Настоящее изобретение относится к обработке аудиосигнала и, в частности, к концепциям генерирования аудиосигнала с улучшенной частотной характеристикой из исходного аудиосигнала.
Хранение или передача аудиосигналов часто подвержены строгим ограничениям скорости передачи данных (битрейт). Ранее, кодеры были вынуждены резко сократить полосу пропускания передаваемого аудио, когда был доступен только очень низкий битрейт. В настоящее время модемные аудиокодеки могут кодировать широкополосные сигналы с использованием способов расширения полосы пропускания (BWE) [1-2].
Эти алгоритмы основаны на параметрическом представлении высокочастотного содержимого (ВЧ), которое генерируется из кодированной по форме сигнала низкочастотной части (НЧ) декодированного сигнала посредством транспонирования в ВЧ-спектральную область (патчинг /«patching»). При этом, во-первых, создается «необработанный» патч, а во-вторых, к «необработанному» патчу применяется постобработка, управляемая по параметрам.
Как правило, упомянутая постобработка применяется для корректировки важных свойств, относящихся к восприятию, которые не учитывались во время высокочастотного генерирования посредством транспонирования и, следовательно, должны корректироваться в результирующем «необработанном» патче апостериори.
Однако, если, например, тонкая спектральная структура в патче, скопированном в некоторую целевую область, значительно отличается от тонкой спектральной структуры исходного контента, то в результате могут возникнуть нежелательные артефакты, которые ухудшат качество восприятия декодированного аудиосигнала. Часто в этих случаях применяемая постобработка не может полностью исправить неправильные свойства «необработанного» патча.
Целью изобретения является улучшение качества восприятия посредством нового адаптивного к сигналу генерирования заполняющего промежутки контента или «необработанного» патч-контента для расчетного высокочастотного сигнала, которые адаптированы по восприятию к НЧ-сигналу.
Благодаря получению уже адаптированного по восприятию «необработанного» сигнала, необходимые меры апостериорной коррекции сводятся к минимуму. Более того, адаптированный к восприятию необработанный сигнал может позволить выбрать более низкую частоту разделения между НЧ и ВЧ, чем традиционные подходы [3].
В схемах BWE восстановление ВЧ спектральной области выше заданной так называемой частоты разделения (переходной частоты) часто осуществляется на основе спектрального патчинга. Как правило, ВЧ-область состоит из нескольких наложенных друг на друга патчей, и каждый из этих патчей формируется из ограниченно-полосовых (ПП) областей НЧ-спектра ниже заданной частоты разделения.
Системы согласно уровню техники эффективно выполняют патчинг в пределах набора фильтров или представления частотно-временного преобразования путем копирования набора коэффициентов смежных подполос из исходного спектра в целевую область спектра.
На следующем этапе тональность, шумность и спектральная огибающая настраиваются так, чтобы они были близки к характеристикам восприятия и огибающей исходного ВЧ-сигнала, которые были измерены в кодере и переданы в потоке битов как дополнительная информация BWE.
Репликация спектральной полосы (SBR) - широко известный прием BWE, используемый в современных аудиокодеках, таких как высокоэффективное усовершенствованное аудиокодирование (High Efficiency Advanced Audio Coding (HE-AAC)), и использует описанные выше методы [1].
Интеллектуальное заполнение промежутков (IGF) обозначает метод полупараметрического кодирования в современных кодеках, таких как MPEG-H 3D Audio или кодек 3gpp EVS [2]. IGF может применяться для заполнения спектральных дыр, введенных процессом квантования в кодере из-за ограничений низкого битрейта.
Обычно, если ограниченный битовый бюджет не позволяет прозрачное кодирование, спектральные дыры сначала появляются в высокочастотной (ВЧ) области сигнала и все больше влияют на весь верхний спектральный диапазон для самых низких битрейтов.
На стороне декодера такие спектральные дыры заменяются через IGF с использованием синтетического ВЧ-контента, генерируемого полупараметрическим способом из низкочастотного (НЧ) контента, и постобработки, управляемой дополнительной параметрической информацией, такой как регулировка спектральной огибающей и спектральный «уровень отбеливания».
Однако после указанной постобработки все еще может существовать остающееся несоответствие, которое может привести к восприятию артефактов. Такое несоответствие обычно может состоять из
- Гармонического рассогласования: артефакты биений из-за микширования гармонических составляющих,
- Фазового несовпадения: дисперсия импульсо-подобного возбуждающего сигнала, приводящая к субъективной потере пульсации в голосовой речи или «медному» сигналу,
- Несоответствие тональности: преувеличенная или слишком низкая тональность.
Поэтому были предложены методы частотной и фазовой коррекции для исправления этих типов рассогласования [3] с помощью дополнительной постобработки. В настоящем изобретении авторы предлагают уже избегать появления этих артефактов в «необработанном» сигнале, а не исправлять их на этапе постобработки, как в современных методах.
Другие реализации BWE основаны на методах временной области для оценки ВЧ-сигнала [4], обычно путем приложения нелинейной функции к НЧ форме сигнала во временной области, такого как выпрямление, возведение в квадрат или степенная функция. Таким образом, искажая НЧ, генерируется богатая смесь консонансных и диссонансных обертонов, которую можно использовать в качестве «необработанного» сигнала для восстановления ВЧ содержания.
В этом случае особенной проблемой является гармоническое рассогласование, поскольку при полифоническом содержании эти методы создают плотную смесь желаемых гармонических обертонов, неизбежно микшированных с нежелательными негармоническими компонентами.
В то время как постобработка может легко увеличить зашумленность, она совершенно не в состоянии удалить нежелательные негармонические тональные компоненты, когда они вводятся в «необработанные» расчетные ВЧ.
Задача настоящего изобретения состоит в том, чтобы предоставить усовершенствованную концепцию для генерирования аудиосигнала с улучшенной частотной характеристикой из исходного аудиосигнала.
Эта задача решается с помощью аудиопроцессора по п.1, способа обработки аудиосигнала по п.17, или компьютерной программы по п.18.
Настоящее изобретение основано на обнаружении того, что улучшенное качество восприятия расширения аудио полосы или заполнение промежутка или, в целом, улучшение частотной характеристики достигают с помощью нового адаптивного по сигналу генерирования заполняющего промежутки контента или «необработанного» патч-контента для расчетного высокочастотного (ВЧ) сигнала. Посредством обеспечения адаптированного по восприятию «необработанного» сигнала можно минимизировать или даже исключить необходимые меры апостериорной коррекции.
Варианты осуществления настоящего изобретения, обозначенные как возбуждение импульсов, синхронизированное по огибающей формы сигнала (Waveform Envelope Synchronized Pulse Excitation - WESPE), основаны на генерировании сигнала, подобного последовательности импульсов, во временной области, при этом фактическое размещение импульса синхронизируется с огибающей временной области. Последняя выводится из низкочастотного (НЧ) сигнала, который доступен на выходе, например, базового кодера или который доступен из любого другого источника исходного аудиосигнала. Таким образом, получается адаптированный к восприятию «необработанный» сигнал.
Аудиопроцессор в соответствии с аспектом изобретения выполнен с возможностью генерирования аудиосигнала с улучшенной частотной характеристикой из исходного аудиосигнала и содержит определитель огибающей для определения временной огибающей по меньшей мере части исходного аудиосигнала. Анализатор выполнен с возможностью анализа временной огибающей для определения значений некоторых признаков временной огибающей. Эти значения могут быть временными значениями или энергиями или другими значениями, связанными с упомянутыми признаками. Синтезатор сигнала расположен для генерирования сигнала синтеза, в котором генерирование сигнала синтеза включает в себе размещения импульсов по отношению к определенным временным значениям, где импульсы являются взвешенными с использованием весов, выведенных из амплитуд временной огибающей, при этом амплитуды связаны с временными значениями, в которых помещаются импульсы. Объединяющий блок предусмотрен для объединения, по меньшей мере полосы сигнала синтеза, которая не включена в исходном аудиосигнале, и исходного аудиосигнала, для получения аудиосигнала с улучшенной частотной характеристикой.
Преимущество настоящего изобретения состоит в том, что, в отличие от несколько «слепого» генерирования более высоких частот из исходного аудиосигнала, например, с использованием нелинейной обработки или подобного, настоящее изобретение обеспечивает легко управляемую процедуру путем определения временной огибающей исходного аудиосигнала и помещения импульсов на некоторые признаки временной огибающей, такие как локальные максимумы временной огибающей или локальные минимумы временной огибающей, или помещения импульсов всегда между двумя локальными минимумами временной огибающей, или в любом другом отношении по отношению к некоторым признакам временной огибающей. Импульс имеет частотное содержание, которое, в целом, является плоским по всему рассматриваемому диапазону частот. Таким образом, даже когда используются импульсы, которые не являются теоретически идеальным импульсами, но близки к ним, частотное содержание таких неидеальных импульсов, например импульсов, которые не соответствуют идеальной форме по Дираку, тем не менее является относительно плоским в интересующем частном диапазоне, например, между 0 и 20 кГц в контексте IGF (интеллектуальное заполнение промежутков) или в диапазоне частот, например, от 8 кГц до 16 кГц или 20 кГц в контексте расширения аудио полосы, при этом исходный сигнал является ограниченным по ширине полосы.
Таким образом, синтезируемый сигнал, состоящий из таких импульсов, обеспечивает плотный и легко управляемый высокочастотный контент. Путем размещения множества импульсов по временной огибающей, которая, например, извлекается из кадра исходного аудиосигнала, обеспечивается придание формы в спектральной области, поскольку частотное содержание разных импульсов, размещенных по отношению к некоторым признакам, накладывается друг на друга в спектральной области, чтобы соответствовать, по меньшей мере, доминирующим признакам, или, в общем, некоторым признакам временной огибающей исходного аудиосигнала. В связи с тем, что фазы спектральных значений, представленных импульсами, привязаны друг к другу, и в связи с тем, что, предпочтительно, либо положительные импульсы, либо отрицательные импульсы помещаются синтезатором сигнала, то и фазы спектральных значения, представленных отдельным импульсом среди различных импульсов, привязаны друг к другу. Таким образом, обеспечивается управляемый сигнал синтеза, имеющий очень полезные характеристики в частотной области. Обычно сигнал синтеза представляет собой широкополосный сигнал, распространяющийся по всему существующему диапазону аудио частот, то есть также простирающийся в НЧ-диапазон. Для того, чтобы фактически генерировать конечный сигнал, который в конечном счете, объединяется с исходным аудиосигналом для улучшения частотной характеристики, по меньшей мере, полосу сигнала синтеза, например, высокочастотную полосу, или сигнал, определяемый полосой пропускания, извлекается и добавляется к исходному аудиосигналу.
Идея изобретения имеет потенциал для реализации полностью во временной области, то есть без какого-либо конкретного преобразования. Временная область представляет собой либо типичную временную область, либо фильтрованную с помощью кодирования с линейным предсказанием (LPC) временную область, т. е. сигнал временной области, который был спектрально отбелен и должен быть окончательно обработан с использованием фильтра синтеза LPC, чтобы повторно ввести исходную спектральную форму для использования при рендеринге аудиосигнала. Таким образом, определение огибающей, анализ, синтез сигнала, выделение полосы сигнала синтеза и окончательное объединение могут быть выполнены во временной области, так что любые типично вызывающие задержку спектрально-временные преобразования или временно-спектральные преобразования могут быть исключены. Однако контекст изобретения также является гибким в том смысле, что несколько процедур, таких как определение огибающей, синтез сигнала и объединение, также могут выполняться частично или полностью в спектральной области. Таким образом, реализация настоящего изобретения, т.е. реализация некоторых процедур, требуемых изобретением, во временной или спектральной области всегда может быть полностью адаптирована к соответствующей структуре типичной конструкции декодера, требуемой для некоторого приложения. Контекст изобретения является гибким даже в контексте LPC речевого кодера, где, например, выполняется улучшение частотной характеристики LPC сигнала возбуждения (например, сигнала TCX). Сочетание сигнала синтеза и исходного аудиосигнала выполняются в LPC временной области и окончательное преобразовании из LPC временной области в нормальную временную область выполняется с фильтрами синтеза LPC, где, в частности, обычно предпочтительная регулировка огибающей сигнала синтеза выполняется на этапе фильтра синтеза LPC для соответствующей спектральной области, представленной по меньшей мере одной полосой сигнала синтеза. Таким образом, как правило, необходимые операции постобработки объединяются с регулировкой огибающей в пределах одной ступени фильтра. Такие операции постобработки могут включать в себя LPC фильтрацию синтеза, фильтрацию выделения акцента, известную из речевых декодеров, другие операции постфильтрации, такие как операции постфильтрации низких частот или другие процедуры постфильтрации для улучшения звука, основанные на LTP (Long Term Prediction - прогнозирование с дальним горизонтом), как в TCX декодерах или других декодерах.
