УРОВЕНЬ ТЕХНИКИ
Настоящее изобретение в целом относится к системам, предназначенным для анализа компьютерных программ. Более конкретно, настоящее изобретение относится к системе и способу статического анализа двоичных исполняемых файлов и исходного кода с использованием нечеткой логики.
Одной из важных стадий процесса разработки современных информационных систем является оценка информационной безопасности компьютерной программы. То есть оценка защищенности информационных ресурсов и информационной системы от несанкционированного доступа, использования, утечки данных, модификации или уничтожения в соответствии со стандартами конфиденциальности, целостности и доступности информации для пользователей. Определение свойств безопасности компьютерной программы обычно включает в себя анализ компонентов программы на предмет наличия уязвимостей, которые нарушают целостность информационной безопасности компьютерной программы. Такой анализ обычно включает в себя декомпиляцию компьютерного программного кода. Важно отметить, что современные компьютерные системы используют и включают в себя программные компоненты, код которых частично или полностью недоступен для такой оценки.
Существуют различные инструменты, позволяющие декомпилировать компьютерный программный код для поиска и идентификации уязвимостей кода компьютерной программы. Более конкретно, применяемые способы включают в себя декомпиляцию компьютерной программы для синтаксического анализа исполняемого кода, идентификацию и рекурсивное моделирование потоков данных, идентификацию и рекурсивное моделирование управляющего потока и итеративное уточнение этих моделей для создания полной модели на уровне основного кода.
Другой метод заключается в применении набора анализов, которые просеивают программный код и идентифицируют ошибки кодирования модели безопасности и/или конфиденциальности программирования. Затем выполняется дальнейшая оценка программы с применением анализа управляющего потока и потока данных.
Другой подход заключается в том, что исходный код преобразуют в промежуточное представление. Модели выводятся для кода, а затем анализируются вместе с заранее заданными правилами для подпрограмм, чтобы определить, обладают ли подпрограммы одной или большим количеством из заранее выбранных уязвимостей.
Указанные подходы часто приводят к большому количеству ложноположительных результатов и не предлагают функций для устранения обнаруженных уязвимостей и ошибок.
Кроме того, нередко медленная разработка методов и инструментов для анализа программного кода и отсутствие приемлемых подходов и программных средств для изучения двоичных образов программ приводит к необходимости систематизировать и автоматизировать системы и методы для анализа компьютерного программного кода. Дополнительно, необходимо решить вопросы, связанные с анализом на предмет наличия уязвимостей в компьютерных программах, код которых частично или полностью недоступен.
Устранение уязвимостей требует не только обнаружения, но и правильного описания правил использования или исправления обнаруженных уязвимостей.
Таким образом, существует необходимость в системе анализа двоичных исполняемых файлов и исходного кода при отсутствии исходного кода, которая точно обнаруживала бы и идентифицировала уязвимости, а также предоставляла бы подробные рекомендации по устранению уязвимостей.
КРАТКОЕ ИЗЛОЖЕНИЕ СУТИ ИЗОБРЕТЕНИЯ
В одном аспекте настоящего изобретения предлагается реализованная на компьютере система статического анализа двоичных исполняемых файлов и исходного кода, выполненная с возможностью обнаружения уязвимостей, недокументированных функций и других ошибок входной программы. Система включает в себя декомпилятор, работающий на процессоре, выполненный с возможностью приема исходного кода входной программы и представления входной программы в виде промежуточного представления (IR) целевого кода на низкоуровневом языке программирования (LLC), а также фронт-энд, работающий на процессоре, выполненный с возможностью приема двоичного представления кода входной программы и представления входной программы в виде целевого IR LLC. Система дополнительно включает в себя анализатор, выполненный с возможностью приема целевого IR LLC и анализа целевого IR LLC для обнаружения уязвимостей, недокументированных функций и ошибок входной программы с применением заранее определенных правил, сохраненных в модуле правил и передаваемых анализатору. Система выполнена с возможностью вывода отчета о безопасности при помощи модуля отчета о безопасности.
В другом аспекте настоящего изобретения, целевой IR LLC является Промежуточным Представлением (IR) Низкоуровневой Виртуальной Машины (LLVM).
В еще одном аспекте настоящего изобретения, в анализаторе системы используется механизм нечеткой логики для уменьшения количества ложноположительных и ложноотрицательных результатов.
В другом аспекте настоящего изобретения предлагается способ анализа двоичных исполняемых файлов и исходного кода входной программы для обнаружения уязвимостей, недокументированных функций и других ошибок входной программы. Способ включает в себя идентификацию представления входной программы, чтобы определить, представлена ли входная программа в исходном коде или двоичном коде. Если входная программа представлена в исходном коде, то способ включает в себя обработку входной программы декомпилятором для представления входной программы в виде Промежуточного Представления (IR) Целевого Кода на Низкоуровневом Языке Программирования (LLC). С другой стороны, если входная программа представлена в исходном коде, то способ предусматривает обработку входной программы с применением стадии фронт-энда для определения представления входной программы и представление входной программы в виде целевого IR LLC. Способ дополнительно включает в себя анализ целевой IR LLC анализатором для обнаружения уязвимостей, недокументированных функций и ошибок входной программы с применением заранее определенных правил, сохраненных в модуле правил и переданных анализатору. Наконец, способ включает в себя вывод отчета о безопасности модулем отчета о безопасности.
КРАТКОЕ ОПИСАНИЕ ФИГУР
Для того чтобы изобретение можно было с легкостью понять, более подробное описание изобретения, кратко изложенного выше, будет представлено со ссылкой на конкретные варианты реализации изобретения, которые проиллюстрированы на прилагаемых чертежах. Необходимо понимать, что на указанных чертежах проиллюстрированы только типичные варианты реализации изобретения и, таким образом, они не должны рассматриваться как ограничивающие объем изобретения, тогда как аспекты изобретения будут дополнительно описаны и объяснены более конкретно и подробно со ссылкой на прилагаемые чертежи.
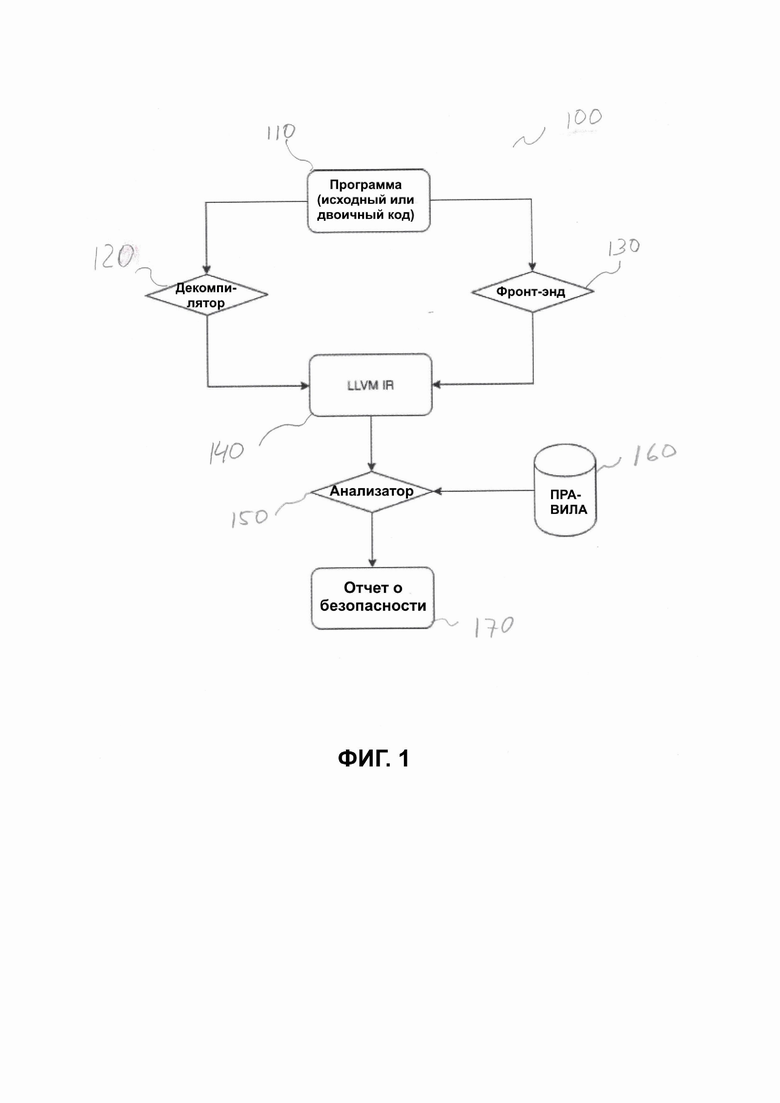
На Фиг. 1 представлена схема системы статического анализа двоичных исполняемых файлов и исходного кода в соответствии с вариантами реализации изобретения;
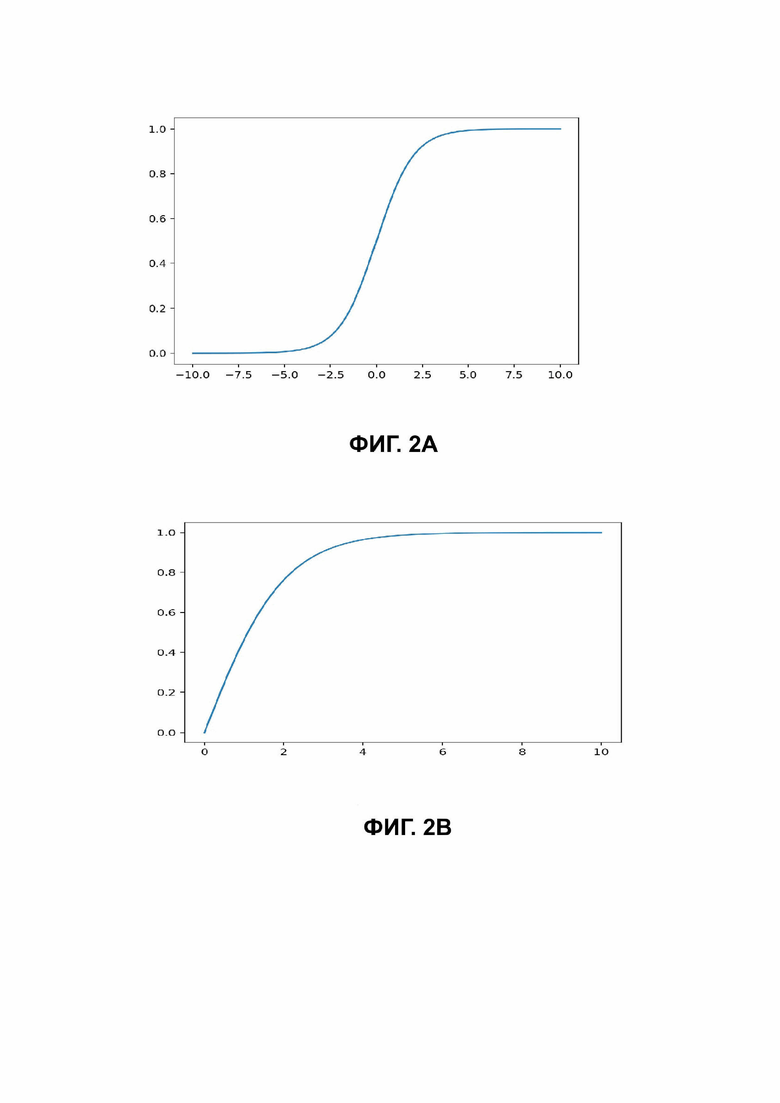
Фиг. 2A-2C иллюстрируют графики результатов работы анализатора системы статического анализа в соответствии с вариантами реализации изобретения;
