Область техники, к которой относится изобретение
Варианты осуществления согласно изобретению относятся к модулям оценки подобия аудиосигналов.
Дополнительные варианты осуществления согласно изобретению относятся к аудиокодерам.
Дополнительные варианты осуществления согласно изобретению относятся к способам оценки подобия между аудиосигналами.
Дополнительные варианты осуществления согласно изобретению относятся к способам для кодирования аудиосигнала.
Дополнительные варианты осуществления согласно изобретению относятся к компьютерной программе для осуществления упомянутых способов.
Обычно, варианты осуществления согласно изобретению относятся к улучшенной психоакустической модели для эффективных перцепционных аудиокодеков.
Уровень техники
Кодирование аудио представляет собой перспективную область техники, поскольку кодирование и декодирование аудиоконтента является важным во многих областях техники, таких как мобильная связь, потоковая передача аудио, широковещательная передача аудио, телевидение и т.д.
Далее предоставляется введение в перцепционное кодирование. Следует отметить, что определения и подробности, поясненные далее, могут необязательно применяться в сочетании с вариантами осуществления, раскрытыми в данном документе.
Перцепционные кодеки
Перцепционные аудиокодеки, такие как MP3 или AAC, широко используются для того, чтобы кодировать аудио в сегодняшних мультимедийных приложениях [1]. Большинство популярных кодеков представляют собой так называемые кодеры на основе формы сигналов, т.е. они сохраняют форму сигналов временной области аудио и главным образом добавляют (неслышимый) шум в него вследствие перцепционно управляемого применения квантования. Квантование типично может происходить в частотно-временной области, но также может применяться во временной области [2]. Чтобы делать аддитивный шум неслышимым, он формируется под управлением психоакустической модели, типично перцепционной маскирующей модели.
В сегодняшних аудиоприложениях, имеется постоянная потребность в более низких скоростях передачи битов. Перцепционные аудиокодеки традиционно ограничивают полосу пропускания аудиосигнала таким образом, чтобы по-прежнему достигать неплохого перцепционного качества при этих низких скоростях передачи битов. Эффективные полупараметрические технологии, такие как репликация полосы пропускания спектра (SBR) [3] в высокоэффективном усовершенствованном кодировании аудио (HE-AAC) [4] или интеллектуальное заполнение промежутков (IGF) [5] в MPEG-H-стандарте трехмерного аудио [6] и улучшенных голосовых 3GPP-услугах (EVS) [7], используются для расширения аудио с ограниченной полосой частот вплоть до полной полосы пропускания на стороне декодера. Такая технология называется "расширением полосы пропускания (BWE)". Эти технологии вставляют оценку отсутствующего высокочастотного контента, управляемого посредством нескольких параметров. Типично, наиболее важная вспомогательная BWE-информация представляет собой связанные с огибающей данные. Обычно, процесс оценки направляется посредством эвристики, а не психоакустической модели.
Перцепционные модели
Психоакустические модели, используемые в кодировании аудио, главным образом основываются на оценке того, маскируется или нет сигнал ошибки перцепционно посредством исходного аудиосигнала, который должен кодироваться. Этот подход хорошо работает, когда сигнал ошибки вызывается посредством процесса квантования, типично используемого в кодерах на основе формы сигналов. Тем не менее, для параметрических представлений сигналов, таких как SBR или IGF, сигнал ошибки должен быть большим, даже когда артефакты являются едва слышимыми.
Это представляет собой следствие того факта, что слуховая система человека не обрабатывает точную форму сигнала аудиосигнала; в определенных ситуациях слуховая система является нечувствительной к фазе, и временная огибающая полосы частот спектра становится основной слуховой информацией, которая оценивается. Например, различные начальные фазы синусоиды (со сглаженным вступлением и смещениями) не имеют воспринимаемого эффекта. Тем не менее, для комплексного гармонического тона, относительные начальные фазы могут быть перцепционно важными, в частности, когда несколько гармоник попадают в одну критическую полосу слуховых частот [8]. Относительные фазы этих гармоник, а также их амплитуды, оказывают влияние на форму временной огибающей, которая представляется в одной критической полосе слуховых частот, которая, в принципе может обрабатываться посредством слуховой системы человека.
С учетом этой ситуации, имеется потребность в концепции для того, чтобы сравнивать аудиосигналы и/или определять параметры кодирования, которые предоставляют улучшенный компромисс между вычислительной сложностью и перцепционной релевантностью и/или которые позволяют впервые использовать параметрические технологии под управлением психоакустической модели.
Сущность изобретения
Вариант осуществления согласно изобретению создает модуль оценки подобия аудиосигналов.
Модуль оценки подобия аудиосигналов выполнен с возможностью получать сигналы огибающей для множества (предпочтительно перекрывающихся) частотных диапазонов (например, с использованием гребенки фильтров или гребенки гамматоновых фильтров и выпрямления и временной фильтрации нижних частот и одного или более процессов адаптации, которые, например, могут моделировать премаскирование и/или постмаскирование в слуховой системе) на основе входного аудиосигнала (например, чтобы выполнять демодуляцию огибающей в подполосах частот спектра).
Модуль оценки подобия аудиосигналов выполнен с возможностью получать информацию модуляции (например, выходные сигналы модуляционных фильтров), ассоциированную с сигналами огибающей для множества частотных диапазонов модуляции (например, с использованием гребенки модуляционных фильтров либо с использованием модуляционных фильтров), при этом информация модуляции описывает (например, в форме выходных сигналов гребенки модуляционных фильтров или в форме выходных сигналов модуляционных фильтров) модуляцию сигналов огибающей (и, например, может рассматриваться как внутреннее представление), Например, модуль оценки подобия аудиосигналов может быть выполнен с возможностью выполнять модуляционный анализ огибающей.
Модуль оценки подобия аудиосигналов выполнен с возможностью сравнивать полученную информацию модуляции (например, внутреннее представление) с опорной информацией модуляции, ассоциированной с опорным аудиосигналом (например, с использованием внутреннего разностного представления, при этом внутреннее разностное представление, например, может описывать разность между полученной информацией модуляции и опорной информацией модуляции, при этом могут применяться одна или более операций взвешивания или операций модификации, таких как масштабирование внутреннего разностного представления на основе степени комодуляции или асимметричное взвешивание положительных и отрицательных значений внутреннего разностного представления) для того, чтобы получать информацию относительно подобия между входным аудиосигналом и опорным аудиосигналом (например, одно значение, описывающее перцепционное подобие между входным аудиосигналом и опорным аудиосигналом).
Этот вариант осуществления согласно изобретению основан на таких выявленных сведениях, что информация модуляции, которая ассоциирована с сигналами огибающей для множества частотных диапазонов модуляции, может получаться с небольшими усилиями (например, с использованием первой гребенки фильтров для того, чтобы получать сигналы огибающей, и с использованием второй гребенки фильтров, которая может представлять собой гребенку модуляционных фильтров для того, чтобы получать информацию модуляции, при этом некоторые незначительные дополнительные этапы обработки также используются для того, чтобы повышать точность).
Кроме того, обнаружено, что такая информация модуляции является хорошо адаптированной к ощущению для человеческого слуха во многих ситуациях, что означает то, что подобие информации модуляции соответствует аналогичному восприятию аудиоконтента, в то время как главное различие состоит в том, что информация модуляции типично указывает то, что аудиоконтент должен восприниматься как отличающийся. Таким образом, посредством сравнения информации модуляции входного аудиосигнала с информацией модуляции, ассоциированной с опорным аудиосигналом, можно прийти к заключению, должен входной аудиосигнал восприниматься как аналогичный аудиоконтенту опорного аудиосигнала или нет. Другими словами, количественный показатель, который представляет подобие или разность между информацией модуляции, ассоциированной с входным аудиосигналом, и информацией модуляции, ассоциированной с опорным аудиосигналом, может служить в качестве (количественной) информации подобия, представляющей подобие между аудиоконтентом входного аудиосигнала и аудиоконтентом опорного аудиосигнала перцепционно взвешенным способом.
Таким образом, информация подобия, полученная посредством модуля оценки подобия аудиосигналов (например, одно скалярное значение, ассоциированное с определенным проходом (например, кадром) входного аудиосигнала (и/или опорного аудиосигнала), оптимально подходит для того, чтобы определять (например, количественным способом) то, насколько "входной аудиосигнал" перцепционно ухудшается относительно опорного аудиосигнала (например, если предполагается, что входной аудиосигнал представляет собой ухудшенную версию опорного аудиосигнала).
Обнаружено, что этот показатель подобия, например, может использоваться для определения качества кодирования аудио с потерями и, в частности, кодирования аудио без сохранения формы сигнала с потерями. Например, информация подобия указывает сравнительно большое отклонение, если "модуляция" (сигнала огибающей) в одном или более частотных диапазонов изменяется значительным образом, что типично должно приводить к ухудшенному ощущению для слуха. С другой стороны, информация подобия, предоставленная посредством модуля оценки подобия, типично должна указывать сравнительно высокое подобие (или, эквивалентно, сравнительно небольшую разность или отклонение), если модуляция в различных полосах частот является аналогичной во входном аудиосигнале и в опорном аудиосигнале, даже если фактические формы сигнала существенно отличаются. Таким образом, результат является согласованным с такими выявленными сведениями, что слушатель-человек типично является не очень чувствительным к фактической форме сигнала, но является более чувствительным относительно модуляционных характеристик аудиоконтента в различных полосах частот.
В качестве вывода, модуль оценки подобия, описанный здесь, предоставляет информацию подобия, которая является хорошо адаптированной к ощущению для человеческого слуха.
В предпочтительном варианте осуществления, модуль оценки подобия аудиосигналов выполнен с возможностью применять множество фильтров или операций фильтрации (например, гребенки фильтров или гребенки гамматоновых фильтров), имеющих перекрывающиеся характеристики фильтра (например, перекрывающиеся полосы пропускания) для того, чтобы получать сигналы огибающей (при этом, предпочтительно, полосы пропускания фильтров или операций фильтрации увеличиваются с увеличением центральных частот фильтров). Например, различные сигналы огибающей могут быть ассоциированы с различными акустическими частотными диапазонами входного аудиосигнала.
Этот вариант осуществления основан на таких выявленных сведениях, что сигналы огибающей могут получаться с небольшими усилиями с использованием фильтров или операций фильтрации, имеющих перекрывающиеся характеристики фильтра, поскольку это является точно согласованным со слуховой системой человека. Кроме того, обнаружено, что преимущественно увеличивать полосу пропускания фильтров или операций фильтрации с увеличением частоты, поскольку это является точно согласованным со слуховой системой человека и, кроме того, помогает поддерживать число фильтров достаточно небольшим при предоставлении хорошего частотного разрешения в перцепционно важной низкочастотной области. Соответственно, различные сигналы огибающей типично ассоциированы с различными акустическими частотными диапазонами входного аудиосигнала, что помогает получать точную информацию подобия, имеющую обоснованное частотное разрешение. Например, различное ухудшение качества сигнала (например, входного аудиосигнала относительно опорного аудиосигнала) в различных частотных диапазонах может рассматриваться таким образом.
В предпочтительном варианте осуществления, модуль оценки подобия аудиосигналов выполнен с возможностью применять выпрямление (например, полуволновое выпрямление) к выходным сигналам фильтров или операции фильтрации, с тем чтобы получать множество выпрямленных сигналов (например, чтобы моделировать внутренние волосковые клетки).
Посредством применения выпрямления к выходным сигналам фильтров или операции фильтрации, можно ассимилировать поведение внутренних волосковых клеток. Кроме того, выпрямление в комбинации с фильтром нижних частот предоставляет сигналы огибающей, которые отражают интенсивности в различных частотных диапазонах. Кроме того, вследствие выпрямления (и возможно фильтрация нижних частот), представление чисел является сравнительно простым (например, поскольку должны представляться только положительные значения). Кроме того, явление фазовой синхронизации и ее потери для верхних частот моделируется посредством упомянутой обработки.
В предпочтительном варианте осуществления, модуль оценки подобия аудиосигналов выполнен с возможностью применять фильтр нижних частот или фильтрацию нижних частот (например, имеющую частоту отсечки, которая меньше 2500 Гц или которая меньше 1500 Гц) к полуволновым выпрямленным сигналам (например, чтобы моделировать внутренние волосковые клетки).
Посредством использования фильтра нижних частот или фильтрации нижних частот (которая, например, может применяться отдельно к каждому сигналу огибающей из множества сигналов огибающей, ассоциированных с различными частотными диапазонами), может моделироваться инертность внутренних волосковых клеток. Кроме того, количество выборок данных уменьшается посредством выполнения фильтрации нижних частот, и последующая обработка фильтрованных по нижним частотам (предпочтительно выпрямленных) полосовых сигналов упрощается. Таким образом, предпочтительно выпрямленный и фильтрованный по нижним частотам выходной сигнал множества фильтров или операций фильтрации может служить в качестве сигналов огибающей.
В предпочтительном варианте осуществления, модуль оценки подобия аудиосигналов выполнен с возможностью применять автоматическую регулировку усиления для того, чтобы получать сигналы огибающей.
Посредством применения автоматической регулировки усиления для того, чтобы получать сигналы огибающей, динамический диапазон сигналов огибающей может быть ограничен, что уменьшает числовые проблемы. Кроме того, обнаружено, что использование автоматической регулировки усиления, которая использует определенные постоянные времени для адаптации усиления, моделирует эффекты маскирования, которые возникают в слуховой системе, так что подобие информации, полученной посредством модуля оценки подобия аудиосигналов, отражает ощущение для человеческого слуха.
В предпочтительном варианте осуществления, модуль оценки подобия аудиосигналов выполнен с возможностью варьировать усиление, применяемое для того, чтобы извлекать сигналы огибающей на основе выпрямленных и фильтрованных по нижним частотам сигналов, предоставленных посредством множества фильтров или операций фильтра на основе входного аудиосигнала.
Обнаружено, что варьирование усиления, которое применяется для того, чтобы извлекать сигналы огибающей на основе выпрямленных и фильтрованных по нижним частотам сигналов, предоставленных посредством множества фильтров или операций фильтра (на основе входного аудиосигнала), представляет собой эффективное средство для реализации автоматической регулировки усиления. Обнаружено, что автоматическая регулировка усиления может легко реализовываться после выпрямления и фильтрации нижних частот сигналов, предоставляемых посредством множества фильтров или операций фильтра. Другими словами, автоматическая регулировка усиления применяется отдельно для каждого частотного диапазона, и обнаружено, что такое поведение является точно согласованным со слуховой системой человека.
В предпочтительном варианте осуществления, модуль оценки подобия аудиосигналов выполнен с возможностью обрабатывать выпрямленные и фильтрованные по нижним частотам версии сигналов, предоставляемых посредством множества фильтров или операций фильтрации (например, предоставленных посредством гребенки гамматоновых фильтров) на основе входного аудиосигнала с использованием последовательности двух или более контуров адаптации (предпочтительно пяти контуров адаптации), которые применяют время-зависимое масштабирование в зависимости от время-зависимых значений усиления (например, чтобы осуществлять многостадийную автоматическую регулировку усиления, при этом значение усиления задается равным сравнительно небольшому значению для сравнительно большого входного сигнала или выходного сигнала соответствующей стадии, и при этом значение усиления задается равным сравнительно большему значению для сравнительно меньшего входного значения или выходного значения соответствующей стадии). Необязательно, предусмотрено ограничение одного или более выходных сигналов, например, таким образом, чтобы ограничивать или исключать перерегулирование, например, "ограничитель".
Модуль оценки подобия аудиосигналов выполнен с возможностью регулировать различные время-зависимые значения усиления (которые ассоциированы с различными стадиями в последовательности контуров адаптации) с использованием различных постоянных времени (например, чтобы моделировать премаскирование во вступлении аудиосигнала и/или моделировать постмаскирование после смещения аудиосигнала).
Следует признавать то, что использование последовательности двух или более контуров адаптации, которые применяют время-зависимое масштабирование в зависимости от время-зависимых значений усиления, является хорошо адаптированным для того, чтобы моделировать различные постоянные времени, которые возникают в слуховой системе человека. При регулировании различных время-зависимых значений усиления, которые используются в различных из каскадных контуров адаптации, могут рассматриваться различные постоянные времени премаскирования и постмаскирования. Кроме того, дополнительные процессы маскирования при адаптации, которые возникают в слуховой системе человека, могут моделироваться таким способом с небольшими вычислительными усилиями. Например, различные постоянные времени, которые используются для того, чтобы регулировать различные время-зависимые значения усиления, могут быть адаптированы к различным постоянным времени, соответственно, в слуховой системе человека.
В завершение, использование последовательности (или каскада) из двух или более контуров адаптации, которые применяют время-зависимое масштабирование в зависимости от значений на время-зависимой шкале, предоставляет сигналы огибающей, которые оптимально подходят для цели получения информации подобия, описывающей подобие между входным аудиосигналом и опорным аудиосигналом.
В предпочтительном варианте осуществления, модуль оценки подобия аудиосигналов выполнен с возможностью применять множество модуляционных фильтров (например, гребенки модуляционных фильтров), имеющих различные (но возможно перекрывающиеся) полосы пропускания, к сигналам огибающей (например, так что компоненты сигналов огибающей, имеющих различные частоты модуляции, по меньшей мере частично разделяются) для того, чтобы получать информацию модуляции (при этом, например, множество модуляционных фильтров, ассоциированных с различными частотными диапазонами модуляции, применяются к первому сигналу огибающей, ассоциированному с первым акустическим частотным диапазоном, при этом, например, множество модуляционных фильтров, ассоциированных с различными частотными диапазонами модуляции, применяются ко второму сигналу огибающей, ассоциированному со вторым акустическим частотным диапазоном, который отличается от первого акустического частотного диапазона).
Обнаружено, что значимая информация, представляющая модуляцию сигналов огибающей (ассоциированных с различными частотными диапазонами), может получаться с небольшим усилием с использованием модуляционных фильтров, которые фильтруют сигналы огибающей. Например, применение набора модуляционных фильтров, имеющих различные полосы пропускания, к одному из сигналов огибающей приводит к набору сигналов (или значений) для данного сигнала огибающей (ассоциированному с данным сигналом огибающей либо ассоциированному с частотным диапазоном входного аудиосигнала). Таким образом, множество модулирующих сигналов могут получаться на основе одного сигнала огибающей, и различные наборы модулирующих сигналов могут получаться на основе множества сигналов огибающей. Каждый из модулирующих сигналов может быть ассоциирован с частотой модуляции или диапазоном частот модуляции. Следовательно, модулирующие сигналы (которые могут выводиться посредством модуляционных фильтров) либо, более точно, их интенсивность может описывать то, как сигнал огибающей (ассоциированный с определенным частотным диапазоном) модулируется (например, модулируется во времени). Таким образом, отдельные наборы модулирующих сигналов могут получаться для различных сигналов огибающей.
Эти модулирующие сигналы могут использоваться для того, чтобы получать информацию модуляции, при этом различные операции постобработки могут использоваться для того, чтобы извлекать информацию модуляции (которая сравнивается с информацией модуляции, ассоциированной с опорным аудиосигналом) из модулирующих сигналов, предоставленных посредством модуляционных фильтров.
В качестве вывода, обнаружено, что использование множества модуляционных фильтров представляет собой простой для реализации подход, который может использоваться при извлечении усиления модуляции для получения информации.
В предпочтительном варианте осуществления, модуляционные фильтры выполнены с возможностью по меньшей мере частично разделять компоненты сигнала огибающей, имеющие различные частоты (например, различные частоты модуляции), при этом центральная частота первого, наименьшего частотного модуляционного фильтра меньше 5 Гц, и при этом центральная частота наибольшего частотного модуляционного фильтра находится в диапазоне между 200 Гц и 300 Гц.
Обнаружено, что использование таких центральных частот модуляционных фильтров покрывает диапазон частот модуляции, который является наиболее релевантным для человеческого восприятия.
В предпочтительном варианте осуществления, модуль оценки подобия аудиосигналов выполнен с возможностью удалять DC-компоненты (компоненты постоянного тока) при получении информации модуляции (например, посредством фильтрации нижних частот выходных сигналов модуляционных фильтров, например, с частотой отсечки в половину центральной частоты соответствующего модуляционного фильтра и посредством вычитания сигналов, получающихся в результате фильтрации нижних частот, из выходных сигналов модуляционных фильтров).
Обнаружено, что удаление DC-компонентов при получении информации модуляции помогает исключать ухудшение информации модуляции посредством сильных DC-компонентов, которые типично включаются в сигналы огибающей. Кроме того, посредством использования удаления DC (постоянной составляющей) при получении информации модуляции на основе сигналов огибающей, крутизна модуляционных фильтров может поддерживаться достаточно небольшой, что упрощает реализацию модуляционных фильтров.
В предпочтительном варианте осуществления, модуль оценки подобия аудиосигналов выполнен с возможностью удалять информацию фазы при получении информации модуляции.
Посредством удаления информации фазы, можно игнорировать эту информацию, которая типично не имеет очень высокую релевантность для слушателя-человека при многих обстоятельствах, при сравнению информации модуляции, ассоциированной с входным аудиосигналом, с информацией модуляции, ассоциированной с опорным аудиосигналом. Обнаружено, что информация фазы выходных сигналов модуляционных фильтров типично должна ухудшать результат сравнения, в частности, если модификация без сохранения формы сигнала (такая как, например, операция кодирования и декодирования без сохранения формы сигнала) применяется к входному аудиосигналу. Таким образом, исключается необходимость классифицировать входной аудиосигнал и опорный аудиосигнал как имеющие небольшой уровень подобия, даже если человеческое восприятие должно классифицировать сигналы как очень похожие.
В предпочтительном варианте осуществления, модуль оценки подобия аудиосигналов выполнен с возможностью получать скалярное значение, представляющее разность между полученной информацией модуляции (например, внутренним представлением) и опорной информацией модуляции, ассоциированной с опорным аудиосигналом (например, значением, представляющим сумму квадратов разности между полученной информацией модуляции, которая может содержать выборочные значения для множества акустических частотных диапазонов и для множества частотных диапазонов модуляции для каждого акустического частотного диапазона, и опорной информацией модуляции, которая также может содержать выборочные значения для множества акустических частотных диапазонов и для множества частотных диапазонов модуляции для каждого акустического частотного диапазона).
Обнаружено, что (одно) скалярное значение может представлять разности между информацией модуляции, ассоциированной с входным аудиосигналом, и информацией модуляции, ассоциированной с опорным аудиосигналом. Например, информация модуляции может содержать отдельные сигналы или значения для различных частот модуляции и для множества частотных диапазонов. Посредством комбинирования разностей между всеми этими сигналами или значениями в одно скалярное значение (которое может принимать форму "показателя расстояния" или "нормы"), можно иметь компактную и значимую оценку подобия между входным аудиосигналом и опорным аудиосигналом. Кроме того, такое одно скалярное значение может легко быть применимым посредством механизма для выбора параметров кодирования (например, параметров кодирования и/или параметров декодирования) или для определения касательно любых других параметров обработки аудиосигналов, которые могут применяться для обработки входного аудиосигнала.
Обнаружено, что определение разностного представления может представлять собой эффективный промежуточный этап для извлечения информации подобия. Например, разностное представление может представлять разности между различными элементами разрешения частоты модуляции (при этом, например, отдельный набор элементов разрешения частоты модуляции может быть ассоциирован с различными сигналами огибающей, ассоциированными с различными частотными диапазонами) при сравнении входного аудиосигнала с опорным аудиосигналом.
Например, разностное представление может представлять собой вектор, при этом каждая запись вектора может быть ассоциирована с частотой модуляции и с рассматриваемым частотным диапазоном (входного аудиосигнала или опорного аудиосигнала). Такое разностное представление оптимально подходит для постобработки и также обеспечивает возможность простого извлечения одного скалярного значения, представляющего информацию подобия.
В предпочтительном варианте осуществления, модуль оценки подобия аудиосигналов выполнен с возможностью определять разностное представление (например, IDR) для того, чтобы сравнивать полученную информацию модуляции (например, внутреннее представление) с опорной информацией модуляции, ассоциированной с опорным аудиосигналом.
В предпочтительном варианте осуществления, модуль оценки подобия аудиосигналов выполнен с возможностью регулировать весовой коэффициент разности между полученной информацией модуляции (например, внутренним представлением) и опорной информацией модуляции, ассоциированной с опорным аудиосигналом, в зависимости от комодуляции между полученными сигналами огибающей или информацией модуляции в двух или более смежных акустических частотных диапазонах или между сигналами огибающей, ассоциированными с опорным сигналом, либо между опорной информацией модуляции в двух или более смежных акустических частотных диапазонах (при этом, например, увеличенный весовой коэффициент предоставляется для разности между полученной информацией модуляции и опорной информацией модуляции в случае, если сравнительно высокая степень комодуляции обнаруживается по сравнению со случаем, в котором сравнительно низкая степень комодуляции обнаруживается) (и при этом степень комодуляции, например, обнаруживается посредством определения ковариации между временными огибающими, ассоциированными с различными акустическими частотными диапазонами).
Обнаружено, что регулирование весового коэффициента разности между полученной информацией модуляции и опорной информацией модуляции (которая, например, может представляться посредством "разностного представления") в зависимости от информации комодуляции является преимущественным, поскольку разности между информацией модуляции могут восприниматься как более сильные слушателем-человеком, если имеется комодуляция в смежных частотных диапазонах. Например, посредством ассоциирования увеличенного весового коэффициента с разностью между полученной информацией модуляции и опорной информацией модуляции в случае, если сравнительно высокая степень комодуляции обнаруживается по сравнению со случаем, в котором сравнительно низкая степень обнаруживается, либо величиной комодуляции, определение информации подобия может быть адаптировано к характеристикам слуховой системы человека. Следовательно, может повышаться качество информации подобия.
В предпочтительном варианте осуществления, модуль оценки подобия аудиосигналов выполнен с возможностью применять более высокие весовые коэффициенты для разностей между полученной информацией модуляции (например, внутренним представлением) и опорной информацией модуляции, ассоциированной с опорным аудиосигналом, указывающих то, что входной аудиосигнал содержит дополнительный сигнальный компонент, по сравнению с разностями между полученной информацией модуляции (например, внутренним представлением) и опорной информацией модуляции, ассоциированной с опорным аудиосигналом, указывающими то, что во входном аудиосигнале отсутствует сигнальный компонент, при определении информации относительно подобия между входным аудиосигналом и опорным аудиосигналом (например, одного скалярного значения, описывающего информацию относительно подобия).
Применение более высоких весовых коэффициентов для разностей между полученной информацией модуляции и опорной информацией модуляции, ассоциированной с опорным сигналом, указывающих то, что аудиосигнал содержит дополнительный сигнальный компонент (по сравнению с разностями, указывающими то, что во входном аудиосигнале отсутствует сигнальный компонент), подчеркивает долю добавленных сигналов (либо сигнальных компонентов или несущих) при определении информации относительно разности между входным аудиосигналом и опорным аудиосигналом. Обнаружено, что добавленные сигналы (либо сигнальные компоненты или несущие) типично воспринимаются как более искажающие по сравнению с отсутствующими сигналами (либо сигнальными компонентами или несущими). Этот факт может учитываться посредством такого "асимметричного" взвешивания положительных и отрицательных разностей между информацией модуляции, ассоциированной с входным аудиосигналом, и информацией модуляции, ассоциированной с опорным аудиосигналом. Информация подобия может быть адаптирована к характеристикам слуховой системы человека таким способом.
