Изобретение относится к области вычислительной техники и предназначено для реализации передачи данных внутри объединенной сетью группы вычислительных устройств, а также обмена данными между разными такими группами вычислительных устройств.
Из уровня техники известен способ работы с распределенной базой данных содержащий этапы, на которых интерфейсный сервер получает запрос на обслуживание базы данных, и запрос на обслуживание базы данных делится на операцию записи и операцию чтения; сервер интерфейса отправляет операцию записи на предварительно назначенный сервер глобальной базы данных для выполнения, а сервер глобальной базы данных передает результат выполнения всем другим серверам распределенной базы данных в цепном режиме; и сервер интерфейса выбирает один сервер распределенной базы данных и отправляет операцию чтения выбранному серверу распределенной базы данных для выполнения (патент CN108241641 A 03.07.2018).
Из уровня техники известно также устройство для реализации распределенной базы данных, содержащее: память первого вычислительного устройства, содержащую часть экземпляра распределенной базы данных на первом вычислительном устройстве, приспособленном для включения во множество вычислительных устройств, которые реализуют посредством сети, функционально соединенной с множеством вычислительных устройств, распределенную базу данных, которая содержит первую запись, находящуюся в логической связи с первым открытым ключом, связанным с первым вычислительным устройством; и процессор первого вычислительного устройства, функционально соединенный с памятью, при этом процессор приспособлен для: приема со второго вычислительного устройства из множества вычислительных устройств первого открытого ключа, связанного со вторым вычислительным устройством, и зашифрованного с помощью первого открытого ключа, связанного с первым вычислительным устройством, и находящегося в логической связи со второй записью распределенной базы данных; расшифровки на первом вычислительном устройстве первого открытого ключа, связанного со вторым вычислительным устройством, с помощью закрытого ключа, находящегося в паре с первым открытым ключом, связанным с первым вычислительным устройством; отправки на второе вычислительное устройство второго открытого ключа, связанного с первым вычислительным устройством, находящегося в логической связи с третьей записью распределенной базы данных и зашифрованного с помощью второго открытого ключа, связанного со вторым вычислительным устройством и находящегося в логической связи с четвертой записью распределенной базы данных; определения команды передачи путем выполнения лексикографического сравнения между вторым открытым ключом, связанным с первым вычислительным устройством, и первым открытым ключом, связанным со вторым вычислительным устройством; и отправки сигнала для внесения в распределенную базу данных команды передачи, приспособленной для передачи значения из каждой исходной записи из множества исходных записей, включая первую запись и четвертую запись, в другую целевую запись из множества целевых записей, включая вторую запись и третью запись, при этом команда передачи подписана с помощью закрытого ключа и приспособлена для исполнения таким образом, чтобы скрыть идентификатор вычислительного устройства, связанного с каждой целевой записью из множества целевых записей, среди набора вычислительных устройств, содержащего первое вычислительное устройство и второе вычислительное устройство (патент RU 2746446 C2 14.04.2021).
Недостатком известного решения является то, что существующие системы, известные из уровня техники организованы в виде сервера, доступ к которому осуществляется через веб интерфейс (сайт), на котором хранятся все документы всех пользователей. И в соответствии с правами при взаимодействии пользователей дается доступ к файлам других пользователей. То есть в существующих системах используют обычную технологию клиент-сервер. Такой вид системы ненадежен вследствие того, что неработоспособность сервера может сделать неработоспособной всю вычислительную сеть. При это неработоспособным сервером следует считать сервер производительности которого не хватает на обслуживание всех клиентов, а также сервер, находящийся в ремонте, профилактике, под атакой (DDos атака например) и т.п.
Техническая проблема заявленной группы изобретений заключается в решении проблемы создания системы распределенной базы данных, реализующей технологию клиент-клиент.
Технический результат заключается в обеспечении возможности реализации системы распределенной базы данных и способа передачи элементов этой базы от одного участника такой системы к другому.
Указанный технический результат достигается в системе распределенной базы данных, содержащей множество вычислительных устройств, соединенных между собой посредством сети, а также сервер с системой обмена сообщений и сервер с серверным диском, функционально соединенные с каждым вычислительным устройством множества вычислительных устройств, каждое из которых содержит память, процессор и устройство вывода, при этом память каждого вычислительного устройства множества вычислительных устройств системы хранит инструкции, приводящие к исполнению процессором функций связанных с отправкой посредством сервера с системой обмена сообщений и сервера с серверным диском на другое вычислительное устройство входящее в множество вычислительных устройств части экземпляра распределенной базы данных, предназначенного для редактирования и/или согласования, а также приемом с другого вычислительного устройства входящего в множество вычислительных устройств экземпляра распределенной базы данных, записи события синхронизации, записи предыдущих событий синхронизации с другими вычислительными устройствами, порядка событий синхронизации, значения для параметра, при этом память первого вычислительного устройства содержит как минимум часть экземпляра распределенной базы данных, выполненного с возможностью передачи множеству вычислительных устройств системы, которые реализуют посредством сети, функционально соединенной с множеством вычислительных устройств системы, распределенную базу данных, каждое из вычислительных устройств множества вычислительных устройств системы выполнены с возможностью обнаруживать поступления сообщения от других вычислительных устройств множества вычислительных устройств системы, и, при отсутствии разрешения на обмен сообщениями запрашивать разрешение на обмен данными с вычислительным устройством, имеющим уникальный идентификатор аккаунта вычислительного устройства от которого пришло сообщение, а, при наличии такого разрешения, в автоматизированном режиме выделения из сообщения ссылки по которой осуществляется автоматическое добавление нового экземпляра в базу данных второго или последующих вычислительных устройств множества вычислительных устройств системы.
Вычислительное устройство содержит звуковое устройство вывода и/или тактильное устройство вывода.
Память вычислительного устройства представляет собой оперативное запоминающее устройство RAM, буфер памяти, жесткий диск, базу данных, стираемое программируемое постоянное запоминающее устройство EPROM, электрически стираемое программируемое постоянное запоминающее устройство EEPROM, постоянное запоминающее устройство ROM.
Значения для параметра представляют собой поля базы данных, количественно характеризующего транзакцию, поля базы данных, количественно характеризующего порядок, в котором происходят события, и/или поле для которого значение может быть сохранено в базе данных.
Дополнительно содержит второе множество вычислительных устройств, которое выполнено с возможностью взаимодействия с первым множеством вычислительных устройств посредством приема-передачи экземпляров распределенной базы данных через назначенные вычислительные устройства первого и второго множеств вычислительных устройств системы.
Уникальный идентификатор аккаунта вычислительного устройства представляет собой адрес электронной почты, номер телефона аккаунта мессенджера, идентификатор аккаунта социальной сети, идентификатор экосистемы (например Сбер ID, Яндекс паспорт и т п), а также идентификатор любой системы, обеспечивающей авторизацию третьей стороне с ограниченным доступом к защищённым ресурсам пользователя без передачи ей (третьей стороне) логина и пароля (пример OAuth2 это как раз любая экосистема может предоставлять такую аутентификацию).
Вычислительное устройство представляет собой персональное вычислительное устройство, настольный компьютер, портативный компьютер, мобильный телефон, карманный персональный компьютер PDA.
Указанный технический результат достигается также в способе реализации распределенной базы данных посредством системы распределённой базы данных, включающий этапы, на которых: создают группу, содержащую множество вычислительных устройств системы распределенной базы данных, для чего с первого вычислительного устройства отправляют часть экземпляра распределенной базы данных, содержащей ссылку для присоединения к группе, вычислительным устройствам, входящим в множество вычислительных устройств системы распределенной базы данных, при этом сформированная часть экземпляра распределенной базы данных сохраняют на первом вычислительном устройстве; для каждого документа, являющегося частью экземпляра распределенной базы данных на первом вычислительном устройстве задают маршрут со списком уникальных идентификаторов аккаунта вычислительных устройств группы, а также правами на редактирование и/или согласование отправляемой части экземпляра распределенной базы данных для каждого из заданных вычислительных устройств группы, при завершении работы с частью экземпляра распределенной базы данных на текущем вычислительном устройстве указанную часть экземпляра пересылают на следующее, указанное в маршруте, вычислительное устройство, а также одновременно отсылают на предшествующие вычислительные устройства, для формирования полного экземпляра распределенной базы данных и отслеживания действий по указанному документу, при этом все части экземпляра распределенной базы данных сохраняются в памяти каждого вычислительного устройства указанного в маршруте.
