[2] Настоящее изобретение, в общем, относится к области техники обработки речи и, в частности, к адаптивному расширению полосы пропускания и к устройству для означенного.
Уровень техники
[3] В современной системе обмена цифровыми аудио-/речевыми сигналами, цифровой сигнал сжимается в кодере; сжатая информация (поток битов) может пакетизироваться и отправляться в декодер через канал связи покадрово. Система кодера и декодера совместно называется "кодеком". Сжатие речи/аудио может использоваться для того, чтобы уменьшать число битов, которые представляют речевой/аудио-сигнал, за счет этого уменьшая скорость передачи битов, необходимую для передачи. Технология сжатия речи/аудио, в общем, может классифицироваться на кодирование во временной области и кодирование в частотной области. Кодирование во временной области обычно используется для кодирования речевого сигнала или для кодирования аудиосигнала на низких скоростях передачи битов. Кодирование в частотной области обычно используется для кодирования аудиосигнала или для кодирования речевого сигнала на высоких скоростях передачи битов. Расширение полосы пропускания (BWE) может быть частью кодирования во временной области или кодирования в частотной области, чтобы формировать сигнал полосы высоких частот на очень низкой скорости передачи битов или на нулевой скорости передачи битов.
[4] Тем не менее, речевые кодеры представляют собой кодеры с потерями, т.е. декодированный сигнал отличается от исходного. Следовательно, одна из целей при кодировании речи состоит в том, чтобы минимизировать искажение (или воспринимаемые потери) на данной скорости передачи битов или минимизировать скорость передачи битов, чтобы достигать данного искажения.
[5] Кодирование речи отличается от других форм кодирования аудио тем, что речь представляет собой гораздо более простой сигнал, чем большинство других аудиосигналов, и гораздо больше статистической информации доступно в отношении свойств речи. Как результат, некоторая звуковая информация, которая является релевантной при кодировании аудио, может быть необязательной в контексте кодирования речи. При кодировании речи, наиболее важный критерий представляет собой сохранение понятности и "удобства восприятия" речи с ограниченным объемом передаваемых данных.
[6] Понятность речи включает в себя, помимо фактического литерального контента, также отличительные черты говорящего, эмоции, интонацию, тембр и т.д., которые являются крайне важными для идеальной понятности. Более абстрактное понятие удобства восприятия ухудшенной речи представляет собой свойство, отличающееся от понятности, поскольку возможно то, что ухудшенная речь является абсолютно понятной, но субъективно раздражающей слушателя.
[7] Избыточность форм речевого сигнала может рассматриваться относительно нескольких различных типов речевого сигнала, таких как вокализованные и невокализованные речевые сигналы. Вокализованные звуки, например, "b", фактически обусловлены колебаниями голосовых связок и являются колебательными. Следовательно, за короткие периоды времени, они хорошо моделируются посредством сумм периодических сигналов, таких как синусоиды. Другими словами, для вокализованной речи, речевой сигнал фактически является периодическим. Тем не менее, эта периодичность может быть переменной в течение длительности речевого сегмента, и форма периодической волны обычно изменяется постепенно между сегментами. Кодирование речи на низкой скорости передачи битов может извлекать значительную выгоду из исследования такой периодичности. Период вокализованной речи также называется "основным тоном", и прогнозирование основного тона зачастую называется "долговременным прогнозированием (LTP)". Напротив, невокализованные звуки, такие как "s", "sh", являются более шумоподобными. Это обусловлено тем, что невокализованный речевой сигнал больше походит на случайный шум и имеет меньшую величину прогнозируемости.
[8] Традиционно, все способы параметрического кодирования речи, такие как кодирование во временной области, используют избыточность, внутренне присущую в речевом сигнале, для того чтобы уменьшать объем информации, который должен отправляться, и оценивать параметры речевых выборок сигнала с короткими интервалами. Эта избыточность главным образом возникает в силу повторения форм речевого сигнала на квазипериодической скорости и медленно изменяющейся огибающей спектра речевого сигнала.
[9] Избыточность форм речевого сигнала может рассматриваться относительно нескольких различных типов речевого сигнала, таких как вокализованный и невокализованный. Хотя речевой сигнал фактически является периодическим для вокализованной речи, эта периодичность может быть переменной в течение длительности речевого сегмента, и форма периодической волны обычно изменяется постепенно между сегментами. Кодирование речи на низкой скорости передачи битов может извлекать значительную выгоду из исследования такой периодичности. Период вокализованной речи также называется "основным тоном", и прогнозирование основного тона зачастую называется "долговременным прогнозированием (LTP)". Что касается невокализованной речи, сигнал больше походит на случайный шум и имеет меньшую величину прогнозируемости.
[10] В любом случае, параметрическое кодирование может использоваться для того, чтобы уменьшать избыточность речевых сегментов посредством отделения компонента возбуждения речевого сигнала от компонента огибающей спектра. Медленно изменяющаяся спектральная огибающая может быть представлена посредством линейного прогнозного кодирования (LPC), также называемого "кратковременным прогнозированием" (STP). Кодирование речи на низкой скорости передачи битов также может извлекать существенную выгоду из исследования такого кратковременного прогнозирования. Преимущество кодирования возникает в силу низкой скорости, на которой изменяются параметры. Тем не менее, параметров редко существенно отличаются от значений, хранимых в течение нескольких миллисекунд. Соответственно, на частоте дискретизации 8 кГц, 12,8 кГц или 16 кГц, алгоритм кодирования речи является таким, что номинальная длительность кадра находится в диапазоне десяти-тридцати миллисекунд. Длительность кадра в двадцать миллисекунд является наиболее распространенным выбором.
[11] Кодирование аудио на основе технологии на базе гребенки фильтров широко используется, например, при кодировании в частотной области. При обработке сигналов, гребенка фильтров представляет собой массив полосовых фильтров, который разделяет входной сигнал на несколько компонентов, каждый из которых переносит одну подполосу частот исходного сигнала. Процесс разложения, выполняемый посредством гребенки фильтров, называется "анализом", и вывод анализа на основе гребенки фильтров упоминается в качестве подполосного сигнала с числом подполос частот, равным числу фильтров в гребенке фильтров. Процесс восстановления называется "синтезом на основе гребенки фильтров". При обработке цифровых сигналов, термин "гребенка фильтров" также обычно применяется к гребенке приемных устройств. Отличие заключается в том, что приемные устройства также преобразуют с понижением частоты подполосы частот в низкую центральную частоту, которая может быть повторно дискретизирована на уменьшенной скорости. Идентичный результат может иногда достигаться посредством недостаточной дискретизации полосовых подполос частот. Вывод анализа на основе гребенки фильтров может иметь форму комплексных коэффициентов. Каждый комплексный коэффициент содержит "действительный элемент" и "мнимый элемент", соответственно, представляющие "косинусный член" и "синусный член" для каждой подполосы частот гребенки фильтров.
[12] В более новых известных стандартах, таких как G.723.1, G.729, G.718, стандарт улучшенного полноскоростного кодирования (EFR), стандарт на основе вокодера с переключаемым режимом (SMV), стандарт адаптивного многоскоростного кодирования (AMR), стандарт многорежимного широкополосного кодирования с переменной скоростью (VMR-WB) или стандарт широкополосного адаптивного многоскоростного кодирования (AMR-WB), приспособлена технология линейного прогнозирования с возбуждением по коду (CELP). Под CELP обычно понимается техническая комбинация кодированного возбуждения, долговременного прогнозирования и кратковременного прогнозирования. CELP в основном используется для того, чтобы кодировать речевой сигнал посредством извлечения выгоды из конкретных характеристик человеческого голоса или вокальной модели формирования человеческого голоса. CELP-кодирование речи является очень популярным алгоритмическим принципом в области сжатия речи, хотя детали CELP для различных кодеков могут существенно отличаться. Вследствие своей популярности, CELP-алгоритм использован в различных стандартах ITU-T, MPEG, 3GPP и 3GPP2. Разновидности CELP включают в себя алгебраическое CELP, ослабленное CELP, CELP с низкой задержкой и линейное прогнозирование с возбуждением векторной суммой и т.п. CELP является общим термином для класса алгоритмов, а не для конкретного кодека.
[13] CELP-алгоритм основан на четырех основных идеях. Во-первых, используется модель "источник-фильтр" речеобразования через линейное прогнозирование (LP). Модель "источник-фильтр" речеобразования моделирует речь в качестве комбинации источника звука, к примеру, голосовых связок, и линейного акустического фильтра, речевого тракта (и характеристики излучения). В реализации модели "источник-фильтр" речеобразования, источник звука или сигнал возбуждения зачастую моделируется в качестве периодической цепочки импульсов для вокализованной речи либо белого шума для невокализованной речи. Во-вторых, адаптивная и фиксированная таблица кодирования используется в качестве ввода (возбуждения) LP-модели. В-третьих, поиск выполняется с замкнутым контуром в "перцепционно взвешенной области". В-четвертых, применяется векторное квантование (VQ).
Сущность изобретения
[14] Вариант осуществления настоящего изобретения описывает способ декодирования кодированного потока аудиобитов и формирования расширения полосы пропускания частот в декодере. Способ содержит декодирование потока аудиобитов для того, чтобы формировать декодированный аудиосигнал полосы низких частот и формировать спектр возбуждения в полосе низких частот, соответствующий полосе низких частот. Область подполосы частот выбирается из полосы низких частот с использованием параметра, который указывает информацию энергии спектральной огибающей декодированного аудиосигнала полосы низких частот. Спектр возбуждения в полосе высоких частот формируется для полосы высоких частот посредством копирования спектра возбуждения в подполосе частот из выбранной области подполосы частот в область подполосы высоких частот, соответствующую полосе высоких частот. С использованием сформированного спектра возбуждения в полосе высоких частот, аудиосигнал расширенной полосы высоких частот формируется посредством применения спектральной огибающей полосы высоких частот. Аудиосигнал расширенной полосы высоких частот суммируется с декодированным аудиосигналом полосы низких частот для того, чтобы формировать выходной аудиосигнал, имеющий расширенную полосу пропускания частот.
[15] В соответствии с альтернативным вариантом осуществления настоящего изобретения, декодер для декодирования кодированного потока аудиобитов и формирования полосы пропускания частот содержит модуль декодирования в полосе низких частот, выполненный с возможностью декодировать поток аудиобитов для того, чтобы формировать декодированный аудиосигнал полосы низких частот и формировать спектр возбуждения в полосе низких частот, соответствующий полосе низких частот. Декодер дополнительно включает в себя модуль расширения полосы пропускания, соединенный с модулем декодирования в полосе низких частот. Модуль расширения полосы пропускания содержит модуль выбора подполосы частот и модуль копирования. Модуль выбора подполосы частот выполнен с возможностью выбирать область подполосы частот из полосы низких частот с использованием параметра, который указывает информацию энергии спектральной огибающей декодированного аудиосигнала полосы низких частот. Модуль копирования выполнен с возможностью формировать спектр возбуждения в полосе высоких частот для полосы высоких частот посредством копирования спектра возбуждения в подполосе частот из выбранной области подполосы частот в область подполосы высоких частот, соответствующую полосе высоких частот.
[16] В соответствии с альтернативным вариантом осуществления настоящего изобретения, декодер для обработки речи содержит процессор и машиночитаемый носитель хранения данных, сохраняющий программирование для выполнения посредством процессора. Программирование включает в себя инструкции для того, чтобы декодировать поток аудиобитов для того, чтобы формировать декодированный аудиосигнал полосы низких частот и формировать спектр возбуждения в полосе низких частот, соответствующий полосе низких частот. Программирование включает в себя инструкции для того, чтобы выбирать область подполосы частот из полосы низких частот с использованием параметра, который указывает информацию энергии спектральной огибающей декодированного аудиосигнала полосы низких частот, и формировать спектр возбуждения в полосе высоких частот для полосы высоких частот посредством копирования спектра возбуждения в подполосе частот из выбранной области подполосы частот в область подполосы высоких частот, соответствующую полосе высоких частот. Программирование дополнительно включает в себя инструкции для того, чтобы использовать сформированный спектр возбуждения в полосе высоких частот для того, чтобы формировать аудиосигнал расширенной полосы высоких частот посредством применения спектральной огибающей полосы высоких частот, и суммировать аудиосигнал расширенной полосы высоких частот с декодированным аудиосигналом полосы низких частот для того, чтобы формировать выходной аудиосигнал, имеющий расширенную полосу пропускания частот.
[17] Альтернативный вариант осуществления настоящего изобретения описывает способ декодирования кодированного потока аудиобитов и формирования расширения полосы пропускания частот в декодере. Способ содержит декодирование потока аудиобитов для того, чтобы формировать декодированный аудиосигнал полосы низких частот и формировать спектр полосы низких частот, соответствующий полосе низких частот, и выбор области подполосы частот из полосы низких частот с использованием параметра, который указывает информацию энергии спектральной огибающей декодированного аудиосигнала полосы низких частот. Способ дополнительно включает в себя формирование спектра полосы высоких частот посредством копирования спектра подполосы частот из выбранной области подполосы частот в область подполосы высоких частот и использование сформированного спектра полосы высоких частот для того, чтобы формировать аудиосигнал расширенной полосы высоких частот посредством применения энергии спектральной огибающей полосы высоких частот. Способ дополнительно включает в себя суммирование аудиосигнала расширенной полосы высоких частот с декодированным аудиосигналом полосы низких частот для того, чтобы формировать выходной аудиосигнал, имеющий расширенную полосу пропускания частот.