Фиг. 3 иллюстрирует график отношения значений, полученных анализатором системы статического анализа, в соответствии с вариантами реализации изобретения; и
Фиг. 4 иллюстрирует блок-схему, на которой представлен способ обнаружения уязвимостей с применением системы статического анализа двоичных исполняемых файлов и исходного кода в соответствии с отказами согласно настоящему изобретению.
ПОДРОБНОЕ ОПИСАНИЕ ИЗОБРЕТЕНИЯ
Ссылка на «конкретный вариант реализации изобретения» или подобное выражение в описании означает, что конкретные признаки, структуры или характеристики, описанные в конкретных вариантах реализации изобретения, включены по меньшей мере в один конкретный вариант реализации настоящего изобретения. Следовательно, формулировка «в конкретном варианте реализации изобретения» или подобное выражение в данном описании не обязательно относится к одному и тому же конкретному варианту реализации изобретения.
В дальнейшем различные варианты реализации настоящего изобретения будут описаны более подробно со ссылкой на прилагаемые чертежи. Тем не менее, необходимо понимать, что настоящее изобретение может быть модифицировано специалистами в данной области техники в соответствии со следующим описанием для достижения превосходных результатов в соответствии с настоящим изобретением. Следовательно, нижеследующее описание необходимо рассматривать как всеобъемлющее и пояснительное описание, относящееся к настоящему изобретению, которое предназначено для специалистов в данной области техники и не предназначено для ограничения формулы настоящего изобретения.
Ссылка на «вариант реализации изобретения», «определенный вариант реализации изобретения» или подобное выражение в описании означает, что связанные с ним признаки, структуры или характеристики, описанные в варианте реализации изобретения, включены по меньшей мере в один вариант реализации настоящего изобретения. Следовательно, формулировки «в варианте реализации изобретения», «в определенном варианте реализации изобретения» или подобное выражение в данном описании не обязательно относится к одному и тому же конкретному варианту реализации изобретения.
Одной из важных стадий процесса разработки информационных систем является оценка защищенности компьютерной программы от несанкционированного доступа, использования, утечки данных, модификации или уничтожения в соответствии со стандартами конфиденциальности, целостности и доступности информации для пользователей. Определение свойств безопасности компьютерной программы обычно включает в себя декомпиляцию кода компьютерной программы и анализ кода на предмет наличия уязвимостей, которые нарушают целостность информационной безопасности компьютерной программы.
Существуют различные инструменты, позволяющие осуществить декомпиляцию компьютерного программного кода для выявления и устранения уязвимостей, которые создают потенциальные риски нарушения безопасности компьютерной программы, и недокументированных функций (т. е. непредусмотренной или недокументированной работы оборудования) компьютерной программы. Методы декомпиляции часто применяются в связи со статическим анализом компьютерной программы. Статический анализ представляет собой вид анализа, который позволяет выявить уязвимости в коде, не исполняя его.
Применялись различные методы, которые включают в себя декомпиляцию для синтаксического анализа исполняемого кода, идентификацию и рекурсивное моделирование потоков данных, идентификацию и рекурсивное моделирование управляющего потока и итеративное уточнение данных моделей для создания полной модели на уровне кода целевой программы.
Обычно декомпилятор представляет собой инструмент обратного проектирования, который преобразует машинный код в форматированный код на Высокоуровневом Языке Программирования (HLL), который играет важную роль в статическом анализе. Существуют различные декомпиляторы, такие как, например, декомпилятор, доступный онлайн, который охватывает 32-битные архитектуры. Цель декомпиляции состоит в том, чтобы создать легко читаемый Код на Высокоуровневом Языке Программирования (HLLC) без каких-либо модификаций или изменений в поведении программы, который может обеспечить анализ целевой программы. Напротив, компилятор представляет собой программу, которая переводит исходный код, написанный на HLL, целевом языке, в код на Низкоуровневом Языке Программирования (LLC), чтобы процессор мог считать и исполнить его. Поскольку декомпилятор обращает вспять процесс компиляции, он выполняет те же шаги преобразования, что и компилятор. Эти инструменты полезны, если исходный код программы недоступен, например, в случае анализа безопасности.
Кроме того, отладчик и дизассемблер могут использоваться в связи со статическим анализом для обратного проектирования. Этот инструмент показывает управляющий поток и поток данных компьютерной программы и дает представление о семантике и поведении программы. Однако, использование ассемблерного кода для статического анализа требует знания архитектуры целевой программы и стоит дорого; и таким образом использование декомпилятора с доступным кодом промежуточного представления может быть разумным выбором, чтобы сэкономить время на проведении анализа.
Методы оптимизации, такие как распространение и исключение, часто используются во время анализа потока данных. Распространение поддерживает возможность исключения кода, в ходе которого удаляются ненужные операторы или недоступные блоки. Методы распространения и исключения могут работать с кодом промежуточного представления Низкоуровневой Виртуальной Машины (LLVM) после двоичной трансляции. Более того, редактирующие методы анализа управляющего потока могут применяться для генерации исходного кода на высокоуровневом языке программирования. Сгенерированный в результате код затем сравнивают с образцом исходного кода для проверки правильности настройки окружения декомпилятора и выявления уязвимостей.
Указанные подходы часто приводят к большому количеству ложноположительных результатов и не предлагают функций для устранения обнаруженных уязвимостей и ошибок. Дополнительно, вопросы, связанные с анализом на предмет наличия уязвимостей в компьютерных программах, код которых частично или полностью недоступен, еще предстоит решить.
Устранение уязвимостей требует не только их обнаружения, но и правильного описания правил для использования или исправления обнаруженных уязвимостей. Известные решения не могут предложить функций, которые устраняли бы обнаруженные уязвимости и недокументированные функции и, например, позволяли бы перенастроить брандмауэр веб-приложений (WAF).
Таким образом, существует необходимость в системе анализа двоичных исполняемых файлов и исходного кода при отсутствии исходного кода, которая точно обнаруживала бы и идентифицировала уязвимости, а также предоставляла подробные рекомендации по устранению уязвимостей. Таким образом, необходимы другие улучшения, позволяющие выявлять и исправлять уязвимости в коде, например, без его выполнения.