В предпочтительном варианте осуществления, модуль оценки подобия аудиосигналов выполнен с возможностью взвешивать положительные и отрицательные значения разности между полученной информацией модуляции и опорной информацией модуляции (которая типично содержит большое число значений) с использованием различных весовых коэффициентов при определении информации относительно подобия между входным аудиосигналом и опорным аудиосигналом.
Посредством применения различных весовых коэффициентов к положительным и отрицательным значениям разности между полученной информацией модуляции и опорной информацией модуляции (или, более точно, между записями вектора, как упомянуто выше), различное влияние добавленных и отсутствующих сигналов или сигнальных компонентов или несущих может рассматриваться с очень небольшими вычислительными усилиями.
Другой вариант осуществления согласно изобретению создает аудиокодер для кодирования аудиосигнала. Аудиокодер выполнен с возможностью определять один или более параметров кодирования (например, параметров кодирования или параметров декодирования, которые предпочтительно передаются в служебных сигналах в аудиодекодер посредством аудиокодера) в зависимости от оценки подобия между аудиосигналом, который должен кодироваться, и кодированным аудиосигналом. Аудиокодер выполнен с возможностью оценивать подобие между аудиосигналом, который должен кодироваться, и кодированным аудиосигналом (например, его декодированной версией) с использованием модуля оценки подобия аудиосигналов, как пояснено в данном документе (при этом аудиосигнал, который должен кодироваться, используется в качестве опорного аудиосигнала, и при этом декодированная версия аудиосигнала, кодированного с использованием одного или более возможных вариантов параметров, используется в качестве входного аудиосигнала для модуля оценки подобия аудиосигналов).
Этот аудиокодер основан на таких выявленных сведениях, что вышеуказанное определение информации подобия оптимально подходит для оценки ощущения для слуха, получаемого посредством кодирования аудио. Например, посредством получения информации подобия с использованием аудиосигнала, который должен кодироваться, в качестве опорного сигнала и с использованием кодированной и затем декодированной версии аудиосигнала, который должен кодироваться, в качестве входного аудиосигнала для определения информации подобия, может оцениваться то, подходит или нет процесс кодирования и декодирования для того, чтобы восстанавливать аудиосигнал, который должен кодироваться, с небольшими перцепционными потерями. Тем не менее, вышеуказанное определение информации подобия акцентирует внимание на ощущении для слуха, которое может достигаться, а не на согласовании форм сигналов. Соответственно, можно узнавать, с использованием полученной информации подобия, то, какие параметры кодирования (из определенного выбора параметров кодирования) предоставляют наилучшее (или, по меньшей мере, достаточно хорошее) ощущение для слуха. Таким образом, вышеуказанное определение информации подобия может использоваться для того, чтобы принимать решение по параметру кодирования, без необходимости идентичности (или подобия) форм сигналов.
Соответственно, параметры кодирования могут выбираться надежно при недопущении непрактичных ограничений (таких как подобие формы сигнала).
В предпочтительном варианте осуществления, аудиокодер выполнен с возможностью кодировать один или более параметров расширения полосы пропускания, которые задают правило обработки, которое должно использоваться на стороне аудиодекодера для того, чтобы извлекать отсутствующий аудиоконтент (например, высокочастотный контент, который не кодируется с сохранением формы сигнала посредством аудиокодера) на основе аудиоконтента другого частотного диапазона, кодированного посредством аудиокодера (например, аудиокодер представляет собой параметрический или полупараметрический аудиокодер).
Обнаружено, что вышеуказанное определение информации подобия оптимально подходит для выбора параметров расширения полосы пропускания. Следует отметить, что параметрическое расширение полосы пропускания, которое представляет собой параметры расширения полосы пропускания, типично не сохраняет форму сигнала. Кроме того, обнаружено, что вышеуказанное определение подобия аудиосигналов является очень подходящим для оценки подобий или разностей в диапазоне верхних аудиочастот, в котором расширение полосы пропускания типично является активным, и в котором слуховая система человека типично является нечувствительной к фазе. Таким образом, концепция обеспечивает возможность определять концепции расширения полосы пропускания, которые, например, могут извлекать высокочастотные компоненты на основе низкочастотных компонентов эффективным и перцепционно точным способом.
В предпочтительном варианте осуществления, аудиокодер выполнен с возможностью использовать интеллектуальное заполнение промежутков (например, как задано в MPEG-H-стандарте трехмерного аудио, например, в версии, доступной на дату подачи настоящей заявки, либо в ее модификациях), и аудиокодер выполнен с возможностью определять один или более параметров интеллектуального заполнения промежутков (интервалов отсутствия сигнала) с использованием оценки подобия между аудиосигналом, который должен кодироваться, и кодированным аудиосигналом (при этом, например, аудиосигнал, который должен кодироваться, используется в качестве опорного аудиосигнала, и при этом, например, декодированная версия аудиосигнала, кодированного с использованием одного или более возможных вариантов параметров интеллектуального заполнения промежутков, используется в качестве входного аудиосигнала для оценки подобия аудиосигналов).
Обнаружено, что вышеуказанная концепция для оценки подобий между аудиосигналами оптимально подходит для использования в контексте "интеллектуального заполнения промежутков", поскольку определение подобия между аудиосигналами рассматривает критерии, которые являются очень важными для ощущения для слуха.
В предпочтительном варианте осуществления, аудиокодер выполнен с возможностью выбирать одну или более ассоциаций между исходным частотным диапазоном и целевым частотным диапазоном для расширения полосы пропускания (например, ассоциацию, которая определяет то, на основе какого исходного частотного диапазона из множества выбираемых исходных частотных диапазонов должен определяться аудиоконтент целевого частотного диапазона) и/или один или более рабочих параметров обработки для расширения полосы пропускания (которые, например, могут определять параметры операции обработки, такой как операция отбеливания или замена случайного шума, которая выполняется при предоставлении аудиоконтента целевого частотного диапазона на основе исходного частотного диапазона и/или адаптации тональных свойств, и/или адаптации спектральной огибающей) в зависимости от оценки подобия между аудиосигналом, который должен кодироваться, и кодированным аудиосигналом.
Обнаружено, что выбор одной или более ассоциаций между исходным частотным диапазоном и целевым частотным диапазоном и/или выбор одного или более рабочих параметров обработки для расширения полосы пропускания может выполняться с хорошими результатами с использованием вышеуказанного подхода для оценки подобия между аудиосигналами. Посредством сравнения "исходного" аудиосигнала, который должен кодироваться, с кодированной и декодированной версией (кодированной и декодированной снова с использованием конкретной ассоциации и/или конкретной обработки между исходным частотным диапазоном и целевым частотным диапазоном либо между исходными частотными диапазонами и целевыми частотными диапазонами), можно определять то, предоставляет ли конкретная ассоциация ощущение для слуха, аналогичное оригиналу, или нет.
То же также применимо для выбора других рабочих параметров обработки. Таким образом, посредством проверки, для различных настроек кодирования аудио (и декодирования аудио), того, насколько хорошо кодированный и декодированный аудиосигнал согласуется с (исходным) входным аудиосигналом, можно узнавать то, какую конкретную ассоциацию (между исходным частотным диапазоном и целевым частотным диапазоном либо между исходными частотными диапазонами и целевыми частотными диапазонами) предоставляет наилучшее подобие (или, по меньшей мере, достаточно хорошее подобие) при сравнении кодированной и декодированной версии аудиоконтента с исходной версией аудиоконтента. Таким образом, могут выбираться соответствующие настройки кодирования (например, соответствующая ассоциация между исходным частотным диапазоном и целевым частотным диапазоном). Кроме того, дополнительные рабочие параметры обработки также могут выбираться с использованием идентичного подхода.
В предпочтительном варианте осуществления, аудиокодер выполнен с возможностью выбирать одну или более ассоциаций между исходным частотным диапазоном и целевым частотным диапазоном для расширения полосы пропускания. Аудиокодер выполнен с возможностью избирательно разрешать или запрещать изменение ассоциации между исходным частотным диапазоном и целевым частотным диапазоном в зависимости от оценки модуляции огибающей (например, аудиосигнала, который должен кодироваться) в старом или новом целевом частотном диапазоне.
Посредством использования такой концепции, может запрещаться изменение ассоциации между исходным частотным диапазоном и целевым частотным диапазоном, если такое изменение ассоциации между исходным частотным диапазоном и целевым частотным диапазоном способствует заметным артефактам. Таким образом, переключение между сдвигами частоты интеллектуального заполнения промежутков может быть ограничено. Например, изменение ассоциации между исходным частотным диапазоном и целевым частотным диапазоном может избирательно разрешаться, если обнаружено, что имеется достаточная модуляция огибающей (например, выше определенного порогового значения), которая (в достаточной степени) маскирует модуляцию, вызываемую посредством изменения ассоциации.
В предпочтительном варианте осуществления, аудиокодер выполнен с возможностью определять интенсивность модуляции огибающей в (старом или новом) целевом частотном диапазоне в частотном диапазоне модуляции, соответствующем частоте кадров кодера, и определять показатель чувствительности в зависимости от определенной интенсивности модуляции (например, так что показатель подобия является обратно пропорциональным интенсивности модуляции).
Аудиокодер выполнен с возможностью определять то, разрешается или запрещается изменять ассоциацию между целевым частотным диапазоном и исходным частотным диапазоном, в зависимости от показателя чувствительности (например, разрешать изменение ассоциации между целевым частотным диапазоном и исходным частотным диапазоном только тогда, когда показатель чувствительности меньше предварительно определенного порогового значения, либо разрешать изменение ассоциации между целевым частотным диапазоном и исходным частотным диапазоном только тогда, когда возникает интенсивность модуляции, которая превышает пороговый уровень в целевом частотном диапазоне).
Соответственно, можно добиться того, что изменение ассоциации между целевым частотным диапазоном и исходным частотным диапазоном возникает только в том случае, если (паразитная) модуляция, вызываемая посредством такого изменения, маскируется в достаточной степени посредством (исходной) модуляции в целевом частотном диапазоне (в который должна вводиться паразитная модуляция). Таким образом, слышимые артефакты могут эффективно исключаться.
Вариант осуществления согласно настоящему изобретению создает аудиокодер для кодирования аудиосигнала, при этом аудиокодер выполнен с возможностью определять один или более параметров кодирования в зависимости от аудиосигнала, который должен кодироваться с использованием нейронной сети. Нейронная сеть обучается с использованием модуля оценки подобия аудиосигналов, как пояснено в данном документе.
Посредством использования нейронной сети, которая обучается с использованием модуля оценки значений подобия аудиосигналов, упомянутого выше, для того, чтобы принимать решение в отношении одного или более параметров кодирования, дополнительно может уменьшаться вычислительная сложность. Другими словами, оценка подобия аудиосигналов, как упомянуто в данном документе, может использоваться для того, чтобы предоставлять обучающие данные для нейронной сети, и нейронная сеть может адаптировать себя (или может адаптироваться) с возможностью принимать решения по параметрам кодирования, которые являются достаточно похожими на решения по параметрам кодирования, которые должны получаться посредством оценки качества звучания с использованием модуля оценки подобия аудиосигналов.
Вариант осуществления согласно настоящему изобретению создает модуль оценки подобия аудиосигналов.
Модуль оценки подобия аудиосигналов выполнен с возможностью получать сигналы огибающей для множества (предпочтительно перекрывающихся) частотных диапазонов (например, с использованием гребенки фильтров или гребенки гамматоновых фильтров и выпрямления и временной фильтрации нижних частот и одного или более процессов адаптации, которые, например, могут моделировать премаскирование и/или постмаскирование в слуховой системе) на основе входного аудиосигнала (например, чтобы выполнять демодуляцию огибающей в подполосах частот спектра).
Модуль оценки подобия аудиосигналов выполнен с возможностью сравнивать аналитическое представление входного аудиосигнала (например, "внутреннее представление", такое как полученная информация модуляции или представление в частотно-временной области) с опорным аналитическим представлением, ассоциированным с опорным аудиосигналом (например, с использованием внутреннего разностного представления, при этом внутреннее разностное представление, например, может описывать разность между полученным аналитическим представлением и опорным аналитическим представлением, при этом могут применяться одна или более операций взвешивания или операций модификации, таких как масштабирование внутреннего разностного представления на основе степени комодуляции или асимметричное взвешивание положительных и отрицательных значений внутреннего разностного представления) для того, чтобы получать информацию относительно подобия между входным аудиосигналом и опорным аудиосигналом (например, одно значение, описывающее перцепционное подобие между входным аудиосигналом и опорным аудиосигналом).
Модуль оценки подобия аудиосигналов выполнен с возможностью регулировать весовой коэффициент разности между полученным аналитическим представлением (например, информацией модуляции; например, внутренним представлением) и опорным аналитическим представлением (например, опорной информацией модуляции, ассоциированной с опорным аудиосигналом) в зависимости от комодуляции (например, между полученными сигналами огибающей или полученной информацией модуляции) в двух или более смежных акустических частотных диапазонах входного аудиосигнала или в зависимости от комодуляции (например, между сигналами огибающей, ассоциированными с опорным сигналом, либо между опорной информацией модуляции) в двух или более смежных акустических частотных диапазонах опорного аудиосигнала (при этом, например, увеличенный весовой коэффициент предоставляется для разности в случае, если сравнительно высокая степень комодуляции обнаруживается по сравнению со случаем, в котором сравнительно низкая степень комодуляции обнаруживается) (и при этом степень комодуляции, например, обнаруживается посредством определения ковариации между временными огибающими, ассоциированными с различными акустическими частотными диапазонами).
Этот вариант осуществления основан на таких выявленных сведениях, что комодуляция в двух или более смежных частотных диапазонах типично имеет такой эффект, что искажения в таких комодулированных частотных диапазонах воспринимаются как более сильные, чем искажения в некомодулированных (или слабо комодулированных) смежных частотных диапазонах. Соответственно, посредством применения весовых коэффициентов к отклонениям между аудиосигналами, которые должны сравниваться (например, между входным аудиосигналом и опорным аудиосигналом), относительно более высоких в сильно комодулированных частотных диапазонах (по сравнению с весовыми коэффициентами в некомодулированных или более слабо комодулированных частотных диапазонах), оценка качества звучания может выполняться таким способом, который является хорошо адаптированным к человеческому восприятию. Типично, разности между полученными аналитическими представлениями, которые могут быть основаны на сигналах огибающей для множества частотных диапазонов, могут сравниваться, и в таких аналитических представлениях, частотные диапазоны, которые содержат сравнительно более высокую комодуляцию, могут иметь более высокие весовые коэффициенты, чем частотные диапазоны, содержащие сравнительно меньшую комодуляцию. Соответственно, оценка подобия может быть хорошо адаптированной к человеческому восприятию.
Вариант осуществления согласно изобретению создает способ оценки подобия между аудиосигналами.
Способ содержит получение сигналов огибающей для множества (предпочтительно перекрывающихся) частотных диапазонов (например, с использованием гребенки фильтров или гребенки гамматоновых фильтров и выпрямления и временной фильтрации нижних частот и одного или более процессов адаптации, которые, например, могут моделировать премаскирование и/или постмаскирование в слуховой системе) на основе входного аудиосигнала (например, чтобы выполнять демодуляцию огибающей в подполосах частот спектра).
Способ содержит получение информации модуляции (например, выходных сигналов модуляционных фильтров), ассоциированной с сигналами огибающей, для множества частотных диапазонов модуляции (например, с использованием гребенки модуляционных фильтров либо с использованием модуляционных фильтров). Информация модуляции описывает (например, в форме выходных сигналов гребенки модуляционных фильтров или в форме выходных сигналов модуляционных фильтров) модуляцию сигналов огибающей (например, сигналов временной огибающей или сигналов спектральной огибающей). Информация модуляции, например, может рассматриваться как внутреннее представление и, например, может использоваться для того, чтобы выполнять модуляционный анализ огибающей.
Способ содержит сравнение полученной информации модуляции (например, внутреннего представления) с опорной информацией модуляции, ассоциированной с опорным аудиосигналом (например, с использованием внутреннего разностного представления, при этом внутреннее разностное представление, например, может описывать разность между полученной информацией модуляции и опорной информацией модуляции, при этом могут применяться одна или более операций взвешивания или операций модификации, таких как масштабирование внутреннего разностного представления на основе степени комодуляции или асимметричное взвешивание положительных и отрицательных значений внутреннего разностного представления) для того, чтобы получать информацию относительно подобия между входным аудиосигналом и опорным аудиосигналом (например, одно значение, описывающее перцепционное подобие между входным аудиосигналом и опорным аудиосигналом).
Вариант осуществления согласно изобретению создает способ для кодирования аудиосигнала, при этом способ содержит определение одного или более параметров кодирования в зависимости от оценки подобия между аудиосигналом, который должен кодироваться, и кодированным аудиосигналом, и при этом способ содержит оценку подобия между аудиосигналом, который должен кодироваться, и кодированным аудиосигналом, как пояснено в данном документе (при этом, например, аудиосигнал, который должен кодироваться, используется в качестве опорного аудиосигнала, и при этом декодированная версия аудиосигнала, кодированного с использованием одного или более возможных вариантов параметров, используется в качестве входного аудиосигнала для модуля оценки подобия аудиосигналов).
Вариант осуществления согласно изобретению создает способ для кодирования аудиосигнала.
Способ содержит определение одного или более параметров кодирования в зависимости от аудиосигнала, который должен кодироваться с использованием нейронной сети, при этом нейронная сеть обучается с использованием способа оценки подобия между аудиосигналами, как пояснено в данном документе.
Вариант осуществления согласно изобретению создает способ оценки подобия между аудиосигналами (например, между входным аудиосигналом и опорным аудиосигналом).
Способ содержит получение сигналов огибающей для множества (предпочтительно перекрывающихся) частотных диапазонов (например, с использованием гребенки фильтров или гребенки гамматоновых фильтров и выпрямления и временной фильтрации нижних частот и одного или более процессов адаптации, которые, например, могут моделировать премаскирование и/или постмаскирование в слуховой системе) на основе входного аудиосигнала (например, чтобы выполнять демодуляцию огибающей в подполосах частот спектра).
Способ содержит сравнение аналитического представления входного аудиосигнала (например, "внутреннего представления", такого как полученная информация модуляции или представление в частотно-временной области) с опорным аналитическим представлением, ассоциированным с опорным аудиосигналом (например, с использованием внутреннего разностного представления, при этом внутреннее разностное представление, например, может описывать разность между полученным аналитическим представлением и опорным аналитическим представлением, при этом могут применяться одна или более операций взвешивания или операций модификации, таких как масштабирование внутреннего разностного представления на основе степени комодуляции или асимметричное взвешивание положительных и отрицательных значений внутреннего разностного представления) для того, чтобы получать информацию относительно подобия между входным аудиосигналом и опорным аудиосигналом (например, одно значение, описывающее перцепционное подобие между входным аудиосигналом и опорным аудиосигналом),
Способ содержит регулирование весового коэффициента разности между полученным аналитическим представлением (например, информацией модуляции; например, внутренним представлением) и опорным аналитическим представлением (например, опорной информацией модуляции, ассоциированной с опорным аудиосигналом) в зависимости от комодуляции. Например, весовые коэффициенты регулируются в зависимости от комодуляции (например, между полученными сигналами огибающей или полученной информацией модуляции) в двух или более смежных акустических частотных диапазонах входного аудиосигнала. Альтернативно, весовые коэффициенты регулируются в зависимости от комодуляции (например, между сигналами огибающей, ассоциированными с опорным сигналом, либо между опорной информацией модуляции) в двух или более смежных акустических частотных диапазонах опорного аудиосигнала. Например, увеличенный весовой коэффициент предоставляется для разности в случае, если сравнительно высокая степень комодуляции обнаруживается по сравнению со случаем, в котором сравнительно низкая степень комодуляции обнаруживается. Степень комодуляции, например, обнаруживается посредством определения ковариации между временными огибающими, ассоциированными с различными акустическими частотными диапазонами.
Эти способы основаны на соображениях, идентичных соображениям для вышеуказанных модулей оценки подобия аудиосигналов и вышеуказанных аудиокодеров.
Кроме того, способы могут дополняться посредством любых признаков, функциональностей и подробностей, поясненных в данном документе относительно модулей оценки подобия аудиосигналов и относительно аудиокодеров. Способы могут дополняться посредством таких признаков, функциональностей и подробностей как отдельно, так в комбинации.
Вариант осуществления согласно изобретению создает компьютерную программу для осуществления способов, поясненных в данном документе, когда компьютерная программа работает на компьютере.
Компьютерная программа может дополняться посредством любых из признаков, функциональностей и подробностей, описанных в данном документе относительно соответствующего оборудования и способов.
Краткое описание чертежей
Далее описываются варианты осуществления согласно настоящему изобретению со ссылкой на прилагаемые чертежи, на которых:
Фиг. 1 показывает принципиальную блок-схему модуля оценки подобия аудиосигналов, согласно варианту осуществления настоящего изобретения;
Фиг. 2a, 2b показывают принципиальную блок-схему модуля оценки подобия аудиосигналов, согласно варианту осуществления настоящего изобретения;
Фиг. 3 показывает принципиальную блок-схему аудиокодера с автоматизированным выбором, согласно варианту осуществления настоящего изобретения;
Фиг. 4 показывает принципиальную блок-схему аудиокодера со стробированием изменений, согласно варианту осуществления настоящего изобретения;
Фиг. 5a показывает принципиальную блок-схему аудиокодера с нейронной сетью в рабочем режиме, согласно варианту осуществления настоящего изобретения;
Фиг. 5b показывает принципиальную блок-схему нейронной сети для использования в аудиокодере в режиме обучения, согласно варианту осуществления настоящего изобретения;
Фиг. 6 показывает принципиальную блок-схему модуля оценки подобия аудиосигналов, согласно варианту осуществления настоящего изобретения;
Фиг. 7 показывает схематичное представление последовательности сигналов и блоков обработки модели слуховой обработки на основе работы авторов Дау и др.;
Фиг. 8 показывает схематичное представление импульсных откликов гребенки гамматоновых фильтров;
Фиг. 9 показывает схематичное представление кортиева органа (модифицированного относительно [14]);
Фиг. 10 показывает принципиальную блок-схему аудиодекодера с использованием IGF;
Фиг. 11 показывает схематичное представление выбора IGF-фрагментов;
Фиг. 12 показывает принципиальную блок-схему формирования элементов для автоматизированного IGF-выбора;
Фиг. 13 показывает схематичное представление выбора IGF-фрагментов для аудиоотрывка "trilogy" через автоматизированное управление, при этом для каждого кадра (окружностей), выбор исходных фрагментов "sT" [0,1,2,3] показывается для каждого из трех целевых фрагментов в качестве наложения черных линий на спектрограмме;
Фиг. 14 показывает схематичное представление выбора уровней IGF-отбеливания для аудиоотрывка "trilogy" через автоматизированное управление, при этом для каждого кадра (окружностей), выбор уровней отбеливания [0,1,2] показывается для каждого из трех целевых фрагментов в качестве наложения черных линий на спектрограмме;
Таблица 1 показывает элементы теста на основе прослушивания;
Таблица 2 показывает условия теста на основе прослушивания;
Фиг. 15 показывает графическое представление абсолютных количественных MUSHRA-показателей предложенных средств автоматизированного и фиксированного IGF-управления; и
Фиг. 16 показывает графическое представление разностных количественных MUSHRA-показателей, сравнивающих предложенное автоматизированное и фиксированное IGF-управление.
Подробное описание вариантов осуществления
Далее описываются варианты осуществления согласно настоящей заявке. Тем не менее, следует отметить, что варианты осуществления, описанные далее, могут использоваться отдельно и также могут использоваться в комбинации.
Кроме того, следует отметить, что признаки, функциональности и подробности, описанные относительно нижеприведенных вариантов осуществления, могут необязательно вводиться в любой из вариантов осуществления, заданных посредством формулы изобретения, как отдельно, так и в комбинации.
Кроме того, следует отметить, что варианты осуществления, описанные далее, могут необязательно дополняться посредством любых из признаков, функциональностей и подробностей, заданных в формуле изобретения.
1. Модуль оценки подобия аудиосигналов согласно фиг. 1
Фиг. 1 показывает принципиальную блок-схему модуля оценки подобия аудиосигналов, согласно варианту осуществления изобретения.
Модуль 100 оценки подобия аудиосигналов согласно фиг. 1 принимает входной аудиосигнал 110 (например, входной аудиосигнал модуля оценки подобия аудиосигналов) и предоставляет, на его основе, информацию 112 подобия, которая, например, может принимать форму скалярного значения.
Модуль 100 оценки подобия аудиосигналов содержит определение 120 сигналов огибающей (или модуль определения сигналов огибающей), которое выполнено с возможностью получать сигналы 122a, 122b, 122c огибающей для множества частотных диапазонов на основе входного аудиосигнала. Предпочтительно, частотные диапазоны, для которых предоставляются сигналы 122a-122c огибающей, могут быть перекрывающимися. Например, модуль определения сигналов огибающей может использовать гребенку фильтров или гребенку гамматоновых фильтров и выпрямление и временную фильтрацию нижних частот и один или более процессов адаптации, которые, например, могут моделировать премаскирование и/или постмаскирование в слуховой системе. Другими словами, определение 120 сигналов огибающей, например, может выполнять демодуляцию огибающей подполос частот спектра входного аудиосигнала.
Кроме того, модуль 100 оценки подобия аудиосигналов содержит определение 160 информации модуляции (или модуль определения информации модуляции), которое принимает сигналы 122a-122c огибающей и предоставляет, на их основе, информацию 162a-162c модуляции. Вообще говоря, определение 160 информации модуляции выполнено с возможностью получать информацию 162a-162c модуляции, ассоциированную с сигналами 122a-122c огибающей для множества частотных диапазонов модуляции. Информация модуляции описывает (временную) модуляцию сигналов огибающей.
Информация 162a-162c модуляции, например, может предоставляться на основе выходных сигналов модуляционных фильтров или на основе выходных сигналов гребенки модуляционных фильтров. Например, информация 162a модуляции может быть ассоциирована с первым частотным диапазоном и, например, может описывать модуляцию первого сигнала 122a огибающей (которая ассоциирована с этим первым частотным диапазоном) для множества частотных диапазонов модуляции. Другими словами, информация 162a модуляции может не представлять собой скалярное значение, а может содержать множество значений (или даже множество последовательностей значений), которые ассоциированы с различными частотами модуляции, которые присутствуют в первом сигнале 122a огибающей, который ассоциирован с первым частотным диапазоном входного аудиосигнала. Аналогично, вторая информация 162b модуляции может не представлять собой скалярное значение, но может содержать множество значений или даже множество последовательностей значений, ассоциированных с различными частотными диапазонами модуляции, которые присутствуют во втором сигнале 122b огибающей, который ассоциирован со вторым частотным диапазоном входного аудиосигнала 110. Таким образом, для каждого из множества рассматриваемых частотных диапазонов (для которых отдельные сигналы 122a-122c огибающей предоставляются посредством модуля 120 определения сигналов огибающей), информация модуляции может предоставляться для множества частотных диапазонов модуляции. Иными словами, для части (например, кадра) входного аудиосигнала 110, предоставляются множество наборов значений информации модуляции, при этом различные наборы ассоциированы с различными частотными диапазонами входного аудиосигнала, и при этом каждый из наборов описывает множество частотных диапазонов модуляции (т.е. каждый из наборов описывает модуляцию одного сигнала огибающей).
Кроме того, модуль оценки подобия аудиосигналов содержит сравнение 180 или модуль сравнения, которое принимает информацию 162a-162c модуляции и также опорную информацию 182a-182c модуляции, которая ассоциирована с опорным аудиосигналом. Кроме того, сравнение 180 выполнено с возможностью сравнивать полученную информацию 162a-162c модуляции (полученную на основе входного аудиосигнала 110) с опорной информацией 182a-182c модуляции, ассоциированной с опорным сигналом, чтобы получать информацию относительно (перцепционно определенного) подобия между входным аудиосигналом 110 и опорным аудиосигналом.