При этом каждое из множества вычислительных устройств группы, выполнено с возможностью при наличии соответствующих прав добавить другие вычислительные устройства в группу, отправив на уникальные идентификаторы аккаунта вычислительных устройств приглашение в виде части экземпляра распределенной базы данных.
При этом из множества вычислительных устройств группы назначается одно вычислительное устройство, взаимодействующее с другим вычислительным устройством второго множества вычислительных устройств другой группы, также предварительно назначенным для взаимодействия.
Заявленная группа изобретений поясняется на графических материалах, где
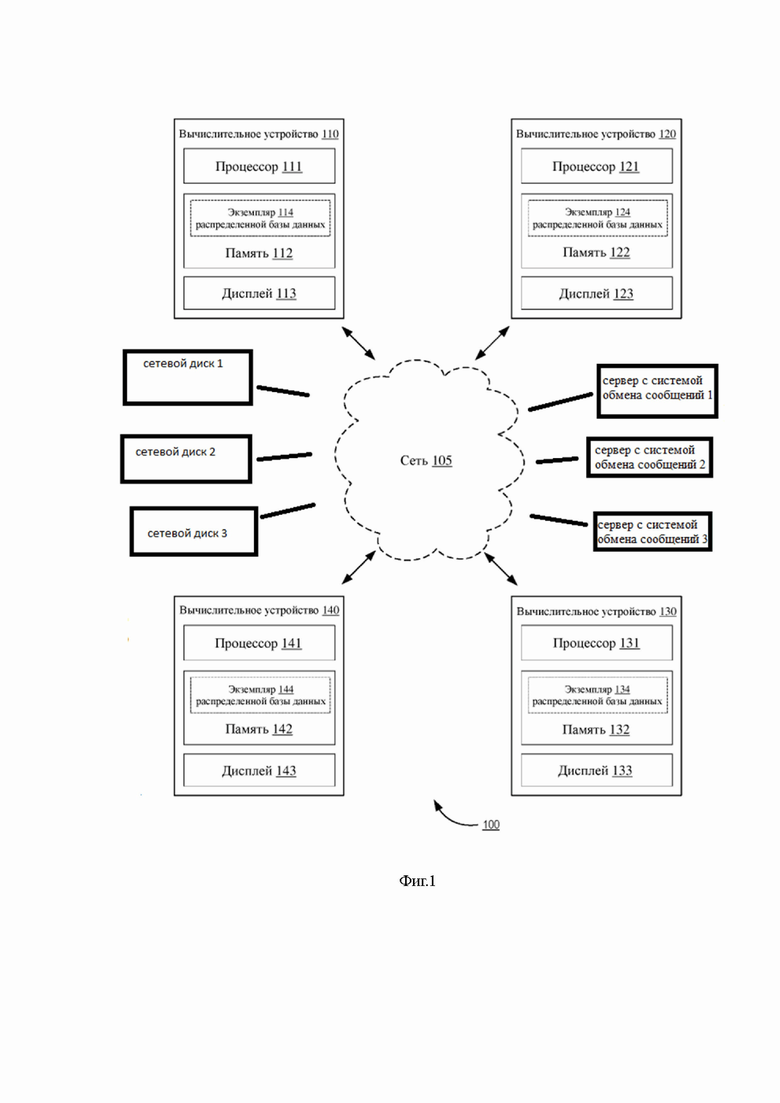
Фиг.1 - представлена структурная схема системы распределенной базы данных, на которой проиллюстрирована система распределенной базы данных согласно варианту осуществления на примере одной группы пользователей из четырех пользователей и четырех вычислительных устройств.
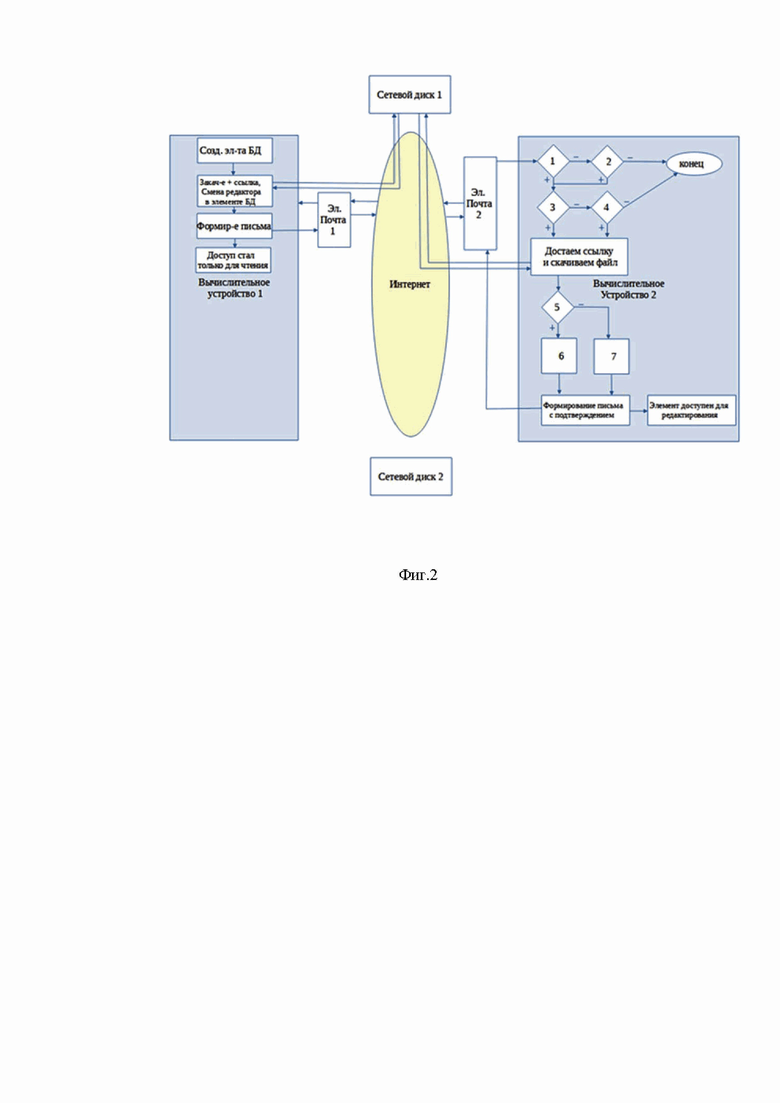
Фиг.2 - структурная схема создания и отправки экземпляра распределенной базы данных на примере сервера обмена сообщениями в виде почтового сервера (электронная почта)
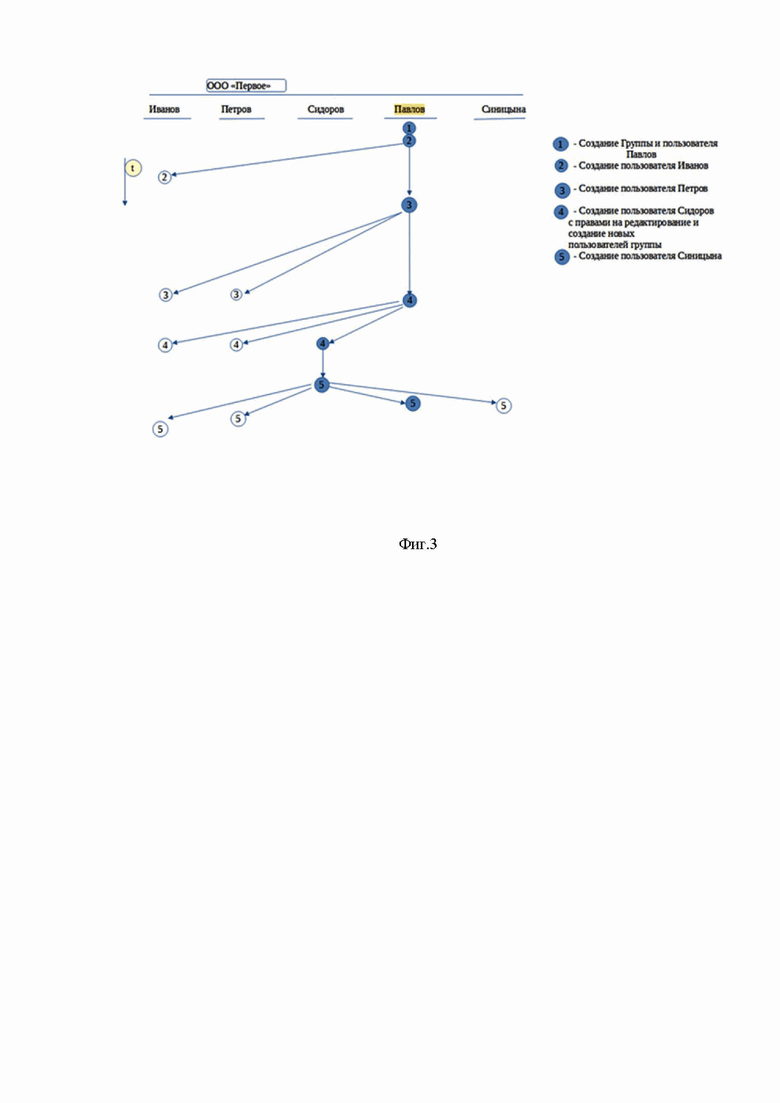
Фиг.3 - структурная схема создания группы из пяти человек
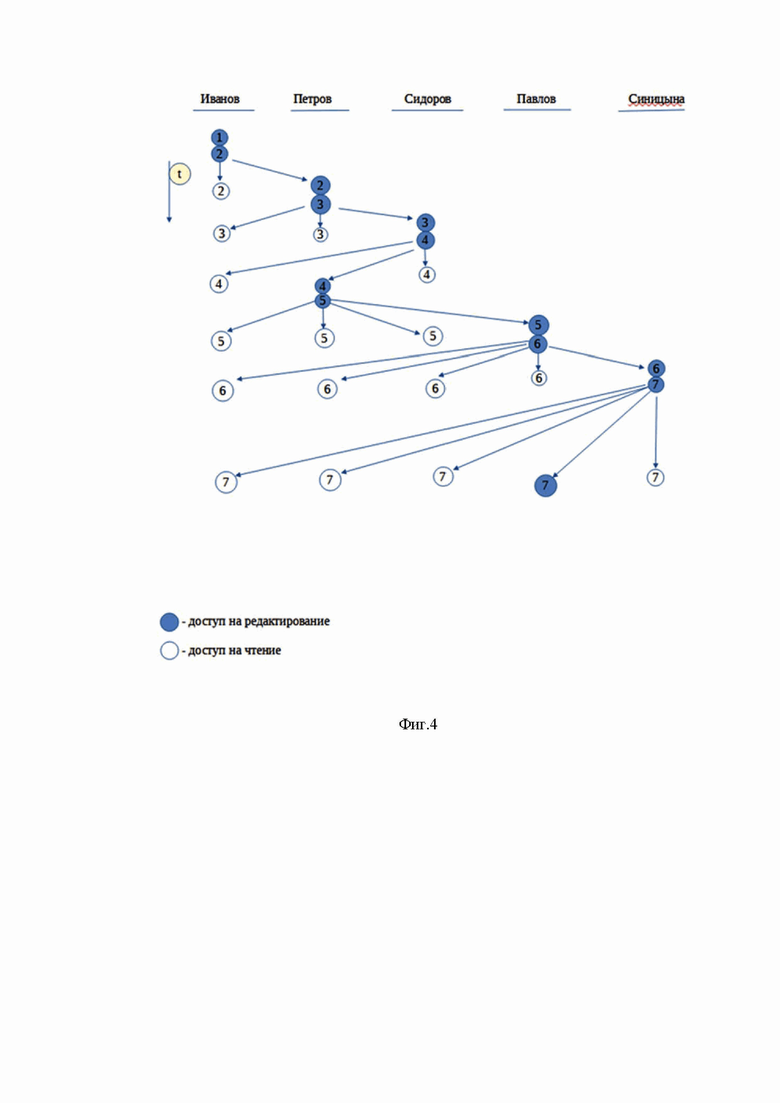
Фиг.4 - структурная схема внутреннего документооборота организации
Фиг.5 - структурная схема отправки документа контрагенту
Отличительной особенностью заявленной группы изобретений является хранение документов каждого пользователя системы на его же вычислительном устройстве. При передаче данных используются сервер передачи сообщений и сервер временного хранения данных с личным или корпоративным аккаунтом пользователя и принятый от другого пользователя документ также хранится на вычислительном устройстве пользователя получателя. То есть заявленная система реализует технологию клиент-клиент.
Это позволяет не использовать огромные сервера с большими постоянно пополняющимися массивами данных, и тем не менее обеспечить получение документов всеми участниками документооборота. При этом в случае необходимости хранение документов пользователя возможно на его личном сервере, или сервере группы, а не на вычислительном устройстве пользователя, но обеспечено это будет после получения экземпляра базы данных на вычислительное устройство пользователя и последующее перенаправление на хранение на сервер, что является дополнительной функцией к текущей схеме работы.
При отправке также будет браться экземпляр распределенной базы данных с личного сервера или сервера группы, перемещаться на вычислительное устройство пользователя и далее отправляться другому пользователю, но основной смысл пересылки документов клиент-клиент сохраняется.
Следует также отметить что количество устройств в одной или разных группах системы распределенной базы данных может быть неограниченным, количество таких групп может быть неограниченным.