Краткое описание чертежей
[18] Для более полного понимания настоящего изобретения и дополнительных его преимуществ далее приводится ссылка на нижеприведенное подробное описание, рассматриваемое вместе с прилагаемыми чертежами, на которых:
[19] Фиг. 1 иллюстрирует операции, выполняемые в ходе кодирования исходной речи с использованием традиционного CELP-кодера;
[20] Фиг. 2 иллюстрирует операции, выполняемые в ходе декодирования исходной речи с использованием CELP-декодера в реализации вариантов осуществления настоящего изобретения, как подробнее описано ниже;
[21] Фиг. 3 иллюстрирует операции, выполняемые в ходе кодирования исходной речи в традиционном CELP-кодере;
[22] Фиг. 4 иллюстрирует базовый CELP-декодер, соответствующий кодеру на фиг. 5 в реализации вариантов осуществления настоящего изобретения, как описано ниже;
[23] Фиг. 5A и 5B иллюстрируют пример кодирования/декодирования с расширением полосы пропускания (BWE), при этом фиг. 5A иллюстрирует операции в кодере со вспомогательной BWE-информацией, в то время как фиг. 5B иллюстрирует операции в декодере с BWE;
[24] Фиг. 6A и 6B иллюстрируют другой пример кодирования/декодирования с BWE без передачи вспомогательной информации, при этом фиг. 6A иллюстрирует операции в кодере, в то время как фиг. 6B иллюстрирует операции в декодере;
[25] Фиг. 7 иллюстрирует пример идеального спектра возбуждения для вокализованной речи или гармонической музыки, когда используется CELP-тип кодека;
[26] Фиг. 8 показывает пример традиционного расширения полосы пропускания декодированного спектра возбуждения для вокализованной речи или гармонической музыки, когда используется CELP-тип кодека;
[27] Фиг. 9 иллюстрирует пример варианта осуществления настоящего изобретения расширения полосы пропускания, применяемого к декодированному спектру возбуждения для вокализованной речи или гармонической музыки, когда используется CELP-тип кодека;
[28] Фиг. 10 иллюстрирует операции в декодере в соответствии с вариантами осуществления настоящего изобретения для реализации сдвига или копирования подполосы частот для BWE;
[29] Фиг. 11 иллюстрирует альтернативный вариант осуществления декодера для реализации сдвига или копирования подполосы частот для BWE;
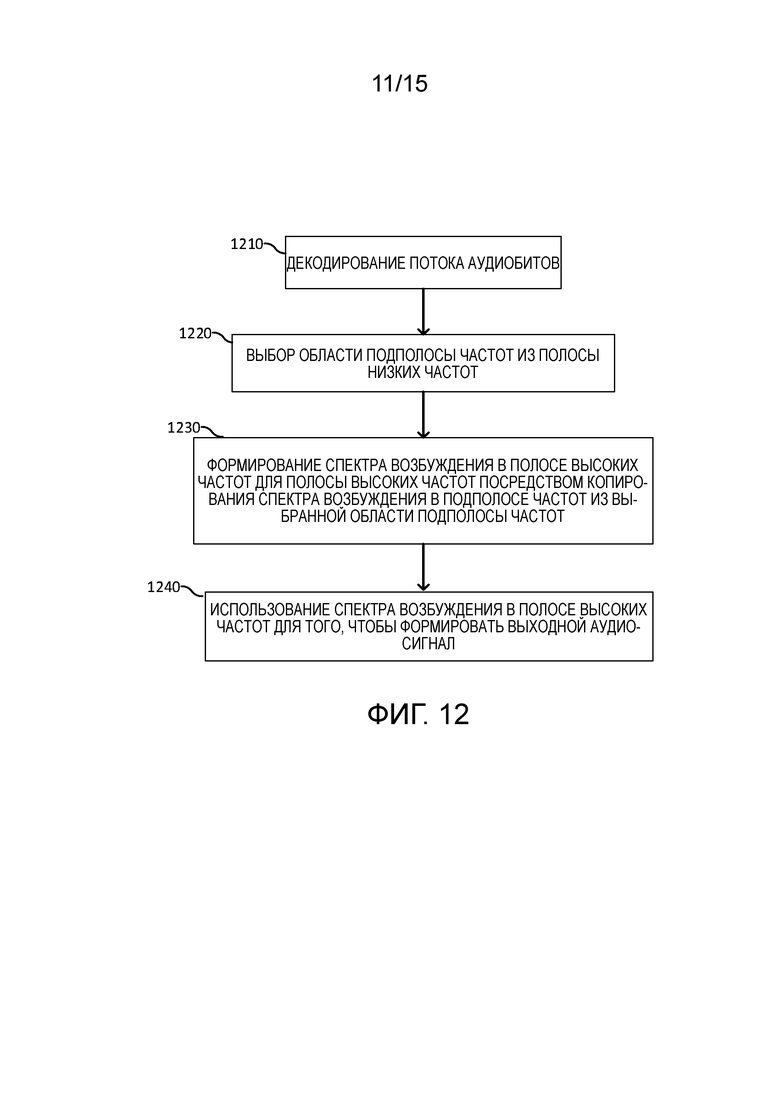
[30] Фиг. 12 иллюстрирует операции, выполняемые в декодере в соответствии с вариантами осуществления настоящего изобретения;
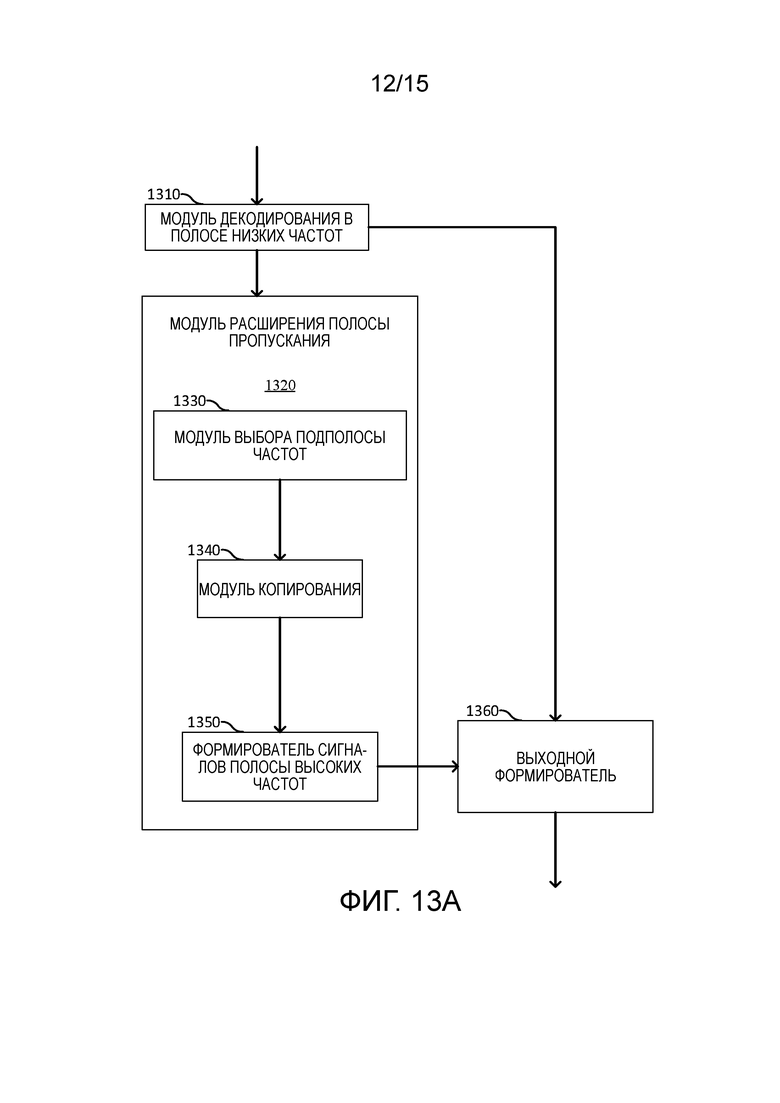
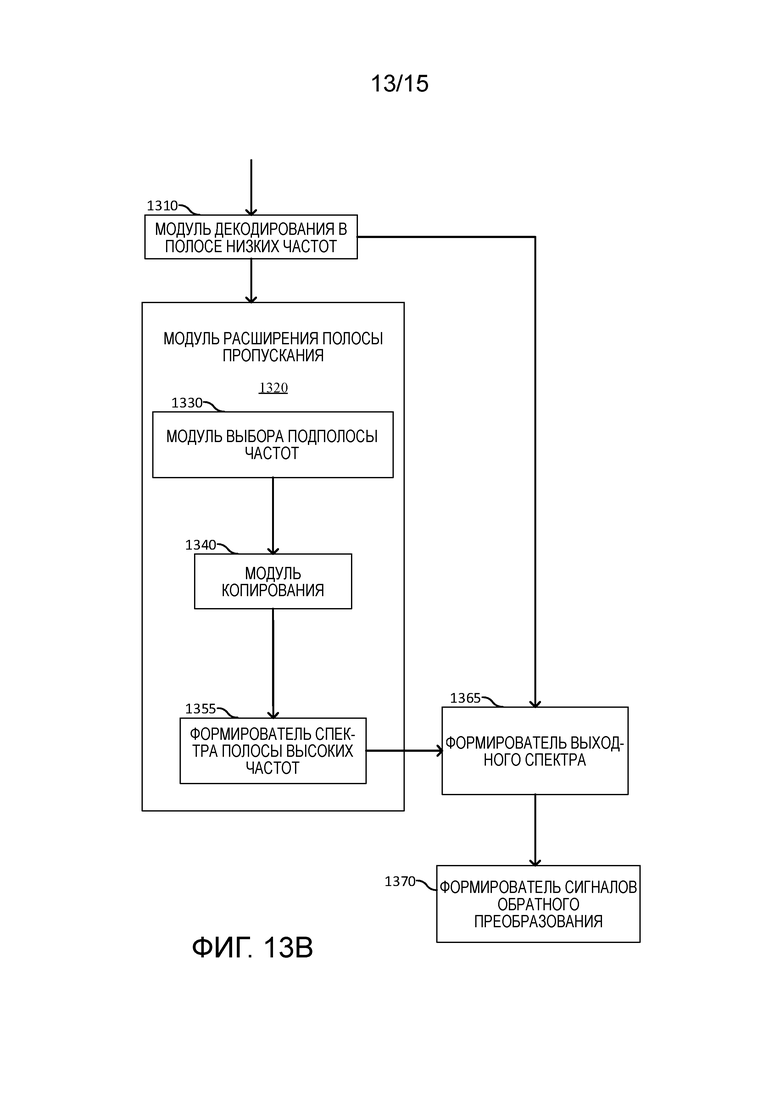
[31] Фиг. 13A и 13B иллюстрируют декодер, реализующий расширение полосы пропускания в соответствии с вариантами осуществления настоящего изобретения;
[32] Фиг. 14 иллюстрирует систему связи согласно варианту осуществления настоящего изобретения; и
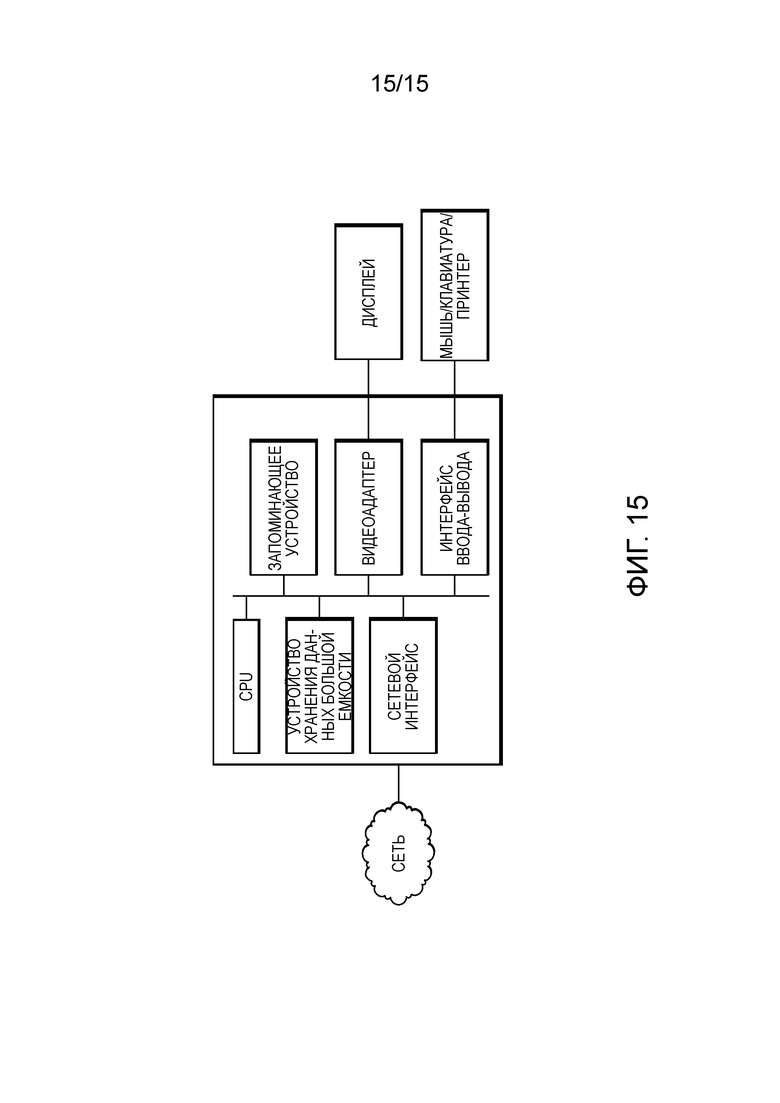
[33] Фиг. 15 иллюстрирует блок-схему системы обработки, которая может использоваться для реализации устройств и способов, раскрытых в данном документе.
Подробное описание иллюстративных вариантов осуществления
[34] В современной системе обмена цифровыми аудио-/речевыми сигналами, цифровой сигнал сжимается в кодере, и сжатая информация или поток битов может пакетизироваться и отправляться в декодер покадрово через канал связи. Декодер принимает и декодирует сжатую информацию, чтобы получать цифровой аудио-/речевой сигнал.
[35] Настоящее изобретение, в общем, относится к кодированию речевых/аудио-сигналов и расширению полосы пропускания речевых/аудио-сигналов. В частности, варианты осуществления настоящего изобретения могут использоваться для того, чтобы улучшать стандарт речевого ITU-T AMR-WB-кодера в области техники расширения полосы пропускания.