Например, сравнение 180 может получать одно значение, описывающее перцепционное подобие между входным аудиосигналом и опорным аудиосигналом, в качестве информации 112 подобия. Кроме того, следует отметить, что сравнение 180, например, может использовать внутреннее разностное представление, при этом внутреннее разностное представление, например, может описывать разность между полученной информацией модуляции и опорной информацией модуляции. Например, могут применяться одна или более операций взвешивания или операций модификации, таких как масштабирование внутреннего разностного представления на основе степени комодуляции и/или асимметричное взвешивание положительных и отрицательных значений внутреннего разностного представления при извлечении информации подобия.
Тем не менее, следует отметить, что дополнительные (необязательные) подробности определения 120 сигналов огибающей, определения 160 информации модуляции и сравнения 180 описываются ниже и могут необязательно вводиться в модуль 100 оценки подобия аудиосигналов по фиг. 1, как отдельно, так и в комбинации.
Необязательно, опорная информация 182a-182c модуляции может получаться с использованием необязательного определения 190 опорной информации модуляции на основе опорного аудиосигнала 192. Определение опорной информации модуляции, например, может выполнять идентичную функциональность, такую как определение 120 сигналов огибающей и определение 160 информации модуляции на основе опорного аудиосигнала 192.
Тем не менее, следует отметить, что опорная информация 182a-182c модуляции также может получаться из другого источника, например, из базы данных или из запоминающего устройства, или из удаленного устройства, которое не представляет собой часть модуля оценки подобия аудиосигналов.
Дополнительно следует отметить, что блоки, показанные на фиг. 1, могут рассматриваться как (функциональные) блоки или (функциональные) модули аппаратной реализации или программной реализации, как подробнее описано ниже.
2. Модуль оценки подобия аудиосигналов согласно фиг. 2
Фиг. 2a и 2b показывают принципиальную блок-схему модуля 200 оценки подобия аудиосигналов, согласно варианту осуществления настоящего изобретения.
Модуль 200 оценки подобия аудиосигналов выполнен с возможностью принимать входной аудиосигнал 210 и предоставлять, на его основе, информацию 212 подобия. Кроме того, модуль 200 оценки подобия аудиосигналов может быть выполнен с возможностью принимать опорную информацию 282 модуляции или вычислять опорную информацию 282 модуляции отдельно (например, идентично тому, как вычисляется информация модуляции). Опорная информация 282 модуляции типично ассоциирована с опорным аудиосигналом.
Модуль 200 оценки подобия аудиосигналов содержит определение 220 сигналов огибающей, которое, например, может содержать функциональность определения 120 сигналов огибающей. Модуль оценки подобия аудиосигналов также может содержать определение 260 информации модуляции, которое, например, может содержать функциональность определения 160 информации модуляции. Кроме того, модуль оценки подобия аудиосигналов может содержать сравнение 280, которое, например, может соответствовать сравнению 180.
Кроме того, модуль 200 оценки подобия аудиосигналов необязательно может содержать определение комодуляции, которое может работать на основе различных входных сигналов и которое может реализовываться различными способами. Примеры для определения комодуляции также показаны в модуле оценки подобия аудиосигналов.
Далее описываются подробности отдельных функциональных блоков или функциональных модулей модуля 200 оценки подобия аудиосигналов.
Определение 220 сигналов огибающей содержит фильтрацию 230, которая принимает входной аудиосигнал 210 и которая предоставляет, на его основе, множество фильтрованных (предпочтительно подвергнутых полосовой фильтрации) сигналов 232a-232e. Фильтрация 230, например, может реализовываться с использованием гребенки фильтров и, например, может моделировать базилярную мембранную фильтрацию. Например, фильтры могут рассматриваться как "слуховые фильтры" и, например, могут реализовываться с использованием гребенки гамматоновых фильтров. Другими словами, полосы пропускания полосовых фильтров, которые выполняют фильтрацию, могут увеличиваться с увеличением центральной частоты фильтров. Таким образом, каждый из фильтрованных сигналов 232a-232e может представлять определенный частотный диапазон входного аудиосигнала, при этом частотные диапазоны быть перекрывающимися (или могут быть неперекрывающимся в некоторых реализациях).
Кроме того, аналогичная обработка может применяться к каждому из фильтрованных сигналов 232a, так что ниже описывается только один тракт обработки для одного данного (характерного) фильтрованного сигнала 232c. Тем не менее, пояснения, предоставленные относительно обработки фильтрованного сигнала 232c, могут распространяться на обработку других фильтрованных сигналов 232a, 232b, 232d, 232e (при этом, в настоящем примере, только пять фильтрованных сигналов показаны для простоты, тогда как значительно более высокое число фильтрованных сигналов может использоваться в фактических реализациях).
Цепочка обработки, которая обрабатывает рассматриваемый фильтрованный сигнал 232c, например, может содержать выпрямление 236, фильтрацию 240 нижних частот и адаптацию 250.
Например, полуволновое выпрямление 236 (которое, например, может удалять отрицательную полуволну и создавать пульсирующие положительные полуволны) может применяться к фильтрованному сигналу 232c, чтобы за счет этого получать выпрямленный сигнал 238. Кроме того, фильтрация 240 нижних частот применяется к выпрямленному сигналу 238, чтобы за счет этого получать сглаженный сигнал 242 нижних частот. Фильтрация нижних частот, например, может содержать частоту отсечки в 1000 Гц, но могут применяться другие частоты отсечки (которые предпочтительно могут составлять меньше 1500 Гц или меньше 2000 Гц).
Фильтрованный по нижним частотам сигнал 242 обрабатывается посредством адаптации 250, которая, например, может содержать множество каскадных стадий "автоматической регулировки усиления" и необязательно одну или более стадий ограничения. Стадии автоматической регулировки усиления также могут рассматриваться как "контуры адаптации". Например, каждая из стадий автоматической регулировки усиления (или адаптивной регулировки усиления) может содержать контурную структуру. Входной сигнал стадии автоматической регулировки усиления (или контура адаптации) (например, для первой стадии автоматической регулировки усиления, фильтрованный по нижним частотам сигнал 242, а для последующих стадий автоматической регулировки усиления, выходной сигнал предыдущей стадии автоматической регулировки усиления) может масштабироваться посредством адаптивной регулировки 254 усиления. Выходной сигнал 259 стадии автоматической регулировки усиления может представлять собой масштабированную версию входного сигнала соответствующей стадии автоматической регулировки усиления или ограниченную версию масштабированной версии 255 (например, в случае если используется необязательное ограничение 256, которое ограничивает диапазон значений сигнала). В частности, усиление, которое применяется в масштабировании 254, может быть время-зависимым и может регулироваться, с постоянной времени, ассоциированной с отдельной стадией автоматической регулировки усиления, в зависимости от масштабированного сигнала 255, предоставленного посредством восприимчивой стадии. Например, фильтрация 257 нижних частот может применяться для того, чтобы извлекать информацию 258 регулировки усиления, которая определяет усиление (или коэффициент масштабирования) адаптивной регулировки 254 усиления. Постоянная времени фильтрации 257 нижних частот может варьироваться в зависимости от стадии, чтобы за счет этого моделировать различные эффекты маскирования, которые возникают в слуховой системе человека. Обнаружено, что использование множества стадий автоматической регулировки усиления способствует очень хорошим результатам, при этом использование пяти каскадных стадий автоматической регулировки усиления рекомендуется (но не является обязательным).
В качестве (необязательной) альтернативы выпрямлению и фильтрации нижних частот, огибающая Гильберта может получаться на основе выходных сигналов 232a-232e фильтров или операции 230 фильтрации, чтобы получать, например, сигнал 242.
Вообще говоря, (необязательно) можно демодулировать выходные сигналы 232a-232e фильтров или операции 230 фильтрации, чтобы получать, например, сигнал 242.
В качестве вывода, адаптация 250 содержит последовательность (или каскад) стадий автоматической регулировки усиления, при этом каждая из стадий регулировки усиления выполняет масштабирование своего входного сигнала (фильтрованного по нижним частотам сигнала 242 или выходного сигнала предыдущей стадии) и необязательно операцию ограничения (чтобы за счет этого исключать чрезмерно большие сигналы). Коэффициент усиления или масштабирования, применяемый на каждой из стадий автоматической регулировки усиления, определяется с использованием контурной структуры обратной связи в зависимости от вывода соответствующей операции масштабирования, при этом некоторая инертность (или задержка) вводится, например, с использованием фильтра нижних частот в тракте обратной связи.
Для получения дальнейшей информации относительно адаптации, также следует обратиться к нижеприведенному описанию, при этом любые из подробностей, описанных ниже, необязательно могут вводиться в адаптацию 250.
Адаптация 250 предоставляет адаптированный сигнал 252, который может представлять собой выходной сигнал последней стадии автоматической регулировки усиления каскада (или последовательности) стадий автоматической регулировки усиления. Адаптированный сигнал 252, например, может рассматриваться как сигнал огибающей и, например, может соответствовать одному из сигналов 122a-122c огибающей.
Альтернативно, логарифмическое преобразование необязательно может применяться для того, чтобы получать сигналы (222a-222e) огибающей.
В качестве другой альтернативы, другое моделирование прямого маскирования необязательно может применяться для того, чтобы получать сигналы (222a-222e) огибающей
Как уже упомянуто, определение 220 сигналов огибающей может предоставлять отдельные сигналы огибающей, ассоциированные с различными частотными диапазонами. Например, один сигнал огибающей может предоставляться в расчете на фильтрованный сигнал 232a-232e (полосовой сигнал).
Далее описываются подробности определения информации модуляции.
Определение информации модуляции принимает множество сигналов 222a-222e огибающей (например, один сигнал огибающей для каждого частотного диапазона рассматриваемого входного аудиосигнала). Кроме того, определение 260 информации модуляции предоставляет информацию 262a-262e модуляции (например, для каждого из рассматриваемых сигналов 222a-222e огибающей). Далее обработка описывается для одного характерного сигнала 222c огибающей, но аналогичная или идентичная обработка может выполняться для всех рассматриваемых сигналов 222a-222e огибающей.
Например, фильтрация 264 применяется к сигналу 222c огибающей. Альтернативно, в пределах фильтрации 264 либо в дополнение к фильтрации 264, может применяться понижающая дискретизация. Фильтрация может выполняться посредством гребенки модуляционных фильтров или посредством множества модуляционных фильтров. Другими словами, различные частотные диапазоны сигнала 222c огибающей могут разделяться посредством инструментального средства 264 фильтрации (при этом упомянутые частотные диапазоны необязательно могут быть перекрывающимися). Таким образом, фильтрация 264 типично предоставляет множество фильтрованных с модуляцией сигналов 266a-266e на основе сигнала 222c огибающей. (Необязательное) удаление DC 270 и (необязательное) удаление 274 информации фазы могут применяться к каждому из фильтрованных с модуляцией сигналов 266a-266e, чтобы за счет этого извлекать постобработанные фильтрованные с модуляцией сигналы 276a-276e. Постобработанные фильтрованные с модуляцией сигналы 276a-276e ассоциированы с различными частотами модуляции (или частотными диапазонами модуляции) в одном частотном диапазоне входного аудиосигнала 210. Другими словами, постобработанные фильтрованные с модуляцией сигналы 276a-276e могут представлять набор значений модуляции, ассоциированных с частотным диапазоном входного аудиосигнала 210, на котором основан сигнал 222c огибающей. Аналогично, могут получаться постобработанные и фильтрованные с модуляцией сигналы, которые ассоциированы с различными частотными диапазонами входных аудиосигналов на основе различных сигналов 222a, 222b, 222d, 222e огибающей и могут представлять дополнительные наборы значений модуляции, ассоциированных с соответствующими частотными диапазонами входного аудиосигнала.
В качестве вывода, определение 260 информации модуляции предоставляет набор значений модуляции для каждого частотного диапазона рассматриваемого входного аудиосигнала.
Например, объем информации может уменьшаться таким образом, что только одно значение модуляции предоставляется для каждой частоты модуляции (или для каждого частотного диапазона модуляции) и для каждого рассматриваемого частотного диапазона (так что каждый из постобработанных фильтрованных с модуляцией сигналов 276a-276e эффективно представляется посредством одного значения (при этом данное одно значение может рассматриваться как значение модуляции).
Далее описываются подробности относительно сравнения 280.
Сравнение 280 принимает наборы 262a-262e значений модуляции, которые предоставляются посредством определения 260 информации модуляции, описанного прежде. Кроме того, сравнение 280 типично принимает наборы 282a-282e опорных значений модуляции, которые типично ассоциированы с опорным аудиосигналом и которые полностью считаются опорной информацией 282 модуляции.
Сравнение 280 необязательно применяет временное сглаживание 284 к отдельным значениям модуляции из наборов 262a-262e значений модуляции. Кроме того, сравнение 280 формирует (или вычисляет) разности между соответствующими значениями модуляции и их ассоциированными опорными значениями модуляции.
Далее обработка описывается для одного отдельного (характерного) значения модуляции (которое ассоциировано с частотой модуляции или частотным диапазоном модуляции и которое также ассоциировано с частотным диапазоном входного аудиосигнала 210). Здесь следует отметить, что рассматриваемое значение модуляции обозначается с помощью 276c, и что его ассоциированное опорное значение модуляции обозначается с помощью 283c. Как можно видеть, временное сглаживание 284c необязательно применяется к значению 276c модуляции до того, как применяется формирование 288c разности. Формирование 288c разности определяет разность между значением 276c модуляции и его ассоциированным опорным значением 283c модуляции. Соответственно, значение 289c разности получается, при этом, необязательно, временное сглаживание 290c может применяться к значению 289c разности. Кроме того, взвешивание 292c применяется к значению 289c разности или к его временно сглаженной версии 291c. Взвешивание 292c, например, может зависеть от информации комодуляции, ассоциированной с частотным диапазоном, с которым ассоциировано значение 289c разности. Кроме того, взвешивание 292c необязательно может также быть зависимым от знака или "асимметричным".
Например, если частотный диапазон, ассоциированный со значением 289c разности, содержит сравнительно высокую комодуляцию с одним или более смежных частотных диапазонов, сравнительно высокий весовой коэффициент может применяться к значению 289c разности либо к его временно сглаженной версии 291c, и если частотный диапазон, с которым ассоциировано значение 289c разности, содержит сравнительно небольшую комодуляцию с одним или более смежных частотных диапазонов, то сравнительно небольшой весовой коэффициент может применяться к значению 289c разности либо к его временно сглаженной версии 291c. Кроме того, сравнительно более высокий весовой коэффициент может применяться к положительным значениям для значения 289c разности или к его временно сглаженной версии 291c по сравнению с отрицательными значениями для значения 289c разности или с его временно сглаженной версией 291c (или наоборот). Другими словами, вообще говоря, зависимое от знака взвешивание может применяться к значению 289c разности либо к его временно сглаженной версии 291. Соответственно, получается взвешенное значение 294c разности.
Тем не менее, вообще говоря, следует отметить, что взвешенные значения разности (или невзвешенные значения разности, в случае если необязательное взвешивание опускается) получаются для каждой рассматриваемой частоты модуляции (или частотного диапазон модуляций) каждого частотного диапазона рассматриваемого входного аудиосигнала. Таким образом, получается сравнительно большое число взвешенных значений разности, которые вводятся в обработку 298 комбинирования или обработку оценки.
Обработка 298 комбинирования или обработка оценки, например, может формировать одно скалярное значение, которое составляет информацию 212 подобия, на основе взвешенных значений разности (которые, вместе, формируют "разностное представление" или "внутреннее разностное представление IDR"). Например, обработка комбинирования или обработка оценки может выполнять комбинирование суммы квадратов взвешенных значений 294a-294e разности, чтобы за счет этого извлекать информацию 212 подобия.
В качестве вывода, определение 220 сигналов огибающей предоставляет сигналы 222a-222e огибающей, например, по одному для каждой на рассматриваемой полосы частот (входного аудиосигнала). Фильтрация или гребенка фильтров, выпрямление, фильтрация нижних частот и адаптация могут использоваться в этой обработке. Определение информации модуляции определяет, например, одно значение модуляции для каждой рассматриваемой частоты модуляции (или частотного диапазона модуляции) и для каждого рассматриваемого частотного диапазона (входного аудиосигнала). Таким образом, предусмотрен один набор значений модуляции для каждого рассматриваемого частотного диапазона (входного аудиосигнала). Фильтрация, удаление DC и удаление информации фазы могут использоваться в этой обработке. В завершение, сравнение 280 сравнивает значения модуляции, полученные на основе входного аудиосигнала, с опорными значениями модуляции, ассоциированными с опорным аудиосигналом, при этом, необязательно, применяется взвешивание значений разности. В завершение, взвешенные значения разности комбинируются в компактную информацию подобия, которая может принимать форму одного скалярного значения. Эффективно, сравнение может определять (скалярное) значение, которое представляет разность между значениями модуляции, полученными на основе входного аудиосигнала, и значениями модуляции, ассоциированными с опорным аудиосигналом. Сравнение, например, может формировать "значение расстояния" или "норму", при этом могут необязательно применяться различные типы взвешивания.
Далее описываются некоторые варианты для определения комодуляции (или информации комодуляции), при этом следует отметить, что информация комодуляции, например, может использоваться для того, чтобы регулировать весовые коэффициенты значений разности (например, значений 289c разности) или их временно сглаженных версий (например, временно сглаженного значения 291c разности).
В качестве примера, комодуляция может определяться на основе сигналов 222a-222e огибающей. Например, модуль 299a определения комодуляции принимает сигналы 222a-222e огибающей и предоставляет, на их основе, информацию 299b комодуляции. Например, модуль 299a определения комодуляции может (например, отдельно) применяют фильтрацию нижних частот к различным сигналам 222a-222e огибающей. Кроме того, модуль 299a определения комодуляции, например, может определять ковариацию двух или более смежных (фильтрованных по нижним частотам) сигналов огибающей, чтобы за счет этого получать информацию комодуляции, ассоциированную с определенным частотным диапазоном. Например, модуль 299a определения комодуляции может определять ковариацию между данным (фильтрованным по нижним частотам) сигналом 222c огибающей и двумя, тремя, четырьмя или более сигналов 222a, 222b, 222d, 222e огибающей, ассоциированных со смежными частотными диапазонами, чтобы за счет этого извлекать информацию комодуляции, ассоциированную с рассматриваемым частотным диапазоном. Тем не менее, модуль определения комодуляции 299 может определять отдельную информацию комодуляции для множества частотных диапазонов (или, эквивалентно, ассоциированную с множеством сигналов огибающей).
Тем не менее, альтернативно, может использоваться модуль 299c определения комодуляции, который определяет информацию 299d комодуляции на основе информации 262a-262e модуляции. Например, модуль 299c определения комодуляции может сравнивать информацию модуляции, ассоциированную со смежными частотными диапазонами, чтобы за счет этого получать информацию комодуляции (например, для различных частотных диапазонов). Например, если модуляция в одном, двух, трех, четырех или более частотных диапазонов, которые являются смежными с данным частотным диапазоном, является аналогичной модуляции в данном частотном диапазоне, сравнительно высокая степень комодуляции может указываться посредством информации комодуляции (и наоборот). Таким образом, аналогично модулю 299a определения комодуляции, модуль 299c определения комодуляции может предоставлять отдельную информацию комодуляции, ассоциированную с различными частотными диапазонами.
Альтернативно, может использоваться модуль 299e определения комодуляции, который определяет информацию 299f комодуляции на основе опорного аудиосигнала. Например, модуль 299e определения комодуляции может определять информацию 299f комодуляции на основе опорной информации 282a-282e модуляции. Например, модуль 299e определения комодуляции может содержать функциональность, идентичную функциональности модуля 299c определения комодуляции.
Тем не менее, модуль 299e определения комодуляции также может определять информацию 299f комодуляции на основе опорного аудиосигнала с использованием подхода, идентичного подходу для модуля 299a определения комодуляции.
Тем не менее, следует отметить, что различные концепции для определения информации комодуляции также могут быть полезными. Кроме того, следует отметить, что определение информации комодуляции должно считаться полностью необязательным.
Необязательно, опорная информация 282a-282e модуляции может получаться с использованием необязательного определения 281a опорной информации модуляции на основе опорного аудиосигнала 281. Определение 281a опорной информации модуляции, например, может выполнять идентичную функциональность, такую как определение 220 сигналов огибающей и определение 260 информации модуляции на основе опорного аудиосигнала 281.
Тем не менее, следует отметить, что опорная информация 282a-282e модуляции также может получаться из другого источника, например, из базы данных или из запоминающего устройства, или из удаленного устройства, которое не представляет собой часть модуля оценки подобия аудиосигналов.
В качестве вывода, фиг. 2a и 2b раскрывают функциональность модуля оценки подобия аудиосигналов, согласно варианту осуществления изобретения. Тем не менее, следует отметить, что отдельные функциональности могут опускаться или существенно модифицироваться без отступления от фундаментальных концепций. Следует отметить, что любые из этих подробностей, которые выходят за рамки концепции модуля 100 оценки подобия аудиосигналов, должны считаться необязательными и могут опускаться или модифицироваться отдельно.
3. Аудиокодер согласно фиг. 3
Фиг. 3 показывает принципиальную блок-схему аудиокодера 300, согласно варианту осуществления настоящего изобретения.
Кодер 300 выполнен с возможностью принимать входной аудиосигнал 310 (который представляет собой аудиосигнал, который должен кодироваться, или "исходный аудиосигнал") и предоставлять, на его основе, кодированный аудиосигнал 312. Кодер 300 содержит кодирование 320 (либо кодер, либо базовый кодер), которое выполнено с возможностью предоставлять кодированный аудиосигнал 312 на основе входного аудиосигнала 310. Например, кодирование 320 может выполнять кодирование в частотной области аудиоконтента, которое может быть основано на концепции AAC-кодирования либо на одном из ее расширений. Тем не менее, кодирование 320, например, может выполнять кодирование в частотной области только для части спектра и может применять определение параметров на основе параметрического расширения полосы пропускания и/или определение параметров параметрического заполнения промежутков (например, в качестве "интеллектуального заполнения промежутков (IGF)"), чтобы за счет этого предоставлять кодированный аудиосигнал (который может представлять собой поток битов, содержащий кодированное представление спектральных значений и кодированное представление одного или более параметров кодирования или параметров расширения полосы пропускания).
Следует отметить, что настоящее описание ссылается на параметры кодирования. Тем не менее, вместо параметров кодирования, все варианты осуществления, в общем, могут использовать "параметры кодирования", которые могут представлять собой параметры кодирования (которые типично используются и посредством кодера и посредством декодера или только посредством кодера), или параметры декодирования (которые типично только используются посредством декодера, но которые типично передаются в служебных сигналах в декодер посредством кодера).
Типично, кодирование 320 может регулироваться до согласно характеристикам сигнала и/или согласно требуемому равенству кодирования, с использованием одного или более параметров 324 кодирования. Параметры кодирования, например, могут описывать кодирование спектральных значений и/или могут описывать один или более признаков расширения полосы пропускания (или заполнения промежутков), таких как ассоциация между исходными фрагментами и целевыми фрагментами, параметр отбеливания и т.д.
Тем не менее, следует отметить, что также могут использоваться различные концепции кодирования, такие как кодирование на основе линейного прогнозирующего кодирования.
Кроме того, аудиокодер содержит определение параметров кодирования, которое выполнено с возможностью определять один или более параметров кодирования в зависимости от оценки подобия между аудиосигналом, который должен кодироваться, и кодированным аудиосигналом. В частности, определение 330 параметров кодирования выполнено с возможностью оценивать подобие между аудиосигналом, который должен кодироваться (т.е. входным аудиосигналом 310), и кодированным аудиосигналом с использованием модуля 340 оценки подобия аудиосигналов. Например, аудиосигнал, который должен кодироваться (т.е. входной аудиосигнал 310), используется в качестве опорного аудиосигнала 192, 281 для оценки подобия посредством модуля 340 оценки подобия аудиосигналов, и декодированная версия 362 аудиосигнала 352, кодированного с использованием одного или более рассматриваемых параметров кодирования, используется в качестве входного сигнала (например, в качестве сигнала 110, 210) для модуля 340 оценки подобия аудиосигналов. Другими словами, кодированная и затем декодированная версия 362 исходного аудиосигнала 310 используется в качестве входного сигнала 110, 210 для модуля оценки подобия аудиосигналов, и исходный аудиосигнал 310 используется в качестве опорного сигнала 192, 281 для модуля оценки подобия аудиосигналов.
Таким образом, определение 330 параметров кодирования, например, может содержать кодирование 350 и декодирование 360, а также выбор 370 параметров кодирования. Например, выбор 370 параметров кодирования может соединяться с кодированием 350 (и необязательно также с декодированием 360), чтобы за счет этого управлять параметрами кодирования, используемыми посредством кодирования 350 (которые типично соответствуют параметрам декодирования, используемым посредством декодирования 360). Соответственно, кодированная версия 352 входного аудиосигнала 310 получается посредством кодирования 350, и кодированная и декодированная версия 362 получается посредством декодирования 360, при этом кодированная и декодированная версия 362 входного аудиосигнала 310 используется в качестве входного сигнала для оценки подобия. Возможная задержка кодека, введенная в тракте передачи сигналов через 350 и 360, предпочтительно должна компенсироваться в прямом тракте 310 до входа в оценку подобия.
Соответственно, выбор 370 параметров кодирования принимает информацию 342 подобия из модуля 340 оценки подобия аудиосигналов. Типично, выбор 370 параметров кодирования принимает информацию 342 подобия для различных параметров кодирования или наборов параметров кодирования и затем определяет то, какой параметр кодирования или какой набор параметров кодирования должен использоваться для предоставления кодированного аудиосигнала 312, который выводится посредством аудиокодера (например, в форме потока аудиобитов, который должен отправляться в аудиодекодер, или сохраняться).
Например, выбор 370 параметров кодирования может сравнивать информацию подобия, которая получается для различных параметров кодирования (или для различных наборов параметров кодирования), и выбирать те параметры кодирования для предоставления кодированного аудиосигнала 312, которые приводят к информации наилучшего подобия или, по меньшей мере, к информации приемлемо хорошего подобия.
Кроме того, следует отметить, что оценка 340 подобия, например, может реализовываться с использованием модуля 100 оценки подобия аудиосигналов согласно фиг. 1 либо с использованием модуля 200 оценки подобия аудиосигналов согласно фиг. 2 (или с использованием любого из других модулей оценки подобия аудиосигналов, поясненных в данном документе). Кроме того, следует отметить, что кодирование 320 необязательно может опускаться. Например, кодированная аудиоинформация 352, которая предоставляется в качестве промежуточной информации при выборе параметра кодирования или параметров кодирования, может поддерживаться (например, сохраняться в качестве временной информации), и может использоваться в предоставлении кодированного аудиосигнала 312.
Следует отметить, что аудиокодер 300 согласно фиг. 3 может дополняться посредством любых из признаков, функциональностей и подробностей, описанных в данном документе, как отдельно, так и в комбинации. В частности, любые из подробностей модуля оценки подобия аудиосигналов, описанного в данном документе, могут вводиться в модуль 340 оценки подобия аудиосигналов.
4. Аудиокодер 400 согласно фиг. 4
Фиг. 4 показывает принципиальную блок-схему аудиокодера 400, согласно варианту осуществления настоящего изобретения.
