Варианты осуществления относятся к аудиопроцессору/способу для обработки аудиосигнала, с тем чтобы получать подполосное представление аудиосигнала. Дополнительные варианты осуществления относятся к аудиопроцессору/способу для обработки подполосного представления аудиосигнала, с тем чтобы получать аудиосигнал. Некоторые варианты осуществления относятся к варьирующимся во времени расположениям частотно-временными плитками (tiles) с использованием неравномерных ортогональных гребенок фильтров на основе анализа/синтеза на основе MDCT (MDCT=модифицированное дискретное косинусное преобразование) и TDAR (TDAR=уменьшение наложения спектров во временной области).
Выше показано, что проектирование неравномерной ортогональной гребенки фильтров с использованием подполосного объединения является возможным [1], [2], [3], и при введении этапа постобработки, называемого "уменьшением наложения спектров во временной области (TDAR)", компактные импульсные отклики являются возможными [4]. Кроме того, использование этой гребенки TDAR-фильтров при кодировании аудио показано как обеспечивающее в результате более высокую эффективность кодирования и/или повышенное перцепционное качество по сравнению с переключением окон кодирования со взвешиванием [5].
Тем не менее, один главный недостаток TDAR представляет собой тот факт, что оно требует двух смежных кадров, чтобы использовать идентичные расположения частотно-временными плитками. Это ограничивает гибкость гребенки фильтров, когда варьирующиеся во времени адаптивные расположения частотно-временными плитками требуются, поскольку TDAR должно быть временно недоступным для того, чтобы переключаться с одного расположения плитками на другое. Такое переключение обычно требуется, когда характеристики входных сигналов изменяются, т.е. когда встречаются переходные части. При равномерном MDCT, это достигается с использованием переключения окон кодирования со взвешиванием [6].
Следовательно, цель настоящего изобретения заключается в том, чтобы улучшать компактность импульсного отклика неравномерной гребенки фильтров, даже когда характеристики входных сигналов изменяются.
Эта цель решается посредством независимых пунктов формулы изобретения.
Преимущественные реализации затрагиваются в зависимых пунктах формулы изобретения.
Варианты осуществления предусматривают аудиопроцессор для обработки аудиосигнала, с тем чтобы получать подполосное представление аудиосигнала. Аудиопроцессор содержит каскад каскадного перекрывающегося критически дискретизированного преобразования, выполненный с возможностью выполнять каскадное перекрывающееся критически дискретизированное преобразование, по меньшей мере, для двух частично перекрывающихся блоков выборок аудиосигнала, с тем чтобы получать наборы подполосных выборок на основе первого блока выборок аудиосигнала и получать наборы подполосных выборок на основе второго блока выборок аудиосигнала. Дополнительно, аудиопроцессор содержит первый каскад частотно-временного преобразования, выполненный с возможностью идентифицировать, в случае если наборы подполосных выборок, которые основаны на первом блоке выборок, представляют различные области на частотно-временной плоскости [например, представление на частотно-временной плоскости первого блока выборок и второго блока выборок] по сравнению с наборами подполосных выборок, которые основаны на втором блоке выборок, один или более наборов подполосных выборок из наборов подполосных выборок, которые основаны на первом блоке выборок, и один или более наборов подполосных выборок из наборов подполосных выборок, которые основаны на втором блоке выборок, которые в комбинации представляют идентичную область на частотно-временной плоскости, и выполнять частотно-временное преобразование идентифицированных одного или более наборов подполосных выборок из наборов подполосных выборок, которые основаны на первом блоке выборок, и/или идентифицированных одного или более наборов подполосных выборок из наборов подполосных выборок, которые основаны на втором блоке выборок, с тем чтобы получать одну или более преобразованных по времени и частоте подполосных выборок, каждая из которых представляет идентичную область на частотно-временной плоскости относительно соответствующей одной из идентифицированных одной или более подполосных выборок либо одной или более их преобразованных по времени и частоте версий. Дополнительно, аудиопроцессор содержит каскад уменьшения наложения спектров во временной области, выполненный с возможностью выполнять комбинирование со взвешиванием двух соответствующих наборов подполосных выборок либо их преобразованных по времени и частоте версий, причем один из них получен на основе первого блока выборок аудиосигнала, и один из них получен на основе второго блока выборок аудиосигнала, с тем чтобы получать подполосные представления с уменьшенным наложением спектров аудиосигнала (102).
В вариантах осуществления, частотно-временное преобразование, выполняемое посредством каскада частотно-временного преобразования, представляет собой перекрывающееся критически дискретизированное преобразование.
В вариантах осуществления, частотно-временное преобразование идентифицированных одного или более наборов подполосных выборок из наборов подполосных выборок, которые основаны на втором блоке выборок, и/или идентифицированных одного или более наборов подполосных выборок из наборов подполосных выборок, которые основаны на втором блоке выборок, выполняемое посредством каскада частотно-временного преобразования, соответствует преобразованию, описанному посредством следующей формулы:
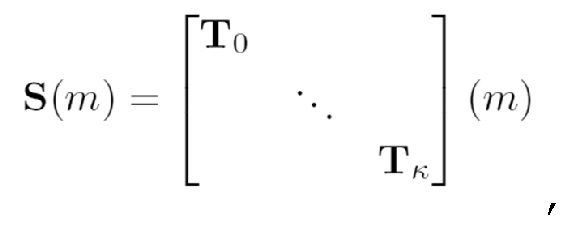
- при этом S(m) описывает преобразование, при этом m описывает индекс блока выборок аудиосигнала, при этом T0...Tk описывают подполосные дискретные отсчеты (выборки) соответствующих идентифицированных одного или более наборов подполосных выборок.
Например, каскад частотно-временного преобразования может быть выполнен с возможностью выполнять частотно-временное преобразование идентифицированных одного или более наборов подполосных выборок из наборов подполосных выборок, которые основаны на втором блоке выборок, и/или идентифицированных одного или более наборов подполосных выборок из наборов подполосных выборок, которые основаны на втором блоке выборок на основе вышеприведенной формулы.
В вариантах осуществления, каскад каскадного перекрывающегося критически дискретизированного преобразования выполнен с возможностью обрабатывать первый набор интервальных элементов (бинов), полученный на основе первого блока выборок аудиосигнала, и второй набор бинов, полученный на основе второго блока выборок аудиосигнала, с использованием второго каскада перекрывающегося критически дискретизированного преобразования из каскада каскадного перекрывающегося критически дискретизированного преобразования, при этом второй каскад перекрывающегося критически дискретизированного преобразования выполнен с возможностью выполнять, в зависимости от характеристик сигналов для аудиосигнала [например, когда характеристики сигналов для аудиосигнала изменяются], первые перекрывающиеся критически дискретизированные преобразования для первого набора бинов и вторые перекрывающиеся критически дискретизированные преобразования для второго набора бинов, причем одно или более первых критически дискретизированных преобразований имеют различные длины по сравнению со вторыми критически дискретизированными преобразованиями.
В вариантах осуществления, каскад частотно-временного преобразования выполнен с возможностью идентифицировать, в случае если одно или более первых критически дискретизированных преобразований имеют различные длины [например, коэффициенты объединения] по сравнению со вторыми критически дискретизированными преобразованиями, один или более наборов подполосных выборок из наборов подполосных выборок, которые основаны на первом блоке выборок, и один или более наборов подполосных выборок из наборов подполосных выборок, которые основаны на втором блоке выборок, которые представляют идентичную частотно-временную часть аудиосигнала.
В вариантах осуществления, аудиопроцессор содержит второй каскад частотно-временного преобразования, выполненный с возможностью выполнять частотно-временное преобразование подполосного представления с уменьшенным наложением спектров аудиосигнала, при этом частотно-временное преобразование, применяемое посредством второго каскада частотно-временного преобразования, является обратным по отношению к частотно-временному преобразованию, применяемому посредством первого каскада частотно-временного преобразования.
В вариантах осуществления, уменьшение наложения спектров во временной области, выполняемое посредством каскада уменьшения наложения спектров во временной области, соответствует преобразованию, описанному посредством следующей формулы:
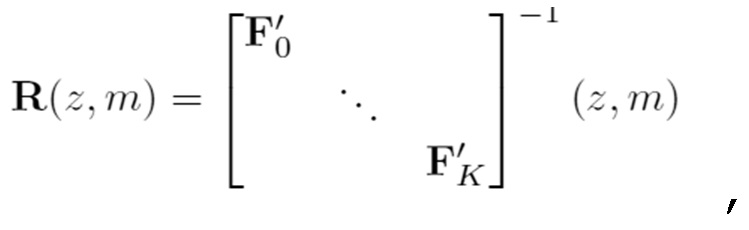
- при этом R(z, m) описывает преобразование, при этом z описывает индекс кадра в z-области, при этом m описывает индекс блока выборок аудиосигнала, при этом F'0…F'k описывают модифицированные версии предварительных перестановочных/свертывающихся матриц на основе перекрывающегося критически дискретизированного преобразования NxN.
В вариантах осуществления, аудиопроцессор выполнен с возможностью предоставлять поток битов, содержащий STDAR-параметр, указывающий то, используется или нет длина идентифицированных одного или более наборов подполосных выборок, соответствующих первому блоку выборок или второму блоку выборок, в каскаде уменьшения наложения спектров во временной области для получения соответствующего подполосного представления с уменьшенным наложением спектров аудиосигнала, или при этом аудиопроцессор выполнен с возможностью предоставлять поток битов, содержащий параметры MDCT-длины [например, параметры коэффициентов объединения (MF)], указывающие длины наборов подполосных выборок.
В вариантах осуществления, аудиопроцессор выполнен с возможностью выполнять объединенное канальное кодирование.
В вариантах осуществления, аудиопроцессор выполнен с возможностью выполнять M/S или MCT в качестве объединенной обработки каналов.
В вариантах осуществления, аудиопроцессор выполнен с возможностью предоставлять поток битов, содержащий, по меньшей мере, один STDAR-параметр, указывающий длину одной или более преобразованных по времени и частоте подполосных выборок, соответствующих первому блоку выборок, и одной или более преобразованных по времени и частоте подполосных выборок, соответствующих второму блоку выборок, используемых в каскаде уменьшения наложения спектров во временной области для получения соответствующего подполосного представления с уменьшенным наложением спектров аудиосигнала либо его кодированной версии [например, его энтропийно или дифференциально кодированной версии].
В вариантах осуществления, каскад каскадного перекрывающегося критически дискретизированного преобразования содержит первый каскад перекрывающегося критически дискретизированного преобразования, выполненный с возможностью выполнять перекрывающиеся критически дискретизированные преобразования для первого блока выборок и второго блока выборок, по меньшей мере, из двух частично перекрывающихся блоков выборок аудиосигнала, с тем чтобы получать первый набор бинов для первого блока выборок и второй набор бинов для второго блока выборок.
В вариантах осуществления, каскад каскадного перекрывающегося критически дискретизированного преобразования дополнительно содержит второй каскад перекрывающегося критически дискретизированного преобразования, выполненный с возможностью выполнять перекрывающееся критически дискретизированное преобразование для сегмента первого набора бинов и выполнять перекрывающееся критически дискретизированное преобразование для сегмента второго набора бинов, причем каждый сегмент ассоциирован с подполосой частот аудиосигнала, с тем чтобы получать набор подполосных выборок для первого набора бинов и набор подполосных выборок для второго набора бинов.
Дополнительные варианты осуществления предусматривают аудиопроцессор для обработки подполосного представления аудиосигнала, с тем чтобы получать аудиосигнал, причем подполосное представление аудиосигнала содержит наборы выборок с уменьшенным наложением спектров. Аудиопроцессор содержит второй каскад обратного частотно-временного преобразования, выполненный с возможностью выполнять частотно-временное преобразование одного или более наборов подполосных выборок с уменьшенным наложением спектров из наборов подполосных выборок с уменьшенным наложением спектров, соответствующих второму блоку выборок аудиосигнала, и/или одного или более наборов подполосных выборок с уменьшенным наложением спектров из наборов подполосных выборок с уменьшенным наложением спектров, соответствующих второму блоку выборок аудиосигнала, с тем чтобы получать одну или более преобразованных по времени и частоте подполосных выборок с уменьшенным наложением спектров, каждая из которых представляет идентичную область на частотно-временной плоскости относительно соответствующей одной из одной или более подполосных выборок с уменьшенным наложением спектров, соответствующих другому блоку выборок аудиосигнала, либо одной или более их преобразованных по времени и частоте версий. Дополнительно, аудиопроцессор содержит каскад обратного уменьшения наложения спектров во временной области, выполненный с возможностью выполнять комбинирования со взвешиванием соответствующих наборов подполосных выборок с уменьшенным наложением спектров либо их преобразованных по времени и частоте версий, с тем чтобы получать подполосное представление с наложением спектров. Дополнительно, аудиопроцессор содержит первый каскад обратного частотно-временного преобразования, выполненный с возможностью выполнять частотно-временное преобразование подполосного представления с наложением спектров, с тем чтобы получать наборы подполосных выборок, соответствующих первому блоку выборок аудиосигнала, и наборы подполосных выборок, соответствующих второму блоку выборок аудиосигнала, при этом частотно-временное преобразование, применяемое посредством первого каскада обратного частотно-временного преобразования, является обратным по отношению к частотно-временному преобразованию, применяемому посредством второго каскада обратного частотно-временного преобразования. Дополнительно, аудиопроцессор содержит каскад каскадного обратного перекрывающегося критически дискретизированного преобразования, выполненный с возможностью выполнять каскадное обратное перекрывающееся критически дискретизированное преобразование для наборов выборок, с тем чтобы получать набор выборок, ассоциированных с блоком выборок аудиосигнала.
Дополнительные варианты осуществления предусматривают способ для обработки аудиосигнала, с тем чтобы получать подполосное представление аудиосигнала. Способ содержит этап выполнения каскадного перекрывающегося критически дискретизированного преобразования, по меньшей мере, для двух частично перекрывающихся блоков выборок аудиосигнала, с тем чтобы получать наборы подполосных выборок на основе первого блока выборок аудиосигнала и получать наборы подполосных выборок на основе второго блока выборок аудиосигнала. Дополнительно, способ содержит этап идентификации, в случае если наборы подполосных выборок, которые основаны на первом блоке выборок, представляют различные области на частотно-временной плоскости по сравнению с наборами подполосных выборок, которые основаны на втором блоке выборок, одного или более наборов подполосных выборок из наборов подполосных выборок, которые основаны на первом блоке выборок, и одного или более наборов подполосных выборок из наборов подполосных выборок, которые основаны на втором блоке выборок, которые в комбинации представляют идентичную область частотно-временной плоскости. Дополнительно, способ содержит этап выполнения частотно-временных преобразований для идентифицированных одного или более наборов подполосных выборок из наборов подполосных выборок, которые основаны на первом блоке выборок, и/или идентифицированных одного или более наборов подполосных выборок из наборов подполосных выборок, которые основаны на втором блоке выборок, с тем чтобы получать одну или более преобразованных по времени и частоте подполосных выборок, каждая из которых представляет идентичную область на частотно-временной плоскости относительно соответствующей одной из идентифицированных одной или более подполосных выборок либо одной или более их преобразованных по времени и частоте версий. Дополнительно, способ содержит этап выполнения комбинирования со взвешиванием двух соответствующих наборов подполосных выборок, причем один из них получен на основе первого блока выборок аудиосигнала либо их преобразованных по времени и частоте версий, и один из них получен на основе второго блока выборок аудиосигнала, с тем чтобы получать подполосные представления с уменьшенным наложением спектров аудиосигнала.
Дополнительные варианты осуществления предусматривают способ для обработки подполосного представления аудиосигнала, с тем чтобы получать аудиосигнал, причем подполосное представление аудиосигнала содержит наборы выборок с уменьшенным наложением спектров. Способ содержит этап выполнения частотно-временных преобразований для одного или более наборов подполосных выборок с уменьшенным наложением спектров из наборов подполосных выборок с уменьшенным наложением спектров, соответствующих второму блоку выборок аудиосигнала, и/или для одного или более наборов подполосных выборок с уменьшенным наложением спектров из наборов подполосных выборок с уменьшенным наложением спектров, соответствующих второму блоку выборок аудиосигнала, с тем чтобы получать одну или более преобразованных по времени и частоте подполосных выборок с уменьшенным наложением спектров, каждая из которых представляет идентичную область на частотно-временной плоскости относительно соответствующей одной из одной или более подполосных выборок с уменьшенным наложением спектров, соответствующих другому блоку выборок аудиосигнала, либо одной или более их преобразованных по времени и частоте версий. Дополнительно, способ содержит этап выполнения комбинирований со взвешиванием соответствующих наборов подполосных выборок с уменьшенным наложением спектров либо их преобразованных по времени и частоте версий, с тем чтобы получать подполосное представление с наложением спектров. Дополнительно, способ содержит этап выполнения частотно-временных преобразований для подполосного представления с наложением спектров, с тем чтобы получать наборы подполосных выборок, соответствующих первому блоку выборок аудиосигнала, и наборы подполосных выборок, соответствующих второму блоку выборок аудиосигнала, при этом частотно-временное преобразование, применяемое посредством первого каскада обратного частотно-временного преобразования, является обратным по отношению к частотно-временному преобразованию, применяемому посредством второго каскада обратного частотно-временного преобразования. Дополнительно, способ содержит этап выполнения каскадного обратного перекрывающегося критически дискретизированного преобразования для наборов выборок, с тем чтобы получать набор выборок, ассоциированных с блоком выборок аудиосигнала.
Согласно концепции настоящего изобретения, уменьшение наложения спектров во временной области между двумя кадрами различных расположений частотно-временными плитками разрешается посредством введения другого этапа симметричного подполосного объединения/подполосного разбиения, который выравнивает расположения частотно-временными плитками двух кадров. После выравнивания расположений плитками, может применяться уменьшение наложения спектров во временной области, и исходные расположения плитками могут восстанавливаться.
Варианты осуществления предусматривают гребенку фильтров с переключаемым уменьшением наложения спектров во временной области (STDAR) с унилатеральным или билатеральным STDAR.
В вариантах осуществления, STDAR-параметры могут извлекаться из параметров MDCT-длины (например, параметров коэффициентов объединения (MF)). Например, при использовании унилатерального STDAR, 1 бит может передаваться в расчете на коэффициент объединения. Этот бит может передавать в служебных сигналах то, используется коэффициент объединения кадра m или m-1 для STDAR. Альтернативно, преобразование может всегда выполняться к более высокому коэффициенту объединения. В этом случае, бит может опускаться.
В вариантах осуществления, может выполняться объединенная обработка каналов, например, инструментальное средство M/S- или многоканального кодирования (MCT) [10]. Например, некоторые или все каналы могут преобразовываться на основе билатерального STDAR в идентичную TDAR-схему размещения и объединенно обрабатываться. Варьирующиеся коэффициенты, к примеру, 2, 8, 1, 2, 16, 32 предположительно не имеют такую вероятность, как равномерные коэффициенты, к примеру, 4, 4, 8, 8, 16, 16. Эта корреляция может использоваться для того, чтобы уменьшать требуемый объем данных, например, посредством дифференциального кодирования.
В вариантах осуществления, меньшее число коэффициентов объединения может передаваться, при этом опускаемые коэффициенты объединения могут извлекаться или интерполироваться из соседних коэффициентов объединения. Например, если коэффициенты объединения фактически являются настолько равномерными, как описано в предыдущем параграфе, все коэффициенты объединения могут интерполироваться на основе нескольких коэффициентов объединения.
В вариантах осуществления, билатеральный STDAR-коэффициент может передаваться в служебных сигналах в потоке битов. Например, некоторые биты в потоке битов требуются для того, чтобы передавать в служебных сигналах STDAR-коэффициент, описывающий предел по текущим кадрам. Эти биты могут энтропийно кодироваться. Дополнительно, эти биты могут кодироваться между собой.
Дополнительные варианты осуществления предусматривают аудиопроцессор для обработки аудиосигнала, с тем чтобы получать подполосное представление аудиосигнала. Аудиопроцессор содержит каскад каскадного перекрывающегося критически дискретизированного преобразования и каскад уменьшения наложения спектров во временной области. Каскад каскадного перекрывающегося критически дискретизированного преобразования выполнен с возможностью выполнять каскадное перекрывающееся критически дискретизированное преобразование, по меньшей мере, для двух частично перекрывающихся блоков выборок аудиосигнала, с тем чтобы получать набор подполосных выборок на основе первого блока выборок аудиосигнала и получать соответствующий набор подполосных выборок на основе второго блока выборок аудиосигнала. Каскад уменьшения наложения спектров во временной области выполнен с возможностью выполнять комбинирование со взвешиванием двух соответствующих наборов подполосных выборок, причем один из них получен на основе первого блока выборок аудиосигнала, и один из них получен на основе второго блока выборок аудиосигнала, с тем чтобы получать подполосное представление с уменьшенным наложением спектров аудиосигнала.
Дополнительные варианты осуществления предусматривают аудиопроцессор для обработки подполосного представления аудиосигнала, с тем чтобы получать аудиосигнал. Аудиопроцессор содержит каскад обратного уменьшения наложения спектров во временной области и каскад каскадного обратного перекрывающегося критически дискретизированного преобразования. Каскад обратного уменьшения наложения спектров во временной области выполнен с возможностью выполнять комбинирование со взвешиванием (и сдвигом) двух соответствующих подполосных представлений с уменьшенным наложением спектров (различных блоков частично перекрывающихся выборок) аудиосигнала, с тем чтобы получать подполосное представление с наложением спектров, при этом подполосное представление с наложением спектров представляет собой набор подполосных выборок. Каскад каскадного обратного перекрывающегося критически дискретизированного преобразования выполнен с возможностью выполнять каскадное обратное перекрывающееся критически дискретизированное преобразование для набора подполосных выборок, с тем чтобы получать набор выборок, ассоциированных с блоком выборок аудиосигнала.
Согласно принципу настоящего изобретения, дополнительный каскад постобработки добавляется в конвейер перекрывающегося критически дискретизированного преобразования (например, MDCT), причем дополнительный каскад постобработки содержит другое перекрывающееся критически дискретизированное преобразование (например, MDCT) вдоль частотной оси и уменьшение наложения спектров во временной области вдоль каждой подполосной временной оси. Это обеспечивает возможность извлечения произвольных шкал частот из спектрограммы перекрывающегося критически дискретизированного преобразования (например, MDCT) с улучшенной временной компактностью импульсной характеристики, при отсутствии введения дополнительной избыточности и уменьшенной кадровой задержки перекрывающегося критически дискретизированного преобразования.
Дополнительные варианты осуществления предусматривают способ для обработки аудиосигнала, с тем чтобы получать подполосное представление аудиосигнала. Способ содержит:
- выполнение каскадного перекрывающегося критически дискретизированного преобразования, по меньшей мере, для двух частично перекрывающихся блоков выборок аудиосигнала, с тем чтобы получать набор подполосных выборок на основе первого блока выборок аудиосигнала и получать соответствующий набор подполосных выборок на основе второго блока выборок аудиосигнала; и
- выполнение комбинирования со взвешиванием двух соответствующих наборов подполосных выборок, причем один из них получен на основе первого блока выборок аудиосигнала, и один из них получен на основе второго блока выборок аудиосигнала, с тем чтобы получать подполосное представление с уменьшенным наложением спектров аудиосигнала.
Дополнительные варианты осуществления предусматривают способ для обработки подполосного представления аудиосигнала, с тем чтобы получать аудиосигнал. Способ содержит:
- выполнение комбинирования со взвешиванием (и сдвигом) двух соответствующих подполосных представлений с уменьшенным наложением спектров (различных блоков частично перекрывающихся выборок) аудиосигнала, с тем чтобы получать подполосное представление с наложением спектров, при этом подполосное представление с наложением спектров представляет собой набор подполосных выборок; и
- выполнение каскадного обратного перекрывающегося критически дискретизированного преобразования для набора подполосных выборок, с тем чтобы получать набор выборок, ассоциированных с блоком выборок аудиосигнала.
Преимущественные реализации затрагиваются в зависимых пунктах формулы изобретения.
Далее описываются преимущественные реализации аудиопроцессора для обработки аудиосигнала, с тем чтобы получать подполосное представление аудиосигнала.
В вариантах осуществления, каскад каскадного перекрывающегося критически дискретизированного преобразования может представлять собой каскад каскадного MDCT (MDCT=модифицированное дискретное косинусное преобразование), MDST (MDST=модифицированное дискретное синусное преобразование) или MLT (MLT=модулированное перекрывающееся преобразование).
В вариантах осуществления, каскад каскадного перекрывающегося критически дискретизированного преобразования может содержать первый каскад перекрывающегося критически дискретизированного преобразования, выполненный с возможностью выполнять перекрывающиеся критически дискретизированные преобразования для первого блока выборок и второго блока выборок, по меньшей мере, из двух частично перекрывающихся блоков выборок аудиосигнала, с тем чтобы получать первый набор бинов для первого блока выборок и второй набор бинов (перекрывающихся критически дискретизированных коэффициентов) для второго блока выборок.
Первый каскад перекрывающегося критически дискретизированного преобразования может представлять собой первый MDCT-, MDST- или MLT-каскад.
Каскад каскадного перекрывающегося критически дискретизированного преобразования дополнительно может содержать второй каскад перекрывающегося критически дискретизированного преобразования, выполненный с возможностью выполнять перекрывающееся критически дискретизированное преобразование для сегмента (собственного поднабора) первого набора бинов и выполнять перекрывающееся критически дискретизированное преобразование для сегмента (собственного поднабора) второго набора бинов, причем каждый сегмент ассоциирован с подполосой частот аудиосигнала, с тем чтобы получать набор подполосных выборок для первого набора бинов и набор подполосных выборок для второго набора бинов.
Второй каскад перекрывающегося критически дискретизированного преобразования может представлять собой второй MDCT-, MDST- или MLT-каскад.
В силу этого, первый и второй каскады перекрывающегося критически дискретизированного преобразования могут иметь идентичный тип, т.е. представлять собой один из MDCT-, MDST- или MLT-каскадов.
В вариантах осуществления, второй каскад перекрывающегося критически дискретизированного преобразования может быть выполнен с возможностью выполнять перекрывающиеся критически дискретизированные преобразования, по меньшей мере, для двух частично перекрывающихся сегментов (собственных поднаборов) первого набора бинов и выполнять перекрывающиеся критически дискретизированные преобразования, по меньшей мере, для двух частично перекрывающихся сегментов (собственных поднаборов) второго набора бинов, причем каждый сегмент ассоциирован с подполосой частот аудиосигнала, с тем чтобы получать, по меньшей мере, два набора подполосных выборок для первого набора бинов, и, по меньшей мере, два набора подполосных выборок для второго набора бинов.
В силу этого, первый набор подполосных выборок может представлять собой результат первого перекрывающегося критически дискретизированного преобразования на основе первого сегмента первого набора бинов, при этом второй набор подполосных выборок может представлять собой результат второго перекрывающегося критически дискретизированного преобразования на основе второго сегмента первого набора бинов, при этом третий набор подполосных выборок может представлять собой результат третьего перекрывающегося критически дискретизированного преобразования на основе первого сегмента второго набора бинов, при этом четвертый набор подполосных выборок может представлять собой результат четвертого перекрывающегося критически дискретизированного преобразования на основе второго сегмента второго набора бинов. Каскад уменьшения наложения спектров во временной области может быть выполнен с возможностью выполнять комбинирование со взвешиванием первого набора подполосных выборок и третьего набора подполосных выборок, с тем чтобы получать первое подполосное представление с уменьшенным наложением спектров аудиосигнала, и выполнять комбинирование со взвешиванием второго набора подполосных выборок и четвертого набора подполосных выборок, с тем чтобы получать второе подполосное представление с уменьшенным наложением спектров аудиосигнала.