Данная система распределенной базы данных и способа передачи ее элементов может быть удобна в частности для электронного документооборота, в том числе с использованием цифровой подписи участников документооборота. При этом, в случае использования электронной подписи, закрытый ключ хранится на вычислительном устройстве или отдельном носителе информации пользователя, а открытый ключ передается в составе элемента распределенной базы данных с помощью программного обеспечения.
В некоторых вариантах осуществления устройство содержит по меньшей мере часть первого экземпляра распределенной базы данных на первом вычислительном устройстве, приспособленном для включения в группу вычислительных устройств, которые реализуют посредством сети, функционально соединенной с группой вычислительных устройств, распределенную базу данных.
Процессор выполнен с возможностью приема экземпляра базы данных с любого устройства сети. Передача данных от одного вычислительного устройства ко второму осуществляется за счет того, что пользователь первого устройства знает уникальный идентификатор аккаунта системы передачи сообщений пользователя другого устройства. Уникальный идентификатор аккаунта системы передачи сообщений может быть, например, адрес электронной почты, номер телефона аккаунта мессенджера, идентификатор аккаунта социальной сети и т. п. Таким образом с помощью программного обеспечения по признаку известного идентификатора друг друга пользователи могут образовывать группы пользователей для обмена данными и хранения распределенной базы данных.
Под текущим экземпляром распределенной базы данных для обмена подразумевается крайний экземпляр цепочки, например, одного документа, который доступен пользователю на редактирование. Все предыдущие экземпляры в таких цепочках с помощью программного обеспечения доступны на чтение, даже если пользователь текущий редактор крайнего экземпляра цепочки. Разные группы пользователей могут обмениваться текущими экземплярами распределенной базы данных с другими группами. Для этого достаточно знать уникальный идентификатор аккаунта системы передачи сообщений хотя бы одного пользователя из другой группы и отправить ему приглашение. Таким образом пользователь второй группы с помощью программного обеспечения сможет принять приглашение и узнать из полученного в приглашении сообщения идентификатор участника первой группы. В дальнейшем пользователь второй группы может отправлять экземпляры распределенной базы данных пользователю первой группы.
Следует отметить что каждому устройству одной группы должны быть доступны сервер с системой обмена сообщений и сервер с серверным диском каждого пользователя этой группы. Это гарантирует получение сообщения и скачивание файла с экземпляром распределенной базы данных для каждого пользователя группы.