Следует отметить, что аудиокодер 400 является аналогичным аудиокодеру 300, так что вышеприведенные пояснения также применяются. Здесь, аудиокодер 400 выполнен с возможностью принимать входной аудиосигнал 410 и предоставлять, на его основе, кодированный аудиосигнал или кодированную аудиоинформацию 412, которая, например, может принимать форму потока битов, содержащего кодированные спектральные значения и кодированные параметры кодирования.
Аудиокодер 400 содержит кодирование 420, которое, например, может соответствовать кодированию 320. Тем не менее, кодирование 420, например, может содержать предоставление 422 параметров расширения полосы пропускания, которое может предоставлять (предпочтительно кодированные) параметры расширения полосы пропускания, которые могут использоваться, на стороне аудиодекодера, для направляемого параметрами расширения полосы пропускания (такого как, например, заполнение промежутков). Таким образом, кодирование, например, может предоставлять кодированные спектральные значения (например, в низкочастотном диапазоне), такие как, например, кодированный квантованный MDCT-спектр. Кроме того, кодирование 420, например, может предоставлять (предпочтительно кодированные) параметры расширения полосы пропускания, которые, например, могут описывать ассоциацию между одним или более исходных фрагментов и одним или более целевых фрагментов и необязательно также уровнем отбеливания. Например, параметры расширения полосы пропускания могут принимать форму вспомогательной информации интеллектуального заполнения промежутков (IGF). Тем не менее, параметры расширения полосы пропускания также могут соответствовать любым другим концепциям расширения полосы пропускания. Таким образом, как кодированные спектральные значения, так и параметры расширения полосы пропускания могут помещаться в кодированное аудиопредставление, которое может принимать форму потока битов.
Кроме того, аудиокодер 400 также содержит определение 430 параметров кодирования, которое может соответствовать определению 330 параметров кодирования. Например, определение 430 параметров кодирования может использоваться для того, чтобы определять один или более параметров расширения полосы пропускания, таких как один или более параметров, описывающих ассоциацию между одним или более исходных фрагментов и одним или более целевых фрагментов в расширении полосы пропускания, и необязательно также параметр, описывающий уровень отбеливания.
Необязательно, определение 430 параметров кодирования также содержит ограничение 480 изменений ассоциации. Ограничение 480 изменений ассоциации выполнено с возможностью предотвращать изменения параметров кодирования, в частности, изменение ассоциации между исходным фрагментом и целевым фрагментом, если такое изменение параметра вызывает слышимое искажение. Например, ограничение 480 изменений ассоциации может содержать определение 484 интенсивности модуляции, которое, например, может определять интенсивность 485 модуляции в сигналах огибающей, при этом частота модуляции, рассматриваемая посредством определения 484 интенсивности модуляции, может соответствовать частоте кадров входного аудиосигнала. Кроме того, ограничение 480 изменений ассоциации может содержать определение 486 показателей чувствительности, которое определяет информацию чувствительности на основе информации интенсивности модуляции, предоставленной посредством определения 484 интенсивности модуляции. Показатель чувствительности, определенный посредством определения 486 показателей чувствительности, например, может описываться посредством того, насколько ощущение для слуха может ухудшаться посредством изменения ассоциации между исходным фрагментом и целевым фрагментом. Если показатель чувствительности, предоставленный посредством определения 486 показателей чувствительности, указывает то, что изменение ассоциации между исходным фрагментом и целевым фрагментом должно оказывать сильное (или значительное, или заметное) влияние на ощущение для слуха, изменение ассоциации между исходным фрагментом и целевым фрагментом предотвращается посредством стробирования 488 изменений ассоциации. Например, оценка показателя чувствительности может выполняться с использованием сравнения 489 с пороговым значением, которое сравнивает показатель 487 чувствительности с пороговым значением, чтобы определять то, должно изменение ассоциации разрешаться или предотвращаться.
Соответственно, информация 424 параметров кодирования предоставляется в форме "ограниченных" параметров кодирования, при этом ограничение налагается посредством ограничения 480 изменений ассоциации на изменение ассоциации между исходным фрагментом и целевым фрагментом.
В качестве вывода, необязательное ограничение 480 изменений ассоциации может предотвращать изменение параметров кодирования в периоды времени, когда такое изменение параметров кодирования приводит к слышимым искажениям. В частности, ограничение 480 изменений ассоциации может предотвращать изменение ассоциации между исходным фрагментом и целевым фрагментом в расширении полосы пропускания, если такое изменение ассоциации приводит к сильному или значительному, или заметному ухудшению ощущения для слуха. Оценка в отношении того, возникает или нет ухудшение ощущения для слуха, осуществляется на основе оценки интенсивности модуляции, как описано выше.
Тем не менее, аудиокодер 400 необязательно может дополняться посредством любых из признаков, функциональностей и подробностей относительно любого из других аудиокодеров, как отдельно, так и в комбинации.
5. Аудиокодер согласно фиг. 5
Фиг. 5a показывает принципиальную блок-схему аудиокодера 500, согласно варианту осуществления настоящего изобретения.
Аудиокодер 500 выполнен с возможностью принимать входной аудиосигнал 510 и предоставлять, на его основе, кодированный аудиосигнал 512. Входной аудиосигнал 510, например, может соответствовать входному аудиосигналу 310, и кодированный аудиосигнал 512, например, может практически соответствовать кодированному аудиосигналу 312.
Аудиокодер 500 также содержит кодирование 520, которое может практически соответствовать кодированию 320, описанному выше. Кодирование 520 принимает информацию 524 параметров кодирования из нейронной сети 530, которая занимает место определения 330 параметров кодирования. Нейронная сеть 530 принимает, например, входной аудиосигнал 510 и предоставляет, на его основе, информацию 524 параметров кодирования.
Следует отметить, что нейронная сеть 530 обучается с использованием обучающих данных 532, которые предоставляются с использованием модуля оценки подобия аудиосигналов, раскрытого в данном документе, либо с использованием определения 330, 430 параметров кодирования, раскрытого в данном документе. Другими словами, параметры кодирования, которые предоставляются в нейронную сеть 530 в качестве части обучающих данных 532, получаются с использованием модуля 100, 200 оценки подобия аудиосигналов, как описано в данном документе.
Соответственно, нейронная сеть 530 типично предоставляет параметры 524 кодирования, которые являются очень похожими на параметры кодирования, которые должны получаться с использованием аудиокодера 300 или аудиокодера 400, который фактически принимает решение по параметрам кодирования с использованием такого модуля 100, 200 оценки подобия аудиосигналов. Другими словами, нейронная сеть 530 обучается с возможностью аппроксимировать функциональность определения 330, 430 параметров кодирования, которая достигается посредством использования параметров кодирования, полученных с использованием модуля 100, 200 оценки подобия аудиосигналов в качестве части обучающих данных для обучения нейронной сети 530.
Ниже предоставляются дополнительные сведения относительно аудиокодера 500 и, в общем, относительно использования нейронной сети 530 в аудиокодере.
Иными словами, определение 330 параметров кодирования или определение 430 параметров кодирования может использоваться для того, чтобы предоставлять обучающие данные для нейронной сети 530 для того, чтобы обучать нейронную сеть с возможностью выполнять функциональность, которая является максимально возможно аналогичной функциональности определения 330, 430 параметров кодирования.
Обучение нейронной сети 530 в режиме обучения показывается на фиг. 5b. Для обучения, предпочтительно различные обучающие входные аудиосигналы и обучающие параметры кодирования, ассоциированные с различными обучающими входными аудиосигналами, предоставляются в нейронную сеть в качестве обучающих данных. Обучающие входные аудиосигналы служат в качестве входных сигналов в нейронную сеть, и обучающие параметры кодирования представляют собой требуемые выходные сигналы нейронной сети. (Обучающие) параметры кодирования, предоставленные в нейронную сеть в качестве обучающих данных, типично получаются заранее с использованием модуля оценки подобия аудиосигналов, как пояснено в данном документе, либо посредством определения параметров кодирования, как пояснено в данном документе (на основе обучающих входных аудиосигналов, которые предоставляются в нейронную сеть в ходе режима обучения).
Тем не менее, следует отметить, что аудиокодер 500 необязательно может дополняться посредством любых из признаков, функциональностей и подробностей, описанных в данном документе, как отдельно, так и в комбинации.
6. Модуль оценки подобия аудиосигналов согласно фиг. 6
Фиг. 6 показывает принципиальную блок-схему аудиодекодера согласно варианту осуществления настоящего изобретения. Модуль 600 оценки подобия аудиосигналов выполнен с возможностью принимать входной аудиосигнал 610 и предоставлять, на его основе, информацию 612 подобия.
Модуль 600 оценки подобия аудиосигналов содержит определение 620 сигналов огибающей, которое выполнено с возможностью получать сигналы 622a-622c огибающей для множества (предпочтительно перекрывающихся) частотных диапазонов на основе входного аудиосигнала 610. Например, гребенка фильтров или гребенка гамматоновых фильтров может использоваться для того, чтобы предоставлять сигналы 622a-622c огибающей. Необязательно, выпрямление и/или временная фильтрация нижних частот, и/или один или более процессов адаптации (которые, например, могут моделировать премаскирование и/или постмаскирование в слуховой системе) также могут использоваться для того, чтобы получать сигналы 622a-622c огибающей.
Кроме того, модуль оценки подобия аудиосигналов выполнен с возможностью получать аналитическое представление 662a-662c. Аналитическое представление 662a-662c, например, может соответствовать сигналам 622a-622c огибающей или, например, может быть основано на сигнале 622a-622c огибающей. Аналитическое представление 662a-662c, например, может представлять собой "внутреннее представление", такое как информация модуляции или представление в частотно-временной области.
Кроме того, модуль 600 оценки подобия аудиосигналов содержит сравнение 680 (или модуль сравнения) и в силу этого выполнен с возможностью сравнивать аналитическое представление 662a-662c входного аудиосигнала с опорным аналитическим представлением 682a-682c, которое ассоциировано с опорным аудиосигналом. Например, сравнение 680 может содержать формирование внутреннего разностного представления, при этом внутреннее разностное представление, например, может описывать разность между полученным аналитическим представлением и опорным аналитическим представлением. Могут применяться одна или более операций взвешивания или операций модификации при определении внутреннего разностного представления, таких как масштабирование внутреннего разностного представления на основе степени комодуляции и/или асимметричное взвешивание положительных и отрицательных значений внутреннего разностного представления. Соответственно, может получаться информация подобия (которая может рассматриваться как информация относительно подобия между входным аудиосигналом и опорным аудиосигналом). Информация подобия, например, может принимать форму одного значения, описывающего перцепционное подобие между входным аудиосигналом и опорным аудиосигналом.
Модуль оценки подобия аудиосигналов выполнен с возможностью регулировать весовой коэффициент разности между полученным аналитическим представлением 662a-662c (например, информацией модуляции или, в общем, "внутренним представлением") и опорной аналитической информацией 682a-682c (например, опорной информацией модуляции, ассоциированной с опорным аудиосигналом) в зависимости от комодуляции (например, между полученными сигналами 622a-622c огибающей или полученной информацией модуляции) в двух или более смежных акустических частотных диапазонах входного аудиосигнала или в зависимости от комодуляции (например, между сигналами огибающей, ассоциированными с опорным сигналом, либо между опорной информацией модуляции, ассоциированной с опорным сигналом) в двух или более акустических частотных диапазонах опорного аудиосигнала. Например, увеличенный весовой коэффициент может предоставляться для разности в случае, если сравнительно высокая степень комодуляции обнаруживается (для рассматриваемого частотного диапазона) по сравнению со случаем, в котором сравнительно низкая степень комодуляции обнаруживается (для рассматриваемого частотного диапазона). Степень комодуляции, например, может обнаруживаться посредством определения ковариации между временными огибающими, ассоциированными с различными акустическими частотными диапазонами (или посредством любой другой концепции).
Другими словами, в модуле 600 оценки подобия аудиосигналов, подчеркиваются (получают относительно более высокие весовые коэффициенты) такие компоненты разности между аналитическим представлением 662a-662c (которое типично содержит множество значений для одного кадра входного аудиосигнала) и опорным аналитическим представлением 682a-682c (которое типично также содержит множество отдельных значений для одного кадра входного аудиосигнала или опорного аудиосигнала), которые ассоциированы с полосами частот, которые имеют сравнительно высокую комодуляцию с другими смежными полосами частот.
Соответственно, в сравнении 680, подчеркиваются разности между аналитическим представлением 662a-662c и опорным аналитическим представлением 682a-682c, которые возникают в полосах частот, которые содержат сравнительно высокую комодуляцию (в то время как разности получают более низкие весовые коэффициенты, если они находятся в полосах частот, которые содержат сравнительно меньшую комодуляцию). Обнаружено, что такая оценка подобия аудиосигналов способствует информации 612 подобия, имеющей хорошую надежность (и согласование с перцепционным ощущением).
Тем не менее, следует отметить, что модуль 600 оценки подобия аудиосигналов необязательно может дополняться посредством любых из признаков, функциональностей и подробностей, описанных в данном документе, как отдельно, так и в комбинации.
7. Соображения относительно оценки качества звучания и подобия аудиосигналов
7.1. Модель Дау
Подход к моделированию, который включает конкретные предположения касательно перцепционной обработки информации временной огибающей, присутствующей в критических полосах частот, предложен в работе авторов Дау и др. [9, 10]. Помимо различных этапов обработки, которые представляют эффективную обработку сигналов периферийной слуховой системы (см. [11]) эта модель предполагает то, что форма временной огибающей, наблюдаемая в каждой критической полосе частот, обрабатывается посредством гребенки модуляционных фильтров. Эта гребенка модуляционных фильтров представляет спектральное разрешение слуховой системы в области модуляции (см. [12]).
Обнаружено, что модель Дау или модель, извлекаемая из (либо на основе) модели Дау, может использоваться с хорошей производительностью для оценки подобия аудиосигналов (например, в модулях оценки подобия аудиосигналов и аудиокодерах, раскрытых в данном документе).
7.2. Преимущество модели для управления BWE
Согласно аспекту изобретения, использование такого подхода к моделированию может быть полезным для параметрических представлений сигналов, таких как BWE. Более конкретно, обнаружено, что для имеющих определенную высоту сигналов, которые зачастую возникают в музыке, репликация низкочастотной части комплекса тонов на верхних частотах должна создавать периодическую структуру огибающей, которая может достаточно хорошо напоминать структуру огибающей исходного сигнала, даже когда сама параметрически представленная форма сигнала существенно отличается от формы исходного сигнала.
Согласно аспекту изобретения, перцепционная модель, которая может оценивать воспринимаемое подобие этой информации временной огибающей, может помогать направлять решения по кодированию, которые затрагивают временную огибающую, такие как регулирование шума и тональности в BWE и аналогичные технологии.
Соответственно, варианты осуществления согласно изобретению используют модель Дау или модель, извлекаемую из нее, для оценки подобия аудиосигналов и для принятия решения в отношении того, какие параметры кодирования должны использоваться.
8. Предложенная психоакустическая модель
8.1. Общие соображения
В этом разделе представляется модель, для которой первые стадии обработки главным образом напоминают модель на основе работы авторов Дау и др. [9], как проиллюстрировано на фиг. 7. На последующих стадиях обработки, модель необязательно расширяется таким образом, что она включает в себя некоторые дополнительные перцепционные явления, и таким образом, чтобы обеспечивать применимость модели для решений по кодированию, которые имеют перцепционные последствия как на локальной, так и на более глобальной временной шкале. В соответствии с исходной моделью на основе работы авторов Дау и др. [9], ввод в модель преобразуется в так называемое внутреннее представление (IR). Этот IR представляет собой преобразование входного сигнала в перцепционную область, которая содержит всю информацию, доступную для дополнительной слуховой обработки. Вследствие добавленного собственного шума в IR, небольшие изменения IR вследствие изменений входного сигнала не должны быть обнаруживаемыми. Этот процесс моделирует перцепционную обнаруживаемость изменений входного сигнала.
Фиг. 7 показывает принципиальную схему последовательности сигналов и блоков обработки модели слуховой обработки на основе работы авторов Дау и др. Модель 700 содержит базилярную мембранную фильтрацию 720, которая, например, может применять базилярную мембранную фильтрацию к входному аудиосигналу 710. Базилярная мембранная фильтрация 720 предоставляет, например, множество полосовых сигналов, которые покрывают различные (возможно перекрывающиеся) частотные диапазоны входных аудиосигналов 710. Выходные сигналы 732a-732e базилярной мембранной фильтрации 720, например, могут соответствовать сигналам 232a-232e, предоставленным посредством фильтрации 230.
Модель 700 также содержит множество параллельных трактов передачи сигналов, которые работают с различными выходными сигналами 732a-732e базилярной мембранной фильтрации 720. Для простоты, показывается только один отдельный тракт обработки, который содержит полуволновое выпрямление и фильтрацию 736 нижних частот, которые, например, могут соответствовать выпрямлению 236 и фильтрации 240 нижних частот определения 220 сигналов огибающей. Кроме того, модель также содержит адаптацию 750, которая, например, может соответствовать адаптации 250. Соответственно, в выводе адаптации, которая принимает результат полуволнового выпрямления и фильтрации 736 нижних частот (которые применяются к соответствующему выходному сигналу 732c базилярной мембранной фильтрации 720), предоставляется сигнал 722c огибающей, который может соответствовать сигналу 222c огибающей. Кроме того, модель 700 также содержит гребенку 760 модуляционных фильтров, которая ассоциирована с частотным диапазоном базилярной мембранной фильтрации 720 (например, с одним выходным сигналом 732c базилярной мембранной фильтрации 720). Другими словами, может быть предусмотрено множество (например, отдельных) гребенок модуляционных фильтров, ассоциированных с различными частотными диапазонами базилярной мембранной фильтрации. Гребенка 760 модуляционных фильтров предоставляет, в выводе, модулирующие сигналы 766a-766e, которые ассоциированы с различными частотами модуляции.
Модель 700 необязательно содержит добавление 768 шума, которое добавляет шум в выходные сигналы гребенки 760 модуляционных фильтров. Модель 700 также содержит "оптимальный детектор" 780, который, например, может соответствовать сравнению 280.
Другими словами, компоненты модели 700, например, могут использоваться в модулях оценки подобия аудиосигналов, раскрытых в данном документе. Соответственно, признаки, функциональности и подробности, описанные ниже относительно отдельных компонентов модели 700, могут необязательно реализовываться отдельно и в комбинации в модулях оценки подобия аудиосигналов и аудиокодерах, раскрытых в данном документе.
8.2. Гребенка гамматоновых фильтров (подробности являются необязательными)
Предложенная модель, которая, например, может использоваться в модулях 120, 220 определения сигналов огибающей или в фильтрации 230, начинается с обработки входного сигнала 110, 210, 710 с помощью гребенки гамматоновых фильтров четвертого порядка, состоящей, например, из 42 фильтров, равномерно разнесенных на перцепционной шкале в частотном диапазоне, охватывающем, например, от 150 Гц до 16 кГц. Эта стадия представляет спектральный анализ сигналов в слуховой улитке. Очевидная особенность в импульсных откликах базилярной мембраны заключается в том, что высокочастотные импульсные отклики гораздо короче низкочастотных импульсных откликов, к примеру, как показано на фиг. 8, который показывает схематичное представление импульсных откликов гребенки гамматоновых фильтров.
Длина временной аналитической функции, которая требуется для того, чтобы достигать частотного разрешения приблизительно в 12% от центральной частоты в соответствии с общими оценками полосы пропускания слухового фильтра (см. [13]), может достигаться с пропорционально меньшими временными окнами по мере того, как центральная частота увеличивается. Это объясняет то, почему импульсные отклики базальных высокочастотных частей базилярной мембраны короче импульсных откликов апикальных низкочастотных частей. Частотное разрешение в 12% от центральной частоты, конечно, означает то, что в абсолютном выражении высокочастотная область базилярной мембраны достигает только неудовлетворительного спектрального разрешения, но высокого временного разрешения, тогда как для низкочастотной области обратное является истинным.
8.3. Внутренние волосковые клетки (подробности являются необязательными)
Каждый вывод гамматонового фильтра обрабатывается посредством простой модели внутренних волосковых клеток, которая, например, состоит из полуволнового выпрямления с последующим фильтром нижних частот с частотой отсечки в 1000 Гц (например, показан по ссылке с номером 736). Вывод этой модели внутренних волосковых клеток представляет степень потенциалов действия на волокна слухового нерва, который здесь предположительно имеет ограниченное временное разрешение.
Полуволновое выпрямление в простой модели волосковых клеток связано с таким фактом, что стереоресницы ("волоски") открывают свои ионные каналы только при подталкивании в одну сторону, что приводит к изменениям потенциала в клетке (см. фиг. 9, который показывает схематичное представление кортиева органа). Темп изменения результирующего потенциала ограничен. Таким образом, частота пульсации в слуховом нерве может синхронизироваться с точной структурой перемещения базилярной мембраны только для относительно низких частот. Это общее поведение реализуется посредством фильтра нижних частот (который, например, также показан по ссылке с номером 736).
Функциональности модели внутренних волосковых клеток, например, могут реализовываться в блоках 236, 240 определения 220 сигналов огибающей.
8,4. Процессы адаптации, маскирование (подробности являются необязательными)
После обработки внутренних волосковых клеток, выполняется последовательность (например) из пяти контуров адаптации (например, включенных в адаптацию 750). Они представляют процессы адаптации, осуществляющиеся в слуховой системе, которые проявляют себя в явлении прямого маскирования (постмаскирования), наблюдаемого после смещения аудиосигнала. Например, каждый контур адаптации состоит из (или содержит) адаптивной регулировки усиления, которая ослабляется посредством фильтрованного по нижним частотам вывода идентичного контура адаптации (т.е. контура обратной связи). Чтобы понимать функцию такого контура адаптации, рассмотрим вступление и смещение сигнала. Во вступлении сигнала, начальное ослабление является небольшим, поскольку не предусмотрено предыдущего ввода-вывода, что приводит к большому выводу c "перерегулированием" контура адаптации. Фильтрованный по нижним частотам вывод должен повышать и начинать ослаблять вывод контура адаптации до тех пор, пока не достигается равновесие.
Для входных сигналов с постоянным уровнем, вывод в установившемся состоянии пяти контуров адаптации, например, может линейно масштабироваться таким образом, что он является очень похожим на преобразование в децибелах в соответствии с нашим восприятием громкости. В этой модели, чтобы исключать значительное перерегулирование во вступлении сигнала, жесткий предел применяется к выводу контуров адаптации, равный подвергнутому преобразованию в децибелах входному сигналу. При смещении сигнала, ослабление должно сохраняться в течение некоторого времени, до тех пор, пока эффект фильтра нижних частот не уменьшится. Это ослабление моделирует эффект прямого маскирования; т.е. пониженную чувствительность к тому, чтобы обнаруживать целевой сигнал, вследствие предыдущего слухового сигнала "маскера".
Такая адаптация, например, может предоставляться посредством адаптации 250.
8.5. Гребенка модуляционных фильтров (подробности являются необязательными)
После контуров адаптации, например, выполняется гребенка 760 модуляционных фильтров. Она состоит из диапазона, например, фильтров шириной в 5 Гц с центральными частотами, например, от 0 Гц до 20 Гц, с последующими фильтрами, например, с Q=4, разделяемыми на шаги, соответствующие полосе пропускания модуляционного фильтра до тех пор, пока не достигается максимальная центральная частота, например, в 243 Гц. Таким образом, спектральное разрешение в области модуляции является более высоким в этой модели, чем в [9], и наибольшая частота модуляции ограничена таким образом, что она в большей степени соответствует максимальным частотам модуляции, которые могут обрабатываться людьми (см. [15]). Выводы фильтра являются, например, комплекснозначными, представляющими только положительные частоты.
Дополнительная модификация (необязательно) вносится в модуляционные фильтры. Для коэффициентом Q только в 4, можно ожидать, что каждый модуляционный фильтр должен ослаблять DC-компонент огибающей только в ограниченной степени. При условии, что DC-компоненты в огибающей имеют высокую амплитуду относительно модулированных компонентов, DC-компонент может играть доминирующую роль в выводе модуляционных фильтров, даже когда они настраиваются на высокие центральные частоты.
Чтобы удалять DC-компонент, вывод каждого модуляционного фильтра, например, фильтруется по нижним частотам с частотой отсечки в половину центральной частоты модуляционного фильтра. Затем абсолютные значения вывода гребенки модуляционных фильтров и фильтра нижних частот, например, вычитаются друг из друга. Таким образом, удаляется DC-компонент, а также информация фазы модуляции, которая здесь предположительно не должна обрабатываться непосредственно посредством слуховой системы. Такая функциональность, например, может выполняться посредством удаления DC 270.
Импликация обработки информации фазы временной должна заключаться в том, что точная временная синхронизация слуховых событий является воспринимаемой. Исследование в работе авторов Vafin и др. [16] показывает то, что слушатели являются нечувствительными к небольшому сдвигу временной синхронизации вступлений. удаление DC является, в частности, релевантным на стадии управления кодером, которая описывается в данном документе (например, ниже (в разделе 9.3)). Эта стадия необязательно требует (или предпочтительно должна иметь) интенсивность модуляций без DC-компонентов в качестве ввода, чтобы принимать решения по тому, разрешается или нет переключение с одного на другой вариант кодирования.
Функциональность гребенки модуляционных фильтров, например, может выполняться посредством фильтрации 264. Функциональность, например, может дополняться посредством удаления DC 270 и посредством удаления 274 информации фазы.
8.6. Внутреннее представление (IR) (подробности являются необязательными)
Результирующие выводы всех модуляционных фильтров во всех слуховых фильтрах составляют, например, внутреннее представление (IR). В принципе, IR исходного и кодированного сигнала могут сравниваться; например, сумма всех квадратов разности по полному IR предоставляет показатель для слышимости разностей между исходным и кодированным сигналом (см. [17]). Например, такое сравнение может выполняться посредством блока 280 сравнения (например, с использованием комбинирования/оценки 298).
Чтобы включать некоторые аспекты дополнительных стадий слуховой обработки, три модификации (необязательно) вносятся в разности между обоими IR (называется "внутренним разностным представлением (IDR)").
Результирующее IDR может использоваться для того, чтобы принимать решения по вариантам кодирования, которые доступны (или, иными словами, решения по параметрам кодирования). Каждый вариант кодирования влечет за собой конкретный выбор параметров, с помощью которых выполняется кодирование. IDR предоставляет показатель, который прогнозирует уровень перцепционного искажения, созданного посредством соответствующего варианта кодирования. Вариант кодирования, который приводит к минимальному прогнозированному перцепционному искажению, затем выбирается (например, с использованием выбора 370 параметров кодирования).
8.7. Прекращение маскирования за счет комодуляции (CMR) (подробности являются необязательными)
Первая (необязательная) модификация IDR связана с комодуляцией полос частот спектра. Обнаружено, что для маскеров, которые временно комодулируются по полосам частот, добавленные тона могут обнаруживаться на гораздо более низких уровнях (см. [18]), чем для временно декоррелированных маскеров. Этот эффект называется "прекращением маскирования за счет комодуляции (CMR)". Также на высоких частотах комодуляция полос частот приводит к меньшему маскированию [19].
Из этого делается вывод, что для комодулированных сигналов, разности в IR между исходным и кодированным сигналом также должны обнаруживаться более легко (например, слушателем-человеком).
Чтобы учитывать этот эффект, IDR необязательно повышающе масштабируется на основе степени комодуляции (например, во взвешивании 292a-292e).
