Область техники, к которой относится изобретение
Настоящее изобретение относится к выделению множества неизвестных аудио источников, микшированных в отдельный монофонический аудио сигнал.
Описание предшествующего уровня техники
Существуют технологии для извлечения источника либо из стереофонических, либо из многоканальных аудио сигналов. Анализ независимых компонент (ICA) представляет собой наиболее известный и исследованный способ. Однако ICA может извлекать только количество источников, равное или меньшее количеству каналов во входном сигнале. По этой причине он не может использоваться при разделении монофонического сигнала.
Извлечение аудио источников из монофонического сигнала может быть полезным для извлечения характеристик сигналов речи, синтеза представления многоканального сигнала, категоризации музыки, отслеживания источников, генерирования дополнительного канала для ICA, генерирования аудио индексов для целей навигации (просмотра), инверсного смешивания (пользователь и профессионал), безопасности и наблюдения, телефонной и беспроводной связи, и проведения телеконференций. Извлечение характеристик сигнала речи (подобных автоматическому детектированию диктора, автоматическому распознаванию речи, детекторам речи/музыки) хорошо разработано. Извлечение информации о произвольном музыкальном инструменте из монофонического сигнала очень плохо исследовано из-за трудностей, связанных с проблемой, которые включают в себя сильно изменяющиеся параметры сигнала и источников, наложение источников во временной и частотной области, и реверберацию и наличия помех в сигналах обычной жизни. Известные технологии включают в себя выравнивание АЧХ и прямое извлечение параметров.
Эквалайзер может применяться к сигналу для извлечения источников, которые занимают известный частотный диапазон. Например, большая часть энергии сигнала речи присутствует в диапазоне 200 Гц - 4 кГц. Звуки бас гитары обычно ограничиваются частотами ниже 1 кГц. Посредством отфильтровывания всего сигнала вне полосы, выбранный источник может либо извлекаться, либо его энергия может усиливаться по отношению к другим источникам. Однако выравнивание АЧХ не является эффективным при извлечении накладывающихся источников.
Один из способов прямого извлечения параметров описывается в 'Audio Content Analysis for Online Audiovisual Data Segmentation and Classification' by Tong Zhang and Jay Kuo (IEEE Transactions on speech and audio processing, vol.9 No.4, маy 2001). Обычные аудио параметры, такие как функция энергетического спектра, средняя частота перехода через ноль, основная частота и результаты отслеживания спектральных пиков, извлекаются. Затем сигнал разделяется на категории (молчание; с музыкальными компонентами; без музыкальных компонент) и субкатегории. Включение фрагмента в определенную категорию основывается на прямом сравнении параметра с набором пределов. Является необходимым предварительное знание источников.
Способ категоризации музыкальных жанров описывается в 'Musical Genre Classification of Audio Signals' by George Tzanetakis and Perry Cook (IEEE Transactions on speech and audio processing, vol.10 No.5, July 2002). Параметры, подобные инструментовки, ритмической структуре и гармоническому содержанию, извлекаются из сигнала и подаются на вход предварительно обучаемого статистического классификатора распознавания структур. 'Acoustic Segmentation for Audio Browsers' by Don Kimbler and Lynn Wilcox использует Марковские модели со скрытыми параметрами для аудио сегментации и классификации.
Сущность изобретения
Настоящее изобретение обеспечивает возможность разделения и категоризации множества произвольных и заранее неизвестных аудио источников, микшированных с уменьшением количества каналов в отдельный монофонический аудио сигнал.
Это достигается посредством разбивки монофонического аудио сигнала на базовые кадры (возможно, перекрывающиеся), разбивки кадров на окна, извлечения ряда описывающих параметров в каждом кадре и использования предварительно обученной нелинейной нейронной сети в качестве классификатора. Каждый выход нейронной сети демонстрирует присутствие заданного типа аудио источника в каждом базовом кадре монофонического аудио сигнала. Нейронная сеть, как правило, имеет столько же выходов, сколько имеется типов аудио источников, которые система обучается различать. Классификатор на основе нейронной сети хорошо приспособлен, чтобы соответствовать изменяющимся в широких пределах параметрам сигнала и источников, наложению источников во временной и частотной области, и реверберации и помехам от сигналов обычной жизни. Выходы классификатора могут использоваться в качестве наборов предварительной обработки данных для создания множества аудио каналов для алгоритма разделения источников (например, ICA) или в качестве параметров в алгоритме пост-обработки (например, категоризации музыки, отслеживания источников, генерирования аудио индексов для целей навигации, инверсного смешивания, безопасности и наблюдения, телефонной и беспроводной связи, и проведения телеконференций).
В первом варианте осуществления монофонический аудио сигнал фильтруется на субполосы. Количество субполос и разброс или однородность субполос зависит от применения. Затем каждая субполоса разбивается на кадры, и извлекаются признаки. Одинаковые или различные сочетания признаков (параметров) могут извлекаться из различных субполос. Некоторые субполосы могут не иметь извлеченных параметров. Каждый параметр субполосы может формировать отдельный входной сигнал для классификатора или сходные параметры могут "сливаться" по субполосам. Классификатор может содержать отдельный выходной узел для каждого заранее заданного аудио источника для улучшения устойчивости классификации каждого конкретного аудио источника. Альтернативно, классификатор может содержать выходной узел для каждой субполосы для каждого заранее заданного аудио источника, чтобы улучшить разделение множества перекрывающихся по частоте источников.
Во втором варианте осуществления один или несколько параметров, например, тональные компоненты или TNR(отношение звук/шум), извлекаются при множестве время-частотных разрешений, а затем масштабируются к размеру базового кадра. Это предпочтительно делается параллельно, но может осуществляться последовательно. Параметры при каждом разрешении могут вводиться в классификатор, или они могут «сливаться» с образованием одного входного сигнала. Подход с множеством разрешений решает проблему нестационарности естественных сигналов. Большинство сигналов могут рассматриваться как квазистационарные только на коротких временных интервалах. Некоторые сигналы изменяются быстрее, некоторые медленнее, например, для речи, с быстро изменяющимися параметрами сигнала, более короткие временные кадры будут приводить к лучшему разделению энергии сигнала. Для струнных инструментов, которые являются более стационарными, более длинные кадры обеспечат более высокое разрешение по частотам без ухудшения разделения сигнала по энергии.