Следует отменить что с помощью программного обеспечения могут обрабатываться неудачные попытки отправки сообщений и закачивание экземпляра на серверный диск. Эти попытки повторяются с заданной периодичностью до успешного результата, что также гарантирует получение экземпляра распределенной базы данных, а значит устойчивость всей системы.
Устройства из разных групп могут быть в разных сетях. Но сервер с системой обмена сообщений и сервер с серверным диском пользователя-контактного лица из другой группы должны быть доступны пользователю-контактному лицу первой группы. И наоборот, сервер с системой обмена сообщений и сервер с серверным диском первого должен быть известен второму. Например, одна группа может быть в локальной сети организации, вторая в локальной сети другой организации, но контактные лица обоих лиц имеют доступ в Интернет. При этом контактные лица имеют два аккаунта системы обмена сообщений и сервера с серверным диском, один аккаунт системы обмена сообщений и один аккаунт с серверным диском для внутренней передачи экземпляра распределенной базы данных, находящийся в локальной сети текущей организации, второй аккаунт системы обмена сообщений и второй аккаунт с серверным диском в сети Интернет для отправки контактному лицу другой группы.
Хранение базы данных на локальном компьютере пользователя можно осуществить например с помощью компактной встраиваемой СУБД SQLite.
SQLite — компактная встраиваемая СУБД. Исходный код библиотеки передан в общественное достояние. Слово «встраиваемый» (embedded) означает, что SQLite не использует парадигму клиент-сервер, то есть движок SQLite не является отдельно работающим процессом, с которым взаимодействует программа, а представляет собой библиотеку, с которой программа компонуется, и движок становится составной частью программы. Таким образом, в качестве протокола обмена используются вызовы функций (API) библиотеки SQLite. Такой подход уменьшает накладные расходы, время отклика и упрощает программу. SQLite хранит всю базу данных (включая определения, таблицы, индексы и данные) в единственном стандартном файле на том компьютере, на котором исполняется программа. Простота реализации достигается за счёт того, что перед началом исполнения транзакции записи весь файл, хранящий базу данных, блокируется; ACID-функции достигаются в том числе за счёт создания файла журнала.
API (application programming interface) - это набор готовых классов, функций, процедур, структур и констант. Вся эта информация предоставляется самим приложением (или операционной системой). При этом пользователю не обязательно понимать, что это API технология обеспечивает взаимодействие модулей. Цель предоставленной информации – использование этих данных при взаимодействии с внешними программами. API различных продуктов используются программистами для создания приложений, которые будут взаимодействовать друг с другом. В общем случае данный механизм применяется с целью объединения работы различных приложений в единую систему. Это достаточно удобно для исполнителей. Ведь в таком случае к другому приложению можно обращаться как к «черному ящику». При этом не имеет значения его внутренний механизм – программист может вообще не знать, что такое API.
Создание и отправка экземпляра распределенной базы данных
Рассмотрим отправку одного сообщения внутри группы на примере с объединением сетью Интернет (создание, отправка, получение, отправка подтверждения). Алгоритм данной функции выглядит следующим образом:
1 - Имеется ли разрешение на прием данных от данного отправителя?
2 - Создать разрешение на прием данных от данного отправителя?
3 - Входит ли пользователь данного (второго) вычислительного устройства в группу, указанную в полученном сообщении?
4 - Создать группу, полученную в сообщении и стать ее участником?
5 - Имеется ли цепочка согласно идентификатору цепочек в полученном элементе распределенной БД?
6 - Элемент добавляется в цепочку и становится крайним в ней.
7 - Создается новая цепочка с первым элементом, который получен от отправителя.
Зная идентификатор пользователя второго вычислительного устройства первое вычислительное устройство с помощью программного обеспечения создает новый элемент распределенной базы данных, которое формируется в виде отдельного файла SQLite на вычислительном устройстве пользователя, файл в свою очередь может, но не обязательно, содержать еще ссылки на неограниченное количество файлов на сетевом диске, и загружает в свой сетевой диск (Яндекс Диск, Google Диск и т.п.). Такой файл закачивается на сервер с серверным диском с помощью API функций сервера. Такие API-функции являются стандартными для таких серверов, что очень удобно используется в других системах для взаимодействия с такими серверами.
На сетевом диске после вызова следующей API-функции формируется уникальная конфиденциальная ссылка на скачивание файла с данного сервера и возвращается первому вычислительному устройству в ответе на данный вызов API-функции.
Эту ссылку, а также данные пользователя и группы в определенном формате первое вычислительное устройство передает в виде сообщения на уникальный аккаунт второго вычислительного устройства (это может быть отправка письма по электронной почте по протоколу SMTP, сообщение в мессенджер или соцсеть через API-функции сервера мессенджера или соцсети).
Второе вычислительное устройство по нажатию кнопки или по достижению определенного интервала времени на таймере (автоматический режим) проверяет на своем аккаунте с уникальным идентификатором наличие поступивших сообщений в определенном формате.
В случае электронной почты это выборка писем (сообщений) по теме и дате по протоколу IMAP или POP3. В случае мессенджера или соцсети - это проверка всех диалогов с другими пользователями на непрочитанные письма и выборка из них, по заранее заданным ключевым словам, через API-функции. Возможно реализовать случай со специально созданным под цели документооборота выделенным сервером обмена сообщений, в этом случае будет проверка базы данных такого сервера, по ключевым словам, или идентификаторам.
При обнаружении поступления заданного сообщения второе вычислительное устройство при отсутствии разрешения на обмен сообщениями с пользователем отправителем запрашивает разрешение пользователя второго вычислительного устройства на обмен данными с другим устройством имеющим уникальный идентификатор первого пользователя, от которого пришло сообщение.
Если разрешение имеется, то второе устройство с помощью программного обеспечения и зная формат сообщения, так как экземпляр программного обеспечения, который посылает и принимает сообщения таким способом идентичен на всех вычислительных устройствах всех групп пользователей, вытаскивает из сообщения ссылку и по полученной из сообщения ссылке с помощью программного обеспечения по протоколу HTTPS скачивает файл распределенной базы данных SQLite, и в соответствии с идентификатором принадлежности к группе устройств из сообщения добавляет новый экземпляр в базу данных второго пользователя.
В случае отсутствия данных о группе устройств из сообщения пользователю предлагает вступить в группу.
Далее в случае обнаружения уже имеющейся цепочки данных предшествующих данному экземпляру в данной группе устройств, добавляется новый экземпляр в имеющуюся цепочку, иначе создается новая. Это реализовывается за счет указания в каждом экземпляре распределенной базы данных документа идентификатора родительской цепочки и соответственно определению по нему принадлежности к этой цепочке, либо новизны экземпляра базы данных.
Если полученный по ссылке экземпляр распределенной базы данных содержал другие ссылки на сетевой диск, то эти файлы также скачиваются по протоколу HTTPS с помощью программного обеспечения как вложения к данному экземпляру распределенной базы данных. Таким образом элемент базы данных передается от одного устройства к другому, причем принятие нового элемента распределенной базы данных может быть в автоматическом режиме благодаря программному обеспечению с реализованным таймером, по достижению интервала которого осуществляется проверка новых сообщений почты, мессенджера или соцсети, обработка сообщений и скачивание файлов выше указанным способом, а создание, редактирование и отправка экземпляра осуществляется либо пользователем вычислительного устройства посредством заполнения или редактирования форм данных и нажатия кнопок управления, либо программным обеспечением при заданных условиях.
После принятия нового элемента распределенной базы данных второе вычислительное устройство отправляет на аккаунт с уникальным идентификатором первого пользователя сообщение с подтверждением скачивания по ссылке файла с элементом распределенной базы данных.
Такое сообщение в определенном формате будет иметь ту же ссылку на скачивание, которую отправлял первый пользователь, но вместо скачивания по ссылке на первом вычислительном устройстве происходит идентификация ссылки в журнале отправленных и полученных сообщений.
При идентификации сообщение помечается полученным другой стороной. Таким образом будет подтверждено скачивание файла другим пользователем. После получения с помощью программного обеспечения такого подтверждения первым вычислительным устройством передача экземпляра распределенной базы данных считается завершенной и первое вычислительное устройство удаляет через API-функцию файл со ссылкой с сетевого диска для освобождения ресурсов для временного хранения других передаваемых элементов распределенной базы данных.