В вариантах осуществления, каскад каскадного перекрывающегося критически дискретизированного преобразования может быть выполнен с возможностью сегментировать набор бинов, полученный на основе первого блока выборок, использованием, по меньшей мере, двух функций кодирования со взвешиванием, и получать, по меньшей мере, два набора подполосных выборок на основе сегментированного набора бинов, соответствующего первому блоку выборок, при этом каскад каскадного перекрывающегося критически дискретизированного преобразования может быть выполнен с возможностью сегментировать набор бинов, полученный на основе второго блока выборок, с использованием, по меньшей мере, двух функций кодирования со взвешиванием, и получать, по меньшей мере, два набора подполосных выборок на основе сегментированного набора бинов, соответствующего второму блоку выборок, при этом, по меньшей мере, две функции кодирования со взвешиванием содержат различную ширину окна кодирования со взвешиванием.
В вариантах осуществления, каскад каскадного перекрывающегося критически дискретизированного преобразования может быть выполнен с возможностью сегментировать набор бинов, полученный на основе первого блока выборок с использованием, по меньшей мере, двух функций кодирования со взвешиванием, и получать, по меньшей мере, два набора подполосных выборок на основе сегментированного набора бинов, соответствующего первому блоку выборок, при этом каскад каскадного перекрывающегося критически дискретизированного преобразования может быть выполнен с возможностью сегментировать набор бинов, полученный на основе второго блока выборок с использованием, по меньшей мере, двух функций кодирования со взвешиванием, и получать, по меньшей мере, два набора подполосных выборок на основе сегментированного набора бинов, соответствующего второму блоку выборок, при этом наклоны фильтра функций кодирования со взвешиванием, соответствующих смежным наборам подполосных выборок, являются симметричными.
В вариантах осуществления, каскад каскадного перекрывающегося критически дискретизированного преобразования может быть выполнен с возможностью сегментировать выборки аудиосигнала на первый блок выборок и второй блок выборок с использованием первой функции кодирования со взвешиванием, при этом каскад перекрывающегося критически дискретизированного преобразования может быть выполнен с возможностью сегментировать набор бинов, полученный на основе первого блока выборок, и набор бинов, полученный на основе второго блока выборок, с использованием второй функции кодирования со взвешиванием, с тем чтобы получать соответствующие подполосные выборки, при этом первая функция кодирования со взвешиванием и вторая функция кодирования со взвешиванием содержат различную ширину окна кодирования со взвешиванием.
В вариантах осуществления, каскад каскадного перекрывающегося критически дискретизированного преобразования может быть выполнен с возможностью сегментировать выборки аудиосигнала на первый блок выборок и второй блок выборок с использованием первой функции кодирования со взвешиванием, при этом каскад перекрывающегося критически дискретизированного преобразования может быть выполнен с возможностью сегментировать набор бинов, полученный на основе первого блока выборок, и набор бинов, полученный на основе второго блока выборок, с использованием второй функции кодирования со взвешиванием, с тем чтобы получать соответствующие подполосные выборки, при этом ширина окна кодирования со взвешиванием первой функции кодирования со взвешиванием и ширина окна кодирования со взвешиванием второй функции кодирования со взвешиванием отличаются друг от друга, при этом ширина окна кодирования со взвешиванием первой функции кодирования со взвешиванием и ширина окна кодирования со взвешиванием второй функции кодирования со взвешиванием отличаются друг от друга на коэффициент, отличающийся от степени двух.
Далее описываются преимущественные реализации аудиопроцессора для обработки подполосного представления аудиосигнала, с тем чтобы получать аудиосигнал.
В вариантах осуществления, каскад обратного каскадного перекрывающегося критически дискретизированного преобразования может представлять собой каскад обратного каскадного MDCT (MDCT=модифицированное дискретное косинусное преобразование), MDST (MDST=модифицированное дискретное синусное преобразование) или MLT (MLT=модулированное перекрывающееся преобразование).
В вариантах осуществления, каскад каскадного обратного перекрывающегося критически дискретизированного преобразования может содержать первый каскад обратного перекрывающегося критически дискретизированного преобразования, выполненный с возможностью выполнять обратное перекрывающееся критически дискретизированное преобразование для набора подполосных выборок, с тем чтобы получать набор бинов, ассоциированный с данной подполосой частот аудиосигнала.
Первый каскад обратного перекрывающегося критически дискретизированного преобразования может представлять собой первый обратный MDCT-, MDST- или MLT-каскад.
В вариантах осуществления, каскад каскадного обратного перекрывающегося критически дискретизированного преобразования может содержать первый каскад суммирования с перекрытием, выполненный с возможностью выполнять конкатенацию набора бинов, ассоциированного с множеством подполос частот аудиосигнала, что содержит комбинирование со взвешиванием набора бинов, ассоциированного с данной подполосой частот аудиосигнала, с набором бинов, ассоциированным с другой подполосой частот аудиосигнала, с тем чтобы получать набор бинов, ассоциированный с блоком выборок аудиосигнала.
В вариантах осуществления, каскад каскадного обратного перекрывающегося критически дискретизированного преобразования может содержать второй каскад обратного перекрывающегося критически дискретизированного преобразования, выполненный с возможностью выполнять обратное перекрывающееся критически дискретизированное преобразование для набора бинов, ассоциированных с блоком выборок аудиосигнала, с тем чтобы получать набор выборок, ассоциированных с блоком выборок аудиосигнала.
Второй каскад обратного перекрывающегося критически дискретизированного преобразования может представлять собой второй обратный MDCT-, MDST- или MLT-каскад.
В силу этого, первый и второй каскады обратного перекрывающегося критически дискретизированного преобразования могут иметь идентичный тип, т.е. представлять собой один из обратных MDCT-, MDST- или MLT-каскадов.
В вариантах осуществления, каскад каскадного обратного перекрывающегося критически дискретизированного преобразования может содержать второй каскад суммирования с перекрытием, выполненный с возможностью суммировать с перекрытием набор выборок, ассоциированных с блоком выборок аудиосигнала, и другой набор выборок, ассоциированных с другим блоком выборок аудиосигнала, причем блок выборок и другой блок выборок аудиосигнала частично перекрываются, с тем чтобы получать аудиосигнал.
Варианты осуществления настоящего изобретения описываются в данном документе со ссылкой на прилагаемые чертежи.
Фиг. 1 показывает принципиальную блок-схему аудиопроцессора, выполненного с возможностью обрабатывать аудиосигнал, с тем чтобы получать подполосное представление аудиосигнала, согласно варианту осуществления;
Фиг. 2 показывает принципиальную блок-схему аудиопроцессора, выполненного с возможностью обрабатывать аудиосигнал, с тем чтобы получать подполосное представление аудиосигнала, согласно дополнительному варианту осуществления;
Фиг. 3 показывает принципиальную блок-схему аудиопроцессора, выполненного с возможностью обрабатывать аудиосигнал, с тем чтобы получать подполосное представление аудиосигнала, согласно дополнительному варианту осуществления;
Фиг. 4 показывает принципиальную блок-схему аудиопроцессора для обработки подполосного представления аудиосигнала, с тем чтобы получать аудиосигнал, согласно варианту осуществления;
Фиг. 5 показывает принципиальную блок-схему аудиопроцессора для обработки подполосного представления аудиосигнала, с тем чтобы получать аудиосигнал, согласно дополнительному варианту осуществления;
Фиг. 6 показывает принципиальную блок-схему аудиопроцессора для обработки подполосного представления аудиосигнала, с тем чтобы получать аудиосигнал, согласно дополнительному варианту осуществления;
Фиг. 7 показывает на схемах пример подполосных выборок (верхний график) и разброс их выборок по времени и частоте (нижний график);
Фиг. 8 показывает на схеме спектральную и временную неопределенность, полученную посредством нескольких различных преобразований;
Фиг. 9 показывает на схемах сравнение двух примерных импульсных характеристик, сформированных посредством подполосного объединения с и без TDAR, простых коротких MDCT-блоков и подполосного объединения на основе матрицы Адамара;
Фиг. 10 показывает блок-схему последовательности операций способа для обработки аудиосигнала, с тем чтобы получать подполосное представление аудиосигнала, согласно варианту осуществления;
Фиг. 11 показывает блок-схему последовательности операций способа для обработки подполосного представления аудиосигнала, с тем чтобы получать аудиосигнал, согласно варианту осуществления;
Фиг. 12 показывает принципиальную блок-схему аудиокодера, согласно варианту осуществления;
Фиг. 13 показывает принципиальную блок-схему аудиодекодера, согласно варианту осуществления;
Фиг. 14 показывает принципиальную блок-схему аудиоанализатора, согласно варианту осуществления;
Фиг. 15 показывает принципиальную блок-схему аудиопроцессора, выполненного с возможностью обрабатывать аудиосигнал, с тем чтобы получать подполосное представление аудиосигнала, согласно дополнительному варианту осуществления;
Фиг. 16 показывает схематичное представление частотно-временного преобразования, выполняемого посредством каскада частотно-временного преобразования на частотно-временной плоскости;
Фиг. 17 показывает принципиальную блок-схему аудиопроцессора, выполненного с возможностью обрабатывать аудиосигнал, с тем чтобы получать подполосное представление аудиосигнала, согласно дополнительному варианту осуществления;
Фиг. 18 показывает принципиальную блок-схему аудиопроцессора для обработки подполосного представления аудиосигнала, с тем чтобы получать аудиосигнал, согласно дополнительному варианту осуществления;
Фиг. 19 показывает схематичное представление STDAR-операции на частотно-временной плоскости;
Фиг. 20 показывает на схемах примерные импульсные отклики двух кадров с коэффициентом объединения 8 и 16 перед STDAR (верхняя часть) и после STDAR (нижняя часть);
Фиг. 21 показывает на схемах компактность импульсного отклика и частотного отклика для повышающего согласования;
Фиг. 22 показывает на схемах компактность импульсного отклика и частотного отклика для понижающего согласования;
Фиг. 23 показывает блок-схему последовательности операций способа для обработки аудиосигнала, с тем чтобы получать подполосное представление аудиосигнала, согласно дополнительному варианту осуществления; и
Фиг. 24 показывает блок-схему последовательности операций способа для обработки подполосного представления аудиосигнала, с тем чтобы получать аудиосигнал, причем подполосное представление аудиосигнала содержит наборы выборок с уменьшенным наложением спектров, согласно дополнительному варианту осуществления.
Идентичные или эквивалентные элементы либо элементы с идентичной или эквивалентной функциональностью обозначаются в нижеприведенном описании посредством идентичных или эквивалентных ссылок с номерами.
В нижеприведенном описании, множество деталей изложено с тем, чтобы обеспечить более полное пояснение вариантов осуществления настоящего изобретения. Тем не менее, специалистам в данной области техники должно быть очевидным, что варианты осуществления настоящего изобретения могут быть использованы на практике без этих конкретных деталей. В других случаях, известные структуры и устройства показаны в форме блок-схемы, а не подробно, чтобы не затруднять понимание вариантов осуществления настоящего изобретения. Помимо этого, признаки различных вариантов осуществления, описанных далее, могут комбинироваться между собой, если прямо не указано иное.
Во-первых, в разделе 1, описывается неравномерная ортогональная гребенка фильтров на основе каскадирования двух MDCT и уменьшения наложения спектров во временной области (TDAR), которая позволяет достигать импульсных откликов, которые являются компактными во времени и по частоте [1]. После этого, в разделе 2, описывается переключаемое уменьшение наложения спектров во временной области (STDAR), которое обеспечивает возможность TDAR между двумя кадрами различных расположений частотно-временными плитками. Это достигается посредством введения другого этапа симметричного подполосного объединения/подполосного разбиения, который выравнивает расположения частотно-временными плитками двух кадров. После выравнивания расположений плитками, применяется регулярное TDAR, и исходные расположения плитками восстанавливаются.
1. Неравномерная ортогональная гребенка фильтров на основе каскадирования двух MDCT и уменьшения наложения спектров во временной области (TDAR)
Фиг. 1 показывает принципиальную блок-схему аудиопроцессора 100, выполненного с возможностью обрабатывать аудиосигнал 102, с тем чтобы получать подполосное представление аудиосигнала, согласно варианту осуществления. Аудиопроцессор 100 содержит каскад 104 каскадного перекрывающегося критически дискретизированного преобразования (LCST) и каскад 106 уменьшения наложения спектров во временной области (TDAR).
Каскад 104 каскадного перекрывающегося критически дискретизированного преобразования выполнен с возможностью выполнять каскадное перекрывающееся критически дискретизированное преобразование, по меньшей мере, для двух частично перекрывающихся блоков 108_1 и 108_2 выборок аудиосигнала 102, с тем чтобы получать набор 110_1,1 подполосных выборок на основе первого блока 108_1 выборок (по меньшей мере, из двух перекрывающихся блоков 108_1 и 108_2 выборок) аудиосигнала 102 и получать соответствующий набор 110_2,1 подполосных выборок на основе второго блока 108_2 выборок (по меньшей мере, из двух перекрывающихся блоков 108_1 и 108_2 выборок) аудиосигнала 102.
Каскад 104 уменьшения наложения спектров во временной области выполнен с возможностью выполнять комбинирование со взвешиванием двух соответствующих наборов 110_1,1 и 110_2,1 подполосных выборок (т.е. подполосных выборок, соответствующих идентичной подполосе частот), причем один из них получен на основе первого блока 108_1 выборок аудиосигнала 102, и один из них получен на основе второго блока 108_2 выборок аудиосигнала, с тем чтобы получать подполосное представление 112_1 с уменьшенным наложением спектров аудиосигнала 102.
В вариантах осуществления, каскад 104 каскадного перекрывающегося критически дискретизированного преобразования может содержать, по меньшей мере, два каскада каскадного перекрывающегося критически дискретизированного преобразования, или другими словами, причем два каскада перекрывающегося критически дискретизированного преобразования соединяются каскадным способом.
Каскад каскадного перекрывающегося критически дискретизированного преобразования может представлять собой каскад каскадного MDCT (MDCT=модифицированное дискретное косинусное преобразование). Каскадный MDCT-каскад может содержать, по меньшей мере, два MDCT-каскада.
Естественно, каскад каскадного перекрывающегося критически дискретизированного преобразования также может представлять собой каскад каскадного MDST (MDST=модифицированное дискретное синусное преобразование) или MLT (MLT=модулированное перекрывающееся преобразование), содержащий, по меньшей мере, два MDST- или MLT-каскада, соответственно.
Два соответствующих набора 110_1,1 и 110_2,1 подполосных выборок могут представлять собой подполосные выборки, соответствующие идентичной подполосе частот (т.е. полосе частот).
Фиг. 2 показывает принципиальную блок-схему аудиопроцессора 100, выполненного с возможностью обрабатывать аудиосигнал 102, с тем чтобы получать подполосное представление аудиосигнала, согласно дополнительному варианту осуществления.
Как показано на фиг. 2, каскад 104 каскадного перекрывающегося критически дискретизированного преобразования может содержать первый каскад 120 перекрывающегося критически дискретизированного преобразования, выполненный с возможностью выполнять перекрывающиеся критически дискретизированные преобразования для первого блока 108_1 (2M) выборок (xi-1(n), 0≤n≤2M-1) и второго блока 108_2 (2M) выборок (xi(n), 0≤n≤2M-1), по меньшей мере, из двух частично перекрывающихся блоков 108_1 и 108_2 выборок аудиосигнала 102, с тем чтобы получать первый набор 124_1 из (M) бинов (LCST-коэффициентов) (Xi-1(k), 0≤k≤M-1) для первого блока 108_1 выборок и второй набор 124_2 из (M) бинов (LCST-коэффициентов) (Xi(k), 0≤k≤M-1) для второго блока 108_2 выборок.
Каскад 104 каскадного перекрывающегося критически дискретизированного преобразования может содержать второй каскад 126 перекрывающегося критически дискретизированного преобразования, выполненный с возможностью выполнять перекрывающееся критически дискретизированное преобразование для сегмента 128_1,1 (собственного поднабора) (Xv, i-1(k)) первого набора 124_1 бинов и выполнять перекрывающееся критически дискретизированное преобразование для сегмента 128_2,1 (собственного поднабора) (Xv, i(k)) второго набора 124_2 бинов, причем каждый сегмент ассоциирован с подполосой частот аудиосигнала 102, с тем чтобы получать набор 110_1,1 подполосных выборок (ŷv, i-1(m)) для первого набора 124_1 бинов и набор 110_2,1 подполосных выборок (ŷv, i(m)) для второго набора 124_2 бинов.
Фиг. 3 показывает принципиальную блок-схему аудиопроцессора 100, выполненного с возможностью обрабатывать аудиосигнал 102, с тем чтобы получать подполосное представление аудиосигнала, согласно дополнительному варианту осуществления. Другими словами, фиг. 3 показывает схему гребенки аналитических фильтров. В силу этого, предполагаются соответствующие функции кодирования со взвешиванием. Следует отметить, что для простоты, на фиг. 3 указывается (только) обработка первой половины подполосного кадра (y[m], 0<=m<N/2) (т.е. только первая строка уравнения (6)).
Как показано на фиг. 3, первый каскад 120 перекрывающегося критически дискретизированного преобразования может быть выполнен с возможностью выполнять первое перекрывающееся критически дискретизированное преобразование 122_1 (например, MDCT i-1) для первого блока 108_1 (2M) выборок (xi-1(n), 0≤n≤2M-1), с тем чтобы получать первый набор 124_1 из (M) бинов (LCST-коэффициентов) (Xi-1(k), 0≤k≤M-1) для первого блока 108_1 выборок, и выполнять второе перекрывающееся критически дискретизированное преобразование 122_2 (например, MDCT i) для второго блока 108_2 (2M) выборок (xi(n), 0≤n≤2M-1), с тем чтобы получать второй набор 124_2 из (M) бинов (LCST-коэффициентов) (Xi(k), 0≤k≤M-1) для второго блока 108_2 выборок.
Подробно, второй каскад 126 перекрывающегося критически дискретизированного преобразования может быть выполнен с возможностью выполнять перекрывающиеся критически дискретизированные преобразования, по меньшей мере, для двух частично перекрывающихся сегментов 128_1,1 и 128_1,2 (собственных поднаборов) (Xv, i-1(k)) первого набора 124_1 бинов и выполнять перекрывающиеся критически дискретизированные преобразования, по меньшей мере, для двух частично перекрывающихся сегментов 128_2,1 и 128_2,2 (собственных поднаборов) (Xv, i(k)) второго набора бинов, причем каждый сегмент ассоциирован с подполосой частот аудиосигнала, с тем чтобы получать, по меньшей мере, два набора 110_1,1 и 110_1,2 подполосных выборок (ŷv, i-1(m)) для первого набора 124_1 бинов и, по меньшей мере, два набора 110_2,1 и 110_2,2 подполосных выборок (ŷv, i(m)) для второго набора 124_2 бинов.
Например, первый набор 110_1,1 подполосных выборок может представлять собой результат первого перекрывающегося критически дискретизированного преобразования 132_1,1 на основе первого сегмента 132_1,1 первого набора 124_1 бинов, при этом второй набор 110_1,2 подполосных выборок может представлять собой результат второго перекрывающегося критически дискретизированного преобразования 132_1,2 на основе второго сегмента 128_1,2 первого набора 124_1 бинов, при этом третий набор 110_2,1 подполосных выборок может представлять собой результат третьего перекрывающегося критически дискретизированного преобразования 132_2,1 на основе первого сегмента 128_2,1 второго набора 124_2 бинов, при этом четвертый набор 110_2,2 подполосных выборок может представлять собой результат четвертого перекрывающегося критически дискретизированного преобразования 132_2,2 на основе второго сегмента 128_2,2 второго набора 124_2 бинов.
В силу этого, каскад 106 уменьшения наложения спектров во временной области может быть выполнен с возможностью выполнять комбинирование со взвешиванием первого набора 110_1,1 подполосных выборок и третьего набора 110_2,1 подполосных выборок, с тем чтобы получать первое подполосное представление 112_1 с уменьшенным наложением спектров (y1,i[m1]) аудиосигнала, при этом каскад 106 уменьшения наложения спектров в области может быть выполнен с возможностью выполнять комбинирование со взвешиванием второго набора 110_1,2 подполосных выборок и четвертого набора 110_2,2 подполосных выборок, с тем чтобы получать второе подполосное представление 112_2 с уменьшенным наложением спектров (y2,i[m2]) аудиосигнала.
Фиг. 4 показывает принципиальную блок-схему аудиопроцессора 200 для обработки подполосного представления аудиосигнала, с тем чтобы получать аудиосигнал 102, согласно варианту осуществления. Аудиопроцессор 200 содержит каскад 202 обратного уменьшения наложения спектров во временной области (TDAR) и каскад 204 каскадного обратного перекрывающегося критически дискретизированного преобразования (LCST).
Каскад 202 обратного уменьшения наложения спектров во временной области выполнен с возможностью выполнять комбинирование со взвешиванием (и сдвигом) двух соответствующих подполосных представлений 112_1 и 112_2 с уменьшенным наложением спектров (yv, i(m), yv, i-1(m)) аудиосигнала 102, с тем чтобы получать подполосное представление 110_1 с наложением спектров (ŷv, i(m)), при этом подполосное представление с наложением спектров представляет собой набор 110_1 подполосных выборок.
Каскад 204 каскадного обратного перекрывающегося критически дискретизированного преобразования выполнен с возможностью выполнять каскадное обратное перекрывающееся критически дискретизированное преобразование для набора 110_1 подполосных выборок, с тем чтобы получать набор выборок, ассоциированных с блоком 108_1 выборок аудиосигнала 102.
Фиг. 5 показывает принципиальную блок-схему аудиопроцессора 200 для обработки подполосного представления аудиосигнала, с тем чтобы получать аудиосигнал 102, согласно дополнительному варианту осуществления. Каскад 204 каскадного обратного перекрывающегося критически дискретизированного преобразования может содержать первый каскад 208 обратного перекрывающегося критически дискретизированного преобразования (LCST) и первый каскад 210 суммирования с перекрытием.
Первый каскад 208 обратного перекрывающегося критически дискретизированного преобразования может быть выполнен с возможностью выполнять обратное перекрывающееся критически дискретизированное преобразование для набора 110_1,1 подполосных выборок, с тем чтобы получать набор 128_1,1 бинов, ассоциированных с данной подполосой частот аудиосигнала (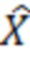 v, i(k)).
v, i(k)).
Первый каскад 210 суммирования с перекрытием может быть выполнен с возможностью выполнять конкатенацию наборов бинов, ассоциированных с множеством подполос частот аудиосигнала, что содержит комбинирование со взвешиванием набора 128_1,1 бинов (v, i(k)), ассоциированных с данной подполосой (v) частот аудиосигнала 102, с набором 128_1,2 бинов (v-1,(k)), ассоциированных с другой подполосой (v-1) частот аудиосигнала 102, с тем чтобы получать набор 124_1 бинов, ассоциированных с блоком 108_1 выборок аудиосигнала 102.
Как показано на фиг. 5, каскад 204 каскадного обратного перекрывающегося критически дискретизированного преобразования может содержать второй каскад 212 обратного перекрывающегося критически дискретизированного преобразования (LCST), выполненный с возможностью выполнять обратное перекрывающееся критически дискретизированное преобразование для набора 124_1 бинов, ассоциированных с блоком 108_1 выборок аудиосигнала 102, с тем чтобы получать набор 206_1,1 выборок, ассоциированных с блоком 108_1 выборок аудиосигнала 102.
Дополнительно, каскад 204 каскадного обратного перекрывающегося критически дискретизированного преобразования может содержать второй каскад 214 суммирования с перекрытием, выполненный с возможностью суммировать с перекрытием набор 206_1,1 выборок, ассоциированных с блоком 108_1 выборок аудиосигнала 102, и другой набор 206_2,1 выборок, ассоциированных с другим блоком 108_2 выборок аудиосигнала, причем блок 108_1 выборок и другой блок 108_2 выборок аудиосигнала 102 частично перекрываются, с тем чтобы получать аудиосигнал 102.
Фиг. 6 показывает принципиальную блок-схему аудиопроцессора 200 для обработки подполосного представления аудиосигнала, с тем чтобы получать аудиосигнал 102, согласно дополнительному варианту осуществления. Другими словами, фиг. 6 показывает схему гребенки синтезирующих фильтров. В силу этого, предполагаются соответствующие функции кодирования со взвешиванием. Следует отметить, что для простоты, на фиг. 6 указывается (только) обработка первой половины подполосного кадра (y[m], 0<=m<N/2) (т.е. только первая строка уравнения (6)).
Как описано выше, аудиопроцессор 200 содержит каскад 202 обратного уменьшения наложения спектров во временной области и каскад 204 обратного каскадного перекрывающегося критически дискретизированного преобразования, содержащий первый каскад 208 обратного перекрывающегося критически дискретизированного преобразования и второй каскад 212 обратного перекрывающегося критически дискретизированного преобразования.
Каскад 104 обратного уменьшения во временной области выполнен с возможностью выполнять первое комбинирование 220_1 со взвешиванием и сдвигом первого и второго подполосных представлений y1,i-1[m1] и y1,i[m1] с уменьшенным наложением спектров, с тем чтобы получать первое подполосное представление 110_1,1 ŷ1,i[m1] с наложением спектров, при этом подполосное представление с наложением спектров представляет собой набор подполосных выборок, и выполнять второе комбинирование 220_2 со взвешиванием и сдвигом третьего и четвертого подполосных представлений y2,i-1[m1] и y2,i[m1] с уменьшенным наложением спектров, с тем чтобы получать второе подполосное представление 110_2,1 ŷ2,i[m1] с наложением спектров, при этом подполосное представление с наложением спектров представляет собой набор подполосных выборок.
Первый каскад 208 обратного перекрывающегося критически дискретизированного преобразования выполнен с возможностью выполнять первое обратное перекрывающееся критически дискретизированное преобразование 222_1 для первого набора 110_1,1 ŷ1,i[m1] подполосных выборок, с тем чтобы получать набор 128_1,1 бинов, ассоциированных с данной подполосой частот аудиосигнала (1,1(k)), и выполнять второе обратное перекрывающееся критически дискретизированное преобразование 222_2 для второго набора 110_2,1 ŷ2,i[m1] подполосных выборок, с тем чтобы получать набор 128_2,1 бинов, ассоциированных с данной подполосой частот аудиосигнала (2,1(k)).
Второй каскад 212 обратного перекрывающегося критически дискретизированного преобразования выполнен с возможностью выполнять обратное перекрывающееся критически дискретизированное преобразование для перекрывающегося и суммированного набора бинов, полученного посредством перекрытия и суммирования наборов 128_1,1 и 128_2,1 бинов, предоставленных посредством первого каскада 208 обратного перекрывающегося критически дискретизированного преобразования, с тем чтобы получать блок 108_2 выборок.
