275). На данном шаге повторяют поиск наиболее частотных секвенций, отнесение файлов, соответствующих сэмплам, содержащим по меньшей мере одну наиболее частотную секвенцию, к очередному семейству и исключение данных файлов и сэмплов из дальнейшей обработки до тех пор, пока все файлы не будут отнесены к какому-либо семейству, либо пока не останутся сэмплы, не содержащие повторяющихся секвенций.
Иными словами, шаг (275) представляет собой совокупность последовательно выполняемых описанных выше шагов (260)…(270), причем они выполняются циклически до тех пор, пока все файлы из множества, полученного на шаге (110), не окажутся отнесены к какому-либо семейству.
В том случае, если по окончании шага (275) в анализируемом множестве сэмплов не осталось ни одного сэмпла, не содержащего повторяющихся секвенций, на этом описываемый способ (200) завершается.
Возможна ситуация, при которой по окончании шага (275) в анализируемом множестве сэмплов осталось какое-то количество сэмплов, причем они не содержат ни одной повторяющейся секвенции. В одном из возможных вариантов реализации способа файлы, соответствующие этим секвенциям, не относят ни к одному из семейств, способ (200) также завершается. В другом возможном варианте реализации в подобном случае способ переходит к шагу (280).
На шаге (280) каждый из файлов, соответствующих сэмплам, в которых нет ни одной повторяющейся секвенции, относят к отдельному семейству. Иными словами, на шаге (280) создают столько новых семейств программ, сколько осталось сэмплов, не содержащих повторяющихся секвенций, и к каждому из этих новых семейств относят один из оставшихся файлов.
На этом описываемый способ (200) завершается.
Ниже приведены дополнительные варианты реализации настоящего изобретения.
В частном варианте реализации способа длина секвенции выбирается в зависимости от количества файлов, в которых была найдена данная секвенция.
В другом частном варианте реализации способа длина секвенции является фиксированной, заранее заданной величиной.
Еще в одном частном варианте реализации способа рассматривают только секвенции, энтропия которых превышает заранее заданный порог.
В частном варианте реализации способа наиболее частотные секвенции находят посредством поиска по хеш-таблице.
В другом частном варианте реализации способа решение о принадлежности каждого файла к данному одному семейству принимается по результатам вычисления для этого файла значения взвешивающей функции, представляющей собой сумму коэффициентов по меньшей мере двух наиболее частотных секвенций, найденных в данном файле.
Еще в одном частном варианте реализации способа каждый коэффициент взвешивающей функции вычисляют как отношение количества файлов, в которых хотя бы один раз присутствует данная секвенция, к исходному количеству файлов.
В другом частном варианте реализации способа в ответ на то, что остались файлы, не содержащие повторяющихся секвенций, эти файлы не относят ни к одном семейству.
В еще одном частном варианте реализации способа длина секвенции выбирается в зависимости от количества сэмплов, в которых была найдена данная секвенция.
Возможен также частный вариант реализации способа, при котором решение о принадлежности каждого файла к данному семейству принимается по результатам вычисления для этого файла значения взвешивающей функции, представляющей собой сумму коэффициентов по меньшей мере двух наиболее частотных секвенций, найденных в сэмпле, соответствующем данному файлу.
В другом частном варианте реализации способа каждый коэффициент взвешивающей функции вычисляют как отношение количества сэмплов, в которых хотя бы один раз присутствует данная секвенция, к исходному количеству сэмплов.
В еще одном частном варианте реализации способа в ответ на то, что остались сэмплы, не содержащие повторяющихся секвенций, файлы, соответствующие этим сэмплам, не относят ни к одном семейству.
Заявленное решение также осуществляется за счет системы кластеризации исполняемых файлов, содержащей:
- долговременную память, выполненную с возможностью хранения упомянутых файлов, а также базы данных;
- вычислительное устройство, выполненное с возможностью выполнения описанного способа.
На Фиг. 4 далее будет представлена общая схема вычислительного устройства (400), обеспечивающего обработку данных, необходимую для реализации заявленного решения.
В общем случае устройство (400) содержит такие компоненты, как: один или более процессоров (401), по меньшей мере одну память (402), средство хранения данных (403), интерфейсы ввода/вывода (404), средство В/В (405), средства сетевого взаимодействия (406).
Процессор (401) устройства выполняет основные вычислительные операции, необходимые для функционирования устройства (400) или функциональности одного или более его компонентов. Процессор (401) исполняет необходимые машиночитаемые команды, содержащиеся в оперативной памяти (402).