В третьем варианте осуществления монофонический аудио сигнал фильтруется на субполосы, и один или несколько параметров в одной или нескольких субполосах извлекаются при множестве время-частотных разрешений, а затем масштабируются к размеру базового кадра. Сочетание фильтра для субполос и множества разрешений может дополнительно улучшить возможности классификатора.
В четвертом варианте осуществления значения на выходных узлах нейронной сети подвергаются отфильтровыванию низких частот для уменьшения шума, а следовательно, и разброса между кадрами при классификации. Без фильтрования низких частот система работает на коротких отрезках сигнала (базовых кадрах) без информации о прошедших или будущих входных сигналах. Фильтрование низких частот уменьшает количество ложных результатов в предположении, что сигнал, как правило, длится в течение более чем одного базового кадра.
Эти и другие признаки и преимущества настоящего изобретения станут очевидны специалистам в данной области из следующего далее подробного описания предпочтительных вариантов осуществления, взятых вместе с прилагаемыми чертежами, в которых:
Краткое описание чертежей
Фиг.1 представляет собой блок-схему разделения множества неизвестных аудио источников, микшированных в отдельный монофонический аудио сигнал, с использованием классификатора на основе нейронных сетей в соответствии с настоящим изобретением.
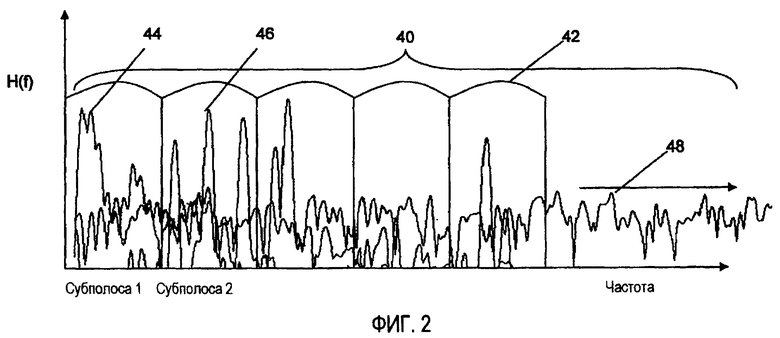
Фиг.2 представляет собой схему, иллюстрирующую фильтрование входного сигнала на субполосы.
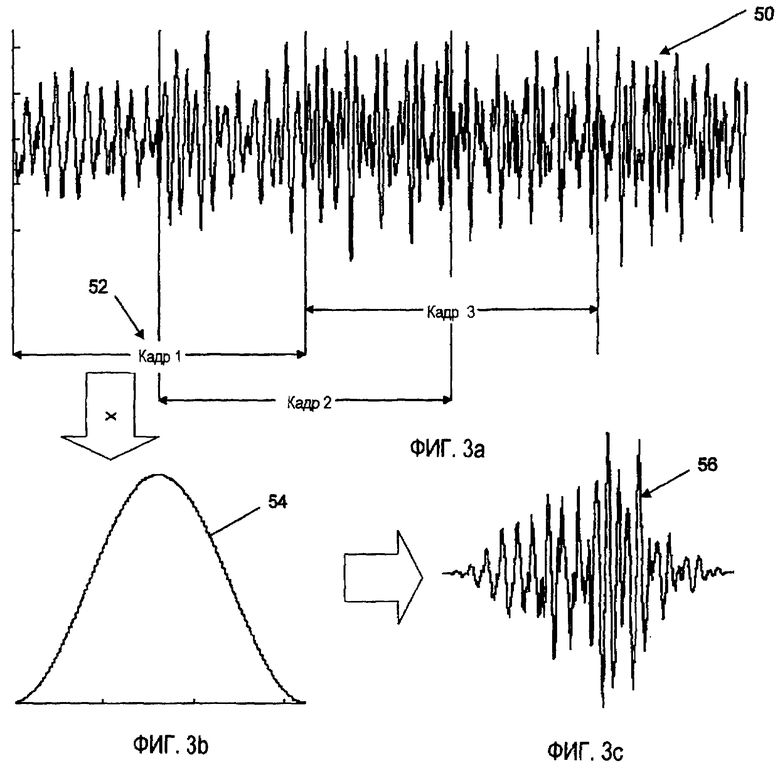
Фиг.3 представляет собой схему, иллюстрирующую разбиение входного сигнала на кадры и окна.
Фиг.4 представляет собой блок-схему операций извлечения тональных компонент при множестве разрешений и параметров TNR.
Фиг.5 представляет собой блок-схему операций для оценки минимального уровня шума.
Фиг.6 представляет собой блок-схему операций для извлечения параметра пика кепстра.
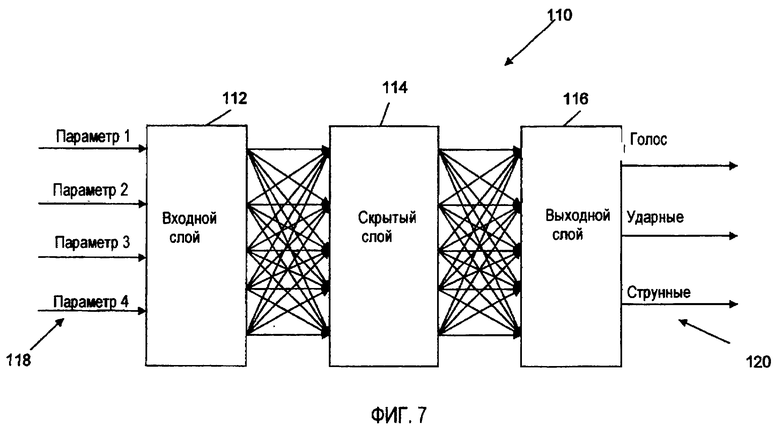
Фиг.7 представляет собой блок-схему типичного классификатора на основе нейронных сетей.
Фиг.8a-8c представляют собой графики аудио источников, которые составляют монофонический сигнал, и выходные сигналы мер классификатора на основе нейронных сетей.