Далее предпочтительные варианты настоящего изобретения поясняются со ссылкой на прилагаемые чертежи, на которых:
Фиг.1 - показана блок-схема варианта осуществления аудиопроцессора в соответствии с настоящим изобретением;
Фиг. 2 - показано более подробное описание предпочтительного варианта осуществления определителя огибающей, показанного на фиг. 1;
Фиг.3а представляет собой вариант для вычисления временной огибающей подполосы или полной полосы аудиосигнала;
Фиг. 3b - показана альтернативная реализация генерирования временной огибающей;
Фиг. 3c - показана блок-схема реализации определения аналитического сигнала по фиг. 3a с использованием преобразования Гильберта;
Фиг. 4 - показан предпочтительный вариант выполнения анализатора, показанного на фиг. 1;
Фиг. 5 - иллюстрирует предпочтительную реализацию синтезатора сигналов по фиг. 1;
Фиг.6 - иллюстрирует предпочтительный вариант осуществления аудиопроцессора как устройства или способа, используемых в контексте базового декодера;
Фиг.7 - иллюстрирует предпочтительную реализацию, где объединение сигнала синтеза и исходного аудиосигнала выполняется в LPC области;
Фиг.8 - показан другой вариант осуществления настоящего изобретения, в котором верхнепропускающий фильтр или фильтр с полосой пропускания, регулировка огибающей и объединение исходного аудиосигнала и сигнала синтеза выполняются в спектральной области;
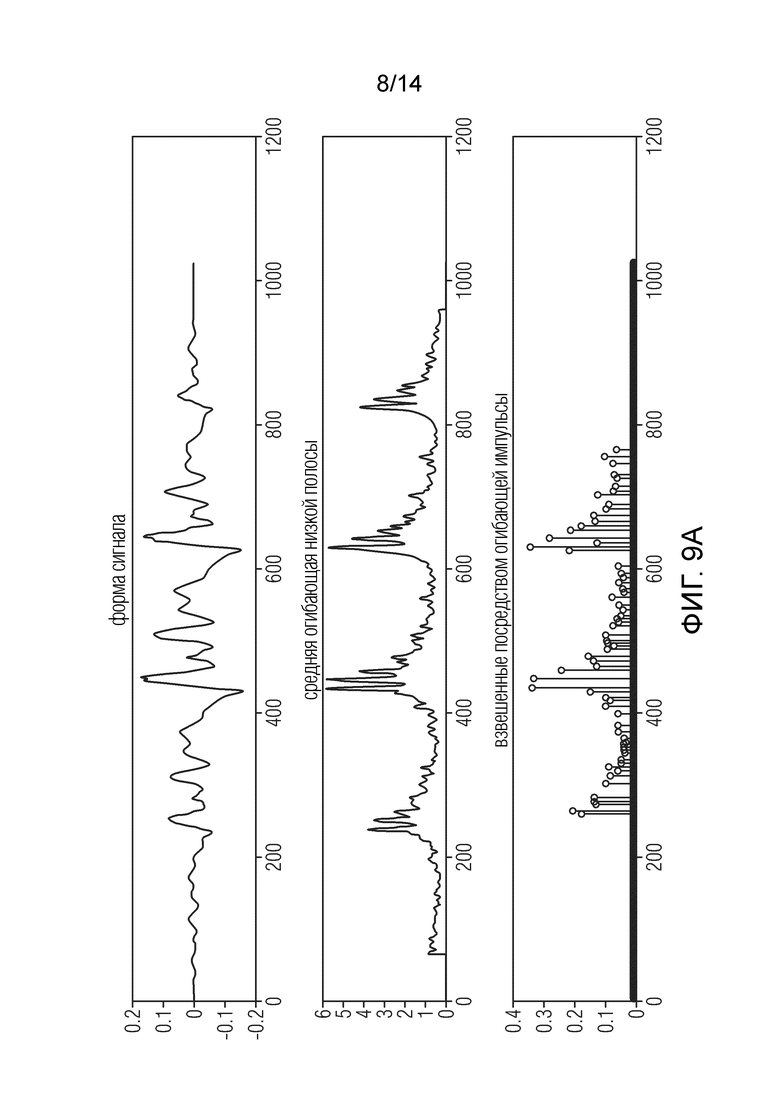
Фиг. 9а - иллюстрирует несколько сигналов в процессе улучшения частотной характеристики по отношению к звуковому элементу «немецкая мужская речь»;
Фиг.9b - иллюстрирует спектрограмму звукового элемента «немецкая мужская речь»;
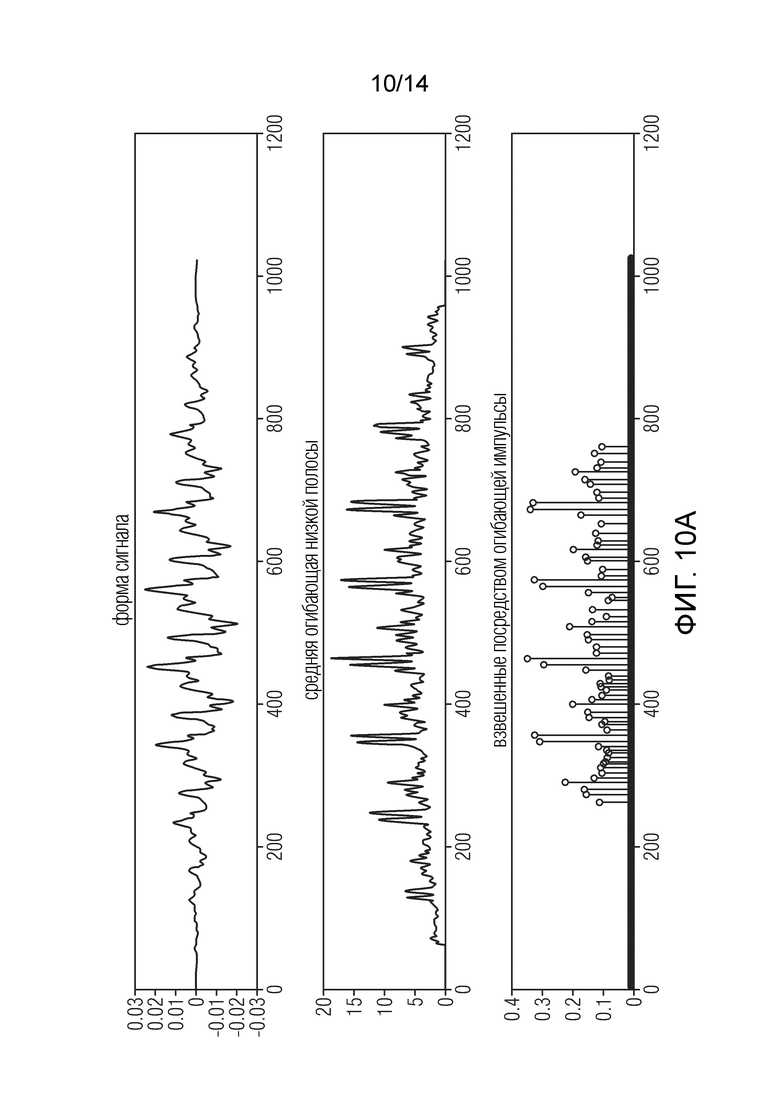
Фиг. 10а - иллюстрирует несколько сигналов в процессе улучшения частотной характеристики по отношению к звуковому элементу «питч-пайп»;
Фиг.10b - показывает спектрограмму звукового элемента «питч-пайп»;
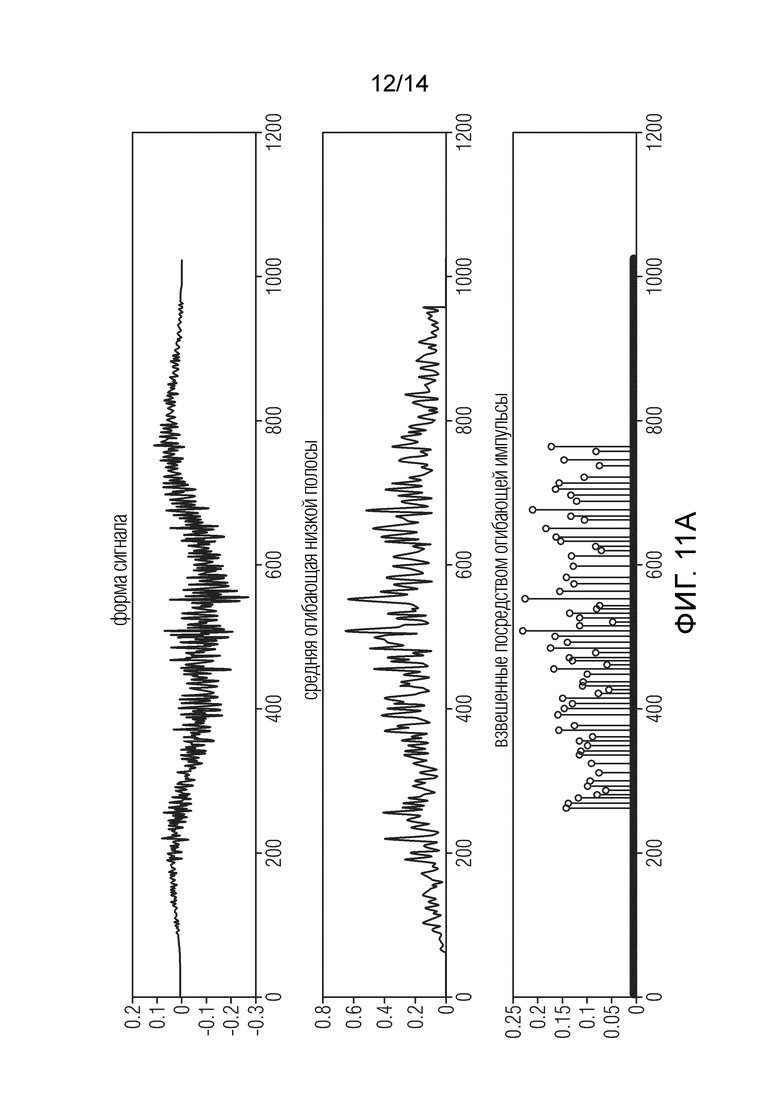
Фиг. 11a - иллюстрирует несколько сигналов в процессе улучшения частотной характеристики по отношению к звуковому элементу «Madonna Vogue»;
Фиг.11b - иллюстрирует несколько сигналов в процессе улучшения частотной характеристики по отношению к звуковому элементу «Madonna Vogue».
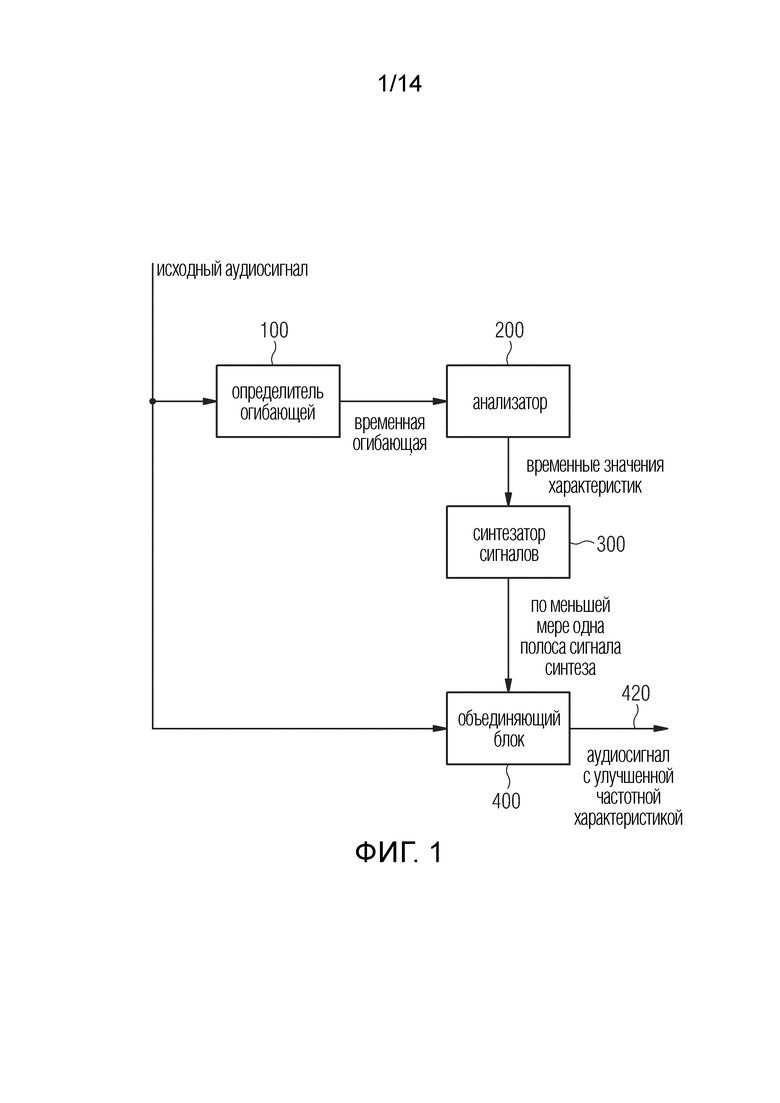
Фиг.1 иллюстрирует аудиопроцессор для генерирования аудиосигнала 420 с улучшенной частотной характеристикой на выходе объединяющего блока 400 из исходного аудиосигнала, вводимого в определитель 100 огибающей, с одной стороны, и ввода в объединяющий блок 400, с другой стороны.