[36] Некоторые частоты являются более важными, чем другие. Важные частоты могут кодироваться с высоким разрешением. Небольшие разности на этих частотах являются значительными, и необходима схема кодирования, которая сохраняет эти разности. С другой стороны, менее важные частоты не обязательно должны быть точными. Более приблизительная схема кодирования может использоваться, даже если некоторые более точные детали теряются при кодировании. Типичная более приблизительная схема кодирования основана на принципе расширения полосы пропускания (BWE). Этот технологический принцип также называется "расширением полосы высоких частот (HBE)", "подполосной репликой (SBR)" или "репликацией полос спектра (SBR)". Хотя название может отличаться, все они имеют аналогичный смысл кодирования/декодирования некоторых подполос частот (обычно полос высоких частот) с небольшим бюджетом по скорости передачи битов (даже нулевым бюджетом по скорости передачи битов) или значительно более низкой скоростью передачи битов, чем нормальный подход кодирования/декодирования.
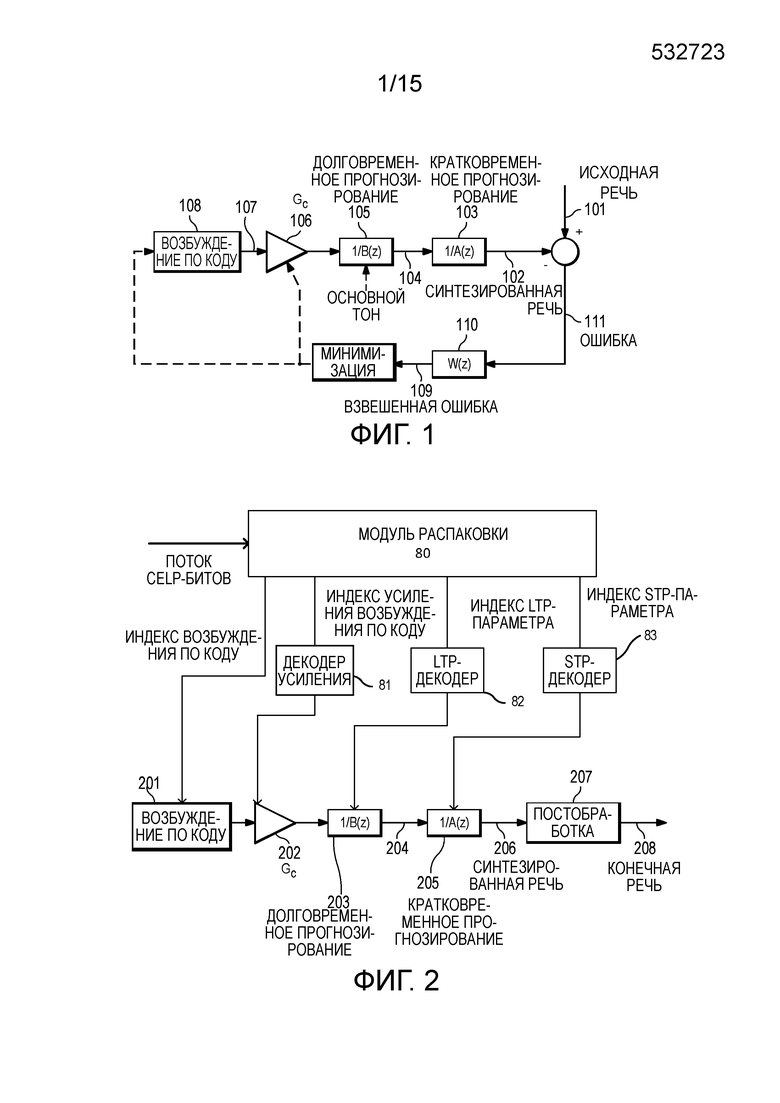
[37] В SBR-технологии, точная спектральная структура в полосе высоких частот копируется из полосы низких частот, и может добавляться некоторый случайный шум. Затем спектральная огибающая в полосе высоких частот формируется посредством использования вспомогательной информации, передаваемой из кодера в декодер. Сдвиг или копирование полосы частот из полосы низких частот в полосу высоких частот нормально является первым этапом для BWE-технологии.
[38] Ниже описываются варианты осуществления настоящего изобретения для улучшения BWE-технологии посредством использования адаптивного процесса, чтобы выбирать сдвиг полосы частот на основе энергетического уровня спектральной огибающей.
[39] Фиг. 1 иллюстрирует операции, выполняемые в ходе кодирования исходной речи с использованием традиционного CELP-кодера.
[40] Фиг. 1 иллюстрирует традиционный начальный CELP-кодер, в котором взвешенная ошибка 109 между синтезированной речью 102 и исходной речью 101 зачастую минимизируется посредством использования подхода по методу анализа через синтез, что означает то, что кодирование (анализ) выполняется посредством перцепционной оптимизации декодированного (синтезирующего) сигнала в замкнутом контуре.
[41] Базовый принцип, который используют все речевые кодеры, представляет собой тот факт, что речевые сигналы представляют высококоррелированные формы сигналов. В качестве иллюстрации, речь может быть представлена с использованием авторегрессивной (AR) модели, как указано в нижеприведенном уравнении (11).
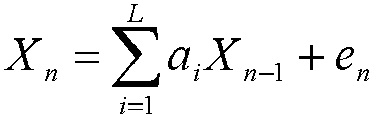 (11)
(11)
[42] В уравнении (11), каждая выборка представляется как линейная комбинация предыдущих L выборок плюс белый шум. Весовые коэффициенты a1, a2, ..., aL, называются "коэффициентами линейного прогнозирования (LPC)". Для каждого кадра, весовые коэффициенты a1, a2, ..., aL, выбираются таким образом, что спектр {X1, X2, ..., XN}, сформированный с использованием вышеуказанной модели, близко совпадает со спектром входного речевого кадра.
[43] Альтернативно, речевые сигналы также могут быть представлены посредством комбинации гармонической модели и шумовой модели. Гармоническая часть модели фактически является представлением в виде ряда Фурье периодического компонента сигнала. В общем, для вокализованных сигналов, гармоническая плюс шумовая модель речи состоит из смеси как гармоник, так и шума. Пропорция гармоники и шума в вокализованной речи зависит от ряда факторов, включающих в себя характеристики говорящего (например, до какой степени голос говорящего является нормальным или хриплым); характер речевого сегмента (например, до какой степени речевой сегмент является периодическим), и от частоты. Верхние частоты вокализованной речи имеют более высокую пропорцию шумоподобных компонентов.
[44] Модель линейного прогнозирования и гармоническая шумовая модель представляют собой два основных способа для моделирования и кодирования речевых сигналов. Модель линейного прогнозирования является очень хорошей при моделировании огибающей спектра речи, тогда как гармоническая шумовая модель является хорошей при моделировании точной структуры речи. Два способа могут комбинироваться с тем, чтобы использовать преимущество своих относительных сильных сторон.
[45] Как указано выше, перед CELP-кодированием, входной сигнал в микрофон переносного телефона фильтруется и дискретизируется, например, на скорости 8000 выборок в секунду. Каждая выборка затем квантуется, например, с 13 битами в расчете на выборку. Дискретизированная речь сегментируется на сегменты или кадры в 20 мс (например, в этом случае 160 выборок).
[46] Речевой сигнал анализируется, и извлекаются его LP-модель, сигналы возбуждения и основной тон. LP-модель представляет огибающую спектра речи. Она преобразуется в набор коэффициентов частот спектральных линий (LSF), который является альтернативным представлением параметров линейного прогнозирования, поскольку LSF-коэффициенты имеют хорошие свойства квантования. LSF-коэффициенты могут скалярно квантоваться, либо более эффективно они могут векторно квантоваться с использованием предварительно подготовленных таблиц кодирования LSF-векторов.
[47] Возбуждение по коду включает в себя таблицу кодирования, содержащую кодовые векторы, которые имеют компоненты, которые независимо выбираются таким образом, что каждый кодовый вектор может иметь приблизительно "белый" спектр. Для каждого субкадра входной речи, каждый из кодовых векторов фильтруется через кратковременный линейный прогнозный фильтр 103 и долговременный прогнозный фильтр 105, и вывод сравнивается с речевыми выборками. В каждом субкадре, кодовый вектор, вывод которого имеет наилучшее совпадение с входной речью (минимизированную ошибку), выбирается для того, чтобы представлять этот субкадр.
[48] Кодированное возбуждение 108 нормально содержит импульсоподобный сигнал или шумоподобный сигнал, которые математически составляются или сохраняются в таблице кодирования. Таблица кодирования доступна как для кодера, так и для приемного декодера. Кодированное возбуждение 108, которое может представлять собой стохастическую или фиксированную таблицу кодирования, может представлять собой словарь векторного квантования, который (неявно или явно) жестко кодируется в кодек. Такая фиксированная таблица кодирования может представлять собой линейное прогнозирование с возбуждением по алгебраическому коду или сохраняться явно.
[49] Кодовый вектор из таблицы кодирования масштабируется посредством надлежащего усиления, чтобы задавать энергию равной энергии входной речи. Соответственно, вывод кодированного возбуждения 108 масштабируется посредством усиления Gc 107 перед прохождением через линейные фильтры.
[50] Кратковременный линейный прогнозный фильтр 103 формирует "белый" спектр кодового вектора, который напоминает спектр входной речи. Эквивалентно, во временной области, кратковременный линейный прогнозный фильтр 103 включает кратковременные корреляции (корреляцию с предыдущими выборками) в белой последовательности. Фильтр, который формирует возбуждение, имеет модель со всеми полюсами формы 1/A(z) (кратковременный линейный прогнозный фильтр 103), причем A(z) называется "прогнозным фильтром" и может получаться с использованием линейного прогнозирования (например, алгоритма Левинсона-Дурбина). В одном или более вариантов осуществления, может использоваться фильтр со всеми полюсами, поскольку он является хорошим представлением человеческого речевого тракта, и поскольку его нетрудно вычислять.
[51] Кратковременный линейный прогнозный фильтр 103 получается посредством анализа исходного сигнала 101 и представляется посредством набора коэффициентов:
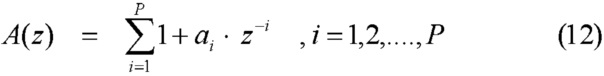
[52] Как описано выше, области вокализованной речи демонстрируют долговременную периодичность. Этот период, известный как основной тон, вводится в синтезированный спектр посредством фильтра 1/(B(z)) основного тона. Вывод долговременного прогнозного фильтра 105 зависит от основного тона и усиления основного тона. В одном или более вариантов осуществления, основной тон может оцениваться из исходного сигнала, остаточного сигнала или взвешенного исходного сигнала. В одном варианте осуществления, функция (B(z)) долговременного прогнозирования может выражаться с использованием уравнения (13) следующим образом.

[53] Взвешивающий фильтр 110 связан с вышеуказанным кратковременным прогнозным фильтром. Один из типичных взвешивающих фильтров может представляться так, как описано в уравнении (14).
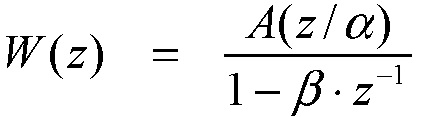 , (14)
, (14)
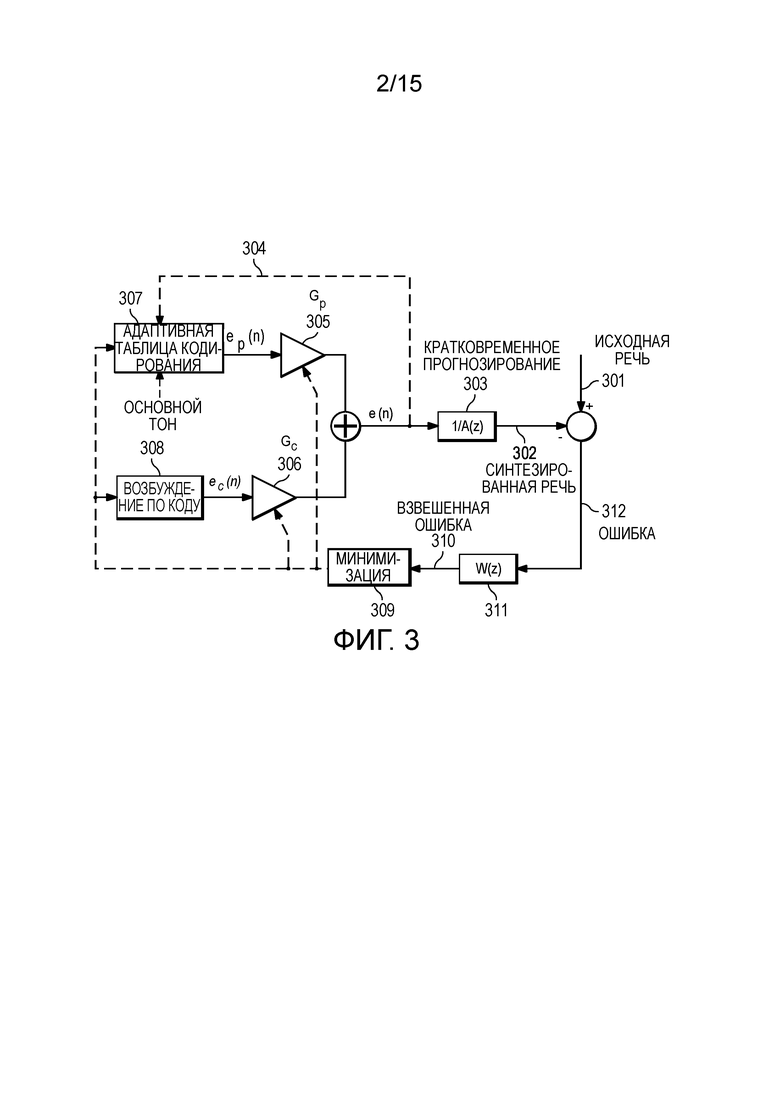
где 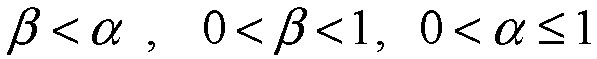 .
.
[54] В другом варианте осуществления, взвешивающий фильтр W(z) может извлекаться из LPC-фильтра посредством использования расширения полосы пропускания, как проиллюстрировано в одном варианте осуществления, в нижеприведенном уравнении (15).
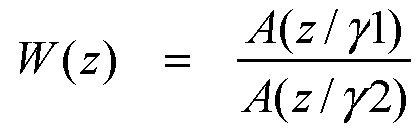 (15),
(15),
В уравнении (15), γ1>γ2, которые являются коэффициентами, с которыми полюса перемещаются к началу координат.