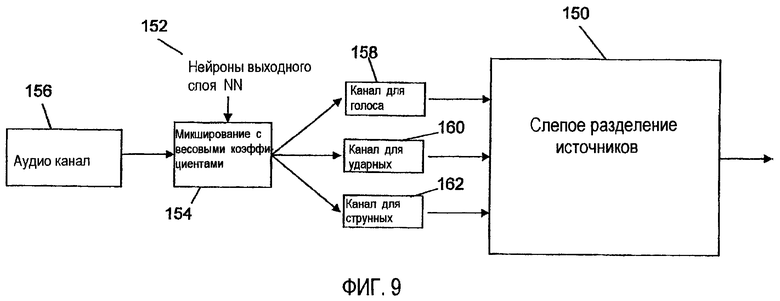
Фиг.9 представляет собой блок-схему системы для использования мер выходных сигналов для инверсного смешивания монофонического сигнала во множество аудио каналов.
Фиг.10 представляет собой блок-схему системы для использования мер выходных сигналов для выполнения стандартной задачи пост-обработки, осуществляемой в отношении монофонического сигнала.
Подробное описание изобретения
Настоящее изобретение обеспечивает способность к выделению и категоризации множества произвольных и заранее неизвестных аудио источников, микшированных с уменьшением количества каналов в один монофонический аудио сигнал.
Как показано на Фиг.1, множество аудио источников 10, например голос, струнные и ударные, микшируются (этап 12) в один монофонический аудио канал 14.
Монофонический сигнал может представлять собой обычный смешанный одинарный сигнал или он может представлять собой один из каналов стерео или многоканального сигнала. В наиболее общем случае, нет априорной информации относительно конкретных типов аудио источников в конкретном смешанном сигнале, самих сигналов, относительно того, сколько различных сигналов содержится, или относительно коэффициентов микширования. Типы аудио источников, которые могли бы включаться в конкретный смешанный сигнал, известны. Например, приложение может представлять собой классификацию источников или преобладающих источников в музыкальном смешанном сигнале. Классификатор будет знать, что возможные источники включают в себя мужской вокал, женский вокал, струнные, ударные и тому подобное. Классификатор не будет знать, какие из этих источников или сколько их включается в конкретный смешанный сигнал, что-либо о конкретных источниках или о том как они микшируются.
Процесс разделения и категоризации множества произвольных и заранее неизвестных аудио источников начинается посредством разбиения монофонического аудио сигнала на последовательность базовых кадров (возможно, перекрывающихся) (этап 16), разбиения кадров на окна (этап 18), извлечения ряда описательных параметров в каждом кадре (этап 20) и использования предварительно обученной нелинейной нейронной сети в качестве классификатора (этап 22). Каждый выход нейронной сети демонстрирует присутствие заданного типа аудио источника в каждом базовом кадре монофонического аудио сигнала. Нейронные сети, как правило, имеют столько же выходов, сколько имеется типов аудио источников, которые система обучена различать.
Рабочие характеристики классификатора на основе нейронной сети, в частности, при разделении и классификации "перекрывающихся источников" могут быть улучшены с помощью ряда способов, включая фильтрование монофонического сигнала в субполосы, извлечение параметров при множестве разрешений и низкочастотное фильтрование величин классификации.
В первом улучшенном варианте осуществления монофонический аудио сигнал может фильтроваться в субполосы (поддиапазоны) (этап 24). Это, как правило, но необязательно, осуществляется перед разбиением на кадры. Количество субполос и разброс или однородность субполос зависит от применения. Затем каждая субполоса разбивается на кадры, и извлекаются параметры. Одинаковые или различные сочетания параметров могут извлекаться из различных субполос. Некоторые субполосы могут не иметь извлеченных параметров. Каждый параметр субполосы может образовывать отдельный вход для классификатора или сходные параметры могут "сливаться" по субполосам (этап 26). Классификатор может содержать отдельный выходной узел для каждого заранее заданного аудио источника, в этом случае извлечение параметров из множества субполос улучшает робастность классификации каждого конкретного аудио источника. Альтернативно, классификатор может содержать выходной узел для каждой субполосы, для каждого заданного аудио источника, в этом случае извлечение параметров из множества субполос улучшает разделение множества источников, перекрывающихся по частоте.
Во втором улучшенном варианте осуществления один или несколько параметров извлекаются при множестве время-частотных разрешений, а затем масштабируются до размера базового кадра. Как показано, монофонический сигнал сначала сегментируется на базовые кадры, разбивается на окна, и извлекаются параметры. Если один или несколько параметров извлекаются при множестве разрешений (этап 28), размер кадра уменьшается на заданную величину (увеличивается на заданную величину) (этап 30) и процесс повторяется. Размер кадра соответствующим образом уменьшается на заданную величину (увеличивается на заданную величину) как целое число от размера базового кадра, установленного для перекрывания и разбиения на окна. В результате будут получены множество экземпляров каждого параметра по эквиваленту базового кадра. Затем эти параметры должны масштабироваться до размера базового кадра, либо независимо, либо вместе (этап 32). Параметры, извлекаемые при меньших размерах кадра, усредняются, а параметры, извлекаемые при больших размерах кадра, интерполируются до размера базового кадра. В некоторых случаях алгоритм может извлекать параметры при множестве разрешений, посредством как увеличения на заданную величину, так и уменьшения на заданную величину, от базового кадра. Кроме того, может быть желательным слияние параметров, извлекаемых при каждом разрешении, с формированием одного входа для классификатора (этап 26). Если параметры для множества разрешений не сливаются, базовое масштабирование (этап 32) может осуществляться внутри цикла и параметры поступают в классификатор при каждом проходе. Более предпочтительно, извлечение при множестве разрешений осуществляется параллельно.
В третьем улучшенном варианте осуществления значения выходных узлов нейронной сети подвергаются пост-обработке с использованием, например, низкочастотного фильтра со скользящим средним значением (этап 34) для уменьшения шума, а следовательно, и разброса между кадрами, при классификации.
Фильтрование субполос
Как показано на Фиг. 2, фильтр 40 субполос (поддиапазонов) разделяет частотные спектры монофонического аудио сигнала на N субполос с однородной или изменяющейся шириной 42. Для цели иллюстрации возможные частотные спектры H(f) показаны для голоса 44, струнных 46 и ударных 48. Посредством извлечения параметров в субполосах, где наложение источников является низким, классификатор может лучше выполнить работу при классификации преобладающего источника в кадре. В дополнение к этому, посредством извлечения параметров в различных субполосах, классификатор может быть способен классифицировать преобладающий источник в каждой из субполос. В этих субполосах, где разделение сигнала является хорошим, достоверность классификации может быть очень сильной, например, вблизи 1. При этом в тех субполосах, где сигналы перекрываются, классификатор может быть менее достоверным, относительно того, что один источник преобладает, например, два или более источников могут иметь сходные выходные величины.