В свете вышеуказанного ограничения существующих систем, в настоящем изобретении раскрыта система статического анализа двоичных исполняемых файлов и исходного кода. В системе статического анализа по настоящему изобретению используется код Промежуточного Представления (IR) LLVM в качестве промежуточного представления для декомпилированных двоичных файлов. Система может восстанавливать высокоуровневую семантику целевой программы. Во время декомпиляции проверяются функции системы, переменные и их типы, которые представляются в байт-коде LLVM. Далее полученный байт-код можно проанализировать с помощью любого метода статического анализа, который может быть запущен с байт-кодом LLVM. Кроме того, описанный в данном документе механизм нечеткой логики позволяет пользователю отфильтровывать и уменьшать количество ложноположительных и ложноотрицательных результатов при обнаружении уязвимостей и недокументированных функций.
Используя фронт-энд стадию компилятора по настоящему изобретению для LLVM, ориентированный на языки программирования, система может представлять любую программу на этом языке как IR LLVM. Например, используя фронт-энд clang, система может преобразовать любую валидную программу C/C++/Objective-C/Objective-C++ в байт-код LLVM. Соответственно, можно применять одни и те же методы статического анализа кода, такие как taint-анализ или символическое выполнение программы и т. п., к программам и программным компонентам независимо от того, доступен исходный код или недоступен, или даже анализировать взаимодействие между компонентами исходного кода, включая двоичные компоненты, такие как сторонние библиотеки, без доступа к исходному коду.
Система статического анализа по настоящему изобретению включает в себя декомпилятор, выполненный с возможностью восстановления представления исходной программы, включая высокоуровневые детали, такие как функции и их аргументы, переменные и их типы. Целью работы декомпилятора является создание представления исходной программы, написанного в IR LLVM, семантически аналогично представлению исходной программы, созданной фронт-энд блоками компилятора для целевых языков программирования.
Декомпилятор может включать в себя набор утилит, предназначенных для автоматической генерации сигнатур двоичных функций. Например, имея в своем распоряжении статическую библиотеку (.a, .lib) или объектный файл (.o, .obj) и список соответствующих файлов заголовков, декомпилятор создает список сигнатур двоичных функций этой библиотеки или объектного файла. Сгенерированный набор сигнатур двоичных функций используется во время декомпиляции для распознавания известных функций, таких как стандартные библиотечные функции и т. п.
Система статического анализа по настоящему изобретению способна правильно и точно восстанавливать границы функций. Система итеративно обрабатывает входной двоичный файл, отделяя фрагменты кода от данных. На стадии восстановления границ система накапливает информацию об управляющем потоке и потоке данных в том, что касается восстановленных функций, включая, например, точную информацию о возможном смещении указателя стека в каждой точке декомпилируемой программы.
Система статического анализа по настоящему изобретению дополнительно включает в себя восстановление высокоуровневой семантики исходной программы для точного восстановления переменных программы. Таким образом, система определяет и решает набор ограничений для типов объектов памяти программы. Система ограничений определяется на основе «естественной» семантики двоичных операций и информации известного типа, например, на основе известных сигнатур функций или восстановленной информации о времени выполнения.
При использовании системы статического анализа по настоящему изобретению для анализа исходного кода и двоичного кода целевой программы могут быть решены следующие задачи.
Может быть определено восстановление и/или определение графа управляющего потока целевой программы. В частности, может быть определен набор подпрограмм целевой программы, включая реализацию восстановления информации о позднем связывании и механизмы для обработки исключений. Граф управляющего потока целевой программы определяет принцип того, как программа должна выполняться во время ее исполнения.
Могут быть восстановлены свойства подпрограмм целевой программы, такие как наборы пунктов назначения для неявных табличных переходов, настройки смещения значения указателя стека для инструкций вызова подпрограмм и определение соглашений о вызове подпрограмм.
Кроме того, может быть определен набор объектов модели памяти программы. Иными словами, определения локальных и глобальных переменных целевой программы и их типов.
Система статического анализа по настоящему изобретению идентифицирует ошибки, которые указывают на уязвимости кода, на основе наборов сигнатур подпрограмм с использованием архивированных наборов программных модулей и определения вхождений подпрограмм целевой программы по наборам определенных сигнатур подпрограмм.
На Фиг. 1-4 проиллюстрированы подробные схемы вариантов реализации настоящего изобретения. В частности, Фиг. 1 иллюстрирует высокоуровневую схему вариантов выполнения системы статического анализа 100 двоичных исполняемых файлов и исходного кода. Входная программа 110, которая может быть двоичным исполняемым кодом или исходным кодом.
В зависимости от типа входной программы 110, входная программа 110 обрабатывается либо декомпилятором 120, либо стадией фронт-энда 130. Более конкретно, если входная программа 110 представлена в виде исходного кода, то для исходного кода входной программы 110 осуществляется процесс компиляции блоком декомпилятора 120 для проверки и представления в виде кода 140 Промежуточного Представления (IR) Низкоуровневой Виртуальной Машины (LLVM) в качестве промежуточного представления входной программы 110.
Процесс компиляции в общем известен в данной области техники и может включать в себя стадии фронт-энда (front-end), миддл-энда (middle-end) и бэк-энда (back-end). На стадии фронт-энда выполняется анализ кода, например, лексический, синтаксический, семантический и т. п., для генерации неоптимизированного промежуточного кода. Стадия миддл-энда включает в себя преобразование вывода фронт-энда в оптимизированный промежуточный код. На стадии бэк-энда оптимизированный промежуточный код транслируется в целевой код на низкоуровневом языке программирования, такой как LLVM.
С другой стороны, если входная программа 110 представлена в двоичном коде, то входная программа 110 обрабатывается блоком фронт-энда 130 для представления в виде кода IR LLVM 140. Блок фронт-энда 130 может быть системой фронт-энда clang. которая переводит любую валидную программу C/C++/Objective-C/Objective-C++ в целевой Код на Низкоуровневом Языке Программирования (LLC), например, байт-код LLVM. Блок фронт-энда 130 может выполнять два вида лингвистического анализа, чтобы сделать код машинно-независимым: синтаксический анализ и семантический анализ. В различных архитектурах, известных в данной области техники, могут применяться разные инструкции оператора и форматы данных.
В соответствии с вариантом реализации настоящего изобретения, во время декомпиляции и выполнения функций фронт-энда, как описано выше, переменные входной программы 110 проверяются и представляются в виде кода IR LLVM 140 как промежуточного представления входной программы 110. Таким образом, код IR LLVM 140 используется для представления, например, информации о потоке данных (информация о переменных) и управляющем потоке (путь выполнения входной программы).
Код IR LLVM 140 данных входной программы 110 в дальнейшем может быть проанализирован для определения уязвимостей безопасности или других известных и/или неизвестных факторов риска с использованием заранее определенных правил модуля данных 160.
Как представлено на Фиг. 1, в соответствии с вариантами реализации настоящего изобретения, код IR LLVM 140 анализируется анализатором 150. Таким образом, анализатор 150 выполнен с возможностью приема и анализа кода IR LLVM 140 для обнаружения уязвимостей и недокументированных функций, на основе заранее определенных правил, с помощью, например, taint-анализа (Taint Analysis, анализ потока пользовательского ввода в коде приложения, чтобы определить, может ли ввод непредвиденных данных повлиять на выполнение программы злонамеренным образом), методы символьной интерпретации (символическое выполнение) и т. п.
В соответствии с вариантом реализации настоящего изобретения, в анализаторе 150 применяются алгоритмы метода статического анализа Static Application Security Testing (статическое тестирование безопасности приложений, SAST) к коду IR LLVM 140, такие как лексический, синтаксический, семантический анализ, taint-анализ, распространение констант, распространение типа, анализ синонимов и анализ графа управляющего потока для определения модели расширенного кода. Моделями расширенного кода могут быть любые из следующих моделей, известных в данной области техники, такие как исходный текст программы, поток токенов, Абстрактное Синтаксическое Дерево (AST), трехадресный код, граф управляющего потока, стандартный или собственный байтовый код и т. п.
Более конкретно, методы лексического, синтаксического и семантического анализа могут применяться для создания внутреннего представления, такого как Абстрактное Cинтаксическое Дерево (AST). В ходе лексического анализа текст программы разбивается на токены, то есть мельчайшие значимые элементы, и генерирует поток токенов. В ходе синтаксического анализа проверяется, является ли этот поток токенов допустимым с точки зрения синтаксиса языка программирования. В ходе семантического анализа проверяется выполнение более сложных условий, таких как соответствие типов данных в операторах присваивания. Полученное AST можно использовать в качестве внутреннего представления или источника для построения других моделей путем преобразования в трехадресный код, чтобы затем построить граф управляющего потока. Граф управляющего потока является основной моделью для алгоритмов SAST.