Степень комодуляции определяется, например, посредством измерения степени ковариации между временными огибающими рассматриваемого слухового фильтра с четырьмя смежными слуховыми фильтрами (с двумя ниже и с двумя выше рассматриваемого фильтра). Например, вывод контуров адаптации с последующим необязательным фильтром нижних частот (с постоянной времени в 0,01 секунд) использован для того, чтобы представлять временные огибающие выводов слухового фильтра.
Это определение степени комодуляции, например, может выполняться посредством модуля 299a определения комодуляции.
В предварительных сравнениях прогнозирований на основе модели с субъективными рейтингами, лучшие прогнозирования получаются посредством включения CMR-эффектов в модель. Однако, насколько известно, CMR до сих пор не учитывается в контексте перцепционного кодирования аудио.
8.8. Временное сглаживание (подробности являются необязательными)
Во-вторых, внутреннее представление (необязательно) временно сглаживается за длительность приблизительно в 100 мс. Это временное сглаживание, например, может выполняться посредством временного сглаживания 290a-290e.
Обуславливание для этого заключается в том, что слушатели-люди, хотя и могут хорошо воспринимать присутствие временных флуктуаций в шуме, являются относительно нечувствительными к подробностям этой стохастической флуктуации. Другими словами, по сути только интенсивность модуляции воспринимается, и не в такой степени временные подробности модуляции. Работа автора Hanna [20] демонстрирует то, что конкретно более длинные маркеры шума, сформированные посредством идентичного генератора шума, не могут отличаться друг от друга.
8.9. Перцепционная асимметрия (подробности являются необязательными)
В-третьих, необязательно считается, что сигнальные компоненты, которые добавляются при кодировании сигнала, приводят к более негативному влиянию с точки зрения качества звучания, чем компоненты, которые удаляются. Базовое предположение заключается в том, что компоненты, которые добавляются, зачастую не должны совместно использовать общие свойства с исходным аудиосигналом и по этой причине должны быть более заметными в качестве артефактов.
Это (необязательно) реализовано посредством асимметричного взвешивания положительных и отрицательных значений разности в IR. Асимметричное взвешивание, например, может выполняться посредством взвешивания 292a-292e.
В предварительных сравнениях прогнозирований на основе модели с субъективными данными, обнаружено, что асимметричное взвешивание приводит к лучшим прогнозированиям.
9. IGF-управление посредством психоакустической модели
Далее описывается то, как расширение полосы пропускания (например, интеллектуальное заполнение промежутков, IGF) (или параметры расширения полосы пропускания) может управляться с использованием модуля оценки подобия аудиосигналов, поясненного в данном документе (например, в аудиокодере, как пояснено в данном документе).
9.1. Инструментальное IGF-средство (подробности являются необязательными)
Интеллектуальное заполнение промежутков (IGF) [5] представляет собой технологию полупараметрического кодирования аудио, введенную впервые в процесс стандартизации для MPEG-H-стандарта трехмерного аудио в 2013 году [21] [6], которая заполняет промежутки в спектре в декодированном аудиосигнале с оценками отсутствующего сигнала, направляемыми посредством компактной вспомогательной информации. В связи с этим, применение IGF не сохраняет форму сигнала. IGF также может выступать в качестве традиционного BWE и может быть выполнено с возможностью заполнять всю пустую высокочастотную область оцененным сигналом, но также может использоваться за рамками традиционной BWE-функциональности таким образом, чтобы смешивать кодированный на основе формы сигналов контент с оцененным контентом, с тем чтобы заполнять оставшиеся промежутки в спектре. Таким образом, контент, который, как известно, является критичным для традиционного BWE, например, сигналы развертки, может точно кодироваться.
На фиг. 10, проиллюстрирован декодер с использованием IGF. После деквантования передаваемых коэффициентов модифицированного дискретного косинусного преобразования (MDCT) (например, квантованного MDCT-спектра 1022, извлеченного из входного потока 1010 битов с использованием демультиплексора и энтропийного декодера 1020) (например, в деквантователе 1040), эти значения (например, деквантованные спектральные значения 1042) и вспомогательная IGF-информация 1024 (которая, например, может извлекаться из входного потока 1010 битов посредством демультиплексора и энтропийного декодера 1020) передаются в IGF-декодер 1050. С использованием вспомогательной информации 1024, IGF-декодер 1050 выбирает MDCT-коэффициенты из передаваемой полосы 1042 низких частот спектра, чтобы ассемблировать оценку 1052 в полосе высоких частот. Следовательно, полоса низких и высоких частот организуется в так называемые исходные IGF-фрагменты и целевые IGF-фрагменты, соответственно.
Как проиллюстрировано на фиг. 11, исходный IGF-диапазон, который протягивается от минимальной IGF-частоты в нижней части спектра вплоть до начальной IGF-частоты, разделяется на четыре перекрывающихся исходных фрагмента sT[i] (при этом, например, I может принимать значения в 0-3). Целевой IGF-диапазон, т.е. полосы высоких частот спектра, которые должны восстанавливаться, определяется посредством начальной и конечной IGF-частоты. С другой стороны, он разделяется максимум на четыре последовательных целевых фрагмента (например, обозначенные с помощью фрагментов [0]-[4]) увеличивающейся полосы пропускания к верхним частотам.
В ходе процесса IGF-декодирования, IGF-диапазон восстанавливается через копирование подходящих исходных фрагментов в их целевые фрагменты и адаптацию тональных свойств [22] и спектральной огибающей [23] таким образом, что они имеют наилучшее совпадение с исходным сигналом, с использованием передаваемой вспомогательной информации.
Следует отметить, что процесс декодирования, описанный в этом разделе, например, может управляться согласно надлежащему предоставлению параметров кодирования посредством аудиокодера. Например, параметры кодирования могут описывать ассоциацию между исходными IGF-фрагментами (например, sT[0]-sT[3]) и целевыми IGF-фрагментами (например, фрагментами [0]-[4]). Эти параметры кодирования, например, могут определяться в аудиокодерах 300 и 400.
9.2. IGF-управление
Чтобы иметь возможность заполнять промежутки в спектре перцепционно наилучшим совпадающим спектральным контентом, IGF имеет множество степеней свободы для того, чтобы создавать такой контент. По существу, сигнал для того, чтобы заполнять полосу высоких частот (HF), состоит из частотно-временных фрагментов (например, sT[0]-sT[3]) исходящих из полосы низких частот (LF). Исходный и целевой спектральный диапазон (например, sT[0]-sT[3] и фрагменты [0]-[4]) для фактического преобразования могут выбираться из многих вариантов для каждого временного кадра отдельно.
Чтобы адаптировать тональность, IGF-отбеливание [22] может использоваться для того, чтобы сглаживать спектр частотно-временного фрагмента, извлеченный из тональной исходной области, который должен вставляться в зашумленную целевую область. IGF предлагает три уровня отбеливания: "отключено", "средний" и "сильный", при этом "сильное" отбеливание состоит из замены исходного контента фрагмента случайным шумом.
Просто гибкий выбор фрагментов и вариантов отбеливания в качестве комбинаций приводит к огромному числу n=(44)*(34)=20736 отдельных комбинаций, где (44) представляют собой вероятности выбора всех различных исходных фрагментов, и (34) представляют собой различные варианты отбеливания, которые являются независимо выбираемыми для каждого фрагмента. (В этом примере, предполагается, что предусмотрено 4 целевых фрагмента, которые могут быть отдельно ассоциированы с 4 исходными фрагментами и которые могут быть отдельно ассоциированы с одним из трех режимов отбеливания).
Предлагается использовать означенную перцепционную модель, как описано выше, для того чтобы осуществлять перцепционно ближайший выбор из этих комбинаций, чтобы оценивать полосу высоких частот. Другими словами, перцепционная модель, описанная в данном документе, например, может использоваться в аудиокодерах 300, 400 для того, чтобы выбирать параметры для интеллектуального заполнения промежутков, например, параметры, описывающие ассоциацию между исходными фрагментами и целевыми фрагментами, и параметры, описывающие режимы отбеливания.
Для этого, IDR, например, используется для того, чтобы извлекать сумму квадратов разностей (например, в сравнении 180 или в сравнении 280), которая служит в качестве показателя для слышимости введенных перцепционных искажений (например, в качестве информации 112, 212, 342, 424 подобия). Следует отметить, что эта сумма необязательно определяется, например, за больший временной интервал, превышающий один кадр кодирования. Это исключает частые изменения между выбранными вариантами кодирования.
Временное сглаживание в модели (см. подраздел 8.8) эффективно исключает потенциальное смещение к чрезмерной тональной оценке в полосе высоких частот.
Тем не менее, решения по кодированию, принимаемые при использовании вышеуказанной стратегии, основаны на по-прежнему чрезвычайно локальных критериях принятия решения и в силу этого не рассматривают перцепционные эффекты, которые могут возникать вследствие простого переключения между двумя вариантами расположения фрагментов. Чтобы исправлять этот эффект, необязательно введен критерий, удостоверяющий стабильность при перцепционной необходимости (который может реализовываться, например, в ограничении 380 изменений ассоциации).
9.3. Критерий стабилизации (необязательный; подробности также являются необязательными)
Как пояснено, IGF обеспечивает возможность множества различных альтернативных вариантов выбора расположения IGF-фрагментов для того, чтобы выбирать исходные и целевые спектральные диапазоны для высокочастотной вставки. Когда точный сдвиг спектральной частотной вставки варьируется во времени на покадровой основе, может возникать такая ситуация, что один непрерывный тональный компонент переключается между различными высокими частотами во времени. Это приводит к очень заметным и раздражающим артефактам. Предполагается, что они возникают, поскольку сдвиг в частоте приводит к модуляциям, введенным в кодированном сигнале на частотах модуляции, которые примерно соответствуют частоте кадров кодера. Чтобы исключать этот тип артефакта, который появляется только на более протяженных временных шкалах, необязательно включено ограничение на переключение между сдвигами IGF-частоты. Это ограничение переключения между сдвигами IGF-частоты (или, эквивалентно, между различными ассоциациями между исходными фрагментами и целевыми фрагментами расширения полосы пропускания) достигается, например, посредством ограничения 480 изменений ассоциации.
Предполагается, что изменение сдвига IGF-частоты (или ассоциации между исходными фрагментами и целевыми фрагментами) разрешается только при условии, что исходный сигнал имеет (сравнительно) сильные компоненты модуляции в диапазоне, который соответствует модуляциям, которые должны вводиться, когда возникает сдвиг IGF-частоты (например, вызываемый посредством изменения ассоциации между исходным фрагментом и целевым фрагментом) (т.е. соответствующий частоте кадров кодера). По этой причине, необязательно извлекается показатель чувствительности (например, в блоке 486), который прогнозирует то, насколько чувствительным должен быть слушатель ко введению сдвига частоты, вызванного посредством изменения расположения фрагментов. Этот показатель чувствительности, например, является просто обратно пропорциональным интенсивности модуляции в модуляционном фильтре, соответствующей частоте кадров кодера. Только тогда, когда чувствительность ниже этого фиксированного критерия, изменение варианта выбора расположения IGF-фрагментов является допустимым. Это, например, может достигаться посредством сравнения 489 с пороговым значением и посредством стробирования 480 изменений ассоциации.
10. Эксперимент (компоновка и подробности являются необязательными)
10.1. Краткое представление
Чтобы оценивать способность предложенной психоакустической модели осуществлять выбор перцепционных параметров технологий параметрического кодирования, подготовлен тест на основе прослушивания в форме теста при использовании нескольких управляющих воздействий со скрытым опорным и привязочным сигналом (MUSHRA) [24]. Элементы теста на основе прослушивания формируются в экспериментальном оффлайновом окружении на основе кодека по MPEG-H-стандарту трехмерного аудио с участием полупараметрического инструментального IGF-средства в двух разновидностях, как описано ниже. Вариант выбора фиксированного расположения фрагментов, комбинированный с обусловленной признаками оценкой уровня отбеливания, сравнивается с автоматизированным выбором обоих параметров, с помешиваемой предложенной психоакустической моделью.
10.2. Формирование элементов
Для теста на основе прослушивания, каждый элемент обрабатывается через оффлайновую цепочку MPEG-H-кодера/декодера. Скорость передачи битов задается равной очень высокому значению, чтобы исключать любое влияние перцепционных эффектов, отличных от эффектов, введенных посредством IGF. Параметры кодера по MPEG-H-стандарту трехмерного аудио устанавливаются таким образом, что любая субоптимальная оценка для полосы IGF-частот должна иметь ясно слышимое влияние. Следовательно, начальная IGF-частота задается равной не выше 4,2 кГц, конечная IGF-частота задается равной 8,0 кГц. Следовательно, исходные элементы имеют ограниченную полосу частот в 8,4 кГц, чтобы обеспечивать возможность лучшего сравнения с обработанными версиями.
За счет этих настроек, расположение IGF-фрагментов ограничивается только 3 целевыми фрагментами, за счет этого существенно уменьшая число возможных комбинаций IGF-параметров, которые должны оцениваться, до числа, которое может обрабатываться с точки зрения вычислительной сложности в практическом эксперименте. Чтобы дополнительно сокращать число комбинаций, эквивалентные комбинации, содержащие, по меньшей мере, одну настройку "сильного" отбеливания, удаляются из набора вследствие того факта, что "сильное" отбеливание состоит из замены случайного шума отдельного фрагмента (см. подраздел 3.2). Первоначально, предусмотрено (23)*(43)=512 различных комбинаций IGF-настроек без "сильного" отбеливания. Если один, два или все три целевых фрагмента фактически используют сильное отбеливание, то это должно приводить к дополнительным 3*(21)*(41)+3*(22)*(42)+1=217 комбинациям. Если обобщить, в итоге остается всего 729 комбинаций для рассмотрения (вместо максимального числа комбинаций n=(33)*(43)=1728 согласно подразделу 9.2).
Чтобы формировать условие сравнения, кодек работает с использованием фиксированного расположения фрагментов "1313" (см. подраздел 10.2), и отбеливание по существу управляется посредством оценки показателя спектральной равномерности (SFM). Это непосредственно соответствует тому, что используется, например, при SBR, при которой адаптивное регулирование копирования не поддерживается, а также текущим реализациям IGF-кодера, и в силу этого составляет удовлетворительное условие сравнения.
Автоматизированный выбор формируется с использованием "подхода на основе метода прямого опробования", реализованного на трех последовательных этапах обработки, как проиллюстрировано на фиг. 6, который показывает схематичное представление формирования элементов для автоматизированного IGF-выбора:
На первом этапе, выводы (например, кодированные и снова декодированные аудиосигналы 1230 для всех наборов параметров) для всех доступных комбинаций расположения IGF-фрагментов и IGF-отбеливания формируются в режиме принудительных постоянных параметров (например, на основе входного сигнала 1210 и с использованием аудиокодера или MPEG-H-кодера и аудиодекодера или MPEG-H-декодера 1224). Таким образом, кодер 1220 не изменяет принудительные параметры расположения IGF-фрагментов и IGF-отбеливания и поддерживает их постоянными в ходе кодирования одной версии. Таким образом, все возможные версии 1230 расположения IGF-фрагментов и IGF-отбеливания для обработанного элемента формируются и сохраняются в WAV-формате.
На втором этапе, перцепционное качество каждого результата обработки, полученного на первом этапе, оценивается посредством анализа этих WAV-файлов через психоакустическую модель 1240 (которая, например, может соответствовать модулю 100, 200 оценки подобия аудиосигналов или содержать аналогичную или идентичную функциональность по сравнению с модулем 100, 200 оценки подобия аудиосигналов) на покадровой основе. В целом, оценки качества для n=729 различных результатов обработки (которые, например, могут соответствовать "информации 112, 212 подобия" для различных входных аудиосигналов) сравниваются (например, посредством блока 1250 принятия решения) для получения данных 1252 для принятия решения и их записи в текстовый файл.
Фиг. 13 и фиг. 14 отображают данные 1252 для принятия решения (которые, например, могут соответствовать выбранным параметрам 324, 424 кодирования), полученные из модели для элемента "trilogy". Следует отметить, что происходит значительный объем переключения и в силу этого динамическая адаптация. Такие данные для принятия решения, например, могут предоставляться посредством выбора 370 параметров кодирования или посредством определения 430 параметров кодирования. Иными словами, фиг. 13 показывает временное развитие того, какой из исходных фрагментов ассоциирован с тремя рассматриваемыми целевыми фрагментами. Фиг. 13 показывает временное развитие того, какой из режимов отбеливания (или уровней отбеливания) используется для трех целевых фрагментов.
На третьем этапе обработки, данные для принятия решения (параметры выбора расположения IGF-фрагментов и IGF-отбеливания в расчете на кадр) подаются из текстового файла в цепочку 1260, 1270 MPEG-H-кодера/декодера, сконфигурированную так, как подробно указано выше, и используемую для того, чтобы осуществлять динамический выбор из имеющихся в распоряжении данных. Результирующий WAV-файл в завершение обеспечивает в результате кодированную и декодированную версию 1272, содержащую автоматизированный выбор за счет предложенной модели.
Компоновка на основе оффлайнового вычисления вместе с "подходом на основе метода прямого опробования" выбирается для того, чтобы демонстрировать пригодность предложенной модели в принципе и в силу этого предоставлять верхний предел качества при использовании этой модели. В реалистичных вариантах применения, например (необязательно), глубокая нейронная сеть (DNN) (например, нейронная сеть 530) может обучать и на практике заменять вывод модели (например, информацию 112, 212, 342 подобия или информацию 324, 424 параметров кодирования) для части своих текущих вычислительных затрат. В такой компоновке, предложенная модель может автоматически снабжать примечаниями большой объем аудиоматериала для надлежащего обучения (например, чтобы получать обучающие данные 532 нейронной сети).
В качестве вывода, функциональность блоков 1220, 1224, 1240, 1250, 1260, например, может выполняться в аудиокодерах 300, 400 (например, посредством блоков 350, 360, 340, 370, 320 или посредством блоков 430, 420). Таким образом, аудиокодеры могут выбирать параметры кодирования с использованием предложенной модели, которая реализуется (полностью или частично) в модулях 100, 200, 340 оценки подобия аудиосигналов. Тем не менее, реализация аудиокодера может быть более эффективной при использовании нейронной сети, как показано в варианте осуществления по фиг. 5, при этом обучающие данные для нейронной сети получаются с использованием предложенной модели (например, с использованием модулей оценки подобия аудиосигналов, описанных в данном документе).
11. Результаты
Набор из 11 музыкальных отрывков, показанных в таблице 1, подготовлен в качестве элементов для MUSHRA-теста на основе прослушивания. Тест всего содержит 5 условий, перечисленных в таблице 2. Прослушивание выполняется 15 слушателями-экспертами в гостиной, к примеру, в окружении с использованием электростатических STAX-наушников и усилителей. В MUSHRA-тесте, все тестируемые элементы сравниваются с оригиналом. Следует отметить, что поскольку использованы оригиналы, которые имеют ограниченную полосу частот в 8,4 кГц по всему диапазону (по причинам, которые пояснены в подразделе 10.2), они соответствуют абсолютному рейтингу "превосходно" по шкале в пределах от "превосходно", "хорошо", "удовлетворительно", "неудовлетворительно" и до "плохо".
Фиг. 15 отображает абсолютные количественные показатели слушателей. Уровни перцепционного качества кодированных элементов получают рейтинг в диапазоне от "удовлетворительно" до "хорошо", как можно видеть в абсолютных количественных показателях. Рейтинг на основе автоматизированного условия представляет собой "хорошо" во всех случаях.
Фиг. 16 показывает разностные количественные показатели предложенного автоматизированного условия и базового условия фиксированного расположения фрагментов. Из этих разностных количественных показателей, можно прийти к выводу, что наблюдается значительное среднее улучшение более чем на 5 MUSHRA-баллов. Элементы "B", "C", "G", "H", "I" и "J" показывают значительные отдельные улучшения в 18, 7, 7, 3, 9 и 10 баллов, соответственно. Ни один из отдельных элементов не ухудшается значительно.
12. Обсуждение
Результаты теста на основе прослушивания показывают значительное общее повышение качества звучания за счет предложенного способа кодирования. Из этого можно сделать два основных вывода. Во-первых, результаты показывают то, что для полупараметрического инструментального IGF-средства, переключение между различными настройками кодера в ходе кодирования одного отрывка на покадровой основе может приводить к повышению перцепционного качества. Во-вторых, показано, что с этой целью новая предложенная психоакустическая модель (и, соответственно, предложенный модуль 100, 200, 340 оценки подобия аудиосигналов) имеет возможность управлять параметрами кодирования параметрического кодера (например, кодирования 320, 420) автоматизированным способом.
Адаптивное кодирование (автоматизированное условие в тесте на основе прослушивания) разрешено для того, чтобы потенциально переключаться между всеми доступными комбинациями выбора расположения фрагментов (например, ассоциации между исходными фрагментами и целевыми фрагментами) и уровнями отбеливания. В большинстве отрывков это приводит к уменьшению шумоподобного (приблизительного) характера на высоких частотах без введения тональных артефактов.
В частности, психоакустическая модель применяется два раза.
С одной стороны, она предоставляет прогнозирования относительно перцепционного ухудшения, ассоциированного с различными вариантами кодирования, доступными на локальной временной шкале. Из них может выбираться наилучший "локальный" вариант кодирования.
Тем не менее, более ранние эксперименты показывают то, что непосредственное применение этого локального оптимума кодирования зачастую приводит к заметным артефактам при переключении. Больше всего, в частности, когда присутствуют стабильные высокочастотные тональные компоненты, переключение на другой вариант расположения фрагментов должно приводить к очень заметным артефактам частотной модуляции.
С другой стороны, она необязательно предоставляет критерий стабильности для того, чтобы исключать артефакты, вызванные посредством несвоевременного переключения вариантов кодирования (при этом такой механизм стабилизации может реализовываться, например, с использованием ограничения изменений ассоциации). Следовательно, модель (или ограничение 480 изменений ассоциации) используется для того, чтобы определять то, в какие моменты в аудиосигнале можно переключаться с одного на другое расположение фрагментов. В качестве критерия для этого, предполагается, что когда исходный аудиоотрывок демонстрирует высокотональные частотные области, без большой модуляции, переключение должно исключаться.
В текущей реализации, определяется то, какой набор обновленных параметров кодирования должен приводить к локально наилучшему качеству в случае допустимости переключения (например, при определении параметров кодирования). По мере того, как аудиоотрывок воспроизводится, вполне может возникать такая ситуация, что должен выбираться другой конкретный набор наилучших параметров кодирования, но переключение на этот набор должно запрещаться в течение длительного времени (например, посредством ограничения изменений ассоциации). Если в силу этого начальные параметры кодирования должны становиться очень субоптимальными, кодер несмотря на это должен поддерживать такой глобально субоптимальный набор в течение большего времени. Необязательный подход к решению этой проблемы заключается в том, чтобы (необязательно) обеспечивать возможность психоакустической модели иметь достаточное упреждение во времени, с тем чтобы учитывать то, как текущие решения по кодированию должны затрагивать качество в отношении будущей части отрывка.
При том, что неплохое общее улучшение наблюдается для способа автоматизированного кодирования по сравнению с фиксированным кодированием, очень большое улучшение наблюдается для отдельных элементов "B", а также значительные улучшения для элементов "C", "G", "I" и "J". Здесь, в соответствии с общими наблюдениями, автоматизированная версия звучит гораздо менее зашумленной, чем фиксированная версия, что поддерживает такое общее понятие, что обусловленный психоакустической моделью подход позволяет выбирать перцепционно подходящую комбинацию выбора расположения фрагментов и уровня отбеливания.
13. Сущность
Хотя показано, чтобы традиционные слуховые маскирующие модели являются очень успешными для управления кодеками с сохранением формы сигнала, обнаружено, что эти модели являются неподходящими для того, чтобы аналогично направлять инструментальные средства параметрического кодирования.
В этом документе, согласно аспекту изобретения, предлагается использовать улучшенную психоакустическую модель на основе возбуждения (которая может реализовываться, например, в модуле оценки подобия аудиосигналов) с тем, чтобы управлять параметризацией (например, параметрами кодирования) технологий перцепционного кодирования без сохранения формы сигнала (например, кодирования 320 или кодирования 420). Из этой модели, так называемое внутреннее разностное представление (IDR) (например, разностное представление 294a-294e) получается для каждого из имеющихся в распоряжении доступных вариантов кодирования. IDR показывается как предоставляющее показатель, который прогнозирует уровень перцепционного искажения, созданного в силу применения соответствующего варианта кодирования. Для управления конечным процессом кодирования, выбирается вариант кодирования, который приводит к минимальному прогнозированному перцепционному искажению, (например, посредством определения 330, 430 параметров кодирования или посредством выбора 370 параметров кодирования).
Продемонстрировано то, что в отличие от традиционных перцепционных моделей, предложенный подход на основе возбуждения может успешно направлять сигнально-адаптивное применение инструментального средства параметрического кодирования в современном аудиокодере на примере MPEG-H-стандарта трехмерного аудио и его полупараметрического инструментального средства на основе интеллектуального заполнения промежутков (IGF). С помощью MUSHRA-теста на основе прослушивания, доказана добротность означенного автоматизированного выбора IGF-параметров. В среднем, условие "автоматизированного выбора параметров" количественно оценено значительно больше чем на 5 MUSHRA-баллов выше простой настройки с использованием схемы фиксированного расположения IGF-фрагментов и отбеливания на основе тональности.
Эксперимент, описанный в этом документе, является главным образом теоретическим, с тем чтобы доказывать применимость принципа такой усовершенствованной модели к тому, чтобы управлять адаптивным выбором IGF-параметров. Известно, что использование текущего "подхода на основе метода прямого опробования" обеспечивается за счет высокой вычислительной сложности.
Следовательно, предполагается, в качестве необязательной модификации, обучать глубокую нейронную сеть (DNN) на выводе модели и в силу этого радикально сокращать сложность при практическом применении предложенной модели.
14. Необязательные дополнения
Далее описываются необязательные дополнения и модификации для "улучшенной психоакустической модели для эффективных перцепционных аудиокодеков".
14.1. Введение в дополнение
Основное описание изобретения, представленное выше, подробно описывает предложенную психоакустическую модель и демонстрирует предпочтительные варианты осуществления с использованием предложенной модели в качестве контроллера для оценки IGF-параметров в кодере по MPEG-H-стандарту трехмерного аудио.
Экспериментальная компоновка обрисовывает эксперимент с использованием исчерпывающего подхода ("на основе метода прямого опробования"), в котором, например, все возможные комбинации параметров, которые должны оцениваться, используются для того, чтобы формировать множество выводов, которые затем сравниваются для того, чтобы выбирать наилучший вывод.
Одновременно следует отметить, что такой подход является чрезвычайно вычислительно сложным.
Таким образом, в итоге предлагается использовать глубокую нейронную сеть (DNN) на практике для того, чтобы необязательно заменять повторное применение затратного аналитического исчисления самой модели.
14.2. DNN-подход
Следует отметить, что использование DNN-подхода является необязательным, применимым в качестве альтернативы концепциям, упомянутым выше, или в комбинации с концепциями, упомянутыми выше.
Такой подход на основе DNN состоит из обучения DNN (например, нейронной сети 530) достаточной партией аудиоматериала, который автоматически снабжен примечаниями посредством вывода предложенной психоакустической модели (например, с использованием модуля оценки подобия аудиосигналов, упомянутого в данном документе) (при этом аудиоматериал, снабжаемый примечаниями посредством вывода психоакустической модели, может рассматриваться в качестве обучающих данных 532 нейронной сети).