Определитель 100 огибающей выполнен с возможностью определения временной огибающей, по меньшей мере, части исходного аудиосигнала. Определитель огибающей может использовать либо полнополосный исходный аудиосигнал, либо, например, только полосу или часть исходного аудиосигнала, которая имеет некоторую нижнюю граничную частоту, такую как частота, например, 100, 200 или 500 Гц. Временная огибающая передается из определителя 100 огибающей в анализатор 200 для анализа временной огибающей для определения значений некоторых признаков временной огибающей. Эти значения могут быть временными значениями или энергиями, или другими значениями, связанными с упомянутыми признаками. Некоторыми признаками могут быть, например, локальные максимумы временной огибающей, локальные минимумы временной огибающей, переходы через ноль временной огибающей или точки между двумя локальными минимумами или точки между двумя локальными максимумами, где, например, точки между такими признаками являются значениями, которые имеют одинаковое временное расстояние до соседних признаков. Таким образом, такие некоторые признаки также могут быть точками, которые находятся на полпути между двумя локальными минимумами или двумя локальными максимумами. Однако, предпочтительно определение локальных максимумов временной огибающей с использованием, например, вычислительной обработки кривой. Временные значения некоторых признаков временной огибающей передаются в синтезатор 300 сигналов для генерирования сигнала синтеза. Генерирование сигнала синтеза включает размещение импульсов относительно определенных временных огибающих, где импульсы взвешены, либо до размещения, либо после размещения с использованием весов, выведенных из амплитуд временной огибающей, причем амплитуды связаны с временными значениями, полученными от анализатора, или связанны с временными значениями, в которые помещены импульсы.
По меньшей мере одна полоса сигнала синтеза или полная высокочастотная полоса сигнала синтеза или несколько отдельных и различных полос сигнала синтеза или даже весь сигнал синтеза передается в объединяющий блок 400 для объединения, по меньшей мере, полосы сигнала синтеза, которая не включена в исходный аудиосигнал, и исходного аудиосигнала для получения аудиосигнала с улучшенной частотной характеристикой.
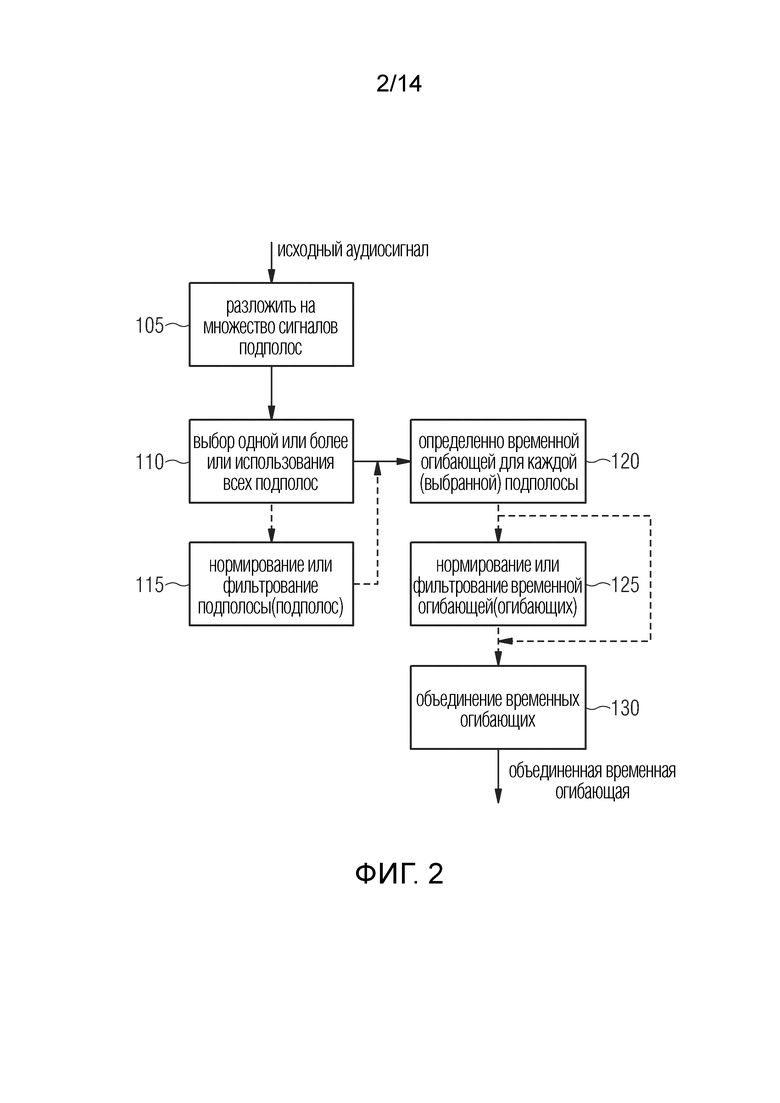
В предпочтительном варианте определитель огибающей сконфигурирован, как показано на фиг. 2. В этом варианте осуществления исходный аудиосигнал, или по меньшей мере часть исходного аудиосигнала, разбивается на множество сигналов подполос, как показано позицией 105. Одна или более, или даже все подполосы выбираются или используются, как показано позицией 110, для определения отдельных временных огибающих для каждой (выбранной) подполосы, как показано позицией 120. Как показано позицией 125, временные огибающие нормируются или фильтруются, и отдельные временные огибающие объединяют друг с другом, как показано позицией 130, чтобы получить конечную временную огибающую на выходе определителя огибающей. Эта конечная временная огибающая может быть объединенной огибающей, как определено процедурой, проиллюстрированной на фиг. 2. В зависимости от реализации может быть предусмотрен дополнительный этап 115 фильтрации для нормирования или фильтрации индивидуально выбранных подполос. Если все подполосы используется, все эти подполосы нормируются или фильтруются, как показано в блоке 115. Процедура нормирования, показанная позицией 125, может быть обойдена, и эта процедура невыполнения нормирования или фильтрации определенных временных огибающих является полезной, когда подполосы, из которых определяются временные огибающие определяются в блоке 120, уже нормированы или соответственно отфильтрованы. Естественно, обе процедуры 115, 125 могут быть выполнены также или, даже в качестве альтернативы, могут выполняться только процедуры определения временной огибающей для каждой (выбранной) подполосы 120, и последующее объединение временных огибающих 130 может выполняться без каких-либо процедур, проиллюстрированных блоком 115 или 125.
В дополнительном варианте осуществления разложение в блоке 105 не может быть выполнено вообще, но может быть заменено на высокопроходную фильтрацию с низкой частотой разделения, такой как частота разделения 20, 50, 100 или, например, частоты ниже 500 Гц, и только одна временная огибающая определяются из результата этой высокопроходной фильтрации. Естественно, высокопроходная фильтрация также может быть исключена, и выводится только одна временная огибающая из исходного аудиосигнала, и, как правило, кадр исходного аудиосигнала, где исходный аудиосигнал предпочтительно обрабатывается в обычно перекрывающихся кадрах, но можно также использовать и неперекрывающиеся кадры. Выбор, показанный в блоке 110, осуществляется в некотором сценарии, когда, например, определенно, что некоторый сигнал подполосы не выполняет конкретные критерии в отношении признаков сигнала подполосы или исключается из определения конечной временной огибающей по любой причине.
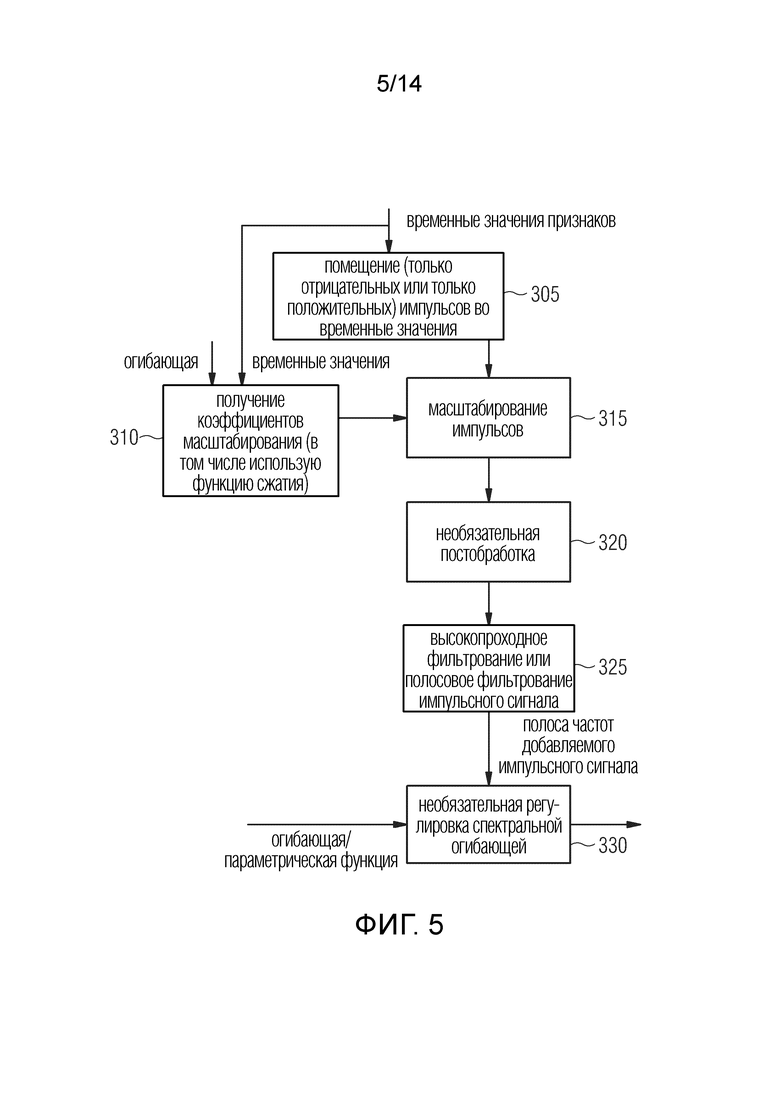
Фиг. 5 иллюстрирует предпочтительную реализацию синтезатора 300 сигналов. Синтезатор 300 сигналов принимает в качестве входных данных от анализатора 200 временные значения признаков и, дополнительно, дополнительную информацию об огибающей. В элементе 310 синтезатор 300 сигналов, показанный на фиг. 5, выводит коэффициенты масштабирования из временной огибающей, которые связаны с временными значениями. Следовательно, блок 310 принимает информацию огибающей, такую как амплитуды огибающей, с одной стороны, и временные значения, с другой стороны. Вывод коэффициентов масштабирования выполняется, например, с использованием функции сжатия, такой как функции квадратного корня, степенная функция с показателем ниже 1,0 или, например, логарифмической функции.
Синтезатор 300 сигналов содержит процедуру размещения 305 импульсов на временных значениях, где, предпочтительно, только отрицательные или только положительные импульсы размещаются для того, чтобы получить синхронизированные фазы соответствующих спектральных значений, которые соотнесены с импульсом. Тем не менее, в других осуществлениях, и в зависимости от, например, других критериев, выведенных из обычно доступного заполнения промежутков или дополнительной информации расширения полосы, выполняется случайное размещение импульсов, как правило, когда тональность сигнала основной полосы не так высока. Размещение отрицательных или положительных импульсы может определяться полярностью первоначальной формы сигнала. Полярность импульсов может быть выбрана таким образом, что она равна полярности исходной формы сигнала, имеющего самый высокий коэффициент амплитуды. Другими словами, это означает, что положительные пики моделируются положительными импульсами и наоборот.