Далее описываются варианты осуществления аудиопроцессоров, показанных на фиг. 1-6, в которых примерно предполагается, что каскад 104 каскадного перекрывающегося критически дискретизированного преобразования представляет собой MDCT-каскад, т.е. первый и второй каскады 120 и 126 перекрывающегося критически дискретизированного преобразования представляют собой MDCT-каскады, и каскад 204 обратного каскадного перекрывающегося критически дискретизированного преобразования представляет собой обратный каскадный MDCT-каскад, т.е. первый и второй каскады 120 и 126 обратного перекрывающегося критически дискретизированного преобразования представляют собой обратные MDCT-каскады. Естественно, нижеприведенное описание также является применимым к другим вариантам осуществления каскада 104 каскадного перекрывающегося критически дискретизированного преобразования и каскада 204 обратного перекрывающегося критически дискретизированного преобразования, к примеру, к каскадному MDST- или MLT-каскаду или к обратному каскадному MDST- или MLT-каскаду.
В силу этого, описанные варианты осуществления могут работать для последовательности MDCT-спектров ограниченной длины и использовать MDCT и уменьшение наложения спектров во временной области (TDAR) в качестве операции подполосного объединения. Результирующая неравномерная гребенка фильтров является перекрывающейся, ортогональной и обеспечивает подполосные ширины k=2n, где n∈N. Вследствие TDAR, может достигаться временно и спектрально более компактная подполосная импульсная характеристика.
Далее описываются варианты осуществления гребенки фильтров.
Реализация гребенки фильтров непосредственно базируется на общих схемах перекрывающегося MDCT-преобразования: Исходное преобразование с перекрытием и кодированием со взвешиванием остается неизменным.
Без потери общности, следующая система обозначений допускает ортогональные MDCT-преобразования, например, в которых функции аналитического и синтезирующего кодирования со взвешиванием являются идентичными.
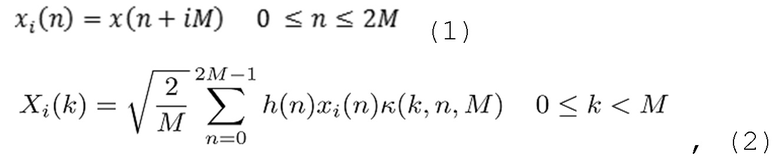
где k(k, n, M) является ядром MDCT-преобразования, и h(n) является подходящей функцией аналитического кодирования со взвешиванием.
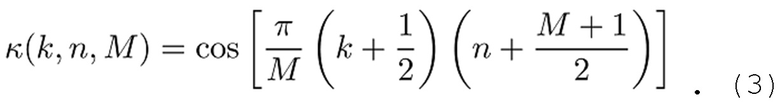
Вывод этого преобразования Xi(k) после этого сегментируется на v подполос частот с отдельными ширинами Nv и снова преобразуется с использованием MDCT. Это приводит к гребенке фильтров с перекрытием во временном и спектральном направлении.
Для упрощения системы обозначений в данном документе, используется один общий коэффициент N объединения для всех подполос частот; тем не менее, любое допустимое переключение/упорядочение функции MDCT-кодирования со взвешиванием может использоваться для того, чтобы реализовывать требуемое частотно-временное разрешение. Ниже содержится дополнительная информация относительно проектирования разрешения.
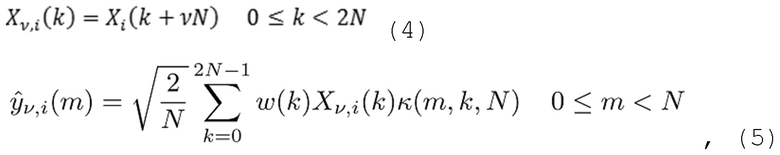
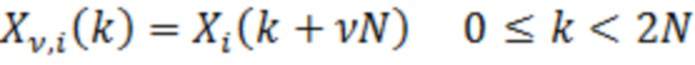 (4)
(4)
где w(k) является подходящей функцией аналитического кодирования со взвешиванием и, в общем, отличается от h(n) по размеру и может отличаться по типу функции кодирования со взвешиванием. Поскольку варианты осуществления применяют функцию кодирования со взвешиванием в частотной области, следует заметить, что временная и частотная избирательность функции кодирования со взвешиванием переставляются.
Для надлежащей обработки границ, дополнительное смещение в N/2 может вводиться в уравнении (4), комбинированное с прямоугольными половинами начального/конечного окна кодирования со взвешиванием на границах. Также для упрощения системы обозначений, это смещение не учитывается здесь.
Вывод 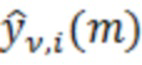 представляет собой список v-векторов отдельных длин Nv коэффициентов с соответствующими полосами
представляет собой список v-векторов отдельных длин Nv коэффициентов с соответствующими полосами 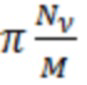 пропускания и временным разрешением, пропорциональным этой полосе пропускания.
пропускания и временным разрешением, пропорциональным этой полосе пропускания.
Тем не менее, эти векторы содержат наложение спектров из исходного MDCT-преобразования и в силу этого демонстрируют плохую временную компактность. Чтобы компенсировать это наложение спектров, TDAR может упрощаться.
Выборки, используемые для TDAR, извлекаются из двух смежных блоков v подполосных выборок в текущем и предыдущем MDCT-кадре i и i-1. Результат представляет собой уменьшенное наложение спектров во второй половине предыдущего кадра и в первой половине второго кадра.
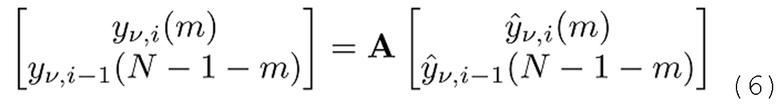
- для 0≤m<N/2 при:
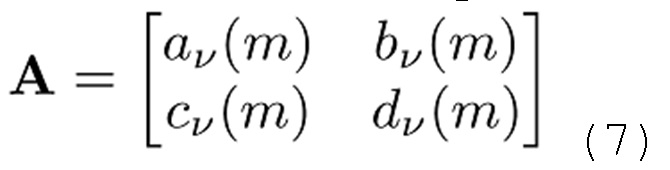
TDAR-коэффициенты av(m), bv(m), cy(m) и dv(m) могут проектироваться с возможностью минимизировать остаточное наложение спектров. Ниже вводится простой способ оценки на основе функции g(n) синтезирующего кодирования со взвешиванием.
Также следует отметить, что, если A является несингулярной, операции (6) и (8) соответствуют биортогональной системе. Дополнительно, если g(n)=h(n) и v(k)=w(k), например, оба MDCT являются ортогональными, и матрица A является ортогональной, полный конвейер составляет ортогональное преобразование.
Чтобы вычислять обратное преобразование, выполняется первое обратное TDAR,
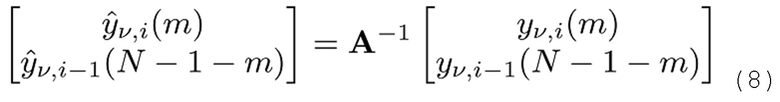
после которого выполняется обратное MDCT, и должно выполняться подавление наложения спектров во временной области (TDAC, хотя подавление наложения спектров осуществляется вдоль частотной оси здесь), с тем чтобы подавлять наложение спектров, сформированное в уравнении 5:
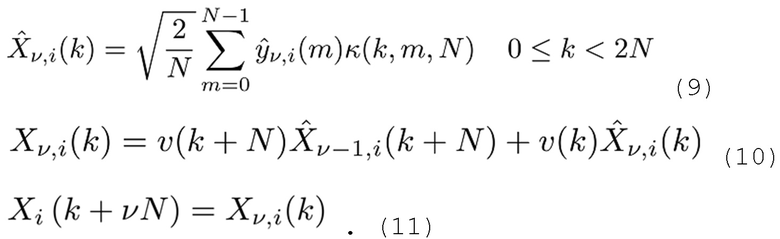
В завершение, начальное MDCT в уравнении 2 инвертируется, и снова выполняется TDAC:
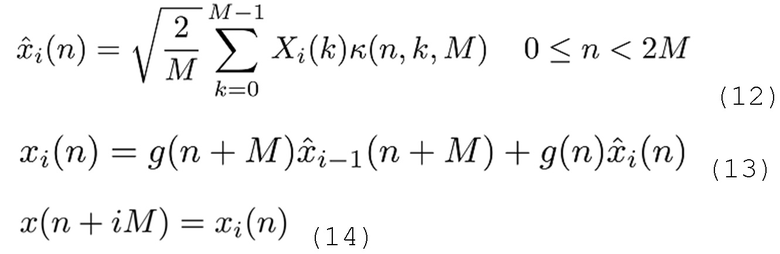
Далее описываются проектные ограничения частотно-временного разрешения. Хотя любое требуемое частотно-временное разрешение является возможным, некоторые ограничения для проектирования результирующих функций кодирования со взвешиванием должны соблюдаться с тем, чтобы обеспечивать обратимость. В частности, наклоны двух смежных подполос частот могут быть симметричными таким образом, что уравнение (6) удовлетворяет условию Принцена-Брэдли [J. Princen, A. Johnson и A. Bradley, "Subband/transform coding using filter bank designs based on time domain aliasing cancellation", in Acoustics, Speech and Signal Processing, IEEE International Conference on ICASSP '87, апрель года 1987, издание 12, стр. 2161-2164]. Схема переключения окон кодирования со взвешиванием, введенная в [B. Edler, "Codierung von Audiosignalen mit überlappender Transformation und adaptiven Fensterfunktionen", Frequenz, издание 43, стр. 252-256, сентябрь 1989 года], первоначально спроектированная с возможностью противостоять эффектам опережающего эхо, может применяться здесь. См. [Olivier Derrien, Thibaud Necciari и Peter Balazs, "A quasi-orthogonal, invertible and perceptually relevant time-frequency transform for audio coding", in EUSIPCO, Ницца, Франция, август 2015 года].
Во-вторых, сумма всех длин вторых MDCT-преобразований должна составлять в сумме общую длину предоставленных MDCT-коэффициентов. Полосы частот могут выбираться с возможностью не преобразовываться с использованием единичной ступенчатой функции кодирования со взвешиванием с нулями в требуемых коэффициентах. Тем не менее, свойства симметрии соседних функций кодирования со взвешиванием должны отслеживаться [B. Edler, "Codierung von Audiosignalen mit überlappender Transformation und adaptiven Fensterfunktionen", Frequenz, издание 43, стр. 252-256, сентябрь 1989 года]. Результирующее преобразование должно давать в результате нули в этих полосах частот, так что исходные коэффициенты могут непосредственно использоваться.
В качестве возможного частотно-временного разрешения, полосы частот коэффициентов масштабирования из наиболее современных аудиокодеров могут непосредственно использоваться.
Далее описывается вычисление коэффициентов уменьшения наложения спектров во временной области (TDAR).
Согласно вышеуказанному временному разрешению, каждая подполосная выборка соответствует M/Nv исходных выборок или интервалу Nv, умноженному на размер, в качестве одной исходной выборки.
Кроме того, величина наложения спектров в каждой подполосной выборке зависит от величины наложения спектров в интервале, который она представляет. Поскольку наложение спектров взвешивается с помощью функции h(n) аналитического кодирования со взвешиванием, использование приближенного значения функции синтезирующего кодирования со взвешиванием в каждом интервале подполосной выборки предполагается в качестве хорошей первой оценки для TDAR-коэффициента.
Эксперименты демонстрируют, что две очень простых схемы вычисления коэффициентов обеспечивают хорошие начальные значения с улучшенной временной и спектральной компактностью. Оба способа основаны на гипотетической функции gv(m) синтезирующего кодирования со взвешиванием длины 2Nv.
1) Для параметрических функций кодирования со взвешиванием, таких как синусоидальные или извлеченные методом Кайзера-Бесселя, может задаваться простое более короткое окно кодирования со взвешиванием идентичного типа.
2) Как для параметрических, так и для табличных функций кодирования со взвешиванием без закрытого представления, окно может разделяться на 2Nv секций равного размера, обеспечивая возможность получения коэффициентов с использованием среднего значения каждой секции:
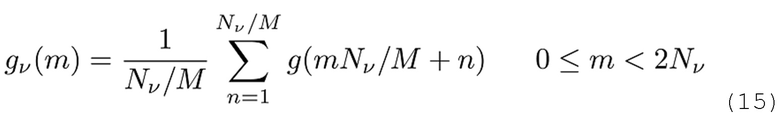
С учетом граничных MDCT-условий и зеркалирования наложения спектров, в таком случае в результате получаются TDAR-коэффициенты:
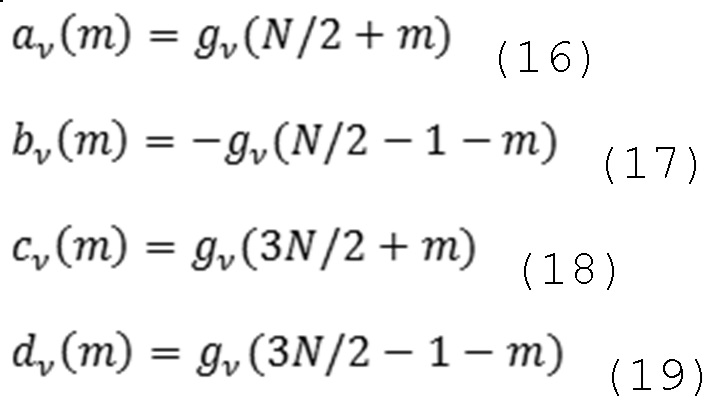
или в случае ортогонального преобразования:
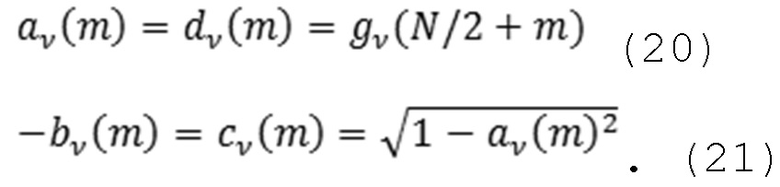
Независимо от того, какое решение по аппроксимации коэффициентов выбрано, при условии, что A является несингулярной, идеальное восстановление всей гребенки фильтров сохраняется. В других отношениях субоптимальный выбор коэффициентов должен затрагивать только величину остаточного наложения спектров в подполосном сигнале yv, i(m); тем не менее, не в сигнале x(n), синтезированном посредством гребенки обратных фильтров.
Фиг. 7 показывает на схемах пример подполосных выборок (верхний график) и разброс их выборок по времени и частоте (нижний график). Снабженная примечаниями выборка имеет более широкую полосу пропускания, но меньший разброс по времени, чем нижние выборки. Функции аналитического кодирования со взвешиванием (нижний график) имеют полное разрешение одного коэффициента в расчете на исходную временную выборку. TDAR-коэффициенты в силу этого должны аппроксимироваться (снабжаться посредством точки) для каждой временной области подполосных выборок (m=256:::384).
Далее описываются результаты (моделирования).
Фиг. 8 показывает спектральную и временную неопределенность, полученную посредством нескольких различных преобразований, как показано в [Frederic Bimbot, Ewen Camberlein и Pierrick Philippe, "Adaptive filter banks using fixed size mdct and subband merging for audio coding-comparison with the mpeg aac filter banks", in Audio Engineering Society Convention, октябрь 2006 года].
Можно видеть, что преобразования на основе матрицы Адамара предлагают сильно ограниченные характеристики частотно-временного компромисса. Для растущих размеров объединения, дополнительное временное разрешение приводит к непропорционально высоким затратам в спектральной неопределенности.
Другими словами, фиг. 8 показывает сравнение спектрального и временного энергетического уплотнения различных преобразований. Встроенные метки обозначают длины кадров для MDCT, коэффициенты разбиения для разбиения Гейзенберга и коэффициенты объединения для всего остального.
Тем не менее, подполосное объединение с TDAR имеет линейный компромисс между временной и спектральной неопределенностью, параллельно простому равномерному MDCT. Их произведение является постоянным, хотя немного выше, чем простое равномерное MDCT. Для этого анализа, синусоидальная функция аналитического кодирования со взвешиванием и извлеченная методом Кайзера-Бесселя функция кодирования со взвешиванием при подполосном объединении демонстрируют наиболее компактные результаты и в силу этого выбираются.
Тем не менее, кажется, что использование TDAR для коэффициента объединения Nv=2 снижает временную и спектральную компактность. Это обусловлено тем, что схема вычисления коэффициентов, введенная в разделе II-B, является слишком упрощенной и не аппроксимирует надлежащим образом значения для крутых наклонов функции кодирования со взвешиванием. Схема числовой оптимизации должна представляться в последующей публикации.
Эти значения компактности вычислены с использованием центра cog тяжести и эффективной длины 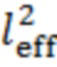 квадратной формы импульсной характеристики
квадратной формы импульсной характеристики 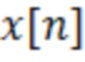 , заданной как [Athanasios Papoulis, "Signal analysis", Electrical and electronic engineering series, McGraw-Hill, Нью-Йорк, Сан-Франциско, Париж, 1977 год].
, заданной как [Athanasios Papoulis, "Signal analysis", Electrical and electronic engineering series, McGraw-Hill, Нью-Йорк, Сан-Франциско, Париж, 1977 год].
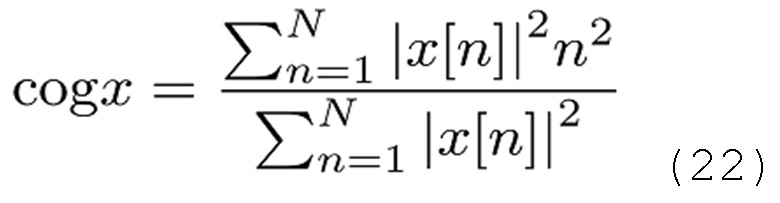
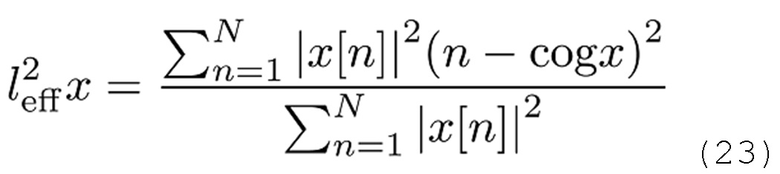
Показаны средние значения всех импульсных характеристик каждой отдельной гребенки фильтров.
Фиг. 9 показывает сравнение двух примерных импульсных характеристик, сформированных посредством подполосного объединения с и без TDAR, простых коротких MDCT-блоков и подполосного объединения на основе матрицы Адамара, как предложено в [O.A. Niamut и R. Heusdens, "Flexible frequency decompositions for cosine-modulated filter banks", in Acoustics, Speech and Signal Processing, 2003. Proceedings (ICASSP '03), 2003 IEEE International Conference on, апрель 2003 года, издание 5, стр. V-449-52, издание 5].
Плохая временная компактность преобразования с объединением на основе матрицы Адамара является четко видимой. Также можно четко видеть, что большинство артефактов наложения спектров в подполосе частот значительно уменьшаются посредством TDAR.
Другими словами, фиг. 9 показывает примерные импульсные характеристики объединенного подполосного фильтра, содержащего 8 из 1024 исходных бинов, с использованием способа, предложенного здесь без TDAR, с TDAR, способа, предложенного в [O.A. Niamut и R. Heusdens, "Subband merging in cosine-modulated filter banks", Signal Processing Letters, IEEE, издание 10, № 4, стр. 111-114, апрель 2003 года], и с использованием меньшей длины MDCT-кадра в 256 выборок.
Фиг. 10 показывает блок-схему последовательности операций способа 300 для обработки аудиосигнала, с тем чтобы получать подполосное представление аудиосигнала. Способ 300 содержит этап 302 выполнения каскадного перекрывающегося критически дискретизированного преобразования, по меньшей мере, для двух частично перекрывающихся блоков выборок аудиосигнала, с тем чтобы получать набор подполосных выборок на основе первого блока выборок аудиосигнала и получать соответствующий набор подполосных выборок на основе второго блока выборок аудиосигнала. Дополнительно, способ 300 содержит этап 304 выполнения комбинирования со взвешиванием двух соответствующих наборов подполосных выборок, причем один из них получен на основе первого блока выборок аудиосигнала, и один из них получен на основе второго блока выборок аудиосигнала, с тем чтобы получать подполосное представление с уменьшенным наложением спектров аудиосигнала.
Фиг. 11 показывает блок-схему последовательности операций способа 400 для обработки подполосного представления аудиосигнала, с тем чтобы получать аудиосигнал. Способ 400 содержит этап 402 выполнения комбинирования со взвешиванием (и сдвигом) двух соответствующих подполосных представлений с уменьшенным наложением спектров (различных блоков частично перекрывающихся выборок) аудиосигнала, с тем чтобы получать подполосное представление с наложением спектров, при этом подполосное представление с наложением спектров представляет собой набор подполосных выборок. Дополнительно, способ 400 содержит этап 404 выполнения каскадного обратного перекрывающегося критически дискретизированного преобразования для набора подполосных выборок, с тем чтобы получать набор выборок, ассоциированных с блоком выборок аудиосигнала.
Фиг. 12 показывает принципиальную блок-схему аудиокодера 150, согласно варианту осуществления. Аудиокодер 150 содержит аудиопроцессор (100), как описано выше, кодер 152, выполненный с возможностью кодировать подполосное представление с уменьшенным наложением спектров аудиосигнала, с тем чтобы получать кодированное подполосное представление с уменьшенным наложением спектров аудиосигнала, и модуль 154 формирования потоков битов, выполненный с возможностью формировать поток 156 битов из кодированного подполосного представления с уменьшенным наложением спектров аудиосигнала.
Фиг. 13 показывает принципиальную блок-схему аудиодекодера 250, согласно варианту осуществления. Аудиодекодер 250 содержит синтаксический анализатор 252 потоков битов, выполненный с возможностью синтаксически анализировать поток 154 битов, с тем чтобы получать кодированное подполосное представление с уменьшенным наложением спектров, декодер 254, выполненный с возможностью декодировать кодированное подполосное представление с уменьшенным наложением спектров, с тем чтобы получать подполосное представление с уменьшенным наложением спектров аудиосигнала, и аудиопроцессор 200, как описано выше.
Фиг. 14 показывает принципиальную блок-схему аудиоанализатора 180, согласно варианту осуществления. Аудиоанализатор 180 содержит аудиопроцессор 100, как описано выше, модуль 182 извлечения информации, выполненный с возможностью анализировать подполосное представление с уменьшенным наложением спектров, с тем чтобы предоставлять информацию, описывающую аудиосигнал.
Варианты осуществления предусматривают уменьшение наложения спектров во временной области (TDAR) в подполосах частот гребенок фильтров неравномерного ортогонального модифицированного дискретного косинусного преобразования (MDCT).
Варианты осуществления добавляют дополнительный этап постобработки в широко используемый конвейер MDCT-преобразования, причем непосредственно этап содержит только другое перекрывающееся MDCT-преобразование вдоль частотной оси и уменьшение наложения спектров во временной области (TDAR) вдоль каждой подполосной временной оси, обеспечивая возможность извлекать произвольные шкалы частот из MDCT-спектрограммы с улучшенной временной компактностью импульсной характеристики, при отсутствии введения дополнительной избыточности и с введением только одной кадровой MDCT-задержки.
2. Варьирующиеся во времени расположения частотно-временными плитками с использованием неравномерных ортогональных гребенок фильтров на основе MDCT-анализа/синтеза и TDAR
Фиг. 15 показывает принципиальную блок-схему аудиопроцессора 100, выполненного с возможностью обрабатывать аудиосигнал, с тем чтобы получать подполосное представление аудиосигнала, согласно дополнительному варианту осуществления. Аудиопроцессор 100 содержит каскад 104 каскадного перекрывающегося критически дискретизированного преобразования (LCST) и каскад 106 уменьшения наложения спектров во временной области (TDAR), оба из которых подробно описываются выше в разделе 1.
Каскад 104 каскадного перекрывающегося критически дискретизированного преобразования содержит первый каскад 120 перекрывающегося критически дискретизированного преобразования (LCST), выполненный с возможностью выполнять LCST 122_1 и 122_2 (например, MDCT) для первого блока 108_1 выборок и второго блока 108_2, соответственно, с тем чтобы получать первый набор 124_1 бинов для первого блока 108_1 выборок и второй набор 124_2 бинов для второго блока 108_2 выборок. Дополнительно, каскад 104 каскадного перекрывающегося критически дискретизированного преобразования содержит второй каскад 126 перекрывающегося критически дискретизированного преобразования (LCST), выполненный с возможностью выполнять LCST 132_1,1-132_1,2 (например, MDCT) для сегментированных наборов 128_1,1-128_1,2 бинов первого набора 124_1 бинов и LCST 132_2,1-132_2,2 (например, MDCT) для сегментированных наборов 128_2,1-128_2,2 бинов второго набора 124_1 бинов, с тем чтобы получать наборы 110_1,1-110_1,2 подполосных выборок, которые основаны на первом блоке 108_1 выборок, и наборы 110_2,1-110_2,2 подполосных выборок, которые основаны на втором блоке 108_1 выборок.
Как уже указано во вводной части, каскад 106 уменьшения наложения спектров во временной области (TDAR) может применять уменьшение наложения спектров во временной области (TDAR) только в том случае, если идентичное расположение частотно-временными плитками используется для первого блока 108_1 выборок и второго блока 108_2 выборок, т.е. если наборы 110_1,1-110_1,2 подполосных выборок, которые основаны на первом блоке 108_1 выборок, представляют идентичные области на частотно-временной плоскости по сравнению с наборами 110_2,1-110_2,2 подполосных выборок, которые основаны на втором блоке 108_2 выборок.
Тем не менее, если характеристики сигналов для входного сигнала изменяются, LCST 132_1,1-132_1,2 (например, MDCT), используемые для обработки сегментированных наборов 128_1,1-128_1,2 бинов, которые основаны на первом блоке 108_1 выборок, могут иметь другую длину кадра (например, коэффициенты объединения) по сравнению с LCST 132_2,1-132_2,2 (например, MDCT), используемыми для обработки сегментированных наборов 128_2,1-128_2,2 бинов, которые основаны на втором блоке 108_2 выборок.
В этом случае, наборы 110_1,1-110_1,2 подполосных выборок, которые основаны на первом блоке 108_1 выборок, представляют различные области на частотно-временной плоскости по сравнению с наборами 110_2,1-110_2,2 подполосных выборок, которые основаны на втором блоке 108_2 выборок, т.е. если первый набор 110_1,1 подполосных выборок представляет область на частотно-временной плоскости, отличающуюся от области третьего набора 110_2,1 подполосных выборок, и второй набор 110_1,2 подполосных выборок представляет область на частотно-временной плоскости, отличающуюся от области четвертого набора 110_2,1 подполосных выборок, и уменьшение наложения спектров во временной области (TDAR) не может применяться непосредственно.
Чтобы преодолевать это ограничение, аудиопроцессор 100 дополнительно содержит первый каскад 105 частотно-временного преобразования, выполненный с возможностью идентифицировать, в случае если наборы 110_1,1-110_1,2 подполосных выборок, которые основаны на первом блоке 108_1 выборок, представляют различные области на частотно-временной плоскости по сравнению с наборами 110_2,1-110_2,2 подполосных выборок, которые основаны на втором блоке 108_2 выборок, один или более наборов подполосных выборок из наборов 110_1,1-110_1,2 подполосных выборок, которые основаны на первом блоке 108_1 выборок, и один или более наборов подполосных выборок из наборов 110_2,1-110_2,2 подполосных выборок, которые основаны на втором блоке 108_2 выборок, которые в комбинации представляют идентичную область на частотно-временной плоскости, и выполнять частотно-временное преобразование идентифицированных одного или более наборов подполосных выборок из наборов 110_2,1-110_2,2 подполосных выборок, которые основаны на втором блоке 108_2 выборок, и/или идентифицированных одного или более наборов подполосных выборок из наборов 110_2,1-110_2,2 подполосных выборок, которые основаны на втором блоке 108_2 выборок, с тем чтобы получать одну или более преобразованных по времени и частоте подполосных выборок, каждая из которых представляет идентичную область на частотно-временной плоскости относительно соответствующей одной из идентифицированных одной или более подполосных выборок либо одной или более их преобразованных по времени и частоте версий.