В случае отправки первым вычислительным устройством элемента распределенной базы данных нескольким вычислительным устройствам на аккаунты с уникальными идентификаторами их пользователей, удаление файла на сетевом диске вычислительным устройством отправителя происходит после получения подтверждения от всех вычислительных устройств, которым первое устройство отправило ссылку на данный экземпляр. Это отслеживается через журнал отправленных и полученных сообщений с помощью программного обеспечения.
Каждое вычислительное устройство получатель после добавления в имеющиеся или создание новой цепочки распределенной базы данных, с помощью программного обеспечения дает пользователю вычислительного устройства доступ к экземпляру базы данных. Это происходит с учетом того, что каждый элемент распределенной базы данных содержит уникальный идентификатор аккаунта пользователя, которому он на данный момент принадлежит - редактору.
Таким образом с помощью программного обеспечения осуществляется доступ к элементу распределенной базы данных в формате чтения, в случае принадлежности элемента другому участнику, либо в формате редактирования, в случае принадлежности элемента данному участнику.
Пользователь, создавший элемент распределенной базы данных и еще не отправивший этот элемент другому пользователю имеет доступ на редактирование. В то же время отправить экземпляр распределенной базы данных может только текущий редактор.
При отправке вычислительное устройство текущего пользователя-отправителя копирует текущий экземпляр, меняет редактора в копии и отправляет новый экземпляр назначенному редактору. Получивший этот экземпляр распределенной базы данных пользователь является текущим редактором экземпляра и имеет доступ на редактирование. Оригинал скопированного экземпляра становится доступным отправителю на его вычислительной машине для чтения, так как не является крайним в цепочке. Копия экземпляра с новым редактором также остается у отправителя, она становится крайним элементом цепочки. Отправителю на его вычислительной машине крайний элемент доступен для чтения, так как он уже не редактор. Таким образом можно совершать обход документа по списку пользователей зная их уникальный идентификатор аккаунта сервера сообщений. Такие идентификаторы (например, электронная почта) известны всем участникам группы о каждом участнике этой группы. И каждый текущий получатель экземпляра будет являться редактором, а значит сможет отправить экземпляр распределенной базы данных дальше.
На фиг. 1 проиллюстрирована распределенная база 100 данных, реализованная на четырех вычислительных устройствах (вычислительное устройство 110, вычислительное устройство 120, вычислительное устройство 130 и вычислительное устройство 140), но следует понимать, что распределенная база 100 данных может использовать набор из любого количества вычислительных устройств, содержащий вычислительные устройства, не показанные на фиг. 1.
Также в Сети 105 может содержатся любое количество почтовых серверов и серверных дисков. Сеть 105 может представлять собой сеть любого типа (например, локальную вычислительную сеть (LAN), глобальную вычислительную сеть (WAN), виртуальную сеть, телекоммуникационную сеть), реализованную в виде проводной сети и/или беспроводной сети и используемую для функционального соединения вычислительных устройств 110, 120, 130, 140. Как более подробно описано в настоящем документе, в некоторых вариантах осуществления, например, вычислительные устройства представляют собой персональные компьютеры, соединенные друг с другом посредством поставщика услуг Интернет (ISP) и Интернета (например, сети 105).
В некоторых вариантах осуществления соединение может быть установлено посредством сети 105 между любыми двумя вычислительными устройствами 110, 120, 130, 140. Как показано на фиг. 1, например, соединение может быть установлено между вычислительным устройством 110 и любым из вычислительного устройства 120, вычислительного устройства 130 или вычислительного устройства 140.
В некоторых вариантах осуществления вычислительные устройства 110, 120, 130, 140 могут осуществлять связь друг с другом (например, отправлять данные на и/или принимать данные) и с сетью посредством промежуточных сетей и/или альтернативных сетей (не показаны на фиг. 1).
Такие промежуточные сети и/или альтернативные сети могут принадлежать к тому же типу и/или другому типу сети в сравнении с сетью 105.
Каждое вычислительное устройство 110, 120, 130, 140 может представлять собой устройство любого типа, приспособленное для отправки данных по сети 105, чтобы отправлять и/или принимать данные с одного или более других вычислительных устройств. Примеры вычислительных устройств показаны на фиг. 1.
Вычислительное устройство 110 содержит память 112, процессор 111 и устройство 113 вывода. Память 112 может представлять собой, например, оперативное запоминающее устройство (RAM), буфер памяти, жесткий диск, базу данных, стираемое программируемое постоянное запоминающее устройство (EPROM), электрически стираемое программируемое постоянное запоминающее устройство (EEPROM), постоянное запоминающее устройство (ROM) и/или т. д. В некоторых вариантах осуществления память 112 вычислительного устройства 110 содержит данные, связанные с экземпляром распределенной базы данных (например, экземпляром114 распределенной базы данных). В некоторых вариантах осуществления память 112 хранит инструкции, приводящие к исполнению процессором модулей, процессов и/или функций, связанных с отправкой на другое вычислительное устройство экземпляра и/или приемом с другого вычислительного устройства экземпляра распределенной базы данных (например, экземпляра 124 распределенной базы данных на вычислительном устройстве 120) записи события синхронизации, записи предыдущих событий синхронизации с другими вычислительными устройствами (посредством обмена как с последующим вычислительным устройством, так и с предыдущими вычислительными устройствами экземплярами распределенной базы данных), порядка событий синхронизации, посредством формирования на каждом вычислительном устройстве отдельного журнала транзакций распределенной базы данных (данный журнал хранится на каждом вычислительном устройстве и не передается), значения для параметра (например, поля базы данных, количественно характеризующего транзакцию, поля базы данных, количественно характеризующего порядок, в котором происходят события, и/или любого другого подходящего поля, для которого значение может быть сохранено в базе данных).
Экземпляр 114 распределенной базы данных может, например, быть приспособлен для проведений операций с данными, включая сохранение, модификацию и/или удаление данных. В некоторых вариантах осуществления экземпляр 114 распределенной базы данных может представлять собой реляционную базу данных, объектную базу данных, постреляционную базу данных и/или базу данных любого другого подходящего типа. Например, экземпляр 114 распределенной базы данных может хранить данные, относящиеся к любой конкретной функции и/или области. Например, экземпляр 114 распределенной базы данных может хранить документы (например, пользователя вычислительного устройства 110), включая значение и/или вектор значений, относящиеся к истории владения конкретным документом.
В целом, вектор может представлять собой любой набор значений для параметра, и параметр может представлять собой любые объект данных и/или поле базы данных, которые могут принимать разные значения. Таким образом, экземпляр 114 распределенной базы данных может иметь ряд параметров и/или полей, каждый из которых связан с вектором значений. Вектор значений используется для определения фактического значения для параметра и/или поля в этом экземпляре 114 базы данных.
Процессор 111 вычислительного устройства 110 может представлять собой любое подходящее устройство обработки, приспособленное для запуска и/или исполнения экземпляра 114 распределенной базы данных.
Например, процессор 111 может быть приспособлен для обновления экземпляра 114 распределенной базы данных в ответ на прием сигнала с вычислительного устройства 120 и/или вызова отправки сигнала на вычислительное устройство 120.
В вариантах осуществления процессор 111 может быть приспособлен для исполнения модулей, функций и/или процессов для обновления экземпляра 114 распределенной базы данных в ответ на прием значения для параметра, сохраненного в другом экземпляре распределенной базы данных (например, экземпляре 124 распределенной базы данных на вычислительном устройстве 120), и/или вызова отправки значения для параметра, сохраненного в экземпляре 114 распределенной базы данных на вычислительном устройстве 110, на вычислительное устройство 120.
В некоторых вариантах осуществления процессор 111 может представлять собой процессор общего назначения, интегральную схему специального назначения (ASIC), процессор цифровой обработки сигналов (DSP) и/или т.п. Дисплей 113 может представлять собой любой подходящий дисплей, такой как, например, жидкокристаллический дисплей (LCD), дисплей на электронно-лучевой трубке (CRT) или т.п.