На этапе 315 импульсы, полученные с помощью блока 305, масштабируются с использованием результата от блока 310, и в отношении этих импульсов осуществляется необязательная дополнительная постобработка 320. Импульсный сигнал доступен, и импульсный сигнал подвергается высокопроходной фильтрации или полосовой фильтрации, как показано в блоке 325, чтобы получить полосу частот импульсного сигнала, то есть, для получения по меньшей мере полосы сигнала синтеза, которая передается в объединяющий блок. Однако, необязательная дополнительная регулировка спектральной огибающей 330 применяются к выходному сигналу с этапа 325 фильтрации, где эта регулировка спектральной огибающей выполняется с использованием некоторой функции огибающей или некоторого выбора параметров огибающей, как они выведены из дополнительной информации, или в качестве альтернативы, выведены из исходного аудиосигнала в контексте, например, приложений для слепого расширения ширины полосы.
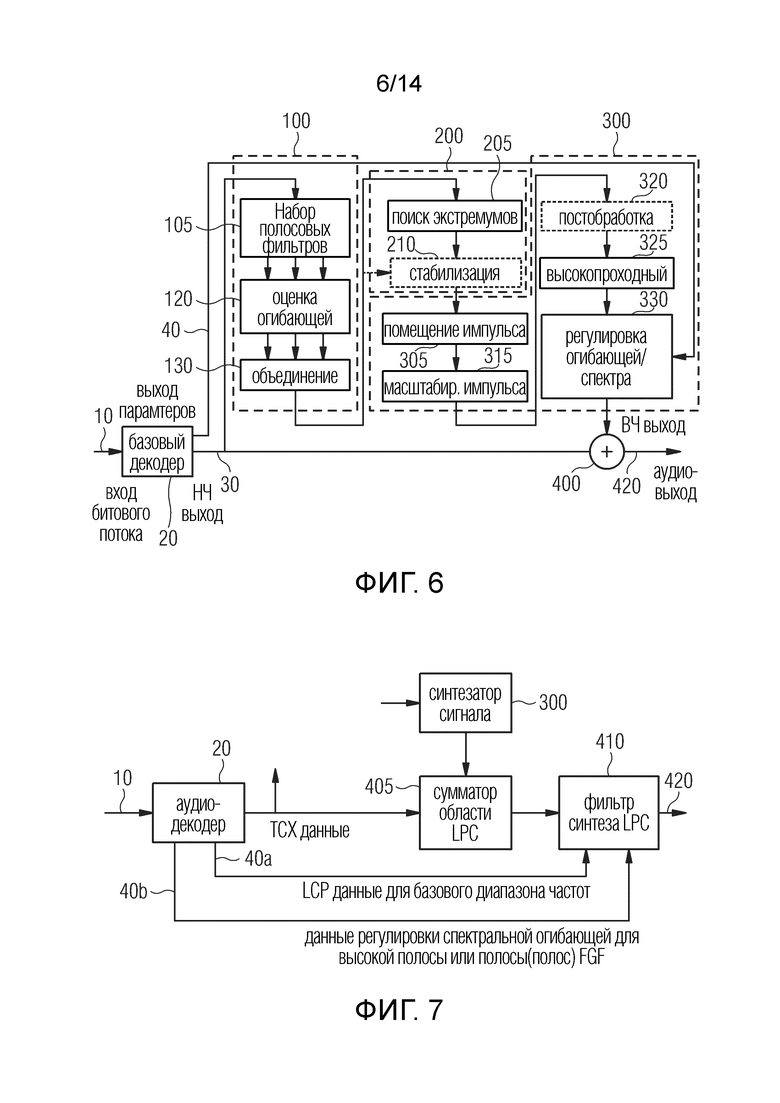
Фиг.6 иллюстрирует предпочтительный вариант осуществления аудиопроцессора или способа обработки аудио для генерирования аудиосигнала с улучшенной частотной характеристикой. Подход, в соответствии с изобретением называемый возбуждением импульсов, синхронизированным по огибающей формы сигнала (WESPE), основан на генерировании сигнала, подобного последовательности импульсов, при этом фактическое размещение импульса синхронизируется с выделенной огибающей во временной области. Это так называемая общая огибающая выводится из НЧ сигнала, который обеспечивается на выходе базового декодера 20, через набор ограниченно-полосовых сигналов, отдельные огибающие которых объединены в одну общую огибающую.
На фиг. 6 показана типичная интеграция обработки WESPE в аудиодекодер, имеющий функцию расширения полосы пропускания (BWE), который также является предпочтительным вариантом реализации нового метода. Эта реализация работает с временными кадрами длительностью, например, 20 мс, необязательно, с временным перекрытием между кадрами, например, 50%.
Преимущества нового предлагаемого метода WESPE BWE
· Устранение артефактов шероховатости и биений
· Гармоничное продолжение сигналов
· Сохранение импульсов
· Подходит как речевой BWE
· Может также работать с музыкой
· BWE разделение может начинаться уже с 2 кГц или ниже
· Саморегулирующийся BWE по тональности, выравниванию высоты тона, гармоничности, фазы
Обработка WESPE состоит из следующих этапов:
1. Оценка 100 временной огибающей: НЧ-сигнал, полученный от базового декодера 20, разделяется (105) на набор ограниченно-полосовых сигналов. Затем временная огибающая определяется 120 для каждого из ограниченно-полосовых сигналов. Необязательно может применяться нормирование или фильтрация отдельных огибающих. Затем все временные огибающие объединяются 130 в общую огибающую. Предпочтительно операция объединения представляет собой процесс усреднения.
2. Размещение синхронизированного импульса: общая огибающая, выведенная на этапе 1, анализируется 205 путем применения расчета кривой, предпочтительно для определения местоположения ее локальных максимумов. Полученные кандидаты на максимумы могут быть, необязательно, повторно выбраны или стабилизированы с учетом их временного расстояния. Импульс Дирака помещается 305 в расчетном «необработанном» сигнале для ВЧ генерирования на месте каждого максимума. Факультативно, этот процесс может поддерживаться дополнительной информацией.
3. Масштабирование амплитуды индивидуального импульса, выведенной из огибающей: последовательность импульсов, собранная на предыдущем этапе 2, взвешивается 315 с помощью временных весов, выведенных из общей огибающей.
4. Постобработка, выбор выделения ВЧ или заполнения промежутка: «Необработанный» сигнал, сгенерированный на этапе 3, необязательно, подвергается постобработке 320, например, путем добавления шума, и фильтруется 325 для использования в качестве ВЧ в BWE или в качестве сигнала целевой плитки для заполнения промежутка.
5. Регулировка энергии: Спектральное распределение энергии отфильтрованного сигнала с этапа 4 регулируется 330 для использования в качестве ВЧ в BWE или в качестве сигнала целевой плитки для заполнения промежутка. Здесь используется дополнительная информация 40 из потока битов о желаемом распределении энергии.
6. Микширование ВЧ сигнала или сигнала заполнения промежутка с НЧ: Наконец, отрегулированный сигнал с этапа 5 микшируется 400 с выходом 30 базового кодера в соответствии с обычным BWE или принципами заполнения промежутка, т. е. проходит высокопроходной фильтр и дополняет НЧ, или заполняет спектральные дыры в промежутках, заполняющих спектральные области.
Далее будет дополнительно объяснена функция каждого из этапов обработки WESPE с приведением примеров сигналов и их влияния на результат обработки.
Правильная оценка общей временной огибающей - это ключевая часть WESPE. Общая огибающая позволяет оценить усредненные и, следовательно, репрезентативные свойства восприятия каждого отдельного временного кадра.
Если НЧ-сигнал очень тональный с шагом f0 и сильным обертонным линейчатым спектром с интервалом Δf0, несколько линий появятся в каждом из отдельных ограниченно-полосовых сигналов, если их ширина полосы может их вместить, создавая сильные когерентные модуляции огибающей за счет биений во всех ограниченно-полосовых полосах. Усреднение временных огибающих сохранит такую когерентную структуру модуляции огибающей, обнаруженную во всех ограниченно-полосовых огибающих, и приведет к сильным пикам в приблизительно равноудаленных местах, расположенных на расстоянии ΔT0=1 / (Δf0). Затем, посредством применения расчета кривой, сильные импульсы будут размещены в этих точках пиков, образуя последовательность импульсов, которая имеет спектр, состоящий из дискретных эквидистантных линий в точках n * Δf0, n=1……N.
В случае, если сильный тональный сигнал либо не имеет обертонов вообще, либо ширина полосы полосовых фильтров не может вместить более одного из этих обертонов в каждой из отдельных полос, структура модуляции не будет отображаться во всех ограниченно-полосовых сигналах и, следовательно, не будет доминировать в усредненной общей огибающей. Результирующее размещение импульсов будет основано на, в основном, неравномерно расположенных максимумах и, следовательно, будет зашумленным.
То же самое верно и для зашумленных НЧ-сигналов, которые демонстрируют случайное локальное размещение максимумов в общей огибающей сигнала: это приводит к псевдослучайному размещению импульсов.
Переходные события сохраняются, так как в этом случае все ограниченно-полосовые сигналы имеют выровненный по времени общий максимум, который, таким образом, также появится в общей огибающей.
Ограничения полосы должны быть рассчитаны таким образом, чтобы они охватывали полосу восприятия, и чтобы они могли вмещать по меньшей мере 2 обертона для наивысшей частоты, которую требуется расщепить. Для лучшего усреднения ограничения полосы могут частично перекрывать их переходные полосы. Таким образом, тональность расчетного сигнала внутренне адаптирована к НЧ-сигналу. Ограничения полосы могут исключать очень низкие частоты ниже, например, 20 Гц.
Синхронизированное временное размещение импульсов и масштабирование импульсов - еще один ключевой аспект WESPE. Синхронизированное размещение импульсов наследует характерные свойства восприятия, сжатые во временных модуляциях общей огибающей, и отпечатывает их в адаптированном по восприятию необработанном полнополосном сигнале.
Следует отметить, что человеческое восприятие высокочастотного контента, как известно, функционирует через оценку модуляций в огибающих критических полос. Как было подробно описано ранее, временное размещение импульсов, синхронизированное с общей НЧ огибающей, обеспечивает сходство и выравнивание релевантной для восприятия временной и спектральной структуры между НЧ и ВЧ.
В случае очень тональных сигналов с сильными и чистыми обертонами, таких как, например, питч-пайп, WESPE может гарантировать с помощью дополнительной необязательной стабилизации, что размещение импульсов точно равноудалено, что приводит к очень тональному ВЧ спектру обертонов «необработанного» сигнала.
Взвешивание импульсов с помощью общей огибающей гарантирует, что доминирующие модуляции сохраняются в сильных импульсах, тогда как менее важные модуляции приводят к слабым импульсам, дополнительно способствуя свойству WESPE обеспечивать внутреннюю адаптацию "необработанного" сигнала к НЧ-сигналу.
В случае сигнала с шумами, если размещение импульсов и взвешивание становится все более случайным, это приводит к последовательно зашумленному «необработанному» сигналу, что является очень желательным признаком.
Остальные этапы обработки, выделение ВЧ, регулировка энергии и микширование являются дальнейшими шагами, которые необходимы, чтобы интегрировать новую обработку WESPE в кодек, чтобы соответствовать полнофункциональному BWE или заполнению промежутков.