В ходе анализа потока данных, в каждой точке программы идентифицируется информация, которая может храниться в переменных, такая как тип переменной, постоянное значение и другие переменные, указывающие на эти данные. Задача анализа потока данных зависит от того, какую информацию необходимо идентифицировать.
Таблица 1
Задача анализа потока данных
Постоянное значение
Задачи анализа потока данных требуют экспоненциально нарастающих затрат времени, причем анализатор (т. е. анализатор 150) осуществляет определенную оптимизацию и делает допущения. Из-за сложности задач анализа потока данных, как правило, анализаторы проводят анализ медленно, он требует большого потребления ресурсов и приводит к ложноположительным результатам. Однако, анализ межпроцедурного потока данных является обязательным для выявления наиболее критических уязвимостей. Taint-анализ применяется для отслеживания меток, присвоенных данным в определенных точках программы. Taint-анализ используется анализатором 150 для обеспечения информационной безопасности и является методом, применяемым для обнаружения уязвимостей, связанных с утечками данных (запись паролей в журналы событий, небезопасная передача данных) и инъекциями данных, такими как SQL-инъекции, межсайтовые сценарии, открытые перенаправления, подделка пути к файлу и т. п.
Как проиллюстрировано на Фиг. 1, модуль правил 160 предоставляет специфическую информацию о программе, такую как правила поиска уязвимостей, анализатору 150. Правила поиска уязвимостей могут быть сформулированы в терминах модели кода и могут описывать, какие индикаторы в коде IR LLVM 140 могут свидетельствовать об уязвимости и/или недокументированной функции. Правила будут варьироваться в зависимости от входной программы 110, например, от языка, на котором она написана, и ее функционала.
В соответствии с вариантом реализации настоящего изобретения, анализатор 150 использует механизм нечеткой логики для минимизации количества как ложноположительных, так и ложноотрицательных результатов (пропущенных уязвимостей и недокументированных функций). В частности, в механизме нечеткой логики используется нечеткий набор пар (P, m), где P - набор положительных значений, каждому из которых присвоен 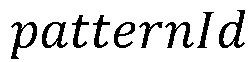 или просто набор , а
или просто набор , а 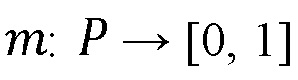 - функция принадлежности, придающая достоверность.
- функция принадлежности, придающая достоверность.
В соответствии с вариантами реализации изобретения, механизм нечеткой логики имеет две функции принадлежности: фоновую (на стороне разработчика) и внешнюю (на стороне клиента).
Фоновая сторона работает как часть процесса разработки. Она накапливает все данные, которые определены ниже, и принимает решения, которые отправляются вместе с обновлениями системы всем клиентам. Для этой части механизма набор P будет набором patternId.
Механизм нечеткой логики учитывает следующие показатели:
• Множество клиентов, подавших жалобу, по проектам;
• Количество клиентов, подавших жалобу, по проектам;
• Множество проектов, из которых поступали жалобы;
• Количество проектов;
• Количество жалоб.
Для реализации этих требований можно применить следующую формулу энтропии (I):
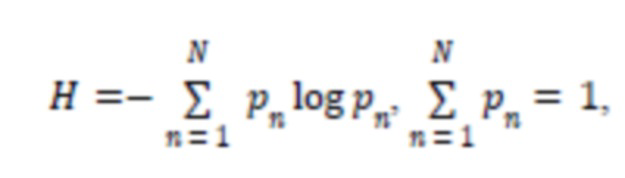
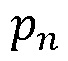 - процент ошибок среди всех ошибок, допущенных для всех проектов (относительно одного шаблона), это единица правила отчета. При применении приведенной выше формулы энтропии (I) для учета множества клиентов результат будет следующим:
- процент ошибок среди всех ошибок, допущенных для всех проектов (относительно одного шаблона), это единица правила отчета. При применении приведенной выше формулы энтропии (I) для учета множества клиентов результат будет следующим:
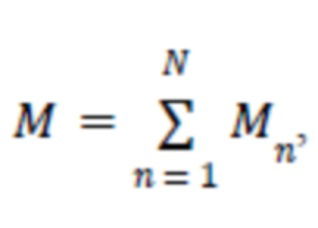
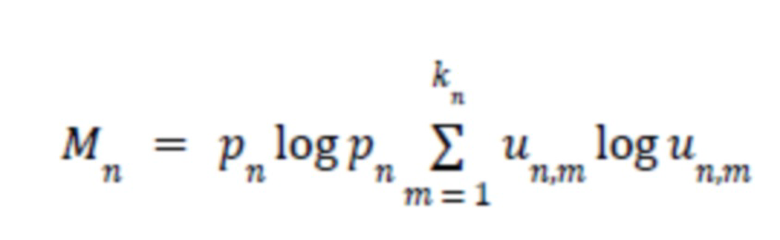
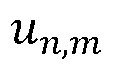 - это количество раз, когда m-й пользователь в n-м проекте жаловался на шаблон, деленное на общее количество жалоб в проекте от всего множества пользователей,
- это количество раз, когда m-й пользователь в n-м проекте жаловался на шаблон, деленное на общее количество жалоб в проекте от всего множества пользователей,
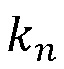 - общее количество пользователей, принявших участие в обзорах n-го проекта. Если только один пользователь пожаловался на шаблон в проекте, то коэффициент перед термином
- общее количество пользователей, принявших участие в обзорах n-го проекта. Если только один пользователь пожаловался на шаблон в проекте, то коэффициент перед термином 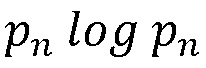 обнуляется, и применяется следующая формула:
обнуляется, и применяется следующая формула:
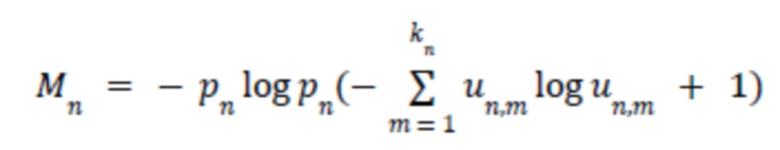
Энтропия уместна, поскольку она максимальна в ситуациях, когда или распределены равномерно. Причем, если их общее количество растет, то увеличивается и максимум.
Например,
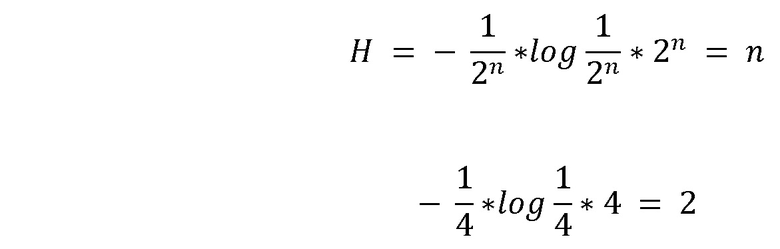
Если количество жалоб не принимается во внимание, то рассматривается следующая функция 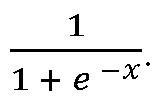 . Графики, иллюстрирующие результаты вышеуказанных вычислений, представлены на Фиг. 2A-2B.
. Графики, иллюстрирующие результаты вышеуказанных вычислений, представлены на Фиг. 2A-2B.
Если рассматривается 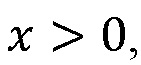 умножить это на два и вычесть единицу, то верно следующее
умножить это на два и вычесть единицу, то верно следующее 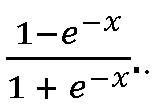 Тогда формула будет иметь такой вид:
Тогда формула будет иметь такой вид:
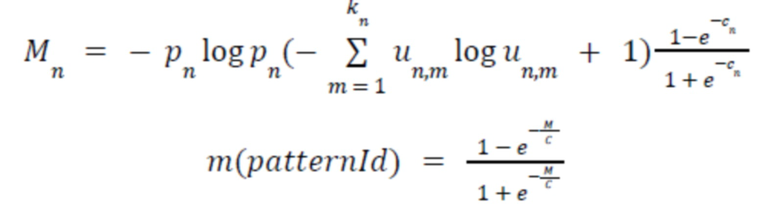
где 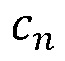 - количество отчетов по проекту и
- количество отчетов по проекту и 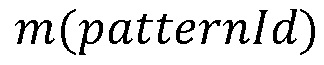 - функция принадлежности.
- функция принадлежности.
Например, если количество проектов равно 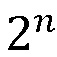 , а количество разных пользователей в проекте равно
, а количество разных пользователей в проекте равно 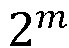 , и все распределения являются единообразными, таким образом, что максимальное значение показателя будет считаться достаточно большим, чтобы последний фактор был приблизительно равен 1. Формула будет иметь следующий вид:
, и все распределения являются единообразными, таким образом, что максимальное значение показателя будет считаться достаточно большим, чтобы последний фактор был приблизительно равен 1. Формула будет иметь следующий вид:
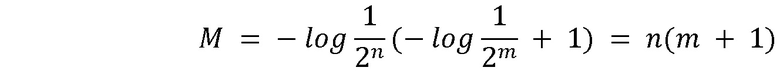
Таким образом, например, при 16 проектах и 4 разных пользователях на один проект, а также при равномерном распределении получается значение (и достаточно большое количество жалоб):

Это максимальное значение, которое может быть достигнуто с 16 проектами и 64 пользователями.