[55] Соответственно, для каждого кадра речи, вычисляются LPC и основной тон, и обновляются фильтры. Для каждого субкадра речи, кодовый вектор, который формирует "наилучший" фильтрованный вывод, выбран таким образом, чтобы представлять субкадр. Соответствующее квантованное значение усиления должно передаваться в декодер для надлежащего декодирования. LPC и значения основного тона также должны квантоваться и отправляться каждый кадр для восстановления фильтров в декодере. Соответственно, индекс кодированного возбуждения, индекс квантованного усиления, индекс квантованного параметра долговременного прогнозирования и индекс квантованного параметра кратковременного прогнозирования передаются в декодер.
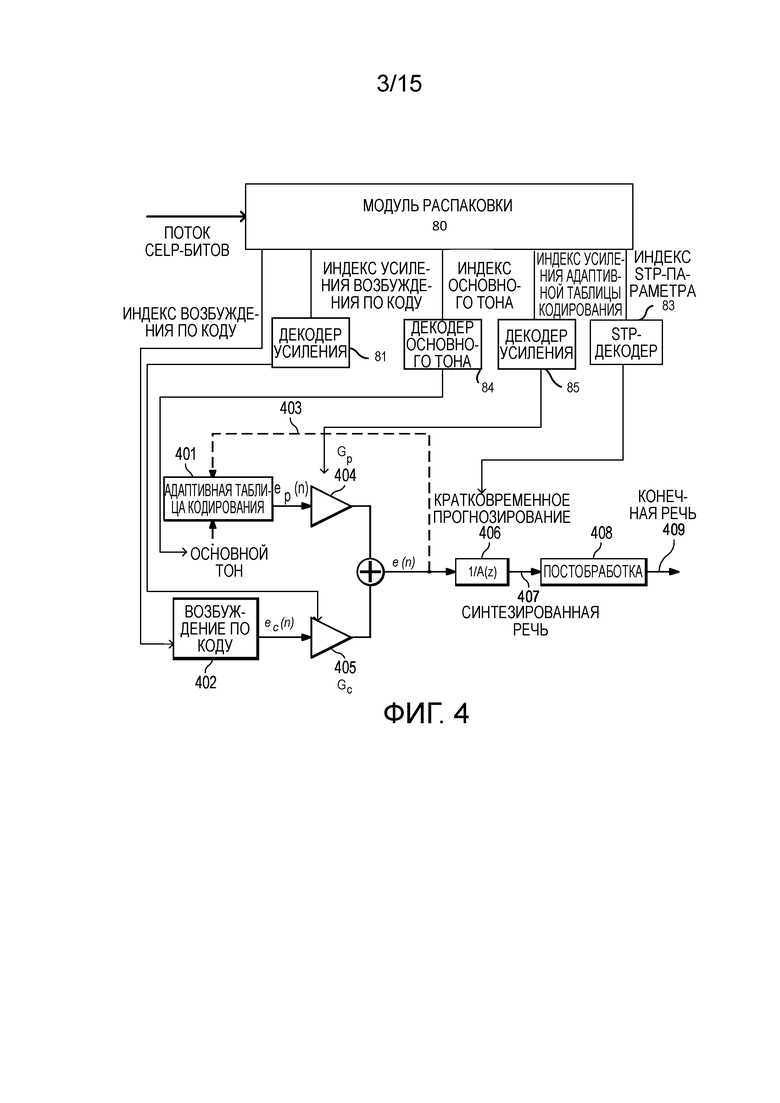
[56] Фиг. 2 иллюстрирует операции, выполняемые в ходе декодирования исходной речи с использованием CELP-декодера в реализации вариантов осуществления настоящего изобретения, как описано ниже.
[57] Речевой сигнал восстановлен в декодере посредством пропускания принимаемых кодовых векторов через соответствующие фильтры. Следовательно, каждый блок, за исключением постобработки, имеет определение, идентичное определению, описанному в кодере по фиг. 1.
[58] Кодированный поток CELP-битов принимается и распаковывается 80 в приемном устройстве. Для каждого принимаемого субкадра, принимаемые индекс кодированного возбуждения, индекс квантованного усиления, индекс квантованного параметра долговременного прогнозирования и индекс квантованного параметра кратковременного прогнозирования используются для того, чтобы находить соответствующие параметры с использованием соответствующих декодеров, например, декодера 81 усиления, долговременного прогнозного декодера 82 и кратковременного прогнозного декодера 83. Например, позиции и знаки амплитуды импульсов возбуждения и алгебраический кодовый вектор возбуждения 402 по коду могут определяться из принимаемого индекса кодированного возбуждения.
[59] Ссылаясь на фиг. 2, декодер представляет собой комбинацию нескольких блоков, которая включает в себя кодированное возбуждение 201, долговременное прогнозирование 203, кратковременное прогнозирование 205. Начальный декодер дополнительно включает в себя блок 207 постобработки после синтезированной речи 206. Постобработка дополнительно может содержать кратковременную постобработку и долговременную постобработку.
[60] Фиг. 3 иллюстрирует традиционный CELP-кодер.
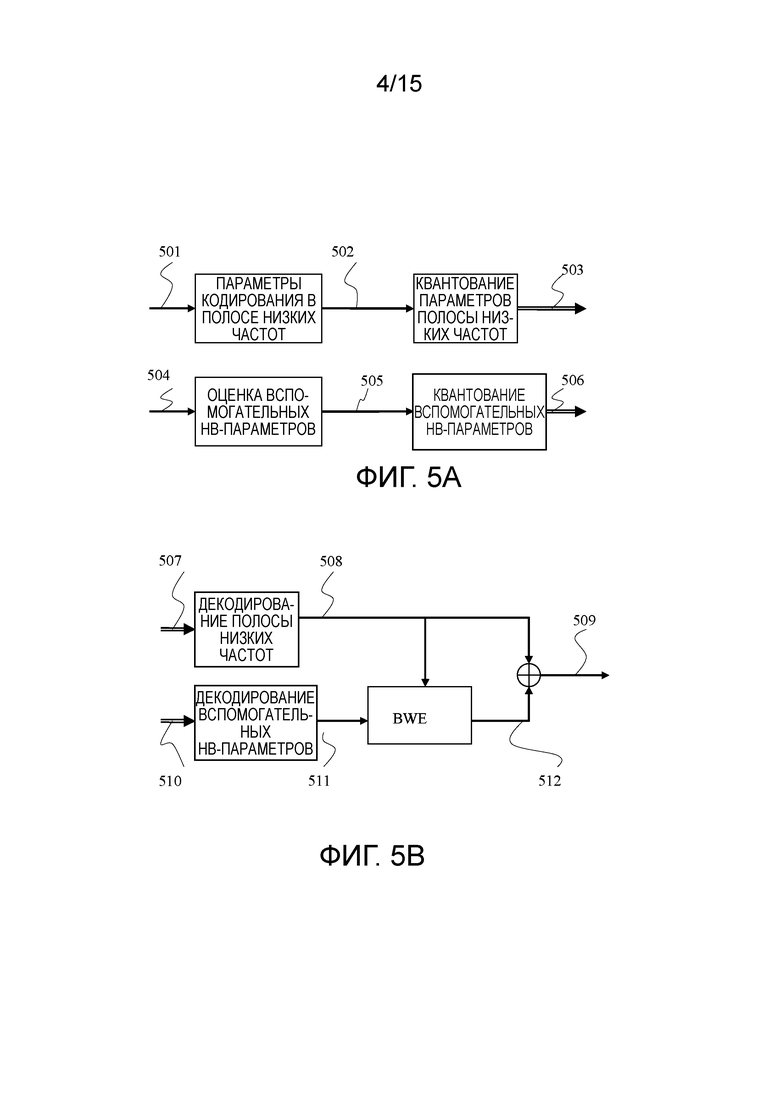
[61] Фиг. 3 иллюстрирует базовый CELP-кодер с использованием дополнительной адаптивной таблицы кодирования для улучшения долговременного линейного прогнозирования. Возбуждение формируется посредством суммирования долей из адаптивной таблицы 307 кодирования и возбуждения 308 по коду, которое может представлять собой стохастическую или фиксированную таблицу кодирования, как описано выше. Записи в адаптивной таблице кодирования содержат задержанные версии возбуждения. Это позволяет эффективно кодировать периодические сигналы, такие как вокализованные звуки.
[62] Ссылаясь на фиг. 3, адаптивная таблица 307 кодирования содержит предыдущее синтезированное возбуждение 304 или повторяющийся цикл основного тона предыдущего возбуждения в периоде основного тона. Запаздывание основного тона может кодироваться с целочисленным значением, когда он является большим или длинным. Запаздывание основного тона зачастую кодируется с более точным дробным значением, когда оно является небольшим или коротким. Периодическая информация основного тона используется для того, чтобы формировать адаптивный компонент возбуждения. Этот компонент возбуждения затем масштабируется посредством усиления Gp 305 (также называемого "усилением основного тона").
[63] Долговременное прогнозирование играет очень важную роль для кодирования вокализованной речи, поскольку вокализованная речь имеет сильную периодичность. Смежные циклы основного тона вокализованной речи являются аналогичными друг другу, что математически означает то, что усиление Gp основного тона в следующем выражении для возбуждения является высоким или близким к 1. Результирующее возбуждение может выражаться как в уравнении (16) в качестве комбинации отдельных возбуждений.
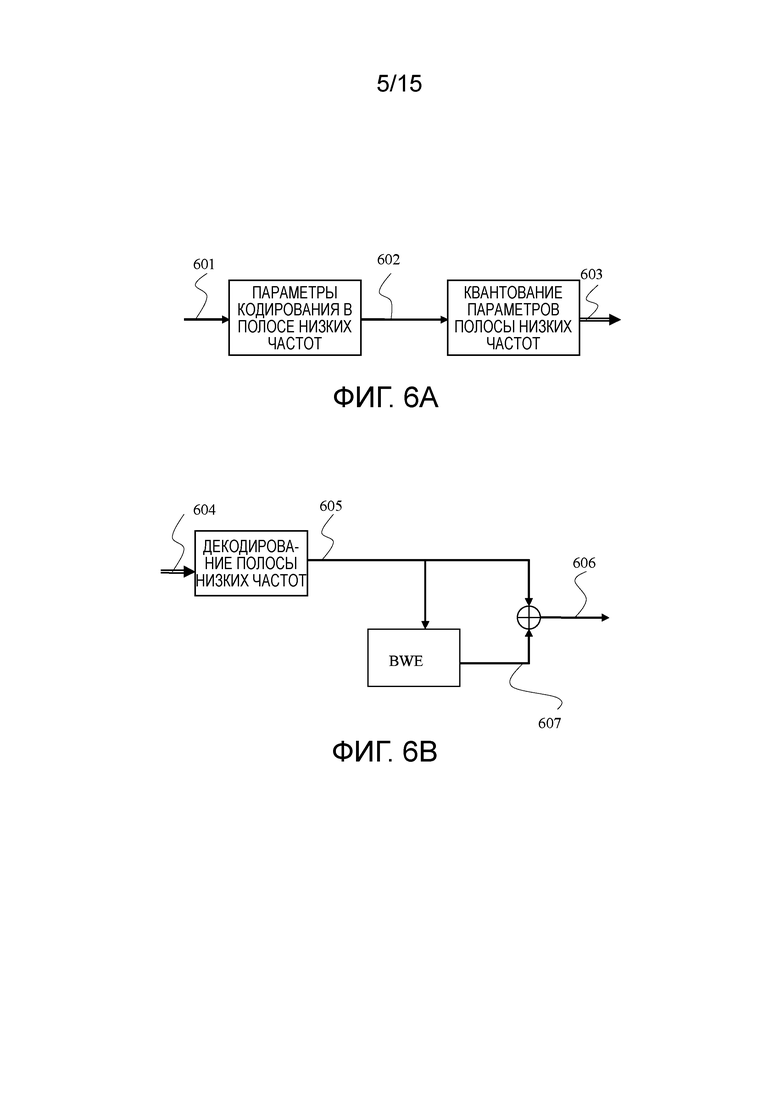
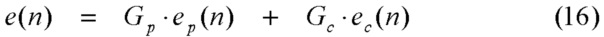 ,
,
где ep(n) является одним субкадром примерной последовательности с индексом посредством n, исходящим из адаптивной таблицы 307 кодирования, которая содержит предыдущее возбуждение 304 через контур обратной связи (фиг. 3); ep(n) может быть адаптивно фильтровано по нижним частотам, поскольку низкочастотная область зачастую является более периодической или более гармонической, чем высокочастотная область; eс(n) исходит из таблицы 308 кодирования кодированного возбуждения (также называемой "фиксированной таблицей кодирования"), которая является текущей долей в возбуждении. Дополнительно, ec(n) также может улучшаться, к примеру, посредством использования улучшения фильтрации верхних частот, улучшения основного тона, улучшения дисперсии, улучшения формант и других.