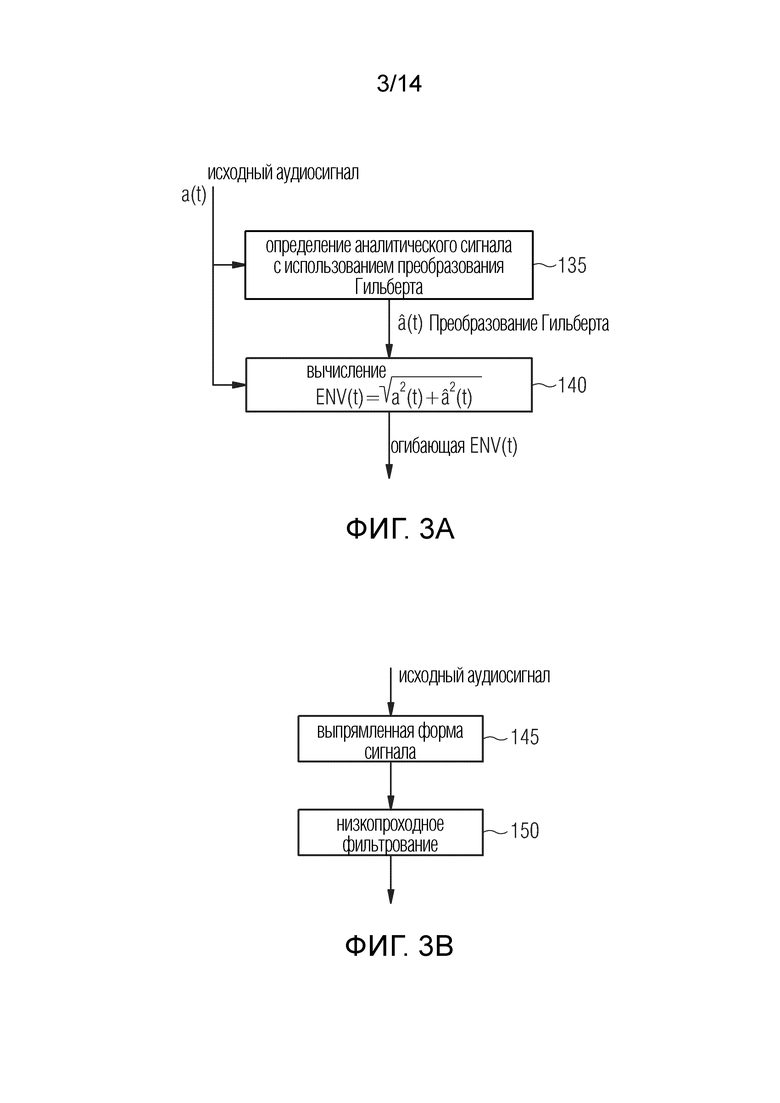
Фиг. 3a иллюстрирует предпочтительную реализацию для определения временной огибающей. Как показано позицией 135, аналитический сигнал определяется с использованием преобразования Гильберта. Выход блока 135, то есть сигнал преобразования Гильберта, используется для вычисления огибающей ENV(t), показанной позицией 140. С этой целью огибающая вычисляется как возведение в квадрат временных значений исходного аудиосигнала в некоторые моменты времени и возведение в квадрат соответствующих значений преобразования Гильберта в некоторые моменты времени, а также сложение возведенных в квадрат значений и вычисление квадратного корня из результата сложения для каждого отдельного момента времени. Посредством этой процедуры временная огибающая определяется с тем же разрешением выборки (сэмпла), что и исходный аудиосигнал a(t). Разумеется, та же самая процедура выполняется, если вход в блок 135 и 140 представляет собой сигнал подполосы, полученный в блоке 105, или выбранный блоком 110 или как нормирован и отфильтрован с помощью блока 115 на фиг. 2.
Другая процедура вычисления временной огибающей проиллюстрирована в блоках 145 и 150 на фиг. 3b. В этом случае форма сигнала исходного аудиосигнала или подполосы исходного аудиосигнала выпрямляется (145), и выпрямленный сигнал подвергается низкопроходной фильтрации (150), и результатом этой низкопроходной фильтрации является огибающая исходного аудиосигнала или является огибающая индивидуального сигнала подполосы, который объединяется с другими такими огибающими от других подполос, предпочтительно посредством усреднения, как проиллюстрировано позицией 130 на фиг.2.
Публикация «Simple empirical algorithm to obtain signal envelope in the three steps”, by C. Jarne, 20 марта 2017 г., иллюстрирует другие процедуры расчета временных огибающих, такие как вычисление мгновенного среднеквадратичного значения (RMS) формы сигнала через скользящее окно с конечной опорой. Другие процедуры состоят в вычислении кусочно-линейной аппроксимации формы сигнала, где огибающая амплитуды создается путем нахождения и соединения пиков формы сигнала в окне, которое перемещается по данным. Дальнейшие процедуры основываются на определении постоянных пиков в исходном аудиосигнале или сигнале подполосы и выведения огибающей путем интерполяции.
Другие процедуры для вычисления временной огибающей включают интерпретацию дополнительной информации, представляющей огибающую, или выполнение предсказания в спектральной области по набору спектральных значений, выведенных из кадра временной области, как известно из TNS (Временное формирование шума/Temporal Noise Shaping), где соответствующие коэффициента предсказания представляют временную огибающую кадра.
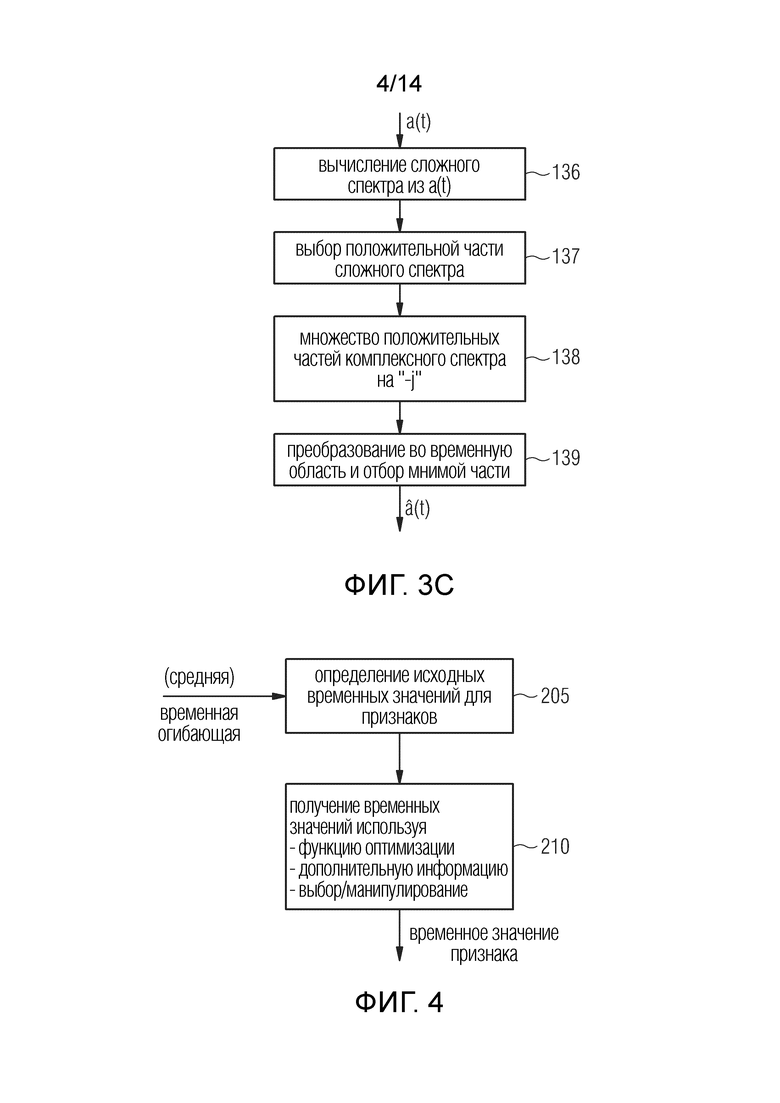
Фиг. 3c иллюстрирует предпочтительную реализацию определения аналитического сигнала с использованием преобразования Гильберта, обозначенного позицией 135 на фиг. 3a. Процедуры для вычисления таких преобразований Гильберта, например, проиллюстрированы в «A Praat-Based Algorithm to Extract the Amplitude Envelope and Temporal Fine Structure Using the Hilbert Transform”, He, Lei, et al, INTERSPEECH 2016-1447, стр. 530-534. На этапе 136 сложный спектр вычисляется из сигнала a(t), например, исходного аудиосигнала или сигнала подполосы. На этапе 137 выбирается положительная часть сложного спектра или отменяется выбор отрицательной части. На этапе 138, положительная часть сложного спектра умножается « - j» и, на этапе 139, результат этого умножения преобразуется во временную область и, взяв мнимую часть, получают аналитический сигнал 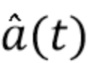 .
.
Разумеется, доступны многие другие процедуры для определения временной огибающей, и следует отметить, что временная огибающая не обязательно должна фактически «огибать» сигнал во временной области, но, конечно, может быть так, что определенные максимумы или минимумы сигнала во временной области выше, или ниже, чем соответствующее значение огибающей в данный момент времени.
Фиг.4 иллюстрирует предпочтительный вариант осуществления процедуры определения временных значений некоторых признаков временной огибающей. С этой целью в блок 205 вводится средняя временная огибающая для определения начальных временных значений для признаков. Эти начальные временные значения могут, например, быть временными значениями фактически найденных максимумов в пределах временной огибающей. Конечные временные значения признаков, при которых размещены фактические импульсы, выводятся из необработанных временных значений или из «начальных» временных значений с помощью функции оптимизации, при помощи дополнительной информации, или с помощью выбора или манипулирования необработанными признаками, как показано блоком 210. Предпочтительно, блок 210 такой, что начальными значениями манипулируют в соответствии с правилом обработки или в соответствии с функцией оптимизации. В частности, функция оптимизации или правило обработки реализованы так, что временные значения помещаются в растр с интервалом T растра. В частности, интервал T растра и/или положение растра во временной огибающей таковы, что значение отклонения между временными значениями и начальными временными значениями имеет предварительно определенную характеристику, где, в вариантах осуществления, значение отклонения является суммой квадратов разностей, и/или заданная характеристика является минимумом. Таким образом, после определения начальных временных значений размещается растр эквидистантных временных значений, который максимально соответствует непостоянному растру исходных временных значений, но теперь отражает четкое и идеальное тональное поведение. Растр может быть определен в области с увеличенным разрешением, имеющей более тонкую временную зернистость по сравнению с областью без увеличенного разрешения, или можно в качестве альтернативы использовать дробную задержку для размещения импульсов с повышением точности субдискретизации.
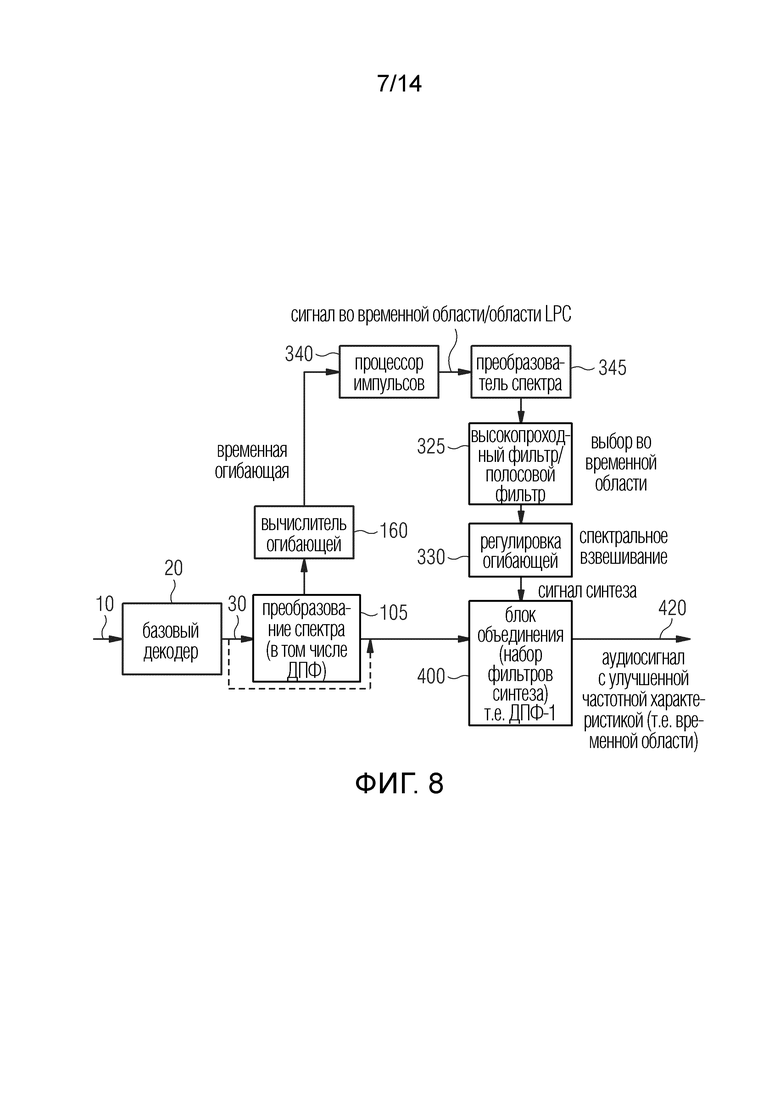
Фиг.7 иллюстрирует дополнительный вариант осуществления настоящего изобретения в контексте LPC обработки. Как показано, например, на фиг. 1 или фиг. 6, аудиопроцессор по фиг. 7 содержит определитель 100 огибающей, анализатор 200 (оба не показаны на фиг. 7) и синтезатор 300 сигналов. В отличие от фиг. 6, однако, выходные данные базового декодера, то есть НЧ выходной сигнал 30, не является аудиосигналом во временной области, а является аудиосигналом, который находится в LPC временной области. Такие данные можно найти, как правило, в TCX кодере (Преобразование кодированного возбуждения/Transform Coded eXcitation) в качестве внутреннего представления сигнала.