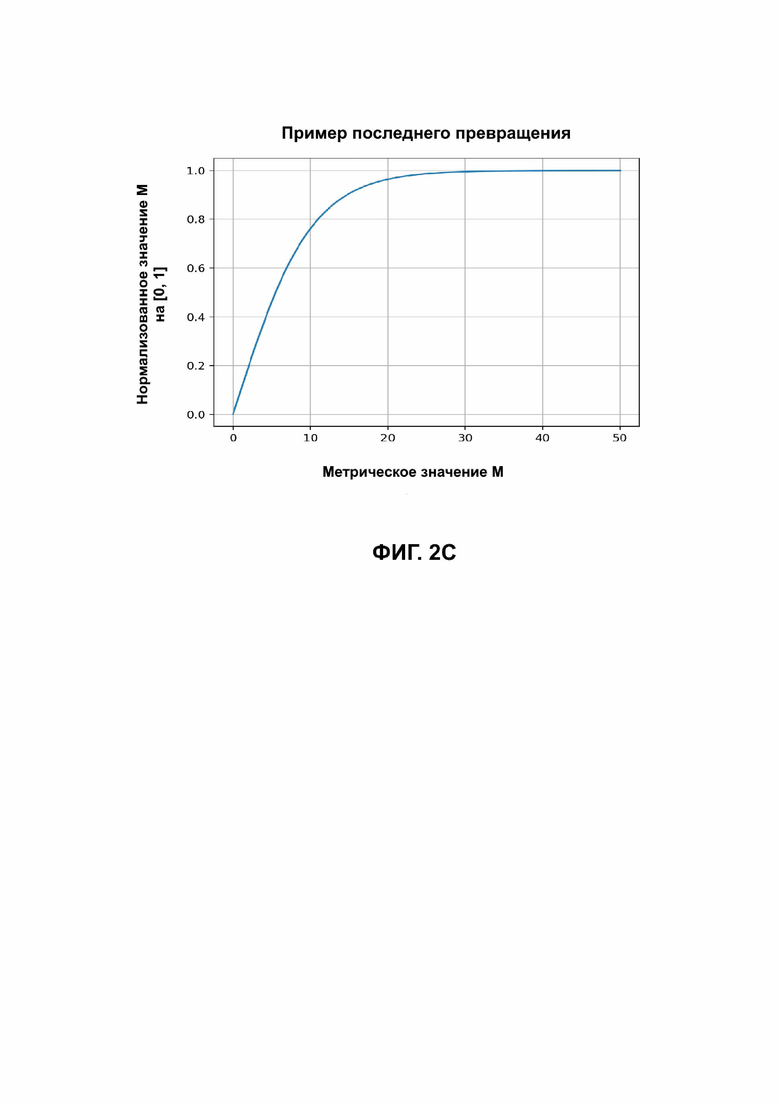
Чтобы отобразить это значение в сегменте 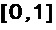 , сигмоидальная кривая может использоваться с аргументом, деленным, например, на 5, таким образом, что, начиная примерно с 12, мы получаем достоверность, равную 1, как представлено на графике Фиг. 2С.
, сигмоидальная кривая может использоваться с аргументом, деленным, например, на 5, таким образом, что, начиная примерно с 12, мы получаем достоверность, равную 1, как представлено на графике Фиг. 2С.
Внешняя сторона (клиентская сторона механизма) накапливает все данные, которые определены ниже, и принимает решения, которые отправляются вместе с обновлениями системы всем клиентам. Для этой части механизма набор P будет установлен равным patternId.
Было определено, что количество положительных результатов в проекте для определенной уязвимости (шаблона), которое, скорее всего, будет ложным, значительно выше, чем у уязвимости с меньшим количеством положительных результатов. Для этой части механизма набор P будет набором положительных результатов для каждого результата анализа. Например, количество случаев обнаружения уязвимости «слабого алгоритма хеширования» в среднем на 200 % выше, чем для других уязвимостей. В такой ситуации анализатору 150 сложно правильно определить уязвимость. Этот триггер будет действителен только при работе с конфиденциальными данными, которые напрямую зависят от контекста программы и не могут быть на 100 % определены анализатором 150. Разумно предположить, что эта уязвимость (шаблон) будет иметь небольшой уровень достоверности.
Было определено, что можно определить зависимость достоверности от числа запускаемых шаблонов с помощью уравнения экспоненциальной регрессии:

Где a равно:

И b равно:
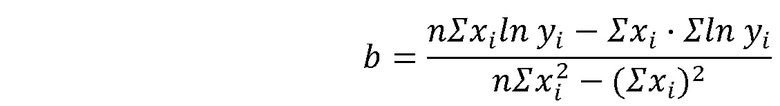
Где x - достоверность, y - отношение количества положительных результатов в шаблоне к общему количеству срабатываний, n - количество сработавших шаблонов.
Чтобы применить данную формулу, все положительные результаты должны быть нормализованы. Например, анализ 138267 строк кода PHP обнаружил 195 положительных результатов. Среди которых было 100 ответов со средней критичностью (серьезность = 2), в которых отработано 7 шаблонов:
Таблица 2
PatternId и количество положительных результатов
Теперь можно определить отношение количества триггеров в шаблоне к общему количеству триггеров. Такой подход будет универсальным для любого количества положительных результатов в проекте, например, 10000 или 100.
Например, учитывая это отношение:
Таблица 3
Значения отношения PatternId
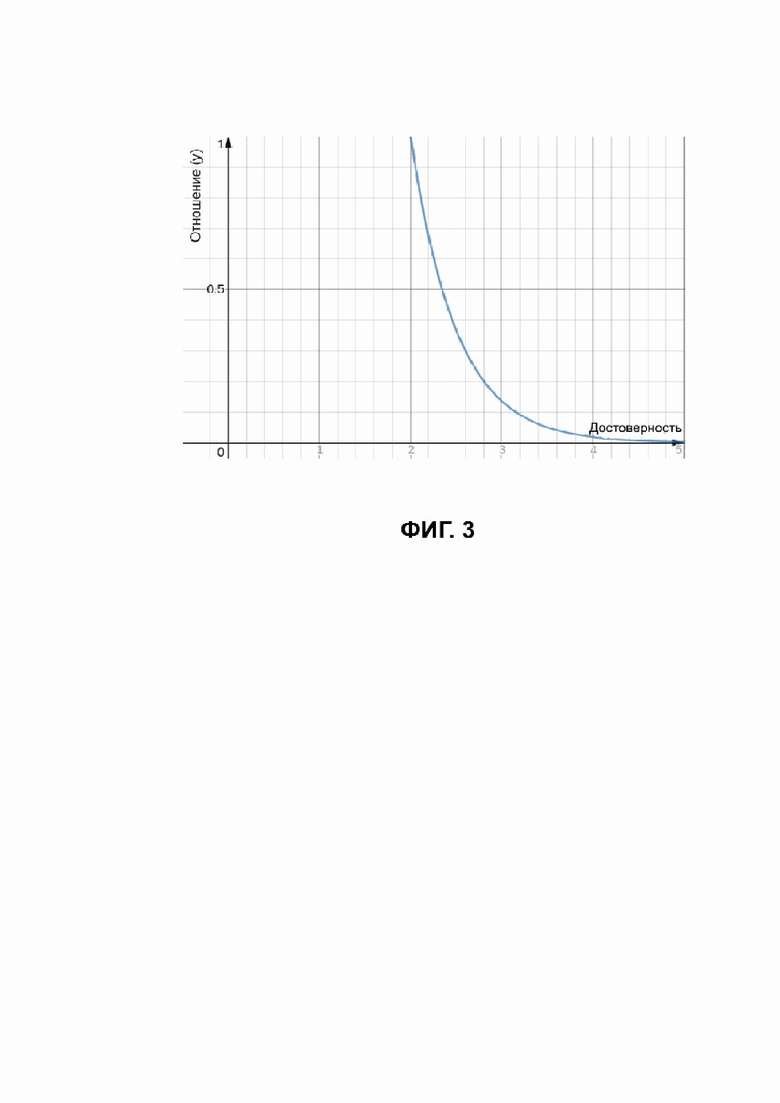
Найденные значения отношения определяют значения y в формуле, представленной на графике Фиг. 3.
Ключевые показатели эффективности, отслеживаемые и анализируемые анализатором 150, включают в себя количество как ложноположительных результатов, так и ложноотрицательных результатов. Следовательно, механизм нечеткой логики, описанный в предыдущих абзацах, позволяет пользователю фильтровать и сокращать количество ложноположительных и ложноотрицательных результатов при обнаружении уязвимостей и недокументированных функций.