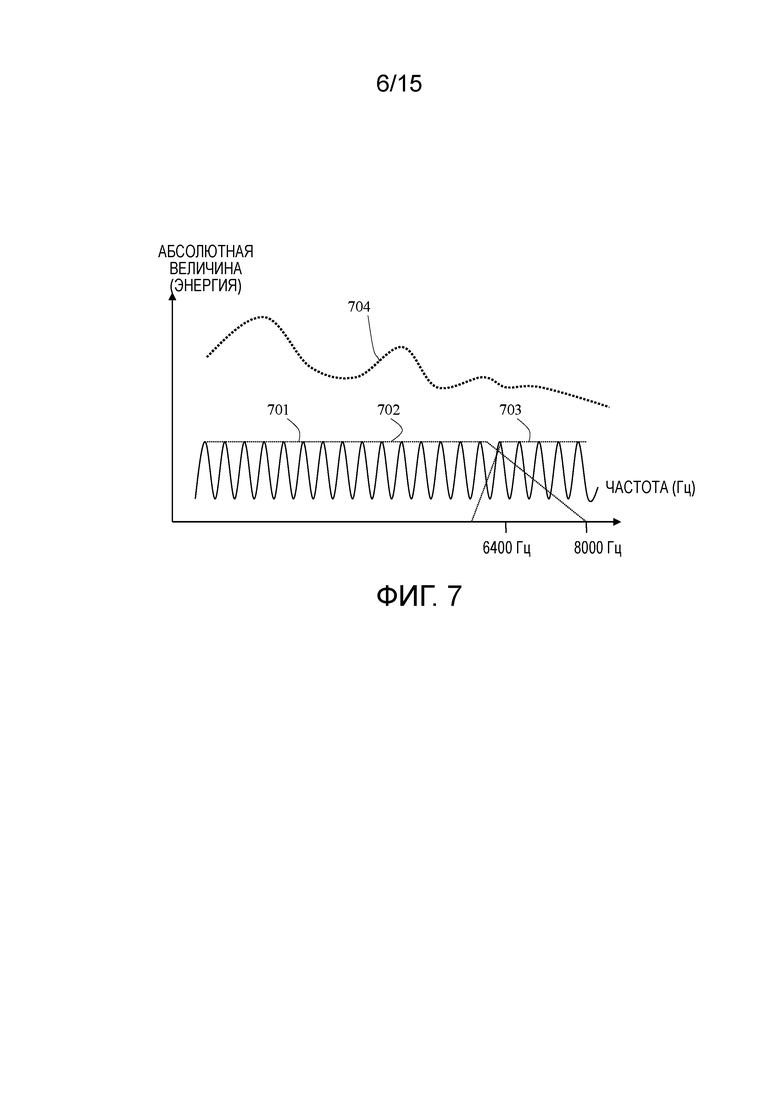
[64] Для вокализованной речи, доля ep(n) из адаптивной таблицы 307 кодирования может быть доминирующей, и усиление Gp 305 основного тона составляет около значения 1. Возбуждение обычно обновляется для каждого субкадра. Типичный размер кадра составляет 20 миллисекунд, и типичный размер субкадра составляет 5 миллисекунд.
[65] Как описано на фиг. 1, фиксированное кодированное возбуждение 308 масштабируется посредством усиления Gc 306 перед прохождением через линейные фильтры. Два масштабированных компонента возбуждения из фиксированного кодированного возбуждения 108 и адаптивной таблицы 307 кодирования суммируются между собой перед фильтрацией через кратковременный линейный прогнозный фильтр 303. Два усиления (Gp и Gc) квантуются и передаются в декодер. Соответственно, индекс кодированного возбуждения, индекс адаптивной таблицы кодирования, индексы квантованного усиления и индекс квантованного параметра кратковременного прогнозирования передаются в приемное аудиоустройство.
[66] Поток CELP-битов, кодированный с использованием устройства, проиллюстрированного на фиг. 3, принимается в приемном устройстве. Фиг. 4 иллюстрирует соответствующий декодер приемного устройства.
[67] Фиг. 4 иллюстрирует базовый CELP-декодер, соответствующий кодеру на фиг. 5. Фиг. 4 включает в себя блок 408 постобработки, принимающий синтезированную речь 407 из основного декодера. Этот декодер является аналогичным фиг. 3, за исключением адаптивной таблицы 307 кодирования.
[68] Для каждого принимаемого субкадра, принимаемые индекс кодированного возбуждения, квантованный индекс усиления кодированного возбуждения, индекс квантованного основного тона, индекс квантованного усиления адаптивной таблицы кодирования и индекс квантованного параметра кратковременного прогнозирования используются для того, чтобы находить соответствующие параметры с использованием соответствующих декодеров, например, декодера 81 усиления, декодера 84 основного тона, декодера 85 усиления адаптивной таблицы кодирования и кратковременного прогнозного декодера 83.
[69] В различных вариантах осуществления, CELP-декодер представляет собой комбинацию нескольких блоков и содержит кодированное возбуждение 402, адаптивную таблицу 401 кодирования, кратковременное прогнозирование 406 и постобработку 408. Каждый блок, за исключением постобработки, имеет определение, идентичное определению, описанному в кодере по фиг. 3. Постобработка дополнительно может включать в себя кратковременную постобработку и долговременную постобработку.
[70] Как уже упомянуто, CELP в основном используется для того, чтобы кодировать речевой сигнал посредством извлечения выгоды из конкретных характеристик человеческого голоса или вокальной модели формирования человеческого голоса. Чтобы более эффективно кодировать речевой сигнал, речевой сигнал может классифицироваться на различные классы, и каждый класс кодируется различным способом. Классификация "вокализованный/невокализованный" или решение по "невокализованному" могут быть важной и базовой классификацией из всех классификаций различных классов. Для каждого класса, LPC- или STP-фильтр всегда используется для того, чтобы представлять спектральную огибающую. Но возбуждение в LPC-фильтр может отличаться. Невокализованные сигналы могут кодироваться с шумоподобным возбуждением. С другой стороны, вокализованные сигналы могут кодироваться с импульсоподобным возбуждением.
[71] Блок возбуждения по коду (указываемый ссылкой с помощью метки 308 на фиг. 3 и 402 на фиг. 4) иллюстрирует местоположение фиксированной таблицы кодирования (FCB) для общего CELP-кодирования. Выбранный кодовый вектор из FCB масштабируется посредством усиления, зачастую помеченного как Gc 306.
[72] Фиг. 5A и 5B иллюстрируют пример кодирования/декодирования с расширением полосы пропускания (BWE). Фиг. 5A иллюстрирует операции в кодере со вспомогательной BWE-информацией, в то время как фиг. 5B иллюстрирует операции в декодере с BWE.
[73] Сигнал 501 полосы низких частот кодируется посредством использования параметров 502 полосы низких частот. Параметры 502 полосы низких частот квантуются, и сформированный индекс квантования может передаваться через канал 503 передачи потоков битов. Сигнал полосы высоких частот, извлеченный из аудио-/речевого сигнала 504, кодируется с небольшим количеством битов посредством использования вспомогательных параметров 505 полосы высоких частот. Квантованные вспомогательные параметры полосы высоких частот (индекс вспомогательной информации) передаются через канал 506 передачи потоков битов.
[74] Ссылаясь на фиг. 5B, в декодере, поток 507 битов полосы низких частот используется для того, чтобы формировать декодированный сигнал 508 полосы низких частот. Вспомогательный поток 510 битов полосы высоких частот используется для того, чтобы декодировать вспомогательные параметры 511 полосы высоких частот. Сигнал 512 полосы высоких частот формируется из сигнала 508 полосы низких частот с помощью вспомогательных параметров 511 полосы высоких частот. Конечный аудио-/речевой сигнал 509 формируется посредством комбинирования сигнала 508 полосы низких частот и сигнала 512 полосы высоких частот.
[75] Фиг. 6A и 6B иллюстрируют другой пример кодирования/декодирования с BWE без передачи вспомогательной информации. Фиг. 6A иллюстрирует операции в кодере, в то время как фиг. 6B иллюстрирует операции в декодере.
[76] Ссылаясь на фиг. 6A сигнал 601 полосы низких частот кодируется посредством использования параметров 602 полосы низких частот. Параметры 602 полосы низких частот квантуются, чтобы формировать индекс квантования, который может передаваться через канал 603 передачи потоков битов.
[77] Ссылаясь на фиг. 6B, в декодере, поток 604 битов полосы низких частот используется для того, чтобы формировать декодированный сигнал 605 полосы низких частот. Сигнал 607 полосы высоких частот формируется из сигнала 605 полосы низких частот без помощи передачи вспомогательной информации. Конечный аудио-/речевой сигнал 606 формируется посредством комбинирования сигнала 605 полосы низких частот и сигнала 607 полосы высоких частот.
[78] Фиг. 7 иллюстрирует пример идеального спектра возбуждения для вокализованной речи или гармонической музыки, когда используется CELP-тип кодека.
[79] Идеальный спектр 702 возбуждения является почти плоским после удаления спектральной LPC-огибающей 704. Идеальный спектр 701 возбуждения в полосе низких частот может использоваться в качестве опорного для кодирования с возбуждением в полосе низких частот. Идеальный спектр 703 возбуждения в полосе высоких частот недоступен в декодере. Теоретически, идеальный или неквантованный спектр возбуждения в полосе высоких частот может иметь энергетический уровень, почти идентичный энергетическому уровню спектра возбуждения в полосе низких частот.
[80] На практике, синтезированный или декодированный спектр возбуждения не выглядит настолько хорошо, как идеальный спектр возбуждения, показанный на фиг. 7.
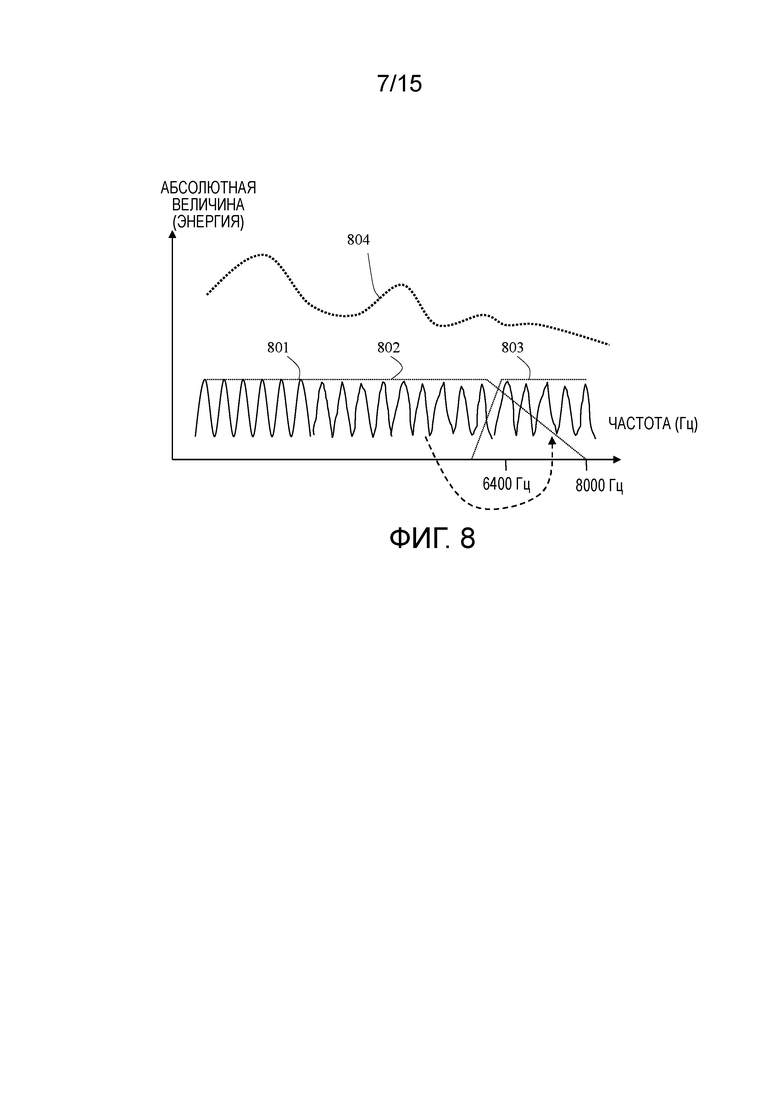
[81] Фиг. 8 показывает пример декодированного спектра возбуждения для вокализованной речи или гармонической музыки, когда используется CELP-тип кодека.
[82] Декодированный спектр 802 возбуждения является почти плоским после удаления спектральной LPC-огибающей 804. Декодированный спектр 801 возбуждения в полосе низких частот доступен в декодере. Качество декодированного спектра 801 возбуждения в полосе низких частот становится хуже или более искаженным, в частности, в области, в которой энергия огибающей является низкой. Это вызывается вследствие ряда причин. Например, две основных причины состоят в том, что CELP-кодирование с замкнутым контуром больше концентрируется на высокоэнергетической области, чем на низкоэнергетической области, и что согласование форм сигналов для низкочастотного сигнала проще, чем для высокочастотного сигнала, вследствие более быстрого изменения высокочастотного сигнала. Для CELP-кодирования с низкой скоростью передачи битов, к примеру, AMR-WB, полоса высоких частот обычно не кодируется, а формируется в декодере с помощью BWE-технологии. В этом случае, спектр 803 возбуждения в полосе высоких частот может просто копироваться из спектра 801 возбуждения в полосе низких частот, и спектральная энергетическая огибающая полосы высоких частот может прогнозироваться или оцениваться из спектральной энергетической огибающей полосы низких частот. Согласно традиционному способу, сформированный спектр возбуждения в полосе высоких частот 803 после 6400 Гц копируется из подполосы частот непосредственно перед 6400 Гц. Это может быть хорошо, если качество спектра является эквивалентным от 0 Гц до 6400 Гц. Тем не менее, для кодека CELP с низкой скоростью передачи битов, качество спектра может варьироваться много от 0 Гц до 6400 Гц. Скопированная подполоса частот из конечной области полосы низких частот непосредственно перед 6400 Гц может иметь плохое качество, которое затем вводит сверхзашумленный звук в область полосы высоких частот от 6400 Гц до 8000 Гц.
[83] Полоса пропускания расширенной полосы высоких частот обычно гораздо меньше полосы пропускания кодированной полосы низких частот. Следовательно, в различных вариантах осуществления, наилучшая подполоса частот из полосы низких частот выбирается и копируется в область полосы высоких частот.
[84] Подполоса частот высокого качества возможно существует в любом местоположении во всей полосе низких частот. Наиболее вероятное местоположение подполосы частот высокого качества находится в области, соответствующей области высокой спектральной энергии (области спектральной форманты).