Впоследствии, каскад 106 уменьшения наложения спектров во временной области может применять уменьшение временной области (TDAR), т.е. посредством выполнения комбинирования со взвешиванием двух соответствующих наборов подполосных выборок либо их преобразованных по времени и частоте версий, причем один из них получен на основе первого блока 108_1 выборок аудиосигнала 102, и один из них получен на основе на втором блоке 108_2 выборок аудиосигнала, с тем чтобы получать подполосные представления с уменьшенным наложением спектров аудиосигнала 102.
В вариантах осуществления, первый каскад 105 частотно-временного преобразования может быть выполнен с возможностью выполнять частотно-временное преобразование либо идентифицированных одного или более наборов подполосных выборок из наборов 110_2,1-110_2,2 подполосных выборок, которые основаны на первом блоке 108_1 выборок, либо идентифицированных одного или более наборов подполосных выборок из наборов 110_2,1-110_2,2 подполосных выборок, которые основаны на втором блоке 108_2 выборок, с тем чтобы получать одну или более преобразованных по времени и частоте подполосных выборок, каждая из которых представляет идентичную область на частотно-временной плоскости относительно соответствующей одной из идентифицированных одной или более подполосных выборок.
В этом случае, каскад 106 уменьшения наложения спектров во временной области может быть выполнен с возможностью выполнять комбинирование со взвешиванием преобразованного по времени и частоте набора подполосных выборок и соответствующего (непреобразованного по времени и частоте) набора подполосных выборок, причем один из них получен на основе первого блока 108_1 выборок аудиосигнала 102, и один из них получен на основе на втором блоке 108_2 выборок аудиосигнала. Это называется в данном документе "унилатеральным STDAR".
Естественно, первый каскад 105 частотно-временного преобразования также может быть выполнен с возможностью выполнять частотно-временное преобразование как идентифицированных одного или более наборов подполосных выборок из наборов 110_2,1-110_2,2 подполосных выборок, которые основаны на первом блоке 108_1 выборок, так и идентифицированных одного или более наборов подполосных выборок из наборов 110_2,1-110_2,2 подполосных выборок, которые основаны на втором блоке 108_2 выборок, с тем чтобы получать одну или более преобразованных по времени и частоте подполосных выборок, каждая из которых представляет идентичную область на частотно-временной плоскости относительно соответствующей одной из преобразованных по времени и частоте версий другой идентифицированной одной или более подполосных выборок.
В этом случае, каскад 106 уменьшения наложения спектров во временной области может быть выполнен с возможностью выполнять комбинирование со взвешиванием двух соответствующих преобразованных по времени и частоте наборов подполосных выборок, причем один из них получен на основе первого блока 108_1 выборок аудиосигнала 102, и один из них получен на основе на втором блоке 108_2 выборок аудиосигнала. Это называется в данном документе "билатеральным STDAR".
Фиг. 16 показывает схематичное представление частотно-временного преобразования, выполняемого посредством каскада 105 частотно-временного преобразования на частотно-временной плоскости.
Как указано на схемах 170_1 и 170_2 по фиг. 16, первый набор 110_1,1 подполосных выборок, соответствующих первому блоку 108_1 выборок, и третий набор 110_2,1 подполосных выборок, соответствующих второму блоку 108_2 выборок, представляют различные области 194_1,1 и 194_2,1 на частотно-временной плоскости таким образом, что каскад 106 уменьшения наложения спектров во временной области не имеет возможность применять уменьшение наложения спектров во временной области (TDAR) к первому набору 110_1,1 подполосных выборок и третьему набору 110_2,1 подполосных выборок.
Аналогично, второй набор 110_1,2 подполосных выборок, соответствующих первому блоку 108_1 выборок, и четвертый набор 110_2,2 подполосных выборок, соответствующих второму блоку 108_2 выборок, представляют различные области 194_1,2 и 194_2,2 на частотно-временной плоскости таким образом, что каскад 106 уменьшения наложения спектров во временной области не имеет возможность применять уменьшение наложения спектров во временной области (TDAR) ко второму набору 110_1,2 подполосных выборок и четвертому набору 110_2,2 подполосных выборок.
Тем не менее, первый набор 110_1,1 подполосных выборок в сочетании со вторым набором 110_1,2 подполосных выборок представляет идентичную область 196 на частотно-временной плоскости относительно третьего набора 110_2,1 подполосных выборок в комбинации с четвертым набором 110_2,2 подполосных выборок.
Таким образом, каскад 105 частотно-временного преобразования может выполнять частотно-временное преобразование первого набора 110_1,1 подполосных выборок и второго набора 110_1,2 подполосных выборок или выполнять частотно-временное преобразование третьего набора 110_2,1 подполосных выборок и четвертого набора 110_2,2 подполосных выборок, с тем чтобы получать преобразованные по времени и частоте наборы подполосных выборок, каждая из которых представляет идентичную область на частотно-временной плоскости относительно соответствующего одного из других наборов подполосных выборок.
На фиг. 16 примерно предполагается, что каскад 105 частотно-временного преобразования выполняет частотно-временное преобразование первого набора 110_1,1 подполосных выборок и второго набора 110_1,2 подполосных выборок, с тем чтобы получать первый преобразованный по времени и частоте набор 110_1,1' подполосных выборок и второй преобразованный по времени и частоте набор 110_1,2' подполосных выборок.
Как указано на схемах 170_3 и 170_4 по фиг. 16, первый преобразованный по времени и частоте набор 110_1,1' подполосных выборок и третий набор 110_2,1 подполосных выборок представляют идентичную область 194_1,1' и 194_2,1 на частотно-временной плоскости таким образом, что уменьшение наложения спектров во временной области (TDAR) может применяться к первому преобразованному по времени и частоте набору 110_1,1' подполосных выборок и третьему набору 110_2,1 подполосных выборок.
Аналогично, второй преобразованный по времени и частоте набор 110_1,2' подполосных выборок и четвертый набор 110_2,2 подполосных выборок представляют идентичную область 194_1,2' и 194_2,3 на частотно-временной плоскости таким образом, что уменьшение наложения спектров во временной области (TDAR) может применяться ко второму преобразованному по времени и частоте набору 110_1,2' подполосных выборок и четвертому набору 110_2,2 подполосных выборок.
Хотя на фиг. 16 только первый набор 110_1,1 подполосных выборок и второй набор 110_1,2 подполосных выборок, соответствующих первому блоку 108_1 выборок, преобразуются по времени и частоте посредством первого каскада 105 частотно-временного преобразования, в вариантах осуществления, также первый набор 110_1,1 подполосных выборок и второй набор 110_1,2 подполосных выборок, соответствующих первому блоку 108_1 выборок и третьему набору 110_2,1 подполосных выборок, и четвертый набор 110_2,2 подполосных выборок, соответствующих второму блоку 108_1 выборок, могут преобразовываться по времени и частоте посредством первого каскада 105 частотно-временного преобразования.
Фиг. 17 показывает принципиальную блок-схему аудиопроцессора 100, выполненного с возможностью обрабатывать аудиосигнал, с тем чтобы получать подполосное представление аудиосигнала, согласно дополнительному варианту осуществления.
Как показано на фиг. 17, аудиопроцессор 100 дополнительно может содержать второй каскад 107 частотно-временного преобразования, выполненный с возможностью выполнять частотно-временное преобразование подполосных представлений с уменьшенным наложением спектров аудиосигнала, при этом частотно-временное преобразование, применяемое посредством второго каскада частотно-временного преобразования, является обратным по отношению к частотно-временному преобразованию, применяемому посредством первого каскада частотно-временного преобразования.
Фиг. 18 показывает принципиальную блок-схему аудиопроцессора 200 для обработки подполосного представления аудиосигнала, с тем чтобы получать аудиосигнал, согласно дополнительному варианту осуществления.
Аудиопроцессор 200 содержит второй каскад 201 обратного частотно-временного преобразования, который является обратным по отношению ко второму каскаду 107 частотно-временного преобразования аудиопроцессора 100, показанного на фиг. 17. Подробно, второй каскад 201 обратного частотно-временного преобразования может быть выполнен с возможностью выполнять частотно-временное преобразование одного или более наборов подполосных выборок с уменьшенным наложением спектров из наборов подполосных выборок с уменьшенным наложением спектров, соответствующих второму блоку выборок аудиосигнала, и/или одного или более наборов подполосных выборок с уменьшенным наложением спектров из наборов подполосных выборок с уменьшенным наложением спектров, соответствующих второму блоку выборок аудиосигнала, с тем чтобы получать одну или более преобразованных по времени и частоте подполосных выборок с уменьшенным наложением спектров, каждая из которых представляет идентичную область на частотно-временной плоскости, которые имеют идентичную длину относительно соответствующей одной из одной или более подполосных выборок с уменьшенным наложением спектров, соответствующих другому блоку выборок аудиосигнала, либо одной или более их преобразованных по времени и частоте версий.
Дополнительно, аудиопроцессор 200 содержит каскад 202 обратного уменьшения наложения спектров во временной области (ITDAR), выполненный с возможностью выполнять комбинирования со взвешиванием соответствующих наборов подполосных выборок с уменьшенным наложением спектров либо их преобразованных по времени и частоте версий, с тем чтобы получать подполосное представление с наложением спектров.
Дополнительно, аудиопроцессор 200 содержит первый каскад 203 обратного частотно-временного преобразования, выполненный с возможностью выполнять частотно-временное преобразование подполосного представления с наложением спектров, с тем чтобы получать наборы 110_1,1-110_1,2 подполосных выборок, соответствующих первому блоку 108_1 выборок аудиосигнала, и наборы 110_2,1-110_2,2 подполосных выборок, соответствующих второму блоку 108_1 выборок аудиосигнала, при этом частотно-временное преобразование, применяемое посредством первого каскада 203 обратного частотно-временного преобразования, является обратным по отношению к частотно-временному преобразованию, применяемому посредством второго каскада 201 обратного частотно-временного преобразования.
Дополнительно, аудиопроцессор 200 содержит каскад 204 каскадного обратного перекрывающегося критически дискретизированного преобразования, выполненный с возможностью выполнять каскадное обратное перекрывающееся критически дискретизированное преобразование для наборов 110_1,1-110_2,2 выборок, с тем чтобы получать набор 206_1,1 выборок, ассоциированных с блоком выборок аудиосигнала 102.
Далее подробнее описываются варианты осуществления настоящего изобретения.
2.1. Уменьшение наложения спектров во временной области
При выражении перекрывающихся преобразований в полифазном обозначении, индекс кадра может выражаться в z-области, где 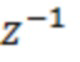 ссылается на предыдущий кадр [7]. В этом обозначении, MDCT-анализ может выражаться следующим образом:
ссылается на предыдущий кадр [7]. В этом обозначении, MDCT-анализ может выражаться следующим образом:
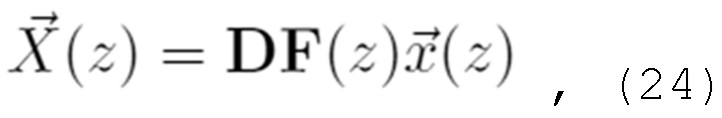
где D является DCT-IV-матрицей NxN, и F(z) является предварительной перестановочной/свертывающейся MDCT-матрицей NxN [7].
Подполосное объединение M и TDAR R(z) затем становятся другой парой блочно-диагональных матриц преобразования:
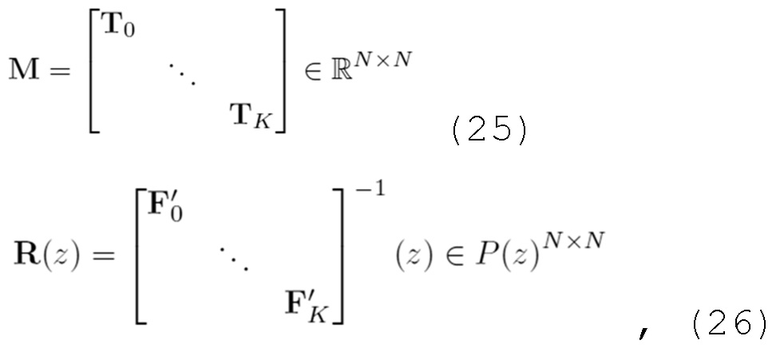
где Tk является подходящей матрицей преобразования (перекрывающимся MDCT в некоторых вариантах осуществления), и 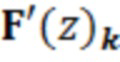 является модифицированным и меньшим вариантом F(z) [4]. Вектор
является модифицированным и меньшим вариантом F(z) [4]. Вектор 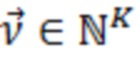 , содержащий размеры субматриц Tk и , называется "подполосной схемой размещения". Полный анализ становится следующим:
, содержащий размеры субматриц Tk и , называется "подполосной схемой размещения". Полный анализ становится следующим:
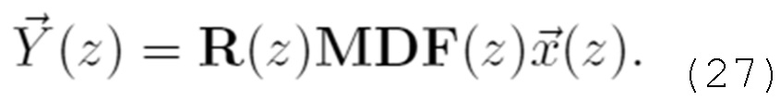
Для простоты, только частный случай равномерных расположений плитками анализируется в M и R(z) здесь, т.е. 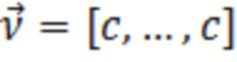 , где
, где 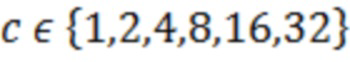 , легко показывать, что варианты осуществления не ограничены означенными.
, легко показывать, что варианты осуществления не ограничены означенными.
2.2. Переключаемое уменьшение наложения спектров во временной области
Поскольку STDAR должно применяться между двумя по-разному преобразованными кадрами, в вариантах осуществления, матрица M подполосного объединения, TDAR-матрица R(z) и подполосная схема  размещения расширяются до варьирующегося во времени обозначения M(m), R(z, m) и
размещения расширяются до варьирующегося во времени обозначения M(m), R(z, m) и  , где m является индексом кадра [8].
, где m является индексом кадра [8].
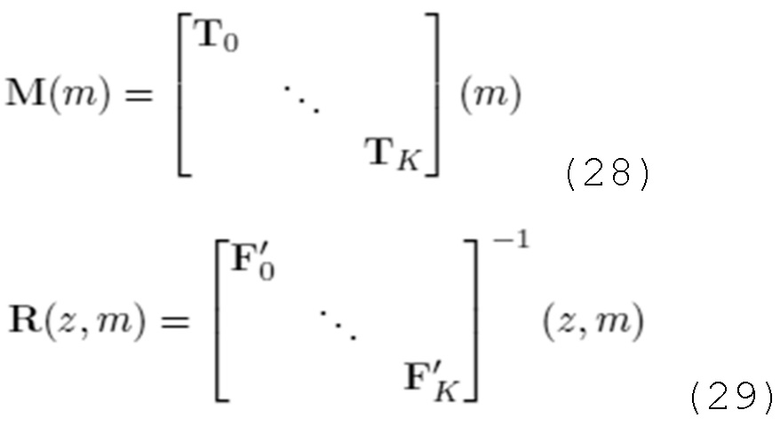
Конечно, STDAR также может расширяться до изменяющихся во времени матриц F(z, m) и D(m); тем не менее, этот сценарий не должен рассматриваться здесь.
Если расположения плитками двух кадров m и m-1 отличаются, т.е.:
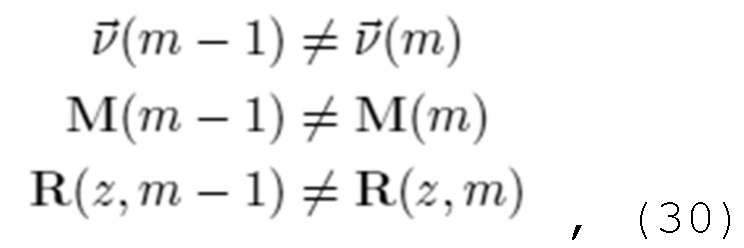
может проектироваться дополнительная матрица S(m) преобразования, которая временно преобразует расположение частотно-временными плитками кадра m таким образом, что оно согласуется с расположением плитками кадра m-1 (обратное согласование). Общее представление STDAR-операции содержится на фиг. 19.
Подробно, фиг. 19 показывает схематичное представление STDAR-операции на частотно-временной плоскости. Как указано на фиг. 19, наборы 110_1,1-110_1,4 подполосных выборок, соответствующих первому блоку 108_1 выборок (кадру m-1), и наборы 110_2,1-110_2,4 подполосных выборок, соответствующих второму блоку 108_2 выборок (кадру m), представляют различные области на частотно-временной плоскости. Таким образом, наборы 110_1,1-110_1,4 подполосных выборок, соответствующих первому блоку 108_1 выборок (кадру m-1), могут преобразовываться по времени и частоте, чтобы получать преобразованные по времени и частоте наборы 110_1,1'-110_1,4' подполосных выборок, соответствующих первому блоку 108_1 выборок (кадру m-1), каждый из которых представляет идентичную область на частотно-временной плоскости относительно соответствующего одного из наборов 110_2,1-110_2,4 подполосных выборок, соответствующих второму блоку 108_2 выборок (кадру m), так что TDAR (R(z, m)) может применяться, как указано на фиг. 19. Впоследствии, обратное частотно-временное преобразование может применяться, чтобы получать наборы 112_1,1-112_1,4 с уменьшенным наложением спектров подполосных выборок, соответствующих первому блоку 108_1 выборок (кадру m-1), и наборы 112_2,1-112_2,4 с уменьшенным наложением спектров подполосных выборок, соответствующих второму блоку 108_2 выборок (кадру m).
Другими словами, фиг. 19 показывает STDAR с использованием прямого повышающего согласования. Расположение частотно-временными плитками релевантной половины кадра m-1 изменяется таким образом, что оно согласуется с расположением частотно-временными плитками кадра m, после которого может применяться TDAR, и исходное расположение плитками восстанавливается. Расположение плитками кадра m не изменяется, как указано посредством единичной матрицы I.
Естественно, также кадр m-1 может преобразовываться таким образом, что он согласуется с расположением частотно-временными плитками кадра m (прямое согласование). В этом случае, S(m-1) рассматривается вместо S(m). Прямое и обратное согласование являются симметричными, так что исследуется только одна из двух операций.
Если посредством этой операции временное разрешение увеличивается посредством этапа подполосного объединения, в данном документе это называется "повышающим согласованием". Если временное разрешение снижается посредством этапа подполосного разбиения, в данном документе это называется "понижающим согласованием". Повышающее и понижающее согласование оцениваются в данном документе.
Тем не менее, эта матрица S(m) снова является блочно-диагональной, при 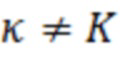 :
:
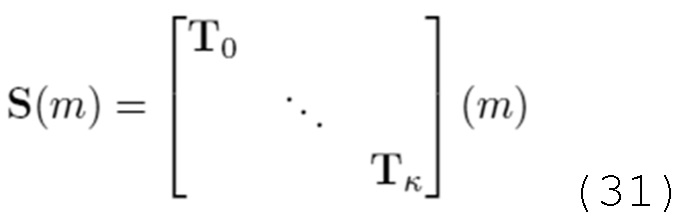
и должна применяться перед TDAR и инвертироваться впоследствии.
Таким образом, анализ становится следующим:
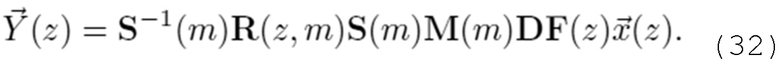
Естественно, только одна половина каждого кадра затрагивается посредством TDAR между двумя кадрами, так что должна преобразовываться только одна половина соответствующего кадра. Как результат, половина S(m) может выбираться в качестве единичной матрицы.
2.3. Дополнительные соображения
Очевидно, порядок импульсного отклика (т.е. порядок строк) каждой матрицы преобразования должен согласовываться с порядком соседних матриц.
В случае традиционного TDAR, особые соображения не должны учитываться, поскольку порядок двух смежных идентичных кадров всегда является равным. Тем не менее, в зависимости от варианта выбора параметров, при введении STDAR, входное упорядочение STDAR S(m) может не быть совместимым с выходным упорядочением подполосного объединения M. В этом случае, два или более коэффициентов, не смежных в запоминающем устройстве, объединенно преобразуются, и в силу этого должны повторно совмещаться перед операцией.
Кроме того, выходное упорядочение STDAR S(m) обычно не является совместимым с входным упорядочением исходного определения TDAR R(z, m). С другой стороны, причина состоит в том, что коэффициенты одной подполосы частот не являются смежными в запоминающем устройстве.
Как переупорядочение, так и неупорядочение могут выражаться как дополнительные перестановочные матрицы P и 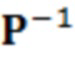 , которые вводятся в конвейер преобразования в соответствующих местах.
, которые вводятся в конвейер преобразования в соответствующих местах.
Порядок коэффициентов в этих матрицах зависит от операции, схемы размещения в запоминающем устройстве и используемых преобразований. Таким образом, общее решение не может быть представлено здесь.
Все введенные матрицы являются ортогональными, так что полное преобразование по-прежнему является ортогональным.
2.4. Оценка
При оценке, DCT-IV и DCT-II рассматриваются для T(m) в S(m), которые используются без перекрытия. Входная длина кадра N=1024 примерно выбирается. В силу этого, система анализируется для различных соотношений r(m) переключений, которые представляют собой соотношение коэффициентов объединения между двумя кадрами, т.е.:
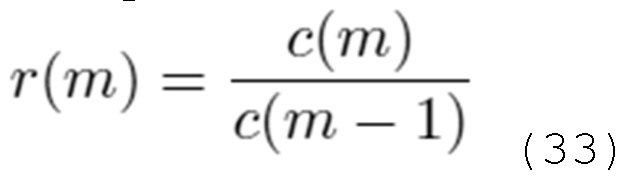
Аналогично случаю, при анализе TDAR, исследование концентрируется на форме и, в частности, на компактности импульсного отклика и частотного отклика полного преобразования [4], [9].
2.5. Результаты
DCT-II обеспечивает в результате наилучшие результаты, так что далее следует сфокусироваться на этом преобразовании. Прямое и обратное согласование являются симметричными и обеспечивают в результате идентичные результаты, так что описываются только результаты прямого согласования.
Фиг. 20 показывает на схемах примерные импульсные отклики двух кадров с коэффициентом объединения 8 и 16 перед STDAR (верхняя часть) и после STDAR (нижняя часть).
Другими словами, фиг. 20 показывает два примерных импульсных отклика двух кадров с различными расположениями частотно-временными плитками, до и после STDAR. Импульсные отклики демонстрируют различные ширины вследствие своей разности в коэффициенте объединения в -c(m-1)=8 и c(m)=16. После STDAR, наложение спектров явно уменьшается, но некоторое остаточное наложение спектров по-прежнему является видимым.
Фиг. 21 показывает на схеме компактность импульсного отклика и частотного отклика для повышающего согласования. Встроенные метки обозначают длину кадра для равномерного MDCT, коэффициенты объединения для TDAR и коэффициенты объединения кадра m-1 и m для STDAR. В силу этого, на фиг. 21 первая кривая 500 обозначает TDAR, вторая кривая 502 обозначает отсутствие TDAR, третья кривая 504 обозначает STDAR при c(m)=4, четвертая кривая 506 обозначает STDAR при c(m)=8, пятая кривая 508 обозначает STDAR при c(m)=16, шестая кривая 518 обозначает STDAR при c(m)=32, седьмая кривая 512 обозначает MDCT, и восьмая кривая 514 обозначает границу Гейзенберга.
Фиг. 22 показывает на схеме компактность импульсного отклика и частотного отклика для понижающего согласования. Встроенные метки обозначают длину кадра для равномерного MDCT, коэффициенты объединения для TDAR и коэффициенты объединения кадра m-1 и m для STDAR. В силу этого, на фиг. 21 первая кривая 500 обозначает TDAR, вторая кривая 502 обозначает отсутствие TDAR, третья кривая 504 обозначает STDAR при c(m)=4, четвертая кривая 506 обозначает STDAR при c(m)=8, пятая кривая 508 обозначает STDAR при c(m)=16, шестая кривая 518 обозначает STDAR при c(m)=32, седьмая кривая 512 обозначает MDCT, и восьмая кривая 514 обозначает границу Гейзенберга.
В силу этого, на фиг. 21 и 22, средняя компактность  импульсного отклика и компактность
импульсного отклика и компактность  частотного отклика [3], [9] широкого спектра гребенок фильтров для повышающего и понижающего согласования, соответственно. Для базового сравнения, равномерное MDCT, а также подполосное объединение с и без TDAR показываются [3], [4] с использованием кривых 512, 500 и 502. Гребенки фильтров STDAR показаны с использованием кривых 504, 506, 508 и 510. Каждая линия представляет все гребенки фильтров с идентичным коэффициентом c объединения. Встроенные метки для каждой точки данных обозначают коэффициенты объединения кадра m-1 и m.
частотного отклика [3], [9] широкого спектра гребенок фильтров для повышающего и понижающего согласования, соответственно. Для базового сравнения, равномерное MDCT, а также подполосное объединение с и без TDAR показываются [3], [4] с использованием кривых 512, 500 и 502. Гребенки фильтров STDAR показаны с использованием кривых 504, 506, 508 и 510. Каждая линия представляет все гребенки фильтров с идентичным коэффициентом c объединения. Встроенные метки для каждой точки данных обозначают коэффициенты объединения кадра m-1 и m.
На фиг. 21, кадр m-1 преобразуется таким образом, что он согласуется с расположением плитками кадра m. Можно видеть, что временная компактность кадра m улучшается без затрат в спектральной компактности. Для компактности кадра m-1, можно видеть улучшение для всех коэффициентов c объединения > 2, но регрессия для коэффициента объединения c=2. Эта регрессия ожидается, поскольку исходное TDAR при c=2 уже приводит к ухудшенной компактности импульсного отклика [4].
Аналогичная ситуация наблюдается на фиг. 22. С другой стороны, кадр m-1 преобразуется таким образом, что он согласуется с расположением плитками кадра m. В этой ситуации, временная компактность кадра m-1 улучшается без затрат в спектральной компактности. Кроме того, коэффициент объединения c=2 остается проблематичным.
В целом, можно четко видеть, что для коэффициентов c объединения > 2, STDAR уменьшает ширину импульсного отклика посредством уменьшения наложения спектров. Для всех коэффициентов объединения, компактность является наилучшей для наименьших коэффициентов r переключения.
2.6. Дополнительные варианты осуществления
Хотя вышеуказанные варианты осуществления главным образом относятся к унилатеральному STDAR, в котором STDAR-операция изменяет расположение частотно-временными плитками только одного из двух кадров таким образом, что оно согласуется с другим, следует отметить, что настоящее изобретение не ограничено такими вариантами осуществления. В отличие от этого, в вариантах осуществления, также может применяться билатеральное STDAR, при котором STDAR-операция изменяет расположение частотно-временными плитками обоих кадров таким образом, что они совпадают между собой. Эта система может использоваться для того, чтобы улучшать системную компактность для очень высоких соотношений переключений, т.е. при которых вместо изменения одного кадра с одного экстремального расположения плитками на другое экстремальное расположение (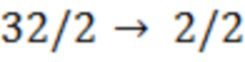 ) плитками, оба кадра могут изменяться на компромиссное расположение
) плитками, оба кадра могут изменяться на компромиссное расположение 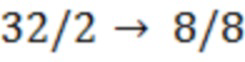 плитками.