В других вариантах осуществления любое из вычислительных устройств 110, 120, 130, 140 содержит другое устройство вывода вместо дисплеев 113, 123, 133, 143 или в дополнение к ним.
Например, любое из вычислительных устройств 110, 120, 130, 140 может содержать звуковое устройство вывода (например, динамик), тактильное устройство вывода и/или т.п. В еще одних вариантах осуществления любое из вычислительных устройств 110, 120, 130, 140 содержит устройство ввода вместо дисплеев 113, 123, 133, 143 или в дополнение к ним. Например, любое из вычислительных устройств 110, 120, 130, 140 может содержать клавиатуру, мышь и/или т.п.
Вычислительное устройство 120 имеет процессор 121, память 122 и дисплей 123, которые могут быть конструктивно и/или функционально подобны процессору 111, памяти 112 и дисплею 113 соответственно. Также экземпляр 124 распределенной базы данных может быть структурно и/или функционально подобен экземпляру 114 распределенной базы данных. Вычислительное устройство 130 имеет процессор 131, память 132 и дисплей 133, которые могут быть конструктивно и/или функционально подобны процессору 111, памяти 112 и дисплею 113 соответственно.
Также экземпляр 134 распределенной базы данных может быть структурно и/или функционально подобен экземпляру 114 распределенной базы данных. Вычислительное устройство 140 имеет процессор 141, память 142 и дисплей 143, которые могут быть конструктивно и/или функционально подобны процессору 111, памяти 112 и дисплею 113 соответственно.
Также экземпляр 144 распределенной базы данных может быть структурно и/или функционально подобен экземпляру 114 распределенной базы данных. Хотя вычислительные устройства 110, 120, 130, 140 показаны как подобные друг другу, каждое вычислительное устройство системы 100 распределенной базы данных может отличаться от других вычислительных устройств. Каждое вычислительное устройство 110, 120, 130, 140 системы 100 распределенной базы данных может представлять собой любое из, например, вычислительного элемента (например, персонального вычислительного устройства, такого как настольный компьютер, портативный компьютер и т. д.), мобильного телефона, карманного персонального компьютера (PDA) и т. д.
Например, вычислительное устройство 110 может представлять собой настольный компьютер, вычислительное устройство 120 может представлять собой смартфон, и вычислительное устройство 130 может представлять собой сервер. В некоторых вариантах осуществления одна или более частей вычислительных устройств 110, 120, 130, 140 могут включать аппаратный модуль (например, процессор цифровой обработки сигналов (DSP), и/или программный модуль (например, модуль компьютерного кода, хранящегося в памяти и/или исполняемого процессором).
В некоторых вариантах осуществления одна или более функций, связанных с вычислительными устройствами 110, 120, 130, 140 (например, функции, связанные с процессорами 111, 121, 131, 141), могут быть включены в один или более модулей. Свойства системы 100 распределенной базы данных, включая свойства вычислительных устройств (например, вычислительных устройств 110, 120, 130, 140), количество вычислительных устройств, и сеть 105 могут быть выбраны любыми способами.
В системе 100 распределенной базы данных одно вычислительное устройство является лидером, и оно создает группу пользователей. Например, это может быть учредитель или директор организации. Когда он создает нового участника, указывая его уникальный идентификатор аккаунта, новому участнику высылается приглашение, которое содержит данные о всей группе пользователей. При создании нового участника ему могут быть назначены права на создание новых пользователей группы. Например, это может быть начальник отдела кадров. Таким образом добавлять новых пользователей в группу может не только лидер, но и любое количество назначенных для этого пользователей. Вычислительное устройство каждого пользователя проверяет права на создание нового участника группы. И если таких прав нет, то функционал создания нового участника программного обеспечения блокируется или доступен только для чтения. Когда назначенный пользователь добавляет нового участника, информация о новом участнике в виде экземпляра распределенной базы данных посылается всем другим участникам группы. Таким образом у каждого участника группы имеется корректная информацию о всех участниках группы.
При создании нового участника группы ему могут быть назначены права на создание документов. Если таких прав в данной группе нет, то можно только пересылать документы, полученные от других пользователей, сам пользователь не может создать новый. Такое распределение прав достигается программным обеспечением.
Рассмотрим пример, когда создается новая группа из пяти человек (фиг.3). Это может быть небольшая организация. Учредитель или предприниматель Павлов создает организацию и пользователя Павлов, который имеет уникальный идентификатор аккаунта сервера передачи сообщений.
Павлов имеет все права на любые действия в этой организации. Он отмечен как создатель группы в экземпляре распределенной базы данных.
С помощью программного обеспечения ему доступно создание и редактирование новых сотрудников группы. Павлов создает Иванова, который является его сотрудником, вводит в форме создания его уникальный идентификатор сервера сообщений, например электронную почту, и не задает ему дополнительных прав в группе.
Иванову отправляется приглашение от вычислительного устройства Павлова вступить в группу, оно отправляется как экземпляр распределенной базы данных со ссылкой. При принятии приглашения вычислительное устройство Иванова скачивает файл по ссылке и добавляет к себе в базу на вычислительном устройстве данные о новой группе и всех ее участниках.
На вычислительном устройстве Иванова будет информация про группу, пользователя Павлов и пользователя Иванов и все это только с доступом на чтение. У Павлова все то же, но с доступом на редактирование, так как у него есть права на редактирование группы и создание и редактирование пользователей в этой группе.
Павлов создает пользователя Петров, который также является его сотрудником, так же без дополнительных прав в группе. Петров принимает приглашение и у него на вычислительном устройстве появляется информация о группе и пользователях Павлов, Иванов, Петров, доступная только для чтения. Вычислительное устройство Павлова высылает вычислительному устройству Иванова экземпляр распределенной базы данных с данными о новом пользователе Петрове, так как это делается для всех участников группы.
Таким образом вычислительное устройство Иванова также имеет данные о группе и пользователях Иванов, Петров, Павлов и с помощью программного обеспечения предоставляет доступ Иванову только для чтения. Павлов же имеет доступ к группе и пользователям Павлов, Иванов, Петров на редактирование. Павлов создает пользователя Сидоров, которые также является его сотрудником. Но Сидорову он дает права в группе на создание и редактирование новых пользователей в группе. Сидоров принимает приглашение. Иванову и Петрову высылаются данные по Сидорову, в том числе его права в группе. Иванов и Петров имеют данные по группе и пользователях Иванов, Петров, Сидоров и Павлов причем только на чтение.
Сидоров и Павлов имеют доступ к данным по группе и пользователях Иванов, Петров, Сидоров на редактирование и данных о пользователе Павлов на чтение, так как он создатель группы.
Сидоров, например, начальник отдела кадров и дальше он создает пользователей системы. Он создает нового пользователя Синицыну, которая является сотрудником Иванова. Дополнительных прав ей не назначает. Синицына принимает приглашение. Иванову, Петрову и Павлову высылается экземпляр распределенной базы данных с информацией по Синицыной. Информация о группе, а также пользователях Иванов, Петров, Сидоров, Павлов, Синицына есть у всех.
У Иванова, Петрова и Синицыной информация доступна только для чтения. У Сидорова и Павлова на редактирование. Сидоров не может редактировать только Павлова. Следует отметить что при поступлении информации о создании нового сотрудника, программное обеспечение проверяет есть ли права у пользователя отправителя данного сообщения на создание нового пользователя и только при наличии таких прав в группе добавляется новый пользователь на вычислительное устройство получателя.
Следует отметить что по истечении заданного в настройках времени и отсутствия подтверждения от пользователя, вычислительное устройство отправителя с помощью программного обеспечения повторяет отправку сообщения с экземпляром распределенной базы данных. Например письмо потерялось и не дошло до получателя, высылается новое письмо и так повторяется через заданные интервалы времени. Таким образом система распределенной базы данных обеспечивает надежность передачи данных между вычислительными устройствами пользователей. Отправку таких повторных сообщений может отменить сам пользователь вычислительного устройства отправителя.
Внутренний документооборот организации
Рассмотрим систему на примере группы из четырех пользователей, которые согласовывают документ внутри одной организации (фиг. 4).