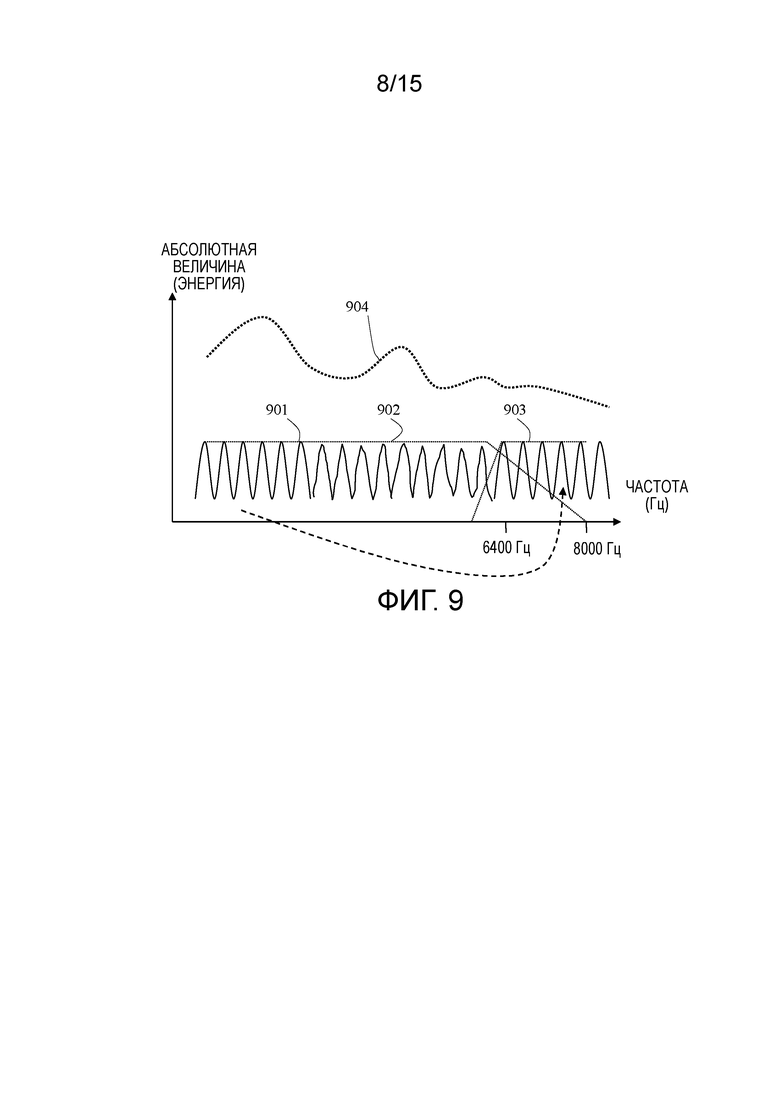
[85] Фиг. 9 иллюстрирует пример декодированного спектра возбуждения для вокализованной речи или гармонической музыки, когда используется CELP-тип кодека.
[86] Декодированный спектр 902 возбуждения является почти плоским после удаления спектральной LPC-огибающей 904. Декодированный спектр 901 возбуждения в полосе низких частот доступен в декодере, но недоступен в полосе 903 высоких частот. Качество декодированного спектра 901 возбуждения в полосе низких частот становится хуже или более искаженным, в частности, в области, в которой энергия спектральной огибающей 904 является более низкой.
[87] В проиллюстрированном случае по фиг. 9, в одном варианте осуществления, подполоса частот высокого качества расположена вокруг первой области речевой форманты (например, приблизительно 2000 Гц в этом примерном варианте осуществления). В различных вариантах осуществления, подполоса частот высокого качества может быть расположена в любом местоположении между 0 и 6400 Гц.
[88] После определения местоположения наилучшей подполосы частот, она копируется из полосы низких частот в полосу высоких частот, как подробнее проиллюстрировано на фиг. 9. Спектр 903 возбуждения в полосе высоких частот в силу этого формируется посредством копирования из выбранной подполосы частот. Перцепционное качество полосы 903 высоких частот на фиг. 9 звучит гораздо лучше, чем для полосы 803 высоких частот на фиг. 8, вследствие улучшенного спектра возбуждения.
[89] В одном или более вариантов осуществления, если огибающая спектра полосы низких частот доступна в частотной области в декодере, наилучшая подполоса частот может определяться посредством поиска наибольшей энергии подполосы частот из всех возможных вариантов подполос частот.
[90] Альтернативно, в одном или более вариантов осуществления, если огибающая спектра частотной области недоступна, местоположение высокой энергии также может определяться из любых параметров, которые могут отражать спектральную энергетическую огибающую или пик спектральной форманты. Местоположение наилучшей подполосы частот для BWE соответствует местоположению наивысшего спектрального пика.
[91] Диапазон поиска начальной точки наилучшей подполосы частот может зависеть от скорости передачи битов в кодеках. Например, для кодека с очень низкой скоростью передачи битов, диапазон поиска может составлять от 0 до 6400-1600=4800Hz (2000-4800 Гц) при условии, что полоса пропускания полосы высоких частот составляет 1600 Гц. В другом примере, для кодека со средней скоростью передачи битов, диапазон поиска может составлять от 2000 Гц до 6400-1600=4800Hz (2000-4800 Гц) при условии, что полоса пропускания полосы высоких частот составляет 1600 Гц.
[92] Поскольку спектральная огибающая изменяется медленно от одного кадра до следующего кадра, начальная точка наилучшей подполосы частот, соответствующая наибольшей энергии спектральной форманты, нормально изменяется медленно. Во избежание флуктуации или частого изменения начальной точки наилучшей подполосы частот между кадрами, некоторое сглаживание может применяться в течение идентичной вокализованной области во временной области, если энергия спектрального пика не изменяется резко от одного кадра до следующего кадра, или не поступает новая вокализованная область.
[93] Фиг. 10 иллюстрирует операции в декодере в соответствии с вариантами осуществления настоящего изобретения для реализации сдвига или копирования подполосы частот для BWE.
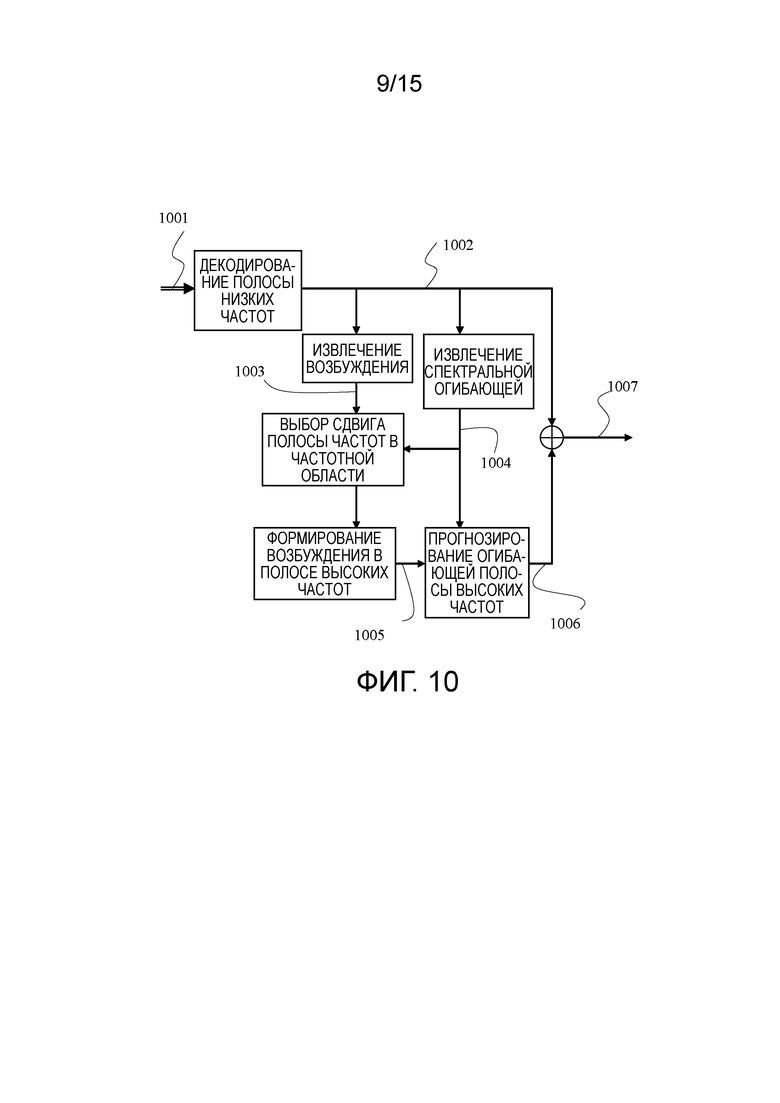
[94] Сигнал 1002 полосы низких частот временной области декодируется посредством использования принимаемого потока 1001 битов. Возбуждение 1003 во временной области в полосе низких частот обычно доступно в декодере. Иногда, возбуждение в частотной области в полосе низких частот также доступно. Если недоступно, возбуждение 1003 во временной области в полосе низких частот может быть преобразовано в частотную область, чтобы получать возбуждение в частотной области в полосе низких частот.
[95] Спектральная огибающая вокализованной речи или музыкального сигнала зачастую представляется посредством LPC-параметров. Иногда, прямая спектральная огибающая частотной области доступна в декодере. В любом случае, информация 1004 распределения энергии может извлекаться из LPC-параметров или из прямой спектральной огибающей частотной области либо из любых параметров, таких как DFT-область или FFT-область. С использованием информации 1004 распределения энергии в полосе низких частот, наилучшая подполоса частот из полосы низких частот выбирается посредством поиска относительно высокого энергетического пика. Выбранная подполоса частот затем копируется из полосы низких частот в область полосы высоких частот. Прогнозная или оцененная спектральная огибающая полосы высоких частот затем применяется к области полосы высоких частот, или возбуждение 1005 в полосе высоких частот во временной области проходит через прогнозный или оцененный фильтр полосы высоких частот, который представляет спектральную огибающую полосы высоких частот. Вывод фильтра полосы высоких частот представляет собой сигнал 1006 полосы высоких частот. Конечный выходной речевой/аудио-сигнал 1007 получается посредством комбинирования сигнала 1002 полосы низких частот и сигнала 1006 полосы высоких частот.
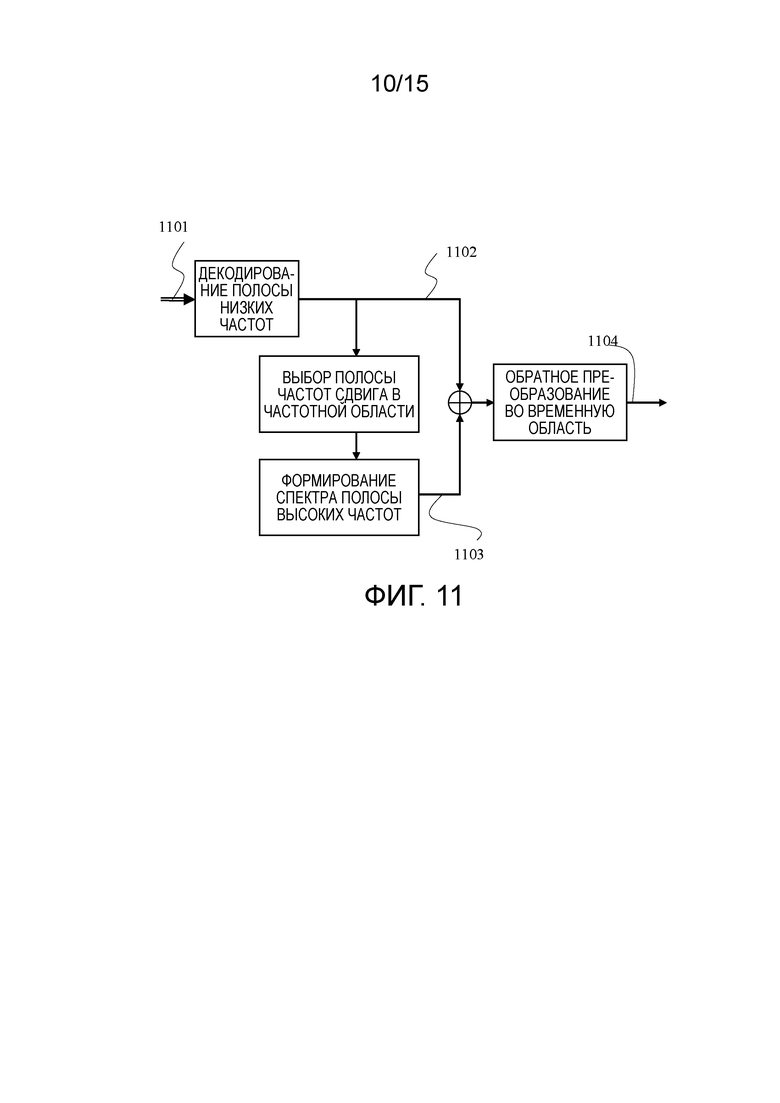
[96] Фиг. 11 иллюстрирует альтернативный вариант осуществления декодера для реализации сдвига или копирования подполосы частот для BWE.
[97] В отличие от фиг. 10, фиг. 11 предполагает то, что спектр полосы низких частот частотной области доступен. Наилучшая подполоса частот в полосе низких частот выбирается посредством простого поиска относительно высокого энергетического пика в частотной области. Затем выбранная подполоса частот копируется из полосы низких частот в полосу высоких частот. После применения оцененной спектральной огибающей полосы высоких частот, формируется спектр 1103 полосы высоких частот. Конечный речевой/аудио-спектр частотной области получается посредством комбинирования спектра 1102 полосы низких частот и спектра 1103 полосы высоких частот. Вывод конечных речевых/аудио-сигналов временной области формируется посредством преобразования речевого/аудио-спектра частотной области во временную область.
[98] Когда анализ и синтез на основе гребенки фильтров доступен в декодере, покрывающем требуемый диапазон спектра, SBR-алгоритм может реализовать сдвиг полосы частот посредством копирования коэффициентов полосы низких частот вывода, соответствующего выбранной полосе низких частот из анализа на основе гребенки фильтров, в область полосы высоких частот.
[99] Фиг. 12 иллюстрирует операции, выполняемые в декодере в соответствии с вариантами осуществления настоящего изобретения.