плитками.
Кроме того, при условии, что ортогональность не нарушается, числовая оптимизация коэффициентов в R(z, m) и S(m) является возможной. Это может повышать производительность STDAR для более низких коэффициентов c объединения или более высоких соотношений r переключений.
Уменьшение наложения спектров во временной области (TDAR) представляет собой способ для того, чтобы улучшать компактность импульсного отклика неравномерных ортогональных модифицированных дискретных косинусных преобразований (MDCT). Традиционно, TDAR является возможным только между кадрами идентичных расположений частотно-временными плитками; тем не менее, варианты осуществления, описанные в данном документе, преодолевают это ограничение. Варианты осуществления предусматривают использование TDAR между двумя последовательными кадрами различных расположений частотно-временными плитками посредством введения другого подполосного объединения или этапа подполосного разбиения. Как следствие, варианты осуществления обеспечивают возможность более гибких и адаптивных расположений плитками гребенки фильтров, при одновременном сохранении компактных импульсных откликов, два атрибута требуются для эффективного перцепционного кодирования аудио.
Варианты осуществления предусматривают способ применения уменьшения наложения спектров во временной области (TDAR) между двумя кадрами различных расположений частотно-временными плитками. До этого, TDAR между такими кадрами является невозможным, что приводит к менее идеальной компактности импульсного отклика, когда расположения частотно-временными плитками должны адаптивно изменяться.
Варианты осуществления вводят другой этап подполосного объединения/подполосного разбиения, чтобы обеспечивать возможность согласования расположений частотно-временными плитками двух кадров до применения TDAR. После TDAR, исходные расположения частотно-временными плитками могут восстанавливаться.
Варианты осуществления предусматривают два сценария. Во-первых, восходящее согласование, при котором временное разрешение каждый увеличивается таким образом, что оно согласуется с временным разрешением другого. Во-вторых, нисходящее согласование, обратный случай.
Фиг. 23 показывает блок-схему последовательности операций способа 320 для обработки аудиосигнала, с тем чтобы получать подполосное представление аудиосигнала. Способ содержит этап 322 выполнения каскадного перекрывающегося критически дискретизированного преобразования, по меньшей мере, для двух частично перекрывающихся блоков выборок аудиосигнала, с тем чтобы получать наборы подполосных выборок на основе первого блока выборок аудиосигнала и получать наборы подполосных выборок на основе второго блока выборок аудиосигнала. Дополнительно, способ 320 содержит этап 324 идентификации, в случае если наборы подполосных выборок, которые основаны на первом блоке выборок, представляют различные области на частотно-временной плоскости по сравнению с наборами подполосных выборок, которые основаны на втором блоке выборок, одного или более наборов подполосных выборок из наборов подполосных выборок, которые основаны на первом блоке выборок, и одного или более наборов подполосных выборок из наборов подполосных выборок, которые основаны на втором блоке выборок, которые в комбинации представляют идентичную область частотно-временной плоскости. Дополнительно, способ 320 содержит этап 326 выполнения частотно-временных преобразований для идентифицированных одного или более наборов подполосных выборок из наборов подполосных выборок, которые основаны на первом блоке выборок, и/или идентифицированных одного или более наборов подполосных выборок из наборов подполосных выборок, которые основаны на втором блоке выборок, с тем чтобы получать одну или более преобразованных по времени и частоте подполосных выборок, каждая из которых представляет идентичную область на частотно-временной плоскости относительно соответствующей одной из идентифицированных одной или более подполосных выборок либо одной или более их преобразованных по времени и частоте версий. Дополнительно, способ 320 содержит этап 328 выполнения комбинирования со взвешиванием двух соответствующих наборов подполосных выборок либо их преобразованных по времени и частоте версий, причем один из них получен на основе первого блока выборок аудиосигнала, и один из них получен на основе второго блока выборок аудиосигнала, с тем чтобы получать подполосные представления с уменьшенным наложением спектров аудиосигнала.
Фиг. 24 показывает блок-схему последовательности операций способа 420 для обработки подполосного представления аудиосигнала, с тем чтобы получать аудиосигнал, причем подполосное представление аудиосигнала содержит наборы выборок с уменьшенным наложением спектров. Способ 420 содержит этап 422 выполнения частотно-временных преобразований для одного или более наборов подполосных выборок с уменьшенным наложением спектров из наборов подполосных выборок с уменьшенным наложением спектров, соответствующих второму блоку выборок аудиосигнала, и/или для одного или более наборов подполосных выборок с уменьшенным наложением спектров из наборов подполосных выборок с уменьшенным наложением спектров, соответствующих второму блоку выборок аудиосигнала, с тем чтобы получать одну или более преобразованных по времени и частоте подполосных выборок с уменьшенным наложением спектров, каждая из которых представляет идентичную область на частотно-временной плоскости относительно соответствующей одной из одной или более подполосных выборок с уменьшенным наложением спектров, соответствующих другому блоку выборок аудиосигнала, либо одной или более их преобразованных по времени и частоте версий. Дополнительно, способ 420 содержит этап 424 выполнения комбинирований со взвешиванием соответствующих наборов подполосных выборок с уменьшенным наложением спектров либо их преобразованных по времени и частоте версий, с тем чтобы получать подполосное представление с наложением спектров. Дополнительно, способ 420 содержит этап 426 выполнения частотно-временных преобразований для подполосного представления с наложением спектров, с тем чтобы получать наборы подполосных выборок, соответствующих первому блоку выборок аудиосигнала, и наборы подполосных выборок, соответствующих второму блоку выборок аудиосигнала, при этом частотно-временное преобразование, применяемое посредством первого каскада обратного частотно-временного преобразования, является обратным по отношению к частотно-временному преобразованию, применяемому посредством второго каскада обратного частотно-временного преобразования. Дополнительно, способ 420 содержит этап 428 выполнения каскадного обратного перекрывающегося критически дискретизированного преобразования для наборов подполосных выборок, с тем чтобы получать набор выборок, ассоциированных с блоком выборок аудиосигнала.
Далее описываются дополнительные варианты осуществления. В силу этого, нижеприведенные варианты осуществления могут комбинироваться с вышеуказанными вариантами осуществления.
Вариант 1 осуществления. Аудиопроцессор (100) для обработки аудиосигнала (102), с тем чтобы получать подполосное представление аудиосигнала (102), причем аудиопроцессор (100) содержит: каскад (104) каскадного перекрывающегося критически дискретизированного преобразования, выполненный с возможностью выполнять каскадное перекрывающееся критически дискретизированное преобразование, по меньшей мере, для двух частично перекрывающихся блоков (108_1; 108_2) выборок аудиосигнала (102), с тем чтобы получать набор (110_1,1) подполосных выборок на основе первого блока (108_1) выборок аудиосигнала (102) и получать соответствующий набор (110_2,1) подполосных выборок на основе второго блока (108_2) выборок аудиосигнала (102); и каскад (106) уменьшения наложения спектров во временной области, выполненный с возможностью выполнять комбинирование со взвешиванием двух соответствующих наборов (110_1,1; 110_1,2) подполосных выборок, причем один из них получен на основе первого блока (108_1) выборок аудиосигнала (102), и один из них получен на основе на втором блоке (108_2) выборок аудиосигнала, с тем чтобы получать подполосное представление (112_1) с уменьшенным наложением спектров аудиосигнала (102).
Вариант 2 осуществления. Аудиопроцессор (100) согласно варианту 1 осуществления, в котором каскад (104) каскадного перекрывающегося критически дискретизированного преобразования содержит: первый каскад (120) перекрывающегося критически дискретизированного преобразования, выполненный с возможностью выполнять перекрывающиеся критически дискретизированные преобразования для первого блока (108_1) выборок и второго блока (108_2) выборок, по меньшей мере, из двух частично перекрывающихся блоков (108_1; 108_2) выборок аудиосигнала (102), с тем чтобы получать первый набор (124_1) бинов для первого блока (108_1) выборок и второй набор (124_2) бинов для второго блока (108_2) выборок.
Вариант 3 осуществления. Аудиопроцессор (100) согласно варианту 2 осуществления, в котором каскад (104) каскадного перекрывающегося критически дискретизированного преобразования дополнительно содержит: второй каскад (126) перекрывающегося критически дискретизированного преобразования, выполненный с возможностью выполнять перекрывающееся критически дискретизированное преобразование для сегмента (128_1,1) первого набора (124_1) бинов и выполнять перекрывающееся критически дискретизированное преобразование для сегмента (128_2,1) второго набора (124_2) бинов, причем каждый сегмент ассоциирован с подполосой частот аудиосигнала (102), с тем чтобы получать набор (110_1,1) подполосных выборок для первого набора бинов и набор (110_2,1) подполосных выборок для второго набора бинов.
Вариант 4 осуществления. Аудиопроцессор (100) согласно варианту 3 осуществления, в котором первый набор (110_1,1) подполосных выборок представляет собой результат первого перекрывающегося критически дискретизированного преобразования (132_1,1) на основе первого сегмента (128_1,1) первого набора (124_1) бинов, при этом второй набор (110_1,2) подполосных выборок представляет собой результат второго перекрывающегося критически дискретизированного преобразования (132_1,2) на основе второго сегмента (128_1,2) первого набора (124_1) бинов, при этом третий набор (110_2,1) подполосных выборок представляет собой результат третьего перекрывающегося критически дискретизированного преобразования (132_2,1) на основе первого сегмента (128_2,1) второго набора (128_2,1) бинов, при этом четвертый набор (110_2,2) подполосных выборок представляет собой результат четвертого перекрывающегося критически дискретизированного преобразования (132_2,2) на основе второго сегмента (128_2,2) второго набора (128_2,1) бинов; и при этом каскад (106) уменьшения наложения спектров во временной области выполнен с возможностью выполнять комбинирование со взвешиванием первого набора (110_1,1) подполосных выборок и третьего набора (110_2,1) подполосных выборок, с тем чтобы получать первое подполосное представление (112_1) с уменьшенным наложением спектров аудиосигнала, при этом каскад (106) уменьшения наложения спектров во временной области выполнен с возможностью выполнять комбинирование со взвешиванием второго набора (110_1,2) подполосных выборок и четвертого набора (110_2,2) подполосных выборок, с тем чтобы получать второе подполосное представление (112_2) с уменьшенным наложением спектров аудиосигнала.
Вариант 5 осуществления. Аудиопроцессор (100) согласно одному из вариантов 1-4 осуществления, в котором каскад (104) каскадного перекрывающегося критически дискретизированного преобразования выполнен с возможностью сегментировать набор (124_1) бинов, полученный на основе первого блока (108_1) выборок, с использованием, по меньшей мере, двух функций кодирования со взвешиванием и получать, по меньшей мере, два сегментированных набора (128_1,1; 128_1,2) подполосных выборок на основе сегментированного набора бинов, соответствующего первому блоку (108_1) выборок; при этом каскад (104) каскадного перекрывающегося критически дискретизированного преобразования выполнен с возможностью сегментировать набор (124_2) бинов, полученный на основе второго блока (108_2) выборок, с использованием, по меньшей мере, двух функций кодирования со взвешиванием, с тем чтобы получать, по меньшей мере, два сегментированных набора (128_2,1; 128_2,2) подполосных выборок на основе сегментированного набора бинов, соответствующего второму блоку (108_2) выборок; и при этом, по меньшей мере, две функции кодирования со взвешиванием содержат различную ширину окна кодирования со взвешиванием.
Вариант 6 осуществления. Аудиопроцессор (100) согласно одному из вариантов 1-5 осуществления, в котором каскад (104) каскадного перекрывающегося критически дискретизированного преобразования выполнен с возможностью сегментировать набор (124_1) бинов, полученный на основе первого блока (108_1) выборок, с использованием, по меньшей мере, двух функций кодирования со взвешиванием и получать, по меньшей мере, два сегментированных набора (128_1,1; 128_1,2) подполосных выборок на основе сегментированного набора бинов, соответствующего первому блоку (108_1) выборок; при этом каскад (104) каскадного перекрывающегося критически дискретизированного преобразования выполнен с возможностью сегментировать набор (124_2) бинов, полученный на основе второго блока (108_2) выборок, с использованием, по меньшей мере, двух функций кодирования со взвешиванием, с тем чтобы получать, по меньшей мере, два набора (128_2,1; 128_2,2) подполосных выборок на основе сегментированного набора бинов, соответствующего второму блоку (108_2) выборок; и при этом наклоны фильтра функций кодирования со взвешиванием, соответствующих смежным наборам подполосных выборок, являются симметричными.
Вариант 7 осуществления. Аудиопроцессор (100) согласно одному из вариантов 1-6 осуществления, в котором каскад (104) каскадного перекрывающегося критически дискретизированного преобразования выполнен с возможностью сегментировать выборки аудиосигнала на первый блок (108_1) выборок и второй блок (108_2) выборок с использованием первой функции кодирования со взвешиванием; при этом каскад перекрывающегося критически дискретизированного преобразования (104) выполнен с возможностью сегментировать набор (124_1) бинов, полученный на основе первого блока (108_1) выборок, и набор (124_2) бинов, полученный на основе второго блока (108_2) выборок, с использованием второй функции кодирования со взвешиванием, с тем чтобы получать соответствующие подполосные выборки; и при этом первая функция кодирования со взвешиванием и вторая функция кодирования со взвешиванием содержат различную ширину окна кодирования со взвешиванием.
Вариант 8 осуществления. Аудиопроцессор (100) согласно одному из вариантов 1-6 осуществления, в котором каскад (104) каскадного перекрывающегося критически дискретизированного преобразования выполнен с возможностью сегментировать выборки аудиосигнала на первый блок (108_1) выборок и второй блок (108_2) выборок с использованием первой функции кодирования со взвешиванием; при этом каскад (104) каскадного перекрывающегося критически дискретизированного преобразования выполнен с возможностью сегментировать набор (124_1) бинов, полученный на основе первого блока (108_1) выборок, и набор (124_2) бинов, полученный на основе второго блока (108_2) выборок, с использованием второй функции кодирования со взвешиванием, с тем чтобы получать соответствующие подполосные выборки; и при этом ширина окна кодирования со взвешиванием первой функции кодирования со взвешиванием и ширина окна кодирования со взвешиванием второй функции кодирования со взвешиванием отличаются друг от друга, при этом ширина окна кодирования со взвешиванием первой функции кодирования со взвешиванием и ширина окна кодирования со взвешиванием второй функции кодирования со взвешиванием отличаются друг от друга на коэффициент, отличающийся от степени двух.
Вариант 9 осуществления. Аудиопроцессор (100) согласно одному из вариантов 1-8 осуществления, в котором каскад (106) уменьшения наложения спектров во временной области выполнен с возможностью выполнять комбинирование со взвешиванием двух соответствующих наборов подполосных выборок согласно следующему уравнению:
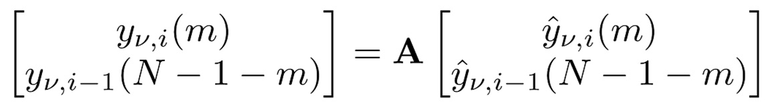
- для 0≤m<N/2 при:
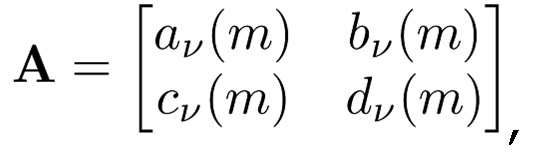
с тем чтобы получать подполосное представление с уменьшенным наложением спектров аудиосигнала, при этом yv, i(m) представляет собой первое подполосное представление с уменьшенным наложением спектров аудиосигнала, yv, i-1(N-1-m) представляет собой второе подполосное представление с уменьшенным наложением спектров аудиосигнала, ŷv, i(m) представляет собой набор подполосных выборок на основе второго блока выборок аудиосигнала, ŷv, i-1(N-1-m) представляет собой набор подполосных выборок на основе первого блока выборок аудиосигнала, av(m) представляет собой ..., bv(m) представляет собой..., cv(m) представляет собой ..., и dv(m) представляет собой....
Вариант 10 осуществления. Аудиопроцессор (200) для обработки подполосного представления аудиосигнала, с тем чтобы получать аудиосигнал (102), причем аудиопроцессор (200) содержит: каскад (202) обратного уменьшения наложения спектров во временной области, выполненный с возможностью выполнять комбинирование со взвешиванием двух соответствующих подполосных представлений с уменьшенным наложением спектров аудиосигнала (102), с тем чтобы получать подполосное представление с наложением спектров, при этом подполосное представление с наложением спектров представляет собой набор (110_1,1) подполосных выборок; и каскад (204) каскадного обратного перекрывающегося критически дискретизированного преобразования, выполненный с возможностью выполнять каскадное обратное перекрывающееся критически дискретизированное преобразование для набора (110_1,1) подполосных выборок, с тем чтобы получать набор (206_1,1) выборок, ассоциированных с блоком выборок аудиосигнала (102).
Вариант 11 осуществления. Аудиопроцессор (200) согласно варианту 10 осуществления, в котором каскад (204) каскадного обратного перекрывающегося критически дискретизированного преобразования содержит первый каскад (208) обратного перекрывающегося критически дискретизированного преобразования, выполненный с возможностью выполнять обратное перекрывающееся критически дискретизированное преобразование для набора (110_1,1) подполосных выборок, с тем чтобы получать набор (128_1,1) бинов, ассоциированный с данной подполосой частот аудиосигнала; и первый каскад (210) суммирования с перекрытием, выполненный с возможностью выполнять конкатенацию наборов бинов, ассоциированных с множеством подполос частот аудиосигнала, что содержит комбинирование со взвешиванием набора (128_1,1) бинов, ассоциированных с данной подполосой частот аудиосигнала (102), с набором (128_1,2) бинов, ассоциированных с другой подполосой частот аудиосигнала (102), с тем чтобы получать набор (124_1) бинов, ассоциированных с блоком выборок аудиосигнала (102).
Вариант 12 осуществления. Аудиопроцессор (200) согласно варианту 11 осуществления, в котором каскад (204) каскадного обратного перекрывающегося критически дискретизированного преобразования содержит второй каскад (212) обратного перекрывающегося критически дискретизированного преобразования, выполненный с возможностью выполнять обратное перекрывающееся критически дискретизированное преобразование для набора (124_1) бинов, ассоциированных с блоком выборок аудиосигнала (102), с тем чтобы получать набор выборок, ассоциированных с блоком выборок аудиосигнала (102).
Вариант 13 осуществления. Аудиопроцессор (200) согласно варианту 12 осуществления, в котором каскад (204) каскадного обратного перекрывающегося критически дискретизированного преобразования содержит второй каскад (214) суммирования с перекрытием, выполненный с возможностью суммировать с перекрытием набор (206_1,1) выборок, ассоциированных с блоком выборок аудиосигнала (102), и другой набор (206_2,1) выборок, ассоциированных с другим блоком выборок аудиосигнала (102), причем блок выборок и другой блок выборок аудиосигнала (102) частично перекрываются, с тем чтобы получать аудиосигнал (102).
Вариант 14 осуществления. Аудиопроцессор (200) согласно одному из вариантов 10-13 осуществления, в котором каскад (202) обратного уменьшения наложения спектров во временной области выполнен с возможностью выполнять комбинирование со взвешиванием двух соответствующих подполосных представлений с уменьшенным наложением спектров аудиосигнала (102) на основе следующего уравнения:
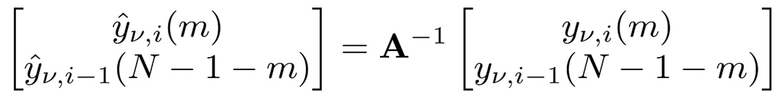
- для 0≤m<N/2 при:
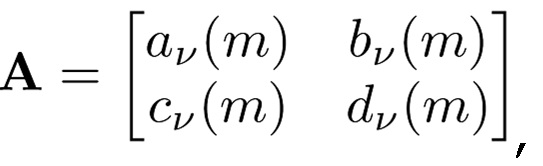
с тем чтобы получать подполосное представление с наложением спектров, при этом yv,i(m) представляет собой первое подполосное представление с уменьшенным наложением спектров аудиосигнала, yv,i-1(N-1-m) представляет собой второе подполосное представление с уменьшенным наложением спектров аудиосигнала, ŷv,i(m) представляет собой набор подполосных выборок на основе второго блока выборок аудиосигнала, ŷv,i-1(N-1-m) представляет собой набор подполосных выборок на основе первого блока выборок аудиосигнала, av(m) представляет собой ..., bv(m) представляет собой ..., cv(m) представляет собой ..., и dv(m) представляет собой ....
Вариант 15 осуществления. Аудиокодер, содержащий: аудиопроцессор (100) согласно одному из вариантов 1-9 осуществления; кодер, выполненный с возможностью кодировать подполосное представление с уменьшенным наложением спектров аудиосигнала, с тем чтобы получать кодированное подполосное представление с уменьшенным наложением спектров аудиосигнала; и модуль формирования потоков битов, выполненный с возможностью формировать поток битов из кодированного подполосного представления с уменьшенным наложением спектров аудиосигнала.
Вариант 16 осуществления. Аудиодекодер, содержащий: синтаксический анализатор потоков битов, выполненный с возможностью синтаксически анализировать поток битов, с тем чтобы получать кодированное подполосное представление с уменьшенным наложением спектров; декодер, выполненный с возможностью декодировать кодированное подполосное представление с уменьшенным наложением спектров, с тем чтобы получать подполосное представление с уменьшенным наложением спектров аудиосигнала; и аудиопроцессор (200) согласно одному из вариантов 10-14 осуществления.
Вариант 17 осуществления: Аудиоанализатор, содержащий: аудиопроцессор (100) согласно одному из вариантов 1-9 осуществления; и модуль извлечения информации, выполненный с возможностью анализировать подполосное представление с уменьшенным наложением спектров, с тем чтобы предоставлять информацию, описывающую аудиосигнал.
Вариант 18 осуществления. Способ (300) для обработки аудиосигнала, с тем чтобы получать подполосное представление аудиосигнала, при этом способ содержит: выполнение (302) каскадного перекрывающегося критически дискретизированного преобразования, по меньшей мере, для двух частично перекрывающихся блоков выборок аудиосигнала, с тем чтобы получать набор подполосных выборок на основе первого блока выборок аудиосигнала и получать соответствующий набор подполосных выборок на основе второго блока выборок аудиосигнала; и выполнение (304) комбинирования со взвешиванием двух соответствующих наборов подполосных выборок, причем один из них получен на основе первого блока выборок аудиосигнала, и один из них получен на основе второго блока выборок аудиосигнала, с тем чтобы получать подполосное представление с уменьшенным наложением спектров аудиосигнала.
Вариант 19 осуществления. Способ (400) для обработки подполосного представления аудиосигнала, с тем чтобы получать аудиосигнал, при этом способ содержит: выполнение (402) комбинирования со взвешиванием двух соответствующих подполосных представлений с уменьшенным наложением спектров аудиосигнала, с тем чтобы получать подполосное представление с наложением спектров, при этом подполосное представление с наложением спектров представляет собой набор подполосных выборок; и выполнение (404) каскадного обратного перекрывающегося критически дискретизированного преобразования для набора подполосных выборок, с тем чтобы получать набор выборок, ассоциированных с блоком выборок аудиосигнала.
Вариант 20 осуществления. Компьютерная программа для осуществления способа согласно одному из вариантов 18 и 19 осуществления.
Хотя некоторые аспекты описаны в контексте оборудования, очевидно, что эти аспекты также представляют описание соответствующего способа, при этом блок или устройство соответствует этапу способа либо признаку этапа способа. Аналогично, аспекты, описанные в контексте этапа способа, также представляют описание соответствующего блока или элемента, или признака соответствующего оборудования. Некоторые или все этапы способа могут выполняться посредством (или с использованием) аппаратного оборудования, такого как, например, микропроцессор, программируемый компьютер либо электронная схема. В некоторых вариантах осуществления, один или более из самых важных этапов способа могут выполняться посредством этого оборудования.
В зависимости от определенных требований к реализации, варианты осуществления изобретения могут реализовываться в аппаратных средствах или в программном обеспечении. Реализация может выполняться с использованием цифрового носителя хранения данных, например, гибкого диска, DVD, Blu-Ray, CD, ROM, PROM, EPROM, EEPROM или флэш-памяти, имеющего сохраненные электронно считываемые управляющие сигналы, которые взаимодействуют (или допускают взаимодействие) с программируемой компьютерной системой таким образом, что осуществляется соответствующий способ. Следовательно, цифровой носитель хранения данных может быть машиночитаемым.
Некоторые варианты осуществления согласно изобретению содержат носитель данных, имеющий электронночитаемые управляющие сигналы, которые допускают взаимодействие с программируемой компьютерной системой таким образом, что осуществляется один из способов, описанных в данном документе.
В общем, варианты осуществления настоящего изобретения могут реализовываться как компьютерный программный продукт с программным кодом, при этом программный код выполнен с возможностью осуществления одного из способов, когда компьютерный программный продукт работает на компьютере. Программный код, например, может сохраняться на машиночитаемом носителе.
Другие варианты осуществления содержат компьютерную программу для осуществления одного из способов, описанных в данном документе, сохраненную на машиночитаемом носителе.
Другими словами, вариант осуществления изобретаемого способа в силу этого представляет собой компьютерную программу, имеющую программный код для осуществления одного из способов, описанных в данном документе, когда компьютерная программа работает на компьютере.
Следовательно, дополнительный вариант осуществления изобретаемых способов представляет собой носитель хранения данных (цифровой носитель хранения данных или машиночитаемый носитель), содержащий записанную компьютерную программу для осуществления одного из способов, описанных в данном документе. Носитель данных, цифровой носитель хранения данных или носитель с записанными данными типично является материальным и/или энергонезависимым.
Следовательно, дополнительный вариант осуществления изобретаемого способа представляет собой поток данных или последовательность сигналов, представляющих компьютерную программу для осуществления одного из способов, описанных в данном документе. Поток данных или последовательность сигналов, например, может быть выполнена с возможностью передачи через соединение для передачи данных, например, через Интернет.
Дополнительный вариант осуществления содержит средство обработки, например, компьютер или программируемое логическое устройство, выполненное с возможностью осуществлять один из способов, описанных в данном документе.
Дополнительный вариант осуществления содержит компьютер, имеющий установленную компьютерную программу для осуществления одного из способов, описанных в данном документе.
Дополнительный вариант осуществления согласно изобретению содержит оборудование или систему, выполненную с возможностью передавать (например, электронно или оптически) компьютерную программу для осуществления одного из способов, описанных в данном документе, в приемное устройство. Приемное устройство, например, может представлять собой компьютер, мобильное устройство, запоминающее устройство и т.п. Оборудование или система, например, может содержать файловый сервер для передачи компьютерной программы в приемное устройство.
В некоторых вариантах осуществления, программируемое логическое устройство (например, программируемая пользователем вентильная матрица) может использоваться для того, чтобы выполнять часть или все из функциональностей способов, описанных в данном документе. В некоторых вариантах осуществления, программируемая пользователем вентильная матрица может взаимодействовать с микропроцессором, чтобы осуществлять один из способов, описанных в данном документе. В общем, способы предпочтительно осуществляются посредством любого аппаратного оборудования.
Оборудование, описанное в данном документе, может реализовываться с использованием аппаратного оборудования либо с использованием компьютера, либо с использованием комбинации аппаратного оборудования и компьютера.