Каждый пользователь знает уникальный идентификатор аккаунта сервера сообщений каждого. Это достигается посредством создания группы и добавления туда новых участников как описано выше. У каждого документа задается маршрут со списком пользователей из этой группы, по которому этот документ передается при завершении работы с ним текущего пользователя путем переназначения текущего редактора и отправки вышеописанным способом. Рассмотрим список из четырех пользователей: Иванов, Петров, Сидоров, Павлов. Иванов создает документ и заполняет маршрут другими пользователями группы, а также задает может ли кто-то из пользователей заменять одного на другого в списке пользователей для обхода документа.
Любой пользователь может добавить нового пользователя в список обхода, новый пользователь будет из этой же группы. Когда Иванов заканчивает работу и отправляет документ, создается второй экземпляр цепочки данного документа (блок), который передается Петрову.
Петров становится текущим редактором документа, второй блок становится крайним в цепочке, предыдущий блок становятся доступным только для чтения у Иванова. Второй блок также доступен только для чтения у Иванова так как редактором в этом блоке указан Петров. Первый блок имеет только Иванов. Второй блок имеют Иванов и Петров. Петров может редактировать документ, так как в текущем втором блоке он отмечен как редактор, и передавать дальше по маршруту. Петров заканчивает работу и отправляет документ. Создается третий блок и передается Сидорову, а также Иванову. Третий блок, доступный для чтения, есть у Иванова и Петрова.
Сидоров может редактировать третий блок. Сидоров, например, внес Петрова в следующую очередь обхода документа по маршруту, до Павлова, чтобы Петров внес еще изменения.
Создается 4-й блок и передается Петрову. Четвертый блок, доступный для чтения, есть у Иванова и Сидорова. Петров может редактировать 4-й блок.
Петров внес изменения и отправил документ дальше. Создается 5-й блок и передается Павлову (например, он начальник и согласует конечную версию документа). 5-й блок, доступный для чтения есть у Иванова, Петрова, Сидорова.
Павлов может редактировать 5-й блок. Павлов вносит в документ еще одного Пользователя - Синицыну, себя ставит по маршруту после Синицыной. Создается 6 блок и передается Синицыной, а также другим пользователям, у которых документ уже побывал, чтобы они могли отслеживать дальнейшие действия по документу.
Следует отметить, что все сведения о маршруте документа отправляются с текущим экземпляром базы данных, таким образом новый маршрут будет у всех пользователей. Синицына может редатировать 6 блок. Иванов, Петров, Сидоров, Павлов только для чтения. Синицына передает дальше.
Создается 7-й блок и передается Павлову. Павлов может редактировать. Иванов, Петров, Сидоров, Синицына имеют 7-й блок с доступом только для чтения.
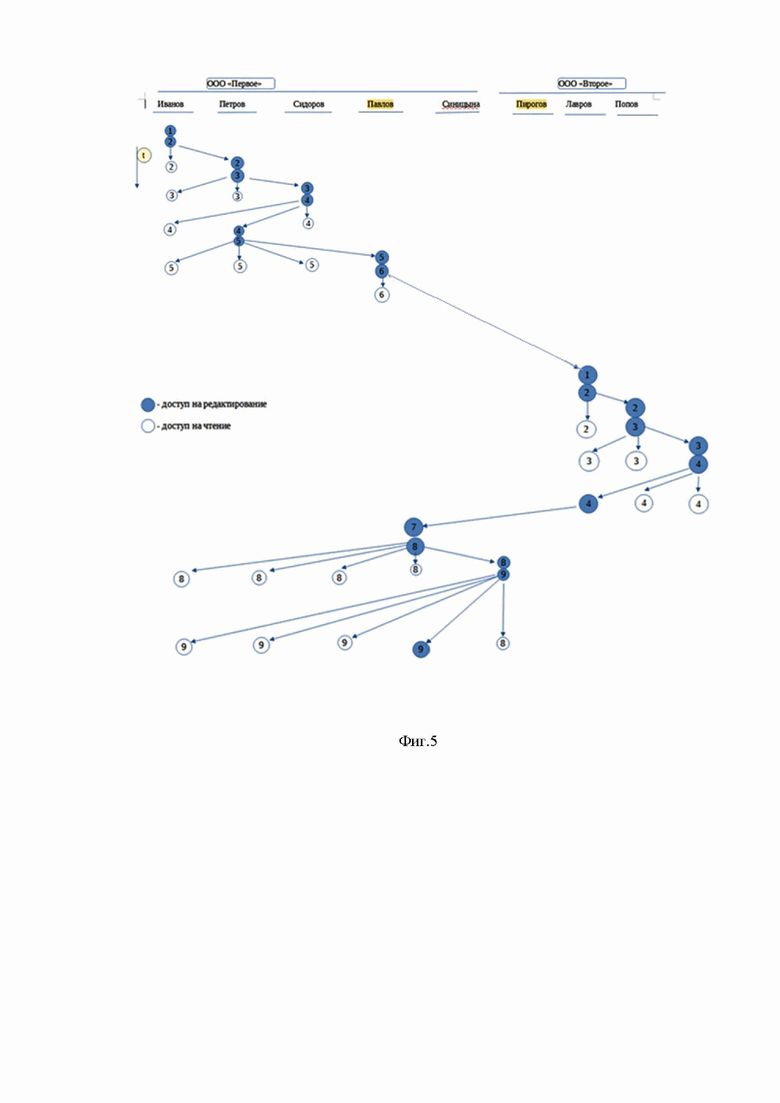
Отправка документа контрагенту
Рассмотрим пример. ООО «Первое», контактное лицо которого Павлов и ООО «Второе», контактное лицо которого Пирогов (фиг.5).
ООО «Второе» уже получило и приняло приглашение от ООО «Первое» и оба ООО знают уникальные идентификаторы сервера сообщений контактных лиц друг друга.
Павлов имеет данные о группе ООО «Второе» и пользователе-контактном лице ООО «Второе» Пирогове. Пирогов имеет данные о группе ООО «Первое» и пользователе-контактном лице ООО «Первое» Павлове.
Павлов имеет в приложении документ, например, проходящий внутренний документооборот, и отправляет его контрагенту. Создается новый блок и отправляется контактному лицу контрагента Пирогову.
Статус в приложении Павлова помечается как у внешней группы, копии нового блока в таком случае своим сотрудникам Иванову, Петрову и Сидорову не отсылаются. Приложение Пирогова принимает новый блок от Иванова и создает новую цепочку, так как по идентификатору цепочки таких не было. По новой цепочке можно запускать внутренний документооборот в ООО «Второе».
Когда он закончится, можно будет вернуть документ в ООО «Первое» контактному лицу Павлову. У Павлова новый блок от Пирогова идентифицируется как новый блок в существующую цепочку. Далее можно продолжать документооборот внутри организации.