[100] Ссылаясь на фиг. 12, способ декодирования кодированного потока аудиобитов в декодере включает в себя прием кодированного потока аудиобитов. В одном или более вариантов осуществления, принимаемый поток аудиобитов CELP-кодирован. В частности, только полоса низких частот кодируется посредством CELP. CELP формирует относительно более высокое качество спектра в области более высокой спектральной энергии, чем в области более низкой спектральной энергии. Соответственно, варианты осуществления настоящего изобретения включают в себя декодирование потока аудиобитов для того, чтобы формировать декодированный аудиосигнал полосы низких частот и спектр возбуждения в полосе низких частот, соответствующий полосе низких частот (этап 1210). Область подполосы частот выбирается из полосы низких частот с использованием информации энергии спектральной огибающей декодированного аудиосигнала полосы низких частот (этап 1220). Спектр возбуждения в полосе высоких частот формируется для полосы высоких частот посредством копирования спектра возбуждения в подполосе частот из выбранной области подполосы частот в область подполосы высоких частот, соответствующую полосе высоких частот (этап 1230). Выходной аудиосигнал формируется с использованием спектра возбуждения в полосе высоких частот (этап 1240). В частности, с использованием сформированного спектра возбуждения в полосе высоких частот, аудиосигнал расширенной полосы высоких частот формируется посредством применения спектральной огибающей полосы высоких частот. Аудиосигнал расширенной полосы высоких частот суммируется с декодированным аудиосигналом полосы низких частот для того, чтобы формировать выходной аудиосигнал, имеющий расширенную полосу пропускания частот.
[101] Как описано выше с использованием фиг. 10 и 11, варианты осуществления настоящего изобретения могут применяться по-разному в зависимости от того, доступна или нет огибающая спектра частотной области. Например, если огибающая спектра частотной области доступна, может выбираться подполоса частот с наибольшей энергией подполосы частот. С другой стороны, огибающая спектра частотной области недоступна, распределение энергии спектральной огибающей может идентифицироваться из параметров линейного прогнозирующего кодирования (LPC), параметров области дискретного преобразования Фурье (DFT) или области быстрого преобразования Фурье (FFT). Аналогично, информация пика спектральной форманты, если доступна (или может вычисляться), может использоваться в некотором варианте осуществления. Если только возбуждение во временной области в полосе низких частот доступно, возбуждение в частотной области в полосе низких частот может вычисляться посредством преобразования возбуждения во временной области в полосе низких частот в частотную область.
[102] В различных вариантах осуществления, спектральная огибающая может вычисляться с использованием любого известного способа, как должно быть известно для специалистов в данной области техники. Например, в частотной области, спектральная огибающая может быть просто набором энергий, которые представляют энергии набора подполос частот. Аналогично, в другом примере, во временной области, спектральная огибающая может быть представлена посредством LPC-параметров. LPC-параметры могут иметь множество форм, к примеру, коэффициенты отражения, LPC-коэффициенты, LSP-коэффициенты, LSF-коэффициенты в различных вариантах осуществления.
[103] Фиг. 13A и 13B иллюстрируют декодер, реализующий расширение полосы пропускания в соответствии с вариантами осуществления настоящего изобретения.
[104] Ссылаясь на фиг. 13A декодер для декодирования кодированного потока аудиобитов содержит модуль 1310 декодирования в полосе низких частот, выполненный с возможностью декодировать поток аудиобитов для того, чтобы формировать спектр возбуждения в полосе низких частот, соответствующий полосе низких частот.
[105] Декодер дополнительно включает в себя модуль 1320 расширения полосы пропускания, соединенный с модулем 1310 декодирования в полосе низких частот и содержащий модуль 1330 выбора подполосы частот и модуль 1340 копирования. Модуль 1330 выбора подполосы частот выполнен с возможностью выбирать область подполосы частот из полосы низких частот с использованием информации энергии спектральной огибающей декодированного потока аудиобитов. Модуль 1340 копирования выполнен с возможностью формировать спектр возбуждения в полосе высоких частот для полосы высоких частот посредством копирования спектра возбуждения в подполосе частот из выбранной области подполосы частот в область подполосы высоких частот, соответствующую полосе высоких частот.
[106] Формирователь 1350 сигналов полосы высоких частот соединяется с модулем 1340 копирования. Формирователь 1350 сигналов полосы высоких частот выполнен с возможностью применять прогнозную спектральную огибающую полосы высоких частот для того, чтобы формировать сигнал временной области полосы высоких частот. Выходной формирователь соединяется с формирователем 1350 сигналов полосы высоких частот и модулем 1310 декодирования в полосе низких частот. Выходной формирователь 1360 выполнен с возможностью формировать выходной аудиосигнал посредством комбинирования сигнала временной области полосы низких частот, полученного посредством декодирования потока аудиобитов, с сигналом временной области полосы высоких частот.
[107] Фиг. 13B иллюстрирует альтернативный вариант осуществления декодера, реализующего расширение полосы пропускания.
[108] Аналогичный фиг. 13A, декодер по фиг. 13B также включает в себя модуль 1310 декодирования в полосе низких частот и модуль 1320 расширения полосы пропускания, который соединяется с модулем 1310 декодирования в полосе низких частот и содержит модуль 1330 выбора подполосы частот и модуль 1340 копирования.
[109] Ссылаясь на фиг. 13B, декодер дополнительно включает в себя формирователь 1355 спектра полосы высоких частот, который соединяется с модулем 1340 копирования. Формирователь 1355 сигналов полосы высоких частот выполнен с возможностью применять энергию спектральной огибающей полосы высоких частот для того, чтобы формировать спектр полосы высоких частот для полосы высоких частот с использованием спектра возбуждения в полосе высоких частот.
[110] Формирователь 1365 выходного спектра соединяется с формирователем 1355 спектра полосы высоких частот и модулем 1310 декодирования в полосе низких частот. Формирователь выходного спектра выполнен с возможностью формировать аудиоспектр частотной области посредством комбинирования спектра полосы низких частот, полученного посредством декодирования потока аудиобитов из модуля 1310 декодирования в полосе низких частот, со спектром полосы высоких частот из формирователя 1355 спектра полосы высоких частот.
[111] Формирователь 1370 сигналов обратного преобразования выполнен с возможностью формировать аудиосигнал временной области посредством обратного преобразования аудиоспектра частотной области во временную область.
[112] Различные компоненты, описанные на фиг. 13A и 13B, могут реализовываться в аппаратных средствах в одном или более вариантов осуществления. В некоторых вариантах осуществления, они могут реализовываться в программном обеспечении и проектироваться с возможностью работать в процессоре сигналов.
[113] Соответственно, варианты осуществления настоящего изобретения могут использоваться для того, чтобы улучшать расширение полосы пропускания в декодере, декодирующем CELP-кодированный поток аудиобитов.
[114] Фиг. 14 иллюстрирует систему 10 связи согласно варианту осуществления настоящего изобретения.
[115] Система 10 связи имеет устройства 7 и 8 аудиодоступа, соединенные с сетью 36 через линии 38 и 40 связи. В одном варианте осуществления, устройство 7 и 8 аудиодоступа представляет собой устройства по протоколу "речь-по-IP" (VoIP), и сеть 36 представляет собой глобальную вычислительную сеть (WAN), коммутируемую телефонную сеть общего пользования (PTSN) и/или Интернет. В другом варианте осуществления, линии 38 и 40 связи представляют собой проводные и/или беспроводные широкополосные соединения. В альтернативном варианте осуществления, устройства 7 и 8 аудиодоступа представляют собой сотовые или мобильные телефоны, линии 38 и 40 связи представляют собой беспроводные мобильные телефонные каналы, и сеть 36 представляет мобильную телефонную сеть.
[116] Устройство 7 аудиодоступа использует микрофон 12, чтобы преобразовывать звук, к примеру, музыка или голос пользователя в аналоговый входной аудиосигнал 28. Интерфейс 16 микрофона преобразует аналоговый входной аудиосигнал 28 в цифровой аудиосигнал 33 для ввода в кодер 22 кодека 20. Кодер 22 формирует кодированный TX-аудиосигнал для передачи в сеть 26 через сетевой интерфейс 26 согласно вариантам осуществления настоящего изобретения. Декодер 24 в кодеке 20 принимает кодированный RX-аудиосигнал из сети 36 через сетевой интерфейс 26 и преобразует кодированный RX-аудиосигнал в цифровой аудиосигнал 34. Интерфейс 18 динамиков преобразует цифровой аудиосигнал 34 в аудиосигнал 30, подходящий для управления громкоговорителем 14.
[117] В вариантах осуществления настоящего изобретения, в которых устройство 7 аудиодоступа представляет собой VoIP-устройство, некоторые или все компоненты в устройстве 7 аудиодоступа реализуются в переносном телефоне. Тем не менее, в некоторых вариантах осуществления, микрофон 12 и громкоговоритель 14 представляют собой отдельные модули, и интерфейс 16 микрофона, интерфейс 18 динамиков, кодек 20 и сетевой интерфейс 26 реализуются в персональном компьютере. Кодек 20 может реализовываться либо в программном обеспечении, работающем на компьютере, либо в специализированном процессоре, либо посредством специализированных аппаратных средств, например, в специализированной интегральной схеме (ASIC). Интерфейс 16 микрофона реализуется посредством аналого-цифрового (A/D) преобразователя, а также другой интерфейсной схемы, расположенной в переносном телефоне и/или в компьютере. Аналогично, интерфейс 18 динамиков реализуется посредством цифро-аналогового преобразователя и другой интерфейсной схемы, расположенной в переносном телефоне и/или в компьютере. В дополнительных вариантах осуществления, устройство 7 аудиодоступа может реализовываться и сегментироваться другими способами, известными в данной области техники.
[118] В вариантах осуществления настоящего изобретения, в которых устройство 7 аудиодоступа представляет собой сотовый или мобильный телефон, элементы в устройстве 7 аудиодоступа реализуются в переносном сотовом телефоне. Кодек 20 реализуется посредством программного обеспечения, выполняемого в процессоре в переносном телефоне, либо посредством специализированных аппаратных средств. В дополнительных вариантах осуществления настоящего изобретения, устройство аудиодоступа может реализовываться в других устройствах, таких как системы проводной и беспроводной цифровой связи между равноправными узлами, такие как домофоны и переносные радиотелефоны. В таких вариантах применения, как потребительские аудиоустройства, устройство аудиодоступа может содержать кодек только с кодером 22 или декодером 24, например, в цифровой микрофонной системе или устройстве воспроизведения музыки. В других вариантах осуществления настоящего изобретения, кодек 20 может использоваться без микрофона 12 и динамика 14, например, в сотовых базовых станциях, которые осуществляют доступ к PTSN.
[119] Обработка речи для улучшения классификации "невокализованный/вокализованный", описанной в различных вариантах осуществления настоящего изобретения, может реализовываться, например, в кодере 22 или декодере 24. Обработка речи для улучшения классификации "невокализованный/вокализованный" может реализовываться в аппаратных средствах или в программном обеспечении в различных вариантах осуществления. Например, кодер 22 или декодер 24 могут быть частью кристалла обработки цифровых сигналов (DSP).
[120] Фиг. 15 иллюстрирует блок-схему системы обработки, которая может использоваться для реализации устройств и способов, раскрытых в данном документе. Конкретные устройства могут использовать все показанные компоненты либо только поднабор компонентов, и уровни интеграции могут варьироваться между устройствами. Кроме того, устройство может содержать несколько экземпляров компонента, к примеру, несколько блоков обработки, процессоров, запоминающих устройств, передающих устройств, приемных устройств и т.д. Система обработки может содержать процессор, оснащенный одним или более устройств ввода-вывода, таких как динамик, микрофон, мышь, сенсорный экран, клавишная панель, клавиатура, принтер, дисплей и т.п. Процессор может включать в себя центральный процессор (CPU), запоминающее устройство, устройство хранения данных большой емкости, видеоадаптер и интерфейс ввода-вывода, соединенные с шиной.
[121] Шина может представлять собой одну или более из любого типа из нескольких шинных архитектур, включающих в себя шину запоминающего устройства или контроллер запоминающего устройства, периферийную шину, видеошину и т.п. CPU может содержать любой тип электронного процессора данных. Запоминающее устройство может содержать любой тип системного запоминающего устройства, такой как статическое оперативное запоминающее устройство (SRAM), динамическое оперативное запоминающее устройство (DRAM), синхронное DRAM (SDRAM), постоянное запоминающее устройство (ROM), комбинация вышеозначенного и т.п. В варианте осуществления, запоминающее устройство может включать в себя ROM для использования при начальной загрузке и DRAM для хранения программ и данных для использования при выполнении программ.
[122] Устройство хранения данных большой емкости может содержать любой тип устройства хранения данных, выполненного с возможностью сохранять данные, программы и другую информацию и обеспечивать доступность данных, программ и другой информации через шину. Устройство хранения данных большой емкости может содержать, например, одно или более из полупроводникового накопителя, жесткого диска, накопителя на магнитных дисках, накопителя на оптических дисках и т.п.
[123] Видеоадаптер и интерфейс ввода-вывода предоставляют интерфейсы, чтобы соединять внешние устройства ввода и вывода с процессором. Как проиллюстрировано, примеры устройств ввода и вывода включают в себя дисплей, соединенный с видеоадаптером, и мышь/клавиатуру/принтер, соединенные с интерфейсом ввода-вывода. Другие устройства могут соединяться с процессором, и может использоваться большее или меньше число интерфейсных плат. Например, последовательный интерфейс, такой как универсальная последовательная шина (USB) (не показана), может использоваться для того, чтобы предоставлять интерфейс для принтера.
[124] Процессор также включает в себя один или более сетевых интерфейсов, которые могут содержать линии проводной связи, такие как Ethernet-кабель и т.п., и/или линии беспроводной связи, для того, чтобы осуществлять доступ к узлам или различным сетям. Сетевой интерфейс дает возможность процессору обмениваться данными с удаленными блоками через сети. Например, сетевой интерфейс может предоставлять беспроводную связь через одно или более передающих устройств/передающих антенн и одно или более приемных устройств/приемных антенн. В варианте осуществления, процессор соединяется с локальной вычислительной сетью или глобальной вычислительной сетью для обработки данных и связи с удаленными устройствами, такими как другие процессоры, Интернет, удаленные средства хранения и т.п.
[125] Хотя это изобретение описано в отношении иллюстративных вариантов осуществления, это описание не имеет намерение трактовки в ограничивающем смысле. Различные модификации и комбинации иллюстративных вариантов осуществления, а также другие варианты осуществления изобретения должны становиться очевидными для специалистов в данной области техники при прочтении описания. Например, различные варианты осуществления, описанные выше, могут комбинироваться между собой.