Эквивалентная функция может также обеспечиваться с использованием частотного преобразования вместо фильтра для субполос.
Разбивка на кадры и окна
Как показано на Фиг. 3a-3c, монофонический сигнал 50 (или каждая субполоса сигнала) разбивается на последовательность базовых кадров 52. Сигнал соответствующим образом разбивается на перекрывающиеся кадры, и предпочтительно, с перекрыванием 50% или больше. Каждый кадр разбивается на окна для уменьшения эффектов разрывов на границах кадров и улучшения разделения по частотам. Хорошо известные окна 54 для анализа включают в себя окна приподнятого косинуса, Хэмминга, Ханнинга и Чебышева и тому подобное. Разбитый на окна сигнал 56 для каждого базового кадра затем передается на извлечение параметров.
Извлечение параметров
Извлечение параметров представляет собой способ вычисления компактного численного представления, которое может использоваться для характеризации базового кадра аудио сигнала. Идея заключается в идентификации ряда параметров, которые сами по себе или в сочетании с другими параметрами, при одном или множестве разрешений, и в одной или во множестве спектральных полос, эффективно выражают различия между различными аудио источниками. Примеры параметров, которые являются пригодными для выделения источников из монофонического аудио сигнала, включают в себя: общее количество тональных компонент в кадре; отношение звук/шум (TNR) и амплитуду пика кепстра. В дополнение к этим параметрам, любой из 17 дескрипторов низкого уровня для аудио сигнала, описанных в описании MPEG-7, или их сочетание могут представлять собой пригодные для использования параметры при различных применениях.
Ниже подробно описаны тональные компоненты, параметры TNR и пики кепстра. В дополнение к этому, параметры тональных компонент и TNR извлекаются при множестве время-частотных разрешений и масштабируются к базовому кадру. Стадии вычисления "дескрипторов низкого уровня" являются доступными в сопроводительной документации для MPEG-7 аудио. (См., например, International Standard ISO/IEC 15938 "Multimedia Content Description Interface", или http://www.chiariglione.org/mpeg/standards/mpeg-7/mpeg-7.htm).
Тональные компоненты
Тональная компонента по существу представляет собой тон, который является относительно сильным по сравнению со средним сигналом. Параметр, который извлекается, представляет собой количество тональных компонент при данном время-частотном разрешении. Процедура оценки количества тональных компонент при одном уровне время-частотного разрешения в каждом кадре иллюстрируется на Фиг. 4 и включает в себя следующие этапы:
1. Выделение кадра монофонического входного сигнала (этап 16).
2. Выделение в виде окна данных, попадающих в кадр (этап 18).
3. Применение частотного преобразования к разбитому на окна сигналу (этап 60), такого как FFT MDCT, и тому подобное. Длина преобразования должна быть равной количеству аудио выборок в кадре, то есть размеру кадра. Увеличение длины преобразования будет понижать временное разрешение без увеличения частотного разрешения. При меньшей длине преобразования длина кадра будет уменьшать разрешение по частоте.
4. Вычисление высоты спектральных линий (этап 62). Для FFT, амплитуда A=Sqrt(Re*Re+Im*Im), где Re и Im представляют собой действительную и мнимую части спектральной линии, получаемой посредством преобразования.
5. Оценка минимального уровня шума для всех частот (этап 64). (См. фиг.5)
6. Подсчет количества компонент, значительно превышающих минимальный уровень шума, например больших, чем заданный фиксированный порог, который выше минимального уровня шума (этап 66). Эти компоненты считаются 'тональными компонентами' и их подсчет представляет собой выходной сигнал классификатора NN (на основе нейронной сети) (этап 68).
Аудио сигналы из обычной жизни могут содержать как стационарные фрагменты с тональными компонентами в них (подобными струнным инструментам), так и нестационарные фрагменты, которые также имеют тональные компоненты в них (подобные фрагментам устной речи). Для эффективного захвата тональных компонентов во всех ситуациях сигнал должен анализироваться при различных уровнях время-частотного разрешения. Практически пригодные для использования результаты могут извлекаться в кадрах, находящихся в пределах приблизительно от 5 мсек до 200 мсек. Следует заметить, что эти кадры предпочтительно являются чередующимися, и множество кадров данной длины могут попадать в один базовый кадр.
Для оценки количества тональных компонент при множестве время-частотных разрешений, приведенная процедура модифицируется следующим образом:
1. Дискретное уменьшение размера кадра, например, в 2 раза (игнорируя перекрывание) (этап 70).
2. Повторение этапов 16, 18, 60, 62, 64 и 66 для нового размера кадра. Частотное преобразование с длиной, равной длине кадра, должно осуществляться для получения оптимального результата время-частотного преобразования.
3. Масштабирование вычисленного количества тональных компонент к размеру базового кадра и выход к NN классификатору (этап 72). Как показано, общее количество тональных компонент при каждом время-частотном разрешении индивидуально подается в классификатор. В более простом осуществлении количество тональных компонент при всех разрешениях извлекалось бы и суммировалось с получением одного отдельного значения.
4. Повторение до тех пор, пока не будет проанализирован наименьший желаемый размер кадра (этап 74).
Для иллюстрации извлечения тональных компонент при множестве разрешений, рассмотрим следующий пример. Базовый размер кадра составляет 4096 выборок. Тональные компоненты извлекаются при длительностях преобразования 1024, 2048 и 4096 (неперекрывающихся для простоты). Типичные результаты могут представлять собой:
При 4096-точечном преобразовании: 5 компонентов.
При 2048-точечных преобразованиях (в целом 2 преобразования в одном базовом кадре): 15 компонентов, 7 компонентов.
При 1024-точечных преобразованиях (в целом 4 преобразования в одном базовом кадре): 3, 10, 17, 4.
Числа, которые будут поступать на входы NN, будут представлять собой 5,22(=15+7), 34(=3+10+17+4) при каждом проходе. Или, альтернативно, значения могут суммироваться 61=5+22+34 и вводиться как одно значение.
Алгоритм для вычисления множества время-частотных разрешений посредством дискретного увеличения является аналогичным.