TCX данные, генерируемые аудиодекодером 20 на фиг. 7, направляются в микшер как показано на фиг. 7 в качестве сумматора 405 области LPC. Синтезатор сигнала генерирует TCX данные с улучшенной частотной характеристикой. Таким образом, сигнал синтеза, генерируемый синтезатором сигнала, выводится из исходного аудиосигнала, являющегося TCX сигналом данных в этом варианте осуществления. Таким образом, на выходе блока 405 доступен аудиосигнал с улучшенной частотной характеристикой, который, однако, все еще находится в LPC временной области. Затем подключенный фильтр 410 синтеза LPC выполняет преобразование сигнала LPC временной области во временную область.
Фильтр синтеза LPC сконфигурирован с возможностью дополнительно выполнять вариант коррекции предискажений, если это требуется, и, кроме того, этот фильтр во временной области выполнен с возможностью также выполнять регулировку спектральной огибающей для полосы сигнала синтеза. Таким образом, фильтр 410 синтеза LPC на фиг.7 не только выполняет фильтрацию синтеза частотного диапазона TCX данных, выводимого аудиодекодером 20, но также выполняет регулировку спектральной огибающей для данных в спектральном диапазоне, который не включен в вывод TCX данных аудиодекодером 20. Обычно эти данные также получаются из кодированного аудиосигнала 10 посредством аудиодекодера 20, извлекающего LPC данные 40a для основного диапазона частот и дополнительно извлекающего регулировку спектральной огибающей для верхней полосы или для IGF (интеллектуального заполнения промежутков), одной или нескольких полос, обозначенных позицией 40b на фиг. 7. Таким образом, объединяющий блок или микшер на фиг. 1 реализуется сумматором 405 области LPC и последовательно подключенным фильтром 410 синтеза LPC на фиг. 7, так что выходной сигнал фильтра 410 синтеза LPC, обозначенный позицией 420, является аудиосигналом во временной области с улучшенной частотной характеристикой. В отличие от процедуры на фиг. 6, где регулировка 330 спектральной огибающей выполняется перед выполнением операции микширования с помощью объединителя 400, на фиг. 7 выполняется регулировка огибающей полосы высоких частот или полосы заполнения после микширования или объединения обоих сигналов.
Фиг. 8 иллюстрирует дальнейшее осуществление процедуры, показанной на фиг. 6. В основном, на фиг. 6 выполняется реализация во временной области, так что блоки 320, 325, 330, 400 реализуются полностью во временной области. В качестве альтернативы, реализация по фиг. 8 относится к преобразованию 105 спектра для низких полос, которое, однако, является необязательной мерой, но операция 105 преобразования спектра 105 на фиг.8 для низких полос преимущественно используется для реализации набора 105 полосовых фильтров на фиг. 6. Кроме того, осуществление по фиг. 8 включает в себя преобразователь 345 спектра для преобразования выходного сигнала процессора 340 импульсов, как правило, включающее размещение импульса 305 и масштабирование импульсов 315 по фиг. 6. Процессор 340 импульсов на фиг. 8 может дополнительно включать в себя блок 210 стабилизатора в качестве необязательной функции, и блок 205 поиска экстремума в качестве необязательной функции.
Однако, процедуры высокопроходной фильтрации 325, регулировки 330 огибающей и объединения низких и высоких полос выполняются набором фильтров синтеза, т. е. выполняются в спектральной области, и вывод набора 400 фильтров синтеза по фиг. 8 предоставляет собой аудиосигнал 420 с улучшенной частотной характеристикой во временной области. Однако, если элемент 400 реализован как простой объединяющий блок для объединения различных полос, выходом блока 400 также может быть сигнал полной спектральной области, обычно состоящий из последовательных блоков спектральных значений, которые в дальнейшем обрабатываются любым необходимым способом.
Далее приведены три примера характеристических сигналов, ширина полосы которых была расширена с помощью WESPE BWE. Частота дискретизации составляла 32 кГц, дискретное преобразование Фурье (ДПФ) (105 на фиг. 8) с односторонним спектром, имеющим 513 линий, использовалось для выделения 8 перекрывающихся ограниченно-полосовых сигналов. Для реализации высокочастотного прохода 4 кГц (325 на фиг.8), регулировки спектральной огибающей (330 на фиг.8) и микширования (400 на фиг.8) НЧ и ВЧ применялось аналогичное ДПФ/ОДПФ (345 на фиг. 8) с 50% перекрытием, организованных в 16 масштабированных с единым коэффициентом полосах. Результирующий сигнал, показанный на спектрограммах, является некодированным PCM (ИКМ) от DC до 4 кГц и сгенерированном посредством WESPE от 4 до 16 кГц.
На фиг. 9a показан короткий отрывок (один блок из 1024 выборок) формы сигнала, общая огибающая и результирующее синхронизированное и масштабированное размещение импульсов WESPE. Большие импульсы с небольшой дисперсией расположены примерно на равном расстоянии в широкой периодической структуре.
На фиг. 9b изображена спектрограмма всего тестового элемента. Вертикальная импульсная структура вокализованной речи поддерживает согласованное выравнивание между НЧ и ВЧ, тогда как фрикативные звуки демонстрируют шум, подобный ВЧ-структуре.
Таким образом, фиг. 9a показывает, как WESPE моделирует речевые импульсы, показывает форму сигнала, общую огибающую и генерирование импульса, где элементом является «немецкая мужская речь». Фиг. 9b показывает, как WESPE моделирует речевые импульсы, и показывает спектрограмму. Элементом является "немецкая мужская речь".
На фиг. 10a показан короткий отрывок (один блок из 1024 выборок) формы сигнала, общая огибающая и результирующее синхронизированное и масштабируемое размещение импульсов WESPE. Отчетливые резкие импульсы расположены на равном расстоянии в узкой периодической структуре. На фиг.10b изображена спектрограмма всего тестового элемента. Горизонтальная линейная структура «питча-пайпа» выдерживает согласование между НЧ и ВЧ, однако ВЧ также несколько шумный и будет полезна дополнительная стабилизация.
Фиг. 10a показывает, как WESPE моделирует гармонические обертоны, и показывает форму сигнала, общую огибающую, и генерирования импульсов. Элементом является «питч-пайп». Фиг. 10b показывает, как WESPE моделирует гармонические обертоны, и показывает спектрограмму. Элементом является «питч-пайп».
Фиг. 11a показывает короткий фрагмент (один блок из 1024 выборок) формы сигнала тестового элемента «Madonna Vogue», общую огибающую и результирующее синхронизированное и масштабируемое размещение импульсов WESPE. Размещение и масштабирование импульсов имеют практически случайную структуру. На фиг. 11b изображена спектрограмма всего тестового элемента. Вертикальные переходные структуры поп-музыки поддерживают согласованное выравнивание между НЧ и ВЧ, тогда как тональность ВЧ в основном низкая.
Фигура 11a показывает, как WESPE моделирует смесь шумов, а также показывает форму сигнала, общую огибающую, и генерирование импульсов. Элементом является «Vogue». Фиг.11b показывает, как WESPE моделирует смесь шумов и показывает спектрограмму. Элементом является «Vogue».
Концевая вставка C.
Первое изображение на фиг. 9a, 10a, 11a иллюстрирует форму сигнала блока из 1024 выборок исходного сигнала низкой полосы. Кроме того, влияние фильтра анализа на извлечение блока выборок показано в том, что форма сигнала равна 0 в начале блока, то есть в выборке 0, и также 0 в конце блока, т. е. в выборке 1023. Такая форма сигнала, для примера, доступна на входе в блок 100 по фиг. 1, или в позиции 30 на фиг. 6. Вертикальная ось на фиг. 9a, 9b, 9c всегда указывает на амплитуду временной области, а горизонтальная ось на этих фигурах всегда указывает на переменную времени и, в частности, номер выборки, как правило, составляющий от 0 до 1023 для одного блока.
Второе изображение на фиг. 9a, 10a, 10b показывает усредненную огибающую низкой полосы и, в частности, только положительную часть огибающей низкой полосы. Естественно, огибающая низкой полосы обычно симметрична и также простирается в отрицательный диапазон. Однако, требуется только положительная часть огибающей низкой полосы. Из фиг. 9a, 10a и 11a видно, что в этом варианте осуществления огибающая была вычислена только при исключении первой пары выборок блока и последней пары выборок блока, что, однако, совсем не является проблемой, поскольку блоки предпочтительно вычисляются с перекрытием. Таким образом, второе изображение на фиг. 9a, 10a, 11a, как правило, иллюстрируют, например, вывод блока 100 на фиг. 1 или вывод блока 130 на фиг. 2.
Третье изображение на фиг. 9а, 10а, 11а, показывает сигнал синтеза после масштабирования импульса, то есть после обработки, при которой импульсы размещаются на временных значениях признаков огибающей и взвешены по соответствующим амплитудам огибающей. Фиг.9а, 10а, 11а показывают, что размещенные импульсы распространяются только от выборки 256 до выборки 768. Таким образом, сигнал, состоящий из взвешенных импульсов, распространяется только на 512 выборки и не имеет какой-либо части перед этими выборками и после этих выборок, то есть покрывает среднюю часть кадра. Это отражает ситуацию, когда предыдущий кадр имеет перекрытие, а следующий кадр также имеет перекрытие. С целью генерирования импульсного сигнала с последующими блоками, импульсный сигнал от следующего блока также будет обрабатываться так, что его первая четверть и последняя четверть отсутствуют, и, следовательно, импульсный сигнал следующего блока будет помещен сразу после проиллюстрированного импульсного сигнала текущего блока на фиг. 9а, 10а, 11а. Эта процедура очень эффективна, поскольку нет необходимости в каких-либо операциях наложения/сложения импульсного сигнала. Однако, если требуется, также могут выполняться любые процедуры наложения/сложения или любые процедуры перекрестного замирания от одного кадра к другому относительно импульсного сигнала.
Фиг. 9b, 10b, 11b иллюстрируют спектрограммы. Горизонтальная ось представляет время, но не время относительно выборок, как на фиг.9a, 10a, 11a, а время относительно номеров блоков ДПФ. Вертикальная ось показывает частотный спектр от низких частот внизу соответствующих фигур до высоких частот вверху соответствующих фигур. Горизонтальный диапазон простирается от 0 до 16 кГц, так что нижняя четверть представляет собой исходный сигнал и верхние три четверти представляют собой сигнал синтеза. Таким образом, фиг. 9b, 10b, 11b иллюстрируют аудиосигнал с улучшенной частотной характеристикой, тогда как только нижняя четверть этих фигур иллюстрирует исходный аудиосигнал.
Фигуры показывают, что структура низкой полосы очень хорошо отражается в высокой полосе. Это особенно заметно по отношению к фиг. 10b, на которой изображен питч-пайп, когда три разных тона питч-пайпа воспроизводятся один за другим слева направо на фиг. 10b. В частности, первая часть слева на фиг. 10b - это самый низкий тон питч-пайпа, средняя часть - это средний тон питч-пайп, а правая часть на фиг. 10b - это самый высокий тон питч-пайп. Питч-пайп, в частности, характеризуется очень тональным спектром, и кажется, что настоящее изобретение особенно полезно для очень хорошего воспроизведения гармонической структуры при более высоких 12 кГц.
По отношению к третьему тестовому элементу, становится понятным, что структура низкой полосы для такого элемента поп музыки очень хорошо трансформируются в диапазон высоких частот с помощью процедуры согласно изобретению.