Оборудование, описанное в данном документе, или любые компоненты оборудования, описанного в данном документе, могут реализовываться, по меньшей мере, частично в аппаратных средствах и/или в программном обеспечении.
Способы, описанные в данном документе, могут осуществляться с использованием аппаратного оборудования либо с использованием компьютера, либо с использованием комбинации аппаратного оборудования и компьютера.
Способы, описанные в данном документе, или любые компоненты оборудования, описанного в данном документе, могут выполняться, по меньшей мере, частично посредством аппаратных средств и/или посредством программного обеспечения.
Вышеописанные варианты осуществления являются просто иллюстративными в отношении принципов настоящего изобретения. Следует понимать, что модификации и изменения компоновок и подробностей, описанных в данном документе, должны быть очевидными для специалистов в данной области техники. Следовательно, они подразумеваются как ограниченные только посредством объема нижеприведенной формулы изобретения, а не посредством конкретных подробностей, представленных посредством описания и пояснения вариантов осуществления в данном документе.
Библиографический список
[1] H. S. Malvar "Biorthogonal and nonuniform lapped transforms for transform coding with reduced blocking and ringing artifacts", IEEE Transactions on Signal Processing, издание 46, номер 4, стр. 1043-1053, апрель 1998 года.
[2] O. A. Niamut и R. Heusdens "Subband merging in cosine-modulated filter banks", IEEE Signal Processing Letters, издание 10, номер 4, стр. 111-114, апрель 2003 года.
[3] Frederic Bimbot, Ewen Camberlein и Pierrick Philippe "Adaptive Filter Banks using Fixed Size MDCT and Subband Merging for Audio Coding - Comparison with the MPEG AAC Filter Banks", in Audio Engineering Society Convention 121, октябрь 2006 года, Audio Engineering Society.
[4] N. Werner и B. Edler, "Nonuniform Orthogonal Filterbanks Based on MDCT Analysis/Synthesis and Time-Domain Aliasing Reduction", IEEE Signal Processing Letters, издание 24, номер 5, стр. 589-593, май 2017 года.
[5] Nils Werner и Bernd Edler "Perceptual Audio Coding with Adaptive Non-Uniform Time/Frequency Tilings using Subband Merging and Time Domain Aliasing Reduction", in 2019 IEEE International Conference on Acoustics, Speech and Signal Processing, 2019 год.
[6] B. Edler "Codierung von Audiosignalen mit  Transformation und adaptiven Fensterfunktionen", Frequenz, издание 43, стр. 252-256, сентябрь 1989 года.
Transformation und adaptiven Fensterfunktionen", Frequenz, издание 43, стр. 252-256, сентябрь 1989 года.
[7] G. D. T. Schuller и M. J. T. Smith "New framework for modulated perfect reconstruction filter banks", IEEE Transactions on Signal Processing, издание 44, номер 8, стр. 1941-1954, август 1996 года.
[8] Gerald Schuller "Time-Varying Filter Banks With Variable System Delay", In IEEE International Conference on Acoustics, Speech and Signal Proecessing (ICASSP, 1997 год, стр. 21-24.
[9] Carl Taswell "Empirical Tests for Evaluation of Multirate Filter Bank Parameters", in Wavelets in Signal and Image Analysis, Max A. Viergever, Arthur A. Petrosian and Franc¸ois G. Meyer, Eds., издание 19, стр. 111-139. Springer Netherlands, Dordrecht, 2001 год.
[10] F. Schuh, S. Dick, R. Füg, C. R. Helmrich, N. Rettelbach и T. Schwegler "Efficient Multichannel Audio Tranform Coding with Low Delay and Complexity", Audio Engineering Society, сентябрь 2016 года [онлайн]. По адресу: http://www.aes.org/e-lib/browse.cfm? elib=18464
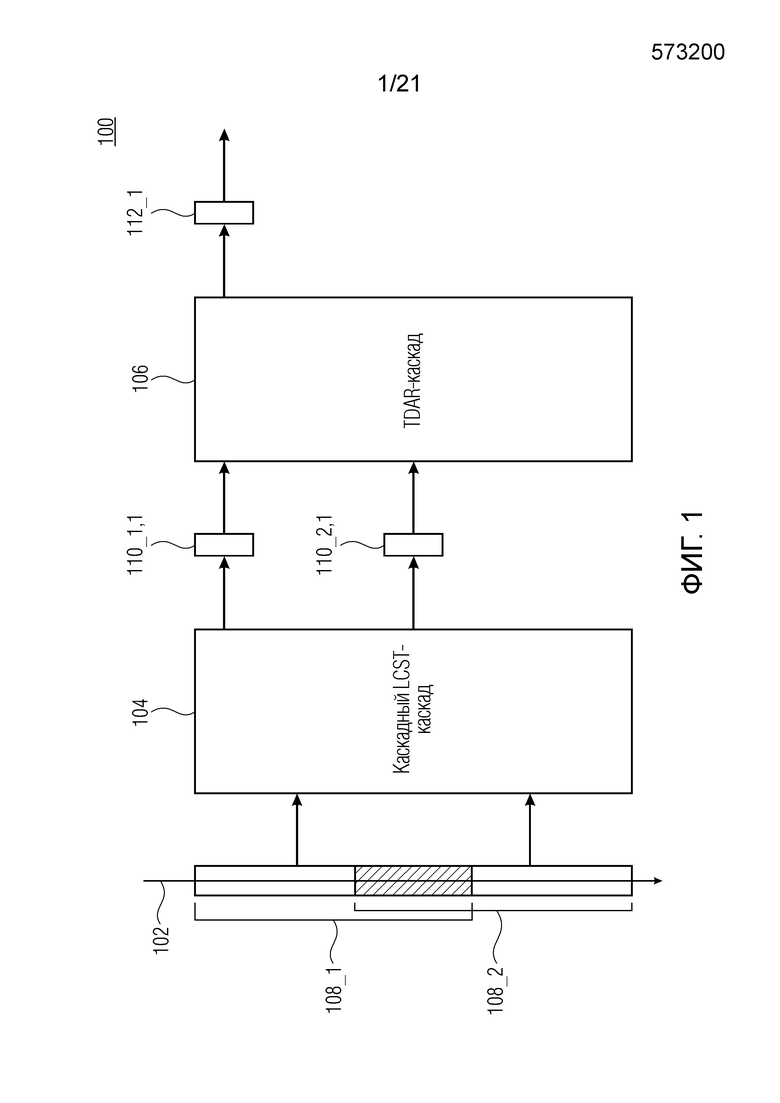
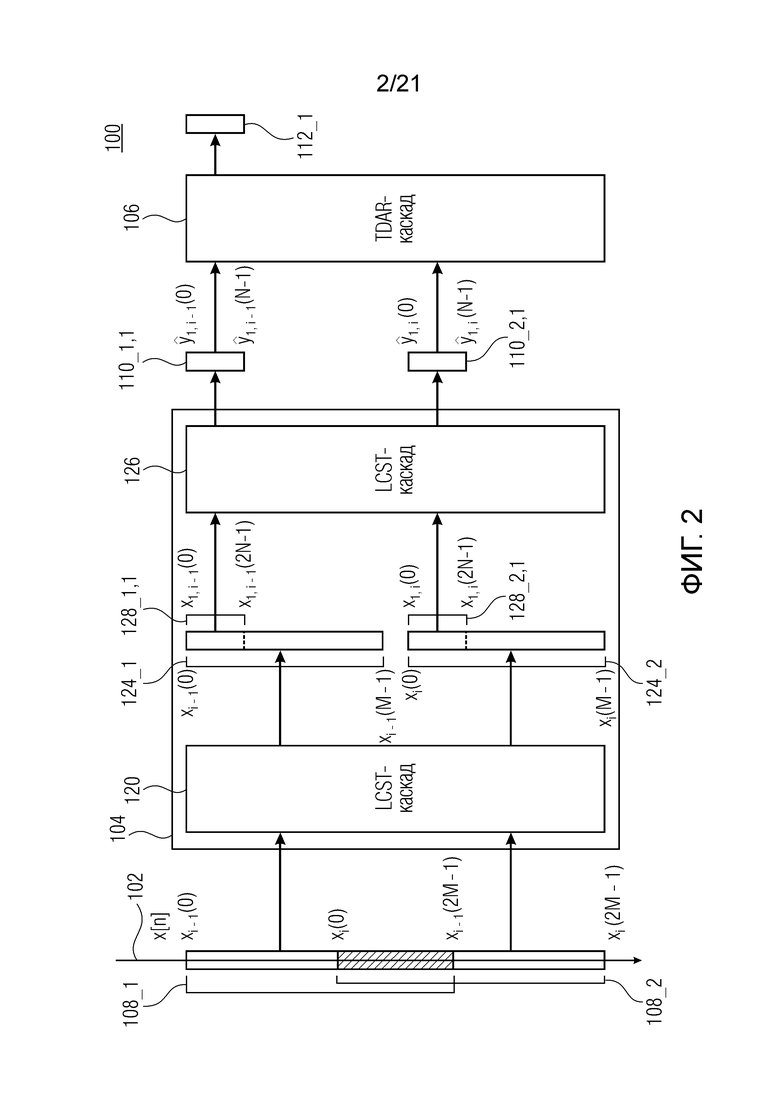
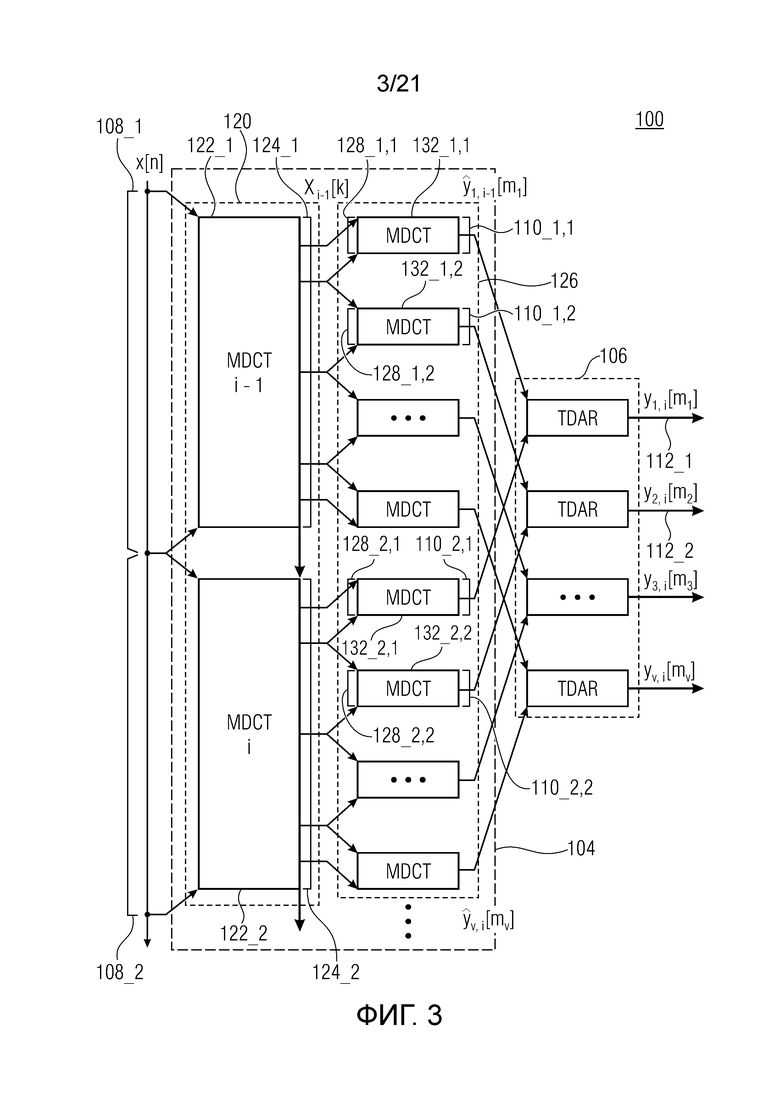
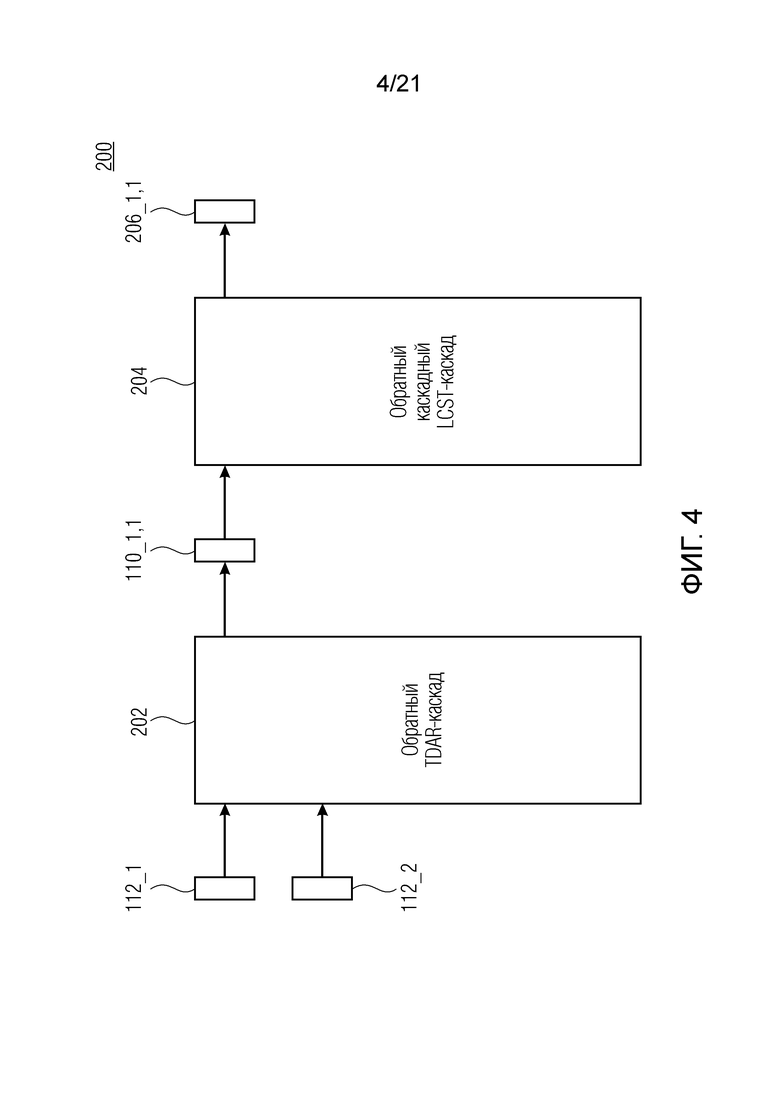
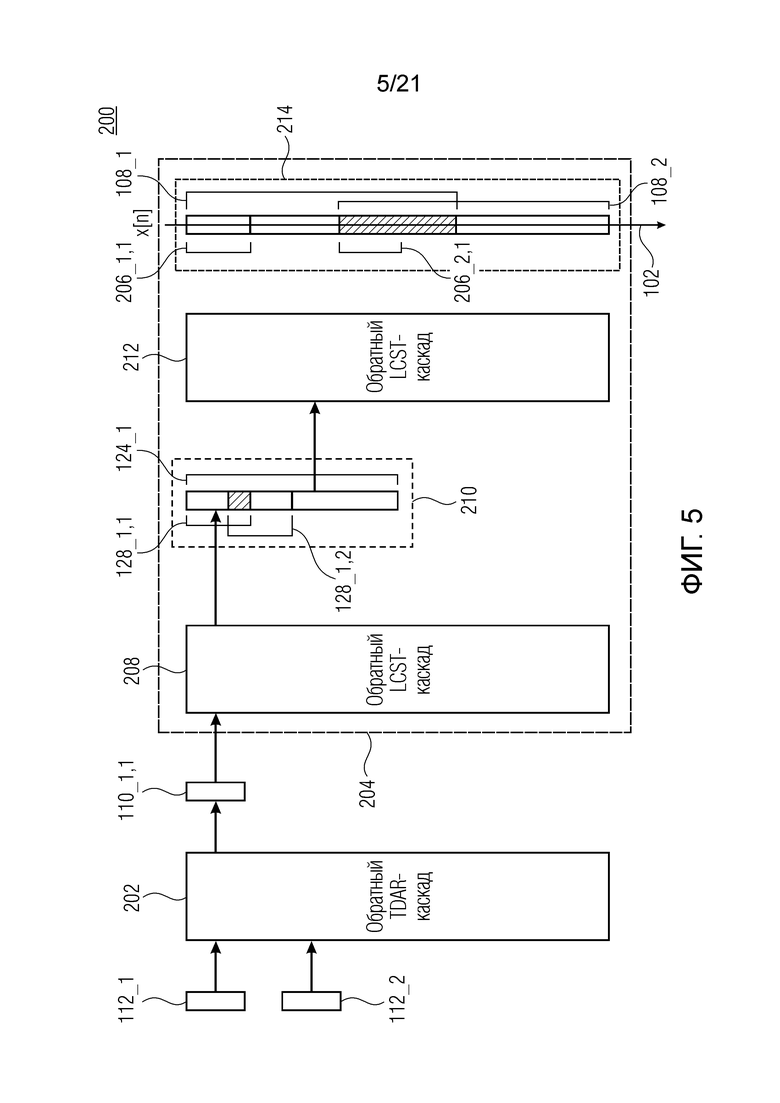
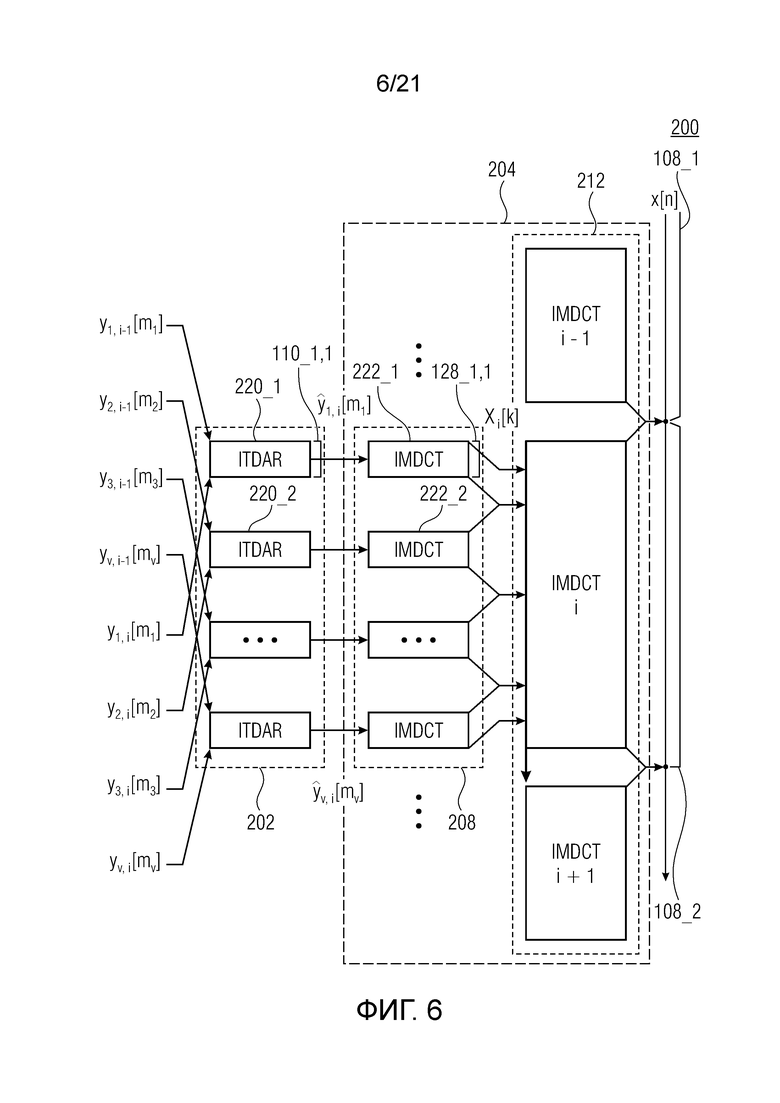
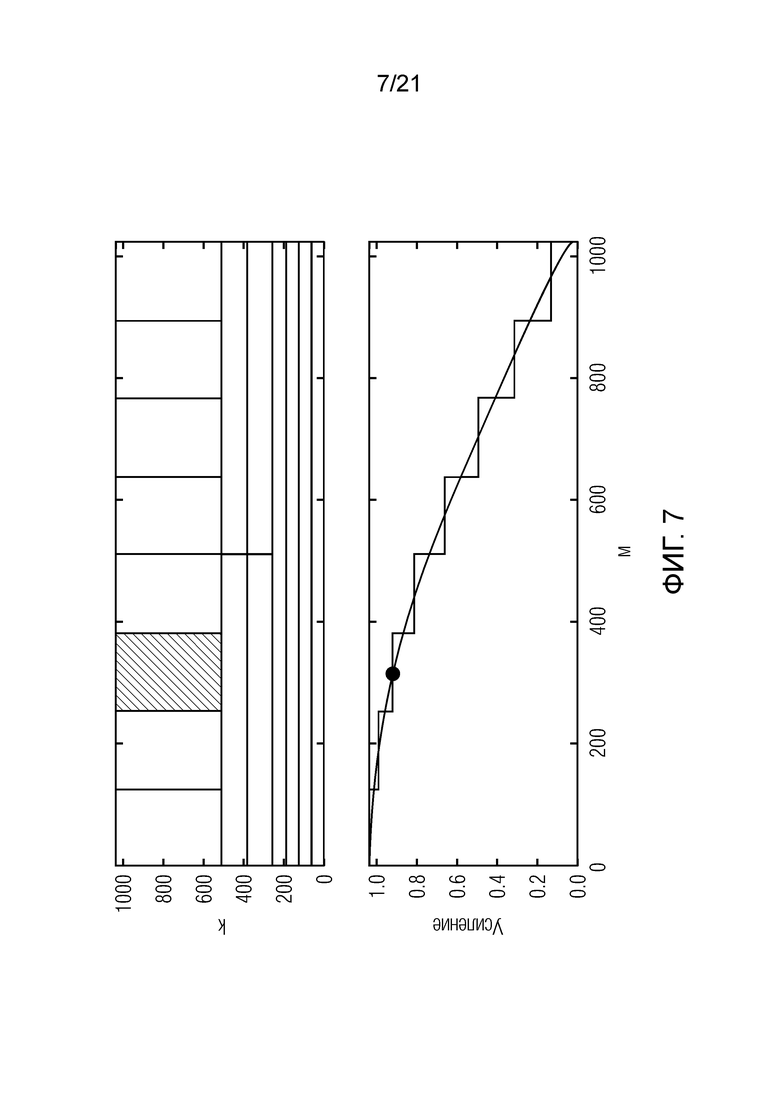
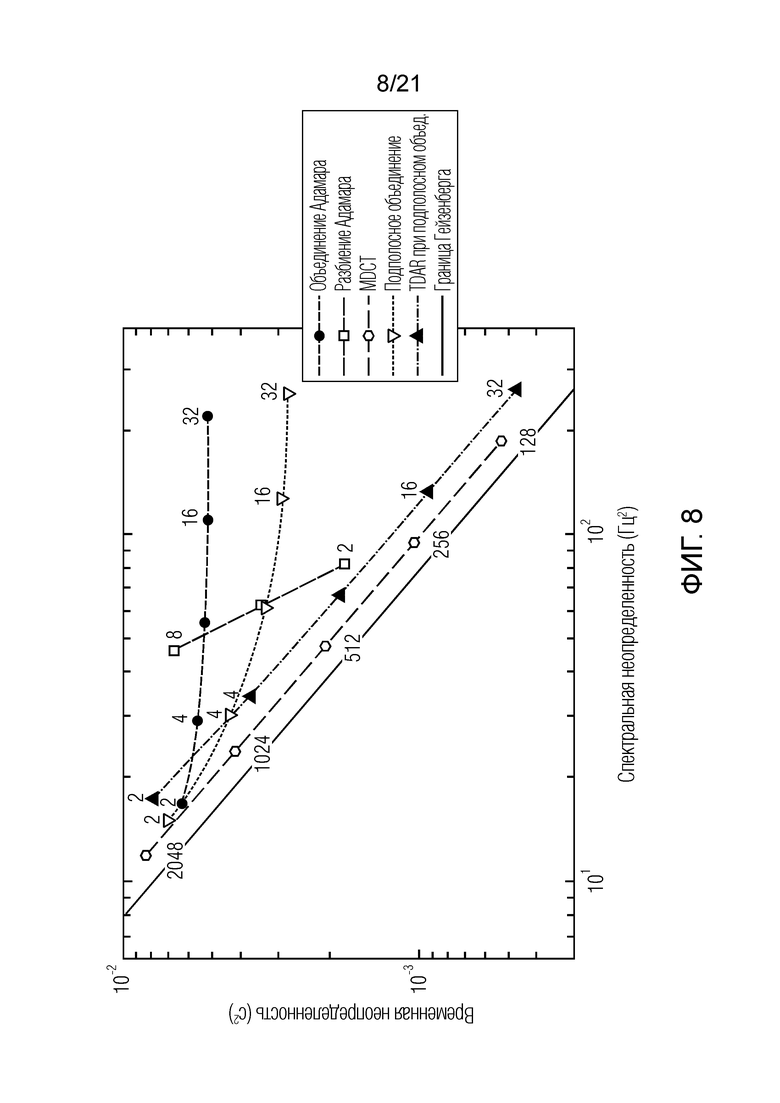
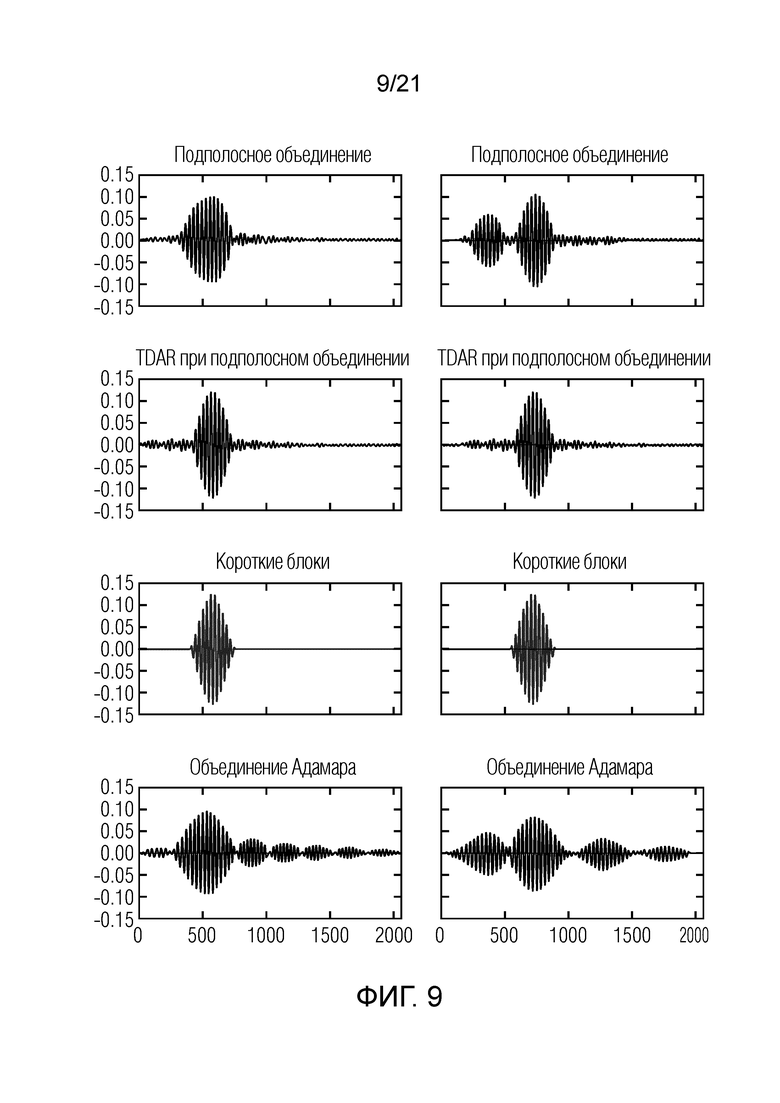
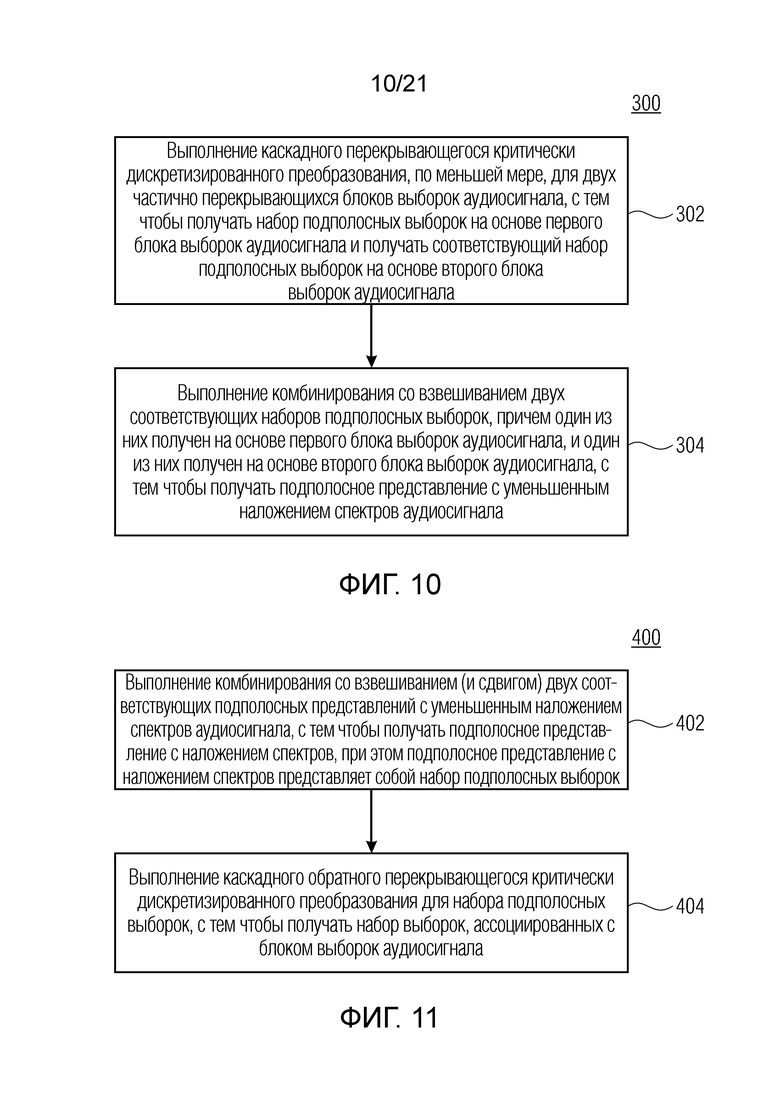
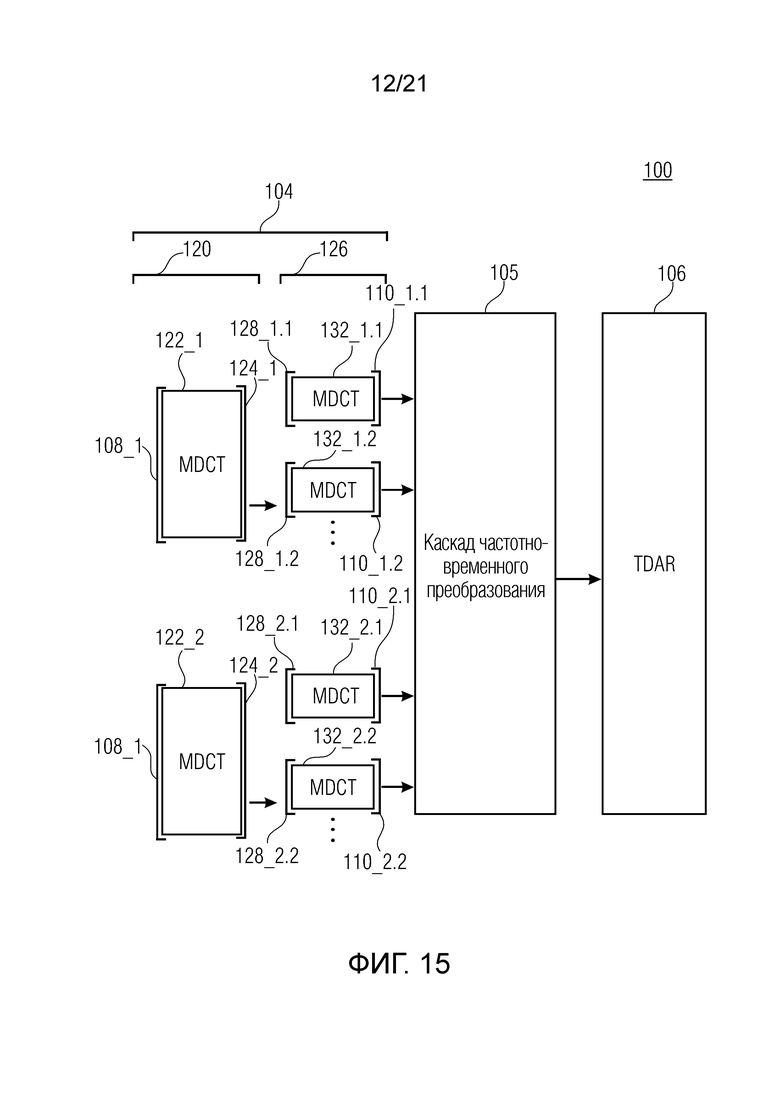
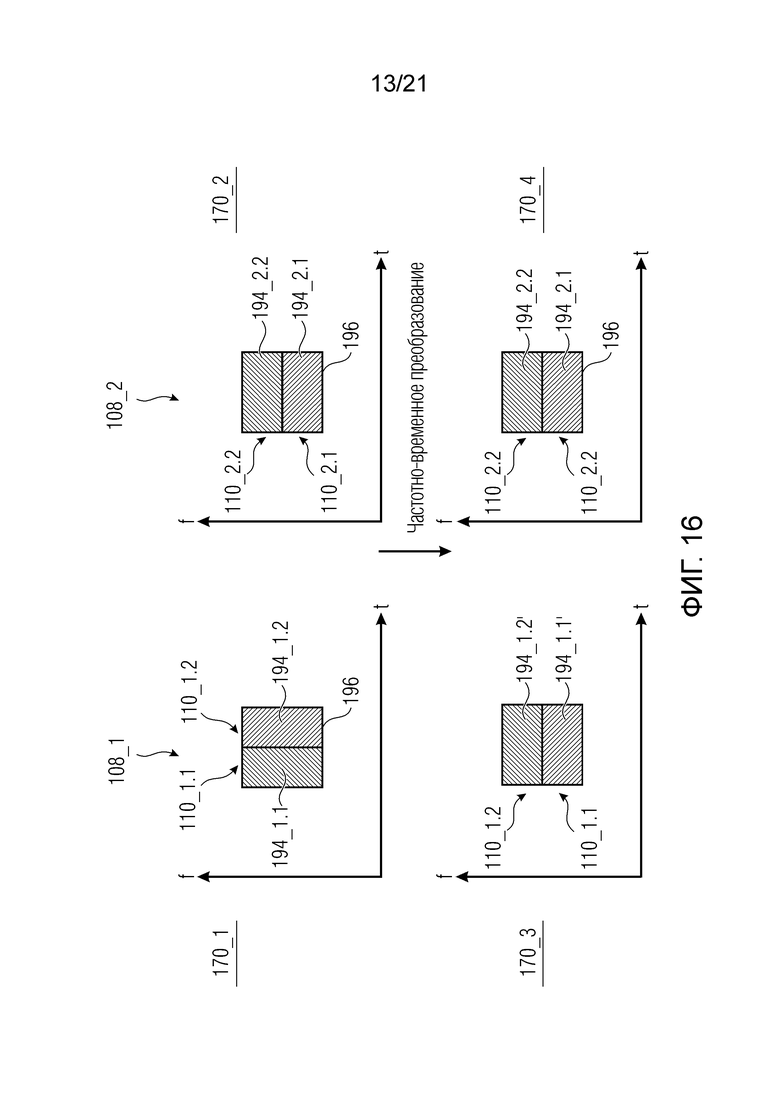
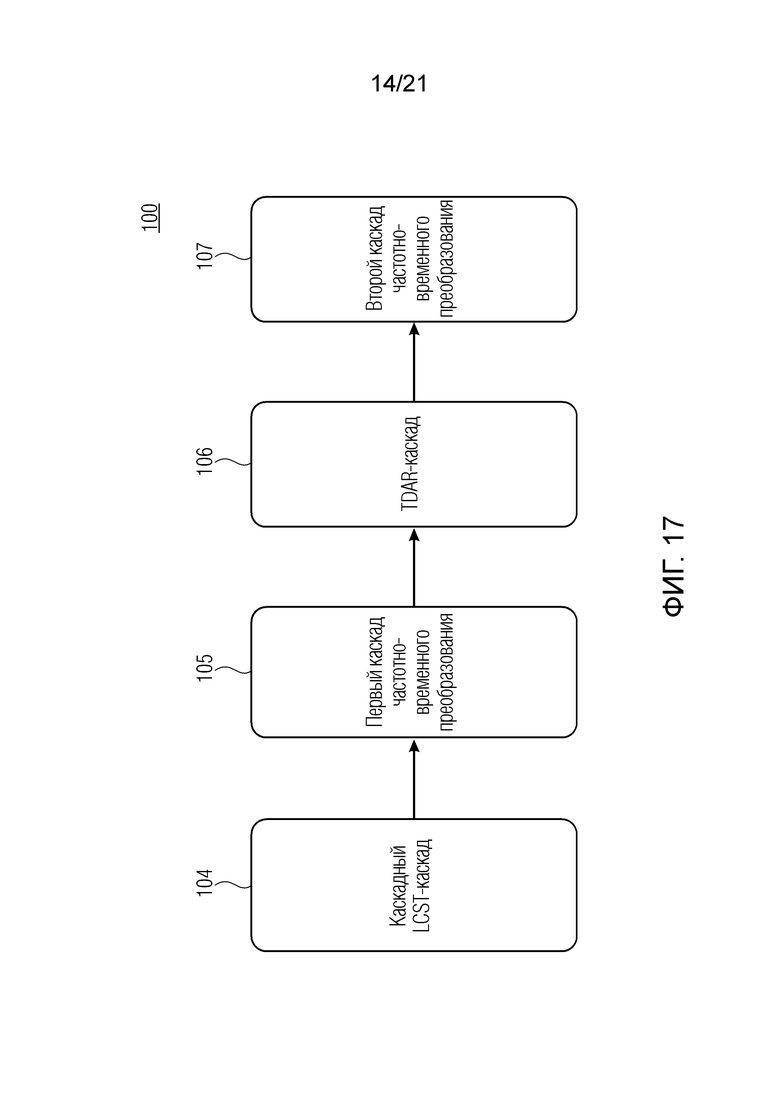
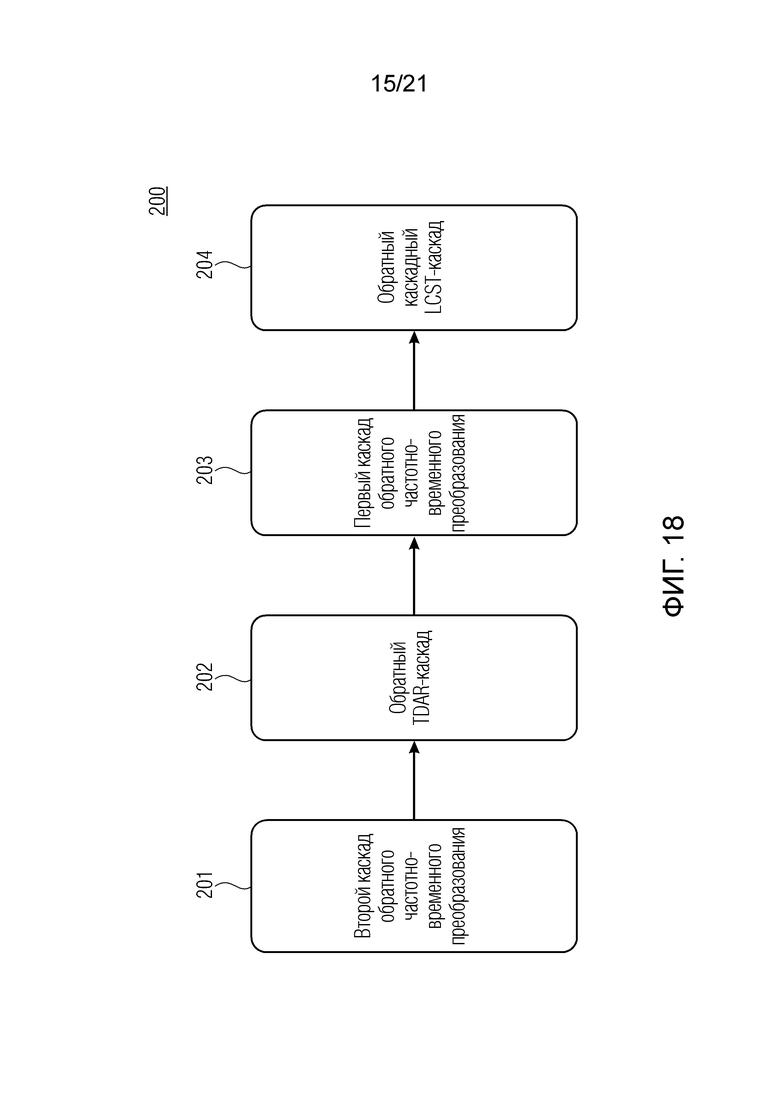
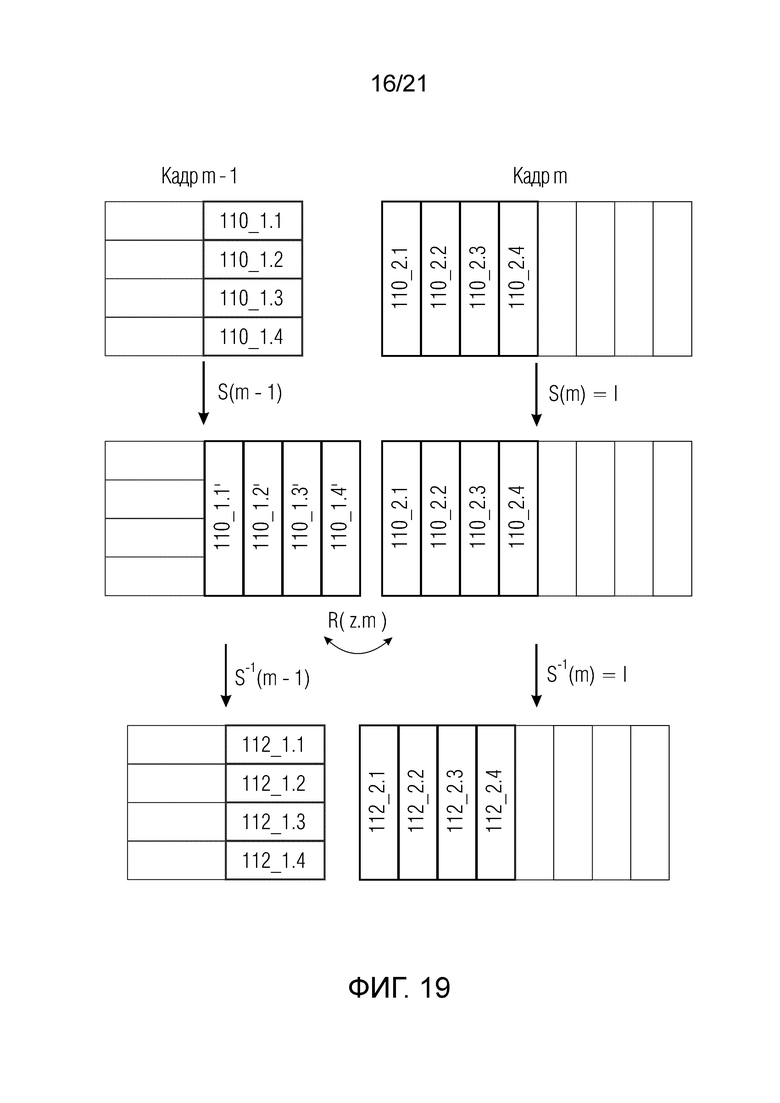
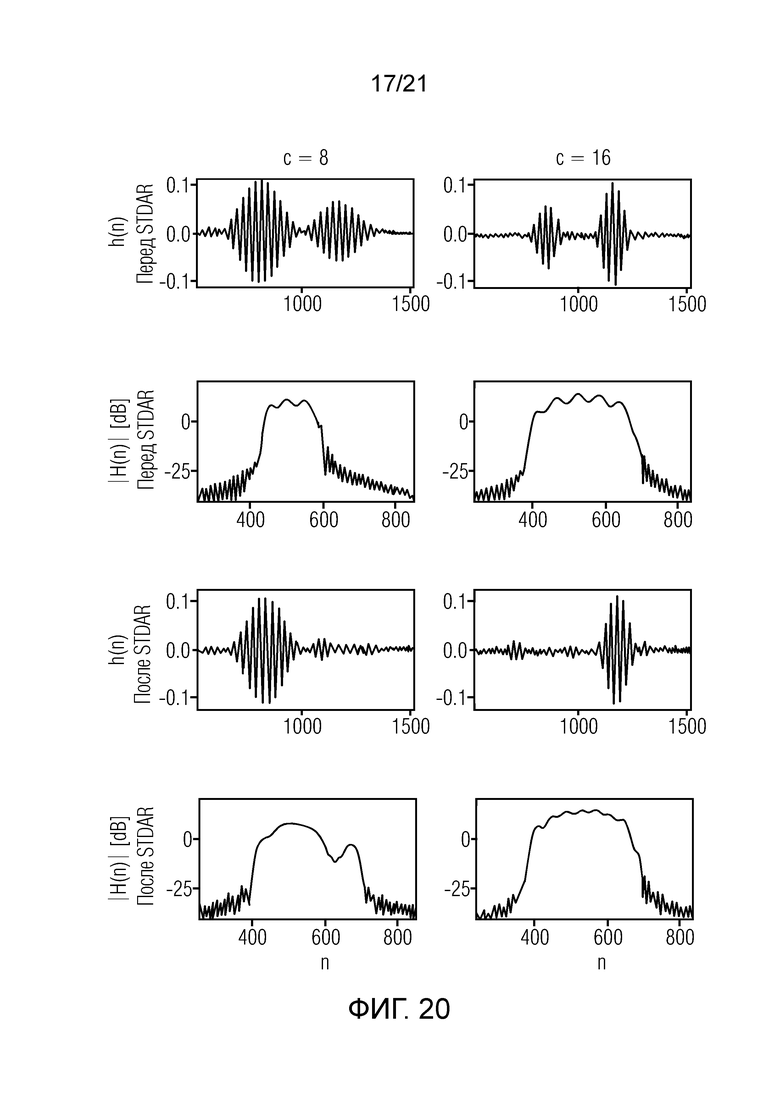
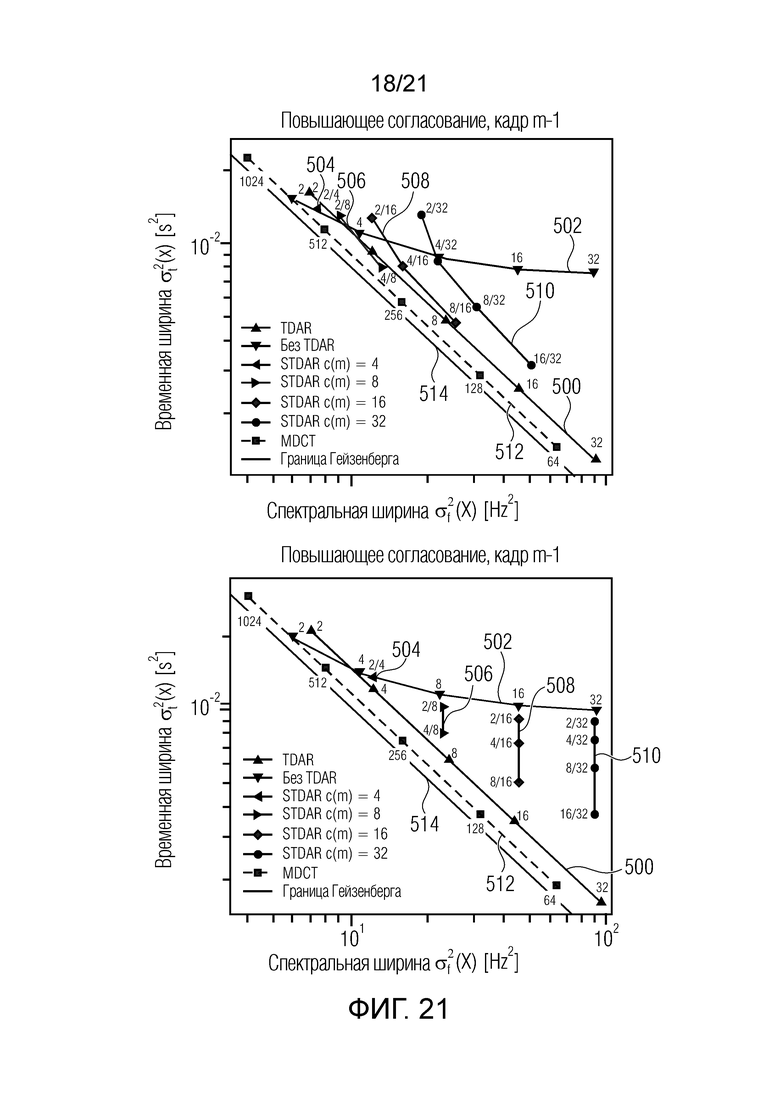
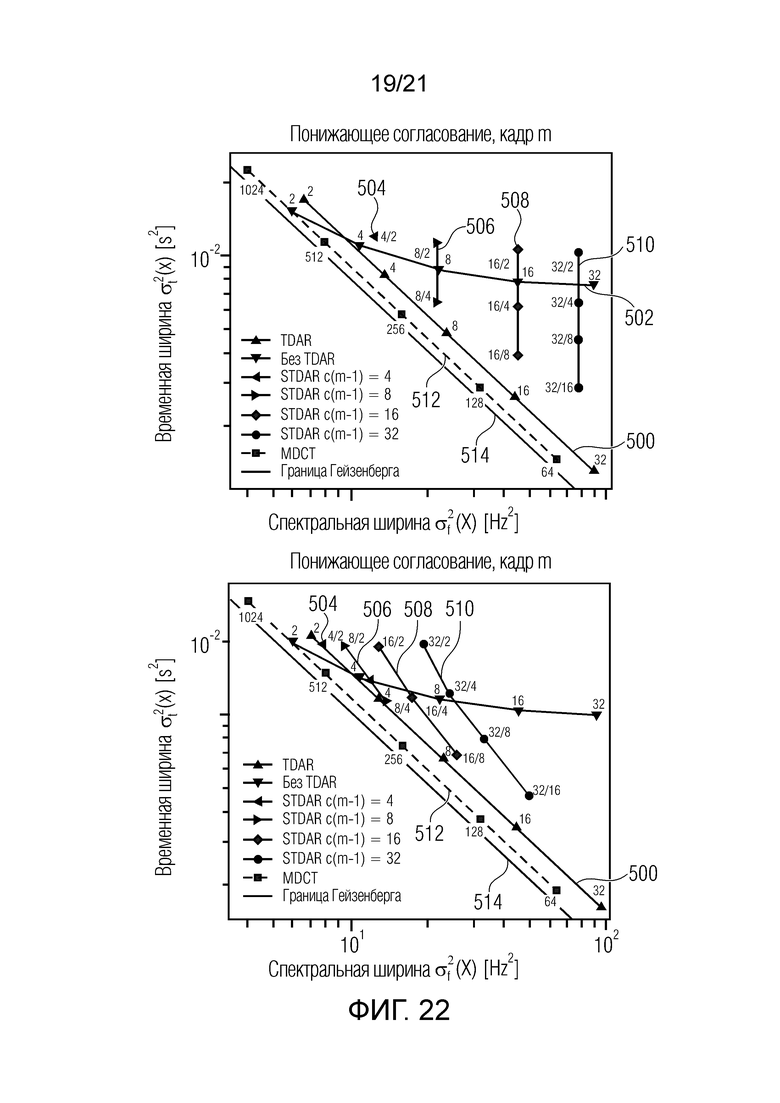
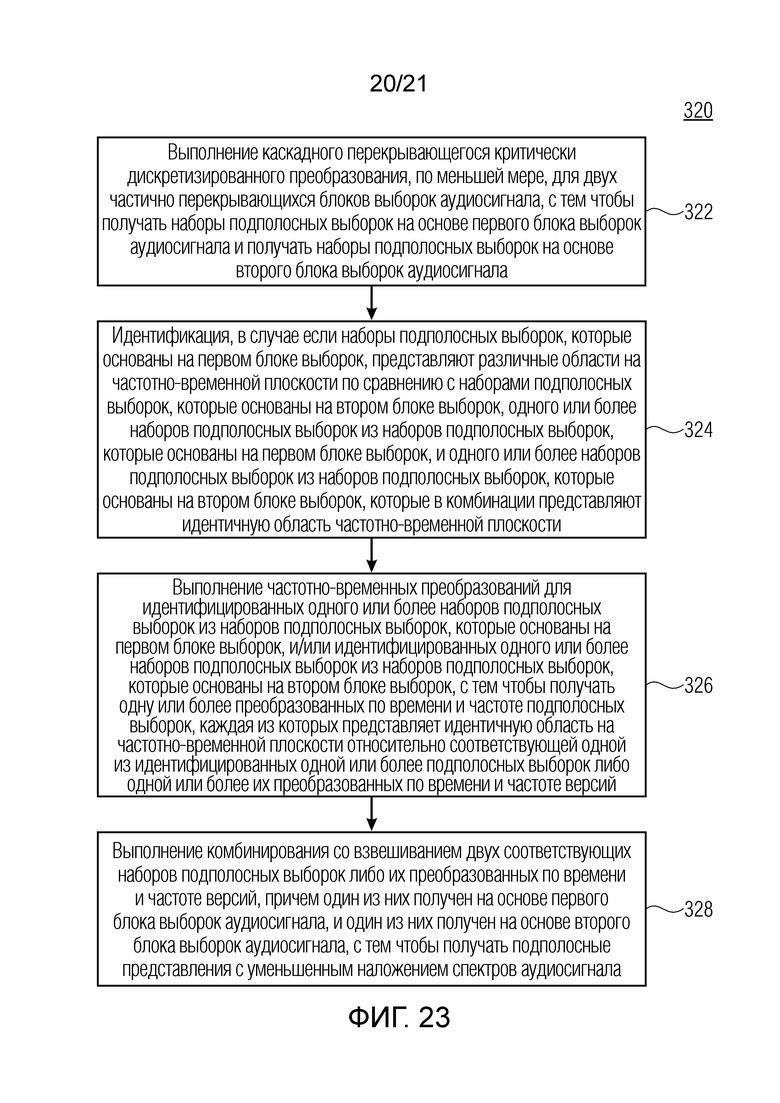
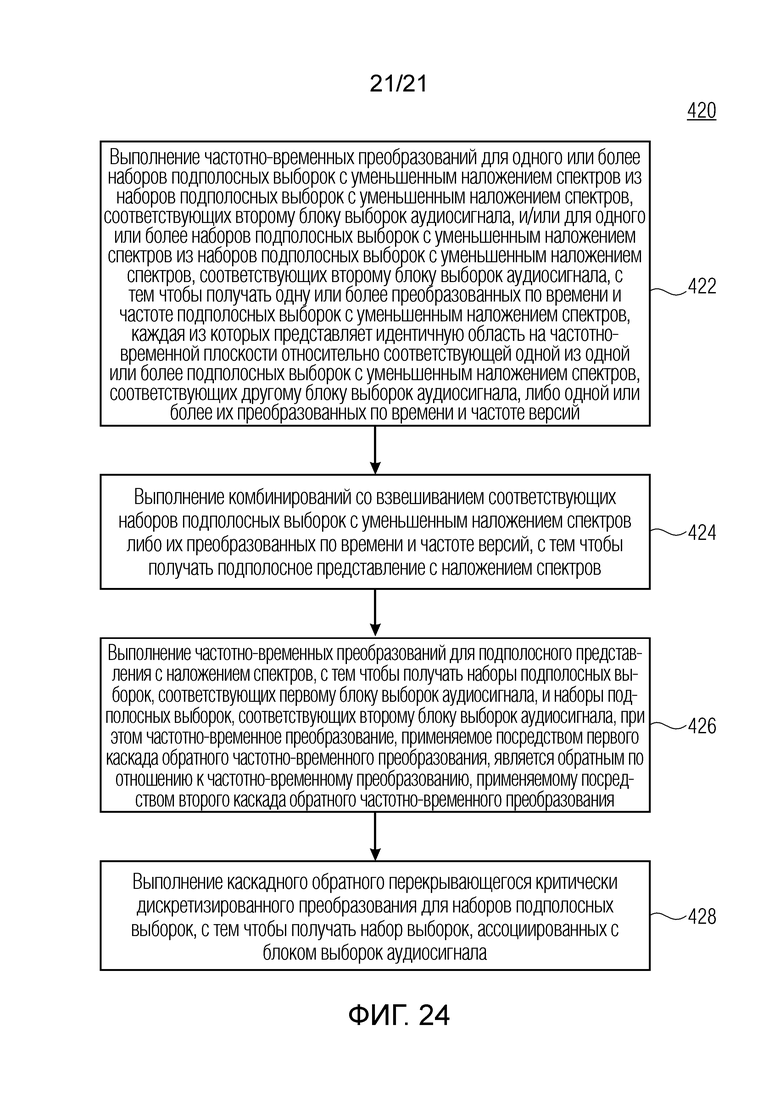
Изобретение относится к области вычислительной техники для обработки аудиоданных. Технический результат заключается в обеспечении компактности импульсного отклика неравномерной гребенки фильтров, даже когда характеристики входных сигналов изменяются. Технический результат достигается за счет выполнения каскадного перекрывающегося критически дискретизированного преобразования, по меньшей мере, для двух частично перекрывающихся блоков выборок аудиосигнала, с тем чтобы получать наборы подполосных выборок на основе первого блока выборок аудиосигнала и получать наборы подполосных выборок на основе второго блока выборок аудиосигнала; идентификации, в случае если наборы подполосных выборок, которые основаны на первом блоке выборок, представляют различные области на частотно-временной плоскости по сравнению с наборами подполосных выборок, которые основаны на втором блоке выборок, одного или более наборов подполосных выборок из наборов подполосных выборок, которые основаны на первом блоке выборок, и одного или более наборов подполосных выборок из наборов подполосных выборок, которые основаны на втором блоке выборок, которые в комбинации представляют идентичную область частотно-временной плоскости. 5 н. и 12 з.п. ф-лы, 24 ил. 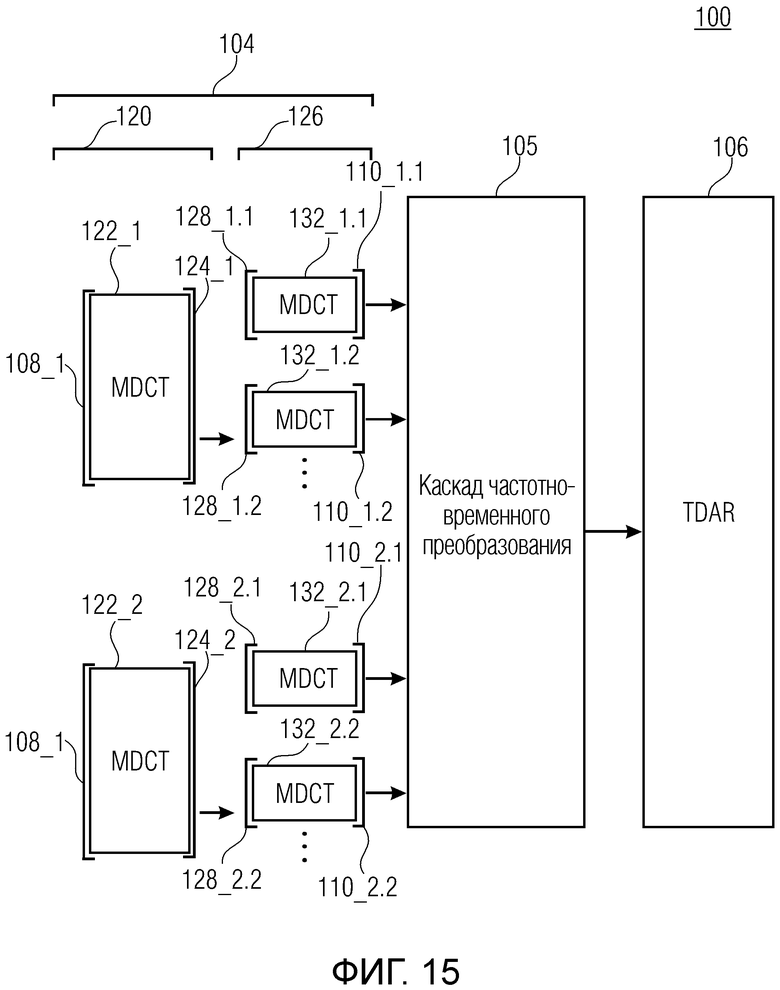
1. Аудиопроцессор (100) для обработки аудиосигнала (102), с тем чтобы получать подполосное представление аудиосигнала (102), причем аудиопроцессор (100) содержит:
каскад (104) каскадного перекрывающегося критически дискретизированного преобразования, выполненный с возможностью выполнять каскадное перекрывающееся критически дискретизированное преобразование в отношении по меньшей мере двух частично перекрывающихся блоков (108_1; 108_2) дискретных отсчетов аудиосигнала (102), с тем чтобы получать наборы (110_1,1; 110_1,2) подполосных дискретных отсчетов на основе первого блока (108_1) дискретных отсчетов аудиосигнала (102) и получать наборы (110_2,1; 110_2,2) подполосных дискретных отсчетов на основе второго блока (108_2) дискретных отсчетов аудиосигнала (102);
первый каскад (105) частотно-временного преобразования, выполненный с возможностью идентифицировать, в случае если наборы (110_1,1; 110_1,2) подполосных дискретных отсчетов, которые основываются на первом блоке (108_1) дискретных отсчетов, представляют отличающиеся области на частотно-временной плоскости по сравнению с наборами (110_2,1; 110_2,2) подполосных дискретных отсчетов, которые основываются на втором блоке (108_2) дискретных отсчетов, один или более наборов подполосных дискретных отсчетов из наборов (110_1,1; 110_1,2) подполосных дискретных отсчетов, которые основываются на первом блоке (108_1) дискретных отсчетов, и один или более наборов подполосных дискретных отсчетов из наборов (110_2,1; 110_2,2) подполосных дискретных отсчетов, которые основываются на втором блоке (108_2) дискретных отсчетов, которые в комбинации представляют одну и ту же область на частотно-временной плоскости, и выполнять частотно-временное преобразование идентифицированных одного или более наборов подполосных дискретных отсчетов из наборов (110_2,1; 110_2,2) подполосных дискретных отсчетов, которые основываются на первом блоке (108_1) дискретных отсчетов, и/или идентифицированных одного или более наборов подполосных дискретных отсчетов из наборов (110_2,1; 110_2,2) подполосных дискретных отсчетов, которые основываются на втором блоке (108_2) дискретных отсчетов, с тем чтобы получать один или более преобразованных по времени и частоте подполосных дискретных отсчетов, каждый из которых представляет ту же самую область на частотно-временной плоскости относительно соответствующего одного из идентифицированных одного или более подполосных дискретных отсчетов либо одной или более их преобразованных по времени и частоте версий; и
каскад (106) уменьшения наложения спектров во временной области, выполненный с возможностью выполнять комбинирование со взвешиванием двух соответствующих наборов подполосных дискретных отсчетов либо их преобразованных по времени и частоте версий, причем один из них получен на основе первого блока (108_1) дискретных отсчетов аудиосигнала (102) и один из них получен на основе второго блока (108_2) дискретных отсчетов аудиосигнала, с тем чтобы получать подполосные представления (112_1-112_2) с уменьшенным наложением спектров аудиосигнала (102).