Отношение тон/шум (TNR)
Отношение тон/шум представляет собой меру отношения общей энергии в тональных компонентах к минимальному уровню шума и также может представлять очень важный параметр для различения различных типов источников. Например, различные виды струнных инструментов имеют различные уровни TNR. Процесс вычисления отношения тон/шум похож на оценку количества тональных компонентов, описанных выше. Вместо подсчета количества тональных компонентов (этап 66), процедура вычисляет отношение общей энергии в тональных компонентах к минимальному уровню шума (этап 76) и выдает на выходе отношение для NN классификатора (этап 78).
Измерение TNR при различных время-частотных разрешениях также является преимуществом при обеспечении большей устойчивости рабочих характеристик для сигналов из обычной жизни. Размер кадра дискретно уменьшается на заданную величину (этап 70) и процедура повторяется для ряда малых размеров кадра. Результаты от меньших кадров масштабируют посредством усреднения их по периоду времени, равному базовому кадру (этап 78). Как и для тональных компонентов, усредненное отношение может выводиться на классификатор при каждом проходе, или они могут суммироваться в одно значение. Также, различные разрешения как для тональных компонентов, так и для TNR, удобно вычислять параллельно.
Для иллюстрации извлечения TNR при множестве разрешений рассмотрим следующий пример. Размер базового кадра составляет 4096 выборок. TNR извлекают при длительностях преобразования 1024, 2048 и 4096 (неперекрывающихся для простоты). Типичные результаты могут представлять собой:
При 4096-точечном преобразовании: отношение 40 дБ.
При 2048-точечных преобразованиях (в целом 2 преобразования в одном базовом кадре): отношения 28 дБ, 20 дБ.
При 1024-точечных преобразованиях (в целом 4 преобразования в одном базовом кадре): отношения 20 дБ, 20 дБ, 16 дБ и 12 дБ.
Отношения, которые должны быть переданы на входы NN, будут представлять собой 40 дБ, 24 дБ и 17 дБ при каждом проходе. Или, альтернативно, значения могут суммироваться (среднее = 27 дБ) и вводиться как одно значение.
Алгоритм для вычисления множества время-частотных разрешений посредством дискретного увеличения на заданную величину является аналогичным.
Оценка минимального уровня шума
Минимальный уровень шума, используемый для оценки тональных компонентов и TNR, представляет собой меру происходящей от окружающей среды или нежелательной части сигнала. Например, если пытаться классифицировать или выделить музыкальные инструменты в реальном акустическом музыкальном представлении, минимальный уровень шума должен представлять собой средний акустический уровень помещения, где музыканты не играют.
Ряд алгоритмов может использоваться для оценки минимального уровня шума в кадре. В одном из осуществлений низкочастотный фильтр КИХ может применяться по отношению к амплитудам спектральных линий. Результат такого фильтрования будет чуть выше, чем реальный минимальный уровень шума, поскольку он содержит энергию как шумящих, так и тональных компонент. Однако это может компенсироваться посредством понижения порогового значения. Как показано на Фиг. 5, более точный алгоритм улучшает простой подход с фильтром КИХ с получением уровня, более близкого к реальному минимальному уровню шума.
Простая оценка минимального уровня шума находится посредством применения фильтра КИХ:

где N i - оцененный минимальный уровень шума для i-той спектральной линии;
A i - высота (амплитуда) спектральных линий после частотного преобразования;
C k - коэффициенты фильтра КИХ; и
L - длина фильтра.
Как показано на Фиг. 5, более точная оценка улучшает начальную оценку низкочастотного КИХ (этап 80), приведенную выше, посредством маркировки компонентов, которые лежат существенно выше минимального уровня шума, например, на 3 дБ выше выходного сигнала КИХ, на каждой частоте (этап 82). После маркировки устанавливается счетчик, например, J=0 (этап 84) и маркированные компоненты (высоты 86) заменяются последними результатами КИХ (этап 88). Этот этап эффективно удаляет энергию тонального компонента из вычисления минимального уровня шума. Низкочастотный КИХ применяется повторно (этап 90), компоненты, которые лежат существенно выше минимального уровня шума, маркируются (этап 92), счетчик увеличивается (этап 94) и маркированные компоненты опять заменяются последними результатами КИХ (этап 88). Этот процесс повторяется в течение желаемого количества итераций, например, 3 (этап 96). Более высокое количество итераций будет приводить к чуть большей точности.
Необходимо отметить, что оценка минимального уровня шума, сама по себе, может использоваться в качестве параметра для описания и разделения аудио источников.
Пики Кепстра
Кепстр-анализ обычно используется в применениях, связанных с обработкой речи. Различные характеристики кепстра могут использоваться в качестве параметров для обработки. Кепстр является также описательным для других типов сигналов с большим количеством высших гармоник. Кепстр представляет собой результат обратного Фурье-преобразования спектра в децибелах, как если бы это был сигнал. Процедура извлечения пика Кепстра представляет собой следующее:
1. Разделение аудио сигнала на последовательность кадров (этап 16).
2. Разбиение на окна сигнала в каждом кадре (этап 18).
4. Вычисление кепстра:
a. Вычисление частотного преобразования разбитого на окна сигнала, например FFT (этап 100);
b. Вычисление логарифма амплитуды высоты спектральных линий (этап 102); и
c. Вычисление обратного преобразования относительно логарифмов амплитуд (этап 104).
5. Пик кепстра представляет собой значение и положение значения максимума в кепстре (этап 106).
Классификатор на основе нейронной сети
Множество известных типов нейронных сетей являются пригодными для работы в качестве классификаторов. Современное состояние области архитектур нейронных сетей и обучающих алгоритмов делает сеть с непосредственной связью (уровневую сеть, в которой каждый слой (уровень) только принимает входные сигналы от предыдущих слоев (уровней)), очень хорошим кандидатом. Существующие обучающие алгоритмы обеспечивают стабильные результаты и хорошую генерализацию.