[126] Хотя настоящее изобретение и его преимущества подробно описаны, следует понимать, что различные изменения, подстановки и изменения могут выполняться в данном документе без отступления от сущности и объема изобретения, заданного посредством прилагаемой формулы изобретения. Например, многие из признаков и функций, поясненных выше, могут быть реализованы в программном обеспечении, аппаратных средствах или микропрограммном обеспечении либо в комбинации вышеозначенного. Кроме того, объем настоящей заявки не имеет намерение быть ограниченным конкретными вариантами осуществления процесса, машины, изделия, композиции, средства, способов и этапов, описанных в подробном описании. Специалисты в данной области техники должны легко принимать во внимание из раскрытия сущности настоящего изобретения, что процессы, машины, изделия, композиции, средства, способы или этапы, существующие в настоящий момент или разработанные впоследствии, которые выполняют практически ту же функцию или достигают практически того же результата, что и соответствующие варианты осуществления, описанные в данном документе, могут быть использованы согласно настоящему изобретению. Соответственно, прилагаемая формула изобретения имеет намерение включать в свой объем такие процессы, машины, изделия, композиции, средства, способы или этапы.

Изобретение относится к области техники обработки речи, в частности к адаптивному расширению полосы пропускания. Технический результат – обеспечение формирования расширенной полосы пропускания частот в декодере. Данный способ включает в себя декодирование потока аудиобитов для того, чтобы формировать декодированный аудиосигнал полосы низких частот и спектр возбуждения в полосе низких частот, соответствующий полосе низких частот. Область подполосы частот выбирается из полосы низких частот с использованием параметра, который указывает информацию энергии спектральной огибающей декодированного аудиосигнала полосы низких частот. Спектр возбуждения в полосе высоких частот формируется для полосы высоких частот посредством копирования спектра возбуждения в подполосе частот из выбранной области подполосы частот в область подполосы высоких частот, соответствующую полосе высоких частот. С использованием сформированного спектра возбуждения в полосе высоких частот аудиосигнал расширенной полосы высоких частот формируется посредством применения спектральной огибающей полосы высоких частот. Аудиосигнал расширенной полосы высоких частот суммируется с декодированным аудиосигналом полосы низких частот для того, чтобы формировать выходной аудиосигнал, имеющий расширенную полосу пропускания частот. 4 н. и 15 з.п. ф-лы, 18 ил.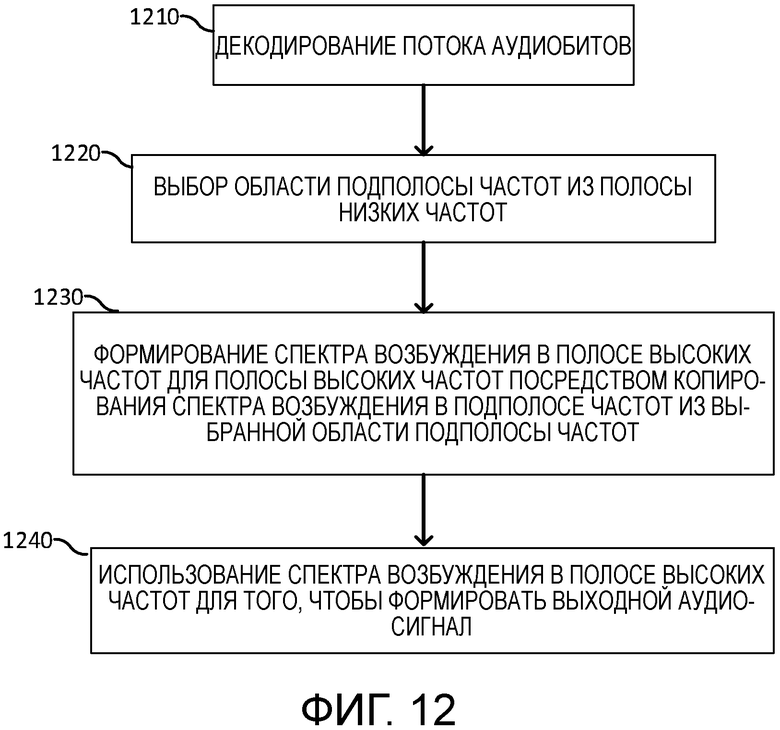
1. Способ декодирования кодированного потока аудиобитов и формирования расширения полосы пропускания частот в декодере, при этом способ содержит этапы, на которых:
декодируют поток аудиобитов для того, чтобы формировать декодированный аудиосигнал полосы низких частот и формировать спектр возбуждения в полосе низких частот, соответствующий полосе низких частот;
выбирают область подполосы частот из полосы низких частот с использованием параметра, который указывает информацию энергии спектральной огибающей декодированного аудиосигнала полосы низких частот, причем начальная точка области подполосы частот соответствует наибольшей энергии спектральной форманты в пределах диапазона поиска, и при этом диапазон поиска является частотной зоной в пределах полосы низких частот;
формируют спектр возбуждения в полосе высоких частот для полосы высоких частот посредством копирования спектра возбуждения в подполосе частот из выбранной области подполосы частот в область подполосы высоких частот в пределах полосы высоких частот;
используют сформированный спектр возбуждения в полосе высоких частот для того, чтобы формировать аудиосигнал расширенной полосы высоких частот посредством применения спектральной огибающей полосы высоких частот; и
суммируют аудиосигнал расширенной полосы высоких частот с декодированным аудиосигналом полосы низких частот для того, чтобы формировать выходной аудиосигнал, имеющий расширенную полосу пропускания частот.
2. Способ по п. 1, в котором диапазон поиска начальной точки зависит от скорости передачи битов в кодеках.
3. Способ по п. 1, в котором выбор области подполосы частот из полосы низких частот с использованием параметра, который указывает информацию энергии спектральной огибающей, содержит этап, на котором выбирают область подполосы частот, имеющую начальную точку, соответствующую наибольшей энергии спектральной огибающей в пределах диапазона поиска.
4. Способ по п. 1, в котором выбор области подполосы частот из полосы низких частот с использованием параметра, который указывает информацию энергии спектральной огибающей, содержит этап, на котором идентифицируют подполосу частот из полосы низких частот посредством использования параметров, отражающих наибольшую энергию спектральной огибающей или пика спектральной форманты, и выбора идентифицированной подполосы частот.
5. Способ по п. 4, в котором способ декодирования применяет технологию расширения полосы пропускания, чтобы формировать полосу высоких частот.
6. Способ по п. 1, в котором применение спектральной огибающей полосы высоких частот содержит этап, на котором применяют прогнозный фильтр полосы высоких частот, представляющий спектральную огибающую полосы высоких частот.
7. Способ по п. 1, дополнительно содержащий этап, на котором формируют выходной аудиосигнал посредством обратного преобразования аудиоспектра частотной области во временную область.
8. Способ по п. 1, в котором копирование спектра возбуждения в подполосе частот из выбранной области подполосы частот в область подполосы высоких частот, соответствующую полосе высоких частот, содержит этап, на котором копируют коэффициенты полосы низких частот вывода из анализа на основе гребенки фильтров в область подполосы высоких частот.
9. Способ по п. 1, в котором поток аудиобитов содержит вокализованную речь или гармоническую музыку.
10. Декодер для декодирования кодированного потока аудиобитов и формирования полосы пропускания частот, причем декодер содержит:
модуль декодирования в полосе низких частот, выполненный с возможностью декодировать поток аудиобитов для того, чтобы формировать декодированный аудиосигнал полосы низких частот и формировать спектр возбуждения в полосе низких частот, соответствующий полосе низких частот; и
модуль расширения полосы пропускания, соединенный с модулем декодирования в полосе низких частот и содержащий модуль выбора подполосы частот и модуль копирования, при этом модуль выбора подполосы частот выполнен с возможностью выбирать область подполосы частот из полосы низких частот с использованием параметра, который указывает информацию энергии спектральной огибающей декодированного аудиосигнала полосы низких частот, причем начальная точка области подполосы частот соответствует наибольшей энергии спектральной форманты в пределах диапазона поиска, и при этом диапазон поиска является частотной зоной в пределах полосы низких частот, при этом модуль копирования выполнен с возможностью формировать спектр возбуждения в полосе высоких частот для полосы высоких частот посредством копирования спектра возбуждения в подполосе частот из выбранной области подполосы частот в область подполосы высоких частот в пределах полосы высоких частот.
11. Декодер по п. 10, в котором диапазон поиска начальной точки зависит от скорости передачи битов в кодеках.
12. Декодер по п. 10, в котором модуль выбора подполосы частот выполнен с возможностью выбирать область подполосы частот, имеющую начальную точку, соответствующую наибольшей энергии спектральной огибающей в пределах диапазона поиска.
13. Декодер по п. 10, в котором модуль выбора подполосы частот выполнен с возможностью идентифицировать подполосу частот из полосы низких частот посредством использования параметров, отражающих наибольшую энергию спектральной огибающей или пик спектральной форманты.
14. Декодер по п. 10, дополнительно содержащий:
формирователь сигналов полосы высоких частот, соединенный с модулем копирования, причем формирователь сигналов полосы высоких частот выполнен с возможностью применять прогнозную спектральную огибающую полосы высоких частот для того, чтобы формировать сигнал временной области полосы высоких частот; и
выходной формирователь, соединенный с формирователем сигналов полосы высоких частот и модулем декодирования в полосе низких частот, при этом выходной формирователь выполнен с возможностью формировать выходной аудиосигнал посредством комбинирования сигнала временной области полосы низких частот, полученного посредством декодирования потока аудиобитов, с сигналом временной области полосы высоких частот.
15. Декодер по п. 14, в котором формирователь сигналов полосы высоких частот выполнен с возможностью применять прогнозный фильтр полосы высоких частот, представляющий прогнозную спектральную огибающую полосы высоких частот.
16. Декодер по п. 10, дополнительно содержащий:
формирователь спектра полосы высоких частот, соединенный с модулем копирования, причем формирователь спектра полосы высоких частот выполнен с возможностью применять оцененную спектральную огибающую полосы высоких частот для того, чтобы формировать спектр полосы высоких частот для полосы высоких частот с использованием спектра возбуждения в полосе высоких частот; и
формирователь выходного спектра, соединенный с формирователем спектра полосы высоких частот и модулем декодирования в полосе низких частот, при этом формирователь выходного спектра выполнен с возможностью формировать аудиоспектр частотной области посредством комбинирования спектра полосы низких частот, полученного посредством декодирования потока аудиобитов, со спектром полосы высоких частот.
17. Декодер по п. 16, дополнительно содержащий формирователь сигналов обратного преобразования, выполненный с возможностью формировать аудиосигнал временной области посредством обратного преобразования аудиоспектра частотной области во временную область.
18. Декодер для обработки речи, содержащий:
процессор; и
машиночитаемый носитель хранения данных, сохраняющий программирование для выполнения посредством процессора, причем программирование включает в себя инструкции для того, чтобы:
декодировать поток аудиобитов для того, чтобы формировать декодированный аудиосигнал полосы низких частот и формировать спектр возбуждения в полосе низких частот, соответствующий полосе низких частот,
выбирать область подполосы частот из полосы низких частот с использованием параметра, который указывает информацию энергии спектральной огибающей декодированного аудиосигнала полосы низких частот, причем начальная точка области подполосы частот соответствует наибольшей энергии спектральной форманты в пределах диапазона поиска, и при этом диапазон поиска является частотной зоной в пределах полосы низких частот,
формировать спектр возбуждения в полосе высоких частот для полосы высоких частот посредством копирования спектра возбуждения в подполосе частот из выбранной области подполосы частот в область подполосы высоких частот в пределах полосы высоких частот,
использовать сформированный спектр возбуждения в полосе высоких частот для того, чтобы формировать аудиосигнал расширенной полосы высоких частот посредством применения спектральной огибающей полосы высоких частот, и
суммировать аудиосигнал расширенной полосы высоких частот с декодированным аудиосигналом полосы низких частот для того, чтобы формировать выходной аудиосигнал, имеющий расширенную полосу пропускания частот.
19. Способ декодирования кодированного потока аудиобитов и формирования расширения полосы пропускания частот в декодере, при этом способ содержит этапы, на которых:
декодируют поток аудиобитов для того, чтобы формировать декодированный аудиосигнал полосы низких частот и формировать спектр полосы низких частот, соответствующий полосе низких частот;
выбирают область подполосы частот из полосы низких частот с использованием параметра, который указывает информацию энергии спектральной огибающей декодированного аудиосигнала полосы низких частот, причем начальная точка области подполосы частот соответствует наибольшей энергии спектральной форманты в пределах диапазона поиска, и при этом диапазон поиска является частотной зоной в пределах полосы низких частот;
формируют спектр полосы высоких частот посредством копирования спектра подполосы частот из выбранной области подполосы частот в область подполосы высоких частот;
используют сформированный спектр полосы высоких частот для того, чтобы формировать аудиосигнал расширенной полосы высоких частот посредством применения энергии спектральной огибающей полосы высоких частот; и
суммируют аудиосигнал расширенной полосы высоких частот с декодированным аудиосигналом полосы низких частот для того, чтобы формировать выходной аудиосигнал, имеющий расширенную полосу пропускания частот.
| Изложница с суживающимся книзу сечением и с вертикально перемещающимся днищем | 1924 |
|
SU2012A1 |
| Приспособление для суммирования отрезков прямых линий | 1923 |
|
SU2010A1 |
| УСТРОЙСТВО И СПОСОБ РАСШИРЕНИЯ ПОЛОСЫ ПРОПУСКАНИЯ АУДИО СИГНАЛА | 2009 |
|
RU2455710C2 |
| СПОСОБ И УСТРОЙСТВО ДЛЯ ОБРАБОТКИ СИГНАЛА | 2008 |
|
RU2449387C2 |
| СПОСОБ И УСТРОЙСТВО ДЛЯ РАСШИРЕНИЯ ШИРИНЫ ПОЛОСЫ АУДИОСИГНАЛА | 2008 |
|
RU2447415C2 |
| CN 103069484 A, 24.04.2013 | |||
| CN 101089951 A, 19.12.2007 | |||
| US 8296157 B2, 23.10.2012 | |||
| Манометрический термометр | 1986 |
|
SU1420389A1 |