2. Аудиопроцессор (100) по предшествующему пункту, в котором частотно-временное преобразование, выполняемое посредством первого каскада частотно-временного преобразования, представляет собой перекрывающееся критически дискретизированное преобразование.
3. Аудиопроцессор (100) по одному из предшествующих пунктов, в котором частотно-временное преобразование идентифицированных одного или более наборов подполосных дискретных отсчетов из наборов (110_2,1; 110_2,2) подполосных дискретных отсчетов, которые основываются на втором блоке (108_2) дискретных отсчетов, и/или идентифицированных одного или более наборов подполосных дискретных отсчетов из наборов (110_2,1; 110_2,2) подполосных дискретных отсчетов, которые основываются на втором блоке (108_2) дискретных отсчетов, выполняемое посредством каскада частотно-временного преобразования, соответствует преобразованию, описанному посредством следующей формулы:
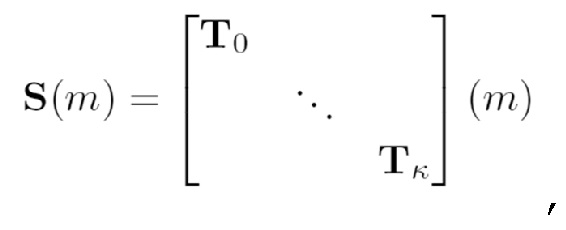
где S(m) описывает преобразование, m описывает индекс блока дискретных отсчетов аудиосигнала, T0…Tk описывают подполосные дискретные отсчеты соответствующих идентифицированных одного или более наборов подполосных дискретных отсчетов.
4. Аудиопроцессор (100) по одному из предшествующих пунктов,
в котором каскад (104) каскадного перекрывающегося критически дискретизированного преобразования выполнен с возможностью обрабатывать первый набор (124_1) интервальных элементов, полученных на основе первого блока (108_1) дискретных отсчетов аудиосигнала, и второй набор (124_2) интервальных элементов, полученных на основе второго блока (124_2) дискретных отсчетов аудиосигнала, с использованием второго каскада (126) перекрывающегося критически дискретизированного преобразования каскада (104) каскадного перекрывающегося критически дискретизированного преобразования,
при этом второй каскад (126) перекрывающегося критически дискретизированного преобразования выполнен с возможностью выполнять, в зависимости от характеристик сигнала у аудиосигнала, первые перекрывающиеся критически дискретизированные преобразования в отношении первого набора (124_1) интервальных элементов, с тем чтобы получать наборы (110_1,1; 110_1,2) подполосных дискретных отсчетов, которые основываются на первом блоке (108_1) дискретных отсчетов, и вторые перекрывающиеся критически дискретизированные преобразования в отношении второго набора (124_2) интервальных элементов, с тем чтобы получать наборы (110_2,1; 110_2,2) подполосных дискретных отсчетов, которые основываются на втором блоке (108_2) дискретных отсчетов, причем одно или более первых критически дискретизированных преобразований имеют отличающиеся длины по сравнению со вторыми критически дискретизированными преобразованиями.
5. Аудиопроцессор (100) по предшествующему пункту, в котором первый каскад частотно-временного преобразования выполнен с возможностью идентифицировать, в случае если одно или более первых критически дискретизированных преобразований имеют отличающиеся длины по сравнению со вторыми критически дискретизированными преобразованиями, один или более наборов подполосных дискретных отсчетов из наборов (110_1,1; 110_1,2) подполосных дискретных отсчетов, которые основываются на первом блоке (108_1) дискретных отсчетов, и один или более наборов подполосных дискретных отсчетов из наборов (110_2,1; 110_2,2) подполосных дискретных отсчетов, которые основываются на втором блоке (108_2) дискретных отсчетов, которые представляют одну и ту же область на частотно-временной плоскости аудиосигнала.
6. Аудиопроцессор (100) по одному из предшествующих пунктов,
при этом аудиопроцессор (100) содержит второй каскад частотно-временного преобразования, выполненный с возможностью выполнять частотно-временное преобразование подполосного представления (112_1) с уменьшенным наложением спектров аудиосигнала (102),
при этом частотно-временное преобразование, применяемое посредством второго каскада частотно-временного преобразования, является обратным по отношению к частотно-временному преобразованию, применяемому посредством первого каскада частотно-временного преобразования.
7. Аудиопроцессор (100) по одному из предшествующих пунктов, в котором уменьшение наложения спектров во временной области, выполняемое посредством каскада уменьшения наложения спектров во временной области, соответствует преобразованию, описанному следующей формулой:
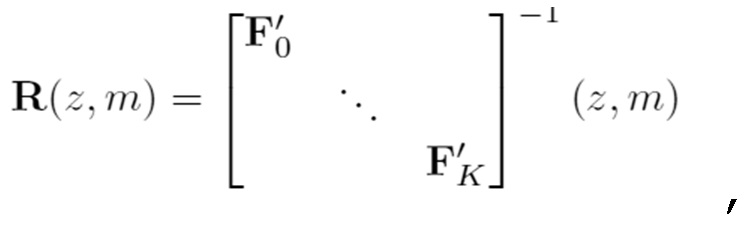
где R(z, m) описывает преобразование, z описывает индекс кадра в z-области, m описывает индекс блока дискретных отсчетов аудиосигнала, F'0…F'k описывают модифицированные версии предварительных перестановочных/свертывающихся матриц на основе перекрывающегося критически дискретизированного преобразования NxN.
8. Аудиопроцессор (100) по одному из предшествующих пунктов,
при этом аудиопроцессор (100) выполнен с возможностью предоставлять поток битов, содержащий параметр STDAR, указывающий то, используется ли длина идентифицированных одного или более наборов подполосных дискретных отсчетов, соответствующих первому блоку дискретных отсчетов или второму блоку дискретных отсчетов, в каскаде уменьшения наложения спектров во временной области для получения соответствующего подполосного представления (112_1) с уменьшенным наложением спектров аудиосигнала (102),
или при этом аудиопроцессор (100) выполнен с возможностью предоставлять поток битов, содержащий параметры длины MDCT, указывающие длины наборов (110_1,1; 110_1,2; 110_2,1; 110_2,2) подполосных дискретных отсчетов.
9. Аудиопроцессор (100) по одному из предшествующих пунктов, при этом аудиопроцессор (100) выполнен с возможностью выполнять объединенное канальное кодирование.
10. Аудиопроцессор (100) по предшествующему пункту, при этом аудиопроцессор (100) выполнен с возможностью выполнять M/S или MCT в качестве объединенной обработки каналов.
11. Аудиопроцессор (100) по одному из предшествующих пунктов, при этом аудиопроцессор (100) выполнен с возможностью предоставлять поток битов, содержащий по меньшей мере один параметр STDAR, указывающий длину одного или более преобразованных по времени и частоте подполосных дискретных отсчетов, соответствующих первому блоку дискретных отсчетов, и одного или более преобразованных по времени и частоте подполосных дискретных отсчетов, соответствующих второму блоку дискретных отсчетов, используемых в каскаде уменьшения наложения спектров во временной области для получения соответствующего подполосного представления (112_1) с уменьшенным наложением спектров аудиосигнала (102) либо его кодированной версии.
12. Аудиопроцессор (100) по одному из предшествующих пунктов, в котором каскад (104) каскадного перекрывающегося критически дискретизированного преобразования содержит первый каскад (120) перекрывающегося критически дискретизированного преобразования, выполненный с возможностью выполнять перекрывающиеся критически дискретизированные преобразования в отношении первого блока (108_1) дискретных отсчетов и второго блока (108_2) дискретных отсчетов из упомянутых по меньшей мере двух частично перекрывающихся блоков (108_1; 108_2) дискретных отсчетов аудиосигнала (102), с тем чтобы получать первый набор (124_1) интервальных элементов для первого блока (108_1) дискретных отсчетов и второй набор (124_2) интервальных элементов для второго блока (108_2) дискретных отсчетов.
13. Аудиопроцессор (100) по предшествующему пункту, в котором каскад (104) каскадного перекрывающегося критически дискретизированного преобразования дополнительно содержит второй каскад (126) перекрывающегося критически дискретизированного преобразования, выполненный с возможностью выполнять перекрывающееся критически дискретизированное преобразование в отношении сегмента (128_1,1) первого набора (124_1) интервальных элементов и выполнять перекрывающееся критически дискретизированное преобразование в отношении сегмента (128_2,1) второго набора (124_2) интервальных элементов, причем каждый сегмент ассоциирован с подполосой частот аудиосигнала (102), с тем чтобы получать набор (110_1,1) подполосных дискретных отсчетов для первого набора интервальных элементов и набор (110_2,1) подполосных дискретных отсчетов для второго набора интервальных элементов.
14. Аудиопроцессор (200) для обработки подполосного представления аудиосигнала, чтобы получать аудиосигнал (102), причем подполосное представление аудиосигнала содержит наборы подполосных дискретных отсчетов с уменьшенным наложением спектров, при этом аудиопроцессор (200) содержит:
второй каскад обратного частотно-временного преобразования, выполненный с возможностью выполнять частотно-временное преобразование одного или более наборов подполосных дискретных отсчетов с уменьшенным наложением спектров из наборов подполосных дискретных отсчетов с уменьшенным наложением спектров, соответствующих первому блоку дискретных отсчетов аудиосигнала, и/или одного или более наборов подполосных дискретных отсчетов с уменьшенным наложением спектров из наборов подполосных дискретных отсчетов с уменьшенным наложением спектров, соответствующих второму блоку дискретных отсчетов аудиосигнала, с тем чтобы получать один или более преобразованных по времени и частоте подполосных дискретных отсчетов с уменьшенным наложением спектров, каждый из которых представляет ту же самую область на частотно-временной плоскости относительно соответствующего одного из одного или более подполосных дискретных отсчетов с уменьшенным наложением спектров, соответствующих другому блоку дискретных отсчетов из первого блока дискретных отсчетов и второго блока дискретных отсчетов аудиосигнала, либо одной или более из их преобразованных по времени и частоте версий,
каскад (202) обратного уменьшения наложения спектров во временной области, выполненный с возможностью выполнять комбинирования со взвешиванием соответствующих наборов подполосных дискретных отсчетов с уменьшенным наложением спектров либо их преобразованных по времени и частоте версий, с тем чтобы получать подполосное представление с наложением спектров,
первый каскад обратного частотно-временного преобразования, выполненный с возможностью выполнять частотно-временное преобразование подполосного представления с наложением спектров, с тем чтобы получать наборы (110_1,1; 110_1,2) подполосных дискретных отсчетов, соответствующих первому блоку (108_1) дискретных отсчетов аудиосигнала, и наборы (110_2,1; 110_2,2) подполосных дискретных отсчетов, соответствующих второму блоку (108_1) дискретных отсчетов аудиосигнала, при этом частотно-временное преобразование, применяемое посредством первого каскада обратного частотно-временного преобразования, является обратным по отношению к частотно-временному преобразованию, применяемому посредством второго каскада обратного частотно-временного преобразования,
каскад (204) каскадного обратного перекрывающегося критически дискретизированного преобразования, выполненный с возможностью выполнять каскадное обратное перекрывающееся критически дискретизированное преобразование в отношении наборов (110_1,1; 110_2; 110_2,1; 110_2,2) дискретных отсчетов, с тем чтобы получать набор (206_1,1) дискретных отсчетов, ассоциированных с блоком дискретных отсчетов аудиосигнала (102).
15. Способ (320) обработки аудиосигнала для получения подполосного представления аудиосигнала, при этом способ содержит этапы, на которых:
выполняют (322) каскадное перекрывающееся критически дискретизированное преобразование в отношении по меньшей мере двух частично перекрывающихся блоков (108_1; 108_2) дискретных отсчетов аудиосигнала (102), с тем чтобы получать наборы (110_1,1; 110_1,2) подполосных дискретных отсчетов на основе первого блока (108_1) дискретных отсчетов аудиосигнала (102) и получать наборы (110_2,1; 110_2,2) подполосных дискретных отсчетов на основе второго блока (108_2) дискретных отсчетов аудиосигнала (102);
идентифицируют (324), в случае если наборы (110_1,1; 110_1,2) подполосных дискретных отсчетов, которые основываются на первом блоке (108_1) дискретных отсчетов, представляют отличающиеся области на частотно-временной плоскости по сравнению с наборами (110_2,1; 110_2,2) подполосных дискретных отсчетов, которые основываются на втором блоке (108_2) дискретных отсчетов, один или более наборов подполосных дискретных отсчетов из наборов (110_1,1; 110_1,2) подполосных дискретных отсчетов, которые основываются на первом блоке (108_1) дискретных отсчетов, и один или более наборов подполосных дискретных отсчетов из наборов (110_2,1; 110_2,2) подполосных дискретных отсчетов, которые основываются на втором блоке (108_2) дискретных отсчетов, которые в комбинации представляют одну и ту же область частотно-временной плоскости,
выполняют (326) частотно-временные преобразования в отношении идентифицированных одного или более наборов подполосных дискретных отсчетов из наборов (110_2,1; 110_2,2) подполосных дискретных отсчетов, которые основываются на первом блоке (108_1) дискретных отсчетов, и/или идентифицированных одного или более наборов подполосных дискретных отсчетов из наборов (110_2,1; 110_2,2) подполосных дискретных отсчетов, которые основываются на втором блоке (108_2) дискретных отсчетов, с тем чтобы получать один или более преобразованных по времени и частоте подполосных дискретных отсчетов, каждый из которых представляет ту же самую область на частотно-временной плоскости относительно соответствующего одного из идентифицированных одного или более подполосных дискретных отсчетов либо одной или более их преобразованных по времени и частоте версий; и
выполняют (328) комбинирование со взвешиванием двух соответствующих наборов подполосных дискретных отсчетов либо их преобразованных по времени и частоте версий, причем один из них получен на основе первого блока (108_1) дискретных отсчетов аудиосигнала (102), и один из них получен на основе второго блока (108_2) дискретных отсчетов аудиосигнала, с тем чтобы получать подполосные представления (112_1; 112_2) с уменьшенным наложением спектров аудиосигнала (102).
16. Способ (420) обработки подполосного представления аудиосигнала для получения аудиосигнала, причем подполосное представление аудиосигнала содержит наборы подполосных дискретных отсчетов с уменьшенным наложением спектров, при этом способ содержит этапы, на которых:
выполняют (422) частотно-временные преобразования в отношении одного или более наборов подполосных дискретных отсчетов с уменьшенным наложением спектров из наборов подполосных дискретных отсчетов с уменьшенным наложением спектров, соответствующих первому блоку дискретных отсчетов аудиосигнала, и/или одного или более наборов подполосных дискретных отсчетов с уменьшенным наложением спектров из наборов подполосных дискретных отсчетов с уменьшенным наложением спектров, соответствующих второму блоку дискретных отсчетов аудиосигнала, с тем чтобы получать один или более преобразованных по времени и частоте подполосных дискретных отсчетов с уменьшенным наложением спектров, каждый из которых представляет ту же самую область на частотно-временной плоскости относительно соответствующего одного из одного или более подполосных дискретных отсчетов с уменьшенным наложением спектров, соответствующих другому блоку дискретных отсчетов из первого блока дискретных отсчетов и второго блока дискретных отсчетов аудиосигнала, либо одной или более из их преобразованных по времени и частоте версий,
выполняют (424) комбинирования со взвешиванием соответствующих наборов подполосных дискретных отсчетов с уменьшенным наложением спектров либо их преобразованных по времени и частоте версий, с тем чтобы получать подполосное представление с наложением спектров,
выполняют (426) частотно-временные преобразования в отношении подполосного представления с наложением спектров, с тем чтобы получать наборы (110_1,1; 110_1,2) подполосных дискретных отсчетов, соответствующих первому блоку (108_1) дискретных отсчетов аудиосигнала, и наборы (110_2,1; 110_2,2) подполосных дискретных отсчетов, соответствующих второму блоку (108_1) дискретных отсчетов аудиосигнала, при этом частотно-временные преобразования, выполняемые в отношении одного или более наборов подполосных дискретных отсчетов с уменьшенным наложением спектров из наборов подполосных дискретных отсчетов с уменьшенным наложением спектров, соответствующих первому блоку дискретных отсчетов аудиосигнала, или одного или более наборов подполосных дискретных отсчетов с уменьшенным наложением спектров из наборов подполосных дискретных отсчетов с уменьшенным наложением спектров, соответствующих второму блоку дискретных отсчетов аудиосигнала, являются обратными по отношению к частотно-временным преобразованиям, выполняемым в отношении подполосного представления с наложением спектров,
выполняют (428) каскадное обратное перекрывающееся критически дискретизированное преобразование в отношении наборов (110_1,1; 110_2; 110_2,1; 110_2,2) дискретных отсчетов, с тем чтобы получать набор (206_1,1) дискретных отсчетов, ассоциированных с блоком дискретных отсчетов аудиосигнала (102).
17. Машиночитаемый носитель данных, на котором сохранен код компьютерной программы, который при его исполнении в компьютере обеспечивает осуществление компьютером способа по одному из пп.15 и 16.
| Станок для изготовления деревянных ниточных катушек из цилиндрических, снабженных осевым отверстием, заготовок | 1923 |
|
SU2008A1 |
| Многоступенчатая активно-реактивная турбина | 1924 |
|
SU2013A1 |
| Способ обработки целлюлозных материалов, с целью тонкого измельчения или переведения в коллоидальный раствор | 1923 |
|
SU2005A1 |
| Приспособление для суммирования отрезков прямых линий | 1923 |
|
SU2010A1 |
| АУДИОПРОЦЕССОР И СПОСОБ ДЛЯ ОБРАБОТКИ АУДИОСИГНАЛА С ИСПОЛЬЗОВАНИЕМ ГОРИЗОНТАЛЬНОЙ ФАЗОВОЙ КОРРЕКЦИИ | 2015 |
|
RU2676416C2 |