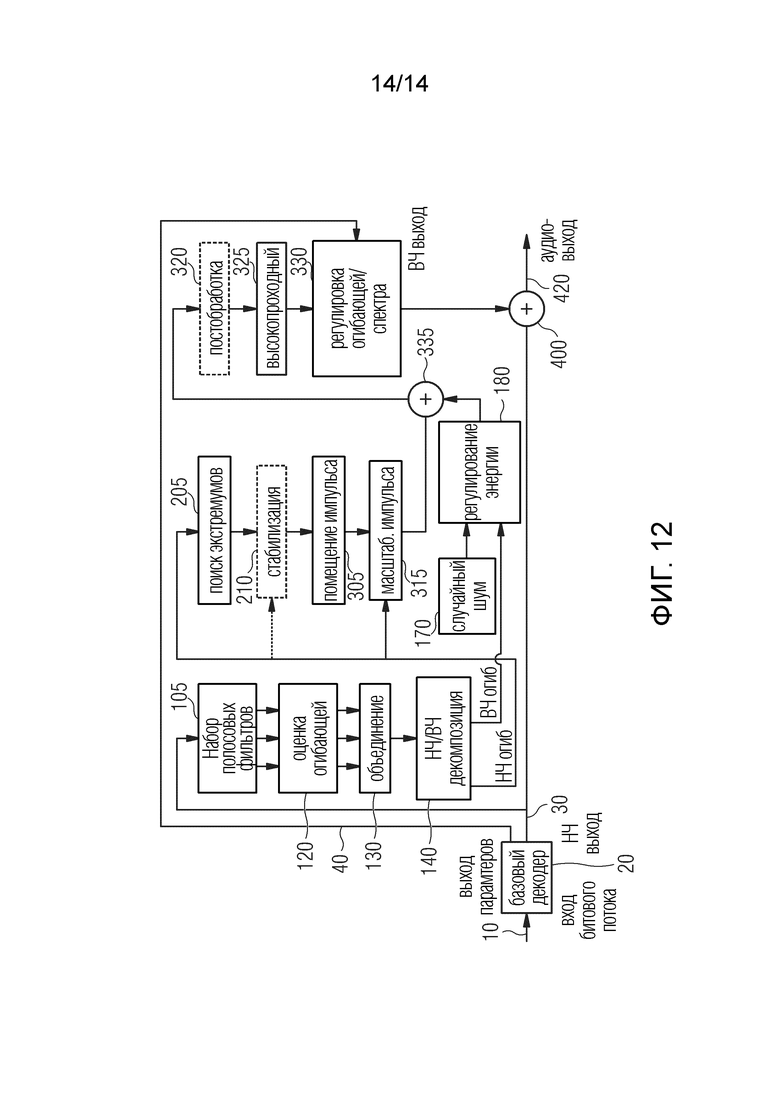
Фиг.12 иллюстрирует дополнительный вариант осуществления, который в определенной степени аналогичен варианту осуществления по фиг.6. Следовательно, аналогичные ссылочные позиции на фиг. 6 обозначают элементы, аналогичные элементам на фиг. 12. В дополнение к особенностям по фиг. 6, вариант реализации по фиг. 12 дополнительно содержит блок 160 НЧ/ВЧ-декомпозиции, генератор 170 случайного шума или псевдослучайного шума, такой как шумовой стол или что-то в этом роде, и регулятор 180 энергии.
Блок 160 НЧ/ВЧ-декомпозиции обеспечивает разложение временной огибающей на НЧ-огибающую и ВЧ-огибающую. Предпочтительно, НЧ огибающая определяется низкопроходной фильтрацией, а ВЧ огибающая определяется вычитанием ВЧ огибающей из НЧ огибающей.
Генератор 170 случайного шума или псевдослучайного шума генерирует сигнал шума и регулятор 180 энергии регулирует энергию шума к энергии ВЧ огибающей, которая также оценивается в блоке 180. Этот шум, энергия которого согласована с энергией ВЧ огибающей (без каких-либо вкладов от НЧ огибающей), добавляется сумматором 335 к взвешенной последовательности импульсов на выходе блока 315. Однако, порядок блоков или этапов обработки 315, 335, например, также можно изменить.
С другой стороны, процедуры, относящиеся к элементам 205-315, применяются только к НЧ огибающей, как определено блоком 160.
Предпочтительный вариант осуществления, основанный на разложении полнополосовой огибающей по меньшей мере на две части, включает следующие блоки или этапы, указанные ниже, или в любом другом технически возможном порядке:
Оценка временной огибающей 100: выпрямление; сжатие с использованием, например, функции x^0,75; последующее разделение 160 огибающей на НЧ огибающую и ВЧ огибающую. НЧ огибающая обеспечивается посредством низкопроходной фильтрации, где частота разделения составляет, например, 2-6 кГц. В одном варианте осуществления ВЧ огибающая представляет собой разность между исходной огибающей и, предпочтительно, отрегулированной с задержкой НЧ огибающей.
Размещение 300 синхронизированных импульсов. НЧ огибающая, выведенная на этапе, описанном выше, анализируется, например, с помощью вычисления кривой, и размещение импульсов выполняется в положениях максимумов НЧ огибающей.
Масштабирование 315 амплитуды индивидуального импульса, выведенной из огибающей: последовательность импульсов, собранная на этапе, описанном выше, взвешивается с помощью временных весов, выведенных из НЧ огибающей.
Энергия ВЧ огибающей оцениваются, и случайный шум той же энергии добавляется 335 к взвешенным импульсам.
Постобработка, выбор извлечения ВЧ или заполнения промежутка: «Необработанный» сигнал, сгенерированный на этапе, описанном выше на выходе блока 335, необязательно, подвергается постобработке 320, например, путем добавления шума, и фильтруется 325 для использования в качестве ВЧ в BWE или как сигнал целевой плитки для заполнения промежутка.
Регулировка 330 энергии: Спектральное распределение энергии отфильтрованного сигнала из оценки энергии, как обрисовано в общих чертах на вышеупомянутом этапе, регулируется для использования в качестве ВЧ в BWE или в качестве сигнала целевой литки для заполнения промежутка. Здесь предпочтительно используется вспомогательная информация из битового потока относительно нужного распределения энергии.
Микширование 400 ВЧ или сигнала заполнения промежутка с НЧ: Наконец, скорректированный сигнал с этапа 5 микшируется с выходным сигналом базового кодера в соответствии с обычным BWE или принципами заполнения промежутка, то есть прохождение HP-фильтра и дополнение НЧ или заполнение спектральных дыр в спектральных областях, заполняющих промежутки.
Здесь следует упомянуть, что все альтернативы или аспекты, как обсуждалось ранее, и все аспекты, определенные независимыми пунктами формулы изобретения в следующей формуле изобретения, могут использоваться индивидуально, т.е. без какой-либо другой альтернативы или объекта, кроме предполагаемой альтернативы, объекта или независимого пункта формулы изобретения. Однако, в другом варианте, две или более альтернатив или аспектов или независимых пунктов формулы могут быть объединены друг с другом, а в другом варианте - все аспекты или альтернативы и все независимые пункты формулы изобретения могут быть объединены друг с другом.
Кодированный согласно изобретению аудиосигнал может быть сохранен на цифровом носителе данных или энергонезависимом носителе данных или может быть передан в среде передачи, такой как беспроводная среда передачи, или проводная среда передачи, такая как Интернет.
Хотя некоторые аспекты были описаны в контексте устройства, ясно, что эти аспекты также представляют описание соответствующего способа, где блок или устройство соответствуют этапу способа или признаку этапа способа. Аналогично, аспекты, описанные в контексте этапа способа, также представляют собой описание соответствующего блока, элемента или функции соответствующего устройства.
В зависимости от некоторых требований реализации изобретение может быть реализовано аппаратно или программно. Реализация может быть выполнена с использованием цифрового носителя данных, например, дискеты, DVD, CD, ROM, PROM, EPROM, EEPROM или флэш-памяти, на которых хранятся электронно-читаемые управляющие сигналы, которые взаимодействуют (или способны взаимодействовать) с программируемой компьютерной системой, чтобы выполнялся соответствующий способ.
Некоторые варианты в соответствии с изобретением содержат носитель данных с электронно-считываемыми управляющими сигналами, которые способны взаимодействовать с программируемой компьютерной системой, так что выполняется один из способов, описанных в настоящей заявке.
Как правило, настоящее изобретение может быть реализовано как компьютерный программный продукт с программным кодом, причем программный код действует для выполнения одного из способов, когда компьютерный программный продукт выполняется на компьютере. Программный код может, например, храниться на машиночитаемом носителе.
Другие варианты содержат компьютерную программу для выполнения одного из описанных способов, хранящуюся на машиночитаемом носителе или энергонезависимом носителе.
Другими словами, вариант осуществления способа согласно настоящему изобретению представляет собой компьютерную программу, имеющую программный код для выполнения одного из способов, описанных в настоящей заявке, когда компьютерная программа выполняется на компьютере.
Следовательно, дополнительным вариантом осуществления способов по изобретению является носитель данных (или цифровой носитель данных, или машиночитаемый носитель), содержащий записанную на нем компьютерную программу для выполнения одного из способов, описанных в настоящей заявке.
Дальнейший вариант осуществления способа по настоящему изобретению, следовательно, представляет собой поток данных или последовательность сигналов, представляющих компьютерную программу для выполнения одного из способов, описанных в настоящей заявке. Поток данных или последовательность сигналов могут, например, сконфигурированы для передачи через соединение для передачи данных, например, через Интернет.
Дополнительный вариант осуществления содержит средство обработки, например компьютер, или программируемое логическое устройство, сконфигурированное или приспособленное для выполнения одного из способов, описанных в настоящей заявке.
Еще один вариант осуществления включает компьютер, на котором установлена компьютерная программа для выполнения одного из способов, описанных в настоящей заявке.
В некоторых вариантах может использоваться программируемое логическое устройство (например, программируемая вентильная матрица) для выполнения некоторых или всех функций способов, описанных в настоящей заявке. В некоторых из них программируемая вентильная матрица может взаимодействовать с микропроцессором для выполнения одного из способов, описанных в настоящей заявке. Обычно способы предпочтительно выполняются с помощью любого аппаратного устройства.
Вышеописанное является просто иллюстрацией принципов настоящего изобретения. Понятно, что модификации и вариации компоновок и деталей, описанных в настоящей заявке, будут очевидны другим специалистам в данной области техники. Следовательно, он должен быть ограничен только объемом приведенной формулы изобретения, а не конкретными деталями, представленными в виде описания и объяснения цели в настоящей заявке.
Источники информации
[1] Dietz, M., Liljeryd, L., Kjörling, K., and Kunz, 0., "Spectral Band Replication, a Novel Approach in Audio Coding," in Audio Engineering Society Convention 112, 2002.
[2] Disch, S., Niedermeier, A., Helmrich, C. R., Neukam, C., Schmidt, K., Geiger, R., Lecomte, J., Ghido, F., Nagel, F., and Edler, B., "Intelligent Gap Filling in Percep-tual Transform Coding of Audio,” in Audio Engineering Society Convention 141, 2016.
[3] Laitinen M-V., Disch S., Oates C., Pulkki V. “Phase derivative correction of bandwidth extended signals for perceptual audio codecs.” In 140th Audio Engineer-ing Society International Convention 2016, AES 2016. Audio Engineering Society. 2016.
[4] Atti, Venkatraman, Venkatesh Krishnan, Duminda A. Dewasurendra, Venkata Chebiyyam, Shaminda Subasingha, Daniel J. Sinder, Vivek Rajendran, Imre Varga, Jon Gibbs, Lei Miao, Volodya Grancharov and Harald Pobloth. "Super-wideband bandwidth extension for speech in the 3GPP EVS codec." 2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) (2015): 5927-5931.