Следовательно, вычислительная сложность переносится в (оффлайновую) подготовительную фазу DNN-обучения для того, чтобы формировать автоматически снабжаемый примечаниями материал (например, в качестве обучающих данных 532 нейронной сети), а также в фазу обучения (например, нейронной сети 530) для того, чтобы оценивать соответствующие весовые коэффициенты DNN-узлов в слоях (например, нейронной сети 530).
В фазе применения, DNN (например, нейронная сеть 530), которая, например, может использоваться в аудиокодере для того, чтобы определять параметры кодирования, имеет только умеренную сложность вследствие своей архитектуры.
Для фактического использования, такой кодер (например, аудиокодер 500) оснащается легко обученной DNN (например, обученной с использованием информации параметров, извлекаемой из обучающей аудиоинформации с использованием модуля оценки подобия аудиосигналов), который близко имитирует вывод описанной аналитической психоакустической модели (например, вывод модуля 100, 200, 340 оценки подобия аудиосигналов, или, например, вывод выбора 330, 430 параметров кодирования).
14.3. Варианты осуществления (подробности являются необязательными)
В реализации, упомянутый вывод модели, который должен обучаться (например, посредством DNN), может представлять собой однозначное число в качестве показателя качества в расчете на аудиокадр (например, полученное посредством модуля оценки подобия аудиосигналов), причем разность в однозначное число получается посредством вычитания показателя качества оригинала и его кодированной версии, либо многозначные числа внутреннего представления или их разности относит. (относительно) многозначных чисел оригинала.
В другой реализации, DNN непосредственно обучается на входном сигнале (возможно с использованием различных представлений, как описано ниже) и данных для принятия решения, полученных из "этапа 2" на фиг. 6 (оптимальное расположение фрагментов и отбеливание) с использованием описанной аналитической психоакустической модели (или с использованием модуля оценки подобия аудиосигналов). Затем DNN-вывод может непосредственно использоваться для того, чтобы управлять кодером (например, MPEG-H-кодеров) таким образом, чтобы адаптировать параметры кодирования перцепционно оптимальным способом (при этом, например, параметры кодирования выводятся посредством нейронной сети). Таким образом, более нет необходимости кодировать входной сигнал с помощью нескольких различных настроек, что требуется в подходе на основе метода прямого опробования, представленном выше.
DNN могут иметь различные топологии (сверточные нейронные сети (CNN), рекуррентные нейронные сети (RNN), ...,). DNN может обучаться на различном вводе (PCM-данных [кадрах], спектральных данных (спектре Фурье, постоянном Q-преобразовании, гребенке гамматоновых фильтров, ...,).
15. Дополнительные комментарии и замечания
Следует отметить, что три уровня IGF-отбеливания ("отключено"==без обработки, "средний"==ослабление тональных пиков, "сильный"==замена шума) также содержат замену шума; в этом случае, контент фрагмента отбрасывается и заменяется посредством декоррелированного шума. Эти режимы, например, могут определяться в аудиокодере. Другими словами, уровень отбеливания "сильное" в IGF технически заменяет исходный фрагмент посредством декоррелированного шума.
Кроме того, в варианте осуществления, необязательно, анализируются только определенные (например, предварительно определенные) спектральные компоненты аудиосигнала, как описано, например, только высокая полоса или полоса высоких частот. Это, например, может быть полезным для того, чтобы уменьшать сложность, например, если только некоторые части спектра затрагиваются посредством решений по кодированию. Например, это является полезным в описанном примере с использованием IGF, поскольку ни одна часть спектра за пределами диапазона между 4,2 кГц и 8,4 кГц не затрагивается посредством результатов анализа.
16. Заключения
В качестве вывода, со времени ранних перцепционных аудиокодеров, таких как MP3, базовая психоакустическая модель, которая управляет процессом кодирования, не претерпела множество серьезных разительных изменений. Между тем, современные аудиокодеры оснащаются инструментальными средствами полупараметрического или параметрического кодирования, такими как расширение полосы пропускания аудиосигнала. Обнаружено, что в силу этого начальная психоакустическая модель, используемая в перцепционном кодере, просто с учетом добавленного шума квантования, стала частично неподходящей.
Вообще говоря, варианты осуществления согласно изобретению предлагают использование улучшенной психоакустической модели возбуждения на основе существующей модели, разработанной в работе авторов Дау и др. в 1997 году, например, для оценки подобия аудиосигналов, например, в аудиокодере. Эта модель на основе модуляции является чрезвычайно независимой от точной формы входного сигнала посредством вычисления внутреннего слухового представления. С использованием примера MPEG-H-стандарта трехмерного аудио и его полупараметрического инструментального средства на основе интеллектуального заполнения промежутков (IGF), демонстрируется то, что можно успешно управлять процессом выбора IGF-параметров, чтобы достигать в целом повышенного перцепционного качества.
Тем не менее, следует отметить, что концепция, раскрытая в данном документе, не ограничена использованием какого-либо конкретного аудиокодера или концепции расширения полосы пропускания.
17. Дополнительные замечания
В настоящем документе, различные изобретаемые варианты осуществления и аспекты описываются, например, в главах "Предложенная психоакустическая модель" и "IGF-управление посредством психоакустической модели".
Тем не менее, признаки, функциональности и подробности, описанные в любых других главах, также могут, необязательно, вводиться в варианты осуществления согласно настоящему изобретению.
Кроме того, дополнительные варианты осуществления задаются посредством прилагаемой формулы изобретения.
Следует отметить, что любые варианты осуществления, заданные посредством формулы изобретения, могут дополняться посредством любых из подробностей (признаков и функциональностей), описанных в вышеуказанных главах.
Кроме того, варианты осуществления, описанные в вышеуказанных главах, могут использоваться отдельно и также могут дополняться посредством любых из признаков в другой главе или посредством любого признака, включенного в формулу изобретения.
Кроме того, следует отметить, что отдельные аспекты, описанные в данном документе, могут использоваться отдельно или в комбинации. Таким образом, подробности могут добавляться в каждый из упомянутых отдельных аспектов без добавления подробностей в другой из упомянутых аспектов.
Также следует отметить, что настоящее раскрытие сущности описывает, явно или неявно, признаки, применимые в аудиокодере (в оборудовании для предоставления кодированного представления входного аудиосигнала). Таким образом, любые из признаков, описанных в данном документе, могут использоваться в контексте аудиокодера.
Кроме того, признаки и функциональности, раскрытые в данном документе по отношению к способу, также могут использоваться в оборудовании (выполненном с возможностью выполнять такую функциональность). Кроме того, любые признаки и функциональности, раскрытые в данном документе относительно оборудования, также могут использоваться в соответствующем способе. Другими словами, способы, раскрытые в данном документе, могут дополняться посредством любых из признаков и функциональностей, описанных относительно оборудования.
Кроме того, любые из признаков и функциональностей, описанных в данном документе, могут реализовываться в аппаратных средствах или в программном обеспечении либо с использованием комбинации аппаратных средств и программного обеспечения, как описано в разделе "Альтернативы реализации".
18. Альтернативы реализации
Хотя некоторые аспекты описываются в контексте оборудования, очевидно, что эти аспекты также представляют описание соответствующего способа, при этом блок или устройство соответствует этапу способа либо признаку этапа способа. Аналогично, аспекты, описанные в контексте этапа способа, также представляют описание соответствующего блока или элемента, или признака соответствующего оборудования. Некоторые или все этапы способа могут выполняться посредством (или с использованием) аппаратного оборудования, такого как, например, микропроцессор, программируемый компьютер либо электронная схема. В некоторых вариантах осуществления, один или более из самых важных этапов способа могут выполняться посредством этого оборудования.
В зависимости от определенных требований к реализации, варианты осуществления изобретения могут реализовываться в аппаратных средствах или в программном обеспечении. Реализация может выполняться с использованием цифрового носителя хранения данных, например, гибкого диска, DVD, Blu-Ray, CD, ROM, PROM, EPROM, EEPROM или флэш-памяти, имеющего сохраненные электронно считываемые управляющие сигналы, которые взаимодействуют (или допускают взаимодействие) с программируемой компьютерной системой таким образом, что осуществляется соответствующий способ. Следовательно, цифровой носитель хранения данных может быть машиночитаемым.
Некоторые варианты осуществления согласно изобретению содержат носитель данных, имеющий электронночитаемые управляющие сигналы, которые допускают взаимодействие с программируемой компьютерной системой таким образом, что осуществляется один из способов, описанных в данном документе.
В общем, варианты осуществления настоящего изобретения могут реализовываться как компьютерный программный продукт с программным кодом, при этом программный код выполнен с возможностью осуществления одного из способов, когда компьютерный программный продукт работает на компьютере. Программный код, например, может сохраняться на машиночитаемом носителе.
Другие варианты осуществления содержат компьютерную программу для осуществления одного из способов, описанных в данном документе, сохраненную на машиночитаемом носителе.
Другими словами, вариант осуществления изобретаемого способа в силу этого представляет собой компьютерную программу, имеющую программный код для осуществления одного из способов, описанных в данном документе, когда компьютерная программа работает на компьютере.
Следовательно, дополнительный вариант осуществления изобретаемых способов представляет собой носитель хранения данных (цифровой носитель хранения данных или машиночитаемый носитель), содержащий записанную компьютерную программу для осуществления одного из способов, описанных в данном документе. Носитель данных, цифровой носитель хранения данных или носитель с записанными данными типично является материальным и/или энергонезависимым.
Следовательно, дополнительный вариант осуществления изобретаемого способа представляет собой поток данных или последовательность сигналов, представляющих компьютерную программу для осуществления одного из способов, описанных в данном документе. Поток данных или последовательность сигналов, например, может быть выполнена с возможностью передачи через соединение для передачи данных, например, через Интернет.
Дополнительный вариант осуществления содержит средство обработки, например, компьютер или программируемое логическое устройство, выполненное с возможностью осуществлять один из способов, описанных в данном документе.
Дополнительный вариант осуществления содержит компьютер, имеющий установленную компьютерную программу для осуществления одного из способов, описанных в данном документе.
Дополнительный вариант осуществления согласно изобретению содержит оборудование или систему, выполненную с возможностью передавать (например, электронно или оптически) компьютерную программу для осуществления одного из способов, описанных в данном документе, в приемное устройство. Приемное устройство, например, может представлять собой компьютер, мобильное устройство, запоминающее устройство и т.п. Оборудование или система, например, может содержать файловый сервер для передачи компьютерной программы в приемное устройство.
В некоторых вариантах осуществления, программируемое логическое устройство (например, программируемая пользователем вентильная матрица) может использоваться для того, чтобы выполнять часть или все из функциональностей способов, описанных в данном документе. В некоторых вариантах осуществления, программируемая пользователем вентильная матрица может взаимодействовать с микропроцессором, чтобы осуществлять один из способов, описанных в данном документе. В общем, способы предпочтительно осуществляются посредством любого аппаратного оборудования.