Как дополнительно проиллюстрировано на Фиг. 1, в соответствии с вариантами реализации настоящего изобретения, система статического анализа 100 включает в себя модуль отчета о безопасности 170. Модуль отчета о безопасности может, среди прочего, позволить пользователю: (a) выделять обнаруженные уязвимости и недокументированные функции даже при анализе запускаемого файла; (b) сравнивать результаты тестирования в рамках одного проекта или разных групп проектов, чтобы отслеживать ход устранения уязвимости или ее возникновения (могут быть приняты во внимание изменения, характерные для процесса написания кода); (c) предоставлять рекомендации для групп кибербезопасности и/или разработчиков, такие как (i) подробные отчеты об уязвимостях и недокументированных функциях, относящиеся к конкретным разработкам, с акцентом на уязвимые фрагменты кода, а также рекомендации по изменению кода для устранения таких уязвимостей, и/или (ii) отчеты по кибербезопасности с подробными рекомендациями по устранению выявленных уязвимостей и недокументированных функций, включая описание методов эксплуатации (с подробными рекомендациями по настройке брандмауэра веб-приложений (WAF) для блокировки и предотвращения любой возможности использования уязвимостей во время исправления кода; (iii) экспортировать отчеты в формате переносимого документа (PDF), включая отчеты, созданные в соответствии с классификацией уязвимостей, принятой в PCI DSS, OWASP Top 2017, OWASP Mobile Top 10 2016, HIPAA или CWE/SANS Top 25; и (iv) получать обновления статуса проверки по электронной почте.
Дополнительно, механизм нечеткой логики может применяться модулем отчета о безопасности 170 для отображения наиболее вероятных ошибок во входной программе 110, например уязвимостей и недокументированных функций.
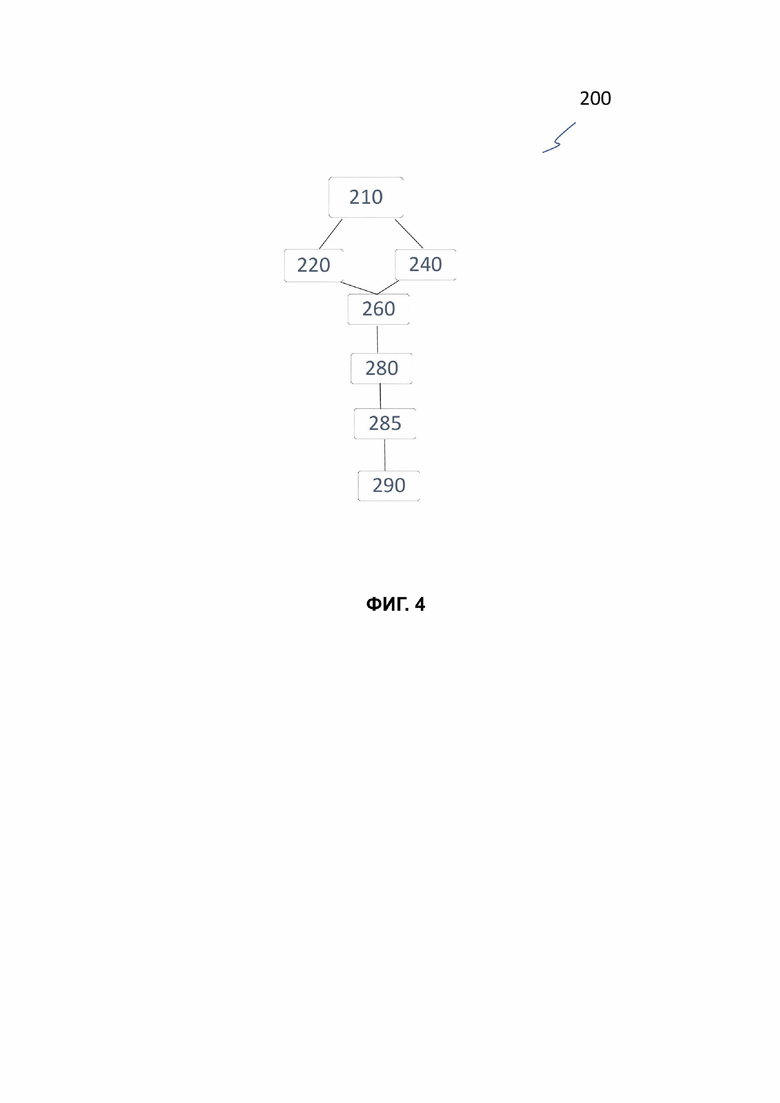
Фиг. 4 представляет собой блок-схему, иллюстрирующую способ обнаружения уязвимостей 200 cогласно настоящему изобретению с использованием системы статического анализа 100 двоичных исполняемых файлов и исходного кода в соответствии с отказами. Способ 200 включает в себя идентификацию представления входной программы 110 (исходного кода или двоичного кода), показанную в блоке 210.
Если входная программа 110 представлена в исходном коде, то декомпилятор 120 системы статического анализа 100 обрабатывает входную программу 110 (как показано в блоке 220) для генерации кода IR LLVM 140, показанного в блоке 260, в качестве промежуточного представления входной программы 110.
В качестве альтернативы, если входная программа 110 представлена в виде двоичного кода, фронт-энд 130 системы 100 статического анализа обрабатывает входную программу 110 (как показано в блоке 240) для генерации кода IR LLVM 140, показанного в блоке 260, в качестве промежуточного представления входной программы 110.
Блок 280 анализирует код IR LLVM 140 с помощью анализатора 150 для обнаружения уязвимостей и недокументированных функций, используя заранее определенные правила модуля 160, с применением, например, taint-анализа, методов символьной интерпретации и т. п.
В соответствии с вариантами реализации настоящего изобретения, в блоке 285 механизм нечеткой логики применяется к результатам блока 280, чтобы минимизировать количество ложноположительных и ложноотрицательных результатов.
Блок 290 генерирует отчет о безопасности с использованием модуля отчета о безопасности 170. Отчет о безопасности может включать в себя: (a) обнаруженные уязвимости и недокументированные функции, даже при анализе исполняемого файла; (b) результаты тестирования в рамках одного проекта или разных групп проектов для отслеживания прогресса устранения или возникновения уязвимости; (c) рекомендации для групп кибербезопасности и/или разработчиков, такие как (i) подробные отчеты об уязвимостях и недокументированных функциях, относящиеся к конкретным разработкам, с акцентом на уязвимые фрагменты кода, а также рекомендации по изменению кода для устранения таких уязвимостей, и/или (ii) отчеты по кибербезопасности с подробными рекомендациями по устранению выявленных уязвимостей и недокументированных функций, включая описание способов эксплуатации (с подробными рекомендациями по настройке брандмауэра веб-приложений (WAF) для блокировки и предотвращения любой возможности использования уязвимостей во время исправлений кода); (iii) экспортировать отчеты в формате переносимого документа (PDF), включая отчеты, созданные в соответствии с классификацией уязвимостей, принятой в PCI DSS, OWASP Top 2017, OWASP Mobile Top 10 2016, HIPAA или CWE/SANS Top 25; и (iv) получать обновления статуса проверки по электронной почте.
Кроме того, механизм нечеткой логики может использоваться модулем отчета о безопасности 170 для включения в отчет о безопасности наиболее вероятных ошибок во входной программе 110, например уязвимостей и недокументированных функций.
В соответствии с вариантом реализации настоящего изобретения, система статического анализа 100 может применяться к исходным кодам, написанным на более чем 30 языках программирования, таких как ABAP, Apex, ASP.NET, COBOL, С#, C/C++, Objective-C, Delphi, Dart, Go, Groovy, HTML5, Java, Java для Android, JavaScript, JSP, Kotlin, Pascal, Perl, PHP, PL/SQL, T/SQL, Python, Ruby, Rust, Scala, Solidity, Swift, TypeScript, VBA, VB.NET, VBScript, Visual Basic 6.0, Vyper и 1С.
Вышеизложенное подробное описание вариантов реализации изобретения предназначено для более четкого описания признаков и сущности настоящего изобретения. Вышеприведенное описание каждого варианта реализации изобретения не предназначено для ограничения объема настоящего изобретения. Все виды модификаций, внесенных в приведенные выше варианты реализации изобретения и эквивалентные конфигурации, находятся в пределах охраняемого правом объема настоящего изобретения. Следовательно, объем настоящего изобретения должен быть истолкован наиболее широко в соответствии с прилагаемой формулой изобретения, в связи с подробным описанием, и должен включать в себя все возможные эквивалентные варианты и эквивалентные устройства.
Настоящее изобретение может быть системой, способом и/или компьютерным программным продуктом. Компьютерный программный продукт может включать в себя машиночитаемый носитель данных (или носители), содержащий машиночитаемые программные инструкции на нем, чтобы обеспечить выполнение процессором аспектов настоящего изобретения.