Настоящее техническое решение относится к области вычислительной техники. Технический результат заключается в повышении качества восприятия посредством адаптивного к сигналу генерирования заполняющего промежутки контента или необработанного патч-контента для расчетного высокочастотного сигнала, которые адаптированы по восприятию к НЧ-сигналу. Технический результат достигается за счёт аудиопроцессора, который содержит: определитель огибающей для определения временной огибающей части исходного аудиосигнала; анализатор для анализа временной огибающей для определения значений признаков временной огибающей; синтезатор сигналов для генерирования сигнала синтеза, причем генерирование содержит размещение импульсов по отношению к определенным временным значениям, при этом импульсы взвешиваются с использованием весов, выведенных из амплитуд временной огибающей, связанных с временными значениями, в которые размещаются импульсы; и объединяющий блок для объединения, по меньшей мере, полосы сигнала синтеза, которая не включена в исходный аудиосигнал, и исходного аудиосигнала, для получения аудиосигнала с улучшенной частотной характеристикой. 3 н. и 17 з.п. ф-лы, 17 ил.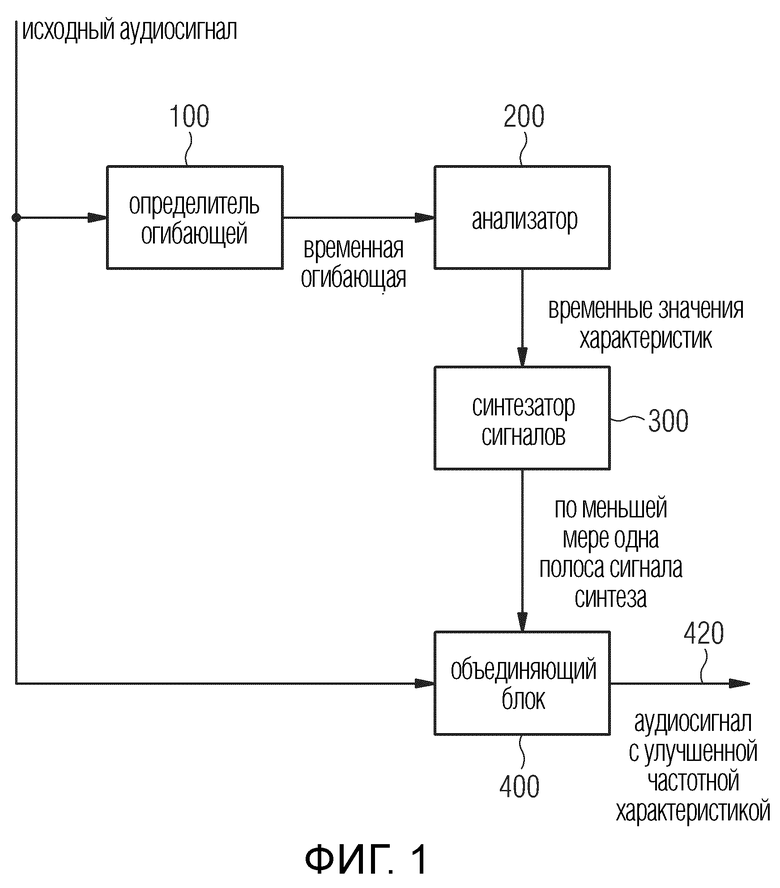
1. Аудиопроцессор для генерирования аудиосигнала (420) с улучшенной частотной характеристикой из исходного аудиосигнала (30), содержащий:
определитель (100) огибающей для определения временной огибающей, по меньшей мере, части исходного аудиосигнала;
анализатор (200) для анализа временной огибающей для определения значений некоторых признаков временной огибающей;
синтезатор (300) сигналов для генерирования сигнала синтеза, причем генерирование содержит размещение импульсов по отношению к определенным временным значениям, при этом импульсы взвешиваются с использованием весов, выведенных из амплитуд временной огибающей, связанных с временными значениями, в которые размещаются импульсы; и
объединяющий блок (400) для объединения, по меньшей мере, полосы сигнала синтеза, которая не включена в исходный аудиосигнал, и исходного аудиосигнала, для получения аудиосигнала (420) с улучшенной частотной характеристикой.
2. Аудиопроцессор по п. 1, в котором анализатор (200) выполнен с возможностью определения временных значений локальных максимумов или локальных минимумов как упомянутых некоторых признаков.
3. Аудиопроцессор по п. 1, в котором определитель (100) огибающей выполнен с возможностью
разложения (105) исходного аудиосигнала на множество сигналов подполос,
вычисления (120) выбранной временной огибающей выбранного сигнала подполосы из множества сигналов подполос, причем выбранная временная огибающая является временной огибающей, или
вычисления (120) по меньшей мере двух временных огибающих из по меньшей мере двух сигналов подполос из множества сигналов подполос и для объединения (130) по меньшей мере двух сигналов подполос для получения объединенной временной огибающей в качестве временной огибающей.
4. Аудиопроцессор по п. 3,
при этом определитель (100) огибающей выполнен с возможностью нормирования (115, 125) или фильтрации выбранных сигналов подполос или временных огибающих перед объединением (130), или
при этом объединение содержит операцию усреднения, или
при этом определитель (100) огибающей выполнен с возможностью вычисления временных огибающих из всех сигналов подполос из множества сигналов подполос, или
при этом определитель (100) огибающей выполнен с возможностью определения единственной широкополосной временной огибающей исходного аудиосигнала в качестве временной огибающей.
5. Аудиопроцессор по п. 1, в котором определитель (100) огибающей выполнен с возможностью определения временной огибающей
с использованием повторителя огибающей, выполненного с возможностью выпрямления (145) формы сигнала и низкочастотной фильтрации (150) выпрямленной формы сигнала, или
с использованием вычисления абсолютных значений или степеней абсолютных значений цифровой формы сигнала с последующей низкочастотной фильтрацией результата, или
с использованием вычисления мгновенного среднеквадратичного значения формы сигнала через скользящее окно с заданной шириной окна, или
с использованием кусочно-линейной аппроксимации формы сигнала, при этом временная огибающая определяется путем нахождения и соединения пиков формы сигнала в скользящем окне, перемещающемся через результат кусочно-линейной аппроксимации, или
с использованием преобразование Гильберта для генерирования аналитического сигнала для формы сигнала и вычисления огибающей из исходного аудиосигнала и аналитического сигнала с использованием операций возведения в квадрат, операций сложения и операций извлечения квадратного корня.
6. Аудиопроцессор по п. 1, причем анализатор (200) выполнен с возможностью
определения (205) начальных временных значений некоторых признаков, и
выведения (210), из начальных временных значений, временных значений с использованием функции оптимизации, или использования дополнительной информации, связанной с исходным аудиосигналом, или выбора или манипулирования дополнительными значениями в соответствии с правилом обработки.
7. Аудиопроцессор по п. 6, в котором правило обработки или функция оптимизации реализованы таким образом, что временные значения помещаются в растр с интервалом (T) растра, при этом интервал (T) растра и положение растра во временной огибающей являются такими, чтобы значение отклонения между временными значениями и начальными временными значениями имело заранее определенную характеристику.
8. Аудиопроцессор по п. 7, в котором значение отклонения представляет собой сумму квадратов разностей, и при этом заданная характеристика является минимальной характеристикой.
9. Аудиопроцессор по п. 1, в котором синтезатор (300) сигналов выполнен с возможностью
размещения (305) только положительных или только отрицательных импульсов для получения последовательности импульсов, и
последующего взвешивания (315) импульсов в последовательности импульсов, или
взвешивания только отрицательных или только положительных импульсов с использованием соответствующих весовых коэффициентов, ассоциированных с временными значениями импульсов в последовательности импульсов, и
размещения взвешенных импульсов на соответствующие временные значения для получения последовательности импульсов.
10. Аудиопроцессор по п. 1,
при этом синтезатор (300) сигналов выполнен с возможностью выведения (310) весов из амплитуд с использованием функции сжатия, причем функция сжатия является функцией из группы функций, содержащей:
степенную функцию со степенью ниже 1, логарифмическую функцию, функцию извлечения квадратного корня и нелинейную функцию, сконфигурированную для уменьшения более высоких значений и увеличения более низких значений.
11. Аудиопроцессор по п. 1, в котором синтезатор (300) сигналов выполнен с возможностью выполнения функции (320) постобработки, причем функция постобработки содержит по меньшей мере одну из группы функций, состоящей из добавления шума, добавления отсутствующей гармоники, обратной фильтрации и регулировки (330) огибающей.
12. Аудиопроцессор по п. 1,
при этом определитель (100) огибающей выполнен с возможностью разложения (160) временной огибающей на низкочастотную часть и высокочастотную часть,
при этом анализатор (200) выполнен с возможностью использования низкочастотной части временной огибающей для анализа.
13. Аудиопроцессор по п. 12, в котором синтезатор (300) сигналов выполнен с возможностью генерирования (170) шума с отрегулированной (180) энергией и добавления (335) шума с отрегулированной (180) энергией к сигналу, содержащему взвешенные или невзвешенные импульсы для получения сигнала синтеза.
14. Аудиопроцессор по п. 1,
при этом синтезатор (300) сигналов выполнен с возможностью высокочастотной фильтрации (325) или полосовой фильтрации (325) сигнала, содержащего размещенные и взвешенные импульсы, чтобы получить, по меньшей мере, полосу сигнала синтеза, которая не включена в исходный аудиосигнал, и для выполнения регулировки (330) спектральной огибающей с полосой сигнала синтеза, или при этом регулировка спектральной огибающей выполняется с использованием значений регулировки огибающей, выведенных из сторонней информации, ассоциированной с исходным аудиосигналом, или с использованием значений регулировки огибающей, выведенных из исходного аудиосигнала или в соответствии с заданной функцией регулировки огибающей.
15. Аудиопроцессор по п. 1, в котором исходный аудиосигнал является аудиосигналом во временной области, при этом по меньшей мере одна полоса сигнала синтеза представляет собой аудиосигнал во временной области, и при этом объединяющий блок (400) выполнен с возможностью выполнения объединения во временной области с использованием добавления выборки за выборкой для выборок по меньшей мере одной полосы сигнала синтеза и соответствующих выборок исходного аудиосигнала (30).
16. Аудиопроцессор по п. 1, в котором исходный аудиосигнал является сигналом возбуждения в области LPC,
при этом упомянутая по меньшей мере одна полоса сигнала синтеза является сигналом возбуждения в области LPC,
при этом объединяющий блок (400) выполнен с возможностью объединения (405) исходного аудиосигнала и по меньшей мере одной полосы путем добавления выборки за выборкой в области LPC,
при этом объединяющий блок (400) выполнен с возможностью фильтрации (410) результата добавления выборки за выборкой с использованием фильтра синтеза LPC для получения аудиосигнала с улучшенной частотной характеристикой, и
при этом фильтр (410) синтеза LPC управляется данными (40a) LPC, ассоциированными с исходным аудиосигналом, в качестве дополнительной информации, и при этом фильтр (410) синтеза LPC дополнительно управляется информацией (40b) огибающей для упомянутой по меньшей мере одной полосы сигнала синтеза.
17. Аудиопроцессор по п. 1, при этом анализатор (200), синтезатор (300) сигналов и объединяющий блок (400) работают во временной области или временной области LPC.
18. Аудиопроцессор по п. 1, в котором определитель (100) огибающей выполнен с возможностью применения спектрального преобразования (105) для извлечения множества сигналов полосы пропускания для последовательности кадров,
при этом синтезатор (300) сигналов выполнен с возможностью использования спектрального преобразования, для извлечения (325) упомянутой по меньшей мере одной полосы сигнала синтеза и для выполнения (330) регулировки огибающей для упомянутой по меньшей мере одной полосы, и
при этом объединяющий блок (400) выполнен с возможностью объединения в спектральной области и использования преобразования во временную область для получения аудиосигнала (420) с улучшенной частотной характеристикой.
19. Способ генерирования аудиосигнала (420) с улучшенной частотной характеристикой из исходного аудиосигнала (30), включающий:
определение (100) временной огибающей, по меньшей мере, части исходного аудиосигнала;
анализ (200) временной огибающей для определения временных значений некоторых признаков временной огибающей;
размещение (305) импульсов по отношению к определенным временным значениям в сигнале синтеза, причем в сигнале синтеза размещенные импульсы взвешены с использованием весов, выведенных из амплитуд временной огибающей, относящихся к временным значениям, где размещены импульсы; и
объединение (400) по меньшей мере полосы сигнала синтеза, которая не включена в исходный аудиосигнал, и исходного аудиосигнала для получения аудиосигнала (420) с улучшенной частотной характеристикой.
20. Физический носитель хранения, имеющий сохраненную на нем компьютерную программу для выполнения, при запуске на компьютере или процессоре, способа обработки звука по п. 19.
| US 8954179 B2, 10.02.2015 | |||
| AU 2009210303 B2, 06.08.2009 | |||
| Способ приготовления лака | 1924 |
|
SU2011A1 |
| АППАРАТНЫЙ БЛОК, СПОСОБ И КОМПЬЮТЕРНАЯ ПРОГРАММА ДЛЯ ПРЕОБРАЗОВАНИЯ РАСШИРЕНИЯ СЖАТОГО АУДИО СИГНАЛА С ПОМОЩЬЮ СГЛАЖЕННОГО ЗНАЧЕНИЯ ФАЗЫ | 2010 |
|
RU2550525C2 |
| СПОСОБ И СИСТЕМА ДЛЯ ВЫРАВНИВАНИЯ ГРОМКОГОВОРИТЕЛЯ В КОМНАТЕ | 2006 |
|
RU2421936C2 |