Память (402), как правило, выполнена в виде ОЗУ и содержит необходимую программную логику, обеспечивающую требуемый функционал.
Средство хранения данных (403) может выполняться в виде HDD, SSD дисков, рейд массива, сетевого хранилища, флэш-памяти, оптических накопителей информации (CD, DVD, MD, Blue-Ray дисков) и т.п.Средство (403) позволяет выполнять долгосрочное хранение различного вида информации, например, вышеупомянутых файлов, промежуточных данных, списков, баз данных и т.п.
Интерфейсы (404) представляют собой стандартные средства для подключения и работы, например, USB, RS232, RJ45, LPT, COM, HDMI, PS/2, Lightning, Fire Wire и т.п.
Выбор интерфейсов (404) зависит от конкретного исполнения устройства (400), которое может представлять собой персональный компьютер, мейнфрейм, сервер, серверный кластер, тонкий клиент, смартфон, ноутбук и т.п.
В качестве средств В/В данных (405) может использоваться клавиатура. Помимо клавиатуры, в составе средств В/В данных также может использоваться: джойстик, дисплей (сенсорный дисплей), проектор, тачпад, манипулятор мышь, трекбол, световое перо, динамики, микрофон и т.п.
Средства сетевого взаимодействия (406) выбираются из устройств, обеспечивающий сетевой прием и передачу данных, например, Ethernet карту, WLAN/Wi-Fi модуль, Bluetooth модуль, BLE модуль, NFC модуль, IrDa, RFID модуль, GSM модем и т.п.С помощью средств (406) обеспечивается организация обмена данными по проводному или беспроводному каналу передачи данных, например, WAN, PAN, ЛВС (LAN), Интранет, Интернет, WLAN, WMAN или GSM.
Компоненты устройства (400) сопряжены посредством общей шины передачи данных (410).
В настоящих материалах заявки были представлены два варианта предпочтительного раскрытия осуществления заявленного технического решения, которые не должны использоваться как ограничивающее иные, частные воплощения его реализации, которые не выходят за рамки испрашиваемого объема правовой охраны и являются очевидными для специалистов в соответствующей области техники.
Изобретение относится к вычислительной технике. Технический результат заключается в обеспечении автоматической кластеризации исполняемых файлов. Способ кластеризации исполняемых файлов, выполняемый на компьютерном устройстве и содержащий шаги, на которых: получают множество исполняемых файлов, определяют формат каждого исполняемого файла по отдельности для каждого формата файлов: находят в файлах повторяющиеся секвенции заданной длины, определяют наиболее частотные секвенции, файлы, которые содержат по меньшей мере одну наиболее частотную секвенцию, относят к одному семейству, исключают все файлы, относящиеся к данному семейству, из дальнейшей обработки, повторяют поиск наиболее частотных секвенций, отнесение файлов, содержащих по меньшей мере одну наиболее частотную секвенцию, к очередному семейству и исключение данных файлов из дальнейшей обработки до тех пор, пока все файлы не будут отнесены к какому-либо семейству либо пока не останутся файлы, не содержащие повторяющихся секвенций, в ответ на то, что остались файлы, не содержащие повторяющихся секвенций, каждый из этих файлов относят к отдельному семейству. 3 н. и 14 з.п. ф-лы, 7 ил.
1. Способ кластеризации исполняемых файлов, выполняемый на компьютерном устройстве, способ, содержащий шаги, на которых:
получают множество исполняемых файлов,
определяют формат каждого исполняемого файла,
по отдельности для каждого формата файлов:
находят в файлах повторяющиеся секвенции заданной длины путём преобразования файла в исходный код, анализа исходного кода с целью определения в нём границ, фрагменты кода внутри которых являются функциями, последующего выделения внутри функций команд, из которых формируют секвенции заданной длины,
определяют наиболее частотные секвенции,
файлы, которые содержат по меньшей мере одну наиболее частотную секвенцию, относят к одному семейству,
исключают все файлы, относящиеся к данному семейству, из дальнейшей обработки,
повторяют поиск наиболее частотных секвенций, отнесение файлов, содержащих по меньшей мере одну наиболее частотную секвенцию, к очередному семейству и исключение данных файлов из дальнейшей обработки до тех пор, пока все файлы не будут отнесены к какому-либо семейству либо пока не останутся файлы, не содержащие повторяющихся секвенций,
в ответ на то, что остались файлы, не содержащие повторяющихся секвенций, каждый из этих файлов относят к отдельному семейству.
2. Способ по п. 1, отличающийся тем, что длина секвенции выбирается в зависимости от количества файлов, в которых была найдена данная секвенция.