Как показано на Фиг. 7, сеть с непосредственной связью 110 содержит входной слой 112, один или несколько скрытых слоев 114 и выходной слой 116. Нейроны во входном слое принимают полный набор извлеченных параметров 118 и соответствующих весовых коэффициентов. Управляемый автономно обучающий алгоритм настраивает весовые коэффициенты, с которыми параметры поступают в каждый из нейронов. Скрытый слой (слои) содержит нейроны с нелинейными функциями активирования. Множество слоев нейронов с нелинейными передаточными функциями дают возможность сети изучать нелинейные и линейные соотношения между входным и выходным сигналами. Количество нейронов в выходном слое равно количеству типов источников, которые классификатор может распознать. Каждый из выходных сигналов сети сигнализирует о присутствии определенного типа источника 120, и величина [0,1] указывает достоверность того, что входной сигнал содержит данный аудио источник. Если используется фильтрование субполос, количество выходных нейронов может быть равно количеству источников, умноженному на количество субполос. В этом случае выходной сигнал нейрона указывает на присутствие конкретного источника в конкретной субполосе. Выходные нейроны могут быть пройдены "как есть", ограниченными порогами для того, чтобы оставить только значения нейронов, превышающие определенный уровень, или снабжаться порогом для того, чтобы оставить только один самый преобладающий источник.
Сеть должна быть предварительно обучена на множестве достаточно представляющих сигналов. Например, для системы, способной к распознаванию четырех различных видов данных, включающих в себя: мужской голос, женский голос, ударные инструменты и струнные инструменты, все эти типы источников должны присутствовать в обучающем множестве в достаточном разнообразии. Благодаря способности к генерализации у нейронной сети, нет необходимости избыточно представлять все возможные виды источников. Каждый набор данных должен проходить через часть для извлечения параметров у алгоритма. Извлеченные параметры затем произвольным образом смешиваются в виде двух наборов данных: обучающего и тестового. Затем один из хорошо известных управляемых алгоритмов обучения используется для обучения сети (например, такой как алгоритм Левенберга-Маркварта).
Робастность классификатора сильно зависит от набора извлеченных параметров. Если вместе параметры вместе различают различные источники, классификатор будет работать хорошо. Реализация фильтрования с множеством разрешений и субполос для получения стандартных аудио параметров представляет собой гораздо более богатый набор параметров для дифференциации и правильной классификации аудио источников в монофоническом сигнале.
В примерном варианте осуществления архитектура сети с непосредственной связью 5-3-3 (5 нейронов во входном слое, 3 нейрона в скрытом слое, и 3 нейрона в выходном слое) с функциями активатора TANSIG (гиперболического тангенса) во всех слоях хорошо работает для классификации трех типов источников; голоса, ударных и струнных. В используемой архитектуре с непосредственной связью каждый нейрон данного слоя соединяется с каждым нейроном предыдущего слоя (за исключением входного слоя). Каждый нейрон во входном слое принимает полный набор извлеченных параметров. Параметры, представленные для сети, включали в себя тональные компоненты для множества разрешений, TNR для множества разрешений и пики кепстра, которые были предварительно нормализованы так, чтобы поместить их в диапазон [-1:1]. Первый выход сети сигнализирует о присутствии голосового источника в сигнале. Второй выход сигнализирует о присутствии струнных инструментов. И наконец, третий выход обучается, чтобы он сигнализировал о присутствии ударных инструментов.
В каждом слое используется активаторная функция 'TANSIG'. Эффективная по вычислениям формула для вычисления выходного сигнала k-ого нейрона в j-ом слое задается как:
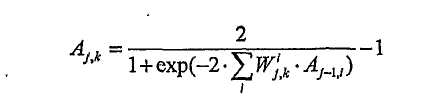
где A j,k - выходной сигнал k нейрона в j-ом слое;
 - i-ый весовой коэффициент этого нейрона (настраивается во время обучения)
- i-ый весовой коэффициент этого нейрона (настраивается во время обучения)
Для входного слоя формула представляет собой
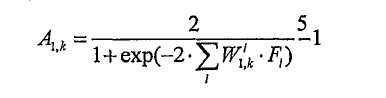
где F i - i-ый параметр;
- i-ый весовой коэффициент этого нейрона (настраивается во время обучения)
Для тестирования простого классификатора, длинный аудио файл состыковывают из трех различных видов аудио сигналов. Голубые линии обозначают реальное присутствие голоса (немецкая речь) 130, ударный инструмент (хай-хэтс) 132 и струнный инструмент (акустическая гитара) 134. Файл составляет приблизительно 800 кадров в длину, из которых первые 370 кадров представляют собой голос, следующие 100 кадров представляют собой ударные и последние 350 кадров представляют собой струнные. Внезапные разрывы в голубых линиях соответствуют периодам молчания во входном сигнале. Зеленые линии представляют собой предсказания для голоса 140, ударных 142 и струнных 144, получаемые посредством классификатора. Выходные значения фильтруются для уменьшения шума. Расстояние, насколько далеко выходной сигнал сети находится либо от 0 либо от 1, представляет собой меру того как определяет классификатор то, что входной сигнал содержит конкретный аудио источник.
Хотя аудио файл представляет собой монофонический сигнал, в котором ни один из аудио источников не присутствует реально в одно и то же время, он является адекватным и более простым для демонстрации возможностей классификатора. Как показано на Фиг. 8c, классификатор идентифицирует струнный инструмент с большой достоверностью и без ошибок. Как показано на Фиг. 8a и 8b, рабочие характеристики сигналов голоса и ударных являются удовлетворительными, хотя имеется некоторое перекрывание. Использование тональных компонент для множества разрешений должно более эффективно различать ударные инструменты и голосовые фрагменты (на самом деле, глухие фрагменты речи).
Выходные сигналы классификатора могут использоваться в качестве входных данных для создания множества аудио каналов для алгоритма разделения источников (например, ICA) или в качестве параметров в алгоритме пост-обработки (например, категоризации музыки, отслеживания источников, генерирования аудио индексов для целей навигации, инверсного смешивания, безопасности и наблюдения, телефонной и беспроводной связи, и проведения телеконференций).