Оборудование, описанное в данном документе, может реализовываться с использованием аппаратного оборудования либо с использованием компьютера, либо с использованием комбинации аппаратного оборудования и компьютера.
Оборудование, описанное в данном документе, или любые компоненты оборудования, описанного в данном документе, могут реализовываться, по меньшей мере частично, в аппаратных средствах и/или в программном обеспечении.
Способы, описанные в данном документе, могут осуществляться с использованием аппаратного оборудования либо с использованием компьютера, либо с использованием комбинации аппаратного оборудования и компьютера.
Способы, описанные в данном документе, или любые компоненты оборудования, описанного в данном документе, могут выполняться, по меньшей мере частично, посредством аппаратных средств и/или посредством программного обеспечения.
Описанные в данном документе варианты осуществления являются просто иллюстративными в отношении принципов настоящего изобретения. Следует понимать, что модификации и изменения компоновок и подробностей, описанных в данном документе, должны быть очевидными для специалистов в данной области техники. Следовательно, они подразумеваются как ограниченные только посредством объема нижеприведенной формулы изобретения, а не посредством конкретных подробностей, представленных посредством описания и пояснения вариантов осуществления в данном документе.
Библиографический список
[1] Herre, J. и Disch, S. "Perceptual Audio Coding", стр. 757-799, Academic press, Elsevier Ltd., 2013 год.
[2] Schuller, G. и Härmä, A. "Low delay audio compression using predictive coding", in 2002 IEEE International Conference on Acoustics, Speech and Signal Processing, издание 2, стр. 1853-1856, 2002 год.
[3] Dietz, M., Liljeryd, L., Kjorling, K. и Kunz, O. "Spectral Band Replication, the Novel Approach in Audio Coding", in Audio Engineering Society Convention 112, 2002 год.
[4] Herre, J. и Dietz, M. "MPEG-4 high-efficiency AAC coding [Standards in the Nutshell]", Signal Processing Magazine, IEEE (издание 25, 2008 год), стр. 137-142, 2008 год.
[5] Disch, S., Niedermeier, A., Helmrich, C. R., Neukam, C., Schmidt, K., Geiger, R., Lecomte, J., Ghido, F., Nagel, F. и Edler, B. "Intelligent Gap Filling in Perceptual Transform Coding of Audio", in Audio Engineering Society Convention 141, 2016 год.
[6] ISO/IEC (MPEG-H) 23008-3, "High efficiency coding and media delivery in heterogeneous environments - Part 3: 3D audio", 2015 год.
[7] 3GPP, TS 26.445, EVS Codec Detailed Algorithmic Description; 3GPP Technical Specification (Release 12), 2014 год.
[8] Laitinen, M.-V., Disch, S. и Pulkki, V. "Sensitivity of Human hearing to Changes in Phase Spectrum", J. Audio Eng. Soc (Journal of the AES), (издание 61, номер 11, 2013 год), стр. 860-877, 2013 год.
[9] Dau, T., Kollmeier, B. и Kohlrausch, A. "Modelling auditory processing of amplitude modulation. I. Detection and masking with narrow-band carriers", J. Acoust. Soc. Am., 102, стр. 2892-2905, 1997 год.
[10] Dau, T. "Modeling auditory processing of amplitude modulation", Ph.D. thesis, 1996 год.
[11] Dau, T., Püschel, D. и Kohlrausch, A. "A quantization model of the 'effective' signal processing in the auditory system. I. Model structure", J. Acoust. Soc. Am., 99, стр. 3615-3622, 1996 год.
[12] Ewert, S., Verhey, J. and Dau, T. "Spectro-temporal processing in the envelope-frequency domain", J. Acoust. Soc. Am., (112), стр. 2921-2931, 2003 год.
[13] Glasberg, B. и Moore, B. "Derivation of auditory filter shapes from notched-noise data", Hearing Research, (47), стр. 103-138, 1990 год.
[14] https://commons.wikimedia.org/wiki/File:Cochlea crosssection.svg, июль 2018 года.
[15] Kohlrausch, A., Fassel, R. и Dau, T. "The influence of carrier level and frequency on modulation and beat detection thresholds for sinusoidal carriers", J. Acoust. Soc. Am., 108, стр. 723-734, 2000 год.
[16] Vafin, R., Heusdens, R., van de Par, S. и Kleijn, W. "Improving modeling of audio signals by modifying transient locations", in Proceedings of the IEEE Workshop on Applications of Signal Processing to Audio, and Acoustics, стр. 143-146, 2001 год.
[17] van de Par, S., Koppens, J., Oomen, W. и Kohlrausch, A. "A new perceptual model for audio coding based on spectro-temporal masking", in 124th AES Convention, 2008 год.
[18] Hall, J., Haggard, M. и Fernandes, M. "Detection in noise by spectro-temporal pattern analysis", J. Acoust. Soc. Am., (76), стр. 50-56, 1984 год.
[19] van de Par, S. и Kohlrausch, A., "Comparison of monaural (CMR) and binaural (BMLD) masking release", J. Acoust. Soc. Am., 103, стр. 1573-1579, 1998 год.
[20] Hanna, T. "Discrimination of reproducible noise as the function of bandwidth and duration", Percept. Psychophys., 36, стр. 409-416, 1984 год.
[21] Herre, J., Hilpert, J., Kuntz, A. и Plogsties, J. "MPEG-H Audio - The New Standard for Universal Spatial/3D Audio Coding", 137th AES Convention, 2014 год.
[22] Schmidt, K. and Neukam, C. "Low complexity tonality control in the Intelligent Gap Filling tool", in 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), стр. 644-648, 2016 год.
[23] Helmrich, C., Niedermeier, A., Disch, S. и Ghido, F. "Spectral Envelope Reconstruction via IGF for Audio Transform Coding", in IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Брисбен, Австралия, 2015 год.
[24] ITU-R, Recommendation BS.1534-1 "Method for subjective assessment of intermediate sound quality (MUSHRA)", Женева, 2003 год.
| название | год | авторы | номер документа |
|---|---|---|---|
| УСТРОЙСТВО И СПОСОБ ДЛЯ ДЕКОДИРОВАНИЯ ИЛИ КОДИРОВАНИЯ ЗВУКОВОГО СИГНАЛА С ИСПОЛЬЗОВАНИЕМ ЗНАЧЕНИЙ ИНФОРМАЦИИ ЭНЕРГИИ ДЛЯ ПОЛОСЫ ЧАСТОТ ВОССТАНОВЛЕНИЯ | 2014 |
|
RU2649940C2 |
| УСТРОЙСТВО И СПОСОБ ДЛЯ ДЕКОДИРОВАНИЯ И КОДИРОВАНИЯ АУДИОСИГНАЛА С ИСПОЛЬЗОВАНИЕМ АДАПТИВНОГО ВЫБОРА СПЕКТРАЛЬНЫХ ФРАГМЕНТОВ | 2014 |
|
RU2643641C2 |
| АУДИОКОДЕР, АУДИОДЕКОДЕР И СВЯЗАННЫЕ СПОСОБЫ С ИСПОЛЬЗОВАНИЕМ ДВУХКАНАЛЬНОЙ ОБРАБОТКИ В ИНФРАСТРУКТУРЕ ИНТЕЛЛЕКТУАЛЬНОГО ЗАПОЛНЕНИЯ ИНТЕРВАЛОВ ОТСУТСТВИЯ СИГНАЛА | 2014 |
|
RU2646316C2 |
| УСТРОЙСТВО И СПОСОБ ДЛЯ КОДИРОВАНИЯ И ДЕКОДИРОВАНИЯ КОДИРОВАННОГО АУДИОСИГНАЛА С ИСПОЛЬЗОВАНИЕМ ВРЕМЕННОГО ФОРМИРОВАНИЯ ШУМА/НАЛОЖЕНИЙ | 2014 |
|
RU2607263C2 |
| УСТРОЙСТВО И СПОСОБ ДЛЯ КОДИРОВАНИЯ ИЛИ ДЕКОДИРОВАНИЯ ЗВУКОВОГО СИГНАЛА С ИНТЕЛЛЕКТУАЛЬНЫМ ЗАПОЛНЕНИЕМ ИНТЕРВАЛОВ В СПЕКТРАЛЬНОЙ ОБЛАСТИ | 2014 |
|
RU2635890C2 |
| АУДИОКОДЕР, АУДИОДЕКОДЕР И АУДИОПРОЦЕССОР, ИМЕЮЩИЙ ДИНАМИЧЕСКИ ИЗМЕНЯЮЩУЮСЯ ХАРАКТЕРИСТИКУ ПЕРЕКОСА | 2007 |
|
RU2418322C2 |
| УСТРОЙСТВО, СПОСОБ И КОМПЬЮТЕРНАЯ ПРОГРАММА ДЛЯ ДЕКОДИРОВАНИЯ КОДИРОВАННОГО АУДИОСИГНАЛА | 2014 |
|
RU2651229C2 |
| УСТРОЙСТВО И СПОСОБ ДЛЯ ДЕКОДИРОВАНИЯ КОДИРОВАННОГО АУДИОСИГНАЛА С ИСПОЛЬЗОВАНИЕМ ФИЛЬТРА РАЗДЕЛЕНИЯ ВОКРУГ ЧАСТОТЫ ПЕРЕХОДА | 2014 |
|
RU2640634C2 |
| КОДЕР И ДЕКОДЕР АУДИОСИГНАЛА, ИСПОЛЬЗУЮЩИЕ ПРОЦЕССОР ЧАСТОТНОЙ ОБЛАСТИ, ПРОЦЕССОР ВРЕМЕННОЙ ОБЛАСТИ И КРОССПРОЦЕССОР ДЛЯ НЕПРЕРЫВНОЙ ИНИЦИАЛИЗАЦИИ | 2015 |
|
RU2668397C2 |
| КОДЕР И ДЕКОДЕР АУДИОСИГНАЛА, ИСПОЛЬЗУЮЩИЕ ПРОЦЕССОР ЧАСТОТНОЙ ОБЛАСТИ С ЗАПОЛНЕНИЕМ ПРОМЕЖУТКА В ПОЛНОЙ ПОЛОСЕ И ПРОЦЕССОР ВРЕМЕННОЙ ОБЛАСТИ | 2015 |
|
RU2671997C2 |
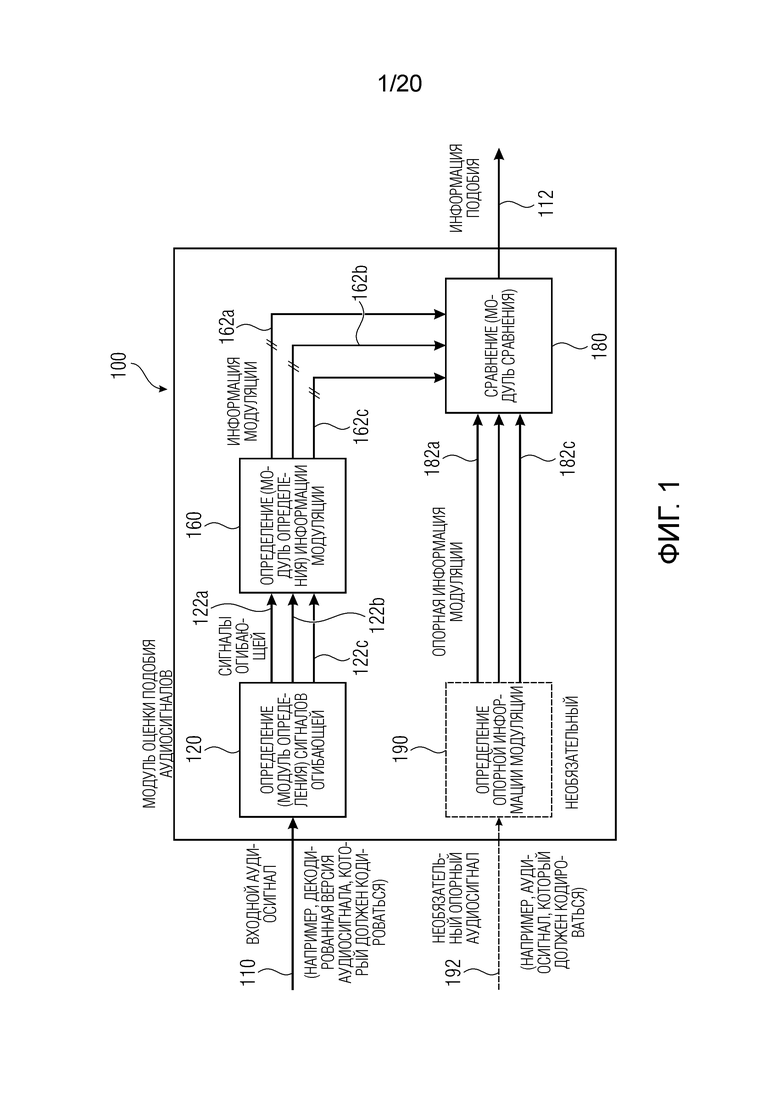
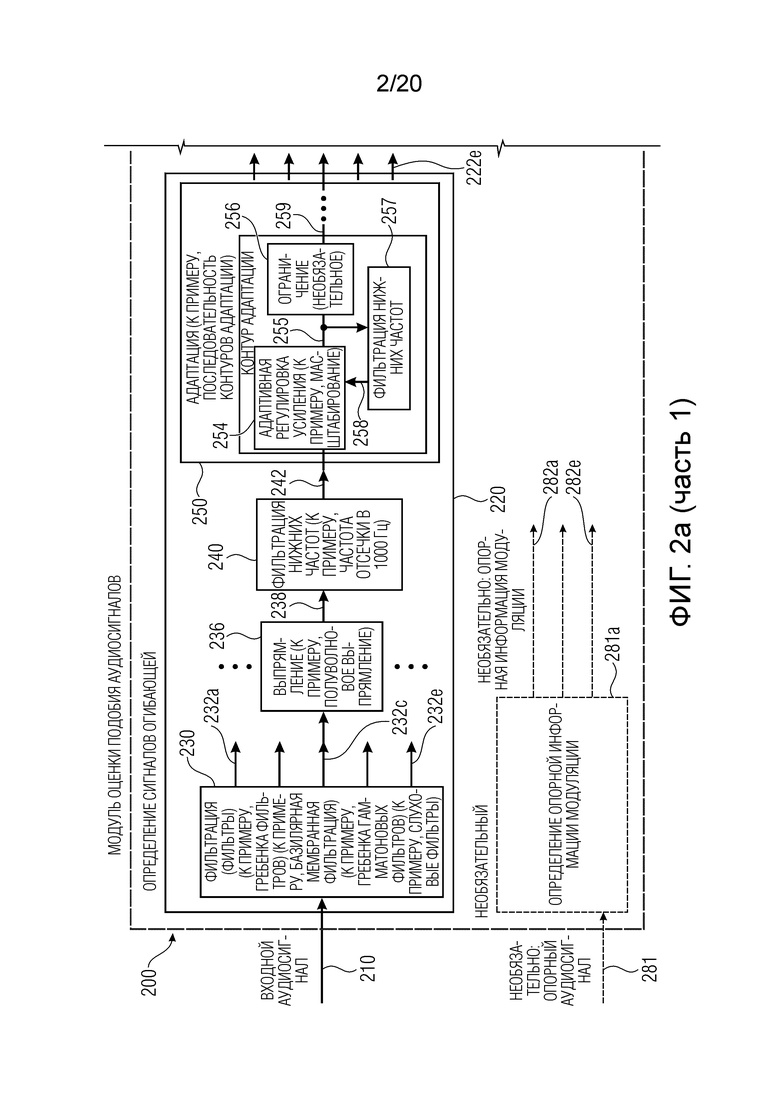
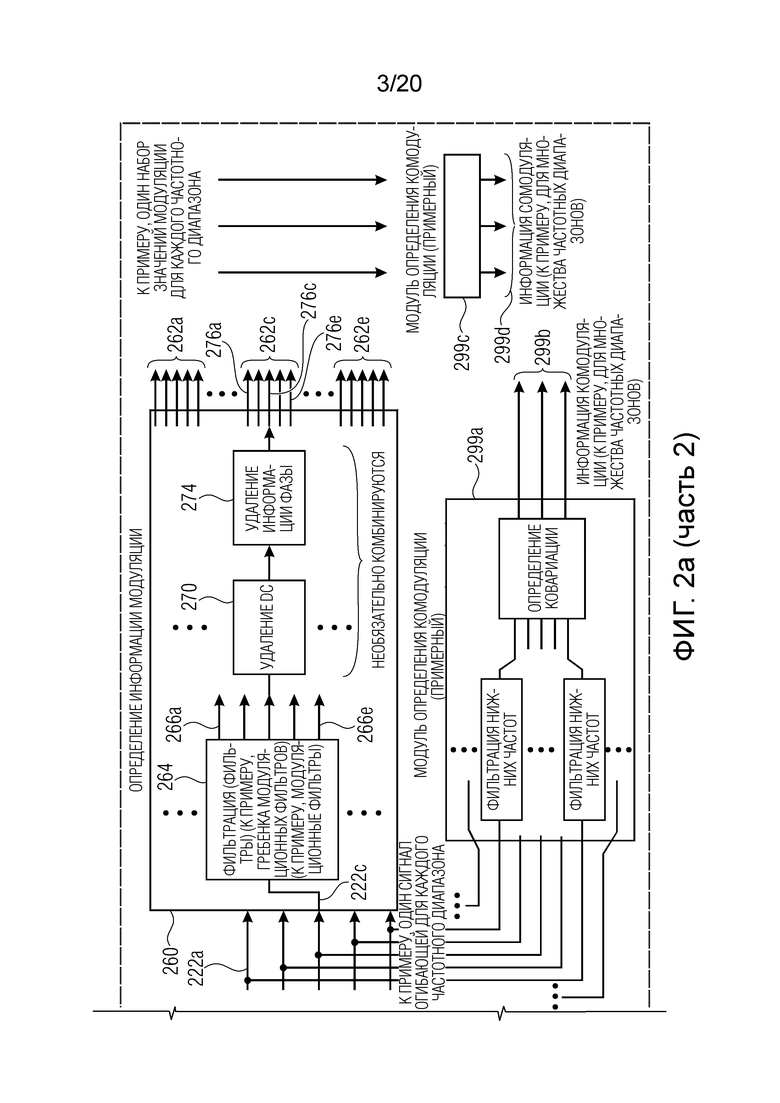
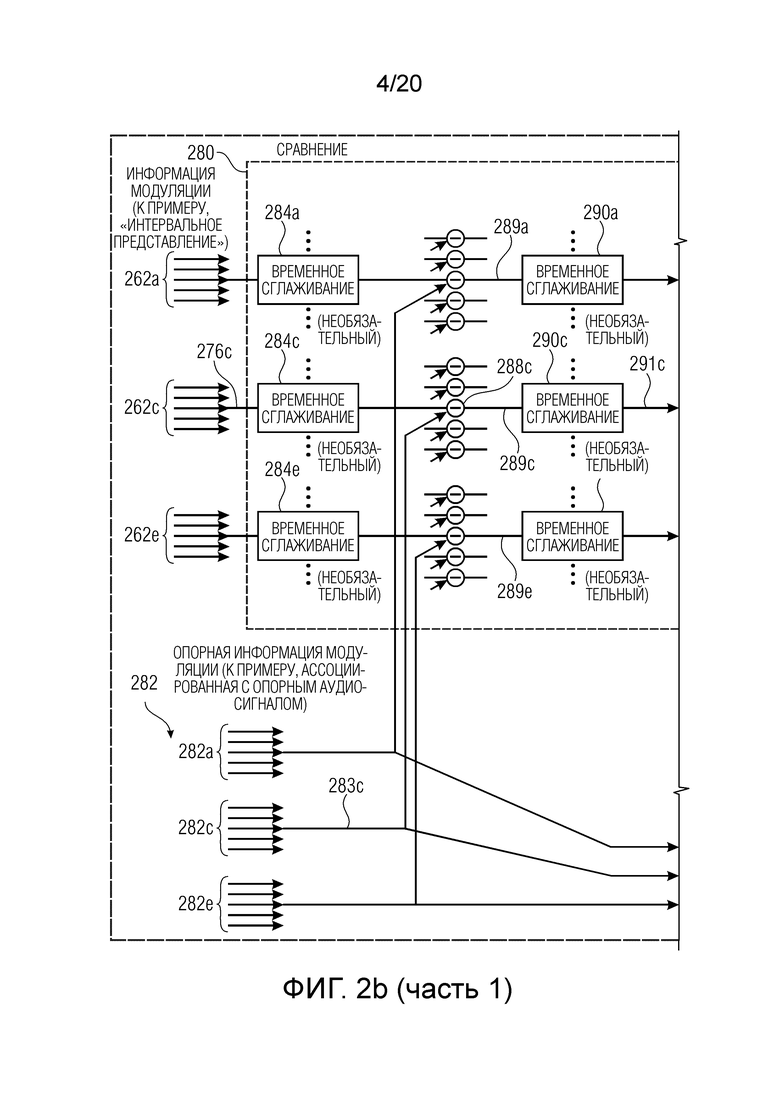
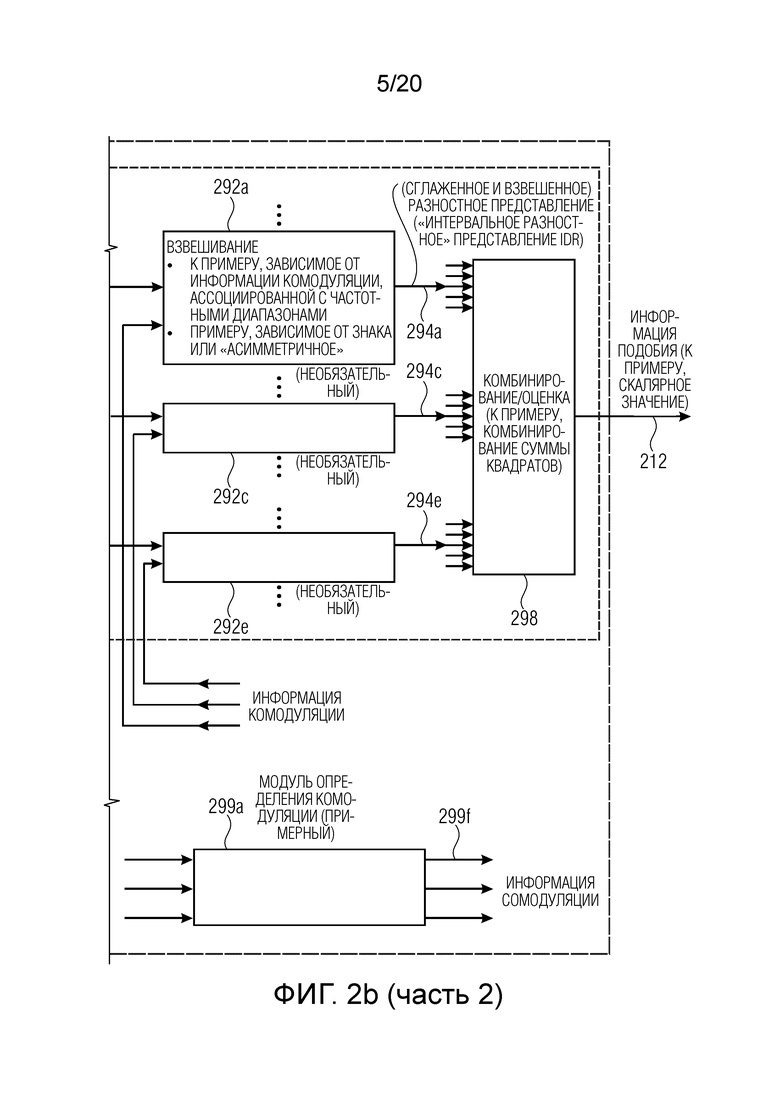
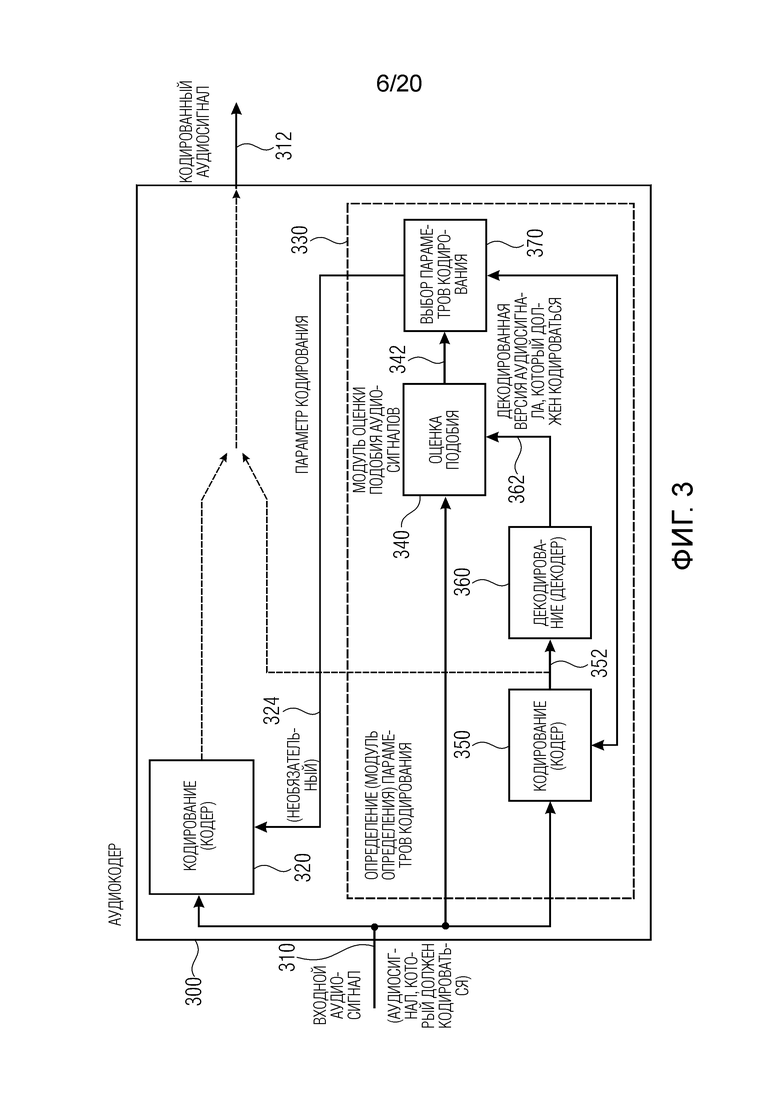
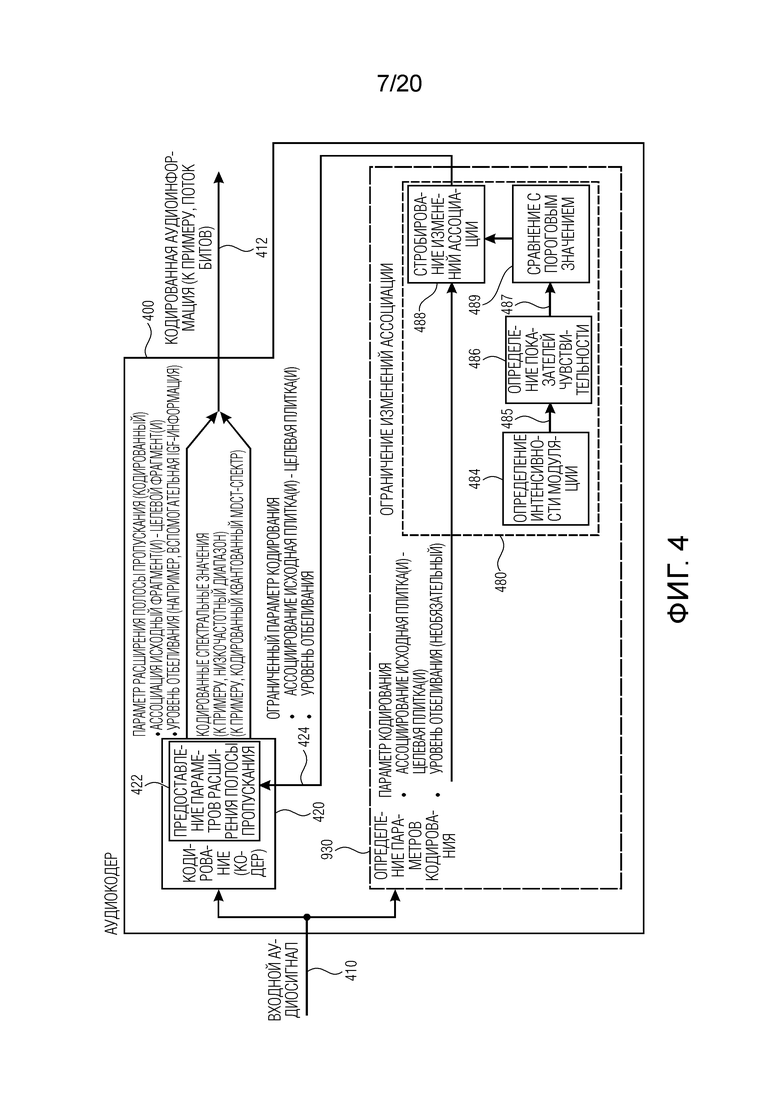
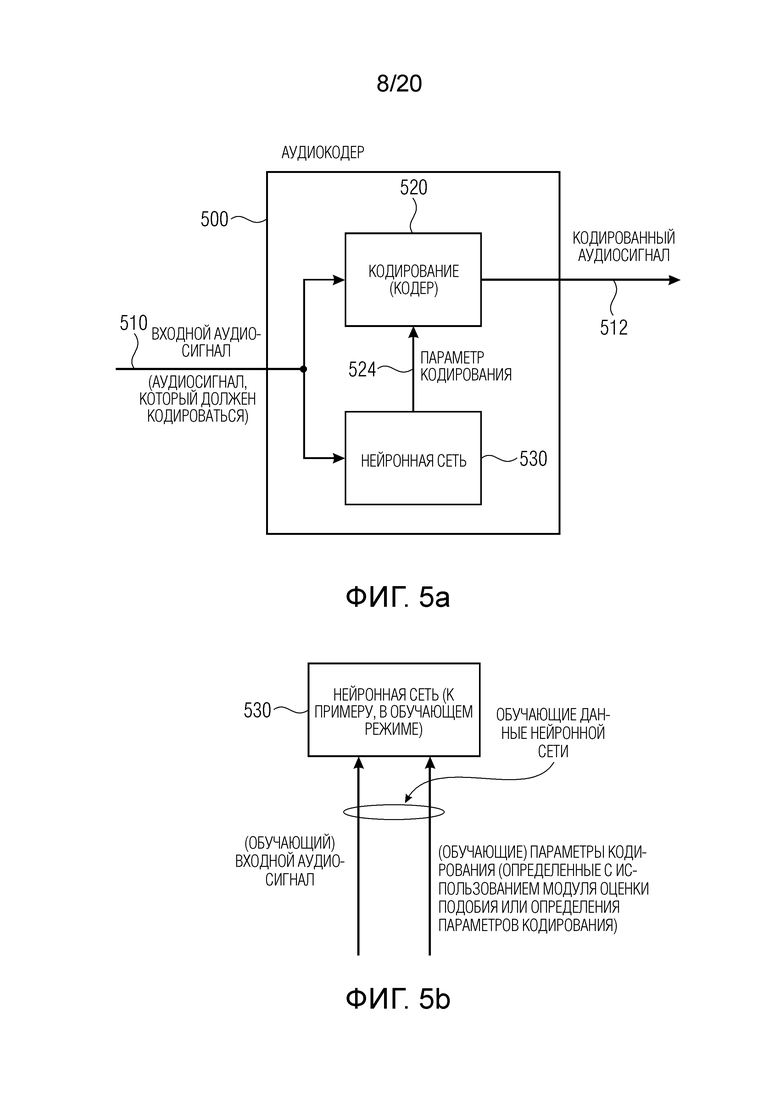
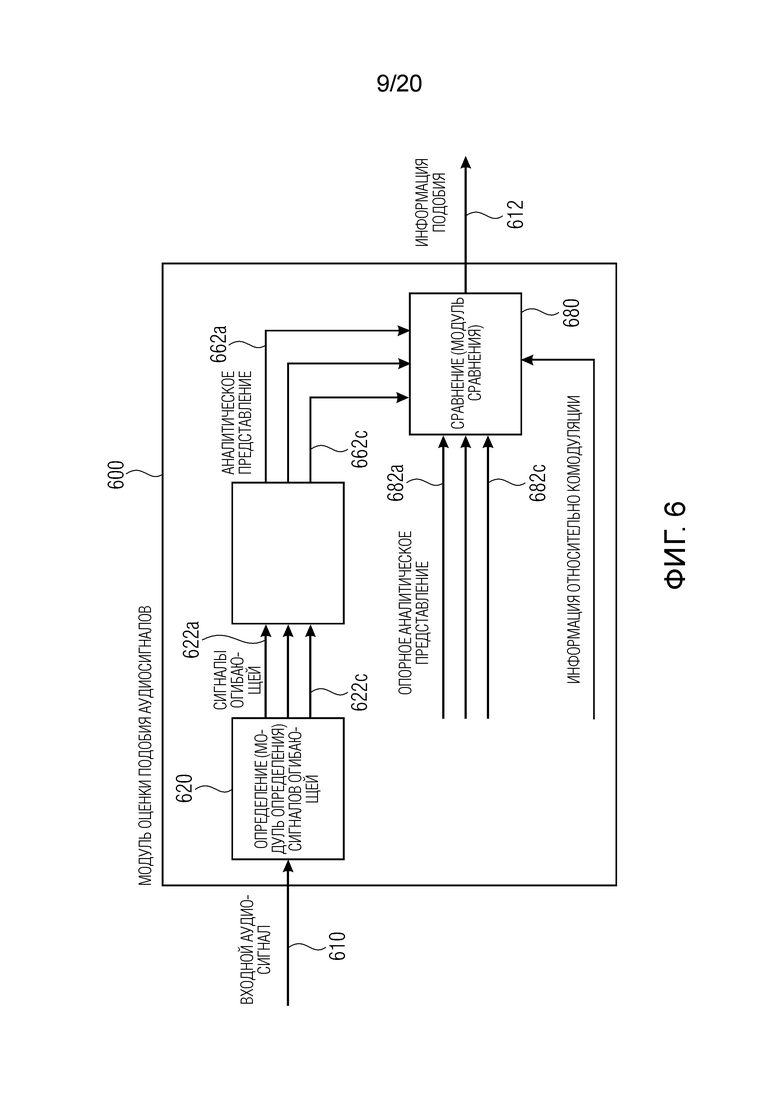
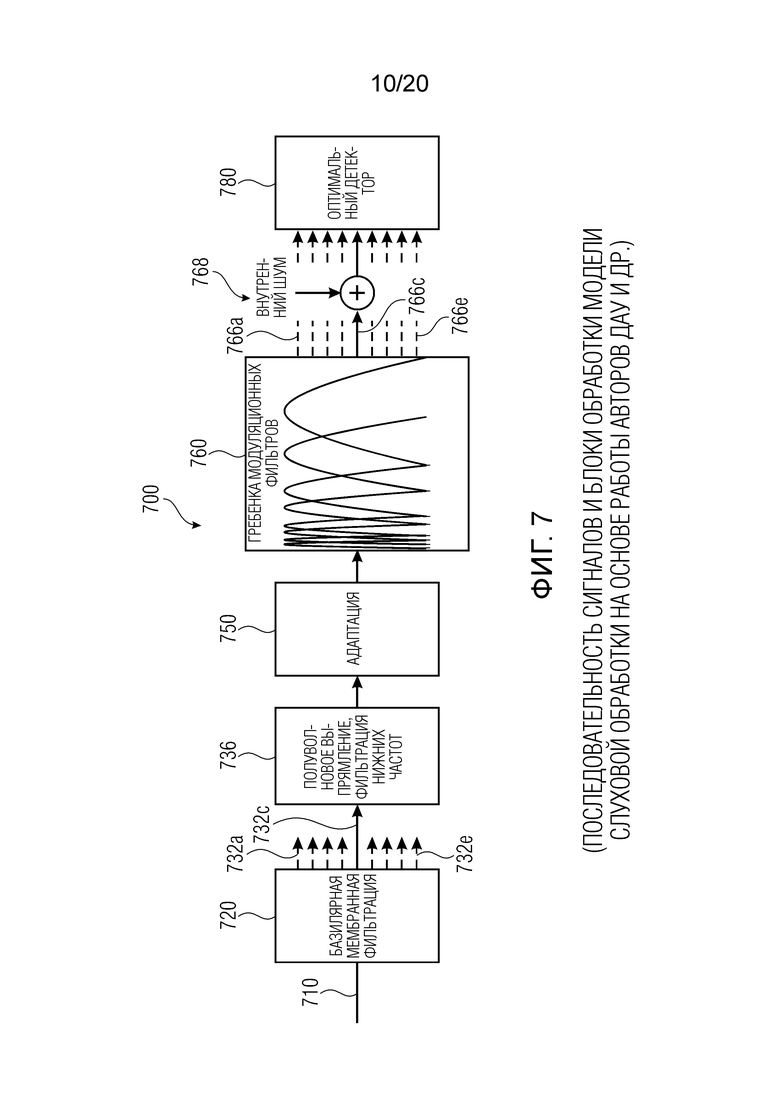
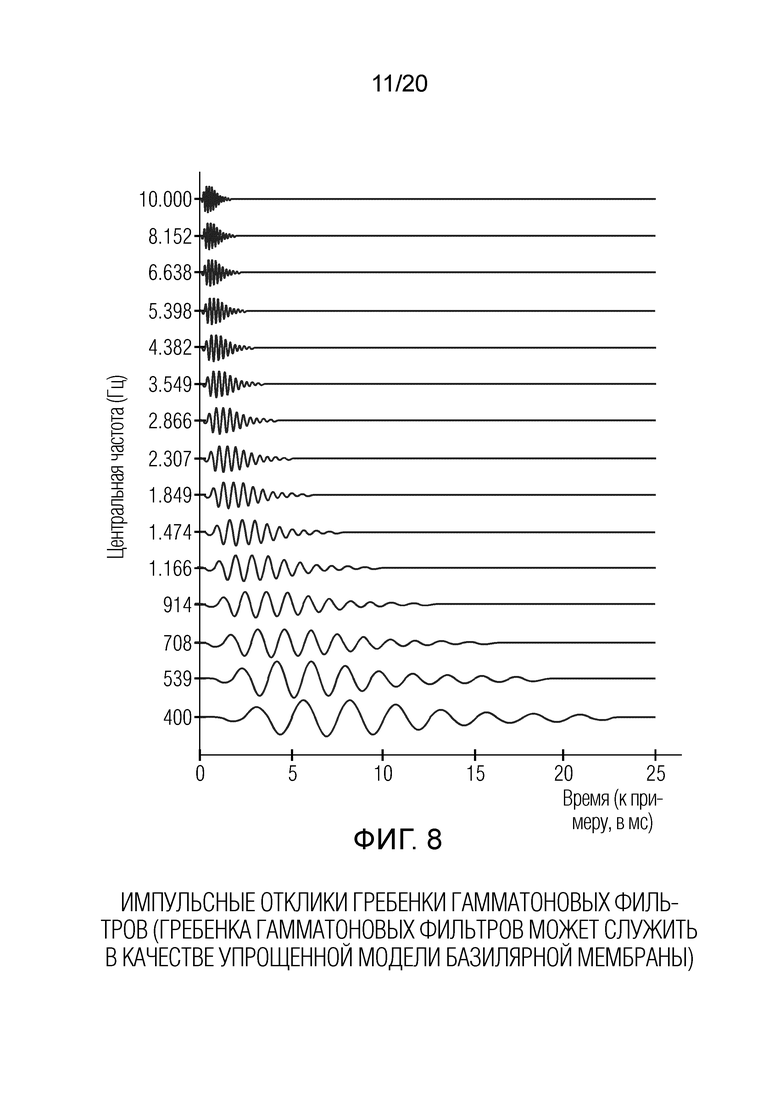
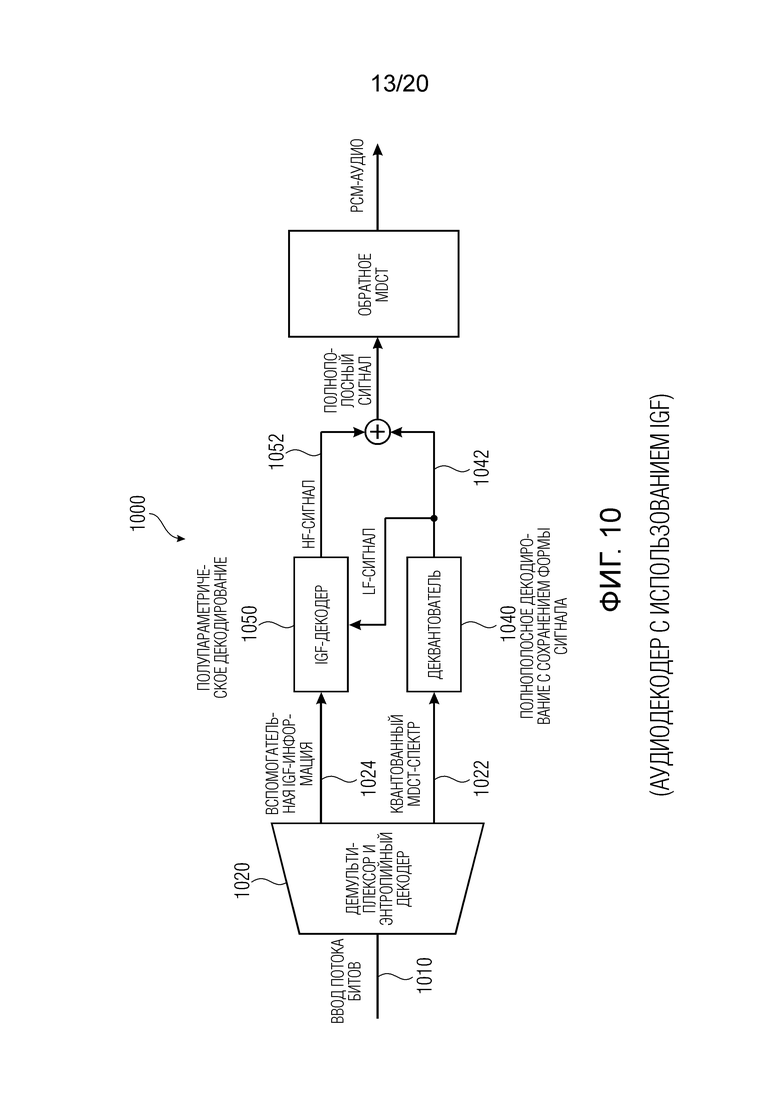
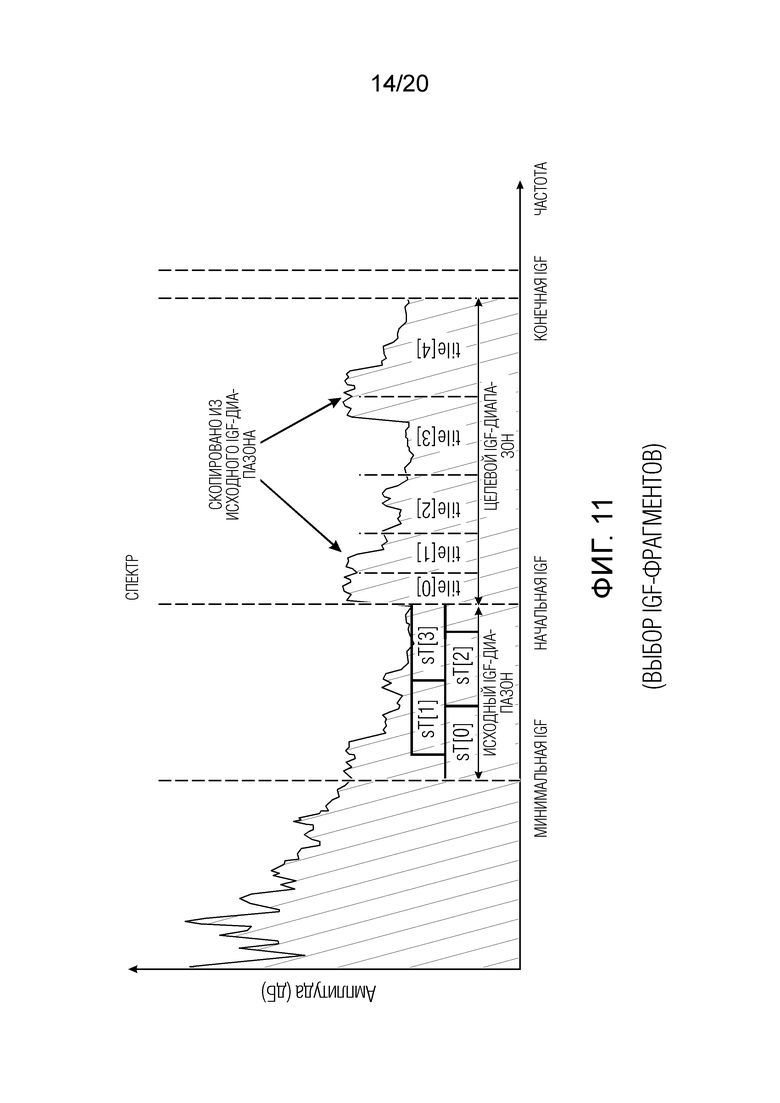
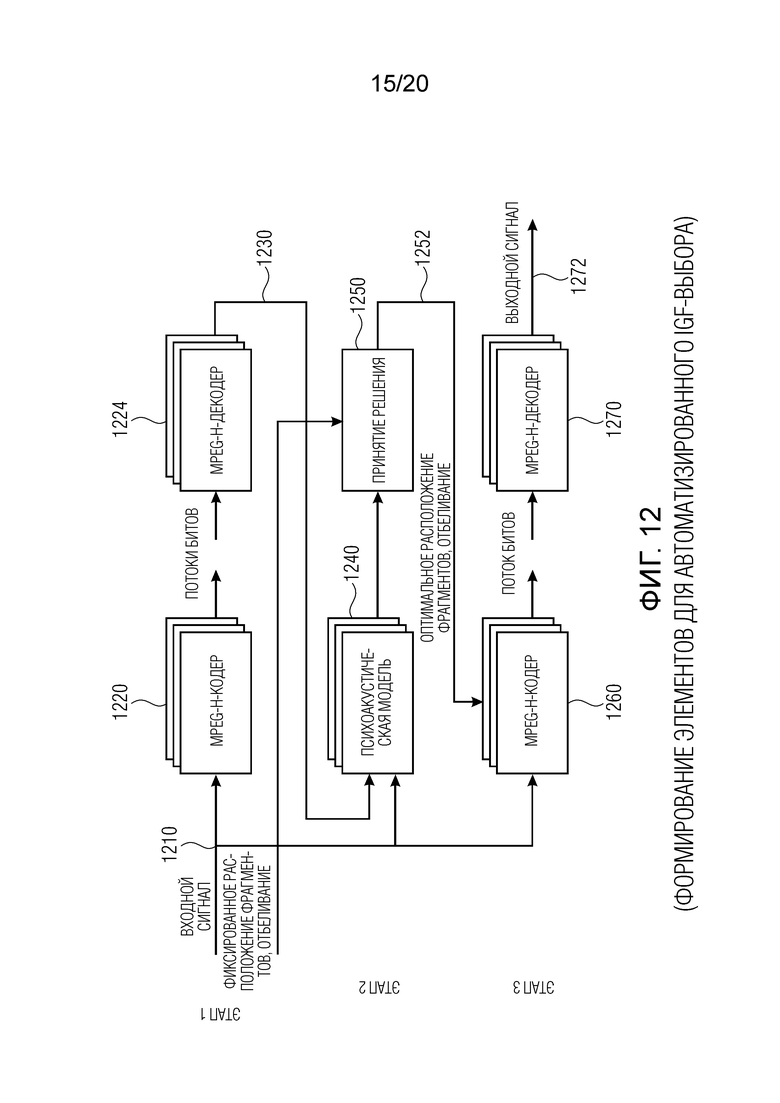


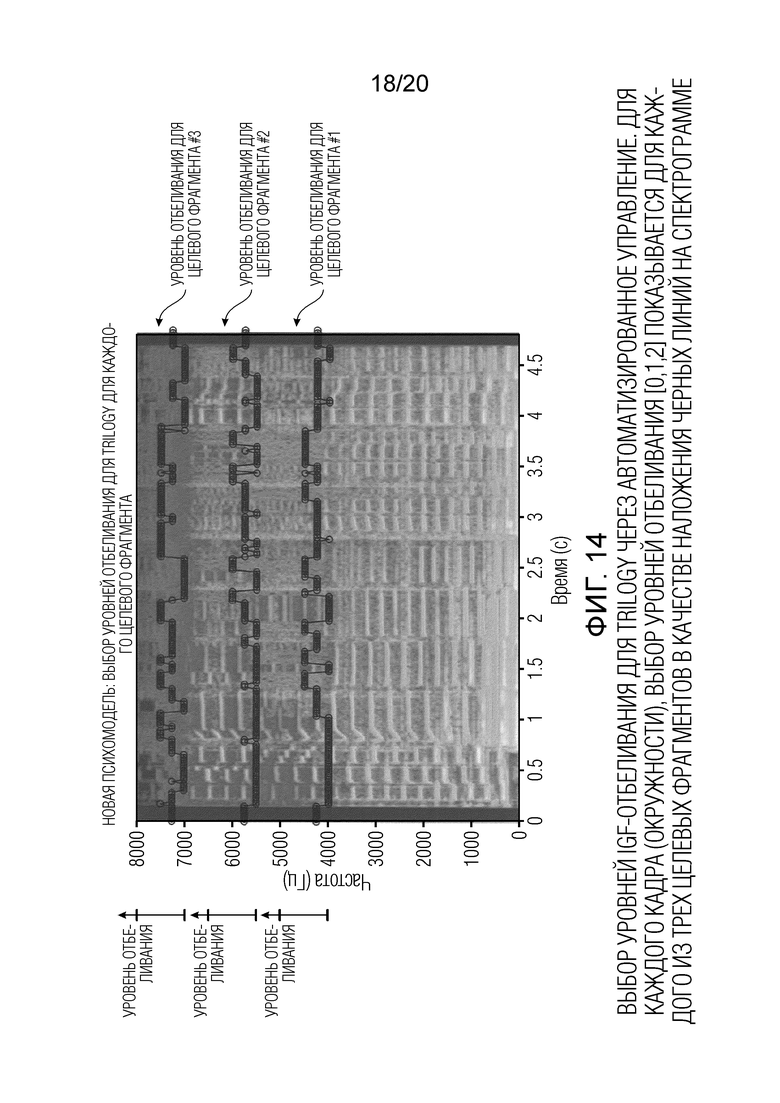

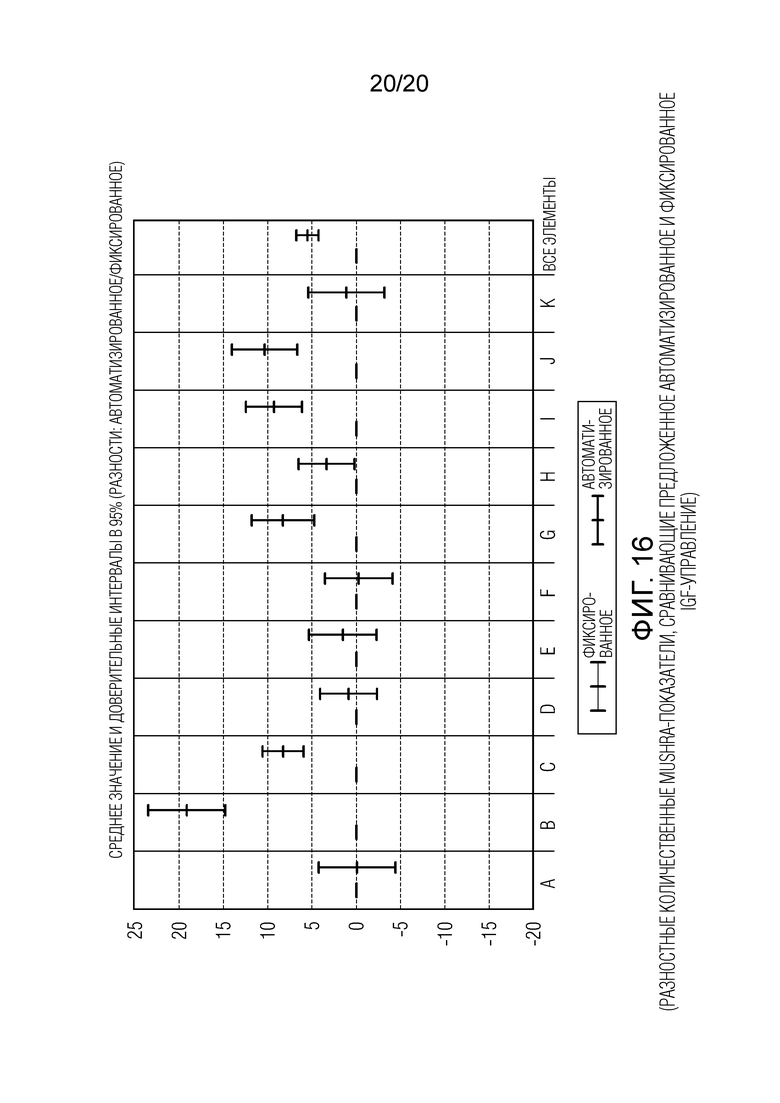
Изобретение относится к области вычислительной техники для обработки аудиоданных. Технический результат заключается в снижении вычислительной сложности при оценке подобия аудиосигналов. Технический результат достигается за счет этапов, на которых получают информацию модуляции, ассоциированную с сигналами огибающей для множества частотных диапазонов модуляции, при этом информация модуляции описывает временную модуляцию сигналов огибающей для множества частотных диапазонов модуляции и содержит множество значений, которые ассоциированы с различными частотами модуляции, которые присутствуют в соответствующем сигнале огибающей; и сравнивают полученную информацию модуляции с опорной информацией модуляции, ассоциированной с опорным аудиосигналом, чтобы получать информацию относительно подобия между входным аудиосигналом и опорным аудиосигналом. 10 н. и 20 з.п. ф-лы, 16 ил., 2 табл.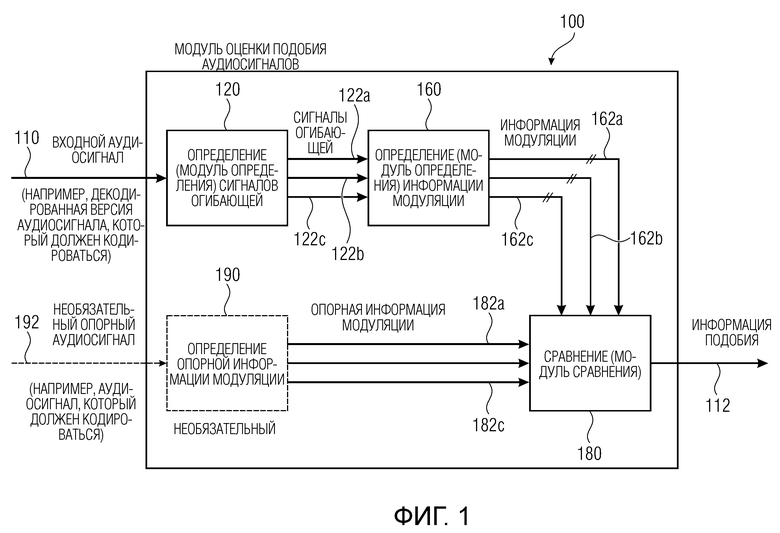
1. Модуль (100; 200; 340) оценки подобия аудиосигналов,
- при этом модуль оценки подобия аудиосигналов выполнен с возможностью получать сигналы (122a-122c; 222a-222e) огибающей для множества частотных диапазонов на основе входного аудиосигнала (110; 210; 362), и
- при этом модуль оценки подобия аудиосигналов выполнен с возможностью получать информацию (162a-162c; 262a-262e) модуляции, ассоциированную с сигналами огибающей для множества частотных диапазонов модуляции, при этом информация модуляции описывает временную модуляцию сигналов огибающей для множества частотных диапазонов модуляции и содержит множество значений, которые ассоциированы с различными частотами модуляции, которые присутствуют в соответствующем сигнале огибающей; и
- при этом модуль оценки подобия аудиосигналов выполнен с возможностью сравнивать полученную информацию модуляции с опорной информацией (182a-182c; 282a-282e) модуляции, ассоциированной с опорным аудиосигналом (310) для того, чтобы получать информацию (112; 212; 342) относительно подобия между входным аудиосигналом и опорным аудиосигналом.
2. Модуль (100; 200; 340) оценки подобия аудиосигналов по п. 1, при этом модуль оценки подобия аудиосигналов выполнен с возможностью применять множество фильтров или операций (230) фильтрации, имеющих перекрывающиеся характеристики фильтра для того, чтобы получать сигналы (122a-122c; 222a-222e) огибающей.
3. Модуль (100; 200; 340) оценки подобия аудиосигналов по п. 1, при этом модуль оценки подобия аудиосигналов выполнен с возможностью применять выпрямление (236) к выходным сигналам (232a-232e) фильтров или операции (230) фильтрации, с тем чтобы получать множество выпрямленных сигналов (238), или при этом модуль оценки подобия аудиосигналов выполнен с возможностью получать огибающую Гильберта на основе выходных сигналов (232a-232e) фильтров или операции (230) фильтрации, или при этом модуль оценки подобия аудиосигналов выполнен с возможностью демодулировать выходные сигналы (232a-232e) фильтров или операции (230) фильтрации.
4. Модуль (100; 200; 340) оценки подобия аудиосигналов по п. 3, при этом модуль оценки подобия аудиосигналов выполнен с возможностью применять фильтр нижних частот или фильтрацию (240) нижних частот к выпрямленным сигналам (238).
5. Модуль (100; 200; 340) оценки подобия аудиосигналов по п. 1, при этом модуль оценки подобия аудиосигналов выполнен с возможностью применять автоматическую регулировку (250) усиления для того, чтобы получать сигналы (222a-222e) огибающей, либо применять логарифмическое преобразование для того, чтобы получать сигналы (222a-222e) огибающей, либо применять моделирование прямого маскирования для того, чтобы получать сигналы (222a-222e) огибающей.
6. Модуль (100; 200; 340) оценки подобия аудиосигналов по п. 5, при этом модуль оценки подобия аудиосигналов выполнен с возможностью варьировать усиление, применяемое для того, чтобы извлекать сигналы (222a-222e) огибающей, на основе выпрямленных и фильтрованных по нижним частотам сигналов (242), предоставленных посредством множества фильтров или операций (240) фильтра на основе входного аудиосигнала.
7. Модуль (100; 200; 340) оценки подобия аудиосигналов по п. 1, при этом модуль оценки подобия аудиосигналов выполнен с возможностью обрабатывать выпрямленные и фильтрованные по нижним частотам версии (242) сигналов (232a-232e), предоставленных посредством множества фильтров или операций (230) фильтрации, на основе входного аудиосигнала (210) с использованием последовательности двух или более контуров (254, 256, 257) адаптации, которые применяют время-зависимое масштабирование в зависимости от время-зависимых значений усиления (258),