Машиночитаемый носитель данных может быть материальным устройством, на котором можно сохранять и хранить инструкции для использования устройством, на котором инструкции выполняются. Машиночитаемый носитель данных может быть, например, но не ограничиваясь этим, электронным запоминающим устройством, магнитным запоминающим устройством, оптическим запоминающим устройством, электромагнитным запоминающим устройством, полупроводниковым запоминающим устройством или любой подходящей комбинацией вышеперечисленного. Неограничивающий перечень более конкретных примеров машиночитаемого носителя данных включает в себя следующее: портативная компьютерная дискета, жесткий диск, оперативное запоминающее устройство (RAM), постоянное запоминающее устройство (ROM), стираемое программируемое постоянное запоминающее устройство (EPROM или флэш-память), статическое оперативное запоминающее устройство (SRAM), постоянное запоминающее устройство в форме портативного компакт-диска (CD-ROM), цифровой универсальный диск (DVD), карта памяти, дискета, механически закодированное устройство, такое как перфокарты или выпуклые структуры в канавке с записанными на них инструкциями, и любая подходящая комбинация вышеперечисленного. Машиночитаемый носитель данных, как используется в данном документе, не должен рассматриваться как короткоживущие сигналы сами по себе, такие как радиоволны или другие свободно распространяющиеся электромагнитные волны, электромагнитные волны, распространяющиеся по волноводу или в другой среде передачи (например, световые импульсы, проходящие по оптоволоконному кабелю) или электрические сигналы, передаваемые по проводам.
Машиночитаемые программные инструкции, описанные в данном документе, могут быть загружены в соответствующие вычислительные/обрабатывающие устройства с машиночитаемого носителя данных или на внешний компьютер или внешнее запоминающее устройство через сеть, например Интернет, локальную вычислительную сеть, территориально глобальную вычислительную сеть и/или беспроводную сеть. Сеть может включать в себя медные кабели передачи, оптические волокна передачи, беспроводную передачу, маршрутизаторы, межсетевые экраны, коммутаторы, шлюзовые компьютеры и/или пограничные серверы. Карта сетевого адаптера или сетевой интерфейс в каждом вычислительном/обрабатывающем устройстве принимает машиночитаемые программные инструкции из сети и пересылает машиночитаемые программные инструкции для хранения на машиночитаемом носителе данных в соответствующем вычислительном/обрабатывающем устройстве.
Машиночитаемые программные инструкции для выполнения операций по настоящему изобретению могут быть инструкциями в ассемблерном коде, инструкциями архитектуры набора команд (ISA), машинными инструкциями, машинно-зависимыми инструкциями, микрокодом, инструкциями встроенного программного обеспечения, данными установки состояния или любым из исходного кода или объектного кода, написанного на любой комбинации одного или большего количества языков программирования, включая объектно-ориентированный язык программирования, такой как Smalltalk, C++ и т. п., и обычные процедурные языки программирования, такие как язык программирования "C" или подобные языки программирования. Машиночитаемые программные инструкции могут выполняться полностью на компьютере пользователя, частично на компьютере пользователя, как автономный пакет программного обеспечения, частично на компьютере пользователя и частично на удаленном компьютере или полностью на удаленном компьютере или сервере. В последнем сценарии удаленный компьютер может быть подключен к компьютеру пользователя через сеть любого типа, включая локальную вычислительную сеть (LAN) или территориально глобальную вычислительную сеть (WAN), либо соединение может быть установлено с внешним компьютером (например, через Интернет с помощью Интернет-провайдера). В некоторых вариантах реализации изобретения, электронные схемы, включая, например, программируемые логические схемы, программируемые пользователем матрицы логических элементов (FPGA) или программируемые логические матрицы (PLA), могут выполнять машиночитаемые программные инструкции, используя информацию о состоянии машиночитаемых программных инструкций для персонализации электронной схемы для реализации аспектов настоящего изобретения.
Аспекты настоящего изобретения описаны в данном документе со ссылкой на иллюстрации в виде структурных схем и/или блок-схем способов, устройств (систем) и компьютерных программных продуктов в соответствии с вариантами реализации настоящего изобретения. Необходимо понимать, что каждый блок иллюстраций в виде структурных схем и/или блок-схем, а также комбинации блоков в иллюстрациях в форме структурных схем и/или блок-схем могут быть реализованы с помощью машиночитаемых программных инструкций.
Указанные машиночитаемые программные инструкции могут быть переданы процессору универсального компьютера, специального компьютера или другого программируемого устройства обработки данных для создания движка, таким образом, что инструкции, которые выполняются с помощью процессора компьютера или другого программируемого устройства обработки данных, создают средства для реализации функций/действий, указанных в блок-схеме и/или в блоке или блоках структурной схемы. Дополнительно, такие машиночитаемые программные инструкции могут храниться на машиночитаемом носителе данных, который может давать указания компьютеру, программируемому устройству обработки данных и/или другим устройствам функционировать определенным образом, таким образом, что машиночитаемый носитель данных, содержащий инструкции, хранящиеся на нем содержит готовое изделие, включая инструкции, которые обеспечивают реализацию аспектов функции/действия, указанного в блок-схеме и/или блоке или блоках структурной схемы.
Кроме того, машиночитаемые программные инструкции могут быть загружены в компьютер, другое программируемое устройство обработки данных или иное устройство, чтобы обеспечить выполнение ряда рабочих шагов на компьютере, другом программируемом устройстве или ином устройстве для выполнения реализуемого на компьютере способа, таким образом, что инструкции, которые выполняются на компьютере, другом программируемом устройстве или ином устройстве, реализуют функции/действия, указанные в блок-схеме и/или блоке или блоках структурной схемы.
Блок-схема и структурные схемы на фигурах иллюстрируют архитектуру, функциональные возможности и работу возможных вариантов выполнения систем, способов и компьютерных программных продуктов в соответствии с различными вариантами реализации настоящего изобретения. В этом отношении каждый блок в блок-схеме или структурных схемах может представлять модуль, сегмент или часть инструкций, которые содержат одну или большее количество исполняемых инструкций для реализации указанной(-ых) логической(-их) функции(-й). В некоторых альтернативных вариантах реализации изобретения, функции, отмеченные в блоке, могут выполняться не в том порядке, который указан на фигурах. Например, два блока, показанные последовательно, фактически могут выполняться по существу одновременно, или блоки могут иногда выполняться в обратном порядке, в зависимости от задействованных функций. Кроме того, будет отмечено, что каждый блок структурных схем и/или иллюстрация блок-схемы, а также комбинации блоков в структурных схемах и/или иллюстрация блок-схемы могут быть реализованы аппаратными системами специального назначения, которые выполняют указанные функции или действия или могут выполняться комбинациями специального оборудования и компьютерных инструкций.
Используемая в данном документе терминология предназначена только для описания конкретных вариантов реализации изобретения и не предназначена для ограничения настоящего изобретения. Используемые в данном документе формы единственного числа дополнительно включают в себя формы множественного числа, если в тексте явно не указано противоположное. Кроме того, необходимо понимать, что термины «содержит» и/или «содержащий», когда они используются в данном описании, определяют наличие заявленных признаков, целых чисел, стадий, операций, элементов и/или компонентов, но не исключают наличия или добавления одного или большего количества других функций, целых чисел, стадий, операций, элементов, компонентов и/или их групп.
Соответствующие структуры, материалы, действия и эквиваленты всех средств или элементов «ступень плюс функция» в приведенной ниже формуле изобретения включают в себя любую структуру, материал или действие для выполнения функции в комбинации с другими заявленными элементами, как конкретно заявлено. Описание настоящего изобретения было представлено в целях иллюстрации и описания, но не должно быть истолковано как исчерпывающее или ограничивающее изобретение описанной формой. Для специалистов в данной области техники будут очевидны многие модификации и вариации, не выходящие за рамки объема и сущности изобретения. Вариант реализации изобретения был выбран и описан для лучшего объяснения принципов изобретения и практического применения, а также для того, чтобы дать возможность другим обычным специалистам в данной области техники понять изобретение для различных вариантов реализации изобретения с различными модификациями, которые подходят для конкретного предполагаемого использования.