Как показано на Фиг. 9, классификатор используется как устройство предварительной обработки данных для алгоритма слепого разделения источников (BSS) 150, такого как ICA, который требует такого же количества входных каналов, как количество источников, которое он пытается выделить. Предположим, что алгоритм BSS желает выделить источники голоса, ударных и струнных из монофонического сигнала, чего он не может сделать. NN классификатор может конфигурироваться выходными нейронами 152 для голоса, ударных и струнных. Значения нейронов используются в качестве весовых коэффициентов для смешивания 154 каждого кадра монофонического аудио сигнала в аудио канале 156, в трех отдельных аудио канала, по одному для голоса 158, ударных 160 и струнных 162. Весовые коэффициенты могут представлять собой реальные значения для нейронов или пороговые значения для идентификации одного доминирующего сигнала на кадр. Это процедура может дополнительно усовершенствоваться с использованием фильтрования субполос и таким образом создавать гораздо больше входных каналов для BSS. BSS использует мощные алгоритмы для дополнительного определения начального разделения источников, обеспечиваемого NN классификатором.
Как показано на Фиг. 10, нейроны выходного слоя NN 170 могут использоваться в постпроцессоре 172, который работает над монофоническим аудио сигналом в аудио канале 174.
Трекинг - алгоритм может применяться к индивидуальным каналам, которые получают с помощью других алгоритмов (например, BSS), которые работают на основе «от кадра к кадру». С помощью выходного сигнала алгоритма связь соседних кадров может стать возможной или более стабильной, или более простой.
Идентификация аудио и поисковая машина аудио - извлеченные шаблоны типов сигналов и, возможно, их длительности, могут использоваться в качестве индексов в базе данных (или в качестве ключа для хэш-таблицы).
Кодер-декодер - информация о типе сигнала позволяет кодеру-декодеру осуществлять точную настройку психоакустической модели, распределения битов или других параметров кодирования.
Входные данные для разделения источников - алгоритмы, такие как ICA, требуют, по меньшей мере, такого же количества входных каналов, сколько есть источников. Алгоритм автора изобретения использоваться для создания множества аудио каналов из одного канала или для увеличения количества доступных каналов с индивидуальными входами.
Инверсное (повторное) смешивание - индивидуальные выделенные каналы могут подвергаться инверсному смешиванию в монофоническое представление (или представление с уменьшенным количеством каналов) с помощью алгоритма пост-обработки (подобного эквалайзеру) на промежуточной стадии.
Безопасность и наблюдение - выходные сигналы алгоритма могут использоваться в качестве параметров в алгоритме постобработки для улучшения восприятия записанного аудио сигнала.
Телефонная и беспроводная связь и телеконференции алгоритм может использоваться для разделения индивидуальных говорящих/источников, и алгоритм пост-обработки может присваивать индивидуальные виртуальные положения в стерео- или многоканальной окружающей среде. Потребуется передача уменьшенного количества каналов (или, возможно, только одного канала).
Хотя показаны и описаны несколько иллюстративных вариантов осуществления настоящего изобретения, многочисленные вариации и альтернативные варианты осуществления появятся для специалистов в данной области. Такие вариации и альтернативные варианты осуществления предусматриваются и могут быть проделаны без отклонения от духа и рамок настоящего изобретения, как определяется в прилагаемой формуле изобретения.





Изобретение относится к выделению множества произвольных и заранее неизвестных аудио источников, микшированных в отдельный монофонический аудио сигнал на основе нейронной сети. Это достигается посредством разбивки монофонического аудио сигнала на базовые кадры (возможно перекрывающиеся), разбивки кадров на окна, извлечения ряда описательных параметров в каждом кадре и использования предварительно обученной нелинейной нейронной сети в качестве классификатора. Каждый выход нейронной сети демонстрирует присутствие заданного типа источника аудио в каждом базовом кадре монофонического аудио сигнала. Выходные сигналы классификатора могут использоваться в качестве входных данных для создания множества аудио каналов для алгоритма разделения источников (например, ICA) или в качестве параметров в алгоритме пост-обработки (например, для категоризации музыки, трекинга источников, для генерирования аудио индексов для целей навигации, инверсного микширования, безопасности и наблюдения, телефонной и беспроводной связи, и телеконференций). Технический результат - классификатор на основе нейронных сетей хорошо приспособлен, чтобы соответствовать изменяющимся в широких пределах параметрам сигнала и источников, временной и частотной области перекрывания источников, и реверберации и помех от сигналов обычной жизни. 3 н. и 25 з.п. ф-лы, 14 ил.
1. Способ выделения источника аудио из монофонического аудио сигнала, содержащий этапы:
(a) создание монофонического аудио сигнала, содержащего результат микширования с уменьшением количества каналов множества неизвестных аудио источников;
(b) разделение аудио сигнала на последовательность базовых кадров;
(c) разбиение каждого кадра на окна;
(d) извлечение из каждого базового кадра множества параметров аудио, которые имеют тенденцию к дифференциации источников аудио; и
(e) применение параметров аудио из каждого упомянутого базового кадра к классификатору на основе нейронной сети (NN), обученному на представительном наборе источников аудио с указанными параметрами аудио, указанный классификатор на основе нейронной сети выдает на выходе, по меньшей мере, одну меру источника аудио, включенного в каждый указанный базовый кадр монофонического аудио сигнала.
2. Способ по п.1, в котором множество неизвестных источников аудио выбираются из множества музыкальных источников, содержащего, по меньшей мере, голос, струнные и ударные.
3. Способ по п.1, дополнительно включающий в себя:
повторение этапов (b)-(d) для другого размера кадра, для извлечения параметров при множестве разрешений; и
масштабирование извлеченных при различных разрешениях параметров аудио к базовому кадру.
4. Способ по п.3, дополнительно содержащий подачу масштабированных параметров при каждом разрешении на NN классификатор.
5. Способ по п.3, дополнительно включающий в себя слияние масштабированных параметров при каждом разрешении в один отдельный параметр, который подается на NN классификатор.
6. Способ по п.1, дополнительно включающий в себя фильтрование кадров во множество частотных субполос и извлечение указанных параметров аудио из указанных субполос.
7. Способ по п.1, дополнительно включающий в себя низкочастотное фильтрование выходных сигналов классификатора.
8. Способ по п.1, в котором один или несколько параметров аудио выбираются из множества, содержащего тональные компоненты, отношение тон/шум (TNR) и пики кепстра.
9. Способ по п.8, в котором тональные компоненты извлекаются посредством:
(f) применения частотного преобразования для разбитого на окна сигнала для каждого кадра;
(g) вычисления амплитуды спектральных линий при частотном преобразовании;
(h) оценки минимального уровня шума;
(i) идентификации в качестве тональных компонентов спектральных компонентов, которые превышают минимальный уровень шума, посредством порогового значения; и
(j) выдачи количества тональных компонентов в качестве параметра тональных компонентов.