Настоящее техническое решение относится к области вычислительной техники. Технический результат заключается в повышении устойчивости аппаратной неисправности в распределенной базе данных (БД). Технический результат достигается за счёт того, что вычислительное устройство (ВУ) отправляет посредством сервера с системой обмена сообщений и сервера с серверным диском на другое ВУ часть экземпляра распределенной базы данных (БД), предназначенной для редактирования и/или согласования, а также принимает с другого ВУ экземпляр распределенной (БД), запись события синхронизации, запись предыдущих событий синхронизации с другими ВУ, порядок событий синхронизации, значение для параметра, при этом первое ВУ содержит часть экземпляра распределенной (БД), выполненного с возможностью передачи множеству ВУ системы, которые реализуют посредством сети распределенную (БД). Каждое из ВУ выполнено с возможностью обнаруживать поступления сообщения от других ВУ и при отсутствии разрешения на обмен сообщениями запрашивать разрешение на обмен данными с ВУ, имеющим уникальный идентификатор аккаунта ВУ, от которого пришло сообщение, а при наличии такого разрешения, в автоматизированном режиме производить выделение из сообщения ссылки, по которой осуществляется автоматическое добавление нового экземпляра в (БД) второго или последующих ВУ. 2 н. и 8 з.п. ф-лы, 5 ил.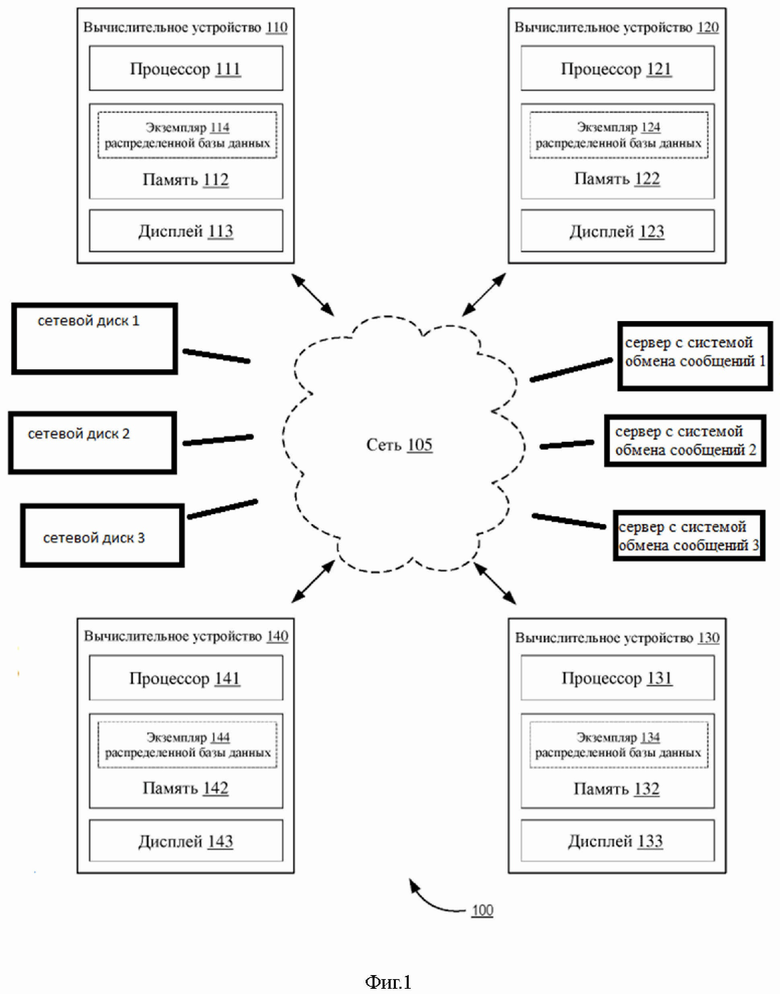
1. Система распределенной базы данных, содержащая множество вычислительных устройств, соединенных между собой посредством сети, а также сервер с системой обмена сообщений и сервер с серверным диском, функционально соединенные с каждым вычислительным устройством множества вычислительных устройств, каждое из которых содержит память, процессор и устройство вывода, при этом
память каждого вычислительного устройства множества вычислительных устройств системы хранит инструкции, приводящие к исполнению процессором функций, связанных с отправкой посредством сервера с системой обмена сообщений и сервера с серверным диском на другое вычислительное устройство, входящее в множество вычислительных устройств части экземпляра распределенной базы данных, предназначенного для редактирования и/или согласования, а также приемом с другого вычислительного устройства множества вычислительных устройств экземпляра распределенной базы данных, записи события синхронизации, записи предыдущих событий синхронизации с другими вычислительными устройствами, порядка событий синхронизации, значения для параметра,
при этом память первого вычислительного устройства содержит как минимум часть экземпляра распределенной базы данных, выполненного с возможностью передачи множеству вычислительных устройств системы, которые реализуют посредством сети, функционально соединенной с множеством вычислительных устройств системы, распределенную базу данных,
каждое из вычислительных устройств множества вычислительных устройств системы выполнены с возможностью обнаруживать поступления сообщения от других вычислительных устройств множества вычислительных устройств системы, и, при отсутствии разрешения на обмен сообщениями запрашивать разрешение на обмен данными с вычислительным устройством, имеющим уникальный идентификатор аккаунта вычислительного устройства, от которого пришло сообщение,
а, при наличии такого разрешения, в автоматизированном режиме выделения из сообщения ссылки, по которой осуществляется автоматическое добавление нового экземпляра в базу данных второго или последующих вычислительных устройств множества вычислительных устройств системы.
2. Система по п. 1, отличающаяся тем, что вычислительное устройство содержит звуковое устройство вывода и/или тактильное устройство вывода.
3. Система по п. 1, отличающаяся тем, что память вычислительного устройства представляет собой оперативное запоминающее устройство RAM, буфер памяти, жесткий диск, базу данных, стираемое программируемое постоянное запоминающее устройство EPROM, электрически стираемое программируемое постоянное запоминающее устройство EEPROM, постоянное запоминающее устройство ROM.
4. Система по п. 1, отличающаяся тем, что значения для параметра представляют собой поля базы данных, количественно характеризующего транзакцию, поля базы данных, количественно характеризующего порядок, в котором происходят события, и/или поле, для которого значение может быть сохранено в базе данных.
5. Система по п. 1, отличающаяся тем, что дополнительно содержит второе множество вычислительных устройств, которое выполнено с возможностью взаимодействия с первым множеством вычислительных устройств посредством приема-передачи экземпляров распределенной базы данных через назначенные вычислительные устройства первого и второго множеств вычислительных устройств системы.
6. Система по п. 1, отличающаяся тем, что уникальный идентификатор аккаунта вычислительного устройства представляет собой адрес электронной почты, номер телефона аккаунта мессенджера, идентификатор аккаунта социальной сети, идентификатор экосистемы.
7. Система по п. 1, отличающаяся тем, что вычислительное устройство представляет собой персональное вычислительное устройство, настольный компьютер, портативный компьютер, мобильный телефон, карманный персональный компьютер PDA.
8. Способ реализации распределенной базы данных посредством системы распределённой базы данных, включающий этапы, на которых:
создают группу, содержащую множество вычислительных устройств системы распределенной базы данных, для чего
с первого вычислительного устройства отправляют часть экземпляра распределенной базы данных, содержащей ссылку для присоединения к группе, вычислительным устройствам, входящим в множество вычислительных устройств системы распределенной базы данных, при этом сформированная часть экземпляра распределенной базы данных сохраняют на первом вычислительном устройстве,
для каждого документа, являющегося частью экземпляра распределенной базы данных на первом вычислительном устройстве, задают маршрут со списком уникальных идентификаторов аккаунта вычислительных устройств группы, а также правами на редактирование и/или согласование отправляемой части экземпляра распределенной базы данных для каждого из заданных вычислительных устройств группы,
при завершении работы с частью экземпляра распределенной базы данных на текущем вычислительном устройстве указанную часть экземпляра пересылают на следующее, указанное в маршруте, вычислительное устройство, а также одновременно отсылают на предшествующие вычислительные устройства, для формирования полного экземпляра распределенной базы данных и отслеживания действий по указанному документу, при этом все части экземпляра распределенной базы данных сохраняются в памяти каждого вычислительного устройства, указанного в маршруте.
9. Способ по п. 8, отличающийся тем, что каждое из множества вычислительных устройств группы выполнено с возможностью добавить другие вычислительные устройства в группу, отправив на уникальные идентификаторы аккаунта вычислительных устройств приглашение в виде части экземпляра распределенной базы данных.
10. Способ по п. 8, отличающийся тем, что из множества вычислительных устройств группы назначается одно вычислительное устройство, взаимодействующее с другим вычислительным устройством второго множества вычислительных устройств другой группы, также предварительно назначенным для взаимодействия.
| СПОСОБЫ И УСТРОЙСТВО ДЛЯ РАСПРЕДЕЛЕННОЙ БАЗЫ ДАННЫХ, СОДЕРЖАЩЕЙ АНОНИМНЫЕ ВХОДНЫЕ ДАННЫЕ | 2017 |
|
RU2746446C2 |
| US 6446092 B1, 03.09.2002 | |||
| Станок для придания концам круглых радиаторных трубок шестигранного сечения | 1924 |
|
SU2019A1 |
| US 10713280 B2, 14.07.2020 | |||
| US 10673623 B2, 02.06.2020 | |||
| US 9607071 B2, 28.03.2017. | |||