- при этом модуль оценки подобия аудиосигналов выполнен с возможностью регулировать различные время-зависимые значения (258) усиления с использованием различных постоянных времени.
8. Модуль (100; 200; 340) оценки подобия аудиосигналов по п. 1, при этом модуль оценки подобия аудиосигналов выполнен с возможностью применять множество модуляционных фильтров (264), имеющих различные полосы пропускания, к сигналам (222a-222e) огибающей, с тем чтобы получать информацию (262a-262e) модуляции, и/или при этом модуль оценки подобия аудиосигналов выполнен с возможностью применять понижающую дискретизацию к сигналам (222a-222e) огибающей, с тем чтобы получать информацию (262a-262e) модуляции.
9. Модуль (100; 200; 340) оценки подобия аудиосигналов по п. 8, в котором модуляционные фильтры (264) выполнены с возможностью по меньшей мере частично разделять компоненты сигнала (222a-222e) огибающей, имеющие различные частоты, при этом центральная частота первого, наименьшего частотного модуляционного фильтра меньше 5 Гц, и при этом центральная частота наибольшего частотного модуляционного фильтра находится в диапазоне между 200 Гц и 300 Гц.
10. Модуль (100; 200; 340) оценки подобия аудиосигналов по п. 8, при этом модуль оценки подобия аудиосигналов выполнен с возможностью удалять DC-компоненты при получении информации (262a-262e) модуляции.
11. Модуль (100; 200; 340) оценки подобия аудиосигналов по п. 8, при этом модуль оценки подобия аудиосигналов выполнен с возможностью удалять информацию фазы при получении информации (262a-262e) модуляции.
12. Модуль (100; 200; 340) оценки подобия аудиосигналов по п. 1, при этом модуль оценки подобия аудиосигналов выполнен с возможностью извлекать скалярное значение (112; 212; 342), представляющее разность между полученной информацией (262a-262e) модуляции и опорной информацией (282a-282e) модуляции, ассоциированной с опорным аудиосигналом (310).
13. Модуль (100; 200; 340) оценки подобия аудиосигналов по п. 1, при этом модуль оценки подобия аудиосигналов выполнен с возможностью определять разностное представление (294a-294e) для того, чтобы сравнивать полученную информацию (262a-262e) модуляции с опорной информацией (282a-282e) модуляции, ассоциированной с опорным аудиосигналом.
14. Модуль (100; 200; 340) оценки подобия аудиосигналов по п. 1, при этом модуль оценки подобия аудиосигналов выполнен с возможностью регулировать весовой коэффициент разности (289a-289e) между полученной информацией (262a-262e) модуляции и опорной информацией (282a-282e) модуляции, ассоциированной с опорным аудиосигналом, в зависимости от комодуляции между полученными сигналами (222a-222e) огибающей или информацией (262a-262e) модуляции в двух или более смежных акустических частотных диапазонах или между сигналами огибающей, ассоциированными с опорным сигналом, либо между опорной информацией (282a-282e) модуляции в двух или более смежных акустических частотных диапазонах.
15. Модуль (100; 200; 340) оценки подобия аудиосигналов по п. 1, при этом модуль оценки подобия аудиосигналов выполнен с возможностью применять более высокие весовые коэффициенты для разностей (289a-289e) между полученной информацией (262a-262e) модуляции и опорной информацией (282a-282e) модуляции, ассоциированной с опорным аудиосигналом, указывающих то, что входной аудиосигнал (210) содержит дополнительный сигнальный компонент, по сравнению с разностями (289a-289e) между полученной информацией (262a-262e) модуляции и опорной информацией (282a-282e) модуляции, ассоциированной с опорным аудиосигналом, указывающими то, что во входном аудиосигнале отсутствует сигнальный компонент, при определении информации (212) относительно подобия между входным аудиосигналом и опорным аудиосигналом.
16. Модуль (100; 200; 340) оценки подобия аудиосигналов по п. 1, при этом модуль оценки подобия аудиосигналов выполнен с возможностью взвешивать положительные и отрицательные значения разности (289a-289e) между полученной информацией (262a-262e) модуляции и опорной информацией (282a-282e) модуляции с использованием различных весовых коэффициентов при определении информации относительно подобия между входным аудиосигналом и опорным аудиосигналом.
17. Аудиокодер (300; 400) для кодирования аудиосигнала (310; 410),
- при этом аудиокодер выполнен с возможностью определять один или более параметров (324; 424) кодирования в зависимости от оценки подобия между аудиосигналом (310; 410), который должен кодироваться, и кодированным аудиосигналом (362),
- при этом аудиокодер содержит модуль (100; 200; 340) оценки подобия аудиосигналов по п. 1, который выполнен с возможностью оценивать подобие между аудиосигналом (310; 410), который должен кодироваться, и кодированным аудиосигналом (352).
18. Аудиокодер (300; 400) по п. 17, при этом аудиокодер выполнен с возможностью кодировать один или более параметров (324; 424) расширения полосы пропускания, которые задают правило обработки, которое должно использоваться на стороне аудиодекодера (1000) для того, чтобы извлекать отсутствующий аудиоконтент (1052) на основе аудиоконтента (1042) другого частотного диапазона, кодированного посредством аудиокодера; и/или
- при этом аудиокодер выполнен с возможностью кодировать один или более конфигурационных параметров аудиодекодера, которые задают правило обработки, которое должно использоваться на стороне аудиодекодера.
19. Аудиокодер (300; 400) по п. 17, при этом аудиокодер выполнен с возможностью поддерживать интеллектуальное заполнение промежутков, и
- при этом аудиокодер выполнен с возможностью определять один или более параметров (324; 424) интеллектуального заполнения промежутков с использованием оценки подобия между аудиосигналом (310; 410), который должен кодироваться, и кодированным аудиосигналом (352).
20. Аудиокодер (300; 400) по п. 17,
- при этом аудиокодер выполнен с возможностью выбирать одну или более ассоциаций между исходным частотным диапазоном (sT[.]) и целевым частотным диапазоном (фрагментом[.]) для расширения полосы пропускания и/или один или более рабочих параметров обработки для расширения полосы пропускания в зависимости от оценки подобия между аудиосигналом (310; 410), который должен кодироваться, и кодированным аудиосигналом (362).
21. Аудиокодер (300; 400) по п. 17,
- при этом аудиокодер выполнен с возможностью выбирать одну или более ассоциаций между исходным частотным диапазоном и целевым частотным диапазоном для расширения полосы пропускания,
- при этом аудиокодер выполнен с возможностью избирательно разрешать или запрещать изменение ассоциации между исходным частотным диапазоном и целевым частотным диапазоном в зависимости от оценки модуляции огибающей в старом или новом целевом частотном диапазоне.
22. Аудиокодер (300; 400) по п. 21,
- при этом аудиокодер выполнен с возможностью определять интенсивность (485) модуляции огибающей в целевом частотном диапазоне в частотном диапазоне модуляции, соответствующем частоте кадров кодера, и определять показатель (487) чувствительности в зависимости от определенной интенсивности модуляции, и
- при этом аудиокодер выполнен с возможностью определять то, разрешается или запрещается изменять ассоциацию между целевым частотным диапазоном и исходным частотным диапазоном в зависимости от показателя чувствительности.
23. Аудиокодер (500) для кодирования аудиосигнала,
- при этом аудиокодер выполнен с возможностью определять один или более параметров (524) кодирования в зависимости от аудиосигнала (510), который должен кодироваться с использованием нейронной сети (530),
- при этом нейронная сеть обучается с использованием модуля (100; 200) оценки подобия аудиосигналов по п. 1.
24. Модуль (600) оценки подобия аудиосигналов,
- при этом модуль оценки подобия аудиосигналов выполнен с возможностью получать сигналы (622a-622c) огибающей для множества частотных диапазонов на основе входного аудиосигнала (610), и
- при этом модуль оценки подобия аудиосигналов выполнен с возможностью сравнивать аналитическое представление (622a-622c) входного аудиосигнала, который соответствует сигналам огибающей или который основан на сигналах огибающей, с опорным аналитическим представлением (682a-682c), ассоциированным с опорным аудиосигналом, чтобы получать информацию (612) относительно подобия между входным аудиосигналом и опорным аудиосигналом,
- при этом модуль оценки подобия аудиосигналов выполнен с возможностью регулировать весовой коэффициент разности между полученным аналитическим представлением (622a-622c) и опорным аналитическим представлением (682a-682c) в зависимости от комодуляции между сигналами огибающей или полученной информацией модуляции в двух или более смежных акустических частотных диапазонах входного аудиосигнала или в зависимости от комодуляции между сигналами огибающей, ассоциированными с опорным аудиосигналом, или между опорной информацией модуляции в двух или более смежных акустических частотных диапазонах опорного аудиосигнала.
25. Способ оценки подобия между аудиосигналами,
- при этом способ содержит этап, на котором получают сигналы огибающей для множества частотных диапазонов на основе входного аудиосигнала, и
- при этом способ содержит этап, на котором получают информацию модуляции, ассоциированную с сигналами огибающей для множества частотных диапазонов модуляции, при этом информация модуляции описывает временную модуляцию сигналов огибающей для множества частотных диапазонов модуляции и содержит множество значений, которые ассоциированы с различными частотами модуляции, которые присутствуют в соответствующем сигнале огибающей; и
- при этом способ содержит этап, на котором сравнивают полученную информацию модуляции с опорной информацией модуляции, ассоциированной с опорным аудиосигналом, чтобы получать информацию относительно подобия между входным аудиосигналом и опорным аудиосигналом.
26. Способ кодирования аудиосигнала,
- при этом способ содержит этап, на котором определяют один или более параметров кодирования в зависимости от оценки подобия между аудиосигналом, который должен кодироваться, и кодированным аудиосигналом,
- при этом способ содержит этап, на котором оценивают подобие между аудиосигналом, который должен кодироваться, и кодированным аудиосигналом по п. 25.
27. Способ кодирования аудиосигнала,
- при этом способ содержит этап, на котором определяют один или более параметров кодирования в зависимости от аудиосигнала, который должен кодироваться с использованием нейронной сети,
- при этом нейронная сеть обучается с использованием способа оценки подобия между аудиосигналами по п. 25.
28. Способ оценки подобия между аудиосигналами,
- при этом способ содержит этап, на котором получают сигналы огибающей для множества частотных диапазонов на основе входного аудиосигнала, и
- при этом способ содержит этап, на котором сравнивают аналитическое представление входного аудиосигнала, который соответствует сигналам огибающей или который основан на сигналах огибающей, с опорным аналитическим представлением, ассоциированным с опорным аудиосигналом, чтобы получать информацию относительно подобия между входным аудиосигналом и опорным аудиосигналом,
- при этом способ содержит этап, на котором регулируют весовой коэффициент разности между полученным аналитическим представлением и опорным аналитическим представлением в зависимости от комодуляции между сигналами огибающей или полученной информацией модуляции в двух или более смежных акустических частотных диапазонах входного аудиосигнала или в зависимости от комодуляции между сигналами огибающей, ассоциированными с опорным аудиосигналом, или между опорной информацией модуляции в двух или более смежных акустических частотных диапазонах опорного аудиосигнала.
29. Носитель хранения данных, содержащий компьютерную программу для осуществления способа по п. 25 или 28, когда компьютерная программа работает на компьютере.
30. Носитель хранения данных, содержащий компьютерную программу для осуществления способа по п. 26 или 27, когда компьютерная программа работает на компьютере.
| Токарный резец | 1924 |
|
SU2016A1 |
| Колосоуборка | 1923 |
|
SU2009A1 |
| Способ приготовления мыла | 1923 |
|
SU2004A1 |
| АУДИОКОДЕР, АУДИОДЕКОДЕР, СПОСОБ ОБЕСПЕЧЕНИЯ КОДИРОВАННОЙ АУДИОИНФОРМАЦИИ, СПОСОБ ОБЕСПЕЧЕНИЯ ДЕКОДИРОВАННОЙ АУДИОИНФОРМАЦИИ, КОМПЬЮТЕРНАЯ ПРОГРАММА И КОДИРОВАННОЕ ПРЕДСТАВЛЕНИЕ С ИСПОЛЬЗОВАНИЕМ СИГНАЛЬНО-АДАПТИВНОГО РАСШИРЕНИЯ ПОЛОСЫ ПРОПУСКАНИЯ | 2014 |
|
RU2641461C2 |
| КЛАССИФИКАТОР НА ОСНОВЕ НЕЙРОННЫХ СЕТЕЙ ДЛЯ ВЫДЕЛЕНИЯ АУДИО ИСТОЧНИКОВ ИЗ МОНОФОНИЧЕСКОГО АУДИО СИГНАЛА | 2006 |
|
RU2418321C2 |