10. Способ по п.9, в котором длина частотного преобразования уравнивает количество аудио выборок в кадре для определенного время-частотного разрешения.
11. Способ по п.10, дополнительно включающий в себя:
повторение этапов (f)-(i) для различных длин кадра и преобразования
и
выдачу общего количества тональных компонентов при каждом время-частотном разрешении.
12. Способ по п.8, в котором TNR параметр извлекается посредством:
(k) применения частотного преобразования к разбитому на окна сигналу для каждого кадра;
(l) вычисление амплитуды спектральных линий при частотном преобразовании;
(m) оценки минимального уровня шума;
(n) определения отношения энергии идентифицированных тональных компонентов к минимальному уровню шума; и
(о) выдачи на выходе отношения как параметра TNR.
13. Способ по п.12, в котором длина частотного преобразования уравнивает количество аудио выборок в кадре для определенного время-частотного разрешения.
14. Способ по п.13, дополнительно включающий в себя:
повторение этапов (k)-(n) для различных длин кадра и преобразования; и
усреднение отношений от различных разрешений по периоду времени, равному базовому кадру.
15. Способ по п.12, в котором минимальный уровень шума оценивается посредством:
(р) применения низкочастотного фильтра для амплитуд спектральных линий,
(q) маркировки компонентов, существенно превышающих выходной сигнал фильтра,
(r) замены маркированных компонентов выходным сигналом низкочастотного фильтра,
(s) повторение этапов (р)-(r) некоторое количество раз и
(t) выдачи на выходе полученных компонентов как оценки минимального уровня шума.
16. Способ по п.1, в котором классификатор на основе нейронной сети включает в себя множество выходных нейронов, каждый из которых показывает присутствие определенного источника аудио в монофоническом аудио сигнале.
17. Способ по п.16, в котором значение для каждого выходного нейрона показывает достоверность того, что базовый кадр содержит определенный аудио источник.
18. Способ по п.16, дополнительно включающий в себя использование значений выходных нейронов для повторного смешивания монофонического аудио сигнала во множество аудио каналов для соответствующих источников аудио в представляющем наборе для каждого базового кадра.
19. Способ по п.18, в котором монофонический аудио сигнал подвергается повторному смешиванию посредством переключения его на аудио канал, идентифицируемый как наиболее выделяющийся.
20. Способ по п.18, в котором классификатор на основе нейронной сети выдает на выходе меру для каждого из аудио источников в представляющем наборе, которая показывает достоверность того, что кадр содержит соответствующий источник аудио, указанный монофонический аудио сигнал ослабляется посредством каждой из указанных мер и направляется в соответствующие аудио каналы.
21. Способ по п.18, дополнительно содержащий обработку указанного множества аудио каналов с использованием алгоритма выделения источников, который требует по меньшей мере такого же количества входных аудио каналов, как и количество аудио источников для разделения указанного множества аудио каналов на равное ему или меньшее множество указанных аудио источников.
22. Способ по п.21, в котором упомянутый алгоритм разделения источников основывается на слепом разделении источников (BSS).
23. Способ по п.1, дополнительно включающий в себя передачу монофонического аудио сигнала и последовательности указанных мер в постпроцессор, который использует указанные меры для дополнения постобработки монофонического аудио сигнала.
24. Способ выделения аудио источников из монофонического аудио сигнала, включающий в себя:
(а) создание монофонического аудио сигнала, содержащего микшированное с уменьшением количества каналов множество неизвестных источников аудио;
(b) разделение аудио сигнала на последовательность базовых кадров;
(c) разбиение каждого кадра на окна;
(d) извлечение множества параметров аудио из каждого базового кадра, которые имеют тенденцию к дифференциации источников аудио;
(e) повторение этапов (b)-(d) для другого размера кадра для извлечения параметров при множестве разрешений;
(f) масштабирование извлеченных при различных разрешениях аудио параметров к базовому кадру; и
(g) применение параметров аудио из каждого упомянутого базового кадра к классификатору на основе нейронной сети (NN), обученному на представляющем наборе источников аудио с указанными аудио параметрами, указанный классификатор на основе нейронной сети имеет множество выходных нейронов, каждый из которых, сигнализирует о присутствии определенного источника аудио в монофоническом аудио сигнале для каждого базового кадра.
25. Классификатор источников аудио, содержащий:
устройство для разделения на кадры для разделения монофонического аудио сигнала, содержащего смешанное с уменьшением количества каналов множество неизвестных источников аудио, на последовательность разбитых на окна базовых кадров;
устройство для извлечения параметров для извлечения множества параметров аудио из каждого базового кадра, которые имеет тенденцию к дифференциации источников аудио; и
классификатор на основе нейронной сети (NN), обученный на представляющем множестве источников аудио с указанными параметрами аудио, указанный классификатор на основе нейронной сети принимает извлеченные параметры аудио и выдает, по меньшей мере, одну меру источника аудио, содержащегося в каждом указанном базовом кадре монофонического аудио сигнала.
26. Классификатор аудио источников аудио по п.25, в котором устройство для извлечения параметров извлекает один или несколько параметров аудио при множестве время-частотных разрешений и масштабирует извлеченные параметры аудио при различных разрешениях к базовому кадру.
27. Классификатор источников аудио по п.25, в котором NN классификатор на основе нейронной сети имеет множество выходных нейронов, каждый из которых сигнализирует о присутствии определенного источника аудио в монофоническом аудио сигнале для каждого базового кадра.
28. Классификатор по п.27, дополнительно содержащий
смеситель, который использует значения выходных нейронов для повторного смешивания монофонического аудио сигнала во множество аудио каналов для соответствующих источников аудио в представляющем наборе для каждого базового кадра.
| Сыр норвежского типа-сладкий | 1983 |
|
SU1132890A1 |
| WO 2004071130 А1, 19.08.2004 | |||
| RU 2005104123 А, 10.07.2005 | |||
| US 2004231498 А1, 25.11.2004 | |||
| US 2004230428 А1, 18.11.2004 | |||
| SOLTAU et al Recognition of music types | |||
| In Proceedings of the IEEE International Conference on Acostincs, Speech, and Signal PRocessing ((ICAAP-1998) | |||
| Seattle, Washington, May 1998. | |||