Изобретение относится к области вычислительной техники для анализа двоичных исполняемых файлов и исходного кода с использованием нечеткой логики. Технический результат заключается в снижении количества ложноположительных и ложноотрицательных результатов и обеспечении функций для устранения обнаруженных уязвимостей и ошибок. Технический результат достигается за счет системы, которая содержит декомпилятор, выполненный с возможностью приема исходного кода входной программы и представления входной программы в промежуточном представлении (IR) целевого кода на низкоуровневом языке программирования (LLC), а также фронт-энд, выполненный с возможностью получения представления двоичного кода входной программы и представления входной программы в виде целевого IR LLC. Система дополнительно содержит анализатор, выполненный с возможностью приема целевого IR LLC и анализа целевого IR LLC для обнаружения уязвимостей, недокументированных функций и ошибок входной программы с использованием заранее определенных правил, сохраненных в модуле правил и передаваемых анализатору. В анализаторе используется механизм нечеткой логики для получения по существу более точных результатов. 2 н. и 12 з.п. ф-лы, 6 ил., 3 табл.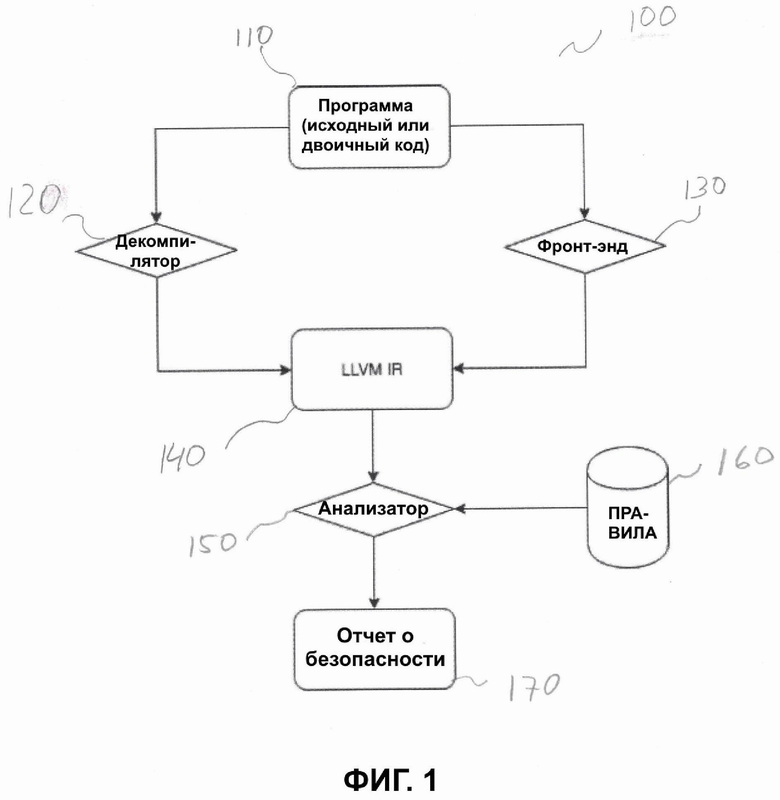
1. Реализуемая на компьютере система статического анализа двоичных исполняемых файлов и исходного кода для обнаружения уязвимостей, недокументированных функций и других ошибок входной программы, включающая в себя:
декомпилятор, работающий на процессоре, выполненный с возможностью приема исходного кода входной программы и представления входной программы в виде промежуточного представления (IR) целевого кода на низкоуровневом языке программирования (LLC);
фронт-энд, работающий на процессоре, выполненный с возможностью приема представления двоичного кода входной программы и представления входной программы в виде целевого IR LLC;
анализатор, настроенный для приема целевого IR LLC и анализа целевого IR LLC для обнаружения уязвимостей, недокументированных функций и ошибок входной программы с использованием заранее определенных правил, хранящихся в модуле правил и передаваемых анализатору, причем анализатор использует механизм нечеткой логики для уменьшения числа ложноположительных и ложноотрицательных результатов; и
модуль отчета о безопасности, выполненный с возможностью вывода отчета о безопасности, в котором отражены уязвимости, недокументированные функции и ошибки входной программы, обнаруженные анализатором.
2. Система по п. 1, отличающаяся тем, что целевой IR LLC является Промежуточным Представлением (IR) Низкоуровневой Виртуальной Машины (LLVM).
3. Система по п. 1, отличающаяся тем, что механизм нечеткой логики использует нечеткий набор пар (P, m), где P - набор положительных значений, всем из которых присвоен patternID, а m: P → [0, 1] - функция принадлежности, определяющая достоверность.
4. Система по п. 1, отличающаяся тем, что механизм нечеткой логики рассматривает множество показателей, причем множество показателей включает в себя:
• множество клиентов, подавших жалобу, по каждому проекту;
• количество клиентов, подавших жалобу, по каждому проекту;
• множество проектов, из которых поступали жалобы;
• количество проектов; и
• количество жалоб.
5. Система по п. 4, отличающаяся тем, что механизм нечеткой логики применяет следующую формулу (I):
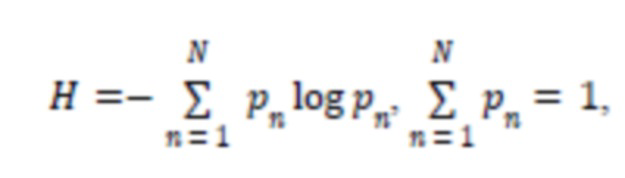 (I)
(I)
где 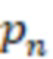 - процент ошибок среди всех ошибок, сделанных для всех проектов относительно одного шаблона.
- процент ошибок среди всех ошибок, сделанных для всех проектов относительно одного шаблона.
6. Система по п. 1, отличающаяся тем, что анализатор выполнен с возможностью использования taint-анализа и/или анализа символьной интерпретации.
7. Система по п. 1, отличающаяся тем, что отчет о безопасности содержит: (a) обнаруженные уязвимости и недокументированные функции; (b) результаты в рамках одного проекта или разных групп проектов для отслеживания прогресса устранения или возникновения уязвимости; (c) рекомендации для групп кибербезопасности и/или разработчиков; и (d) рекомендации по настройке брандмауэра веб-приложений (WAF) для блокировки и предотвращения возможности использования уязвимостей во время исправлений входной программы.
8. Реализуемый на компьютере способ анализа двоичных исполняемых файлов и исходного кода входной программы для обнаружения уязвимостей, недокументированных функций и других ошибок входной программы, включающий в себя:
идентификацию представления входной программы, чтобы определить, представлена входная программа в исходном коде или двоичном коде;
если входная программа представлена в исходном коде, обработку входной программы декомпилятором для представления входной программы в промежуточном представлении (IR) целевого кода на низкоуровневом языке программирования (LLC);
если входная программа представлена в исходном коде, обработка входной программы фронт-эндом для представления входной программы и представления входной программы в целевой IR LLC;
анализ анализатором целевой IR LLC для обнаружения уязвимостей, недокументированных функций и ошибок входной программы с использованием заранее определенных правил, сохраненных в модуле правил и передаваемых анализатору, причем анализатор использует механизм нечеткой логики для уменьшения количества ложноположительных и ложноотрицательных результатов; и
вывод отчета о безопасности, в котором отражены уязвимости, недокументированные функции и ошибки входной программы, обнаруженные анализатором, модулем отчета о безопасности.
9. Реализуемый на компьютере способ по п. 8, отличающийся тем, что целевой IR LLC является Промежуточным Представлением (IR) Низкоуровневой Виртуальной Машины (LLVM).
10. Реализуемый на компьютере способ по п. 8, отличающийся тем, что механизм нечеткой логики использует нечеткий набор пар (P, m), где P - набор положительных значений, всем из которых присвоен patternID, а m: P → [0, 1] - функция принадлежности, определяющая достоверность.
11. Реализуемый на компьютере способ по п. 8, отличающийся тем, что механизм нечеткой логики рассматривает множество показателей, причем множество показателей включает в себя:
• множество клиентов, подавших жалобу, по каждому проекту;
• количество клиентов, подавших жалобу по каждому проекту;
• множество проектов, из которых поступали жалобы;
• количество проектов; и
• количество жалоб.
12. Реализуемый на компьютере способ по п. 11, отличающийся тем, что в механизме нечеткой логики используется следующая формула (I):
(I)
где - процент ошибок среди всех ошибок, сделанных для всех проектов относительно одного шаблона.
13. Реализуемый на компьютере способ по п. 8, отличающийся тем, что анализатор выполнен с возможностью использования taint-анализа и/или анализа символьной интерпретации.
14. Реализуемый на компьютере способ по п. 9, отличающийся тем, что отчет о безопасности включает в себя: (a) обнаруженные уязвимости и недокументированные функции; (b) результаты в рамках одного проекта или разных групп проектов для отслеживания прогресса устранения или возникновения уязвимости; (c) рекомендации для групп кибербезопасности и/или разработчиков; и (d) рекомендации по настройке WAF для блокировки и предотвращения возможности использования уязвимостей во время исправлений входной программы.
| Способ приготовления лака | 1924 |
|
SU2011A1 |
| Способ приготовления лака | 1924 |
|
SU2011A1 |
| Станок для придания концам круглых радиаторных трубок шестигранного сечения | 1924 |
|
SU2019A1 |
| Способ получения цианистых соединений | 1924 |
|
SU2018A1 |
| Система и способ выявления уязвимостей с использованием перехвата вызовов функций | 2018 |
|
RU2697948C1 |