3. Способ по п. 1, отличающийся тем, что длина секвенции является фиксированной, заранее заданной величиной.
4. Способ по п. 1, отличающийся тем, что рассматривают только секвенции, энтропия которых превышает заранее заданный порог.
5. Способ по п. 1, отличающийся тем, что наиболее частотные секвенции находят посредством поиска по хеш-таблице.
6. Способ по п. 1, отличающийся тем, что решение о принадлежности каждого файла к данному одному семейству принимается по результатам вычисления для этого файла значения взвешивающей функции, представляющей собой сумму коэффициентов по меньшей мере двух наиболее частотных секвенций, найденных в данном файле.
7. Способ по п. 6, отличающийся тем, что каждый коэффициент взвешивающей функции вычисляют как отношение количества файлов, в которых хотя бы один раз присутствует данная секвенция, к исходному количеству файлов.
8. Способ по п. 1, отличающийся тем, что в ответ на то, что остались файлы, не содержащие повторяющихся секвенций, эти файлы не относят ни к одном семейству.
9. Способ кластеризации исполняемых файлов, выполняемый на компьютерном устройстве, способ, содержащий шаги, на которых:
получают множество исполняемых файлов,
определяют формат каждого исполняемого файла,
запускают каждый исполняемый файл в виртуальной среде, соответствующей его формату,
из каждого исполняемого файла создают сэмпл, в котором из кода исключены библиотечные функции и устойчивые конструкции, и сохраняют полученный сэмпл,
после получения сэмплов, соответствующих всем полученным файлам:
находят в сэмплах повторяющиеся секвенции заданной длины путём анализа машинного кода сэмпла с целью определения в нём границ, фрагменты кода внутри которых являются функциями, последующего выделения внутри функций команд, из которых формируют секвенции заданной длины,
определяют наиболее частотные секвенции,
файлы, соответствующие сэмплам, которые содержат по меньшей мере одну наиболее частотную секвенцию, относят к одному семейству,
исключают файлы и сэмплы, соответствующие данному семейству, из дальнейшей обработки,
повторяют поиск наиболее частотных секвенций, отнесение файлов, соответствующих сэмплам, содержащим по меньшей мере одну наиболее частотную секвенцию, к очередному семейству и исключение данных файлов и сэмплов из дальнейшей обработки до тех пор, пока все файлы не будут отнесены к какому-либо семейству либо пока не останутся сэмплы, не содержащие повторяющихся секвенций,
в ответ на то, что остались сэмплы, не содержащие повторяющихся секвенций, каждый из файлов, соответствующих этим сэмплам, относят к отдельному семейству.
10. Способ по п. 9, отличающийся тем, что длина секвенции выбирается в зависимости от количества сэмплов, в которых была найдена данная секвенция.
11. Способ по п. 9, отличающийся тем, что длина секвенции является фиксированной, заранее заданной величиной.
12. Способ по п. 9, отличающийся тем, что рассматривают только секвенции, энтропия которых превышает заранее заданный порог.
13. Способ по п. 9, отличающийся тем, что наиболее частотные секвенции находят посредством поиска по хеш-таблице.
14. Способ по п. 9, отличающийся тем, что решение о принадлежности каждого файла к данному семейству принимается по результатам вычисления для этого файла значения взвешивающей функции, представляющей собой сумму коэффициентов по меньшей мере двух наиболее частотных секвенций, найденных в сэмпле, соответствующем данному файлу.
15. Способ по п. 14, отличающийся тем, что каждый коэффициент взвешивающей функции вычисляют как отношение количества сэмплов, в которых хотя бы один раз присутствует данная секвенция, к исходному количеству сэмплов.
16. Способ по п. 9, отличающийся тем, что в ответ на то, что остались сэмплы, не содержащие повторяющихся секвенций, файлы, соответствующие этим сэмплам, не относят ни к одном семейству.
17. Система кластеризации исполняемых файлов, содержащая:
- долговременную память, выполненную с возможностью хранения используемых файлов и данных;
- вычислительное устройство, выполненное с возможностью выполнения способа по любому из пп. 1-16.
| Устройство для закрепления лыж на раме мотоциклов и велосипедов взамен переднего колеса | 1924 |
|
SU2015A1 |
| US 10546143 B1, 28.01.2020 | |||
| US 6928434 B1, 09.08.2005 | |||
| Токарный резец | 1924 |
|
SU2016A1 |
| Способ очистки сальварсана | 1950 |
|
SU91213A1 |

